
ธนาคารไทยกำลังทดสอบและเริ่มนำ Graph-LLM ระบบปัญญาประดิษฐ์แนวใหม่ที่ผสานกราฟนิวรัลเน็ตเวิร์ก (GNN) เข้ากับเวกเตอร์เชิงฝังตัวของธุรกรรม (transaction embeddings) และความสามารถเชิงเหตุผลของ Large Language Models มาใช้ในการสกัดกั้นการฟอกเงินและการฉ้อโกงแบบเรียลไทม์ โดยผลทดสอบนำร่องในธนาคารไทยบางแห่งชี้ให้เห็นว่าโมเดลนี้สามารถลดอัตรา False‑Positive ได้ประมาณ 35–60% ขณะที่อัตราการตรวจจับกรณีทุจริต/ฟอกเงินเพิ่มขึ้นราว 20–45% และลดเวลาตั้งแจ้งเตือนจากระดับเฉลี่ยเป็นนาทีลงไปสู่การตอบสนองเชิงเวลาจริงภายในไม่กี่วินาทีถึงไม่กี่สิบวินาที ซึ่งหมายความว่าธนาคารสามารถป้องกันความเสียหายและจำกัดการแพร่กระจายของวงจรการทุจริตได้เร็วขึ้นและแม่นยำขึ้น
บทความนี้จะพาเจาะลึกว่า Graph-LLM ทำงานอย่างไร ตั้งแต่การสร้างกราฟเครือข่ายความสัมพันธ์ลูกค้าและบัญชี การฝังตัวเวกเตอร์ของพฤติกรรมธุรกรรมเพื่อจับลักษณะเชิงบริบท ไปจนถึงการใช้ LLM ในการให้เหตุผลเชิงนามธรรมเพื่อแยกสัญญาณจริงจากสัญญาณรบกวน เราจะนำเสนอตัวเลขผลลัพธ์การทดสอบเชิงเปรียบเทียบ ตัวอย่างเคสการจับพฤติกรรมผิดปกติ การประเมินผลต่อการปฏิบัติตามกฎเกณฑ์ และ roadmap การนำไปใช้จริงที่ครอบคลุมเฟสการนำร่อง การรวมระบบกับระบบ AML เดิม การรับรองความโปร่งใสและการอธิบายผล (explainability) รวมทั้งแผนการขยายใช้งานเชิงพาณิชย์ที่คาดว่าจะใช้เวลา 6–18 เดือนสำหรับการนำไปใช้อย่างเป็นรูปธรรมในเครือข่ายธนาคารไทย
บทนำ: ทำไมธนาคารต้องพัฒนาเครื่องมือตรวจจับการฟอกเงินและการฉ้อโกง
บทนำ: ทำไมธนาคารต้องพัฒนาเครื่องมือตรวจจับการฟอกเงินและการฉ้อโกง
ระบบป้องกันการฟอกเงิน (AML) และการตรวจจับการฉ้อโกงของธนาคารในยุคดิจิทัลเผชิญกับปัญหาที่เพิ่มความซับซ้อนทั้งด้านปริมาณข้อมูลและความรวดเร็วของธุรกรรม สถิติจากงานศึกษาหลายฉบับชี้ให้เห็นว่าอัตรา false‑positive ในระบบแจ้งเตือนแบบกฎ (rules‑based) อยู่ในช่วงประมาณ 70–95% — หมายความว่าจำนวนมากของการแจ้งเตือนที่ระบบสร้างขึ้นไม่ใช่เหตุการณ์ที่มีความเสี่ยงจริง แต่ต้องผ่านกระบวนการตรวจสอบด้วยทรัพยากรคน ซึ่งสร้างต้นทุนทั้งทางการเงินและเวลาของหน่วยงานปฏิบัติตามกฎ (compliance).

ผลกระทบจาก false‑positive และการขาดความสามารถในการตรวจจับเชิงสาเหตุ (contextual detection) มีหลายมิติ: ความล่าช้าในการอนุมัติการจ่ายเงินหรือการโอนที่สำคัญ อาจทำให้ลูกค้าได้รับประสบการณ์การใช้งานที่แย่และหันไปใช้บริการคู่แข่ง ขณะเดียวกันทีมตรวจสอบต้องรับภาระงานจำนวนมหาศาล ส่งผลให้องค์กรต้องเพิ่มคน ลดประสิทธิภาพการปฏิบัติงาน และเสี่ยงต่อความผิดพลาดในการประเมินเคสที่มีความเสี่ยงจริง นอกจากนี้การแจ้งเตือนที่ล้นหลามยังเพิ่มภาระการปฏิบัติตามกฎ (regulatory reporting) และอาจทำให้ธนาคารเผชิญค่าปรับหรือความเสียหายด้านชื่อเสียงหากไม่สามารถตอบสนองต่อเหตุการณ์เสี่ยงได้ทันเวลา
ในบริบทของระบบการชำระเงินแบบทันที (real‑time payments) และพฤติกรรมผู้บริโภคที่เปลี่ยนไป ธนาคารต้องการระบบตรวจจับที่ไม่เพียงแต่แม่นยำขึ้น แต่ต้องทำงานแบบเรียลไทม์เพื่อลดผลกระทบต่อการดำเนินธุรกิจและประสบการณ์ลูกค้า ภายในกรอบนี้ เทคโนโลยีใหม่ ๆ อย่างการผสานระหว่าง Graph Neural Networks (GNN) กับ Large Language Models (LLM) และการใช้เวกเตอร์แทนคุณลักษณะธุรกรรม (transaction vectors) กลายเป็นทางเลือกที่น่าสนใจ เนื่องจากสามารถจับโครงสร้างความสัมพันธ์ระหว่างบัญชี ผู้เกี่ยวข้อง และรูปแบบการโอนเงินที่ซับซ้อน ซึ่งกฎแบบเดิมมองไม่เห็น
ทำไมการรวมกันของ GNN, LLM และเวกเตอร์ธุรกรรมจึงให้ผลที่ดีกว่า? สรุปเป็นข้อ ๆ ดังนี้
- GNN สามารถเรียนรู้รูปแบบเครือข่าย (network patterns) เช่น กลุ่มบัญชีที่เชื่อมโยงกันหรือเส้นทางการโอนเงินหลายทอด ซึ่งมีประโยชน์ต่อการระบุกลุ่มการฟอกเงินแบบกระจาย
- เวกเตอร์ธุรกรรม ช่วยแทนข้อมูลเชิงตัวเลขและพฤติกรรมเป็นตัวแทนเชิงสเปซ ทำให้สามารถเทียบเคียงและค้นหากลุ่มธุรกรรมที่คล้ายคลึงแบบรวดเร็ว (vector search) เพื่อการตรวจจับเรียลไทม์
- LLM เพิ่มมิติของความเข้าใจเชิงบริบทและข้อความ (เช่น หมายเหตุการโอน ข้อมูล KYC ที่ไม่เป็นเชิงโครงสร้าง) ช่วยให้ระบบสามารถให้เหตุผลเชิงคำอธิบาย (explainability) และลดการพึ่งพากฎการตั้งค่าแข็งตัว
การเชื่อมต่อองค์ประกอบเหล่านี้เป็นรูปแบบที่มักเรียกว่า Graph‑LLM — ระบบที่ใช้การฝังเครือข่าย (graph embeddings) และเวกเตอร์ธุรกรรมควบคู่กับความสามารถในการตีความของ LLM เพื่อให้การแจ้งเตือนมีความเฉพาะเจาะจงสูงขึ้น ลดสัญญาณรบกวน (false alarms) และรองรับการตัดสินใจเชิงปฏิบัติการแบบเรียลไทม์ แต่คำถามสำคัญที่ธนาคารต้องพิจารณาต่อไปคือ: จะออกแบบสถาปัตยกรรมให้ผสานข้อมูลภายในและภายนอกอย่างไรให้ปลอดภัยและเป็นไปตามกฎ รวมถึงจะปรับการทำงานของโมเดลให้ตอบโจทย์ความเร็วและการอธิบายเหตุผลสำหรับผู้ตรวจสอบได้อย่างไร?
