
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์ม "Sim‑to‑Real RL" สำหรับหุ่นยนต์คลังสินค้า ซึ่งสัญญาว่าจะพลิกโฉมการพัฒนาและดีพลอยหุ่นยนต์ในภาคโลจิสติกส์โดยอาศัยการเทรนในซิมูเลชันที่จำลองสภาพจริงอย่างแม่นยำ แทนการพึ่งพาการทดลองภาคสนามในสเกลใหญ่ แพลตฟอร์มนี้ใช้หลักการ Reinforcement Learning ที่ปรับพฤติกรรมผ่านการทดลองเสมือนจริง—รวมทั้งแบบจำลองฟิสิกส์ การรบกวนจากเซนเซอร์ และความไม่แน่นอนของสภาพแวดล้อม—เพื่อลดความเสี่ยง ค่าใช้จ่าย และเวลาที่ต้องใช้ในการนำโมเดลไปใช้งานจริง
บทความนี้จะสรุปประเด็นสำคัญของแนวทาง Sim‑to‑Real RL จากสตาร์ทอัพไทย อธิบายขั้นตอนการเทรนในซิมให้เลียนแบบสภาพจริงอย่างไร ให้เห็นภาพว่าการลดการทดลองภาคสนามสามารถทำได้มากเพียงใด พร้อมนำเสนอคู่มือทีละขั้นตอนสำหรับการนำแพลตฟอร์มไปใช้ในคลังสินค้า ตัวชี้วัดการทดสอบ (เช่น อัตราความสำเร็จของงาน ความเร็วในการเรียนรู้ ความทนทานต่อการเปลี่ยนแปลงสภาพแวดล้อม และระยะเวลาในการดีพลอย) และตัวอย่างกรณีศึกษาเบื้องต้นที่แสดงผลลัพธ์การประหยัดเวลาและต้นทุนเพื่อช่วยให้ผู้ประกอบการตัดสินใจลงทุนได้รวดเร็วขึ้น
ภาพรวมและปัญหาเชิงบริบท
ภาพรวมและปัญหาเชิงบริบท
การนำปัญญาประดิษฐ์โดยเฉพาะเทคนิค Reinforcement Learning (RL) มาใช้กับหุ่นยนต์ภายในคลังสินค้ากำลังกลายเป็นแนวทางสำคัญในการเพิ่มประสิทธิภาพงานโลจิสติกส์ เช่น การหยิบจับ (pick‑and‑place), การจัดเส้นทางภายในคลัง (path planning) และการประสานงานหลายหุ่น (multi‑agent coordination) อย่างไรก็ตาม การฝึกสอนนโยบายด้วย RL บนฮาร์ดแวร์จริงเผชิญกับข้อจำกัดเชิงปฏิบัติที่สำคัญ ทั้งด้านต้นทุน เวลา และความเสี่ยงต่ออุปกรณ์และสินค้าคงคลัง ตัวอย่างเชิงประจักษ์แสดงให้เห็นว่า RL มักต้องการการทดลองหลายหมื่นถึงหลายล้านก้าว (steps/episodes) เพื่อให้ได้พฤติกรรมที่เสถียร ซึ่งหมายถึงชั่วโมงการทำงานต่อเนื่องของมอเตอร์ แขนกล และเซ็นเซอร์ ส่งผลให้เกิดการสึกหรอของชิ้นส่วนและความเป็นไปได้ในการเกิดความเสียหายที่ต้องซ่อมแซม
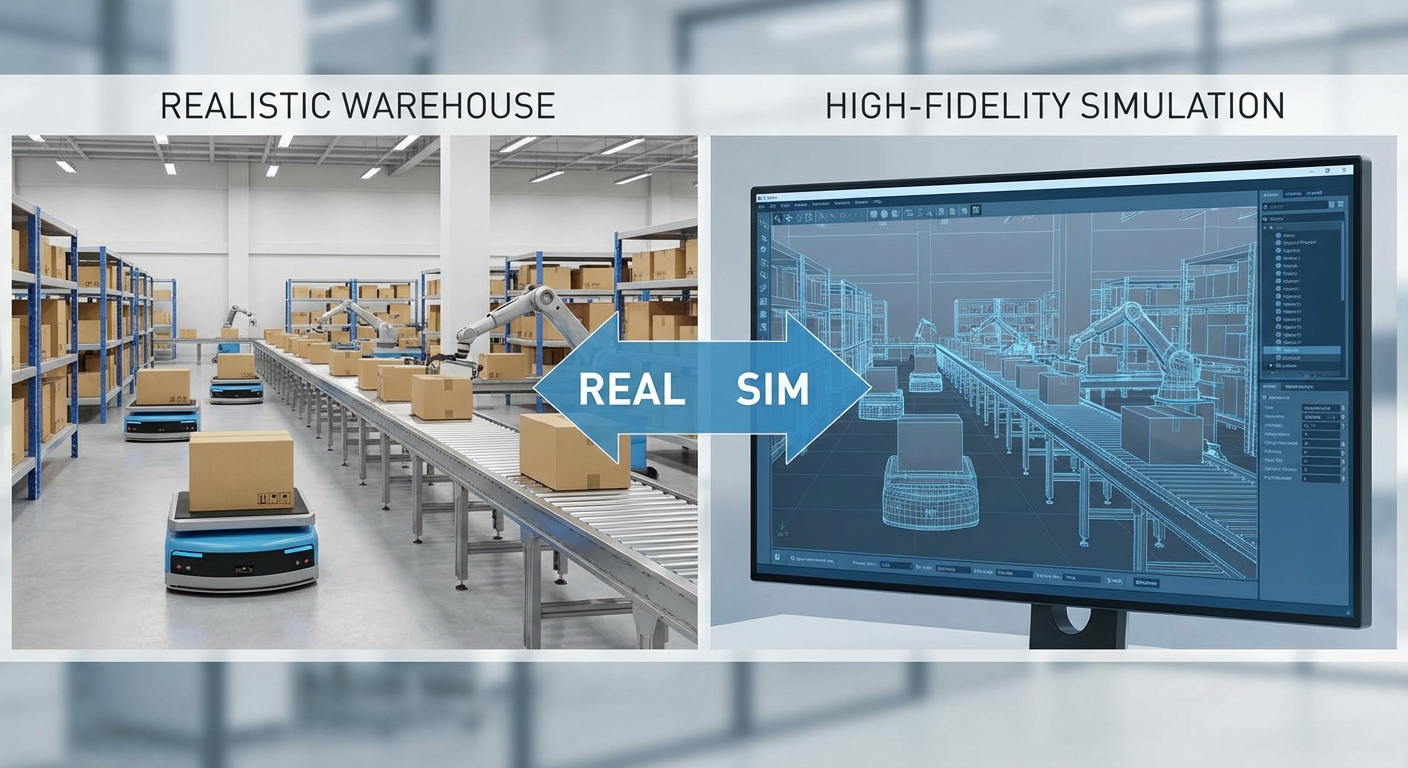
ความท้าทายของการเทรน RL บนฮาร์ดแวร์จริง ได้แก่การสึกหรอของอุปกรณ์จากการทำงานซ้ำ ๆ ความเสี่ยงต่อสินค้าคงคลังเมื่ออัลกอริทึมยังไม่เสถียร ค่าใช้จ่ายในการซ่อมบำรุงและ downtime ที่มาพร้อมกับการทดสอบภาคสนาม รวมถึงความไม่แน่นอนของสภาพแวดล้อมจริงที่ยากต่อการควบคุมและทำซ้ำ ตัวอย่างเช่น การทดสอบนโยบายหยิบของที่ต้องลองหลายร้อยรอบในสภาพแวดล้อมจริงอาจเกิดการชนกับชั้นวางหรือชิ้นส่วนอื่น ๆ ทำให้เกิดความเสียหายต่อสินค้าหรือชิ้นส่วนหุ่นยนต์ ซึ่งค่าใช้จ่ายต่อเหตุการณ์อาจอยู่ในหลักพันถึงหลักหมื่นบาทขึ้นกับขนาดและประเภทอุปกรณ์
เหตุผลในการใช้ซิมูเลชันเพื่อลดการทดลองภาคสนาม มีทั้งเชิงเทคนิคและเชิงธุรกิจ: ซิมูเลชันช่วยให้การทดลองมีความเร็ว (speed-up) เพิ่มการทำซ้ำได้ไม่จำกัดในสภาวะที่คุมได้ ลดความเสี่ยงต่ออุปกรณ์จริง และทำให้สามารถสำรวจพารามิเตอร์ต่าง ๆ เช่น น้ำหนักของวัตถุ ความฝืด หรือความคลาดเคลื่อนของเซ็นเซอร์ในรูปแบบที่หลากหลาย (domain randomization) เพื่อปรับปรุงความทนทานของนโยบายต่อความแตกต่างระหว่างซิมและโลกจริง (sim‑to‑real gap) โดยปกติการฝึกในซิมสามารถลดจำนวนรอบการทดลองบนฮาร์ดแวร์จริงอย่างมีนัยสำคัญ — ตัวอย่างเช่น ผู้ปฏิบัติงานอาจลดการทดสอบจริงจากหลายพันรอบเหลือหลักร้อยเพื่อการปรับแต่งสุดท้ายก่อนนำไปดีพลอยจริง
บทบาทของสตาร์ทอัพไทย ในการขับเคลื่อนเทคโนโลยี Sim‑to‑Real RL มีความสำคัญทั้งในเชิงนวัตกรรมและการนำไปสู่ภาคอุตสาหกรรมจริง สตาร์ทอัพไทยสามารถนำเสนอแพลตฟอร์มที่ออกแบบมาเพื่อตอบโจทย์บริบทโลจิสติกส์ในประเทศ เช่น รูปแบบคลังขนาดกลาง‑เล็ก การรวมฮาร์ดแวร์ที่มีใช้อยู่จริงในตลาดไทย และการรองรับภาษาและมาตรฐานการปฏิบัติงานของลูกค้าในประเทศ นอกจากนี้ สตาร์ทอัพยังทำหน้าที่เป็นสะพานเชื่อมระหว่างงานวิจัยกับการประยุกต์ใช้งานจริง โดยร่วมมือกับมหาวิทยาลัย หน่วยงานวิจัย และผู้ให้บริการระบบคลังสินค้า เพื่อลดเวลาในการพัฒนา ช่วยลดต้นทุนการนำร่อง และเพิ่มโอกาสในการปรับขยายการใช้งานอัตโนมัติในเชิงพาณิชย์
สรุปได้ว่า แพลตฟอร์ม Sim‑to‑Real RL ที่สตาร์ทอัพไทยพัฒนาให้ความสำคัญกับการลดจำนวนการทดลองภาคสนาม ลดความเสี่ยงต่ออุปกรณ์และสินค้าจริง ตลอดจนเร่งรัดกระบวนการพัฒนาและดีพลอยอัตโนมัติ ความสามารถในการปรับแต่งตามบริบทและการบูรณาการกับระบบโลจิสติกส์ในประเทศจะเป็นปัจจัยสำคัญที่ทำให้ผู้ประกอบการไทยยอมรับและนำเทคโนโลยีนี้ไปใช้เชิงธุรกิจอย่างแพร่หลาย
แนวคิดพื้นฐานของ Sim‑to‑Real RL
แนวคิดพื้นฐานของ Sim‑to‑Real RL
Sim‑to‑Real Reinforcement Learning (RL) เป็นแนวทางการฝึกนโยบายควบคุมหรือพฤติกรรมของหุ่นยนต์ในสภาพแวดล้อมจำลอง (simulation) เพื่อให้สามารถนำไปใช้งานจริงได้โดยลดจำนวนการทดลองภาคสนามที่มีค่าใช้จ่ายสูงและเสี่ยงต่ออุปกรณ์จริง แนวคิดหลักคือใช้ความสามารถในการจำลองสถานการณ์ต่างๆ ในคอมพิวเตอร์เพื่อสำรวจนโยบายและเรียนรู้พฤติกรรมโดยไม่ต้องใช้อุปกรณ์จริงเป็นหลัก แต่ข้อจำกัดสำคัญที่ต้องจัดการคือสิ่งที่เรียกว่า reality gap ซึ่งเป็นความแตกต่างระหว่างโลกจริงกับซิมูเลเตอร์
Reality gap หมายถึงความแตกต่างในพารามิเตอร์ทางกายภาพ (เช่น ความเสียดทาน ความเฉื่อย ความยืดหยุ่นของวัสดุ), สัญญาณเซนเซอร์ (noise, resolution), และลักษณะของสภาพแวดล้อม (แสง เงา วัตถุรบกวน) ระหว่างซิมกับโลกจริง ผลกระทบที่ชัดเจนคือการที่นโยบายที่ทำงานได้ดีในซิมอาจล้มเหลวเมื่อนำไปใช้จริง — อาจแสดงผลลัพธ์ลดลงอย่างฉับพลันหรือเกิดเหตุการณ์ไม่ปลอดภัย การวัด gap มักทำโดยการเปรียบเทียบเมตริกเช่นอัตราความสำเร็จ (success rate), cumulative reward, หรืออัตราการละเมิดข้อจำกัดความปลอดภัย ระหว่างการประเมินในซิมและในสนามจริง
