
สตาร์ทอัพไทยเผยโฉม "Synthetic‑EHR Studio" เครื่องมือสร้างข้อมูลผู้ป่วยเทียมที่เลียนแบบโครงสร้างและลักษณะของบันทึกสุขภาพอิเล็กทรอนิกส์ (EHR) จริงอย่างใกล้เคียง ช่วยให้นักวิจัย สถาบันการแพทย์ และบริษัทเทคโนโลยีสามารถฝึกฝนและทดสอบโมเดลปัญญาประดิษฐ์ด้านการแพทย์ได้รวดเร็วขึ้นโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยจริง ซึ่งลดความเสี่ยงการละเมิดความเป็นส่วนตัว ต้นทุนด้านการขออนุญาต และข้อจำกัดทางกฎระเบียบที่มักทำให้การแบ่งปันข้อมูลใช้เวลานานเป็นเดือนหรือเป็นปี
บทความนี้จะสรุปประเด็นสำคัญของ Synthetic‑EHR Studio ได้แก่ วิธีการสร้างข้อมูลเทียมที่ยังคงความสมจริงสำหรับงานวิเคราะห์เชิงคลินิก ประโยชน์ต่อการพัฒนาโมเดลวินิจฉัยและประเมินผลการรักษา กรณีใช้งานจริงในโรงพยาบาลและงานวิจัย รวมถึงข้อควรระวังเรื่องความเที่ยงตรงของข้อมูลและการยืนยันผลก่อนนำไปใช้ในทางคลินิก เพื่อให้ผู้อ่านเห็นภาพชัดเจนว่าผลิตภัณฑ์นี้อาจเปลี่ยนแปลงการวิจัยและการดูแลผู้ป่วยในระบบสุขภาพไทยอย่างไร
คำนำ: ภาพรวมของ Synthetic‑EHR Studio และเหตุผลที่น่าสนใจ
คำนำ: ภาพรวมของ Synthetic‑EHR Studio และเหตุผลที่น่าสนใจ
Synthetic‑EHR Studio เป็นผลิตภัณฑ์จากสตาร์ทอัพไทยที่นำเสนอแพลตฟอร์มสร้างข้อมูลผู้ป่วยเทียม (synthetic health data) ที่ออกแบบมาเพื่อรองรับการพัฒนาโมเดลด้านการแพทย์และการวิจัยสุขภาพโดยไม่ละเมิดความเป็นส่วนตัวของผู้ป่วย ผลิตภัณฑ์นี้ถูกพัฒนาโดยบริษัท SynthMed Labs (Thailand) ซึ่งระบุสถานะการเปิดตัวว่าขณะนี้อยู่ในระยะ pilot ร่วมกับพันธมิตรสถาบันการแพทย์และกลุ่มโรงพยาบาลระดับภูมิภาค และได้รับเงินทุนเริ่มต้น (seed funding) จากกองทุนสตาร์ทอัพในประเทศเพื่อเร่งพัฒนาเทคโนโลยีและขยายการใช้งานเชิงพาณิชย์
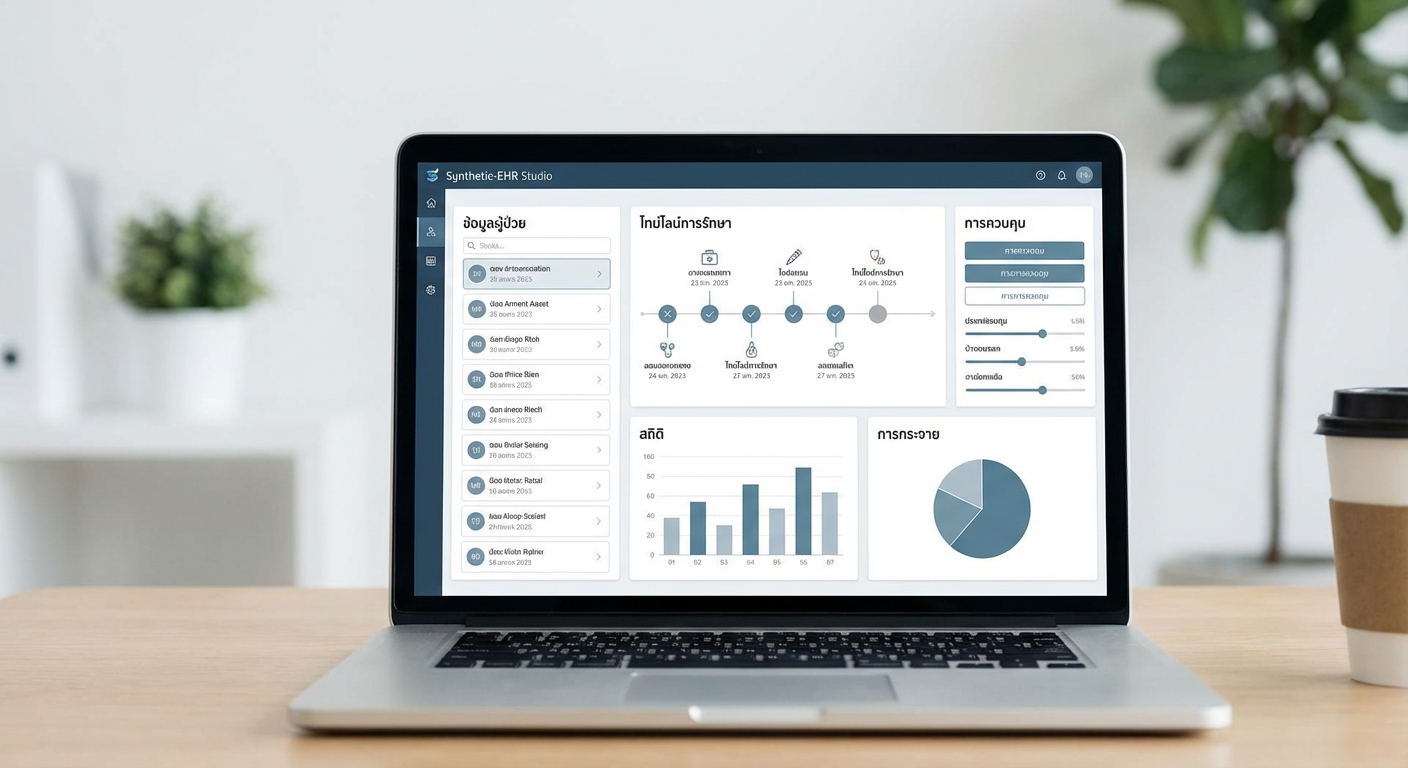
ในเชิงฟีเจอร์ Synthetic‑EHR Studio มุ่งเน้นการสร้างชุดข้อมูลสุขภาพที่มีความหลากหลายและครบมิติ เพื่อให้ทีมพัฒนา AI และนักวิจัยสามารถทดสอบและเทรนโมเดลได้อย่างใกล้เคียงกับสภาพแวดล้อมจริง โดยฟีเจอร์หลักประกอบด้วย:
- การสร้างรายงาน EHR แบบแถว-เวลา (time‑series) — ครอบคลุมสัญญาณชีวภาพ เวชภัณฑ์ ผลการตรวจแลป และการรักษาเป็นลำดับเวลา เพื่อจำลองเส้นทางการรักษาจากการเข้าโรงพยาบาลจนถึงผลลัพธ์
- ข้อความแพทย์และบันทึกคลินิกสังเคราะห์ — ข้อมูลข้อความที่รักษาโครงสร้างทางภาษาและรูปแบบการบันทึกจริง แต่ตัดข้อมูลระบุตัวตนออกอย่างปลอดภัย
- ภาพรังสีและภาพทางการแพทย์สังเคราะห์ — โมดูลสร้างภาพรังสี (เช่น X‑ray, CT) และสังเคราะห์ภาพเพื่อใช้ฝึกโมเดลภาพทางการแพทย์ โดยยังคงลักษณะทางคลินิกที่จำเป็นสำหรับการวินิจฉัย
- เครื่องมือปรับแต่ง (configuration) และการประเมินคุณภาพข้อมูล — ผู้ใช้สามารถกำหนดสัดส่วนโรค เพศ อายุ ความรุนแรง และทดสอบความเหมือนจริงของข้อมูลผ่านเมตริกทางสถิติและการประเมินโดยผู้เชี่ยวชาญ
สาเหตุที่ Synthetic‑EHR Studio ถูกมองว่าน่าสนใจและตอบโจทย์ตลาดไทยมีหลายประการ ประการแรกคือเรื่อง ความเป็นส่วนตัว — การสร้างข้อมูลสังเคราะห์ช่วยลดความเสี่ยงจากการเปิดเผยข้อมูลส่วนบุคคลและช่วยให้การปฏิบัติตามกฎระเบียบ PDPA และกรอบกำกับดูแลข้อมูลสุขภาพเป็นไปได้ง่ายขึ้น ประการที่สองคือความสามารถในการ แชร์ข้อมูลระหว่างสถาบัน โดยไม่ต้องโยกย้ายหรือเปิดเผยข้อมูลผู้ป่วยจริง ทำให้เครือโรงพยาบาลและศูนย์วิจัยสามารถร่วมกันทดสอบโมเดลและแลกเปลี่ยนชุดข้อมูลได้มากขึ้นโดยไม่ติดข้อจำกัดทางกฎหมายหรือจริยธรรม
สุดท้าย ผลิตภัณฑ์นี้ช่วย ลดเวลาการพัฒนาโมเดล และต้นทุนของการเตรียมชุดข้อมูลจริง ตัวอย่างเช่น ในการใช้งานภายในของทีมพัฒนา พบว่าการใช้ข้อมูลสังเคราะห์สามารถลดเวลาที่ต้องใช้ในการรวบรวมและทำความสะอาดข้อมูลจากหลายเดือนเหลือเพียงสัปดาห์ ส่งผลให้การทดลองไอเดียและการปรับพารามิเตอร์โมเดลเกิดขึ้นได้รวดเร็วขึ้น ซึ่งสอดรับกับแนวโน้มการเติบโตของธุรกิจสุขภาพดิจิทัลในไทยและภูมิภาคที่ต้องการนวัตกรรมด้าน AI เพื่อยกระดับการดูแลผู้ป่วยอย่างปลอดภัยและมีประสิทธิภาพ
ทำไมข้อมูลเทียม (Synthetic Data) จึงสำคัญ: ปัญหาจากข้อมูลจริง
ทำไมข้อมูลเทียม (Synthetic Data) จึงสำคัญ: ปัญหาจากข้อมูลจริง
ข้อมูลเวชระเบียนอิเล็กทรอนิกส์ (EHR) ถือเป็นทรัพยากรสำคัญสำหรับการพัฒนาระบบการแพทย์ด้วยปัญญาประดิษฐ์ แต่การใช้งานข้อมูลจริงเผชิญกับปัญหาเชิงโครงสร้างและความเสี่ยงที่รัดกุม เช่น ความเสี่ยงต่อการละเมิดความเป็นส่วนตัวของผู้ป่วยและความซับซ้อนทางกฎหมาย ทั้งนี้กฎคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA ในไทย และ HIPAA ในสหรัฐฯ กำหนดกรอบการใช้ข้อมูลที่เข้มงวด ซึ่งส่งผลให้การเข้าถึงข้อมูลจริงเพื่อการวิจัยหรือพัฒนาโมเดลต้องผ่านกระบวนการอนุมัติและควบคุมอย่างเข้มข้น
