
เตือนสัญญาณสำคัญต่อระบบสุขภาพสหรัฐฯ: เครื่องมือปัญญาประดิษฐ์ที่เริ่มแพร่หลายในการวินิจฉัยและการจัดการผู้ป่วยในแผนกเวชศาสตร์ถูกเปิดเผยว่ามีช่องโหว่ด้านความปลอดภัยและการกำกับดูแล หลังจากรายงานฉบับล่าสุดชี้ว่าเกิดข้อผิดพลาดในการประมวลผลข้อมูลและการตัดสินใจที่ส่งผลกระทบต่อการรักษาจริง ๆ รวมถึงกรณีที่ระบบให้การวินิจฉัยผิดพลาดหรือข้ามปัจจัยเสี่ยงของผู้ป่วย ซึ่งทั้งหมดนี้สะท้อนถึงความเสี่ยงเชิงระบบหากไม่เร่งปฏิรูปการตรวจสอบหลังการนำไปใช้
บทนำนี้จะชี้ประเด็นสำคัญของรายงาน: (1) ความผิดพลาดเชิงเทคนิคและการออกแบบที่พบในการใช้งานจริง, (2) ช่องว่างในการกำกับดูแลหลังการนำ AI มาใช้ในแผนกเวชศาสตร์ ทั้งการตรวจสอบความปลอดภัยและการรายงานเหตุการณ์ไม่พึงประสงค์, และ (3) ข้อเสนอแนะเร่งด่วนจากผู้เชี่ยวชาญ เช่น การตรวจสอบหลังการใช้งานแบบเป็นระบบ การกำหนดมาตรฐานความปลอดภัย และนโยบายระดับชาติที่ชัดเจนเพื่อปกป้องความปลอดภัยของผู้ป่วย หากไม่ดำเนินการทันที ผลกระทบต่อคุณภาพการรักษาและความเชื่อมั่นในระบบสาธารณสุขอาจทวีความรุนแรงขึ้น
ภาพรวมปัญหา: ทำไมต้องเตือนสัญญาณ
ภาพรวมปัญหา: ทำไมต้องเตือนสัญญาณ
การนำปัญญาประดิษฐ์ (AI) เข้ามาใช้ในแผนกเวชศาสตร์ของสหรัฐฯ เป็นทั้งโอกาสทางการแพทย์และความท้าทายด้านความปลอดภัยในเวลาเดียวกัน ในด้านโอกาส AI ช่วยเพิ่มประสิทธิภาพการวินิจฉัย เช่น การอ่านภาพถ่ายรังสี การประเมินผลแลบ และการสนับสนุนการตัดสินใจทางคลินิก ทำให้แพทย์สามารถทำงานได้เร็วขึ้นและลดภาระงานซ้ำซ้อน แต่ในด้านความเสี่ยง การใช้งานที่ขยายตัวอย่างรวดเร็วโดยไม่มีระบบกำกับดูแลที่เข้มแข็งเพียงพอสามารถนำไปสู่ข้อผิดพลาดที่ส่งผลต่อชีวิตผู้ป่วยได้โดยตรง
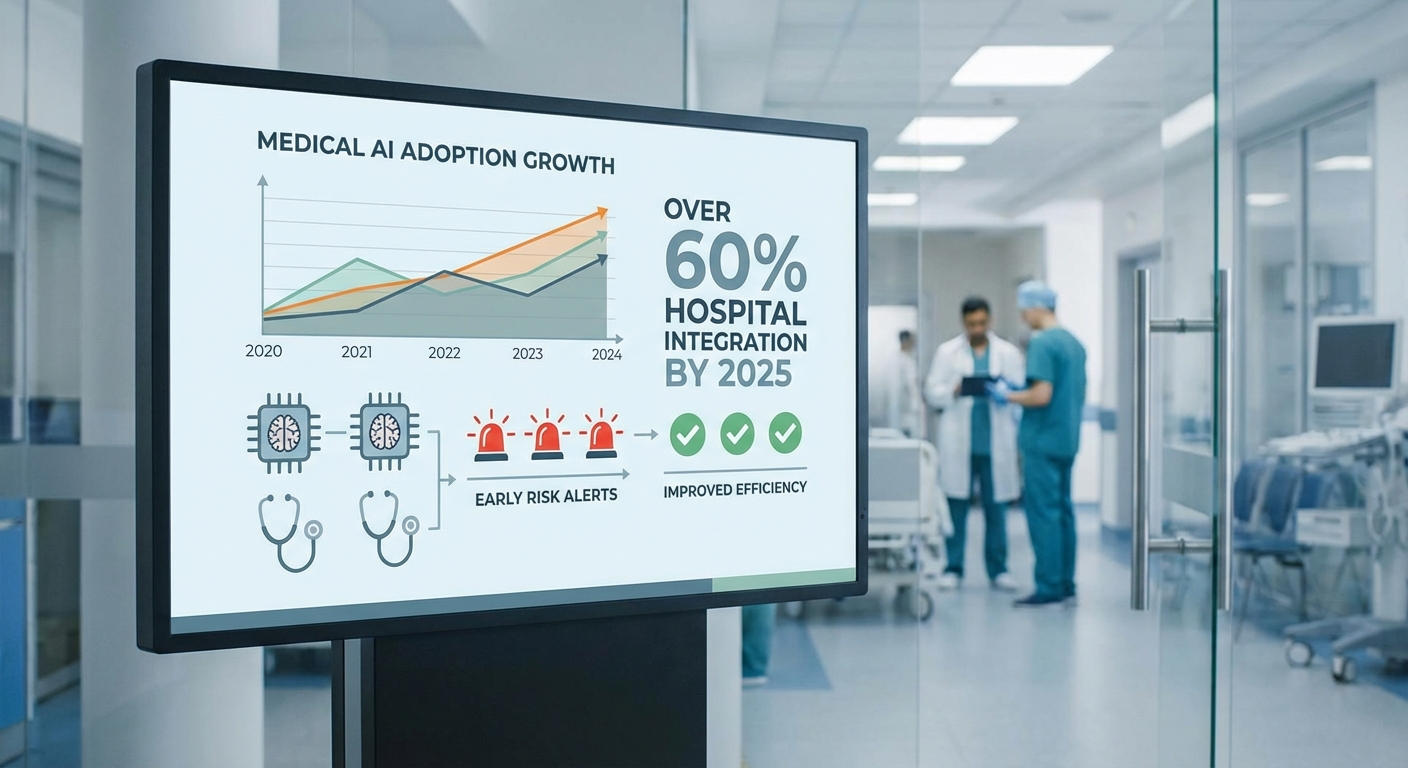
ในช่วงไม่กี่ปีที่ผ่านมา การนำ AI มาใช้ในงานอ่านภาพรังสีและการประเมินผลแลบเติบโตอย่างทวีคูณ—มีการพัฒนาและเปิดตัวซอฟต์แวร์ทางการแพทย์ที่ขับเคลื่อนด้วย AI เป็นจำนวนหลายร้อยรายการจากผู้ผลิตทั้งรายใหญ่และสตาร์ทอัพ การนำไปใช้งานในโรงพยาบาลขนาดกลางถึงใหญ่เพิ่มขึ้นชัดเจน โดยเฉพาะระบบที่ช่วยตรวจหาความผิดปกติในภาพเอกซเรย์หรือ CT ซึ่งช่วยลดเวลาเฉลี่ยในการรายงานผล อย่างไรก็ตาม การเติบโตนี้มาพร้อมกับรายงานเหตุการณ์ความผิดพลาดและการถอนการรับรองซอฟต์แวร์จากบางผู้ผลิต ซึ่งกระตุ้นคำถามต่อความน่าเชื่อถือของผลลัพธ์และกระบวนการประเมินความปลอดภัยก่อนนำสู่การใช้งานจริง
ตัวอย่างเหตุการณ์ล่าสุดที่ทำให้เกิดการถกเถียงอย่างกว้างขวาง ได้แก่กรณีซอฟต์แวร์วิเคราะห์ภาพถูกรายงานว่ามีอัตราการพลาดการวินิจฉัยในกลุ่มผู้ป่วยบางกลุ่ม และการที่บางชิ้นส่วนซอฟต์แวร์ถูกถอนการรับรองหรือเรียกคืนจากตลาดโดยผู้ผลิตหรือหน่วยงานกำกับ สิ่งเหล่านี้ชี้ให้เห็นถึงช่องว่างในกระบวนการทดสอบภายใต้เงื่อนไขต่าง ๆ และความไม่แน่นอนของผลการทำงานเมื่อระบบ AI ถูกใช้งานกับประชากรผู้ป่วยที่หลากหลาย
เหตุผลที่ต้องเน้นการกำกับดูแล มีความชัดเจนและเร่งด่วน: ผลกระทบจากความผิดพลาดของระบบ AI สามารถเป็นอันตรายต่อชีวิตผู้ป่วยได้โดยตรง และยังส่งผลกระทบต่อความเชื่อมั่นของประชาชนต่อระบบสาธารณสุข การขาดมาตรการกำกับดูแลที่ชัดเจนอาจนำไปสู่การใช้งานเครื่องมือที่ไม่ได้รับการยืนยันความปลอดภัยในบริบทการรักษาจริง ดังนั้น การพัฒนามาตรฐานการประเมิน ความโปร่งใสของอัลกอริทึม การติดตามหลังการใช้งาน (post-market surveillance) และการบังคับใช้การรายงานเหตุการณ์ความปลอดภัย จึงเป็นสิ่งจำเป็นเพื่อปกป้องผู้ป่วยและรักษาความเชื่อมั่นของสาธารณะ
- ผลกระทบต่อผู้ป่วย: ข้อผิดพลาดในการวินิจฉัยหรือการตัดสินใจที่อิง AI อาจนำไปสู่การวินิจฉัยผิดพลาด การรักษาที่ไม่เหมาะสม หรือความล่าช้าในการรักษา
- ผลกระทบต่อระบบสาธารณสุข: เหตุการณ์ความปลอดภัยที่เกิดขึ้นซ้ำ ๆ จะลดความเชื่อมั่นและอาจนำไปสู่การชะลอหรือยกเลิกการนำเทคโนโลยีที่มีศักยภาพไปใช้
- ความจำเป็นเชิงกำกับ: ต้องมีการกำหนดมาตรฐานการทดสอบ การตรวจสอบหลังการวางตลาด และข้อบังคับที่ตอบโจทย์ความหลากหลายของผู้ป่วย รวมถึงมาตรการความโปร่งใสและการตรวจสอบโดยบุคคลที่สาม
หลักฐานเชิงสถิติและกรณีตัวอย่าง
หลักฐานเชิงสถิติและกรณีตัวอย่าง