เทคนิคหลักในการปิดช่องว่าง (Closing the Gap)
งานวิจัยและการปฏิบัติอุตสาหกรรมใช้ชุดเทคนิคร่วมกันเพื่อลด reality gap และเพิ่มความสามารถในการถ่ายโอนนโยบายจากซิมสู่จริง หลักๆ ได้แก่:
- Domain Randomization — การสุ่มพารามิเตอร์และสภาพแวดล้อมในซิมอย่างกว้าง เช่น มวลของวัตถุ ค่าเสียดทาน ค่าความหน่วงของมอเตอร์ สีและความเข้มของแสง หรือ noise ในเซนเซอร์ เป้าหมายคือการสร้างนโยบายที่ทนต่อความแปรปรวนและไม่พึ่งพาการตั้งค่าที่แม่นยำจนเกินไป งานหลายชิ้นรายงานว่าการใช้ domain randomization อย่างเหมาะสมสามารถลดความต้องการ fine‑tuning ในโลกจริงได้อย่างมีนัยสำคัญ
- System Identification — การประมาณพารามิเตอร์ของระบบจริง (เช่น โมเมนต์เฉื่อย เสียดทาน ค่าความหน่วง) โดยเก็บข้อมูลการเคลื่อนที่และการตอบสนองจากฮาร์ดแวร์จริง แล้วปรับซิมูเลเตอร์ให้มี fidelity ใกล้เคียงความเป็นจริงมากขึ้น วิธีนี้ช่วยให้ซิมสะท้อนพฤติกรรมจริงได้แม่นยำขึ้นและลดช่องว่างระหว่างโดเมน
- Dynamics Randomization — คล้ายกับ domain randomization แต่เน้นการสุ่มพารามิเตอร์เชิงพลวัต (dynamics) ของระบบ เช่น การเปลี่ยนแปลงในโมเดลแรงบิด มวล หรือแรงเสียดทาน เพื่อให้นโยบายเรียนรู้วิธีจัดการกับการเปลี่ยนแปลงทางพลวัตที่อาจเกิดขึ้นในโลกจริง
- Domain Adaptation / Transfer Learning — ใช้วิธีเรียนรู้เชิงปรับตัว เช่น fine‑tuning บนข้อมูลจริงจำนวนน้อย หรือใช้ representation learning ที่แยกส่วนคุณลักษณะร่วมระหว่างซิมกับจริง เทคนิค adversarial domain adaptation หรือการแมปฟีเจอร์ระหว่างโดเมนก็เป็นทางเลือกเพื่อลดการพึ่งพาฟีเจอร์เฉพาะโดเมน
- Curriculum Learning — การจัดลำดับความยากของงานฝึกจากง่ายไปยาก (เช่น เริ่มจากงานภายในแชนเนลที่มีข้อผันผวนน้อย แล้วค่อยขยายความซับซ้อน) ช่วยให้นโยบายค่อยๆ เรียนรู้พฤติกรรมพื้นฐานก่อนจะเผชิญกับความแปรปรวนสูงในซิม นำไปสู่การเรียนรู้ที่มั่นคงขึ้นและย้ายได้ดีขึ้น
ความสัมพันธ์ระหว่าง Fidelity ของซิมกับความสามารถในการย้ายโมเดล
ความเชื่อมโยงระหว่าง fidelity ของซิม (ความเที่ยงตรงทางฟิสิกส์และการจำลองเซนเซอร์) กับความสำเร็จในการย้ายโมเดลสู่โลกจริงเป็นเรื่องของสมดุล ไม่ได้หมายความว่ายิ่ง fidelity สูงยิ่งดีกว่าเสมอไป:
- ซิมที่มี high fidelity ช่วยจำลองรายละเอียดได้แม่นยำ จึงลดความคลาดเคลื่อนเฉพาะด้าน แต่มีค่าใช้จ่ายด้านคอมพิวเตอร์สูงและมีความเสี่ยงที่โมเดลจะ overfit กับความซับซ้อนของซิม
- ซิมที่มี low-to-moderate fidelity พร้อมกับการใช้ domain/dynamics randomization กลับส่งผลให้โมเดลมีความทนทานต่อความแปรปรวนของโลกจริงได้ดีกว่าในหลายกรณี เพราะนโยบายเรียนรู้ลักษณะทั่วไปแทนที่จะพึ่งพารายละเอียดจำเพาะของซิม
- จึงเกิดแนวทางแบบผสม (hybrid) — ใช้ system identification เพื่อปรับพารามิเตอร์หลักแล้วเติมด้วย randomization และ domain adaptation เพื่อครอบคลุมความไม่แน่นอนที่เหลือ เทคนิคนี้ให้ผลลัพธ์ที่ดีที่สุดในเชิงปฏิบัติสำหรับแอปพลิเคชันเชิงอุตสาหกรรม
ภาพรวมเวิร์กโฟลว์การเทรน (ตัวอย่าง)
เวิร์กโฟลว์เชิงปฏิบัติที่นิยมนำมาใช้ในโครงการ Sim‑to‑Real RL สำหรับหุ่นยนต์คลังสินค้ามีลำดับขั้นตอนหลักดังนี้:
- เก็บข้อมูลระบบจริง (Data collection & System ID) — เก็บข้อมูลการเคลื่อนไหว การตอบสนองของมอเตอร์ และการอ่านเซนเซอร์จากฮาร์ดแวร์จริงเพื่อประมาณพารามิเตอร์
- ปรับตั้งซิมูเลเตอร์ (Simulator setup) — กำหนดโมเดลพื้นฐานและพารามิเตอร์ที่ได้จาก system ID พร้อมกำหนดขอบเขตของการ randomization (เช่น ช่วงมวล ค่าเสียดทาน noise ของเซนเซอร์)
- ฝึกนโยบายในซิม (RL training) — ใช้อัลกอริทึม RL (PPO, SAC, TD3 เป็นต้น) ร่วมกับ domain/dynamics randomization และ curriculum learning เพื่อพัฒนา policy ที่ทนทาน
- ประเมินและคัดกรอง (Validation) — ทดสอบ policy บนชุดสถานการณ์ซิมที่ไม่ได้เห็นก่อน และวัดเมตริกเช่น success rate, reward distribution, safety violations
- ส่งทดลองในโลกจริงแบบค่อยเป็นค่อยไป (Sim‑to‑Real transfer) — เริ่มด้วยการทดสอบที่มีความเสี่ยงต่ำ และเก็บข้อมูลการทำงานจริงเพื่อนำมาทำ fine‑tuning หรือปรับพารามิเตอร์ซิมเพิ่มเติม
- การเรียนรู้ต่อเนื่อง (Online fine‑tuning & Monitoring) — ปรับนโยบายอย่างต่อเนื่องจากข้อมูลจริงและตรวจสอบตัวชี้วัดด้านประสิทธิภาพและความปลอดภัยเป็นระยะ
โดยสรุป Sim‑to‑Real RL เป็นกลยุทธ์ที่ผสานข้อได้เปรียบของการจำลองกับการปรับตัวต่อโลกจริง การจัดการ reality gap อย่างเป็นระบบผ่าน domain randomization, system identification, domain adaptation และ curriculum learning ทำให้สามารถลดการทดลองภาคสนามที่แพงและเสี่ยงลงได้อย่างมีนัยสำคัญ ขณะที่การออกแบบซิมที่เหมาะสมร่วมกับเวิร์กโฟลว์การทดสอบและการปรับจูนอย่างค่อยเป็นค่อยไปจะเป็นปัจจัยกำหนดความสำเร็จของการย้ายโมเดลสู่การใช้งานจริงในสภาพแวดล้อมคลังสินค้า
สถาปัตยกรรมระบบและ pipeline การเทรน
สถาปัตยกรรมระบบและ pipeline การเทรน
สถาปัตยกรรมของแพลตฟอร์ม Sim‑to‑Real RL ถูกออกแบบเป็นระบบแบบโมดูลาร์ที่เชื่อมต่อกันผ่าน message bus และ API ชั้นกลาง เพื่อให้รองรับการขยายตัว (scalability) การทดสอบแบบอัตโนมัติ และการดีพลอยสู่ฮาร์ดแวร์จริงอย่างปลอดภัย ส่วนประกอบสำคัญประกอบด้วย simulator engine, sensor models (LiDAR, camera, proprioceptive), environment parameter manager, reward shaping module, training orchestrator (distributed RL), ระบบ monitoring/dashboard และโมดูลที่รับผิดชอบการดีพลอยสู่ฮาร์ดแวร์จริง การเชื่อมต่อระหว่างโมดูลเป็นไปตามสถาปัตยกรรม microservice — แต่ละบริการรันภายใน container และสื่อสารผ่าน gRPC/ROS2/ZeroMQ เพื่อให้สามารถสเกลแบบอิสระและอัปเดตแบบต่อเนื่อง (continuous integration)
