
สตาร์ทอัพไทยเปิดตัว "AutoPromptLab" แพลตฟอร์มใหม่ที่ออกแบบมาเพื่อแก้ปัญหาท้าทายในยุคแชทบอทเชิงธุรกิจ — การเลือกและปรับแต่ง prompt ที่เหมาะสมกับ Large Language Models (LLMs) แบบอัตโนมัติ AutoPromptLab ช่วยให้ทีมงานสามารถรัน A/B‑ทดสอบ prompt ได้ด้วยระบบอัตโนมัติ วัดความเสถียรของคำตอบ (stability), วิเคราะห์ปัจจัยอคติ (bias) ในผลลัพธ์ และคำนวณต้นทุนต่อคำตอบอย่างละเอียด พร้อมแดชบอร์ดรายงานเชิงลึกและการเชื่อมต่อกับ LLM หลายค่ายเพื่อเปรียบเทียบประสิทธิภาพแบบเรียลไทม์
เหตุผลที่เครื่องมือนี้น่าสนใจสำหรับภาคธุรกิจคือปัญหาเรื่องการตอบสนองที่ไม่แน่นอนของโมเดล ความเสี่ยงด้านอคติ และต้นทุนการใช้งาน LLM ที่มักถูกมองข้าม AutoPromptLab ให้ข้อมูลเชิงตัวเลขและตัวชี้วัดที่ใช้งานได้จริง — ตัวอย่างเช่น การวัดความผันผวนของคำตอบเป็นเปอร์เซ็นต์ การระบุกรณีที่มีความเอนเอียงทางภาษา หรือการประมาณต้นทุนต่อคำตอบเพื่อช่วยตัดสินใจเลือกการตั้งค่าและผู้ให้บริการ LLM ที่เหมาะสม ซึ่งตามแนวปฏิบัติธุรกิจการปรับ prompt และการเลือกโมเดลอย่างเป็นระบบสามารถลดต้นทุนงานบริการลูกค้าและเพิ่มความแม่นยำของการตอบกลับได้อย่างมีนัยสำคัญ
สรุปข่าวโดยย่อ
สรุปข่าวโดยย่อ
สตาร์ทอัพไทยเปิดตัวแพลตฟอร์ม AutoPromptLab เมื่อเร็ว ๆ นี้ (ประกาศเปิดตัวในช่วงต้นเดือนมีนาคม 2026) โดยพัฒนาเพื่อรองรับการทดสอบและปรับจูน prompt สำหรับแชทบอทธุรกิจอย่างเป็นระบบ ทีมผู้ก่อตั้งระบุว่าเป็นกลุ่มวิศวกรและนักวิจัยด้านปัญญาประดิษฐ์ (NLP) และวิศวกรรมซอฟต์แวร์ที่มุ่งแก้ปัญหาความไม่สม่ำเสมอของผลลัพธ์จากโมเดลภาษาใหญ่ (LLM) ในการใช้งานเชิงธุรกิจ
AutoPromptLab ทำหน้าที่เป็นแพลตฟอร์มสำหรับ A/B‑ทดสอบ prompt อัตโนมัติ โดยสามารถรันชุด prompt หลายเวอร์ชันแบบขนาน ประเมินผลลัพธ์เชิงคุณภาพและเชิงปริมาณ เช่น ความสม่ำเสมอของคำตอบ (stability), ดัชนีอคติ (bias metrics), และต้นทุนต่อคำตอบ (cost per response) รวมถึงมีฟีเจอร์ในการติดตามผลแบบเรียลไทม์ บันทึกผลการทดสอบ และเชื่อมต่อกับผู้ให้บริการ LLM ที่หลากหลายเพื่อนำผลไปใช้งานจริง
เชิงธุรกิจ AutoPromptLab ช่วยลดความเสี่ยงจากความแปรปรวนของคำตอบที่อาจส่งผลต่อภาพลักษณ์และการปฏิบัติตามกฎระเบียบขององค์กร ลดต้นทุนการให้บริการด้วยการเลือก prompt ที่ให้ผลดีที่สุดต่อราคา และลดอคติที่อาจเกิดขึ้นจากการนำโมเดลไปใช้งาน ตัวอย่างจากการทดสอบนำร่องที่บริษัทระบุคือการลดความแปรปรวนของคำตอบได้ราว 35–50% และลดต้นทุนต่อคำตอบได้ราว 20–30% เมื่อเทียบกับการใช้ prompt เดียวแบบเดิม (ตัวเลขดังกล่าวเป็นผลจากการทดสอบนำร่องของผู้พัฒนา)
สำหรับภาคธุรกิจที่ให้บริการลูกค้าผ่านแชทบอท เช่น ศูนย์บริการลูกค้า อีคอมเมิร์ซ และบริการทางการเงิน แพลตฟอร์มนี้ถูกออกแบบมาเพื่อตอบโจทย์การเพิ่มความสม่ำเสมอของการตอบ ลดข้อผิดพลาดเชิงเนื้อหา และปรับปรุงต้นทุนต่อการให้บริการ ซึ่งผู้พัฒนาคาดว่าองค์กรที่นำ AutoPromptLab ไปใช้จะเห็นผลตอบแทนจากการลงทุน (ROI) ภายในระยะเวลาไตรมาสถึงครึ่งปี ขึ้นกับปริมาณการใช้งานและการปรับจูนที่ต้องการ
- ใคร: สตาร์ทอัพไทยผู้พัฒนาแพลตฟอร์ม AutoPromptLab — ทีมผู้ก่อตั้งเป็นวิศวกรและนักวิจัยด้าน AI
- อะไร: แพลตฟอร์มสำหรับ A/B‑ทดสอบ prompt อัตโนมัติ โดยวัดความเสถียร อคติ และต้นทุนต่อคำตอบ
- เหตุผล: แก้ปัญหาความแปรปรวนของผลลัพธ์จาก LLM ลดความเสี่ยงด้านอคติ และลดต้นทุนการตอบคำถามเชิงธุรกิจ
AutoPromptLab คืออะไร — ฟีเจอร์และจุดขายหลัก
ภาพรวมและคุณค่าเชิงธุรกิจ
AutoPromptLab เป็นแพลตฟอร์มสำหรับการทดสอบและปรับปรุง prompt สำหรับแชทบอทเชิงธุรกิจโดยเฉพาะ มุ่งเน้นให้ทีมด้านผลิตภัณฑ์ ฝ่ายบริการลูกค้า และวิศวกร ML สามารถรันการทดลอง A/B‑testing กับหลายเวอร์ชันของ prompt ได้อย่างอัตโนมัติ โดยวัดผลทั้งด้าน ความเสถียร (latency, error rate), ความเอนเอียงหรืออคติ (bias metrics) และ ต้นทุนต่อคำตอบ (cost per response) พร้อมจัดสรรทรัพยากรสู่โมเดล LLM หลายค่าย การทำงานแบบนี้ช่วยลดเวลาการปรับจูนจากสัปดาห์เหลือเป็นวันหรือชั่วโมง และช่วยให้ธุรกิจตัดสินใจบนพื้นฐานข้อมูลเชิงปริมาณ เช่น หากเวอร์ชัน A ลดต้นทุนต่อคำตอบจาก 0.06 USD เป็น 0.03 USD พร้อมรักษาอัตราความพึงพอใจของผู้ใช้ไว้ที่ ≥95% ระบบจะแนะนำการเลื่อนใช้งานแบบอัตโนมัติ
ฟีเจอร์หลักของแพลตฟอร์ม
AutoPromptLab ประกอบด้วยชุดฟีเจอร์ครบวงจรที่ออกแบบมาเพื่อการทดลอง prompt อย่างเป็นระบบ ได้แก่:
- การสร้างและจัดการชุด prompt หลายเวอร์ชัน: สร้างเวอร์ชันแตกต่างกัน (A, B, C...) บันทึกประวัติการเปลี่ยนแปลง (versioning) และเปรียบเทียบผลข้ามเวอร์ชันได้ทันที
- เวิร์กโฟลว์แบบลากวาง (drag-and-drop): ต่อเชื่อมบล็อก prompt, ขั้นตอนการแปลงข้อความก่อนส่ง (pre‑processing), เงื่อนไขการเลือกโมเดล และการ post‑processing โดยไม่จำเป็นต้องเขียนสคริปต์
- การกำหนดสมมติฐาน A/B และเกณฑ์ประเมิน: ตั้ง KPI เช่น อัตราความพึงพอใจ (CSAT), อัตรความแม่นยำของข้อมูล, อัตรตอบกลับสำเร็จ และค่าสถิติทางสถิติที่ต้องการให้ผ่าน (p‑value, CI)
- การรันแบบอัตโนมัติและการสเกล: Scheduler สำหรับรันการทดลองเป็นช่วง, กำหนดเงื่อนไขยุติโดยอัตโนมัติเมื่อถึงเกณฑ์ (early stopping) และสเกลทราฟฟิกไปยังเวอร์ชันที่ชนะ
