
ในยุคที่โมเดลภาษาขนาดใหญ่ (Large Language Models หรือ LLM) ถูกนำมาใช้งานอย่างแพร่หลายทั้งในภาคธุรกิจและการบริการสาธารณะ ความแม่นยำและความน่าเชื่อถือของผลลัพธ์กลายเป็นปัจจัยสำคัญ แต่ปัญหา “model drift” หรือการเบี่ยงเบนของโมเดลจากพฤติกรรมที่คาดหวัง สามารถเกิดขึ้นได้ทุกเมื่อและส่งผลกระทบต่อความเชื่อมั่นของผู้ใช้และการตัดสินใจทางธุรกิจ สตาร์ทอัพไทยเปิดตัวบริการใหม่ชื่อ 'Model Drift Forensics' ที่สัญญาว่าจะตรวจจับการเบี่ยงเบนแบบเรียลไทม์ พร้อมอธิบายสาเหตุ ย้อนรอยแหล่งข้อมูลต้นทาง และทำการ rollback อัตโนมัติเพื่อคืนสถานะโมเดลที่เสถียร ช่วยให้องค์กรลดความเสี่ยงจากผลลัพธ์ที่คลาดเคลื่อนและปกป้องความน่าเชื่อถือของระบบ AI ได้อย่างเป็นรูปธรรม
บริการดังกล่าวรวมฟีเจอร์สำคัญทั้งการเฝ้าติดตามเชิงพฤติกรรมแบบ real-time การให้เหตุผลเชิงสาเหตุ (root-cause explanation) การบันทึก lineage ของข้อมูลตั้งแต่ต้นทางจนถึงการประมวลผล และกลไก rollback ที่สามารถย้อนกลับไปยังเวอร์ชันหรือข้อมูลฝึกสอนก่อนหน้าโดยอัตโนมัติ ทำให้องค์กรสามารถลดเวลาการแก้ไขจากระดับวันเหลือเป็นชั่วโมงหรือวินาทีในหลายกรณี ตัวอย่างการใช้งานเช่น ระบบแชตบอตที่เริ่มให้คำตอบผิดพลาด ระบบคะแนนเครดิตที่เปลี่ยนแปลงอย่างไม่คาดฝัน หรือโมเดลทางการแพทย์ที่เริ่มแสดงผลลัพธ์เบี่ยงเบน—ทั้งหมดนี้จะถูกตรวจจับ อธิบายสาเหตุ และแก้ไขอย่างเป็นระบบ ช่วยให้การนำ AI ไปใช้งานในภาคการเงิน สุขภาพ และบริการลูกค้าทำได้อย่างมั่นคงและสอดคล้องกับข้อกำหนดด้านความรับผิดชอบ (governance) มากขึ้น
บทนำ: ทำไม Model Drift ถึงเป็นความเสี่ยงที่องค์กรไทยต้องรู้
บทนำ: ทำไม Model Drift ถึงเป็นความเสี่ยงที่องค์กรไทยต้องรู้
ในยุคที่ระบบปัญญาประดิษฐ์ โดยเฉพาะ Large Language Models (LLMs) ถูกนำมาใช้งานเชิงพาณิชย์และบริการลูกค้าอย่างกว้างขวาง ปัญหา Model Drift กลายเป็นความเสี่ยงเชิงปฏิบัติการที่องค์กรต้องให้ความสำคัญอย่างเร่งด่วน โดยสรุป Model Drift หมายถึงการเปลี่ยนแปลงของความสัมพันธ์ระหว่างข้อมูลนำเข้า (input) และผลลัพธ์ของโมเดลเมื่อเวลาผ่านไป ผลลัพธ์คือประสิทธิภาพของโมเดลอาจลดลง เกิดการตอบกลับที่ผิดพลาดหรือมีอคติเพิ่มขึ้น ซึ่งต่อเนื่องไปสู่ความเสี่ยงด้านภาพลักษณ์และการดำเนินงานขององค์กร
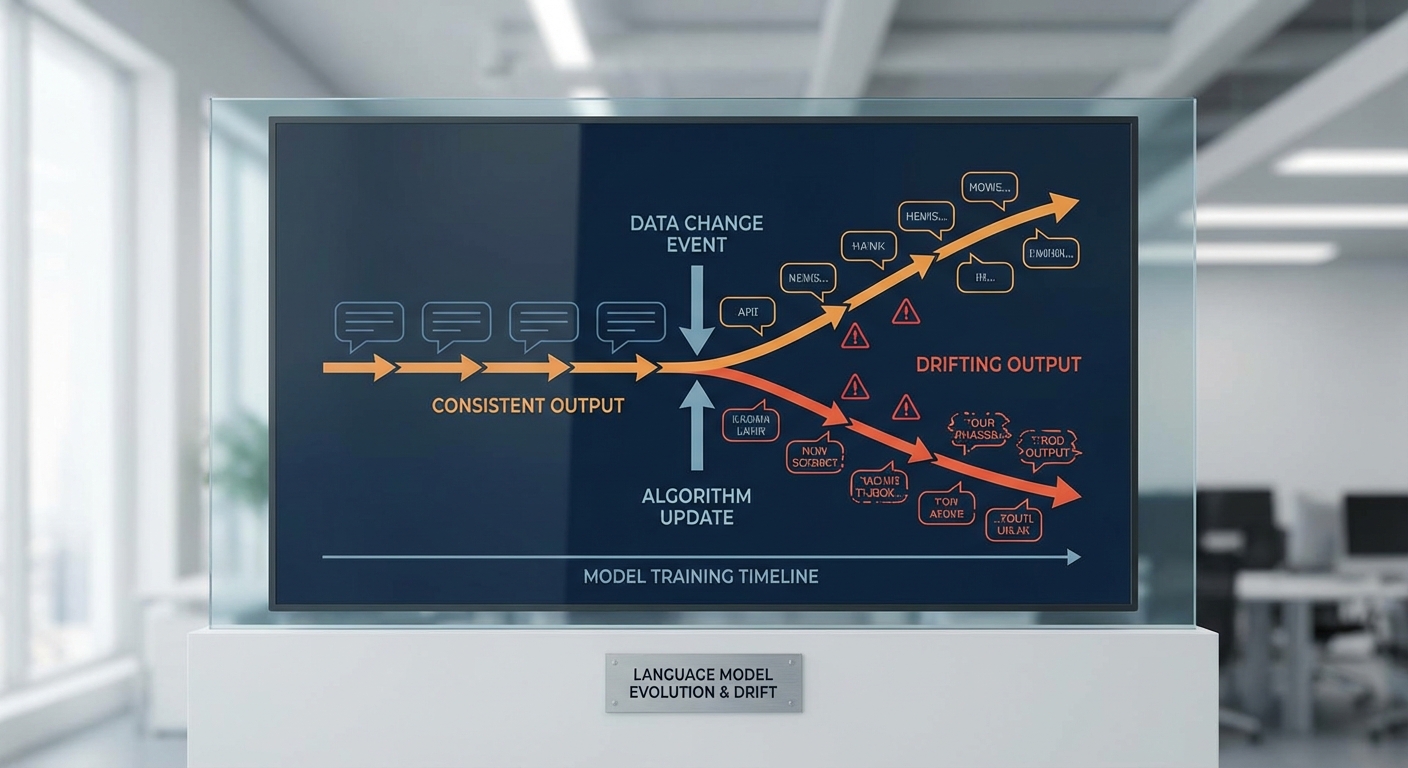
ในบริบทของ LLM ปรากฏการณ์นี้อาจแสดงออกได้หลายรูปแบบ เช่น โมเดลเริ่ม "hallucinate" หรือให้ข้อมูลไม่ตรงกับข้อเท็จจริงเมื่อโลกภายนอกมีการเปลี่ยนแปลงอย่างรวดเร็ว (เช่น เหตุการณ์ใหม่ ๆ สโลแกนหรือคำศัพท์ใหม่ในภาษาไทย) นอกจากนี้ยังมีลักษณะเฉพาะที่มักพบ ได้แก่
- การเปลี่ยนแปลงของการแจกแจงข้อมูล (Data Distribution Change): การกระจายของคำถามหรือเนื้อหาที่ผู้ใช้ส่งเข้ามาเปลี่ยนไป ทำให้โมเดลที่ฝึกกับข้อมูลเก่าไม่เหมาะสมกับข้อมูลปัจจุบัน
- Concept Drift: ความหมายหรือกฎเกณฑ์ของป้ายกำกับ (labels) หรือบริบทที่ใช้ตัดสินใจเปลี่ยนไป เช่น นิยามของ "ความเสี่ยง" ในงานการเงินที่ปรับตามนโยบายใหม่
- ปัญหาในเส้นทางข้อมูล (Data Pipeline Issues): การเปลี่ยนแปลงสคีมา การสูญเสียฟีเจอร์ หรือการ preprocess ที่เปลี่ยนทำให้ข้อมูลเข้าโมเดลไม่ตรงตามที่คาดหวัง
ผลกระทบเชิงธุรกิจของ Model Drift มีความรุนแรงและหลากหลาย ทั้งในเชิงต้นทุนและความเสี่ยงทางกฎหมาย ตัวอย่างผลกระทบที่สำคัญได้แก่ การให้ข้อมูลผิดพลาด ที่อาจนำไปสู่การตัดสินใจทางธุรกิจที่ผิดพลาด, การสูญเสียความเชื่อมั่นของลูกค้า เมื่อระบบตอบกลับไม่น่าเชื่อถือ, และ ความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ (compliance) หากโมเดลสร้างผลลัพธ์ที่ละเมิดข้อกำหนดด้านความเป็นธรรมหรือการปกป้องข้อมูล การแก้ไขปัญหาเหล่านี้มักมีต้นทุนสูงทั้งด้านเวลา แรงงาน และการฟื้นฟูภาพลักษณ์
สถิติและงานวิจัยชี้ให้เห็นว่า Model Drift ไม่ใช่ปัญหาที่เกิดขึ้นเพียงบางครั้ง แต่อาจเกิดได้รวดเร็วในหลายโดเมน — โดยงานวิจัยและเคสสตัดดี้หลายชิ้นรายงานว่า การเสื่อมลงของประสิทธิภาพสามารถสังเกตได้ภายใน 3–6 เดือน ขึ้นอยู่กับความผันผวนของข้อมูลและความถี่ในการเปลี่ยนแปลงของสภาพแวดล้อมการทำงาน ซึ่งหมายความว่าองค์กรที่ยังไม่มีมาตรการตรวจจับและตอบสนองแบบเรียลไทม์มีความเสี่ยงที่จะเผชิญกับผลกระทบทั้งเชิงการเงินและชื่อเสียงได้ในระยะเวลาอันสั้น
ด้วยเหตุนี้ องค์กรไทยที่นำ LLM มาใช้ในกระบวนการสำคัญของธุรกิจจึงจำเป็นต้องวางกรอบการติดตามการเปลี่ยนแปลงของโมเดล การย้อนรอยข้อมูลต้นทาง (data provenance) และกลไกการกู้คืนหรือ rollback อย่างเป็นระบบ เพื่อป้องกันไม่ให้ความเสี่ยงจาก Model Drift แปรเปลี่ยนเป็นความเสียหายเชิงกลยุทธ์
อะไรคือ 'Model Drift Forensics' — ฟีเจอร์หลักของบริการ
อะไรคือ "Model Drift Forensics" — ฟีเจอร์หลักของบริการ
ภาพรวมและวัตถุประสงค์
Model Drift Forensics เป็นชุดฟีเจอร์เชิงสังเกตการณ์และวิเคราะห์ที่ออกแบบมาเพื่อจับ ตีความ และแก้ไขการเบี่ยงเบนของพฤติกรรมโมเดลภาษา (LLM) แบบเรียลไทม์ (real-time) โดยมุ่งเน้นไปที่การผสานการตรวจจับเชิงสถิติ การอธิบายสาเหตุ (explainability) และการย้อนรอยแหล่งข้อมูลต้นทาง (data lineage/root-cause tracing) เข้ากับนโยบายการ rollback อัตโนมัติหรือกึ่งอัตโนมัติ พร้อมทั้งเก็บ audit trail สำหรับการตรวจสอบภายหลัง เพื่อให้ผู้ดูแลระบบและผู้บริหารสามารถตัดสินใจเชิงธุรกิจได้อย่างรวดเร็วและมีความรับผิดชอบ
