สตาร์ทอัพไทยเปิดตัว "Tiny‑LLM Hub" แพลตฟอร์มใหม่ที่ออกแบบมาให้โรงงานและผู้ประกอบการอุตสาหกรรมรันโมเดลภาษาขนาดเล็ก (small LLMs) หลายตัวแบบ multi‑tenant บนอุปกรณ์ปลายทางโดยไม่ต้องพึ่งพาคลาวด์ตลอดเวลา จุดเด่นคือสถาปัตยกรรมที่อนุญาตให้แชร์เวกเตอร์และเวทที่ผ่านการควอนไทซ์ (quantized vectors/weights) ระหว่างโมเดล ลดขนาดหน่วยความจำและภาระคำนวณ ทำให้ latency ต่ำลงอย่างมีนัยสำคัญและช่วยลดค่าใช้จ่ายคลาวด์เมื่อเทียบกับการยิงคำขอไปยังเซิร์ฟเวอร์ระยะไกล
ทีมพัฒนาเผยผลเบนช์มาร์กตัวอย่างที่แสดงการลด latency ระหว่างประมาณ 20–60% และการลดค่าใช้จ่ายคลาวด์ได้สูงสุดราว 50% ในกรณีใช้งานบางประเภท ขณะที่กรณีใช้งานจริงในโรงงาน เช่น การตรวจสอบคุณภาพด้วยภาพแบบเรียลไทม์ การซัพพอร์ตช่างซ่อมบำรุงแบบ on‑device และการประมวลผลข้อมูลเซนเซอร์แบบต่อเนื่อง ช่วยให้ระบบตอบสนองเร็วขึ้น ลดการพึ่งพาแบนด์วิดท์ และเพิ่มความทนทานเมื่อเครือข่ายไม่เสถียร Tiny‑LLM Hub จึงเสนอทางเลือกสำหรับการปรับใช้ AI ที่คุ้มค่าทางเศรษฐกิจและตอบโจทย์การใช้งานภาคอุตสาหกรรมอย่างชัดเจน
บทนำ: ทำไม Tiny‑LLM Hub ถึงสำคัญ
บทนำ: ทำไม Tiny‑LLM Hub ถึงสำคัญ
Tiny‑LLM Hub เป็นแพลตฟอร์มที่พัฒนาขึ้นโดยสตาร์ทอัพไทยเพื่อให้สามารถ รันหลายโมเดลภาษาใหญ่ขนาดเล็ก (tiny LLMs) แบบ multi‑tenant บนอุปกรณ์อุตสาหกรรม ได้พร้อมกัน ด้วยแนวคิดการแชร์เวกเตอร์และเวทที่ถูกควอนไทซ์ เพื่อลดการใช้หน่วยความจำและแบนด์วิดท์ลงอย่างมาก ผลลัพธ์ที่สตาร์ทอัพนำเสนอคือการย้ายการประมวลผลบางส่วนจากคลาวด์ลงสู่ edge/OT (Operational Technology) ของโรงงานหรือไซต์อุตสาหกรรม ทำให้ระบบตอบสนองเร็วขึ้นและค่าใช้จ่ายรวมลดลง
ปัญหาหลักที่ Tiny‑LLM Hub ตั้งใจแก้ไขได้แก่ latency สูงจากการส่งข้อมูลไปกลับคลาวด์ ซึ่งในงานอุตสาหกรรมบางประเภทการหน่วงเวลาเพียงระดับร้อยมิลลิวินาทีถึงหลักวินาทีก็อาจกระทบต่อการควบคุมหรือการตัดสินใจเชิงเวลาจริง นอกจากนี้ยังเป็นการตอบโจทย์ ค่าใช้จ่ายคลาวด์ที่สูง โดยเฉพาะค่า egress และค่า inference ต่อการเรียกใช้งานซ้ำ ๆ รวมถึงข้อจำกัดทางทรัพยากรของอุปกรณ์ edge ที่มีหน่วยประมวลผลและหน่วยความจำน้อย ทำให้ไม่สามารถรันโมเดลขนาดใหญ่เต็มรูปแบบได้
ตามที่ผู้พัฒนาระบุ ผลิตภัณฑ์นี้ลดเวลาแฝงในการตอบสนองจากระดับหลายร้อยมิลลิวินาทีลงสู่ช่วงสองหลัก (ตัวอย่างเช่นประมาณ 20–50 ms ในงานตรวจสอบสายการผลิตบางกรณี) และสามารถลดต้นทุนคลาวด์รวมได้หลายสิบเปอร์เซ็นต์เมื่อย้าย inference จำนวนมากไปทำที่ edge พร้อมกับการใช้การควอนไทซ์เวทและเวกเตอร์ที่ช่วยลดการใช้หน่วยความจำได้ถึง 4–8 เท่า ข้อมูลเชิงตัวอย่างเหล่านี้สะท้อนถึงความเป็นไปได้ที่ Tiny‑LLM Hub จะช่วยให้แอปพลิเคชันอัจฉริยะในภาคอุตสาหกรรม เช่น การบำรุงรักษาเชิงคาดการณ์ (predictive maintenance), การตรวจสอบคุณภาพด้วยภาพ และผู้ช่วยสำหรับผู้ปฏิบัติงานภาคสนาม มีประสิทธิภาพมากขึ้น
ภาพรวมของผลประโยชน์ที่คาดว่าจะได้รับจาก Tiny‑LLM Hub ได้แก่:
- ลด latency: ให้การตอบสนองแบบใกล้เคียงเวลาจริง เหมาะกับการควบคุมเชิงอุตสาหกรรมและการวิเคราะห์ที่ต้องการการตัดสินใจทันที
- ลดค่าใช้จ่ายคลาวด์: ลดการเรียกใช้งาน inference บนคลาวด์และค่า egress ทำให้ค่าใช้จ่ายรวมต่ำลง
- รองรับ multi‑tenant บนอุปกรณ์เดี่ยว: รันหลายโมเดลสำหรับงานและลูกค้าหลายรายบนฮาร์ดแวร์เดียว โดยจัดสรรทรัพยากรร่วมกัน
- ประหยัดทรัพยากรด้วยการควอนไทซ์: แชร์เวกเตอร์และเวทที่ถูกควอนไทซ์เพื่อลดการใช้หน่วยความจำและเก็บโมเดลได้มากขึ้นบน edge
- ความเป็นส่วนตัวและความพร้อมใช้งาน: ลดการส่งข้อมูลสำคัญขึ้นคลาวด์ ช่วยให้ปฏิบัติการยังคงทำงานได้แม้เครือข่ายจะขัดข้อง
ด้วยบริบทค่าใช้จ่ายและความต้องการด้านความเร็วในโรงงานอุตสาหกรรม Tiny‑LLM Hub จึงเข้ามาตอบโจทย์เชิงปฏิบัติได้ชัดเจน ทั้งในแง่เทคนิคและเศรษฐศาสตร์ของการนำเทคโนโลยี LLM ไปใช้ในสภาพแวดล้อมที่มีข้อจำกัดด้านทรัพยากรและต้องการความเชื่อถือได้สูง
สถาปัตยกรรมของ Tiny‑LLM Hub: แนวคิดและองค์ประกอบหลัก
สถาปัตยกรรมของ Tiny‑LLM Hub: แนวคิดและองค์ประกอบหลัก
สถาปัตยกรรมของ Tiny‑LLM Hub ถูกออกแบบมาเพื่อให้แพลตฟอร์มสามารถรันโมเดลขนาดเล็กหลายตัวแบบ multi‑tenant บนอุปกรณ์อุตสาหกรรมได้อย่างมีประสิทธิภาพ โดยลดการซ้ำซ้อนของเวกเตอร์และเวทที่ควอนไทซ์ (quantized weights) เพื่อประหยัดหน่วยความจำและค่าใช้จ่ายคลาวด์พร้อมทั้งยังคงความยืดหยุ่นของการจัดการผ่านคลาวด์ ส่วนสำคัญประกอบด้วย: โมดูลการแยกแยะผู้เช่า (multi‑tenant isolation), ชั้นสำหรับแชร์เวกเตอร์และเวทที่ควอนไทซ์, runtime ที่ทำงานบนอุปกรณ์ และโมดูล orchestration/monitoring ที่ผสานกับคลาวด์เพื่อบริหาร lifecycle และเทเลเมทรีเชิงปริมาณ