ข้อมูลเชิงสถิติจากฐานข้อมูลและงานวิจัยล่าสุดชี้ชัดว่าปัญหาเกี่ยวกับเครื่องมือซอฟต์แวร์ทางการแพทย์และระบบปัญญาประดิษฐ์ (AI) ที่ใช้งานในสหรัฐฯ มีแนวโน้มเพิ่มขึ้น ทั้งในแง่จำนวนเหตุการณ์ที่ถูกรายงานต่อหน่วยงานกำกับดูแลและงานวิจัยเชิงระบบที่ประเมินผลกระทบต่อผู้ป่วย ตัวอย่างเช่น การวิเคราะห์ฐานข้อมูลการแจ้งเหตุอุปกรณ์การแพทย์ขององค์การอาหารและยาสหรัฐฯ (FDA MAUDE / Medical Device Reports) แสดงให้เห็นการเพิ่มขึ้นของการแจ้งเตือนหรือรายงานที่เกี่ยวข้องกับซอฟต์แวร์การแพทย์ในช่วงไม่กี่ปีที่ผ่านมา — งานวิเคราะห์หลายชิ้นรายงานการเติบโตของการแจ้งเหตุที่เกี่ยวข้องกับซอฟต์แวร์อยู่ในช่วงประมาณ 30–60% เมื่อเปรียบเทียบช่วงสามปีล่าสุด (อ้างอิง: FDA MAUDE; รายงานการวิเคราะห์เชิงระบบที่สังเคราะห์ข้อมูลฐานข้อมูล MDR)
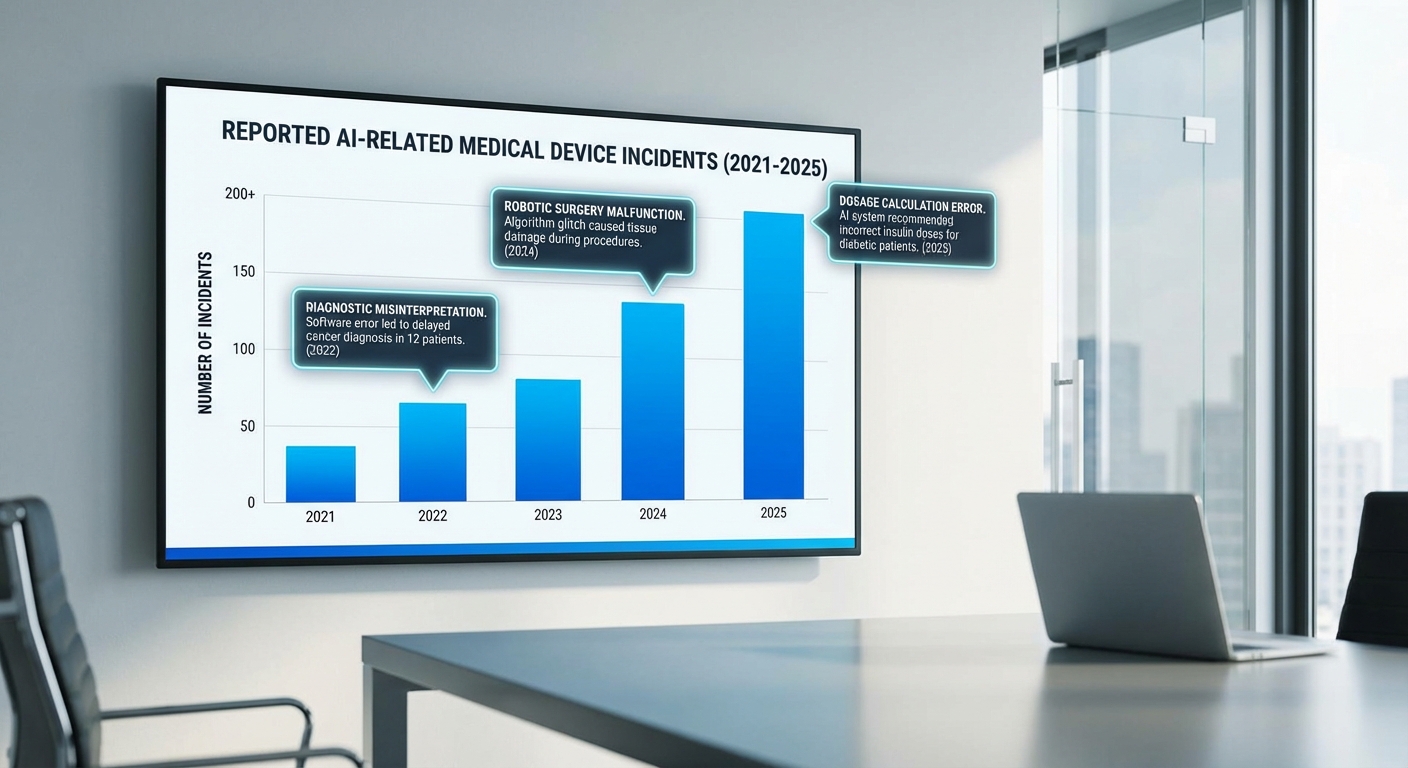
งานวิจัยเชิงระบบและรีวิวจากกลุ่มนักวิชาการยังชี้ว่าอัตราข้อผิดพลาดของโมเดล AI ที่นำไปสู่ผลลัพธ์ทางคลินิกที่ไม่พึงประสงค์ไม่ใช่เรื่องเล็กน้อย ตัวอย่างรายงานวิชาการชั้นนำ (เช่นงานที่ศึกษาผลกระทบของอัลกอริธึมต่อการจัดสรรทรัพยากรทางการแพทย์) ระบุว่ามีกรณีของ bias และความไม่สามารถทั่วไป (lack of generalizability) ของโมเดลที่ส่งผลให้เกิดการประเมินความเสี่ยงหรือระดับความรุนแรงของโรคผิดพลาดในกลุ่มผู้ป่วยย่อย — ส่งผลต่อการตัดสินใจรักษาและการจัดสรรทรัพยากร ตัวเลขสำคัญจากการสังเคราะห์งานวิจัยชี้ว่าอย่างน้อยในจำนวนการประเมินหลายร้อยกรณี พบการตัดสินใจที่ผิดพลาดหรือไม่เหมาะสมจากระบบอัตโนมัติในระดับที่เพียงพอจะกระทบต่อความปลอดภัยของผู้ป่วย (อ้างอิง: งานวิจัยเชิงระบบและรายงานจากหน่วยงานที่เกี่ยวข้อง)
ตัวอย่างเคสจริง (กรณีศึกษา)
- กรณีอัลกอริธึมจัดลำดับผู้ป่วย (triage) ที่มีอคติทางเชื้อชาติ: งานศึกษาเชิงสถิติที่เป็นที่อ้างอิงในวงการสาธารณสุขเผยแพร่ในวารสารวิชาการระบุว่าอัลกอริธึมหนึ่งที่ใช้ประเมินความจำเป็นในการให้บริการสุขภาพชุมชนชี้ชวนให้เกิดการประเมินความเสี่ยงต่ำกว่าความเป็นจริงสำหรับผู้ป่วยผิวดำ ผลลัพธ์คือผู้ป่วยกลุ่มนี้ได้รับการส่งต่อและการเข้าถึงการรักษาน้อยลงเมื่อเทียบกับผู้ป่วยผิวขาว ซึ่งนำไปสู่การเลื่อนการรักษาและเพิ่มความเสี่ยงต่อภาวะแทรกซ้อน (อ้างอิง: Obermeyer et al., Science 2019 และการวิเคราะห์ภายหลัง)
- กรณีการแนะนำแผนการรักษาที่ไม่สอดคล้องกับบริบทผู้ป่วย: มีรายงานข่าวและการสืบสวนจากสื่อวิชาชีพที่ชี้ว่าเครื่องมือ AI ในระบบให้คำแนะนำการรักษาในโรงพยาบาลบางแห่งให้การรักษาเชิงรุกหรือยาที่ไม่เหมาะสมกับภาวะร่วมของผู้ป่วย ส่งผลให้มีการให้การรักษาที่ไม่จำเป็นและเกิดผลข้างเคียง บางกรณีผู้ป่วยต้องเข้ารับการรักษาเพิ่มเติมหรือการรักษาแบบประคับประคองเพิ่มขึ้น (อ้างอิง: สื่อสืบสวนด้านการแพทย์ และรายงานภายในองค์กรที่เผยแพร่ต่อสาธารณะ)
- กรณีการวินิจฉัยผิดพลาดจากโมเดลภาพทางรังสีวิทยา: มีเคสตัวอย่างจากหน่วยงานวิจัยที่รายงานว่าโมเดลตรวจอ่านภาพรังสีบางรุ่นให้ผลบวก-ลบเท็จในผู้ป่วยกลุ่มที่มีเงื่อนไขร่วมหรือภาพที่มีคุณภาพต่ำ ส่งผลให้เกิดการเลื่อนหรือพลาดโอกาสในการผ่าตัด/การรักษาเฉพาะจุด บางรายงานชี้ว่าการยึดมั่นในการอ่านผลจาก AI โดยไม่ตรวจสอบโดยแพทย์เพิ่มความเสี่ยงของความล่าช้าในการวินิจฉัย
ผลลัพธ์ที่เกิดขึ้นต่อผู้ป่วย
จากสถิติและกรณีตัวอย่างข้างต้น ผลกระทบต่อผู้ป่วยครอบคลุมตั้งแต่การเลื่อนการรักษา (delayed care), การได้รับการรักษาที่ไม่จำเป็น (เช่นการได้รับยาหรือหัตถการที่ไม่เหมาะสม), ไปจนถึงภาวะแทรกซ้อนที่รุนแรงขึ้นซึ่งต้องการการรักษาเพิ่มเติมหรือการนอนโรงพยาบาลนานขึ้น งานสังเคราะห์ข้อมูลจากฐานรายงานเหตุการณ์ของ FDA และการรีวิวทางวิชาการชี้ว่าความเสี่ยงเหล่านี้สามารถแปลเป็นภาระด้านสุขภาพและต้นทุนทางการแพทย์ที่เพิ่มขึ้น และยังสะท้อนถึงช่องว่างในการกำกับดูแล การทดสอบเชิงคลินิกที่ไม่เพียงพอ และการขาดมาตรการตรวจสอบหลังการวางตลาด (post-market surveillance) ที่เข้มแข็ง (อ้างอิง: FDA MAUDE, รายงานเชิงวิชาการ และรายงานสืบสวนจากสื่อวิชาชีพ)
ช่องว่างด้านกฎระเบียบและการกำกับดูแล
ช่องว่างด้านกฎระเบียบและการกำกับดูแล
ในสหรัฐอเมริกา กรอบกฎหมายที่เกี่ยวข้องกับซอฟต์แวร์การแพทย์ (software as a medical device — SaMD) และระบบปัญญาประดิษฐ์ในคลินิกอยู่ภายใต้การกำกับของหลายหน่วยงานหลัก ได้แก่ สำนักงานคณะกรรมการอาหารและยา (FDA), The Joint Commission และกฎหมายความเป็นส่วนตัวอย่าง HIPAA อย่างไรก็ดี ข้อกังวลสำคัญเกิดจากช่องโหว่ในขอบเขตอำนาจและกระบวนการกำกับดูแลที่ออกแบบมาสำหรับอุปกรณ์แบบดั้งเดิม มากกว่าระบบซอฟต์แวร์ที่มีลักษณะเรียนรู้และเปลี่ยนแปลงได้ตลอดเวลา