Real-time detection: เมตริกส์และเกณฑ์ที่ใช้
การตรวจจับแบบเรียลไทม์ใช้ชุดเมตริกส์เชิงคุณภาพและเชิงสถิติ เพื่อระบุการเปลี่ยนแปลงของพฤติกรรมโมเดลเมื่อเทียบกับ baseline ที่กำหนดไว้ ตัวอย่างเมตริกส์และ threshold ที่ระบบใช้ได้แก่:
- Perplexity — การเพิ่มขึ้นของ perplexity เป็นสัญญาณว่าการคาดเดาของโมเดลแย่ลง เช่น การเพิ่มขึ้น >20–30% เมื่อเทียบกับค่าเฉลี่ย 7 วันถือเป็นเหตุการณ์ที่น่าสนใจ และการเพิ่มขึ้น >50% อาจถูกมองเป็น critical
- Confidence / Softmax max-prob — ค่า confidence เฉลี่ยต่อคำ (หรือความน่าจะเป็นสูงสุดของ token) หากลดลงมากกว่า 10–15% จะถือเป็น warning และหากลดลงเกิน 25% ให้ยกระดับเป็น critical
- Distribution shift tests — การทดสอบการเปลี่ยนแปลงการแจกแจงของ input/embedding/output เช่น KL divergence, Population Stability Index (PSI), Kolmogorov–Smirnov (KS) test, Maximum Mean Discrepancy (MMD). ค่าตัวอย่างเช่น PSI: <0.1 = ไม่มีการเปลี่ยนแปลง, 0.1–0.25 = ปานกลาง, >0.25 = สำคัญ
- Label-level/behavioral checks — อัตราความผิดพลาดของ task-specific metrics (เช่น F1/accuracy) สำหรับชุดทดสอบสด หากลดลงเกินค่า threshold ที่กำหนด (เช่น >10% จาก baseline) จะถูกแจ้งเตือน
ระบบรองรับการปรับแต่งค่า threshold ผ่าน UI หรือ API และสามารถใช้เทคนิค smoothing เช่น EWMA เพื่อหลีกเลี่ยง false positives จากเสียงรบกวนชั่วคราว
Explainability: อธิบายว่าทำไมโมเดลเปลี่ยนพฤติกรรม
หลังจากตรวจจับการเบี่ยงเบน ระบบจะเรียกใช้งานชุดเครื่องมืออธิบายเพื่อหาสาเหตุว่าเหตุใดโมเดลจึงเปลี่ยนพฤติกรรม โดยรวมถึง:
- SHAP / Feature importance — คำนวณค่าการมีส่วนร่วมของฟีเจอร์หรือ embedding dimension ต่อผลลัพธ์ เพื่อชี้ว่า token หรือฟีเจอร์ใดผลักให้เกิดการเปลี่ยนแปลง
- Counterfactuals — สร้างตัวอย่างกรณีศึกษาเชิงตรงข้าม (what-if) เพื่อดูว่าการเปลี่ยน input เล็กน้อยจะเปลี่ยนผลลัพธ์หรือความเชื่อมั่นของโมเดลอย่างไร ช่วยชี้ชัดสาเหตุเชิงเหตุผล
- Attention analysis / gradient-based methods — ตรวจสอบน้ำหนัก attention หรือการไหลของ gradient (เช่น Integrated Gradients) เพื่อระบุส่วนของข้อความที่โมเดลให้ความสำคัญเมื่อเกิด drift
- Influence functions & example-based explanations — ระบุตัวอย่างเทรนหรือข้อมูลอินพุตที่มีอิทธิพลสูงต่อพฤติกรรมปัจจุบัน เพื่อเชื่อมโยงการเปลี่ยนแปลงกับข้อมูลต้นทาง
ผลลัพธ์การอธิบายจะถูกรวมเป็นรายงาน (visual & textual) พร้อมคะแนนความเชื่อมั่นของการตีความ เพื่อให้ทีมงานสามารถประเมินความน่าเชื่อถือของ root-cause hypothesis ได้
Forensics & rollback: ย้อนรอย lineage, checkpoints และนโยบายการย้อนกลับ
สำหรับการสืบสวนเชิงลึก (forensics) ระบบเก็บข้อมูลเชิงโปรเวแนนซ์ (provenance) แบบครบถ้วน — รวมถึงแหล่งข้อมูลที่ใช้ฝึก, preprocessing pipeline, timestamp ของ batch, seed ของการฝึก, และ metadata ของ deployment (เวอร์ชัน, container image, config) — ซึ่งทำให้สามารถย้อนรอย (root-cause tracing) ไปถึงข้อมูลต้นทางได้ภายในคลิกเดียว
ด้านการบริหารเวอร์ชัน ระบบใช้แนวทาง checkpointing และ immutable model artifacts (hashed model IDs) เพื่อให้สามารถ rollback ไปยังเวอร์ชันที่เสถียรล่าสุดได้อย่างรวดเร็ว นโยบายการ rollback แบ่งได้เป็นสองรูปแบบหลัก:
- อัตโนมัติ (Auto-rollback) — เมื่อเมตริกส์สำคัญ (เช่น perplexity, confidence, PSI) ข้าม threshold แบบ critical ระบบจะทำการย้อนกลับทันทีไปยัง checkpoint ที่กำหนดไว้ (เช่น เวอร์ชันก่อนหน้า หรือเวอร์ชันที่ผ่านมาตรฐานความเสถียร) พร้อมเก็บเหตุการณ์ใน audit trail
- กึ่งอัตโนมัติ (Semi-auto / Approval-based) — สำหรับเหตุการณ์ที่เป็น warning หรือกรณีที่ rollback อาจกระทบฟีเจอร์ใหม่ ระบบจะสร้าง ticket พร้อมข้อมูลวิเคราะห์ และรอการอนุมัติจากผู้ดูแลก่อนทำการย้อนกลับ
นอกจากนี้ระบบสนับสนุนกลยุทธ์การคืนสถานะแบบค่อยเป็นค่อยไป (canary rollback / incremental traffic shifting) และการทดลองแบบ parallel shadow testing เพื่อทดสอบเวอร์ชันเก่าหรือแก้ไขโดยไม่กระทบผู้ใช้ทันที
Alerting, Severity และการปรับค่านโยบาย
ระบบแจ้งเตือนสามารถกำหนดรูปแบบและช่องทางได้ (เช่น Slack, Email, Webhook, PagerDuty) โดยแต่ละแจ้งเตือนจะมีข้อมูลสำคัญประกอบด้วยเมตริกส์ที่ข้าม threshold, ความรุนแรง, ลิงก์ไปยังรายงาน explainability, และคำแนะนำเชิงปฏิบัติการ ตัวอย่างการแมปความรุนแรง:
- Info — เบี่ยงเบนเล็กน้อย (เช่น deviation 5–10%) แสดงเป็นรายงานเชิงสถิติแบบวันต่อวัน
- Warning — เบี่ยงเบนปานกลาง (10–25%) พร้อมคำแนะนำให้ตรวจสอบและอาจเปิดการทดสอบเพิ่มเติม
- Critical — เบี่ยงเบนสูง (>25% หรือค่าทดสอบสถิติข้ามเกณฑ์ เช่น KS p-value <0.01, PSI >0.25) ระบบสามารถสั่ง rollback อัตโนมัติและส่งการแจ้งเตือนทันทีถึงทีมรักษาความปลอดภัย/ปฏิบัติการ
