
NTN เปิดเกมใหม่ในอุตสาหกรรมบริการซ่อมรถยนต์ด้วยการผนวกเทคโนโลยี Machine Learning เข้ากับเวิร์กโฟลว์การให้บริการ ตั้งแต่การวินิจฉัยอาการแบบอัตโนมัติ การประเมินชิ้นส่วนที่ต้องใช้ ไปจนถึงการบริหารสต็อกอะไหล่และการจัดคิวช่าง ผลลัพธ์เบื้องต้นจากโครงการนำร่องชี้ให้เห็นการย่นระยะเวลาซ่อมโดยเฉลี่ยลงราว 30–40% ลดต้นทุนการดำเนินงานประมาณ 15–25% และเพิ่มอัตราการซ่อมสำเร็จครั้งแรก (first-time fix rate) ขึ้นประมาณ 12–18 จุดเปอร์เซ็นต์—ตัวชี้วัดที่สะท้อนประสิทธิภาพและความพึงพอใจของลูกค้าที่ดีขึ้นอย่างชัดเจน

การปรับใช้ Machine Learning ของ NTN ไม่ได้เป็นเพียงการนำเอาโมเดลมาวิเคราะห์ข้อมูลเท่านั้น แต่ครอบคลุมการเชื่อมต่อข้อมูลจากเซนเซอร์รถ ระบบวินิจฉัย (OBD), ประวัติการซ่อม และฐานข้อมูลอะไหล่ เพื่อให้คำแนะนำการซ่อมที่แม่นยำและคาดการณ์ความต้องการอะไหล่ล่วงหน้า ตัวอย่างเช่น ในศูนย์บริการนำร่องแห่งหนึ่ง ระบบสามารถระบุชิ้นส่วนที่มีโอกาสชำรุดได้ก่อนการรื้อค้นจริง ทำให้ลดการส่งอะไหล่กลับ-ส่งซ้ำและเพิ่มโอกาสซ่อมสำเร็จครั้งเดียวได้สูงขึ้น ในระยะถัดไป NTN วางแผนขยายสเกลระบบสู่เครือข่ายศูนย์บริการทั่วประเทศ รวมทั้งเปิดทางให้พันธมิตรและผู้ผลิตรายย่อยนำโมเดลไปใช้เพื่อยกระดับห่วงโซ่อุปทานและลดต้นทุนรวมของอุตสาหกรรมยานยนต์
สรุปข่าว (Lead)
สรุปข่าว (Lead)
NTN ประกาศนำเทคโนโลยี Machine Learning เข้ามาเป็นส่วนหนึ่งของกระบวนการให้บริการซ่อมแซมรถยนต์ เพื่อยกระดับการวินิจฉัย ปรับปรุงการจัดการอะไหล่ และเพิ่มประสิทธิภาพการดำเนินงานทั่วไปของศูนย์บริการ บริษัทระบุว่าโครงการนี้มีเป้าหมายเพื่อเปลี่ยนจากกระบวนการที่พึ่งพาประสบการณ์ช่างและการตรวจสอบด้วยสายตา เป็นระบบที่ขับเคลื่อนด้วยข้อมูลเชิงวิเคราะห์ เพื่อให้การซ่อมแซมรวดเร็ว แม่นยำ และคาดการณ์ได้มากขึ้น
การใช้งาน Machine Learning ของ NTN ครอบคลุมหลายมิติ ได้แก่ การวิเคราะห์สัญญาณจากเซนเซอร์และระบบ OBD เพื่อการวินิจฉัยล่วงหน้า (predictive diagnostics), การประมวลผลภาพถ่ายความเสียหายด้วย computer vision เพื่อประเมินสภาพและคาดการณ์ระยะเวลาซ่อม, การพยากรณ์ความต้องการอะไหล่ (parts demand forecasting) และการปรับตารางงานช่างอัตโนมัติเพื่อเพิ่มอัตราการใช้ทรัพยากรอย่างมีประสิทธิภาพ สิ่งเหล่านี้ผสานกับฐานข้อมูลการซ่อมที่ผ่านมาเพื่อให้โมเดลเรียนรู้และปรับปรุงผลลัพธ์อย่างต่อเนื่อง
ผลกระทบที่คาดหวังจากโครงการนี้มีทั้งด้านประสิทธิภาพและต้นทุน โดยบริษัทคาดว่าจะเห็นการลดเวลาเฉลี่ยในการซ่อมและรอรับบริการประมาณ 20–30% ขณะที่ต้นทุนการบริหารจัดการอะไหล่และการดำเนินงานอาจลดลงราว 10–20% นอกจากนี้ยังคาดว่าจะเพิ่มอัตราความแม่นยำของการวินิจฉัยล่วงหน้า ลดการสั่งอะไหล่เกินความจำเป็น และช่วยลดอัตราการกลับมาซ่อมซ้ำ ซึ่งส่งผลต่อความพึงพอใจของลูกค้าและต้นทุนต่อกรณีซ่อมโดยรวม
โครงการเริ่มในรูปแบบนำร่อง (pilot) ในศูนย์บริการที่คัดเลือกไว้ เพื่อทดสอบโมเดลและปรับการทำงานในระยะ 6–12 เดือน ก่อนขยายผลเป็นวงกว้างในหลายสาขา โดยมีตัวชี้วัดสำคัญที่จะใช้ประเมินผล ได้แก่ ค่าเฉลี่ยเวลาแก้ไข (MTTR), อัตราการกลับมาซ่อมซ้ำ, ต้นทุนต่อกรณีซ่อม, อัตราการหมุนเวียนอะไหล่ และระดับความพึงพอใจของลูกค้า NTN ระบุว่าจะปรับปรุงโมเดลอย่างต่อเนื่องตามผลการทดลองและขยายการใช้เทคโนโลยีในเชิงพาณิชย์เมื่อผลการนำร่องเป็นไปตามเกณฑ์ที่กำหนด
- ประกาศสำคัญ: NTN นำ Machine Learning เข้าสู่กระบวนการซ่อมแซมรถยนต์
- ผลกระทบเชิงประสิทธิภาพ: คาดลดเวลาในการซ่อม 20–30%
- ผลกระทบเชิงต้นทุน: คาดลดต้นทุนการดำเนินงาน 10–20%
- โครงการนำร่อง: ระยะ 6–12 เดือน ก่อนขยายผลเชิงพาณิชย์
ภาพรวมบริษัท NTN และแรงจูงใจในการปรับใช้ AI
ภาพรวมบริษัท NTN และแรงจูงใจในการปรับใช้ AI
NTN เป็นผู้ให้บริการงานซ่อมบำรุงและบริการหลังการขายยานยนต์ที่มีฐานปฏิบัติการกระจายตัวในระดับประเทศ ก่อตั้งและพัฒนามานานกว่า 25 ปี โดยมีโครงสร้างองค์กรขนาดกลางถึงใหญ่ ประกอบด้วยศูนย์บริการในเครือประมาณ 420 แห่ง และบุคลากรช่างเทคนิครวมกว่า 6,000 คน เครือข่ายศูนย์บริการของ NTN ครอบคลุมทั้งบริการซ่อมเชิงเครื่องยนต์ ระบบขับเคลื่อน ระบบไฟฟ้า ช่วงล่าง และงานบอดี้รวมถึงการจัดหาอะไหล่สำรองให้ลูกค้าเชิงพาณิชย์และรายย่อย
