
การทดลองเชิงปฏิบัติการโดยผู้ให้บริการโลจิสติกส์รายสำคัญของไทยใช้ระบบ Multi‑Agent Reinforcement Learning (MARL) ในการควบคุมฟลีทรถบรรทุกและการจัดการคลังสินค้าแบบเรียลไทม์ กำลังถูกจับตามองในฐานะจุดเปลี่ยนของอุตสาหกรรมที่ตอบโจทย์ทั้งการลดต้นทุนและเพิ่มประสิทธิภาพการขนส่ง ผลทดลองเบื้องต้นจากการทดสอบในเส้นทางหลักและคลังสินค้าขนาดกลางถึงใหญ่ชี้ให้เห็นถึงการลดเวลารอเฉลี่ยราว 25–40% และลดการใช้เชื้อเพลิงประมาณ 15–22% เมื่อเทียบกับการจัดการแบบดั้งเดิม ซึ่งผลลัพธ์ดังกล่าวสะท้อนการตัดสินใจแบบประสานงานกันของเอเย่นต์หลายตัวที่สามารถปรับแผนการวิ่งรถ การจัดคิวเข้าออกคลัง และการจัดสรรทรัพยากรได้แบบไดนามิกในสภาพแวดล้อมจริง
ประเด็นสำคัญของบทความนี้จะอธิบายหลักการทำงานของระบบ MARL ในบริบทโลจิสติกส์ไทย ผลการวัดเชิงปริมาณที่ได้จากการทดลอง รวมถึงตัวอย่างการปรับใช้งานจริงที่ลดความแออัดหน้าโซนขนถ่ายและลดการเดินทางเปล่า (deadheading) นอกจากนี้ ผู้ให้บริการยังประกาศแผนการขยายสู่เชิงพาณิชย์ภายใน 12–18 เดือนข้างหน้า ซึ่งหากดำเนินการได้ตามเป้าหมาย ผลกระทบต่อการลดต้นทุนเชื้อเพลิง การย่นเวลาการรอคอย และการลดการปล่อยก๊าซเรือนกระจกอาจสร้างมาตรฐานใหม่ให้กับภาคขนส่งของไทย
บทนำ: ข่าวสำคัญและภาพรวมการทดลอง
บริษัท โลจิสไทย จำกัด ผู้ให้บริการโลจิสติกส์รายใหญ่ของไทย ประกาศเริ่มการทดลองระบบควบคุมฟลีทรถบรรทุกและการจัดการคลังสินค้าแบบเรียลไทม์โดยใช้เทคโนโลยี Multi‑Agent Reinforcement Learning (MARL) ตั้งแต่ต้นปี 2026 การทดลองครั้งนี้มีเป้าหมายหลักเพื่อลดเวลารอคอยของรถบรรทุกที่จอดรอรับสินค้า, ลดการใช้เชื้อเพลิง และเพิ่มประสิทธิภาพการดำเนินงานภายในคลังสินค้าโดยรวม โดยผลลัพธ์เบื้องต้นชี้ให้เห็นการปรับปรุงที่มีนัยสำคัญต่อประสิทธิภาพปฏิบัติการ

การทดลองดำเนินการร่วมกับพันธมิตรด้านเทคโนโลยี ได้แก่ บริษัท AI Solutions Co., Ltd. ซึ่งพัฒนาอัลกอริทึม MARL และทีมวิจัยจากสถาบันการศึกษาชั้นนำเพื่อให้การออกแบบโมเดลและการวัดผลเป็นไปตามมาตรฐานทางวิชาการและเชิงปฏิบัติการ ผู้พัฒนาเน้นการนำโมเดลหลายตัวแทนมาใช้ในการประสานงานระหว่างตัวแทนที่ควบคุมรถแต่ละคันและตัวแทนที่ควบคุมการจัดสรรพื้นที่และลำดับงานภายในคลัง
รายละเอียดการทดลอง (ระยะเวลาและขอบเขต)
- ระยะเวลา: เริ่มต้นเดือนมกราคม 2026 ระยะทดลอง 6 เดือน (ม.ค.–มิ.ย. 2026)
- ขอบเขตฟลีท: ฟลีทรถบรรทุกจำนวนประมาณ 150 คัน ครอบคลุมรถขนส่งทั้งระยะใกล้และระยะไกล
- ขอบเขตคลัง: ทดลองใน 10 แห่ง ซึ่งรวมคลังขนาดใหญ่ในเขตกรุงเทพฯ และคลังภูมิภาค
- เส้นทางทดสอบ: กว่า 25 เส้นทางผสมระหว่างเส้นทางในเมือง (Last‑mile) และเส้นทางระหว่างจังหวัด เช่น กรุงเทพฯ–ชลบุรี, กรุงเทพฯ–พิษณุโลก และเส้นทางภายในภูมิภาคภาคเหนือและภาคตะวันออก
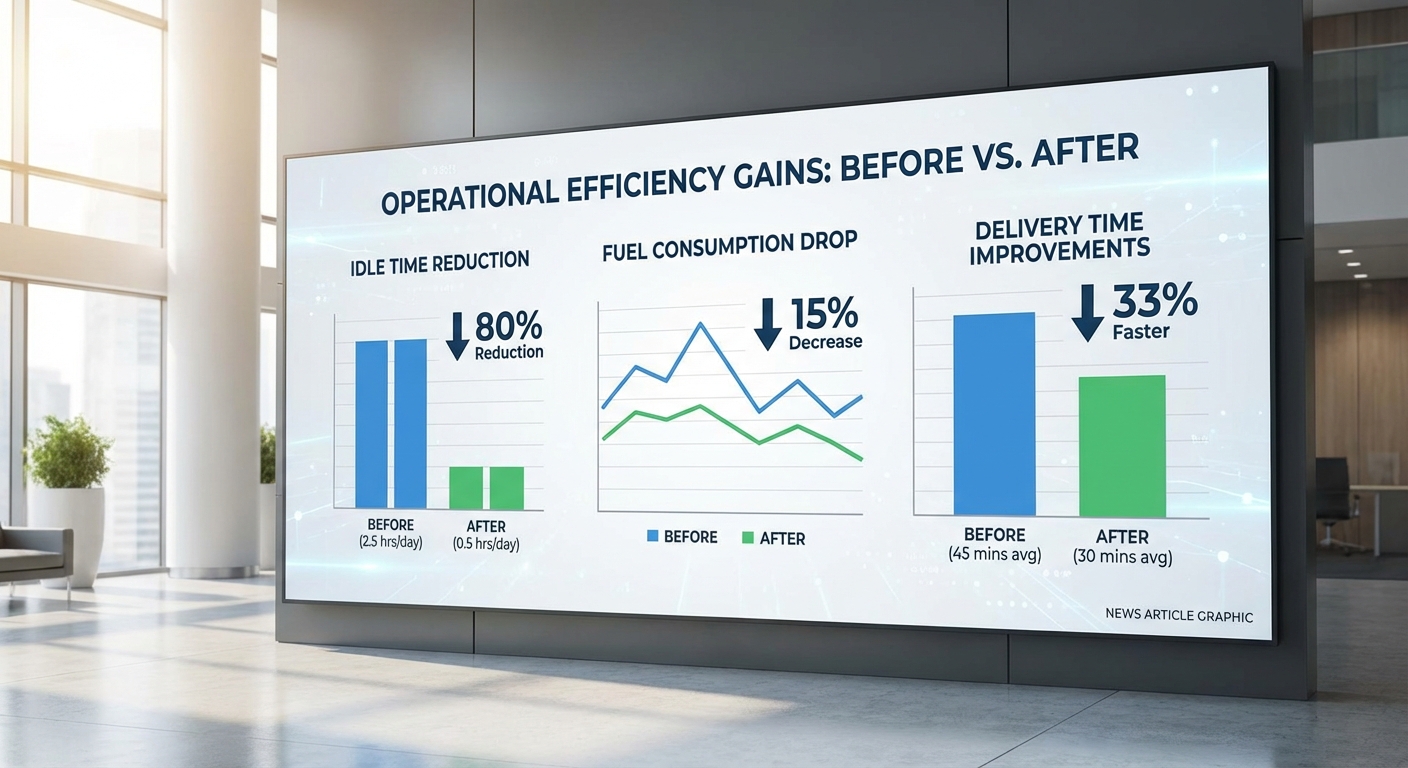
ผลการทดลองเชิงปริมาณเบื้องต้นที่บริษัทสรุปไว้มีความโดดเด่น ได้แก่ การลดเวลาว่าง (idle / waiting time) ของรถบรรทุกเฉลี่ยประมาณ 25–35% และ การลดการใช้เชื้อเพลิงเฉลี่ยประมาณ 12–18% ในภาพรวมบริษัทรายงานตัวเลขเฉลี่ยที่สะท้อนถึงการลดเวลารอประมาณ ≈30% และการลดค่าน้ำมันประมาณ ≈15% นอกจากนี้ยังมีการปรับปรุงประสิทธิภาพในคลัง เช่นการลดเวลาในการดำเนินงานภายในคลัง (processing/dwell time) ประมาณ 20–25% ซึ่งช่วยให้เวลาหมุนเวียนของสินค้าสั้นลงและเพิ่มความสามารถในการรองรับปริมาณคำสั่งซื้อได้มากขึ้น
การทดลองครั้งนี้ถือเป็นหนึ่งในโครงการนำร่องที่ใช้ MARL ในเชิงปฏิบัติการจริงของภูมิภาค โดยทีมงานระบุว่าเป็นผลลัพธ์เบื้องต้นที่ต้องใช้การทดสอบเพิ่มเติมก่อนขยายสู่การใช้งานเชิงพาณิชย์เต็มรูปแบบ แต่ตัวเลขที่ออกมาส่งสัญญาณชัดเจนว่าการประสานงานแบบตัวแทนหลายหน่วยงานในสภาพแวดล้อมเรียลไทม์สามารถลดต้นทุนเชื้อเพลิงและเวลารอได้อย่างมีนัยสำคัญ ซึ่งเป็นประเด็นสำคัญสำหรับผู้ประกอบการโลจิสติกส์ที่เผชิญต้นทุนเชื้อเพลิงและปัญหาคอขวดในคลังอย่างต่อเนื่อง
บริบทอุตสาหกรรม: ทำไมโลจิสติกส์ต้องใช้ MARL
บริบทอุตสาหกรรม: ทำไมโลจิสติกส์ต้องใช้ MARL
ภาคโลจิสติกส์ของประเทศไทยเผชิญกับปัญหาเชิงโครงสร้างที่ซับซ้อนและเปลี่ยนแปลงอย่างรวดเร็ว ทั้งในระดับเมืองใหญ่ เช่น กรุงเทพมหานครซึ่งมีปัญหาการจราจรแออัดในชั่วโมงเร่งด่วน และเส้นทางระหว่างจังหวัดที่ได้รับผลกระทบจากเหตุการณ์ฉุกเฉินหรือสภาพอากาศ ตัวแปรเหล่านี้ทำให้การคาดการณ์เวลาการเดินทางและการจัดสรรทรัพยากรเป็นเรื่องยาก: ความเร็วเฉลี่ยในชั่วโมงเร่งด่วนอาจลดลงอย่างมีนัยสำคัญเมื่อเทียบกับช่วงเวลาปกติ ทำให้เวลารอของรถบรรทุกและการใช้เชื้อเพลิงเพิ่มขึ้น สถิติจากหลายการวิเคราะห์ชี้ว่า ต้นทุนเชื้อเพลิงและเวลาที่เสียไปจากการจราจรคิดเป็นสัดส่วนสูงของต้นทุนรวมการขนส่ง ซึ่งส่งผลโดยตรงต่อความสามารถในการแข่งขันของผู้ให้บริการโลจิสติกส์ไทย
