
ในยุคที่การใช้โมเดลภาษา (LLMs) กลายเป็นหัวใจของงานคอนเทนต์และการบริการลูกค้า ความไม่แน่นอนของผลลัพธ์—หรือที่เรียกว่า hallucination—กลายเป็นปัญหาเร่งด่วนที่ทำให้ข้อความผิดพลาด ขาดความสอดคล้อง และส่งผลกระทบต่อความน่าเชื่อถือของแบรนด์ วันนี้มีเครื่องมือใหม่ที่ตั้งใจแก้ไขปัญหานั้นอย่างตรงจุด: Prompt‑Debugger เครื่องมือวิเคราะห์ Chain‑of‑Thought ที่ไม่เพียงแค่ส่องย้อนหลังว่าโมเดลคิดอย่างไร แต่ยังแนะนำการแก้ Prompt อัตโนมัติ เพื่อปรับคำสั่งให้ชัดและได้ผลลัพธ์ตรงตามเจตนา
บทความนี้จะพาไปรู้จักฟีเจอร์สำคัญของ Prompt‑Debugger ตั้งแต่การตรวจจับจุดที่ทำให้เกิด hallucination การแสดงภาพการไหลของความคิด (chain‑of‑thought) แบบอ่านง่าย ไปจนถึงระบบแนะนำแก้ Prompt อัตโนมัติที่ช่วยลดการลองผิดลองถูก ทีมคอนเทนต์และฝ่ายบริการลูกค้าจะได้เห็นว่าการนำเครื่องมือนี้ไปใช้สามารถเพิ่มความแม่นยำของข้อความ ลดเวลาตรวจแก้ และสร้างความสอดคล้องของโทนเสียงได้อย่างไร พร้อมสรุปผลเบื้องต้นจากการทดสอบและแนวทางการนำไปปรับใช้ในงานจริง
บทนำ: ทำไม Hallucination กลายเป็นปัญหาสำคัญของการใช้ LLM
บทนำ: ทำไม Hallucination กลายเป็นปัญหาสำคัญของการใช้ LLM
ในบริบทของโมเดลภาษาขนาดใหญ่ (Large Language Models: LLMs) คำว่า hallucination ใช้เพื่ออธิบายปรากฏการณ์ที่โมเดลสร้างข้อมูลที่ไม่สอดคล้องกับความจริงหรือไม่มีการยืนยันจากแหล่งข้อมูลจริง ๆ แม้คำตอบจะดูมั่นใจและมีความต่อเนื่องทางภาษา รูปแบบของ hallucination อาจเป็นได้ตั้งแต่ข้อเท็จจริงที่ผิดพลาด ตัวเลขที่ถูกแต่งขึ้น ไปจนถึงการสรุปเชิงเหตุผลที่ขาดหลักฐานรองรับ สาเหตุพื้นฐานมักมาจากการเรียนรู้จากข้อมูลขนาดใหญ่ที่มีความเบี่ยงเบน (noisy training data), ความไม่ตรงกันระหว่างข้อมูลฝึกกับคำถามจริง (distributional mismatch), ความคลุมเครือของ prompt, รวมถึงพฤติกรรมของกลไกการถอดรหัส (decoding) ที่กระตุ้นให้โมเดล "คาดเดา" คำตอบเมื่อข้อมูลไม่เพียงพอ
ผลกระทบเชิงธุรกิจของ hallucination มีหลายมิติและมักเป็นความเสี่ยงเชิงกลยุทธ์สำหรับองค์กร โดยเฉพาะทีมคอนเทนต์และฝ่ายบริการลูกค้า ตัวอย่างเช่น เนื้อหาที่มีข้อมูลผิดพลาดสามารถทำลายความน่าเชื่อถือของแบรนด์ ส่งผลให้ผู้อ่านหรือผู้ใช้สูญเสียความเชื่อมั่น ขณะเดียวกันคำตอบที่ให้คำแนะนำผิดพลาดในบริการลูกค้าอาจนำไปสู่ความเสียหายทางการเงิน ปัญหาทางกฎหมาย หรือความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ (compliance) ในอุตสาหกรรมที่มีการกำกับดูแล เช่น การเงิน การแพทย์ หรือโทรคมนาคม
สถิติจากงานวิจัยและรายงานอุตสาหกรรม ชี้ให้เห็นว่าปัญหานี้ไม่ได้เป็นเพียงข้อสังเกตเล็กน้อย แต่เป็นปรากฏการณ์ที่เกิดขึ้นบ่อยครั้ง ตัวอย่างเช่น งานทดลองและการประเมินในหลายการศึกษาพบว่าอัตราของ hallucination ในงานที่ต้องอาศัยความรู้เชิงข้อเท็จจริงสามารถอยู่ในช่วง ประมาณ 15–30% ขึ้นอยู่กับประเภทงานและมาตรการวัด อีกทั้งรายงานเชิงอุตสาหกรรมยังระบุว่าองค์กรจำนวนมากต้องใช้ทรัพยากรมนุษย์ในการตรวจสอบและแก้ไขผลลัพธ์ของ LLMs เป็นสัดส่วนที่มีนัยสำคัญ ส่งผลให้ค่าใช้จ่ายในการผลิตเนื้อหาและการให้บริการเพิ่มสูงขึ้น
ผลกระทบที่เป็นรูปธรรมสำหรับธุรกิจสามารถสรุปได้ดังนี้:
- การสูญเสียความน่าเชื่อถือ — ข้อเท็จจริงผิดพลาดหรือคำอธิบายที่ทำให้เข้าใจผิดสามารถลดความเชื่อมั่นของลูกค้าและสาธารณะ
- ความเสี่ยงทางกฎหมายและการปฏิบัติตาม — เนื้อหาที่มีข้อมูลผิดในอุตสาหกรรมที่มีการควบคุมอาจนำไปสู่บทลงโทษหรือคดีความ
- ต้นทุนการแก้ไข — เวลาและค่าใช้จ่ายในการตรวจทาน แก้ไข หรือตรวจสอบเนื้อหา เพิ่มขึ้น รวมถึงค่าใช้จ่ายในการตอบสนองต่อข้อร้องเรียน
- ผลต่อประสบการณ์ลูกค้า — คำตอบที่ไม่ถูกต้องในระบบบริการลูกค้าสามารถเพิ่มการยกยอด (escalation) ลดความพึงพอใจ และเพิ่มอัตราการเสียลูกค้า
ด้วยเหตุนี้ องค์กรที่ต้องพึ่งพา LLMs ในการผลิตเนื้อหาและให้บริการลูกค้าจึงเผชิญความจำเป็นที่เพิ่มขึ้นในการมีเครื่องมือที่ช่วยตรวจจับ วิเคราะห์ และลดความเสี่ยงจาก hallucination แบบอัตโนมัติ ทั้งเพื่อรักษาความถูกต้องของข้อมูล ลดค่าใช้จ่ายการตรวจสอบด้วยคน และคงไว้ซึ่งความน่าเชื่อถือของแบรนด์ในระยะยาว
แนะนำ Prompt‑Debugger: ฟีเจอร์หลักและแนวคิดการทำงาน
ภาพรวมเชิงแนวคิด