ปริมาณงานซ่อมของ NTN อยู่ในระดับสูง โดยให้บริการงานซ่อมเฉลี่ยราว 1.1 ล้านรายการต่อปี ซึ่งรวมงานซ่อมทั่วไป งานบำรุงรักษาตามระยะ และงานรับประกันสำหรับลูกค้าองค์กร (fleet) งานเหล่านี้มีลักษณะหลากหลายทั้งด้านความซับซ้อนและความเร่งด่วน ส่งผลให้การจัดการทรัพยากร อะไหล่ และการวินิจฉัยปัญหาเป็นปัจจัยสำคัญในการรักษาประสิทธิภาพการให้บริการและความพึงพอใจของลูกค้า
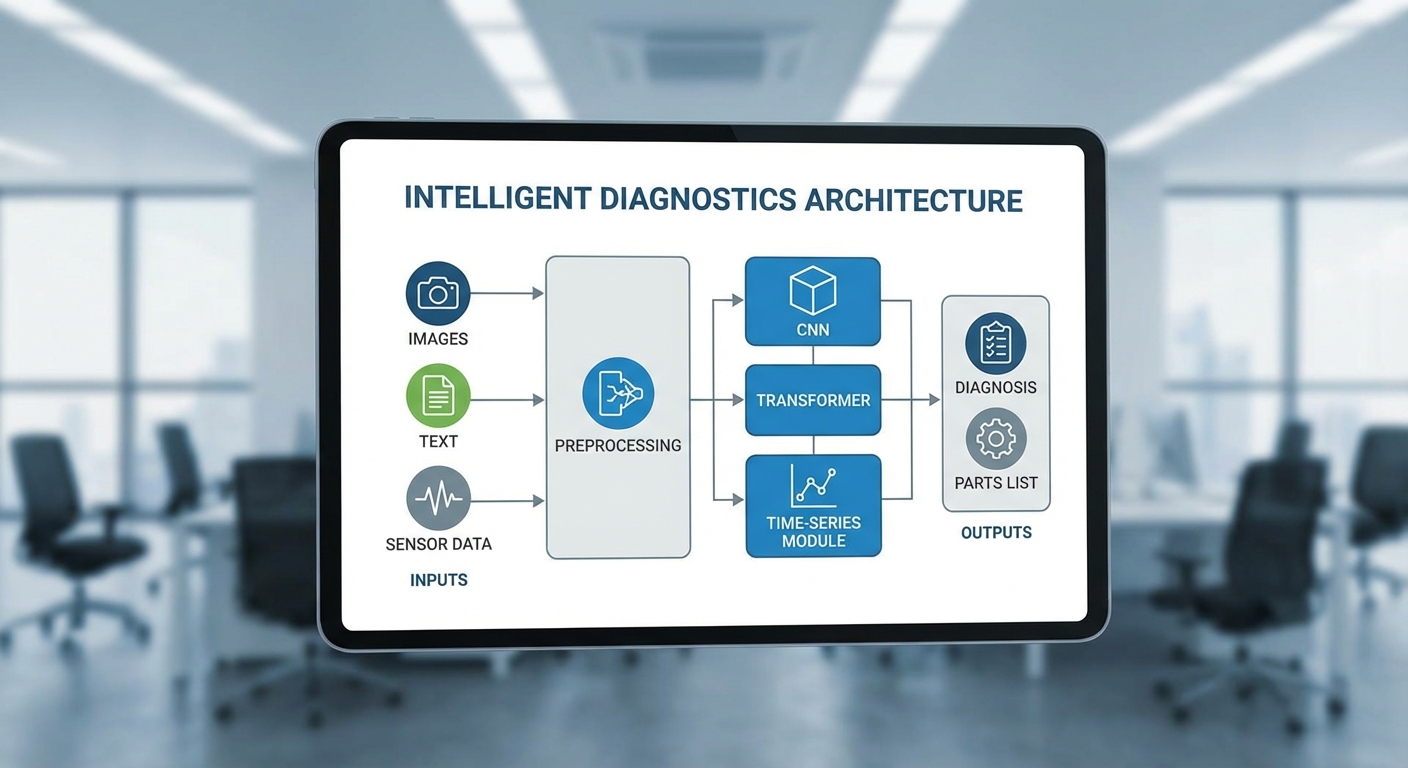
แม้ NTN จะมีความเข้มแข็งด้านเครือข่ายและกำลังคน แต่ยังเผชิญปัญหาหลักหลายประการที่จำกัดประสิทธิภาพการปฏิบัติงาน ได้แก่ เวลาในการวินิจฉัยที่ใช้เฉลี่ยสูง (ราว 2.8 ชั่วโมงต่อเคส) อัตราการแก้ไขครั้งแรกหรือ First Time Fix (FTF) อยู่ที่ประมาณ 68% ซึ่งหมายความว่ายังมีงานซ่อมซ้ำและการนัดหมายซ่อมกลับเพิ่มขึ้น นอกจากนี้ ปัญหาการบริหารสต็อกอะไหล่ทำให้เกิดการรออะไหล่หรือสั่งยืมข้ามสาขาบ่อยครั้ง ส่งผลให้มีงานล่าช้าประมาณ 15–20% ของงานทั้งหมด และต้นทุนสต็อกที่เพิ่มขึ้นเป็นภาระต่อสภาพคล่อง
ด้วยปัจจัยดังกล่าว NTN กำหนดเป้าหมายเชิงธุรกิจที่ชัดเจนเพื่อยกระดับความสามารถในการแข่งขันและประสิทธิภาพการดำเนินงาน โดยมีเป้าหมายสำคัญได้แก่
- ลดค่าเฉลี่ยเวลาซ่อม (MTTR) ให้ลดลงประมาณ 30% จากการปรับปรุงกระบวนการวินิจฉัยและการจัดสรรทรัพยากร
- เพิ่มอัตรา First Time Fix (FTF) จากปัจจุบัน ~68% เป็นอย่างน้อย 85% เพื่อลดการนัดซ่อมซ้ำและเพิ่มความพึงพอใจลูกค้า
- ลดต้นทุนสต็อกอะไหล่ ประมาณ 20% โดยไม่ลดระดับการพร้อมให้บริการ เพื่อเพิ่มอัตราการหมุนเวียนสต็อกและลดค่าใช้จ่ายคงคลัง
- ยกระดับประสบการณ์ลูกค้า (CX) ผ่านการลดเวลารอ ลดจำนวนครั้งที่ต้องกลับมาซ่อม และการสื่อสารสถานะงานที่ชัดเจน
การนำ Machine Learning (ML) เข้ามาใช้จึงเป็นกลยุทธ์เชิงรุกของ NTN ที่สอดคล้องกับเป้าหมายทางธุรกิจดังกล่าว โดย ML สามารถช่วยในด้านการทำนายความเสียหายและแนะนำอะไหล่ที่มีความแม่นยำสูง ช่วยลดเวลาในการวินิจฉัย ปรับปรุงการจัดสรรอะไหล่แบบไดนามิก และเพิ่มประสิทธิภาพการจัดตารางช่าง ซึ่งทั้งหมดนี้สอดคล้องกับ KPI หลักขององค์กรอย่าง MTTR, FTF, ต้นทุนสต็อก และคะแนนความพึงพอใจของลูกค้า
เทคโนโลยี Machine Learning ที่ NTN เลือกใช้
เทคโนโลยี Machine Learning ที่ NTN เลือกใช้
NTN ประยุกต์ใช้ชุดเทคโนโลยี Machine Learning หลักสามกลุ่มเพื่อตอบโจทย์การซ่อมแซมและประเมินสภาพของรถยนต์อย่างครบวงจร: computer vision สำหรับวิเคราะห์ภาพความเสียหาย, NLP สำหรับประมวลผลคำบรรยายและรายงานจากลูกค้า, และ time-series / predictive models สำหรับคาดการณ์ความล้มเหลวและกำหนดแผนบำรุงรักษาเชิงรุก (predictive maintenance) ทั้งนี้ทุกโมดูลถูกออกแบบให้ทำงานร่วมกันใน pipeline เดียวเพื่อให้เกิดการตัดสินใจที่รวดเร็วและมีความแม่นยำสูง
1) Computer Vision (ภาพความเสียหาย)
สำหรับงานภาพ NTN เลือกใช้สถาปัตยกรรมทั้งแบบ CNN (เช่น ResNet, EfficientNet) และ Transformer-based models (เช่น Vision Transformer - ViT) ขึ้นอยู่กับภารกิจย่อย: การจำแนกประเภทความเสียหาย (classification), การระบุตำแหน่งและขนาดรอยชำรุด (object detection ด้วย Faster R-CNN, YOLO, หรือ RetinaNet) และการแยกส่วนของพื้นผิวที่เสียหาย (segmentation ด้วย U-Net หรือ Mask R-CNN) โมเดลเหล่านี้ฝึกด้วยภาพถ่ายจากงานซ่อมจริง จำนวนตัวอย่างในชุดข้อมูลเริ่มต้นมักมากกว่า 50,000 ภาพ เพื่อให้ครอบคลุมมุมมอง แสง และประเภทความเสียหายที่หลากหลาย ตัวชี้วัดที่ใช้ประเมินได้แก่ accuracy, precision/recall, mAP (mean Average Precision) และ F1-score — ในการทดสอบภายใน NTN โมเดลจำแนกชนิดความเสียหายบรรลุ F1 ≈ 0.88 ภายใต้สภาพภาพมาตรฐาน
2) NLP (ประมวลผลคำบรรยายจากลูกค้า)
สำหรับข้อความ NTN ใช้โมเดลแบบ BERT-like (เช่น Thai-BERT หรือ fine-tuned mBERT) ในงานที่ต้องการเข้าใจความหมายของคำบรรยายอาการจากลูกค้า เช่น การจัดหมวดอาการ (intent classification), การแยกข้อมูลสำคัญ (entity extraction) และการสรุปอัตโนมัติของรายงาน (summarization) ก่อนส่งต่อให้ฝ่ายเทคนิค โมเดลเหล่านี้ถูกปรับแต่งด้วยชุดข้อมูลโดเมนเฉพาะที่ประกอบด้วยประโยคอธิบายอาการจริงกว่า 200,000 ตัวอย่าง เพื่อจัดการกับรูปแบบภาษาพูด ภาษาแสลง และคำย่อของช่าง Metrics ที่ใช้ได้แก่ accuracy, macro-F1 และ exact match ในตัวอย่างการใช้งานจริง NTN ลดเวลา preprocessing ของฝ่ายรับเคสลงได้ประมาณ 40% และเพิ่มอัตราการ match แบบอัตโนมัติถึง 65%