องค์ประกอบหลักและการเชื่อมต่อ
- Simulator engine — ฟิสิกส์เอนจินรองรับ contact dynamics, rigid & soft body, friction model และ high-frequency substepping เพื่อให้การจำลองการจับ การลาก และการปะทะมีความเที่ยงตรง ตัวเอนจินสามารถรันแบบ headless บน GPU/CPU หรือเป็น instance แบบ lightweight สำหรับ distributed rollout
- Sensor models — โมดูลจำลองเซนเซอร์ต่างๆ ประกอบด้วย LiDAR (raycasting/voxel), RGB/D camera (pinhole model, motion blur, exposure), และ proprioceptive sensors (joint positions, torques, IMU) โดยแต่ละโมดูลใส่ noise models, latency และ failure modes เพื่อเลียนแบบความไม่แน่นอนของโลกจริง ตัวอย่างเช่นการเพิ่ม multi-path noise ใน LiDAR หรือ rolling shutter ในกล้อง
- Environment parameter manager — จัดการ domain randomization, procedural generation และ distribution ของพารามิเตอร์ (พื้นผิว, น้ำหนักวัตถุ, friction, lighting) พร้อมสนับสนุน curriculum schedules และ Bayesian optimization สำหรับ tuning พารามิเตอร์ที่สำคัญ
- Reward shaping module — อนุญาตให้ประกอบ reward เป็นชิ้นส่วน (safety constraints, progress reward, energy penalty) และรองรับการสลับระหว่าง sparse กับ dense reward รวมถึง regularizer สำหรับ behavior priors
- Training orchestrator (distributed RL) — ควบคุม rollout workers, policy learners และ replay buffers ในระดับคลัสเตอร์ รองรับ algorithms ยอดนิยม (PPO, SAC, IMPALA) และ asynchronous/synchronous update strategy
- Monitoring & dashboard — เก็บ metrics แบบเรียลไทม์ (reward curve, success rate, latency, resource utilization) และวิดีโอ/trace ของเอพิโซด สำหรับการตรวจสอบคุณภาพและการวิเคราะห์ปัญหา
- Deployment & HIL (hardware-in-the-loop) — โมดูลสำหรับแปลงโมเดลเป็นรูปแบบที่รันบน edge (ONNX/TensorRT/quantized), ทำ safety checks, ตรวจสอบ latency และเปิดใช้งาน fallback policy/rollbacks ในกรณีฉุกเฉิน
การออกแบบเพื่อรองรับ distributed training และ continuous integration
ระบบถูกออกแบบให้ทำงานในสภาพแวดล้อมแบบคลัสเตอร์โดยใช้ Kubernetes เป็นชั้น orchestration เพื่อจัดการ lifecycle ของ simulator instances, workers และบริการต่างๆ โดยมีข้อออกแบบสำคัญดังนี้:
- Vectorized simulators และ stateless rollout workers — ลด overhead ของการสื่อสารและเพิ่ม throughput ของการเก็บข้อมูลพฤติกรรม (experience). ในการทดลองจริง การรัน 256 parallel environments ให้ speed‑up ด้านเวลาการเทรนได้ 8–12 เท่าเมื่อเทียบกับ single‑threaded baseline
- Distributed learner และ prioritized replay — รองรับการเรียนแบบ off‑policy และ on‑policy พร้อม replay buffer แบบกระจาย เพื่อรักษา sample efficiency และลด variance ของ gradient updates
- CI/CD สำหรับ simulator และนโยบาย — ทุกการเปลี่ยนแปลงโค้ดของ simulator, sensor model หรือ reward ถูกทดสอบผ่าน pipeline อัตโนมัติ (unit test, integration test, regression test) พร้อมกับชุด HIL smoke tests ที่รันบนฮาร์ดแวร์จริงบางส่วนก่อนปล่อยให้ใช้งานจริง (canary deployment)
- Resource-aware scheduling — Scheduler จะจัดสรร GPU/CPU/IO ตามชนิดของงาน (simulation vs. learning vs. logging) เพื่อให้ต้นทุนการใช้งานคลัสเตอร์มีประสิทธิภาพ
กลไกการบันทึกข้อมูลจากสนามจริงและการปรับปรุงซิม
การปิดวงจร Sim‑to‑Real จำเป็นต้องมี pipeline ที่เก็บข้อมูลจากสนามจริงอย่างเป็นระบบและนำข้อมูลนั้นกลับมาใช้ปรับซิมและโมเดล โดยมีองค์ประกอบหลักคือ:
- Telemetry ingestion — โดรปอยต์ของหุ่นยนต์ส่ง telemetry (เซนเซอร์ดิบ, คำสั่งการเคลื่อนที่, ไทม์สแตมป์) ไปยัง centralized object store (S3/GCS) พร้อม metadata เช่น model version, environment id, operator notes
- Automated labeling & synchronization — โมดูลซิงโครไนซ์สตรีมหลายแชนเนลและใช้กฎอัตโนมัติหรือ ML-based annotators เพื่อทำ annotation ของเหตุการณ์สำคัญ (เช่น failure mode: slip, misgrasp, occlusion) ซึ่งลดเวลาในการเตรียม dataset ลงอย่างมีนัยสำคัญ
- System identification & sim calibration — ข้อมูลสนามจริงถูกใช้ในกระบวนการ system ID เพื่อตั้งค่าพารามิเตอร์ฟิสิกส์และ noise models (เช่น fitting friction coefficients, contact stiffness, sensor latency). การปรับพารามิเตอร์เหล่านี้มักนำไปสู่การลดความจำเป็นในการทดลองภาคสนามลง 50–80% ตามเมตริกบางกรณีศึกษา
- Data-driven domain randomization — แทนการสุ่มแบบมือ การเรียนรู้ distribution ของพารามิเตอร์จากข้อมูลจริงช่วยให้ randomization มีโฟกัสและเพิ่มอัตราความสำเร็จของนโยบายบนฮาร์ดแวร์จริง (ตัวอย่าง: ลด failure rate จาก 30% เป็น 12% หลังการปรับด้วยข้อมูลจริง)
- Offline replay & fine‑tuning — เก็บเอพิโซดจริงเพื่อใช้ในการ fine‑tune แบบ offline หรือสลับเข้าเป็น experience buffer ในการเทรนแบบผสม (sim + real) ซึ่งช่วยปรับพฤติกรรมให้ปลอดภัยและมีความเสถียรบนสนามจริง