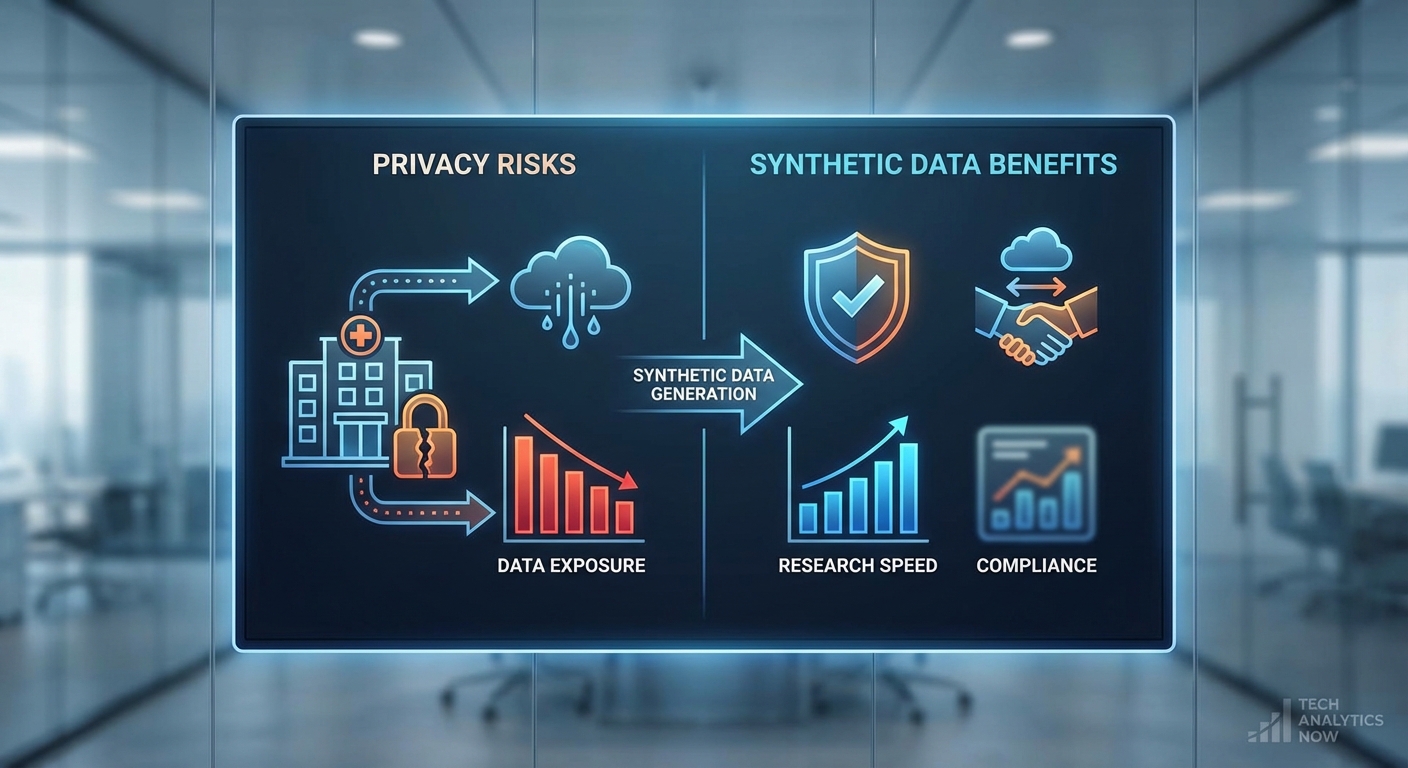
ข้อจำกัดในการเข้าถึง EHR จริงในโรงพยาบาลและสถาบันวิจัยมีหลายมิติ ได้แก่:
- ข้อกำหนดด้านความยินยอมและจริยธรรม: การใช้ข้อมูลผู้ป่วยจริงมักต้องได้รับความยินยอมจากผู้ป่วยหรือคณะกรรมการจริยธรรม (IRB) ซึ่งใช้เวลาและทรัพยากรสูง
- การปกป้องข้อมูลและการละเมิดการไม่เปิดเผยตัวตน: แม้จะทำการ de‑identify ข้อมูลแล้วยังมีความเสี่ยงที่สามารถเชื่อมโยงกลับไปยังบุคคลได้ (re‑identification)
- ข้อจำกัดทางเทคนิคและเชิงองค์กร: ข้อมูลถูกเก็บเป็น silo ในระบบต่าง ๆ ใช้รูปแบบและมาตรฐานไม่สอดคล้องกัน ทำให้การรวบรวมและข้ามระบบเป็นไปได้ยาก
- ค่าใช้จ่ายและความเสี่ยงทางกฎหมาย: สถาบันต้องรับผิดชอบต่อการเก็บ การส่งมอบ และการปกป้องข้อมูล หากเกิดเหตุละเมิดอาจเผชิญบทลงโทษและความเสียหายทางชื่อเสียง
ผลจากปัจจัยข้างต้นทำให้การทดลองและการพัฒนาโมเดล AI ด้านการแพทย์มีอุปสรรคชัดเจน ได้แก่ ข้อมูลตัวอย่างน้อยสำหรับโรหายาก (rare diseases), การไม่สามารถแชร์ชุดข้อมูลข้ามองค์กรเพื่อตรวจสอบความทนทานของโมเดล, และความล่าช้าในการขออนุญาตใช้งานข้อมูล ซึ่งทั้งหมดชะลอจังหวะนวัตกรรม
นอกจากนี้ เหตุการณ์ละเมิดข้อมูลสุขภาพส่งผลทางเศรษฐกิจรุนแรง ตัวอย่างเชิงสากลที่น่าอ้างอิงคือ รายงาน Cost of a Data Breach ของ IBM ซึ่งระบุว่าอุตสาหกรรมสุขภาพมีค่าเฉลี่ยต้นทุนจากการละเมิดข้อมูลสูงสุดเมื่อเทียบกับอุตสาหกรรมอื่น โดยค่าเฉลี่ยระดับโลกอยู่ที่ประมาณ $10.93 ล้านต่อการละเมิด ในรายงานปีล่าสุด ยิ่งไปกว่านั้น การรั่วไหลของข้อมูลผู้ป่วยมีผลกระทบทั้งค่าตรวจสอบฟื้นฟูการรักษาความปลอดภัย ค่าปรับทางกฎหมาย และความเสียหายต่อความเชื่อมั่นของผู้ป่วย ซึ่งล้วนส่งผลต่องบประมาณของหน่วยงานสาธารณสุขและองค์กรเอกชน
ด้วยเหตุนี้ ข้อมูลเทียม (Synthetic Data) จึงมีบทบาทสำคัญในการแก้ปัญหา: ข้อมูลเทียมสามารถจำลองลักษณะทางสถิติและความสัมพันธ์เชิงวินิจฉัยของ EHR จริง โดยไม่เปิดเผยตัวตนของผู้ป่วย ทำให้สามารถแชร์ชุดข้อมูลระหว่างหน่วยงานหรือสตาร์ทอัพเพื่อทดสอบโมเดลได้อย่างปลอดภัยมากขึ้น
ข้อดีเชิงปฏิบัติของการใช้ข้อมูลเทียมประกอบด้วย:
- ลดภาระด้านเอกสารและกระบวนการอนุญาต: ลดความจำเป็นในการขอความยินยอมหรือการจัดการสัญญาเข้าถึงข้อมูลจริง ทำให้การทดลองและการทำ Proof‑of‑Concept เร็วขึ้น
- เพิ่มการแชร์ข้อมูลเพื่อความร่วมมือ: นักพัฒนา นักวิจัย และผู้ประกอบการสามารถแลกเปลี่ยนชุดข้อมูลที่มีความเป็นส่วนตัวคุ้มครอง ส่งเสริมการตรวจสอบซ้ำและการปรับปรุงโมเดล
- ความสามารถในการจำลองกรณีหายากและการปรับสมดุลข้อมูล: ข้อมูลเทียมช่วยสร้างตัวอย่างสำหรับโรคที่มีผู้ป่วยจำนวนน้อย ช่วยลดปัญหา class imbalance และทดสอบโมเดลในสถานการณ์ต่าง ๆ
- เร่งการทดลองและลดความเสี่ยงทางกฎหมาย: ส่งผลให้วงจรพัฒนา (development cycle) สั้นลง ลดโอกาสเกิดค่าปรับหรือเหตุการณ์ละเมิดข้อมูลจากการใช้ชุดข้อมูลจริง
สรุปคือ ในบริบทที่ความเป็นส่วนตัวและข้อกำกับดูแลเข้มงวด ข้อมูลเทียมกลายเป็นเครื่องมือเชิงกลยุทธ์ที่จะช่วยทั้งเร่งการพัฒนาเทคโนโลยีการแพทย์และลดความเสี่ยงจากการใช้ข้อมูลผู้ป่วยจริง ซึ่งสอดคล้องกับการเติบโตของโซลูชันอย่าง Synthetic‑EHR Studio ที่มุ่งให้หน่วยงานต่าง ๆ สามารถทดลองและสร้างนวัตกรรมได้เร็วขึ้นโดยไม่ละเมิดสิทธิส่วนบุคคล
เทคโนโลยีเบื้องหลัง: โมเดลและเทคนิคที่ใช้
เทคโนโลยีเบื้องหลัง: โมเดลการสร้างข้อมูล (Generative Models)
เพื่อสร้างข้อมูลผู้ป่วยเทียมที่มีความสมจริงทั้งเชิงสถิติและเชิงคลินิก Synthetic‑EHR Studio ประยุกต์ใช้ชุดโมเดลการสร้างข้อมูลหลากหลายตัวอย่างเป็นชั้น ๆ โดยเลือกโมเดลตามชนิดของข้อมูลและข้อจำกัดด้านความเป็นส่วนตัว ดังนี้
- GANs (Generative Adversarial Networks) — ใช้เวอร์ชันที่ปรับแต่งสำหรับข้อมูลทางการแพทย์ เช่น conditional GAN (cGAN) เพื่อสร้างเรคคอร์ดที่มีป้ายกำกับโรคหรือกลุ่มอายุเฉพาะ เหมาะกับการรักษาความสัมพันธ์แบบไม่เชิงเส้นระหว่างฟีเจอร์แบบตาราง (tabular) และตัวแปรจํานวนมาก
- VAEs (Variational Autoencoders) — ใช้สำหรับการหาพื้นที่ตัวแทน (latent space) ที่ต่อเนื่อง ซึ่งช่วยให้สามารถสุ่มตัวอย่างและปรับแต่งสภาพผู้ป่วยได้อย่างเป็นระบบ เช่น สร้างเวอร์ชันที่มีค่า lab ต่างกันเล็กน้อยเพื่อวิเคราะห์ความไวของโมเดล
