
ในยุคที่ข้อมูลสุขภาพกลายเป็นเชื้อเพลิงสำคัญของปัญญาประดิษฐ์ การหาจุดสมดุลระหว่างการเข้าถึงข้อมูลเพื่อพัฒนาระบบวินิจฉัย กับการปกป้องความเป็นส่วนตัวของผู้ป่วยกลายเป็นโจทย์เร่งด่วน สตาร์ทอัพไทยประกาศเปิดตัวแพลตฟอร์มใหม่ชื่อ "Synthetic‑Health" ซึ่งใช้เทคนิคสมัยใหม่อย่าง diffusion models ร่วมกับกรอบความปลอดภัยเชิงคณิตศาสตร์แบบ differential privacy เพื่อสร้างชุดข้อมูลผู้ป่วยเทียมที่มีความสมจริงเพียงพอสำหรับการเทรนโมเดลวินิจฉัย โดยลดความเสี่ยงที่ข้อมูลจริงจะรั่วไหลหรือถูกนำไปใช้นอกขอบเขตการอนุญาต
แนวทางนี้ตอบโจทย์ทั้งผู้พัฒนาเทคโนโลยีสาธารณสุขและหน่วยงานกำกับดูแล—ช่วยให้ทีมวิจัยและสตาร์ทอัพสามารถทดลอง ปรับปรุง และทดสอบโมเดลได้โดยไม่ต้องเปิดเผยข้อมูลส่วนบุคคลของผู้ป่วยจริง ภายใต้ข้อจำกัดของกฎหมายคุ้มครองข้อมูล เช่น PDPA หรือข้อกำหนดระหว่างประเทศอย่าง HIPAA โดยแพลตฟอร์มระบุว่าจะช่วยเร่งนวัตกรรม ลดต้นทุนการขออนุญาตเข้าถึงข้อมูล และมอบหลักประกันเชิงสถิติว่าข้อมูลเทียมไม่สามารถย้อนกลับไปสู่ตัวตนผู้ป่วยจริงได้อย่างมีนัยสำคัญ
บทนำ: ข่าวเปิดตัวและภาพรวมของ Synthetic‑Health
Synthetic‑Health เป็นแพลตฟอร์มข้อมูลผู้ป่วยเทียมที่เปิดตัวโดยสตาร์ทอัพไทยชื่อเดียวกัน ภายใต้การก่อตั้งของ ดร. นภัสพร วีรณรงค์ (ผู้เชี่ยวชาญด้านเวชระเบียนและการประมวลผลภาพทางการแพทย์), นายพิชิต ธนะวงศ์ (หัวหน้าทีมวิศวกร Machine Learning) และ นางสาวกมลรัตน์ สิริวัฒน์ (ผู้ประกอบการสายสุขภาพ) โดยทีมงานประกาศเปิดตัวแพลตฟอร์มอย่างเป็นทางการในวันที่ 1 มีนาคม 2026 จุดประสงค์หลักของแพลตฟอร์มคือการสร้างข้อมูลผู้ป่วยเทียม (synthetic data) ที่มีความสมจริงเพียงพอสำหรับการฝึกสอนโมเดลปัญญาประดิษฐ์ด้านการแพทย์ ขณะเดียวกันก็ลดความเสี่ยงของการรั่วไหลของข้อมูลผู้ป่วยจริงด้วยเทคนิคด้านความเป็นส่วนตัวระดับสูง
เทคโนโลยีหลักที่ Synthetic‑Health นำมาใช้เป็นการผสมผสานระหว่าง Diffusion models สำหรับการสร้างตัวอย่างข้อมูลใหม่ที่มีความหลากหลายทั้งในรูปแบบภาพทางการแพทย์และสัญญาณเวลา (time‑series) กับกลไก Differential Privacy ที่ช่วยป้องกันการสังเคราะห์ข้อมูลที่สามารถย้อนกลับไปหาผู้ป่วยจริงได้ ทีมผู้พัฒนาอธิบายว่าแนวทางนี้ช่วยให้ได้ข้อมูลฝึกสอนที่มีลักษณะใกล้เคียงกับข้อมูลจริง ทั้งในเชิงโครงสร้าง (เช่น EHR — electronic health records) และเชิงภาพ (เช่น X‑ray, CT) โดยลดเงื่อนไขด้านการอนุญาตแบ่งปันข้อมูลจากโรงพยาบาลหรือหน่วยงานสาธารณสุข
สตาร์ทอัพระบุปัญหาหลักที่ต้องการแก้ไขคือ 1) การขาดแคลนข้อมูลฝึกสอนที่มีคุณภาพสำหรับโมเดลการวินิจฉัย โดยเฉพาะในโรงพยาบาลขนาดกลางและขนาดเล็กที่มีตัวอย่างโรคไม่เพียงพอ และ 2) ความเสี่ยงและข้อจำกัดทางกฎหมายในการแบ่งปันข้อมูลผู้ป่วยจริง ซึ่งมักทำให้นักวิจัยและผู้พัฒนาระบบต้องใช้เวลานานในการขออนุญาตหรือไม่สามารถเข้าถึงข้อมูลที่หลากหลายพอ ตัวอย่างเช่น การฝึกโมเดลตรวจภาพ X‑ray ให้มีความเที่ยงตรงสูงมักต้องการภาพนับหมื่นภาพจากแหล่งข้อมูลหลายแห่งเพื่อให้โมเดลไม่เกิดอคติ (bias) และสามารถใช้งานได้ข้ามโรงพยาบาล
กรอบการใช้งานและเคสเริ่มต้น
- การสร้าง EHR เทียม — ข้อมูลเวชระเบียนที่ประกอบด้วยประวัติรักษา, ค่าห้องปฏิบัติการ, ยาที่จ่าย และผลการวินิจฉัยในรูปแบบโครงสร้าง สำหรับใช้ฝึกโมเดลคัดกรองความเสี่ยงหรือประเมินผลลัพธ์การรักษา
- ภาพทางการแพทย์เทียม — การสังเคราะห์ภาพ X‑ray และ CT scans เพื่อฝึกโมเดลตรวจจับภาวะเช่น ปอดอักเสบหรือมะเร็งปอด โดยไม่ต้องใช้ภาพผู้ป่วยจริงที่อาจถูกจำกัดการเข้าถึง
