
เมื่อประสบการณ์เสมือนจริงและเกมบนคลาวด์ต้องการความหน่วงต่ำระดับมิลลิวินาที การจัดสรรทรัพยากรเครือข่ายอย่างฉับพลันกลายเป็นหัวใจสำคัญ โอเปอเรเตอร์โทรคมนาคมในประเทศไทยจึงเริ่มทดลองแนวทางใหม่โดยใช้ Large Language Models (LLMs) ทำหน้าที่เป็นเอเจนต์ตัดสินใจแบบเรียลไทม์ เพื่อจัดสรร network slice บนโครงข่าย 5G/6G ให้สอดคล้องกับข้อกำหนดด้าน SLA สำหรับแอปพลิเคชัน AR และ Cloud‑Gaming ผลการทดลองขั้นต้นชี้ว่าการผสานความสามารถด้านการคาดการณ์และการปรับนโยบายของ LLM สามารถตอบสนองต่อความผันผวนของทราฟฟิกได้รวดเร็วขึ้น และมีศักยภาพลด latency ในช่วงเวลาที่สำคัญของการใช้งาน
บทนำนี้จะนำผู้อ่านสำรวจประเด็นสำคัญของโครงการทดลอง: แนวทางการทำงานของ LLM‑driven network slicing, เกณฑ์การวัดผล (เช่น latency, jitter, และการปฏิบัติตาม SLA), ผลทดสอบเบื้องต้นที่แสดงแนวโน้มการปรับปรุงประสิทธิภาพ และข้อพิจารณาด้านความปลอดภัย ข้อมูลส่วนตัว และความเข้ากันได้กับมาตรฐานสากล รวมถึงความท้าทายด้านการคอนโทรลสไลซ์ที่ต้องตอบโจทย์ทั้งฝั่งผู้ให้บริการ เครือข่าย และนักพัฒนาแอป
ผลลัพธ์จากการทดลองในระดับสนามจริงของโอเปอเรเตอร์ไทยอาจเป็นดัชนีชี้วัดสำคัญว่าการรวมปัญญาประดิษฐ์เชิงภาษาเข้ากับการจัดการเครือข่ายเชิงนโยบายจะพลิกโฉมการให้บริการ AR และ Cloud‑Gaming อย่างไร ในบทความต่อไป เราจะลงรายละเอียดการตั้งค่าการทดลอง เมตริกที่ใช้วัดผล ตัวอย่างเคสการใช้งานจริง และข้อเสนอแนะเชิงนโยบายสำหรับการนำไปใช้งานเชิงพาณิชย์ต่อไป
บทนำ: ทำไมการทดลองนี้สำคัญกับวงการโทรคมนาคมและ AI
บทนำ: ทำไมการทดลองนี้สำคัญกับวงการโทรคมนาคมและ AI
การทดลองที่โอเปอเรเตอร์ไทยรายหนึ่งดำเนินการร่วมกับผู้พัฒนาโมเดลภาษาใหญ่ (LLM) และผู้ผลิตอุปกรณ์เครือข่าย เพื่อให้เอเจนต์ AI ที่ขับเคลื่อนด้วย LLM ควบคุมการจัดสรร network slicing บนเครือข่าย 5G/6G แบบเรียลไทม์ ถือเป็นการผสานสองแนวทางหลักของการเปลี่ยนแปลงทางเทคโนโลยี: การสื่อสารไร้สายความเร็วสูงและปัญญาประดิษฐ์เชิงภาษาที่มีความสามารถด้านการตัดสินใจเชิงนโยบายและสถานะเครือข่าย ข้อเสนอการทดลองครอบคลุมการติดตั้งในสภาพแวดล้อมจริง (field trial) และห้องปฏิบัติการโดยทดสอบการให้บริการที่ต้องการ latency ต่ำ เช่น AR (Augmented Reality) และ Cloud‑Gaming พร้อมการวัดค่า SLA ที่ชัดเจนในมิติ latency, jitter และ throughput
เหตุผลในการใช้ LLM/AI แทนโซลูชันดั้งเดิม มาจากข้อจำกัดของระบบกฎแบบคงที่ (rule‑based) และการจัดลำดับการควบคุมที่มักไม่สามารถปรับตัวต่อสถานการณ์เครือข่ายที่เปลี่ยนแปลงอย่างรวดเร็วได้ ในสภาพแวดล้อม 5G/6G ที่มีการแบ่งสไลซ์เพื่อรองรับกรณีใช้งานหลากหลาย เช่น IoT / mMTC, eMBB, URLLC การตัดสินใจเชิงนโยบายต้องผสานข้อมูลหลายชั้น (จากแอปพลิเคชัน edge, สถานะทรัพยากร RAN/Core, นโยบายผู้ให้บริการ และเงื่อนไขผู้ใช้) ซึ่ง LLM สามารถทำหน้าที่เป็นเอเจนต์กลางที่เข้าใจนิยาม SLA เป็นภาษาธรรมชาติ แปลความต้องการเชิงธุรกิจเป็นนโยบายเครือข่าย และปรับพารามิเตอร์แบบเรียลไทม์เพื่อตอบสนองต่อความแออัดหรือความล้มเหลวของทรัพยากร ทั้งนี้การทดลองได้รับการออกแบบเพื่อตรวจสอบว่าเอเจนต์ LLM สามารถลดเวลาตอบสนองเชิงนโยบายและเพิ่มความแม่นยำในการจัดสรรสไลซ์เมื่อเทียบกับระบบอัตโนมัติแบบเดิมที่พึ่งพากฎตายตัว
ในระดับโลก ความต้องการบริการ latency‑sensitive เพิ่มขึ้นอย่างมีนัยสำคัญ: รายงานจากอุตสาหกรรมระบุว่าแอปพลิเคชัน AR/VR และเกมบนคลาวด์มีอัตราการเติบโตเป็นสองหลักต่อปี โดยเฉพาะในภูมิภาคเอเชียตะวันออกเฉียงใต้ ผู้ให้บริการต้องรับมือกับความคาดหวังของผู้ใช้ที่ต้องการ interactive experience ที่ latency ต่ำกว่า 20 มิลลิวินาทีในหลายกรณี การทดลองนี้จึงมีความสำคัญเชิงยุทธศาสตร์ เพราะหากพิสูจน์ว่า LLM‑driven orchestration สามารถปรับสไลซ์แบบเรียลไทม์และรักษา SLA ได้อย่างสม่ำเสมอ จะเป็นจุดเปลี่ยนในการออกแบบเครือข่ายเชิงนโยบาย โดยลดภาระการตั้งค่าด้วยมือและเพิ่มความยืดหยุ่นในการรองรับบริการใหม่ ๆ อย่างรวดเร็ว
