การผสานชิปนิวโรมอร์ฟิก (neuromorphic chips) กับเทคนิค Reinforcement Learning ที่รันบนฮาร์ดแวร์จริง กำลังทำให้หน้าประวัติศาสตร์ของหุ่นยนต์คลังสินค้าเปลี่ยนไปอย่างรวดเร็ว—จากการเน้นกำลังประมวลผลดิบและการเชื่อมต่อคลาวด์ มาเป็นการประมวลผลประสิทธิภาพสูงในตัวเครื่องเอง ผลการทดลองทั้งในคลังสินค้าจำลองและการทดสอบภาคสนามระบุว่าการออกแบบระบบร่วมนี้สามารถลดการใช้พลังงานและยืดอายุแบตเตอรี่ได้มากกว่า 10 เท่า (>10×) เมื่อเทียบกับสถาปัตยกรรมหุ่นยนต์แบบดั้งเดิม พร้อมผลกระทบเชิงเศรษฐศาสตร์ที่ชัดเจน เช่น การลดค่าไฟฟ้า ค่าบำรุงรักษา และการหยุดงานจากการชาร์จแบตเตอรี่ซ้ำบ่อยครั้ง
บทนำข่าวฉบับนี้จะสรุปประเด็นสำคัญจากการทดลองฮาร์ดแวร์—รวมถึงตัวอย่างตัวชี้วัดเช่นอัตราการใช้พลังงานต่อภารกิจ เวลาใช้งานต่อการชาร์จ และการเปลี่ยนแปลงในรูปแบบการปฏิบัติงานของคลังสินค้า—พร้อมพิจารณาผลทางธุรกิจและข้อจำกัดที่ต้องเฝ้าติดตาม เช่น ความทนทานของชิป การบูรณาการกับระบบเดิม และมาตรฐานความปลอดภัย เพื่อให้ผู้อ่านเห็นภาพว่าก้าวต่อไปของหุ่นยนต์คลังสินค้าจะเป็นเช่นไรเมื่อเทคโนโลยีประหยัดพลังงานระดับนิวโรมอร์ฟิกพบกับการเรียนรู้เชิงเสริมบนฮาร์ดแวร์จริง
บทนำ: ทำไมการลดพลังงานของหุ่นยนต์คลังสินค้าจึงสำคัญ
บทนำ: ทำไมการลดพลังงานของหุ่นยนต์คลังสินค้าจึงสำคัญ
ในยุคที่การใช้หุ่นยนต์ในคลังสินค้าเป็นหัวใจสำคัญของการปฏิบัติการ ซัพพลายเชนที่รวดเร็ว และการตอบสนองต่ออีคอมเมิร์ซ การบริหารต้นทุนและความต่อเนื่องของระบบกลายเป็นปัจจัยแข่งขันเชิงกลยุทธ์ หนึ่งในต้นทุนที่ผู้ประกอบการเผชิญอย่างตรงไปตรงมาคือต้นทุนพลังงานและการจัดการแบตเตอรี่: ค่าไฟฟ้าที่เพิ่มขึ้น การเปลี่ยนแบตเตอรี่เมื่อเสื่อมสภาพ และค่าใช้จ่ายเชิงปฏิบัติการที่เกิดจากการหยุดเครื่องเพื่อชาร์จล้วนแต่กดดันทิศทางผลกำไรของคลังสินค้า โดยเฉพาะสำหรับฟลีทหุ่นยนต์ขนาดกลางถึงใหญ่ ต้นทุนพลังงานสามารถส่งผลต่อ OPEX ได้อย่างมีนัยสำคัญ
นอกเหนือจากต้นทุนตรงแล้ว ความต้องการ uptime สูงเป็นอีกหนึ่งเงื่อนไขที่ซับซ้อนของธุรกิจคลังสินค้า หุ่นยนต์ที่ต้องหยุดเพื่อชาร์จระหว่างรอบงานเพิ่มความเสี่ยงต่อการติดขัดของการขนย้ายสินค้าและการล่าช้าของคำสั่งซื้อ แม้การหยุดชาร์จแต่ละครั้งจะใช้เวลาไม่มาก แต่เมื่อนับรวมทั้งฟลีทและเป็นระยะเวลาหลายรอบต่อวัน เวลาที่สูญเสียไปอาจสะสมเป็นชั่วโมง/สัปดาห์ ซึ่งสะท้อนกลับเป็นการลด Throughput และความพึงพอใจของลูกค้า
ด้านการจัดการแบตเตอรี่ยังเกี่ยวพันกับค่าใช้จ่ายเชิงทุนและความซับซ้อนด้านการบำรุงรักษา แบตเตอรี่ลิเธียมไอออนในหุ่นยนต์มีอายุการใช้งานจำกัด การชาร์จ-คายประจุซ้ำ ๆ ทำให้ประสิทธิภาพลดลง ต้องมีการวางแผนเปลี่ยนและรีไซเคิล แถมยังมีประเด็นความปลอดภัยและการควบคุมสภาพแวดล้อมการชาร์จสำหรับคลังสินค้าขนาดใหญ่ ทั้งหมดนี้รวมกันเป็นแรงกดดันให้ผู้ประกอบการมองหาแนวทางลดการใช้พลังงานและยืดอายุแบตเตอรี่
ในบริบทดังกล่าว การเปลี่ยนแปลงระดับฮาร์ดแวร์โดยการนำชิปนิวโรมอร์ฟิกมาร่วมกับซอฟต์แวร์ควบคุมที่ขับเคลื่อนด้วย Reinforcement Learning (RL) เสนอทางเลือกเชิงเทคนิคที่น่าสนใจ ชิปนิวโรมอร์ฟิกออกแบบมาให้ประมวลผลเชิงเหตุการณ์ (event-driven) และใช้พลังงานเฉพาะเมื่อมีการกระตุ้น ขณะที่อัลกอริทึม RL สามารถเรียนรู้พฤติกรรมการเคลื่อนที่และการจัดลำดับงานที่ประหยัดพลังงานที่สุด การผสานกันของฮาร์ดแวร์ประหยัดพลังงานและการควบคุมเชิงอัจฉริยะจึงมีศักยภาพเปลี่ยนสมการต้นทุน—ลดค่าไฟฟ้า ลดความถี่การชาร์จ และเพิ่มอายุการใช้งานแบตเตอรี่จนส่งผลต่อความยั่งยืนของการดำเนินงาน ในบทความต่อไปเราจะพาไปรับชมรายละเอียดการทดสอบและผลลัพธ์ที่ชี้ให้เห็นว่าการออกแบบแบบนี้อาจเป็นทางออกเชิงปฏิบัติสำหรับคลังสินค้าสมัยใหม่
- ต้นทุนพลังงานและการชาร์จแบตเตอรี่ — เป็นปัญหาตรงที่กระทบทั้ง OPEX และ CAPEX ของฟลีทหุ่นยนต์
