
ท่ามกลางการเติบโตอย่างรวดเร็วของปัญญาประดิษฐ์ในภาคการเงิน ธนาคารไทยเริ่มหันมาใช้แนวทางใหม่ที่เรียกว่า Synthetic‑KYC — การสร้างข้อมูลลูกค้าจำลองโดยอาศัยเทคโนโลยีสมัยใหม่อย่าง Large Language Models (LLM) และ Generative Adversarial Networks (GAN) เพื่อทดสอบและพัฒนาระบบ KYC/AML โดยไม่ต้องเปิดเผยข้อมูลส่วนบุคคลของลูกค้าจริง แนวทางนี้ไม่เพียงลดความเสี่ยงด้านความเป็นส่วนตัวและการละเมิดข้อกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) แต่ยังช่วยให้ทีมพัฒนาและหน่วยงานตรวจสอบภายในสามารถเร่งวงจรการทดสอบ ทดลองสถานการณ์ความเสี่ยง และปรับปรุงโมเดลได้รวดเร็วยิ่งขึ้น
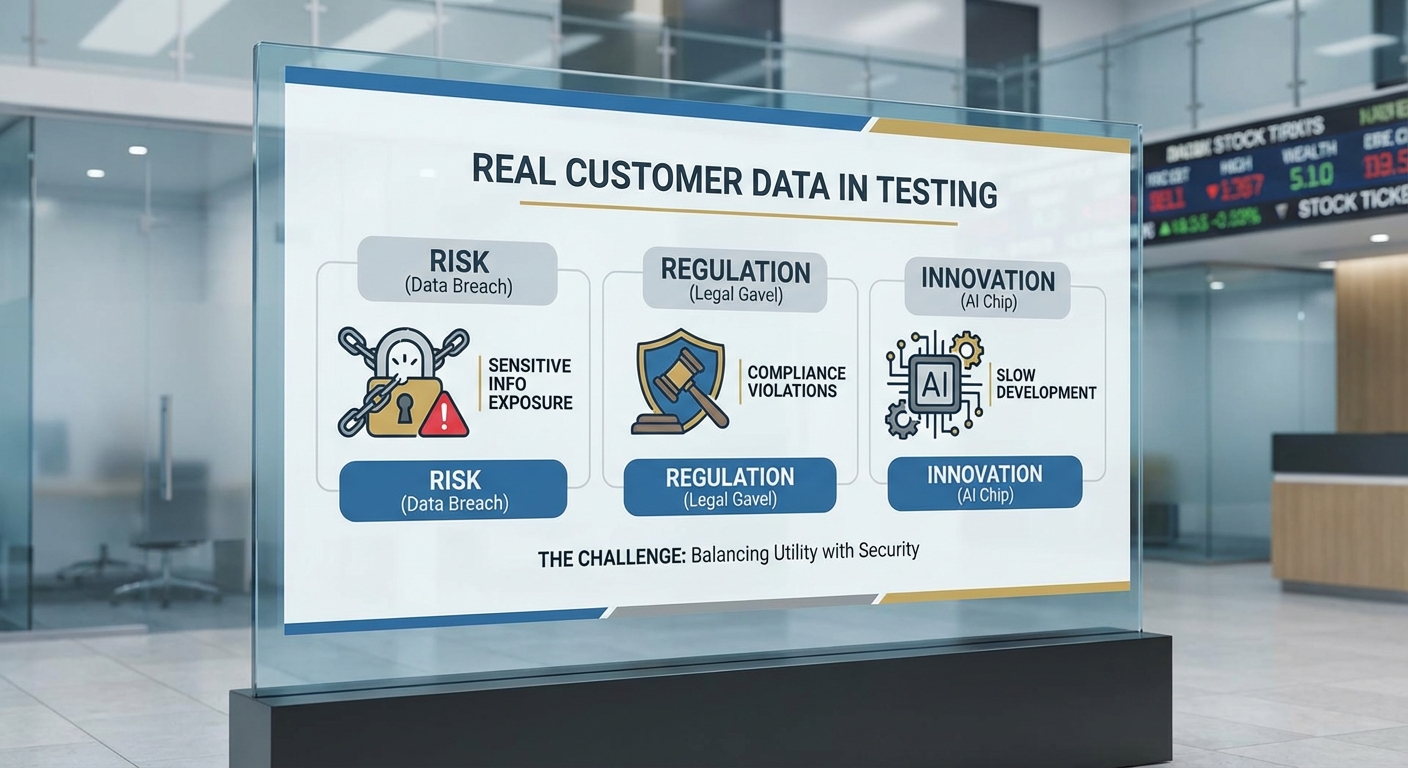
บทนำข่าวชิ้นนี้จะชี้ให้เห็นประเด็นสำคัญที่ผู้อ่านควรรู้ ได้แก่ วิธีการทำงานของ Synthetic‑KYC (การสังเคราะห์เรคคอร์ดที่รักษาโครงสร้างเชิงสถิติและความสมเหตุสมผลเชิงธุรกรรม), ผลประโยชน์เชิงปฏิบัติทั้งด้านความปลอดภัยข้อมูลและความคล่องตัวในการพัฒนา, รวมถึงตัวอย่างโครงการนำร่องในประเทศที่รายงานว่าในการทดลองบางกรณีสามารถลดการใช้ข้อมูลจริงในการทดสอบได้กว่า 90% และย่นเวลาการเตรียมชุดทดสอบจากหลายสัปดาห์เหลือเพียงไม่กี่วัน สุดท้าย เราจะสำรวจข้อควรระวังด้านคุณภาพของข้อมูลจำลอง ความเสี่ยงจากการสร้างข้อมูลที่บิดเบือน และแนวทางการปฏิบัติตามกฎระเบียบที่ธนาคารควรพิจารณาเมื่อนำ Synthetic‑KYC มาใช้งานจริง
บทนำ: ทำไมธนาคารไทยหันมาใช้ Synthetic‑KYC
บทนำ: ทำไมธนาคารไทยหันมาใช้ Synthetic‑KYC
ในยุคที่การขับเคลื่อนธุรกิจธนาคารพึ่งพาเทคโนโลยีดิจิทัลและปัญญาประดิษฐ์มากขึ้น ธนาคารต้องเผชิญกับความขัดแย้งระหว่างความจำเป็นในการทดสอบระบบอย่างรวดเร็วและความรับผิดชอบในการปกป้องข้อมูลลูกค้า การใช้ข้อมูลจริง (production data) สำหรับการพัฒนาระบบ ทดสอบโมเดล AI หรือให้ผู้ให้บริการรายที่สามเข้าทดสอบ มักนำไปสู่ความเสี่ยงด้านการเปิดเผยข้อมูลส่วนบุคคล เช่น การรั่วไหลของข้อมูล (data breach) ความผิดพลาดของการตั้งค่าการเข้าถึง และความเป็นไปได้ของการเชื่อมโยงกลับไปยังตัวบุคคล (re‑identification) ซึ่งในทางปฏิบัติสามารถสร้างความเสียหายทั้งทางการเงินและชื่อเสียงแก่สถาบันการเงินได้อย่างรวดเร็ว
ภายใต้บริบทกฎหมายคุ้มครองข้อมูลส่วนบุคคลของไทย (PDPA) ที่มีผลบังคับใช้และการตรวจสอบการปฏิบัติตามข้อกำหนดเพิ่มขึ้น ธนาคารต้องให้ความสำคัญกับหลักการ เช่น การจำกัดวัตถุประสงค์, การได้รับความยินยอม และ การลดข้อมูลให้เหลือน้อยที่สุด (data minimization) ในการใช้งานข้อมูลลูกค้า ปัญหาหลักคือการทดสอบระบบและการสร้างชุดข้อมูลสำหรับฝึกสอนโมเดล AI ต้องการข้อมูลที่สมจริงและหลากหลาย แต่การนำข้อมูลจริงมาใช้โดยไม่มีมาตรการที่แข็งแรงอาจเข้าข่ายละเมิด PDPA หรือมาตรฐานความปลอดภัยข้อมูล เช่น ISO/IEC 27001 ซึ่งธนาคารไทยหลายแห่งถูกกดดันให้หาทางออกที่สอดคล้องทั้งด้านความปลอดภัยและความสามารถในการแข่งขัน
แรงผลักดันอีกด้านหนึ่งมาจากความเร่งด่วนในการพัฒนา AI ภายในองค์กร—ไม่ว่าจะเป็นการสร้างระบบ KYC อัตโนมัติ การตรวจจับการฉ้อโกง หรือการปรับปรุงประสบการณ์ลูกค้า ธนาคารต้องการชุดข้อมูลที่มีฉลาก (labelled data) และเคสที่หลากหลายสำหรับฝึกและทดสอบโมเดล แต่การได้มาซึ่งข้อมูลเหล่านี้จากลูกค้าจริงมักใช้เวลานาน มีค่าใช้จ่ายด้านการจัดการสิทธิ์ และเสี่ยงต่อการเปิดเผยข้อมูล จึงทำให้เทคโนโลยีสร้างข้อมูลจำลองหรือ synthetic‑KYC ที่ผลิตโดย LLM (Large Language Models) และ GAN (Generative Adversarial Networks) กลายเป็นทางเลือกที่น่าสนใจ เพราะสามารถจำลองโปรไฟล์ลูกค้า สถานการณ์การทำธุรกรรม และข้อมูลเชิงโครงสร้าง/เชิงข้อความได้โดยไม่เปิดเผยข้อมูลต้นฉบับ
แนวโน้มระดับโลกชี้ให้เห็นว่าธนาคารชั้นนำและสถาบันการเงินในสหรัฐ ยุโรป และเอเชียเริ่มทดลองใช้ synthetic data อย่างจริงจังเพื่อการทดสอบระบบและการแลกเปลี่ยนข้อมูลกับพาร์ทเนอร์ ตัวอย่างเช่น โครงการนำร่องในหลายธนาคารสำนักวิจัยและสตาร์ทอัพด้านเทคโนโลยีการเงินแสดงให้เห็นว่า synthetic data ช่วยลดความเสี่ยงการเปิดเผยข้อมูลขณะเดียวกันยังรักษาคุณภาพเชิงสถิติที่จำเป็นต่อการประเมินประสิทธิภาพของโมเดลได้ ธนาคารไทยจึงเริ่มนำร่องในลักษณะเดียวกันภายใน sandbox ขององค์กร และร่วมมือกับผู้ให้บริการเทคโนโลยีเพื่อประเมินความสอดคล้องกับ PDPA และมาตรฐานความปลอดภัย ก่อนจะขยายการใช้งานในวงกว้าง
สรุปคือ การเปลี่ยนไปใช้ synthetic‑KYC สะท้อนถึงความพยายามของธนาคารไทยในการบรรลุสมดุลระหว่างการปฏิบัติตามกฎหมายคุ้มครองข้อมูล การลดความเสี่ยงจากการใช้ข้อมูลจริง และการเร่งพัฒนาเทคโนโลยี AI ภายในองค์กร ทั้งยังเป็นแนวทางที่สอดคล้องกับแนวปฏิบัติระดับโลกที่ส่งเสริมการใช้เทคโนโลยีเพื่อความเป็นส่วนตัว (privacy‑enhancing technologies) ร่วมกับกรอบควบคุมความเสี่ยงด้านไอทีและข้อมูล
Synthetic‑KYC คืออะไร: เทคโนโลยีเบื้องหลัง LLM, GAN และแนวทางอื่น
Synthetic‑KYC คืออะไร: เทคโนโลยีเบื้องหลัง LLM, GAN และแนวทางอื่น
Synthetic‑KYC หมายถึงกระบวนการสร้างชุดข้อมูลลูกค้าแบบจำลอง (synthetic data) ที่เลียนแบบลักษณะสถิติ ความสัมพันธ์ และความสมเหตุสมผลของข้อมูล KYC (Know Your Customer) จริง แต่ไม่ผูกกับบุคคลจริง เป้าหมายคือให้ทีมพัฒนาระบบทดสอบ การฝึกโมเดล และการตรวจสอบความปลอดภัยสามารถใช้ข้อมูลที่มีคุณภาพเชิงสถิติและเชิงบริบท โดยไม่ต้องเปิดเผยข้อมูลส่วนบุคคลจริง ในทางปฏิบัติ Synthetic‑KYC มักผสมผสานเทคโนโลยีหลายชนิด เช่น LLM (Large Language Models) สำหรับสร้างข้อความและฟิลด์เชิงอธิบาย, GAN/VAEs/Diffusion สำหรับสร้างภาพหรือข้อมูลเชิงโครงสร้าง, และเทคนิคความเป็นส่วนตัวเชิงคณิตศาสตร์อย่าง differential privacy เพื่อจำกัดการรั่วไหลของข้อมูลจริง