ผู้ใช้สามารถปรับแต่งนโยบายเหล่านี้ได้ผ่านแดชบอร์ด (เช่น การตั้งค่า sensitivity, cooldown windows, rate-limiting ของ alerts, และการกำหนดเวอร์ชันเป้าหมายสำหรับ rollback) เพื่อให้สอดคล้องกับความเสี่ยงเชิงธุรกิจและ SLA
Audit trail และการเก็บหลักฐานเพื่อการตรวจสอบ
ทุกเหตุการณ์ drift, รายงาน explainability, การตัดสินใจ rollback และการกระทำที่ตามมาจะถูกเก็บเป็น audit trail ที่ไม่สามารถแก้ไขได้ (immutable logs) พร้อมเมตาดาต้าและแฮชเชื่อมโยงกับโมเดล/ข้อมูลต้นทาง ทำให้สามารถรัน post-mortem, ปฏิบัติตามข้อกำหนดด้านความปลอดภัย และสร้างรายงานความสอดคล้องสำหรับหน่วยงานตรวจสอบได้อย่างครบถ้วน
สถาปัตยกรรมระบบและการทำงานเบื้องหลัง
ภาพรวมสถาปัตยกรรมและการไหลของข้อมูล (Request → Inference → Monitoring → Forensic → Rollback)
สถาปัตยกรรมของบริการ Model Drift Forensics ถูกออกแบบให้รองรับการตรวจจับเบี่ยงเบนของ LLM แบบเรียลไทม์ โดยมี flow หลักจากการรับคำขอจนถึงการย้อนรอยและ rollback อัตโนมัติดังนี้: เมื่อได้รับ request ระบบจะทำการ ingestion ข้อมูลเชิงพฤติกรรม (input payload, request metadata) และสแนปช็อตของ feature ที่เกี่ยวข้อง แล้วส่งคำขอไปยังโมเดลเพื่อทำ inference ผลลัพธ์และ metadata ทั้งหมด (latency, model version, tokenization trace) จะถูกบันทึกอย่างเรียลไทม์ ในขณะเดียวกัน layer ของ monitoring จะเก็บ metric และเหตุการณ์เพื่อตรวจหา drift แบบทันที (หรือเกือบทันที) หากเกณฑ์การเบี่ยงเบนถูกฝ่าฝืน ระบบจะส่งข้อมูลไปยัง forensic analysis ซึ่งเรียกใช้ explainability engine และ lineage store เพื่อระบุสาเหตุ พร้อมทั้งเปิดกระบวนการ orchestration สำหรับ rollback ตามนโยบายที่กำหนดไว้
ส่วนประกอบหลัก: Ingestion, Observability, Explainability, Lineage, Orchestration
สถาปัตยกรรมประกอบด้วยโมดูลหลัก 5 ส่วนที่เชื่อมต่อกันผ่าน event bus/streaming layer:
- Ingestion: รับข้อมูลจาก API gateway และ client streams โดยใช้ Kafka/streaming (เช่น Apache Kafka, Kinesis) สำหรับการส่งต่อแบบเรียลไทม์ พร้อม schema capture (Apache Avro/JSON Schema และ Schema Registry) เพื่อรักษาความถูกต้องของข้อมูลและรองรับการย้อนรอย
- Observability / Monitoring: metric collectors และ log shippers ส่งข้อมูลไปยัง Prometheus สำหรับ metrics และ Grafana สำหรับ visualization รวมถึงระบบ drift detectors ที่ทำงานบน stream (online statistical tests, population stability index, embedding-distance metrics) เพื่อแจ้งเตือนทันทีเมื่อพบความผิดปกติ
- Explainability Engine: ใช้เทคนิคเช่น SHAP, counterfactual analysis, attention attribution หรือ embedding-based attribution ที่ทำงานแบบ on-demand หรือ sampled เพื่ออธิบายว่าพารามิเตอร์/feature ใดเป็นสาเหตุของ drift
- Lineage Store / Metadata Catalog: เก็บ provenance ของ data และ model (feature store snapshots, dataset versions, model versions) ในรูปแบบ metadata catalog ที่สามารถค้นย้อนกลับได้ เช่นฐานข้อมูลแบบ graph หรือ ML metadata store เพื่อการ forensic ที่แม่นยำ
- Orchestration & Rollback: ประสานงานระหว่าง model registry (เช่น MLflow), feature store snapshots และ CI/CD pipeline สำหรับโมเดล เพื่อทำการ rollback อัตโนมัติหรือกึ่งอัตโนมัติ โดยมีขั้นตอนการ validate ก่อนสลับทราฟฟิก
เทคโนโลยีที่นิยมและการจัดการสถานะ (State) ในระบบแบบเรียลไทม์
การนำสถาปัตยกรรมนี้ไปใช้งานจริงมักเลือกใช้เทคโนโลยีที่รองรับการสตรีมและการจัดการ state อย่างมีประสิทธิภาพ: Apache Kafka สำหรับ event streaming และการทำ partition เพื่อขยายตัว, Schema Registry สำหรับ schema capture, Prometheus/Grafana สำหรับ metrics และ alerting, MLflow หรือ Model Registry อื่นๆ สำหรับการติดตาม model versions, และ feature store (เช่น Feast หรือ Hopsworks) สำหรับเก็บ snapshot ของ features ที่ใช้อ้างอิงเมื่อย้อนรอย
การจัดการ state มีความสำคัญสูงในระบบเรียลไทม์: เพื่อให้การตรวจจับ drift มีความสอดคล้อง ระบบจะใช้การเก็บ state แบบ windowed (sliding windows), checkpointing และ compacted topics ใน Kafka เพื่อรับประกัน ordering และ exactly-once หรือ idempotent การประมวลผลเมื่อจำเป็น นอกจากนี้ lineage store ควรบันทึก pointer ไปยัง snapshot ของ feature store และ model registry เพื่อให้สามารถ reproduce inference ได้อย่างแน่นอน
ประเด็นเชิงปฏิบัติ: latency trade-offs, storage ของ logs, retention policy และ scalability
การตรวจจับแบบเรียลไทม์ต้องแลกมาด้วยการออกแบบ latency trade-offs ที่ชัดเจน: การตรวจสอบเชิงลึก (เช่น full explainability per request) จะเพิ่ม latency ให้กับ path ของคำขอ ดังนั้นระบบมักแบ่งเป็น fast-path และ analysis-path — ส่งผลลัพธ์ตอบกลับผู้ใช้ทันทีใน fast-path และทำการวิเคราะห์เชิงลึกแบบอะซิงโครนัสหรือแบบ sampled ใน analysis-path เพื่อชั่งน้ำหนักระหว่างความแม่นยำของ diagnostics และประสบการณ์ผู้ใช้
