
แรงกดดันจากการแข่งขันระดับโลกและมาตรฐานคุณภาพที่เข้มงวดทำให้โรงงานยานยนต์ไทยต้องเปลี่ยนผ่านสู่โรงงานอัจฉริยะอย่างเร่งด่วน ในบทนำนี้เราขอพาเข้าสู่แนวทางปฏิบัติที่จับต้องได้: การสร้าง Digital Twin แบบเรียลไทม์ที่ผสาน Foundation Models (โมเดลฐานความรู้ขนาดใหญ่) กับเทคนิค sensor‑fusion เพื่อให้สายการผลิตสามารถปรับตัวเชิงคาดการณ์ได้ทันที—ช่วยลดเวลาตั้งเครื่อง ปรับจูนสายการผลิต และลดของเสียที่เกิดจากการทดลองค่าพารามิเตอร์ ตัวอย่างเชิงปฏิบัติชี้ว่าแนวทางดังกล่าวสามารถลดเวลาตั้งเครื่องได้อย่างมีนัยสำคัญ (เช่น 30–50% ในกรณีศึกษาต้นแบบ) และลดของเสียได้ในระดับสองหลัก (ประมาณ 20–40%) เมื่อออกแบบและใช้งานอย่างเหมาะสม
บทความฉบับนี้เป็นคู่มือเชิงปฏิบัติการสำหรับผู้บริหารและวิศวกรในอุตสาหกรรมยานยนต์ โดยจะครอบคลุมประเด็นสำคัญ ได้แก่ สถาปัตยกรรมระบบ Digital Twin แบบเรียลไทม์ รายละเอียดฮาร์ดแวร์ (เซนเซอร์, EDGE devices, PLC, กริปเปอร์) และซอฟต์แวร์ (data pipeline, MLOps, foundation models, control loop) เทคนิค sensor‑fusion เพื่อนำข้อมูลจากภาพ กล้องความร้อน แรงบิด และสัญญาณไทม์ซีรีส์มารวมเป็นสถานะเดียวของระบบ รวมถึงตัวอย่างสถิติ ประเมินค่า ROI และแนวทางนำไปใช้จริงในโรงงานที่มีความหลากหลายของผลิตภัณฑ์
หากคุณเป็นผู้บริหารที่ต้องการตัดสินใจเชิงกลยุทธ์ หรือนักวิศวกรที่ต้องการแผนปฏิบัติการตั้งแต่การเลือกฮาร์ดแวร์จนถึงการปรับจูนโมเดล บทความนี้จะให้แผนงานทีละขั้นตอน กรณีตัวอย่างที่นำไปใช้จริง และตัวชี้วัดเพื่อวัดผลความสำเร็จ เตรียมตัวให้พร้อมสำหรับการเปลี่ยนสายการผลิตจากการตอบสนองเชิงปฏิกิริยาไปสู่การปรับตัวเชิงคาดการณ์อย่างแท้จริง
บทนำ: ทำไม Digital Twin เรียลไทม์จึงสำคัญต่อโรงงานยานยนต์ไทย
บทนำ: ทำไม Digital Twin เรียลไทม์จึงสำคัญต่อโรงงานยานยนต์ไทย
ในบริบทของอุตสาหกรรมยานยนต์ที่มีการแข่งขันสูงและความต้องการผลิตภัณฑ์ที่หลากหลาย โรงงานยานยนต์ไทยเผชิญกับความท้าทายเชิงปฏิบัติการหลายประการ ได้แก่ ความหลากหลายของรุ่นสินค้า (model mix) ที่เพิ่มขึ้น ความถี่ในการเปลี่ยนสายการผลิต (changeover) และความเสี่ยงของการเกิดของเสียเมื่อพารามิเตอร์การผลิตไม่ได้ถูกตั้งค่าหรือปรับอย่างแม่นยำ ระบบ Digital Twin แบบเรียลไทม์เข้ามาเป็นกลไกสำคัญในการตอบโจทย์เหล่านี้ โดยให้ภาพจำลองขั้นตอนการผลิตและสถานะอุปกรณ์ที่อัพเดตแบบทันที ทำให้ผู้บริหารและวิศวกรสามารถมองเห็นปัญหาเชิงสาเหตุ (root cause) และตัดสินใจได้เร็วขึ้นเพื่อลดผลกระทบต่อไลน์การผลิต
ความท้าทายสำคัญที่พบในสายการผลิตยานยนต์ ได้แก่ (1) การรองรับหลายรุ่นสินค้าในสายเดียวที่ต้องเปลี่ยนพารามิเตอร์บ่อยครั้ง ส่งผลให้ เวลาตั้งเครื่อง (setup/changeover) เพิ่มขึ้น (2) กระบวนการปรับตั้งพารามิเตอร์ที่ต้องพึ่งพาทักษะและการทดลองเชิงกายภาพ นำไปสู่ของเสียจากการตั้งค่าที่ไม่ถูกต้อง และ (3) ข้อมูลจากเซนเซอร์หลายแหล่งที่อยู่ในรูปแบบต่างกัน ทำให้ยากต่อการรวมข้อมูลเพื่อวิเคราะห์เชิงสาเหตุและคาดการณ์ ก่อนมีการตัดสินใจแก้ไข
จากมุมมองเชิงธุรกิจ การนำ Digital Twin แบบเรียลไทม์ผสานกับการรวมข้อมูลจากเซนเซอร์ (sensor fusion) และความสามารถของ Foundation Models ในการเรียนรู้รูปแบบเชิงซับซ้อน สามารถสร้างผลลัพธ์ที่จับต้องได้ เช่น ลดเวลา setup ได้ระหว่าง 30–60% ในกรณีศึกษาโรงงานที่ปรับใช้ระบบจำลองและอัตโนมัติ, ลดของเสีย (scrap/waste) ได้ 20–40% เมื่อระบบคาดการณ์และปรับพารามิเตอร์แบบเรียลไทม์ พร้อมทั้งช่วยเพิ่มตัวชี้วัดประสิทธิภาพโดยรวมของอุปกรณ์ (OEE) จากการลด downtime และเพิ่มคุณภาพของชิ้นงาน ตัวเลขเหล่านี้เป็นการอ้างอิงเชิงอุตสาหกรรมที่สะท้อนช่วงผลลัพธ์จากงานปรับปรุงกระบวนการด้วยเทคโนโลยีดิจิทัล
ภาพรวมของโซลูชันที่บทความนี้จะอธิบายต่อไปคือการผสานกันของ 3 ส่วนหลัก: (1) Digital Twin แบบเรียลไทม์ ที่จำลองสถานะเครื่องจักรและกระบวนการแบบ streaming, (2) Sensor‑Fusion เพื่อรวมข้อมูลจากเวิร์คสเตชัน เซนเซอร์การวัดคุณภาพ และ PLC ให้เป็นมุมมองเดียวที่มีบริบทสอดคล้องกัน และ (3) Foundation Models ที่ใช้เรียนรู้รูปแบบ ความสัมพันธ์เชิงเวลาระหว่างพารามิเตอร์การผลิตและผลลัพธ์คุณภาพ ซึ่งร่วมกันจะทำให้เกิดการปรับแบบเชิงคาดการณ์ (predictive adjustment) ก่อนเกิดข้อผิดพลาด ช่วยลดเวลาตั้งเครื่อง ลดของเสีย และเพิ่มความเสถียรของการผลิต
โดยสรุป โรงงานยานยนต์ไทยที่ต้องการเพิ่มความสามารถในการแข่งขันระยะยาวจำเป็นต้องพิจารณาลงทุนใน Digital Twin แบบเรียลไทม์ควบคู่ไปกับการรวมข้อมูลเซนเซอร์และโมเดลพื้นฐานเชิงปัญญาประดิษฐ์ เนื่องจากเทคโนโลยีเหล่านี้ให้ทั้งความแม่นยำในการตัดสินใจ ความเร็วในการตอบสนองต่อเหตุการณ์ และผลลัพธ์เชิงธุรกิจที่วัดได้ เช่นการลดเวลา setup, ลดของเสีย และการเพิ่ม OEE ซึ่งเป็นปัจจัยสำคัญในการรักษาต้นทุนและคุณภาพในอุตสาหกรรมยานยนต์สมัยใหม่
ภาพรวมโซลูชัน: สถาปัตยกรรม Digital Twin แบบเรียลไทม์
โซลูชัน Digital Twin แบบเรียลไทม์สำหรับโรงงานยานยนต์ประกอบด้วยเลเยอร์เชิงสถาปัตยกรรมหลายชั้นที่เชื่อมโยงตั้งแต่ฮาร์ดแวร์บนสายการผลิตจนถึงโมเดลภายในคลาวด์ เพื่อให้สามารถคาดการณ์ ปรับกระบวนการ และแนะนำการตัดสินใจเชิงปฏิบัติการได้ทันที ส่วนประกอบหลักได้แก่ เซนเซอร์และเอ็กซ์คิวชันปลายทาง (sensors & actuators) บนสายการผลิต, edge gateway สำหรับการกรองและแปลงสัญญาณ, message broker (เช่น MQTT/Kafka) สำหรับการส่งข้อมูลที่ทนทาน, ระบบประมวลผลแบบเรียลไทม์ (stream processing) และ digital twin state store ที่เก็บสถานะเชิงเวลาของอุปกรณ์และสายการผลิต

Data flow — จากเซนเซอร์ถึง Digital Twin
การไหลของข้อมูลเริ่มจากเซนเซอร์หลากชนิด (เช่น กล้องความละเอียดสูง, ไมโครโฟน, accelerometer/vibration sensor, temperature/pressure sensor, PLC signals) ซึ่งส่งสัญญาณดิบไปยัง edge gateway ที่ติดตั้งใกล้สายการผลิต เพื่อลดปริมาณข้อมูลและระยะเวลาในการสื่อสาร ขั้นตอนที่สำคัญได้แก่:
