
โรงงานไทยกำลังก้าวเข้าสู่ยุคใหม่ของการออกแบบและการผลิตด้วยการนำระบบ Neural‑CAD ที่ผสานความสามารถจาก Large Language Models (LLMs) มาใช้ในการแปลงสเปกระบุความต้องการเป็นโมเดล 3D‑CAD และชุดคำสั่งเครื่องจักร (G‑Code) โดยอัตโนมัติ เทคโนโลยีนี้ช่วยย่นเวลาจากการออกแบบเชิงมือและการแปลงไฟล์ด้วยมือมนุษย์ เป็นกระบวนการที่เชื่อมต่อตั้งแต่สเปกต้นน้ำจนถึงการขึ้นชิ้นงาน ส่งผลให้กลุ่มตัวอย่างนำร่องสามารถลดเวลาการพัฒนาโปรโตไทป์ได้กว่า 70% ซึ่งแปลเป็นการประหยัดทั้งเวลา เงินทุน และจำนวนรอบการทำซ้ำของการออกแบบ
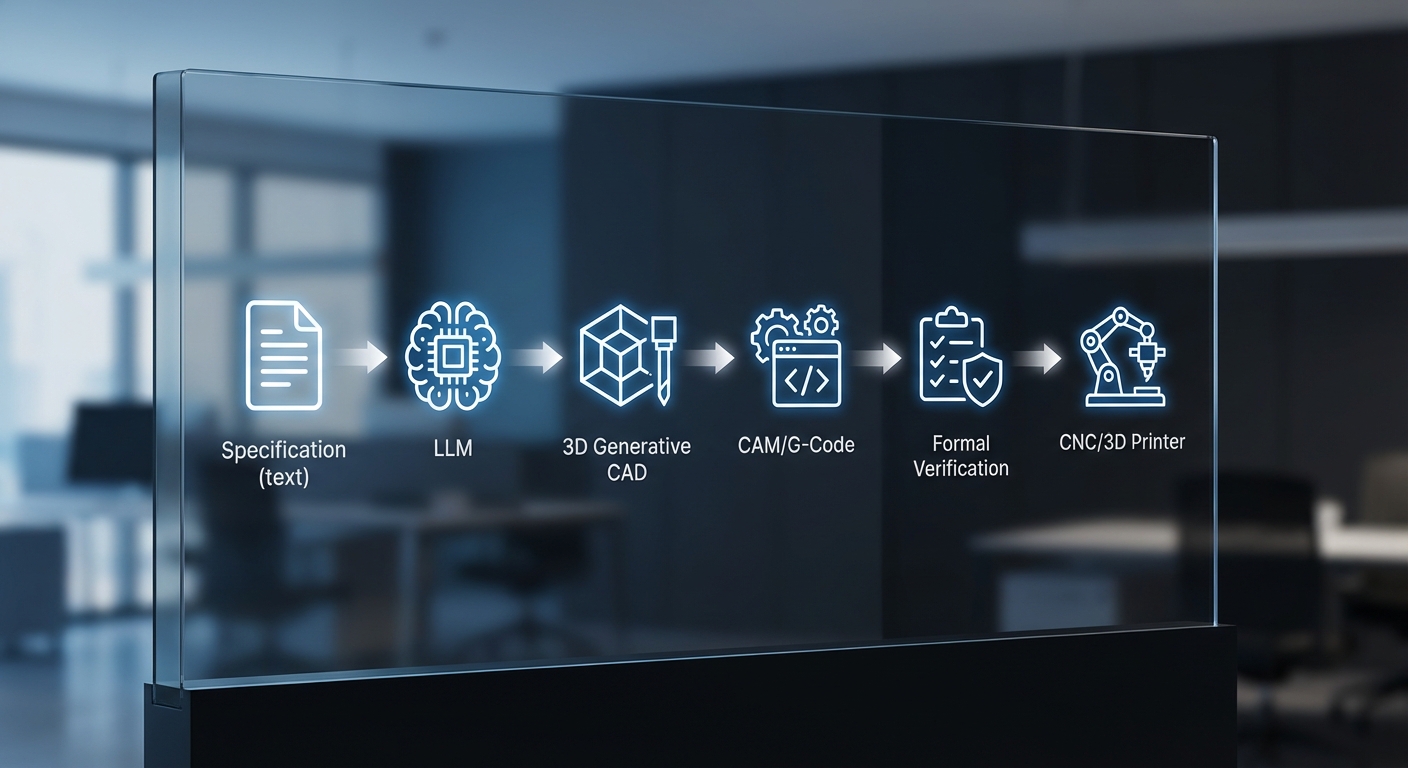
สิ่งที่ทำให้การประยุกต์ใช้นี้แตกต่างจากระบบอัตโนมัติทั่วไปคือการบูรณาการขั้นตอน formal verification เข้ามาตรวจจับข้อผิดพลาดเชิงเรขาคณิตและตรรกะก่อนส่งไฟล์ไปยังเครื่องจักรจริง—ทั้งการชนกันของชิ้นส่วน มิติที่ขัดแย้ง หรือคำสั่งการเคลื่อนที่ที่อาจทำให้เครื่องจักรเสียหาย ผู้พัฒนาโซลูชันรายงานว่าเวิร์กโฟลว์ใหม่ช่วยลดความเสี่ยงของความเสียหายต่อเครื่องจักรอย่างมีนัยสำคัญ อีกทั้งยังเพิ่มความเร็วในการวนรอบการออกแบบ ทำให้โรงงานสามารถทดสอบแนวคิดใหม่ ๆ ได้บ่อยขึ้นและมีความน่าเชื่อถือมากขึ้นในขั้นตอนการผลิต
บทนำ: ทำไม Neural‑CAD ถึงเป็นจุดเปลี่ยนของการผลิต
บทนำ: ทำไม Neural‑CAD ถึงเป็นจุดเปลี่ยนของการผลิต
ในภาคการผลิตปัจจุบัน การแปลงสเปกเชิงวิศวกรรม (technical specification) ให้กลายเป็นโมเดล 3D‑CAD และคำสั่งเครื่องจักร (G‑Code) ยังคงเป็นกระบวนการที่พึ่งพาความเชี่ยวชาญของมนุษย์สูง ทั้งการตีความข้อกำหนด การออกแบบชิ้นงาน การกำหนดพาธเครื่องมือ และการตรวจสอบความปลอดภัยก่อนการขึ้นเครื่องจริง ปัญหาที่พบบ่อยได้แก่ ระยะเวลาพัฒนาโปรโตไทป์ที่ยาว (บางโครงการกินเวลาหลายสัปดาห์ถึงหลายเดือน) ความไม่สอดคล้องระหว่างสเปกกับผลลัพธ์ใน CAD/CAM และต้นทุนจากการทดสอบบนเครื่องจักรจริงที่เกิดจากข้อผิดพลาดของ G‑Code ซึ่งอาจทำให้เกิดชิ้นงานเสีย หยุดการผลิต หรือความเสี่ยงด้านความปลอดภัยของเครื่องจักร
Neural‑CAD เข้ามาเป็นแนวทางใหม่โดยผสานความสามารถของ Large Language Models (LLMs) กับระบบสร้าง CAD เชิงกำเนิด (generative CAD) และ CAM pipeline อัตโนมัติ โดย LLM ทำหน้าที่ตีความสเปกภาพรวมภาษาธรรมชาติ แปลงข้อกำหนดจุดประสงค์ ความคลาดเคลื่อน และเงื่อนไขการผลิตไปเป็นพารามิเตอร์ที่เครื่องมือ CAD เข้าใจ จากนั้นโมดูล generative CAD จะสร้างแบบสามมิติที่สอดคล้องกับสเปก และระบบ CAM/G‑Code generator จะสังเคราะห์เส้นทางเครื่องมือตามมาตรฐานการผลิต สุดท้ายแทรกชั้นของ formal verification เพื่อวิเคราะห์แบบจำลองและโค้ดก่อนส่งขึ้นเครื่องจริง
การรวมกันขององค์ประกอบทั้งสาม — LLM, generative CAD/CAM และ formal verification — เปลี่ยนจากกระบวนการที่เป็นงานมือขึ้นมาเป็น pipeline อัตโนมัติที่มีการตรวจสอบเชิงตรรกะและเชิงเรขาคณิตในตัว ผลลัพธ์เชิงคาดหมายจากการทดลองเบื้องต้นในโรงงานไทยที่เริ่มนำระบบ Neural‑CAD ไปใช้งานแสดงให้เห็นว่าเวลาพัฒนาโปรโตไทป์ลดลงอย่างมาก กลุ่มตัวอย่างรายงานลดเวลาการพัฒนากว่า 70% จากการตัดขั้นตอนการแปลสเปกด้วยมือ การลดรอบแก้แบบ และการลดครั้งการทดสอบที่ต้องทำบนเครื่องจริง
ข้อดีสำคัญนอกเหนือจากการประหยัดเวลาได้แก่ การลดข้อผิดพลาดระหว่างการตีความสเปก ซึ่งช่วยลดค่าใช้จ่ายจากการ rework และการหยุดเครื่อง การเพิ่มความสอดคล้องของผลลัพธ์กับสเปกต้นทาง (traceability) และการเสริมความมั่นใจผ่านการตรวจสอบเชิง formal ที่สามารถตรวจจับปัญหา เช่น การชนกันของเครื่องมือ (collisions), พาธที่ไม่ต่อเนื่อง, หรือเงื่อนไขความคลาดเคลื่อนที่ละเมิดข้อกำหนด ก่อนจะเกิดความเสียหายเมื่อขึ้นเครื่องจริง สิ่งเหล่านี้ทำให้ Neural‑CAD เป็นจุดเปลี่ยนที่ตอบโจทย์ทั้งด้านความเร็ว คุณภาพ และความปลอดภัยในการผลิตสมัยใหม่
- ปัญหาที่แก้ได้: ลดการพึ่งพางานมือในการแปลงสเปกและเขียน G‑Code
- แนวทางเทคโนโลยี: LLM → generative CAD → CAM/G‑Code → formal verification
- ผลลัพธ์เชิงคาดหมาย: ลดเวลาพัฒนา ลดข้อผิดพลาด เพิ่มความสอดคล้องของสเปกและ traceability
Neural‑CAD และบทบาทของ LLM: นิยามและองค์ประกอบหลัก
Neural‑CAD และบทบาทของ LLM: นิยามและองค์ประกอบหลัก
Neural‑CAD คือระบบการออกแบบเชิงคอมพิวเตอร์ที่ผสานเทคโนโลยีปัญญาประดิษฐ์สมัยใหม่เพื่อแปลงสเปกภาษาธรรมชาติเป็นโมเดล 3D‑CAD และไฟล์ G‑Code สำหรับเครื่องจักรโดยอัตโนมัติ ในบริบทนี้ Large Language Models (LLMs) ทำหน้าที่เป็นตัวตีความสเปก (specification) ของผู้ใช้งาน — ไม่ว่าจะเป็นข้อกำหนดมิติ ความคลาดเคลื่อน วัสดุ หรือการประกอบ — แล้วแปลงเป็นตัวแทนเชิงเรขาคณิต (geometric representation) ที่เหมาะสมสำหรับโมดูลต่อไป การผสานกันของ LLM, generative CAD, CAM/G‑Code generator และ formal verification จึงเป็นองค์ประกอบสำคัญที่ทำให้กระบวนการจากสเปกถึงการขึ้นเครื่องจริงเป็นไปอย่างรวดเร็วและปลอดภัย