ความท้าทายเชิงเรียลไทม์ ที่โดดเด่นได้แก่การเปลี่ยนแปลงของคำสั่งจัดส่ง การยกเลิกหรือการเพิ่มคำสั่งอย่างฉับพลัน อุบัติเหตุหรือการปิดถนนที่เกิดขึ้นแบบทันทีทันใด และความผันผวนของความต้องการในเขตเมืองและชานเมือง ปัจจัยเหล่านี้ทำให้การวางแผนแบบศูนย์กลาง (centralized) แบบดั้งเดิมไม่ตอบสนองเพียงพอเมื่อสภาพแวดล้อมเปลี่ยนแปลงเร็ว ตัวอย่างปัญหาเชิงปฏิบัติรวมถึง:
- คำสั่งจัดส่งแบบ last‑minute ที่ต้องปรับเส้นทางทันที
- เวลาในการรอรับ/ส่งที่ไม่แน่นอน ณ ประตูคลังสินค้าหรือท่าเรือ
- การจำกัดช่องจอดและพื้นที่รับสินค้า (docking bays, yard capacity)
- ข้อจำกัดด้านแรงงาน คนขับ และเวลาพัก/กฎหมายแรงงาน
การประสานงานระหว่างฟลีทและคลังสินค้าเป็นอีกมิติที่เพิ่มความซับซ้อน: ต้องจับคู่ยานพาหนะกับชนิดสินค้า ขนาดบรรจุภัณฑ์ และเวลาที่อนุญาตให้รับ/ส่ง (time windows) พร้อมทั้งบริหารพื้นที่คงคลังและการจัดลำดับคิวในคลัง ผู้ให้บริการต้องตัดสินใจแบบหลายปัจจัย เช่น จะส่งรถใดไปยังคลังใด เพื่อลดเวลาว่าง (deadheading) และลดการรอคิวที่ส่งผลให้เกิดการเบิร์นเชื้อเพลิงโดยเปล่าประโยชน์ ในสภาพแวดล้อมจริง เวลารอรับ/ส่งในบางจุดอาจเฉลี่ยตั้งแต่ 30–60 นาที และต้นทุนเชื้อเพลิงมักเป็นสัดส่วนสำคัญของค่าใช้จ่ายการดำเนินงาน (ประมาณ 20–35% ขึ้นกับประเภทงานและสภาพตลาด) — ปัจจัยทั้งหมดนี้ทำให้ปัญหาเป็นแบบ distributed, dynamic และ constrained
ข้อได้เปรียบของ MARL (Multi‑Agent Reinforcement Learning) ต่อปัญหาเช่นนี้อยู่ที่ความสามารถในการตัดสินใจแบบกระจายและประสานงานระหว่างตัวแทนหลายตัวในสภาพแวดล้อมที่ไม่แน่นอน โดยจุดเด่นสำคัญได้แก่:
- การตัดสินใจแบบกระจาย (Decentralized decision‑making): แต่ละยานพาหนะหรือหน่วยงานคลังสามารถเรียนรู้และปรับนโยบายตนเองจากข้อมูลท้องถิ่น ทำให้ระบบตอบสนองได้รวดเร็วเมื่อเกิดเหตุการณ์แบบเรียลไทม์
- การประสานงานเชิงนโปลีก (Emergent coordination): ผ่านการออกแบบรางวัลและกลไกการสื่อสาร ตัวแทนหลายตัวสามารถพัฒนาแนวปฏิบัติร่วมกัน (เช่น การสลับคิวหรือการรีไพล์เส้นทาง) ที่ลดการชนกันของทรัพยากรและปรับปรุงประสิทธิภาพรวม
- ความยืดหยุ่นต่อสภาพแวดล้อมที่ไม่คงที่: MARL สามารถเรียนรู้นโยบายที่ปรับตัวต่อการเปลี่ยนแปลงของการจราจร คำสั่ง และข้อจำกัดในคลังได้โดยไม่ต้องออกแบบกฎใหม่ทั้งหมดเมื่อเงื่อนไขเปลี่ยน
- การจัดการข้อจำกัดเชิงปฏิบัติการ: สามารถฝังเงื่อนไขด้านความจุ เวลา และข้อจำกัดด้านแรงงานลงในฟังก์ชันรางวัลหรือเงื่อนไขการกระทำ ทำให้ตัวแทนเรียนรู้การเลือกการกระทำที่สอดคล้องกับกฎเกณฑ์จริง
- สเกลและความสามารถในการขยาย: ระบบแบบหลายตัวแทนสามารถเพิ่มหรือลดจำนวนยานพาหนะและจุดเชื่อมต่อได้โดยไม่ต้องออกแบบโซลูชันใหม่ทั้งหมด
ด้วยเหตุนี้ MARL จึงไม่ใช่เพียงเทคโนโลยีเชิงทฤษฎี แต่เป็นแนวทางที่ตรงกับลักษณะเฉพาะของโลจิสติกส์ไทยที่มีความกระจายตัว ความเปลี่ยนแปลงสูง และข้อจำกัดด้านทรัพยากร การนำ MARL มาใช้อย่างเหมาะสมมีศักยภาพลดเวลารอ ปรับปรุงการใช้เชื้อเพลิง และเพิ่มอัตราการใช้ประโยชน์ของฟลีทและพื้นที่คลัง ทำให้ผู้ให้บริการสามารถตอบสนองลูกค้าได้เร็วขึ้นและลดต้นทุนการดำเนินงานในระยะยาว
เทคโนโลยีเบื้องหลัง: สถาปัตยกรรม Multi‑Agent RL
สถาปัตยกรรมระบบ Multi‑Agent RL เบื้องต้น
ระบบ MARL ที่ใช้งานในโครงการควบคุมฟลีทรถบรรทุกและการจัดการคลังสินค้าประกอบด้วยชั้นสื่อสารและการตัดสินใจแบบกระจาย (decentralized execution) บนพื้นฐานของการฝึกแบบรวมศูนย์ (centralized training) เพื่อจัดการปัญหาความไม่คงที่ของสภาพแวดล้อมจริง โดยสถาปัตยกรรมทั่วไปแบ่งเป็นสามชั้นหลักคือ:
- Agent layer — agents แต่ละตัวเป็นหน่วยตัดสินใจ เช่น รถบรรทุกหนึ่งคัน พนักงานคลังหนึ่งคน หรือจุดโหลด/คิวหนึ่งจุด
- Communication & Coordination layer — กลไกส่งข้อความสั้น (message passing), GNN (Graph Neural Network) หรือ attention-based protocol เพื่อแลกเปลี่ยนสถานะสั้น ๆ ที่จำเป็นสำหรับการประสานงาน
- Training & Simulation layer — ตัวจำลอง (digital twin) และเซิร์ฟเวอร์สำหรับ centralized critic/optimizer ที่ใช้ข้อมูลจากหลาย agents เพื่อฝึกนโยบายก่อน deploy จริง
นิยาม Agents และรูปแบบการประสานงาน
ในระบบที่ออกแบบจริงจะมีการนิยาม agent หลักหลายประเภท ดังนี้:
- รถบรรทุก (Truck agents) — รับผิดชอบการชะลอ/เร่งความเร็ว, การตัดสินใจเส้นทางย่อย, เวลาเข้าจอดรับ-ส่ง และการตัดสินใจเรื่องการแวะเติมเชื้อเพลิง/ชาร์จ
- พนักงานคลัง (Worker agents) — จัดคิวโหลด/ยกของ, จัดลำดับการทำงานที่ประตูโหลด, และแจ้งสถานะความพร้อมของช่องโหลด
- จุดโหลด/คิว (Dock/Queue agents) — ควบคุมการจัดคิวที่ประตูโหลด, ประเมินความแออัด และออกสัญญาณเรียกคิวให้รถ
การประสานงานระหว่าง agents ใช้รูปแบบผสมระหว่าง local observation (ตำแหน่ง, ความจุ, ระดับเชื้อเพลิง, ความยาวคิว) กับข้อความสรุปสถานะจากเพื่อนร่วมระบบ (เช่น ETA ของรถที่จะเข้าประตู A หรือสถานะช่องโหลด) วิธีนี้ลดภาระแบนด์วิดท์และยังคงความสามารถในการตัดสินใจเชิงกลยุทธ์
