
การผสานเทคโนโลยี Retrieval‑Augmented Generation (RAG) เข้ากับฐานข้อมูลเวกเตอร์แบบเรียลไทม์ที่เชื่อมต่อกับระบบ Core‑Banking กำลังเปลี่ยนโฉมหน้าการให้บริการลูกค้าของธนาคารไทย — จากการรอคอยเป็นนาทีสู่การตอบคำถามเป็นวินาที ด้วยความสามารถในการค้นหาเอกสารที่เกี่ยวข้องแบบเวกเตอร์และสังเคราะห์คำตอบทันที ระบบสามารถตอบคำถามเชิงธุรกรรมหรือให้ข้อมูลเชิงเอกสารได้ภายใน 1–3 วินาที พร้อมแสดงแหล่งที่มาเพื่อยืนยันความถูกต้อง ซึ่งส่งผลโดยตรงต่อประสบการณ์ลูกค้า การลดค่าใช้จ่ายด้านคอลเซ็นเตอร์ และการเพิ่มประสิทธิภาพการปฏิบัติงานภายในองค์กร
บทความนี้จะวิเคราะห์การนำ RAG ร่วมกับฐานข้อมูลเวกเตอร์เรียลไทม์ที่เชื่อมต่อกับ Core‑Banking มาใช้งานในบริบทของธนาคารไทยโดยเจาะลึกทั้งมุมมองทางเทคนิคและการกำกับดูแล เราจะสาธิตตัวอย่างการทำงานแบบเรียลไทม์ การออกแบบ Audit Trail เพื่อยืนยันแหล่งข้อมูลและเส้นทางการสืบค้น ตลอดจนข้อควรระวังด้านความปลอดภัย ความสอดคล้องตามกฎระเบียบ และแนวทางปฏิบัติที่แนะนำสำหรับการนำไปใช้อย่างรับผิดชอบและสามารถตรวจสอบได้
บทนำ: ทำไม RAG + เวกเตอร์เรียลไทม์จึงเป็นเกมเชนเจอร์สำหรับธนาคาร
บทนำ: ทำไม RAG + เวกเตอร์เรียลไทม์จึงเป็นเกมเชนเจอร์สำหรับธนาคาร
ในยุคที่ลูกค้าคาดหวังการตอบกลับทันทีและข้อมูลที่ถูกต้อง ธนาคารต้องการระบบที่ไม่เพียงแค่ตอบคำถามได้ แต่ต้องตอบได้อย่างมีบริบทและยืนยันแหล่งที่มาของข้อมูลได้จริง Retrieval‑Augmented Generation (RAG) ร่วมกับ ฐานข้อมูลเวกเตอร์แบบเรียลไทม์ (real‑time vector database) ตอบโจทย์นี้โดยการผสานความสามารถของโมเดลภาษากับการค้นคืนข้อมูลเชิงความหมายจากแหล่งข้อมูลภายใน เช่น บันทึกธุรกรรม นโยบายความเสี่ยง และการสนทนากับลูกค้า ทำให้คำตอบมีความเกี่ยวข้องและตรวจสอบที่มาของข้อมูลได้
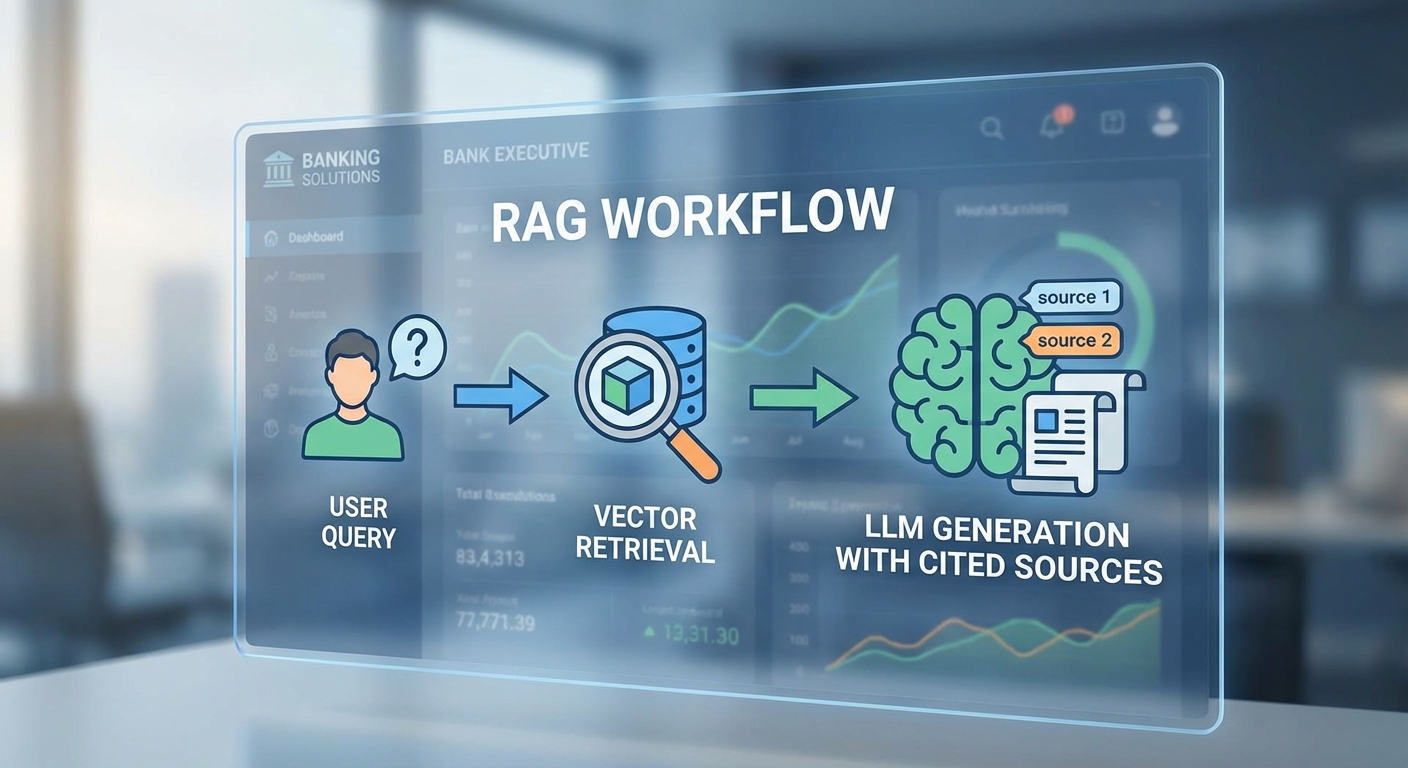
RAG ทำงานโดยขั้นตอนหลักคือ: สร้าง embedding ของคำถาม/บริบท → ค้นหาเอกสารหรือบันทึกที่เกี่ยวข้องโดยใช้ similarity search → ส่งข้อมูลที่ค้นได้เข้าไปเป็น "บริบท" ให้กับโมเดลภาษาเพื่อสร้างคำตอบที่มีความเฉพาะเจาะจง สำหรับ ฐานข้อมูลเวกเตอร์ นั้นประกอบด้วยการแปลงข้อความหรือเรคอร์ดเป็นเวกเตอร์ (embeddings) และใช้ดัชนีสำหรับการค้นหาความใกล้เคียงเชิงความหมาย ซึ่งเมื่อออกแบบเป็นแบบเรียลไทม์ จะสามารถอัปเดตเวกเตอร์ทันทีเมื่อเกิดธุรกรรมหรือเหตุการณ์ใหม่ ทำให้ข้อมูลที่คืนกลับเป็นปัจจุบันเสมอ
เชิงธุรกิจ ข้อได้เปรียบชัดเจนคือการลด latency ในการให้บริการลูกค้าและเพิ่มความแม่นยำของคำตอบ ตัวอย่างเช่น ระบบที่ออกแบบดีสามารถตั้งเป้า latency แบบ conversational อยู่ระหว่าง 0.5–3 วินาที สำหรับการตอบคำถามทั่วไป เช่น ยอดเงินปัจจุบัน สถานะคำสั่งชำระ หรือสรุปการเคลื่อนไหวบัญชี ในการทดสอบ POC หลายโครงการของธนาคารและฟินเทค พบว่าการผสาน RAG กับฐานข้อมูลเวกเตอร์ช่วยลดเวลาตอบกลับจากระดับหลายสิบวินาทีหรือต้องรอเจ้าหน้าที่มาเป็นคำตอบแบบเรียลไทม์ภายในไม่กี่วินาที
ผลทางธุรกิจที่สำคัญได้แก่
- ประสบการณ์ลูกค้าที่ดีขึ้น — คำตอบที่มีบริบทและยืนยันแหล่งที่มา ช่วยสร้างความเชื่อมั่นและลดความจำเป็นในการโอนสาย
- ลดเวลารอตอบ (reduced wait/handling time) — จากการค้นคืนเชิงความหมายและการประมวลผลที่รวดเร็ว ทำให้ลดเวลาเฉลี่ยในการตอบคำถามและเพิ่มปริมาณการให้บริการต่อพนักงาน
- ความแม่นยำและการตรวจสอบย้อนกลับ (audit trail) — ทุกคำตอบสามารถแนบแหล่งข้อมูลต้นทาง เช่น หมายเลขธุรกรรม ช่วงเวลาบันทึก หรือเอกสารประกอบ ซึ่งสำคัญต่อการตรวจสอบภายในและการปฏิบัติตามกฎระเบียบ
- รองรับการสอบถามเชิงธุรกรรม — การผสานเวกเตอร์ที่อัปเดตแบบเรียลไทม์กับ Core‑Banking ช่วยให้ระบบสามารถตอบคำถามเชิงธุรกรรมแบบละเอียด เช่น การตรวจสอบการคืนเงิน สถานะคำสั่งโอน หรือสาเหตุการปฏิเสธ ได้ทันที
สำหรับธนาคารไทยที่ต้องรับมือกับปริมาณคำถามจำนวนมากและข้อกำหนดทางกฎระเบียบที่เข้มงวด การลงทุนในสถาปัตยกรรม RAG + เวกเตอร์เรียลไทม์ที่เชื่อมต่อกับ Core‑Banking เป็นการวางรากฐานเทคโนโลยีที่จะช่วยเพิ่มประสิทธิภาพ ลดความเสี่ยงเชิงปฏิบัติการ และยกระดับความพึงพอใจของลูกค้าอย่างเป็นรูปธรรม
