
ในยุคที่ปัญญาประดิษฐ์ก้าวหน้าอย่างรวดเร็ว ChatGPT รุ่นใหม่กำลังกลายเป็นหนึ่งในนวัตกรรมที่มีศักยภาพเปลี่ยนโฉมหน้าการดูแลสุขภาพ ตั้งแต่การช่วยคัดกรองอาการเริ่มต้น การสนันสนุนการตัดสินใจทางคลินิก ไปจนถึงการลดภาระเอกสารทางการแพทย์และเพิ่มประสิทธิภาพการสื่อสารกับผู้ป่วย การทดลองใช้งานในหน่วยบริการและคลินิกบางแห่งรายงานว่าการนำระบบภาษาธรรมชาติไปช่วยงานเอกสารและการแปลผลเบื้องต้นสามารถลดเวลาในการบันทึกเวชระเบียนและรอคำปรึกษาได้เป็นอย่างมาก ซึ่งสะท้อนให้เห็นถึงโอกาสและความท้าทายที่มาพร้อมกันในระบบสาธารณสุขยุคดิจิทัล
บทความเชิงสอนฉบับนี้จะพาคุณลงลึกถึงภาพรวมทางเทคนิคเบื้องหลัง ChatGPT รุ่นใหม่ — ทั้งสถาปัตยกรรม LLM, การปรับแต่งด้วยข้อมูลทางการแพทย์, เทคนิค Retrieval-Augmented Generation (RAG) และการสร้าง embedding ทางคลินิก — พร้อมแนวทางการบูรณาการกับระบบบันทึกสุขภาพอิเล็กทรอนิกส์ (EHR) ตามมาตรฐานอย่าง FHIR/HL7, ข้อกำหนดด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ (เช่น การจัดการข้อมูลที่เป็นความลับ, audit trail และการประเมินความเสี่ยง) รวมทั้งกรณีศึกษาจากการใช้งานจริงและขั้นตอนการออกแบบ pilot ที่ชัดเจนเพื่อการทดสอบในสภาพแวดล้อมทางการแพทย์ การอ่านต่อจะช่วยให้ผู้บริหารด้านสาธารณสุข ผู้พัฒนาระบบ และทีมคลินิกเข้าใจทั้งศักยภาพ ข้อจำกัด และแนวทางปฏิบัติที่ปลอดภัยเมื่อนำ ChatGPT เข้าสู่การดูแลผู้ป่วย
บทนำ: ทำไม ChatGPT รุ่นใหม่จึงสำคัญต่อการดูแลสุขภาพ
บทนำ: ทำไม ChatGPT รุ่นใหม่จึงสำคัญต่อการดูแลสุขภาพ
ในช่วงไม่กี่ปีที่ผ่านมา โมเดลภาษาขนาดใหญ่ (Large Language Models หรือ LLM) อย่าง ChatGPT ได้พัฒนาไปสู่ความสามารถที่เหนือชั้น ทั้งในด้านการเข้าใจข้อความทางคลินิกที่ซับซ้อน การปรับแต่งด้วยข้อมูลเฉพาะทาง (domain-specific fine-tuning) และความรวดเร็วในการให้ผลลัพธ์ที่ใกล้เคียงเวลาจริง ในบริบทของการแพทย์ ความก้าวหน้าดังกล่าวไม่เพียงแต่เป็นเทคโนโลยีเชิงทดลอง แต่กำลังกลายเป็นเครื่องมือปฏิบัติการที่สามารถยกระดับงานคลินิกและการจัดการองค์กรได้จริง

พัฒนาการที่สำคัญของ LLM ที่เกี่ยวข้องกับการแพทย์ ได้แก่ การฝึกด้วยชุดข้อมูลทางการแพทย์เฉพาะทาง การนำเทคนิค Retrieval-Augmented Generation (RAG) มาใช้เพื่อลดข้อผิดพลาดจากการคาดเดาข้อมูล (hallucination) และการสนับสนุนข้อมูลหลายมิติ (multimodal) เช่น การวิเคราะห์บันทึกผู้ป่วย รังสีภาพ และข้อความจากอุปกรณ์สื่อสารในโรงพยาบาล งานวิจัยและการทดสอบเชิงปฏิบัติการบางชิ้นชี้ว่าโมเดลที่ได้รับการปรับแต่งในโดเมนการแพทย์สามารถเพิ่มความถูกต้องในการให้คำแนะนำทางคลินิกได้เป็นหลักหลายสิบเปอร์เซ็นต์เมื่อเทียบกับเวอร์ชันทั่วไป และช่วยลดเวลาที่ใช้ในการค้นหาเอกสารอ้างอิงหรือคำแนะนำการรักษาได้อย่างมีนัยสำคัญ
ในมิติเชิงคลินิกและเชิงองค์กร ChatGPT รุ่นใหม่มีศักยภาพในการสร้างประโยชน์ที่วัดผลได้ เช่น ลดเวลาการบันทึกเอกสาร (documentation) ซึ่งงานทดลองบางชุดรายงานว่าลดเวลาที่แพทย์ต้องใช้ในการกรอกบันทึกได้ประมาณ 30–50% ผู้ช่วยการตัดสินใจทางการแพทย์อัตโนมัติสามารถช่วยคัดกรองผู้ป่วย เพิ่มความเร็วในการให้บริการทางไกล และขยายการเข้าถึงการดูแล โดยเฉพาะในพื้นที่ชนบทหรือระบบที่มีบุคลากรจำกัด นอกจากนี้ยังช่วยปรับปรุงกระบวนการทางธุรการ เช่น การนัดหมาย การสรุปการจำหน่าย และการส่งต่อข้อมูลระหว่างหน่วยงาน ทำให้องค์กรมีประสิทธิภาพและลดต้นทุนการดำเนินงาน
ผู้รับประโยชน์หลักจากเทคโนโลยีนี้ได้แก่
- แพทย์ — ลดภาระการบันทึก เพิ่มความรวดเร็วในการเข้าถึงหลักฐานเชิงคลินิก และรองรับการตัดสินใจที่ซับซ้อน
- ผู้ช่วยพยาบาลและบุคลากรหน้าเคาน์เตอร์ — เพิ่มประสิทธิภาพในการจัดการงานประจำและการสื่อสารกับผู้ป่วย
- ผู้ป่วย — การเข้าถึงข้อมูลและคำแนะนำที่รวดเร็วขึ้น รวมถึงการบริการทางไกลที่มีคุณภาพ
- ทีม IT และฝ่ายบริหารโรงพยาบาล — โอกาสในการปรับปรุงระบบเวิร์กโฟลว์ เพิ่มความคุ้มค่าในการลงทุน และออกแบบสถาปัตยกรรมข้อมูลที่รองรับการขยายตัว
บทความฉบับนี้จะสำรวจภาพรวมเชิงเทคนิคของ ChatGPT รุ่นใหม่ที่เกี่ยวข้องกับการแพทย์, การยืนยันทางคลินิกและผลการทดลอง, กรณีศึกษาการใช้งานจริง, ความท้าทายด้านความปลอดภัยและจริยธรรม, แนวทางการปฏิบัติ (best practices) ในการปรับใช้ และการประเมินผลตอบแทนจากการลงทุน (ROI) สำหรับองค์กรสุขภาพ กลุ่มผู้อ่านที่บทความมุ่งเน้นได้แก่ ผู้บริหารโรงพยาบาล ผู้รับผิดชอบฝ่ายไอที แพทย์และบุคลากรสาธารณสุข ผู้พัฒนาผลิตภัณฑ์ด้านสุขภาพ และนักลงทุนที่สนใจเทคโนโลยีทางการแพทย์ — เพื่อให้ผู้อ่านได้รับทั้งความเข้าใจเชิงกลยุทธ์และแนวทางปฏิบัติที่นำไปใช้ได้จริง
