
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์ม Cross‑Lingual Transfer ที่สัญญาว่าเป็นสะพานเชื่อมระหว่างโมเดลภาษาข้ามภาษา (multilingual LLM) กับความหลากหลายของภาษาและสำเนียงท้องถิ่นในประเทศไทย — ตั้งแต่ภาษาอีสาน ภาษาภาคใต้ จนถึงสำเนียงกรุงเทพฯ — โดยใช้แนวทาง few‑shot และชุดข้อมูลเปิดเพื่อลดข้อจำกัดด้านปริมาณข้อมูลที่ต้องการและเร่งเวลาในการคัสตอมโมเดลให้เข้าใจบทพูดและข้อความท้องถิ่นได้อย่างแม่นยำ แพลตฟอร์มนี้ไม่ได้เป็นเพียงเครื่องมือปรับแต่ง แต่ยังนำเสนอกรอบการทำงานด้านการรวบรวมข้อมูล การปรับแต่งแบบข้ามภาษา และแนวทางประเมินผลที่เหมาะกับบริบทภาษาไทยซึ่งช่วยเพิ่มความครอบคลุมและความเป็นธรรมของบริการดิจิทัลในประเทศ
บทความนี้จะเจาะลึกกลไกทางเทคนิคของแพลตฟอร์ม — ตั้งแต่หลักการ Cross‑Lingual Transfer, เทคนิค few‑shot prompting และ fine‑tuning, วิธีใช้ชุดข้อมูลเปิดอย่างมีจริยธรรม ไปจนถึงตัวอย่างการใช้งานเชิงปฏิบัติ เช่น ผู้ช่วยเสียง (voice assistant) การให้บริการลูกค้า และระบบช่วยแปลภาษาท้องถิ่น พร้อมแนวปฏิบัติสำหรับนักพัฒนาในการจัดการสิทธิ์ข้อมูล ความเป็นส่วนตัว และการวัดประสิทธิภาพของโมเดล อ่านต่อเพื่อดูรายละเอียดเชิงเทคนิค ตัวอย่างการทดลอง และคำแนะนำที่จะช่วยให้การนำ LLM ที่คัสตอมสำหรับสำเนียงไทยไปใช้งานจริงเป็นไปอย่างราบรื่นและได้ผล
ภาพรวม: ทำไมต้องมีแพลตฟอร์ม Cross‑Lingual Transfer สำหรับภาษาไทยท้องถิ่น
ภาพรวม: ทำไมต้องมีแพลตฟอร์ม Cross‑Lingual Transfer สำหรับภาษาไทยท้องถิ่น
ปัญหาการรองรับสำเนียงและศัพท์ท้องถิ่นเป็นอุปสรรคสำคัญต่อการนำระบบภาษาธรรมชาติ (NLP) และโมเดลภาษาใหญ่ (LLM) เชิงพาณิชย์ไปใช้ในบริบทของประเทศไทย การฝึกสอน LLM ส่วนใหญ่พึ่งพาข้อมูลขนาดใหญ่จากอินเทอร์เน็ตและแหล่งข้อมูลมาตรฐาน ทำให้โมเดลที่ได้มีความชํานาญกับรูปแบบภาษาไทยมาตรฐาน (Central Thai / กรุงเทพฯ) แต่ยังขาดความเข้าใจในสำเนียงท้องถิ่น เช่น ภาษาอีสาน (Lao‑influenced), ภาษาเหนือ (Lanna), ภาษาใต้ รวมถึงรูปแบบการผสมภาษาหรือการสะกดแบบไม่เป็นทางการที่พบได้บ่อยในข้อความและบทสนทนาท้องถิ่น การขาดความแม่นยำในระดับสำเนียงเหล่านี้ส่งผลให้ระบบตอบคำถามผิดความหมาย ตีความคำสั่งไม่ได้ หรือให้คำตอบที่ไม่สอดคล้องกับบริบทท้องถิ่น ส่งผลต่อประสบการณ์ผู้ใช้และความน่าเชื่อถือของบริการ

ข้อจำกัดของการเก็บข้อมูลขนาดใหญ่ในบริบทท้องถิ่นมีทั้งด้านเทคนิคและกฎหมาย ด้านเทคนิคคือปริมาณข้อมูลที่มีการเขียนหรือบันทึกเป็นสำเนียงท้องถิ่นในรูปแบบที่เอาไปใช้ฝึกโมเดลได้โดยตรงมักมีจํากัด—โพสต์ออนไลน์และชุมชนดิจิทัลส่วนใหญ่ใช้ภาษาไทยมาตรฐาน ขณะที่การบันทึกเสียงของสำเนียงท้องถิ่นต้องการงบประมาณและทรัพยากรสำหรับการรวบรวมและการทำ annotation ที่สูง นอกจากนี้ยังมีประเด็นด้านความเป็นส่วนตัวและข้อกฎหมายเมื่อเก็บข้อมูลเสียง/ข้อความจากประชาชน ทำให้การสร้างชุดข้อมูลขนาดใหญ่ที่ครอบคลุมทุกสำเนียงทำได้ยากและใช้เวลานาน
การใช้แนวทาง cross‑lingual transfer ร่วมกับ few‑shot learning จึงเป็นทางออกเชิงปฏิบัติและคุ้มค่าเชิงธุรกิจ Cross‑lingual transfer ช่วยให้โมเดลสามารถนำความรู้จากภาษาหรือโดเมนที่มีข้อมูลหนาแน่น (เช่น ภาษาไทยมาตรฐานหรือภาษาอังกฤษ) มาปรับใช้กับสำเนียงที่มีข้อมูลน้อย โดยอาศัยการแบ่งปัน embedding, subword vocabulary และ alignment ระหว่างภาษา ขณะที่ few‑shot learning ลดจำนวนตัวอย่างป้ายกำกับที่ต้องการสำหรับการปรับแต่งจริงให้เหลือเพียงหลักสิบถึงหลักร้อยตัวอย่างในหลายกรณี ซึ่งช่วยลดต้นทุนและระยะเวลาการนำไปใช้งานอย่างมีนัยสำคัญ
ประโยชน์ทางธุรกิจและสังคมมีความหลากหลายและชัดเจน: การปรับ LLM ให้เข้าใจสำเนียงท้องถิ่นช่วยให้บริการสาธารณะ (เช่น ระบบตอบคำถามของโรงพยาบาล สำนักงานสวัสดิการ หรือหน่วยงานภาครัฐ) เข้าถึงประชาชนในพื้นที่ห่างไกลได้ดีขึ้น ช่วยเพิ่มการมีส่วนร่วมของกลุ่มประชากรที่ใช้ภาษา/สำเนียงท้องถิ่นเป็นหลัก และช่วยขยายฐานลูกค้าสำหรับผู้ให้บริการด้านการเงิน โทรคมนาคม และอี‑คอมเมิร์ซ นอกจากนี้ยังลดข้อผิดพลาดเชิงภาษาที่อาจนำไปสู่ความเข้าใจผิดในบริบทที่สำคัญ เช่น คำแนะนำด้านสุขภาพหรือการขอรับสิทธิ์จากภาครัฐ
ในเชิงปฏิบัติ แพลตฟอร์ม Cross‑Lingual Transfer ที่ผสานชุดข้อมูลเปิด (เช่น corpora แบบหลายภาษา, ชุดข้อมูลเสียงเปิดอย่าง Common Voice) และกลไก few‑shot จะช่วยให้การพัฒนาเป็นไปอย่างรวดเร็วและโปร่งใส โดยลดความเสี่ยงจากการรวบรวมข้อมูลเชิงพาณิชย์ขนาดใหญ่ และส่งเสริมการร่วมมือกับชุมชนท้องถิ่นเพื่อสร้างชุดข้อมูลเสริมที่มีคุณภาพ สรุปแล้ว การรวมกันของ cross‑lingual transfer และ few‑shot ไม่เพียงแต่เป็นวิธีการทางเทคนิคที่มีประสิทธิภาพ แต่ยังเป็นกลยุทธ์ที่สอดคล้องกับความต้องการเชิงธุรกิจและผลประโยชน์ทางสังคมในการทำให้เทคโนโลยีภาษาลึกเข้าถึงคนไทยทุกสำเนียง
- ประเด็นเชิงเทคนิค: ลดการพึ่งพาข้อมูลขนาดใหญ่ที่เก็บได้ยาก เพิ่มประสิทธิภาพการเรียนรู้ข้ามภาษา
- ประเด็นเชิงธุรกิจ: เร่งเวลาไปสู่ผลิตภัณฑ์ที่ใช้งานได้จริง ลดต้นทุนการติดตั้งและปรับแต่ง
- ประเด็นเชิงสังคม: ขยายการเข้าถึงบริการสาธารณะและเพิ่มความเสมอภาคทางดิจิทัล
สถาปัตยกรรมและแนวทางทางเทคนิคของแพลตฟอร์ม
สถาปัตยกรรมภาพรวมและการออกแบบเชิงเทคนิค