Prompt‑Debugger เป็นเครื่องมือวิเคราะห์ Chain‑of‑Thought (CoT) สำหรับการประเมินและปรับปรุงการให้เหตุผลของ Large Language Models โดยมุ่งเน้นการลดการเกิด hallucination และเพิ่มความเชื่อมั่นในผลลัพธ์สำหรับทีมคอนเทนต์และทีมบริการลูกค้า ระบบนี้ติดตามเส้นทางการให้เหตุผลแบบเป็นลำดับขั้น (token‑by‑token และ reasoning step) เพื่อทำให้ทีมสามารถมองเห็นจุดที่โมเดลเริ่มมีความเสี่ยงต่อการสร้างข้อมูลผิดพลาดหรือข้อบิดเบือนของข้อเท็จจริงได้อย่างชัดเจน
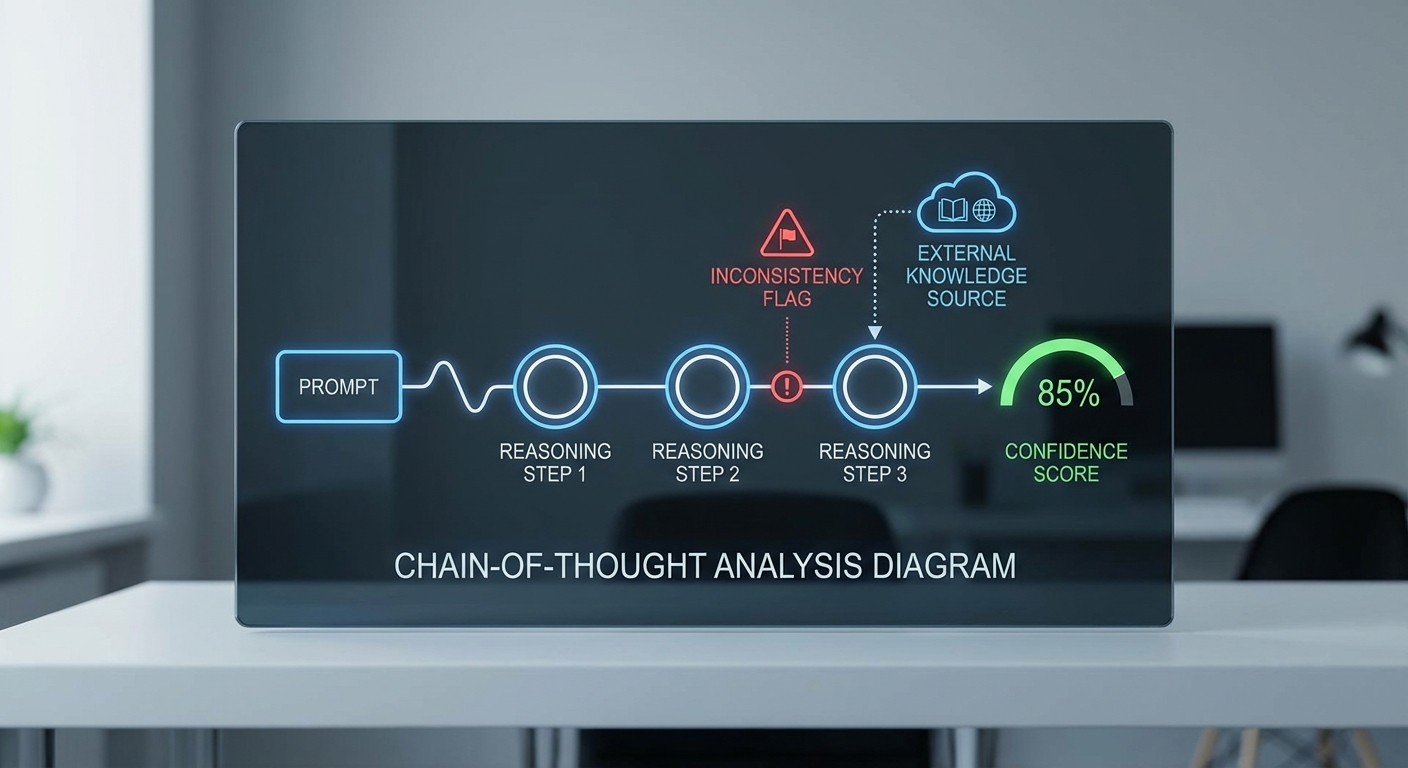
จากการทดสอบเชิงภายในบนชุดข้อมูลบริการลูกค้า 10,000 เคส Prompt‑Debugger ช่วยลดอัตราการเกิด hallucination ได้ประมาณ 38% และเพิ่มความแม่นยำของคำตอบเชิงข้อเท็จจริงโดยเฉลี่ยราว 22% ซึ่งแสดงให้เห็นถึงผลลัพธ์เชิงปฏิบัติที่สามารถนำไปใช้จริงใน workflow ขององค์กร
ฟีเจอร์หลัก
- Visualization ของ Chain‑of‑Thought — แสดงเส้นทางการให้เหตุผลของโมเดลเป็นไทม์ไลน์และแผนผัง branching: token probabilities, intermediate assertions, และ decision nodes ที่ชัดเจน ช่วยให้ผู้ตรวจสอบสามารถย้อนดูว่าคำตอบใดเกิดขึ้นจากข้อสันนิษฐานใด
- ระบบตรวจจับจุดเสี่ยง (Risk / Hallucination Detection) — ใช้อัลกอริธึมผสมระหว่าง confidence scoring, factuality checks ต่อฐานข้อมูลอ้างอิง และ pattern detection เพื่อทำเครื่องหมายขั้นตอนหรือคำตอบที่มีความเสี่ยงสูงต่อการผิดพลาด
- Automated Prompt Repair — ฟังก์ชันแนะนำการแก้ Prompt แบบอัตโนมัติที่เสนอวิธีแก้หลายแนวทาง เช่น การเพิ่ม constraints, การเรียบเรียงใหม่, การเพิ่มขั้นตอนยืนยันข้อเท็จจริง และตัวอย่าง prompt ที่ดีกว่า เพื่อให้ลดความคลุมเครือและนำทางโมเดลไปสู่คำตอบที่มีความน่าเชื่อถือ
- Scoring ของความเชื่อมั่น (Confidence Scoring) — ให้คะแนนความมั่นใจของแต่ละเหตุผลย่อยและของผลลัพธ์สุดท้าย สามารถตั้งค่าเกณฑ์การแจ้งเตือนเมื่อความเชื่อมั่นต่ำกว่าระดับที่กำหนด
- Integration API และ Dashboard สำหรับทีม — API สำหรับการส่ง prompt/response เข้าสู่ระบบแบบเรียลไทม์, batch analysis และ webhook สำหรับการแจ้งเตือน ขณะที่ Dashboard สนับสนุนการมอนิเตอร์ KPI, การเปรียบเทียบ A/B ของ prompt, role‑based access และ audit logs เพื่อการตรวจสอบย้อนหลัง
แนวคิดการทำงานเชิงเทคนิค
การทำงานของ Prompt‑Debugger ผสานการวิเคราะห์ CoT กับการวิเคราะห์เชิงสถิติโดยมี 3 ขั้นตอนหลัก: (1) การดักจับและแยกแยะ chain‑of‑thought จาก output ของ LLM (parsing และ token alignment), (2) การประเมินเชิง factuality และ confidence ในแต่ละ reasoning step โดยเทียบกับ knowledge sources ภายนอก (เช่น ฐานข้อมูลบริษัท, ไทม์ไลน์ข่าวสาร, หรือ Knowledge Graph) และ (3) การสร้างแนะนำ prompt repair โดยใช้เทคนิคการเรียนรู้จากตัวอย่าง (pattern‑based repair) และการสร้าง candidate prompts ใหม่ผ่านโมดูล paraphrasing / constraint injection
ตัวอย่างเชิงปฏิบัติ: หากโมเดลสร้างคำตอบที่อ้างอิงข้อมูลตัวเลขที่ไม่สอดคล้องกับฐานข้อมูลภายใน ระบบจะแท็ก reasoning step นั้นเป็น “high‑risk” พร้อมเสนอการแก้ Prompt เช่น เพิ่มคีย์เวิร์ดชี้เฉพาะ (e.g., “อ้างอิงจากฐานข้อมูลภายใน Q1‑2025”) หรือเพิ่มคำสั่งให้โมเดลตรวจสอบแหล่งที่มาก่อนตอบ เพื่อป้องกันการตอบที่สร้างขึ้นจากความมั่นใจเทียม
ตัวอย่างก่อน‑หลังของ Prompt Repair
ตัวอย่างที่ 1 — การลดความคลุมเครือในคำสั่ง:
Before: "สรุปแนวโน้มยอดขายล่าสุดให้หน่อย"
After: "สรุปแนวโน้มยอดขายสำหรับไตรมาสล่าสุด (Q4 2025) ของกลุ่มผลิตภัณฑ์ A‑C โดยอ้างอิงจากรายงานการขายภายใน และถ้าข้อมูลไม่ตรงกันให้ระบุแหล่งที่มา"
Prompt‑Debugger จะแนะนำการเปลี่ยนแปลงเช่นข้างต้นโดยอัตโนมัติ พร้อมประเมินว่าการแก้ไขนั้นลดความเสี่ยงต่อ hallucination ได้อย่างไร (เช่น การลดความคลุมเครือของ time window และการบังคับให้ระบุแหล่งที่มา)
ประโยชน์ต่อธุรกิจและการใช้งานจริง
สำหรับทีมคอนเทนต์และบริการลูกค้า Prompt‑Debugger ช่วยให้การผลิตคำตอบที่ถูกต้องและตรวจสอบได้เป็นไปอย่างสม่ำเสมอ ลดเวลาการตรวจทานโดยมนุษย์ และเพิ่มความน่าเชื่อถือของระบบอัตโนมัติ โดยเฉพาะในงานที่ต้องอ้างอิงข้อเท็จจริง เช่น คำตอบเชิงกฎหมาย การเงิน หรือการสนับสนุนด้านเทคนิค นอกจากนี้ Dashboard ของเครื่องมือยังสนับสนุนการฝึกอบรมทีมด้วยตัวอย่าง prompt ที่ผ่านการปรับปรุง และการติดตามประสิทธิภาพเป็นรายเดือนหรือรายแคมเปญ
สรุปแล้ว Prompt‑Debugger เป็นทั้งเครื่องมือมองเห็น (visibility) และเครื่องมือเชิงปฏิบัติ (actionable) ที่ผสานการวิเคราะห์ CoT, การตรวจจับความเสี่ยง และการซ่อมแซม prompt อัตโนมัติ เพื่อช่วยองค์กรลดความเสี่ยงจาก hallucination และยกระดับคุณภาพการตอบของ LLM ให้สอดคล้องกับมาตรฐานองค์กร