ด้านเทคนิค มีความแตกต่างสำคัญระหว่างเครื่องมือที่ใช้: LLM เป็นโมเดลที่ฝึกบนข้อมูลเชิงภาษา ทำงานโดยการทำนายโทเค็นต่อโทเค็น จึงเหมาะสำหรับการสร้างฟิลด์ข้อความ KYC เช่น ชื่อ-นามสกุล, อาชีพ, คำอธิบายที่อยู่, ประวัติการติดต่อ หรือคำอธิบายพฤติกรรมลูกค้า LLM สามารถสร้างข้อความที่ต่อเนื่อง มีความหมาย และรักษาบริบทได้ดี แต่มีความเสี่ยงของการจดจำข้อมูลจริง (memorization) หากโมเดลถูกฝึกด้วยข้อมูลที่มีข้อมูลเฉพาะตัวจำนวนน้อย ในทางกลับกัน GAN (Generative Adversarial Networks) และ VAE (Variational Autoencoders) ทำงานแบบคู่ขนานระหว่างตัวสร้างและตัวจำแนก (หรือโดยการเข้ารหัส/ถอดรหัส) เหมาะสมอย่างยิ่งสำหรับการสร้างรูปภาพ (เช่น รูปถ่ายบัตรประชาชน, ลายเซ็น) และข้อมูลเชิงโครงสร้างหรือเชิงตาราง (tabular data) โดยเฉพาะเมื่อต้องการรักษาความสัมพันธ์เชิงสถิติระหว่างฟีเจอร์หลายมิติ
นอกจาก GAN/VAE ยังมีโมเดลสมัยใหม่เช่น diffusion models สำหรับภาพ (ตัวอย่างเช่น Stable Diffusion) และโมเดลเฉพาะทางสำหรับข้อมูลตาราง เช่น CTGAN หรือ TVAE สำหรับสร้างข้อมูลธุรกรรมและรูปแบบเวลา (time‑series) มีงานวิจัยและการนำไปใช้จริงที่ระบุว่าการใช้โมเดลเหล่านี้ในโครงการนำร่องสามารถลดการใช้ข้อมูลจริงในการทดสอบได้ระหว่าง 50–90% ขึ้นกับระดับความเข้มงวดของข้อกำหนดความเป็นส่วนตัวและความต้องการความสมจริงของข้อมูล
เพื่อป้องกันการรั่วไหลของข้อมูลจริง มีเทคนิคเชิงคณิตศาสตร์และแนวทางปฏิบัติที่ควรนำมาประยุกต์ใช้ร่วมกัน ได้แก่
- Differential privacy (DP) — การฝึกโมเดลด้วยกลไกเช่น DP‑SGD โดยตั้งพารามิเตอร์ epsilon เพื่อควบคุมขอบเขตการรั่วไหลของข้อมูลแต่ละตัวอย่าง วิธีนี้ช่วยลดความเป็นไปได้ที่โมเดลจะจำข้อมูลจริงแบบตรงตัว
- K‑anonymity, l‑diversity, t‑closeness — เทคนิคการประมวลผลหลังสร้าง (post‑processing) เพื่อให้แน่ใจว่าบันทึกแต่ละรายการไม่สามารถถูกระบุตัวบุคคลได้จากการผสมของฟีเจอร์สำคัญ เช่น ทำให้กลุ่มข้อมูลมีความคล้ายคลึงกันอย่างน้อย k รายการ
- Membership inference testing และการโจมตีจำลอง — การทดสอบว่ามีโอกาสที่ข้อมูลจริงจะถูก "ดึงกลับ" (reconstructed) จากโมเดลหรือไม่ หากพบความเสี่ยงจะต้องปรับพารามิเตอร์ DP หรือลดการโอเวอร์ฟิต
- Hybrid approaches — การผสม LLM สำหรับฟิลด์ข้อความกับ GAN/VAEs สำหรับภาพ รวมทั้งการใช้กฎธุรกิจ (business rules) และการตรวจสอบโดยมนุษย์ เพื่อเพิ่มความสมเหตุสมผลและลดความเสี่ยงของการเกิดข้อมูลที่ใกล้เคียงบุคคลจริง
ตัวอย่างประเภทข้อมูล KYC ที่สามารถสร้างได้มีความหลากหลาย เช่น
- ข้อมูลส่วนบุคคลเชิงข้อความ — ชื่อ-นามสกุล (แบบปลอมแต่สอดคล้องกับบริบททางวัฒนธรรม), วันเกิดที่สมเหตุสมผล, อาชีพ, คำอธิบายที่อยู่อาศัยที่มีรูปแบบไปรษณีย์และเขตที่เป็นไปได้
- ข้อมูลเชิงโครงสร้าง/ตาราง — ประวัติธุรกรรม (วันที่ เวลา หมวดหมู่ จำนวนเงิน), ความสัมพันธ์ทางบัญชี, เครดิตสกอร์จำลอง ที่รักษาการแจกแจงสถิติและความสัมพันธ์ระหว่างฟีเจอร์
- เอกสารประจำตัวเชิงภาพ — รูปภาพบัตรประชาชนหรือพาสปอร์ตจำลองที่ไม่ตรงกับใบหน้าบุคคลจริง (ใช้ GAN/Diffusion เพื่อสร้างภาพใบหน้าสังเคราะห์ และผสมองค์ประกอบบัตรโดยไม่ตรงกับข้อมูลบุคคลจริง) รวมถึงลายนิ้วมือหรือลายเซ็นจำลอง
- สัญญาณพฤติกรรม — รูปแบบการล็อกอิน พฤติกรรมการใช้งานแอปพลิเคชัน รูปแบบการใช้จ่ายตามเวลาและสถานที่ เพื่อใช้ทดสอบระบบตรวจจับการฉ้อโกงและการวิเคราะห์ความเสี่ยง
ท้ายที่สุด การออกแบบ Synthetic‑KYC ที่มีประสิทธิภาพต้องคำนึงถึง trade‑off ระหว่างความเป็นส่วนตัวและคุณภาพของข้อมูล โดยใช้การประเมินผลเชิงสถิติ (เช่น การเปรียบเทียบการแจกแจง, ค่า correlation, ค่า Wasserstein distance) ร่วมกับการทดสอบเชิงปฏิบัติการ (เช่น การฝึกโมเดลตรวจจับการฉ้อโกงบนข้อมูลจำลองแล้วเทียบประสิทธิภาพกับข้อมูลจริง) และการทดสอบการรั่วไหล (membership inference) หากวางกรอบและเครื่องมืออย่างรัดกุม Synthetic‑KYC จะช่วยให้ธนาคารสามารถพัฒนาระบบได้รวดเร็วขึ้น ลดการพึ่งพาข้อมูลจริง และสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและการกำกับดูแล
ประโยชน์เชิงธุรกิจและ KPI ที่ธนาคารควรวัด
ประโยชน์เชิงธุรกิจของการนำ Synthetic‑KYC มาใช้
การนำเทคนิคสร้างข้อมูลลูกค้าจำลองจาก LLM/GAN มาใช้ในกระบวนการทดสอบและพัฒนาระบบ KYC ช่วยให้ธนาคารลดการพึ่งพาข้อมูลจริงในหลายกิจกรรมอย่างมีนัยสำคัญ ตัวอย่างเช่น ในการทดสอบเชิงบูรณาการ (integration testing) และการทดสอบระบบอัตโนมัติ (automation/test harness) ธนาคารสามารถลดการใช้ข้อมูลจริงได้ประมาณ 60–90% ขึ้นกับลักษณะงานและความละเอียดของข้อมูลที่ต้องการ ซึ่งช่วยลดความเสี่ยงด้านการรั่วไหลของ PII และภาระงานด้านการอนุมัติการเข้าถึงข้อมูล (data access approvals)
ในเชิงค่าใช้จ่ายและเวลา ผลเชิงธุรกิจที่จับต้องได้รวมถึงการลดค่าใช้จ่ายด้าน Compliance (เช่น ค่า audit, ค่า legal review และค่า GDPR/PDPA controls) โดยประมาณ 30–50% ในขณะที่เวลาในการทดสอบ (testing cycle time) มักลดลงอย่างชัดเจน — บางองค์กรรายงานการลดลงระหว่าง 30–60% เนื่องจากไม่ต้องรอการเตรียมชุดข้อมูลจริง/การขออนุญาต และสามารถสเกลการทดสอบได้ด้วยข้อมูลจำลองที่ผลิตได้ตามความต้องการ