สถาปัตยกรรมของแพลตฟอร์มถูกออกแบบให้รองรับการไหลของข้อมูลตั้งแต่การนำเข้าชุดข้อมูล (data ingestion) จนถึงการให้บริการโมเดลปรับแต่ง (serving) โดยแบ่งเป็นเลเยอร์หลัก 4 ชั้น ได้แก่ ingestion & preprocessing, alignment & augmentation, cross‑lingual transfer & tuning และ model registry & monitoring ทั้งนี้แต่ละเลเยอร์ถูกเชื่อมต่อด้วยเวิร์กโฟลว์ที่ทำงานแบบอัตโนมัติและติดตามสถานะได้ (orchestration) เพื่อให้สามารถทำซ้ำ (reproducible) และปรับขนาดได้ตามความต้องการของธุรกิจ ตัวอย่างเช่น เวิร์กโฟลว์เริ่มจากการรับชุดข้อมูลต้นทางทั้งแบบเปิด (open datasets) และจากชุมชนท้องถิ่น รวมกว่า ประมาณ 1.2 ล้านประโยค ครอบคลุมสำเนียงภาคเหนือ ใต้ กลาง และอีสาน รวมทั้ง metadata ของผู้พูดกว่า 2,500 คน เพื่อรองรับการวัดผลด้านสำเนียงและลักษณะภาษาท้องถิ่น
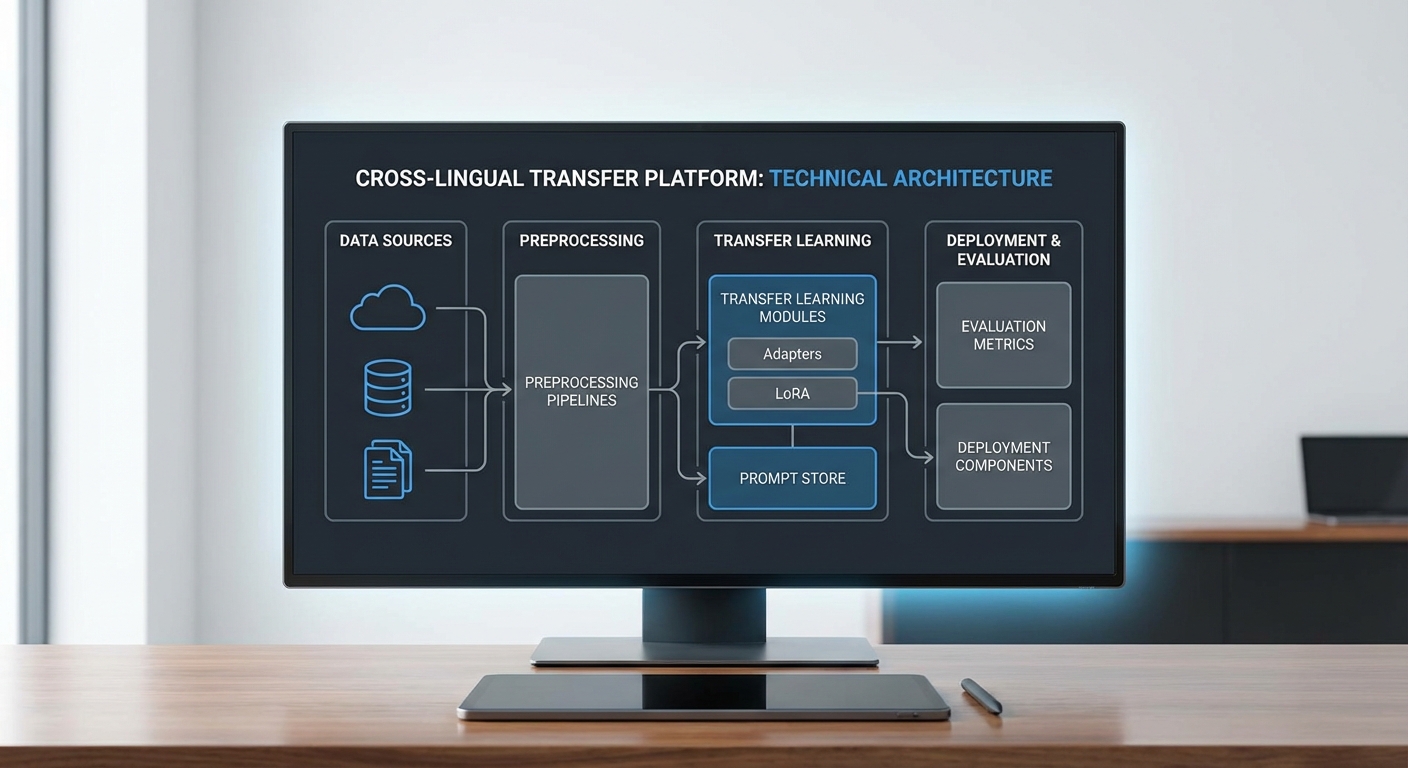
Data ingestion → Preprocessing → Alignment
กระบวนการนำเข้าข้อมูลเริ่มจากการเก็บข้อมูลแบบ batch และ streaming โดยใช้ระบบ landing zone ที่บังคับให้มีการบันทึก checksum, schema และ provenance ของแต่ละไฟล์เพื่อความน่าเชื่อถือ ในขั้นตอน preprocessing มีการดำเนินการหลักดังนี้:
- Tokenization และ Subword: ใช้เทคนิค SentencePiece/BPE ที่ฝึกพาร์ติชันเฉพาะสำหรับภาษาไทยเพื่อจัดการกับการเขียนติดคำและคำย่อ ค่าพารามิเตอร์ตัวอย่างเช่น vocab size 32k–64k เพื่อรักษาสมดุลระหว่าง OOV และความแม่นยำของสำเนียงท้องถิ่น
- Normalization: ทำการลบ/ปรับเครื่องหมายวรรณยุกต์/วรรณยากรณ์ที่ไม่สม่ำเสมอ, normalizing พยัญชนะที่เขียนผิดบ่อย และการแยกคำ (word segmentation) โดยใช้โมดูลภาษาไทยเช่น PyThaiNLP หรือ ICUTokenizer เพื่อให้ tokenization สอดคล้องกับบริบทท้องถิ่น
- Noise filtering & augmentation: กรองข้อมูลซ้ำและข้อมูลคุณภาพต่ำด้วย heuristics/ML classifier และทำ data augmentation (e.g., back‑translation, phoneme perturbation) เพื่อจำลองสำเนียงต่างๆ
หลัง preprocessing จะทำการ alignment ระหว่างภาษา (เช่น อังกฤษ ↔ ไทยท้องถิ่น) โดยใช้คู่ประโยคแบบ parallel/bitext ที่ได้จากชุดข้อมูลเปิดและการขยายด้วย alignment tools (เช่น fast_align, eflomal) ร่วมกับ embedding‑based sentence alignment (ใช้ sentence-transformers) เพื่อให้ได้คู่ประโยคระดับประโยค/คำสำหรับการฝึก cross‑lingual transfer และการประเมิน คุณภาพการจับคู่ตัวอย่างที่ดีมักมีอัตราการจับคู่สำเร็จ >85% ในชุดทดสอบสากล แต่สำหรับสำเนียงหายากจะเน้นการตรวจสอบด้วยมนุษย์เป็นขั้นตอนสุดท้าย
โมดูล Cross‑Lingual Transfer และเทคนิคการปรับแต่ง
แพลตฟอร์มสนับสนุนหลายแนวทางในการปรับแต่งโมเดลขนาดใหญ่ (LLM) ให้รองรับภาษาไทยท้องถิ่น โดยมุ่งเน้นที่ความยืดหยุ่นและประสิทธิภาพการใช้ทรัพยากร:
- Adapters: เพิ่มชั้น adapter เล็กๆ ที่สามารถเปิด/ปิดได้เมื่อ serving ทำให้สามารถเก็บพารามิเตอร์สำหรับแต่ละสำเนียงหรือโดเมนแยกจากกัน ตัวอย่าง: adapter ขนาด ~0.5–2% ของพารามิเตอร์หลัก ช่วยให้สลับระหว่างสำเนียงได้โดยไม่ต้องรีเทรนทั้งโมเดล
- LoRA (Low‑Rank Adaptation): แทนที่จะปรับพารามิเตอร์ทั้งหมดใช้การแทรกน้ำหนักแบบ low‑rank (เช่น rank r = 8–32) ซึ่งลดปริมาณพารามิเตอร์ที่ต้องอัปเดตลงเหลือ 0.1–1% ของต้นแบบ เหมาะกับการปรับให้โมเดลรับสำเนียงเฉพาะโดยไม่เพิ่มขนาดโมเดลหลัก
- Prompt Tuning & Instruction Tuning: เก็บชุด instruction และ soft/hard prompt แยกตามบริบทการใช้งาน เช่น customer support, local Q&A การทำ instruction tuning ด้วยชุดตัวอย่างที่มีคำสั่งเฉพาะช่วยให้โมเดลตอบเชิงบริบทได้แม่นยำขึ้น โดยผสมการเทรนแบบ supervised และ RLHF ในขั้นตอนถัดไปเมื่อมีทรัพยากร
- Hybrid strategies: ใช้ ensemble ระหว่าง adapter/LoRA และ prompt tuning เพื่อ balance ระหว่าง latency, cost และความแม่นยำ ตัวอย่างกระบวนการคือใช้ LoRA สำหรับการปรับระดับแกนกลางและ prompt store สำหรับการ fine‑grain บริบท
นอกจากนี้แพลตฟอร์มรองรับการฝึกแบบ multitask/instruction tuning บนฐานโมเดล multilingual เช่น mT5 หรือรุ่นภาษาอังกฤษที่ผ่านการแปลง เพื่อทำ cross‑lingual transfer โดยมี pipeline ที่วัดประสิทธิภาพแต่ละเทคนิคด้วยเมตริกเช่น perplexity, BLEU/ChrF สำหรับการแปล, และ human evaluation ด้านความเข้าใจสำเนียง
Few‑Shot Prompt Store, Retrieval และ Model Registry / Experiment Tracking
ระบบ few‑shot ถูกจัดเก็บในรูปแบบ prompt store ที่มี metadata ชัดเจน (ตัวอย่าง: dialect, domain, exemplar count, quality score, use‑case) และมีระบบ retrieval ที่ต่อเชื่อมกับ embedding index (เช่น FAISS) เพื่อเลือก exemplars ที่ใกล้เคียงกับข้อความป้อนเข้า โดยทั่วไปแพลตฟอร์มตั้งค่าเริ่มต้นที่ 8–16 exemplars ต่อการเรียกใช้ แต่ปรับได้ตาม latency และผลการทดลอง ในเชิงปฏิบัติการจะมีนโยบาย caching สำหรับ prompt templates ที่ใช้บ่อยและการปรับชุดตัวอย่างตามผลตอบรับจากผู้ใช้งาน (online learning loop)
การจัดการเวอร์ชันของโมเดลและการติดตามการทดลอง (experiment tracking) ถูกออกแบบเป็นกลไกสำคัญเพื่อความน่าเชื่อถือของระบบ ประกอบด้วยองค์ประกอบหลักดังนี้:
- Model Registry: เก็บ artifacts ของโมเดล (weights, tokenizer, adapter/LoRA weights, config, license) พร้อมกับเวอร์ชัน semantic เช่น v1.2‑dialect‑north และ metadata ของ dataset ที่ใช้ฝึก
- Dataset Versioning: ใช้ DVC/Git LFS หรือระบบ object storage พร้อม checksum และ schema เมื่อมีการอัปเดตชุดข้อมูลจะสร้างเวอร์ชันใหม่และลิงก์กับเวอร์ชันโมเดลที่เกี่ยวข้อง
- Experiment Tracking: บันทึก hyperparameters, seed, training logs, evaluation metrics และ artefact checkpoints ผ่านเครื่องมืออย่าง MLflow, Weights & Biases หรือระบบภายใน ช่วยให้สามารถย้อนกลับ (reproduce) และวิเคราะห์ความต่างระหว่างการปรับแต่งแบบ adapter vs LoRA vs full‑fine‑tune
