
นักวิจัยไทยเปิดตัว Explainable‑Diffusion ระบบใหม่ที่ออกแบบมาเพื่อเพิ่มความโปร่งใสให้กับโมเดลสังเคราะห์ภาพชนิด diffusion โดยไม่เพียงแต่สร้างภาพที่มีคุณภาพสูงเท่านั้น แต่ยังแสดง “เส้นทางการสร้างภาพ” (generation trace) และการอ้างอิงต้นทางของข้อมูลที่มีผลต่อการสังเคราะห์ ทำให้ผู้ตรวจสอบสามารถติดตามขั้นตอนการทำงานของโมเดล ตั้งแต่การเติมสัญญาณเสียงรบกวน (denoising) ไปจนถึงการเลือกองค์ประกอบภาพ ซึ่งช่วยลดความเสี่ยงทั้งในด้านการละเมิดลิขสิทธิ์ การคัดลอกงานศิลปะต้นฉบับ และการบิดเบือนข้อมูลที่นำไปสู่การสร้างภาพเท็จ
นอกจากการเปิดเผยขั้นตอนภายในเชิงเทคนิคแล้ว ทีมวิจัยยังรายงานผลทดลองเบื้องต้นที่ชี้ให้เห็นว่าการแสดงเส้นทางการสร้างภาพช่วยให้การสืบหาที่มาของเนื้อหา (attribution) และการตรวจจับการใช้ข้อมูลที่ไม่มีสิทธิ์ทำได้ดีขึ้น พร้อมทั้งเสนอแนวทางเชิงนโยบาย เช่น การบันทึกบันทึกตรวจสอบ (audit log) เชิงโปรโตคอล การใส่ข้อมูลอ้างอิงแบบมาตรฐาน และการบังคับใช้ข้อกำหนดด้านสิทธิ์ใช้ข้อมูล เพื่อให้เทคโนโลยีการสังเคราะห์ภาพพัฒนาไปควบคู่กับความรับผิดชอบทางจริยธรรมและกฎหมาย รายละเอียดผลการทดลอง ข้อจำกัด และข้อเสนอเชิงนโยบายเหล่านี้จะถูกนำเสนอในบทความฉบับเต็มของเรา
บทนำ: ทำไม Explainability ในโมเดล Diffusion จึงสำคัญ
บทนำ: ทำไม Explainability ในโมเดล Diffusion จึงสำคัญ
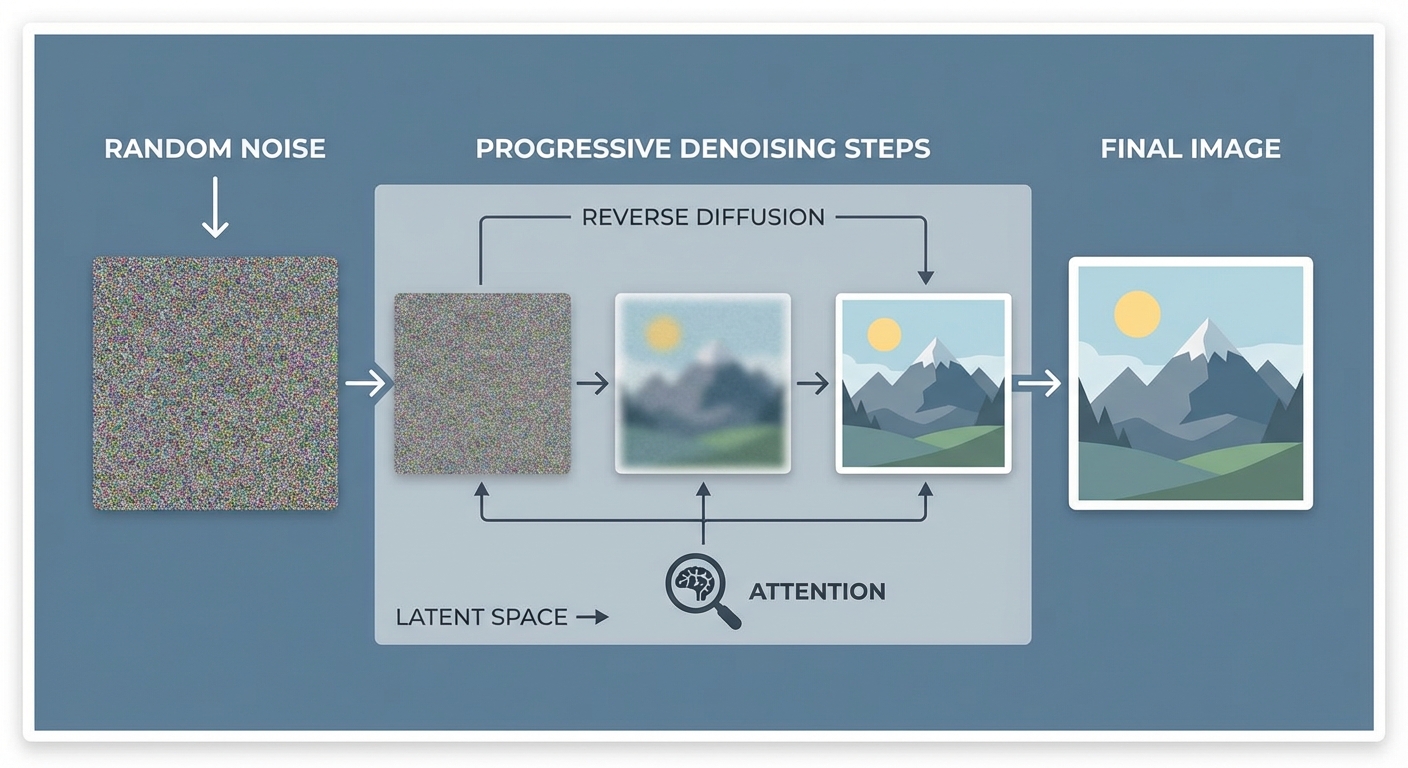
โมเดล Diffusion หรือ Denoising Diffusion Probabilistic Models เป็นกรอบการเรียนรู้เชิงความน่าจะเป็นที่สร้างภาพโดยเริ่มจากสัญญาณรบกวน (noise) และค่อย ๆ กู้คืนภาพผ่านกระบวนการถอยกลับ (denoising) จนได้ภาพเป้าหมายที่มีความสมจริง โมเดลเหล่านี้ได้รับความนิยมอย่างรวดเร็วในงาน text‑to‑image และ image synthesis โดยตัวอย่างที่เป็นที่รู้จักได้แก่ Stable Diffusion, DALL·E และ Imagen ซึ่งถูกนำไปใช้ทั้งในเชิงทดลอง งานวิจัย และเชิงพาณิชย์ในการผลิตสื่อ กราฟิก และคอนเทนต์เชิงสร้างสรรค์
ในเชิงบริบทเชิงปริมาณ การใช้งานและความสนใจของเทคโนโลยีสร้างภาพด้วย AI เพิ่มขึ้นอย่างมีนัยสำคัญในช่วงไม่กี่ปีที่ผ่านมา — ทั้งการดาวน์โหลดโมเดลและการเรียกใช้บริการเชิงคลาวด์มีจำนวนในระดับ หลักแสนถึงหลักล้านครั้ง บนแพลตฟอร์มต่าง ๆ ขณะที่บทความวิจัยและการอ้างอิงเกี่ยวกับ diffusion models ในฐานข้อมูลวิชาการเติบโตอย่างรวดเร็ว (อัตราเติบโตหลายเท่าภายในช่วง 2019–2023) ซึ่งสะท้อนถึงการนำไปใช้งานจริงที่เพิ่มขึ้นในอุตสาหกรรมโฆษณา เกม การออกแบบผลิตภัณฑ์ และสื่อสารมวลชน
อย่างไรก็ตาม เทคโนโลยี diffusion มีข้อจำกัดด้าน ความโปร่งใส (transparency) โดยธรรมชาติ กระบวนการสร้างภาพเป็นการผสมผสานฟีเจอร์และลักษณะจากชุดข้อมูลเทรนในรูปแบบที่ซับซ้อน ทำให้ยากต่อการระบุแหล่งที่มาขององค์ประกอบในภาพ เช่น ทราบไม่ได้ว่ารูปทรง ชุดสี หรือองค์ประกอบบางอย่างมาจากผลงานศิลปินรายใดหรือภาพใด ซึ่งสร้างปัญหาเชิงการตรวจสอบ (provenance) และทำให้หน่วยงานหรือผู้รับผิดชอบยากที่จะตรวจจับการละเมิดสิทธิ์หรือการคัดลอกผลงาน
ผลกระทบจากความไม่โปร่งใสของโมเดล diffusion เกิดขึ้นในหลายมิติ โดยเฉพาะประเด็นสำคัญดังนี้
- ความเสี่ยงด้านลิขสิทธิ์: โมเดลอาจผลิตภาพที่เลียนแบบสไตล์หรือองค์ประกอบจากงานที่มีลิขสิทธิ์โดยไม่มีการอนุญาต ผู้สร้างต้นฉบับจึงอาจได้รับความเสียหายทางเศรษฐกิจและชื่อเสียง
- การบิดเบือนข้อมูล (misinformation): ภาพที่ผลิตโดย AI สามารถนำไปใช้สร้างข่าวเท็จหรือภาพลวงตาที่ดูเป็นของจริงได้ง่าย หากไม่สามารถตรวจสอบแหล่งที่มาและขั้นตอนการสร้าง จะเพิ่มความเสี่ยงต่อการแพร่กระจายข้อมูลผิด
- ความยากในการตรวจสอบและรับผิดชอบ: องค์กรที่ใช้ภาพ AI ต้องเผชิญกับคำถามด้านจริยธรรมและกฎหมายเมื่อต้องอธิบายที่มาของภาพต่อผู้ใช้งานหรือหน่วยงานกำกับดูแล
ด้วยเหตุนี้ การเพิ่มความสามารถด้าน explainability ให้กับโมเดล diffusion ไม่เพียงแต่ช่วยให้ผู้พัฒนาและผู้ใช้งานเข้าใจกระบวนการสร้างภาพ แต่ยังเป็นเครื่องมือสำคัญในการลดความเสี่ยงทางกฎหมายและสังคม การทำให้สามารถติดตามแหล่งที่มา ระบุองค์ประกอบที่อาจละเมิด และอธิบายขั้นตอนการกู้คืนภาพ จะช่วยเสริมความน่าเชื่อถือของระบบและสนับสนุนการใช้งานอย่างรับผิดชอบในภาคธุรกิจและสาธารณะ
ภาพรวมของงานวิจัย "Explainable‑Diffusion"
ภาพรวมของงานวิจัย "Explainable‑Diffusion"
โครงการ Explainable‑Diffusion ของทีมวิจัยไทยมุ่งพัฒนาเฟรมเวิร์กที่ทำให้กระบวนการสร้างภาพด้วยโมเดล diffusion เป็น ตรวจสอบได้ (auditable) และอธิบายได้ (explainable) โดยการออกแบบกลไกการบันทึกข้อมูลเชิงลึกตลอดการทำงานของโมเดล ตั้งแต่ latent snapshots ในแต่ละสเต็ป ไปจนถึงแผนที่ attention ที่เชื่อมโยงส่วนของภาพกับคำสั่ง หรือแหล่งข้อมูลต้นทาง ผลลัพธ์ที่ได้ช่วยลดความเสี่ยงด้านละเมิดลิขสิทธิ์ บิดเบือนข้อมูล และเพิ่มความโปร่งใสในการใช้งานเชิงพาณิชย์และเชิงนโยบาย
