
ผู้ให้บริการคลาวด์รายใหญ่ในไทยประกาศเปิดตัวบริการ Fine‑tune สำหรับ Large Language Models (LLMs) ขนาดใหญ่โดยใช้เทคนิค 4‑bit/QLoRA ซึ่งเป็นการผสานระหว่างการควอนไทซ์ระดับ 4‑บิตและวิธีการ Low‑Rank Adaptation (QLoRA) เพื่อลดความซับซ้อนด้านฮาร์ดแวร์และต้นทุนการเทรนได้อย่างมีนัยสำคัญ — โดยเฉพาะสำหรับโมเดลขนาดราว 70B พารามิเตอร์ที่ตอนนี้สามารถเทรนได้ด้วยต้นทุนต่ำลงถึง 8–12 เท่า เมื่อเทียบกับกระบวนการเทรนแบบเต็มพารามิเตอร์แบบเดิม ทำให้การปรับแต่งโมเดลขนาดใหญ่ไม่ใช่เรื่องไกลตัวสำหรับองค์กรไทยทั้งภาคเอกชนและหน่วยงานรัฐที่ต้องการนำ AI ระดับสูงมาใช้ในงานจริง
นอกจากการลดต้นทุนแล้ว บริการนี้ยังมาพร้อมแพลตฟอร์ม MLOps ครบวงจรที่สนับสนุนการจัดการเวอร์ชัน การทำงานร่วมกัน และการติดตามประสิทธิภาพแบบอัตโนมัติ รวมถึงตัวเลือกด้านความเป็นส่วนตัวและการควบคุมข้อมูล (on‑premise / VPC / encrypted workflows) และระบบสเกลอัตโนมัติที่ปรับทรัพยากรตามความต้องการใช้งานจริง — เหมาะสำหรับองค์กรที่ต้องการทดลอง ปรับแต่ง และนำ LLM ขนาดใหญ่สู่การใช้งานเชิงพาณิชย์โดยยังคงรักษามาตรฐานด้านความปลอดภัยและค่าใช้จ่ายที่จับต้องได้
ภาพรวม: บริการ Fine‑tune 4‑bit/QLoRA จากผู้ให้บริการคลาวด์ไทย
ภาพรวม: บริการ Fine‑tune 4‑bit/QLoRA จากผู้ให้บริการคลาวด์ไทย
ผู้ให้บริการคลาวด์ไทยได้เปิดตัวบริการ Fine‑tune สำหรับ Large Language Models (LLMs) ขนาดใหญ่โดยใช้เทคนิค 4‑bit quantization ร่วมกับ QLoRA ทำให้การปรับแต่งโมเดลขนาดสูง เช่น 70B เป็นไปได้ในโครงสร้างพื้นฐานที่มีทรัพยากรจำกัดกว่าเดิม โดยผู้ให้บริการระบุว่าการออกแบบนี้สามารถลดการใช้หน่วยความจำและต้นทุนการเทรนได้อย่างมีนัยสำคัญ — โดยเฉลี่ยลดต้นทุนลงราว 8–12 เท่า เมื่อเทียบกับการเทรนแบบเต็มความแม่นยำหรือการปรับแต่งในสภาพแวดล้อมดั้งเดิม
หลักการทำงานของบริการนี้คือการทำ quantization น้ำหนักของโมเดลเป็นระดับ 4‑bit เพื่อลดขนาดของพารามิเตอร์ลงอย่างมาก และผนวกกับเทคนิค LoRA (Low‑Rank Adaptation) ที่ปรับพารามิเตอร์เป็นชุดเล็ก ๆ สำหรับการเรียนรู้เพิ่มเติม (adapters) แทนการเปลี่ยนพารามิเตอร์ทั้งหมด ทำให้สามารถ fine‑tune โมเดลขนาด 70B ขึ้นไปได้โดยไม่จำเป็นต้องมีฮาร์ดแวร์ที่ใหญ่โตเท่าเดิม ผลลัพธ์คือทั้งการลดการใช้ VRAM และเวลาในการเทรน รวมถึงการลดต้นทุนคำนวณโดยรวม
นอกเหนือจากการลดภาระด้านฮาร์ดแวร์ บริการนี้ยังผสานความสามารถของ MLOps อย่างครบวงจร ได้แก่:
- Pipelines สำหรับจัดการขั้นตอนการเตรียมข้อมูล การเทรน และการประเมินผลอย่างเป็นระบบ
- Experiment tracking บันทึกผลทดลอง เวอร์ชันของข้อมูล และพารามิเตอร์ เพื่อให้สามารถย้อนกลับและเปรียบเทียบได้ชัดเจน
- Model registry จัดเก็บโมเดลที่ผ่านการตรวจสอบพร้อมเมตาดาต้า รองรับการ deploy อัตโนมัติ การควบคุมเวอร์ชัน และ governance
ด้านความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนด ผู้ให้บริการเสนอทางเลือกด้านสถาปัตยกรรมเพื่อตอบโจทย์ลูกค้าองค์กร ได้แก่ VPC ที่แยกเครือข่ายส่วนตัว, ตัวเลือก on‑premises หรือโซลูชันแบบไฮบริดสำหรับลูกค้าที่ต้องการเก็บข้อมูลภายในองค์กร และ private endpoints เพื่อจำกัดการเข้าถึง นอกจากนี้ยังรองรับการเข้ารหัสข้อมูลทั้งระหว่างการส่งผ่านและการจัดเก็บ รวมถึงการตั้งค่าการควบคุมการเข้าถึงเชิงบทบาท (RBAC) และการปฏิบัติตามมาตรฐานการคุ้มครองข้อมูลที่เป็นที่ยอมรับ
อีกประเด็นสำคัญคือความสามารถด้าน autoscaling — ทั้งในขั้นตอนการเทรนและการให้บริการหลังเทรน ระบบสามารถปรับขนาด compute อัตโนมัติตามโหลดการทำงาน (เช่น เพิ่ม/ลด GPU nodes ในช่วงทดลองหรือการ inference spike) ช่วยลดต้นทุนในช่วงเวลาที่ความต้องการต่ำ และรักษาคุณภาพการให้บริการเมื่อปริมาณคำขอเพิ่มขึ้น พร้อมรองรับนโยบายการใช้ node แบบ spot/preemptible เพื่อลดค่าใช้จ่ายเพิ่มเติม
โดยสรุป บริการ Fine‑tune 4‑bit/QLoRA จากผู้ให้บริการคลาวด์ไทยมุ่งเสนอทางเลือกที่สมดุลระหว่างประสิทธิภาพ ความคุ้มค่า และความปลอดภัยสำหรับองค์กร — ช่วยให้ธุรกิจสามารถปรับใช้ LLM ขนาดใหญ่ (เช่น 70B) ได้จริงจังและยั่งยืน ด้วยเครื่องมือ MLOps เพื่อลดความซับซ้อนในการนำโมเดลเข้าสู่การใช้งานเชิงพาณิชย์และการควบคุมด้านความเป็นส่วนตัวตามข้อกำหนดขององค์กร
ทำความเข้าใจเชิงเทคนิค: 4‑bit Quantization และ QLoRA คืออะไร
ทำความเข้าใจเชิงเทคนิค: 4‑bit Quantization และ QLoRA คืออะไร
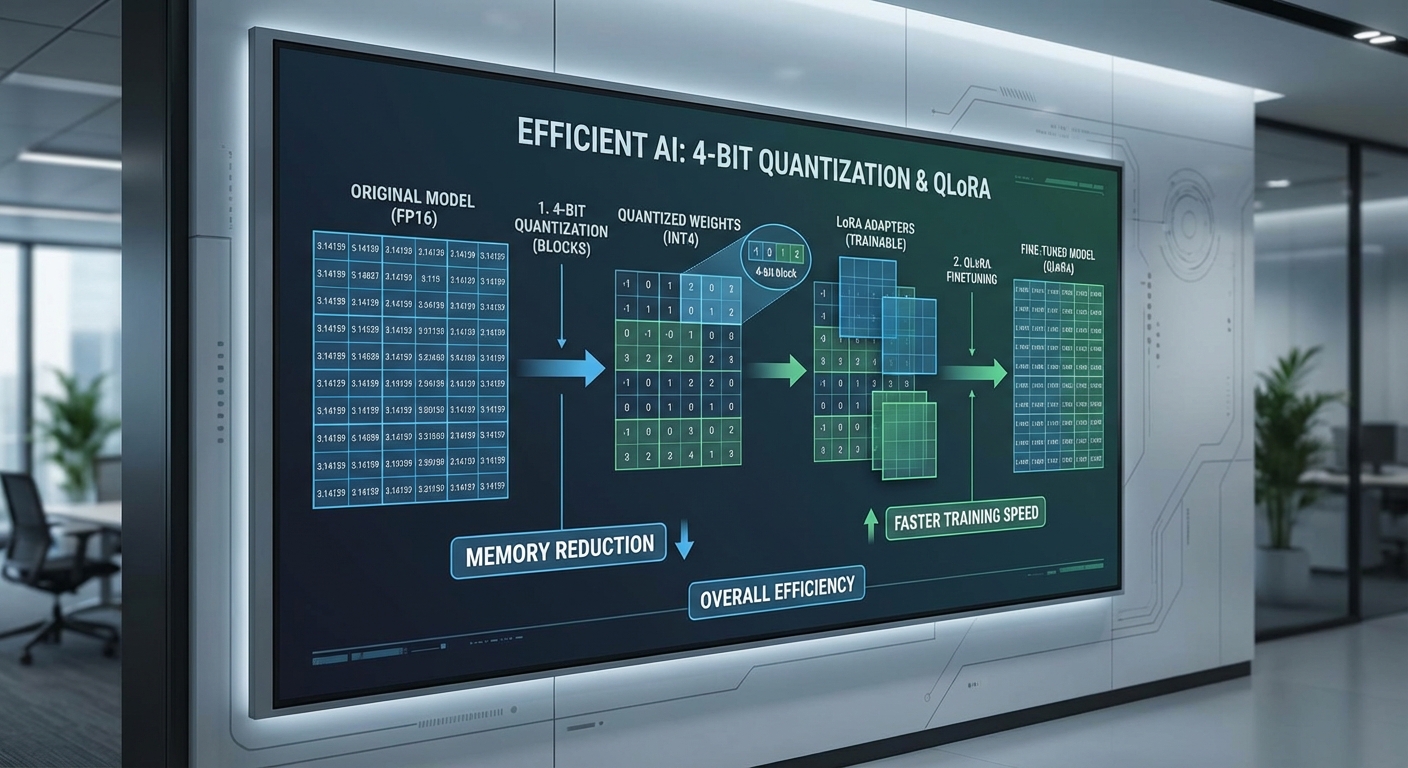
