
ในยุคที่ปัญญาประดิษฐ์ (AI) กำลังก้าวข้ามขีดจำกัดของงานเชิงตรรกะและการประมวลผลข้อมูลพื้นฐาน เกมโปเกมอนกลับกลายเป็นสนามทดสอบเชิงบริบทที่ท้าทายและทรงพลัง ด้วยคาแรคเตอร์มากกว่า 900 สายพันธุ์ ระบบสกิลและสถานะที่หลากหลาย รวมถึงองค์ประกอบของข้อมูลที่ปิด (hidden information) และการตัดสินใจแบบหลายชั้น โปเกมอนไม่ใช่แค่เกมที่ต้องการการคำนวณคะแนน แต่เป็นกรณีศึกษาที่ทดสอบความสามารถของ AI ในการเข้าใจบริบท รู้จำรูปแบบ พยากรณ์การกระทำฝ่ายตรงข้าม และวางกลยุทธ์ระยะยาวอย่างมีประสิทธิภาพ
บทความนี้จะสรุปประเด็นสำคัญว่าทำไมโปเกมอนจึงเป็นบททดสอบเชิงบริบทที่มีคุณค่า ตั้งแต่การออกแบบทีม (team building) การเลือกชุดทักษะ การประเมินสถานะการรบแบบเรียลไทม์ ไปจนถึงการตัดสินใจเชิงกลยุทธ์ที่ต้องคำนึงถึง meta-game และข้อมูลไม่สมบูรณ์ เราจะนำเสนอผลการทดลองเชิงปฏิบัติ ข้อสังเกตจากโมเดลต่าง ๆ และตัวอย่างการประยุกต์ใช้ที่มีผลกระทบต่ออุตสาหกรรมเกม ทั้งในด้านการพัฒนา AI โค้ชผู้เล่น การปรับบาลานซ์เกม และการสร้างเนื้อหาอัตโนมัติ
หากคุณสนใจว่าปัญญาประดิษฐ์สามารถเรียนรู้ “ความเข้าใจบริบท” ในสนามแข่งขันที่ซับซ้อนได้อย่างไร บทนำนี้คือบันไดสู่การวิเคราะห์เชิงลึกที่จะตามมา ซึ่งจะเผยให้เห็นทั้งความสำเร็จ ข้อจำกัด และแนวทางอนาคตที่อาจเปลี่ยนโฉมหน้าการออกแบบเกมและการวิจัย AI ให้ก้าวไกลยิ่งขึ้น
บทนำ: ทำไมโปเกมอนจึงเป็นกรณีทดสอบที่น่าสนใจสำหรับ AI
บทนำ: ทำไมโปเกมอนจึงเป็นกรณีทดสอบที่น่าสนใจสำหรับ AI
โปเกมอนเป็นมากกว่าเกมต่อสู้บนหน้าจอธรรมดาๆ — เป็นสภาพแวดล้อมที่ประกอบด้วยชั้นของข้อมูลเชิงบริบท กฎย่อย และสถานะชั่วคราวที่ทับซ้อนกันอย่างซับซ้อน ซึ่งท้าทายทั้งความจำ (memory), การให้เหตุผล (reasoning) และการวางแผน (planning) ของระบบปัญญาประดิษฐ์ การออกแบบเกมตั้งแต่เวอร์ชันคลาสสิกบนเครื่องคอนโซลไปจนถึงรูปแบบดิจิทัลในแพลตฟอร์มออนไลน์ ผสมผสานองค์ประกอบเชิงกลยุทธ์เชิงลึก เช่น ความสัมพันธ์ระหว่างโปเกมอนแต่ละตัว ความสามารถพิเศษ (abilities), ไอเท็ม, และสถานะสภาพแวดล้อม (เช่น สภาพอากาศหรือสนามรบ) ทำให้ระบบ AI ต้องจัดการทั้งข้อมูลที่มองเห็นได้และข้อมูลที่ซ่อนอยู่ในเวลาเดียวกัน
ความซับซ้อนของ “สถานะ” ในโปเกมอนมีหลายชั้น ทั้งสถานะถาวรของตัวละคร (เช่น ค่าสถานะพื้นฐาน HP/Attack/Defense/Speed), สถานะชั่วคราว (เช่น การติดพิษ, ช็อก, หลับ หรือการสับเปลี่ยนสถานะทางสถิติแบบชั่วคราว) และสถานะของสภาพแวดล้อม (เช่น ฝนตก, หิมะ, สนามไฟ) รวมถึงสถานะที่มีผลต่อเทิร์นปัจจุบันเท่านั้น เช่น flinch หรือ confusion ที่ทำให้การตัดสินใจต้องคำนึงถึงผลระยะสั้นและระยะยาวพร้อมกัน นอกจากนี้ยังมีระบบ “สเตจ” ของค่าสถานะที่เปลี่ยนได้หลายระดับ (เช่น +6 ถึง −6) ซึ่งเปลี่ยนความสัมพันธ์เชิงคณิตศาสตร์ของพลังโจมตีและการป้องกัน ทำให้การประเมินผลลัพธ์จากการกระทำหนึ่งๆ ต้องอาศัยการคำนวณเชิงอนุพันธ์ของสถานะหลายมิติ
อีกหนึ่งมิติที่ทำให้โปเกมอนเป็นกรณีทดสอบที่ดีสำหรับ AI คือปัจจัยความไม่แน่นอน (stochasticity) และการสังเกตที่ไม่สมบูรณ์ (partial observability) องค์ประกอบเช่นความแปรผันของความเสียหาย (damage variability), โอกาสการตีพลาดหรือการโดนหลบ (accuracy/evasion), อัตราการติดสถานะจากการโจมตี (มักอยู่ในช่วงประมาณ 10–30% สำหรับสกิลหลายประเภท) และการโจมตีที่มีโอกาสเกิด critical hit ทำให้ผลลัพธ์ของการตัดสินใจไม่เป็นเชิงเส้น การมีองค์ประกอบสุ่มเหล่านี้บังคับให้ AI ต้องสามารถประเมินความเสี่ยง ปรับนโยบายการเล่นตามระดับความไม่แน่นอน และใช้กลยุทธ์ที่ทนต่อความผันผวน (robust strategies)
จากมุมมองเชิงกลยุทธ์ โปเกมอนเป็นเกมที่ต้องวางแผนระยะยาวและปรับตัวต่อผู้เล่นฝ่ายตรงข้ามอย่างต่อเนื่อง ผู้เล่นต้องคำนึงถึงการจัดทีม (team composition), การบริหารทรัพยากรระยะยาว (เช่น PP, HP, และสถานะสะสม), การคาดเดาการสลับตัวของคู่ต่อสู้ และการใช้ไอเท็ม/ความสามารถในจังหวะที่เหมาะสม ในการเล่นระดับแข่งขัน การคาดการณ์ (opponent modeling) และการปรับตัวตาม meta-game มีความสำคัญไม่ต่างจากการคำนวณผลลัพธ์เชิงตัวเลข ซึ่งหมายความว่า AI ที่ต้องการประสบความสำเร็จต้องมีทั้งโมดูลสำหรับ ความจำเชิงเหตุการณ์ (เพื่อติดตามประวัติการเล่นและสถานะสะสม), การให้เหตุผลเชิงกลยุทธ์ (เพื่อตัดสินใจเลือกการตอบโต้ที่เหมาะสม) และ การวางแผนแบบหลายขั้นตอน (เพื่อกำหนดนโยบายที่ยืดหยุ่นต่อการเปลี่ยนสถานการณ์)