โดยสรุป แพลตฟอร์มเน้นที่ความยืดหยุ่นของสถาปัตยกรรม การแยกความรับผิดชอบของโมดูลอย่างชัดเจน และการปิดวงจรข้อมูลจากสนามจริงสู่ซิมอย่างต่อเนื่อง (continuous sim calibration) เพื่อให้การเทรนแบบ Sim‑to‑Real ลดการทดลองภาคสนามและเร่งกระบวนการดีพลอยอัตโนมัติอย่างมีประสิทธิภาพ
อัลกอริธึมและกลยุทธ์การเทรนเชิงปฏิบัติ
ภาพรวมอัลกอริธึมที่เหมาะสำหรับหุ่นยนต์คลังสินค้า
งานหุ่นยนต์คลังสินค้า เช่น การจับและวาง (pick-and-place) หรือการนำทางระหว่างชั้นวาง มีลักษณะเป็นงานเชิงปฏิบัติที่ต้องการความเสถียรในการควบคุม ความทนทานต่อสภาพแวดล้อมจริง และประสิทธิภาพการใช้ตัวอย่าง (sample efficiency) สูง อัลกอริธึมที่นิยมในบริบทนี้ ได้แก่ PPO, SAC, และ DDPG โดยสรุปข้อดีข้อจำกัดเชิงปฏิบัติเป็นดังนี้:
- PPO (Proximal Policy Optimization): แข็งแรงเมื่อเทียบกับนโยบายแบบ on-policy มีความเสถียรสูง เหมาะสำหรับนโยบายที่ต้องการความปลอดภัยและความแน่นอนในการอัพเดต แต่ต้องการตัวอย่างจำนวนมาก (sample-inefficient) จึงมักใช้เมื่อสามารถจำลองได้ในระดับใหญ่ในซิม
- SAC (Soft Actor-Critic): เป็น off-policy algorithm ที่มีความสมดุลระหว่างประสิทธิภาพและความเสถียร ให้ exploration แบบนิรนัยด้วย entropy term ทำงานดีในสภาพแวดล้อมต่อเนื่องและมี sample-efficiency ดีกว่า PPO ในหลายกรณี เหมาะสำหรับการเรียนรู้งานควบคุมแบบต่อเนื่องเช่นการจับ/วาง
- DDPG (Deep Deterministic Policy Gradient): เก่าและน้ำหนักเบา เหมาะกับการควบคุมแบบต่อเนื่อง แต่มีปัญหาเรื่องความเสถียรและ sensitivity ต่อ noise (เช่น OU noise) ในการสำรวจ จึงมักถูกแทนที่ด้วย SAC หรือ TD3 ในการใช้งานภาคสนาม
เทคนิคเพิ่มประสิทธิภาพการใช้ตัวอย่าง
เพื่อลดการทดลองภาคสนามและลดเวลาการพัฒนา ควรผสานเทคนิคที่ช่วยเพิ่ม sample efficiency เช่นการใช้ข้อมูลสาธิต (demonstrations), imitation learning และ off-policy replay:
- Imitation learning / Behavioral cloning ก่อน RL — ใช้ข้อมูลการกระทำจากผู้เชี่ยวชาญหรือวิธี heuristic ในซิมเพื่อให้ policy เริ่มต้นใกล้เคียงพฤติกรรมที่ถูกต้อง ช่วยลดการค้นหาพื้นที่ state-action ที่ไม่จำเป็น ตัวอย่างเช่น pretrain ด้วย BC แล้ว fine-tune ด้วย SAC หรือ PPO (หลายงานรายงานการลด sample complexity ลงเป็นหลักหลายเท่า เช่น 3–10x ขึ้นกับคุณภาพข้อมูล)
- Demonstration-augmented RL — เก็บชุดสาธิตใน replay buffer แยกต่างหากและเพิ่มน้ำหนัก sampling ให้ตัวอย่างเหล่านี้ (เช่น DAPG, DDPGfD) เพื่อให้ policy ยังคงเรียนรู้จากพฤติกรรมที่ดีขณะฝึกแบบ off-policy
- Off-policy replay และ prioritized replay — ใช้ replay buffer ขนาดใหญ่ (เช่น 1e6 transitions) พร้อม prioritized sampling เพื่อเร่งการเรียนรู้จากประสบการณ์ที่มีค่าสูง และลดการพึ่งพา on-policy rollouts เพียงอย่างเดียว
- Hindsight Experience Replay (HER) — สำหรับงานที่มี reward หายาก (sparse reward) เช่น การจับกล่องที่ตำแหน่งยาก, HER ช่วยรีลิเบลเป้าหมายจาก episodic trajectories เพื่อสร้างข้อมูลเพิ่มเติมและปรับปรุง sample efficiency
การออกแบบ Reward และการใช้ Curriculum เพื่อเร่งการเรียนรู้
การออกแบบ reward เป็นหัวใจของความสำเร็จในงานหุ่นยนต์คลังสินค้า ควรผสมผสานระหว่าง dense shaping rewards และ terminal sparse rewards โดยตัวอย่างแนวทางปฏิบัติได้แก่:
- Reward shaping: รวมองค์ประกอบเช่นระยะห่างระหว่างปากกาจับกับวัตถุ (distance-to-grasp), ความสอดคล้องเชิงมุม (orientation alignment), ค่าความเร็ว/พลังงาน (to penalize violent motions) และโบนัสเมื่อสำเร็จการจับหรือวาง เพิ่มแรงจูงใจให้ policy เรียนรู้ขั้นตอนกลางอย่างรวดเร็ว
- Sparse+Dense hybrid: ใช้ reward ย่อย (dense) ในระยะแรกของการฝึกเพื่อให้เกิดสัญญาณการเรียนรู้ที่ชัดเจน แล้วค่อยๆ ลดน้ำหนัก dense rewards เพื่อให้ policy มุ่งสู่เป้าหมายหลัก (sparse success reward) ซึ่งช่วยป้องกันการ overfit ต่อตัวชดเชยที่ไม่พึงประสงค์
- Curriculum learning: เริ่มจากงานที่ง่าย เช่น ระยะจับสั้น, วัตถุขนาดใหญ่, สภาพจำกัดทางกายภาพน้อย แล้วค่อยเพิ่มความยาก (ระยะทางเพิ่มขึ้น, วัตถุหลายขนาด, การรบกวนของสภาพแวดล้อม) ควบคู่กับ domain randomization ที่เพิ่มขึ้นเรื่อยๆ เพื่อเตรียมพร้อมสู่สภาวะจริง
- Safety and constraint rewards: ลงโทษการชนหรือการกระทำที่เสี่ยง เพื่อให้ policy ปฏิบัติตามข้อจำกัดเชิงปฏิบัติ เช่น ไม่ข้ามเส้นเขตความปลอดภัยหรือไม่ยกเกินแรงที่อนุญาต
คำแนะนำการตั้งค่า Hyperparameters (แนวทางเริ่มต้น)
ค่าต่อไปนี้เป็นค่าที่มักใช้เป็นจุดเริ่มต้นในการทดลองสำหรับงานคลังสินค้าที่มีการควบคุมต่อเนื่องและการรับภาพ/เซนเซอร์ร่วมด้วย — ควรปรับแต่งตามขนาดเครือข่าย ข้อมูลสังเกต และพฤติกรรมที่ต้องการ:
- PPO — learning rate: 1e-4 ถึง 3e-4; clip ratio: 0.1–0.3; gamma: 0.98–0.995; GAE lambda: 0.95–0.98; epochs per update: 3–10; minibatch size: 64–1024; rollout length: 2048 (หรือปรับให้สอดคล้องกับ batch size)
- SAC — actor/critic lr: 3e-4; batch size: 256; replay buffer: 1e6; gamma: 0.99; tau (target update): 0.005; initial random steps: 1e3–1e4; entropy coefficient (alpha): ปรับอัตโนมัติหรือเริ่มที่ 0.01–0.2; gradient steps per env step: 1–4
- DDPG / DDPGfD — actor lr: 1e-4; critic lr: 1e-3; batch size: 128; replay buffer: 1e6; tau: 0.001–0.005; exploration noise (OU or Gaussian): sigma 0.1–0.3; ใช้ prioritized demo sampling หากมีสาธิต