เทคโนโลยีเบื้องหลัง: สถาปัตยกรรมและการฝึกสอนเฉพาะทาง
เทคโนโลยีเบื้องหลัง: สถาปัตยกรรมและการฝึกสอนเฉพาะทาง
โมเดล ChatGPT รุ่นใหม่สำหรับการดูแลสุขภาพมักออกแบบเป็นชั้นซ้อนระหว่าง โมเดลหลักทั่วไป (general LLM) กับ โมเดลเฉพาะทางทางคลินิก (clinical LLM) โดยทั่วไปสถาปัตยกรรมประกอบด้วยโมเดลขนาดใหญ่เป็นฐาน (base model) ขนาดตั้งแต่หลายร้อยล้านถึงหลายร้อยพันล้านพารามิเตอร์ ซึ่งให้ความยืดหยุ่นด้านภาษาและความสามารถเชิงสถิติ จากนั้นนำมา fine-tune ด้วยข้อมูลทางการแพทย์ เช่น บันทึกผู้ป่วยจากชุดข้อมูลสาธารณะ (เช่น MIMIC), วารสารทางการแพทย์ (PubMed), และคู่มือการรักษา ทำให้ได้โมเดลเฉพาะทางที่ตอบโจทย์เชิงคลินิก ตัวอย่างเช่น โมเดลขนาด 7–70 พันล้านพารามิเตอร์เป็นขนาดยอดนิยมสำหรับการใช้งานเชิงคลินิก ที่ให้สมดุลระหว่างประสิทธิภาพกับต้นทุนการประมวลผล
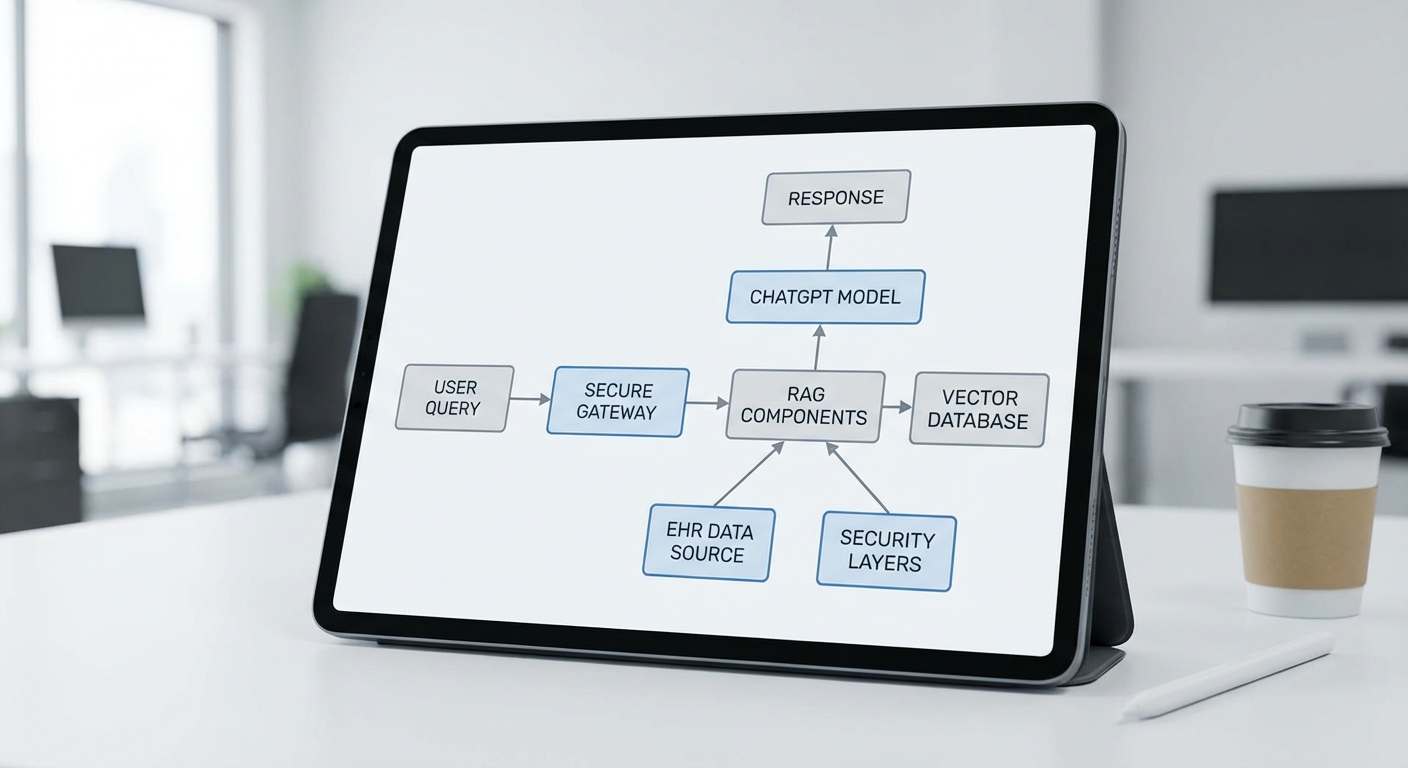
การฝึกสอนเฉพาะทางมักใช้เทคนิคหลายรูปแบบร่วมกัน ได้แก่ supervised fine-tuning, instruction tuning และ RLHF (Reinforcement Learning from Human Feedback) สำหรับข้อมูลทางการแพทย์ จะมีการเพิ่มชุดคำสั่งเชิงคลินิกและตัวอย่างคำตอบที่ถูกต้องเพื่อปรับพฤติกรรม นอกจากนี้เทคนิคประหยัดทรัพยากร เช่น LoRA หรือ adapter-based tuning ถูกนำมาใช้เมื่อองค์กรต้องการปรับโมเดลขนาดใหญ่โดยไม่ต้องฝึกทั้งโมเดลใหม่ทั้งหมด
สำหรับการเชื่อมโยงความรู้เชิงคลินิกและลดความเสี่ยงจากข้อมูลที่ผิดพลาด ระบบมักใช้โครงสร้าง Retrieval-Augmented Generation (RAG) ร่วมกับฐานข้อมูลเวกเตอร์ (vector databases) เช่น FAISS, Milvus, Pinecone หรือ Weaviate กระบวนการหลักประกอบด้วย:
- การแบ่งข้อความเป็นชิ้น (chunking) และสร้าง embedding ด้วยโมเดล embedding ขนาดเหมาะสม (มิติ 768–3,072 เป็นที่พบบ่อย)
- การเก็บในอินเด็กซ์เวกเตอร์ เพื่อรองรับการค้นหาแบบ nearest-neighbor (เช่น top-k = 5–20)
- การเรียกข้อมูล (retrieval) และการจัดลำดับผลลัพธ์ (reranking) โดยใช้ cross-encoder เพื่อเพิ่มความแม่นยำก่อนนำเข้าชุดบริบทให้กับตัวสร้างภาษา
- การใส่บริบทที่ได้เข้าไปใน prompt (knowledge grounding) เพื่อให้โมเดลสร้างคำตอบที่อ้างอิงแหล่งข้อมูลจริง
การตั้งค่า context window เป็นอีกปัจจัยสำคัญในการประยุกต์ใช้กับข้อมูลคลินิก บันทึกผู้ป่วยมักยาวและมีรายละเอียดสูง โมเดลที่รองรับ context ขนาดใหญ่ (เช่น 8k–32k tokens) จะช่วยให้สามารถใส่ทั้งประวัติการรักษา ผลแลบ และบันทึกผู้ป่วยก่อนหน้าไว้ในบริบทเดียว อย่างไรก็ตาม เมื่อข้อมูลยาวเกินกว่าขีดจำกัด จะใช้กลยุทธ์เช่น sliding window, สรุปอัตโนมัติ (abstractive/summarization), หรือการเลือก retrieval เฉพาะส่วนที่เกี่ยวข้องแบบ dynamic เพื่อรักษาความสอดคล้องของคำตอบ
ด้านความปลอดภัยและความเป็นส่วนตัว มีการบังคับใช้มาตรการหลายชั้นเพื่อปกป้องข้อมูลผู้ป่วยและลดความเสี่ยงจากการเกิด hallucination ได้แก่
- การลบระบุตัวบุคคล (de-identification) ก่อนนำข้อมูลเข้าสู่ pipeline — ทั้งการลบ PHI/PII และการใช้เทคนิค regex/ML-based named-entity recognition เพื่อซ่อนข้อมูลที่ระบุตัวตนได้
- Privacy-preserving training เช่น Differential Privacy (DP-SGD) ที่ช่วยลดความเสี่ยงการย้อนกลับข้อมูลจากโมเดล โดยแลกกับการลด precision เล็กน้อย — องค์กรมักตั้งค่า epsilon ให้สมดุลกับการใช้งานเชิงคลินิก
- สถาปัตยกรรมการประมวลผลปลอดภัย เช่น การใช้ secure enclaves, encryption-at-rest และ in-transit, การควบคุมสิทธิ์ (RBAC) และ audit logs เพื่อตรวจสอบการเข้าถึงข้อมูล
- การออกแบบเพื่อลด hallucination โดยใช้ RAG ร่วมกับการอ้างอิงแหล่งที่มา (source attribution), confidence calibration, และการเพิ่ม human-in-the-loop สำหรับกรณีคำตอบมีความเสี่ยงสูง — งานประเมินภายในบางชุดข้อมูลชี้ว่า RAG ร่วมกับ reranker สามารถลดอัตราคำตอบที่ขัดแย้งกับแหล่งข้อมูลได้อย่างมีนัยสำคัญ (ตัวเลขการลดขึ้นอยู่กับงาน: บางการทดลองระบุการลด hallucination ประมาณ 30–60%)
สุดท้าย การประยุกต์ใช้งานเชิงคลินิกต้องคำนึงถึงการตรวจสอบคุณภาพอย่างต่อเนื่อง (continuous monitoring) โดยใช้ metrics เช่น factuality, precision/recall ต่อ entity ทางการแพทย์, อัตราการอ้างอิงแหล่งที่มาที่ถูกต้อง และการติดตามเหตุการณ์ไม่พึงประสงค์ที่เกิดจากคำตอบของโมเดล เพื่อให้แน่ใจว่าโมเดลเฉพาะทางไม่เพียงแต่มีความชำนาญ แต่ยังปฏิบัติตามมาตรฐานความปลอดภัยและกฎหมายที่เกี่ยวข้อง
กรณีการใช้งาน (Use Cases) ที่เปลี่ยนเกมในเวชปฏิบัติ
กรณีการใช้งาน (Use Cases) ที่เปลี่ยนเกมในเวชปฏิบัติ