- Pre-processing ที่ edge: การทำ denoising, resampling, encoding (เช่น ภาพเป็น JPEG/ROI, สัญญาณเป็น FFT features) และการรัน inference เบื้องต้นเพื่อคัดกรองเหตุการณ์ (event filtering)
- ส่งข้อมูลไปยัง message broker: ข้อมูลเชิงเหตุการณ์หรือ telemetry ถูกส่งด้วยโปรโตคอลที่เหมาะสม — MQTT สำหรับข้อความขนาดเล็ก/low-overhead หรือ Kafka สำหรับ throughput สูงและ retention เป็นระยะเวลา เพื่อรองรับการ replay และ analytics
- Real-time processing: stream processors (เช่น Apache Flink/ksqlDB หรือ edge-based stream engines) ทำการ aggregation, windowing และ feature extraction เพิ่มเติม ก่อนอัพเดต digital twin state store ซึ่งอาจเป็น time-series DB (เช่น InfluxDB/Timescale), stateful store (เช่น Redis Streams) หรือ event store เพื่อบันทึกสถานะปัจจุบันและประวัติ
- Synchronization: การทำ snapshot และ delta sync ระหว่าง plant server (on-premises) กับ cloud ช่วยให้ digital twin ในระดับคลาวด์และระดับโรงงานสะท้อนสถานะเดียวกัน โดยใช้เหตุการณ์และ compact diff เพื่อประหยัดแบนด์วิธ
บทบาทของ Foundation Models ในสถาปัตยกรรม
Foundation models ถูกนำมาใช้ในหลายมิติของระบบ Digital Twin โดยเฉพาะเมื่อนำมารวมกับ sensor‑fusion เพื่อให้เกิดการรับรู้เชิงมัลติโมดอลและการให้เหตุผลเชิงบริบท ตัวอย่างการใช้งานมีดังนี้:
- Multimodal perception: โมเดลพื้นฐานที่ฝึกทั้งภาพ ข้อความ และสัญญาณเชิงเวลา ใช้จัดเก็บและตีความข้อมูลจากกล้อง ไมโครโฟน และเซนเซอร์วัดการสั่นสะเทือน ทำให้ระบบสามารถตรวจจับสภาพผิดปกติที่ซับซ้อน เช่น รอยร้าวร่วมกับเสียงผิดปกติ หรือการสั่นที่สัมพันธ์กับอุณหภูมิสูง
- Anomaly explanation: เมื่อระบบ stream processing พบ anomalous pattern, foundation model สามารถสร้างคำอธิบายเชิงเหตุผล (natural language explanation) ผสานภาพตัวอย่างหรือแผนภูมิ เพื่อช่วยช่างเทคนิคเข้าใจสาเหตุได้รวดเร็วขึ้น แทนที่จะเห็นเพียงตัวเลขหรือ threshold crossing
- Contextual recommendations: โมเดลให้คำแนะนำเชิงบริบทเกี่ยวกับการปรับพารามิเตอร์เครื่องจักร, ลำดับการปรับตั้งเครื่อง (setup sequence) หรือวิธีลดของเสีย โดยประเมินจากประวัติการผลิต สเปควัสดุ และข้อจำกัดเชิงเวลาของการสั่งงาน
- Continual learning & personalization: foundation models ที่ถูก fine‑tune ด้วยข้อมูลโรงงานเฉพาะ สามารถปรับตัวเมื่อกระบวนการเปลี่ยนแปลง เช่น เปลี่ยนชนิดชิ้นส่วนหรือสูตรการผลิต ช่วยให้คำแนะนำมีความแม่นยำมากขึ้นเมื่อเวลาผ่านไป
การพิจารณา Latency และ Availability — Edge vs Cloud
การตัดสินใจว่าจะรัน inference ที่ edge หรือ cloud ขึ้นกับความต้องการด้านความหน่วง (latency), ความพร้อมใช้งาน (availability), ความเป็นส่วนตัว และทรัพยากรคำนวณ:
- Inference ที่ edge (ใกล้แหล่งข้อมูล): เหมาะสำหรับ use‑case ที่ต้องการตอบสนองทันที เช่น การควบคุมวงปิด (closed-loop control), การหยุดฉุกเฉิน (E‑stop), หรือตรวจจับความผิดปกติที่ต้องการการตอบสนองภายใน 10–200 ms ตัวอย่างเช่น การตรวจจับการกระแทกหรือการสั่นผิดปกติเพื่อตัดการจ่ายพลังงานทันที
- Inference ที่ cloud / plant server: เหมาะสำหรับงานที่ต้องการพลังคำนวณสูง (เช่น LLMs ขนาดใหญ่, multimodal reasoning) หรือการวิเคราะห์เชิงประวัติยาว เช่น การวิเคราะห์สาเหตุจากข้อมูลหลายเดือน ซึ่งมีความหน่วงยอมรับได้ในระดับวินาทีถึงนาที และต้องการการเข้าถึงชุดข้อมูลขนาดใหญ่
- Hybrid approach: การออกแบบทั่วไปคือรัน model เบาๆ ที่ edge เพื่อการตอบสนองเชิงเวลาจริง และส่งเหตุการณ์หรือ sample ที่สำคัญไปยังคลาวด์สำหรับการวิเคราะห์เชิงลึกและการอธิบายด้วย foundation models โดยระบบต้องรองรับ fallback เช่นเมื่อเครือข่ายขาดหาย edge จะเก็บเหตุการณ์ (store‑and‑forward) และใช้ local policies จัดการชั่วคราว
- SLA และเกณฑ์เวลา: ปรับเส้นแบ่ง (cutoff) ตาม SLA ของการใช้งาน เช่น control loop ต้อง <200 ms, operator assistance <2 s, batch diagnosis <1 ชั่วโมง ข้อกำหนดเหล่านี้ช่วยกำหนดว่าฟังก์ชันใดต้องอยู่บน edge และใดสามารถไปที่ cloud ได้
สรุปแล้ว สถาปัตยกรรม Digital Twin แบบเรียลไทม์สำหรับโรงงานยานยนต์ควรผสานการจัดการสัญญาณจากเซนเซอร์ การกรองและประมวลผลที่ edge, การส่งข้อมูลที่ทนทานผ่าน MQTT/Kafka, การประมวลผลแบบสตรีมเพื่ออัพเดต state store ของ digital twin และการใช้งาน foundation models ทั้งในแบบ edge‑optimized และ cloud‑scale เพื่อให้ได้ทั้งความเร็ว ความแม่นยำ และคำอธิบายเชิงบริบทที่นำไปสู่การตัดสินใจที่ดีขึ้น ตัวอย่างการปรับใช้ที่ประสบผลมักลดเวลาตั้งเครื่องและของเสียได้อย่างมีนัยสำคัญเมื่อออกแบบ data flow และ inference placement อย่างรอบคอบ
องค์ประกอบระบบ: เซนเซอร์ ฮาร์ดแวร์ และ data pipeline
เซนเซอร์หลักและบทบาทเชิงปฏิบัติการ
ระบบ Digital Twin สำหรับโรงงานยานยนต์ที่ต้องการการปรับสายการผลิตเชิงคาดการณ์แบบเรียลไทม์ จำเป็นต้องผสานชุดเซนเซอร์หลายชนิดเพื่อจับมิติของกระบวนการทั้งเชิงภาพ เสียง สภาพเครื่องและตำแหน่งชิ้นงาน โดยเซนเซอร์หลักที่มักใช้ ได้แก่:
- Industrial Camera (Vision) — สำหรับตรวจจับข้อบกพร่อง (surface defects, alignment, missing parts) และการมอนิเตอร์สายการประกอบแบบภาพต่อภาพ ตัวอย่างอัตราเฟรมทั่วไป 30–200 fps ขึ้นกับความเร็วสายการผลิต; แนะนำใช้การบีบอัด H.264/H.265 หรือส่งเฉพาะภาพ ROI เป็นไฟล์เหตุการณ์
- Accelerometer / Vibration sensor — ตรวจสอบสภาพเครื่องจักร แบริ่ง และการสั่นสะเทือนให้ความถี่ตัวอย่างสูง (1 kHz–20 kHz ขึ้นกับการวิเคราะห์สเปกตรัม) ใช้ตรวจหาการสึกหรอหรือการหลุดของชิ้นส่วน
- Acoustic sensor / Microphone — จับเสียงผิดปกติของมอเตอร์ ปั๊ม หรือกระบวนการตอกลม (sampling 16–96 kHz) ช่วยวิเคราะห์คลื่นเสียงร่วมกับ ML เพื่อจำแนกความผิดปกติ
- Thermistor / Thermocouple / Thermal camera — วัดอุณหภูมิจุดติดตั้งและตรวจจับ hot‑spot ของชิ้นส่วนหรือเครื่องมือ (sampling ช้ากว่า: 0.1–1 Hz ถึงหลาย Hz สำหรับ thermal camera)