ขอบเขตอำนาจของ FDA และปัญหาการจัดประเภท SaMD — FDA มีอำนาจในการกำกับดูดซอฟต์แวร์ที่ถูกจัดว่าเป็นอุปกรณ์การแพทย์ แต่การจับจุดว่า “ซอฟต์แวร์ใดคืออุปกรณ์การแพทย์” ยังคงมีความไม่ชัดเจน สถานะของซอฟต์แวร์มักถูกกำหนดจากคำอ้างอิงทางการแพทย์และความเสี่ยงต่อผู้ป่วย ซึ่งทำให้เกิดช่องว่างเมื่อต้องประเมินเครื่องมือ AI ที่ทำหน้าที่เป็นตัวช่วยตัดสินใจมากกว่าการวินิจฉัยโดยตรง ตัวอย่างเช่น ซอฟต์แวร์ที่วิเคราะห์ภาพหรือให้คำแนะนำการรักษาบางกรณีจะถูกจัดเข้าข่าย SaMD ในขณะที่แอปพลิเคชันอื่นที่ทำงานใกล้เคียงกันอาจถูกยกเว้น ทำให้มาตรฐานการตรวจสอบและการทดสอบไม่สม่ำเสมอ
การอนุมัติแบบ pre-market (เช่น 510(k)) และข้อจำกัดในการสะท้อนการใช้งานจริง — ประวัติการอนุมัติอุปกรณ์การแพทย์ของสหรัฐฯ แสดงให้เห็นว่าอุปกรณ์จำนวนมากได้รับการอนุมัติผ่านกระบวนการ 510(k) ซึ่งเป็นเส้นทางที่เน้นการเปรียบเทียบความเทียบเท่ากับอุปกรณ์เดิม มากกว่าการพิสูจน์ประสิทธิผลทางคลินิกภายใต้สภาพแวดล้อมจริง ประมาณร้อยละ 80–90 ของการนำเข้าสู่ตลาดอุปกรณ์การแพทย์ผ่านช่องทางนี้ ซึ่งสะท้อนว่าหลายระบบซอฟต์แวร์ที่ได้รับการ “cleared” อาจไม่ได้รับการทดสอบในสภาพคลินิกที่หลากหลายหรือในสภาพการณ์ที่เกิดเหตุการณ์ผิดปกติ ตัวอย่างเช่น เครื่องมือ AI ที่ให้ผลแม่นยำในการทดลองภายใต้ชุดข้อมูลที่คัดกรอง แต่เมื่อใช้งานจริงในโรงพยาบาลที่ข้อมูลผู้ป่วยและกระบวนการทางคลินิกแตกต่างออกไป กลับแสดงผลลัพธ์ที่ลดลงหรือเกิดความเสี่ยงต่อผู้ป่วย
การตรวจสอบหลังการวางระบบ (post-market surveillance) ที่ไม่เพียงพอ — แม้ FDA จะมีระบบรายงานเหตุการณ์ไม่พึงประสงค์ เช่น ฐานข้อมูล MAUDE และโปรแกรม MedSun แต่การใช้งานจริงเผยข้อจำกัดชัดเจน: การรายงานจากผู้ใช้ปลายทาง (เช่น แพทย์ พยาบาล หรือโรงพยาบาล) มักไม่ครบถ้วนหรือไม่ต่อเนื่อง การรายงานบางส่วนเป็นภาระสำหรับบุคลากรทางการแพทย์และอาจละเลยเมื่อเหตุการณ์เกี่ยวกับการตัดสินใจของระบบ AI มีสาเหตุร่วมจากหลายปัจจัย นอกจากนี้ กฎบังคับให้ผู้ผลิตรายงานเหตุการณ์นั้นมีขอบเขตจำกัด และสำหรับกรณีที่ซอฟต์แวร์มีการอัปเดตบ่อยครั้งหรือเป็นระบบเรียนรู้ต่อเนื่อง การติดตามผลต่อเนื่องเชิงประสิทธิภาพ (real-world performance metrics) ยังขาดมาตรฐานที่ชัดเจน
- การจัดประเภทที่ไม่แน่นอน — ทำให้การบังคับใช้มาตรฐานการทดสอบและการพิสูจน์ความปลอดภัยไม่สม่ำเสมอ
- 510(k) มุ่งเป้าไปที่ความเทียบเท่า — ไม่ได้ชี้ชัดถึงประสิทธิผลทางคลินิกในบริบทการใช้งานจริง ทำให้ความเสี่ยงแฝงอาจไม่ถูกค้นพบจนกว่าจะมีการใช้งานอย่างแพร่หลาย
- การรายงานเหตุการณ์ไม่เพียงพอ — ระบบรายงานปัจจุบันมีช่องว่าง ทั้งในแง่ความสม่ำเสมอ คุณภาพของข้อมูล และแรงจูงใจในการรายงานจากผู้ใช้งาน
- ขาดมาตรฐานการเฝ้าระวังประสิทธิภาพ AI — ไม่มีข้อบังคับที่ชัดเจนเกี่ยวกับเมตริกการติดตาม เช่น ความล้า (drift) ของโมเดล, การบ่งชี้ความคลาดเคลื่อนของข้อมูล, หรือข้อกำหนดในการทดสอบหลังการอัปเดต
ผลลัพธ์รวมแล้วคือความเสี่ยงที่ระบบ AI จะถูกนำไปใช้ในสภาพแวดล้อมคลินิกโดยไม่มีการประเมินผลในระยะยาวและไม่มีกลไกการแก้ไขที่มีประสิทธิภาพเมื่อเกิดปัญหา เพื่อเสริมความปลอดภัยต่อผู้ป่วย จำเป็นต้องมีการปรับปรุงกรอบกฎระเบียบทั้งในส่วนของการจัดประเภท SaMD, การกำหนดมาตรฐานการทดสอบก่อนนำออกสู่ตลาดที่สะท้อนการใช้งานจริง และการสร้างระบบตรวจสอบหลังตลาดที่บังคับใช้ได้จริง รวมถึงมาตรการด้านความโปร่งใสของข้อมูลและการรายงานที่เอื้อต่อการติดตามและแก้ไขปัญหาอย่างทันท่วงที
ความเสี่ยงเชิงคลินิก: จุดบกพร่องที่ส่งผลต่อผู้ป่วย
ความเสี่ยงเชิงคลินิก: จุดบกพร่องที่ส่งผลต่อผู้ป่วย
เมื่อระบบปัญญาประดิษฐ์ (AI) ถูกผนวกเข้าเป็นส่วนหนึ่งของการวินิจฉัยและการตัดสินใจทางคลินิก ความเสี่ยงเชิงคลินิกที่เกิดขึ้นไม่ได้เป็นเพียงเรื่องเทคนิคเท่านั้น แต่มีผลโดยตรงต่อผลลัพธ์ของผู้ป่วย การเกิด false negative หรือ false positive สามารถเปลี่ยนแปลงเส้นทางการรักษา การส่งต่อ และทรัพยากรที่ใช้ในระบบสุขภาพได้อย่างมีนัยสำคัญ ตัวอย่างเช่น การพลาดการตรวจพบอาการของโรคหลอดเลือดสมอง (false negative) อาจทำให้พลาดหน้าต่างการให้ยาละลายลิ่มเลือด (tPA) ขณะที่การแจ้งเตือนผิดพลาด (false positive) ในระบบคัดกรองมะเร็งอาจนำไปสู่การตรวจเพิ่มเติมที่ไม่จำเป็น การผ่าตัดหรือการส่งตัวผู้ป่วยข้ามศูนย์ที่อาจเพิ่มความเสี่ยงและค่าใช้จ่ายโดยรวม