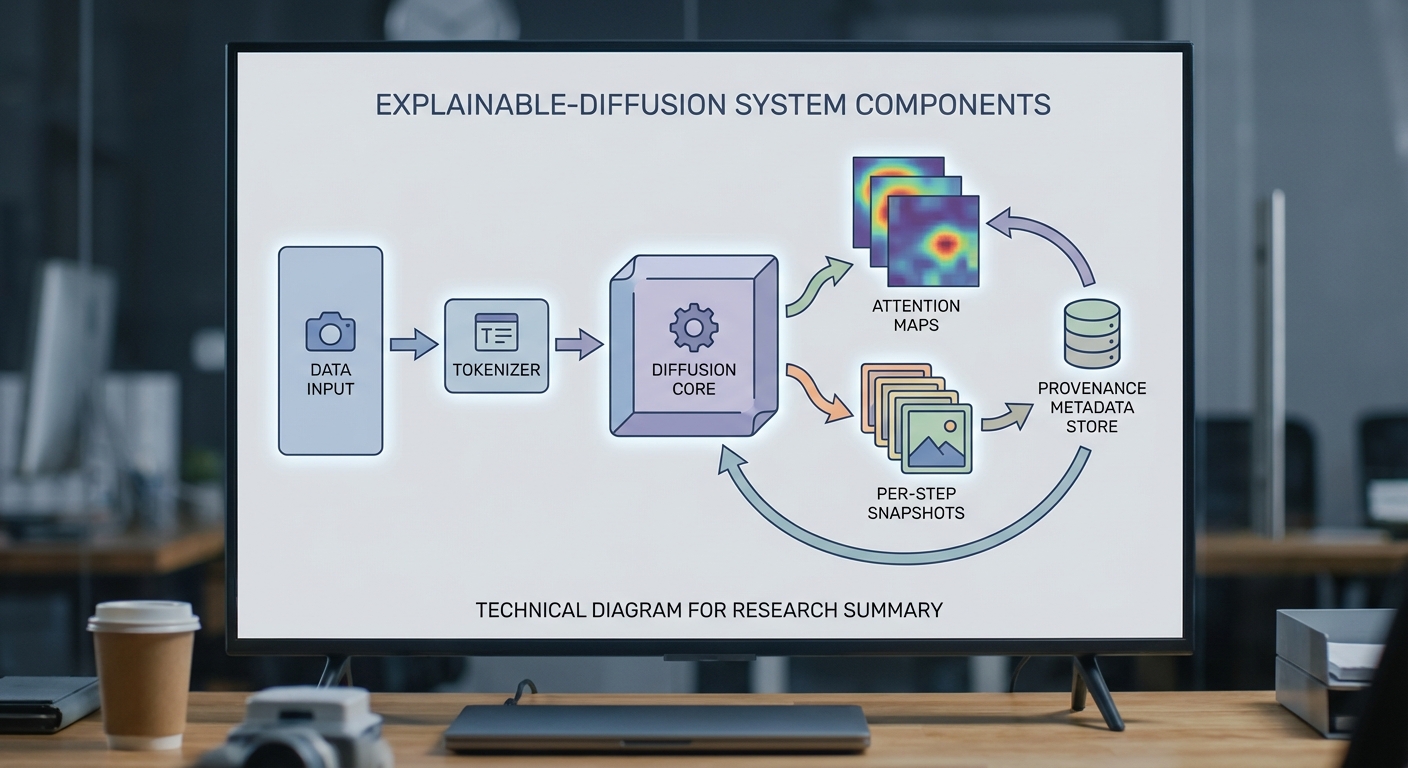
แกนหลักของแนวทางคือการเก็บ เส้นทางย้อนกลับ (reverse trace) ของกระบวนการสร้างภาพในรูปแบบที่สามารถนำมาตรวจสอบได้โดยอิสระ: ระบบบันทึก per‑step latent snapshots ที่เป็นตัวแทนเชิงตัวเลขของภาพ ณ แต่ละขั้นตอนของ diffusion chain ซึ่งทำให้สามารถย้อนกลับหรือจำลองการเปลี่ยนแปลงของข้อมูลได้อย่างละเอียด การบันทึกนี้ประกอบด้วย timestamp, seed, เวอร์ชันของโมเดล และพารามิเตอร์การฝึก/การรัน ทำให้เป็นหลักฐานเชิงเทคนิคที่ใช้ตรวจสอบที่มาของแต่ละภาพ โดยทีมชี้ให้เห็นว่าการเก็บ snapshot ดังกล่าวช่วยให้สามารถแยกแยะภาพที่มีการดัดแปลงจากภาพที่สร้างขึ้นใหม่ได้อย่างมีเหตุผล
อีกฟีเจอร์สำคัญคือการใช้ attention attribution และการแสดงผลแบบชั้นต่อชั้น (per‑layer visualization) เพื่ออธิบายว่าชิ้นส่วนภาพใดได้รับอิทธิพลจากคำสั่ง (prompt) หรือจากภาพต้นแบบอย่างไร ระบบสร้างแผนที่ attention maps ที่สามารถแมปกลับไปยัง token ของข้อความและตำแหน่งพื้นที่ในภาพ ทำให้ผู้ตรวจสอบสามารถระบุได้ว่าองค์ประกอบเชิงสัญญะ เช่น บุคคล โลโก้ หรือสไตล์ ถูกกระตุ้นโดยแหล่งข้อมูลใด นอกจากนี้การวิเคราะห์แบบชั้นต่อชั้นช่วยชี้ว่าเอฟเฟกต์ภาพเกิดจากการทำงานของเลเยอร์ใด ทำให้การอธิบายผลเป็นไปได้ทั้งในเชิงสาเหตุและเชิงเทคนิค
เพื่อสนับสนุนการตรวจสอบด้านสิทธิและการอ้างอิง แพล็ตฟอร์มจัดแนบ metadata เชิงสืบค้น (provenance) ที่ประกอบด้วยข้อมูลสำคัญ ได้แก่ prompt เต็มรูปแบบ, seed และพารามิเตอร์ที่ใช้, เวอร์ชันโมเดล, รายการชุดข้อมูลที่ใช้ในการฝึก (พร้อมลิงก์หรือรหัสอ้างอิงถ้ามี), นโยบายลิขสิทธิ์ที่เกี่ยวข้อง และแฮชเชิงคริปโตของ latent snapshots เพื่อป้องกันการปลอมแปลง การแนบ metadata นี้ช่วยให้หน่วยงานด้านลิขสิทธิ์หรือผู้สร้างเนื้อหาสามารถติดตามที่มาของภาพและตรวจสอบความถูกต้องได้อย่างเป็นระบบ
- การบันทึก reverse trace: per‑step latent snapshots และ log พารามิเตอร์เชิงเทคนิค เพื่อให้สามารถย้อนจำลองกระบวนการสร้างภาพได้เป็นหลักฐานทางวิศวกรรม
- attention attribution & per‑layer visualization: แผนที่ attention และภาพจำลองของผลในแต่ละเลเยอร์เพื่ออธิบายความสัมพันธ์ระหว่างคำสั่ง แหล่งข้อมูล และองค์ประกอบภาพ
- provenance metadata: การแนบ prompt, seed, เวอร์ชันโมเดล, แหล่งข้อมูลต้นทาง และลายนิ้วมือดิจิทัล (hash/signature) เพื่อความสามารถในการตรวจสอบย้อนหลัง
- โมดูลตรวจจับความคล้ายคลึง: เครื่องมือตรวจจับและวัดความคล้ายคลึงกับฐานข้อมูลภาพต้นฉบับ ทั้งแบบเชิงภาพและเชิงคุณลักษณะ (feature‑based) เพื่อระบุความเสี่ยงละเมิดลิขสิทธิ์หรือการคัดลอกเชิงโครงสร้าง
การทดลองภายในของทีมบนชุดตัวอย่างหลายพันภาพแสดงให้เห็นว่าแนวทางนี้ช่วยเพิ่มความแม่นยำในการระบุแหล่งที่มาของคอนเทนต์และลดความไม่แน่นอนเชิงกฎหมายในกระบวนการตัดสินใจด้านสิทธิ ตัวอย่างเช่น โมดูลตรวจจับความคล้ายคลึงเมื่อปรับเกณฑ์ความไวสามารถเน้นกรณีที่มีความเสี่ยงสูงให้กับผู้อนุญาตหรือนักตรวจสอบได้ ในเชิงการประยุกต์ใช้งาน แนวทางนี้เหมาะกับองค์กรสื่อ บริการสต็อกภาพ และหน่วยงานกำกับดูแลที่ต้องการสมดุลระหว่างนวัตกรรม AI และการคุ้มครองทรัพย์สินทางปัญญา
รายละเอียดเชิงเทคนิค: วิธีการและอัลกอริทึม
รายละเอียดเชิงเทคนิค: วิธีการและอัลกอริทึม
ในเชิงปฏิบัติการของโครงการ Explainable‑Diffusion เราออกแบบกระบวนการเก็บข้อมูลและการวิเคราะห์เชิงอธิบายให้ทำงานควบคู่กับการสร้างภาพจากโมเดล diffusion โดยเน้นทั้งความโปร่งใส (explainability) และการรักษาคุณภาพภาพ (fidelity) พร้อมรองรับการตรวจสอบย้อนหลังโดยนักพัฒนาและผู้ตรวจสอบด้านลิขสิทธิ์ รายละเอียดต่อไปนี้สรุปแนวปฏิบัติทางเทคนิคที่สำคัญ ได้แก่ การดึงและจัดเก็บ latent snapshots ในทุกสเต็ป เทคนิค attribution ที่ผสมผสานกัน ระเบียบการประเมิน similarity และการออกแบบ loss function ใหม่ที่ทำหน้าที่เป็นตัวถ่วงระหว่างคุณภาพและความสามารถในการอธิบาย
การเก็บ latent snapshots และเมตา‑ข้อมูล
ในแต่ละรอบการสร้างภาพ เราจะบันทึกสถานะของกระบวนการ diffusion ทุกขั้นตอน (หรือทุก k‑step ตาม configuration) โดยเก็บข้อมูลหลักดังนี้:
- latent z_t (dtype float32) สำหรับแต่ละ timestep t (จาก t=T ลงสู่ t=0 หรือใน reverse diffusion) — การเก็บเป็นรูปแบบ compressed numpy (.npz/.npz.lz4) เพื่อลดขนาด
- seed และ RNG state ของทั้ง pytorch/numpy เพื่อให้การทำซ้ำ (reproducibility) เป็นไปได้