สำหรับ storage ของ logs และ traces ควรกำหนดนโยบาย retention ที่มีชั้น (hot, warm, cold): logs และ metrics ระยะสั้น (เช่น 7–30 วัน) เก็บในระบบที่ตอบสนองได้เร็ว (Prometheus TSDB + object storage เช่น S3 สำหรับ snapshots), ขณะที่ raw request/response traces และ forensic artifacts ที่ต้องเก็บนานกว่าอาจย้ายไปยัง cold storage ที่มีค่าใช้จ่ายต่ำกว่า การประมาณขนาดตัวอย่างเช่น ระบบที่มี 1 ล้านคำขอต่อวันอาจสร้าง logs หลักสิบถึงหลายร้อย GB ต่อวัน ขึ้นกับระดับการบันทึก จึงต้องใช้การบีบอัด (gzip/parquet) และ partitioning เพื่อความคุ้มค่า
ในแง่ของ scalability ควรออกแบบให้สามารถ scale แบบ horizontal: partitioned Kafka topics, stateless inference workers ที่สามารถเพิ่ม/ลดจำนวนตามโหลด, Prometheus federation หรือระบบ metrics ที่รองรับการกระจาย (เช่น Thanos/Cortex) และ feature store ที่รองรับการอ่าน/เขียนพร้อมกันจำนวนมาก รวมถึงการใช้ autoscaling และ backpressure control ใน streaming pipelines
กระบวนการ Forensic Analysis ถึง Rollback อัตโนมัติ
เมื่อระบบ monitoring พบสัญญาณ drift ขั้นตอน forensic จะประกอบด้วย: (1) เก็บชุดตัวอย่างที่เกี่ยวข้องจาก stream และ feature snapshots, (2) เรียกใช้งาน explainability engine เพื่อสร้าง attribution และ hypothesis, (3) ตรวจสอบ lineage เพื่อระบุว่าการเปลี่ยนแปลงมาจาก dataset, feature transformation หรือ model version และ (4) ถ้าพบสาเหตุชัดเจนและตรงตามนโยบาย ระบบ orchestration จะยกเลิกเวอร์ชันปัจจุบันโดยทำ rollback ผ่าน model registry (เช่น MLflow) และ restore feature store snapshot หรือเปลี่ยน routing ของทราฟฟิกกลับไปยัง model ที่ผ่านการ validated
กระบวนการ rollback ควรบรรจุขั้นตอนการ validate อัตโนมัติก่อนสลับทราฟฟิกจริง เช่นรันชุดเทส A/B หรือ shadow traffic ตรวจสอบ metrics สำคัญ (latency, accuracy proxies, business KPIs) และใช้ CI/CD สำหรับโมเดลที่มีการทดสอบเชิงพฤติกรรมก่อน deploy กลับ ระบบ orchestration ควรรองรับ manual override และ audit trail เพื่อการปฏิบัติการที่ปลอดภัยและสามารถตรวจสอบย้อนหลังได้
ตัวอย่างเคสศึกษา: จากการตรวจจับถึงการ rollback ในสถานการณ์จริง
ตัวอย่างเคสศึกษา: จากการตรวจจับถึงการ rollback ในสถานการณ์จริง (แชทบอทธนาคาร)
กรณีศึกษาเชิงสมมติ: ธนาคารใหญ่ในประเทศไทยใช้แชทบอทที่ขับเคลื่อนด้วย LLM เพื่อรองรับการสอบถามลูกค้าเกี่ยวกับธุรกรรมและคำแนะนำการเงินเชิงพอดแคสต์ ในช่วงเช้าหลังปล่อยแคมเปญส่งเสริมการขาย มีสัญญาณความเชื่อมั่น (confidence) ของโมเดลลดลงอย่างรวดเร็ว ระบบตรวจจับของบริการ "Model Drift Forensics" ของสตาร์ทอัพไทยรายงานว่า confidence ของคำตอบชุดหนึ่งร่วงจากค่าเฉลี่ย 0.87 เป็น 0.55 ภายใน 30 นาที ซึ่งต่ำกว่าธรันช์โฮลเดอร์ที่ตั้งไว้ 0.70
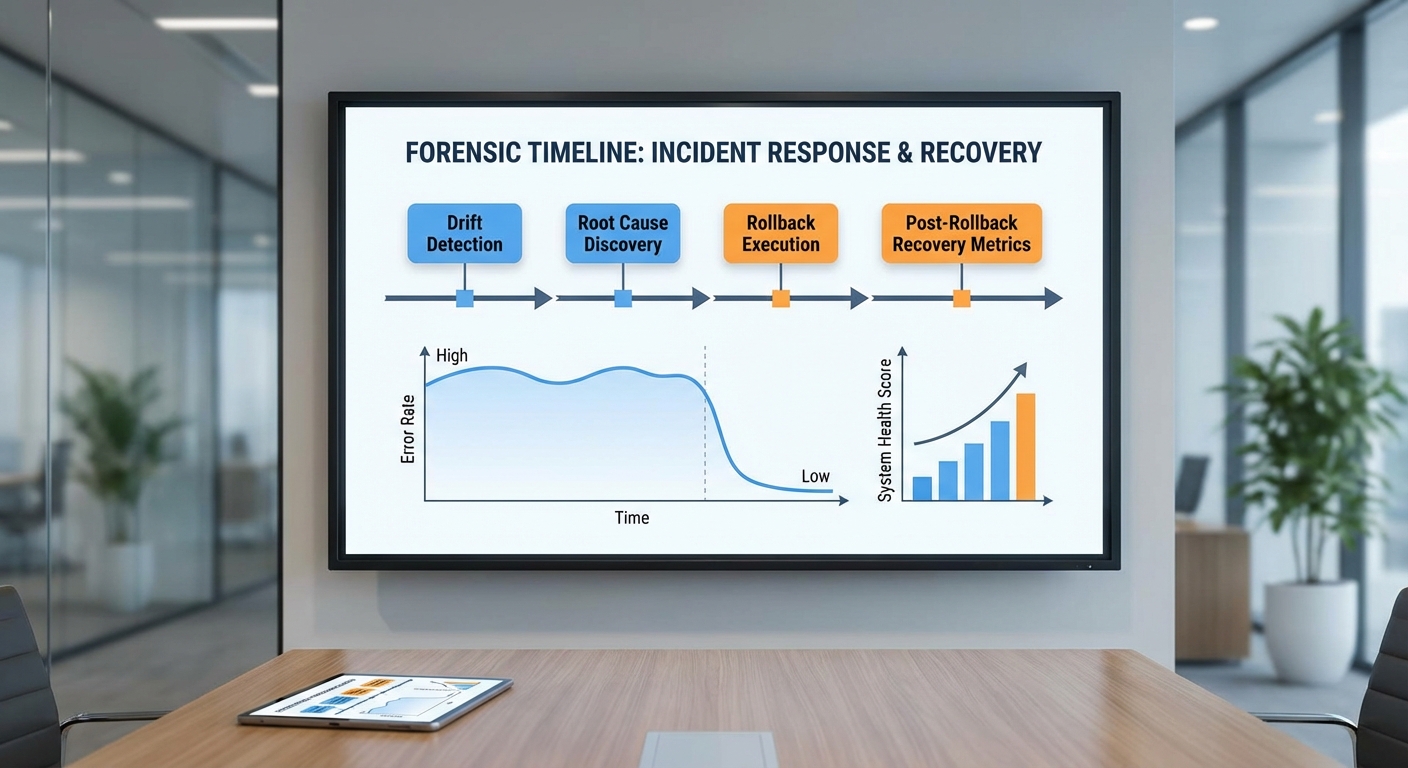
Timeline แบบ Step-by-step
- Detect (T0 = 08:15) – ระบบตรวจจับการเปลี่ยนแปลงสถิติเรียลไทม์: confidence score ลดลง 37%, อัตราความผิดพลาด (error rate) เพิ่มจาก 3% เป็น 12% ในคำตอบด้านธุรกรรมภายใน 30 นาที จึงส่ง alert แบบ high-priority ไปยังทีม SRE และทีม ML Ops
- Investigate (T0 + 20 นาที) – เปิด forensic trace โดยเรียกใช้งาน data lineage layer: พบว่าชุดข้อมูลอินพุตล่าสุดมาจาก Data Source X (ระบบประมวลผลธุรกรรมภายใน) ซึ่งเพิ่งมี deployment ของ ETL งานใหม่ มีการเปลี่ยน schema ในฟิลด์ merchant_category และมีค่า missing/unknown เพิ่มขึ้น 8% ส่งผลให้ feature encoding ผิดรูปและส่งผลต่อ embedding distribution
- Identify root cause (T0 + 40 นาที) – วิเคราะห์ร่วมกับทีม data engineering ยืนยันสาเหตุหลักเป็นการเปลี่ยนค่า schema และการป้อนข้อมูลที่มี bias จากระบบ partner (ค่า merchant_category ถูกแมปเป็นค่าคงที่ "OTH" สำหรับกลุ่มธุรกรรมใหม่) ทำให้โมเดลให้คำตอบที่ไม่สอดคล้องกับบริบททางการเงินและ confidence ลดลง
- Decide rollback (T0 + 55 นาที) – ทีมตัดสินใจใช้ rollback playbook อัตโนมัติ: revert โมเดลไปยังเวอร์ชันก่อนหน้า (v2026-02-18) และ restore feature snapshot ของวันที่ T-1 เพื่อยกเลิกผลกระทบจาก schema ใหม่ พร้อมเปิดการแจ้งเตือนห้าม deploy ข้อมูลจาก Data Source X จนกว่าจะตรวจสอบเสร็จ
- Execute and validate (T0 + 80–T0 + 200 นาที) – ระบบดำเนินการ rollback อัตโนมัติภายใน 10 นาที เรียกคืน snapshot ของ feature store และ reroute traffic 30% → 100% กลับไปยังโมเดลก่อนหน้า จากนั้นเริ่มรันชุดทดสอบเชิงพาณิชย์ (synthetic & live shadow traffic) เพื่อตรวจวัดผลลัพธ์
ผลลัพธ์เชิงตัวเลขก่อน–หลังการ rollback
ผลลัพธ์ที่ทีมรายงานภายใน 2 ชั่วโมงหลังการตัดสินใจ rollback ได้แก่:
- Error rate ลดลงจาก 12% เป็น 4% (ภายใน 2 ชั่วโมง)
- Average confidence score ฟื้นกลับจาก 0.55 เป็น 0.85
- Mean time to recovery (MTTR) สำหรับกรณีนี้คือประมาณ 3.3 ชั่วโมง (ตั้งแต่การตรวจจับถึง validated rollback); เมื่อเทียบกับกรณีที่ไม่มี playbook MTTR เฉลี่ยอาจยืดถึง 8–12 ชั่วโมง
- KPI ด้านประสบการณ์ลูกค้า (เช่น CSAT สำหรับคำถามธุรกรรม) ฟื้นจาก 73% เป็น 89% ภายใน 24 ชั่วโมงหลัง rollback และไม่มีการเพิ่มของ incident repeat rate ในสัปดาห์ถัดมา
บทเรียนเชิงปฏิบัติการและข้อคิดเห็น