- Diffusion / Score-based Models — นำมาใช้กับข้อมูลภาพทางการแพทย์ (เช่น X‑ray, CT) และยังมีการทดลองนำมาปรับใช้กับข้อมูลตารางและ time-series โดยผ่านการแปลงสัญญาณเชิงต่อเนื่อง ผลที่ได้มักมีความละเอียดและความสมจริงสูงในเชิงภาพ
- Transformer-based (GPT-style) Models — ใช้สำหรับสร้างบันทึกทางคลินิก (clinical notes) โดยฝึกแบบ fine‑tune บนโคเปอร์สที่ผ่านการ de‑identify แล้ว สามารถสร้างข้อความที่รักษาโครงสร้างภาษา เหตุการณ์ทางการแพทย์ และการอ้างอิงยาที่สอดคล้องกับบริบท
- Time-series Synthesis — โมเดลเช่น TimeGAN หรือ RNN/Transformer แบบ autoregressive ถูกนำมาใช้เพื่อให้ได้สัญญาณชีวภาพ (vital signs, lab trajectories) ที่รักษา coherence ทางเวลา (temporal dynamics) และปฏิกิริยาต่อการรักษา

การรวมข้อมูลแบบม็อดัลหลายประเภท (Multi‑modal Integration)
ระบบออกแบบมาเพื่อรวมแหล่งข้อมูล EHR หลายม็อดัล ทั้ง structured tabular (diagnoses, meds, labs), unstructured clinical text (notes, discharge summaries), medical images (X‑ray, CT, ultrasound) และ waveforms (ECG). แนวทางรวมข้อมูลที่ใช้ประกอบด้วย:
- Latent joint representations: กำเนิด latent space ร่วมโดยใช้ encoder เฉพาะม็อดัลแล้วรวมผ่าน fusion layer (เช่น cross‑modal transformers หรือ contrastive learning) เพื่อให้ตัวอย่างเทียมสะท้อนความสัมพันธ์ข้ามม็อดัล
- Conditional synthesis: สร้างแต่ละม็อดัลโดยมีเงื่อนไขจากม็อดัลอื่น เช่น สร้างภาพ X‑ray ที่สอดคล้องกับ diagnosis code และ clinical note โดยใช้ conditional diffusion หรือ cGAN ร่วมกับ attention จากข้อความ
- Hybrid pipelines: ใช้โมเดลแตกต่างกันตามม็อดัล — ตัวอย่างเช่น GPT-style สำหรับ notes, diffusion สำหรับภาพ, และ TimeGAN สำหรับสัญญาณเวลา แล้วรวมผลผ่าน alignment metrics และ consistency checks เพื่อรักษา coherence ระหว่างม็อดัล
การประเมินความสมจริงไม่ใช่เพียงดูความคล้ายคลึงของการแจกแจงค่าฟีเจอร์เท่านั้น แต่ต้องตรวจสอบความสัมพันธ์เชิงลำดับเวลา (temporal correlations), ความสัมพันธ์ระหว่างข้อความและค่าทางคลินิก, รวมถึงการตรวจสอบโดยแพทย์ (clinician review) ซึ่งมักใช้เมตริกเช่น KS‑test, Wasserstein distance และ TSTR (Train on Synthetic, Test on Real) เพื่อวัดประสิทธิภาพเชิงปฏิบัติการ
เทคนิคลดความเสี่ยงการเปิดเผยข้อมูลจริง (Privacy‑Preserving Techniques)
เพื่อให้มั่นใจว่า dataset เทียมไม่เปิดเผยตัวตนหรือรายละเอียดที่สามารถย้อนกลับไปยังผู้ป่วยจริงได้ ระบบนำเทคนิคความเป็นส่วนตัวหลายชั้นมาใช้ร่วมกันตามหลัก Defense‑in‑Depth ได้แก่:
- Differential Privacy (DP): การฝึกโมเดลด้วยกลไก DP‑SGD เพื่อจำกัดข้อมูลที่แต่ละตัวอย่างมีอิทธิพลต่อพารามิเตอร์ของโมเดล โดยใช้ privacy budget (ε) ที่ตั้งค่าอย่างรอบคอบ — ตัวอย่างเช่น การเลือก ε ระหว่าง ~1–10 เพื่อสมดุลระหว่าง utility กับความเป็นส่วนตัว และใช้ privacy accounting (Moments Accountant / Rényi DP) เพื่อตรวจสอบค่า cumulative privacy loss
- Federated Learning และ Secure Aggregation: ในกรณีต้องใช้ข้อมูลจากหลายโรงพยาบาล ระบบรองรับการฝึกแบบกระจาย (federated) ร่วมกับ secure aggregation และ client‑level DP เพื่อลดความเสี่ยงจากการรวบรวมข้อมูลดิบไปยังศูนย์กลาง
- De‑identification และ Safe‑Release Pipeline: ใช้การผสมของ rule‑based และ ML‑based NER สำหรับลบ PHI จากข้อความ เช่น ชื่อ, ที่อยู่, หมายเลขประจำตัว หลังจากนั้นจึงใช้การสร้างข้อมูลเทียมและผ่านการตรวจสอบ reconstruction risk ก่อนปล่อย
- K‑anonymity, l‑diversity, t‑closeness: เทคนิคแบบสถิติเพิ่มเติมที่นำมาใช้หลังการสร้างข้อมูลเพื่อป้องกันการเชื่อมโยง (linkage attacks) โดยปรับกลุ่มข้อมูลให้คุณสมบัติร่วมกันของ quasi‑identifiers อยู่ในระดับที่ยอมรับได้
- Mitigation ของ Membership Inference และ Reconstruction Attacks: นอกจาก DP แล้วยังมีการใช้ regularization, adversarial training และ output‑limiting (เช่น การจำกัดความแม่นยำของสถิติที่เผยแพร่) เพื่อทำให้การโจมตีประเภท membership inference ทำได้ยากขึ้น
ในการทดสอบภายในของสตูดิโอ ใช้ชุดการประเมินแบบหลายมิติ ทั้งการวัด utility (เช่น AUC ของโมเดลพยากรณ์ที่ฝึกบนข้อมูลเทียมเทียบกับข้อมูลจริง โดยใช้ TSTR) และการวัด privacy risk (เช่น success rate ของ membership inference, reconstruction error) — ตัวอย่างเช่น การตั้งค่า DP+federation สามารถลดความเสี่ยงของการโจมตีแบบ membership inference ลงอย่างมีนัยสำคัญ ในขณะที่ยังรักษาประสิทธิภาพการพยากรณ์ไว้ที่ระดับใกล้เคียงกับข้อมูลจริงตามเกณฑ์การใช้งานเชิงคลินิก