ภาพรวมทางเทคนิค: จาก Core‑Banking มาสู่ Vector Store และ LLM
ภาพรวมเชิงเทคนิคของ Pipeline
ภาพรวมทางเทคนิคเริ่มจากการดึงข้อมูลจากระบบ Core‑Banking ซึ่งประกอบด้วยข้อมูลธุรกรรม (transactional), ข้อมูลลูกค้า (KYC) และข้อมูลผลิตภัณฑ์ (product data) ผ่านชั้นเชื่อมต่อข้อมูลที่รองรับ Change Data Capture (CDC) หรือการส่งข้อมูลแบบสตรีมมิ่ง เพื่อให้สามารถอัปเดตฐานข้อมูลเวกเตอร์แบบ near‑real‑time ได้ ความต้องการเชิงปฏิบัติการมักกำหนดเป้าหมายค่าหน่วงเวลา (latency) สำหรับการอัปเดตและการตอบคำถามของระบบ RAG ให้ต่ำกว่า 200–1000 ms ขึ้นอยู่กับระดับการให้บริการ (SLA) ของธนาคาร
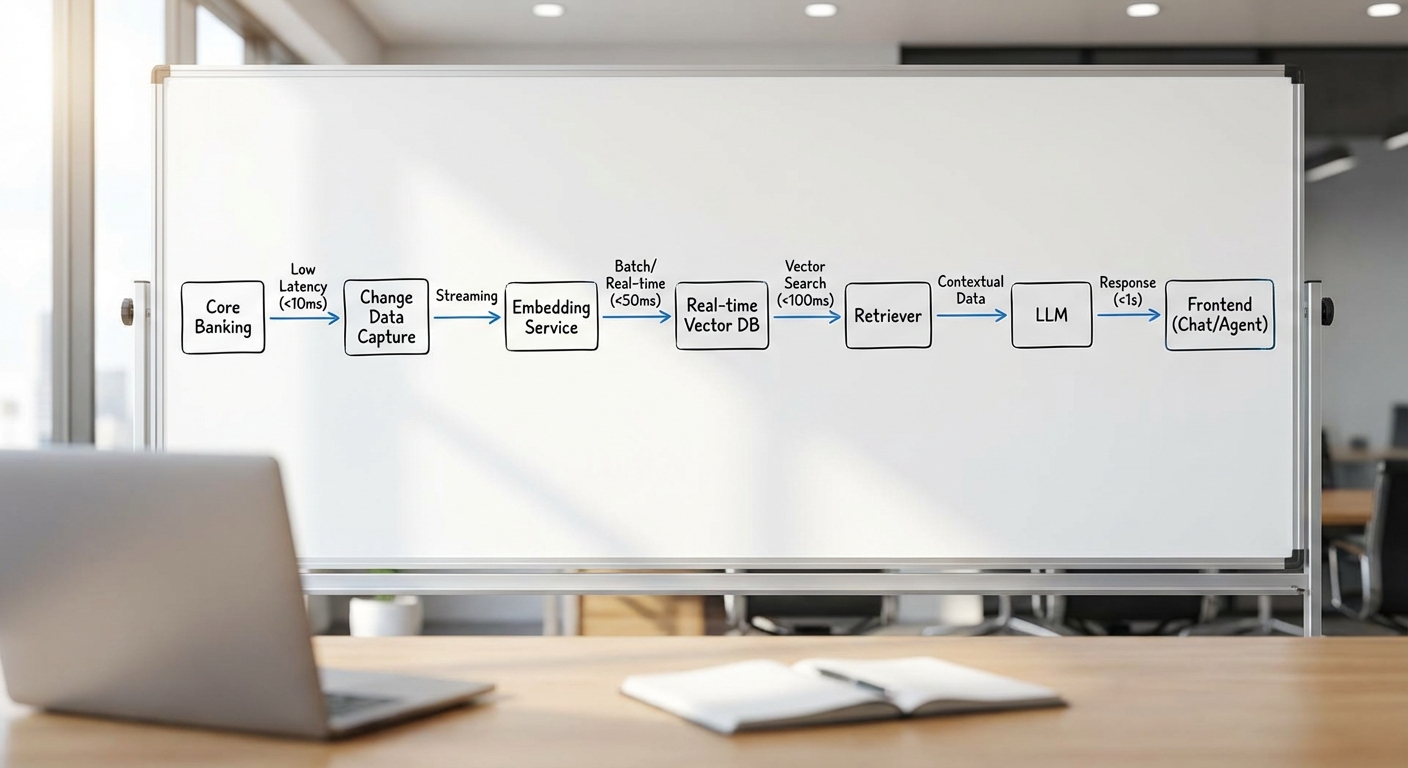
Data connectors: CDC / Streaming และการจัดการความสอดคล้องของข้อมูล
การเชื่อมต่อกับ Core‑Banking มักใช้เครื่องมือ CDC เช่น Debezium ร่วมกับระบบสตรีมมิ่งอย่าง Apache Kafka เพื่อจับการเปลี่ยนแปลงแบบเรียลไทม์ (inserts/updates/deletes) และผลักเหตุการณ์ไปยัง pipeline ของ embedding โดยแนวทางปฏิบัติที่สำคัญได้แก่:
- การทำ upsert ลงใน Vector Store: ทุกเหตุการณ์ CDC จะมี primary key จาก Core‑Banking (เช่น transaction_id, account_id) ที่ใช้เป็นตัวระบุในการอัปเดตหรือลบเวกเตอร์
- การจัดการ tombstone/soft delete: เมื่อข้อมูลถูกลบ จะส่งสัญญาณเพื่อลบหรือทำมาร์กเวกเตอร์เป็น inactive เพื่อคงความสอดคล้องทางธุรกรรม
- การรับประกันความสืบเนื่อง (at‑least‑once / exactly‑once): ใช้ Kafka offsets และ idempotent consumers เพื่อหลีกเลี่ยงการอัปเดตซ้ำหรือสูญหายของเวกเตอร์
- เมตาดาต้าเชิงโปรเวแนนซ์: แต่ละข้อความของ Kafka ควรเก็บ metadata เช่น source_table, commit_timestamp, tx_id สำหรับ Audit Trail
การสร้าง Embedding: Batch vs Streaming และการเลือก Feature
การสร้าง embedding แบ่งออกเป็นสองแนวทางหลัก: Batch สำหรับฐานข้อมูลประวัติและการประมวลผลเชิงวิเคราะห์ และ Streaming สำหรับข้อมูลที่ต้องการความสดใหม่ เช่น รายการเคลื่อนไหวบัญชีแบบเรียลไทม์
- Batch embedding: เหมาะสำหรับการย้ายข้อมูลขนาดใหญ่ (millions of records) โดยทำในช่วงเวลาที่กำหนด เช่น คืนละ 1 ครั้ง หรือแบบ incremental hourly ใช้สำหรับสร้าง embedding ของเอกสารประวัติ ข้อดีคือประหยัดทรัพยากรและสามารถใช้เวอร์ชันโมเดลใหม่ๆ เพื่อรีโปรเซสได้
- Streaming embedding: ใช้สำหรับเหตุการณ์ CDC ที่ต้องการตอบกลับทันที โดยอาจทำ synchronous embedding ผ่าน microservice ที่เรียกโมเดล embedding (local/managed inference) และส่งผลลัพธ์ไปยัง Vector DB แบบ upsert ความท้าทายคือ latency และการจัดคิวเมื่อปริมาณสูง
- Feature selection: ข้อความ (transaction descriptions, account notes), ฟีเจอร์เชิงตัวเลข (amounts, balances) และฟีเจอร์เชิงหมวดหมู่ (transaction type, merchant category) ควรถูกแปลงเป็น representation ที่เหมาะสม — เช่น การรวม text embedding กับ numeric embeddings หรือการคอนแคทแบบ learnable projection เพื่อให้เวกเตอร์สะท้อนบริบทครบถ้วน
- พารามิเตอร์เชิงปฏิบัติการ: ขนาด embedding ปกติ 768–1536 มิติสำหรับโมเดลสมัยใหม่, latency target ของการสร้าง embedding แบบ streaming มักต้องอยู่ภายใน 50–200 ms ต่อเหตุการณ์เพื่อให้ pipeline ยังคง near‑real‑time
Indexing ใน Vector DB: อัลกอริธึมและกลยุทธ์การอัปเดต
หลังจากได้ embedding แล้ว จะต้องทำการจัดเก็บและ index ใน Vector DB เช่น Milvus, Faiss, Pinecone หรือ Weaviate โดยเลือกกลยุทธ์ตามขนาดและความต้องการ:
- Index types: HNSW ให้ latency ต่ำและความแม่นยำสูงสำหรับการค้นหา nearest neighbors; IVF + PQ เหมาะสำหรับ dataset ขนาดใหญ่เพื่อลดพื้นที่จัดเก็บ