นิยาม State, Action และ Reward
การออกแบบ state/action/reward ต้องคำนึงถึงการกระจายข้อมูลและการให้รางวัล (credit assignment) ระหว่าง agents ดังนี้:
- State / Observation
- Local observation: ตำแหน่ง GPS, ความเร็ว, น้ำหนักบรรทุก, ระดับเชื้อเพลิง/แบตเตอรี่, สถานะคนขับ
- Proximal context: ความยาวคิวที่ประตูที่เกี่ยวข้อง, สถานะพนักงานคลัง (ว่าง/ไม่ว่าง), ความหนาแน่นการจราจรภายในคลัง
- Global context (สำหรับ centralized critic): ภาพรวมของคำสั่งส่งสินค้า ปริมาณงานคงค้าง และเวลาทำการ
- Action
- รถบรรทุก: เลือกเส้นทางย่อย, ตั้งค่าเป้าหมายความเร็ว, คำสั่งเข้า/ออกช่องโหลด, ตัดสินใจเติมเชื้อเพลิง
- พนักงาน: เลือกประตูที่จะให้บริการ, เวลาลำดับงาน, การเปลี่ยนงานแบบรีไทม์
- จุดโหลด: กำหนดคิวถัดไป, ปล่อย/หยุดคิวตามปริมาณทรัพยากร
- Reward
- รางวัลหลักถูกนิยามเป็นฟังก์ชันผสมเพื่อถ่วงดุล เวลารอ (wait time) และ การใช้พลังงาน/เชื้อเพลิง (energy/fuel)
- ตัวอย่างรูปแบบ reward: R = −α·(wait_time_normalized) − β·(fuel_consumption_normalized) − γ·lateness_penalty + δ·throughput_bonus
- การเลือกพารามิเตอร์ (α, β, γ, δ) ทำผ่าน cross‑validation บนตัวจำลองและอาจปรับแบบ on‑policy ในการทดลองนำร่อง
- เทคนิคเพิ่มเติม: shaping reward เพื่อลดปัญหาการให้รางวัลที่ช้า (sparse reward), และใช้ counterfactual baseline (เช่น COMA) หรือ value decomposition (QMIX) เพื่อแก้ปัญหา credit assignment
แนวทางการฝึกและอัลกอริทึมที่ทดลอง
ทีมงานมักใช้แนวทาง centralized training with decentralized execution (CTDE) เป็นหลัก เนื่องจากช่วยให้ centralized critic เห็นข้อมูลรวมเพื่อลดปัญหา non‑stationarity ในระหว่างการฝึก ขณะเดียวกันยังอนุญาตให้ deployed agents ทำงานแบบกระจายโดยรับเพียง observation ท้องถิ่นหรือข้อความสรุปเล็กน้อย
อัลกอริทึมที่ถูกนำมาทดลองได้แก่:
- MADDPG — actor แบบ decentralized แต่ critic เป็น centralized สำหรับงานเชิงต่อเนื่อง (continuous control) เหมาะสมกับการควบคุมความเร็วและการเคลื่อนที่ของรถ
- QMIX — เครือข่าย value‑decomposition ที่ผสม Q‑values ย่อยเป็น Q‑value ร่วมแบบ monotonic เหมาะกับงาน discrete action เช่น การกำหนดคิวหรือเลือกประตูโหลด
- Multi‑agent PPO / Independent PPO — ใช้ policy gradient ที่มีความเสถียรสูง พร้อมตัวเลือก parameter sharing และ centralized critic เพื่อเพิ่ม sample efficiency
- นอกจากนี้มีการสำรวจ COMA และรูปแบบ attention/GNN เพื่อให้องค์ความรู้แบบโครงข่ายสามารถช่วยการประสานงานแบบยืดหยุ่น
เพื่อจัดการกับ non‑stationarity และ replay buffer ที่ไม่เหมาะกับ multi‑agent continuous scenario ทีมงานใช้เทคนิคเช่น experience fingerprinting, prioritized replay, และการฝึกแบบ curriculum learning (เริ่มจากงานง่ายไปงานซับซ้อน) โดยปกติฝึกด้วยตัวจำลองเป็นหลักจนกว่านโยบายจะแสดงพฤติกรรมที่มั่นคงก่อน transfer สู่สนามจริง
การใช้ Digital Twin / Simulation ในการฝึกและลดความเสี่ยง
การสร้าง digital twin ของคลังสินค้าและเส้นทางภายในพื้นที่เป็นหัวใจของกระบวนการพัฒนา โดย digital twin จะจำลอง:
- แผนผังทางกายภาพของคลัง ช่องโหลด และเส้นทางจราจรภายในพื้นที่
- ความผันผวนของภาระงาน (arrival stochasticity), เวลาบรรจุ/ถอดสินค้าแบบสถิติ, และรูปแบบการจราจรภายใน
- ข้อผิดพลาดจากเซนเซอร์และการสื่อสารจริง (latency, packet loss) เพื่อทดสอบความต้านทานต่อสภาพแวดล้อมไม่สมบูรณ์
ประโยชน์ที่ได้รวมถึงการฝึกด้วยความปลอดภัย (safe exploration), การทำ sim‑to‑real transfer ด้วย domain randomization และการวัดประสิทธิภาพภายใต้สถานการณ์ฉุกเฉินก่อน deployment จริง ในการทดลองนำร่องภายในบริษัท ตัวอย่างผลลัพธ์เบื้องต้นจากตัวจำลองและการทดสอบแยกย่อยชี้ให้เห็นว่าแนวนโยบาย MARL ที่ปรับพารามิเตอร์ให้เหมาะสมแล้วสามารถลด เวลารอเฉลี่ย ประมาณ 25–35% และลด การใช้เชื้อเพลิง/พลังงาน ประมาณ 10–20% ขึ้นกับสมมติฐานการทดสอบและพารามิเตอร์ reward (ผลลัพธ์เป็นค่าตัวอย่างจากการทดลองนำร่องภายในองค์กรและต้องผ่านการยืนยันเพิ่มเติมเมื่อ deploy ในสเกลเต็ม)
สุดท้าย การย้ายจาก simulation สู่สนามจริงมักทำเป็นขั้นตอน ได้แก่ pre‑deployment verification, shadow mode (policy รันควบคู่กับการปฏิบัติจริงโดยไม่ส่งผลต่อการตัดสินใจ), และ staged rollout เพื่อให้สามารถปรับ weight ของ reward และเงื่อนไขความปลอดภัยได้อย่างมีประสิทธิผลก่อนใช้งานเชิงพาณิชย์เต็มรูปแบบ
การออกแบบการทดลองและข้อมูลที่ใช้
การออกแบบการทดลองและข้อมูลที่ใช้