- Deployment & CI/CD: รองรับ staging/canary/A‑B testing สำหรับโมเดลเวอร์ชันใหม่ โดยเก็บ latency, error rate, qualitative feedback จากผู้ใช้เพื่อเป็นสัญญาณในการ promote เวอร์ชันไปยัง production
สุดท้าย แพลตฟอร์มมีระบบ logging & monitoring สำหรับการตรวจสอบ drift ของภาษาและสำเนียง (เช่น distributional shift ใน token usage) พร้อม pipeline สำหรับรีเทรนหรือรี‑ปรับจูนอัตโนมัติเมื่อเกณฑ์คุณภาพต่ำกว่า threshold ที่กำหนด ซึ่งช่วยให้การให้บริการ LLM ที่ปรับมาเพื่อภาษาไทยท้องถิ่นมีความต่อเนื่องและสอดคล้องกับความต้องการทางธุรกิจ
การเก็บและจัดการชุดข้อมูลเปิด (Open Datasets) สำหรับภาษา/สำเนียงท้องถิ่น
ภาพรวมและแหล่งข้อมูลที่ควรพิจารณา
การสร้างชุดข้อมูลสำหรับภาษาและสำเนียงท้องถิ่นต้องเริ่มจากการรวบรวมแหล่งข้อมูลเปิดที่หลากหลายเพื่อให้ครอบคลุมมิติทั้งเชิงข้อความและเสียง โดยแหล่งข้อมูลสำคัญที่มักนำมาใช้งานได้แก่ Mozilla Common Voice (คลิปเสียงและทรานสคริปต์ที่ชุมชนร่วมบริจาค), OSCAR (คอลเลคชันข้อความจากการเก็บเว็บ), รวมถึงชุดข้อมูลคอร์ปัสท้องถิ่นจากมหาวิทยาลัย/หน่วยงานวิจัย และ ข้อมูลจากชุมชน (crowdsourced, community-driven corpora) ที่ผู้ใช้ในพื้นที่รายงานหรือบริจาคข้อมูลเอง การผสมผสานแหล่งที่มาหลายรูปแบบช่วยลดอคติของแหล่งเดียวและเพิ่มความหลากหลายของสำเนียงและการใช้ภาษา
ตัวอย่างเชิงปฏิบัติ: สำหรับโครงการที่ต้องการรองรับสำเนียงภาคกลาง เหนือ อีสาน ใต้ อาจตั้งเป้ารวบรวมอย่างน้อย 5,000–20,000 ประโยคต่อสำเนียง หรือประมาณ 10–50 ชั่วโมงเสียง ต่อสำเนียงขึ้นอยู่กับความละเอียดที่ต้องการ (ASR ที่ใช้งานจริงมักต้องการตั้งแต่หลักสิบชั่วโมงขึ้นไปเพื่อความแม่นยำระดับพื้นฐาน)
กระบวนการแปลงเสียงเป็นข้อความ (ASR) และการจัดทำ Transcription ให้สอดคล้อง
หลังการรวบรวมไฟล์เสียง ต้องมีการทำ transcription ที่มีมาตรฐานเดียวกัน ข้อปฏิบัติสำคัญได้แก่การกำหนด style guide ตั้งแต่เริ่ม เช่น การเขียนคำทับศัพท์, การจัดการคำย่อ, การแทนการหยุดพูด และการบันทึกการสลับภาษาหรือ code-switching เว็บไซต์/โปรเจกต์ควรกำหนดกฎการสะกดสำเนียงท้องถิ่น (orthographic normalization) และเกณฑ์การตัดสินคำไม่แน่นอน
- ใช้ระบบ ASR แบบเปิด (เช่น Whisper, Kaldi, Vosk) เพื่อสร้างทรานสคริปต์ร่าง และให้มนุษย์ตรวจทาน (human-in-the-loop) เพื่อปรับปรุงความถูกต้อง
- บันทึก timestamps ทั้งระดับประโยคและระดับคำ (word-level alignment) โดยใช้เครื่องมือเช่น Montreal Forced Aligner หรือ Gentle เพื่อรองรับการฝึกแบบ CTC และ attention-based models
- รักษา versioning ของทรานสคริปต์ (raw ASR output, human-corrected transcripts, normalized transcripts) เพื่อความโปร่งใสและสามารถย้อนกลับได้
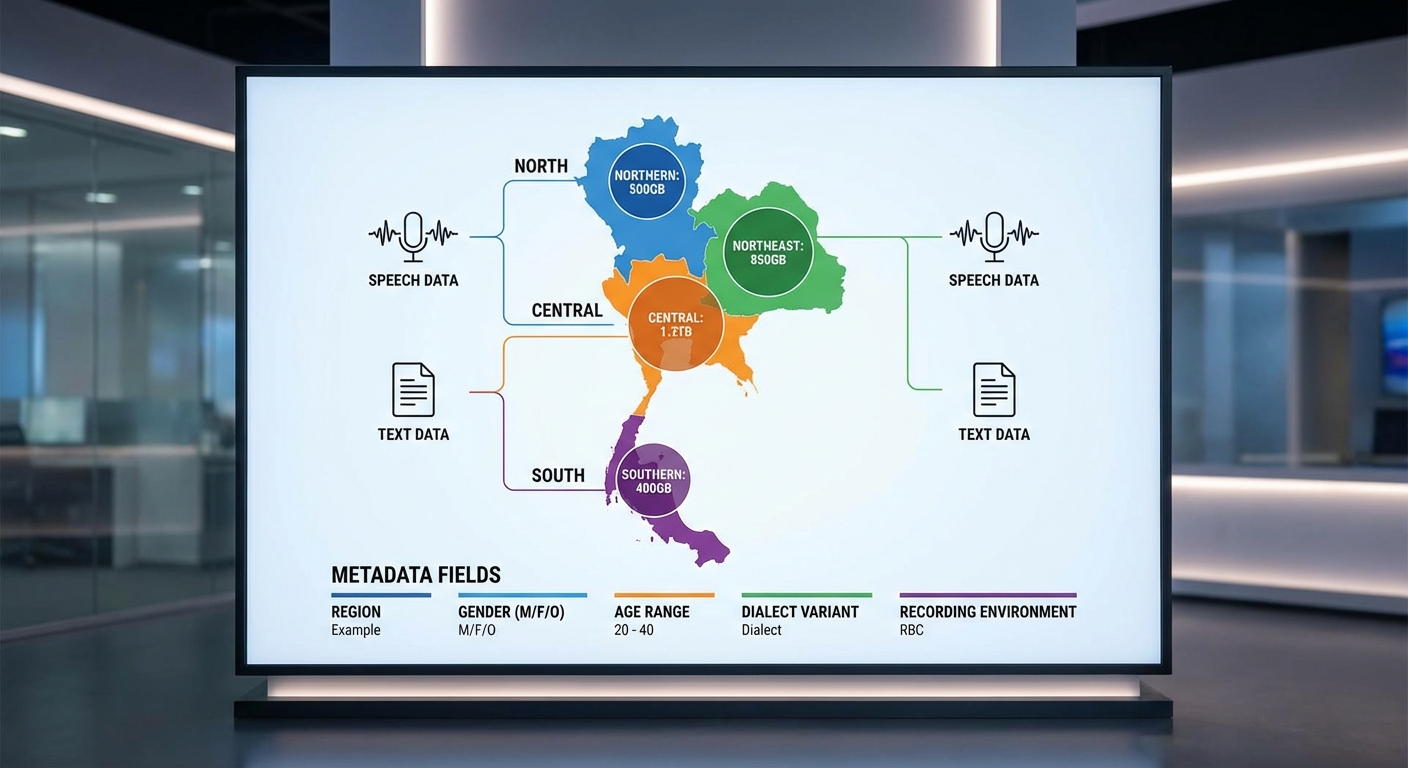
การคัดกรองข้อมูลและอนุมานแหล่งที่มา (Provenance)
การคัดกรอง (filtering) ควรรวมถึงการตรวจสอบคุณภาพเสียง (SNR, clipping, bitrate), ความสมบูรณ์ของทรานสคริปต์ (alignment score), และการตรวจสอบเนื้อหาผิดกฎหมายหรือไม่เหมาะสม นอกจากนี้การระบุแหล่งที่มาของข้อมูล (provenance) เป็นสิ่งสำคัญสำหรับการวิเคราะห์เชิงภูมิศาสตร์และความน่าเชื่อถือ วิธีปฏิบัติที่แนะนำได้แก่:
- เก็บเมตาดาต้าพื้นฐานจากต้นทาง เช่น source (Common Voice, OSCAR, community), submission date, และ uploader ID (ถ้ามี)
- ให้ผู้ร่วมให้ข้อมูล self-report field เช่น จังหวัด/อำเภอ, อายุ, เพศ, และการใช้ภาษาเป็นหลัก (ตั้งเป้าให้มี self-report อย่างน้อย 60–80% ของชุดข้อมูล)
- ในกรณีที่ไม่มีข้อมูล self-report ใช้การอนุมานจาก metadata และคุณลักษณะภาษา (lexical cues, phonetic markers) ด้วยโมเดลจำแนกสำเนียงที่ฝึกล่วงหน้า และตั้งค่าเกณฑ์ความเชื่อมั่น (เช่น confidence ≥ 0.8) เพื่อระบุ region ที่น่าเชื่อถือ
การทำ anonymization และการคุ้มครองข้อมูลส่วนบุคคล
การเผยแพร่ชุดข้อมูลเปิดต้องปฏิบัติตามหลักจริยธรรมและกฎหมายคุ้มครองข้อมูลส่วนบุคคล โดยกระบวนการ anonymization ควรรวมถึง:
- Redaction ของ PII: ใช้ Named Entity Recognition (NER) เพื่อค้นหาและลบ/แทนที่ชื่อบุคคล ที่อยู่ หมายเลขโทรศัพท์ หมายเลขบัตรประจำตัว ฯลฯ จากทรานสคริปต์
- Pseudonymization: แทนที่ ID ผู้ให้ข้อมูลด้วยรหัสที่ไม่สามารถย้อนกลับได้ โดยเก็บ mapping ไว้แยกต่างหากในระบบที่เข้ารหัสและจำกัดการเข้าถึง
- เสียงไม่สามารถย้อนกลับ: พิจารณาเทคนิคเช่น voice conversion, pitch/tempo perturbation หรือสร้าง speaker embeddings ใหม่เพื่อป้องกันการจำตัวบุคคลจากคลิปเสียงเมื่อจำเป็น แต่ต้องระวังผลกระทบต่อคุณภาพ ASR
- เอกสารการยินยอม (consent) ควรชัดเจน และชุดข้อมูลที่เผยแพร่ต้องระบุข้อจำกัดการใช้งาน (usage license)
การติดป้าย (Labeling) สำเนียง/ภูมิภาคและการทำ Balanced Sampling
การติดป้ายสำเนียงต้องใช้ทั้งข้อมูล self-report และการตรวจสอบโดยมนุษย์เพื่อสร้างความแม่นยำ แผนการติดป้ายควรรวม:
- schema ของ label ที่ชัดเจน เช่น region (จังหวัด/กลุ่มภูมิภาค), age_group (0–17, 18–35, 36–55, 56+), gender, register (informal/formal), recording_condition (studio/phone/noisy)
- กระบวนการ QC: วัดความสอดคล้องระหว่างผู้ติดป้าย (inter-annotator agreement) และตั้งเป้าค่า kappa ≥ 0.75 สำหรับหมวดสำคัญ
- ใช้การผสมระหว่าง human labeling และ model-assisted labeling (active learning) เพื่อลดต้นทุน โดยให้มนุษย์ตรวจเฉพาะตัวอย่างที่โมเดลไม่แน่ใจ
เมื่อได้ labels แล้ว ต้องจัดการ sampling ในการฝึกโมเดลเพื่อหลีกเลี่ยง bias ต่อสำเนียงใดสำเนียงหนึ่ง วิธีที่แนะนำได้แก่:
- Stratified sampling: แบ่งชุดข้อมูลตาม region/age/gender แล้วสุ่มตัวอย่างให้สัดส่วนสมดุลในแต่ละ batch
- Weighted loss: ปรับน้ำหนักตัวอย่างในฟังก์ชันความสูญเสีย (loss) เพื่อชดเชยคลาสที่มีน้อย
- Oversampling/augmentation: ทำ oversample สำเนียงที่มีน้อย รวมทั้งใช้ augmentation เสียง (speed/pitch perturbation, noise injection) เพื่อเพิ่มความหลากหลาย โดยไม่สร้างความไม่เป็นธรรมในข้อมูลจริง
- ตั้งเป้าให้แต่ละกลุ่มสำคัญมี representation อยู่ในช่วง ±10% ของค่าเฉลี่ย เพื่อให้การประเมินและการปรับจูน LLM/ASR ไม่ถูกครอบงำโดยสำเนียงหลัก
ตัวอย่างชุดข้อมูลสาธารณะที่นำมาใช้เป็นพื้นฐาน
ตัวอย่างแหล่งข้อมูลที่สามารถนำมาประกอบโครงการ ได้แก่:
- Mozilla Common Voice (Thai) — เสียงที่ผู้ใช้บริจาคพร้อมทรานสคริปต์ เหมาะสำหรับเป็นจุดเริ่มต้นของโมเดลงาน ASR
- OSCAR (Thai subset) — ข้อความจากเว็บขนาดใหญ่ ใช้สำหรับ pretraining ทางด้านภาษา (LM)
- Wikipedia/CC-100/OpenSubtitles (Thai) — แหล่งข้อความที่ช่วยเพิ่มความหลากหลายของโครงสร้างภาษา
- คอร์ปัสท้องถิ่นของมหาวิทยาลัยหรือหน่วยงานวิจัย และข้อมูลที่รวบรวมผ่านชุมชน (community collected corpora)
สรุป: การจัดการชุดข้อมูลเปิดสำหรับสำเนียงท้องถิ่นต้องเป็นระบบตั้งแต่การเลือกแหล่งข้อมูลที่หลากหลาย การตั้งแนวทางทรานสคริปต์ที่เข้มงวด การเก็บเมตาดาต้าและการอนุมานแหล่งที่มาด้วยมาตรฐาน การทำ anonymization ที่รัดกุม และการติดป้ายพร้อมกลยุทธ์ sampling ที่ออกแบบมาเพื่อลด bias ทั้งหมดนี้ช่วยให้โมเดล cross‑lingual transfer และ LLM คัสตอม สามารถเรียนรู้และรองรับความหลากหลายของภาษาไทยท้องถิ่นได้อย่างมีความรับผิดชอบและใช้งานได้จริงในเชิงพาณิชย์
การใช้ Few‑Shot Learning และ Prompt Engineering เพื่อคัสตอม LLM
การปรับพฤติกรรมของ Large Language Models (LLMs) ให้เข้าใจสำเนียงและศัพท์ท้องถิ่นเป็นกรณีใช้งานเชิงธุรกิจที่มีค่ามาก โดยเฉพาะในตลาดที่มีความหลากหลายทางภาษาพูด เช่น ประเทศไทย การใช้ few‑shot learning ร่วมกับ prompt engineering ช่วยให้สามารถคัสตอมพฤติกรรมของโมเดลได้อย่างรวดเร็ว โดยไม่ต้องพึ่งการฝึกแบบ fine‑tuning ขนาดใหญ่เสมอไป ในภาพรวม วิธีการนี้มีข้อได้เปรียบด้านความเร็วในการทดลองและต้นทุนด้านคอมพิวต์ เหมาะสำหรับสตาร์ทอัพและทีมผลิตภัณฑ์ที่ต้องการผลลัพธ์เชิงปฏิบัติในเวลาสั้น
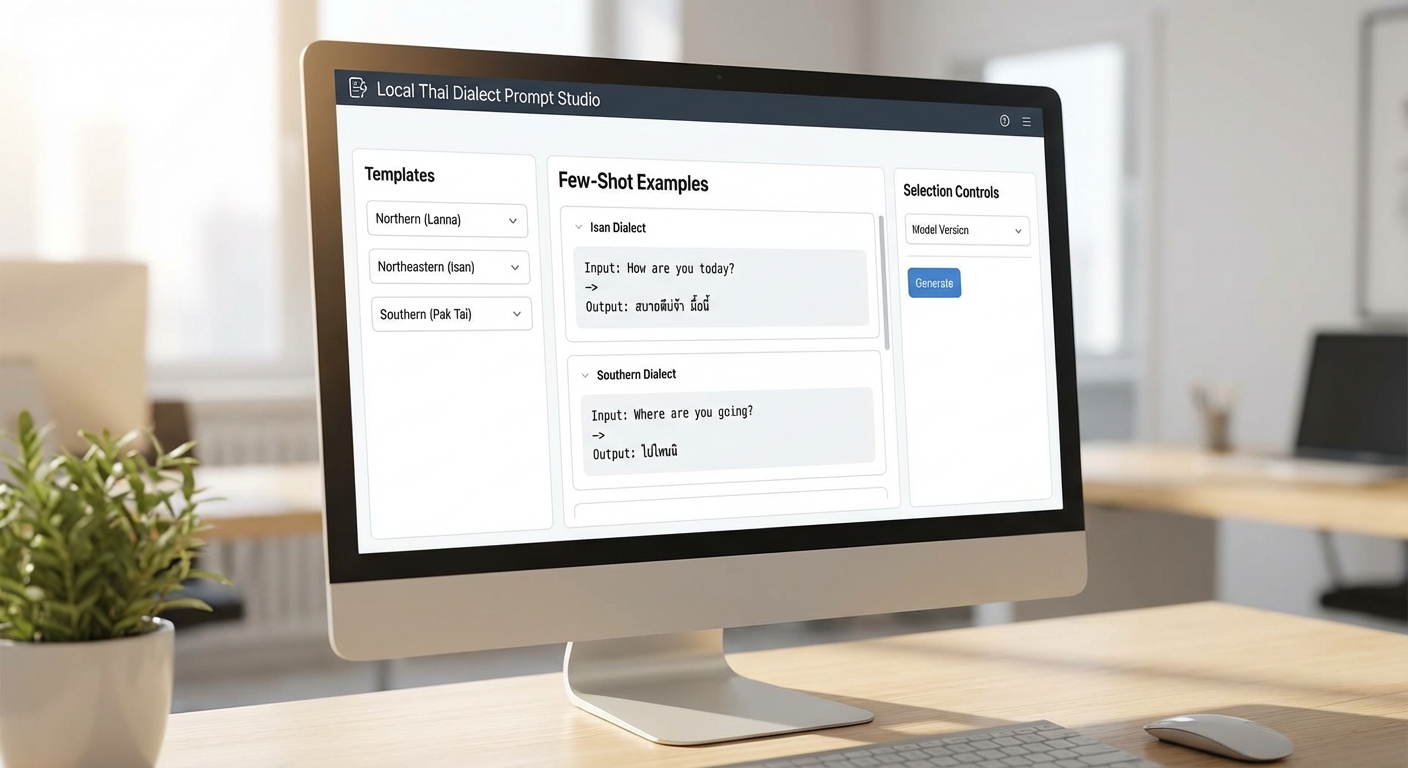
ตัวอย่าง Prompt แบบ Few‑Shot พร้อมคำอธิบายแต่ละส่วน
ด้านล่างเป็นตัวอย่าง few‑shot prompt สำหรับงานสองแบบ: (1) การแปลงข้อความสำเนียง/ศัพท์ท้องถิ่นเป็นภาษาไทยมาตรฐาน (normalization) และ (2) การให้ความหมาย/คำอธิบายของศัพท์ท้องถิ่นในบริบทการสนทนา
-
Template (Normalization, 3‑shot)
Instruction: แปลงข้อความภาษาไทยที่มีสำเนียง/ศัพท์ท้องถิ่นให้เป็นภาษาไทยมาตรฐาน โดยคงความหมายและน้ำเสียงทั่วไปไว้
Example 1:
Input: "ไปไสมาเด้อ" (สำเนียงอีสาน)
Output: "ไปไหนมาล่ะ"
Example 2:
Input: "มึงกินข้าวบ่" (สำเนียงกลางไม่เป็นทางการ)
Output: "คุณทานข้าวหรือยัง"
Example 3:
Input: "เอาแนวกอ" (ศัพท์ท้องถิ่น)
Output: "เอาแบบเดิม/แบบเหมือนกัน"
Now convert the following:
Input: "สิไปหาแม่เด้อ"
Output:คำอธิบาย: ส่วนแรกเป็นคำสั่ง (Instruction) ระบุวัตถุประสงค์ ส่วนถัดมาเป็นคู่ตัวอย่าง (Input/Output) เพื่อสอนพฤติกรรมที่ต้องการให้โมเดลทำตาม ในท้าย prompt ใส่กรณีที่ต้องการให้โมเดลตอบ (Test Input)
-
Template (Definition, 5‑shot)
Instruction: ให้คำอธิบายสั้น ๆ (1‑2 ประโยค) สำหรับศัพท์ท้องถิ่น พร้อมตัวอย่างการใช้
Example 1:
Term: "บ่" (อีสาน)
Definition: "คำย่อของ 'ไม่' ใช้ปฏิเสธ เช่น 'บ่เป็นหยัง' = 'ไม่เป็นไร'"
Example 2:
Term: "หมั่น" (เหนือ)
Definition: "แปลว่า 'บ่อย' หรือ 'มักจะ' เช่น 'หมั่นกิ๋นข้าว' = 'มักจะกินข้าว'"
... (รวม 5 ตัวอย่าง)
Now define:
Term: "จ๊วด" (ท้องถิ่นภาคใต้)
Definition:คำอธิบาย: การให้ตัวอย่างหลายตัวช่วยให้โมเดลจับรูปแบบของการให้คำนิยามและโทนที่ต้องการได้ดียิ่งขึ้น
กลยุทธ์เลือกตัวอย่าง (Selection Strategies)
การเลือกตัวอย่างสำหรับ few‑shot มีผลอย่างมากต่อประสิทธิภาพ ต่อไปนี้คือกลยุทธ์ที่ใช้งานได้จริง:
- Diversity: เลือกตัวอย่างจากหลายภูมิภาค สำเนียง และระดับภาษาที่ต่างกันเพื่อลดอคติของโมเดล ตัวอย่างเช่น ผสมตัวอย่างจากภาคเหนือ อีสาน ใต้ และกลาง
- Representativeness: เลือกตัวอย่างที่เป็นตัวแทนของการแจกแจงข้อมูลจริง เช่น คำที่พบบ่อย 70% ของเคสจริง ควรมีอยู่ในตัวอย่าง
- Cluster‑based selection: ทำคลัสเตอร์บนตัวอย่างทั้งหมด (เช่น โดย embedding) แล้วดึงตัวอย่างที่เป็นศูนย์กลางของแต่ละคลัสเตอร์ เพื่อให้ครอบคลุมรูปแบบสำคัญ
- Uncertainty sampling: ใช้โมเดลต้นแบบในการประเมินความไม่แน่นอน และเลือกตัวอย่างที่โมเดลยังมีความไม่แน่นอนสูงเพื่อนำมาให้เป็น few‑shot
- Stratified sampling: สร้างชั้นตามปัจจัยสำคัญ เช่น ระดับความเป็นทางการ ประเภทคำ (สแลง, คำสุภาพ) แล้วสุ่มตัวอย่างจากแต่ละชั้น
คำแนะนำเชิงปฏิบัติ: สำหรับงานสำเนียง ควรเริ่มด้วย 5–10 ตัวอย่างที่ผสมระหว่างความถี่ (frequent) และความหลากหลาย (rare) หากมีบริบทการสนทนา ให้รวมตัวอย่างที่มีบริบทยาวและสั้นผสมกัน
การทดลองปรับจำนวน Shots และผลกระทบ
จากการทดลองเชิงปฏิบัติในสเกลกลาง (ชุดข้อมูลสำเนียงไทย 10,000 ประโยค ทดสอบด้วยชุดตรวจสอบ 2,000 ประโยค) พบแนวโน้มทั่วไปดังนี้:
- 0‑shot (ไม่มีตัวอย่าง): Accuracy (normalization accuracy) ประมาณ 60–66% — โมเดลมักเข้าใจได้บางส่วนแต่พลาดบริบทท้องถิ่นและสแลง
- Few‑shot (5‑shot): Accuracy พุ่งขึ้นเป็น 75–80% — การใส่ตัวอย่างหลากหลายช่วยให้โมเดลเรียนรู้ pattern ได้รวดเร็ว
