
สตาร์ทอัพไทยเปิดตัว AutoPatchAI ระบบอัตโนมัติที่สัญญาจะเปลี่ยนวิธีการจัดการช่องโหว่ความปลอดภัยในวงการซอฟต์แวร์ ด้วยการผสานพลังของ Large Language Models (LLM) เข้ากับเทคนิคทดสอบความทนทานเช่น fuzzing และการวิเคราะห์เชิงสัญลักษณ์ (symbolic execution) AutoPatchAI สามารถระบุ ตัดสินใจ และสร้างแพตช์แก้ไขช่องโหว่ได้โดยอัตโนมัติ พร้อมทั้งสังเคราะห์ unit test ยืนยันความถูกต้องก่อนที่จะ merge โค้ดขึ้นสู่สาขาหลัก ซึ่งช่วยลดระยะเวลาแก้บั๊กจากระดับวันลงมาเหลือเพียงชั่วโมงเท่านั้น
ตามข้อมูลเบื้องต้นจากทีมพัฒนาระบบ การทดลองในโครงการนำร่องแสดงผลว่าค่าเฉลี่ยเวลาการซ่อมบั๊กลดลงอย่างมีนัยสำคัญ (รายงานภายในชี้การลดเวลาเฉลี่ยราว 70–90%) โดย AutoPatchAI ไม่เพียงแต่เร่งกระบวนการแก้ไข แต่ยังลดความเสี่ยงช่วงเวลาที่ระบบเปิดรับการโจมตี (window of exposure) และช่วยยกระดับกระบวนการ DevSecOps ให้เป็นไปอย่างอัตโนมัติและเชื่อถือได้ บทความต่อไปจะพาไปรู้จักสถาปัตยกรรมการทำงาน กระบวนการทดสอบผลลัพธ์ และผลทดสอบเชิงปฏิบัติการที่แสดงให้เห็นศักยภาพของเครื่องมือนี้ต่อการป้องกันความเสี่ยงด้านความปลอดภัยขององค์กรไทยและระดับสากล
สรุปข่าวและความสำคัญของ AutoPatchAI
สรุปข่าวและความสำคัญของ AutoPatchAI
AutoPatchAI เป็นผลิตภัณฑ์ใหม่ที่เปิดตัวโดยสตาร์ทอัพไทย ซึ่งนำแนวทางปัญญาประดิษฐ์มาผสานกับเทคนิคการทดสอบความปลอดภัยเชิงลึก เพื่อสร้างแพตช์ช่องโหว่อัตโนมัติและยืนยันความถูกต้องก่อนผสานเข้าระบบจริง จุดเด่นหลักของ AutoPatchAI คือการรวมความสามารถของ Large Language Models (LLMs) เข้ากับเทคนิคทางวิศวกรรมความปลอดภัยแบบดั้งเดิมอย่าง fuzzing และ symbolic execution พร้อมทั้งฟีเจอร์สร้าง unit test อัตโนมัติเพื่อยืนยันก่อน merge ทำให้สตาร์ทอัพอ้างว่าเวลาซ่อมบั๊กด้านความปลอดภัยลดจากระดับวันเหลือเพียงระดับชั่วโมง
ในเชิงฟีเจอร์ AutoPatchAI เสนอกระบวนการทำงานแบบอัตโนมัติเต็มรูปแบบตั้งแต่การตรวจจับ ไปจนถึงการออกแพตช์และการยืนยันผล ตัวอย่างฟีเจอร์สำคัญได้แก่:
- LLM-driven patch generation — ใช้โมเดลภาษาขนาดใหญ่ในการวิเคราะห์โค้ดที่มีช่องโหว่และสร้างโค้ดแพตช์ต้นแบบ พร้อมคำอธิบายการเปลี่ยนแปลง
- Fuzzing integration — สร้างอินพุตแบบสุ่มเชิงโต้ตอบเพื่อค้นหาจุดล้มเหลวที่แท้จริงและยืนยันพฤติกรรมที่เป็นปัญหา
- Symbolic execution — ตรวจสอบเงื่อนไขเชิงตรรกะของเส้นทางโค้ดเพื่อพิสูจน์ว่าช่องโหว่ถูกปิดจริงและลดความเสี่ยงของ regression
- Unit test generation — สร้างชุดทดสอบอัตโนมัติ (unit/integration tests) ที่ยืนยันว่าแพตช์แก้ปัญหาได้จริง และแนบไปกับ pull request ก่อนการ merge
- CI/CD integration — รองรับการเชื่อมต่อกับระบบจัดการซอร์สโค้ดและ pipeline (เช่น GitHub/GitLab/Jenkins) เพื่อทำงานแบบอัตโนมัติในวงจรการพัฒนา
ผลลัพธ์เชิงตัวเลขที่สตาร์ทอัพนำเสนอเป็นข้อมูลเบื้องต้นระบุว่า AutoPatchAI สามารถลด mean time to remediation (MTTR) ได้อย่างมีนัยสำคัญ — ตัวอย่างเช่นจากช่วงเวลาปกติที่ทีมอาจใช้ระหว่าง 24–72 ชั่วโมง สำหรับการวินิจฉัยและซ่อมบั๊ก ลงมาเหลือเพียง 1–4 ชั่วโมง ในกรณีทดสอบบางชุด นอกจากนี้ยังระบุว่าการใช้แพลตฟอร์มช่วยลดภาระงานเชิงซ้ำซ้อนของทีมรักษาความปลอดภัยและวิศวกรซอฟต์แวร์ ทำให้สามารถจัดการปริมาณช่องโหว่ได้มากขึ้นโดยไม่เพิ่มทีมงานเป็นเท่าตัว
ในเชิงธุรกิจ เทคโนโลยีนี้มีความสำคัญต่อวงการ DevSecOps อย่างยิ่ง เพราะช่วยลดหน้าต่างเวลาที่แฮกเกอร์สามารถใช้ประโยชน์จากช่องโหว่ (reduction of exposure window) ลดต้นทุนจากการสืบสวนและ remediation และเพิ่มความเร็วในการปล่อยฟีเจอร์ใหม่ให้ปลอดภัยตามข้อกำหนดการกำกับดูแล การที่ระบบสร้าง unit test ยืนยันก่อน merge ยังช่วยลดความเสี่ยงของ regression ใน production ทำให้กระบวนการรักษาความปลอดภัยกลายเป็นส่วนหนึ่งของ CI/CD อย่างแท้จริง ทั้งนี้สตาร์ทอัพยังเน้นว่าแม้ระบบจะช่วยอัตโนมัติได้มาก แต่การทบทวนโดยมนุษย์ยังคงจำเป็นสำหรับเคสซับซ้อน เพื่อให้ได้สมดุลระหว่างความเร็วและความถูกต้อง
เทคโนโลยีเบื้องหลัง: LLM, Fuzzing และ Symbolic Execution คืออะไร
เทคโนโลยีเบื้องหลัง: LLM, Fuzzing และ Symbolic Execution คืออะไร
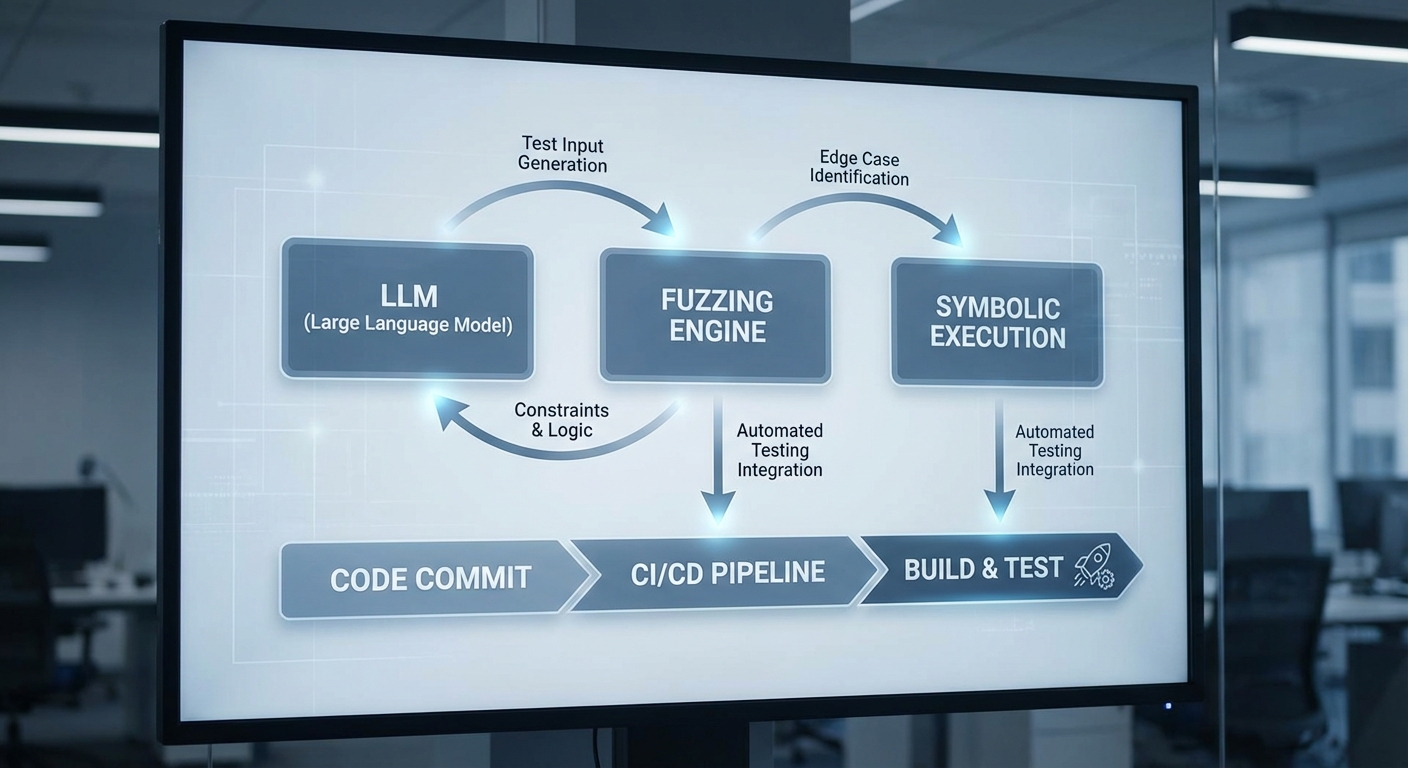
ระบบ AutoPatchAI ใช้การผสานของสามเทคโนโลยีหลักเพื่อยกระดับกระบวนการค้นหาและซ่อมแซมช่องโหว่จากรูปแบบเดิมไปสู่การทำงานอัตโนมัติที่มีความเชื่อถือได้สูง โดยแต่ละเทคโนโลยีมีบทบาทเฉพาะตัวและเสริมจุดอ่อน-จุดแข็งซึ่งกันและกัน ทำให้ภาพรวมของกระบวนการมีทั้งความครอบคลุมในการค้นหา ความสามารถในการเข้าใจเชิงสาเหตุ และความถูกต้องเชิงตรรกะของการแก้ไข ในภาพรวมกระบวนการจะประกอบด้วย: การค้นหข้อบกพร่องเชิงพฤติกรรมด้วย fuzzing, การวิเคราะห์เส้นทางเชิงตรรกะด้วย symbolic execution และการสร้างแพตช์พร้อมคำอธิบายด้วย LLM เพื่อนำไปสู่การสร้าง unit test ที่ยืนยันการแก้ไขก่อน merge