- Torque / Force sensor — วัดแรงบิดและแรงดันในขณะขันหรืออัดชิ้นส่วน สำคัญสำหรับการควบคุมคุณภาพทางกล (sampling 1–500 Hz)
- RFID / UWB / Barcode — ติดตามสถานะชิ้นงานและตำแหน่งบนสายการผลิต ให้ข้อมูลอ็อบเจ็กต์เป็นเหตุการณ์ไม่ต่อเนื่อง
ตัวอย่างเชิงตัวเลขเพื่อให้เห็นภาพ: กล้องความเร็วสูง 1 MP ที่ 200 fps ให้ข้อมูลดิบประมาณ 200 MB/s (~17 TB/วัน) หากไม่บีบอัด ขณะที่ accelerometer ที่ 10 kHz (16‑bit) จะให้ข้อมูลประมาณ 20–40 MB/วัน ต่อช่องสัญญาณ — ซึ่งแสดงความจำเป็นของการประมวลผลและบีบอัดที่ Edge
เกณฑ์การเลือกฮาร์ดแวร์และการออกแบบ Edge Node
การเลือกฮาร์ดแวร์ต้องพิจารณาจากสเปกเซนเซอร์ ปริมาณข้อมูล ความต้องการ latency และสภาวะแวดล้อมโรงงาน โดยหลักการสำคัญคือความทนทาน ความแม่นยำเวลา และความสามารถในการประมวลผลที่เพียงพอ:
- Edge compute — CPU แบบหลายคอร์ (4–16 cores), RAM (8–64 GB) ขึ้นกับโมเดล, GPU/NPU สำหรับงาน vision/ML แบบเรียลไทม์ (เช่น NVIDIA Jetson, Intel Movidius หรือ industrial GPUs) และหน่วยเก็บข้อมูลแบบ NVMe สำหรับบัฟเฟอร์ชั่วคราว
- เครือข่ายและการซิงก์เวลา — NIC ที่รองรับ hardware timestamping และ PTP (IEEE 1588) สำหรับซิงโครไนซ์แบบไมโครวินาทีในกรณีต้องการ alignment ข้ามเซนเซอร์; หากไม่ต้องการความแม่นยำสูง NTP ก็เพียงพอ
- อินเทอร์เฟซเซนเซอร์ — รองรับ analog/digital IO, EtherCAT, Modbus, CAN, GigE Vision, USB3, MIPI โดยเลือก interface ตาม latency และ determinism ที่ต้องการ
- ความทนทานทางอุตสาหกรรม — กรณีติดตั้งในโซนร้อน/สกปรก ควรใช้เครื่องระดับ IP65–IP67, กราวด์ดิ้ง, และแหล่งจ่ายไฟสำรอง (UPS) สำหรับ edge node
การติดตั้งเชิงปฏิบัติการและการบำรุงรักษา
การติดตั้งต้องคำนึงตำแหน่ง มุมมอง และการป้องกันสัญญาณรบกวน เช่น:
- กล้อง: กำหนดมุมมองและแสงส่องสว่างให้สม่ำเสมอ ใช้เลนส์และฟิลเตอร์ที่เหมาะสม ติดตั้งอย่างมั่นคงเพื่อหลีกเลี่ยง motion blur
- เซนเซอร์สั่นสะเทือน: ยึดติดกับจุดที่เป็นตัวแทนของสภาพเครื่องจริง ลดสัญญาณรบกวนด้วย mount ที่สอดคล้องและใช้สายเคเบิลที่มีการเชื่อมกราวด์
- อุปกรณ์วัดแรงบิด/แรง: ติดตั้งตามคำแนะนำผู้ผลิตและ calibate เป็นระยะ เช่น ทุก 3–6 เดือน ขึ้นกับความถี่การใช้งาน
- RFID/ตำแหน่ง: วางตำแหน่งตัวอ่านเพื่อให้ครอบคลุมเส้นทางและลดการขาดสัญญาณ
นอกจากนี้ต้องมีแผนการบำรุงรักษา (SLA) สำหรับการอัปเดตเฟิร์มแวร์ การสอบเทียบ และการตรวจสุขภาพของเซนเซอร์ (health metrics) เพื่อป้องกันการลื่นไถลของข้อมูลหรือ drift ที่จะส่งผลต่อความเที่ยงตรงของ Digital Twin

การออกแบบ Data Pipeline: รูปแบบข้อมูล เวลา และมาตรการคุณภาพ
Data pipeline ต้องรองรับการไหลของข้อมูลจากเซนเซอร์ไปยัง Edge แล้วส่งต่อไปยังระบบกลาง/คลาวด์ พร้อมกับรักษา latency, determinism และความถูกต้องของเวลา ดังนี้
- Time synchronization — ใช้ PTP (IEEE 1588) สำหรับการซิงค์ระดับไมโครวินาทีในระบบที่ต้องการ alignment ข้ามเซนเซอร์ เช่น การจับภาพพร้อมสัญญาณสั่นสะเทือน ขณะที่ NTP เพียงพอสำหรับการมอนิเตอร์ทั่วไป ควรเปิดใช้งาน hardware timestamping บน NIC และบันทึกทั้ง wall‑clock timestamp และ monotonic timestamp เพื่อป้องกันการย้อนเวลา (time rollback)
- การจัดรูปแบบข้อมูล — แบ่งข้อมูลเป็นสองชั้น: (1) Telemetry / time‑series (เช่น accelerometer, temp, torque) บันทึกด้วยรูปแบบคอลัมน์-แนวเวลา เช่น InfluxDB/Timescale หรือไฟล์ Parquet สำหรับการวิเคราะห์เป็นกลุ่ม และ (2) Event / payload (เช่นภาพ defect, audio clip) เก็บเป็น object (H.264, WAV/Opus, PNG/JPEG) พร้อม metadata ใน JSON/Protobuf (metadata fields: sensor_id, location_id, sampling_rate, units, calibration_date, firmware_version, timezone, mount_angle, health_status)
- มาตรการคุณภาพข้อมูล — มี pipeline สำหรับ cleansing เช่น การลบ duplicate, การกรองสัญญาณรบกวน (band-pass filter สำหรับ vibration), การตรวจจับ outlier, การเติมค่าขาด (interpolation) และการ normalise ค่าย้อนกลับกับการคาลิเบรตเมื่อมีการเปลี่ยนแปลงค่าเบสไลน์
- การลดปริมาณข้อมูล (downsampling) และการบีบอัด — ใช้วิธี decimation, feature extraction (เช่น RMS, FFT bins สำหรับ vibration) ที่ Edge ส่งเฉพาะ features เป็นระยะ แล้วส่ง raw data ก็ต่อเมื่อเกิดเหตุการณ์ (event‑driven capture) สำหรับสื่อภาพ/วิดีโอใช้ H.264/H.265 หรือ JPEG2000; สำหรับเทเลมีทรีใช้ delta encoding + LZ4/Snappy เพื่อลด latency ในการ decompress
- การจัดเก็บแบบ Hot/Cold — ข้อมูลร้อน (hot) เช่น time‑series ล่าสุด 7–90 วันเก็บในฐานข้อมูล time‑series หรือ object store แบบที่เข้าถึงเร็วเพื่อใช้งาน real‑time analytics และเหตุการณ์ที่ต้องตอบสนองทันที ข้อมูลเย็น (cold) เช่น raw video ระยะยาวเก็บใน S3‑class object store และจัดเก็บในรูปแบบ columnar (Parquet) พร้อม lifecycle policy ให้ย้ายไปสู่ Glacier/Archive เพื่อลดต้นทุน
ตัวอย่างนโยบายปฏิบัติการ: เก็บฟีเจอร์สรุปจาก accelerometer เป็นรายวินาทีในฐานข้อมูล time‑series ทุกวัน และเก็บ raw waveform เพียง 24–72 ชั่วโมงบน edge ก่อนย้ายไปยัง object store ถ้าไม่มีเหตุการณ์พิเศษ ขณะที่ภาพ defect เก็บ raw file ไปยัง object store พร้อม metadata สำหรับ traceability
การผสาน Sensor‑Fusion และความปลอดภัยของข้อมูล
เพื่อให้ Digital Twin มีความเที่ยงตรงสูง ต้องออกแบบขั้นตอนการผสานข้อมูล (sensor‑fusion) ที่รวมเวลาและ metadata ก่อนเข้าโมเดล foundation models — การทำ feature alignment จำเป็นต้องอาศัย timestamp ที่เที่ยงตรงและ metadata ที่ครบถ้วน เช่น frame_id, sensor_transform (rigid‑body offsets) และ confidence metrics ต่อมาเลือกนำข้อมูลที่ผ่านการทำความสะอาดและการบีบอัดแล้วเข้า inference pipeline ทั้งบน edge (latency ต่ำ) และ cloud (training / global analytics)
