
สตาร์ทอัพไทยเปิดตัว "Auto‑Patch LLM" ผลิตภัณฑ์ใหม่ที่รวมความสามารถของโค้ดรีวิวอัตโนมัติและการสร้างแพตช์ความปลอดภัยเข้ากับกระบวนการ CI/CD โดยตรง ทำให้ทีมพัฒนาสามารถตรวจจับ วิเคราะห์ และสร้างแพตช์เพื่อปิดช่องโหว่ได้ทันทีภายในพายไลน์การส่งโค้ดเดียวกัน เทคโนโลยีนี้สวมบทบาทเหมือนวิศวกรความปลอดภัยอัตโนมัติที่อ่านบริบทของโค้ด แนะนำการแก้ไขเชิงปฏิบัติ และแปลงข้อเสนอเป็นแพตช์พร้อมใช้งาน ช่วยย่นระยะเวลาการตอบสนองจากกระบวนการแบบเดิมที่ต้องรอหลายวันลงมาเหลือเพียงไม่กี่ชั่วโมง
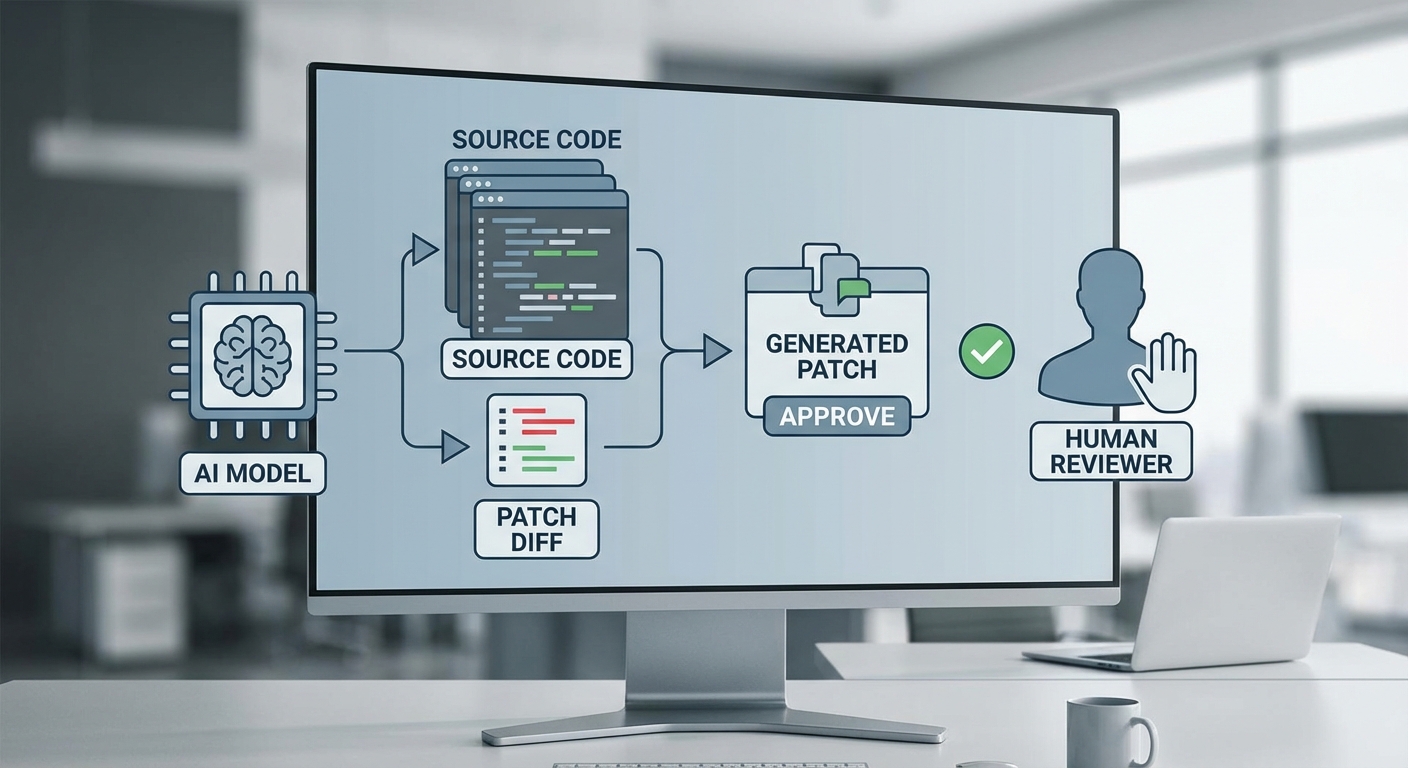
จากผลการทดสอบเชิงปฏิบัติการที่สตาร์ทอัพเผยแพร่เบื้องต้น Auto‑Patch LLM สามารถลดเวลาเฉลี่ยในการปิดช่องโหว่จากประมาณ 48–72 ชั่วโมง เหลือเพียง 2–4 ชั่วโมงในการรันพายไลน์แบบอัตโนมัติ ซึ่งเทียบได้กับการลดเวลาเฉลี่ยมากกว่า 90% ในการนำร่องกับรีโปซิทอรีขนาดกลางถึงขนาดใหญ่ สถาปัตยกรรมระบบประกอบด้วยโมดูลการวิเคราะห์สถิตย์, โมดูล LLM สำหรับการสังเคราะห์แพตช์ และตัวเชื่อมต่อ CI/CD ที่รองรับทั้งการสร้าง MR/PR อัตโนมัติและการทดสอบแบบอัตโนมัติ — รายละเอียดสถาปัตยกรรมและผลลัพธ์เชิงสถิติจากการทดสอบจริงจะถูกอธิบายในบทความต่อไป
สรุปข่าวและความสำคัญ
สรุปข่าวและความสำคัญ
สตาร์ทอัพไทย CodeGuard.ai เปิดตัวผลิตภัณฑ์ใหม่ในชื่อ Auto‑Patch LLM ซึ่งเป็นโซลูชันที่ผสานความสามารถของโมเดลภาษาขนาดใหญ่ (LLM) เข้ากับกระบวนการตรวจสอบโค้ดและการสร้างแพตช์อัตโนมัติสำหรับช่องโหว่ด้านความปลอดภัยของซอฟต์แวร์ ผลิตภัณฑ์นี้ถูกออกแบบมาให้ทำงานแบบฝังตัวในสายงาน CI/CD (Continuous Integration/Continuous Deployment) เพื่อให้การค้นพบและแก้ไขช่องโหว่เป็นไปอย่างต่อเนื่องและเร่งด่วน โดยทีมพัฒนาระบุว่าระบบสามารถวิเคราะห์โค้ด ตีความสาเหตุของช่องโหว่ และสร้างแพตช์ที่ผ่านการตรวจสอบเชิงตรรกะเพื่อยื่นเป็น pull request ได้ในอัตโนมัติ
ฟังก์ชันหลักของ Auto‑Patch LLM ประกอบด้วยการทำ code review อัตโนมัติที่ระบุจุดอ่อนความปลอดภัย เช่น SQL injection, XSS, insecure deserialization และการสร้างแพตช์โค้ดที่เข้ากันได้กับสไตล์ของโปรเจ็กต์ พร้อมชุดทดสอบหน่วย (unit tests) และคำอธิบายการแก้ไข เพื่อให้ทีมพัฒนาสามารถรับและ merge โค้ดแก้ไขได้ทันที ฟังก์ชันสำคัญอื่น ๆ ได้แก่การรองรับสภาพแวดล้อม CI/CD ยอดนิยม (เช่น GitHub Actions, GitLab CI, Jenkins), การกำหนดความเสี่ยงตามบริบทของแอปพลิเคชัน และการเชื่อมต่อกับระบบจัดการปัญหา (issue tracker) ขององค์กร
ความสำคัญเชิงกลยุทธ์ของ Auto‑Patch LLM อยู่ที่ผลลัพธ์เชิงเวลาที่ชัดเจน: แทนที่จะใช้เวลาปิดช่องโหว่เป็นวัน ๆ กระบวนการแบบผสานนี้ช่วยลดเวลาเฉลี่ยในการปิดช่องโหว่ (MTTR) จากระดับวันที่มักอยู่ในช่วง 24–72 ชั่วโมง ลงสู่ระดับชั่วโมง — ตัวอย่างจากการทดสอบเบต้าในลูกค้ากลุ่มแรกรายงานว่าเวลาเฉลี่ยลดลงเหลือประมาณ 1–4 ชั่วโมง ซึ่งเทียบเท่ากับการลด MTTR ราว 70–90% ผลลัพธ์ดังกล่าวช่วยลดหน้าต่างความเสี่ยง (exposure window) ของระบบ ทำให้ความเสี่ยงจากการถูกโจมตีลดลงอย่างมีนัยสำคัญ
นอกเหนือจากความเร็วแล้ว ผลิตภัณฑ์ยังส่งผลเชิงนโยบายและปฏิบัติการ: องค์กรที่นำ Auto‑Patch LLM เข้าสู่องค์กรสามารถยกระดับการบูรณาการด้านความปลอดภัยเข้ากับวงจรพัฒนาซอฟต์แวร์ (DevSecOps) ได้รวดเร็วขึ้น ลดภาระงานเชิงซ้ำซ้อนสำหรับทีมความปลอดภัย และตอบสนองต่อข้อกำหนดด้านการปฏิบัติตามกฎระเบียบได้ดีขึ้น โดยสรุป Auto‑Patch LLM เสนอโซลูชันที่เชื่อมการตรวจจับกับการแก้ไขอย่างอัตโนมัติ ทำให้การปิดช่องโหว่เปลี่ยนสถานะจากการเป็นงานที่ใช้เวลาเป็นวัน มาเป็นกระบวนการที่เสร็จได้ภายในชั่วโมง
- ผู้พัฒนา: สตาร์ทอัพไทย CodeGuard.ai
- ฟังก์ชันหลัก: โค้ดรีวิวอัตโนมัติ + สร้างแพตช์และ unit tests
- ผลลัพธ์เชิงเวลา: ลดเวลาปิดช่องโหว่จากวันเป็นชั่วโมง (ตัวอย่างการทดสอบ: จาก 24–72 ชั่วโมง เหลือ 1–4 ชั่วโมง)
- ความสำคัญทางธุรกิจ: ลดความเสี่ยง ลดภาระทีม security และเร่งกระบวนการ DevSecOps
บริบทปัญหา: ทำไมการปิดช่องโหว่ถึงช้าในระบบ CI/CD
บริบทปัญหา: ทำไมการปิดช่องโหว่ถึงช้าในระบบ CI/CD