ChatGPT รุ่นใหม่เปิดประตูสู่นวัตกรรมเชิงปฏิบัติที่สามารถเปลี่ยนรูปแบบการให้บริการด้านสุขภาพได้อย่างชัดเจน ทั้งในมิติของประสิทธิภาพการทำงาน ความปลอดภัย และประสบการณ์ของผู้ป่วย โดยเฉพาะในสามด้านหลักที่โรงพยาบาลและคลินิกมักให้ความสำคัญ: triage และ pre-consultation, การอัตโนมัติของเอกสารทางคลินิก และ การให้ความรู้แก่ผู้ป่วย ซึ่งแต่ละด้านมีกรณีการใช้งานเชิงตัวเลขและสถานการณ์สมมติที่ช่วยให้เห็นภาพการประยุกต์ใช้งานได้ชัดเจน
Triage และ pre-consultation เพื่อช่วยคัดกรองผู้ป่วย
ระบบ triage อัตโนมัติที่ขับเคลื่อนด้วยโมเดลภาษาขั้นสูงสามารถรับข้อมูลอาการเบื้องต้นจากผู้ป่วยก่อนเข้าพบแพทย์ และจัดลำดับความเร่งด่วนโดยอัตโนมัติ ตัวอย่างเชิงตัวเลข: ในสถานการณ์สมมติ โรงพยาบาลขนาดกลางที่มีผู้ป่วยนอกรับ 400 รายต่อวัน หากนำระบบ pre-consultation เข้ามาช่วยคัดกรองและจัดลำดับ จะสามารถลดเวลารอคอยเฉลี่ยจาก 90 นาทีเหลือ 55 นาที (ลดลงประมาณ 39%) และช่วยแบ่งเบาภาระพยาบาลเบื้องต้นได้ถึง ประมาณ 30–45% ของการคัดกรองทั้งหมด นอกจากนี้ ระบบสามารถตั้งค่าการตรวจจับสัญญาณอันตราย (red flags) เช่น อาการเจ็บหน้าอกรุนแรงหรือหายใจลำบาก ซึ่งจะยกระดับผู้ป่วยไปยังช่องทางฉุกเฉินทันที ทำให้ลดความเสี่ยงจากความล่าช้าในการรักษา
อัตโนมัติในการจัดทำ clinical notes และ discharge summaries
หนึ่งในภาระที่ใช้เวลามากในการปฏิบัติการแพทย์คือการบันทึกข้อมูลทางคลินิกและการเขียนสรุปผู้ป่วย ระบบที่ใช้ ChatGPT สามารถสร้าง S.O.A.P. notes, progress notes และ discharge summaries จากบันทึกการพบผู้ป่วยรวมถึงผลตรวจทางห้องปฏิบัติการและการสั่งยาอย่างเป็นโครงสร้าง ตัวอย่างสถานการณ์สมมติ: แพทย์เฉลี่ยใช้เวลาบันทึกทางคลินิกประมาณ 2 ชั่วโมงต่อวัน หากระบบช่วยย่นย่อและเขียนโน้ตอัตโนมัติได้ 50–70% จะทำให้แพทย์คืนเวลาได้ 1–1.4 ชั่วโมงต่อวัน ซึ่งเมื่อรวมครอบคลุมทีมแพทย์ 20 คนต่อแผนก จะหมายถึงการคืนเวลาเป็นผู้ป่วยเพิ่มขึ้นหลายชั่วโมงต่อวันหรือการลดชั่วโมงการทำงานล่วงเวลาที่มีต้นทุนสูง สำหรับ discharge summaries ระบบสามารถสร้างร่างเอกสารที่ครบถ้วนทั้งการวินิจฉัย การรักษาที่ทำไป ยาที่จ่าย และคำแนะนำหลังการรักษา ใช้เวลาเพียง 2–5 นาทีต่อราย เทียบกับการเขียนด้วยมือที่อาจกินเวลา 15–25 นาที ซึ่งหมายถึงการประหยัดเวลาเฉลี่ย 10–20 นาทีต่อผู้ป่วย และลดความผิดพลาดเชิงเอกสารที่เป็นสาเหตุของปัญหาการคิดค่ารักษาหรือการติดตามผล
Patient education และการสื่อสารที่เข้าใจง่ายสำหรับผู้ป่วย
การสื่อสารข้อมูลทางการแพทย์ให้ผู้ป่วยเข้าใจง่ายเป็นหัวใจสำคัญของการปฏิบัติที่มีคุณภาพ ChatGPT สามารถปรับข้อความให้เหมาะสมกับระดับการอ่าน ความเข้าใจทางภาษา และความต้องการเชิงวัฒนธรรม เช่น แปลงรายงานการรักษาเป็นคำอธิบายแบบง่าย ตลอดจนสร้างแผนการดูแลที่บ้านแบบทีละขั้นตอน (step-by-step) หรือข้อความเตือนยาที่เขียนในภาษาท้องถิ่น ตัวอย่างเชิงตัวเลขจากการทดลองนำร่อง (สมมติ) พบว่าเอกสารให้ความรู้ที่ปรับตามระดับความเข้าใจช่วยเพิ่มความเข้าใจคำแนะนำการรักษาได้ ขึ้น 20–35% และอาจลดอัตราการกลับมารักษาแบบฉุกเฉินภายใน 30 วันลงได้ประมาณ 10–15% เมื่อระบุปัจจัยเสี่ยงและคำแนะนำที่ชัดเจน รวมทั้งระบบสามารถส่งข้อความติดตามผลอัตโนมัติและวัดการปฏิบัติตามคำแนะนำ (adherence) ซึ่งเป็นข้อมูลเชิงปฏิบัติที่ช่วยฝ่ายบริหารวางแผนบริการหลังการรักษา
- ประโยชน์ด้านประสิทธิภาพ: ลดเวลาในการคัดกรองและเขียนเอกสาร ทำให้เพิ่มเวลาพบผู้ป่วยต่อวันและลดต้นทุนแรงงาน
- ประโยชน์ด้านคุณภาพ: ลดข้อผิดพลาดจากการบันทึกด้วยมือ สร้างความสม่ำเสมอของข้อมูล และเพิ่มความชัดเจนของคำแนะนำสำหรับผู้ป่วย
- ข้อควรพิจารณาเชิงนโยบาย: ต้องมีการตรวจสอบ การยืนยันข้อมูลโดยผู้เชี่ยวชาญ และการผสานรวมกับระบบ EHR เพื่อให้มั่นใจในความปลอดภัยและการปฏิบัติตามกฎระเบียบ
โดยสรุปแล้ว การนำ ChatGPT รุ่นใหม่มาใช้ในเวชปฏิบัติไม่ได้เพียงเพิ่มความสะดวก แต่ยังสร้างรูปแบบการปฏิบัติที่มีประสิทธิภาพมากขึ้น หากบริหารจัดการความเสี่ยงด้านความถูกต้องของข้อมูลและการคุ้มครองความเป็นส่วนตัวอย่างรอบคอบ เทคโนโลยีเหล่านี้สามารถเป็นเครื่องมือเชิงกลยุทธ์ที่ช่วยให้ระบบสุขภาพตอบสนองได้รวดเร็วขึ้น ปลอดภัยขึ้น และมุ่งเน้นผู้ป่วยได้มากขึ้น
มาตรฐานความปลอดภัย กฎหมาย และจริยธรรม
มาตรฐานความปลอดภัยและการปฏิบัติตามกฎระเบียบ
