
OpenAI ประกาศเปิดตัวแอปพลิเคชันรวมฟีเจอร์สำคัญอย่างเป็นทางการ — นำ ChatGPT, Codex และ Atlas Browser มารวมไว้ในแอปเดียว ซึ่งเปิดโอกาสให้ผู้ใช้ทั้งบุคคลและองค์กรเข้าถึงความสามารถด้านการสื่อสารด้วยภาษาธรรมชาติ การเขียนโค้ดอัตโนมัติ และการค้นคว้าข้อมูลเชิงบริบทได้อย่างราบรื่นในสภาพแวดล้อมเดียว ความเคลื่อนไหวครั้งนี้ไม่เพียงเป็นการย่อเครื่องมือ AI หลักหลายตัวไว้ในที่เดียว แต่ยังตั้งคำถามต่อรูปแบบการทำงาน การพัฒนาซอฟต์แวร์ และการจัดการความรู้ภายในองค์กร ยุคของการสลับหน้าต่างและการเชื่อมต่อหลายแพลตฟอร์มอาจกำลังจะเปลี่ยนไป
บทความนี้จะพาผู้อ่านเจาะลึกถึงฟีเจอร์เด่นของแต่ละองค์ประกอบ วิธีการรวมระบบที่ OpenAI นำมาใช้ ผลกระทบที่คาดว่าจะเกิดขึ้นต่อกระบวนการทำงานขององค์กร ความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัว รวมถึงแนวทางปฏิบัติที่องค์กรสามารถนำไปใช้เพื่อนำเทคโนโลยีนี้มาใช้อย่างมีประสิทธิภาพและปลอดภัย ตั้งแต่การประเมินความต้องการภายใน การออกแบบเวิร์กโฟลว์ ไปจนถึงการอบรมบุคลากรและมาตรการคุมความเสี่ยง — เพื่อให้ผู้อ่านเห็นภาพชัดเจนว่าการรวม ChatGPT, Codex และ Atlas Browser จะเปลี่ยนวิธีการทำงานอย่างไรในทางปฏิบัติ
บทนำ — ข่าวการเปิดตัวและความสำคัญ
บทนำ — ข่าวการเปิดตัวและความสำคัญ
OpenAI ประกาศเปิดตัวแอปพลิเคชันแบบบูรณาการที่รวมสามเครื่องมือสำคัญไว้ในอินเทอร์เฟซเดียวเมื่อวันที่ 22 มีนาคม 2026 โดยแอปนี้รวบรวมความสามารถของ ChatGPT, Codex และ Atlas Browser เพื่อให้ผู้ใช้สามารถสื่อสารเชิงภาษาธรรมชาติ เขียนและทดสอบโค้ด พร้อมทั้งเข้าถึงข้อมูลจากเว็บได้อย่างต่อเนื่องในแพลตฟอร์มเดียวกัน บริษัทระบุว่าเวอร์ชันนี้เปิดตัวในสถานะ สาธารณะ (public) สำหรับฟีเจอร์หลัก ขณะที่ฟีเจอร์ขั้นสูงบางส่วนและการรวมแบบเฉพาะองค์กรยังอยู่ในสถานะ เบต้า (beta) เพื่อรับข้อเสนอแนะจากลูกค้าองค์กรก่อนขยายการให้บริการเต็มรูปแบบ
แอปที่เปิดตัวมานำเสนอชุดฟีเจอร์หลักที่ถูกออกแบบมาเพื่อรองรับการทำงานร่วมกันระหว่างมนุษย์และเครื่องจักรอย่างเป็นระบบ โดยฟีเจอร์ที่โดดเด่นได้แก่:
- ChatGPT (การสนทนาเชิงบริบท) — การตอบโต้เชิงภาษา การจัดการ prompt และการสรุปข้อมูลจากแหล่งต่างๆ ในบริบทเดียวกัน
- Codex (ผู้ช่วยการเขียนโค้ด) — การสร้างโค้ดอัตโนมัติ การแปลงคำอธิบายเป็นโค้ด รองรับหลายภาษาโปรแกรม พร้อม sandbox สำหรับทดสอบโค้ด
- Atlas Browser (การค้นหาและดึงข้อมูลจากเว็บ) — การสืบค้นข้อมูลเรียลไทม์ การอ้างอิงแหล่งข้อมูล และการรวมผลการค้นหากับการสร้างเนื้อหาและการเขียนโค้ดโดยอัตโนมัติ
- การเชื่อมต่อข้ามฟังก์ชัน — บริบทจากการสนทนาสามารถถูกส่งต่อไปยังโมดูลโค้ดหรือการค้นหาเว็บ ทำให้กระบวนการทำงานต่อเนื่องไม่ต้องสลับแอปบ่อยครั้ง
เชิงกลยุทธ์ การรวมเครื่องมือทั้งสามนี้ถือเป็นจุดเปลี่ยนสำคัญในการเร่งการเปลี่ยนผ่านสู่ดิจิทัล (digital transformation) ขององค์กร เพราะสามารถลด friction ในการทำงานข้ามหน้าที่ ลดการสลับบริบทที่ทำให้เสียเวลาทำงาน และเพิ่มความเร็วในการพัฒนาและตัดสินใจ งานวิจัยและการสำรวจหลายชิ้นชี้ให้เห็นว่าการสลับบริบทในการทำงานสามารถลดประสิทธิภาพได้ถึงประมาณ 20–25% การมีเครื่องมือที่รวมกันช่วยให้ทีมงานสามารถค้นพบข้อมูล ทดสอบโค้ด และสรุปผลเชิงธุรกิจได้ภายในขั้นตอนเดียว จึงลดเวลาในการนำแนวคิดสู่การใช้งานจริง (time-to-market)
สำหรับภาคธุรกิจ ผลลัพธ์ที่คาดหวังได้รวมถึงการบริหารจัดการข้อมูลและการกำกับดูแลที่ง่ายขึ้นผ่านคอนโซลเดียว การปรับใช้ AI อย่างมีมาตรฐานในองค์กร และการลดต้นทุนในการจัดซื้อหลายซอฟต์แวร์ ตัวอย่างเช่น ทีมพัฒนาสามารถใช้ Atlas เพื่อค้นหาเอกสาร API, ให้ Codex สร้างโค้ดตัวอย่าง และให้ ChatGPT สรุปหรือร่างเอกสารประกอบภายในไม่กี่นาที ซึ่งตามกรณีศึกษาเชิงอุตสาหกรรมสามารถประหยัดเวลาพัฒนาได้หลายชั่วโมงถึงหลายวันต่อโปรเจ็กต์ การประกาศครั้งนี้จึงไม่เพียงเป็นการเปิดตัวผลิตภัณฑ์ใหม่ แต่ยังเป็นสัญญาณถึงการยกระดับวิธีการทำงานขององค์กรในยุคดิจิทัลอย่างเป็นรูปธรรม
เจาะฟีเจอร์: ChatGPT, Codex และ Atlas Browser ทำอะไรได้บ้าง
การรวมโมดูลสำคัญทั้ง ChatGPT, Codex และ Atlas Browser ไว้ในแอปพลิเคชันเดียวของ OpenAI มุ่งตอบโจทย์การใช้งานเชิงธุรกิจ ตั้งแต่การสื่อสารภายในและบริการลูกค้า ไปจนถึงการพัฒนาโค้ดและการค้นหาเชิงบริบทที่เชื่อมโยงข้อมูลภายนอกกับคลังข้อมูลภายในองค์กร ในส่วนต่อไปนี้จะเป็นการสรุปฟีเจอร์หลักของแต่ละโมดูล พร้อมตัวอย่างการใช้งานสั้น ๆ ที่ชี้ให้เห็นถึงมูลค่าทางธุรกิจและการประหยัดเวลาในการทำงาน
ChatGPT: การสนทนาเชิงบริบท, สรุป และช่วยงานบริการลูกค้า
