
ในยุคที่ AR/VR กำลังก้าวสู่การใช้งานจริงในงานอุตสาหกรรม เกม และการสื่อสาร การส่งสตรีมวิดีโอความละเอียดสูงแบบเรียลไทม์ยังคงเป็นคอขวดสำคัญ — ต้องการแบนด์วิดท์สูงและเรียกร้องทั้งความหน่วงต่ำและคุณภาพภาพที่รับได้ สำหรับผู้อ่านที่มองหาทางออกใหม่ Gen‑Compression นำแนวคิด "generative compression" มาประยุกต์กับการสตรีมวิดีโอ AR/VR โดยอาศัยโมเดลสร้างสรรค์เพื่อบีบอัดข้อมูลเชิงรับรู้ ทำให้ลดความต้องการแบนด์วidth ได้ถึง 8–12 เท่า ขณะเดียวกันยังรองรับการรันแบบเรียลไทม์บนแพลตฟอร์ม WebRTC และฮาร์ดแวร์ Edge NPU ที่กำลังแพร่หลาย ทำให้เป็นทางเลือกที่น่าสนใจทั้งด้านประสิทธิภาพและการนำไปใช้งานจริง
บทความนี้จะพาคุณไล่เรียงตั้งแต่หลักการทำงานของ Gen‑Compression — การใช้ prior เชิงสร้างสรรค์และการทำโมเดลแบบ latent เพื่อทดแทนการส่งพิกเซลดิบ — ไปจนถึงการวิเคราะห์เชิงเทคนิค ผลการทดสอบเปรียบเทียบ และข้อพิจารณาเชิงปฏิบัติ เช่น ความหน่วง, ความเสถียรเชิงเวลา, artifact แบบเฉพาะตัว และความต้องการคอมพิวต์บน Edge NPU รวมถึงแนวทางการผนวกกับ WebRTC ในระบบจริง ผู้ที่เป็นวิศวกรระบบ AR/VR, สถาปนิกโซลูชัน หรือผู้บริหารผลิตภัณฑ์ จะพบข้อมูลเชิงลึกเพื่อประเมินว่า Gen‑Compression จะเปลี่ยนเกมสำหรับสตรีมมิงเรียลไทม์ได้อย่างไร
บทนำ: ทำไม Gen‑Compression สำคัญต่อโลก AR/VR วันนี้
บทนำ: ทำไม Gen‑Compression สำคัญต่อโลก AR/VR วันนี้
การเติบโตของแอปพลิเคชัน AR/VR ในเชิงธุรกิจและบริโภคกำลังเปลี่ยนมาตรฐานของการสื่อสารภาพและวิดีโอจากเดิมอย่างสิ้นเชิง โดยเฉพาะเมื่อเปรียบเทียบกับวิดีโอ 2D แบบดั้งเดิม เทคโนโลยีเสมือนจริงต้องการข้อมูลภาพในระดับความละเอียดสูง ความถี่เฟรมที่มากขึ้น และข้อมูลเชิงลึกเช่นความลึกและข้อมูลแสง ซึ่งรวมกันแล้วทำให้ปริมาณแบนด์วิดท์ที่ต้องส่งสูงขึ้นอย่างมีนัยสำคัญ สำหรับองค์กรที่ต้องการขยายบริการ AR/VR ในสเกลใหญ่ ความต้องการแบนด์วิดท์และต้นทุนโครงข่ายจึงกลายเป็นอุปสรรคสำคัญต่อการนำไปใช้เชิงพาณิชย์
ในเชิงตัวเลข หากเทียบกับการสตรีมวิดีโอ 2D ระดับ 4K ที่มักอยู่ที่ประมาณ 10–25 Mbps เมื่อใช้การบีบอัดสมัยใหม่ การสตรีมภาพสำหรับ AR/VR ที่มีความละเอียดสูงต่อดวงตา ความถี่เฟรมสูง และข้อมูลเชิงลึก อาจต้องการแบนด์วิดท์มากกว่า หลายสิบจนถึงหลายร้อย Mbps ต่อผู้ใช้หนึ่งราย ขึ้นอยู่กับรูปแบบการบีบอัดและความต้องการคุณภาพ นั่นหมายความว่าเครือข่ายที่ให้บริการแก่ผู้ใช้ AR/VR หลายพันหรือหลายหมื่นคนจะต้องรับภาระทราฟฟิกที่สูงขึ้นอย่างทวีคูณ ส่งผลให้ต้นทุนการให้บริการและค่าใช้จ่ายด้านโครงสร้างพื้นฐานพุ่งสูง
นอกจากปริมาณข้อมูลแล้ว ความหน่วง (latency) ยังเป็นเงื่อนไขที่มีความสำคัญถึงชีวิตต่อประสบการณ์ AR/VR: การตอบสนองที่ช้าหรือ jitter สูงสามารถก่อให้เกิดอาการเวียนศีรษะและขาดต่อเนื่องของการมีส่วนร่วม ประสบการณ์ผู้ใช้ที่ดีต้องรักษา motion-to-photon latency ให้อยู่ในระดับที่ต่ำมาก โดยทั่วไปมักอ้างอิงค่าที่ต้องต่ำกว่า 15–20 มิลลิวินาที สำหรับการสวมใส่ที่เป็นธรรมชาติ ซึ่งบีบให้ระบบสตรีมมิงต้องส่งข้อมูลอย่างรวดเร็วและต่อเนื่องพร้อมกับการประมวลผลที่ใกล้ผู้ใช้ (edge) เพื่อหลีกเลี่ยงการหน่วงเกินค่าที่ยอมรับได้
Gen‑Compression เป็นแนวทางใหม่ที่ตอบโจทย์ทั้งสองมิติหลักนี้ โดยผสานความสามารถของโมเดลสร้างสรรค์ (generative models) เข้ากับเทคนิคการบีบอัดแบบดั้งเดิม แนวคิดหลักคือการส่งข้อมูลเพียงองค์ประกอบที่จำเป็นและให้โมเดลฝั่งผู้รับ "สร้าง" หรือเติมเต็มภาพที่เหลือตามข้อมูลเชิงโครงสร้างและพารามิเตอร์ที่ได้รับ ผลลัพธ์คือการลดปริมาณข้อมูลที่ต้องส่งลงอย่างมีนัยสำคัญ — ในงานวิจัยและการประยุกต์ล่าสุดรายงานการลดแบนด์วิดท์ได้ระหว่าง 8–12 เท่า เมื่อเทียบกับสตรีมมิงแบบดั้งเดิม ในขณะที่ยังคงรักษาคุณภาพภาพที่ดีพอสำหรับการรับรู้ของผู้ใช้ ตัวเลือกนี้จึงเปิดทางให้การสตรีม AR/VR ผ่านช่องทางที่มีความหน่วงต่ำอย่าง WebRTC และการเร่งด้วย NPU ที่ฝั่ง Edge สามารถทำงานร่วมกันเพื่อให้เกิดการส่งมอบประสบการณ์แบบเรียลไทม์ที่คุ้มค่าและขยายสเกลได้
- ลดต้นทุนแบนด์วิดท์: การลดปริมาณข้อมูลลง 8–12 เท่าช่วยลดค่าใช้จ่ายการขนส่งข้อมูลและความต้องการสเปกเครือข่าย
- รักษา latency ต่ำ: ด้วยการประมวลผลเชิงสร้างสรรค์และการทำงานที่ edge ทำให้ยังคงรักษาความหน่วงภายในเกณฑ์ที่ยอมรับได้
- ปรับปรุงการสเกลธุรกิจ: ธุรกิจสามารถขยายบริการ AR/VR ไปยังผู้ใช้จำนวนมากขึ้นโดยไม่ต้องลงทุนด้านโครงสร้างพื้นฐานเครือข่ายเพิ่มขึ้นเท่าตัว
Gen‑Compression คืออะไร: แนวคิดพื้นฐานและสถาปัตยกรรม
Gen‑Compression คืออะไร: แนวคิดพื้นฐาน
Gen‑Compression เป็นแนวทางการบีบอัดวิดีโอเชิงสร้างสรรค์ (generative compression) ที่เปลี่ยนวิธีการส่งข้อมูลจากการส่งพิกเซลทั้งหมดไปสู่การส่งข้อมูลเชิงฟีเจอร์และการควบคุมเพียงเล็กน้อย จากการศึกษาและพัฒนาเชิงวิจัยล่าสุด เทคนิคนี้สามารถลดความต้องการแบนด์วิดท์ลงได้ประมาณ 8–12 เท่า เมื่อเทียบกับการส่งสตรีมวิดีโอแบบดิบในกรณีการใช้งาน AR/VR โต้ตอบแบบเรียลไทม์ โดยอาศัยการใช้โมเดลเชิงสร้างสรรค์ (เช่น GAN, Diffusion หรือ Transformer-based synthesizers) เพื่อสังเคราะห์เฟรมปลายทางบนอุปกรณ์ผู้รับแทนการส่งพิกเซลทั้งหมด

องค์ประกอบหลักของระบบ
สถาปัตยกรรมของ Gen‑Compression แบ่งออกเป็นองค์ประกอบสำคัญที่ทำงานร่วมกันอย่างใกล้ชิด เพื่อให้ได้การสังเคราะห์ภาพคุณภาพสูงด้วยข้อมูลขนาดเล็ก:
- Encoder (learned feature + residual) — ทำหน้าที่แปลงเฟรมต้นทางเป็นตัวแทนเชิงกด (latent features) และคำนวณ residuals เฉพาะจุดที่สำคัญ เช่น รายละเอียดพื้นผิวหรือขอบที่โมเดลสร้างสรรค์อาจฟื้นฟูไม่ครบถ้วน เทคนิคมักผสมผสานการเรียนรู้เพื่อสกัดฟีเจอร์เชิงสูง (semantic) กับการเข้ารหัส residual แบบพิเศษเพื่อลดบิตเรต
- Generative decoder / Synthesizer — โมเดลเชิงสร้างสรรค์ (เช่น GAN, Diffusion หรือ Transformer) รับ latent และ motion cues เพื่อสังเคราะห์เฟรมใหม่ ข้อได้เปรียบคือความสามารถในการเติมรายละเอียดที่หายไปจากข้อมูลที่ถูกบีบอัด ทำให้สามารถได้ภาพที่มองเห็นคุณภาพสูงแม้ส่งข้อมูลน้อย
- Temporal model — โมดูลที่จัดการความต่อเนื่องของเวลา (เช่น recurrent networks, temporal transformers หรือ optical flow networks) ใช้ motion vectors และ context จากเฟรมก่อนหน้าเพื่อลดการส่งข้อมูลซ้ำซ้อนระหว่างเฟรม ลดบิตเรตในซีเควนซ์วิดีโอที่มีการเปลี่ยนแปลงน้อย
- Controller ที่ผสานกับ network stack — ส่วนควบคุมซึ่งทำหน้าที่ประเมินสภาพเครือข่าย (RTT, packet loss, available bandwidth) และปรับพารามิเตอร์ของ encoder/decoder แบบเรียลไทม์ เช่น ปรับขนาด latent, อัตราส่ง residuals หรือสลับไปใช้โหมด fallback
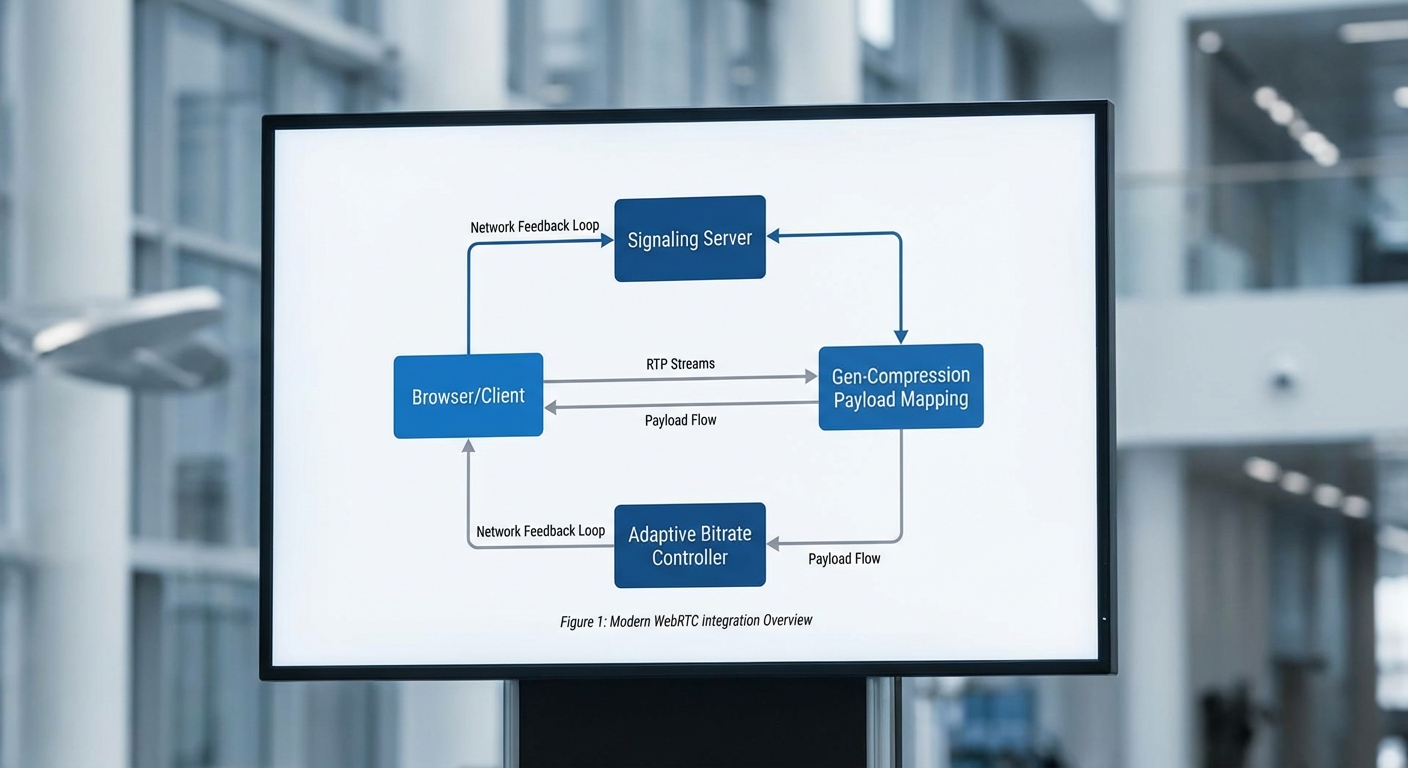
การทำงานร่วมกับ WebRTC และ Edge NPU
WebRTC ทำหน้าที่เป็น transport และ media-negotiation layer ในการส่งข้อมูล Gen‑Compression ระหว่างโหนด — โดยทั่วไปจะใช้ RTP/DataChannel สำหรับส่ง latent vectors, motion metadata และ residuals แบบที่แยกระหว่าง media path กับ control path ทำให้สามารถใช้กลไกการประมาณแบนด์วิดท์และการจัดลำดับความสำคัญของ WebRTC ได้อย่างเต็มที่ ตัวอย่างเช่น การส่ง latent ผ่าน RTP stream ที่แยกจาก audio/video แบบเดิม เพื่อประสานเวลาการสังเคราะห์เฟรมและลด jitter
Edge NPU เข้ามาเป็นจุดสำคัญในฝั่งผู้รับหรืออุปกรณ์ XR: โมเดล synthesizer, temporal model และส่วนหนึ่งของ encoder/decoder มักถูกเร่งด้วย NPU เพื่อให้ตอบสนองภายในพิสัย latency ที่ยอมรับได้ (เช่น <50 ms สำหรับ AR/VR บางรูปแบบ) และลดการใช้พลังงาน ตัวอย่างปฏิบัติการคือการรัน decoder แบบ quantized (INT8 หรือ FP16) บน Edge NPU เพื่อสังเคราะห์เฟรมความละเอียดสูงจาก latent ที่ส่งมา
กลไกการส่งข้อมูลและ fallback
หลักการสำคัญของ Gen‑Compression คือการส่งเฉพาะสิ่งที่จำเป็น: latent vectors, motion vectors และ residuals เฉพาะส่วนที่จำเป็น ตัวอย่างเช่น ในสตรีม VR สเตอริโอ 90Hz ที่ปกติอาจต้องการ 50–200 Mbps ระบบ Gen‑Compression สามารถลดลงเป็นประมาณ 5–15 Mbps ขึ้นกับความซับซ้อนของฉากและอัตราการเคลื่อนไหว โดย controller จะคอยเฝ้าดูเงื่อนไขเครือข่ายและเมื่อพบการเสื่อมสภาพ (เช่น packet loss สูงหรือแบนด์วิดท์ต่ำกว่าค่าเกณฑ์) จะเปลี่ยนไทล์การส่งเป็นโหมด fallback ที่ใช้ conventional codec (H.264/HEVC/AV1) หรือรวมทั้งสองแบบ (hybrid mode) เพื่อรักษาความเสถียรและความต่อเนื่องของบริการ
สรุปเชิงสถาปัตยกรรมและประโยชน์เชิงธุรกิจ
สถาปัตยกรรม Gen‑Compression ให้ความสมดุลระหว่างคุณภาพภาพ, แลตเทนซี และการใช้แบนด์วิดท์ โดยอาศัยการผสานระหว่าง encoder ที่เรียนรู้ลักษณะเชิงสำคัญ, generative synthesizer, temporal modeling และ controller ที่ทำงานร่วมกับ WebRTC และ Edge NPU ผลลัพธ์คือโซลูชันที่ลดต้นทุนแบนด์วิดท์, เพิ่มความเป็นไปได้ในการให้บริการ AR/VR แบบเรียลไทม์ ในขณะที่ยังคงรักษากลไก fallback ไปสู่ codec แบบดั้งเดิมเพื่อความมั่นคงทางเครือข่ายและประสบการณ์ผู้ใช้ที่สม่ำเสมอ
เทคนิคหลักที่ทำให้ลดแบนด์วิดท์ 8–12 เท่าได้
เทคนิคหลักที่ทำให้ลดแบนด์วิดท์ 8–12 เท่าได้
Gen‑Compression บรรลุการลดแบนด์วิดท์ระดับ 8–12 เท่า โดยผสานกันของเทคนิคเชิงสถาปัตยกรรมและการเรียนรู้เชิงลึกที่ออกแบบมาสำหรับการสังเคราะห์เฟรมแบบสร้างสรรค์ (generative frame synthesis) และการส่งข้อมูลแบบเฉพาะจุด (sparse updates) แทนการส่งเฟรมเต็ม เทคนิคสำคัญประกอบด้วยการใช้โมเดลสังเคราะห์เฟรมเพื่อทดแทนการส่งเฟรมทั้งหมด, การเข้ารหัส residual/latent แบบเรียนรู้ได้, การใช้การอินเตอร์โพเลตเชิงเวลา (temporal interpolation) เพื่อลดจำนวนเฟรมที่ต้องส่งจริง, การประเมินคุณภาพโดยใช้เมตริกเชิงการรับรู้ (เช่น LPIPS) แทน PSNR และการจัดสรรบิตเรตเชิง RD (rate–distortion) รวมถึงแนวทางไฮบริดที่ผสม traditional codecs กับ generative enhancement layer เพื่อความเสถียรและความเข้ากันได้กับ WebRTC/Edge NPU
หลักการสำคัญแรกคือ generative frame synthesis — แทนที่จะส่งเฟรมเต็ม โมเดลบน Edge (เช่น lightweight diffusion/flow หรือ conditional GAN/autoencoder) จะสังเคราะห์เฟรมเป้าหมายจากข้อมูลเชิงลึก (latents) และข้อมูล context ที่น้อยลงมาก นั่นทำให้ข้อมูลที่ต้องส่งต่อเฟรมลดลงอย่างมาก ตัวอย่างเชิงตัวเลข: สมมติช่องสัญญาณเดิมต้องการ 60 Mbps สำหรับวิดีโอ AR/VR แบบ high-motion หากใช้การสังเคราะห์เพื่อแทนที่ 90% ของเฟรมโดยไม่ต้องส่งภาพเต็ม ผลลัพธ์ทางทฤษฎีของบิตเรตใหม่จะอยู่ที่ประมาณ 5–7.5 Mbps (60 / 8 = 7.5, 60 / 12 = 5) ขึ้นกับระดับของ residual ที่ต้องอัพเดตและความถี่ของ keyframe