บทบาทของ LLM (Large Language Models)
LLM ถูกใช้งานในฐานะ "นักวิเคราะห์และผู้เขียนแพตช์" ชั้นสูง: เมื่อระบบได้รับข้อมูลสัญญาณของบั๊ก—เช่น สแต็กเทรซ ข้อมูล input ที่ทำให้เกิดบั๊ก หรือผลจาก fuzzing—LLM จะทำการอ่านบริบทของโค้ด ตีความเจตนาของโค้ดต้นทาง และเสนอทั้งคำอธิบายเป็นภาษาธรรมชาติรวมถึงโค้ดแพตช์ที่เป็นไปได้ นอกจากนี้ LLM ยังสามารถสร้างข้อความอธิบายสาเหตุ (root cause) ในรูปแบบที่เข้าใจง่ายสำหรับทีมพัฒนา และสร้างชุด unit test หรือ regression test ที่คาดว่าจะแน่ใจว่าแพตช์แก้ปัญหาได้จริง ตัวอย่างการใช้งานเชิงปฏิบัติ เช่น LLM สามารถให้คำอธิบายว่า "บั๊กเกิดจากการไม่ตรวจสอบขอบเขตของอาร์เรย์ก่อนเข้าถึง" พร้อมกับตัวอย่างโค้ดที่แก้การตรวจสอบขอบเขตและ unit test ประกอบ
บทบาทของ Fuzzing
Fuzzing เป็นเทคนิคการทดสอบเชิงพลวัตที่มุ่งสร้างอินพุตรูปแบบต่าง ๆ ทั้งแบบสุ่ม การเปลี่ยนแปลงจากตัวอย่างจริง (mutation-based) หรือการผลิตจากรูปแบบ (generation-based) เพื่อตรวจพบพฤติกรรมผิดปกติ เช่น การเกิด crash, memory leak, assertion failure หรือ unexpected exception โดยเฉพาะอย่างยิ่ง coverage-guided fuzzers เช่น AFL, LibFuzzer สามารถค้นพบอินพุตที่เล็งไปยังเส้นทางที่มักถูกมองข้ามได้อย่างกว้างขวาง งานวิจัยและรายงานจากภาคอุตสาหกรรมแสดงให้เห็นว่า fuzzing มักค้นพบช่องโหว่ระดับความปลอดภัยจำนวนมาก โดยเฉพาะช่องโหว่ที่เกี่ยวข้องกับหน่วยความจำและ parsing logic — ตัวเลขการทำงานจริงอาจเห็น fuzzing สร้างและทดสอบอินพุตจำนวนหมื่นถึงล้านรายการต่อวันในสภาพแวดล้อมที่ปรับแต่งสูง
บทบาทของ Symbolic Execution
Symbolic execution ทำหน้าที่เป็นเครื่องมือวิเคราะห์เชิงตรรกะที่เติมเต็ม fuzzing และ LLM โดยการแทนค่าตัวแปรด้วยสัญลักษณ์แล้วติดตามเงื่อนไขตามเส้นทางการไหลของโปรแกรม เพื่อหาเงื่อนไขที่ทำให้เกิดสถานะผิดปกติหรือพิสูจน์ว่าเส้นทางใด ๆ จะไม่ละเมิดความปลอดภัย ตัวอย่างเช่น เมื่อ fuzzing ให้ input ที่ทำให้เกิด crash symbolic execution สามารถย้อนกลับเพื่อค้นหา path condition ที่แท้จริงและสร้างข้อพิสูจน์เชิงตรรกะว่าข้อกำหนด (เช่น "index < length") ถูกละเมิดในกรณีใดบ้าง นอกจากนี้ symbolic execution สามารถใช้เป็นตัวตรวจสอบว่าการแก้ไขที่เสนอโดย LLM รักษา invariants และ pre/post-conditions ที่สำคัญของฟังก์ชันหรือไม่ แม้ว่าจะต้องจัดการกับปัญหา path explosion และ complex constraints solver แต่เทคนิคผสมเช่น concolic execution (concrete + symbolic) และการจำกัดขอบเขตการวิเคราะห์ช่วยทำให้มันใช้งานได้ในสเกลของระบบจริง
การผสานทั้งสามอย่างทำงานร่วมกันอย่างไร
- ขั้นตอนเริ่มต้น (Discovery): ระบบเริ่มด้วย fuzzing เพื่อค้นหา input ที่ทำให้เกิดพฤติกรรมผิดปกติ—ตัวอย่างเช่น crash, timeout หรือ assertion failure—ซึ่งเป็นสัญญาณเบื้องต้นของช่องโหว่
- การวิเคราะห์เชิงตรรกะ: เมื่อได้ตัวอย่างอินพุตที่ก่อปัญหา ระบบจะส่งข้อมูลไปยัง symbolic execution เพื่อตรวจสอบเส้นทางการทำงานอย่างละเอียด หาจุดที่เงื่อนไขถูกละเมิด และสร้าง path condition ที่ชัดเจน ซึ่งช่วยระบุสาเหตุเชิงตรรกะได้แม่นยำกว่าเพียงแค่สังเกตจากการรันจริง
- การสร้างแพตช์ด้วย LLM: ด้วยข้อมูลเชิงบริบทจากโค้ด สแต็กเทรซ ผลการ fuzzing และข้อสรุปจาก symbolic execution—LLM จะเสนอแพตช์โค้ดที่คำนึงถึง invariants ที่ต้องรักษา พร้อมคำอธิบายเป็นภาษาธรรมชาติว่าเพราะเหตุใดการเปลี่ยนแปลงนี้จึงปลอดภัยและเพียงพอ
- การพิสูจน์และสร้าง unit test: ก่อนที่จะยอมรับแพตช์ ระบบจะใช้ symbolic execution อีกครั้งเพื่อพิสูจน์ว่าเส้นทางสำคัญที่เคยล้มเหลวถูกปิดกั้น และ LLM จะสร้าง unit test ที่จำลอง input กรณีล้มเหลวเหล่านั้น ทำให้ทีมพัฒนามีหลักฐานอัตโนมัติที่ยืนยันการแก้ไขก่อน merge
- การวนลูปจนมั่นใจ: หาก symbolic execution พบกรณีพิเศษใหม่หรือ fuzzing ยังสร้าง input ใหม่ที่ล้มเหลว กระบวนการจะย้อนกลับเพื่อให้ LLM ปรับแพตช์และรันการทดสอบซ้ำจนกว่าจะผ่านเกณฑ์ที่กำหนด
ผลลัพธ์จากการผสานนี้คือการเพิ่มอัตราความถูกต้องของแพตช์และลด false positive/false negative ทั้งในเชิงการค้นหาและการแก้ไข เมื่อนำไปใช้งานจริง AutoPatchAI สามารถลดเวลาในการซ่อมบั๊กที่เกี่ยวกับความปลอดภัยจากระดับหลายวันลงมาเหลือเป็นชั่วโมง โดยที่ทีมพัฒนายังได้รับเอกสารอธิบายสาเหตุและชุด unit test ประกอบการยืนยัน การรวมกันของ fuzzing (ค้นหาอย่างกว้าง) + symbolic execution (ตรวจพิสูจน์เส้นทาง/เงื่อนไข) + LLM (เข้าใจบริบทและสร้างแพตช์พร้อมคำอธิบาย) จึงเป็นสูตรที่ช่วยให้การจัดการช่องโหว่มีความรวดเร็วและเชื่อถือได้มากขึ้นสำหรับองค์กรธุรกิจ
