
กระทรวงดิจิทัลเดินหน้าทดสอบโครงการนำร่อง "AI Model Passport" ซึ่งใช้เทคโนโลยีบล็อกเชนเป็นฐานบันทึกสเปกของโมเดล แหล่งข้อมูลการเทรน และประวัติการปรับปรุงโมเดล เพื่อยกระดับความโปร่งใสและความรับผิดชอบในการใช้งานปัญญาประดิษฐ์ทั้งในภาครัฐและภาคเอกชน โครงการนี้มุ่งสร้างแหล่งข้อมูลที่ตรวจสอบย้อนหลังได้ (audit trail) ลดความคลุมเครือของที่มาของข้อมูล และช่วยให้การตัดสินใจเชิงนโยบายและการปฏิบัติงานมีความชัดเจนยิ่งขึ้น
บทนำของโครงการเน้นการกำหนดมาตรฐานข้อมูลเมตา (metadata) สำหรับสเปกโมเดล การจัดการความเป็นส่วนตัว และการตรวจสอบต้นทางข้อมูล โดยใช้สมบัติไม่เปลี่ยนแปลงของบล็อกเชนเป็นหลักประกัน เพื่อให้หน่วยงานรัฐและผู้พัฒนาเอกชนสามารถพิสูจน์แหล่งที่มา ต้นเหตุของข้อผิดพลาด และการปฏิบัติตามกฎระเบียบได้อย่างเป็นรูปธรรม โครงการนำร่องนี้ยังตั้งเป้าที่จะเป็นแบบอย่างสำหรับกรอบกำกับดูแลระดับชาติ ช่วยลดความเสี่ยงจากการใช้งาน AI ที่ขาดความรับผิดชอบและเสริมสร้างความเชื่อมั่นของประชาชนต่อระบบดิจิทัลของรัฐและภาคธุรกิจ
บทนำ: ทำไมต้องมี AI Model Passport ในยุคระบบดิจิทัลของภาครัฐ
บทนำ: ทำไมต้องมี AI Model Passport ในยุคระบบดิจิทัลของภาครัฐ
ในยุคที่หน่วยงานภาครัฐและภาคเอกชนเริ่มนำระบบปัญญาประดิษฐ์ (AI) มาใช้ในการตัดสินใจเชิงนโยบาย บริการสาธารณะ และการให้สิทธิประโยชน์แก่ประชาชน ความโปร่งใสและความรับผิดชอบกลายเป็นเงื่อนไขสำคัญที่ไม่อาจมองข้ามได้ ระบบ AI ที่ขาดข้อมูลเมตา (metadata) เช่น สเปกของโมเดล แหล่งข้อมูลที่ใช้ฝึก และประวัติการเทรนนิ่ง มีโอกาสนำไปสู่ความเสี่ยงเชิงระบบ ทั้งการเกิดอคติ (bias) การเลือกปฏิบัติ (discrimination) และปัญหาด้านความน่าเชื่อถือของผลลัพธ์เมื่อนำไปใช้กับประชากรกลุ่มอื่นๆ

ตัวอย่างเชิงประจักษ์ที่มักถูกนำมาอ้างถึงคืองานวิจัยด้านการรู้จำใบหน้าของ Joy Buolamwini และ Timnit Gebru (2018) ซึ่งพบว่าอัตราความผิดพลาดของระบบสูงสุดถึงประมาณ 34% สำหรับผู้หญิงผิวคล้ำ ขณะที่ระบบเดียวกันมีอัตราความผิดพลาดเพียงประมาณ 0.8% สำหรับผู้ชายผิวสว่าง เหตุการณ์เช่นนี้สะท้อนว่าหากไม่มีการเปิดเผยที่มาของชุดข้อมูลและกระบวนการเทรนนิ่ง ผลลัพธ์จากโมเดลอาจสร้างความไม่เป็นธรรมหรือความเสี่ยงต่อสิทธิพลเมืองได้ นอกจากนี้ กรณีการใช้โมเดลคาดการณ์พฤติการณ์อาชญากรรม (เช่น COMPAS ในสหรัฐฯ) ยังแสดงให้เห็นปัญหาเรื่องความเอนเอียงที่ส่งผลต่อการตัดสินใจด้านคดีความและโทษ
สำหรับระบบราชการ ความสามารถในการตรวจสอบย้อนหลัง (auditability) และการรับผิดชอบ (accountability) เป็นเรื่องจำเป็นต่อการรักษาไว้ซึ่งความชอบธรรมของการให้บริการสาธารณะ เจ้าหน้าที่ต้องสามารถชี้แจงได้ว่าโมเดลใดถูกนำมาใช้ สเปกทางเทคนิคเป็นอย่างไร แหล่งที่มาของข้อมูลเป็นอย่างไร และมีการประเมินผลกระทบต่อกลุ่มเปราะบางหรือไม่ การขาดซึ่งกลไกเหล่านี้อาจทำให้หน่วยงานไม่สามารถตอบคำถามเช่น “เหตุใดจึงตัดสิทธิ์ประชาชนรายนี้” หรือ “โมเดลทำงานผิดผลาดเพราะข้อมูลไม่เป็นตัวแทนหรือไม่” ได้อย่างชัดเจน
เพื่อตอบโจทย์ดังกล่าว กระทรวงดิจิทัลได้ริเริ่มโครงการนำร่อง AI Model Passport ที่มีวัตถุประสงค์เพื่อบันทึกและเผยแพร่ข้อมูลเมตาของโมเดลในรูปแบบที่ตรวจสอบได้และคงทนต่อการแก้ไข โดยตัว Passport จะระบุรายละเอียดพื้นฐาน เช่น สเปกของโมเดล (architecture, hyperparameters), แหล่งข้อมูลที่ใช้ฝึก (data provenance), ประวัติการเทรนนิ่ง (training logs, versions), ผลการประเมินความเป็นธรรมและความแม่นยำ (evaluation metrics) รวมถึงเงื่อนไขการใช้งานและข้อจำกัดของโมเดล การเก็บข้อมูลเหล่านี้บนเทคโนโลยีบล็อกเชนในการทดลองนำร่องช่วยให้เกิดความโปร่งใสและความน่าเชื่อถือทางเทคนิค เนื่องจากสามารถตรวจสอบย้อนหลังและยืนยันความสมบูรณ์ของข้อมูลได้
โดยสรุป AI Model Passport ไม่ได้เป็นเพียงเอกสารด้านเทคนิคเท่านั้น แต่เป็นกลไกเชิงนโยบายที่ผสานทั้งความโปร่งใส การตรวจสอบย้อนหลัง และความรับผิดชอบ เพื่อให้การนำ AI มาใช้ในงานราชการและบริการสาธารณะเป็นไปอย่างยุติธรรม ปลอดภัย และสอดคล้องกับหลักสิทธิมนุษยชนและกฎหมายที่เกี่ยวข้อง
- ความเสี่ยงจากโมเดลที่ไม่มีข้อมูลเมตา: เกิดอคติและการเลือกปฏิบัติ, ขาดต้นทางข้อมูลที่ชัดเจน (data provenance), ยากต่อการปรับปรุงหรือแก้ไข
- ความต้องการความรับผิดชอบ: ระบบราชการต้องการการตรวจสอบย้อนกลับและหลักฐานที่ชัดเจนเมื่อตัดสินใจที่มีผลต่อประชาชน
- หลักการเบื้องต้นของ AI Model Passport: ระบุสเปกของโมเดล, แหล่งข้อมูล, ประวัติการเทรนนิ่ง, ผลการประเมิน และข้อจำกัดของการใช้งาน
AI Model Passport คืออะไร: ส่วนประกอบและมาตรฐานที่ควรมี