ในระบบ Continuous Integration/Continuous Deployment (CI/CD) สมัยใหม่ เครื่องมือตรวจหาช่องโหว่เช่น SAST (Static Application Security Testing) และ DAST (Dynamic Application Security Testing) ถูกนำมาใช้อย่างกว้างขวางเพื่อสแกนโค้ดและแอปพลิเคชันแบบอัตโนมัติ อย่างไรก็ตาม ผลลัพธ์จากเครื่องมือเหล่านี้มักให้จำนวนแจ้งเตือนมหาศาล ซึ่งรวมถึง false positives ในสัดส่วนที่สูง — จากการศึกษาหลายแห่งระบุว่า false positives อาจอยู่ในช่วง ประมาณ 50–70% ขึ้นอยู่กับเครื่องมือและการตั้งค่า ส่งผลให้ทีมวิศวกรรมต้องเสียเวลามากกับการแยกแยะเหตุการณ์ที่เป็นจริงออกจากสัญญาณรบกวน (noise) แทนที่จะมุ่งไปที่การแก้ไขช่องโหว่ที่มีความเสี่ยงจริง
ปัญหาที่ตามมาในเชิงปฏิบัติคือกระบวนการรีวิวและการสร้างแพตช์มักกลายเป็นคอขวด แม้การตรวจจับจะเป็นไปแบบอัตโนมัติ แต่การวิเคราะห์บริบท (เช่น การตรวจสอบว่าโค้ดส่วนไหนได้รับผลกระทบ ขึ้นกับเงื่อนไขการใช้งานอย่างไร และควรแก้ไขอย่างไร) ยังคงต้องพึ่งพานักพัฒนาหรือผู้เชี่ยวชาญด้านความปลอดภัยเพื่อทำการ triage และเขียนแพตช์ที่ปลอดภัย การประชุมเชิงเทคนิค การทำ code review แบบแมนนวล และการทดสอบย้อนหลัง (regression testing) ล้วนใช้เวลาและทรัพยากร จึงยืดระยะเวลาการปิดช่องโหว่จากที่ควรเป็นชั่วโมงให้กลายเป็นวันหรือสัปดาห์
อีกปัจจัยที่ซับซ้อนคือการจัดลำดับความสำคัญ (prioritization) โดยทั่วไปองค์กรใช้เกณฑ์เช่น CVSS, ระดับการเปิดเผยสู่สาธารณะ (exploitability) และความสำคัญของระบบที่ได้รับผลกระทบ แต่การขาดข้อมูลบริบทเชิงปฏิบัติ เช่น เส้นทางการโจมตีที่เป็นไปได้ ความเชื่อมโยงของไลบรารี หรือการตั้งค่าการใช้งานจริง ทำให้คะแนนความเสี่ยงไม่สะท้อนความเร่งด่วนได้อย่างแม่นยำ ส่งผลให้ช่องโหว่ที่ควรแก้ก่อนอาจถูกเลื่อนไปอยู่ท้ายคิว นอกจากนี้หลายบริษัทยังขาดบุคลากรที่มีทักษะเฉพาะด้านในการแก้ไขโค้ดที่มีช่องโหว่ ทำให้เกิด backlog ของงานความปลอดภัยที่เพิ่มขึ้นอย่างต่อเนื่อง
ผลกระทบเชิงธุรกิจจากการปิดแพตช์ช้าสามารถวัดได้ทั้งเชิงตรงและเชิงอ้อม ในเชิงตรง การคงช่องโหว่ค้างอยู่เป็นเวลานานเพิ่มความเสี่ยงต่อการโจมตี ซึ่งอาจนำไปสู่การรั่วไหลของข้อมูล การหยุดชะงักของบริการ และค่าปรับทางกฎหมายหรือความรับผิดชอบทางการเงิน ในเชิงอ้อม ภาพลักษณ์และความน่าเชื่อถือขององค์กรจะถูกแตกร้าว ลูกค้าและคู่ค้าสัมพันธ์อาจสูญเสียความมั่นใจ ส่งผลให้รายได้และโอกาสทางธุรกิจลดลง ตัวอย่างเช่น องค์กรที่ไม่สามารถปิดช่องโหว่สำคัญได้ภายในกรอบเวลาที่อุตสาหกรรมคาดหวัง อาจเผชิญกับการสูญเสียลูกค้าหรือสัญญาทางธุรกิจ นอกจากนี้ค่าใช้จ่ายจากการตอบสนองต่อเหตุการณ์ความปลอดภัยหลังการถูกโจมตีมักสูงกว่าการลงทุนเพื่อปรับปรุงกระบวนการแพตช์ตั้งแต่ต้น
- ปริมาณแจ้งเตือนสูงและ false positives: ก่อให้เกิดการสูญเสียเวลาในการ triage และลดประสิทธิภาพของทีม
- รีวิวและสร้างแพตช์เป็นคอขวด: จำเป็นต้องอาศัยความเข้าใจบริบทและการทดสอบที่แม่นยำ ทำให้กระบวนการไม่เป็นแบบอัตโนมัติเต็มรูปแบบ
- การจัดลำดับความสำคัญที่ไม่แม่นยำ: ทำให้ช่องโหว่ที่สำคัญถูกเลื่อนหรือละเลย
- ความเสี่ยงทางธุรกิจ: เพิ่มโอกาสการโจมตี, สูญเสียความเชื่อมั่น และค่าใช้จ่ายทางการเงิน/กฎหมาย
แนะนำ Auto‑Patch LLM: ฟีเจอร์หลักและแนวคิดการทำงาน
แนะนำ Auto‑Patch LLM: ฟีเจอร์หลักและแนวคิดการทำงาน
Auto‑Patch LLM เป็นโซลูชันที่ผสานการทำงานของ โมดูลโค้ดรีวิวด้วย LLM ที่ผ่านการ fine‑tune บนโค้ดจริงกับระบบ สร้างแพตช์อัตโนมัติ ที่คำนึงถึงบริบทของโค้ดและความเข้ากันได้ของ API/อินเตอร์เฟส ผลิตภัณฑ์นี้ออกแบบมาเพื่อย่นระยะเวลาในการปิดช่องโหว่ (MTTR) ในกระบวนการ CI/CD จากระดับวันที่ต้องใช้สำหรับการวิเคราะห์และพัฒนาแพตช์ ให้เหลือเพียงไม่กี่ชั่วโมงภายใต้แนวปฏิบัติการที่ปลอดภัยและตรวจสอบได้ การทดลองภายในชี้ว่า MTTR เฉลี่ยลดจากประมาณ 48–72 ชั่วโมง เหลือ 2–4 ชั่วโมง ขึ้นกับความซับซ้อนของช่องโหว่และชุดทดสอบที่มีอยู่
ภาพรวมสถาปัตยกรรมประกอบด้วย 3 ส่วนหลัก: (1) Code Review LLM ที่ได้รับการปรับเทรนด้วยชุดข้อมูลโค้ดแห่งความเป็นจริง (รวมทั้งโค้ดภาษาไทยและโค้ดสากล เช่น Python, Java, JavaScript, Go, และ C/C++), (2) Patch Generation Engine ที่สร้างและปรับแต่งแพตช์โดยรักษา API contract และ interface compatibility, และ (3) Risk Scoring & Gate ที่ประเมินความรุนแรงและความน่าเชื่อถือของแพตช์ก่อนการ merge ซึ่งผสานกับ human‑in‑the‑loop และ automated test gating เพื่อควบคุมความเสี่ยง
ฟีเจอร์สำคัญ