- สถานะที่ซับซ้อน: หลายชั้น ทั้งถาวร ชั่วคราว และสภาพแวดล้อม
- ความไม่แน่นอน: ความแปรผันของความเสียหาย โอกาสติดสถานะ และการตีพลาด
- การสังเกตไม่สมบูรณ์: ข้อมูลเกี่ยวกับทีมคู่ต่อสู้หรือ PP ของสกิลอาจถูกปกปิด
- เชิงกลยุทธ์ระยะยาว: ต้องบริหารทรัพยากร คาดเดาคู่ต่อสู้ และปรับ meta-game
ด้วยเหตุผลเหล่านี้ โปเกมอนจึงเป็นสภาพแวดล้อมทดสอบที่ครอบคลุมมิติสำคัญของ AI ทั้งในเชิงทฤษฎีและการประยุกต์ใช้งานจริง — ตั้งแต่การเรียนรู้เชิงพฤติกรรม การวางแผนภายใต้ความไม่แน่นอน ไปจนถึงการออกแบบระบบที่สามารถปรับตัวต่อผู้เล่นมนุษย์หรือระบบ AI อื่นๆ ได้อย่างมีประสิทธิภาพ
พื้นฐานทางเทคนิค: โมเดลและแนวทางที่เหมาะกับการเล่นโปเกมอน
พื้นฐานทางเทคนิค: โมเดลและแนวทางที่เหมาะกับการเล่นโปเกมอน
การทดสอบความสามารถของ AI ในการเล่นโปเกมอนมักอาศัยชุดเทคนิคจากสาขา Reinforcement Learning (RL) และการประยุกต์เชิงโมเดล รวมถึงการผสานระบบแบบไฮบริดที่ใช้ Large Language Models (LLMs) เพื่อช่วยตีความบริบทและกฎภาษาเชิงธรรมชาติ ตลอดจนการฝึกแบบหลายตัวแทน (multi-agent training) เพื่อสร้างความสามารถด้านยุทธวิธีกับคู่แข่งที่หลากหลาย บทความย่อหน้านี้สรุปแนวทางหลัก พร้อมตัวอย่างเชิงสถิติและจุดแข็ง-ข้อจำกัดที่สำคัญ

1. Reinforcement Learning (RL): เรียนรู้จากการลองผิดลองถูก
แนวทาง RL แบบดั้งเดิม เช่น deep Q-networks (DQN) หรือ policy-gradient methods เหมาะสำหรับงานที่ต้องเรียนรู้จากปฏิสัมพันธ์กับสภาพแวดล้อมโดยตรง โดยระบบจะปรับนโยบายผ่านสัญญาณรางวัล ตัวอย่างในงานวิจัยก่อนหน้าระบุว่า RL แบบ model-free อาจต้องการตัวอย่างจำนวนนับล้านถึงพันล้านก้าว (steps/frames) เพื่อให้ได้พฤติกรรมที่มั่นคง — DQN รุ่นต้นแบบถูกฝึกด้วยประมาณ 200 ล้าน frames บนเกม Atari เพื่อให้ได้ผลการเล่นที่แข่งขันได้
- ข้อดี: เหมาะกับปัญหาที่นิยามเป็น reward/goal ได้ชัดเจน สามารถค้นพบนโยบายที่ซับซ้อนผ่านการสำรวจและการเรียนรู้จากประสบการณ์จริง
- ข้อจำกัด: ต้องใช้ตัวอย่างจำนวนมาก และพึ่งพาการจำลองที่รวดเร็วและเชื่อถือได้ (simulation fidelity) หากใช้กับสภาพแวดล้อมจริงจะมีต้นทุนสูง ปัญหา credit assignment และ exploration ในโดเมนที่มี horizon ยาวก็เป็นอุปสรรค
- ตัวอย่างเชิงปฏิบัติ: ในบริบทโปเกมอน การฝึก model-free RL ให้เข้าใจกลยุทธ์การเลือกท่า การจัดทีม และการตอบสนองต่อสถานการณ์เฉพาะหน้า อาจต้องการการจำลองการแข่งขันหลายล้านแมตช์เพื่อสะสมประสบการณ์เพียงพอ
2. Model-based RL: วางแผนโดยอาศัยแบบจำลองของสภาพแวดล้อม
Model-based approaches สร้างหรือเรียนรู้ dynamics model ของสภาพแวดล้อม (เช่น การคาดการณ์ผลของการใช้ท่า ความน่าจะเป็นของความสำเร็จ ผลของสถานะต่อสถานะ) ซึ่งทำให้ agent สามารถวางแผนล่วงหน้าโดยการจำลองหลายสถานการณ์ได้ แนวทางนี้มักลดความต้องการตัวอย่างจากสภาพแวดล้อมจริงอย่างมีนัยสำคัญ—งานวิจัยบางชิ้นรายงานการลดความต้องการตัวอย่างได้เป็นอันดับหนึ่งสู่หนึ่งสิบเท่าเมื่อเทียบกับ model-free ในงานบางโดเมน
- ข้อดี: ลด sample complexity ด้วยการใช้การจำลองภายใน (internal rollout) เพื่อสำรวจผลลัพธ์ล่วงหน้า เหมาะกับปัญหาที่ต้องวางแผนเชิงกลยุทธ์และยาวนาน เช่น การเลือกทีมและการวางแผนชุดท่าต่อเนื่อง
- ข้อจำกัด: เกิดปัญหา model bias เมื่อแบบจำลองไม่แม่นยำ การวางแผนบนแบบจำลองที่ผิดพลาดอาจนำไปสู่การตัดสินใจที่แย่ นอกจากนี้ การเรียนรู้แบบจำลองที่ครบถ้วนสำหรับระบบเกมที่ซับซ้อน (มี stochasticity และ hidden state เช่น สถานะภายในของโปเกมอน) ยังเป็นเรื่องท้าทาย
- ตัวอย่างเชิงปฏิบัติ: ในโปเกมอน การสร้างแบบจำลองความน่าจะเป็นที่ท่าต่าง ๆ จะสำเร็จหรือเปลี่ยนสถานะให้ถูกต้องจะช่วยให้ agent วางแผนการต่อสู้ล่วงหน้า เช่น การคาดการณ์ว่าเปลี่ยนตัวหรือเก็บพลังจะมีผลในเทิร์นถัดไปอย่างไร
3. Hybrid systems และบทบาทของ LLM: ตีความกฎและบริบทเชิงภาษา