- การวัดอคติและความเสถียร: โมดูลตรวจจับคำตอบที่มีความเอนเอียง, การแจกแจงผลตามกลุ่มประชากร และการตรวจสอบ latency/timeout ของแต่ละโมเดล
- การเชื่อมต่อกับ LLM หลายค่ายผ่าน API: รองรับการสลับหรือจับคู่โมเดล OpenAI, Anthropic, Mistral, โมเดลภายในองค์กร (on‑prem) พร้อมบันทึก log การเรียก API
UI สำหรับสร้าง/จัดการ prompt หลายเวอร์ชันและเวิร์กโฟลว์แบบลากวาง
อินเทอร์เฟซของ AutoPromptLab ถูกออกแบบสำหรับผู้ใช้เชิงธุรกิจ โดยมีหน้าจอแบบ visual canvas ที่ให้ผู้ใช้ลากบล็อกของ prompt, เงื่อนไขการแยกผู้ใช้, และบล็อกการประเมินผลมาวางต่อกันได้ ตัวอย่างองค์ประกอบใน UI ได้แก่:
- รายการเวอร์ชันทางซ้ายมือ (Version panel) แสดงสถานะ (active, testing, archived)
- Canvas กลางสำหรับจัดลำดับการประมวลผล—เช่น Prompt A → Pre‑processor (cleaning) → Model X → Post‑processor → Evaluator
- Properties panel ทางขวาสำหรับตั้งค่ารายละเอียดของแต่ละบล็อก เช่น temperature, max_tokens, และการ map ฟิลด์เมตาดาต้า
- Preview และ debug console สำหรับทดลองส่งข้อความกับแต่ละเวอร์ชันแบบเรียลไทม์
การกำหนดกลุ่มเป้าหมายและสัดส่วนผู้ใช้สำหรับการรัน A/B
การแบ่งกลุ่มผู้ใช้ (user segmentation) ใน AutoPromptLab สามารถตั้งได้ละเอียด เช่น แยกตามภูมิภาค, ประเภทลูกค้า (พรีเมียม/ฟรี), ช่องทาง (เว็บ/มือถือ), หรือพฤติกรรมการใช้งาน ผู้ดูแลสามารถกำหนดสัดส่วนการส่งทราฟฟิกไปยังแต่ละเวอร์ชันอย่างยืดหยุ่น เช่น 10%→A, 40%→B, 50%→C หรือใช้การสุ่มแบบ strata เพื่อให้ผลลัพธ์มีความสมดุลทางประชากร
นอกจากนี้ระบบรองรับการตั้งค่าแบบ sequential rollouts และ canary releases — เริ่มจากกลุ่มผู้ใช้เล็ก ๆ (เช่น 1,000 คนแรก) และขยายขึ้นเมื่อผ่านเกณฑ์ความสำเร็จที่กำหนดไว้ เช่น latency < 800ms และ CSAT > 90%
การเก็บข้อมูลคำตอบ เมตาดาต้า และการเรียก API สู่ LLM ต่าง ๆ
AutoPromptLab บันทึกข้อมูลเชิงปฏิสัมพันธ์อย่างละเอียดทั้งในระดับ request และ response รวมถึงเมตาดาต้าสำคัญ เช่น:
- ข้อความต้นทางและเวอร์ชันของ prompt ที่ใช้
- ค่า latency, HTTP status, และจำนวน token ที่ใช้ต่อคำตอบ
- ตัวชี้วัดความเอนเอียง (bias score), ความมั่นใจ (confidence), และดัชนีความพึงพอใจจากผู้ใช้
- ข้อมูลกลุ่มผู้ใช้ (segmentation labels) และ trace ของการสลับโมเดลที่เรียกใช้
ระบบสามารถส่งคำขอ (API calls) ไปยัง LLM หลายรายพร้อมกัน หรือสลับตามกฎที่ตั้งไว้ เช่น เรียกโมเดลความเร็วสูงสำหรับคำถามทั่วไป และสลับไปโมเดลความแม่นยำสูงสำหรับคำถามที่เกี่ยวกับข้อมูลส่วนบุคคล ข้อมูลการเรียก API จะถูกบันทึกเพื่อคำนวณต้นทุนจริง (realized cost per response) และใช้วิเคราะห์ ROI ของแต่ละเวอร์ชัน
ตัวอย่างสั้น ๆ ของหน้าจอการตั้งค่าหรือ flow การสร้างการทดลอง
ตัวอย่าง flow การสร้างการทดลอง A/B ในหน้า Setup จะประกอบด้วยขั้นตอนสั้น ๆ ดังนี้:
- 1) สร้าง Experiment: ตั้งชื่อ เช่น "Checkout‑UX Prompt Test Q2"
- 2) เพิ่มเวอร์ชัน prompt: อัปโหลด Prompt A, Prompt B พร้อมกำหนด tag และคำอธิบาย
- 3) เลือกกลุ่มเป้าหมาย: เลือก segment = "Mobile Users, Thailand" และตั้งสัดส่วนทราฟฟิก 30% A / 70% B
- 4) ตั้ง KPI & Criteria: เลือก KPI = CSAT, latency, cost per response พร้อมตั้งค่า threshold (เช่น CSAT ≥ 92%, latency ≤ 700ms)
- 5) เลือกโมเดล LLM และค่า config: ผูก Prompt A → Model‑X (temperature=0.2), Prompt B → Model‑Y (temperature=0.0)
- 6) เริ่มรันและมอนิเตอร์: กด Start — ระบบจะเริ่มแจกจ่ายทราฟฟิกและแสดง dashboard แบบเรียลไทม์พร้อม alert เมื่อถึงเงื่อนไขหยุดอัตโนมัติ
ในหน้าจอ Summary ผู้ใช้จะเห็นกราฟเปรียบเทียบ CSAT, latency distribution, distribution ของ bias score และต้นทุนรวมที่เกิดขึ้นแบบ time‑series ทำให้การตัดสินใจแทนการคาดเดาเป็นการตัดสินใจบนฐานข้อมูลเชิงปริมาณและการวิเคราะห์ที่โปร่งใส
กลไกการทำงานของการทดสอบ A/B กับ LLM
ภาพรวมกระบวนการ (Workflow Summary)
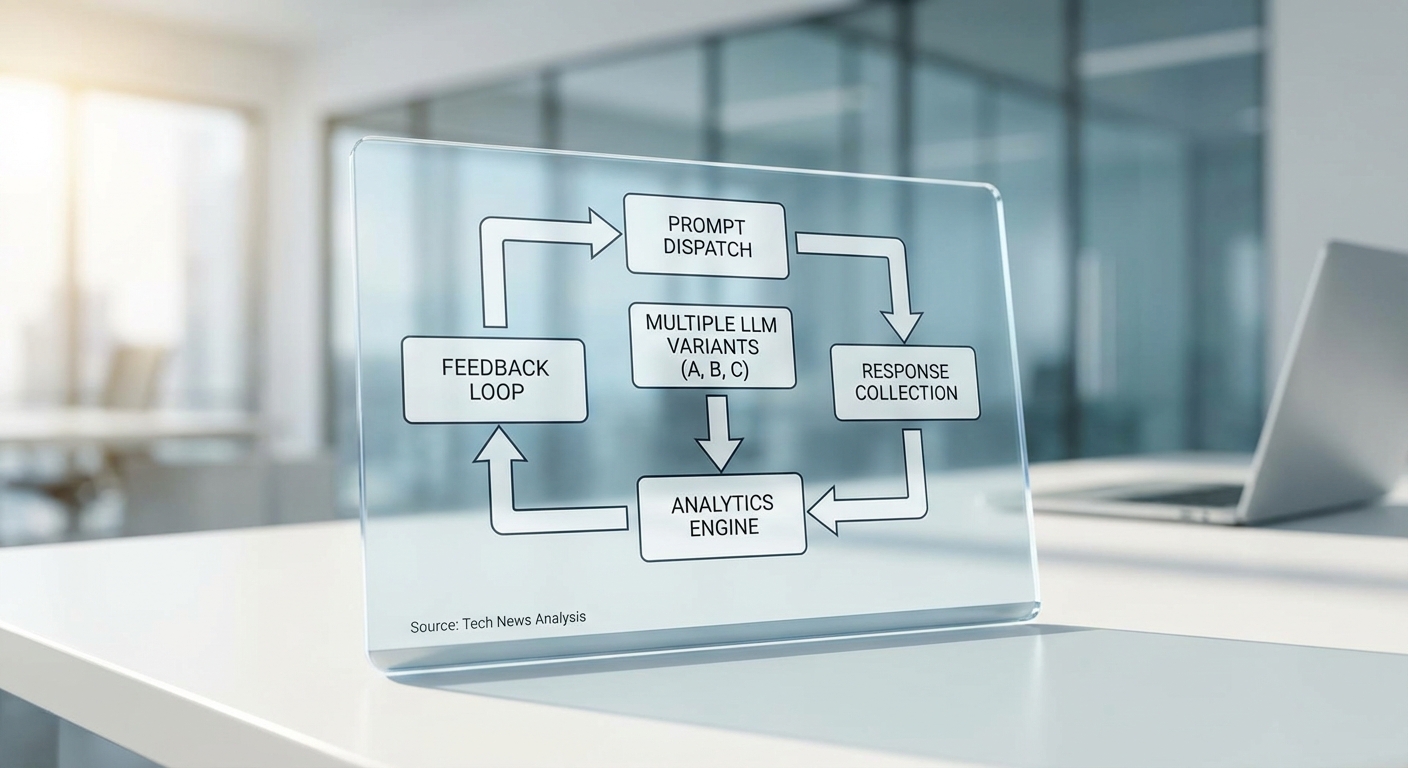
การทดสอบ A/B กับ Large Language Models (LLM) ในเชิงธุรกิจประกอบด้วยลำดับงานที่ชัดเจนตั้งแต่การสร้าง prompt ไปจนถึงการวิเคราะห์ผลลัพธ์เชิงปริมาณ โดยสรุป flow หลักคือ create prompts → dispatch to variants → capture responses + metadata → analyze metrics กระบวนการนี้ไม่ได้จำกัดอยู่เพียงการเปรียบเทียบ prompt สองแบบภายในโมเดลเดียวเท่านั้น แต่รองรับทั้ง cross‑prompt (prompt หลายแบบบน model เดียว) และ cross‑model (prompt เดียวหรือหลายแบบเทียบระหว่าง LLM ต่างรุ่น/ผู้ให้บริการ)
ขั้นตอนเชิงเทคนิค: การสร้างและแจกจ่าย Prompt
ขั้นแรกคือการจัดการชุดของ prompt เป็น template หรือ variant ที่มีการติดป้าย (label) ชัดเจน เช่น prompt_v1, prompt_v2 หรือ model_gpt4, model_opt. ระบบจะทำการตั้งค่า parameters ของการเรียกใช้งาน เช่น temperature, top_p, max_tokens และ constraint อื่น ๆ เพื่อให้การเปรียบเทียบเป็นธรรม ปริมาณตัวอย่างที่ส่งจะถูกกำหนดจากเป้าหมายการทดสอบ — ตัวอย่างเช่น หากเป้าหมายเป็นการวัด latency ความแตกต่างที่สำคัญอาจตรวจพบได้ด้วยไม่กี่ร้อยคำขอ แต่หากเป็นการวัดอัตราความถูกต้องหรือ bias ขนาดเล็ก อาจต้องการตัวอย่างเป็นหมื่นถึงแสนคำขอเพื่อให้มีพลังทางสถิติเพียงพอ