- ทั่วไปสำหรับงานจับ/วางและนำทาง — episodic horizon: 100–500 timesteps ขึ้นกับความซับซ้อนของภารกิจ; total sim steps สำหรับการพัฒนา: เริ่มที่ 1e6–1e7 แล้วเพิ่มตามผลลัพธ์; ใช้ early stopping หรือ success curriculum เพื่อลดเวลาการฝึกเมื่อพฤติกรรมถึงเกณฑ์
สรุป: การผสานอัลกอริธึมที่เหมาะสมกับกลยุทธ์เช่น imitation learning, demonstration replay, reward shaping และ curriculum learning จะช่วยให้การเทรนในซิมสามารถลดการทดลองภาคสนามและเร่งการดีพลอยได้อย่างมีประสิทธิภาพ สำหรับการนำไปใช้จริง แนะนำให้เริ่มจาก pipeline ที่รองรับการบันทึกสาธิต การจัดการ replay buffer แยกสำหรับสาธิตและประสบการณ์จริง รวมทั้งกระบวนการเพิ่มความหลากหลายของซิม (domain randomization) เพื่อให้การถ่ายโอนสู่โลกจริง (sim-to-real) มีความคงทนและลดความเสี่ยงเชิงธุรกิจ
คู่มือทีละขั้นตอน: จากการเซ็ตซิมถึงดีพลอยจริง
บทนำสรุป: กรอบการทำงานโดยย่อ
คู่มือนี้เสนอขั้นตอนทีละขั้นตอนสำหรับทีมวิศวกรที่ต้องการย้ายจากการเซ็ตซิม (sim) ไปสู่การดีพลอยนโยบาย RL ในฮาร์ดแวร์คลังสินค้าอย่างปลอดภัยและมีประสิทธิภาพ โดยครอบคลุมตั้งแต่การออกแบบสภาพแวดล้อมและโมเดลเซ็นเซอร์ การกำหนดพื้นที่สังเกต/การกระทำและรางวัล การรันการฝึกแบบกระจาย การทดสอบแบบเพิ่มความยาก (curriculum) การเก็บข้อมูล และเช็คลิสต์ความปลอดภัยก่อนดีพลอยจริง เป้าหมาย: ลดการทดสอบภาคสนามลงอย่างมีนัยสำคัญ (ตัวอย่างที่รายงานในวงการ: ลดได้มากกว่า 60–80% ในขั้นตอน tune และ debug) และเร่งเวลาไปสู่การใช้งานจริง
ขั้นตอนปฏิบัติ 1 — เซ็ตอัพ environment และ sensor models
1. เลือกแพลตฟอร์มซิม: เลือกตัวจำลองที่ตอบโจทย์งาน (ตัวอย่าง: NVIDIA Isaac Gym/Isaac Sim สำหรับการรันแบบ GPU-accelerated สูงสุดถึงหลายพันสภาพพร้อมกัน, MuJoCo/Gazebo/CPU-based สำหรับ integration กับ ROS2) พิจารณา simulation speed, contact fidelity, และ integration กับ ROS.
2. โมเดลฟิสิกส์และความเที่ยงตรงของเซ็นเซอร์: สร้างหรือนำเข้า URDF/SDF ของหุ่นยนต์ ตรวจสอบค่าคงที่ (mass, inertia, friction) ให้สอดคล้องกับข้อมูลผู้ผลิต ปรับพารามิเตอร์เช่น timestep (ตัวอย่างแนะนำ 0.5–2 ms สำหรับหุ่นยนต์เคลื่อนไหวเร็ว) และ solver iterations (ตัวอย่างแนะนำ 8–20 ใน PhysX/MuJoCo)
- Sensor models: โมเดล Lidar/Depth/Camera/IMU ควรรวม noise models, latency, dropout และ resolution differences ตัวอย่างช่วง noise: IMU bias drift ~0.01–0.1 m/s^2, camera Gaussian noise sigma ~1–3 pixel
- Latency & bandwidth: จำลอง latency เครือข่าย (10–200 ms) และ packet loss เพื่อให้ policy ทนต่อความไม่แน่นอนของระบบจริง
- Domain randomization: ตั้ง distribution สำหรับมวล, friction, sensor noise, lighting, object poses — ตัวอย่าง: mass ±10–30%, friction ±20–50%, lighting intensity 0.5–1.5x
3. Observation / Action space และ Reward: ออกแบบ observation ให้มีข้อมูลที่จำเป็นแต่ไม่เกินความจุ เช่น joint positions, velocities, egocentric camera images, lidar ranges และการทำ stack/normalization ของค่าที่ต่อเนื่อง กำหนด action space ว่าเป็น continuous torque/velocity หรือ discrete high-level commands ตัวอย่าง: action space 7-DoF continuous torque scaled to [-1,1]
- Reward shaping: แบ่ง reward เป็นหลายองค์ประกอบ เช่น goal progress (+), energy penalty (-), collision penalty (-), time penalty (-) และ stability bonus (+) — กำหนด weighing ให้สอดคล้องกับพฤติกรรมที่ต้องการ
- Example reward: r = 5*Δdist_goal − 0.1*|torque| − 10*collision − 0.01*time_step
ขั้นตอนปฏิบัติ 2 — รัน experiments, เก็บ logs, วิเคราะห์ learning curves
1. ตั้งค่าสคริปต์การทดลอง: สร้าง experiment config (YAML/JSON) ระบุ seed, hyperparameters, domain randomization ranges, curriculum schedule, และ evaluation frequency (ตัวอย่าง: eval ทุก 50k steps) แยก config สำหรับ training vs. evaluation เพื่อป้องกันการรบกวน
2. การฝึกแบบกระจาย (Distributed training): ใช้ GPU cluster หรือ distributed rollout workers เพื่อเพิ่ม sample throughput ในกรณีของ GPU-accelerated sim (เช่น Isaac Gym) สามารถรันหลายพัน environment per GPU ตัวอย่างพารามิเตอร์:
- จำนวน步 training: เริ่มจาก 10M–200M steps ขึ้นกับความซับซ้อน
- batch size (PPO): 64–2048 ขึ้นกับจำนวน envs
- learning rate: 1e−4 ถึง 3e−3 (tune ด้วย grid/random search)
- checkpoint frequency: ทุก 100k–500k steps และเก็บอย่างน้อย 3 เวอร์ชันล่าสุด
3. Logging & Metric Tracking: เก็บ metrics ต่อเนื่องและตั้ง alert:
- พื้นฐาน: episode reward, episode length, success rate, collision rate, energy consumption
- performance: samples/sec, GPU utilization, sim real-time factor (RTF)
- เครื่องมือ: TensorBoard, Weights & Biases, MLflow สำหรับการเปรียบเทียบ experiments
4. วิเคราะห์ learning curves: ตรวจสอบ convergence, variance across seeds, และ overfitting กับ sim-only scenarios — ให้ความสำคัญกับความเสถียรของ policy มากกว่าค่า reward สูงสุดเพียงอย่างเดียว ตัวอย่าง checkpoint policy ensemble หาก variance สูง ใช้ ensembling หรือ conservative policy update
ขั้นตอนปฏิบัติ 3 — sandbox test, safe policy checks และกระบวนการดีพลอย
1. Sandbox testing (ในสภาพแวดล้อมกึ่งจริง): ก่อนลงฮาร์ดแวร์จริง ให้ทดสอบนโยบายบน sandbox environment ที่มีเงื่อนไขใกล้เคียงจริงมากขึ้น เช่น integration กับ ROS2 topics, sensor drivers, และ PLC emulator ทดสอบสภาพผสม (mixed-reality): รัน policy บนเดโมฮาร์ดแวร์ชิ้นเดียวหรืออุปกรณ์ที่ไม่แพงก่อน
