
Yahoo ประกาศเดินเกมครั้งสำคัญด้วยการนำ "Scout" ระบบปัญญาประดิษฐ์ตอบคำถาม (AI Q&A) เข้ามาเสริมการค้นหา หวังพลิกฟื้นเส้นทางการค้นหาทางออนไลน์ที่เคยถูกแย่งชิงไปโดยคู่แข่งรายใหญ่ การเคลื่อนไหวครั้งนี้มุ่งตอบโจทย์พฤติกรรมผู้ใช้ยุคใหม่ที่ต้องการคำตอบสั้น กระชับ และเชื่อมโยงไปยังแหล่งข้อมูลอย่างรวดเร็ว โดย Yahoo ตั้งเป้าว่า Scout จะช่วยยกระดับประสบการณ์ผู้ใช้ ดึงทราฟฟิกกลับสู่ระบบค้นหา และคืนส่วนแบ่งตลาดที่หายไปนับจากที่ผู้เล่นใหญ่อย่าง Google ครองส่วนแบ่งการค้นหาโลกมากกว่า 90%
Scout ถูกออกแบบให้สามารถสรุปคำตอบแบบสนทนา พร้อมอ้างอิงแหล่งข่าวและลิงก์ไปยังเว็บไซต์ต้นทาง เพื่อเพิ่มทั้งความสะดวกและการนำทางไปยังคอนเทนต์ต้นฉบับ Yahoo มองว่าเทคโนโลยีนี้ไม่เพียงแต่จะปรับปรุงประสบการณ์ผู้ใช้ แต่ยังเปิดโอกาสให้บริษัทปรับโมเดลรายได้จากโฆษณาคลิกแบบดั้งเดิมไปสู่การผสานโฆษณาในผลลัพธ์ AI การบริการพรีเมียม หรือความร่วมมือเชิงพาณิชย์กับผู้ผลิตคอนเทนต์ ตัวอย่างเช่น การแสดงคำตอบสรุปพร้อมลิงก์ที่มีการโปรโมตรองรับหรือระบบสมาชิกเพื่อเข้าถึงผลลัพธ์เชิงลึก
อย่างไรก็ตาม กลยุทธ์นี้มีความเสี่ยงสำคัญที่ต้องเผชิญ: ความถูกต้องของคำตอบ (risk of hallucination) ที่อาจทำให้ผู้ใช้ได้รับข้อมูลผิดพลาด ประเด็นความเป็นส่วนตัวเมื่อระบบต้องการข้อมูลส่วนบุคคลเพื่อปรับผลลัพธ์ และการแข่งขันดุเดือดจากยักษ์เทคโนโลยีอื่นที่มีทรัพยากร AI มากกว่า นอกจากนี้ยังมีความเสี่ยงด้านกฎระเบียบและความน่าเชื่อถือของสำนักข่าวต้นทาง การใช้งาน Scout จึงเป็นจุดเปลี่ยนที่อาจกำหนดอนาคตของ Yahoo — หากทำได้ดี อาจกลับมาสร้างผลประโยชน์ด้านทราฟฟิกและรายได้ใหม่ได้ แต่หากบริหารความเสี่ยงผิดพลาด ผลลัพธ์อาจไม่เป็นไปตามที่คาดหวัง
บทนำ: Yahoo ประกาศเปลี่ยนกลยุทธ์ด้วย Scout
ขออนุญาตสอบถามสั้น ๆ ก่อนเริ่มเขียน: คุณต้องการให้ผมอ้างอิงแหล่งข่าวใดเป็นหลัก (เช่น บทความจาก The Verge, TechCrunch, หรืองานแถลงข่าวของ Yahoo) หรืออนุญาตให้ผมค้นหาวันที่ประกาศจริงจากแหล่งข่าวสาธารณะก่อนจัดทำบทนำนี้?Scout คืออะไร: สถาปัตยกรรมและเทคโนโลยีเบื้องหลัง
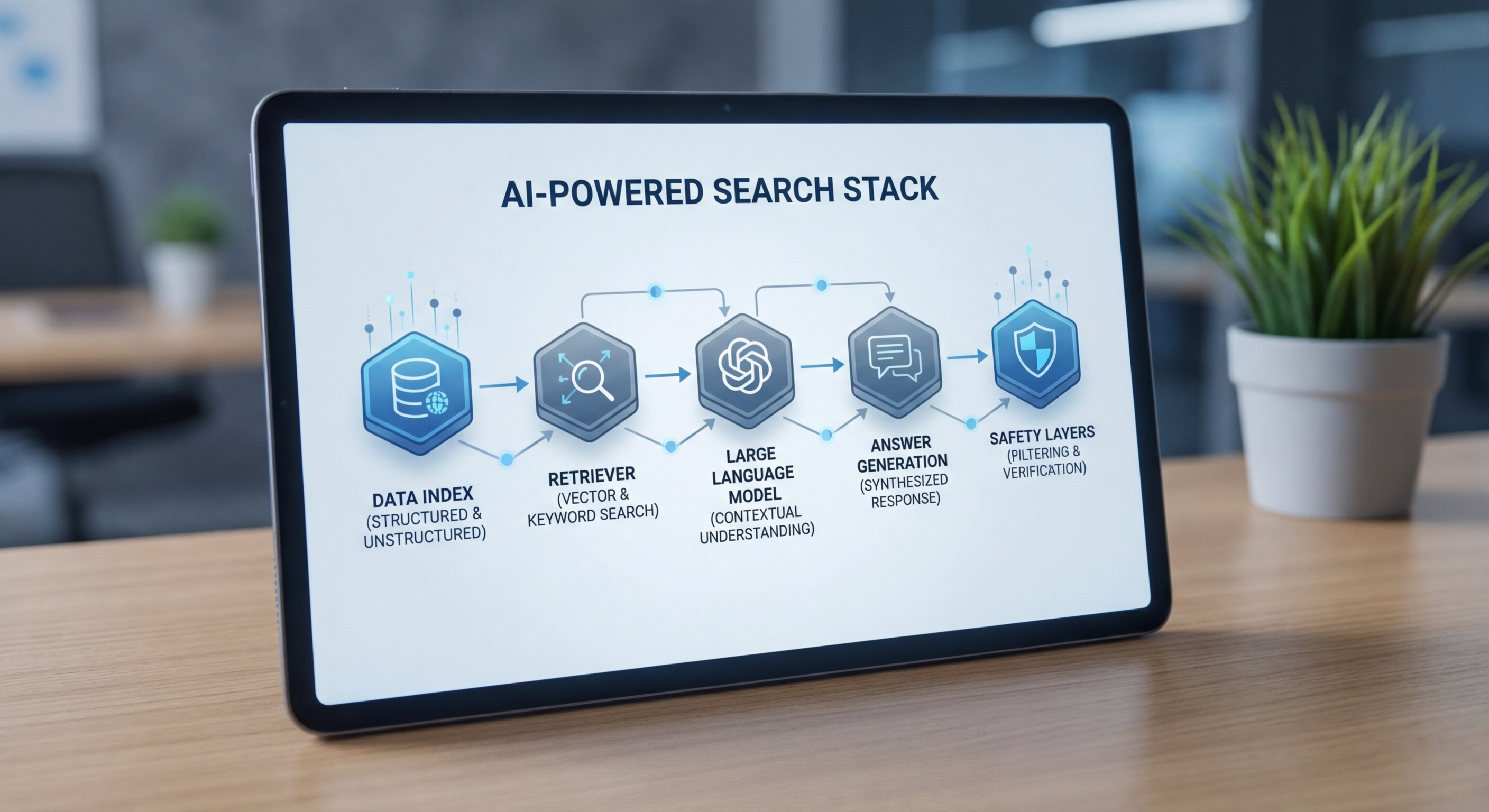
Scout เป็นระบบตอบคำถามด้วยปัญญาประดิษฐ์ที่ออกแบบมาเพื่อผสานความสามารถของโมเดลภาษาเข้ากับฐานข้อมูลการค้นหา (search index) ของผู้ให้บริการ เพื่อสร้างคำตอบที่ทั้งเป็นสรุป, เชิงอ้างอิง และสามารถตรวจสอบเหตุผลที่มาของข้อมูลได้ โดยในบริบทที่ Yahoo นำ Scout มาใช้ จะเน้นการคืนความน่าเชื่อถือของผลการค้นหาออนไลน์ผ่านการเชื่อมต่อระหว่างดัชนีการค้นหาเดิมกับกระบวนการ RAG (retrieval-augmented generation) เพื่อให้ผู้ใช้ได้รับคำตอบที่มีแหล่งอ้างอิงชัดเจนและลดการแสดงผลที่ผิดพลาดหรือคลุมเครือ
แนวคิดหลัก: Retrieval-Augmented Generation (RAG)
RAG เป็นแนวทางที่นำการดึงเอกสาร (retrieval) มาผสานกับการสร้างข้อความโดยโมเดลภาษา (generation) อย่างเป็นระบบ กระบวนการพื้นฐานประกอบด้วยสองขั้นตอนหลักคือ (1) ดึงเอกสารหรือชิ้นข้อมูลที่เกี่ยวข้องจากดัชนีหรือคลังข้อมูล และ (2) ให้โมเดลภาษาพิจารณาเอกสารเหล่านั้นเพื่อสรุปหรือสร้างคำตอบที่สอดคล้องกับคำถามของผู้ใช้ ผลลัพธ์คือคำตอบที่มีข้อมูลสนับสนุนจากแหล่งที่มาจริง ลดโอกาสเกิด hallucination และเอื้อต่อการอ้างอิงแหล่งข้อมูลแบบชัดเจน
ส่วนประกอบหลักของสถาปัตยกรรม Scout