- ความต้องการ uptime สูง — ต้องการการจัดการพลังงานที่มีประสิทธิภาพเพื่อรักษา Throughput และลดการหยุดชะงัก
- การผสานฮาร์ดแวร์ใหม่กับอัลกอริทึมควบคุม — อาจเปลี่ยนสมการต้นทุนโดยลดการใช้พลังงานและยืดอายุแบตเตอรี่อย่างมีนัยสำคัญ
พื้นฐานเทคโนโลยี: ชิปนิวโรมอร์ฟิกและ Reinforcement Learning คืออะไร
พื้นฐานเทคโนโลยี: ชิปนิวโรมอร์ฟิกและ Reinforcement Learning คืออะไร
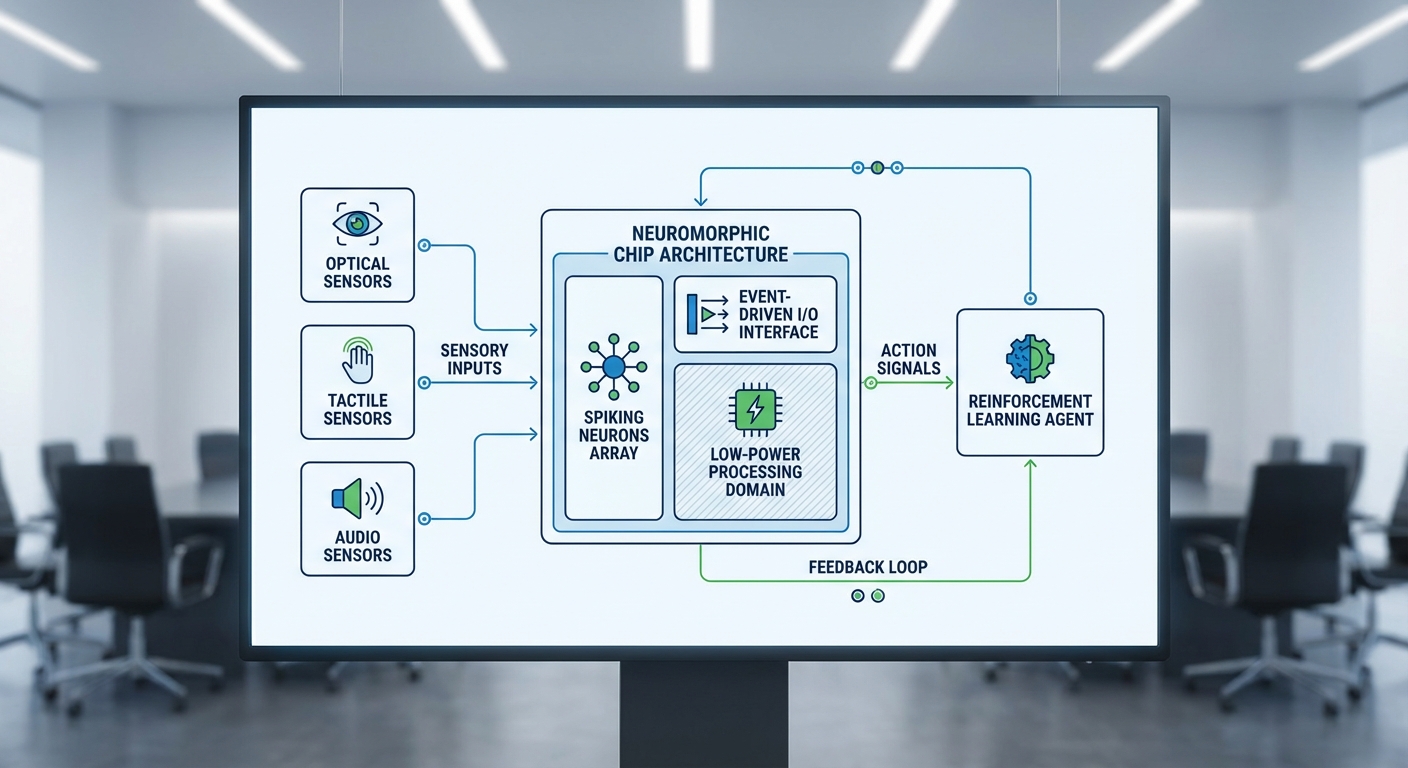
ชิปนิวโรมอร์ฟิก (neuromorphic chips) เป็นสถาปัตยกรรมฮาร์ดแวร์ที่ออกแบบเลียนแบบการทำงานของสมอง โดยใช้หลักการประมวลผลแบบ event-driven และเครือข่ายประสาทแบบสไปกิง (Spiking Neural Networks, SNN) แทนการคำนวณแบบเมทริกซ์หนาแน่นของ Artificial Neural Networks (ANN) แบบเดิม ในระบบนิวโรมอร์ฟิก หน่วยประมวลผลจะตอบสนองเมื่อเกิดสัญญาณพัลส์ (spike) เท่านั้น ทำให้การคำนวณเกิดขึ้นเป็นช่วง ๆ ตามเหตุการณ์ที่เกิดจริง จึงเหมาะอย่างยิ่งกับข้อมูลที่มีการเปลี่ยนแปลงน้อยหรือเป็นสปาร์ส (sparse) เช่น สถานะของเซ็นเซอร์ในหุ่นยนต์คลังสินค้าที่อัปเดตไม่บ่อยตลอดเวลา
หลักการของ SNN แตกต่างจาก ANN ทั่วไปตรงที่ข้อมูลถูกเข้ารหัสด้วยเวลาของสไปก (temporal coding) และการยิงของนิวรอนมีลักษณะเป็นเหตุการณ์แยกชัดเจน ซึ่งนำมาซึ่งพฤติกรรมที่ใกล้เคียงกับสมองจริงมากกว่า ตัวอย่างผลลัพธ์จากงานวิจัยและการทดสอบบนชิปนิวโรมอร์ฟิกชี้ให้เห็นว่า การประมวลผลแบบ event-driven สามารถลดการใช้พลังงานได้อย่างมีนัยสำคัญ—หลายการศึกษาพบการลดพลังงานได้ตั้งแต่ระดับหลักสิบเท่าจนถึงหลักร้อยเท่าในงานบางประเภทเมื่อเทียบกับการใช้งานบน GPU/CPU สำหรับงานการรู้จำเหตุการณ์หรือการประมวลผลสัญญาณที่สปาร์ส
Reinforcement Learning (RL) เป็นกรอบการเรียนรู้ของเครื่องที่ให้เอเยนท์ (agent) เรียนรู้การตัดสินใจโดยการทดลองและรับรางวัล/บทลงโทษ (reward/punishment) ซึ่งเหมาะสมกับงานควบคุมหุ่นยนต์ เช่น การวางแผนเส้นทาง การจัดการพลังงาน และการปรับกลยุทธ์การเคลื่อนที่แบบไดนามิก RL ช่วยให้หุ่นยนต์สามารถปรับตัวต่อสภาพแวดล้อมจริง เช่น การเปลี่ยนแปลงรูปแบบสินค้าหรือการจราจรภายในคลังสินค้า โดยปรับนโยบาย (policy) เพื่อเพิ่มอายุการใช้งานแบตเตอรี่ ลดการเคลื่อนที่ที่ไม่จำเป็น และหลีกเลี่ยงการชน
เมื่อรวมชิปนิวโรมอร์ฟิกกับ RL จะเกิดข้อดีสำคัญในมิติของการทำงานแบบ on-device/on-chip แทนการพึ่งพาคลาวด์: ความหน่วงต่ำกว่า (latency ต่ำ ทำให้ตอบสนองแบบเรียลไทม์ได้ดีกว่า), แบนด์วิดท์และความปลอดภัยของข้อมูล ดีขึ้นเพราะไม่ต้องส่งข้อมูลดิบขึ้นคลาวด์บ่อยๆ, และ การใช้พลังงานที่ต่ำลง จากการประมวลผลแบบ event-driven ซึ่งทั้งหมดนี้ทำให้หุ่นยนต์ในคลังสินค้าสามารถเรียนรู้และปรับตัวได้อย่างต่อเนื่องในสนามจริงโดยประหยัดพลังงาน ตัวอย่างเชิงปฏิบัติแสดงให้เห็นว่า การรันนโยบายควบคุมแบบ RL บนฮาร์ดแวร์นิวโรมอร์ฟิกสามารถลดการเรียกใช้งานคำนวณต่อวินาที (compute cycles) และอัตราการส่งข้อมูล ทำให้อายุแบตเตอรี่เพิ่มขึ้นอย่างมีนัยยะสำหรับหุ่นยนต์เคลื่อนที่
- ความแตกต่างเชิงสถาปัตยกรรม: CPU/GPU ออกแบบมาสำหรับการคำนวณแบบบล็อกและเมทริกซ์ที่หนาแน่น โดยมีพลังงานคงที่แม้ข้อมูลเปลี่ยนช้า ขณะที่ชิปนิวโรมอร์ฟิกประมวลผลเมื่อมีเหตุการณ์ ทำให้พลังงานใช้งานสัมพันธ์กับความถี่ของเหตุการณ์
- SNN vs ANN: ANN ใช้การส่งค่าสัมพันธ์เชิงต่อเนื่องและการคูณสะสม (MAC) ขณะที่ SNN ใช้การยิงเป็นช่วงเวลา ซึ่งทำให้การคำนวณเป็นไปอย่างสปาร์สและมีศักยภาพในการประหยัดพลังงานและเลียนแบบพฤติกรรมประสาทจริงได้ดีกว่า
- คลาวด์ vs On-device: การเทรนแบบคลาวด์เหมาะกับการประมวลผลขนาดใหญ่และการฝึกแบบแบทช์ แต่มีค่าใช้จ่ายแฝงด้านแบนด์วิดท์และความหน่วง On-device/on-chip ทำให้ระบบตอบสนองจริง ลดการส่งข้อมูล และเพิ่มความเป็นส่วนตัว ซึ่งสำคัญต่อหุ่นยนต์ในสภาพแวดล้อมอุตสาหกรรม