การนำ ChatGPT รุ่นใหม่มาใช้ในบริบทการดูแลสุขภาพต้องสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและความมั่นคงของข้อมูลอย่างเคร่งครัด ตัวอย่างเช่นการปฏิบัติตาม HIPAA ในสหรัฐฯ จำเป็นต้องมีการควบคุมการเข้าถึงข้อมูลผู้ป่วย การเข้ารหัสข้อมูลระหว่างการส่งและจัดเก็บ (in-transit and at-rest encryption) และการทำข้อตกลงทางธุรกิจ (Business Associate Agreements) กับผู้ให้บริการคลาวด์หรือผู้พัฒนา AI ในสหภาพยุโรปและพื้นที่ที่บังคับใช้ GDPR จะเน้นไปที่หลักการของการคัดเลือกข้อมูล (data minimization), สิทธิของเจ้าของข้อมูล (data subject rights) และการประเมินผลกระทบด้านการคุ้มครองข้อมูล (Data Protection Impact Assessment - DPIA) ก่อนใช้งานระบบใหม่ ๆ
นอกจากนี้ ควรนำแนวทางด้านการปกป้องข้อมูลขั้นสูงมาประยุกต์ใช้ เช่น differential privacy, federated learning และการเข้ารหัสแบบ homomorphic ในบางกรณีเพื่อลดความเสี่ยงของการเปิดเผยข้อมูลผู้ป่วยโดยตรง และต้องมีนโยบายการเก็บรักษาข้อมูล (retention policy) รวมทั้งการจัดการการเข้าถึง (role-based access control) ที่ชัดเจนเพื่อให้สอดคล้องกับทั้งกฎหมายและมาตรฐานอุตสาหกรรม
การตรวจสอบประสิทธิภาพของโมเดลและการทำ validation ทางคลินิก
ก่อนนำ ChatGPT ไปใช้ในการตัดสินใจด้านการแพทย์ ต้องผ่านกระบวนการตรวจสอบทางเทคนิคและการประเมินผลทางคลินิกอย่างเป็นระบบ ขั้นตอนสำคัญได้แก่ การแบ่งชุดข้อมูลสำหรับฝึก/ทดสอบ/validation ที่ไม่ซ้ำกัน การตรวจวัดมาตรฐานประสิทธิภาพเชิงสถิติ (เช่น sensitivity, specificity, AUC-ROC, precision-recall, calibration) และการทดสอบแบบภายนอก (external validation) บนข้อมูลจากสถาบันหรือประชากรที่แตกต่างกัน
ในบริบทการใช้งานจริง ควรพิจารณาการทดลองเชิงคลินิกหรือการประเมินผลแบบ prospective เพื่อวัดผลเชิงคลินิก (clinical endpoints) เช่น ผลต่อการวินิจฉัย การลดเวลารอคอย หรืออัตราการเกิดข้อผิดพลาดทางการแพทย์ นอกจากนี้การวางแผนสำหรับ post-deployment monitoring เป็นสิ่งจำเป็น โดยรวมถึงการตั้งค่าเกณฑ์เตือนเมื่อ performance ลดลง การตรวจจับ dataset shift และการทำ audit trails ที่บันทึกการเรียกใช้โมเดล เวอร์ชันของโมเดล และข้อมูลนำเข้า/ผลลัพธ์เพื่อใช้ในการสอบสวนเหตุการณ์
ประเด็นจริยธรรม: ความเอนเอียง (bias), ความโปร่งใส (transparency) และความรับผิดชอบ
ปัญหาจริยธรรมเป็นหัวใจสำคัญเมื่อใช้ AI ทางการแพทย์ เนื่องจากโมเดลอาจสะท้อนหรือขยายความไม่เป็นธรรมจากข้อมูลฝึก (historical bias) ทำให้กลุ่มประชากรบางกลุ่มได้รับผลลัพธ์ที่แย่ลง การประเมินความยุติธรรมควรใช้เมตริกที่เหมาะสม (เช่น equalized odds, demographic parity) และมีกลยุทธ์ลด bias เช่น การเสริมข้อมูลที่ขาดความหลากหลาย การรีเวทน้ำหนัก (reweighing) หรือการออกแบบอัลกอริทึมที่คำนึงถึงความยุติธรรม
อีกด้านหนึ่งคือความโปร่งใสและการอธิบายได้ (explainability) ผู้ให้บริการต้องสามารถอธิบายข้อจำกัดของโมเดล วิธีการทำงานโดยคร่าว ๆ และเหตุผลเบื้องหลังคำแนะนำที่ระบบให้ ตัวอย่างเทคนิคที่ใช้ได้แก่ SHAP, LIME หรือการจัดทำ model cards และ datasheets for datasets เพื่อให้ผู้ดูแลทางคลินิกและผู้ป่วยเข้าใจความเชื่อมั่นและขอบเขตการใช้งาน
สุดท้าย เรื่องความรับผิดชอบ (accountability) ต้องมีการกำหนดบทบาทและกระบวนการตัดสินใจชัดเจน—ใครเป็นผู้รับผิดชอบเมื่อเกิดข้อผิดพลาดทางคลินิก การจัดการกรณีเหตุการณ์ไม่พึงประสงค์ และแนวทางการชดใช้ ความรับผิดชอบควรรวมทั้งฝ่ายคลินิก ฝ่ายเทคนิค และผู้พัฒนา ในเชิงปฏิบัติองค์กรควรตั้งคณะกำกับดูแล AI (AI governance board), แต่งตั้งเจ้าหน้าที่คุ้มครองข้อมูล (DPO) และจัดทำ SOP ที่รวมถึงการทดสอบความปลอดภัย การตรวจสอบหลังใช้งาน และแผนตอบสนองเมื่อเกิดเหตุ
- ข้อเสนอเชิงปฏิบัติ: ดำเนิน DPIA ก่อนใช้งาน, ทำ BAA/DPA ให้เรียบร้อย, ใช้การเข้ารหัสและการควบคุมการเข้าถึง
- การตรวจสอบทางคลินิก: ต้องมีการทดสอบภายในและภายนอก พร้อมเกณฑ์ performance ทางคลินิกและการติดตามหลังใช้งาน
- การจัดการจริยธรรม: วางนโยบายลด bias, จัดทำ model cards, ให้คำอธิบายผู้ใช้ และกำหนดกระบวนการความรับผิดชอบชัดเจน
- การเตรียมความพร้อมทางกฎหมาย: ติดตามกรอบกฎหมายที่เปลี่ยนแปลง (เช่น FDA SaMD, EU AI Act) และปรับแนวนโยบายองค์กรให้สอดคล้อง
การบูรณาการกับระบบโรงพยาบาล (EHR/EMR) — ขั้นตอนและทางเลือก
การนำ ChatGPT รุ่นใหม่เข้าไปใช้งานในระบบการแพทย์ จำเป็นต้องออกแบบกระบวนการบูรณาการกับ EHR/EMR อย่างเป็นระบบ ทั้งด้านมาตรฐานการสื่อสาร การออกแบบ data pipeline และการตัดสินใจเรื่องสภาพแวดล้อมการปรับใช้ (deployment) เพื่อให้เกิดความปลอดภัย ความถูกต้องของข้อมูล และประสบการณ์ใช้งานที่ตอบโจทย์คลินิก ในส่วนนี้จะให้แนวทางเชิงปฏิบัติและตัวเลือกเชิงสถาปัตยกรรมที่ชัดเจนสำหรับทีมเทคนิคและฝ่ายบริหารโรงพยาบาล
มาตรฐานการสื่อสาร: FHIR, HL7 และการออกแบบ API