ในเชิงเทคนิค แพลตฟอร์มแบ่งงานเป็นสองระนาบหลักคือ control plane (ที่อยู่บนคลาวด์หรือโครงสร้างการจัดการศูนย์ข้อมูล) สำหรับการกำหนดนโยบาย, lifecycle ของโมเดล, การจัดการ tenancy และการมอนิเตอร์ และ data/exec plane (ที่รันบนอุปกรณ์อุตสาหกรรม) สำหรับ inference จริง ๆ ซึ่งประกอบด้วย runtime, local caches และชั้นการแชร์ข้อมูลเพื่อหลีกเลี่ยง duplication ของเวกเตอร์และเวทที่ควอนไทซ์ ช่วยให้การใช้ทรัพยากรหน่วยความจำและ I/O ดีขึ้นอย่างมีนัยสำคัญ
สถิติและตัวอย่างเชิงประมาณการจากการออกแบบระบบแบบนี้ชี้ว่า การแชร์เวกเตอร์และเวทที่ควอนไทซ์สามารถลดการใช้หน่วยความจำซ้ำซ้อนได้ 60–80% ขึ้นกับลักษณะโมเดลและอัตราการซ้อนทับของเวกเตอร์ ส่วนการใช้ควอนไทซ์ระดับ 4‑bit/8‑bit จะลดขนาดเวทได้ประมาณ 8 เท่า (4‑bit) และ 4 เท่า (8‑bit) เมื่อเทียบกับ float32 ซึ่งส่งผลให้ค่าใช้จ่ายสตอเรจและการถ่ายโอนข้อมูลลดลงอย่างมีนัยสำคัญ (องค์กรที่ดำเนินการจริงมักรายงานการลดค่าใช้จ่ายคลาวด์เฉพาะ inference ได้ประมาณ 30–60% ขึ้นกับโทโพโลยีการรันและอัตราการคิดงานบนอุปกรณ์)
องค์ประกอบหลักและการย่อยฟังก์ชัน
- โมดูล multi‑tenant isolation
- Tenancy management — บัญชีผู้เช่า (tenant registry), การพิสูจน์สิทธิ์และการมอบสิทธิ์, namespace แยกเพื่อความเป็นส่วนตัวและการบังคับนโยบาย
- Resource quotas — การกำหนดโควต้าทรัพยากรต่อผู้เช่า (CPU, memory, NPU/VPU time, I/O bandwidth) พร้อมระบบ policing และ backpressure เพื่อป้องกัน noisy neighbor
- Per‑tenant model routing — กฎการส่งคำขอให้โมเดลตาม tenant, versioning และ feature‑flag เพื่อให้แต่ละผู้เช่าสามารถชี้ไปยังโมเดล/เวอร์ชันของตนเองหรือกลุ่มโมเดลที่แชร์ร่วมได้
- ชั้นการแชร์เวกเตอร์และเวทที่ควอนไทซ์
- Shared vector store — อินเด็กซ์เวกเตอร์แบบแบ่งพื้นที่ (sharded vector index) ที่สนับสนุน namespace ต่อ tenant แต่เก็บข้อมูลฐานร่วมเพื่อหลีกเลี่ยงการสำเนา เช่น การใช้ fingerprinting และ reference counting เพื่อลด duplication
- Shared quantized weights — ที่เก็บโมเดลในรูปแบบ chunked และควอนไทซ์ (4‑bit/8‑bit) พร้อม metadata สำหรับการแมปโมดูลย่อยไปยังชิ้นน้ำหนักที่ถูกแชร์ ระบบรองรับ memory‑mapped loading และ lazy loading เพื่อลด peak memory
- ผลทางปฏิบัติ — ลด I/O และความจำในการโหลดโมเดลซ้ำได้มาก ส่งผลให้ throughput เพิ่มขึ้นและ startup latency ต่ำลง
- Runtime บนอุปกรณ์ (Edge/On‑premises)
- Scheduler — ตัดสินใจ dispatch งานแบบ latency‑sensitive หรือ throughput‑oriented โดยคำนึงถึงโควต้าของ tenant, priority, batching และ preemption policy (ตัวอย่าง: real‑time control ของอุปกรณ์อุตสาหกรรมได้สิทธิ์เรียกใช้งานสูงสุด)
- Hardware acceleration passthrough — รองรับการเชื่อมต่อกับ NPU, VPU, GPU หรือ DSP ผ่าน driver/firmware interface (เช่น passthrough แบบ kernel driver หรือ SR‑IOV‑style) เพื่อให้ runtime สามารถรัน kernels บนฮาร์ดแวร์เฉพาะได้โดยตรง ลด latency และเพิ่มประสิทธิภาพการใช้พลังงาน
- Fallback to cloud — เมื่อทรัพยากรท้องถิ่นไม่พอหรือมีคำขอเกินโควต้า ระบบสามารถ offload งานไปยังคลาวด์แบบยืดหยุ่น โดยรักษาสถานะ (state) และคิวงาน ทำ warm‑up ให้โมเดลในคลาวด์ และใช้ hybrid batching เพื่อลดผลกระทบต่อ latency
- Orchestration & Monitoring ที่เชื่อมต่อคลาวด์
- Control plane บนคลาวด์จัดการ lifecycle ของโมเดล (deploy, rollback, versioning), การกระจายเวอร์ชันควอนไทซ์ไปยัง edge, และการบังคับนโยบายความปลอดภัย
- Telemetry & monitoring — เก็บ metrics เช่น latency, throughput, model hotness, memory pressure และการใช้ accelerators เพื่อนำไปปรับนโยบาย scheduler และ autoscaling ของทั้ง edge และ cloud
- Policy & cost control — ระบบวิเคราะห์การใช้งานเพื่อแนะนำการย้ายงานระหว่าง edge/cloud เพื่อควบคุมค่าใช้จ่าย พร้อมระบบ alert และ SLA enforcement
ไดอะแกรมเชิงฟังก์ชัน (สรุปการไหลของงาน)
- Request flow — คำขอเข้ามายังอุปกรณ์ → Tenant routing → Scheduler ตรวจสอบ quota/priority → Lookup ใน shared vector store / shared weight store → Dispatch ไปยัง accelerator หรือ fallback ไปยัง cloud
- State & lifecycle flow — Control plane ส่งนโยบายและเวอร์ชันโมเดล → Edge ดึงเฉพาะ chunk ของเวทที่จำเป็น (lazy, mmap) → Telemetry ส่งกลับเมตริกและ logs → Control plane ปรับแต่งการแจกจ่ายตามข้อมูล