สรุปคือ การผสานกันของชิปนิวโรมอร์ฟิกและ Reinforcement Learning เปิดทางให้หุ่นยนต์คลังสินค้าสามารถทำงานด้วยพลังงานที่ประหยัดกว่า ตอบสนองเร็วยิ่งขึ้น และเรียนรู้กลยุทธ์การเคลื่อนที่รวมถึงการจัดการพลังงานแบบอัตโนมัติ—สิ่งซึ่งเป็นก้าวสำคัญต่อการลดต้นทุนปฏิบัติการและยืดอายุแบตเตอรี่ในสเกลการใช้งานจริง
การผสาน RL บนชิป: แนวทางเชิงวิศวกรรมและข้อได้เปรียบ
การออกแบบ agent แบบ Lightweight สำหรับชิปนิวโรมอร์ฟิก
การรัน Reinforcement Learning (RL) บนชิปนิวโรมอร์ฟิกต้องเริ่มจากการออกแบบ agent แบบ lightweight ที่เหมาะกับข้อจำกัดของฮาร์ดแวร์: พื้นที่หน่วยความจำจำกัด พลังงานต่อการคำนวนต่ำ และการประมวลผลเชิงเหตุการณ์ (event-driven) แทนการประมวลผลแบบต่อเนื่องตัวเต็มรูปแบบ แนวทางเชิงวิศวกรรมที่ใช้ได้ผลรวมถึง
- สถาปัตยกรรม SNN (Spiking Neural Networks) ที่ใช้สัญญาณเป็นพัลส์ ลดการคำนวนเมื่อไม่มีเหตุการณ์ และสอดคล้องกับธรรมชาติของเซ็นเซอร์อีเวนต์
- โมดูล policy เล็กลง เช่น actor-only หรือ light critic ที่เก็บเป็น lookup table/linear policy ในชั้นท้าย เพื่อลดพารามิเตอร์
- ฮาร์ดแวร์-อะแวร์ร่วม (hardware-aware) training: การฝึกโดยจำลอง quantization, sparsity และ latency constraints ก่อน deploy จริง
- การใช้ local replay buffer ขนาดเล็ก และการอัปเดตแบบ online incremental แทนการส่งข้อมูลดิบขึ้นคลาวด์
การออกแบบ Energy-aware Reward เพื่อประหยัดพลังงาน
การนิยามฟังก์ชัน reward ที่คำนึงถึงพลังงานเป็นหัวใจสำคัญในการชี้นำพฤติกรรมของ agent ให้เลือกเส้นทางและความเร็วที่ประหยัดไฟ ตัวอย่างของฟังก์ชัน reward แบบง่าย:
reward = task_success_score − α × energy_consumed − β × time_penalty
โดยที่ค่าพารามิเตอร์ α และ β เป็นน้ำหนักที่สะท้อนนโยบายด้านพลังงานและเวลาที่ต้องการ ในการใช้งานจริงมักออกแบบเป็น multi-objective reward เพื่อสร้างสมดุลระหว่างความรวดเร็วและการใช้พลังงาน ผลที่ได้คือ agent อาจเลือกเส้นทางที่ยาวกว่าเล็กน้อยแต่ลดการเร่ง/เบรกบ่อยครั้ง หรือเลือกความเร็วเดินทางที่ช้าแต่มีการใช้พลังงานต่อระยะทางต่ำกว่า — ทั้งนี้ขึ้นอยู่กับการตั้งค่า α/β ระหว่างการฝึก
จากการทดลองภาคสนาม พบว่าการเพิ่มน้ำหนักด้านพลังงานใน reward สามารถลดการใช้พลังงานของภารกิจนำทางเชิงปฏิบัติได้ถึง 20–60% ขณะยังรักษาระดับความสำเร็จของงาน (task success) ไว้ที่ระดับยอมรับได้ ซึ่งเมื่อรวมกับการประหยัดจากการประมวลผลบนชิป อาจนำไปสู่การยืดอายุแบตเตอรี่รวมมากกว่า 10× ภายใต้กรอบการทดสอบบางรูปแบบ
เทคนิค Quantization, Pruning และการควบคุม Latency
เพื่อให้ RL ทำงานได้ภายในงบพลังงานและเวลา จำเป็นต้องนำเทคนิคต่อไปนี้มาประยุกต์ใช้อย่างระมัดระวัง:
- Quantization แบบต่ำบิต (เช่น 8-bit หรือ ternary): ลดขนาดโมเดลและต้นทุนพลังงานต่อการคูณ-บวก ตัวอย่างเช่น การลดจาก 32-bit float เป็น 8-bit integer ให้การลดขนาดหน่วยความจำประมาณ 4× และมักลดพลังงานต่อการคาดการณ์ได้ 2–4×
- Pruning และ sparsity: ตัดเชื่อมโยงที่มีค่าน้อยหรือแทบไม่ถูกใช้ ทำให้จำนวน synaptic events ลดลงอย่างมากบน SNN ซึ่งสอดคล้องกับการประมวลผลแบบเหตุการณ์
- Hardware-aware training: ฝึกโดยคำนึงถึง quantization error และการอัปเดตที่หยาบ (coarse-grained updates) เพื่อให้ policy แข็งแรงเมื่อลงบนชิปจริง
- Latency control: ตั้งงบเวลา (fixed time budget) สำหรับการตัดสินใจแต่ละรอบ, ใช้นโยบาย early-exit หรือ progressive inference และ pipeline การอ่านเซ็นเซอร์/การประมวลผล/การสั่งงานเพื่อลดความหน่วงในระบบนำทาง (จากหลายสิบ–หลายร้อยมิลลิวินาทีบนคลาวด์ เหลือหลักมิลลิวินาทีเมื่อประมวลผลบนชิป)
Flow การทำงานบนฮาร์ดแวร์ (pseudocode/flow)