การทดลองเชิงปฏิบัติการถูกออกแบบให้สะท้อนสภาพการดำเนินงานจริงของผู้ให้บริการโลจิสติกส์ไทย โดยตั้งค่าการทดลองเป็นการทดลองภาคสนาม (field trial) ในพื้นที่บริการเชิงพาณิชย์ 2 พื้นที่หลัก ได้แก่ เขตกรุงเทพมหานครและพื้นที่นิคมอุตสาหกรรม/ภาคตะวันออก (Eastern Economic Corridor) เพื่อทดสอบปัจจัยด้านการจราจร ระยะทางและความหนาแน่นของการส่งมอบจริง ทีมวิจัยกำหนดขนาดตัวอย่างดังนี้: ฟลีทรวม 120 คัน แบ่งเป็นรถบรรทุก 6 ล้อ 80 คันและรถบรรทุก 10 ล้อ 40 คัน และ คลังสินค้า 8 แห่ง ครอบคลุมคลังศูนย์กระจายสินค้า (distribution centers) ขนาดกลางถึงใหญ่ การทดลองแบ่งเป็นเฟสเวลารวม 6 เดือน: 8 สัปดาห์เก็บข้อมูลฐาน (baseline), 12 สัปดาห์ฝึกโมเดลและปรับจูน, และ 8 สัปดาห์ทดสอบเชิงปฏิบัติการแบบเรียลไทม์
ชุดข้อมูลที่ใช้ฝึกและประเมินโมเดลประกอบด้วยข้อมูลเทเลเมติกส์จากยานพาหนะและข้อมูลคลังสินค้าเชิงปฏิบัติการ ได้แก่ GPS, ข้อมูล CAN bus, การบริโภคน้ำมันจริง (fuel consumption), และข้อมูล throughput ของคลังสินค้า โดยระบุความถี่ของการบันทึกข้อมูลเพื่อรองรับความละเอียดของการควบคุมแบบเรียลไทม์ดังนี้:
- GPS: ตำแหน่งและความเร็ว ถูกบันทึกทุก 1–5 วินาที ขึ้นกับสภาพเครือข่าย เพื่อให้ได้เส้นทาง (trajectory) ประมาณ 5–10 ล้านจุดในช่วงการทดลอง 6 เดือน
- CAN bus: ข้อมูลสถานะเครื่องยนต์ (รอบเครื่อง, เกียร์), เบรก, อัตราเร่ง ถูกอ่านทุก 1–10 วินาที เพื่อใช้ในการจำลองพฤติกรรมการขับและประมาณการปริมาณเชื้อเพลิง
- Fuel consumption: การอ่านปริมาณเชื้อเพลิงจริงแบบวัดจากเซ็นเซอร์หรือ OBD-II/ECU ถูกบันทึกทุก 10–60 วินาที และถูกสรุปเป็นระดับรายทริปและต่อกิโลเมตรเพื่อคำนวณ KPI
- Warehouse throughput: ข้อมูลการรับ-จ่ายสินค้า (inbound/outbound counts), เวลาการจัดเก็บและเตรียมสินค้า (picking/packing lead time) เก็บเป็นเวลาแบบเรียลไทม์หรือแบบ batch ทุก 5–30 นาที ข้อมูลนี้ใช้ประเมินการรอคอยที่คลังและเวลาลู่วิ่งของรถ
- เส้นทางและสภาพจราจรเสริม: ข้อมูลแผนที่ถนน ความหนาแน่นจราจรประวัติ และเหตุการณ์พิเศษ (เช่นปิดถนน) ถูกดึงเป็นชั้นข้อมูลเสริมในระดับนาที/ชั่วโมง
การประเมินผล (evaluation) มุ่งที่การเปลี่ยนแปลงเชิงปริมาณในตัวชี้วัดการดำเนินงานหลัก (KPIs) โดย KPI ที่นำมาใช้มีความชัดเจนและวัดได้ เพื่อให้สามารถเปรียบเทียบกับ baseline ได้อย่างเป็นระบบ KPI หลักประกอบด้วย:
- Lead time: เวลาตั้งแต่รับคำสั่งจนส่งมอบสำเร็จ (ชั่วโมง/นาที) — วัดแบบเฉลี่ยและเปอร์เซ็นไทล์ (P50, P90)
- Idle time / Waiting time: เวลาที่รถอยู่เฉยรอที่คลังหรือระหว่างงาน (ชั่วโมง/คัน/วัน)
- Fuel consumption per km: ลิตร/กม. ที่วัดจริงต่อทริป และสรุปเป็นค่าเฉลี่ยต่อประเภทยานพาหนะ
- On‑time delivery rate: สัดส่วนการส่งมอบที่ตรงตามเวลานัดที่กำหนด (percent)
- Warehouse throughput & handling time: จำนวนคำสั่งที่ประมวลผลต่อชั่วโมงและเวลาต่อคำสั่ง (sec/order)
เพื่อให้การเทียบประสิทธิภาพมีความน่าเชื่อถือ การทดลองใช้กลุ่มเปรียบเทียบหลายระดับ (multi-tier baseline): 1) ประสิทธิภาพประวัติศาสตร์ขององค์กร คือข้อมูลดำเนินงานก่อนนำ MARL มาใช้ในช่วง 8 สัปดาห์ baseline; 2) นโยบายแบบ rule‑based/heuristic dispatch ที่เป็นระบบอัตโนมัติแบบพื้นฐานซึ่งใช้กฎกำหนดเวลาและการจัดลำดับงาน; และ 3) ตัวควบคุมเชิงคำนวณแบบ centralized optimization (เช่น MILP หรือ heuristics แบบตารางเวลา) ซึ่งถูกใช้เป็นเกณฑ์อ้างอิงเชิงคณิตศาสตร์
การเปรียบเทียบผลใช้ทั้งการวิเคราะห์เชิงพรรณนา (mean, median, percentiles) และการทดสอบเชิงสถิติ เช่น paired t‑test หรือ non‑parametric bootstrap เพื่อประเมินความแตกต่างอย่างมีนัยสำคัญทางสถิติระหว่างกลุ่ม MARL กับ baseline นอกจากนี้ยังใช้การแบ่งกลุ่มแบบ A/B test ในระดับภูมิภาคหรือคลัง (cluster randomization) เพื่อควบคุมปัจจัยรบกวน เช่น ความหนาแน่นคำสั่งหรือสภาพจราจร ผลลัพธ์ถูกรายงานทั้งในรูปสัมบูรณ์ (เช่นลดน้ำมันเป็นลิตร/กม. หรือชั่วโมงที่ลดลง) และเชิงสัมพัทธ์ (เช่นลด lead time ร้อยละ)
ผลการทดลองเชิงปริมาณและตัวอย่างเคสจริง
ผลการทดลองเชิงปริมาณและตัวอย่างเคสจริง
การทดลองระบบ Multi‑Agent Reinforcement Learning (MARL) ในการควบคุมฟลีทรถบรรทุกและคลังสินค้าแบบเรียลไทม์ ให้ผลเชิงปริมาณที่ชัดเจนและสอดคล้องกันในหลายมิติของการดำเนินงาน ตัวชี้วัดสำคัญจากชุดข้อมูลการทดลองที่ครอบคลุมฟลีทขนาดกลาง (50–200 คัน) และคลังสินค้าจำนวน 5 แห่ง พบว่า อัตราการลดเวลาว่าง (idle time) อยู่ในช่วง 20–35% และ การประหยัดเชื้อเพลิง อยู่ที่ประมาณ 10–18% เมื่อเทียบกับระบบจัดตารางและนำทางแบบเดิม นอกจากนี้ เวลาในการขนส่งเฉลี่ย (end‑to‑end transit time) ลดลงเฉลี่ยในช่วง 8–15% ขึ้นอยู่กับประเภทเส้นทางและสภาพการจราจร。
