
ในยุคที่โมเดลภาษาขนาดใหญ่ (LLMs) กลายเป็นหัวใจสำคัญของนวัตกรรมเชิงพาณิชย์ ความต้องการชุดข้อมูลคุณภาพสูงเพื่อการเทรนและปรับจูนเพิ่มขึ้นอย่างทวีคูณ แต่ความเสี่ยงด้านความเป็นส่วนตัว สิทธิ์ในข้อมูล และความถูกต้องของแหล่งที่มาเป็นอุปสรรคสำคัญ ตลาดข้อมูลสังเคราะห์แบบมีใบรับรอง (certified synthetic data marketplace) จึงเกิดขึ้นเป็นทางเลือกเชิงปฏิบัติ ที่ช่วยให้ผู้พัฒนาและธุรกิจสามารถซื้อขายชุดเทรนที่ปลอดภัย ตรวจสอบได้ และเหมาะสำหรับการใช้งานเชิงพาณิชย์โดยไม่ละเมิดนโยบายความเป็นส่วนตัวหรือกฎหมายคุ้มครองข้อมูล
บทนำนี้เป็นการชี้นำสู่ภาพรวมของแนวทางและองค์ประกอบสำคัญที่ผู้อ่านจะได้พบในบทความ: วิธีการสร้างข้อมูลสังเคราะห์ที่ผ่านมาตรฐาน Differential Privacy เพื่อปกป้องข้อมูลต้นทาง แนวทางการให้คะแนนคุณภาพข้อมูล (data quality scoring) เพื่อประเมินความคุ้มค่าในการนำไปใช้งาน เทคนิค Proof‑of‑Provenance สำหรับยืนยันแหล่งที่มาและเส้นทางการแปรรูปข้อมูล รวมถึงสถาปัตยกรรมแพลตฟอร์มตลาดที่จะผสานกระบวนการเหล่านี้อย่างปลอดภัยและโปร่งใส ตลอดจนแนวปฏิบัติด้านการตรวจสอบและการปฏิบัติตามกฎระเบียบที่ช่วยสร้างความเชื่อมั่นระหว่างผู้ขายและผู้ซื้อ
หากคุณเป็นผู้พัฒนาระบบ LLM ผู้บริหารฝ่ายข้อมูล หรือผู้ลงทุนในเทคโนโลยีข้อมูล บทความฉบับสมบูรณ์นี้จะช่วยให้เข้าใจทั้งหลักการเชิงเทคนิค มาตรฐานการประเมินความเสี่ยง และกรอบปฏิบัติที่ควรใช้เมื่อสร้าง ซื้อ หรือขายชุดข้อมูลสังเคราะห์สำหรับการใช้งานเชิงพาณิชย์ เพื่อให้การลงทุนด้านข้อมูลขององค์กรปลอดภัย เกิดประสิทธิผล และสอดคล้องกับข้อกำหนดทางกฎหมายและจริยธรรม
ภาพรวม: ทำไมตลาดข้อมูลสังเคราะห์แบบมีใบรับรองจึงเกิดขึ้น
ภาพรวม: ทำไมตลาดข้อมูลสังเคราะห์แบบมีใบรับรองจึงเกิดขึ้น
ในช่วงไม่กี่ปีที่ผ่านมา ความต้องการข้อมูลคุณภาพสูงเพื่อใช้ในการเทรนโมเดลภาษาใหญ่ (Large Language Models — LLM) ของภาคธุรกิจเพิ่มขึ้นอย่างมีนัยสำคัญ โมเดลสมัยใหม่มีพารามิเตอร์ตั้งแต่หลักหลายสิบล้านจนถึงหลายร้อยพันล้านและต้องการชุดข้อมูลที่หลากหลาย ครอบคลุม และมีปริมาณมหาศาล — โดยทั่วไปชุดข้อมูลเทรนนิ่งที่มีขนาดเป็นเทราไบต์หรือมากกว่านั้นเป็นข้อกำหนดพื้นฐานสำหรับการได้มาซึ่งประสิทธิภาพที่น่าเชื่อถือสำหรับการใช้งานเชิงพาณิชย์ นอกจากนี้องค์กรต้องการข้อมูลที่มีคุณภาพด้านความถูกต้อง ความครบถ้วน และความเท่าเทียม (fairness) เพื่อให้ LLM ตอบโจทย์งานเฉพาะด้าน เช่น การวิเคราะห์ทางการแพทย์ การให้คำแนะนำทางการเงิน หรือการสนับสนุนลูกค้าอัตโนมัติ

อย่างไรก็ดี การนำข้อมูลจริง (real-world data) มาใช้ฝึกโมเดลในเชิงพาณิชย์เผชิญข้อจำกัดด้านกฎหมายและความเป็นส่วนตัวอย่างชัดเจน กฎระเบียบระดับชาติและระดับภูมิภาค เช่น GDPR, CCPA รวมถึงข้อบังคับเฉพาะอุตสาหกรรมอย่าง HIPAA ในด้านสุขภาพ ทำให้องค์กรต้องระมัดระวังการใช้ข้อมูลส่วนบุคคล การเผยแพร่ข้อมูลจริงอาจเสี่ยงต่อบทลงโทษ คดีความ หรือความเสียหายต่อชื่อเสียง แม้จะผ่านการทำให้เป็นนิรนาม (anonymization) ก็ยังมีกรณีศึกษาที่แสดงว่าสามารถย้อนกลับได้หรือมีความเสี่ยงในการระบุตัวบุคคลเมื่อรวมกับแหล่งข้อมูลอื่น
ในบริบทนี้ ข้อมูลสังเคราะห์ที่ได้รับการรับรอง (certified synthetic data) จึงเป็นคำตอบที่ตอบโจทย์เชิงธุรกิจและกฎหมายพร้อมกัน ข้อมูลสังเคราะห์สามารถถูกสร้างขึ้นเพื่อรักษาลักษณะเชิงสถิติและรูปแบบเชิงบริบทของข้อมูลจริงโดยไม่เปิดเผยข้อมูลประจำตัวของบุคคลจริง แพลตฟอร์มที่ผสานเทคนิคเช่น differential privacy, การให้คะแนนคุณภาพข้อมูล (data quality scoring) และ proof‑of‑provenance ช่วยยกระดับความน่าเชื่อถือ ทำให้สามารถแจกจ่ายและใช้งานเชิงพาณิชย์ได้โดยมีหลักฐานยืนยันทั้งความปลอดภัยและที่มาของข้อมูล
แนวโน้มตลาดสะท้อนความต้องการดังกล่าว: รายงานจากการวิเคราะห์ตลาดหลายแห่งคาดว่าอุตสาหกรรมข้อมูลสังเคราะห์จะมีอัตราการเติบโตเฉลี่ยต่อปี (CAGR) ประมาณ 25–35% ในช่วงปี 2023–2030 และการสำรวจผู้บริหารด้านข้อมูลจากองค์กรหลากหลายขนาดชี้ว่า ร้อยละ 40–60 ขององค์กรมีแผนหรือเริ่มนำข้อมูลสังเคราะห์เข้ามาใช้เพื่อขับเคลื่อนโครงการ AI ภายใน 1–2 ปีข้างหน้า ตัวเลขเหล่านี้สะท้อนความต้องการลดความเสี่ยงด้านกฎหมาย ขยายการทดสอบโมเดลอย่างปลอดภัย และเพิ่มความสามารถในการแบ่งปันชุดข้อมูลระหว่างพันธมิตรเชิงพาณิชย์
สรุปแล้ว ตลาดข้อมูลสังเคราะห์แบบมีใบรับรองเกิดขึ้นจากการผสานปัจจัยเชิงเทคนิคและเชิงกฎระเบียบ: ความต้องการข้อมูลปริมาณมากและคุณภาพสูงสำหรับ LLM, ความเสี่ยงทางกฎหมายและความเป็นส่วนตัวจากการใช้ข้อมูลจริง, และความต้องการโซลูชันที่สามารถยืนยันคุณภาพ ความปลอดภัย และที่มาของข้อมูลได้ในเชิงโปรแกรมและเชิงกฎหมาย แพลตฟอร์มที่ให้บริการชุดเทรนแบบมีใบรับรองจึงตอบโจทย์องค์กรที่ต้องการนำ AI เข้าสู่การใช้งานเชิงพาณิชย์อย่างมั่นคงและเป็นไปตามข้อกำหนด
- แรงผลักดันเชิงธุรกิจ: ความต้องการ LLM คุณภาพสูงสำหรับงานเชิงพาณิชย์ที่เพิ่มขึ้นอย่างต่อเนื่อง
- แรงผลักดันเชิงกฎระเบียบ: ความเสี่ยงจากการใช้ข้อมูลจริงภายใต้กฎหมายคุ้มครองข้อมูลส่วนบุคคล
- ข้อได้เปรียบของ certified synthetic data: การปกป้องความเป็นส่วนตัว, สามารถแจกจ่ายเชิงพาณิชย์, มีการรับรองคุณภาพและแหล่งที่มา
หลักการพื้นฐานทางเทคนิค: Differential Privacy สำหรับชุดเทรน
ความหมายของ Differential Privacy และการตีความค่า ε
Differential Privacy (DP) เป็นกรอบมาตรฐานเพื่อวัดระดับการปกป้องความเป็นส่วนตัวเมื่อข้อมูลบุคคลถูกใช้ในการฝึกโมเดลหรือสร้างข้อมูลสังเคราะห์ โดยนิยามในเชิงคณิตศาสตร์ว่า ผลลัพธ์ของการคำนวณ (เช่น พารามิเตอร์โมเดลหรือตัวอย่างสังเคราะห์) แทบจะไม่เปลี่ยนไปเมื่อมีการเพิ่มหรือนำระเบียนของบุคคลหนึ่ง ๆ เข้าออกจากชุดข้อมูล ค่า ε (epsilon) เป็นพารามิเตอร์หลักที่บ่งชี้ความเข้มของการปกป้อง: ค่า ε ยิ่งเล็ก ยิ่งให้การปกป้องข้อมูลมากขึ้น แต่ในทางกลับกัน utility ของโมเดลมักจะลดลง
การตีความทั่วไปของค่า ε:
- ε < 1 — บ่งชี้การปกป้องระดับสูง (strong privacy); เหมาะกับข้อมูลที่มีความอ่อนไหวสูง แต่มักมีการสูญเสีย utility ชัดเจน
- 1 ≤ ε ≤ 10 — มาตรฐานปานกลางที่เห็นในงานอุตสาหกรรมเชิงพาณิชย์หลายแห่ง (trade‑off ระหว่างความปลอดภัยและประสิทธิภาพ)
- ε > 10 — ให้การปกป้องจำกัด (weak privacy); utility ใกล้เคียงกับ non‑DP training แต่ความเสี่ยงการรั่วไหลข้อมูลสูงขึ้น
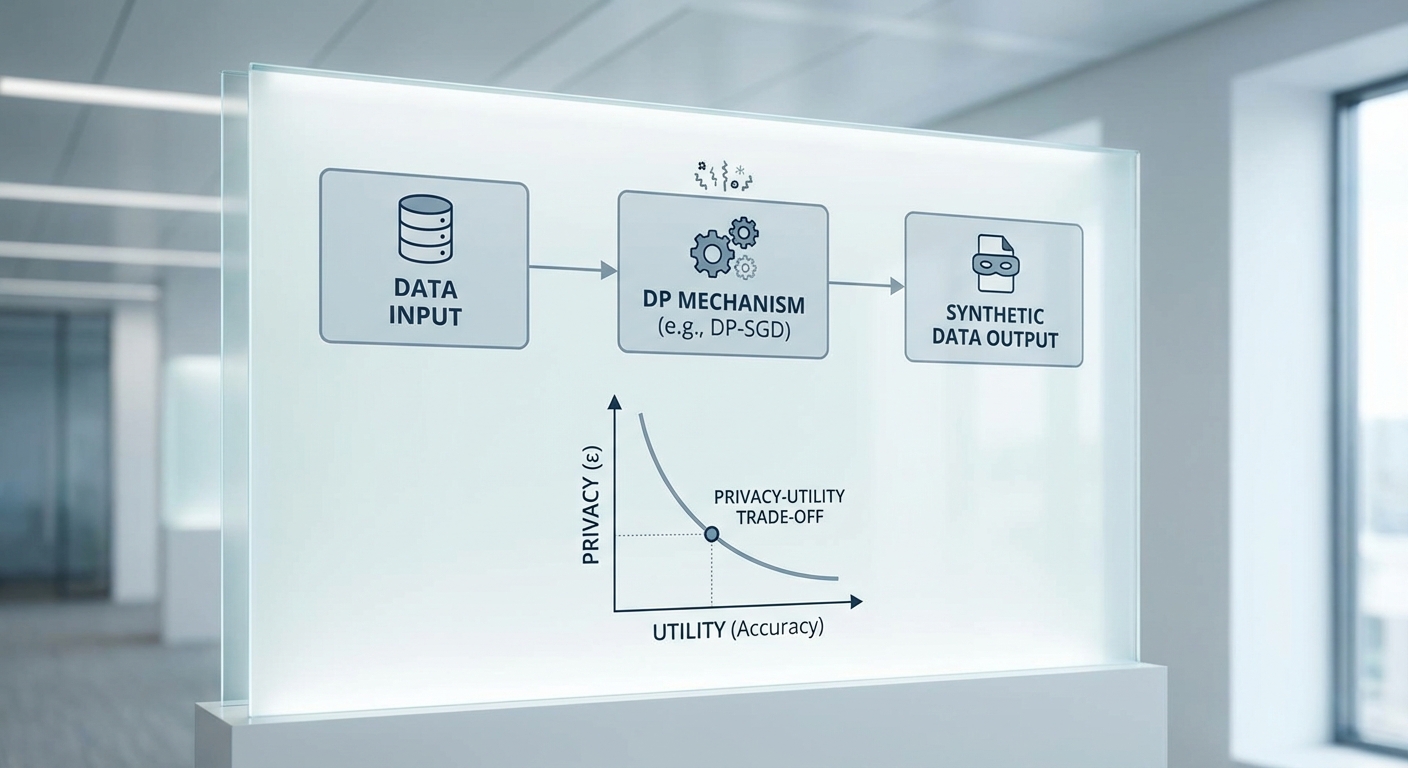
เทคนิคการสังเคราะห์ข้อมูลแบบมี DP: DP‑SGD และ pipelines ยอดนิยม