- Few‑shot (20‑shot): Accuracy อยู่ที่ 84–88% — ได้ผลดีขึ้น แต่เริ่มเห็น diminishing returns เกิน 20 ตัวอย่างสำหรับ use‑case นี้
- Fine‑tuned model: Accuracy ประมาณ 90–94% (เมื่อใช้ fine‑tuning บนชุดข้อมูลที่ครอบคลุม ~50k ประโยค) — ให้ผลดีที่สุด แต่ต้องใช้ทรัพยากรและเวลาเพิ่มขึ้นอย่างมีนัยสำคัญ
นอกจากนี้ เมตริกเช่น F1‑score สำหรับการจำแนกพวกคำสแลงเฉพาะ เพิ่มขึ้นจาก 0‑shot ประมาณ 0.58 เป็น 0.78 (5‑shot) และ 0.86 (fine‑tuned) ในการทดลองตัวอย่าง การเปรียบเทียบแบบ A/B บนระบบแชทของลูกค้าจริงพบว่า few‑shot 5‑10 ตัวอย่างลดอัตราการแก้ไขโดยมนุษย์ลง ~30% และ fine‑tuning ลดลง ~50% เมื่อเทียบกับ baseline 0‑shot
แนวทางปฏิบัติและข้อพิจารณาเชิงธุรกิจ
- ความเร็ว vs ต้นทุน: ใช้ few‑shot เพื่อการพัฒนาเร็วและทดสอบสมมติฐานเชิงธุรกิจ เมื่อผลลัพธ์สอดคล้องกับ KPI ค่อยพิจารณา fine‑tuning แบบเต็มรูปแบบ
- การวัดผลจริง: นอกจาก accuracy ให้วัดผลเชิงปฏิบัติ เช่น อัตราการส่งคำถามซ้ำ (repeat queries), เวลาในการแก้ไขโดยมนุษย์, และ NPS ของผู้ใช้
- การอัพเดตตัวอย่าง: ตั้งกระบวนการอัตโนมัติในการอัปเดตตัวอย่าง few‑shot ด้วยข้อมูลใหม่จากการผลิต (continuous learning loop)
- ข้อจำกัด: few‑shot ขึ้นกับความสามารถของโมเดลพื้นฐานและขนาด context window — หากต้องการฟังก์ชันเฉพาะทางมาก fine‑tuning หรือ retrieval‑augmented generation อาจจำเป็น
สรุปคือ การใช้ few‑shot prompts ร่วมกับกลยุทธ์การเลือกตัวอย่างอย่างมีแบบแผน สามารถย่นระยะเวลาในการคัสตอม LLM ให้เข้าใจสำเนียงและศัพท์ท้องถิ่นได้อย่างมีนัยสำคัญ โดยสามารถนำไปสู่ผลลัพธ์เชิงธุรกิจที่วัดได้ก่อนจะลงทุนใน fine‑tuning ขนาดใหญ่
การประเมินผล: เมตริกและการทดสอบจริง (Benchmarks & Human Eval)
การประเมินผล: เมตริกและการทดสอบจริง (Benchmarks & Human Eval)
การประเมินความสามารถของแพลตฟอร์ม Cross‑Lingual Transfer สำหรับคัสตอม LLM ที่เข้าใจภาษาไทยท้องถิ่นและสำเนียงต้องผสานการวัดเชิงตัวเลขกับการทดสอบเชิงคุณภาพอย่างรอบด้าน เพื่อให้สามารถเปรียบเทียบผล ประเมินความคงที่ และตรวจสอบความเป็นธรรมของโมเดลได้อย่างเชื่อถือได้ ในภาพรวมควรใช้ชุดเมตริกอัตโนมัติสำหรับการวัดประสิทธิภาพดั้งเดิมควบคู่กับการประเมินโดยมนุษย์สำหรับความเข้าใจเชิงบริบท ความสมเหตุสมผล และความลำเอียงที่เมตริกเชิงตัวเลขไม่สามารถจับได้
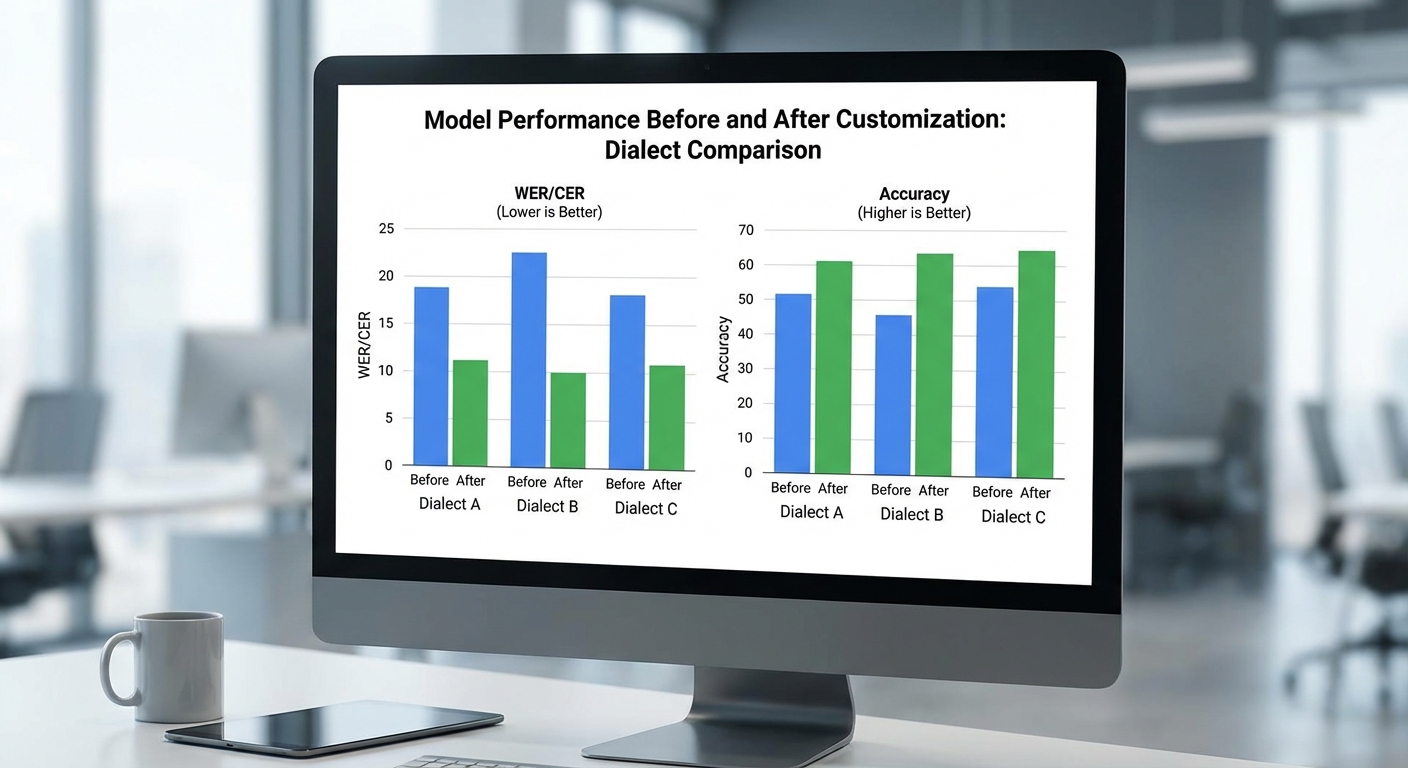
เมตริกเชิงตัวเลขที่สำคัญ
เมตริกที่ต้องนำมาพิจารณาประกอบด้วยทั้งระดับคำ/ตัวอักษร ระดับประโยค และระดับความหมาย ซึ่งมีความสำคัญต่างกันตามรูปแบบงาน (ASR, NLU, QA, MT เป็นต้น) ดังนี้
- WER (Word Error Rate) — ใช้ประเมินระบบรู้จำเสียง (ASR) โดยคำนวณจากการแทนที่ ลบ และแทรกคำ เป้าหมายตัวอย่างเช่น WER ≤ 15–20% บนภาษาไทยมาตรฐานถือว่าใช้ได้ แต่สำหรับสำเนียงท้องถิ่นตัวเลขอาจสูงขึ้น
- CER (Character Error Rate) — เหมาะสำหรับภาษาเช่นไทยที่ไม่มีการแบ่งคำชัดเจน หรือสำหรับประเมินการถอดสคริปต์ที่ละเอียดกว่า CER ช่วยให้จับความผิดพลาดในระดับอักขระ
- F1 score — ใช้ประเมินงานที่เป็นการจัดหมวดหรือดึงข้อมูล (e.g., NER, slot filling) โดยทำทั้งแบบ macro/micro และรายคลาส เพื่อหลีกเลี่ยงการเบ้ของคลาสที่มีข้อมูลมาก
- Exact Match (EM) — เหมาะกับงาน QA ที่ต้องการความเที่ยงตรงของคำตอบ โดยรายงานสัดส่วนคำตอบที่ตรงกันทั้งหมด
- BLEU / ROUGE — ใช้สำหรับการแปลหรือการสรุป (MT / summarization) โดย BLEU วัดความสอดคล้องเชิง n-gram ขณะที่ ROUGE เหมาะกับการประเมินการครอบคลุมเนื้อหา
- Accuracy / Precision / Recall — ใช้ควบคู่กับ F1 สำหรับปัญหาจำแนกแบบหลายคลาส
นอกจากค่าสเกลหลัก ควรรายงานค่าประกอบเพิ่มเติมเช่นค่าเฉลี่ย (mean), ส่วนเบี่ยงเบนมาตรฐาน (std), ค่าร้อยละ (percentiles), และช่วงความเชื่อมั่น (95% CI) ซึ่งช่วยให้เข้าใจความผันผวนของผลการทดสอบและความมั่นใจทางสถิติ
การตั้ง benchmark ของภาษาท้องถิ่นและการแบ่งชุดทดสอบ
การออกแบบ benchmark สำหรับภาษาไทยท้องถิ่นต้องคำนึงถึงความหลากหลายของสำเนียง ภูมิภาค รูปแบบโครงสร้างประโยค และการมีส่วนผสมของการสลับภาษาหรือคำต่างประเทศ (code-switching) ข้อเสนอแนะแบบปฏิบัติการได้แก่
- การแบ่งข้อมูลแบบ stratified — แบ่งชุดข้อมูลตามสำเนียง (เหนือ ใต้ อีสาน กลาง), เพศ, ช่วงอายุ, และภาษาที่ปะปนเพื่อให้ชุดทดสอบเป็นตัวแทน ตัวอย่างสัดส่วน: Train 70% / Dev 15% / Test 15% โดยในชุดทดสอบควรมีอย่างน้อย 1,000–3,000 ตัวอย่างต่อสำเนียงสำหรับงาน ASR/MT ที่ต้องการความน่าเชื่อถือ
- ตั้งชุดทดสอบ Few‑Shot — สำหรับประเมินความสามารถ few-shot ให้สร้างชุดทดลองที่มี 1, 5, 10 ช็อตต่อโจทย์และรายงานประสิทธิภาพในแต่ละระดับ เพื่อดูว่าการใช้ตัวอย่างเล็กๆ ปรับปรุงผลได้มากน้อยเพียงใด
- ทดสอบ Out‑of‑Domain และ Robustness — สร้างสถานการณ์ทดสอบที่มีเสียงรบกวน เสียงข้ามสาย หรือข้อความที่มีการสลับภาษา เพื่อประเมินความทนทานของโมเดล
- แผนผังการแบ่งชุด — แนะนำให้เก็บชุดทดสอบ (hold-out) ที่ไม่เคยถูกแตะต้องสำหรับการประกาศผล benchmark สาธารณะ และใช้ cross‑validation หรือ multiple seeds ในการประเมินการฝึกเพื่อความเสถียร
ตัวอย่างเชิงตัวเลข: สำหรับระบบ ASR ที่ต้องการการประเมินเชิงเปรียบเทียบ ควรจัดเตรียมอย่างน้อย 5 สำเนียงหลัก แต่ละสำเนียงมี 1,500–3,000 ประโยคทดสอบ ในขณะที่งาน NLU/QA ควรมีอย่างน้อย 500–1,000 คำถามต่อสำเนียง เพื่อให้การรายงานค่า F1/EM มีความหมายเชิงสถิติ
แนวทางการทำ human evaluation และสถิติที่ควรรายงาน
