
เมื่อองค์กรนำ LLM เข้าสู่ระบบการให้บริการเชิงธุรกิจ ความคาดหวังด้านความแม่นยำและความต่อเนื่องของการทำงานสูงขึ้นอย่างมาก แต่ข้อผิดพลาดหรือการเบี่ยงเบนของโมเดลแม้เพียงเล็กน้อยก็สามารถส่งผลกระทบต่ออัตราการแปลงลูกค้า (conversion), ประสบการณ์ผู้ใช้ และรายได้ได้ทันที บทนำนี้ชวนให้ตั้งคำถามว่าเราจะมองเห็นและไล่สาเหตุของปัญหาเหล่านั้นอย่างทันท่วงทีได้อย่างไร—คำตอบหนึ่งที่โดดเด่นคือการออกแบบแพลตฟอร์มสังเกตการณ์ (observability) แบบครบวงจรที่ผสาน Telemetry‑Prompt‑Trace เข้ากับเมตริกเชิงธุรกิจ เพื่อสร้างภาพเชิงสาเหตุ-ผลที่สามารถตอบกลับแบบเรียลไทม์ การศึกษาในองค์กรที่นำ observability มาปรับใช้รายงานว่าการระบุสาเหตุและลดเวลาในการคืนค่าการให้บริการ (MTTR) สามารถลดลงได้ประมาณ 30–50% และการตรวจจับความผิดปกติแบบ real‑time สามารถทำได้ภายในไม่กี่วินาทีถึงไม่กี่นาที ขึ้นกับสถาปัตยกรรมของระบบ
บทความฉบับนี้จะสรุปประเด็นสำคัญของการออกแบบแพลตฟอร์มดังกล่าว ได้แก่ วิธีการรวบรวมและผสานข้อมูล Telemetry (เช่น เมตริกทรัพยากรและประสิทธิภาพ), Prompt logs (บริบทของคำสั่งและพฤติกรรมการตอบกลับของ LLM) และ Distributed Tracing (เส้นทางการประมวลผลข้ามบริการ) พร้อมทั้งการเชื่อมโยงกับเมตริกธุรกิจเช่นอัตราการแปลง การคืนสินค้า และรายได้ที่สร้างจากฟีเจอร์ AI เราจะยกตัวอย่างสถิติและกรณีศึกษาเพื่อแสดงให้เห็นว่าการติดตามเชิงสาเหตุแบบเรียลไทม์ช่วยลดความเสี่ยงเชิงธุรกิจได้อย่างไร รวมถึงแนะนำแนวปฏิบัติที่เป็นประโยชน์สำหรับทีม SRE, ML Ops และผู้นำด้านผลิตภัณฑ์ที่ต้องการยกระดับความน่าเชื่อถือของ LLM ในระบบ production
บทนำ: ทำความเข้าใจกับความเสี่ยงและโอกาสของ LLM ในธุรกิจ
บทนำ: ทำความเข้าใจกับความเสี่ยงและโอกาสของ LLM ในธุรกิจ
การนำ Large Language Models (LLMs) เข้าสู่องค์กรกลายเป็นแนวโน้มสำคัญที่เร่งตัวขึ้นในช่วงไม่กี่ปีที่ผ่านมา — หน่วยงานวิจัยและสำรวจหลายแห่งรายงานว่าประมาณ 60% ของบริษัทด้านเทคโนโลยีวางแผนจะปรับใช้ LLM ภายใน 2 ปีข้างหน้า และองค์กรจำนวนมากอยู่ในช่วงทดลองใช้งานหรือขยายขีดความสามารถที่ขับเคลื่อนด้วยโมเดลภาษา นี่สะท้อนถึงการลงทุนที่เพิ่มขึ้นทั้งในด้านโครงสร้างพื้นฐาน การจัดการข้อมูล และการพัฒนาแอปพลิเคชันที่ใช้ LLM เพื่อยกระดับประสบการณ์ลูกค้าและเพิ่มประสิทธิภาพเชิงปฏิบัติการ
แม้ LLM จะนำเสนอโอกาสทางธุรกิจที่ชัดเจน เช่น การอัตโนมัติการตอบคำถาม การเขียนเนื้อหาที่ปรับให้เหมาะกับลูกค้า และการวิเคราะห์ข้อความขนาดใหญ่ แต่ความเสี่ยงเชิงปฏิบัติการก็ไม่อาจมองข้ามได้ การตอบสนองที่ผิดพลาดหรือเบี่ยงเบนสามารถทำลายความเชื่อมั่นของผู้ใช้ ส่งผลกระทบต่อการปฏิบัติตามข้อกำหนด และสร้างค่าใช้จ่ายในการแก้ไข นอกจากนี้ ความผันผวนของพฤติกรรมโมเดลเมื่อเวลาเปลี่ยนไปหรือเมื่อสภาพแวดล้อมการใช้งานเปลี่ยนแปลง ก็เป็นความท้าทายที่องค์กรต้องเตรียมพร้อม
- Hallucination: โมเดลให้ข้อมูลที่ไม่ถูกต้องหรือสร้างข้อเท็จจริงขึ้นมา ส่งผลต่อความน่าเชื่อถือของคำตอบ
- Prompt drift: การเปลี่ยนแปลงของรูปแบบคำสั่งหรือบริบททำให้ผลลัพธ์เปลี่ยนไปจากที่คาดหวัง ซึ่งยากต่อการตรวจจับถ้าไม่มีการบันทึก prompt อย่างครบถ้วน
- Latency: ความหน่วงเวลาของการตอบสนองมีผลโดยตรงต่อประสบการณ์ผู้ใช้และอัตราการยกเลิกงาน (drop-off) ในแอปพลิเคชันเชิงธุรกิจ
- ความเสี่ยงด้านความเป็นส่วนตัวและการปฏิบัติตามกฎระเบียบ: การจัดการข้อมูลนำเข้าและผลลัพธ์ต้องสอดคล้องกับนโยบายความปลอดภัยและกฎหมาย
เพราะเหตุนี้ องค์กรต้องการมากกว่าเพียงการติดตั้งโมเดล — พวกเขาต้องการแพลตฟอร์มสังเกตการณ์ (observability) แบบครบวงจรที่สามารถเชื่อมโยงสัญญาณเชิงเทคนิคกับผลลัพธ์ทางธุรกิจได้อย่างเป็นเหตุเป็นผล แนวทางที่กำลังได้รับความสนใจคือการผสานข้อมูลจากสามชั้นหลัก: Telemetry (เมตริกระบบและสภาพแวดล้อม), Prompt (อินพุตและบริบทที่ป้อนให้โมเดล) และ Trace (ลำดับการดำเนินงานและการเรียกใช้งาน) — แล้วนำมารวมกับเมตริกเชิงธุรกิจ เช่น อัตรา conversion, รายได้ต่อการโต้ตอบ, หรือต้นทุนการสนับสนุนลูกค้า เพื่อให้ทีมสามารถวัดผลและไล่สาเหตุข้อผิดพลาดของ LLM ได้แบบเรียลไทม์
เป้าหมายของบทความนี้คือการอธิบายแนวทางปฏิบัติและสถาปัตยกรรมเชิงปฏิบัติที่ช่วยให้องค์กรบูรณาการข้อมูล Telemetry‑Prompt‑Trace เข้ากับเมตริกทางธุรกิจอย่างครบถ้วน — ทั้งในแง่การตั้งค่า SLO/SLI สำหรับ LLM, การแจ้งเตือนเชิงบริบทเมื่อเกิด hallucination หรือ drift, และการวัดผลทางการเงินของการปรับปรุงคุณภาพคำตอบ ผู้บริหารและทีมวิศวกรรมจะได้เห็นกรอบการทำงานที่สามารถลดความเสี่ยง เพิ่มความน่าเชื่อถือ และเชื่อมโยงการปฏิบัติการของโมเดลกับเป้าหมายเชิงธุรกิจได้อย่างชัดเจน
ทำไม Observability สำหรับ LLM จึงแตกต่างจากระบบเดิม
ทำไม Observability สำหรับ LLM จึงแตกต่างจากระบบเดิม
Observability สำหรับแอปพลิเคชันที่ขับเคลื่อนด้วย Large Language Models (LLM) แตกต่างอย่างมีนัยสำคัญจากระบบซอฟต์แวร์แบบเดิม เนื่องจาก ผลลัพธ์ของ LLM มีความไม่แน่นอน (non‑determinism) และขึ้นอยู่กับปัจจัยเชิงบริบท เช่น พารามิเตอร์การสุ่ม (temperature, top‑k/top‑p), การตัดคำ (tokenization) และข้อมูลนำเข้า (prompts, retrieved context) เพียงเปลี่ยนคำสั่งหรือค่าพารามิเตอร์เล็กน้อยอาจทำให้คำตอบเปลี่ยนแปลงอย่างมาก ตัวอย่างเช่น การเพิ่ม temperature จาก 0.2 เป็น 0.8 อาจเพิ่มความแปรปรวนของคำตอบและโอกาสเกิด hallucination หลายเท่า ส่งผลให้การวัดเพียงค่า error rate หรือ success/failure แบบเดิมไม่พอสำหรับการวินิจฉัยปัญหา