4‑bit quantization คือกระบวนการแปลงน้ำหนัก (weights) ของโมเดลจากตัวแทนแบบความแม่นยำสูง (เช่น 32‑bit floating point) ให้เป็นตัวแทนที่ใช้จำนวนบิตน้อยลง เช่น 4‑bit เพื่อลดขนาดของพารามิเตอร์และปริมาณการเคลื่อนย้ายข้อมูลระหว่างหน่วยความจำกับตัวประมวลผล ผลลัพธ์เชิงทฤษฎีคือการลดขนาดหน่วยความจำของพารามิเตอร์ลงเหลือประมาณ 1/8 เมื่อเทียบกับ 32‑bit และลดลงคร่าวๆ เหลือครึ่งหนึ่งเมื่อเทียบกับ 8‑bit ในทางปฏิบัติ เทคนิคสมัยใหม่ (เช่น การทำ per‑channel scaling, quantization แบบบล็อก และฟอร์แมตเฉพาะอย่าง NF4/GPTQ) ช่วยลดความผิดพลาดจากการปัดเศษ ทำให้การทำงานในระดับ 4‑bit สามารถรักษาประสิทธิภาพได้ดีพอสำหรับหลายงานเชิงภาษาและการทำความเข้าใจข้อความ
QLoRA เป็นแนวทางที่ผสมผสานการใช้ 4‑bit quantization กับแนวคิดของ LoRA adapters (Low‑Rank Adapters) เพื่อให้การปรับแต่ง (fine‑tune) ของ Large Language Models (LLMs) มีประสิทธิภาพด้านหน่วยความจำและค่าใช้จ่ายมากขึ้น โดยหลักการสำคัญคือ
- ฐานโมเดลถูกเก็บในรูปแบบที่ถูกควอนไทซ์ (quantized) เช่น 4‑bit และถูกตรึง (frozen) — ทำให้ไม่ต้องจัดเก็บหรืออัปเดตพารามิเตอร์ขนาดใหญ่ทั้งหมดในหน่วยความจำขณะฝึก
- การเปลี่ยนแปลงของโมเดลถูกแทนด้วย LoRA adapters ซึ่งเป็นเมทริกซ์ความละเอียดต่ำ (low‑rank) — adapters เหล่านี้เก็บไว้ใน FP16/FP32 และเป็นส่วนเดียวที่ถูกอัปเดตระหว่างการฝึก ทำให้ต้องใช้หน่วยความจำน้อยมากสำหรับ gradient และ optimizer states
- การคำนวณขณะ forward-pass ผสานกันระหว่างน้ำหนักที่ควอนไทซ์กับเอาต์พุตของ LoRA adapters — ด้วยการสนับสนุนทางฮาร์ดแวร์และไลบรารีเฉพาะ (เช่น bitsandbytes) การทำงานแบบนี้สามารถรักษาความเร็วและลดการใช้แบนด์วิดท์หน่วยความจำได้อย่างมาก
ผลลัพธ์เชิงปฏิบัติของ QLoRA คือสามารถปรับแต่งโมเดลขนาดใหญ่ (เช่น 65–70B พารามิเตอร์) บนฮาร์ดแวร์ที่มีหน่วยความจำจำกัด (เช่น GPU 48–80 GB) โดยไม่ต้องใช้คลัสเตอร์ขนาดใหญ่ วิธีนี้ลดต้นทุนการฝึกและเวลาในการทดลองอย่างมีนัยสำคัญ — ตัวอย่างเช่น การลดต้นทุนโดยรวมได้หลายเท่าตามการใช้งานจริง ทั้งนี้ขึ้นกับสถาปัตยกรรมของโมเดลและพารามิเตอร์การฝึก (บทความและการทดลองจากชุมชนรายงานการลดต้นทุนในช่วงกว้าง ซึ่งสอดคล้องกับกรณีการใช้งานในข่าวที่ระบุการลด 8–12 เท่า)
ข้อจำกัดและการทดสอบที่จำเป็น — แม้ QLoRA และ 4‑bit quantization จะให้ประโยชน์ด้านทรัพยากรอย่างชัดเจน แต่มีข้อพึงระวังสำคัญที่ธุรกิจและทีม MLOps ต้องคำนึงถึง:
- ความแม่นยำอาจลดลงในบางเคส — บางงานเฉพาะด้าน (เช่นงานที่ต้องการความละเอียดเชิงตัวเลขสูงหรือการประมาณค่าอย่างแม่นยำ) อาจได้รับผลกระทบจากการควอนไทซ์ แต่อย่างไรก็ตาม เทคนิคเช่น per‑channel quantization, GPTQ, หรือการใช้ฟอร์แมต NF4 มักช่วยลดการเสื่อมประสิทธิภาพได้
- ความเสี่ยงด้านความไม่เสถียรเชิงตัวเลข — การฝึกบนน้ำหนักควอนไทซ์ต้องการการปรับแต่ง hyperparameter และ optimizer strategy (เช่น learning rate ที่ต่าง การ warmup หรือการใช้ gradient clipping) เพื่อลดปัญหา divergence
- การทดสอบ/validation ที่ละเอียด — ต้องมีชุดทดสอบที่ครอบคลุมทั้งด้านความแม่นยำ (accuracy, F1, perplexity) และการประเมินเชิงพฤติกรรม (bias, hallucination, robustness) โดยแนะนำให้ใช้ pipeline MLOps ที่ออโตเมตการทดสอบ หน่วยวัด และการแทรกแซงย้อนกลับได้
แนวทางบรรเทา (mitigation) ที่แนะนำเมื่อใช้งาน 4‑bit + QLoRA ได้แก่:
- เพิ่ม LoRA rank หรือขนาดของ adapters เล็กน้อย หากพบการสูญเสียความแม่นยำ
- ใช้การวัดเชิงเปรียบเทียบ (calibration) และการควอนไทซ์แบบต่อช่อง (per‑channel) หรือบล็อกเพื่อปรับสเกลให้เหมาะสม
- เก็บส่วนสำคัญของโมเดลในความแม่นยำสูง (เช่น layer บางส่วนหรือ embedding) หากเป็นจุดที่สำคัญต่อผลลัพธ์
- ออกแบบกระบวนการ validation และ CI/CD สำหรับ ML ที่ครอบคลุม (A/B tests, regression tests, metrics drift detection) เพื่อจับการเปลี่ยนแปลงคุณภาพทันที
- ใช้การฝึกแบบผสมความแม่นยำ (mixed precision) และเทคนิค memory‑saving อื่น ๆ (เช่น gradient checkpointing) ควบคู่กันเมื่อจำเป็น
โดยสรุป การผนวก 4‑bit quantization กับ QLoRA ให้ช่องทางที่เป็นประโยชน์สำหรับองค์กรที่ต้องการปรับใช้และปรับแต่ง LLM ขนาดใหญ่อย่างคุ้มค่าในเชิงทรัพยากรและต้นทุน แต่ต้องแลกมาด้วยความจำเป็นในการออกแบบการทดลองและกระบวนการทดสอบที่รัดกุม เพื่อรักษามาตรฐานคุณภาพและควบคุมความเสี่ยงเชิงตัวเลขในการใช้งานเชิงธุรกิจ
วิเคราะห์ต้นทุนและประสิทธิภาพ: ตัวอย่างการเทรนโมเดล 70B
วิเคราะห์ต้นทุนและประสิทธิภาพ: ตัวอย่างการเทรนโมเดล 70B
การนำเทคนิค 4‑bit quantization / QLoRA มาใช้ในการ Fine‑tune โมเดลขนาดใหญ่ เช่น โมเดล 70B มีผลเชิงปฏิบัติที่เห็นได้ชัดทั้งด้านต้นทุนและการใช้ทรัพยากรฮาร์ดแวร์ เมื่อเปรียบเทียบกับการเทรนแบบ full‑precision (FP16/FP32) ตัวอย่างสมมติจากการทดลองและการประมาณการเชิงอุตสาหกรรมแสดงให้เห็นว่า ต้นทุนการเทรนสามารถลดลงในช่วงประมาณ 8–12 เท่า โดยไม่สูญเสียประสิทธิภาพเชิงการใช้งานมากนัก (ภายใต้การปรับ hyperparameter และการตรวจสอบคุณภาพผลลัพธ์อย่างเหมาะสม)