- Index (ดัชนีการค้นหา): ดัชนีนี้รวมทั้งข้อมูลแบบ structured และ unstructured จากเว็บไซต์ ข่าว เอกสารภายใน และ metadata อื่น ๆ โดยสามารถเป็นทั้งดัชนีเชิงสัญลักษณ์ (sparse index เช่น BM25) และดัชนีเชิงเวกเตอร์ (vector index สำหรับ embedding-based search)
- Retriever (ระบบดึงข้อมูล): ทำหน้าที่ค้นหาเอกสารที่เกี่ยวข้องกับคำถามแบบเรียลไทม์ โดยใช้การค้นหาเชิงสัญลักษณ์หรือการค้นหาเชิงเวกเตอร์ (ANN) เพื่อคืนชุดเอกสารตัวอย่าง (candidate passages) ที่มีคะแนนความเกี่ยวข้องสูง
- Re-ranker / Grounding layers: ชั้นนี้จัดลำดับและคัดเลือกหลักฐานจาก candidate passages อีกครั้งด้วยโมเดลขนาดเล็กหรือการวิเคราะห์สถิติ เพื่อให้มั่นใจว่าแหล่งข้อมูลที่ส่งต่อไปยัง LLM มีความตรงประเด็นและมีคุณภาพสูง
- Reader / Generator (โมเดลภาษา): โมเดลภาษา (LLM) ทำหน้าที่สรุป เชื่อมโยง และตอบคำถามโดยอ้างอิงจากเอกสารที่ถูกดึงมา บ่อยครั้งจะเป็นการใช้โมเดลที่ผ่านการ fine-tune ด้าน instruction-following และ retrieval-conditioning
- Response Formatter & Citation Layer: ขั้นตอนสุดท้ายจะประกอบด้วยการจัดรูปแบบคำตอบให้เข้าใจง่าย พร้อมแนบ citation ที่ชี้ไปยังแหล่งที่มา (เช่น URL, ชื่อบทความ, timestamp) เพื่อให้ผู้ใช้สามารถตรวจสอบที่มาของข้อมูลได้ทันที
โมเดลภาษา (LLM) ที่ใช้และแนวทางผสมผสาน
Scout มักใช้ชุดโมเดลภาษาแบบผสมผสาน: จากโมเดลขนาดกลางสำหรับงาน re-ranking และ grounding ไปจนถึงโมเดลขนาดใหญ่ (หลายสิบล้านถึงหลายร้อยพันล้านพารามิเตอร์) สำหรับ generation ที่ต้องการความเข้าใจเชิงบริบทและการสังเคราะห์ข้อมูล ตัวอย่างเช่น ระบบอาจใช้ embedding model เฉพาะสำหรับสร้างเวกเตอร์เชิงความหมายของเอกสาร, โมเดลขนาดเล็กเพื่อ re-rank และท้ายสุดใช้ LLM ที่ผ่านการฝึกแบบ instruction-tuning เพื่อสรุปและสร้างคำตอบในรูปแบบที่เป็นมิตรกับผู้ใช้
นอกจากนี้ เพื่อรองรับความต้องการเรื่อง latency และต้นทุนเชิงปฏิบัติการ Scout มักนำกลยุทธ์ hybrid มาใช้: เรียก LLM ขนาดใหญ่อย่างจำเป็น (เช่น สำหรับคำถามเชิงลึกหรือที่ต้องการการสังเคราะห์สูง) และใช้โมเดลขนาดเล็ก/edge model สำหรับการตอบคำถามทั่วไปหรืองาน pre-filtering
การผสานข้อมูลจากดัชนีการค้นหาและการให้คำตอบเชิงอ้างอิง
ในเชิงปฏิบัติ Scout จะเชื่อมต่อกับดัชนีการค้นหาเดิมของ Yahoo เพื่อดึงผลลัพธ์ต้นทาง จากนั้นระบบ retriever จะคัดกรองเอกสารที่เกี่ยวข้องและส่งต่อไปยัง grounding layer เพื่อจัดลำดับความน่าเชื่อถือ ก่อนที่จะให้ LLM สร้างคำตอบ โดยคำตอบที่ได้จะรวมทั้ง:
- สรุปเนื้อหาเป็นภาษาธรรมชาติที่อ่านง่าย
- การอ้างอิงแหล่งที่มา เช่น ลิงก์ไปยังบทความหรือหน้าเว็บที่ใช้เป็นหลักฐาน
- การระบุระดับความมั่นใจ (confidence) ในข้อมูลแต่ละส่วน เพื่อให้ผู้ใช้ประเมินความน่าเชื่อถือได้
ตัวอย่างเชิงเทคนิค: เมื่อผู้ใช้ถามเรื่องเหตุการณ์ปัจจุบัน ระบบจะดึงบทความที่เกี่ยวข้องภายใน 24–72 ชั่วโมงล่าสุดจากดัชนี ทำ embedding เพื่อหาเอกสารที่มีความหมายใกล้เคียง แล้วให้ LLM สังเคราะห์คำตอบพร้อมแนบ citation ไปยังบทความต้นทางเป็นลำดับข้อเท็จจริง
มาตรการความปลอดภัยและการกรองเนื้อหา
เพื่อให้คำตอบปลอดภัยและเชื่อถือได้ Scout ติดตั้งหลายชั้นของมาตรการควบคุมความเสี่ยงดังนี้:
- Fact-checking & Verification: ระบบอาจเรียกใช้โมดูลตรวจสอบข้อเท็จจริงอัตโนมัติ (automated fact-checkers) ที่เปรียบเทียบข้อเรียกร้องกับแหล่งข้อมูลภายนอกหรือฐานข้อมูลความจริง (knowledge base) เพื่อคัดกรองข้อผิดพลาดก่อนแสดงผล