AI Model Passport เป็นเอกสารเชิงเมตาดาต้า (metadata) และบันทึกการทำงานของโมเดลที่ออกแบบมาเพื่อเพิ่มความโปร่งใส ความรับผิดชอบ และความสามารถในการตรวจสอบย้อนกลับของโมเดลปัญญาประดิษฐ์ ในบริบทที่กระทรวงดิจิทัลทดลองบันทึกสเปก แหล่งข้อมูล และประวัติการเทรนบนบล็อกเชน พาสปอร์ตจะทำหน้าที่เป็นแหล่งข้อมูลเชิงบ่งชี้ว่าระบบใดถูกสร้างอย่างไร ใช้ข้อมูลใด และผ่านการประเมินด้านความปลอดภัยหรือความเป็นธรรมมาอย่างไร การเก็บข้อมูลในรูปแบบที่เป็นมาตรฐานช่วยให้หน่วยงานราชการและภาคเอกชนสามารถตรวจสอบและบริหารความเสี่ยงได้อย่างเป็นระบบ

องค์ประกอบสำคัญที่ควรมีใน AI Model Passport
- Metadata ของโมเดล (Model specification): ชื่อรุ่น (model name), หมายเลขเวอร์ชัน, สถาปัตยกรรม (เช่น Transformer, CNN), ขนาด (จำนวนพารามิเตอร์ เช่น >1B), license, จุดประสงค์การใช้งาน และระดับความเสี่ยงที่ประเมินไว้
- Provenance ของข้อมูล (Dataset provenance): รายการชุดข้อมูลที่ใช้ (dataset IDs หรือ hash), แหล่งที่มาของข้อมูล (source URL หรือองค์กรเจ้าของ), ใบอนุญาตการใช้งาน, วันที่รวบรวม และรายละเอียดการคัดกรองข้อมูลหรือการลบข้อมูลส่วนบุคคล
- Training log (ประวัติการเทรนนิ่ง): ระบุ dataset IDs ที่ใช้ในแต่ละเฟสของการเทรน, hyperparameters หลัก (เช่น learning_rate, batch_size, optimizer), ค่า seed สำหรับการสุ่ม, จำนวน epoch, ค่าทรัพยากรที่ใช้ (เช่น GPU-hours หรือ FLOPs), และ timeline ที่แสดงวันที่เริ่ม-สิ้นสุดของการเทรน
- ผลการประเมิน (Evaluation results): เมตริกประสิทธิภาพที่สำคัญตามบริบท (เช่น accuracy, F1, AUC, BLEU ฯลฯ), ชุดทดสอบที่ใช้ (IDs), ค่า fairness metrics (เช่น disparate impact) และรายงานการทดสอบ robustness/adversarial
- Metadata ด้านความปลอดภัยและการควบคุม (Security & Safety metadata): รายการช่องโหว่ที่ค้นพบ, การทดสอบความเป็นส่วนตัว (privacy audits, differential privacy parameters ถ้ามี), การควบคุมการเข้าถึง (access controls), และมาตรการแก้ไขความเสี่ยง
- Governance และการติดตาม (Governance): ข้อมูลเจ้าของโมเดล, ผู้รับผิดชอบทางเทคนิค, นโยบายการอัปเดต, และประวัติการเปลี่ยนแปลง (audit trail)
มาตรฐานอ้างอิงและการเชื่อมโยงเชิงแนวปฏิบัติ
AI Model Passport ควรสอดคล้องกับมาตรฐานสากลที่มีอยู่เพื่อความเข้ากันได้และการยอมรับในระดับสากล เช่น Model Cards ที่นำเสนอโดย Google และ ML Commons ซึ่งเน้นการสื่อสารจุดประสงค์ ขอบเขตการใช้งาน และข้อจำกัดของโมเดล และ Datasheets for Datasets ที่ให้แบบฟอร์มสำหรับการบันทึกรายละเอียดของชุดข้อมูล นอกจากนี้ ควรพิจารณาให้สอดคล้องกับข้อกำหนดของ EU AI Act โดยเฉพาะข้อกำหนดเกี่ยวกับการประเมินความเสี่ยง, การตรวจสอบความเป็นธรรม และการเก็บบันทึก (record-keeping) สำหรับระบบที่อยู่ในกลุ่ม high-risk
รูปแบบการบันทึกข้อมูลและโครงสร้าง (JSON/Schema)
เพื่อให้สามารถเชื่อมต่อ ระบบอัตโนมัติ และจัดเก็บบนบล็อกเชนได้อย่างมีประสิทธิภาพ แนะนำให้กำหนด Schema ในรูปแบบ JSON Schema ที่ระบุฟิลด์บังคับ (required) และฟิลด์ไม่บังคับ (optional) เช่น:
- ฟิลด์บังคับ (required):
- model_spec: { name, version, architecture, parameter_count }
- provenance: { dataset_ids[], dataset_hashes[], data_licenses[] }
- training_log: { start_date, end_date, hyperparameters{learning_rate, batch_size, epochs, seed}, compute_cost{gpu_hours, flops} }
- evaluation: { test_dataset_id, metrics{metric_name: value}, fairness_metrics{} }
- governance: {owner, contact, license}
- ฟิลด์ไม่บังคับ (optional):
- training_checkpoint_hashes
- raw_data_access_policies
- privacy_parameters (e.g., differential_privacy_epsilon)
- external_audit_reports
การใช้งานจริง: ตัวอย่างและสถิติประกอบการพิจารณา
ตัวอย่างเช่น โมเดลภาษาขนาดกลางที่มีจำนวนพารามิเตอร์ประมาณ 1–5 พันล้าน อาจระบุในพาสปอร์ตว่าใช้ชุดข้อมูลรวม 12 ชุด มีค่า seed และ hyperparameters ชัดเจน และใช้ทรัพยากรเทรนรวม 2,400 GPU-hours ซึ่งข้อมูลเช่นนี้ช่วยให้หน่วยงานที่ตรวจสอบสามารถประเมินความเสี่ยงด้านพลังงาน ความเป็นส่วนตัว และการลอกเลียนแบบข้อมูลได้ ในการสำรวจภาคอุตสาหกรรม พบว่าการมีเอกสารการตรวจสอบย้อนกลับ (provenance) ลดเวลาในการประเมินความเสี่ยงเบื้องต้นลงได้มากกว่า 40% เมื่อเทียบกับการไม่มีเอกสาร
ข้อเสนอแนะเชิงปฏิบัติ