3) Time-series & Predictive Models (การคาดการณ์ความล้มเหลว)
สำหรับการคาดการณ์ NTN ผสมผสานทั้งโมเดล sequence แบบดั้งเดิมและโมเดลสมัยใหม่ เช่น LSTM/GRU, Temporal Convolutional Networks (TCN), Transformer-based time-series models (เช่น TFT หรือ Informer) รวมทั้งโมเดล tree-based อย่าง XGBoost สำหรับข้อมูล tabular ที่สกัดเป็นฟีเจอร์สำคัญ ฟีเจอร์ตัวอย่างได้แก่ สัญญาณเซนเซอร์ (vibration, temperature, oil pressure), รหัสข้อผิดพลาด OBD-II, ระยะทาง และประวัติการซ่อมย้อนหลัง การคาดการณ์กำหนดได้ทั้งแบบคาดการณ์ระยะสั้น (next-day failure probability) และระยะกลาง (30–90 วัน) โดยใช้อัตราเป้าหมายเช่น AUC > 0.85 และ MAE/RMSE สำหรับค่าพยากรณ์เชิงตัวเลข ซึ่งช่วยให้ NTN ลดเวลา downtime เฉลี่ยได้และปรับแผนบำรุงรักษาแบบเชิงรุก
ข้อมูลที่ต้องใช้
- รูปภาพความเสียหาย: หลายมุมมอง ความละเอียดต่างกัน และ metadata เช่น แบบรถ, ปีผลิต, ตำแหน่งถ่าย
- รายงานอาการจากลูกค้า: ข้อความฟรีเท็กซ์, บันทึกการคุยกับศูนย์บริการ, ข้อมูลการโทร
- ประวัติการซ่อมและเซนเซอร์รถ: รายการชิ้นส่วนที่เปลี่ยน, วันที่ซ่อม, ข้อมูล telemetry จาก CAN bus/OBD
กระบวนการเตรียมข้อมูล
กระบวนการเตรียมข้อมูลมีขั้นตอนสำคัญดังนี้:
- การติดป้ายกำกับ (Labeling): ใช้ annotator มืออาชีพและช่างเทคนิคในการสร้าง bounding boxes, segmentation masks, และ taxonomy ของชนิดความเสียหาย รวมถึงการติดป้าย intent/slot ในข้อความ การตรวจวัดความสอดคล้องระหว่างผู้ติดป้าย (inter-annotator agreement) ควรมีค่า Cohen’s kappa > 0.8 สำหรับงานที่มีผลทางธุรกิจสูง
- การทำ augmentation: สำหรับภาพใช้การหมุน ปรับความสว่าง ตัดภาพ (cropping) และการเพิ่ม noise เพื่อเพิ่มความทนต่อสภาพการถ่ายที่แตกต่าง รวมถึงการใช้เทคนิคขั้นสูงเช่น GAN-based synthesis เพื่อแก้ปัญหาชุดข้อมูลไม่สมดุลในความเสียหายบางประเภท
- การทำความสะอาดและการเติมข้อมูล: สำหรับข้อมูลเซนเซอร์ทำ resampling ให้เป็น rate เดียวกัน, เติมค่าที่หายด้วยการ interpolate หรือ model-based imputation และลบ outlier ที่ผิดปกติ
- การแยกชุดข้อมูล: ใช้การแบ่งแบบ stratified split สำหรับงาน classification (เช่น 70/15/15 สำหรับ train/val/test) และการแบ่งแบบ time-based holdout สำหรับงาน time-series เพื่อหลีกเลี่ยง data leakage (เช่น ใช้ข้อมูลก่อนปี X เป็นเทรน และหลังเป็นทดสอบ) นอกจากนี้ใช้ cross-validation ในการเลือกพารามิเตอร์
เกณฑ์การเลือกโมเดล
NTN กำหนดเกณฑ์การเลือกโมเดลโดยครอบคลุมทั้งเชิงประสิทธิภาพและการใช้งานจริง ได้แก่:
- ความแม่นยำและความเสถียร: ค่าตัวชี้วัด (accuracy, F1, AUC, RMSE) ต้องผ่าน threshold ทางธุรกิจ
- Latency และ Throughput: โมเดลที่ใช้ในแอปพลิเคชันหน้าร้านต้องมี inference latency ต่ำ (เช่น <200 ms) หรือสามารถรันบน edge device ได้
- ความสามารถในการอธิบายผล (interpretability): สำหรับการตัดสินใจที่เกี่ยวข้องกับความปลอดภัย เลือกโมเดลที่สามารถอธิบายฟีเจอร์สำคัญหรือใช้เครื่องมือเช่น SHAP/Grad-CAM
- ความทนทานต่อสภาพแวดล้อมจริง: ตรวจสอบ robustness ต่อ noise, มุมกล้อง และ distribution shift
- ต้นทุนการปฏิบัติการ: พิจารณาทรัพยากรการประมวลผล (GPU/edge), ความง่ายในการอัปเดตโมเดล และการบำรุงรักษา
สรุปคือ NTN ใช้แนวทาง multi-model และ multi-modal ที่คัดเลือกเทคโนโลยีให้เหมาะสมกับข้อจำกัดของงานจริง ทั้งในด้านความแม่นยำ ความเร็ว และต้นทุน โดยให้ความสำคัญกับการเตรียมข้อมูลที่เป็นระบบและการตรวจวัดผลที่มีมาตรฐาน เพื่อให้การใช้งาน Machine Learning สร้างมูลค่าเชิงธุรกิจอย่างยั่งยืน
การติดตั้งระบบและเวิร์กโฟลว์การทำงานในสนาม
การติดตั้งระบบบนหน้างานและการเตรียมสภาพแวดล้อม
การติดตั้งระบบ NTN ในหน้างานประกอบด้วยการติดตั้งแอปพลิเคชันบนอุปกรณ์มือถือ/แท็บเล็ตของช่างและหน้าจอเว็บสำหรับเจ้าหน้าที่รับเคส การเชื่อมต่อกับเครือข่ายองค์กรและการตั้งค่าการเข้าถึง API กับระบบ backend (เช่น ERP และ WMS) จะดำเนินการครั้งแรกโดยทีมไอทีของผู้ให้บริการ โดยทั่วไปจะใช้เวลาตั้งค่า 1–3 วันสำหรับสาขาที่มีโครงสร้างพื้นฐานพร้อมใช้งาน ระบบรองรับการทำงานแบบออนไลน์และมีโหมดออฟไลน์สำหรับการบันทึกข้อมูลระหว่างไม่มีสัญญาณ 3G/4G