ในเชิงปฏิบัติ LLM จะรับข้อความสเปก เช่น “เพลา Φ20 ±0.02 mm ยาว 100 mm ทำจากเหล็กกล้า ต้องทนแรงบิด 200 Nm” แล้วสกัดข้อมูลสำคัญเป็นพารามิเตอร์เชิงตัวเลข เงื่อนไขความทนทาน และเงื่อนไขการประกอบ จากนั้นแปลงเป็น representation เช่น B‑Rep, CSG, mesh หรือ implicit field ที่โมดูล generative CAD เข้าใจได้ กระบวนการนี้มักใช้เทคนิคหลายชั้น เช่น prompt engineering, semantic parsing และการ fine‑tune LLM ด้วยชุดข้อมูลออกแบบทางวิศวกรรม เพื่อให้ความแม่นยำในการตีความสูงพอสำหรับการสร้างแบบที่พร้อมผลิตจริง
โมดูล generative 3D‑CAD จะรับ representation ดังกล่าวและสร้างโมเดล 3D โดยใช้วิธีการผสมผสานระหว่าง neural networks (เช่น diffusion models, graph neural networks หรือ implicit neural representations) และ parametric modelling (เช่นสูตรพารามิเตอร์และ constraint‑based modelling) เพื่อให้ได้แบบที่สามารถปรับค่า (parametric) ได้ตามสเปก ตัวอย่างเช่น ระบบอาจสร้างเพลาที่เป็นพารามิเตอร์โดยระบุค่าเส้นผ่านศูนย์กลาง ความยาว และความโค้ง แล้วทดลองปรับค่าต่าง ๆ เพื่อตรวจสอบความเป็นไปได้ทางการผลิตและการประกอบก่อนส่งต่อไปยังขั้นตอน CAM
- LLM เป็นตัวตีความสเปกเป็น representation ทางเรขาคณิต: แยกข้อมูลเชิงเทคนิค (มิติ, ความคลาดเคลื่อน, วัสดุ, เงื่อนไขการทำงาน) แล้วแมปไปยัง primitive/geometric constructs หรือพารามิเตอร์ของโมเดล
- Generative CAD (neural + parametric): สร้างแบบ 3D โดยใช้เครือข่ายประสาทและแบบจำลองพารามิเตอร์ เพื่อให้โมเดลสามารถปรับแต่งและตรวจสอบภายในอัตโนมัติ เช่นสร้างหลายตัวเลือกดีไซน์ตามข้อจำกัดต้นทุน/น้ำหนัก/ความแข็งแรง
- CAM / G‑Code generator: แปลงโมเดล 3D เป็น toolpaths ที่พร้อมสำหรับ CNC และ 3D printers (รวมถึงการเลือกเครื่องมือ, feed/speed, การวางชิ้นงาน) และส่งออกเป็น G‑Code ที่ตรงกับโปรไฟล์เครื่องจักร
- Formal verification layer: ตรวจพิสูจน์ความถูกต้องเชิงเรขาคณิตและกระบวนการก่อนขึ้นเครื่อง เช่นการตรวจ collision, การยืนยันฟิตติ้งตาม tolerance, ความสามารถของเครื่องมือ, stress/strain checks แบบจำลอง และการวิเคราะห์ความเสี่ยงของ toolpath
บทบาทของ formal verification เป็นตัวตัดสินใจขั้นสุดท้ายก่อนส่ง G‑Code ไปยังเครื่องจักร โดยใช้เทคนิคจากหลายสาขา ได้แก่ SMT/constraint solvers, interval arithmetic, symbolic geometry checks และการจำลองแบบไดนามิก เพื่อยืนยันเงื่อนไขที่อาจก่อให้เกิดความเสียหาย เช่นการชนกันของเครื่องมือ/แม่พิมพ์, การตัดชิ้นงานนอก tolerance, หรือการสั่งการที่เกินขีดจำกัดทางกลของเครื่องจักร ในการทดสอบภายในหลายระบบ ตัวชั้น verification สามารถตรวจจับข้อผิดพลาดเชิงโครงสร้างและ toolpath ที่มีความเสี่ยงสูงได้มากกว่า 90% ของกรณีที่สำคัญ ซึ่งช่วยลดการขึ้นเครื่องผิดพลาดและชิ้นงานเสียหาย
สรุปได้ว่า Neural‑CAD เป็นการรวมกันของความสามารถในการเข้าใจภาษามนุษย์ (ผ่าน LLM), การสร้างแบบด้วย AI ที่ยืดหยุ่น (generative CAD), การแปลงเป็นกระบวนการผลิตจริง (CAM/G‑Code), และการรับรองความปลอดภัยเชิงคณิตศาสตร์ (formal verification) เพื่อให้โรงงานสามารถลดเวลาในการพัฒนาโปรโตไทป์ได้อย่างมีนัยสำคัญ — ในกรณีศึกษาบางกลุ่มพบว่าเวลาพัฒนาลดลงกว่า 70% พร้อมกับอัตราข้อผิดพลาดลดลงอย่างชัดเจนก่อนการขึ้นเครื่องจริง
สถาปัตยกรรม pipeline เชิงปฏิบัติการ: จากสเปกสู่เครื่องจักรอย่างปลอดภัย
ภาพรวมสถาปัตยกรรม pipeline เชิงปฏิบัติการ
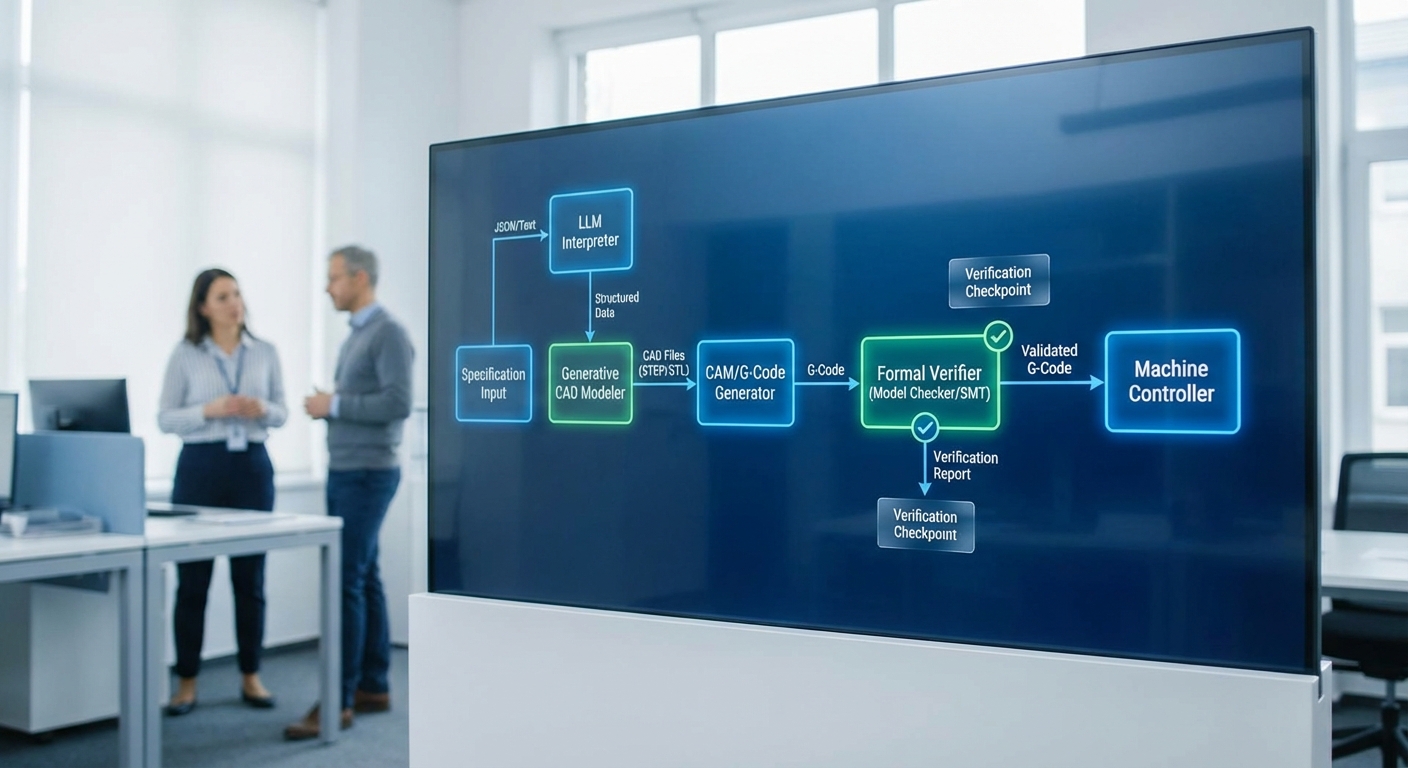
สถาปัตยกรรมของ pipeline เชิงปฏิบัติการสำหรับระบบ Neural‑CAD ที่ผสาน Large Language Models (LLMs) เพื่อแปลงสเปกเป็นโมเดล 3D‑CAD และ G‑Code ต้องออกแบบให้ครบตั้งแต่การรับสเปกจนถึงการส่งคำสั่งให้เครื่องจักรจริงอย่างปลอดภัยและตรวจสอบได้ โดยโฟลว์หลักประกอบด้วย การรับสเปก (Input) → การ preprocessing & prompt engineering → การสร้างโมเดล 3D → การคำนวณ toolpath/CAM → การตรวจพิสูจน์ความถูกต้องเชิง formal (Verification) → การ deploy/รันบนเครื่องจักร พร้อม audit trail ที่จับทุกขั้นตอนเพื่อการตรวจย้อนหลังและการรับรองความปลอดภัย

1) อินพุตและการ preprocessing
อินพุตสามารถรับได้ทั้งในรูปแบบข้อความ/JSON ที่ระบุข้อกำหนดผลิตภัณฑ์ (เช่น มิติ, ความทนทาน tolerance, surface finish, BOM, ฟังก์ชันการใช้งาน) และไฟล์ CAD มาตรฐานเช่น STEP, IGES, STL ที่ให้ข้อมูลเรขาคณิตโดยตรง ระบบจะมีขั้นตอน preprocessing เพื่อ:
- แปลงสเปกข้อความหรือ JSON ให้เป็นโครงข้อมูลมาตรฐาน (canonical spec) ที่มีฟิลด์ชัดเจน เช่น dimensions, tolerances, material, critical_features
- ตรวจสอบความครบถ้วน (completeness check) — เช่น ถ้ามิติที่เป็น critical ขาดระบบจะยิง prompt ให้ผู้ใช้ชี้แจงก่อนเดินต่อ
- normalize ไฟล์ CAD (healing/repair) กับ mesh/solid validation เพื่อลดความผิดพลาดจากไฟล์ที่ขาดหรือเสีย
2) Prompt engineering และการสร้างคำสั่งเชิงบริบท (Contextualization)