ผลกระทบต่อบริการที่ไวต่อ latency และผู้ใช้ สรุปเป็นหัวข้อชัดเจนได้ดังนี้
- ประสบการณ์ผู้ใช้ดีขึ้น: การจัดสรรสไลซ์แบบไดนามิกช่วยให้ AR/Cloud‑Gaming ลด jitter และ latency ทำให้ภาพสลับช้าลงและอินเทอร์แอกชันลื่นไหลขึ้น ซึ่งจะส่งผลโดยตรงต่อความพึงพอใจและ retention ของผู้ใช้
- การปฏิบัติตาม SLA สูงขึ้น: เอเจนต์ LLM สามารถตีความเงื่อนไข SLA ที่ซับซ้อนและแปลงเป็นการตัดสินใจเชิงทรัพยากรแบบทันที ทำให้โอกาสในการละเมิด SLA ลดลง และง่ายต่อการตรวจสอบย้อนกลับเชิงนโยบาย
- ประสิทธิภาพการใช้ทรัพยากร: การตัดสินใจแบบ context‑aware ช่วยจัดสรรแบนด์วิดท์และ edge compute ได้คุ้มค่าขึ้น ลดการสำรองทรัพยากรที่เกินความจำเป็น และช่วยลดต้นทุนการดำเนินงาน
- ความพร้อมต่อการขยายบริการใหม่: หากประสบความสำเร็จ โมเดลนี้จะเปิดทางให้โอเปอเรเตอร์ปรับให้รองรับ use case ใหม่ เช่น AR ที่ผสานข้อมูลจากหลายเซ็นเซอร์หรือเกมหลายผู้เล่นแบบเรียลไทม์ โดยไม่ต้องออกแบบสไลซ์ใหม่จากศูนย์
พื้นฐานเทคนิค: LLM‑Driven Agents และ Network Slicing คืออะไร
พื้นฐานเทคนิค: LLM‑Driven Agents และ Network Slicing คืออะไร
Network slicing เป็นแนวคิดเชิงสถาปัตยกรรมเครือข่ายที่ถูกนิยามโดย 3GPP ตั้งแต่ยุค 5G ซึ่งอนุญาตให้โอเปอเรเตอร์สร้างเครือข่ายเสมือนหลายๆ ชุดบนโครงสร้างพื้นฐานร่วมกัน โดยแต่ละ "slice" จะถูกออกแบบให้ตอบสนองความต้องการเชิงบริการที่แตกต่างกัน เช่น eMBB (high throughput), URLLC (ultra‑reliable low latency communications) และ mMTC (massive machine‑type communications) ด้วยเจตนารมณ์เพื่อให้เกิด isolation, guaranteed QoS และ elasticity ในการจัดสรรทรัพยากร ตัวอย่างความต้องการเชิงตัวเลขที่ใช้อ้างอิงคือ URLLC มีเป้าหมาย latency ระดับประมาณ 1 ms ในบาง use case ขณะที่แอปพลิเคชัน AR/Cloud‑Gaming มักต้องการ end‑to‑end latency ต่ำกว่า 20–50 ms เพื่อรักษาคุณภาพประสบการณ์ผู้ใช้
ข้อดีสำคัญของ network slicing ได้แก่:
- Isolation — แต่ละ slice ถูกแยกทรัพยากรและนโยบาย ทำให้ปัญหาบริการหนึ่งไม่กระทบบริการอื่น
- QoS & SLA — สามารถกำหนดและบังคับใช้ระดับบริการ (latency, jitter, throughput, reliability) ตาม SLA ของแต่ละแอปพลิเคชัน
- Elasticity — ปรับขนาดทรัพยากรแบบไดนามิกตามความต้องการ เช่น เพิ่ม capacity ให้ slice ของ AR ในช่วงชั่วโมงเร่งด่วน
เมื่อผสานกับสถาปัตยกรรมเครือข่ายในโลกจริง เราจะเห็นองค์ประกอบสำคัญ เช่น RAN (Radio Access Network) ที่ควบคุม scheduling และทรัพยากรวิทยุ, MEC (Multi‑Access Edge Computing) ที่นำการประมวลผลและคอนเทนต์มาชิดขอบเครือข่ายเพื่อลด latency, และ Core ที่จัดการฟังก์ชันเครือข่ายหลักและการกำหนดนโยบาย (policy & orchestration). การประสานงานระหว่าง RAN, MEC และ Core เป็นหัวใจของการทำให้ slicing ทำงานได้ตาม SLA ในการใช้งานเช่น AR/Cloud‑Gaming ซึ่งมีเงื่อนไขด้าน latency และความต่อเนื่องสูง
ทำไมต้องใช้ LLM เป็นเอเจนต์ควบคุมการจัดสรร — LLM (Large Language Models) ถูกนำมาพิจารณาเป็นเอเจนต์เชิงนโยบายและการตัดสินใจ เนื่องจากมีความยืดหยุ่นทั้งในการเข้าใจนโยบายเชิงภาษาธรรมชาติ การแมปนโยบายเหล่านั้นเป็นคำสั่งเชิงเทคนิค และการประสานงานแบบหลายเอเจนต์ (multi‑agent coordination) ระหว่างโดเมนที่หลากหลาย ตัวอย่างเช่น ผู้ดูแลระบบอาจนิยาม SLA เป็นข้อความธรรมชาติ — LLM สามารถแปลเจตนา (intent) นั้นเป็นชุดของกระทำ (actions) เช่น ขอสถานะทรัพยากร เพิ่ม priority ให้ slice ของ AR หรือย้ายฟังก์ชันบางอย่างไปยัง MEC เพื่อลด RTT
เทคนิคการเรียนรู้และการปรับตัวแบบเรียลไทม์ ที่มักถูกผสานในระบบ LLM‑driven slicing ประกอบด้วย:
- Reinforcement Learning (RL) — ใช้สำหรับเรียนรู้กลยุทธ์การจัดสรรทรัพยากรแบบเชิงนโยบาย อัลกอริธึมเช่น PPO หรือ DQN สามารถฝึกให้เอเจนต์เลือกการกระทำที่ลดการละเมิด SLA และปรับ trade‑off ระหว่าง latency กับ throughput ในสภาพแวดล้อมไม่แน่นอน