เพื่อให้พาสปอร์ตมีประสิทธิภาพสูงสุด ควรกำหนดบังคับขั้นต่ำของฟิลด์ (minimal required schema) สำหรับโมเดลทุกประเภท และเพิ่มระดับข้อมูลเฉพาะสำหรับโมเดลความเสี่ยงสูง (high-risk) เช่น รายงาน external audit และผลการทดสอบ fairness เชิงลึก การบันทึกบนบล็อกเชนสามารถใช้เป็นชั้นสำหรับความไม่สามารถเปลี่ยนแปลงได้ (tamper-evidence) ของ hash ที่ชี้ไปยัง JSON record ฉบับสมบูรณ์ ทำให้ทั้งภาครัฐและเอกชนสามารถตรวจสอบความถูกต้องของพาสปอร์ตได้โดยไม่จำเป็นต้องเปิดเผยข้อมูลดิบทั้งหมด
เทคโนโลยีเบื้องหลัง: ทำไมเลือกบล็อกเชนและสถาปัตยกรรมการจัดเก็บข้อมูล
เทคโนโลยีเบื้องหลัง: ทำไมเลือกบล็อกเชนและสถาปัตยกรรมการจัดเก็บข้อมูล
การนำแนวคิด AI Model Passport มาบันทึกสเปก โมเดล แหล่งข้อมูล และประวัติการเทรนนิ่งบนบล็อกเชน มีเหตุผลเชิงเทคนิคและเชิงนโยบายชัดเจน โดยเฉพาะในบริบทของหน่วยงานรัฐและองค์กรขนาดใหญ่ที่ต้องการ ความโปร่งใส และความรับผิดชอบ (accountability) ต่อสาธารณะและผู้กำกับดูแล การใช้บล็อกเชนมอบคุณลักษณะสำคัญสองประการคือ ความไม่เปลี่ยนแปลง (immutability) ของระเบียนและ เส้นทางตรวจสอบย้อนหลัง (audit trail) ที่ตรวจสอบได้ ทั้งสองประการนี้ช่วยลดความเสี่ยงจากการปลอมแปลงข้อมูลสเปกโมเดลหรือการปรับเปลี่ยนประวัติการเทรนโดยไม่เปิดเผยได้อย่างมีนัยสำคัญ
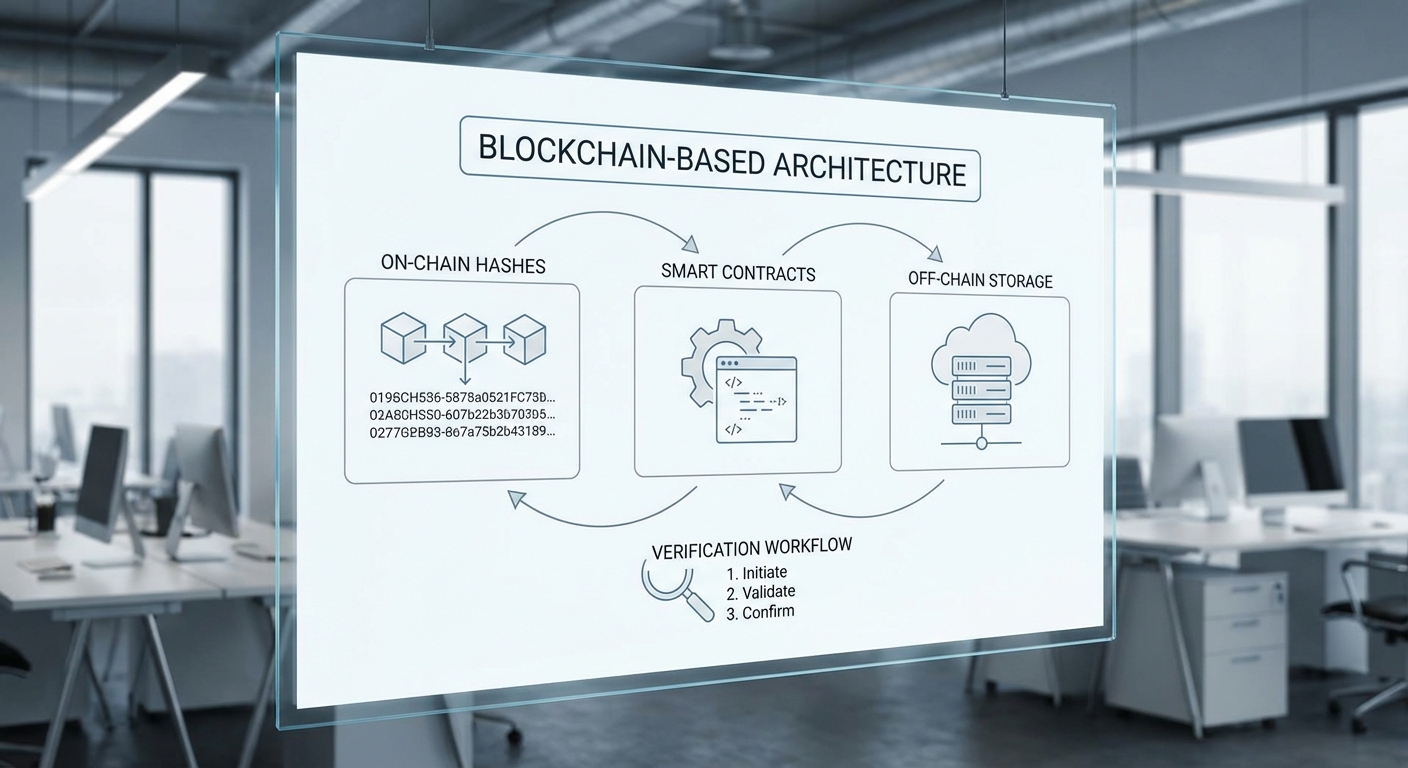
เชิงสถาปัตยกรรม ปฏิบัติการทั่วไปที่เป็นที่ยอมรับคือการบันทึก แฮชของ metadata (เช่น hash ของไฟล์ model card, สเปก hyperparameter, digest ของชุดข้อมูล) ลงบนบล็อกเชน ขณะที่ ข้อมูลต้นทางหรือข้อมูลขนาดใหญ่ (large artifacts) ถูกเก็บนอกเครือข่าย (off-chain) เช่น ในระบบเก็บข้อมูลกระจาย (IPFS/Arweave) หรือในสตอเรจแบบคลาวด์ที่เข้ารหัส การออกแบบเช่นนี้ผสานข้อดีของทั้งสองโลก: บล็อกเชนให้ความแน่นอนเชิงพิสูจน์ว่า metadata นั้นเคยมีอยู่และไม่ถูกเปลี่ยน ขณะที่ off-chain storage ช่วยแก้ปัญหาเรื่องค่าใช้จ่ายและความสามารถในการปรับขนาด (scalability) เมื่อจัดเก็บไฟล์ขนาดใหญ่
รายละเอียดเชิงเทคนิคที่มักใช้ร่วมกันประกอบด้วย:
- Hashing (เช่น SHA-256): สร้าง digest ของไฟล์หรือชุดข้อมูลเพื่อใช้เป็นลายนิ้วมือดิจิทัลที่บันทึกบนบล็อกเชน
- Merkle tree: สร้างโครงสร้างแบบต้นไม้เพื่อลดขนาดข้อมูลที่ต้องตรวจสอบ และอำนวยความสะดวกในการยืนยันความสมบูรณ์ของส่วนย่อย (partial proofs)
- Pointers / Content Identifiers (CID): บันทึกที่อยู่แบบชี้ไปยัง off-chain storage (ตัวอย่างเช่น CID ของ IPFS หรือ URL พร้อมลายเซ็น) แทนการเก็บไฟล์ทั้งชุดบน chain
- Timestamping: การประทับเวลาบนบล็อกเชนช่วยสร้างพยานหลักฐานของลำดับเหตุการณ์ เช่น เวลาที่โมเดลถูกเทรนหรือปรับรุ่น
การใช้ สมาร์ทคอนแทรกต์ ทำหน้าที่เป็นกลไกในการยืนยันความถูกต้องและนโยบายการตรวจสอบอัตโนมัติ ตัวอย่างการประยุกต์คือ:
- สมาร์ทคอนแทรกต์ทำหน้าที่เป็น registry ของเวอร์ชันโมเดล: เมื่อมีการเผยแพร่โมเดลใหม่ จะเรียกฟังก์ชันที่ตรวจสอบลายเซ็นกิจกรรมและบันทึก hash/metadata
- การตรวจสอบความสอดคล้อง (attestation): สมาร์ทคอนแทรกต์สามารถบังคับให้ผู้เผยแพร่แนบการพิสูจน์ เช่น การเซ็นด้วยคีย์ของหน่วยงาน หรือการตรวจสอบผลประเมิน (evaluation metrics) ที่มาจากหน่วยงานที่เชื่อถือได้
- การออกใบอนุญาตหรือสิทธิการเข้าถึงแบบอัตโนมัติ: สมาร์ทคอนแทรกต์สามารถจัดการ token-based access หรือการมอบสิทธิให้แก่ผู้ขออย่างเป็นระบบ
ในด้านความเป็นส่วนตัวและการปกป้องข้อมูลสำคัญ การออกแบบต้องผสานเทคนิคเชิงคริปโตกราฟีเพื่อให้เป็นทั้ง โปร่งใส และ คุ้มครองข้อมูลส่วนบุคคลหรือข้อมูลที่เป็นความลับทางการค้า เทคนิคสำคัญ ได้แก่:
- การเข้ารหัส (encryption): ข้อมูลจริงที่เก็บ off-chain ควรถูกเข้ารหัสทั้งในขณะพัก (at rest) และระหว่างการส่ง (in transit) โดยใช้การเข้ารหัสแบบสมมาตรสำหรับประสิทธิภาพ และใช้การเข้ารหัสแบบอสมมาตรสำหรับการจัดการคีย์และการสื่อสารที่ปลอดภัย
- การควบคุมการเข้าถึง (access control): ใช้ระบบสิทธิ (ACL), capability tokens หรือระบบจัดการคีย์ (KMS) เพื่อให้เฉพาะผู้มีสิทธิเท่านั้นที่สามารถถอดรหัสและเข้าถึง artefact ได้ ส่วนการบันทึกการให้สิทธิสามารถเก็บเป็นเหตุการณ์บน chain เพื่อให้ตรวจสอบย้อนหลังได้
- Selective disclosure: แทนที่จะเปิดเผยข้อมูลทั้งหมด ผู้ให้ข้อมูลสามารถเผยเฉพาะคุณลักษณะที่จำเป็น เช่น สัดส่วนข้อมูลฝึกจากภูมิภาคต่างๆ หรือเมตริกการประเมิน โดยใช้ credential-based systems (เช่น Verifiable Credentials) ที่ยืนยันความถูกต้องโดยไม่เปิดเผยแหล่งที่มา
- Zero-Knowledge Proofs (ZKP): ใช้เพื่อพิสูจน์สมบัติของโมเดลหรือชุดข้อมูล (เช่น การไม่มีข้อมูลจากกลุ่มที่ต้องคุ้มครอง หรือการได้มาตรฐานบางประการ) โดยไม่ต้องเปิดเผยข้อมูลต้นทาง ZKP ช่วยให้หน่วยงานสามารถแสดงความสอดคล้องต่อกฎระเบียบได้โดยรักษาความลับของข้อมูลภายใน