หลัง preprocessing ระบบจะทำ prompt engineering แบบเป็นขั้นเป็นตอน โดยผสานข้อมูลจาก canonical spec, ตัวอย่าง (few‑shot examples) และข้อจำกัดเชิงเครื่องจักร (machine constraints เช่น spindle rpm, max feed, stroke limits) เข้าไปใน prompt เพื่อให้ LLM สร้างคำอธิบายเชิงเรขาคณิตและสเต็ปการออกแบบที่สอดคล้องกับมาตรฐาน CAD เช่น:
- ใช้ templates พร้อมตัวอย่างการแปลงสเปกเป็นโมเดล (e.g., “จาก dimension A=50±0.1 ให้สร้าง boss ระดับ tolerance X และ chamfer ขนาด Y”)
- ระบุ acceptance criteria ที่เป็นเชิงตัวเลข (pass/fail thresholds) เพื่อให้ผลลัพธ์สามารถนำไป verify อัตโนมัติได้
- บันทึก prompt versioning และผลลัพธ์ของ LLM ไว้ในระบบ audit trail เพื่อความโปร่งใส
3) การสร้างโมเดล 3D (Neural‑CAD generation)
โมดูล Neural‑CAD จะรับ output จาก LLM ในรูปแบบเชิงโครงสร้าง (structured instructions หรือ intermediate representation เช่น feature trees) แล้วทำการสังเคราะห์เป็นโมเดล CAD จริง (B‑REP/NURBS หรือ solid) โดยกระบวนการสำคัญมีดังนี้:
- แปลง feature tree เป็นคำสั่ง CAD API (เช่น สร้าง extrude, revolve, fillet) และจัดการประวัติ (history tree) เพื่อให้สามารถแก้ไขย้อนหลังได้
- ทำ geometric validation เบื้องต้น: ตรวจสอบ manifoldness, normal consistency และ surface continuity
- แนบ metadata สำคัญ เช่น tolerance per feature, functional annotations, และ critical surfaces ที่จะถูกเน้นในการ verify
ตัวอย่างเชิงข้อมูล: ในกลุ่มตัวอย่าง pilot โรงงานไทย รายงานว่าสเตจการสร้างโมเดลด้วย Neural‑CAD ลดเวลาสร้างแบบดั้งเดิมลงกว่า 70% เมื่อเทียบกับวิธี manual
4) CAM และการคำนวณ Toolpath
เมื่อได้โมเดล CAD ในรูปแบบที่เป็นทางการ ระบบ CAM จะสร้างเส้นทางเครื่องมือ (toolpath) และแปลงเป็น G‑Code โดยคำนึงถึงข้อจำกัดของเครื่องจักรและชิ้นงาน:
- การเลือก strategy (roughing/finishing), cutting parameters (cutting speed, feed rate, depth of cut) โดยอิงกับวัสดุและเครื่องจักร
- จำลอง tool‑toolholder และ workholding เพื่อให้ toolpath เป็นไปได้จริง (reachability analysis)
- สร้าง metadata ของ G‑Code เช่น estimated cycle time, spindle load profile และ coolant usage
5) Formal verification: การพิสูจน์ความถูกต้องเชิงระบบ
จุดเด่นของ pipeline คือการนำเทคนิค formal verification มาตรวจจับข้อผิดพลาดก่อนรันจริง ลดความเสี่ยงการชนหรือการผลิตชิ้นงานที่ไม่เป็นไปตามสเปก ระบบ verification ประกอบด้วยหลายชั้น:
- Geometric collision detection: การจำลองเชิงเรขาคณิตแบบ high‑fidelity ระหว่าง tool, holder, fixturing และชิ้นงานเพื่อตรวจหา collision โดยใช้ deterministic collision engines และ spatial indexing (เช่น BVH) — ผลการทดสอบภายในรายงานการตรวจจับ collision ที่อัตราสูง (>90%) ในกรณีฉีด fault scenarios
- Tolerance and manufacturability checks: คำนวณการเบี่ยงเบนเชิงรูปทรงเมื่อใช้พารามิเตอร์การตัดจริง เปรียบเทียบกับ tolerance ที่กำหนดเพื่อตรวจหา tolerance violations หรือ critical feature out‑of‑spec
- Reachability & toolpath feasibility: วิเคราะห์ว่า toolpaths ทุก segment สามารถเข้าถึงได้จริงโดยไม่มี singularity หรือ axis limit violations หากพบจุดที่ไม่สามารถเข้าถึง ระบบจะคืนค่า (reject/repair) พร้อมข้อเสนอแก้ไข
- Model checking & SMT solvers: แปลงเงื่อนไขความถูกต้องเชิงตรรกะ (เช่น “feature A ต้องมี clearance ≥ 2 mm จาก feature B ภายใน tolerance”) เป็นสูตรเชิงคณิต แล้วใช้ SMT solvers (เช่น Z3) ตรวจหาความขัดแย้ง (unsat cores) หรือสถานการณ์ที่ทำให้เงื่อนไขล้มเหลว — วิธีนี้ช่วยตรวจสอบ invariants ของการออกแบบในระดับฟังก์ชัน
- Failure mode simulation: จำลองสถานการณ์ผิดพลาด (e.g., tool breakage, fixture shift, thermal expansion) เพื่อประเมินความเสี่ยงและกำหนด safety margins
6) เกณฑ์อนุมัติและ human‑in‑the‑loop
ผลการ verify ถูกเปรียบเทียบกับ acceptance criteria ที่ตั้งไว้ หากผ่านอัตโนมัติจะเข้าสู่ขั้นตอน deploy หากไม่ผ่านจะมีการแจ้งเตือนพร้อมรายงานข้อผิดพลาดเชิงเทคนิคและคำแนะนำการแก้ไข ผู้เชี่ยวชาญยังสามารถสั่ง override ได้โดยต้องลงลายมือชื่อดิจิทัลและแนบเหตุผลเพื่อความรับผิดชอบ
7) Audit trail, traceability และการจัดเก็บหลักฐาน
ทุกขั้นตอนของ pipeline จะถูกบันทึกเป็น audit trail ในรูปแบบที่ค้นคืนได้และทนการดัดแปลง (tamper‑evident):
- เก็บสเปกดั้งเดิม (text/JSON) พร้อม metadata ของไฟล์ CAD (STEP/IGES) และ hash ของไฟล์
- บันทึก prompt กับเวอร์ชันของโมเดล LLM, intermediate representations, ผลลัพธ์ CAD และ G‑Code
- เก็บผลการ verification, SMT trace, collision reports และ logs ของ simulators พร้อม timestamp และผู้อนุมัติ
- ใช้ digital signatures และ hashing (เช่น SHA‑256) เพื่อให้ตรวจสอบแหล่งที่มาและป้องกันการแก้ไขย้อนหลัง