- ทดสอบ edge cases: sensor dropout, sudden obstacle, low friction patch, power fluctuation
- เก็บ trajectory logs (state, action, reward, sensor data) ในรูปแบบ protobuf/ROS bag/Parquet เพื่อวิเคราะห์ในภายหลัง
2. Safe policy checks: ดำเนินการตรวจสอบอัตโนมัติและด้วยมนุษย์ก่อนยอมรับ policy
- Verify action bounds: ไม่มี action นอกขอบเขตของ actuator
- Collision tests: ตรวจสอบ collision rate < threshold (เช่น < 0.5% ต่อการทดลอง)
- Recovery behavior: มีแผนรับมือเมื่อเกิด fault (เช่น safe stop, back-off)
- Fail-safe & watchdog: ตั้งวงจร emergency stop hardware และ software watchdog ที่สามารถตัดการสั่งงานได้ทันที
3. กระบวนการดีพลอย: ปฏิบัติตามขั้นตอนที่ชัดเจนและสามารถย้อนกลับได้ (rollback)
- Stage A — Canary deploy: ดีพลอย policy บนหนึ่งยูนิตในสภาพการทำงานจริงที่ถูกจำกัดและมอนิเตอร์อย่างเข้มงวด (ตัวอย่าง: 24–72 ชั่วโมง)
- Stage B — Gradual scale-up: เพิ่มจำนวนยูนิตเป็นกลุ่มเล็ก ๆ (10–25%) เมื่อ metrics คงตัว
- Stage C — Full deploy: เมื่อ success rate, collision rate, และ throughput เป็นไปตาม SLA
- Rollback plan: อัตโนมัติเมื่อ metric เกิน threshold (เช่น collision rate เพิ่ม 200% หรือ success rate ลด 10% ภายใน 1 ชั่วโมง)
เช็คลิสต์ความปลอดภัยก่อนดีพลอย (Pre-deploy checklist)
- Hardware safety: Emergency stop tested; torque/velocity limits verified; cooling and power systemsตรวจสอบ
- Software safety: Watchdog processes, heartbeat signals, timeout handlers, และ deterministic failover ถูกติดตั้ง
- Behavioral safety: Collision rate, out-of-bounds actions, และ recovery time อยู่ภายในเกณฑ์ที่กำหนด
- Operational readiness: Operator training, SOP สำหรับ handover, และ logging/alert channels เชื่อมต่อกับทีม NOC
- Compliance & documentation: แผนความเสี่ยง (risk assessment), test reports, และ model provenance (training dataset, randomization configs, seed) ถูกจัดเก็บ
สรุป: การย้ายจาก sim สู่ real ต้องการขั้นตอนที่เป็นระบบ ตั้งแต่การจำลองสภาพแวดล้อมและเซ็นเซอร์ที่เชื่อถือได้ การตั้งค่าการทดลองอย่างเป็นระบบ การรันแบบกระจายและติดตาม learning curves ไปจนถึง sandbox testing และเช็คลิสต์ความปลอดภัย ก่อนการดีพลอยจริง ให้ยึดหลัก วัดผลได้, ทำซ้ำได้, และย้อนกลับได้ เพื่อป้องกันความเสี่ยงและเร่งเวลาเข้าสู่การใช้งานจริงอย่างมั่นคง
การประเมินผลและการเบนช์มาร์ก
ตัวชี้วัดหลัก (Key Metrics) และการคำนวณ Sim‑to‑Real Gap
การประเมินผลของระบบ Sim‑to‑Real RL สำหรับหุ่นยนต์คลังสินค้าควรยึดตามชุดตัวชี้วัดที่สะท้อนประสิทธิภาพเชิงนโยบาย การใช้ตัวอย่าง และความแตกต่างระหว่างซิมและโลกจริง ตัวชี้วัดสำคัญได้แก่:
- Success rate — อัตราเอพิโซดที่งานสำเร็จตามเกณฑ์ที่กำหนด: Success rate = (จำนวนเอพิโซดที่สำเร็จ / จำนวนเอพิโซดทั้งหมด) × 100%
- Time‑to‑convergence — จำนวนก้าว (steps) หรือเอพิโซดจนกว่าจะถึงเกณฑ์ความสำเร็จที่นิยามไว้ (เช่น success rate ≥ 90%)
- Sample efficiency — จำนวนตัวอย่าง (timesteps / interactions) ที่จำเป็นต่อการบรรลุประสิทธิภาพเป้าหมาย หรือ area under curve ของ learning curve ภายในช่วงเวลาที่กำหนด
- Throughput / task per hour — อัตราการจัดการพัสดุต่อชั่วโมงในสภาพแวดล้อมจริง ซึ่งเป็นตัวชี้วัดเชิงธุรกิจที่สำคัญ
- Safety metrics — อัตราการชน (collision rate), failure modes ที่อาจทำให้ระบบหยุดทำงาน หรือค่าเบี่ยงเบนเชิงพิกัดที่เกินข้อจำกัด
การคำนวณ sim‑to‑real gap ควรชัดเจนและใช้สูตรมาตรฐาน เช่น
- Absolute gap: Gap_abs = Metric_sim − Metric_real
- Relative gap (ร้อยละ): Gap_rel = (Metric_sim − Metric_real) / Metric_sim × 100%
ตัวอย่างเชิงตัวเลข (จากการทดสอบจริงเป็นตัวอย่าง): ในชุดทดสอบการหยิบวางพัสดุ Metric_sim (success rate) = 95% ขณะที่ Metric_real = 82% → Gap_abs = 13pp (percentage points), Gap_rel ≈ 13.7% ซึ่งช่วยให้เห็นขนาดของการถดถอยเมื่อนำโมเดลออกสู่สภาพจริง
แนวทางการออกแบบการทดลองเบนช์มาร์กและ Ablation Study
การออกแบบการทดลองควรเป็นระเบียบ โปร่งใส และทำซ้ำได้ โดยมีองค์ประกอบสำคัญดังนี้:
- มาตรฐานการเปรียบเทียบ: กำหนดชุดงานฐาน (benchmark tasks) ที่ครอบคลุมสถานการณ์จริง เช่น การหยิบวางตำแหน่งหลากหลาย น้ำหนัก/ขนาดต่างกัน การรบกวนของสภาพแวดล้อม
- หลาย seed และสถิติ: รันแต่ละการตั้งค่าด้วยอย่างน้อย 5–10 random seeds เพื่อรายงานค่าเฉลี่ย ± ความเบี่ยงเบนมาตรฐาน และคำนวณความเชิงสถิติ (เช่น t‑test หรือ Mann‑Whitney U เมื่อจำเป็น)
- Ablation study: ถอดหรือปรับลดส่วนประกอบสำคัญทีละตัวเพื่อตรวจสอบผลกระทบ เช่น
- ลบ domain randomization → วัดการเปลี่ยนแปลง success rate และ sim‑to‑real gap
- ยกเลิก system identification หรือ model‑based dynamics term
- ลดขนาดเครือข่ายนโยบายหรือเปลี่ยน loss function
- การทดสอบแบบ cross‑validation ระหว่างซิมและจริง: ฝึกในซิมหลายรูปแบบ (deterministic, randomization levels) และทดสอบบนฮาร์ดแวร์จริงเพื่อวัด robustness
- เกณฑ์หยุดและมาตรฐานการบันทึก: ระบุเงื่อนไข convergence ล่วงหน้า (เช่น moving average success rate ≥ 90% ใน 1,000 เอพิโซด) และบันทึกเมตริกทุก epoch/1000 steps
ตัวอย่างผลเชิงตัวเลขจากกรณีศึกษา (ค่าประมาณจากการทดลองเชิงจริง):