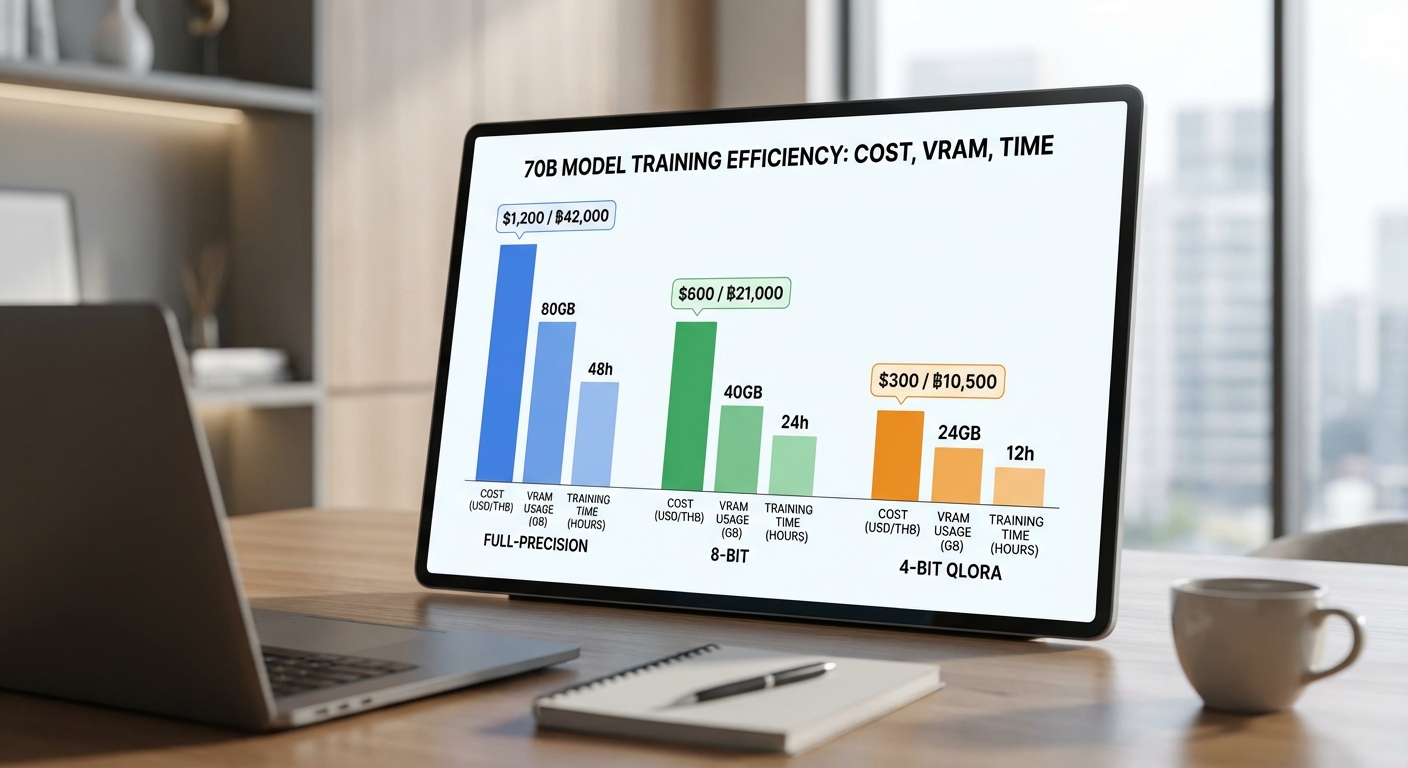
ตัวอย่างสมมติที่ชัดเจน: หากการเทรน 70B แบบ full‑precision ต้องใช้ต้นทุนรวมประมาณ USD 150,000–300,000 (ประมาณ 5.25–10.5 ล้านบาท เมื่อใช้อัตราแลกเปลี่ยนประมาณ 1 USD = 35 THB) การใช้ 4‑bit/QLoRA จะลดต้นทุนลงเหลือราว USD 12,500–37,500 (ประมาณ 0.44–1.31 ล้านบาท) — ให้ช่วงอัตราการลดประมาณ 8x–12x ตามสภาพแวดล้อมการเทรนและเวลา GPU ที่ใช้ ตัวอย่างเชิงตัวเลขหนึ่งอาจสรุปได้ดังนี้:
- Full‑precision (สมมติ): USD 240,000 ≈ THB 8,400,000
- 4‑bit / QLoRA (สมมติ 12x ลด): USD 20,000 ≈ THB 700,000
- ช่วงทั่วไป (ประมาณ): Full‑precision USD 150k–300k → QLoRA USD 12.5k–37.5k
สาเหตุสำคัญที่ทำให้เกิดการลดต้นทุนได้มากคือการลดการใช้หน่วยความจำพารามิเตอร์ (VRAM) อย่างมีนัยสำคัญ: โมเดล 70B เมื่อเก็บพารามิเตอร์เป็น FP16 จะใช้งานพารามิเตอร์ราว 70B × 2 ไบต์ ≈ 140 GB สำหรับน้ำหนักเพียงอย่างเดียว ในขณะที่การ quantize เป็น 4‑bit จะลดลงเป็นประมาณ 35 GB สำหรับน้ำหนัก จึงเป็นการลดขนาดพารามิเตอร์ลงประมาณ 4 เท่า การประหยัดนี้ยังทำให้สามารถรันการเทรนบนจำนวน GPU ที่น้อยลงหรือบน GPU ที่มีหน่วยความจำต่ำกว่า (เช่น จากการต้องใช้ cluster ขนาดใหญ่บรรดา A100/H100 หลายเครื่อง ลดมาเป็น 1–2 เครื่องที่มี VRAM เพียงพอ) ส่งผลโดยตรงต่อต้นทุนเช่าเครื่องและค่าไฟ
จาก benchmark เบื้องต้นที่รายงานโดยชุมชนและผู้ให้บริการคลาวด์พบข้อสังเกตเชิงปฏิบัติที่สำคัญดังนี้:
- การลด VRAM (ตัวเลขโดยประมาณ): พื้นที่เก็บพารามิเตอร์ลดลง ~4x, แต่เมื่อรวม optimizer states และ activations ค่า VRAM ต่อ GPU รวมอาจลดลงโดยรวมประมาณ 3–6x ขึ้นกับเทคนิคเช่น activation checkpointing และการจัดการ optimizer
- throughput และเวลาเทรน: QLoRA มักอนุญาตให้ใช้ batch size ที่ใหญ่ขึ้นและลดการสื่อสารระหว่าง GPU จึงเห็น throughput ที่เพิ่มขึ้น 1.5–3x และในหลายกรณีลดเวลาเทรนลง 2–4x เมื่อเทียบกับการเทรนแบบ distributed full‑precision (ขึ้นกับสถาปัตยกรรม GPU และการปรับ tuning)
- ผลกระทบต่อความแม่นยำ: การทดลองชี้ว่า QLoRA สามารถรักษาค่าประสิทธิภาพ (เช่น perplexity หรือคะแนน downstream) ให้อยู่ในระดับที่ใกล้เคียงกับการเทรนแบบ full‑precision — โดยความแตกต่างมักเป็นเพียง เล็กน้อย (เช่น <1–3% ในเมตริกบางตัว) หากมีการปรับ hyperparameters และชุดข้อมูล validation อย่างเหมาะสม
- latency trade‑off ในการให้บริการ: ขนาดโมเดลที่ลดลงช่วยให้โมเดลเข้าพื้นที่ cache ได้ดีขึ้นและลดการถ่ายโอนหน่วยความจำ ทำให้ latency ต่อ token บางกรณีเทียบเคียงหรือดีกว่า แต่ผลลัพธ์ขึ้นกับว่าฮาร์ดแวร์รองรับ 4‑bit kernel ที่ปรับแต่งมาแล้วหรือไม่
ข้อควรระวังและคำแนะนำเชิงปฏิบัติ: แม้ QLoRA จะลดต้นทุนอย่างชัดเจน แต่ผลลัพธ์จริงขึ้นกับปัจจัยหลายอย่าง — เช่น ขนาดและความหลากหลายของชุดข้อมูลเทรน, การตั้งค่า LoRA rank และ alpha, การใช้ activation checkpointing และการรองรับไดรเวอร์/ไลบรารี kernel บน GPU จึงควรทำ A/B testing และ validation กับชุดทดสอบเชิงประยุกต์ก่อนนำขึ้น production เพื่อยืนยันว่า ต้นทุนที่ลดลงไม่ได้แลกมาด้วยการเสียหายของคุณภาพ
สรุป: สำหรับองค์กรที่มองหาการลดต้นทุนอย่างมีนัยสำคัญในการปรับแต่ง LLM ขนาดใหญ่ การใช้ 4‑bit/QLoRA เป็นทางเลือกที่ให้ผลตอบแทนด้านต้นทุนต่อประสิทธิภาพสูง — โดยเฉพาะเมื่อต้องการสเกลทดลองหรือปรับใช้ระบบในสภาพแวดล้อมที่ต้องคุมงบประมาณและรักษาความเป็นส่วนตัวของข้อมูลภายในองค์กร
ฟีเจอร์ MLOps และสถาปัตยกรรมแพลตฟอร์ม
ฟีเจอร์ MLOps และสถาปัตยกรรมแพลตฟอร์ม
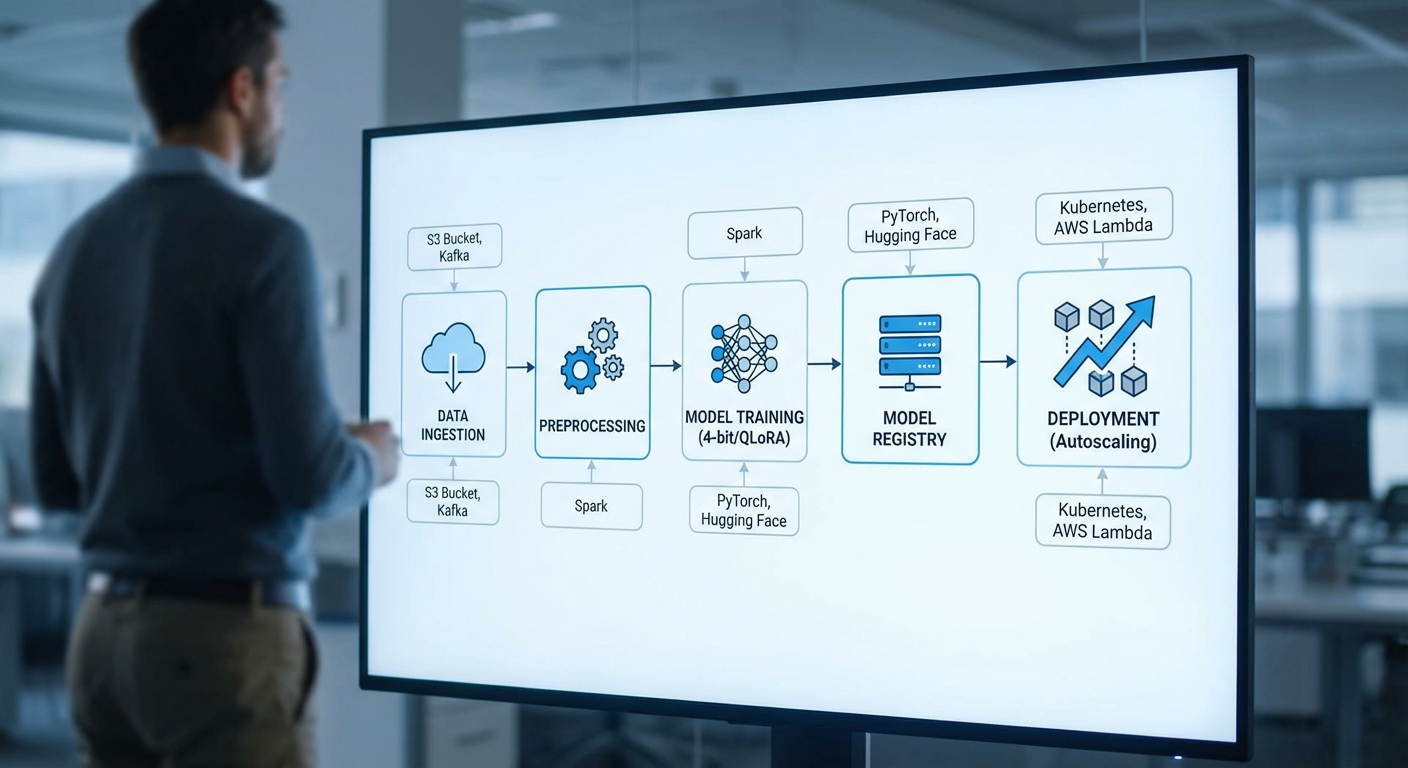
แพลตฟอร์มที่ผู้ให้บริการคลาวด์ไทยเปิดตัวสำหรับการ Fine‑tune แบบ 4‑bit/QLoRA ถูกออกแบบมาให้รองรับวงจร MLOps แบบครบวงจร ตั้งแต่การจัดการข้อมูลขั้นต้นจนถึงการนำโมเดลขึ้นใช้งานจริงและการมอนิเตอร์หลังการดีพลอย ในเชิงสถาปัตยกรรมจะประกอบด้วยโมดูลหลัก ได้แก่ data pipelines แบบอัตโนมัติ, dataset versioning, ระบบติดตามการทดลอง (experiment tracking), registry สำหรับโมเดลและ artifacts, CI/CD สำหรับโมเดล และระบบมอนิเตอร์ที่เชื่อมต่อกับ metric store เพื่อให้ทีมวิจัยและทีมปฏิบัติการสามารถทำงานร่วมกันอย่างเป็นระบบและตรวจสอบได้

ในส่วนของ data pipelines และ dataset versioning แพลตฟอร์มรองรับการใช้งานแบบอัตโนมัติและเชื่อมต่อกับแหล่งข้อมูลภายนอก (S3, GCS, DB) มีการทำ pre-processing, data validation และ data lineage โดยแพลตฟอร์มจะเก็บเวอร์ชันของชุดข้อมูลทุกครั้งที่มีการเปลี่ยนแปลง (hashing ของไฟล์, metadata snapshots) เพื่อให้การทดลองสามารถย้อนกลับและทำซ้ำได้ ตัวอย่างเครื่องมือและแนวปฏิบัติที่รองรับได้แก่ การใช้ Delta/Lake formats, immutable dataset snapshots และการทำ drift detection เมื่อข้อมูลเชิงสถิตเปลี่ยนไป