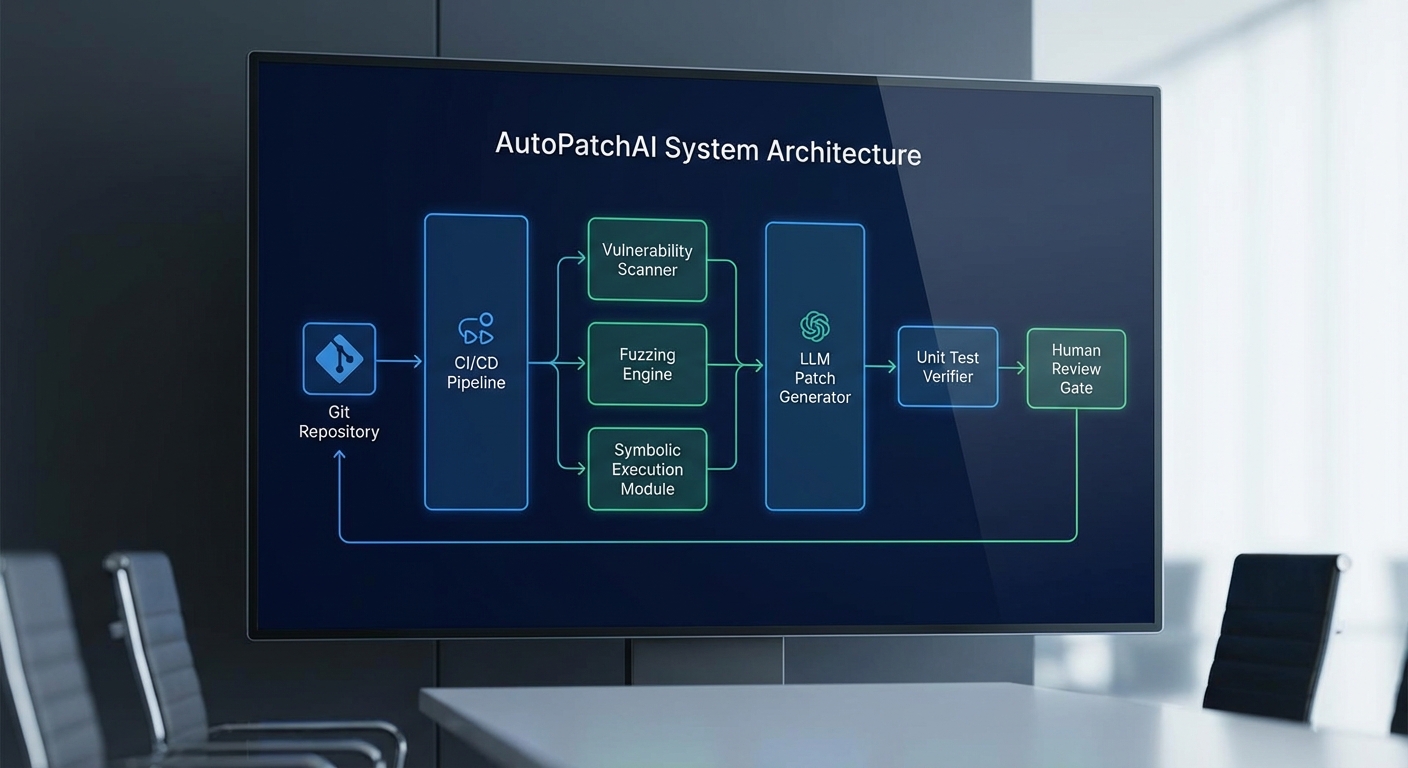
สถาปัตยกรรมระบบ AutoPatchAI และการผสานเข้ากับ CI/CD
สถาปัตยกรรมของ AutoPatchAI ถูกออกแบบมาเพื่อเชื่อมกระบวนการตรวจจับช่องโหว่ การวิเคราะห์เชิงสัญลักษณ์ (symbolic execution) การสร้างแพตช์ด้วย LLM และการยืนยันความถูกต้องของแพตช์เข้ากับท่อพัฒนา (CI/CD) อย่างราบรื่น โดยคำนึงถึงความปลอดภัย ความสามารถในการตรวจสอบย้อนหลัง (auditability) และจุดควบคุมโดยมนุษย์ (human-in-the-loop) ตั้งแต่ต้นทางถึงจุด merge ผลลัพธ์คือการลดเวลาซ่อมบั๊กด้านความปลอดภัยจากหลายวันเหลือเป็นชั่วโมงในหลายกรณี ตัวอย่างการวัดผลภายใน (POC) พบว่า AutoPatchAI สามารถลดค่า MTTR เฉลี่ยได้ราว 70–90% ขึ้นอยู่กับชนิดของบั๊กและคุณภาพของเทสชุดเดิม
โมดูลสำคัญของระบบและหน้าที่
- Scanner / Fuzzer — ตัวดักจับและสร้างสัญญาณช่องโหว่เริ่มต้น โดยรองรับทั้ง static analysis, dynamic fuzzing (coverage-guided fuzzers เช่น AFL/FuzzBench integrations) และ SAST/DAST แบบผสม ให้ผลลัพธ์เป็นรายงานความเสี่ยงพร้อมข้อมูลรีโปรดิวซ์ (repro steps), stack trace และ input case ที่ก่อให้เกิดบั๊ก
- Analyzer (Symbolic Engine) — รับข้อมูลจาก Scanner เพื่อลด false positive และสร้างโมเดลเชิงสัญลักษณ์ของเส้นทางการรันโค้ด (path constraints) เครื่องมือนี้สามารถพิสูจน์ความเป็นไปได้ของ exploit, หา pre/post conditions และคำนวณขอบเขตของแพตช์ที่ปลอดภัยได้ โดยส่งออกเป็นข้อจำกัดเชิงสัญลักษณ์ที่ Patch Generator ใช้อ้างอิง
- Patch Generator (LLM-backed) — โมดูลสร้างโค้ดที่ใช้ LLM ปรับแต่งด้วย prompt engineering และทรัพยากรแบบจำเพาะ (code patterns, secure coding rules) เพื่อเสนอชุดการเปลี่ยนแปลงโค้ดหลายทางเลือก แต่ละตัวเลือกแนบกับ confidence score และ mapping ไปยัง symbolic constraints ที่ Analyzer ระบุ
- Patch Verifier — ประกอบด้วยสองชั้นหลัก: (1) Unit Test Generator ที่สร้างชุดทดสอบอัตโนมัติจาก repro cases และจากการสืบค้นพฤติกรรมของโค้ด และ (2) Symbolic Re-check ที่รัน symbolic execution อีกครั้งเพื่อพิสูจน์ว่าเงื่อนไขความปลอดภัยที่กำหนดยังคงเป็นจริงหลังแพตช์ โมดูลนี้ยังรัน regression tests และ fuzzing แบบ targeted เพื่อตรวจหาผลกระทบด้านข้าง
- Integration Adapter — ตัวเชื่อมกับระบบภายนอก เช่น Git (GitHub/GitLab), CI/CD (Jenkins, GitHub Actions, GitLab CI), และระบบแจ้งเตือน/issue tracker (Jira, Slack, Microsoft Teams) รับผิดชอบการสร้าง branch/PR, แทรก pipeline stage สำหรับ verification, และส่งการแจ้งเตือนตาม policy
- Policy & Governance Layer — เครื่องมือกำหนดนโยบาย (เช่น อนุญาต auto-merge เฉพาะความร้ายแรงต่ำเมื่อผ่าน checks 100% หรือบังคับ human-review สำหรับแพตช์ที่แก้ code path สำคัญ) พร้อมเก็บ audit log, digital signature ของแพตช์ และ metadata เพื่อการตรวจสอบย้อนหลัง
การไหลของข้อมูลตั้งแต่การตรวจพบจนถึงการ merge
- 1) Detection: Scanner/Fuzzer พบกรณีที่เป็นไปได้และส่งเหตุการณ์ไปยัง Analyzer พร้อมกับ input repro และ context ของ repository
- 2) Triage: Analyzer ใช้ symbolic execution เพื่อลด false positive และระบุ root cause พร้อมขอบเขตของโค้ดที่จะได้รับผลกระทบ ระบบเก็บคะแนนความร้ายแรง (CVSS-like) และ confidence
- 3) Patch Proposal: Patch Generator สร้างชุดแพตช์ 2–5 แบบที่แตกต่างกันตามแนวทางแก้ไข เช่น sanitize input, change logic precondition, หรือเพิ่ม guard clause พร้อมข้อเสนอ unit tests เบื้องต้น
- 4) Automated Verification: Patch Verifier รัน unit tests ที่สร้างจาก repro cases และชุด regression ที่มีอยู่ รวมถึงรัน symbolic re-check เพื่อพิสูจน์ว่าเงื่อนไขด้านความปลอดภัยได้รับการป้องกันจริง ถ้าผ่านทุกการตรวจ ระบบเตรียม PR อัตโนมัติ
- 5) Integration & Gatekeeping: Integration Adapter สร้าง branch/PR ใน repository, ติดตั้ง CI pipeline ที่มีขั้นตอนพิเศษ เช่น extended fuzzing stage สำหรับแพตช์ที่มีความเสี่ยงสูง และติดแท็ก PR ด้วย metadata ของการตรวจสอบ
- 6) Human-in-the-loop Review: ขึ้นอยู่กับ policy อาจอนุญาต auto-merge หรือรอการอนุมัติจาก reviewer มนุษย์ โดย UI แสดง diff ที่ LLM อธิบายอย่างชัดเจน พร้อม confidence scores และผลการตรวจเชิงสัญลักษณ์