- Fault tolerance — Local health checks, circuit breaker สำหรับ offload, และการซิงก์ checkpoint ระหว่าง edge กับ cloud เพื่อรับประกัน continuity ของงาน
โดยรวมแล้วสถาปัตยกรรมของ Tiny‑LLM Hub มุ่งเน้นการผสมผสานระหว่างการอนุญาตให้หลายผู้เช่าใช้งานร่วมกันอย่างปลอดภัย ประสิทธิภาพของการแชร์เวกเตอร์และเวทที่ควอนไทซ์เพื่อลดต้นทุนทรัพยากร และ runtime บนฮาร์ดแวร์อุตสาหกรรมที่สามารถใช้ประโยชน์จาก NPU/VPU ได้เต็มที่ พร้อมกลไก fallback ไปยังคลาวด์เมื่อจำเป็น ซึ่งทั้งหมดนี้ถูกประสานผ่าน control plane ที่มอนิเตอร์และปรับจูนแบบเรียลไทม์เพื่อตอบโจทย์ทั้งด้านความเร็ว ความคุ้มค่า และการปฏิบัติงานเชิงอุตสาหกรรม
นวัตกรรมทางเทคนิค: Quantization, Vector & Weight Sharing, และ Multi‑Tenant
การควอนไทซ์ (Quantization) — รูปแบบที่ใช้และการแลกเปลี่ยนระหว่างขนาดกับความแม่นยำ
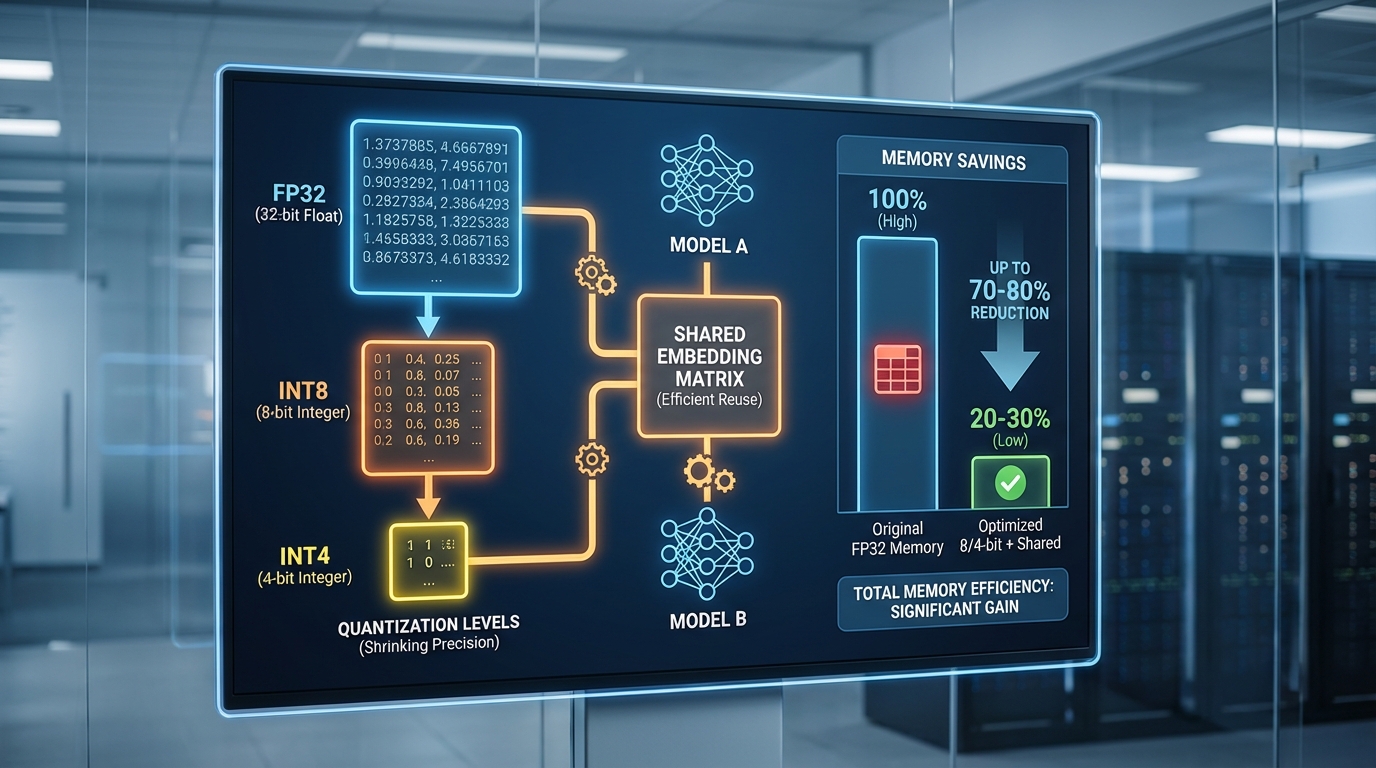
หนึ่งในหัวใจสำคัญที่ทำให้ Tiny‑LLM Hub สามารถรันหลายโมเดลขนาดเล็กบนอุปกรณ์อุตสาหกรรมได้คือการนำเทคนิคการควอนไทซ์ระดับสูงมาใช้ร่วมกันอย่างเป็นระบบ โดยระบบรองรับหลายรูปแบบ เช่น 8‑bit (INT8), 4‑bit (INT4) และเทคนิคสมัยใหม่ที่พัฒนาเพื่อโมเดลภาษาใหญ่ (เช่น GPTQ, AWQ, SmoothQuant และ QLoRA-based workflows) ซึ่งแต่ละรูปแบบมี trade‑off ระหว่างขนาดโมเดล ความแม่นยำ และ latency ดังนี้
- 8‑bit (INT8): เมื่อเทียบกับ FP32 ขนาดไฟล์ลดลงประมาณ 4× ทำให้ memory footprint ลดลงอย่างมากและส่งผลให้สามารถรันโมเดลขนาดใหญ่กว่าเดิมบนหน่วยความจำเดียวกันได้ โดยความเสียหายต่อความแม่นยำมักจะอยู่ในระดับเล็กน้อย (single-digit เปอร์เซ็นต์ของ metric บางตัว) หากใช้การปรับปรุงเช่น per-channel scale และ calibration
- 4‑bit (INT4) & advanced 4‑bit schemes: ให้การลดขนาดสูงสุด (ประมาณ 8× เมื่อเทียบกับ FP32) เหมาะสำหรับการลดค่าใช้จ่ายและเพิ่มจำนวน tenants ที่รองรับ แต่ต้องใช้เทคนิคขั้นสูง (เช่น groupwise quantization, GPTQ/AWQ) และ/หรือการทำ quantization‑aware fine‑tuning (เช่น QLoRA) เพื่อรักษาความแม่นยำให้อยู่ในระดับยอมรับได้
- เทคนิคผสมและ hybrid approaches: Tiny‑LLM Hub ใช้แนวทางผสม เช่น quantize ส่วนใหญ่ของน้ำหนักเป็น 4‑bit แต่เก็บ layer สำคัญเป็น 8‑bit หรือ FP16 (selective higher‑precision layers) เพื่อรักษาคุณภาพของการสร้างภาษาและความแม่นยำของ downstream tasks
ตัวอย่างเชิงตัวเลข: โมเดลขนาด 7B หากเก็บเป็น FP32 จะใช้พื้นที่ประมาณ 28GB → เมื่อแปลงเป็น 8‑bit จะเหลือประมาณ 7GB (ลด 4×) และเป็น 4‑bit จะเหลือประมาณ 3.5GB (ลด 8×) ทำให้ Tiny‑LLM Hub สามารถวางโมเดลหลายตัวในหน่วยความจำของอุปกรณ์อุตสาหกรรมเดียวได้ และลดต้นทุนคลาวด์/ฮาร์ดแวร์ได้ชัดเจน อย่างไรก็ตามการเลือกระดับควอนไทซ์ต้องพิจารณา workload: งานที่ต้องการความแม่นยำสูง (เช่น การวินิจฉัยทางการแพทย์หรือกฎหมาย) อาจต้องเลือก 8‑bit หรือ hybrid approach มากกว่า 4‑bit
การแชร์เวกเตอร์และน้ำหนัก (Shared Embedding / KV‑Cache / Weight Sharing)
อีกฟีเจอร์สำคัญของ Tiny‑LLM Hub คือการลดการทำซ้ำของข้อมูลในหน่วยความจำเมื่อรันหลายโมเดลพร้อมกัน โดยใช้กลยุทธ์ต่อไปนี้:
- Shared embedding tables: เมื่อโมเดลหลายตัวใช้ tokenizer และ vocabulary เดียวกัน (หรือ compatible) ระบบจะเก็บตาราง embedding เพียงชุดเดียวและให้โมเดลต่าง ๆ ชี้ไปยังตารางนั้นผ่าน namespace/permission เท่านั้น ซึ่งช่วยลด memory duplication ได้มากโดยเฉพาะในกรณีที่รันหลายเวอร์ชันของโมเดลที่มีชั้น embedding ร่วมกัน
- KV‑cache sharing และ deduplication: สำหรับการ inference แบบ streaming หรือ multi‑turn conversation ระบบสามารถเก็บค่า Key/Value ของ context ที่ซ้ำกันไว้ร่วมกัน และใช้ pointer หรือ reference สำหรับ tenant ที่ต้องการ หากหลายคำขอมี prefix หรือบริบทที่ซ้ำกัน จะทำให้ลดการคำนวณซ้ำและลด latency ได้อย่างมีนัยสำคัญ
- Memory mapping และ zero‑copy I/O: Tiny‑LLM Hub ใช้ memory‑mapped files (mmap) และโครงสร้างข้อมูลแบบ read‑only สำหรับน้ำหนักที่ควอนไทซ์แล้ว ทำให้หลาย process/tenant สามารถใช้ข้อมูลเดียวกันแบบ zero‑copy บน CPU/GPU memory ช่วยประหยัดแบนด์วิดท์และเวลาโหลดโมเดล
ผลลัพธ์เชิงปฏิบัติ: การแชร์ embedding + KV caching ทำให้ memory usage ต่อ tenant ลดลงอย่างมีนัยสำคัญ — ทีมวิศวกรรมของ Hub รายงานว่าในการทดสอบ multi‑tenant จริง การแชร์ลด memory duplication ได้ถึง 40–70% และลด latency ของคำขอที่มีบริบทซ้ำกันได้ 20–60% ขึ้นกับ pattern ของคำขอ