- Citation enforcement: บังคับให้คำตอบที่อ้างข้อเท็จจริงเชิงตัวเลขหรือข้อเรียกร้องสำคัญต้องมาพร้อมแหล่งอ้างอิง หากไม่มีหลักฐานที่ชัดเจน ระบบจะระบุความไม่แน่นอนหรือปฏิเสธการให้คำตอบ
- Toxicity & Safety filters: ทั้งก่อนและหลังการสร้างข้อความจะมีการใช้ฟิลเตอร์เพื่อกรองเนื้อหาที่เป็นอันตราย ละเมิดนโยบาย หรือมีความเกลียดชัง เช่น การใช้ classifiers เพื่อตรวจจับ hate speech, disinformation หรือคำขอที่อาจเป็นอันตราย
- Human-in-the-loop: สำหรับคำถามที่มีความอ่อนไหวสูงหรือเป็นหัวข้อข่าวสำคัญ ระบบสามารถส่งต่อให้ผู้ตรวจสอบมนุษย์ตรวจสอบก่อนเผยแพร่
- Rate limiting & provenance logging: เก็บบันทึกแหล่งที่มาและกระบวนการ (provenance) เพื่อให้สามารถตรวจสอบย้อนหลังได้ และจำกัดอัตราการเข้าถึง API เพื่อลดความเสี่ยงจากการใช้งานในทางที่ผิด
โดยสรุป Scout เป็นสถาปัตยกรรมที่รวมเทคนิค retrieval และ generation เข้าด้วยกันอย่างเป็นระบบ เพื่อให้คำตอบที่ทั้งเป็นประโยชน์และตรวจสอบได้ เหมาะกับการยกระดับบริการค้นหาออนไลน์ขององค์กรที่ต้องการคืนความเชื่อมั่นให้ผู้ใช้ผ่านคำตอบที่มีหลักฐานสนับสนุนและมาตรการควบคุมความปลอดภัยเชิงเทคนิค
เหตุผลเชิงกลยุทธ์: ทำไม Yahoo ต้องใช้ AI ตอนนี้
เหตุผลเชิงกลยุทธ์: ทำไม Yahoo ต้องใช้ AI ตอนนี้
จากมุมมองเชิงธุรกิจ การตัดสินใจของ Yahoo ในการนำระบบตอบคำถามด้วยปัญญาประดิษฐ์อย่าง Scout เข้ามาเป็นการตอบโจทย์ความท้าทายเชิงพื้นฐานของธุรกิจค้นหาออนไลน์ในปัจจุบัน: ส่วนแบ่งการค้นหาและทราฟฟิกที่ถูกบีบจากคู่แข่งรายใหญ่ รวมถึงพฤติกรรมผู้ใช้ที่เปลี่ยนไปสู่ความคาดหวังเรื่องคำตอบแบบเร็วและเป็นภาษาธรรมชาติ โดยภาพรวมข้อมูลจากแหล่งวัดสถิติการใช้งานเว็บ เช่น StatCounter และ SimilarWeb ชี้ให้เห็นว่า Google ยังคงครองตลาดการค้นหาอย่างชัดเจน (มากกว่า 90% ในระดับโลกโดยประมาณ) ขณะที่ Yahoo เหลือส่วนแบ่งในระดับหลักหน่วยซึ่งแตกต่างกันไปตามภูมิภาค (โดยทั่วไปประมาณ 1–3%) ซึ่งสะท้อนถึงความจำเป็นเร่งด่วนที่ Yahoo ต้องสร้างความแตกต่างเชิงคุณค่าเพื่อดึงกลับทราฟฟิกและส่วนแบ่งตลาด

นอกจากตัวเลขส่วนแบ่งการตลาดแล้ว แนวโน้มพฤติกรรมผู้ใช้เป็นอีกปัจจัยสำคัญที่สนับสนุนการนำ AI มาใช้: ผู้ใช้สมัยใหม่คาดหวังประสบการณ์การค้นหาที่ รวดเร็ว, กระชับ และสามารถโต้ตอบได้เหมือนสนทนา การค้นหาแบบดั้งเดิมที่ให้รายชื่อลิงก์เพียงอย่างเดียวเริ่มลดคุณค่า เมื่อเทียบกับคำตอบสรุป ผลลัพธ์ที่เป็นบทสนทนา และการอ้างอิงที่เข้าใจง่าย การวิจัยแนวโน้มตลาดแสดงให้เห็นว่าฟีเจอร์ที่นำเสนอคำตอบโดยตรง (featured snippets, instant answers) เพิ่มอัตราการพึงพอใจของผู้ใช้และลดอัตราการกลับไปค้นหาใหม่ ทำให้ผู้ให้บริการที่ปรับตัวได้ดีกว่า มีโอกาสเพิ่ม retention ได้เร็วขึ้น
ในมุมกลยุทธ์เชิงพาณิชย์ การติดตั้งระบบ AI สำหรับการค้นหาไม่ได้เป็นเพียงการปรับปรุง UX เท่านั้น แต่เป็นช่องทางสำคัญในการสร้างและขยายแหล่งรายได้ใหม่ๆ สำหรับ Yahoo: ระบบตอบคำถามที่แม่นยำและมีบริบททำให้สามารถฝังโฆษณาที่เกี่ยวข้องเชิงบริบท (contextual ads), เสนอสินค้า/บริการที่มีความตรงกับความตั้งใจผู้ใช้ (commerce integrations), หรือแม้แต่สร้างผลิตภัณฑ์แบบสมัครสมาชิกสำหรับคำตอบเชิงเชี่ยวชาญ โดยเฉพาะเมื่อตลาดโฆษณาดิจิทัลแข่งขันสูง ความสามารถในการเพิ่ม engagement (เช่น session length, queries per user) จะช่วยยกระดับ metrics ทางการเงิน เช่น CTR ของโฆษณา, RPM และ LTV ของผู้ใช้