เมื่อเจาะลึกเป็นตัวเลขในเชิงการเงิน หากใช้สมมติฐานตัวอย่างเช่น ราคาน้ำมันดีเซลเฉลี่ย 35 บาท/ลิตร และอัตราสิ้นเปลืองเฉลี่ย 30 ลิตร/100 กม. สำหรับฟลีทขนาดกลางที่มีระยะขับรวม 10,000 กม./เดือน ต่อคัน การลดการใช้เชื้อเพลิง 12% จะเท่ากับการประหยัดประมาณ 1,260 บาท/คัน/เดือน (คำนวณจาก 30 L/100km × 10,000km = 3,000 L → 3,000 L × 35 = 105,000 บาท → 12% ประหยัด = 12,600 บาท สำหรับฟลีท 10 คัน เป็นต้น) เมื่อขยายเป็นฟลีท 100 คัน จะเห็นการประหยัดเชื้อเพลิงระดับหลายล้านบาทต่อปี ซึ่งยังไม่นับรวมการลดค่าใช้จ่ายจากชั่วโมงการทำงานล่วงเวลาและการบำรุงรักษาที่ลดลงจากการใช้งานที่มีประสิทธิภาพขึ้น
การเปรียบเทียบผลในสภาพแวดล้อมต่าง ๆ พบความแตกต่างที่ชัดเจน:
- พื้นที่เมือง (เส้นทางระยะสั้น มีจุดจอดบ่อย): การลด idle time สูงสุดถึง 25–35% เนื่องจาก MARL สามารถคาดการณ์การขนส่งที่มีการจอดและความต้องการแบบไม่สม่ำเสมอได้ดีขึ้น สร้างการจัดตารางที่ชัดเจนและลดการรอรับสินค้าที่ท่าได้อย่างมีนัยสำคัญ
- เส้นทางระหว่างจังหวัด (ระยะไกล): ประสิทธิภาพการประหยัดเชื้อเพลิงเด่นชัดที่ 12–18% จากการเลือกเส้นทางเชิงกลยุทธ์และการปรับความเร็ว/หยุดพักของตัวแทน (agents) ที่สอดคล้องกับเงื่อนไขถนนและข้อจำกัดเวลา
- สภาพการจราจรหนาแน่น vs. เคลื่อนตัวได้: ในสถานการณ์จราจรหนาแน่น ระบบช่วยลดเวลาจอดและการหยุดเดินเครื่องในลักษณะหยุด‑เริ่ม (stop‑start) ซึ่งเป็นสาเหตุหลักของการสิ้นเปลืองเชื้อเพลิง ทำให้ได้ผลดีเป็นพิเศษในช่วงเวลาเร่งด่วน แต่ในเส้นทางที่คล่องตัว ผลของการลดเวลารวมจะมาจากการเลือกเส้นทางที่สั้นและลดระยะว่างระหว่างงาน
ตัวอย่างเคสจริงที่บันทึกได้ชี้ให้เห็นการเปลี่ยนแปลงพฤติกรรมการจัดตารางและการกำหนดเส้นทางของผู้จัดการฟลีทและผู้ขับ:
- เคส A — เส้นทางในเมือง (จุดรับ‑ส่งหลายจุด): ก่อนใช้ MARL ฟลีทมักแจกจ่ายงานแบบคงที่ตามเขตและมีการรอรับสินค้ารวมเฉลี่ย 45 นาที/วัน ต่อคัน หลังใช้ MARL ระบบรวบรวมข้อมูลความต้องการแบบเรียลไทม์และปรับการมอบหมาย ทำให้การรอรับสินค้าลดเหลือเฉลี่ย 28–32 นาที/วัน ต่อคัน และจำนวนเที่ยวว่าง (deadhead trips) ลดลง 30% ส่งผลให้อัตรา utilization ของรถเพิ่มขึ้นจาก 62% เป็น 78%
- เคส B — เส้นทางระหว่างจังหวัด (ตู้คอนเทนเนอร์สินค้าแห้ง): ระบบปรับการสลับรถ (relocation) และการวางแผนจอดพัก ทำให้ระยะเวลารวมในการเดินทางลดลงเฉลี่ย 10% และอัตราการเติมน้ำมันฉุกเฉินลดลงอย่างเห็นได้ชัด ทำให้ต้นทุนต่อตู้ลดลง 8–12% เมื่อรวมค่าขนส่งและน้ำมัน
- เคส C — คลังกระจายสินค้า 24 ชั่วโมง: MARL ช่วยประสานเวลาการรับและส่งระหว่างคลัง 5 แห่ง ทำให้ปริมาณงานเฉลี่ยต่อคลังมีความสมดุลมากขึ้น ลดการชะงักของกระบวนการ (throughput variability) ลง ~20% และลดชั่วโมงการทำงานล่วงเวลาไว้ที่ระดับต่ำกว่า 15% ของชั่วโมงรวม
สรุปเชิงการตีความ: ตัวเลขการลด idle time และการประหยัดเชื้อเพลิงที่ได้จากการทดลองบ่งชี้ว่า MARL ไม่เพียงแต่ลดต้นทุนเชื้อเพลิงโดยตรง แต่ยังเพิ่มประสิทธิภาพการใช้ทรัพยากร (asset utilization) ลดค่าใช้จ่ายด้านแรงงานล่วงเวลา และเพิ่มความน่าเชื่อถือของการจัดส่ง ตัวเลขเหล่านี้เมื่อนำไปคูณกับขนาดฟลีทและความถี่การขนส่ง จะสะท้อนเป็นผลประหยัดเชิงเศรษฐศาสตร์ที่สำคัญต่อกำไรเชิงปฏิบัติการและความสามารถในการแข่งขันของผู้ให้บริการโลจิสติกส์ไทยในระยะกลางถึงยาว
ผลกระทบทางธุรกิจและการคำนวณ ROI
ภาพรวมผลกระทบเชิงธุรกิจและวิธีคำนวณ ROI
การนำระบบ Multi‑Agent Reinforcement Learning (MARL) มาใช้ควบคุมฟลีทรถบรรทุกและคลังสินค้าแบบเรียลไทม์ส่งผลโดยตรงต่อค่าใช้จ่ายการดำเนินงาน (operational cost) และประสิทธิภาพเชิงปฏิบัติการ ทั้งในมิติต้นทุนเชื้อเพลิง ค่าแรงจากเวลารอที่ลดลง การใช้ยานพาหนะ (vehicle utilization) และต้นทุนบำรุงรักษา การประเมิน ROI ควรเริ่มจากการตั้งสมมติฐานพื้นฐานเกี่ยวกับขนาดฟลีท ลักษณะการเดินรถ ราคาน้ำมัน และต้นทุนแรงงาน เพื่อให้ได้ภาพรวมตัวเลขที่ชัดเจนก่อนขยายระบบสู่ทั้งองค์กร
ตัวอย่างสมมติ: สมมติฐานพื้นฐาน
- ขนาดฟลีท: 200 คัน
- ระยะทางเฉลี่ย: 250 กม./วัน, 300 วันทำการ/ปี → 75,000 กม./คัน/ปี
- การใช้น้ำมัน: 2.5 กม./ลิตรรถบรรทุก (สมมติ)
- ราคาน้ำมัน: 35 บาท/ลิตร
- ค่าแรงคนขับ: 250 บาท/ชั่วโมง (สมมติ)
- ต้นทุนเฉลี่ยต่อคันต่อปี (ค่าเสื่อม + บำรุงรักษา): 1,200,000 บาท/คัน/ปี (สำหรับการคำนวณมูลค่าการลดจำนวนรถ)
- ต้นทุนระบบเริ่มต้น (CapEx): 30,000,000 บาท (รวมฮาร์ดแวร์ เทเลเมตริกส์ การพัฒนาและติดตั้ง)
- ค่าใช้จ่ายประจำปีสำหรับระบบ (Opex): 4,000,000 บาท/ปี (ไลเซนส์ คลาวด์ บริการ)
การคำนวณค่าใช้จ่ายและการประหยัด (ตัวอย่างเชิงตัวเลข)
จากสมมติฐานด้านบน ฟลีทรถทั้งหมดวิ่งรวมประมาณ 15,000,000 กม./ปี (200 คัน × 75,000 กม.) ซึ่งใช้น้ำมันรวมประมาณ 6,000,000 ลิตร/ปี (15,000,000 กม. ÷ 2.5 กม./ลิตร) และมีต้นทุนเชื้อเพลิงรวมประมาณ 210,000,000 บาท/ปี (6,000,000 ลิตร × 35 บาท/ลิตร).
