โลกข่าวสารเข้าสู่จุดเปลี่ยนเมื่อเทคโนโลยีสร้างสรรค์สื่อด้วยปัญญาประดิษฐ์ (AI) ทำให้ภาพและคลิปเสียงที่ดูจริงแต่เป็นการปลอมแปลง หรือที่เรียกว่า deepfake เพิ่มจำนวนและซับซ้อนขึ้น ส่งผลให้ความเชื่อมั่นของผู้อ่านต่อข่าวสารดั้งเดิมสั่นคลอน ในบริบทนี้ เบราว์เซอร์และแพลตฟอร์มดิจิทัลชั้นนำจึงเริ่มผลักดันแนวคิด "AI‑Provenance"—มาตรฐานการฝังเมตาดาต้าในไฟล์มีเดียที่ระบุแหล่งที่มา โมเดลที่ใช้ และข้อมูลพรอมต์หรือพารามิเตอร์ที่สร้างเนื้อหา เพื่อช่วยให้สาธารณะและผู้ตรวจสอบสามารถแยกแยะแหล่งที่มาของสื่ออย่างรวดเร็วและเป็นระบบ
มาตรการดังกล่าวไม่ได้เป็นเพียงการติดแท็กอย่างง่าย แต่หมายถึงการสร้างเครื่องมือเชิงนโยบายและเทคนิคที่เอื้อต่อการตรวจสอบย้อนกลับ (audit trail) การลงลายมือชื่อดิจิทัล และการประเมินความน่าเชื่อถือของเนื้อหาโดยอัตโนมัติ ผลลัพธ์ที่คาดหวังคือการลดการแพร่กระจายของ deepfake เพิ่มความโปร่งใสในกระบวนการผลิตสื่อ และคืนความเชื่อมั่นให้กับสำนักข่าวและผู้บริโภคข้อมูล — ประเด็นที่บทความนี้จะขยายทั้งบริบททางเทคนิค ตัวอย่างการนำไปใช้ และผลกระทบต่อวงการสื่อสารมวลชน
1. บริบท: ทำไมต้องมี AI‑Provenance ตอนนี้
1. บริบท: ทำไมต้องมี AI‑Provenance ตอนนี้
ในรอบไม่กี่ปีที่ผ่านมา เราเห็นการเติบโตอย่างรวดเร็วของสื่อสังเคราะห์ที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ (AI‑generated content) โดยเฉพาะภาพและวิดีโอที่เรียกกันว่า deepfake ซึ่งยากต่อการแยกแยะด้วยสายตา ข้อมูลเชิงอุตสาหกรรมและงานวิจัยหลายชิ้นชี้ให้เห็นถึงการเพิ่มขึ้นอย่างทวีคูณของคอนเทนต์ประเภทนี้ ตั้งแต่การทดลองเชิงสาธิตไปจนถึงการใช้งานเชิงพาณิชย์และการโจมตีเพื่อหลอกลวง ตัวอย่างเช่น รายงานเชิงวิเคราะห์ในช่วงปลายทศวรรษที่ผ่านมาเคยระบุจำนวนวิดีโอ deepfake บนอินเทอร์เน็ตหลายพันชิ้น และการมาถึงของโมเดลที่ให้ผลลัพธ์เทียบเท่าคุณภาพสูงในต้นปี 2020s ทำให้การสร้างภาพและเสียงเทียมเป็นเรื่องที่เข้าถึงได้ง่ายและมีต้นทุนต่ำขึ้นอย่างมาก

ผลกระทบต่อความเชื่อมั่นของสาธารณะและสื่อมวลชนมีความชัดเจน: เมื่อผู้บริโภคไม่มั่นใจว่าสื่อที่เห็นเป็นของจริงหรือถูกดัดแปลง จะเกิดการลดทอนความน่าเชื่อถือของแหล่งข่าวทั้งแบบดั้งเดิมและดิจิทัล การบิดเบือนด้วยสื่อสังเคราะห์สามารถถูกนำไปใช้เพื่อจูงใจความเชื่อ ปลุกปั่นทางการเมือง หรือสร้างความเสียหายต่อภาพลักษณ์ขององค์กร ตัวอย่างเชิงเหตุการณ์ที่เกิดผลกระทบชัดเจน ได้แก่ การใช้เสียงสังเคราะห์ในการฉ้อโกงธุรกรรมจนเกิดความเสียหายทางการเงิน และวิดีโอปราศรัยหรือเหตุการณ์ที่ถูกตัดต่อจนเปลี่ยนความหมายเดิม ส่งผลให้สื่อสารมวลชนและหน่วยงานตรวจสอบข่าวต้องเผชิญกับต้นทุนและภาระงานที่เพิ่มขึ้นเพื่อยืนยันความถูกต้องของคอนเทนต์
ในเชิงเทคโนโลยี หลายปัจจัยทำให้การติดแท็กแหล่งที่มา (provenance) กลายเป็นความจำเป็น ได้แก่:
- การเข้าถึงและความสามารถของเครื่องมือสร้างคอนเทนต์: เครื่องมือสังเคราะห์ภาพ เสียง และวิดีโอมีอินเตอร์เฟซใช้งานง่าย และโมเดลที่ทรงพลังทำให้ผลลัพธ์สมจริงมากขึ้น
- การกระจายแบบทันทีและระดับโลก: เครือข่ายสังคมออนไลน์ช่วยให้คอนเทนต์ปลอมแพร่กระจายได้เร็วและกว้าง ส่งผลให้เนื้อหาที่เป็นเท็จสามารถกลายเป็นวาระสาธารณะก่อนที่จะได้รับการตรวจสอบ
- ความยากในการตรวจจับโดยอัตโนมัติ: โมเดลสังเคราะห์รุ่นใหม่ปรับปรุงข้อบกพร่องที่เคยเป็นสัญญาณบ่งชี้การปลอม ทำให้การตรวจจับด้วยวิธีเดิมมีประสิทธิภาพลดลง
- ความต้องการทางกฎระเบียบและความรับผิดชอบของแพลตฟอร์ม: ผู้ให้บริการเบราว์เซอร์ แพลตฟอร์มสื่อ และผู้ลงโฆษณาเผชิญแรงกดดันจากภาครัฐและสาธารณะให้สามารถตรวจสอบแหล่งที่มาและความถูกต้องของคอนเทนต์ได้
ดังนั้น verifiable provenance — ข้อมูลต้นทางที่ตรวจสอบได้ที่ระบุว่าไฟล์มีเดียถูกสร้างหรือแก้ไขโดยโมเดลใด เวลาใด และโดยใคร (รวมถึงเมตาดาต้าเกี่ยวกับพรอมต์หรือพารามิเตอร์เมื่อเหมาะสม) — จึงไม่ใช่เรื่องเชิงเทคนิคเพียงอย่างเดียว แต่เป็นเครื่องมือพื้นฐานเชิงนโยบายและการดำเนินการเพื่อฟื้นฟูความเชื่อมั่นของสาธารณะต่อสื่อและระบบสารสนเทศ การมีมาตรฐานที่ชัดเจนช่วยให้ผู้ประกอบการสื่อ ผู้โฆษณา และผู้กำกับดูแลสามารถติดตาม ตรวจสอบ และรับผิดชอบต่อแหล่งที่มาของเนื้อหาได้อย่างเป็นรูปธรรม ลดความเสี่ยงทางปฏิบัติการและความเสียหายเชิงสาธารณะในระดับกว้าง
