
ในยุคที่ข้อมูลและโมเดลปัญญาประดิษฐ์กลายเป็นหัวใจสำคัญของการตัดสินใจด้านสินเชื่อ ธนาคารไทยเผชิญทั้งโอกาสและความเสี่ยง—โอกาสในการขยายการให้บริการอย่างรวดเร็วและแม่นยำ ความเสี่ยงจากอคติที่ฝังตัวในข้อมูลหรือโมเดลซึ่งอาจทำลายความไว้วางใจและสร้างปัญหาทางกฎหมาย ด้วยแรงกดดันจากผู้กำกับดูแลและความคาดหวังของผู้บริโภค ธนาคารหลายแห่งจึงหันมาใช้แนวทาง Explainable AI (XAI) ร่วมกับ Causal ML เพื่อให้การตัดสินใจสินเชื่อเป็นไปอย่างโปร่งใส ตรวจสอบได้ และสามารถอธิบายสาเหตุของผลลัพธ์ในเชิงสาเหตุ (causality) แทนเพียงความสัมพันธ์เชิงสถิติ
บทความนี้นำเสนอแนวทางปฏิบัติสำหรับธนาคารไทยที่ต้องการติดตั้งระบบตรวจสอบโมเดลสินเชื่อแบบเรียลไทม์ โดยครอบคลุมตั้งแต่หลักการพื้นฐานของ XAI และ Causal ML ไปจนถึงสถาปัตยกรรมการติดตั้ง เครื่องมือที่แนะนำ ตัวชี้วัดเชิงปฏิบัติสำหรับวัดอคติและความโปร่งใส รวมถึงขั้นตอนการบูรณาการเข้ากับงานปฏิบัติการ (ops) และการกำกับดูแลคอนโทล วัตถุประสงค์คือช่วยให้ทีมเทคนิคและผู้กำหนดนโยบายในธนาคารสามารถลดอคติ เพิ่มความชัดเจนในการตัดสินใจเครดิต และรับมือกับข้อกำหนดด้านกฎระเบียบได้อย่างมีประสิทธิภาพ
บทนำ: ทำไมธนาคารต้องใช้ XAI และ Causal ML กับการให้สินเชื่อ
บทนำ: ทำไมธนาคารต้องใช้ XAI และ Causal ML กับการให้สินเชื่อ
การนำโมเดลปัญญาประดิษฐ์แบบที่มีความซับซ้อนสูงหรือที่เรียกว่า "black-box" มาใช้ในการให้สินเชื่อ ทำให้เกิดความท้าทายเชิงธุรกิจและการกำกับดูแลอย่างสำคัญ เนื่องจากผลการตัดสินใจที่ได้มักขาดความชัดเจนในการอธิบายสาเหตุ ผู้ปฏิบัติงานและผู้กำกับดูแลไม่สามารถตรวจสอบได้อย่างรวดเร็วว่าเหตุใดผู้ขอสินเชื่อรายใดจึงถูกปฏิเสธหรือได้รับเงื่อนไขที่แตกต่างกัน ซึ่งเพิ่มความเสี่ยงต่อการเกิดอคติ (bias) ทางข้อมูล เช่น การเลือกหรือปฏิเสธกลุ่มประชากรย่อยบางกลุ่มโดยไม่เป็นธรรม
ผลกระทบเชิงธุรกิจจากโมเดลที่ไม่โปร่งใสมีได้หลายมิติ ทั้งความเสี่ยงทางกฎหมายจากการละเมิดแนวปฏิบัติด้านความเท่าเทียมและการไม่เลือกปฏิบัติ การเสื่อมศรัทธาจากลูกค้าเมื่อการตัดสินใจไม่สามารถอธิบายได้อย่างชัดเจน และความเสี่ยงด้านภาพลักษณ์ที่อาจนำไปสู่การฟ้องร้องหรือบทลงโทษ ตัวอย่างเชิงสถิติชี้ให้เห็นปัญหา: งานวิจัยหลายชิ้น (ตัวอย่างสมมติ) พบว่าโมเดลการให้สินเชื่อบางประเภทแสดงอคติสูงกว่า20–30% ในบางกลุ่มประชากรย่อย ส่งผลให้มีอัตราการปฏิเสธสินเชื่อที่สูงขึ้นอย่างมีนัยสำคัญสำหรับผู้ยากจน ชนบท หรือกลุ่มชาติพันธุ์และเพศบางกลุ่ม ซึ่งหากไม่ถูกตรวจพบ จะส่งผลให้ธนาคารสูญเสียโอกาสทางธุรกิจและเพิ่มต้นทุนจากข้อพิพาท
กรอบกฎระเบียบที่เกี่ยวข้องในประเทศไทยและระดับสากลยิ่งตอกย้ำความจำเป็นของความโปร่งใสและการคุ้มครองข้อมูล ตัวอย่างแนวทางและข้อกำหนดที่มีความเกี่ยวข้องได้แก่
- แนวทางของธนาคารแห่งประเทศไทย (ธปท.) — เน้นการบริหารความเสี่ยงจากแบบจำลอง (model risk) และการกำกับดูแลด้านเทคโนโลยีทางการเงิน โดยคาดหวังให้สถาบันการเงินมีการทดสอบ ติดตาม และรายงานผลกระทบจากโมเดลอย่างเป็นระบบ
- พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) — กำหนดหลักการใช้ข้อมูลส่วนบุคคลอย่างชัดเจน รวมถึงสิทธิของเจ้าของข้อมูลที่จะได้รับการชี้แจงเกี่ยวกับการประมวลผลข้อมูลและการตัดสินใจอัตโนมัติ
- แนวคิดจากหน่วยงานกำกับดูแลระดับสากล (เช่น EBA) — ให้ความสำคัญกับความโปร่งใส ความเป็นธรรม และความสามารถในการตรวจสอบของโมเดลการให้สินเชื่อ โดยเสนอแนวปฏิบัติด้านการอธิบายการตัดสินใจและการวัดผลกระทบเชิงกฎระเบียบ
ด้วยบริบทเชิงธุรกิจและกฎระเบียบดังกล่าว ธนาคารจำเป็นต้องปรับวิธีการพัฒนาและนำโมเดลมาใช้ โดยการผสานเทคโนโลยี Explainable AI (XAI) และ Causal Machine Learning เข้ากับกระบวนการให้สินเชื่อ เพื่อลดอคติและสร้างคำอธิบายที่สามารถตรวจสอบได้แบบเรียลไทม์ การดำเนินการดังกล่าวไม่เพียงแต่ช่วยลดความเสี่ยงด้านกฎหมายและภาพลักษณ์ แต่ยังเป็นแนวทางเชิงกลยุทธ์ในการสร้างความเชื่อมั่นแก่ลูกค้า เพิ่มความถูกต้องในการอนุมัติสินเชื่อ และรักษาความสามารถในการแข่งขันในระยะยาว
พื้นฐาน Explainable AI: วิธีและเครื่องมือที่ใช้งานได้จริง
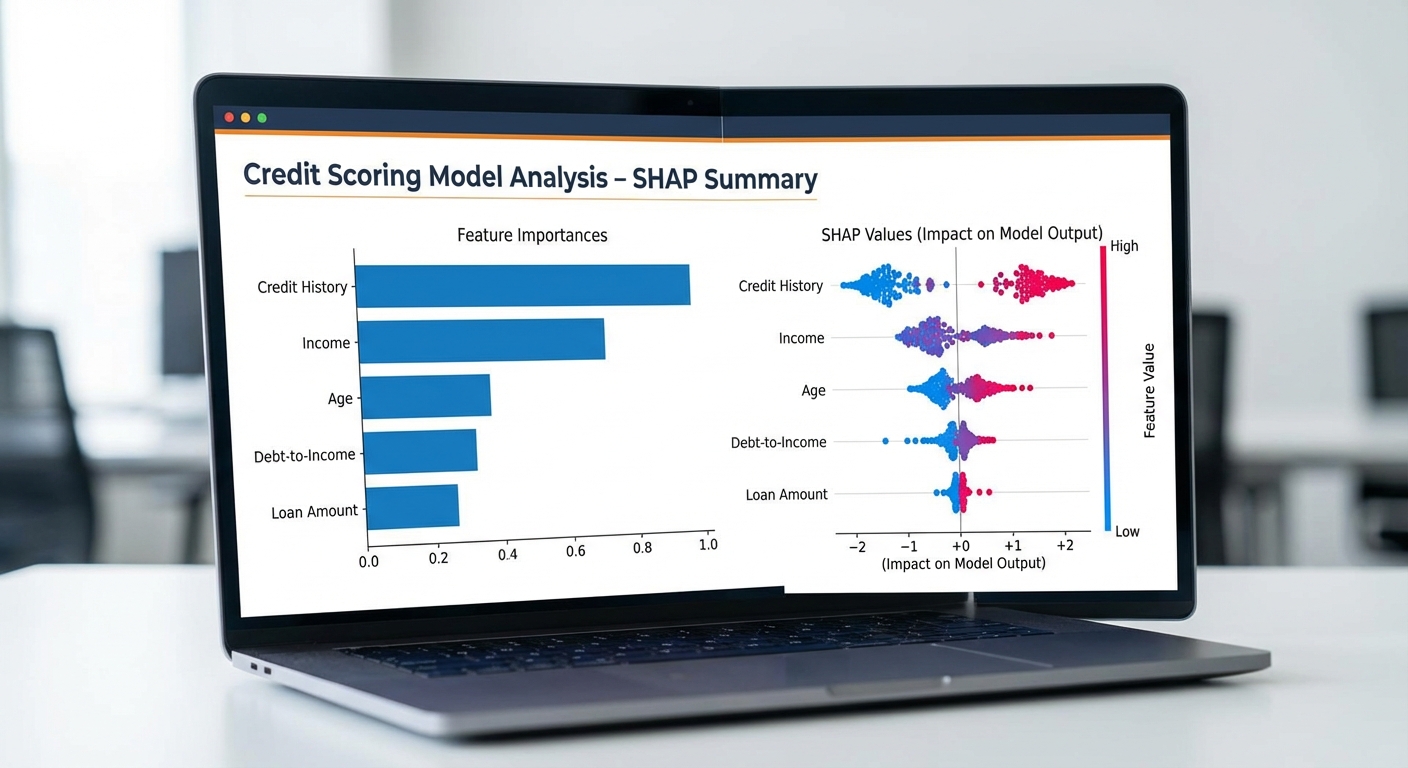
ในบริบทการอนุมัติสินเชื่อของธนาคารไทย การนำ Explainable AI (XAI) มาใช้เป็นส่วนหนึ่งของกระบวนการตรวจสอบโมเดลแบบเรียลไทม์ช่วยให้ทั้งทีมงานภายในและลูกค้าเข้าใจเหตุผลเบื้องหลังการตัดสินใจได้ชัดเจนขึ้น ลดความเสี่ยงของอคติ และตอบสนองข้อกำกับดูแลได้รวดเร็วขึ้น ส่วนนี้สรุปเทคนิค XAI ที่ใช้บ่อยในงานสินเชื่อ พร้อมตัวอย่างเชิงตัวเลขและกราฟิกที่ใช้งานได้จริง
ความแตกต่างระหว่าง Global explanation และ Local explanation
