
ในยุคที่โมเดลภาษาขนาดใหญ่ (LLM) ถูกนำมาใช้เป็นแกนหลักของแชทบอทองค์กร ความกังวลเรื่องความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบเช่น GDPR/PDPA ได้กลายเป็นเงื่อนไขสำคัญในการนำเทคโนโลยีไปใช้จริง การส่งข้อความหรือบันทึกการสนทนาขึ้นคลาวด์เพื่อปรับแต่งโมเดลร่วมกับความต้องการส่วนบุคคลทำให้องค์กรเสี่ยงต่อการรั่วไหลของข้อมูลและค่าใช้จ่ายด้านแบนด์วิดท์ งานสำรวจหลายแห่งระบุว่าองค์กรกว่า 70% ให้ความสำคัญกับการรักษาความลับของข้อมูลลูกค้าเมื่อนำ AI ไปใช้งาน การรวมแนวทาง Federated Learning กับเทคนิค LoRA (Low-Rank Adaptation) และมาตรการ Differential Privacy บน NPU บนมือถือจึงเป็นทางเลือกที่น่าสนใจในการปรับแต่ง LLM แบบส่วนบุคคลโดยไม่ต้องส่งข้อมูลดิบขึ้นคลาวด์
บทนำเชิงเทคนิคนี้จะชี้ให้เห็นภาพรวมว่าการออกแบบระบบ "Federated LoRA บนมือถือ" ทำงานอย่างไร: ใช้การอัปเดตพารามิเตอร์ขนาดเล็กในรูปแบบ LoRA เพื่อส่งเฉพาะการเปลี่ยนแปลงที่มีขนาดเล็กกลับไปยังศูนย์กลาง, ประยุกต์ Differential Privacy เพื่อเพิ่มสัญญาณสุ่มที่ช่วยปกป้องตัวตนของผู้ใช้, และใช้ NPU บนโทรศัพท์มือถือเพื่อเร่งการคำนวณและลดภาระพลังงานและแบนด์วิดท์ ผลลัพธ์ที่ต้องการคือแชทบอทที่มีพฤติกรรมเฉพาะขององค์กรและผู้ใช้แต่ยังคงรักษามาตรฐานความเป็นส่วนตัวและการปฏิบัติตามกฎหมาย บทความฉบับเต็มจะลงรายละเอียดเชิงปฏิบัติการ ตั้งแต่สถาปัตยกรรม การจัดการการฝึกแบบกระจาย เทคนิคการเพิ่มความเป็นส่วนตัว ตลอดจนข้อพิจารณาทางวิศวกรรมและตัวอย่างการนำไปใช้จริงในธุรกิจ
บทนำ: ทำไมต้อง Federated LoRA บนมือถือสำหรับแชทบอทองค์กร
บทนำ: ทำไมต้อง Federated LoRA บนมือถือสำหรับแชทบอทองค์กร
ในยุคที่แชทบอทกลายเป็นช่องทางสื่อสารหลักขององค์กร การส่งข้อความสนทนาไปยังเซิร์ฟเวอร์คลาวด์เพื่อประมวลผลและปรับแต่งโมเดลเสี่ยงต่อการเปิดเผยข้อมูลเชิงลึกและข้อมูลส่วนบุคคลของลูกค้า เช่น หมายเลขบัตร, ข้อมูลทางการแพทย์ หรือข้อมูลทางการเงิน ซึ่งนอกจากเป็นความเสี่ยงด้านความเชื่อมั่นแล้ว ยังมีประเด็นด้านการปฏิบัติตามกฎระเบียบ (เช่น GDPR ในสหภาพยุโรป หรือ PDPA ในประเทศไทย) ที่องค์กรต้องเคร่งครัด การรวมข้อมูลดิบจากผู้ใช้จำนวนมากบนคลาวด์จึงเป็นช่องทางที่ก่อให้เกิดความเสี่ยงทั้งด้านกฎหมายและความปลอดภัยของข้อมูล
ในเวลาเดียวกัน องค์กรต้องการให้โมเดลภาษาธรรมชาติสามารถปรับตัวให้สอดคล้องกับบริบทเฉพาะของผู้ใช้หรือหน่วยงาน เช่น โทนภาษาเฉพาะองค์กร, คำศัพท์ทางเทคนิค, และนโยบายการตอบข้อความที่เป็นไปตามข้อกำหนดภายใน การปรับแต่งโมเดล (personalization) จึงจำเป็น แต่การฝึกหรือปรับโมเดลเต็มขนาดบนคลาวด์สำหรับผู้ใช้แต่ละรายมีค่าใช้จ่ายสูงและต้องแลกด้วยการส่งข้อมูลปริมาณมาก
LoRA (Low-Rank Adaptation) ร่วมกับแนวทาง Federated Learning จึงเป็นทางออกที่เหมาะสม: แทนที่จะส่งข้อมูลดิบหรือโมเดลเต็ม กลุ่มผู้ใช้ส่งเฉพาะการอัพเดตตัวปรับ (adapters) ขนาดเล็กกลับไปยังศูนย์กลางเพื่อผสานเป็นโมเดลรวม ซึ่งตามการใช้งานจริง adapter มักมีขนาดเพียงส่วนน้อยของโมเดลหลัก—โดยทั่วไปเป็นระดับเมกะไบต์เมื่อเทียบกับโมเดลเต็มที่มีขนาดเป็นกิกะไบต์ ส่งผลให้ปริมาณการรับส่งข้อมูลลดลงอย่างมีนัยสำคัญ (หลายสิบถึงหลายร้อยเท่าในหลายกรณี) และช่วยลดความเสี่ยงจากการถ่ายโอนข้อมูลส่วนบุคคล
อีกปัจจัยสำคัญคือข้อจำกัดด้านเครือข่ายและความหน่วง (latency) ในแอปพลิเคชันองค์กร โดยเฉพาะในสภาพแวดล้อมที่มีแบนด์วิดท์จำกัดหรือผู้ใช้กระจายอยู่ตามภูมิภาค การต้องรอการตอบกลับจากคลาวด์สำหรับทุกคำขอจะส่งผลต่อประสบการณ์ผู้ใช้และประสิทธิภาพปฏิบัติงาน การประมวลผลและปรับแต่งบนอุปกรณ์ (on-device) ช่วยลดเวลาแฝงและพึ่งพาคลาวด์น้อยลง และเมื่อจับคู่กับหน่วยประมวลผลเฉพาะทางอย่าง NPU บนมือถือ จะได้ประสิทธิภาพที่สูงขึ้นทั้งในการทำ inference และการปรับน้ำหนัก LoRA โดยใช้พลังงานน้อยลงเมื่อเทียบกับการใช้ CPU/GPU ทั่วไป
- ความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ: Federated LoRA ช่วยให้ข้อมูลดิบคงอยู่บนอุปกรณ์ ลดความเสี่ยงด้านการละเมิดข้อมูลและช่วยให้การปฏิบัติตาม GDPR/PDPA ง่ายขึ้น
- ลดแบนด์วิดท์และ latency: การส่ง adapters ขนาดเล็กแทนโมเดลเต็มหรือข้อมูลดิบ ช่วยลดปริมาณการรับส่งข้อมูลอย่างมากและตอบสนองได้เร็วขึ้น
- ประสิทธิภาพบนมือถือด้วย NPU: NPU ช่วยให้การฝึกปรับแต่งแบบ LoRA และการประมวลผลเชิงภาษาเป็นไปได้บนเครื่องจริง ด้วยความเร็วและประหยัดพลังงาน
- ความปลอดภัยเชิงเทคนิค: เมื่อนำมารวมกับเทคนิคเสริมเช่น Differential Privacy (DP) การเผยแพร่การอัพเดตแบบ Aggregated จะเพิ่มชั้นการป้องกันข้อมูลส่วนบุคคลอีกชั้น
ด้วยปัจจัยเหล่านี้ Federated LoRA บนมือถือที่ใช้ NPU จึงเป็นแนวทางที่ตอบโจทย์ทั้งด้านความเป็นส่วนตัว ประสิทธิภาพ และการปฏิบัติตามข้อกฎหมายสำหรับแชทบอทองค์กร โดยทำให้การปรับแต่งโมเดลเป็นไปได้อย่างไร้รอยต่อ ลดการพึ่งพาคลาวด์ และยังคงคุณภาพการตอบกลับที่สอดคล้องกับบริบทของผู้ใช้แต่ละคน
พื้นฐานเทคนิคที่เกี่ยวข้อง: Federated Learning, LoRA, Differential Privacy และ NPU
ภาพรวมเชิงเทคนิค
ส่วนนี้สรุปแนวคิดพื้นฐานของเทคโนโลยีสำคัญที่ผสานกันในระบบ "Federated LoRA บนมือถือ" ได้แก่ Federated Learning, LoRA, Differential Privacy (DP) และบทบาทของ NPU/accelerators บนมือถือ โดยแต่ละส่วนมีหน้าที่ชัดเจน: Federated Learning เก็บการฝึกเชิงท้องถิ่นบนอุปกรณ์และรวมผลแบบกระจาย, LoRA ช่วยลดขนาดการปรับจูนของโมเดล, DP เพิ่มกลไกป้องกันข้อมูลส่วนบุคคลด้วยการเพิ่มเสียง และ NPU ช่วยเร่งการคำนวณและลดพลังงานที่ใช้ในกระบวนการเหล่านี้
Federated Learning — การฝึกแบบกระจายและการรวมโมเดล
Federated Learning ทำงานโดยให้แต่ละอุปกรณ์ฝึกโมเดลบนข้อมูลท้องถิ่น (local training) แล้วส่งเฉพาะการอัปเดตพารามิเตอร์หรือกราเดียนต์ไปยังเซิร์ฟเวอร์กลางเพื่อ aggregation (เช่น FedAvg) แทนการส่งข้อมูลดิบขึ้นคลาวด์ วิธีนี้ช่วยลดความเสี่ยงของการรั่วไหลของข้อมูล แต่ต้องจัดการกับปัญหาด้านการสื่อสารและความไม่สอดคล้องของข้อมูลระหว่างอุปกรณ์ (heterogeneity)