ข้อควรระวัง: การแชร์ข้อมูลข้าม tenant ต้องออกแบบ namespace, access control และการเข้ารหัสข้อมูลให้รัดกุม เพื่อหลีกเลี่ยงการรั่วไหลของบริบทหรือข้อมูลลับระหว่างลูกค้า
นโยบาย Multi‑Tenant: Isolation, Scheduling และการป้องกันการโจมตี (Model Poisoning / Side‑Channel)
การให้บริการหลาย tenant บนอุปกรณ์เดียวต้องอาศัยนโยบายจัดการทรัพยากรและความปลอดภัยที่เข้มงวด Tiny‑LLM Hub นำแนวปฏิบัติดังต่อไปนี้มาใช้เป็นมาตรฐาน:
- Isolation ของเทราด์และโมเดล: ใช้ container/process isolation (เช่น Linux containers, cgroups) รวมกับ namespace ของไฟล์และหน่วยความจำ เพื่อให้ tenant แต่ละรายไม่มีสิทธิ์เข้าถึงหน่วยความจำของกันและกัน มากกว่านั้นโมเดลที่ได้รับการยืนยัน (signed model bundles) จะถูกตรวจสอบลายเซ็นก่อนโหลดเพื่อลดความเสี่ยงของ model poisoning
- Fair scheduling และ per‑tenant priority: ระบบจัดคิวแบบขั้นสูง (เช่น weighted fair queuing หรือ priority queues ร่วมกับ token‑bucket rate limits) เพื่อให้แน่ใจว่า tenant ทุกรายได้รับ SLA ที่สอดคล้องกับสัญญา — ผู้ใช้ระดับพรีเมียมสามารถได้ latency ที่ดีกว่า แต่ระบบยังคงมีกลไกป้องกันการกดทรัพยากร (abuse protection) โดยอัตโนมัติ
- Resource quotas และ admission control: แต่ละ tenant ถูกกำหนด quota ของ CPU/GPU memory, max concurrency, และ KV cache slots เมื่อต้องการเกินขีดจำกัด ระบบจะใช้ eviction policies (LRU, weighted eviction) และ preemption policy ที่โปร่งใส
- การป้องกัน model poisoning และ integrity checks: ก่อนลงบริการโมเดล ทุกรุ่นต้องผ่านกระบวนการ vetting ได้แก่ checksum/signature verification, behavioral testing กับชุดตัวอย่าง (sanity tests), และ anomaly detection ระหว่าง runtime หากพบท่าทีของการ poisoning (เช่น พฤติกรรมตอบสนองเป็นอันตรายหรือเปลี่ยนแปลงสถิติการตอบ) ระบบจะกักโมเดลและแจ้งผู้ดูแลทันที
- การป้องกัน side‑channel attacks: Tiny‑LLM Hub นำมาตรการลดช่องทางขโมยข้อมูลผ่าน microarchitectural channels มาใช้ เช่น partitioning caches ระหว่าง tenants, flushing sensitive caches on context switch, ใช้ constant‑time primitivesในจุดวิกฤต และสามารถรันส่วนที่เสี่ยงบน hardware trusted execution environments (เช่น SGX/TEE) เมื่อจำเป็น
นอกจากนี้ Hub ยังผสมผสานนโยบายการเข้ารหัส (data‑at‑rest และ in‑transit), logging แบบ immutable และการแสดงผลการใช้งาน (metering) ต่อ tenant เพื่อความโปร่งใสและการตรวจสอบย้อนหลัง (auditing) ซึ่งเป็นสิ่งที่องค์กรธุรกิจให้ความสำคัญ
สรุปเชิงเทคนิค: การรวมกันของ quantization ขั้นสูง, การแชร์ embedding/kv‑cache และการบริหารจัดการ multi‑tenant แบบครบวงจร เป็นสิ่งที่ทำให้ Tiny‑LLM Hub เพิ่มความหนาแน่นของโมเดลบนฮาร์ดแวร์อุตสาหกรรมได้อย่างมีประสิทธิภาพ โดยลดทั้ง latency และค่าใช้จ่าย แต่ยังต้องแลกด้วยการออกแบบนโยบายความปลอดภัย ลำดับความสำคัญ และมาตรการตรวจสอบเพื่อรักษาความถูกต้องและความเป็นส่วนตัวของแต่ละ tenant
การปรับใช้บนอุปกรณ์อุตสาหกรรมและการจัดการทรัพยากร
รูปแบบการติดตั้ง (Deployment Patterns)
Tiny‑LLM Hub ออกแบบมาเพื่อรองรับการติดตั้งบนอุปกรณ์อุตสาหกรรมหลากหลายรูปแบบ ทั้งบน PLC, gateway, และ edge servers โดยคำนึงถึงข้อจำกัดด้านทรัพยากรเป็นสำคัญ รูปแบบการติดตั้งหลักมี 3 แบบคือ containerized runtime, lightweight agent และ native binary เพื่อให้ธุรกิจเลือกโมเดลการนำไปใช้ที่เหมาะสมที่สุดกับสภาพแวดล้อมของตน
- Containerized runtime — เหมาะสำหรับ edge servers หรือ gateway ที่รองรับ Docker/OCI runtime ให้ความยืดหยุ่นในการจัดการเวอร์ชันและการคอนฟิก โดยสามารถรันเป็น Pod ใน Kubernetes รุ่นเบาที่ปรับแต่งสำหรับ edge ได้ ตัวอย่างการใช้งาน: gateway แบบ industrial-class ที่มี CPU 4‑8 cores และ RAM 8–16 GB สามารถรันหลาย container แบบ multi‑tenant ได้อย่างเสถียร
- Lightweight agent — สำหรับอุปกรณ์ที่มีทรัพยากรจำกัด (เช่น gateway ขนาดเล็กหรือ edge box) ให้ติดตั้งเป็นบริการขนาดเล็กที่ใช้ IPC/gRPC ในการสื่อสารกับซอฟต์แวร์ภายใน โดย agent จะจัดการ lifecycle ของโมเดล, quota, และ health checks แบบเบ็ดเสร็จ ช่วยลด overhead ของ container runtime