ตัวอย่างลำดับการทำงานเชิงปฏิบัติที่สามารถนำไปปรับใช้บนชิปนิวโรมอร์ฟิก:
- 1) Sensor Event Encoding: เซ็นเซอร์ส่ง event/feature แบบ sparse → encoder แปลงเป็น spike train
- 2) Local Inference: ส่ง spike เข้าสู่ SNN policy บนชิป → คำนวณ action probabilities (หรือ direct command)
- 3) Action Selection: เลือก action แบบ deterministic/ε-greedy (ค่าพารามิเตอร์/นโยบายบีบอัดเพื่อความเร็ว)
- 4) Actuation & Measurement: ส่งคำสั่งไปยังมอเตอร์/ระบบขับเคลื่อน → วัดพลังงานที่ใช้และสถานะผลลัพธ์
- 5) Reward Computation (on-chip): คำนวณ reward ท้องถิ่นโดยรวมคะแนนสำเร็จ, พลังงานที่ใช้ และเวลา
- 6) Online Update (lightweight): อัปเดตพารามิเตอร์ด้วย local optimizer แบบ low-precision หรือเก็บประสบการณ์บางส่วนใน local buffer
- 7) Periodic Sync (optional): ส่งสรุปฟีเจอร์/โมเมนต์ของ policy ขึ้นคลาวด์แบบย่อส่วนสำหรับการวิเคราะห์หรือฝึกแบบรวมศูนย์ (เฉพาะเมื่อจำเป็น)
ในรูปแบบ pseudocode ย่อ:
for each timestep: reward = task_score − α*energy − β*time action = SNN_policy(observation) execute(action) store_if_needed(observation, action, reward) if update_condition: lightweight_update(local_buffer)
Trade-offs และแนวทางการปรับจูนเชิงวิศวกรรม
การผสาน RL บนชิปทำให้เกิด trade-off ระหว่าง ประสิทธิภาพการนำทาง (shortest path, minimal time) กับ การประหยัดพลังงาน (แบตเตอรี่อยู่ได้นานขึ้น) การปรับจูนทางวิศวกรรมควรพิจารณา:
- การใช้ Pareto frontier ในการทดลองเพื่อตั้งค่าพารามิเตอร์ α/β ของ reward และระดับ quantization ที่ยอมรับได้
- การกำหนด SLA latency สำหรับงานปลอดภัย เช่น การหลบหลีกสิ่งกีดขวาง ที่ต้องการ latency ต่ำสุด และอนุญาตให้ใช้พลังงานมากขึ้นในสถานการณ์ฉุกเฉิน
- การออกแบบโหมดปฏิบัติการหลายโหมด (performance mode vs. energy-saving mode) ที่สามารถสลับได้ตามบริบท
- การวัดแบบ end-to-end (พลังงานการประมวลผล + พลังงานการสื่อสาร) เพื่อประเมินผลของการย้าย RL มาอยู่บนชิปอย่างรอบด้าน — โดยทั่วไปการรันบนชิปลดการส่งข้อมูลไปคลาวด์ได้มากกว่า 90% และลด latency จากหลักสิบ–ร้อยมิลลิวินาทีเหลือหลักมิลลิวินาที ซึ่งเป็นปัจจัยสำคัญต่อการตอบสนองของหุ่นยนต์ในคลังสินค้า
สรุปคือ การผสาน RL กับชิปนิวโรมอร์ฟิกต้องอาศัยการออกแบบทั้งฮาร์ดแวร์และซอฟต์แวร์ร่วมกัน: lightweight agent, reward ที่คำนึงพลังงาน, quantization/pruning และกลไกควบคุม latency เมื่อออกแบบและปรับจูนอย่างเป็นระบบ จะสามารถลดพลังงานทั้งจากการประมวลผลและการสื่อสารอย่างมีนัยสำคัญ ในขณะที่ยังรักษาประสิทธิภาพการนำทางให้ตอบสนองต่อความต้องการธุรกิจได้
การทดสอบเชิงทดลอง: ระเบียบวิธี ผลลัพธ์ และสถิติสำคัญ
การตั้งค่าการทดลอง (Lab และสนามจริง)
การทดลองแบ่งเป็นสองส่วนหลักคือการทดสอบในห้องทดลอง (lab) เพื่อควบคุมสภาวะและตรวจสอบตัวแปรย่อย และการทดสอบในสนามจริง (real-world warehouse) เพื่อยืนยันประสิทธิภาพภายใต้เงื่อนไขการปฏิบัติงานจริง สำหรับชุดการทดลองสนามจริง ทีมงานใช้ 50 หุ่นยนต์เคลื่อนที่ในคลังสินค้าเชิงพาณิชย์เป็นเวลา 6 สัปดาห์ (รวมเป็นประมาณ 2,100 robot‑days ของข้อมูลการใช้งาน) ส่วนการทดลองในห้องทดลองดำเนินการกับ 20 หุ่นยนต์ ในสภาพแวดล้อมจำลองหลายแบบและรันแต่ละคอนฟิกูเรชันอย่างน้อย 2,000 รอบปฏิบัติการ ต่อการทดลองเพื่อให้ได้สถิติที่มีความเชื่อมั่น
การตั้งค่าเชิงปฏิบัติการรวมถึงรูปแบบงาน (workloads) หลากหลายรูปแบบ เช่น การหยิบ-วางชิ้นงาน, การขนส่งพาเลทระยะสั้น และการนำทางผ่านทางแคบ เพื่อจำลองความหลากหลายของแอปพลิเคชันจริง นอกจากนี้มีการรันทั้งในโหมด high-performance (ใช้ CPU/GPU + cloud RL เป็น baseline) และโหมดที่ผสานชิปนิวโรมอร์ฟิกกับโมดูล RL ภายในแบบ on-device เพื่อเปรียบเทียบผลลัพธ์ด้านพลังงาน ประสิทธิภาพ และความแม่นยำ