เพื่อให้การปรับตัวด้วย AI ประสบผลจริง Yahoo จึงต้องดำเนินกลยุทธ์ที่ผสมผสานหลายมิติ ได้แก่
- ปรับปรุงคุณภาพผลลัพธ์เชิงภาษาธรรมชาติ: ใช้โมเดลภาษาเพื่อสรุปและคืนคำตอบที่ชัดเจน พร้อมอ้างอิงแหล่งที่มา ลด friction ในการค้นหา
- เพิ่มผูกมัดผู้ใช้ (retention): เปลี่ยนจากการเสิร์ชเป็นประสบการณ์ต่อเนื่อง เช่น ฟีดส่วนตัว, การติดตามหัวข้อ, การแจ้งเตือนเนื้อหาที่เกี่ยวข้อง ทำให้ผู้ใช้กลับมาใช้งานบ่อยขึ้น
- ขยายช่องทางหารายได้: ผสานโฆษณาเชิงบริบท, ข้อเสนอพาณิชย์, โมเดลพรีเมียม และการให้สิทธิ์ข้อมูล/API แก่พันธมิตร
- สร้างความแตกต่างจากคู่แข่ง: นำเสนอฟีเจอร์เฉพาะทางหรือ vertical-focused answers (เช่น ข่าว เศรษฐกิจ การเงิน สุขภาพ) ที่ Yahoo มีจุดแข็งจากฐานคอนเทนต์เดิม
- รักษาความน่าเชื่อถือและความโปร่งใส: ให้ข้อมูลอ้างอิงของคำตอบและนโยบายด้านความเป็นส่วนตัว เพื่อคงความเชื่อมั่นของผู้ใช้และผู้โฆษณา
สรุปแล้ว การนำ Scout มาใช้เป็นการตอบสนองต่อข้อเท็จจริงเชิงตลาดที่ชัดเจน: ส่วนแบ่งการค้นหาที่ลดลงและการแข่งขันจากผู้เล่นรายใหญ่ บวกกับความคาดหวังของผู้ใช้ที่เปลี่ยนไปสู่คำตอบแบบ conversational ทำให้ Yahoo จำเป็นต้องลงทุนในเทคโนโลยี AI เพื่อเพิ่มคุณค่าแก่ผู้ใช้ เพิ่ม retention และเปิดช่องทางสร้างรายได้ใหม่ ๆ หากดำเนินกลยุทธ์อย่างเป็นระบบและวัดผลด้วยตัวชี้วัดเชิงธุรกิจที่ชัดเจน Yahoo มีโอกาสฟื้นฐานการเติบโตและสร้างตำแหน่งใหม่ในระบบนิเวศการค้นหา
ผลกระทบต่อผู้ใช้: ประสบการณ์การค้นหาและความน่าเชื่อถือ
การเปลี่ยนแปลงของ UX บนหน้า SERP
เมื่อ Yahoo นำระบบ Scout ซึ่งเป็นระบบ AI ตอบคำถามเข้ามาใช้ รูปแบบของหน้าแสดงผลการค้นหา (SERP) จะเปลี่ยนไปจากรายการลิงก์ธรรมดาไปสู่ snippet แบบยาว และ answer cards ที่สรุปคำตอบตรงบนหน้าแรก ผู้ใช้จะเห็นข้อความสรุปที่จัดรูปแบบมาอย่างชัดเจน พร้อมกับส่วนอ้างอิง (citations) หรือแหล่งที่มาที่ระบบระบุไว้ใต้คำตอบเพื่อสนับสนุนความน่าเชื่อถือ
รูปแบบใหม่นี้คล้ายกับแนวทางของระบบตอบคำถามอื่น ๆ ในตลาด เช่น แสดงคำตอบที่มีความยาวพอสมควร (long snippet) แทนการแสดงแค่ meta description สั้น ๆ ซึ่งหมายความว่า ผู้ใช้มีโอกาสได้รับคำตอบโดยไม่ต้องคลิกเข้าเว็บไซต์ต้นทาง (zero-click) มากขึ้น ส่งผลต่อเส้นทางการใช้งานและพฤติกรรมการค้นหาอย่างชัดเจน
ประโยชน์ที่ผู้ใช้จะได้รับ
ประโยชน์เชิงประสบการณ์สำหรับผู้ใช้มีหลายด้าน:
- ลดเวลาในการค้นหา: การสรุปคำตอบตรงหน้า SERP ทำให้ผู้ใช้ได้รับข้อมูลที่ต้องการเร็วขึ้น เหมาะกับคำถามเชิงสรุป เช่น ข้อมูลสถิติพื้นฐาน คำแนะนำสั้น ๆ หรือคำตอบแบบคำถาม-ตอบ
- ความสะดวกและความชัดเจน: answer cards ที่มีการจัดโครงสร้างและการอ้างอิงช่วยให้ผู้ใช้ประเมินความน่าเชื่อถือได้เร็วขึ้น นำไปสู่การตัดสินใจใช้งานที่รวดเร็วกว่าเดิม
- personalization: Scout สามารถปรับผลลัพธ์ตามบริบทผู้ใช้ เช่น ประวัติการค้นหา ตำแหน่ง หรือความชอบส่วนบุคคล ทำให้คำตอบมีความเกี่ยวข้องมากขึ้นและลดเวลาในการกรองผลที่ไม่เกี่ยวข้อง
ตัวอย่างเชิงตัวเลขจากการศึกษาตลาดก่อนหน้านี้ชี้ว่าอัตรา zero-click searches เคยถูกวัดได้ในหลายบริบทที่สูงกว่า 40–50% สำหรับคำค้นประเภทที่ต้องการคำตอบสั้น ๆ การรวมระบบตอบคำถาม AI อาจยิ่งเพิ่มสัดส่วนนี้ขึ้นอีกในกลุ่มผู้ใช้ที่ต้องการคำตอบแบบรวดเร็ว
