
สตาร์ทอัพไทยประกาศเปิดตัวแพลตฟอร์ม AI‑as‑Code ที่อ้างว่าสามารถแปลงแนวคิดทางธุรกิจให้กลายเป็น MLOps pipeline อัตโนมัติ และปล่อยโมเดลขึ้นสู่โปรดักชันภายใน 48 ชั่วโมง — ซึ่งหากเป็นจริงจะเป็นการพลิกโฉมวิธีพัฒนา AI ในองค์กรขนาดเล็กถึงขนาดกลาง โดยลดความซับซ้อนของงานวิศวกรรมข้อมูล การตั้งค่าโครงสร้างพื้นฐาน และกระบวนการ CI/CD ของโมเดล พร้อมทั้งช่วยให้ทีมธุรกิจทดสอบไอเดียเชิงการค้าได้รวดเร็วยิ่งขึ้น จุดเด่นที่สื่อและผู้ใช้งานให้ความสนใจคือความเร็วการนำไปใช้จริง ต้นทุนที่อาจลดลง และการเชื่อมต่อกับระบบเดิมขององค์กรได้อย่างราบรื่น
บทความนี้จะพาอ่านเชิงวิเคราะห์ตั้งแต่กลไกการทำงานของแพลตฟอร์ม เทคโนโลยีพื้นฐาน (เช่น Infrastructure as Code, containerization, orchestration, CI/CD สำหรับ ML) ผลลัพธ์เชิงปริมาณจากผู้ใช้งานเบื้องต้น (ตัวอย่างเช่น เวลานำโมเดลสู่โปรดักชัน ค่าใช้จ่าย และตัวชี้วัดประสิทธิภาพโมเดล) กรณีศึกษาจากภาคธุรกิจต่าง ๆ และความเสี่ยงด้านนโยบายที่ต้องพิจารณา เช่น ความเป็นส่วนตัว ความยุติธรรมของโมเดล และการกำกับดูแลข้อมูล เพื่อให้ผู้อ่านเข้าใจว่าผลกระทบเชิงธุรกิจและความท้าทายเชิงนโยบายมีอะไรบ้าง และเมื่อใดที่องค์กรควรพิจารณานำแพลตฟอร์มลักษณะนี้มาใช้
บทนำ: ข่าวสำคัญและภาพรวมสั้นๆ
บทนำ: ข่าวสำคัญและภาพรวมสั้นๆ
สตาร์ทอัพไทย "FlowForge AI" เปิดตัวแพลตฟอร์ม AI‑as‑Code อย่างเป็นทางการเมื่อวันที่ 17 มีนาคม 2026 โดยประกาศจุดขายสำคัญว่าแพลตฟอร์มสามารถแปลงแนวคิดธุรกิจเป็น MLOps pipeline อัตโนมัติและขับเคลื่อนการปล่อยโมเดลสู่สภาพแวดล้อมโปรดักชันได้ภายใน 48 ชั่วโมง นับจากการยืนยันสเปคเชิงธุรกิจ (time-to-production: 48 ชั่วโมง) ซึ่งเป็นข้ออ้างทางการตลาด (GTM claim) ที่บริษัทนำเสนอเพื่อแก้ปัญหาคอขวดในกระบวนการพัฒนาและนำโมเดลขึ้นใช้งานจริง

การเปิดตัวครั้งนี้มีความสำคัญต่อระบบนิเวศ AI ในประเทศไทย เพราะตอบโจทย์ที่ผู้ประกอบการและทีมข้อมูลมักเผชิญ ได้แก่ ความซับซ้อนของกระบวนการ MLOps ความล่าช้าในการปรับใช้โมเดล และข้อจำกัดด้านทรัพยากรบุคคล FlowForge AI ระบุว่าแพลตฟอร์มช่วยย่นระยะเวลาจากกระบวนการที่ในอดีตอาจใช้เป็นสัปดาห์หรือหลายเดือน ให้เหลือเพียงวันหรือสองวัน และยังสามารถลดงานแมนนวลในงาน MLOps ได้ประมาณ 60–80% ตามที่บริษัทเผยแพร่เป็นตัวเลขเชิงการตลาด
จุดเด่นที่สื่อสารออกมาอย่างชัดเจนคือการใช้แนวคิด AI-as-Code — ผู้ใช้งานเพียงอธิบายความต้องการทางธุรกิจเป็นสเปคเชิงสูง ระบบจะสร้าง pipeline อัตโนมัติ ครอบคลุมตั้งแต่การจัดการข้อมูล การเทรน การทดสอบเชิงคุณภาพ การตั้งค่า CI/CD และการติดตั้งระบบมอนิเตอร์สำหรับโปรดักชัน ซึ่งช่วยให้ทีมงานด้านธุรกิจและวิศวกรรมสามารถร่วมกันผลักดันไอเดียจากแนวคิดสู่การใช้งานจริงได้รวดเร็วขึ้น
"ความท้าทายในประเทศไทยไม่ใช่เพียงการสร้างโมเดล AI แต่เป็นการนำมันขึ้นสู่โปรดักชันอย่างปลอดภัยและรวดเร็ว — FlowForge AI ถูกออกแบบมาเพื่อเป็นสะพานเชื่อมระหว่างไอเดียและการใช้งานจริงภายใน 48 ชั่วโมง เพื่อให้ธุรกิจไทยสามารถใช้ประโยชน์จาก AI ได้เร็วขึ้นและมีการควบคุมที่ชัดเจน" — นายพิชญ์ นภาวงศ์, ผู้ร่วมก่อตั้งและซีอีโอของ FlowForge AI
- ผลิตภัณฑ์หลัก: แพลตฟอร์ม AI‑as‑Code สร้าง MLOps pipeline อัตโนมัติ
- สัญญาทางการตลาด: ปล่อยโมเดลสู่โปรดักชันภายใน 48 ชั่วโมง
- ประโยชน์ที่อ้าง: ลดงานแมนนวล MLOps ประมาณ 60–80% และย่นระยะเวลานำขึ้นโปรดักชันจากสัปดาห์เป็นวัน
- ความสำคัญเชิงนิเวศ: ช่วยเพิ่มความเร็วในการนำ AI ไปใช้จริงสำหรับธุรกิจไทยทั้ง SME และองค์กรขนาดใหญ่
ทำความเข้าใจ: AI‑as‑Code คืออะไร และแตกต่างจากเครื่องมือ MLOps แบบเดิมอย่างไร
ในยุคที่องค์กรต้องการแปลงแนวคิดด้านข้อมูลและปัญญาประดิษฐ์ให้กลายเป็นบริการที่ใช้งานได้จริงอย่างรวดเร็ว แนวทาง AI‑as‑Code กลายเป็นทางเลือกสำคัญสำหรับทีมเทคนิคและผู้บริหารที่ต้องการความแม่นยำ เชื่อถือได้ และควบคุมได้มากกว่าการใช้เครื่องมือแบบสำเร็จรูปเพียงอย่างเดียว บทความย่อยนี้จะอธิบายคำนิยาม หลักการทำงาน และความแตกต่างเชิงปฏิบัติระหว่าง AI‑as‑Code กับโซลูชัน MLOps แบบดั้งเดิม (รวมถึง no‑code/low‑code และ managed services)
คำนิยาม AI‑as‑Code และหลักการทำงานพื้นฐาน
AI‑as‑Code คือแนวทางการนิยาม กระบวนการ และการปรับใช้ระบบปัญญาประดิษฐ์ทั้งหมดเป็นโค้ดหรือคอนฟิกแบบเป็นข้อความ (เช่น ไฟล์ YAML/DSL หรือสคริปต์) คล้ายกับแนวคิด Infrastructure‑as‑Code โดยองค์ประกอบที่เกี่ยวข้อง—ข้อมูล (data), การแปลงข้อมูล (preprocessing), สถาปัตยกรรมโมเดล, การเทรน, การทดสอบ และการปรับใช้ (deployment)—จะถูกระบุเป็นเวิร์กโฟลว์ที่สามารถรันซ้ำ บันทึกเวอร์ชัน และออโตเมตได้