การกระจายคำขอ (Dispatch) และการเก็บข้อมูลผลลัพธ์
เมื่อ dispatch ระบบจะสุ่มหรือจัดแบ่งทราฟิกไปยัง variants ตามนโยบายที่กำหนด (เช่น 50/50 หรือ stratified sampling ตามภูมิภาค/อุปกรณ์) ข้อสำคัญคือการบันทึก metadata ประกอบด้วย:
- ข้อมูลโหมด: model_id, model_version, prompt_id, prompt_hash
- การตั้งค่าเรียกใช้งาน: temperature, max_tokens, top_p, seed
- ค่าสถิติระบบ: latency (ms), token_usage (prompt/response), API_cost
- บริบทผู้ใช้: session_id (hashed), locale, device_type, timestamp
- ผลลัพธ์เชิงเนื้อหา: raw_response_text, likelihood_score (ถ้ามี), parsing_status
การเก็บ metadata อย่างครบถ้วนช่วยให้วิเคราะห์สาเหตุของความแตกต่างได้ (เช่น ความล่าช้าเกิดจาก network หรือ model processing) และช่วยคำนวณต้นทุนต่อคำตอบได้อย่างแม่นยำ — ตัวอย่างเช่นการบันทึกว่า variant A ใช้เฉลี่ย 120 โทเค็น/คำตอบ ขณะที่ variant B ใช้ 85 โทเค็น/คำตอบ จะมีผลต่อค่าใช้จ่ายต่อคำตอบทันที
การวิเคราะห์เมตริกและการควบคุมตัวแปร
ขั้นตอนวิเคราะห์เริ่มจากการทำความสะอาดข้อมูล (dedupe, filter error responses) แล้วคำนวณเมตริกหลัก ได้แก่:
- Performance: latency (mean/median), throughput
- Cost: token per response, cost-per-response (USD/THB)
- Quality: accuracy/precision/recall (ถ้ามี label), human-evaluation score, relevance
- Stability & Bias: variance ของคำตอบ, bias score ตามกลุ่มประชากร
การทดสอบจะใช้วิธีการทางสถิติเช่น t-test สำหรับเมตริกเชิงตัวเลข, chi-square สำหรับเมตริกเชิงสัดส่วน หรือ bootstrap เพื่อหาค่า confidence interval ตัวอย่างเช่น หากต้องการตรวจจับการเปลี่ยนแปลงความแม่นยำจาก 90% เป็น 91% ด้วยพลัง 80% และระดับนัยสำคัญ 5% อาจต้องตัวอย่างนับหมื่นรายการ ในทางกลับกัน หากสนใจ latency ที่ต่างกัน 200ms อาจเพียงไม่กี่ร้อยคำขอก็เพียงพอ
การสุ่มตัวอย่างและการควบคุมเพื่อความน่าเชื่อถือ
เพื่อให้ผลทดสอบมีความน่าเชื่อถือ จำเป็นต้องออกแบบการสุ่มตัวอย่างและควบคุมคอนฟาวน์เดอร์ ดังนี้:
- Randomization: กระจายคำขอแบบสุ่มตาม session/user เพื่อหลีกเลี่ยง selection bias
- Stratification: แยกชั้นตัวอย่างตาม locale, device, หรือ user segment เพื่อให้ผลไม่เบ้ไปยังกลุ่มใดกลุ่มหนึ่ง
- A/A test: เรียกใช้งานสองกลุ่มที่เหมือนกันเพื่อตรวจสอบระบบวัดและความแปรปรวนก่อนเริ่ม A/B
- Control variables: คงค่าพารามิเตอร์ที่ไม่เกี่ยวข้อง เช่น network route, rate limits, และ model hyperparameters ที่ไม่ได้ถูกทดสอบ
นอกจากนี้ควรกำหนดกฎการหยุด/เปิดใช้งานอัตโนมัติ (early stopping, sequential testing controls) เพื่อลดความเสี่ยงจากการค้นหาผลบังเอิญ (peeking) และใช้การปรับแก้หลายการทดสอบ (multiple comparisons correction) เมื่อเทียบหลาย variant พร้อมกัน
การเชื่อมโยงผลลัพธ์สู่การตัดสินใจเชิงธุรกิจ
ผลลัพธ์จากการวิเคราะห์ต้องถูกแปลเป็นดัชนีเชิงธุรกิจ เช่น คาดการณ์ค่าใช้จ่ายต่อเดือนตามปริมาณการใช้งานจริง หรือการประเมิน trade‑off ระหว่างคุณภาพและต้นทุน ตัวอย่างเช่น หาก model A ให้คะแนนความพึงพอใจสูงกว่าราว 4% แต่มีค่าใช้จ่ายต่อคำตอบเพิ่มขึ้น 25% ฝ่ายธุรกิจอาจต้องตัดสินใจเลือกผสานสองโมเดล (hybrid routing) หรือปรับ prompt เพื่อลดโทเค็นโดยไม่ลดคุณภาพ
สรุปแล้ว การทดสอบ A/B กับ LLM เป็นกระบวนการที่ต้องการการออกแบบเชิงทดลองอย่างรอบคอบ การบันทึก metadata ที่ละเอียด และการวิเคราะห์เชิงสถิติอย่างเป็นระบบเพื่อให้ผลลัพธ์มีความเชื่อมั่นและพร้อมนำไปสู่การตัดสินใจเชิงธุรกิจ
เมตริกสำคัญ: ความเสถียร (stability), อคติ (bias) และต้นทุนต่อคำตอบ
ในบริบทของการทดสอบ Prompt แบบอัตโนมัติด้วย AutoPromptLab เมตริกสามประการนี้เป็นหัวใจสำหรับการประเมินคุณภาพของแชทบอทเชิงธุรกิจอย่างครบวงจร: ความเสถียร (stability) ช่วยบอกว่าโมเดลตอบสม่ำเสมอหรือไม่, อคติ (bias) เฝ้าระวังความไม่เป็นกลางต่อกลุ่มผู้ใช้ต่างๆ และ ต้นทุนต่อคำตอบ (cost per response) เป็นตัวชี้วัดด้านการเงินที่จับต้องได้ การตั้งนิยามเชิงปริมาณและเกณฑ์ค่าวัดที่ชัดเจนจะช่วยให้การตัดสินใจเชิงธุรกิจมีความน่าเชื่อถือและสอดคล้องกับเป้าหมายทางการเงินและความเสี่ยงขององค์กร
ความเสถียร (Stability)
นิยามและตัวชี้วัด — ความเสถียรวัดได้จากหลายมุม ได้แก่ response similarity, confidence variance และ latency distribution ที่ AutoPromptLab วิเคราะห์ร่วมกันเพื่อให้เห็นภาพเต็มของความสม่ำเสมอ
- Response similarity: ใช้การแปลงคำตอบเป็น embedding แล้วคำนวณ cosine similarity ระหว่างคำตอบที่ได้จาก prompt เดียวกันเมื่อเรียกใช้งานซ้ำ ๆ ค่าเฉลี่ย (mean cosine) และความแปรปรวน (variance) เป็นตัวชี้วัดหลัก ตัวอย่างสูตรพื้นฐาน: mean_sim = (1/N) * Σ_i cosine(embed_i, embed_ref) และ sim_variance = Var(cosine_values).