จากเคสศึกษานี้ มีบทเรียนสำคัญที่ชัดเจน:
- ความสำคัญของการเข้าถึง lineage อย่างรวดเร็ว – การมี data lineage แบบเรียลไทม์ช่วยให้ระบุต้นทางของ drift ได้ภายในนาที แทนที่จะต้องไล่ log ทีละชิ้นเป็นชั่วโมง
- Pre-built rollback playbooks ลดเวลาและความผิดพลาดของการตัดสินใจมนุษย์ ระบบอัตโนมัติที่รวมขั้นตอน revert model, restore feature snapshot และ reroute traffic ทำให้ MTTR ลดลงอย่างมีนัยสำคัญ
- ตรวจสอบและควบคุม data contracts – การตั้ง guardrails สำหรับ schema และการตรวจสอบ data quality ก่อน ingest สามารถป้องกัน drift ประเภทนี้ได้ตั้งแต่ต้น
- ผสานทีมข้ามฟังก์ชัน – การติดต่อระหว่าง ML Ops, Data Engineering และ SRE ที่รวดเร็วเป็นปัจจัยสำคัญในการตัดสินใจ rollback ที่เหมาะสมและปลอดภัย
สรุปแล้ว กรณีศึกษานี้แสดงให้เห็นว่าเมื่อมีระบบตรวจจับและ forensic ที่ผสานกับ lineage และ playbook สำหรับ rollback อย่างดี การตอบสนองต่อ LLM drift สามารถทำได้อย่างรวดเร็วและมีประสิทธิภาพ คืนค่าประสิทธิภาพของบริการ (KPI) ได้ภายในไม่กี่ชั่วโมง ลดความเสี่ยงทางธุรกิจและรักษาประสบการณ์ลูกค้าให้ต่อเนื่อง
ผลกระทบต่อธุรกิจและโมเดลธุรกิจของสตาร์ทอัพ
ผลกระทบต่อธุรกิจและโมเดลธุรกิจของสตาร์ทอัพ
บริการ Model Drift Forensics จะส่งผลเชิงธุรกิจอย่างชัดเจนต่อทั้งลูกค้าและผู้ให้บริการสตาร์ทอัพ เนื่องจากการเบี่ยงเบนของ LLM อาจก่อให้เกิดความเสี่ยงทั้งทางการเงินและชื่อเสียง ตัวอย่างเช่น การตอบที่ออกนอกบริบทหรือให้ข้อมูลผิดพลาดสามารถนำไปสู่ความเสียหายด้านกฎหมาย ค่าสินไหมทดแทน และการสูญเสียความเชื่อมั่นของลูกค้า ซึ่งสำหรับองค์กรขนาดกลาง-ใหญ่ ความเสียหายต่อเหตุการณ์สามารถประเมินค่าได้เป็นหลักแสนถึงหลักล้านบาท ขึ้นอยู่กับอุตสาหกรรมและความร้ายแรงของผลลัพธ์ บริการตรวจจับ อธิบาย ที่ย้อนรอยต้นทางข้อมูลและรองรับ rollback อัตโนมัติ จะช่วยลดความถี่และผลกระทบของเหตุการณ์เหล่านี้ ทำให้ลูกค้าสามารถกลับสู่สถานะที่ปลอดภัยได้รวดเร็วขึ้นและลดต้นทุนการจัดการวิกฤต
คุณค่าทางธุรกิจ ที่ชัดเจนคือการลดความเสียหายเชิงการเงินและชื่อเสียง รวมถึงการเพิ่มความไว้วางใจของลูกค้าและผู้ใช้งาน ทั้งนี้ยังช่วยให้องค์กรสามารถปฏิบัติตามข้อกำหนดด้านความปลอดภัยและกฎระเบียบได้ง่ายขึ้น ตัวอย่างเช่น การมีระบบย้อนรอย (provenance) และ audit trail ที่แน่นอนสนับสนุนกระบวนการตรวจสอบภายในและการตอบคำถามจากหน่วยงานกำกับดูแลได้อย่างรวดเร็ว ซึ่งเป็นจุดขายสำคัญสำหรับลูกค้าองค์กรที่มีข้อกำหนดด้านการควบคุมข้อมูล เช่น ธนาคาร ประกัน และองค์กรภาครัฐ
โมเดลรายได้ที่เป็นไปได้ สำหรับสตาร์ทอัพที่ให้บริการลักษณะนี้มักจะผสมผสานหลายรูปแบบเพื่อเพิ่มเสถียรภาพทางรายได้และตอบโจทย์ลูกค้าที่หลากหลาย โดยโมเดลที่ควรพิจารณาได้แก่
- Subscription (SaaS tiers): แพ็กเกจระดับพื้นฐานสำหรับการมอนิเตอร์ทั่วไป ไปจนถึงแพ็กเกจองค์กรที่รวมฟีเจอร์เต็มรูปแบบ เช่น การแจ้งเตือนเชิงบริบท การย้อนรอยข้อมูล และ SLA ระดับสูง
- Per-model / per-entity pricing: เก็บค่าบริการตามจำนวนโมเดล LLM ที่ถูกมอนิเตอร์หรือปริมาณคำขอ เพื่อให้ลูกค้าที่มีสถาปัตยกรรมหลายโมเดลจ่ายตามการใช้งานจริง
- Per-incident / Retainer: คิดค่าบริการเมื่อเกิดเหตุการณ์สำคัญ (forensic investigation fee) หรือรูปแบบค่าบริการรายเดือนแบบ retainer สำหรับองค์กรที่ต้องการการเตรียมพร้อมและ response team ตลอดเวลา
- Professional services & integration: ให้บริการติดตั้ง เชื่อมต่อกับระบบ internal (SIEM, MDM, data catalogs) ปรับแต่ง alerts และออกแบบ governance workflows
- Managed forensics / SOC-as-a-service: บริการระดับสูงสำหรับลูกค้าองค์กรที่รวมทีมผู้เชี่ยวชาญ ตรวจสอบเชิงลึก และจัดการเหตุการณ์แบบ end-to-end รวมถึงให้รายงานสำหรับหน่วยงานกำกับ
โครงสร้างรายได้ผสมผสานเช่นนี้ช่วยให้สตาร์ทอัพมีรายได้ที่ทนทาน (recurring revenue) ขณะเดียวกันก็รับโอกาสรายได้เพิ่มจากบริการเชิงลึกที่มีมาร์จิ้นสูง โดยเฉพาะ professional services และ managed forensics ที่มักให้มาร์จิ้นสูงกว่า SaaS แบบบริสุทธิ์ แม้ว่าจะมีต้นทุนบุคลากรและการดำเนินงานสูงกว่า
โอกาสตลาด (TAM) และทิศทางการเติบโต ตลาด observability และ MLOps กำลังเติบโตอย่างรวดเร็ว เนื่องจากองค์กรหลายแห่งขยายการใช้งานโมเดล AI/LLM ในระดับองค์กร ความต้องการสำหรับ organization-wide ML governance เกิดขึ้นทั้งในภาคการเงิน โทรคมนาคม การแพทย์ และภาครัฐ นักวิเคราะห์หลายสถาบันประเมินว่า TAM ของโซลูชันที่เกี่ยวข้องกับ MLOps, ML observability และ AI governance มีมูลค่าเป็นพันล้านถึงหมื่นล้านดอลลาร์ทั่วโลกภายในช่วง 3–7 ปีข้างหน้า โดยมีอัตราการเติบโตต่อปี (CAGR) ที่สูงกว่าสาขาเทคโนโลยีแบบเดิม การเติบโตนี้เปิดโอกาสให้ผู้ให้บริการใหม่สามารถเข้าไปคาบเกี่ยวกับตลาดที่ยังขาดผู้เล่นเชี่ยวชาญด้าน forensic สำหรับ LLM
สำหรับผู้ให้บริการไทย โอกาสในภูมิภาคเอเชียตะวันออกเฉียงใต้มีความโดดเด่นด้วยเหตุผลหลายประการ: ค่าใช้จ่ายปฏิบัติการที่แข่งขันได้ ความรู้ด้านภาษาและบริบทท้องถิ่น ความเข้าใจต่อข้อกำหนดด้านข้อมูลส่วนบุคคลในภูมิภาค และเครือข่ายธุรกิจกับองค์กรภาครัฐและเอกชนในประเทศเพื่อนบ้าน นอกจากนี้การที่รัฐบาลประเทศต่างๆ เริ่มให้ความสำคัญกับการกำกับดูแล AI ทำให้ผู้ให้บริการที่นำเสนอโซลูชันที่ตอบโจทย์ด้าน compliance และ audit trail มีตำแหน่งทางการตลาดที่แข็งแกร่ง