ด้าน experiment tracking, reproducibility และ model registry แพลตฟอร์มรวมระบบติดตามการทดลองที่บันทึก hyperparameters, config files, seed, environment/container image, และ checkpoint ของโมเดล โดยมี artifact store เพื่อเก็บ checkpoints และ weights อย่างเป็นระบบ ทำให้การเรียกใช้งาน checkpoint เพื่อ resume การฝึกหรือทำการ reproduce เป็นไปอย่างราบรื่น ระบบ model registry มีฟีเจอร์การกำหนดสถานะ (staging, production), การจัดการเวอร์ชัน, การผนวก metadata ด้านความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนด (compliance tags), พร้อมระบบอนุมัติและกฎการเข้าถึง (RBAC) สำหรับองค์กรที่ต้องการความมั่นคงของข้อมูล
สำหรับ CI/CD ของโมเดลและการดีพลอย แพลตฟอร์มรองรับ pipeline อัตโนมัติที่รวม unit/validation tests ของโมเดล, performance regression tests, และ canary deployment workflows ก่อนที่จะผลักโมเดลขึ้น production ระบบรองรับการ rollback อัตโนมัติเมื่อ SLO หรือ metric หลักตกต่ำ รวมถึงสามารถตั้ง trigger ให้ retrain เมื่อเกิด data drift หรือเมื่อ performance ตกเกินเกณฑ์ที่กำหนด
ในเชิงการจัดการทรัพยากรและ autoscaling แพลตฟอร์มมี GPU pool ที่สามารถปรับขนาดได้ทั้งในระดับการฝึก (training) และการให้บริการตอบคำถาม (inference) โดยรองรับการผสมระหว่าง spot instances และ on‑demand instances เพื่อปรับสมดุลระหว่างต้นทุนและความเสถียร ตัวอย่างการใช้งานเช่น การใช้ spot สำหรับงาน fine‑tune แบบ batch (ซึ่งมี checkpointing และ resume) ช่วยลดต้นทุนได้มาก โดยแพลตฟอร์มจะจัดการ preemption ผ่านการเก็บ checkpoint เป็นระยะและการย้ายงานไปยัง node ใหม่เมื่อจำเป็น นโยบาย autoscaling สามารถตั้งได้เป็นแบบตามคิวงาน (queue length), ตามการใช้งาน GPU utilization, หรือแบบตาม target cost-per-experiment เพื่อให้รองรับการสเกลจากไม่กี่ GPU ไปถึงระดับร้อย GPU ได้โดยอัตโนมัติ
- ประสิทธิภาพต้นทุน: การผสม QLoRA (4‑bit) กับการใช้ spot instances สามารถลดต้นทุนการเทรนสำหรับโมเดลขนาด 70B ได้ประมาณ 8–12 เท่า เมื่อเทียบกับการ fine‑tune แบบเต็ม precision และใช้ on‑demand ตลอดเวลา (ตัวอย่างเชิงตัวเลข: สมมติค่าใช้จ่ายเดิมอยู่ที่ระดับแสนดอลลาร์ เทคโนโลยีและสถาปัตยกรรมนี้สามารถลดลงเหลือหลักหมื่นดอลลาร์ในบางกรณี ขึ้นกับตัวแปรเช่นระยะเวลาการฝึกและราคาสปอต)
- reproducibility: checkpoints เป็นระยะ, การบันทึก config และ container image, รวมทั้งการจัดเก็บ seed และ dependency tree เพื่อให้การทดลองสามารถทำซ้ำได้อย่างแม่นยำ
- การจัดการ spot/on‑demand: policy สำหรับการคิดค่าใช้จ่ายและ failover, การใช้ mixed instance pools และการตั้ง priority ของงาน (low‑priority batch vs. high‑priority interactive)
สุดท้าย แพลตฟอร์มได้ออกแบบชุดตัวชี้วัด (KPIs) ที่องค์กรควรติดตามอย่างเคร่งครัดเพื่อควบคุมทั้งด้านต้นทุนและคุณภาพ ได้แก่:
- Cost per experiment / Cost per training hour: ต้นทุนเฉลี่ยต่อการทดลองหรือชั่วโมงการเทรน เพื่อประเมิน ROI ของการปรับแต่งแต่ละครั้ง
- Model performance metrics: accuracy, F1, ROUGE/BLEU (สำหรับ NLP), latency distribution และ tail latency (p95/p99)
- SLOs และ SLA adherence: อัตราการตอบสนองที่ผ่านเกณฑ์, availability ของ endpoint (เช่น 99.9%) และ recovery time objective (RTO)
- Resource utilization: GPU utilization, memory utilization, spot interruption rate และ queue wait time เพื่อปรับกลยุทธ์การจัดสรรทรัพยากร
- Reproducibility indicators: จำนวนการทดลองที่สามารถ reproduce ได้, snapshot rate ของ dataset และ checkpoint frequency
สรุปแล้ว สถาปัตยกรรม MLOps ของแพลตฟอร์มนี้เน้นไปที่ความสามารถในการทำงานแบบครบวงจร (from data versioning to deployment and monitoring), การปรับสเกลทรัพยากรและการ optimize ต้นทุนด้วยการใช้ spot/on‑demand อย่างชาญฉลาด และชุดเครื่องมือด้าน reproducibility ที่ทำให้องค์กรสามารถทำงานกับโมเดลขนาดใหญ่ เช่น 70B แบบมีการควบคุมต้นทุนและความเสถียรที่เพียงพอสำหรับการนำไปใช้งานเชิงธุรกิจจริง
ความเป็นส่วนตัว ความมั่นคง และการปฏิบัติตามกฎระเบียบ
ตัวเลือกการแยกสภาพแวดล้อมและการจัดเก็บข้อมูลในประเทศ
ผู้ให้บริการคลาวด์ที่นำเสนอการ Fine‑tune แบบ 4‑bit/QLoRA ควรมีตัวเลือกด้าน data residency เพื่อให้ข้อมูลและโมเดลถูกเก็บไว้ภายในประเทศ (เช่น เซิร์ฟเวอร์ในไทย) ซึ่งช่วยลดความเสี่ยงด้านข้อบังคับข้ามพรมแดนและตอบโจทย์ PDPA ของไทย รวมถึงข้อกำหนดเฉพาะสำหรับหน่วยงานภาครัฐและสถาบันการเงิน ตัวเลือกเพิ่มเติมที่จำเป็นได้แก่ VPC (Virtual Private Cloud) และ private endpoints ที่อนุญาตให้เชื่อมต่อแบบแยกตารางผ่านเครือข่ายภายในของลูกค้าเท่านั้น เพื่อให้เกิด isolation ระหว่างทรัพยากรขององค์กรและสาธารณะ