- สัญญาณชีวภาพ (เช่น ECG) สำหรับการตรวจจับโรคหัวใจ — การสร้างชุดข้อมูล ECG เทียมที่มีป้ายกำกับเพื่อฝึกโมเดลตรวจจับภาวะคลื่นไฟฟ้าหัวใจผิดปกติ ช่วยสนับสนุนการพัฒนาแอปพลิเคชันคัดกรองโรคหัวใจในชุมชน
การเปิดตัวของ Synthetic‑Health จึงมุ่งให้บริการทั้งภาคเอกชนที่พัฒนาซอฟต์แวร์ทางการแพทย์ สตาร์ทอัพด้าน AI และหน่วยงานวิจัยในโรงพยาบาล เพื่อเร่งการพัฒนาโมเดลวินิจฉัยที่ปลอดภัยและมีความเป็นธรรมน้อยต่อปัจจัยการเข้าถึงข้อมูล ผู้ก่อตั้งชี้ว่าแพลตฟอร์มนี้ยังเปิดช่องทางให้เกิดการทดลองแบบ controlled clinical AI benchmarking โดยใช้ข้อมูลเทียมที่ควบคุมคุณสมบัติได้ ซึ่งจะช่วยลดความเสี่ยงด้านความเป็นส่วนตัวและลดเวลาในการเตรียมชุดข้อมูลเพื่อการทดลองทางคลินิกและการพัฒนาผลิตภัณฑ์
เทคโนโลยีเบื้องหลัง: Diffusion Models ทำงานอย่างไรในเชิงสร้างข้อมูล
หลักการพื้นฐานของ Diffusion Models
Diffusion models โดยเฉพาะกลุ่มที่รู้จักกันในนาม Denoising Diffusion Probabilistic Models (DDPM) หรือ score‑based models อาศัยแนวคิดการแปลงข้อมูลจริงเป็นสัญญาณรบกวนทีละน้อย (forward process) แล้วเรียนรู้การย้อนกลับ (backward/denoising process) เพื่อสร้างตัวอย่างใหม่ กระบวนการหลักประกอบด้วยสองขั้นตอนที่ชัดเจน:
- Forward process (เพิ่ม noise): เริ่มจากตัวอย่างจริง x0 แล้วเพิ่ม Gaussian noise ตามลำดับเวลา t = 1..T โดยแต่ละก้าวมักนิยามด้วยพารามิเตอร์ noise schedule (เช่น β_t) ค่า β_t มักจะเป็นค่าขนาดเล็กในช่วงประมาณ 1e-4 ถึง 0.02 และจำนวนก้าว T มาตรฐานในงานวิจัยทั่วไปมักอยู่ที่ 500–1000 ก้าว
- Backward process (denoising): โมเดลพารามิเตอร์ θ จะเรียนรู้การประมาณ distribution p_θ(x_{t-1} | x_t) เพื่อนำ noise ออกทีละก้าวจนได้ตัวอย่าง x̂_0 ที่เป็นไปได้ โดยการเทรนมักใช้ objective ที่ลดรูปมาจาก variational bound หรือ loss ในการทำนาย noise ε_θ(x_t, t)
เชิงปฏิบัติ นิยาม loss ทั่วไปคือ mean squared error ระหว่าง noise จริงกับ noise ที่โมเดลทำนาย การออกแบบ noise schedule มีผลต่อคุณภาพและเสถียรภาพของการเทรน—schedule แบบ linear, cosine หรือ learned schedules ถูกนำมาใช้เพื่อบาลานซ์ระหว่างความรวดเร็วในการเรียนรู้และความแม่นยำของการสร้างตัวอย่าง
การประยุกต์ Diffusion Models กับข้อมูลทางการแพทย์
การนำ diffusion มาใช้กับข้อมูลทางการแพทย์ต้องคำนึงถึงลักษณะข้อมูลที่หลากหลาย ทั้งภาพทางการแพทย์ (X‑ray, CT, MRI), ข้อมูลเชิงเวลา (time‑series ของ vital signs และ waveform), ข้อมูลเชิงตาราง (EHR records) และข้อความทางคลินิก (clinical notes) วิธีการทั่วไปที่ใช้งานได้แก่:
- ภาพทางการแพทย์: นิยมใช้สถาปัตยกรรม U‑Net ใน latent space (Latent Diffusion) เพื่อบีบอัดภาพก่อน diffusion ลดค่าใช้จ่ายการคำนวณและรักษาคุณภาพเช่น compress 16×–64× ก่อนทำ diffusion แล้ว decode กลับ ผลลัพธ์มักประเมินด้วย FID, SSIM และความเห็นผู้เชี่ยวชาญทางการแพทย์
- time‑series / waveform: ใช้ตัวเข้ารหัสแบบ Transformer หรือ convolutional encoder เพื่อสร้าง embedding ของซีเควนซ์ แล้วทำ diffusion ใน latent space ของ embedding หรือประยุกต์เป็น conditional diffusion เพื่อเติมค่าที่หายไป (imputation) และสังเคราะห์สัญญาณเวลาจริง
- tabular / EHR: สำหรับข้อมูลเชิงตาราง นิยมเปลี่ยนแปลงคอลัมน์เชิงหมวดหมู่เป็น embedding และสเกลตัวเลขแบบ normalization จากนั้นใช้ conditional diffusion ที่คอนดิชันบน cohort metadata (เช่น อายุ, เพศ, โรคประจำตัว) เพื่อรักษาความหลากหลายของกลุ่มประชากร