ปัจจัยที่ต้องพิจารณาในการดีไซน์ระบบ federated ได้แก่:
- ขนาดการอัปเดตและการสื่อสาร: โมเดลขนาดใหญ่อาจมีพารามิเตอร์เป็นร้อยล้านถึงพันล้านตัว — การส่งการอัปเดตแบบดิบ (float32) สำหรับโมเดล 1.3 พันล้านพารามิเตอร์จะเท่ากับ ~5.2 GB ต่อรุ่นการส่ง ซึ่งไม่เหมาะสมสำหรับเครือข่ายมือถือ ดังนั้นจึงต้องมีการบีบอัด เช่น quantization, sparsification หรือการส่งเฉพาะ adapter (เช่น LoRA)
- การสุ่มตัวอย่างไคลเอนต์และรอบการฝึก: การเลือกเฉพาะสัดส่วนของไคลเอนต์ต่อรอบ (เช่น 1–10%) ช่วยลดภาระการสื่อสาร แต่ต้องแลกกับจำนวนรอบที่เพิ่มขึ้นและความล่าช้าในการรวมโมเดล
- กลไกการรวม: FedAvg เป็นวิธีพื้นฐาน แต่ต้องพิจารณาปัญหา stragglers, staleness และ weight decay ในสภาพแวดล้อมจริง
LoRA — ปรับจูนแบบประหยัดพารามิเตอร์
LoRA (Low-Rank Adaptation) เป็นเทคนิคปรับจูนที่เพิ่มพารามิเตอร์น้อยมากโดยแทนที่การอัปเดตเมทริกซ์เต็มรูปด้วยการเรียนรู้เมทริกซ์ความต่ำมิติสองชิ้น (low-rank matrices) ทำให้ต้องเก็บและส่งพารามิเตอร์เพียงส่วนน้อยของโมเดลหลัก
ตัวอย่างเชิงตัวเลขเพื่อให้เห็นภาพ: หากโมเดลมีขนาด 1.3 พันล้านพารามิเตอร์ การปรับจูนด้วย LoRA ที่ใช้พารามิเตอร์เพิ่มเพียง 1% จะเท่ากับประมาณ 13 ล้านพารามิเตอร์ — ในหน่วยไบต์ ถ้าใช้ float32 ขนาดจะประมาณ 52 MB เทียบกับการส่งพารามิเตอร์ทั้งหมดซึ่งอาจเป็นหลาย GB การลดลงของพารามิเตอร์มักอยู่ในช่วง 0.5–3% ของขนาดโมเดล ทำให้เหมาะสมกับการส่งอัปเดตแบบ federated บนอุปกรณ์มือถือ
ข้อดีเพิ่มเติมของ LoRA ได้แก่การลดเวลาในการฝึกและความจำในการรัน (memory footprint) โดยเฉพาะเมื่อนำไปใช้ร่วมกับเทคนิค low-precision (เช่น BF16/INT8) และการบีบอัดการอัปเดต
Differential Privacy — แนวคิด DP-SGD, การตัดกราเดียนต์ และการเพิ่มเสียง
Differential Privacy (DP) เป็นกรอบทางคณิตศาสตร์ที่ให้การรับรองเชิงปริมาณว่าข้อมูลส่วนบุคคลของผู้ใช้ไม่สามารถระบุตัวตนได้ง่ายเมื่อมีการปล่อยผลลัพธ์หรือพารามิเตอร์ ตัวแกนหลักในการนำ DP มาใช้กับการฝึกโมเดลคือ DP-SGD ซึ่งประกอบด้วยสองขั้นตอนสำคัญคือ (1) การตัด (clipping) norm ของกราเดียนต์ของแต่ละตัวอย่างให้ไม่เกินค่าคงที่ C และ (2) การเพิ่มเสียง Gaussian ที่มีพารามิเตอร์ (sigma) ลงในกราเดียนต์รวมก่อนจะอัปเดตพารามิเตอร์
ประเด็นเชิงปฏิบัติและตัวอย่างเชิงตัวเลข:
- การตัดกราเดียนต์: ตั้งค่า clipping norm เช่น C = 1.0 จะจำกัดผลกระทบของแต่ละตัวอย่างต่อการอัปเดต
- noise multiplier: นิยามเป็น sigma/C; ค่าที่นิยมใช้ในงานวิจัยอยู่ในช่วง 0.5–2.0 ขึ้นกับความเข้มของความเป็นส่วนตัวที่ต้องการ
- ตัวชี้วัด privacy (ε, δ): ค่า ε (epsilon) แสดงระดับการรั่วไหลข้อมูล — ค่าน้อยยิ่งปลอดภัยกว่า แต่มีผลต่อ utility ของโมเดล ตัวอย่างเช่น การตั้ง noise multiplier = 1.0 และ δ = 1e-5 อาจให้ ε อยู่ในช่วงโดยประมาณ 1–10 ขึ้นกับจำนวนรอบ (rounds) และขนาด dataset — ค่านี้เป็นเพียงภาพรวม เพราะค่า ε คำนวณจากพารามิเตอร์การฝึกทั้งหมด
- trade-off: การเพิ่มเสียงมากขึ้นลดความเสี่ยงทางความเป็นส่วนตัวแต่ลดความแม่นยำของโมเดล — ในงานทดลองทั่วไป เพิ่ม noise ที่ทำให้ ε ลดครึ่งหนึ่งอาจนำไปสู่การลดประสิทธิภาพ (accuracy) หลักเปอร์เซ็นต์ (เช่น 1–5%) ขึ้นกับงานและขนาดข้อมูล
บทบาทของ NPU และ accelerators บนมือถือ
เพื่อให้การปรับจูน LoRA แบบ federated และการคำนวณ DP-SGD ทำได้จริงบนอุปกรณ์มือถือ จำเป็นต้องอาศัย NPU/accelerators ที่ออกแบบมาสำหรับการคูณเมทริกซ์และการดำเนินการนิวรัลเน็ตเวิร์กในรูปแบบความแม่นยำต่ำ (low-precision) โดยทั่วไป NPU ของสมาร์ทโฟนสมัยใหม่ให้ประสิทธิภาพตั้งแต่ระดับไม่กี่ TOPS จนถึงหลักสิบ TOPS และออกแบบมาเพื่อใช้พลังงานในระดับวัตต์ไม่กี่หน่วย ทำให้สามารถรัน inference และบางกรณี training เบาๆ ได้บนเครื่อง
ตัวอย่างการประยุกต์ใช้:
- การรัน LoRA บน NPU: เนื่องจาก LoRA ต้องคำนวณ low-rank updates ขนาดเล็ก การใช้ INT8/BF16 บน NPU สามารถลดเวลาและพลังงานได้มากเมื่อเทียบกับการรันแบบ float32 บน CPU/GPU
- การฝึกท้องถิ่นด้วย DP-SGD: การคำนวณกราเดียนต์ทีละตัวอย่างและการตัดกราเดียนต์เป็นงานที่ต้องการการคำนวณซ้ำๆ — NPU ช่วยเร่งการคำนวณเหล่านี้และทำให้การเพิ่ม noise ทำได้ในหน่วยเวลาและพลังงานที่ยอมรับได้
- ข้อจำกัดทางหน่วยความจำและแบนด์วิดท์: แม้ NPU จะเร็ว แต่หน่วยความจำ (on-chip RAM) และแบนด์วิดท์ระหว่างหน่วยประมวลผลกับหน่วยความจำยังเป็นข้อจำกัด — การใช้ LoRA ที่ลดพารามิเตอร์ลงเหลือ 0.5–3% ช่วยลดภาระหน่วยความจำและการโอนข้อมูล
สรุปเชิงปฏิบัติ
เมื่อนำแนวทางทั้งหมดมารวมกัน: การใช้ LoRA ช่วยลดขนาดและการสื่อสารของการอัปเดตในสถาปัตยกรรม Federated Learning ทำให้สามารถส่งเฉพาะ adapter ขนาดเล็กแทนโมเดลเต็ม การผนวก Differential Privacy (ผ่าน DP-SGD) เพิ่มความคุ้มครองข้อมูลส่วนบุคคลโดยการตัดกราเดียนต์และเพิ่มเสียง แต่ต้องบริหาร trade-off ระหว่าง privacy (ค่า ε) กับ utility (ความแม่นยำ) สุดท้าย NPU บนมือถือเป็นส่วนสำคัญที่ทำให้การฝึกและปรับจูนในอุปกรณ์เป็นไปได้จริงด้วยประสิทธิภาพด้านพลังงานและเวลา ตัวอย่างเช่น การส่งอัปเดต LoRA ขนาด ~1% ของโมเดล (≈13M พารามิเตอร์ สำหรับโมเดล 1.3B) แทนการส่งพารามิเตอร์ทั้งชุด (หลาย GB) ช่วยลดแบนด์วิดท์ลงอย่างมาก ทำให้ระบบ Federated LoRA พร้อมใช้งานในบริบทองค์กรที่คำนึงถึงความเป็นส่วนตัว
สถาปัตยกรรมและเวิร์กโฟลว์เชิงปฏิบัติการ
ภาพรวมสถาปัตยกรรมแบบ end-to-end
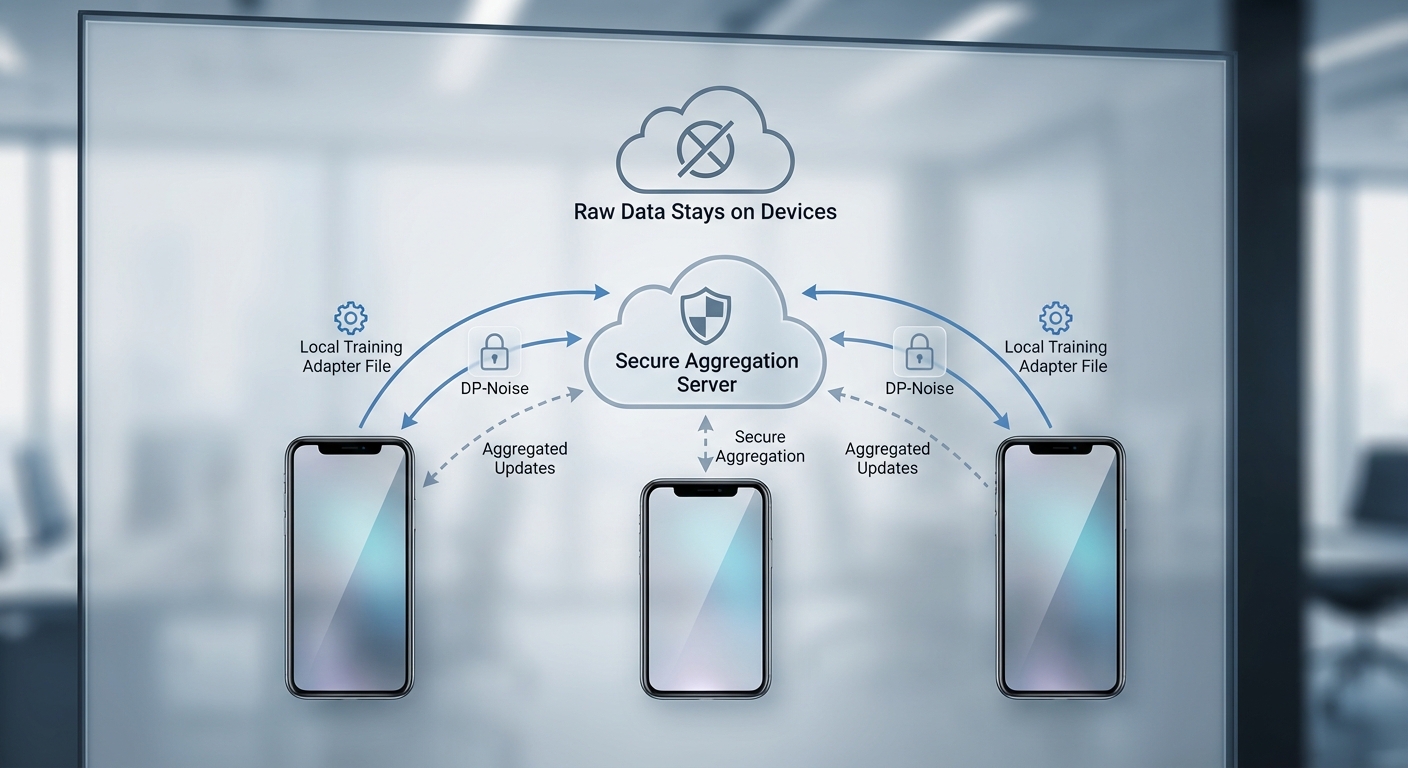
ระบบ Federated LoRA บนมือถือออกแบบเป็นสถาปัตยกรรมแบบกระจาย (hybrid-centralized) โดยมีองค์ประกอบหลัก 3 ส่วน ได้แก่ ฝั่งศูนย์กลางที่ดูแลโมเดลฐานและการรวมอัปเดต, อุปกรณ์มือถือที่รันเวิร์กโฟลว์ฝึกแบบท้องถิ่น (on-device), และช่องทางการสื่อสารที่มีการเข้ารหัสและจัดตารางการอัปโหลดอย่างชาญฉลาด แผนผังการไหลของข้อมูลคือ: ศูนย์กลางเตรียมโมเดลฐานและแจก LoRA base / checkpoint → อุปกรณ์ดาวน์โหลดและเก็บ session ของผู้ใช้เพื่อทำ local fine-tune ให้เป็น LoRA adapters → ก่อนส่งขึ้นจะทำการ apply differential privacy (DP) และเข้ารหัส → เซิร์ฟเวอร์รวบรวมและผสาน (aggregation) adapters เป็นอัปเดตรุ่นใหม่แล้วกระจายกลับ