สรุปคือ Synthetic‑EHR Studio ไม่ได้พึ่งพาโมเดลใดโมเดลหนึ่งเพียงอย่างเดียว แต่ใช้สถาปัตยกรรมแบบผสม (ensemble/hybrid) พร้อมกระบวนการประเมินและควบคุมความเสี่ยงเชิงเทคนิค เพื่อให้ได้ข้อมูลเทียมที่มีคุณภาพสูง ใช้งานได้จริงสำหรับการพัฒนาโมเดลทางการแพทย์ และสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบ
การประเมินคุณภาพข้อมูลเทียมและมาตรวัดความเป็นส่วนตัว
ภาพรวมและหลักการพื้นฐาน
การประเมินคุณภาพของข้อมูลผู้ป่วยเทียม (Synthetic‑EHR) จำเป็นต้องพิจารณาอย่างรอบด้านทั้งแง่มุมของ fidelity หรือความใกล้เคียงกับข้อมูลจริง, utility หรือความสามารถในการใช้งานเพื่อฝึกโมเดลทางคลินิก และความเสี่ยงด้านความเป็นส่วนตัวที่อาจทำให้เกิดการระบุตัวตนผู้ป่วยจริงได้ การประเมินเหล่านี้ควรใช้ชุดมาตรวัดเชิงสถิติและการทดสอบเชิงปฏิบัติการ (operational tests) เพื่อให้ผลลัพธ์สามารถนำไปใช้ตัดสินใจเชิงธุรกิจและการนำไปใช้งานจริงได้อย่างมีเหตุผล
มาตรวัดความใกล้เคียง (Fidelity)
Fidelity หมายถึงการที่ข้อมูลเทียมสะท้อนลักษณะการแจกแจงและความสัมพันธ์เชิงสถิติของข้อมูลจริงได้อย่างแม่นยำ มาตรวัดสำคัญได้แก่:
- Distributional similarity — เปรียบเทียบการแจกแจงของแต่ละฟีเจอร์ เช่น การแจกแจงของอายุ ค่าเลือด และการกระจายชนิดโรค
- Statistical distances — ค่าต่าง ๆ เช่น Kolmogorov–Smirnov (KS) distance สำหรับตัวแปรเชิงต่อเนื่อง และ Wasserstein distance (หรือ Earth Mover's Distance) สำหรับการวัดความแตกต่างของการแจกแจงแบบหลายมิติ
- Multivariate measures — เช่น Maximum Mean Discrepancy (MMD) หรือการเปรียบเทียบ covariance structure เพื่อจับความแตกต่างของความสัมพันธ์ระหว่างฟีเจอร์
ตัวอย่างเชิงตัวเลข: ในการทดลองเบื้องต้นของทีมงาน Synthetic‑EHR Studio พบว่า median KS ต่อฟีเจอร์เท่ากับ 0.012 และค่าเฉลี่ย Wasserstein อยู่ที่ 0.18 ซึ่งบ่งชี้ว่าการแจกแจงเชิงเดี่ยวใกล้เคียงกันมาก แต่ยังมีช่องว่างในมิติร่วม (multivariate)
มาตรวัดความสามารถใช้งาน (Utility)
Utility วัดจากประสิทธิภาพของโมเดล downstream เมื่อฝึกด้วยข้อมูลเทียมเทียบกับข้อมูลจริง วิธีปฏิบัติทั่วไปมีสองแนวทางหลัก:
- Train-on-synthetic, test-on-real: ฝึกโมเดลด้วยข้อมูลเทียมแล้วทดสอบบนชุดข้อมูลจริง (held-out real) เพื่อประเมินการใช้งานจริง
- Augmentation test: ผสมข้อมูลเทียมกับข้อมูลจริงเพื่อดูว่าช่วยปรับปรุงหรือทำให้โมเดลเสถียรขึ้นหรือไม่
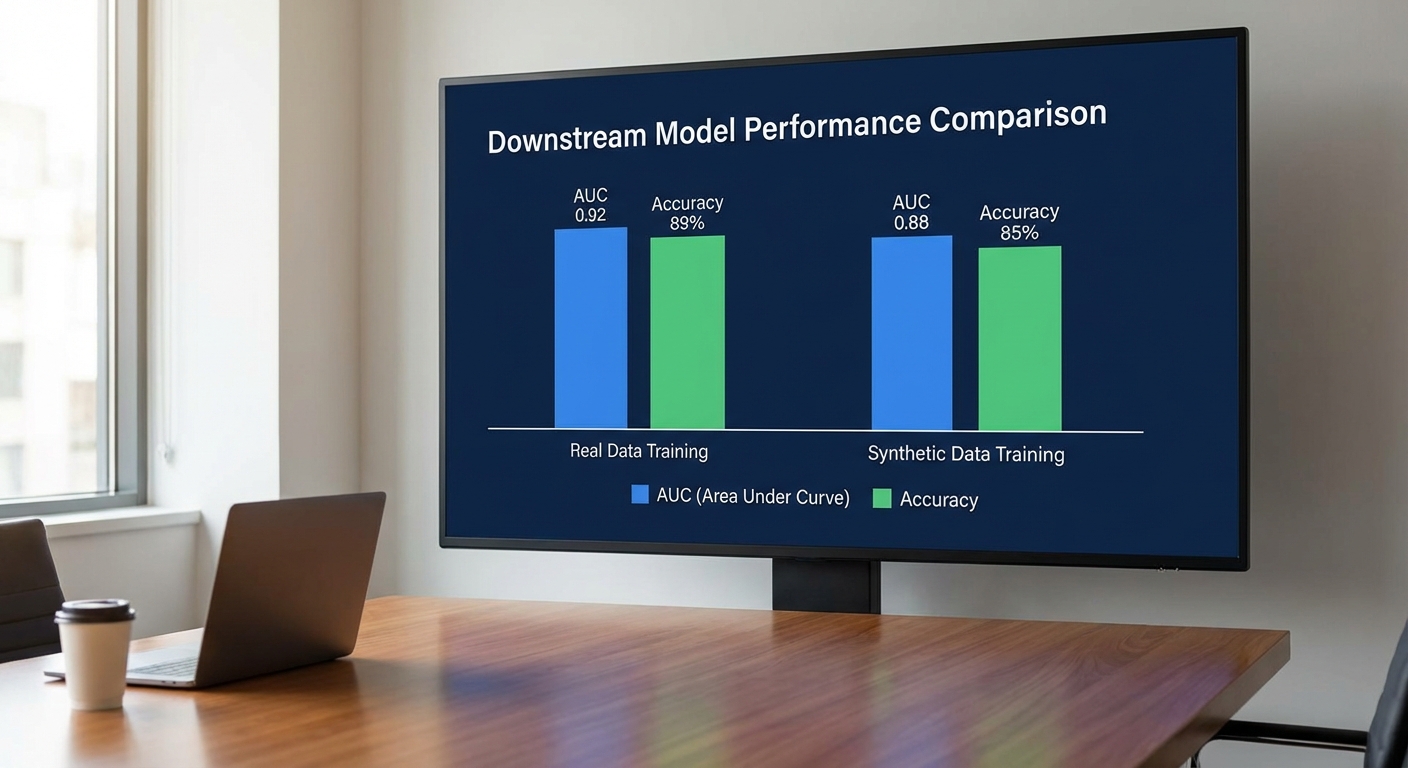
มาตรวัดที่ใช้ ได้แก่ AUC (ROC), accuracy, F1-score และการวัดค่า calibration เช่น Brier score ตัวอย่างเชิงตัวเลขจากกรณีศึกษา:
- งานพยากรณ์การกลับมารักษา 30‑วัน (30‑day readmission) ของผู้ป่วยเบาหวาน: โมเดลฝึกด้วยข้อมูลจริงมี AUC = 0.82; โมเดลฝึกด้วยข้อมูลเทียมมี AUC = 0.79 — ลดลง 0.03 หรือ ~3.7%
- เกณฑ์เชิงปฏิบัติ: หากการลดลงของ AUC ไม่เกิน 5% หรือการคงไว้ซึ่ง utility ≥ 95% ของโมเดลจริง ถือว่า utility อยู่ในระดับยอมรับได้สำหรับการใช้งานเชิงพัฒนา
การประเมินความเสี่ยงด้านความเป็นส่วนตัว
แม้ว่าข้อมูลเทียมจะถูกออกแบบเพื่อป้องกันการเปิดเผยตัวตน แต่ต้องมีการประเมินความเสี่ยงเชิงปฏิบัติ เช่น การระบุผู้ป่วยจากข้อมูลเทียม (re‑identification) และการโจมตีแบบ membership inference การวัดสำคัญได้แก่:
- Re‑identification rate — สัดส่วนของเรคคอร์ดเทียมที่สามารถจับคู่กลับเป็นผู้ป่วยจริงโดยใช้เทคนิคเช่น record linkage; ค่าตัวอย่างที่ยอมรับได้มักต่ำกว่า 0.1% หรือใกล้เคียงกับ baseline ของการสุ่ม
- Membership inference AUC — การฝึก attacker model เพื่อตรวจสอบว่าบันทึกใดเป็นส่วนหนึ่งของชุดฝึกต้นฉบับ ค่าที่แย่สำหรับ attacker คือ AUC ≈ 0.5 (สุ่ม) หาก AUC ของ attacker สูงกว่า 0.6–0.7 แสดงความเสี่ยงที่ชัดเจน
ในกรณีศึกษาของ Synthetic‑EHR Studio ทีมงานทดลองโจมตีแบบ membership inference บนโมเดล generative และพบว่า attacker AUC = 0.52 และอัตรา re‑identification อยู่ที่ 0.08% หลังจากใช้กลยุทธ์การป้องกัน (differential privacy tuned + record suppression) ทำให้ผลอยู่ในเกณฑ์ปลอดภัยเชิงปฏิบัติการ
แนวทางการทดสอบเชิงปฏิบัติและเกณฑ์เชิงธุรกิจ
เพื่อให้การประเมินสอดคล้องกับการตัดสินใจเชิงธุรกิจ แนะนำกระบวนการต่อไปนี้:
- กำหนดชุดทดสอบจริง (holdout real) ที่แยกจากข้อมูลฝึก generative model
- คำนวณมาตรวัด fidelity ทั้งเชิงเดี่ยวและเชิงร่วม (KS per feature, Wasserstein, MMD, covariance similarity)
- รัน classifier แบบ adversarial (discriminator) เพื่อประเมินความสามารถในการแยก real vs synthetic — เกณฑ์ที่ดีคือ classifier AUC ≤ 0.6 หรือ accuracy ใกล้เคียง 50%
- ประเมิน utility ด้วยการฝึกโมเดลทางคลินิกที่เป็นกรณีใช้งานจริง (เช่น พยากรณ์ภาวะแทรกซ้อน) โดยวัดการลดลงของ AUC/accuracy — ตั้งเป้าการลดลงไม่เกิน 5% หรือ retention ≥ 95%
- ทดสอบ privacy ด้วยการพยายาม re‑identify และ membership inference; ตั้งเกณฑ์ว่า re‑identification rate ควรอยู่ต่ำกว่า 0.1% และ attacker membership AUC ใกล้เคียง 0.5–0.55
สรุปเชิงปฏิบัติการสำหรับผู้บริหาร
การประเมินข้อมูลเทียมต้องเป็นกรอบการทดสอบที่ชัดเจน มีทั้งมาตรวัดสถิติและการทดสอบเชิงปฏิบัติการ (adversarial tests) เพื่อชั่งน้ำหนักระหว่างความแม่นยำเชิงวิทยาศาสตร์และความปลอดภัยด้านข้อมูล ตัวอย่างตัวเลขจากการทดสอบเบื้องต้นของ Synthetic‑EHR Studio แสดงให้เห็นว่าข้อมูลเทียมสามารถรักษา utility ได้ในระดับที่ยอมรับได้ (AUC ลดลงไม่เกิน ~3–4%) ขณะเดียวกันความเสี่ยงการระบุตัวตนถูกควบคุมให้อยู่ในระดับต่ำ (<0.1%) ซึ่งเป็นสัญญาณบวกสำหรับการนำไปใช้ในงานพัฒนาโมเดลและพัฒนานวัตกรรมทางการแพทย์ภายใต้ข้อกำหนดด้านกฎหมายและจริยธรรม
กรณีใช้งานจริงและตัวอย่างการนำไปใช้
กรณีใช้งานจริงและตัวอย่างการนำไปใช้
Synthetic‑EHR Studio ถูกนำไปใช้ในหลายบริบททั้งงานวิจัยและการใช้งานทางคลินิก โดยเฉพาะในกรณีที่ข้อมูลผู้ป่วยจริงมีข้อจำกัดด้านปริมาณหรือความเป็นส่วนตัว ตัวอย่างหนึ่งที่เห็นผลชัดเจนคือการเร่งพัฒนาโมเดลวินิจฉัยเฉียบพลัน เช่น การทำนายภาวะช็อกติดเชื้อ (sepsis prediction) ทีมวิจัยสามารถใช้ข้อมูลเทียมเพื่อเพิ่มขนาดชุดข้อมูลการฝึก (data augmentation) ได้ประมาณ 2–5x ทำให้โมเดลมีโอกาสเรียนรู้รูปแบบที่หลากหลายขึ้น โดยยังคงมีการยืนยันผลขั้นสุดท้ายกับชุดข้อมูลจริงที่แยกสำรองไว้เพื่อลดความเสี่ยงของการ overfit กับข้อมูลเทียม การเพิ่มขนาด dataset ในลักษณะนี้ช่วยลดเวลาในการเก็บตัวอย่างจริงจากเดือนเหลือเป็นสัปดาห์และทำให้การทดลองเปลี่ยนเวอร์ชันของโมเดลเร็วขึ้นอย่างมีนัยสำคัญ
ในมิติการฝึกอบรมและการจำลองการรักษา (simulation) ข้อมูลผู้ป่วยเทียมถูกนำมาใช้เป็นชุดเคสสำหรับการเรียนการสอนแพทย์และบุคลากรทางการแพทย์ ตัวอย่างเช่น สถาบันการแพทย์สามารถสร้างชุดเคสเทียมที่ครอบคลุมเหตุการณ์หายาก เช่น ภาวะแทรกซ้อนหลังผ่าตัดหรือปฏิกิริยารุนแรงต่อยารักษาโรค ส่งให้แพทย์ฝึกฝนโดยไม่เสี่ยงต่อผู้ป่วยจริง หรือใช้เป็นสคริปต์สำหรับการซ้อมทีมฉุกเฉิน (code blue simulation) การใช้งานเช่นนี้ช่วยให้ผู้เรียนได้ปฏิบัติในสถานการณ์ที่มีความหลากหลายและความยากระดับต่าง ๆ โดยไม่ต้องพึ่งข้อมูลที่หายากจากประวัติผู้ป่วยจริง
ในด้านการพัฒนาซอฟต์แวร์และการทดสอบระบบสารสนเทศการแพทย์ (HIS, EMR) ข้อมูลเทียมช่วยให้ผู้พัฒนาสามารถทำ stress testing และตรวจสอบฟังก์ชันการทำงานข้ามโมดูลได้อย่างปลอดภัย เช่น การจำลองการรับส่งเวชระเบียนจำนวนมากเพื่อทดสอบประสิทธิภาพการประมวลผล การตรวจสอบการทำงานร่วมกับเครื่องมือแพทย์ (device integration) หรือการทดสอบกรณีมุม (edge cases) ที่แทบจะหาไม่ได้จากข้อมูลจริงในระยะสั้น ตัวอย่างการใช้งานจริงคือการสร้างชุดข้อมูลเทียมจำนวนหลายหมื่นเรคคอร์ดเพื่อทดสอบการบันทึก-เรียกดูข้อมูลเวลาจริงและการรักษาความสอดคล้องของฟิลด์ทางคลินิกก่อนเปิดให้ใช้งานจริง
อีกหนึ่งบทบาทสำคัญคือการอำนวยความสะดวกในความร่วมมือระหว่างสถาบันทางการแพทย์ เมื่อแลกเปลี่ยนข้อมูลผู้ป่วยจริงมีข้อจำกัดด้านกฎระเบียบและข้อตกลงด้านความเป็นส่วนตัว สถาบันต่าง ๆ สามารถแชร์ชุดข้อมูลเทียมเป็นขั้นต้นเพื่อร่วมกันพัฒนาโมเดลพื้นฐานและรัน benchmark ข้ามสถาบันโดยไม่ต้องเปิดเผยข้อมูลดิบ ตัวอย่างเช่น เครือข่ายโรงพยาบาล 5 แห่งอาจแลกเปลี่ยน synthetic cohorts ที่มีคุณสมบัติสะท้อนประชากรของแต่ละแห่ง ทำให้ฝ่ายวิจัยสามารถออกแบบโมเดลร่วมกันและตกลงมาตรฐานการประเมิน ก่อนที่จะไปสู่การตรวจสอบและปรับจูนขั้นสุดท้ายด้วยชุดข้อมูลจริงที่จำกัดและควบคุมการเข้าถึง
- เร่งการพัฒนาโมเดลวินิจฉัย — ขยายข้อมูลฝึก 2–5x เพื่อลดความเบ้ของข้อมูลและเพิ่มความทนทานของโมเดล
- งานฝึกอบรมและซ้อมจำลอง — สร้างเคสฝึกหัดและสถานการณ์หายากสำหรับการเรียนการสอนและการซ้อมทีมฉุกเฉิน