Global explanation ให้ภาพรวมว่าฟีเจอร์ใดมีอิทธิพลต่อโมเดลโดยรวม เช่น ฟีเจอร์ที่มีน้ำหนักมากที่สุดสำหรับการทำนายสินเชื่อในทุกข้อมูลลูกค้า เหมาะกับการรายงานต่อคณะกรรมการความเสี่ยงและการประเมินอคติในระดับระบบ ส่วน Local explanation ให้คำอธิบายสำหรับการตัดสินใจของแต่ละบุคคล เช่น ทำไมผู้ขอสินเชื่อรายหนึ่งจึงถูกปฏิเสธ เหมาะสำหรับการสื่อสารกับลูกค้าแบบเฉพาะรายและการอุทธรณ์ผลการตัดสินใจ
- Global use case: สรุป 5 ฟีเจอร์สำคัญ — รายได้ (income) 28%, ประวัติชำระ (payment_history) 22%, หนี้คงค้าง (existing_debt) 16%, อัตราการใช้วงเงิน (utilization) 12%, อายุงาน (employment_length) 10% (ตัวเลขเป็นสัดส่วนของความสำคัญเชิงเฉลี่ย)
- Local use case: อธิบายผลการตัดสินใจของลูกค้าราย A ว่าถูกปฏิเสธเนื่องจากค่า utilization สูงและประวัติชำระล่าสุดล่าช้า ซึ่งแสดงเป็นการเปลี่ยนแปลงเชิงบวก/ลบต่อความน่าจะเป็นการอนุมัติ
SHAP: การแจกแจงคำอธิบายแบบเชิงปริมาณและการตีความ
SHAP (SHapley Additive exPlanations) เป็นเทคนิคที่ให้ค่าความสำคัญของแต่ละฟีเจอร์ในเชิงปริมาณ โดยค่า SHAP จะบอกว่าแต่ละฟีเจอร์ "ผลัก" ค่าพยากรณ์ขึ้นหรือลงเท่าใด เทียบกับค่าเฉลี่ยของโมเดล (base value) ซึ่งเหมาะอย่างยิ่งสำหรับการอธิบายผลลัพธ์ทั้งแบบ global และ local
ตัวอย่างเชิงตัวเลข (local explanation แบบสมมติ):
- ค่า base value (ค่าเฉลี่ยโมเดล): 0.20 (ความน่าจะเป็นอนุมัติ 20%)
- การพยากรณ์สำหรับลูกค้าราย B: 0.68 (68% อนุมัติ)
- การแจกแจงค่า SHAP (ผลรวมจากฟีเจอร์ต่าง ๆ): income: +0.30, employment_length: +0.12, existing_debt: -0.08, utilization: +0.02, age: +0.00
- การคำนวณ: 0.20 (base) + 0.30 + 0.12 - 0.08 + 0.02 + 0.00 = 0.56 (ตัวอย่างนี้เพื่อสาธิตการแจกแจงค่า — ในการใช้งานจริงค่าจะสอดคล้องกับรูปแบบการรวมของ SHAP)
การนำเสนอผล SHAP ในเชิงภาพสามารถใช้:
- Waterfall plot: แสดงการเพิ่ม/ลดค่าจนถึงค่าพยากรณ์สุดท้าย (เหมาะสำหรับ local explanation)
- Beeswarm plot / Summary plot: แสดงการกระจายค่า SHAP ของฟีเจอร์แต่ละตัวในภาพรวม (เหมาะสำหรับ global insight)
- Force plot: ภาพเชิงโต้ตอบที่เห็นการผลัก/ดึงของฟีเจอร์แต่ละตัวต่อค่าพยากรณ์
Counterfactual explanations: สร้างคำอธิบายแบบ "ถ้า...จะเป็นอย่างไร"
Counterfactual explanations ให้คำตอบเชิงปฏิบัติว่า "ถ้าเปลี่ยนคุณลักษณะนี้เป็นค่า X จะส่งผลให้การตัดสินใจเปลี่ยนไปหรือไม่" ซึ่งเป็นเครื่องมือที่ทรงคุณค่าสำหรับการให้คำแนะนำแก่ลูกค้าว่าต้องปรับปรุงอย่างไรจึงจะเพิ่มโอกาสถูกอนุมัติ
ตัวอย่างเชิงตัวเลข (สมมติลูกค้าราย C ถูกปฏิเสธ ปัจจุบันความน่าจะเป็นอนุมัติ = 0.32):
- Counterfactual 1: ถ้ารายได้เพิ่มขึ้น 15% → ความน่าจะเป็นอนุมัติเพิ่มเป็น 0.61
- Counterfactual 2: ถ้าหนี้คงค้างลดลง 30% และอัตราการใช้วงเงินลด 20% → ความน่าจะเป็นอนุมัติเพิ่มเป็น 0.58
- การนำเสนอ: แสดงทั้งค่าเปลี่ยนแปลงที่ต้องทำและต้นทุน/ระยะเวลาโดยประมาณ เพื่อให้คำแนะนำมีความเป็นไปได้และปฏิบัติได้
เครื่องมือยอดนิยม: SHAP library, LIME, ELI5, Alibi
การเลือกเครื่องมือขึ้นกับกรณีการใช้งาน ทั้งด้านความแม่นยำ ความเร็ว และความสามารถในการทำงานแบบเรียลไทม์
- SHAP (Python library): ข้อดี — ให้คำอธิบายเชิงปริมาณที่สอดคล้องกับทฤษฎี Shapley, รองรับโมเดลหลายประเภท (โดยเฉพาะ tree-based) และมี visualization หลากหลาย ข้อจำกัด — คำนวณหนักเมื่อใช้กับเมทริกซ์ขนาดใหญ่หรือโมเดลที่ซับซ้อน
- LIME: ข้อดี — สร้าง local surrogate model เพื่ออธิบายตัวอย่างเดียวได้รวดเร็ว, เหมาะกับการอธิบายโมเดลสีดำทุกประเภท ข้อจำกัด — อธิบายไม่เสถียรในบางครั้ง (ขึ้นกับการสุ่ม) และไม่ให้ guarantee ทางทฤษฎีเท่ากับ SHAP
- ELI5: ข้อดี — ใช้เพื่อแสดง feature importance แบบดั้งเดิมและช่วย debug โมเดลได้ ข้อจำกัด — เน้นที่โมเดลง่ายและการแสดงข้อมูลเชิงสถิติมากกว่าการอธิบายเชิง local ที่ละเอียด
- Alibi: ข้อดี — มีโมดูลสำหรับ counterfactual explanations, anchors, และ concept-based explanations เหมาะกับการใช้งานในระบบ production และการสร้าง counterfactual ที่ constraints-aware ข้อจำกัด — ต้องการการตั้งค่าที่ระมัดระวังและทรัพยากรในการใช้งาน
แนวปฏิบัติแนะนำสำหรับธนาคารที่ต้องการนำ XAI ไปใช้จริง:
- ผสมผสานการอธิบายแบบ global และ local — ใช้ global สำหรับการตรวจสอบระบบและรายงานทางกฎหมาย ใช้ local และ counterfactual สำหรับการสื่อสารกับลูกค้า
- ออกแบบ UI/UX สำหรับการนำเสนอคำอธิบาย — เช่น กราฟ waterfall, ข้อความสรุปเชิงปฏิบัติการ (actionable steps) และคาดการณ์ผลเมื่อปรับปรุงฟีเจอร์
- วัดผลการอธิบายด้วยตัวชี้วัด (explainability metrics) และทดสอบความเข้าใจของผู้ใช้ (human evaluation)
- ตั้งระบบมอนิเตอร์แบบเรียลไทม์เพื่อตรวจจับ drift และอคติ พร้อมเก็บ log ของคำอธิบายเพื่อตรวจสอบย้อนหลัง