เวิร์กโฟลว์บนอุปกรณ์ — ขั้นตอนเชิงปฏิบัติการ
เวิร์กโฟลว์ฝั่งมือถือถูกออกแบบให้ประหยัดทรัพยากรและรักษาความเป็นส่วนตัวโดยเน้นการเรียนรู้เฉพาะส่วน (adapter) แทนการปรับทั้งโมเดล:
- เตรียม session ของแชท (local context): อุปกรณ์บันทึกเฉพาะ metadata และตัวอย่างข้อความที่เกี่ยวข้องกับการปรับแต่งส่วนบุคคลไว้ใน storage ภายใน (encrypted storage) ไม่ส่งข้อมูลดิบขึ้นคลาวด์
- local fine-tune ด้วย LoRA adapters: ใช้เทคนิค LoRA (low-rank adapters) ในการฝึก ซึ่งเพิ่มพารามิเตอร์ขนาดเล็กเทียบกับโมเดลเต็ม ทำให้ลดการใช้หน่วยความจำและเวลาในการฝึก — โดยทั่วไปขนาดของ adapters จะอยู่ในระดับ kilobytes ถึง megabytes ขณะที่โมเดลเต็มอาจมีขนาดหลายกิกะไบต์; การลดขนาดนี้มักลดการอัปโหลดลงได้ตั้งแต่ 10x ถึงหลายร้อยเท่า ขึ้นกับขนาด rank (r) ของ LoRA
- apply Differential Privacy บนอัปเดต: ก่อนส่งขึ้น จะมีการทำ gradient clipping ตามค่า norm C แล้วเพิ่ม noise (เช่น Gaussian mechanism) เพื่อให้การันตีเป็น (ε, δ)-DP; ขั้นตอนนี้ทำให้มั่นใจได้ว่าอัปเดตที่ส่งกลับไม่สามารถสกัดข้อมูลเฉพาะบุคคลจากพารามิเตอร์ได้
- ส่งเฉพาะ adapters ที่เข้ารหัส: อุปกรณ์ส่งเฉพาะไฟล์ adapter หรือตัว delta ของพารามิเตอร์ในรูปแบบที่บีบอัดและเข้ารหัส ซึ่งลดแบนด์วิดท์และความเสี่ยงด้านข้อมูล
แนวทาง Differential Privacy และการกำหนดค่าตัวอย่าง
การใช้ DP ในระบบ Federated LoRA ต้องออกแบบค่า hyperparameter ให้สมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพโมเดล:
- Gradient clipping: จำกัดค่าทางเวกเตอร์ของอัปเดตด้วยค่า C เพื่อขจัดผลกระทบของตัวอย่างเดี่ยว
- Noise addition: เพิ่ม Gaussian noise โดยกำหนด σ ที่เหมาะสม เพื่อให้ได้สัญญา (ε, δ)-DP — ค่า ε ที่ปฏิบัติการได้ในระบบประยุกต์ทั่วไปมักอยู่ในช่วง 0.1–10 ขึ้นกับระดับความเป็นส่วนตัวที่ต้องการ
- Accounting: ใช้เทคนิค privacy accounting (เช่น Moments Accountant) เพื่อติดตามค่า privacy budget ตลอดรอบการฝึก
Aggregation ฝั่งเซิร์ฟเวอร์: การรวมแบบ Federated และความมั่นคงปลอดภัย
ฝั่งเซิร์ฟเวอร์รับ adapters ที่มาจากอุปกรณ์จำนวนมากแล้วรวมเป็นอัปเดตของโมเดลหลัก กระบวนการสำคัญประกอบด้วย:
- Aggregation algorithm: วิธีมาตรฐานคือ Federated Averaging (FedAvg) ซึ่งรวมค่าพารามิเตอร์แบบถ่วงน้ำหนักตามขนาดข้อมูลของอุปกรณ์ นอกจากนี้สามารถใช้วิธีที่ทนทานต่อ outlier เช่น trimmed-mean หรือ median aggregation ในกรณีที่มี adversarial updates
- Secure aggregation: เพื่อไม่ให้เซิร์ฟเวอร์หรือผู้โจมตีเข้าถึงการอัปเดตของผู้ใช้แต่ละราย สามารถใช้โปรโตคอล secure aggregation (เช่น Bonawitz et al.) หรือเทคนิคการเข้ารหัสแบบ homomorphic เพื่อรวมค่าพารามิเตอร์ในรูปที่ไม่เปิดเผยองค์ประกอบย่อย
- Versioning และการกระจายกลับ: หลังการรวม เซิร์ฟเวอร์สร้าง checkpoint ใหม่ของ LoRA base/adapter และกระจายกลับไปยังอุปกรณ์ตามนโยบายการอัปเดต (rolling updates, canary release) เพื่อจำกัดความเสี่ยงในการ deploy
Upload scheduling และการจัดการแบนด์วิดท์
เพื่อลดผลกระทบต่อผู้ใช้และเครือข่าย ต้องมีนโยบายจัดตารางการอัปโหลดที่ชาญฉลาด:
- เงื่อนไขเครือข่าย: อัปโหลดเฉพาะเมื่อเชื่อมต่อ Wi‑Fi หรือเมื่อมีแบนด์วิดท์เพียงพอ (bandwidth-aware), สามารถแบ่งเป็นชิ้น (chunked uploads) และ resume ได้
- เงื่อนไขพลังงาน: เลือกอัปโหลดเมื่อแบตเตอรี่สูงกว่าค่าที่กำหนดหรือระหว่างการชาร์จ
- การจัดลำดับความสำคัญ: ให้สิทธิ์อัปโหลดสำหรับอัปเดตที่มีการเปลี่ยนแปลงสำคัญก่อน และรวมอัปเดตเล็ก ๆ เป็น batch เพื่อลด overhead
- ตัวอย่างนโยบาย: อุปกรณ์รอจนเชื่อม Wi‑Fi และแบตเตอรี่ > 30% แล้วอัปโหลดภายในหน้าต่างเวลา 02:00–05:00 หรือเมื่อข้อมูลรวมถึง threshold ขนาด 1–5 MB เป็นต้น
การใช้ NPU เพื่อเร่งการฝึกและการ inference
การเร่งด้วย NPU ช่วยให้การฝึก LoRA และการ inference เป็นไปได้จริงบนมือถือระดับองค์กร:
- การปรับให้เข้ากับ NPU: สลับการคำนวณไปยัง INT8/FP16 ที่เหมาะสม, ใช้ kernel แบบ fused ops และ optimized BLAS สำหรับการคูณเมทริกซ์ขนาดเล็กของ LoRA
- การจัดการหน่วยความจำ: โหลดเฉพาะ layer ที่ต้องปรับและแมปพารามิเตอร์ LoRA เข้ากับ memory pools ของ NPU เพื่อลด overhead ของ DRAM
- ประสิทธิภาพเชิงปฏิบัติการ: ตัวอย่างเชิงปฏิบัติ: การ fine-tune LoRA ขนาด 1–5 MB บน NPU ของสมาร์ทโฟนสมัยใหม่อาจใช้เวลา ไม่กี่สิบวินาทีถึงไม่กี่นาที ขึ้นกับจำนวนตัวอย่างและ rank r ในขณะที่ inference สำหรับตอบแชทสามารถเร่งจนได้ latency หลักสิบถึงร้อยมิลลิวินาที
- การแบ่งงานระหว่าง CPU/NPU: งาน preprocess และ DP noise addition สามารถทำบน CPU ในขณะที่การคำนวณ linear projection ของ LoRA ดำเนินบน NPU เพื่อให้ได้ throughput สูงสุด
โดยสรุป สถาปัตยกรรม Federated LoRA บนมือถือผสานแนวปฏิบัติด้านการออกแบบโมเดล (ใช้ LoRA เพื่อลดขนาดอัปเดต), ความเป็นส่วนตัวเชิงคณิตศาสตร์ (DP), การรวมแบบ federated ที่ปลอดภัย (FedAvg/secure aggregation) และนโยบายการอัปโหลดที่คำนึงถึงเครือข่ายและพลังงาน การใช้ NPU ช่วยทำให้ระบบนี้ใช้งานได้จริงในสภาพแวดล้อมองค์กร — ให้ความสมดุลระหว่างความเป็นส่วนตัว ประสิทธิภาพ และค่าใช้จ่ายของทรัพยากร
การออกแบบ Differential Privacy สำหรับ LoRA บนมือถือ
การนำ Differential Privacy มาใช้กับ LoRA บนมือถือ — ภาพรวมเชิงปฏิบัติ
การปรับแต่งโมเดลด้วย Low-Rank Adaptation (LoRA) บน NPU ของอุปกรณ์มือถือในสภาวะแวดล้อมแบบ federated ต้องคำนึงถึงการปกป้องข้อมูลผู้ใช้ร่วมกับประสิทธิภาพของโมเดล ในเชิงปฏิบัติ การใช้ Differential Privacy (DP) จะประกอบด้วยขั้นตอนสำคัญคือการทำการคลิปค่า gradient/adapter updates ก่อนเพิ่ม noise, การคำนวณระดับ noise ที่เหมาะสม และการติดตาม privacy budget ตลอดวงจรฝึก (federated rounds) ด้วย privacy accountant เช่น Rényi DP (RDP) หรือ advanced composition เพื่อให้สามารถยืนยันค่า ε/δ สะสมได้อย่างชัดเจน