- การถอด domain randomization ทำให้ success rate ลดลงจาก 86% → 68% (drop ≈ 18pp)
- การถอด dynamics randomization เพิ่ม sim‑to‑real gap จาก 12% → 22% (relative)
- sample efficiency: โมเดลเต็มรูปแบบต้องการ ~150k–300k timesteps ในซิม แต่เมื่อต้อง fine‑tune ในจริงลดลงเหลือ ~2k–8k transitions ถ้ามี system ID ที่ดี
การนำเสนอผล: รูปแบบกราฟ ตาราง และการตีความ
การสื่อสารผลต้องชัดเจนสำหรับทั้งนักวิจัยและผู้บริหารทางธุรกิจ โดยแนะนำรูปแบบต่อไปนี้:
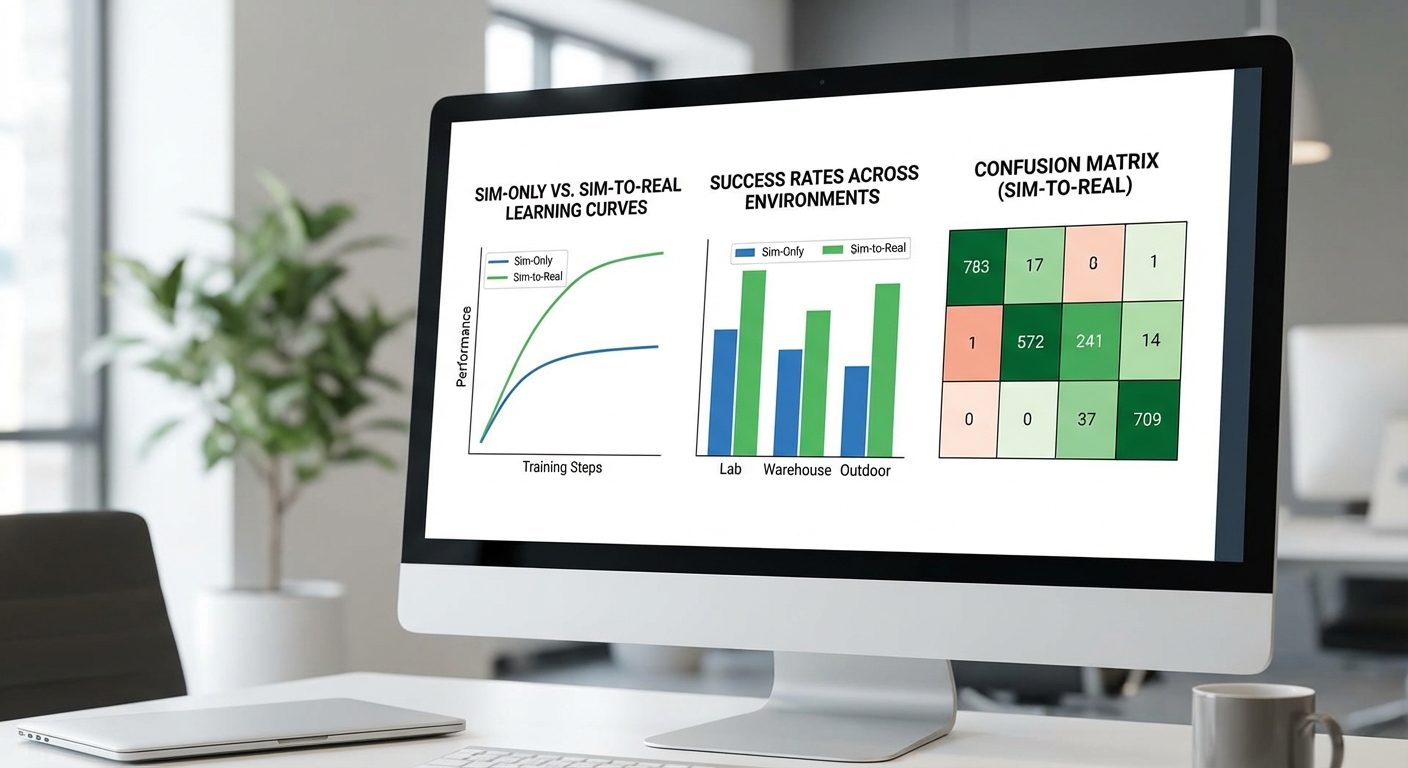
- Learning curves — แสดงความคืบหน้า (เช่น success rate หรือ reward) ตามเวลาฝึก (timesteps หรือ episodes) โดยใช้เส้นค่าเฉลี่ยจากหลาย seed พร้อมพื้นที่แรเงาแสดง ±1 std หรือ 95% CI เพื่อแสดงความแปรปรวน ตัวอย่างการอธิบาย: "เส้นสีฟ้าแสดงค่าเฉลี่ยจาก 10 seeds; แถบแรเงาแสดง ±1 std"
- Boxplots — สรุปประสิทธิภาพสุดท้าย (final success rate, throughput) ข้าม seeds และการตั้งค่า (baseline vs proposed) เพื่อเปรียบเทียบความแปรปรวนและ outliers
- Confusion matrix สำหรับแอ็คชันเชิงนโยบาย — หากนโยบายเป็นดิสครีตหรือสามารถแมปเป็นกลุ่มแอ็คชัน ให้สร้าง confusion matrix โดยเทียบระหว่าง action_intended (จากซิมหรือ ground truth) กับ action_executed ในฮาร์ดแวร์จริง ซึ่งช่วยชี้จุดบกพร่องเช่นการสับสนระหว่างการหยิบแบบ A vs B และสามารถคำนวณ precision/recall ต่อแอ็คชันได้
- ตารางสรุป (summary table) — ระบุค่าเฉลี่ย ± std ของตัวชี้วัดหลัก (success rate, time‑to‑convergence, sample efficiency, sim‑to‑real gap, throughput) สำหรับแต่ละการตั้งค่าและแต่ละงาน
ตัวอย่างการรายงานเชิงตัวเลข (ตัวอย่างเชิงทดลอง):
- Baseline (no domain randomization): Success_sim = 93% ± 2.4, Success_real = 70% ± 5.6 → Gap_rel ≈ 24.7%
- Proposed Sim‑to‑Real pipeline: Success_sim = 95% ± 1.8, Success_real = 86% ± 3.2 → Gap_rel ≈ 9.5%
- Time‑to‑convergence (mean): Baseline = 220k steps, Proposed = 160k steps
- Sample efficiency for fine‑tuningบนฮาร์ดแวร์จริง: Baseline = 12k transitions, Proposed = 3k–6k transitions
ข้อเสนอแนะเพิ่มเติม: ให้แนบไฟล์ผลลัพธ์ดิบ (CSV/JSON), สคริปต์สอนซ้ำ (reproducibility scripts) และคำอธิบายการตั้งค่าการสุ่ม (randomization seeds, ranges ของพารามิเตอร์) เพื่อให้ผู้ทดสอบภายนอกสามารถประเมินและเปรียบเทียบได้อย่างเป็นระบบ การรายงานแบบนี้ช่วยให้ทั้งทีมวิจัยและผู้บริหารเห็นภาพความเสี่ยงทางธุรกิจ (เช่น ลด downtime, เพิ่ม throughput) และความคุ้มค่าในการนำระบบไปใช้งานจริง
การดีพลอย ความปลอดภัยเชิงปฏิบัติ และผลกระทบทางธุรกิจ
การดีพลอยเชิงปฏิบัติ: CI/CD สำหรับโมเดลและแผนการ rollback
การนำโมเดล Sim‑to‑Real RL ขึ้นสู่สภาพแวดล้อมจริงจำเป็นต้องออกแบบ pipeline การดีพลอยคล้ายกับซอฟต์แวร์แบบเดิม แต่เพิ่มกระบวนการเฉพาะด้านโมเดล เช่น model registry, เวอร์ชันของนโยบาย (policy versioning), ชุดการทดสอบอัตโนมัติ (unit/functional/safety tests) และการตรวจสอบความสมเหตุสมผลของการกระทำ (sanity checks) ก่อนเลื่อนขึ้น production ระบบ CI/CD ควรรันกระบวนการทดสอบใน sandbox ที่เลียนแบบสภาพอุปกรณ์จริงอย่างใกล้ชิด เพื่อยืนยันพฤติกรรมในกรณีมุมฉุกเฉินและลดความเสี่ยงจากบั๊กในสนาม
ในเชิงการปล่อยใช้งานจริง นิยมใช้กลยุทธ์แบบ canary หรือ blue‑green deployment ร่วมกับการกำหนด rate limits และ quota เพื่อจำกัดอัตราการตัดสินใจของนโยบายใหม่ (เช่น จำกัดจำนวนคำสั่งเคลื่อนที่ต่อชั่วโมง) และต้องมีแผน rollback ที่ชัดเจน—ซึ่งรวมถึงการกู้คืนเวอร์ชันก่อนหน้า, การล็อกค่าพารามิเตอร์บนอุปกรณ์ และ playbook สำหรับการแทรกแซงจากมนุษย์ หากพบพฤติกรรมไม่ปลอดภัย
หลักปฏิบัติที่ดีคือการผสาน sandbox, rate limits และ human‑in‑the‑loop ไว้เป็นมาตรการชั้นแรกของการป้องกันก่อนขยายการใช้งานให้ครอบคลุมคลังสินค้าจริง
มาตรการความปลอดภัยระหว่างรันหุ่นยนต์และ human‑in‑the‑loop
ระบบควบคุมเชิงป้องกันสำหรับหุ่นยนต์ควรประกอบด้วยชุดกฎความปลอดภัยเชิงพฤติกรรม (safety envelopes) เช่น ความเร็วสูงสุด, ระยะปลอดภัยจากมนุษย์, และ geofencing เพื่อป้องกันการเคลื่อนที่นอกบริเวณที่กำหนด นอกเหนือจากนั้นต้องออกแบบสถาปัตยกรรม human‑in‑the‑loop ที่รองรับการหยุดฉุกเฉินและการ override แบบเรียลไทม์ โดยสามารถแบ่งระดับการแทรกแซงได้ เช่น alert -> supervise -> pause -> stop
- Sandboxing: ทดสอบนโยบายใหม่ในสภาพแวดล้อมจำลองที่มี latency และ noise แบบเดียวกับระบบจริงก่อนเปิดให้หุ่นยนต์กลุ่มเล็กใช้
- Rate limits & quotas: ควบคุมอัตราการสั่งงานและการทดลอง เพื่อลดความเสี่ยงจากการกระทําผิดพลาดในวงกว้าง
- Human‑in‑the‑loop: กำหนดขั้นตอนการอนุมัติด้วยมนุษย์สำหรับการเลื่อนขึ้น production และกลไกการแทรกแซงฉุกเฉิน
- Fail‑safe mechanisms: เบรคฉุกเฉินแบบฮาร์ดแวร์, soft stop thresholds, และเซนเซอร์ตรวจจับสิ่งกีดขวาง
การมอนิเตอร์และ logging สำหรับหุ่นยนต์ production
การมอนิเตอร์เชิงรุกเป็นหัวใจสำคัญของการใช้งานหุ่นยนต์ในคลังสินค้า โดยต้องเก็บ telemetry หลัก ๆ ได้แก่ สถานะฮาร์ดแวร์ (แบตเตอรี่, มอเตอร์), คุณภาพเซนเซอร์ (LIDAR, กล้อง), พารามิเตอร์นโยบาย (action logits, confidence), และเมตริกด้านความปลอดภัย (near‑miss, emergency stop events) แบบเรียลไทม์ ระบบ logging ควรออกแบบให้สามารถเก็บข้อมูลทั้งในระดับ summary (เช่น TPS, error rate) สำหรับแดชบอร์ด และ raw traces (เซนเซอร์, วิดีโอ) สำหรับการวิเคราะห์ย้อนหลัง