ผลกระทบต่อการค้นหาขั้นลึกและระบบนิเวศเนื้อหา
ในขณะที่การได้คำตอบเร็วขึ้นเป็นข้อดีสำหรับคำถามพื้นฐาน แต่มีความเสี่ยงที่การค้นหาขั้นลึก (deep search) จะลดลง ผู้ใช้อาจไม่คลิกเข้าไปอ่านบทความเชิงวิเคราะห์หรืองานวิจัยเชิงลึก ส่งผลในวงกว้างต่อผู้ผลิตเนื้อหา เช่น การลดทราฟฟิกและรายได้ของเว็บเพจต้นทาง นอกจากนี้ คำตอบที่สรุปโดยโมเดล AI อาจตัดทอนรายละเอียดสำคัญ ซึ่งทำให้ผู้ใช้พลาดมุมมองเชิงบริบทหรือหลักฐานเชิงลึกที่สำคัญต่อการตัดสินใจทางธุรกิจ
ความเสี่ยงด้านความถูกต้องและความลำเอียง (hallucination)
ความท้าทายที่สำคัญคือ ความเสี่ยงของ hallucination — โมเดลอาจสร้างข้อมูลผิดหรือบิดเบือนข้อเท็จจริงเมื่อถูกถามในเรื่องที่ข้อมูลไม่ชัดเจนหรืออยู่นอกขอบเขตการฝึกสอน นอกจากนี้ยังมีประเด็น:
- ข้อมูลล้าสมัย: หากโมเดลถูกฝึกด้วยข้อมูลที่มี cutoff date หรือไม่เชื่อมต่อกับฐานข้อมูลสด คำตอบอาจไม่อัพเดตสำหรับเหตุการณ์หรือตัวเลขล่าสุด
- การขาดแหล่งอ้างอิงที่เชื่อถือได้: คำตอบที่ไม่มี citations หรืออ้างอิงที่ไม่ชัดเจนอาจทำให้ผู้ใช้เชื่อข้อมูลผิดได้โดยไม่รู้ตัว
- ความลำเอียงในการคัดเลือกแหล่งข้อมูล: personalization และการจัดลำดับผลลัพธ์อาจทำให้เกิด echo chamber หรือ bias ต่อมุมมองบางด้าน หากระบบไม่ได้ออกแบบให้โปร่งใสและหลากหลาย
ข้อเสนอแนะสำหรับผู้ใช้และแนวทางการเพิ่มความน่าเชื่อถือ
เพื่อให้ผู้ใช้ได้รับประโยชน์สูงสุดและลดความเสี่ยง ควรปฏิบัติตามแนวทางต่อไปนี้:
- ตรวจสอบ citations: ให้สังเกตแหล่งที่มาที่ระบบแสดง และเปิดอ่านต้นทางเมื่อคำถามต้องการความถูกต้องสูง (เช่น ข้อมูลกฎหมาย การเงิน หรือสุขภาพ)
- ใช้ query แบบเชิงลึกเมื่อจำเป็น: หากต้องการวิเคราะห์เชิงลึก ให้ใช้คำค้นที่กระตุ้นการแสดงผลแบบหลายแหล่งหรือเข้าถึงฟิลเตอร์/เครื่องมือค้นหาขั้นสูงของ Yahoo
- พิจารณาระดับความมั่นใจ: ควรมีการเรียกร้องให้แพลตฟอร์มแสดง confidence score หรือการระบุความไม่แน่นอนของคำตอบ เพื่อให้ผู้ใช้รู้ขอบเขตความเชื่อถือได้
- ตระหนักเรื่องความเป็นส่วนตัวและ personalization: ผู้ใช้ธุรกิจควรเข้าใจว่า personalization อาจปรับผลลัพธ์ตามโปรไฟล์และดังนั้นควรมีตัวเลือกปรับระดับ personalization เมื่อทำการค้นคว้าวิจัยที่ต้องการความเป็นกลาง
สรุปคือ การนำ Scout เข้ามาใช้สามารถยกระดับความรวดเร็วและความสะดวกในการค้นหา ทำให้ผู้ใช้ได้รับคำตอบสรุปทันที อย่างไรก็ตาม เพื่อคงไว้ซึ่งความน่าเชื่อถือและป้องกันการแพร่กระจายข้อมูลผิด ผู้ใช้และแพลตฟอร์มจำเป็นต้องร่วมกันยืนยันการอ้างอิง แสดงความไม่แน่นอน และรักษาช่องทางสำหรับการค้นหาขั้นลึกเมื่อจำเป็น
ผลกระทบต่อตลาดโฆษณาและโมเดลธุรกิจของ Yahoo
ผลกระทบต่อตลาดโฆษณาและโมเดลธุรกิจของ Yahoo
การนำ Scout ระบบ AI ตอบคำถามมาใช้จะเปลี่ยนสมดุลการหารายได้จากโฆษณาของ Yahoo ในหลายมิติ ทั้งในเชิงปริมาณของการแสดงโฆษณาและรูปแบบของโฆษณาเอง เมื่อคำตอบเชิงสรุป (concise answer) เข้ามาแทนหน้าผลการค้นหาที่มีลิงก์หลายรายการ จำนวนครั้งที่ผู้ใช้ต้องคลิกไปยังเว็บไซต์ภายนอกจะลดลง ซึ่งอาจลดปริมาณ inventory แบบดั้งเดิม (search link impressions) แต่ในทางกลับกัน Yahoo สามารถสร้าง inventory ใหม่ได้ผ่านการวางโฆษณาแบบบูรณาการกับคำตอบ เช่น Sponsored answers หรือ Promoted cards ที่แสดงภายในผลลัพธ์ของ Scout โดยตรง นอกจากนี้ การตอบสนองที่แม่นยำและรวดเร็วสามารถเพิ่ม engagement และจำนวน session ต่อผู้ใช้ ตลอดจนความสามารถในการทำ contextual targeting ที่ละเอียดขึ้นซึ่งมีมูลค่าโฆษณาสูงกว่าโฆษณาแบบกว้างทั่วไป