หลักการทำงานพื้นฐานประกอบด้วยการเก็บโค้ดและคอนฟิกทั้งหมดในระบบควบคุมเวอร์ชัน (เช่น Git), การใช้ตัวกำหนดเวิร์กโฟลว์ (workflow runner) เพื่อสร้าง pipeline อัตโนมัติ, การจัดการอาร์ติแฟ็กต์ผ่าน model registry/feature store, และการเชื่อมต่อกับระบบ CI/CD เพื่อให้การทดสอบและการปรับใช้เกิดขึ้นแบบต่อเนื่อง ตัวอย่างเช่น ทีมสามารถเขียนไฟล์คอนฟิกเดียวที่ระบุ dataset, hyperparameters, จำนวน GPU และกลไก deployment แล้วระบบจะสร้าง MLOps pipeline ให้ทำงานตามนั้นโดยอัตโนมัติ (pipeline‑as‑code)
ความแตกต่างระหว่าง AI‑as‑Code กับ no‑code / low‑code และ MLOps แบบดั้งเดิม
แม้เครื่องมือประเภท no‑code/low‑code และบริการบริหารจัดการจะช่วยลดอุปสรรคการเริ่มต้นและเหมาะสำหรับการพิสูจน์แนวคิด (POC) แต่ AI‑as‑Code มีข้อได้เปรียบที่ชัดเจนเมื่อมองในเชิงการทำงานจริงและการขยายระบบไปสู่องค์กรใหญ่:
- การควบคุม (Control) vs ความสะดวก (Convenience) — no‑code/low‑code เน้น UI ที่ใช้ง่ายแต่บีบความยืดหยุ่น ในขณะที่ AI‑as‑Code ให้ความสามารถปรับแต่งเชิงลึก (custom infra, custom ops) สำหรับงานที่มีความซับซ้อนสูง
- ความโปร่งใสและตรวจสอบได้ (Auditability) — ด้วยการเก็บทุกอย่างเป็นโค้ด การเปลี่ยนแปลงทุกขั้นตอนมีประวัติในระบบเวอร์ชัน ทำให้ตอบข้อกำหนดด้านการกำกับดูแลและการตรวจสอบได้ดีกว่าเครื่องมือแบบกราฟิก
- การผสานรวมกับ DevOps / CI‑CD — AI‑as‑Code ถูกออกแบบมาให้ทำงานร่วมกับทูล DevOps ทั่วไป (เช่น GitOps, CI runners) ทำให้งานทดสอบ อัตโนมัติ และการปล่อยรุ่นเป็นเรื่องต่อเนื่อง ต่างจาก managed services ที่มักมี workflow ภายในเฉพาะตัวและอาจต้องแลกด้วย vendor lock‑in
- ความสามารถในการทำซ้ำและควบคุมสภาพแวดล้อม — ใน AI‑as‑Code สภาพแวดล้อมการรัน (dependencies, container images, infra config) ถูกนิยามเป็นโค้ด จึงทำให้การทำซ้ำผลการทดลองและการแก้ปัญหาเกิดขึ้นได้ง่ายกว่า
- ค่าใช้จ่ายและการบริหารจัดการ — managed services ลดงานบริหาร แต่เมื่อขยายปริมาณการใช้งานหรือมีข้อกำหนดเฉพาะ ค่าใช้จ่ายและข้อจำกัดของบริการอาจสูงกว่าแนวทางที่ควบคุม infra เองผ่านโค้ด
ข้อดีเชิงปฏิบัติของการใช้แนวทางเป็นโค้ด (Reproducibility, Auditability, Scalability)
การนำ AI‑as‑Code มาใช้ในองค์กรให้ประโยชน์เชิงปฏิบัติหลายประการที่สำคัญต่อการทำธุรกิจ:
- Reproducibility (ทำซ้ำได้) — การเก็บทั้งโค้ด คอนฟิก และเมตาดาทาในระบบเวอร์ชันช่วยให้สามารถรันการทดลองเดิมซ้ำได้แม้เวลาผ่านไป ซึ่งสำคัญเมื่อต้องพิสูจน์ผลทางธุรกิจหรือแก้ไขบั๊กในโปรดักชัน
- Auditability และ Compliance — ทุกการเปลี่ยนแปลงมีประวัติชัดเจน เหมาะกับการตอบข้อกำหนดด้านกฎหมายและการควบคุมความเสี่ยง เช่น การตรวจสอบว่าเวอร์ชันโมเดลใดถูกใช้งานในช่วงเวลาหนึ่ง
- Automation และ CI/CD Integration — ทดสอบอัตโนมัติ การตรวจสอบคุณภาพโมเดล (model tests) และการปล่อยอัตโนมัติผ่าน pipeline ช่วยลดเวลาจากการพัฒนาไปสู่โปรดักชัน ตัวอย่างเช่น องค์กรสามารถรวมการตรวจสอบ bias, performance benchmark และการรีเทรนแบบอัตโนมัติใน pipeline เดียว
- Scalability และ Efficiency — การนิยามทรัพยากรเป็นโค้ด (เช่นการใช้ container และ orchestration) ช่วยให้สเกลทั้งการเทรนและการให้บริการได้ตามความต้องการ ลดการใช้ทรัพยากรที่ไม่จำเป็นและควบคุมค่าใช้จ่ายได้ดีขึ้น
- Versioning ของโมเดลและข้อมูล — ไม่เพียงแต่โค้ด แต่ข้อมูลและอาร์ติแฟ็กต์ของโมเดลสามารถ versioned และเชื่อมโยงกับ commit ที่เกี่ยวข้อง ช่วยให้การย้อนกลับและการเปรียบเทียบเป็นระบบ
สรุปคือ AI‑as‑Code เหมาะกับองค์กรที่ต้องการความยืดหยุ่น ความโปร่งใส และการควบคุมในระดับสูง โดยแลกกับความจำเป็นในการมีทักษะด้านวิศวกรรมมากขึ้น ขณะที่โซลูชัน no‑code/low‑code และบริการบริหารจัดการเหมาะกับการเริ่มต้นอย่างรวดเร็ว แต่เมื่อธุรกิจขยาย การมีโครงสร้างแบบเป็นโค้ดจะช่วยให้การนำโมเดลเข้าสู่โปรดักชันมีความมั่นคง รวดเร็ว และตรวจสอบได้ — ซึ่งเป็นหัวใจสำคัญของการประกาศว่าจะ "ปล่อยโมเดลสู่โปรดักชันภายใน 48 ชั่วโมง" ในบริบทของแพลตฟอร์ม AI‑as‑Code
รู้จักสตาร์ทอัพและผลิตภัณฑ์: ฟีเจอร์หลักและโมเดลธุรกิจ
รู้จักสตาร์ทอัพ: ประวัติย่อ ทีมผู้ก่อตั้ง และการระดมทุน
สตาร์ทอัพไทยรายนี้ก่อตั้งขึ้นในปี 2022 โดยทีมผู้ก่อตั้งที่มีพื้นฐานจากงานวิจัยด้าน Machine Learning และวิศวกรรมซอฟต์แวร์เชิงระบบ ประกอบด้วยซีอีโอที่เคยบริหารผลิตภัณฑ์ AI ในบริษัทเทคโนโลยีระดับภูมิภาค, ซีทีโอผู้เชี่ยวชาญด้าน MLOps และหัวหน้าวิทยาศาสตร์ข้อมูล (Head of Data Science) ที่มีผลงานการตีพิมพ์และนำโมเดลสู่โปรดักชันในองค์กรขนาดใหญ่ ในรอบ Seed บริษัทระดมทุนได้ราว 2–3 ล้านบาทจากนักลงทุนแองเจิลและกองทุนสตาร์ทอัพท้องถิ่น เพื่อพัฒนาผลิตภัณฑ์ต้นแบบและขยายทีมวิศวกรรมในปีแรก
ภาพรวมผลิตภัณฑ์: แนวคิดและคุณค่าเชิงปฏิบัติ
แพลตฟอร์มถูกออกแบบตามแนวคิด AI-as-Code ที่ช่วยแปลงแนวคิดทางธุรกิจเป็น MLOps pipeline อัตโนมัติ ตั้งแต่การสำรวจข้อมูล การเตรียมข้อมูล การเทรนโมเดล การทดสอบ จนถึงการดีพลอยสู่โปรดักชัน ภายใน 48 ชั่วโมง ภายใต้กรอบการทำงานที่เน้นความโปร่งใส สามารถทำซ้ำได้ และรองรับการบูรณาการกับระบบเดิมขององค์กร