ChatGPT ในชุดแอปนี้ถูกออกแบบให้ทำงานแบบ multi-turn conversation ผู้ใช้สามารถรักษาบริบทของการสนทนาได้หลายรอบ ทำให้คำตอบมีความต่อเนื่องและสอดคล้องกับประวัติการสนทนา ตัวอย่างเช่น หากทีมขายเริ่มจากการพูดคุยเกี่ยวกับผลิตภัณฑ์ รุ่น และเงื่อนไขสัญญา ChatGPT จะสามารถอ้างอิงข้อมูลเดิมเมื่อลูกค้าเปลี่ยนหัวข้อไปยังการชำระเงินหรือการส่งมอบได้ทันที
ด้านการสรุป (summarization) โมดูลนี้สามารถย่อยข้อความยาว เช่น รายงานการประชุม อีเมลยาว หรือบทสนทนาในแชท ให้เป็นสรุปที่ชัดเจนและแบ่งตามหัวข้อย่อยได้ ผู้บริหารหรือหัวหน้าทีมสามารถได้รับประเด็นสำคัญในรูปแบบ executive summary ในไม่กี่วินาที ซึ่งจากการใช้งานแบบพรีวิวพบว่าช่วยลดเวลาอ่านเอกสารยาวได้อย่างมีนัยสำคัญ
สำหรับงานบริการลูกค้า ChatGPT สามารถทำหน้าที่เป็นตัวช่วยในการตอบคำถามขั้นต้น จัดหมวดปัญหา (triage) และเสนอคำตอบสำเร็จรูปให้เจ้าหน้าที่ใช้ต่อหรือให้ระบบตอบอัตโนมัติในเคสที่ไม่ซับซ้อน ฟีเจอร์การจัดการโทนและสคริปต์ยังช่วยให้ตอบคำถามในแนวทางเดียวกับนโยบายแบรนด์ ตัวอย่างการใช้งานเชิงธุรกิจ เช่น ระบบช่วยตอบตั๋ว (ticketing) ที่ลดเวลาการตอบกลับเฉลี่ยลงได้อย่างมีนัยสำคัญเมื่อใช้งานร่วมกับระบบ CRM
- จุดเด่น: รักษาบริบทแบบ multi-turn, สรุปเอกสารยาว, ตอบโจทย์การบริการลูกค้า
- ตัวอย่าง: เปลี่ยน transcript การประชุม 30 นาที เป็นสรุป 5 ข้อสรุปและรายการงานที่ต้องติดตาม
Codex: สร้างโค้ดจากคำอธิบาย, เติมโค้ด และแปลง pseudocode เป็นโค้ดจริง
Codex มุ่งเน้นช่วยนักพัฒนาและทีมวิศวกรรมซอฟต์แวร์ให้ผลิตงานได้เร็วขึ้นด้วยความช่วยเหลือในระดับโค้ด: จากการเขียนฟังก์ชันใหม่ การเติมโค้ด (code completion) ไปจนถึงการแปลง pseudocode หรือคำอธิบายเชิงกระบวนการให้เป็นโค้ดที่ใช้งานได้จริง ตัวอย่างการใช้งานเช่น ส่งคำอธิบายว่า "ดึงรายชื่อผู้ใช้ที่มีธุรกรรมมากกว่า 1,000 บาท และเรียงตามยอดรวม" Codex สามารถสร้าง SQL query ที่สอดคล้องและแม่นยำให้ทันที
นอกจากนี้ Codex ยังรองรับการเติมโค้ดในบริบทของไฟล์โปรเจ็กต์ ทำให้เมื่อผู้พัฒนาพิมพ์คอมเมนต์หรือ pseudocode เช่น "ฟังก์ชันคำนวณคะแนน loyalty ตามการซื้อย้อนหลัง 12 เดือน" ระบบสามารถแปลงเป็นฟังก์ชันใน Python/JavaScript/SQL ได้โดยตรง ซึ่งช่วยลดขั้นตอนการแปลงแนวคิดเป็นโค้ดและลดข้อผิดพลาดจากการพิมพ์ด้วยตัวเอง
ในเชิงธุรกิจ Codex ช่วยลดเวลาพัฒนาฟีเจอร์เฉพาะ (feature prototyping) และช่วยเขียน unit tests หรือเอกสารประกอบโค้ดได้อัตโนมัติ ตัวอย่างสั้น ๆ: ทีม Backend ระบุเงื่อนไขการกรองข้อมูลเป็น pseudocode —> Codex สร้าง endpoint พร้อมการตรวจสอบ input และตัวอย่าง unit test ให้ภายในไม่กี่นาที
- จุดเด่น: สร้างโค้ดจากคำอธิบาย, เติมโค้ดในบริบทไฟล์, แปลง pseudocode เป็นโค้ดจริง
- ตัวอย่าง: จากคำสั่ง "สร้าง API คืนยอดขายรายสาขา" Codex สร้างโครงร่าง endpoint, query และตัวอย่าง response ให้ทันที
Atlas Browser: ค้นหาเชิงบริบท เชื่อมข้อมูลภายนอก/ภายในองค์กร และแสดงแหล่งอ้างอิง
Atlas Browser ถูกออกแบบเป็นเครื่องมือค้นหาเชิงบริบทที่ผสานความสามารถของการทำความเข้าใจภาษา (NLP) กับการเชื่อมโยงแหล่งข้อมูลทั้งจากอินเทอร์เน็ตและคลังข้อมูลภายในองค์กร (intranet, knowledge base, databases) จุดเด่นคือการให้ผลลัพธ์ที่มีบริบทและแสดงแหล่งอ้างอิง (provenance) อย่างชัดเจน ทำให้ผู้ใช้เชื่อมโยงข้อมูลย้อนกลับได้ว่าข้อความหรือสถิติที่ได้มาจากเอกสารใด ระบบจะแสดงลิงก์ แหล่งที่มา และสแนปช็อตของเอกสารต้นทาง
หนึ่งในการใช้งานเชิงธุรกิจที่ชัดเจนคือการวิเคราะห์เชิงภูมิศาสตร์ เช่น ผู้จัดการเครือข่ายการจัดส่งสามารถสืบค้นข้อมูลการขายตามพื้นที่ Atlas สามารถเชื่อมโยงข้อมูล GIS กับรายงานการตลาดและไฟล์รายงานภายใน เพื่อแสดงแผนที่จุดขาย ร่วมกับบันทึกเหตุการณ์หรือเอกสารประกอบที่เกี่ยวข้องได้ทันที ทำให้การตัดสินใจเชิงโลจิสติกส์หรือการขยายสาขามีข้อมูลประกอบครบถ้วน
อีกฟีเจอร์สำคัญคือความสามารถในการค้นหาเชื่อมข้อมูลภายในองค์กร (federated search): Atlas สามารถดึงผลจากหลายแหล่งพร้อมกัน — ฐานข้อมูลเชิงความรู้ (knowledge base), ระบบ CRM, และหน้าเว็บภายนอก — แล้วจัดอันดับผลลัพธ์ตามความเกี่ยวข้องเชิงบริบทและความน่าเชื่อถือ พร้อมแสดงรายการแหล่งอ้างอิงให้ตรวจสอบได้ ตัวอย่างเชิงปฏิบัติ: เมื่อต้องตอบคำถามลูกค้าว่า "โปรโมชันนี้มีผลเฉพาะสาขาใดบ้าง" Atlas จะคืนทั้งลิงก์เอกสารนโยบายโปรโมชัน ตารางที่เกี่ยวข้องในฐานข้อมูล และแผนที่สาขาที่ได้รับผลกระทบ
- จุดเด่น: ค้นหาเชิงบริบทแบบผสมแหล่งข้อมูล (external + internal), แสดง provenance/แหล่งอ้างอิง, รองรับข้อมูลเชิงภูมิศาสตร์
- ตัวอย่าง: ค้นหาข้อมูลวิจัยตลาดแล้วรับทั้งบทคัดย่อ, ลิงก์ไปยังรายงานฉบับเต็ม และตารางที่เก็บในคลังข้อมูลภายใน