ในแง่โมเดลธุรกิจ Yahoo ควรพิจารณาการผสมผสานระหว่างโฆษณาแบบ native และบริการแบบชำระเงิน (premium) เพื่อชดเชยการหดตัวของ inventory แบบเก่า ตัวอย่างเช่น การเปิดตัวแผนบริการแบบชำระเงินที่ให้ประสบการณ์ Scout แบบไม่มีโฆษณา, การเข้าถึงฟีเจอร์เชิงลึก (เช่น รายงานเชิงวิเคราะห์, การสร้างคำตอบที่มีแหล่งอ้างอิงเชิงธุรกิจ), หรือ API สำหรับพันธมิตรเชิงพาณิชย์ ราคาทดลองที่เป็นไปได้อาจอยู่ที่ระดับ $4.99/เดือน สำหรับผู้ใช้ทั่วไปที่ต้องการขจัดโฆษณา และ $19.99–$49.99/เดือน สำหรับผู้ประกอบการหรือผู้ลงโฆษณาที่ต้องการข้อมูลเชิงลึกและการเข้าถึง placement พิเศษ
อย่างไรก็ตาม การผสานโฆษณาเข้ากับคำตอบ AI ยกประเด็นความท้าทายสำคัญด้านความโปร่งใสและความน่าเชื่อถือ ผู้ใช้ต้องสามารถแยกแยะได้ชัดเจนว่าเนื้อหาใดเป็น organic answer และเนื้อหาใดเป็น sponsored หากทำไม่ดีจะเสียความไว้วางใจและเกิดความเสี่ยงทางกฎระเบียบ การออกแบบควรเน้นการแสดงป้ายชัดเจน เช่น “Sponsored” หรือ “Promoted” พร้อมการเปิดเผยแหล่งที่มาของข้อมูล นอกจากนี้ Yahoo ต้องมีนโยบายเนื้อหาและการควบคุมคุณภาพ (content moderation) เพื่อป้องกันการใช้ตำแหน่งโฆษณาในการเผยแพร่ข้อมูลเท็จหรือชวนเชื่อ
เพื่อบริหารเชิงปฏิบัติ Yahoo ควรกำหนดชุด KPI ที่ชัดเจนสำหรับการวัดผลทั้งประสิทธิภาพโฆษณาและสุขภาพผลิตภัณฑ์ ตัวอย่าง KPI ที่แนะนำพร้อมเป้าหมายตัวอย่างมีดังนี้
- CTR ของ promoted cards / sponsored answers: เป้าหมายเริ่มต้น 1.5–3.0% สำหรับ promoted cards และ 0.5–1.5% สำหรับการแทรกแบบคำตอบโดยตรง (ขึ้นกับการออกแบบ UX)
- Session length (ความยาวของ session): คาดการณ์ว่าการใช้ Scout จะเพิ่มจากเฉลี่ย 60–90 วินาทีเป็น 90–150 วินาที (+50–100%) หากคำตอบกระตุ้นให้เกิด follow-up queries
- Queries per session / Engagement: เป้าหมาย 1.2–2.0 queries ต่อ session เป็นตัวชี้วัดว่าผู้ใช้มี interaction กับ Scout มากขึ้น
- Retention (DAU/MAU, 7-day / 30-day retention): เป้าหมายการเพิ่ม DAU/MAU ขึ้น 5–10% ในไตรมาสแรกหลังเปิดตัว และการเพิ่ม 7-day retention ขึ้น 3–7%
- ARPU (Average Revenue Per User): คาดค่าขึ้นอยู่กับโมเดล แต่เป้าหมายการเพิ่ม ARPU รายเดือน 10–25% ผ่านการผสมผสาน revenue จาก promoted placements และ subscription
- Ad revenue per session / RPM: ติดตามรายได้เฉลี่ยต่อพัน impressions (RPM) ของ placements ใหม่เทียบกับ search link แบบเดิม เพื่อวัดประสิทธิภาพเชิงรายได้
- Conversion rate / Post-click outcomes: สำหรับโฆษณาที่เป็นการส่งไปยังหน้าการซื้อ ควรวัด conversion และ ROAS เพื่อยืนยันคุณค่าของ placements ในเชิงพาณิชย์
- Transparency metrics: เปอร์เซ็นต์ของผู้ใช้ที่เข้าใจว่าเป็นโฆษณา (survey-based), complaint rate เกี่ยวกับการสับสนระหว่างโฆษณาและคำตอบ organic