เลือกมาตรฐานที่ชัดเจน — ปัจจุบัน FHIR (Fast Healthcare Interoperability Resources) เป็นมาตรฐานหลักสำหรับการเชื่อมต่อแบบ RESTful/JSON ที่ได้รับการยอมรับอย่างกว้างขวางในระบบ EHR สมัยใหม่ ขณะที่ HL7 v2 ยังคงใช้กันมากในระบบส่งข้อความดั้งเดิม และ CDA/HL7 v3 ยังพบในการแลกเปลี่ยนเอกสารคลินิก การออกแบบ API ควรรองรับทั้ง FHIR REST (GET/POST/PUT/PATCH) และกลไกการแจ้งเตือนแบบ subscription/event (เช่น FHIR Subscriptions และ webhook) เพื่อรองรับทั้งคำขอแบบเรียลไทม์และการประมวลผลแบบแบตช์
- SMART on FHIR: ใช้สำหรับการยืนยันตัวตนและการมอบสิทธิ์ (OAuth2/OpenID Connect) ให้แอปสามารถทำงานภายในบริบทของผู้ใช้ที่ล็อกอิน
- Terminology: บังคับใช้มาตรฐานรหัสเช่น SNOMED CT, LOINC, ICD-10 เพื่อให้ผลลัพธ์ของ LLM มีความสอดคล้องกับข้อมูลคลินิก
- การรักษาความปลอดภัยของ API: ใช้ mutual TLS, JWT, rate limiting และการตรวจสอบแอดดิตล็อก (audit logs) เพื่อให้สอดคล้องกับข้อกำหนดทางกฎหมาย (เช่น HIPAA, PDPA)
- API patterns: แนะนำให้ใช้ façade API (thin API layer) ที่แปลง FHIR/HL7 เป็นรูปแบบข้อมูลที่เหมาะสำหรับการเรียกใช้ LLM และเก็บ logic การเข้า-ออกข้อมูลไว้ในชั้นเดียวกัน
การออกแบบ data pipeline และการ mapping ระหว่าง fields ใน EHR
การเชื่อมต่อ ChatGPT กับข้อมูลคลินิกต้องเริ่มจากการนิยาม data pipeline ที่ชัดเจน ซึ่งครอบคลุมการสกัด (extract), การแปลง (transform), การทำความสะอาดและการทำ de-identification ก่อนจะส่งข้อมูลเข้าโมเดล หลักการปฏิบัติที่ควรนำไปใช้ ได้แก่:
- Canonical model: สร้างโมเดลข้อมูลกลางบนพื้นฐาน FHIR resources (เช่น Patient, Encounter, Condition, Observation, MedicationRequest) เพื่อเป็นจุดเชื่อมระหว่างระบบต้นทางหลายระบบ
- Field mapping ตัวอย่าง:
- Problem list (EHR proprietary) → Condition.code (SNOMED/ICD-10)
- Lab result → Observation.code (LOINC), valueQuantity.value, valueQuantity.unit, referenceRange
- Medication order → MedicationRequest.medicationCodeableConcept, dosageInstruction
- Vitals → Observation (LOINC code เช่น 8480-6 สำหรับความดัน)
- Terminology mapping: ใช้ชุดแมประหว่างรหัส (mapping tables) หรือบริการ terminology server (เช่น Ontoserver) เพื่อแปลงรหัสภายในเป็น SNOMED/LOINC/ICD ก่อนส่งให้ LLM
- บริบทและขอบเขตข้อมูล (context window): ออกแบบการตัดข้อความ (context truncation) และการคัดเลือกข้อมูลเพื่อส่งไปยัง LLM — ตัวอย่างเช่น ส่งเฉพาะ encounter ล่าสุด 12 เดือน หรือสรุปสั้นจาก progress notes ไม่ใช่ทั้ง record เพื่อควบคุมค่าใช้จ่ายและลด latency
- De-identification และ governance: สำหรับ use case ที่ไม่ต้องการส่ง PHI ดิบ ให้ใช้เทคนิค de-identification (hashing, tokenization) หรือสร้าง embeddings บนข้อมูลที่ถูกลบตัวตนก่อน
- สถาปัตยกรรมการส่งข้อมูล: เลือกระหว่าง synchronous API call (สำหรับงานตอบโต้แบบเรียลไทม์) และ asynchronous pipeline (เช่น Kafka/Message Queue + worker) สำหรับการประมวลผลแบตช์หรืองานที่ไม่ต้องการผลลัพธ์ทันที
ตัวอย่างเชิงปฏิบัติ: หากต้องการให้ ChatGPT ช่วยสรุปเคสผู้ป่วยขณะแพทย์เข้าชมห้องตรวจ ให้ pipeline ดังนี้ — ดึง Encounter + Recent Observations + Active Medications → map เป็น FHIR resources → สร้าง prompt template ที่มี sections (summary, problems, meds, labs) → เรียก LLM ด้วย context ที่จำกัดไว้ (เช่น 2–3 KB) → เก็บผลลัพธ์พร้อม audit trail
ทางเลือกการปรับใช้: cloud vs on-premise vs hybrid
เมื่อตัดสินใจปรับใช้ ChatGPT ในบริบทของโรงพยาบาล ต้องชั่งน้ำหนักข้อดีข้อเสียของแต่ละรูปแบบการปรับใช้ ดังนี้
- Cloud (SaaS / managed API)
- ข้อดี: เร็วในการนำไปใช้, สามารถเข้าถึงโมเดลรุ่นล่าสุด, ความสามารถในการสเกลโดยอัตโนมัติ, ค่าเริ่มต้นต่ำสำหรับทีมพัฒนา
- ข้อเสีย: ประเด็นความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ (data residency), latency อาจสูงขึ้นเมื่อมีการส่งข้อมูลข้ามเครือข่าย, ค่าใช้จ่ายตามการเรียกใช้งาน
- ข้อเสนอเชิงปฏิบัติ: ถ้าต้องใช้ cloud ให้พิจารณา de-identification หรือส่งเฉพาะ context ที่ไม่ใช่ PHI ไปยังเซิร์ฟเวอร์สาธารณะ
- On-premise
- ข้อดี: ควบคุมข้อมูลเต็มที่, เหมาะสำหรับงานที่มี PHI สูงหรือเงื่อนไขด้านกฎหมายเข้มงวด, latency ต่ำภายในเครือข่ายภายใน
- ข้อเสีย: ค่าใช้จ่าย CAPEX สูง, ต้องมีทีมปฏิบัติการและความเชี่ยวชาญ, การอัปเดตโมเดลและการสเกลอาจซับซ้อน
- ข้อเสนอเชิงปฏิบัติ: เหมาะกับระบบที่ต้องการการตอบสนองทันที (real-time) เช่น ผู้ช่วยในห้องฉุกเฉิน หรือการประเมินผลที่มี PHI ระดับสูง