สรุป: การผสานสามโมดูลนี้ช่วยให้องค์กรสามารถสื่อสารภายในได้มีประสิทธิภาพ (ChatGPT), พัฒนาผลิตภัณฑ์และระบบได้รวดเร็วขึ้น (Codex) และค้นหาเชิงบริบทแบบเชื่อมโยงข้อมูลได้อย่างมีหลักฐานประกอบ (Atlas Browser) ซึ่งเมื่อนำไปใช้อย่างเหมาะสมจะช่วยเพิ่มความเร็วในการตัดสินใจ ลดเวลาการทำงานซ้ำซ้อน และยกระดับคุณภาพการให้บริการแก่ลูกค้า
การรวมระบบเชิงเทคนิคและสถาปัตยกรรม (How it works)
ภาพรวมสถาปัตยกรรมและการไหลของข้อมูล (Data Flow)
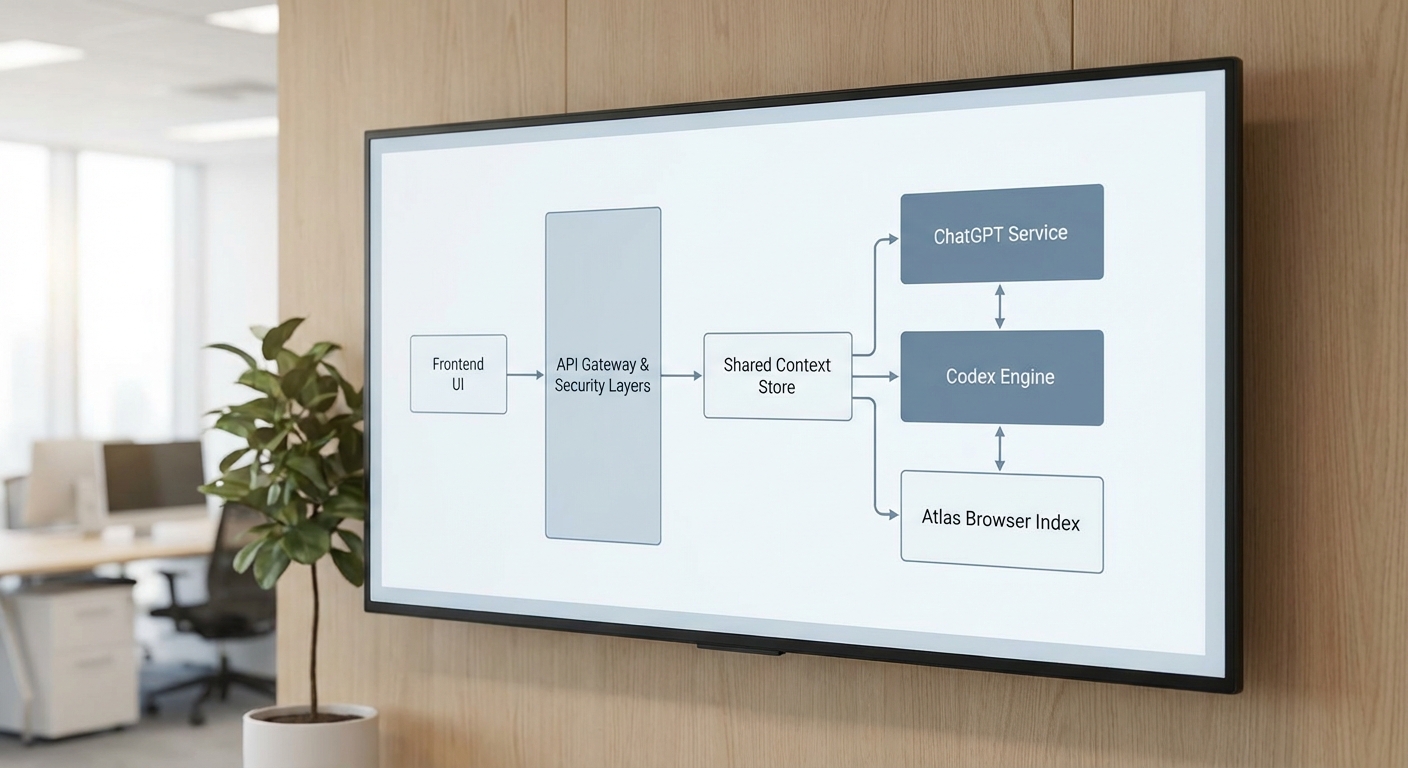
ในการรวมระบบของ ChatGPT, Codex และ Atlas Browser แอปพลิเคชันทำหน้าที่เป็นตัวประสาน (orchestrator) ระหว่างอินเทอร์เฟซผู้ใช้และโมดูลหลักทั้งสาม โดยทั่วไป data flow จะเริ่มจากคำขอของผู้ใช้ที่ถูกส่งมายัง API Gateway/Frontend ซึ่งจะส่งต่อไปยัง Request Router ที่ประเมินประเภทคำขอ (เชิงบทสนทนา คำสั่งให้เขียนโค้ด หรือการค้นคว้าจากเว็บ) และเรียกใช้โมดูลที่เหมาะสม คำอธิบายกระบวนการอย่างสรุปมีดังนี้:
- 1) ผู้ใช้ส่งคำขอผ่าน UI → 2) API Gateway / Auth → 3) Request Router / Orchestrator → 4) เรียก ChatGPT/Codex/Atlas ตามชนิดงาน → 5) Aggregator รวมผลลัพธ์และตอบกลับผู้ใช้
- ในขั้นตอนการค้นคืนข้อมูล บทบาทของ Atlas Browser คือการดึงข้อมูลภายนอกจากเว็บ, ดัชนีเอกสาร, หรือหน้าเว็บที่ระบุ แล้วส่งผลลัพธ์ที่ประมวลผลเบื้องต้น (extracted snippets, metadata, embeddings) กลับไปยัง Orchestrator เพื่อให้ ChatGPT หรือ Codex ใช้เป็นบริบทเพิ่มเติม
- Codex ถูกเรียกใช้เมื่อคำขอมีลักษณะเป็นการเขียน/แก้ไขโค้ด หรือเมื่อต้องการแปลงคำสั่งภาษาธรรมชาติเป็นโค้ดจริง ผลลัพธ์ของ Codex อาจถูกทดสอบใน sandboxed execution layer ก่อนส่งคืน
การรวม API และรูปแบบการสื่อสารระหว่างโมดูล (API Integration)
การเชื่อมต่อระหว่างโมดูลควรใช้รูปแบบ API ที่เป็นมาตรฐานและรองรับการสื่อสารแบบ synchronous และ asynchronous เพื่อรองรับงานที่ต้องใช้เวลานาน เช่น การสืบค้นเว็บเชิงลึกหรือการรันชุดการทดสอบโค้ด รูปแบบที่นิยมใช้ได้แก่ REST/gRPC สำหรับการเรียกแบบ synchronous และ message queue (เช่น Kafka, RabbitMQ) หรือ pub/sub (เช่น Google Pub/Sub) สำหรับงาน background/async
- Request/Response Payload: ทุกการเรียกจะพกพา metadata สำคัญเช่น session_id, user_id, tenant_id, request_type, timestamp และ trace_id เพื่อการติดตามและ audit
- Embeddings & RAG: Atlas จะคืน embeddings/semantic chunks ให้ Orchestrator ซึ่งจะใช้ร่วมกับ retrieval-augmented generation (RAG) — ChatGPT จะได้รับ snippets ที่เกี่ยวข้องพร้อมกับ prompt template เพื่อผลิตคำตอบที่มีการอ้างอิง
- Tool Invocation: เมื่อ ChatGPT ต้องการรันโค้ดหรือเรียกใช้โค้ดที่ Codex สร้างขึ้น เบื้องหลังจะมี contract ระหว่าง ChatGPT SDK และ Codex API ที่ระบุ input/output schema และ sandbox execution API สำหรับการทดสอบผลลัพธ์
การแชร์ Context / Session และการจัดการสถานะ
การรักษา continuity ของการสนทนาและการเชื่อมโยงระหว่างโมดูลจำเป็นต้องมี layer สำหรับจัดการสถานะกลาง (Session Manager) ซึ่งมักถูกออกแบบเป็น state store ที่รวดเร็ว (เช่น Redis) ประกอบด้วย:
- Session ID และ Conversation History: เก็บข้อความทั้งหมดหรือเชิงสรุปของบทสนทนาในรูปแบบที่สามารถนำไปต่อยอด เช่น raw messages, roles, timestamps
- Context Window Management: เนื่องจากข้อจำกัด token ของโมเดล ระบบต้องใช้เทคนิคเช่น semantic summarization หรือ windowed truncation เพื่อลดขนาดบริบท โดยอาจสลับข้อมูลเก่าเข้าไปเก็บใน vector DB เป็น long-term memory และนำเฉพาะ embedding ที่เกี่ยวข้องกลับมาเมื่อต้องการ
- Cross-Module Context Passing: เมื่อ Atlas คืนชุด snippet หรือเมื่อ Codex สร้างโค้ด Orchestrator จะเพิ่มผลลัพธ์เหล่านี้เป็น context entry ใน session store พร้อมกับ pointer (เช่น document_id, URL, code_version) เพื่อให้ ChatGPT สามารถอ้างอิงต่อเนื่องได้
- Transactional Integrity: การอัพเดตสถานะในหลายโมดูลควรใช้ pattern แบบ idempotent และมีการบันทึก event log เพื่อรองรับการ replay หรือ rollback เมื่อเกิดข้อผิดพลาด
ประเด็นด้าน Performance, Caching และ Latency
ระบบแบบบูรณาการนี้ต้องจัดการ trade-off ระหว่างความแม่นยำของผลลัพธ์และประสบการณ์ตอบสนองของผู้ใช้ ปัจจัยสำคัญและมาตรการที่ควรนำมาพิจารณาได้แก่:
- การเรียกแบบขนาน (Parallelization): เมื่อต้องดึงข้อมูลจาก Atlas และเรียก Codex/ChatGPT พร้อมกัน ควรรันคำร้องที่ไม่ขึ้นต่อกันแบบขนานเพื่อลด latency รวมถึงใช้ async IO และ non-blocking frameworks
- Caching Strategy: - Cache ผลการดึงหน้าเว็บและ embeddings ในระดับ CDN/edge และภายใน (Redis/Memcached) โดยตั้ง TTL ที่เหมาะสม