- Differential Privacy และ Secure MPC: ใช้ร่วมกับการเปิดเผยผลลัพธ์หรือการประเมินเพื่อป้องกันการสกัดคืนข้อมูลจากผลลัพธ์ของโมเดล
สรุปภาพรวมการออกแบบต้องคำนึงถึงข้อได้เปรียบและข้อจำกัด: บล็อกเชนให้ ความน่าเชื่อถือเชิงพิสูจน์ แต่มีต้นทุนและข้อจำกัดด้านขนาดข้อมูลและ latency ดังนั้นการบันทึกเพียงแฮช/metadata บน-chain และเก็บ artifact จริงแบบ off-chain จึงเป็นแนวปฏิบัติที่สมดุล นอกจากนี้ การผสานสมาร์ทคอนแทรกต์สำหรับการยืนยันอัตโนมัติและการใช้เทคนิคคริปโตกราฟีสมัยใหม่ เช่น ZKP และ selective disclosure จะช่วยให้ระบบ AI Model Passport สามารถตอบโจทย์ทั้งความโปร่งใส ความรับผิดชอบ และความเป็นส่วนตัวที่ภาครัฐและภาคเอกชนต้องการ
รายละเอียดการทดลองของกระทรวง: ขอบเขต ผู้ร่วมทดสอบ และตัวชี้วัดความสำเร็จ
รายละเอียดการทดลองของกระทรวง: ขอบเขต ผู้ร่วมทดสอบ และตัวชี้วัดความสำเร็จ
โครงการนำร่อง AI Model Passport ถูกออกแบบเป็นการทดลองเชิงปฏิบัติการขนาดกลางเพื่อประเมินความเป็นไปได้ของการบันทึกสเปก โมเดล แหล่งข้อมูล (data provenance) และประวัติการเทรนนิ่งบนระบบบล็อกเชน เป้าหมายหลักคือการเพิ่มความโปร่งใสและความรับผิดชอบของโมเดลที่ใช้ในงานราชการและบริการภาครัฐร่วมกับภาคเอกชน ภารกิจสำคัญประกอบด้วยการลงทะเบียนโมเดล การยืนยันแหล่งข้อมูล และการตรวจสอบย้อนหลัง (audit trail) โดยโครงสร้างการทดลองแบ่งเป็น 3 ระยะหลัก: การเตรียมความพร้อมและ onboarding (เดือนที่ 0–1), การลงทะเบียนและยืนยันข้อมูล (เดือนที่ 2–4) และการตรวจสอบและประเมินผลเชิงปฏิบัติการ (เดือนที่ 5–6)

ในแง่ของผู้เข้าร่วมทดสอบ โครงการเชิญหน่วยงานราชการตัวอย่างที่มีการใช้ AI ในงานบริการประชาชนและการตัดสินใจอัตโนมัติ รวมถึงหน่วยงานที่เกี่ยวข้องกับข้อมูลประชากรและการให้สิทธิประโยชน์ ตัวอย่างหน่วยงานที่เข้าร่วมได้แก่ กรมการปกครอง และ สำนักบริการข้อมูลภาครัฐ (ชื่อเป็นตัวอย่างเพื่ออธิบายกรอบการทดลอง) ขณะเดียวกันภาคเอกชนมีผู้ให้บริการคลาวด์ ผู้พัฒนาโมเดล AI รายกลาง-รายใหญ่ และสตาร์ทอัพด้าน Computer Vision และ Natural Language Processing ร่วมทดสอบด้วย โดยแบ่งบทบาทเป็นผู้พัฒนาโมเดล (model owners), ผู้ให้ข้อมูล (data providers) และผู้ตรวจสอบอิสระ (third‑party auditors)
ประเภทของโมเดลที่ทดลองประกอบด้วย: NLP (เช่น บอทตอบคำถามบริการประชาชน), Computer Vision (เช่น ระบบยืนยันตัวตนและตรวจสอบเอกสาร), และ Decision Systems (เช่น ระบบให้คะแนนคุณสมบัติผู้ขอสิทธิประโยชน์) แต่ละประเภทจะมีการกำหนดเมตาดาต้าที่ต้องบันทึกบนบล็อกเชนต่างกัน เช่น สเปกสถาปัตยกรรม, ชุดข้อมูลที่ใช้เทรน/เทส, ค่าพารามิเตอร์เชิงสถิติ, และลำดับขั้นตอนการเทรนนิ่ง (training log)
เพื่อวัดผลความสำเร็จของการทดลอง กระทรวงกำหนดชุดตัวชี้วัดหลัก (Key Performance Indicators - KPIs) ดังนี้
- อัตราการลงทะเบียนโมเดล (Registration rate): จำนวนโมเดลที่ลงทะเบียนบน AI Model Passport ต่อช่วงเวลา เป้าหมายเชิงทดลองตัวอย่างคือ ลงทะเบียน 50 โมเดลภายใน 6 เดือน (ตัวเลขตัวอย่างเพื่อประเมินศักยภาพของระบบ)
- เวลาในการยืนยันข้อมูล/ตอบคำร้องขอ (Verification time): เวลาตั้งแต่มีคำร้องขอข้อมูลหรือการตรวจสอบไปจนถึงการยืนยันสถานะ ตัวอย่างเป้าหมายเชิงทดลองคือการลดค่าเฉลี่ยจาก 14 วันเหลือ 2 วัน โดยการใช้ข้อมูลเชิงเทคนิคจากบล็อกเชนและ API อัตโนมัติเพื่อลดกระบวนการแมนนวล
- จำนวนการตรวจสอบย้อนหลังที่สำเร็จ (Audit incidents resolved): จำนวนกรณีที่ดำเนินการตรวจสอบย้อนหลังและตรวจสอบแหล่งที่มาได้ครบถ้วน เป้าหมายคือเพิ่มจำนวนการตรวจสอบที่เสร็จสมบูรณ์ต่อเดือนจากฐานตัวอย่างเป็นสองเท่า
- มาตรวัดความเชื่อมั่นของผู้ใช้ (User trust metrics): คะแนนจากแบบสำรวจความพึงพอใจและดัชนีความเชื่อมั่น เช่น Net Promoter Score (NPS) หรือความเชื่อมั่นต่อความถูกต้องของข้อมูล เป้าหมายเชิงทดลองคือการเพิ่มค่า NPS ขึ้น 20–30% เมื่อเทียบกับการให้บริการเดิมที่ไม่มี Passport
- เปอร์เซ็นต์โมเดลที่มีข้อมูลความโปร่งใสครบถ้วน (Completeness rate): สัดส่วนโมเดลที่มีเมตาดาต้าครบตามมาตรฐาน (เช่น ข้อมูลแหล่งข้อมูล, ไลเซนส์, หมุดเวลาการเทรน) เป้าหมายเชิงทดลองคือ >85% ภายในช่วงนำร่อง
- การลดข้อร้องเรียนจากประชาชน (Complaint reduction): วัดจากจำนวนเรื่องร้องเรียนเกี่ยวกับการตัดสินใจของระบบอัตโนมัติ คาดการณ์เชิงทดลองว่าการมี Passport จะช่วยลดข้อร้องเรียนลงประมาณ 25–40% เนื่องจากการเพิ่มความโปร่งใสและช่องทางตรวจสอบย้อนหลัง