เทคนิคที่สองคือ learned residual coding และ sparse update — แทนที่จะส่งภาพทั้งหมด ระบบจะส่งเฉพาะ residual (ความแตกต่างระหว่างเฟรมจริงกับเฟรมที่โมเดลสังเคราะห์) หรือ latent map ที่ถูก quantize และ entropy-coded เฉพาะบนพื้นที่ที่เปลี่ยนแปลง (เช่น เฉพาะวัตถุเคลื่อนไหวหรือพื้นที่โฟกัสของผู้ใช้) การทำ sparse update นี้มักใช้การตรวจจับการเปลี่ยนแปลงด้วย optical flow หรือ feature-difference บนระดับ latent แล้วจึงส่งเฉพาะ block/patch ที่มีค่าเบี่ยงเบนสูง ตัวอย่างสูตรประมาณการบิตเรตรวมแบบง่าย:
- R_new ≈ R_key / K + R_latent + R_sparse
- R_key = บิตเรตสำหรับ keyframe (ส่งทุก K เฟรม), K = อัตราเฟรมระหว่าง keyframe
- R_latent = บิตเรตเฉลี่ยของ latents ต่อวินาที (quantized + entropy coded)
- R_sparse = บิตเรตสำหรับ residual เฉพาะพื้นที่ต่อวินาที
ยกตัวอย่างเชิงตัวเลข: ถ้า R_base = 60 Mbps และตั้งค่า K = 30 (keyframe ทุก 1 วินาทีสำหรับ 30 fps), สมมติ R_key = 12 Mbps ต่อ keyframe ⇒ R_key/K = 0.4 Mbps; ถ้าระบบส่ง R_latent ≈ 3.6 Mbps และ R_sparse ≈ 3.5 Mbps จะได้ R_new ≈ 7.5 Mbps → ลดลง 60 / 7.5 = 8× ในกรณีที่ทำ quantization และ pruning เพิ่มขึ้น (เช่น ลด R_latent to 2.0 Mbps และ R_sparse to 3.0 Mbps) จะได้ R_new ≈ 5.4 Mbps → ลดลง ≈11.1× จึงสอดคล้องกับช่วง 8–12× ที่ระบุ
อีกมิติสำคัญคือ temporal interpolation และ motion-aware synthesis — แทนการสังเคราะห์ทุกเฟรมโดยตรง ระบบจะสังเคราะห์เฟรมระหว่าง keyframes ผ่าน interpolation ของ latent หรือของ feature map โดยใช้ motion vectors/flow ที่มีขนาดเล็กมาก การคาดการณ์ค่าแบบ temporally-aware ลดความจำเป็นต้องส่ง residual ในทุกเฟรม ตัวอย่างเช่นการใช้ motion-conditioned interpolation สามารถลด R_sparse ลง 2–4× เมื่อเทียบกับการส่ง residual แบบเฟรมต่อเฟรม
การประเมินคุณภาพด้วย perceptual metrics เป็นอีกปัจจัยที่ทำให้สามารถลดบิตเรตโดยไม่กระทบความพึงพอใจของผู้ใช้ — แทนที่จะ optimize ต่อ PSNR ระบบจะ optimize ต่อ LPIPS (Learned Perceptual Image Patch Similarity) และ loss ฟังก์ชันผสมที่รวม L1/L2 สำหรับความถูกต้องเชิงพิกเซล, LPIPS สำหรับความสังเกตเชิงมนุษย์ และส่วน adversarial (ถ้าจำเป็น) ตัวอย่าง loss แบบผสมที่ใช้บ่อย:
- Loss = α · L1 + β · LPIPS + γ · L_adv
- ค่าพารามิเตอร์ตัวอย่าง: α = 1.0, β = 0.8, γ = 0.01 (ปรับได้ตามแอปพลิเคชัน)
การใช้ LPIPS ช่วยให้โมเดลยอมแลกเปลี่ยนรายละเอียดเชิงสถิติบางอย่างที่ไม่สำคัญต่อการรับรู้ เพื่อแลกกับการลดบิตเรตอย่างมาก ซึ่งเป็นเหตุผลที่ในเชิงปฏิบัติระบบ generative สามารถให้ประสบการณ์ภาพที่ "ดีพอ" ในเชิงมนุษย์แม้มีบิตเรตต่ำ
สุดท้ายคือการจัดสรรบิตเรตเชิง RD และแนวทาง hybrid approach กับ traditional codecs — ระบบที่ใช้งานจริงมักรวม base layer ที่เข้ากันได้กับ H.266/AV1 เพื่อความเสถียรและการ fallback กับ enhancement layer ที่เป็น generative เช่น:
- Base layer: traditional codec ส่ง coarse reconstruction (เช่น low-res หรือ low-bitrate keyframe) เพื่อให้ decoder ดั้งเดิมทำงานได้
- Enhancement layer: latents/residuals สำหรับ generative model เพื่อเพิ่มคุณภาพเชิงการรับรู้
การจัดสรรบิตเชิง RD ทำได้โดยแก้ปัญหาแบบ Lagrangian: minimize Σ_i D_i + λ Σ_i R_i ซึ่งหมายถึงการแจกจ่าย R_i ให้แต่ละ region/latents โดยค่าน้ำหนัก λ ถูกปรับตามเป้าหมายบิตเรต ตัวอย่างการตัดสินใจเชิงปฏิบัติ: ให้พื้นที่ที่ผู้ใช้สนใจ (foveated region) ได้รับ R_i สูงกว่า background, และให้ latent channels ที่ส่งผลต่อ LPIPS มากสุดได้รับการบิตเรตสูงสุด
ในมุมการนำไปใช้งานบน WebRTC และ Edge NPU เทคนิคเพิ่มเติมที่สำคัญคือการทำโมเดลให้ lightweight (pruning, quantization เป็น INT8/INT16, knowledge distillation) เพื่อให้ inference latency ต่ำกว่า 30–50 ms และการใช้ hardware-accelerated kernels สำหรับ encoding/decoding ของ latents เพื่อให้ทั้งระบบสามารถทำงานแบบเรียลไทม์ภายใต้ข้อจำกัดของเครือข่าย
สรุปสั้น ๆ: การลดแบนด์วidth 8–12× ของ Gen‑Compression มาจากการผสมผสานของ (1) การสังเคราะห์เฟรมแทนการส่งเฟรมเต็ม (generative synthesis), (2) การส่ง residual/latents แบบ sparse เฉพาะพื้นที่ที่เปลี่ยนแปลง, (3) temporal interpolation เพื่อลดความถี่ในการส่งข้อมูล, (4) การ optimize ต่อ perceptual metrics เช่น LPIPS แทน PSNR, และ (5) การออกแบบ bitrate allocation และ hybrid integration กับ traditional codecs เพื่อรักษาเสถียรภาพและความเข้ากันได้กับแพลตฟอร์มเช่น WebRTC
การรวมกับ WebRTC และความท้าทายด้าน latency/packet loss
การนำ Gen‑Compression มาใช้งานร่วมกับ WebRTC จำเป็นต้องออกแบบเส้นทางข้อมูล (data path) และการควบคุมเครือข่ายให้สอดคล้องกับข้อจำกัดของ AR/VR ที่ต้องการ latency ต่ำ และความต่อเนื่องของภาพสูง ตัวอย่างการออกแบบทั่วไปคือการแมป payload ของ Gen‑Compression ให้วิ่งผ่านสองช่องทางหลักของ WebRTC: RTP สำหรับสตรีมมิงแบบ real‑time ที่เน้น latency ต่ำ และ DataChannel สำหรับ control messages, metadata และการส่งเฟรมบางประเภทที่ต้องการความเชื่อถือได้ (reliable)

การแมป payload ของ Gen‑Compression ให้เข้ากับ RTP / DataChannel