ด้วยเหตุนี้จึงจำเป็นต้องเก็บสัญญาณทั้งเชิงระบบ (telemetry) และเชิงเนื้อหา (content signals) ควบคู่กันไป telemetry เช่น latency, error rate, throughput, CPU/GPU utilization ยังคงเป็นพื้นฐานที่ช่วยตรวจจับปัญหาเชิงโครงสร้าง เช่น คอขวดของทรัพยากรหรือข้อผิดพลาดของระบบ แต่ signal ระดับเนื้อหา เช่น prompts, completions, embeddings, retrieval contexts, และ metadata ของการเรียกโมเดล (model version, sampling params) จะให้ข้อมูลเชิงสาเหตุที่แท้จริงว่าทำไม LLM ถึงตอบผิดหรือสร้างผลลัพธ์ที่ไม่ต้องการ การไม่จับ record ของ prompt และ completion ทำให้การย้อนสอบสวน (root‑cause analysis) กลายเป็นการคาดเดา ตัวอย่างจากองค์กรบางแห่งที่เก็บ prompt+completion พบว่าสามารถลดเวลาแก้ปัญหาเฉลี่ยลงได้ถึง 30–50%
อีกประเด็นที่แตกต่างคือการมีโมเดลซ้อนหลายชั้น (multi‑stage pipelines) และการผสานกับบริการภายนอก เช่น retrieval‑augmented generation (RAG), tool calling, หรือ ensemble ของโมเดล เมื่อเกิดปัญหา ต้องสามารถ trace ต้นทางได้ว่าเป็นที่แหล่งความรู้ (retrieval) ผิดพลาด โมเดลหลักตอบผิด หรือมีปัญหาที่การประมวลผลหลัง (post‑processing) ดังนั้น observability สำหรับ LLM ต้องรองรับการเชื่อมโยงข้อมูลแบบ end‑to‑end ตั้งแต่ request ID, prompt history, vector search hits, token‑level timing จนถึงการเรียก API ภายนอกและผลลัพธ์สุดท้าย เพื่อสร้าง trace ที่สามารถผูกกับเหตุการณ์เชิงธุรกิจได้
สุดท้าย การประเมินผลกระทบจริงต่อธุรกิจต้องเชื่อมโยงสัญญาณเทคนิคกับตัวชี้วัดเชิงธุรกิจ เช่น อัตราการแปลง (conversion), ค่าเฉลี่ยรายได้ต่อผู้ใช้ (ARPU), อัตราการคืนสินค้า หรือเวลาเฉลี่ยในการแก้ปัญหาลูกค้า (MTTR) การตั้งค่า alert ที่อิงแต่ latency หรือ error rate อาจพลาดกรณีที่คำตอบดูสำเร็จทางเทคนิคแต่มีความคลาดเคลื่อนทางเนื้อหา (semantic drift) ซึ่งทำให้ KPI ธุรกิจเสียหายได้ ตัวอย่างเช่น หาก LLM สร้างคำตอบที่ทำให้ลูกค้าพึงพอใจลดลง 10% อาจส่งผลต่อ conversion ลดลง 2–5% ดังนั้น observability ควรมีความสามารถในการเชื่อมต่อเหตุการณ์เชิงเทคนิคกับเหตุการณ์เชิงธุรกิจโดยอัตโนมัติ เช่น การแมป request ID ไปยัง session ของผู้ใช้และการติดตามการกระทำถัดไป (clicks, purchases, support escalations)
- สิ่งที่ต้องเก็บร่วมกัน — telemetry (latency, error, throughput, resource metrics) + content signals (raw prompts, system/user messages, completions, embeddings, retrieval hits, tool calls, model version, sampling params)
- ความจำเป็นของ trace แบบ end‑to‑end — เชื่อมโยง API call, data retrieval, token timing และการประมวลผลหลัง เข้ากับ transaction หรือ session ทางธุรกิจ
- การวัดผลที่เหมาะสม — นอกจาก metrics ทางเทคนิคแล้ว ต้องมีการตั้ง metric เชิงความถูกต้องเชิงเนื้อหา (semantic accuracy), อัตรา hallucination, และ cohort‑based monitoring เพื่อตรวจจับ model/data drift
- การแจ้งเตือนเชิงบริบท — alert ควรระบุสาเหตุเชิงเนื้อหา เช่น “อัตรา hallucination เพิ่มขึ้นในกลุ่มคำถามประเภทการเงิน” แทนที่จะเตือนเพียงว่า latency สูง
สรุปแล้ว Observability สำหรับ LLM ต้องเป็นกรอบการสังเกตที่รวมทั้ง telemetry‑prompt‑trace และเชื่อมโยงกับตัวชี้วัดธุรกิจ เพื่อให้ทีมวิศวกรรมและผู้บริหารมองเห็นทั้งสัญญาณทางเทคนิคและผลกระทบทางธุรกิจอย่างชัดเจน การออกแบบระบบสังเกตการณ์ที่รองรับบริบทของ LLM จะช่วยให้สามารถระบุสาเหตุของข้อผิดพลาดได้แบบเรียลไทม์ ลดความเสี่ยงทางธุรกิจ และเพิ่มความไว้วางใจในการใช้ AI ในระบบงานสำคัญ
องค์ประกอบหลัก: Telemetry, Prompt และ Trace — นิยามและบทบาท
องค์ประกอบหลัก: Telemetry, Prompt และ Trace — นิยามและบทบาท
การสังเกตการณ์ระบบ LLM แบบครบวงจรต้องอาศัยองค์ประกอบสามส่วนที่ทำงานสอดประสานกัน ได้แก่ Telemetry สำหรับมอนิเตอร์เชิงตัวเลขและเหตุการณ์, Prompt capture สำหรับบันทึกบริบทและรูปแบบคำสั่งที่ป้อนให้โมเดล, และ Trace สำหรับการติดตามการไหลของการเรียกใช้งานแบบกระจาย (distributed tracing) ระหว่างโมดูลต่าง ๆ ทั้งสามส่วนนี้เมื่อเชื่อมโยงด้วยคีย์ร่วม (เช่น request_id, session_id, trace_id และ timestamp) จะช่วยให้ทีมธุรกิจและวิศวกรรมสามารถระบุสาเหตุของข้อผิดพลาดหรือการถดถอยของคุณภาพ (regression) ได้แบบเรียลไทม์
1) Telemetry — นิยาม ข้อมูลที่ควรเก็บ และรูปแบบ
นิยาม: Telemetry คือชุดข้อมูลเชิงวัดที่บันทึกเป็นเมตริกและลอกรายเหตุการณ์ เพื่อให้เห็นภาพการทำงานของระบบในเชิงปริมาณ เช่น เวลาในการตอบ (latency), อัตราความผิดพลาด (error rate), การใช้โทเค็น (token usage) และต้นทุนต่อการเรียกใช้งาน (cost per call)
ข้อมูลที่ควรเก็บ (ตัวอย่าง):
- Latency: p50, p95, p99 ของเวลา end-to-end (ms) แยกตาม endpoint, model_version, region
- Error rates: จำนวนข้อผิดพลาด/จำนวนคำขอ แยกตามประเภทข้อผิดพลาด (timeout, model error, input validation)
- Token usage: input_tokens, output_tokens, total_tokens ต่อคำขอ
- Cost per call: คำนวณจาก token pricing + infra cost (ตัวอย่าง: cost_per_call = total_tokens * price_per_token + compute_cost)
- Throughput: requests/sec, concurrent requests
รูปแบบการเก็บ: เมตริกเชิงเวลา (time series) เช่น Prometheus/InfluxDB format: metric_name{label="value", model="gpt-4"} value timestamp. สำหรับลอกรายเหตุการณ์ใช้ structured JSON log เช่น:
- log = { "timestamp": "2026-03-12T10:23:45Z", "request_id": "r-123", "model_version": "v2.1", "latency_ms": 345, "input_tokens": 120, "output_tokens": 45, "cost_usd": 0.0045, "status": "ok" }
2) Prompt capture — นิยาม ข้อมูลที่ควรเก็บ และรูปแบบการเก็บ
นิยาม: Prompt capture คือการบันทึกรายละเอียดของคำสั่งที่ส่งถึงโมเดล รวมทั้งบริบทที่เกี่ยวข้อง เพื่อให้สามารถย้อนกลับและวิเคราะห์ว่ารูปแบบคำสั่งหรือบริบทใดส่งผลต่อผลลัพธ์หรือข้อผิดพลาด
ข้อมูลที่ควรเก็บ (ตัวอย่าง):
- Prompt text และ template: ข้อความเต็มของ prompt และตัวระบุ template id
- Versioning ของ prompt: prompt_version (เช่น semver หรือ hash) + changelog/commit_id