เทคนิคที่ใช้บ่อยในการฝึกโมเดลภายใต้ DP ได้แก่ DP‑SGD ซึ่งเป็นการดัดแปลงขั้นตอน Stochastic Gradient Descent โดยทำสองอย่างสำคัญต่อแต่ละตัวอย่างย่อย (per‑example): (1) clipping ขนาดของ gradient ตามค่าคงที่ C เพื่อจำกัดอิทธิพลของแต่ละระเบียน และ (2) เติมสุ่ม noise (มักเป็น Gaussian) ลงใน gradient ก่อนอัปเดตพารามิเตอร์ วิธีนี้ถูกเสนอครั้งแรกโดย Abadi et al. (2016) และใช้กันอย่างแพร่หลาย
นอกจากนี้ยังมีแนวทางเฉพาะสำหรับการสร้างข้อมูลสังเคราะห์ เช่น
- PATE (Private Aggregation of Teacher Ensembles) — แบ่งข้อมูลจริงเป็นหลายส่วนเทรน "teacher" models แล้วใช้การโหวตรวมพร้อมการเพิ่ม noise เพื่อฝึก "student" model ที่ให้ DP สูง เหมาะกับการสังเคราะห์ที่ต้องการความแม่นยำของป้ายกำกับ
- DP‑GAN / PATE‑GAN — ผสม GAN เข้ากับกลไก DP เพื่อสร้างตัวอย่างภาพหรือข้อความที่มีการปกป้องข้อมูลต้นฉบับ
- Hybrid pipelines — ใช้ public pre‑training ตามด้วย DP‑fine‑tuning (ช่วยลดผลกระทบต่อ utility) หรือใช้ public data เป็นตัวช่วยในการสร้างคุณสมบัติร่วม
Trade‑off ระหว่าง Privacy และ Utility: สถิติและตัวอย่างผลการทดลอง
ในบริบทของโมเดลภาษา (LLM) และชุดเทรนเพื่อสังเคราะห์ข้อมูล งานวิจัยหลายชิ้นรายงาน trade‑off ที่เด่นชัด โดยปัจจัยสำคัญได้แก่ขนาดของโมเดล ขนาดและความหลากหลายของข้อมูล วิธีก่อนฝึก (pre‑training) และการตั้งพารามิเตอร์ DP (เช่น ε, clipping norm C, noise multiplier σ) ผลการทดลองทั่วไปที่พบได้ในวรรณกรรมและการทดลองภาคปฏิบัติ ได้แก่:
- เมื่อใช้ DP‑SGD กับโมเดลขนาดเล็กถึงกลาง: หากลด ε จาก ~10 ลงสู่ ~1 จะพบการลดประสิทธิภาพเช่น accuracy/F1 หรือความชัน (perplexity) ของภาษาในช่วง ประมาณ 10–30% (ช่วงกว้างขึ้นตามลักษณะข้อมูล) — ค่าตัวอย่างนี้สะท้อนแนวโน้มที่หลายงานรายงาน แต่ตัวเลขอาจแตกต่างตามชุดข้อมูลและเมตริก
- การใช้ public pre‑training ก่อน DP‑fine‑tuning มักช่วยชดเชยการสูญเสีย utility ได้มาก: หลายงานรายงานว่า DP‑fine‑tuning บนโมเดลที่ pre‑trained ขนาดใหญ่สามารถทำให้การลดคุณภาพอยู่ในระดับ ต่ำกว่า 10% แม้เมื่อ ε อยู่ในช่วง 1–3
- PATE และวิธี ensemble บางแบบให้ privacy ที่เข้มข้นขึ้นสำหรับ label protection แต่แลกด้วยความซับซ้อนและการต้องการข้อมูลมากขึ้น
ตัวอย่างเชิงตัวเลข (ตัวอย่างเพื่อความเข้าใจ ไม่ใช่ค่าตายตัว): ในการทดลองฝึกโมเดลภาษา LSTM ขนาดเล็กบนชุดข้อมูลภาษาขนาดกลาง พบว่าเมื่อกำหนด ε ≈ 0.5–1.0 perplexity เพิ่มขึ้นประมาณ 20–50% เมื่อเทียบกับ non‑DP; ขณะที่ ε ≈ 5–10 ผลกระทบน้อยลง (perplexity เพิ่มขึ้นเพียง 5–15%) ทั้งนี้หากใช้ public pre‑training ผลกระทบเชิงความแม่นยำสามารถลดลงครึ่งหนึ่งหรือมากกว่า
แนวปฏิบัติในการเลือกพารามิเตอร์และการวัดผล
ในการใช้งานเชิงพาณิชย์ ควรปฏิบัติตามแนวทางดังนี้:
- กำหนดนโยบายความเสี่ยงและค่า ε ที่ยอมรับได้ — ร่วมกับฝ่ายกฎหมายและความเสี่ยง เพื่อเลือกระดับ ε ที่สอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและความเสี่ยงทางธุรกิจ (ตัวอย่างเช่นองค์กรบางแห่งตั้งเป้า ε ≤ 1 สำหรับข้อมูลอ่อนไหว แต่บางกรณีเชิงพาณิชย์อาจยอมรับ ε ระหว่าง 1–10)
- ใช้ privacy accountant (เช่น Rényi DP accountant) เพื่อคำนวณ composition ของ ε เมื่อมีการฝึกซ้ำหรือใช้ข้อมูลหลายครั้ง — บันทึกและรายงาน ε และ δ ให้ชัดเจน
- ปรับแต่ง clipping norm และ noise multiplier — ทำ grid search บน validation set เพื่อหาระดับ clipping C ที่สมดุลและ noise multiplier ที่ให้ privacy budget ตามต้องการ ในการทดลองจริง ค่าที่เหมาะสมขึ้นกับการแจกแจง gradient
- ใช้เทคนิคลดผลกระทบ — public pre‑training, larger batch sizes พร้อม privacy amplification by subsampling, data augmentation, และการเลือกตัวชี้วัด downstream ที่สำคัญ (เช่น perplexity, accuracy, F1) เพื่อประเมินผลกระทบต่อการใช้งานจริง
- ตรวจสอบด้วยการทดสอบเชิงปฏิบัติ — นอกจาก metric ทั่วไป ควรทดสอบโมเดลบนงานเชิงพาณิชย์จริง เช่น การตอบคำถาม การสรุปข้อความ หรือการผลิตเนื้อหาเชิงธุรกิจ เพื่อยืนยันว่าคุณภาพยังอยู่ในระดับที่ยอมรับได้
สรุปคือ การนำ DP มาใช้กับชุดเทรนเพื่อสร้างข้อมูลสังเคราะห์เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการคุ้มครองความเป็นส่วนตัวในตลาดข้อมูลเชิงพาณิชย์ แต่ต้องยอมรับว่าเป็นการแลกเปลี่ยนระหว่าง privacy และ utility การเลือกค่า ε, การออกแบบ pipeline (เช่น DP‑SGD vs PATE) และการใช้เทคนิคเสริมอย่าง public pre‑training จะกำหนดความสำเร็จเชิงปฏิบัติการและเชิงพาณิชย์ของชุดเทรนสังเคราะห์อย่างชัดเจน
คะแนนคุณภาพข้อมูล (Data Quality Scoring): เมตริกและการประเมิน
คะแนนคุณภาพข้อมูล (Data Quality Scoring): เมตริกและการประเมิน
การประเมินคุณภาพข้อมูลสังเคราะห์สำหรับการใช้งานเชิงพาณิชย์กับ LLM จำเป็นต้องใช้ชุดเมตริกเชิงสถิติและเชิงงานร่วมกัน เพื่อวัดทั้งความสอดคล้องกับการแจกแจงจริง (fidelity), ความหลากหลาย (diversity), ความถูกต้องของป้ายกำกับ (label correctness), การเลื่อนของการแจกแจง (distributional shift) และประสิทธิภาพบนงานปลายทาง (downstream task performance) ข้อเสนอแนะด้านล่างให้กรอบการให้คะแนนที่สามารถนำไปใช้อย่างเป็นมาตรฐานโดยผู้ขายและผู้ซื้อในตลาดข้อมูลสังเคราะห์

เมตริกสำคัญและวิธีคำนวณ
- Fidelity / Statistical distances
- Kullback–Leibler divergence (KL) — วัดความแตกต่างของความน่าจะเป็น p_real และ q_synth: KL(p||q)=Σ p(x) log(p(x)/q(x)) (ประมาณด้วย histogram หรือ kernel density เมื่อเป็นข้อมูลต่อเนื่อง)
- Jensen–Shannon divergence (JS) — ค่าที่สมมาตรกว่าและมีค่าสูงสุดจำกัด ช่วยเปรียบเทียบความคล้ายของการแจกแจง (ใช้บ่อยสำหรับข้อความ/คุณสมบัติ)
- Wasserstein (Earth Mover's Distance) — วัดระยะเชิงเรขาคณิตระหว่างการแจกแจง เหมาะกับตัวแทนเชิงฟีเจอร์ที่มีความหมายเชิงระยะ
- Maximum Mean Discrepancy (MMD) — ใช้ kernel เพื่อจับความแตกต่างของ moments หลายมิติ
- การคำนวณต้องระบุวิธีการประมาณ (binning, KDE, feature embedding) และรายงานความไม่แน่นอน (CI/bootstrapping)
- Diversity
- Distinct-n (distinct-1, distinct-2): สัดส่วน n-gram ที่ไม่ซ้ำในชุดสังเคราะห์ แสดงความหลากหลายของคำ/วลี
- Type-token ratio และ entropy ของ distribution คำ