- Upsert และ merge: การอัปเดตเวกเตอร์แบบ near‑real‑time ต้องรองรับ upsert API และ background compaction/merge เพื่อจัดการ fragmentation ของ index
- Hybrid search: ผสานการค้นหาแบบ sparse (BM25 จาก text index) กับ dense vector search เพื่อเพิ่มความแม่นยำโดยเฉพาะเมื่อใช้ข้อมูล text หนัก เช่นคำอธิบายธุรกรรม
- การปรับพารามิเตอร์เช่น ef_search (เช่น 128) และ top_k (เช่น 50 → ส่งไปให้ reranker) ควรมีการทดสอบ A/B เพื่อให้ได้จุดสมดุลระหว่างความเร็วและความแม่นยำ
Retriever + Reranker + LLM: กลไกการรวมผล การให้เหตุผล และการอ้างอิงแหล่งข้อมูล
สเตจการดึงและสังเคราะห์ข้อมูลสำหรับการตอบคำถามลูกค้าโดยใช้ RAG ประกอบด้วยสามชั้นหลัก:
- Retriever (dense/sparse): เริ่มจากการดึง top‑N candidate (เช่น N=50) โดยใช้ hybrid search ที่รวมคะแนน BM25 และ similarity ของเวกเตอร์
- Reranker (cross‑encoder): ส่ง top‑N ไปให้โมเดล reranker (เช่น cross‑encoder เล็กๆ) เพื่อคำนวณความเกี่ยวข้องเชิงละเอียดและลดเป็น top‑K (เช่น K=5) โดยพิจารณา score combination: α·semantic_score + β·freshness_score + γ·trust_score (เช่น วัดจาก source_type และ KYC reliability)
- LLM + RAG: LLM จะรับ context จาก top‑K snippets พร้อมเมตาดาต้า (transaction_id, timestamp, source_table) เพื่อสร้างคำตอบ โดยต้องฝัง provenance ใน output เช่น "ยอดล่าสุดคือ 12,345.67 บาท (อ้างอิง transaction_id=TX1234, เวลา=2026‑03‑04 10:12:03)"
เพื่อรักษา Audit Trail และความสามารถตรวจสอบได้ ระบบต้องเก็บ:
- mapping ระหว่าง vector_id และ primary key ของ Core‑Banking
- เวอร์ชันของโมเดล embedding และรายการ preprocessing ที่ใช้
- hash ของ source snippet และ timestamp ของการเข้าถึง เพื่อสามารถยืนยันแหล่งข้อมูลเมื่อเกิดข้อพิพาท
ในเชิงการให้เหตุผล (explainability) ควรออกแบบ prompt และ pipeline ให้ LLM ระบุแหล่งที่มาซ้ำพร้อมคะแนนความมั่นใจ (confidence) และแนบรายการ proof elements ที่ดึงมาจาก vector store — โดยต้องมีนโยบาย redaction สำหรับข้อมูลที่เป็น PII และต้องสอดคล้องกับข้อกำหนดด้านการคุ้มครองข้อมูลของธนาคาร
ตัวอย่างการทำงาน (ตัวอย่างเชิงปฏิบัติ)
เมื่อผู้ใช้ถามว่า "ยอดบัญชีปัจจุบันเท่าไหร่" ขั้นตอนจะเป็นดังนี้: CDC แจ้งเหตุการณ์ล่าสุด → streaming embedding service คำนวณ embedding ของรายการธุรกรรมล่าสุดและ upsert ไปยัง Vector DB ภายใน ~100 ms → Retriever ดึง top‑50 แล้ว Reranker เหลือ top‑3 ที่เกี่ยวข้องที่สุด (เช่น transaction ล่าสุดและ posting balance snapshot) → LLM สร้างคำตอบพร้อมอ้างอิง transaction_id และ timestamp โดยระบบบันทึกคำตอบพร้อม Audit Trail (mapping, embedding_version, model_version, และ hashes) เพื่อให้สามารถตรวจสอบย้อนกลับได้
เชื่อมต่อแบบเรียลไทม์และการอัปเดตข้อมูลเวกเตอร์
เชื่อมต่อแบบเรียลไทม์และการอัปเดตข้อมูลเวกเตอร์
การเชื่อมต่อฐานข้อมูลแกนกลาง (core‑banking) กับระบบ Retrieval‑Augmented Generation (RAG) จำเป็นต้องออกแบบ pipeline แบบเรียลไทม์ที่มั่นคงและตรวจสอบย้อนกลับได้ โดยทั่วไปใช้แนวทาง CDC (Change Data Capture) เพื่อดักจับเหตุการณ์ INSERT/UPDATE/DELETE จากฐานข้อมูลธุรกรรมแล้วส่งเป็นสตรีมไปยังบริการแปลงเป็นเวกเตอร์ (stream‑to‑vector). ตัวอย่างเทคโนโลยีที่นิยมประกอบด้วย Debezium + Kafka/Kafka Connect สำหรับ CDC, Apache Flink หรือ Kafka Streams สำหรับการประมวลผลสตรีมและ windowing, และบริการ embedding/encoder ที่รันเป็น microservice (เช่น SentenceTransformers on‑prem, OpenAI/Cohere บนคลาวด์) ก่อนเก็บลง Vector DB เช่น Pinecone, Milvus หรือ Weaviate เพื่อการค้นคืนแบบ nearest‑neighbor. ความถี่การอัปเดตสามารถแบ่งระดับตามความสำคัญ: hot‑path (ตัวอย่าง: อัปเดตภายใน 0.5–2 วินาทีสำหรับธุรกรรมที่ต้องให้คำตอบลูกค้าแบบทันที), warm (2–60 วินาทีสำหรับข้อมูลสนับสนุน), และ cold (>60 วินาทีสำหรับข้อมูลสำรองหรือวิเคราะห์เป็นกลุ่ม).