- Context snapshot: system messages, conversation history (last N messages), user profile snapshot (non-PII) และตัวแปรที่ถูกแทรก (placeholders)
- Input features: client_app, locale, user_role, input_length, embeddings_id ถ้ามี
- Metadata สำหรับ debugging: prompt_hash, prompt_diff_against_previous_version, redaction_flag
รูปแบบการเก็บ: บันทึกเป็น structured event หรือ object storage ด้วย schema ชัดเจน เช่น JSON record ที่เชื่อมต่อกับ request_id:
- { "request_id":"r-123", "prompt_id":"p-45", "prompt_version":"v1.3.0", "prompt_text":"System: ... User: ...", "context_snapshot":[{"role":"user","text":"..."}], "input_features":{"locale":"th-TH","client":"web"} }
ข้อควรระวังด้านความเป็นส่วนตัว: ต้องมีนโยบาย redaction/hashing ของ PII ก่อนบันทึก และเก็บเฉพาะข้อมูลที่จำเป็นตามกฎระเบียบ
3) Trace — นิยาม ข้อมูลที่ควรเก็บ และรูปแบบ
นิยาม: Trace คือการติดตามเส้นทางการประมวลผลหนึ่งคำขอตั้งแต่จุดเข้าไปจนถึงจุดออก โดยแยกเป็น span ย่อย ๆ ของแต่ละโมดูล (preprocessing, tokenization, model_inference, postprocessing, downstream calls) เพื่อระบุคอขวด เวลาในแต่ละขั้นตอน และลำดับเหตุการณ์แบบ end-to-end
ข้อมูลที่ควรเก็บ (ตัวอย่าง):
- Trace and span identifiers: trace_id, span_id, parent_span_id
- ชื่อ span/โมดูล: e.g., client_receive, preprocessor.normalize, tokenizer.encode, model.infer, postprocessor.format
- เวลา: start_timestamp, end_timestamp, duration_ms ของแต่ละ span
- Attributes: model_version, prompt_id, input_tokens, output_tokens, node_id/host, error_code
- Events: exceptions, retries, cache_hit/cache_miss
รูปแบบการเก็บ: ใช้มาตรฐาน OpenTelemetry/OTLP หรือ Zipkin/Jaeger format เพื่อให้สามารถจัดการและ visualize trace ได้ทันที ตัวอย่างโครงสร้าง span แบบย่อ:
- { "trace_id":"t-abc", "span_id":"s-001", "parent_id":"s-000", "name":"model.infer", "start":"2026-03-12T10:23:45.123Z", "end":"2026-03-12T10:23:45.567Z", "duration_ms":444, "attributes":{ "model_version":"v2.1", "prompt_id":"p-45", "input_tokens":120 } }
การเชื่อมโยง Telemetry, Prompt และ Trace: ทั้งสามส่วนต้องมีคีย์ร่วมเช่น request_id/trace_id และ timestamp ที่แม่นยำเพื่อทำ correlation query เช่น การค้นหา ทุก trace ที่มี latency p95 เกินเกณฑ์และดู prompt_version ที่เกี่ยวข้องพร้อม context snapshot และค่า token/cost ที่เกิดขึ้น วิธีนี้ช่วยให้วิเคราะห์ปัญหาเชิงสาเหตุ (root cause) ได้เร็วขึ้นและชี้ขาดได้ในเชิงธุรกิจ (เช่นต้นทุนต่อคำขอเพิ่มขึ้น 30% เนื่องจาก output token เพิ่มขึ้นหลังการอัปเดต prompt)
ตัวอย่างเชิงปฏิบัติ: หากระบบรายงานว่า p95 latency เพิ่มจาก 350ms เป็น 780ms ในช่วง 24 ชั่วโมง ให้สืบค้นดังนี้: 1) หา trace_id ของคำขอ latency สูงสุด, 2) เปิด prompt capture เพื่อตรวจสอบ prompt_version และ context snapshot, 3) ตรวจสอบ span-level timings เพื่อดูว่าคอขวดอยู่ใน tokenizer/model_infer/หรือ network และ 4) ตรวจสอบ token usage และ cost_per_call เพื่อประเมินผลกระทบทางธุรกิจ
ผสานเมตริกธุรกิจกับสัญญาณระบบ: วิธีเชื่อม KPI และ SLO เข้ากับ Observability
ผสานเมตริกธุรกิจกับสัญญาณระบบ: แนวทางเชื่อม KPI กับ SLI/SLO
เมื่อองค์กรใช้ LLM และระบบสังเกตการณ์แบบครบวงจร การเชื่อม KPI ทางธุรกิจ เช่น revenue per conversation, conversion rate, และ churn เข้ากับ SLI/SLO ทางเทคนิค เป็นหัวใจหลักในการทำให้ทั้งทีมธุรกิจและทีมวิศวกรรมสามารถสื่อสารและตอบสนองได้ตรงจุด ไม่เพียงแต่แจ้งเตือนเมื่อเกิด error count สูง แต่ต้องแจ้งเตือนเมื่อตัวชี้วัดทางธุรกิจมีโอกาสได้รับผลกระทบ โดยการแมปและตั้งเกณฑ์ต้องอ้างอิงทั้งความถี่ (frequency), ระดับความรุนแรง (severity) และผลกระทบเชิงรายได้ (business impact).
แนวทางปฏิบัติเริ่มจากการกำหนด SLI ที่วัดได้ชัดเจน เช่น response accuracy, prompt failure rate, latency (p95), และ hallucination rate จากนั้นตั้ง SLO ที่สอดคล้องกับเป้าหมายธุรกิจ เช่น target ของ response accuracy อาจตั้งที่ 92% เพื่อรักษา conversion rate ที่คาดหวัง การทดสอบเชิงสาเหตุ (causal testing) และการวัดการเชื่อมโยงเชิงสถิติก่อนตั้งค่า SLO จะช่วยลดความเสี่ยงจากการตั้งเกณฑ์ไม่สอดคล้องกับผลลัพธ์เชิงธุรกิจ
ตัวอย่าง Mapping Matrix ระหว่าง KPI และ SLI/SLO
- KPI: Revenue per conversation
- SLI ที่เกี่ยวข้อง: response accuracy, prompt success rate, average token cost per response
- SLO ตัวอย่าง: response accuracy ≥ 92% (rolling 7d), prompt failure rate ≤ 0.5% (rolling 1d)
- Threshold ตัวอย่าง: หาก revenue per conversation ลดลง ≥ 10% ใน 24 ชม ให้ถือเป็น business-impact incident และยกระดับเป็น P1 หลังจากยืนยัน correlation กับ SLI
- KPI: Conversion rate
- SLI ที่เกี่ยวข้อง: latency (p95), response relevance (semantic score), hallucination rate
- SLO ตัวอย่าง: latency p95 ≤ 800ms (rolling 1h), hallucination rate ≤ 2% (rolling 7d)
- Threshold ตัวอย่าง: absolute drop ของ conversion ≥ 2% หรือ relative drop ≥ 10% ใน 12 ชม ให้ trigger alert และเปิด trace เพื่อตรวจสอบ prompt-model changes
- KPI: Churn / Retention
- SLI ที่เกี่ยวข้อง: session abandonment rate, error rate per session, first-response quality
- SLO ตัวอย่าง: session abandonment ≤ 8% (rolling 30d), first-response quality score ≥ 90%
- Threshold ตัวอย่าง: หาก churn rate เพิ่มขึ้น ≥ 0.5 percentage point เดือนต่อเดือน ให้สืบค้นสาเหตุร่วมกับ prompt/policy changes และ model drift
- KPI: Cost / Token spend
- SLI ที่เกี่ยวข้อง: average tokens per conversation, retry rate, prompt size growth