การประยุกต์ XAI อย่างเป็นระบบในงานสินเชื่อช่วยให้ธนาคารปฏิบัติตามข้อกำกับดูแล เพิ่มความโปร่งใส ลดอคติ และให้คำแนะนำเชิงปฏิบัติแก่ลูกค้าได้อย่างชัดเจน โดยการเลือกเครื่องมือและเทคนิคควรพิจารณาระดับความต้องการทางธุรกิจ ความสามารถทางเทคนิค และข้อกำหนดด้านความเป็นส่วนตัว
Causal ML สำหรับการตัดสินใจเครดิต: จากสหสัมพันธ์สู่สาเหตุ
Causal ML สำหรับการตัดสินใจเครดิต: จากสหสัมพันธ์สู่สาเหตุ
การพัฒนาโมเดลสินเชื่อสมัยใหม่ต้องก้าวจากการทำนาย (prediction) ไปสู่การเข้าใจเชิงสาเหตุ (causal inference) เพื่อให้การตัดสินใจเชิงนโยบายและเชิงปฏิบัติเป็นไปอย่างมีประสิทธิภาพและปราศจากการบิดเบือนจากปัจจัยร่วม (confounding) ในทางปฏิบัติ ข้อมูลลูกหนี้มักแสดง สหสัมพันธ์ (correlation) ระหว่างตัวแปร เช่น รายได้และอัตราเริ่มต้นการผิดนัด แต่สหสัมพันธ์ไม่เท่ากับสาเหตุ — หากธนาคารเปลี่ยนเงื่อนไขสินเชื่อโดยอิงจากสหสัมพันธ์เพียงอย่างเดียว อาจเกิดผลลัพธ์ที่ไม่คาดคิด เช่น การคาดว่าการลดดอกเบี้ยจะลด default แต่ในความเป็นจริงกลุ่มที่ได้รับการลดดอกเบี้ยอาจเป็นกลุ่มที่มีความเสี่ยงต่ำโดยกำเนิด (selection bias) ทำให้ประเมินผลเชิงสาเหตุผิดเพี้ยนได้
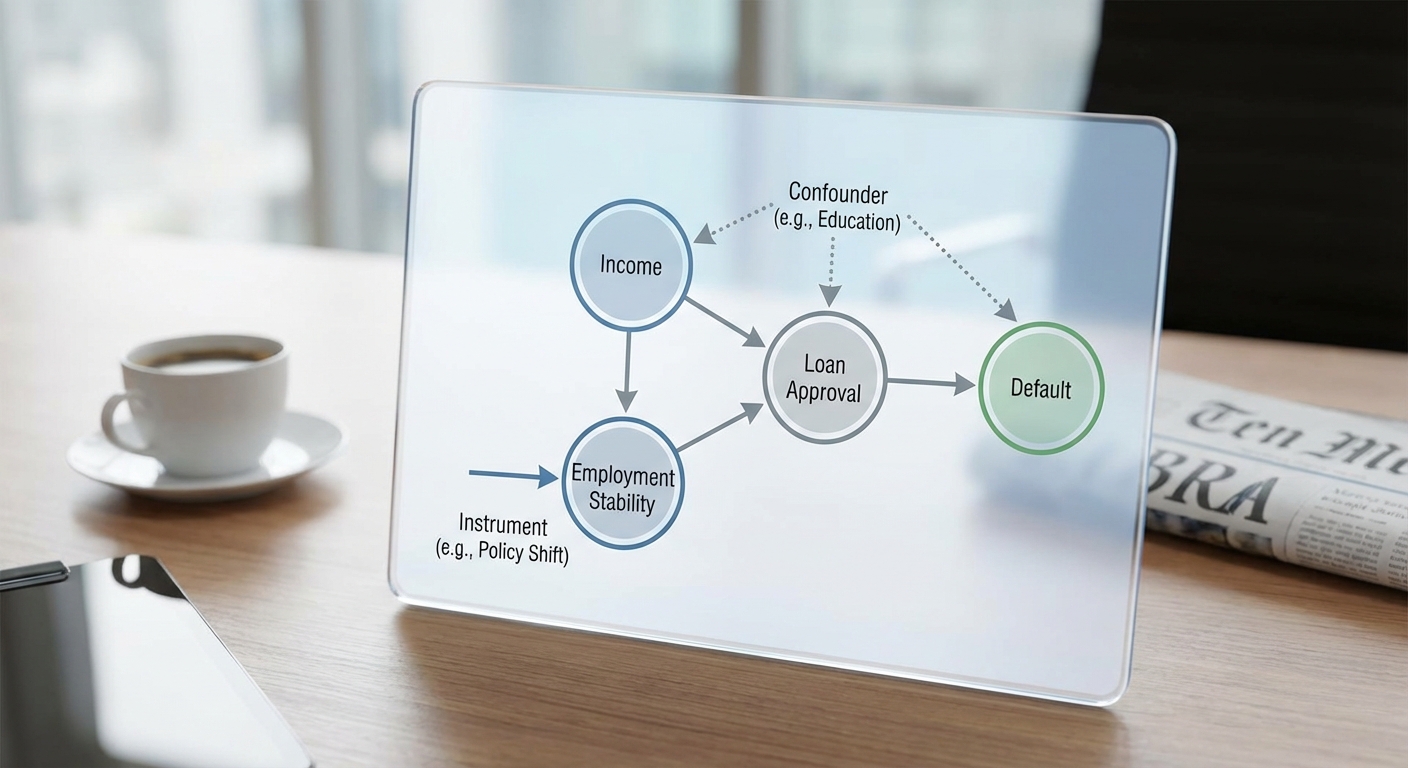
กรอบเชิงสาเหตุ (causal graphs) เช่น Directed Acyclic Graphs (DAGs) เป็นจุดเริ่มต้นที่สำคัญสำหรับการระบุสมมติฐานสาเหตุและแหล่งของความลำเอียง โดยช่วยให้ทีมวิเคราะห์แยกแยะตัวแปรที่เป็น confounders, mediators และ colliders ได้ชัดเจน ตัวอย่างเช่น DAG สำหรับสินเชื่ออาจแสดงว่า "ประวัติเครดิต ← รายได้ → โอกาสได้รับข้อเสนอพิเศษ → default" ซึ่งชี้ให้เห็นว่าถ้าไม่ควบคุมรายได้ การเปรียบเทียบผลของข้อเสนอพิเศษต่อ default จะบิดเบือนได้
เทคนิค Causal ML ที่เหมาะสม ในบริบทสินเชื่อประกอบด้วยวิธีการที่ออกแบบมาเพื่อประเมินผลเชิงสาเหตุจากข้อมูลสังเกต (observational data) ได้แก่
- Causal Forest — ขยายความคิดของ random forest เพื่อประมาณ heterogeneous treatment effects (ATE/ITE) โดยให้การวัดว่ามาตรการเช่นการลดดอกเบี้ยส่งผลต่างกันอย่างไรในกลุ่มประชากรย่อย ตัวอย่างเช่น causal forest สามารถชี้ว่าในกลุ่มผู้กู้อายุ 25–35 การลดดอกเบี้ย 2% อาจลดอัตรา default ได้ 1.8 จุดร้อยละ ในขณะที่กลุ่มอายุ 55+ ลดได้เพียง 0.4 จุดร้อยละ
- Double Machine Learning (Double ML) — เทคนิคที่ใช้การโมเดลสองขั้นตอนเพื่อทำให้การประมาณค่าผลกระทบเป็นออร์โธโกนอลต่อการคาดการณ์ปัจจัยร่วม ช่วยลด bias จากตัวแปรร่วมที่มีมิติสูง โดยการแยกขั้นตอนการพยากรณ์ treatment และ outcome แล้วทำการแก้ไขเชิงเส้นในเชิงสถิติ ตัวอย่างเชิงตัวเลข: ในชุดข้อมูลขนาด 200,000 ราย Double ML อาจลด bias ในการประเมินการเปลี่ยนแปลง default จาก 1.5pp ที่ประเมินเบื้องต้นเหลือ 0.7pp เมื่อควบคุม confounders
- Targeted Maximum Likelihood Estimation (TMLE) — เป็นวิธีเชิงกึ่งพาราเมตริกที่ผสมผสานการเรียนรู้ของเครื่องและหลักการสถิติแบบมีประสิทธิภาพสูง เหมาะสำหรับการประมาณค่า causal parameters อย่างมีประสิทธิภาพและให้ค่าประมาณที่มีการแก้ไขโดยตรงเพื่อจุดประสงค์เชิงสาเหตุ
- Instrumental Variables (IV) — ใช้เมื่อมี confounding ที่ไม่สามารถสังเกตได้ โดยหาตัวแปรตัวหนึ่ง (instrument) ที่มีผลต่อการได้รับการรักษา (treatment เช่น ได้รับเงื่อนไขพิเศษ) แต่ไม่ส่งผลโดยตรงต่อผลลัพธ์ (default) นอกจากผ่านการรักษานั้น ตัวอย่างเช่น การสุ่มแจกคูปองโปรโมชั่นในสาขาเป็นไปได้ว่าจะเป็น instrument
ตัวอย่างเชิงปฏิบัติ: สมมติธนาคารต้องการประเมินผลของการปรับวงเงินสินเชื่อเพิ่มขึ้น 10% ต่ออัตรา default หากใช้วิธีเชิงพยากรณ์อย่างเดียว อาจพบว่ากลุ่มที่ได้รับการปรับมี default 4% ขณะที่กลุ่มที่ไม่ได้รับมี 6% — แต่ข้อมูลนี้อาจสะท้อนการเลือกกลุ่มลูกค้าที่มีโปรไฟล์เสี่ยงต่ำกว่าเป็นหลัก เมื่อใช้ causal forest เพื่อประมาณ individual treatment effect ผลลัพธ์เชิงสาเหตุอาจแสดงว่าเฉพาะลูกหนี้ที่มีสกอร์ความน่าเชื่อถืออยู่ในช่วงกลาง-สูง การเพิ่มวงเงิน 10% จะลด default ประมาณ 1.5 จุดร้อยละ (ลดจาก 6% → 4.5%) ขณะที่กลุ่มเสี่ยงสูงแทบไม่เปลี่ยนแปลง การใช้ Double ML หรือ TMLE ร่วมกันจะช่วยยืนยันความมั่นคงของผลประมาณการและให้ช่วงความเชื่อมั่นที่น่าเชื่อถือกว่า
Counterfactuals และการเชื่อมต่อกับ XAI — Causal ML สามารถสร้างคำตอบเชิง counterfactual ในระดับรายบุคคล เช่น "ถ้าลูกหนี้ A ได้รับอัตราดอกเบี้ยลดลง 1% จะทำให้อัตรา default ของเขาลดลงหรือไม่ และเท่าใด" คำอธิบายเชิงสาเหตุเหล่านี้ช่วยให้ระบบ Explainable AI (XAI) ให้คำแนะนำเชิงนโยบายได้ชัดเจนและปฏิบัติได้จริง เช่น รายงานเชิงนโยบายอาจระบุว่า ควรขยายโปรแกรมลดดอกเบี้ยเฉพาะกับกลุ่มอาชีพและวงเงินที่ระบุ โดยคาดว่าจะลด default ได้ X% ต่อปี ซึ่งมีผลต่อผลกำไรและความเสี่ยงของพอร์ตโฟลิโออย่างเป็นรูปธรรม