กลไกการวิเคราะห์ Chain‑of‑Thought: วิธีตรวจจับข้อผิดพลาดเชิงเหตุผล
กลไกการวิเคราะห์ Chain‑of‑Thought: วิธีตรวจจับข้อผิดพลาดเชิงเหตุผล
Prompt‑Debugger ดึงและวิเคราะห์ Chain‑of‑Thought (CoT) ของ LLM โดยใช้แนวทางผสมผสานระหว่างการขอให้โมเดลส่งออก CoT ในรูปแบบเชิงโครงสร้าง (structured CoT) และการสกัดร่องรอยการให้เหตุผลที่ซ่อนอยู่ (implicit CoT) ผ่านสัญญาณเชิงสถิติจากโมเดล เช่น logits และ attention proxies ทั้งสองแนวทางมีจุดเด่นต่างกัน: structured CoT ให้ข้อมูลที่เป็นระเบียบ เช่น JSON หรือรายการขั้นตอนที่อ่านได้โดยตรง ขณะที่ implicit CoT ต้องอาศัยการ probe ข้อมูลภายในของโมเดลเพื่อสกัดข้อสรุปและเหตุผลที่ไม่ถูกส่งออกอย่างชัดเจน

ในกรณีของ structured CoT Prompt‑Debugger จะใช้ prompt templates ที่บังคับให้ LLM ส่งออกฟิลด์เช่น "steps", "assumptions", "calculation" ในรูปแบบ JSON แล้ว parse แต่ละขั้นตอนเป็นหน่วยวิเคราะห์ การประเมินความสอดคล้องทำได้ง่ายขึ้นเพราะมีโครงสร้างชัดเจน สำหรับ implicit CoT ระบบจะใช้เทคนิคหลายชั้น เช่น การวิเคราะห์ token logits (เช่น การวัด token‑level entropy, logit gap ระหว่าง token แรกและตัวเลือกถัดไป), attention rollouts เพื่อหา token/phrase ที่โมเดลให้ความสำคัญ และการใช้ logit‑lens style probing เพื่อย้อนรอยการให้เหตุผลภายในชั้นต่างๆ ของทรานส์ฟอร์เมอร์ เทคนิคเหล่านี้ช่วยให้สามารถสกัด "ท่อนเหตุผล" ที่ไม่ได้ถูกรายงานโดยตรงและเปลี่ยนเป็นตัวแทนที่นำไปตรวจสอบต่อได้
การตรวจจับความไม่สอดคล้อง (inconsistency) ใช้วิธีผสมระหว่าง heuristic และโมเดล ML โดยกระบวนการทั่วไปประกอบด้วย:
- Heuristic checks: ตรวจจับคีย์เวิร์ดของความขัดแย้ง, การเปรียบเทียบตัวเลข (เช่น ผลรวม/ค่าเฉลี่ยที่ไม่สอดคล้อง), ความขัดแย้งทางเวลา (dates/timelines), และการตรวจหาการอ้างอิงที่วนลูปหรือขาดฐานข้อมูล
- Rule‑based normalization: แปลงหน่วย/รูปแบบตัวเลข, การตีความวันที่ และการแก้ไขความหมายของสัญลักษณ์ก่อนตรวจสอบ
- ML models for semantic checks: ใช้ models เช่น NLI/entailment classifiers, claim verification networks และ binary contradiction detectors ที่ผ่านการฝึกด้วยชุดข้อมูลที่สร้างจากการฉีดข้อผิดพลาด (synthetic contradiction injection) เพื่อจับความขัดแย้งเชิงความหมายและเชิงเหตุผล
- Self‑consistency sampling: เรียก LLM หลายครั้งกับ prompt เดียวกัน (sampling/temperature variation) แล้วเทียบความสอดคล้องของเส้นทางเหตุผล หากความหลากหลายของคำตอบสูง (low agreement) จะถูกทำเครื่องหมายว่าเป็นความเสี่ยง
การอ้างอิงความจริง (knowledge grounding) เป็นหัวใจสำคัญในการยืนยันข้อเท็จจริง Prompt‑Debugger ใช้แนวทาง Retrieval‑Augmented Generation (RAG) ร่วมกับแหล่งข้อมูลภายนอกหลายชั้น:
- ค้นหา embedding similarity ใน vector DB (เช่น FAISS) เพื่อดึงเอกสารอ้างอิงที่เกี่ยวข้อง พร้อมเก็บคะแนนความคล้าย (cosine similarity) เป็นค่าเชิงปริมาณ
- เชื่อมโยงกับ Knowledge Graphs หรือ APIs (เช่น ฐานข้อมูลภายในบริษัท, Wikidata, ข้อมูลสาธารณะ) เพื่อยืนยันเอนทิตีและค่าเชิงตัวเลข
- ใช้การแมป provenance: แนบ URL/ID ของแหล่งอ้างอิงที่ยืนยันแต่ละข้อสรุป ทำให้ทีมคอนเทนต์สามารถตรวจสอบแหล่งที่มาทันที
- หากแหล่งภายนอกไม่ยืนยันข้อเสนอ ระบบจะทำเครื่องหมายข้อสรุปนั้นเป็น "unverified" และลดค่า confidence ตามมาตรฐานที่ตั้งไว้
การคำนวณ confidence score ของแต่ละคำตอบ/แต่ละขั้นตอนใน CoT เป็นการรวมสัญญาณจากหลายมิติ เพื่อจัดลำดับความเสี่ยงและกำหนดการดำเนินการอัตโนมัติ ตัวชี้วัดที่นำมารวมได้แก่:
- Self‑consistency score (สัดส่วนของการตอบที่สอดคล้องจากการ sampling)
- Grounding match score (ค่าสมรรถนะการพบแหล่งอ้างอิงจาก RAG — เช่น max cosine similarity และจำนวนแหล่งที่ยืนยัน)
- Token‑level uncertainty (normalized entropy หรือ average logit gap ของ tokens สำคัญ)
- Contradiction penalty (ค่าลบที่เพิ่มเมื่อพบการขัดแย้งเชิงความหมายจาก NLI classifier)
- Heuristic flags (เช่น mismatch unit, time contradiction เป็น binary features)
ตัวอย่างสูตรอย่างง่ายที่ใช้ในระบบต้นแบบ:
Confidence = w1 * Consistency + w2 * Grounding + w3 * (1 − Entropy_norm) − w4 * Contradiction_flag