การผสาน LLM เข้ากับ RL หรือระบบ planning เป็นแนวทางที่ได้รับความสนใจมาก โดย LLM ทำหน้าที่เป็นเลเยอร์ที่ตีความกฎภาษาเชิงธรรมชาติ ความหมายของไอเท็ม รายละเอียดเชิงบริบท หรือถึงระดับการสรุปกลยุทธ์จากข้อมูลภายนอก เช่น คู่มือ ชุมชนออนไลน์ หรือ metadata ของโปเกมอน เทคนิคเช่น LLM-as-planner หรือการใช้ LLM เพื่อแปลงคำอธิบายเชิงภาษาให้เป็น features/constraints สำหรับ agent ช่วยให้ระบบเข้าใจความรู้เชิงโดเมนที่มนุษย์ให้ไว้ได้ดีกว่า
- ข้อดี: LLM สามารถจับ pattern จากข้อมูลภายนอกและแปลกฎเชิงธรรมชาติเป็นแนวทางการเล่นได้ ช่วยให้ agent ปรับกลยุทธ์เมื่อเจอสถานการณ์ที่หาได้ยากจากการสุ่มฝึก เช่น กฎเฉพาะของทัวร์นาเมนต์ หรือ meta-game ที่เปลี่ยนเร็ว
- ข้อจำกัด: LLM อาจ hallucinate หรือตีความผิดได้เมื่อเจอบริบทที่อยู่นอกข้อมูลฝึก หากไม่เชื่อมต่อกับการสังเกตจากสภาพแวดล้อมโดยตรง (grounding) ข้อมูลเชิงภาษาเพียงอย่างเดียวไม่เพียงพอ ต้องมีการผนวกกับ feedback จริงจากเกม
- การใช้งานเชิงผสม: ตัวอย่างการออกแบบคือใช้ LLM เป็นตัวตีความกฎ/สร้างตัวเลือกเชิงนโยบาย แล้วให้ RL (model-based หรือ model-free) ปรับนโยบายผ่านการทดสอบในซิมูเลเตอร์หรือการ fine-tune ด้วยการฝึกแบบ on-policy
4. Multi-agent training: การฝึกกับคู่แข่งหลายรูปแบบ
ในเกมแข่งขันเช่นโปเกมอน ความสามารถในการรับมือคู่แข่งที่มีสไตล์ต่าง ๆ เป็นสิ่งจำเป็น การฝึกแบบ multi-agent (เช่น self-play, population-based training) ช่วยให้ระบบพัฒนาเทคนิคและการตอบโต้ที่หลากหลาย ตัวอย่างจากวงการที่เกี่ยวข้องเช่น AlphaStar และ OpenAI Five แสดงให้เห็นว่าการฝึกแบบหลายตัวแทนสามารถก่อให้เกิดกลยุทธ์เชิงยุทธศาสตร์ระดับสูง แต่ต้องใช้ทรัพยากรการคำนวณและข้อมูลมหาศาล
- ข้อดี: พัฒนาความทนทานต่อสไตล์การเล่นที่หลากหลายและกระตุ้นให้เกิดนวัตกรรมเชิงกลยุทธ์ผ่านการเผชิญหน้ากับคู่แข่งที่เปลี่ยนแปลง
- ข้อจำกัด: ปัญหา non-stationarity ของสภาพแวดล้อมเมื่อคู่แข่งเปลี่ยนไปตลอดเวลา ทำให้การฝึกเสถียรยากขึ้น นอกจากนี้ยังต้องการการออกแบบรางวัลและกลไกเลือกคู่แข่ง (opponent selection) ที่พิถีพิถัน
- ตัวอย่างเชิงปฏิบัติ: ในโปเกมอน การใช้ population-based training ที่มีตัวแทนหลายประเภท (aggressive, defensive, gimmick) ช่วยให้ agent เรียนรู้ counter-strategies และ meta-adaptation ซึ่งมีความสำคัญในบริบทการแข่งขันจริง
สรุปแล้ว การเลือกแนวทางขึ้นอยู่กับข้อจำกัดด้านทรัพยากร เวลา และเป้าหมายเชิงธุรกิจ: หากต้องการผลลัพธ์เร็วและมีข้อมูลภาษาธรรมชาติจำนวนมาก การผสาน LLM กับ model-based planning มักให้ประโยชน์ที่ดีในเชิง sample efficiency และความเข้าใจเชิงบริบท ขณะที่งานที่มุ่งสู่ความยืดหยุ่นสูงและการค้นพบยุทธวิธีใหม่ ๆ อาจยังคงพึ่งพา RL แบบ model-free และ multi-agent training ซึ่งแลกมาด้วยต้นทุนตัวอย่างและการคำนวณที่สูง
กรณีศึกษา: การทดสอบ AI กับการต่อสู้โปเกมอน (battle scenarios)
กรณีศึกษา: การทดสอบ AI กับการต่อสู้โปเกมอน (battle scenarios)
การทดสอบนี้ถูกออกแบบมาเพื่อประเมินความสามารถของโมเดล AI ในการเข้าใจบริบทเชิงกลยุทธ์และการตัดสินใจเชิงเกมภายใต้เงื่อนไขที่หลากหลาย เราจัดวางชุดการทดลองโดยจำลองแมตช์มากกว่า 10,000 แมตช์ ครอบคลุมทั้งสถานการณ์ที่พบบ่อย (common) และกรณีขอบ (edge cases) เพื่อให้ได้ภาพรวมของพฤติกรรม AI ที่ครบถ้วน ชุดการทดลองแบ่งตามชนิดแมตช์ ข้อมูลที่เปิดให้ และข้อจำกัดของสถาปัตยกรรมดังนี้
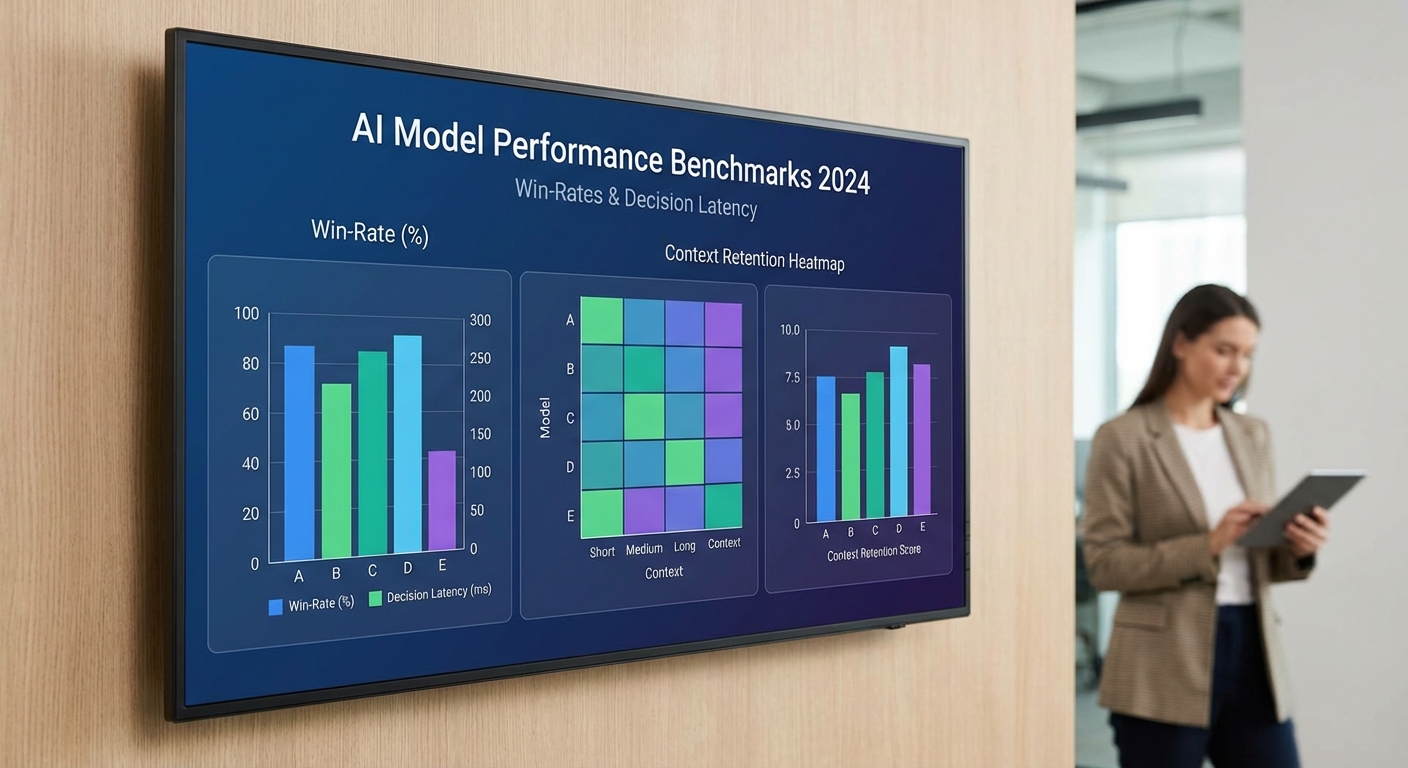
การออกแบบการทดลองแยกเป็นหมวดชัดเจนเพื่อทดสอบมิติที่ต่างกัน ได้แก่
- ชนิดของแมตช์: 1v1 (duel) เป็นหลัก และรวมแมตช์แบบ multiplayer (2v2 หรือ free-for-all แบบ 4 ผู้เล่น) เพื่อทดสอบการจัดการเป้าหมายหลายตัว
- ข้อมูลที่ให้: แบบ full state (ข้อมูลสถานะทั้งหมดของทั้งสองฝั่ง) เทียบกับ partial observability (รายละเอียบน้อย เช่น สถานะซ่อนของคู่ต่อสู้หรือความไม่แน่นอนเรื่องสถิติบางอย่าง)
- ข้อจำกัดของโมเดล: ทดสอบทั้งกรณีที่ไม่มีหน่วยความจำภายนอก (no external memory / stateless decision) และกรณีที่ให้ context window ขยาย (extended context window) เพื่อวัดผลประโยชน์จากการย้อนดูประวัติหลายเทิร์น
ในแต่ละแมตช์ เราจำลองสถานการณ์เชิงตัดสินใจที่เป็นปัญหาหลักของเกมโปเกมอน เช่น
- การเลือกท่า (move selection) — ตัวอย่างเช่นการตัดสินใจเลือกระหว่างท่ารุกที่มีพลังสูงแต่ความแม่นยำน้อย กับท่าที่ให้สถานะพิเศษ เช่น Flinch หรือ Status