- สนับสนุนการส่งออกรายงาน compliance (PDF/JSON) สำหรับการตรวจสอบโดย QA, ลูกค้า หรือหน่วยงานกำกับ
ผลลัพธ์เชิงปฏิบัติการและตัวชี้วัด
การนำ pipeline ดังกล่าวไปใช้งานจริงให้ประโยชน์เชิงธุรกิจ เช่น ลดเวลาโปรโตไทป์ลงมากกว่า 70% ในกลุ่มตัวอย่างโรงงานไทยที่ทดลองใช้ นอกจากนี้ระบบ formal verification ช่วยลดความเสี่ยงการชนและการผลิตชิ้นงานผิดพลาดจากการรันครั้งแรก ทำให้ลดค่าใช้จ่ายในการ rework และ downtime ของเครื่องจักร ระบบ audit trail ยังเสริมความสามารถในการตรวจสอบย้อนกลับและรับรองการปฏิบัติตามมาตรฐานอุตสาหกรรม
สรุปได้ว่า สถาปัตยกรรม pipeline เชิงปฏิบัติการต้องผสานการจัดการสเปกที่เป็นมาตรฐาน การ prompt engineering ที่มีบริบทเชิงเครื่องจักร การสร้างโมเดล CAD คุณภาพ การคำนวณ toolpath ที่ตระหนักถึงข้อจำกัดในโลกจริง พร้อมกลไก formal verification ชั้นสูงและ audit trail ที่เชื่อถือได้ เพื่อให้การแปลงสเปกเป็นการผลิตจริงเป็นไปอย่างปลอดภัย ตรวจสอบได้ และมีประสิทธิภาพทางธุรกิจ
กรณีศึกษา: โรงงานไทยทดลองใช้งาน — ผลลัพธ์เชิงตัวเลข
กรณีศึกษา: โรงงานไทยทดลองใช้งาน — ผลลัพธ์เชิงตัวเลข
การทดลองใช้งาน Neural‑CAD ร่วมกับ Large Language Model (LLM) และโมดูล formal verification ดำเนินการกับกลุ่มตัวอย่างโรงงานขนาดกลาง 3 แห่ง ในช่วงระยะเวลา 6 เดือน โดยมีการพัฒนาและทดสอบรวมทั้งสิ้น 24 โปรโตไทป์ ผลลัพธ์ที่ได้แสดงให้เห็นการเปลี่ยนแปลงเชิงปริมาณทั้งด้านเวลา ต้นทุนความเสี่ยง และคุณภาพงานผลิตอย่างชัดเจน โดยเฉพาะในส่วนของการลดเวลาพัฒนาและการตรวจจับข้อผิดพลาดก่อนขึ้นเครื่องจักรจริง
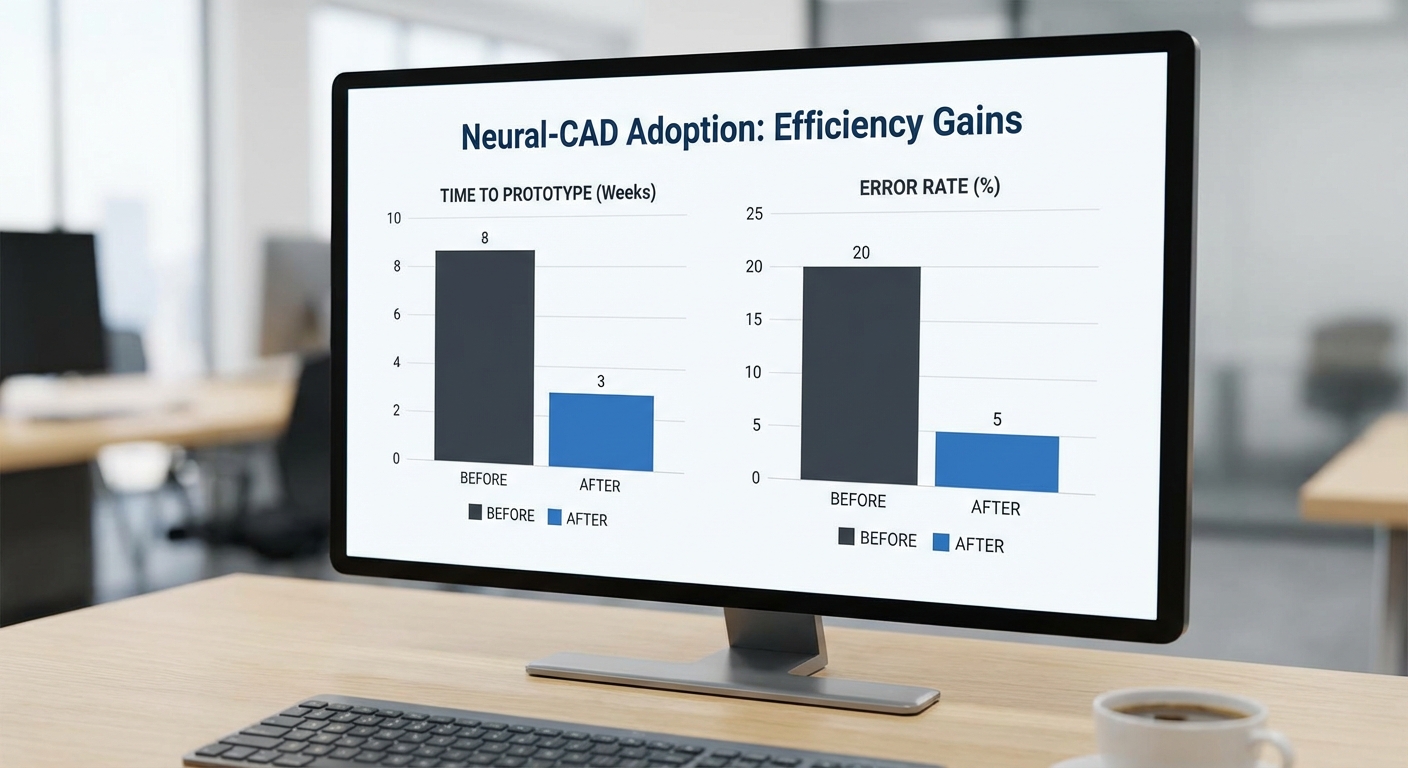
การลดเวลาพัฒนาโปรโตไทป์ เป็นหนึ่งในผลลัพธ์ที่โดดเด่นที่สุด: เวลาพัฒนาเฉลี่ยต่อโปรโตไทป์ลดลงจากประมาณ 21.2 วัน เมื่อใช้กระบวนการเดิม เหลือเพียง ~6.1 วัน เมื่อใช้ Neural‑CAD + LLM ซึ่งเท่ากับการลดเวลาเฉลี่ยกว่า 70% (ในบางกรณีที่มีความซับซ้อนสูง พบการลดเวลาได้ถึง 82% เช่น จาก 28 วัน เหลือ 5 วัน) การลดเวลานี้มาจากการที่ระบบสามารถแปลงสเปกเป็นโมเดล 3D‑CAD และ G‑Code อัตโนมัติ รวมถึงเสนอการแก้ไขเชิงออกแบบที่ผ่านการตรวจสอบทางคณิตศาสตร์ก่อนส่งออกไฟล์ไปยังเครื่องจักร
การตรวจจับข้อผิดพลาดก่อนขึ้นเครื่อง มีการปรับปรุงอย่างมีนัยสำคัญ: ก่อนการใช้งาน Neural‑CAD อัตราการตรวจจับปัญหาที่เกี่ยวข้องกับการผลิตในขั้นตอนก่อนเครื่องจักร (เช่น การชนกันของเครื่องมือ/ชิ้นงาน, ความไม่สอดคล้องของ tolerance, การจับยึดผิดพิกัด) อยู่ในระดับต่ำประมาณ 18% หลังจากทดสอบระบบที่ติดตั้ง formal verification อัตราการตรวจพบข้อผิดพลาดเหล่านี้เพิ่มเป็น ~91% ซึ่งเพิ่มขึ้นถึง 73 จุดเปอร์เซ็นต์ ส่งผลให้ความเสี่ยงของการเกิดเหตุเครื่องจักรเสียหายและของเสียลดลงอย่างมีนัยสำคัญ
โดยสรุปตัวเลขเชิงรายละเอียดจากการทดลอง (24 โปรโตไทป์, โรงงาน 3 แห่ง)
- จำนวนเหตุการณ์ข้อผิดพลาดที่ตรวจพบก่อนขึ้นเครื่อง: รวมทั้งหมด 37 กรณี (เฉลี่ย 1.54 กรณีต่อโปรโตไทป์)
- การจำแนกประเภทข้อผิดพลาดที่พบ:
- Collision (การชนกันระหว่างเครื่องมือ/ชิ้นงาน/fixture): 11 กรณี
- Tolerance mismatch (ความคลาดเคลื่อนของ tolerance ที่อาจทำให้ชิ้นงานไม่ผ่านการวัด): 16 กรณี
- Incorrect fixturing (การจัดยึดชิ้นงานไม่เหมาะสม): 10 กรณี
- การลดเหตุการณ์ที่ส่งผลต่อเครื่องจักรจริง: จำนวนเหตุการณ์จริงที่เกิดขึ้นระหว่างการกัด/กลึงในช่วงทดลองลดลงจากระดับอ้างอิง โดยประมาณ 78% (จาก 9 เหตุการณ์ในช่วงก่อนการติดตั้งเหลือ 2 เหตุการณ์ในช่วงทดลอง)
- การลดของเสียและงานแก้ไข (rework): โรงงานรายงานการลดสัดส่วนชิ้นงานที่ต้องแก้ไขหลังการขึ้นเครื่องลงเฉลี่ย 64%
ตัวอย่างข้อผิดพลาดที่ระบบตรวจจับและแก้ไขก่อนการผลิตจริง ได้แก่
- Collision: ระบบจำลองเส้นทางเครื่องมือและตรวจพบการชนของ holder กับชิ้นงานในขั้นตอนเปลี่ยนมุม (1 โปรโตไทป์) — ระบบแนะนำการปรับตำแหน่ง fixture และปรับ toolpath ให้หลีกเลี่ยง ทำให้ไม่ต้องหยุดเครื่องและไม่เกิดความเสียหาย
- Tolerance mismatch: พารามิเตอร์ tolerance ของรูย่อยที่ต้องการการประกอบกับชิ้นส่วนอื่นไม่สอดคล้องกับข้อกำหนดด้านการผลิต (3 โปรโตไทป์) — ระบบระบุค่าความคลาดเคลื่อนที่เป็นปัญหา พร้อมเสนอการแก้ไข tolerance หรือออกแบบให้มี clearance เพียงพอ
- Incorrect fixturing: การจัดยึดชิ้นงานไม่รองรับแรงตัดในมุมหนึ่ง ทำให้มีความเสี่ยงต่อการเคลื่อนของชิ้นงาน (2 โปรโตไทป์) — Neural‑CAD ให้รูปแบบการจับยึดที่ปรับปรุงแล้วและปรับเส้นทาง G‑Code เพื่อลดแรงกระทำที่วิกฤต
นอกจากนี้ การผสาน LLM ทำให้การแปลงสเปกเป็นโมเดลและการให้เหตุผลเชิงบริบทเร็วขึ้น ระบบยังสามารถส่งคำอธิบายเชิงวิศวกรรมว่าทำไมการแก้ไขนั้นจำเป็นและมีผลต่อกระบวนการผลิตอย่างไร ซึ่งช่วยให้วิศวกรและผู้ปฏิบัติงานบนโรงงานตัดสินใจได้รวดเร็วและแม่นยำยิ่งขึ้น ผลสัมฤทธิ์เชิงตัวเลขจากการทดลองนี้ชี้ชัดว่า Neural‑CAD + formal verification เป็นเครื่องมือที่มีศักยภาพในการย่นระยะเวลา เพิ่มความปลอดภัย ลดของเสีย และยกระดับความพร้อมของการขึ้นสู่การผลิตจริงสำหรับโรงงานขนาดกลางในไทย