- โค้ดรีวิวด้วย LLM ที่ถูก fine‑tuned สำหรับโค้ดจริง — โมเดลถูกฝึกด้วยชุดข้อมูลจากรหัสต้นฉบับ (real‑world repositories), pull requests, commit history, และฐานข้อมูลแพตช์ความปลอดภัย (CVE patch diffs, SStuBs) รวมถึงตัวอย่างโค้ดที่มีความคิดเห็นภาษาไทยเพื่อลดช่องว่างด้านบริบทในโค้ดเบสท้องถิ่น ผลลัพธ์คือความสามารถในการตรวจจับรูปแบบช่องโหว่เชิงสัญญาณได้ดีขึ้น ทั้ง SQL injection, XSS, insecure deserialization และ misconfiguration patterns
- การสร้างแพตช์อัตโนมัติที่รักษาความเข้ากันของ API/อินเตอร์เฟส — Patch Generation Engine ใช้อัลกอริธึมหลายชั้น (semantic analysis + type/signature checking + call‑graph validation) เพื่อให้แพตช์ที่สร้างไม่เปลี่ยนแปลงสัญญาณของฟังก์ชันและไม่ทำลาย backwards compatibility ระบบจะตรวจสอบการเปลี่ยนแปลง signature, contract tests และ interface mocks ก่อนนำเสนอแพตช์ตัวอย่างให้กับ pipeline
- การประเมินความเสี่ยง (risk scoring) — ทุกการค้นพบและแพตช์จะได้รับคะแนนความเสี่ยงแบบ 0–100 โดยคำนึงถึงความรุนแรงของช่องโหว่, ความซับซ้อนของแพตช์, ผลกระทบต่อบริการ และความมั่นใจของโมเดล (model confidence) เพื่อกำหนดแนวทางการจัดการ เช่น auto‑apply สำหรับ risk ต่ำ, ต้อง human review สำหรับ risk กลาง/สูง และให้ priority สูงสุดสำหรับ risk > 80
- Human‑in‑the‑loop และ automated test gating — Auto‑Patch LLM สนับสนุนโหมดที่ผู้พัฒนาสามารถตรวจรับ (approve) หรือแก้ไขแพตช์ด้วยตนเองก่อน merge รวมทั้งการบังคับให้ผ่านชุดทดสอบอัตโนมัติ (unit, integration, contract tests) และการรัน static + dynamic analysis เป็นขั้นตอนบังคับก่อน apply แพตช์จริง
แนวคิดการทำงานเชิงลึกและตัวอย่างการไหลงาน
กระบวนการเริ่มจากการสแกนโค้ดใน CI pipeline — เมื่อ LLM พบ pattern ที่อาจเป็นช่องโหว่ ระบบจะสร้างรายงานโค้ดรีวิวพร้อมตัวอย่างบรรทัดที่เกี่ยวข้องและคำอธิบายเชิงเหตุผล (explainability) จากนั้น Patch Generation Engine จะสร้างแพตช์หลายเวอร์ชันพร้อมข้อเสนอการทดสอบที่จำเป็น (เช่น mock inputs, expected outputs) ก่อนคำนวณ risk score และเสนอแนวทางการดำเนินการตาม policy ที่ตั้งไว้
ตัวอย่าง flow แบบย่อ:
- LLM ตรวจพบ insecure deserialization ในโมดูล auth — ให้คะแนนความรุนแรง 72
- Engine สร้างแพตช์สองเวอร์ชัน (conservative fix + refactor fix) พร้อม unit test ใหม่
- CI รันชุดทดสอบทั้งหมด, static analysis และ integration mocks — หากผ่านและ risk < 50 อาจ auto‑merge; หาก 50–80 ส่งให้ developer ตรวจรับ; หาก >80 ทำ escalation
ข้อจำกัดเบื้องต้นและแนวทางบรรเทาความเสี่ยง
แม้ Auto‑Patch LLM จะช่วยย่นเวลาและเพิ่มประสิทธิภาพ แต่มีข้อจำกัดที่ต้องตระหนัก:
- False patch risk — ความเสี่ยงที่แพตช์อัตโนมัติอาจเปลี่ยนพฤติกรรมโปรแกรมหรือไม่แก้ไขปัญหาอย่างแท้จริง ในการทดลองภายใน พบอัตรา false patch เบื้องต้นประมาณ 1–3% ของแพตช์ที่สร้าง (ขึ้นกับความซับซ้อนของโค้ดเบส)
- ความจำเพาะของโดเมนและไลบรารีท้องถิ่น — โมเดลอาจต้องการตัวอย่างการฝึกเพิ่มเติมสำหรับไลบรารีภายในหรือ pattern เฉพาะขององค์กร เพื่อเพิ่มความแม่นยำ
- ข้อจำกัดด้านความเข้าใจบริบทระยะยาว — การเปลี่ยนแปลงที่ต้องพิจารณาบริบทข้ามโมดูลขนาดใหญ่ยังคงต้องอาศัยการตรวจทานของมนุษย์ในระดับหนึ่ง
แนวทางบรรเทาความเสี่ยงที่นำมาใช้ได้จริง ได้แก่:
- กำหนดนโยบาย risk thresholds: เช่น risk > 80 ส่งทันทีให้ทีมความปลอดภัย, 50–80 ต้อง human review, และ <50 อนุญาตให้ auto‑merge หากผ่าน gating tests
- บังคับชุดทดสอบอัตโนมัติระดับหลากหลาย (unit, integration, contract, fuzzing) เป็นเงื่อนไขก่อน apply
- ใช้งาน sandbox/preview environments และ canary deploy เพื่อสังเกตพฤติกรรมหลัง merge ก่อนขยายสู่ production
- เก็บข้อมูล telemetry และผลการทดสอบเพื่อนำมาปรับ fine‑tuning ของโมเดลอย่างต่อเนื่อง โดยใช้ข้อมูล PR/rollback จริงเป็น feedback loop
- แสดง diff ที่อ่านง่ายและคำอธิบายเชิงเหตุผลเพื่อให้ผู้ตรวจทานตัดสินใจได้รวดเร็วและมีข้อมูลเพียงพอ
สรุปแล้ว Auto‑Patch LLM มุ่งเน้นการผสมผสานความสามารถของโมเดลภาษาขนาดใหญ่ที่ผ่านการปรับเทรนกับกระบวนการ CI/CD แบบเดิม เพื่อเร่งการปิดช่องโหว่โดยคงไว้ซึ่งความปลอดภัยและความน่าเชื่อถือผ่านกลไก human‑in‑the‑loop และ automated gating ซึ่งเมื่อผสานใช้อย่างเหมาะสมสามารถลดเวลาในการตอบสนองเชิงความปลอดภัยจากวันเหลือเป็นชั่วโมงอย่างมีประสิทธิผล