- Self-BLEU / Self-ROUGE — วัดความซ้ำซ้อนภายในชุด; ค่าต่ำบ่งชี้ความหลากหลายสูง
- Label correctness
- สร้างเมทริกจาก confusion matrix: accuracy, precision, recall, F1 ต่อคลาส
- สำหรับ multilabel ใช้ micro/macro F1 และ AUC-ROC ต่อคลาส
- วัดความไม่สอดคล้องของป้ายกำกับ (label noise rate) โดยเทียบกับ gold labels บนชุดตัวอย่างตรวจสอบ
- Distributional shift metrics
- Population Stability Index (PSI) — สำหรับตัวแปรเชิงหมวดหมู่/เชิงต่อเนื่อง เปรียบเทียบ bin ของ real vs synthetic
- Adversarial validation accuracy — ฝึก classifier เพื่อแยกข้อมูล real vs synth; ค่า accuracy ใกล้ 50% แสดงความคล้ายสูง
- รายงาน per-feature shift, per-subgroup shift (เช่น เพศ/กลุ่มภาษาท้องถิ่น) เพื่อวัด bias หรือการละเลยบางกลุ่ม
- Downstream task performance
- Perplexity — สำหรับ language modeling: perplexity = exp(cross-entropy); เปรียบเทียบโมเดลที่เทรนด้วย real vs synth บนชุดทดสอบ real
- Benchmark task metrics — accuracy, F1, BLEU, ROUGE, exact match (EM) บนชุดมาตรฐานเช่น GLUE/SuperGLUE, SQuAD, LAMBADA, Wikitext-103
- วัดความเปลี่ยนแปลงประสิทธิภาพเมื่อใช้ synthetic-only, real-only และ mixed-data training
กระบวนการ benchmark และ standard test suites สำหรับผู้ขาย
แนะนำกระบวนการ benchmark แบบมาตรฐานที่ผู้ขายต้องผ่านก่อนการเสนอขายชุดเทรนสังเคราะห์:
- ชุดทดสอบมาตรฐาน (baseline test suites): กำหนดชุดชุดทดสอบที่เป็นสาธารณะและเป็นที่ยอมรับ เช่น GLUE/SuperGLUE (classification), SQuAD (QA), LAMBADA (long-range coherence), Wikitext-103 หรือ C4/WMT สำหรับ LM/perplexity
- สคริปต์การทดสอบมาตรฐาน: ให้ vendor รันสคริปต์ที่กำหนดไว้ (same hyperparameters, same model architecture, fixed random seeds) เพื่อให้ผลลัพธ์เปรียบเทียบได้
- สามโหมดการทดลอง: real-only, synthetic-only, mixed (ตัวอย่างเช่น 25/75, 50/50, 75/25) พร้อมการทำซ้ำหลายรัน (≥5 seeds) และรายงาน mean ± 95% CI
- adversarial validation และ subgroup checks: รายงาน adversarial validation accuracy และ PSI ต่อฟีเจอร์สำคัญ รวมถึง per-class metrics เพื่อให้เห็น bias
- รายงาน metadata และ DP: ระบุค่า differential privacy (ε, δ) ที่ใช้, กระบวนการสร้างข้อมูล, proof-of-provenance และมาตรฐานการเก็บบันทึกเชิงตรรกะ
- สถิติสำคัญที่ต้องรายงาน: JS, Wasserstein, MMD, distinct-n, self-BLEU, per-class F1, perplexity, และผลการทดสอบความเป็นไปได้ในการสกัดข้อมูลต้นฉบับ (membership inference tests)
ตัวอย่างตัวเลขเปรียบเทียบ (illustrative)
ด้านล่างเป็นตัวอย่างผลลัพธ์เชิงตัวเลขที่แสดงให้เห็นรูปแบบการเปลี่ยนแปลงประสิทธิภาพเมื่อใช้ข้อมูลสังเคราะห์ในการเทรนโมเดล NLP/LLM (ตัวเลขเป็นตัวอย่างสมมติที่สื่อประเด็นเท่านั้น):
- งานการจำแนกข้อความ (sentiment classification) — โมเดลขนาดกลางเทรนด้วย 100k ตัวอย่าง
- Real-only: Accuracy = 88.2%, F1 (macro) = 0.86
- Synthetic-only: Accuracy = 84.5%, F1 (macro) = 0.82
- Mixed 50/50: Accuracy = 89.0%, F1 (macro) = 0.87
- สรุป: synthetic-only ลดประสิทธิภาพ ~3.7pp ใน accuracy แต่การผสมข้อมูล (augmentation) สามารถปรับปรุงขึ้นเหนือ real-only เล็กน้อย
- งาน language modeling (perplexity on Wikitext-103) — same model family
- Real-only: Perplexity = 18.5
- Synthetic-only: Perplexity = 22.3
- Mixed 70% real / 30% synth: Perplexity = 19.1
- สรุป: ความแตกต่างของ perplexity สะท้อนความ fidelity; mixing ลดช่องว่างได้มาก
- เมตริกการแจกแจง (ตัวอย่าง)
- JS divergence (unigram distribution): real vs synth = 0.06 (ดี) ต่อ synth รุ่นต่ำคุณภาพ = 0.18
- Adversarial validation accuracy: 52% (ยากแยก) ต่อรุ่นคุณภาพต่ำ = 79% (ง่ายแยก)
การรายงานควรมีการทดสอบเชิงสถิติ: ใช้ paired t-test หรือ bootstrap เพื่อยืนยันความแตกต่างของ metric เช่น F1/accuracy ระหว่างรันต่าง ๆ และรายงานค่า p-value และขนาดผล (effect size) หากต้องการยืนยันความเทียบเท่าหรือด้อยกว่า
สุดท้าย ควรประเมินความเสี่ยงเชิงปฏิบัติการด้วยการทำ membership inference, attribute inference tests และ stress tests ในเงื่อนไข dataset shift จริง เพื่อให้คะแนนคุณภาพข้อมูล (Data Quality Score) เป็นตัวเลขเชิงรวมที่ประกอบด้วย sub-scores (fidelity, diversity, label correctness, distributional robustness, downstream performance) และมีการ threshold ที่ชัดเจนสำหรับการใช้งานเชิงพาณิชย์
Proof‑of‑Provenance: การพิสูจน์แหล่งที่มาและความถูกต้องของชุดข้อมูล
ในบริบทของข้อมูลสังเคราะห์สำหรับการใช้งานเชิงพาณิชย์ Proof‑of‑Provenance (PoP) เป็นกรอบการรับรองที่ออกแบบมาเพื่อให้สามารถตรวจสอบย้อนกลับได้ว่า ชุดข้อมูลถูกสร้าง ปรับเปลี่ยน และถ่ายโอนอย่างไร โดยคงความโปร่งใสและความน่าเชื่อถือไว้สำหรับผู้ซื้อ ผู้ควบคุม และผู้ตรวจสอบอิสระ PoP ไม่เพียงแต่ยืนยันแหล่งที่มา แต่ยังรวมถึงการบันทึกเหตุการณ์เชิงเวลา (timestamps), ข้อมูลเมตา (metadata) ที่สำคัญ เช่น พารามิเตอร์ของกระบวนการสังเคราะห์ และห่วงโซ่การครอบครอง (chain‑of‑custody) ซึ่งเป็นหัวใจของการจัดการความเสี่ยงและการปฏิบัติตามกฎระเบียบในการซื้อขายข้อมูล

องค์ประกอบหลักของ PoP
- Metadata: รายละเอียดเชิงบรรยายของชุดข้อมูล เช่น เวอร์ชันของโมเดลสังเคราะห์, พารามิเตอร์ของกระบวนการ (ตัวอย่างเช่นค่า epsilon ของ Differential Privacy), ขอบเขตข้อมูล (schema), ขนาดชุดข้อมูล และคะแนนคุณภาพข้อมูล (quality scores)
- Timestamps: เวลาที่เกิดเหตุการณ์สำคัญ เช่น เวลาเริ่ม/สิ้นสุดการสร้างข้อมูล, เวลาที่มีการเซ็นรับรอง และเวลาที่มีการบันทึกลง ledger เพื่อยืนยันลำดับเหตุการณ์และป้องกันการแก้ไขย้อนหลัง
- Provenance chain / Chain‑of‑custody: บันทึกการถ่ายโอนและการเปลี่ยนแปลงชุดข้อมูลแต่ละขั้นตอน (ผู้สร้าง → ผู้ตรวจสอบอิสระ → ตลาด → ผู้ซื้อ) รวมถึงข้อมูลประจำตัวของแต่ละฝ่ายและการเซ็นรับรองที่เกี่ยวข้อง
เทคนิคเชิงคริปโตกราฟิกที่ใช้
PoP พึ่งพาเทคนิคคริปโตเพื่อให้เกิดความไม่สามารถปฏิเสธและความสมบูรณ์ของข้อมูล โดยเทคนิคที่พบบ่อยได้แก่:
- Digital signatures: ผู้สร้างชุดข้อมูลหรือผู้ให้บริการตลาดเซ็นชื่อดิจิทัลบนเมตาดาต้าและค่าแฮชของชุดข้อมูลเพื่อรับประกันความถูกต้องและความไม่สามารถปฏิเสธ ตัวอย่างเช่น การใช้โครงสร้างคีย์สาธารณะ / คีย์ส่วนตัว (PKI) เพื่อให้ผู้ซื้อสามารถตรวจสอบได้ว่าลายเซ็นตรงกับเจ้าของที่ประกาศไว้