อีกด้านหนึ่ง Synthetic‑KYC ยังส่งผลต่อความเร็วในการปล่อยฟีเจอร์ใหม่ (time‑to‑market): ด้วยการที่ทีมวิศวกรรมสามารถทดสอบเงื่อนไข edge case และสถานการณ์ผิดปกติได้อย่างครอบคลุม ระบบจะสามารถติดตั้ง patch หรือเปิดฟีเจอร์ใหม่ได้เร็วขึ้น โดยลดความล่าช้าที่เกิดจากกระบวนการรีดวงจรอนุมัติข้อมูลจริง นอกจากนี้ยังช่วยลดต้นทุนต่อกรณีทดสอบ (cost per test case) เมื่อเทียบกับการใช้ข้อมูลจริงที่ต้องผ่านกระบวนการทำ anonymization และ legal review
ตัวชี้วัดที่แนะนำ (KPI) และแนวทางการวัดผล
- Data reduction rate — สัดส่วนการลดการใช้ข้อมูลจริงเทียบกับ baseline ก่อนใช้ Synthetic‑KYC. สูตรตัวอย่าง: (จำนวนเรคคอร์ดจริงที่ใช้หลังใช้งาน / จำนวนเรคคอร์ดจริงที่ใช้ก่อนใช้งาน) และรายงานเป็นเปอร์เซ็นต์การลดลง ตัวชี้วัดเป้าหมายที่แนะนำคือ >70% ในสภาพแวดล้อม UAT/Integration
- Privacy risk score — ค่าประเมินความเสี่ยงด้านความเป็นส่วนตัวของชุดข้อมูลจำลอง ประกอบด้วยเมตริกย่อยเช่น re‑identification risk, membership‑inference probability และค่า ε ของ Differential Privacy (ถ้านำมาใช้). ตัวอย่างการให้คะแนน: 0–1 โดยที่ค่ายิ่งต่ำแสดงความเสี่ยงยิ่งต่ำ. เป้าหมายเชิงปฏิบัติคือ privacy risk < 0.1 หรือ membership‑inference success rate < 1% สำหรับข้อมูลที่สำคัญ
- Testing cycle time — เวลาเฉลี่ยจากการเริ่มต้นการทดสอบจนปิดกรณีทดสอบในแต่ละ sprint/feature. วัดเป็นชั่วโมงหรือวัน. เป้าหมายเชิงธุรกิจที่เป็นไปได้คือการลดลง 30–60% เทียบกับ baseline ภายใน 3–6 เดือนหลังนำ Synthetic‑KYC มาใช้
- Cost per test case — ค่าใช้จ่ายทั้งหมดที่เกี่ยวข้องกับการเตรียมและรันกรณีทดสอบ (รวมค่า governance, legal review, time of engineers) หารด้วยจำนวนกรณีทดสอบ. Synthetic‑KYC ควรลดค่านี้อย่างมีนัยสำคัญ; ตัวอย่างเป้าหมายคือการลดค่าใช้จ่ายต่อเคสลง 40–70% ในระยะสั้น
- Model fidelity / Statistical similarity metrics — การวัดความใกล้เคียงเชิงสถิติระหว่างชุดข้อมูลจำลองกับชุดจริง เช่น KL‑divergence, Jensen‑Shannon distance, Wasserstein distance, distribution coverage และ propensity score‑based tests. ควรกำหนด threshold เฉพาะงาน (เช่น JS < 0.05 สำหรับฟีเจอร์หลัก) และต้องตรวจสอบว่าจำนวนและความหลากหลายของ edge cases ถูกแทนที่อย่างเพียงพอ
- Model performance delta — ความแตกต่างของประสิทธิภาพโมเดลเมื่อฝึก/ทดสอบบนข้อมูลจำลองเทียบกับข้อมูลจริง (เช่น ΔAUC, ΔF1, ΔAccuracy). นิยาม: performance_on_synthetic − performance_on_real. เกณฑ์ยอมรับได้มักจะอยู่ในช่วง ±1–3% สำหรับโมเดลที่เป็น customer‑facing mission‑critical; สำหรับโมเดลภายในอาจยอมรับ ±5% ขึ้นไป ขึ้นกับระดับความเสี่ยง
- Deployment velocity / Time‑to‑market — ระยะเวลาตั้งแต่เริ่มพัฒนาฟีเจอร์จนถึงการเปิดใช้จริง. Synthetic‑KYC ควรแสดงผลเป็นการลดเวลานี้ (เช่นลดลงเป็นสัปดาห์) และสามารถเชื่อมโยงกับมูลค่าทางธุรกิจ เช่น revenue enablement หรือ reduction in opportunity cost
- Governance & Audit readiness — จำนวนประเด็น compliance ที่พบในการตรวจสอบ (audit findings) และเวลาที่ต้องใช้ในการตอบข้อค้นพบ ตัวชี้วัดนี้สะท้อนคุณภาพของกระบวนการควบคุมข้อมูลจำลองและการจัดทำเอกสาร
เพื่อให้ KPI มีความน่าเชื่อถือ ควรปฏิบัติตามแนวทางปฏิบัติ เช่นเก็บชุดข้อมูลจริงสำรองเป็น holdout (เช่น 10–30%) เพื่อใช้ประเมิน Model Performance Delta อย่างเป็นอิสระ ตรวจวัด Privacy Risk ด้วยการยิงคำทดสอบแบบ adversarial (เช่น membership inference, linkage attack simulations) และรันการทดสอบสถิติเพื่อวัด fidelity เป็นประจำ (เช่นทุก release หรือทุกเดือน)
สุดท้าย ควรกำหนดระดับการยอมรับ (acceptance thresholds) สำหรับแต่ละ KPI ที่สอดคล้องกับระดับความเสี่ยงของแอปพลิเคชัน เช่น งานที่เกี่ยวข้องกับการตัดสินเครดิตหรือการป้องกันการฟอกเงินจะมีเกณฑ์ Model Performance Delta และ Privacy Risk ที่เข้มงวดกว่างานทดลองภายใน การวัดผลอย่างเป็นระบบและการนำ KPI เหล่านี้ไปผูกกับระบบ Governance จะช่วยให้ธนาคารได้ประโยชน์เชิงธุรกิจจริง ทั้งในด้านลดต้นทุน เพิ่มความเร็ว และรักษามาตรฐานความเป็นส่วนตัวของลูกค้า
การออกแบบสถาปัตยกรรมและ pipeline สำหรับ Synthetic‑KYC
การออกแบบสถาปัตยกรรมและ pipeline สำหรับ Synthetic‑KYC: ภาพรวมเชิงสถาปัตยกรรม
การนำเทคโนโลยี Synthetic‑KYC มาใช้ในบริบทของธนาคารต้องเริ่มจากการออกแบบสถาปัตยกรรมที่คำนึงทั้งความปลอดภัยข้อมูลและความสามารถในการทดสอบระบบอย่างอิสระ โดยโครงสร้างหลักควรจัดเป็นโมดูลที่ชัดเจน ได้แก่ data ingestion, privacy filters, synthetic data generator, validation & metrics, storage & lineage และการเชื่อมต่อกับ environment ทดสอบ (staging) เพื่อให้สามารถควบคุมการไหลของข้อมูลและตรวจสอบย้อนหลังได้ตลอดวงจร
สถาปัตยกรรมที่เหมาะสมจะกำหนดหน้าที่ของแต่ละชั้นอย่างชัดเจน เพื่อแยกการจัดการข้อมูลจริง (production PII) ออกจากข้อมูลจำลอง ทั้งนี้เพื่อป้องกันการรั่วไหลของข้อมูลจริงระหว่างกระบวนการฝึก (training) และการทดสอบ (testing) และเพื่อให้สอดคล้องกับข้อกำหนดกฎระเบียบ เช่น พ.ร.บ. คุ้มครองข้อมูลส่วนบุคคล (PDPA) และมาตรฐานสากลด้านความปลอดภัย