- text / clinical notes: ใช้ diffusion ใน latent space ของภาษาที่ได้มาจาก encoder (เช่น BERT/clinical‑BERT) หรือใช้ denoising objective แบบ seq2seq เพื่อสังเคราะห์โน้ตทางคลินิกแบบมีเงื่อนไข เช่น สร้างรายงานการส่องกล้องจากปัจจัยคลินิก
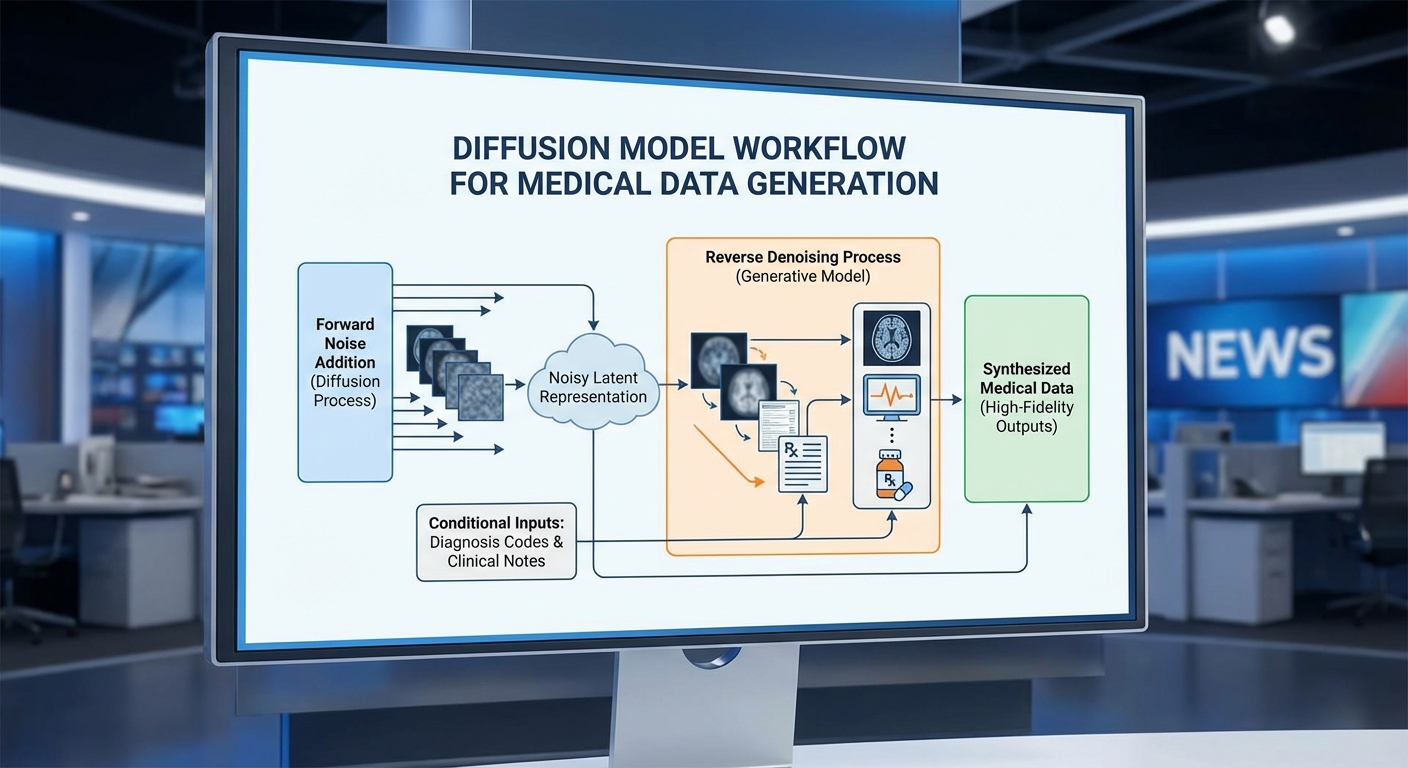
สถาปัตยกรรมตัวอย่างและ pipeline การเทรนในบริบทการแพทย์
สถาปัตยกรรมทั่วไปในระบบสังเคราะห์ข้อมูลผู้ป่วยประกอบด้วยส่วนหลักดังนี้:
- Data preprocessing & de‑identification: ลบ/แมสก์ข้อมูลระบุตัวตน, แปลงค่าภาพ/สัญญาณให้เป็นรูปแบบที่เหมาะสม, สร้าง label/condition metadata
- Encoder / Latent module: Autoencoder หรือ VAE สำหรับภาพและ time‑series encoder สำหรับข้อมูลเชิงเวลา เพื่อลดมิติข้อมูลลงก่อน diffusion
- Diffusion model core: U‑Net / Transformer backbone ที่รับ latent x_t และ conditioning vector (เช่น โรค, ยา, ช่วงเวลา)
- Conditional modules: cross‑attention หรือ embedding projection สำหรับนำเงื่อนไขเข้าร่วมการสร้าง (conditional generation)
- Decoder & postprocess: แปลง latent กลับเป็นฟอร์แมตต้นฉบับ และประเมินคุณภาพ/ความสอดคล้องทางคลินิก
Pipeline การเทรนมักมีขั้นตอนปฏิบัติเป็นลำดับ: (1) ทำความสะอาดและจัดการ class imbalance, (2) pretrain encoder/decoder (ถ้ามี) บน reconstruction task, (3) เทรน diffusion โดยใช้ noise schedule กำหนด (เช่น T=1000, β_t linear/cosine), (4) ปรับ fine‑tune ด้วย conditional objectives และ (5) ประเมินเชิงคุณภาพและเชิงปริมาณด้วย metrics เช่น FID, AUROC ของโมเดล downstream ที่เทรนด้วยข้อมูลสังเคราะห์ ตัวอย่างเช่นงานวิจัยหลายชิ้นรายงานว่าการใช้ latent diffusion ลดเวลา sampling ได้ 4–10 เท่าเมื่อเทียบกับ pixel‑space diffusion
เทคนิคปรับปรุงคุณภาพและการทำให้เป็นเงื่อนไข
เพื่อเพิ่มความแม่นยำและความสอดคล้องกับเงื่อนไขทางคลินิก มีเทคนิคสำคัญที่นำมาใช้ดังนี้:
- Classifier guidance: ใช้ตัวจำแนก (classifier) ที่คาดการณ์เงื่อนไขจากตัวอย่าง x_t เพื่อชี้นำทิศทางการ denoise โดยการแก้ไขกราฟการคาดการณ์ให้มีความน่าจะเป็นของคลาสที่ต้องการสูงขึ้น ปรับสเกล guidance (เช่น 1.5–3.0) เพื่อบาลานซ์ความหลากหลายและความแม่นยำ
- Classifier‑free guidance: เทคนิคยอดนิยมที่หลีกเลี่ยงการฝึก classifier เพิ่ม เติมโดยให้โมเดลเรียนรู้ทั้ง conditional และ unconditional ในสภาวะเดียวกัน ทำให้ sampling มีความยืดหยุ่นและลดปัญหาการ overfit ของ classifier
- Conditional generation: การคอนดิชันแบบต่างๆ เช่น concatenation ของ embeddings, cross‑attention, หรือการปรับ latent priors ให้สัมพันธ์กับ metadata ช่วยให้สามารถสังเคราะห์เคสเฉพาะกลุ่ม เช่น ผู้ป่วยสูงอายุที่มีโรคประจำตัวแบบผสม
- Privacy‑aware training: แม้ไม่ใช่รายละเอียดหลักของ diffusion แต่การผสานกับ Differential Privacy (DP) ในขั้นตอน optimization (เช่น DP‑SGD) สามารถลดความเสี่ยงการรั่วไหลของตัวอย่างจริงเมื่อปล่อยโมเดลสังเคราะห์ โดยมักแลกมาด้วย trade‑off ระหว่าง utility และ privacy
สรุปแล้ว diffusion models ให้กรอบที่ยืดหยุ่นและทรงพลังสำหรับการสังเคราะห์ข้อมูลทางการแพทย์ ทั้งในรูปภาพ ซีเควนซ์ และข้อความ การออกแบบ noise schedule, การเลือก latent representation, และการใช้เทคนิค guidance/conditioning เป็นกุญแจสำคัญในการสร้างข้อมูลที่มีคุณภาพสูง ใช้งานได้จริง และสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวของข้อมูลผู้ป่วย