- ทดสอบซอฟต์แวร์การแพทย์ — ใช้ข้อมูลเทียมในการทดสอบโหลด ความถูกต้องของฟังก์ชัน และการรวมระบบโดยไม่กระทบข้อมูลจริง
- แลกเปลี่ยนข้อมูลระหว่างสถาบัน — อนุญาตการร่วมมือเชิงวิจัยและ benchmarking ข้ามโรงพยาบาลโดยไม่ต้องเปิดเผยข้อมูลผู้ป่วยจริงในขั้นต้น
ในการนำไปใช้งานจริง ควรปฏิบัติตามแนวปฏิบัติที่ดี เช่น เก็บชุดข้อมูลจริงสำรองไว้สำหรับการยืนยัน, ใช้วิธีผสมระหว่างข้อมูลจริงและเทียม (hybrid training), และประเมินความสมจริง (fidelity) และประโยชน์เชิงปฏิบัติ (utility) ของข้อมูลเทียมก่อนใช้งานเชิงคลินิกเต็มรูปแบบ การนำ Synthetic‑EHR Studio มาใช้ในทีมที่มีนโยบายชัดเจนเรื่องการตรวจสอบและการ validate จะช่วยให้การพัฒนาเทคโนโลยีการแพทย์รวดเร็วขึ้นโดยยังคงมาตรฐานด้านความปลอดภัยและความเป็นส่วนตัวของผู้ป่วย
ความท้าทายด้านจริยธรรม กฎหมาย และการกำกับดูแล
ความท้าทายด้านจริยธรรม กฎหมาย และการกำกับดูแล
การใช้ข้อมูลผู้ป่วยเทียม (synthetic EHR) เพื่อเร่งพัฒนาโมเดลการแพทย์นำมาซึ่งประโยชน์ด้านนวัตกรรมและการปกป้องความเป็นส่วนตัว แต่ขณะเดียวกันก็สร้างความท้าทายด้านจริยธรรม กฎหมาย และการกำกับดูแลอย่างมีนัยสำคัญ ประเด็นสำคัญที่ต้องพิจารณาได้แก่ความเสี่ยงของการฟื้นคืนข้อมูลจริง (re‑identification), ความรับผิดชอบทางกฎหมายเมื่อข้อมูลเทียมสะท้อนหรือรั่วไหลข้อมูลบุคคล, และปัญหาจริยธรรมจากการใช้ข้อมูลเทียมที่อาจขยายความไม่เท่าเทียมหรือบิดเบือนผลการวิจัย
หนึ่งในความเสี่ยงเชิงเทคนิคที่ชัดเจนคือการ re‑identification หรือการระบุตัวตนกลับจากข้อมูลเทียม แม้ข้อมูลจะถูกสร้างขึ้นจากการเรียนรู้เชิงสถิติ งานวิจัยจากชุมชนนักวิทยาการข้อมูลและความมั่นคงแสดงให้เห็นว่าโมเดลการสร้างข้อมูล (เช่น GANs หรือ large generative models) อาจ 'memorize' ตัวอย่างจากชุดข้อมูลฝึกและอาจถูกโจมตีโดยเทคนิคเช่น membership inference, model inversion หรือ extraction attack ซึ่งในสถานการณ์จริงอาจทำให้ผู้โจมตีสามารถเชื่อมโยงเร็กคอร์ดเทียมกับบุคคลจริงได้ ตัวอย่างเชิงประจักษ์แสดงว่าในบางการทดลองการโจมตีสามารถดึงข้อมูลข้อความหรือการบันทึกที่ขึ้นกับแต่ละบุคคลออกมาได้ จึงจำเป็นต้องประเมินความเสี่ยงเชิงปริมาณ (เช่น อัตราความสำเร็จการโจมตี, ค่าความใกล้เคียงเชิงสถิติระหว่างข้อมูลเทียมกับจริง) ก่อนการปล่อยใช้งาน
ในมิติกฎหมายและการกำกับดูแล สตาร์ทอัพไทยต้องปฏิบัติตาม พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ซึ่งมีผลบังคับใช้ในประเทศไทย โดยหลักการ PDPA แยกระหว่างข้อมูลที่เป็น personal data และข้อมูลที่ได้รับการทำให้เป็นนิรนาม (anonymized) หากข้อมูลเทียมยังสามารถเชื่อมโยงกลับไปยังบุคคลได้ จะยังคงอยู่ภายใต้ข้อจำกัดของ PDPA เช่น ข้อกำหนดเรื่องการได้รับความยินยอม การแจ้งวัตถุประสงค์ และการปฏิบัติเรื่องการโอนข้อมูลไปต่างประเทศ นอกจากนี้ยังมีแนวทางและข้อแนะนำจากองค์กรสากลที่ควรนำมาประยุกต์ เช่น หลักการของ GDPR ที่ชี้ว่าเฉพาะเมื่อข้อมูลถูกทำให้เป็นนิรนามอย่างแท้จริงจึงอยู่นอกขอบเขตกฎหมาย, แนวปฏิบัติจาก NIST และมาตรฐาน ISO/IEC (เช่น ISO/IEC 20889 เกี่ยวกับเทคนิคการทำให้เป็นนิรนาม) รวมถึงหลักการ AI ของ OECD และแนวทางการกำกับดูแลของสหภาพยุโรปที่กำลังพัฒนา (EU AI Act) ซึ่งเน้นความโปร่งใส ความรับผิดชอบ และการประเมินความเสี่ยง
ด้านจริยธรรม มีประเด็นสำคัญที่เจ้าของแพลตฟอร์มและผู้ใช้งานต้องใส่ใจ ได้แก่ ความยุติธรรมและอคติ (bias) เพราะโมเดลที่สร้างข้อมูลเทียมอาจสะท้อนหรือขยายความไม่สมดุลของชุดข้อมูลต้นทาง ส่งผลให้โมเดลทางการแพทย์มีประสิทธิภาพไม่เท่ากันในกลุ่มประชากรบางกลุ่ม และประเด็นความโปร่งใสต่อผู้ป่วย — แม้ข้อมูลจะเป็นเทียม ผู้ป่วยควรได้รับข้อมูลว่าข้อมูลของพวกเขาอาจถูกนำมาใช้ในการสร้างสารสนเทศเทียม และมีกระบวนการให้สิทธิในการคัดค้าน/ถอนความยินยอมเมื่อจำเป็น
เพื่อบริหารความเสี่ยงเหล่านี้ ขอเสนอแนวปฏิบัติสำคัญสำหรับผู้พัฒนา ผู้ให้บริการ และผู้ใช้งานดังนี้
- Governance และนโยบายภายใน — จัดตั้งคณะกรรมการกำกับดูแลข้อมูล (Data Governance Board) ที่รวมผู้เชี่ยวชาญด้านความเป็นส่วนตัว จริยธรรม กฎหมาย และคลินิก เพื่อกำหนดนโยบายการสร้างและใช้งานข้อมูลเทียม เช่น ข้อกำหนดในการทดสอบความเสี่ยง, ระดับการป้องกันที่ยอมรับได้ และแนวทางการเปิดเผยข้อมูลต่อสาธารณะ
- การประเมินความเสี่ยงเชิงเทคนิค (Technical DPIA) — ดำเนินการประเมินผลกระทบต่อความเป็นส่วนตัว (Data Protection Impact Assessment) ที่รวมการทดสอบการโจมตีสมมติ เช่น membership inference, model inversion, และการวัดความใกล้เคียงเพื่อประเมินโอกาส re‑identification ก่อนเผยแพร่ข้อมูลหรือโมเดล