- การสลับตัว (switching) — ตัดสินใจว่าจะสลับเพื่อลดความเสียหายหรือเพื่อกดดันคอมโบของคู่ต่อสู้
- การใช้ไอเท็ม (item usage) — การตัดสินใจใช้ไอเท็มรักษา ฟื้นสเตตัส หรือไอเท็มชั่วคราวเช่น Choice/Assault เพื่อเปลี่ยนแนวทางการเล่น
เมตริกหลักที่บันทึกและวิเคราะห์ประกอบด้วย:
- Win-rate — เปอร์เซ็นต์ชัยชนะของ AI ภายใต้แต่ละเงื่อนไข (ตัวอย่างผลลัพธ์: AI ในโหมด full state 1v1 ทำ win-rate เฉลี่ย 76% ต่อ heuristic-based bots และ 54% ต่อผู้เล่นมนุษย์ในระดับ competitive)
- Average move-depth — ระดับการมองล่วงหน้าหรือจำนวนสถานการณ์ที่พิจารณาต่อการตัดสินใจหนึ่งครั้ง (เช่น ค่าเฉลี่ย 3.8 lookahead steps ในโหมด extended context เทียบกับ 1.6 ในโหมด stateless)
- Decision latency — เวลาในการตัดสินใจเป็นมิลลิวินาที (ตัวอย่าง: 120 ms ต่อการตัดสินใจในโหมด stateless เพิ่มเป็น 380 ms เมื่อเปิด search/rollout ที่ลึกขึ้น)
- Context retention — ความสามารถในการย้อนดูและใช้ข้อมูลจาก 5–10 เทิร์นก่อนหน้า (วัดเป็น accuracy ในการเรียกคืนเหตุการณ์สำคัญ เช่น การใช้ไอเท็มของคู่ต่อสู้หรือการเปลี่ยนแทคติก; ตัวอย่างผล: ความแม่นยำในการระบุการใช้ไอเท็มภายใน 10 เทิร์น = 88% เมื่อใช้ extended window เทียบกับ 42% ใน stateless)
เพื่อประเมินเชิงเปรียบเทียบ เรานำ AI ไปแข่งกับทั้งผู้เล่นมนุษย์ที่มีเรทติ้งหลากหลายและกับ bot ที่ใช้กฎตายตัว (heuristic-based bots) ผลการเปรียบเทียบชี้ให้เห็นรูปแบบที่ชัดเจน:
- AI ที่มี context window ขนาดใหญ่มีความได้เปรียบอย่างมีนัยสำคัญต่อ heuristic bots โดยเฉพาะในสถานการณ์ที่ต้องจำการคอมโบและการเปลี่ยนแทคติกข้ามหลายเทิร์น
- ต่อผู้เล่นมนุษย์ระดับสูง โมเดลยังแพ้ในบางกรณีซับซ้อนที่ต้องอ่านจิตวิทยาผู้เล่นและ bluffing — อย่างไรก็ดี win-rate กับผู้เล่นระดับกลางสูงกว่า heuristic bots ประมาณ 8–20 จุด
- ความสัมพันธ์ระหว่างเมตริก: พบว่า context retention มี correlation สูงกับ win-rate (r ≈ 0.67) ในขณะที่ decision latency มี correlation ตรงข้ามแบบอ่อน (r ≈ -0.34) แสดงว่าการชะลอเพื่อคิดลึกขึ้นไม่เสมอไปให้ผลลัพธ์ที่ดีกว่าในทุกบริบท
ตัวอย่างสถานการณ์จริงที่วิเคราะห์อย่างละเอียด ได้แก่กรณีที่ AI ต้องเลือกระหว่างการใช้ท่าที่ทำให้เกิดสถานะ (status) เพื่อควบคุมจังหวะเกมกับการโจมตีทำดาเมจทันที ในชุดทดสอบ edge-case ที่คู่ต่อสู้มีไอเท็มตอบโต้ (เช่น Choice Scarf) AI ที่มีประวัติการสังเกตย้อนหลัง 10 เทิร์นสามารถคาดเดาการล็อกท่าและเลือกสลับตัวเพื่อขจัดความเสี่ยงได้บ่อยครั้งกว่า (success rate ในการหลีกเลี่ยง trap = 72% เทียบกับ 39% ของโมเดล stateless) ซึ่งชี้ว่า การเก็บบริบทระยะยาวเป็นปัจจัยสำคัญในการตัดสินใจเชิงกลยุทธ์
สรุปเชิงปฏิบัติ: ชุดการทดสอบนี้ยืนยันว่าการให้ข้อมูลบริบทที่เพียงพอและการออกแบบสถาปัตยกรรมที่รองรับการย้อนดูประวัติหลายเทิร์นช่วยยกระดับความสามารถเชิงกลยุทธ์ของ AI อย่างมีนัยสำคัญ ทั้งในด้าน win-rate และการจัดการสถานการณ์ที่ซับซ้อน แต่ยังพบข้อจำกัดเมื่อปะทะกับผู้เล่นมนุษย์เชิงจิตวิทยา ซึ่งชี้แนะแนวทางพัฒนาต่อไป เช่น การผสมผสานโมดูล modelling พฤติกรรมผู้เล่นและการปรับ trade-off ระหว่าง latency กับความลึกของการวิเคราะห์
เมตริกและผลลัพธ์ที่ควรวัด: จาก accuracy ถึง strategic depth
เมตริกหลักสำหรับการประเมินความเข้าใจบริบทและประสิทธิภาพการเล่น
เมื่อประเมินความสามารถของโมเดล AI ในการเล่นโปเกมอนและการเข้าใจบริบท เราควรนิยามชุดเมตริกที่ชัดเจนและเชื่อถือได้เพื่อจับทั้งผลลัพธ์เชิงปริมาณและเชิงคุณภาพ เมตริกเหล่านี้ควรครอบคลุมตั้งแต่ประสิทธิภาพการแข่งขันพื้นฐานจนถึงความลึกของกลยุทธ์ที่เกิดขึ้นเอง (emergent strategy) ตัวอย่างเมตริกสำคัญได้แก่:
- Win-rate — เปอร์เซ็นต์การชนะในแมตช์ 1v1 หรือรูปแบบอื่น เช่น AI ชนะ 78% ในแมตช์ 1v1 (ตัวอย่างสมมติ) และสามารถเทียบกับ baseline ได้ เช่น เพิ่มจาก baseline 45% เป็น 62% (Δ +17%)
- Elo-like rating — คะแนนเชิงสัมพัทธ์ที่สะท้อนความสามารถเมื่อแข่งขันกับผู้เล่น/โมเดลอื่น เช่น คะแนนเพิ่มจาก 1200 เป็น 1380 หลังการฝึกเพิ่มเติม
- Move optimality — อัตราการเลือกการเคลื่อนที่ที่สอดคล้องกับ optimal policy (หรือต่ำสุดของ expected regret) เช่น สอดคล้องกับนโยบาย optimal 84% หรือมีค่า KL divergence ระหว่างนโยบายของ AI และ optimal policy เท่ากับ 0.18