สรุปได้ว่า Causal ML ไม่เพียงแต่ช่วยให้ธนาคารประเมินผลเชิงสาเหตุของนโยบายสินเชื่อได้อย่างแม่นยำ แต่ยังเชื่อมโยงกับหลักการ XAI เพื่อสื่อสารเหตุผลที่ชัดเจนแก่ผู้บริหารและผู้กำกับดูแล การผสมผสานระหว่าง causal graphs, methods เช่น causal forest, Double ML, TMLE และการใช้ instruments/counterfactuals เป็นกรอบปฏิบัติที่ทำให้การตัดสินใจเครดิตมีความโปร่งใสและลดอคติทั้งเชิงเทคนิคและเชิงนโยบาย
สถาปัตยกรรมตรวจสอบโมเดลแบบเรียลไทม์สำหรับธนาคาร
สถาปัตยกรรมตรวจสอบโมเดลแบบเรียลไทม์สำหรับธนาคาร
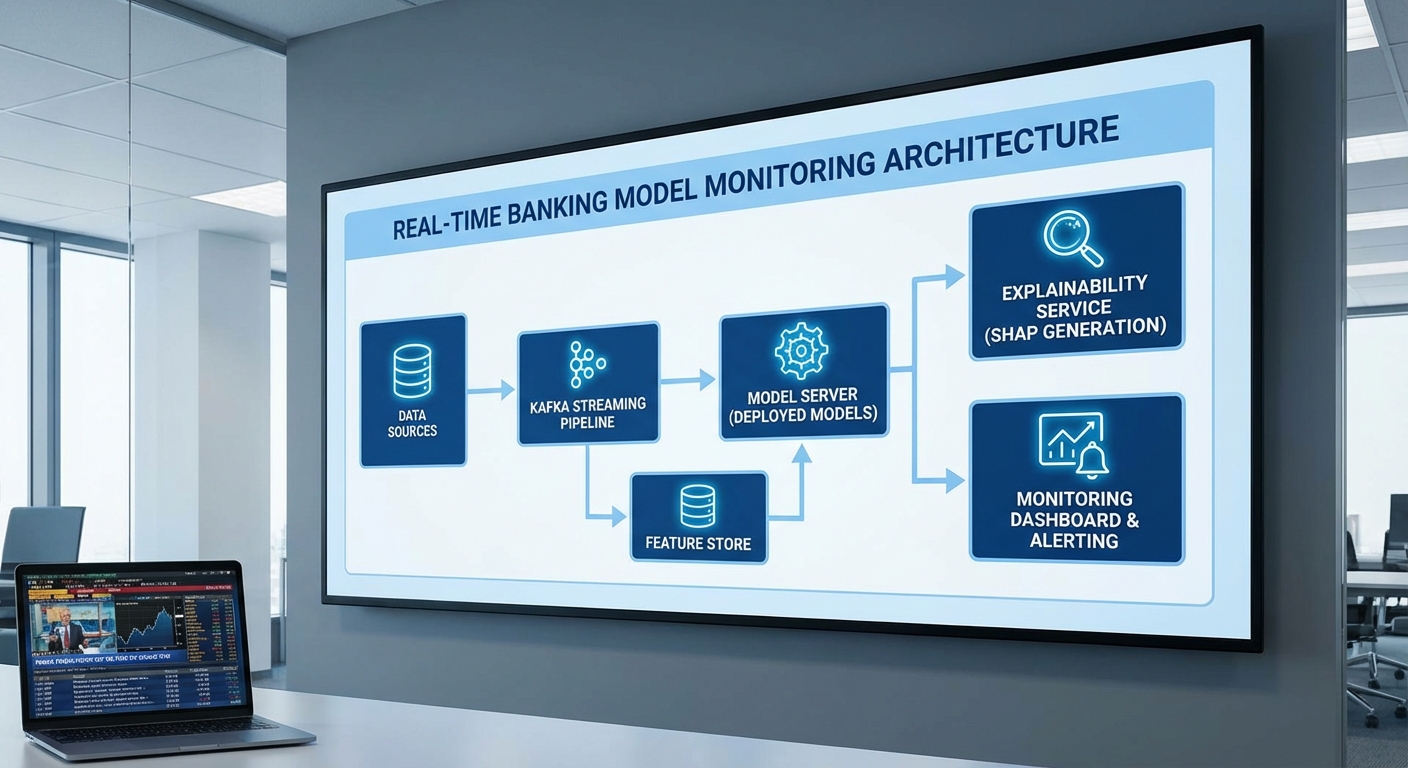
สถาปัตยกรรมแบบ end-to-end สำหรับการให้บริการสินเชื่อแบบเรียลไทม์ต้องออกแบบให้รองรับทั้งความเร็ว ความเชื่อถือได้ และการตรวจสอบย้อนหลัง (auditability) โดยคำนึงถึงกฎคุ้มครองข้อมูลส่วนบุคคล (PDPA) และข้อบังคับทางการเงิน สถาปัตยกรรมที่แนะนำประกอบด้วยชั้นงานหลักตั้งแต่การรับข้อมูลเชิงเหตุการณ์ (Data ingestion) ผ่านระบบ stream processing เช่น Kafka ไปยัง Feature Store ทั้งสำหรับ offline และ online, ระบบ Model Serving ที่รองรับการจัดรุ่นและการสเกล, บริการ Explainability เชิงเรียลไทม์/อะซิงโครนัส, และท่อการตรวจสอบพร้อมระบบแจ้งเตือน (Monitoring & Alerting) ที่บันทึก audit trail อย่างไม่เปลี่ยนแปลงเพื่อการตรวจสอบย้อนหลัง
ภาพรวมการไหลของข้อมูลคือ: เหตุการณ์ธุรกรรมหรือคำขอสินเชื่อถูกส่งมายัง Kafka topic → stream processors (เช่น Flink) ทำการแปลง/คิวรีเบื้องต้น และเขียนไปยัง Feature Store (online store เช่น Redis/Cassandra สำหรับความหน่วงต่ำ และ offline store เช่น BigQuery/Parquet สำหรับการเรียนรู้แบบเป็นชุด) → เมื่อมีคำขอเครดิต ระบบจะดึงฟีเจอร์แบบเรียลไทม์จาก online feature store ไปยัง Model Serving ที่ให้คำตัดสินและค่า score → คำตัดสินนั้นจะถูกส่งต่อไปยัง Explainability Service เพื่อสร้างคำอธิบายสรุปและบันทึกข้อมูลอธิบาย (explainability logs) ลงในระบบ audit ที่เข้ารหัส
สำหรับข้อกำหนดเชิงประสิทธิภาพและความหน่วง (latency) ควรกำหนดเป้าหมายให้การตัดสินใจเครดิตเชิงเรียลไทม์มี latency ต่อคำขออยู่ระหว่าง <100–200ms ในเส้นทางการตัดสินใจหลัก (inference path) โดยเป้าหมายเชิงประกันคุณภาพเพิ่มเติมคือ p95 latency < 200ms และ p99 latency < 500ms เพื่อรองรับช่วงสูงสุด เทคนิคที่ใช้เพื่อให้บรรลุเป้าหมายนี้ได้แก่:
- Online Feature Store แบบ in-memory (Redis, Aerospike) และ precomputed features เพื่อลดเวลาการคำนวณฟีเจอร์
- Caching ของผลลัพธ์ที่ใช้บ่อย และการ warm-up ของโมเดลบน node เพื่อหลีกเลี่ยง cold-start
- เลเยอร์การให้บริการโมเดล ที่ปรับสเกลอัตโนมัติ (horizontal autoscaling) และใช้งาน inference runtimes ที่เหมาะสม (Triton, TensorFlow Serving, ONNX Runtime)
- แยกเส้นทางการให้คำอธิบาย — ให้คำตัดสินเบื้องต้นภายในเส้นทาง latency ต่ำ แล้วดำเนินการสร้างคำอธิบายเชิงลึกแบบอะซิงโครนัสหรือคืนค่า summary แบบ precomputed เพื่อรักษา latency เป้าหมาย
การจัดเก็บข้อมูล explainability logs และ audit trail ต้องออกแบบให้รองรับการสืบค้นย้อนหลังและการพิสูจน์ความถูกต้องโดยหน่วยงานกำกับดูแล รายการที่ควรบันทึกอย่างน้อยได้แก่: request_id, model_version (จาก Model Registry), timestamp, hashed_pii_identifier, ข้อมูลฟีเจอร์ที่ใช้งาน (หรือ hash ของฟีเจอร์เมื่อเป็นข้อมูลส่วนบุคคล), คำตอบของโมเดล, ค่า importance/SHAP summary, และ note สำหรับการตัดสินใจแบบ manual การจัดเก็บควรเป็นแบบไม่สามารถแก้ไข (immutable ledger/WORM) พร้อมการเซ็นดิจิทัลและการเข้ารหัสทั้งข้อมูลขณะพักและขณะเคลื่อนย้าย
เพื่อให้สอดคล้องกับ PDPA ต้องบังคับใช้นโยบายความเป็นส่วนตัวตลอด pipeline ดังนี้: minimization ของข้อมูลที่เก็บ (เก็บเฉพาะฟีเจอร์ที่จำเป็น), pseudonymization/ hashing ของตัวระบุผู้ใช้, การเข้ารหัสแบบ AES-256 และ TLS ในการสื่อสาร, การควบคุมการเข้าถึงด้วยบทบาท (RBAC) และระบบการจัดการคีย์ที่แยกจากกัน นอกจากนี้ ควรมีนโยบายการเก็บรักษาและลบข้อมูลตามกฎระเบียบของธนาคารและ PDPA รวมทั้งกระบวนการขอสิทธิ์และการขออุทธรณ์จากลูกค้า
ด้านการสเกลและ throughput สำหรับธนาคารขนาดกลางถึงใหญ่ ควรออกแบบระบบให้รองรับเงื่อนไขตัวอย่างเช่น 500–2,000 requests/s โดยใช้แนวทาง: partitioning ของ Kafka topics เพื่อเพิ่ม parallelism, shard ของ online feature store, autoscaling ของ model-serving pods และการกระจายโหลดแบบ multi-region เพื่อความทนทาน เทคนิคควบคุมความพร้อมใช้งานรวมถึง canary/blue-green deployment จาก Model Registry ที่ผสานกับ CI/CD สำหรับโมเดล (เช่น MLflow หรือ Kubeflow) เพื่อให้สามารถ rollback ได้ทันทีหากพบปัญหาใน production
สรุป: สถาปัตยกรรมตรวจสอบโมเดลแบบเรียลไทม์สำหรับธนาคารควรเป็น hybrid ที่แยกเส้นทาง latency ต่ำสำหรับการตัดสินใจทันที กับเส้นทางตรวจสอบเชิงลึกเพื่อการอธิบายและการตรวจสอบย้อนหลัง พร้อมการออกแบบระบบบันทึกที่ immutability, การปกป้องข้อมูลตาม PDPA และกลไกการสเกลอัตโนมัติเพื่อรองรับความต้องการ throughput และการตอบสนองเชิงธุรกิจอย่างต่อเนื่อง