องค์ประกอบหลักของ pipeline: ingest → sanitize → synthesize → validate → deploy
การออกแบบ pipeline ควรยึดลำดับการทำงานที่เป็นมาตรฐานดังนี้:
- Ingest: ดึงข้อมูลจากแหล่งต้นทาง (core banking, CRM, logs) ผ่านช่องทางที่เชื่อมต่อแบบปลอดภัย (VPN, VPC peering) และทำ metadata capture (timestamp, source, owner)
- Sanitize (privacy filters): ทำการลบ/ปิดบัง PII โดยใช้เทคนิคผสม เช่น masking, tokenization, generalization และการประเมินความเสี่ยงการระบุตัวตน (re‑identification risk)
- Synthesize (synthetic data generator): ใช้โมเดลเช่น LLM/GAN/Variational Autoencoders ที่กำหนดค่าความเป็นส่วนตัว (privacy budget) เพื่อสร้างข้อมูลจำลองที่รักษาความสัมพันธ์เชิงสถิติ
- Validate: ตรวจความถูกต้องทางสถิติและวัด privacy risk ด้วยชุดเมทริกซ์ เช่น propensity score, KS‑test, chi‑square, model utility tests และการประเมิน re‑identification probability
- Deploy: ส่งมอบชุดข้อมูลจำลองไปยังสภาพแวดล้อมทดสอบ (staging) ผ่านกระบวนการ CI/CD พร้อมการบันทึกเวอร์ชันและการอนุมัติแบบอัตโนมัติ
เครื่องมือและมาตรฐานที่สนับสนุน
การเลือกเครื่องมือควรครอบคลุมความต้องการด้านความเป็นส่วนตัว การตรวจวัด และการผนวกรวมกับงาน DevOps/ML Ops ตัวอย่างแนวทางและเครื่องมือที่แนะนำได้แก่:
- Privacy frameworks: Differential Privacy (DP), Local Differential Privacy (LDP), k‑anonymity, l‑diversity — ใช้ประกอบกับนโยบาย PDPA/ISO 27001
- Synthetic data validators: SDV (Synthetic Data Vault), Synthpop, ydata‑synthetic และชุดเครื่องมือวัดความเที่ยงตรง เช่น propensity score matching, distributional similarity metrics
- ML/Model registry & orchestration: MLflow, Kubeflow, Seldon สำหรับจัดการเวอร์ชันโมเดลและการดีพลอย
- CI/CD integration: GitLab CI, Jenkins, ArgoCD ร่วมกับ Terraform/Ansible สำหรับการปรับสภาพแวดล้อม staging และการอัตโนมัติของ pipeline
- Data storage & format: Delta Lake, Apache Iceberg, Parquet สำหรับรองรับ time travel, ACID และ schema evolution
Validation & metrics: วัดความเป็นประโยชน์และความเสี่ยงด้านความเป็นส่วนตัว
การตรวจสอบชุดข้อมูลจำลองต้องมีทั้งมิติของ utility และ privacy โดยแนะนำชุดเมทริกซ์ต่อไปนี้เป็นมาตรฐานภายใน:
- Utility metrics: distributional similarity (KS, Chi‑square), feature correlation preservation, model performance delta (AUC, RMSE) เมื่อนำชุดจำลองไปเทรน/ทดสอบโมเดลจริง
- Privacy metrics: re‑identification risk (probability), disclosure risk scoring, membership inference risk และการตรวจวัด privacy budget (ε) ในกรณีใช้ Differential Privacy
- Operational metrics: generation time, throughput (records/sec), failure rate และเวลาในการย้อนกลับ (rollback) เมื่อพบปัญหา
ตัวอย่างเกณฑ์เชิงกลยุทธ์: ยอมรับได้เมื่อ re‑identification risk ต่ำกว่า 0.05 และ model utility delta ไม่เกิน 5% เมื่อเทียบกับชุดข้อมูลจริง (ค่าตัวอย่างและเกณฑ์ควรกำหนดตามนโยบายความเสี่ยงของสถาบัน)
Storage, lineage และ audit trail ที่จำเป็น
การเก็บรักษา lineage และ audit trail เป็นหัวใจสำคัญสำหรับการตรวจสอบย้อนหลังและปฏิบัติตามกฎระเบียบ ควรออกแบบดังนี้:
- Metadata & data catalog: ใช้ Apache Atlas หรือ Data Catalog ภายในเพื่อบันทึกรายละเอียด dataset (source, schema, transformation history, owner)
- Versioning: ใช้ระบบจัดการเวอร์ชันของ data lake เช่น Delta Lake / Iceberg เพื่อบันทึก snapshot/commit และรองรับ time travel
- Immutable audit logs: บันทึกกิจกรรมสำคัญ (ingest, sanitize, synthesize, validate, deploy) ลงใน WORM storage หรือ ledger ที่มีการทำ hashing/cryptographic signing ของแต่ละบันทึก เพื่อตรวจสอบความสมบูรณ์
- Reproducibility records: เก็บค่า seed ของการสุ่ม, config ของโมเดล, weight/version ของโมเดล, pipeline run IDs และ container image hash เพื่อให้สามารถ reproduce ชุดข้อมูลจำลองได้ในกรณีที่อนุญาต
- Access control & monitoring: บังคับใช้ RBAC, MFA และการเข้ารหัสข้อมูลทั้งขณะเก็บและขณะส่ง พร้อมส่ง logs ไปยัง SIEM สำหรับการตรวจจับการเข้าถึงผิดปกติ
การผสานเข้ากับ environment ทดสอบ (staging) และการบริหารจัดการเวอร์ชัน
เมื่อชุดข้อมูลจำลองผ่านการ validate แล้ว การนำไปใช้ใน staging ควรเป็นกระบวนการอัตโนมัติผ่าน CI/CD pipeline ที่มีขั้นตอนอนุมัติ (approval gates) และการทดสอบอัตโนมัติ (unit tests, integration tests) โดยมีแนวทางปฏิบัติเช่น:
- จัดเก็บ artifacts ของชุดข้อมูลจำลองใน repository แยก (dataset registry) พร้อม metadata และ hash
- ตั้ง policy สำหรับการเลือกเวอร์ชันที่สามารถนำไปใช้ได้ (e.g., release tags, expiry dates)
- ใช้ feature flags หรือ isolated namespaces ใน Kubernetes เพื่อจำกัดการเข้าถึงและป้องกันผลกระทบต่อระบบจริง
- บันทึกการ deploy แต่ละครั้งใน audit trail พร้อมผลการทดสอบและผู้อนุมัติ เพื่อการตรวจสอบย้อนหลัง