สุดท้าย ต้องปฏิบัติตามหลักความปลอดภัยข้อมูล: การเข้ารหัสช่องทาง (TLS), การยืนยันตัวตนของอุปกรณ์ (certificates), การลงลายเซ็นต์ข้อมูล/metadata เพื่อป้องกันการปลอมแปลง และการจัดการสิทธิ์ในการเข้าถึงข้อมูลตามบทบาท (RBAC) เพื่อคงความน่าเชื่อถือของ Digital Twin ในการตัดสินใจเชิงปฏิบัติการและเชิงพยากรณ์
การผสาน Foundation Models ใน Digital Twin: บทบาทและวิธีใช้งาน
บทบาทของ Foundation Models ใน Digital Twin ทางอุตสาหกรรม
Foundation Models เช่น Large Language Models (LLMs), multimodal transformers และ visual encoders ทำหน้าที่เป็นชั้นวิเคราะห์เชิงบริบทเหนือข้อมูลดิบจาก Digital Twin โดยแปลงสัญญาณเซ็นเซอร์หลายมิติให้เป็นตัวแทนเชิงความหมาย (semantic embeddings) และสร้างการตีความเหตุการณ์เป็นภาษาธรรมชาติที่เข้าใจได้สำหรับผู้ปฏิบัติงานและผู้บริหาร ตัวอย่างการใช้งานเช่นการเชื่อมสัญญาณสั่นสะเทือน (vibration), เสียง (acoustic), อุณหภูมิ (thermal) และภาพจากกล้องความร้อน เข้าด้วยกันแล้วให้โมเดลระบุรูปแบบที่สอดคล้องกับสาเหตุของข้อบกพร่อง ทำให้ระบบ Digital Twin ไม่เพียงแสดงสถานะ แต่ยังอธิบายสาเหตุและเสนอคำแนะนำเชิงปฏิบัติการแบบเรียลไทม์
ตัวอย่าง Use Cases ที่นำเสนอคุณค่าเชิงปฏิบัติการ
ตัวอย่างการประยุกต์ใช้งานที่ชัดเจนได้แก่:
- การแปลสัญญาณหลายช่องเป็นสาเหตุของข้อบกพร่อง — โมเดล multimodal จะรวม embeddings จากสัญญาณสั่นสะเทือน, คลื่นเสียง และภาพเชิงความร้อน เพื่อตรวจจับรูปแบบร่วม (correlated patterns) ที่บ่งชี้การสึกหรอของตลับลูกปืน, การเบียดของเพลา หรือการตั้งชิ้นงานผิดตำแหน่ง ตัวอย่างเชิงปฏิบัติการ: เมื่อค่าพลังงานย่านความถี่เฉพาะเพิ่มขึ้นพร้อมกับ hotspot บนภาพความร้อน โมเดลจะรายงาน "ความเป็นไปได้สูงของการหลวมของตลับลูกปืน — แนะนำหยุดเครื่องเพื่อตรวจสอบและเปลี่ยนชิ้นส่วนภายใน 2 ชั่วโมง"
- การสรุปเหตุการณ์แบบภาษาธรรมชาติสำหรับผู้ปฏิบัติงาน — LLM ที่ fine‑tuned บนพจนานุกรมอุตสาหกรรมและบันทึกการซ่อม จะสร้างสรุปแบบสั้นและชัดเจนสำหรับช่าง เช่น "พบการสั่นผิดปกติที่มอเตอร์ M3 บริเวณช่วงการทำงานที่ 1.2–1.4 kHz; คาดว่าเป็นการหลุดของชุดยางรองแรงสั่น — แนะนำเปลี่ยนยางรองและตรวจสอบ alignment"
- แจ้งเตือนที่อธิบายได้ (explainable alerts) — แทนการส่งสัญญาณเตือนแบบ binary, Foundation Models สามารถรวมข้อมูลการวิเคราะห์สาเหตุ, ความเชื่อมั่น (confidence score) และขั้นตอนการแก้ไขเป็นข้อความที่อธิบายได้ พร้อมอ้างอิงข้อมูลเชิงตัวเลข (เช่น ค่า RMS สั่นสะเทือน, อุณหภูมิสูงสุด) เพื่อให้ผู้รับทราบเหตุผลของการเตือนและระดับความเร่งด่วน
แนวทางการผสานและสถาปัตยกรรมการใช้งาน
การนำ Foundation Models มาเชื่อมกับ Digital Twin ต้องพิจารณาเชิงสถาปัตยกรรมและการทำงานร่วมของระบบ:
- Inference APIs — ใช้ API สำหรับการเรียกใช้งานแบบเรียลไทม์ (low‑latency inference) หรือแบบ batch สำหรับการวิเคราะห์ย้อนหลัง โดยควรออกแบบ pipeline ที่แยก preprocessing ของสัญญาณ (feature extraction, windowing, FFT) ออกจากการเรียกโมเดลเพื่อให้สามารถสเกลได้
- On‑premise vs Cloud — เลือกแบบ on‑premise เมื่อมีข้อจำกัดด้านความเป็นส่วนตัว/ความปลอดภัย หรือความต้องการ latency ต่ำสุด (เช่น การสั่งหยุดเครื่องอัตโนมัติ) ในขณะที่ cloud ให้ประโยชน์ด้านสเกล ความยืดหยุ่น และการอัปเดตโมเดลอย่างรวดเร็ว การออกแบบแบบ hybrid (edge inference + cloud orchestration) มักเป็นทางเลือกที่สมดุล
- การใช้ multimodal embeddings — กำหนดสถาปัตยกรรมที่จัดแนว embeddings จากช่องข้อมูลต่างชนิด (audio, waveform, images, SCADA metrics, PLC events) เข้าสู่เวกเตอร์สเปซร่วมผ่านการเรียนรู้แบบขนานหรือ cross‑modal transformers เพื่อให้ LLM หรือ downstream classifier สามารถดึงบริบทข้ามมิติได้อย่างแม่นยำ
- เทคนิคเพิ่มประสิทธิภาพ — ใช้ quantization, model distillation, หรือตัวเร่งฮาร์ดแวร์ (GPU/TPU/Inference accelerator) และ batching/streaming เพื่อให้การตอบสนองเป็นไปตาม SLA ของการผลิต
การจัดการ Model Lifecycle: Fine‑tuning, Monitoring และ Retraining
เพื่อให้ Foundation Models ให้ผลลัพธ์ที่เชื่อถือได้และมีความแม่นยำต่อสภาพแวดล้อมโรงงาน ควรจัดการวงชีวิตโมเดลดังนี้:
- Fine‑tuning และปรับจูน — เริ่มจากการใช้ pre‑trained models แล้ว fine‑tune ด้วยข้อมูลจำเพาะของโรงงาน (เช่น log การซ่อม, สัญญาณผิดปกติที่ได้รับการยืนยัน) โดยพิจารณาเทคนิคแบบประหยัดทรัพยากรเช่น LoRA, adapters หรือ prompt‑tuning สำหรับ LLM เพื่อลดความต้องการคำนวณและรักษาความเป็นส่วนตัวของข้อมูล
- Prompt Engineering — ออกแบบ prompt ที่มีบริบท (context windows) รวมทั้งตัวอย่างการตอบที่ต้องการ (few‑shot examples) และ template สำหรับข้อความสรุปหรือคำแนะนำเชิงปฏิบัติการ เพื่อให้ผลลัพธ์ของ LLM มีความสอดคล้องเป็นมาตรฐานและสามารถตรวจสอบได้
- การใช้ Embeddings สำหรับการผสานข้อมูลหลายมิติ — สร้างดัชนี embeddings เพื่อการค้นคืนเหตุการณ์ที่คล้ายกัน (similar incident retrieval) และใช้ RAG (retrieval‑augmented generation) เพื่อให้ LLM มีข้อมูลบริบทเชิงประวัติศาสตร์ช่วยประกอบการตัดสินใจ
- Monitoring Drift และการตั้งค่า Retraining Schedule — ติดตาม data drift และ concept drift ด้วยเมตริกเช่น distribution divergence (KS test, population stability index), embedding drift (cosine similarity trend), และ performance degradation บนชุด validation ควรกำหนดนโยบาย retraining ตามระดับความเปลี่ยนแปลง เช่น retrain แบบอัตโนมัติเมื่อ performance ลดลงเกิน 5–10% หรือ schedule retraining ทุก 4–12 สัปดาห์ ขึ้นกับความผันผวนของข้อมูล
- Governance และ Explainability — บันทึกการตัดสินใจของโมเดลและแหล่งข้อมูลที่ใช้ (data lineage), เปิดใช้งานเทคนิคอธิบายเช่น SHAP, attention visualization หรือ chain‑of‑thought ที่ถูกปรับแต่งเพื่อให้การแจ้งเตือนมีคำอธิบายที่ตรวจสอบได้