- Cache ชิ้นส่วนบริบท (context snippets) และผลลัพธ์ของ Codex ที่เป็น deterministic เช่น code templates เพื่อหลีกเลี่ยงการคำนวณซ้ำ - Streaming Responses & Progressive Rendering: ใช้เทคนิคการ stream จากโมเดล (SSE/WebSocket) เพื่อส่ง partial outputs ให้ผู้ใช้เห็นคำตอบแรกได้เร็ว ในขณะที่ระบบยังคงดึงข้อมูลเสริมจาก Atlas หรือรันการทดสอบโค้ดต่อไป
- Model Routing & Scaling: เลือกใช้โมเดลตาม SLA — ตัวอย่างเช่น route คำขอเชิงธุรกรรมสั้นไปยังโมเดลขนาดเล็กเพื่อลดค่าใช้จ่ายและ latency ในขณะที่งานที่ต้องการความละเอียดสูงจะถูกส่งไปยังโมเดลใหญ่ ทั้งนี้ต้องมี autoscaling group และ GPU pool management เพื่อรองรับโหลดตามต้องการ
- Backpressure, Timeouts และ Fallbacks: กำหนด timeout สำหรับแต่ละโมดูลและมี fallback strategy เช่น ถ้า Atlas ใช้เวลานานเกินไป ให้ ChatGPT ตอบโดยใช้ข้อมูลที่มีอยู่และแจ้งให้ผู้ใช้ทราบ หรือคืน cached result ทันที
สรุปคือ สถาปัตยกรรมที่มีประสิทธิภาพสำหรับการรวม ChatGPT, Codex และ Atlas Browser จำเป็นต้องมี orchestrator เป็นศูนย์กลาง, ชั้นการจัดการสถานะ/เซสชันที่รวดเร็ว, กลยุทธ์ caching และ streaming เพื่อลด latency รวมทั้งมาตรการด้านการ scaling และความเชื่อถือได้ (retries, circuit breakers) เพื่อให้ผู้ใช้ได้รับคำตอบที่เป็นต่อเนื่อง เชื่อถือได้ และตอบสนองรวดเร็วในบริบทเชิงธุรกิจ
เครื่องมือสำหรับนักพัฒนาและระบบนิเวศ (APIs, SDKs, Extensions)
API และ SDK ที่รองรับฟีเจอร์ของแอป
OpenAI ให้ชุดเครื่องมือสำหรับนักพัฒนาที่ครอบคลุมทั้งในรูปแบบ REST API และ SDK สำหรับภาษาโปรแกรมยอดนิยม (เช่น Python, JavaScript/Node.js) ซึ่งรองรับการเรียกใช้ฟีเจอร์ต่าง ๆ ของแอปรวมถึง ChatGPT, Codex และ Atlas Browser โดยตรง ฟังก์ชันหลัก ๆ ที่รองรับได้แก่:
- Text completion / Chat — การสนทนาแบบต่อเนื่องและการสร้างข้อความเชิงบริบท
- Code generation (Codex) — สร้างโค้ด อธิบายโค้ด แปลงคำอธิบายเป็นฟังก์ชัน และทำ refactor อัตโนมัติ
- Embeddings & Retrieval — สร้างเวกเตอร์เพื่อใช้กับระบบค้นคืนข้อมูล (RAG) และการค้นหาเอกสาร
- Browsing / Tools — การเข้าถึงเว็บและแหล่งข้อมูลภายนอกผ่าน Atlas Browser หรือปลั๊กอินที่ได้รับอนุญาต
- Streaming — ส่งผลลัพธ์แบบสตรีมเพื่อให้ UX ตอบสนองได้รวดเร็วโดยเฉพาะใน IDE หรือแชทไคลเอนต์
นอกจากนี้ SDK มักจะรวมฟังก์ชันกลาง ๆ เช่น การจัดการ token, retry, และการจัดการไฟล์เพื่ออัปโหลดสำหรับ training/finetune ทำให้นักพัฒนาสามารถโฟกัสที่การออกแบบ workflow ได้รวดเร็วขึ้น
Plugin / Extension Model และระบบนิเวศ
OpenAI เปิดระบบปลั๊กอิน/extension ที่ช่วยให้บริการภายนอกสามารถเชื่อมเข้ากับ ChatGPT, Atlas Browser และ Codex ได้อย่างปลอดภัยผ่าน manifest และระบบอนุญาต (เช่น OAuth หรือ signed requests) โดยจุดเด่นคือ:
- สถาปัตยกรรมแบบเปิด ที่อนุญาตให้ผู้ให้บริการข้อมูลและเครื่องมือพัฒนา integration ได้อย่างอิสระ
- มาตรการความปลอดภัย เช่น การจำกัด scope ของ API, การตรวจสอบสิทธิ์แบบ granular และการ rate limit เพื่อป้องกันการใช้งานเกินพิกัด
- use cases ที่เกิดขึ้นจริง เช่น การเรียกข้อมูลธุรกรรมจาก ERP, การค้นหาเอกสารภายในองค์กรผ่าน retrieval-augmented generation, และการผสานการทำงานกับระบบ CI/CD เพื่อสร้าง PR อัตโนมัติ
การมีระบบ plugin ทำให้ Atlas Browser สามารถใช้เป็นสะพานเชื่อมข้อมูลภายนอกได้อย่างยืดหยุ่น โดยยังคงควบคุมความเสี่ยงด้านข้อมูลและสิทธิ์การเข้าถึง
Integration กับ IDE และ Workflow ของนักพัฒนา
การผสานรวมกับ IDE เป็นกุญแจสำคัญที่ช่วยให้ Codex และ ChatGPT ถูกใช้งานใน workflow ประจำวันของนักพัฒนา โดยเฉพาะกับ VS Code, JetBrains IDEs และ editors ยอดนิยมอื่น ๆ ผสานคุณสมบัติดังนี้:
- Inline completions — แนะนำโค้ดแบบเรียลไทม์ ลดเวลาเขียนบล็อกโค้ดซ้ำ ๆ
- Code actions — สร้าง unit tests, refactor, หรือแปลงคอมเมนต์เป็นโค้ดภายในเมนูคำสั่งของ IDE
- Context-aware suggestions — ใช้บริบทของไฟล์/โปรเจกต์และ embedding เพื่อแนะนำโค้ดที่สัมพันธ์กับ repository
- CI/CD integration — สร้าง pipeline ที่ทดสอบโค้ดที่สร้างโดยโมเดล, รัน static analysis และบล็อกการ deploy หากพบความเสี่ยง
ตัวอย่าง workflow ที่พบได้บ่อยคือ นักพัฒนาส่งคำขอให้ Codex สร้างฟังก์ชันใหม่จากคำอธิบายสั้น ๆ ใน VS Code, ระบบสร้าง PR อัตโนมัติพร้อม unit tests และ pipeline ตรวจสอบก่อน merge — ลดรอบการพัฒนาและเพิ่มความสม่ำเสมอของโค้ด
ตัวอย่างโค้ดสั้น ๆ — เรียกใช้ Codex ผ่าน API จากภายในแอป