การเข้ารหัสและการจัดการคีย์สำหรับโมเดลและชุดข้อมูล
การปกป้องโมเดลและ dataset ต้องเริ่มจากการเข้ารหัสทั้งในสถานะพัก (encryption at rest) และระหว่างการส่งข้อมูล (encryption in transit) โดยระบบควรสนับสนุน:
- การเข้ารหัสที่ระดับบล็อกหรือไฟล์ สำหรับ weights ของโมเดลและชิ้นส่วนข้อมูลฝึก (เช่น S3 bucket ที่เข้ารหัส)
- KMS/HSM (Key Management Service / Hardware Security Module) ที่รองรับการจัดการคีย์แบบลูกค้าควบคุม (BYOK/CUSTOMER‑MANAGED KEYS) และการหมุนคีย์อัตโนมัติพร้อมบันทึก audit log
- การเข้ารหัสระหว่างการใช้งานหน่วยความจำ เท่าที่เป็นไปได้ เช่น การใช้ secure enclaves (Intel SGX) หรือ memory encryption เพื่อลดความเสี่ยงเมื่อทำการ fine‑tune หรือ inference บนคลาวด์
- นโยบายการเก็บรักษาและลบข้อมูล ที่ชัดเจน เช่น ระยะเวลาเก็บ artifacts ทางการเทรน การลบ snapshots ที่ไม่จำเป็น และการทำลายคีย์เมื่อสิ้นสุดสัญญา
การประเมินความเสี่ยงเมื่อใช้ Third‑Party Cloud และโมเดล Quantized
เมื่อใช้ผู้ให้บริการคลาวด์ภายนอก ต้องมีการประเมินความเสี่ยงเชิงระบบ (risk assessment) ที่ครอบคลุมความเสี่ยงด้านความเป็นส่วนตัวและความมั่นคง ตัวอย่างหัวข้อการประเมินได้แก่:
- การรั่วไหลของข้อมูลจากการเทรน — QLoRA และการ quantization แบบ 4‑bit อาจเปลี่ยนรูปแบบการเก็บความจำของโมเดล แต่ไม่ทำให้โมเดลปลอดภัยต่อการรั่วไหลโดยอัตโนมัติ ดังนั้นต้องทดสอบการโจมตีแบบ membership inference, model inversion และ model extraction เพื่อวัดความโน้มเอียงของโมเดลในการจดจำข้อมูลเฉพาะ
- การจัดการข้อมูล PII — ดำเนินการลบหรือทำให้ไม่ระบุตัวตน (redaction/anonymization) ก่อนส่งข้อมูลไปฝึก หรือใช้เทคนิคเช่น Differential Privacy (DP‑SGD) ในการ fine‑tune เพื่อลดความเสี่ยงการจำข้อมูลต้นฉบับ
- การประเมินความเสี่ยงเชิงซัพพลายเชน — ตรวจสอบความน่าเชื่อถือของ base model, checkpoints และ third‑party libraries เพื่อป้องกันการฝังโค้ดไม่พึงประสงค์หรือช่องโหว่ซอฟต์แวร์
- การควบคุมการเข้าถึงและบทบาท — ใช้ RBAC, MFA, และนโยบาย least‑privilege สำหรับทีม MLOps ที่เข้าถึงชุดข้อมูลและโมเดล รวมถึงการบันทึกกิจกรรม (audit trails) เพื่อการสืบสวนเหตุการณ์ได้
แนวทางปฏิบัติหลังการเทรน (Post‑train inspection และการตรวจสอบเชิงลึก)
หลังการ Fine‑tune ควรมีขั้นตอนตรวจสอบเชิงลึกเพื่อหาความเสี่ยงด้านข้อมูลที่อาจเกิดขึ้น โดยแนวทางสำคัญได้แก่:
- รันชุดทดสอบโจมตี (red‑teaming) และเครื่องมือวัดการรั่วไหล เช่น membership inference tests และ extraction trials เพื่อให้คะแนนความเสี่ยงเชิงปฏิบัติ
- ค้นหาและระบุข้อความที่อาจเป็น PII หรือข้อมูลความลับด้วยการค้นหาภายใน embeddings/weights (embedding leakage scan) และลบหรือ mask ข้อมูลที่มีความเสี่ยงสูง
- จัดทำ Model Card และ Data Provenance รายละเอียดแหล่งข้อมูลที่นำมาใช้ การตั้งค่าการเทรน (รวมถึงการใช้ DP หรือ not), ขอบเขตการใช้งานที่ปลอดภัย และการจำกัด (usage constraints) สำหรับผู้ใช้ภายในและภายนอก
- กำหนดกระบวนการตรวจจับความเบี่ยงเบนของโมเดล (drift detection) และการติดตามคำขอ (query logging) เพื่อระบุพฤติกรรมที่อาจบ่งชี้การโจมตีหรือการใช้งานผิดวัตถุประสงค์
ข้อกำหนดการปฏิบัติตามกฎระเบียบและการรับรองมาตรฐาน
สำหรับองค์กรการเงินและหน่วยงานภาครัฐ ควรเรียกร้องให้ผู้ให้บริการมีการรับรองและการประเมินตามมาตรฐานที่เกี่ยวข้อง เช่น ISO 27001, ISO 27701, SOC 2, PCI‑DSS (สำหรับธุรกรรมบัตรเครดิต), CSA STAR และการตรวจสอบตาม PDPA ของไทย รวมทั้งการทดสอบ penetration test และการตรวจสอบด้านความปลอดภัยอย่างสม่ำเสมอ ผู้ให้บริการควรสามารถให้หลักฐานการตรวจสอบ (audit report) และสัญญาที่รวมข้อกำหนด SLAs ด้านความมั่นคงและความเป็นส่วนตัว
ข้อเสนอเชิงปฏิบัติสำหรับองค์กร
สรุปแนวทางปฏิบัติที่แนะนำสำหรับองค์กรที่ต้องการใช้บริการ Fine‑tune แบบ 4‑bit/QLoRA บนคลาวด์ภายนอก:
- เลือกโซลูชันที่มีตัวเลือก data residency ในประเทศไทย และ VPC/Private endpoints เพื่อความแยกขาดจากทราฟฟิกสาธารณะ
- บังคับใช้การเข้ารหัสทั้ง at‑rest และ in‑transit พร้อม KMS/HSM และนโยบาย BYOK/Customer‑managed keys
- นำเทคนิคความเป็นส่วนตัวเชิงกลไก เช่น Differential Privacy และการทำ data minimization มาใช้ ขณะเดียวกันทดสอบความเสี่ยงการรั่วไหลจากโมเดล quantized ด้วยการโจมตีจำลอง