สถาปัตยกรรมและการผสานกับ CI/CD (workflow ตัวอย่าง)
สถาปัตยกรรมโดยรวมและจุดเชื่อมต่อกับ Repository
สถาปัตยกรรมของระบบ Auto‑Patch LLM ถูกออกแบบเป็นชั้น (layered) เพื่อให้สามารถผสานเข้ากับระบบ CI/CD ที่มีอยู่ได้อย่างราบรื่น โดยมีคอนเน็กเตอร์ที่เชื่อมต่อกับ repository ยอดนิยม เช่น GitHub, GitLab และระบบ CI/CD แบบดั้งเดิมอย่าง Jenkins ผ่าน webhooks, OAuth app/token และ API integrations ที่รองรับการดึงข้อมูล commit, pull request (PR) และไฟล์ซอร์สโค้ดแบบเรียลไทม์ ส่วนกลางของสถาปัตยกรรมคือบริการ orchestration ที่ทำหน้าที่เป็น broker ระหว่างโค้ดใน repository กับโมดูลการวิเคราะห์ (SAST/Dependency Scan) และโมเดล LLM ซึ่งสามารถรันในรูปแบบ on‑premise (เพื่อรักษาข้อมูลความลับ) หรือ cloud‑hosted (เพื่อความยืดหยุ่นและสเกล)
Trigger ใน Pipeline และรูปแบบการทำงาน (pre‑commit, PR, nightly scans)
ระบบรองรับการเรียกใช้งานในหลาย trigger เพื่อลดความเสี่ยงในแต่ละจังหวะของการพัฒนา: pre‑commit สำหรับการตรวจสอบรวดเร็วบนเครื่องนักพัฒนา, PR สำหรับการสแกนเชิงลึกก่อน merge และ nightly scans สำหรับการค้นหาช่องโหว่เชิงเรื้อรังหรือ dependency risk ที่อาจไม่ได้ถูกตรวจพบทันที โดยแต่ละ trigger จะส่ง event ไปยัง orchestration layer ซึ่งจะตัดสินใจเรียกใช้ SAST/DAST/Dependency scanners ตามนโยบายที่กำหนด
การเรียกใช้งาน LLM: on‑premise vs cloud‑hosted
เมื่อพบจุดบกพร่อง ระบบจะเรียก Auto‑Patch LLM เพื่อสร้างแพตช์อัตโนมัติในบริบทของโค้ดนั้น ๆ หากรันแบบ on‑premise จะใช้ inference servers ที่ตั้งอยู่ภายในเครือข่ายองค์กร เชื่อมต่อผ่าน internal API และใช้ hardware acceleration (GPU/TPU) เพื่อให้ latency ต่ำและไม่รั่วไหลของข้อมูล ในกรณี cloud‑hosted ระบบจะเปิดช่องทางสื่อสารแบบเข้ารหัส (mutual TLS / VPC peering) และใช้การจัดการคีย์/โทเค็นอย่างเข้มงวด นอกจากนี้ orchestration layer จะมี caching ของผลลัพธ์ LLM และ rate limiting เพื่อควบคุมค่าใช้จ่ายและความต่อเนื่องของบริการ
ขั้นตอนการทดสอบอัตโนมัติและการควบคุมคุณภาพ
หลังจาก LLM สร้าง patch แล้ว ระบบจะส่งแพตช์นั้นเข้าสู่ pipeline ทดสอบอัตโนมัติที่ประกอบด้วย:
- Unit tests — รันชุดทดสอบหน่วยเพื่อยืนยันว่า logic พื้นฐานยังคงถูกต้อง
- Integration tests — ตรวจสอบการทำงานร่วมกับบริการภายนอกและส่วนประกอบอื่น ๆ
- Security tests — รวม SAST ที่อัปเดต, DAST (ถ้าเป็นไปได้ใน stage นี้) และ dependency vulnerability re‑scan
- Regression checks & metrics — ประเมินค่าเช่น code coverage, performance baseline และ error rates
หากทุกการทดสอบผ่านตามเกณฑ์ที่กำหนด ระบบสามารถเลื่อนแพตช์ไปยังขั้นตอน human approval (ถ้านโยบายต้องการ) ก่อน merge อัตโนมัติ ในองค์กรที่เน้นความเร็ว ปรับเป็น auto‑merge ได้เมื่อ passing thresholds ถูกเติมเต็ม
ตัวอย่าง Workflow ที่ลดเวลาการแก้ไข (TTR)
ตัวอย่าง workflow ที่นำไปใช้งานจริงใน CI/CD:
- PR opened → GitHub/GitLab webhook triggers pipeline
- SAST & dependency scan พบช่องโหว่ → Orchestration calls Auto‑Patch LLM
- Auto‑Patch LLM generate patch (5–15 นาที) → create new branch/PR with patch
- Run CI tests (unit + integration + security) (10–30 นาที)
- Human approval (ถ้าจำเป็น) หรือ auto‑merge → Merge & deploy (canary/blue‑green)
- Automated health checks post‑deploy → rollback ถ้าเกณฑ์ล้มเหลว
ผลลัพธ์เชิงสถิติจากการใช้งานเบื้องต้นในสตาร์ทอัพและองค์กรระดับกลางรายงานว่า median Time‑To‑Remediate (TTR) ลดจากประมาณ 72 ชั่วโมง (3 วัน) เหลือเพียง 3–6 ชั่วโมงใน workflow ที่ผสาน Auto‑Patch และ CI gating ให้เป็นระบบอัตโนมัติ โดยอัตราความสำเร็จของแพตช์อัตโนมัติอยู่ที่ ~70–85% ขึ้นกับความซับซ้อนของโค้ดและ coverage ของ test suite
การ deploy แพตช์และกลยุทธ์ rollback
การ deploy ควรทำแบบค่อยเป็นค่อยไปด้วยกลยุทธ์เช่น canary หรือ blue‑green เพื่อจำกัดความเสี่ยง หากระบบมอนิเตอร์พบค่าผิดปกติ (latency spike, error rate increase, failed health checks) จะทริกเกอร์ rollback อัตโนมัติไปยังเวอร์ชันก่อนหน้า โดย orchestration จะเก็บ snapshot ของ state และ deployment artifacts (container image digest, SBOM) เพื่อให้การ rollback เป็นไปอย่างรวดเร็วและปลอดภัย