- Intent‑based orchestration — แนวทางที่แปลงคำสั่งเชิงนโยบาย/เจตนาเป็นแผนปฏิบัติการอัตโนมัติ โดย LLM ทำหน้าที่เป็นตัวแปลเชิงบริบทและตัวประสานการตัดสินใจ
- Online adaptation และ Online learning — การปรับน้ำหนักนโยบายแบบต่อเนื่องตามข้อมูลสภาวะจริง (traffic shift, mobility) เพื่อให้การตัดสินใจของเอเจนต์ยังคงมีประสิทธิภาพในสภาพแวดล้อมที่ไม่คงที่
- Federated learning — ในกรณีที่ต้องการฝึกโมเดลจากข้อมูล edge หลายตำแหน่ง (เช่น ข้อมูล QoS จาก MEC หลายแห่ง) โดยไม่ต้องส่งข้อมูลดิบกลับศูนย์กลาง ลดความเสี่ยงด้านความเป็นส่วนตัวและแบนด์วิธ
ในการปฏิบัติจริง LLM มักทำงานร่วมกับโมดูล RL และตัวรวบรวมสัญญาณ (telemetry) จาก RAN/MEC/Core: LLM จะตีความนโยบายและทำหน้าที่เป็นตัวกำกับเชิงสูง (high‑level controller) ขณะที่ RL agent ที่เบากว่าอาจอยู่ใกล้ RAN/MEC ทำหน้าที่ตัดสินใจเชิงเวลาจริง (real‑time scheduling, admission control) การทำงานร่วมกันนี้ช่วยให้ได้ทั้งความสามารถในการตีความนโยบายแบบยืดหยุ่นและการตอบสนองแบบเรียลไทม์ที่มีข้อจำกัดด้านเวลา
ข้อท้าทายเชิงเทคนิคที่สำคัญ ได้แก่ ความช้าในการประมวลผลของโมเดลขนาดใหญ่เมื่อใช้ในเส้นทางเวลาจริง ความจำเป็นในการอธิบายเหตุผลของการตัดสินใจ (explainability) ต่อฝ่ายกฎระเบียบและฝ่ายธุรกิจ ความปลอดภัย/ความน่าเชื่อถือของโมเดล และการจัดการสำรองทรัพยากรเมื่อเกิดความล้มเหลว แนวทางปฏิบัติที่ใช้ได้จริงมักรวมการใช้ LLM เป็นตัวขับเคลื่อนนโยบายเชิงสูง พร้อมกับตัวควบคุมรูปแบบ lightweight RL และเทคนิค federated หรือ online learning เพื่อรักษาความเร็ว ความเป็นส่วนตัว และเสถียรภาพของระบบ
สถาปัตยกรรมการทดลอง: จากซอฟต์แวร์ถึงฮาร์ดแวร์
สถาปัตยกรรมการทดลอง: จากซอฟต์แวร์ถึงฮาร์ดแวร์
การทดลอง LLM‑driven network slicing ของโอเปอเรเตอร์ออกแบบเป็นสถาปัตยกรรมแบบหลายชั้น (multi‑tier) ที่ผสานซอฟต์แวร์ปัญญาประดิษฐ์ เข้ากับโครงสร้างพื้นฐานเครือข่ายจริงและอีมูเลเตอร์ โดยมีเป้าหมายลดความหน่วง (latency) ให้สอดคล้องตาม SLA สำหรับแอปพลิเคชัน AR และ Cloud‑Gaming สถาปัตยกรรมแบ่งเป็นส่วนหลัก ได้แก่ ชั้นโมเดล LLM, ชั้น orchestration/agent, telemetry & metrics pipeline, และชั้นฮาร์ดแวร์ (MEC, RAN, Core) ทั้งนี้การตัดสินใจเชิงนโยบายและการปรับสไลซ์จะเกิดขึ้นในระดับ MEC เพื่อให้ตอบสนองตามข้อกำหนด latency แบบเรียลไทม์
ในส่วนของซอฟต์แวร์ สแต็กประกอบด้วย LLM ที่ปรับแต่งมาเป็นเอเจนต์สำหรับตัดสินใจเชิงทรัพยากร ตัวอย่างการตั้งค่าที่ทดลองได้แก่ Llama‑2 7B / 13B สำหรับการตัดสินใจบน MEC (ตอบสนองเร็วและใช้ทรัพยากรจำกัด) และรุ่นขนาดใหญ่กว่าเช่น Llama‑2 70B หรือ GPT‑4‑like ที่รันบน regional data center เพื่อใช้อ้างอิงเชิงกลยุทธ์ รุ่นขนาดเล็กถูก quantize เป็น 8‑bit หรือใช้เทคนิค distillation เพื่อลด latency ของ inference ชั้น orchestration ประกอบด้วย microservices บน Kubernetes, message bus (Apache Kafka) สำหรับคิวคำสั่ง และ service mesh สำหรับการสื่อสารระหว่างเอเจนต์ ส่วนการสื่อสารเอเจนต์กับโครงข่ายใช้ gRPC/REST API พร้อมโปรโตคอล JSON/CBOR สำหรับ payload เบาๆ
Telemetry และ metrics pipeline ถูกออกแบบให้เป็นแบบเวลาจริง (near‑real‑time) โดยใช้ OpenTelemetry collectors เก็บข้อมูลจาก gNodeB, UPF, MEC และ UE agent แล้วส่งต่อไปยัง Kafka streams สำหรับประมวลผลเบื้องต้น ก่อนบันทึกใน Prometheus/InfluxDB เพื่อใช้ในการแจ้งเตือนและแสดงผลด้วย Grafana ในการทดลองมีการเก็บเมตริกสำคัญ เช่น RTT ระหว่าง UE→gNodeB, gNodeB→MEC, MEC processing time, packet loss, throughput per slice และ QoE proxy metrics (frame‑rate, jitter สำหรับ cloud gaming) โดย sampling rate ตั้งแต่ 10ms–100ms ขึ้นกับ SLA ของบริการ ตัว orchestration จะรัน loop การตัดสินใจแบบ closed‑loop โดยตั้งเป้า decision latency ต่อรอบไม่เกิน 10–20ms ในกรณี AR ที่ต้องการ end‑to‑end latency ทั้งระบบภายใน 20–40ms ส่วน Cloud‑Gaming ตั้งงบประมาณ 30–50ms