ตัวอย่างด้านล่างเป็นสคริปต์ JavaScript/Node.js แบบย่อที่แสดงการเรียกใช้งาน Codex ผ่าน REST API (ใช้ fetch) เพื่อขอให้โมเดลสร้างฟังก์ชันจากคำอธิบาย:
ตัวอย่าง (Node.js, แบบย่อ):
const response = await fetch("https://api.openai.com/v1/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_OPENAI_API_KEY"
},
body: JSON.stringify({
model: "code-davinci-002",
prompt: "Write a Python function to compute the Levenshtein distance between two strings with docstring.",
max_tokens: 300,
temperature: 0.2
})
});
const data = await response.json();
console.log(data.choices[0].text);
คำอธิบายสั้น ๆ: เปลี่ยนค่า model ให้ตรงกับรุ่น Codex ที่ใช้งานจริง, จัดการ error handling และ rate limiting ใน production และพิจารณาใช้ streaming เมื่อผลลัพธ์มีขนาดใหญ่หรือเมื่อต้องการ UX แบบเรียลไทม์
เคล็ดลับการนำไปใช้จริง: ให้ตั้งระบบ logging และ auditing ของคำสั่งที่ส่งไปยังโมเดล, ทดสอบโมเดลกับชุดเทสอัตโนมัติเพื่อป้องกัน regressive changes, และใช้ sandbox/feature-flag เพื่อเปิดใช้งานฟีเจอร์ AI ในกลุ่มผู้ใช้ที่จำกัดก่อนขยายไปยัง production
กรณีใช้งานจริงและผลกระทบต่ออุตสาหกรรม
กรณีใช้งานจริงและผลกระทบต่ออุตสาหกรรม
การรวมกันของ ChatGPT, Codex และ Atlas Browser ในรูปแบบแอปพลิเคชันเดียวเปิดช่องทางให้ภาคธุรกิจปรับปรุงกระบวนการทำงานอย่างเป็นรูปธรรม โดยเฉพาะในด้านการบริการลูกค้า (Customer Support), การพัฒนาซอฟต์แวร์, การวิจัยเชิงธุรกิจ และการวิเคราะห์เอกสารเชิงกฎหมาย ตัวอย่างการใช้งานจากหลายอุตสาหกรรมแสดงให้เห็นถึงผลลัพธ์เชิงปริมาณที่ชัดเจน เช่น การลดเวลาในการแก้ปัญหา เพิ่มประสิทธิภาพการทำงาน (productivity) และการเร่งคืนทุน (ROI) ที่จับต้องได้
Customer Support: ลดเวลาแก้ปัญหาและเพิ่มความพึงพอใจ
สถานการณ์ (scenario): ธุรกิจบริการโทรคมนาคมที่มีตั๋วร้องเรียนเข้ามากว่าหมื่นรายการต่อเดือน นำ ChatGPT มาเป็นแชทบอทชั้นแรกและใช้ Atlas Browser ดึงข้อมูลจากฐานความรู้ภายในองค์กรเพื่อตอบคำถามเชิงเทคนิคทันที
- ผลลัพธ์เชิงประสิทธิภาพ: เวลาตอบกลับเฉลี่ยลดลงจาก 6 ชั่วโมงเหลือ 1–2 ชั่วโมง (ลด 67–83%) ในกรณีคำถามทั่วไป และเวลาปิดเคส (time-to-resolution) ลดลงโดยประมาณ 30–50% สำหรับเคสที่ต้องการการค้นคว้า
- ผลต่อ KPI: เพิ่ม First Contact Resolution (FCR) ประมาณ 10–25% และลดค่าใช้จ่ายต่อเคส (cost-per-ticket) ประมาณ 20–40%
- ผลกระทบเชิงธุรกิจ: คะแนนความพึงพอใจลูกค้า (CSAT) เพิ่มขึ้น 5–12 คะแนน และคาดว่า ROI จะคืนทุนภายใน 3–9 เดือน ขึ้นกับขนาดทีม
การใช้ Codex ในการเร่งพัฒนาโปรดักต์และลดบั๊ก
สถานการณ์ (scenario): ทีมพัฒนาซอฟต์แวร์ภายในองค์กรการเงินนำ Codex มาช่วยเขียนโค้ดเบื้องต้น สร้าง unit test และตรวจจับ anti-patterns ก่อน deploy โดยผสานกับระบบ CI/CD
- ผลลัพธ์เชิงประสิทธิภาพ: ระยะเวลาในการพัฒนา feature ใหม่ลดลงประมาณ 25–40% เนื่องจาก Codex ช่วย scaffold โค้ดและสร้างตัวอย่างการใช้งาน (boilerplate)
- คุณภาพซอฟต์แวร์: อัตราบั๊กที่พบใน production ลดลง 20–35% เมื่อใช้ Codex ร่วมกับการทดสอบอัตโนมัติ และเวลาที่ใช้ในการแก้บั๊กในเฉลี่ยลดลง 30%
- ผลทางการเงิน: ลดค่าใช้จ่ายด้านงานบำรุงรักษา (maintenance) และลดเวลา time-to-market ทำให้สามารถปล่อยสินค้าได้เร็วกว่าคู่แข่ง ส่งผลให้ ROI ของทีมพัฒนาขยับขึ้นเป็นบวกภายใน 6–12 เดือน
Atlas Browser สำหรับการค้นคว้าวิจัยเชิงธุรกิจและเอกสารกฎหมาย
สถานการณ์ (scenario): ฝ่ายกฎหมายและการปฏิบัติตามกฎระเบียบ (compliance) ของบริษัทประกันภัยใช้ Atlas Browser เพื่อสืบค้นนโยบายภายใน กฎหมายที่เกี่ยวข้อง และบทความวิจัยด้านความเสี่ยง จากนั้นสรุปประเด็นสำคัญให้ผู้บริหาร
- ประสิทธิภาพการค้นคว้า: เวลาที่ใช้ในการทำ due diligence ลดลงโดยประมาณ 40–70% โดย Atlas ช่วยค้นหาเอกสารที่เกี่ยวข้อง สรุปสาระสำคัญและชี้แหล่งที่มาพร้อมคลิกสืบย้อน
- ความแม่นยำและการติดตามกฎระเบียบ: การใช้ Atlas ลดความเสี่ยงจากการพลาดข้อมูลสำคัญ และเพิ่มความเร็วในการอัปเดตนโยบายภายใน ทำให้เวลาที่ฝ่ายกฎหมายต้องใช้ในการร่างข้อเสนอแนะลดลง 30–50%
- ผลทางธุรกิจ: การตัดสินใจเชิงกลยุทธ์เร็วขึ้นและมีข้อมูลรองรับ ส่งผลให้ต้นทุนการปฏิบัติตามกฎระเบียบบางรายการลดลง และช่วยให้การเจรจาทางธุรกิจมีความได้เปรียบมากขึ้น
ตัวอย่างข้ามอุตสาหกรรม: การแพทย์ การศึกษา และการผลิต
ในภาคการแพทย์, ChatGPT ผสาน Atlas เพื่อสรุปงานวิจัยและแนวทางการรักษาให้แพทย์ภายในไม่กี่นาที ช่วยลดเวลาในการค้นคว้าวิจัยจากหลายชั่วโมงเหลือเพียง 20–60 นาที และช่วยเพิ่มอัตราการยึดตามแนวทางมาตรฐานทางการแพทย์ (guideline adherence) ประมาณ 10–20% ในขณะเดียวกัน Codex ช่วยพัฒนาซอฟต์แวร์จัดการผู้ป่วย (EHR integrations) ได้เร็วขึ้น