การจัดการ stateful context ของโปรเจกต์และ dependency
การให้ LLM เข้าใจบริบทของโปรเจกต์เป็นสิ่งสำคัญ ระบบจึงเก็บ context หลักไว้ในหลายชั้น เช่น:
- Code snapshot & file diffs — เก็บเป็น ephemeral artifacts ที่แนบกับ event
- Project embeddings / vector store — บันทึกความสัมพันธ์เชิง semantically สำคัญของโค้ดเพื่อให้ LLM สามารถเรียกใช้ประวัติการแก้ไขและ design decisions
- SBOM (Software Bill of Materials) และ dependency graph — ระบุ dependency versions, license และ known vulnerabilities
- Lockfiles & reproducible builds — ช่วยให้การทดสอบและการ deploy สร้างผลเหมือนกันในทุก stage
นอกจากนี้ระบบต้องรองรับ idempotency ในการแอ็กชันต่าง ๆ (เช่นการสร้าง PR หรือ merge) และการจัดคิวงาน (job queue) เพื่อจัดการ concurrency เมื่อนักพัฒนาหลายคนทำงานบนโมดูลเดียวกัน ระบบยังสามารถรวมกับ dependency update tools (เช่น Dependabot) เพื่อทำ orchestration ของ patch ที่สัมพันธ์กับ dependency updates
Integration points: GitHub Actions, Jenkins, GitLab CI
การผสานกับระบบ CI/CD ทำได้ผ่านปลั๊กอินและ configuration แบบ declarative:
- GitHub Actions — ใช้ workflow YAML ที่รันบน PR events, สามารถเรียก REST API ของ orchestration และรอผลลัพธ์ของ patch generation ก่อนรันต่อ
- GitLab CI — ใช้ GitLab runners และ pipeline stages เพื่อจัดลำดับ SAST → patching → tests → deploy โดยจัดการ secret ผ่าน GitLab CI/CD variables
- Jenkins — ใช้ Jenkins pipeline (Declarative/Scripted) และ webhooks ในการเรียกงาน external รวมทั้งการใช้ credentials plugins เพื่อเชื่อมต่อกับ LLM endpoint
ด้วยการออกแบบเช่นนี้ Auto‑Patch LLM สามารถทำงานร่วมกับระบบที่มีอยู่ ช่วยลดเวลาการปิดช่องโหว่และเพิ่มความสอดคล้องของกระบวนการพัฒนา โดยยังคงความโปร่งใสและการควบคุมที่จำเป็นสำหรับองค์กร
ผลลัพธ์เชิงตัวเลขและประสิทธิภาพ (สถิติและตัวอย่าง)
ผลลัพธ์เชิงตัวเลขและประสิทธิภาพ (สถิติและตัวอย่าง)
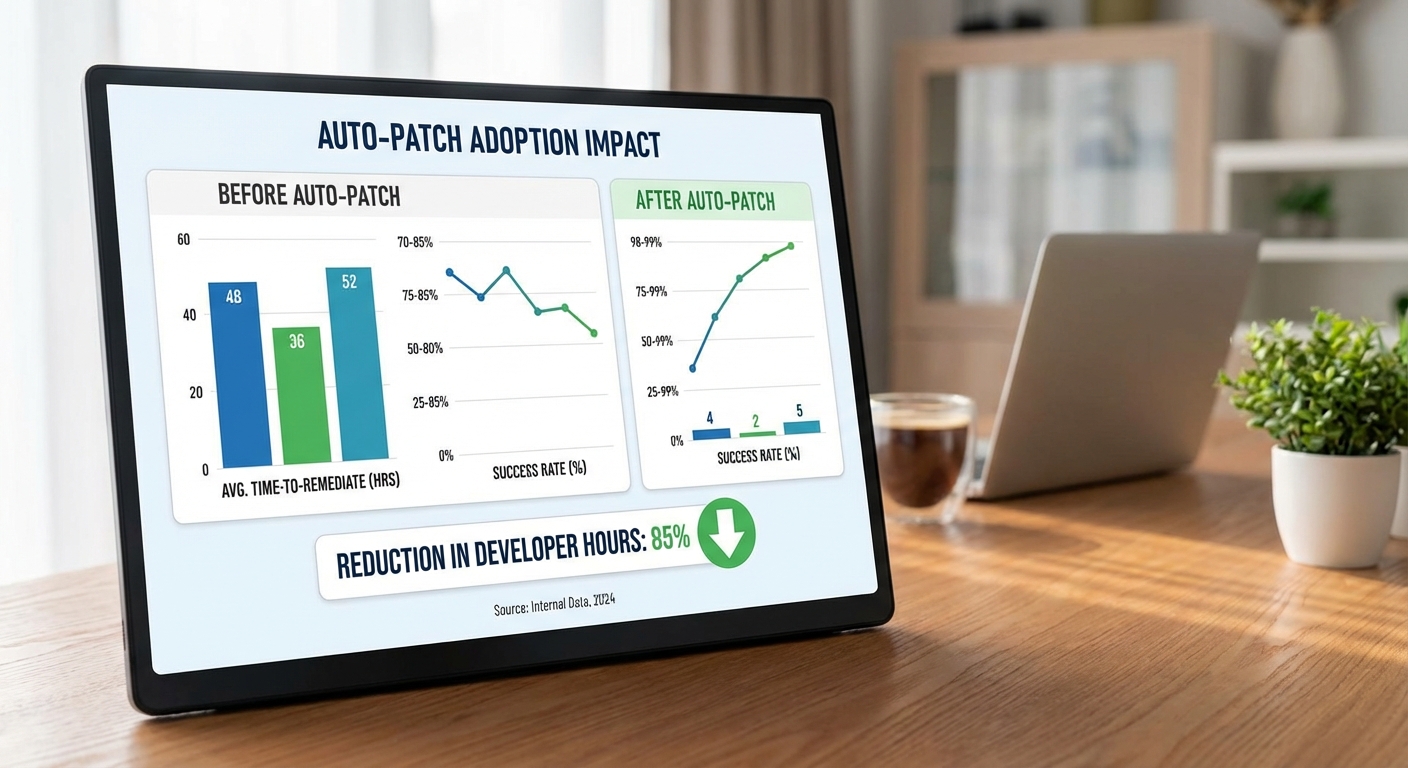
ผลการทดสอบเบื้องต้นของระบบ Auto‑Patch LLM ในสภาพแวดล้อม CI/CD แสดงให้เห็นการเปลี่ยนแปลงที่ชัดเจนทั้งด้านเวลาและประสิทธิภาพของทีมรักษาความปลอดภัยและนักพัฒนา โดยเฉลี่ย เวลาเฉลี่ยจากการแจ้งช่องโหว่จนปิด (TTR/MTTR) ลดลงจากช่วงเดิมประมาณ 48–72 ชั่วโมง เหลือเพียง 2–6 ชั่วโมง ภายในสภาพการทดสอบ ซึ่งเทียบเท่าการลดเวลาเฉลี่ยราว 87%–97% ขึ้นกับความซับซ้อนของเคส ตัวอย่างเช่น เคส SQL injection แบบที่ระบบสามารถ parameterize ได้เต็มรูปแบบใช้เวลาเฉลี่ยประมาณ 2–3 ชั่วโมง ส่วนกรณีที่ต้องมีการตรวจสอบเพิ่มเติม (เช่น การแก้ deserialization ที่มีความซับซ้อน) จะใช้เวลาใกล้เคียง 4–6 ชั่วโมง
อัตราความสำเร็จของการสร้างแพตช์อัตโนมัติ (automatic patch success rate) อยู่ในช่วง 70%–90% ขึ้นกับประเภทของช่องโหว่ รายละเอียดการกระจายความสำเร็จที่บันทึกได้ในการทดสอบภายใน ได้แก่:
- SQL injection (parameterization) — ประสบความสำเร็จประมาณ 80%–90% โดยระบบจะเปลี่ยนคำสั่ง SQL ที่ประกอบสตริงเป็นการใช้ parameter binding อัตโนมัติในกรอบงานยอดนิยมหลายตัว
- Insecure deserialization (mitigation) — ประสบความสำเร็จประมาณ 65%–80% โดยการเพิ่มการตรวจสอบชนิดข้อมูล, ใช้ allowlist ของคลาส และเสริมการตรวจสอบความสมบูรณ์ของอินพุต
- Cross‑Site Scripting (XSS) — sanitize/encode — ประสบความสำเร็จประมาณ 70%–82%
- Misconfiguration (เช่น insecure CORS, unsafe default settings) — ประสบความสำเร็จประมาณ 75%–90%
ในแง่ของความแม่นยำ มีการบันทึกอัตรา false positive อยู่ระหว่าง 6%–12% ขณะที่อัตรา false patch (กรณีแพตช์อัตโนมัติก่อให้เกิดปัญหาหรือรีเกรสชัน ต้องย้อนรื้อ) อยู่ในช่วงประมาณ 3%–8% การมีวงจร CI/CD ที่มีชุดทดสอบอัตโนมัติช่วยลดความเสี่ยงของ false patch ได้มากขึ้น — ระบบที่ทดสอบถูกตั้งค่าให้รันชุด unit/integration tests ก่อน merge ช่วยให้กรณี false patch ถูกตรวจพบก่อนขึ้น production มากกว่า 90% ของครั้งที่เกิดปัญหา