งานวิจัยและรายงานเชิงประจักษ์ระบุว่าอัตรา false negatives และ false positives ในโมเดลด้านรังสีวินิจฉัยและการคัดกรองมีค่ากระจัดกระจายอยู่ในช่วงที่กว้าง (ตัวอย่างเช่น 5–25% ขึ้นอยู่กับงานและชุดข้อมูล) ซึ่งผลกระทบที่เกิดขึ้นไม่ได้วัดเพียงตัวเลข แต่รวมถึงผลต่อการตัดสินใจเชิงคลินิก เช่น การเลื่อนนัด การส่งต่อผู้ป่วยไปยังศูนย์การดูแลเฉพาะทาง และการเปลี่ยนแปลงแผนการรักษา องค์กรสุขภาพที่พึ่งพาการตัดสินใจแบบอัตโนมัติอาจพบว่าอัตราความผิดพลาดเล็กน้อยก็สามารถสะสมจนเกิดความเสี่ยงด้านความปลอดภัยอย่างมีนัยสำคัญ
อีกปัจจัยสำคัญคือ ความลำเอียง (bias) ของโมเดล ซึ่งมักเกิดจากชุดข้อมูลเทรนนิ่งที่ไม่เป็นตัวแทนของประชากรในโลกจริง เมื่อข้อมูลฝึกสอนมีการกระจุกตัวตามเชื้อชาติ เพศ อายุ หรือกลุ่มทางสังคม เงื่อนไขของผู้ป่วยบางกลุ่มจะถูกตีความผิดพลาดหรือถูกละเลย งานวิจัยคลาสสิก เช่น กรณีที่แสดงว่าระบบคัดกรองบางระบบให้คะแนนความต้องการการดูแลสำหรับผู้ป่วยกลุ่มคนผิวดำต่ำกว่าความเป็นจริง เป็นตัวอย่างที่ชี้ให้เห็นว่าผลลัพธ์ทางคลินิกอาจเสื่อมสภาพสำหรับกลุ่มเปราะบาง ผลที่ตามมาคือการเข้าถึงการรักษาที่ลดลง การวินิจฉัยล่าช้า และความไม่เป็นธรรมทางสุขภาพ
การขาดความสอดคล้องด้านข้อมูลและการเชื่อมต่อกับระบบข้อมูลคนไข้ (EHR) ยังเพิ่มความเสี่ยงเชิงคลินิกอีกระดับหนึ่ง ปัญหาที่พบบ่อยได้แก่ ฟอร์แมตข้อมูลไม่ตรงกัน ข้อมูลเมตาที่หายไป การแมปโค้ดโรค/หัตถการไม่ถูกต้อง และภาวะ data drift เมื่อสภาพประชากรหรือแนวทางการรักษาเปลี่ยน ระบบ AI ที่ไม่ได้รับการอัปเดตหรือทวนสอบกับข้อมูลจริงจาก EHR จะให้คำแนะนำที่ไม่สอดคล้องกับเวิร์กโฟลว์ของทีมคลินิก ผลที่ตามมาคือการเพิ่มขั้นตอนงาน (workload) ของบุคลากร เกิดการละเลยการแจ้งเตือนสำคัญ และทำให้เกิดความล่าช้าในการตอบสนองต่อภาวะฉุกเฉิน
ในสถานการณ์ฉุกเฉินเมื่อระบบ AI ล้มเหลวหรือให้ข้อมูลที่ขัดแย้ง ผู้ป่วยอาจได้รับผลกระทบหนักหากไม่มีแผนสำรองที่ชัดเจน ได้แก่ การขาดนโยบายการสลับไปใช้การตัดสินใจโดยแพทย์มนุษย์ การไม่มีช่องทางสื่อสารที่รวดเร็วระหว่างทีม การขาดการฝึกอบรมการโอเวอร์ไรด์คำสั่งของระบบ หรือการบันทึกเหตุการณ์ไม่เพียงพอ สถานการณ์ดังกล่าวทำให้การจัดลำดับความสำคัญของเคสฉุกเฉินผิดพลาดและเพิ่มความเสี่ยงต่อเหตุไม่พึงประสงค์
- ผลกระทบจาก false negative/positive: ผู้อำนวยการรักษาอาจตัดสินใจช้า/ผิดพลาด ส่งผลต่อการใส่เครื่องมือรักษา การส่งต่อผู้ป่วย และค่าใช้จ่ายที่เพิ่มขึ้น
- Bias จากข้อมูลเทรนนิ่ง: การวินิจฉัยหรือการให้คำแนะนำที่ด้อยกว่าสำหรับกลุ่มเชื้อชาติ เพศ หรือกลุ่มอายุหนึ่ง ๆ นำไปสู่ความไม่เป็นธรรมและผลลัพธ์ทางสุขภาพที่แย่ลง
- Interoperability และเวิร์กโฟลว์: การเชื่อมต่อกับ EHR ที่ไม่สมบูรณ์ ทำให้การแจ้งเตือนไม่สอดคล้อง เกิดการทำงานซ้ำซ้อน และลดประสิทธิภาพของทีมคลินิก
- การจัดการกรณีฉุกเฉิน: หากไม่มีแผนรับมือ ระบบล้มเหลวอาจทำให้ผู้ป่วยพลาดการรักษาเร่งด่วน การซ้อมแผนและการกำหนดบทบาทรับผิดชอบเป็นสิ่งจำเป็น

สาเหตุทางเทคนิคที่ทำให้ AI ขาดความน่าเชื่อถือ
สรุปภาพรวมของปัญหาทางเทคนิค
ในบริบทของแผนกเวชศาสตร์ที่นำเครื่องมือปัญญาประดิษฐ์ (AI) มาใช้เพื่อการวินิจฉัย การตัดสินใจรักษา หรือการคัดกรองผู้ป่วย ความน่าเชื่อถือของโมเดลถูกกำหนดโดยปัจจัยทางเทคนิคหลายประการ ได้แก่ data drift, การขาดการทดสอบแบบภายนอก (external validation), ภาวะ overfitting, ข้อจำกัดด้านความโปร่งใสในการอธิบายผลลัพธ์ (explainability) และคุณภาพของข้อมูลต้นทาง ปัญหาเหล่านี้ไม่เพียงทำให้ประสิทธิภาพโมเดลลดลง แต่ยังเสี่ยงต่อความปลอดภัยของผู้ป่วยและการตัดสินใจทางคลินิกที่ผิดพลาดได้
Data drift — เมื่อโลกเปลี่ยนและโมเดลไม่ตามทัน
Data drift เกิดขึ้นเมื่อการกระจายของข้อมูลที่ใช้ป้อนโมเดลในภาคสนามเบี่ยงเบนไปจากข้อมูลที่ใช้ฝึกสอน (training data) ซึ่งอาจเป็นผลมาจากการเปลี่ยนแปลงในประชากรผู้ป่วย นโยบายการตรวจรักษา เทคโนโลยีการตรวจ หรือการเข้าถึงบริการสุขภาพ ตัวอย่างเช่น โมเดลคัดกรองภาวะหัวใจล้มเหลวที่ฝึกด้วยข้อมูลผู้ป่วยเพศชายวัยกลางคนอาจทำงานได้ไม่ดีเมื่อนำไปใช้กับชุมชนสูงอายุหรือผู้หญิง การเปลี่ยนแปลงเช่นนี้ถ้าไม่ถูกตรวจจับจะทำให้อัตราการผิดพลาดเพิ่มขึ้นและเกิดผลกระทบร้ายแรงต่อผู้ป่วย
การตรวจจับและวัดระดับ data drift ควรใช้ทั้งการทดสอบเชิงสถิติ (เช่น Kolmogorov–Smirnov test สำหรับตัวแปรเชิงตัวเลข, Chi-square test สำหรับตัวแปรเชิงหมวดหมู่) และเมตริกเชิงปริมาณเช่น Population Stability Index (PSI) ซึ่งทั่วไปถือว่า PSI > 0.2 เป็นสัญญาณของการ drift ที่มีนัยสำคัญ นอกจากนี้เทคนิคการวัดระยะทางระหว่างการกระจายข้อมูล เช่น Earth Mover's Distance (EMD) หรือตรวจสอบค่าผิดปกติ (outlier detection) เป็นเครื่องมือที่ควรบูรณาการในระบบมอนิเตอร์