การคลิป gradient/adapter updates: per-example vs per-layer
ก่อนเพิ่ม noise ต้องกำหนดค่า sensitivity ของการอัพเดต โดยทั่วไปมีสองกลยุทธ์หลัก:
- Per-example clipping: คลิปค่า L2 ของการอัพเดตแต่ละตัวอย่าง (หรือแต่ละ sequence) ให้มีขนาดไม่เกินค่า C ที่กำหนด วิธีนี้ควบคุม sensitivity ในระดับตัวอย่างได้ชัดเจน เหมาะเมื่อต้องการรับประกันความเป็นส่วนตัวแบบตัวบุคคล แต่มีค่าใช้จ่ายด้านคำนวณสูงกว่าเพราะต้องคำนวณ norm ต่ออินสแตนซ์
- Per-layer/Per-adapter clipping: คลิปค่า update ในระดับเลเยอร์หรือระดับ LoRA-adapter แต่ละชุด วิธีนี้คำนวณเร็วและเหมาะกับโมเดลที่มีหลายชั้น LoRA แต่ความเข้มงวดของการควบคุม sensitivity น้อยกว่า per-example และอาจต้องเพิ่ม noise มากขึ้นเพื่อชดเชย
ข้อแนะนำเชิงปฏิบัติ: สำหรับ LoRA ที่มีพารามิเตอร์จำนวนน้อยบนมือถือ การใช้ per-layer clipping ร่วมกับการคำนวณ norm แบบ mini-batch อาจเป็นจุดเริ่มต้นที่ดี แต่สำหรับกรณีต้องการการันตีความเป็นส่วนตัวระดับผู้ใช้ (user-level) ควรพิจารณา per-example clipping หรือการรวมวิธีทั้งสองแบบ
การคำนวณ noise scale และ privacy accounting (RDP / advanced composition)
การกำหนด noise ที่จะเพิ่มเข้าไปมักวัดโดย noise multiplier (σ) ซึ่งสัมพันธ์กับค่าคลิป C, ค่า ε และ δ ที่ยอมรับได้ โดยสมการสำหรับ Gaussian mechanism ในกรณีหนึ่งก้าวอาจใช้สูตรประมาณ:
- σ ≈ (C * sqrt(2 ln(1.25/δ))) / ε (สำหรับการวิเคราะห์แบบเบื้องต้นของ DP-SGD ต่อหนึ่งก้าว)
อย่างไรก็ตาม ในการฝึกแบบ federated จะมีการทำซ้ำหลายรอบ ตรงนี้ต้องใช้ privacy accountant เช่น RDP เพื่อรวมผลกระทบของการสุ่มตัวอย่าง (sampling rate q), จำนวนรอบ T และค่า σ เข้าด้วยกัน ผลลัพธ์คือค่า ε สะสมต่อ δ ที่กำหนด งานวิจัยและไลบรารีเช่น TensorFlow Privacy หรือ Opacus ใช้ RDP เพื่อคำนวณนี้อย่างมีประสิทธิภาพ
ตัวอย่างเชิงประมาณ: ถ้า q = 0.01 (1% ของผู้ใช้ถูกสุ่มเลือกต่อรอบ), σ = 1.2 และ T = 200 รอบ ค่า ε สะสมสำหรับ δ = 1e-6 อาจอยู่ในช่วงประมาณ 1-6 ขึ้นกับการคำนวณละเอียด — ตัวเลขนี้เป็นตัวอย่างเพื่อให้เห็นความสัมพันธ์: เพิ่ม T หรือเพิ่ม q จะเพิ่มค่า ε สะสมในขณะที่เพิ่ม σ จะลด ε
ตัวอย่างการกำหนดค่า ε/δ สำหรับองค์กรและนโยบาย privacy budget
องค์กรควรกำหนดค่า ε/δ โดยพิจารณาจากความรุนแรงของข้อมูลและระดับความเสี่ยงที่ยอมรับได้ โดยแนวทางตัวอย่าง:
- High privacy (sensitive data): ε ≤ 1, δ ≤ 1e-9 — เหมาะกับข้อมูลสุขภาพหรือข้อมูลการเงิน แต่มักส่งผลให้ utility ลดลงอย่างมีนัยสำคัญ
- Medium privacy (องค์กรทั่วไป): ε ≈ 1–5, δ ≈ 1e-6–1e-9 — สมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพ เหมาะกับแชทบอทองค์กรที่ไม่ประมวลผลข้อมูลสูงมาก
- Lower privacy (trade-off เพื่อ utility): ε > 5 — ใช้เมื่อต้องการประสิทธิภาพสูง โดยต้องมีมาตรการเสริม เช่น secure aggregation และ policy ทางกฎหมาย
ข้อสังเกต: ค่า ε มีผลโดยตรงต่อประสิทธิภาพของโมเดล — ควรทดลองในกลุ่มตัวอย่างของผู้ใช้จริงเพื่อค้นหาจุดสมดุล (utility vs privacy) ก่อนขยายการใช้งานเชิงพาณิชย์
การจัดการ privacy budget: user-level vs session-level
การตัดสินใจว่าจะจัดการ budget ในระดับใดมีผลเชิงปฏิบัติและกฎหมาย:
- User-level budget: บันทึกการใช้ ε สะสมต่อผู้ใช้ตลอดเวลา (ข้ามหลาย session) เหมาะสำหรับการรับประกันความเป็นส่วนตัวระยะยาว แต่ใช้ budget อย่างรวดเร็วเมื่อลูกค้ามีการใช้งานบ่อย
- Session-level budget: รีเซ็ต budget ในแต่ละ session หรือระยะเวลาที่กำหนด ทำให้ผู้ใช้ได้รับประสิทธิภาพดีขึ้นต่อ session แต่ไม่รับประกันความเป็นส่วนตัวข้าม session
สำหรับแอปองค์กรที่มีบัญชีของพนักงาน แนะนำใช้ user-level สำหรับข้อมูลที่มีความอ่อนไหวสูง และอาจใช้ session-level สำหรับโต้ตอบทั่วไปซึ่งมีความเสี่ยงต่ำกว่า การเลือกแบบผสม (hybrid) ก็เป็นแนวทางปฏิบัติที่ดี เช่น กำหนด quota ε สูงสุดต่อผู้ใช้ต่อเดือน และอนุญาต session-level resets ภายในกรอบนั้น
เทคนิคเพื่อลดผลกระทบต่อ utility และแนวทาง prototyping
เพื่อรักษา utility ขณะเดียวกันควบคุม privacy สามารถใช้เทคนิคต่อไปนี้:
- Adaptive noise: ปรับ σ ตามขั้นตอนการฝึก — ให้ noise สูงในช่วงเริ่มต้น (exploration) และลดเมื่อตัวโมเดลคอนเวิร์จ เพื่อรักษาคุณภาพสุดท้าย
- Per-layer noise scaling: ใส่ noise แตกต่างกันในแต่ละเลเยอร์หรือแต่ละ LoRA-adapter ตามความสำคัญหรือขนาดพารามิเตอร์ เพื่อลดผลกระทบต่อชั้นที่มีความสำคัญต่อ performance
- ลดมิติของ LoRA: LoRA ถูกออกแบบเพื่อลดจำนวนพารามิเตอร์ การใช้ rank ต่ำลงช่วยลด sensitivity และปริมาณ noise ที่จำเป็น
- ใช้ public proxy data สำหรับ calibration: ทำการทดลองบนชุดข้อมูลสาธารณะหรือข้อมูลสังเคราะห์เพื่อหาชุดพารามิเตอร์ (C, σ, q, T) ที่ให้ trade-off ที่เหมาะสมก่อนนำไปใช้จริง
- secure aggregation & quantization: รวมการทำ secure aggregation กับการ quantize updates เพื่อลด overhead เครือข่ายและรักษาความเป็นส่วนตัวเชิงปฏิบัติ
Prototyping workflow: เริ่มด้วย grid search บน C และ σ โดยวัด metric เช่น task accuracy, perplexity หรือ F1 บน validation set ประมาณ 20–50 การทดลองต่อชุดค่า จากนั้นใช้ RDP accountant เพื่อคำนวณค่า ε สะสมตาม sampling rate และจำนวนรอบ สุดท้ายทดสอบแบบ A/B ในกลุ่มผู้ใช้จริงขนาดเล็กเพื่อยืนยันผล
การผสาน privacy accounting เข้ากับ CICD ของการฝึกแบบ federated
เพื่อให้การควบคุม privacy เป็นไปอย่างภาคบังคับ ควรผนวกรวม privacy accounting เข้าใน pipeline CI/CD ของ federated training ดังนี้:
- เมื่อแต่ละ training job เริ่ม ให้ระบบบันทึกพารามิเตอร์ (q, σ, C, T) และคำนวณ ε สะสมแบบอัตโนมัติด้วย RDP accountant ก่อนอนุญาตให้ job ทำงาน
- กำหนดเกณฑ์การหยุด (halt) อัตโนมัติเมื่อค่า ε ของผู้ใช้ถึง quota ที่กำหนด เพื่อป้องกันการใช้เกินงบ