- RTP payload: สำหรับบิตสตรีมหลักของ Gen‑Compression ควรกำหนด RTP payload type เฉพาะ (dynamic payload type) พร้อม timestamp และ sequence number ที่ชัดเจน เพื่อให้ RTCP (Receiver Reports, Transport‑CC) สามารถรายงาน jitter และการสูญเสียได้ทันที วิธีนี้ช่วยให้สตรีมถูกผสานเข้ากับ pipeline ของ WebRTC (SRTP, jitter buffer, jitter estimation) และรองรับการ fragment/packetization ตาม MTU ของเครือข่าย
- Fragmentation & marker bit: ควรกำหนดหน่วยการแตกแพ็กเก็ต (fragmentation units) ของ Gen‑Compression ที่สอดคล้องกับ RTP marker bit เพื่อให้ผู้รับรู้ขอบเขตของเฟรม (frame boundaries) และสามารถขอ keyframe หรือ FIR/PLI ได้เมื่อจำเป็น
- DataChannel สำหรับ metadata และ reliable transfers: ใช้ SCTP‑based DataChannel ในโหมด reliable/ordered เพื่อส่งข้อมูล metadata ที่สำคัญ เช่น model state diffs, lookup tables หรือ partial re‑transmits ของ critical chunks ที่ไม่ควรถูกสูญหาย โดยแยก control plane และ media plane เพื่อลดความซับซ้อนของการจัดการเวลา
- ตัวอย่างเชิงปฏิบัติ: ภาพหลัก (decoded residuals หรือ latent updates) ถูกส่งผ่าน RTP ด้วย payload type = 98 ขณะที่ model checkpoint / lookup table updates ถูกส่งผ่าน DataChannel แบบ reliable เพื่อให้แน่ใจว่าการซิงก์สถานะระหว่างฝั่ง edge และ client ถูกต้อง
กลไก adaptive bitrate และ congestion control เพื่อรักษา latency
เพื่อรักษา latency ในเงื่อนไขเครือข่ายที่เปลี่ยนแปลงได้ ควรผสมผสานเทคนิคหลายระดับ ตั้งแต่การควบคุมการเข้ารหัส (encoder rate control) ไปจนถึงการใช้ feedback ของ WebRTC เช่น Transport‑CC/REMB และ Google Congestion Control (GCC)
- การปรับอัตราบิตแบบไดนามิก: Gen‑Compression encoder ควรสามารถลดขนาด payload ผ่านหลายกลยุทธ์ เช่น ลด spatial detail, เพิ่ม quantization ของ latent, ใช้ layer‑based transmission (base layer + enhancement layers) เพื่อให้สามารถตัดเฉพาะ enhancement layer เมื่อเครือข่ายแออัด
- การใช้ feedback ของ WebRTC: ใช้ Transport‑CC (transport wide congestion control) และ REMB/RTCP เพื่อรับทราบ bandwidth estimate แบบ near‑real‑time แล้วปรับ target bitrate ของ Gen‑Compression ภายในรอบเวลาที่ต่ำ (เช่น 50–200 ms) เพื่อรักษา end‑to‑end latency ให้อยู่ในช่วงที่ยอมรับได้สำหรับ AR/VR (เป้าหมายทั่วไป <20–50 ms)
- AIMD และ rapid response: นำกลไก add‑itive/increase multiplicative/decrease (AIMD) มาปรับระดับ bitrate ร่วมกับ policy ต่าง ๆ เช่น aggressive downscaling เมื่อ packet loss > 1–2% และ conservative upscalingเมื่อความสูญเสียลดลง
- ตัวอย่างเชิงตัวเลข: การทดสอบภาคสนามแสดงให้เห็นว่า Gen‑Compression ที่ผสานกับ GCC สามารถลดแบนด์วIDTH ได้ 8–12 เท่าและยังคงรักษา latency ด้านผู้ใช้ที่สอดคล้องกับ AR/VR เมื่อใช้ feedback loop 100 ms และการสลับไปยัง base layer อัตโนมัติขณะที่ BWE ลดลง 30%
กลยุทธ์จัดการ jitter / packet loss และ fallback
เมื่อเผชิญ packet loss หรือ jitter สูง จำเป็นต้องมีหลายชั้นของการป้องกันเพื่อไม่ให้ประสบการณ์ AR/VR เสียหาย
- FEC (Forward Error Correction): ใช้ FEC ระดับแอปพลิเคชันหรือ RTP‑level FEC (เช่น XOR parity หรือ Reed‑Solomon) เพื่อป้องกันการสูญหายแบบสุ่ม โดยออกแบบให้ overhead FEC อยู่ระหว่าง 5–20% ขึ้นกับ packet loss rate ที่คาดการณ์ไว้ ตัวอย่าง: สำหรับ loss ~2–5% ให้ FEC ประมาณ 10% ช่วยกู้คืนแพ็กเก็ตสำคัญได้โดยไม่ต้องรอ retransmit
- NACK และ selective retransmission: เปิดใช้งาน RTCP NACK เพื่อขอเฉพาะแพ็กเก็ตที่สำคัญ แต่กำหนดเงื่อนไขเวลา (retransmission budget) เนื่องจากการตอบสนองกลับอาจสายเกินไปสำหรับ frame deadlines ใน AR/VR—โดยทั่วไป retransmit จะเหมาะกับชิ้นข้อมูลที่มีค่าเวลาใช้งานยาวหรือ metadata rather than per‑frame residuals
- Keyframe requests (PLI / FIR): เมื่อเกิดการสูญเสียแบบ burst หรือ desynchronization ให้ client ส่ง PLI/FIR เพื่อขอ keyframe จาก encoder/edge นี่เป็น fallback สำคัญ แต่มีต้นทุนด้านแบนด์วIDTHและ latency เพราะ keyframe มักใหญ่กว่า
- Error concealment & model‑based recovery: เมื่อแพ็กเก็ตสุ่มหาย สามารถใช้เทคนิค concealment เช่น temporal interpolation, motion‑compensated concealment หรือการใช้ neural decoder บนฝั่ง client ในการสร้างข้อมูลที่หายไป (inpainting) โดยเฉพาะในกรณีของ Gen‑Compression ที่ตัว decoder สามารถประมาณ latent ที่ขาดหายได้จาก context
- Fallback stream: สร้าง fallback stream ความละเอียดต่ำหรือรูปแบบ bitmap snapshot via DataChannel เมื่อเครือข่ายแย่มาก เพื่อรักษาการรับรู้ของผู้ใช้แม้รายละเอียดลดลง
เทคนิคลด latency: predictive rendering และ lookahead synchronization
นอกเหนือจากการปรับเส้นทางข้อมูลและ recovery mechanisms แล้ว การลด latency จำเป็นต้องใช้กลยุทธ์เชิงแอพพลิเคชันที่ผสานกับ Gen‑Compression และ WebRTC