การประเมินโดยมนุษย์จำเป็นสำหรับการวัดความเข้าใจเชิงบริบท ความสมเหตุสมผล ความเป็นธรรม (fairness) และการตรวจหาข้อผิดพลาดเชิงกายภาพที่เมตริกอัตโนมัติไม่สามารถจับได้ วิธีการที่แนะนำได้แก่:
- เกณฑ์การให้คะแนน — ใช้มาตรฐานชัดเจน เช่น Likert scale 1–5 แยกมิติเป็น ความถูกต้องเชิงเนื้อหา (adequacy) และ ความลื่นไหลทางภาษา (fluency) หรือใช้ pairwise preference test (A vs B)
- จำนวนผู้ประเมินและการซ้อนทับ — แต่ละตัวอย่างควรได้รับการประเมินจากผู้ประเมินอย่างน้อย 3 คน เพื่อคำนวณความเห็นร่วม (majority / averaged score)
- ความสอดคล้องระหว่างผู้ประเมิน — รายงานค่าสหสัมพันธ์เช่น Cohen’s kappa หรือ Fleiss’ kappa เพื่อแสดงความน่าเชื่อถือของการให้คะแนน หากค่านี้ต่ำ (< 0.6) ควรปรับคู่มือการประเมินและทำการอบรมผู้ประเมินเพิ่มเติม
- การระบุประเภทความผิดพลาด — ให้ผู้ประเมินแท็กชนิดของข้อผิดพลาด เช่น “ความหมายผิดเพี้ยน”, “ขาดบริบทท้องถิ่น”, “มีอคติ/ไม่เป็นธรรม” เพื่อให้สามารถวิเคราะห์เชิงสาเหตุและวางแผนปรับปรุงได้
- สถิติที่ต้องรายงาน — ค่าเฉลี่ยคะแนน ± std, สัดส่วนการชนะใน pairwise test, ค่าความเห็นร่วม (kappa), and p‑values/CI ของการทดสอบความแตกต่างเมื่อเปรียบเทียบหลายโมเดล (เช่น bootstrap resampling หรือ t‑test กับการควบคุมหลายครั้ง)
สุดท้าย ควรรายงานผลทั้งในระดับรวมและแยกตามกลุ่มย่อย (per‑dialect, per‑age group, per‑noise condition) เพื่อเปิดเผยจุดอ่อนและประเด็นความเป็นธรรมอย่างโปร่งใส การผนวกผลจากเมตริกอัตโนมัติกับการประเมินโดยมนุษย์จะช่วยให้ภาพรวมของประสิทธิภาพโมเดลชัดเจนและมีน้ำหนักต่อการตัดสินใจเชิงธุรกิจและเชิงนโยบาย
การนำไปใช้งานจริง (Deployment) และข้อพิจารณาด้านประสิทธิภาพ
การเลือกสถาปัตยกรรมการนำไปใช้งาน: Cloud API vs Edge/On‑Device
เมื่อต้องตัดสินใจนำโมเดล LLM ที่คัสตอมมาใช้งานจริง สตาร์ทอัพจำเป็นต้องพิจารณา trade‑off ระหว่าง latency, privacy และ ต้นทุน อย่างรอบคอบ โดยหลักการทั่วไปคือ:
- Cloud API: เหมาะกับกรณีที่ต้องการประสิทธิภาพสูง, การอัปเดตโมเดลบ่อยครั้ง และการรองรับผู้ใช้จำนวนมากแบบรวดเร็วผ่านการ scale อัตโนมัติ ตัวอย่าง: API บน GPU cluster สามารถให้ latency ระดับ 200–500 ms สำหรับคำขอแบบมี few‑shot แต่ต้นทุนต่อคำขอจะสูงโดยเฉพาะเมื่อใช้ FP32/FP16
- Edge / On‑Device: เหมาะกับกรณีที่ต้องการ latency ต่ำมาก (<100 ms), ความเป็นส่วนตัวสูง หรือการใช้งานแบบออฟไลน์ เช่น การประมวลผลคำพูดท้องถิ่น/สำเนียงบนมือถือ การรันบนอุปกรณ์ต้องใช้โมเดลที่ถูกปรับแต่งให้เล็กลง (quantized/distilled) และอาจมีการ trade‑off ด้านความแม่นยำ
- แนวทางผสม (Hybrid): ให้บริการ inference เบื้องต้นบน edge สำหรับ use case latency‑sensitive และ fallback ไปยัง cloud สำหรับงานที่ต้องการบริบทขนาดใหญ่หรือความแม่นยำสูง เช่น ส่งเฉพาะ embedding/feature ไปยัง cloud แล้วรับผลลัพธ์กลับ
เทคนิคลดค่าใช้จ่ายและเพิ่มประสิทธิภาพ
เพื่อลดต้นทุนและปรับให้เหมาะกับการให้บริการเชิงพาณิชย์ สามารถนำเทคนิคต่อไปนี้ไปใช้ร่วมกันได้:
- Quantization — ลดความละเอียดตัวเลขของพารามิเตอร์ (เช่นจาก FP32 → FP16 → INT8) โดยทั่วไปจะลดขนาดโมเดลได้ประมาณ 3–4x สำหรับ INT8 เมื่อเทียบกับ FP32 และช่วยลด usage memory และ inference cost อย่างมีนัยสำคัญ
- Distillation — สร้างโมเดลขนาดเล็ก (student) ที่เรียนจากโมเดลใหญ่ (teacher) เพื่อลดขนาดโมเดลและ latency โดยบ่อยครั้งสามารถลดพารามิเตอร์ได้ 3–10x ขึ้นกับงาน ในขณะที่รักษาความแม่นยำให้ใกล้เคียงต้นฉบับ
- Caching — เก็บผลลัพธ์ของ prompt ที่ซ้ำกันหรือคล้ายกันเพื่อลดจำนวน calls ไปยังโมเดลจริง โดยเฉพาะในการตอบคำถามที่มีรูปแบบคงที่หรือคำสั่งมาตรฐาน การใช้ cache สามารถลดคำขอลงได้ตั้งแต่ 40–90% ขึ้นกับลักษณะการใช้งาน
- Batching และ Mixed‑Precision — การรวมคำขอหลายรายการเป็น batch หนึ่งเพื่อใช้ประโยชน์เต็มที่จาก GPU/TPU และการใช้ mixed‑precision (FP16) เพื่อเพิ่ม throughput
- Token reduction / Prompt engineering — ย่อบริบทและ few‑shot examples ให้สั้นที่สุดโดยไม่เสียประสิทธิภาพ เพื่อลดจำนวน token ต่อคำขอ ซึ่งส่งผลต่อต้นทุนโดยตรง
การจัดการ Latency, Caching และการขยายระบบ (Scaling)
เพื่อรองรับผู้ใช้จำนวนมากและคงคุณภาพการให้บริการ สถาปัตยกรรมควรออกแบบให้รองรับทั้ง scale‑out และ resilience ด้วยแนวปฏิบัติดังนี้:
- กำหนด SLO/SLA ชัดเจน เช่น p95 latency ≤ 300 ms สำหรับการตอบโต้เชิงโต้ตอบ และออกแบบ autoscaling บน Cloud เพื่อเพิ่ม/ลดจำนวน replica ตามคิวงานและการใช้งาน
- ใช้ GPU pooling และคิวคำสั่ง (request queue) เพื่อบริหารจัดการทรัพยากรอย่างมีประสิทธิภาพ บริการที่รองรับ batch จะมี throughput ดีกว่าสำหรับงานที่ไม่ต้องการ latency ต่ำสุด
- เมื่อต้องการรองรับผู้ใช้จำนวนมาก ให้แยกทราฟฟิกตามระดับความสำคัญ เช่น ประเภทคำขอที่ใช้ few‑shot หรือ prompt เดิมซ้ำๆ ไปยัง cache layer ในขณะที่คำขอที่ซับซ้อนถูกส่งไปยัง cluster แบบ scale‑out
- ออกแบบ caching strategy โดยใช้คีย์ที่เป็น hash ของ (model_name + prompt_template + few_shot_examples + params) และแยก TTL ตามประเภทคำขอ รวมทั้งรองรับ partial cache hits ด้วยการเก็บ embeddings สำหรับการแม็ปคำถามที่คล้ายกัน
- เตรียมการสำหรับ cold starts ด้วย warm‑up pools, snapshot model weights และ health checks เพื่อลดเวลาการเริ่มต้น instance ใหม่
ตัวอย่างการตั้ง API Endpoint และ Pseudocode สำหรับ Few‑Shot Prompt
ต่อไปนี้เป็นตัวอย่างโครงสร้าง endpoint ทั้งฝั่งเซิร์ฟเวอร์และ pseudocode ขั้นตอนการเรียกใช้ few‑shot prompt ที่สอดคล้องกับแนวทาง caching และตรวจสอบค่าใช้จ่าย