2. AI‑Provenance คืออะไร: แนวคิดและองค์ประกอบสำคัญ
AI‑Provenance หมายถึงชุดข้อมูลเชิงเมตา (provenance metadata) ที่ติดมากับไฟล์มีเดียเพื่อบันทึกแหล่งที่มาและประวัติการสร้างหรือแก้ไขด้วยเครื่องมือปัญญาประดิษฐ์ โดยมีเป้าหมายเพื่อเพิ่มความโปร่งใส ตรวจสอบต้นทาง และยืนยันความสมบูรณ์ของเนื้อหา เพื่อรับมือกับการแพร่กระจายของเนื้อหาเทียม (deepfakes) และการบิดเบือนข้อมูลที่ซับซ้อนขึ้นในยุคของโมเดล generative AI
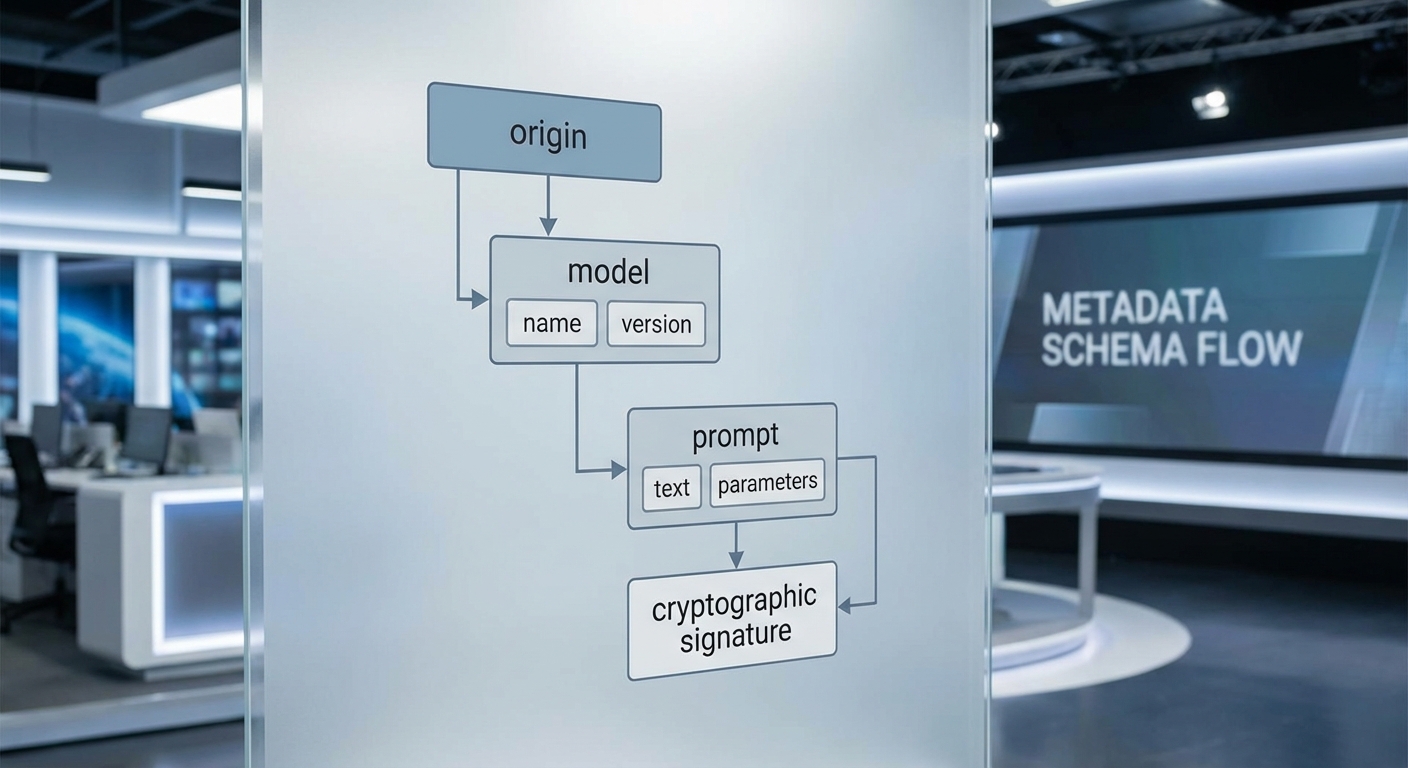
องค์ประกอบหลักของ AI‑Provenance
AI‑Provenance ต้องประกอบด้วยข้อมูลหลายมิติที่ช่วยให้ผู้รับสามารถติดตามแหล่งที่มาและการเปลี่ยนแปลงของไฟล์ได้อย่างครบถ้วน โดยองค์ประกอบสำคัญที่มักถูกเสนอและนำไปใช้งาน ได้แก่:
- Source / Origin — ข้อมูลต้นทางของไฟล์หรือสื่อ เช่น ผู้สร้างเริ่มต้น (creator), โฮสต์หรือที่มาของไฟล์ (origin URL/IP), เวลาเริ่มต้นของการสร้าง (timestamp) และการอ้างอิงถึงเอกสารต้นฉบับ (original asset identifier)
- Model Identifier & Version — ข้อมูลเกี่ยวกับโมเดล AI ที่สร้างหรือแก้ไขสื่อ รวมถึงชื่อโมเดล (e.g., "StableDiffusion-v2"), เวอร์ชัน หมายเลขการปล่อย (release/build) และผู้ให้บริการหรือผู้พัฒนาโมเดล (model provider)
- Prompt / Generation Parameters — ข้อความพรอมต์หรือพารามิเตอร์ที่ใช้ในการสร้าง เช่น ข้อความพรอมต์ (prompt text), ค่า seed, temperature, guidance scale, และการตั้งค่าพิเศษอื่น ๆ ที่มีผลต่อผลลัพธ์ เพื่อให้สามารถ reproduce หรือตรวจสอบเจตนาการสร้างได้
- Transformation History — บันทึกตามลำดับของการปรับแก้หรือแปลงไฟล์ (edit operations) รวมถึงเครื่องมือที่ใช้ (tool identifier), เวลาที่ดำเนินการ, ผู้ดำเนินการ (actor) และคำอธิบายการเปลี่ยนแปลง เช่น "crop", "color-correct", "face-swap", "AI-enhancement"
- Signatures & Integrity Proofs — หลักฐานการยืนยันความสมบูรณ์ของข้อมูล เช่น แฮชเชิงคริปโตกราฟิก (SHA-256), ลายเซ็นดิจิทัล (RSA/ECDSA), ใบรับรอง (certificates) และการประทับเวลา (trusted timestamping) เพื่อป้องกันการปลอมแปลงเมตาและเนื้อหา
สเปคตัวอย่างและมาตรฐานที่เกี่ยวข้อง
มาตรฐานและความพยายามร่วมกันจากภาคส่วนเทคโนโลยีเป็นกุญแจสำคัญในการทำให้ AI‑Provenance ใช้งานได้จริงและข้ามแพลตฟอร์ม ตัวอย่างของมาตรฐานและโครงการที่เกี่ยวข้องได้แก่:
- C2PA (Coalition for Content Provenance and Authenticity) — กลไกการจัดเก็บ manifest และการลงลายเซ็นสำหรับเนื้อหาดิจิทัล ซึ่งออกแบบมาเพื่อบันทึก provenance ของไฟล์มีเดียและรองรับการตรวจสอบข้ามระบบ
- Content Authenticity Initiative (CAI) — โครงการริเริ่มโดย Adobe ที่ผลักดันแนวทางการติดเมตาเชิงความจริงเพื่อเพิ่มความโปร่งใสของเนื้อหา
- W3C และกลุ่มวิจัยด้าน Provenance — ความพยายามเชิงมาตรฐานสำหรับการอธิบาย provenance บนเว็บและการเชื่อมต่อกับเทคโนโลยีเว็บอื่น ๆ
- แนวปฏิบัติ: Model Cards และ Datasheets — แนวคิดในการให้ข้อมูลเชิงบริบทของโมเดล (model card) และชุดข้อมูล (dataset datasheet) เพื่อลดช่องว่างด้านความเข้าใจของผู้ใช้งานเกี่ยวกับความสามารถและข้อจำกัดของโมเดล
ตัวอย่าง manifest เชิงแนวคิด (ตัวอย่างแสดงฟิลด์สำคัญ): { "origin": {"creator":"publisher@example.com","url":"https://news.example/article/123","timestamp":"2026-02-10T12:34:56Z"}, "model": {"id":"StableDiffusion","version":"2.1","provider":"ExampleAI Ltd."}, "prompt": {"text":"Aerial photo of city skyline at sunset","seed":123456,"parameters":{"guidance":7.5}}, "transformations":[{"op":"upscale","tool":"ImageEnhanceX","timestamp":"2026-02-10T12:40:00Z","actor":"editor@example.com"}], "signatures":[{"signer":"publisher@example.com","alg":"ECDSA","hash":"sha256:...","cert":"..."}] }
ประโยชน์ของการติด AI‑Provenance ในไฟล์มีเดีย
การติด AI‑Provenance ให้กับไฟล์มีเดียส่งผลเชิงบวกทั้งในมิติความน่าเชื่อถือทางสื่อและการคุ้มครองเชิงกฎหมาย โดยประโยชน์ที่สำคัญได้แก่:
- Traceability — สามารถติดตามที่มาของภาพหรือวิดีโอได้ชัดเจน ตั้งแต่ผู้สร้างจนถึงขั้นตอนการแก้ไข ช่วยให้ผู้ใช้และผู้ตรวจสอบเข้าใจบริบทของเนื้อหา
- ลดการบิดเบือนข้อมูล (Mitigate Deepfakes) — การมีบันทึก provenance และลายเซ็นดิจิทัลทำให้การปลอมแปลงหรือการนำเนื้อหาไปใช้ผิดวัตถุประสงค์ตรวจจับได้ง่ายขึ้น ลดความเสี่ยงของการถูกใช้ในเชิงสาธารณะผิด ๆ
- สนับสนุนความรับผิดชอบของผู้ให้บริการ — แพลตฟอร์มและผู้พัฒนาโมเดลสามารถออกหลักฐานยืนยันแหล่งที่มาและการตั้งค่าการสร้าง เพื่อรับผิดชอบต่อผลงานที่ระบบสร้างหรือเผยแพร่
- อำนวยความสะดวกด้านปฏิบัติตามกฎระเบียบ — ข้อมูล provenance ช่วยสนับสนุนการตรวจสอบทางกฎหมายและนโยบายองค์กร เช่น การพิสูจน์สิทธิ์ต้นฉบับ หรือการปฏิบัติตามข้อกำหนดด้านการเปิดเผยการใช้ AI
สรุปคือ AI‑Provenance เป็นกรอบการปฏิบัติที่ผสานกันระหว่างเมตาดาต้าเชิงบริบท การลงลายเซ็นเชิงคริปโตกราฟิก และการยอมรับมาตรฐานข้ามองค์กร หากนำไปใช้ร่วมกับมาตรฐานอย่าง C2PA และแนวทางของ W3C จะช่วยยกระดับความน่าเชื่อถือของสื่อดิจิทัลในเชิงระบบและลดอันตรายจากการบิดเบือนข้อมูลในวงกว้าง
3. บทบาทของเบราว์เซอร์และแพลตฟอร์มในการผลักดันมาตรฐาน
3. บทบาทของเบราว์เซอร์และแพลตฟอร์มในการผลักดันมาตรฐาน
เบราว์เซอร์และแพลตฟอร์มทำหน้าที่เป็นชั้นกลางสำคัญที่จะผลักดันให้แนวปฏิบัติเรื่อง AI‑Provenance กลายเป็นมาตรฐานสากล โดยเบราว์เซอร์มีบทบาททั้งในเชิงเทคนิคและเชิงประสบการณ์ผู้ใช้ เช่น การอ่านและแสดง metadata ที่ฝังมาในไฟล์มีเดีย (เช่น manifests ของ C2PA) และการแสดงองค์ประกอบบ่งชี้ (badge/indicator) ใน UI เมื่อเบราว์เซอร์ตรวจพบแหล่งที่มาหรือข้อมูลการสร้างของไฟล์นั้น ๆ ฟีเจอร์ดังกล่าวช่วยให้ผู้ใช้สามารถเห็นสภาวะของความน่าเชื่อถือได้ทันที โดยไม่ต้องสลับไปยังแอปภายนอกหรือผู้เชี่ยวชาญ
ในเชิงนโยบาย แพลตฟอร์มโซเชียลมีเดียและบริการคลาวด์สามารถบังคับใช้การแนบ metadata ก่อนอนุญาตให้โพสต์หรือเผยแพร่ได้ ตัวอย่างมาตรการที่แพลตฟอร์มสามารถดำเนินการได้ประกอบด้วย:
- ปฏิเสธการอัปโหลด: ปฏิเสธไฟล์ที่ส่งเข้ามาหากไม่พบ metadata ขั้นพื้นฐาน (เช่น provenance.manifest หรือ signature) ตามข้อกำหนดของแพลตฟอร์ม
- คำเตือนต่อผู้ใช้: แสดงแบนเนอร์หรือกล่องแจ้งเตือนเมื่อแฟ้มมี provenance ไม่ครบถ้วนหรือมาจากแหล่งที่ไม่ผ่านการยืนยัน
- ลดการกระจายเนื้อหา: ลดอันดับ (downrank) ของคอนเทนต์ที่ไม่มีแท็ก provenance ในฟีดหรือการค้นหาเพื่อชะลอการแพร่กระจายของเนื้อหาที่อาจเป็น deepfake
- ข้อกำหนด API และ developer policy: บังคับให้ผู้พัฒนาที่ใช้ API อัปโหลดสื่อ ต้องแนบฟิลด์ metadata เช่น provenance.model, provenance.prompt, provenance.creator, และ signatures
มีผู้เล่นสำคัญในอุตสาหกรรมที่ประกาศสนับสนุนแนวคิดนี้และเริ่มดำเนินการนำร่องเพื่อทดสอบการใช้งานจริง ได้แก่ Adobe (ผ่านโครงการ Content Authenticity Initiative), กลุ่มมาตรฐาน C2PA (Coalition for Content Provenance and Authenticity) ที่มีสมาชิกจากหลายองค์กรเช่น BBC, Microsoft, Intel และ Arm รวมถึงผู้ให้บริการตรวจสอบความถูกต้องของภาพอย่าง Truepic ตลอดจนสตูดิโอข่าวและแพลตฟอร์มสื่อที่เริ่มทดลองผสาน metadata ในเวิร์กโฟลว์การเผยแพร่
การทดลองนำร่องจากอุตสาหกรรมรายงานผลลัพธ์เชิงบวกหลายประการ: การแสดง badge/indicator ใน UI ช่วยเพิ่มอัตราการรับรู้ของผู้ใช้ต่อแหล่งที่มาของคอนเทนต์ และการบังคับแนบ metadata ก่อนโพสต์ลดการเผยแพร่ของเนื้อหาที่ไร้แหล่งที่มาได้อย่างมีนัยสำคัญในช่วงการทดสอบ (ตัวเลขเบื้องต้นจากโครงการนำร่องบางส่วนระบุการลดการกระจายของเนื้อหาปลอมได้ตั้งแต่หลักสิบเปอร์เซ็นต์ขึ้นไป ขึ้นกับมาตรการที่ใช้) อย่างไรก็ตาม ผู้เชี่ยวชาญยังเตือนว่าการบังคับใช้ต้องคำนึงถึงประเด็นความเป็นส่วนตัว การจัดการคีย์ดิจิทัล และการรองรับกรณีผู้ใช้ต้องการเผยแพร่เนื้อหาจากแหล่งออฟไลน์หรือในบริบทที่ไม่สามารถลงลายลักษณ์อักษรได้
สรุปได้ว่า การผสานกันระหว่างการแสดงผลในเบราว์เซอร์ (เช่น badge/indicator และ viewer สำหรับ metadata) กับนโยบายเชิงบังคับของแพลตฟอร์ม (เช่น ปฏิเสธการโพสต์, คำเตือน, หรือการลดการกระจาย) จะเป็นเครื่องมือสำคัญในการทำให้มาตรฐาน AI‑Provenance เกิดผลจริงเชิงปฏิบัติ ทั้งนี้ความสำเร็จขึ้นกับการร่วมมือของผู้ผลิตเบราว์เซอร์ ผู้ให้บริการแพลตฟอร์ม ผู้พัฒนามาตรฐาน และชุมชนนักพัฒนา เพื่อออกแบบระบบที่ปลอดภัย ใช้งานได้จริง และคำนึงถึงสิทธิของผู้ใช้