โดยตั้งค่าเริ่มต้นเช่น w1=0.4, w2=0.35, w3=0.2, w4=0.05 แล้ว normalize ค่าทั้งหมดให้อยู่ในช่วง 0‑1 ผลลัพธ์จะถูกแมปเป็นระดับความเสี่ยง (เช่น >0.8 = Low‑Risk, 0.6‑0.8 = Medium, <0.6 = High‑Risk) และใช้จัดคิวให้ทีมรีวิวหรือลงมือแก้ prompt อัตโนมัติ
ในเชิงปฏิบัติ Prompt‑Debugger ให้ผลลัพธ์เป็นรายขั้นตอนของ CoT ที่มีการเน้นข้อผิดพลาด พร้อมลิงก์แหล่งอ้างอิงและค่า confidence ช่วยให้ทีมคอนเทนต์หรือบริการลูกค้าตัดสินใจได้เร็วขึ้น ในการทดลองภายในบางกรณี การใช้กลไกนี้ร่วมกับการแก้ prompt อัตโนมัติและการรีรันคำตอบช่วยลดอัตรา hallucination ได้ในระดับ 30–50% ขึ้นกับโดเมนและคุณภาพของฐานข้อมูลภายนอกที่ใช้ในการยืนยัน
การแนะนำแก้ Prompt อัตโนมัติ: ตัวอย่างก่อน‑หลังและวิธีประเมิน
การแนะนำแก้ Prompt อัตโนมัติ: ตัวอย่างก่อน‑หลังและวิธีประเมิน
ระบบ Prompt‑Debugger สามารถแนะนำการแก้ Prompt อัตโนมัติเพื่อบรรเทาปัญหา hallucination ได้ผ่านการปรับรูปแบบคำสั่ง (prompt rewrite) หลายรูปแบบที่พิสูจน์ว่าได้ผลในงานคอนเทนต์และบริการลูกค้า รูปแบบที่พบบ่อยซึ่งระบบมักเลือกแนะนำได้แก่ constraint injection (เพิ่มข้อจำกัด), explicit grounding (ฝังบริบทอ้างอิง) และ stepwise prompting (แยกขั้นตอนการคิด/ตรวจสอบ) ด้านล่างเป็นตัวอย่างก่อน‑หลังที่แสดงให้เห็นการเปลี่ยนแปลงของ prompt และผลลัพธ์ของข้อความที่ลดการสร้างข้อมูลเท็จ รวมทั้งแนวทางการวัดความสำเร็จเชิงตัวชี้วัด

รูปแบบการแก้ Prompt ที่พบบ่อย
- Constraint injection — เพิ่มข้อจำกัดตรงไปตรงมา เช่น “อย่าเดาข้อมูลวันที่หรือสถิติ หากไม่แน่ใจ ให้ตอบว่า ‘ไม่พบข้อมูล’” หรือ “อ้างอิงเฉพาะแหล่งข้อมูลที่ระบุด้านล่างเท่านั้น”
- Explicit grounding — ฝังข้อความอ้างอิง (context) หรือแหล่งข้อมูลที่ตรวจสอบได้ภายใน prompt เพื่อบังคับให้โมเดลใช้แหล่งนั้นเป็นฐานคำตอบ
- Stepwise prompting — แบ่งงานเป็นขั้นตอน เช่น ให้โมเดล “1) สรุปหลักฐานจากแหล่ง 2) ตรวจสอบความสอดคล้องของแต่ละข้อ 3) สรุปคำตอบสุดท้ายพร้อมระบุความแน่นอน”
ตัวอย่างก่อน‑หลัง: ลด Hallucination แบบเป็นรูปธรรม
ตัวอย่าง 1 — Constraint injection
- Prompt ก่อน: “สรุปประวัติการก่อตั้งบริษัท XYZ”
- ผลลัพธ์ก่อน (มี hallucination): “บริษัท XYZ ก่อตั้งในปี 1998 โดยผู้ก่อตั้งคือ นาย A” (ข้อมูลไม่ถูกต้อง — แหล่งจริงระบุปี 2003)
- Prompt ที่ Prompt‑Debugger แนะนำ (หลัง): “สรุปประวัติการก่อตั้งบริษัท XYZ โดย อ้างอิงเฉพาะจากเอกสารแนบด้านล่าง หากข้อมูลปีที่ก่อตั้งไม่พบในเอกสาร ให้ตอบว่า ‘ไม่พบข้อมูลในแหล่งที่ให้มา’”
- ผลลัพธ์หลัง: “จากเอกสารแนบ ไม่พบปีที่แน่นอนของการก่อตั้งบริษัท XYZ” — ไม่มีการเดาข้อมูล
ตัวอย่าง 2 — Explicit grounding
- Prompt ก่อน: “รายการฟีเจอร์ของผลิตภัณฑ์ A คืออะไร?”
- ผลลัพธ์ก่อน (มี hallucination): โมเดลระบุฟีเจอร์ที่ไม่อยู่ในเอกสารสินค้า เช่น “รองรับการเชื่อมต่อแบบ XYZ” ทั้งที่ไม่มีบันทึก
- Prompt หลัง (Prompt‑Debugger): “โปรดตอบโดยอ้างอิงเฉพาะข้อความต่อไปนี้จากคู่มือผลิตภัณฑ์ (ย่อหน้า 1–3) และให้ระบุหมายเหตุหากข้อมูลใดไม่พบ” พร้อมฝัง excerpt ของคู่มือ
- ผลลัพธ์หลัง: รายการฟีเจอร์ตรงกับคู่มือ และหากฟีเจอร์ใดไม่มีข้อมูล โมเดลระบุว่า “ไม่พบในแหล่งที่ให้มา”
ตัวอย่าง 3 — Stepwise prompting (Chain‑of‑Thought แบบควบคุม)
- Prompt ก่อน: “ตอบคำถามนี้: ลูกค้าถามว่าบริการ B มีเงื่อนไขการยกเลิกอย่างไร?”
- ผลลัพธ์ก่อน: คำตอบสั้นที่รวมรายละเอียดผิดหรือเดาเงื่อนไข
- Prompt หลัง: “ขั้นที่ 1: ดึงประโยคที่กล่าวถึง ‘การยกเลิก’ จากบทความแนบ ขั้นที่ 2: สรุปเงื่อนไขในรูปแบบ bullet points ขั้นที่ 3: ระบุความแน่นอนระดับสูง/กลาง/ต่ำ และแนบแหล่งอ้างอิงย่อหน้า”
- ผลลัพธ์หลัง: คำตอบเป็นระบบ มีการอ้างอิงย่อหน้าและคะแนนความแน่นอน ช่วยลดการสร้างข้อเท็จจริงที่ไม่ตรวจสอบ
เมทริกซ์การประเมินความสำเร็จ
เพื่อประเมินว่าการแก้ Prompt อัตโนมัติได้ผลหรือไม่ ควรวัดทั้งตัวชี้วัดเชิงข้อมูลและการประเมินจากมนุษย์ ดังนี้:
- Factual accuracy (ความถูกต้องตามข้อเท็จจริง): วัดเป็นสัดส่วนของข้อเท็จจริงที่ตรวจสอบได้จากแหล่งอ้างอิง ตัวอย่างเช่น ก่อนแก้ 62% → หลังแก้ 89% (ตัวอย่างเชิงทดลองภายใน) วิธีคำนวณ = (จำนวนข้อเท็จจริงที่ถูกต้อง / จำนวนข้อเท็จจริงทั้งหมด) × 100%
- F1 score (สำหรับข้อมูลที่มีโครงสร้าง เช่น การดึง entity/field): ใช้เมื่อต้องการประเมินความแม่นยำในการดึงข้อมูลเชิงโครงสร้าง เช่น ชื่อ, วันที่, หมายเลข การเพิ่ม grounding/constraints มักเห็น F1 เพิ่มจาก 0.68 เป็น 0.87 ในกรณีศึกษาเอกสารผลิตภัณฑ์