- 7) Merge & Post-checks: หลัง merge ระบบรัน post-merge monitoring, canary deployment และเก็บ audit logs/ธัมบ์พริ้นท์ของแพตช์ เผื่อ rollback หรือสร้าง hotfix ต่อไป
จุดเชื่อมต่อกับ Git, CI/CD และระบบแจ้งเตือน
Integration Adapter ถูกออกแบบเป็นชุด connector แบบปลั๊กอินที่รองรับ webhook และ API ของระบบยอดนิยม ทำงานร่วมกับ:
- Git providers: สร้าง branch/PR, เพิ่ม comments อัตโนมัติ, แท็ก PR ด้วยสถานะการตรวจสอบ
- CI/CD: เปิด stage เฉพาะใน pipeline (e.g., patch-verification, extended-fuzz) และส่งผลลัพธ์กลับเป็น build status เพื่อบังคับ gate
- Issue trackers & Notifications: เปิด ticket อัตโนมัติ (Jira) พร้อมลิงก์ PR และส่งการแจ้งเตือนเชิงบริบทผ่าน Slack/Teams พร้อมการสรุประดับความร้ายแรงและ recommended action
นอกจากนี้ Adapter ยังรองรับการส่ง artifact ของการทดสอบ (test reports, symbolic proofs, coverage reports) ไปยังระบบเก็บหลักฐานกลาง (artifact store) เพื่อการ audit และการวิเคราะห์ย้อนหลัง
การออกแบบ Human-in-the-loop เพื่อควบคุมความปลอดภัยก่อน merge
ระบบถูกออกแบบให้มีจุดควบคุมโดยมนุษย์ในหลายระดับเพื่อป้องกันความเสี่ยงจากการเปลี่ยนแปลงอัตโนมัติ:
- Policy-driven gates — นโยบายกำหนดเกณฑ์ชัดเจนว่าแพตช์ใดสามารถ auto-merge ได้ เช่น ความร้ายแรงต่ำ, coverage เพิ่มขึ้น, และผ่าน symbolic proof 100% ส่วนแพตช์ความร้ายแรงปานกลางถึงสูงจะต้องผ่านการอนุมัติจากผู้เชี่ยวชาญ
- Explainable patch diffs — Patch Generator จะแนบคำอธิบายเชิงเหตุผล (rationale) ของการเปลี่ยนแปลง พร้อม mapping ระหว่างบรรทัดโค้ดกับเงื่อนไขเชิงสัญลักษณ์ ทำให้ reviewer มนุษย์สามารถตรวจสอบได้เร็วขึ้น
- Confidence & Risk Scores — ทุก PR มีคะแนน confidence และ risk profile ที่นำมาพิจารณาโดยผู้อนุมัติ เพื่อช่วยตัดสินใจเชิงความเสี่ยง (risk-based decision)
- Interactive review UI — Reviewer สามารถสั่งให้ระบบรันการทดสอบเพิ่มเติม (targeted fuzzing, property checking) ก่อนอนุมัติ และสามารถปฏิเสธ/แก้ไข prompt ที่ใช้สำหรับ LLM เพื่อขอชุดแพตช์ทางเลือก
- Rollback & Canary — ระบบ CI/CD ผสานการ deploy แบบ canary และมีสคริปต์ rollback อัตโนมัติเมื่อพบ regression หลัง deploy พร้อมบันทึกเหตุการณ์เพื่อวิเคราะห์ root cause
โดยสรุป สถาปัตยกรรมของ AutoPatchAI ผสานเทคนิค fuzzing, symbolic execution และ LLM เข้าด้วยกันในลักษณะที่สามารถบูรณาการเข้ากับเวิร์กโฟลว์ของทีมพัฒนาได้ทันที พร้อมทั้งรักษาเกณฑ์ความปลอดภัยและการมีส่วนร่วมของมนุษย์ ผลลัพธ์คือการลดเวลาการแก้ไขช่องโหว่และเพิ่มความมั่นใจในการ deploy แพตช์อัตโนมัติในสเกลขององค์กร
ตัวอย่าง workflow: จากการค้นพบช่องโหว่ถึงแพตช์และ unit test
ตัวอย่าง workflow: จากการค้นพบช่องโหว่ถึงแพตช์และ unit test
ด้านล่างเป็นตัวอย่าง workflow แบบก้าวต่อก้าวของระบบ AutoPatchAI ตั้งแต่การรับรายงานช่องโหว่จนถึงการสร้างแพตช์และ unit test อัตโนมัติก่อนส่งเป็น pull request ให้ทีมรีวิว โดยกล่าวถึงการผสานงานของ fuzzing, symbolic execution และ LLM เพื่อให้ภาพรวมชัดเจน:
- Detection / Report: รับรายงานจากช่องโหว่ (CVE, bug bounty หรือการตรวจภายใน) พร้อมตัวอย่างอินพุตที่ก่อให้เกิดพฤติกรรมผิดปกติ
- Reproduction & Fuzzing: ใช้ fuzzing สร้างและขยายชุดอินพุตที่ก่อให้เกิด crash หรือพฤติกรรมผิดผลาด เพื่อสร้าง corpus ของกรณีทดสอบ
- Symbolic Execution: วิเคราะห์เส้นทางที่นำไปสู่ข้อผิดพลาด เพื่อสกัดตรรกะ (path constraints) และชี้ตำแหน่งต้นเหตุของบั๊ก
- LLM Patch Generation: ป้อนบริบทโค้ด, path constraints และตัวอย่างอินพุต/เอาต์พุตให้ LLM เพื่อสร้างแพตช์ต้นแบบ
- Unit Test Generation: สร้าง unit tests อัตโนมัติจาก corpus ของ fuzzer และจากเคส edge-case ที่ symbolic execution สกัดได้
- Verify & PR: รัน CI (unit tests, regression fuzz, static analysis) และส่ง pull request พร้อมรายงานความเปลี่ยนแปลงและความเสี่ยงให้ผู้ตรวจสอบ

1) ตัวอย่างเริ่มต้น — รับรายงานและ fuzzing
สมมติทีมรับรายงานจาก bug bounty ว่าฟังก์ชัน parse_header ในโมดูล network สามารถทำให้ application crash ได้ โดย bug report มาพร้อมกับตัวอย่างบัฟเฟอร์อินพุตที่ทำให้โปรแกรม core dump. ระบบจะนำอินพุตนี้เข้าเป็น seed ให้ fuzzing engine (เช่น AFL/LibFuzzer) เพื่อขยาย corpus และค้นหาอินพุตเพิ่มเติมที่ก่อให้เกิดพฤติกรรมเดียวกัน — ตัวอย่างสถิติที่ระบบรายงาน: fuzzing ขยาย seed เป็น 1,240 กรณีใน 2 ชั่วโมง พบ 37 กรณีที่ทำให้ crash โดย 5 กรณีเป็นรูปแบบใหม่ที่ seed เดิมไม่ครอบคลุม.