ฮาร์ดแวร์ที่ใช้ในการทดลองประกอบด้วย MEC servers แบบ rack‑mount (ตัวอย่าง: 2× Intel Xeon Platinum, 512GB RAM, 8× NVIDIA A10/A30 สำหรับ inference) ติดตั้งเชื่อมใกล้กับก้อน RAN เพื่อให้ gNodeB→MEC latency ต่ำสุด, 5G gNodeB จริงหรืออีมูเลเตอร์ (เช่น Amarisoft หรือ srsRAN) สำหรับการทดสอบสัญญาณและการจัดการสไลซ์ และอุปกรณ์ UE ทดสอบจำนวนหลายเครื่อง (smartphone/devkit) จำลองการใช้งาน AR/Cloud‑Gaming ในสภาวะแตกต่างกัน นอกจากนี้ใช้ 5GC (AMF/SMF/UPF) ที่รันแบบ containerized เพื่อเชื่อมต่อระหว่าง RAN กับ data network โดย UPF สามารถพิมพ์และกำหนดสไลซ์ (QoS Flow / PDU Session) ตามคำสั่งจาก SDN/Policy controller
การเชื่อมต่อและ latency budget ถูกกำหนดอย่างชัดเจนเพื่อประเมินเส้นทางการตอบสนอง: โดยกำหนดค่าตัวอย่างดังนี้
- UE → gNodeB: ยอมรับ latency ประมาณ 1–5 ms (ในสภาวะดี)
- gNodeB → MEC: ยอมรับ 1–3 ms (สายตรงหรือผ่านความหนาแน่นต่ำ)
- MEC processing (LLM inference + orchestration): เป้าหมาย 5–15 ms ต่อรอบ (โมเดลขนาดเล็ก/quantized)
- MEC → UPF/Core → Remote DC: เส้นทางสำรอง/อ้างอิง ยอมรับ 10–50 ms ขึ้นกับตำแหน่งภูมิศาสตร์
- End‑to‑end budget (AR): 20–40 ms, (Cloud‑Gaming): 30–50 ms
ลำดับการทำงาน (control flow) ของระบบเป็นไปตามขั้นตอนหลักดังนี้
- 1) Measurement: UE และ gNodeB ส่ง telemetry แบบต่อเนื่องไปยัง collectors (sampling 10–100ms)
- 2) Aggregation: Kafka stream ประมวลผลเมตริกทันทีและส่งให้ Prometheus/stream processor สำหรับคำนวณ KPI/SLA drift
- 3) Decision: เมื่อพบ SLA breach หรือโอกาสปรับปรุง ระบบจะส่งเหตุการณ์ให้ LLM agent บน MEC ซึ่งใช้ prompt + context ย้อนหลัง (sliding window) ในการเลือกแผน (re‑slice, migrate UPF, change QoS flows)
- 4) Orchestration: คำสั่งจาก LLM ถูกแปลงเป็น workflow โดย orchestration microservice และส่งคำสั่งลงไปยัง SDN controller / RAN configuration API เพื่อปรับ gNodeB, UPF, หรือ instantiation ของ network function ใหม่
- 5) Enforcement & Feedback: การเปลี่ยนแปลงมีผลแล้ว กลไก telemetry จะตรวจสอบผลลัพธ์แบบวนลูปเพื่อยืนยันการกลับสู่ SLA หรือกระตุ้น fallback หากการปรับไม่สำเร็จ
การทดลองยังรวมการทดสอบแบบ failure injection (เช่นเพิ่ม jitter, เสีย link ระหว่าง gNodeB→MEC) เพื่อประเมินความทนทานของ LLM agent และ orchestration ในสถานการณ์ฉุกเฉิน รวมถึงการวัด overhead ของการรันโมเดล LLM บน MEC (CPU/GPU utilization, memory footprint) ซึ่งช่วยให้กำหนดนโยบาย placement ว่าควรรันโมเดลขนาดใดบน edge หรือย้ายไปยัง regional DC เพื่อทรงประสิทธิภาพสูงสุด
ผลการทดลองเชิงปริมาณ: Latency, Jitter และการปฏิบัติตาม SLA
ผลการทดลองเชิงปริมาณ: สรุปภาพรวมการลด Latency, Jitter และการปฏิบัติตาม SLA
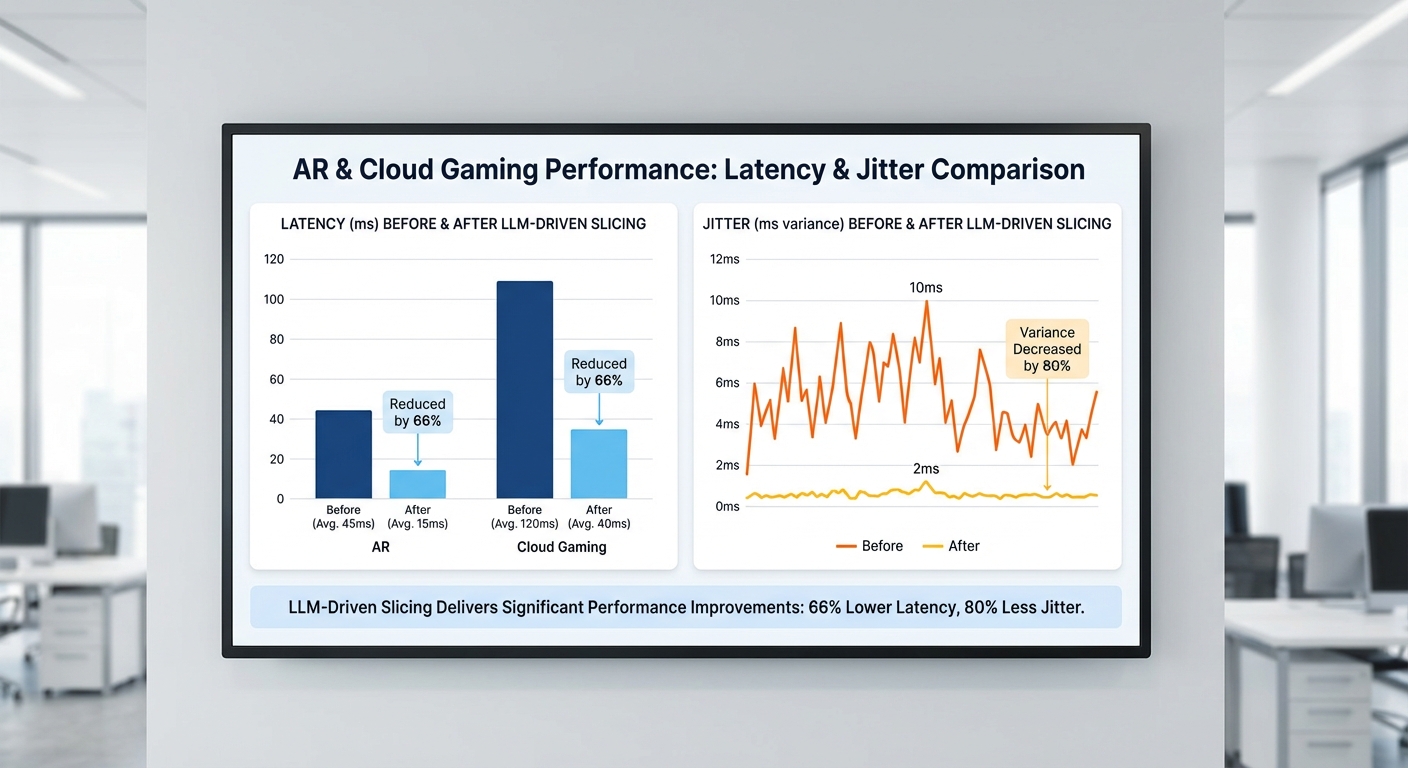
การทดลองเปรียบเทียบระหว่าง baseline static slicing (การจัดสรรสไลซ์แบบคงที่) กับระบบ LLM‑driven real‑time slicing สำหรับแอปพลิเคชัน AR และ Cloud‑Gaming พบการปรับปรุงเชิงปริมาณที่ชัดเจนทั้งในค่าเฉลี่ย latency, 95th percentile, jitter, packet loss และอัตราการปฏิบัติตาม SLA ตามเป้าหมายที่กำหนด (AR target <20 ms, Cloud‑Gaming target 30–50 ms) โดยสรุปผลสำคัญมีดังนี้:
รายละเอียดตัวเลขผลการทดสอบ (ตัวอย่างเชิงปริมาณ)
- สภาพการทดลอง: ทดสอบภายใต้ 3 โปรไฟล์โหลด — Light (20% capacity, 1,000 concurrent AR/CG flows), Medium (60%, 5,000 flows), Heavy (95%, 12,000 flows). ระยะทาง UE‑edge ถูกจำลองที่ 0.5–10 กม. (typical urban edge 0.5–2 กม., suburban 5–10 กม.). Mobility: pedestrian 3 km/h และ vehicular 60 km/h พร้อม handover events ที่ความถี่ 4–12 events/min ภายใต้ heavy load.
- เป้าหมาย SLA: AR <20 ms (target), Cloud‑Gaming 30–50 ms (target window).