เทคโนโลยีเบื้องต้น: Graph‑LLM คืออะไร ผสมผสาน GNN, embedding และ LLM อย่างไร
ภาพรวมเทคโนโลยีเบื้องต้น: Graph‑LLM คืออะไร
Graph‑LLM คือสถาปัตยกรรมเชิงผสมผสานที่นำความสามารถของ Graph Neural Networks (GNN) มาเชื่อมต่อกับการแทนความหมายเชิงเวกเตอร์ของธุรกรรม (transaction embeddings) และความสามารถในการให้เหตุผลเชิงภาษาธรรมชาติของ Large Language Models (LLM) เพื่อสร้างระบบตรวจจับความเสี่ยงทางการเงินที่มีทั้งความแม่นยำและความอธิบายได้ง่ายสำหรับผู้ปฏิบัติงาน ระบบดังกล่าวออกแบบมาเพื่อจับแพทเทิร์นเครือข่าย (network patterns) ที่ซับซ้อน เช่น วงจรการโอนเงินเป็นทอดๆ (layering), เครือข่ายบัญชีที่ทำงานร่วมกัน (collusive rings) หรือพฤติกรรมการใช้งานที่เปลี่ยนแปลงอย่างฉับพลัน โดยยังคงสามารถส่งคำอธิบายที่มนุษย์อ่านได้และช่วยลดการแจ้งเตือนผิดพลาด (false positives)
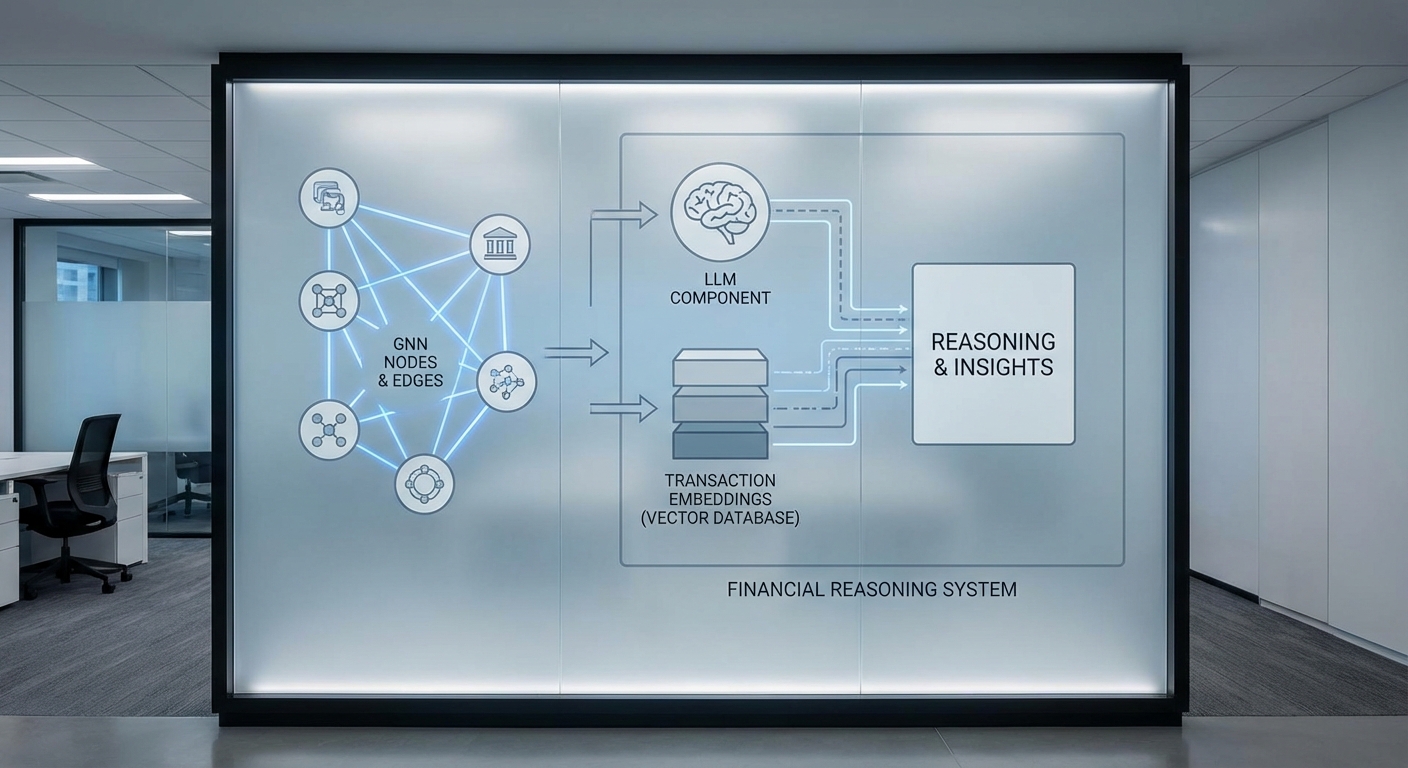
GNN: โหนด (บัญชี) ขอบ (ธุรกรรม) และการจับแพทเทิร์นเครือข่าย
หลักการทำงานของ GNN คือการเรียนรู้ตัวแทน (representations) ของโหนดภายในกราฟโดยอาศัยข้อมูลทั้งจากคุณสมบัติภายในโหนดและจากบริบทเชิงโครงสร้างรอบข้าง ในบริบทของธนาคาร:
- โหนด แทนบัญชีผู้ใช้ บัญชีธุรกิจ หรือแม้แต่เครื่องมือชำระเงิน (เช่น วอลเล็ต) โดยมีฟีเจอร์พื้นฐานเช่นประเภทบัญชี อายุบัญชี และคะแนนความเสี่ยงเบื้องต้น
- ขอบ แทนธุรกรรมระหว่างโหนด แต่ละขอบสามารถมีฟีเจอร์ได้แก่จำนวนเงิน เวลา ช่องทางการชำระ (channel) และรหัสร้านค้า (merchant)
- GNN ทำงานโดยกระบวนการ message passing — ข้อมูลฟีเจอร์จะถูกส่งผ่านระหว่างโหนดตามขอบและรวม (aggregate) เพื่อให้แต่ละโหนดได้ “เห็น” บริบทเครือข่ายของตน เช่น จำนวนโอนเข้าออกซ้ำๆ ในช่วงเวลาสั้น หรือโครงสร้างวงแหวนที่บ่งชี้การฟอกเงิน
- เวอร์ชันขั้นสูง เช่น Temporal GNN หรือ Graph Attention Networks จะเพิ่มน้ำหนักเชิงเวลาและความสำคัญของเพื่อนร่วมกราฟ ช่วยจับแพทเทิร์มที่เกิดขึ้นแบบเรียลไทม์หรือลำดับเหตุการณ์ (sequential patterns)
ผลลัพธ์จาก GNN คือ embedding ของแต่ละโหนด/ขอบที่เข้ารหัสทั้งพฤติกรรมเชิงบุคคลและบริบทเครือข่าย ซึ่งเหมาะสำหรับการจำแนกความเสี่ยง (anomaly scoring) และค้นหากลุ่มบัญชีที่มีความสัมพันธ์กัน
การสร้าง Transaction Embeddings และการเก็บใน Vector DB
การสร้าง embedding จากธุรกรรมเป็นหัวใจสำคัญในการทำให้ข้อมูลเชิงธุรกรรมสามารถนำไปใช้งานร่วมกับทั้ง GNN และ LLM ได้อย่างมีประสิทธิภาพ โดยข้อมูลที่มักถูกใช้ประกอบด้วย:
- amount — จำนวนเงิน (สามารถทำ normalization หรือ binning เพื่อรับมือค่าผิดปกติ)
- time — พฤติกรรมตามเวลา เช่น เวลาของวัน วันในสัปดาห์ และการกระจายตามช่วงเวลา (temporal encoding)
- merchant — ประเภทหรือรหัสร้านค้าที่ช่วยจับแพทเทิร์นธุรกิจ (e.g., ร้านค้าขายของอิเล็กทรอนิกส์ vs. บริการ)
- channel — ช่องทางการทำธุรกรรม เช่น สาขา แอป โมบายแบงก์กิ้ง หรือการโอนระหว่างประเทศ
การแปลงฟีเจอร์เหล่านี้เป็นเวกเตอร์มักผ่านสเต็ป เช่น การฝังเชิงหมวดหมู่ (categorical embedding), การเข้ารหัสเวลา (positional/temporal encoding) และการรวมเชิงสถิติ (aggregation over window) เพื่อให้ได้ transaction embedding ขนาดคงที่ ซึ่งสามารถเก็บใน vector database (เช่น FAISS, Milvus หรืออื่นๆ) สำหรับการค้นหาความใกล้เคียง (approximate nearest neighbor search) ในระดับเรียลไทม์ได้
เมื่อนำ embeddings ของธุรกรรมรวมกับ embedding ของโหนดจาก GNN จะช่วยให้ระบบสามารถ:
- ค้นหาธุรกรรมที่คล้ายกันทั้งเชิงมูลค่าและบริบท (e.g., เซตการโอนที่เกิดช่วงกลางคืนไปยังร้านค้าเดียวกัน)
- ดึงประวัติธุรกรรมที่เกี่ยวข้องมาเป็นบริบทสำหรับการวินิจฉัยโดย LLM
- ทำการ clustering หรือ anomaly detection บนเวกเตอร์เพื่อกรองเหตุการณ์ที่น่าสงสัยก่อนส่งต่อให้ผู้วิเคราะห์
บทบาทของ LLM: ให้เหตุผล อธิบาย และลด False‑Positive
LLM ทำหน้าที่เป็นชั้นที่ให้เหตุผลเชิงภาษาธรรมชาติและแปลงผลเชิงตัวเลข/เวกเตอร์เป็นคำอธิบายที่มนุษย์เข้าใจได้ โดยในระบบ Graph‑LLM LLM มักถูกใช้ร่วมกับเทคนิค RAG (retrieval‑augmented generation) ดังนี้:
- การดึงบริบทเชิงเวกเตอร์ — เมื่อ GNN และระบบ embedding ระบุเหตุการณ์ที่มีคะแนนเสี่ยงสูง ระบบจะดึงธุรกรรมและซับกราฟที่เกี่ยวข้องจาก vector DB มาจัดเตรียมเป็นบริบทให้ LLM
- การให้เหตุผลเชิงเชื่อมโยง — LLM ใช้บริบทที่ดึงมาเพื่ออธิบายเหตุการณ์ เช่น ระบุลำดับการโอน จำนวนเงินที่ซ้ำลักษณะ และความเชื่อมโยงกับบัญชีที่เพิ่งเปิดใหม่ ซึ่งช่วยให้ผู้ปฏิบัติงานเข้าใจได้รวดเร็วขึ้น
- การลด False‑Positive — ด้วยคำอธิบายเชิงบริบท LLM สามารถกรองการแจ้งเตือนที่ไม่มีพฤติกรรมเสี่ยงจริง เช่น กรณีการคืนเงินตามนโยบาย (refund) หรือการเคลื่อนไหวทางการเงินที่มีเหตุผลชัดเจน LLM จะคืนคำอธิบายพร้อมเหตุผลสนับสนุน (e.g., “การโอนเกิดจากการคืนสินค้าจากร้าน X พร้อมใบเสร็จ”) ซึ่งช่วยลดภาระงานของทีมวิเคราะห์และลดอัตรา false alarm ได้อย่างมีนัยสำคัญ
นอกจากนี้ LLM ยังสามารถสร้าง actionable triage เช่น แนะนำการสอบสวนต่อ (เช่น คำถามที่ต้องสอบถามลูกค้า, เอกสารที่ต้องเรียกดู) หรือจัดกลุ่มเหตุการณ์ที่ต้องการการตรวจสอบด้วยมนุษย์ ตัวอย่างเช่น ธนาคารที่เริ่มนำ LLM เข้ามาช่วยทดสอบภายในอาจสังเกตการลด false positives ในระบบแจ้งเตือนราว 30–60% ขึ้นอยู่กับคุณภาพบริบทและการเทรนโมเดล