- SLO ตัวอย่าง: average tokens per conversation ≤ 120 tokens (rolling 7d)
- Threshold ตัวอย่าง: token spend เพิ่มขึ้น >15% สัปดาห์ต่อสัปดาห์ ให้แจ้งทีมค่าใช้จ่ายและพิจารณา rate-limiting หรือ prompt-optimization
การตั้ง Threshold และ Alert โดยคำนึงถึงผลกระทบทางธุรกิจ
การตั้งค่า alert ควรพิจารณา ผลกระทบเชิงธุรกิจเป็นสำคัญ ไม่ใช่เพียงแค่นับจำนวนข้อผิดพลาด ตัวอย่างแนวปฏิบัติสำคัญได้แก่:
- ใช้ระดับความรุนแรงแบบสร้างจากผลกระทบ (impact-based severity): แยก P1/P2/P3 ตามผลกระทบทางรายได้หรือประสบการณ์ลูกค้า เช่น การลดลงของ revenue per conversation มากกว่า 10% = P1 แม้ error count จะไม่สูง
- ตั้ง Composite Alerts และ Correlation Rules: ตัวอย่างเช่น alert จะถูกยกระดับเมื่อพบว่าผลิตภัณฑ์เกิด latency spike พร้อมกับ drop ของ conversion rate และเพิ่มขึ้นของ prompt failure rate
- ใช้ SLO Burn Rate และ Budgeting: กำหนด SLO burn rate เพื่อวัดว่าระบบกำลังใช้ budget ของ SLO เร็วกว่าที่คาดหรือไม่ — เช่น หาก burn rate ใน 1 ชั่วโมง > 3x ให้ trigger incident
- ใช้ Rolling Windows และ Anomaly Detection: แทนที่จะตั้ง threshold แบบคงที่ ให้ใช้ baseline แบบ seasonality-aware และโมเดล anomaly detection เพื่อจับการเปลี่ยนแปลงที่มีความหมายเชิงธุรกิจ
- กำหนด Escalation ที่ชัดเจนและ Runbooks ที่ผสานข้อมูลธุรกิจ: เมื่อเกิด alert ระบุขั้นตอนที่ต้องดึงข้อมูล revenue/transactions ล่าสุด, traces ของ request ที่เกี่ยวข้อง, และ prompt versions เพื่อให้การตัดสินใจแก้ไขเป็นไปอย่างรวดเร็วและสอดคล้องกับผลกระทบ
ตัวอย่างเชิงตัวเลข: งานวิเคราะห์ภายในขององค์กรหนึ่งพบว่า prompt failure rate ที่เพิ่มจาก 0.5% เป็น 2% ในช่วง 6 ชม ส่งผลให้ conversion rate ลดลง 4% และ revenue per conversation ลดประมาณ 5% — สัญญาณนี้เพียงพอที่จะยกระดับเป็น incident ระดับสูงเพราะมีผลกระทบเชิงรายได้
ตัวอย่าง Dashboard ที่รวม Business Metrics และ Telemetry
Dashboard ที่มีประสิทธิภาพต้องผสานมุมมองทั้งธุรกิจและเทคนิคในหน้าเดียว เพื่อให้ทีมสามารถมองเห็นความเชื่อมโยงแบบ real-time ตัวอย่างองค์ประกอบของ dashboard:
- Header metrics (cards): revenue per conversation, conversion rate, daily active conversations, churn rate — พร้อม delta เปรียบเทียบ 1h/24h/7d
- Telemetry timeline (side-by-side): latency p50/p95, prompt failure rate, model version deployment events, token spend — แสดงเป็นกราฟเวลาที่ซิงก์กัน
- Correlation panel: scatter plot หรือ heatmap แสดงความสัมพันธ์ระหว่าง response accuracy กับ conversion rate หรือระหว่าง latency กับ abandonment rate
- Trace & Prompt inspector: เมื่อคลิกช่วงเวลาที่ผิดปกติ ให้เปิด trace waterfall และตัวอย่าง prompt+response รวมทั้งคะแนนความเหมาะสม (relevance/hallucination) เพื่อลดเวลาไล่สาเหตุ
- Alert & Incident timeline: แสดง alert ที่เปิดอยู่, SLO burn rate, และ runbook links — พร้อมปุ่มย้ายงานไปยัง incident management (เช่นเปิด ticket หรือเรียก webhook)
การออกแบบควรยึดหลักให้ธุรกิจมองเห็นผลลัพธ์ได้ทันที (single-pane-of-glass) และสามารถ drill-down ไปยัง telemetry รายงานเชิงเทคนิคได้ภายในคลิกเดียว เพื่อเร่งการตัดสินใจเช่น rollback model, disable prompt template, หรือ scale up infra
แนวทางปฏิบัติสรุปและการกำกับดูแล
สรุปคำแนะนำเชิงปฏิบัติ:
- เริ่มจากการแมป KPI กับ SLI/SLO และทดลองปรับ threshold โดยอิงจากข้อมูลเชิงสถิติและผลกระทบทางธุรกิจ
- ตั้ง alert แบบ impact-first (composite & burn-rate based) แทนการพึ่งพา error count เพียงอย่างเดียว
- จัดกระบวนการร่วมกันระหว่างทีมธุรกิจและวิศวกรรม (SLO review cadence, post-incident analysis ที่รวมผลกระทบทางรายได้)
การผสานเมตริกธุรกิจกับสัญญาณระบบอย่างเป็นระบบช่วยให้การตอบสนองต่อปัญหา LLM มีความรวดเร็วและสอดคล้องกับเป้าหมายเชิงธุรกิจ ลดเวลาที่ใช้ในการไล่สาเหตุและลดความเสี่ยงต่อรายได้ขององค์กร
ไล่สาเหตุข้อผิดพลาด LLM แบบเรียลไทม์: เวิร์กโฟลว์และเทคนิคสำคัญ
ไล่สาเหตุข้อผิดพลาด LLM แบบเรียลไทม์: เวิร์กโฟลว์และเทคนิคสำคัญ
การไล่สาเหตุ (root‑cause) ข้อผิดพลาดของระบบที่ขับเคลื่อนด้วย LLM ในแบบเรียลไทม์ จำเป็นต้องอาศัยเวิร์กโฟลว์ที่ผสานข้อมูลจาก telemetry, prompt และ trace เข้าด้วยกันอย่างแนบเนียน เพื่อให้ทีมสามารถสกัดสาเหตุที่แท้จริงได้อย่างรวดเร็วและเชื่อถือได้ เวิร์กโฟลว์มาตรฐานประกอบด้วย 1) การตรวจจับ (detection) ของความผิดปกติทั้งเชิงตัวเลขและเชิงข้อความ 2) การวิเคราะห์ (analysis) โดยใช้เทคนิค prompt diffing, embedding‑based semantic search และ causal inference เบื้องต้น และ 3) การตอบสนอง (remediation) แบบอัตโนมัติหรือกึ่งอัตโนมัติ เช่น auto‑rollback, throttling และ circuit breakers ที่มีเงื่อนไขเชิงบริบทประกอบการตัดสินใจ
การตรวจจับ (Detection) — การตรวจจับต้องทำทั้งบน metric และ textual drift พร้อมกัน: บนชั้น metric ใช้ anomaly detection เช่น change‑point detection, EWMA หรือ isolation forest สำหรับ latency, error rate, token cost และอัตราการ conversion ทางธุรกิจ โดยตั้งค่า sliding window ในช่วง 5–30 นาทีและใช้เกณฑ์เช่น 3σ หรือ percentile-based thresholds เพื่อจำกัด false positives ในขณะเดียวกันต้องตรวจจับ textual drift โดยการคำนวณ embedding similarity ระหว่าง prompt/completion ใหม่กับ distribution ประวัติ เช่น หาก cosine similarity ลดลงต่ำกว่า 0.75 หรือมีเพิ่มขึ้นของ KL divergence ของ token distribution ถือเป็นสัญญาณ drift เทคนิคนี้ช่วยจับกรณีที่ prompt ถูกแก้ไขเล็กน้อยแต่ส่งผลใหญ่ต่อผลลัพธ์