การขาดการทดสอบแบบภายนอกและการประเมินในบริบทจริง
โมเดลที่ผ่านการทดสอบเฉพาะบนชุดข้อมูลภายใน (internal validation) มักให้ค่าประสิทธิภาพสูงกว่าความเป็นจริงเมื่อนำไปใช้ภายนอก เนื่องจากความแตกต่างของประชากร เทคนิคการเกินคาดหวัง เช่น cross-validation ภายในชุดเดียวกันไม่สามารถทดแทนการทดสอบในสถานการณ์จริงได้ การทดสอบแบบ external validation ควรรวมถึงการตรวจสอบโมเดลกับข้อมูลจากหลายศูนย์การแพทย์ (multi-center), ช่วงเวลาที่ต่างกัน (temporal validation) และการทดลองเชิงสังเกต/ทดลองเชิงคลินิกแบบ prospective เพื่อประเมินความมั่นคงของผลลัพธ์
ตัวอย่างของการประเมินเชิงปฏิบัติ ได้แก่ การดำเนินการ “silent deployment” หรือ “shadow mode” ที่ระบบทำงานคู่ขนานโดยไม่ส่งผลต่อการตัดสินใจของแพทย์ เพื่อเก็บข้อมูลการทำงานจริงโดยไม่เสี่ยงต่อผู้ป่วย อีกแนวทางคือการใช้การทดลองเชิงสุ่ม (randomized controlled trial) หรือการศึกษาคลินิกเชิงสังเกตที่แสดงถึงการเปลี่ยนแปลงของผลลัพธ์ด้านสุขภาพเมื่อใช้โมเดล
Overfitting และปัญหาคุณภาพข้อมูล
Overfitting เกิดเมื่อโมเดลเรียนรู้รายละเอียดและเสียงรบกวนของชุดฝึกจนสูญเสียความสามารถทั่วไป (generalization) ไปยังข้อมูลใหม่ ซึ่งมักมีสาเหตุจากโมเดลที่ซับซ้อนเกินไป ขนาดชุดข้อมูลไม่เพียงพอ หรือสัญญาณบ่งชี้ (labels) ที่มีความไม่แน่นอน ตัวอย่างเช่น โมเดลวินิจฉัยที่เรียนรู้จุดบอดของภาพถ่ายจากโรงพยาบาลหนึ่งอาจไม่สามารถทำงานกับภาพจากเครื่องมือถ่ายอื่นได้
ด้านคุณภาพข้อมูล ประเด็นสำคัญได้แก่ การมี missing values, ตำแหน่ง labeling ที่ไม่สอดคล้อง (label noise), ความไม่สมดุลของคลาส (class imbalance) และความเบี่ยงเบนเชิงระบบ (systematic bias) ทั้งหมดนี้ส่งผลต่อความเชื่อถือของผลลัพธ์ การแก้ไขรวมถึงการทำ data cleaning, การใช้เทคนิคการจัดการ missing (imputation ที่เหมาะสม), การทำ augmentation และการตรวจสอบ inter-rater reliability สำหรับป้ายกำกับคลินิก
ข้อจำกัดด้านความโปร่งใส (Explainability) และผลต่อการยอมรับทางคลินิก
แม้จะมีเครื่องมือช่วยอธิบายคำตัดสินของโมเดล เช่น SHAP หรือ LIME ก็ยังมีข้อจำกัดที่สำคัญในสภาพแวดล้อมคลินิก: การอธิบายเชิงสถิติหรือเชิงคุณสมบัติอาจไม่สอดคล้องกับตรรกะการแพทย์, การอธิบายมักเป็นเชิงประมาณค่า (approximation) และอาจถูกตีความผิดได้โดยผู้ใช้งานที่ไม่มีพื้นฐานทางคณิตศาสตร์เพียงพอ ข้อจำกัดเหล่านี้ทำให้แพทย์ไม่สามารถตรวจสอบแหล่งที่มาของคำแนะนำได้อย่างมั่นใจ ซึ่งลดระดับการยอมรับและเพิ่มความเสี่ยงต่อการตัดสินใจที่ผิดพลาด
นอกจากนี้ เครื่องมืออธิบายมักไม่แสดงความไม่แน่นอนของคำทำนายอย่างชัดเจน การไม่มีการประเมินความไว้วางใจ (confidence/uncertainty quantification) รวมทั้งการไม่ระบุขอบเขตการใช้งาน (intended use) ของโมเดล จะทำให้การตีความผลลัพธ์ในบริบทคลินิกมีความเสี่ยง
การทดสอบและเมตริกที่ควรใช้ในการประเมินโมเดลทางการแพทย์
- เมตริกประสิทธิภาพพื้นฐาน: AUC-ROC, AUC-PR (สำหรับข้อมูลไม่สมดุล), ความไว (sensitivity), ความจำเพาะ (specificity), ค่า PPV/NPV, F1-score
- เมตริกการปรับเทียบ (Calibration): Brier score, Calibration plot, Hosmer–Lemeshow test, Calibration slope/ intercept, Expected Calibration Error (ECE)
- เมตริกความไม่แน่นอน: การใช้ prediction intervals, Bayesian credible intervals, ensemble variance, Monte Carlo dropout, conformal prediction เพื่อประเมินความเชื่อถือได้ของการทำนาย
- การทดสอบการเปลี่ยนแปลงข้อมูล: Population Stability Index (PSI), Kolmogorov–Smirnov (KS) test, Chi-square, Earth Mover's Distance (EMD) เพื่อจับสัญญาณ data drift
- การตรวจสอบทั่วไป: การวิเคราะห์ตามกลุ่มย่อย (subgroup analysis) เพื่อดู performance disparity, ความไวต่อ adversarial perturbations, stress testing ในสถานการณ์ edge cases
- การวัดผลเชิงคลินิก: Decision curve analysis, Net benefit, การวัดผลลัพธ์ที่จับต้องได้ (clinical endpoints) เช่น อัตราการป้องกันเหตุการณ์ไม่พึงประสงค์, อัตราการรักษาผิดพลาด
- มาตรฐานการตรวจสอบภายนอก: การทำ external validation across centers, temporal validation, และ prospective validation / randomized evaluation
บทสรุปเชิงปฏิบัติ