การผสาน GNN, Embedding และ LLM ให้เป็นระบบตรวจจับอัจฉริยะ
การรวมทั้งสามส่วนทำได้ตามลำดับการประมวลผลแบบสตรีมมิงหรือแบตช์:
- 1) อินเจสชันและสร้าง embedding — ธุรกรรมถูกประมวลผลทันทีเพื่อสร้าง transaction embedding (amount, time, merchant, channel) และส่งต่อไปยัง vector DB
- 2) อัปเดตกราฟและรัน GNN — ข้อมูลธุรกรรมอัปเดตเป็นขอบใหม่ในกราฟ โหนดที่เกี่ยวข้องได้รับการอัปเดต embedding ผ่าน GNN (message passing/temporal updates) เพื่อประเมินคะแนนความเสี่ยงเชิงโครงสร้าง
- 3) ดึงบริบทจาก Vector DB — เมื่อ GNN หรือโมดูล scoring ให้สัญญาณเตือน ระบบจะดึงธุรกรรมที่คล้ายกัน และซับกราฟที่เกี่ยวข้องมาจัดเป็นบริบท
- 4) LLM ให้เหตุผลและจัดลำดับความสำคัญ — LLM ใช้บริบทเชิงเวกเตอร์และข้อมูลเมตาเพื่ออธิบาย เหตุผลประกอบการตัดสินใจ และให้คำแนะนำการดำเนินการ ลดการแจ้งเตือนผิดพลาดด้วยการให้เหตุผลเชิงตรรกะและเชื่อมโยงหลักฐาน
การออกแบบต้องคำนึงถึงประเด็นปฏิบัติการ เช่น latency (เป้าหมายระบบเรียลไทม์มักอยู่ในระดับ 100–500 ms สำหรับการตอบสนองเบื้องต้น), throughput, และกลไก feedback loop จากผู้วิเคราะห์เพื่อนำผลลัพธ์มาปรับปรุงโมเดล (online learning) นอกจากนี้ยังต้องมีการควบคุมความเสี่ยงด้านความเป็นส่วนตัวและการอธิบายผลต่อหน่วยงานกำกับดูแล
สรุปคือ Graph‑LLM ผสานประโยชน์จาก GNN ในการจับโครงสร้างเครือข่าย, transaction embeddings ในการจัดการบริบทเชิงพฤติกรรมและเก็บใน vector DB เพื่อการค้นหาอย่างรวดเร็ว, และ LLM ในการให้เหตุผลเชิงภาษาธรรมชาติและลด false alarms — ผลลัพธ์คือระบบตรวจจับที่แม่นยำขึ้น อธิบายได้ และปฏิบัติการได้จริงสำหรับธนาคารที่ต้องการตรวจจับการฟอกเงินและการฉ้อโกงแบบเรียลไทม์
สถาปัตยกรรมระบบและการทำงานแบบเรียลไทม์
การออกแบบสถาปัตยกรรมสำหรับระบบตรวจจับฟอกเงินและการฉ้อโกงแบบเรียลไทม์โดยใช้ Graph‑LLM ต้องตอบโจทย์ทั้งความแม่นยำในการลด False‑Positive และข้อจำกัดด้านประสิทธิภาพ (latency/throughput) ของธุรกรรมธนาคาร การจัดวางสแต็กหลักจะประกอบด้วยชั้น Data Ingestion (streaming), Graph Builder, Feature Store, Vector DB สำหรับการค้นหาแบบ Approximate Nearest Neighbor (ANN), GNN inference pipeline, LLM reasoning/explain layer และ Alerting Engine ที่เชื่อมกับระบบ core banking และ SIEM อย่างปลอดภัยและทนทาน
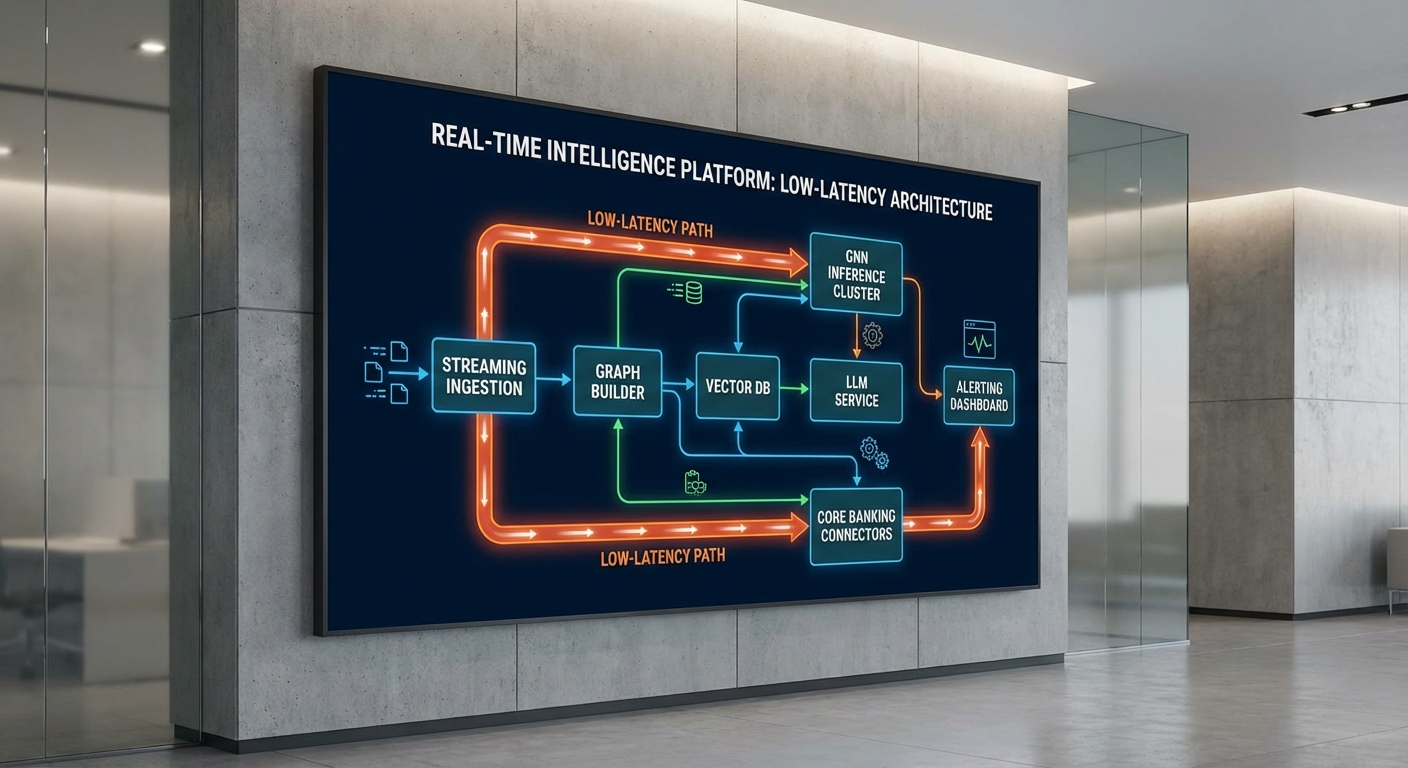
Flow งานแบบสตรีมมิง (end‑to‑end)
- Ingest → Transform: ใช้ระบบ streaming เช่น Kafka/Pulsar หรือ CDC (Debezium) จาก core banking เพื่อรับเหตุการณ์ธุรกรรมที่มี TPS ระหว่าง 1k–10k โดยแต่ละข้อความจะผ่าน preprocessing/validation (10–50 ms) และ feature extraction เบื้องต้น (10–100 ms)
- Graph Update: บันทึกโหนดและเอดจ์แบบ incremental (edge-centric updates) ไปยัง graph store ที่รองรับการอัปเดตแบบไลฟ์ (เช่น Nebula/JanusGraph หรือ DGraph) โดยออกแบบให้เป็น append-only และใช้ causal ordering เพื่อรักษาความสอดคล้อง ระยะเวลาอัปเดตมาตรฐาน 20–200 ms ขึ้นอยู่กับการ replicate
- Embedding: สร้าง/อัปเดตเวกเตอร์ embedding ของโหนดหรือธุรกรรมโดยเรียกใช้งานโมดูล embedding service (อาจเป็น lightweight transformer หรือ siamese encoder) และบันทึกลง Vector DB (HNSW/IVF) สำหรับการค้นหาเชิงความคล้ายคลึง
- Similarity Search: ค้นหาเพื่อนบ้านเชิงใกล้ (ANN) เพื่อค้นหาคอนเน็กชันที่น่าสงสัยด้วย HNSW (low‑latency) หรือ IVF + PQ (สำหรับสเกลใหญ่) — เวลาค้นหาเป้าหมาย 1–20 ms ต่อ query
- GNN Inference: ดึง subgraph โดยใช้ neighbor sampling แล้วส่งชุดข้อมูลเข้าสู่ GNN (เช่น GraphSAGE/GAT) ที่ให้ผลลัพธ์เป็น risk score แบบกราฟ โดยทำเป็น batch เพื่อเพิ่มประสิทธิภาพของ GPU/CPU (latency ขึ้นกับขนาด batch; เป้าหมายรวม 20–200 ms)
- LLM Explain: นำผลจาก GNN และข้อมูล context (features, history, neighbor examples) ไปให้ LLM เพื่อสร้างคำอธิบายเชิงเหตุผลและลด False‑Positive โดย LLM อาจเป็นรุ่นขนาดกลาง (latency 50–800 ms) หรือใช้ cached templates/augmentations เพื่อลดเวลา
- Alert: Alerting engine จะรวมคะแนนความเสี่ยง คำอธิบายจาก LLM และกฎทางธุรกิจก่อนส่งต่อไปยัง SIEM/Case Management หรือ human analyst ผ่านช่องทาง API, Syslog, CEF
องค์ประกอบสำคัญและการจัดการประสิทธิภาพ
เพื่อให้ได้ latency ตามเป้าหมาย <1–5 วินาที ต่อธุรกรรมสำหรับการแจ้งเตือนทันที ต้องคำนึงถึงการออกแบบชั้นต่าง ๆ ดังนี้:
- Data Ingestion (Streaming): ใช้ Kafka/Pulsar เพื่อรองรับ throughput ขนาด 1k–10k TPS; ตั้ง partition เพียงพอและใช้ batching ระดับเครือข่าย (ตั้งค่า linger.ms และ batch.size) เพื่อลด overhead
- Graph Builder: ออกแบบ incremental updates แบบ asynchronous พร้อม transactional write-ahead log และใช้ sharding ของกราฟตามบัญชีหรือกลุ่มความเสี่ยงเพื่อลด contention
- Feature Store: แยกเป็น Online Store (Redis/RocksDB) สำหรับค่า feature ที่เรียกใช้บ่อยและ Offline Store (Parquet บน S3) สำหรับการฝึกซ้ำและ re‑training