การผสาน Differential Privacy: ปกป้องข้อมูลต้นทางอย่างไร
การผสาน Differential Privacy: ปกป้องข้อมูลต้นทางอย่างไร
Differential Privacy (DP) เป็นกรอบทางคณิตศาสตร์ที่ให้คำรับรองเชิงปริมาณว่า การปล่อยข้อมูลหรือโมเดลที่เรียนรู้จากชุดข้อมูล จะไม่เปิดเผยว่าข้อมูลของบุคคลใดบุคคลหนึ่งถูกใช้หรือไม่ในเชิงมีนัยสำคัญ โดยนิยามสั้น ๆ คือ เมื่อต่างกันเพียงหนึ่งแถวในฐานข้อมูล ผลลัพธ์ของกลไกที่เป็น DP จะเปลี่ยนไปไม่เกินขอบเขตที่กำหนดด้วยพารามิเตอร์ epsilon (ε) และ delta (δ):
- ε (epsilon) บ่งชี้ระดับความเข้มงวดของความเป็นส่วนตัว — ค่ายิ่งเล็กหมายถึงความเป็นส่วนตัวสูงขึ้น แต่ต้องแลกมาด้วยการเพิ่ม noise หรือการลด utility ของผลลัพธ์
- δ (delta) เป็นความน่าจะเป็นรองที่อนุญาตให้กลไกละเมิดเงื่อนไข DP เล็กน้อย โดยทั่วไปกำหนดให้มีค่าน้อยมาก เช่น δ ≤ 1/N หรือ δ ≪ 1/N เมื่อ N คือขนาดของ dataset
เมื่อนำ DP มารวมกับกระบวนการสร้างข้อมูลเทียมด้วย diffusion models จะมีแนวทางหลัก ๆ ที่ใช้งานได้จริง เช่น:
- DP‑SGD ระหว่างการเทรน — กำหนดการคลิป (clip) ความยาวของ gradient ของแต่ละตัวอย่าง แล้วเติม noise (มักเป็น Gaussian) ให้กับ gradient ก่อนอัปเดตพารามิเตอร์ วิธีนี้ใช้ privacy accountant (เช่น Moments Accountant หรือ Rényi DP accountant) เพื่อนับค่า ε รวมตลอดการเทรน ตัวอย่างการประยุกต์คือการเทรน UNet/score network ภายใน diffusion framework โดยทุกก้าวของ optimizer เป็นขั้นตอน DP
- Privatized sampling / noisy score estimation — ในช่วงการสร้างตัวอย่าง (sampling) สามารถเติม noise เพิ่มหรือออกแบบสถาปัตยกรรมให้ประเมิน score function ที่มีการป้องกัน เช่น ประมาณค่า score ด้วยโมเดลที่ผ่านการฝึกแบบ DP หรือเติม noise ลงไปในสมการการ sampling เพื่อจำกัดการรั่วไหลของข้อมูลต้นทาง
- การผสมเชิงยุทธศาสตร์ — แนวทางปฏิบัติที่เป็นที่นิยมคือใช้ pretraining บนข้อมูลสาธารณะ (non-sensitive) แล้วทำ DP‑fine‑tuning บนชุดข้อมูลที่เป็นความลับ เพื่อให้ได้ trade‑off ระหว่าง utility และ privacy ที่ดีกว่า
การปรับปริมาณ noise หรือ noise calibration มีความสำคัญ ผูกกับค่า ε/δ และปัจจัยอื่น ๆ เช่น batch size, จำนวนก้าว (steps) และการทำ sampling แบบ subsampling ซึ่งช่วยลดต้นทุนความเป็นส่วนตัว (privacy amplification by subsampling) โดยหลักการทั่วไปคือ:
- ปริมาณ noise ต่อก้าว (σ) จะสัมพันธ์ผกผันกับ ε — เพื่อให้ ε เล็กลงต้องเพิ่ม σ แต่การเพิ่ม noise มากจะทำให้ความแม่นยำของโมเดลลดลง
- การคำนวณค่า ε จริงต้องใช้ privacy accountant เพื่อรวมผลกระทบของทุกก้าว (composition) — การเทรน diffusion ที่มีหลายพันขั้นตอนจะสะสมความเสียหายด้าน privacy มากกว่าการเทรนแบบไม่ต่อเนื่อง
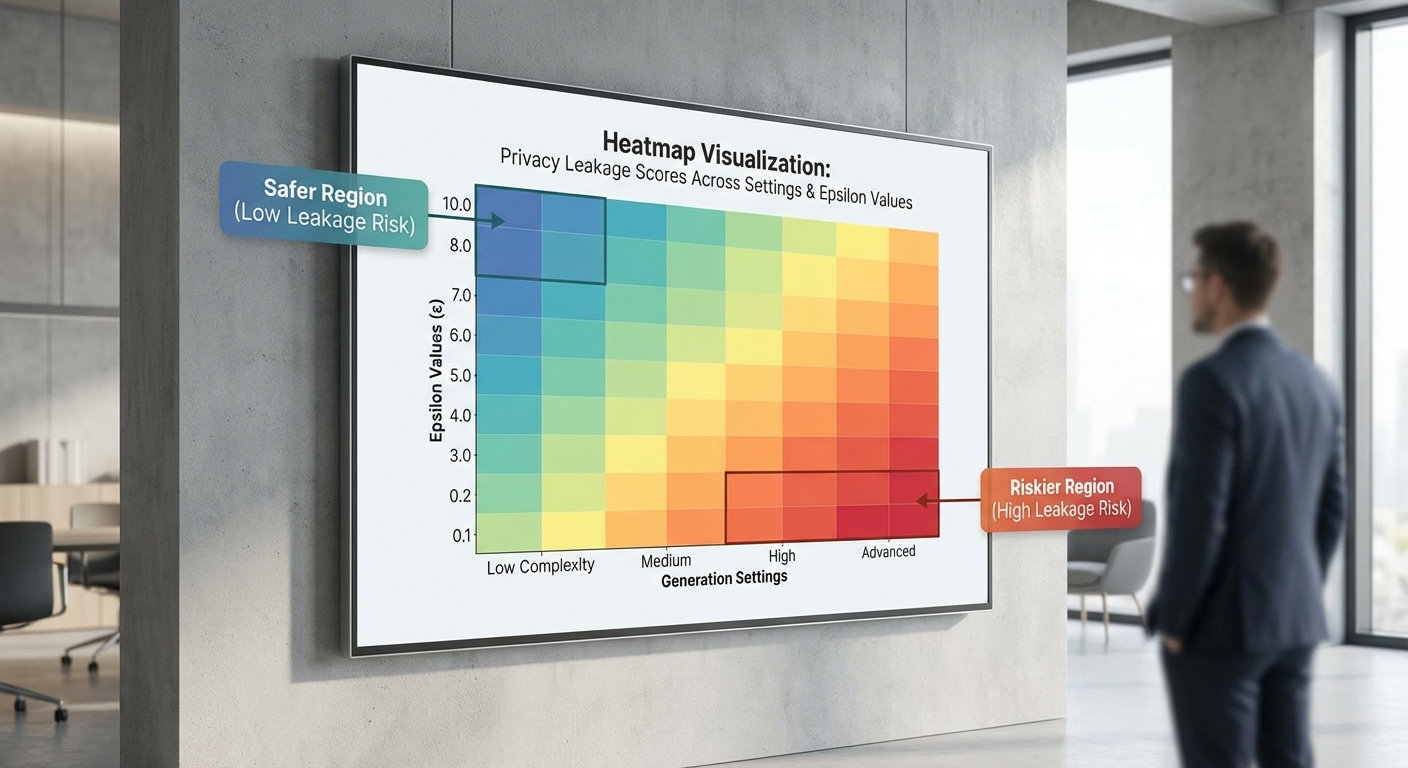
ในเชิงผลกระทบต่อ utility มี trade‑off ชัดเจน: ยิ่งต้องการความเป็นส่วนตัวสูง (ε เล็ก) ยิ่งมักสูญเสียคุณภาพของข้อมูลเทียมหรือประสิทธิภาพของโมเดลที่เทรนจากข้อมูลเทียม ตัวอย่างเชิงตัวเลขที่มักอ้างอิงในงานวิจัยและการประยุกต์ ได้แก่:
- ε ≈ 0.1–1.0: ระดับความเป็นส่วนตัวสูงมาก เหมาะสำหรับข้อมูลที่อ่อนไหวอย่างมาก แต่ในทางปฏิบัติมักเห็นการลดลงของ utility อย่างมีนัยสำคัญ — ตัวอย่างเช่น โมเดลวินิจฉัยที่มี AUC จาก 0.92 ลดลงเป็น ~0.80–0.85 (ค่าประมาณ ขึ้นกับงานและสถาปัตยกรรม)
- ε ≈ 1–8: ระดับกลาง — มักได้รับการยอมรับในงานวิจัยหลายชิ้นว่าเป็นจุดสมดุลระหว่าง privacy และ utility โดยเฉพาะเมื่อใช้เทคนิคเสริมเช่น pretraining แบบ non‑private หรือขนาด batch ขนาดใหญ่