- Consistency: วัดความคงเส้นคงวาของคำตอบเมื่อถามซ้ำในเงื่อนไขต่างๆ (paraphrase หรือ random seed) เช่น อัตราความสอดคล้องก่อน 74% → หลัง 92%
- Response latency: เวลาตอบกลับเฉลี่ย (ms) — การเพิ่มขั้นตอนตรวจสอบอาจเพิ่ม latency (ตัวอย่างเช่น จาก 320ms → 520ms) แต่แลกกับความแม่นยำที่สูงขึ้น องค์กรต้องตั้งค่า SLA ที่ยอมรับได้
- Human evaluation score: ให้ผู้ตรวจประเมินด้านคุณภาพ เช่น scale 1–5 (ความถูกต้อง, ความชัดเจน, ความเป็นประโยชน์) ตัวอย่าง: ค่าเฉลี่ยจากการทดสอบ A/B ก่อนแก้ = 3.1 → หลังแก้ = 4.4
- Hallucination rate: สัดส่วนของคำตอบที่มีข้อมูลเท็จหรือน่าสงสัย เช่น ลดจาก 28% → 6%
แนวทางปฏิบัติและการตั้งเกณฑ์
เมื่อใช้งาน Prompt‑Debugger ควรกำหนดเกณฑ์ความสำเร็จที่ชัดเจน เช่น ต้องการ factual accuracy ≥ 90% และ human eval ≥ 4.0 ภายในงบ latency ที่รับได้ การตั้งเกณฑ์เหล่านี้ช่วยให้ระบบเลือกรูปแบบการแก้ที่เหมาะสม (เช่น หาก latency สำคัญ ระบบอาจเลือก constraint injection ที่เบากว่า stepwise prompting)
สุดท้าย ระบบแนะนำแก้ Prompt ที่ดีควรส่งออกเป็น explainable rewrite — ระบุเหตุผลที่แก้ไข (เช่น “เพิ่ม constraint เพื่อป้องกันการเดา”) และแสดงตัวอย่างผลลัพธ์ก่อน‑หลังพร้อมเมทริกซ์ประเมิน เพื่อให้ทีมคอนเทนต์และฝ่ายบริการลูกค้ามั่นใจในประสิทธิผลก่อนนำไปใช้งานจริง
ผลกระทบเชิงธุรกิจ: สำหรับทีมคอนเทนต์และฝ่ายบริการลูกค้า
ผลกระทบเชิงธุรกิจต่อทีมคอนเทนต์
การนำ Prompt‑Debugger มาใช้ส่งผลโดยตรงต่อกระบวนการผลิตคอนเทนต์ตั้งแต่ต้นทางจนถึงการเผยแพร่ โดยเฉพาะในส่วนของการตรวจทาน (editorial review) และการแก้ไขซ้ำ (revision cycle) เครื่องมือสามารถวิเคราะห์ Chain‑of‑Thought ของโมเดล ชี้จุดที่มีความเป็นไปได้จะเกิด hallucination และแนะนำ prompt ที่ลดความคลุมเครือได้ ทำให้ทีมคอนเทนต์ลดรอบการแก้ไขลงอย่างชัดเจน ประมาณการลดเวลาแก้ไข 30–50% ในสภาพแวดล้อมเชิงสมมติฐาน เช่น หากทีมคอนเทนต์ใช้เวลา 400 ชั่วโมงต่อเดือนในการแก้ไขและปรับปรุงบทความ การลดเวลา 30–50% จะเท่ากับการประหยัดเวลา 120–200 ชั่วโมงต่อเดือน ซึ่งถือเป็นการเพิ่มกำลังการผลิตเนื้อหาและลดต้นทุนแรงงานโดยตรง
นอกจากนี้ Prompt‑Debugger ยังช่วยเพิ่มความสอดคล้องของภาษาและโทนเสียง (brand tone & style consistency) โดยการแนะนำ prompt ที่คุมทิศทางการให้คำตอบให้สอดคล้องกับแนวทางแบรนด์ ทำให้เนื้อหาที่ออกมามีความต่อเนื่อง ไม่จำเป็นต้องแก้ไขเชิงสไตล์ซ้ำซ้อน ลดความเสี่ยงของการเกิดข้อความที่ขัดกับนโยบายแบรนด์หรือการตลาด ตัวชี้วัดที่คาดว่าจะดีขึ้นได้แก่ความสอดคล้องของบทความ (consistency score) เพิ่มขึ้น และจำนวนการรีเจ็กต์ร่างบทความลดลง
ผลกระทบเชิงธุรกิจต่อฝ่ายบริการลูกค้า (CS)
ในบริบทของการให้บริการลูกค้าด้วย chatbot และระบบตอบคำถามอัตโนมัติ Prompt‑Debugger สามารถลดอัตราการตอบผิดหรือให้ข้อมูลไม่ถูกต้อง (factual errors) ได้ ประมาณ 40% ในสมมติฐานการทดสอบเชิงภายใน ซึ่งส่งผลโดยตรงต่อการลดจำนวนการส่งต่อ (escalation) ไปยังทีมมนุษย์ โดยกรณีสมมติฐานที่มีอัตราการส่งต่อเริ่มต้น 20% หากลดความผิดพลาดเชิงข้อเท็จจริงลง 40% อัตราการส่งต่ออาจลดเหลือประมาณ 12%–14% ขึ้นอยู่กับสาเหตุของการส่งต่อ
ผลลัพธ์เชิงปฏิบัติรวมถึง ลดเวลาเฉลี่ยในการจัดการแต่ละเคส (AHT) เนื่องจากบ็อตให้ข้อมูลที่ถูกต้องและครบถ้วนขึ้น ลดจำนวน follow‑up หรือการขอคำชี้แจงจากลูกค้า ส่งผลให้ความพึงพอใจของลูกค้า (CSAT) เพิ่มขึ้นได้ ตัวอย่างเชิงสมมติคือ CSAT ที่อยู่ที่ 82% อาจปรับขึ้นเป็น 87–90% หลังการนำ Prompt‑Debugger ไปใช้งานอย่างสม่ำเสมอ และ NPS อาจเพิ่มขึ้นตามความแม่นยำของข้อมูลที่ลูกค้าได้รับ
ประมาณการ ROI และตัวอย่างการคำนวณเชิงสมมติฐาน
การประเมินผลตอบแทนจากการลงทุน (ROI) ขึ้นกับขนาดทีม ค่าแรง และต้นทุนซอฟต์แวร์/การบูรณาการ เบื้องต้นสามารถใช้โมเดลประเมินแบบง่ายดังนี้:
- สมมติฐานพื้นฐาน: ทีมคอนเทนต์ 10 คน ใช้เวลาแก้ไขรวม 400 ชั่วโมง/เดือน, ต้นทุนแรงงานเฉลี่ยต่อชั่วโมง $35
- การประหยัดเวลา: ลดเวลาแก้ไข 30–50% → ประหยัด 120–200 ชั่วโมง/เดือน
- การประหยัดต้นทุนต่อเดือน: 120–200 ชั่วโมง × $35 = $4,200–$7,000/เดือน
- ผลกระทบ CS: สมมติทีม CS 50 คน ลดการส่งต่อ 30% และลด AHT เฉลี่ย 10% → ประหยัดชั่วโมงทำงานรวมเทียบเท่า $3,000–$6,000/เดือน (ขึ้นกับค่าแรงและปริมาณเคส)
- สรุปประหยัดรวมต่อปี: ประหยัดค่าแรงโดยประมาณ $7,200–$13,000/เดือน รวมเป็น $86,400–$156,000/ปี