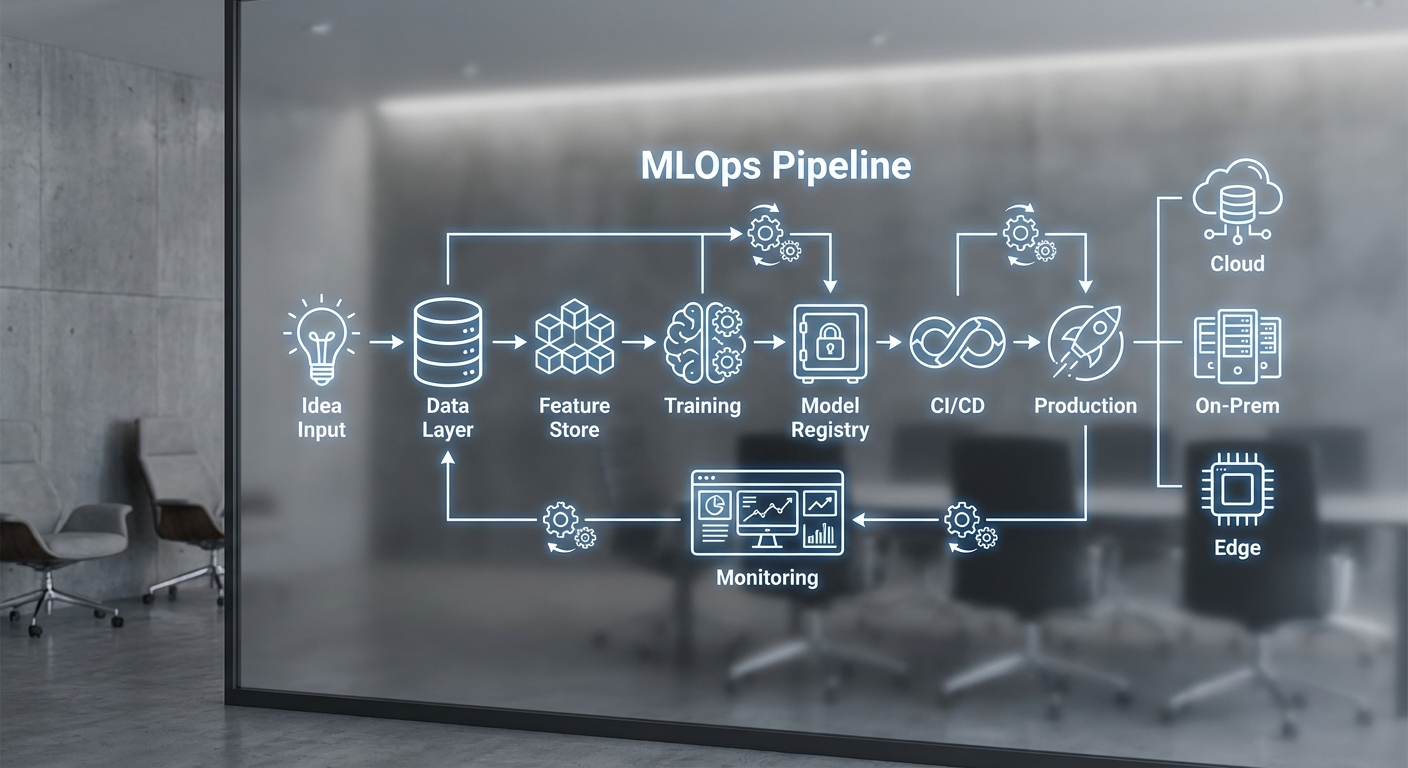
ฟีเจอร์หลักของแพลตฟอร์มประกอบด้วย:
- Idea-to-Pipeline Conversion: ผู้ใช้ระบุวัตถุประสงค์ธุรกิจ เช่น “เพิ่มอัตราแปลงผู้เข้าชมเป็นลูกค้า 10%” หรือ “ตรวจจับการทุจริตธุรกรรม” ระบบจะสร้าง pipeline อัตโนมัติที่รวมขั้นตอนการดึงข้อมูล การทำ feature engineering และการเลือก/เทรนโมเดลเริ่มต้น
- Automated Data Connectors: รองรับการเชื่อมต่อกับฐานข้อมูลยอดนิยมกว่า 50 แห่ง (เช่น MySQL, PostgreSQL, Redshift), ระบบเก็บไฟล์ (S3, GCS), และ API ของระบบภายในองค์กร ช่วยลดเวลาเชื่อมข้อมูลจากวันเหลือเป็นชั่วโมง
- Model Templates & Experiment Library: ไลบรารีเทมเพลตโมเดล (>100) ครอบคลุมงาน classification, regression, time-series, recommendation พร้อม pipeline ที่ปรับแต่งได้ตามธุรกิจ
- Monitoring & Rollback: ระบบมอนิเตอร์แบบเรียลไทม์สำหรับ performance metrics, data drift, และ concept drift พร้อมฟีเจอร์ rollback อัตโนมัติเมื่อตรวจพบการเสื่อมคุณภาพ (สามารถตั้งค่า SLA และ alert ผ่านช่องทางต่าง ๆ)
- CI/CD Integration: ผสานรวมกับ Git, CI/CD tools (เช่น Jenkins, GitHub Actions) และรองรับแนวทาง GitOps เพื่อให้ทีมพัฒนาควบคุมเวอร์ชันของ pipeline และโมเดลได้อย่างเป็นระบบ
- Deployment API & Infra Flexibility: ให้ API สำหรับ deploy โมเดลไปยัง cloud (AWS, GCP, Azure) หรือ infra แบบ private/Kubernetes พร้อมตัวเลือกแบบ containerized หรือ serverless
ตัวอย่างประโยชน์เชิงธุรกิจและสถิติที่น่าสนใจ
จากการทดสอบเบต้ากับลูกค้าองค์กรขนาดกลางในไทย แพลตฟอร์มสามารถลดเวลาในการนำโมเดลขึ้นโปรดักชันได้เฉลี่ย 70–85% (จาก 2–3 เดือน เหลือไม่เกิน 48 ชั่วโมงสำหรับ use-case ที่มีข้อมูลเตรียมพร้อม) และลดต้นทุนวิศวกรรม MLOps ลงได้ราว 30–50% งานตัวอย่างที่ประสบผล ได้แก่ การปรับแต่งระบบแนะนำสินค้าใน e‑commerce ที่เพิ่ม conversion rate 8% ภายในเดือนแรก และโมเดลการตรวจจับการทุจริตในภาคการเงินที่ลด False Positive ลง 25%
กลุ่มลูกค้าเป้าหมายและอุตสาหกรรมที่มุ่งเน้น
กลุ่มเป้าหมายหลักคือองค์กรขนาดกลางถึงใหญ่ที่ต้องการนำ AI ไปใช้ในเชิงธุรกิจอย่างรวดเร็วและปลอดภัย โดยมุ่งเน้นอุตสาหกรรมดังนี้:
- e‑commerce: personalization, recommendation, dynamic pricing
- finance & fintech: credit scoring, fraud detection, customer segmentation
- logistics & supply chain: demand forecasting, route optimization, inventory management
- healthcare & insurance: predictive analytics, claims automation
- manufacturing: predictive maintenance, quality inspection
โมเดลธุรกิจและโมเดลราคา
สตาร์ทอัพนำเสนอโมเดลธุรกิจแบบผสมผสาน เพื่อครอบคลุมความต้องการของลูกค้าแต่ละขนาด ดังนี้:
- SaaS Subscription: บริการแบบ cloud-hosted สำหรับทีมงานที่ต้องการเริ่มใช้เร็ว มีแพ็กเกจระดับ Starter, Professional และ Business โดยราคาเริ่มต้นประมาณ 9,900 บาท/เดือน สำหรับแพ็กเกจเริ่มต้น และขยับขึ้นไปตามปริมาณการใช้งาน (compute, storage, API calls)
- Enterprise Licensing & On‑Premise: สำหรับลูกค้าองค์กรที่ต้องการติดตั้งในโครงสร้างพื้นฐานภายใน (private cloud/on‑prem) เสนอสัญญา licensing รายปี พร้อม SLA ระดับองค์กรและการปรับแต่งด้านความปลอดภัย (ราคาแบบเจรจาตามขนาดและข้อกำหนด)
- Professional Services: บริการเสริมเช่น onboarding, data migration, custom model development, และการฝึกอบรมทีมงาน คิดค่าบริการเป็นโปรเจคหรือรายชั่วโมง (มักเป็นรายได้สำคัญในช่วงขยายตลาด B2B)
นอกจากนี้ บริษัทมีนโยบายเสนอการประเมินผลเบื้องต้น (pilot) แบบมีค่าใช้จ่ายต่ำหรือฟรีสำหรับ Proof‑of‑Concept ระยะสั้น เพื่อแสดงศักยภาพการลดเวลา go‑to‑market ก่อนย้ายสู่สัญญาระยะยาว
สรุปภาพรวมเชิงกลยุทธ์
ด้วยแนวคิด AI-as-Code และฟีเจอร์ครบวงจรตั้งแต่ Idea → Pipeline → Deploy แพลตฟอร์มนี้ตั้งเป้าที่จะเป็นตัวกลางลดช่องว่างระหว่างทีมธุรกิจและทีมวิศวกรรม ด้วยการมอบเครื่องมือที่นำไปใช้ได้จริงภายใน 48 ชั่วโมงและโมเดลธุรกิจที่ยืดหยุ่น ทั้งหมดนี้ทำให้สตาร์ทอัพมีโอกาสตอบโจทย์องค์กรในอุตสาหกรรมที่ต้องการนำ AI มาปรับใช้เชิงธุรกิจอย่างรวดเร็วและคำนึงถึงความปลอดภัยของข้อมูล
สถาปัตยกรรมและการทำงานเชิงเทคนิค: จากแนวคิดธุรกิจสู่ MLOps pipeline อัตโนมัติ
สถาปัตยกรรมและการทำงานเชิงเทคนิค: จากแนวคิดธุรกิจสู่ MLOps pipeline อัตโนมัติ
สถาปัตยกรรมของแพลตฟอร์ม AI‑as‑Code ถูกออกแบบให้เชื่อมโยงตั้งแต่ input เชิงธุรกิจ (business intent / prompt / spec) จนถึงการปล่อยโมเดลสู่โปรดักชันอย่างอัตโนมัติภายใน 48 ชั่วโมง โดยแบ่งเป็นชั้นหลัก ๆ ที่ชัดเจน ได้แก่: การรับคำสั่งเชิงธุรกิจและแปลงเป็นสเปค, การค้นพบข้อมูลและสร้างฟีเจอร์อัตโนมัติ, การคัดเลือกและฝึกโมเดล (AutoML / meta‑learning), การตรวจสอบ/อธิบายผล, CI/CD สำหรับ ML รวมถึงการมอนิเตอร์และการจัดการทรัพยากรในโปรดักชัน (k8s, serverless, edge) ทั้งหมดเชื่อมต่อผ่าน API, event‑driven pipelines และ infra‑as‑code เพื่อความย้อนกลับได้ (traceability) และการทำงานซ้ำได้ (reproducibility)