การเก็บข้อมูลเพื่อวิเคราะห์ตัวชี้วัดจะผสมผสานระหว่างข้อมูลเชิงระบบ (เช่น log บล็อกเชน, API response time, จำนวน transaction) และข้อมูลเชิงพฤติกรรม (เช่น แบบสำรวจความพึงพอใจของผู้ใช้, จำนวนคำร้องขอตรวจสอบจากประชาชน) โดยกำหนดกระบวนการรายงานผลเป็นรายเดือนและรายไตรมาส สำหรับตัวอย่างเชิงตัวเลขระหว่างการทดลอง (สมมติฐานเชิงการออกแบบ) ได้แก่: ลงทะเบียน 50 โมเดลใน 6 เดือน; ค่าเฉลี่ยเวลา verify ลดจาก 14 วันเป็น 2 วัน; จำนวนการตรวจสอบย้อนหลังที่สำเร็จเพิ่มเป็น 120 รายการใน 6 เดือน; และข้อร้องเรียนที่เกี่ยวข้องกับความไม่โปร่งใสลดลงราว 30% เมื่อเปรียบเทียบกับช่วงก่อนนำร่อง
สุดท้าย กระทรวงได้กำหนดมาตรการประกันคุณภาพ (quality assurance) และการตรวจสอบอิสระเป็นส่วนหนึ่งของการทดลอง เพื่อให้แน่ใจว่าตัวชี้วัดสะท้อนผลปฏิบัติจริงและสามารถนำไปสู่ข้อเสนอเชิงนโยบายที่ชัดเจนในระยะยาว หากผลลัพธ์เชิงทดลองเป็นไปตามเป้าหมาย กระทรวงจะพิจารณาขยายขอบเขตการใช้ AI Model Passport สู่หน่วยงานอื่น ๆ และการบูรณาการกับระบบราชการดิจิทัลระดับชาติ
ประเด็นความเป็นส่วนตัว ทรัพย์สินทางปัญญา และข้อกฎหมายที่ต้องพิจารณา
ประเด็นความเป็นส่วนตัว ทรัพย์สินทางปัญญา และข้อกฎหมายที่ต้องพิจารณา
การเผยแพร่ข้อมูล provenance ของชุดข้อมูลและประวัติการเทรนนิ่งบนบล็อกเชนเพื่อความโปร่งใส แม้มีประโยชน์ด้านความรับผิดชอบ (accountability) แต่ย่อมก่อให้เกิดความเสี่ยงด้าน ข้อมูลส่วนบุคคล (PII) และข้อมูลเชิงความลับ ตัวอย่างเช่น กรณีการเปิดเผย metadata ที่ดูเหมือนไม่มีชื่อผู้ป่วยอาจถูกเชื่อมโยงกับแหล่งข้อมูลอื่นจนสามารถย้อนกลับมาระบุตัวบุคคลได้ (re-identification) — ปรากฏการณ์ที่เคยเกิดในเหตุการณ์เช่น AOL search log และ Netflix Prize ที่แสดงให้เห็นว่าการลบตัวชี้วัดตรงๆ ไม่เพียงพอในการปกป้องความเป็นส่วนตัว นอกจากนี้ รายงานด้านความปลอดภัยข้อมูลชี้ว่าค่าใช้จ่ายเฉลี่ยของการรั่วไหลข้อมูลระดับโลกมีมูลค่าหลายล้านดอลลาร์ (เช่น IBM Cost of a Data Breach Report 2023 ระบุค่าเฉลี่ยประมาณ 4.45 ล้านดอลลาร์สหรัฐ) ซึ่งสะท้อนความเสี่ยงทางการเงินและชื่อเสียงขององค์กรทั้งภาครัฐและเอกชน
ในมิติเชิงสิทธิทางปัญญา (IP) มีคำถามสำคัญเกี่ยวกับว่า ใครเป็นเจ้าของโมเดล ใครมีสิทธิที่จะแจกจ่าย metadata หรือเผยแพร่รายละเอียดเชิงเทคนิคของโมเดล บ่อยครั้งโมเดลเกิดจากการผสมผสานชุดข้อมูลหลายแหล่ง ซึ่งอาจมีเงื่อนไขการใช้งานที่จำกัดโดยลิขสิทธิ์ สัญญาอนุญาต หรือนโยบายผู้ให้บริการ หาก metadata ระบุแหล่งข้อมูลที่มีเงื่อนไขสัญญาจะนำมาซึ่งความเสี่ยงทางกฎหมาย เช่นการละเมิดสัญญาหรือการเปิดเผย trade secrets นอกจากนี้ ในบางเขตอำนาจกฎหมาย (เช่น EU) ยังมีสิทธิพิเศษเกี่ยวกับฐานข้อมูล (database rights) ที่อาจปกป้ององค์ประกอบของชุดข้อมูล ซึ่งต้องพิจารณาเมื่อเผยแพร่ข้อมูล provenance ระดับละเอียด
กรอบกฎหมายที่เกี่ยวข้องในบริบทไทยและระหว่างประเทศมีความสำคัญต่อการออกแบบ "AI Model Passport" ในประเทศไทย พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล พ.ศ. 2562 (PDPA) กำหนดหลักการสำคัญ เช่น ฐานทางกฎหมายของการประมวลผล ข้อผูกมัดด้านการรักษาความปลอดภัย และสิทธิของเจ้าของข้อมูล (เช่น สิทธิขอเข้าถึง แก้ไข หรือลบ) ซึ่งอาจขัดแย้งกับลักษณะไม่เปลี่ยนได้ของบล็อกเชน นอกจากนี้ต้องพิจารณากฎหมายลิขสิทธิ์ (Copyright Act B.E. 2537) กฎหมายอาญาไซเบอร์ และแนวปฏิบัติระหว่างประเทศ เช่น หลักการของ GDPR (สำหรับการโอนข้อมูลข้ามพรมแดน) และแนวทางการกำกับดูแล AI ของสหภาพยุโรป (EU AI Act) ที่กำลังถูกผลักดัน ซึ่งแม้จะยังไม่บังคับใช้ในไทย แต่เป็นมาตรฐานอ้างอิงสำหรับผู้ให้บริการข้ามชาติ
เพื่อจัดการความเสี่ยงเหล่านี้ ควรนำแนวทางปฏิบัติหลายชั้นมาประยุกต์ใช้ ได้แก่ data minimization (เก็บและเผยเฉพาะข้อมูลที่จำเป็น), การใช้ pointers แทนการเก็บ raw data บนบล็อกเชน (เช่น hashes, URIs หรือ commitments ที่ชี้ไปยังข้อมูลที่เก็บแบบ off‑chain), และการกำหนด access control อย่างเคร่งครัด การใช้บล็อกเชนแบบ permissioned จะช่วยจำกัดผู้เข้าถึง metadata ที่อาจมีความละเอียดสูงขึ้น นอกจากนี้ควรมีการทำ Data Protection Impact Assessment (DPIA) และการปรึกษาเจ้าหน้าที่คุ้มครองข้อมูล (DPO) รวมถึงผู้เชี่ยวชาญด้านกฎหมายก่อนเปิดเผยข้อมูลใด ๆ
- มาตรการทางเทคนิค: เก็บเฉพาะฟิลด์คุณลักษณะที่จำเป็นสำหรับการตรวจสอบ เช่น ประเภทของแหล่งข้อมูล, ขอบเขตเวลา, license ที่เกี่ยวข้อง, ขนาดโดยรวมของตัวอย่าง และค่าแฮชของ dataset แทนการเก็บข้อมูลดิบบน chain; ใช้การเข้ารหัสและระบบกุญแจสาธารณะ/ส่วนตัวสำหรับการเข้าถึง metadata ที่ละเอียด