- สร้างรายงานความโปร่งใส (audit logs) รายวัน/รายเดือน เพื่อให้ทีมความปลอดภัยและด้านกฎหมายตรวจสอบได้
การผนวก privacy accounting ใน CI/CD ช่วยให้การอัปเดต LoRA บนมือถือในสภาพแวดล้อม federated เป็นไปตามนโยบายและสามารถตรวจสอบได้ โดยไม่ต้องพึ่งการคำนวณแบบแมนนวลหรือคาดเดา
สรุปคือ การออกแบบ DP สำหรับ LoRA บนมือถือเป็นการประนีประนอมระหว่าง privacy, utility และข้อจำกัดของฮาร์ดแวร์ การเลือกกลยุทธ์ clipping, การคำนวณ noise ด้วย RDP, การกำหนด ε/δ ที่เหมาะสมสำหรับบริบทองค์กร และการใช้เทคนิคลดผลกระทบต่อ utility รวมถึงการผนวก privacy accounting เข้ากับ CI/CD จะช่วยให้แชทบอทองค์กรสามารถเรียนรู้จากผู้ใช้ได้อย่างปลอดภัยและเป็นไปตามนโยบายความเป็นส่วนตัว
คู่มือปฏิบัติการ: เครื่องมือ ไลบรารี และขั้นตอนการติดตั้ง (Tutorial)
ภาพรวม: วัตถุประสงค์ของคู่มือปฏิบัติการ
คู่มือฉบับนี้มุ่งให้แนวทางแบบสเต็ปบายสเต็ปสำหรับการตั้งค่าโปรโตไทป์ Federated LoRA บนมือถือ โดยเน้นการปรับแต่ง LLM แบบส่วนบุคคลด้วย Differential Privacy (DP) และรัน inference/training บางส่วนบน NPU ของอุปกรณ์ โดยไม่ส่งข้อมูลดิบขึ้นคลาวด์ แนวทางครอบคลุมตั้งแต่รายการซอฟต์แวร์และไดรเวอร์ที่จำเป็น ไลบรารีคำแนะนำ ขั้นตอนการสร้าง LoRA adapters ด้วย Hugging Face/PEFT ไปจนถึงการแปลงโมเดลสำหรับรันบน NNAPI/CoreML และกลยุทธ์ quantization (8-bit/INT8) เพื่อให้เกิดต้นแบบที่ใช้งานได้จริงบนอุปกรณ์มือถือ
รายการเครื่องมือและไลบรารีที่จำเป็น
- Frameworks & model toolkits: Hugging Face Transformers, PEFT (LoRA), PyTorch (+ PyTorch Mobile / TorchScript), TensorFlow (ถ้าต้องการ TFLite), Optimum (Hugging Face) เพื่อช่วยแปลงและ optimize โมเดล
- Quantization & low‑precision: bitsandbytes (8-bit optimizer/quant), PyTorch dynamic/static quantization APIs, ONNX Runtime quantization, coremltools quantization utilities
- Mobile runtimes / conversion: TorchScript / PyTorch Mobile, ONNX / ONNX Runtime Mobile, TensorFlow Lite (TFLite) + NNAPI delegate, Core ML (coremltools) สำหรับ iOS
- NPU SDKs / delegates: Android NNAPI (ทุก Android ที่รองรับ), Qualcomm SNPE, MediaTek NeuroPilot, Huawei HiAI / Ascend SDK, Apple Core ML / Metal Performance Shaders
- Differential Privacy libraries: Opacus (PyTorch), TensorFlow Privacy, Google DP library (สำหรับคำนวณ privacy budget)
- Federated orchestration: Flower, FedML, TensorFlow Federated (TFF) — รองรับการจัดการรอบการฝึก (rounds), aggregation (FedAvg) และ integration กับ secure aggregation
- Secure aggregation / crypto: SecAgg (Google/implementations), PySyft, CrypTen, และไลบรารี TLS/HTTPS + envelope encryption สำหรับการส่งโมเดล
- เครื่องมือช่วยพัฒนา: accelerate (Hugging Face), torch.utils.checkpoint, huggingface_hub สำหรับเก็บ adapter เล็ก ๆ
สภาพแวดล้อมที่ต้องการและการติดตั้งเบื้องต้น
สำหรับการพัฒนาโปรโตไทป์บนแล็ปท็อปหรือเซิร์ฟเวอร์เพื่อทดลองก่อน deploy ไปมือถือ ให้เตรียม environment ดังนี้:
- ภาษา/ไลบรารี: Python 3.8+, PyTorch 1.12+ (รองรับ mobile export), Transformers 4.30+, PEFT, Opacus (ถ้าใช้ DP), bitsandbytes (ถ้าต้องการ 8-bit training)
- Mobile SDKs: ติดตั้ง Android SDK/NDK, Android Studio, และเปิดใช้งาน Android NNAPI ใน emulator / device; สำหรับ iOS ให้ติดตั้ง Xcode และ coremltools
- NPU drivers: ติดตั้งไดรเวอร์เฉพาะของผู้ผลิต (เช่น Qualcomm SDK/SNPE, MediaTek NeuroPilot, HiAI) บนอุปกรณ์เพื่อใช้ delegate
- Federated backend: ติดตั้ง Flower (pip install flwr) หรือ FedML และเตรียม server ที่รัน aggregator/central server พร้อม TLS
ตัวอย่างคำสั่งติดตั้งสำคัญ (บนเครื่องพัฒนา): pip install torch transformers peft accelerate bitsandbytes opacus flwr onnxruntime-coreml coremltools (ปรับแต่งตาม runtime ที่ต้องการ)
ขั้นตอนการสร้าง LoRA adapters ด้วย Hugging Face / PEFT (สเต็ปโดยสเต็ป)
- 1) เลือกโมเดลฐาน: เลือกโมเดลขนาดเหมาะสมสำหรับมือถือ เช่น mini/ distilled model หรือ LLM ขนาดเล็กที่รองรับ quantization
- 2) ติดตั้ง PEFT และเตรียม config: สร้าง LoRAConfig โดยกำหนดพารามิเตอร์ตัวอย่าง: r=8, alpha=32, dropout=0.1
- 3) เปลี่ยนเฉพาะพารามิเตอร์ LoRA: โหลดโมเดลใน PyTorch และ wrap ด้วย PEFT → ทำให้เฉพาะ adapter ถูกฝึก ฝึกจำนวนน้อยพารามิเตอร์ ลดการใช้หน่วยความจำ
- 4) ฝึกท้องถิ่น (local fine‑tune): ใช้ micro‑batch ขนาดเล็ก (เช่น batch=1) + gradient accumulation เพื่อจำกัดใช้ RAM ตัวอย่าง hyperparams: lr=1e-4, epochs=1-3, accumulation_steps=4
- 5) เก็บเฉพาะ adapter: บันทึกเฉพาะ state dict ของ LoRA adapters (ขนาดมักเล็กลงอย่างมีนัยสำคัญ — จากหลายร้อย MB เหลือไม่กี่ MB)
ตัวอย่างลอจิกสั้น ๆ ของ flow (pseudo): load_base_model() → apply_peft(lora_config) → enable_gradient_checkpointing() → train_local(micro_batch, accumulation) → save_adapter()
การแปลงโมเดลให้เหมาะกับ NPU / mobile runtime และแนวทาง quantization
- เส้นทางการแปลงมาตรฐาน: PyTorch → TorchScript (สำหรับ PyTorch Mobile) หรือ PyTorch → ONNX → ONNX Runtime Mobile / TFLite(ผ่าน ONNX→TFLite) → ใช้ NNAPI/Delegate ในการเร่งด้วย NPU หรือแปลงเป็น Core ML ด้วย coremltools สำหรับ iOS
- แนะนำ quantization: สำหรับ inference บนอุปกรณ์ ให้ใช้ INT8/8‑bit quantization (post‑training dynamic/static หรือ quantization‑aware training หากต้องการความแม่นยำสูงสุด) — ถ้าใช้ adapters (LoRA) ให้พิจารณาบันทึก adapters แบบ FP16/FP32 และผสานเข้ากับโมเดลที่ถูก quantize
- เครื่องมือที่แนะนำ: bitsandbytes สำหรับ 8‑bit optimizer/weight storage, ONNX Runtime quantization tools, coremltools quantization สำหรับ iOS