- ร้องขอ audit reports และมาตรฐานความปลอดภัย รวมถึงกำหนด SLA ด้านการแจ้งเหตุละเมิดข้อมูลที่ชัดเจน
- ติดตั้งกระบวนการ post‑train inspection เช่น embedding leakage scans, red‑teaming, และ logging/monitoring ต่อเนื่องเพื่อการควบคุมความเสี่ยงหลังส่งมอบ
การผสมผสานตัวเลือกทางเทคนิค (VPC, data residency, encryption, KMS/HSM), กระบวนการปฏิบัติงาน (RBAC, audit logs, pen test) และการประเมินความเสี่ยงเฉพาะด้านสำหรับโมเดลที่ถูก quantize จะช่วยให้การนำ Fine‑tune แบบ 4‑bit/QLoRA มาใช้ในองค์กรมีความปลอดภัยและสอดคล้องกับข้อกำหนดของหน่วยงานการเงินและภาครัฐได้มากขึ้น
กรณีใช้งานตัวอย่างและผลประโยชน์เชิงธุรกิจ
กรณีใช้งานตัวอย่างและผลประโยชน์เชิงธุรกิจ
การเปิดให้บริการ Fine‑tune แบบ 4‑bit/QLoRA สำหรับ LLM ขนาดใหญ่ พร้อมระบบ MLOps, การปรับแต่งความเป็นส่วนตัว และสเกลอัตโนมัติ ช่วยให้ธุรกิจหลายประเภทสามารถนำโมเดลขนาด 70B มาใช้งานจริงได้ในต้นทุนที่ต่ำลงอย่างมีนัยสำคัญและเวลาที่เร็วยิ่งขึ้น ข้อได้เปรียบเชิงธุรกิจสำคัญได้แก่ ต้นทุนการเทรนลดลงประมาณ 8–12 เท่า (สำหรับขั้นตอนการ fine‑tune) ทำให้ค่าใช้จ่ายรวมในการพัฒนาและดูแลรักษาโมเดล (TCO) บางรายงานประเมินว่าสามารถลดได้อย่างมีนัยสำคัญในระดับ 30–60% ขึ้นกับกรณีการใช้งานและสถาปัตยกรรมการใช้งาน
ตัวอย่าง: ธนาคาร — ธนาคารที่ต้องการปรับแต่ง LLM เพื่อใช้เป็น chatbot ฝ่ายบริการลูกค้าและที่ปรึกษาทางการเงินภายใน สามารถใช้การเทคนิค 4‑bit/QLoRA ลดข้อจำกัดด้านฮาร์ดแวร์และต้นทุนการทดลอง ทำให้สามารถทดลองสคริปต์และชุดข้อมูลภายในได้บ่อยขึ้นและปล่อยรุ่นปรับปรุงได้เร็วขึ้น ในทางปฏิบัติ ธนาคารที่เคยใช้กระบวนการพัฒนาโมเดลแบบเดิมซึ่งอาจกินเวลาเป็นปี จะสามารถปรับเป็นรอบการอัปเดตภายใน 6–12 เดือน โดยคงมาตรฐานความปลอดภัยข้อมูลผ่านการปรับใช้ on‑premise หรือ private cloud และการผนวกฟีเจอร์ MLOps สำหรับการทดสอบอัตโนมัติและการตรวจสอบประสิทธิภาพ ผลลัพธ์เชิงธุรกิจที่วัดได้ ได้แก่ reduction in cost per conversation ลดลง, อัตราการแก้ปัญหาโดยไม่ต้องย้ายไปเจ้าหน้าที่ (deflection rate) เพิ่มขึ้น และเวลาเฉลี่ยในการให้บริการ (average handling time) ลดลง ตัวอย่างเช่น การลดต้นทุนต่อการเทรนและการทดลองลง 8–12 เท่า อาจแปลเป็นการลด CAPEX/OPEX ในระยะ 12 เดือนแรกได้มากกว่าร้อยละ 40–50
ตัวอย่าง: e‑commerce — ร้านค้าออนไลน์และแพลตฟอร์ม marketplace ที่ต้องการปรับโมเดลภาษาให้เข้าใจสำเนียงไทย คำศัพท์ท้องถิ่น และบริบทการซื้อขายในประเทศ สามารถใช้การ fine‑tune ในระดับ 4‑bit เพื่อสร้างรุ่นโมเดลที่มีความชำนาญด้านภาษาท้องถิ่นโดยไม่ต้องลงทุนทรัพยากรมหาศาล การปรับภาษาและคำศัพท์ท้องถิ่นช่วยลดข้อผิดพลาดจากการแปลอัตโนมัติ (translation/localization errors) ซึ่งเป็นสาเหตุของคำสั่งซื้อที่ยกเลิกหรือการแปลง (cart abandonment) โดยเฉลี่ยการปรับปรุงคุณภาพภาษาอาจช่วยเพิ่มอัตรา conversion ได้ระหว่าง 3–12% ขึ้นกับขนาดฐานผู้ใช้และประเภทสินค้า นอกจากนี้ การฝังโมเดลที่ปรับเฉพาะในระบบแนะนำสินค้า (recommendation) และระบบค้นหา (search) ยังช่วยเพิ่มค่าหน้าเฉลี่ยต่อคำสั่งซื้อ (average order value) และลดอัตราการคืนสินค้า เนื่องจากคำอธิบายและคำแนะนำมีความสอดคล้องกับความคาดหวังของผู้บริโภคมากขึ้น
ตัวอย่าง: หน่วยงานภาครัฐ — หน่วยงานที่มีข้อมูลภายในขนาดใหญ่และมีข้อจำกัดด้านความเป็นส่วนตัว เช่น เอกสารราชการ รายงานภายใน หรือข้อมูลบุคคล สามารถใช้โซลูชัน fine‑tune ที่รองรับการปรับแต่งความเป็นส่วนตัว (privacy‑preserving fine‑tuning) และการรันบนสภาพแวดล้อมที่ควบคุมได้ (data residency/on‑prem) เพื่อวิเคราะห์เอกสาร ออกสรุปอัตโนมัติ และค้นหานโยบายที่เกี่ยวข้อง โดยไม่ต้องเผยแพร่ข้อมูลไปยังผู้ให้บริการภายนอก ตัวอย่างผลลัพธ์เชิงธุรกิจ ได้แก่ การลดเวลาการตรวจวิเคราะห์เอกสารจากระดับสัปดาห์เหลือระดับวัน รวมทั้งลดภาระงานมนุษย์ (manual review) ลงได้ถึง 60–80% ในบางกระบวนการ และเพิ่มความสอดคล้องด้านการปฏิบัติตามข้อกำหนด (compliance) ผ่านการติดตาม audit trail และการควบคุมเวอร์ชันของโมเดลด้วยระบบ MLOps
เพื่อวัดผลเชิงธุรกิจอย่างเป็นระบบ ควรกำหนดชุด KPI หลักที่สอดคล้องกับเป้าหมายของแต่ละกรณีใช้งาน ดังนี้
- ค่าใช้จ่ายและผลตอบแทน — Total Cost of Ownership (TCO), ต้นทุนการเทรนต่อรุ่น (cost per fine‑tune), ระยะเวลาคืนทุน (payback period)
- ความเร็วในการปล่อยใช้งาน — time‑to‑market สำหรับรุ่นใหม่, จำนวนรุ่นที่ปล่อยต่อไตรมาส (deployment frequency)
- ประสิทธิภาพการให้บริการลูกค้า — อัตราการแก้ปัญหาอัตโนมัติ (self‑service resolution rate), average handling time, CSAT/NPS
- คุณภาพภาษาและการแปล — อัตราความผิดพลาดจากการแปล/localization error rate, Intent recognition accuracy, F1‑score สำหรับการจัดหมวดหมู่ภาษา