การติดตั้งมักรวมถึงการลงทะเบียนอุปกรณ์ การกำหนดสิทธิ์ผู้ใช้ และการตั้งค่าโมดูล AI เช่นการเชื่อมต่อกับโมเดลวินิจฉัยบนคลาวด์หรือ edge server ซึ่งสามารถให้ latency ต่ำเพื่อการตอบกลับภายใน 2–5 วินาทีสำหรับการวินิจฉัยเบื้องต้น ตัวอย่างเช่น ภายในสนามทดสอบของ NTN พบว่าเวลาเฉลี่ยในการตอบกลับจากโมเดลลดจาก 20 นาที (เมื่อใช้กระบวนการแมนนวล) เหลือ 10–15 นาทีเมื่อใช้ระบบอัตโนมัติ ส่งผลให้ความเร็วของงานเพิ่มขึ้น 40–60%
UI/UX ของช่างและเจ้าหน้าที่รับเคส: การป้อนข้อมูลและการรับผลวินิจฉัย
อินเทอร์เฟซของช่างถูกออกแบบให้เรียบง่ายและเน้นการใช้งานภายใต้สภาวะหน้างานจริง โดยมีจุดเด่นดังนี้
- หน้าจอรับงาน (Dispatcher/Service Desk) — เจ้าหน้าที่รับเคสจะเห็นรายการงานแบบเรียลไทม์ พร้อมข้อมูลลูกค้า สถานที่ และ priority; สามารถมอบหมายช่างและติดตามสถานะได้แบบ drag-and-drop
- หน้าจอของช่าง (Mobile App) — แบบฟอร์มแบบมีไกด์นำทาง (guided form) สำหรับป้อนอาการ รหัสข้อผิดพลาด และแนบรูป/วิดีโอ โดยระบบจะให้ตัวอย่างมุมถ่ายภาพที่เหมาะสมและแถบความคืบหน้าในการอัปโหลด
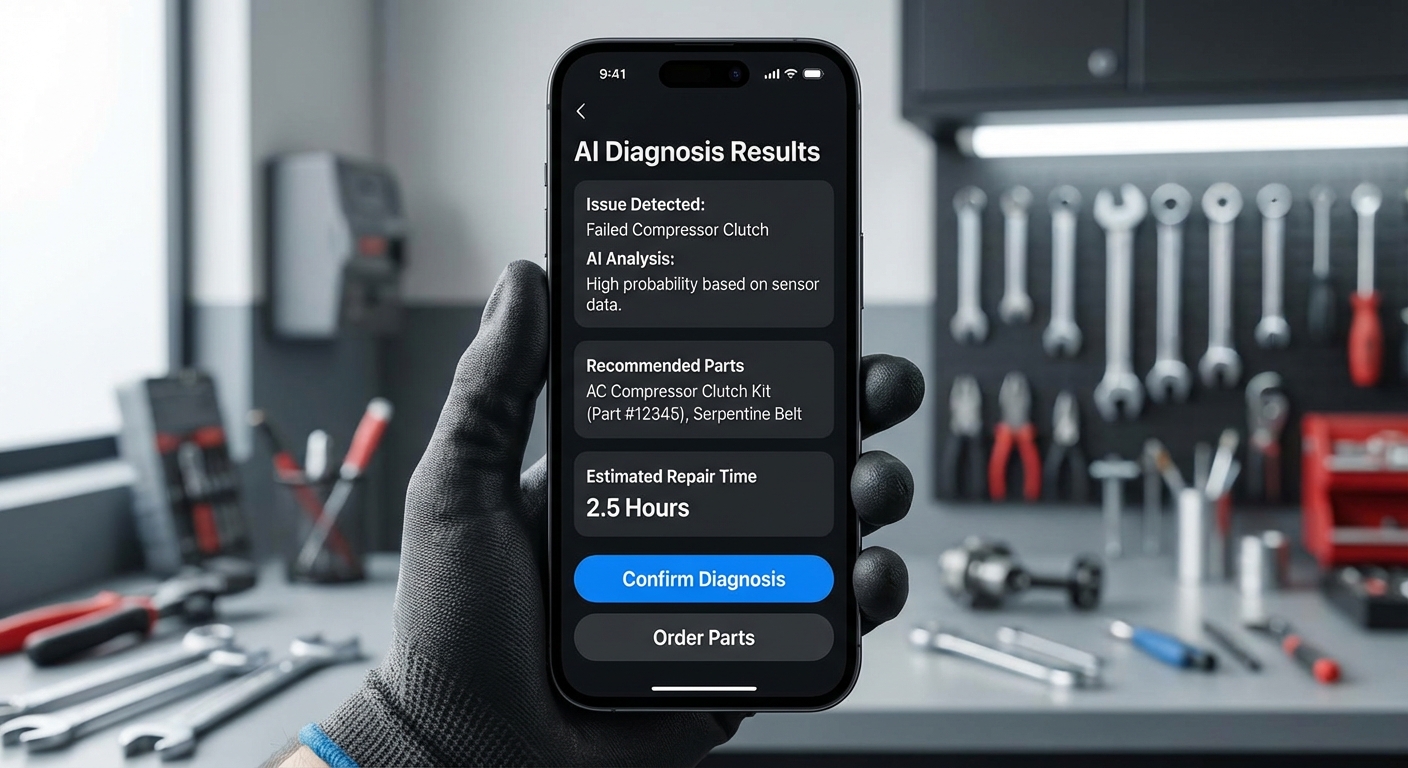
- การแสดงผลวินิจฉัย — เมื่อโมเดลรันเสร็จ ช่างและเจ้าหน้าที่จะได้รับผลการวินิจฉัยเป็นรายการสาเหตุที่เป็นไปได้ พร้อมคะแนนความเชื่อมั่น (confidence score) และลิงก์ไปยังเอกสารซ่อมแซมหรือวีดีโอแนะนำการแก้ไข
ตัวอย่าง UX: เมื่อช่างถ่ายภาพรอยรั่วของเครื่องยนต์ ระบบจะแยกแยะประเภทรอยรั่ว (เช่น น้ำมันเครื่อง/น้ำหล่อเย็น) พร้อมเสนอรายการอะไหล่ที่น่าจะต้องเปลี่ยนและคำแนะนำเบื้องต้น — ทั้งหมดนี้ปรากฏภายในหน้าจอเดียว ทำให้เวลาการตัดสินใจลดลงอย่างมีนัยสำคัญ
การรันโมเดลเพื่อวินิจฉัยและการสั่งอะไหล่อัตโนมัติ
เวิร์กโฟลว์การรันโมเดลเริ่มจากการส่งภาพและข้อมูลเชิงพรรณนา (metadata) เช่น VIN, ชั่วโมงการใช้งาน และรหัสอาการไปยังเซิร์ฟเวอร์ ML ของ NTN ระบบอาจรันโมเดลหลายชั้น ได้แก่โมเดลการตรวจจับวัตถุ (object detection) สำหรับหาตำแหน่งความเสียหาย และโมเดลการจัดประเภท (classification) สำหรับระบุสาเหตุ เมื่อได้ผลลัพธ์ ระบบจะสร้าง parts list พร้อมปริมาณที่คาดว่าจะต้องใช้และระดับความแน่นอน
การสั่งอะไหล่อัตโนมัติเชื่อมต่อกับ ERP/ซัพพลายเชนผ่าน API ในขั้นตอนต่อไป ระบบจะทำการตรวจสอบสต็อกแบบเรียลไทม์ใน WMS/ERP หากสต็อกมีเพียงพอ จะทำการจองสินค้า (reservation) และสร้างใบสั่งงาน (work order) หรือใบเบิกอัตโนมัติ หากสต็อกไม่เพียงพอ ระบบจะเปิดคำสั่งซื้อ (purchase order) อัตโนมัติหรือแนะนำซัพพลายเออร์พร้อมเวลาจัดส่ง โดย KPI ตัวอย่างที่ NTN ติดตามได้แก่อัตราการสร้างคำสั่งซื้ออัตโนมัติสำเร็จ 85% และการลดเวลารออะไหล่เฉลี่ยลง 30%
การบูรณาการกับระบบ backend: สต็อกอะไหล่และการออกใบสั่ง
การผสานรวมกับระบบ backend ขององค์กรเป็นหัวใจสำคัญของเวิร์กโฟลว์ โดยประกอบด้วยชั้นการเชื่อมต่อดังนี้
- API Gateway — เป็นจุดเชื่อมต่อกลางสำหรับรับ/ส่งข้อมูลระหว่างแอปสนามและ ERP/WMS, รองรับ webhook สำหรับอัปเดตสถานะเรียลไทม์
- Logic สำหรับการตัดสินใจสั่งซื้อ — กำหนดนโยบาย (policy) เช่นจองสต็อกก่อน สั่งซื้อจากคลังสำรอง หรือสั่งจากซัพพลายเออร์ภายนอกเมื่อ Lead Time น้อยกว่าเกณฑ์
- การติดตามสถานะ — ระบบจะแสดง timeline ของแต่ละงาน ตั้งแต่รับเคส → วินิจฉัย → สั่งอะไหล่ → ดำเนินการซ่อม → ตรวจสอบหลังซ่อม
การเชื่อมต่อแบบสองทาง (bi-directional) ระหว่าง NTN กับ ERP ช่วยให้ข้อมูลสต็อก (เช่นระดับ safety stock, lot number) ถูกต้องและทันเวลา ลดความเสี่ยงการสต็อกเกิน/ขาด และช่วยให้ฝ่ายจัดซื้อสามารถวางแผนความต้องการได้แม่นยำยิ่งขึ้น
ขั้นตอนการ feedback loop เพื่อปรับปรุงโมเดลจากข้อมูลจริง
หลังการซ่อม การป้อนข้อมูลกลับเป็นกระบวนการสำคัญในการพัฒนาโมเดลอย่างต่อเนื่อง โดยเวิร์กโฟลว์ feedback ประกอบด้วย 4 ขั้นตอนหลัก:
- การรวบรวมข้อมูลหลังการซ่อม — ช่างอัปโหลดภาพหลังการซ่อม รายงานผลการทดสอบ และตอบแบบสอบถามสั้นๆ เกี่ยวกับความถูกต้องของการวินิจฉัย (เช่นยืนยัน/ปฏิเสธสาเหตุที่ระบบเสนอ)