การวิเคราะห์ (Analysis) — เมื่อเกิด alert แบบบริบท (contextual alert) ระบบควรรวบรวม payload อัตโนมัติ ได้แก่ prompt template เวอร์ชัน, user input, model parameters (temperature, top_p), trace id ของ request, stack traces จากบริการที่เกี่ยวข้อง และเมตริกธุรกิจในช่วงเวลาที่เกี่ยวข้อง จากนั้นใช้เทคนิคต่อไปนี้:
- Prompt diffing: ทำ diff ทั้งระดับ token (edit distance) และระดับความหมาย (semantic diff) ระหว่าง prompt template ปัจจุบันกับเวอร์ชันก่อนหน้า เพื่อหาจุดเปลี่ยนแปลงที่อาจเป็นสาเหตุ การเปลี่ยนคีย์เวิร์ดหรือการสลับ slot มักเป็นสาเหตุอันดับต้น ๆ
- Embedding‑based semantic search บน logs: แปลง logs, completions และ error messages เป็น embeddings แล้วค้นหาข้อความที่มีความหมายใกล้เคียงเพื่อนำมาประกอบสาเหตุ (เช่น พบ pattern เดิมใน request อื่น ๆ ที่ล้มเหลว) — วิธีนี้ลดเวลาค้นหาและเพิ่มความแม่นยำในการหาเหตุซ้ำ
- Tracing stack และ dependency mapping: แม็ป trace ระดับ distributed tracing เพื่อระบุ service, third‑party API หรือ knowledge‑base call ที่มี latency/err spike ร่วมกับการเปลี่ยนแปลง prompt
- การแยกปัจจัย (factor attribution): สร้างคะแนนสาเหตุ (root‑cause score) โดยผสานสัญญาณจากความเปลี่ยนแปลงของ prompt, model version, parameter drift, external API errors และ business metric delta — ให้ผลลัพธ์แบบ ranked hypotheses
- causal inference เบื้องต้น: ใช้เทคนิค quasi‑experimental เช่น interrupted time series, difference‑in‑differences หรือ propensity matching เมื่อเป็นไปได้เพื่อแยกความสัมพันธ์จากสาเหตุ ตัวอย่างเช่น เปรียบเทียบ cohort ของ requests ก่อน/หลังการ deploy prompt template ใหม่
ผลลัพธ์จากการวิเคราะห์ควรถูกแปลงเป็น alert ที่มีบริบทครบถ้วน (contextual alert) ได้แก่ snippet ของ prompt diff, ตัวอย่าง completion ที่ล้มเหลว, trace id ที่เกี่ยวข้อง, และคะแนนความเชื่อมั่นของ hypothesis เพื่อให้วิศวกรและทีมสินค้าเข้าใจได้ทันที วงจรทำซ้ำแบบนี้สามารถลด Mean Time To Repair (MTTR) ได้อย่างมีนัยสำคัญ — องค์กรมักรายงานการลด MTTR ประมาณ 30–60% และการตรวจจับล่วงหน้าที่เร็วขึ้น 2–10 เท่าเมื่อผสาน telemetry‑prompt‑trace เข้าด้วยกัน
การตอบสนอง (Remediation) — กลยุทธ์การแก้ไขควรมีทั้งทางอัตโนมัติและมนุษย์เข้ามาตรวจสอบ:
- Auto‑rollback ของ prompt templates: เมื่อระบบยืนยันความผิดปกติร่วมกับคะแนนความเชื่อมั่นสูง (เช่น anomaly on metric + prompt diff similarity > threshold) ให้ระบบ revert ไปใช้เวอร์ชันก่อนหน้าอัตโนมัติ พร้อมแท็กเหตุผลและบันทึกการเปลี่ยนแปลงใน CI/CD ของ prompt
- Throttling และ dynamic rate limiting: หากข้อผิดพลาดก่อให้เกิดการเพิ่มขึ้นของ cost หรือ downstream failures ให้ปรับ QPS ลงชั่วคราว (เช่น ลด 30–90%) จนกว่าจะมีการตรวจสอบ
- Circuit breakers และ safety gates: ติดตั้ง circuit breaker ที่วัดจาก combined signal (error rate + semantic drift) เพื่อป้องกันการแพร่กระจายของความผิดพลาดไปยังระบบอื่น ๆ และสลับไปใช้ fallback template หรือ deterministic handler เมื่อจำเป็น
- Human‑in‑the‑loop verification: สำหรับการแก้ไขที่อาจมีผลกระทบทางธุรกิจสูง ให้ส่ง alert พร้อมปุ่ม approve/rollback ให้กับ on‑call โดยมีข้อมูล context และ reproduction steps อัตโนมัติ
สรุปแล้ว การไล่สาเหตุ LLM แบบเรียลไทม์ที่มีประสิทธิผลต้องอาศัยการบูรณาการข้อมูลแบบครบวงจร (telemetry + prompt + trace) และการใช้เทคนิคที่หลากหลายตั้งแต่ anomaly detection, embedding‑based semantic analysis, causal inference จนถึง remediation อัตโนมัติ เช่น auto‑rollback, throttling และ circuit breakers การออกแบบเวิร์กโฟลว์เช่นนี้จะช่วยให้ทีมสินค้าและวิศวกรรมตอบสนองต่อเหตุการณ์ได้รวดเร็ว ลดผลกระทบต่อธุรกิจ และรักษาความเชื่อมั่นของผู้ใช้ได้อย่างต่อเนื่อง
สถาปัตยกรรมและการปรับใช้: ออบเซอร์เวบิลิตี้สเกลสูงและการจัดการข้อมูลเชิงความเป็นส่วนตัว
การออกแบบระบบ observability สำหรับ Large Language Models (LLM) ที่รองรับสเกลสูงต้องผสานแนวทางทางสถาปัตยกรรมหลายชั้น เพื่อให้สามารถเก็บ token traces ระดับมหาศาล วิเคราะห์แบบเรียลไทม์ และยังคงรักษาความเป็นส่วนตัวของผู้ใช้ได้ในเวลาเดียวกัน บทความส่วนนี้อธิบายแนวทางเชิงเทคนิคแบบไฮบริด ตั้งแต่วิธีการ ingest ข้อมูลไปจนถึงนโยบาย sampling/retention และมาตรการป้องกันข้อมูลส่วนบุคคล (PII).
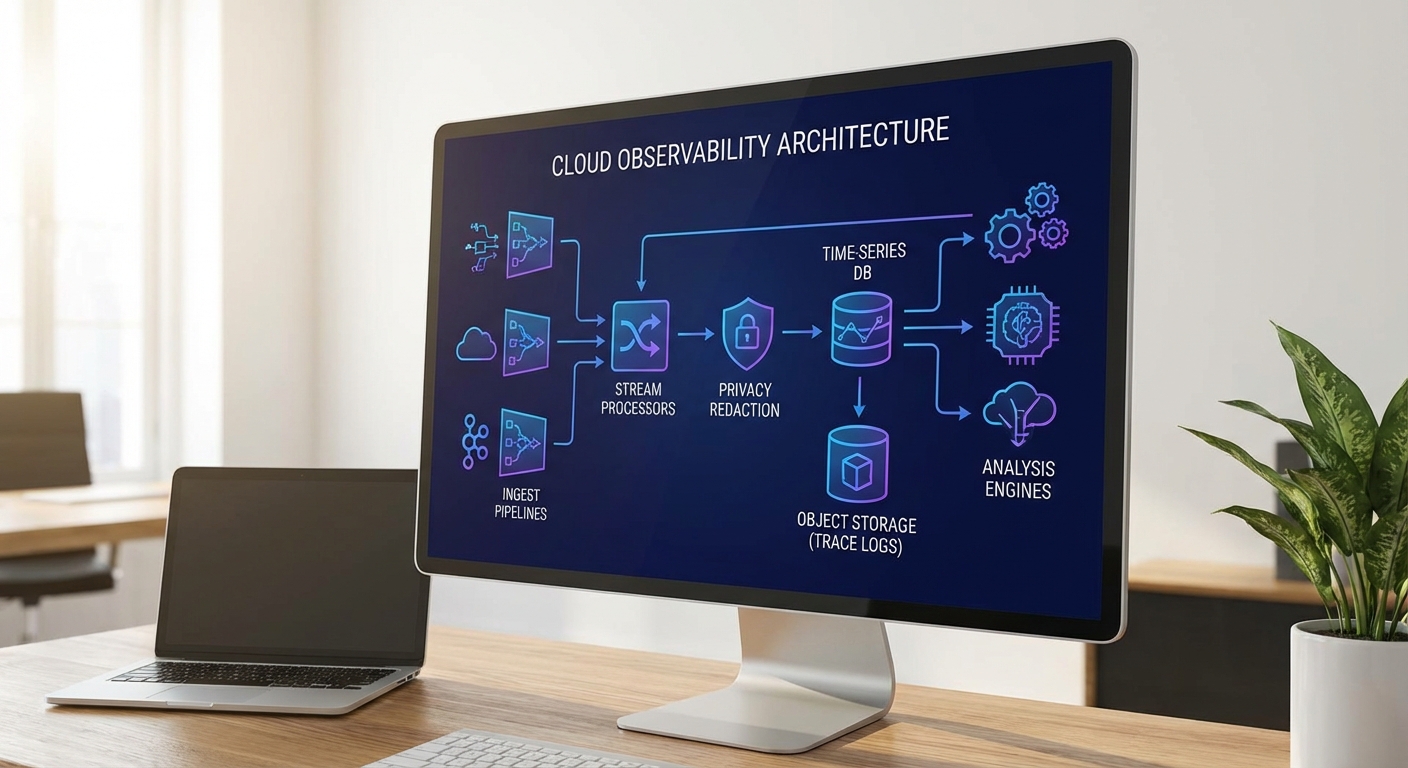
สถาปัตยกรรมแบบไฮบริด: ingestion → processing → storage → analysis
สถาปัตยกรรมแนะนำเป็นแบบไฮบริดที่แยกความรับผิดชอบเป็นเลเยอร์ชัดเจน:
- Ingestion layer: ใช้ SDK/sidecar ในบริการ inference เพื่อส่ง telemetry (prompt, response metadata, latency, model logits) ไปยัง message broker เช่น Kafka หรือ Pulsar โดยมี agent เช่น Fluentd/Vector สำหรับ log shipping และการทำ pre-filtering (เช่น initial redaction หรือ PII tagging)
- Processing layer (stream + batch): ประมวลผลแบบสตรีมด้วย Flink/Beam หรือ Spark Streaming สำหรับการตรวจจับเหตุการณ์แบบเรียลไทม์ (anomaly, latency spike, hallucination signal) และใช้ batch job (Spark) สำหรับการคำนวณเชิงกลุ่มและการสร้าง aggregated metrics ในช่วงเวลาที่กำหนด
- Storage layer: แยกประเภทข้อมูลตามลักษณะการใช้งาน — time-series DB (เช่น Prometheus, InfluxDB) สำหรับเมตริกเชิงเวลา; object storage (เช่น S3/GCS/MinIO) สำหรับ token traces และ artifacts ขนาดใหญ่; และ data warehouse/columnar store (เช่น Snowflake, BigQuery, Parquet ใน data lake) สำหรับการวิเคราะห์เชิงลึกและการการันตีการค้นคืน
- Analysis layer: dashboards แบบเรียลไทม์ (Grafana/Observability UI), ML-based root-cause analysis, trace replay tools สำหรับการ debug LLM และ BI/OLAP สำหรับการวิเคราะห์เชิงธุรกิจ