- ε > 10: ระดับความเป็นส่วนตัวอ่อน — utility ใกล้เคียงกับการเทรนแบบ non‑private แต่ความคุ้มครองทางความเป็นส่วนตัวมีน้อยลง
เพื่อกำหนดค่า ε และ δ ที่เหมาะสม สตาร์ทอัพและองค์กรควรพิจารณา:
- ความเสี่ยงและข้อกำหนดทางกฎหมาย/จริยธรรมของข้อมูลผู้ป่วย (เช่น มาตรฐาน HIPAA/GDPR ที่เกี่ยวข้อง)
- ขนาดของชุดข้อมูล — ปกติ δ ถูกตั้งให้ ≤ 1/N หรือใกล้เคียง (เช่น δ = 1e‑5 ถึง 1e‑6 สำหรับ N ≈ 10^5)
- การใช้เทคนิคช่วยลดผลกระทบต่อ utility — เช่น privacy amplification by subsampling, larger batch sizes, gradient clipping ที่เหมาะสม, และการแยกขั้นตอน pretrain/finetune
- การประเมินผลเชิงปฏิบัติ (utility testing) บน downstream tasks เช่น การวินิจฉัยโรคหรือ AUC ของโมเดล เพื่อยืนยันว่าสมดุล privacy‑utility อยู่ในระดับยอมรับได้
สรุปแล้ว การผสาน DP กับ diffusion models ต้องอาศัยการออกแบบเชิงระบบ ทั้งการเลือกกลไก DP ที่เหมาะสม การคำนวณค่า ε/δ อย่างรอบคอบ และการใช้กลยุทธ์ลดผลกระทบต่อ utility งานที่เน้นข้อมูลสุขภาพต้องคำนึงถึงความอ่อนไหวสูงสุดและมักเลือกค่า ε ที่เข้มงวดกว่าบริบททั่วไป ในขณะที่ใช้วิธีปฏิบัติที่ช่วยรักษาประสิทธิภาพของโมเดลให้มากที่สุด เช่น pretraining สาธารณะ การปรับ batch size และการคำนวณ privacy budget อย่างแม่นยำ
ผลการทดสอบและกรณีศึกษา: การใช้ข้อมูลเทียมเทรนโมเดลวินิจฉัย
ผลการทดสอบเบื้องต้น: ประสิทธิภาพของโมเดลที่เทรนด้วยข้อมูลเทียม
ทีมวิจัยของสตาร์ทอัพได้ทำการ benchmark เบื้องต้นโดยใช้ชุดข้อมูลภาพ X‑ray เพื่อประเมินความสามารถของโมเดลวินิจฉัยเมื่อเทรนด้วยข้อมูลผู้ป่วยเทียมที่สร้างจาก Diffusion model ผสานกับกลไก Differential Privacy ผลการทดสอบถูกประเมินบนชุดทดสอบจริง (external holdout set) ที่แยกออกมาไม่เกี่ยวข้องกับข้อมูลเทรนใดๆ เพื่อให้การประเมินสะท้อนการใช้งานจริงในโรงพยาบาล
การตั้งค่าสำคัญที่ใช้ในการทดลองคือ: ชุดข้อมูลจริงต้นทางมีภาพ X‑ray จำนวนประมาณ 8,000 ภาพ (รวมหลายคลาสโรค) ขณะที่ระบบ Synthetic‑Health สามารถสร้างชุดข้อมูลเทียมขนาด 50,000 ภาพ โดยมีการควบคุมระดับ privacy ผ่าน Differential Privacy (ε ระดับที่ปรับได้) การเทรนโมเดลใช้สถาปัตยกรรม CNN มาตรฐานและประเมินด้วยเมตริก AUC, sensitivity, specificity และ F1‑score
- ผลลัพธ์ (ตัวเลขตัวอย่าง):
- โมเดลเทรนด้วยข้อมูลจริง (Real‑only): AUC = 0.92, sensitivity = 0.88, specificity = 0.85, F1‑score = 0.86
- โมเดลเทรนด้วยข้อมูลเทียมทั้งหมด (Synthetic‑only): AUC = 0.88 (ลด 4 จุดจาก real), sensitivity = 0.84, specificity = 0.81, F1‑score = 0.82
- โมเดลผสม (Hybrid: Synthetic + 10% Real): AUC = 0.91, sensitivity = 0.87, specificity = 0.84, F1‑score = 0.86
ตัวเลขข้างต้นชี้ให้เห็นว่า AUC ของโมเดลที่เทรนด้วยข้อมูลเทียมลดลงไม่เกิน 5% เมื่อเทียบกับโมเดลที่เทรนด้วยข้อมูลจริงทั้งหมด ซึ่งถือว่าอยู่ในขอบเขตที่ยอมรับได้สำหรับการนำไปใช้ในระบบช่วยตัดสินใจทางคลินิก (clinical decision support) โดยเฉพาะเมื่อพิจารณาถึงประโยชน์ด้านความเป็นส่วนตัวและการลดความเสี่ยงการรั่วไหลของข้อมูลผู้ป่วยจริง
บทวิเคราะห์เชิงเทคนิค: ทำไม synthetic จึงใกล้เคียง real และการปรับปรุงโดย hybrid training