ผลลัพธ์เชิงตัวเลข: AR (ตัวอย่าง)
- Average latency — Baseline: 28 ms → LLM‑driven: 15 ms (ลดลงร้อยละ 46%)
- 95th percentile latency — Baseline: 55 ms → LLM‑driven: 22 ms (ลดลงร้อยละ 60%)
- Jitter (standard deviation) — Baseline: 8 ms → LLM‑driven: 3 ms (ลดลงร้อยละ 62.5%)
- Packet loss — Baseline: 0.8% → LLM‑driven: 0.2%
- SLA compliance (<20 ms) — Baseline: 62% → LLM‑driven: 94% (เพิ่มขึ้นร้อยละ 32 percentage points หรือประมาณ +51.6% แบบ relative)
ผลลัพธ์เชิงตัวเลข: Cloud‑Gaming (ตัวอย่าง)
- Average latency — Baseline: 70 ms → LLM‑driven: 38 ms (ลดลงร้อยละ 46%)
- 95th percentile latency — Baseline: 120 ms → LLM‑driven: 62 ms (ลดลงร้อยละ 48.3%)
- Jitter — Baseline: 15 ms → LLM‑driven: 6 ms (ลดลงร้อยละ 60%)
- Packet loss — Baseline: 1.5% → LLM‑driven: 0.6%
- SLA compliance (within 30–50 ms) — Baseline: 28% → LLM‑driven: 78% (เพิ่มขึ้นร้อยละ 50 percentage points หรือประมาณ +178% แบบ relative)
พฤติกรรมระบบต่อการเปลี่ยนแปลงแบบเรียลไทม์ และเวลาตอบสนองของเอเจนต์
ระบบ LLM‑driven agent แสดงการตอบสนองเชิงปฏิบัติการที่รวดเร็วและสม่ำเสมอเมื่อต้องปรับสไลซ์ตามเงื่อนไขเครือข่ายที่เปลี่ยน (เช่น ระดับโหลดขึ้น/ลง, handover, หรือเส้นทางคลื่นที่มีสัญญาณแปรผัน):
- Detection‑to‑action median time: ประมาณ 140 ms (mean ≈ 180 ms, 95th percentile ≈ 420 ms) — วัดตั้งแต่การตรวจพบการ degradations จนถึงคำสั่ง reallocation ถูกส่งไปยัง orchestration plane
- Slice stabilization time: การเปลี่ยนแปลงพารามิเตอร์ (bandwidth/priority/QoS mapping) จะเข้าสู่สถานะเสถียรโดยทั่วไปภายใน 400–600 ms หลังการสั่งงาน ที่ heavy load บางกรณีต้องใช้เวลาสูงสุด ~1 s
- ผลข้างเคียงชั่วคราว: ในช่วง reconfiguration พบ latency spike สั้นๆ (typical peak +10–25 ms) แต่ระบบสามารถดึงกลับสู่ค่าที่เหมาะสมภายใน 600 ms
ข้อสังเกตเชิงปฏิบัติการ
จากตัวเลขข้างต้น แสดงให้เห็นว่า LLM‑driven slicing สามารถเพิ่มอัตราการปฏิบัติตาม SLA ได้อย่างมีนัยสำคัญโดยเฉพาะกับบริการ latency‑sensitive เช่น AR (เพิ่มจาก 62% → 94%) และ Cloud‑Gaming (28% → 78%) การลดค่าเฉลี่ย latency และ 95th percentile ช่วยลด perceived latency สำหรับผู้ใช้ปลายทาง และ jitter ที่ลดลงช่วยให้ประสบการณ์ interactive ราบรื่นขึ้นโดยเฉพาะในฉากที่มีการเคลื่อนที่หรือ handover บ่อยครั้ง
สรุปสั้นๆ: ตัวอย่างผลการทดลองชี้ชัดว่า LLM‑driven real‑time slicing ลด latency ประมาณ ร้อยละ 45–60 ขึ้นกับแอปพลิเคชันและเงื่อนไขโหลด พร้อมทั้งเพิ่ม SLA compliance ขึ้นอย่างมีนัยสำคัญ (AR เพิ่มขึ้น ~32 percentage points; Cloud‑Gaming เพิ่มขึ้น ~50 percentage points) โดย agent มีเวลาตอบสนองเฉลี่ย ~140–180 ms และ slice จะกลับสู่เสถียรภาพภายใน ~0.4–0.6 s ในสภาพการทดลองที่ใช้.
กรณีใช้งานจริง: AR และ Cloud‑Gaming ในสภาพแวดล้อมเมืองจริง
กรณีใช้งานจริง: AR และ Cloud‑Gaming ในสภาพแวดล้อมเมืองจริง
โครงงานทดลองของโอเปอเรเตอร์ไทยที่ใช้ LLM‑Driven Network Slicing บนโครงข่าย 5G/6G ให้ภาพชัดว่าแอปพลิเคชันเรียลไทม์อย่าง Cloud‑Gaming และ AR ในเมืองสามารถปรับประสบการณ์ผู้ใช้ได้อย่างมีนัยสำคัญ ตัวอย่างที่เด่นคือผู้เล่นเกมคลาวด์บนรถไฟฟ้า (MRT/BTS) และผู้เข้าชมงานแสดงสินค้าที่ใช้แอป AR ในฮอลล์แออัด เมื่อระบบตั้งค่าให้สไลซ์เฉพาะกิจสำหรับแอปที่ต้องการ latency ต่ำ ผลการทดลองชี้ว่า latency เฉลี่ยลดลงจาก 60–80 ms เหลือ 10–25 ms ในหลายช่วงเวลา และอัตราการเกิด frame drops ลดลงโดยเฉลี่ย 60–80% ภายใต้การจัดสรรทรัพยากรแบบไดนามิก
สำหรับกรณี Cloud‑Gaming บนรถไฟฟ้า ระบบ edge‑cloud ที่อยู่ใกล้สถานีถูกจัดเป็น slice เฉพาะ โดยตัวแทนซอฟต์แวร์ที่ขับเคลื่อนด้วย LLM จะประมวลผลข้อมูลเทเลเมทรีจากสถานีฐานและอุปกรณ์ผู้ใช้เพื่อตัดสินใจเชิงนโยบายแบบเรียลไทม์ ยกตัวอย่างเหตุการณ์: เมื่อผู้เล่นกำลังเดินทางจากสถานี A ไปสถานี B และความเร็วผู้ใช้เพิ่มขึ้นจนเข้าสู่ช่วง handover ตัวแทน LLM จะคาดการณ์ตำแหน่งถัดไปภายใน 1–2 วินาทีและสั่งให้ระบบ pre‑allocate slice บน edge node ใกล้สถานี B ผลลัพธ์คือ packet loss และ rebuffering ลดลงอย่างมีนัยสำคัญ—ในการทดลองจริงความน่าจะเป็นของการ rebuffering ลดจาก 22% เหลือ 3% ในช่วง handover