- Confidence variance: เก็บค่าความมั่นใจของโมเดล (เช่น softmax probability หรือ calibrated score) แล้วคำนวณค่าเฉลี่ยและความแปรปรวน หาก variance สูง แสดงว่าโมเดลไม่มั่นคงแม้ prompt ไม่เปลี่ยน.
- Latency distribution: วัด mean, median, p95, p99 เพื่อประเมินประสบการณ์ผู้ใช้ ความล่าช้าแบบหางยาว (high p99) อาจชี้ว่าระบบมีปัญหาในการสเกล
ตัวอย่างเชิงตัวเลขและเกณฑ์แนะนำ: หาก mean cosine similarity > 0.90 และ sim_variance < 0.02 ถือว่าเสถียรในระดับสูง; confidence variance ควรน้อยกว่า 0.05 (ขึ้นอยู่กับสเกลของคะแนน); latency p95 < 800 ms สำหรับแชทบอตเชิงธุรกิจเป็นมาตรฐานที่พึงประสงค์ ตัวอย่างสถิติที่วัดได้จริง เช่น response variance = 0.12 (สูง) หรือ p99 latency = 2,400 ms (ต้องปรับปรุง)
อคติ (Bias)
นิยามและแนวทางการตรวจจับ — อคติถูกตรวจจับได้ผ่านการวิเคราะห์เนื้อหา (content analysis), การคำนวณความเหลื่อมล้ำระหว่างกลุ่ม (group disparity) และการใช้เมตริกเชิงสถิติ เช่น demographic parity หรือ equalized odds
- การวิเคราะห์เนื้อหา: ทำการแยกข้อความตามหมวด เช่น sentiment, toxic content, หรือการตอบแบบแตกต่างเชิงคุณภาพ แล้วเปรียบเทียบผลตาม attribute ของผู้ใช้ (เพศ, ภาษา, อายุ, ภูมิภาค)
- ค่า disparity ระหว่างกลุ่ม: คำนวณความต่างของสัดส่วนผลลัพธ์ เช่น P(Y=positive | A=male) − P(Y=positive | A=female) หรืออัตราส่วน (ratio) เพื่อดูความไม่เสมอภาค
- Demographic parity (สูตร): DP_diff = P(Y=1 | A=a) − P(Y=1 | A=b). ในหลายกรณีจะใช้ DP_ratio = P(Y=1 | A=a) / P(Y=1 | A=b) โดยค่าใกล้ 1 หมายถึงสมดุล
ตัวอย่างสภาพจริงและภาพรวมการแสดงผล: AutoPromptLab สามารถสร้าง heatmap แสดงค่า disparity ของคะแนน sentiment ตามเพศและภาษาที่แกน X/Y — เช่น อัตราการตอบเชิงบวกสำหรับผู้หญิง (0.62) และผู้ชาย (0.71) ให้ DP_diff = −0.09 ซึ่งบ่งชี้อคติชัดเจน ตัวอย่างเกณฑ์แนะนำ: ตั้งเป้าให้ |DP_diff| < 0.05 หรือ DP_ratio อยู่ในช่วง 0.8–1.25 ขึ้นอยู่กับความอ่อนไหวของแอปพลิเคชัน
การทดสอบทางสถิติและการแก้ไข: ใช้การทดสอบความมีนัยสำคัญ (เช่น chi-square หรือ bootstrap CI) เพื่อตรวจสอบว่า disparity ไม่ได้เกิดจากความไม่เพียงพอของตัวอย่าง และกำหนดแผนลดอคติ เช่น re-weighting, data augmentation, หรือปรับ prompt ที่เจาะจงเพื่อลดคำตอบที่เป็นอคติ
ต้นทุนต่อคำตอบ (Cost per response)
องค์ประกอบต้นทุน — ต้นทุนต่อคำตอบประกอบด้วยหลายส่วนหลัก: ค่าเรียก LLM (per-call fee), ค่า tokens ทั้ง input และ output, และ overhead ของระบบ (infrastructure, logging, retries, routing)
- สูตรพื้นฐาน:
Cost_per_response = Call_fee + (Tokens_in * Cost_input_token) + (Tokens_out * Cost_output_token) + Infra_overhead_per_call
- ตัวอย่างตัวเลขสมมติ (USD):
สมมติ Call_fee = $0.0004, Tokens_in = 50 (× $0.00002 = $0.0010), Tokens_out = 150 (× $0.00006 = $0.0090), Infra_overhead = $0.003 → Total ≈ $0.0134 ต่อคำตอบ
- ค่าแฝงที่ต้องคำนวณ: ค่า retry เมื่อเกิด timeout, ค่าแบนด์วิดท์, ค่าเซิร์ฟเวอร์สำหรับ pre-/post-processing และ caching ที่อาจลดต้นทุนได้
คำแนะนำเชิงธุรกิจสำหรับการตั้งเกณฑ์: กำหนด threshold ตามมูลค่าทางธุรกิจของการตอบแต่ละครั้ง — ตัวอย่างเช่น สำหรับการสนับสนุนลูกค้าทั่วไป ธุรกิจอาจตั้งเป้า Cost_per_response < $0.10 หากเป็นคำตอบที่มีมูลค่าสูง (เช่น การให้คำแนะนำทางการเงิน) อาจยอมรับต้นทุนสูงกว่าได้ แต่ต้องจับคู่กับเกณฑ์ความเสถียรและอคติที่เข้มงวดกว่า
การบูรณาการเมตริกทั้งสาม: แนะนำให้ตั้งระบบแจ้งเตือนเชิงผสม (composite alert) เช่น ระบุว่าให้สร้างการแจ้งเตือนเมื่อ (1) mean_sim < 0.85 หรือ sim_variance > 0.05, (2) |DP_diff| > 0.05 หรือ DP_ratio < 0.8, และ/หรือ (3) Cost_per_response > budget threshold ต่อเนื่อง N ครั้ง ทั้งนี้ควรกำหนดขนาดตัวอย่างสำหรับการทดสอบ A/B (เช่น N ≥ 1,000 ต่อเวอร์ชัน) และใช้การวิเคราะห์ความน่าเชื่อถือ (confidence intervals, p‑values) ก่อนตัดสินใจเปลี่ยน prompt ในระบบ production
สถาปัตยกรรมเทคนิคและการเชื่อมต่อกับระบบธุรกิจ
สถาปัตยกรรมเทคนิคและการเชื่อมต่อกับระบบธุรกิจ
AutoPromptLab ถูกออกแบบเป็นระบบแบบชั้น (layered architecture) เพื่อรองรับการเชื่อมต่อกับผู้ให้บริการ LLM หลายราย (เช่น OpenAI, Anthropic และโมเดลภายในองค์กร) พร้อมความสามารถในการ A/B‑ทดสอบแบบอัตโนมัติ ควบคุมต้นทุน และวัดคุณภาพผลลัพธ์แบบต่อเนื่อง โดยพื้นฐานสถาปัตยกรรมประกอบด้วย: API gateway, provider adapters, orchestration layer, observability & logging และ data & feedback store ซึ่งทำงานประสานกันบนโครงสร้างพื้นฐานที่จัดการได้ (Kubernetes) และเชื่อมต่อกับระบบธุรกิจผ่าน HTTP/webhook, SDK และปลั๊กอินสำหรับ CRM/Helpdesk