- ข้อตกลงทางกฎหมาย: สัญญาแชร์ข้อมูล (data sharing agreements) ควรกำหนดขอบเขตสิทธิ ใช้สิทธิในการแจกจ่าย metadata การรับประกันไม่เปิดเผยข้อมูลความลับ และการจัดสรรความรับผิดชอบ (indemnities, liability caps)
- การกำกับดูแลภายใน: กำหนดบทบาทหน้าที่ชัดเจน (เช่น เจ้าของข้อมูล เจ้าหน้าที่ความปลอดภัย ผู้ควบคุมการเข้าถึง) มีนโยบาย retention และการลบข้อมูลที่สอดคล้องกับ PDPA แม้จะใช้ pointer บน chain ก็ควรมีกลไกให้ pointer นั้นชี้ไปยังสถานะที่สามารถเพิกถอนหรือเปลี่ยนแปลงได้
- การประเมินความเสี่ยงและทดสอบ: ดำเนินการทดสอบการโจมตีแบบ linkage/re-identification, ตรวจสอบสัญญาอนุญาตของแหล่งข้อมูล และทำการ audit ประจำเพื่อยืนยันความสอดคล้องทางกฎหมายและความปลอดภัย
- การปรึกษาผู้เชี่ยวชาญ: ก่อนเปิดตัวระบบ ให้ปรึกษาทีมกฎหมายด้านเทคโนโลยี ข้อมูลส่วนบุคคล และทรัพย์สินทางปัญญา รวมทั้งพิจารณาคำแนะนำจากหน่วยกำกับดูแลหรือหน่วยงานภาครัฐที่เกี่ยวข้อง
สรุปคือ โครงการ "AI Model Passport" มีศักยภาพสร้างความโปร่งใสและความรับผิดชอบ แต่ต้องออกแบบเชิงกฎหมายและเชิงเทคนิคอย่างรอบคอบเพื่อป้องกันการละเมิดความเป็นส่วนตัวและสิทธิทางปัญญา ควรเน้นหลักการ minimization, purpose limitation, governance และ contractual clarity พร้อมการประเมินผลกระทบเชิงกฎหมายอย่างต่อเนื่อง เพื่อให้ระบบส่งเสริมความน่าเชื่อถือโดยไม่สร้างความเสี่ยงด้านกฎหมายหรือความเสียหายต่อบุคคลและองค์กร
ผลกระทบต่อภาครัฐ ภาคเอกชน และประชาชน: โอกาสและความท้าทายเชิงนโยบาย
ผลกระทบต่อภาครัฐ ภาคเอกชน และประชาชน: โอกาสและความท้าทายเชิงนโยบาย
การนำระบบ AI Model Passport มาใช้ในหน่วยงานภาครัฐและภาคเอกชนจะเปลี่ยนกระบวนการจัดซื้อจัดจ้างและการบริหารความเสี่ยงของโมเดลอย่างมีนัยสำคัญ โดยพาสปอร์ตที่บันทึกสเปกของโมเดล แหล่งที่มาของชุดข้อมูล และประวัติการเทรนนิ่งบนบล็อกเชน สามารถทำให้หน่วยงานราชการตรวจสอบที่มาที่ไปของเทคโนโลยีได้ง่ายขึ้นก่อนการนำไปใช้งานจริง ตัวอย่างเช่น เทศบาลอาจกำหนดให้โมเดลที่จะเข้าร่วมประกวดราคาหรือให้บริการสาธารณะต้องมีพาสปอร์ตที่ผ่านการตรวจสอบจากหน่วยงานกลางหรือผู้ตรวจสอบอิสระเป็นเงื่อนไขในการยื่นซองประมูล ซึ่งจะช่วยยืนยันมาตรฐานความโปร่งใสและความรับผิดชอบของผู้เสนอราคาได้อย่างเป็นรูปธรรม
ประโยชน์หลักที่คาดว่าจะเกิดขึ้นได้แก่:
- เพิ่มความโปร่งใส — การเปิดเผยสเปกและแหล่งข้อมูลช่วยให้เจ้าหน้าที่ตรวจสอบความสอดคล้องกับกฎหมายและนโยบายได้รวดเร็วขึ้น และลดช่องว่างในการประเมินความเสี่ยงก่อนนำไปใช้
- ลดความเสี่ยงความลำเอียงในบริการสาธารณะ — งานวิจัยบางชิ้นชี้ว่า การตรวจสอบแหล่งข้อมูลและกระบวนการเทรนนิ่งสามารถลดความเบี่ยงเบนเชิงระบบได้ในระดับที่มีนัยสำคัญ (มีการประเมินช่วงการลดได้ประมาณ 10–30% ในบางเคส) ซึ่งทำให้บริการสาธารณะที่ใช้ AI เป็นธรรมและมีความน่าเชื่อถือยิ่งขึ้น
- เพิ่มความเชื่อมั่นของประชาชน — การสื่อสารข้อมูลเกี่ยวกับพารามิเตอร์และที่มาของข้อมูลต่อนโยบายสาธารณะ จะช่วยเสริมความไว้วางใจของผู้ใช้บริการว่าเทคโนโลยีถูกคัดเลือกและตรวจสอบอย่างรัดกุม
ในขณะเดียวกัน มีความท้าทายด้านการปฏิบัติและผลกระทบต่อนวัตกรรมของภาคเอกชนที่ต้องพิจารณา ได้แก่:
- ภาระการปฏิบัติตามสำหรับผู้พัฒนา — ผู้พัฒนาโดยเฉพาะสตาร์ทอัพและผู้ให้บริการขนาดกลางอาจเผชิญต้นทุนในการจัดทำพาสปอร์ตและการตรวจสอบภายนอก ต้นทุนเริ่มต้นอาจอยู่ในระดับตั้งแต่หลายหมื่นบาทจนถึงหลายล้านบาท ขึ้นกับความซับซ้อนของโมเดลและระดับการรับรองที่ต้องการ
- สถานะการเปิดเผยข้อมูลเชิงพาณิชย์ — ข้อมูลเกี่ยวกับสเปกโมเดลหรือชุดข้อมูลอาจถือเป็นความลับทางการค้า การบังคับให้เปิดข้อมูลทั้งหมดอาจขัดต่อแรงจูงใจในการพัฒนาและการลงทุน การออกแบบนโยบายจึงต้องมีสมดุลระหว่างความโปร่งใสกับการคุ้มครองทรัพย์สินทางปัญญา
- ความเสี่ยงด้านความเป็นส่วนตัวและความปลอดภัย — การบันทึกข้อมูลบนบล็อกเชนอาจให้ความมั่นคงในความไม่เปลี่ยนแปลง (immutability) แต่ต้องระวังไม่ให้ข้อมูลส่วนบุคคลหรือเมตาดาต้าที่อาจระบุตัวบุคคลถูกเผยแพร่โดยไม่จำเป็น
- ผลต่อความคล่องตัวนวัตกรรม — หากข้อกำหนดเข้มงวดหรือกระบวนการรับรองช้า อาจทำให้การนำโมเดลรุ่นใหม่เข้าตลาดชะลอตัวได้ ส่งผลให้ภาคเอกชนสูญเสียความสามารถในการแข่งขัน
เชิงนโยบายมีโอกาสหลายประการที่รัฐสามารถนำ AI Model Passport มาใช้เพื่อผลประโยชน์สาธารณะและส่งเสริมนิเวศนวัตกรรม:
- ใช้เป็นเกณฑ์รับรองก่อนจัดซื้อ — กำหนดให้พาสปอร์ตที่ผ่านการรับรองหรือมีการประเมินจากผู้ตรวจสอบอิสระเป็นเงื่อนไขหนึ่งของการประกวดราคาสาธารณะหรือการจัดซื้อราชการ ตัวอย่างการใช้งาน เช่น การยื่นซองประมูลระบบคัดกรองสวัสดิการต้องแนบพาสปอร์ตและรายงานการทดสอบความลำเอียง
- ส่งเสริมตลาดบริการตรวจสอบอิสระ — รัฐสามารถเร่งสร้างตลาดสำหรับผู้ตรวจสอบโมเดลอิสระและมาตรฐานการรับรอง ซึ่งจะเปิดโอกาสให้ผู้ให้บริการที่เป็นกลางสร้างรายได้และขยายบริการตรวจสอบครบวงจร
- ออกแบบมาตรการช่วยเหลือสำหรับผู้ประกอบการขนาดเล็ก — เช่น มาตรการทางการเงิน สนับสนุนเชิงเทคนิค หรือเวทีร่วมพัฒนา เพื่อบรรเทาภาระต้นทุนและส่งเสริมการแข่งขันอย่างเป็นธรรม
- ใช้แนวทางแบบค่อยเป็นค่อยไป — นำนโยบายแบบเฟสชัน (phased rollout) โดยกำหนดโมเดลความเสี่ยงสูงให้มีข้อกำหนดเข้มงวดก่อน และขยายไปยังโมเดลความเสี่ยงต่ำ เพื่อรักษาสมดุลระหว่างความปลอดภัยและนวัตกรรม
โดยสรุป AI Model Passport มีศักยภาพในการยกระดับความโปร่งใสและความรับผิดชอบของการใช้ AI ในภาครัฐและภาคเอกชน ช่วยเพิ่มความเชื่อมั่นของประชาชนและลดความเสี่ยงจากความลำเอียง อย่างไรก็ดี การออกแบบนโยบายต้องคำนึงถึงภาระการปฏิบัติตาม ความลับทางการค้า ต้นทุนการตรวจสอบ และมาตรการสนับสนุนสำหรับผู้ประกอบการโดยเฉพาะรายเล็ก เพื่อให้การนำพาสปอร์ตไปใช้สร้างประโยชน์สูงสุดโดยไม่เป็นอุปสรรคต่อการพัฒนานวัตกรรม
ข้อเสนอแนะและโรดแมปการขยายผล: จากนำร่องสู่การนำไปใช้จริง
ข้อเสนอแนะและโรดแมปการขยายผล: จากนำร่องสู่การนำไปใช้จริง
เพื่อให้โครงการ AI Model Passport บรรลุเป้าหมายด้านความโปร่งใสและความรับผิดชอบของโมเดลทั้งในภาครัฐและภาคเอกชน จำเป็นต้องกำหนดกรอบนโยบายและมาตรฐานเชิงเทคนิคที่ชัดเจน ควบคู่กับโรดแมปการขยายผลในช่วง 12–24 เดือนข้างหน้า โดยข้อเสนอที่สำคัญแบ่งเป็น 3 มิติหลัก ได้แก่ มาตรฐาน metadata และฟิลด์บังคับ, การผสานพาสปอร์ตเข้ากับกระบวนการจัดซื้อและประเมินความเสี่ยง, และกลไกกำกับดูแลพร้อมการสนับสนุนทางเทคนิคและบุคลากร
มาตรฐาน metadata และฟิลด์บังคับ — ให้กำหนดชุดฟิลด์ขั้นต่ำที่ต้องถูกบันทึกในพาสปอร์ตของทุกโมเดลก่อนนำไปใช้งานหรือเสนอในการจัดซื้อ ภาคตัวอย่างฟิลด์บังคับประกอบด้วย:
- ข้อมูลประจำตัวโมเดล: ชื่อโมเดล, รุ่น (version), วันที่สร้าง/ปรับปรุง
- ผู้พัฒนา/เจ้าของ: หน่วยงานหรือบริษัทผู้พัฒนา, ข้อมูลติดต่อ, ใบอนุญาต
- แหล่งข้อมูลการเทรน: รายการแหล่งข้อมูล (พร้อมระดับการเข้าถึง: สาธารณะ/เชิงพาณิชย์/ข้อมูลภายใน), สัดส่วนข้อมูลสังเคราะห์/จริง
- เมตริกประสิทธิภาพ: ชุดตัวชี้วัดการทดสอบที่ใช้, ผลลัพธ์บนชุดข้อมูลมาตรฐาน และการประเมินความถูกต้อง
- การประเมินความเสี่ยงและความเป็นธรรม: รายงานการทดสอบ bias, ความเสี่ยงทางความปลอดภัย และระดับความเสี่ยงเชิงปฏิบัติการ
- ข้อจำกัดการใช้งาน: ขอบเขตการใช้งานที่อนุญาต/ห้าม, คำแนะนำการกำกับดูแลเมื่อใช้ในบริบทเฉพาะ
- ประวัติการเทรนและปรับปรุง: ลิงก์ไปยัง model card, hash ของเวอร์ชันและ pointer ไปยังที่เก็บข้อมูลแบบ off‑chain
- ทรัพยากรและผลกระทบสิ่งแวดล้อม: ข้อมูล compute, ประมาณการการใช้พลังงาน/คาร์บอน ถ้ามี
การเชื่อมต่อกับการจัดซื้อจัดจ้างและการประเมินความเสี่ยง — ให้พิจารณาบังคับใช้พาสปอร์ตเป็นเงื่อนไขเบื้องต้นของการเสนอราคาหรือสัญญาจัดซื้อภาครัฐ โดยมีแนวปฏิบัติหลักดังนี้:
- ผสานระบบพาสปอร์ตกับระบบ e‑procurement ของรัฐผ่าน API มาตรฐาน เพื่อให้ระบบการจัดซื้อสามารถดึงข้อมูล metadata และสถานะความเสี่ยงอัตโนมัติ
- กำหนดกลไกการให้คะแนนความเสี่ยง (risk scoring) ที่พิจารณาจากฟิลด์เช่น แหล่งข้อมูล, การประเมิน bias, และผลการตรวจสอบอิสระ โดยคะแนนนี้จะใช้เป็นเกณฑ์ในการอนุมัติหรือกำหนดมาตรการบรรเทา
- ออกแนวทางการจัดชั้นความเสี่ยง (risk classification) สำหรับการใช้งานโมเดล เช่น เกณฑ์สำหรับการใช้งานที่มีผลต่อชีวิต/สิทธิ์พลเมือง ต้องการการอนุมัติระดับสูงและการตรวจสอบอิสระเพิ่มเติม
- รวมพาสปอร์ตเข้าเป็นส่วนหนึ่งของสัญญา (contractual requirement) โดยเฉพาะข้อกำหนดเรื่องการแจ้งการเปลี่ยนแปลงหรือการอัปเดตโมเดล
กลไกกำกับดูแล คู่มือ และการสนับสนุนทางเทคนิค — เพื่อให้ระบบมีความน่าเชื่อถือ ควรจัดตั้งองค์ประกอบกำกับดังต่อไปนี้:
- หน่วยตรวจสอบอิสระ (Independent Audit Unit): จัดตั้งหน่วยงานหรือผู้ออกใบรับรองอิสระเพื่อทำการตรวจสอบ model passports, ดำเนินการออดิทเชิงเทคนิค และออกใบรับรองความสอดคล้อง (certification)
- มาตรฐานการตรวจสอบและคู่มือ: ออกคู่มือวิธีการตรวจสอบ (audit playbook) ที่ครอบคลุมวิธีการทดสอบ bias, security pen‑test, และการตรวจสอบความถูกต้องของ metadata รวมถึงเทมเพลต model card