ส่วนประกอบเทคนิคเชิงลึก: LLM, Generative CAD, CAM และ Formal Verification
ภาพรวมเชิงเทคนิคของส่วนประกอบหลัก
ระบบ Neural‑CAD ที่ผสาน Large Language Models (LLM), Generative CAD, CAM และ Formal Verification ประกอบด้วยชั้นเทคนิคหลายชั้นที่ทำงานร่วมกัน ตั้งแต่การแปลงสเปกเป็นตัวแทนเชิงเรขาคณิต ไปจนถึงการสร้าง toolpath และการยืนยันสมบัติด้านความปลอดภัยก่อนส่งคำสั่งไปยังเครื่องจักร ในส่วนนี้จะอธิบายแนวทางเชิงเทคนิคของแต่ละองค์ประกอบ รวมถึงตัวอย่างแนวคิดโค้ดเชิงอธิบายและมาตรฐานข้อมูลที่เกี่ยวข้อง
Fine‑tuning LLM กับโดเมนวิชาชีพ (สเปกท้องถิ่นและตัวอย่าง CAD)
การปรับแต่ง LLM สำหรับแปลงสเปกภาษาไทยหรือสเปกเฉพาะอุตสาหกรรมไทยจำเป็นต้องใช้ชุดข้อมูลที่สอดคล้องกับโครงสร้างของเอกสารวิศวกรรม เช่น ข้อกำหนดมิติ ความคลาดเคลื่อน (tolerances), วัสดุ, เงื่อนไขการประกอบ และตัวอย่างไฟล์ CAD/feature trees ที่จับคู่อธิบายเป็นข้อความ — กระบวนการหลักประกอบด้วย:
- การเตรียมข้อมูล: รวบรวมคู่ข้อมูล spec text → parametric specification / CAD operation sequence โดยใช้รูปแบบเชิงโครงสร้าง เช่น JSON ที่เก็บพารามิเตอร์ (มิติ, tolerance, material) และ reference ไปยังไฟล์ STEP/STL
- เทคนิคการฝึก: เริ่มด้วย Supervised Fine‑Tuning (SFT) บนชุดคู่ข้อความ‑โครงสร้าง ตามด้วย Instruction Tuning หรือ Reinforcement Learning with Human Feedback (RLHF) เพื่อเพิ่มคุณภาพการตอบคำถามเชิงปฏิบัติการ และใช้เทคนิคประหยัดทรัพยากรเช่น LoRA/Adapter สำหรับการปรับใน domain เฉพาะ
- การเพิ่มสมรรถนะเชิงโครงสร้าง: ใช้ tokenization แบบผสมรวมคำเฉพาะทาง เช่น หน่วย (mm, μm), ฟีเจอร์ CAD (boss, pocket, fillet) และหัวข้อการผลิต เพื่อให้โมเดลเข้าใจคำสั่งเชิงเทคนิคได้แม่นยำ
- การประเมิน: นอกจาก metrics ทางภาษา (BLEU/ROUGE) ให้ประเมินผลด้วยตัวชี้วัดเชิงเรขาคณิต เช่น chamfer distance, IoU สำหรับเมช และความถูกต้องของพารามิเตอร์ (exact match ของ tolerance/diameter)
ตัวอย่างแนวคิดการเรียกใช้โมเดลหลัง fine‑tuning (เชิงอธิบาย): Prompt: "ออกแบบ shaft ϕ20 ±0.05 พร้อม keyway 5x2" → Output: JSON { "features":[{"type":"cylinder","d":20,"tol":0.05},{"type":"keyway","w":5,"d":2,"position":"axial"}]}
Generative CAD: implicit surfaces และ parametric templates
Generative CAD สามารถแบ่งเป็นสองพาราไดม์หลักที่ใช้งานจริงในระบบ Neural‑CAD:
- Parametric templates / feature‑based modeling: ใช้ชุดพารามิเตอร์และข้อจำกัด (constraints) เพื่อสร้างชิ้นงานแบบประวัติศาสตร์ (history‑based) หรือแบบพาราเมตริก (parametric). ข้อดีคือควบคุมความสามารถผลิต (manufacturability) ได้ง่าย และสามารถผนวก validation rules เช่น min wall thickness หรือ standard hole sizes. ตัวอย่าง: feature_tree = [{op:"extrude", profile:circle(d=20)}, {op:"cut", profile:keyway(w=5,h=2)}]
- Neural implicit models (SDF, Occupancy, DeepSDF): แทนรูปร่างเป็นฟังก์ชันต่อเนื่อง f(x,y,z) ซึ่งแยกภายใน/ภายนอกโดยใช้ Signed Distance Function (SDF) หรือ occupancy probability. ข้อดีคือความยืดหยุ่นในการสร้างรูปทรงที่ซับซ้อนและการอินเตอร์โพลเลตระหว่างตัวอย่าง ตัวอย่าง pipeline: LLM → latent vector → decoder network → SDF → marching cubes → mesh → surface fitting เพื่อแปลงเป็น B‑rep หรือพารามิเตอร์ที่สามารถแก้ไขได้
การผสานทั้งสองแนวทางมักให้ผลดีที่สุด: ใช้ parametric templates สำหรับฟีเจอร์ที่ต้องการควบคุมเชิงวิศวกรรม และใช้ implicit models สำหรับส่วนรูปร่างอิสระที่ต้องการความสวยงามหรือการปรับรูปแบบอัตโนมัติ
การแปลงจาก implicit → CAD practical steps (เชิงอธิบาย): 1) ประเมิน SDF บนกริด 3D 2) ทำ marching cubes เพื่อได้ mesh 3) ทำ surface fitting (NURBS) หรือ feature extraction เพื่อสร้าง B‑rep/parametric representation
จาก CAD เป็น toolpath (CAM): การแปลงเป็น G‑Code
กระบวนการ CAM ในระบบอัตโนมัติประกอบด้วยขั้นตอนสำคัญหลายอย่างที่ต้องคำนึงทั้งเชิงเรขาคณิตและข้อจำกัดของเครื่องจักร:
- Feature recognition: วิเคราะห์ B‑rep/mesh เพื่อหา features ที่จะกัด/เจาะ เช่น pockets, holes, faces และเลือกกลยุทธ์การเครื่องมือตามฟีเจอร์
- Path planning: สร้าง toolpath โดยใช้เทคนิคเช่น adaptive slicing, curvature‑based stepdown, trochoidal milling สำหรับงานกัดหนัก และ spline interpolation สำหรับลักษณะผิวเรียบ
- Kinematics & post‑processing: แปลง toolpath ใน frame ของเครื่องจักร (linear vs rotary axes) คำนวณ inverse kinematics สำหรับ 5‑axis และใช้ post‑processor ตามมาตรฐาน G‑code ของผู้ผลิต (RS‑274 / ISO 6983 หรือ STEP‑NC / ISO 14649)