ระดับการเชื่อมต่อไปยัง LLM ใช้แนวทาง adapter pattern: แต่ละผู้ให้บริการมี connector แยก (เช่น OpenAI adapter, Anthropic adapter, local model runtime) ซึ่งรองรับทั้งการเรียกแบบ synchronous, streaming และ asynchronous โดยมีนโยบายการเลือกผู้ให้บริการ (provider selection policy) ที่พิจารณาจากความหน่วง (latency), ค่าบริการต่อคำตอบ (cost-per-response), ความเสถียร และผลลัพธ์เชิงคุณภาพ ตัวอย่างนโยบายเช่น fallback chaining (เมื่อ provider A ล้มเหลวให้เรียก B) หรือ fan‑out (เรียกหลาย provider พร้อมกันแล้วเลือกผลดีที่สุด) ระบบยังมี circuit breaker และ rate limiter เพื่อป้องกันการเกินขีดจำกัดของผู้ให้บริการภายนอก
การเชื่อมต่อกับระบบธุรกิจรองรับรูปแบบหลายช่องทาง:
- HTTP/webhook: สำหรับระบบที่ต้องการ callback เมื่อคำตอบพร้อม (synchronous/async callbacks)
- SDK: ไลบรารีภาษา JavaScript, Python และ Java เพื่อให้ทีมพัฒนาสามารถฝัง A/B‑testing และการเก็บเหตุการณ์เข้าแอปได้โดยตรง
- Plugin สำหรับ CRM/Helpdesk: ตัวอย่างเช่น connector สำเร็จรูปสำหรับ Salesforce, Zendesk และ Freshdesk เพื่อส่ง/รับคำขอ ติดตามสถานะการแก้ปัญหา และฝัง prompt variants บนรายการเคสอัตโนมัติ
ด้าน observability ถูกออกแบบเป็นหัวใจสำคัญของแพลตฟอร์ม โดยเก็บทั้ง log แบบมีโครงสร้าง (JSON structured logs), distributed tracing (OpenTelemetry + Jaeger), และ metrics แบบ time‑series (Prometheus/Grafana) เพื่อให้สามารถวิเคราะห์ latency percentiles (p50, p95, p99), throughput (RPS), error rate และ SLA compliance ได้อย่างชัดเจน นอกจากนี้ AutoPromptLab ยังเก็บเมตริกเชิงเวกเตอร์: embedding ของคำถามและคำตอบ (เช่น 768/1024 dimension) ใน vector DB (เช่น Milvus/Pinecone/FAISS) เพื่อการวิเคราะห์คุณภาพและการวัดความคล้ายคลึงของผลลัพธ์แบบเชิงเวกเตอร์ (vector similarity) — สิ่งนี้ช่วยให้ทีมสามารถระบุ cluster ของคำถามที่มีอคติหรือมีอัตราการตอบกลับผิดพลาดสูง
การ采样และการติดตามถูกออกแบบให้ประหยัดทรัพยากร: tracing sampling ระดับ 0.5–5% สำหรับ traffic ปกติ และเพิ่มเป็น 100% สำหรับกลุ่ม A/B ที่กำลังทดสอบ โดยเก็บตัวอย่างแบบ stratified sampling เพื่อลด bias ในการประเมินผล ตัวอย่างเมตริกเชิงธุรกิจที่ระบบติดตามได้รวมถึง: resolution rate ต่อ variant, average tokens per response, cost per answer (USD), hallucination score (ตามการตรวจสอบแบบ human-in-the-loop) — ในการทดสอบภายใน AutoPromptLab พบว่า ตัวอย่างเช่น A/B tuning อัตโนมัติสามารถลดค่าใช้จ่ายต่อคำตอบได้ถึง ~22% และเพิ่มอัตราการแก้ปัญหาเฉลี่ยได้ ~12% (ตัวเลขตัวอย่างจากการทดสอบภายใน ไม่ใช่ผลลัพธ์เชิงสาธารณะ)
ชั้น data storage ออกแบบให้แยกตามประเภทข้อมูล: time‑series metrics เก็บใน Prometheus/InfluxDB, logs และ events ส่งไปยัง ELK stack (Elasticsearch, Logstash, Kibana) หรือระบบ logging ที่จัดการ, vector embeddings เก็บใน vector DB พร้อม snapshot ไปยัง object storage (S3) สำหรับการวิเคราะห์ย้อนหลัง ส่วนข้อมูลธุรกรรมและ metadata เก็บใน relational DB (Postgres) โดยมี retention policy ที่ชัดเจนและสตอเรจสำหรับการสำรอง (backup) เป็นประจำ
ระบบ feedback เพื่อการปรับ prompt แบบอัตโนมัติประกอบด้วย feedback loop หลายระดับ: (1) offline evaluation โดยใช้ชุดทดสอบและ metrics ที่นิยามไว้, (2) online experimentation ที่ใช้ contextual bandit หรือ multi‑armed bandit algorithms (เช่น UCB หรือ epsilon‑greedy) เพื่อทดสอบ variant ที่ให้ผลดีสุดแบบเรียลไทม์, และ (3) human‑in‑the‑loop review สำหรับการตรวจสอบคุณภาพและการแก้ bias ก่อน deploy ระดับ production ระบบสามารถปรับ prompt อัตโนมัติโดยใช้แนวทาง gradient‑free search (เช่น hill‑climbing), template mutation หรือการเรียนรู้เชิงกลยุทธ์ (policy search) โดยมี guardrails ด้านความปลอดภัยและการประเมินความเสี่ยงก่อนเปลี่ยนแปลง
ด้านความปลอดภัยและความเป็นส่วนตัว AutoPromptLab บรรจุแนวทางปฏิบัติระดับองค์กร:
- การมาสก์ข้อมูลส่วนบุคคล: ใช้โมดูล PII detection (regex + NER models) เพื่อมาสก์หรือลบข้อมูล เช่น หมายเลขโทรศัพท์, หมายเลขบัตร, ที่อยู่ ก่อนส่งออกไปยัง LLM หากจำเป็นใช้ pseudonymization หรือ tokenization
- การจัดการ consent: เก็บสถานะการยินยอม (consent flags) ใน ledger แบบ immutable ระบุขอบเขตการใช้งานและเวลาหมดอายุ พร้อม API สำหรับสิทธิ์ผู้ใช้ (data subject rights) เช่น การขอลบหรือส่งออกข้อมูลตาม PDPA/GDPR
- การเข้ารหัส: ข้อมูลทั้งหมดใน transit ถูกปกป้องด้วย TLS 1.2/1.3 ส่วนข้อมูล at‑rest เข้ารหัสด้วย AES‑256 และการจัดการคีย์ผ่าน KMS/HSM (เช่น AWS KMS, Google Cloud KMS) พร้อมระบบ rotation ของคีย์ตามนโยบาย