สรุปได้ว่า Model Drift Forensics ไม่เพียงลดความเสี่ยงและปกป้องแบรนด์ของลูกค้าเท่านั้น แต่ยังสร้างโมเดลรายได้ที่หลากหลายและยั่งยืนสำหรับสตาร์ทอัพ โดยเฉพาะอย่างยิ่งหากสามารถจับจุดความต้องการขององค์กรในการกำกับดูแลโมเดล (ML governance) และเชื่อมโยงกับบริการระดับองค์กร เช่น managed forensics และ professional integration ความได้เปรียบเชิงภูมิศาสตร์และความชำนาญด้านภาษา/กฎระเบียบของผู้ให้บริการไทยยังเป็นคีย์สำคัญในการขยายสู่ตลาดภูมิภาคที่กำลังเติบโต
ข้อกังวลด้านความเป็นส่วนตัว กฎระเบียบ และความท้าทายเชิงเทคนิค
ข้อกังวลด้านความเป็นส่วนตัว กฎหมาย และความท้าทายเชิงเทคนิค
การนำระบบ Model Drift Forensics มาใช้งานในระดับองค์กรย่อมต้องเผชิญกับประเด็นด้านความเป็นส่วนตัวโดยเฉพาะการจัดการข้อมูลส่วนบุคคล (PII) ที่ปรากฏใน logs และ metadata ของคำถาม-คำตอบจาก LLM โดยทั่วไป logs อาจบรรจุทั้งข้อความดิบ (raw prompts), ผลลัพธ์ของโมเดล, token-level attribution และข้อมูลเชิงบริบทอื่นๆ ซึ่งหากไม่มีการควบคุมจะนำไปสู่ความเสี่ยงในการละเมิด PDPA (พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคลของไทย) และกฎระเบียบที่เกี่ยวข้องในภูมิภาค ASEAN การปฏิบัติตามหลักการเช่น lawful basis, data minimization, การเปิดเผยนโยบายการเก็บข้อมูล และการตอบสนองต่อคำขอจากเจ้าของข้อมูล จึงเป็นพื้นฐานที่ต้องมีตั้งแต่การออกแบบระบบ
เพื่อให้เห็นมิติทางเทคนิคอย่างเป็นรูปธรรม ตัวอย่างการประเมินความเสี่ยง: หากระบบบันทึก metadata ขนาดเฉลี่ย 1 KB ต่อคำขอ และมีคำขอ 100 ล้านรายการต่อเดือน นั่นเท่ากับประมาณ 100 GB/วัน หรือกว่า 3 TB/เดือนสำหรับ metadata เพียงอย่างเดียว ซึ่งยังไม่รวมข้อความดิบหรือ embeddings ที่อาจมีขนาดใหญ่กว่าหลายเท่า ค่าใช้จ่ายด้าน storage และ compute สำหรับการทำ observability (เช่น การคำนวณ drift metric แบบเรียลไทม์) จึงสามารถเพิ่มขึ้นอย่างมีนัยสำคัญ การออกแบบต้องคำนึงถึงการ sampling, aggregation และ retention policy เพื่อจำกัด overhead โดยไม่สูญเสียความสามารถในการสืบย้อน (forensics)
อีกด้านหนึ่งคือความเสี่ยงของ false positives และ false negatives ในการตรวจจับ drift — การแจ้งเตือนผิดพลาดมากเกินไปอาจกระทบต่อความเชื่อมั่นของทีมปฏิบัติการและก่อให้เกิดการหยุดระบบที่ไม่จำเป็น ในขณะที่การพลาดการเตือน (false negative) อาจปล่อยให้โมเดลทำงานผิดไปเป็นระยะเวลานานและส่งผลต่อธุรกิจ การออกแบบนโยบายตอบสนอง (response policy) จึงควรมีหลายชั้น ได้แก่ การตั้งค่าเกณฑ์ความเชื่อมั่น (confidence thresholds), การจัดลำดับความสำคัญของเหตุการณ์, การตรวจสอบโดยมนุษย์ (human-in-the-loop) ก่อนการทำ rollback อัตโนมัติ และการบันทึกเหตุผลเชิงตรรกะเพื่อการ audit ภายหลัง
- นโยบายการตอบสนองเชิงปฏิบัติ: แยกระดับการตอบสนองเป็น stage (monitor → alert → mitigate → rollback) พร้อมเกณฑ์สำหรับแต่ละขั้น และกำหนดจุดที่ต้องมีการอนุมัติจากผู้รับผิดชอบก่อนทำการ rollback แบบอัตโนมัติ
- การจัดการ PII ใน logs: ใช้ data minimization โดยเก็บเฉพาะ metadata ที่จำเป็น, ใช้การทำ pseudonymization/tokenization หรือ hashing สำหรับฟิลด์ที่เป็น PII และตั้ง retention period ที่ชัดเจนตามนโยบาย PDPA
- มาตรการทางเทคนิค: บังคับใช้ encryption-at-rest และ encryption-in-transit, การควบคุมการเข้าถึงแบบละเอียด (role-based access control, least privilege), การจัดการคีย์ด้วย KMS/HSM และการเก็บ audit trail สำหรับการเข้าถึงข้อมูล
นอกจากนี้ ควรเตรียมกลไกลดความเสี่ยงจากการ rollback ที่อาจส่งผลกระทบต่อธุรกิจ เช่น การสำรองโมเดลและ state checkpoint ก่อนการเปลี่ยนแปลง, การทดสอบ rollback ใน sandbox/kanary environment ด้วยชุดข้อมูลจำลองและทราฟฟิกจริงในสเกลเล็กเพื่อประเมินผลกระทบ และการกำหนดแผนกู้คืน (runbook) ที่ครอบคลุมสถานการณ์ยอดนิยม การฝึกซ้อมการ rollback เป็นประจำ (disaster recovery drills) จะช่วยให้ทีมเตรียมพร้อมและลดเวลาหยุดทำงาน (MTTR)
สรุปข้อเสนอเชิงปฏิบัติที่ควรนำไปใช้ร่วมกับระบบ Model Drift Forensics ได้แก่:
- ดำเนิน Data Protection Impact Assessment (DPIA) ก่อนเปิดใช้เพื่อตรวจหาความเสี่ยงต่อสิทธิของเจ้าของข้อมูล
- ออกแบบ retention และ sampling policy เพื่อลดปริมาณข้อมูลที่เก็บไม่จำเป็น
- ใช้เทคนิคการปกป้องข้อมูล (pseudonymization, tokenization, differential privacy เมื่อจำเป็น)
- บังคับใช้ encryption-at-rest, TLS และการจัดการคีย์อย่างเข้มงวด
- ออกแบบ multi-stage response workflow พร้อม human approval สำหรับกรณีสำคัญ และทดสอบ rollback ใน sandbox ก่อนนำขึ้น production
การผสานมาตรการด้านความปลอดภัย ความเป็นส่วนตัว และการออกแบบเชิงสถาปัตยกรรมเพื่อลด overhead เป็นสิ่งสำคัญต่อความสำเร็จของโซลูชันตรวจจับและย้อนรอย drift โดยไม่เพิ่มความเสี่ยงต่อธุรกิจหรือสร้างต้นทุนที่ไม่ยั่งยืน
คำแนะนำสำหรับองค์กรที่ต้องการนำบริการไปใช้ (Implementation Checklist)