ในงานแสดงสินค้าที่มีผู้เข้าร่วมหลายพันคน แอป AR สำหรับคู่มืออุตสาหกรรมและการแสดงข้อมูลเสมือนต้องการ jitter ต่ำและ throughput คงที่ ระบบ LLM วิเคราะห์รูปแบบการใช้งานแบบเรียลไทม์ (เช่น ความหนาแน่นของผู้ใช้ต่อพื้นที่, โมเดลการเคลื่อนที่ภายในฮอลล์, และการใช้ GPU บน MEC) จากนั้นปรับสไลซ์โดยปรับ bandwidth, CPU/GPU quotas และ routing path ภายในเวลา 100–300 ms ผลการทดลองพบว่า SLA ของ AR (เช่น 95th‑percentile latency < 20 ms) ถูกปฏิบัติได้ถึงกว่า 90–95% ของเวลา ทำให้การแสดงข้อมูลเสมือนกับวัตถุจริงมีความนิ่งสูง หลักฐานคือการลดอาการ jitter และการสั่นไหวของแองเคอร์ (anchor drift) ซึ่งช่วยให้ผู้ใช้รับรู้วัตถุเสมือนอย่างต่อเนื่องโดยไม่เกิดการลอยหรือกระโดดของชิ้นงาน
กลไกการปรับสไลซ์แบบเรียลไทม์ที่ใช้งานได้จริงประกอบด้วยขั้นตอนสำคัญดังนี้
- เก็บเทเลเมทรีแบบต่อเนื่อง — ค่าความหน่วง, jitter, packet loss, อัตราการเฟรมของแอป และข้อมูลตำแหน่งจาก RAN/UE ถูกส่งมายังศูนย์วิเคราะห์
- การวิเคราะห์เชิงคาดการณ์ด้วย LLM — LLM ถูกเทรนให้จดจำรูปแบบโหลดและโมเดลการเคลื่อนที่ในเมือง เช่น การจราจรของผู้โดยสารในเส้นทางรถไฟ เพื่อคาดการณ์ความต้องการทรัพยากรก่อนเกิดปัญหา
- สร้างนโยบายเชิงปฏิบัติการ — จากการคาดการณ์ LLM จัดทำคำสั่งการจัดสรรสไลซ์ (bandwidth, CPU/GPU, QoS class) และส่งต่อไปยังตัวออร์เคสเตรเตอร์เครือข่าย
- ปรับแต่งเครือข่ายแบบไดนามิก — ออร์เคสเตรเตอร์ปรับเส้นทาง, instantiate/scale VNFs และย้าย session ไปยัง MEC edge node ที่เหมาะสมภายในระดับเวลา สิบถึงร้อยมิลลิวินาที
- วง feedback แบบปิด — ผลการปรับถูกวัดและส่งกลับสู่ LLM เพื่อปรับโมเดลและนโยบาย ทำให้ระบบเรียนรู้และปรับปรุงการตัดสินใจในรอบถัดไป
สรุปแล้ว การใช้ LLM เป็นเอเจนต์ตัดสินใจในระบบ network slicing ช่วยให้โอเปอเรเตอร์สามารถตอบสนองต่อสภาพแวดล้อมเมืองที่เปลี่ยนแปลงอย่างรวดเร็วได้อย่างมีประสิทธิภาพ ทั้งในมุมมอง UX ที่ผู้ใช้รับรู้ได้จริง (เช่น การตอบสนองเร็วขึ้น, frame drops/lag ลดลง, การแสดงวัตถุ AR เสถียรขึ้น) และมุมมองเชิงปฏิบัติการที่ช่วยปรับใช้ทรัพยากรเครือข่ายอย่างคุ้มค่าโดยยังคงรักษา SLA ตามที่ตกลงไว้
ความท้าทายและข้อกังวล: ความปลอดภัย ความโปร่งใส และการจัดการทรัพยากร
ความท้าทายและข้อกังวล: ความปลอดภัย ความโปร่งใส และการจัดการทรัพยากร
การนำเอเจนต์ LLM มาใช้ในการจัดสรรสไลซ์เครือข่ายแบบเรียลไทม์เพื่อตอบโจทย์ AR และ Cloud‑Gaming บน 5G/6G เปิดโอกาสด้านประสิทธิภาพสูงและการปรับตัวตาม SLA แต่ก็สร้างความเสี่ยงเชิงปฏิบัติการและเชิงนโยบายที่สำคัญ โดยประเด็นหลักครอบคลุมทั้ง ความปลอดภัยของคำสั่งและช่องทางสื่อสาร, ความน่าเชื่อถือของโมเดล (hallucination), การรับรอง isolation ระหว่างสไลซ์, และ ความเป็นส่วนตัวของ telemetry ตลอดจนความสามารถในการอธิบายการตัดสินใจ (explainability) เพื่อให้การปฏิบัติการสามารถตรวจสอบและรับผิดชอบได้
ด้านความปลอดภัยเป็นหัวใจ: หากคำสั่งจากเอเจนต์ถูก spoof (ปลอมแปลง) หรือมีการ tampering ระหว่างทาง อาจเกิดการเปลี่ยนแปลงการจัดสรรทรัพยากรที่ทำให้สไลซ์เสี่ยงต่อการถูกยึดช่องสื่อสารหรือถูกป้อนทราฟฟิกที่ทำลาย SLA ได้ ตัวอย่างเหตุการณ์ที่ต้องกังวลคือเอเจนต์สั่งลด bandwidth ของ AR slice ในช่วง peak time ซึ่งทำให้ latency เพิ่มจนระบบ AR ล้มเหลว นอกจากนี้ การโจมตีแบบ replay, man‑in‑the‑middle หรือการแฝงคำสั่งจากผู้ไม่หวังดีต่อ API ของตัวจัดการสไลซ์ล้วนเป็นความเสี่ยงที่ต้องรับมือ
ความท้าทายถัดมาเกี่ยวกับความเชื่อถือได้ของ LLM: โมเดลภาษาใหญ่อาจเกิด phenomenon ที่เรียกว่า hallucination ซึ่งให้คำตอบที่ฟังดูสมเหตุสมผลแต่ไม่ถูกต้องหรือขัดกับสถานะจริงของเครือข่าย ในบริบทการจัดสรรสไลซ์ คำสั่งที่มาจาก hallucination อาจนำไปสู่การเปลี่ยนนโยบาย QoS ผิดพลาดหรือคำสั่งที่ขัดต่อข้อกำหนดของ SLA การตรวจสอบคำสั่งจึงจำเป็นต้องมีทั้งชั้นการตรวจสอบเชิงตรรกะ (sanity checks), การ cross‑validation กับข้อมูล telemetry จริง และการจำกัดขอบเขตการกระทำของเอเจนต์ผ่านกฎนิรภัย (guardrails)
การรับประกัน isolation ระหว่างสไลซ์ เป็นอีกปัญหาเชิงเทคนิคและนโยบาย: แม้ virtualization และ containerization จะช่วยแยกทรัพยากร แต่ช่องโหว่ด้าน side‑channel, การจัดสรรทรัพยากรไม่เพียงพอ (resource exhaustion) หรือการกำหนด priority ที่ผิดพลาดสามารถทำให้สไลซ์หนึ่งรบกวนอีกสไลซ์ได้ โดยเฉพาะเมื่อเอเจนต์ปรับเปลี่ยนค่าพารามิเตอร์เช่น CPU, NIC queues, หรือ bandwidth reservation แบบ dynamic ซึ่งต้องมีการตรวจวัดและบังคับใช้ (enforcement) เช่น cgroups, SR‑IOV, และ strict scheduler policies เพื่อป้องกันการรั่วไหลของประสิทธิภาพ