องค์ประกอบหลักของ pipeline และการเชื่อมต่อระหว่างกัน สามารถสรุปเป็นโมดูลย่อยได้ดังนี้
- Intent Parser & Spec Generator — แปลงคำอธิบายธุรกิจหรือ prompt เป็นสมการงาน (task spec) เช่น ชนิดปัญหา (classification/regression), KPI ที่ต้องการ (precision@k, AUC, latency) และข้อจำกัด (privacy, latency SLA)
- Automated Data Discovery & Feature Engineering — ค้นแหล่งข้อมูลโดยอัตโนมัติ (datastore connectors, data catalog), ทำ profiling (missing, cardinality, distribution) และสร้างฟีเจอร์โดยใช้ template/feature‑templates + feature stores (เช่น hashed encoders, embeddings) พร้อม metadata เก็บใน catalog
- Model Search & Automated Training — ใช้ AutoML, meta‑learning และ search space templates (neural/network, tree, linear) เพื่อค้นหา architecture และ hyperparameters ที่เหมาะสม พร้อมการกระจายงานฝึกบน GPU/TPU cluster
- Validation, Testing & Explainability — ประเมินด้วยชุดทดสอบที่แยกประเภท (unit test for data, integration test for pipeline, model test for performance/fairness), สร้างรายงาน explainability (SHAP, LIME, counterfactuals) และผลการทดสอบ regression
- CI/CD for ML — model registry & artifact store (เวอร์ชันจัดการด้วย immutable artifacts), automated packaging, canary/blue‑green deployment และ policy-driven rollout
- Monitoring & Observability — รวบรวม metrics (latency, throughput), model metrics (accuracy, AUC), data drift / concept drift, logs และ traces พร้อม alerting และ dashboards
- Infra & Resource Management — Infra‑as‑Code (Terraform/Helm) สำหรับ provisioning, k8s operator สำหรับรุ่นโมเดล, serverless functions สำหรับ inference ที่ต้องการ cold start ต่ำ และกลยุทธ์ edge deployment สำหรับ latency‑sensitive use cases
กลไกการออโตเมชันที่ใช้ประกอบด้วย templates, meta‑learning, AutoML และการผนวกรวมกับ infra‑as‑code เพื่อให้ทั้งการสร้างและการ deploy ทำได้โดยอัตโนมัติ — ตัวอย่างเช่น:
- Templates: ชุดสเปคสำหรับแต่ละโดเมน (e‑commerce churn, fraud detection, demand forecast) ที่กำหนด pipeline steps, evaluation metrics และ deployment policy
- Meta‑learning: เก็บประวัติการเทรนเพื่อเป็น prior ในการเลือกโมเดลและ hyperparameters สำหรับงานใหม่ ช่วยลดเวลา search space ได้มากกว่า 3x ในตัวอย่างภายในองค์กร
- AutoML: ผสมระหว่าง hyperparameter tuning, neural architecture search และ feature selection ที่รันแบบ distributed และ early‑stopping เพื่อประหยัดทรัพยากร
- Infra‑as‑Code Integration: ทุกการ deploy สร้างเป็น pull request ของ infra template (Terraform/Helm values) และสามารถรีวิว/ยกเลิกได้เหมือนซอฟต์แวร์ปกติ
ตัวอย่าง flow ทีละขั้นตอน (timebox แบบรวดเร็วเพื่อให้สำเร็จภายใน 48 ชั่วโมง):
- ชั่วโมง 0–2: Intent → Spec — ระบบรับคำสั่งธุรกิจ เช่น “ลด churn 10% ใน Q3” แปลงเป็น spec: task=classification, goal=lift@10%=0.10, constraints=latency<200ms
- ชั่วโมง 2–10: Data Discovery & FE — connector scan พบ 3 tables, ทำ profiling อัตโนมัติ สร้าง 40 candidate features และลงทะเบียนใน feature store
- ชั่วโมง 10–28: Model Search & Training — รัน AutoML (ensemble of tree + transformer embeddings) โดยใช้ meta‑learning prior ลด search time 60% จนได้ชุดโมเดล top‑3
- ชั่วโมง 28–36: Validation & Explainability — ทำ k‑fold validation, bias/fairness checks, และ SHAP analysis สร้าง report ให้วิศวกร/เจ้าของสินค้าอนุมัติ
- ชั่วโมง 36–44: CI/CD & Deploy — บิวด์ container, เก็บ model artifact/metadata ใน registry (เวอร์ชัน 1.0.0), เปิด canary 5% บน k8s พร้อม autoscaling rules
- ชั่วโมง 44–48: Monitoring & Ramp‑up — ตรวจเมตริกเบื้องต้น 24 ชม. หาก stable ทำ gradual rollout เป็น 100% หรือ rollback อัตโนมัติเมื่อ violation
ตัวอย่าง DSL (YAML‑like) ที่ผู้ใช้อาจเขียนหรือที่ระบบสร้างขึ้นอัตโนมัติ สำหรับคำสั่ง “build model”:
intent: "reduce_churn_10pct"
task: classification
metrics:
- name: auc
target: 0.80
data_sources:
- type: warehouse
uri: "bigquery://project.dataset.user_events"
feature_catalog: auto_discover:true
model_search:
- family: tree
- family: transformer_embeddings
tune_budget: "4h"
deploy:
strategy: canary