4. การนำไปปฏิบัติทางเทคนิค: ฟอร์แมต การลงลายเซ็น และการเก็บประวัติ
4. การนำไปปฏิบัติทางเทคนิค: ฟอร์แมต การลงลายเซ็น และการเก็บประวัติ
การปฏิบัติด้าน *AI‑provenance* จำเป็นต้องผสานทั้งการฝังเมตาดาต้า (metadata), กลไกการลงลายเซ็นดิจิทัล และระบบบันทึกการเปลี่ยนแปลง (chain‑of‑custody) อย่างสอดคล้องเพื่อให้ข้อมูลมีความน่าเชื่อถือและตรวจสอบย้อนกลับได้ ในการออกแบบเชิงเทคนิครูปแบบการเก็บเมตาดาต้าสามารถแบ่งได้เป็น 3 แนวทางหลัก: embedded (ฝังในไฟล์), sidecar (ไฟล์คู่) และ server‑anchored (ยืนยันบนเซิร์ฟเวอร์/ledger ภายนอก) แต่ละทางเลือกมีผลต่อความทนทานต่อการแก้ไข ความสามารถในการพกพา และประเด็นความเป็นส่วนตัว
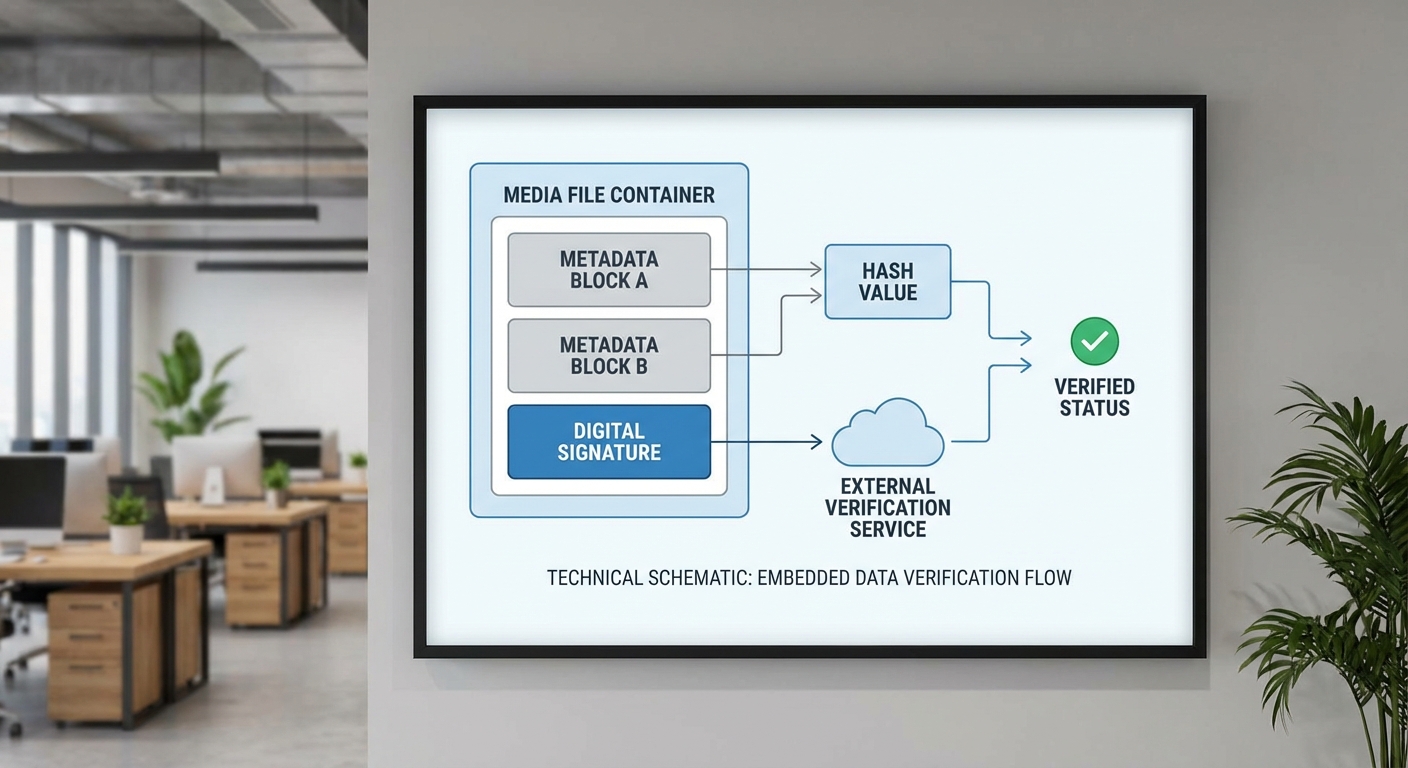
รายละเอียดเชิงเทคนิคของแต่ละแนวทาง:
- Embedded metadata: ใช้มาตรฐานเช่น EXIF, XMP หรือ IPTC ในภาพและไฟล์มีเดียอื่นๆ โดยบรรจุข้อมูล provenance เช่น model_identifier, prompt_hash, generation_parameters ลงในช่อง XMP หรือ JSON‑LD ภายในไฟล์ ข้อดีคือความทนทานต่อการแยกไฟล์และการพกพา แต่ข้อด้อยคือบางกระบวนการ (เช่น การคอมเพรสหรือการส่งผ่านแพลตฟอร์มบางแห่ง) อาจตัดข้อมูลนี้ออกได้
- Sidecar files: เก็บ metadata แยกออกเป็นไฟล์คู่ (.xmp, .json) ที่เชื่อมโยงกับไฟล์ต้นฉบับผ่านชื่อหรือ hash ของไฟล์ ข้อดีคือไม่ทำลายไบนารีต้นฉบับและง่ายต่อการเข้ารหัสหรือจัดการสิทธิ์ ข้อเสียคือต้องรับประกันการพ่วงไฟล์ตลอดวงจรชีวิตของสื่อ
- Server‑anchored / ledger‑anchored: เก็บเฉพาะ pointer หรือ hash ของไฟล์ และบันทึก metadata ฉบับเต็มในเซิร์ฟเวอร์ที่เชื่อถือได้หรือในบล็อกเชน (เช่นการใช้ Merkle anchoring) วิธีนี้เหมาะสำหรับการยืนยันความสมบูรณ์และการออก timestamp ส่วนข้อจำกัดคือขึ้นกับความน่าเชื่อถือและความพร้อมใช้งานของผู้ให้บริการ
การยืนยันความสมบูรณ์และกันการปลอมแปลงจำเป็นต้องใช้เทคนิคเชิงคริปโตกราฟีหลายแบบร่วมกัน:
- เริ่มจากการคำนวณ hash (เช่น SHA‑256) ของไฟล์ต้นฉบับและของ metadata แต่ละขั้นตอน เพื่อเป็นตัวชี้วัดสถานะที่ไม่เปลี่ยนแปลง
- เซ็นด้วยคีย์สาธารณะ/ส่วนตัว (เช่น Ed25519 หรือ ECDSA) บนค่า hash หรือบนเอกสาร metadata (JSON Web Signatures / COSE / CMS) เพื่อยืนยันตัวตนของผู้สร้างหรือผู้แปลง
- ใช้ timestamping ที่เชื่อถือได้ (RFC 3161 TSA หรือบริการ timestamping แบบกระจาย เช่น OpenTimestamps / blockchain anchoring) เพื่อยืนยันลำดับเวลาและป้องกันการย้อนเวลา (backdating)
- สำหรับ asset ที่ผ่านการแปลงหลายขั้นตอน ควรใช้โครงสร้างแบบ append‑only transformation log ที่แต่ละเหตุการณ์ (actor, operation, input_hash, output_hash, parameters) ถูกเซ็นและเชื่อมด้วย Merkle tree เพื่อให้ตรวจสอบ chain‑of‑custody ได้ครบถ้วน
การออกแบบ metadata schema ควรประกอบด้วยฟิลด์สำคัญ เช่น creator_id (หรือ fingerprint ของโมเดล), model_hash หรือ model_family, generation_timestamp, prompt_digest (ไม่จำเป็นต้องเก็บ prompt ฉบับเต็ม), parameters (temperature, seed, version) และ signature ของข้อมูลเหล่านี้ ตัวอย่างเช่น ใน XMP อาจเก็บ xmp:CreatorTool และ prov:wasDerivedFrom และใน sidecar JSON เก็บรายการ transformation เป็นอาเรย์ของเหตุการณ์ที่เซ็นแล้ว
ความท้าทายสำคัญคือการบาลานซ์ระหว่างความโปร่งใสกับการคุ้มครองความเป็นส่วนตัวหรือความลับทางการค้า ซึ่งสามารถแก้ไขได้ด้วยแนวทางต่างๆ ดังต่อไปนี้:
- Hashing และ commitments: แทนที่จะเผย prompt เต็มรูปแบบ ให้เก็บ prompt_hash หรือ commitment (เช่น SHA‑256 หรือ Pedersen commitment) พร้อม salt ซึ่งเปิดเผยต่อผู้ตรวจสอบเฉพาะเมื่อมีสิทธิ์
- Selective disclosure / encryption: เก็บฟิลด์ที่ละเอียดอ่อนใน sidecar ที่เข้ารหัสเฉพาะผู้มีสิทธิ์หรือในรูปแบบที่สามารถถอดเฉพาะโดยผู้รับรอง (auditor) โดยใช้ public‑key encryption หรือระบบการแบ่งกุญแจ (threshold encryption)