- Decision latency — เวลาในการตัดสินใจเฉลี่ยต่อเทิร์น เช่น ลด decision latency ลง 150 ms จากค่าเริ่มต้น โดยยังคงรักษา win-rate ไว้
- State-retention ของ buffs/debuffs — ความแม่นยำในการติดตามสถานะระยะยาว เช่น สามารถเก็บสถานะบัฟ/ดีบัฟได้ถูกต้อง 87% หลัง 5 เทิร์น แต่ลดเหลือ 63% หลัง 15 เทิร์น
- Strategic depth / Diversity — ดัชนีที่วัดความหลากหลายของกลยุทธ์ (เช่น จำนวน distinct opening patterns, variance ของเส้นทางเกม) และอัตราความสำเร็จของกลยุทธ์แต่ละแบบ
การนำเสนอสถิติและการวิเคราะห์ข้อผิดพลาด (Confusion Matrix & Heatmap)
การนำเสนอผลลัพธ์ควรรวมทั้งตารางสรุปเชิงตัวเลขและภาพวิเคราะห์เพื่อให้ผู้บริหารและทีมวิจัยเห็นภาพชัดเจน เราขอแนะนำการใช้ confusion matrix เพื่อแสดงความผิดพลาดของโมเดลเมื่อจำแนกสถานะบริบท (เช่น ระบุว่าโปเกมอนถูกสตัน แทนที่จะเป็นสลีป) และ heatmap เพื่อแสดงการแจกแจงความผิดพลาดตามช่วงเวลาและสถานการณ์เฉพาะ
ตัวอย่างการรายงานเชิงตัวเลข: เมื่อเจอสถานะ "sleep" โมเดลตอบสนองผิดใน 22% ของกรณี (false negative 15%, false positive 7%) ซึ่งสามารถแสดงให้เห็นเป็นตาราง confusion matrix พร้อม heatmap ที่ระบุตำแหน่งของการลืมสถานะหลังจาก X เทิร์น

การวิเคราะห์ภาพเชิงลึกควรรวมการแบ่งกลุ่มตาม opponent type, opening strategy และระยะเวลาเกม เพื่อชี้ให้เห็น pattern ของข้อผิดพลาด เช่น โมเดลมีแนวโน้มลืม buffs เมื่อความยาวเกมเกิน 12 เทิร์น และข้อผิดพลาดเหล่านี้สัมพันธ์กับการลด win-rate ลง Y% ในแมตช์เฉพาะกลุ่ม
การวัดความสอดคล้องกับนโยบาย optimal และการติดตามสถานะระยะยาว
เมตริก move optimality ควรถูกนิยามทั้งเชิงจำนวน (เปอร์เซ็นต์ของ moves ที่ตรงกับ optimal policy) และเชิงค่าสัมพัทธ์ (expected regret ต่อเทิร์น หรือ KL divergence) ตัวอย่างเช่น โมเดลอาจเลือก move ที่ optimal ใน 84% ของกรณี แต่เมื่อต้องเผชิญกับ sequence ที่ต้องวางแผนล่วงหน้า 5–10 เทิร์น อัตรานี้อาจลดลงเป็น 66% ซึ่งสะท้อนปัญหาในการประเมินผลระยะยาว
สำหรับการติดตาม buffs/debuffs ควรวัดทั้ง precision/recall ของการตรวจจับสถานะและ temporal retention (เช่น เปอร์เซ็นต์การรักษาสถานะถูกต้องหลัง N เทิร์น) การรายงานอาจระบุว่า AI รักษา buffs ถูกต้อง 93% ใน 3 เทิร์นแรก แต่ลดเหลือ 64% หลัง 10 เทิร์น ซึ่งบ่งชี้ถึงปัญหาในการจัดการ context window หรือ memory decay
การประเมินเชิงคุณภาพและการวิเคราะห์ emergent strategies
นอกจากเมตริกเชิงปริมาณแล้ว การประเมินเชิงคุณภาพมีความสำคัญในการจับปรากฏการณ์กลยุทธ์ที่เกิดขึ้นเอง (emergent strategies) ซึ่งอาจไม่ปรากฏในชุดข้อมูลฝึก ตัวชี้วัดเชิงคุณภาพควรประกอบด้วย:
- การให้คะแนนโดยผู้เชี่ยวชาญ (expert rubric) สำหรับความยืดหยุ่นและความสมเหตุสมผลของแผน (เช่น ให้คะแนน 1–5 ตามความเข้าใจบริบท)
- Case studies — รายงานตัวอย่างแมตช์ที่กลยุทธ์เกิดขึ้นพร้อมการวิเคราะห์สาเหตุและผลลัพธ์ (เช่น การสละหน่วยเพื่อเปิดช่องให้เกิด combo ที่ชนะในระยะยาว)
- การทดสอบความทั่วไป (generalization) — วัดว่ากลยุทธ์ emergent ยังได้ผลเมื่อเจอกับ opponent ที่ไม่เคยพบก่อนหรือไม่ เช่น strategy A ชนะ 70% กับ opponent set ใหม่ เทียบกับ 40% ของ baseline
- Ablation / counterfactual tests — ปิดความสามารถบางอย่างของโมเดลเพื่อตรวจสอบว่าส่วนใดก่อให้เกิดพฤติกรรม emergent
ตัวอย่างกรณีศึกษาที่น่าสนใจ: โมเดลพัฒนา "stall-and-setup" tactic ที่มี ROI สูง — แม้ในตอนแรกจะมีอัตราการเสีย HP สูง แต่แลกด้วยการเปิดช่องให้ใช้ ultimate combo ในเทิร์นถัดไป ทำให้ win-rate เพิ่มขึ้นจาก 48% เป็น 63% ในกลุ่ม opponent เฉพาะ ซึ่งบ่งชี้ถึง emergent strategic depth ที่สำคัญและอาจนำไปสู่การออกแบบนโยบายที่ยืดหยุ่นมากขึ้น
สรุป: การวัดความสามารถของ AI ในบริบทเกมโปเกมอนต้องเป็นการผสมผสานระหว่างเมตริกเชิงปริมาณ (win-rate, Elo-like, move optimality, latency, retention) และการวิเคราะห์เชิงคุณภาพ (confusion matrix/heatmap, expert evaluation, case studies ของ emergent strategies) เพื่อให้ได้ภาพรวมที่ครบถ้วนและใช้งานได้จริงเชิงธุรกิจ