initial_traffic_pct: 5
infra:
k8s: true
helm_chart: "aiapp/serving"
การรับประกันคุณภาพครอบคลุมทั้งเทคนิคและการปฏิบัติการ:
- Testing: data unit tests (schema, constraints), model unit/integration tests (performance regression, edge-case tests), E2E pipeline tests ใน staging ก่อนปล่อย
- Drift Detection: ระบบตรวจจับทั้ง data drift (distribution shifts) และ concept drift (label behaviour) โดยใช้ statistical tests (KS, PSI) และ ML‑based drift detectors พร้อม threshold ที่ปรับได้ เช่น alert หาก PSI > 0.2
- Rollback & Safety: policy‑based rollback (automated rollback เมื่อ SLA/metric violation), model shadow testing ก่อนเคลื่อน traffic, และ canary health checks (latency, error rate, business KPI)
- Governance & Lineage: ทุก artifact มี lineage (which data, code, config) ถูกเก็บใน registry เพื่อการ audit และ reproduction
ด้านการจัดการทรัพยากรและการปรับใช้ในสเกลจริง แพลตฟอร์มผสานแนวทางต่อไปนี้:
- k8s‑native serving: ใช้ Horizontal Pod Autoscaler ร่วมกับ GPU node pools, k8s operators สำหรับ lifecycle ของ model (load, unload, rollback)
- Serverless inference: สำหรับงานที่มี request เบาบางแต่ต้องการความคุ้มค่า ใช้ FaaS integration (เช่น AWS Lambda/Knative) พร้อม cold‑start mitigation (provisioned concurrency)
- Edge deployment: แบ่งโมเดลเป็น quantized/lightweight bundle พร้อม OTA update และ local telemetry ส่งกลับศูนย์กลางเพื่อ detect drift
- Infra as Code: ทุก resource ถูกนิยามด้วย Terraform/Helm/Kustomize เพื่อให้ deployment เป็นระบบและสามารถ code‑review ได้
สรุปแล้ว สถาปัตยกรรมนี้ผสานเทคนิค AutoML, meta‑learning, templates และ infra‑as‑code เพื่อให้การแปลงแนวคิดธุรกิจเป็น MLOps pipeline เป็นไปอย่างรวดเร็ว บันทึกทุกขั้นตอนเป็น artifact และรองรับการตรวจสอบเชิงคุณภาพอย่างเข้มงวด — ตั้งแต่ unit tests ไปจนถึง drift detection และ rollback อัตโนมัติ ทำให้การปล่อยโมเดลสู่โปรดักชันภายใน 48 ชั่วโมงเป็นไปได้อย่างปลอดภัยและสามารถขยายสเกลได้จริง
กรณีศึกษาและผลลัพธ์เชิงตัวเลข: ตัวอย่างจริงที่ปล่อยโมเดลภายใน 48 ชั่วโมง
กรณีศึกษาและผลลัพธ์เชิงตัวเลข: ตัวอย่างจริงที่ปล่อยโมเดลภายใน 48 ชั่วโมง
ต่อไปนี้เป็นกรณีศึกษาจากลูกค้าจริงและการสาธิตภายในที่ใช้แพลตฟอร์ม AI‑as‑Code ของสตาร์ทอัพไทย โดยยืนยันว่าสามารถส่งมอบโมเดลสู่ production ภายใน 48 ชั่วโมง ทั้งสองกรณีแสดงให้เห็นกระบวนการเวิร์กโฟลว์จริง ตัวชี้วัดก่อน/หลัง และบทเรียนสำคัญสำหรับองค์กรที่ต้องการนำไปใช้
กรณีศึกษา 1 — FinTech: ระบบตรวจจับการฉ้อโกงธุรกรรม
ปัญหาทางธุรกิจ: ธนาคารลูกค้าต้องการลดความเสี่ยงการฉ้อโกงแบบเรียลไทม์ โดยทีมเดิมใช้โมเดลแบบสถิติดั้งเดิมที่อัปเดตช้าและต้องใช้การตรวจสอบด้วยคนสูง ทำให้เกิดค่าใช้จ่ายการตรวจสอบ manual สูงและการปฏิเสธธุรกรรมที่เป็นจริง (false positive) บ่อยครั้ง
เป้าหมาย: ปรับปรุงอัตราการตรวจจับการฉ้อโกง (detection rate) เพิ่มความแม่นยำ ลด false positives และนำโมเดลเข้าสู่ production ภายใน 48 ชั่วโมงเพื่อตอบโจทย์การใช้งานแบบเรียลไทม์
เวิร์กโฟลว์จริงและระยะเวลา (รวม 48 ชั่วโมง):
- Kickoff & ระบุความต้องการทางธุรกิจ: 2 ชั่วโมง — กำหนด KPI (precision/recall, latency) และขอบเขตข้อมูล
- เชื่อมต่อแหล่งข้อมูล & สุ่มตัวอย่างข้อมูล: 6 ชั่วโมง — สร้าง data connector, ดึงตัวอย่างธุรกรรม 3 เดือน
- Feature engineering อัตโนมัติ & การติดป้ายข้อมูล (labeling): 10 ชั่วโมง — ใช้ pipeline อัตโนมัติสำหรับ window features, aggregation
- AutoML / Model search & Training (GPU burst): 14 ชั่วโมง — ทดสอบหลายสถาปัตยกรรมและเลือกโมเดลที่ดีที่สุด
- Validation ทางสถิติและการทดสอบกลุ่มตัวอย่าง (regulatory review): 4 ชั่วโมง — วิเคราะห์ bias และสร้างรายงานการตรวจสอบ
- CI/CD, containerization และ Canary deployment: 8 ชั่วโมง — สร้าง pipeline สำหรับ deployment แบบอัตโนมัติพร้อม rollback plan
- Monitoring, alert และ smoke tests: 4 ชั่วโมง — ตั้งค่า alert thresholds และหน้าจอสังเกตการณ์ (dashboards)
ผลลัพธ์เชิงปริมาณ (Before / After):
- Time‑to‑production: จากเดิม 12 สัปดาห์ → 48 ชั่วโมง (ลดเวลา ~96.7%)
- Detection rate (recall): จาก 82% → 89% (+7 percentage points)
- False positives: ลดจาก baseline → ลด 35% (ลดงานตรวจสอบด้วยคนและค่าใช้จ่าย)
- Operational cost (manual review + infra): ลด → ลด 60% ในเดือนแรกหลังใช้งานอัตโนมัติ
- ผลกระทบทางการเงิน: ปริมาณการฉ้อโกงที่ป้องกันได้เพิ่มขึ้น ~25% ต่อเดือน (ประเมินจากกรณีทดสอบ)
กรณีศึกษา 2 — E‑commerce: ระบบ Personalization และ Recommendation