ภาพรวมและวัตถุประสงค์ของเช็กลิสต์
เอกสารเช็กลิสต์นี้จัดทำขึ้นเพื่อเป็นแนวทางเชิงปฏิบัติสำหรับทีมเทคนิคและผู้บริหารที่ต้องการนำบริการ Model Drift Forensics มาใช้งานในองค์กร ช่วงเริ่มต้นจะเน้นการทดลองเชิงพยากรณ์ (pilot) เพื่อตรวจสอบความเป็นไปได้ทางเทคนิคและมูลค่าทางธุรกิจ ก่อนขยายใช้งานระดับองค์กร เช็กลิสต์ครอบคลุมทั้งการเตรียมข้อมูลและ instrumentation, การกำหนด KPI ที่ต้องติดตาม, การออกแบบ governance playbooks, การฝึกซ้อมเหตุการณ์ drift และการวัดผล ROI หลังการติดตั้ง
Pilot scope และแผนการทดลอง (Pilot Plan)
ตั้งขอบเขตของ pilot ให้ชัดเจนก่อนเริ่ม เช่น ประเภทโมเดล (LLM ทางภาษา/เชิงธุรกิจ), ชุดงาน (use cases) ที่ต้องการสังเกต, ระยะเวลา และปริมาณทราฟฟิกตัวอย่าง ตัวอย่างแผน pilot ที่แนะนำ:
- ระยะเวลา: 4–8 สัปดาห์ เพื่อเก็บสัญญาณ drift ได้อย่างน่าเชื่อถือ
- ขอบเขต: 1–3 use cases ที่เป็นตัวแทนธุรกิจ (เช่น customer support auto-reply, content generation, decision support)
- การจราจร: ใช้ปริมาณคำขอจริงอย่างน้อย 10k–50k request ในช่วง pilot หรือจำลองทราฟฟิกให้เทียบเท่า
- เกณฑ์ผ่าน (success criteria): การจับเหตุ drift ที่มี precision ≥ 80% และลดเวลาเฉลี่ยในการรีเคชัน (MTTR) ลงอย่างชัดเจนเมื่อเทียบก่อนใช้
การเตรียมข้อมูลและ Instrumentation
การจับสัญญาณ drift และการย้อนรอย (forensics) ขึ้นอยู่กับมาตรฐานการบันทึกข้อมูลที่ละเอียดและสม่ำเสมอ กำหนด schema ของ logging ให้ครอบคลุมสิ่งต่อไปนี้:
- Logging schema: timestamp, request_id, user_id (หรือ anonymized id), model_version, input_payload (หรือ hash ของ input), output, confidence scores, latency_ms, inference_metadata (hardware/cluster), routing_info (canary/production)
- Feature snapshots: บันทึก snapshot ของ feature vector / embeddings สำคัญตามช่วงเวลา เช่น ทุกคำขอหรือแบบ sampling (แนะนำเก็บ full snapshot ในช่วง pilot และ sampling หลัง production)
- Model registry integration: เก็บ metadata ของโมเดลทุกเวอร์ชันใน registry (hash ของ weights, training-data-tag, date-trained, eval-metrics) เพื่อให้ย้อนรอยได้อย่างแม่นยำ
- Data retention & security: นโยบายเก็บข้อมูล ระยะเวลา (เช่น 90–365 วันสำหรับ raw inputs ขึ้นกับข้อกำหนดความเป็นส่วนตัว), การเข้ารหัส ขอบเขตการเข้าถึง และการ anonymization ของ PII
- Observability tools: เปิดใช้งาน tracing, distributed logging และ metrics exporter (Prometheus/Grafana, ELK/Opensearch) เพื่อให้สามารถสร้าง dashboard สำหรับ drift
กำหนด KPI ที่ต้องเฝ้าดู
กำหนด KPI เชิงเทคนิคและเชิงธุรกิจที่ชัดเจนเพื่อใช้เป็นเกณฑ์การแจ้งเตือนและประเมินผล:
- Accuracy / Task success rate: เปรียบเทียบกับ baseline ก่อน deployment — ตัวอย่างเกณฑ์แจ้งเตือน: ลดลงเกิน 3–5%
- Latency: เวลา inference เฉลี่ยและเปอร์เซ็นไทล์ (P95/P99) — แจ้งเตือนเมื่อเพิ่มขึ้นเกิน 20–30%
- False positive/negative rate ของการตรวจจับ drift: ประเมินประสิทธิภาพของระบบตรวจจับ drift เอง — ควรตั้งเป้า < 10–20% false alarm ในช่วง production
- Distributional metrics: KL divergence, PSI (Population Stability Index), embedding distance เทียบกับ reference distribution — เกณฑ์แจ้งเตือนเช่น PSI > 0.2
- Business KPIs: อัตราคืนเงิน, CSAT หรือ conversion rate ที่เกี่ยวข้องกับ use case — กำหนด impact threshold ทางธุรกิจ เช่น ลด CSAT > 5% ต้อง trigger incident
Governance Playbooks และการบริหารความเสี่ยง
จัดทำ playbook ที่ชัดเจนครอบคลุมขั้นตอนปฏิบัติเมื่อระบบตรวจพบ drift รวมถึงบทบาทความรับผิดชอบและช่องทางสื่อสาร:
- Incident severity levels: กำหนดระดับความรุนแรง (S0 – S3) ตามผลกระทบต่อธุรกิจและผู้ใช้งาน
- Rollback playbook: ระบุกลยุทธ์การ rollback อัตโนมัติและแบบ manual เช่น automatic rollback to last stable model, blue-green deployment, canary promotion/rollback, หรือ feature-flag disablement พร้อม checklist ของการตรวจสอบก่อน rollback
- Audit trail: บันทึกเหตุการณ์อัตโนมัติทั้งหมด (who, what, when, why) ในที่จัดเก็บที่ไม่สามารถแก้ไขได้ (immutable logs หรือ WORM storage) พร้อมการลงลายมือชื่อดิจิทัลหรือ hash เพื่อความน่าเชื่อถือ
- Stakeholder communication plan: ระบุผู้รับผิดชอบแต่ละระดับ (SRE, ML Engineer, Product Owner, Legal, Customer Support, CISO) และช่องทางการแจ้ง (email, pager, Slack, incident dashboard) รวมถึง template ข้อความสำหรับการสื่อสารภายในและแจ้งลูกค้า
- Approval & change control: ระบุการอนุมัติสำหรับการ deploy/rollback แบบ manual รวมถึงการทวนสอบหลังเหตุการณ์ (postmortem) และมาตรการป้องกันซ้ำ
การฝึกซ้อม (Drift Incident Drills) และทีมรับมือ
การฝึกซ้อมเป็นรากฐานสำคัญในการลดเวลาในการตอบสนองและเพิ่มความมั่นใจของทีม แนะนำการจัดฝึกซ้อมเป็นวงรอบอย่างสม่ำเสมอ:
- ความถี่: ฝึกซ้อมเต็มรูปแบบทุก 3–6 เดือน และออกแบบ tabletop exercises แบบย่อยทุกเดือน