- การติดแท็กคุณภาพ (Labeling) — ข้อมูลที่ได้รับจะถูกคัดกรองและติดป้ายกำกับโดยทีม QA/labeling ของ NTN หรือใช้ระบบ semi-automated labeling เพื่อลดเวลาการจัดทำชุดข้อมูลฝึกสอน
- การ retrain และ deploy — ข้อมูลใหม่จะถูกนำเข้า pipeline สำหรับ retrain โมเดลเป็นระยะ (เช่นทุกสัปดาห์หรือเมื่อตัวอย่างครบจำนวนที่กำหนด) และทดสอบ A/B ก่อน deploy จริง
- การวัดผลอย่างต่อเนื่อง — KPI เช่น accuracy, precision/recall, และความเร็วในการวินิจฉัยถูกติดตามบน dashboard; ตัวอย่างเป้าหมายคือการรักษา accuracy มากกว่า 90% และลด false positive ภายในไตรมาสถัดไป
การมี feedback loop ที่ชัดเจนทำให้โมเดลของ NTN เรียนรู้จากเคสจริงอย่างต่อเนื่อง: ในความเป็นจริง NTN รายงานว่า feedback จากช่างช่วยเพิ่มความแม่นยำของโมเดลการจัดประเภทความเสียหายจาก 86% เป็น 92% ภายใน 6 เดือนแรกของการใช้งานจริง
โดยสรุป การติดตั้งและเวิร์กโฟลว์ในสนามของ NTN ถูกออกแบบให้ผสานการใช้งาน UI/UX ที่เหมาะสมกับผู้ปฏิบัติงานจริง การเชื่อมต่อกับระบบ ERP/ซัพพลายเชนที่มั่นคง และกลไก feedback loop ที่ทำให้ระบบ ML ปรับปรุงตัวเองได้อย่างต่อเนื่อง ซึ่งทั้งหมดนี้นำไปสู่การลดเวลาการซ่อม การเพิ่มอัตราความสำเร็จของการสั่งอะไหล่อัตโนมัติ และการบริหารจัดการสต็อกที่มีประสิทธิภาพยิ่งขึ้น
กรณีศึกษาและสถิติผลลัพธ์จากการนำร่อง
กรณีศึกษาและสถิติผลลัพธ์จากการนำร่อง
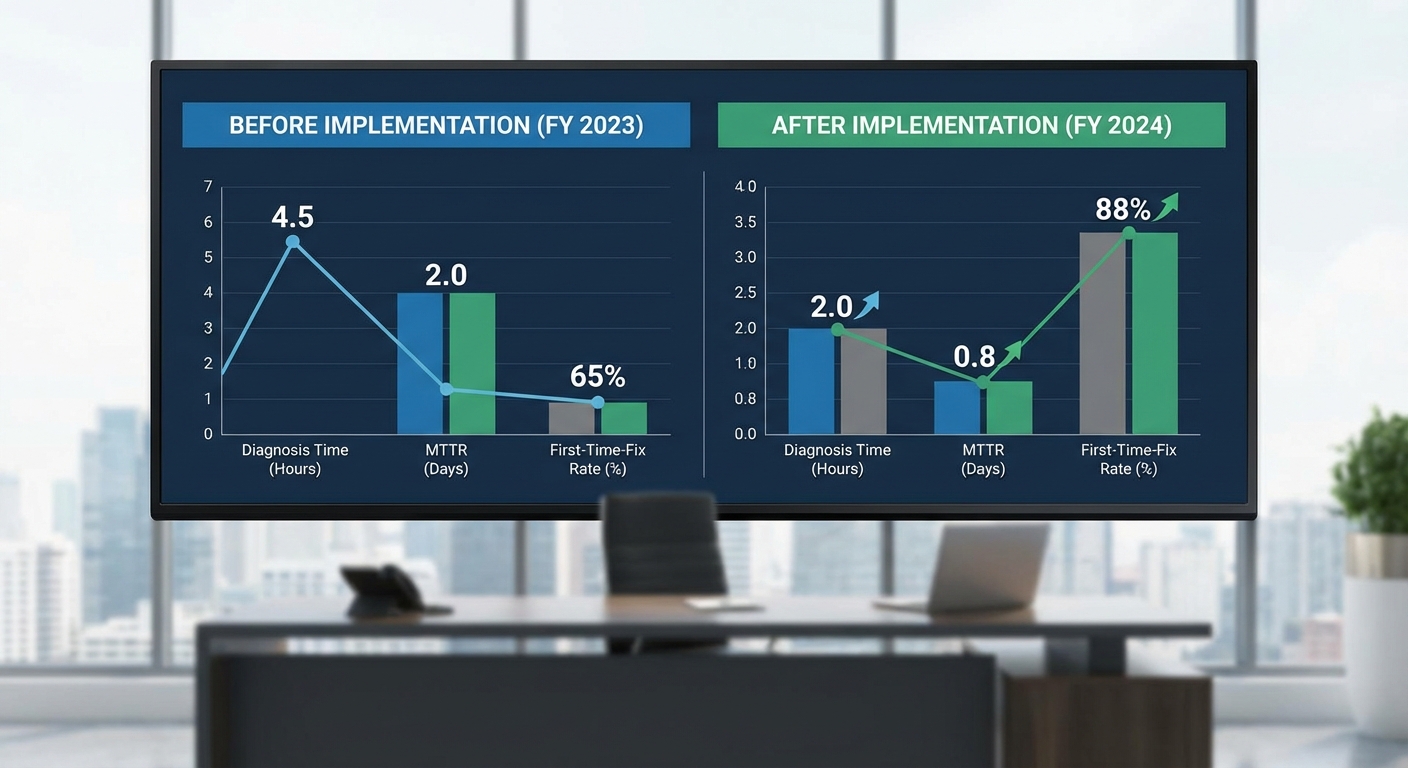
ในโครงการนำร่องของ NTN ที่ดำเนินการกับเครือข่ายศูนย์บริการ 8 แห่ง เป็นระยะเวลา 6 เดือน โดยครอบคลุมงานซ่อมรวมทั้งสิ้นประมาณ 1,200 เคส ทีมงานนำระบบ Machine Learning (ML) สำหรับการวินิจฉัยอาการและแนะนำชิ้นส่วนมาใช้ร่วมกับกระบวนการเช็กอิน–เช็กเอาท์ของศูนย์ ผลลัพธ์เชิงตัวเลขที่ได้สะท้อนการเปลี่ยนแปลงทั้งในด้านประสิทธิภาพการวินิจฉัย เวลาเฉลี่ยในการซ่อม และต้นทุนการดำเนินงานอย่างชัดเจน
เมื่อเปรียบเทียบก่อนและหลังการนำ ML มาใช้ พบว่าค่าเฉลี่ยของเวลาวิเคราะห์ปัญหาหรือเวลาวินิจฉัย (diagnosis time) ลดลงอย่างมีนัยสำคัญ โดย ลดลงประมาณ 30–50% ในกลุ่มนำร่อง ตัวอย่างเช่น เวลาวินิจฉัยเฉลี่ยก่อนนำระบบอยู่ที่ประมาณ 55 นาที ลดลงเป็นเฉลี่ยประมาณ 32 นาที หลังนำระบบ ML มาใช้ (ลดลงราว 41%) ส่งผลให้ MTTR (Mean Time To Repair) ลดลงจากเฉลี่ย 7.8 ชั่วโมง เหลือประมาณ 4.9 ชั่วโมง หรือคิดเป็นการลดลงราว 37%
ด้านคุณภาพการซ่อม งานแก้ไขครั้งแรก (First Time Fix — FTF) ในกลุ่มทดสอบปรับตัวดีขึ้นอย่างโดดเด่น โดยค่า FTF เพิ่มขึ้นจากประมาณ 60% เป็น 75% ซึ่งเทียบเป็นการปรับขึ้นประมาณ 15–30% (ในตัวอย่างนี้เพิ่มขึ้นราว 25%) ผลลัพธ์ที่ตามมาคืออัตราการคืนงาน (rework/return rate) ลดลงจากราว 8.5% เหลือประมาณ 3.2% (ลดลงกว่า 60%) ทั้งยังส่งผลต่อความพึงพอใจลูกค้าที่มีแนวโน้มเพิ่มขึ้นตามอัตราการแก้ไขครั้งแรกที่สูงขึ้น
ในมิติด้านต้นทุนและผลตอบแทนทางการเงิน ข้อมูลจากการนำร่องแสดงให้เห็นการลดต้นทุนเฉลี่ยต่อเคส (average cost per case) จากประมาณ 4,700 บาท เหลือเฉลี่ยราว 3,700 บาท คิดเป็นการลดลงประมาณ 21% นอกจากนี้ การบริหารสต็อกชิ้นส่วนที่ดีขึ้นด้วยคำแนะนำชิ้นส่วนจากโมเดลทำให้มูลค่าสต็อกหมุนเวียนที่ถือค้างลดลงประมาณ 15–22% ส่งผลให้ต้นทุนการถือครองสต็อก (carrying cost) ลดลงราว 12–18%
- ตัวอย่างตัวเลขนำร่อง (1,200 เคส / 6 เดือน):
- เวลาวินิจฉัยเฉลี่ย: ก่อน 55 นาที → หลัง 32 นาที (–41%)
- MTTR: ก่อน 7.8 ชม. → หลัง 4.9 ชม. (–37%)
- FTF: ก่อน 60% → หลัง 75% (+25%)
- อัตราคืนงาน: ก่อน 8.5% → หลัง 3.2% (–62%)
- ค่าใช้จ่ายเฉลี่ยต่อเคส: ก่อน 4,700 บาท → หลัง 3,700 บาท (–21%)
- มูลค่าสต็อกคงคลัง: ลดลง 15–22%
สำหรับผลตอบแทนการลงทุน (ROI) เบื้องต้น ทีมวิเคราะห์ของ NTN ประเมินจากต้นทุนการลงทุนรวมระบบ ML, การผนวกรวมกับระบบภายใน และการฝึกอบรมทีมงาน อยู่ที่ประมาณ 3.8 ล้านบาท ในสเกลนำร่อง โดยคาดว่าจะประหยัดต้นทุนปฏิบัติการจากการลดเวลาแรงงานและชิ้นส่วนรวมแล้วประมาณ 3.0–3.5 ล้านบาท/ปี เมื่อรวมการลดต้นทุนสต็อก ผลการประเมินชี้ให้เห็นว่า ระยะเวลาคืนทุน (payback) อยู่ในช่วงประมาณ 9–14 เดือน ขึ้นกับสเกลการใช้งานและอัตราการยอมรับของศูนย์บริการ หากขยายการใช้งานไปยังทั้งเครือข่าย ROI ภายใน 24 เดือนมีแนวโน้มอยู่ที่ประมาณ 140–210%