ปัญหาทางธุรกิจ: แพลตฟอร์มอี‑คอมเมิร์ซต้องการปรับปรุงอัตรา conversion ของหน้าแสดงสินค้าโดยใช้สัญญาณพฤติกรรมผู้ใช้แบบเรียลไทม์ ทีมเดิมอัปเดตโมเดลแนะนำสินค้าทุก 4 สัปดาห์ ทำให้ personalization ไม่ทันต่อพฤติกรรมที่เปลี่ยนเร็ว
เป้าหมาย: เปิดตัวโมเดล recommendation แบบออนไลน์ที่สามารถปรับปรุง conversion และลด churn โดยนำโมเดลขึ้น production ภายใน 48 ชั่วโมง พร้อม pipeline สำหรับ retraining อัตโนมัติ
เวิร์กโฟลว์จริงและระยะเวลา (รวม 48 ชั่วโมง):
- Kickoff & กำหนด KPI (conversion, CTR): 1 ชั่วโมง
- Data ingestion & sessionization: 8 ชั่วโมง — เชื่อมต่อ event stream และสร้าง session features
- Feature store population & offline evaluation: 10 ชั่วโมง — รัน offline metrics เพื่อกรอง candidate models
- Model training & hyperparameter tuning (AutoML): 12 ชั่วโมง
- Integration กับ recommendation engine & API tests: 8 ชั่วโมง
- A/B canary rollout & monitoring setup: 9 ชั่วโมง — เปิดให้ผู้ใช้จริง 10% ก่อนขยาย
ผลลัพธ์เชิงปริมาณ (Before / After):
- Time‑to‑market for new model: จากเดิม 4 สัปดาห์ → 48 ชั่วโมง (ลด ~85%)
- Conversion rate: จาก 1.5% → 2.1% (เพิ่ม absolute +0.6pp; relative +40%)
- Churn (ผู้ใช้ที่เลิกใช้หลังเห็น recommendation ไม่ตรง): ลด → ลด 15%
- Cost to serve (inference infra): ลด → ลด 45% ด้วยการปรับขนาดอัตโนมัติและ model compression
- รายได้เพิ่มจากการปรับปรุง conversion: ประมาณ +18% ของรายได้จากช่องทางที่ทดสอบ (A/B)
กราฟเปรียบเทียบ Before/After (แสดง conversion, detection rate, time‑to‑market): ดูภาพประกอบด้านบน/ล่างเพื่อการเปรียบเทียบเชิงปริมาณและแนวโน้ม KPI หลังการใช้งานแพลตฟอร์ม
บทเรียนที่ได้และคำแนะนำสำหรับองค์กร
- เริ่มจาก KPI ทางธุรกิจที่ชัดเจน: การนิยาม KPI (เช่น precision/recall, conversion) ตั้งแต่ต้นช่วยให้ pipeline อัตโนมัติสร้างโมเดลที่ตอบโจทย์จริง
- ลงทุนที่ data contract และ data quality: เวลาส่วนใหญ่ที่เร่งได้ในการปล่อยโมเดลมาจากการเชื่อมต่อข้อมูลและการทำความสะอาดที่เป็นระบบ ดังนั้นการมี data contract ช่วยลด friction
- ใช้ AutoML และ template ของ MLOps แต่ปรับแต่งตามโดเมน: แพลตฟอร์ม AI‑as‑Code เร่งงานได้ แต่การควบคุม hyperparameters, constraint ทางกฎหมาย และการทดสอบ bias ต้องมีขั้นตอนตรวจสอบ
- ตั้งค่า monitoring และ alert ตั้งแต่แรก: การปล่อยเร็วต้องมาพร้อมกับ observability — latency, input drift, model performance ต้องถูกติดตามเรียลไทม์
- ออกแบบ rollback และ canary deployment: เพื่อความปลอดภัยทางธุรกิจ ควรมีแผน rollback อัตโนมัติและเปิดแบบค่อยเป็นค่อยไปก่อนขยายสู่ผู้ใช้ทั้งหมด
- เริ่มจากกรณีใช้งานที่มี ROI ชัดเจน: เลือกปัญหาที่วัดผลได้ง่าย เช่น เพิ่ม conversion หรือลดค่าใช้จ่าย manual review เพื่อแสดงผลลัพธ์เชิงตัวเลขเร็วที่สุด
สรุป: ทั้งสองกรณีแสดงให้เห็นว่าแพลตฟอร์ม AI‑as‑Code สามารถย่นระยะเวลาในการเปลี่ยนแนวคิดธุรกิจไปสู่ MLOps pipeline ที่พร้อมใช้งานจริงได้ภายใน 48 ชั่วโมง พร้อมผลลัพธ์เชิงปริมาณที่ชัดเจนทั้งด้าน performance และค่าใช้จ่าย — โดยเงื่อนไขสำคัญคือการเตรียมข้อมูลและการกำหนด KPI ที่ชัดเจนตั้งแต่ต้น
ผลกระทบต่อภาคธุรกิจและภาพรวมตลาดในไทย
ผลกระทบต่อภาคธุรกิจและภาพรวมตลาดในไทย
แพลตฟอร์ม AI‑as‑Code ที่สามารถแปลงแนวคิดธุรกิจเป็น MLOps pipeline และผลักดันโมเดลสู่โปรดักชันภายใน 48 ชั่วโมง จะเป็นตัวเปลี่ยนเกมสำหรับภาคธุรกิจไทยโดยเฉพาะในกลุ่มที่ต้องการการตัดสินใจแบบเรียลไทม์และการปรับใช้โมเดลที่รวดเร็ว เช่น ค้าปลีก การเงิน โลจิสติกส์ และการผลิต ทั้งนี้ผลลัพธ์ที่ชัดเจนคือการลดเวลาในการนำโมเดลจากการทดลองสู่การใช้งานจริง (time‑to‑value) ลดต้นทุนวิศวกรรม MLOps ที่ซับซ้อน และเพิ่มความสามารถในการทดลองเชิงนวัตกรรมอย่างต่อเนื่อง
อุตสาหกรรมที่ได้ประโยชน์สูงสุด ได้แก่:
- ค้าปลีก — ตัวอย่างการใช้งาน: ระบบพยากรณ์อุปสงค์ (demand forecasting), การปรับราคาตามเวลาจริง (dynamic pricing), การแนะนำสินค้าส่วนบุคคล (personalized recommendation) ซึ่งแพลตฟอร์มช่วยให้โมเดลรีเทรนและปรับใช้ได้เร็วเมื่อตลาดเปลี่ยน
- การเงินและธนาคาร — ตัวอย่าง: การให้คะแนนเครดิต (credit scoring) แบบไดนามิก, ตรวจจับการทุจริต (fraud detection) ด้วยการอัปเดตโมเดลทันทีเพื่อตอบโจทย์พฤติกรรมผู้ใช้ที่เปลี่ยนเร็ว
- โลจิสติกส์และขนส่ง — ตัวอย่าง: การปรับเส้นทางขนส่งแบบเรียลไทม์ (route optimization), การคาดการณ์เวลาการมาถึง (ETA) และการจัดสต็อกแบบ just‑in‑time โดยลดความล่าช้าในการ deploy โมเดลที่ปรับปรุงแล้ว
- การผลิต — ตัวอย่าง: การบํารุงรักษาเชิงคาดการณ์ (predictive maintenance), การควบคุมคุณภาพอัตโนมัติผ่านภาพ (visual inspection) ที่ต้องการการนำโมเดลขึ้นโปรดักชันอย่างต่อเนื่องเพื่อรักษาความแม่นยำ