- Merkle trees และ Merkle proofs: สำหรับชุดข้อมูลขนาดใหญ่ จะสร้างต้นไม้ Merkle จากแฮชของบล็อกข้อมูลย่อย ทำให้สามารถยืนยันได้ว่า sample ใดๆ เป็นส่วนหนึ่งของชุดข้อมูลโดยไม่ต้องเปิดเผยทั้งชุด — ขนาดของหลักฐานมีสเกลเป็นลอการิทึม (log n) ของจำนวนรายการ ช่วยให้การยืนยันเป็นไปได้อย่างมีประสิทธิภาพและเป็นส่วนตัว
- Hash anchoring บน ledger / blockchain: แฮชของเมตาดาต้า หรือ root hash ของ Merkle tree ถูกบันทึกลงในบล็อกเชนสาธารณะหรือบัญชีแยกประเภทแบบ permissioned เพื่อให้เกิดหลักฐานการไม่เปลี่ยนแปลงและ timestamp ที่ตรวจสอบได้ การบันทึกบน ledger ทำให้เกิด audit trail ที่ทนทานต่อการแก้ไขย้อนหลัง
- Attestations จาก third‑party: ผู้ตรวจสอบอิสระสามารถลงนามยืนยันผลการตรวจสอบ (เช่น การทดสอบคุณภาพหรือการตรวจสอบ DP) เป็น attestations แบบดิจิทัล ซึ่งรวมเข้าไปใน provenance chain
การผสาน PoP เข้ากับกระบวนการตลาดและการตรวจสอบจาก third parties — ตัวอย่าง flow
ต่อไปนี้เป็นตัวอย่างลำดับขั้นตอนในการสร้างใบรับรอง PoP และการตรวจสอบโดยผู้ซื้อใน marketplace ข้อมูลสังเคราะห์:
- 1) การเตรียมและสร้างชุดข้อมูล — ผู้สร้างชุดข้อมูลสังเคราะห์บันทึกเมตาดาต้า (เวอร์ชันโมเดล, พารามิเตอร์ DP, seed, ขนาด), แยกตัวอย่างตัวอย่าง (samples) เป็นบล็อก และคำนวณแฮชแต่ละบล็อก
- 2) การสร้างโครงสร้างคริปโต — รวมแฮชบล็อกเป็น Merkle tree และคำนวณ root hash; สร้างลายเซ็นดิจิทัลบนเมตาดาต้าและ root hash ด้วยคีย์ส่วนตัวของผู้สร้าง เพื่อให้ได้ใบรับรองดิจิทัลเบื้องต้น
- 3) การจดบันทึกบน ledger — บันทึก root hash และลิงก์ไปยังเมตาดาต้าสำคัญลงบนบล็อกเชนหรือ ledger ภายนอก (on‑chain anchoring) เพื่อให้เกิด timestamp ที่ตรวจสอบได้ โดยเก็บข้อมูลเพิ่มเติมที่เป็นรายละเอียดสำหรับการตรวจสอบแบบ off‑chain เพื่อประหยัดค่าใช้จ่าย
- 4) การลงรายการใน marketplace — ใบรับรอง PoP ประกอบด้วยเมตาดาต้า, ลายเซ็นของผู้สร้าง, root hash, anchor transaction ID บน ledger, และคะแนนคุณภาพข้อมูล ผู้ขายนำใบรับรองนี้ไปแสดงบน marketplace พร้อมตัวอย่างเชิงพิสูจน์ (Merkle proofs) ที่สามารถแจกให้ผู้สนใจ
- 5) การตรวจสอบโดยผู้ซื้อ — ผู้ซื้อเมื่อพิจารณาจะ: (ก) ตรวจสอบลายเซ็นดิจิทัลว่าออกโดยคีย์ที่ประกาศไว้, (ข) ตรวจสอบว่า root hash ตรงกับการบันทึกบน ledger (anchoring), (ค) ขอรับ Merkle proof สำหรับตัวอย่างสุ่มเพื่อยืนยันการมีอยู่ของตัวอย่างเหล่านั้นในชุดข้อมูล, และ (ง) ตรวจสอบค่า DP และคะแนนคุณภาพ หากจำเป็น ผู้ซื้ออาจร้องขอการ attestations จาก third‑party auditor เพื่อยืนยันกระบวนการสร้างหรือผลการทดสอบคุณภาพ
ผลประโยชน์และข้อควรระวังในการนำ PoP มาใช้ในเชิงพาณิชย์
การนำ PoP มาใช้ช่วยเพิ่มความเชื่อมั่น ลดความเสี่ยงจากการฉ้อฉล และสนับสนุนการปฏิบัติตามข้อกำหนดทางกฎหมาย เช่น การพิสูจน์ว่าชุดข้อมูลไม่ละเมิดสิทธิส่วนบุคคล หรือมีการรักษาความเป็นส่วนตัวตามที่ประกาศ อย่างไรก็ดี มีข้อจำกัดเช่น ค่าใช้จ่ายในการจดบันทึกบนบล็อกเชน การจัดการ PKI และความจำเป็นต้องมีมาตรฐานกลางในการออกใบรับรองและการแลกเปลี่ยน attestations เพื่อให้กระบวนการนี้ทำงานได้อย่างมีประสิทธิภาพในระดับอุตสาหกรรม
สรุปได้ว่า Proof‑of‑Provenance สำหรับข้อมูลสังเคราะห์เป็นกลไกเชิงปฏิบัติที่ผสานทั้ง metadata, chain‑of‑custody, และเทคนิคคริปโตกราฟิก (เช่น digital signatures และ Merkle proofs) พร้อมการยืนยันบน ledger เพื่อสร้างความโปร่งใสและความน่าเชื่อถือในตลาดข้อมูลยุคใหม่ — โดยแนะนำให้ผู้ประกอบการผสาน PoP เข้ากับนโยบาย DP และระบบการให้คะแนนคุณภาพข้อมูล เพื่อรองรับการทำธุรกรรมเชิงพาณิชย์อย่างปลอดภัยและตรวจสอบได้
สถาปัตยกรรมแพลตฟอร์มตลาด (Marketplace) สำหรับชุดเทรนที่มีใบรับรอง
ภาพรวมและการไหลของข้อมูล
สถาปัตยกรรมของแพลตฟอร์มตลาดข้อมูลสังเคราะห์สำหรับ LLM ที่ผสาน Differential Privacy (DP), คะแนนคุณภาพข้อมูล และ Proof‑of‑Provenance (PoP) ออกแบบเป็นชั้น (layered architecture) เพื่อแยกความรับผิดชอบ ระบุจังหวะการทำงานชัดเจน และรองรับการตรวจสอบย้อนหลัง (auditability) โดยทั่วไปการไหลของข้อมูลจะเป็นดังนี้: ผู้ขาย (seller) อัปโหลดเมตาดาต้าและตัวอย่าง -> แพลตฟอร์มรันกระบวนการสร้างข้อมูลสังเคราะห์ภายใต้ค่าพารามิเตอร์ DP ที่กำหนด -> เครื่องมือประเมินคุณภาพให้คะแนน (quality scoring engine) -> PoP service สร้างตราประทับเชิงลายลักษณ์และ anchoring -> รายการผลลัพธ์ถูกเผยแพร่บน catalog/market UI ผู้ซื้อ (buyer) ตรวจสอบตัวอย่างและข้อมูลเมตา -> ดำเนินการซื้อ ชำระเงิน และดาวน์โหลดไฟล์ที่ลงนามและเข้ารหัสไว้

ส่วนประกอบหลักของแพลตฟอร์ม
- Seller Onboarding & Compliance: ระบบ KYC/KYB, แบบฟอร์มเมตาดาต้า (schema-based metadata), การยืนยันสิทธิ์แหล่งข้อมูล (source attestations) และ sandbox เพื่อรันการทดสอบต้นแบบก่อนขึ้นตลาด
- Data Generation Pipeline: โมดูลสำหรับรันโมเดลสังเคราะห์ (on-demand หรือ pre-generate) พร้อม logging ของ seed, model version, hyperparameters และสมุดบันทึกการกระจาย noise ตาม DP
- DP Parameter Management: ระบบบริหารค่า epsilon/δ แบบ centralized ledger พร้อม accountant (เช่น Rényi DP accountant หรือ zCDP) เพื่อคำนวณการประกอบกันของงบประมาณความเป็นส่วนตัว และ API เพื่อขอ/จองงบประมาณ DP ต่อสัญญาหรือ per-request
- Quality Scoring Engine: คำนวณดัชนีคุณภาพเชิงปริมาณ เช่น coverage, diversity, utility (downstream task performance), statistical distance (MMD, KL divergence) และ metrics เฉพาะโดเมน เช่น FID สำหรับภาพ หรือ perplexity สำหรับข้อความ ผลลัพธ์ออกเป็นคะแนนรวมและ breakdown รายการย่อย
- Proof‑of‑Provenance (PoP) Service: สร้าง manifest ที่ลงนามด้วยคีย์ของแพลตฟอร์มและผู้ขาย, สร้าง Merkle root ของชิ้นข้อมูล, anchor hash ลงบน public ledger (optionally) และออก cryptographic receipt ให้ผู้ซื้อสามารถตรวจสอบได้
- Catalog / Market UI & API: หน้าแสดงรายการพร้อมตัวกรองตามโดเมน, epsilon range, quality score, ราคา และ license terms; API/SDK สำหรับการค้นหาและดึงเมตาแบบโปรแกรมมิ่ง
- Payment & Delivery: ระบบชำระเงินและสัญญาอัตโนมัติ (escrow, smart contracts หากต้องการ), การออก license token, signed & encrypted download package พร้อม expiring URLs / token-based access