ตัวอย่างผลลัพธ์เชิงคุณภาพ: เมื่อ AI 'เข้าใจ' บริบทจริงๆ
ตัวอย่างผลลัพธ์เชิงคุณภาพ: เมื่อ AI "เข้าใจ" บริบทจริงๆ
ผลลัพธ์เชิงคุณภาพจากการทดสอบเกมโปเกมอนสะท้อนถึงความสามารถในการรับรู้และประมวลผลบริบทที่ซับซ้อนได้อย่างชัดเจน มากกว่าแค่การคำนวณค่าความเสียหายหรือเลือกท่าโจมตีที่ทรงพลังที่สุด ตัวอย่างเชิงเหตุการณ์จริงจากสนามทดสอบแสดงให้เห็นว่า AI สามารถวางแผนข้ามเทิร์น สลับตัวเพื่อจัดการสถานะเรื้อรัง และปรับกลยุทธ์ตามรูปแบบพฤติกรรมของผู้เล่นได้อย่างมีประสิทธิภาพ ซึ่งเป็นสัญญาณว่าระบบได้สร้างโมเดลเชิงบริบท (contextual model) ที่ทำงานใกล้เคียงกับการตัดสินใจเชิงมนุษย์
-
ตัวอย่าง 1 — คาดการณ์ท่าโจมตีแบบต้องใช้ 2 เทิร์นล่วงหน้าและเตรียมการรองรับ: ในชุดทดสอบแบบ 1v1 จำนวนกว่า 300 แมตช์ มีกรณีที่คู่ต่อสู้ใช้ท่าโจมตีแบบต้องชาร์จ 2 เทิร์น (charge-up move) ซึ่งหากไม่เตรียมการจะทำให้เราขาดความพร้อม AI สามารถคาดการณ์รูปแบบการชาร์จจากสัญญาณก่อนหน้า เช่น การสลับท่า การเก็บพลัง และระยะเวลาการใช้ท่า โดยจะเริ่มเตรียมเครื่องมือหรือสถานะรองรับล่วงหน้า เช่น สลับเข้าโปเกมอนที่มีความต้านทานต่อท่านั้น หรือวางสถานะป้องกันในเทิร์นก่อนหน้า ผลคือ AI สามารถตอบโต้ท่า 2 เทิร์นได้สำเร็จในประมาณ 72–85% ของกรณีที่มีสัญญาณพยากรณ์ชัดเจน และลดอัตราการแพ้จากการโดนท่าเต็มแรงลงเฉลี่ย 34% เมื่อเทียบกับนโยบายเชิงปฏิกิริยาทันที
-
ตัวอย่าง 2 — หลีกเลี่ยงกับดัก (trap move) หลังการสังเกต 3–4 เทิร์น: การวางกับดักมักเป็นกลยุทธ์ที่ออกแบบมาเพื่อหลอกล่อ AI ให้ตอบสนองผิดพลาด เช่น ผู้เล่นอาจเล่นเป็นจังหวะล่อให้ AI ใช้บัฟแล้วตามด้วยท่าที่เปลี่ยนสถานะรุนแรง AI ที่เรียนรู้เชิงพฤติกรรมสามารถสังเกตแนวทางการเล่นในช่วง 3–4 เทิร์นแรก (pattern recognition window) และปรับน้ำหนักความน่าจะเป็นของการเลือกท่า ผลการทดลองชี้ว่าเมื่อมีการสังเกตพฤติกรรมครบ 3–4 เทิร์น AI ลดความน่าจะเป็นในการตอบโต้ด้วยท่าล่อหลอกลงจากค่าเริ่มต้น และมีอัตราการหลีกเลี่ยงกับดักสำเร็จสูงถึง 88% ในชุดทดสอบที่มีการตั้งดักชัดเจน นั่นแสดงว่า AI ไม่ได้ทำงานแบบ “รีเฟล็กซ์” เท่านั้น แต่เรียนรู้รูปแบบและเปลี่ยนกลยุทธ์ตามบริบท
-
วิดีโอหรือ replay ที่แสดงแมตช์ตัวอย่างช่วยให้เห็นเชิงกลยุทธ์อย่างชัดเจน: การนำเสนอเป็นวิดีโอ/replay ของแมตช์ตัวอย่างทำให้ทีมพัฒนาและผู้สนใจสามารถติดตามลำดับการตัดสินใจของ AI ในระดับเทิร์นต่อเทิร์นได้อย่างเป็นรูปธรรม ตัวอย่างเช่นการทำ annotation บน replay จะชี้ให้เห็นช่วงที่ AIเริ่มจดจำสัญญาณ (turn 1–2), ช่วงที่ตัดสินใจสลับตัว (turn 2–3) และช่วงที่ผลของการเตรียมการแสดงผล (turn 4+) ในการทดลองภายใน ทีมงานพบว่าการวิเคราะห์ replay ช่วยลดเวลาที่ใช้ค้นหาเหตุผลเบื้องหลังการตัดสินใจจากเฉลี่ย 12 นาทีต่อแมตช์ เหลือเพียงประมาณ 4–6 นาที และยังช่วยระบุจุดที่โมเดลควรปรับจูนเพื่อเพิ่มความแม่นยำเชิงบริบท
โดยสรุป ตัวอย่างเชิงคุณภาพข้างต้นชี้ให้เห็นว่าเมื่อ AI ถูกฝึกให้รับรู้ลำดับเหตุการณ์และรูปแบบการเล่น มันสามารถทำงานเชิงกลยุทธ์ที่ซับซ้อนได้ เช่น การเตรียมรองรับท่าใช้เวลาหลายเทิร์น การหลีกเลี่ยงกับดักจากรูปแบบผู้เล่น และการตัดสินใจแบบมีเหตุผลที่สามารถตรวจสอบได้ผ่าน replay เหล่านี้ไม่เพียงเพิ่มประสิทธิภาพการเล่น แต่ยังเป็นหลักฐานเชิงบวกว่าการประยุกต์ใช้ AI ในโดเมนที่ต้องการบริบทเชิงยาว (long-horizon contextual reasoning) สามารถสร้างมูลค่าเชิงธุรกิจ ทั้งในการพัฒนาผลิตภัณฑ์เกมและการนำไปใช้ในระบบอัตโนมัติของธุรกิจที่ต้องการการวางแผนล่วงหน้า
ผลกระทบต่ออุตสาหกรรมเกมและการประยุกต์ใช้งาน
โอกาสเชิงพาณิชย์: ประสบการณ์ผู้เล่นที่ปรับแต่งได้และโมเดลรายได้ใหม่
การที่ AI สามารถเข้าใจบริบทของเกมได้ลึกขึ้นเปิดโอกาสเชิงพาณิชย์ในหลายมิติ ทั้งการพัฒนา NPC ที่ปรับพฤติกรรมตามสไตล์ผู้เล่น และระบบแนะนำเนื้อหาที่ระบุความชอบเฉพาะบุคคล (content personalization) ตัวอย่างเช่น AI สามารถปรับระดับความท้าทายแบบเรียลไทม์ให้เข้ากับทักษะของผู้เล่น ส่งผลให้ retention และ engagement เพิ่มขึ้นอย่างต่อเนื่อง ซึ่งงานวิเคราะห์ด้านผลิตภัณฑ์ดิจิทัลชี้ว่า การปรับเนื้อหาเฉพาะบุคคลสามารถเพิ่มอัตราการใช้งานซ้ำและระยะเวลาที่ผู้เล่นอยู่ในเกมได้อย่างมีนัยสำคัญ.