การควบคุม windowing และ consistency มีผลต่อความสด (freshness) ของเวกเตอร์อย่างมาก ควรออกแบบให้รองรับทั้ง event‑time และ processing‑time window (เช่น tumbling สำหรับ batch commit, sliding สำหรับการรวมเหตุการณ์ขนาดเล็ก) และผสมการทำ micro‑batching เพื่อลดค่าใช้จ่ายของการทำ embedding ตาม real throughput. สำหรับ consistency ใช้กลยุทธ์ผสม: เก็บความถูกต้องเชิงธุรกรรม (strong consistency) บน ledger และ metadata ของเวกเตอร์ (เช่น source_id, commit_timestamp, LSN/offset) แต่อนุญาตให้ index เวกเตอร์มี eventual consistency เพื่อแลกกับความหน่วงต่ำ โดยต้องมีกลไกตรวจสอบ causal links ระหว่างเวกเตอร์กับ transaction เพื่อให้สามารถยืนยันแหล่งข้อมูลและสร้าง Audit Trail ได้เสมอ.
เมื่อข้อมูลธุรกรรมเปลี่ยนแปลง การคำนวณ embedding ใหม่ควรออกแบบให้มีหลายระดับของการกระตุ้น (recompute triggers): การสร้าง/ลบ/เปลี่ยนแปลงที่มีผลสำคัญต่อความหมาย (เช่น ยอดเงิน, สถานะธุรกรรม) ควรถูกจัดเป็น high‑priority และสั่งให้ re‑embed ทันที ขณะที่การเปลี่ยนแปลงเล็กน้อยอาจรวมเป็น batch เพื่อประสิทธิภาพ เทคนิคที่ใช้ได้แก่ partial re‑embedding (เฉพาะ chunk/field ที่เปลี่ยน), delta detection เพื่อประเมินว่า embedding เก่าหมดอายุหรือไม่ และ priority queue สำหรับงานการคำนวณแบบทันที ซึ่งสามารถลดเวลาการตอบกลับจริงต่อผู้ใช้ได้ ตัวอย่างเช่น embedding model ขนาดกลางอาจใช้เวลา 50–300 ms ต่อรายการบน GPU; เมื่อนำมาใช้จริง ควรรองรับ batching (เช่น 16–128 รายการต่อ batch) เพื่อเพิ่ม throughput เป็นพันรายการต่อวินาทีสำหรับระบบระดับธนาคาร.
การเก็บเวอร์ชันของเวกเตอร์และนโยบายย้อนกลับ (versioning / TTL) เป็นหัวใจของการตรวจสอบและการกู้คืนระบบ ควรกำหนด metadata ประกอบด้วย: vector_id, version_id, source_transaction_id, commit_timestamp, source_lsn และ status (active/obsolete/tombstone). นโยบายเก็บรักษาอาจเป็นรูปแบบผสม เช่นเก็บเวอร์ชันล่าสุดพร้อมสำรองระยะสั้น (last N versions หรือ retention window เช่น 30–90 วัน) และใช้ TTL เพื่อทำความสะอาดโดยอัตโนมัติ เพื่อให้สามารถย้อนกลับ (rollback) โดยการเลือกเวอร์ชันก่อนหน้า หรือใช้ CDC replay ในการ rebuild index หากเกิดความผิดพลาด ตัวอย่างกลยุทธ์: เก็บเวอร์ชันทันที 3 รุ่นล่าสุดสำหรับทุกเวกเตอร์และเก็บรุ่นเพิ่มเติมเฉพาะรายการที่มีการเปลี่ยนแปลงบ่อยหรืออยู่ในข้อพิพาททางกฎหมาย/การเงิน.
การวัด freshness ควรตั้งค่าเป้าหมาย RTO/RPO และตัวชี้วัดเชิงปฏิบัติการที่ชัดเจน ตัวอย่างเป้าหมายเชิงธุรกิจ: RTO (Recovery Time Objective) สำหรับเส้นทางตอบคำถามลูกค้าอาจตั้งไว้ที่ <2 วินาที (จากคำขอถึงผลลัพธ์พร้อมแหล่งอ้างอิง) และสำหรับการกู้คืนระบบหลังเหตุขัดข้องอาจอยู่ที่ <5 นาที สำหรับ index rebuild แบบ partial. RPO (Recovery Point Objective) สำหรับความสดของข้อมูลธุรกรรมอาจตั้งไว้ที่ <5 วินาที (เช่นยอมให้สูญเสียข้อมูลเพียงไม่กี่วินาทีของเหตุการณ์หากมีการล้มเหลว) หรือเข้มงวดยิ่งขึ้นเป็น <1 วินาทีสำหรับสินค้าบริการบางประเภท. ตัวชี้วัดที่ติดตามได้แก่ ingestion latency (เวลาตั้งแต่ commit ใน core‑db จนถึง upsert ใน vector DB), embedding latency, index upsert time, และ staleness metric (เช่น median/95th percentile ของ age‑of‑data ในผลการค้น) — ควรกำหนด SLO/SLA: ตัวอย่าง median ingestion latency <500 ms, 95th percentile <2 s สำหรับเส้นทาง hot‑path.
สุดท้าย ต้องมี Audit Trail ที่เชื่อมโยงเวกเตอร์กับแหล่งที่มาอย่างแน่นหนา เพื่อสนับสนุนการตรวจสอบและการอธิบายคำตอบได้อย่างโปร่งใส โดยเก็บทั้ง metadata ของเวกเตอร์ (version, source_lsn, commit_ts) และลิงก์ไปยังบันทึกธุรกรรมจริงใน core‑banking ทำให้เมื่อผู้ตรวจสอบหรือผู้ใช้งานขอพิสูจน์ สามารถย้อนกลับไปยังต้นทางธุรกรรมที่เป็นแหล่งข้อมูลของคำตอบได้อย่างรวดเร็วและเป็นระบบ.
Audit Trail และการอ้างอิงแหล่งข้อมูลเพื่อความโปร่งใส
กลไกการแสดงแหล่งอ้างอิงในคำตอบของระบบ RAG
เมื่อธนาคารผสาน Retrieval‑Augmented Generation (RAG) กับฐานข้อมูลเวกเตอร์เรียลไทม์เพื่อเชื่อมต่อกับระบบ Core‑Banking กลไกที่ทำให้คำตอบของ LLM มาพร้อมกับแหล่งอ้างอิงเริ่มจากการบันทึกและส่งกลับข้อมูลเมตา (metadata) ของเอกสารที่ถูกดึงมา ได้แก่ source snippets (ช่วงข้อความที่นำมาใช้), doc IDs (รหัสเอกสารภายใน), และ timestamps (เวลากู้ข้อมูล) ซึ่งจะแสดงพร้อมกับคำตอบในรูปแบบที่อ่านง่ายสำหรับลูกค้าและผู้ตรวจสอบภายในตัวอย่างเช่น:
- Snippet: "ยอดเงินคงเหลือ 12,345.67 บาท" (แสดงช่วงประโยคที่ระบบอ้างอิง)
- Doc ID: core_txn_20260201_12345
- Timestamp: 2026-02-01T12:34:56Z
ในเชิงปฏิบัติ ระบบจะแสดงระดับความเชื่อมั่น (confidence / retrieval score) และลำดับการดึง (retrieval rank) เพื่อให้ผู้รับข้อมูลเห็นว่าแหล่งใดมีอิทธิพลต่อคำตอบมากที่สุด ทั้งนี้การแสดง snippets และ doc IDs ช่วยให้ผู้ตรวจสอบสามารถกดย้อนกลับไปยังบันทึกต้นทางใน Core‑Banking ได้ทันทีเพื่อยืนยันความถูกต้อง
การเก็บบันทึกแบบ immutable logs สำหรับการตรวจสอบย้อนหลัง