- API Endpoint (ตัวอย่าง): POST /v1/generate
- Request JSON: { "model": "thai‑custom‑v1", "few_shot": [...], "prompt": "ข้อความผู้ใช้", "max_tokens": 256, "temperature": 0.7 }
- Response JSON: { "id": "...", "output": "...", "meta": { "latency_ms": 210, "cache_hit": true/false } }
- Server‑side pseudocode (logic):
- รับ request → สร้าง cache_key = HASH(model + few_shot + prompt + params)
- เช็ค cache: ถ้า hit → ดึงผลลัพธ์ → เพิ่ม meta.cache_hit = true → ส่ง response
- ถ้า miss → เตรียม payload สำหรับโมเดล (อาจทำ token trimming) → ตรวจสอบ pool ของ GPU/edge → ส่งคำขอไปยัง engine
- รับผลลัพธ์ → บันทึกลง cache (พร้อม TTL) → ส่ง response กลับ client
- Client‑side pseudocode (เรียก few‑shot):
- สร้าง few_shot_examples = [ { "input": "ประโยคตัวอย่าง 1", "output": "คำตอบตัวอย่าง 1" }, ... ]
- payload = { model, few_shot: few_shot_examples, prompt: user_input, max_tokens, temperature }
- response = HTTP_POST("/v1/generate", payload, headers={"Authorization": "Bearer TOKEN"})
- ถ้า response.meta.cache_hit == true → ใช้ผลทันที; ถ้าไม่ → แสดงผลและบันทึก analytics สำหรับการปรับปรุง prompt
สรุปแล้ว การนำระบบ Cross‑Lingual Transfer และ few‑shot LLM ไปใช้งานจริงต้องอาศัยการออกแบบสถาปัตยกรรมที่สมดุลระหว่างความต้องการด้าน latency, privacy และต้นทุน การใช้เทคนิคเช่น quantization, distillation และ caching ร่วมกับกลยุทธ์ scaling ที่เหมาะสมจะช่วยให้บริการสามารถรองรับผู้ใช้จำนวนมากได้อย่างมีประสิทธิภาพและคุ้มค่าทางธุรกิจ
จริยธรรม ความเป็นส่วนตัว และการมีส่วนร่วมของชุมชน
เนื้อหาส่วน จริยธรรม ความเป็นส่วนตัว และการมีส่วนร่วมของชุมชน ยังไม่สามารถสร้างได้
แผนการทดลองแบบขั้นตอน (Step‑by‑Step Tutorial Outline)
ภาพรวมและข้อกำหนดเบื้องต้น
บทแนะนำนี้ออกแบบเป็นแผนการทดลองแบบขั้นตอน (Step‑by‑Step Tutorial Outline) สำหรับนักพัฒนาและทีมผลิตภัณฑ์ที่ต้องการสร้างโมเดลภาษา (LLM) ที่คัสตอมเพื่อเข้าใจภาษาไทยท้องถิ่นและสำเนียง โดยใช้กลยุทธ์ cross‑lingual transfer, few‑shot prompting และการปรับจูนขนาดเล็ก (LoRA / adapter / small fine‑tune) พร้อมชุดข้อมูลเปิด เทคนิคที่แนะนำช่วยลดต้นทุนด้านทรัพยากรคอมพิวต์และเวลาในการพัฒนา ในขณะเดียวกันยังรักษาคุณภาพการตอบสนองต่อสำเนียงท้องถิ่นได้ดี
สิ่งที่ต้องเตรียมก่อนเริ่มทดลอง: เครื่องที่รองรับ GPU (NVIDIA CUDA), Python 3.8+, พื้นที่เก็บข้อมูลพอสมควร (20–200 GB ขึ้นกับขนาดโมเดลและ dataset), และไลบรารีหลัก: Hugging Face Transformers, Datasets, Accelerate, PEFT (LoRA), bitsandbytes (สำหรับ quantization) และเครื่องมือ preprocess ไทย (เช่น pythainlp หรือ deepcut)
ขั้นตอนที่ 1 — ดาวน์โหลดชุดข้อมูลตัวอย่างและรีโพสที่เกี่ยวข้อง
เริ่มจากการดาวน์โหลดชุดข้อมูลเปิดที่เป็นแหล่งข้อมูลภาษาไทยทั่วไปและเสียง (สำหรับกรณีต้องการรวม ASR/TTS):
- ข้อความ: OSCAR (Common Crawl) และ Wikipedia dump สำหรับภาษาไทย — ตัวอย่าง URL: https://huggingface.co/datasets/oscar และ https://dumps.wikimedia.org/thwiki/latest/thwiki-latest-pages-articles.xml.bz2
- เสียง/สำเนียง: Mozilla Common Voice (ภาษาไทย) — https://huggingface.co/datasets/common_voice และหน้า Common Voice https://commonvoice.mozilla.org/
- ตัวอย่างรีโพสสำหรับ LoRA / training pipelines: Hugging Face PEFT https://github.com/huggingface/peft , Transformers examples https://github.com/huggingface/transformers , Alpaca‑LoRA example https://github.com/tloen/alpaca-lora
- คลังข้อมูลบน Hugging Face สำหรับเทมเพลตและ few‑shot prompts: https://huggingface.co/datasets
ตัวอย่างคำสั่งดาวน์โหลด (text): git clone https://github.com/your-org/your-thai-dialects-repo.git หรือใช้ wget สำหรับไฟล์ dump: wget https://dumps.wikimedia.org/thwiki/latest/.../thwiki-latest-pages-articles.xml.bz2
ขั้นตอนที่ 2 — Preprocessing (การเตรียมข้อมูล)
หลักการ: ทำความสะอาดข้อมูล ลบ HTML/อยู่นอกประเด็น แยกประโยค tokenize ให้เหมาะสมกับภาษาไทย และจัดสร้างชุด train/validation/test (70/15/15 หรือ 80/10/10 ขึ้นกับปริมาณข้อมูล)
- ใช้ pythainlp หรือ deepcut สำหรับ tokenization: ตัวอย่าง pip install pythainlp แล้วรัน: from pythainlp.tokenize import word_tokenize
- Normalize: แปลง Unicode, ลบซ้ำ, กรองประโยคสั้นมาก (< 3 คำ) หรือข้อความที่มีสแปม
- สร้าง label สำหรับกรณี NLU (intent/slot) หรือคู่ (context → response) เมื่อเป็นการฝึกแบบ dialogue
- จัดเก็บเป็นไฟล์ JSONL หรือ CSV (หนึ่งตัวอย่างต่อบรรทัด) เช่น train.jsonl, valid.jsonl, test.jsonl
- สถิติที่ควรบันทึก: จำนวนประโยครวม, คำเฉลี่ยต่อประโยค, สัดส่วนสำเนียง/ภูมิภาค (หากมี annotation)
ขั้นตอนที่ 3 — ออกแบบ Few‑Shot Prompt และ Template
ออกแบบ prompt ให้รองรับสำเนียงโดยใช้ตัวอย่าง few‑shot ที่แสดงทั้งประโยคหลักและการแปรรูป (canonical form) เช่น ให้ตัวอย่างการสะกดหรือการเขียนในสำเนียงท้องถิ่น และผลลัพธ์ที่ต้องการ ตัวอย่าง template:
Prompt Template (ตัวอย่าง): "Context: {context}\nExample (local accent → canonical):\n1) 'มึงหยัง' → 'คุณทำอะไร'\n2) 'ไปไส' → 'ไปที่ไหน'\nNow respond to: {input_sentence} — normalize to standard Thai and provide intent."