- Hybrid
- ข้อดี: ผสมความยืดหยุ่นของ cloud กับความปลอดภัยของ on-premise — ตัวอย่างสถาปัตยกรรม: เก็บ PHI ดิบไว้ในเครือข่ายภายในและรัน pre-processing/de-identification on-premise แล้วส่งคอนเท็กซ์ที่ปลอดภัยหรือ embeddings ไปยัง cloud LLM
- ข้อเสีย: ความซับซ้อนในการออกแบบและการจัดการมากขึ้น ต้องมีการกำหนด policy ชัดเจนว่าอะไรไปที่ไหน
- ข้อเสนอเชิงปฏิบัติ: ใช้ hybrid สำหรับองค์กรขนาดใหญ่ที่ต้องการนวัตกรรมอย่างรวดเร็วแต่ยังต้องคงขอบเขตการปฏิบัติตามข้อกำหนด
ปัจจัยที่ควรนำมาพิจารณาก่อนตัดสินใจ ได้แก่: ปริมาณข้อมูลต่อวัน, ข้อกำหนดด้าน latency (เช่น ต้องการตอบภายใน 200–500 ms สำหรับงานคลินิกจริงหรือไม่), ข้อจำกัดด้านกฎหมายและ data residency, งบประมาณและทรัพยากรบุคคล ตัวอย่างเชิงตัวเลข: การเรียกใช้ LLM ผ่าน cloud อาจเพิ่มเวลา inference ระหว่าง 100 ms ถึงหลายวินาที ขึ้นกับขนาดโมเดลและเครือข่าย ในขณะที่ on-premise inference ที่ออกแบบดีอาจให้ latency ต่ำกว่า 200 ms แต่ต้องลงทุนฮาร์ดแวร์และทีมปฏิบัติการ
เช็คลิสต์เชิงปฏิบัติ
- กำหนด use case ให้ชัด: real-time clinical support vs. retrospective summarization
- ออกแบบ canonical data model และ mapping table สำหรับรหัสทางการแพทย์ (SNOMED/LOINC/ICD)
- กำหนดนโยบาย PHI: de-identify / tokenization หรือเก็บทั้งหมดบนเครือข่ายภายใน
- เลือกสถาปัตยกรรม deployment โดยพิจารณา latency, compliance และต้นทุน — หากเลือก hybrid วางโฟลว์ de-identification on-premise
- ติดตั้ง logging, audit trail และกระบวนการตรวจสอบคุณภาพผลลัพธ์อย่างต่อเนื่อง
การบูรณาการ ChatGPT กับ EHR เป็นโครงการที่ผสมผสานด้านเทคนิคและนโยบายอย่างเข้มข้น การวางแผนล่วงหน้าในเรื่องมาตรฐานข้อมูล การแมปฟิลด์ การจัดการ latency และการเลือกรูปแบบ deployment ที่สอดคล้องกับข้อกำหนดทางกฎหมาย จะเป็นปัจจัยสำคัญที่กำหนดความสำเร็จและความยั่งยืนของโครงการ
ผลลัพธ์และสถิติจากงานวิจัยและกรณีศึกษาจริง
ผลลัพธ์และสถิติจากงานวิจัยและกรณีศึกษาจริง
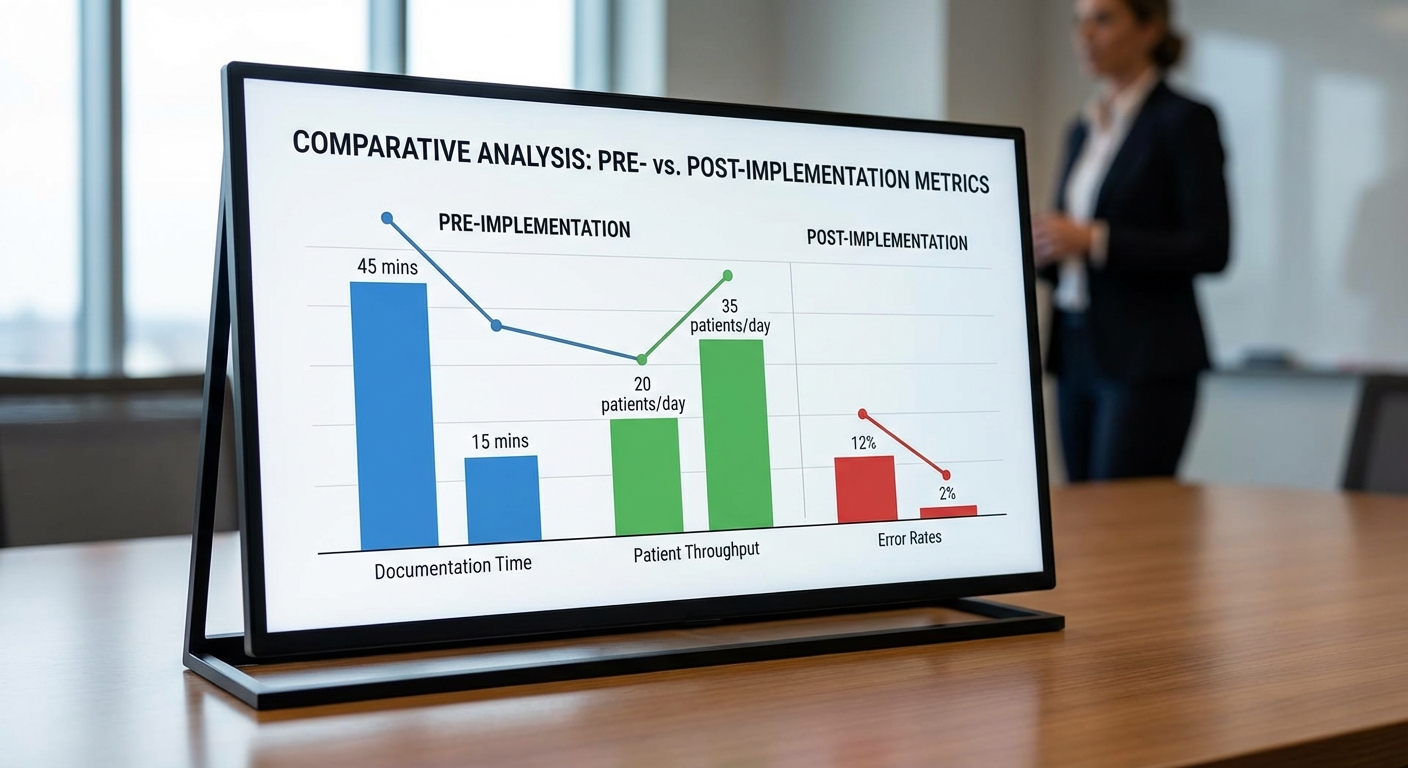
จากงานวิจัยเชิงประยุกต์และโครงการนำร่อง (pilot projects) หลายฉบับที่ทดสอบ ChatGPT รุ่นใหม่ในบริบทการดูแลสุขภาพ พบผลลัพธ์เชิงบวกในหลายมิติ โดยเฉพาะการลดเวลาการทำงานเอกสาร (documentation) การเพิ่ม throughput ของผู้ป่วย และการตอบสนองต่อคำถามเชิงคลินิกอย่างรวดเร็ว ตัวอย่างเช่น ในโครงการนำร่องระดับโรงพยาบาลขนาดกลาง (N = 200 ผู้ให้บริการ/เคส) รายงานว่าเวลาในการเขียนบันทึกทางการแพทย์ลดลงเฉลี่ย 28% (ช่วงประมาณ 20–35%) เมื่อเทียบกับกระบวนการเดิมที่ใช้คนทำเพียงอย่างเดียว
นอกจากการลดเวลา documentation แล้วยังมีรายงานการปรับปรุงด้านอื่น ๆ ดังนี้:
- Throughput ของผู้ป่วยเพิ่มขึ้นโดยรวม 10–18% ในหน่วยผู้ป่วยนอกที่ใช้ระบบช่วยตอบคำถามและสรุปเคสเบื้องต้น (ตัวอย่างจากโครงการ N = 150 เคสในคลินิกเฉพาะทาง)
- การปฏิบัติตามแนวทางปฏิบัติ (guideline adherence) เพิ่มขึ้นเฉลี่ย 12–16% ในงานวิจัยเชิงควบคุมขนาดเล็ก (N = 120 ผู้ปฏิบัติการ) เมื่อระบบเสนอข้อเสนอแนะตามแนวทางที่อัปเดต
- ความเร็วในการให้คำตอบจากระบบตอบคำถามเบื้องต้นลดลงจากเวลาเฉลี่ยของการตอบแบบแมนนวลหลายนาที เหลือเฉลี่ย 30–90 วินาที ในการให้คำตอบพื้นฐาน (ตัวอย่างจากระบบ triage อัตโนมัติในโครงการนำร่อง N = 300 เคส)
- ตัวชี้วัดความพึงพอใจของผู้ป่วยและบุคลากรในบางโครงการเพิ่มขึ้นเล็กน้อย โดยคะแนนความพึงพอใจเพิ่มประมาณ 5–12% หลังการใช้งานเป็นเวลา 3–6 เดือน
อย่างไรก็ดี ผลลัพธ์เหล่านี้มาพร้อมกับข้อจำกัดสำคัญที่ต้องคำนึงถึงก่อนตีความหรือขยายผลเชิงระบบ ได้แก่:
- ขนาดตัวอย่างและระยะเวลาการศึกษา: โครงการส่วนใหญ่เป็น pilot ที่มีขนาดจำกัด (โดยมาก N ระหว่าง 100–400) และระยะเวลาสั้น (3–6 เดือน) ทำให้ยังไม่สามารถสรุปผลระยะยาวได้
- การคัดเลือกสถานที่และเคส: งานวิจัยหลายชิ้นดำเนินการในโรงพยาบาลหรือคลินิกที่มีความพร้อมด้านดิจิทัลสูง ซึ่งทำให้ผลลัพธ์อาจไม่สามารถทั่วไปได้กับสถานพยาบาลที่มีทรัพยากรจำกัด
- ตัวชี้วัดที่ใช้วัดผลมีความหลากหลาย: วิธีการวัดเวลา documentation หรือการนับ throughput ไม่ได้มาตรฐานเดียวกันในทุกการศึกษา ส่งผลต่อความเปรียบเทียบข้ามการศึกษาที่จำกัด
- ปัจจัยชวนคลาดเคลื่อน (confounders): การฝึกอบรมบุคลากร การปรับเวิร์กโฟลว์ และการสนับสนุนด้านไอทีในช่วงทดลองอาจมีผลต่อการปรับปรุงมากกว่าระบบ AI เพียงอย่างเดียว
- ความเสี่ยงด้านความถูกต้องเชิงคลินิกและความปลอดภัย: แม้จะลดเวลาได้ แต่ยังพบกรณีที่ระบบให้ข้อมูลคลาดเคลื่อนหรือไม่ครบถ้วน จึงต้องมีการตรวจสอบโดยผู้เชี่ยวชาญ (human-in-the-loop)