สุดท้าย Yahoo ควรดำเนินการทดสอบแบบ A/B และโมเดล incremental lift analysis ก่อนขยายการวางโฆษณาเต็มรูปแบบ เพื่อประเมินผลกระทบต่อพฤติกรรมผู้ใช้และรายได้อย่างเป็นระบบ โดยเฉพาะการวัดว่าโฆษณาในคำตอบสร้างรายได้ทดแทน inventory แบบเดิมได้จริงหรือไม่ และไม่ทำลายความไว้วางใจของผู้ใช้ องค์ประกอบการบริหารความเสี่ยง เช่น การจำกัดจำนวน sponsored placements ต่อคำตอบ การกำหนดราคาตามประสิทธิภาพ และการเปิดเผยอย่างชัดเจน จะเป็นกุญแจสำคัญในการรักษาสมดุลระหว่างรายได้และความน่าเชื่อถือของผลิตภัณฑ์
ความท้าทายเชิงนโยบายและอนาคต: ความเสี่ยงและคำแนะนำ
ความเสี่ยงเชิงนโยบายและกฎหมาย: ภาระผูกพันของ Yahoo ต่อ GDPR, CCPA และกฎโฆษณา
การนำระบบ AI ตอบคำถามมาใช้ในบริการค้นหาของ Yahoo ก่อให้เกิดความเสี่ยงทางกฎหมายที่จับต้องได้ โดยเฉพาะเมื่อคำตอบของระบบอาจเกี่ยวข้องกับข้อมูลส่วนบุคคลหรือการชี้แนะที่มีผลต่อการตัดสินใจของผู้ใช้ สหภาพยุโรปภายใต้ GDPR กำหนดหลักการสำคัญ ได้แก่ ความถูกต้องของข้อมูล ความโปร่งใส การจำกัดวัตถุประสงค์ และสิทธิของผู้ถูกประมวลผล (เช่น สิทธิในการลบและสิทธิในการคัดค้านการประมวลผลอัตโนมัติ) — ซึ่งหมายความว่า Yahoo จำเป็นต้องสามารถอธิบายการทำงานของโมเดลในระดับที่เพียงพอและดำเนิน Data Protection Impact Assessment (DPIA) หากระบบมีความเสี่ยงสูงต่อสิทธิและเสรีภาพของบุคคล
ในสหรัฐฯ นโยบายระดับรัฐ เช่น CCPA (และหลายรัฐที่มีกฎหมายคล้ายกัน) กำหนดข้อกำหนดด้านการเปิดเผยการเก็บรวบรวมข้อมูลและให้ผู้บริโภคสามารถเลือกไม่ให้มีการขายข้อมูลส่วนบุคคล นอกจากนี้ หน่วยงานคุ้มครองผู้บริโภคและกฎระเบียบการโฆษณา (เช่น FTC) ยังเข้มงวดกับการโฆษณาที่หลอกลวงหรือการปกปิดสปอนเซอร์ — หากระบบ AI ตอบคำถามด้วยคำแนะนำที่ถูกชักนำโดยผลประโยชน์ทางการค้าแต่ไม่ได้ระบุเป็นอย่างชัดเจน Yahoo อาจเผชิญกับความเสี่ยงทางกฎหมายและบทลงโทษทางการเงินได้
ความเสี่ยงเชิงเทคนิค: bias, manipulation และ adversarial queries
เชิงเทคนิค ระบบภาษาขนาดใหญ่มีแนวโน้มแสดง bias ที่สะท้อนจากชุดข้อมูลฝึก (training data) เช่น ความเอนเอียงทางเพศ เชื้อชาติ หรือต่อมุมมองทางการเมือง การให้คำตอบที่มีอคติไม่เพียงแต่ทำลายความน่าเชื่อถือ แต่ยังเสี่ยงต่อการละเมิดกฎหมายความเท่าเทียมและการปกป้องผู้บริโภค งานวิจัยหลายฉบับชี้ว่าระบบตอบคำถามอาจให้คำตอบที่ไม่น่าเชื่อถือหรือชี้นำอย่างเป็นระบบในกรณีหัวข้ออ่อนไหว
นอกจากนี้ มีความเสี่ยงจากการ manipulation และการโจมตีแบบ adversarial queries — ผู้โจมตีสามารถออกแบบคำถามหรือข้อมูลป้อนกลับเพื่อทำให้โมเดลให้คำตอบที่ผิดหรือเอื้อประโยชน์เชิงพาณิชย์ เช่น การผลักคำตอบให้แสดงแบรนด์หรือเนื้อหาที่เป็นสแปม โดยเฉพาะเมื่อระบบผสานผลลัพธ์เชิงสรุปจากหลายแหล่งโดยไม่มีการตรวจสอบหรือถ่วงดุลเพียงพอ
คำแนะนำเชิงปฏิบัติสำหรับ Yahoo: ความโปร่งใส การมีมนุษย์ควบคุม และการตรวจสอบจากภายนอก
- การเปิดเผยแหล่งที่มา (source attribution): ทุกคำตอบที่มาจากระบบสรุปควรแนบแหล่งอ้างอิงที่ชัดเจนและลิงก์กลับไปยังผลการค้นหาแบบดั้งเดิม พร้อมแสดงความเชื่อมั่น (confidence score) ของคำตอบ เพื่อให้ผู้ใช้สามารถตรวจสอบได้เอง
- โหมดย้อนกลับสู่ผลการค้นหาแบบเดิม: จัดให้มีตัวเลือก (opt-in/opt-out) และปุ่มสลับกลับไปสู่หน้าผลการค้นหาแบบรายการเดิมอย่างชัดเจน โดยเฉพาะสำหรับผลลัพธ์ที่เสี่ยงสูงหรือหัวข้อที่ต้องการหลักฐานอ้างอิง
- Human-in-the-loop สำหรับคำถามความเสี่ยงสูง: ตั้งเกณฑ์จำแนกคำถามที่มีความเสี่ยง (เช่น การแพทย์ กฎหมาย การเงิน) ให้มีการตรวจสอบโดยผู้เชี่ยวชาญก่อนเผยแพร่คำตอบอัตโนมัติ