การผสาน Foundation Models เข้ากับ Digital Twin ไม่ใช่เพียงการเพิ่มชั้น AI แต่เป็นการยกระดับระบบให้สามารถให้เหตุผล อธิบาย และชี้นำการกระทำเชิงปฏิบัติการได้อย่างเป็นรูปธรรม ในสภาพแวดล้อมการผลิตที่ต้องการความรวดเร็วและความน่าเชื่อถือ การออกแบบสถาปัตยกรรมที่คำนึงถึงการผสานข้อมูลหลายมิติ การบริหาร lifecycle ของโมเดล และนโยบายการ deploy ที่เหมาะสมจะเป็นหัวใจสำคัญในการสร้างมูลค่าเชิงธุรกิจอย่างยั่งยืน
การทำ Sensor‑Fusion และ Real‑time Inference: อัลกอริทึมและเทคนิคสำคัญ
แนวทางการรวมข้อมูลจากเซนเซอร์ (Sensor Fusion) และการคัดเลือกฟีเจอร์
การออกแบบระบบ Sensor‑Fusion สำหรับ Digital Twin เชิงอุตสาหกรรมต้องเริ่มจากการกำหนด *representation* ของข้อมูลจากหลายแหล่งอย่างเป็นระบบ ประเด็นสำคัญได้แก่ การจัดการเวลา (timestamp alignment), การปรับเทียบเซนเซอร์ (calibration), การลดมิติ (dimensionality reduction) และการคัดเลือกฟีเจอร์ (feature selection) ที่มีผลต่อการประเมินสถานะของเครื่องจักร ตัวอย่างเทคนิคที่ใช้บ่อยได้แก่ PCA/ICA สำหรับลดมิติแบบไม่กำกับ, mutual information หรือ feature importance จาก tree‑based models เพื่อคัดเลือกฟีเจอร์ที่สัมพันธ์กับค่าตอบสนอง และการเรียนรู้แอตเทนชัน (attention) ภายในโมเดลลึกเพื่อกำหนดน้ำหนักของสัญญาณแต่ละช่องในแบบไดนามิก
ในทางปฏิบัติ โรงงานอาจมีเซนเซอร์หลายร้อยจุดที่ส่งข้อมูลที่ 10–1000 Hz ดังนั้นการกรอง (pre‑filtering), การซิงโครไนซ์ และการบีบอัดเชิงเวลาจึงจำเป็นเพื่อลดภาระของ pipeline ตัวอย่างเช่น ถ้าโรงงานมี 200 ช่องสัญญาณที่ 100 Hz นั่นคือข้อมูลเข้า 20,000 ตัวอย่าง/วินาที — การเลือกเฉพาะฟีเจอร์สำคัญและการสังเคราะห์ฟีเจอร์ (feature aggregation) เป็นกุญแจเพื่อรักษา latency ต่ำและ throughput สูง
รูปแบบการ Fusion: Early, Late และ Hybrid
- Early fusion (concatenate raw features): นำสัญญาณดิบหรือฟีเจอร์ย่อยมารวมเป็นเวกเตอร์เดียวก่อนป้อนเข้าโมเดลเดียว ข้อดีคือโมเดลสามารถเรียนรู้ความสัมพันธ์ข้ามช่องสัญญาณได้เต็มที่ แต่ต้องแลกมาด้วยโมเดลที่ใหญ่ขึ้นและความเสี่ยงต่อ overfitting รวมถึงความอ่อนไหวต่อการขาดข้อมูลช่องใดช่องหนึ่ง
- Late fusion (ensemble of model outputs): ฝังโมเดลย่อยสำหรับแต่ละเซนเซอร์หรือกลุ่มเซนเซอร์ แล้วรวมผลลัพธ์สุดท้ายผ่าน weighted averaging, stacking หรือ meta‑learner ข้อดีคือ modularity ง่ายต่อการทดสอบและอัปเดตแต่ละโมดูล และขึ้นตรงต่อการขาดข้อมูลของโมดูลใดโมดูลหนึ่ง
- Hybrid approaches: ผสมทั้งสอง เช่น ทำ early fusion ภายในกลุ่มเซนเซอร์ที่มีลักษณะคล้ายกัน แล้วใช้ late fusion ระหว่างกลุ่ม ผลลัพธ์คือได้ทั้งความสามารถในการจับความสัมพันธ์เชิงลึกและความยืดหยุ่นเชิงโมดูล
การเลือก strategy ขึ้นกับวัตถุประสงค์: หากต้องการ latency ต่ำสุดและโมเดลที่เล็กกว่า อาจเลือก late fusion พร้อม model pruning; หากต้องการ accuracy สูงสุดในการคาดการณ์เหตุการณ์หายาก อาจใช้ early/hybrid ด้วย attention หรือ cross‑modal transformers
State Estimation และ Smoothing สำหรับ Digital Twin
การประเมินสถานะ (state estimation) ของ Digital Twin จำเป็นต้องรองรับระบบไม่เชิงเส้นและสัญญาณที่มีเสียงรบกวน เทคนิคหลักที่ใช้ได้แก่:
- Kalman Filter (KF) และ Extended Kalman Filter (EKF): KF สำหรับระบบเชิงเส้นและ Gaussian noise; EKF ขยายไปยังระบบไม่เชิงเส้นโดยการ linearize สมการสถานะรอบๆ จุดทำงาน เหมาะกับการประเมินสถานะแบบ low‑dimensional และมีอัตราอัปเดตสูง (เช่น 100–1000 Hz) แต่การ linearization อาจทำให้ประสิทธิภาพลดลงในระบบที่มี nonlinearity รุนแรง
- Particle Filter: เหมาะกับระบบที่มี distribution แบบ multimodal หรือ non‑Gaussian โดยใช้อนุภาคเป็นตัวแทนของ posterior distribution — ตัวอย่างการใช้งานในโรงงานคือ localization ของหุ่นยนต์หรือการติดตามเฟสของกระบวนการ อย่างไรก็ตาม particle count ที่พอเพียง (1000–10000) จะเพิ่มต้นทุนคำนวณและหน่วยความจำ
- Neural state estimators: ใช้ RNN, LSTM, Transformer หรือ Neural ODE ในการเรียนรู้ dynamics จากข้อมูลเชิงเวลา ข้อได้เปรียบคือรองรับ nonlinearity และสามารถเรียน smoothing/denoising ในตัว แต่ต้องการข้อมูลฝึกสอนมากและการตรวจสอบความถูกต้องเพื่อหลีกเลี่ยง drift ในการประเมินระยะยาว
การทำ smoothing เพิ่มความเสถียรของสถานะ เช่น Rauch–Tung–Striebel (RTS) smoother ที่ใช้คู่กับ KF/EKF เพื่อย้อนกลับปรับปรุงค่าที่คาดการณ์แล้ว หรือใช้ windowed smoothing ใน neural estimators เพื่อรวมบริบทเชิงเวลา (เช่น sliding window 100–500 ms) โดยต้องออกแบบให้ไม่ละเมิดข้อจำกัด latency ของระบบ
ออกแบบ Inference Pipeline ให้มี Latency ต่ำและรองรับ High Throughput
การปรับระบบให้ทำงานเรียลไทม์ต้องพิจารณาทั้งซอฟต์แวร์และฮาร์ดแวร์ในมุมของ latency และ throughput พร้อมกัน เทคนิคปฏิบัติที่สำคัญมีดังนี้:
- Micro‑batching และ dynamic batching: ใช้ micro‑batch ขนาดเล็กเพื่อลด latency เมื่อมีคำขอเข้าระบบไม่ต่อเนื่อง และใช้ dynamic batching เมื่อโหลดสูงเพื่อเพิ่ม throughput โดยต้องตั้งนโยบาย timeout/threshold เพื่อควบคุม trade‑off ระหว่าง latency และประสิทธิภาพ
- Model quantization & pruning: เทคนิคเช่น INT8 quantization (post‑training หรือ quantization‑aware training) มักลดขนาดโมเดลได้ ~4× และลด latency 2–4× บนฮาร์ดแวร์ที่รองรับ การ prune และ weight‑sharing ช่วยลดคำนวณโดยไม่กระทบ accuracy มากนัก
- Operator fusion และ graph optimization: ใช้ runtime เช่น TensorRT, ONNX Runtime, TFLite เพื่อรวม operator ลด memory access และ latency — สำคัญสำหรับ pipeline ที่มีหลายโมดูลต่อเนื่อง (e.g., preproc → model → postproc)
- Edge inference accelerators: เลือกฮาร์ดแวร์ตามกรณีใช้งาน — Edge TPU / Coral เหมาะกับโมเดลเล็กและ latency ต่ำ; NVIDIA Jetson/TX/Orin ให้ throughput สูงและรองรับการประมวลผลภาพ; NPU/AI accelerator บน PLC/SoC ช่วยรวมการประมวลผลใกล้แหล่งข้อมูลเพื่อลดแบนด์วิดท์เครือข่าย ตัวอย่างเช่นการdeploy model บน Jetson Orin อาจให้ throughput หลายพัน inference/s สำหรับโมเดลขนาดกลางในขณะที่รักษา latency <50 ms