ตัวอย่างตัวเลขเชิงปริมาณ: ที่ระดับการให้บริการ 1,000 requests/sec และค่าเฉลี่ย 50 tokens/request ระบบจะสร้างประมาณ 4.32 พันล้านโทเค็นต่อวัน — หากเก็บทุกอย่างแบบ raw จะกลายเป็นต้นทุนและความเสี่ยงด้าน privacy ที่ไม่ยั่งยืน ดังนั้นการออกแบบเลเยอร์แต่ละส่วนต้องรองรับการลดขนาด (downsampling), compression และการกักกันข้อมูลที่ละเอียดอ่อน
นโยบายการ sampling และ retention เพื่อลดต้นทุนและรักษา privacy
นโยบาย sampling/retention ที่ชัดเจนเป็นหัวใจสำคัญในการจัดการต้นทุนและความเป็นส่วนตัว ตัวอย่างแนวปฏิบัติที่แนะนำ:
- Sampling แบบผสม (hybrid sampling): เก็บ full traces แบบสุ่มเชิงนโยบาย (probabilistic sampling) เช่น 0.5–2% ของคำขอทั้งหมด แต่เก็บ 100% ของคำขอที่เกิดข้อผิดพลาดหรือมีสัญญาณ anomaly เพื่อสนับสนุนการวิเคราะห์สาเหตุ
- Stratified / adaptive sampling: เพิ่มอัตราการเก็บสำหรับกลุ่มสำคัญ (high-value customers, sensitive endpoints) และลดสำหรับ background traffic โดยใช้ reservoir sampling หรือ dynamically adjusting sampling rate เมื่อเกิด spike ของ error
- Retention tiers: ใช้การจัดเก็บแบบชั้น เช่น
- Hot (full traces): 7–30 วัน สำหรับการ debug แบบเรียลไทม์
- Warm (summaries / compressed traces): 30–90 วัน สำหรับการวิเคราะห์ trends
- Cold (aggregated metrics, DP-sanitized aggregates): 1–5 ปี ตามข้อกำหนดทางกฎหมายหรือธุรกิจ
- Compression และ deduplication: ใช้ delta encoding, gzip/lz4 และรูปแบบ columnar (Parquet) เพื่อลดขนาดเก็บ token traces ลงได้ 5–20x ขึ้นอยู่กับความซ้ำซ้อนของข้อความ
ตัวอย่างผลลัพธ์เชิงการคำนวณ: ถ้าตั้ง sampling ที่ 1% และเก็บ full traces ของ error ที่ 100% จะลดปริมาณ raw traces ลงได้มากกว่า 95% ขณะที่ยังคงข้อมูลเชิงเหตุผลเพียงพอสำหรับการวิเคราะห์ข้อผิดพลาด
ข้อควรระวังด้านความเป็นส่วนตัว: redaction, differential privacy และการจัดการ consent
การจัดการ PII ต้องเป็นไปตามหลักความปลอดภัยและกฎหมาย (เช่น GDPR, CCPA) พร้อมแนวปฏิบัติทางเทคนิคคือ:
- Redaction ก่อนเก็บ: ทำ redaction เบื้องต้นที่ edge/ingestion layer โดยใช้ชุดกฎ regex และ ML-based PII detectors (NER) เพื่อลบหรือมาร์กข้อมูลที่เป็น PII เช่น หมายเลขบัตร, เบอร์โทรศัพท์, เลขประจำตัว
- Tokenization / hashing / format-preserving encryption: หากต้องการเก็บบางฟิลด์เพื่อการ debug ให้เก็บเป็นรูปแบบที่ไม่สามารถย้อนกลับได้ (hash + salt หรือ FPE) และจัดการคีย์ด้วย KMS/Hardware Security Module
- Differential Privacy (DP) สำหรับการวิเคราะห์สรุป: เมื่อต้องเผยแพร่ aggregated analytics ให้ใช้ DP mechanisms เพื่อลดความเสี่ยงการ re-identification — ค่าพารามิเตอร์ epsilon ที่เหมาะสมมักอยู่ในช่วง 0.1–1 ขึ้นกับความสมดุลระหว่าง utility และ privacy
- Consent และ data subject rights: แนบ metadata ในแต่ละ trace ระบุสถานะ consent, retention windows และ provenance เพื่อสนับสนุนการลบข้อมูลตามคำขอ (right to be forgotten) และตรวจสอบการเข้าถึงผ่าน audit log
- การควบคุมการเข้าถึง: ใช้ RBAC/ABAC, network isolation, การเข้ารหัสทั้งใน transit และ at rest และการตรวจสอบการใช้งานเพื่อลดความเสี่ยงของการรั่วไหล
เทคนิค PII detection แบบ ML มักให้ recall สูงกว่า 90% ในโดเมนที่ผ่านการเทรนมา แต่ควรจัดกระบวนการ fallback สำหรับ false negatives เช่นการเพิ่ม human-in-the-loop สำหรับตัวอย่างที่มีความเสี่ยงสูง
การปรับใช้บนคลาวด์และ edge: แนวทางผสมเพื่อลดแบนด์วิดท์และเพิ่มความเป็นส่วนตัว
การปรับใช้แบบไฮบริด (cloud + edge) ช่วยลดความหน่วงและปริมาณข้อมูลที่จะส่งไปยัง cloud โดยแนวทางปฏิบัติรวมถึง:
- Edge aggregation & local sampling: ดำเนินการ redaction, sampling และ pre-aggregation ที่ edge/edge gateway เพื่อลดแบนด์วิดท์ เช่น สรุป token-level statistics หรือส่งเฉพาะเหตุการณ์ที่สำคัญ
- Region-aware storage: เก็บข้อมูลที่มีข้อกำหนดด้าน data residency ใน region เฉพาะ และใช้ replication เฉพาะกรณีที่สอดคล้องกับนโยบาย compliance
- Autoscaling และ multi-tenant isolation: ใช้ Kubernetes สำหรับ orchestration พร้อมการตั้งค่า autoscaling ของ ingestion/stream processors และแยก resource per-tenant เพื่อป้องกัน noisy neighbor
- Cold storage & archiving: ย้ายข้อมูลที่ผ่านการ sanitize ไปยัง S3 Glacier หรือ equivalent เพื่อการเก็บระยะยาวที่มีต้นทุนต่ำ และกำหนด retention lifecycle policies อัตโนมัติ
สุดท้าย ควรออกแบบระบบให้สามารถตรวจวัดค่าใช้จ่ายและผลกระทบทาง privacy ได้อย่างต่อเนื่อง (CPM, cost per token stored, privacy leakage metrics) และทบทวนค่าเริ่มต้นของ sampling/retention เมื่อปริมาณหรือความเสี่ยงเปลี่ยนแปลง
สรุป — ระบบ observability สำหรับ LLM ที่สเกลสูงต้องอาศัยสถาปัตยกรรมแบบไฮบริด การจัดการข้อมูลเป็นชั้น การใช้ sampling/retention อย่างมีนโยบาย และมาตรการปกป้อง PII (redaction, tokenization, differential privacy และการจัดการ consent) เพื่อให้ได้ทั้งความสามารถในการ debug แบบเรียลไทม์และการปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวขององค์กร
กรณีศึกษาและผลลัพธ์เชิงตัวเลข: ตัวอย่างการลด MTTR และผลกระทบทางธุรกิจ
ตัวอย่าง A — องค์กรบริการลูกค้า: ลด MTTR จาก 3.2 ชั่วโมงเป็น 22 นาที ด้วย Telemetry + Prompt Trace
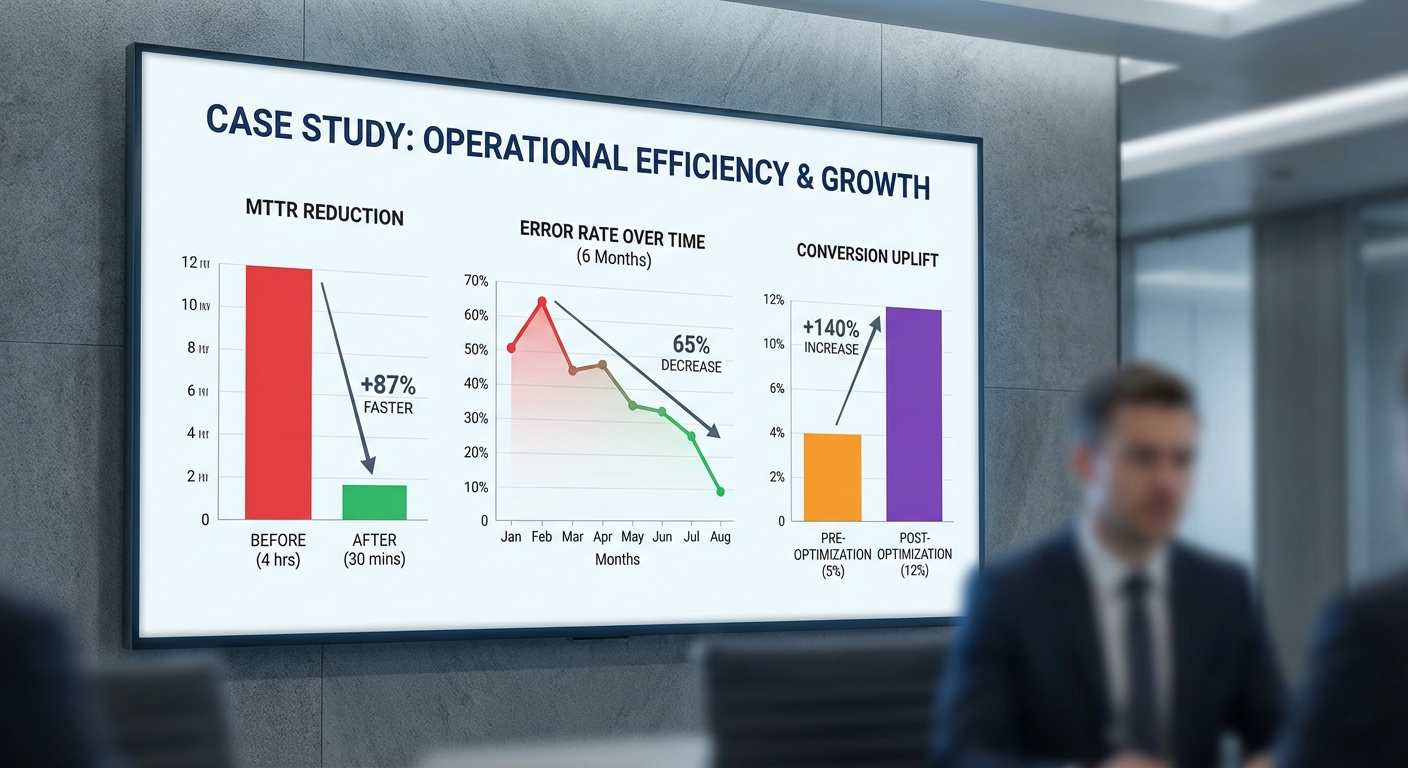
องค์กรบริการลูกค้าขนาดกลางซึ่งใช้ LLM ในการช่วยตอบคำถามและดำเนินการเคส ได้นำแพลตฟอร์ม observability แบบครบวงจรที่ผสาน telemetry, prompt trace และ trace ของการเรียก API เข้ามาใช้ ผลลัพธ์ภายใน 6 สัปดาห์แรกชัดเจน: Mean Time To Resolve (MTTR) ลดจากเฉลี่ย 3.2 ชั่วโมง (192 นาที) เหลือ 22 นาที หรือเป็นการลดลงประมาณ 88.5%.