- มาตรการเชิงเทคนิค — ใช้เทคนิคลดความเสี่ยง เช่น differential privacy (พร้อมการรายงานค่า epsilon), การควบคุมความจำ (memorization control), การจำกัดการเข้าถึงแบบ granular, และการลดความเที่ยงตรง (fidelity reduction) เมื่อจำเป็นเพื่อแลกกับความเป็นส่วนตัว
- การตรวจสอบภายนอกและการ audit — จัดให้มีการตรวจสอบโดยบุคคลที่สาม (independent audit) เป็นระยะเพื่อทดสอบความเสี่ยงและการปฏิบัติตามนโยบาย รวมถึงเก็บ audit trail ของการเข้าถึงข้อมูลและการใช้งานโมเดล
- ความโปร่งใสและรายงาน — ออก transparency report ประจำไตรมาสหรือพนักที่ระบุมาตรการปกป้องข้อมูล, ผลการประเมินความเสี่ยง (เช่น อัตราการโจมตีจำลอง), ค่าพารามิเตอร์ privacy (เช่น epsilon ถ้าใช้ DP), และการเปลี่ยนแปลงเวอร์ชันของโมเดล/ชุดข้อมูลพร้อมเหตุผลในการอัปเดต
- ข้อตกลงทางกฎหมายและการจัดสัญญา — ระบุความรับผิดชอบและขอบเขตการใช้ใน Data Processing Agreement (DPA) กับผู้ขายและลูกค้า รวมถึงมาตรการชดเชยเมื่อเกิดเหตุละเมิด และข้อจำกัดการนำข้อมูลไปใช้เชิงพาณิชย์
- จริยธรรมเชิงปฏิบัติ — ตั้งคณะกรรมการจริยธรรมสถานพยาบาลหรือ Institutional Review Board (IRB) สำหรับโครงการที่ใช้ข้อมูลเทียมในงานวิจัยทางคลินิก และกำหนดกระบวนการเพื่อรับฟังผู้มีส่วนได้ส่วนเสีย (เช่น ตัวแทนผู้ป่วย)
สรุปคือ สตาร์ทอัพที่ให้บริการ Synthetic‑EHR ควรมองการพัฒนาทางเทคนิคควบคู่ไปกับกรอบการกำกับดูแลและจริยธรรมอย่างเป็นระบบ โดยการวัดและรายงานความเสี่ยงเชิงปริมาณ การนำมาตรการคุ้มครองที่พิสูจน์ได้มาใช้ และการสร้างความโปร่งใสต่อผู้ใช้งานและหน่วยงานกำกับดูแล จะช่วยให้การใช้ข้อมูลเทียมเป็นเครื่องมือเร่งการวิจัยได้อย่างปลอดภัยและยั่งยืน
ผลกระทบเชิงนิเวศและโอกาสทางธุรกิจในประเทศไทย
ผลกระทบเชิงนิเวศและโอกาสทางธุรกิจในประเทศไทย
การนำระบบสร้างข้อมูลผู้ป่วยเทียม (Synthetic‑EHR) มาใช้ในระบบบริการสุขภาพของไทยมีศักยภาพในการเร่งนวัตกรรมทางการแพทย์อย่างชัดเจน ในแง่การพัฒนาโมเดลการวินิจฉัยและระบบสนับสนุนการตัดสินใจทางคลินิก ข้อมูลเทียมสามารถช่วยลดระยะเวลาการเตรียมชุดข้อมูลและการอนุญาตด้านความเป็นส่วนตัวจากหลายเดือนเหลือเพียงสัปดาห์ ทำให้วงจรการทดลองและการปรับปรุงโมเดล (iteration cycle) ถูกย่อให้สั้นลง ซึ่งประเมินได้ว่าอาจลดเวลาพัฒนาผลิตภัณฑ์ได้ถึง 30–50% ในโครงการที่เน้นการทดสอบตามข้อมูลจริงซ้ำๆ ตัวอย่างเช่น การฝึกโมเดล NLP เพื่อสกัดข้อมูลจากบันทึกแพทย์ หากใช้ข้อมูลเทียมที่มีความหลากหลายเพียงพอ จะช่วยให้ทีมวิจัยลดความเสี่ยงจากการเข้าถึงข้อมูลผู้ป่วยจริงและเร่งการนำต้นแบบ (prototype) ไปสู่การทดลองในสภาพแวดล้อมจริงได้เร็วขึ้น
ในมุมมองเชิงเศรษฐศาสตร์ การใช้ Synthetic‑EHR สามารถสร้างผลประหยัดด้านต้นทุนได้หลายด้าน ทั้งการลดภาระค่าใช้จ่ายในการจัดเตรียมข้อมูล (data curation) ค่าใช้จ่ายด้านกฎหมายและการปฏิบัติตาม PDPA (พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล) ตลอดจนลดค่าใช้จ่ายจากการดำเนินการศึกษาวิจัยที่ต้องใช้ข้อมูลจริง ตัวแทนธุรกิจและนักวิเคราะห์ในอุตสาหกรรมประเมินว่าองค์กรที่ยืดหยุ่นด้านข้อมูลอาจลดต้นทุนการพัฒนาและทดสอบโมเดลได้ระหว่าง 20–60% ขึ้นอยู่กับขนาดโครงการและระดับความซับซ้อนของข้อมูล นอกจากนี้ยังมีผลทางอ้อมในการลดการใช้ทรัพยากรบุคคลที่ต้องใช้เวลาจัดการข้อมูลมือ (manual annotation) ซึ่งช่วยให้บุคลากรทางการแพทย์สามารถโฟกัสกับงานด้านคลินิกได้มากขึ้น
โอกาสทางธุรกิจในประเทศไทยมีความหลากหลายและสามารถขยายได้ทั้งในระดับภายในประเทศและการส่งออกความสามารถไปยังภูมิภาคอาเซียน โมเดลธุรกิจที่เหมาะสมได้แก่:
- SaaS (Software as a Service): ให้บริการสร้างชุดข้อมูลเทียมและเวิร์กโฟลว์การประมวลผลผ่านแพลตฟอร์มคลาวด์ ด้วยรูปแบบสมัครสมาชิกแบบชั้น (tiered subscription) สถาบันการแพทย์ขนาดเล็กถึงขนาดใหญ่สามารถเข้าถึงเทคโนโลยีได้โดยไม่ต้องลงทุนโครงสร้างพื้นฐาน
- Licensing และ Data Licensing: อนุญาตให้หน่วยงานวิจัยหรือบริษัทยาเช่าใช้ชุดข้อมูลเทียมที่ได้รับการปรับแต่งตามความต้องการเฉพาะโครงการ พร้อมสัญญาควบคุมการใช้งานและการตรวจสอบ
- Collaboration กับโรงพยาบาลและสถาบันวิจัย: รูปแบบความร่วมมือเชิงพาร์ทเนอร์ เช่น โครงการวิจัยร่วม (co-development), การตั้งศูนย์ทดสอบ (pilot center) และการแบ่งรายได้จากการพาณิชย์ผลงานที่เกิดจากการใช้ข้อมูลเทียม