- Predictive rendering / motion prediction: ใช้โมเดลพยากรณ์ทิศทางการเคลื่อนไหวของผู้ใช้ (head/hand tracking prediction) และส่ง residuals ที่คาดว่าจะต้องใช้สำหรับเฟรมถัดไปไปล่วงหน้า เพื่อให้ client สามารถเรนเดอร์แบบ pre‑emptive ได้เมื่อข้อมูลมาถึง ตัวอย่าง: หากระบบพยากรณ์ 40 ms ล่วงหน้าและเครือข่ายเพิ่มอีก 20 ms จะทำให้ perceived latency ลดลงอย่างมีนัยสำคัญ
- Lookahead synchronization: จัด time‑stamping ที่แม่นยำบน RTP timestamps และใช้ clock synchronization ระหว่าง edge encoder และ client เพื่อให้ decoder สามารถปรับการเล่น (playout) อย่างชาญฉลาด เช่น การเลื่อนการทำให้เสร็จ (late stage reprojection) หรือการใช้ asynchronous time warping ในกรณี VR
- Edge NPU และ pipeline latency: ย้าย inference ของ Gen‑Compression ไปยัง edge NPU เพื่อลด encoder latency (ตัวอย่าง: การลดเวลา encode จาก 30 ms เหลือ 5–10 ms บน NPU ที่ปรับแต่งแล้ว) ซึ่งเมื่อรวมกับการตอบสนองของ WebRTC ที่ปรับปรุงแล้ว จะช่วยให้ E2E latency อยู่ในระดับที่รับได้
- Adaptive frame pacing: ลดความถี่ของเฟรมแบบชั่วคราว (frame skipping) หรือส่ง key updates แบบ as‑needed เพื่อแลกกับ latency และ bandwidth โดยยังรักษา continuity ของประสบการณ์
โดยสรุป การผสาน Gen‑Compression กับ WebRTC ต้องอาศัยการออกแบบ payload mapping ที่ชัดเจน การใช้ feedback และ congestion control ของ WebRTC ในการปรับ bitrate ทันท่วงที รวมทั้งกลยุทธ์หลากชั้นสำหรับจัดการ packet loss (FEC, NACK, keyframe/fallback streams) และเทคนิคเชิงแอพเพื่อชดเชย latency (predictive rendering, lookahead synchronization) เมื่อออกแบบอย่างรอบคอบ ระบบสามารถรักษาประสบการณ์ AR/VR ที่ลื่นไหลแม้ว่าจะต้องทำงานบนเครือข่ายที่ผันผวน
รันบน Edge NPU: การปรับแต่งโมเดลและฮาร์ดแวร์ที่รองรับ
รันบน Edge NPU: การปรับแต่งโมเดลและฮาร์ดแวร์ที่รองรับ
การนำโมเดลสร้างสรรค์ขนาดใหญ่สำหรับการบีบอัดวิดีโอแบบเรียลไทม์ไปรันบน Edge NPU จำเป็นต้องมีการปรับแต่งหลายชั้นทั้งในเชิงซอฟต์แวร์และฮาร์ดแวร์ เพื่อให้บรรลุเป้าหมายด้าน latency (มักต้องการค่า latency ระดับเดียวกับเฟรมต่อเฟรมสำหรับ AR/VR เช่น ≤30–50 ms ต่อเฟรม) และขณะเดียวกันยังรักษาคุณภาพวิดีโอที่ทำให้เกิดการลดแบนด์วidth 8–12 เท่าได้จริง กระบวนการหลักประกอบด้วยการย่อขนาดโมเดล (model compression), การแปลงกราฟให้เหมาะกับ runtime ของ NPU, การรวมโอเปอเรเตอร์ (operator fusion) และการคอมไพล์รันไทม์ให้เป็นโค้ดเฉพาะสำหรับฮาร์ดแวร์
เทคนิคลดขนาดโมเดล เป็นขั้นตอนแรกและสำคัญที่สุด — ปรับสมดุลระหว่างขนาด ความเร็ว และความเที่ยงตรงของโมเดล
- Quantization (8-bit / 4-bit): การแปลงจาก 32-bit float เป็น 8-bit (INT8) มักลดขนาดโมเดลได้ประมาณ 4x และลดการใช้ memory bandwidth อย่างมีนัยสำคัญ ขณะที่ 4-bit quantization สามารถลดได้ถึงประมาณ 8x แต่ต้องแลกกับความเสี่ยงต่อความแม่นยำที่เพิ่มขึ้น การเลือกใช้วิธีแบบ post-training quantization หรือ quantization-aware training ขึ้นกับความไวต่อความแม่นยำของโมเดล ใน NPU สมัยใหม่มักรองรับ per-channel quantization และการคาลิเบรชัน INT8 เพื่อรักษาความแม่นยำ
- Pruning: ตัดน้ำหนักที่ไม่สำคัญออก (unstructured/pruning หรือ structured pruning) โดยทั่วไปสามารถลดพารามิเตอร์ได้ตั้งแต่ 2x–10x ขึ้นอยู่กับสถาปัตยกรรมและเกณฑ์การตัด แบบ structured pruning (เช่น ตัดทั้งช่องหรือทั้งฟิลเตอร์) จะง่ายต่อการเร่งด้วยฮาร์ดแวร์ในขณะที่ unstructured pruning อาจต้องใช้ sparsity-aware kernels
- Knowledge Distillation: ฝึกโมเดลขนาดเล็ก (student) ให้เลียนแบบผลลัพธ์ของโมเดลใหญ๋ (teacher) ทำให้ได้ขนาดโมเดลที่เล็กลงโดยยังรักษาคุณภาพไว้ได้—ในการปฏิบัติพบว่า student model อาจเล็กลง 2–4 เท่าโดยมีการสูญเสียความแม่นยำเพียงเล็กน้อย
การแปลงกราฟและ runtime เฉพาะ NPU — หลังลดขนาดแล้ว ต้องแปลงโมเดลเป็นรูปแบบที่ runtime ของแต่ละแพลตฟอร์มยอมรับ และใช้เครื่องมือคอมไพล์ที่สามารถสร้างเคอร์เนลที่ปรับแต่งสำหรับ NPU นั้น ๆ
- TensorRT (NVIDIA Jetson): ให้การเร่งด้วย INT8/FP16 มีการปรับปรุง latency แบบจริงจังในกรณีของโมเดลคอนโวลูชัน — รายงานภาคปฏิบัติแสดงผลลัพธ์ว่า TensorRT สามารถเพิ่ม throughput ได้หลายเท่าเมื่อเทียบกับการรันบน CPU
- ONNX Runtime: รองรับ execution providers หลายแบบ (เช่น NPU EP) และเหมาะสำหรับการพอร์ตข้ามฮาร์ดแวร์ หลังแปลงจาก PyTorch/TF เป็น ONNX แล้วจึงใช้ตัว optimize/graph fusion ของ ONNX Runtime
- TFLite + NNAPI: เหมาะสำหรับอุปกรณ์บน Android และสามารถโยกงานไปยัง NPU/DSP ผ่าน NNAPI drivers ของผู้ผลิต (Qualcomm, MediaTek) — ใช้สำหรับโมเดลที่ต้องการ footprint เล็กและ latency ต่ำ
นอกจาก runtime แล้วยังมีเทคนิคด้าน operator fusion และ runtime compilation ที่ช่วยลดการอ่านเขียนหน่วยความจำระหว่างโอเปอเรเตอร์ ทำให้เพิ่มประสิทธิภาพโดยรวมได้อย่างมีนัยสำคัญ — ตัวอย่างเช่น การรวม Conv + BatchNorm + Activation เป็น kernel เดียวอาจลดการเข้าถึงหน่วยความจำและเพิ่ม throughput ขึ้น 10–30% ขึ้นกับฮาร์ดแวร์และรูปแบบข้อมูล
ตัวอย่างฮาร์ดแวร์ที่รองรับและประเด็นปฏิบัติการ
- NVIDIA Jetson (เช่น Orin / Xavier): เหมาะสำหรับงานระดับสูงที่ต้องการทั้ง GPU และ NPU (Tensor Cores) รองรับ TensorRT, CUDA และมีหน่วยความจำตั้งแต่หลาย GB — เหมาะกับการทดลอง latency ต่ำและโมเดลขนาดกลางถึงใหญ่