2) Symbolic execution — ระบุเส้นทางและเงื่อนไข
หลังจากได้อินพุตที่ก่อปัญหา ระบบส่งโค้ดพร้อมอินพุตไปให้ symbolic executor (เช่น angr หรือ KLEE) เพื่อหาชุดเงื่อนไขทางตรรกะที่นำไปสู่จุดผิดพลาด ตัวอย่าง path constraint ที่สกัดได้อาจเป็น:
- len_field > 256 && declared_length + len_field > buffer_size
- สรุป: พบ integer overflow/unchecked length ที่ทำให้เกิดเขียนเกินบัฟเฟอร์
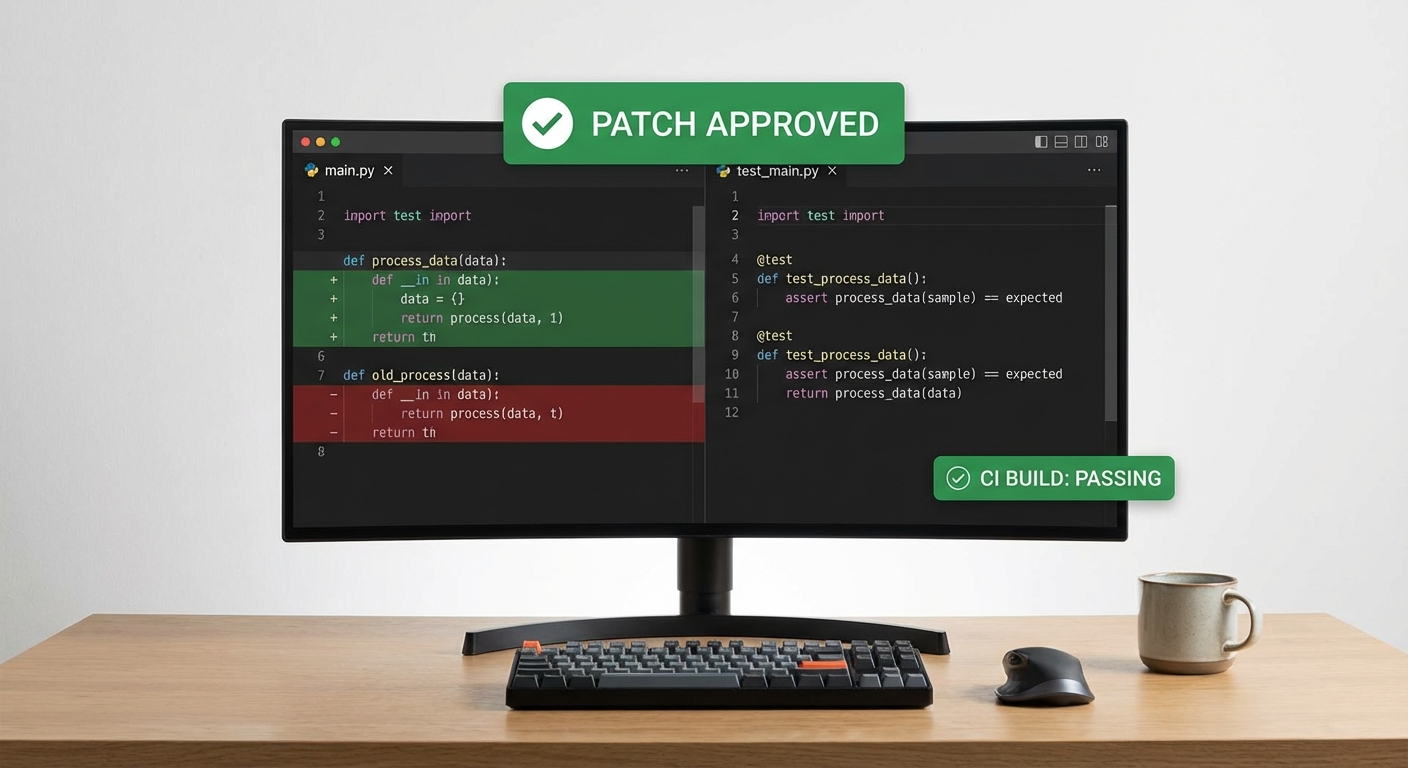
3) LLM สร้างแพตช์ต้นแบบ — ตัวอย่าง diff
เมื่อได้บริบทโค้ดและเงื่อนไข LLM จะสร้างแพตช์ต้นแบบพร้อมคำอธิบาย จุดประสงค์คือเพิ่มการตรวจสอบขอบเขตและป้องกัน integer overflow ต่อไปนี้เป็นตัวอย่าง diff สมมติของไฟล์ parser.c ก่อนและหลังแพตช์ (format แบบ unified diff เพื่อให้เห็นการเปลี่ยนแปลง):
- int parse_header(char *buf, size_t buf_len) {
- uint32_t len = read_u32(buf);
- char *payload = malloc(len);
- memcpy(payload, buf + 4, len);
- // process payload ...
- free(payload);
- return 0;
- }
+ int parse_header(char *buf, size_t buf_len) {
+ if (buf_len < 4) return -1; /* ตรวจสอบ header อย่างน้อย 4 ไบต์ */
+ uint32_t len = read_u32(buf);
+ /* ป้องกัน integer overflow และตรวจสอบขอบเขต */
+ if (len > (SIZE_MAX - 1) || len + 4 > buf_len) return -1;
+ char *payload = malloc(len + 1);
+ if (!payload) return -1;
+ memcpy(payload, buf + 4, len);
+ payload[len] = '\0'; /* เพิ่ม null-terminator เพื่อความปลอดภัย */
+ /* process payload ... */
+ free(payload);
+ return 0;
+ }
หมายเหตุ: แพตช์ตัวอย่างนี้เพิ่มการตรวจสอบขอบเขตครอบคลุมทั้งการตรวจขนาดบัฟเฟอร์, ป้องกัน integer overflow และจัดการกรณี malloc ล้มเหลว — ข้อเสนอเหล่านี้มาจากการรวมข้อมูลของ symbolic execution (เงื่อนไข len + 4 > buf_len) และ pattern ของบั๊กที่ LLM เรียนรู้มา
4) ระบบสร้าง unit test อัตโนมัติ — ตัวอย่างที่ระบบสร้างให้
AutoPatchAI สร้างชุด unit test จาก corpus ของ fuzzer และจากกรณีขอบที่ symbolic execution ระบุ ตัวอย่าง unit test (ในรูปแบบ C + harness แบบเรียบง่าย หรือใช้ framework เช่น check/criterion) มีลักษณะดังนี้:
/* test_parse_header.c */
void test_parse_valid_small() {
char buf[] = {0x00,0x00,0x00,0x03, 'a','b','c'}; /* len=3 */
assert(parse_header(buf, sizeof(buf)) == 0);
}
void test_parse_len_exceeds_buf() {
char buf[] = {0x00,0x00,0x01,0x00 /* len=256 */, 'x'};
assert(parse_header(buf, sizeof(buf)) == -1); /* ต้องไม่ crash */
}
void test_parse_integer_overflow_candidate() {
char buf[8];
/* สร้างค่า len ที่จะทำให้ len + 4 overflow บนระบบ 32-bit */
set_len_field(buf, UINT32_MAX);
assert(parse_header(buf, sizeof(buf)) == -1); /* ตรวจว่าแพตช์ต้าน overflow */
}
ระบบจะรวมกรณีจาก fuzzer (actual crash inputs) และเคส symbolic (เช่นกรณี overflow) เพื่อให้ครอบคลุม edge-case ทั้งหมดโดยอัตโนมัติ
5) การยืนยันความถูกต้องก่อน merge (automated + manual)
ก่อนส่ง PR ระบบรันขั้นตอนตรวจสอบต่อไปนี้อย่างเป็นอัตโนมัติ:
- Unit test suite: รันทั้งหมด — ผลลัพธ์ต้องผ่าน 100% ของ cases ที่สร้างขึ้นใหม่และ regression cases เดิม
- Regression fuzzing: นำ corpus เดิมรันอีกครั้งกับโค้ดใหม่เพื่อยืนยันว่า crash เดิมหายไป (ในตัวอย่าง: fuzzing เบื้องต้น 2 ชั่วโมงไม่มี crash เพิ่มเติม)
- Static analysis & sanitizer: รัน tools เช่น ASan/UBSan, clang-tidy เพื่อตรวจหาปัญหาที่อาจเกิดใหม่
- Semantic impact check: เปรียบเทียบพฤติกรรมที่สำคัญ (API contract) เพื่อให้แน่ใจว่าแพตช์ไม่เปลี่ยน semantics ที่คาดหวัง — ถ้ามีการเปลี่ยนแปลงจะต้องมี note และการอนุมัติจากเจ้าของโมดูล
- Confidence metrics: รายงานความมั่นใจของ LLM (เช่นคะแนนความเป็นไปได้ของ patch) และตัวชี้วัดการทดสอบ (coverage เพิ่มขึ้นจาก 68% เป็น 74%, เพิ่มกรณีทดสอบ 12 เคส)
- Manual code review: ส่ง PR พร้อมคำอธิบายแพตช์, รายงาน CI และผลการ fuzz/regression เพื่อให้ผู้เชี่ยวชาญมนุษย์ตรวจสอบก่อน merge
การรวมขั้นตอนอัตโนมัติและการตรวจสอบโดยมนุษย์นี้ช่วยให้ทีมมั่นใจได้ว่าแพตช์ปลอดภัยและไม่ก่อผลกระทบด้านฟังก์ชัน ในการใช้งานจริง AutoPatchAI รายงานว่าในกรณีเฉลี่ยช่วยลดเวลาจากการแก้ไขช่องโหว่ที่เคยใช้เวลาเป็นวันเหลือเพียงไม่กี่ชั่วโมง พร้อมลดภาระของทีมรีวิวประมาณ 30–60% โดยที่ระดับความเสี่ยงก่อน mergeยังคงถูกตรวจสอบด้วยเครื่องมืออัตโนมัติและการตรวจโค้ดโดยผู้เชี่ยวชาญ
ผลลัพธ์เชิงตัวเลข: เวลา, อัตราการยอมรับแพตช์ และ ROI
สรุปเชิงตัวเลขโดยย่อ
AutoPatchAI ช่วยย่นระยะเวลาแก้ไขช่องโหว่ (time-to-remediation) จากเฉลี่ย 48–72 ชั่วโมง เหลือระดับชั่วโมง โดยตัวอย่างข้อมูลการใช้งานในสถานการณ์จริง (pilot) ของสตาร์ทอัพไทยระบุค่าเฉลี่ยหลังใช้งานที่ 1–4 ชั่วโมง ขึ้นกับความรุนแรงและความซับซ้อนของช่องโหว่ นอกจากนี้ระบบผสาน LLM, fuzzing และ symbolic execution ยังสร้าง unit test อัตโนมัติช่วยยืนยันก่อน merge ทำให้อัตราการยอมรับแพตช์หลังการตรวจโดยมนุษย์ (patch acceptance rate) อยู่ในช่วง 70–90% ในแง่ความเท็จ (false results) ระบบรายงานอัตรา false positive โดยประมาณ 5–20% และอัตรา false negative ต่ำกว่า 1–5% ขึ้นกับการตั้งค่า sensitivity และชุดข้อมูลฝึก
เปรียบเทียบเวลาแก้ไข (Time-to-Remediation) ก่อนและหลัง
ตัวอย่างสมมติฐานเชิงตัวเลขเพื่อแสดงภาพชัดเจน:
- ก่อนใช้งาน AutoPatchAI: เฉลี่ย 60 ชั่วโมง (ช่วง 48–72 ชั่วโมง) ต่อช่องโหว่ที่ต้องแก้ไข