สรุปคือ การออกแบบสถาปัตยกรรม Synthetic‑KYC ที่ปลอดภัยและมีประสิทธิภาพต้องผสานมาตรฐานความเป็นส่วนตัว เครื่องมือวัดคุณภาพข้อมูล และกระบวนการจัดเก็บ lineage/ audit ที่เข้มงวด เพื่อให้ธนาคารสามารถใช้ข้อมูลจำลองในการทดสอบระบบ ลดการเปิดเผยข้อมูลจริง และยังคงสามารถตรวจสอบย้อนกลับได้ตามข้อกำหนดทางกฎหมายและการกำกับดูแลภายในองค์กร
ความเสี่ยง ข้อจำกัด และการรับรองความสมจริงของข้อมูลสังเคราะห์
ภาพรวมความเสี่ยงหลักที่ควรตระหนัก
การนำ Synthetic‑KYC มาใช้ในธนาคารเพื่อลดการเปิดเผยข้อมูลจริงมีประโยชน์ด้านความเป็นส่วนตัวและความยืดหยุ่นของการทดสอบระบบ แต่ต้องยอมรับความเสี่ยงเชิงเทคนิคและเชิงนโยบายอย่างรอบด้าน ประเด็นสำคัญได้แก่ การขยายอคติ (bias amplification) เมื่อตัวสร้างข้อมูลเรียนรู้การกระจายจากชุดข้อมูลจริงที่มีอคติแล้วทำให้แบบจำลองสังเคราะห์มีการบิดเบือนมากขึ้น, การฟิตเกิน (overfitting) ของตัวสร้างข้อมูลที่สามารถจดจำหรือทำซ้ำระเบียนจริงบางส่วนได้, รวมถึงช่องโหว่ด้านความเป็นส่วนตัวเช่น membership inference และ reconstruction attacks ที่อาจอนุมานได้ว่าบุคคลใดอยู่ในชุดข้อมูลฝึกหรือแม้แต่สร้างข้อมูลเชิงละเอียดกลับมาได้
ตัวอย่างเชิงปฏิบัติ: งานประเมินความเสี่ยงของโมเดลจำลองในบริบทต่าง ๆ แสดงให้เห็นว่า การโจมตีแบบ membership inference สามารถระบุความเป็นสมาชิกได้มากกว่า 50% ในกรณีโมเดลที่ “overfit” หรือไม่มีการป้องกันด้านความเป็นส่วนตัวที่เหมาะสม ขณะที่การโจมตีเชิง reconstruction อาจสามารถสร้างค่าเชิงละเอียดของฟีเจอร์บางอย่างได้เมื่อมีสัญญาณซ้ำในชุดข้อมูลต้นทาง ทั้งนี้ผลกระทบจริงขึ้นกับขนาดชุดข้อมูล วิธีการสร้าง และมาตรการป้องกันที่นำมาใช้
การวัดความสมจริงของข้อมูลสังเคราะห์ (Evaluation Metrics)
การประเมินต้องครอบคลุมมิติด้านสถิติ ประสิทธิภาพการใช้งานจริง และความเสี่ยงด้านความเป็นส่วนตัว โดยใช้ชุดมาตรวัดที่ชัดเจน เช่น
- Statistical similarity: การเปรียบเทียบการแจกแจงฟีเจอร์ (marginal/conditional distributions) เช่น KS‑test, Chi‑square, KL divergence, Wasserstein distance และการตรวจสอบอัตราส่วนกลุ่มย่อย (subgroup parity)
- Downstream model utility: ทดสอบประสิทธิภาพของโมเดลงานจริงโดยใช้ข้อมูลสังเคราะห์เป็นข้อมูลฝึก (เช่น AUC, F1, accuracy) และเปรียบเทียบกับการฝึกด้วยข้อมูลจริงเป็น baseline — หากประสิทธิภาพของงานธุรกรรมสำคัญลดลงมาก อาจบ่งชี้ว่าข้อมูลสังเคราะห์ไม่สะท้อนพฤติกรรมจริงเพียงพอ
- Privacy risk metrics: วัดความเสี่ยงจากการโจมตี เช่น การประเมินความสำเร็จของ membership inference attacks (advantage, precision/recall ของผู้โจมตี), เชิงวัดการรั่วไหลข้อมูลเชิงละเอียดจาก reconstruction attacks และการคำนวณค่า epsilon ในกรอบ Differential Privacy เพื่อแสดงงบประมาณความเป็นส่วนตัว
แนวทางทดสอบเชิงรุกและการลดความเสี่ยง
ธนาคารควรนำแนวปฏิบัติแบบหลายชั้น (defense‑in‑depth) มาใช้ ทั้งในขั้นตอนการสร้างข้อมูล การทดสอบ และการควบคุมใช้งานจริง ตัวอย่างแนวทางปฏิบัติสำคัญ ได้แก่
- Red‑team and adversarial testing: จัดทีมภายในหรือภายนอกจำลองการโจมตี (membership inference, model inversion, reconstruction) อย่างต่อเนื่อง เพื่อประเมินความเสี่ยงเชิงปฏิบัติและค้นหาช่องโหว่ก่อนนำข้อมูลสังเคราะห์ไปใช้งานจริง
- ใช้ Differential Privacy และควบคุม Privacy budget: นำกลไกเช่น DP‑SGD หรือ PATE มาใช้ในการฝึกตัวสร้าง เพื่อจำกัดการรั่วไหลข้อมูลตัวอย่าง ค่า epsilon ควรถูกกำหนดเป็นนโยบายองค์กรและทดสอบผลกระทบต่อคุณภาพ — โดยทั่วไปค่า epsilon ยิ่งต่ำยิ่งให้ความเป็นส่วนตัวสูงขึ้นแต่จะลดคุณภาพของข้อมูลสังเคราะห์
- ป้องกัน overfitting ของ generator: ใช้มาตรการเช่น early stopping, regularization, k‑fold validation และการสำรองชุดข้อมูล holdout ที่เป็นจริงเพื่อตรวจจับการจดจำตัวอย่างจริงโดยไม่ตั้งใจ
- การตรวจจับและลด bias: ประเมินผลกระทบต่อกลุ่มย่อย (demographic parity, equalized odds) และใช้เทคนิคการปรับสมดุล (reweighting, targeted augmentation, debiasing layers) เพื่อป้องกันการขยายอคติจากข้อมูลต้นทางไปสู่ชุดสังเคราะห์
- Post‑processing และ outlier filtering: ตรวจสอบและลบเรคคอร์ดสังเคราะห์ที่มีลักษณะเป็น outlier หรืออาจสอดคล้องกับระเบียนจริงอย่างใกล้ชิด (high similarity threshold) ก่อนนำไปใช้งาน
- ตรวจสอบโดยมนุษย์และ governance: ตั้งกลไกการอนุมัติ การเก็บบันทึกการสร้างข้อมูล และการตรวจสอบโดยทีมความเสี่ยง/Compliance เพื่อให้มีการติดตามผลและความรับผิดชอบ
แนวทางปฏิบัติที่แนะนำสำหรับการนำไปใช้ในธนาคาร
เพื่อให้การใช้ Synthetic‑KYC ปลอดภัยและเชื่อถือได้ ธนาคารควรกำหนดนโยบายและกระบวนการที่ชัดเจน เช่น การกำหนดเกณฑ์การยอมรับ (acceptance criteria) สำหรับความสมจริงและความเสี่ยง, การทดสอบแบบอัตโนมัติและแบบเชิงรุก (continuous red‑teaming), และการกำหนดค่า privacy budget ที่สมเหตุสมผลต่อการใช้แต่ละงาน นอกจากนี้ควรบูรณาการการประเมินผลทั้งเชิงสถิติและเชิงงาน (statistical tests + downstream utility) และมีแผนสำรองเมื่อระดับความเสี่ยงเกินเกณฑ์ที่ยอมรับได้
สรุปคือ Synthetic‑KYC ให้ประโยชน์เชิงปกป้องข้อมูลต้นทาง แต่ไม่ใช่ทางออกอัตโนมัติ: ต้องออกแบบการสร้างและการประเมินอย่างรอบด้าน โดยใช้การทดสอบเชิงรุก เทคนิคความเป็นส่วนตัวเช่น Differential Privacy การลดอคติเชิงระบบ และการกำกับดูแลระดับองค์กรเพื่อรักษาสมดุลระหว่าง ความเป็นส่วนตัว, ความสมจริง และ ความสามารถในการใช้งานเชิงธุรกิจ.