ด้านการจ้างงาน แพลตฟอร์มลักษณะนี้จะเปลี่ยนรูปแบบความต้องการทักษะในตลาดแรงงานไทยอย่างชัดเจน โดย ลดงานที่ต้องใช้การตั้งค่า infrastructure และกระบวนการเชิงเทคนิคซ้ำๆ แต่เพิ่มความต้องการสำหรับบทบาทเชิงวิศวกรรมและการจัดการที่มีทักษะสูง เช่น MLOps engineers, ML engineers, data engineers และ ML platform engineers โดยเฉพาะทักษะด้านการออกแบบ pipeline, การจัดการโมเดลในโปรดักชัน, ความเข้าใจด้านการกำกับดูแลโมเดล (model governance) และความสามารถในการทำงานร่วมกับทีมธุรกิจเพื่อนำกรณีการใช้งานสู่ผลลัพธ์เชิงธุรกิจ
การเปลี่ยนแปลงนี้ยังมีผลต่อการฝึกอบรมและการพัฒนาทรัพยากรมนุษย์: องค์กรจะต้องลงทุนในการอัพสกิลพนักงานผ่านโปรแกรมภายในหรือความร่วมมือกับมหาวิทยาลัย และสถาบันฝึกอบรม เพื่อสร้างแรงงานที่สามารถใช้งานและดูแลระบบ MLOps ได้อย่างมีประสิทธิภาพ ซึ่งในทางหนึ่งแพลตฟอร์ม low‑code/auto‑MLOps จะช่วยลดช่องว่างทักษะ (skill gap) โดยอนุญาตให้ทีมธุรกิจและ data scientist เกิดผลลัพธ์ได้เร็วขึ้นโดยไม่จำเป็นต้องมีทีม infra ขนาดใหญ่
ในมิติของตลาดและโอกาสทางธุรกิจ สถานะของสตาร์ทอัพไทยในสาย AI‑as‑Code มีศักยภาพเติบโตระดับภูมิภาคได้สูง — รายงานตลาด AI ระดับภูมิภาค จากแหล่งข้อมูลเชิงวิเคราะห์หลายแห่ง (เช่น IDC, McKinsey และรายงานตลาดภูมิภาค) ชี้ว่า การลงทุนและการนำ AI มาใช้ในภูมิภาคเอเชียตะวันออกเฉียงใต้มีแนวโน้มเติบโตอย่างรวดเร็ว โดยอัตราการเติบโตประจำปี (CAGR) ของการใช้จ่ายด้าน AI และระบบอัตโนมัติในภูมิภาคมักอยู่ในช่วงประมาณ 20–30% ขึ้นกับสาขาอุตสาหกรรม ซึ่งหมายความว่าตลาดไทยมีมูลค่าโอกาสเป็นร้อยล้านถึงพันล้านดอลลาร์ในช่วง 3–5 ปีข้างหน้า หากสตาร์ทอัพสามารถจับคู่กับลูกค้าองค์กรและพันธมิตรเชิงยุทธศาสตร์ได้
การตอบรับจากนักลงทุนและพันธมิตรในภูมิภาคมีแนวโน้มเป็นบวก: นักลงทุนในเวที SEA ให้ความสนใจเพิ่มขึ้นกับโซลูชันที่ลดการบูรณาการเชิงเทคนิคและเร่งผลลัพธ์เชิงธุรกิจ ผู้ให้บริการโครงสร้างพื้นฐาน (เช่น cloud providers) และผู้เล่นระบบนิเวศเช่นผู้ให้บริการซอฟต์แวร์องค์กรและผู้ให้บริการด้านโทรคมนาคมมองเห็นโอกาสการเป็นพันธมิตรเชิงกลยุทธ์ในการขยายตลาด ทั้งนี้การร่วมมือจะช่วยสตาร์ทอัพไทยเร่งการนำสินค้าเข้าสู่ตลาดต่างประเทศและสร้างรายได้เชิงซ้อน (recurring revenue) จากการให้บริการแบบแพลตฟอร์ม
สรุปแล้ว แพลตฟอร์ม AI‑as‑Code ที่นำเสนอ MLOps อัตโนมัติภายใน 48 ชั่วโมง จะเป็นตัวเร่งนวัตกรรมที่สำคัญสำหรับภาคธุรกิจไทย ช่วยลดอุปสรรคด้านเทคนิคและเวลา เพิ่มความสามารถในการทดลองเชิงธุรกิจ ตลอดจนเปิดโอกาสให้สตาร์ทอัพไทยขยายสู่ตลาดภูมิภาคหากสามารถจับคู่ผลิตภัณฑ์กับความต้องการเชิงธุรกิจและสร้างเครือข่ายพันธมิตรทั้งในเชิงเทคโนโลยีและการเงินได้อย่างเหมาะสม
ความเสี่ยง นโยบาย และแนวทางในอนาคต
ความเสี่ยงด้านจริยธรรมของการอัตโนมัติในงาน ML และแนวทางลด bias
การผลักดันให้กระบวนการพัฒนาโมเดลเป็นแบบอัตโนมัติเต็มรูปแบบ (AI‑as‑Code → MLOps pipeline อัติโนมัติ) แม้ว่าจะเพิ่มความเร็วและลดค่าใช้จ่าย แต่ยังสร้างความเสี่ยงด้านจริยธรรมที่สำคัญ เช่น การสูญเสียความรับผิดชอบของมนุษย์ (accountability), ความโปร่งใสที่ลดลง, และการขยายผลของความลำเอียงในข้อมูลต้นทางที่อาจส่งผลต่อการตัดสินใจเชิงระบบ ตัวอย่างเช่น ในงานวิจัยและกรณีศึกษาหลายฉบับพบว่าโมเดลที่ใช้ข้อมูลฝึกที่ไม่สมดุลสามารถแสดงผลลัพธ์ที่แยกแยะกลุ่มผู้ใช้บางกลุ่มได้มากกว่าอีกกลุ่มหนึ่งเป็นตัวเลขที่นับได้เป็นหลักสิบเปอร์เซ็นต์ในบางบริบท
แนวทางเพื่อลด bias ควรรวมถึงการนำแนวปฏิบัติแบบ Human‑in‑the‑Loop, การทดสอบ fairness ก่อนนำขึ้น production (pre‑deployment fairness testing), การใช้ชุดข้อมูลที่มีความหลากหลายและมีการตรวจสอบ provenance ของข้อมูล, และการใช้เทคนิคทางเทคนิคเช่น differential privacy หรือ reweighing/augmentation เพื่อชดเชยความไม่สมดุล นอกจากนี้ ระบบควรสร้าง model cards และ datasheets เป็นมาตรฐานเพื่อเก็บข้อมูลบริบทการฝึก การจำกัดวงข้อมูล (scope) และข้อจำกัดของโมเดลอย่างชัดเจน เพื่อให้ผู้ใช้งานและผู้ควบคุมสามารถประเมินความเสี่ยงทางจริยธรรมได้ตั้งแต่ต้นจนจบของวงจรชีวิตโมเดล
ประเด็นความปลอดภัยของข้อมูลและการปฏิบัติตามกฎหมายคุ้มครองข้อมูล
การนำแพลตฟอร์มที่แปลงแนวคิดธุรกิจเป็น pipeline อัตโนมัติมาใช้ ยิ่งทำให้ประเด็นการคุ้มครองข้อมูลมีความสำคัญมากขึ้น โดยเฉพาะเมื่อแพลตฟอร์มนั้นจัดการข้อมูลส่วนบุคคล ข้อมูลอ่อนไหว หรือข้อมูลเชิงพาณิชย์ที่สำคัญ ความเสี่ยงรวมถึงการรั่วไหลของข้อมูลจากการตั้งค่าที่ไม่ปลอดภัย, การเข้าถึงโดยไม่ได้รับอนุญาต, และความเสี่ยงจากการส่งข้อมูลข้ามพรมแดนที่ขัดกับข้อกฎหมาย เช่น พ.ร.บ.คุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) หรือกรอบข้อบังคับระหว่างประเทศ