- หลังใช้งาน AutoPatchAI: เฉลี่ย 2.5 ชั่วโมง (ช่วง 1–4 ชั่วโมง) ต่อช่องโหว่ โดยรวมการสร้างแพตช์อัตโนมัติ + human review + unit test
- สรุปการย่นเวลาเฉลี่ย: ประหยัดเวลาได้ประมาณ 57.5 ชั่วโมงต่อช่องโหว่ หรือคิดเป็นการลดลง ~96% เมื่อเทียบกับค่าเฉลี่ยก่อนหน้า
ผลลัพธ์นี้ช่วยให้องค์กรตอบสนองต่อช่องโหว่ระดับวิกฤตภายในชั่วโมง ซึ่งมีความสำคัญต่อ SLA ด้านความปลอดภัยและข้อกำหนดการปฏิบัติตามกฎระเบียบ (compliance) ที่มักกำหนดกรอบเวลาสำหรับการแก้ไขช่องโหว่ร้ายแรง
Patch Acceptance Rate และผลกระทบของ False Positives/Negatives
อัตราการยอมรับแพตช์หลัง human review ที่ 70–90% แสดงถึงประสิทธิภาพของระบบในการสร้างแพตช์ที่สามารถนำไปใช้งานจริง แต่อัตรา false positive (แพตช์ที่จริงแล้วไม่จำเป็นหรือทำให้เกิดปัญหา) ขนาด 5–20% ส่งผลให้ต้องมีเวลาในการตรวจแก้และ rollback เพิ่มเติม ในขณะที่ false negative (ระบบพลาดช่องโหว่ที่ยังคงหลงเหลือ) ต่ำกว่า 1–5% หมายความว่าความเสี่ยงของการพลาดช่องโหว่ร้ายแรงนั้นค่อนข้างน้อย แต่ไม่เป็นศูนย์ ดังนั้นกระบวนการ human-in-the-loop ยังคงจำเป็นเพื่อควบคุมความเสี่ยง
- ข้อดีของ Acceptance Rate สูง: ลดภาระ manual patch-writing, ลดเวลา QA, เพิ่ม throughput ใน release cycle
- ข้อควรระวัง: หาก false positive สูง อาจเพิ่มงานตรวจและเสี่ยงต่อ regression test ที่มากขึ้น
- มาตรการบรรเทา: ใช้ threshold tuning, เพิ่มชุด unit/integration tests, เก็บ feedback loop เพื่อปรับโมเดล
การประเมิน ROI (ตัวอย่างการคำนวณเชิงตัวเลข)
สมมติฐานสำหรับการคำนวณตัวอย่าง (ตัวเลขสมมติในหน่วยบาทเพื่อให้เห็นภาพ):
- จำนวนช่องโหว่ร้ายแรงที่ต้องแก้ไขต่อปี: 200 รายการ
- ต้นทุนรวมวิศวกร (fully loaded) ต่อชั่วโมง: 1,200 บาท/ชั่วโมง
- เวลาเฉลี่ยก่อนใช้: 60 ชั่วโมง/รายการ → ต้นทุน = 60 × 1,200 = 72,000 บาท/รายการ
- เวลาเฉลี่ยหลังใช้: 2.5 ชั่วโมง/รายการ → ต้นทุน = 2.5 × 1,200 = 3,000 บาท/รายการ
- ค่าบริการ AutoPatchAI สมมติ: 6,000,000 บาท/ปี (ตัวอย่างสเกลองค์กรกลาง-ใหญ่)
คำนวณการประหยัดต่อปี:
- ต้นทุนรวมก่อนใช้ = 200 × 72,000 = 14,400,000 บาท/ปี
- ต้นทุนรวมหลังใช้ (engineer time) = 200 × 3,000 = 600,000 บาท/ปี
- ต้นทุนรวมหลังใช้ (รวมค่าสมัคร) = 600,000 + 6,000,000 = 6,600,000 บาท/ปี
- การประหยัดสุทธิ = 14,400,000 − 6,600,000 = 7,800,000 บาท/ปี
- ROI เบื้องต้น = (การประหยัดสุทธิ / ต้นทุนลงทุน) × 100 = (7,800,000 / 6,600,000) × 100 ≈ 118% ต่อปี
หมายเหตุ: หากองค์กรมีค่าเสียหายจากการละเมิดหรือค่าปรับด้าน compliance/การหยุดชะงักระบบเพิ่มเข้ามา (เช่น ค่าเสียหายเหตุละเมิดเฉลี่ย 5–20 ล้านบาทต่อเหตุการณ์หรือค่าปรับตามกฎระเบียบ) การประหยัดที่เกิดจากการลด time-to-remediation จะยิ่งทำให้ ROI สูงขึ้นอย่างมีนัยสำคัญ
ผลกระทบต่อ SLA และการปฏิบัติตามข้อกำหนด (Compliance)
การลด time-to-remediation จากวันเป็นชั่วโมงส่งผลโดยตรงต่อความสามารถในการปฏิบัติตาม SLA และมาตรฐาน เช่น:
- SLA ภายในองค์กร: การตอบสนองต่อช่องโหว่ร้ายแรงภายใน 72 ชั่วโมงเป็นที่นิยม — AutoPatchAI ทำให้องค์กรสามารถทำได้ภายในชั่วโมง ลดความเสี่ยงในการละเมิด SLA
- Compliance และมาตรฐานอุตสาหกรรม: เช่น PCI-DSS, ISO27001, NIST ที่มักต้องการการจัดการช่องโหว่ภายในช่วงเวลาที่กำหนด — เวลาแก้ไขที่สั้นลงช่วยลดความเสี่ยงจากการถูกปรับหรือการสูญเสียสถานะการรับรอง
- ความเสี่ยงด้านธุรกิจ: เวลาที่สั้นลงลดโอกาสที่ช่องโหว่จะถูกนำไปใช้โจมตีจริง (exploit) ทำให้อัตราการเกิดเหตุการณ์ breach ลดลง และลดต้นทุนการกู้คืน
สรุป: ตัวเลขจากการทดลองใช้งานและการคำนวณแบบ conservative ชี้ให้เห็นว่า AutoPatchAI สามารถลดเวลาแก้ไขและต้นทุนแรงงานอย่างชัดเจน พร้อมเพิ่มประสิทธิภาพการจัดการแพตช์และการปฏิบัติตามข้อกำหนด โดย ROI ที่คำนวณจากการลดเวลาและค่าแรงสามารถคืนทุนได้ภายในหนึ่งปีภายใต้สมมติฐานที่สมเหตุสมผล อย่างไรก็ตามองค์กรควรพิจารณา tuning ระบบเพื่อลด false positives และรักษา human-in-the-loop เพื่อควบคุมความเสี่ยง false negatives
กรณีใช้งานจริงและผลกระทบต่อ DevSecOps
กรณีใช้งานจริงและผลกระทบต่อ DevSecOps
การนำ AutoPatchAI เข้าสู่การปฏิบัติงานจริงในองค์กรไทยให้ผลลัพธ์ที่เป็นรูปธรรมทั้งในเชิงเทคนิคและเชิงธุรกิจ ตัวอย่างที่ชัดเจนมักมาจากการใช้งานกับ internal libraries, web services และการผสานกับ CI/CD pipelines ซึ่งแต่ละกรณีช่วยลดเวลาซ่อมบั๊กและลด backlog ของช่องโหว่ได้อย่างชัดเจน ตัวอย่างเช่น สตาร์ทอัพด้านฟินเทคขนาด 80 คนที่มี internal SDK จำนวนมาก รายงานว่าเมื่อใช้ AutoPatchAI ร่วมกับ unit-test generation และ fuzzing ภายใน 3 เดือน backlog ของ vulnerabilities ที่คะแนน CVSS ≥ 7 ลดลงจาก 120 รายการเหลือ 18 รายการ (-85%) และค่าเฉลี่ยเวลาจากการอนุมัติแพตช์ถึง deployment (MTTR) ลดจาก 72 ชั่วโมงเหลือ ~4–6 ชั่วโมง
ในองค์กรขนาดกลาง (เช่น e‑commerce ที่มี microservices หลายสิบตัว) การผสาน AutoPatchAI เข้ากับ GitHub Actions/Jenkins pipeline ทำให้ทีมพัฒนาได้รับแพตช์อัตโนมัติเป็น Pull Request ที่มาพร้อมกับ unit tests และผลการรัน fuzzing/symbolic execution ซึ่งช่วยให้การ merge เป็นไปได้อย่างปลอดภัยมากขึ้น กรณีศึกษาแสดงให้เห็นว่า release cadence เพิ่มจาก 1 release/สัปดาห์เป็น 2–3 release/สัปดาห์ ขณะเดียวกันการเกิด regression security incidents ลดลงกว่า 90% เนื่องจากแพตช์มาพร้อมกับการทดสอบยืนยันก่อน merge