เพื่อให้ Audit Trail มีความน่าเชื่อถือและตรวจสอบได้ตามข้อกำหนดทางกฎระเบียบ ระบบต้องเก็บบันทึกการเรียกใช้งานอย่างละเอียดในรูปแบบ immutable (append‑only) โดยบันทึกแต่ละรายการควรประกอบด้วยฟิลด์สำคัญ เช่น:
- Query: ข้อความคำถามของผู้ใช้ (redacted/pseudonymized เมื่อจำเป็น)
- Retrieved Docs: รายการ doc IDs, snippets, retrieval score และเวลากู้ข้อมูล
- Model Output: คำตอบที่ LLM ส่งกลับพร้อม metadata ของโมเดล (รุ่น, prompt template, temperature)
- Traceability Info: content hashes (SHA‑256), digital signatures, และ reference to vector embedding IDs
- Access Context: user id (pseudonymized/hashed), client IP, และ role ที่ขอข้อมูล
ตัวอย่างเทคโนโลยีที่ใช้จัดเก็บ immutable logs ได้แก่ ระบบ message queue แบบ append‑only (เช่น Kafka), storage แบบ WORM (Write Once Read Many) บน S3 with Object Lock, หรือ ledger ที่ใช้เทคนิค Merkle tree/hash chaining เพื่อให้การแก้ไขย้อนหลังสามารถตรวจจับได้โดยทันที เทคนิคเหล่านี้ช่วยลดเวลาในการตรวจสอบภายในได้อย่างมาก — ธนาคารหลายแห่งรายงานว่าการมี Audit Trail แบบเรียลไทม์ช่วยลดเวลาในการค้นหาแหล่งที่มาจากหลายชั่วโมงเหลือเพียงไม่กี่นาทีในการตอบคำร้องของลูกค้า
แนวปฏิบัติด้าน compliance: การเข้ารหัส, tamper‑evidence และ retention policies
เพื่อให้สอดคล้องกับข้อกำหนดทางกฎหมายและมาตรฐานความปลอดภัย ข้อปฏิบัติที่ควรบังคับใช้มีดังนี้:
- Encryption: ข้อมูลทั้งหมดต้องถูกเข้ารหัสทั้ง in transit (TLS 1.2/1.3 สำหรับการสื่อสารระหว่างบริการ) และ at rest (AES‑256 หรือเทียบเท่า) โดยใช้ระบบจัดการคีย์ที่ปลอดภัย (HSM / KMS) และมีการหมุนคีย์ตามนโยบาย
- Tamper‑evidence: ใช้การลงลายดิจิทัล (digital signature) และ hashing (เช่น Merkle trees หรือ HMAC chaining) เพื่อทำให้บันทึกทุกรายการสามารถตรวจสอบได้ว่ามีการแก้ไขหรือไม่ รวมถึงการทำ notarization/periodic anchoring กับ timestamping service ที่เชื่อถือได้
- Immutable Storage: เก็บ logs ใน storage แบบ append‑only หรือ WORM เพื่อป้องกันการลบ/แก้ไขแบบไม่พึงประสงค์ และบันทึกเหตุการณ์การเข้าถึง (access logs) ที่ละเอียดพร้อมระบบแจ้งเตือนเมื่อมีการเข้าถึงที่ผิดปกติ
- Retention Policies: กำหนดระยะเวลาเก็บข้อมูลให้สอดคล้องกับกฎระเบียบ (เช่น เก็บ transactional audit ไม่น้อยกว่า 5–10 ปี หรือเป็นไปตามข้อกำหนดของหน่วยงานกำกับดูแล) พร้อมนโยบาย legal hold และการลบอย่างปลอดภัยเมื่อหมดอายุ
- Access Controls & Separation of Duties: ใช้ RBAC/ABAC เพื่อจำกัดการเข้าถึงข้อมูล audit trail เฉพาะบุคลากรที่ได้รับมอบหมาย และเก็บบันทึกการเข้าถึงเพื่อวัตถุประสงค์ของการตรวจสอบ
นอกจากนี้ ควรมีนโยบายเฉพาะสำหรับข้อมูลส่วนบุคคล (PII) เช่น การทำ redaction หรือ pseudonymization ก่อนบันทึกลงใน logs หากไม่จำเป็นต้องใช้ข้อมูลดิบเพื่อวัตถุประสงค์ของการสอบสวน ทั้งนี้เพื่อให้สอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคลและลดความเสี่ยงด้านความเป็นส่วนตัว
การนำ Audit Trail ไปใช้เชิงปฏิบัติและประโยชน์เชิงธุรกิจ
เมื่อระบบสามารถแสดงแหล่งอ้างอิงอย่างโปร่งใสและเก็บ immutable logs ได้ ธนาคารจะได้ประโยชน์ทั้งด้านปฏิบัติการและความน่าเชื่อถือ ได้แก่ การตอบคำถามลูกค้าได้ภายในวินาทีพร้อมหลักฐานอ้างอิง, ลดเวลาการตรวจสอบภายใน, เพิ่มประสิทธิภาพการแก้ข้อพิพาท และเตรียมพร้อมต่อการตรวจสอบของหน่วยงานกำกับดูแล ตัวอย่างเช่น การให้ลูกค้าได้รับคำตอบพร้อม snippet และ doc ID ที่ชี้ไปยังรายการธุรกรรมใน Core‑Banking จะช่วยให้การยืนยันยอดหรือการตรวจสอบรายการถอน-ฝากเป็นไปอย่างรวดเร็วและโปร่งใส
โดยสรุป การออกแบบ Audit Trail ที่ดีสำหรับสถาปัตยกรรม RAG + Real‑time Vector DB ควรผสานการแสดงแหล่งอ้างอิงในผลลัพธ์, การเก็บ immutable และ cryptographically‑verifiable logs, พร้อมนโยบาย encryption, retention และควบคุมการเข้าถึงอย่างเข้มงวด เพื่อให้ระบบตอบสนองรวดเร็วและสอดคล้องกับข้อกำหนดด้านกฎระเบียบและความเชื่อมั่นของลูกค้า
ตัวอย่างประสิทธิภาพและสถิติ: วัดความสำเร็จด้วยตัวเลข
ตัวอย่างประสิทธิภาพและสถิติ: วัดความสำเร็จด้วยตัวเลข
การผสาน Retrieval-Augmented Generation (RAG) กับฐานข้อมูลเวกเตอร์แบบเรียลไทม์ที่เชื่อมต่อกับระบบ Core‑Banking สามารถวัดความสำเร็จได้ด้วยตัวชี้วัดเชิงปริมาณที่ชัดเจน ในการทดลองเชิงปฏิบัติการของธนาคาร (benchmarking ภายในหรือการทดสอบสมมติ) พบว่า latency เฉลี่ยอยู่ในช่วง 0.5–3 วินาที สำหรับคำถามลูกค้าทั่วไป เช่น ตรวจสอบยอดบัญชี ยอดเดินบัญชีล่าสุด หรือสอบถามค่าธรรมเนียมบริการ โดยมีสัดส่วนคำตอบที่ตอบได้ภายใน 2 วินาทีราว 92% ของคำขอทั้งหมด ซึ่งสอดคล้องกับ SLA เชิงประสบการณ์ลูกค้าที่ต้องการการตอบสนองเป็นวินาที
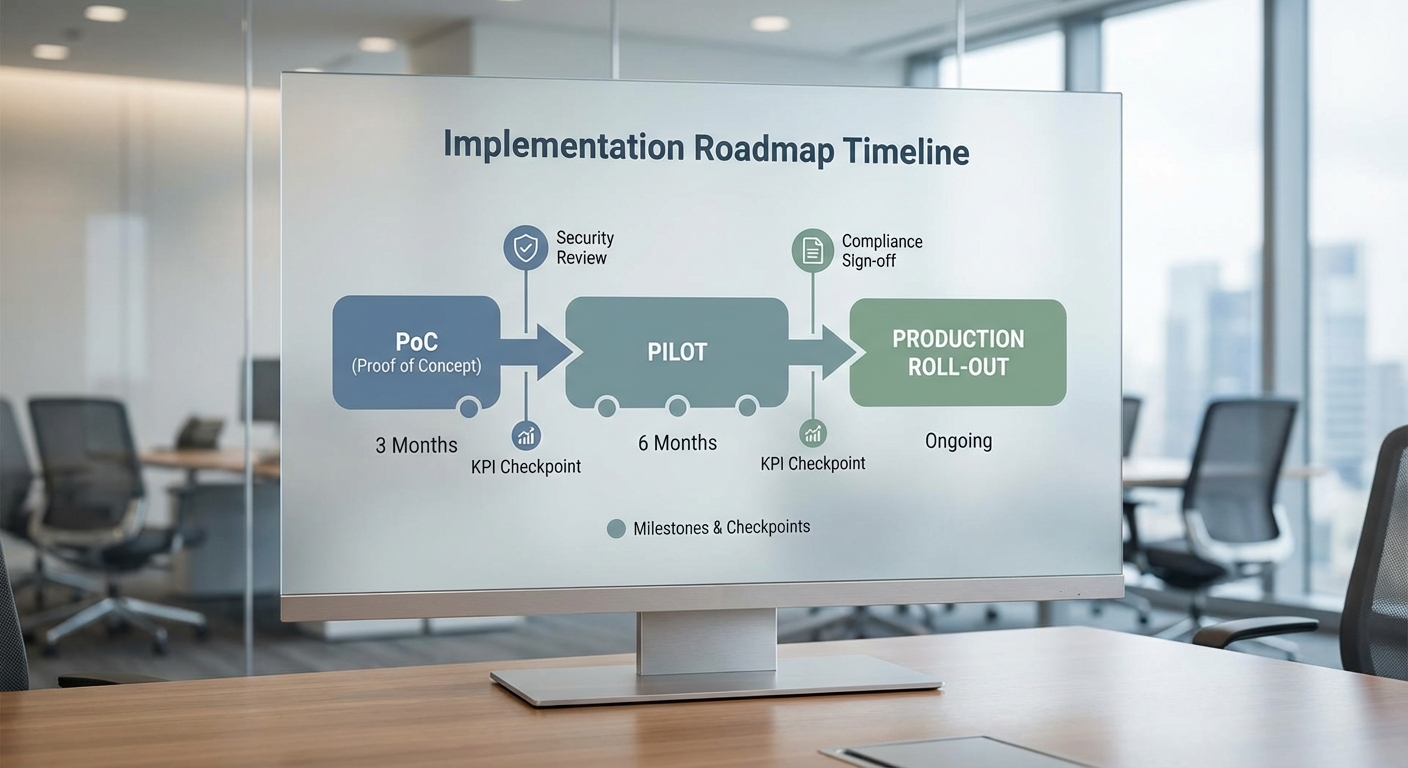
ด้านคุณภาพการดึงข้อมูล (retrieval) จากฐานเวกเตอร์ที่ผ่านการ tune และการทำ relevance feedback แสดงค่า precision ในการดึงข้อมูลอยู่ที่ 90–95% (ตัวอย่างสมมติจากการทดสอบ A/B) และ recall อยู่ในช่วง 85–92% ขึ้นกับขอบเขตของข้อมูลที่ใช้ในการสร้าง embeddings ในขณะเดียวกัน อัตราการอ้างอิงแหล่งข้อมูลที่ถูกต้อง (correct source attribution) ระหว่างระบบ RAG กับ Core‑Banking อยู่ที่ประมาณ 97–99% เมื่อระบบถูกออกแบบให้แนบ audit trail ของแหล่งที่มาทุกครั้งที่ให้คำตอบ