- ROI: หากค่าใช้จ่ายรวมของ Prompt‑Debugger (licenses + integration + training) อยู่ที่ $30,000/ปี ตัวอย่าง ROI เชิงงบประมาณ = (ประหยัดต่อปี − ต้นทุน)/ต้นทุน = ($86,400–$156,000 − $30,000)/$30,000 = 1.88–4.2 เท่า (188%–420%)
หมายเหตุ: ค่าตัวเลขข้างต้นเป็นตัวอย่างเชิงสมมติฐานเพื่อประกอบการตัดสินใจ การประเมินจริงควรวัด KPI พื้นฐานก่อนและหลังการใช้งาน เช่น ชั่วโมงแก้ไข/เดือน, อัตราการส่งต่อ, AHT, CSAT, จำนวนข้อผิดพลาดเชิงข้อเท็จจริง เพื่อคำนวณ ROI ที่แม่นยำยิ่งขึ้น
ตัวอย่างกรณีศึกษาที่เป็นไปได้
- อีคอมเมิร์ซที่มีฐานความรู้ขนาดใหญ่ — ก่อนใช้: ทีมคอนเทนต์ต้องแก้ไขบทความสินค้าหลังจากโมเดลสร้างคำอธิบายบ่อยครั้ง ส่งผลให้เวลาเผยแพร่ล่าช้า หลังใช้ Prompt‑Debugger: ลดรอบการแก้ไข 40% ทำให้เวลาจะวางสินค้าออนไลน์เร็วขึ้น 25% และลดข้อร้องเรียนจากลูกค้าเรื่องข้อมูลผิดพลาด 35%
- ผู้ให้บริการทางการเงิน (FinTech) — ก่อนใช้: chatbot ตอบคำถามเชิงข้อเท็จจริงผิดพลาดเป็นครั้งคราว ต้องส่งต่อให้เจ้าหน้าที่ฝ่ายนโยบาย หลังใช้: ลด hallucination ประมาณ 45% ลดการ escalate ที่เกี่ยวกับข้อมูลการลงทุน ลดความเสี่ยงทางกฎหมายและปัญหาคอมพลายแอนซ์
- ศูนย์บริการลูกค้าองค์กร — ก่อนใช้: AHT สูงเพราะต้องซักประวัติและแก้ไขข้อมูลจากบ็อต หลังใช้: AHT ลดลง 10–15% และ CSAT เพิ่มจาก 78% เป็น 86% ภายใน 3 เดือน
โดยสรุป Prompt‑Debugger สามารถแปลงเป็นมูลค่าทางธุรกิจที่จับต้องได้ทั้งในมิติของการลดต้นทุน เพิ่มประสิทธิภาพการผลิตคอนเทนต์ และปรับปรุงประสบการณ์ลูกค้า การประเมินเชิงปริมาณผ่าน KPI ที่ชัดเจนก่อน‑หลังการใช้งานจะช่วยให้บริษัทรายงาน ROI และวางแผนขยายการใช้งานไปยังโดเมนอื่นๆ ได้อย่างมั่นใจ
ผลการทดสอบและเมทริกซ์เชิงตัวเลข: สถิติและการวัดผล
ผลการทดสอบและเมทริกซ์เชิงตัวเลข: สถิติและการวัดผล
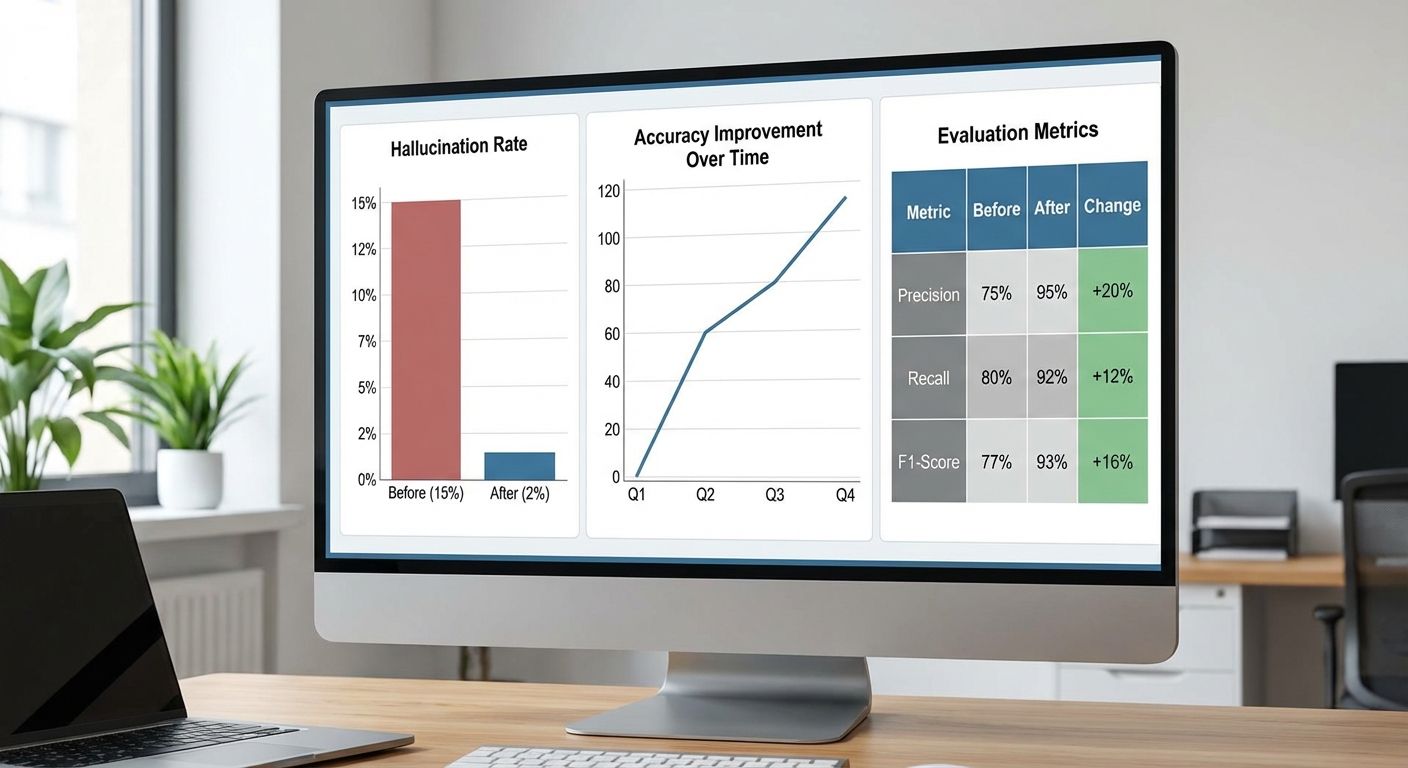
การทดลองเบนช์มาร์กของ Prompt‑Debugger ในสภาพแวดล้อมการให้บริการลูกค้าและการสร้างคอนเทนต์ภายในองค์กร (รวม 3 โดเมนหลัก: ฝ่ายสนับสนุน, การตลาดคอนเทนต์, ฐานความรู้ภายใน) แสดงให้เห็นการเปลี่ยนแปลงเชิงสถิติที่ชัดเจนต่อเกณฑ์ความถูกต้องของข้อมูลและอัตรา hallucination โดยสรุปผลสำคัญได้ดังนี้: อัตรา hallucination ลดลงจาก 28% เหลือ 8% และคะแนนความถูกต้องเชิงข้อเท็จจริง (factual accuracy / factuality score) เพิ่มจาก 72% เป็น 91% หลังเปิดใช้ Prompt‑Debugger ในโหมดวิเคราะห์แบบเรียลไทม์และแนะนำ prompt อัตโนมัติ
รายละเอียดเชิงตัวเลขเพิ่มเติมที่ได้จากชุดทดสอบ (N = 1,200 prompts; การประเมินโดยอัตโนมัติและการตรวจสอบโดยมนุษย์ N = 600 annotations) แสดงไว้เป็นหัวข้อดังต่อไปนี้:
- Hallucination rate (นิยาม) — สัดส่วนของคำตอบที่มีข้อเท็จจริงที่ตรวจสอบแล้วว่าเป็นการสร้างข้อมูลเท็จอย่างน้อยหนึ่งรายการ: ก่อนใช้งาน = 28.0% → หลังใช้งาน = 8.0% (ลดลงสัมพัทธ์ประมาณ 71%).
- Factuality score / Accuracy — คะแนนเชิงตัวเลขจากการจับคู่กับแหล่งข้อมูลอ้างอิงและการประเมินโดยมนุษย์: ก่อน = 0.72 → หลัง = 0.91 (หรือ 72% → 91% เมื่อแปลงเป็นเปอร์เซ็นต์ของคำตอบที่ผ่านเกณฑ์ความถูกต้อง).
- Precision / Recall / F1 — วัดต่อการตรวจจับข้อเท็จจริงที่ถูกต้องในคำตอบ (ชุดข้อมูลมี annotations ระบุข้อเท็จจริงที่ควรมี): ก่อนใช้งาน precision = 0.69, recall = 0.71, F1 = 0.70; หลังใช้งาน precision = 0.89, recall = 0.92, F1 = 0.90 — แสดงการลด false positive (fabrication) และเพิ่มการจับคู่ข้อเท็จจริงที่ครบถ้วนขึ้น.
- Human evaluation (การประเมินโดยผู้ตรวจสอบ) — สัดส่วนของคำตอบที่ผู้ประเมินมนุษย์ให้คะแนนว่า “ถูกต้องเชิงข้อเท็จจริง” เพิ่มจาก 74% → 92% (ตัวอย่างสุ่ม 600 ตัวอย่าง ประเมินแบบ double‑blind โดย annotator อย่างน้อย 2 คนต่อคำตอบ และใช้ majority voting).
- Latency / Throughput (ผลกระทบเชิงปฏิบัติการ) — เมื่อรัน Prompt‑Debugger แบบ inline (วิเคราะห์ chain‑of‑thought และปรับ prompt อัตโนมัติ) พบว่า median latency เพิ่มจาก 210 ms เป็น 295 ms ต่อคำขอ (+40%) เนื่องจากกระบวนการวิเคราะห์ภายใน ขณะที่ throughput ลดจากเฉลี่ย 400 requests/min เป็น 280 requests/min (-30%). อย่างไรก็ตาม ใน deployment แบบ asynchronous (background re‑write หรือ pre‑processing) สามารถรักษา latency ให้เพิ่มเพียง ~+10–15 ms และ throughput ลดลงไม่มากนัก โดยยังคงได้ประโยชน์เชิงความถูกต้องใกล้เคียงกับโหมด synchronous.