- Vector DB (ANN): เลือก HNSW เมื่อชุดข้อมูลอยู่ในหน่วยความจำและต้องการ latency ต่ำสุด (1–5 ms); ใช้ IVF+PQ เมื่อข้อมูลขนาดใหญ่มาก (หลักสิบล้านเวกเตอร์) พร้อมชาร์ดและ replication เพื่อเพิ่ม throughput ตัวอย่างพารามิเตอร์: HNSW (M=48, efConstruction=200, efSearch=100–200)
- Batching สำหรับ GNN: ใช้ neighbor sampling (e.g., GraphSAGE sampling 10–25 neighbors) และ mini‑batch ขนาด 32–256 เพื่อให้ GPU utilization สูงและ latency ยังอยู่ในข้อจำกัด (trade‑off ระหว่าง throughput กับ per‑query latency)
- Model Serving (GPU/CPU): จัดวาง pool ของ GPU สำหรับ inference latency‑sensitive (real‑time) และ CPU nodes สำหรับ background / fallback tasks; ใช้ autoscaling และ warm‑pool เพื่อหลีกเลี่ยง cold start
- Failover และ Degraded Mode: ออกแบบ active‑active multi‑AZ replication สำหรับ critical components (Kafka, Vector DB replicas, model replicas) และ fallback rules engine ที่ทำงานเมื่อโมเดลไม่พร้อม ทำให้ระบบยังคงแจ้งเตือนได้แม้ในโหมด degraded แต่ด้วยความระมัดระวังเพิ่มขึ้น
ตัวอย่าง SLA, Latency Budget และการวางแผนความจุ
การกำหนด SLA ควรรวมถึงเป้าหมายเช่น 99.9% ของธุรกรรมต้องประมวลผลแจ้งเตือนภายใน 5 วินาที และ p99 latency ของ ANN & GNN inference อยู่ในกรอบ 200–500 ms ต่อขั้นตอน ตัวอย่างการคำนวณความจุสำหรับ 5k TPS:
- Kafka topic partitions ≥ 100 เพื่อรองรับ parallel consumers
- Vector DB sharding 10–20 shards พร้อม replication 2x เพื่อให้ค้นหา ANN ที่ขนานกันและมี throughput สูง
- GPU pool (เช่น NVIDIA A10/A100): ประมาณ 4–16 GPUs ขึ้นกับขนาดโมเดลและ batching (ทดสอบให้ได้ throughput ที่รองรับ ~500–2,000 inferences/s per GPU)
- Redis cluster สำหรับ online features ที่รองรับ latency <5 ms และ throughput หลายแสน queries/s
ตัวอย่าง SLA ทางธุรกิจ: ระบบต้องตรวจจับกรณีที่มีความเสี่ยงสูงและส่ง alert ไปยัง SIEM ภายใน ≤5 วินาที สำหรับ 99.9% ของเหตุการณ์ โดยมี fallback detection (heuristic rules) ให้บริการเมื่อ ML stack ไม่พร้อม
การผสานกับ Core Banking และ SIEM
การเชื่อมต่อกับระบบ core banking ควรใช้ API แบบ asynchronous (event‑driven) และ protocol มาตรฐาน (ISO 20022 / REST over TLS) โดยมี CDC layer สำหรับการดึงข้อมูล historic และ real‑time updates ส่วน SIEM จะรับ alerts ผ่าน CEF/Syslog หรือ REST webhook พร้อม payload ที่ประกอบด้วย risk score, explanation จาก LLM และ evidence links ไปยัง subgraph ใน graph store เพื่อให้ SOC analyst สามารถ triage ได้อย่างรวดเร็ว
โดยสรุป การออกแบบต้องรักษาสมดุลระหว่างความเร็วกับความแม่นยำ: ใช้ HNSW/IVF สำหรับ ANN, batching และ neighbor sampling สำหรับ GNN เพื่อเพิ่ม throughput, GPU serving สำหรับ latency‑sensitive inference, และ LLM เพื่อให้คำอธิบายเชิงเหตุผลที่ช่วยลด False‑Positive ทั้งหมดต้องถูกผนวกเข้ากับกลไก failover, replication และ SLA ที่ชัดเจนเพื่อรองรับสภาพการใช้งานจริงของธนาคาร
กรณีศึกษาเชิงตัวเลข: ผลการทดลองเปรียบเทียบก่อนและหลังนำ Graph‑LLM มาใช้
ภาพรวมการทดลอง (Pilot Project)
การทดลองนำ Graph‑LLM มาใช้เป็นโครงการนำร่องกับธนาคารสมมติ "ธนาคารเอ็กซ์" ที่มีปริมาณรายการธุรกรรมรายวันระดับกลาง‑สูง (เฉลี่ย 2 ล้านรายการ/วัน) โดยออกแบบให้ Graph‑LLM ผสานกราฟนอร์ก (GNN) สำหรับวิเคราะห์ความเชื่อมโยงของบัญชี และเวกเตอร์ตัวแทนธุรกรรมสำหรับบริบทเชิงเวลา ผลการทดลองรันแบบคู่ขนานกับระบบ rules‑based เดิมเป็นระยะเวลา 3 เดือน เพื่อประเมินเมตริกเชิงคุณภาพและเชิงปริมาณทั้งในด้านความแม่นยำ ความไว และภาระงานตรวจสอบด้วยคน
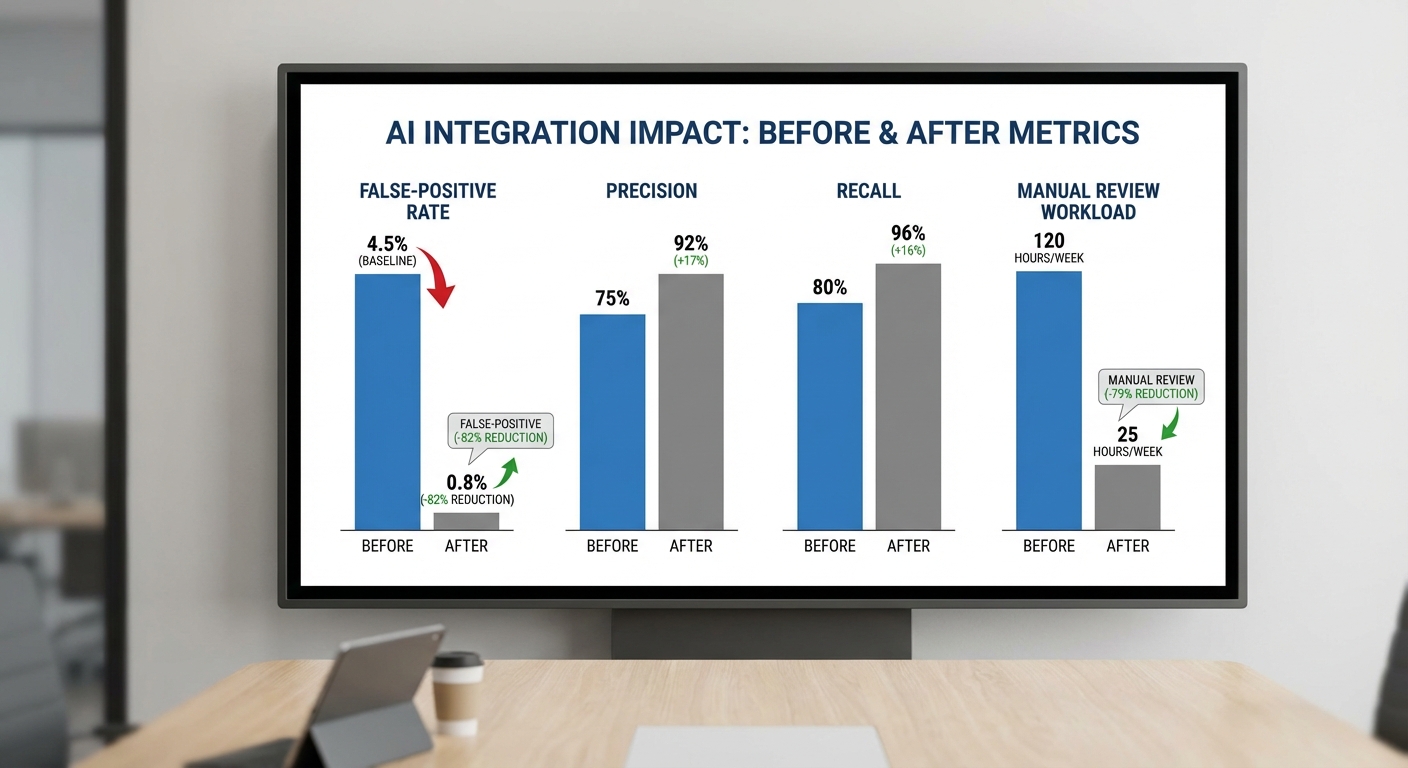
ผลลัพธ์เชิงตัวเลข (Key Metrics)
ผลการทดลองแสดงการเปลี่ยนแปลงที่เด่นชัดทั้งด้าน False‑Positive, Precision, Recall, เวลาแจ้งเตือน และต้นทุนงานตรวจสอบ โดยตัวอย่างเมตริกเปรียบเทียบสรุปได้ดังนี้
- False‑Positive Rate (FPR): ระบบ rules‑based เดิมมี FPR ประมาณ 90%; หลังใช้ Graph‑LLM ลดลงเหลือประมาณ 30–40% (ค่าเฉลี่ย pilot = 35%)
- Precision: เพิ่มจาก ~10% ในระบบเดิม เป็นระหว่าง 60–75% ภายใต้ Graph‑LLM (ค่าเฉลี่ย pilot = 65%)
- Recall (Sensitivity): เพิ่มจาก ~70% เป็น ~82–88% ขึ้นกับประเภทพฤติกรรมที่ตรวจจับ โดย Graph‑LLM แสดงความสามารถดีขึ้นในการจับเครือข่ายบัญชีที่กระจายความเสี่ยง
- Time‑to‑alert (latency): เวลาตั้งแต่เกิดเหตุการณ์ถึงการแจ้งเตือนเฉลี่ยลดจาก ~40 นาที เหลือ ~5–10 นาที เนื่องจาก GNN ประมวลผลความเชื่อมโยงแบบต่อเนื่องร่วมกับเวกเตอร์ธุรกรรม
- เวลาตรวจสอบต่อเคส (manual review): เฉลี่ยลดจาก 20 นาที ต่อเคส เหลือเพียง 5–7 นาที ต่อเคส เนื่องจาก Graph‑LLM ให้คำอธิบายเชิงบริบทและลำดับเหตุการณ์ที่ชัดเจน
- ปริมาณเคสที่ต้องตรวจสอบด้วยคน: ลดลงประมาณ 50–80% ขึ้นกับเกณฑ์นำส่ง (pilot รายงานค่าเฉลี่ยลด 60%)
- ผลกระทบต่อต้นทุนการดำเนินงาน: ธนาคารตัวอย่างที่มี ~200,000 alerts/ปี จากระบบเดิม ลดเหลือ ~80,000 alerts/ปี ภายใต้ค่าตรวจสอบเฉลี่ย 300 บาท/เคส เท่ากับการลดต้นทุนตรงด้านงานตรวจสอบประมาณ 36 ล้านบาท/ปี (คาดการณ์จาก pilot)
ตัวอย่างเหตุการณ์จริงที่ Graph‑LLM ตรวจจับได้