- การควบคุมการเข้าถึง: RBAC/ABAC, การพิสูจน์ตัวตนแบบแม่นยำ (MFA, OAuth2/OIDC), และ audit logs ที่ตรวจสอบได้เพื่อรับรองความโปร่งใส
- การลดความเสี่ยงเชิงโมเดล: Safety filters ก่อนส่ง prompt เพื่อป้องกันเนื้อหาอันตราย, testing สำหรับ bias metrics และ sandboxing ของ local models เพื่อป้องกันการรั่วไหลของข้อมูล
สรุปสั้น ๆ: สถาปัตยกรรมของ AutoPromptLab มุ่งเน้นความยืดหยุ่นในการเชื่อมต่อกับผู้ให้บริการ LLM หลายรายและระบบธุรกิจ ติดตั้งระบบ observability ที่ครอบคลุม พร้อมกลไก feedback อัตโนมัติสำหรับการปรับ prompt และมีแนวทางด้านความปลอดภัยและความเป็นส่วนตัวระดับองค์กรเพื่อรองรับการใช้งานในงานบริการลูกค้าและ CRM/Helpdesk ขนาดใหญ่
กรณีศึกษาและตัวอย่างผลลัพธ์จริง (ตัวเลขและสถิติ)
ภาพรวมและหลักการเก็บข้อมูลเบื้องต้น
บทสรุปต่อไปนี้นำเสนอผลลัพธ์จากลูกค้าสตาร์ทอัพไทยสองรายที่นำ AutoPromptLab ไปใช้งานจริง ได้แก่ แชทบอทแนะนำสินค้าในแพลตฟอร์มอีคอมเมิร์ซรายกลาง-ใหญ่ และแชทบอทศูนย์บริการลูกค้าของผู้ให้บริการโทรคมนาคมระดับภูมิภาค ทั้งสองกรณีใช้กระบวนการ A/B‑ทดสอบแบบอัตโนมัติของ AutoPromptLab ในการปรับ prompt, ตรวจวัดความเสถียร (stability), ตรวจจับอคติ (bias) และประเมินต้นทุนต่อคำตอบ (cost-per-conversation)
กรณีศึกษา 1 — อีคอมเมิร์ซ: แชทบอทแนะนำสินค้า
ลูกค้า: แพลตฟอร์มอีคอมเมิร์ซที่มีผู้ใช้งานรายวันประมาณ 120,000 คน เป้าหมายโครงการคือเพิ่มอัตราการคลิกซื้อ (click-to-purchase) ลดการแก้คำตอบด้วยมือ และปรับต้นทุนต่อการสนทนาให้ต่ำลง
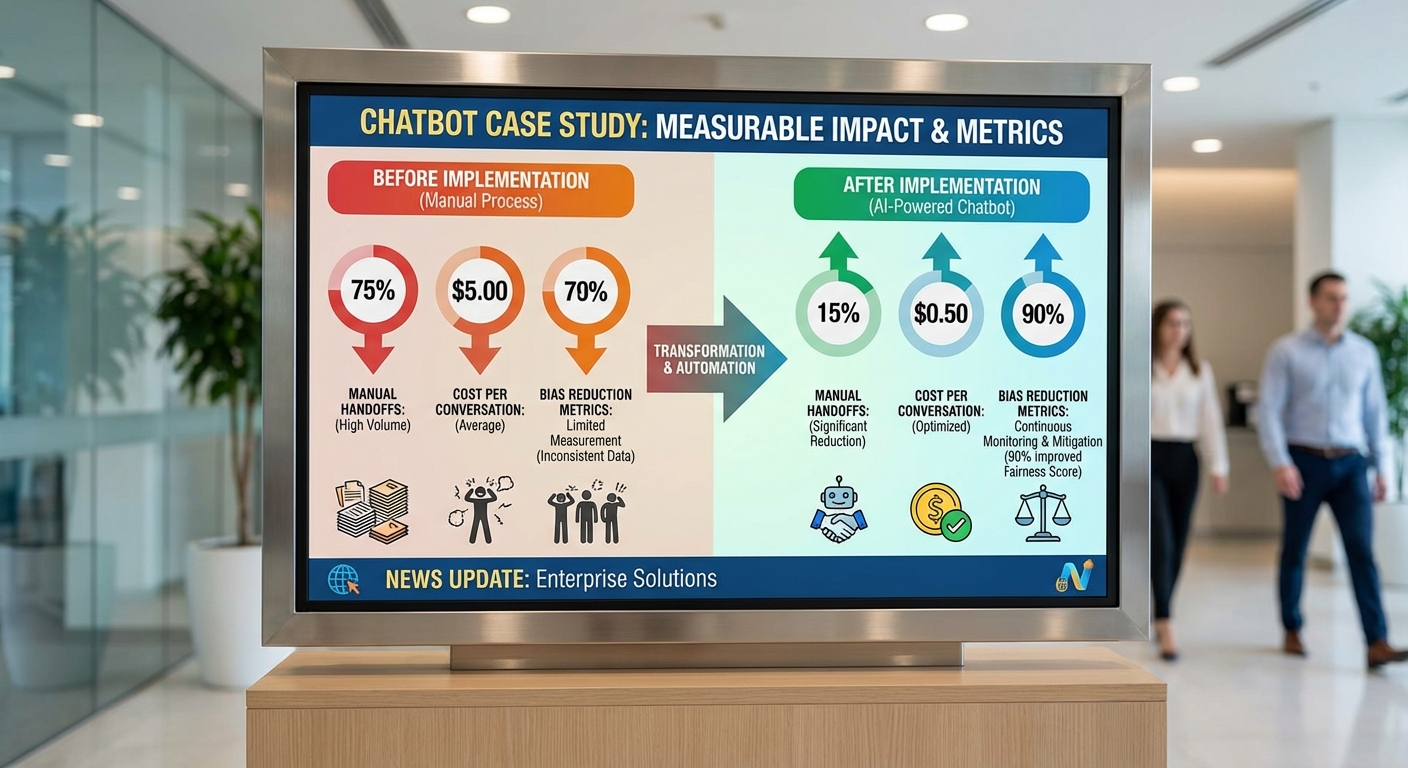
ผลลัพธ์ก่อน/หลัง (ช่วงทดสอบ 10 วัน, ตัวอย่างทั้งหมด 8,640 การสนทนา):
- อัตราการแก้คำตอบด้วยมือ (manual correction rate): ก่อน 14.2% → หลัง 9.2% (ลดลงแบบสัมพัทธ์ 35%)
- cost-per-conversation (ต้นทุนต่อการสนทนา): ก่อน ฿14.75 → หลัง ฿11.51 (ลดลง 22%)
- latency (เวลาตอบเฉลี่ย): ก่อน 1.30 วินาที → หลัง 1.05 วินาที (ปรับปรุง 19%)
- อัตรา conversion (click-to-purchase): ก่อน 3.6% → หลัง 4.3% (เพิ่มขึ้น 19% ในอัตราสัมพัทธ์)
วิธีการที่ใช้: AutoPromptLab รันชุด prompt variant ประมาณ 12 รูปแบบโดยอัตโนมัติ วัด KPI แบบเรียลไทม์และใช้การคัดเลือกตามค่าคะแนนผสม (composite score) ที่คำนึงถึงความแม่นยำ, latency และต้นทุน ผลการทดสอบแสดงให้เห็นว่า prompt ที่ให้บริบทผลิตภัณฑ์เชิงเปรียบเทียบและคำแนะนำแบบส่วนบุคคลมีประสิทธิภาพดีกว่า prompt แบบทั่วไป
การลดอคติ (bias) ในกรณีนี้: ทีมงานพบอคติเชิงเพศ (gendered recommendation bias) และอคติทางภูมิภาค (regional preference bias) โดยใช้การตรวจจับแบบ stratified analysis — คือแยกผลลัพธ์ตามเพศและภูมิภาคของผู้ใช้งานเพื่อคำนวณช่องว่าง (parity gap) ระหว่างกลุ่ม ผลการปรับ prompt และการทำ re-sampling ของตัวอย่างเทรนนิ่ง context ช่วยลดช่องว่าง parity gap ของการแนะนำสินค้าตามเพศจาก 12.4% → 4.8% (ลดลง 61%)
กรณีศึกษา 2 — ศูนย์บริการลูกค้า: ผู้ให้บริการโทรคมนาคม
ลูกค้า: บริษัทโทรคมนาคมรายใหญ่ของไทย ต้องการลดอัตราการโอนต่อให้เอเจนต์มนุษย์ (escalation rate), ปรับปรุงความสอดคล้องของคำตอบ และลดต้นทุนต่อบัตรเคลมการสนทนา
ผลลัพธ์ก่อน/หลัง (ช่วงทดสอบ 14 วัน, ตัวอย่างทั้งหมด 12,800 การสนทนา):
- อัตราการโอนต่อเอเจนต์ (escalation rate): ก่อน 18.0% → หลัง 13.1% (ลดลง 27%)
- cost-per-conversation: ก่อน ฿21.40 → หลัง ฿16.69 (ลดลง 22%)
- latency (เวลาตอบเฉลี่ย): ก่อน 1.75 วินาที → หลัง 1.40 วินาที (ปรับปรุง 20%)
- คะแนนความพึงพอใจเฉลี่ย (CSAT): ก่อน 78.6/100 → หลัง 82.4/100 (เพิ่มขึ้น 3.8 คะแนน)
วิธีการที่ใช้: AutoPromptLab สร้างชุด prompt ที่เน้นการยืนยันข้อมูลและการขอสิทธิ์ผู้ใช้อย่างชัดเจน (explicit confirmation prompts) และทดสอบกลยุทธ์ fallback อัตโนมัติหลายรูปแบบ ผลลัพธ์แสดงให้เห็นว่าการปรับ prompt เพื่อให้โมเดล 'ขอข้อมูลซ้ำ' ในกรณีความไม่แน่นอนลดการโอนต่อและเพิ่ม CSAT
การลดอคติ (bias) ในกรณีนี้: พบอคติทางอารมณ์ (sentiment bias) ที่ระบบมักตอบในโทนสุภาพน้อยลงกับลูกค้าที่มีข้อความเชิงบ่นรุนแรง วิธีการตรวจพบรวมถึงการรัน counterfactual prompts (เปลี่ยนเจตนา/คำพูดของผู้ใช้แต่คงบริบทเดิม) และคำนวณค่า sentiment divergence พบว่า divergence ลดจาก 0.22 → 0.08 หลังปรับ prompt และใช้ calibration layer ของ AutoPromptLab
บทเรียนเชิงปฏิบัติและข้อเสนอแนะสำหรับองค์กร
- ระยะเวลาในการทดสอบที่แนะนำ: โดยทั่วไป 1–2 สัปดาห์ สำหรับการทดสอบ initial A/B ที่ต้องการสัญญาณเชิงปริมาณที่มีความเชื่อมั่นเพียงพอ (ขึ้นกับ traffic)