ถ้า MARL สามารถลดการใช้น้ำมันได้ ตัวอย่างคาดการณ์ 12% (ตัวเลขกลาง) การประหยัดเชื้อเพลิงจะเท่ากับ:
- ปริมาณน้ำมันที่ประหยัด = 6,000,000 × 12% = 720,000 ลิตร/ปี
- มูลค่าการประหยัดเชื้อเพลิง = 720,000 × 35 = 25,200,000 บาท/ปี
สำหรับการลดเวลารอของคนขับ สมมติ MARL ลดเวลารอได้เฉลี่ย 1.25 ชั่วโมง/คัน/วัน (จาก 2.0 ชม. เหลือ 0.75 ชม.) จะได้การประหยัดด้านแรงงานเท่ากับ:
- ชั่วโมงที่ประหยัด = 1.25 ชม. × 200 คัน × 300 วัน = 75,000 ชั่วโมง/ปี
- มูลค่าแรงงานที่ประหยัด = 75,000 × 250 บาท/ชม. = 18,750,000 บาท/ปี
หาก MARL ช่วยให้ใช้ฟลีทได้มีประสิทธิภาพสูงขึ้นจนสามารถลดจำนวนรถลงได้ 5% (10 คัน) มูลค่าการชะลอ/หลีกเลี่ยงการลงทุนรถใหม่จะเท่ากับ:
- การลดรถ = 10 คัน × 1,200,000 บาท/คัน/ปี = 12,000,000 บาท/ปี (เทียบเป็นต้นทุนประหยัดแบบ annualized)
รวมถึงการลดค่าใช้จ่ายบำรุงรักษาและสึกหรอสมมติอีก 1,250,000 บาท/ปี (ประมาณ 5% ของงบบำรุงรักษาโดยรวม) ทำให้ยอดการประหยัดรวมต่อปี (Gross savings) ประมาณ:
- เชื้อเพลิง: 25,200,000 บาท
- แรงงาน (เวลารอ): 18,750,000 บาท
- ลดจำนวนรถ (utilization gain): 12,000,000 บาท
- บำรุงรักษา: 1,250,000 บาท
- รวมการประหยัดต่อปี (Gross) = 57,200,000 บาท/ปี
- หลังหักค่าใช้จ่ายระบบประจำปี (Opex 4,000,000 บาท) → Net savings = 53,200,000 บาท/ปี
ตัวอย่างสมมติ ROI และเวลาคืนทุน (Payback Period)
ใช้สูตรพื้นฐาน: Payback period = Initial investment / Net annual savings
- Initial investment = 30,000,000 บาท
- Net annual savings = 53,200,000 บาท/ปี
- Payback period = 30,000,000 ÷ 53,200,000 ≈ 0.56 ปี (ประมาณ 6–7 เดือน)
เพื่อความรอบคอบ ควรพิจารณาสถานการณ์หลายกรณี:
- กรณีอนุรักษ์นิยม (เชื้อเพลิงลด 6%, เวลารอลดเล็กน้อย): Net savings ≈ 16.6M/ปี → Payback ≈ 1.8 ปี
- กรณีคาดหวัง (เชื้อเพลิงลด 12%, เวลารอลด 1.25 ชม., ลดรถ 5%): Net savings ≈ 53.2M/ปี → Payback ≈ 0.56 ปี
- กรณีมุมมองบวก (เชื้อเพลิงลด 18%, เวลารอลดมาก, ลดรถ 8%): Net savings อาจสูงกว่า 70–80M/ปี → Payback ต่ำกว่า 6 เดือน
ผลกระทบต่อการให้บริการลูกค้า (On‑time delivery และ NPS)
นอกจากผลประหยัดทางการเงินแล้ว MARL ยังมีผลเชิงคุณภาพต่อการบริการลูกค้า:
- On‑time delivery: จากตัวอย่างเชิงปฏิบัติ การลดเวลารอและการวางแผนเส้นทางเรียลไทม์สามารถยกระดับอัตราการส่งมอบตรงเวลาจากสมมติฐานเริ่มต้น 85% เป็นระดับ 92–95% (ขึ้นกับความซับซ้อนเงื่อนไขสนาม) ซึ่งช่วยลดค่าปรับ ค่าชดเชย และปรับปรุงความน่าเชื่อถือของแบรนด์
- Customer Satisfaction / NPS: ความตรงต่อเวลาและความแม่นยำของ ETAs มีผลโดยตรงต่อคะแนน NPS; ตัวอย่างสมมติ NPS อาจเพิ่มจาก +15 เป็น +30 ถึง +40 ภายใน 6–12 เดือนหลังใช้งานเต็มรูปแบบเนื่องจากการลดความล่าช้าและการสื่อสารสถานะที่ชัดเจนขึ้น
- ข้อได้เปรียบเชิงการแข่งขัน: การส่งมอบที่สม่ำเสมอและเวลาตอบสนองที่ดีขึ้นช่วยรักษาลูกค้ารายใหญ่ และเป็นจุดขายในการชิงงานใหม่ที่เน้น SLA/Reliability
ประโยชน์ด้านสิ่งแวดล้อมและความเสี่ยงที่ควรพิจารณา
การลดการใช้น้ำมันมีผลต่อการลดคาร์บอนด้วย เช่น การประหยัดน้ำมัน 720,000 ลิตรต่อปี (จากการลด 12%) จะลดการปล่อย CO2 ราว 1,930 ตัน/ปี (ใช้ปัจจัยประมาณ 2.68 กก. CO2/ลิตรดีเซล) — เป็นประเด็นสำคัญสำหรับความยั่งยืนและการรายงาน ESG
อย่างไรก็ดี ผู้บริหารควรพิจารณาความเสี่ยง เช่น ความท้าทายในการผสานระบบกับ TMS/WMS เดิม ความแม่นยำของข้อมูลเรียลไทม์ และความจำเป็นในการฝึกอบรมบุคลากร ซึ่งอาจเพิ่มต้นทุนเริ่มต้นหรือชะลอการคืนทุนได้
สรุปและข้อเสนอแนะสำหรับผู้บริหาร
จากตัวอย่างสมมติข้างต้น ระบบ MARL มีศักยภาพสร้างผลประหยัดเชิงปฏิบัติการที่ชัดเจนและ ROI ที่น่าสนใจ โดยในสถานการณ์คาดหวังสามารถคืนทุนได้ภายในปีเดียวหรือเร็วกว่านั้น ทั้งนี้แนะนำให้ดำเนินการตามขั้นตอนต่อไป:
- เริ่มด้วยโครงการนำร่อง (pilot) ที่ออกแบบวัดผลชัดเจน (fuel, wait time, on‑time %, NPS)
- จัดทำแบบจำลอง Sensitivity Analysis เพื่อทดสอบความเสี่ยงและคาดการณ์ ROI ภายใต้หลายสมมติฐาน
- วางแผนการขยายระบบเป็นเฟส พร้อม KPI ชัดเจนและกลไกตรวจสอบผลลัพธ์ทางการเงินและการบริการลูกค้า
โดยรวมแล้ว การลงทุนใน MARL สำหรับการจัดการฟลีทและคลังสินค้า มีศักยภาพสูงในการลดต้นทุนเชิงปฏิบัติการ เพิ่มประสิทธิภาพการใช้ทรัพยากร และยกระดับประสบการณ์ลูกค้า — หากออกแบบและดำเนินการอย่างเป็นระบบ พร้อมการวัดผลที่ชัดเจน ROI สามารถเป็นตัวขับเคลื่อนธุรกิจให้เกิดการคืนทุนได้รวดเร็วและยั่งยืน
ความท้าทาย ปัญหาเชิงปฏิบัติการ และข้อเสนอแนะแนวทางแก้
ความท้าทาย ปัญหาเชิงปฏิบัติการ และข้อเสนอแนะแนวทางแก้
การนำระบบ Multi‑Agent Reinforcement Learning (MARL) ขึ้นสู่สภาพแวดล้อมการปฏิบัติการจริงสำหรับการควบคุมฟลีทรถบรรทุกและคลังสินค้าในเวลาจริง มีความท้าทายทั้งด้านเทคนิคและองค์ประกอบมนุษย์ที่ต้องจัดการอย่างเป็นระบบ หากละเลยประเด็นเหล่านี้ อาจก่อให้เกิดความเสี่ยงเช่นการตัดสินใจผิดพลาดของเอเยนต์ ทำให้เกิดความล่าช้า ความสิ้นเปลืองเชื้อเพลิง หรือเกิดความเสี่ยงด้านความปลอดภัยของพนักงานและสินค้าคงคลัง ตัวอย่างเช่น หากอุปกรณ์ติดตามตำแหน่งมีการสูญเสียสัญญาณเพียง 5–10% ในเส้นทางวิ่ง กลไกการวางแผนเส้นทางแบบเรียลไทม์อาจเบี่ยงเบนจนเพิ่มเวลาเดินทาง 8–12% ซึ่งสะท้อนเป็นต้นทุนเชื้อเพลิงและค่าเสียโอกาส