- รูปแบบการฝึก: สร้างสถานการณ์หลากหลาย เช่น gradual drift, sudden concept shift, data poisoning suspicion, infrastructure-induced latency spike
- ตัวชี้วัดความพร้อม: เวลาเฉลี่ยในการตรวจพบ (MTTD), เวลาเฉลี่ยในการแก้ไข (MTTR), คุณภาพการสื่อสารต่อ stakeholders (timeliness & completeness)
- บันทึกผลและปรับปรุง: ทุก drill ต้องมี postmortem ที่ระบุ root cause, gaps ใน playbook และ action items พร้อมกำหนดผู้รับผิดชอบและเวลาเสร็จสิ้น
การวัดผล ROI หลังการติดตั้ง
กำหนดเมตริกเพื่อวัดมูลค่าทางธุรกิจและประสิทธิภาพของโซลูชันหลังการติดตั้ง:
- ลดจำนวน incident: เปรียบเทียบจำนวนและความรุนแรงของเหตุ drift ก่อนและหลังการใช้ — ตัวอย่างเป้าหมาย: ลด incident ที่มีผลกระทบต่อผู้ใช้ลง ≥ 50%
- ลด MTTR: วัดการลดเวลาเฉลี่ยในการแก้ไข (เช่น ลดจาก 8 ชั่วโมงเป็น ≤2 ชั่วโมง)
- ค่าใช้จ่ายการปฏิบัติการ: มูลค่าที่ลดได้จากการลด manual intervention และเวลาของทีม (FTE-hours saved)
- มูลค่าทางธุรกิจ: การป้องกันการสูญเสียรายได้, เพิ่ม retention/CSAT, ลดความเสี่ยงทางความรับผิดชอบ (compliance fines)
- ค่าใช้จ่ายโครงการ: คำนวณ payback period และ NPV โดยรวมค่าใช้จ่าย license, infra, integration, และค่าแรงในการบริหารระบบ
แผนการขยาย (Scale-up) และการนำไปใช้ในระดับองค์กร
เมื่อ pilot ผ่านเกณฑ์แล้ว ให้วางแผนขยายการใช้งานอย่างเป็นขั้นตอนเพื่อควบคุมความเสี่ยงและต้นทุน:
- เฟสการขยาย: pilot → limited rollout (บาง business unit) → full rollout (องค์กรทั้งหมด)
- Automation & standardization: สร้าง templates สำหรับ logging schema, alert rules, dashboard, และ playbooks เพื่อการนำไปใช้ซ้ำ
- Capacity planning: ประเมิน storage, compute และ retention requirements ของ feature snapshots และ logs ก่อนขยาย
- Training & change management: แผนฝึกอบรมสำหรับ SRE, ML Engineers, Product Managers และทีมสนับสนุน พร้อมเนื้อหา playbook และการฝึกซ้อมเพิ่มเติม
เช็กลิสต์ฉบับย่อสำหรับการนำไปใช้
- กำหนด Pilot scope, ระยะเวลา และ success criteria
- นิยาม KPIs ทั้ง technical และธุรกิจ พร้อม threshold แจ้งเตือน
- Integrate model registry และบันทึก feature snapshots เป็นมาตรฐาน
- เขียน rollback playbook แบบอัตโนมัติและแบบ manual พร้อม approval flow
- ตั้งระบบ audit trail ที่ immutable และเข้าถึงได้สำหรับการตรวจสอบ
- จัดทำ stakeholder communication plan พร้อม templates และช่องทางการแจ้ง
- ฝึกซ้อม incident drills เป็นประจำและบันทึก postmortem
- วัด ROI โดยติดตาม reduction in incidents, MTTR, cost savings และ business impact
- วางแผน scale-up เป็นเฟสและเตรียม automation/standardization
เช็กลิสต์นี้ออกแบบมาเพื่อให้ทีมเทคนิคและผู้บริหารมีกรอบการดำเนินงานที่ชัดเจนเมื่อต้องนำโซลูชัน Model Drift Forensics ไปใช้งานจริง การปฏิบัติตามขั้นตอนเหล่านี้จะช่วยลดความเสี่ยง เพิ่มความโปร่งใสในการตัดสินใจ และชี้วัดมูลค่าทางธุรกิจได้อย่างเป็นรูปธรรม
บทสรุป
Model Drift Forensics ผสานการตรวจจับ (real-time detection), การอธิบายสาเหตุ (explainability) และการย้อนรอยข้อมูลต้นทางพร้อมฟีเจอร์ rollback อัตโนมัติไว้ในโซลูชันเดียว ทำให้องค์กรสามารถระบุจุดที่โมเดล LLM เบี่ยงเบนจากพฤติกรรมปกติ ตรวจสอบแหล่งที่มาของข้อมูลที่ก่อให้เกิดการเปลี่ยนแปลง และกลับสู่สถานะก่อนหน้าได้อย่างรวดเร็วและมีความโปร่งใส ตัวอย่างการใช้งานเชิงทดลองและการนำร่องภายในองค์กรขนาดกลางถึงใหญ่แสดงให้เห็นว่ากระบวนการระบุและแก้ไขเหตุการณ์สามารถลดเวลาจากระดับชั่วโมงหรือหลายวันให้เหลือเพียงไม่กี่นาทีถึงไม่กี่ชั่วโมง ข้อมูลเชิงปฏิบัติการเหล่านี้สะท้อนถึงการลดความเสี่ยงต่อบริการและการลดผลกระทบต่อผู้ใช้เมื่อเกิดการเบี่ยงเบน
การนำ Model Drift Forensics ไปใช้จริงต้องเตรียมทั้งในมิติทางเทคนิค (เช่น การติดตั้งการมอนิเตอร์แบบเรียลไทม์, การบันทึก lineage ของข้อมูล, เวอร์ชันคอนโทรลของโมเดล, การเชื่อมต่อกับระบบ CI/CD และ incident response) รวมถึงกรอบกำกับดูแล (governance) และนโยบายความเป็นส่วนตัวที่ชัดเจน เช่น การควบคุมการเข้าถึง การล็อกข้อมูลเพื่อการตรวจสอบย้อนหลัง และการใช้เทคนิคปกป้องความเป็นส่วนตัว (privacy-preserving logging หรือ differential privacy ในบางกรณี) การลงทุนด้านเหล่านี้ตอบแทนด้วยความเสถียรของบริการ ความน่าเชื่อถือที่เพิ่มขึ้นต่อผู้ใช้งาน และความพร้อมในการปฏิบัติตามข้อกำหนดทางกฎหมายหรือมาตรฐานที่เกี่ยวข้อง
มุมมองอนาคต ชุดเครื่องมือแบบ Forensics จะกลายเป็นองค์ประกอบสำคัญของ MLOps สำหรับ LLM โดยคาดว่าจะมีการเชื่อมต่อแบบมาตรฐานกับระบบ deployment, observability และ governance มากขึ้น เทคโนโลยีดังกล่าวยังมีแนวโน้มพัฒนาไปสู่การอธิบายเชิงสาเหตุที่แม่นยำขึ้น การรวมเข้ากับการควบคุมเชิงนโยบายอัตโนมัติ และการรองรับสภาพแวดล้อมที่กระจายข้อมูล (เช่น federated learning) สำหรับองค์กรที่ต้องการรักษาความต่อเนื่องของบริการและความเชื่อมั่นของผู้ใช้ การลงทุนใน Model Drift Forensics ถือเป็นกลยุทธ์สำคัญเพื่อบริหารความเสี่ยงเชิงปฏิบัติการและเตรียมความพร้อมรับข้อกำกับดูแลในอนาคต