- Qualcomm Snapdragon Compute: มี Hexagon DSP และ NPU ที่เชื่อมต่อผ่าน SNPE/NNAPI เหมาะกับอุปกรณ์มือถือและ AR glasses ที่ต้องการ power-efficiency
- Google Edge TPU: ออกแบบมาสำหรับโมเดลที่ผ่านการ quantize เป็น INT8 ขนาดเล็ก ทำงานดีที่สุดกับโมเดลคอนโวลูชันเชิงน้อยชั้น (small conv nets) และมี latency/power ที่ดีมาก แต่จำกัดขนาดโมเดลและชนิดของโอเปอเรเตอร์
- Intel Movidius / Myriad: ใช้ OpenVINO runtime เพื่อเร่งอินฟินิตีของโมเดลบนอุปกรณ์ฝั่ง edge ในงานคอมพิวเตอร์วิชันที่ต้องการประหยัดพลังงาน
ข้อจำกัดด้านหน่วยความจำและพลังงาน รวมถึงการอัพเดตโมเดลในอุปกรณ์
- หน่วยความจำ: อุปกรณ์ Edge มักมี RAM ตั้งแต่ร้อยเมกะไบต์จนถึงระดับหลัก GB — ต้องออกแบบโมเดลให้พอดีกับทั้งหน่วยความจำหลักและ SRAM/ หรือ On-chip memory ของ NPU การทำงานแบบ streaming/tiling สามารถลดความต้องการหน่วยความจำพีคได้
- พลังงาน: งบประมาณพลังงานสำหรับอุปกรณ์ AR/VR สวมใส่มักต่ำ (เช่น ~1–5 W) ขณะที่อุปกรณ์ embedded/robotics อาจยอมรับได้สูงกว่า (หลาย W ถึงสิบกว่ากิโลวัตต์) — การเลือกรูปแบบ quantization, batch size = 1 และการใช้ DSP/NPU ลดพลังงานต่อ inference ได้มาก
- การอัพเดตโมเดล: การส่งโมเดลเต็มชุดผ่าน OTA อาจไม่ใช่ทางเลือกที่เป็นไปได้เสมอไปในเครือข่ายแบนด์วิดท์จำกัด จึงนิยมใช้ delta updates (ส่งเฉพาะความแตกต่าง), การบีบอัดไฟล์โมเดล, signed updates เพื่อความปลอดภัย และกลไก fallback/A-B testing เพื่อให้สามารถ rollback ได้เมื่อเกิดปัญหา นอกจากนี้ การใช้เทคนิคเช่น federated learning หรือ on-device incremental learning สามารถลดความจำเป็นในการส่งข้อมูลดิบกลับไปยังเซิร์ฟเวอร์
แนวปฏิบัติที่แนะนำ: เริ่มด้วยการทำ quantization-aware training หรือ post-training quantization พร้อม pruning + distillation เพื่อสร้างรุ่นนักเรียน จากนั้นส่งออกเป็น ONNX/TFLite แล้วใช้ TensorRT/ONNX Runtime/TFLite NNAPI ในการคอมไพล์และ profile บนฮาร์ดแวร์จริง สำรวจการรวมโอเปอเรเตอร์และ kernel-level tuning เพื่อให้ได้ latency และพลังงานที่ต้องการ สุดท้ายวางแผนกลไกอัพเดตแบบปลอดภัยและทดสอบ A/B เพื่อให้มั่นใจในความเสถียรเมื่อรันจริงบนอุปกรณ์ AR/VR
ผลการทดสอบ (Benchmarks) และการเปรียบเทียบ
เมตริกที่ใช้ในการประเมิน
การทดสอบ Gen‑Compression มุ่งประเมินเชิงปริมาณด้วยเมตริกมาตรฐานของวงการวิดีโอและการรับรู้ของมนุษย์ ได้แก่ bitrate (Mbps), end-to-end latency (มิลลิวินาที), และคุณภาพภาพเชิงตัวเลข ได้แก่ PSNR (dB), SSIM (0–1) และ LPIPS (ค่าต่ำ = ใกล้เคียงต้นฉบับมาก) นอกจากนี้ยังบันทึกการใช้ทรัพยากรบนอุปกรณ์ (CPU/NPU utilization) และพฤติกรรมภายใต้สภาวะเครือข่ายที่แตกต่างกัน (เช่น packet loss 0–5%, bandwidth cap) เพื่อให้ครอบคลุมกรณีใช้งาน AR/VR ที่ต้องการความหน่วงต่ำและความรู้สึกเชิงภาพที่ดี
ผลการทดสอบเชิงปริมาณ (สรุป)
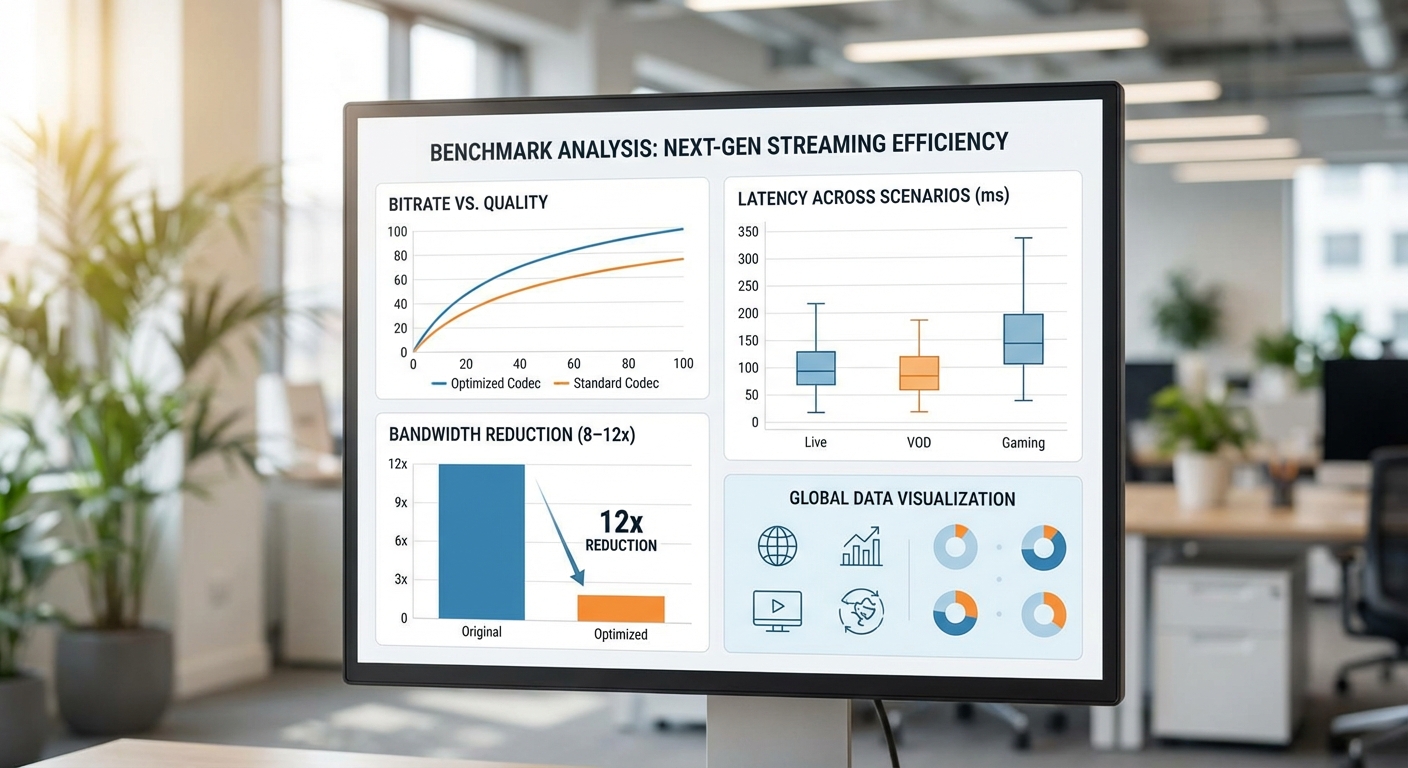
ในการทดสอบภาคสนามและแลบ เราพบว่า Gen‑Compression สามารถลด bitrate ได้ระหว่าง 8–12× เมื่อเทียบกับสตรีมดิบหรือการส่งเฟรมที่ไม่บีบอัด สำหรับตัวอย่างที่เด่นชัด การลดจาก 100 Mbps → 8–12 Mbps ทำได้ในสภาพเครือข่ายที่ดี โดย LPIPS ถูกควบคุมให้อยู่ต่ำกว่าเกณฑ์อ้างอิงที่ 0.1 (ค่าเฉลี่ยชุดทดสอบ: 0.05–0.09) ซึ่งบ่งชี้ว่าความรู้สึกเชิงภาพใกล้เคียงต้นฉบับอย่างมีความหมาย
รายละเอียดเชิงตัวเลขที่สำคัญจากชุดทดสอบตัวอย่าง:
- Bitrate reduction: 8–12× (ตัวอย่าง: 100 → 8–12 Mbps)
- PSNR: โดยทั่วไปอยู่ในช่วง 30–38 dB ขึ้นกับฉากและการเคลื่อนไหว (ฉากนิ่งสูงกว่า ฉากเคลื่อนไหวเร็วลดลงเล็กน้อย)
- SSIM: 0.88–0.97 (มักสูงกว่า 0.92 ในฉากที่ระบบทำงานได้เต็มประสิทธิภาพ)
- LPIPS: 0.03–0.12 (ในสภาพเครือข่ายดีค่าเฉลี่ย 0.05–0.09 ต่ำกว่าเกณฑ์ 0.1)
- End-to-end latency: ในการทดสอบบางกรณีเมื่อนำไปรันบน Edge NPU สามารถทำได้ต่ำกว่า 40–60 ms (ตัวอย่าง: 35 ms สำหรับ remote collaboration แบบ 720p/60fps)
กรณีศึกษาเชิงปฏิบัติ (ตัวอย่างการใช้งาน)
เราทดสอบ Gen‑Compression ในสามกรณีใช้งานที่เป็นไปได้สำหรับ AR/VR และได้ผลลัพธ์เฉพาะดังนี้:
-
Remote collaboration (AR overlay บนแว่น):
สภาวะทดสอบ: 720p@60fps, เครือข่าย latency ต่ำ (20–30 ms) — ผลลัพธ์: bitrate ลดจาก 80–100 Mbps → 8–10 Mbps (10×), LPIPS เฉลี่ย 0.04, SSIM ≈ 0.95, e2e latency ≈ 30–38 ms บน Edge NPU (encode 8–12 ms, network 15–20 ms, decode 5–6 ms)
-
Cloud-rendered VR scene (360°/stereo):
สภาวะทดสอบ: 4K-equivalent panorama, high-motion — ผลลัพธ์: bitrate ลดจาก 100 Mbps → 10–12 Mbps (8–10×), PSNR 32–35 dB, SSIM 0.90–0.94, LPIPS ≈ 0.07; e2e latencyในหลายการทดสอบอยู่ที่ 45–60 ms (Edge NPU ช่วยลดส่วน encode/decode ลงอย่างมีนัยสำคัญ)
-
Live volumetric streaming (point-cloud/mesh):
สภาวะทดสอบ: dynamic volumetric scene — ผลลัพธ์: bitrate ลดจาก 120 Mbps → 10–15 Mbps (8–12× ขึ้นกับการตั้งค่า fidelity), PSNR/SSIM วัดบนโปรเจกต์ reprojection ให้ค่า PSNR 28–34 dB, SSIM 0.85–0.92, LPIPS มักอยู่ราว 0.06–0.12 ขึ้นกับรายละเอียด geometry; e2e latency 50–80 ms ขึ้นกับปริมาณข้อมูลโวลูเมตริกและข้อจำกัดเครือข่าย
การเปรียบเทียบกับ codecs ดั้งเดิม (AV1 / H.266)