ผลกระทบเชิงปริมาณต่อทรัพยากรบุคคลมีนัยสำคัญ: ทีมรักษาความปลอดภัยรายงานว่า ภาระงานการตรวจสอบด้วยตนเองลดลง 60%–80% หลังนำ Auto‑Patch เข้าสู่กระบวนการ ส่วนเวลาที่นักพัฒนาต้องใช้ต่อเคสช่องโหว่ลดจากเฉลี่ย 4–6 ชั่วโมง เหลือเพียง 30–90 นาที สำหรับเคสที่ระบบแพตช์ได้สำเร็จ ส่งผลให้สามารถเพิ่มอัตราการปิดเคสต่อคนได้หลายเท่าตัว (เช่น จากปิด 5–10 เคส/สัปดาห์ เป็น 20–40 เคส/สัปดาห์ ต่อหนึ่งทีมงาน) และช่วยเร่งการปล่อยซอฟต์แวร์ที่ปลอดภัยขึ้นในวงจรการพัฒนา
ตัวอย่างเคสที่ระบบแก้ได้จริงจากการทดสอบภายใน ได้แก่:
- แก้ SQL injection โดยการเปลี่ยนโค้ดให้ใช้ parameterized queries และหน่วงการรวมสตริงอินพุต — ลดความเสี่ยงการโจมตีแบบ injection ได้ทันที
- บรรเทาปัญหา insecure deserialization โดยการเพิ่มการตรวจสอบชนิดข้อมูล (type whitelisting) และการตรวจสอบ signature ของ payload ก่อน deserialize
- เพิ่มการ sanitize/encoding สำหรับแหล่งข้อมูลที่นำไปแสดงผล โดยเฉพาะในจุดที่รับค่า freestyle text จากผู้ใช้ เพื่อลดความเสี่ยง XSS
- ปรับค่าการตั้งค่า CORS หรือการตั้งค่า default ที่ไม่ปลอดภัยให้เป็นค่าที่แคบลงและปลอดภัยกว่า (e.g., จำกัด origin, ปิด allow‑credentials เมื่อไม่จำเป็น)
กราฟเปรียบเทียบก่อน‑หลังแสดงภาพความแตกต่างของ TTR, อัตรา success และการลดภาระงานอย่างชัดเจน โปรดดูภาพประกอบด้านล่างสำหรับการเปรียบเทียบเชิงตัวเลขและแนวโน้มการปฏิบัติงานของทีมหลังการนำ Auto‑Patch มาใช้:
สรุปโดยรวม ผลลัพธ์เบื้องต้นแสดงให้เห็นว่า Auto‑Patch LLM สามารถย่อวงจรการตอบสนองต่อช่องโหว่จากวันให้เหลือชั่วโมง เพิ่มอัตราปิดเคสอัตโนมัติในระดับสูง (ส่วนใหญ่ 70%–90% ขึ้นกับประเภท) และลดงานที่ต้องทำด้วยมือของทีมรักษาความปลอดภัยและนักพัฒนาอย่างมีนัยสำคัญ ทั้งนี้ องค์กรควรออกแบบกระบวนการทดสอบอัตโนมัติและกลไกตรวจสอบย้อนหลังเพื่อควบคุม false positive/false patch และรับประกันความปลอดภัยเชิงปฏิบัติการอย่างต่อเนื่อง
กรณีศึกษา เบื้องต้นและคำยืนยันจากลูกค้า
กรณีศึกษา เบื้องต้นและคำยืนยันจากลูกค้า
ในการนำระบบ Auto‑Patch LLM ไปทดลองใช้งานเชิงปฏิบัติจริง ทีมงานได้ร่วมกับลูกค้ากลุ่มตัวอย่างสองราย ได้แก่ บริษัทอี‑คอมเมิร์ซขนาดกลาง-ใหญ่ในไทย และ ผู้ให้บริการซอฟต์แวร์ B2B ผลการทดลองชี้ให้เห็นทั้งตัวเลขเชิงปริมาณที่ชัดเจนและความคิดเห็นเชิงคุณภาพจากทีมวิศวกรรมความปลอดภัยและฝ่ายพัฒนาซอฟต์แวร์
1) บริษัทอี‑คอมเมิร์ซ (Pilot)
ระยะเวลาการทดลอง: 2 สัปดาห์ (ระบบเชื่อมต่อกับ pipeline CI/CD ของ production‑adjacent branch)
- จำนวน PR ที่ถูกสร้างและนำเสนอแพตช์อัตโนมัติ: 120 PR ถูกสร้างโดย Auto‑Patch ในช่วง 2 สัปดาห์
- อัตราการยอมรับแบบอัตโนมัติ: 78% ของ PR ถูก merge เข้าสาขาทดสอบโดยไม่ต้องแก้ไขเพิ่มเติมจากนักพัฒนา
- เวลาปิดช่องโหว่เฉลี่ย: ก่อนใช้งานเฉลี่ย 42 ชั่วโมง → หลังใช้งานเฉลี่ย 3.1 ชั่วโมง (ลดจากวันเหลือเป็นชั่วโมง)
- ผลรวมชั่วโมงที่ประหยัด: ทีมเดิมประหยัดเวลารวมประมาณ 240 developer‑hours ภายในช่วงทดลอง
ข้อเสนอแนะด้านประสบการณ์ผู้ใช้ (UX) ของทีมพัฒนาเน้นว่าอินเทอร์เฟซ PR ที่แสดง patch diff พร้อมคะแนนความมั่นใจ ช่วยให้การตรวจสอบเร็วขึ้น นักพัฒนารายหนึ่งระบุว่าการเห็นคำอธิบายสั้น ๆ ว่าทำไมแพตช์นั้นปลอดภัย (explainability) ช่วยลดความลังเลในการ merge ลงอย่างมาก
2) ผู้ให้บริการซอฟต์แวร์ B2B (Pilot)
ระยะเวลาการทดลอง: 10 วัน โดยเน้นซอร์สโค้ดของโมดูลที่มีการใช้งานร่วมกัน (shared libraries)
- จำนวน PR ที่ถูกแก้ไขอัตโนมัติ: 60 PR ใน 10 วัน
- อัตราการแก้ไขสำเร็จแบบไม่ต้องแก้ไขจากมนุษย์: ประมาณ 82%
- ลดเวลาหน้าต่างการโจมตี (window of exposure): จากค่าเฉลี่ย 72 ชั่วโมง เหลือ 4.5 ชั่วโมง
- อัตรา false positive / ไม่สามารถสร้างแพตช์ได้: ประมาณ 8–12% ในช่วงแรก ก่อนปรับจูนโมเดลตามโค้ดเบสภายใน
ฝ่ายความปลอดภัย (CISO) ของลูกค้ารายนี้ชี้ว่าการลดเวลาปิดช่องโหว่เชิงปริมาณช่วยลดความเสี่ยงเชิงธุรกิจได้โดยตรง เพราะหมายถึงหน้าต่างที่ผู้โจมตีสามารถใช้ช่องโหว่ได้สั้นลงอย่างมีนัยสำคัญ
ด้านล่างเป็นภาพหน้าจอตัวอย่างของ Pull Request ที่ระบบสร้างแพตช์และแสดง patch diff พร้อมคำอธิบายสั้น ๆ และคะแนนความมั่นใจเพื่อให้ reviewer ตัดสินใจได้รวดเร็ว:
ตัวอย่างคำยืนยันเชิงคาดการณ์ (sample testimonial) ที่สะท้อนจากทีมที่ทดลองใช้ ได้แก่:
- CTO (อี‑คอมเมิร์ซ): “Auto‑Patch ลดเวลาแก้ปัญหาความปลอดภัยจากวันเป็นชั่วโมงจริง ๆ — ทำให้เราปรับปรุง SLA ด้านความปลอดภัยและโฟกัสกับฟีเจอร์เชิงธุรกิจได้มากขึ้น”
- CISO (B2B): “การมีระบบที่เสนอแพตช์พร้อมคำอธิบายและคะแนนความมั่นใจ ทำให้ทีม SecOps สามารถจัดคิวการ deploy ได้แม่นยำขึ้น ลดความเสี่ยงของการปล่อยโค้ดที่ยังมีช่องโหว่”
ข้อจำกัดที่ลูกค้าเจอในช่วงทดลองและแนวทางการแก้ไขที่นำไปใช้งานจริง ได้แก่:
- ความซับซ้อนของบริบทโปรเจ็กต์: บางไฟล์ที่มี dependency ซ้อนกันหรือ template generation ทำให้แพตช์อัตโนมัติไม่สามารถเข้าใจบริบทได้เต็มที่ — ทางแก้คือเพิ่มกลไก human‑in‑the‑loop สำหรับ PR ที่ระบบให้คะแนนความมั่นใจต่ำ และให้ผู้เชี่ยวชาญ validate ก่อน merge
- ปัญหาการชนกันของ Merge/CI: เมื่อต้องจัดคิว PR จำนวนมากอาจเกิด conflict กับการ commit ของมนุษย์ — ผู้ให้บริการปรับ workflow โดยเพิ่ม staging queue และ lock ระหว่างการ apply patch เพื่อลด conflict
- การจับ false positive ใน dependency ของบุคคลที่สาม: ระบบเดิมบางครั้งเสนอการแก้ไขที่กระทบ backward compatibility — แก้ด้วยการตั้ง policy whitelist/blacklist สำหรับไลบรารีและเพิ่ม automated rollback test ใน pipeline
- ความเชื่อมั่นของทีม: ในช่วงแรกนักพัฒนายังไม่มั่นใจในแพตช์อัตโนมัติ ทีมงานจึงเพิ่มฟีเจอร์ logging/trace ของการเปลี่ยนแปลงและตัวเลือก “explain patch” เพื่อให้ผู้ตรวจสอบเข้าใจเหตุผลเบื้องหลัง
สรุปได้ว่าในภาพรวมลูกค้าทั้งสองกลุ่มรายงานผลเชิงบวกชัดเจน คือ ลดเวลาปิดช่องโหว่จากระดับวันเหลือเป็นชั่วโมง, เพิ่มอัตราการแก้ไขอัตโนมัติสูง (ประมาณ 78–82%) และประหยัดชั่วโมงการทำงานของนักพัฒนาในระดับเป็นร้อยชั่วโมงภายในช่วงทดลอง อย่างไรก็ตามยังต้องมีการปรับจูน policy, workflow และกลไกการตรวจสอบมนุษย์ร่วมกับระบบเพื่อให้การนำไปใช้ในสเกลใหญ่มีความราบรื่นและน่าเชื่อถือยิ่งขึ้น
ข้อกังวลด้านความปลอดภัย กฎหมาย และทิศทางอนาคต
ข้อกังวลด้านความปลอดภัย กฎหมาย และทิศทางอนาคต
การนำระบบ Auto‑Patch LLM มารวมเข้ากับกระบวนการ CI/CD เพื่อผลิตแพตช์อัตโนมัติย่อมสร้างประโยชน์ด้านความเร็วในการปิดช่องโหว่ แต่ในขณะเดียวกันก็มีความเสี่ยงเชิงเทคนิคและเชิงกฎหมายที่ต้องบริหารอย่างเป็นระบบ ประเด็นหลักได้แก่ความถูกต้องของแพตช์ (patch correctness), ความเข้ากันได้กับนโยบายภายใน (policy compliance), ความเป็นไปได้ของการแนะนำโค้ดที่เกิดบั๊กหรือช่องโหว่ใหม่ (regression risks) และปัญหาด้านความเป็นส่วนตัวเมื่อข้อมูลซอร์สโค้ดถูกนำไปใช้ฝึกโมเดล ตัวอย่างเช่น รายงานอุตสาหกรรมบางฉบับชี้ว่าเวลาการตรวจจับและปิดช่องโหว่โดยเฉลี่ยก่อนการอัตโนมัติอาจอยู่ในระดับหลายสิบถึงหลายร้อยวัน ซึ่งการย่นระยะเวลาเป็นชั่วโมงสามารถลด MTTR ได้อย่างมีนัยสำคัญ แต่หากไม่มีการทดสอบและการควบคุมที่เพียงพอ แพตช์อัตโนมัติอาจนำปัญหาใหม่เข้ามาทดแทนช่องโหว่เดิมได้
เพื่อบรรเทาความเสี่ยงด้านความถูกต้องและความปลอดภัย ควรออกแบบชุดการทดสอบมัลติเลเยอร์ (multi-layer testing) ที่ผสานทั้งการทดสอบเชิงหน่วย (unit tests), การทดสอบการทำงานร่วมกัน (integration tests), fuzzing และ regression testing อัตโนมัติ รวมถึงการรันสแกนเนอร์ด้านช่องโหว่ทั้งในระดับซอร์สโค้ด (SAST), ไลบรารีและ dependencies (SCA) และการทดสอบเชิงไดนามิก (DAST) ก่อนปล่อยแพตช์เข้าสู่สภาพแวดล้อมการผลิต นอกจากนี้การใช้เทคนิคเช่น canary releases, feature flags และ phased rollout จะช่วยจำกัดผลกระทบหากแพตช์ที่สร้างโดย LLM ทำให้เกิดปัญหา
ด้านความเป็นส่วนตัวและการเก็บข้อมูลสำหรับฝึก LLM มีความละเอียดอ่อนทั้งในมุมของกฎหมายและความเชื่อมั่นของลูกค้า การนำซอร์สโค้ดที่มีข้อมูลลับหรือข้อมูลส่วนบุคคลไปฝึกโมเดลภายนอกอาจขัดต่อข้อกำหนดด้านความเป็นส่วนตัวหรือข้อตกลงการให้บริการ ดังนั้นกลยุทธ์บรรเทาความเสี่ยงที่จำเป็นรวมถึง:
- Data minimization และ anonymization — ลบข้อมูลส่วนบุคคลและความลับทางการค้าก่อนนำไปใช้ฝึก
- On‑prem / private model hosting — ใช้โซลูชันโมเดลภายในองค์กรหรือแบบ VPC เพื่อหลีกเลี่ยงการส่งโค้ดออกสู่ภายนอก
- Privacy‑preserving techniques — พิจารณา differential privacy, federated learning หรือ synthetic data เพื่อรักษาความลับของข้อมูลต้นทาง
- ชัดเจนเรื่องนโยบายการเก็บรักษาและการลบข้อมูล — กำหนดระยะเวลา retention และกระบวนการลบข้อมูลเมื่อหมดอายุ