การลด MTTR เกิดจากการระบุสาเหตุได้เร็วขึ้นด้วยข้อมูลเชิงสัญญาณที่ละเอียด เช่น timing ของแต่ละ prompt token, เวอร์ชันของ prompt ที่ใช้, และ telemetry metrics (response latency, error traces) ทำให้ทีมสามารถย้อนกลับไปยัง prompt-version ที่ก่อปัญหาในเวลาเฉลี่ยจากเดิมที่ต้องใช้เวลาค้นหา 47 นาที เหลือเพียง 6 นาที นอกจากนี้ ความถี่ของคำตอบที่ไม่เกี่ยวข้องหรือ hallucination ลดจากราว 7.4% เหลือ 2.1% ช่วยลดจำนวนเคสที่ต้องเปิดซ้ำและปรับปรุงความพึงพอใจของลูกค้า (CSAT เพิ่มขึ้นประมาณ 6–8%)
ตัวอย่าง B — อีคอมเมิร์ซ: Prompt‑Versioning ลด Error‑Induced Churn ลง 18% ภายใน 3 เดือน
ร้านค้าอีคอมเมิร์ซระดับชาติที่ใช้ LLM เป็นตัวช่วยสร้างคำอธิบายสินค้าและตอบคำถามก่อนการซื้อ ได้นำแนวปฏิบัติ prompt‑versioning ผสานกับระบบ observability เพื่อตรวจจับ prompt เวอร์ชันที่ก่อให้เกิดคำตอบผิดพลาดหรือให้ข้อมูลที่ขัดแย้งกับสต็อกสินค้า ผลลัพธ์ภายใน 3 เดือนแสดงว่า error‑induced churn ลดลง 18% เมื่อเทียบกับช่วงก่อนหน้านั้น
ผลกระทบทางธุรกิจที่วัดได้เพิ่มเติมรวมถึงอัตรา conversion ที่เพิ่มขึ้นโดยเฉลี่ย +3.2 จุดเปอร์เซ็นต์ ในหน้าสินค้าที่ตรวจสอบ และรายได้ต่อการเยี่ยมชม (revenue per visit) เพิ่มขึ้นประมาณ 1.8% นอกจากนี้ ค่าใช้จ่ายต่อการโต้ตอบที่สำเร็จ (cost per successful interaction) ลดจากประมาณ $0.12 เหลือ $0.07 เนื่องจากลดจำนวนการรีทรายหลายครั้งและการแทรกแซงของเจ้าหน้าที่มนุษย์
สรุปตัวเลขสำคัญและแนวโน้มเชิงเมตริก
- MTTR (ตัวอย่าง A): จาก 3.2 ชั่วโมง (192 นาที) → 22 นาที (ลด ~88.5%)
- Error‑induced churn (ตัวอย่าง B): ลดลง 18% ภายใน 3 เดือน หลังเริ่มใช้ prompt‑versioning + observability
- Hallucination rate: ตัวอย่าง A ลดจาก ~7.4% → 2.1% (สอดคล้องกับการปรับ prompt และการตรวจจับเวอร์ชันที่มีปัญหา)
- Latency (average response time): ลดจาก ~850 ms → ~420 ms เมื่อใช้ telemetry เพื่อลด bottleneck ในการเรียกโมเดล (ลด ~50%)
- Cost per successful interaction: ลดจาก ~$0.12 → ~$0.06–$0.08 ขึ้นกับกรณีใช้งาน (ประหยัดค่าใช้จ่ายด้าน human‑in‑the‑loop และ retry)
- Accuracy / relevance trend: ความแม่นยำของคำตอบ (measured by automated QA + human sampling) เพิ่มจาก ~86% → ~93–95% หลังการปรับ prompt และการติดตามเหตุการณ์แบบเรียลไทม์
ข้อสังเกตเชิงธุรกิจ: การผสาน telemetry, prompt trace และ trace ของการเรียกใช้งานช่วยให้ทีมสามารถลดเวลาในการตรวจจับและแก้ไขปัญหา (MTTR) ได้อย่างรวดเร็ว ลดอัตราการหลุดของลูกค้าที่เกิดจากข้อผิดพลาดของโมเดล และเพิ่มอัตรา conversion โดยตรง ผลรวมเหล่านี้ส่งผลให้ต้นทุนต่อการโต้ตอบที่สำเร็จลดลง ในขณะที่ความถูกต้องและความพึงพอใจของลูกค้าเพิ่มขึ้นอย่างเป็นรูปธรรม
สรุป — กรณีศึกษาทั้งสองชี้ให้เห็นว่าแพลตฟอร์ม observability ที่บูรณาการ Telemetry‑Prompt‑Trace กับเมตริกธุรกิจ ไม่เพียงแต่ช่วยลด MTTR แต่ยังมีผลทางเศรษฐศาสตร์ที่จับต้องได้ เช่น การลด churn, การเพิ่ม conversion และการลดต้นทุนต่อการให้บริการ ซึ่งทั้งหมดนี้เป็นตัวขับเคลื่อนความสามารถในการแข่งขันขององค์กรในยุค AI
ความท้าทาย ปัญหาทางกฎหมาย และแนวปฏิบัติที่แนะนำ
ความท้าทายเชิงเทคนิคและการดำเนินงาน
การผสานรวม Telemetry–Prompt–Trace เพื่อสังเกตการณ์ LLM แบบเรียลไทม์เผชิญกับความท้าทายด้านปริมาณข้อมูลและต้นทุนอย่างชัดเจน ปริมาณเหตุการณ์ (events) และการเก็บทั้ง prompt, context, trace ของการประมวลผล และเมตริกธุรกิจ อาจสูงถึงหลายล้านเหตุการณ์ต่อวันในสภาพแวดล้อมขนาดองค์กร ซึ่งแปลเป็นปริมาณข้อมูลได้หลายสิบ TB ต่อเดือน หากไม่มีนโยบายการจัดเก็บและการคัดกรองที่เหมาะสม ค่าใช้จ่ายด้าน storage และการประมวลผลในการค้นคืน (query) อาจเพิ่มขึ้นอย่างรวดเร็ว
อีกความท้าทายสำคัญคือการจัดการกับ false positives ในระบบแจ้งเตือน เมื่อใช้เงื่อนไขตรวจจับเพียงสัญญาณเดี่ยวจะเกิดการแจ้งเตือนเกินความจำเป็น ส่งผลให้ทีมถูกเบี่ยงเบนทรัพยากรและเกิด alert fatigue การเชื่อมสัญญาณหลายมิติ (เช่น latency spike + อัตราผิดพลาดของการตอบ + การลดลงของ KPI ธุรกิจ) และการตั้งระดับความรุนแรงเป็นสิ่งจำเป็น แต่การออกแบบโลจิกดังกล่าวซับซ้อนและต้องทดสอบอย่างต่อเนื่อง
ปัญหาทางกฎหมายและจริยธรรม
การบันทึก prompt และ trace เพื่อตรวจสอบการตัดสินใจของโมเดลย่อมขัดแย้งกับข้อกำหนดด้านความเป็นส่วนตัว หากข้อมูลภายใน prompt มี PII (Personally Identifiable Information) หรือข้อมูลที่อ่อนไหว องค์กรต้องใช้แนวทางที่ชัดเจน ได้แก่ data minimization, การลบหรือทำให้ไม่สามารถระบุตัวตน (pseudonymization/tokenization), การเข้ารหัสทั้งที่เหลือ (at-rest) และระหว่างทาง (in-transit) และนโยบาย retention ที่ชัดเจนเพื่อตอบคำขอจากผู้ใช้และข้อกำกับดูแล
นอกจากนี้ มีความต้องการด้านความโปร่งใส (transparency) ในบางโดเมน เช่น การตัดสินสินเชื่อ, การประกันภัย หรือการให้คำปรึกษาทางการแพทย์ ซึ่งหน่วยงานกำกับดูแลอาจเรียกร้องให้เปิดเผยเหตุผลหรือหลักเกณฑ์ที่ใช้ในการตัดสินใจของระบบ AI ในบริบทนี้องค์กรต้องเตรียมบันทึกการตัดสินใจ (decision records), model cards และ justification logs ที่สามารถอธิบายผลลัพธ์ได้โดยไม่ละเมิดความเป็นส่วนตัวของผู้ใช้
แนวปฏิบัติที่แนะนำสำหรับการสร้างแพลตฟอร์มสังเกตการณ์ที่เชื่อถือได้