- Partitioning และ model‑offloading: แยก inference ระหว่าง edge และ cloud — ทำหน้าที่ latency‑sensitive (เช่น state estimation, anomaly detection แบบเรียลไทม์) บน edge และ offload งาน heavy analytics หรือ retraining ไปยังคลาวด์
นอกจากนี้ ต้องออกแบบระบบคิวและ backpressure (เช่น token bucket หรือ leaky queue) เพื่อป้องกัน overload และ latency spike, ทำ warm‑up scripts สำหรับ model เพื่อหลีกเลี่ยง cold start, และติดตั้ง monitoring metrics (p99 latency, throughput, queue length, GPU util) เพื่อควบคุม SLO ของระบบ ในงานที่ต้องการปรับสายการผลิตแบบเชิงคาดการณ์ ค่า latency เป้าหมายทั่วไปคือ 20–100 ms สำหรับการควบคุมแบบ closed‑loop และอาจผ่อนคลายสำหรับงาน analytics แบบ near‑real‑time
บทสรุปเชิงเทคนิค
การผสาน Foundation Models กับ Sensor‑Fusion ใน Digital Twin ของโรงงานยานยนต์ต้องอาศัยการออกแบบหลายชั้น ตั้งแต่การคัดเลือกฟีเจอร์และการซิงโครไนซ์สัญญาณ จนถึงการเลือก strategy ของ fusion (early/late/hybrid) และตัวเลือกของ state estimator (EKF, particle filter, neural estimators) ที่สอดคล้องกับลักษณะ nonlinearity และ noise ของกระบวนการ สุดท้าย การออกแบบ inference pipeline ที่คำนึงถึง batching, quantization, operator fusion และการใช้ edge accelerators จะเป็นปัจจัยตัดสินในการทำให้ระบบทำงานเรียลไทม์ พร้อมรองรับ throughput สูงและรักษา SLO ที่ภาคการผลิตต้องการ
การปรับสายการผลิตเชิงคาดการณ์และการวัดผล (KPIs, ตัวอย่างสถิติ)
การนำผลลัพธ์จาก Digital Twin และ Foundation Models ไปสู่การปรับสายการผลิตเชิงคาดการณ์แบบอัตโนมัติ
เมื่อ Digital Twin แบบเรียลไทม์ทำงานร่วมกับ foundation models และการรวมข้อมูลจาก sensor‑fusion แล้ว ผลลัพธ์หลักที่ได้คือชุดพยากรณ์พารามิเตอร์การตั้งเครื่อง (เช่น ความเร็วรอบ แรงบิด อุณหภูมิการอัดขึ้นรูป) และช่วงค่าที่คาดว่าจะลดของเสียหรือข้อบกพร่องได้ทันที ระบบสามารถแปลงพยากรณ์เหล่านี้เป็นคำสั่งปรับพารามิเตอร์อัตโนมัติ (set‑points) ผ่าน PLC หรือระบบควบคุมกลางโดยมีเงื่อนไขความมั่นใจ (confidence threshold) ของโมเดลเป็นตัวกำกับก่อนส่งคำสั่งจริง
กระบวนการเชื่อมต่อมี 3 ขั้นตอนสำคัญ: (1) วิเคราะห์ฟีเจอร์สำคัญจาก sensor‑fusion และ Digital Twin เพื่อระบุพารามิเตอร์ที่มีผลต่อคุณภาพและเวลาในการตั้งเครื่อง (2) ให้ foundation model พยากรณ์ค่าเป้าหมายของพารามิเตอร์เหล่านั้นพร้อมค่าความไม่แน่นอน (prediction interval หรือ confidence score) และ (3) ส่งคำสั่งปรับอัตโนมัติโดยมี logic ยืนยัน (safety checks) เช่น เงื่อนไขความต่างจากค่าปัจจุบันไม่เกิน X% หรือให้ผู้ควบคุมยืนยัน (human‑in‑the‑loop) หากความเชื่อมั่นต่ำกว่าเกณฑ์
KPIs ที่ต้องวัดและวิธีคำนวณ (ตัวอย่างเชิงตัวเลขและผลลัพธ์ก่อน‑หลัง)
KPIs สำคัญที่ควรติดตามประกอบด้วย Setup Time, Scrap Rate, First Pass Yield (FPY), OEE (Overall Equipment Effectiveness), MTTR และ Prediction Accuracy ของโมเดล ต่อไปนี้เป็นสูตรการคำนวณและตัวอย่างตัวเลขเพื่อประกอบ
- Setup Time (เวลาในการตั้งเครื่อง)
สูตร: Setup Time = เวลารวมที่ใช้ในการเตรียมเครื่อง (นาที) / จำนวนรอบการตั้งเครื่อง
ตัวอย่าง: ก่อนใช้ Digital Twin = 120 นาที/รอบ; หลังปรับอัตโนมัติ = 45–60 นาที/รอบ. การลดลงเชิงเปอร์เซ็นต์: - 120 → 60 = (120−60)/120 × 100 = 50% ลดลง - 120 → 45 = (120−45)/120 × 100 = 62.5% ลดลง (หมายเหตุ: เคสศึกษาและนิยามการวัดอาจรายงานช่วงการลด 37–60% ขึ้นอยู่กับสภาพไลน์และวิธีวัด) - Scrap Rate (อัตราของเสีย)
สูตร: Scrap Rate (%) = (จำนวนชิ้นของเสีย / จำนวนชิ้นผลิตทั้งหมด) × 100
ตัวอย่าง: ก่อน = 8% ของการผลิต; หลัง = 4.8–6% (ลดประมาณ 25–40%). เช่น หากก่อนมีของเสีย 8,000 ชิ้นจาก 100,000 ชิ้น → 8%; หลังเป็น 5,000 ชิ้น → 5% (ลด 37.5%) - First Pass Yield (FPY)
สูตร: FPY (%) = (จำนวนชิ้นที่ผ่านการผลิตโดยไม่ต้อง rework / จำนวนชิ้นผลิตทั้งหมด) × 100
ตัวอย่าง: ก่อน FPY = 92%; หลัง FPY = 95–97% ซึ่งสะท้อนการลด rework และของเสีย - OEE (Overall Equipment Effectiveness)
สูตร: OEE = Availability × Performance × Quality - Availability = (เวลาทำงานจริง / เวลาที่ควรจะทำงาน) - Performance = (จำนวนจริง / จำนวนมาตรฐานในเวลานั้น) - Quality = (จำนวนชิ้นที่ดี / จำนวนชิ้นทั้งหมด) ตัวอย่างก่อน/หลัง (สมมติฐาน): - ก่อน: Availability 85%, Performance 90%, Quality 92% → OEE = 0.85×0.90×0.92 = 70.38% - หลัง: Availability 90%, Performance 93%, Quality 95% → OEE = 0.90×0.93×0.95 = 79.57% ผลลัพธ์: OEE เพิ่มขึ้น ≈ 9.2 percentage points (ประมาณเพิ่ม 13% จากฐานเดิม) - MTTR (Mean Time To Repair)
สูตร: MTTR = เวลารวมในการซ่อมแซม / จำนวนเหตุการณ์ความขัดข้อง ตัวอย่าง: ก่อน MTTR = 60 นาที/เหตุการณ์; หลัง = 40–48 นาที/เหตุการณ์ (ลด downtime 20–30%) - Prediction Accuracy ของโมเดล
วิธีวัด: สำหรับการพยากรณ์เชิงต่อเนื่องใช้ MAE (Mean Absolute Error), RMSE, R²; สำหรับการพยากรณ์เชิงจำแนกใช้ Accuracy, Precision, Recall, F1-score
ตัวอย่างเชิงตัวเลข: โมเดลพยากรณ์เวลา setup มี MAE = 6 นาที, RMSE = 8 นาที, R² = 0.82 → คาดการณ์ค่าได้แม่นยำในระดับการใช้งานจริง ไลน์ผลิตมักตั้งเกณฑ์รับได้ที่ MAE < 10 นาที และ confidence > 0.9 ก่อนให้ระบบปรับอัตโนมัติ
Dashboard การวัดผลเชิงปฏิบัติการและการทดสอบ A/B ก่อนนำไปใช้จริง
การสร้าง dashboard ควรนำเสนอทั้งข้อมูลเรียลไทม์และข้อมูลเชิงสรุปเพื่อการตัดสินใจของฝ่ายการผลิตและวิศวกรรม โดยองค์ประกอบสำคัญได้แก่:
- มุมมอง KPI หัวข้อเดียว: Setup Time, Scrap Rate, FPY, OEE, MTTR พร้อมค่าเปรียบเทียบค่าเฉลี่ยย้อนหลัง 7/30/90 วัน