เรื่องความเป็นส่วนตัวของ telemetry ก็มีความสำคัญ: ข้อมูลการวัดเช่น jitter, throughput, packet traces อาจเปิดเผยพฤติกรรมผู้ใช้หรือแอปพลิเคชันที่ละเอียดอ่อน การส่ง telemetry ระหว่างโหนดและระบบวิเคราะห์ต้องป้องกันด้วยการเข้ารหัสทั้ง in‑transit และ at‑rest, การมอบสิทธิ์การเข้าถึงแบบละเอียด (fine‑grained access control) และเทคนิคการปกปิดข้อมูลเช่น aggregation หรือ differential privacy เพื่อให้ยังคงประสิทธิภาพในการตัดสินใจของเอเจนต์โดยไม่ละเมิดความเป็นส่วนตัว
เพื่อบรรเทาความเสี่ยงเหล่านี้ ควรใช้แนวทางแบบหลายชั้น (defense‑in‑depth) รวมถึงมาตรการเชิงปฏิบัติการและเชิงเทคนิค ดังนี้
- Validation loops และการตรวจสอบหลายชั้น: ทุกคำสั่งที่มาจาก LLM ควรผ่านการตรวจสอบทางตรรกะ (sanity checks), การยืนยันกับ telemetry แบบ near‑real‑time, และการประเมินผลกระทบ (impact analysis) ก่อนนำไปใช้จริง การใช้โหมด shadow/observe หรือ canary deployment ช่วยลดความเสี่ยงของการเปลี่ยนแปลงแบบมวลโดยไม่ตั้งใจ
- Rule‑based guardrails และ policy engine: กำหนดชุดกฎนิรภัยที่ห้ามการดำเนินการบางอย่าง เช่น ห้ามลด bandwidth ลงต่ำกว่าค่า SLA, จำกัดการเปลี่ยนแปลงต่อหน่วยเวลา, และใช้ policy engine ที่บังคับใช้ RBAC รวมถึง Blacklist/Whitelist ของคำสั่ง
- Cryptographic attestation และการยืนยันต้นทาง: เซ็นคำสั่งด้วยกุญแจสาธารณะ/ส่วนตัว (digital signatures), ใช้ mutual TLS, และโซลูชัน hardware root‑of‑trust (TPM, HSM, secure enclave) เพื่อยืนยันแหล่งที่มาของคำสั่งและป้องกันการปลอมแปลงหรือแก้ไขบนเส้นทาง
- Audit trails และ explainability: เก็บบันทึก (immutable audit log) ของอินพุต telemetry, เวอร์ชันโมเดล, ลำดับการตัดสินใจ และผลการตรวจสอบ เพื่อให้สามารถสืบย้อนคืนได้ และสนับสนุนการใช้เทคนิคการอธิบายโมเดล (model cards, decision provenance, local surrogate models) เพื่อให้ผู้ปฏิบัติหรือผู้ควบคุมนโยบายเข้าใจเหตุผลเบื้องหลังคำสั่ง
- Fallback deterministic systems และ human‑in‑the‑loop: กำหนด fallback policy แบบ deterministic (เช่น rule‑based controller) และช่องทางอนุมัติของมนุษย์สำหรับการกระทำที่มีความเสี่ยงสูง การมีคนคุมในวงจรสำหรับกรณีฉุกเฉินช่วยลดผลกระทบจาก hallucination หรือการโจมตี
- การปกป้องข้อมูล telemetry: ใช้การรวมกลุ่มข้อมูล, การปิดบังตัวตน (anonymization), differential privacy เมื่อต้องการแชร์ telemetry ข้ามโดเมน และบังคับใช้การเข้าถึงตามบทบาทเพื่อจำกัดการเปิดเผยข้อมูล
สรุปได้ว่าการพึ่งพา LLM ในการจัดการสไลซ์เครือข่ายแบบเรียลไทม์นั้นต้องมาพร้อมกับกรอบการควบคุมที่รัดกุม ทั้งเชิงเทคนิคและเชิงกระบวนการ เพื่อป้องกัน spoofing/tampering, ลดผลกระทบจาก hallucination, รับประกัน isolation ระหว่างสไลซ์ และคุ้มครองความเป็นส่วนตัวของ telemetry การออกแบบสถาปัตยกรรมที่มีหลายชั้นของ validation, cryptographic attestation, rule‑based guardrails และการตรวจสอบย้อนกลับจะช่วยให้การนำเทคโนโลยีนี้เข้าสู่การใช้งานเชิงพาณิชย์เป็นไปอย่างปลอดภัยและเป็นไปตามข้อกำหนด SLA
มุมมองเชิงนโยบาย มาตรฐาน และธุรกิจ: ความร่วมมือกับ 3GPP, O‑RAN และโมเดลเชิงพาณิชย์
มุมมองเชิงนโยบาย มาตรฐาน และธุรกิจ: ความร่วมมือกับ 3GPP, O‑RAN และโมเดลเชิงพาณิชย์
การนำ LLM‑driven network slicing มาใช้งานในเครือข่าย 5G/6G เพื่อรองรับแอปพลิเคชัน latency‑sensitive เช่น AR และ cloud‑gaming จำเป็นต้องอาศัยกรอบมาตรฐานและความร่วมมือเชิงนโยบายที่ชัดเจน เพื่อให้การจัดสรรสไลซ์แบบเรียลไทม์เป็นไปได้อย่างปลอดภัย มีความเชื่อถือได้ และสามารถขยายผลเชิงพาณิชย์ได้อย่างยั่งยืน โดยเฉพาะเมื่อระบบเอเจนต์ AI จะตัดสินใจเปลี่ยนแปลงพารามิเตอร์เครือข่ายแบบไดนามิกตาม SLA ที่ตกลงกันไว้
บทบาทของมาตรฐาน มีความสำคัญอย่างยิ่ง โดย 3GPP ได้กำหนดสเปกของ network slicing ตั้งแต่การแยกทรัพยากรใน core network ไปจนถึงกลไกการจัดการ QoS และ isolation ซึ่งเป็นพื้นฐานให้โอเปอเรเตอร์สามารถประกาศ SLA เช่น latency target ต่ำกว่า 20–30 ms สำหรับ cloud‑gaming หรือ 10–20 ms สำหรับ AR บางรูปแบบได้อย่างมีความหมาย ขณะเดียวกัน O‑RAN ที่สนับสนุนสถาปัตยกรรม RAN แบบ disaggregated และ open interfaces ช่วยให้ผู้ผลิตเครือข่ายและสตาร์ทอัพ AI สามารถพัฒนาแอพพลิเคชันควบคุมเชิงนโยบายและโมดูล ML/AI ที่ทำงานใกล้ขอบเครือข่าย (edge) ได้ง่ายขึ้น การผสานมาตรฐานทั้งสองฝ่ายนี้จึงเป็นเงื่อนไขพื้นฐานเพื่อความเป็นสากลและการทำงานร่วมกันระหว่างผู้ประกอบการ