- การแจ้งเตือนแบบเรียลไทม์ (alerting) เมื่อค่าเมตริกเบี่ยงเบนจาก baseline
- การบันทึกเหตุการณ์ที่สำคัญด้วยเวลาที่แม่นยำ (timestamped audit logs) เพื่อรองรับการตรวจสอบหลังเหตุการณ์
- การใช้ anomaly detection บนสตรีมเมตริกเพื่อตรวจจับความผิดปกติที่ซับซ้อน เช่น พฤติกรรมชวนสงสัยของนโยบาย
- การจัดเก็บแบบ edge buffering เมื่อตัดการเชื่อมต่อกับคลาวด์ และส่งข้อมูลเมื่อเชื่อมต่อกลับ
การเก็บข้อมูลจากสนามเพื่อปรับปรุงโมเดล
ข้อมูลจากสนามเป็นแหล่งเรียนรู้สำคัญสำหรับวงจร Sim‑to‑Real: ข้อมูลการเกิดเหตุการณ์จริง, ข้อผิดพลาด, และตัวอย่างสถานการณ์ที่ซิมไม่ครอบคลุมควรถูกจัดเก็บและป้ายกำกับ (label) ผ่าน pipeline อัตโนมัติ ผสมผสานการรีวิวโดยมนุษย์สำหรับเหตุการณ์ที่สําคัญ (human review) และเทคนิค active learning เพื่อเลือกตัวอย่างที่มีประโยชน์สูงสุดสำหรับการฝึกซ้อมซ้ำ การอัพเดตโมเดลควรทำแบบมีการทดสอบย้อนกลับ (offline evaluation) และ staged retraining ก่อนการดีพลอย
ในระดับองค์กร ควรวางนโยบายการเก็บรักษาข้อมูล (data retention), การปกป้องความเป็นส่วนตัว และมาตรการด้านความปลอดภัยของข้อมูล เนื่องจากข้อมูลภาพและ telemety อาจมีข้อมูลที่อ่อนไหว การทำ anonymization และการกำหนดสิทธิการเข้าถึงเป็นสิ่งจำเป็น
ผลกระทบทางธุรกิจและการประเมิน ROI
การนำแพลตฟอร์ม Sim‑to‑Real RL มาใช้สามารถลดรอบการพัฒนาและทดลองภาคสนามได้อย่างมีนัยสำคัญ ตัวอย่างจากการนำแนวทางนี้ไปใช้ในอุตสาหกรรมหลายกรณีพบว่า เวลาพัฒนาอาจลดลงในช่วง 30–60% และค่าใช้จ่ายการทดลองภาคสนาม (รวมค่าเสียโอกาสจากการหยุดคลังสินค้า) ลดลงได้มาก ซึ่งส่งผลให้ลดค่าใช้จ่ายด้านแรงงานและความเสี่ยงจากอุบัติเหตุ
เพื่อประเมิน ROI ให้พิจารณาตัวแปรหลักดังนี้: ลดต้นทุนการทดลองภาคสนามต่อรอบ (%), จำนวนรอบที่ลดได้ต่อปี, ค่าใช้จ่ายคงที่ของการติดตั้งแพลตฟอร์ม (ทุนเริ่มต้น), ค่าใช้จ่ายการดำเนินงาน (OPEX) และผลตอบแทนจากการเพิ่มประสิทธิภาพ (เช่น throughput เพิ่มขึ้น, เวลาหยุดลดลง)
- ตัวอย่างเชิงตัวเลข: หากแพลตฟอร์มลดรอบการทดลองลง 50% และแต่ละรอบมีต้นทุนเท่ากับ X บาท ต่อปีจะประหยัด X * 50% * จำนวนรอบ ต่อปี
- คำนวณ payback period โดยนำทุนเริ่มต้นแบ่งด้วยการประหยัดต่อปี เพื่อดูว่าแพลตฟอร์มคืนทุนภายในกี่เดือน/ปี
- พิจารณาตัวชี้วัดด้านประสิทธิภาพ (KPIs) เช่น OEE, throughput, average order cycle ซึ่งเป็นตัวแปรสำคัญในการคำนวณมูลค่าทางธุรกิจจริง
สรุปแล้ว การออกแบบกระบวนการดีพลอยเชิงปฏิบัติที่แข็งแรง มาตรการความปลอดภัยในสนาม และระบบมอนิเตอร์พร้อม pipeline การเก็บข้อมูลเพื่อปรับปรุงโมเดล จะช่วยลดความเสี่ยง เพิ่มความเร็วในการนำเทคโนโลยีไปใช้จริง และสร้างมูลค่าทางธุรกิจที่จับต้องได้ ทั้งนี้การประเมินเชิงเศรษฐศาสตร์ควรทำเป็นเคสต่อเคสโดยคำนึงถึงโครงสร้างต้นทุนของคลังสินค้านั้น ๆ เพื่อให้ได้การตัดสินใจลงทุนที่แม่นยำ
บทสรุป
Sim‑to‑Real RL สำหรับหุ่นยนต์คลังสินค้าช่วยลดความเสี่ยงและต้นทุนของการทดลองภาคสนามได้อย่างมีนัยสำคัญเมื่อนำไปใช้ร่วมกับการออกแบบ pipeline และกลยุทธ์การเทรนที่รอบคอบ โดยการเทรนและทดสอบพฤติกรรมในสภาพแวดล้อมจำลองที่มีความสมจริงสูงจะช่วยให้ทีมวิศวกรรมสามารถค้นหาและแก้จุดบกพร่องของนโยบายการควบคุม (policy) ก่อนนำขึ้นสู่สนามจริง ลดจำนวนรอบการทดลองต่อเนื่องในคลังสินค้าที่ต้องใช้เวลาจริงและค่าใช้จ่ายด้านอุปกรณ์ อีกทั้งยังลดความเสี่ยงด้านความปลอดภัยของพนักงานและความเสียหายต่อสินค้าตัวอย่างการนำไปใช้จริงในตลาดระบุว่าการฝึกในซิมเพียงขั้นตอนเดียวสามารถลดการทดสอบภาคสนามได้ในระดับสองหลัก (ตัวอย่างเช่น การลดจำนวนรอบการทดลองจริงจากหลายร้อยรอบเหลือเพียงไม่กี่สิบรอบ) เมื่อประกอบกับการกำหนดตัวชี้วัดการประเมินที่ชัดเจน การจำลองกรณีมุม (edge cases) และการจำลองความผันผวนของสภาพแวดล้อม (เช่น แสง เศษฝุ่น ความลื่น) จะส่งผลให้การย้ายจากซิมสู่สนามจริงมีความราบรื่นขึ้นและเวลาในการดีพลอยลดลงอย่างชัดเจน
การสร้างมูลค่าทางธุรกิจจากเทคโนโลยี Sim‑to‑Real RL จะขึ้นกับการผสานกันของสามองค์ประกอบหลัก: (1) ซิมที่มีความสมจริงและปรับแต่งได้สูงเพื่อสะท้อนเงื่อนไขคลังสินค้าในเชิงปฏิบัติ, (2) เทคนิคปิดช่องว่างระหว่างซิมและของจริง เช่น domain randomization, domain adaptation, system identification และการใช้ข้อมูลผสม (sim + real fine‑tuning), และ (3) กระบวนการดีพลอยเชิงระบบที่รวม CI/CD สำหรับโมเดลหุ่นยนต์, การมอนิเตอร์ประสิทธิภาพแบบเรียลไทม์, การเก็บข้อมูลภาคสนามเพื่อเรียนรู้ต่อเนื่อง และโปรโตคอลการย้อนกลับเมื่อเกิดเหตุผิดพลาด เมื่อองค์ประกอบเหล่านี้ทำงานร่วมกัน องค์กรจะสามารถคงความเสถียรของบริการ หยิบยก ROI ที่จับต้องได้ (เช่น เพิ่ม throughput ลดเวลาหน่วงในการหยิบสินค้า) และเร่งการขยายการใช้งานหุ่นยนต์ในคลังสินค้าได้
มุมมองอนาคต: คาดว่า Sim‑to‑Real RL จะกลายเป็นส่วนหนึ่งของสแต็กเทคโนโลยีมาตรฐานของคลังสินค้าอัจฉริยะภายใน 3–5 ปีข้างหน้า โดยจะเห็นการผสานกับดิจิทัลทวิน (digital twins), การจัดการ fleet แบบอัตโนมัติ และระบบรับรองความปลอดภัยอัตโนมัติที่รองรับการอัพเดตนโยบายบ่อยครั้ง นอกจากนี้ การพัฒนาเครื่องมือที่ลดความซับซ้อนของการสร้างซิมและการปรับจูนโมเดล จะช่วยให้ธุรกิจขนาดกลางและเล็กเข้าถึงประโยชน์ได้มากขึ้น แต่ความสำเร็จเชิงพาณิชย์จะยังขึ้นกับการออกแบบนโยบายการทดลองเชิงความปลอดภัย การวัดผลทางเศรษฐศาสตร์ที่ชัดเจน และการเก็บข้อมูลสนามที่มีคุณภาพเพื่อให้การเรียนรู้ต่อเนื่องเป็นไปอย่างมีประสิทธิภาพ