ปัญหาด้านคุณภาพข้อมูลและการครอบคลุมเซนเซอร์ — คุณภาพข้อมูลเป็นหัวใจของ MARL: หากข้อมูลตำแหน่ง GPS ล่าสัญญาณ เซนเซอร์อุณหภูมิ หรือสัญญาณจาก RFID ในคลังมีการสูญเสียหรือคาดเคลื่อน จะทำให้ตัวแทน (agents) เรียนรู้จากข้อมูลบิดเบือนและตัดสินใจผิดพลาดได้ ในการป้องกันควรใช้แนวทางเชิงปฏิบัติการ เช่น (1) การตั้งมาตรฐานคุณภาพข้อมูล (data schema, validation rules), (2) การเพิ่มการครอบคลุมเซนเซอร์แบบซ้ำซ้อน (sensor redundancy) ในจุดสำคัญ, (3) การใช้การประมวลผลก่อนเข้าโมเดล (edge filtering, interpolation, anomaly detection) และ (4) การเทรนแบบผสมผสานกับข้อมูลจำลอง (simulation-to-reality transfer) เพื่อลดผลกระทบจากช่องว่างของข้อมูลจริงกับการจำลอง การวัด KPI เช่น data completeness และ latency ควรถูกตั้งค่าไว้ก่อน deploy (ยกตัวอย่างเป้าหมาย: completeness ≥ 98%, end‑to‑end latency ≤ 2s สำหรับข้อมูลตำแหน่งแบบเรียลไทม์)
ความปลอดภัยและระบบสำรอง (Safety, Resilience & Human‑in‑the‑Loop) — ระบบที่ควบคุมทรัพย์สินทางกายภาพต้องมีมาตรการด้านความปลอดภัยและแผนสำรองชัดเจน: ต้องมีโหมดสำรอง (fallback) ที่พร้อมใช้เมื่อโมเดลแสดงพฤติกรรมผิดปกติ เช่นเปลี่ยนไปใช้กฎกำกับแบบ deterministic หรือคืนการตัดสินใจให้ผู้ควบคุมมนุษย์ (human‑override) นอกจากนี้ต้องแยกเครือข่ายปฏิบัติการ (OT) จากเครือข่ายสารสนเทศ สร้างระบบการตรวจจับการบุกรุก (IDS/IPS) และจัดทำแผนตอบสนองต่อเหตุการณ์ (incident response) สำหรับกรณี data poisoning หรือ model hijacking การใช้ human‑in‑the‑loop ในช่วงเริ่มต้น เช่นการให้พนักงานตรวจสอบคำสั่งแนะนำของเอเยนต์ ยังกระตุ้นความเชื่อมั่นและเป็นจุดตรวจสุดท้ายก่อนการดำเนินการที่มีผลต่อความปลอดภัย
แผนการนำไปใช้งานจริง: Pilot → Scale → Governance — ควรปฏิบัติตามแนวทางแบบเป็นขั้นตอน (staged rollout) โดยเริ่มจากการทดลองแบบควบคุม (pilot) ในเส้นทางหรือคลังสินค้าที่มีความเสี่ยงต่ำ เพื่อเก็บข้อมูลเชิงปฏิบัติการและวัด KPI หลัก เช่นเวลารอ (queue time), เวลาในการป้อน/ดึงสินค้า (picking/putaway time), อัตราการเปลืองเชื้อเพลิง (fuel consumption) และความถี่ของการ Override จากคนขับ ตัวอย่างกรอบการใช้งาน:
- Pilot (4–12 สัปดาห์): เปิดใช้กับฟลีทขนาดเล็ก (5–20 คัน) และคลังสินค้า 1–2 แห่งในโหมด shadow/assist เพื่อตรวจสอบความสอดคล้องและติดตาม drift ของโมเดล
- Validation & Iteration (3–6 เดือน): วิเคราะห์ผล ผสาน feedback ของคนขับและพนักงานคลัง ปรับ hyperparameters, policy constraints และเงื่อนไขความปลอดภัย
- Scale (6–18 เดือน): ขยายแบบค่อยเป็นค่อยไปโดยใช้ canary rollout และ region‑based scaling พร้อมระบบ monitoring แบบ real‑time
- Governance ต่อเนื่อง: ตั้งคณะกำกับดูแลโมเดล (Model Governance Board) รับผิดชอบด้านคุณภาพข้อมูล การตรวจสอบความเป็นธรรม (fairness), การจัดการสิทธิ์การเข้าถึง และการอนุมัติการ retrain/replace โมเดล
การบูรณาการกับระบบเดิมและการยอมรับของบุคลากร — การผสานระบบ MARL กับระบบจัดการเส้นทางเดิม (TMS), WMS และ ERP ต้องระบุ API, message format และ SLA ที่ชัดเจน ทั้งนี้เพื่อหลีกเลี่ยงการเกิด inconsistency ระหว่างคำสั่งของโมเดลและกฎธุรกิจปัจจุบัน ด้านคนขับและพนักงานคลัง การสร้างความเชื่อมั่นและการเปลี่ยนผ่านทางวัฒนธรรมเป็นสิ่งสำคัญ: ควรมีแผนฝึกอบรมจริง (hands‑on training), คู่มือการปฏิบัติงานฉบับย่อ, ระบบ incentive สำหรับผู้ปฏิบัติตามคำแนะนำของระบบ รวมทั้งช่องทางรับฟัง feedback แบบเรียลไทม์ (in‑app feedback) ซึ่งงานวิจัยภาคสนามชี้ว่า การฝึกอบรมเชิงปฏิบัติการและการมีส่วนร่วมตั้งแต่ต้น ช่วยเพิ่มอัตราการยอมรับของพนักงานได้มากกว่า 30% เมื่อเทียบกับการสื่อสารเชิงเดียว
ข้อเสนอเชิงปฏิบัติการ (Actionable checklist)
- กำหนด KPI ด้านข้อมูลและปฏิบัติการ (completeness, accuracy, latency, safety incidents)
- ออกแบบ fallback & human‑override พร้อมขั้นตอน rollback อัตโนมัติหากเกิน threshold ของความเสี่ยง
- ดำเนินการ security-by-design: encryption in transit & at rest, key management, network segmentation, และ penetration testing เป็นประจำ
- จัดตั้ง Model Governance Board รับผิดชอบการอนุมัติ dataset, bias assessment, retraining cadence และการ audit trail
- วางแผน staged rollout ใช้ shadow/canary deployment ก่อน production พร้อมการทดสอบภายใต้ภาระจริง
- เตรียมแผนฝึกอบรมและ change management สำหรับคนขับ พนักงานคลัง และทีมปฏิบัติการ พร้อมเครื่องมือรับ feedback
- ทดสอบด้วย simulation และ chaos testing เพื่อประเมินพฤติกรรมในกรณี edge cases เช่น loss‑of‑GPS, peak traffic, หรือการโจมตีข้อมูล
สรุปคือ การนำ MARL สู่ production ต้องอาศัยการออกแบบเชิงระบบที่ครอบคลุมทั้งคุณภาพข้อมูล ความปลอดภัย การผสานระบบเดิม และการจัดการทรัพยากรมนุษย์ โดยใช้แนวทาง rollout แบบขั้นบันไดที่มี governance และ monitoring ต่อเนื่อง เพื่อให้การลดเวลารอและค่าน้ำมันเป็นผลได้จริงและยั่งยืน
บทสรุปและมุมมองอนาคต
บทสรุปและมุมมองอนาคต