- ผลกระทบเชิงการตลาดและการขาย — conversion rate uplift, average order value (AOV), churn reduction
- ความเป็นส่วนตัวและความปลอดภัย — ปริมาณข้อมูลที่ถูกส่งออกนอกดาต้าเซ็นเตอร์ (data egress), การปฏิบัติตามนโยบายข้อมูล (compliance pass rate), จำนวนเหตุการณ์ข้อมูลรั่วไหล
- การปฏิบัติการของโมเดล — latency, throughput, fallback rate (อัตราที่ต้องส่งต่อไปยังมนุษย์), model drift rate และเวลาตรวจจับปัญหา (MTTR)
การวัด KPI เหล่านี้ควรจับคู่กับกระบวนการ MLOps ที่ชัดเจน เช่น การตั้ง baseline ก่อนผลิตจริง, automated testing pipeline, continuous monitoring ของ performance และ drift detection เพื่อให้การปรับปรุงโมเดลเป็นไปอย่างต่อเนื่องและสามารถประเมินผลทางธุรกิจได้อย่างชัดเจน การผสานการลดต้นทุนด้วย 4‑bit/QLoRA กับระบบ MLOps และความสามารถด้านความเป็นส่วนตัว ทำให้ทั้งองค์กรการเงิน, e‑commerce และหน่วยงานภาครัฐ สามารถนำ LLM ขนาดใหญ่ไปใช้งานจริงได้โดยคุ้มค่าทั้งด้านการเงิน ความเร็ว และความปลอดภัย
แนวทางการเริ่มต้นสำหรับองค์กร: checklist และคำถามที่ต้องถามผู้ให้บริการ
ภาพรวมแนวทางการเริ่มต้น
สำหรับองค์กรที่สนใจใช้บริการ Fine‑tune แบบ 4‑bit/QLoRA กับ LLM ขนาดใหญ่ ควรเริ่มด้วยกรอบการทำงานที่เป็นระบบเพื่อประเมินความคุ้มค่าและลดความเสี่ยง ทั้งนี้ กระบวนการควรครอบคลุมตั้งแต่การนิยาม use case ที่ชัดเจน การเตรียมข้อมูล การทดลองแบบ pilot ไปจนถึงการวางแผนสเกลเชิงปฏิบัติการและการรับประกันคุณภาพ (SLA) ของผู้ให้บริการ
แนวทางที่แนะนำคือเริ่มจากวงจรสั้น ๆ: ตรวจสอบความเหมาะสมของ use case → เตรียม dataset และ pipeline → ทดลอง pilot แบบควบคุม → ประเมิน KPI และความเสี่ยง → ขยายสเกลแบบค่อยเป็นค่อยไป การทำงานแบบเป็นขั้นตอนจะช่วยให้องค์กรสามารถเปรียบเทียบต้นทุน ผลลัพธ์ และข้อจำกัดด้านความเป็นส่วนตัวได้อย่างเป็นรูปธรรมก่อนการลงทุนขนาดใหญ่
Checklist: Use case → Dataset → Pilot → Scale
- Use case (นิยามและความคุ้มค่า)
- กำหนดวัตถุประสงค์เชิงธุรกิจ เช่น เพิ่มประสิทธิภาพการตอบลูกค้า ลดเวลาการสร้างเนื้อหา หรือปรับปรุงการสืบค้นข้อมูลภายใน
- คำนวณความคุ้มค่าที่คาดหวัง เช่น ลดค่าแรงคนตอบข้อซักถาม, เวลาในการสร้างเนื้อหา หรือลดต้นทุนการค้นหา
- ประเมินความจำเป็นในการปรับแต่งแบบเต็มรูปแบบ vs. parameter‑efficient tuning (เช่น QLoRA)
- Dataset (เตรียมข้อมูลและคุณภาพ)
- ระบุแหล่งข้อมูล: ข้อมูลภายใน (logs, knowledge base), ข้อมูลที่มีลิขสิทธิ์ หรือข้อมูลสาธารณะ
- ขนาดตัวอย่างแนะนำสำหรับ QLoRA: เริ่มต้นที่ระดับ 10k–100k ตัวอย่าง หรือ 1M–100M โทเค็น ขึ้นกับความซับซ้อนของงาน (ตัวอย่างสมมติ)
- ทำความสะอาด (deduplication, normalization), แยกชุด train/val/test และจัดทำชุดตรวจสอบความเอนเอียง (bias) และความเป็นส่วนตัว
- จัดทำ metadata และมาตรฐาน labeling เพื่อให้สามารถทำ MLOps และการติดตามผลได้
- Pilot (ทดลองควบคุม)
2–6 สัปดาห์ ขึ้นกับความซับซ้อนและทรัพยากรที่ต้องการ - กำหนด KPI ชัดเจน (ดูหัวข้อ KPI ด้านล่าง) และเกณฑ์การผ่าน/ไม่ผ่าน
- ทดสอบหลายค่า configuration: pre‑trained model ต่าง ๆ (เช่น 7B/13B/70B) และ hyperparameters ของ QLoRA
- ทดสอบเรื่อง latency ภายใต้เงื่อนไขการใช้งานจริง (p99 latency, throughput)
- วางแผนทรัพยากรเชิงโครงสร้าง: auto‑scaling, batch vs real‑time serving, caching
- ระบุข้อกำหนดด้านความเป็นส่วนตัวและ data residency ก่อนย้ายงานสู่ production
- เตรียมแผน contingency: การย้อนกลับเวอร์ชันโมเดลเมื่อประสิทธิภาพลดลงหรือเกิด incident
คำถามสำคัญที่ควรถามผู้ให้บริการ
- โมเดลและการสนับสนุนเทคนิค
- รุ่นของ pre‑trained models ที่รองรับ (เช่น 7B/13B/70B) และการรับรองความเข้ากันได้กับ QLoRA
- รองรับการปรับแต่งบางพารามิเตอร์ (LoRA adapters), การผสานกับ pipeline ของเรา และการ export โมเดลหลัง fine‑tune หรือไม่
- Pricing model
- คิดค่าบริการอย่างไร: per GPU‑hour, per job, หรือ subscription แบบ flat fee
- ค่าจัดเก็บข้อมูล (storage) คิดเป็น GB‑month เท่าไร และมีค่า I/O หรือ egress แยกต่างหากหรือไม่
- มีค่าใช้จ่ายเพิ่มเติมสำหรับ MLOps (CI/CD, monitoring), auto‑scaling หรือการสนับสนุน 24/7 หรือไม่
- ตัวอย่างสมมติ: หากคิด GPU ที่ $3/ชั่วโมง และต้องการ 500 GPU‑hours ค่าใช้จ่าย GPU = $1,500 (ใช้เพื่อประเมินงบประมาณเบื้องต้น)
- Service Level Agreement (SLA) และการสนับสนุน
- ระดับ SLA สำหรับ availability (เช่น 99.5%/99.9%) และการตอบสนองต่อ incident ในระดับต่าง ๆ
- การสนับสนุนทางเทคนิค: response time, ช่องทางติดต่อ, และการให้บริการแบบ dedicated account manager หรือไม่