- การสนับสนุนทางเทคนิค: จัดทีมสนับสนุน (helpdesk/technical advisory) และชุด SDK/API แบบเปิดเพื่อช่วยผู้พัฒนาเชื่อมต่อกับระบบบล็อกเชนและมาตรฐาน metadata
- มาตรการแรงจูงใจและการบังคับใช้: มาตรการจูงใจเช่น สิทธิ์เข้าถึงโครงการภาครัฐ, การลดขั้นตอนประเมินสำหรับผู้ที่ผ่านการรับรอง และบทลงโทษสำหรับการไม่ปฏิบัติตาม
แผนโรดแมป 12–24 เดือน (ตัวอย่าง)
- เดือน 0–3 (ปรับแต่งนำร่อง): สรุปผลนำร่อง ปรับปรุงฟิลด์บังคับ และออกร่างมาตรฐาน metadata พร้อมต้นแบบ API
- เดือน 3–6 (ภาคีและการมีส่วนร่วม): จัดรับฟังความคิดเห็นจากหน่วยงานภาครัฐ เอกชน และหน่วยงานกำกับ พร้อมทดลองเชื่อมระบบ e‑procurement กับพาสปอร์ตในหน่วยงานนำร่องเพิ่มเติม
- เดือน 6–12 (พัฒนาระบบและออกคู่มือ): ปรับระบบให้พร้อมใช้งานทางเทคนิค ออกคู่มือการตรวจสอบและมาตรการความปลอดภัย จัดตั้งหน่วยตรวจสอบอิสระขั้นต้น และเริ่มการอบรมบุคลากร
- เดือน 12–18 (ขยายเชิงรุก): เปิดให้หน่วยงานสำคัญของรัฐทั้งหมดใช้งานพาสปอร์ตเป็นเงื่อนไขการจัดซื้อ เริ่มโครงการรับรองผู้พัฒนา และขยายการฝึกอบรมเชิงลึก
- เดือน 18–24 (มาตรฐานเชิงรากฐานและการประเมินผล): ขยายระบบไปยังภาคเอกชนที่ให้บริการแก่รัฐ ปรับปรุงตามผลการประเมิน และสถาปนากลไกการบังคับใช้ถาวร
การฝึกอบรมและการพัฒนาความสามารถบุคลากร — ให้จัดหลักสูตรและการรับรองสำหรับบทบาทหลัก ได้แก่ เจ้าหน้าที่จัดซื้อ, ผู้ประเมินความเสี่ยง, นักตรวจสอบโมเดล และผู้พัฒนา โดยคาดว่าอย่างน้อยร้อยละ 60 ของทีมจัดซื้อและทีมตรวจสอบที่เกี่ยวข้องควรผ่านการอบรมขั้นต้นภายใน 12 เดือนแรก
รายการตรวจสอบสำหรับหน่วยงานที่ประสงค์จะเข้าร่วม (Check‑list)
- จัดทำบัญชีรายชื่อโมเดลที่ใช้งานพร้อมสถานะ (นำร่อง/ใช้งานจริง)
- แต่งตั้งผู้รับผิดชอบด้าน AI Governance และ Data Protection Officer
- ยอมรับแบบฟอร์ม metadata มาตรฐาน และเตรียมข้อมูลพื้นฐานสำหรับแต่ละโมเดล
- ทดสอบการเชื่อมต่อ API กับระบบพาสปอร์ต และยืนยันกระบวนการ anchor hash บนบล็อกเชน
- เข้าร่วมการอบรมเบื้องต้นด้านการประเมินความเสี่ยง AI และการใช้คู่มือออดิท
- จัดเตรียมแผนการตอบสนองต่อเหตุการณ์ (incident response) สำหรับโมเดลที่มีผลกระทบสูง
- ลงนามข้อตกลงการแลกเปลี่ยนข้อมูล (MoU) กับหน่วยงานกลางเพื่อรองรับการตรวจสอบอิสระ
โดยสรุป การขยายผลของ AI Model Passport จำเป็นต้องอาศัยการประสานงานเชิงนโยบาย เทคนิคร่วมสมัย และการลงทุนในบุคลากรและกลไกกำกับดูแล หากปฏิบัติตามโรดแมปเชิงปฏิบัติการข้างต้น ภายใน 12–24 เดือนแรกคาดว่าจะสามารถยกระดับการตรวจสอบและความน่าเชื่อถือของโมเดลที่ใช้ในภาครัฐได้อย่างมีนัยสำคัญ โดยช่วยลดความเสี่ยงและสร้างความเชื่อมั่นแก่ประชาชนและคู่ค้าทางธุรกิจ
บทสรุป
การทดลองระบบ "AI Model Passport" บนบล็อกเชนโดยกระทรวงดิจิทัลเป็นความพยายามที่มุ่งสร้างความโปร่งใสและความรับผิดชอบของโมเดล AI โดยบันทึกสเปกของโมเดล แหล่งข้อมูลการเทรนนิ่ง และประวัติการฝึกอบรมอย่างมีเอกลักษณ์ การเก็บข้อมูลบนบล็อกเชนช่วยให้สามารถตรวจสอบแหล่งที่มา (data provenance) และเส้นทางการพัฒนาโมเดลได้ง่ายขึ้น แต่การออกแบบต้องคำนึงถึงความเป็นส่วนตัวและทรัพย์สินทางปัญญาอย่างรัดกุม เช่น การใช้การเก็บข้อมูลแบบ off-chain พร้อมแฮชบน-chain, การเข้ารหัสและการควบคุมสิทธิ์การเข้าถึง, รวมถึงเทคนิคความเป็นส่วนตัวขั้นสูงเช่น zero-knowledge proofs เพื่อไม่ให้ข้อมูลที่เป็นความลับถูกเปิดเผยโดยไม่จำเป็น
การนำร่องของกระทรวงเป็นโอกาสสำคัญในการทดสอบสถาปัตยกรรม เทคโนโลยี นโยบาย และมาตรฐานที่จำเป็นก่อนการขยายผลในวงกว้าง โดยจะช่วยประเมินความสามารถด้านการทำงานร่วมกันของระบบ (interoperability), มาตรฐานเมตาดาต้า, กระบวนการตรวจสอบและรับรอง (audit & certification) รวมถึงการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคลและกฎหมายทรัพย์สินทางปัญญา ตัวชี้วัดความสำเร็จของโครงการนำร่องอาจรวมถึงความแม่นยำของข้อมูลแหล่งที่มา ความรวดเร็วในการตรวจสอบ และระดับความมั่นใจของผู้ใช้งานทั้งภาครัฐและเอกชน
มองไปข้างหน้า หากการทดลองประสบผลสำเร็จ AI Model Passport สามารถเป็นรากฐานสร้างความเชื่อมั่นในการใช้ AI ของระบบราชการและภาคเอกชน ช่วยลดความเสี่ยงจากการใช้ข้อมูลไม่เหมาะสมและเพิ่มความสามารถในการตรวจสอบย้อนหลัง อย่างไรก็ตามความสำเร็จจะต้องอาศัยกรอบกฎหมายที่ชัดเจน มาตรฐานสากล ความร่วมมือระหว่างหน่วยงาน และการลงทุนในโครงสร้างพื้นฐานที่ขยายตัวได้รวมทั้งเทคโนโลยีรักษาความเป็นส่วนตัว กระทรวงควรเดินหน้าแบบทดลอง-ปรับปรุง (iterative pilot) และเปิดรับข้อเสนอแนะจากผู้มีส่วนได้เสียเพื่อให้การขยายผลเป็นไปอย่างสมดุลระหว่างความโปร่งใสและการคุ้มครองข้อมูลเชิงพาณิชย์