- Feedrate & motion planning: วางโปรไฟล์ความเร็วโดยคำนึงถึงความเร่งและ jerk ของแกนเพื่อลดการสั่น การวาง feed/speed ยังอาจใช้โมเดลการตัดเฉือน (cutting force models) เพื่อปรับให้ปลอดภัย
ตัวอย่างแนวคิดการแปลงฟีเจอร์เป็นคำสั่ง (เชิงอธิบาย): for each pocket: compute zigzag paths → apply helical entry → for each segment: emit G1 X.. Y.. Z.. F.. ; postprocess to machine-specific codes
ไฟล์และมาตรฐานที่เกี่ยวข้อง: STEP (ISO 10303) สำหรับข้อมูล CAD เชิงพารามิเตอร์, STL/OBJ สำหรับ mesh, G‑code (RS‑274 / ISO 6983) สำหรับคำสั่งเครื่อง, และ STEP‑NC (ISO 14649) เป็นทางเลือกสำหรับการแลกเปลี่ยนข้อมูล CAM ที่มี semantically rich
Formal verification และการตรวจจับข้อผิดพลาดก่อนรัน G‑Code
Formal verification ในบริบทการขึ้นรูปชิ้นงานและการผลิตมุ่งตรวจสอบสมบัติด้านความปลอดภัย (safety properties) และความถูกต้องของ toolpath ก่อนการรันจริง บางสมบัติสำคัญได้แก่: ความปลอดภัยจากการชน (no collision), ขอบเขตการเคลื่อนที่ของแกน (axis limits), ข้อจำกัดของความเร็ว/ความเร่ง, และรอยต่อทางเครื่องจักร (fixture interference)
- Model checking: สร้างโมเดลสถานะที่อธิบายพฤติกรรมของเครื่อง (ตำแหน่งแกน, ความเร็ว, สถานะเครื่องมือ) แล้วใช้ model checker เพื่อตรวจสอบสูตรแบบ temporal logic (เช่น LTL/CTL) เช่น G (tool_clear_of_fixture) (ตลอดเวลา tool ต้องไม่ชนกับ fixture)
- SMT solvers และ symbolic reasoning: แปลงเงื่อนไขเชิงคณิตศาสตร์ของ toolpath เป็นสูตรเชิงตรรกะและใช้ SMT (เช่น Z3) ตรวจหาข้อยกเว้น เช่น ตรวจสอบว่าไม่มีค่าพารามิเตอร์ใดทำให้ spindle_speed เกิน limit หรือ axis_position เกินขอบเขต ตัวอย่างเชิงอธิบาย: assert (forall t. axis_x(t) ∈ [xmin,xmax])
- Collision detection algorithms: ใช้ Bounding Volume Hierarchies (BVH), AABB trees หรือ GJK สำหรับตรวจ collision ระหว่าง tool, workpiece และ fixtures ในทั้ง discrete sampling และ continuous collision detection เพื่อตรวจหา grazing/penetration ระหว่างการเคลื่อนที่
- Hybrid verification: ผสานการตรวจเชิงสัญลักษณ์ (SMT) กับการตรวจเชิงเรขาคณิต (collision simulation) เพื่อยืนยันสมบัติทั้งเชิงคณิตและเชิงเรขาคณิต เช่น ตรวจสอบทางคณิตว่า feedrate ปลอดภัยและใช้ simulation เพื่อตรวจ collision แบบต่อเนื่อง
ตัวอย่างสมบัติและการเขียนเชิงอธิบายสำหรับ SMT/Model Checking: Property: ∀t ∈ [0,T], distance(tool(t), fixture) ≥ clearance. ในเชิง SMT แปลงเป็นข้อผูกมัดและให้ solver หา model ที่ละเมิด หาก solver คืน satisfiable แสดงว่ามีกรณีชนที่ต้องแก้ไข
นอกจากนี้ระบบควรมีการตรวจสอบแบบสถิติ (probabilistic verification) เพื่อประเมินความเสี่ยงจากความไม่แน่นอน เช่น ความคลาดเคลื่อนเชิงตำแหน่งและสวมชิ้นส่วน และต้องสอดคล้องกับมาตรฐานความปลอดภัยอุตสาหกรรมที่เกี่ยวข้อง เช่น ISO 10303 / ISO 14649 (ข้อมูล), ISO 6983 (G‑code), และมาตรฐานด้าน functional safety เช่น IEC 61508 ที่ใช้เป็นแนวทางการออกแบบระบบที่ต้องการความสามารถในการตรวจจับความผิดพลาด
การประสานงานเชิงระบบและตัวชี้วัดความสำเร็จ
การผสานทุกชั้นต้องมีแนวทางการทวนสอบ (audit trail) ของการตัดสินใจจาก LLM (เช่น logging ของ prompt/response), versioning ของ template/feature definitions และ traceability ของแต่ละโครงงานจากสเปกไปสู่ G‑code. ตัวชี้วัดสำคัญได้แก่อัตราการลดข้อผิดพลาดก่อนรัน (error catch rate), เวลาตั้งแต่สเปกถึงรันจริง (time‑to‑first‑cut), และคุณภาพชิ้นงาน (surface finish, dimensional accuracy). รายงานภาคสนามบางโครงการในไทยชี้ว่ากลุ่มตัวอย่างที่นำ Neural‑CAD มาใช้ลดเวลาพัฒนาโปรโตไทป์ได้มากกว่า 70% เมื่อเทียบกับเวิร์กโฟลว์ดั้งเดิม ซึ่งสะท้อนประสิทธิภาพของการผสานทั้ง LLM, generative CAD, CAM และ formal verification
ผลประโยชน์, ROI และข้อควรระวังทางความปลอดภัยและกฎหมาย
ผลประโยชน์เชิงธุรกิจ, ROI และข้อควรระวังทางความปลอดภัยและกฎหมาย
ผลประโยชน์เชิงธุรกิจโดยสรุป
การนำระบบ Neural‑CAD ที่ผสานกับ LLM เพื่อแปลงสเปกเป็นโมเดล 3D‑CAD และ G‑Code อัตโนมัติ พร้อมการทำ formal verification ก่อนขึ้นเครื่อง ผลการทดลองกลุ่มตัวอย่างชี้ว่าเวลาพัฒนาโปรโตไทป์ลดลงกว่า 70% ซึ่งส่งผลโดยตรงต่อการลดต้นทุน การลดสต็อกชิ้นส่วนสำรอง และการเร่งความเร็วการออกสู่ตลาด (time‑to‑market) ในเชิงธุรกิจแล้วเทคโนโลยีนี้ช่วยให้บริษัทสามารถทดลองไอเดียได้บ่อยขึ้นด้วยทรัพยากรเท่าเดิม เพิ่มอัตราการเรียนรู้ (learning velocity) ของทีม R&D และลดความเสี่ยงจากการผลิตซ้ำที่มีข้อบกพร่อง
ตัวอย่างการคำนวณ ROI (แบบประเมิน)
ต่อไปนี้เป็นตัวอย่างการคำนวณแบบง่ายเพื่อประเมิน ROI จากการลดเวลา 70% ในการพัฒนาโปรโตไทป์:
- สมมติฐานพื้นฐาน — เวลาพัฒนาเดิม: 10 สัปดาห์ (50 วันทำการ); ค่าแรงทีมวิศวกรรมเฉลี่ย: 8,000 บาท/วัน; ค่าใช้จ่ายวัสดุและเครื่องมือสำหรับโปรโตไทป์: 400,000 บาท/ครั้ง.