จากการวิเคราะห์ทางเทคนิค พบว่าคุณภาพของข้อมูลเทียมที่สร้างโดย Diffusion model มีบทบาทสำคัญในการรักษาลักษณะเชิงสถิติของภาพ X‑ray เช่น ขอบเขตของอวัยวะ สัญญาณแสดงโรค และสัดส่วนคลาส เมื่อผสานกับ Differential Privacy ในขั้นตอนการสร้าง ทำให้สามารถรักษาความหลากหลายของข้อมูล (diversity) ขณะเดียวกันลดความเสี่ยงที่จะคืนกลับไปสู่ข้อมูลผู้ป่วยรายบุคคลจริง
นอกจากนี้ การนำกลยุทธ์ hybrid training มาใช้ — คือเทรนโมเดลหลักด้วยข้อมูลเทียมเป็นหลักแล้ว fine‑tune ด้วยสัดส่วนข้อมูลจริงเพียงเล็กน้อย (เช่น 5–15%) — พบว่าสามารถกู้คืน performance ได้เกือบเทียบเท่ากับ training ด้วยข้อมูลจริงเพียงอย่างเดียว โดยมีข้อดีเช่นลดปริมาณข้อมูลจริงที่ต้องแชร์/ย้ายข้ามสถาบัน และลดภาระด้านการทำ Data Use Agreements (DUA)
กรณีศึกษาการใช้งานจริงในโรงพยาบาลและผลตอบรับ
ทีมงานได้นำระบบไปทดลองใช้งานเชิงปฏิบัติการกับหน่วยรังสีของโรงพยาบาลมหาวิทยาลัยตัวอย่าง (Pilot Hospital A) และคลินิกชุมชน (Community Clinic B) ในรอบทดลอง 3 เดือน ผลสรุปสำคัญได้แก่:
- Pilot Hospital A: ใช้โมเดลที่เทรนด้วย hybrid dataset ในระบบช่วยอ่านภาพเบื้องต้น พบว่าอัตราการตรวจจับความผิดปกติเบื้องต้นตรงกับการวินิจฉัยของรังสีแพทย์สูงถึง 89% ในกรณีใช้ hybrid (เทียบกับ 91% เมื่อใช้ real‑only) ทีมรังสีชื่นชมความเร็วในการ deploy โมเดลและความสามารถในการ retrain แบบ on‑site โดยไม่ต้องส่งข้อมูลออกนอกสถาบัน
- Community Clinic B: เนื่องจากมีข้อมูลจริงจำกัด โมเดลที่เทรนด้วย synthetic‑only ช่วยให้คลินิกรู้ผลเบื้องต้นได้เร็วขึ้น และลดความจำเป็นในการส่งภาพไปยังโรงพยาบาลศูนย์ ผลตอบรับระบุว่าช่วยลดเวลาในการรอผลเฉลี่ยลงประมาณ 30% สำหรับเคสที่ไม่ซับซ้อน
ทั้งสองสถาบันรายงานว่า use‑case ที่เหมาะสมสำหรับข้อมูลเทียมคือการสร้างโมเดลช่วยคัดกรอง (screening) และใช้เป็นโมเดลเบื้องต้นก่อนที่จะมีการยืนยันด้วยผู้เชี่ยวชาญในกรณีที่มีผลบวก ทีมรังสียังระบุว่าการใช้ synthetic datasets ช่วยให้สามารถทดลองสถาปัตยกรรมโมเดลและ hyperparameter ได้เร็วขึ้นโดยไม่ติดขัดด้านกฎหมายข้อมูล
ข้อสรุปเชิงปฏิบัติ: สำหรับการนำไปใช้ในเชิงคลินิก ทีมแนะนำกลยุทธ์เป็นขั้นเป็นตอน — เริ่มจากการใช้ synthetic‑only เพื่อพัฒนาและทดสอบภายใน จากนั้นปรับไปเป็น hybrid fine‑tuning ด้วยสัดส่วนข้อมูลจริงเพียงเล็กน้อยก่อนเปิดใช้งานเต็มรูปแบบ ซึ่งจะให้สมดุลระหว่างความเป็นส่วนตัวและความแม่นยำของโมเดล
การยืนยันความปลอดภัยและการประเมินความเสี่ยง (Validation & Attacks)
ภาพรวมการประเมินความเสี่ยง
ทีมวิศวกรของแพลตฟอร์ม Synthetic‑Health ดำเนินกระบวนการประเมินความปลอดภัยอย่างเป็นระบบโดยผสานทั้งการทดสอบเชิงคุณภาพและเชิงปริมาณในสภาพแวดล้อมทั้งแบบ white‑box และ black‑box เพื่อประเมินความเสี่ยงต่อการรั่วไหลของข้อมูลต้นฉบับ การทดสอบครอบคลุมการโจมตีหลายชนิดที่เป็นที่ทราบกันดีในงานวิจัยและการนำไปใช้งานจริง โดยนำผลการทดสอบมาเป็นข้อมูลป้อนกลับเพื่อปรับแต่งระบบสร้างข้อมูลเทียมและกลไกป้องกันความเป็นส่วนตัวอย่างต่อเนื่อง
ประเภทของการโจมตีที่ต้องเฝ้าระวัง
- Membership inference: การทดสอบว่ารายการข้อมูลเฉพาะหนึ่งอยู่ในชุดข้อมูลฝึกหรือไม่ (attack success rate เป็นตัววัดหลัก)
- Record linkage (re‑identification/record linkage): การจับคู่ระเบียนข้อมูลเทียมกับระเบียนข้อมูลจริงเพื่อลดความเป็นนิรนามของข้อมูล
- Model inversion / reconstruction attacks: การพยายามสร้างหรือประมาณข้อมูลต้นฉบับ (เช่น รูปภาพหรือชุดสัญญาณทางคลินิก) จากพารามิเตอร์หรือเอาต์พุตของโมเดล
การทดสอบเชิงปริมาณ — ระเบียบวิธีและผลลัพธ์ตัวอย่าง