- Native binary — กรณี PLC หรืออุปกรณ์ real‑time ที่มีข้อจำกัดด้าน OS/latency สูง สามารถคอมไพล์ Tiny‑LLM Hub เป็น native static binary ที่ปรับแต่งสำหรับสถาปัตยกรรม (ARM/ARM64, x86) เพื่อลด footprint และ dependency ให้เหลือน้อยที่สุด
การบริหารทรัพยากรฮาร์ดแวร์ (CPU, RAM, NPU/VPU)
การจัดสรรทรัพยากรเป็นหัวใจสำคัญของการรัน multi‑tenant LLM บนอุปกรณ์อุตสาหกรรม Tiny‑LLM Hub ใช้แนวทางผสมเพื่อให้มั่นใจว่าสามารถรองรับหลายผู้เช่า (tenants) ได้อย่างเป็นธรรมและมีประสิทธิภาพ
- Quota per tenant: ระบบกำหนด quota บน CPU shares, memory limit (cgroups/containers) และจำนวน concurrent sessions ต่อ tenant เพื่อป้องกัน noisy neighbour และการใช้ทรัพยากรเกินขอบเขต ตัวอย่างเช่น กำหนด tenant แบบ low‑priority ได้ CPU 0.5–1 core และ RAM 512 MB–1 GB ในขณะที่ tenant สำคัญอาจได้ 2–4 cores และ 4–8 GB
- Dynamic model swapping & memory management: Hub รองรับการสลับโมเดลแบบรันไทม์ (hot swap) โดยใช้เทคนิค memory‑mapped files และการเก็บเวกเตอร์/เวทแบบ quantized ใน storage tier เพื่อลดการใช้ RAM การสลับโมเดลจะทำผ่าน prefetch pipeline ที่คาดการณ์การเรียกใช้งาน เพื่อลด cold start latency
- Hardware acceleration (VPU/NPU passthrough): เมื่ออุปกรณ์มี VPU/NPU หรือ accelerator เฉพาะทาง Hub จะทำ passthrough ให้โมเดลเรียกใช้งานผ่าน driver (เช่น OpenCL, oneAPI, หรือ vendor SDK) โดยรองรับการแบ่งเวลา (time‑slice) และ binding ของโพรเซสต่อ accelerator เพื่อให้หลาย tenant สามารถแชร์ NPU ได้อย่างยุติธรรมและมีประสิทธิภาพ ตัวอย่างเช่น อุปกรณ์ที่มี NPU ระดับ edge สามารถลดเวลา inference ได้ 3–10 เท่าตามความซับซ้อนของโมเดล
กลไกความต่อเนื่อง: Health Check, OTA และ Fallback Hybrid Cloud
การทำงานต่อเนื่อง (continuity) สำคัญต่อการใช้งานในสภาพแวดล้อมอุตสาหกรรม Tiny‑LLM Hub จึงผสานกลไกตรวจสอบสถานะ การอัปเดตโมเดลแบบ OTA และนโยบาย fallback เพื่อรักษาความเสถียรและคุณภาพของการให้บริการ
- Health check และ monitoring: แต่ละ instance ของ Hub มีการแจ้งค่า liveness/readiness, latency metrics, memory/CPU usage และ confidence score ของการตอบกลับ ไปยัง central management หรือ local NMS ผ่าน telemetry (Prometheus/OTLP) เพื่อให้ระบบอัตโนมัติสามารถตัดสินใจ scale, restart หรือ migrate โมเดลได้ทันท่วงที
- OTA model updates & versioning: การอัปเดตโมเดลทำในรูปแบบแพ็กเกจที่ลงนามดิจิทัล (signed model bundles) และรองรับ delta updates เพื่อลดแบนด์วิดท์ — ตัวอย่างเช่น การส่งเฉพาะ weight diffs สามารถลดขนาดข้อมูลที่ต้องดาวน์โหลดได้เป็นหลักสิบเปอร์เซ็นต์เมื่อเทียบกับการดาวน์โหลดโมเดลทั้งชุด ระบบรองรับ A/B deployment และ rollback อัตโนมัติหากพบ regression ในค่าความแม่นยำหรือ latency
- Offline inference & local cache: Hub ถูกออกแบบให้ทำ inference แบบ offline ได้เต็มรูปแบบโดยใช้โมเดลที่เก็บอยู่ใน local storage และ cache ของเวกเตอร์/embedding สำหรับกรณีที่ไม่มีการเชื่อมต่อ โดยสามารถกำหนดนโยบาย eviction (LRU, priority‑based) เพื่อจัดการพื้นที่เก็บ
- Fallback hybrid cloud: เมื่อการร้องขอมีความซับซ้อนเกินกว่าความสามารถของโมเดลบนอุปกรณ์ หรือต้องการความแม่นยำสูงสุด Hub สามารถส่งคำร้องไปยังคลาวด์แบบ hybrid ด้วยนโยบายที่กำหนด เช่น กรณี confidence score ต่ำกว่าธreshold, request type เป็น batch analytic หรือในช่วงเวลาที่ local resource ถูกใช้งานหนัก กลไกนี้รองรับการส่ง metadata ของ session เพื่อให้คลาวด์สามารถให้ผลลัพธ์เสริมและคืนสถานะอย่างต่อเนื่อง
สรุป — Tiny‑LLM Hub มุ่งเน้นให้ธุรกิจอุตสาหกรรมสามารถนำโมเดลขนาดเล็กมารันแบบ multi‑tenant บนอุปกรณ์จริงได้อย่างปลอดภัยและมีประสิทธิภาพ โดยการเสนอรูปแบบติดตั้งที่ยืดหยุ่น การบริหารทรัพยากรที่ละเอียด และกลไกความต่อเนื่องที่รวม OTA, health checks, offline operation และ fallback ไปยังคลาวด์ เพื่อรองรับทั้งงานที่ต้องการ latency ต่ำและงานที่ต้องการความแม่นยำสูงในสภาพแวดล้อมอุตสาหกรรม
ประสิทธิภาพและผลเบนช์มาร์ก: latency, throughput และการลดค่าใช้จ่าย
ผลการทดสอบเชิงปริมาณ: latency และ throughput
จากข้อมูลเบต้าและการทดสอบที่สตาร์ทอัพเผยแพร่ Tiny‑LLM Hub แสดงให้เห็นการปรับปรุงค่า latency อย่างมีนัยสำคัญสำหรับ use‑cases แบบเรียลไทม์ โดยสรุปเป็นค่าเฉลี่ยลดลงประมาณ 2–10× ขึ้นกับขนาดโมเดลและฮาร์ดแวร์ที่ใช้ ตัวอย่างที่รายงาน ได้แก่ โมเดลขนาดกลาง (ประมาณ 3B) ที่รันบนอุปกรณ์ edge ระดับอุตสาหกรรมมี median latency (p50) อยู่ที่ประมาณ 20–60 ms เทียบกับการรันบนคลาวด์ GPU ซึ่งมีค่า 120–300 ms ส่วนค่า tail latency (p95–p99) ลดลงมากในสภาพแวดล้อม edge ที่มีการจัดการทรัพยากรแบบ multi‑tenant และการแชร์เวกเตอร์-เวทที่ควอนไทซ์