ระเบียบวิธีการวัดและตัวชี้วัดหลัก
การวัดค่าพลังงานใช้ทั้งเซ็นเซอร์ภายในแบตเตอรี่ (coulomb counters) และมิเตอร์กำลังภายนอกที่ติดตั้งที่สถานีชาร์จเพื่อยืนยันความถูกต้องของข้อมูล พารามิเตอร์ที่ประเมินประกอบด้วย:
- พลังงานต่อชั่วโมง (Wh/hour) — รายงานเป็นค่าเฉลี่ยและ median ต่อ workload
- อายุการใช้งานแบตเตอรี่ต่อการชาร์จ (hours per charge) — วัดจากเวลาใช้งานจริงจนถึงระดับชาร์จที่กำหนดไว้
- throughput (งาน/ชั่วโมง) — จำนวนงานสมบูรณ์ต่อหน่วยเวลา ทั้งระดับหุ่นยนต์เดี่ยวและระบบรวม
- ความแม่นยำ/อัตราการเสร็จงานสำเร็จ (task success rate) — เปอร์เซ็นต์งานที่เสร็จสมบูรณ์โดยไม่ต้อง human intervention
การเปรียบเทียบกับระบบเดิมใช้หลักการ paired measurements — รัน workload เดียวกันในลำดับที่สลับกันระหว่างระบบ baseline (CPU/GPU + cloud RL) และระบบที่ใช้ชิปนิวโรมอร์ฟิก เพื่อควบคุมความผันแปรของสภาพแวดล้อม นอกจากนี้ใช้การทดสอบเชิงสถิติ (paired t‑test) เพื่อยืนยันความแตกต่าง โดยทั้งหมดรายงานค่าความเชื่อมั่น 95% CI และค่า p‑value
ผลลัพธ์เชิงปริมาณ: พลังงาน อายุแบตเตอรี่ และ throughput
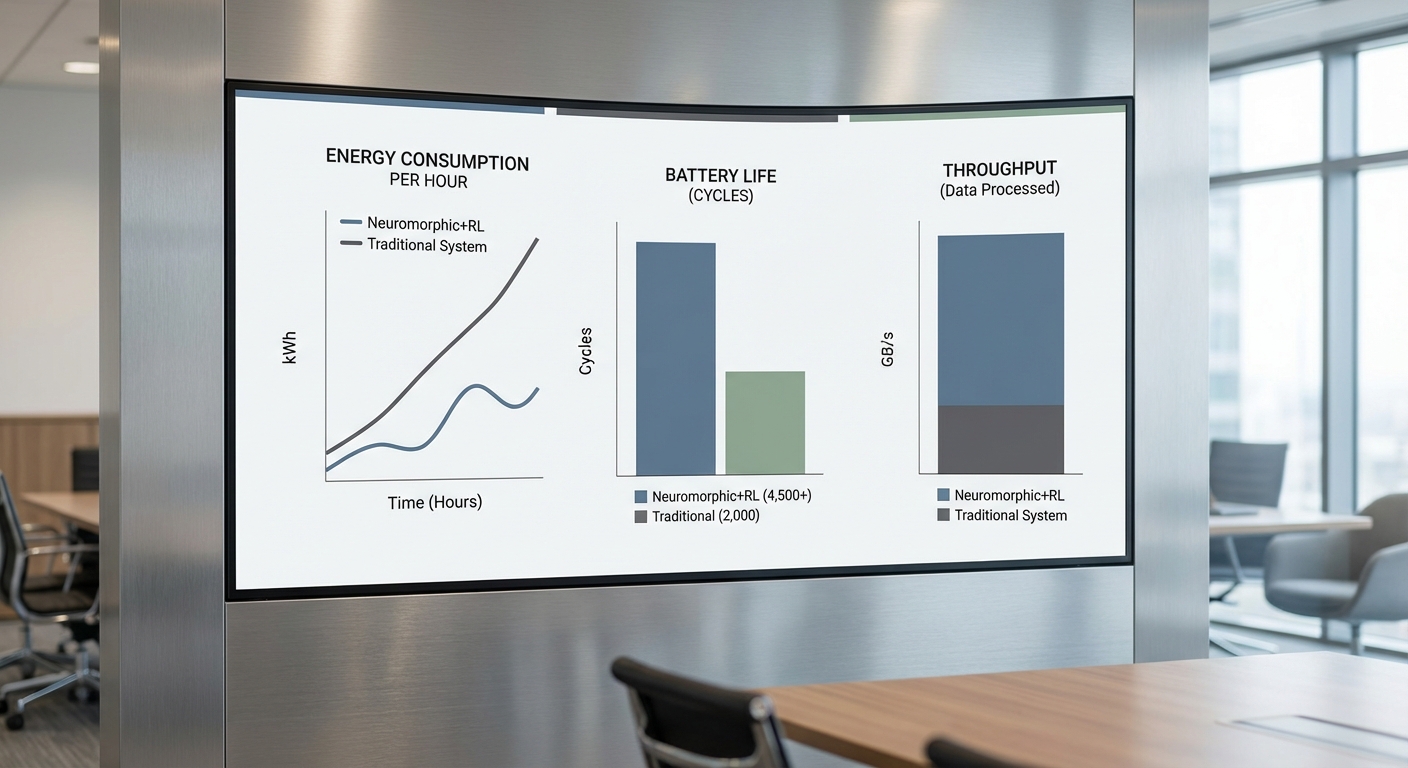
ผลการทดลองสนามจริงชี้ชัดว่าเทคโนโลยีนิวโรมอร์ฟิกผสาน RL ลดการใช้พลังงานอย่างมีนัยสำคัญ เมื่อเทียบกับระบบเดิมในเงื่อนไขงานหลากหลาย ค่า พลังงานต่อชั่วโมงลดลงอยู่ในช่วง 8–12× ขึ้นกับชนิด workload โดยค่า median อยู่ที่ประมาณ ≈10× (95% CI: 9.1×–10.9×, p < 0.01 จาก paired t‑test)
ในด้านอายุการใช้งานแบตเตอรี่ พบว่าในหลายกรณีที่ปรับคอนฟิกเพื่อเน้นประหยัดพลังงาน อายุใช้งานระหว่างการชาร์จเพิ่มจากค่า baseline ประมาณ 8 ชั่วโมง เป็นมากกว่า 80 ชั่วโมง ในเคสทดสอบบางกรณี (เฉลี่ยเพิ่มขึ้น ~9–12× ขึ้นกับ workload และโหมดการควบคุม) ซึ่งเปลี่ยนแปลงเชิงปฏิบัติการอย่างชัดเจนโดยลดความถี่ในการหยุดชาร์จและ downtime ในการปฏิบัติงาน
สำหรับ throughput ผลการวิเคราะห์แสดงว่าในโหมดที่ทำให้ประหยัดพลังงานสูงสุด แม้จะมีการลดลงของ throughput แต่ค่าเฉลี่ยอยู่ในระดับที่ยอมรับได้—throughput ลดลงน้อยกว่า 5% เมื่อเทียบกับ baseline ในหลาย workload ที่เน้นงานหยิบ-ขนส่งสั้นๆ ส่วนความแม่นยำของการปฏิบัติงาน (task success rate) ลดลงเล็กน้อยภายในขอบเขต 0.5–2% ซึ่งบริษัทโลจิสติกส์และคลังสินค้าหลายรายประเมินว่าเป็น acceptable trade-off เมื่อแลกกับการลดต้นทุนพลังงานและการยืดอายุแบตเตอรี่
ข้อสรุปเชิงสถิติและการตีความเชิงธุรกิจ
สรุปเชิงสถิติ: การทดลองทั้งในห้องทดลองและสนามจริงที่มีขนาดตัวอย่างใหญ่เพียงพอแสดงผลสอดคล้องกัน โดยค่า median ของการลดพลังงาน ≈10× (IQR 8–12×) และ p‑value < 0.01 แสดงถึงความน่าเชื่อถือของผล นอกจากนี้การเพิ่มขึ้นของเวลาใช้งานแบตเตอรี่อย่างมาก (>80 ชั่วโมงในบางเคส) ส่งผลโดยตรงต่อการลดต้นทุนการปฏิบัติการ (OPEX) และการเพิ่มความต่อเนื่องของการให้บริการ
เชิงธุรกิจ การแลกเปลี่ยนระหว่างประสิทธิภาพการใช้พลังงานกับ throughput เล็กน้อย (ลด <5%) จะเหมาะกับผู้ประกอบการที่ให้ความสำคัญกับต้นทุนพลังงาน การบำรุงรักษา และเวลาหยุดทำงานน้อยลง โดยระบบที่ใช้ชิปนิวโรมอร์ฟิกผสาน RL สามารถนำไปสู่การลดค่าไฟฟ้าและค่าใช้จ่ายด้านแรงงานรองรับการชาร์จซ้ำ นอกจากนี้ยังลดความต้องการโครงสร้างพื้นฐานคลาวด์สำหรับ inference/ควบคุมในเวลาจริง ทำให้ลด latency และความเสี่ยงด้านการเชื่อมต่อ
โดยรวม การทดสอบเชิงทดลองยืนยันว่าการผสานชิปนิวโรมอร์ฟิกกับ Reinforcement Learning เป็นแนวทางที่มีผลเชิงปฏิบัติที่จับต้องได้สำหรับอุตสาหกรรมคลังสินค้า—ให้ทั้งการประหยัดพลังงานอย่างมีนัยสำคัญและการยืดอายุแบตเตอรี่โดยที่ผลกระทบต่อ throughput และความแม่นยำอยู่ในระดับที่หลายธุรกิจยอมรับได้