ในหนึ่งเคสจำลองจาก pilot ระบบ rules‑based เดิมไม่สามารถจับเครือข่ายบัญชีที่มีกลยุทธ์ "กระจายยอด‑หมุนเวียน" ได้ เนื่องจากแต่ละบัญชีมียอดธุรกรรมต่ำไม่ถึงเกณฑ์สัญญาณ แต่เมื่อนำข้อมูลเป็นกราฟ (บัญชีเชื่อมโยงตาม IP, อุปกรณ์, หมายเลขผู้รับโอน) และเวกเตอร์บริบทของธุรกรรมเข้า Graph‑LLM ระบบสามารถสกัด pattern ของการย้ายเงินทีละเล็กน้อยผ่านบัญชีม้าหลายชั้น (smurfing + layering) และเชื่อมโยงกลับไปยังบัญชีควบคุมเดียวกันภายใน 24 ชั่วโมง
Graph‑LLM ไม่เพียงแต่ยกธงเตือน แต่ยังให้คำอธิบายเชิงเหตุผล เช่น "กลุ่มบัญชี A → B → C มีการหมุนเวียนยอด 7‑12 ครั้ง ภายใน 3 วัน โดยมีความซ้ำซ้อนของผู้รับและ IP" ซึ่งช่วยผู้ตรวจสอบมนุษย์ย่นระยะการวิเคราะห์และตัดสินใจว่าเป็นเหตุต้องยกระดับการสอบสวนหรือไม่
ข้อสรุปเชิงปฏิบัติการ
จากผลการทดลองในระดับ pilot สามารถสรุปได้ว่า Graph‑LLM ให้ประโยชน์เชิงปริมาณและเชิงปฏิบัติการชัดเจน: ลด False‑Positive อย่างมีนัยสำคัญ เพิ่ม Precision และปรับปรุง Recall สำหรับรูปแบบการฉ้อโกงเชิงเครือข่าย ลดภาระงานตรวจสอบด้วยคนทั้งในด้านจำนวนเคสและเวลาต่อเคส ซึ่งแปลเป็นการลดต้นทุนและเพิ่มประสิทธิภาพการปฏิบัติตามกฎระเบียบ (regulatory efficiency) สำหรับธนาคารที่ต้องจัดการกับปริมาณ alerts จำนวนมาก
การนำ Graph‑LLM ไปขยายผลสู่การใช้งานจริงควรประกอบด้วยการปรับจูนเกณฑ์นำส่ง (thresholds), การผสานข้อมูลภายนอก (KYC, sanctions lists) และการตรวจสอบความโปร่งใสของคำอธิบายผลลัพธ์ เพื่อให้ได้ทั้งความแม่นยำในการตรวจจับและการยอมรับจากทีมปฏิบัติการ (operational buy‑in)
ความเสี่ยง จริยธรรม และการปฏิบัติตามกฎระเบียบ
ความเสี่ยง จริยธรรม และการปฏิบัติตามกฎระเบียบ
การประยุกต์ใช้ Graph‑LLM ที่ผสาน GNN กับเวกเตอร์ธุรกรรม เพื่อการตรวจจับฟอกเงินและการฉ้อโกงแบบเรียลไทม์ แม้จะให้ประสิทธิภาพด้านการลด false‑positive และเพิ่มความไวในการตรวจจับ แต่ยังยกประเด็นความเสี่ยงเชิงจริยธรรมและการปฏิบัติตามกฎระเบียบที่ต้องจัดการอย่างเป็นระบบ โดยเฉพาะเมื่อระบบตัดสินใจอัตโนมัติมีผลต่อสิทธิและการดำเนินธุรกิจของลูกค้า ทั้งนี้หน่วยงานกำกับ เช่น ธปท. และ AMLO คาดหวังให้สถาบันการเงินสามารถอธิบายการตัดสินใจและเก็บหลักฐานการตรวจสอบได้อย่างชัดเจน
ความโปร่งใสและการอธิบายผล (Explainability) — ระบบต้องสามารถสร้าง human‑readable rationale สำหรับแต่ละการแจ้งเตือน เพื่อให้เจ้าหน้าที่ภายในและหน่วยงานกำกับสามารถตรวจสอบเหตุผลได้อย่างรวดเร็ว ตัวอย่างรูปแบบการอธิบายที่เป็นประโยชน์ได้แก่: "บัญชี A มีความเชื่อมโยงกับเครือข่ายบัญชีที่มีพฤติกรรมโอนเงินซ้ำในช่วง 7 วัน จำนวน 12 ครั้ง; จำนวนเงินเฉลี่ยต่อรายการสูงกว่าค่าเฉลี่ยกลุ่มอุตสาหกรรม 4 เท่า" ข้อมูลเช่นนี้ควรถูกแนบกับผลคาดการณ์ของโมเดล (score, confidence) และลิงก์ไปยังฟีเจอร์สำคัญที่มีอิทธิพลต่อการตัดสินใจ (feature attribution) เพื่อให้การตรวจสอบโดย ธปท./AMLO ทำได้โดยตรงและรวดเร็ว
การคุ้มครองข้อมูลส่วนบุคคล — การใช้ข้อมูลธุรกรรมและเครือข่ายความสัมพันธ์ย่อมเกี่ยวข้องกับข้อมูลส่วนบุคคลระดับสูง ดังนั้นต้องมีมาตรการดังต่อไปนี้เป็นมาตรฐาน:
- Pseudonymization ก่อนนำข้อมูลเข้าสู่สถาปัตยกรรม training และ inference เพื่อป้องกันการระบุตัวบุคคลในชั้นข้อมูลที่ใช้วิเคราะห์
- การกำหนดระยะเวลาเก็บรักษา (data retention) ให้สอดคล้องกับกฎระเบียบ เช่น การเก็บหลักฐานธุรกรรมเพื่อวัตถุประสงค์ AML ตามที่ AMLO/ธปท. กำหนด — และกำหนดนโยบายอัตโนมัติสำหรับการลบข้อมูลเมื่อหมดอายุ
- การควบคุมการเข้าถึง โดยใช้หลัก least privilege, การบันทึกการเข้าถึง (access logs) และการตรวจสอบสิทธิ์แบบหลายปัจจัยสำหรับบุคลากรที่เข้าถึงข้อมูลดิบหรือเหตุผลการตัดสินใจ
การตรวจสอบและ Validation ก่อนนำไปใช้งานจริง — ก่อนขึ้นระบบ production จำเป็นต้องดำเนินการตรวจสอบและทดสอบหลายมิติ ได้แก่
- Stress testing โดยจำลองปริมาณธุรกรรมสูงสุดและรูปแบบการโจมตีทางธุรกิจ เพื่อยืนยันเวลาตอบสนองของระบบแจ้งเตือนแบบเรียลไทม์
- Adversarial testing เช่น การสร้างตัวอย่างธุรกรรมที่ถูกปรับแต่ง (perturbation) เพื่อพยายามหลอกโมเดล และการทดสอบการโจมตีแบบ data‑poisoning เพื่อประเมินความทนทานของโมเดล
- Back‑testing และ A/B testing กับฐานข้อมูลเหตุการณ์จริงย้อนหลัง เพื่อตรวจวัดตัวชี้วัดสำคัญ (precision, recall, false positive rate, detection latency) และประเมินผลกระทบต่อภาระงานของทีมตรวจสอบ
- Monitoring model drift — ตั้งค่า metric monitoring (เช่น distribution ของฟีเจอร์, score distribution, KPI ทางธุรกิจ) พร้อม alert thresholds และกระบวนการ retraining ที่มีเวอร์ชันคอนโทรล
- Human‑in‑the‑loop — กำหนดระดับการตัดสินใจที่ต้องมีผู้ตรวจสอบมนุษย์สำหรับรายงานที่มีความเสี่ยงสูงหรือที่โมเดลมีความไม่แน่นอนสูง และบันทึกการตัดสินใจของมนุษย์เพื่อใช้เป็นข้อมูลสำหรับการฝึกอบรมและปรับปรุงโมเดลต่อไป
ความเสี่ยงของ bias และการเลือกปฏิบัติ — โมเดลที่อาศัยข้อมูลเครือข่ายและเวกเตอร์ธุรกรรมอาจสะท้อนอคติจากข้อมูลต้นทาง เช่น การให้ความสำคัญกับกลุ่มลูกค้าที่มีพฤติกรรมทางการเงินเฉพาะกลุ่มมากกว่ากลุ่มอื่น ซึ่งอาจนำไปสู่การเลือกปฏิบัติทางการเงินได้ ต้องมีมาตรการเพื่อตรวจจับและลด bias ดังนี้:
- การวัด fairness metrics (เช่น disparity ของ false positive/negative ระหว่างกลุ่มประชากรหรือเซกเมนต์ลูกค้าต่างๆ)
- การปรับ sampling, reweighting หรือ adversarial de‑biasing ระหว่าง training
- การทำ periodic bias audits โดยทีมอิสระหรือผู้ตรวจสอบภายนอก และการทำ impact assessment ก่อนเปิดใช้ฟีเจอร์ที่อาจส่งผลกระทบสูง
Audit trail และการรายงานต่อหน่วยงานกำกับ — ระบบต้องจัดเก็บบันทึกเชิงโครงสร้าง (structured audit logs) สำหรับทุกขั้นตอน ได้แก่ ชุดข้อมูลที่ใช้ (with pseudonymization metadata), เวอร์ชันของโมเดล, พารามิเตอร์การฝึก, เหตุผลของการตัดสินใจในรูปแบบอ่านได้สำหรับมนุษย์, รายการผู้ใช้ที่เข้าถึงหรือแก้ไขผลการแจ้งเตือน และเวลาที่เกี่ยวข้อง ทั้งหมดนี้ควรพร้อมสำหรับการรายงานตามข้อกำหนดของ ธปท. และ AMLO โดยมีระบบค้นหาและการส่งมอบหลักฐานแก่หน่วยงานกำกับในรูปแบบมาตรฐาน
ข้อสรุปเชิงปฏิบัติ — เพื่อให้การนำ Graph‑LLM มาใช้เป็นไปอย่างรับผิดชอบและสอดคล้องกฎระเบียบ ธนาคารควรบูรณาการมาตรการความโปร่งใส การคุ้มครองข้อมูล และกระบวนการตรวจสอบแบบต่อเนื่อง ตั้งแต่การออกแบบ (privacy‑by‑design และ explainability‑by‑design) จนถึงการปฏิบัติการจริง โดยมีนโยบายการทดสอบ (stress/adversarial/back‑testing), การติดตาม model drift, และกลไก human‑in‑the‑loop ที่ชัดเจนเพื่อลดความเสี่ยงทางกฎหมาย จริยธรรม และเชิงปฏิบัติการ พร้อมจัดเตรียมรายงานและ audit trail สำหรับการตรวจสอบโดย ธปท. และ AMLO
ความท้าทายเชิงปฏิบัติการและแนวทางปฏิบัติที่ดีที่สุด
ความท้าทายเชิงปฏิบัติการและแนวทางปฏิบัติที่ดีที่สุด
การนำ Graph‑LLM ที่ผสาน GNN กับเวกเตอร์ธุรกรรมมาใช้ในธนาคารไทยเพื่อการตรวจจับฟอกเงินและการฉ้อโกงแบบเรียลไทม์ มีความท้าทายเชิงปฏิบัติการที่สำคัญหลายประการ ตั้งแต่คุณภาพข้อมูลพื้นฐาน การสร้างกราฟจากข้อมูลที่กระจายอยู่ในหลายระบบ ไปจนถึงความต้องการด้านสเกลและต้นทุนโครงสร้างพื้นฐาน ในทางปฏิบัติ ธนาคารควรเริ่มด้วยการวิเคราะห์ช่องว่าง (gap analysis) และกำหนด KPI เชิงปริมาณ เช่น เป้าหมายลดอัตรา False‑Positive ลง X% ภายใน Y เดือน, ความหน่วง (latency) สำหรับ alert แบบเรียลไทม์ที่ต้องไม่เกิน 100–500 ms ในเส้นทางการแจ้งเตือนสำคัญ และการรักษา precision/recall ในระดับที่ธุรกิจยอมรับได้
การเตรียมข้อมูล (Data preparation) เป็นหัวใจหลักและมักสร้างความท้าทายมากที่สุด ในเชิงปฏิบัติการต้องจัดการกับ Data cleaning (การลบข้อมูลซ้ำ ข้อมูลผิดพลาด และการจัดรูปแบบให้เป็นมาตรฐาน), entity resolution (การจับคู่บุคคล บัญชี บริษัท ที่มีตัวตนเดียวกันแต่มีหลาย representation) และ time windowing (การเลือกหน้าต่างเวลาเช่น 24 ชั่วโมง, 7 วัน, 90 วัน เพื่อสร้างลำดับเหตุการณ์และคุณสมบัติกราฟ) นอกจากนี้ ต้องพิจารณาการบาลานซ์ตัวอย่างของ negative/positive samples โดยใช้เทคนิคเช่น undersampling/oversampling, SMOTE หรือการปรับ loss function ด้วย class weights เพื่อหลีกเลี่ยงโมเดลที่ลำเอียงต่อคลาสที่มีจำนวนมาก ตัวอย่างเชิงประสบการณ์งานวิจัยและการใช้งานเชิงพาณิชย์บางแห่งรายงานการลด False‑Positive ได้ราว 20–40% เมื่อมีการทำ data curation และ entity resolution อย่างเป็นระบบ
สเกลและการ deploy — การตัดสินใจระหว่าง batch กับ stream processing จะขึ้นกับกรณีการใช้งาน: batch เหมาะสำหรับการประเมินความเสี่ยงแบบรายวันหรือการอัปเดตกราฟขนาดใหญ่เป็นระยะ ในขณะที่ stream processing (เช่น Kafka + Flink/Beam) จำเป็นสำหรับการแจ้งเตือนเรียลไทม์ ระบบจริงมักใช้สถาปัตยกรรมผสม (hybrid): stream สำหรับการตรวจจับเบื้องต้นและ batch สำหรับการรีเทรนโมเดลหรือการคำนวณคุณสมบัติย้อนหลัง ข้อควรระวังด้านสเกลของ GNN/LLM ได้แก่ การทำ horizontal scaling โดยใช้ model sharding, multi‑instance inference (Triton, TorchServe) และการจัดการทรัพยากรด้วย autoscaling สำหรับ GPU/CPU การลดต้นทุนสามารถทำได้ด้วยการใช้ spot/preemptible GPU instances สำหรับงานไม่เร่งด่วน การทำ quantization (เช่น INT8), pruning, และ knowledge distillation เพื่อลดขนาดและ latency ของโมเดล รวมถึงการนำ caching มาจัดการกับการค้นหาเวกเตอร์ (Faiss, Milvus) และการทำ batched inference เพื่อลด overhead
แนวปฏิบัติที่ดีที่สุด (Best practices) — แนะนำให้ธนาคารปฏิบัติตามหลักการดังนี้:
- Start with pilot: เริ่มจากโครงการนำร่องในสโคปจำกัด (เช่น หน่วยธุรกิจหนึ่งหรือกลุ่มลูกค้าเฉพาะ) เพื่อทดสอบสมมติฐานด้านข้อมูลและการทำงานของ pipeline ก่อนขยายสู่ระบบระดับองค์กร
- Hybrid human‑AI workflow: ออกแบบกระบวนการที่ผสานการตัดสินใจของโมเดลกับการตรวจสอบโดยผู้เชี่ยวชาญ (analyst review) โดยให้โมเดลจัดลำดับความสำคัญของ alert และมนุษย์เป็นผู้สรุปผลสุดท้าย เพื่อลดความเสี่ยงจาก false negatives/positives
- Metric‑driven rollout: กำหนดเมตริกชัดเจน (precision, recall, FPR, alert-to-investigation ratio, mean time to investigate) และใช้ A/B testing หรือ progressive rollout เพื่อประเมินผลกระทบเชิงธุรกิจก่อน scale
- Continuous monitoring: ติดตั้ง pipeline สำหรับการเฝ้าระวัง performance แบบเรียลไทม์ (data drift, model drift, latency, error rates) และตั้ง automated alarms เมื่อเมตริกเบี่ยงเบน