เพื่อให้ AI ในแผนกเวชศาสตร์มีความน่าเชื่อถือในระยะยาว จำเป็นต้องผสานการออกแบบโมเดลที่คำนึงถึงความทนทาน (robustness) กับเฟรมเวิร์กการตรวจสอบที่ครอบคลุม ซึ่งรวมถึงการมอนิเตอร์ data drift แบบเรียลไทม์ การวัดความไม่แน่นอน การทดสอบแบบ external และการอธิบายผลที่มีขอบเขตจำกัดแต่ชัดเจน โดยทุกเมตริกและการทดสอบควรถูกกำหนดเป็นส่วนหนึ่งของข้อตกลงทางคลินิกและนโยบายการกำกับดูแลภายในก่อนนำระบบเข้าสู่การใช้งานจริง
การจัดการภายในโรงพยาบาล: นโยบาย วินิฉัย และการอบรม
การคัดเลือกและประเมินซัพพลายเออร์: มาตรฐาน เอกสาร และการเปิดเผย
ก่อนการจัดซื้อหรือบูรณาการเครื่องมือ AI ในแผนกเวชศาสตร์ โรงพยาบาลต้องกำหนดมาตรฐานการประเมินซัพพลายเออร์อย่างชัดเจนและเป็นลายลักษณ์อักษร ซึ่งรวมถึงข้อกำหนดด้านความปลอดภัยของผู้ป่วย ความโปร่งใสทางเทคนิค และความสามารถในการรับผิดชอบต่อการเปลี่ยนแปลงระบบ ตัวอย่างเอกสารที่ควรขอจากซัพพลายเออร์ได้แก่:
- รายงานผลการทดสอบทางคลินิกและการทดสอบภายนอก (validation datasets, external validation studies) พร้อมการแยกผลตามกลุ่มประชากร เช่น อายุ เพศ เชื้อชาติ เพื่อประเมินความเป็นกลางของแบบจำลอง
- ตัวชี้วัดประสิทธิภาพ เช่น sensitivity, specificity, AUC, positive/negative predictive values และอัตราการ override ของคลินิกในสภาวะทดลอง
- คำอธิบายขอบเขตและข้อจำกัดของระบบ (limitations, known failure modes) รวมถึงสถานการณ์ที่ผลลัพธ์ไม่ควรนำไปใช้เป็นฐานตัดสินใจเพียงอย่างเดียว
- เอกสารความปลอดภัยและการทดสอบเชิงรุก เช่น penetration test, SBOM (Software Bill of Materials), และผลการตรวจสอบความเสี่ยงด้านไซเบอร์
- เงื่อนไขสัญญา ได้แก่ การเข้าถึง logs, change control, สิทธิ์ในการถอนการใช้งานและรับผิดชอบในกรณีเกิดเหตุผิดพลาด, การสำรองข้อมูล และนโยบายการอัปเดต/patch
การขอเอกสารเหล่านี้ไม่เพียงแต่เป็นเรื่องระยะสั้น แต่ควรถูกกำหนดเป็นข้อกำหนดในสัญญา (contractual requirement) เพื่อให้โรงพยาบาลสามารถตรวจสอบ ติดตาม และบังคับใช้ได้เมื่อเกิดความเสี่ยงหรือเหตุผิดพลาด
การทดสอบก่อนนำไปใช้ (Pilot) และเกณฑ์การยอมรับ
การนำ AI เข้าใช้งานเชิงคลินิกต้องเริ่มด้วยโครงการนำร่องที่มีการออกแบบอย่างเป็นระบบ ไม่ใช่การเปิดใช้ทันทีแบบระบบกว้าง โดยควรกำหนดแผน pilot ที่ชัดเจน รวมถึงเกณฑ์การประเมินก่อนขยายการใช้งาน ตัวอย่างองค์ประกอบของ pilot ที่แนะนำ:
- ขอบเขตและเป้าหมาย ระบุประเภทผู้ป่วย หน่วยงาน และการวัดผลสำเร็จที่ต้องการ เช่น การปรับปรุงอัตราการวินิจฉัยผิดพลาด ลดเวลาในการตัดสินใจ หรือไม่เพิ่มภาระงานของบุคลากร
- ระยะเวลาและขนาดตัวอย่าง กำหนดระยะเวลา (เช่น 3–6 เดือน) และจำนวนกรณีที่เพียงพอสำหรับการวิเคราะห์เชิงสถิติ
- ตัวชี้วัด (KPIs) เช่น sensitivity/specificity ≥ ค่าที่กำหนด (ตัวอย่าง: AUC ≥ 0.85 เป็นเกณฑ์อ้างอิงในงานบางประเภท), อัตราการ override ของคลินิก < 10%, การเปลี่ยนแปลงในอัตราอุบัติการณ์ไม่พึงประสงค์ และเวลาตอบสนองของระบบ
- การทดสอบแบบจริง (prospective) และแบบตัดสินย้อนหลัง (retrospective) รวมทั้งการประเมินผลกระทบต่อกลุ่มย่อยและการทดสอบความทนทานต่อข้อมูลที่แปรผัน (robustness)
- แผนยกเลิก (rollback) และเกณฑ์ที่ชัดเจนเมื่อระบบต้องหยุดใช้งาน เช่น การลดลงของ KPI เกิน 10% หรือการเกิดอุบัติการณ์ที่เกี่ยวข้องกับความปลอดภัยผู้ป่วย
การตั้งคณะกรรมการกำกับดูแล AI ภายในโรงพยาบาล
การกำกับดูแลในระดับองค์กรเป็นหัวใจสำคัญของการใช้ AI อย่างรับผิดชอบ โรงพยาบาลควรตั้ง AI Governance Board ที่มีอำนาจกำหนดนโยบาย ตัดสินใจคัดเลือกซัพพลายเออร์ และเป็นศูนย์กลางการจัดการเหตุผิดพลาด คณะกรรมการควรประกอบด้วยตัวแทนจากหลายหน่วยงานเพื่อให้มุมมองหลากหลายและมีความสมดุล:
- ผู้นำทางการแพทย์ (หัวหน้าแผนก/แพทย์เฉพาะทาง)
- ผู้เชี่ยวชาญด้านข้อมูลและวิทยาการคอมพิวเตอร์ (data scientists / informaticians)
- เจ้าหน้าที่ความปลอดภัยระบบสารสนเทศและไซเบอร์ (CISO)
- เจ้าหน้าที่ความปลอดภัยผู้ป่วย/คุณภาพ (patient safety/quality officer)
- ตัวแทนฝ่ายกฎหมาย/การเงิน/จัดซื้อ
- ตัวแทนการพยาบาลและฝ่ายปฏิบัติการ
- ผู้เชี่ยวชาญจริยธรรมหรือผู้แทนชุมชน เมื่อเหมาะสม
บทบาทหลักของคณะกรรมการ ได้แก่ การอนุมัตินโยบายการใช้ AI, การอนุมัติผลการทดลองนำร่อง, การทบทวนรายงานเหตุการณ์และการตัดสินใจเชิงกลยุทธ์เกี่ยวกับการแพร่ขยายระบบ รวมถึงการกำหนดมาตรการด้านความโปร่งใสต่อผู้ป่วยและสาธารณะ
การอบรมบุคลากรคลินิก: ข้อจำกัด การใช้งาน และการตอบสนองเมื่อระบบขัดแย้ง