- Abstracted metadata: เผยข้อมูลระดับสรุป เช่น ชื่อรุ่นโมเดล (model family), ฟังก์ชันความสามารถ, ค่า hyperparameters หลัก แต่ไม่เผย prompt ฉบับสมบูรณ์หรือขั้นตอนภายในที่เป็นความลับทางการค้า
- Verifiable claims / VC และ selective disclosure protocols: ใช้มาตรฐานอย่าง W3C Verifiable Credentials หรือ JSON‑LD digital signatures กับกลไก selective disclosure/zero‑knowledge proof เพื่อยืนยันคุณสมบัติของโมเดลโดยไม่เปิดเผยข้อมูลเชิงลึก
โดยสรุป การนำ AI‑provenance ไปปฏิบัติจริงต้องออกแบบระบบ metadata ให้รองรับทั้งรูปแบบฝังในไฟล์และภายนอก, ใช้การลงนามดิจิทัลและ timestamping เพื่อให้แน่ใจว่า chain‑of‑custody ไม่สามารถปรับแก้ได้โดยไม่ทิ้งร่องรอย และจัดการข้อมูลที่เป็นความลับด้วยเทคนิค selective disclosure และการเข้ารหัส เพื่อรักษาสมดุลระหว่างความโปร่งใสทางสาธารณะกับการคุ้มครองทรัพย์สินทางปัญญาและข้อมูลส่วนบุคคล
5. ความท้าทายด้านความเป็นส่วนตัว ความปลอดภัย และกฎหมาย
5. ความท้าทายด้านความเป็นส่วนตัว ความปลอดภัย และกฎหมาย
การนำมาตรฐาน AI‑Provenance มาใช้ในไฟล์มีเดียเพื่อระบุแหล่งที่มา โมเดล และพรอมต์ เป็นแนวทางที่มุ่งเพิ่มความน่าเชื่อถือของข้อมูล แต่ในทางปฏิบัติย่อมเกิดความตึงเครียดระหว่างความโปร่งใสกับความเป็นส่วนตัวและความปลอดภัยของข้อมูลได้อย่างชัดเจน โดยเฉพาะเมื่อ metadata ที่ฝังมากับไฟล์ — เช่น EXIF ในภาพถ่าย, ตราประทับเวลาการสร้าง, ข้อมูลอุปกรณ์ หรือรหัสไอดีของโมเดล — อาจเปิดเผยข้อมูลส่วนบุคคล เช่น ตำแหน่งที่อยู่ เวลา หรือข้อมูลประจำตัวของผู้สร้าง ในการปฏิบัติจริง การศึกษาหลายชิ้นชี้ว่าไฟล์ที่ถูกแชร์ในระดับสาธารณะยังคงมี metadata ที่สามารถนำไปสู่การระบุตัวตนหรือสถานที่ได้ในสัดส่วนที่มีความสำคัญ (ประมาณช่วงกว้าง 20–50% ในงานวิจัยต่าง ๆ ขึ้นกับแหล่งข้อมูลและประเภทไฟล์) ซึ่งสะท้อนความเสี่ยงเชิงปฏิบัติที่ต้องบริหารจัดการอย่างระมัดระวัง
อีกประเด็นสำคัญคือความเสี่ยงจากการเปิดเผยรายละเอียดของโมเดลและพรอมต์ที่ถือเป็นกรรมสิทธิ์หรือเป็นความลับทางการค้า การเผยแพร่ชื่อโมเดล พารามิเตอร์ หรือพรอมต์ที่ใช้ในการผลิตสื่อบางประเภท อาจทำให้คู่แข่งสามารถทำซ้ำหรือปรับปรุงเทคนิคการปลอมแปลง (เช่น deepfake) ได้ง่ายขึ้น นอกจากนี้ยังเปิดช่องให้เกิดการโจมตีเชิงวิชาการ เช่น model inversion และ prompt‑injection ที่สามารถสกัดข้อมูลฝึกหรือชี้เป้าผู้ให้ข้อมูล การเปิดเผยต้นทางที่ละเอียดจนเกินไปอาจทำให้การสืบสวนย้อนกลับ (forensic traceability) ส่งผลร้ายต่อความปลอดภัยของแหล่งข่าว นักวิจัย หรือนักสร้างสรรค์ที่ต้องการคุ้มครองแหล่งที่มา
ในด้านกฎหมาย มีช่องว่างและความไม่สอดคล้องกันระหว่างเขตอำนาจศาลที่เป็นอุปสรรคสำคัญต่อการบังคับใช้มาตรฐานเดียวกัน ความแตกต่างระหว่างกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น GDPR (สหภาพยุโรป), CCPA/CPRA (รัฐแคลิฟอร์เนีย), และกฎหมายท้องถิ่นเช่น PDPA ของไทย ทำให้เกิดคำถามว่าใครเป็นผู้ควบคุมข้อมูล (data controller) หรือผู้ประมวลผล (data processor) เมื่อ provenance ถูกฝังในไฟล์ที่ถูกส่งข้ามพรมแดน นอกจากนี้กฎหมายแต่ละประเทศให้ความคุ้มครองและบทลงโทษต่างกัน ทำให้การบังคับใช้มาตรฐานข้ามประเทศ — โดยเฉพาะกรณีที่มีการละเมิดหรือการรั่วไหลของข้อมูล — เป็นเรื่องยุ่งยาก ทั้งในแง่การร้องขอให้ลบข้อมูล การเรียกร้องค่าชดเชย และการสืบสวนทางอาญาข้ามพรมแดน
ความเสี่ยงด้านความปลอดภัยยังรวมถึงความเป็นไปได้ที่ระบบ provenance จะถูกแฮ็กหรือปลอมแปลง หากคีย์การลงลายเซ็นดิจิทัลหรือโครงสร้างบัญชีแยกมาก (ledger) ถูกบุกรุก ผู้โจมตีสามารถแก้ไขหรือประดิษฐ์ข้อมูลแหล่งที่มาได้ ทำลายความน่าเชื่อถือของทั้งระบบ นอกจากนั้น การผสมผสานข้อมูล provenance กับแหล่งข้อมูลภายนอก (data linkage) ยังอาจนำไปสู่การย้อนกลับเพื่อระบุตัวบุคคล (de‑anonymization) ซึ่งก่อให้เกิดความเสี่ยงต่อความปลอดภัยและสิทธิพลเมือง
- การลดข้อมูลโดยคัดกรอง (metadata minimization): เฉพาะข้อมูลที่จำเป็นเท่านั้นควรถูกฝัง พร้อมนโยบายชัดเจนว่าใครและเมื่อใดจึงสามารถเปิดเผยข้อมูลที่ละเอียดได้
- การเปิดเผยแบบมีเงื่อนไข (selective disclosure): ใช้การเข้ารหัสและการแบ่งสิทธิ์เข้าถึง เพื่อให้เฉพาะผู้มีสิทธิเท่านั้นที่สามารถอ่านข้อมูล provenance เต็มรูปแบบ