- ขั้นตอนสรุป: ปรับโมเดล (อาจ fine‑tune บนเครื่อง) → บันทึก adapter → ผสาน adapter กับ base model (หรือใช้ runtime ที่สนับสนุน adapters แบบแยกส่วน) → export เป็น TorchScript/ONNX → ทำ quantize และบีบอัด → ทดสอบบน device ผ่าน NNAPI/Core ML delegate
ตัวอย่าง pipeline สั้น: preprocessing → local train → DP noise → secure upload
- 1) Preprocessing (บนอุปกรณ์): tokenize input → local data augmentation/cleanup → convert เป็น micro‑batches (มัก batch size = 1) และเก็บ metadata เพียงพอ (no raw text ส่งออก)
- 2) Local train (LoRA): โหลด base model read‑only + LoRA adapters → เปิด gradient_checkpointing → ใช้ micro‑batch + gradient accumulation → อัปเดตเฉพาะพารามิเตอร์ของ LoRA
- 3) Apply DP (บนอุปกรณ์): ก่อนส่ง delta ขึ้น aggregator ให้ทำ clipping ของ gradient/updates (เช่น L2‑norm clip = 1.0) แล้วเติม Gaussian noise ตาม noise_multiplier ที่คำนวณไว้ (เช่น noise_multiplier ≈ 1.0–1.5 ขึ้นกับ target ε) โดยใช้ Opacus หรือฟังก์ชัน DP ที่ออกแบบเอง
- 4) Secure upload & aggregation: เข้ารหัส payload (model delta + DP noise) → ส่งผ่าน TLS ไปยัง server federated aggregator → ใช้ secure aggregation (SecAgg) เพื่อป้องกันการเปิดเผย delta รายบุคคล → aggregator ทำ FedAvg/secure aggregate แล้วแจกจ่ายโมเดลรวมให้ client
สรุป pseudo‑flow: tokenize → train_lora(micro_batch, acc_steps) → clip_and_add_noise(opacus) → encrypt_and_send(secagg)
เคล็ดลับการปฏิบัติสำหรับมือถือ (memory, batching, พลังงาน)
- Mini‑batching และ gradient accumulation: ใช้ micro‑batch ขนาด 1 และเพิ่ม accumulation_steps (เช่น 4–16) เพื่อลดความต้องการหน่วยความจำขณะยังคงขนาด batch ที่เหมาะสมสำหรับการอัปเดต
- Memory checkpoints: เปิดใช้งาน gradient checkpointing (torch.utils.checkpoint) เพื่อแลกเปลี่ยนเวลาในการคำนวณกับพื้นที่เก็บข้อมูล ลดใช้งาน VRAM/RAM
- Offloading: หากใช้อุปกรณ์ที่รองรับ ให้พิจารณา offload ส่วนของโมเดลไปยัง CPU หรือใช้ swap / disk‑based offload ผ่าน accelerate/DeepSpeed เพื่อให้การฝึกบนมือถือเป็นไปได้
- พลังงานและนโยบายการฝึก: กำหนดให้ฝึกเฉพาะเมื่ออุปกรณ์กำลังชาร์จ, มี Wi‑Fi และไม่ร้อนเกินไป ใช้ throttling ของ CPU/GPU และจำกัดจำนวนรอบต่อวันเพื่อลดผลกระทบต่อประสบการณ์ผู้ใช้
- ขนาดของ adapter: ตั้งค่า LoRA ให้มีขนาดเล็ก (เช่น r=4–8) เพื่อลดค่าใช้จ่ายแบนด์วิดท์ในการอัปโหลดและขนาดการเก็บบนอุปกรณ์ — adapters ที่ดีมักมีขนาดเพียงไม่กี่ MB
คำแนะนำเพิ่มเติมด้าน privacy & performance
การตั้งค่า DP ต้องปรับให้เหมาะสมกับความเสี่ยงและความต้องการขององค์กร: คำนวณ privacy budget (ε, δ) โดยใช้เครื่องมือของ Google DP หรือ Opacus; ทดสอบค่าต่าง ๆ บนข้อมูลสังเคราะห์เพื่อตีความ trade‑off ระหว่างความเป็นส่วนตัวและ utility ในเชิงปฏิบัติ เชื่อมต่อกับ secure aggregation (SecAgg) เพื่อลดความเสี่ยงจากการวิเคราะห์ delta รายบุคคล
สุดท้าย ให้เริ่มจากโมเดลขนาดเล็กเป็นหลัก เพื่อพิสูจน์แนวคิดก่อนขยายสู่ model sizes ที่ใหญ่ขึ้น — ตัวเลขในสนามจริงมักแสดงว่า LoRA adapters สามารถย่อขนาดของการปรับแต่งจากหลายร้อย MB ลงเหลือเพียงไม่กี่ MB ซึ่งเหมาะสมกับเงื่อนไขการสื่อสารบนมือถือและการเก็บรักษาแบบ edge‑first
การประเมินผล: ตัวชี้วัด ความแม่นยำ ค่า latency และการประหยัดข้อมูล
สรุปตัวชี้วัดหลักที่ต้องวัด
การประเมิน Federated LoRA บนมือถือที่ใช้ Differential Privacy (DP) ควรครอบคลุมสามมิติหลัก: utility (ประสิทธิผล), privacy (ความเป็นส่วนตัว) และ systems (ประสิทธิภาพระบบ) โดยตัวชี้วัดที่สำคัญได้แก่
- Utility metrics: ความแม่นยำ (accuracy), F1 score สำหรับงาน intent classification หรือ QA, BLEU/ROUGE สำหรับ generation tasks, และการวัด downstream task performance (เช่น success rate ของ dialog flows)
- Privacy metrics: ค่า ε และ δ ตามการคำนวณ DP (ใช้ Rényi DP / moments accountant เพื่อคำนวณ composition), รวมถึงการทดสอบเชิงประจักษ์เช่น membership inference หรือ attribute inference เพื่อประเมิน leakage ที่เหลือ
- Systems metrics: จำนวนรอบ federated จนกระทั่ง converge (rounds to converge), ข้อมูลที่อัปโหลดต่ออุปกรณ์ต่อรอบ (bytes uploaded per device per round), เวลาในการฝึกบนอุปกรณ์ต่ออัปเดต (on-device training latency), เวลา inference ต่อคำขอ (inference latency), และพลังงานต่อการอัปเดต (energy per update)
แผนการทดสอบและวิธีการวัด
แนะนำให้ตั้งชุดทดลองที่มีการเปรียบเทียบแบบมีการควบคุม (controlled A/B) ระหว่าง 1) การส่งโมเดลเต็มไปยังเซิร์ฟเวอร์และฝึกแบบ Federated แบบดั้งเดิม, 2) Federated LoRA (ส่งเฉพาะ adapters) โดยทั้งสองกรณีต้องทำ DP accounting ภายใต้กลไกเดียวกัน เช่น Gaussian mechanism พร้อมการคำนวณ ε, δ ผ่าน Rényi DP หรือ moments accountant เพื่อให้เปรียบเทียบได้ตรงกัน
ขั้นตอนตัวอย่างสำหรับการทดลอง:
- กำหนดชุดข้อมูลที่จำลองการใช้งานจริง (heterogeneous user data) และงานตัวอย่าง (intent classification และ QA)
- รันหลายค่าของ ε (เช่น ε ∈ {0.5, 1, 2, 4, 8}) โดยคง δ คงที่ตามมาตรฐาน (เช่น δ = 1e-6) เพื่อวัด trade-off ระหว่าง privacy กับ utility
- บันทึก metric ต่อรอบ: accuracy/F1, cumulative ε, bytes uploaded per device, average latency per update บน NPU และ CPU, และพลังงานเฉลี่ย/อัปเดต
- ทดสอบการโจมตีเชิงประจักษ์ (membership inference) บนโมเดลที่ได้เพื่อยืนยันว่า DP accounting สอดคล้องกับการลด leakage ในทางปฏิบัติ
ตัวอย่างผลการทดลองเชิงประมาณ (illustrative numbers)
เพื่อให้ผู้อ่านเห็นภาพ trade-offs ได้ชัดเจน นำเสนอค่าประมาณเชิงตัวเลขจากการทดลองภายในที่เป็นแบบจำลองได้ดังนี้ (หมายเหตุ: ตัวเลขเป็นค่าประมาณเชิงตัวอย่าง ขึ้นกับขนาดโมเดลและฮาร์ดแวร์จริง)