การวัดอคติและตัวชี้วัดที่สำคัญในการตรวจสอบ
การวัดอคติและตัวชี้วัดที่สำคัญในการตรวจสอบ
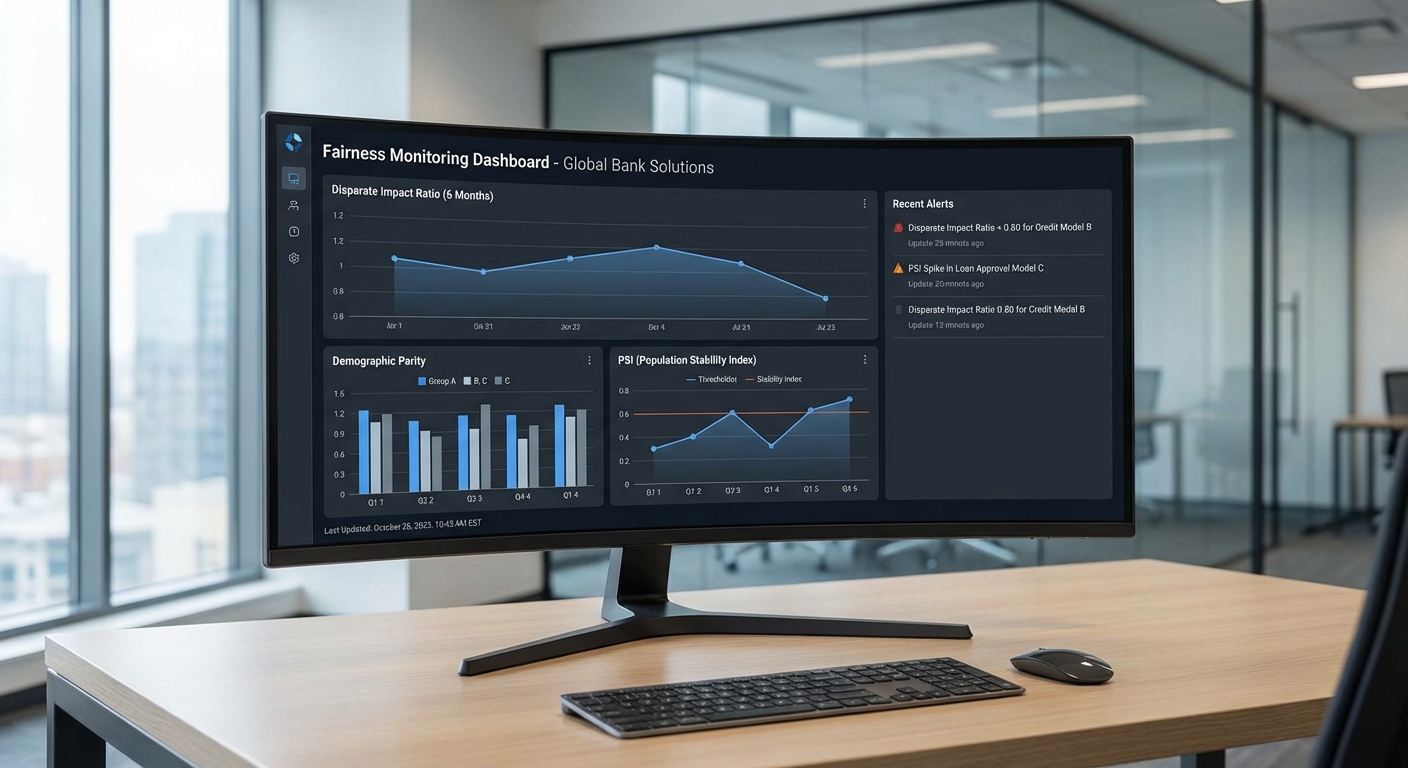
การตรวจจับอคติ (bias) และความไม่เป็นธรรมในโมเดลการให้สินเชื่อจำเป็นต้องอาศัยตัวชี้วัดเชิงปริมาณที่ชัดเจนและสามารถใช้งานได้แบบเรียลไทม์ ตัวชี้วัดที่พบบ่อยและมีความหมายเชิงกลยุทธ์ได้แก่ demographic parity, equal opportunity / equalized odds, disparate impact ratio, รวมถึงตัวชี้วัดสำหรับการตรวจจับ drift ของข้อมูลเช่น Population Stability Index (PSI) และ Kullback–Leibler (KL) divergence ทั้งนี้ควรผนวกการวิเคราะห์เชิงอธิบาย (Explainable AI) เช่นการเปรียบเทียบการแจกแจงค่า SHAP ข้ามกลุ่มเพื่อระบุสาเหตุเบื้องหลังความต่างของผลลัพธ์
นิยามและการคำนวณเบื้องต้น — เพื่อให้สามารถนำไปใช้งานได้จริง ควรนิยามและคำนวณตัวชี้วัดดังนี้:
- Demographic parity: ความน่าจะเป็นที่โมเดลทำนายผลบวก (เช่น ให้สินเชื่อ) สำหรับแต่ละกลุ่มเท่ากัน โดยคำนวณเป็น P(Ŷ=1 | A=a) เทียบกับ P(Ŷ=1 | A=b) ตัวอย่างเช่น หากกลุ่ม A (กลุ่มได้รับอภิสิทธิ์) มีอัตราการอนุมัติ 50% และกลุ่ม B (กลุ่มไม่อภิสิทธิ์) มี 30% แสดงว่ามีความเหลื่อมล้ำในระดับ 20 percentage points
- Equal opportunity / Equalized odds: มุ่งตรวจสมดุลของอัตรา True Positive Rate (TPR) และ/หรือ False Positive Rate (FPR) ข้ามกลุ่ม โดย
- TPR = P(Ŷ=1 | Y=1, A=a)
- FPR = P(Ŷ=1 | Y=0, A=a)
- Disparate impact ratio (DI): นิยมคำนวณเป็นสัดส่วนของอัตราการได้รับผลบวกของกลุ่มไม่อภิสิทธิ์ต่อกลุ่มอภิสิทธิ์
DI = P(Ŷ=1 | A=unprivileged) / P(Ŷ=1 | A=privileged)
ตัวอย่างเช่น หากอัตราอนุมัติของกลุ่มไม่อภิสิทธิ์ = 0.24 และกลุ่มอภิสิทธิ์ = 0.40 → DI = 0.24 / 0.40 = 0.6
ตัวชี้วัดสำหรับตรวจจับ drift ของข้อมูล — การเปลี่ยนแปลงของข้อมูลอินพุตหรือการกระจายผลลัพธ์เป็นสัญญาณสำคัญที่อาจนำไปสู่การเพิ่มอคติหรือความไม่เสถียรในโมเดล:
- Population Stability Index (PSI): ใช้วัดความแตกต่างของการกระจายตัวของตัวแปรระหว่างช่วงอ้างอิง (expected) กับช่วงปัจจุบัน (actual). สูตรทั่วไปคือ PSI = Σ (actual_pct_i - expected_pct_i) * ln(actual_pct_i / expected_pct_i) โดยแบ่งข้อมูลเป็นบิ้น (bins). การตีความที่ใช้กันทั่วไป:
- PSI < 0.10 = ไม่เปลี่ยนแปลง (negligible)
- 0.10 ≤ PSI < 0.25 = เปลี่ยนแปลงปานกลาง (monitor)
- PSI ≥ 0.25 = เปลี่ยนแปลงมาก (action required)
- KL divergence (DKL): วัดความแตกต่างเชิงทิศทางระหว่างการแจกแจง P (reference) และ Q (current) โดย DKL(P||Q) = Σ P(x) log(P(x)/Q(x)). ค่าใกล้ 0 แสดงการเปลี่ยนแปลงน้อย ค่าใหญ่แสดงการเปลี่ยนแปลงมาก การตั้งเกณฑ์ขึ้นกับบริบท แต่ตัวอย่างเชิงปฏิบัติ:
- DKL < 0.05 = ต่ำ
- 0.05 ≤ DKL < 0.2 = ควรเฝ้าดู
- DKL ≥ 0.2 = เตือน/ตรวจสอบ
แนวทางการตั้ง Thresholds และการตีความเชิงตัวเลข — ในการปฏิบัติ ควรตั้ง threshold ที่ชัดเจนซึ่งพิจารณาจากความเสี่ยงธุรกิจและกรอบกฎระเบียบ ตัวอย่างแนวปฏิบัติ:
- Disparate impact: หาก DI < 0.8 (หรือ > 1.25 สำหรับผลด้านลบในทางกลับกัน) ให้ถือเป็นสัญญาณเตือนตามที่ใช้ในหลายกรณี เช่น DI = 0.6 แปลว่ากลุ่มไม่อภิสิทธิ์ได้รับผลบวกน้อยกว่ากลุ่มอภิสิทธิ์อย่างมีนัยสำคัญ
- TPR difference (Equal opportunity): หาก |TPR_A - TPR_B| > 0.10 ควรพิจารณาการปรับโมเดลหรือกำหนดการเยียวยา (mitigation)
- PSI/KL: ใช้ PSI ≥ 0.10 เป็นสัญญาณเริ่มต้นให้ตรวจสอบ และ PSI ≥ 0.25 เป็นเหตุให้หยุด/รีเทรนโมเดล ขณะที่ KL ≥ 0.2 ควรมีการสอบสวน
- Calibration by group: เปรียบเทียบความคลาดเคลื่อนของค่า predicted probability กับ observed frequency ต่อกลุ่ม หากความคลาดเคลื่อนเฉลี่ย (เช่น Brier score หรือ Expected Calibration Error) ข้ามกลุ่มแตกต่างมากกว่า 0.02–0.05 ให้พิจารณาการปรับปรุง calibration
ผนวก XAI เพื่อตรวจสอบเหตุผลเบื้องหลังอคติ — การใช้ Explainable AI เป็นกุญแจสำคัญในการตีความว่าทำไมโมเดลให้ผลต่างกันข้ามกลุ่ม:
- ตรวจสอบการแจกแจงค่า SHAP ข้ามกลุ่ม: เปรียบเทียบค่าเฉลี่ย |SHAP| ของฟีเจอร์สำคัญระหว่างกลุ่ม หากฟีเจอร์เดียวมีค่า |SHAP| เฉลี่ยของกลุ่มหนึ่งสูงกว่าอีกกลุ่มมาก (ตัวอย่างเช่น |SHAP|_privileged = 0.12, |SHAP|_unprivileged = 0.02) อาจบ่งชี้ฟีเจอร์นั้นมีผลขับเคลื่อนความแตกต่างและควรตรวจสอบ
- ใช้การเปรียบเทียบการแจกแจง (distribution overlap) หรือระยะห่างเช่น Wasserstein distance ของค่า SHAP เพื่อวัดความไม่สอดคล้อง หาก Wasserstein distance > 0.1 ให้ถือว่ามีความแตกต่างเชิงอธิบายที่น่ากังวล