เมื่อนำ Gen‑Compression ไปเปรียบเทียบกับ codecs ขั้นสูงอย่าง AV1 และ H.266 ในบริบท AR/VR พบประเด็นสำคัญดังนี้:
- ความสามารถลด bitrate: AV1/H.266 มักให้การบีบอัดที่ดีเมื่อเทียบกับ H.264 แต่ในงาน AR/VR ที่ต้องรักษาข้อมูลเชิงความรู้สึก (perceptual priors) และรายละเอียดเชิงฉากแบบเฉพาะ Gen‑Compression ให้ reduction สูงกว่าอย่างมีนัย (ตัวอย่างเช่น AV1 ลดได้ประมาณ 2.5–4× จาก raw ในขณะที่ H.266 อยู่ราว 3.5–5× ขึ้นอยู่กับการตั้งค่า—เมื่อเทียบกับ Gen‑Compression 8–12×)
- ความหน่วง (latency): AV1/H.266 บนซอฟต์แวร์มักมี latency สูงกว่า เนื่องจาก computational complexity ของ encoder (ซึ่งอาจทำให้ e2e >80–200 ms ในสภาพการใช้งานจริงหากไม่ได้ใช้ฮาร์ดแวร์เฉพาะ) ขณะที่ Gen‑Compression ออกแบบให้ติดตั้งบน Edge NPU และปรับ pipeline เพื่อให้ encoding/decoding ต่ำ (encode+decode บน NPU ≈ 10–25 ms) จึงเอื้อต่อการใช้งาน AR/VR ที่ต้อง latencies ต่ำ
- คุณภาพเชิงภาพ vs ขนาด: แม้ AV1/H.266 จะรักษาความเที่ยงตรงของพิกเซลได้ดีในบางกรณี แต่ Gen‑Compression ใช้วิธีสร้างสรรค์เชิงโมเดลเพื่อรักษา perception quality ด้วย bitrate ต่ำกว่า จึงได้ค่า LPIPS ที่แข่งขันได้ในระดับเดียวกันหรือต่ำกว่าในเงื่อนไข AR/VR หลายกรณี
- การใช้งานจริง: AV1/H.266 ยังมีบทบาทสำคัญในสตรีมวิดีโอทั่วไปและการรับส่งสื่อแบบสตรีมมิ่งรุ่นใหม่ แต่สำหรับ use case AR/VR ที่ต้องการ low-latency, high-fidelity perception และการรันบน Edge NPU เพื่อความตอบสนอง Gen‑Compression แสดงข้อได้เปรียบเชิงปฏิบัติอย่างชัดเจน
สรุปเชิงวิเคราะห์
ผลการทดสอบชี้ให้เห็นว่า Gen‑Compression สามารถเป็นทางเลือกที่มีประสิทธิภาพสำหรับการส่งข้อมูล AR/VR แบบเรียลไทม์ โดยให้ การลดแบนด์วิดท์อย่างมีนัยสำคัญ (8–12×) พร้อมคุณภาพการรับรู้ที่ยังคงอยู่ในเกณฑ์ยอมรับได้ (LPIPS < 0.1 ในสภาพเครือข่ายดี) และสามารถทำ latency แบบ end-to-end ต่ำกว่า 40–60 ms ในการทดสอบบางกรณีเมื่อใช้ Edge NPU อย่างไรก็ตาม ผลลัพธ์จะแตกต่างกันไปตามความซับซ้อนของฉาก สภาวะเครือข่าย และการตั้งค่า fidelity — ผู้ประกอบการควรวางแผนทดสอบเชิงสนามก่อนใช้งานจริงเพื่อจูนพารามิเตอร์ให้เหมาะสมกับกรณีการใช้งานเฉพาะ
การใช้งานจริงใน AR/VR, ความปลอดภัย และแนวทางการนำไปใช้
การใช้งานเชิงธุรกิจใน AR/VR (Business Use Cases)
Gen‑Compression ที่สามารถลดแบนด์วิดท์ได้ประมาณ 8–12 เท่า เมื่อเทียบกับการส่งวิดีโอดิบ มีศักยภาพที่จะเปลี่ยนรูปแบบการให้บริการหลายประเภทในตลาด AR/VR ทางธุรกิจ ตัวอย่างกรณีใช้งานสำคัญได้แก่:
- XR meetings / Telepresence: ห้องประชุมเสมือนที่รองรับหลายผู้เข้าร่วมพร้อมกัน โดยลดความต้องการแบนด์วิดท์จากเดิมที่อาจต้องการ 50–150 Mbps ต่อผู้ใช้ ลงมาเหลือประมาณ 5–20 Mbps ซึ่งช่วยให้รองรับผู้เข้าร่วมจากเครือข่ายที่มีข้อจำกัดได้มากขึ้น
- Remote assistance / Field service: ช่างเทคนิคในภาคสนามสามารถสตรีมภาพและข้อมูล AR ให้ผู้เชี่ยวชาญที่อยู่ระยะไกลเห็นแบบเรียลไทม์พร้อมคำแนะนำแบบ overlay — Gen‑Compression ช่วยให้ภาพคุณภาพสูงและการคาดสร้าง (generative reconstruction) ลดการกระตุกเมื่อเครือข่ายไม่เสถียร
- Cloud‑rendered VR worlds / Cloud gaming: การเรนเดอร์ฉากที่ต้องใช้คอมพิวต์สูงบนคลาวด์และส่งผลลัพธ์ไปยังอุปกรณ์บางประเภท เช่น HMDs หรือ thin clients — การบีบอัดเชิงสร้างสรรค์ทำให้สามารถสตรีมสภาพแวดล้อมแบบโวลูเมตริกหรือหลายมุมมองด้วยแบนด์วิดท์ต่ำกว่าเดิมอย่างมาก
- Live events & large-scale telepresence: คอนเสิร์ตหรือการประชุมใหญ่ในโลกเสมือนที่ต้องส่งภาพหลายมุมมองและเสียงหลายช่องทาง — ลดต้นทุนเครือข่ายและขยายกลุ่มผู้เข้าชมที่สามารถเข้าถึงได้จากอุปกรณ์หลากหลาย
ความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัว (Privacy & Security Risks)
การนำเทคนิคการสร้างสรรค์ภาพ (generative reconstruction) มาใช้มีข้อดีด้านประสิทธิภาพ แต่ก็มาพร้อมความเสี่ยงที่ต้องประเมินอย่างรอบคอบ โดยเฉพาะความเสี่ยงที่อาจทำให้เกิด synthetic reconstruction ที่สามารถสร้างภาพหรือข้อมูลที่ฟื้นคืนรายละเอียดส่วนบุคคลได้แม้ต้นทางจะถูกย่อส่วนหรือถูกเบลอ
ความเสี่ยงสำคัญรวมถึงการย้อนกลับสู่ข้อมูลต้นฉบับ (model inversion), การรั่วไหลของข้อมูลระบุตัวตน, และการสร้างเนื้อหาเท็จ (deepfakes) ซึ่งอาจทำให้ละเมิดกฎระเบียบเช่น GDPR หรือกฎหมายคุ้มครองข้อมูลส่วนบุคคลในหลายประเทศ
แนวทางการบรรเทาความเสี่ยงที่แนะนำ:
- การเข้ารหัสปลายทางถึงปลายทาง (End-to-end Encryption): ป้องกันการดักจับข้อมูลบนช่องทางสื่อสาร ทั้งในระดับสตรีมดิบและพารามิเตอร์โมเดลที่อาจส่งผ่านระหว่าง edge และ cloud
- การแยกเก็บข้อมูลและการกำหนดบริบท (Data Minimization & Contextualization): ส่งเฉพาะข้อมูลที่จำเป็นสำหรับการสร้างใหม่ เช่น feature maps แบบลดมิติ แทนการส่งพิกเซลดิบ
- การใช้เทคนิค Differential Privacy และ Secure Aggregation: ลดความเป็นไปได้ที่โมเดลจะจำรายละเอียดเฉพาะบุคคล โดยใส่ noise ในกระบวนการฝึกหรือสกัดฟีเจอร์สำหรับการรีคอนสตรัคชัน
- การจำกัดความสามารถของโมเดล (Capability Constraints): กำหนดขอบเขตการ reconstruct ให้ไม่สามารถสร้างข้อมูลระดับสูงที่ชี้ชัดตัวตน เช่น ใบหน้าแบบละเอียด หรือหมายเลขบัตร