การตีความเชิงบริบทและข้อเสนอแนะเชิงนโยบายและปฏิบัติการมีความสำคัญ ดังนี้:
- ให้มองผลลัพธ์เหล่านี้เป็น สัญญาณเชิงบวกจากการนำร่อง แต่อย่าใช้เป็นหลักฐานเด็ดขาดสำหรับการขยายในวงกว้างโดยไม่ผ่านการประเมินเพิ่มเติม เช่น การทดลองแบบสุ่ม (RCT) หรือการศึกษาข้ามสถานที่ในระยะยาว
- แนะนำการนำไปใช้แบบค่อยเป็นค่อยไปพร้อมระบบตรวจสอบ KPI เช่น เวลา documentation, throughput, อัตราการกลับมารักษา (readmission) และความแม่นยำของคำแนะนำเชิงคลินิก
- ต้องรักษาหลักการ human-in-the-loop โดยให้บุคลากรทางการแพทย์ตรวจสอบข้อเสนอแนะจากระบบก่อนนำไปใช้จริง เพื่อลดความเสี่ยงเชิงคลินิกและปัญหาทางกฎหมาย
- การออกแบบการศึกษาในอนาคตควรเพิ่มขนาดตัวอย่างและความหลากหลายของสถานพยาบาล พร้อมการติดตามผลระยะยาว (≥12 เดือน) เพื่อประเมินผลต่อประสิทธิภาพการรักษาและผลลัพธ์ของผู้ป่วยอย่างชัดเจน
แนวทางนำไปใช้จริง: แผนการทำ Pilot และ Checklist แบบทีละขั้น
บทนำสั้น: วัตถุประสงค์ของ Pilot
ก่อนเริ่มการทดลองใช้งาน ChatGPT รุ่นใหม่ในสภาพแวดล้อมการดูแลสุขภาพ ต้องกำหนดกรอบเป้าหมายและตัวชี้วัดที่ชัดเจนเพื่อประเมินความสำเร็จของโครงการ เป้าหมาย (Goals) อาจรวมถึงการลดเวลาในการทำงานของบุคลากร การเพิ่มความแม่นยำในการสรุปข้อมูลผู้ป่วย และการยกระดับความพึงพอใจของผู้ป่วย/บุคลากร ส่วน KPI ที่วัดผลได้ ให้ระบุเป็นตัวเลข เช่น เวลาที่ประหยัดได้ (time saved) เป้าหมายลด 20–30% สำหรับงานเอกสาร, ความแม่นยำ (accuracy) ของการตอบคำถามทางการแพทย์ต้องไม่ต่ำกว่า 95% เมื่อเทียบกับผู้เชี่ยวชาญ, และ ความพึงพอใจ (satisfaction) ของบุคลากรไม่ต่ำกว่า 80% หลังการใช้งานจริง
แผนการทำ Pilot แบบทีละขั้น (Step-by-step)
ระยะเวลาแนะนำสำหรับ pilot อยู่ที่ 6–12 สัปดาห์ ขึ้นกับขนาด use case และปริมาณข้อมูล โดยแบ่งขั้นตอนหลักดังนี้
- 1. เลือก Use Case ขนาดเล็กและมีความเสี่ยงต่ำ: เลือกงานที่มีขอบเขตชัดเจน เช่น การสรุปบันทึกการเยี่ยมผู้ป่วย (discharge summary draft), ช่วยตอบคำถามทั่วไปสำหรับพนักงานเวร, หรือช่วยตรวจสอบรายการยาเบื้องต้น โดยเลือก 1–3 หน่วยงานนำร่องและจำนวนเคสต่อวันที่คงที่ (เช่น 30–100 เคส/สัปดาห์)
- 2. เตรียม Dataset และการทำ Data Governance:
- รวบรวมตัวอย่างข้อมูลที่เป็นตัวแทน (clinical notes, lab results) แยกชุดข้อมูลเป็น train/validation/test (เช่น 70/15/15)
- ดำเนินการ de-identification และตรวจสอบการปฏิบัติตามกฎหมายคุ้มครองข้อมูล (เช่น PDPA / HIPAA หากเกี่ยวข้อง)
- กำหนดโครงสร้าง metadata เพื่อการติดตาม (source, timestamp, clinician id, outcome label)
- 3. ปรับแต่งโมเดล (Model Tuning) และ Prompt Engineering:
- ทำการ fine-tune หรือปรับ prompt กับ dataset เฉพาะทางเพื่อลด hallucination และเพิ่มความแม่นยำ
- ตั้งค่าพารามิเตอร์เช่น temperature, max tokens และ confidence threshold เพื่อควบคุมพฤติกรรม
- จัดสร้างชุดทดสอบทางคลินิก (clinical validation set) อย่างน้อย 200–500 ตัวอย่างสำหรับประเมินเบื้องต้น
- 4. การบูรณาการระบบ (Integration):
- เชื่อมต่อผ่าน API กับระบบ EHR โดยยึดมาตรฐานเช่น FHIR/HL7
- ตั้งค่า sandbox environment ก่อนเปิดใน production มี fallback และ rollback plan ชัดเจน
ติดตั้งระบบ logging และ audit trail เพื่อบันทึกการโต้ตอบและผลลัพธ์ทั้งหมด - 5. การฝึกอบรมบุคลากร (Training):
- จัด session สำหรับทีมแพทย์และพยาบาล ครอบคลุมการใช้งาน ข้อจำกัดของโมเดล และขั้นตอนการตรวจสอบผลลัพธ์
- เตรียมคู่มือการใช้งาน, checklist ในการยืนยันผล, และช่องทางรายงานข้อผิดพลาด
- จัด simulation/role-play เพื่อตรวจสอบ workflow และระบุจุดเสี่ยง
- 6. เปิดใช้งานแบบกำกับดูแล (Supervised Rollout): เริ่มต้นด้วยการให้โมเดลเป็น assistive tool (ไม่รับผิดชอบการตัดสินใจสุดท้าย) โดยบุคลากรต้องยอมรับหรือปรับแก้ผลลัพธ์ก่อนนำไปใช้จริง
การตั้งค่าความปลอดภัยและการกำกับดูแล
การรักษาความปลอดภัยและความเป็นส่วนตัวเป็นข้อบังคับที่ต้องมีในทุกขั้นตอน:
- ใช้การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง (TLS, at-rest encryption)
- กำหนดสิทธิ์การเข้าถึงตามบทบาท (RBAC) และการยืนยันตัวตนแบบมัลติแฟคเตอร์
- ติดตั้งระบบตรวจจับการรั่วไหลของข้อมูลและการใช้งานที่ผิดปกติ
- เตรียมแผนรับมือกรณี adverse events และช่องทางแจ้งเหตุฉุกเฉิน
การประเมินผล (Metrics & Evaluation)
ระบุชุดตัวชี้วัดหลักและวิธีการวัดผลอย่างเป็นระบบ:
- Time Saved: วัดเวลาที่ใช้ต่อเคสก่อนและหลังใช้งาน (ตัวอย่าง: ลดจาก 30 นาทีเป็น 20 นาที = ประหยัด 33%)