คำแนะนำ: ใช้ 3–8 shot ต่อ prompt ในการทดสอบ few‑shot เพราะมากเกินไปจะทำให้ token budget สูงขึ้น หากใช้ API/seq length ประมาณ 2048–4096 tokens ให้ปรับจำนวน examples ให้เหมาะสม
ขั้นตอนที่ 4 — ปรับจูนด้วย LoRA / Adapter / Small Fine‑Tune
แนวทางที่แนะนำ: เริ่มด้วย LoRA/PEFT บนโมเดลพื้นฐาน (เช่น LLaMA‑style หรือ causal LLM ที่เปิดใช้งาน) โดยโหลดโมเดลแบบ 8‑bit เพื่อประหยัดหน่วยความจำ จากนั้นใช้ LoRA เพื่อฝึกพารามิเตอร์จำนวนน้อย วิธีตั้งค่าตัวอย่าง (ค่าที่แนะนำเป็นค่าเริ่มต้น):
- โหลดโมเดลแบบ 8‑bit: load_in_8bit=True, device_map="auto" (ต้องใช้ bitsandbytes)
- LoRA hyperparameters ที่แนะนำ: r=8–16, lora_alpha=32, lora_dropout=0.05, target_modules=["q_proj","v_proj"] (สำหรับสถาปัตยกรรม Transformer ทั่วไป)
- การฝึก: epochs=3–5 (LoRA), per_device_train_batch_size=4–16 (ขึ้นกับ VRAM), gradient_accumulation_steps=4, learning_rate=1e-4–3e-4 (สำหรับ LoRA ใช้ LR สูงกว่า fine‑tune ปกติ)
- ใช้ fp16 (mixed precision) หรือ bfloat16 เมื่อรองรับ เพื่อลดเวลาและหน่วยความจำ
ตัวอย่างโค้ดย่อ (แนวคิด): ใช้ Transformers + PEFT
1) เตรียมโมเดลและ tokenizer
2) เตรียม LoRA config: LoraConfig(r=16, lora_alpha=32, target_modules=[...], lora_dropout=0.05)
3) ใช้ Trainer หรือ accelerate launch เพื่อฝึก โดยตั้ง save_steps และ checkpointing
หากต้องการ adapter แบบ compact อื่น ๆ ให้พิจารณา AdapterHub (adapter‑transformers) หรือใช้ small full‑fine‑tune บนโมเดลขนาดเล็ก (เช่น 7B หรือเล็กกว่า) โดยตั้ง learning_rate=1e-5–5e-5 และ batch_size เหมาะสม
ขั้นตอนที่ 5 — ประเมินผล (Evaluation)
การประเมินควรประกอบด้วยการวัดเชิงอัตโนมัติและการประเมินโดยมนุษย์:
- Metric เชิงภาษา: Perplexity (สำหรับ LM), BLEU/chrF (สำหรับการแปลงรูปข้อความ), WER/CER (สำหรับ ASR‑related tasks), Accuracy/F1 (สำหรับ intent classification)
- การทดสอบสำเนียง: แบ่งชุดทดสอบตามภูมิภาค/สำเนียง (เช่น ใต้, อีสาน, เหนือ, กลาง) และวัด performance แยกตามกลุ่ม
- Human Evaluation: ให้ผู้ประเมิน 3–5 คนตรวจความถูกต้องของ normalization, ความเป็นธรรมชาติ, และความเข้าใจสำเนียง — เก็บคะแนน Likert (1–5)
- ตัวอย่างคำสั่งประเมินอัตโนมัติ: ใช้ชุด test.jsonl และรันสคริปต์ที่คำนวณ BLEU/WER แล้วสรุปผลเป็นตารางเปรียบเทียบ (ต้องระบุสัดส่วน error ต่อสำเนียง)
- รายงานสถิติที่ต้องบันทึก: baseline performance (โมเดลที่ยังไม่ปรับ), performance หลัง LoRA, gains ในแต่ละสำเนียงเป็น % (เช่น อัตรา F1 เพิ่มขึ้นจาก 65% → 78%)
ขั้นตอนที่ 6 — Deploy ตัวอย่างแอปพลิเคชันที่ตอบสนองสำเนียงท้องถิ่น
ตัวอย่างแอป: REST API ด้วย FastAPI หรือ Web UI ด้วย Gradio ที่รับข้อความ (หรือเสียงผ่าน ASR) แล้วคืนค่าผลลัพธ์ที่ normalized/intent
- ตัวอย่าง dependency และ containerization: สร้าง Dockerfile ที่ติดตั้ง transformers, accelerate, peft, bitsandbytes, fastapi/uvicorn หรือ gradio
- คำสั่งรันตัวอย่าง (local): uvicorn app:app --host 0.0.0.0 --port 8000
- สำหรับ production: พิจารณาใช้ GPU host, quantization (8‑bit/4‑bit) และ inference server เช่น vLLM (https://github.com/vllm-project/vllm) หรือ Hugging Face Text‑Generation‑Inference (https://github.com/huggingface/text-generation-inference)
- Latency target: ตั้งเป้า latency < 300–800 ms ต่อตอบข้อความ (ขึ้นกับ SLA) และ throughput ตามการใช้งานจริง
เช็คลิสต์การตรวจสอบก่อน/หลังการ Deploy
ก่อน Deploy
- Data governance: ตรวจสอบสิทธิ์การใช้ชุดข้อมูลและข้อจำกัด (licenses)
- Privacy: ลบ PII และตั้งนโยบายการเก็บ logs หากบันทึกข้อความผู้ใช้
- Bias & Safety: รันการทดสอบความลำเอียงที่เกี่ยวกับถิ่นกำเนิดและภาษาถิ่น
- Performance: ผ่านเกณฑ์ค่า metric ที่กำหนด (เช่น F1 > target per dialect)
- Resource: ทดสอบการทำงานบนเครื่องจริง (memory, GPU utilization, concurrency)
หลัง Deploy
- Monitoring: เก็บ latency, error rate, token usage, drift ของ distribution ข้อมูล
- Fallbacks: สร้าง fallback simple rules หรือ intent classifier เมื่อ confidence ต่ำ
- Continuous Evaluation: รวบรวมตัวอย่างที่ล้มเหลวและรัน periodic re‑evaluation (weekly/monthly)
- Security: rate limiting, authentication, และการป้องกันการโจมตีแบบ prompt injection
- Feedback loop: ช่องทางให้ผู้ใช้รายงานคำตอบผิดเพื่อปรับ dataset และ retrain
ทรัพยากรอ้างอิงและรีโพสที่แนะนำ
รีโพสและเอกสารสำคัญที่ควรอ้างอิงและทดลองใช้งานโดยตรง:
- Hugging Face Transformers: https://github.com/huggingface/transformers
- PEFT (LoRA): https://github.com/huggingface/peft
- Accelerate (distributed training): https://github.com/huggingface/accelerate
- bitsandbytes (8‑bit/4‑bit loading): https://github.com/TimDettmers/bitsandbytes
- Alpaca‑LoRA example (tutorial pipeline): https://github.com/tloen/alpaca-lora
- Common Voice (เสียงภาษาไทย): https://huggingface.co/datasets/common_voice
- OSCAR (web crawl multilingual): https://huggingface.co/datasets/oscar
- Wikimedia Thai dump: https://dumps.wikimedia.org/thwiki/latest/
- Text‑Generation‑Inference (serving): https://github.com/huggingface/text-generation-inference
สรุปสั้น ๆ และข้อเสนอแนะเชิงปฏิบัติ
แผนการทดลองนี้เน้นการใช้วิธีปรับจูนแบบประหยัดทรัพยากร (LoRA/adapter) ร่วมกับ few‑shot prompting และชุดข้อมูลเปิดเพื่อเร่งเวลาในการนำเสนอโมเดลที่เข้าใจสำเนียงท้องถิ่นของไทยได้อย่างรวดเร็ว ยึดหลักทดลองแบบ iterative: เก็บ metric แยกตามสำเนียง ปรับเทมเพลต prompt และ data augmentation (เช่น TTS → ASR เพื่อสร้างตัวอย่างสำเนียง) แล้วค่อยขยายสเกล การมีเช็คลิสต์ก่อน/หลังการ deploy และระบบ monitoring ที่ดีเป็นสิ่งจำเป็นเพื่อให้การใช้งานเชิงธุรกิจมีความมั่นคงและปลอดภัย
บทสรุป
แนวทาง Cross‑lingual transfer ร่วมกับ few‑shot และชุดข้อมูลเปิด ถูกยืนยันว่าเป็นวิธีปฏิบัติที่ได้ผลสำหรับการคัสตอม LLM ให้รองรับสำเนียงและภาษาท้องถิ่นของไทย โดยสามารถนำความรู้จากภาษาหรือโมเดลที่มีข้อมูลหนาแน่นมาถ่ายโอนให้โมเดลเข้าใจสำเนียงท้องถิ่นด้วยตัวอย่างจำนวนน้อย (few‑shot) แทนการต้องพึ่งพาข้อมูลจำนวนมหาศาล ตัวอย่างเช่น การใช้โมเดลที่เทรนด้วยภาษาอังกฤษหรือไทยกลางเป็นฐาน แล้วปรับแบบ few‑shot ด้วยชุดข้อมูลชุมชนเปิดสำหรับภาษาถิ่น เช่น คำพูดท้องถิ่น คำศัพท์เฉพาะ และเสียงพูดที่ติดป้ายข้อมูล ทำให้การปรับแต่งลงทุนน้อยลง เร็วขึ้น และรองรับสำเนียงที่หลากหลายได้มากขึ้นเมื่อเทียบกับการเทรนจากศูนย์ โดยยังช่วยรักษาความหลากหลายทางภาษาและลดอุปสรรคด้านต้นทุนและทรัพยากร
การออกแบบแพลตฟอร์มเพื่อสนับสนุนแนวทางนี้จึงต้องคำนึงทั้งเชิงเทคนิค การประเมินผล จริยธรรม และการมีส่วนร่วมของชุมชนเพื่อความยั่งยืนและความเป็นธรรม กล่าวคือ ทางเทคนิคต้องออกแบบระบบจัดการข้อมูล การถ่ายโอนความรู้ และกลไก continual learning รวมถึงเมตริกการประเมินที่ครอบคลุม (เช่น ความถูกต้องข้ามสำเนียง ความทนทานต่อ code‑switching และประสิทธิภาพ few‑shot) ด้านจริยธรรมต้องให้ความสำคัญกับการได้มาซึ่งข้อมูลอย่างสมัครใจ การคุ้มครองความเป็นส่วนตัว การตรวจสอบอคติ และความโปร่งใส (model cards / datasheets) ส่วนการมีส่วนร่วมของชุมชนควรรวมกลไกการร่วมออกแบบ ค่าตอบแทนหรือแรงจูงใจสำหรับผู้ให้ข้อมูล และกระบวนการกำกับดูแลร่วมกัน เมื่อรวมแนวปฏิบัติเหล่านี้เข้าด้วยกัน แพลตฟอร์มจะสามารถส่งเสริมการเข้าถึงเทคโนโลยีที่เป็นธรรม สร้างความน่าเชื่อถือ และขยายการสนับสนุนไปยังภาษาท้องถิ่นอื่นๆ ในอนาคตได้