ในด้าน throughput ผลการทดสอบระบุว่าอุปกรณ์ที่ใช้งาน Tiny‑LLM Hub สามารถรองรับคำขอพร้อมกันได้เพิ่มขึ้นอย่างมีนัยสำคัญ เนื่องจากขนาดโมเดลลดลงหลังการ quantization และการแชร์เวกเตอร์/เวทช่วยลดแบนด์วิดท์หน่วยความจำ ตัวอย่างเชิงตัวเลขจากเบต้า: การประมวลผลแบบต่อเนื่องสำหรับโมเดล 3B บนอุปกรณ์ edge เพิ่ม throughput ประมาณ 3–6× เมื่อเทียบกับกรณีรัน inference บนเครื่องเสมือน GPU เดียวกันในคลาวด์ (workload ที่มี batch size เล็กและ latency-sensitive)
ตัวอย่างการลดค่าใช้จ่ายคลาวด์เมื่อย้าย inference ไปที่ edge
ผลการวิเคราะห์ต้นทุนจากการทดสอบเบต้าแสดงการลดค่าใช้จ่ายคลาวด์ได้ระหว่าง 40–80% เมื่อย้าย inference ที่มีความสำคัญไปยัง edge โดยคำนวณรวมต้นทุนของ instance GPU, ค่าเครือข่าย (egress) และ overhead ของ autoscaling ตัวอย่างสมมติที่ใช้ในรายงานเบต้า:
- กรณีคลาวด์: workload inference 1 ล้านคำขอต่อเดือน ใช้ GPU บนคลาวด์ ต้นทุนประมาณ $5,000/เดือน
- ย้ายไปที่ edge: โดยใช้ Tiny‑LLM Hub บนอุปกรณ์อุตสาหกรรมและการจัดการ multi‑tenant ต้นทุนรวมฮาร์ดแวร์และการบำรุงรักษาประมาณ $1,000–3,000/เดือน (ลด 40–80%)
- กรณีผสม (hybrid): latency‑sensitive requests บน edge ที่เหลือใช้คลาวด์สำหรับ workloads ที่ต้องการความแม่นยำสูงสุด ลดค่าใช้จ่ายรวมได้ราว 50–65%
ตังอย่างเชิงตัวเลขเพิ่มเติมเพื่อภาพรวม: ถ้า per‑inference บนคลาวด์อยู่ที่ $0.005 การย้ายไปที่ edge และเพิ่มประสิทธิภาพผ่าน quantization สามารถลดต้นทุนต่อคำขอเหลือประมาณ $0.001–0.002 ซึ่งสะท้อนการลดต้นทุนรวมตามสัดส่วนที่ระบุข้างต้น
การลดขนาดโมเดลและผลกระทบต่อความแม่นยำ (quantization)
การใช้เทคนิค quantization และการแชร์เวกเตอร์‑เวททำให้ขนาดโมเดลและการใช้หน่วยความจำน้อยลงอย่างมีนัยสำคัญ ตัวอย่างเชิงตัวเลขจากเบต้า:
- โมเดล 7B ในรูปแบบ FP16: ประมาณ 14 GB ของหน่วยความจำ
- หลัง quantization เป็น 8‑bit: ลดเหลือประมาณ 7–8 GB
- หลัง quantization เป็น 4‑bit (หรือ Q4/Q4_0 variants): ลดเหลือประมาณ 3–4 GB
- การแชร์เวกเตอร์/เวท ในสถาปัตยกรรม multi‑tenant เพิ่มการใช้ซ้ำที่ช่วยลด footprint ต่อ tenant ได้อีก 20–50%
อย่างไรก็ตาม การลดความละเอียดของตัวเลขมีผลต่อความแม่นยำ: เบต้ารายงานว่าการใช้ quantization บางรุ่นอาจทำให้ความแม่นยำลดลงเล็กน้อยในช่วง 0.5–3% ขึ้นกับลักษณะงาน (เช่น classification, NER, หรือ generation ที่ละเอียด) ดังนั้นการนำไปใช้งานจริงต้องมีการทดสอบเปรียบเทียบเพื่อประเมิน trade‑off ระหว่าง latency/cost กับ accuracy
แนวทางปฏิบัติสำหรับการวัดและยืนยันผล
เพื่อให้การย้ายงานไปยัง Tiny‑LLM Hub เป็นไปอย่างปลอดภัยและมีข้อมูลรองรับ ควรดำเนินการดังนี้:
- ตั้งชุดเบนช์มาร์กแบบเรียลสำหรับ use‑case ขององค์กร และบันทึกค่า p50, p95, p99 latency และ throughput ก่อน/หลังการย้าย
- รันการทดสอบ A/B แบบเป็นวงกว้างเพื่อตรวจสอบผลกระทบต่อความแม่นยำ (precision/recall หรือ metric เฉพาะงาน) โดยระบุช่วงความแตกต่างที่ยอมรับได้ (เช่น ≤1%)
- วิเคราะห์ต้นทุนรวม (TCO) โดยรวมต้นทุนฮาร์ดแวร์ edge, การติดตั้ง, การบำรุงรักษา เปรียบเทียบกับต้นทุนคลาวด์ที่ลดลงจากจำนวน request ที่ย้ายมา
- ติดตามดัชนีชี้วัดระบบอย่างต่อเนื่อง เช่น CPU/GPU utilization, memory footprint, network egress, และพลังงาน เพื่อประเมินความยั่งยืนของ deployment
สรุปคือ Tiny‑LLM Hub ให้แนวทางลด latency และค่าใช้จ่ายได้ชัดเจนสำหรับแอพพลิเคชันที่ต้องการตอบสนองแบบเรียลไทม์ โดยแลกมาด้วยการต้องบริหารควบคุมความแม่นยำผ่านการทดสอบ A/B และการเลือกเทคนิค quantization ที่เหมาะสมกับงานแต่ละประเภท
กรณีใช้งานตัวอย่างและผลกระทบในภาคอุตสาหกรรม
กรณีใช้งานตัวอย่างและผลกระทบในภาคอุตสาหกรรม
Tiny‑LLM Hub ถูกออกแบบมาเพื่อตอบโจทย์การนำโมเดลภาษาขนาดเล็ก (small LLMs) ไปใช้งานจริงบนอุปกรณ์อุตสาหกรรมแบบ multi‑tenant โดยใช้กลไกการแชร์เวกเตอร์และเวทที่ถูกควอนไทซ์ เพื่อลดขนาดหน่วยความจำและ latency ทำให้เกิดกรณีใช้งานที่เห็นผลชัดเจนในสายการผลิต หุ่นยนต์ และระบบตัดสินใจแบบสหสาขา (multimodal) ภายในโรงงาน ตัวอย่างต่อไปนี้เป็นภาพรวมของ use case ที่ Tiny‑LLM Hub สามารถช่วยได้จริงและผลกระทบเชิงตัวเลขที่สังเกตได้จากการทดลองต้นแบบ (pilots).