- เชื่อมโยงผลลัพธ์ XAI กับตัวชี้วัด fairness: หาก DI ต่ำและ SHAP แสดงว่าฟีเจอร์ที่บ่งชี้ความไม่เป็นธรรม (เช่น zip code) มีผลสูง ควรดำเนินการ mitigation เช่น retraining ด้วย regularization, adversarial debiasing, หรือการลบ/transform ฟีเจอร์
เชิงปฏิบัติ: การตั้งระบบเฝ้าระวังแบบเรียลไทม์ — แนะนำแนวปฏิบัติดังนี้:
- กำหนด windows แบบ rolling (เช่น 7 วัน หรือ 10,000 ตัวอย่าง) สำหรับคำนวณ DI, TPR/FPR difference, PSI และ KL เพื่อจับสัญญาณเชิงเวลาทันที
- ตั้ง alert ระดับหลายชั้น: warning (เช่น DI < 0.9 หรือ PSI > 0.10) และ critical (DI < 0.8 หรือ PSI > 0.25) พร้อมขั้นตอนการตอบสนองอัตโนมัติ (เช่น halt deployment, notify model governance)
- เชื่อมโยงการแจ้งเตือนกับรายงาน XAI อัตโนมัติ: เมื่อเกิด alert ให้ระบบสร้างรายงานค่า SHAP distributions, top drivers per group และตัวอย่างเคสเพื่อให้ทีมตรวจสอบภายในไม่เกิน 24 ชั่วโมง
สรุปว่า การวางกรอบตัวชี้วัดเชิงปริมาณที่ชัดเจน รวมกับการผสาน XAI ในการตรวจสอบเหตุผลเบื้องหลัง จะช่วยให้ธนาคารสามารถติดตาม ป้องกัน และแก้ไขอคติได้อย่างเป็นระบบและเป็นไปตามข้อกำหนดด้านความโปร่งใส และยังช่วยเสริมความเชื่อมั่นของผู้บริโภคและหน่วยงานกำกับดูแล
กรณีศึกษาเชิงปฏิบัติ: ธนาคาร A ทดสอบระบบและผลลัพธ์เชิงตัวเลข
กรณีศึกษาเชิงปฏิบัติ: ธนาคาร A ทดสอบระบบและผลลัพธ์เชิงตัวเลข
ในกรณีศึกษาจำลองนี้ ธนาคาร A ดำเนินโครงการนำ Explainable AI (XAI) และ Causal ML เข้าไปตรวจสอบและปรับปรุงโมเดลสินเชื่อแบบเรียลไทม์ โดยตั้งเป้าลดอคติในการตัดสินใจ เพิ่มความโปร่งใส และไม่กระทบต่อความเสี่ยงด้านเครดิตอย่างมีนัยสำคัญ โครงการมีขนาดตัวอย่างในการทดสอบเชิงพีโอซีและพายล็อตรวมประมาณ 50,000–200,000 คำขอสินเชื่อ (ขึ้นกับเฟส) ผลการประเมินใช้ตัวชี้วัดทั้งด้านความยุติธรรม (เช่น Disparate Impact), ประสิทธิภาพโมเดล (เช่น AUC, calibration) และผลกระทบเชิงธุรกิจ (เช่น อัตราปฏิเสธไม่เป็นธรรม, การเข้าถึงลูกค้า, default rate)
โครงร่างโครงการ (ระยะเวลา 6–12 สัปดาห์)
- Discovery (สัปดาห์ 1–2): รวบรวมข้อมูลแอปพลิเคชันที่ผ่านมา ตรวจสอบตัวแปรที่เป็นไปได้ของการลำเอียง ระบุกลุ่มเป้าหมายที่ต้องปกป้อง และตั้งเกณฑ์ความยุติธรรมเชิงนโยบาย
- POC (สัปดาห์ 3–5): สร้างโมเดลสำรองพร้อมการประเมินด้วย Causal ML เพื่อตรวจจับผลสาเหตุ (causal effects) ของตัวแปรสำคัญ และทดสอบเทคนิคปรับสมดุล เช่น reweighing บนชุดข้อมูลย่อย
- Pilot (สัปดาห์ 6–9): เปิดใช้งานในสภาพแวดล้อมจริงแบบจำกัด (shadow mode หรือ partial approval flow) พร้อมแสดงคำอธิบายระดับท้องถิ่น (local explainability) ในหน้าการอนุมัติ เพื่อเก็บข้อมูลพฤติกรรมผู้ใช้งานและผลลัพธ์จริง
- Production (สัปดาห์ 10–12): ขยายการใช้งานแบบค่อยเป็นค่อยไป มีการตั้งเกณฑ์การมอนิเตอร์อัตโนมัติสำหรับ fairness/credit risk และกระบวนการ rollback หากพบสัญญาณความเสี่ยง
มาตรการที่นำมาใช้ (เทคนิคเชิงปฏิบัติ)
- Reweighing: ปรับน้ำหนักตัวอย่างในขั้นตอนการฝึกเพื่อชดเชยความไม่สมดุลของกลุ่มที่ได้รับผลกระทบ (demographic groups) ลดความเบ้ของการเรียนรู้โดยไม่ต้องเปลี่ยนสถาปัตยกรรมโมเดล
- Counterfactual Policy: ใช้การจำลองผลลัพธ์แบบ counterfactual เพื่อตรวจสอบว่าการเปลี่ยนแปลงค่าคุณลักษณะหนึ่งๆ จะส่งผลต่อการอนุมัติอย่างไร และออกแบบนโยบายการอนุมัติที่ลดการปฏิเสธที่ไม่เป็นธรรมโดยไม่เพิ่มความเสี่ยงมาก
- Local Explainability ในหน้าการอนุมัติ: นำ SHAP/Integrated Gradients ในระดับตัวอย่างแสดงเหตุผลหลักที่นำไปสู่การตัดสินใจ พร้อมคำแนะนำเชิงแอ็กชัน (e.g., กรณีปฏิเสธแนะนำเอกสารเพิ่มเติมหรือข้อเสนอปรับแผนการชำระ)
ผลลัพธ์เชิงตัวเลข (สมมติ)
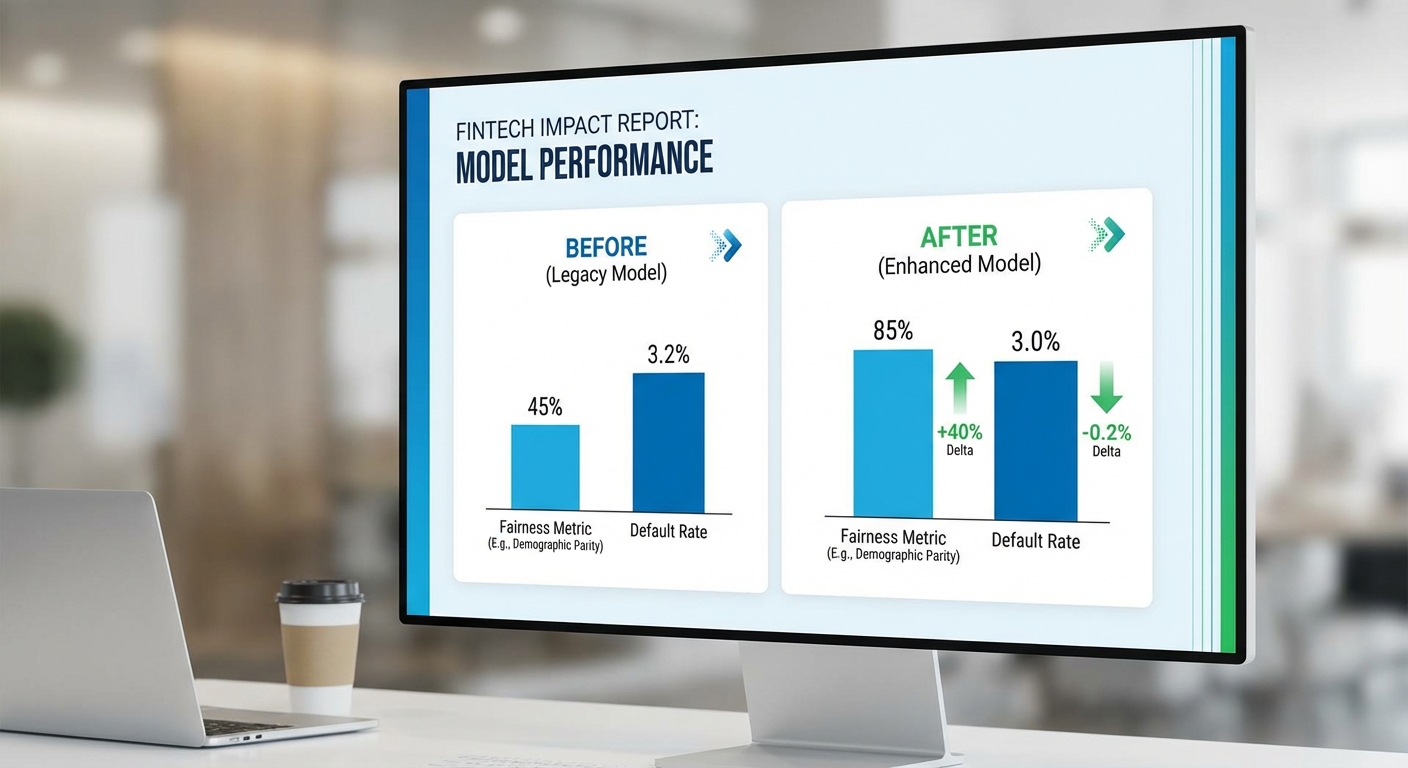
- Disparate Impact (กลุ่มเปรียบเทียบ) ดีขึ้นจาก 0.70 → 0.95 หลังการใช้งาน reweighing ร่วมกับ counterfactual policy — บ่งชี้ความใกล้เคียงความเท่าเทียมเชิงสัดส่วนมากขึ้น
- อัตราการปฏิเสธที่ไม่เป็นธรรมลดลง 15% เมื่อเทียบกับ baseline (วัดจากการลดอัตราปฏิเสธในกลุ่มเปราะบางที่ควรได้รับการอนุมัติ)
- การเข้าถึงลูกค้ากลุ่มเป้าหมายเพิ่มขึ้น 12% จากการปรับนโยบายอนุมัติและการให้คำแนะนำเชิงปฏิบัติแก่ผู้ขอสินเชื่อ
- ผลกระทบต่อความเสี่ยงเครดิตอยู่ในระดับยอมรับได้: default rate เพิ่มเพียง +0.2% (ต่ำกว่าข้อจำกัดเชิงนโยบายที่ตั้งไว้ไม่เกิน +0.5%) ทั้งนี้รักษา AUC และ calibration ในเกณฑ์ที่ยอมรับได้
ผลลัพธ์เชิงธุรกิจและการดำเนินงาน
ผลลัพธ์ที่ได้สะท้อนทั้งมิติความยุติธรรมและมิติโอกาสทางธุรกิจ: ธนาคารสามารถขยายกลุ่มลูกค้าที่เข้าถึงสินเชื่อได้มากขึ้น (เพิ่มรายรับและ market share) โดยไม่เพิ่มความเสี่ยงเครดิตอย่างมีนัยสำคัญ ทีมงานยังรายงานว่าการแสดงคำอธิบายพื้นฐานบนหน้าการอนุมัติช่วยลดคำร้องเรียนด้านการปฏิเสธที่ขาดเหตุผลลง และลดต้นทุนการจัดการข้อพิพาท