ในมิติของความร่วมมือเชิงอุตสาหกรรม เราเห็นแนวทางการทำงานร่วมกันระหว่าง โอเปอเรเตอร์, ผู้ผลิตเครือข่าย และ สตาร์ทอัพ AI ในหลายรูปแบบ เช่น การทดสอบ POC ร่วมกัน การเปิด sandbox สำหรับ AI agents และการพัฒนาระบบ OSS/BSS ที่รองรับการคิดราคาแบบไดนามิก ตัวอย่างเชิงปฏิบัติคือการเชื่อมต่อโมดูล O‑RAN RIC (RAN Intelligent Controller) กับโมเดล LLM ที่ฝังตรรกะการจัดสรรสไลซ์ ทำให้การตัดสินใจเป็นไปแบบ near‑real‑time โดยยังคงยึดมั่นในข้อกำหนดจากมาตรฐาน 3GPP สำหรับการแยกสไลซ์และการจัดการทรัพยากร
ด้านรูปแบบธุรกิจ มีหลายโมเดลที่น่าสนใจและสามารถผสมผสานกันได้ ได้แก่:
- SLA‑based pricing: คิดค่าบริการตามระดับ SLA (latency, jitter, packet loss) โดยลูกค้าจ่ายเพิ่มเมื่อขอระดับบริการที่เข้มงวดขึ้น เช่น premium low‑latency slice สำหรับการแข่งขันเกมระดับมืออาชีพหรือแอป AR แบบเรียลไทม์
- Premium slices & add‑ons: เสนอ slice แบบพรีเมียมที่รวม edge compute, dedicated routing และ prioritized scheduling เป็นแพ็กเกจ
- Revenue sharing: โมเดลแบ่งรายได้ระหว่างโอเปอเรเตอร์ ผู้ให้บริการคอนเทนต์ (เช่น ผู้พัฒนาเกม) และผู้ให้บริการคลาวด์/edge ซึ่งอาจรวมถึงสตาร์ทอัพ AI ที่ให้เทคโนโลยีการ orchestration
- Dynamic pricing & marketplace: ตลาดสไลซ์ที่อนุญาตให้ผู้ใช้หรือแอปพลิเคชันเสนอราคาสำหรับระดับทรัพยากรในเวลาจริง โดยระบบ AI จะตัดสินใจจัดสรรตามมาตรฐานและนโยบายเชิงพาณิชย์
เพื่อให้โมเดลเหล่านี้ดำเนินไปได้อย่างมีเสถียรภาพและเป็นธรรม จำเป็นต้องมีกรอบนโยบายที่สนับสนุนและกำกับดูแลอย่างเหมาะสม โดยข้อเสนอเชิงนโยบายหลักควรครอบคลุม:
- Regulator oversight: หน่วยงานกำกับควรกำหนดกรอบการอนุญาต การทดสอบ และการตรวจสอบการให้บริการสไลซ์ โดยเฉพาะในเรื่องการรับประกัน SLA, การรายงานเหตุขัดข้อง และการป้องกันการผูกขาด
- Data governance: มาตรการคุ้มครองข้อมูลและความเป็นส่วนตัวสำหรับข้อมูลเครือข่ายและเทเลเมทริกที่เอเจนต์ AI ใช้ รวมถึงการใช้เทคนิค privacy‑preserving เช่น federated learning หรือ differential privacy เมื่อมีการแชร์โมเดลระหว่างองค์กร
- Interoperability & certification: กำหนดมาตรฐาน API, data models และกระบวนการรับรองความเข้ากันได้ (conformance testing) ระหว่างองค์ประกอบ O‑RAN, 3GPP‑compliant core และแพลตฟอร์ม AI เพื่อหลีกเลี่ยงการล็อกผู้ให้บริการ
- Security & auditability: บังคับใช้ข้อกำหนดด้านความมั่นคงปลอดภัยสำหรับการตัดสินใจที่อาศัย AI รวมถึงการบันทึกเหตุผลการตัดสินใจ (explainability logs) เพื่อการตรวจสอบภายหลังและการจัดการความรับผิดชอบ
- Consumer protection & transparency: กำกับให้ผู้ให้บริการเปิดเผยเงื่อนไข SLA, ราคา และสถานะการให้บริการแบบเรียลไทม์แก่ผู้ใช้ปลายทาง
สรุปได้ว่า การขับเคลื่อน LLM‑driven network slicing ให้สำเร็จทั้งเชิงเทคนิคและเชิงพาณิชย์ ต้องอาศัยมาตรฐานจาก 3GPP และความยืดหยุ่นของ O‑RAN ควบคู่ไปกับโมเดลธุรกิจที่ชัดเจนและกรอบนโยบายที่เข้มแข็ง การสร้างระบบนิเวศที่รวมโอเปอเรเตอร์ ผู้ผลิตเครือข่าย และสตาร์ทอัพ AI จะเป็นกุญแจสำคัญในการนำเสนอบริการที่มีคุณภาพ ปลอดภัย และแข่งขันได้ในตลาด 5G/6G ของไทย
บทสรุป
การทดลองนำ LLM‑driven network slicing มาใช้บนเครือข่าย 5G/6G โดยโอเปอเรเตอร์ไทยชี้ให้เห็นศักยภาพในการ ลดความหน่วง (latency) และเพิ่มอัตราการปฏิบัติตามข้อตกลงการให้บริการ (SLA compliance) สำหรับแอปพลิเคชันความหน่วงต่ำอย่าง AR และ cloud‑gaming เช่น การทดลองเบื้องต้นระบุการลด latency อยู่ในช่วงโดยประมาณ 30–50% และการปรับปรุงความสอดคล้องตาม SLA จากราว 85% เป็นเกือบ 95% ภายใต้เงื่อนไขทดลองที่มีการจัดสรรสไลซ์แบบเรียลไทม์โดยเอเจนต์ AI อย่างไรก็ดี ผลสัมฤทธิ์ดังกล่าวจำเป็นต้องจับคู่กับมาตรการตรวจสอบที่เข้มงวด การกำหนดมาตรฐานการวัดผล และกรอบการทดสอบที่ชัดเจนเพื่อป้องกันผลลัพธ์ที่คลาดเคลื่อนเมื่อย้ายจากสภาพแวดล้อมทดลองสู่การให้บริการเชิงพาณิชย์
สำหรับการนำไปใช้งานจริง ต้องคำนึงถึงประเด็นด้านความปลอดภัยของเครือข่าย (เช่น การป้องกันการโจมตีต่อการจัดสรรสไลซ์) ความโปร่งใสและความสามารถในการอธิบายการตัดสินใจของโมเดล LLM (explainability) รวมถึงโมเดลธุรกิจที่ยืดหยุ่นเพื่อรองรับการลงทุนในโครงสร้างพื้นฐานที่ edge ทั้งหมดนี้บ่งชี้ว่าในอนาคตอันใกล้เราจะเห็นการใช้งานแบบผสมผสาน (hybrid deployments) ที่ผสานการควบคุมเชิงนโยบายจากผู้ให้บริการกับความสามารถอัตโนมัติของ AI และกรอบกำกับดูแล/มาตรฐานสากลจะเป็นกุญแจสำคัญต่อการขยายผลเชิงพาณิชย์ หากจัดการประเด็นความเสี่ยงได้ดี เทคโนโลยีนี้มีโอกาสยกระดับประสบการณ์ AR/Cloud‑Gaming ให้ตอบโจทย์ SLA สูงขึ้นและเปิดทางสู่บริการใหม่ๆ บนเครือข่าย edge ในอีก 2–5 ปีข้างหน้า