ตัวอย่างตัวชี้วัดเชิงปฏิบัติ (KPIs) ที่แนะนำสำหรับโครงการมีดังนี้:
- Average Latency: เป้าหมาย 0.5–3 วินาที สำหรับคำถามทั่วไป (SLA: ≥90% คำขอตอบภายใน 2 วินาที)
- Retrieval Precision / Recall: Precision 90–95%, Recall 85–92%
- Correct Source Attribution Rate: ≥97% (ทุกคำตอบต้องแนบแหล่งอ้างอิงหรือ transaction id)
- MTTR (Mean Time To Recover): เป้าหมาย ≤30 นาทีสำหรับเหตุการณ์ที่ส่งผลต่อการให้บริการตอบคำถาม
- CSAT (Customer Satisfaction): ≥90% ในแบบสำรวจหลังการโต้ตอบแบบอัตโนมัติ
- Error Rate (ข้อมูลผิด/คำตอบไม่ตรง): เป้าหมาย <1% ของคำขอทั้งหมด
- Audit Coverage: 100% ของคำตอบต้องมี audit trail แบบยืนยันแหล่งที่มา (transaction id, timestamp, document id)
นอกจากค่าสถิติแบบรวมแล้ว การนำเสนอกรณีตัวอย่างคำถามและคำตอบจริงช่วยให้เห็นภาพการทำงานของระบบชัดเจนยิ่งขึ้น ตัวอย่างด้านล่างเป็น Q&A เชิงปฏิบัติที่แสดงทั้งความเร็วและการอ้างอิงแหล่งที่มา:
-
คำถาม: "ยอดเงินคงเหลือในบัญชีออมทรัพย์เลขที่ XXX‑XXXX‑XXXX ของผมเป็นเท่าไร ณ วันนี้?"
คำตอบ (ระบบ): "ยอดเงินคงเหลือปัจจุบัน ณ เวลา 2026-03-04T09:12:05Z คือ 125,430.50 บาท (รวมรายการรอหัก) — อ้างอิง: CoreDB.transaction_id=TX20260304091205, record_id=ACC123456789" -
คำถาม: "ค่าธรรมเนียมโอนระหว่างธนาคารนอกเครือข่ายเป็นเท่าไร หากโอน 50,000 บาท?"
คำตอบ (ระบบ): "ค่าธรรมเนียมปกติสำหรับการโอนทันทีระหว่างธนาคารนอกเครือข่ายคือ 25 บาท (ถ้ามีโปรโมชั่นอาจเปลี่ยนแปลง) — อ้างอิง: FeeSchedule.doc_id=FEE2026-01, effective_date=2026-01-01" -
คำถาม: "รายการหนี้บัตรเครดิตล่าสุดมีรายการใดบ้างที่ยังไม่ชำระ?"
คำตอบ (ระบบ): "รายการคงค้างล่าสุด ณ 2026-03-03: ยอดคงเหลือ 12,350.00 บาท, transaction_id=CC_TX_987654321, due_date=2026-03-20 — อ้างอิง: CoreDB.transaction_id=CC_TX_987654321"
จากตัวอย่างข้างต้นเห็นได้ว่าระบบไม่ได้เพียงให้คำตอบอย่างรวดเร็ว แต่ยังแนบ audit trail ที่ชัดเจน (transaction_id, timestamp, document_id) เพื่อให้สามารถติดตามและตรวจสอบย้อนหลังได้อย่างแม่นยำ ซึ่งเป็นข้อกำหนดสำคัญสำหรับการปฏิบัติตามกฎระเบียบและการตรวจสอบภายในของสถาบันการเงิน
สุดท้าย การติดตามและรายงานสถิติเหล่านี้เป็นหัวใจของการปรับปรุงประสิทธิภาพอย่างต่อเนื่อง ธนาคารควรกำหนดรอบการประเมิน (เช่น รายสัปดาห์/รายเดือน) เพื่อตรวจสอบค่า latency distribution, precision/recall per intent, จำนวนคำตอบที่ต้อง human‑in‑the‑loop และอัตราการผิดพลาด เพื่อให้มั่นใจว่าโซลูชัน RAG + เวกเตอร์เรียลไทม์ ยังคงส่งมอบประสบการณ์ที่รวดเร็ว ถูกต้อง และตรวจสอบได้สำหรับลูกค้าและหน่วยงานกำกับดูแล
ความเสี่ยง ข้อจำกัด และแนวทางป้องกัน
ความเสี่ยง ข้อจำกัด และแนวทางป้องกัน
การผสานระบบ Retrieval‑Augmented Generation (RAG) ที่ใช้ฐานข้อมูลเวกเตอร์แบบเรียลไทม์กับระบบ Core‑Banking เพื่อให้บริการตอบคำถามลูกค้าเป็นวินาที แม้จะเพิ่มประสิทธิภาพด้านการตอบสนองและประสบการณ์ลูกค้า แต่ย่อมมาพร้อมความเสี่ยงเชิงเทคนิคและเชิงกฎหมายที่ต้องบริหารอย่างเป็นระบบ ความเสี่ยงสำคัญได้แก่ hallucination ของโมเดลภาษา (LLM) ที่อาจให้ข้อมูลผิด/สร้างข้อมูลไม่เป็นความจริง, การรั่วไหลของข้อมูลส่วนบุคคลและข้อมูลทางการเงิน, รวมถึงความเสี่ยงการไม่ปฏิบัติตามข้อกำหนด PDPA และกฎระเบียบทางการเงินอื่นๆ
เรื่อง hallucination นับเป็นข้อจำกัดเชิงเทคนิคที่สำคัญ เพราะแม้ระบบ RAG จะช่วยลดโอกาสผิดพลาดโดยการอ้างอิงเอกสารจริง แต่ยังพบได้ว่าคำตอบของ LLM อาจผสมข้อมูลที่ไม่ถูกต้องหรือสร้างข้อเท็จจริงขึ้นเอง งานวิจัยและการประเมินในเชิงอุตสาหกรรมชี้ว่าอัตราการเกิด hallucination ขึ้นอยู่กับบริบทและการปรับแต่ง อาจอยู่ในระดับตั้งแต่หลักเปอร์เซ็นต์จนถึงหลักสิบเปอร์เซ็นต์ในงานบางประเภท แนวทางลดความเสี่ยงที่ควรนำมาใช้ร่วมกันได้แก่:
- Source grounding และ provenance — บังคับให้ทุกคำตอบต้องแนบ reference ID ของแหล่งข้อมูลจากฐานเวกเตอร์ (เช่น document ID, timestamp, confidence score) และใช้กลไกการจัดอันดับผลการค้นหาเชิงความน่าเชื่อถือ (source scoring) เพื่อให้ผู้ใช้งานและ auditor สามารถตรวจสอบที่มาของข้อมูลได้
- Confidence thresholds และ safe‑fallback — ตั้งค่าเกณฑ์ความเชื่อมั่น (confidence threshold) สำหรับคำตอบอัตโนมัติ หากคะแนนความเชื่อมั่นต่ำกว่าระดับที่กำหนดให้ระบบส่งคำถามไปยัง human‑in‑the‑loop หรือแสดงข้อความเตือนและขออนุญาตผู้ใช้ก่อนดำเนินการ
- Human‑in‑the‑loop (HITL) — กำหนดการตรวจสอบโดยบุคลากรด้านความเสี่ยงหรือเจ้าหน้าที่บริการลูกค้าสำหรับคำตอบที่เกี่ยวข้องกับการตัดสินใจเชิงการเงิน ข้อมูลส่วนบุคคล หรือเมื่อคำถามมีความไม่แน่นอนสูง
ด้านความปลอดภัยของข้อมูลและการคุ้มครองข้อมูลส่วนบุคคล ควรจัดมาตรการเชิงรุกเพื่อป้องกันการรั่วไหลจากทั้งฝั่งฐานข้อมูลเวกเตอร์และการเชื่อมต่อกับ Core‑Banking ได้แก่:
- การเข้ารหัสและการแยกโซนเครือข่าย — ใช้การเข้ารหัสข้อมูลทั้งขณะพัก (encryption‑at‑rest) และระหว่างส่งข้อมูล (encryption‑in‑transit) รวมทั้งแยกฐานข้อมูลเวกเตอร์และ Core‑Banking ให้อยู่ใน VPC/isolated subnet พร้อม firewall และ private endpoints
- การจำกัดการเข้าถึงแบบleast privilege และ SSO/RBAC — บังคับใช้ Single Sign‑On (SSO) และ Role‑Based Access Control (RBAC) พร้อม MFA สำหรับการเข้าถึงระบบที่สำคัญ รวมถึงการกำหนดสิทธิ์แยกชัดเจนระหว่าง service accounts, operator, และ auditor
- Data minimization และ tokenization — หลีกเลี่ยงการส่งข้อมูล PII หรือ PAN/เลขบัญชีแบบเต็มไปยังโมเดล; ทำการ anonymize, pseudonymize หรือ tokenization ก่อนสร้าง embedding และใช้นโยบาย retention ที่จำกัดการเก็บ embedding ที่มีข้อมูลละเอียดอ่อน
- ป้องกันการโจมตีบน embeddings — พิจารณาใช้เทคนิคเช่น differential privacy, embedding pruning หรือ hashing เพื่อลดความเป็นไปได้ของการ reconstruct ข้อมูลต้นฉบับจากเวกเตอร์ และตั้งข้อจำกัดใน query เช่น k‑nearest limit, rate limiting, และ query pattern monitoring
ในด้านนโยบายและการกำกับดูแล (governance) แนะนำให้ธนาคารจัดตั้งกรอบงานที่ชัดเจน ครอบคลุมการอนุมัติ การตรวจสอบ และการประเมินผลอย่างสม่ำเสมอ ได้แก่:
- Approval workflows — กำหนดวงจรการอนุมัติ (change approval) สำหรับการ deploy รุ่นโมเดลใหม่ การปรับพารามิเตอร์ของ RAG และการเพิ่มแหล่งข้อมูล โดยต้องผ่านการประเมินความเสี่ยงจากทีมความเสี่ยง/กฎหมายก่อนใช้งานจริง
- Audit reviews และ tamper‑evident audit trail — เก็บบันทึกการเรียกใช้งาน (requests), คำตอบ, source IDs และการแก้ไขข้อมูลในรูปแบบ tamper‑evident logs ที่สามารถตรวจสอบย้อนหลังได้ เพื่อสนับสนุนการตรวจของ regulator และการร้องขอสิทธิของเจ้าของข้อมูลตาม PDPA
- Periodic model evaluation และ red‑team testing — ดำเนินการทดสอบประสิทธิภาพและความปลอดภัยของโมเดลเป็นระยะ (เช่น รายไตรมาส) รวมถึงการทำ red‑team/penetration testing เพื่อลองโจมตีเชิงสังคมและเชิงเทคนิคเพื่อค้นหาช่องโหว่ (เช่น prompts‑injection, data exfiltration via chaining queries)
- นโยบายการปฏิบัติตาม PDPA และการทำ DPIA — ดำเนินการ Data Protection Impact Assessment (DPIA) สำหรับโครงการที่เกี่ยวข้องกับ PII ระบุพื้นฐานทางกฎหมายของการประมวลผล แจ้งผู้ใช้และจัดการสิทธิของเจ้าของข้อมูลตามข้อกำหนด ทั้งการเข้าถึง แก้ไข และขอให้ลบข้อมูล
สุดท้าย ควรมีกระบวนการตอบสนองต่อเหตุการณ์และการรายงานเพื่อรองรับกรณีละเมิดข้อมูล รวมถึงการตั้งทีมรับมือเหตุการณ์ (incident response), การแจ้งเตือนอัตโนมัติเมื่อพบพฤติกรรมผิดปกติ (SIEM/UEBA), และแผนสื่อสารกับ regulator และลูกค้า การผสานเทคนิคเชิงเทคนิค (เช่น encryption, RBAC, monitoring) กับนโยบายองค์กร (approval workflows, audits, periodic evaluations) จะช่วยลดความเสี่ยงให้เหลือน้อยที่สุดและสร้างความเชื่อมั่นต่อทั้งหน่วยงานกำกับและลูกค้า
Roadmap การนำไปใช้จริงและกรณีศึกษาเชิงปฏิบัติ
Roadmap การนำไปใช้จริง: PoC → Pilot → Production
การนำระบบ RAG (Retrieval‑Augmented Generation) ผสานกับฐานข้อมูลเวกเตอร์เรียลไทม์และการเชื่อมต่อกับ Core‑Banking ให้ใช้ได้จริงในสภาพแวดล้อมธนาคาร ควรออกแบบเป็นเฟสชัดเจน ได้แก่ Proof of Concept (PoC), Pilot และ Production โดยในแต่ละเฟสต้องระบุขอบเขต ทีมงาน ระยะเวลา งบประมาณ และเกณฑ์ประเมินความสำเร็จ เพื่อควบคุมความเสี่ยงและรับรองความปลอดภัยของข้อมูลลูกค้า
PoC (ระยะทดลองเบื้องต้น): ขอบเขต PoC ควรเป็นกรณีใช้งานเฉพาะ เช่น ตอบคำถามบัญชีสะสม/ยอดบัญชีธุรกรรมย้อนหลัง และการอ้างอิงแหล่งที่มา (Audit Trail) สำหรับช่องทางหนึ่ง เช่น เว็บแชทหรือแอปธนาคาร ตัวอย่างทีมที่ต้องมี: Product Owner, Data Scientist, ML Engineer, Backend Engineer (API/CICD), DBA/Vector‑DB Specialist, Security/Compliance, และ Subject Matter Expert (SME) จากฝ่ายบริการลูกค้า ระยะเวลาที่แนะนำคือ 3–6 เดือน โดยกิจกรรมสำคัญได้แก่ การเก็บและทำความสะอาดข้อมูล เลือกตัวแทนแหล่งข้อมูล (core ledger, FAQs, policy docs) การตั้งค่า vector DB แบบ real‑time การสร้าง pipeline RAG และการทดสอบเบื้องต้น (functional, latency, basic security scan)
- ตัวอย่างระยะเวลา PoC: เดือนที่ 1: วิเคราะห์ความต้องการและข้อมูล; เดือนที่ 2: สร้าง pipeline และ prototype; เดือนที่ 3–4: ทดสอบภายในและปรับจูน; เดือนที่ 5–6: UAT และประเมินผล
- งบประมาณตัวอย่าง PoC: 500,000 – 1,500,000 บาท (ขึ้นกับขอบเขตการใช้ data และค่าบริการ cloud/third‑party)
- KPIs สำหรับ PoC: latency retrieval < 500 ms (เฉลี่ย), ความถูกต้องของการอ้างอิงแหล่งข้อมูล ≥ 85%, CSAT แบบเชิงคุณภาพจากกลุ่มทดสอบ > baseline
Pilot (ขยายช่วงทดลองเชิงปฏิบัติการ): หาก PoC ประสบความสำเร็จ ให้ขยายเป็น Pilot โดยครอบคลุมช่องทางการสื่อสารหลายช่อง (omnichannel) และกลุ่มลูกค้าจริงแบบจำกัด เช่น 1–5% ของผู้ใช้ทั้งหมด Pilot ควรมีการทดสอบภาระ (load test), การทำงานร่วมกับ Core‑Banking ผ่าน API แบบเรียลไทม์ และการตรวจสอบการเก็บ Audit Trail อย่างละเอียด ระยะเวลาแนะนำ 4–9 เดือน งบประมาณตัวอย่าง 2–6 ล้าน บาท ขึ้นกับจำนวนผู้ใช้และการจัดเตรียม infra