- การลงลายเซ็นและการตรวจสอบแบบทนการปลอมแปลง: ใช้ระบบลายเซ็นดิจิทัลและเมตริกความน่าเชื่อถือ แต่ต้องเตรียมแผนรับมือหากกุญแจถูกบุกรุก
- กรอบกฎหมายและข้อตกลงระหว่างประเทศ: ผลักดันมาตรฐานร่วมและข้อตกลงระหว่างหน่วยงานกำกับดูแล เพื่อให้การบังคับใช้มีพื้นฐานทางกฎหมายและกลไกความร่วมมือข้ามพรมแดน
- นโยบายคุ้มครองแหล่งข่าวและสิทธิเสรีภาพ: ออกแนวทางยกเว้นหรือกระบวนการ redaction สำหรับกรณีที่การเปิดเผย provenance อาจมีผลเสียต่อความปลอดภัยของบุคคลหรือสิทธิขั้นพื้นฐาน
สรุปได้ว่า การออกแบบและนำมาตรฐาน AI‑Provenance มาใช้ในวงกว้างต้องคำนึงถึงชุดมาตรการทางเทคนิค นโยบายเชิงองค์กร และกรอบกฎหมายเชิงสากลควบคู่กันไป ความโปร่งใสต้องเดินคู่กับการคุ้มครองข้อมูลและความมั่นคง มิฉะนั้น ระบบ provenance ที่ตั้งใจป้องกันการหลอกลวงอาจกลับกลายเป็นช่องทางเปิดเผยข้อมูลอ่อนไหวหรือถูกบ่อนทำลายโดยผู้ประสงค์ร้าย
6. ผลกระทบต่อสื่อมวลชนและการตรวจสอบข้อเท็จจริง (fact‑checking)
6. ผลกระทบต่อสื่อมวลชนและการตรวจสอบข้อเท็จจริง (fact‑checking)
มาตรฐาน AI‑Provenance ซึ่งกำหนดการติดแท็กข้อมูลแหล่งที่มา โมเดล และพรอมต์ภายในไฟล์มีเดีย จะมีผลขับเคลื่อนกระบวนการตรวจสอบข้อเท็จจริงของสื่อมวลชนอย่างเป็นระบบ โดยลดความซับซ้อนของการพิสูจน์แหล่งที่มาและการยืนยันความถูกต้องของเนื้อหา เมื่อข้อมูล provenance ถูกฝังมาในไฟล์ตั้งแต่ต้นทาง ผู้ตรวจสอบสามารถเข้าถึงข้อมูลเชิงเทคนิค (เช่น ลายนิ้วมือดิจิทัลของโมเดล, เวลาและตำแหน่งการสร้าง, ข้อมูลผู้สร้าง) ได้ทันทีโดยไม่ต้องอาศัยการติดต่อแหล่งข่าวหรือการวิเคราะห์เอ็กซ์เทนซีฟซึ่งกินเวลาและทรัพยากร
จากงานทดสอบเชิงปฏิบัติการ ตัวอย่างหนึ่งของสำนักข่าวนำร่องระบุว่า เวลาเฉลี่ยในการยืนยันความถูกต้อง ลดลงอย่างมีนัยสำคัญ — จากค่าเฉลี่ยก่อนมีมาตรฐานประมาณ 5.2 ชั่วโมง เหลือเพียง 1.4 ชั่วโมง (ลดลง ~73%) — เนื่องจากระบบอัตโนมัติสามารถตรวจจับและยืนยัน metadata ของไฟล์ได้โดยทันที นอกจากนี้ยังพบว่า ต้นทุนต่อการตรวจสอบ ลดลงทั้งด้านแรงงานและเวลา ทำให้ทีมตรวจสอบสามารถกระจายกำลังไปยังเคสที่มีความซับซ้อนสูงกว่าได้มากขึ้น
เพื่อประเมินผลของการนำ provenance มาใช้ สื่อมวลชนสามารถตั้งตัวชี้วัดเชิงปริมาณ (KPIs) ดังนี้
- เวลาเฉลี่ยในการยืนยัน (Average verification time) — เวลาตั้งแต่รับแจ้งเนื้อหา จนยืนยันความถูกต้องหรือปฏิเสธ (เป้าหมายเชิงปฏิบัติการ เช่น < 2 ชั่วโมงสำหรับข่าวด่วน)
- อัตราการปฏิเสธเนื้อหาเทียม (Fake content rejection rate) — เปอร์เซ็นต์ของเนื้อหาที่ตรวจพบและถูกระบุว่าเป็นเท็จก่อนแพร่กระจายต่อ
- False positive / False negative rates — อัตราการระบุผิดพลาด (ระบุเนื้อหาถูกต้องว่าเป็นเท็จ หรือไม่สามารถจับเนื้อหาเท็จได้) เป็นตัวชี้วัดคุณภาพของระบบอัตโนมัติและกระบวนการผสมผสานมนุษย์–เครื่อง
- ต้นทุนต่อการตรวจสอบ (Cost per verification) — ค่าใช้จ่ายโดยเฉลี่ยต่อเคสหลังนำระบบ provenance มาใช้
- ระดับความเชื่อมั่นของผู้อ่าน (Reader trust score) — การสำรวจเชิงสถิติที่วัดระดับความเชื่อใจต่อแหล่งข่าวก่อนและหลังการประกาศมาตรการ provenance
- อัตราการแพร่กระจายของข้อมูลเท็จ (Misinformation spread reduction) — ตัวชี้วัดผลกระทบต่อการลดการถูกแชร์หรือนำไปใช้ซ้ำ
ตัวอย่างเชิงปฏิบัติการจากโครงการนำร่องในหลายองค์กรชี้ให้เห็นถึงรูปแบบการใช้งานที่ชัดเจน: สื่อบางแห่งผสานระบบ provenance เข้ากับแดชบอร์ดตรวจสอบอัตโนมัติที่แยกแยะไฟล์ตามระดับความน่าเชื่อถือ (trusted, unverified, flagged) ทำให้ผู้สื่อข่าวและบรรณาธิการสามารถตั้งมาตรการตอบโต้ (เช่น แสดงคำเตือน, ระงับการเผยแพร่ชั่วคราว, หรือส่งต่อให้ทีม fact‑check) ได้ทันที งานทดสอบอื่น ๆ รายงานว่าอัตรา false negative ลดจากประมาณ 12% เหลือ 3–4% เมื่อมีการรวมทั้ง metadata เชิงลายเซ็นดิจิทัลและการตรวจจับความผิดปกติของคอนเทนต์
นอกจากการลดเวลาและต้นทุนแล้ว มาตรฐาน provenance ยังช่วยเพิ่มความโปร่งใสของการรายงานข่าว ทำให้ผู้อ่านสามารถตรวจสอบแหล่งที่มาได้ด้วยตนเองหรือผ่านลิงก์ที่สื่อให้มา ผลที่ตามมาคือ ระดับความเชื่อมั่นของผู้อ่านต่อสำนักข่าวมีแนวโน้มสูงขึ้น ซึ่งสามารถวัดได้จากการสำรวจหลังเผยแพร่และอัตราการยอมรับคอร์เร็คชัน (correction acceptance) ที่เพิ่มขึ้น การที่สื่อสามารถแสดงหลักฐานเชิงเทคนิคของเนื้อหาได้ทันทียังช่วยลดข้อพิพาทและค่าทดแทนที่อาจเกิดจากการเผยแพร่ข้อมูลผิดพลาด