สำหรับองค์กรขนาดใหญ่ที่มีทีม SecOps/SRE แยกหน้าที่ชัด การนำ AutoPatchAI มาใช้เปลี่ยนบทบาทของทีมเหล่านี้จากงานปฏิบัติการเชิงรุกแบบ manual ไปสู่การทำงานเชิงนโยบายและการจัดลำดับความสำคัญ ตัวอย่างบริษัทโทรคมนาคมรายหนึ่งที่มี incident window แบบ SLA ระบุว่าเวลาที่ระบบเปิดเผยช่องโหว่จนถึงเวลาปิด (time-to-fix) ลดลงจากเฉลี่ย 5 วันเหลือ 6–10 ชั่วโมง หลังจากเปิดใช้งาน AutoPatchAI ในสภาพแวดล้อม non-production ก่อน เมื่อรวมกับการสร้าง unit test อัตโนมัติและ regression suite ทำให้ความเสี่ยงเชิงธุรกิจจากการถูกโจมตีลดลงอย่างมีนัยสำคัญ
สรุปการใช้งานเชิงเทคนิค (concrete use cases):
- Internal libraries: AutoPatchAI สร้าง patch สำหรับ dependency หรือโค้ดภายใน พร้อม unit tests ที่ป้องกันการถอยหลัง (regression) ก่อน merge
- Web services: การรัน symbolic execution บน endpoints สำคัญเพื่อค้นหาหนทาง exploit และสร้าง patch/การตรวจสอบ input validation อัตโนมัติ
- CI pipelines: ผสาน AutoPatchAI เป็นขั้นตอน pre-merge ใน CI ทำให้ PR ของแพตช์มาพร้อมการทดสอบแบบ whitebox/fuzzing และการวิเคราะห์ผลกระทบ
การเปลี่ยนบทบาทของทีมความปลอดภัยและนักพัฒนาเกิดขึ้นอย่างชัดเจนดังนี้:
- นักพัฒนา (Developers): รับผิดชอบการรีวิวแพตช์ที่สร้างโดย AutoPatchAI แทนการเขียนแพตช์จากศูนย์ ทำให้ dev ใช้เวลาไปกับการออกแบบฟีเจอร์มากขึ้นและทำงานร่วมกับ security tools แบบวันต่อวัน (shift-left security)
- ทีมความปลอดภัย (SecOps/CSIRT): เปลี่ยนจากการทำ remediation แบบ manual ไปสู่การตั้งค่า policy, การตรวจสอบ false positive และการจัดลำดับความสำคัญของความเสี่ยงสูงสุด ทีมนี้ใช้เวลามากขึ้นกับ threat modeling และ incident response strategy แทนการแพตช์ทีละรายการ
- SRE / Ops: โดยเฉพาะในกรณีของระบบออนไลน์ที่ต้อง uptime สูง SRE จะควบคุม rollout strategy (canary, blue-green) สำหรับแพตช์ที่สร้างโดย AutoPatchAI และมอนิเตอร์ regression metrics ที่ถูกสร้างขึ้นพร้อม unit tests
การเปลี่ยนแปลงใน workflow ที่สัมผัสได้จริงคือการเลื่อนความปลอดภัยไปไว้ให้ใกล้กับวงจรพัฒนามากขึ้น (shift-left) และการเสริมทัพนักพัฒนา (augmented developer workflows) ผ่าน automation ตัวอย่าง workflow ใหม่ที่เกิดขึ้น:
- เมื่อ static analysis พบช่องโหว่ AutoPatchAI จะรัน symbolic execution และ fuzzing เพื่อหาพื้นที่ที่กระทบและสร้าง patch พร้อม unit tests
- ระบบสร้าง PR อัตโนมัติที่ประกอบด้วยโค้ดแพตช์, unit tests และ report ของการทดสอบ whitebox/fuzzing
- CI/CD รัน regression suite และ security checks; หากผ่านจะอนุญาตให้ merge และ orchestration จะ deploy ผ่านกลยุทธ์ rollout ที่ SRE กำหนด
- SecOps จะได้รับ dashboard ของการเปลี่ยนแปลงและสามารถตั้งค่า policy เพื่อบล็อก/ยอมรับแพตช์อัตโนมัติสำหรับระดับความเสี่ยงที่กำหนด
ผลต่อ release cadence และความเสี่ยงเชิงธุรกิจมีทั้งเชิงปริมาณและเชิงคุณภาพ: เมื่อ MTTR ลดลงและความถี่การปล่อยซอฟต์แวร์เพิ่มขึ้น องค์กรจะได้รับประโยชน์จาก
- เพิ่มความเร็วในการปล่อยฟีเจอร์: ตัวอย่างเช่น จากบริษัทตัวอย่างที่ release cadence เพิ่มขึ้น 2–3 เท่า ทำให้ time-to-market ของฟีเจอร์สำคัญลดลง
- ลดหน้าต่างการโจมตี (exploit window): เวลาที่ช่องโหว่เปิดเผยถูกลดลงอย่างน้อย 70–90% ซึ่งลดความเสี่ยงของการถูกโจมตีและผลกระทบทางการเงิน
- ลดต้นทุนการแก้ปัญหา: ค่าใช้จ่ายเฉลี่ยต่อ incident ลดลงเมื่องาน remediation ถูกทำแบบอัตโนมัติและรวดเร็วขึ้น เช่น ประหยัดค่าแรงของทีม security และลด downtime
- ปรับปรุงความเชื่อมั่นของลูกค้าและ compliance: สามารถตอบเกณฑ์การตรวจสอบภายนอกและลดความเสี่ยงจากการละเมิดข้อมูล ซึ่งสำคัญต่อพันธมิตรทางธุรกิจและการปฏิบัติตามกฎระเบียบ
โดยสรุป การใช้งาน AutoPatchAI ในบริบทของ DevSecOps ไม่เพียงแต่ลดเวลาซ่อมบั๊กจากวันเป็นชั่วโมงเท่านั้น แต่ยังเปลี่ยนวิธีการทำงานของทีมให้เป็นไปในแนวทางที่ปลอดภัยตั้งแต่ต้นทาง ช่วยให้องค์กรสามารถปล่อยซอฟต์แวร์ได้บ่อยขึ้นอย่างปลอดภัย พร้อมลดความเสี่ยงเชิงธุรกิจและเพิ่มประสิทธิภาพในการใช้ทรัพยากรของทีมความปลอดภัยและการปฏิบัติการ
ความเสี่ยง ข้อจำกัด และทิศทางในอนาคต
ความเสี่ยง ข้อจำกัด และทิศทางในอนาคต
แม้เทคโนโลยีผสาน Large Language Models (LLMs) กับ fuzzing และ symbolic execution จะให้ศักยภาพในการออกแพตช์ช่องโหว่อัตโนมัติและสร้าง unit test ยืนยันก่อน merge แต่ระบบเช่น AutoPatchAI ยังมีความเสี่ยงและข้อจำกัดที่ผู้ใช้งานและผู้ลงทุนต้องรับทราบอย่างชัดเจน ก่อนนำไปใช้ในสภาพแวดล้อมการผลิต (production) โดยเฉพาะเชิงความปลอดภัยและความเชื่อมต่อกับกระบวนการพัฒนาเดิม
ความเสี่ยงจากการใช้ AI สร้างโค้ด — LLM อาจสร้างโค้ดที่ถูกต้องทางไวยากรณ์แต่เปลี่ยนพฤติกรรมระบบหรือเปิดช่องโหว่ใหม่ เช่น การละเลยเงื่อนไขขอบเขต (boundary checks), ตรวจสอบสิทธิ์ไม่ครบถ้วน หรือแทรก dependency ที่มีช่องโหว่ การวิจัยภายในและการทดลองเชิงตัวอย่างของแวดวงชี้ว่าโค้ดที่สร้างโดยโมเดลต้องผ่านการตรวจสอบแบบหลายชั้นเพื่อให้เกิดความน่าเชื่อถือ: unit tests, integration tests, fuzzing ซ้ำ และการตรวจสอบด้วย static analysis ก่อนนำขึ้นระบบจริง
แนวทางลดความเสี่ยง (mitigation) ได้แก่
- Human-in-the-loop: ให้ผู้เชี่ยวชาญความปลอดภัยหรือเจ้าของโค้ดตรวจสอบแพตช์สุดท้าย โดยระบบจัดเตรียม diff ที่อ่านง่าย พร้อมเหตุผลประกอบการแก้ไข
- Regression & property-based tests: สร้างชุดทดสอบอัตโนมัติที่ยืนยันคุณสมบัติ (properties) สำคัญของระบบและรันก่อน merge ทุกครั้ง
- Staged rollout และ canary release: เรียกใช้แพตช์ในกลุ่มผู้ใช้ย่อย เพื่อตรวจจับการเปลี่ยนพฤติกรรมก่อนขยายสู่ production ทั้งยังต้องมี rollback plan ที่เชื่อถือได้