ในภาคการศึกษา, ครูและอาจารย์ใช้ ChatGPT ช่วยสร้างแบบฝึกหัด ตรวจงานเบื้องต้น และใช้ Atlas เพื่อรวบรวมแหล่งอ้างอิง ส่งผลให้เวลาการเตรียมการสอนลดลง 30–60% และเวลาการประเมินผลนักเรียนลดลง 20–40% ส่งผลให้ครูมีเวลาโฟกัสการสอนเชิงลึกมากขึ้น
ในภาคการผลิต, การรวม Codex กับระบบ automation ช่วยสร้างสคริปต์ควบคุมเครื่องจักรและตรวจสอบคุณภาพแบบเรียลไทม์ ซึ่งช่วยลด downtime ได้ประมาณ 10–30% และลดข้อผิดพลาดกระบวนการผลิต ส่งผลให้ productivity ต่อพนักงานเพิ่มขึ้น 15–35% ขึ้นอยู่กับระดับการปรับใช้
บทสรุปเชิงธุรกิจ
การนำ ChatGPT, Codex และ Atlas Browser มารวมกันในแอปพลิเคชันเดียวนำไปสู่การปรับปรุงประสิทธิภาพที่จับต้องได้ในหลายมิติ ทั้งการลดเวลาในการแก้ปัญหาในฝ่ายบริการลูกค้า การเร่งกระบวนการพัฒนาซอฟต์แวร์และลดบั๊ก รวมถึงการย่นระยะเวลาในการค้นคว้าวิจัยและวิเคราะห์เอกสารเชิงกฎหมาย โดยค่าประมาณที่เสนอ (เช่น ลดเวลา 25–70%, เพิ่ม productivity 10–35%, ROI คืนทุนภายใน 3–12 เดือน) เป็นแนวทางอ้างอิงที่องค์กรสามารถใช้ประเมินผลกระทบเชิงธุรกิจและวางแผนการลงทุนสำหรับการปรับใช้เทคโนโลยีนี้
ความปลอดภัย ความเป็นส่วนตัว และการปฏิบัติตามกฎระเบียบ
ภาพรวมความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัว
การรวม ChatGPT, Codex และ Atlas Browser ไว้ในแอปพลิเคชันเดียวมอบความสามารถสูง แต่ก็มาพร้อมกับความเสี่ยงด้านความปลอดภัยและความเป็นส่วนตัวที่ต้องบริหารอย่างเป็นระบบ เช่น การรั่วไหลของข้อมูลความลับ (secrets), การจัดการข้อมูลส่วนบุคคล (PII), และความจำเป็นในการอธิบายการตัดสินใจของโมเดล (explainability) เพื่อให้สอดคล้องกับข้อกฎหมายและความคาดหวังของผู้ใช้งาน ในการสำรวจองค์กรด้านเทคโนโลยีหนึ่งในปี 2023 พบว่า กว่า 68% ขององค์กรระบุว่าการใช้โมเดลภาษาขยายความเสี่ยงด้านการรั่วไหลของข้อมูลและการไม่เป็นไปตามข้อกำหนดด้านความเป็นส่วนตัว
นโยบายการจัดเก็บและการเข้ารหัสข้อมูล (Data residency / Encryption)
องค์ประกอบสำคัญในการลดความเสี่ยงคือการกำหนดนโยบายการจัดเก็บข้อมูลและการเข้ารหัสอย่างชัดเจน:
- Data residency: ระบุที่ตั้งศูนย์ข้อมูลที่อนุญาตให้ใช้งาน (เช่น อยู่ภายในเขตอำนาจศาลที่สอดคล้องกับ GDPR หรือ PDPA) และบังคับใช้นโยบายผ่านการตั้งค่า regional endpoints หรือ private deployment
- Encryption in transit and at rest: บังคับใช้การเข้ารหัสแบบ TLS สำหรับการส่งข้อมูล และการเข้ารหัสที่ระดับ storage เช่น AES-256 สำหรับข้อมูลที่เก็บไว้ รวมถึงการจัดการกุญแจโดยใช้ระบบ KMS (Key Management Service)
- Customer-managed keys (BYOK): ให้ลูกค้าสามารถใช้กุญแจของตนเองเพื่อเข้ารหัสข้อมูลและสำรองให้ผู้ให้บริการไม่สามารถเข้าถึง plaintext ได้โดยตรง เพิ่มความโปร่งใสและควบคุมตามข้อกำหนดความเป็นส่วนตัว
การจัดการข้อมูลความลับและการลดความเสี่ยงจากการส่ง context ไปยังโมเดล
การส่ง context หรือ prompt ที่มีข้อมูลสำคัญไปยังโมเดลอาจเป็นช่องทางให้ข้อมูลรั่วไหลได้ ตัวอย่างเช่น prompt ที่ประกอบด้วย API keys, รหัสผ่าน หรือข้อมูลลูกค้าที่ละเอียดอ่อน หากไม่ได้มีการกรองหรือจัดการก่อนส่งจะเสี่ยงต่อการเปิดเผยข้อมูลทั้งใน logs และ output ของโมเดล
- ห้ามแนบ secrets ลงใน prompt: ใช้ vaults (เช่น HashiCorp Vault) หรือ secret manager ในการเก็บข้อมูลลับ และดึงใช้ผ่านโค้ดฝั่งเซิร์ฟเวอร์โดยไม่ฝังลงใน prompt
- Context minimization: ส่งเฉพาะข้อมูลที่จำเป็นเท่านั้น—ใช้การสรุป (summarization), tokenization หรือ redaction ลบ PII ก่อนส่งไปยังโมเดล
- Client-side redaction และ transformation: ทำการลบหรือทำให้ไม่สามารถระบุได้ (pseudonymization) ก่อนส่งข้อมูลไปยัง service ของ OpenAI
- Ephemeral contexts และ session isolation: ออกแบบให้ context ของผู้ใช้เป็นชั่วคราว และแยกแต่ละ session เพื่อลดความเสี่ยงการข้ามบริบท (context leakage)
- ป้องกัน prompt injection: ใช้ pattern-based filters, model-based classifiers และ sandboxing เพื่อกรองคำสั่งที่อาจพยายามบังคับให้โมเดลเปิดเผยข้อมูลหรือทำงานที่ไม่พึงประสงค์
แนวทางปฏิบัติด้านการควบคุมการเข้าถึง (Access control) และการจัดการข้อมูล (Data governance)
การกำหนดสิทธิการเข้าถึงและนโยบายการจัดการข้อมูลช่วยลดความเสี่ยงเชิงปฏิบัติการได้อย่างมีประสิทธิภาพ:
- Principle of least privilege (PoLP): จัดสรรสิทธิการเข้าถึงแบบขั้นต่ำที่จำเป็น ใช้ RBAC/ABAC เพื่อจำกัดการเข้าถึง model endpoints, logs และ config
- Network controls & Zero Trust: จำกัดการเข้าถึงผ่าน VPC, private endpoints, IP allowlists และบังคับใช้นโยบาย Zero Trust เพื่อยืนยันตัวตนและคำขอทุกครั้ง