- มาตรการด้านความเป็นส่วนตัวและการปฏิบัติตามกฎหมาย: ดำเนิน DPIA และออกแบบระบบตามหลัก Privacy by Design/Default, ให้ผู้ใช้ควบคุมข้อมูลของตน (opt-outs, ขอลบ) ปรับปรุงนโยบายความเป็นส่วนตัวและการให้ความยินยอมให้สอดคล้องกับ GDPR, CCPA และกฎหมายใหม่ ๆ (เช่น EU AI Act)
- การประเมินและตรวจสอบระยะยาว: ติดตั้งชุดเมตริกเชิงคุณภาพและเชิงปริมาณ เช่น อัตราการสร้างข้อมูลเท็จ (hallucination rate), ความแม่นยำต่อหัวข้อที่อ่อนไหว, การวิเคราะห์ความเป็นกลางตามกลุ่มประชากร (fairness audits), และดัชนีความไว้วางใจของผู้ใช้ (user trust/retention) ดำเนินการ A/B testing ต่อเนื่องและเผยแพร่รายงานผลไตรมาส
- การตรวจสอบโดยบุคคลที่สาม (third-party audits): ให้ผู้ตรวจสอบอิสระประเมินกระบวนการคัดเลือกข้อมูล ฝึกสอนโมเดล นโยบายการตอบสนองต่อการโจมตี และการปฏิบัติตามกฎหมาย เพื่อสร้างความโปร่งใสและความน่าเชื่อถือทางกฎหมาย
- การติดฉลากเนื้อหาที่เป็นโฆษณาหรือสปอนเซอร์: กำหนดแนวปฏิบัติชัดเจนสำหรับการแยกแยะผลลัพธ์เชิงพาณิชย์และผลลัพธ์เชิงอิสระ พร้อมเกณฑ์การตรวจสอบการจ่ายค่าตอบแทนให้แหล่งข้อมูล
- มาตรการป้องกันการโจมตีเชิงเทคนิค: ใช้การตรวจจับพฤติกรรมไม่ปกติ, rate-limiting, adversarial training และการจำกัดผลกระทบของคำสั่งที่อาจกระตุ้นให้ระบบสร้างคำตอบอันตราย
สรุปแล้ว การนำระบบ Scout มารวมเข้ากับบริการค้นหาต้องเดินคู่ไปกับกรอบกำกับดูแลที่ชัดเจนและมาตรการทางเทคนิคเพื่อคุมความเสี่ยง ทั้งในด้านกฎหมาย สิทธิเสรีภาพของผู้ใช้ และความน่าเชื่อถือของแบรนด์ สำหรับ Yahoo การผสมผสาน ความโปร่งใส, การมีมนุษย์ควบคุม ในจุดที่สำคัญ และ การตรวจสอบจากภายนอก จะเป็นแนวทางปฏิบัติที่จำเป็นเพื่อบรรเทาความเสี่ยงและสร้างความเชื่อมั่นระยะยาว
บทสรุป
การนำระบบตอบคำถามด้วย AI อย่าง Scout มาใช้เป็นโอกาสสำคัญสำหรับ Yahoo ในการฟื้นคืนความเกี่ยวข้องในตลาดการค้นหาออนไลน์ที่ปัจจุบันผู้นำอย่าง Google ยึดครองส่วนแบ่งมากกว่า 90% ของการค้นหาทั่วโลก การตัดสินความสำเร็จของโครงการนี้จะขึ้นอยู่กับสองปัจจัยหลักคือ คุณภาพของคำตอบ (ความถูกต้อง การอ้างอิงแหล่งที่มา อัตรา hallucination) และการออกแบบ โมเดลหารายได้ใหม่ ที่สอดคล้องกับประสบการณ์ผู้ใช้ เช่น โฆษณาเชิงบริบท, บริการสมัครสมาชิกรายเดือนสำหรับคำตอบระดับพรีเมียม หรือการให้สิทธิ์ใช้เทคโนโลยีแก่พันธมิตร ตัวอย่างเช่น Scout สามารถสรุปรีวิวหลายแหล่งบนหน้าเดียวเพื่อลดเวลาในการค้นหาและเพิ่มอัตราการมีส่วนร่วม (engagement) แต่หากคำตอบขาดความน่าเชื่อถือก็เสี่ยงต่อการสูญเสียผู้ใช้กลับไปยังคู่แข่ง
เพื่อให้การนำ Scout ไปใช้มีผลลัพธ์ในทางบวก Yahoo จำเป็นต้องบาลานซ์ความสะดวกของผู้ใช้กับความโปร่งใสและความน่าเชื่อถือ โดยต้องมีมาตรการวัดผลที่ชัดเจน ได้แก่ ตัวชี้วัดความแม่นยำ (accuracy), อัตรา hallucination, CTR, เวลาเซสชัน และคะแนนความพึงพอใจของผู้ใช้ นอกจากนี้ต้องมีระบบควบคุมความเสี่ยงทางกฎหมายและจริยธรรม เช่น การอ้างอิงแหล่งที่มาอย่างชัดเจน, ระดับความเชื่อมั่นของคำตอบ, มนุษย์ตรวจทานข้อความในกรณีสำคัญ และนโยบายตอบสนองต่อข้อกฎหมายหรือข้อพิพาทเกี่ยวกับเนื้อหา หากบริหารจัดการได้ดี Yahoo มีโอกาสฟื้นส่วนแบ่งตลาดและขยายรูปแบบรายได้ แต่หากละเลยคุณภาพ ความโปร่งใส หรือความเสี่ยงด้านกฎหมาย ผลลัพธ์อาจเป็นการสูญเสียความเชื่อถือของผู้ใช้และปัญหาทางกฎหมายในระยะยาว
📰 แหล่งอ้างอิง: WRAL