- ชาร์ตแนวโน้มเวลา (time series) ของพยากรณ์ vs ค่ารีลไทม์ พร้อมช่วงความเชื่อมั่น (prediction intervals)
- แผงแสดงสาเหตุของข้อบกพร่องที่จัดลำดับตามความสำคัญ (root cause ranking) และการเชื่อมโยงไปยัง sensor ที่เกี่ยวข้อง
- ระบบแจ้งเตือนแบบ threshold และ anomaly detection เมื่อโมเดลพยากรณ์ค่าผิดปกติหรือ confidence ต่ำ
- ฟีเจอร์ drill‑down เพื่อดูรายการเหตุการณ์ (event log) ที่โมเดลทำการปรับและผลลัพธ์หลังปรับ
ก่อนขยายใช้งานเต็มรูปแบบ ควรทำ A/B testing บนสายผลิตบางส่วนตามขั้นตอนต่อไปนี้:
- กำหนดกลุ่มตัวอย่าง: แบ่งไลน์/กะเป็น A (control) ไม่ใช้การปรับอัตโนมัติ และ B (treatment) ใช้ Digital Twin + model ปรับอัตโนมัติ
- กำหนดระยะเวลาและขนาดตัวอย่างเพื่อให้มีพลังทางสถิติ (เช่น อย่างน้อย 4‑8 สัปดาห์ ขึ้นกับอัตราการผลิตและความถี่ของการตั้งเครื่อง)
- กำหนด metrics ที่จะเปรียบเทียบล่วงหน้า: Setup Time, Scrap Rate, OEE, MTTR, FPY และความแม่นยำของการพยากรณ์
- รันการทดสอบและวิเคราะห์ผลด้วยสถิติ: ใช้ t‑test หรือ Mann‑Whitney สำหรับค่าเฉลี่ย, chi‑square สำหรับสัดส่วน, และวิเคราะห์ขนาดผล (effect size) เพื่อประเมินความสำคัญเชิงธุรกิจ
- เกณฑ์ยอมรับ: ตัวอย่างเช่น หากกลุ่ม B ลด Setup Time ลงอย่างน้อย 20% และ Scrap Rate ลดลงอย่างน้อย 15% โดยมีค่า p < 0.05 และไม่มีผลกระทบร้ายแรงต่อคุณภาพ ให้ขยายการใช้งาน
- วางแผน rollback และการตรวจสอบผลข้างเคียง: บันทึกทุกการเปลี่ยนแปลงพารามิเตอร์, ระยะเวลา recovery, และ feedback ของผู้ปฏิบัติงาน
โดยสรุป การใช้ Digital Twin แบบเรียลไทม์ผสานกับ foundation models และ sensor‑fusion ทำให้โรงงานสามารถคาดการณ์พารามิเตอร์การตั้งเครื่องและสั่งปรับอัตโนมัติได้อย่างมีหลักการ รองรับการวัดผลด้วย KPI มาตรฐาน และลดเวลา setup, ของเสีย และ downtime ตามตัวอย่างเชิงตัวเลขข้างต้นเมื่อผ่านการทดสอบ A/B ที่มีการควบคุมอย่างเป็นระบบ
คู่มือการนำไปปฏิบัติแบบทีละขั้นตอนและข้อควรระวัง
ภาพรวม Roadmap แบบ 6–12 เดือน (สรุปขั้นตอน)
สำหรับโครงการสร้าง Digital Twin เรียลไทม์ ที่ผสาน Foundation Models กับ Sensor‑Fusion แนะนำ roadmap ระยะสั้น 6–12 เดือน แบ่งเป็นเฟสหลัก 5 ขั้นตอนคือ Assessment → PoC → Pilot Line → Scale Up → Continuous Optimization โดยมีกิจกรรมและเกณฑ์ความสำเร็จชัดเจนในแต่ละเฟสเพื่อควบคุมความเสี่ยงและวัดผลเชิงธุรกิจ (เช่น ลดเวลาตั้งเครื่อง ลดของเสีย เพิ่ม OEE)
- เดือน 0–1 (Assessment): สำรวจความพร้อมด้านโครงสร้างพื้นฐาน เซนเซอร์ ระบบเครือข่าย ข้อมูลประวัติ และปัญหาทางกระบวนการที่ต้องแก้ไข จัดทีมหลักและกำหนด KPI
- เดือน 2–3 (PoC): พัฒนาต้นแบบขนาดเล็กบนสายการผลิตหนึ่งหรือส่วนย่อย ใช้ Sensor‑Fusion เบื้องต้นและ Foundation Model แบบปรับแต่งเล็กน้อย เพื่อตรวจสอบความเป็นไปได้ทางเทคนิคและผลลัพธ์ KPI
- เดือน 4–6 (Pilot Line): ขยาย PoC ไปยังหนึ่งสายการผลิตเต็มรูปแบบ ทดสอบ integration กับ MES/PLC และ workflow ของผู้ปฏิบัติงาน เก็บข้อมูลที่เพียงพอสำหรับฝึกและปรับโมเดล
- เดือน 7–12 (Scale Up): ขยายระบบสู่หลายสายการผลิต/โรงงาน เรียกใช้งาน MLOps, ระบบ monitoring และ governance เต็มรูปแบบ พร้อมแผนสำรองและ disaster recovery
- ต่อเนื่อง: Continuous Optimization — ปรับแต่งโมเดลตาม drift, analytics เพื่อหาโอกาสเพิ่มเติม ลดของเสีย และวัด RoI อย่างต่อเนื่อง
Checklist แบบทีละขั้นตอนสำหรับทีมโรงงาน
ต่อไปนี้เป็น checklist รายการงานที่ควรทำเป็นลำดับ โดยแบ่งตามเฟสงานเพื่อให้ทีมปฏิบัติได้จริงและติดตามความคืบหน้าได้สะดวก
- Assessment:
- ทำแผนที่กระบวนการ (process mapping) และระบุ pain points เช่น ช่วงเวลาตั้งเครื่อง (setup time), สาเหตุของของเสีย (scrap)
- ตรวจสอบโครงสร้างพื้นฐาน IT/OT: bandwidth, edge compute, timestamp synchronization (PTP/NTP)
- ทำการวัดคุณภาพข้อมูล (data inventory): ความถี่ ความครบถ้วน ความถูกต้อง และ latency
- กำหนด KPI ชัดเจน: ลด setup time (%) ลด scrap (%) เพิ่ม throughput หรือ OEE
- Team & Governance:
- แต่งตั้งทีมแกนกลาง: plant engineers, data engineers, ML engineers, MLOps, cybersecurity specialist, change manager
- กำหนดบทบาทและ SLA ภายใน: ใครรับผิดชอบ data ingestion, model retraining, deployment, monitoring
- Technology Selection:
- เลือกแพลตฟอร์ม sensor-fusion (edge vs cloud), data lake/warehouse, และ framework สำหรับ Foundation Models
- ประเมินความเข้ากันได้กับ PLC/MES และการรองรับโปรโตคอล OT (OPC UA, MQTT)
- พิจารณาเรื่อง latency: เฟส real‑time decision อาจต้อง edge inference
- PoC (Proof of Concept):
- กำหนดขอบเขตชัดเจน (1 line, 1 use case เช่น predictive setup or anomaly detection)
- เตรียม dataset ที่เป็นตัวแทนและแยกชุดทดสอบ/เทรน
- สร้าง baseline model และทดสอบด้วย metrics ที่กำหนด (precision, recall, MAE, latency)
- ประเมินผลความคุ้มค่าเชิงธุรกิจก่อนขยาย (expected reduction in setup time, scrap)
- Pilot Line:
- deploy ระบบ monitoring และ logging สำหรับทั้ง data pipeline และ model behavior
- ฝึกอบรมผู้ปฏิบัติงานและซัพพอร์ตช่างเทคนิคในช่วง pilot
- เก็บ feedback loop จาก operator เพื่อปรับ UX และคำแนะนำการตัดสินใจ (actionable recommendations)
- Scale Up & MLOps:
- ตั้งกระบวนการ CI/CD สำหรับโมเดลและซอฟต์แวร์ (automated testing, canary rollout)
- ติดตั้งระบบ monitoring สำหรับ model drift, data quality, latency, resource usage
- กำหนด policy สำหรับ retraining frequency, versioning และ rollback
- Operations & Continuous Optimization:
- กำหนด KPIs รายเดือน/ไตรมาสและ dashboard สำหรับผู้บริหาร
- ตรวจสอบและจัดการ model drift โดยใช้ automated alerts และ scheduled retraining
- จัดกระบวนการ continuous improvement ด้วย A/B testing ของกลยุทธ์การปรับสายการผลิต