- Security & Observability: KMS integration, encryption at rest (AES‑256), TLS 1.3 ในการส่งข้อมูล, RBAC/ABAC, audit logging, SIEM/IDS, และระบบแจ้งเตือนเหตุการณ์
API / SDK ที่ผู้ซื้อและผู้ขายต้องเตรียม (Integration points)
แพลตฟอร์มควรให้ชุด API/SDK ชัดเจนสำหรับทั้งฝั่งผู้ขายและผู้ซื้อ เพื่ออำนวยความสะดวกการผสานระบบและการตรวจสอบอัตโนมัติ จุดเชื่อมต่อสำคัญได้แก่:
- Seller SDK/API:
- Upload manifest & dataset metadata (schema validation)
- Sign dataset manifests (client-side signing) และส่ง public key
- Request DP generation job (parameters: model_version, epsilon, seed, generation_mode)
- Webhook สำหรับรับสถานะ job (queued, running, completed, failed)
- Audit export API (logs of generation steps, noise seeds, accountant reports)
- Buyer SDK/API:
- Catalog search & filter (by domain, epsilon, quality score, license)
- Request sample or test-run (small DP-limited sample)
- Purchase API (initiate order, escrow/smart-contract integration, receipt)
- Download API (issue time-limited signed URL, return PoP manifest and verification helper)
- Verification SDK สำหรับตรวจสอบ PoP (verify signatures, Merkle proofs, anchor hashes)
- Platform Internal APIs:
- DP Accountant API (query remaining budget, simulate composition)
- Quality Scoring API (submit evaluation jobs, fetch scores and reports)
- PoP Anchor API (issue anchor transaction and return tx id)
- Monitoring & Audit APIs (access logs, access history per asset)
Workflow การซื้อขาย (ตัวอย่างลำดับการทำงาน)
ตัวอย่าง workflow แบบเต็มรูปแบบประกอบด้วยขั้นตอนสำคัญ:
- 1. Onboarding: ผู้ขายส่ง KYC, metadata, และ public signing key -> แพลตฟอร์มอนุมัติหรือขอข้อมูลเพิ่มเติม
- 2. Pre‑flight Validation: ผู้ขายอัปโหลด raw dataset/description -> แพลตฟอร์มรันตรวจสอบความสอดคล้องของเมตาและนโยบาย เช่น PII detection, license checks
- 3. DP Job Submission: ผู้ขาย/แพลตฟอร์มสั่ง generate synthetic set โดยกำหนดค่า DP (เช่น epsilon=1.0) -> DP accountant จองงบประมาณและตรวจสอบการประกอบ
- 4. Scoring & PoP: เมื่อ generate เสร็จ quality scoring engine ให้คะแนนและรายงาน -> PoP service สร้าง signed manifest, Merkle root และ anchor hash
- 5. Listing: รายการพร้อมเมตา, ค่าพารามิเตอร์ DP, คะแนนคุณภาพ และ PoP receipt ปรากฏบน catalog
- 6. Purchase & Delivery: ผู้ซื้อสั่งซื้อผ่าน API/UI -> ระบบชำระเงินยืนยัน -> แพลตฟอร์มออก license token และ signed download URL (เข้ารหัสด้วย KMS-managed key)
- 7. Post‑purchase Auditing: แพลตฟอร์มบันทึกการดาวน์โหลดและการใช้งานเชิงสัญญา (compliance logs) และเปิดให้ตรวจสอบ PoP โดยผู้ซื้อตรวจสอบความถูกต้องของ manifest
ข้อกำหนดด้านความปลอดภัยและ SLA ที่ควรระบุในสัญญา
สัญญาระหว่างแพลตฟอร์ม ผู้ขาย และผู้ซื้อควรระบุข้อกำหนดด้านความปลอดภัยและระดับการให้บริการอย่างชัดเจน ได้แก่:
- การเข้ารหัส: Encryption at rest (AES‑256 หรือเทียบเท่า) และ encryption in transit (TLS 1.3) พร้อมการจัดการคีย์ผ่าน KMS (key rotation, HSM สำหรับกุญแจสำคัญ)
- การควบคุมการเข้าถึง: RBAC/ABAC, least privilege, MFA สำหรับบัญชีผู้ขาย/ผู้ดูแล, รวมถึง capability-based tokens สำหรับดาวน์โหลดและการตรวจสอบการเรียกใช้งาน
- การนำทางประวัติและการตรวจสอบ: เก็บ audit logs อย่างน้อย 12 เดือน (หรือเป็นไปตามข้อกำหนดทางกฎหมาย) และสามารถส่งออกให้ผู้ถือสิทธิ์เพื่อตรวจสอบ
- DP Guarantees: ระบุค่า epsilon/δ ที่รับประกันจริง ห้ามเกินค่าสูงสุดที่ตกลงกัน และระบุกลไกตรวจสอบ (DP accountant report, signed proof of noise seeds หรือ attestations)
- ความพร้อมให้บริการ (SLA): ตัวอย่างเช่น uptime 99.95% สำหรับ catalog/API, ระยะเวลาเฉลี่ยการตอบกลับสำหรับ incident severity level 1 ภายใน 1 ชั่วโมง, recovery time objective (RTO) และ recovery point objective (RPO) สำหรับบริการการเก็บข้อมูล
- การแจ้งเหตุละเมิด: ระบุเวลาการแจ้งเตือนเมื่อเกิด data breach (เช่น ภายใน 72 ชั่วโมง), แผนตอบสนอง และข้อกำหนดด้านการเยียวยา
- การจัดการข้อมูลและการเก็บรักษา: กำหนดนโยบาย retention, นโยบายลบข้อมูล (right-to-erasure) และการทำ data provenance เพื่อให้สามารถยืนยันต้นทางได้ตลอดเวลา
- การตรวจสอบจากภายนอก: ระบุการตรวจสอบความปลอดภัยเป็นระยะ (penetration test, third‑party audit) และการเปิดเผยผลการตรวจสอบต่อคู่สัญญาที่เกี่ยวข้อง
ตัวอย่างเชิงปฏิบัติและเกณฑ์ตัวชี้วัด
ในการใช้งานจริง แพลตฟอร์มสามารถกำหนดเกณฑ์เพื่อช่วยผู้ซื้อประเมินความเหมาะสม เช่น:
- คะแนนคุณภาพรวม ≥ 80 ให้ถือว่า "Production‑ready"
- ค่า epsilon ≤ 1.0 สำหรับ use‑case ที่ต้องการความเป็นส่วนตัวสูง (เช่น ข้อมูลสุขภาพ)
- เวลาเฉลี่ยในการรันงาน generation และ scoring ≤ 2 ชั่วโมงสำหรับชุดข้อมูลขนาดกลาง (ตัวอย่าง: 10K records)
- เปอร์เซ็นต์ความถูกต้องของ PoP verification = 100% (manifest signatures และ Merkle proofs ต้องผ่านการตรวจสอบ)
สรุปแล้ว การออกแบบสถาปัตยกรรมตลาดสำหรับชุดเทรนที่มีใบรับรองต้องคำนึงถึงความสมดุลระหว่างความปลอดภัย ความโปร่งใส และประสบการณ์ผู้ใช้ โดยต้องมีชั้นการยืนยันตัวตน การจัดการงบประมาณ DP แบบชัดเจน ระบบประเมินคุณภาพที่เชื่อถือได้ และบริการ PoP ที่สามารถตรวจสอบย้อนหลังได้ — ทั้งหมดนี้ต้องสนับสนุนด้วย API/SDK ที่ชัดเจนและ SLA ที่กำหนดได้จริงเพื่อสร้างความเชื่อมั่นทางการค้า
โมเดลธุรกิจ การตั้งราคา และกรอบนโยบายการอนุญาตใช้งาน
โมเดลธุรกิจและแหล่งรายได้ที่เป็นไปได้
สำหรับแพลตฟอร์มซื้อขายชุดข้อมูลสังเคราะห์แบบมีใบรับรอง (certified synthetic data marketplace) มีโมเดลรายได้หลายรูปแบบที่สามารถผสมผสานให้เหมาะสมกับคุณค่าเชิงพาณิชย์ของข้อมูล ได้แก่ การขายเป็นชุด (dataset packs), การสมัครสมาชิก (subscription), ระบบชำระตามการใช้งาน (pay‑per‑use API), สัญญาอนุญาตใช้งาน (licensing) ในรูปแบบต่าง ๆ และค่าบริการเสริม เช่น ค่าตรวจสอบ/รับรอง (certification fees) และค่าบริการตรวจสอบการปฏิบัติตามมาตรฐาน (audit fees).