- กิจกรรมสำคัญใน Pilot: load & stress testing, security penetration testing, privacy impact assessment, integration tests กับ core banking, การตั้งค่า failover และ human‑in‑the‑loop workflow
- KPIs สำหรับ Pilot: ลดเวลาตอบเฉลี่ยจากช่องทางออนไลน์ลงอย่างน้อย 70% (ตัวอย่าง: จาก 30 วินาที → ≤ 10 วินาที), CSAT เพิ่มขึ้น 5–15 จุด, deflection rate (การลดการโทรเข้าคอลเซ็นเตอร์) ≥ 20% ในกลุ่มทดลอง
เกณฑ์ขึ้นสู่ Production และการรับรองความพร้อม
ก่อนขึ้นสู่ Production ธนาคารต้องกำหนดเกณฑ์ชัดเจนเพื่อรับรองความน่าเชื่อถือและความปลอดภัยของระบบ ตัวอย่างเกณฑ์สำคัญได้แก่:
- SLA และประสิทธิภาพ: Availability ≥ 99.9% (หรือ RTO/RPO ที่ตกลงกันได้), Median retrieval latency ≤ 300–500 ms ภายใต้โหลดปกติ และ 95th percentile latency ภายใต้โหลดสูงต้องยังคงยอมรับได้
- Security Audit: ผ่าน penetration test และ vulnerability assessment จากฝ่ายความปลอดภัยภายในหรือผู้ตรวจสอบภายนอก รวมถึงการเข้ารหัสข้อมูลขณะพักและระหว่างการส่งข้อมูล การจัดการสิทธิ์ (RBAC) และการทำ anonymization สำหรับข้อมูลที่มีความเสี่ยง
- User Acceptance Testing (UAT): กลุ่มผู้ใช้งานภายในและตัวแทนลูกค้าต้องยอมรับการทำงานของระบบ โดยเกณฑ์การรับรองควรรวมถึงอัตราความถูกต้องของคำตอบและความถูกต้องของการอ้างอิงแหล่งข้อมูล (source attribution accuracy ≥ 90%)
- Governance & Compliance: ผ่านการทบทวนทางกฎหมายและการปฏิบัติตามข้อกำหนดของธนาคารกลาง เช่น การเก็บบันทึก Audit Trail ที่ตรวจสอบได้ และนโยบายการเก็บข้อมูลตาม PDPA
ตัวชี้วัดหลังใช้งาน (Post‑Deployment KPIs) และการวัดความสำเร็จ
หลังขึ้น Production ต้องติดตามตัวชี้วัดเชิงปริมาณและเชิงคุณภาพเป็นระยะ เพื่อวัดผลกระทบเชิงธุรกิจและความถูกต้องของระบบ ตัวชี้วัดสำคัญได้แก่:
- เวลาเฉลี่ยในการตอบ (Average Response Time): เป้าหมายเช่น ลดลงจาก 30 วินาทีเป็น ≤ 3–10 วินาที ขึ้นกับกรณีใช้งาน
- Customer Satisfaction (CSAT) และ NPS: คาดหวังการเพิ่ม CSAT อย่างน้อย 5–15 คะแนนภายใน 3–6 เดือนหลังใช้งาน
- Cost per Contact / Cost to Serve: ลดต้นทุนบริการลูกค้าโดยรวม ≥ 15–30% จากการลดจำนวนสายเรียกเข้าและเวลาทำงานของเจ้าหน้าที่
- Containment / Deflection Rate: เปอร์เซ็นต์คำถามที่ระบบตอบได้โดยไม่ต้อง escalate ไปยังเจ้าหน้าที่มนุษย์ ≥ 20–40%
- Accuracy ของ Source Attribution และ Audit Trail Completeness: เปอร์เซ็นต์การอ้างอิงแหล่งข้อมูลที่ตรวจสอบได้ ≥ 90% และ log ทุกคำตอบที่เกี่ยวข้องถูกเก็บตามข้อกำหนดการตรวจสอบ
- Model Drift & Data Freshness: ติดตามอัตราความล้าสมัยของข้อมูล (staleness) และความเปลี่ยนแปลงของ metrics เช่น F1/precision/recall สำหรับ retrieval ทุกเดือน
วิธีการวัดความสำเร็จควรรวมทั้งการวัดเชิงเทคนิคและเชิงธุรกิจ เช่น การรัน A/B test ระหว่างกลุ่มที่ใช้ระบบใหม่กับกลุ่มควบคุม การตั้ง baseline ก่อน deploy และรายงานผลแบบรายสัปดาห์/รายเดือน พร้อม dashboard ที่แสดง SLA, latency, throughput, CSAT, cost per contact และจำนวนเหตุการณ์ด้านความปลอดภัย นอกจากนี้ควรกำหนดช่วงตรวจสอบ (burn‑in period) 30–90 วันหลัง go‑live เพื่อตรวจจับปัญหาเบื้องต้นและปรับ tuning
ข้อเสนอแนะเชิงการบริหารหลังใช้งาน: ให้จัด governance board ข้ามสายงานสำหรับการตัดสินใจด้าน retraining frequency (เช่น ทุก 1–3 เดือนหรือเมื่อเกิด drift เกินเกณฑ์) การจัดสรรงบประมาณ OPEX สำหรับฐานข้อมูลเวกเตอร์ การตั้งค่า incident response playbook และการทำ audit ภายนอกเป็นประจำ (6–12 เดือน) เพื่อรับรองความสอดคล้องกับนโยบายภายในและกฎหมายภายนอก
บทสรุป
การผสาน RAG (Retrieval‑Augmented Generation) กับฐานข้อมูลเวกเตอร์เรียลไทม์และระบบ Core‑Banking ช่วยให้ธนาคารสามารถตอบคำถามลูกค้าได้เป็นวินาที โดยโมเดลจะเรียกข้อมูลจากเวกเตอร์สโตร์ที่อัปเดตแบบเรียลไทม์และยืนยันแหล่งที่มาผ่าน Audit Trail ซึ่งสร้างความเชื่อมั่นและลดความเสี่ยงจาก hallucination ตัวอย่างการพิสูจน์แนวคิด (PoC) มักแสดงผลตอบกลับภายในประมาณ 1–3 วินาทีเมื่อระบบสแต็กถูกออกแบบอย่างเหมาะสม และการมี Audit Trail ทำให้สามารถระบุแหล่งข้อมูลที่ถูกใช้อ้างอิงในแต่ละคำตอบได้ ช่วยให้การตรวจสอบย้อนหลังเป็นไปได้จริง ลดข้อพิพาท และเพิ่มความโปร่งใสต่อผู้ตรวจสอบภายในและหน่วยงานกำกับดูแล
การนำไปใช้งานเชิงผลิตจริงต้องคำนึงถึงสถาปัตยกรรมการอัปเดตข้อมูล (เช่น streaming change‑data‑capture ไปยังเวกเตอร์สโตร์), มาตรการความปลอดภัยข้อมูล (encryption-at-rest/in-transit, tokenization, granular IAM), และกรอบ governance ที่ชัดเจน (data lineage, retention policy, audit logging และการทดสอบความถูกต้องของแหล่งข้อมูล) พร้อมการตั้ง KPI ที่วัดผลได้ เช่น latency (วินาทีต่อคำตอบ), precision/accuracy ของคำตอบ, อัตราการอ้างอิงแหล่งที่มา, การลดงานแมนนวล, CSAT และผลการตรวจสอบ compliance เพื่อพิสูจน์มูลค่าทางธุรกิจและควบคุมความเสี่ยง การดำเนินงานแบบเป็นขั้นตอน (pilot → scale) พร้อมการมอนิเตอร์และ feedback loop จะช่วยให้ธนาคารได้ประโยชน์จากการตอบคำถามแบบเรียลไทม์ที่เชื่อถือได้และสามารถวัดผลได้อย่างเป็นรูปธรรมในระยะยาว