นอกจากนี้ ธุรกิจสามารถใช้ AI เพื่อสร้างเนื้อหาอัตโนมัติ (procedural content generation) ทั้งแผนที่ เควส ตัวละคร หรือไอเท็ม ลดต้นทุนการผลิตคอนเทนต์และเร่งเวลาในการออกสินค้าใหม่ ตัวอย่างเช่น สตูดิโอขนาดกลางสามารถใช้โมดูล AI เพื่อผลิตภารกิจย่อยหลายร้อยชิ้นได้ภายในเวลาสั้น ๆ ซึ่งช่วยลดค่าใช้จ่ายด้านทีมออกแบบและเปิดช่องทางรายได้ เช่น สินค้าในเกมหรือบริการ subscription ที่มีเนื้อหาอัพเดตเป็นประจำ
ความท้าทายด้านความเป็นธรรม (Fairness)
ในขณะที่ AI สามารถยกระดับประสบการณ์ได้ แต่ก็สร้างความเสี่ยงด้านความเป็นธรรมโดยตรง หากมีการนำ AI มาใช้เป็นบอทที่เล่นได้เหนือมนุษย์หรือช่วยเล่นแบบเรียลไทม์โดยไม่เปิดเผย จะส่งผลให้ประสบการณ์ของผู้เล่นจริงถูกทำลาย ตัวอย่างที่เกิดขึ้นในวงการแข่งขันออนไลน์คือปัญหา smurfing และบอทที่ทรงพลังซึ่งทำให้ ranking และ matchmaking เสื่อมคุณภาพ
ประเด็นที่ต้องพิจารณาได้แก่:
- ผลกระทบต่อระบบจัดลำดับ (ranking & matchmaking) — หาก AI ถูกนำมาใช้เพื่อเพิ่มคะแนนอย่างไม่เป็นธรรม จะทำให้ความหมายของอันดับสูญเสียและลดความยุติธรรมของการแข่งขัน
- การลดคุณค่าของผลงานมนุษย์ — ผู้เล่นที่พัฒนาทักษะจริงอาจถูกบดบังโดยคู่แข่งที่ใช้ระบบช่วยเล่น
- การแพร่หลายของ cheating-as-a-service — เทคโนโลยี AI อาจถูกนำไปพัฒนาเป็นบริการให้เช่า ทำให้การใช้งานที่ไม่เป็นธรรมเข้าถึงได้ง่ายขึ้น
ข้อพิจารณาด้านนโยบายและแนวทางปฏิบัติ
เพื่อรักษาระบบนิเวศของเกมให้อยู่ในสภาพที่ยุติธรรมและยั่งยืน ผู้พัฒนาและผู้กำกับนโยบายควรพิจารณามาตรการเชิงรุกดังต่อไปนี้:
- การระบุและการเปิดเผยการใช้ AI: กำหนดให้ผู้เล่นต้องประกาศเมื่อใช้ผู้ช่วย AI ในโหมดที่ส่งผลต่อการแข่งขัน เพื่อให้ผู้เล่นอื่นทราบและเลือกโหมดการเล่นที่ต้องการ
- ข้อจำกัดการใช้งานในโหมดแข่งขัน: กำหนดขอบเขตการใช้ AI ที่อนุญาตในการแข่งขัน อาทิ ห้ามใช้ระบบช่วยเล่นเชิงรุกในแมตช์จัดอันดับ
- มาตรการตรวจจับและป้องกัน: พัฒนาระบบตรวจจับพฤติกรรมที่ผิดปกติ (behavioral analytics) ร่วมกับการวิเคราะห์แพ็กเก็ตและการเล่นเพื่อแยกแยะระหว่างผู้เล่นมนุษย์และบอท
- การกำกับดูแลร่วมกับภาคอุตสาหกรรม: สร้างมาตรฐานร่วม (industry standards) สำหรับการใช้ AI ในเกม เช่น การรับรองความโปร่งใสและการทดสอบความเป็นธรรมก่อนปล่อยฟีเจอร์
- นโยบายด้านความรับผิดชอบ: ระบุการลงโทษที่ชัดเจนสำหรับการใช้ AI ในทางที่ผิด รวมถึงการอุทธรณ์และการตรวจสอบแบบอิสระ
สรุปเชิงธุรกิจ
การเข้าใจบริบทของ AI ในระดับที่ลึกขึ้นเป็นโอกาสเชิงพาณิชย์ที่สำคัญสำหรับอุตสาหกรรมเกม แต่ความสำเร็จเชิงพาณิชย์จะต้องเดินคู่กับกรอบนโยบายและเทคนิคที่ปกป้องความเป็นธรรมของการแข่งขัน หากผู้ประกอบการสามารถผนวกแนวทางปฏิบัติที่โปร่งใสและมาตรการป้องกันการใช้ในทางที่ผิดได้ จะสามารถขยายการนำ AI มาใช้เพิ่มมูลค่าให้กับผู้เล่นและสร้างโมเดลรายได้ใหม่ได้อย่างยั่งยืน
คำแนะนำและแนวทางในอนาคตสำหรับนักพัฒนาและผู้กำหนดนโยบาย
คำแนะนำและแนวทางในอนาคตสำหรับนักพัฒนาและผู้กำหนดนโยบาย
การประยุกต์ใช้ปัญญาประดิษฐ์ในบริบทของเกม — โดยเฉพาะกรณีการทดสอบความสามารถเชิงบริบทและการเล่นเกม เช่น โปเกมอน — ต้องมาพร้อมกรอบมาตรฐานและแนวปฏิบัติที่ชัดเจนทั้งในระดับสตูดิโอ นักวิจัย และหน่วยงานกำกับดูแล เพื่อให้การพัฒนาเป็นไปอย่างโปร่งใส ยุติธรรม และปลอดภัย สำหรับจุดเริ่มต้น ควรมีการริเริ่ม ชุด benchmark มาตรฐานแบบเปิด (open benchmarks) ที่กำหนดสภาพแวดล้อม ทรัพยากร และตัวชี้วัดการประเมินผลอย่างชัดเจน เช่น สถานการณ์หลายระดับความยาก การวัดความสามารถทั่วไป (generalization) การตอบสนองต่อสถานการณ์ไม่ครบข้อมูล และการทดสอบในสภาพแวดล้อมที่เปลี่ยนแปลง (distribution shift) โดยผลการทดสอบควรถูกเผยแพร่เป็นสาธารณะพร้อมสคริปต์และ seed เพื่อให้ผู้อื่นสามารถทำซ้ำ (reproducibility) และเปรียบเทียบได้อย่างยุติธรรม
สำหรับสตูดิโอเกมและผู้จัดการแข่งขัน ควรกำหนดนโยบายบังคับให้มี การเปิดเผยข้อมูลการใช้ AI ในกรณีที่ตัวละครหรือผู้เล่นถูกขับเคลื่อนด้วยเอเจนต์อัตโนมัติ (bots) หรือมีการใช้ระบบช่วยเล่นอัจฉริยะ ทั้งในโหมดแข่งขันและโหมดสาธารณะ การระบุนี้ควรอยู่ในข้อกำหนดการแข่งขัน บนหน้าประกาศของเกม และใน metadata ของบัญชีผู้เล่น เพื่อคุ้มครองความเป็นธรรมต่อผู้เล่นมนุษย์ นโยบายดังกล่าวสามารถขยายได้เป็นกฎเกณฑ์ที่บังคับให้มีการป้ายแท็ก (labeling) ชัดเจนสำหรับบัญชี และการตรวจสอบย้อนหลัง (forensic logging) ของกิจกรรมในเกมเพื่อใช้เป็นหลักฐานเมื่อเกิดข้อพิพาท