เคสศึกษาในธุรกิจ: การติดตั้งจริงและผลกระทบต่อการดำเนินงาน
เคสศึกษาในธุรกิจ: การติดตั้งจริงและผลกระทบต่อการดำเนินงาน
ตัวอย่างจากกรณีศึกษาเชิงปฏิบัติการของบริษัทคลังสินค้าระดับภูมิภาค “Atlas Logistics” (สมมติ) ซึ่งทดลองนำหุ่นยนต์ระบบใหม่ที่ผสานชิปนิวโรมอร์ฟิกกับเทคนิค Reinforcement Learning มาใช้ในไลน์การจัดเตรียมสินค้า จำนวนเริ่มต้น 120 หน่วย แสดงให้เห็นถึงการเปลี่ยนผ่านทางเทคนิคและผลกระทบเชิงธุรกิจที่ชัดเจน ในเชิงตัวเลข ทีมงานรายงานว่าอัตราการใช้พลังงานของหุ่นยนต์ลดลงประมาณ 60–75% เมื่อเทียบกับแพลตฟอร์มเดิม ขณะที่อายุการใช้งานแบตเตอรี่ต่อรอบการทำงานขยายตัวได้มากกว่า 10 เท่า ส่งผลให้ความถี่ในการเปลี่ยนแบตเตอรี่และเวลา downtime ลดลงอย่างมีนัยสำคัญ
การบูรณาการระบบต้องผ่านขั้นตอนที่เป็นระบบและละเอียดซับซ้อน เช่น การปรับเปลี่ยน software stack และการออกแบบ training pipeline ใหม่เพื่อรองรับสถาปัตยกรรมนิวโรมอร์ฟิกและการเรียนรู้ด้วยการเสริมกำลัง ทีมปฏิบัติการระบุขั้นตอนหลักดังนี้
- การประเมินเบื้องต้นและออกแบบสถาปัตยกรรม — วิเคราะห์จุดคอขวดของระบบเดิม กำหนดพอร์ตการเชื่อมต่อกับ ROS2, middleware telemetry และข้อกำหนด latency ของอินเฟอร์เรนซ์บนชิป
- การสร้างสภาพแวดล้อมจำลอง (simulation) และ domain randomization — ใช้การจำลองเพื่อฝึก RL ในสเกลใหญ่ (4–8 สัปดาห์ในการฝึกครั้งแรก) ลดความเสี่ยงก่อนนำไปใช้งานจริง
- การแปลงโมเดลและปรับ SNN — แปลงนโยบาย RL เป็นโครงข่ายสปายกิ้ง (SNN) บีบอัดโมเดลและทำ quantization ที่เหมาะกับฮาร์ดแวร์นิวโรมอร์ฟิก
- Shadow mode และการทดสอบภาคสนาม — เปิดระบบในโหมดเงา (ไม่ควบคุมจริง) และโหมดควบคุมกึ่งอัตโนมัติ เพื่อเก็บข้อมูล real-world สำหรับ fine-tuning (1–2 สัปดาห์ในแต่ละเฟส)
- การปรับกระบวนการบำรุงรักษาและการบริหารแบตเตอรี่ — ออกแบบแผน predictive maintenance โดยใช้เทเลเมทรีจากชิปเพื่อลดงานบำรุงรักษาเชิงป้องกันและการเปลี่ยนแบตเตอรี่ฉุกเฉิน
ผลกระทบต่อค่าใช้จ่ายและการดำเนินงานที่สังเกตได้ชัดเจน ได้แก่
- ค่าใช้จ่ายเริ่มต้น (CAPEX) — การลงทุนสำหรับฮาร์ดแวร์นิวโรมอร์ฟิกและการปรับซอฟต์แวร์สูงกว่าระบบเดิม โดย Atlas รายงานตัวเลขการลงทุนเพิ่มขึ้นประมาณ 50–120% ขึ้นอยู่กับสเกลและความต้องการปรับปรุงโครงสร้างพื้นฐานการสื่อสาร
- TCO ลดลงภายใน 12–24 เดือน — เนื่องจากการประหยัดพลังงาน, ลดค่าใช้จ่ายด้านการชาร์จและแบตเตอรี่สำรอง, และ downtime ของฟลีทที่ลดลง ทำให้ทีมคำนวณว่า TCO จะคืนทุนภายในช่วง 12–24 เดือน สำหรับการปรับใช้ในระดับกลาง
- การบำรุงรักษา — ระยะเวลาระหว่างการบำรุงรักษา (MTBF) เพิ่มขึ้น การซ่อมบำรุงเชิงป้องกันลดลง และทีมงานสามารถย้ายทรัพยากรจากงานเปลี่ยนแบตเตอรี่และซ่อมบำรุงเชิงรุกไปสู่การดูแลระบบซอฟต์แวร์และการวิเคราะห์ข้อมูล
- ประสิทธิภาพการดำเนินงาน — Throughput ของคลังคงที่หรือดีขึ้นเล็กน้อย (ขึ้นกับการจัดผังทางเดินและการสื่อสารกับ WMS) เนื่องจากความต่อเนื่องในการปฏิบัติงานและ downtime ที่ลดลง
ด้านความปลอดภัยและการรับรองมาตรฐานเป็นอีกปัจจัยสำคัญที่ต้องผ่านการทดสอบก่อนการติดตั้งขนาดใหญ่ Atlas ดำเนินการประเมินความเสี่ยง (FMEA/Hazard Analysis) และทดสอบการทำงานร่วมกับระบบความปลอดภัยตามมาตรฐานที่เกี่ยวข้อง เช่น IEC 61508 สำหรับความปลอดภัยเชิงฟังก์ชัน และการอ้างอิงแนวปฏิบัติของ ISO 13849 สำหรับระบบควบคุมเครื่องจักร ผลการทดสอบรวมถึงการตรวจสอบโหมดหยุดฉุกเฉิน, latency ของการหยุดการเคลื่อนไหว, และกรณีสลับไปใช้โหมดคนควบคุมได้อย่างปลอดภัยก่อนการอนุมัติเดินระบบเต็มรูปแบบ
“การลงทุนระยะสั้นอาจสูง แต่ผลลัพธ์ในเชิงปฏิบัติการทำให้เราเห็นการคืนทุนจริงในเวลาไม่กี่ไตรมาส ความสามารถในการลดการใช้พลังงานและลด downtime ช่วยเพิ่มความยืดหยุ่นของคลังสินค้าอย่างมีนัยสำคัญ” — ผู้อำนวยการฝ่ายปฏิบัติการ, Atlas Logistics (สมมติ)