แพลตฟอร์มมักทำรายได้หลักจากการหักค่านายหน้า/ค่าธรรมเนียมแพลตฟอร์ม (marketplace commission) ระหว่าง 10%–40% ของราคาขาย ขณะที่ผู้ขายสามารถตั้งราคาแบบพหุรูปแบบเพื่อตอบโจทย์ลูกค้ารายย่อยและองค์กร เช่น ขายลิขสิทธิ์เชิงพาณิชย์แบบครั้งเดียวสำหรับชุดข้อมูลเฉพาะงาน หรือให้สิทธิแบบ subscription สำหรับการเข้าถึงไลบรารีข้อมูลที่อัปเดตอย่างต่อเนื่อง
- Dataset packs: ขายเป็นแพ็ก (standard, premium, enterprise) พร้อม metadata, DP attestations และคะแนนคุณภาพข้อมูล
- Subscription: แบบรายเดือน/รายปี สำหรับการเข้าถึงชุดข้อมูลหลายชุด และสิทธิ์ดาวน์โหลด/ใช้ API รวมถึงการอัปเดตเพิ่ม dataset ใหม่
- Pay‑per‑use API: คิดค่าบริการตามปริมาณเรียกใช้งาน (per request, per 1K records, per 1M tokens) เหมาะสำหรับการทดลองและใช้งานแบบ on‑demand
- Licensing: สัญญาเชิงพาณิชย์ (commercial), ภายในองค์กร (internal‑only), สำหรับงานวิจัย (research‑only), หรืออนุญาตให้กระจายต่อ (redistribution) โดยมีการกำหนด field‑of‑use และข้อจำกัด
- Certification & audit fees: ค่าบริการตรวจสอบ DP (เช่น การวัด epsilon), การรับรอง provenance, และตรวจสอบการปฏิบัติตามข้อกำหนดความเป็นส่วนตัว
ตัวอย่างแผนราคาและ SLA (ข้อเสนอเชิงตัวอย่าง)
ตัวอย่างแผนราคาเป็นแนวทางเพื่อใช้ตั้งสมมติฐานธุรกิจ โดยตัวเลขควรปรับตามมูลค่าชุดข้อมูลและตลาดเป้าหมาย (ท้องถิ่น/ระดับโลก)
- แพ็กเริ่มต้น (Starter dataset pack): ราคา $1,000–$5,000 ต่อชุด (รวม metadata, DP attestation ระดับพื้นฐาน epsilon 1–5, คะแนนคุณภาพข้อมูลเบื้องต้น)
- แพ็กมาตรฐาน (Standard subscription): $499/เดือน — เข้าถึงไลบรารีชุดข้อมูลขนาดกลาง, API quota 100K requests/เดือน, การรับรอง provenance พื้นฐาน, รายงานคะแนนคุณภาพรายไตรมาส
- แพ็กองค์กร (Enterprise): $15,000+/เดือน หรือสัญญาแบบปี มี SLA ขยาย (SLA uptime 99.9%), DP attestation ระดับสูง (ระบุ epsilon เช่น ≤0.5 สำหรับบาง dataset), audit rights, onboarding & dedicated support
- Pay‑per‑use API: $0.10 ต่อ 1K records หรือ $2.00 ต่อ 1M tokens — เหมาะกับการทดลองหรือการใช้งานที่ไม่ต่อเนื่อง
- ค่าตรวจสอบ/รับรองเพิ่มเติม: DP verification $5,000–$50,000 ขึ้นกับความซับซ้อนและ scope; การตรวจสอบ provenance/forensic audit $10,000+ ต่อการตรวจสอบ
ตัวอย่าง SLA (Service Level Agreement) ที่เสนอให้ลูกค้าองค์กรควรมีองค์ประกอบต่อไปนี้:
- Availability: 99.9% uptime ต่อปี พร้อมเครดิต SLA (เช่น 5%–20% ของค่าบริการรายเดือนเป็นเครดิตเมื่อไม่เป็นไปตามมาตรฐาน)
- Response time: API latency <200ms (p95) สำหรับ endpoints แบบเรียกข้อมูลสั้นๆ
- Support & RTO/RPO: 响应เวลา support 1 ชั่วโมงสำหรับระดับ Critical, RTO (Recovery Time Objective) 4 ชั่วโมงสำหรับบริการสำคัญ
- Data Quality Guarantee: รับประกันระดับคะแนนคุณภาพขั้นต่ำ (เช่น F1, coverage % หรือ error rate ต่ำกว่าเกณฑ์) พร้อมเครดิตหรือสิทธิ์คืนเงินบางส่วนหากไม่เป็นไปตามข้อตกลง
- Privacy Guarantees: ระบุค่า DP (epsilon) ที่รับรองและขอบเขตการรับประกันความเป็นส่วนตัว พร้อมข้อจำกัดความรับผิด
ประเภทไลเซนซ์และข้อจำกัดการใช้งานที่พบบ่อย
ไลเซนซ์เป็นหัวใจสำคัญของแพลตฟอร์มข้อมูลเชิงพาณิชย์ โดยรูปแบบไลเซนซ์ที่พบบ่อย ได้แก่:
- Commercial license (เชิงพาณิชย์): อนุญาตใช้ข้อมูลเพื่อผลิตสินค้า/บริการเชิงพาณิชย์ อาจมีค่าลิขสิทธิ์เพิ่มเติม (royalty) หรือ revenue share
- Internal‑use only: จำกัดการใช้งานภายในองค์กรห้ามเผยแพร่หรือจำหน่ายต่อ
- Research‑only / Non‑commercial: อนุญาตใช้งานเพื่อการศึกษาและงานวิจัยเท่านั้น ห้ามใช้งานเชิงพาณิชย์
- Redistribution / Sublicensing: ระบุว่าอนุญาตให้แจกจ่ายหรือสับไลเซนซ์ต่อได้หรือไม่ และภายใต้เงื่อนไขใด
- Field‑of‑Use restrictions: จำกัดสาขาหรือกรณีการใช้งาน (เช่น ห้ามใช้ในระบบทางการแพทย์, การทหาร, หรือการบังคับใช้กฎหมายโดยเฉพาะ)
- Territorial and temporal limits: จำกัดเขตอาณาจักรและระยะเวลาการใช้ (เช่น สิทธิ์รายปีหรือสิทธิ์ถาวรแบบหนึ่งครั้ง)
- Output/IP rules: ระบุสิทธิในผลลัพธ์ของโมเดลที่ฝึกจากชุดข้อมูล (เช่น ผู้ซื้อเป็นเจ้าของ output แต่ผู้ขายอาจรักษาสิทธิใน dataset itself)
กรอบสัญญาและประเด็นทางกฎหมายที่ต้องกำหนดชัดเจน
ในสัญญาระหว่างผู้ขาย ผู้ซื้อ และแพลตฟอร์ม ควรกำหนดประเด็นทางกฎหมายต่อไปนี้อย่างชัดเจนเพื่อจำกัดความเสี่ยงและสร้างความชัดเจนทางความรับผิดชอบ:
- Representations & Warranties: ผู้ขายต้องให้คำรับรองว่าข้อมูลถูกสร้างหรือได้มาอย่างถูกต้องตามกฎหมาย ไม่มีการละเมิดสิทธิบุคคลหรือเงื่อนไขสัญญาใด ๆ และ DP/quality attestations ถูกต้อง ณ เวลาจัดส่ง
- Compliance: ระบุภาระหน้าที่ที่ชัดเจนเกี่ยวกับการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น GDPR, CCPA, HIPAA เมื่อเกี่ยวข้อง), กฎหมายการส่งออกข้อมูล และข้อบังคับเฉพาะอุตสาหกรรม
- Liability & Limitation of Liability: กำหนดวงเงินความรับผิดสูงสุด (caps), ข้อยกเว้น (เช่น ความเสียหายทางอ้อมหรือพาณิชย์เสียหาย) และข้อยกเว้นสำหรับการกระทำโดยเจตนาหรือประมาทเลินเล่อร้ายแรง
- Indemnification: ระบุภาระการชดเชยความเสียหายหากฝ่ายหนึ่งถูกฟ้องร้องจากการใช้ dataset (เช่น คดีละเมิดลิขสิทธิ์หรือการละเมิดความเป็นส่วนตัว) รวมถึงกระบวนการแจ้งข้อเรียกร้องและสิทธิในการควบคุมการต่อสู้คดี
- Audit & Verification Rights: ให้สิทธิแก่ผู้ซื้อหรือผู้ตรวจสอบอิสระในการตรวจสอบ provenance, DP attestations และ log ที่เกี่ยวข้อง ภายใต้เงื่อนไขความลับและขอบเขตที่กำหนด
- Warranty remedies & SLA credits: ระบุวิธีเยียวยาเมื่อมีการละเมิด SLA หรือเมื่อข้อมูลไม่เป็นไปตามเกณฑ์คุณภาพ (เช่น เครดิตค่าบริการ, ฟรี remediation, หรือการยกเลิกสัญญาในกรณีร้ายแรง)
- Data breach & incident response: กำหนดขั้นตอนการรายงานเหตุละเมิดข้อมูล, เวลาการแจ้งล่วงหน้า (เช่น ภายใน 72 ชั่วโมง), และมาตรการเยียวยา
- Insurance & indemnity funds: แนะนำให้มีข้อกำหนดประกันภัยความรับผิด (cyber liability, professional indemnity) และในบางกรณีให้มี escrow หรือ reserve fund สำหรับค่าสินไหมทดแทน
- IP ownership & derivative works: ชัดเจนว่าใครเป็นเจ้าของ IP ของ dataset, metadata, และผลงานที่ได้จากการฝึกโมเดล พร้อมเงื่อนไขการอนุญาตใช้งานต่อ
- Export controls & sanctions: ระบุข้อจำกัดการส่งออกข้อมูลและการห้ามให้บริการแก่บุคคลหรือประเทศที่อยู่ภายใต้ sanctions
ข้อควรระวังพิเศษ: แม้จะมี proof‑of‑provenance และคะแนนคุณภาพ ข้อมูลที่สังเคราะห์ยังอาจมีความเสี่ยงเรื่องสิทธิของแหล่งข้อมูลต้นทางหรือการรั่วไหลของข้อมูลเชิงระบุตัวบุคคล การเปิดเผยค่า DP (epsilon) ควรสอดคล้องกับคำอธิบายในสัญญาและไม่ถือเป็นการรับประกันเต็มรูปแบบในทุกบริบท
คำแนะนำสั้น ๆ สำหรับผู้ซื้อและผู้ขาย: ผู้ซื้อควรดำเนินการ due diligence (ตรวจสอบ provenance, DP attestations, sample testing และประเมินความเสี่ยงทางกฎหมาย) และต่อรองข้อกำหนดด้าน SLA, indemnity และ audit rights ส่วนผู้ขายควรกำหนดรูปแบบไลเซนซ์ให้ชัดเจน, มีการรับรองและการป้องกันทางกฎหมาย (warranty limits) และเตรียมเอกสารการยืนยันแหล่งที่มาของข้อมูลพร้อมหลักฐานการปฏิบัติตามกฎหมายเพื่อรองรับการตรวจสอบจากลูกค้าและหน่วยงานกำกับดูแล
การบูรณาการกับ LLM และกรณีศึกษาเชิงปฏิบัติ
ขั้นตอนการผสาน dataset สังเคราะห์ที่มีใบรับรองเข้ากับ pipeline การเทรน/finetune ของ LLM
การนำชุดเทรนสังเคราะห์แบบมีใบรับรอง (certified synthetic dataset) ไปใช้จริงกับโมเดลภาษาใหญ่ (LLM) ต้องออกแบบ pipeline ให้รองรับ metadata ของชุดข้อมูล (เช่น คะแนนคุณภาพข้อมูล, Proof‑of‑Provenance, และค่าความเป็นส่วนตัวเชิงสถิติ) โดยขั้นตอนสำคัญรวมถึง:
- นำเข้าและตรวจสอบ metadata: โหลดไฟล์ dataset พร้อมกับอ่านฟิลด์การพิสูจน์และคะแนน เช่น quality_score, provenance_hash, dp_epsilon ก่อนใช้งาน
- การเตรียม Data Loader: สร้าง data loader ที่รองรับการ sampling ตามน้ำหนักจากคะแนนคุณภาพ (importance sampling) และสามารถผสานตัวอย่างจากหลายแหล่ง (real/synthetic) ได้ง่าย เช่น การตั้ง sampling_probability = w_quality / sum(w_quality)
- การทำ tokenization และ preprocessing แบบสอดคล้อง: ตรวจสอบให้ tokenizer และ preproc pipeline ตรงกับที่ใช้ในการฝึกต้นแบบ (pretrained checkpoint) — รวมถึงการ handle special tokens และ max_length
- การแบ่งชุดข้อมูล: แยกชุดเป็น train/val/test โดยเก็บ provenance ไว้ เพื่อให้สามารถย้อนกลับได้ในกรณีต้องตรวจสอบผลกระทบของตัวอย่างแต่ละชุด
- การผสานเข้ากับ training loop: ให้ data loader ส่ง batch ที่ประกอบด้วย token ids, attention masks, provenance metadata และ quality weight เพื่อใช้ทั้งในการ loss weighting และการบันทึกเหตุการณ์ (auditing)
การตั้งค่า Differential Privacy สำหรับการเทรนต่อ (fine‑tuning)
เมื่อใช้ชุดสังเคราะห์ที่มีค่า DP metadata ควรกำหนดนโยบาย DP สำหรับการ fine‑tune อย่างชัดเจน ซึ่งรวมถึงการเลือกอัลกอริทึมและพารามิเตอร์ที่เหมาะสม ตัวอย่างการตั้งค่าทั่วไป:
- อัลกอริทึม: DP‑SGD (ผ่าน Opacus / TensorFlow Privacy / JAX privacy libs)
- clipping_norm: 0.5–1.5 (ค่าเริ่มต้นแนะนำ 1.0)
- noise_multiplier: 0.8–1.5 ขึ้นกับข้อผูกมัดด้าน privacy; ค่านี้มีผลโดยตรงต่อค่า ε (epsilon)
- batch_size และ microbatch: batch_size ใหญ่ช่วยลด ε; microbatch ระบุการประมวลผลภายใน TPUs/GPU
- epochs: จำกัดจำนวน epochs เพื่อลด cumulative privacy loss
- privacy accounting: ใช้ Rényi DP (RDP) accountant เพื่อคำนวณค่า ε และ δ ที่เป็นผลลัพธ์
ตัวอย่างตัวเลขเชิงปฏิบัติ: หากใช้ noise_multiplier = 1.2, clipping_norm = 1.0, batch_size = 512, epochs = 3 และ delta = 1e‑5 ผลลัพธ์ RDP accounting อาจให้ค่า ε ≈ 2.5–4.0 ขึ้นกับต้นแบบข้อมูลและการสุ่ม (sampling rate) — บริษัทควรตั้งค่าเป้าหมาย ε ตามนโยบายความเสี่ยงขององค์กรและข้อกำหนดกฎหมาย
การวัดผลกระทบต่อประสิทธิภาพโมเดลและการตรวจสอบ bias
การประเมินผลต้องทำทั้งเชิงปริมาณ (quantitative) และเชิงคุณภาพ (qualitative) ก่อนและหลังการเปลี่ยนมาใช้ synthetic dataset และ/หรือ DP fine‑tuning ดังนี้:
- เมตริกหลักของงาน: classification — accuracy, F1; QA — EM, F1; generation — perplexity, ROUGE/ BLEU, human eval
- เมตริกความเชื่อมั่นและการปรับเทียบ: Expected Calibration Error (ECE), reliability diagrams
- ตรวจจับ bias และ fairness slicing: คำนวณ metrics แยกตามกลุ่มย่อย (เช่น เพศ, อายุ, ภูมิภาค) เพื่อหาความไม่เท่าเทียม (e.g., disparity in F1 > threshold)
- การทดสอบการรั่วไหลของข้อมูล (PII leakage): membership inference attack simulation, exposure testing โดยเฉพาะถ้ามีการ fine‑tune ด้วยข้อมูลจริงบางส่วน
- การวัดผลก่อน/หลัง (before/after): ทำ A/B test หรือ k‑fold cross‑validation โดยเก็บ metrics ทั้งบน validation set เดิมและชุดทดสอบอิสระ
ตัวอย่างเชิงตัวเลข: บริษัทฟินเทค A มีโมเดล baseline ที่ผ่านการเทรนด้วยข้อมูลจริงเต็มรูปแบบได้ accuracy = 92.0%, F1 = 0.90. เมื่อเปลี่ยนมาใช้ synthetic-only certified dataset และ fine‑tune โดยไม่ใช้ข้อมูล PII ใด ๆ พบว่า accuracy = 87.4% (คิดเป็น 95% ของเดิม), F1 ลดเหลือ 0.855. เมื่อใช้กลยุทธ์ผสม (80% synthetic + 20% minimal real with DP fine‑tuning, ε ≈ 3.0) สามารถยกระดับกลับมาเป็น accuracy = 90.1% (98% ของเดิม) และ F1 = 0.885
Checklist สำหรับ Validation, Auditing และ Proof‑of‑Provenance
ก่อนนำไปใช้งานเชิงพาณิชย์ ควรผ่าน checklist ที่ครอบคลุมทั้งคุณภาพความถูกต้อง ความเป็นส่วนตัว และการปฏิบัติตามกฎระเบียบ:
- Metadata ตรวจสอบ: ยืนยัน signature/ hash ของ dataset, ตรวจสอบ timestamp, data origin, และคะแนนคุณภาพ (quality_score)
- Privacy validation: ตรวจสอบค่า DP claims (ε, δ) ด้วย privacy accountant; ทดสอบ membership inference และ exposure metrics
- Performance validation: เปรียบเทียบ metrics ก่อน/หลัง (accuracy, F1, perplexity, ROUGE) บนชุดทดสอบอิสระที่มีตัวแทนของงานจริง
- Bias & fairness checks: รัน sliced analysis, counterfactual tests, และ embedding‑based bias detection
- Provenance audit trail: ยืนยัน proof‑of‑provenance (Merkle proofs หรือ digital signatures) และบันทึกการเข้าถึง/การใช้งานเพื่อตรวจสอบย้อนหลัง
- Operational safety: ตรวจสอบ behaviour กับ prompt edge cases, hallucination rate, และ rejection policies สำหรับข้อมูลที่มีความเสี่ยง
- Regulatory compliance: ยืนยันว่าใช้ dataset สอดคล้องกับ GDPR, PDPA หรือข้อกำหนดเฉพาะอุตสาหกรรม
กรณีศึกษาเชิงปฏิบัติ
กรณีศึกษา 1 — บริษัทฟินเทค (สมมติ): บริษัทให้บริการสินเชื่อออนไลน์ต้องการลดการใช้ข้อมูลลูกค้าที่มี PII ในการเทรนโมเดลจัดอันดับเครดิต เวอร์ชัน baseline เทรนด้วยข้อมูลจริงเต็มรูปแบบได้ผลลัพธ์ดังนี้: accuracy = 92.0%, F1 = 0.90. บริษัทเลือกใช้ certified synthetic dataset ที่มีคะแนนคุณภาพเฉลี่ย 0.87 และ proof‑of‑provenance โดยตั้งค่า pipeline ดังนี้ — data loader ทำ weighted sampling ตาม quality_score, fine‑tune ด้วย DP‑SGD (clipping=1.0, noise_multiplier=1.2, batch_size=512, epochs=3) ผลลัพธ์ที่วัดได้:
- ใช้ synthetic only: accuracy = 87.4% (≈95% ของ baseline), F1 = 0.855
- ใช้ synthetic (80%) + limited real (20%) + DP fine‑tuning ε≈3.0: accuracy = 90.1% (≈98% ของ baseline), F1 = 0.885
- PII leakage tests: synthetic-only ส่งผลให้อัตรา membership exposure ลดลง >90% เทียบกับการใช้ข้อมูลจริงเต็มรูป
สรุปข้อค้นพบ: ชุดสังเคราะห์ที่ได้รับการรับรองช่วยลดความเสี่ยงด้าน PII อย่างมีนัยสำคัญ ในขณะที่การผสมกับข้อมูลจริงเล็กน้อยภายใต้ DP สามารถทดแทนความเสียหายด้านประสิทธิภาพได้อย่างมาก
กรณีศึกษา 2 — ผู้ให้บริการ Chatbot ด้านสุขภาพ (สมมติ): องค์กรต้องการลดการเปิดเผยข้อมูลทางการแพทย์ที่ละเอียดอ่อน โดยเปลี่ยนมาใช้ synthetic dialogues ที่มี proof‑of‑provenance และคะแนนความเป็นประโยชน์ (utility score) การทดลองแบ่งเป็น 3 กลุ่ม: real only, synthetic only, และ synthetic + DP fine‑tune แบบผสม ผลลัพธ์สรุปได้ดังนี้:
- generation perplexity (val): real only = 10.8, synthetic only = 12.6, synthetic+DP = 11.3
- human evaluation (helpfulness, 1–5): real only = 4.6, synthetic only = 4.2, synthetic+DP = 4.4
- PII leakage (automated scanner): real only = baseline high, synthetic only ≈ 95% reduction, synthetic+DP ≈ 98% reduction
ข้อเสนอแนะ: ใช้ synthetic dataset สำหรับ pre‑training ของ domain dialogue และ fine‑tune สุดท้ายด้วยข้อมูลจริงเพียงเล็กน้อยภายใต้ DP เพื่อลดผลกระทบด้านคุณภาพ
สรุปการใช้งานเชิงปฏิบัติ
การบูรณาการ certified synthetic datasets เข้ากับ LLM pipeline เป็นกระบวนการที่ต้องออกแบบทั้งด้านเทคนิคและการกำกับดูแล (governance) ให้สอดคล้องกัน — ตั้งแต่ data loader ที่รองรับ metadata, การตั้งค่า DP ที่เหมาะสม, การวัดผลก่อน/หลังที่ครอบคลุม, จนถึง checklist สำหรับ validation และ proof‑of‑provenance. กรณีศึกษาทางธุรกิจชี้ชัดว่า การใช้ synthetic datasets อย่างมีแบบแผนสามารถลดความเสี่ยงด้าน PII ได้อย่างมาก ในขณะที่ยังรักษาประสิทธิภาพของโมเดลให้อยู่ในระดับที่ยอมรับได้ โดยการผสมผสานกับ DP fine‑tuning อย่างระมัดระวังจะช่วยกู้คืนประสิทธิภาพได้ใกล้เคียงกับการใช้ข้อมูลจริงเต็มรูปแบบ