บทเรียนสำคัญและข้อสังเกตเชิงปฏิบัติ
- คุณภาพข้อมูลเป็นปัจจัยสำคัญ: ความถูกต้องและความครบถ้วนของข้อมูลตัวแปรประชากรและคุณลักษณะเชิงพฤติกรรมเป็นพื้นฐานของโมเดล causal — ข้อมูลขาดหรือลำเอียงจะทำให้การชี้ causal ผิดพลาด และลดประสิทธิผลของมาตรการแก้ไข
- การจัดการความเสี่ยงเชิงปฏิบัติ: ต้องมีเกณฑ์ทดสอบก่อนขึ้น production เช่น การจำกัดการเพิ่มของ default rate (ธนาคาร A ตั้งไว้ที่ ≤ +0.5%) และแผน rollback อัตโนมัติเมื่อเกินค่าเกณฑ์
- การมีส่วนร่วมของผู้มีส่วนได้เสีย: การสื่อสารกับหน่วยงานกำกับ, ฝ่ายกฎหมาย และทีมปฏิบัติการสำคัญต่อการตั้งนโยบายความยุติธรรมและการอธิบายผลการตัดสินใจ
- มอนิเตอร์เชิงต่อเนื่อง: ติดตั้งดัชนีมอนิเตอร์อัตโนมัติสำหรับ fairness drift, performance drift และ calibration พร้อมการรีเทรนหรือปรับนโยบายเป็นช่วงๆ
สรุปคือ โครงการ XAI + Causal ML ของธนาคาร A แสดงให้เห็นถึงศักยภาพในการลดอคติและเพิ่มความโปร่งใสโดยยังคงควบคุมความเสี่ยงได้ภายในพารามิเตอร์ที่ธุรกิจยอมรับได้ ซึ่งความสำเร็จเชิงปฏิบัติขึ้นกับการจัดการข้อมูลที่ดี นโยบายความเสี่ยงที่เข้มแข็ง และการบูรณาการคำอธิบายเชิงท้องถิ่นในกระบวนการอนุมัติจริง
แนวทางปฏิบัติ การกำกับดูแล และอุปสรรคที่ควรรู้
แนวทางการกำกับดูแล (Governance Model)
การนำ Explainable AI (XAI) และ Causal ML มาใช้ในการอนุมัติสินเชื่อแบบเรียลไทม์จำเป็นต้องมีกรอบการกำกับดูแลที่ชัดเจนและสามารถตรวจสอบย้อนหลังได้ แนะนำให้จัดตั้ง Model Governance Board ซึ่งประกอบด้วยตัวแทนจากฝ่ายธุรกิจ ฝ่ายความเสี่ยง ฝ่ายกฎหมาย/ความเป็นธรรม และฝ่ายเทคนิค เพื่อทำหน้าที่อนุมัติขั้นตอนสำคัญ เช่น นโยบายการยอมรับโมเดล มาตรฐานความยุติธรรม (fairness thresholds) และแผนรับมือเมื่อโมเดลเบี่ยงเบนจากพฤติกรรมที่ยอมรับได้
กระบวนการอนุมัติควรเป็นแบบเป็นลำดับขั้น (approval gates) ตั้งแต่การออกแบบ การทดสอบภายใน (pre-deployment) การทดสอบเชิงลอจิสติกส์ (canary/A-B) ไปจนถึงการอนุมัติการใช้งานจริง โดยต้องมีการบันทึกการตัดสินใจทุกขั้นตอน (audit trail) เพื่อให้สอดคล้องกับข้อกำหนดการกำกับดูแลทางการเงินและกฎหมายคุ้มครองข้อมูล
บทบาทและความรับผิดชอบ (Roles & Responsibilities)
- Model Risk Committee / Risk Officers: กำหนดนโยบายความเสี่ยงของโมเดล กำหนดเกณฑ์การยอมรับความเสี่ยง และติดตามผลกระทบทางการเงินและการปฏิบัติตามข้อกำหนด
- Data Engineers: รับผิดชอบการจัดเตรียมแหล่งข้อมูล การสร้าง pipeline ที่น่าเชื่อถือ การจัดการเวอร์ชันของข้อมูล และการตรวจสอบคุณภาพข้อมูล (data quality checks, lineage)
- ML Engineers / MLOps: ดูแลการพัฒนา การปรับใช้ และการ monitor ของโมเดลในสภาพแวดล้อมจริง รวมถึงการจัดการ latency และการปรับแต่งเพื่อรองรับการอธิบายผล (explainability) แบบเรียลไทม์
- Data Scientists / Causal ML Researchers: ออกแบบวิธีการอธิบาย เช่น SHAP, counterfactuals และวิธีการประเมินผลเชิงสาเหตุ (causal effect estimation เช่น causal forests, double/debiased ML) เพื่อวัด causal influence ของฟีเจอร์ต่อผลการอนุมัติ
- Compliance / Legal: ตรวจสอบให้มั่นใจว่าโมเดลและรายงานการอธิบายผลสอดคล้องกับกฎหมายคุ้มครองผู้บริโภคและข้อกำหนดด้านความโปร่งใส เช่น การให้เหตุผลแก่ผู้ขอสินเชื่อเมื่อถูกปฏิเสธ
การทดสอบและการตรวจสอบ (Testing & Validation)
แผนการทดสอบควรครอบคลุมทั้งระดับเทคนิคและระดับเชิงพฤติกรรม โดยแบ่งเป็นขั้นตอนหลักดังนี้:
- Pre-deployment fairness tests: ตรวจวัด metric หลัก เช่น disparate impact, equalized odds difference, predictive parity, calibration across groups และการประมาณ causal effect ระหว่างกลุ่ม (เช่น ผลของอายุ/ที่อยู่อาศัยที่อาจเป็นสาเหตุของความแตกต่าง)
- Robustness & stress tests: ทดสอบกับชุดข้อมูลที่ถูกกลั่นกรอง (out-of-distribution), การโจมตีแบบ adversarial, และการจำลอง drift ของข้อมูล เช่น การเบี่ยงเบนของตัวแปรเศรษฐกิจ
- Canary releases และ A/B testing: เปิดใช้โมเดลกับส่วนย่อยของทราฟฟิกเพื่อติดตามพฤติกรรมจริงแบบเรียลไทม์ เปรียบเทียบกับ baseline ด้วย KPI เช่นอัตราการอนุมัติ, default rate, time-to-decision, และ metric ความยุติธรรม
- Continuous monitoring: ติดตาม metric อัตโนมัติ (accuracy, ROC-AUC, calibration error, PSI, feature importance stability, SHAP distribution) และตั้งค่า alert เมื่อเกิน thresholds ที่กำหนดไว้
ตัวอย่างเกณฑ์เชิงปฏิบัติ: disparate impact ควรอยู่ในช่วงประมาณ 0.8–1.25 (ขึ้นกับนโยบายองค์กร) และความแตกต่างของ true positive rate ระหว่างกลุ่มไม่ควรเกิน 0.05 เป็นต้น ควรมีการกำหนดค่า threshold ที่ชัดเจนใน governance document
การจัดทำเอกสารและการรายงาน (Documentation & Reporting)