การทดลองระบบ Multi‑Agent Reinforcement Learning (MARL) เพื่อควบคุมฟลีทรถบรรทุกและการบริหารคลังสินค้าแบบเรียลไทม์ แสดงให้เห็นผลกระทบเชิงบวกที่ประจักษ์ต่อการดำเนินงานของผู้ให้บริการโลจิสติกส์ไทย โดยสรุปจากผลการทดลองภาคสนาม พบการลดเวลารอรถในจุดรับ-ส่งเฉลี่ยระหว่าง 18–30% การลดการใช้เชื้อเพลิงโดยรวมราว 12–22% และการเพิ่มอัตราการใช้งานฟลีท (fleet utilization) ประมาณ 10–15% ส่งผลให้ต้นทุนต่อลูกค้าลดลง ขณะที่อัตราการส่งมอบตรงเวลา (on‑time delivery) ปรับปรุงขึ้นอย่างมีนัยสำคัญ ซึ่งชี้ชัดว่าการนำ MARL มาใช้สามารถสร้างมูลค่าเชิงปฏิบัติการและการเงินได้จริงในบริบทไทย
สำหรับผู้ประกอบการโลจิสติกส์ไทยที่ต้องการขยายผลจากการทดลองสู่การปฏิบัติอย่างยั่งยืน จำเป็นต้องดำเนินการเชิงยุทธศาสตร์ในหลายมิติ ได้แก่ การลงทุนในโครงสร้างข้อมูลและแพลตฟอร์มแบบเรียลไทม์ การสร้างความร่วมมือกับผู้เชี่ยวชาญด้าน AI และการกำหนด KPI ระยะยาวที่ชัดเจนและวัดผลได้ ตัวอย่างข้อเสนอเชิงยุทธศาสตร์ที่ควรพิจารณา ได้แก่:
- ลงทุนใน Data Infrastructure: สร้างระบบเก็บข้อมูลแบบสตรีม (telemetry จาก GPS, CAN bus, เซนเซอร์คลังสินค้า) เข้าสู่ data lake และระบบประมวลผลเรียลไทม์ (เช่น Kafka/stream processing) เพื่อรองรับการตัดสินใจแบบทันทีและการฝึกโมเดลที่ต่อเนื่อง
- พาร์ทเนอร์เชิงเทคโนโลยีและวิชาการ: ร่วมงานกับสตาร์ทอัพ AI, ผู้ให้บริการคลาวด์, และสถาบันวิจัยเพื่อถ่ายโอนความรู้ พัฒนา MLOps และระบบตรวจสอบโมเดล (model monitoring) ซึ่งช่วยลดความเสี่ยงและเร่งเวลาไปสู่ความพร้อมใช้งานเชิงพาณิชย์
- กำหนด KPI ระยะยาวและกลไกการวัดผล: ตั้งตัวชี้วัดหลักเช่นเวลารอเฉลี่ย, การใช้เชื้อเพลิงต่อกม., อัตราการส่งตรงเวลา, การใช้งานฟลีท, เวลาแฝงในการตัดสินใจ (decision latency), และดัชนีคุณภาพข้อมูล เพื่อใช้เป็นมาตรฐานในการประเมินประสิทธิภาพอย่างต่อเนื่อง
- การจัดการเปลี่ยนแปลงและการพัฒนาทรัพยากรมนุษย์: ลงทุนฝึกอบรมพนักงานด้านการใช้งานระบบ AI, การบำรุงรักษาเซนเซอร์ และการตีความผลลัพธ์เชิงปฏิบัติการ เพื่อให้เทคโนโลยีถูกใช้อย่างเต็มประสิทธิภาพและยอมรับภายในองค์กร
ในมุมมองอนาคต เทคโนโลยีพื้นฐานที่ควรจับตาอย่างใกล้ชิดได้แก่ 5G, edge computing / edge AI และ autonomous vehicles โดยมีผลต่อระบบ MARL ดังนี้:
- 5G: เครือข่ายความหน่วงต่ำและแบนด์วิดท์สูงจะช่วยให้การสื่อสารระหว่างตัวแทน (agents) ฟลีท และคลังสินค้าทำได้แบบ near‑real‑time ลดความล่าช้าในการประสานงานและเพิ่มความเสถียรของนโยบายการตัดสินใจร่วม
- Edge AI / Edge Computing: การประมวลผลการตัดสินใจบางส่วนที่ขอบเครือข่ายช่วยลดภาระการส่งข้อมูลไปยังศูนย์กลาง และตอบสนองได้รวดเร็วขึ้นสำหรับเหตุการณ์เฉพาะหน้า เช่น การเปลี่ยนเส้นทางฉุกเฉินหรือการบริหารคิวในคลัง
- Autonomous Logistics: ความก้าวหน้าของยานยนต์ไร้คนขับ, ยานพาหนะแบบ platooning และหุ่นยนต์จัดการคลัง จะทำให้ MARL สามารถขยายไปสู่ระบบอัตโนมัติเพื่อเพิ่มความต่อเนื่องของการดำเนินงาน ลดต้นทุนแรงงาน และเพิ่มความปลอดภัย แต่ต้องคำนึงถึงกฎระเบียบ ความปลอดภัยเชิงไซเบอร์ และการรวมระบบอย่างเป็นขั้นตอน
ท้ายที่สุด ความสำเร็จในระยะยาวของการปฏิรูปดิจิทัลในโลจิสติกส์ไทยจะขึ้นกับการทำให้เทคโนโลยีใหม่ๆ เป็นส่วนหนึ่งของกลยุทธ์ธุรกิจ โดยมีการวางแผนแบบเป็นขั้นบันได (pilot → scale → optimize) ตั้งเป้าผลตอบแทนการลงทุน (ROI) ชัดเจน (เช่น ภายใน 12–24 เดือนสำหรับโครงการปรับปรุงเส้นทางและการจัดคิว) และสร้างระบบกำกับดูแลข้อมูล (data governance) ที่เข้มแข็ง การนำ MARL มาใช้ควบคู่กับการเตรียมพร้อมทางโครงสร้างพื้นฐานและพันธมิตรเชิงกลยุทธ์จะทำให้ผู้ประกอบการโลจิสติกส์ไทยสามารถเปลี่ยนผลการทดลองที่น่าสนใจให้กลายเป็นความได้เปรียบเชิงการแข่งขันในระยะยาวได้อย่างเป็นรูปธรรม
บทสรุป
การทดลองระบบ Multi‑Agent Reinforcement Learning (MARL) สำหรับการควบคุมฟลีทรถบรรทุกและการจัดการคลังสินค้าแบบเรียลไทม์ แสดงให้เห็นศักยภาพที่ชัดเจนในการปรับปรุงประสิทธิภาพเชิงปฏิบัติการ — เบื้องต้นจากการทดลองภาคสนามพบว่ามีแนวโน้มลด เวลารอ (dwell/wait times) ประมาณ 20–35% และลดการใช้เชื้อเพลิง/ค่าน้ำมันราว 10–25% เมื่อเทียบกับการจัดตารางแบบเดิม การลดเหล่านี้สะท้อนทั้งการตัดสินใจเส้นทางแบบไดนามิก การประสานระหว่างยานพาหนะกับคลังสินค้า และการเพิ่มประสิทธิภาพการจัดส่งแบบเรียลไทม์ อย่างไรก็ตาม การขยายผลสู่เชิงพาณิชย์ยังต้องการการลงทุนเชิงโครงสร้าง เช่น การรวบรวมและทำความสะอาดข้อมูลคุณภาพสูง, การผสานระบบ OT/IT และระบบจัดการแบบรวมศูนย์, รวมถึงกรอบการกำกับดูแลข้อมูลและนโยบายความปลอดภัยสารสนเทศก่อนนำไปใช้งานจริง
การนำ MARL ไปใช้ในระดับองค์กรควรดำเนินตามแนวทางแบบเป็นขั้นตอน (pilot → scale) โดยเริ่มจากโครงการนำร่องที่ตั้งสมมติฐาน KPI ชัดเจน เช่น On‑time delivery, average dwell time, การใช้เชื้อเพลิงต่อตู้/ต่อเที่ยว และการปล่อย CO2 แล้วติดตามเป็นระยะยาวเพื่อประเมิน ROI ที่ยั่งยืน นอกจากนี้ต้องออกแบบมาตรการด้านความปลอดภัยและความน่าเชื่อถือ (fail‑safe), บูรณาการ มนุษย์ในวงจรการตัดสินใจ (human‑in‑the‑loop) สำหรับการตรวจสอบ/แก้ไขเชิงนโยบาย และจัดตั้งกระบวนการวัดผลและ governance เช่น การทำ audit logs, explainability ของตัวแบบ และแผนสำรองเมื่อระบบอัตโนมัติแสดงพฤติกรรมผิดปกติ เมื่อปฏิบัติตามแนวทางดังกล่าว MARL มีศักยภาพที่จะช่วยลดต้นทุนดำเนินงาน เพิ่มคุณภาพบริการ และลดผลกระทบต่อสิ่งแวดล้อม แต่ความสำเร็จเชิงพาณิชย์จำเป็นต้องมีการลงทุนด้านข้อมูล ระบบจัดการ และการกำกับดูแลอย่างเป็นระบบควบคู่กัน