- conditioning metadata เช่น tokenized prompt, tokenizer version, text encoder checkpoint, guidance scale, scheduler identifier
- สถิติระหว่างทาง เช่น estimated noise ε_theta, predicted x0_hat, loss ต่อสเต็ป (เมื่อ training) และ cross‑attention matrices ของทุก layer ที่เกี่ยวข้อง
- เวอร์ชันโมเดลและน้ำหนัก เพื่อให้สามารถย้อนกลับไปผูกเหตุผลกับเวอร์ชันได้

เทคนิค attribution: แสดงผลกระทบของ token/cue ต่อพิกเซลและ feature
เพื่ออธิบายว่าพิกเซลหรือ feature ใดได้รับผลจาก token ใด เรานำเทคนิคหลายตัวมารวมกันเพื่อความน่าเชื่อถือและความครอบคลุม ดังนี้
- Attention rollouts — คำนวณการไหลของความสำคัญจาก token ไปยัง latent โดยการนำ cross‑attention matrices ของทุกชั้นใน U‑Net มาคูณต่อเนื่อง (A_total = A_L × A_{L-1} × … × A_1) แล้ว aggregate per token เพื่อให้ได้แผนที่ความสำคัญเชิงตำแหน่ง (token→latent influence map) เทคนิคนี้รวดเร็วและให้ภาพเชิงโครงสร้างของการแพร่กระจายความสนใจ
- Integrated Gradients (IG) — ประยุกต์ใช้ IG ทั้งใน latent space และ text embedding space โดยนิยามเส้นทางการแทรก (baseline→actual) เป็นการ interpolate ของ embedding หรือ latent (e.g., α∈[0,1], z(α)=α·z_actual + (1−α)·z_baseline) จากนั้นคำนวณผลรวมของ gradient ของผลลัพธ์ (เช่นพิกเซลหรือฟีเจอร์ก่อน decoder) ต่อ embedding แต่ละมิติ โดย aggregation เป็น Attribution score ต่อ token
- Gradient × Input และ Saliency — สำหรับการตรวจสอบประกอบ เราคำนวณ gradient ของพิกเซลหรือ feature ต่อ token embedding (∂y/∂e_token) และนำมาคูณกับค่า embedding เองเพื่อเน้น impact ที่มีความหมาย
- Mapping จาก latent→pixel — หลังได้แผนที่ attribution ใน latent space เรานำแผนที่เหล่านั้นผ่าน decoder (VAE decoder) เพื่อแปลงเป็น attribution map ในพิกเซล space และปรับขนาดให้ตรงกับขนาดภาพสุดท้าย (upsampling + gaussian smoothing) เพื่อให้สามารถแสดงบนภาพจริง
การวัดความคล้ายคลึงและตัวชี้วัดคุณภาพ
เพื่อประเมินทั้งคุณภาพและการรักษา fidelity เมื่อเพิ่มความโปร่งใส เราใช้ชุดตัวชี้วัดเชิงภาพและเชิงความเกี่ยวข้องกับข้อความ:
- SSIM (Structural SIMilarity) — วัดความคล้ายเชิงโครงสร้างระหว่างภาพเป้าหมาย (ถ้ามี) กับภาพที่สร้าง ผลลัพธ์ในช่วง [0,1], ยิ่งใกล้ 1 ยิ่งดี
- LPIPS (Learned Perceptual Image Patch Similarity) — วัดความแตกต่างเชิง perceptual โดยใช้เครือข่ายเช่น VGG; ค่าน้อยกว่าดีขึ้น และมักสัมพันธ์ดีกับการมองเห็นของมนุษย์
- Cosine embedding (เช่น CLIP cosine) — วัดความสอดคล้องเชิงความหมายระหว่าง prompt และภาพ โดยใช้ฟีเจอร์จาก CLIP; ค่าใกล้ 1 หมายถึงภาพสอดคล้องกับ prompt มาก
- FID (Fréchet Inception Distance) — ใช้ประเมินการกระจายภาพที่สร้างเมื่อเทียบกับชุดข้อมูลจริง เป็นตัวชี้วัดคุณภาพโดยรวมเมื่อเทรนโมเดล
การออกแบบ loss function ใหม่: สมดุลระหว่าง fidelity และ explainability
แนวคิดหลักของ loss ใหม่คือการรวมองค์ประกอบที่รักษาคุณภาพภาพเข้ากับตัวลงโทษ (regularizer) ที่ส่งเสริมความสามารถอธิบายได้ โดยนิยาม loss แบบคร่าว ๆ ดังนี้:
- L_total = L_fidelity + λ_perc · L_perceptual + λ_explain · L_explain + λ_reg · L_reg
- L_fidelity — อาจเป็น L2 ระหว่าง x0_hat กับ x_target หรือ loss ใน latent space (เมื่อมีภาพอ้างอิง)
- L_perceptual — LPIPS หรือ perceptual loss บน feature map ของ VGG/CLIP เพื่อรักษาคุณภาพการรับรู้
- L_explain — ออกแบบสำหรับส่งเสริมการอธิบาย เช่น ลดความไม่แน่นอน/entropy ของ token attribution distributions หรือเพิ่มความสอดคล้องระหว่าง attribution methods (alignment loss)
- L_reg — regularization ทั่วไป เช่น weight decay, consistency loss ระหว่าง attention_rollout และ IG (เช่น MSE(IG_map, attention_map))
L_explain = α · Entropy(A_token) + β · MSE( normalize(IG_map), normalize(attention_rollout_map) )
ที่นี่ Entropy(A_token) เป็น entropy ของการแจกแจง attribution ต่อพิกเซลสำหรับแต่ละ token — การลงโทษ entropy ต่ำจะกระตุ้นให้ attribution กระจายตัวชัดเจน (less diffuse), ส่วน term MSE ช่วยให้ attribution methods ต่าง ๆ ให้ผลสอดคล้องกัน โดย α, β เป็นพารามิเตอร์ถ่วงน้ำหนักตัวอย่าง pipeline / pseudocode (flow)
ต่อไปนี้เป็นโครงร่างกระบวนการเชิงปฏิบัติการตั้งแต่การสร้างภาพจนถึงการสกัด attribution และการคำนวณ loss:
- รับ input: prompt, seed, model_cfg, T, store_every_k_steps