- บริการเสริม (professional services): ให้คำปรึกษาด้านการออกแบบชุดข้อมูลเทียม การทำ validation, การจัดการ compliance และการฝึกอบรมบุคลากร
อย่างไรก็ตาม การนำไปใช้จริงยังเผชิญอุปสรรคสำคัญที่ต้องจัดการอย่างเป็นระบบ ประการแรกคือ ความเชื่อมั่นของผู้ใช้งาน — แพทย์ นักวิจัย และผู้ป่วยจำเป็นต้องมั่นใจว่าสินค้าหรือบริการที่พัฒนาจากข้อมูลเทียมมีความถูกต้องเพียงพอและไม่ก่อให้เกิดความเสี่ยงทางคลินิก ประการที่สองคือการรับรองมาตรฐานและการปฏิบัติตามกฎระเบียบ ทั้งการยืนยันความเป็นไปได้ของข้อมูลเทียมผ่านการประเมินทางวิชาการและการนำไปสู่การรับรองโดยหน่วยงานที่เกี่ยวข้อง เช่น การสอดคล้องกับ PDPA และหลักเกณฑ์ของ สำนักงานคณะกรรมการอาหารและยา (อย.) ในลักษณะของเครื่องมือสนับสนุนการตัดสินใจทางการแพทย์ ประการที่สามคือการลงทุนด้านทักษะบุคลากร — โรงพยาบาลและสถาบันวิจัยต้องมีทีมงานที่มีความเชี่ยวชาญทั้งด้านวิทยาศาสตร์ข้อมูล (data science) และด้านสารสนเทศการแพทย์ (clinical informatics) ซึ่งอาจต้องใช้เวลาและงบประมาณในการฝึกอบรม
ข้อเสนอแนะเพื่อการนำ Synthetic‑EHR มาใช้ในเชิงยั่งยืนในบริบทประเทศไทย ได้แก่:
- จัดตั้งโครงการนำร่องร่วมกับโรงพยาบาลมหาวิทยาลัยและหน่วยงานรัฐเพื่อสร้างกรณีศึกษาที่ตรวจวัดได้ (KPIs) เช่น ความเร็วในการพัฒนาต้นแบบ, อัตราความแม่นยำของโมเดล, และผลประหยัดต้นทุน
- พัฒนากรอบกำกับดูแลภายใน (governance) ที่ชัดเจน ครอบคลุมการประเมินความเสี่ยง การตรวจสอบคุณภาพข้อมูล และการพิสูจน์ความเป็นไปได้ทางคลินิก ก่อนยกระดับสู่การใช้งานจริง
- ออกแบบโมเดลธุรกิจที่ยืดหยุ่น โดยผสมผสาน SaaS กับการให้บริการเชิงวิชาชีพ และพิจารณารูปแบบการแบ่งรายได้กับคู่ค้า เพื่อกระจายความเสี่ยงและสร้างแรงจูงใจให้หน่วยงานสาธารณสุขเข้าร่วม
- ลงทุนในโครงการพัฒนาทักษะ (upskilling) สำหรับเจ้าหน้าที่ทางการแพทย์และวิศวกรข้อมูล รวมถึงสร้างหลักสูตรร่วมกับมหาวิทยาลัยเพื่อเติมเต็มความต้องการแรงงาน
- โปร่งใสในการสื่อสารกับประชาชนเกี่ยวกับการใช้งานข้อมูลเทียมและการปกป้องความเป็นส่วนตัว เพื่อเสริมสร้างความเชื่อมั่นและการยอมรับของสังคม
สรุปแล้ว Synthetic‑EHR Studio ในบริบทประเทศไทยเสนอทั้งผลประโยชน์เชิงนิเวศที่ช่วยขับเคลื่อนนวัตกรรมทางการแพทย์และโอกาสทางธุรกิจที่หลากหลาย หากบริหารจัดการความเสี่ยงด้านกฎระเบียบ ความเชื่อมั่น และการพัฒนาทักษะอย่างเป็นระบบ เทคโนโลยีนี้มีศักยภาพช่วยยกระดับระบบสุขภาพไทยให้มีความรวดเร็ว มีประสิทธิภาพ และพร้อมแข่งขันในตลาดระดับภูมิภาคได้อย่างยั่งยืน
บทสรุป
Synthetic‑EHR Studio เป็นเครื่องมือที่มีศักยภาพสูงในการเร่งพัฒนาโมเดลด้านการแพทย์โดยลดข้อจำกัดด้านการเข้าถึงข้อมูลผู้ป่วยจริง ซึ่งช่วยให้ทีมวิจัยและสตาร์ทอัพสามารถทดลองและปรับจูนโมเดลได้เร็วขึ้นโดยไม่ต้องใช้ข้อมูลส่วนบุคคลของผู้ป่วยโดยตรง งานวิจัยต่างประเทศชี้ว่าในหลายกรณีข้อมูลเทียมสามารถทดแทนข้อมูลจริงได้บางส่วนและลดความต้องการข้อมูลจริงลงได้ประมาณ 30–70% ขึ้นกับลักษณะงานและวิธีสร้างข้อมูล ผลลัพธ์เหล่านี้สะท้อนถึงศักยภาพเชิงปฏิบัติที่สามารถเร่งนวัตกรรมทางการแพทย์ได้อย่างมีนัยสำคัญ หากมีการใช้ร่วมกับมาตรการป้องกันความเป็นส่วนตัวที่เหมาะสม
อย่างไรก็ดี การใช้งาน Synthetic‑EHR ต้องมาพร้อมการประเมินความเสี่ยงและมาตรการทางเทคนิคอย่างเคร่งครัด ได้แก่ การทดสอบเชิงปริมาณระหว่าง utility vs privacy (ความคุ้มค่าทางวิทยาศาสตร์เทียบกับความเสี่ยงการเปิดเผยข้อมูล), การนำเทคนิคเช่น differential privacy, membership inference testing, และการตรวจสอบการรั่วไหลของข้อมูลไปใช้จริง รวมถึงกรอบการตรวจรับรองคุณภาพข้อมูลเทียม (synthetic data validation) เพื่อยืนยันว่าโมเดลที่ฝึกด้วยข้อมูลเทียมให้ผลลัพธ์เชื่อถือได้ ตัวอย่างเชิงนโยบายได้แก่การกำหนดมาตรฐานการทำลายข้อมูลต้นฉบับ การบันทึกการใช้งาน และการ Audit trail เพื่อให้สามารถตรวจสอบย้อนกลับได้เมื่อเกิดเหตุความไม่เป็นไปตามข้อกำหนด
ในบริบทของไทย จำเป็นต้องมีทั้งนโยบายที่ชัดเจนและความร่วมมือข้ามภาคส่วน—ภาครัฐ สถาบันแพทย์ และภาคเอกชน—เพื่อใช้ประโยชน์จาก Synthetic‑EHR อย่างปลอดภัยและคุ้มค่า มุมมองในอนาคตรวมถึงการตั้ง Regulatory sandbox สำหรับการทดลองเชิงควบคุม สนับสนุนการวิจัยเพื่อหาข้อบ่งชี้เชิงปริมาณของการใช้งานจริง และการสร้างกรอบมาตรฐานระดับประเทศเมื่อเทคโนโลยีพร้อม การดำเนินการเช่นนี้จะช่วยให้ไทยสามารถเร่งพัฒนาโซลูชันด้านการแพทย์ด้วย AI ได้อย่างรวดเร็ว แต่ยังคงคุ้มครองความเป็นส่วนตัวของผู้ป่วยเป็นสำคัญ