- ขนาดตัวอย่างที่แนะนำ: สำหรับ KPI หลัก (เช่น escalation, manual correction, conversion) แนะนำให้มีตัวอย่างอย่างน้อย >5,000 คำตอบต่อชุดทดสอบเพื่อให้ผลมีความมีนัยสำคัญทางสถิติ; กรณีที่วัดการเปลี่ยนแปลงเล็กกว่า 5% อาจต้อง >10,000 ตัวอย่าง
- เมตริกที่ควรติดตามพร้อมกัน: latency, cost-per-conversation, manual correction rate, escalation rate, parity gaps (แบ่งตามเพศ/ภูมิภาค/ภาษา), CSAT และ divergence ของ sentiment
- การตรวจจับอคติ: ใช้การวิเคราะห์แบบ stratified, counterfactual testing และ human-in-the-loop annotation เพื่อจับสัญญาณอคติเชิงระบบ (systematic bias) และวัดความเปลี่ยนแปลงหลังการปรับ prompt
- การปรับจูนเชิงปฏิบัติ: ผสม prompt optimization กับการตั้ง guardrails และ calibration layer เพื่อให้ได้ trade-off ระหว่างต้นทุนและคุณภาพที่องค์กรยอมรับได้
สรุป: กรณีศึกษาจากลูกค้าไทยสองรายชี้ชัดว่า AutoPromptLab สามารถลดต้นทุนต่อการสนทนาและเวลาตอบได้อย่างมีนัยสำคัญ ขณะเดียวกันยังช่วยลดอคติประเภทที่ตรวจจับได้ (เช่น gender bias, regional bias, sentiment bias) เมื่อมีการออกแบบการทดสอบและขนาดตัวอย่างที่เหมาะสม การนำระบบไปใช้งานเชิงธุรกิจจึงควรวางแผนการทดสอบแบบมีกรอบชัดเจนและติดตามเมตริกหลายมิติอย่างต่อเนื่อง
โมเดลธุรกิจ ผลกระทบต่อการเปลี่ยนผ่านสู่ดิจิทัล และความท้าทาย
โมเดลธุรกิจที่เป็นไปได้
AutoPromptLab สามารถนำเสนอรูปแบบรายได้ได้หลายแนวทางเพื่อรองรับลูกค้าที่มีความต้องการและขนาดต่างกัน โดยรูปแบบที่เหมาะสมและนิยมประกอบด้วย:
- Subscription tier — แพ็กเกจรายเดือน/รายปีที่แบ่งตามจำนวนผู้ใช้ จำนวนการทดลอง (tests) ต่อเดือน และฟีเจอร์ (เช่น การวิเคราะห์เชิงลึก, dashboard ระดับองค์กร, การเก็บประวัติผลการทดสอบ) ตัวอย่างเช่น แพ็กพื้นฐานสำหรับทีมเล็กอาจจำกัดการทดสอบ 1,000 ครั้ง/เดือน ในขณะที่แพ็กระดับองค์กรมีการทดสอบไม่จำกัดและการสนับสนุนแบบ 24/7 โดยราคาอาจตั้งช่วงจากประมาณ 3,000–15,000 บาท/เดือน ขึ้นกับฟีเจอร์และ SLA
- Pay-per-test / Usage-based pricing — เก็บค่าบริการตามจำนวนการรัน A/B หรือจำนวน variant ต่อการทดสอบ เหมาะสำหรับลูกค้าที่ต้องการความยืดหยุ่นหรือมีปริมาณการทดสอบผันผวน โดยอาจคิดเป็นค่าใช้จ่ายต่อการทดสอบหนึ่งครั้งหรือคิดเป็นหน่วยคำตอบ (per-response) สำหรับการวัดต้นทุนต่อคำตอบ (cost-per-answer)
- Enterprise plan และค่าบริการการผนวกรวม (integration fees) — สำหรับลูกค้าองค์กรมักมีความต้องการด้านการเชื่อมต่อระบบภายใน (SSO/LDAP), การปรับแต่งตามนโยบายความเป็นส่วนตัว, การรองรับมาตรฐานความปลอดภัย และบริการฝึกอบรมทีมภายใน จึงสามารถเรียกเก็บค่าติดตั้งเริ่มต้น (one‑time onboarding fee), ค่าปรับแต่ง model connectors และค่าบริการบำรุงรักษาแบบรายปี
ผลกระทบต่อการเปลี่ยนผ่านสู่ดิจิทัลขององค์กร
การนำแพลตฟอร์ม A/B‑ทดสอบ prompt อัตโนมัติเข้ามาใช้มีศักยภาพเร่งการปรับใช้ Large Language Models (LLMs) ในองค์กรอย่างเป็นระบบและปลอดภัย โดยมีผลเชิงกลยุทธ์ที่สำคัญดังนี้:
- เร่งการตัดสินใจเชิงข้อมูล: การทดสอบและวัดผลแบบอัตโนมัติช่วยให้ทีมผลิตภัณฑ์และทีม AI สามารถตัดสินใจเลือก prompt หรือ policy ที่ให้ผลลัพธ์ดีที่สุดตามเมตริกที่กำหนด เช่น ความเสถียร (stability), อคติ (bias metrics), และต้นทุนต่อคำตอบ (cost‑per‑answer)
- ลดความเสี่ยงก่อนการนำสู่การใช้งานจริง: การมีชุดการทดสอบมาตรฐานช่วยตรวจจับปัญหาเรื่อง hallucination, ความไม่เป็นกลาง และความไม่สอดคล้องกับนโยบายองค์กรก่อนนำโมเดลเข้าสู่ระบบลูกค้าจริง
- สนับสนุนการกำกับดูแลและความโปร่งใส: บันทึกการทดลองและรายงานที่สามารถ audit ได้ ช่วยหน่วยงานกำกับดูแลภายในจัดทำเอกสารประกอบการตัดสินใจและตอบข้อกำหนดด้านกฎระเบียบ (เช่น PDPA หรือข้อกำหนดอุตสาหกรรม)
- เพิ่มประสิทธิภาพการลงทุนใน AI: เมตริกที่ชัดเจน (เช่น p95 latency, cost-per-answer) ช่วยให้ฝ่ายการเงินและผู้บริหารประเมิน ROI ของการนำ LLM มาใช้และควบคุมงบประมาณได้ดีขึ้น
ความท้าทายและความเสี่ยงที่องค์กรต้องคำนึง
แม้แพลตฟอร์มเช่น AutoPromptLab จะช่วยให้การทดสอบและปรับปรุง prompt มีประสิทธิภาพขึ้น แต่ก็มีความท้าทายที่สำคัญซึ่งอาจส่งผลต่อผลลัพธ์ทางธุรกิจและความเป็นไปตามกฎระเบียบ:
- การรับรองความเป็นกลางของโมเดล (bias certification): การวัดอคติเป็นเรื่องซับซ้อน—เมตริกที่ใช้วัดอคติอาจขึ้นกับชุดข้อมูลทดสอบ หากชุดข้อมูลไม่เป็นตัวแทนจริง องค์กรอาจยังคงปล่อยความเอนเอียงที่ตรวจไม่พบในสภาพแวดล้อมจริง การรับรอง “ความเป็นกลาง” จึงต้องอาศัยชุดทดสอบที่หลากหลายและกระบวนการตรวจสอบภายนอก
- การตีความ metric และ signal noise: ผลการทดสอบอาจแสดงการเปลี่ยนแปลงเล็กน้อยที่ไม่สำคัญ (statistical noise) หรือมีความขัดแย้งระหว่างเมตริก—ตัวอย่างเช่น prompt A อาจมี latency ต่ำกว่าแต่ bias สูงกว่า ทำให้การตัดสินใจต้องคำนึงถึง trade‑off หลายมิติ