ความเสี่ยงหลักและวิธีลดผลกระทบ (Risk & Mitigation)
การนำ Digital Twin และ Foundation Models มาใช้ในโรงงานมีความเสี่ยงหลายมิติ ทั้งเชิงเทคนิคและเชิงมนุษย์ ดังนี้คือประเด็นสำคัญพร้อมแนวทางบรรเทา
- คุณภาพของข้อมูล (Data Quality):
- ความเสี่ยง: ข้อมูลขาด/ผิดพลาด ทำให้โมเดลให้ผลลวง
- Mitigation: ติดตั้ง data validation ที่ edge, ใช้ schema checks, time-series anomaly detection เพื่อป้องกันข้อมูลเสียเข้าสู่ pipeline
- Model Drift และความไม่เสถียรของโมเดล:
- ความเสี่ยง: performance ลดลงเมื่อสภาวะหรือวัตถุดิบเปลี่ยน
- Mitigation: ตั้ง monitoring สำหรับ performance metrics, threshold-based alerts, pipeline สำหรับ retraining โดยใช้ข้อมูลใหม่เป็นระยะ และสร้าง fallback rules (rule-based logic) เมื่อตรวจพบ drift
- การฝึกอบรมและการยอมรับของผู้ปฏิบัติงาน:
- ความเสี่ยง: operator ไม่ยอมรับคำแนะนำจากระบบหรือใช้ผิดวิธี
- Mitigation: จัด training แบบมีส่วนร่วม สาธิตกรณีใช้งานจริง สร้าง KPI ที่รวมคนปฏิบัติงาน และมีช่องทาง feedback เพื่อปรับปรุง UI/UX
- ความปลอดภัยของข้อมูลและไซเบอร์ (Cybersecurity):
- ความเสี่ยง: การรั่วไหลของข้อมูลกระบวนการหรือการโจมตีระบบ OT
- Mitigation: แยกระบบ OT/IT, ใช้ network segmentation, encryption at-rest และ in-transit, MFA, regular penetration testing และ polity สำหรับการเข้าถึงข้อมูล
- กฎหมายแรงงานและความรับผิดชอบ:
- ความเสี่ยง: การนำระบบอัตโนมัติอาจกระทบการจ้างงานหรือสิทธิแรงงาน
- Mitigation: ทำ engagement กับสหภาพแรงงาน แจ้งแผนการเปลี่ยนแปลงล่วงหน้า เสนอการฝึกอาชีพ (upskilling/reskilling) และทำการประเมินผลกระทบต่อแรงงาน (impact assessment)
- Compliance และข้อกำกับดูแลข้อมูล:
- ความเสี่ยง: ผิดกฎหมายคุ้มครองข้อมูลหรือข้อบังคับภาคอุตสาหกรรม
- Mitigation: ตรวจสอบข้อกฎหมายท้องถิ่น/สากล ลงนาม NDA กับซัพพลายเออร์ จัดทำ data governance framework และบันทึก audit trail สำหรับทุกการเปลี่ยนแปลงโมเดล
แนวทางการจัดการ Change Management และการสื่อสาร
การเปลี่ยนแปลงทางเทคโนโลยีต้องมาพร้อมกับการบริหารเปลี่ยนแปลงอย่างเป็นระบบ เพื่อให้การนำ Digital Twin ประสบผลสำเร็จและยั่งยืน
- จัดทำแผนสื่อสาร (communication plan) ที่ชัดเจน แยกระดับผู้รับสาร: ผู้บริหาร ปฏิบัติงานเชิงเทคนิค และผู้ปฏิบัติงานหน้าสาย
- กำหนด early adopters และ champions ภายในโรงงานเพื่อช่วยกระจายการยอมรับ
- จัด training แบบ role-based: การใช้งานหน้าจอคำแนะนำ การอ่าน dashboard การแก้ปัญหาเบื้องต้น และขั้นตอน escalation
- ตั้งช่องทาง feedback และ KPI ที่วัดการยอมรับ เช่น adoption rate, time-to-action หลังระบบแจ้งเตือน
การวัดผลและการดูแลหลังใช้งาน (Operations & KPIs)
หลังจากสเกลระบบแล้ว ต้องมีกระบวนการดูแลรักษาและวัดผลชัดเจนเพื่อให้เกิดผลเชิงธุรกิจอย่างต่อเนื่อง
- KPIs แนะนำ: reduction in setup time (%), reduction in scrap/waste (%), OEE improvement, model precision/recall, mean time to detect anomalies, operator adoption rate
- ตั้ง dashboard แบบ near‑real‑time สำหรับผู้บริหารและทีมปฏิบัติการ พร้อมรายงานสรุปรายสัปดาห์/รายเดือน
- วางแผน MLOps: retraining schedule, data retention policy, model versioning, automated testing และ incident management
- จัด audit และ compliance check เป็นระยะ (quarterly) รวมถึงทบทวนผลกระทบด้านแรงงานและการฝึกอบรมต่อเนื่อง
สรุปแล้ว โครงการ Digital Twin ที่ผสาน Foundation Models กับ Sensor‑Fusion ต้องเริ่มจากการวางแผนเชิงกลยุทธ์ มีทีมที่ครบถ้วน โปร่งใสด้าน governance และมีการบริหารความเสี่ยงเชิงรุก โดยใช้ roadmap 6–12 เดือนเป็นกรอบเวลาเพื่อประเมินผลและขยายผลอย่างมีเหตุผลและยั่งยืน
บทสรุป
การผสาน Digital Twin เรียลไทม์ กับ Foundation Models และ sensor‑fusion สามารถแปลงข้อมูลเซนเซอร์หลายรูปแบบให้เป็นการตัดสินใจเชิงคาดการณ์ที่จับต้องได้ทางธุรกิจ — เช่น ลดเวลาในการตั้งเครื่อง (setup time) และลดของเสีย (scrap/waste) — แต่ผลลัพธ์เชิงปริมาณจะเกิดขึ้นได้เมื่อมีการออกแบบสถาปัตยกรรมข้อมูลและกระบวนการวัดผลอย่างรัดกุม ตัวอย่างจาก PoC ในอุตสาหกรรมยานยนต์ชี้ว่าแนวทางดังกล่าวสามารถลดเวลาเซ็ตอัพได้ในระดับประมาณ 20–40% และลดของเสียได้ในเกณฑ์ 15–30% (ผลแตกต่างตามสภาพสายการผลิตและคุณภาพข้อมูล) โดยปัจจัยสำคัญคือการซิงโครไนซ์ข้อมูลแบบเรียลไทม์, การคาลิเบรตเซนเซอร์, การนิยาม ground truth และการควบคุม latency เพื่อให้โมเดลเชื่อถือได้ทั้งเชิงพยากรณ์และเชิงปฏิบัติการ
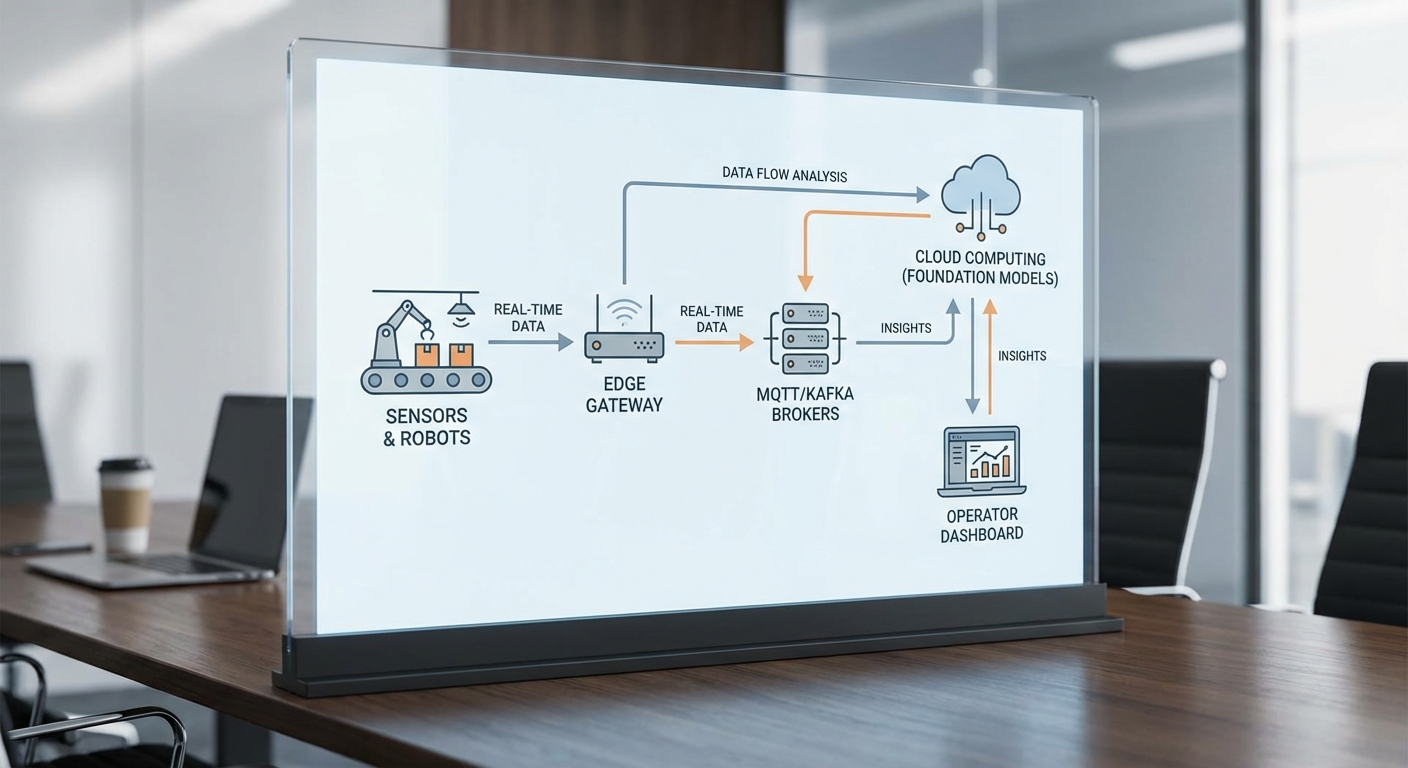
การนำไปใช้งานที่ได้ผลต้องเริ่มจาก PoC ขนาดเล็ก และการวัด KPI อย่างเป็นระบบ — ตัวอย่าง KPI ที่แนะนำได้แก่ OEE (Overall Equipment Effectiveness), เวลาตั้งเครื่อง (setup time), อัตราของเสีย (scrap rate), MTTR/Downtime, ค่าความแม่นยำของการพยากรณ์ (prediction accuracy) และอัตรา false positive/negative ในการแจ้งเตือน ระหว่างรัน PoC ให้เน้น คุณภาพข้อมูล (data quality), การจัดการโมเดล (model governance & MLOps), เวิร์กโฟลว์การ retraining และการตรวจวัด ROI อย่างต่อเนื่อง รวมถึงแผนการเปลี่ยนแปลงองค์กร (change management) เช่น การฝึกทักษะพนักงานและการตั้งทีมข้ามสายงานเพื่อรองรับการตัดสินใจแบบเรียลไทม์
มุมมองอนาคตชี้ว่าเมื่อนำแนวทางนี้ไปสู่การขยายผล โรงงานจะสามารถพัฒนาเป็นระบบควบคุมแบบปิด (closed‑loop control) ที่ปรับสายการผลิตแบบอัตโนมัติ, ผสานข้อมูลกับซัพพลายเชนเพื่อเพิ่มความยืดหยุ่น และใช้เทคนิคเช่น federated learning หรือ continual learning เพื่อปรับตัวแบบต่อเนื่อง การลงทุนมักคืนทุนได้ในช่วงเวลาแตกต่างกัน (มักอยู่ในกรอบ 6–18 เดือนสำหรับการปรับใช้ระดับโรงงาน) แต่ความสำเร็จระยะยาวพึ่งพาการวางมาตรฐานข้อมูล การกำกับดูแลโมเดล และการเปลี่ยนวัฒนธรรมองค์กรให้ยอมรับการตัดสินใจที่ขับเคลื่อนด้วยข้อมูล