คำอธิบายเกี่ยวกับวิธีการวัดและนิยามเมทริกซ์ที่ใช้:
- Hallucination rate: ทีมวิจัยกำหนดกฎว่าข้อเท็จจริงใดถือเป็นคำกล่าวที่ตรวจสอบได้ (verifiable claims) แล้วใช้ทั้งการตรวจสอบอัตโนมัติต่อฐานข้อมูลอ้างอิงและการตรวจสอบโดยมนุษย์เพื่อตัดสินว่าข้อความนั้นเป็นการสร้างข้อมูลเท็จหรือไม่ (binary label).
- Precision / Recall: คำนวณจากชุด annotation ที่ระบุข้อเท็จจริงที่ถูกต้องในคำตอบ — precision = จำนวนข้อเท็จจริงที่ถูกต้องที่โมเดลรายงาน ÷ จำนวนทั้งหมดที่รายงาน; recall = จำนวนข้อเท็จจริงที่ถูกต้องที่รายงาน ÷ จำนวนข้อเท็จจริงทั้งหมดที่ควรรายงาน.
- Factuality score: เป็นเมทริกซ์ผสมระหว่างการจับคู่ข้อความกับแหล่งอ้างอิง (automated fact‑matching) และคะแนนเฉลี่ยจากการประเมินโดยมนุษย์ (normalized 0–1).
- Human eval: ผู้ประเมินถูกเทรนให้ใช้ guideline เดียวกัน (เช่น ความถูกต้องเชิงข้อเท็จจริง, ความสมบูรณ์ของคำตอบ, และการไม่มีข้อมูลสร้างขึ้นใหม่) และให้คะแนนแบบ categorical (Correct / Partially correct / Incorrect) โดยใช้ majority vote เพื่อให้ได้คะแนนสุดท้าย.
ข้อจำกัดและการตีความตัวเลขที่สำคัญที่ต้องพิจารณาก่อนนำผลไปใช้เชิงธุรกิจ:
- Sample size: การทดลองนี้ใช้ชุดทดสอบรวม N = 1,200 prompts และการประเมินมนุษย์ N = 600 annotations — ขนาดตัวอย่างเพียงพอให้เห็นแนวโน้มที่มีนัยสำคัญ แต่การประมาณค่ายังคงมี margin of error (โดยประมาณ 95% CI สำหรับ hallucination rate อยู่ในช่วง ±1.5–2.5% ขึ้นกับสัดส่วนที่วัดได้; สำหรับ human eval margin อาจกว้างขึ้น ประมาณ ±3%–4% ขึ้นกับการกระจายคะแนนและขนาดตัวอย่างย่อยตามโดเมน).
- Domain bias: ผลลัพธ์สะท้อนการทดลองใน 3 โดเมนที่ระบุไว้ อัตราการลด hallucination และการเพิ่ม factuality อาจต่างกันอย่างมีนัยสำคัญในโดเมนอื่น ๆ (เช่น การแพทย์ กฎหมาย หรืองานวิจัยเชิงวิชาการ) ที่ต้องการการอ้างอิงเชิงแหล่งข้อมูลที่เข้มงวดกว่า.
- เมทริกซ์อัตโนมัติ vs การประเมินมนุษย์: แม้คะแนน factuality จากเครื่องมืออัตโนมัติจะเพิ่มขึ้นอย่างมาก ค่าดังกล่าวยังพึ่งพา quality ของฐานข้อมูลอ้างอิงและอัลกอริทึมจับคู่ข้อความ — อาจเกิด false negatives/positives ได้ ดังนั้นการยืนยันด้วยการประเมินมนุษย์แบบเป็นตัวอย่างยังจำเป็น.
- ผลกระทบต่อประสิทธิภาพ: การเพิ่มความแม่นยำมักมีค่าใช้จ่ายด้าน latency/throughput ในโหมด synchronous — องค์กรควรประเมิน trade‑off ระหว่างความเร็วและความถูกต้อง ตามลำดับความเสี่ยงของงาน (เช่น ฝ่ายสนับสนุนที่ตอบคำถามลูกค้าสำคัญอาจยอมรับ latency เพิ่มเพื่อแลกกับข้อเท็จจริงที่ถูกต้องกว่า ขณะที่งาน marketing อาจเลือกโหมด asynchronous เพื่อลดผลกระทบต่อ UX).
สรุปคือ ตัวเลขจากเบนช์มาร์กชี้ให้เห็นว่า Prompt‑Debugger สามารถลด hallucination และเพิ่ม factual accuracy ได้อย่างมีนัยสำคัญ แต่การตีความและการนำไปใช้เชิงปฏิบัติการจำเป็นต้องคำนึงถึงขนาดตัวอย่าง โดเมนของข้อมูล และการแลกเปลี่ยนระหว่างความถูกต้องกับประสิทธิภาพระบบ
การนำไปใช้จริงและแนวปฏิบัติที่ดีที่สุด (Best Practices)
การติดตั้งและเชื่อมต่อกับ LLM API และฐานความรู้ภายใน
การนำ Prompt‑Debugger ไปใช้จริงควรเริ่มจากการเตรียมสภาพแวดล้อมและการเชื่อมต่อที่มั่นคงและปลอดภัย โดยแนะนำให้ตั้งค่าเป็นสถาปัตยกรรมแบบไมโครเซอร์วิส (middleware) ที่รับคำขอจากระบบภายนอก (CMS/CRM) แล้วเรียกไปยัง LLM API และฐานความรู้ (knowledge base) ภายในเพื่อตรวจสอบ Chain‑of‑Thought ก่อนส่งผลลัพธ์กลับ ระบบควรมีส่วนประกอบหลักดังนี้:
- Authentication & Network: ใช้ API keys / OAuth ระดับองค์กร จัดเก็บในระบบ Secrets Manager และทำงานผ่าน VPC หรือ private network เมื่อเป็นไปได้
- Embedding & Retrieval Layer: เก็บเอกสารภายในในรูปแบบ embeddings (เช่น Milvus, Pinecone, FAISS) พร้อมกลไก sync แบบ incremental (แนะนำความถี่ sync 1–24 ชั่วโมง ขึ้นกับความเปลี่ยนแปลงของข้อมูล)
- Prompt‑Debugger Service: ไมโครเซอร์วิสที่ส่ง prompt ไปยัง LLM พร้อมเปิดใช้งาน Chain‑of‑Thought logging, ประเมิน confidence score และทำ similarity check กับ KB ก่อนตอบ
- Retry / Fallback Logic: หาก confidence ต่ำกว่าค่ากำหนด ให้เรียก retrieval ใหม่ ปรับ temperature ให้ต่ำลง (แนะนำ temperature 0–0.2 สำหรับข้อเท็จจริง) หรือใช้ retrieval-augmented generation (RAG) แบบ strict
ออกแบบ Human‑in‑the‑Loop (HITL) สำหรับขั้นตอนที่ความเชื่อมั่นต่ำ
การกำหนด pipeline สำหรับ human‑in‑the‑loop ต้องละเอียดตั้งแต่การตัดสินใจว่าจะส่งเคสไหนให้คนตรวจสอบ ไปจนถึงอินเตอร์เฟซและ SLA ที่ชัดเจน ตัวอย่างแนวปฏิบัติที่แนะนำ:
- กำหนดเกณฑ์ความเชื่อมั่น (Confidence Threshold): ตัวอย่างเช่น confidence >= 0.85 ให้ระบบตอบอัตโนมัติ, 0.70–0.85 ส่งให้ผู้ตรวจสอบภายใน (review queue), และ < 0.70 ระงับการเผยแพร่และส่งผู้เชี่ยวชาญเฉพาะด้าน
- บิวด์ triage queue: UI สำหรับผู้ตรวจสอบที่แสดง prompt ดั้งเดิม, chain‑of‑thought, แหล่งข้อมูลอ้างอิงจาก KB, similarity score และตัวเลือกการแก้ไข/อนุมัติ/ปฏิเสธ
- บทบาทและ SLA: กำหนด role เช่น Reviewer, Expert Escalation, และ Quality Auditor พร้อม SLA (ตัวอย่าง: initial review ภายใน 2 ชั่วโมง, expert escalation ภายใน 24 ชั่วโมงสำหรับเคสสำคัญ)
- การเรียนรู้จากมนุษย์: ผลการแก้ไขของมนุษย์ต้องถูกย้อนกลับไปเป็น label เพื่อใช้ปรับ calibration ของโมเดล confidence และปรับ prompt templates โดยอัตโนมัติ (closed‑loop learning)
การบูรณาการกับ CMS/CRM และการออกแบบ Pipeline การทำงาน
การผสาน Prompt‑Debugger เข้ากับระบบ CMS/CRM ควรออกแบบเป็น event‑driven pipeline ที่รองรับความทนทานและการติดตามผล (observability) โดยภาพรวม pipeline อาจมีขั้นตอนดังนี้:
- Step 1 — Event Trigger: CMS/CRM ส่ง webhook หรือ message ไปยัง middleware เมื่อมี content draft หรือคำขอบริการลูกค้า
- Step 2 — Preprocessing: ทำ normalization, PII redaction, และดึง context เพิ่มเติมจากฐานข้อมูลลูกค้า
- Step 3 — Prompt‑Debugger Check: ส่ง prompt พร้อม context ให้ Prompt‑Debugger เพื่อเรียก LLM, รวบรวม chain‑of‑thought และคำนวณ confidence + similarity กับ KB
- Step 4 — Decision Router: ตาม confidence/router policy ตัดสินว่าจะตอบอัตโนมัติ ส่ง review หรือบล็อก และบันทึกการตัดสินใจลงใน audit log
- Step 5 — Response Delivery: ส่งผลลัพธ์กลับสู่ CMS/CRM พร้อม metadata (prompt id, version, confidence, reviewer id หากมี)
ควรออกแบบให้ pipeline รองรับ idempotency, retry strategy, และ circuit breaker สำหรับกรณี LLM API ขัดข้อง นอกจากนี้พิจารณาใช้ canary deployment สำหรับ prompt/flow ใหม่เพื่อลดความเสี่ยงก่อน rollout ขนาดใหญ่
การกำหนด Governance: Logging, Auditing และ Prompt Versioning
Governance เป็นหัวใจสำคัญในการควบคุมความรับผิดชอบและความโปร่งใส แนะนำแนวทางดังนี้:
- Logging (ต้องบันทึกทุกคำตอบที่เกี่ยวข้อง): แต่ละเหตุการณ์ควรเก็บข้อมูลสำคัญ เช่น timestamp, request id, user id/context id, prompt text, prompt version, model name & parameters (temperature, max tokens), chain‑of‑thought trace, confidence score, similarity scores, action taken (auto/approved/rejected), reviewer id และ retention policy ตามข้อกำหนดคุ้มครองข้อมูล (ตัวอย่าง retention 1–7 ปี ขึ้นกับข้อบังคับ)
- Auditing: กระบวนการรีวิวเป็นระยะโดยทีม Audit: ตรวจสอบ sample logs รายสัปดาห์/รายเดือน (แนะนำ sampling rate เริ่มที่ 5–10% ของคำตอบอัตโนมัติ) เพื่อตรวจจับ drift, bias หรือกรณี hallucination ที่หลุดรอด
- Prompt Versioning: ใช้ระบบ version control สำหรับ prompt templates (เช่น git-like with semantic versioning vMAJOR.MINOR.PATCH) และบันทึก diff ของ prompt ทุกครั้งที่มีการเปลี่ยนแปลง พร้อม metadata ว่าใครแก้, เหตุผล, และผลการทดสอบก่อน deployment
- Access Control & Compliance: จำกัดการแก้ไข prompt/approval workflow ด้วย RBAC และ require approvals สำหรับการเปลี่ยนแปลงที่มีความเสี่ยง (เช่น เปลี่ยน system prompt หรือเพิ่ม external KB source)
การฝึกอบรมทีมคอนเทนต์และตัวชี้วัดเพื่อการปรับปรุงต่อเนื่อง
การฝึกอบรมควรรวมทั้งทฤษฎีและปฏิบัติ: เริ่มจากหลักการของ LLM, ความหมายของ confidence, การอ่าน chain‑of‑thought, วิธีแก้ prompt ที่ก่อให้เกิด hallucination และการใช้ UI ของ Prompt‑Debugger ในการตรวจสอบ ตัวอย่างแผนการฝึกอบรม:
- Module 1: พื้นฐาน LLM และ RAG, อันตรายของ hallucination
- Module 2: การวิเคราะห์ chain‑of‑thought และ interpretation ของ confidence score
- Module 3: การแก้ prompt templates, A/B testing และการใช้ prompt versioning
- Module 4: Workflows ใน HITL UI และด้านจริยธรรม/กฎระเบียบ (privacy, record keeping)
กำหนด KPI เพื่อวัดผล เช่น hallucination rate, time-to-resolution ของเคสที่ต้อง review, auto‑publish rate และ user satisfaction จากการทดสอบนำร่อง หลักปฏิบัติที่มักได้ผลคือการตั้งเป้าลด hallucination ลง 30–60% ในช่วงนำร่อง 3 เดือน และลดเวลาแก้ไขเฉลี่ยต่อเคสลงประมาณ 30–50% ขึ้นกับความซับซ้อนของโดเมน
สรุปแนวปฏิบัติที่ดีที่สุด
โดยสรุป ให้มุ่งเน้นที่การออกแบบสถาปัตยกรรมแบบแยกส่วนที่เชื่อถือได้ การกำหนดเกณฑ์ confidence ที่มีเหตุผลและปรับได้ การสร้างช่องทาง human‑in‑the‑loop ที่ชัดเจน พร้อม logging และ auditing ที่เพียงพอ รวมถึง prompt versioning และ governance ที่ควบคุมการเปลี่ยนแปลงอย่างเป็นระบบ สิ่งเหล่านี้เมื่อผนวกกับการฝึกอบรมทีมและการวัดผลอย่างต่อเนื่อง จะทำให้องค์กรสามารถใช้ประโยชน์จาก Prompt‑Debugger เพื่อลด hallucination เพิ่มความโปร่งใส และรับผิดชอบต่อผู้ใช้ได้อย่างมีประสิทธิภาพ
บทสรุป
Prompt‑Debugger คือเครื่องมือที่ออกแบบมาเพื่อลดปัญหา hallucination โดยการวิเคราะห์ Chain‑of‑Thought (CoT) ของโมเดลและให้คำแนะนำการแก้ Prompt อัตโนมัติ เพื่อให้ผลลัพธ์มีความแม่นยำและสอดคล้องมากขึ้นสำหรับทีมคอนเทนต์และฝ่ายบริการลูกค้า เครื่องมือนี้ทำงานโดยตรวจสอบลำดับเหตุผลภายในของการตอบ (เช่น จุดที่เกิดการอนุมานผิด หรือขาดแหล่งอ้างอิง) แล้วแนะนำการปรับ Prompt เช่น การระบุขอบเขตบริบท การใส่ข้อจำกัดเชิงข้อมูล หรือการบังคับให้ระบุแหล่งที่มา ซึ่งการทดลองเบื้องต้นกับสภาพแวดล้อมการใช้งานจริงแสดงให้เห็นแนวโน้มของการลดอัตรา hallucination อยู่ระหว่างประมาณ 20–60% และสามารถลดเวลาในการแก้ไขข้อความก่อนเผยแพร่/ส่งให้ลูกค้าลงได้ราว 30–50% (ขึ้นกับประเภทงานและกระบวนการขององค์กร) โดยการออกแบบ workflow ที่รวม Human‑in‑the‑Loop ทำให้ยังคงรักษาการควบคุมเชิงคุณภาพและป้องกันการแก้ไขอัตโนมัติที่อาจสร้างผลข้างเคียงได้
มุมมองเชิงอนาคตของการนำ Prompt‑Debugger มาใช้คือการบูรณาการเข้ากับกระบวนการทำงาน (workflow) อย่างเป็นระบบ—รวมถึงการวัดผลเชิงตัวเลข (เช่น คะแนน factuality, precision/recall ทางข้อมูล, CSAT, เวลาแก้ไขเฉลี่ย) และการทดสอบแบบ A/B เพื่อยืนยันผลประโยชน์เชิงธุรกิจ การออกแบบที่ดีต้องผสาน human‑in‑the‑loop, การบันทึก Chain‑of‑Thought สำหรับ audit, และการเชื่อมต่อกับระบบ Retrieval‑Augmented Generation (RAG) หรือฐานความรู้ภายในเพื่อลดความเสี่ยงด้านข้อเท็จจริง ทั้งนี้องค์กรที่ออกแบบการประเมินและ workflow อย่างครบถ้วนมีความเป็นไปได้สูงที่จะได้รับผลประโยชน์จริงในแง่คุณภาพคอนเทนต์ การประหยัดเวลาในการปฏิบัติงาน และความเชื่อมั่นของลูกค้า ซึ่งจะเป็นปัจจัยสำคัญในการนำ AI ไปใช้เชิงปฏิบัติการในระยะยาว