- Governance ของ Prompt และ Versioning: จัดตั้ง Prompt Registry ที่เก็บเวอร์ชันของ prompt, metadata ของบริบทการใช้งาน, ผู้อนุมัติ และการเปลี่ยนแปลงทุกครั้ง ให้ prompt เป็นสิ่งที่ immutable เมื่อถูกนำไปใช้จริง พร้อม workflow การอนุมัติและการทดสอบก่อน deployment
- Synthetic Testing และ Golden Datasets: สร้างชุดทดสอบสังเคราะห์ที่ครอบคลุมกรณีมุม (corner cases), ข้อโจมตีเชิงตัวอย่าง (adversarial prompts) และชุดข้อมูลอ้างอิง (golden datasets) เพื่อรันทดสอบอัตโนมัติทั้งใน staging และก่อนการเปลี่ยนแปลง prompt/model ใด ๆ
- Continuous Evaluation และ Canary/Shadow Deployments: ใช้ pipeline ที่ทำการประเมินโมเดลแบบเรียลไทม์ (online evaluation) และแบบเป็นช่วง (batch) ทั้งใน production โดยใช้ canary หรือ shadow traffic ก่อนเปิดใช้งานเต็มรูปแบบ เพื่อตรวจจับ regression และ drift
- SLO ที่ผูกกับ KPI ธุรกิจ: กำหนด SLO เช่น latency median/95th percentile, อัตร hallucination/higher-confidence errors, อัตรการแก้ปัญหาผ่าน LLM (resolution rate) และผูกกับ KPI ธุรกิจ เช่น CSAT, conversion หรือเวลาตอบสนอง ตัวอย่าง: ตั้งเป้า CSAT ≥ 90% หรือ latency 95th ≤ 800 ms แล้วออกแบบการแจ้งเตือนเมื่อ SLO เบี่ยงเบน
- การออกแบบ Alerting เพื่อลด False Positives: ใช้การตรวจจับความผิดปกติแบบ multi-signal correlation, dynamic baselining, และ debounce windows รวมทั้งจัดลำดับความสำคัญของ alerts และรวมการแจ้งเตือนที่เกี่ยวข้องเป็น incidentเดียว โดยสำรอง alert suppression และ periodic tuning ของ threshold
- Playbooks และ Incident Response: พัฒนา incident playbooks ที่เป็นรูปธรรมสำหรับเหตุการณ์ทั่วไป (เช่น โมเดลเกิด hallucination เป็นชุด, การรั่วไหลของ PII, ความล้มเหลวของ integration) ระบุบทบาท (owner, comms, legal), ขั้นตอนการกักกัน (containment), การย้อนกลับ (rollback), การสื่อสารภายใน/ภายนอก และขั้นตอน postmortem
- Tabletop Exercises และการฝึกซ้อม: จัด tabletop exercises อย่างน้อยทุก 6–12 เดือน โดยจำลองเหตุการณ์จริงหลายรูปแบบ (เช่น data leak, model drift, regulator inquiry) เพื่อทดสอบ playbook, การประสานงานข้ามทีมและเวลาตอบสนอง วัดผลเป็นตัวชี้วัด เช่น Mean Time To Detect (MTTD) และ Mean Time To Resolve (MTTR)
- นโยบายความเป็นส่วนตัวและการปฏิบัติตามข้อกำกับ: รวมการประเมินผลกระทบด้านความเป็นส่วนตัว (DPIA), การจัดการคำขอข้อมูลจากผู้ใช้ (DSAR), การควบคุมการเข้าถึงแบบมีกฎ และการบันทึกการเข้าถึงข้อมูลเพื่อรองรับการตรวจสอบจากภายในและภายนอก
โดยสรุป การออกแบบแพลตฟอร์มสังเกตการณ์ AI ที่ผสาน Telemetry‑Prompt‑Trace กับเมตริกธุรกิจต้องเดินสองแนวทางควบคู่กันคือการสร้างความสามารถทางเทคนิคที่ยืดหยุ่นและคุ้มค่า ในขณะเดียวกันก็ต้องวางกรอบกฎหมายและจริยธรรมที่เข้มแข็ง การนำแนวปฏิบัติเช่น prompt versioning, synthetic testing, SLO ผูกกับ KPI และ tabletop exercises มาใช้เป็นกลไกสำคัญที่จะช่วยให้องค์กรสามารถตรวจจับ แก้ไข และป้องกันปัญหา LLM แบบเรียลไทม์ได้อย่างมีประสิทธิภาพและเชื่อถือได้
บทสรุป
การผสาน Telemetry‑Prompt‑Trace เข้ากับเมตริกทางธุรกิจทำให้องค์กรสามารถไล่สาเหตุของข้อผิดพลาดใน LLM ได้อย่างแม่นยำและลดผลกระทบต่อประสบการณ์ผู้ใช้และรายได้ได้อย่างมีประสิทธิภาพ โดย Telemetry ให้ภาพเชิงปริมาณ (เช่น latency, error rate, token usage), Prompt‑trace เชื่อมโยงคำสั่งกับผลลัพธ์ของโมเดล และ Trace ช่วยย้อนกลับเหตุการณ์การทำงานแบบ end‑to‑end เมื่อนำข้อมูลเหล่านี้มาผสานกับ KPI ทางธุรกิจ — เช่น อัตราการแปลง (conversion), อัตราการยกเลิก (churn) หรือรายได้ต่อผู้ใช้ — ทีมงานสามารถระบุสาเหตุรากฐาน (root cause) ของปัญหา เช่น hallucination, latency spike หรือ prompt drift และลดเวลาการแก้ไข (MTTR) ได้อย่างมีนัยสำคัญ (ตัวอย่างเช่นมีงานศึกษาชี้ว่า observability สามารถลด MTTR ได้ในระดับหลักสิบเปอร์เซ็นต์ในหลายกรณี). นอกเหนือจากการเก็บข้อมูลเชิงเทคนิคแล้ว การออกแบบสถาปัตยกรรมที่รองรับการเก็บและเชื่อมโยงสัญญาณเหล่านี้ การตั้งค่า SLO ที่ผูกกับ KPI ทางธุรกิจ และแนวปฏิบัติด้านความเป็นส่วนตัว (เช่น การลดข้อมูลส่วนบุคคล, การทำ anonymization, การเข้ารหัส และการกำกับดูแลข้อมูล) กลายเป็นหัวใจสำคัญของการนำแพลตฟอร์ม observability มาใช้งานอย่างยั่งยืน ปลอดภัย และสอดคล้องกับข้อบังคับต่าง ๆ
มุมมองอนาคตชี้ให้เห็นว่าแพลตฟอร์ม observability ที่ผสาน Telemetry‑Prompt‑Trace กับเมตริกธุรกิจจะพัฒนาไปสู่การตรวจจับเชิงคาดการณ์และการตอบสนองอัตโนมัติ (automated remediation) มากขึ้น โดยใช้การเรียนรู้จากเหตุการณ์ซ้ำและ playbook ที่เชื่อมโยงกับ SLO/KPI เพื่อยกระดับความน่าเชื่อถือของระบบ LLM ในระดับองค์รวม อีกทั้งการกำหนดมาตรฐานการสังเกตการณ์ การวัดค่า hallucination/ความถูกต้องเชิงธุรกิจ และกรอบปฏิบัติด้านความเป็นส่วนตัว-จริยธรรมจะช่วยให้องค์กรสามารถขยายการใช้งาน LLM ได้อย่างมั่นคงและเป็นไปตามกฎระเบียบ ในระยะยาว ความสามารถในการเชื่อมโยงสัญญาณเชิงเทคนิคกับผลลัพธ์ทางธุรกิจจะกลายเป็นข้อได้เปรียบเชิงแข่งขันสำคัญสำหรับองค์กรที่ต้องการใช้ AI ในการขับเคลื่อนคุณค่าทางธุรกิจอย่างต่อเนื่อง