- Governance board: ตั้งคณะกรรมการกำกับดูแลข้ามหน่วยงาน (risk, compliance, IT, data science) เพื่ออนุมัติการเปลี่ยนแปลงโมเดล การกำหนดนโยบายการเข้าถึงข้อมูล และการตรวจสอบความเป็นธรรมและความสามารถในการอธิบาย (explainability)
เช็คลิสต์การพัฒนาและนำสู่การทำงานจริง (Checklist)
- ประเมินคุณภาพข้อมูล: missing values, inconsistent formats, duplicates
- ดำเนินงาน entity resolution และสร้าง canonical IDs สำหรับบุคคล/บัญชี/หน่วยงาน
- ออกแบบ time windowing และ sampling strategy (sliding vs tumbling windows)
- จัดการ class imbalance: กำหนดวิธี oversample/undersample หรือใช้ weighted loss
- เลือกสถาปัตยกรรมการประมวลผล: batch + stream hybrid พร้อมสเปค latency ที่ชัดเจน
- วางแผนการ scale: inference servers, model sharding, autoscaling policies
- นำเทคนิคลดต้นทุน: quantization, distillation, spot/preemptible instances, batched inference
- สร้าง human‑in‑loop UI และ feedback loop เพื่อปรับปรุงโมเดลอย่างต่อเนื่อง
- ติดตั้ง monitoring & observability: data drift detectors, model performance dashboards, audit logs
- จัดตั้ง governance board และนโยบายความปลอดภัยข้อมูล/ความเป็นส่วนตัว
โดยสรุป การนำ Graph‑LLM มาปรับใช้ในสภาพแวดล้อมของธนาคารไทยต้องมีการเตรียมข้อมูลอย่างเข้มข้น การออกแบบระบบประมวลผลที่รองรับทั้งการทำงานแบบเรียลไทม์และแบบแบตช์ การควบคุมค่าใช้จ่ายเชิงสถาปัตยกรรม และกระบวนการกำกับดูแลที่ชัดเจน การปฏิบัติตามแนวทางข้างต้นจะช่วยลดความเสี่ยง เพิ่มความแม่นยำของระบบ แจ้งเตือนที่สำคัญจริง และลดภาระงานของเจ้าหน้าที่ในการตรวจสอบ alert ทั้งยังช่วยให้การขยายผลไปสู่การใช้งานระดับองค์กรเป็นไปอย่างยั่งยืน
Roadmap การนำไปใช้ในธนาคารไทยและผลกระทบต่อภาคการเงิน
Roadmap การนำ Graph‑LLM ไปใช้ในธนาคารไทยและผลกระทบต่อภาคการเงิน
สรุปไทม์ไลน์ 6–18 เดือน (PoC → Pilot → Rollout)
การนำ Graph‑LLM ซึ่งผสานกราฟนิวรัลเน็ตเวิร์ก (GNN) กับเวกเตอร์ธุรกรรม มาปรับใช้ในระบบตรวจจับการฟอกเงิน (AML) และการฉ้อโกง ควรถูกออกแบบเป็นเฟสที่ชัดเจนเพื่อควบคุมความเสี่ยงด้านข้อมูลและการกำกับดูแล โดยแนะนำไทม์ไลน์ 3 ระยะหลัก: 0–3 เดือน (PoC), 3–9 เดือน (Pilot), และ 9–18 เดือน (Rollout สู่ production).
- 0–3 เดือน (Proof of Concept)
- Milestone: สร้าง PoC บนชุดข้อมูลจำกัด (เช่น ธุรกรรมชำระเงินระหว่างบุคคล 1–3 ประเภท, ประวัติการแจ้งเตือนย้อนหลัง 6–12 เดือน)
- Resource: ทีม Data Science 2–4 คน, วิศวกร Data 1–2 คน, SME ฝ่ายปฏิบัติตามกฎระเบียบ (Compliance) 1–2 คน, ค่าใช้จ่ายเบื้องต้นประมาณ 0.5–2 ล้านบาท ขึ้นกับการใช้คลาวด์และการเช่าโมเดล
- กิจกรรมสำคัญ: ประเมินคุณภาพการลด False‑Positive (เป้าหมายทดลอง: ลด 30–50% จากระบบเดิม), ทดสอบความสามารถ realtime inference, ตั้ง KPI เบื้องต้น (precision, recall, latency)
- 3–9 เดือน (Pilot ขยายกลุ่มธุรกรรม)
- Milestone: ขยายการทดสอบสู่ subset การทำธุรกรรมที่หลากหลาย (เช่น การโอนต่างธนาคาร บัตรเครดิต การฝากถอน) และเชื่อมข้อมูลหน่วยงานภายในเพิ่มเติม (KYC, ประวัติการร้องเรียน)
- Resource: ขยายทีมเป็น Data Science/ML 5–8 คน, DevOps/ML Ops 2–4 คน, Compliance & SAR (Suspicious Activity Report) analyst 3–6 คน, งบประมาณเพิ่มเติม 2–10 ล้านบาท สำหรับการปรับสเกลและการตรวจสอบด้านกฎหมาย
- ความร่วมมือ: ประสานงานกับ regulator เช่น ธนาคารแห่งประเทศไทย (ธปท.) และ ปปง. เพื่อขอคำชี้แจงด้านการแลกเปลี่ยนข้อมูลและการรายงาน, รวมถึงร่วมมือกับ third‑party vendors (ผู้ให้บริการคลาวด์, ผู้ให้บริการ Graph DB เช่น Neo4j/TigerGraph, ผู้ให้บริการ LLM)
- KPIs: ลด False‑Positive ให้ได้ตามเป้า (ตัวอย่างการคาดการณ์: ลด 40–60% ในกลุ่มที่เป็นเป้าทดสอบ), เพิ่มอัตราการจับการฉ้อโกงจริง (true positive) ขึ้น 20–40%, latency ต่อการแจ้งเตือน ≤ 1–5 วินาทีในงานแบบ realtime
- 9–18 เดือน (Rollout สู่ production)
- Milestone: ขยายระบบสู่ production ครอบคลุมธุรกรรมทั้งหมด เชื่อมต่อกับระบบ core banking, แจ้งเตือนอัตโนมัติและ workflow สำหรับการตรวจสอบแบบมนุษย์ (human-in-the-loop)
- Resource: ทีมบำรุงรักษาและตรวจสอบโมเดล (Model Governance) ประมาณ 8–15 คน, ค่าโครงสร้างพื้นฐานและสัญญาบริการต่อปี 10–50 ล้านบาท ขึ้นกับขนาดธนาคารและ SLA
- ความร่วมมือเพิ่มเติม: ลงนามข้อตกลง MOU กับ regulator สำหรับ sandbox การทดสอบ, จัดตั้งกระบวนการ Audit และ Explainability กับผู้ตรวจสอบภายนอก (external auditors) และ vendor ด้านความโปร่งใสของโมเดล
- ผลลัพธ์ที่คาดหวัง: การลดงาน manual review ลงอย่างมีนัยสำคัญ (ประมาณ 40–70%), ลดเวลาตรวจสอบต่อเคสจากชั่วโมงเหลือเป็นนาที และ ROI ที่ชัดเจนเมื่อเทียบกับต้นทุนในการปฏิบัติตามกฎและค่าปรับ
แหล่งลงทุนและการคาดการณ์ ROI
การลงทุนแบ่งเป็น 3 หมวดหลัก: 1) งานวิจัยและพัฒนา (R&D/PoC), 2) โครงสร้างพื้นฐาน (คลาวด์, Graph DB, LLM inference), และ 3) การปรับกระบวนการองค์กร (training, governance). ธนาคารขนาดกลางสามารถเริ่มด้วยงบประมาณรวมในช่วง ประมาณ 3–15 ล้านบาท สำหรับ 12 เดือนแรก ขณะที่ธนาคารใหญ่หรือสถาบันที่ต้องการ high‑availability อาจต้องใช้งบประมาณ > 20 ล้านบาท.