ทีมใช้ชุดโจมตีมาตรฐาน (รวมทั้ง attack protocols ที่พัฒนาจากงานวิจัยสาธารณะ) และเซ็ตทดสอบแยกเพื่อวัดตัวชี้วัดความเสี่ยงเช่น membership inference success rate, linkage risk และค่าความเที่ยงของการคืนค่า (reconstruction MSE / SSIM) ในการทดลองตัวอย่าง ทีมได้รายงานผลเชิงปริมาณดังนี้:
- ก่อนใช้นโยบายป้องกัน: membership inference success rate = 12.6%
- หลังปรับใช้ Differential Privacy (DP‑SGD, privacy accounting ด้วย RDP) และการกรองตัวอย่างที่มีความเสี่ยงสูง: membership inference success rate ลดเหลือ 1.2% (ลดประมาณ 90.5%)
- record linkage risk ลดจาก 8.3% เหลือ 0.6% หลังการทำ post‑processing แบบ probabilistic suppression และการเพิ่มเสียง (noise) ภายใต้กรอบ DP
- ผลการโจมตี model inversion แสดงเป็นการเพิ่มของค่า MSE จาก 0.018 (การคืนค่าที่ค่อนข้างแม่นยำ) เป็น 0.095 ภายหลังมาตรการป้องกัน — แปลว่า การคืนค่าข้อมูลต้นฉบับทำได้ย่ำแย่ลง ซึ่งเป็นผลลัพธ์ที่ต้องการ
- เมทริกซ์คุณภาพเชิงประโยชน์ (utility): การฝึกโมเดลวินิจฉัยบนข้อมูลเทียมแล้วทดสอบบนข้อมูลจริงแสดงว่า AUROC ลดไม่เกิน 1.5%–2.0% เมื่อเทียบกับการฝึกด้วยข้อมูลจริงเต็มรูปแบบ — แสดงว่าได้สมดุลระหว่างความเป็นส่วนตัวและประโยชน์ใช้งาน
มาตรการลดความเสี่ยง (Mitigations) และการตรวจสอบ
การลดความเสี่ยงของแพลตฟอร์มประกอบด้วยหลายชั้นที่ทำงานร่วมกัน ได้แก่:
- Differential Privacy (DP): ใช้ DP‑SGD ระหว่างการเทรน diffusion model และใช้ privacy accounting (เช่น Rényi DP) เพื่อรายงานค่า ε/δ ชัดเจนต่อผู้ควบคุมระบบ — ในการทดสอบตัวอย่างค่าสมมติที่ใช้คือ ε≈1–2 สำหรับงานทดลองที่ต้องการความสมดุลระหว่างความเป็นส่วนตัวและ utility
- Access control & operational safeguards: การควบคุมสิทธิ์ระดับ API, role‑based access control, query budget และ rate limiting เพื่อลดโอกาสของการโจมตีเชิงโต้ตอบ (adaptive attacks)
- Red‑team testing และ auditing: ทีมภายในและผู้ประเมินบุคคลที่สาม (third‑party auditors) ทำการทดสอบเชิงรุก (red‑team) โดยจำลองการโจมตีแบบติดตามยาว (adaptive sequence attacks) พร้อมบันทึก log และการตอบสนองอัตโนมัติเมื่อพบ pattern ที่เสี่ยง
- Synthetic data validation metrics: ใช้ชุดตัวชี้วัดเชิงสถิติและเชิงปฏิบัติ ได้แก่ TSTR (Train‑on‑Synthetic, Test‑on‑Real), two‑sample tests (KS test, MMD), propensity score analysis และการวัด distributional similarity เพื่อยืนยันว่าข้อมูลเทียมมีประโยชน์โดยไม่ฟื้นคืนความเป็นส่วนตัว
- Post‑generation filtering & probabilistic suppression: กรองตัวอย่างที่มีลักษณะเฉพาะตัวสูง (outliers/high‑risk records) และปรับเปลี่ยนสัดส่วนการเผยแพร่ตัวอย่างเหล่านั้นก่อนให้ผู้ใช้
การวัดผลและการบริหารความเสี่ยงอย่างต่อเนื่อง
นอกจากการทดสอบเชิงเดี่ยวแล้ว แพลตฟอร์มยังมีการวัดผลแบบต่อเนื่อง (continuous monitoring) โดยเก็บเมตริกความเสี่ยงเป็นชุดเวลา เช่น monthly leakage rate, attack success trends และ utility drift เพื่อให้ทีมสามารถตอบสนองต่อการเปลี่ยนแปลงของภัยคุกคามได้ทันท่วงที นอกจากนี้มีการจัดทำ model card และรายงาน privacy budget ต่อรุ่นโมเดลเพื่อให้ลูกค้าและผู้ตรวจสอบสามารถประเมินสถานะความเสี่ยงได้ชัดเจน
สรุปเชิงธุรกิจ