การใช้งาน AI อย่างปลอดภัยขึ้นกับความเข้าใจของบุคลากรที่ต้องรับผลกระทบโดยตรง การอบรมจึงต้องครอบคลุมทั้งด้านทฤษฎีและการปฏิบัติ โดยมีองค์ประกอบสำคัญดังนี้:
- การอบรมเบื้องต้นและการรับรองความชำนาญ ให้บุคลากรผ่านการอบรมก่อนการใช้งานจริงและต้องผ่านการประเมินความเข้าใจ (competency test) โดยมีการต่ออายุการรับรองเป็นประจำ (เช่น รายปี)
- เนื้อหาที่ต้องสื่อสารชัดเจน ได้แก่ ขอบเขตการใช้ของระบบ ข้อจำกัดที่สำคัญ รูปแบบข้อผิดพลาดที่เป็นไปได้ การตีความผลลัพธ์ และวิธีการตรวจสอบความสมเหตุสมผลของคำแนะนำ
- แนวปฏิบัติเมื่อผลลัพธ์ขัดแย้งกับการตัดสินใจของแพทย์ เช่น ต้องมีขั้นตอนระบุเหตุผลการยอมรับหรือปฏิเสธคำแนะนำของ AI, บันทึกใน chart ว่ามีการ override, และต้องมีการปรึกษาผู้เชี่ยวชาญหากความเสี่ยงสูง
- การฝึกซ้อมสถานการณ์ (simulation) โดยจัดสถานการณ์จำลองที่ AI ให้คำแนะนำผิดพลาด เพื่อฝึกการตอบสนองและการแจ้งเหตุอย่างเป็นระบบ
- คู่มือด่วนและช่องทางรายงาน แจก quick-reference card และกำหนดช่องทางการรายงานปัญหา (safety reporting system) ที่ต้องทำเป็นมาตรฐานภายในโรงพยาบาล
ขั้นตอนเมื่อเกิดเหตุผิดพลาดและการติดตามผล
แม้จะมีการป้องกันครบถ้วน โรงพยาบาลต้องมีขั้นตอนรับมือเหตุผิดพลาดที่ชัดเจนและรวดเร็ว:
- การหยุดใช้งานชั่วคราว หากพบปัญหาที่อาจเป็นอันตรายต่อผู้ป่วย ให้หยุดระบบทันทีตามแผน rollback และแจ้งฝ่ายที่เกี่ยวข้อง
- การอนุรักษ์หลักฐาน เก็บ logs, snapshots ของโมเดล เวอร์ชันซอฟต์แวร์ และข้อมูลอินพุตที่เกี่ยวข้องสำหรับการตรวจสอบและวิเคราะห์
- การสืบสวนและวิเคราะห์สาเหตุราก (RCA) ดำเนิน RCA โดยคณะกรรมการที่เกี่ยวข้อง ร่วมกับซัพพลายเออร์หากจำเป็น และบันทึกผลการวิเคราะห์พร้อมมาตรการแก้ไข
- การสื่อสารภายในและภายนอก แจ้งผู้ป่วย/ครอบครัวตามหลักการความโปร่งใสหากมีผลกระทบต่อการดูแล และรายงานต่อหน่วยงานกำกับดูแลตามกฎหมายหรือข้อบังคับที่เกี่ยวข้อง
- การปรับปรุงนโยบายและการอบรม ใช้บทเรียนจากเหตุการณ์ปรับปรุงข้อกำหนดการคัดเลือกซัพพลายเออร์ แผน pilot และหลักสูตรอบรม เพื่อป้องกันการเกิดซ้ำ
- การติดตามหลังการแก้ไข ดำเนินการ monitoring แบบต่อเนื่องหลังแก้ไขจนกว่าจะยืนยันว่าปัญหาหมดไป โดยใช้ตัวชี้วัดที่ชัดเจนและระยะเวลาที่กำหนด
สรุป การนำ AI เข้าสู่การดูแลผู้ป่วยต้องอยู่บนพื้นฐานของกระบวนการคัดเลือกที่เข้มงวด การทดสอบเชิงคลินิกที่เป็นระบบ คณะกรรมการกำกับดูแลที่มีความหลากหลายทางวิชาชีพ และการอบรมบุคลากรที่มุ่งเน้นการรับรู้ข้อจำกัดและการตอบสนองเมื่อระบบไม่สอดคล้องหรือเกิดความผิดพลาด การปฏิบัติตามแนวทางดังกล่าวจะช่วยลดความเสี่ยงต่อความปลอดภัยของผู้ป่วยและสร้างความเชื่อมั่นในระยะยาว
ข้อเสนอเชิงนโยบายและแนวปฏิบัติที่แนะนำ
ข้อเสนอเชิงนโยบายและแนวปฏิบัติที่แนะนำ
เพื่อรับประกันความปลอดภัยของผู้ป่วยและความน่าเชื่อถือของเครื่องมือปัญญาประดิษฐ์ที่ใช้ในศูนย์การแพทย์ จำเป็นต้องมีกรอบนโยบายและแนวปฏิบัติที่ชัดเจนและบังคับใช้ได้จริง ทั้งในระดับชาติและหน่วยบริการสุขภาพ เริ่มจากการติดตามหลังการวางระบบ (post-market surveillance) แบบต่อเนื่องและการรายงานเหตุการณ์ที่โปร่งใสเพื่อให้หน่วยกำกับดูแล ผู้ให้บริการ และสาธารณชนสามารถมองเห็นปัญหาเชิงระบบและตอบสนองอย่างทันท่วงที การสื่อสารเชิงสถิติที่ชัดเจน เช่น อัตราการผิดพลาดในประชากรย่อย การเปลี่ยนแปลงประสิทธิภาพตามเวลา และเหตุการณ์ที่มีผลต่อความปลอดภัย ควรถูกเผยแพร่เป็นระยะโดยมีมาตรฐานการรายงานที่ชัดเจน
แนวปฏิบัติที่ควรบังคับใช้ในการติดตามและรายงาน ได้แก่ กำหนดระบบรายงานเหตุการณ์ที่เป็นศูนย์กลางและเข้าถึงได้ (เช่นรีจิสเตอร์แห่งชาติสำหรับเหตุการณ์ AI ทางการแพทย์) พร้อมเส้นตายการรายงานที่แตกต่างตามความรุนแรงของเหตุการณ์ (เช่น รายงานเหตุการณ์ร้ายแรงภายใน 7 วัน รายงานเหตุการณ์อื่นภายใน 30 วัน) และการเปิดเผยข้อมูลสรุปเชิงสถิติเป็นรายไตรมาส เพื่อให้เกิดความโปร่งใสและสามารถวิเคราะห์แนวโน้มเชิงระบบได้อย่างต่อเนื่อง มาตรการเหล่านี้ควรรวมทั้งข้อมูลเชิงเทคนิคของโมเดล ข้อมูลสถิติการใช้งาน และผลกระทบต่อผลลัพธ์ทางคลินิก
ด้านการวัดความปลอดภัยและการยืนยันทางคลินิก (clinical validation metrics) ควรมีมาตรฐานกลางที่กำหนดชุดตัวชี้วัดขั้นต่ำ เช่น ความไว (sensitivity), ความจำเพาะ (specificity), อัตราค่าบวกเท็จ (false positive rate), ค่า calibration, และการประเมินความเท่าเทียมของผลลัพธ์ระหว่างกลุ่มประชากรย่อย นอกจากนี้ต้องบังคับให้มีการทดสอบข้ามศูนย์ (cross-center validation) ในประชากรและบริบทการรักษาที่หลากหลาย ก่อนอนุญาตให้ใช้งานจริงในวงกว้าง ตัวอย่างแนวทางปฏิบัติได้แก่ การกำหนดขนาดตัวอย่างขั้นต่ำสำหรับการทดสอบภายนอก การทดสอบแบบ prospective multicenter studies และการเปิดเผยชุดข้อมูลที่ใช้ในการทดสอบพร้อมเอกสาร (dataset documentation / datasheets) เพื่อให้การตีความผลการทดสอบเป็นไปอย่างมีหลักฐาน