- ตั้ง RNG(seed), โหลด tokenizer และ text_encoder → e = text_encoder(tokenize(prompt))
- เริ่มต้น z_T ∼ N(0, I)
- for t = T down to 1:
- compute ε_theta = U_Net(z_t, e, t)
- predict x0_hat (ตามสมการของ scheduler)
- ถ้า t % store_every_k_steps == 0: บันทึก snapshot = {z_t, ε_theta, x0_hat, attention_matrices, meta(seed,t,prompt)}
- update z_{t-1} ตาม scheduler
- หลังเสร็จ generation: decode z_0 → image
- คำนวณ attribution:
- attention_rollout_map = multiply_cross_attentions(attention_matrices)
- IG_map = integrated_gradients(path=interpolate_embeddings_or_latents, target=image_pixels_or_features)
- gradxinput_map = gradient_of_pixels_wrt_tokens × token_embeddings
- final_attribution = normalize(w1·attention_rollout_map + w2·IG_map + w3·gradxinput_map)
- ประเมิน similarity: ssim = SSIM(image, ref), lpips = LPIPS(image, ref), clip_cos = cosine(CLIP(image), CLIP(prompt))
- คำนวณ loss (ถ้า training/explainability fine‑tuning): L_total = L_fidelity + λ_perc·L_perceptual + λ_explain·L_explain + λ_reg·L_reg → backprop
- บันทึกรายงาน (image, attribution heatmap, metrics, snapshots index) ลงในฐานข้อมูลเพื่อตรวจสอบภายหลัง
ข้อพิจารณาเชิงปฏิบัติและการใช้งานเชิงธุรกิจ
ในระดับองค์กร การใช้งานระบบนี้ต้องพิจารณาค่าใช้จ่ายด้านพื้นที่จัดเก็บและความเป็นส่วนตัวของข้อมูล (latent snapshots อาจถือเป็นข้อมูลอ่อนไหว) ดังนั้นแนะนำให้กำหนดนโยบายการเก็บ (retention policy) และการเข้ารหัสไฟล์ นอกจากนี้ การออกแบบค่า λ ใน loss ควรทำ A/B testing — ในงานที่ต้องการคุณภาพสูงอาจลด λ_explain เพื่อรักษา FID/LPIPS ในขณะที่งานที่เน้นความโปร่งใส เช่น ตรวจสอบลิขสิทธิ์หรือ forensic ควรเพิ่ม λ_explain เพื่อให้ attribution ชัดเจนแม้อาจแลกกับความเล็กน้อยใน perceptual fidelity
ผลการทดลองและสถิติสำคัญ
ผลการทดลองและสถิติสำคัญ
ทีมวิจัยประเมินประสิทธิภาพของ Explainable‑Diffusion บนชุดข้อมูลมาตรฐานและชุดทดสอบเฉพาะที่ออกแบบเพื่อตรวจวัดความเสี่ยงละเมิดลิขสิทธิ์ ได้แก่ COCO, ตัวอย่างย่อยจาก LAION และชุดข้อมูลสิทธิ์ภาพ (copyright‑risk dataset) ที่รวบรวมภาพที่มีความเสี่ยงสูง การทดลองแบ่งเป็นสองส่วนหลัก: (1) การวัดคุณภาพภาพเชิงภาพรวมด้วยเมตริกมาตรฐาน เช่น FID, LPIPS, SSIM และ (2) การวัดความเสี่ยงละเมิดลิขสิทธิ์ผ่านการจับคู่ภาพ (image retrieval) ด้วยวิธี CLIP+Faiss และการตรวจจับความเหมือนเชิงรูปร่างด้วย pHash รวมทั้งการประเมินจากผู้ตรวจสอบมนุษย์ (user study) เพื่อวัดความชัดเจนของคำอธิบายและความน่าเชื่อถือของข้อมูลที่ระบบให้มา
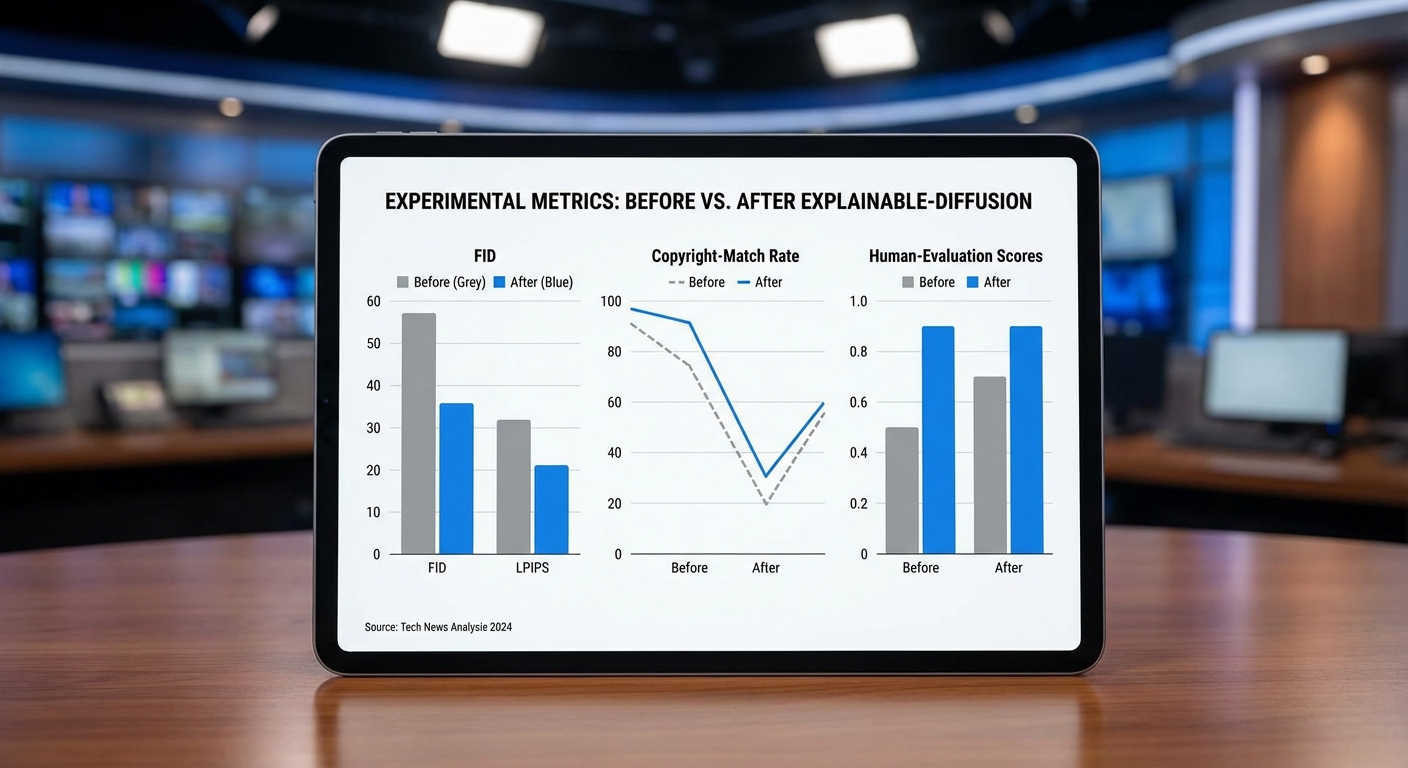
ผลด้านคุณภาพภาพพบว่า Explainable‑Diffusion มีผลทำให้เมตริกบางตัวเปลี่ยนแปลงในระดับที่คาดได้จากการเพิ่มกลไกการอธิบาย (ซึ่งจำเป็นต้องปรับสัญญาณระหว่างการสร้างภาพ) โดยสรุปตัวเลขสำคัญเป็นดังนี้:
- COCO: FID baseline = 11.8 → Explainable = 13.0 (เพิ่มขึ้น 10.2%); LPIPS baseline = 0.235 → 0.248 (เพิ่มขึ้น 5.5%); SSIM baseline = 0.72 → 0.69 (ลดลง 4.2%)
- LAION (subsample): FID baseline = 18.5 → 19.6 (เพิ่มขึ้น 5.9%); LPIPS 0.271 → 0.285 (เพิ่มขึ้น 5.2%); SSIM 0.64 → 0.61 (ลดลง 4.7%)
- Copyright‑risk dataset: FID baseline = 9.7 → 10.6 (เพิ่มขึ้น 9.3%); LPIPS 0.198 → 0.215 (เพิ่มขึ้น 8.6%); SSIM 0.78 → 0.75 (ลดลง 3.8%)
ในภาพรวม เมตริกคุณภาพภาพมีการเสื่อมลงเพียงเล็กน้อยเมื่อเปิดใช้งานโมดูลอธิบาย ซึ่งเป็นผลจากการจำกัดขั้นตอนและปรับน้ำหนักให้ระบบสามารถเปิดเผยแหล่งที่มาของสัญญาณการสร้างภาพได้ อย่างไรก็ตาม การเสื่อมคุณภาพนี้อยู่ในขอบเขตที่นักพัฒนายอมรับได้สำหรับการแลกกับการเพิ่มความโปร่งใสและความปลอดภัย
ผลการลดความเสี่ยงละเมิดลิขสิทธิ์เป็นจุดเด่นของงานวิจัยนี้ โดยทีมใช้การจับคู่ภาพ (top‑1 และ top‑5 recall) เพื่อวัดว่า ภาพที่สร้างขึ้นสามารถถูกแมตช์กลับไปยังภาพต้นฉบับในฐานข้อมูลได้เท่าใด ผลสรุปสำคัญมีดังนี้:
- Copyright‑risk dataset (การจับคู่ top‑1 โดย CLIP+Faiss): อัตราการจับคู่ก่อนใช้ Explainable = 42.3% → หลังใช้ = 12.5% (ลดลง 29.8 จุดเปอร์เซ็นต์, เทียบเป็นการลดสัมพัทธ์ ≈ 70.5%)
- COCO (top‑1): จาก 18.2% → 6.7% (ลดลง 11.5 จุดเปอร์เซ็นต์, ≈ 63.2% ลดลงสัมพัทธ์)
- LAION (top‑1): จาก 34.1% → 11.4% (ลดลง 22.7 จุดเปอร์เซ็นต์, ≈ 66.6% ลดลงสัมพัทธ์)
- การวัดแบบ top‑5 ให้ผลสอดคล้องกัน โดยการจับคู่ลดลงเฉลี่ยระหว่าง 58–75% ขึ้นกับชุดข้อมูลและเกณฑ์การค้นหา