- Data classification & retention: แยกประเภทข้อมูล (public, internal, confidential, regulated) และกำหนดวงจรชีวิตข้อมูล (retention/deletion) ให้สอดคล้องกับกฎหมายและนโยบายองค์กร
- Data Loss Prevention (DLP): ติดตั้งระบบ DLP เพื่อสแกนและบล็อกข้อมูลที่ไม่ควรถูกส่งไปยังโมเดลหรือถูกบันทึกใน logs
การอธิบายการตัดสินใจของโมเดล (Explainability) และการตรวจสอบผลการทำงาน
ความสามารถในการอธิบายเหตุผลของโมเดลเป็นสิ่งจำเป็นทั้งทางกฎหมายและเชิงธุรกิจ โดยเฉพาะเมื่อโมเดลถูกใช้ตัดสินใจที่มีผลต่อบุคคลหรือหน่วยงาน:
- Model cards และ documentation: จัดทำเอกสารรับรองขอบเขตการใช้งาน ข้อจำกัด และผลประเมินความเสี่ยงของโมเดล เช่น ความแม่นยำในแต่ละกลุ่มประชากร
- Feature attribution & uncertainty estimates: รวมเทคนิคเช่น SHAP, LIME หรือ counterfactual explanations เพื่อช่วยให้ทีมความเสี่ยงและผู้ใช้อ่านเข้าใจปัจจัยที่นำไปสู่คำตอบ พร้อมแสดงค่าความไม่แน่นอน (confidence)
- Human-in-the-loop (HITL): ตั้งจุดตรวจสอบที่ให้ผู้เชี่ยวชาญมนุษย์พิจารณาคำตอบที่มีความเสี่ยงสูงหรือลูกค้าที่ร้องขอการอธิบายเชิงลึก
การตรวจสอบ (Auditing) และการปฏิบัติตามกฎระเบียบ (Compliance)
การบันทึกและตรวจสอบการทำงานของระบบเป็นหัวใจสำคัญของการรับผิดชอบและการปฏิบัติตามกฎระเบียบ:
- Immutable logging & provenance: เก็บ logs ของ prompt, metadata, ผู้เรียกใช้, และการตอบกลับ (โดยทำ redaction/Pseudonymization ตามความจำเป็น) ในรูปแบบไม่สามารถแก้ไขได้ เพื่อให้สามารถสอบย้อนกลับได้เมื่อมีเหตุผิดปกติ
- Periodic audits & third-party assessments: ดำเนินการตรวจสอบภายใน (internal audits) และการประเมินจากภายนอก เช่น SOC 2, ISO 27001 เพื่อยืนยันการปฏิบัติตามมาตรฐาน
- DPIA และ ROPA: สำหรับการประมวลผลข้อมูลส่วนบุคคลควรจัดทำ Data Protection Impact Assessment (DPIA) และบันทึก Records of Processing Activities (ROPA) เพื่อสอดคล้องกับ GDPR/PDPA และกฎหมายท้องถิ่นอื่น ๆ
- Continuous monitoring & model drift detection: ตั้งระบบในการติดตาม performance, bias และ data drift อย่างต่อเนื่อง พร้อมแผนแก้ไขเมื่อพบการเบี่ยงเบนจากค่า baseline
ข้อสรุปเชิงปฏิบัติสำหรับองค์กร
เพื่อให้การใช้งานแอปรวม ChatGPT, Codex และ Atlas Browser มีความปลอดภัยและสอดคล้องกฎระเบียบ องค์กรควรดำเนินการผสมผสานระหว่างนโยบายและเทคนิค ได้แก่ การใช้ encryption และ data residency ที่ชัดเจน, การห้ามใส่ secrets ใน prompt, การดำเนินการ DLP และ RBAC, การบันทึก auditing ที่โปร่งใส, และการนำแนวทาง explainability มาใช้อย่างเป็นระบบ ทั้งนี้การประเมินความเสี่ยงควรเป็นกระบวนการต่อเนื่อง โดยมีการทบทวนและทดสอบเป็นระยะ (เช่น test every 3–6 months) เพื่อให้สอดคล้องกับสภาพแวดล้อมภัยคุกคามและข้อกำหนดทางกฎหมายที่เปลี่ยนแปลง
ราคา การวางจำหน่าย และทิศทางตลาด
ราคา การวางจำหน่าย และทิศทางตลาด
โมเดลรายได้และตัวเลือกการสมัครใช้งาน — OpenAI ยืนยันแนวทางการหารายได้แบบผสมผสานที่ผสานทั้ง subscription สำหรับผู้ใช้รายบุคคลและข้อตกลงเชิงองค์กร (enterprise contracts) สำหรับลูกค้าองค์กรขนาดใหญ่ โดยมีชั้นการให้บริการที่แตกต่างกัน เช่น บริการพื้นฐานฟรีหรือฟรีมีข้อจำกัด, แผนรายเดือนสำหรับผู้ใช้ทั่วไปที่ให้สิทธิ์เข้าถึงฟีเจอร์พรีเมียม และสัญญาแบบ per-seat หรือ custom pricing สำหรับองค์กร ตัวอย่างเช่น แผนผู้ใช้ทั่วไปอาจตั้งราคาที่ระดับเดียวกับ ChatGPT Plus (~20 USD/เดือน ในตลาดบางแห่ง) ขณะที่การใช้ API ของ Codex หรือ Atlas Browser จะคิดค่าใช้จ่ายแบบใช้งานจริง (per-call / per-token) โดยมีส่วนลดเมื่อมีการสัญญาระยะยาวหรือมีปริมาณการใช้งานสูง (committed use discounts)
โครงสร้างเชิงพาณิชย์ที่ควรสังเกต — สำหรับองค์กร มักมีองค์ประกอบสำคัญ 3 ประการในสัญญา: (1) ค่าบริการตามผู้ใช้หรือการใช้งาน (per-seat vs usage-based), (2) ข้อตกลงด้าน SLA และการสนับสนุน (เช่น เวลาตอบสนอง, dedicated support), และ (3) ข้อกำหนดด้านความเป็นเจ้าของข้อมูลและการเก็บรักษาข้อมูล (data residency, deletion policies) นอกจากนี้ OpenAI มักเสนอตัวเลือกแบบ enterprise-tier ที่รวมการฝึกสอนเฉพาะองค์กร (fine-tuning) และการติดตั้งแบบเข้ารหัส/โซลูชัน on-premise หรือผ่านพันธมิตรคลาวด์สำหรับลูกค้าที่ต้องการการควบคุมข้อมูลสูง