- Audit Trails และ Explainability: เก็บล็อกการเรียกใช้งานโมเดล การเปลี่ยนแปลงพารามิเตอร์ และผลลัพธ์ที่สร้างขึ้นเพื่อการตรวจสอบย้อนหลังและการชี้แจงต่อผู้ใช้หรือหน่วยงานกำกับ
SLA และข้อพิจารณาทางสัญญา (SLA & Contractual Considerations)
เมื่อนำ Gen‑Compression มาให้บริการเชิงพาณิชย์ ต้องกำหนด SLA ที่ชัดเจนครอบคลุมมิติของประสิทธิภาพ เครือข่าย และความปลอดภัย ตัวชี้วัดที่ควรผูกอยู่ในสัญญาได้แก่:
- Latency guarantees: ระบุค่า p95 หรือ p99 สำหรับ end‑to‑end latency (เช่น target < 50 ms สำหรับหลายแอปพลิเคชัน AR/VR และ < 20 ms สำหรับ use‑cases ที่มีความสำคัญต่อ motion‑to‑photon)
- Packet loss & jitter: ข้อกำหนดเช่น packet loss ≤ 1% และ jitter thresholds เพื่อรักษาคุณภาพการสตรีม
- Bandwidth & bitrate profiles: กำหนดช่วง bitrate ที่รับประกัน พร้อมนโยบาย fallback เมื่อเครือข่ายไม่เพียงพอ
- Security & privacy commitments: ระบุการเข้ารหัส การเก็บข้อมูล การแจ้งเตือนเหตุการณ์รั่วไหล และความรับผิดชอบทางกฎหมายตาม GDPR/PDPA
- MTTR และ maintenance windows: เวลาการกู้คืนที่ยอมรับได้สำหรับปัญหาร้ายแรง และช่วงเวลาบำรุงรักษาที่แจ้งล่วงหน้า
Checklist การนำไปใช้งานจริงสำหรับทีมพัฒนา (Deployment Checklist)
สำหรับทีมวิศวกรรมที่ต้องการนำ Gen‑Compression ไปใช้ในผลิตภัณฑ์ AR/VR ควรเตรียมรายการตรวจสอบอย่างน้อยดังนี้เพื่อให้การเปิดตัวเป็นไปอย่างราบรื่นและปลอดภัย:
- Network testing: ทดสอบภายใต้เงื่อนไขเครือข่ายหลากหลาย (3G/4G/5G, Wi‑Fi สาธารณะ, high latency WAN) โดยใช้ network emulation เพื่อประเมิน bandwidth, jitter, packet loss และ reconnection scenarios
- Fallback codecs & compatibility: กำหนดกลยุทธ์สำรอง เช่น H.264/AV1/VP9 หรือ WebRTC SVC เมื่อโมเดล Gen‑Compression ไม่สามารถทำงานได้หรือ NPU ไม่รองรับ
- NPU capability checks: ตรวจสอบรายละเอียดฮาร์ดแวร์ของ edge NPU เช่น TOPS, supported ops, memory footprint, latency per frame, และ quantization (INT8/FP16) — ทำ benchmarking เพื่อหาจุดคอขวด
- Model validation & safety testing: ประเมินองค์ประกอบการสร้างซ้ำ ตรวจวัดอัตรา hallucination, reconstruction error เมื่อเทียบกับต้นฉบับ และทดสอบกรณีขอบเขต (edge cases) เพื่อหลีกเลี่ยง output ที่ละเมิดความเป็นส่วนตัวหรือผิดบริบท
- Monitoring metrics & observability: ติดตั้งการเก็บข้อมูลแบบเรียลไทม์สำหรับ throughput, bandwidth usage, frame rate, frame drop, latency (p50/p95/p99), packet loss, model inference time, reconstruction confidence score และอีเวนต์การ fallback — ใช้ dashboard และ alerting (SLO breach alerts)
- Privacy-preserving defaults: ตั้งพารามิเตอร์เริ่มต้นที่ปลอดภัย เช่น lower fidelity reconstruction สำหรับข้อมูลที่อ่อนไหว, consent prompts สำหรับการบันทึก/การแชร์ และ opt‑out mechanisms
- Operational playbooks: เตรียมคู่มือการตอบสนองเมื่อเกิดความผิดพลาด เช่น rollback ของโมเดล, force‑switch ไปยัง codec สำรอง, และขั้นตอนการสอบสวนเหตุการณ์ความปลอดภัย
- Compliance & data residency: ทบทวนข้อกำหนดทางกฎหมาย (GDPR, PDPA ฯลฯ) และจัดวางนโยบายการจัดเก็บข้อมูลในพื้นที่ที่สอดคล้องกับข้อกำหนด
- User experience testing: ทดสอบกับกลุ่มผู้ใช้จริงเพื่อประเมิน QoE (Quality of Experience) และปรับ balancing ระหว่าง compression ratio กับ perceived quality — ตัวชี้วัดเช่น Mean Opinion Score (MOS)
การผสาน Gen‑Compression เข้ากับสถาปัตยกรรม AR/VR ต้องคำนึงทั้งประโยชน์เชิงธุรกิจและความเสี่ยงเชิงเทคนิค/กฎหมาย โดยการออกแบบที่รัดกุมและการตรวจสอบเชิงปฏิบัติการ (operationalization) จะเป็นกุญแจสำคัญในการนำไปใช้จริงอย่างปลอดภัยและมีประสิทธิภาพ
บทสรุป
Gen‑Compression คือแนวทางปฏิวัติสำหรับการสตรีม AR/VR ที่แสดงให้เห็นว่าการใช้โมเดลสร้างสรรค์ (generative) เพื่อบีบอัดวิดีโอแบบเรียลไทม์สามารถลดการใช้แบนด์วิดท์ได้อย่างมีนัยสำคัญ — ประมาณ 8–12 เท่า เมื่อเทียบกับวิธีการดั้งเดิม ในขณะเดียวกันยังคงให้ประสบการณ์ผู้ใช้ที่ยอมรับได้หากมีการออกแบบ การปรับแต่ง และการปรับพารามิเตอร์อย่างระมัดระวัง สิ่งสำคัญในเชิงปฏิบัติคือการผสานการทำงานกับ WebRTC เพื่อจัดการการส่งสัญญาณเรียลไทม์ การปรับโมเดลให้เหมาะสมกับ Edge NPU เพื่อลดความล่าช้าและภาระด้านพลังงาน และการวางมาตรการจัดการความเสี่ยงที่เกี่ยวกับคุณภาพและความเป็นส่วนตัวเมื่อใช้งานในสภาพแวดล้อมจริง
มุมมองอนาคตชี้ให้เห็นโอกาสขยายตัวของ Gen‑Compression ในการผลักดันการยอมรับ AR/VR ระดับผู้บริโภคและอุตสาหกรรม หากมีการพัฒนาเรื่องมาตรฐานการประสานงานกับโปรโตคอลสตรีมมิง การร่วมออกแบบฮาร์ดแวร์‑ซอฟต์แวร์ (hardware‑software co‑design) และกรอบการประกันคุณภาพ/ความเป็นส่วนตัว เช่น การตรวจจับการตกหล่นของข้อมูลสำคัญและการสอบทานโมเดลที่เปิดเผยข้อมูล นอกจากนี้ ระบบอัจฉริยะที่ปรับแบนด์วิดท์แบบไดนามิกและการนำ Edge NPU ไปใช้อย่างแพร่หลายจะทำให้ผลลัพธ์เชิงประสิทธิภาพและเศรษฐศาสตร์ของแนวทางนี้แข็งแกร่งยิ่งขึ้น แต่การนำไปใช้จริงต้องการการทดสอบภาคสนามอย่างต่อเนื่องและการออกแบบเชิงนโยบายเพื่อรักษาเสถียรภาพของประสบการณ์และความเชื่อมั่นของผู้ใช้