กรณีศึกษาเบื้องต้น: พายล็อตของธนาคารไทยและผลลัพธ์เชิงตัวเลข
กรณีศึกษาเบื้องต้น: พายล็อตของธนาคารไทย — โครงการ "KYC‑Synth Pilot"
ธนาคารพาณิชย์รายใหญ่ในไทยได้ริเริ่มโครงการพายล็อต (pilot) ภายใต้ชื่อภายในว่า KYC‑Synth Pilot เพื่อทดสอบการใช้ข้อมูลลูกค้าจำลอง (synthetic KYC) ที่สร้างจากโมเดล LLM และ GAN โดยเป้าหมายหลักคือการลดการเปิดเผยข้อมูลจริงในการพัฒนาระบบและการทดสอบซอฟต์แวร์ ควบคู่ไปกับการรักษาความแม่นยำของโมเดลทางธุรกิจ เช่น ระบบตรวจจับการฉ้อโกงและการให้บริการลูกค้าแบบอัตโนมัติ
ขอบเขต เทคโนโลยี และระยะเวลาโครงการ
ขอบเขตพายล็อตครอบคลุมการสร้างชุดข้อมูล KYC จำลองสำหรับการทดสอบฟีเจอร์ 5 ด้าน ได้แก่ การยืนยันตัวตน, การตรวจสอบเอกสาร, การจัดกลุ่มความเสี่ยงลูกค้า, การจำลองกรณีฉ้อโกง และการทดสอบ UI/UX สำหรับทีม Front‑end โดยมีขนาดตัวอย่าง synthetic dataset ทั้งสิ้นประมาณ 3.2 ล้านเรคคอร์ด ซึ่งออกแบบให้มีการกระจายตัวแปร (distribution) ใกล้เคียงกับฐานข้อมูลจริงแต่ผ่านการป้องกันการย้อนรอยข้อมูลบุคคล
ด้านเทคโนโลยี โครงการผสมผสาน LLM (Large Language Model) สำหรับสร้างฟิลด์ข้อความเช่นที่อยู่และประวัติทางการเงินที่เป็นภาษาธรรมชาติ ร่วมกับ GAN (Generative Adversarial Networks) เพื่อสร้างฟิลด์เชิงตัวเลขและ categorical ที่ต้องมีความสัมพันธ์เชิงสถิติแบบซับซ้อน นอกจากนี้ใช้กรอบการประกันความเป็นส่วนตัวเช่น differential privacy และ privacy‑testing toolkit เพื่อประเมินความเสี่ยงการรั่วไหลของข้อมูลต้นทาง
ระยะเวลาโครงการพายล็อตใช้เวลาทั้งสิ้น 6 เดือน แบ่งเป็นเฟสสำคัญคือ การเก็บความต้องการและเตรียมข้อมูล (4 สัปดาห์), การออกแบบและเทรนโมเดล (12 สัปดาห์), การประเมินคุณภาพและการปรับเทียบ (6 สัปดาห์) และการทดสอบเชิงประยุกต์ร่วมกับทีม QA/DevOps (4 สัปดาห์)
ผลลัพธ์เชิงตัวเลข
โครงการพายล็อตรายงานผลเชิงตัวเลขที่สำคัญดังนี้ ซึ่งเป็นตัวอย่างผลลัพธ์จากการประเมินภายในของทีม:
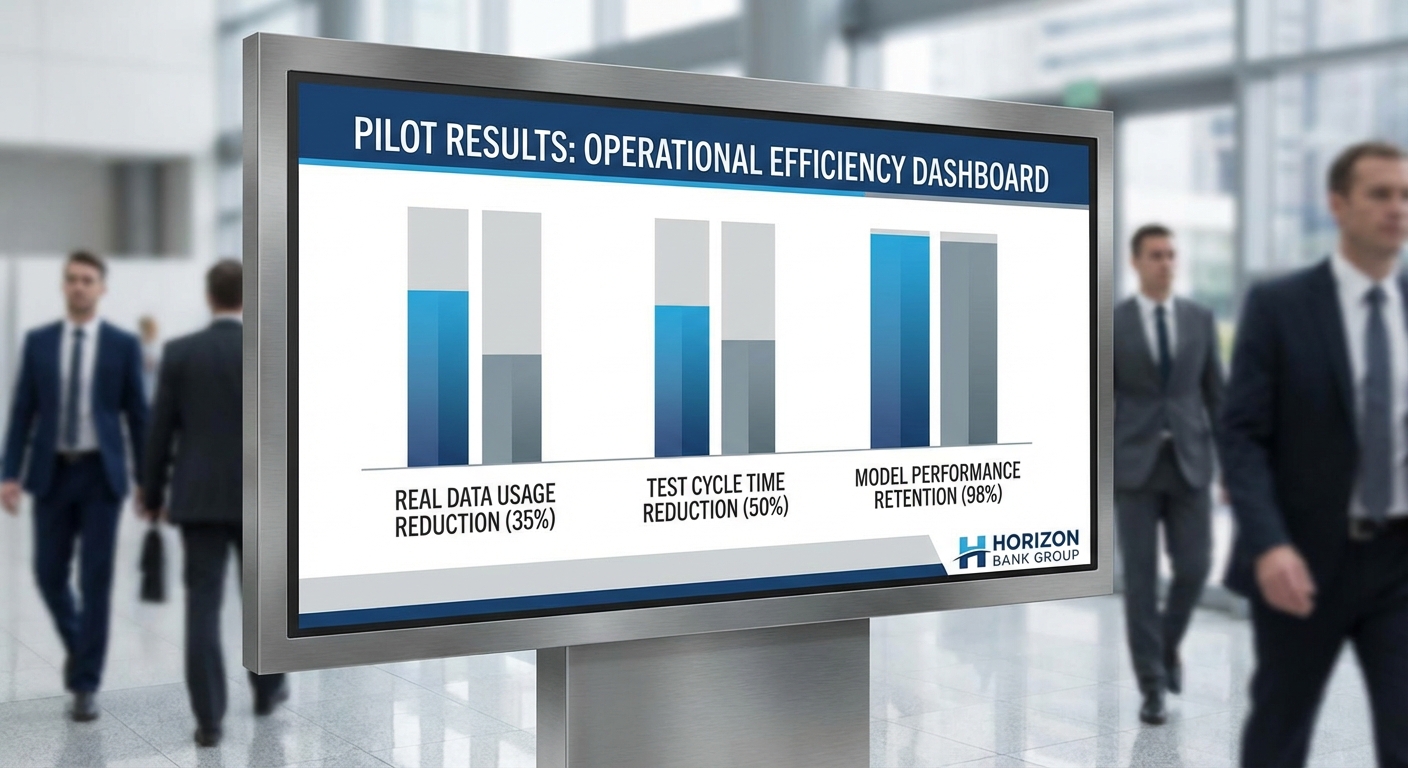
- ลดการใช้ข้อมูลจริงสำหรับการทดสอบลงประมาณ 70% (จากชุดทดสอบ 1.5 ล้านเรคคอร์ด ลดใช้ข้อมูลจริงเหลือ 450,000 เรคคอร์ด และแทนที่ด้วย synthetic 1.05 ล้านเรคคอร์ด)
- ลดเวลาในการออกแบบและรันการทดสอบระบบ (testing cycles) ประมาณ 40% เนื่องจากไม่ต้องขออนุญาตข้อมูลจริงและสามารถสร้างเคสทดสอบเฉพาะได้ทันที
- ประสิทธิภาพโมเดลธุรกิจที่ใช้ข้อมูลจำลองยังรักษาระดับความแม่นยำได้ดี — ตัวอย่างเช่นโมเดลตรวจจับการฉ้อโกงมีค่า AUC จาก 0.920 (เมื่อใช้ข้อมูลจริงทั้งหมด) เหลือ 0.915 เมื่อฝึกร่วมด้วย synthetic data (ลดลงเพียง ~0.5%) ซึ่งถือว่ายอมรับได้ในเชิงปฏิบัติการ
- จำนวนเคส edge‑case ที่จับได้เพิ่มขึ้นราว 25% เนื่องจากสามารถสร้างสถานการณ์ผิดปกติ (rare scenarios) ที่หายากในข้อมูลจริงได้ง่ายขึ้น
- การประเมินความเสี่ยงการรั่วไหล (privacy risk score) ลดลงโดยประมาณ 85% เมื่อเทียบกับการเปิดเผยชุดข้อมูลจริงในการทดสอบภายนอก ตามมาตรการ threat‑modeling และการทดสอบการย้อนรอย
บทเรียนเชิงปฏิบัติการที่สำคัญ
จากการดำเนินพายล็อต ทีมงานสรุปบทเรียนเชิงปฏิบัติการได้หลายประการที่ควรนำไปใช้ก่อนขยายสเกล:
- ทีมที่ต้องมีอย่างชัดเจน: Data Science, Data Engineering, Privacy & Compliance, Legal, QA และ DevOps/Platform — โดยเฉพาะทีม Privacy ต้องร่วมออกแบบเกณฑ์การสร้าง synthetic และการประเมินความเสี่ยงตั้งแต่ต้น
- ความร่วมมือกับผู้ให้บริการภายนอก: การใช้โมเดล LLM เชิงพาณิชย์หรือบริการ GAN from vendor มีข้อดีเรื่องเวลาและความเชี่ยวชาญ แต่ต้องมีการตรวจสอบ SLA ด้านความเป็นส่วนตัวและการถ่ายโอนข้อมูล จุดที่ทำให้สำเร็จคือการเลือกผู้ให้บริการที่ยอมให้รันโมเดลบน VPC ของธนาคารหรือให้บริการแบบ on‑premise
- ปัญหาและความท้าทาย: พบเรื่อง distribution mismatch ในกลุ่มประชากรย่อยบางกลุ่มซึ่งทำให้โมเดล downstream ตอบสนองด้อยลงในกรณีเฉพาะ การแก้ไขต้องอาศัยการปรับเทียบ (calibration) และการผสมข้อมูลจริงในสัดส่วนเล็กน้อยเพื่อรักษาความเป็นตัวแทน
- การวัดและการตรวจสอบ: จำเป็นต้องมีชุดเกณฑ์วัดคุณภาพ synthetic อย่างเป็นระบบ เช่น statistical similarity, model‑utility metrics และ privacy‑risk metrics ก่อนอนุญาตให้ใช้ในสภาพแวดล้อมการทดสอบจริง
- การจัดการเปลี่ยนแปลงภายในองค์กร: ต้องมีการฝึกอบรมผู้มีส่วนได้ส่วนเสียและจัดกระบวนการ governance เพื่อให้ทีม QA และผู้พัฒนายอมรับการใช้ synthetic data แทนข้อมูลจริงในส่วนที่เหมาะสม
สรุปได้ว่าโครงการพายล็อตของธนาคารไทยชี้ให้เห็นว่า synthetic‑KYC เป็นแนวทางที่เป็นไปได้และให้ผลตอบแทนเชิงธุรกิจ ทั้งการลดการพึ่งพาข้อมูลจริงและการเร่งความเร็วในการทดสอบ อย่างไรก็ตามการใช้งานในระดับองค์กรต้องอาศัยกรอบการวัดคุณภาพและความเป็นส่วนตัวที่เข้มงวด รวมทั้งความร่วมมือข้ามหน่วยงานและกับผู้ให้บริการภายนอกเพื่อให้ผลลัพธ์มีความน่าเชื่อถือและปลอดภัย