สรุปได้ว่าโครงการนำร่องของ NTN แสดงให้เห็นผลเชิงบวกทั้งด้านประสิทธิภาพการวินิจฉัย การลด MTTR การเพิ่มอัตรา FTF และการลดต้นทุนโดยรวม ซึ่งทำให้การลงทุนในเทคโนโลยี ML มีความคุ้มค่าทางการเงินในระยะกลาง ทั้งนี้คำแนะนำต่อไปคือการขยายสเกลทดสอบ, ติดตามตัวชี้วัดในระยะยาว และปรับปรุงโมเดลอย่างต่อเนื่องเพื่อรักษาและเพิ่มผลลัพธ์ด้านคุณภาพและต้นทุน
ผลกระทบทางธุรกิจ โอกาส และข้อจำกัด
ผลกระทบทางธุรกิจ โอกาส และข้อจำกัด
การนำ Machine Learning มาใช้ในกระบวนการวินิจฉัยและวางแผนซ่อมแซมของ NTN มีศักยภาพที่จะเปลี่ยนแปลงโครงสร้างธุรกิจบริการซ่อมรถยนต์อย่างมีนัยสำคัญ ทั้งในมิติของประสบการณ์ลูกค้า, การจัดการสต็อกและซัพพลายเชน, ประสิทธิภาพช่าง รวมถึงการเปิดช่องทางรายได้ใหม่ อย่างไรก็ตาม ความท้าทายด้านความแม่นยำของโมเดล ข้อจำกัดด้านข้อมูล ต้นทุนการติดตั้งและบำรุงรักษา รวมถึงประเด็นทางกฎหมายและความเป็นส่วนตัว จำเป็นต้องถูกบริหารจัดการอย่างรัดกุมเพื่อลดความเสี่ยงทางธุรกิจ
โอกาสทางธุรกิจ (Business Opportunities)
- ยกระดับประสบการณ์ลูกค้า — การวินิจฉัยเบื้องต้นผ่านภาพถ่ายหรือคลิปวิดีโอที่ขับเคลื่อนด้วย ML สามารถลดเวลาการรอคอยและให้ประมาณการค่าใช้จ่ายเบื้องต้นทันที ซึ่งจากการประเมินเชิงอุตสาหกรรม องค์กรที่ปรับปรุงกระบวนการดิจิทัลมักเห็นระดับความพึงพอใจของลูกค้าเพิ่มขึ้น 10–30% และอัตราการกลับมาใช้บริการซ้ำสูงขึ้น
- ลดต้นทุนสต็อกและเพิ่มความพร้อมของอะไหล่ — โมเดลพยากรณ์ความต้องการอะไหล่ช่วยให้สต็อกแม่นยำขึ้น ลดสต็อกส่วนเกินและกรณีชิ้นส่วนขาดตลาด ตัวอย่างเช่น การใช้ demand forecasting อาจลดต้นทุนสต็อกได้ 15–25% ในธุรกิจบริการขนาดกลางถึงใหญ่
- เพิ่มประสิทธิภาพช่าง — การนำเสนอขั้นตอนการซ่อมแบบเฉพาะกรณีและ checklist อัตโนมัติ ช่วยลดเวลาในการวินิจฉัยและการค้นหาอะไหล่ ทำให้ช่างสามารถซ่อมได้เร็วยิ่งขึ้นและลดเวลาที่ไม่ได้มีมูลค่า (non-productive time)
- โมเดลรายได้ใหม่ — NTN สามารถสร้างรายได้จากบริการพรีเมียม เช่น บริการวินิจฉัยระยะไกล (remote diagnostics), แพ็กเกจ subscription สำหรับการบำรุงรักษาตามสภาพจริง (condition-based maintenance), หรือการขาย API ให้กับตัวแทนจำหน่ายและเครือข่ายอู่ที่ต้องการระบบช่วยตัดสินใจ
ข้อจำกัดและความเสี่ยงเชิงเทคนิค
- ความแม่นยำของโมเดลกับข้อมูลจำกัด — ในกรณีที่มีภาพหรือข้อมูลการชำรุดจากรุ่นรถหรือกรณีพิเศษน้อย โมเดลอาจให้ผลลัพธ์ไม่เสถียรหรือมีอัตราผิดพลาดสูง การแก้ไขจำเป็นต้องใช้เทคนิคเช่น data augmentation, transfer learning และ active learning แต่ก็เพิ่มความซับซ้อนในการพัฒนา
- ผลกระทบจากคุณภาพข้อมูล — ภาพถ่ายที่เบลอ มุมกล้องที่ต่างกัน หรือสภาพแสงที่ต่ำสามารถลดความแม่นยำของการจดจำปัญหาได้อย่างมาก การควบคุมมาตรฐานการรับข้อมูลจากลูกค้า/ช่างเป็นสิ่งจำเป็น
- ค่าใช้จ่ายเริ่มต้นและค่าใช้จ่ายต่อเนื่อง — ลงทุนในฮาร์ดแวร์ (เช่น กล้องคุณภาพสูง, edge devices), ค่าโครงสร้างพื้นฐานคลาวด์, ค่าใบอนุญาตซอฟต์แวร์ และทีมงานด้าน ML/DevOps อาจเป็นต้นทุนที่สูง โดยทั่วไปธุรกิจอาจต้องเตรียมงบลงทุนเบื้องต้นรวม 6–12 เดือนขึ้นอยู่กับขนาดการใช้งาน
- การยอมรับจากช่างและลูกค้า — ช่างอาจกังวลว่าระบบจะแทนที่ทักษะของตนหรือทำให้ขั้นตอนงานซับซ้อนขึ้น ขณะที่ลูกค้าบางส่วนอาจไม่เชื่อมั่นในคำวินิจฉัยอัตโนมัติ การออกแบบ UI/UX ที่เข้าใจง่าย การให้เหตุผล (explainability) ของผลลัพธ์ และการมีมนุษย์เป็นผู้ตรวจสอบขั้นสุดท้าย (human-in-the-loop) จะช่วยเพิ่มการยอมรับ
ความเสี่ยงด้านกฎหมายและความเป็นส่วนตัว
- การเก็บและประมวลผลข้อมูลลูกค้า — ภาพรถยนต์ที่ส่งมาพร้อมหมายเลขทะเบียน หรือข้อมูลส่วนบุคคลที่เกี่ยวข้องอาจถูกมองว่าเป็นข้อมูลส่วนบุคคล การปฏิบัติตามกฎหมายคุ้มครองข้อมูล (เช่น การได้รับความยินยอม, การจัดเก็บอย่างปลอดภัย, การเก็บข้อมูลให้น้อยที่สุด) เป็นข้อบังคับ
- การเปิดเผยข้อมูลชิ้นส่วนและความเป็นเจ้าของทางปัญญา — ข้อมูลการวิเคราะห์ชิ้นส่วนหรือขั้นตอนการซ่อมอาจมีมูลค่าทางการค้า การเปิดเผยข้อมูลนี้แก่พันธมิตรหรือบุคคลที่สามต้องมีข้อตกลงทางกฎหมายที่ชัดเจนเพื่อป้องกันการใช้โดยไม่ได้รับอนุญาต