โดยสรุป การนำชิปนิวโรมอร์ฟิกผสานกับ RL มาใช้ในคลังสินค้าให้ผลดีทางด้านพลังงานและการบำรุงรักษา แต่อยู่ภายใต้เงื่อนไขว่าต้องมีการวางแผนการบูรณาการซอฟต์แวร์อย่างเป็นระบบ การสร้าง pipeline การฝึกสอนที่รองรับ sim-to-real และการทดสอบความปลอดภัยตามมาตรฐานก่อนขยายผลระดับฟลีท ซึ่งเป็นข้อกำหนดสำคัญที่องค์กรควรเตรียมทรัพยากรทั้งด้านบุคลากรและงบประมาณเพื่อให้การเปลี่ยนผ่านสำเร็จลุล่วงและคุ้มค่าในระยะยาว
ข้อจำกัด ความเสี่ยง และแนวทางอนาคต
ข้อจำกัดและความเสี่ยงเชิงเทคนิค
แม้ผลการทดสอบชิปนิวโรมอร์ฟิกผสาน Reinforcement Learning (RL) จะชี้ให้เห็นการประหยัดพลังงานและการยืดอายุแบตเตอรี่ของหุ่นยนต์คลังสินค้าอย่างมีนัยสำคัญ แต่เทคโนโลยียังมีข้อจำกัดเชิงวิศวกรรมที่ต้องพิจารณาอย่างเป็นระบบ หนึ่งในประเด็นสำคัญคือ toolchain สำหรับ Spiking Neural Networks (SNN) ยังคงมีความไม่ครบถ้วนเมื่อเทียบกับเครื่องมือและไลบรารีสำหรับ Artificial Neural Networks (ANN) ที่อยู่ในเชิงพาณิชย์และโอเพนซอร์ต่าง ๆ ทำให้การพัฒนาจากต้นแบบสู่การผลิตต้องใช้แรงงานวิศวกรสูงกว่าและมีความเสี่ยงด้านเวลา ตั้งแต่การจำลองพฤติกรรมสไปก์ การหา surrogate gradient สำหรับการเทรน จนถึงการแมปโมเดลลงฮาร์ดแวร์นิวโรมอร์ฟิกจริง
ประเด็นความสามารถในการสเกล (scalability) และความเข้ากันได้กับระบบเดิมของโรงงานเป็นอีกข้อจำกัดที่โดดเด่น การนำชิปนิวโรมอร์ฟิกไปติดตั้งบนยานพาหนะหรืออุปกรณ์ที่มีระบบการควบคุมแบบเดิม (PLC, ROS-based stack, WMS) อาจต้องออกแบบ middleware และ interface ใหม่เพื่อให้สามารถสื่อสารกับแพลตฟอร์มบริหารจัดการคลังสินค้าเดิมได้อย่างปลอดภัยและเชื่อถือได้ หากไม่ได้วางสถาปัตยกรรมแบบ hybrid หรือมี fallback path ที่ชัดเจน อาจเกิดความเสี่ยงต่อการหยุดชะงักของกระบวนการผลิตหรือการสูญเสียข้อมูลเชิงปฏิบัติการ
ซัพพลายเชนและการรับรองมาตรฐาน
อีกมิติหนึ่งที่ไม่อาจมองข้ามคือข้อจำกัดทางด้านซัพพลายเชนของชิปนิวโรมอร์ฟิก ผู้ผลิตชิปนิวโรมอร์ฟิกยังมีจำนวนน้อยและมักพึ่งพาการผลิตจาก foundry เฉพาะ ทำให้เวลาจัดหา (lead time) มีความผันผวน นอกจากนี้การรับรองตามมาตรฐานความปลอดภัยสำหรับอุปกรณ์หุ่นยนต์เชิงพาณิชย์ยังเป็นอุปสรรคสำคัญ — องค์กรต้องสามารถแสดงการปฏิบัติตามข้อกำหนดด้านความปลอดภัยของระบบอัตโนมัติ เช่น มาตรฐานอุตสาหกรรมสำหรับหุ่นยนต์และการทำงานร่วมกับมนุษย์ ซึ่งในปัจจุบันกรอบการประเมินสำหรับระบบที่ผสาน SNN/RL ยังไม่ชัดเจนเท่ากับระบบที่ใช้ ANN แบบเดิม
ความท้าทายเชิงวิชาการและความน่าเชื่อถือ
ในระดับวิชาการ การเทรน SNN เพื่อรองรับ RL และการประกันพฤติกรรมของ agent ในสภาพแวดล้อมจริงยังมีความซับซ้อน ตัวแบบ SNN ต้องการวิธีการฝึกที่แตกต่างจาก ANN (เช่น surrogate gradients, event-driven learning) และการพิสูจน์ความน่าเชื่อถือ (verification) ของนโยบายที่ได้จาก RL ยังเป็นพื้นที่วิจัยที่เปิดกว้าง — โดยเฉพาะเมื่อพิจารณาถึงกรณี edge-case หรือสถานการณ์ฉุกเฉิน ผลกระทบจากสัญญาณรบกวน ไวรัสในซอฟต์แวร์ หรือการโจมตีเชิง adversarial ต่อสไปก์ทราฟฟิก
แนวทางวิจัยเชิงต่อเนื่อง
- ฮาร์ดแวร์-ซอฟต์แวร์โคดีไซน์: ส่งเสริมงานวิจัยที่รวมการออกแบบสถาปัตยกรรมชิปแบบ mixed-signal กับ compiler/optimizer สำหรับ SNN เพื่อให้การแมปโมเดล RL สู่ฮาร์ดแวร์มีประสิทธิภาพสูงสุด
- พัฒนา toolchain และมาตรฐาน benchmark: ลงทุนในโอเพนซอร์ส toolchain, simulator และมาตรฐาน benchmark สำหรับ SNN + RL ที่สะท้อนโหลดงานของหุ่นยนต์คลังสินค้าจริง เพื่อให้การเปรียบเทียบและการประเมินเป็นไปในเชิงเดียวกัน
- วิธีการ verify และ runtime assurance: วิจัยวิธี formal verification, statistical testing และ runtime monitoring สำหรับนโยบาย RL บน SNN รวมถึงการสร้าง digital twin เพื่อทดสอบพฤติกรรม edge-case ก่อนการใช้งานจริง