ข้อเสนอแนะเชิงนโยบายและแนวทางปฏิบัติสำหรับธนาคาร
ข้อเสนอแนะเชิงนโยบายและโครงสร้างการกำกับดูแล (Governance, Risk & Compliance)
จัดตั้งคณะกรรมการกำกับพิเศษ (Synthetic‑KYC Governance Board) ที่ประกอบด้วยตัวแทนจากหน่วยงานความเสี่ยง ฝ่ายปฏิบัติการ ฝ่ายกฎหมาย ฝ่ายคุ้มครองข้อมูล และทีมเทคนิค โดยมอบอำนาจกำหนดนโยบายการใช้ synthetic data, การรับรองความปลอดภัย และการอนุญาตการเข้าถึงข้อมูลจำลอง ซึ่งคณะกรรมการควรกำหนดตัวชี้วัดความเสี่ยง (KRI) เช่น ระดับความเสี่ยงการเปิดเผยตัวตน (re‑identification risk), การเบี่ยงเบนเชิงสถิติ (statistical divergence) และผลกระทบต่อความถูกต้องของโมเดล (model utility).
สร้างนโยบาย R&C เฉพาะสำหรับ Synthetic Data ซึ่งครอบคลุมวงจรชีวิตของข้อมูลตั้งแต่การออกแบบ สร้าง ทดสอบ เก็บบันทึก การทำลาย และการเผยแพร่ โดยรวมข้อกำหนดด้านการจำแนกข้อมูล (data classification), การทำ Data Protection Impact Assessment (DPIA) สำหรับการทดลอง และการจัดชั้นสิทธิ์การเข้าถึงแบบ Role‑based Access Control (RBAC) พร้อมระบบบันทึก (audit trail) เพื่อใช้ในการตรวจสอบย้อนหลัง.
แนวทางการเลือก Vendor/เทคโนโลยี และการทำ Due Diligence
การคัดเลือกผู้ให้บริการหรือโซลูชัน Synthetic‑KYC ควรใช้ checklist ตรวจสอบแง่มุมด้านความเป็นส่วนตัว ความปลอดภัย ความสามารถในการอธิบายผล และการรับประกันเชิงสัญญา (SLA/SLR) ดังตัวอย่างต่อไปนี้:
- การปฏิบัติตามมาตรฐานและการรับรอง: มีการรับรองด้านความมั่นคงปลอดภัย (เช่น ISO 27001, SOC2) และสอดคล้องกับกฎ PDPA/PDPL/มาตรการคุ้มครองข้อมูลที่เกี่ยวข้องหรือไม่
- เทคนิคการสร้างข้อมูล: ระบุชัดว่าใช้ LLM, GAN, หรือ hybrid approach และมีความสามารถในการควบคุม trade‑off ระหว่าง privacy vs utility หรือการใส่ Differential Privacy (ค่า ε) ได้หรือไม่
- การตรวจสอบและทดสอบความเสี่ยง: สนับสนุนการทดสอบการโจมตี (membership inference, record linkage) และให้รายงาน re‑identification risk ที่สามารถตรวจสอบได้
- ความโปร่งใสและความสามารถในการอธิบาย: รายงานวิธีการป้อนข้อมูล, preprocessing, hyperparameters, และมี capability ในการให้ audit logs และ model lineage
- สัญญาและ SLA: ระบุระดับบริการ ความรับผิดชอบต่อเหตุการณ์ข้อมูลรั่วไหล เงื่อนไขการตรวจสอบโดย third‑party และข้อกำหนดในการเก็บสำเนา/ลบข้อมูล
- การบริหารจัดการซัพพลายเชน: ตรวจสอบ subcontractors และการเข้าถึงข้อมูลโดยบุคคลที่สาม
แนะนำให้ธนาคารทำ PoC ขนาดเล็กกับผู้ให้บริการอย่างน้อย 2 แห่ง เพื่อเปรียบเทียบผลลัพธ์เชิงสถิติและการใช้งานจริงก่อนตัดสินใจเชิงสัญญา
โปรโตคอลการยืนยันความถูกต้อง (Validation Protocol)
กำหนดชุดการทดสอบกระบวนการตรวจสอบและวัดผลอย่างเป็นระบบ ซึ่งรวมถึงการทดสอบด้านความเป็นส่วนตัว ความเที่ยงตรงทางสถิติ และการใช้งานสำหรับการพัฒนาระบบ:
- มาตรวัดความเป็นส่วนตัว: ประเมิน re‑identification risk, membership inference risk และหากใช้ Differential Privacy ให้ระบุค่า ε ที่ยอมรับได้ในนโยบาย (ตัวอย่างเช่น ธนาคารอาจตั้งค่าเป้าหมาย re‑identification risk <0.01% ขึ้นอยู่กับความเสี่ยงของกรณีใช้งาน)
- มาตรวัดประสิทธิภาพเชิงสถิติ: ใช้ KS statistic, Jensen‑Shannon divergence, distribution overlap และค่าเฉลี่ย/ค่ามัธยฐานและความแปรปรวนเพื่อเปรียบเทียบข้อมูลจริงกับ synthetic
- มาตรวัดความสามารถในการใช้งาน (utility): เปรียบเทียบประสิทธิภาพของโมเดล ML ที่ฝึกด้วยข้อมูลจริงเทียบกับข้อมูลสังเคราะห์ (เช่น เปลี่ยนแปลง AUC/DPR ไม่เกิน 2–5% เป็นเกณฑ์ตัวอย่าง)
- การทดสอบเชิงรุก: ดำเนิน adversarial testing, linkage attack simulation และ penetration test ของ environment ที่เก็บ synthetic data
- เวอร์ชันนิ่งและ lineage: บันทึกเวอร์ชันของโมเดลและชุดข้อมูล รวมถึงพารามิเตอร์การสร้าง เพื่อให้สามารถย้อนกลับและ reproduce การทดลองได้
ผลการทดสอบควรถูกจัดเป็นรายงานมาตรฐาน (validation report) ที่ประกอบด้วย KPI, ค่าตัวชี้วัดเชิงสถิติ, การประเมินความเสี่ยง และคำแนะนำการปรับพารามิเตอร์ ก่อนอนุมัติให้ใช้งานในสภาพแวดล้อมการผลิตหรือการทดสอบที่มีความละเอียดอ่อน
การฝึกอบรมบุคลากรและการเปลี่ยนแปลงองค์กร
ออกแบบโปรแกรมฝึกอบรมเชิงปฏิบัติ (role‑based) สำหรับทีมเทคนิค ทีมทดสอบ ทีมปฏิบัติการ และผู้บริหาร โดยครอบคลุมพื้นฐานของ synthetic data, ความเสี่ยงด้านความเป็นส่วนตัว, การอ่านผล validation report และขั้นตอนการตอบสนองเมื่อพบเหตุการณ์ พร้อมจัดให้มี tabletop exercises และการทดสอบตอบสนองต่อเหตุการณ์อย่างน้อยปีละหนึ่งครั้ง.