โดยสรุป การรับมาตรฐาน AI‑Provenance ไม่เพียงแต่ช่วยเร่งกระบวนการตรวจสอบข้อเท็จจริงและลดต้นทุนปฏิบัติการ แต่ยังเป็นเครื่องมือสำคัญในการยกระดับคุณภาพการรายงานและความน่าเชื่อถือของสื่อในระยะยาว — ทั้งนี้ความสำเร็จเชิงปฏิบัติการขึ้นอยู่กับการออกแบบ KPI ที่เหมาะสม การผสานระบบอัตโนมัติกับการตรวจสอบโดยมนุษย์ และการทดสอบในสภาพแวดล้อมจริงเป็นรอบ ๆ
7. โร้ดแมปการนำไปใช้และข้อเสนอแนะสำหรับผู้มีส่วนได้ส่วนเสีย
7. โร้ดแมปการนำไปใช้และข้อเสนอแนะสำหรับผู้มีส่วนได้ส่วนเสีย
การนำมาตรฐาน AI‑Provenance ไปใช้ในวงกว้างต้องอาศัยความร่วมมือเชิงเทคนิค นโยบาย และการดำเนินงานจากหลายฝ่าย ทั้งเบราว์เซอร์และแพลตฟอร์ม ผู้พัฒนาโมเดล สำนักงานข่าว และหน่วยงานกำกับดูแล ส่วนนี้สรุปขั้นตอนเชิงปฏิบัติ ไทม์ไลน์คาดการณ์ และ milestones ที่ควรตั้งเป้าเพื่อให้การติดแท็กแหล่งที่มา‑โมเดล‑พรอมต์ในไฟล์มีเดียเป็นจริงได้อย่างรวดเร็ว มีความน่าเชื่อถือ และคำนึงถึงความเป็นส่วนตัวและการแข่งขันทางธุรกิจ
หลักการนำไปใช้เบื้องต้น — ให้มุ่งเน้นที่การออกแบบ API และโพรโทคอลแบบเปิด (open, extensible) ที่สนับสนุนการลงลายดิจิทัล (signing) ของ metadata, การเปิดเผยตัวระบุโมเดล (model identifiers) ในรูปแบบที่ตรวจสอบได้ และการเก็บร่องรอยของกระบวนการ (audit trail) โดยไม่เปิดเผยข้อมูลส่วนบุคคลหรือทีละรายละเอียดของพรอมต์ที่อาจเป็นความลับทางธุรกิจ ตัวอย่างฟิลด์ขั้นต่ำที่ควรกำหนด ได้แก่: model_id, model_version, provenance_signature, generation_timestamp, prompt_hash (หรือ prompt metadata แบบย่อย), source_author และ toolchain_version
แนวทางปฏิบัติสำหรับผู้มีส่วนได้ส่วนเสียหลัก — แบ่งตามบทบาทเพื่อความชัดเจนและการปฏิบัติได้จริง:
- เบราว์เซอร์และแพลตฟอร์ม: เปิด API สาธิต (pilot API) สำหรับแนบและตรวจสอบ AI‑provenance metadata ในไฟล์มีเดีย, พัฒนา UI/UX ให้ผู้ใช้เห็นสถานะ provenance (เช่น ไอคอน/แบนเนอร์แสดงว่ารูปหรือวิดีโอผ่านการสร้างด้วยโมเดลใด/ได้รับการยืนยันหรือไม่), ปรับนโยบายเนื้อหาเพื่อให้แอ็กชันชัดเจนเมื่อ metadata ขาดหรือถูกดัดแปลง
- ผู้พัฒนาโมเดล: ให้เผยแพร่ตัวระบุโมเดลที่ตรวจสอบได้ (รวมถึง repository URL และ fingerprint), สนับสนุนการลงลายของผลลัพธ์และ metadata ด้วยคีย์สาธารณะ/ส่วนตัว และรายงานวิธีการฝึก (training provenance) อย่างสรุปเมื่อจำเป็นตามมาตรฐาน
- สำนักข่าวและองค์กรสื่อ: ผสานการสร้างและการตรวจสอบ provenance เข้ากับเวิร์กโฟลว์การผลิต (CMS, DAM), กำหนดจุดตรวจสอบ (checkpoint) ก่อนเผยแพร่ เช่น ต้องมี signature และ model_id ที่ยืนยันได้สำหรับเนื้อหาที่ใช้ AI พร้อมอบรมบรรณาธิการและนักข่าวในการอ่านค่า metadata และจัดทำบันทึกการตัดสินใจ
- ผู้กำกับดูแลและหน่วยงานกำหนดมาตรฐาน: ออกแนวทางขั้นต่ำสำหรับการเปิดเผย metadata, ระบุข้อกำหนดด้านความเป็นส่วนตัว (เช่น ห้ามเก็บหรือเผยแพร่พรอมต์ที่มีข้อมูลส่วนบุคคลโดยไม่ได้รับความยินยอม) และส่งเสริมการทดสอบความเข้ากันได้ร่วมกับผู้เล่นสำคัญ
ไทม์ไลน์และ milestones ที่แนะนำ — แบ่งเป็นเฟสเพื่อลดความเสี่ยงและเร่งการรับรอง
- ช่วง 0–90 วัน (ต้น): ตั้งคณะทำงานร่วม (consortium pilots) ระหว่าง 2–3 เบราว์เซอร์หลัก ผู้พัฒนาโมเดลรายใหญ่ และสำนักข่าวนำร่อง ผลลัพธ์ที่คาดหวัง: สเปคฉบับร่าง, ตัวอย่าง API สำหรับแนบ/ตรวจสอบ metadata, reference implementation แบบโอเพนซอร์สสำหรับการลงลายดิจิทัล
- ช่วง 90–180 วัน: เปิดตัวโปรแกรมนำร่อง (pilot program) ในสเกลจำกัด — เบราว์เซอร์เปิดฟีเจอร์เป็น experimental flag, แพลตฟอร์ม social media ทดลองแสดง badge/provenance layer, สำนักข่าว 3–5 แห่งทดลองผนวก provenance ในกระบวนการผลิต ผลลัพธ์ที่คาดหวัง: ข้อมูลเชิงปฏิบัติ (เช่น อัตราการตรวจจับ metadata หาย/ถูกแก้ไข), ปรับปรุงสเปคตาม feedback
- ช่วง 6 เดือน: ปรับปรุงสเปคเป็นเวอร์ชัน 1.0, เริ่มสนับสนุนในเบราว์เซอร์หลัก (ในโหมดมาตรฐาน) และเปิด SDK/plug‑in สำหรับ CMS ติดตั้งในสำนักข่าวเพิ่มเติม ผลลัพธ์ที่คาดหวัง: การยอมรับจากผู้ใช้ขั้นต้น, ตัวชี้วัดเช่นอัตราการแสดง badge ต่อเนื้อหาที่สร้างด้วย AI