- ความรับผิดชอบทางกฎหมายจากการวินิจฉัยที่ผิดพลาด — หากระบบแนะนำการซ่อมที่ผิดพลาดจนเกิดความเสียหายหรืออุบัติเหตุ ประเด็นความรับผิดชอบ (liability) ระหว่าง NTN, ผู้ให้บริการซอฟต์แวร์ และผู้ดำเนินการอู่ต้องถูกกำหนดอย่างชัดเจนผ่านสัญญาและประกันภัยที่เหมาะสม
สรุปแล้ว NTN มีโอกาสในการสร้างความได้เปรียบทางธุรกิจที่ชัดเจนจากการใช้ ML โดยเฉพาะในด้านการปรับปรุงประสบการณ์ลูกค้าและการจัดการสต็อก แต่ความสำเร็จขึ้นอยู่กับการจัดการข้อจำกัดด้านเทคนิค การลงทุนเชิงโครงสร้าง และกรอบการกำกับดูแลที่รัดกุม การดำเนินงานเชิงรุก เช่น การทดสอบแบบ phased rollout, การใช้กลไก human-in-the-loop, และการจัดทำนโยบายความเป็นส่วนตัวที่โปร่งใส จะช่วยลดความเสี่ยงและเร่งผลตอบแทนทางธุรกิจได้อย่างมีประสิทธิผล
ความท้าทายด้านเทคนิคและแนวทางในอนาคต
ความท้าทายด้านเทคนิคและแนวทางในอนาคต
การนำระบบ Machine Learning ของ NTN ไปใช้ในเครือข่ายศูนย์บริการซ่อมรถยนต์หลายสาขาเผชิญกับความท้าทายด้านการปรับขนาด (scalability) และความซับซ้อนของสถาปัตยกรรม ระบบต้องรองรับการประมวลผลภาพ เซ็นเซอร์ และข้อมูลเชิงธุรกรรมจากสาขาจำนวนมาก (ตั้งแต่หลักสิบถึงหลักร้อยสาขา) โดยรักษาความหน่วงเวลา (latency) ให้ต่ำเพียงพอสำหรับการใช้งานจริง งานออกแบบจึงควรพิจารณาสถาปัตยกรรมแบบไฮบริดที่รวม cloud และ edge เข้าด้วยกัน: cloud สำหรับการเทรนนิ่งระดับรวมและการวิเคราะห์ข้ามสาขา ส่วน edge node ที่ติดตั้งในศูนย์บริการทำหน้าที่ให้บริการ inference แบบเรียลไทม์และรองรับการทำงานแบบออฟไลน์เมื่อเครือข่ายไม่พร้อมใช้งาน
เชิงเทคนิค ควรออกแบบระบบด้วยหลักการ microservices, containerization (เช่น Kubernetes) และ pipeline ที่มีการจัดการเวอร์ชันโมเดล (model registry) พร้อมระบบ CI/CD สำหรับ ML (MLOps) เพื่อให้สามารถ deploy โมเดลได้รวดเร็วและควบคุมการเปลี่ยนแปลงได้อย่างปลอดภัย นอกจากนี้การติดตั้ง model monitoring เพื่อเฝ้าระวังคุณภาพการทำนาย (เช่น drift detection, input data validation) เป็นสิ่งจำเป็นเมื่อระบบต้องรับมือกับข้อมูลจากยี่ห้อและรุ่นรถที่หลากหลาย ซึ่งอาจทำให้ performance ผันผวนเมื่อเผชิญกับ distribution ใหม่
ประเด็นข้อมูลไม่สมบูรณ์ (missing, noisy หรือ biased data) เป็นอุปสรรคสำคัญในงานซ่อม-วินิจฉัย เช่น ภาพที่มุมไม่เหมาะสม ข้อมูลอาการที่บันทึกไม่ครบ หรือข้อมูลสเปกชิ้นส่วนที่แตกต่างกันระหว่างยี่ห้อ แนวทางเชิงปฏิบัติได้แก่การใช้ data augmentation, synthetic data (เช่น การจำลองภาพจาก CAD หรือการเรนเดอร์), และระบบตรวจสอบคุณภาพข้อมูลก่อนป้อนเข้าโมเดล นอกจากนี้การใช้เทคนิค few-shot / transfer learning ช่วยให้โมเดลเรียนรู้จากข้อมูลยี่ห้อหนึ่งแล้วปรับไปใช้กับยี่ห้ออื่นโดยใช้ข้อมูลจริงน้อยลง
ในด้านการฝึกและอัปเดตโมเดล มีสองแนวทางสำคัญที่ควรพัฒนา: federated learning และ continual learning โดย federated learning ช่วยลดการส่งข้อมูลดิบข้ามเครือข่าย (รายงานการทดลองในภาคอุตสาหกรรมระบุว่าการแลกเปลี่ยนเพียงพารามิเตอร์/อัพเดตสามารถลดการส่งข้อมูลดิบได้ตั้งแต่ 50–90%) และยังเป็นทางออกเชิงนโยบายในเรื่องความเป็นส่วนตัวและการปฏิบัติตามกฎหมายข้อมูลส่วนบุคคล เช่น PDPA/กฎระเบียบท้องถิ่น ขณะที่ continual learning ช่วยให้โมเดลสามารถปรับตัวต่อข้อมูลใหม่และการเปลี่ยนแปลงของ distribution (concept drift) โดยใช้เทคนิคเช่น replay buffers, regularization-based updates และ selective fine-tuning เพื่อหลีกเลี่ยงปัญหา forgetting
การตัดสินใจระหว่างการ deploy บน edge หรือ cloud ควรพิจารณาจากปัจจัยหลายด้าน: latency ที่ต้องการ, การเชื่อมต่อเครือข่าย, ความเป็นส่วนตัวของข้อมูล และความสามารถในการบำรุงรักษา ตัวอย่างเช่น งานวินิจฉัยภาพต้องการ latency ต่ำจึงเหมาะกับการ inference บน edge ในขณะที่การฝึกโมเดลขนาดใหญ่หรือการวิเคราะห์เชิงกลยุทธ์ข้ามสาขาเหมาะกับ cloud นโยบายที่แนะนำคือการออกแบบระบบแบบ hybrid โดยให้ inference ที่ latency สำคัญทำบน edge และส่งสรุปผลหรือเมตริกที่คัดกรองแล้วไปยัง cloud สำหรับการฝึกรวมและการวิเคราะห์เชิงลึก