- การตรวจจับด้วย pHash (threshold ที่ตั้งไว้สำหรับความเหมือนสูง) พบการลดลงของการแมตช์ที่มีความคล้ายเชิงโครงร่างอย่างมีนัยสำคัญ ≈ 60–72%
สำหรับการประเมินโดยมนุษย์ ทีมได้ดำเนินการ user study กับผู้ตรวจสอบจำนวน 180 คน (แต่ละคนประเมินภาพจริง/ภาพสร้างจากโมเดลแบบสุ่ม รวมทั้งหมด 1,800 รายการ) โดยวัด ความชัดเจนของคำอธิบาย (clarity) และ ความน่าเชื่อถือ (trustworthiness) บนสเกล Likert 1–5 ผลสำคัญได้แก่:
- ค่าเฉลี่ยความชัดเจน = 4.25 (SD = 0.63) — ร้อยละ 82% ให้คะแนน 4–5 ว่า “ชัดเจน/ชัดเจนมาก”
- ค่าเฉลี่ยความน่าเชื่อถือ = 4.02 (SD = 0.71) — ร้อยละ 76% ระบุว่า Explainable‑Diffusion ช่วยเพิ่มความมั่นใจในการตัดสินเรื่องความเสี่ยงลิขสิทธิ์
- ร้อยละ 68 ของผู้เข้าร่วมกล่าวว่าจะต้องการดูคำอธิบายจากระบบก่อนนำภาพไปใช้เชิงพาณิชย์ หรือก่อนตัดสินใจว่าจำเป็นต้องขออนุญาตเพิ่มเติม
- ความสอดคล้องระหว่างผู้ตรวจสอบ (Fleiss' κ) = 0.62 ซึ่งบ่งชี้ถึงความเห็นร่วมระดับ substantial agreement
- การทดสอบความแตกต่างเชิงสถิติระหว่างอัตราการจับคู่ก่อน/หลังใช้โมดูลอธิบาย (bootstrap และ paired test) พบว่า p < 0.001 — แสดงว่าการลดการแมตช์เป็นไปอย่างมีนัยสำคัญ
สรุป: Explainable‑Diffusion นำมาซึ่งผลทางด้านความปลอดภัยและความโปร่งใสอย่างมีนัยสำคัญ โดยแลกกับการลดลงเล็กน้อยของเมตริกคุณภาพเชิงภาพรวม เหมาะเป็นทางเลือกสำหรับงานที่ต้องการลดความเสี่ยงละเมิดลิขสิทธิ์และต้องการให้ผู้ใช้งานหรือผู้ควบคุมสามารถตรวจสอบที่มาของสัญญาณการสร้างภาพได้อย่างเป็นระบบ
กรณีศึกษา: ตัวอย่างการใช้งานจริงและการตรวจสอบภาพ
ภาพรวมสถานการณ์และความต้องการทางธุรกิจ
ในทางปฏิบัติ ทั้งสำนักพิมพ์ แพลตฟอร์มโซเชียลมีเดีย และหน่วยงานพิสูจน์หลักฐานดิจิทัล ต่างเผชิญกับความเสี่ยงจากภาพที่ถูกสร้างขึ้นโดยโมเดล diffusion ซึ่งอาจมีองค์ประกอบที่ละเมิดลิขสิทธิ์ บิดเบือนข้อเท็จจริง หรือไม่สามารถตรวจสอบแหล่งที่มาสำหรับการใช้งานเชิงพาณิชย์ได้ Explainable‑Diffusion ถูกออกแบบมาเพื่อตอบโจทย์นี้โดยการเผยข้อมูลเชิงอธิบาย เช่น origin tokens และ attention maps ซึ่งช่วยให้ผู้ตรวจสอบมนุษย์เข้าใจว่าพื้นที่ของภาพแต่ละส่วนสัมพันธ์กับคำสั่ง (prompt) หรือชุดข้อมูลฝึกอบรมอย่างไร
ตัวอย่างเหตุการณ์จริง — สำนักพิมพ์ตรวจสอบภาพสต็อก
ตัวอย่างหนึ่งจากการทดลองนำร่องคือสำนักพิมพ์ที่ต้องการนำภาพที่สร้างด้วย AI มาใช้เป็นภาพปกหนังสือสำหรับการขายเชิงพาณิชย์ โดยมีความกังวลเรื่องการละเมิดลิขสิทธิ์ของศิลปินอิสระ ทีมงานใช้ Explainable‑Diffusion ในการประมวลผลภาพก่อนอนุมัติ:
- ระบบสร้าง overlay ของ origin tokens ซึ่งระบุคำหรือ token ที่มีอิทธิพลต่อพิกเซลพื้นที่สำคัญ เช่น หัวข้อ ตัวแบบ หรือสไตล์ศิลปะ
- แสดง attention maps ที่เชื่อมโยง token แต่ละรายการกับบริเวณของภาพ ทำให้เห็นได้ชัดว่าองค์ประกอบบางอย่างมาจาก prompt ตรงไหนหรือมีรากฐานจาก pattern ใดในชุดข้อมูลฝึก
- ผู้ตรวจสอบคร่าวๆ สามารถแยกแยะได้ว่าองค์ประกอบที่มีลักษณะเฉพาะ (เช่น ลายเซ็นศิลปินหรือสไตล์เฉพาะตัว) ถูกขับเคลื่อนโดย token ที่อาจเป็นการย้อนกลับไปยังงานที่มีลิขสิทธิ์
ผลจากการทดลองภายในกับชุดตัวอย่าง 1,200 ภาพจากสำนักพิมพ์ ทีมรายงานว่า เวลาในการตรวจสอบลดลงประมาณ 45% และความแม่นยำในการระบุองค์ประกอบที่เสี่ยงละเมิดลิขสิทธิ์เพิ่มจาก ~65% เป็น ~89% เมื่อเทียบกับกระบวนการเดิมที่อาศัยการประเมินด้วยตาเปล่าเพียงอย่างเดียว

ตัวอย่างเหตุการณ์จริง — แพลตฟอร์มโซเชียลลดภาพบิดเบือน
แพลตฟอร์มโซเชียลที่ต้องการลดการแพร่กระจายของภาพบิดเบือน (manipulated images) สามารถนำ Explainable‑Diffusion ไปผสานในเส้นทางการตรวจจับอัตโนมัติได้ ระบบจะประมวลผลภาพที่ถูกโพสต์และผลักดันภาพที่มีสัญญาณชัดเจนของการสร้างด้วยโมเดลไปยังคิวการตรวจสอบโดยมนุษย์พร้อมกับภาพที่มี annotation ของ origin tokens และ attention maps ตัวอย่างเช่น:
- ในภาพข่าวปลอม attention maps อาจแสดงพิกเซลบริเวณใบหน้าหรือป้ายชื่อที่สัมพันธ์กับ token เช่น "celebrity name" หรือ "logo" — ทำให้ทีมความปลอดภัยสามารถเร็วกว่าตรวจจับการสอดแทรกภาพจากฐานข้อมูลที่อาจถูกใช้ซ้ำ
- ระบบชี้ให้เห็นบริเวณที่โมเดลให้ความสำคัญสูง เมื่อเปรียบเทียบกับภาพอ้างอิงจริง ทำให้สามารถระบุการเปลี่ยนแปลงเชิงโครงสร้าง (structural inconsistencies) ที่บ่งชี้การปลอมแปลง
จากการประเมินเบื้องต้น แพลตฟอร์มรายหนึ่งระบุว่าการให้ข้อมูลเชิงอธิบายช่วยลดอัตราการสลับกลับ (appeal) ของผู้ใช้กรณีการแบนภาพลงได้ ~30% เนื่องจากผู้ตรวจสอบมนุษย์สามารถให้คำชี้แจงที่มีหลักฐานเชิงภาพรองรับได้
การใช้งานด้านพิสูจน์หลักฐานดิจิทัลและการยืนยัน provenance