- Accuracy / Clinical Concordance: เปรียบเทียบผลลัพธ์กับผู้เชี่ยวชาญ โดยใช้สัดส่วนความตรงกัน ≥95% เป็นเกณฑ์พิจารณา
- Safety / Adverse Events: จำนวนเหตุการณ์ที่เกี่ยวกับความผิดพลาดของข้อมูลหรือคำแนะนำที่เป็นอันตราย ต้องเป็น 0 หรืออยู่ภายในระดับที่ยอมรับได้ตามนโยบาย
- User Satisfaction: สำรวจความพึงพอใจของบุคลากรและผู้ป่วย (Net Promoter Score หรือคะแนนความพึงพอใจ ≥80%)
- Operational Metrics: อัตราการยอมรับข้อเสนอของโมเดลโดยผู้ใช้, latency เฉลี่ยต่อการตอบสนอง (เช่น <200 ms สำหรับคำขอภายในระบบ)
ใช้การทดสอบเชิงสถิติ (เช่น t-test หรือ chi-square) ในการเปรียบเทียบก่อน/หลัง และกำหนดระดับนัยสำคัญ (p < 0.05) สำหรับผลลัพธ์เชิงปริมาณ
เกณฑ์ตัดสินใจสำหรับการขยายผล (Go/No-Go Criteria)
หลังสิ้นสุดช่วง pilot ให้ทบทวนและตัดสินใจขยายผลโดยยึดเกณฑ์ดังต่อไปนี้เป็นหลัก:
- ยอมรับ หาก: KPI หลักทุกตัว (time saved, accuracy, satisfaction) บรรลุตามเป้าหมายหรือเหนือกว่า; ไม่มีเหตุการณ์เชิงลบที่ร้ายแรง; ต้นทุนในการดำเนินงานแสดง ROI ในระยะเวลาที่กำหนด (เช่น 12–24 เดือน)
- ปรับปรุงก่อนขยาย หาก: บาง KPI บรรลุ แต่มีประเด็นความปลอดภัยหรือความแม่นยำที่ต้องแก้ไข; ต้องปรับ workflow หรือเพิ่ม training
- ยกเลิก หาก: KPI หลักไม่เป็นไปตามเป้าหมายอย่างมีนัยสำคัญ, เกิดเหตุการณ์ที่เสี่ยงต่อผู้ป่วย, หรือค่าใช้จ่ายเกินกว่าความคุ้มค่า
Checklist สำหรับทีมแพทย์
- กำหนด use case และขอบเขตของการใช้งานอย่างชัดเจน
- ยอมรับกระบวนการยืนยันผลลัพธ์ (human-in-the-loop) ก่อนนำไปใช้จริง
- เข้าร่วมการฝึกอบรมและทดลองใช้งานแบบ simulation
- ลงทะเบียนข้อผิดพลาดหรือความไม่สอดคล้องผ่านช่องทางที่กำหนด
- ประเมินความแม่นยำจากตัวอย่างทดสอบและให้ feedback สำหรับการปรับปรุงโมเดล
- ยินยอมผู้ป่วยหากมีการใช้ข้อมูลผู้ป่วยในกระบวนการ (consent) ตามนโยบาย
Checklist สำหรับทีมไอทีและข้อมูล
- จัดเตรียมสภาพแวดล้อม sandbox และ production พร้อมระบบ rollback
- ดำเนินการ de-identification และตรวจสอบ compliance (PDPA/HIPAA)
- ติดตั้ง logging, monitoring, และ alerting สำหรับ latency, error rate, และ security events
- จัดการสิทธิ์การเข้าถึง (RBAC) และการยืนยันตัวตนแบบ MFA
- เตรียมแผน backup, disaster recovery และ audit trail
- จัดทำเอกสารการติดตั้ง, configuration และ runbook สำหรับการบำรุงรักษา
สรุปและข้อเสนอแนะเชิงปฏิบัติ
การทำ pilot ที่มีโครงสร้างและเกณฑ์ชัดเจนจะช่วยลดความเสี่ยงและเพิ่มโอกาสสำเร็จในการนำ ChatGPT มาใช้ในภาคการแพทย์ แนะนำให้เริ่มจาก use case ขนาดเล็ก มีการกำกับดูแลจากทีมคลินิกและทีมไอทีอย่างใกล้ชิด สร้างวง feedback loop เพื่อปรับปรุงโมเดลและ workflow อย่างต่อเนื่อง ก่อนตัดสินใจขยายผลโดยยึดข้อมูลเชิงปริมาณและความปลอดภัยเป็นเกณฑ์หลัก
บทสรุป
ChatGPT รุ่นใหม่มีศักยภาพสูงในการยกระดับประสิทธิภาพการดูแลสุขภาพทั้งในด้านการสนับสนุนการตัดสินใจทางคลินิก การคัดกรองผู้ป่วย การจัดทำบันทึกและสรุปรายงานทางการแพทย์ รวมถึงการช่วยลดภาระงานซ้ำซ้อนของบุคลากรทางการแพทย์ อย่างไรก็ดี ผลลัพธ์เชิงบวกเหล่านี้จะเกิดขึ้นได้จริงก็ต่อเมื่อมีการออกแบบเชิงระบบเพื่อจัดการความเสี่ยงด้านความปลอดภัยและจริยธรรม เช่น การตั้งมาตรการควบคุม (guardrails), การทำให้แบบจำลองมีความอธิบายได้ (explainability), การลดความลำเอียงของข้อมูล, การคุ้มครองข้อมูลส่วนบุคคลและการปฏิบัติตามข้อกำหนดด้านกฎระเบียบ งานวิจัยและโครงการนำร่องบางแห่งรายงานการลดเวลาบันทึกและภาระงานของผู้ให้บริการได้ในช่วงประมาณ 20–40% แต่ก็แสดงให้เห็นถึงความจำเป็นในการตรวจสอบความถูกต้องและความปลอดภัยอย่างต่อเนื่องก่อนการขยายใช้งานในวงกว้าง
การนำ ChatGPT เข้าสู่การปฏิบัติจริงอย่างประสบความสำเร็จต้องอาศัยการบูรณาการกับระบบข้อมูลสุขภาพมาตรฐาน (เช่น FHIR) การกำหนดมาตรวัดผลเชิงชัดเจน (เช่น เวลาในการให้บริการ ความแม่นยำของการวินิจฉัย อุบัติการณ์ปัญหาด้านความปลอดภัย) และการทดสอบผ่านโครงการนำร่องที่มีการควบคุมและมีมนุษย์คอยทวนสอบ (human-in-the-loop) ก่อนปรับใช้ในระดับโรงพยาบาลหรือระบบสุขภาพ ในภาพอนาคต หากมีการวางกรอบกำกับ ดูแล และวัดผลอย่างเข้มแข็ง เทคโนโลยีนี้อาจเปลี่ยนรูปแบบการดูแลผู้ป่วยให้เป็นไปอย่างมีประสิทธิภาพมากขึ้น รองรับการแพทย์เชิงป้องกันและการดูแลระยะไกลได้ดียิ่งขึ้น แต่ความสำเร็จจะขึ้นกับการสร้างความน่าเชื่อถือ ความโปร่งใส และการพิสูจน์ผลลัพธ์ทางคลินิกผ่านการทดลองเชิงควบคุมและการประเมินผลแบบต่อเนื่อง
📰 แหล่งอ้างอิง: Healthcare Dive