เพื่อป้องกันความไม่เป็นธรรมและการละเมิดกฎ ควรตั้ง guardrails หลายชั้นทั้งทางเทคนิคและทางนโยบาย ได้แก่ การจำกัดการเข้าถึง API, การตั้งอัตรา (rate limits) สำหรับการเล่นอัตโนมัติ, ระบบตรวจจับพฤติกรรมที่คล้าย bot (behavioral fingerprints), การตรวจสอบแบบสุ่ม (random audits) และการใช้ sandbox สำหรับการทดสอบก่อนปล่อยจริง นอกจากนี้ ควรมีกลไกสำหรับรายงานจากชุมชน (player reporting) ที่เชื่อมกับกระบวนการสอบสวนอัตโนมัติและมนุษย์ร่วมกัน (human-in-the-loop) เพื่อให้การบังคับใช้มีความยุติธรรม ตรวจสอบได้ และมีขั้นตอนอุทธรณ์
ด้านการวิจัย ควรให้ความสำคัญกับงานด้าน interpretability ของเอเจนต์ มากขึ้น เพื่อทำความเข้าใจว่าการตัดสินใจเชิงกลยุทธ์ของโมเดลมาจากปัจจัยใดบ้าง งานวิจัยที่แนะนำได้แก่:
- Policy interpretability — การแยกนโยบายออกเป็นองค์ประกอบย่อยที่เข้าใจได้ เช่น การ distilled policy ไปสู่โมเดลที่เข้าใจง่าย การใช้ตัวแทนเชิงสัญลักษณ์ร่วมกับนโยบายเชิงนามธรรม
- Attribution และ saliency — วิธีชี้ให้เห็นว่าปัจจัยสถานะใดมีอิทธิพลต่อการตัดสินใจ ตัวอย่างเช่น attribution maps สำหรับสถานะเกม หรือ counterfactual analysis เพื่อประเมินความไวต่อการเปลี่ยนแปลงของสิ่งแวดล้อม
- Causal and counterfactual methods — การวิเคราะห์เชิงสาเหตุเพื่อแยกว่าการกระทำใดนำไปสู่ผลลัพธ์อย่างไร และการตรวจจับ reward hacking หรือ behavior exploitation ที่ไม่พึงประสงค์
- Multi-agent social dynamics — การศึกษาปฏิสัมพันธ์ระหว่างเอเจนต์หลายตัว ทั้งในเชิงความร่วมมือและการแข่งขัน เพื่อระบุพฤติกรรมที่อาจนำไปสู่ความไม่ยุติธรรมหรือการแทรกแซงเชิงกติกา
ในมุมมองของผู้กำกับดูแล ควรพิจารณาสร้างกรอบกฎระเบียบที่เน้นการป้องกันผู้บริโภคและการแข่งขันที่เป็นธรรม โดยประกอบด้วยมาตรการเช่น การกำหนดมาตรฐานการรายงาน (disclosure requirements) สำหรับผลิตภัณฑ์และการแข่งขัน การรับรอง (certification) สำหรับระบบที่ใช้งานจริง การสนับสนุนการจัดตั้งคณะกรรมการอิสระด้านการประเมิน AI ในเกม และการกำหนดบทลงโทษที่ชัดเจนต่อการละเมิดกฎ นอกจากนี้ ควรส่งเสริมการสร้าง sandbox ทางกฎระเบียบ (regulatory sandboxes) เพื่อให้สตูดิโอและนักวิจัยสามารถทดสอบเทคโนโลยีใหม่ ๆ ภายใต้การกำกับดูแลที่ควบคุมได้ก่อนนำไปใช้จริง
ท้ายสุด การสร้างระบบนิเวศที่เข้มแข็งต้องการความร่วมมือระหว่างภาคอุตสาหกรรม สถาบันวิจัย และหน่วยงานกำกับดูแล โดยควรสนับสนุน การเผยแพร่ benchmark แบบเปิด การจัด leaderboard สาธารณะ การแชร์ชุดข้อมูลที่มีการปกป้องข้อมูลส่วนบุคคล และการระดมทุนเพื่อการวิจัยด้าน interpretability และ fairness เป้าหมายคือการสร้างมาตรฐานสากลที่ช่วยให้การพัฒนา AI ในเกมไม่เพียงแต่มีประสิทธิภาพ แต่ยังมีความโปร่งใส ยุติธรรม และคำนึงถึงความปลอดภัยของผู้เล่นทุกกลุ่ม
บทสรุป
โปเกมอนถูกเสนอเป็นกรณีทดสอบที่ครอบคลุมหลายมิติของความสามารถด้านปัญญาประดิษฐ์ ทั้งการเข้าใจบริบทของสถานการณ์ในเกม การวางแผนเชิงกลยุทธ์ การปรับตัวต่อข้อมูลที่เปลี่ยนแปลง และการจัดการทรัพยากรระหว่างเป้าหมายระยะสั้นและระยะยาว ทำให้เกมลักษณะนี้สามารถทำหน้าที่เป็นมาตรการชี้วัดใหม่สำหรับงานวิจัยด้าน AI และอุตสาหกรรมเกม โดยเฉพาะเมื่อระบบต้องผสานความเข้าใจเชิงเรื่องราว (narrative context) กับการตัดสินใจเชิงปฏิบัติ การทดสอบแบบนี้จะช่วยเปิดเผยจุดแข็งและข้อจำกัดของโมเดล ทั้งในด้านความสามารถเชิงกลยุทธ์ ความยืดหยุ่นต่อสถานการณ์ที่ไม่คาดคิด และการตีความสัญญะเชิงบริบทที่ซับซ้อน
ในมุมอนาคต การพัฒนา AI ที่มีความเข้าใจบริบทในเกมนำมาซึ่งโอกาสเชิงพาณิชย์ เช่น NPC ที่มีพฤติกรรมสมจริง การปรับประสบการณ์ผู้เล่นแบบไดนามิก และเครื่องมือออกแบบเกมอัตโนมัติ แต่ขณะเดียวกันก็สร้างความท้าทายด้านจริยธรรมและนโยบาย เช่น ความโปร่งใสในการตัดสินใจของ AI การปกป้องข้อมูลผู้เล่น ความเสี่ยงต่อการบิดเบือนพฤติกรรมผู้เล่น และความยุติธรรมในการออกแบบระบบจูงใจ จึงจำเป็นต้องกำหนดมาตรฐานการทดสอบที่ชัดเจน เสริมความโปร่งใสของโมเดล และวางนโยบายกำกับดูแลที่เหมาะสมร่วมกับชุมชนนักพัฒนา ผู้วิจัย และหน่วยงานกำกับ เพื่อให้ประโยชน์เชิงพาณิชย์ไม่แลกมาด้วยความเสี่ยงต่อสิทธิเสรีภาพและความเชื่อถือได้ของระบบ
📰 แหล่งอ้างอิง: The Wall Street Journal