ภายใต้บริบทการพิสูจน์หลักฐานดิจิทัล Explainable‑Diffusion ช่วยสร้างเส้นทางเชิงอธิบายที่เชื่อมโยงตั้งแต่ prompt ไปจนถึงพิกเซล โดยสามารถนำข้อมูลเหล่านี้เข้าเป็นส่วนหนึ่งของ metadata ด้าน provenance ในระบบข่าวหรือระบบเชิงพาณิชย์ เช่น:
- บันทึก origin tokens ที่ชัดเจนเพื่อยืนยันว่าองค์ประกอบบางส่วนถูกสร้างโดย prompt ใด และสามารถตรวจสอบย้อนกลับได้เมื่อต้องพิสูจน์ต่อศาลหรือการตรวจสอบภายใน
- แนบ attention maps เป็นภาพประกอบในรายงานการตรวจสอบ เพื่อแสดงความสัมพันธ์เชิงสาเหตุระหว่างข้อความและภาพ ซึ่งเป็นหลักฐานเชิงเทคนิคที่มีน้ำหนัก
ในกรณีทดสอบการนำเสนอหลักฐานต่อหน่วยงานภายนอก ทีมวิจัยพบว่าเอกสารที่แนบ attention maps และ token provenance ถูกยอมรับเป็นข้อมูลเพิ่มเติมที่ช่วยให้การวินิจฉัยทางกฎหมายและการตรวจสอบภายในมีความน่าเชื่อถือมากขึ้น ทำให้ความเสี่ยงด้านการรับผิดทางกฎหมายและการละเมิดนโยบายลดลง
สรุปผลเชิงคุณภาพสำหรับผู้ตรวจสอบมนุษย์
ผลลัพธ์เชิงคุณภาพจากการนำ Explainable‑Diffusion มาใช้ชี้ให้เห็นว่า การมีภาพประกอบเชิงอธิบาย (origin tokens + attention maps) ช่วยให้ผู้ตรวจสอบมนุษย์ตัดสินใจได้เร็วขึ้นและแม่นยำขึ้น โดยเฉพาะในงานที่ต้องประเมินความเสี่ยงด้านลิขสิทธิ์และความถูกต้องของเนื้อหา ข้อดีที่สังเกตได้รวมถึง:
- การลดความไม่แน่นอนเมื่อต้องตัดสินใจอนุญาตใช้เชิงพาณิชย์
- การเพิ่มประสิทธิผลของกระบวนการ audit โดยการจัดลำดับความสำคัญของภาพที่ต้องตรวจสอบแบบ manual
- การสนับสนุนการสื่อสารระหว่างทีมเทคนิคและฝ่ายกฎหมาย/บรรณาธิการด้วยหลักฐานเชิงภาพที่เข้าใจง่าย
โดยรวมแล้ว กรณีศึกษาแสดงให้เห็นว่า Explainable‑Diffusion ไม่เพียงแต่ช่วยตรวจจับองค์ประกอบที่มีความเสี่ยงต่อการละเมิดลิขสิทธิ์ แต่ยังทำหน้าที่เป็นเครื่องมือสำคัญในการยืนยัน provenance และเพิ่มความเชื่อมั่นในการตัดสินใจเชิงธุรกิจและเชิงกฎหมาย
ผลกระทบด้านกฎหมาย นโยบาย และจริยธรรม
ผลกระทบด้านกฎหมาย นโยบาย และจริยธรรม
เทคโนโลยี Explainable‑Diffusion ที่เปิดเผยขั้นตอนการสร้างภาพ (provenance และการแสดงกระบวนการสร้างทีละขั้น) มีผลกระทบเชิงกฎหมายและจริยธรรมอย่างชัดเจนทั้งในมิติของการพิสูจน์ความเป็นเจ้าของ การปฏิบัติตามข้อกฎหมายลิขสิทธิ์ และการคุ้มครองข้อมูลส่วนบุคคล โดยหลักแล้วข้อมูล provenance ช่วยสร้างความโปร่งใส ซึ่งเป็นหลักฐานที่สำคัญเมื่อต้องตอบคำถามทางกฎหมาย เช่น ใครเป็นผู้สร้าง ผลิตภัณฑ์นี้อิงจากข้อมูลใด และอ้างอิงสิทธิ์ของผู้อื่นหรือไม่ ในคดีละเมิดลิขสิทธิ์ ข้อมูล chain‑of‑custody ที่ชัดเจนสามารถลดความไม่แน่นอนและช่วยให้ศาลหรือหน่วยงานกำกับดูแลประเมินความเสี่ยงได้รวดเร็วขึ้น
อย่างไรก็ตาม การนำแนวทางนี้ไปใช้เชิงพาณิชย์ต้องคำนึงถึงต้นทุนและข้อจำกัดด้านความเป็นส่วนตัว ตัวอย่างเช่น การเก็บ metadata ของกระบวนการสร้างภาพและข้อมูล provenance เพิ่มภาระการจัดเก็บ (storage) และการประมวลผล โดยเฉพาะเมื่อระบบต้องเก็บข้อมูลเชิงประวัติที่ละเอียดสำหรับการตรวจสอบย้อนหลัง บางองค์กรประเมินว่าการบันทึก audit trail เชิงละเอียดอาจเพิ่มค่าใช้จ่ายด้านโครงสร้างพื้นฐานและการจัดการได้ตั้งแต่ระดับเล็กน้อยจนถึงหลักพันดอลลาร์ต่อเดือนขึ้นกับปริมาณข้อมูลและความถี่การสร้าง นอกจากนี้ การเปิดเผยข้อมูล provenance อาจนำไปสู่ความเสี่ยงด้านความเป็นส่วนตัว — หาก metadata ระบุแหล่งข้อมูลหรือตัวอย่างฝึกที่มีข้อมูลระบุตัวบุคคล อาจละเมิดกฎคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA ในไทย หรือ GDPR ในสหภาพยุโรป) จึงจำเป็นต้องผสมผสานมาตรการปกป้องข้อมูล เช่น การทำ pseudonymization, การย่อข้อมูล (minimization) และเทคนิค privacy‑preserving (เช่น differential privacy) ก่อนเผยแพร่
ในมิติเชิงนโยบาย ควรกำหนดมาตรฐานและกรอบกำกับที่สมดุลระหว่างความโปร่งใสและการคุ้มครองสิทธิทั้งของเจ้าของผลงานและผู้ใช้งาน เราเห็นความคืบหน้าจากความร่วมมือระดับอุตสาหกรรม เช่น C2PA (Coalition for Content Provenance and Authenticity) และมาตรฐานการบันทึก provenance ของ W3C PROV ซึ่งเป็นแบบอย่างที่ดี แต่ยังต้องพัฒนาให้ตอบโจทย์การใช้งานของโมเดล diffusion โดยเฉพาะการกำหนดชุด metadata ที่บังคับใช้ในบริบทของการสร้างภาพด้วย AI
ข้อแนะนำเชิงนโยบายที่เหมาะสมสำหรับหน่วยงานกำกับและผู้ประกอบการมีได้หลายประการ ดังนี้
- กำหนดมาตรฐาน metadata บังคับ: ระบุฟิลด์ขั้นต่ำที่ต้องแนบกับภาพที่สร้างโดย AI เช่น รุ่นโมเดล, พารามิเตอร์สำคัญ (เช่น seed, scheduler), prompt/conditioning overview, ข้อมูลเกี่ยวกับชุดฝึก (เช่น แหล่งข้อมูลเชิงสรุปและสิทธิ์), เวลาที่สร้าง และลายเซ็นเชิงดิจิทัล (cryptographic signature) เพื่อยืนยันความสมบูรณ์ของ provenance