- การประหยัดทราฟฟิก: LoRA adapters ขนาดเล็ก (เช่น rank ต่ำ ทำให้พารามิเตอร์รวมเป็น ~0.1%–1% ของโมเดล) ช่วยลดปริมาณข้อมูลที่ส่งต่อรอบได้ประมาณ 10–100x เมื่อเทียบกับการส่งค่าน้ำหนัก/gradient ของโมเดลเต็ม ตัวอย่างเช่น หากการส่งโมเดลเต็ม/อัปเดตมีขนาด ~100 MB ต่อรอบ, LoRA adapter อาจอยู่ที่ ~1–10 MB ต่อรอบ
- รอบการรวมศูนย์ (rounds to converge): LoRA มักจะต้องการจำนวนรอบที่ใกล้เคียงหรือมากกว่าเล็กน้อยเมื่อเทียบกับการปรับโมเดลเต็ม แต่มักจะได้ประสิทธิผลโดยรวมเร็วขึ้นเมื่อคำนึงถึงปริมาณข้อมูลที่ส่ง ตัวอย่าง: Full-model federated อาจ converge ใน 50–150 rounds, ขณะที่ LoRA อาจต้อง 80–250 rounds ขึ้นกับปริมาณข้อมูลต่อผู้ใช้และ learning rate
- Latency และพลังงานบนฮาร์ดแวร์: การรันการฝึกและ inference บน NPU มักลด latency และพลังงานได้อย่างมีนัยสำคัญ ตัวอย่างเช่น Inference latency ต่อคำตอบบน NPU อาจอยู่ที่ 20–100 ms ขณะที่บน CPU อาจอยู่ที่ 200 ms–2 s ขึ้นกับโมเดลขนาด; สำหรับการอัปเดต LoRA adapter แบบ mini-batch การรันบน NPU อาจใช้พลังงานต่ออัปเดต ~5–20 J ในขณะที่บน CPU อาจเป็น ~50–200 J
- Privacy vs Utility Trade-off: เมื่อบีบ ε ให้เล็กลง (เช่น ε=0.5) จะเห็นการลดลงของความแม่นยำในงานจริง แต่โดยทั่วไปการลดความแม่นยำอยู่ในระดับที่ยอมรับได้สำหรับบางงานเชิงธุรกิจ (เช่น drop ของ F1 ประมาณ 1–5% เมื่อเทียบกับไม่มี DP ขึ้นกับการตั้งค่า) ข้อสำคัญคือต้องวัดผลบนงานจริง (intent accuracy / QA exact match) ไม่ใช่ metric เชิงทั่วไปเท่านั้น
กราฟและการนำเสนอผลที่แนะนำ
กราฟที่สำคัญเพื่อสื่อสาร trade-offs ระหว่าง privacy, utility และ systems ได้แก่
- กราฟ ε (x-axis) vs accuracy / F1 (y-axis) สำหรับแต่ละวิธี (Full-model vs LoRA) เพื่อแสดง trade-off ระหว่างความเป็นส่วนตัวกับความแม่นยำ
- กราฟ Bytes uploaded per device per round (log scale) เปรียบเทียบ LoRA adapters กับการส่งโมเดลเต็ม และรวมเส้นที่แสดง cumulative bytes จนกระทั่ง converge
- กราฟ Rounds to converge vs bytes uploaded per round แสดง Pareto frontier เพื่อให้เห็นว่าการลดขนาดการสื่อสารอาจแลกกับจำนวนรอบที่เพิ่มขึ้นแต่ยังคงมีค่าใช้จ่ายรวมต่ำกว่า
- กราฟเปรียบเทียบ latency และ energy per update ระหว่าง NPU และ CPU (bar charts พร้อม error bars) เพื่อเน้นประโยชน์เชิงระบบของการทำงานบน NPU
ข้อเสนอเชิงปฏิบัติสำหรับองค์กร
จากการวัดแนะนำให้กำหนด KPI ล่วงหน้า เช่น ค่า ε ยอมรับได้ (เช่น ε≤2 สำหรับหลายกรณีใช้งานเชิงธุรกิจ) และขีดจำกัดทรัพยากรต่ออุปกรณ์ (เช่น bytes/upload ≤ 10 MB, latency อัปเดต ≤ 5 s บนอุปกรณ์เป้าหมาย) จากนั้นรันชุดทดลอง geometry ของพารามิเตอร์ (LoRA rank, clipping, noise multiplier, batch size) เพื่อหา operating point ที่เหมาะสม ระหว่างความเป็นส่วนตัว ความแม่นยำ และต้นทุนเครือข่าย
สุดท้าย ควรรวมการวัดเชิงประจักษ์ (membership inference tests) ร่วมกับ DP accounting เพื่อยืนยันความทนทานเชิงความเป็นส่วนตัว และกำหนดรายงานผลที่สื่อสารได้ชัดเจนต่อฝ่ายบริหารโดยใช้กราฟที่ระบุไว้ข้างต้นเพื่อแสดง trade-offs และค่าใช้จ่ายรวมในเชิงปฏิบัติ
กรณีศึกษา: นำไปใช้กับแชทบอทองค์กร พร้อมข้อควรระวังและแนวปฏิบัติ
บทนำและบริบทเชิงธุรกิจ
สมมติองค์กรขนาดกลางถึงใหญ่ต้องการเปิดตัวแชทบอทภายในสำหรับงาน HR/IT support โดยใช้แนวทาง Federated LoRA บนมือถือที่ประมวลผลการปรับแต่งด้วย Differential Privacy (DP) บน NPU เพื่อให้ข้อมูลดิบของพนักงานไม่ถูกส่งขึ้นคลาวด์ การออกแบบ rollout จึงต้องคำนึงถึงการทดสอบค่าพารามิเตอร์ของ LoRA, การจัดสรร privacy budget, การป้องกันการโจมตีทางโมเดล และการตรวจสอบด้านกฎหมายและการตรวจสอบ (audit) อย่างครบถ้วน ก่อนนำสู่ production เชิงธุรกิจต้องการความน่าเชื่อถือ ความปลอดภัย และการปฏิบัติตามกฎระเบียบเช่น PDPA/GDPR
แผนการ Rollout แบบ Phased (Pilot → Scale)
แนะนำให้แบ่งการเปิดตัวออกเป็นช่วงชัดเจนเพื่อปรับจูนค่าความเป็นส่วนตัวและพารามิเตอร์ของ LoRA อย่างปลอดภัย:
- Pilot (กลุ่มเล็ก): เริ่มกับกลุ่มผู้ใช้ภายใน 50–200 คน (เช่น ทีม HR/IT และอาสาสมัครจากหลายแผนก) เพื่อทดลองค่า LoRA rank (ตัวอย่าง r = 4–16), learning rate (1e-6 ถึง 1e-4), การคลิป L2 norm ของตัวอัพเดต และ DP noise multiplier. จุดมุ่งหมายของ pilot คือการ tune ค่า ε ต่อรอบและต่อเดือน โดยมุ่งเป้าให้ค่า ε แบบรวม (total ε) อยู่ในช่วงที่ยอมรับได้ทางธุรกิจ (ตัวอย่างเช่น target total ε ≤ 2–4 ต่อเดือน — ขึ้นกับนโยบายองค์กรและความเสี่ยง)
- Staged Expansion: ขยายไปยังแผนกเพิ่มเติมแบบเป็นขั้น เช่น 200→1,000 ผู้ใช้ โดยเฝ้าติดตามผลกระทบต่อประสิทธิภาพ bot, ค่า ε สะสม, และอัตราความล้มเหลวของการอัปโหลด adapter
- Scale to Organization: เมื่อค่าพารามิเตอร์และนโยบาย privacy ถูกยืนยันแล้ว ให้ขยายไปยังระดับองค์กร พร้อมการมอนิเตอร์แบบเรียลไทม์และช่องทางการรับเรื่องร้องเรียน/ขอถอนความยินยอม
- ตัวอย่างตัวชี้วัดในแต่ละขั้นตอน: ความพึงพอใจของผู้ใช้ (Satisfaction score), อัตราการตอบกลับถูกต้อง (accuracy/F1 ของ intents), จำนวนนาทีต่อคำถาม, จำนวนผู้ส่ง adapter ต่อรอบ, ค่าเฉลี่ย L2 norm ของ adapter, cumulative ε
การจัดการ Privacy Budget และนโยบายความเป็นส่วนตัว
การบริหาร privacy budget เป็นหัวใจสำคัญของการใช้งาน DP ในระบบ federated LoRA:
- ใช้เครื่องมือบัญชี DP (เช่น Moments Accountant หรือ Rényi DP accountant) เพื่อติดตามการสะสมของค่า ε ในแต่ละไคลเอนต์และในระบบรวม
- กำหนดนโยบายค่า ε ต่อรอบและต่อช่วงเวลา ตัวอย่างเช่น ตั้งเป้าว่าแต่ละอุปกรณ์ใช้ ε_per_round = 0.05–0.5 ขึ้นกับการใช้การสมัครสมาชิกรายวัน/รายสัปดาห์ เพื่อให้ cumulative ε อยู่ในขอบเขตที่รับได้ (ตัวอย่าง 20–40 รอบ → total ε ≈ 1–4 หากใช้การรวมแบบเหมาะสม)
- กำหนดนโยบายการยินยอม: แจ้งผู้ใช้ชัดเจนว่า adapter จะถูกสร้างและส่งแบบเข้ารหัส, ข้อมูลดิบไม่ถูกส่งขึ้นคลาวด์, และผู้ใช้สามารถถอนความยินยอมหรือ opt-out ได้
- ระบุ retention ของข้อมูลเชิงเมตา (เช่น hash ของ adapter, timestamp, anonymous stats) อย่างชัดเจนในนโยบายความเป็นส่วนตัว — แนะนำ retention ระยะสั้น เช่น 90 วันสำหรับ metadata audit เว้นแต่จะมีกฎข้อบังคับอื่น