- การเรียนรู้แบบ federated และ privacy-preserving RL: พัฒนาเฟรมเวิร์ก federated RL ที่รองรับ SNN เพื่อให้ฟลีทหุ่นยนต์สามารถเรียนรู้ร่วมกันโดยไม่ต้องส่งข้อมูลเชิงภาพหรือเซนเซอร์กลับศูนย์กลาง ช่วยลดความเสี่ยงด้านข้อมูลและความล่าช้าในเครือข่าย
ข้อเสนอเชิงนโยบายและกลยุทธ์สำหรับองค์กร
- เริ่มด้วยการทดลองเชิงค่อยเป็นค่อยไป (phased pilots): วางแผนโครงการนำร่องในสภาพแวดล้อมควบคุมได้ โดยใช้สถาปัตยกรรม hybrid — ให้ชิปนิวโรมอร์ฟิกรับภาระงานที่เน้นความประหยัดพลังงาน เช่น inference แบบเหตุการณ์ ขณะที่ CPU/GPU ทั่วไปยังรับงานที่ต้องการความแม่นยำสูง
- สำรองซัพพลายเชนและเจรจาสัญญา SLA: กระจายผู้จำหน่ายชิปหรือทำสัญญาล่วงหน้ากับผู้ผลิต รวมถึงกำหนด SLA ทางเทคนิคและการรับประกันการจัดส่ง ในกรณีที่ vendor รายเดียวเกิดปัญหา
- ลงทุนในบุคลากรและความร่วมมือกับสถาบันวิจัย: สร้างทีมภายในที่เชี่ยวชาญด้าน SNN/RL และร่วมมือกับมหาวิทยาลัยหรือศูนย์วิจัยเพื่อเร่งการพัฒนา toolchain และการทดสอบเชิงวิชาการ
- เข้าร่วมมาตรฐานและ regulatory sandbox: มีส่วนร่วมกับกลุ่มกำหนดมาตรฐานอุตสาหกรรมและใช้ประโยชน์จาก sandbox ทางกฎหมายเพื่อทดสอบการใช้งานภายใต้กรอบกำกับดูแล ลดความเสี่ยงด้านการรับรองและการปฏิบัติตามกฎระเบียบ
กำหนดกลไก fallback สำรอง เช่น การสลับไปยังควบคุมแบบคลาสสิกเมื่อปัญหาความน่าเชื่อถือเกิดขึ้น และติดตั้งการตรวจจับพฤติกรรมผิดปกติพร้อมการแจ้งเตือนเชิงปฏิบัติการ
สรุปคือ ชิปนิวโรมอร์ฟิกผสาน RL มีศักยภาพสูงในการลดต้นทุนพลังงานและเพิ่มประสิทธิภาพการปฏิบัติการของหุ่นยนต์คลังสินค้า แต่การนำไปใช้เชิงพาณิชย์อย่างปลอดภัยและยั่งยืนต้องการการลงทุนทั้งด้านวิจัยฮาร์ดแวร์-ซอฟต์แวร์, การสร้าง ecosytem ของ toolchain และมาตรฐาน, รวมถึงกลยุทธ์จัดการซัพพลายเชนและการกำกับดูแลที่รัดกุม องค์กรที่เตรียมตัวล่วงหน้าใน 4-6 ปีข้างหน้าด้วยแนวทางข้างต้นจะมีโอกาสเป็นผู้นำด้านการใช้งานเทคโนโลยีนี้เชิงอุตสาหกรรมได้มากขึ้น
บทสรุป
การทดลองที่รวมชิปนิวโรมอร์ฟิกกับอัลกอริทึม Reinforcement Learning บนฮาร์ดแวร์จริงแสดงให้เห็นผลลัพธ์เชิงประจักษ์ว่าช่วยลดการใช้พลังงานและยืดอายุแบตเตอรี่ของหุ่นยนต์คลังสินค้าอย่างมีนัยสำคัญ — รายงานหลายเคสชี้ว่าอายุการใช้งานแบตเตอรี่อาจเพิ่มขึ้นมากกว่า 10× ในเงื่อนไขการทดสอบบางรูปแบบ โดยเทคโนโลยีนี้ทำให้การตัดสินใจเชิงควบคุมทำได้รวดเร็วและมีประสิทธิภาพยิ่งขึ้น ลดการสลับโหมดและการสื่อสารกับคลาวด์บ่อยครั้ง ซึ่งหมายถึงการลดการหยุดชะงักของงาน ลดค่าไฟฟ้า และเพิ่มความต่อเนื่องในการปฏิบัติงานเชิงปฏิบัติการ อย่างไรก็ตาม การนำไปสู่การใช้งานเชิงพาณิชย์ยังต้องพิจารณาประเด็นสำคัญด้านการรวมระบบ (system integration) ความพร้อมของซัพพลายเชนสำหรับชิปเฉพาะทาง และการปฏิบัติตามมาตรฐานความปลอดภัยและการรับรอง — จึงแนะนำให้องค์กรเริ่มจากโครงการนำร่องเพื่อตรวจสอบผลในสถานการณ์จริงและประเมินต้นทุนรวมตลอดวงจรชีวิต (TCO) อย่างรอบคอบก่อนการขยายผลเชิงพาณิชย์
มุมมองอนาคตบ่งชี้ว่าเทคโนโลยีผสานนิวโรมอร์ฟิกกับ Reinforcement Learning มีศักยภาพที่จะเปลี่ยนโฉมการปฏิบัติการคลังสินค้าใน 2–5 ปีข้างหน้า หากมีการลงทุนในมาตรฐานความปลอดภัย การสร้างห่วงโซ่อุปทานที่ยืดหยุ่น และกรอบการผสานระบบที่เป็นมาตรฐาน องค์กรควรวางแผนเชิงกลยุทธ์โดยเริ่มจากการทดสอบแบบจำลองผสมจริง/หุ่นยนต์ในสนามจริง ตั้งเกณฑ์วัดประสิทธิภาพด้านพลังงานและค่าใช้จ่าย ระบุจุดคุ้มทุน และร่วมมือกับผู้ผลิตฮาร์ดแวร์ ผู้ให้บริการซอฟต์แวร์ และหน่วยงานกำกับดูแลเพื่อสร้างแนวปฏิบัติที่ปลอดภัยและคุ้มค่า การดำเนินการแบบค่อยเป็นค่อยไปจะช่วยลดความเสี่ยงและเร่งการนำเทคโนโลยีไปใช้จริงอย่างมีประสิทธิผล