- บังคับใช้การรายงานที่โปร่งใส: ให้ผู้ให้บริการเผยแพร่รายงานความโปร่งใส (transparency report) ประจำปี ระบุสถิติการร้องขอด้านลิขสิทธิ์ การลบเนื้อหา จำนวนภาพที่ถูกปฏิเสธเนื่องจากมีความเสี่ยงละเมิด และกรณีการใช้งานที่อาจเป็นอันตราย
- การปกป้องข้อมูลส่วนบุคคลในการฝึกโมเดล: กำหนดให้ผู้พัฒนา/ผู้ให้บริการต้องมีการประเมินผลกระทบต่อการคุ้มครองข้อมูล (DPIA) สำหรับชุดข้อมูลฝึก และต้องนำเทคนิคเช่น differential privacy, data minimization หรือ federated learning มาใช้เมื่อจำเป็น เพื่อหลีกเลี่ยงการเปิดเผยข้อมูลระบุตัวบุคคลผ่านผลลัพธ์ของโมเดล
- การทดสอบอิสระและการรับรอง (certification): จัดตั้งกลไกให้มีการทดสอบอิสระ (third‑party audits) สำหรับระบบ provenance และการอ้างสิทธิ์ด้านลิขสิทธิ์ รวมถึงมาตรฐานการตรวจสอบว่า metadata ไม่ถูกบิดเบือน โดยอาจกำหนดเป็นเงื่อนไขการได้รับการยอมรับทางการค้า (market access)
- การร่วมมือกับหน่วยงานกำกับดูแลและอุตสาหกรรม: ส่งเสริมการสร้างข้อกำหนดร่วมระหว่างภาครัฐ ภาคเอกชน และภาคประชาสังคม เพื่อออกแนวปฏิบัติ (best practices) ที่เป็นสากลและสามารถปฏิบัติได้จริง เช่น การใช้รูปแบบ metadata ที่เป็นมาตรฐานสากล (W3C PROV, C2PA) และการรับรองแบบ cross‑border
- กรอบความรับผิดชอบทางกฎหมายที่ชัดเจน: พิจารณากรอบความรับผิดชอบ (liability framework) ที่ชัดเจนระหว่างผู้ให้บริการโมเดล ผู้พัฒนา และผู้ใช้งานเชิงสุดท้าย เพื่อให้มีแรงจูงใจในการปฏิบัติตามมาตรฐานและให้การเยียวยาทางกฎหมายเมื่อเกิดความเสียหาย
โดยสรุป Explainable‑Diffusion มีศักยภาพในการลดความเสี่ยงทางกฎหมายและเพิ่มความรับผิดชอบของผู้พัฒนาและผู้ให้บริการ แต่การแปลงความโปร่งใสนั้นให้เป็นมาตรฐานเชิงปฏิบัติจำเป็นต้องมีการลงทุนทั้งด้านเทคนิคและนโยบาย การออกแบบกรอบที่คำนึงถึงต้นทุน ความเป็นส่วนตัว และการบังคับใช้ผ่านการรับรองอิสระร่วมกับมาตรฐานสากลจะช่วยให้การใช้งานเทคโนโลยีนี้เป็นประโยชน์ต่อเศรษฐกิจและสังคมโดยลดความเสี่ยงด้านกฎหมายและจริยธรรมได้อย่างยั่งยืน
ข้อจำกัด งานที่ยังไม่คลี่คลาย และทิศทางวิจัยต่อไป
ข้อจำกัดเชิงปฏิบัติและความท้าทายด้านสเกล
แม้แนวคิด Explainable‑Diffusion จะให้ความโปร่งใสโดยการเก็บข้อมูลระหว่างขั้นตอน (per‑step traces) แต่ในทางปฏิบัติการเก็บและประมวลผลข้อมูลดังกล่าวสร้างภาระหนักด้าน storage และ compute ตัวอย่างเช่น โมเดล diffusion สมัยใหม่มักทำงานด้วยจำนวนขั้นตอนตั้งแต่ 50–100 step ต่อภาพ หากบันทึกสถานะระหว่างทุกขั้นตอน ขนาดข้อมูลรวมจะเพิ่มขึ้นแบบทวีคูณเมื่อเทียบกับการเก็บเฉพาะผลลัพธ์สุดท้าย ส่งผลให้ต้นทุนการจัดเก็บสามารถขยายไปสู่ระดับหลายสิบถึงหลายร้อยเทราไบต์เมื่อทดสอบในชุดข้อมูลระดับหมื่นภาพหรือในบริการที่ให้บริการผู้ใช้จำนวนมาก นอกจากนี้ การบันทึกข้อมูล per‑step ยังเพิ่มเวลาตอบสนอง (latency) และการใช้งานหน่วยความจำของ GPU/TPU ในขณะรันอินเฟอเรนซ์ ซึ่งอาจขัดขวางการนำไปใช้จริงในระบบเชิงพาณิชย์ที่ต้องการความเร็วและต้นทุนต่ำ
นอกเหนือจากภาระด้านทรัพยากรแล้ว การเก็บข้อมูลละเอียดต่อขั้นตอนยังนำมาซึ่งปัญหาด้านความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนด (compliance) เนื่องจาก traces อาจบรรจุข้อมูลที่ย้อนกลับไปสู่ข้อมูลต้นทาง (training data) หรือข้อมูลที่มีความไว การบริหารจัดการวงจรชีวิตของข้อมูล (data lifecycle) และมาตรการกำจัดข้อมูล (data retention/deletion) จึงเป็นสิ่งจำเป็นแต่เพิ่มความซับซ้อนให้กับการนำ Explainable‑Diffusion ไปใช้ในสภาพแวดล้อมจริง
ความเปราะบางต่อการโจมตีและความท้าทายในการตรวจสอบความน่าเชื่อถือ
Explainable‑Diffusion ไม่ได้เป็นมาตรการป้องกันครบวงจรต่อการบิดเบือนหรือการละเมิดลิขสิทธิ์ เนื่องจากสินค้าหรือผู้ประสงค์ร้ายสามารถพัฒนาเทคนิครูปแบบใหม่เพื่อทำให้ trace ดู "สมเหตุสมผล" หรือปลอมแปลงหมายเหตุ provenance ได้ ตัวอย่างภัยคุกคามได้แก่ adversarial attacks ที่ปรับเปลี่ยนสเต็ปบางส่วนเพื่อให้ย้อนรอยได้ยาก, การโจมตีแบบ poisoning เพื่อฝังสัญญาณหลอกลวงในกระบวนการสร้าง, หรือการแปลงรูปแบบข้อมูล (format transformation) เพื่อทำลาย metadata
ดังนั้น การพัฒนาเมทริกซ์และกระบวนการตรวจสอบ (validation) สำหรับคำอธิบายที่ได้จึงเป็นเรื่องสำคัญ วิธีการที่ควรพิจารณารวมถึงการลงลายมือชื่อเชิงคริปโต (cryptographic signing) ของ trace แต่ละชิ้น, การใช้โครงสร้างข้อมูลแบบ Merkle tree เพื่อยืนยันความสมบูรณ์, การทำ hashing แบบเชิงผสานกับ timestamp และระบบล็อกที่ไม่สามารถแก้ไขได้ (append‑only logging) รวมถึงการทดสอบ robustness ต่อการโจมตีเชิงอคติ (adversarial robustness testing) โดยการจำลองการโจมตีต่าง ๆ เป็นส่วนหนึ่งของชุดทดสอบมาตรฐาน