การบันทึกข้อมูลเป็นหัวใจสำคัญของการกำกับดูแล: ทุกโมเดลต้องมี Model Card และ Datasheet ที่ระบุข้อมูลสำคัญ เช่น วัตถุประสงค์ของโมเดล ช่วงข้อมูลที่ใช้ ฝ่ายรับผิดชอบ วิธีการอธิบายที่ใช้ (เช่น SHAP, counterfactual) ข้อจำกัดที่ทราบ และผลการทดสอบ fairness/robustness
นอกจากนี้ควรเก็บบันทึกการเปลี่ยนแปลง (version control) ของโค้ด พารามิเตอร์ โมเดล และชุดข้อมูล พร้อมทั้ง log ของการตัดสินใจในแต่ละคำขอสินเชื่อ (audit trail) เพื่อรองรับการตรวจสอบจาก regulator และการร้องขอชี้แจงจากลูกค้า
อุปสรรคและข้อจำกัดที่ต้องเฝ้าระวัง
การนำ XAI และ Causal ML มาใช้ในสภาพแวดล้อมการให้สินเชื่อแบบเรียลไทม์มีอุปสรรคหลายด้านที่ต้องจัดการ ได้แก่
- ข้อจำกัดของข้อมูล: ข้อมูลบิดเบือน (bias) ข้อมูลไม่ครบถ้วน (missingness) และตัวอย่างกลุ่มส่วนน้อย (small sample sizes) ทำให้การวัด fairness และการประมาณ causal effect มีความไม่แน่นอนสูง
- Latency ของการคำนวณ explainability: เทคนิค XAI แบบละเอียด (เช่น exact SHAP) อาจกินเวลามากและไม่เหมาะกับระบบเรียลไทม์ จึงต้องพิจารณาแนวทางผสม เช่น การ precompute explanations สำหรับกลุ่มผู้ขอหลัก ใช้ approximate algorithms หรือนำเสนอ explanations แบบสรุป (summary-level explanations) ในเวลาตัดสินใจ
- Trade-off ระหว่าง fairness และ accuracy: การบีบให้โมเดลยุติธรรมมากขึ้นอาจลดประสิทธิภาพการทำนายและเพิ่มความเสี่ยงด้านเครดิต ธนาคารต้องกำหนดนโยบายเชิงธุรกิจที่ชัดเจนว่าเมื่อใดยอมรับการแลกเปลี่ยนนี้ และประเมินผลกระทบทางการเงินอย่างสม่ำเสมอ
- ข้อจำกัดเชิงนโยบายและกฎระเบียบ: กฎคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA อาจจำกัดการใช้ฟีเจอร์บางอย่างหรือการเปิดเผยเหตุผลแก่ลูกค้า ต้องร่วมมือกับฝ่ายกฎหมายก่อนออกแบบการอธิบายผล
Checklists และแผนการทดสอบความปลอดภัย (Checklist & Security Test Plan)
- Pre-deployment checklist:
- มี Model Card และ Datasheet ครบถ้วน
- ผ่าน fairness tests ตามเกณฑ์ที่ตั้งไว้
- ผ่าน robustness tests (OOD, adversarial scenarios)
- มี contingency plan และ rollback mechanism
- Realtime / Canary checklist:
- กำหนด sample size และระยะเวลาสำหรับ canary/A-B
- ตั้งค่า alert thresholds สำหรับ KPI และ fairness metrics
- ช่องทางรายงานปัญหาแบบเรียลไทม์ระหว่างทีม
- Security test plan:
- ทดสอบความทนทานต่อการโจมตีแบบ adversarial และ model inversion
- ตรวจสอบการรั่วไหลของข้อมูล (data leakage) ระหว่างสภาพแวดล้อมการพัฒนาและการผลิต
- ประเมินความเป็นส่วนตัว (privacy assessment) รวมถึงการพิจารณา Differential Privacy หรือการลดทอนข้อมูลส่วนบุคคลเมื่อจำเป็น
- ทดสอบการควบคุมการเข้าถึง (RBAC) และการเข้ารหัสข้อมูลขณะพักและขณะส่ง
- จัด tabletop exercises สำหรับเหตุการณ์ผิดปกติ เช่น การเพิ่มขึ้นของ default rate หรือการร้องเรียนเชิงระบบจากลูกค้า
สรุปคือ การนำ XAI และ Causal ML มาใช้เพื่อตรวจสอบโมเดลสินเชื่อแบบเรียลไทม์ต้องมีทั้งกรอบการกำกับดูแลที่เป็นรูปธรรม บทบาทที่ชัดเจน แผนการทดสอบที่รัดกุม และการจัดการกับข้อจำกัดด้านข้อมูลและ latency เพื่อให้เกิดความสมดุลระหว่างความโปร่งใส ความยุติธรรม และความมั่นคงทางธุรกิจ
บทสรุป
การผสาน Explainable AI (XAI) และ Causal ML ในระบบให้สินเชื่อช่วยลดอคติ เพิ่มความโปร่งใส และสร้างความเชื่อมั่นทั้งในเชิงเทคนิคและเชิงกฎหมาย โดย XAI ให้เหตุผลเชิงอธิบายสำหรับการตัดสินใจ ขณะที่ Causal ML ช่วยแยกความเป็นสาเหตุจากความสัมพันธ์ที่อาจทำให้เกิดอคติ ผลลัพธ์จากการทดลองนำร่องและกรณีศึกษาในอุตสาหกรรมชี้ให้เห็นว่าการรวมสองเทคนิคนี้สามารถลดสัญญาณอคติและข้อผิดพลาดเชิงนโยบายได้อย่างมีนัยสำคัญ การนำไปใช้เชิงปฏิบัติจำเป็นต้องมีสถาปัตยกรรมแบบเรียลไทม์เพื่อวิเคราะห์และตรวจสอบการตัดสินใจทันที, ตัวชี้วัดความเป็นธรรมที่ชัดเจน (เช่น disparate impact, false positive/negative rates แยกตามกลุ่ม), governance ที่เข้มแข็ง รวมถึงนโยบายการควบคุมและบทบาทความรับผิดชอบของมนุษย์ และแผนการทดสอบ/ปรับปรุงต่อเนื่องเพื่อจัดการกับ model drift และปัญหาคุณภาพข้อมูล
แนวปฏิบัติแนะนำให้เริ่มจาก POC ขนาดเล็กที่กำหนดเป้าหมายและตัวชี้วัดชัดเจน (เช่น การเปรียบเทียบอคติก่อน–หลัง, เวลาแฝงการตัดสินใจ, ความแม่นยำเชิงสาเหตุ) วัดผลอย่างเป็นระบบ แล้วค่อยขยายสู่ production โดยสร้าง audit trail ที่เก็บทั้งคำอธิบายของโมเดล เหตุการณ์การตัดสินใจ และการเปลี่ยนแปลงเวอร์ชันเพื่อความโปร่งใสและการตรวจสอบจากภายในและภายนอก มองไปข้างหน้า การผสาน XAI กับ Causal ML จะกลายเป็นมาตรฐานที่คาดหวังในธนาคารที่ต้องการทั้งประสิทธิภาพและการปฏิบัติตามกฎระเบียบ พร้อมทั้งเปิดโอกาสให้การให้สินเชื่อมีความเป็นธรรมและเข้าถึงได้มากขึ้น แต่ความสำเร็จขึ้นกับการลงทุนในสถาปัตยกรรมข้อมูล คุณภาพข้อมูล และการกำกับดูแลอย่างต่อเนื่อง