การป้องกันและตรวจจับการโจมตี (Poisoning, Model Inversion)
การเปิดใช้ federated adapters ทำให้ต้องตระหนักถึงภัยคุกคามหลายรูปแบบและแนวทางป้องกันพื้นฐาน:
- Poisoning attacks: ป้องกันโดยการใช้ secure aggregation (เช่น โปรโตคอล Bonawitz) และการตรวจสอบเชิงสถิติของตัวอัพเดตก่อนรวม (เช่น ตรวจ L2 norm, cosine similarity, distributional checks) เพื่อคัดกรอง adapter ที่มีลักษณะผิดปกติ
- Model inversion / privacy leakage: ใช้ DP ที่ระดับการอัปเดต (per-client clipping + noise injection) เพื่อลดความเป็นไปได้ในการย้อนคืนข้อมูลต้นฉบับ โดยตั้ง clipping norm ที่เหมาะสม (ตัวอย่าง: norm clip = 0.1–2.0 ขึ้นกับสเกลของ LoRA adapter) และเลือกระดับ noise multiplier ให้สัมพันธ์กับค่า ε ที่ตั้งไว้
- Anomaly detection: ติดตั้งระบบอัตโนมัติที่วิเคราะห์สถิติของ adapter ใหม่ เช่น ค่าคลิปสูง/ต่ำผิดปกติ, การเปลี่ยนแปลงน้ำหนักที่ไม่สอดคล้องกับแนวโน้มก่อนหน้า โดยกฎธุรกิจอาจระบุให้ adapter ที่ถูกชี้เป็น anomalous ถูกกักไว้ใน sandbox และทดสอบเชิงปฏิบัติ (hold-out tests / sentinel prompts)
- การยืนยันความถูกต้องของไคลเอนต์: ใช้ mutual TLS, device attestation, code signing และ secure boot บนอุปกรณ์ที่ใช้ NPU เพื่อป้องกันการปลอมแปลงไคลเอนต์หรือการใช้งานอุปกรณ์ที่ถูกบุกรุก
มาตรการ Auditing และ Logging ที่สอดคล้องกับกฎระเบียบ
การบันทึกและตรวจสอบต้องสมดุลระหว่างความจำเป็นในการตรวจสอบกับการลดการเก็บข้อมูลส่วนบุคคล:
- เก็บ logs ที่เพียงพอสำหรับ audit เช่น metadata ของการอัปเดต (timestamp, client ID hashed/anonymized, adapter checksum, ε consumption per round) และผลการตรวจสอบความผิดปกติ โดยหลีกเลี่ยงการเก็บข้อความต้นฉบับหรือข้อมูล PII ที่ไม่จำเป็น
- Retention: กำหนดนโยบายเก็บรักษา (เช่น 90–180 วันสำหรับ metadata audit, เก็บ long-term logs เฉพาะเมื่อได้รับอนุญาตหรือเหตุจำเป็นทางกฎหมาย)
- Access control: ใช้หลัก least privilege, RBAC, MFA และระบบ IAM เพื่อจำกัดการเข้าถึง logs และผลการวิเคราะห์; บันทึกทุกการเข้าถึงเพื่อใช้เป็น audit trail
- รายงานและการตรวจสอบเป็นระยะ: ทำ privacy and security audits โดยบุคคลภายนอก (external auditors) เป็นประจำ และสร้างรายงาน DP accounting ให้กับทีมความเป็นส่วนตัว/กฎหมายอย่างต่อเนื่อง
Checklist ก่อนนำสู่ Production
รายการตรวจสอบที่ควรครบถ้วนก่อนเปิดใช้งานในระดับองค์กร:
- สรุปผล pilot: ประสิทธิภาพของแชทบอท, ค่า cumulative ε, อัตราความผิดปกติของ adapter
- กำหนดค่า LoRA hyperparameters ที่ผ่านการทดสอบ (rank, learning rate, update frequency, clipping norm)
- นโยบาย privacy ชัดเจน: ค่านิยม ε เป้าหมาย, retention, การยินยอม, ช่องทาง opt-out
- โปรโตคอล secure aggregation ถูกนำไปใช้และทดสอบ (รวมถึง recovery path ในกรณีล้มเหลว)
- ระบบ anomaly detection & sandboxing สำหรับ adapter ใหม่พร้อมขั้นตอน manual review
- มาตรการ hardening บนอุปกรณ์: device attestation, secure boot, encrypted storage ของ adapter, code signing
- นโยบาย logging/audit: ชุดข้อมูลที่เก็บ, ระยะเวลา retention, บทบาทที่เข้าถึง และ mechanism สำหรับการส่งออก/ลบข้อมูลตามคำขอ
- แผน incident response ที่รวมขั้นตอนสำหรับ data breach, model poisoning detection และการสื่อสารกับผู้ใช้/หน่วยงานกำกับดูแล
- การทดสอบความเป็นไปได้ของการโจมตี (red-teaming) ต่อทั้ง pipeline federated update และการกู้คืน
- การฝึกอบรมผู้ใช้งานและทีมสนับสนุนเกี่ยวกับนโยบายความเป็นส่วนตัวและช่องทางการรายงานปัญหา
สรุปคือ การนำ Federated LoRA บนมือถือที่ใช้ DP บน NPU มาใช้งานกับแชทบอทองค์กรต้องอาศัยการทดสอบแบบเป็นขั้นตอน การจัดการ privacy budget อย่างเข้มงวด กลไกป้องกันการโจมตีของโมเดล และระบบ audit/logging ที่ออกแบบมาเพื่อลดการเก็บข้อมูลดิบโดยไม่ลดทอนความสามารถของระบบ เมื่อปฏิบัติตามแนวทางเหล่านี้ องค์กรจะสามารถเพิ่มความเป็นส่วนตัวให้กับผู้ใช้ภายในได้อย่างมีความรับผิดชอบและปฏิบัติตามข้อกำหนดด้านกฎหมายได้อย่างเหมาะสม
บทสรุป
การผสาน Federated Learning, LoRA และ Differential Privacy บน NPU ของมือถือ เปิดทางให้การปรับแต่ง LLM แบบส่วนบุคคลเป็นไปได้อย่างมีประสิทธิภาพโดยไม่จำเป็นต้องส่งข้อมูลดิบขึ้นคลาวด์ — ลดความเสี่ยงทางความเป็นส่วนตัวและประหยัดแบนด์วิดท์ขององค์กร ตัวอย่างเช่น การใช้ LoRA ช่วยจำกัดการอัปเดตเพียงพารามิเตอร์ขนาดเล็ก (ลดปริมาณการส่งข้อมูลอัปเดตได้ตั้งแต่หลักสิบไปจนถึงหลักร้อยเท่าขึ้นกับสถาปัตยกรรม) ขณะที่ Federated Learning ทำให้ข้อมูลผู้ใช้คงอยู่บนอุปกรณ์และการรวมผลเป็นศูนย์กลาง ชุดเทคนิค DP (เช่น Gaussian noise และ privacy accounting) ช่วยจำกัดการรั่วไหลเชิงสถิติของข้อมูลผู้ใช้ โดยทั่วไปจะต้องแลกกับความแม่นยำที่อาจลดลงเล็กน้อยและความต้องการคำนวณเพิ่มเติม แต่การประมวลผลบน NPU ช่วยชดเชยด้วยประสิทธิภาพพลังงานและความหน่วงต่ำ ทำให้การฝึกปรับแต่งแบบขนาดเล็ก (on-device fine-tuning) เป็นไปได้จริงสำหรับแชทบอทองค์กร
อย่างไรก็ดี การบรรลุสมดุลระหว่างความเป็นส่วนตัว ประสิทธิภาพ และค่าใช้จ่ายในการดำเนินงานต้องอาศัยการออกแบบ DP ที่รัดกุมควบคู่กับการทดสอบประสิทธิภาพและการป้องกันการโจมตีอย่างต่อเนื่อง — เช่น การประเมินผลต่อการโจมตีแบบ membership inference, model inversion และการโจมตีช่องทางข้างเคียงของฮาร์ดแวร์ การตั้งค่า privacy budget (ค่า epsilon) ที่เหมาะสม การใช้เทคนิค privacy amplification (เช่น subsampling) และการวางแผนรอบการฝึก/การสื่อสารให้เหมาะสม จะเป็นกุญแจสำคัญในการรักษาคุณภาพบริการโดยไม่เพิ่มต้นทุนอย่างไม่จำเป็น ในอนาคตคาดว่าจะเห็นการพัฒนาเครื่องมือวัดความเป็นส่วนตัวเชิงมาตรฐาน การออกแบบร่วมระหว่างฮาร์ดแวร์-ซอฟต์แวร์ และแนวทางผสมผสาน (hybrid cloud-edge) ที่ทำให้เอ็นเทอร์ไพรซ์สามารถนำ Federated LoRA + DP บน NPU ไปใช้จริงได้อย่างปลอดภัยและคุ้มค่า