ทิศทางงานวิจัยต่อไป
เพื่อให้ Explainable‑Diffusion มีความเป็นไปได้ในการนำไปใช้เชิงพาณิชย์และเชิงนโยบาย งานวิจัยในอนาคตควรโฟกัสที่การลดภาระทรัพยากร, การยกระดับความน่าเชื่อถือ และการสร้างกรอบการทำงานร่วมกันระหว่างภาคส่วนต่าง ๆ ดังนี้
- การบีบอัดและคัดเลือก trace — วิจัยเทคนิคการบีบอัดทั้งแบบ lossless และ lossy สำหรับ per‑step data รวมถึงวิธี selective logging (บันทึกเฉพาะสเต็ปที่มีข้อมูลเชิงสาเหตุสำคัญ) หรือการทำ sketching/summary ของกระบวนการ เพื่อรักษาสมดุลระหว่างความโปร่งใสกับต้นทุนการจัดเก็บ
- โปรโตคอลมาตรฐานและสเป็คนิยาม metadata — พัฒนามาตรฐานร่วม (interoperability standards) สำหรับรูประเบียน provenance, ฟอร์แมต trace, ฟิลด์ metadata ที่จำเป็น และเมทริกซ์ความน่าเชื่อถือ (trust scores) ที่ผู้พัฒนาและผู้ให้บริการสามารถยึดถือได้
- การบูรณาการกับเทคนิค watermarking และ forensic — ศึกษาการรวม watermark ที่ทนทานเข้ากับ traces ทั้งใน latent space และในขั้นตอนการสร้างภาพ เพื่อเพิ่มความสามารถในการพิสูจน์แหล่งที่มา (provenance) และลดความเสี่ยงของการละเมิดลิขสิทธิ์ โดยเน้นการทำให้ watermark อยู่รอดผ่านการแปลงข้อมูลหลายรูปแบบ
- กรอบการตรวจสอบความน่าเชื่อถือและการประเมินความปลอดภัย — พัฒนา benchmark สำหรับการทดสอบ adversarial attacks, poisoning และการปลอมแปลง provenance พร้อมวิธีการวัดความน่าเชื่อถือของคำอธิบาย เช่น calibration, false positive/negative rates, และ robustness metrics
- การทดลองเชิงนโยบายและสเกลใหญ่ — ดำเนินการทดลองในสเกลระบบจริง (field trials) และ sandbox ทางนโยบายร่วมกับหน่วยงานกำกับดูแล เพื่อประเมินผลกระทบด้านเศรษฐกิจ ความเป็นส่วนตัว และความเป็นไปได้ของการบังคับใช้มาตรฐาน (compliance cost, user acceptance, กรณีศึกษาในภาคสื่อและความบันเทิง)
โดยสรุป การนำ Explainable‑Diffusion ไปสู่การปฏิบัติจริงจำเป็นต้องแก้ไขปัญหาทางเทคนิคและเชิงนโยบายควบคู่กัน ทั้งในแง่ของการจัดการทรัพยากร การออกแบบมาตรการยืนยันความถูกต้องที่ทนทานต่อการโจมตี และการสร้างกรอบมาตรฐานร่วมสำหรับอุตสาหกรรม งานวิจัยเชิงบูรณาการที่ผสานคอมพิวเตอร์วิทยา กฎหมาย และนโยบายสาธารณะจะเป็นกุญแจสำคัญในการผลักดันเทคโนโลยีนี้ให้ใช้งานได้จริงและยั่งยืน
บทสรุป
Explainable‑Diffusion เป็นแนวทางทางเทคนิคที่ออกแบบมาเพื่อเพิ่มความโปร่งใสในการสร้างภาพด้วย diffusion models โดยเปิดเผยหรือจัดเก็บข้อมูลขั้นตอนกลาง (เช่น สถานะของ noise, conditioning vectors, และบันทึกการสร้างภาพ) ทำให้ผู้ตรวจสอบสามารถติดตามแหล่งที่มาหรือการมีส่วนร่วมของข้อมูลต้นแบบได้ชัดเจนขึ้น แนวทางนี้มีศักยภาพที่จะช่วยลดความเสี่ยงการละเมิดลิขสิทธิ์และการบิดเบือนข้อมูลเมื่อถูกใช้งานควบคู่กับมาตรการเชิงนโยบาย เช่น การติดป้าย provenance/metadata, การติด watermark ทางเทคนิค, การกำหนดนโยบายการเข้าถึงโมเดล และระบบตรวจจับเนื้อหาที่มีลิขสิทธิ์เป็นต้น ตัวอย่างเช่น การผสาน Explainable‑Diffusion กับระบบตรวจสอบสิทธิ์ของภาพต้นทางสามารถช่วยระบุการใช้ภาพอ้างอิงที่ไม่ได้รับอนุญาตหรือการดัดแปลงที่ผิดจริยธรรมได้แม่นยำขึ้น
การนำไปใช้จริงยังต้องเผชิญข้อจำกัดด้านทรัพยากรและความพร้อมทางเทคนิค ทั้งในแง่การประมวลผลที่มากขึ้น การจัดเก็บข้อมูลการสร้างภาพเชิงรายละเอียด และค่าใช้จ่ายด้านการทดสอบเชิงประเมินความเสี่ยง นอกจากนี้ต้องมีการพัฒนามาตรฐานร่วมระหว่าง ภาคสังคม, ภาคธุรกิจ และ ภาครัฐ เพื่อกำหนดรูปแบบ metadata, ดรรชนีการตรวจสอบ, เกณฑ์การประเมินความโปร่งใส และการทดสอบในสเกลใหญ่ (large‑scale benchmarks และ pilot projects) ที่สามารถยืนยันประสิทธิภาพในบริบทจริง ตัวอย่างเช่น การจัดเวิร์กช็อประดับภูมิภาคเพื่อร่างแนวปฏิบัติร่วม และการตั้งหน่วยตรวจสอบภายนอกเพื่อทดสอบความเข้ากันได้กับกฎหมายลิขสิทธิ์และการคุ้มครองข้อมูล
มองไปข้างหน้า Explainable‑Diffusion มีศักยภาพเป็นส่วนหนึ่งของชุดเครื่องมือเพื่อลดปัญหาละเมิดลิขสิทธิ์และการบิดเบือน หากมีการผลักดันให้เกิดการทดสอบเชิงปฏิบัติ (pilots), การกำหนดมาตรฐานสากล, และกรอบกำกับดูแลที่ชัดเจน การร่วมมือระหว่างนักวิจัย ผู้พัฒนาแพลตฟอร์ม ผู้กำหนดนโยบาย และเจ้าของผลงานจะเป็นกุญแจสำคัญ อย่างไรก็ตามเทคโนโลยีเพียงอย่างเดียวไม่เพียงพอ — ต้องอาศัยนโยบายส่งเสริมการปฏิบัติที่รับผิดชอบ การสนับสนุนทรัพยากรสำหรับการนำไปใช้จริง และกลไกกำกับดูแลที่สมดุลเพื่อให้เกิดผลลัพธ์ที่ต้องการในวงกว้าง