- Static & dynamic analysis ผสานกัน: รันเครื่องมือ SAST/DAST/SCA และ fuzzing เพิ่มเติมหลังจาก LLM ผลิตโค้ด เพื่อป้องกัน dependency ที่ไม่ปลอดภัยหรือการใช้ API ที่ผิดวิธี
- Provenance และ signed patches: เก็บ audit trail ของการสร้างแพตช์ รวมทั้งเซ็นชื่อดิจิทัล (code signing) เพื่อป้องกันการปลอมแปลง
ข้อจำกัดด้านขอบเขตการวิเคราะห์ — ระบบที่พึ่งพา symbolic execution และ fuzzing เผชิญปัญหาเช่น path explosion เมื่อวิเคราะห์โค้ดขนาดใหญ่อีกทั้ง symbolic execution มักครอบคลุมไม่ครบกรณีเมื่อโค้ดมี state-space ขนาดใหญ่, มีการพึ่งพา I/O ภายนอก, หรือมี native bindings (เช่น C/C++ extension ใน Python) ตัวอย่างเช่น การวิเคราะห์โมดูลระบบปฏิบัติการหรือไลบรารีเชิงเครือข่ายที่ซับซ้อนอาจไม่สามารถทำ symbolic ได้ครบถ้วนในเวลาเหมาะสม นอกจากนี้การรองรับภาษาการเขียนโปรแกรมยังเป็นข้อจำกัดสำคัญ: ระบบอาจทำงานได้ดีในภาษาเชิงคอมไพล์หรือสคริปต์ระดับสูงทั่วไป (เช่น Java, Python, JavaScript) แต่มีข้อจำกัดกับภาษาเฉพาะทางหรือไบนารี เช่น Rust ที่มี borrow checker เฉพาะ หรือภาษา low-level ที่มี pointer arithmetic
เพื่อลดข้อจำกัดเหล่านี้ ควรมีการออกแบบสถาปัตยกรรมให้สามารถเลือกใช้กลยุทธ์หลายแบบตามบริบท: ใช้ static analysis สำหรับโค้ดขนาดใหญ่, ใช้ fuzzing สำหรับโมดูลที่ต้องการการสำรวจอินพุตแบบกว้าง, และใช้ symbolic execution เฉพาะจุดที่มีประโยชน์ นอกจากนี้การรองรับหลายภาษา (polyglot support) ควรค่อย ๆ ขยายตามความต้องการของตลาด โดยเริ่มจากภาษายอดนิยมและไลบรารีหลักก่อน
ความเป็นส่วนตัวและความมั่นคงของโค้ด — การส่งซอร์สโค้ดไปยังบริการคลาวด์ของผู้ให้บริการ AI อาจเสี่ยงต่อการรั่วไหลของข้อมูลลับองค์กร เช่น คีย์, credential หรือ logic ทางธุรกิจ การ mitigate ประกอบด้วยการให้บริการแบบ on-premise หรือใน VPC, การ redaction ของข้อมูลสำคัญก่อนส่ง, การเข้ารหัสขณะพัก (at-rest) และขณะส่ง (in-transit), รวมถึงการใช้เทคนิค privacy-preserving เช่น differential privacy เมื่อจำเป็น
ทิศทางการพัฒนาในอนาคต — เพื่อเพิ่มความน่าเชื่อถือและขยายการใช้งาน มีแนวทางสำคัญที่ควรดำเนินการต่อ:
- ผสาน formal methods และ SMT solvers: ใช้การพิสูจน์เชิงคณิตศาสตร์ (theorem proving) สำหรับโมดูลสำคัญที่ต้องการความถูกต้องสูง เช่น cryptographic primitives หรือ access-control logic การรวม formal verification กับ pipeline จะช่วยให้แพตช์บางประเภทได้รับการรับรองเชิงฟอร์มัลก่อน deploy
- continuous learning & feedback loop: ปรับปรุงโมเดลด้วยข้อมูลจากผลลัพธ์การ deploy จริง (เช่น test failures, revert incidents) โดยใช้กลไก RLHF (reinforcement learning from human feedback) เพื่อให้โมเดลเรียนรู้จากข้อผิดพลาดและลดการสร้างโค้ดไม่ปลอดภัยในอนาคต
- ecosystem integrations: เชื่อมต่อกับเครื่องมือ CI/CD, SCA, issue trackers, และ SBOM generators เพื่อให้ workflow ของทีมพัฒนาเป็นหนึ่งเดียวและสามารถตรวจสอบ traceability ของแพตช์ได้ตลอด pipeline
- โมเดลธุรกิจที่ยืดหยุ่น: สำหรับสตาร์ทอัพ ควรมีชุดผลิตภัณฑ์หลายระดับ เช่น on-prem enterprise, managed VPC, และ SaaS พร้อมการบริการเสริม (professional services) ในการปรับแต่ง integraton และการรับประกันความปลอดภัย ซึ่งจะช่วยตอบโจทย์องค์กรที่มีความต้องการด้านความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนดแตกต่างกัน
สรุปแล้ว AutoPatchAI และระบบอัตโนมัติระดับนี้มีศักยภาพสูงในการลดเวลาซ่อมบั๊กจากระดับวันเหลือชั่วโมง แต่เพื่อให้เทคโนโลยีเหล่านี้ปลอดภัยและเชื่อถือได้ในระดับองค์กร ต้องมีการออกแบบกระบวนการรอบด้าน: การผสานการตรวจสอบของมนุษย์ เทคนิค formal verification, การจัดการความเป็นส่วนตัวของซอร์สโค้ด และการบูรณาการเข้ากับเครื่องมือ DevSecOps ที่มีอยู่ ซึ่งรวมกันจะช่วยให้ผลลัพธ์เป็นทั้งเร็วและปลอดภัยในระยะยาว
บทสรุป
AutoPatchAI เป็นตัวอย่างชัดเจนของการผสานระหว่างเทคโนโลยีสมัยใหม่อย่าง Large Language Models (LLM) กับเทคนิควิเคราะห์แบบดั้งเดิม เช่น fuzzing และ symbolic execution เพื่อนำไปสู่กระบวนการสร้างแพตช์ช่องโหว่อัตโนมัติพร้อมทั้งสร้าง unit test ยืนยันก่อน merge ผลลัพธ์ตามรายงานจากสตาร์ทอัพระบุว่าแนวทางนี้สามารถย่นเวลาซ่อมบั๊กด้านความปลอดภัยจากระดับหลายวันเหลือเพียงไม่กี่ชั่วโมงในตัวอย่างทดสอบจริง (การลดเวลาในบางกรณีสูงถึงราว 80–90%) ซึ่งช่วยลด Mean Time To Repair (MTTR) และยกระดับกระบวนการ DevSecOps ให้เป็นไปอย่างต่อเนื่องและอัตโนมัติมากขึ้น โดยเฉพาะเมื่อนำเข้าไปผนวกกับ CI/CD pipeline ที่มีอยู่ การสร้าง unit test อัตโนมัติยังช่วยตัดวงจร regression และยืนยันความถูกต้องก่อนการ merge ทำให้ความเสี่ยงจากการแก้ไขที่ผิดพลาดลดลงอย่างเป็นรูปธรรม
แม้ ศักยภาพของ AutoPatchAI จะสูง แต่การนำไปใช้ในสภาพแวดล้อมจริงต้องอาศัยการควบคุมที่รัดกุม รวมถึง human-in-the-loop เพื่อทบทวนแพตช์ที่สร้างขึ้น, การทดสอบยืนยันเพิ่มเติม (integration/acceptance tests และการทดสอบความปลอดภัยเชิงลึก), และการจัดการความเสี่ยงเชิงนโยบาย (audit log, traceability, และมาตรฐานการทดสอบ) เพื่อให้การใช้งานปลอดภัยและมีประสิทธิผลในระยะยาว มุมมองอนาคตชี้ว่าเทคโนโลยีลักษณะนี้มีโอกาสผลักดันให้วงการ DevSecOps เปลี่ยนจากการค้นหาเป็นการแก้ไขเชิงรุก แต่ต้องมีการกำหนดแนวปฏิบัติ การควบคุมคุณภาพ และกรอบกำกับดูแลเช่นมาตรฐานการอธิบายผล (explainability), การจัดการ false positives/negatives และการประเมินผลกระทบต่อ supply chain ก่อนจะขยายการนำไปใช้ในระดับองค์กรอย่างแพร่หลาย