นอกจากนี้ นโยบายควรส่งเสริมการตรวจสอบโดยบุคคลที่สามอย่างเป็นทางการและกำหนดความรับผิดชอบระหว่างผู้ที่เกี่ยวข้องให้ชัดเจน มาตรการแนะนำ ได้แก่ การรับรองโดยองค์กรอิสระที่ผ่านมาตรฐานสากล (third-party certification), การตรวจสอบโค้ดหรือโมเดลเมื่อจำเป็น, และการกำหนดเงื่อนไขความรับผิดชอบในสัญญาระหว่างผู้พัฒนา ผู้ขาย และผู้ให้บริการสุขภาพ เพื่อหลีกเลี่ยงช่องว่างความรับผิดชอบที่อาจส่งผลต่อผู้ป่วย นโยบายควรกำหนดว่าผู้พัฒนาต้องรับผิดชอบต่อข้อบกพร่องเชิงออกแบบหรือข้อมูลฝึกซ้อมที่ไม่เพียงพอ ผู้ให้บริการสุขภาพรับผิดชอบต่อการใช้งานและการควบคุมคุณภาพในบริบทการดูแลจริง ส่วนผู้ขายต้องรับผิดชอบต่อการบำรุงรักษาและการอัปเดตระบบอย่างปลอดภัย
ข้อเสนอเชิงนโยบายและแนวปฏิบัติสรุปแบบกระทำได้ (actionable) :
- กำหนดระบบ post-market surveillance และรีจิสเตอร์เหตุการณ์ระดับชาติ พร้อมกรอบเวลาการรายงานที่ชัดเจน (เช่น ภายใน 7 วันสำหรับเหตุการณ์ร้ายแรง)
- บังคับใช้มาตรฐาน clinical validation metrics ที่รวมทั้ง sensitivity, specificity, calibration, subgroup analysis และการทดสอบข้ามศูนย์ก่อนการอนุญาตใช้งาน
- สนับสนุน/บังคับการทดสอบภายนอกโดยสถาบันอิสระ และเปิดเผยผลการทดสอบรวมถึงชุดข้อมูลที่ใช้ในการตรวจสอบ
- กำหนดความรับผิดชอบตามสัญญา ระบุความรับผิดชอบของผู้พัฒนา ผู้ขาย และผู้ให้บริการ รวมถึงข้อเรียกร้องประกันภัยและกลไกการชดเชยผู้ป่วย
- ส่งเสริมความโปร่งใสต่อสาธารณะ ผ่าน model cards, algorithmic impact statements และรายงานสรุปประสิทธิภาพที่เข้าใจได้สำหรับผู้ป่วยและผู้ดูแล
- มีส่วนร่วมของผู้ป่วยในการออกแบบและทดสอบ โดยจัดให้มีคณะผู้แทนผู้ป่วยสำหรับการประเมินความเสี่ยงและการสื่อสารความเสี่ยงก่อนใช้งาน
การนำมาตรการข้างต้นไปใช้จะต้องอาศัยความร่วมมือระหว่างหน่วยกำกับดูแล ผู้เชี่ยวชาญทางการแพทย์ ผู้พัฒนาเทคโนโลยี และตัวแทนผู้ป่วย การผสมผสานระหว่างกรอบกฎเกณฑ์ที่เข้มงวด การตรวจสอบอิสระ และความโปร่งใสเชิงปฏิบัติจะช่วยลดความเสี่ยงและสร้างความเชื่อมั่นว่าการนำ AI เข้ามาใช้ในเวชศาสตร์จะเพิ่มคุณภาพการรักษาโดยไม่ลดทอนความปลอดภัยของผู้ป่วย
บทสรุป
การนำเครื่องมือปัญญาประดิษฐ์ (AI) มาใช้ในแผนกเวชศาสตร์ของสหรัฐฯ ให้ประโยชน์ด้านประสิทธิภาพการวินิจฉัย การคัดกรอง และการจัดลำดับความเร่งด่วนของผู้ป่วย แต่รายงานเหตุการณ์และงานวิเคราะห์หลายชิ้นชี้ให้เห็นช่องโหว่ด้านความปลอดภัย เช่น การขาดการตรวจสอบหลังการนำมาใช้จริง (post-market surveillance) ความไม่เพียงพอของการประเมินความเสี่ยงเชิงคลินิก และปัญหาอคติในชุดข้อมูลที่นำมาฝึก ทำให้เกิดความเสี่ยงต่อความผิดพลาดในการวินิจฉัยหรือการรักษา ตัวอย่างในโรงพยาบาลบางแห่งแสดงเหตุการณ์ความล่าช้าในการวินิจฉัยหรือการแจ้งเตือนผิดพลาดซึ่งส่งผลต่อผลลัพธ์ของผู้ป่วย ส่งสัญญาณว่าจำเป็นต้องเร่งเสริมกรอบการกำกับดูแลและมาตรการความปลอดภัยเพื่อปกป้องผู้ป่วยอย่างเร่งด่วน
เพื่อแก้ปัญหาดังกล่าว จำเป็นต้องมีความร่วมมือเชิงระบบระหว่างผู้พัฒนา ผู้จำหน่าย โรงพยาบาล และหน่วยกำกับดูแลในการกำหนดมาตรฐานทางเทคนิคและคลินิก สร้างความโปร่งใสเรื่องวิธีการพัฒนาและข้อมูลฝึก (model cards, data sheets) บังคับใช้การประเมินก่อนใช้จริงที่เข้มงวด รวมถึงระบบรายงานเหตุการณ์ที่มีประสิทธิภาพและการติดตามผลในโลกจริง (real-world monitoring) การออกแบบให้มี clinician-in-the-loop, การทดสอบกับชุดข้อมูลมาตรฐานข้ามประชากร และการตรวจสอบอิสระเป็นกุญแจสำคัญที่จะลดความเสี่ยงและเพิ่มความเชื่อมั่นของผู้ใช้งานและผู้ป่วย
มุมมองในอนาคต หากหน่วยงานกำกับและผู้มีส่วนได้ส่วนเสียเร่งจัดวางกรอบการกำกับที่เน้นการประเมินความเสี่ยงเชิงคลินิก การตรวจสอบหลังการนำไปใช้ และระบบรายงานเหตุการณ์ที่มีประสิทธิภาพ จะช่วยรักษาสมดุลระหว่างนวัตกรรมและความปลอดภัย ส่งผลให้ AI ทางการแพทย์สามารถยกระดับการดูแลผู้ป่วยได้อย่างยั่งยืน ทั้งนี้การลงทุนด้านนโยบาย การวิจัยภาคสนาม และการมีส่วนร่วมของผู้ป่วยจะเป็นตัวเร่งให้มาตรฐานเหล่านี้มีผลบังคับใช้จริงและลดความเสียหายต่อผู้ป่วยในระยะยาว
📰 แหล่งอ้างอิง: Military.com