มาตรการขั้นต่ำที่ควรมีคือการนำหลักการ data minimization, การทำ pseudonymization และ anonymization ตามความเหมาะสม, เข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง (encryption in transit & at rest), การควบคุมสิทธิ์แบบละเอียด (role‑based access control) พร้อมระบบล็อกและ audit trail ที่ตรวจสอบได้ นอกจากนี้ แพลตฟอร์มควรสนับสนุนการบริหารจัดการความยินยอม (consent management), การตั้งค่า data residency เพื่อให้ลูกค้าสามารถเลือกเก็บข้อมูลภายในพื้นที่ที่สอดคล้องกับกฎหมาย และการรับรองความปลอดภัยเช่น SOC2 / ISO27001 เพื่อสร้างความเชื่อมั่นต่อคู่ค้าและหน่วยงานกำกับดูแล
ทิศทางพัฒนาระยะกลาง–ยาวและ roadmap ฟีเจอร์ที่แนะนำ
ในระยะกลางถึงระยะยาว สตาร์ทอัพที่พัฒนาแพลตฟอร์มประเภทนี้ควรวาง roadmap ที่เน้นทั้งประสิทธิภาพทางเทคนิคและการรับรองความปลอดภัย/จริยธรรม เช่น:
- ระบบตรวจจับและแจ้งเตือน model drift และ data drift พร้อมกลไก rollback/auto‑retrain
- แดชบอร์ด Explainability / XAI สำหรับลูกค้าและผู้ควบคุมดูแล เพื่ออธิบายการตัดสินใจของโมเดลในระดับฟีเจอร์
- โมดูลตรวจสอบ fairness อัตโนมัติที่สามารถรายงาน metric เปรียบเทียบระหว่างกลุ่มประชากร
- ฟีเจอร์ปกป้องความเป็นส่วนตัว เช่น federated learning, differential privacy และเครื่องมือสร้างข้อมูลสังเคราะห์ (synthetic data) เพื่อใช้ในการทดสอบ
- การเชื่อมต่อแบบปลอดภัยกับผู้ให้บริการคลาวด์ระดับโลกและตัวเลือกโฮสติ้งในประเทศ เพื่อรองรับข้อกำหนด data residency
- policy‑as‑code และ compliance checks อัตโนมัติสำหรับ PDPA/GDPR ให้เป็นส่วนหนึ่งของ CI/CD pipeline
ฟีเจอร์เหล่านี้จะช่วยให้แพลตฟอร์มไม่เพียงแต่เร็ว แต่ยังเชื่อถือได้และสอดคล้องกับข้อบังคับเมื่อขยายสู่ตลาดองค์กรหรือภาครัฐ
ข้อเสนอแนะเชิงนโยบายเพื่อสนับสนุนสตาร์ทอัพและการประสานงานภาครัฐ
การสร้างระบบนิเวศที่ปลอดภัยและเติบโตได้ต้องอาศัยกรอบนโยบายที่สมดุล รัฐควรพิจารณามาตรการต่อไปนี้เพื่อสนับสนุนสตาร์ทอัพด้าน AI‑as‑Code โดยไม่ลดทอนการคุ้มครองพลเมือง:
- จัดตั้ง regulatory sandbox สำหรับการทดลองระบบ MLOps ที่ควบคุมเงื่อนไขอย่างชัดเจน เพื่อให้สตาร์ทอัพทดสอบเทคโนโลยีจริงภายใต้การกำกับ
- ออกแนวทางมาตรฐานด้านความโปร่งใส (transparency) และการประเมินผลกระทบจริยธรรม (AI impact assessment) ที่เป็นรูปธรรมและปฏิบัติได้จริง
- สนับสนุนชุดข้อมูลเปิด (open datasets) ที่มีการอนุญาตใช้งานชัดเจนเพื่อช่วยการฝึกและการประเมินโมเดล โดยคำนึงถึงการคุ้มครองข้อมูลส่วนบุคคล
- ให้แรงจูงใจด้านภาษีหรือเงินทุนสนับสนุนสำหรับสตาร์ทอัพที่ลงทุนในความปลอดภัยข้อมูลและการปฏิบัติตามมาตรฐานจริยธรรม
- ส่งเสริมความร่วมมือระหว่างภาคการศึกษา อุตสาหกรรม และหน่วยงานกำกับดูแล เพื่อพัฒนามาตรฐานการทดสอบและการรับรอง (certification) สำหรับแพลตฟอร์ม AI
นโยบายเหล่านี้จะช่วยให้สตาร์ทอัพไทยสามารถแข่งขันกับผู้ให้บริการสากลได้โดยใช้ข้อได้เปรียบด้านความเข้าใจบริบทท้องถิ่น ความสอดคล้องด้านกฎหมาย และการบริการเชิงแนวดิ่ง (vertical specialization) ที่ตอบโจทย์องค์กรไทยได้ดีกว่า
บทสรุปเชิงยุทธศาสตร์
สตาร์ทอัพที่เสนอแพลตฟอร์ม AI‑as‑Code ควรยึดหลักการว่า ความเร็วไม่ควรมาทดแทนความปลอดภัยและความเป็นธรรม ในการนำโมเดลสู่โปรดักชัน การลงทุนเชิงเทคนิคในการตรวจจับ drift, fairness testing, privacy‑preserving techniques และการออกแบบ governance ที่ชัดเจน จะเป็นปัจจัยสำคัญในการสร้างความเชื่อมั่นต่อลูกค้าและหน่วยงานกำกับดูแล ขณะเดียวกัน ภาครัฐสามารถส่งเสริมด้วย sandbox, มาตรฐานการประเมิน และแรงจูงใจทางเศรษฐกิจ เพื่อให้เทคโนโลยีนี้เติบโตอย่างยั่งยืนและเป็นประโยชน์ต่อสังคมโดยรวม
บทสรุป
แพลตฟอร์ม AI‑as‑Code ของสตาร์ทอัพไทยเป็นก้าวสำคัญที่ช่วยลดเวลาและต้นทุนในการนำโมเดลสู่โปรดักชัน โดยสามารถแปลงแนวคิดธุรกิจเป็น MLOps pipeline อัตโนมัติและปล่อยโมเดลใช้งานได้ภายใน 48 ชั่วโมง ทำให้ธุรกิจทั้งขนาดกลาง-เล็กและองค์กรขนาดใหญ่สามารถทดลอง พัฒนา และนำ AI สู่การใช้งานจริงได้รวดเร็วขึ้นจากเดิมที่อาจใช้เป็นสัปดาห์หรือเป็นเดือน การลดขั้นตอนกลางด้วยโค้ดและพิมพ์ซ้ำได้ช่วยเพิ่มความคล่องตัว ลดค่าใช้จ่ายด้านวิศวกรรม และเร่งกระบวนการทดลอง (rapid prototyping) ที่สำคัญต่อการแข่งขันทางธุรกิจในยุคดิจิทัล
อย่างไรก็ตาม ความเร็วและประสิทธิภาพดังกล่าวต้องมาควบคู่กับมาตรการด้านความปลอดภัย ข้อกำกับดูแล และการประเมินคุณภาพของโมเดลอย่างเข้มงวด ทั้งการตรวจสอบความถูกต้องของข้อมูล การประเมินความเอนเอียง (bias) การอธิบายการตัดสินใจของโมเดล (explainability) และการติดตามหลังการนำไปใช้ (monitoring & observability) เพื่อให้การนำ AI ไปใช้เกิดผลดีอย่างยั่งยืน ในอนาคต แพลตฟอร์มประเภทนี้มีศักยภาพผลักดันการยอมรับ AI ในภาคธุรกิจให้กว้างขึ้น แต่ความสำเร็จระยะยาวจะขึ้นกับมาตรฐานการกำกับดูแล การสร้างกรอบการประเมินคุณภาพ และความร่วมมือระหว่างผู้พัฒนา ภาคอุตสาหกรรม และหน่วยงานกำกับดูแลเพื่อสร้างระบบนิเวศที่ปลอดภัยและน่าเชื่อถือ