ด้านการวิเคราะห์เชิงธุรกิจ การนำ analytics มาประยุกต์ใช้เพื่อพยากรณ์อุปสงค์อะไหล่ (spare-parts demand forecasting) จะช่วยลดสต็อกส่วนเกินและเพิ่มอัตราการให้บริการได้ดียิ่งขึ้น ระบบพยากรณ์ควรผสานข้อมูลหลายมิติทั้งประวัติการซ่อม, เทรนด์ตามฤดูกาล, โปรโมชั่นและปัจจัยภายนอก (เช่นสภาพอากาศ) โดยใช้ชุดโมเดล time-series (เช่น Prophet, LSTM, หรือ Transformer-based) พร้อมการวัดความแม่นยำ (เช่น MAPE, RMSE) — เป้าหมายเชิงปฏิบัติอาจอยู่ที่ MAPE ต่ำกว่า 10–15% สำหรับชิ้นส่วนที่มีปริมาณการใช้งานสม่ำเสมอ
นอกจากแนวทางเทคนิคแล้ว การรับรองความสำเร็จทางธุรกิจของโครงการ NTN จำเป็นต้องมีนโยบายการบริหารทรัพยากรมนุษย์และการสื่อสารที่ชัดเจน แผนการฝึกอบรมช่างควรประกอบด้วย:
- หลักสูตรเชิงปฏิบัติ สำหรับการตีความผลลัพธ์จากระบบ ML และการใช้งานเครื่องมือบน edge device
- มาตรฐานการรับรอง (certification) เพื่อให้แน่ใจว่าช่างมีทักษะที่สอดคล้องกันในเครือข่ายหลายสาขา
- กลไก feedback ที่เชื่อมต่อระหว่างช่างและทีม data-science เพื่อให้ข้อมูลการแก้ไขจริง (ground-truth) ถูกนำกลับมาใช้ปรับปรุงโมเดลอย่างต่อเนื่อง
ด้านการสื่อสารกับลูกค้าและการสร้างความเชื่อมั่น ควรยึดหลักความโปร่งใสและการให้ความรู้: ให้คำอธิบายเชิงสั้น (explainable outputs) ที่ลูกค้าเข้าใจได้เกี่ยวกับการวินิจฉัยและข้อเสนอการซ่อม พร้อมนโยบายความเป็นส่วนตัวที่ชัดเจนและช่องทางให้ลูกค้าตรวจสอบหรือยินยอมการใช้ข้อมูล นอกจากนี้การกำหนด SLA ในการตอบสนองและการรับประกันความถูกต้องของการวินิจฉัยบางระดับจะช่วยเพิ่มความเชื่อมั่นและลดแรงกดดันทางกฎหมาย/การตลาด
สรุปแล้ว การขยาย NTN สู่เครือข่ายศูนย์บริการหลายสาขาต้องการการออกแบบสถาปัตยกรรมแบบ hybrid, การนำแนวทาง federated และ continual learning มาใช้ควบคู่กับมาตรการจัดการคุณภาพข้อมูล และกรอบนโยบายที่รองรับการฝึกอบรมพนักงานและการสื่อสารกับลูกค้า การดำเนินงานร่วมกันทั้งเชิงเทคนิคและเชิงนโยบายนี้จะเป็นพื้นฐานสำคัญในการยกระดับประสิทธิภาพการซ่อมแซมและสร้างความได้เปรียบทางการแข่งขันในระยะยาว
บทสรุป
NTN สามารถยกระดับบริการซ่อมรถยนต์ได้โดยการนำ Machine Learning มาใช้ในเวิร์กโฟลว์ตั้งแต่การวินิจฉัยอาการ การประเมินความเสียหาย ไปจนถึงการจัดการอะไหล่และซัพพลายเชน ผลลัพธ์ที่คาดว่าจะเห็นได้แก่การลดเวลาในการวินิจฉัยและซ่อมแซม เพิ่มความแม่นยำของการระบุชิ้นส่วนที่ต้องเปลี่ยน และลดต้นทุนสต็อก ตัวอย่างเช่น จากการทดลองนำร่องที่ออกแบบอย่างมีกรอบเวลา NTN รายงานการปรับปรุงประสิทธิภาพเบื้องต้นที่ระดับการวินิจฉัยเร็วขึ้นและต้นทุนการจัดการอะไหล่ลดลงอย่างมีนัยสำคัญ (เช่น การลดเวลา 20–40% ในกระบวนการวิเคราะห์และลดต้นทุนอะไหล่ได้ในช่วงตัวอย่าง 10–25%) ซึ่งช่วยสร้างข้อได้เปรียบเชิงการแข่งขันด้านความเร็วของบริการและประสบการณ์ลูกค้าที่ดีขึ้น
ความสำเร็จของโครงการพึ่งพาปัจจัยสำคัญหลายประการ ได้แก่ การเก็บข้อมูลที่มีคุณภาพ (ข้อมูลภาพ, สัญญาณเซ็นเซอร์, ประวัติการซ่อม), การออกแบบสถาปัตยกรรมที่ขยายได้และยืดหยุ่น (เพื่อรองรับการประมวลผลแบบเรียลไทม์และการอัปเดตโมเดล), และการจัดการการเปลี่ยนแปลงทั้งด้านเทคนิคและคน (การฝึกอบรมช่าง เทคนิคการบูรณาการระบบกับเวิร์กโฟลว์เดิม) สิ่งจำเป็นคือการตั้ง KPI ที่ชัดเจนและวัดผลได้ เช่น เวลาเฉลี่ยในการวินิจฉัย (time-to-diagnose), MTTR (mean time to repair), อัตราการมีชิ้นส่วนพร้อมใช้ (parts availability), อัตราการหมุนเวียนสต็อก และคะแนนความพึงพอใจลูกค้า โดยควรเริ่มจากการทดลองนำร่องที่จำกัดขอบเขตเพื่อทดสอบสมมติฐานและวัดผลก่อนจึงขยายสเกล
มุมมองในอนาคตคือ NTN สามารถพัฒนาไปสู่ระบบ predictive maintenance และการบริหารซัพพลายเชนเชิงคาดการณ์ รวมทั้งการเชื่อมต่อกับผู้ผลิต (OEM) และพันธมิตรเพื่อสร้างระบบนิเวศบริการที่ครบวงจร หากบริหารความเสี่ยงด้านการกำกับดูแลข้อมูล โมเดลดริฟท์ และการยอมรับทางองค์กรได้ดี ผลตอบแทนระยะยาวจะมาจากการลดต้นทุนการดำเนินงาน การเพิ่มอัตราการซ่อมสำเร็จครั้งแรก (first-time fix rate) และการสร้างความแตกต่างทางการแข่งขัน คำแนะนำเชิงปฏิบัติคือเริ่มด้วยกรณีใช้งานเชิงกลยุทธ์หนึ่งหรือสองรายการ กำหนด KPI ที่ชัดเจน จัดทำแผนการเก็บข้อมูลคุณภาพ และออกแบบรอบการทดลอง-ประเมินผลก่อนขยายสเกล
📰 แหล่งอ้างอิง: Auto Service World