- นโยบายการรับประกันผลลัพธ์ (ถ้ามี) เช่น performance baseline ที่ต้องทำได้ใน pilot
- Data residency และความเป็นส่วนตัว
- ข้อมูลจะถูกเก็บและประมวลผลที่ใด (regional data centers) และสามารถผูกกับ cloud region ในไทยได้หรือไม่
- รองรับการเข้ารหัสข้อมูลขณะพัก/ขณะส่งข้อมูล (at‑rest, in‑transit) และเทคนิคการลดการรั่วไหลของข้อมูลในกระบวนการ fine‑tune (e.g., differential privacy, private training enclaves)
- เงื่อนไขการลบข้อมูลหลังสิ้นสุดสัญญา และนโยบายการสำรองข้อมูล
- การจัดการความเสี่ยงและการปฏิบัติตามข้อกำหนด
- มีการ audit และรายงานความปลอดภัย (SOC2/ISO27001) หรือไม่
- นโยบายการจัดการ bias, adversarial robustness และการตรวจจับ output ที่ไม่เหมาะสม
- ข้อตกลงความรับผิดชอบ (liability) กรณีเกิดเหตุข้อมูลรั่วไหลหรือความเสียหายจากโมเดล
KPI แนะนำสำหรับ Pilot
- Cost per fine‑tune
- คำนวณรวมค่า GPU‑hours, storage, I/O และค่า MLOps ที่เกี่ยวข้อง เพื่อเปรียบเทียบกับงบประมาณเป้าหมาย
- ตัวอย่างเป้าหมายเชิงกลยุทธ์: ต้นทุนการ fine‑tune ลดลงเมื่อเทียบกับ fp16 แบบเต็ม (สอดคล้องกับประสิทธิภาพที่ผู้ให้บริการอ้างว่า ลด 8–12 เท่า)
- Accuracy delta / performance uplift
- วัดความแตกต่างของประสิทธิภาพ (เช่น accuracy, F1, BLEU หรือ metric ที่เกี่ยวข้องกับงาน) ระหว่าง base model กับ fine‑tuned model
- ตั้งเกณฑ์ขั้นต่ำ เช่น absolute improvement 1–5% หรือการเพิ่มขึ้นของ KPI ทางธุรกิจ (เช่นอัตราการแก้ไขปัญหาต่อครั้ง เพิ่มขึ้น X%)
- Latency และ throughput
- วัด latency เฉลี่ยและ percentiles ที่สำคัญ (p95, p99) ภายใต้รูปแบบการใช้งานจริง
- ตั้งเกณฑ์การให้บริการ เช่น p95 < 500 ms สำหรับการตอบโต้แบบ real‑time หรือ throughput ที่รองรับจำนวนคำขอต่อวินาทีที่ต้องการ
- Reliability และ resource efficiency
- วัดการใช้งานจริงของ GPU‑hours ต่องาน, memory footprint (หลัง 4‑bit quantization) และการเรียกใช้งานซ้ำ (cache hit rate)
- เปรียบเทียบค่าใช้จ่ายต่อคำตอบ/ต่อทรานแซคชัน เพื่อประเมินความคุ้มค่าระยะยาว
สรุปคือ ให้เริ่มจากการตั้งสมมติฐานธุรกิจชัดเจน เตรียมข้อมูลคุณภาพสูง และรัน pilot ที่มี KPI เป็นรูปธรรมพร้อมคำถามเชิงลึกต่อผู้ให้บริการด้านราคา SLA และการปกป้องข้อมูล หากผลลัพธ์ใน pilot ตอบโจทย์ทั้งด้านต้นทุนและประสิทธิภาพ ค่อยขยายสเกลโดยมี MLOps, governance และ contingency plan ที่ชัดเจนเพื่อจำกัดความเสี่ยงเมื่อขึ้นสู่งาน production
บทสรุป
บริการ Fine‑tune แบบ 4‑bit/QLoRA ที่ผู้ให้บริการคลาวด์ไทยเปิดตัวเป็นจุดเปลี่ยนสำคัญสำหรับองค์กรไทยที่ต้องการใช้ Large Language Models (LLM) ขนาดใหญ่โดยไม่ต้องแบกรับต้นทุนสูงแบบเดิม — ผู้ประกอบการระบุว่าสามารถเทรนโมเดลขนาด ~70B ด้วยต้นทุนที่ลดลงประมาณ 8–12 เท่า เมื่อใช้การควอนไทซ์ 4‑bit ร่วมกับเทคนิค QLoRA และ LoRA adapter ซึ่งช่วยลดความต้องการหน่วยความจำ GPU และเวลาเทรนลงอย่างมาก ฟีเจอร์ที่มาพร้อมบริการครอบคลุมทั้ง MLOps สำหรับการจัดการวงจรชีวิตโมเดล (เวอร์ชันคอนโทรล, การติดตามเมตริก, การตรวจจับการถดถอยของประสิทธิภาพ), การสเกลอัตโนมัติเมื่อต้องการรับโหลดสูง, และตัวเลือกด้านความเป็นส่วนตัวที่สำคัญ เช่น การรันบนสภาพแวดล้อมเฉพาะลูกค้า (VPC/on‑premises), การเข้ารหัสข้อมูลทั้งขณะพักและขณะส่ง, การควบคุมสิทธิ์การเข้าถึง และนโยบายการเก็บรักษาข้อมูลที่ช่วยให้องค์กรสามารถปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบได้ดียิ่งขึ้น.
แม้ข้อได้เปรียบด้านต้นทุนจะชัดเจน แต่องค์กรยังควรดำเนินการแบบทดลอง (pilot) ที่มีการวางแผนอย่างเป็นระบบก่อนขยายสเกล: เริ่มจากชุดข้อมูลตัวแทนงานจริง เพื่อประเมิน trade‑off ระหว่างการประหยัดทรัพยากรกับความแม่นยำของโมเดล (วัดด้วยเมตริกที่เหมาะสม เช่น F1, ROUGE, Accuracy ตามประเภทงาน), ตรวจจับความแตกต่างเชิงคุณภาพด้วย A/B testing, วัดค่าใช้จ่ายจริงทั้งแบบ CAPEX/OPEX (เช่น ค่า GPU ต่อชั่วโมง, ค่าเก็บข้อมูล, ค่าเครือข่าย) และประเมิน latency, throughput รวมทั้งความเสี่ยงด้านความเป็นส่วนตัวและการกำกับดูแล การทำ pilot ยังควรรวมการตั้งค่า MLOps เพื่อทดลองการสเกลอัตโนมัติ, การมอนิเตอร์แบบเรียลไทม์ และกลไก rollback — เมื่อผลทดลองยืนยันความคุ้มค่าและคุณภาพ จึงค่อยวางแผนขยายสู่การใช้งานจริงแบบค่อยเป็นค่อยไป. ในระยะยาว คาดว่า 4‑bit/QLoRA จะช่วยปลดล็อกกรณีใช้งานใหม่ๆ (เช่น ผู้ช่วยภายในองค์กร, การสืบค้นเอกสารเชิงบริบท, การวิเคราะห์ภาษาไทยเชิงลึก) พร้อมกระตุ้นให้เกิดระบบนิเวศ MLOps ภายในประเทศที่แข็งแกร่งขึ้น แต่ต้องจับตาด้านการกำกับ ดูแลข้อมูล และมาตรฐานการประเมินผลเพื่อให้การนำไปใช้เป็นไปอย่างปลอดภัยและมีประสิทธิผล.