- หลังใช้ Neural‑CAD — เวลาลดลง 70% เหลือ 3 สัปดาห์ (15 วันทำการ). ต้นทุนแรงงานลดจาก 400,000 บาท (50 × 8,000) เหลือ 120,000 บาท (15 × 8,000) — ประหยัด 280,000 บาทต่อโปรเจ็กต์.
- รวมต้นทุนวัสดุ (สมมติไม่เปลี่ยน) ประหยัดรวม = 280,000 บาท จากต้นทุนรวมก่อนหน้า 800,000 บาท (แรงงาน + วัสดุ) => ลดต้นทุนโดยรวมประมาณ 35% ต่อโปรโตไทป์.
- หากบริษัททำโปรโตไทป์ 20 ชุดต่อปี: ประหยัดโดยรวม = 20 × 280,000 = 5,600,000 บาท/ปี. หากค่าใช้จ่ายการลงทุนระบบ Neural‑CAD และการปรับปรุงกระบวนการรวม 2,000,000 บาท (ครั้งเดียว) จะคืนทุนภายใน ~0.36 ปี (ประมาณ 4–5 เดือน).
หมายเหตุ: ตัวอย่างข้างต้นเป็นการประเมินเชิงสาธิต ค่าเฉลี่ยจริงขึ้นกับความซับซ้อนของผลิตภัณฑ์ จำนวนโปรเจ็กต์ต่อปี และโครงสร้างต้นทุนของโรงงาน
ความเสี่ยงด้านความปลอดภัยและกฎหมายที่ต้องบริหาร
แม้ผลลัพธ์จะน่าสนใจ แต่การนำ LLM มาช่วยแปลสเปกเป็นโมเดลและ G‑Code ก่อให้เกิดความเสี่ยงที่ต้องจัดการอย่างเป็นระบบ ได้แก่:
- ความผิดพลาดจากการแปลสเปกโดย LLM — LLM อาจให้ผลลัพธ์ไม่ถูกต้อง (hallucination) หรือแปลความหมายของข้อกำหนดผิด ส่งผลให้โมเดล CAD หรือ G‑Code ไม่สอดคล้องกับความต้องการทางวิศวกรรม.
- ความรับผิดชอบทางกฎหมายเมื่อเกิดความเสียหาย — หากผลิตภัณฑ์ชำรุดหรือก่อให้เกิดอุบัติเหตุ อาจเกิดคำถามเรื่องความรับผิดชอบระหว่างผู้พัฒนาโมเดล LLM, เจ้าของระบบ Neural‑CAD และผู้ผลิตเครื่องจักร.
- การละเมิดทรัพย์สินทางปัญญา (IP) — LLM ที่ฝึกด้วยข้อมูลภายนอกอาจผลิตชิ้นงานที่เข้าใกล้หรือซ้ำกับสิทธิบัตร/งานออกแบบของผู้อื่น
- ขาด traceability ของการตัดสินใจอัตโนมัติ — หากไม่มีบันทึกเชิงเหตุผลตั้งแต่สเปกต้นทางจนถึง G‑Code อาจสอบสวนหาที่มาของความผิดพลาดได้ยาก
- ความมั่นคงของข้อมูลและความเป็นส่วนตัว — การส่งสเปกที่มีข้อมูลลับผ่านระบบ LLM อาจเสี่ยงต่อการรั่วไหลหรือการโจมตีทางไซเบอร์
แนวทาง mitigations และคำแนะนำเชิงกำกับดูแล
เพื่อให้การใช้งาน Neural‑CAD ปลอดภัยและสอดคล้องกับกฎหมาย แนะนำแนวทางปฏิบัติเป็นหมวดดังนี้:
- Audit trail และ traceability — เก็บบันทึกแบบ immutable ของทุกขั้นตอน (input spec, เวอร์ชันของโมเดล LLM, รหัสการแปล, ผลลัพธ์ CAD/G‑Code) พร้อม metadata เวลา ผู้ดำเนินการ และลายเซ็นดิจิทัล เพื่อให้สามารถสืบย้อนเชิงเหตุผลได้.
- Human‑in‑the‑loop checkpoints — กำหนดจุดตรวจสอบโดยมนุษย์สำหรับขั้นตอนสำคัญ เช่น การอนุมัติภาพ CAD ก่อนแปลงเป็น G‑Code และการตรวจสอบการทำงานของ G‑Code ผ่าน simulation หรือ dry run ก่อนสั่งเครื่องจักรจริง.
- มาตรฐานการตรวจสอบและการยืนยันผล (standardized verification protocols) — ใช้ชุดทดสอบอัตโนมัติ (unit tests, regression tests), formal verification สำหรับคุณลักษณะที่มีความเสี่ยงสูง และ validation suite ที่จำลองเงื่อนไขการผลิตจริง.
- การควบคุมและตรวจสอบโมเดล — บังคับใช้การ versioning ของโมเดล การทดสอบเชิงประสิทธิภาพหลังการปรับ (post‑training validation), monitoring สำหรับ drift และกระบวนการรับรองความถูกต้องโดยผู้เชี่ยวชาญเป็นระยะ.
- กฎหมายและสิทธิ์ทาง IP — ทำสัญญาชัดเจนกับผู้ให้บริการโมเดล/third‑party รวมถึงนโยบายการใช้ข้อมูลฝึกสอน ตรวจสอบสิทธิ์ทรัพย์สินทางปัญญา และพิจารณาประกันความรับผิด (product liability insurance) ในกรณีความเสียหาย.
- การกำกับเชิงองค์กร — จัดตั้ง governance board ระดับองค์กรที่ประกอบด้วยฝ่ายวิศวกรรม กฎหมาย ความปลอดภัย และคุณภาพ เพื่อกำหนดนโยบายการใช้งาน, SLA และเกณฑ์การอนุมัติผลิตภัณฑ์ที่ใช้ระบบอัตโนมัติ.
- การทดสอบในสภาพแวดล้อมจำลองและการรับรองจากบุคคลที่สาม — ก่อนนำไปใช้งานจริง ควรมีการรับรองโดยสถาบันทดสอบภายนอก (third‑party certification) และการทดสอบแบบ stress test, fault injection, และ pilot run กับชิ้นงานทดแทน.
สรุปแล้ว การนำ Neural‑CAD + LLM มาใช้ในโรงงานไทยมีศักยภาพในการเพิ่มความเร็วและลดต้นทุนอย่างชัดเจน แต่ต้องควบคู่กับมาตรการด้านความปลอดภัย เทคนิคการตรวจสอบ และกรอบกฎหมายเชิงรุกเพื่อบริหารความเสี่ยงทั้งด้านคุณภาพ ความปลอดภัย และความรับผิดชอบทางกฎหมาย ซึ่งการออกแบบกระบวนการควบคุมเหล่านี้อย่างเป็นระบบจะช่วยให้ธุรกิจได้รับผลตอบแทนจากการลงทุนอย่างยั่งยืนและปลอดภัย
ข้อเสนอแนะและทิศทางอนาคตสำหรับอุตสาหกรรมไทย
ข้อเสนอแนะเชิงปฏิบัติ: เริ่มต้นด้วยโครงการ Pilot ขนาดเล็กที่มีเกณฑ์วัดผลชัดเจน
แนะนำให้เริ่มจากโครงการนำร่อง (pilot) ขนาดเล็ก โดยเลือกงานผลิตหรือชิ้นส่วนที่มีความเสี่ยงเชิงการผลิตไม่สูงและมีความชัดเจนด้านสเปก เช่น ชิ้นส่วนรองหรือโปรโตไทป์ภายในโรงงาน เป้าหมายของ pilot ควรกำหนดเป็นตัวชี้วัดเชิงปริมาณ (KPIs) เช่น เวลาในการพัฒนาโปรโตไทป์ (time-to-prototype), อัตราการตรวจจับข้อผิดพลาดก่อนขึ้นเครื่อง (pre‑build error detection rate), อัตราการผ่านครั้งแรก (first‑pass yield) และลดเวลารวมในการทำ CAM/G‑Code เป็นสัดส่วน (%) เทียบกับกระบวนการเดิม
กรอบเวลาที่แนะนำ คือ 3–6 เดือนสำหรับ pilot แรก เพื่อให้มีเวลารวบรวมข้อมูลเปรียบเทียบ สร้างแบล็กบ็อกซ์สำหรับการวัดผล และปรับ workflow รายงานผลควรทำแบบสม่ำเสมอ (สัปดาห์ละครั้ง) พร้อมสรุปสำคัญเมื่อสิ้นสุดรอบ pilot เพื่อกำหนดแผน scale‑up หากผลชี้ว่าลดเวลาพัฒนาโปรโตไทป์ได้ตามเป้าหมาย (ตัวอย่าง: >50–70%) ควรดำเนินการขยายขั้นต่อไป
การวาง Governance และ Audit Trail เพื่อความโปร่งใสและความน่าเชื่อถือ
การนำ Neural‑CAD และ LLM มาประยุกต์ในสายการผลิตจำเป็นต้องมี data governance และ audit trail ที่รัดกุม ตั้งแต่การจัดการเวอร์ชันของสเปก CAD, โมเดล LLM/Neural‑CAD, ไปจนถึง G‑Code ที่สร้างขึ้น คำแนะนำเชิงปฏิบัติประกอบด้วย:
- กำหนดบทบาทและหน้าที่ (roles & responsibilities): owner ของสเปก, reviewer สำหรับการยืนยันความถูกต้อง, verification engineer สำหรับการรัน formal checks และ gatekeeper ในการอนุมัติ G‑Code ก่อนส่งขึ้นเครื่อง
- วางกระบวนการ change control และ approval workflow โดยกำหนดเกณฑ์การอัปเดตโมเดลและสเปก เช่น การทดสอบ regression, performance baseline
- สร้าง audit trail อัตโนมัติ: เก็บ metadata ของการแปลงสเปกเป็น 3D‑CAD, เวอร์ชันของ LLM, พารามิเตอร์ที่ใช้ในการสร้าง G‑Code และผลการรัน formal verification เพื่อให้ตรวจสอบย้อนหลังได้และรองรับการสืบสวนเมื่อเกิดปัญหา
- นโยบาย access control และการเข้ารหัสข้อมูลที่เกี่ยวข้องกับ IP และข้อมูลลูกค้า เพื่อรักษาความลับทางเทคนิคและปฏิบัติตามข้อกำหนดด้านความปลอดภัย
การลงทุนด้านบุคลากรและ Data Pipelines
การนำระบบอัตโนมัติขั้นสูงมาใช้ต้องการทีมผสมที่มีทักษะเฉพาะด้าน ควรวางแผนการลงทุนด้านบุคลากรดังนี้:
- จัดตั้งทีมแกนกลาง: Project Manager, CAD/CAM Engineer, Control/Machine Engineer, Data Engineer, ML/AI Engineer, และ Verification/Formal Methods Engineer
- งบประมาณการฝึกอบรม (upskilling): ให้ทุนเวลาและทรัพยากรสำหรับการฝึกงาน cross‑training ระหว่างทีม CAD, ช่างเครื่อง และทีม AI เพื่อให้เกิดความเข้าใจซึ่งกันและกัน
- สร้าง data pipelines ที่เชื่อถือได้: ระบบจัดเก็บ CAD บันทึก BOM, ประวัติการตั้งค่าเครื่องจักร, ข้อมูล telemetry จากเซนเซอร์ CNC, และ repository ของ G‑Code พร้อมเวอร์ชัน ควรมีการทำ ETL, data validation และ metadata enrichment เพื่อให้เครื่องมือ Neural‑CAD และระบบการตรวจสอบทำงานได้อย่างแม่นยำ
- ใช้แนวทาง MLOps/ModelOps: เวิร์กโฟลว์ CI/CD สำหรับโมเดล, การทดสอบแบบอัตโนมัติ (unit, integration), และกลไกการ rollback เมื่อโมเดลแสดงผลนอกเกณฑ์
ทิศทางเทคโนโลยีที่ควรติดตามและเตรียมการขยายในระยะยาว
เทคโนโลยีรอบข้าง Neural‑CAD กำลังพัฒนาอย่างรวดเร็ว โรงงานควรติดตามและเตรียมผสานแนวทางต่อไปนี้เพื่อเพิ่มประสิทธิภาพและความยืดหยุ่น:
- Auto‑tuning CAM: ระบบที่สามารถปรับพารามิเตอร์ CAM อัตโนมัติตามชนิดวัสดุ เครื่องจักร และเป้าหมายคุณภาพ จะช่วยลดการปรับจูนด้วยมือและเพิ่ม throughput — ควรทดสอบร่วมกับ pilot เพื่อเก็บชุดข้อมูลพารามิเตอร์เชิงประสบการณ์ (process recipes)
- Digital Twin Integration: สร้าง digital twin ของชิ้นงานและเครื่องจักรเพื่อทำ virtual commissioning และ simulation ของ G‑Code แบบ real‑time การบูรณาการนี้ช่วยลดความเสี่ยงก่อนขึ้นเครื่องจริง และให้ loop feedback สำหรับการพัฒนาโมเดลในสภาพแวดล้อมที่ใกล้เคียงจริง
- การใช้ Formal Methods ขั้นสูง: ขยายขอบเขตการใช้ formal verification ไม่เพียงแต่ตรวจจับข้อผิดพลาดพื้นฐาน แต่รวมถึงการพิสูจน์สมบัติความปลอดภัยเชิงเรขาคณิต (geometric safety), ความสมบูรณ์ของ tool‑path และการพิสูจน์ไม่เกิด collision ภายใต้ขอบเขตสภาวะที่กำหนด การวัดความครอบคลุมของการพิสูจน์ (coverage metrics) จะเป็นตัวชี้วัดสำคัญ
- Connective feedback loops: ผสานข้อมูลจากการผลิตจริง (sensor telemetry, in‑process inspection) เพื่อนำข้อมูลย้อนกลับมา retrain โมเดล และปรับกระบวนการอย่างต่อเนื่อง ซึ่งจะเปลี่ยน pilot ที่ประสบผลสำเร็จให้เป็น capability ระดับโรงงานได้
คำแนะนำเชิงกลยุทธ์เพื่อการขยายและการบริหารความเสี่ยง
เมื่อ pilot ประสบความสำเร็จ ควรวาง roadmap การขยาย (scale‑up) แบบเป็นขั้นตอน: ขยายจากชิ้นส่วนไม่วิกฤติ → สายการผลิตเฉพาะ → โรงงานทั้งฝ่าย โดยมีเกตการตัดสินใจ (go/no‑go gates) ตาม KPIs และ audit results นอกจากนี้ ควรเตรียมแผนบริหารความเสี่ยงครอบคลุม:
- แผนสำรอง (fallback) หากระบบอัตโนมัติไม่ผ่านการตรวจสอบในกรณีฉุกเฉิน
- การทดสอบเชิงรับรอง (certification) สำหรับชิ้นงานที่มีข้อกำหนดความปลอดภัยหรือมาตรฐานอุตสาหกรรม
- การสร้างพันธมิตรเชิงเทคนิคกับผู้จำหน่ายเครื่องมือ CAM, ผู้พัฒนา LLM/Neural‑CAD และสถาบันวิจัย เพื่อเข้าถึงนวัตกรรมและสแตนด์บายทางวิชาการ
สรุปคือ โรงงานไทยควรเริ่มอย่างเป็นขั้นเป็นตอน โดยนำ pilot ที่มีเกณฑ์วัดผลชัดเจนมาเป็นฐาน สร้าง governance และ audit trail เพื่อความโปร่งใส ลงทุนในบุคลากรและ data pipelines ที่แข็งแรง และเฝ้าติดตามเทคโนโลยีอย่าง auto‑tuning CAM, digital twin และ formal methods ขั้นสูง เพื่อให้การนำ Neural‑CAD + LLM เข้าสู่การผลิตเป็นไปอย่างปลอดภัย มีความน่าเชื่อถือ และสามารถขยายผลได้ในระยะยาว
บทสรุป
การนำระบบ Neural‑CAD ซึ่งผสานความสามารถของ LLM กับ generative CAD และ formal verification มาใช้ในโรงงานไทยแสดงให้เห็นผลลัพธ์เชิงปฏิบัติที่ชัดเจน: กระบวนการแปลงสเปกเป็นโมเดล 3D‑CAD และ G‑Code ทำได้โดยอัตโนมัติ ลดขั้นตอนที่ต้องพึ่งพาการออกแบบด้วยมือและการแปลงข้อมูลแบบเดิม ๆ ส่งผลให้กลุ่มตัวอย่างในไทยลดเวลาการพัฒนาโปรโตไทป์มากกว่า 70% รวมทั้งสามารถตรวจจับข้อผิดพลาดสำคัญก่อนขึ้นเครื่อง (pre‑machine verification) ได้อย่างมีประสิทธิภาพ โดยการใช้ formal verification เพื่อยืนยันเงื่อนไขด้านมิติ ความปลอดภัย และการปฏิบัติตามข้อกำหนดเชิงวิศวกรรม ทำให้ลดความเสี่ยงของการผลิตซ้ำซ้อนและค่าใช้จ่ายจากความผิดพลาดในขั้นตอนการผลิตจริง
แม้เทคโนโลยีดังกล่าวจะให้ประโยชน์เชิงธุรกิจอย่างรวดเร็ว แต่มุมมองเชิงอนาคตชี้ชัดว่าการใช้งานเชิงพาณิชย์ในวงกว้างจำเป็นต้องมีกระบวนการกำกับดูแลที่เข้มงวด การทดสอบยืนยัน (validation & verification) หลายชั้น และการจัดการความเสี่ยงที่เป็นระบบ เช่น การตั้งมาตรฐานการตรวจสอบ การผนวกรวมกับระบบ PLM/MES การตรวจติดตามผลหลังการใช้งาน และแผนการอบรมทักษะบุคลากร เพื่อให้การประยุกต์ใช้งานนำมาซึ่งผลประโยชน์ทางธุรกิจอย่างยั่งยืน โดยยังคงรับประกันความปลอดภัย คุณภาพ และความน่าเชื่อถือของผลิตภัณฑ์ในระยะยาว