ความเสี่ยง ข้อจำกัด และแนวปฏิบัติที่ดีที่สุด
สรุปความเสี่ยงและข้อจำกัดหลัก
การใช้และซื้อขายข้อมูลสังเคราะห์สำหรับฝึก Large Language Models (LLMs) แม้จะให้ประโยชน์ด้านความเป็นส่วนตัวและลดความเสี่ยงจากการเปิดเผยข้อมูลต้นทาง แต่ยังคงมีความเสี่ยงทางเทคนิคและกฎหมายที่ต้องพิจารณาอย่างรอบคอบ ทั้งนี้ความเสี่ยงหลักได้แก่ ข้อมูลรั่วไหล (leakage) ผ่านการโจมตีเช่น model inversion หรือ membership inference, overfitting ของโมเดลต่อตัวอย่างสังเคราะห์, coverage gaps ที่ทำให้ชุดข้อมูลไม่ครอบคลุมกรณีการใช้งานจริง และ false sense of compliance ที่ผู้ใช้อาจเชื่อว่าการใช้ข้อมูลสังเคราะห์เท่ากับการปฏิบัติตามกฎความเป็นส่วนตัวทั้งหมดโดยไม่ตรวจสอบเงื่อนไขทางกฎหมายอื่น ๆ
เชิงเทคนิค การศึกษาเชิงวิจัยชี้ให้เห็นว่าเทคนิคการโจมตีเช่น membership inference และ model inversion สามารถได้ผลเมื่อโมเดลถูกฝึกบนชุดข้อมูลที่ overfit หรือเมื่อกระบวนการสร้างสังเคราะห์ไม่รัดกุม นอกจากนี้ การตั้งค่า Differential Privacy (DP) ที่ไม่เหมาะสม—เช่นการใช้ค่า epsilon สูงโดยไม่ระบุบริบท—สามารถให้ความรู้สึกปลอดภัยเทียมได้: โดยทั่วไปแนวปฏิบัติมักแนะนำว่า epsilon ที่ต่ำกว่า 1 จะรัดกุมมากกว่า ขณะที่ค่า epsilon ในช่วงหลายหน่วยอาจให้ความคุ้มครองน้อยลง
ด้านกฎหมายและความรับผิดชอบ มีปัจจัยเสี่ยงสำคัญเช่น สิทธิของเจ้าของข้อมูลต้นทาง (data subject rights), ข้อจำกัดด้านลิขสิทธิ์และทรัพย์สินทางปัญญา หากข้อมูลต้นทางมีข้อจำกัดทางกฎหมายหรือสัญญาจำกัดการใช้งาน ข้อสังเกตที่สำคัญคือการมี “ใบรับรอง” ทางเทคนิคไม่จำเป็นต้องเท่ากับการยกเว้นความรับผิดชอบทางกฎหมาย ผู้ซื้อและผู้ขายต้องระบุเงื่อนไขการรับประกัน ความรับผิดชอบ และกระบวนการจัดการเหตุละเมิดอย่างชัดเจน
แนวปฏิบัติที่ดีที่สุด — สำหรับผู้ขาย
- โปร่งใสต่อกระบวนการสร้าง: ระบุวิธีการสร้างสังเคราะห์อย่างชัดเจน (โมเดลพื้นฐาน, พารามิเตอร์ DP, ขนาดตัวอย่าง, การปรับแต่ง) และเผยแพร่เอกสารประกอบ เช่น data sheets และ generation reports
- ระบุพารามิเตอร์ความเป็นส่วนตัว: แจ้งค่า DP (epsilon, delta) พร้อมคำอธิบายความหมายของค่าเหล่านั้นในบริบทการใช้งาน และให้ตัวชี้วัด privacy-utility tradeoff
- ทดสอบต่อการโจมตี: ดำเนินการทดสอบ membership inference, model inversion และการโจมตีแบบ adversarial ก่อนวางจำหน่าย พร้อมเผยผลทดสอบหรือสรุปการดำเนินการบรรเทาความเสี่ยง
- คะแนนคุณภาพและรายงานความครอบคลุม: ให้คะแนนคุณภาพข้อมูล (data quality scores) พร้อมรายงานการครอบคลุม (coverage report) และตัวอย่างเชิงสถิติ เช่น การกระจายคุณลักษณะหลัก ความสอดคล้องกับการแจกแจงจริง
- พิสูจน์แหล่งที่มา (Proof-of-Provenance): ใช้ระบบพิสูจน์ที่ตรวจสอบได้ (เช่น cryptographic ledger หรือ hash-based provenance) เพื่อแสดงที่มาของชุดข้อมูลและการเปลี่ยนแปลง
- สัญญาและการรับประกัน: ระบุเงื่อนไขการใช้งาน ลิขสิทธิ์ การรับประกันความเป็นส่วนตัว และการจำกัดความรับผิดชอบอย่างชัดเจนในสัญญา
แนวปฏิบัติที่ดีที่สุด — สำหรับผู้ซื้อ
- ตรวจสอบอิสระ: ขอรายงานการทดสอบจาก third‑party audit หรือให้ผู้เชี่ยวชาญอิสระทดสอบความเป็นส่วนตัวและคุณภาพก่อนตกลงซื้อ
- ขอข้อมูลตัวอย่างและ pilot testing: ขอชุดตัวอย่างและดำเนินการทดสอบในสภาพแวดล้อมจริง (pilot) เพื่อวัดผลกระทบต่อประสิทธิภาพโมเดลและพฤติกรรมการรั่วไหลของข้อมูล
- ประเมิน coverage และ bias: ตรวจสอบรายงานการครอบคลุม (เช่น demographic coverage, edge cases) และทดสอบความลำเอียง (bias) ที่อาจเกิดขึ้นจากการสังเคราะห์
- กำหนด SLA และกลไกตรวจจับ: ระบุ Service Level Agreement ที่รวมการทดสอบความปลอดภัยเป็นระยะ มาตรการแจ้งเตือนเมื่อพบเหตุผิดปกติ และกระบวนการแก้ไข
- รวมข้อกำหนดทางกฎหมายในสัญญา: ระบุภาระผูกพันของผู้ขายในการตอบสนองต่อคำร้องของเจ้าของข้อมูลต้นทาง การรับประกันการลบข้อมูล และการชดเชยความเสียหายหากมีการละเมิด
Pre‑purchase checklist (รายการตรวจสอบก่อนทำสัญญา)
- เอกสารการสร้างและสเปค: ขอ data sheet, generation pipeline description, list ของโมเดลพื้นฐานและพารามิเตอร์
- พารามิเตอร์ Differential Privacy: ระบุค่า epsilon, delta และคำอธิบาย trade‑offs (พร้อมตัวอย่างผลต่อ utility)
- ผลการทดสอบความเป็นส่วนตัว: ผลการทดสอบ membership inference, model inversion, และ adversarial attacks พร้อมสรุปการป้องกัน
- รายงานคุณภาพและ coverage: สถิติเปรียบเทียบการแจกแจงคุณลักษณะสำคัญ ระบุช่องว่าง (gaps) และมาตรการบรรเทา
- Proof‑of‑Provenance: ข้อมูลพิสูจน์ที่มาและวิธีการตรวจสอบ (hashes, ledger entries)
- ตัวอย่างข้อมูลและสิทธิ์ทดสอบ: สิทธิ์ในการรัน pilot tests กับชุดตัวอย่างภายใต้ NDA
- การตรวจสอบโดยบุคคลที่สาม: รายงาน audit หรือการตรวจสอบจากหน่วยงานอิสระ (ถ้ามี)
- เงื่อนไขสัญญา: ข้อกำหนด SLA, การรับประกัน, ระยะเวลาค้ำประกัน, ข้อจำกัดความรับผิด, และกระบวนการแจ้งเตือนผิดปกติ
- การปฏิบัติตามกฎหมาย: การยืนยันว่าการใช้งานสอดคล้องกับกฎหมายที่เกี่ยวข้อง (เช่น PDPA, GDPR) และการจัดการคำขอของเจ้าของข้อมูล
- แผนการอัปเดตและการถอน: นโยบายการอัปเดตชุดข้อมูล กระบวนการถอน/ลบข้อมูล และความถี่ของการรีวิวความปลอดภัย
โดยสรุป ตลาดข้อมูลสังเคราะห์ที่มีใบรับรองสามารถเสนอโอกาสเชิงพาณิชย์ขนาดใหญ่ได้ แต่ต้องเข้าใจข้อจำกัดเชิงเทคนิคและกฎหมายอย่างชัดเจน ผู้ขายต้องดำเนินการโปร่งใสและทดสอบอย่างรัดกุม ในขณะที่ผู้ซื้อต้องยืนยันด้วยการตรวจสอบอิสระ การทดสอบเชิงปฏิบัติ และสัญญาที่ชัดเจนก่อนการนำไปใช้ในระบบการผลิต
บทสรุป
Certified synthetic data marketplaces สามารถลดอุปสรรคด้านความเป็นส่วนตัวและเปิดทางให้ข้อมูลถูกนำมาใช้เชิงพาณิชย์กับโมเดลภาษา (LLM) ได้อย่างปลอดภัย โดยการออกใบรับรองและมาตรฐานที่ชัดเจนทำให้ผู้ซื้อมั่นใจได้ว่าชุดข้อมูลผ่านการคุ้มครองข้อมูลส่วนบุคคลและปฏิบัติตามข้อกฎหมาย ข้อสำคัญคือต้องมีการวัดคุณภาพข้อมูลและการพิสูจน์ต้นทางอย่างเข้มงวด เพื่อให้ชุดข้อมูลสังเคราะห์มีคุณค่าในการเทรนหรือปรับแต่ง LLM ในเชิงพาณิชย์โดยไม่สูญเสียประสิทธิภาพการใช้งานและไม่ละเมิดสิทธิส่วนบุคคล
การผสานเทคนิคสำคัญอย่าง Differential Privacy (เพื่อให้การคุ้มครองเชิงคณิตศาสตร์), data quality scoring (วัดความเที่ยงตรง ความครอบคลุม ความสมจริงและการเบี่ยงเบนเมื่อเทียบกับข้อมูลจริง) และ Proof‑of‑Provenance (พิสูจน์แหล่งที่มา ลิขสิทธิ์และข้อตกลงการใช้งาน) พร้อมกับสถาปัตยกรรมแพลตฟอร์มที่รองรับการตรวจสอบอัตโนมัติ การออกใบรับรอง และระบบจัดการสิทธิ์ จะช่วยสร้างความน่าเชื่อถือ ลดความเสี่ยงด้านความรับผิดชอบ และทำให้เกิดโมเดลธุรกิจที่ยั่งยืนสำหรับทั้งผู้ขายและผู้ซื้อ ตัวอย่างองค์ประกอบที่สำคัญคือค่า ε ของ DP ที่ออกแบบให้สมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพ, เมตริกการให้คะแนนคุณภาพข้อมูลเช่น fidelity / utility / label accuracy, และบันทึกการพิสูจน์ต้นทางที่ตรวจสอบได้ (audit logs, cryptographic hashes, smart contracts)
มุมมองอนาคต: ตลาดข้อมูลสังเคราะห์แบบมีใบรับรองมีศักยภาพจะเป็นกระบอกเสียงสำคัญสำหรับการนำ LLM มาใช้ในภาคธุรกิจและภาครัฐ หากเกิดการกำหนดมาตรฐานระดับอุตสาหกรรม การยอมรับทางกฎหมาย (เช่นการตีความ GDPR/PDPA ต่อข้อมูลสังเคราะห์) และการพัฒนาเครื่องมือวัดคุณภาพร่วมกัน ตลาดจะขยายตัวอย่างรวดเร็ว ทั้งนี้ความท้าทายยังคงอยู่ที่การปรับสมดุลระหว่าง utility กับ privacy, ความเป็นสากลของเมตริกการให้คะแนน, ระบบจูงใจให้ผู้ให้ข้อมูลเข้าร่วม และการออกแบบกฎเกณฑ์การกำกับดูแลที่โปร่งใส ถ้ามาตรการเหล่านี้ได้รับการแก้ไขอย่างรอบด้าน ตลาดที่เชื่อถือได้จะเปิดทางให้เกิดรูปแบบรายได้ใหม่สำหรับเจ้าของข้อมูล ผู้สร้างชุดข้อมูล และผู้พัฒนาโมเดล ปลดล็อกการใช้งาน LLM ในเคสเชิงพาณิชย์ที่ต้องการความปลอดภัยและความรับผิดชอบสูงได้จริง