1) สายการผลิต — Inferencing แบบเรียลไทม์เพื่อลด downtime และเพิ่มอัตราตรวจจับข้อบกพร่อง
การนำ Tiny‑LLM Hub ไปรันโมเดลตรวจจับข้อบกพร่องบน edge ร่วมกับกล้องความละเอียดสูงและเซ็นเซอร์แรงดัน ช่วยให้การตัดสินใจเป็นแบบเรียลไทม์โดยไม่ต้องส่งภาพหรือข้อมูลดิบขึ้นคลาวด์ ผลการทดลองกับโรงงานชิ้นส่วนยานยนต์ในรูปแบบ pilot แสดงให้เห็นว่า:
- อัตราการตรวจจับข้อบกพร่อง (detection accuracy) เพิ่มจาก ~87% เป็น ~96% หลังติดตั้งโมเดลบนอุปกรณ์ edge และใช้ข้อมูลเวกเตอร์ร่วมกันเพื่อลด false negatives
- Downtime เฉลี่ยของสายการผลิต ลดลงประมาณ 30–40% เนื่องจากการแจ้งเตือนแบบเรียลไทม์และการตอบสนองอัตโนมัติ
- Throughput ของสายการผลิตเพิ่มขึ้น 8–15% จากการลดรอบเวลาที่ต้องหยุดตรวจสอบด้วยมือ
- Latency การตัดสินใจ ลดจาก ~250–300 ms (เมื่อเรียกใช้คลาวด์) เหลือ ~30–60 ms บน edge ทำให้ระบบตอบสนองทันเวลาสำหรับการคัดเสียหรือแยกชิ้นอย่างรวดเร็ว
2) หุ่นยนต์และเครื่องจักร — Local LLM ช่วยแปลผลเซ็นเซอร์และสั่งการได้เร็วขึ้น ลดการพึ่งพาคลาวด์
ในงานด้านโรบอติกส์ Tiny‑LLM Hub ช่วยให้หุ่นยนต์สามารถตีความข้อมูลจากเซ็นเซอร์หลายชนิด (LiDAR, IMU, กล้อง, ไมโครโฟน) และแปลงเป็นคำสั่งการควบคุมเชิงเหตุผลได้ทันที ตัวอย่าง pilot ในคลังสินค้า/โรงงานผลิตพบว่าการรันโมเดลภาษาท้องถิ่นบนอุปกรณ์ควบคุมของหุ่นยนต์นำไปสู่ผลลัพธ์ดังนี้:
- เวลาแฝง (control loop latency) ลดจาก ~180–220 ms เหลือ 20–50 ms เมื่อคำสั่งการและการตีความเซ็นเซอร์ไม่ต้องพึ่งพา round‑trip ไปยังคลาวด์
- การเรียกใช้คลาวด์ลดลง ประมาณ 75–90% ซึ่งแปลเป็นการประหยัดค่าใช้จ่ายคลาวด์ตรงจุดและความมั่นคงของระบบในกรณีเครือข่ายไม่เสถียร
- อัตราการแทรกแซงจากมนุษย์ ลดลงราว 35–45% เนื่องจากหุ่นยนต์สามารถอธิบายสถานะและขอคำสั่งเฉพาะกรณีที่ซับซ้อนขึ้นได้ด้วยภาษาธรรมชาติ
3) ระบบช่วยตัดสินใจแบบสหสาขา (multimodal) ในโรงงาน — ลดเวลาในการวิเคราะห์และเพิ่มความแม่นยำของการตัดสินใจ
Tiny‑LLM Hub ช่วยรวมข้อมูลจากภาพ กล้องความร้อน ข้อมูลซีเควนซ์ของ PLC และบันทึกเสียง เพื่อสร้างคำสรุปและคำแนะนำเชิงปฏิบัติการให้กับทีมวิศวกรและฝ่ายผลิต ตัวอย่าง pilot ในโรงงานอุตสาหกรรมหนักแสดงผลเช่น:
- เวลาสืบสวนเหตุขัดข้อง (incident investigation) ลดจากเฉลี่ย 4 ชั่วโมงต่อเหตุการณ์ เหลือ 30–60 นาที เมื่อระบบสามารถสรุปข้อมูลเชิงสาเหตุจากข้อมูลหลายแหล่งได้ทันที
- First‑time‑fix rate เพิ่มจาก 60% เป็น 82–88% เนื่องจากคำแนะนำที่แม่นยำและบริบทหลายมิติช่วยให้ทีมแก้ปัญหาได้ถูกจุดตั้งแต่ครั้งแรก
- การลดค่าใช้จ่ายคลาวด์ โดยรวมประมาณ 50–70% สำหรับงาน inferencing ที่เปลี่ยนจากคลาวด์เป็น edge และการใช้เวกเตอร์ร่วมกันช่วยลดการซ้ำซ้อนของข้อมูล
สรุปผลที่สังเกตได้จากหลาย pilot ชี้ให้เห็นว่า Tiny‑LLM Hub ไม่ได้เป็นเพียงโซลูชันด้าน latency หรือค่าใช้จ่ายเท่านั้น แต่ยังเพิ่มความสามารถเชิงปฏิบัติการให้กับโรงงาน เช่น การตอบสนองฉุกเฉินที่เร็วขึ้น การตรวจจับปัญหาที่แม่นยำขึ้น และการตัดสินใจเชิงสหสาขาที่สามารถทำได้บนแพลตฟอร์มเดียว ด้วยการติดตั้งแบบ multi‑tenant ผู้ประกอบการสามารถรันโมเดลหลายชุดบนฮาร์ดแวร์ที่มีอยู่ ลดความจำเป็นในการลงทุนฮาร์ดแวร์เพิ่ม และขยายการใช้งานไปยังแอปพลิเคชันใหม่ๆ ได้อย่างยืดหยุ่น
ความเสี่ยงทางเทคนิคและการกำกับดูแล พร้อมทิศทางในอนาคต
ความเสี่ยงทางเทคนิคและการกำกับดูแล พร้อมทิศทางในอนาคต
การนำ Tiny‑LLM Hub มาใช้งานในสภาพแวดล้อม multi‑tenant บนอุปกรณ์อุตสาหกรรมสร้างประโยชน์เชิงเศรษฐศาสตร์และด้านประสิทธิภาพ แต่ก็เปิดช่องโหว่ด้านเทคนิคและการกำกับดูแลที่ต้องวางมาตรการเชิงรุก ข้อกังวลหลักครอบคลุมทั้งความปลอดภัยของการแยก tenant, ความแม่นยำของโมเดลหลังการ quantization, การจัดการ lifecycle ของโมเดล รวมถึงประเด็นด้านกฎหมายและความเป็นส่วนตัว การประเมินความเสี่ยงต้องอาศัยทั้งมาตรการทางวิศวกรรมและนโยบายองค์กรควบคู่กัน
ความเสี่ยงด้านความปลอดภัย — ในระบบ multi‑tenant ความเสี่ยงสำคัญได้แก่การรบกวนการแยก (isolation), การโจมตีแบบ model extraction และ side‑channel attacks ที่อาศัยการสังเกตพฤติกรรมฮาร์ดแวร์เพื่อสกัดข้อมูลเชิงลึก ตัวอย่างเช่น attacker อาจพยายามเรียกใช้งานโมเดลซ้ำๆ เพื่อสกัดพารามิเตอร์ หรือใช้การสังเกตเวลาการประมวลผล/การใช้พลังงานเพื่อเดาค่าน้ำหนัก การลดความเสี่ยงควรรวมถึง:
- Isolation ระดับฮาร์ดแวร์และซอฟต์แวร์ — ใช้ container sandboxing, process-level isolation, และหากเป็นไปได้เทคโนโลยี trusted execution environments (เช่น Intel SGX หรือ ARM TrustZone) เพื่อป้องกันการเข้าถึงหน่วยความจำร่วมโดยไม่ได้รับอนุญาต
- จำกัดการเข้าถึงและ Rate‑limiting — บังคับใช้การตรวจสอบสิทธิ์ระดับ API, quota per tenant และการตรวจจับพฤติกรรมเรียกใช้งานผิดปกติเพื่อชะลอการโจมตีแบบ extraction
- Watermarking และ fingerprinting โมเดล — ฝังตราประทับเชิงตัวเลขในพฤติกรรมการตอบกลับของโมเดลเพื่อพิสูจน์ความเป็นเจ้าของและช่วยตรวจจับการขโมยโมเดล
- ป้องกัน side‑channel — ออกแบบอัลกอริทึมที่ทำงานแบบ constant‑time เมื่อเป็นไปได้, เพิ่ม jitter/noise ในเวลาตอบกลับในระดับที่ไม่กระทบ UX มาก และแยกทรัพยากรฮาร์ดแวร์ระหว่าง tenants
ประเด็นเชิงปฏิบัติการ (Operational) — การนำ quantized models มารันแบบแชร์เวกเตอร์/เวทบนอุปกรณ์อุตสาหกรรมสร้างความท้าทายด้านความถูกต้องและการบริหารวงจรชีวิต (lifecycle) ของโมเดล นโยบายเชิงปฏิบัติการควรครอบคลุม:
- Pipeline การทดสอบ accuracy หลัง quantization — อัตโนมัติ CI/CD สำหรับโมเดลที่รวมชุดทดสอบ benchmark ทางธุรกิจ (end‑to‑end), micro‑benchmarks latency/throughput, และการวัด degradation ของ metric สำคัญ ยกตัวอย่าง การ quantize เป็น int8 มักลดขนาดโมเดลได้ราว 3–4x และลด latency แบบ on‑device ได้ 20–60% แต่การเสีย accuracy อาจอยู่ในช่วงเล็กน้อยถึงระดับสำคัญ (0–5% ขึ้นกับงาน) จึงต้องตั้งเกณฑ์ยอมรับความเสียหาย (acceptance thresholds)
- กลไก Canary, Shadow และ Rollback — เปิดใช้งานเวอร์ชันใหม่ด้วยการทดสอบแบบ canary และ shadow traffic ก่อนเปิดให้ทุก tenant ใช้จริง หาก metric หลักลดลงให้สามารถ rollback อัตโนมัติได้ พร้อมเก็บ snapshot ของเวทและคอนฟิก
- Monitoring และ Drift Detection — ติดตาม latency, throughput, error rate, และ metric คุณภาพ (เช่น F1, top‑k accuracy) รวมทั้งการเปลี่ยนแปลง distribution ของ input (concept/data drift) และ alerting ที่ผูกกับนโยบาย SLA
- การจัดการเวอร์ชันและ Provenance — บันทึก metadata ของโมเดล (เวอร์ชัน, ผู้ฝึก, dataset, quantization config) และใช้ signing/attestation เพื่อยืนยันความถูกต้องของโมเดลก่อน deploy
ประเด็นทางกฎหมายและความเป็นส่วนตัว — การรันโมเดลบนอุปกรณ์อุตสาหกรรมที่เก็บหรือประมวลผลข้อมูลเซ็นซิทีฟตกอยู่ภายใต้ข้อกฎหมายเช่น PDPA และในบางกรณี GDPR/CCPA ข้อควรพิจารณารวมถึงการทำ Data Protection Impact Assessment (DPIA), การจำกัดการส่งข้อมูลระหว่าง tenants, นโยบายการเก็บ log ที่ชัดเจน และการออกแบบเพื่อลดการส่งข้อมูล PII ไปยังคลาวด์ โดยการ inference บน device จะช่วยลดความเสี่ยงการรั่วไหลของข้อมูล แต่ต้องมีมาตรการให้แน่ใจว่า embeddings หรือ outputs ที่แชร์ไม่สามารถย้อนกลับไปหาข้อมูลต้นทางได้ (ใช้ differential privacy, output filtering, หรือ rate‑limiting)
ทิศทางอนาคตของผลิตภัณฑ์ — Tiny‑LLM Hub ควรวาง roadmap เชิงเทคนิคและเชิงพาณิชย์เพื่อรองรับความต้องการที่เปลี่ยนไป ดังประเด็นต่อไปนี้:
- รองรับโมเดลขนาดหลากหลาย — จาก tiny ไปสู่ medium‑sized LLMs โดยใช้เทคนิคเช่น model sharding, offloading ระหว่าง CPU/GPU/NPU และ pipeline parallelism เพื่อให้สามารถสเกลตามความต้องการ enterprise โดยคำนึงถึงข้อจำกัดด้านพลังงานและความร้อนของอุปกรณ์อุตสาหกรรม
- Interoperability กับ vector DB ยอดนิยม — ให้การเชื่อมต่อมาตรฐานกับ Milvus, FAISS, Weaviate, Pinecone ฯลฯ รวมทั้งสนับสนุน schema ของ embeddings, versioned indices, และการซิงค์ metadata เพื่อให้ retrieval ร่วมกับ multi‑tenant embeddings เป็นไปอย่างปลอดภัยและมีประสิทธิภาพ
- Integration กับ MLOps tools — เชื่อมต่อกับ MLflow, Kubeflow, Seldon/BentoML เพื่อ orchestration การฝึก/ทดสอบ/deploy รวมถึงการทำ A/B testing, lineage tracking และ automated compliance checks ซึ่งจะช่วยให้หน่วยงานองค์กรใช้ Tiny‑LLM Hub ในกระบวนการ CI/CD ของโมเดลได้ง่ายขึ้น
- Model marketplace แบบ on‑device — ออกแบบตลาดสำหรับโมเดลที่ลงนามและตรวจสอบแล้ว ผู้ใช้กลุ่มองค์กรสามารถเลือกโมเดลที่ผ่านการรับรองตามกรณีใช้งาน, เงื่อนไขไลเซนซ์ และระดับ SLA โดยต้องมีระบบการคิดค่าบริการ, license enforcement, และ secure provenance เพื่อป้องกันการนำโมเดลละเมิดลิขสิทธิ์เข้ามาใช้งาน
- แนวทางโอเพนซอร์ส vs เชิงพาณิชย์ — การเปิดซอร์สบางส่วน (เช่น agent runtime, connector APIs) ช่วยสร้างชุมชนและความน่าเชื่อถือ ขณะเดียวกันฟีเจอร์ระดับองค์กร (secure enclaves integration, advanced monitoring, commercial‑grade support) สามารถอยู่ในรูปแบบ commercial edition เพื่อสร้างรายได้ ควรวางกลยุทธ์ไฮบริดที่รักษาบาลานซ์ระหว่างนวัตกรรมและการสร้างรายได้
สรุปคือการบริหารความเสี่ยงของ Tiny‑LLM Hub ต้องผสานมาตรการเชิงเทคนิค (isolation, watermarking, constant‑time ops), กระบวนการปฏิบัติการที่เข้มงวด (CI/CD สำหรับโมเดล, canary, monitoring), และการกำกับดูแลด้านกฎหมาย/ความเป็นส่วนตัว ในขณะเดียวกัน roadmap ควรมุ่งไปสู่การรองรับโมเดลขนาดกลาง การทำงานร่วมกับระบบค้นหาและ vectorDB ชั้นนำ การเชื่อมต่อกับเครื่องมือ MLOps และการออกแบบ marketplace ที่ปลอดภัย เพื่อให้ผลิตภัณฑ์เติบโตอย่างยั่งยืนและตอบโจทย์องค์กรได้จริง
บทสรุป
สตาร์ทอัพไทยเปิดตัว Tiny‑LLM Hub เป็นโซลูชันสำหรับอุตสาหกรรมที่เน้นการรันหลายโมเดลขนาดเล็กแบบ multi‑tenant บนอุปกรณ์ edge โดยใช้เทคนิค quantization ร่วมกับการแชร์เวกเตอร์และเวท (shared vectors/weights) เพื่อลดการใช้หน่วยความจำและ latency ผลลัพธ์เชิงสถิติเบื้องต้นชี้ให้เห็นการลด latency และค่าใช้จ่ายคลาวด์เมื่อเทียบกับการรันโมเดลขนาดใหญ่บนคลาวด์แบบดั้งเดิม แต่ประสิทธิผลจริงจะขึ้นกับเงื่อนไขของระบบ เช่น ฮาร์ดแวร์ edge ที่ใช้ ขนาดและสถาปัตยกรรมของโมเดล งาน (workload) ที่รัน และการออกแบบสถาปัตยกรรม multi‑tenant ซึ่งการแชร์เวทช่วยให้ประหยัดหน่วยความจำโดยเฉพาะเมื่อมีหลายเทนานต์ที่ใช้ฟีเจอร์หรือเซตของเวทร่วมกัน
การอ่านผลเบนช์มาร์กและการประเมินเชิงปริมาณต้องทำอย่างมีบริบท: รายงานค่า latency หรือเปอร์เซ็นต์การลดค่าใช้จ่ายต้องระบุฮาร์ดแวร์ โมเดล และลักษณะงานอย่างชัดเจน และต้องพิจารณาประเด็นด้านความปลอดภัย (เช่น การแยกเทนานต์ การเข้ารหัสเวท และการป้องกันข้อมูลภายในอุปกรณ์) ข้อจำกัดด้านความแม่นยำจากการ quantization และกลยุทธ์การอัปเดตโมเดล (model refresh, rollout แบบค่อยเป็นค่อยไป และการตรวจสอบหลัง-deployment) ก่อนนำไปใช้งานจริง ในอนาคตคาดว่า Tiny‑LLM Hub จะผลักดันการนำ LLM ขนาดเล็กสู่ edge ในภาคอุตสาหกรรมมากขึ้น พร้อมความจำเป็นในการพัฒนาเครื่องมือ MLOps สำหรับการจัดการโมเดลแบบ multi‑tenant, มาตรฐานความปลอดภัย และกรอบการทดสอบเบนช์มาร์กที่โปร่งใส เพื่อให้ตัวเลข latency และค่าใช้จ่ายที่ประกาศใช้งานได้อย่างน่าเชื่อถือในสภาพแวดล้อมการผลิต