- ช่องทางลงทุน: งบกลางด้านเทคโนโลยี, การร่วมลงทุนกับผู้ให้บริการภายนอกแบบ SaaS, การใช้โครงการทดลองภายใน Sandbox ของ regulator เพื่อลดความเสี่ยงด้านกฎ
- การคืนทุน (ROI): คาดว่า ROI สามารถเห็นผลภายใน 12–18 เดือน เมื่อรวมประหยัดจากการลดงาน manual, ค่าปรับที่หลีกเลี่ยงได้ และมูลค่าทางธุรกิจจากการลด false alerts ตัวอย่างเชิงตัวเลข: หากธนาคารมีต้นทุนการวิเคราะห์แจ้งเตือนเฉลี่ย 500–1,500 บาทต่อเคส และลดจำนวนเคสที่ต้องตรวจสอบได้ 50% พร้อมกับเพิ่มการจับการฉ้อโกงที่มีมูลค่าเฉลี่ย 2–5 ล้านบาทต่อเหตุการณ์ สถาบันสามารถคืนทุนจากการลดค่าใช้จ่ายและหลีกเลี่ยงค่าเสียหายภายใน 1–1.5 ปี
- ตัวชี้วัดทางการเงิน: ลด OPEX ด้าน AML ได้ 25–45% ต่อปี, ลดค่าเสียโอกาสจากการระงับบริการแก่ลูกค้าที่ถูกต้องโดยไม่จำเป็น (false positives) ส่งผลต่อ NPS และรายได้
ผลกระทบระยะยาวต่อการปฏิบัติตามกฎ การบริการลูกค้า และต้นทุน
การนำ Graph‑LLM มาใช้จะมีผลกระทบหลายด้านดังนี้:
- การปฏิบัติตามกฎ (Compliance): ความสามารถในการจับรูปแบบเชิงกราฟและบริบทเชิงภาษาของ LLM ช่วยให้สามารถสร้าง SAR ที่มีความชัดเจนและมีหลักฐานสนับสนุนมากขึ้น ทำให้ลดความเสี่ยงค่าปรับจาก regulator และเพิ่มความสามารถในการตรวจสอบย้อนหลัง (audit trail) ซึ่งเป็นที่ต้องการของ ธปท. และ ปปง..
- การบริการลูกค้า: ลด False‑Positive ส่งผลให้ลูกค้าที่ถูกต้องไม่ถูกขัดจังหวะบริการ ช่วยเพิ่มประสบการณ์ลูกค้า (Customer Experience) และ NPS ตัวอย่างเช่น หากลดการระงับบัญชีผิดพลาดได้ 50% จะส่งผลโดยตรงต่อ retention และรายได้จากการใช้งานบริการออนไลน์
- การลดต้นทุนและเพิ่มประสิทธิภาพ: อัตโนมัติที่เพิ่มขึ้นจะลดชั่วโมงงาน manual ของเจ้าหน้าที่ ลดค่าใช้จ่ายบุคลากร และย่นเวลาในการตัดสินใจ ทำให้ต้นทุนต่อการตรวจสอบลดลงอย่างมีนัยสำคัญ
- ผลต่ออุตสาหกรรม: การนำเทคโนโลยีลักษณะนี้มาใช้เป็นวงกว้างจะกระตุ้นให้เกิดนวัตกรรมด้าน SaaS สำหรับธนาคาร เช่น โซลูชัน Graph‑AML แบบรวม (managed services) ที่รองรับการเชื่อมต่อข้อมูลข้ามสถาบัน อีกทั้งช่วยยกระดับมาตรฐานการวิเคราะห์ความเสี่ยงของระบบการเงินของประเทศ
สรุปแล้ว Roadmap ที่ออกแบบอย่างเป็นขั้นตอนและการมีส่วนร่วมระหว่างฝ่ายเทคนิค ฝ่ายปฏิบัติตามกฎ และ regulator จะช่วยให้ธนาคารไทยสามารถนำ Graph‑LLM มาใช้ได้อย่างปลอดภัย มีประสิทธิภาพ และเห็นผลทางธุรกิจชัดเจนภายในกรอบเวลา 6–18 เดือน โดยมีผลระยะยาวทั้งในด้านการลดความเสี่ยง การปรับปรุงประสบการณ์ลูกค้า และการลดต้นทุนปฏิบัติการ.
บทสรุป
Graph‑LLM ที่ผสานความสามารถของ Graph Neural Networks (GNN) กับเวกเตอร์แทนค่าธุรกรรม (transaction embeddings) แสดงศักยภาพชัดเจนในการลดอัตรา false‑positive และเพิ่มความแม่นยำในการตรวจจับการฟอกเงินและการฉ้อโกงแบบเรียลไทม์ เมื่อออกแบบสถาปัตยกรรมร่วมกับ governance ที่เข้มแข็ง เช่น การจัดการข้อมูล (data lineage), มาตรการความเป็นส่วนตัว และความสามารถในการอธิบายผล (explainability) โมเดลเชิงกราฟช่วยจับความสัมพันธ์เชิงโครงสร้างของเครือข่ายการทำธุรกรรม ในขณะที่เวกเตอร์ธุรกรรมเพิ่มมิติคุณลักษณะเชิงพฤติกรรม ทำให้ระบบคัดกรองแจ้งเตือนมีความคัดกรุ้งมากขึ้น ตัวอย่าง PoC ในภาคการเงินบางกรณีรายงานการลด false‑positive ระหว่าง 30–50% พร้อมการเพิ่มค่า Precision/Recall ที่สังเกตได้เมื่อเทียบกับระบบกฎแบบเดิม (rule‑based) — ทั้งนี้ผลลัพธ์ขึ้นกับคุณภาพข้อมูลและการตั้งค่าเมตริกการประเมินผลอย่างเคร่งครัด
การนำ Graph‑LLM ไปใช้เชิงปฏิบัติการควรเริ่มจากโครงการนำร่อง (PoC) ที่กำหนดเมตริกชัดเจน เช่น Precision, Recall, F1‑score, False Positive Rate, Time‑to‑Detect และค่าใช้จ่ายต่อการสอบสวน (cost per investigation) พร้อมแผนการปรับปรุงข้อมูล (data enrichment, deduplication, feature engineering) และกระบวนการ human‑in‑the‑loop เพื่อให้การตัดสินใจที่สำคัญได้รับการยืนยันโดยผู้เชี่ยวชาญและสอดคล้องกับกฎระเบียบ AML/KYC การกำหนด governance ต้องครอบคลุมการทดสอบความเบี่ยงเบน (bias testing), การควบคุมการเข้าถึงข้อมูล และกลไกติดตาม (monitoring) เพื่อลดความเสี่ยงเชิงปฏิบัติการและทางกฎหมาย การตั้งเป้าผลการทดลองและวงเวลาที่ชัดเจน จะช่วยให้การปรับจูนโมเดลและกระบวนการทำงานเป็นไปอย่างมีประสิทธิภาพ
มุมมองอนาคตชี้ว่า Graph‑LLM จะกลายเป็นส่วนสำคัญของระบบป้องกันการทุจริตเมื่อองค์กรสามารถบริหารจัดการปัจจัยสำคัญได้ ได้แก่ คุณภาพข้อมูล การอธิบายผลลัพธ์ การอัปเดตโมเดลอย่างต่อเนื่อง และความร่วมมือข้ามสถาบัน เช่น การใช้ sandbox ทางกฎระเบียบหรือเฟเดอเรตเต็ดเลิร์นนิงเพื่อแลกเปลี่ยนรูปแบบความเสี่ยงโดยไม่เปิดเผยข้อมูลดิบ ในระยะยาว ธนาคารที่ผสานเทคโนโลยีนี้อย่างรอบคอบจะได้ประโยชน์จากการลดงานตรวจสอบซ้ำ เพิ่มอัตราการจับผู้กระทำผิดจริง และปรับปรุงประสบการณ์ลูกค้า โดยมีข้อควรระวังเรื่องต้นทุนการพัฒนา การดูแลรักษา และการติดตามการลอกเลียนแบบสัญญาณ (signal drift) ที่ต้องบริหารอย่างต่อเนื่อง