นอกจากนี้ ควรจัดทำ playbook สำหรับการจัดการเหตุข้อมูลรั่วไหล การจำแนกเหตุการณ์ (incident classification), ช่องทางการรายงานภายใน และขั้นตอนประสานกับทีมกฎหมายและหน่วยงานกำกับดูแล เพื่อให้การดำเนินการเป็นไปอย่างรวดเร็วและเป็นมาตรฐาน
การประสานกับหน่วยงานกำกับดูแลและแนวทางการเผยแพร่ผลการทดลอง
สร้างช่องทางการสื่อสารเชิงรุกกับหน่วยงานกำกับ เช่น ธนาคารแห่งประเทศไทย คณะกรรมการคุ้มครองข้อมูลส่วนบุคคล หรือหน่วยงานกำกับที่เกี่ยวข้อง โดยมีมาตรฐานการรายงานล่วงหน้า (pre‑notification) สำหรับการทดลองที่มีความเสี่ยงสูง และกำหนดรอบการรายงานผล (เช่น รายงานเบื้องต้นเมื่อเริ่ม PoC, รายงานผลสรุปทุกไตรมาส) พร้อมเอกสารแนบ validation report และ risk assessment.
แนวทางการเผยแพร่ผลการทดลองต่อสาธารณะหรือหน่วยงานกำกับ ควรเป็นไปอย่างสมดุลระหว่างความโปร่งใสและการปกป้องความลับทางการค้า โดยแนะนำให้เผยแพร่สรุปเชิงเทคนิคที่ไม่เปิดเผยข้อมูลส่วนบุคคลหรือรายละเอียดที่อาจนำไปสู่การโจมตี เช่นการเผยแพร่ whitepaper/summary ที่ประกอบด้วยเป้าหมายการทดลอง เมตริกความเป็นส่วนตัวและ utility (เช่น re‑identification risk, divergence metrics, ผลกระทบต่อโมเดล) และบทเรียนที่ได้ โดยสามารถจัดทำเวอร์ชันสำหรับหน่วยงานกำกับที่มีข้อมูลเชิงลึกมากขึ้นภายใต้ NDA.
การวัดความสำเร็จและการรายงานต่อหน่วยงานกำกับ
กำหนดชุด KPI ที่ชัดเจนเพื่อประเมินผลสำเร็จของการนำ Synthetic‑KYC มาใช้ ตัวอย่าง KPI ได้แก่:
- อัตราการลดการใช้ข้อมูลจริง: เปอร์เซ็นต์การทดสอบที่ใช้ synthetic แทนข้อมูลจริง (เป้าหมายเช่นลดการใช้ข้อมูลจริง ≥70%)
- ระดับความเสี่ยงการเปิดเผยตัวตน: ค่าระบุ re‑identification risk เฉลี่ยของชุดข้อมูล (ต้องต่ำกว่าค่า threshold ที่ธนาคารกำหนด)
- ผลกระทบต่อประสิทธิภาพโมเดล: การเปลี่ยนแปลงค่า AUC/Precision/Recall เมื่อใช้ synthetic แทน real (เป้าหมายลดลงไม่เกินที่ยอมรับได้ เช่น ≤5%)
- จำนวนเหตุการณ์ความปลอดภัย/การละเมิดข้อมูล: จำนวนและระดับความรุนแรงของ incident ที่เกิดขึ้นต่อชุดข้อมูล synthetic เทียบกับ baseline
- ระยะเวลาและต้นทุนการทดสอบ: เวลาที่ลดลงในการเตรียม environment ทดสอบและต้นทุนทางปฏิบัติการ
การรายงานต่อหน่วยงานกำกับควรกำหนดความถี่และรูปแบบ เช่น รายงานเบื้องต้นเมื่อเริ่มโครงการ รายงานสถานะรายไตรมาส และรายงานสรุปเมื่อสิ้นสุด PoC/การนำไปใช้ โดยทุกรายงานควรมีส่วนที่ชี้ชัดค่าตัวชี้วัดที่เกี่ยวข้อง ผลการประเมินความเสี่ยง และแผนการแก้ไข/ปรับปรุง หากพบช่องโหว่หรือเหตุการณ์ที่มีความเสี่ยงสูงต้องมีขั้นตอนแจ้งเตือนฉุกเฉินภายในกรอบเวลาที่กำหนด
สรุป ธนาคารควรผสานแนวทางด้าน governance, การประเมินความเสี่ยงเชิงเทคนิคและนโยบายเชิงปฏิบัติการเข้าด้วยกันอย่างเป็นระบบ การเลือก vendor ต้องอิงกับการทดสอบเปรียบเทียบจริง และการรายงานต่อหน่วยงานกำกับต้องโปร่งใสแต่คำนึงถึงการปกป้องความลับของระบบและข้อมูล ตัวชี้วัดที่วัดได้จะช่วยให้ธนาคารตัดสินใจอย่างมีข้อมูล และสร้างความเชื่อมั่นต่อทั้งผู้กำกับและลูกค้าต่อไป
บทสรุป
Synthetic‑KYC เป็นเครื่องมือสำคัญที่ช่วยลดการพึ่งพาข้อมูลจริงในการพัฒนาและทดสอบระบบของธนาคาร โดยใช้เทคนิคเช่น LLM และ GAN ในการสร้างข้อมูลลูกค้าจำลองที่มีลักษณะและรูปแบบการใช้ข้อมูลใกล้เคียงของจริง ผลการทดลองและงานวิจัยเบื้องต้นในต่างประเทศชี้ว่า synthetic data สามารถลดการใช้ข้อมูลจริงได้อย่างมีนัยสำคัญ (ตัวอย่างเช่นช่วงประมาณ 50–90% ขึ้นอยู่กับงานและมาตรฐานการสร้างข้อมูล) แต่การนำไปใช้ต้องออกแบบทั้งด้านเทคนิคและการกำกับดูแลอย่างรอบคอบ เพื่อรักษา ความเป็นส่วนตัว (เช่น การผสานเทคนิค differential privacy) และตรวจสอบ ความเป็นธรรม ของข้อมูล (bias testing, fairness metrics) รวมถึงการตั้งมาตรฐานคุณภาพข้อมูลและการวัดประสิทธิผลของข้อมูลจำลองด้วยตัวชี้วัดเช่น utility score, privacy leakage, และ bias metrics
สำหรับธนาคารไทย ควรเริ่มจากการพายล็อตเชิงยุทธศาสตร์ที่มีกระบวนการชัดเจน ตั้งขอบเขตการใช้งาน การวัดผล และการประเมินความเสี่ยงก่อนขยายใช้ เช่น กำหนด KPI ที่วัดได้ (การลดการเปิดเผยข้อมูลจริง, ความถูกต้องของโมเดลที่ฝึกด้วยข้อมูลจำลอง, ค่าการรั่วไหลของข้อมูล) จัดให้มีการทดสอบแบบ red‑team และ audit trail, รวมถึงการจัดทำนโยบาย governance, การควบคุมการเข้าถึง และการบันทึกการใช้งานเพื่อความโปร่งใส นอกจากนี้ควรประสานงานกับหน่วยงานกำกับเช่น ธนาคารแห่งประเทศไทยและหน่วยงานคุ้มครองข้อมูลส่วนบุคคล (PDPA) เพื่อพัฒนากรอบการกำกับที่เป็นมาตรฐาน เสริมด้วยการแลกเปลี่ยนแนวปฏิบัติที่ดีที่สุดกับภาคอุตสาหกรรมและสถาบันวิจัย
มุมมองอนาคต: หากออกแบบและกำกับอย่างรัดกุม Synthetic‑KYC จะเป็นเครื่องมือที่ช่วยเร่งนวัตกรรม ลดความเสี่ยงด้านการรั่วไหลของข้อมูล และลดต้นทุนการทดสอบระบบ แต่ความสำเร็จต้องการชุดมาตรฐานการประเมิน, กระบวนการรับรองคุณภาพข้อมูลจำลอง และการประเมินความเสี่ยงอย่างต่อเนื่อง ธนาคารไทยควรมุ่งสู่การขยายการใช้งานอย่างรับผิดชอบผ่านการพายล็อตที่พิสูจน์ผลได้ ก่อนนำไปใช้ในวงกว้างเพื่อสร้างสมดุลระหว่างนวัตกรรมและการคุ้มครองสิทธิ์ของลูกค้า