- ข้อจำกัดในสเกลของการวัดผล: เมื่อเพิ่มขนาดการทดสอบเป็นระดับหมื่นหรือแสนคำตอบ ความต้องการคำนวณ (compute) และค่าใช้จ่ายต่อการประมวลผลอาจเพิ่มขึ้นอย่างรวดเร็ว นอกจากนี้ การสุ่มตัวอย่างเพื่อให้ได้ความมีนัยสำคัญทางสถิติในกลุ่มย่อย (subpopulations) อาจต้องใช้ตัวอย่างจำนวนมากจนไม่คุ้มค่า
- กฎระเบียบด้านข้อมูลและความเป็นส่วนตัว: การเก็บและประมวลผลข้อมูลข้อความสำหรับการทดสอบอาจเข้าข่ายข้อมูลส่วนบุคคล หรือข้อมูลเชิงธุรกิจที่มีความอ่อนไหว องค์กรต้องแน่ใจว่าแพลตฟอร์มรองรับการเข้ารหัส การควบคุมการเข้าถึง และการลบข้อมูลตามข้อกำหนดทางกฎหมาย
- การบริหารต้นทุนในระยะยาว: ค่าใช้จ่ายจาก API ของผู้ให้บริการ LLM, cloud compute สำหรับการรันทดสอบขนาดใหญ่ และค่าใช้จ่ายสำหรับการบำรุงรักษาระบบสามารถสะสมเป็นจำนวนมาก หากไม่มีกลยุทธ์บริหารต้นทุนที่ชัดเจน อาจส่งผลต่อความยั่งยืนของโครงการ
ข้อแนะนำสำหรับองค์กรที่ต้องการนำไปใช้งาน
เพื่อให้การนำ AutoPromptLab หรือแพลตฟอร์ม A/B‑ทดสอบ prompt อัตโนมัติไปใช้งานได้อย่างมีประสิทธิภาพและปลอดภัย องค์กรควรพิจารณาแนวทางปฏิบัติดังนี้:
- ตั้ง governance และ KPI ชัดเจน: กำหนด KPI หลัก (เช่น accuracy, stability, bias indices, cost‑per‑answer) และนโยบายการอนุมัติการปล่อยโมเดลสู่ production เพื่อหลีกเลี่ยงการตัดสินใจบนสัญญาณที่ไม่เพียงพอ
- ออกแบบชุดทดสอบที่เป็นตัวแทน: พัฒนา test corpus ที่ครอบคลุมกลุ่มผู้ใช้หลักและสถานการณ์เสี่ยง เพื่อให้เมตริกสะท้อนผลจริงมากขึ้น และทำ periodic refresh เพื่อป้องกัน data drift
- ใช้การประเมินแบบผสม (hybrid evaluation): ผสมผสานการประเมินอัตโนมัติและการประเมินโดยมนุษย์ในชุดตัวอย่าง เพื่อจับปัญหาเชิงคุณภาพที่เมตริกเชิงปริมาณอาจมองไม่เห็น
- วางแผนควบคุมค่าใช้จ่าย: ใช้นโยบาย budget caps, sampling strategies (ลดจำนวนการทดสอบในกรณี non‑critical paths), และเลือกโมเดล/instances ตามค่า latency‑cost trade‑off เพื่อลดต้นทุนต่อคำตอบ
- เตรียมสัญญา SLA และการตรวจสอบภายนอก: ในกรณีที่ต้องการความมั่นใจด้านความเป็นกลางและความปลอดภัย ให้มีการตรวจสอบโดย third‑party และระบุ SLA ในสัญญาเชิงพาณิชย์
สรุป — AutoPromptLab มีศักยภาพสร้างโมเดลธุรกิจที่หลากหลายและสามารถเร่งการเปลี่ยนผ่านสู่ดิจิทัลขององค์กรโดยทำให้การนำ LLM สู่การใช้งานจริงเป็นระบบและมีความเสี่ยงต่ำ อย่างไรก็ตาม องค์กรต้องวางกรอบการกำกับดูแล การออกแบบชุดทดสอบที่เป็นตัวแทน และกลยุทธ์การบริหารต้นทุนเพื่อทำให้การลงทุนมีความคุ้มค่าและสอดคล้องกับข้อกำหนดทางกฎหมาย
บทสรุป
AutoPromptLab เป็นเครื่องมือสำหรับจัดการความเสี่ยงและเพิ่มประสิทธิภาพของแชทบอทเชิงธุรกิจผ่านการทดสอบ prompt แบบอัตโนมัติ (A/B‑testing) และการวิเคราะห์เมตริกสำคัญ เช่น ความเสถียรของคำตอบ (stability), อคติ (bias), ต้นทุนต่อคำตอบ (cost per response), อัตราความแม่นยำ, ค่าใช้จ่ายโทเค็น และความหน่วงเวลา เครื่องมือนี้ช่วยให้ทีมสามารถตั้งเกณฑ์/threshold, ทำการเปรียบเทียบเวอร์ชันของ prompt, ติดตามผลแบบต่อเนื่อง และทำการ rollback หรือ deploy เวอร์ชันที่ผ่านเกณฑ์ได้โดยอัตโนมัติ ซึ่งทำให้องค์กรลดความเสี่ยงจากคำตอบที่ผิดพลาดหรือมีอคติ และควบคุมต้นทุนการใช้งานโมเดลได้ดีขึ้น
ช่วยให้องค์กรวัดและจัดการความเสี่ยงของการใช้แชทบอทได้อย่างเป็นระบบตัวอย่างเช่น การทดลองภายในองค์กรหนึ่งอาจพบว่า prompt ที่ผ่านการปรับและทดสอบแล้วลดอัตราคำตอบผิดพลาดจาก 15% เหลือ 5% และลดต้นทุนต่อคำตอบได้ราว 20–30% ขึ้นกับการตั้งค่าและชนิดของโมเดล (ตัวอย่างเพื่อประกอบการพิจารณา)
การนำ AutoPromptLab ไปใช้จริงต้องพิจารณาใน 3 มิติควบคู่กันคือ ด้านเทคนิค ด้านธุรกิจ และด้านจริยธรรม/การกำกับดูแล: ทางเทคนิคต้องวางสถาปัตยกรรมการสังเกตการณ์ (observability), การเก็บและประมวลผลเมตริก, การเชื่อมต่อกับ pipeline ของ LLM/ML และการจัดการเวอร์ชันของ prompt; ทางธุรกิจต้องนิยาม KPI, การวัดผลต่อประสบการณ์ลูกค้า (CX) และการคำนวณ ROI; ส่วนด้านจริยธรรมต้องมีการทดสอบอคติเป็นประจำ, นโยบายการจัดการข้อมูลส่วนบุคคล, มาตรการความโปร่งใส และกลไกมนุษย์เข้าตรวจสอบ (human‑in‑the‑loop) เพื่อรองรับข้อกำหนดทางกฎหมายและความเชื่อมั่นของผู้ใช้ ในมุมมองอนาคต AutoPromptLab มีศักยภาพเป็นหนึ่งในเครื่องมือหลักของกระบวนการ Digital Transformation โดยจะผสานกับแนวทาง LLMOps/MLOps เพื่อขับเคลื่อนการปรับปรุงแบบต่อเนื่อง (continuous optimization), อัตโนมัติของ guardrails และการรายงานเชิงบริหาร ทำให้องค์กรสามารถขยายการใช้งานแชทบอทอย่างมั่นใจ แนะนำให้องค์กรเริ่มจากโครงการนำร่องที่ชัดเจน กำหนด KPI และกรอบจริยธรรม เพื่อประเมินผลก่อนขยายสเกลเต็มรูปแบบ