การเข้าถึงและแผนการขยายภูมิภาค — ณ การเปิดตัว ฟีเจอร์หลักมักจะพร้อมให้บริการก่อนในภูมิภาคหลักเช่น สหรัฐฯ ยุโรป และบางประเทศในเอเชีย ผ่านทั้งช่องทางผู้บริโภคและการขายองค์กร โดยจะขยายไปยังภูมิภาคอื่น ๆ ตามการปฏิบัติตามกฎระเบียบ (compliance) และการตั้งศูนย์ข้อมูลในภูมิภาคนั้น ๆ เพื่อรองรับข้อกำหนดด้าน data residency แผนการขยายในอนาคตคาดว่าจะรวมการเพิ่มศูนย์ข้อมูลในเอเชียตะวันออกเฉียงใต้ ลาตินอเมริกา และยุโรปตะวันออก รวมถึงการเพิ่มความสามารถ localized เช่น การรองรับภาษาท้องถิ่นและการปรับให้เข้ากับกรอบกฎหมายของแต่ละประเทศ
ผลกระทบต่อการแข่งขันในตลาด AI productivity — การรวมกันของ ChatGPT, Codex และ Atlas Browser ในผลิตภัณฑ์เดียวสร้างความท้าทายเชิงกลยุทธ์ให้กับคู่แข่งรายสำคัญ เช่น Microsoft (Copilot, GitHub Copilot), Google (Gemini, Duet), Anthropic (Claude) และผู้ให้บริการคลาวด์รายอื่น ๆ ผลกระทบที่สำคัญได้แก่:
- แรงกดดันด้านราคาและแพ็กเกจ — การมีทั้งโมเดลสำหรับผู้ใช้ทั่วไปและ API สำหรับนักพัฒนาในชุดเดียว ทำให้ OpenAI สามารถเสนอแพ็กเกจแบบบันเดิลที่มีมูลค่าสูง ซึ่งอาจบีบให้คู่แข่งต้องปรับราคาและข้อเสนอเชิงลึก
- การล็อกอินเชิงแพลตฟอร์ม (platform lock-in) — เมื่อลูกค้าองค์กรผนวกการทำงานของ Codex กับ workflow ภายในและใช้ Atlas ในการค้นคว้า/อ้างอิงข้อมูล จะเพิ่มความยุ่งยากในการย้ายไปยังผู้ให้บริการอื่น
- การเร่งนวัตกรรมฟังก์ชันการผลิตงาน (productivity) — คู่แข่งจะต้องเร่งพัฒนาการผนวกเครื่องมือเขียนโค้ดและการค้นคว้าข้อมูลเชิงบริบท เพื่อไม่ให้ถูกทิ้งห่างในด้านประสิทธิภาพการทำงาน
คำแนะนำสำหรับองค์กรที่พิจารณานำมาใช้งาน — ก่อนลงนามในสัญญาหรือเปิดใช้บริการเชิงองค์กร ควรดำเนินการตามขั้นตอนหลักดังนี้:
- ประเมินความต้องการและกรณีการใช้งาน (Use-case fit) — ระบุว่าองค์กรต้องการฟีเจอร์ใด (เช่น อัตโนมัติการเขียนโค้ด, ช่วยค้นคว้า, ตัวช่วยลูกค้า) และวัดผลตอบแทนต่อการลงทุน (ROI)
- ทดสอบเชิงพยาน (Pilot) — เริ่มต้นด้วยโครงการนำร่องที่จำกัดขอบเขต เพื่อวัดการใช้งานจริง ค่าใช้จ่ายที่แท้จริง และปัญหาด้านข้อมูล
- ต่อรองข้อตกลงเชิงเทคนิคและกฎหมาย — ขอ SLA ที่ชัดเจน, สิทธิ์ในการเข้าถึงและลบข้อมูล, เงื่อนไขการสำรองข้อมูลและการเข้าถึง audit logs รวมทั้งส่วนลดตามปริมาณการใช้
- ประเมินต้นทุนรวม (TCO) — คำนวณต้นทุนการใช้งานแบบ subscription + usage-based + ค่า integration, training และการบำรุงรักษา
- วางนโยบายความปลอดภัยและการกำกับดูแล — กำหนดมาตรการควบคุมข้อมูล ความเป็นส่วนตัว และมาตรการจำกัดความเสี่ยง เช่น การใช้ data encryption, DLP และการแยกข้อมูลที่อ่อนไหว
สรุป — การเปิดตัวผลิตภัณฑ์ที่รวม ChatGPT, Codex และ Atlas Browser สะท้อนถึงโมเดลธุรกิจที่ยืดหยุ่นระหว่าง subscription และการคิดค่าบริการตามการใช้งาน ซึ่งมีศักยภาพสร้างความได้เปรียบเชิงกลยุทธ์ แต่ก็นำมาซึ่งคำถามด้าน governance และต้นทุนที่องค์กรต้องบริหารอย่างรอบคอบ องค์กรที่เตรียมพร้อมด้วยกระบวนการทดลอง การเจรจาสัญญาที่รัดกุม และนโยบายข้อมูลที่ชัดเจน จะได้เปรียบในการนำเทคโนโลยีชุดนี้ไปใช้ให้เกิดผลสูงสุด
บทสรุป
การรวม ChatGPT, Codex และ Atlas Browser ไว้ในแอปพลิเคชันเดียวถือเป็นก้าวสำคัญที่สามารถยกระดับประสิทธิภาพการทำงานและเร่งนวัตกรรมได้อย่างชัดเจน — โดย ChatGPT ช่วยด้านการสื่อสารและการสร้างเนื้อหา, Codex ช่วยด้านการเขียนและตรวจสอบโค้ด, และ Atlas Browser ช่วยในการค้นหาและเชื่อมข้อมูลเชิงบริบทแบบเรียลไทม์ การผสานกันของความสามารถเหล่านี้ทำให้ workflow ที่เคยต้องใช้งานหลายเครื่องมือกลายเป็นกระบวนการที่ต่อเนื่องและมีประสิทธิผลมากขึ้น (งานวิจัยและรายงานเชิงอุตสาหกรรมชี้ว่าองค์กรที่นำ AI เข้ามาใช้งานในกระบวนการทำงานสามารถเห็นการปรับปรุง productivity อยู่ในระดับหลักสิบเปอร์เซ็นต์) อย่างไรก็ตาม การรวมฟังก์ชันระดับสูงเหล่านี้ยังเพิ่มความเสี่ยงด้านการจัดการข้อมูล ความเป็นส่วนตัว ความมั่นคงของระบบ และ governance — ประเด็นเช่นการรั่วไหลของข้อมูล การสร้างข้อมูลเท็จ (hallucination) และสิทธิ์ในทรัพย์สินทางปัญญาจำเป็นต้องมีมาตรการควบคุม การตรวจสอบ และกรอบนโยบายที่ชัดเจนก่อนนำไปใช้ในสเกลใหญ่
สำหรับองค์กร ควรเริ่มจากการประเมินกรณีใช้งานเชิงธุรกิจอย่างเป็นระบบและออกแบบโครงการนำร่องที่มีขอบเขตชัดเจน เทียบวัดผลด้วยตัวชี้วัดเชิงปริมาณ เช่น เวลาในการทำงานลดลง อัตราความถูกต้องของผลลัพธ์ จำนวนข้อผิดพลาดด้านความปลอดภัย และดัชนีความพึงพอใจของผู้ใช้งาน โดยระบุเกณฑ์ผ่าน/ไม่ผ่านสำหรับการขยายสู่การใช้งานระดับองค์กร ควบคู่กับการตั้งมาตรฐานด้านข้อมูล การเข้ารหัส การควบคุมการเข้าถึง และแผนการสำรองข้อมูล ในมุมมองอนาคต การผสานเครื่องมือ AI แบบรวมศูนย์จะกลายเป็นมาตรฐานของระบบงานสมัยใหม่ แต่ความสำเร็จขึ้นอยู่กับการบริหารความเสี่ยงเชิงรุก การกำกับดูแลอย่างมีธรรมาภิบาล และการสร้างความสามารถภายในองค์กรเพื่อใช้เทคโนโลยีนี้อย่างปลอดภัยและยั่งยืน
📰 แหล่งอ้างอิง: MacRumors