- ช่วง 12–18 เดือน: บูรณาการบนแพลตฟอร์มหลักอย่างกว้างขวาง, ผู้พัฒนาโมเดลรายใหญ่ทั้งหลายเผยแพร่ model identifiers และรองรับ signing, สำนักข่าวหลักหลายแห่งผสานขั้นตอนตรวจสอบเข้ากับ workflow ผลลัพธ์ที่คาดหวัง: เป้าหมายเชิงตัวเลขที่เป็นไปได้ เช่น >50% ของเนื้อหาที่ติดแท็กที่สร้างด้วย AI ในแพลตฟอร์มที่เข้าร่วมภายใน 12 เดือน และการลดรายงานกรณี deepfake ที่ไม่ได้รับการติดแท็ก
- 18 เดือนขึ้นไป: ขยายการใช้งานระหว่างประเทศ ปรับมาตรฐานตามข้อกำกับดูแลท้องถิ่น และทำการประเมินผลเชิงอิสระ (third‑party audits) เพื่อตรวจสอบประสิทธิผลของมาตรการ
ข้อเสนอเชิงนโยบายที่ต้องคำนึงถึง — โปร่งใส แต่ต้องรักษาความเป็นส่วนตัวและการแข่งขัน:
- กำหนดหลักการ โปร่งใสแบบมีเงื่อนไข — ระบุข้อมูลขั้นต่ำที่ต้องเปิดเผย (เช่น model_id, signature, timestamp) แต่ไม่บังคับให้เปิดเผยพรอมต์ดิบหรือข้อมูลที่เป็นความลับทางการค้า
- สนับสนุนเทคนิคที่รักษาความเป็นส่วนตัว — เช่น การใช้ prompt hashing, selective disclosure, หรือลงลายแบบ zero‑knowledge proofs เมื่อเหมาะสม เพื่อให้ตรวจสอบความถูกต้องได้โดยไม่ต้องเปิดเผยข้อมูลทั้งหมด
- ป้องกันการผูกขาดทางเทคนิค — ส่งเสริมสเปคแบบเปิดและความเข้ากันได้ข้ามผู้ให้บริการ; หลีกเลี่ยงการกำหนดรูปแบบปิดที่เอื้อประโยชน์ต่อผู้เล่นรายใดรายหนึ่ง
- กำหนดกรอบการกำกับดูแลเชิงผลลัพธ์ — เน้นการวัดผล (e.g., การลดเหตุการณ์ deepfake ที่เข้าหาเป้าหมายสาธารณะ) มากกว่าการบังคับวิธีการทางเทคนิคเพียงอย่างเดียว
การวัดความสำเร็จและตัวชี้วัด (KPIs) — ระบุ KPIs ชัดเจนเพื่อประเมินผลความคืบหน้า เช่น อัตราการติดแท็กต่อเนื้อหาที่สร้างด้วย AI, จำนวนการตรวจสอบสำเร็จผ่าน signature, อัตราการรายงาน/ป้องกัน deepfake ที่ลดลง, และระดับความไว้วางใจของผู้ใช้ตามผลสำรวจ หลังจาก 12 เดือน ควรมีการทบทวนเชิงปริมาณและเชิงคุณภาพเพื่อนำไปสู่การปรับสเปค/นโยบายในรอบถัดไป
สรุปคือ โร้ดแมปนี้เน้นการเริ่มจากการทดลองนำร่องที่มีการร่วมมือแบบข้ามภาคส่วนภายใน 90–180 วันแรก ขยายเป็นการบูรณาการเชิงแพลตฟอร์มและการยอมรับของผู้ใช้ในช่วง 6–18 เดือน ขณะเดียวกันผู้กำกับดูแลควรออกแนวทางที่สมดุลระหว่างความโปร่งใส ความเป็นส่วนตัว และการแข่งขันทางธุรกิจ เพื่อให้การติดแท็กแหล่งที่มา‑โมเดล‑พรอมต์กลายเป็นมาตรฐานปฏิบัติที่ช่วยลดความเสี่ยงของ deepfake และเพิ่มความน่าเชื่อถือของข่าวสารได้อย่างยั่งยืน
บทสรุป
AI‑Provenance เป็นกลไกสำคัญที่จะช่วยลดผลกระทบจาก deepfake และเพิ่มความน่าเชื่อถือของสื่อโดยการติดแท็กข้อมูลต้นทางของไฟล์มีเดีย เช่น แหล่งที่มา โมเดล และ พรอมต์ ซึ่งช่วยให้ผู้ใช้งานและระบบตรวจสอบสามารถย้อนกลับแหล่งที่มาหรือประเมินความน่าเชื่อถือได้ ตัวอย่างเช่น โครงการด้านความโปร่งใสและการพิสูจน์แหล่งที่มาที่มีอยู่แล้ว เช่น Content Authenticity Initiative (CAI) และมาตรฐาน C2PA แสดงให้เห็นแนวทางการฝังเมทาดาทาและลายเซ็นดิจิทัลเพื่อยืนยันที่มาของเนื้อหา อย่างไรก็ตาม การออกแบบมาตรฐานต้องรักษาสมดุลระหว่างความโปร่งใสกับสิทธิความเป็นส่วนตัวของผู้สร้างและผู้ใช้—เช่นการใช้กลไกการเปิดเผยแบบเลือกได้ (selective disclosure) หรือการเข้ารหัสแบบใช้หลักฐานเชิงคณิตศาสตร์ เพื่อหลีกเลี่ยงการเปิดเผยข้อมูลส่วนบุคคลโดยไม่จำเป็น
ความสำเร็จในการผลักดัน AI‑Provenance ต้องอาศัยความร่วมมือระดับสากลระหว่าง ผู้พัฒนาเบราว์เซอร์ แพลตฟอร์มโซเชียล ผู้ผลิตโมเดล AI สื่อมวลชน และ หน่วยงานกำกับดูแล เพื่อให้เกิดการยอมรับเชิงปฏิบัติ เช่น การกำหนดมาตรฐานทางเทคนิค ข้อกำหนดการตรวจสอบ และกรอบทางกฎหมายที่ชัดเจน ในอนาคตอันใกล้ (3–5 ปี) เราคาดว่าจะเห็นการนำมาตรฐานร่วมไปใช้จริงในวงกว้างควบคู่กับเครื่องมือพิสูจน์ความถูกต้องที่ใช้คริปโตกราฟีและเมทาดาทาแบบมาตรฐาน ตัวชี้วัดความสำเร็จได้แก่ระดับการยอมรับของผู้ให้บริการสื่อ อัตราการลดเหตุการณ์ deepfake ที่ส่งผลกระทบต่อสาธารณะ และความสามารถในการตรวจสอบย้อนกลับโดยไม่ละเมิดความเป็นส่วนตัวของผู้เกี่ยวข้อง—ซึ่งทั้งหมดนี้ทำได้ก็ต่อเมื่อทุกฝ่ายร่วมมือกันอย่างเป็นรูปธรรม