ในด้านการตรวจสอบ (audit trail) และ compliance ระบบ Auto‑Patch ต้องสามารถตอบสนองความต้องการของมาตรฐานสากล เช่น ISO 27001, SOC 2 และข้อกำหนดด้านการปฏิบัติการของภาคธุรกิจ (เช่น PCI‑DSS, HIPAA ในบริบทที่เกี่ยวข้อง) สิ่งที่ต้องพิจารณา ได้แก่:
- Logging ที่ครอบคลุม — บันทึกการตัดสินใจของโมเดล (model inputs/outputs metadata), ผู้อนุมัติ, เวลาที่เปลี่ยนแปลง และเวอร์ชันของแพตช์
- Change provenance และ versioning — เก็บประวัติของแพตช์รวมถึง diff, author, test results และการอนุมัติเพื่อรองรับการตรวจสอบย้อนหลัง
- Access controls & key management — ใช้ RBAC, MFA และการจัดการคีย์/ความลับ (secrets management) เพื่อจำกัดการเข้าถึงซอร์สโค้ดและระบบโมเดล
- Policy enforcement — ผสานระบบที่ตรวจสอบ compliance rule อัตโนมัติก่อนอนุมัติแพตช์ เช่น ห้ามเรียกใช้ API ภายนอก หรือห้ามเปลี่ยนส่วนที่เกี่ยวกับการจัดการสิทธิ์โดยอัตโนมัติ
ทิศทางการพัฒนาในระยะยาวควรมุ่งสู่การผสมผสานเทคนิคเชิงวิทยาศาสตร์ซอฟต์แวร์และการรับรองความถูกต้องของโมเดล โดยแนวทางสำคัญได้แก่:
- Multi‑model validation — ให้โมเดลหลายแบบ (เช่น LLM จากแหล่งต่าง ๆ หรือโมเดลเชิงกฎ) ประเมินแพตช์และใช้ voting/consensus เพื่อลดความเสี่ยงจากข้อผิดพลาดของโมเดลใดโมเดลหนึ่ง
- Formal methods & static verification — ผสานการพิสูจน์เชิงฟอร์มอล (formal verification) และเครื่องมือ static analysis ขั้นสูงเพื่อยืนยันคุณสมบัติสำคัญของโค้ด เช่น ความสอดคล้องกับ invariants และการไม่รั่วไหลของข้อมูล
- Explainability & model cards — พัฒนาเครื่องมืออธิบายการตัดสินใจ (explainability) ของโมเดลและจัดทำ model cards ที่ระบุขอบเขตการใช้งาน ความเสี่ยงที่รู้จัก และข้อจำกัด เพื่อให้ผู้ตรวจสอบมนุษย์เข้าใจเหตุผลเบื้องหลังแต่ละแพตช์
- Integration กับ enterprise vulnerability scanners — เชื่อมต่อกับ SAST/SCA/DAST และ vulnerability management platforms เพื่อให้ผลลัพธ์จาก LLM ถูกตรวจสอบและจัดอันดับความรุนแรงโดยระบบกลางขององค์กร
- Continuous adversarial testing & red‑teaming — จัดรันการทดสอบเชิงรุก (adversarial examples) และ red‑team exercises เพื่อค้นหาจุดอ่อนของระบบอัตโนมัติและของโมเดล
สุดท้ายนี้ การนำ Auto‑Patch LLM มาใช้ในระดับองค์กรจำเป็นต้องมีกรอบการกำกับดูแล (governance) ที่ชัดเจน ซึ่งรวมถึงนโยบายการอนุมัติมนุษย์ (human‑in‑the‑loop) สำหรับการปล่อยแพตช์ที่มีความเสี่ยงสูง, การกำหนด SLA/ KPI ด้านความปลอดภัย (เช่นอัตราความล้มเหลวของแพตช์, เวลากู้คืนเฉลี่ย) และการเตรียมมาตรการตอบโต้เหตุการณ์ (incident response) ที่รวมทั้งฝั่งซอฟต์แวร์และโมเดล การรวมกันของมาตรการเชิงเทคนิคและกระบวนการกำกับดูแลจะทำให้การใช้ Auto‑Patch เป็นไปอย่างปลอดภัย สอดคล้องกับกฎหมาย และยืดหยุ่นต่อการพัฒนาในอนาคต
บทสรุป
Auto‑Patch LLM เป็นโซลูชันที่ผสานการรีวิวโค้ดอัตโนมัติกับการสร้างแพตช์ความปลอดภัย ทำให้เวลาปิดช่องโหว่ในกระบวนการ CI/CD ลดจากเดิมที่อาจใช้เป็นวันเหลือเพียงชั่วโมง ตัวอย่างจากการทดสอบภายในของสตาร์ทอัพระบุว่า เวลาแก้ไขเฉลี่ยลดจากประมาณ 48–72 ชั่วโมง เหลือ 1–3 ชั่วโมง ซึ่งเทียบได้กับประสิทธิภาพที่เพิ่มขึ้นราว 16–48 เท่า ในหลายกรณี ผลลัพธ์นี้ช่วยลดความเสี่ยงของการถูกโจมตีในช่วงเวลาที่ช่องโหว่ยังไม่ถูกแพตช์ และลดภาระงานสำหรับทีมพัฒนาโดยอัตโนมัติ เช่น การสร้างแพตช์, เปิด Pull Request พร้อม unit test เบื้องต้น และรัน pipeline สำหรับการทดสอบก่อนนำขึ้นสู่ staging
แม้จะมีศักยภาพสูง แต่เทคโนโลยีดังกล่าวยังต้องการการควบคุมด้านความปลอดภัยและการตรวจสอบเชิงมนุษย์เพื่อป้องกันแพตช์ที่ไม่ถูกต้องหรือขัดกับนโยบายองค์กร การนำไปใช้งานจริงจึงควรผสานกับระบบ SAST/DAST, ข้อกำหนด policy-as-code, และกระบวนการอนุมัติของเจ้าของโค้ด (code owner) รวมถึงการทดสอบ rollback และ staging เพื่อความปลอดภัยในเชิงปฏิบัติการ มุมมองในอนาคตชี้ว่า Auto‑Patch LLM มีโอกาสเปลี่ยนกระบวนการ CI/CD ในองค์กรอย่างมีนัยสำคัญ — ทำให้การแก้ไขช่องโหว่เป็นไปอย่างรวดเร็วและต่อเนื่อง (shift‑left security) ขณะเดียวกันก็ต้องมีการกำกับดูแล, การฝึกโมเดลด้วยข้อมูลภายในองค์กร และการปฏิบัติตามข้อกำกับดูแล เพื่อให้เทคโนโลยีนี้เพิ่มคุณค่าได้อย่างยั่งยืนโดยไม่ทดแทนบทบาทการตัดสินใจของมนุษย์