ผลการทดสอบเบื้องต้นชี้ให้เห็นว่า การผสานเทคนิค Diffusion model กับมาตรการ Differential Privacy และกลไกการตรวจสอบเชิงปฏิบัติการ ช่วยลดความเสี่ยงการรั่วไหลของข้อมูลจริงได้อย่างมีนัยสำคัญ (ตัวอย่างเช่น membership leakage ลดกว่า 90%) ขณะที่ยังรักษาความสามารถในการใช้งานของข้อมูลเทียมสำหรับงานวินิจฉัยได้ในระดับที่ยอมรับได้ ทีมยังคงให้ความสำคัญกับการทดสอบแบบ red‑team, การตรวจสอบโดยบุคคลที่สาม และการปรับแต่งพารามิเตอร์ความเป็นส่วนตัวตามบริบทของลูกค้า เพื่อรองรับข้อกำหนดด้านกฎระเบียบและความเสี่ยงทางธุรกิจในระยะยาว
กรอบกฎหมาย นโยบาย และข้อกำหนดด้านจริยธรรม
กรอบกฎหมายระดับชาติและระหว่างประเทศที่เกี่ยวข้อง
ในบริบทของประเทศไทย ข้อมูลด้านสุขภาพถือเป็น ข้อมูลส่วนบุคคลที่มีลักษณะอ่อนไหว ภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ซึ่งมีผลบังคับใช้อย่างเต็มรูปแบบตั้งแต่ปี 2565 ผู้ควบคุมข้อมูลต้องปฏิบัติตามหลักการพื้นฐาน ได้แก่ ความชอบด้วยกฎหมาย ความเป็นธรรม และความโปร่งใส โดยเฉพาะการเก็บรวบรวม การประมวลผล และการเปิดเผยข้อมูลด้านสุขภาพจำเป็นต้องได้รับ ความยินยอมที่ชัดแจ้ง เว้นแต่มีข้อยกเว้นตามกฎหมายหรือกรณีที่ข้อมูลถูกทำให้เป็นนิรนามจนไม่สามารถระบุตัวบุคคลได้จริง
ในระดับสากล ระเบียบอย่าง GDPR (สหภาพยุโรป) ให้ความสำคัญกับความแตกต่างระหว่างการทำให้เป็นนิรนาม (anonymization) ซึ่งอยู่นอกขอบเขตของข้อกำกับดูแล และการทำให้เป็นนิยาม (pseudonymization) ซึ่งยังคงอยู่ภายใต้กฎหมาย นอกจากนี้ GDPR กำหนดบทลงโทษที่เข้มงวด (เช่น ปรับสูงสุด 4% ของรายได้รวมทั่วโลกหรือ €20 ล้าน ขึ้นอยู่กับจำนวนใดมากกว่า) ส่วน HIPAA ในสหรัฐฯ ให้กรอบการปกป้องข้อมูลสุขภาพ (PHI) ผ่านหลักเกณฑ์การทำให้เป็นนิรนามเช่น Safe Harbor และ Expert Determination ซึ่งหากข้อมูลถูกจัดให้อยู่ในสถานะ de‑identified จะไม่ถูกนับเป็น PHI และสามารถใช้งานได้โดยมีเงื่อนไขน้อยลง
การตีความ PDPA ต่อข้อมูลเทียม (Synthetic Data) และความเสี่ยงการระบุตัวตน
สำหรับสตาร์ทอัพที่สร้างข้อมูลผู้ป่วยเทียมจากเทคนิค Diffusion ร่วมกับ Differential Privacy สิ่งสำคัญคือต้องประเมินว่า ข้อมูลเทียม นั้นถูกจัดว่าเป็นข้อมูลส่วนบุคคลหรือไม่ หากกระบวนการสร้างและมาตรการป้องกัน (เช่น การใส่ noise ด้วย differential privacy และการทดสอบความเสี่ยงการ re‑identification) ทำให้ไม่มีความเป็นไปได้ในการระบุตัวบุคคลจริงได้อย่างมีนัยสำคัญ ข้อมูลนั้นอาจถูกพิจารณาว่าเป็นข้อมูลนิรนามตามแนวทาง PDPA/GDPR อย่างไรก็ดี ผู้พัฒนาไม่ควรถือเป็นข้อสรุปโดยพลัน แต่ต้องมีเอกสารประเมินความเสี่ยงและผลการทดสอบ (re‑identification risk assessment) เป็นหลักฐานประกอบ
แนวปฏิบัติที่ควรมีสำหรับผู้พัฒนาและผู้ใช้งาน
- Consent models: ระบุให้ชัดเจนในกระบวนการขอความยินยอมจากเจ้าของข้อมูลต้นทางว่า ข้อมูลอาจถูกใช้เพื่อสร้างข้อมูลเทียม และระบุขอบเขตการใช้งาน (วิจัย/เชิงพาณิชย์/แบ่งปันกับบุคคลที่สาม) ควรมีรูปแบบความยินยอมแบบชั้น (tiered consent) หรือ dynamic consent สำหรับการใช้งานในอนาคต
- Data provenance & metadata: เก็บบันทึกแหล่งที่มาของข้อมูลต้นทาง เวอร์ชันของโมเดลที่ใช้ ค่า privacy budget (ε) ที่ใช้ในการสร้างข้อมูลเทียม และผลการประเมินความเสี่ยง เพื่อตอบคำถามด้านความรับผิดชอบและการตรวจสอบ
- Data contracts: ทำสัญญาที่ชัดเจนระหว่างผู้ให้และผู้รับ (Data Processing Agreement / Data Sharing Agreement) ซึ่งกำหนดข้อจำกัดการใช้ เช่น ห้ามพยายาม re‑identify, สิทธิการตรวจสอบทางเทคนิค, ข้อกำหนดการรายงานเหตุผิดปกติ และมาตรการชดใช้ความเสียหาย
- Privacy engineering: นำหลัก Privacy by Design/Default มาประยุกต์ ตั้งแต่การออกแบบโพรเซสการสร้างข้อมูล การทดสอบเพื่อลดความเสี่ยงการรั่วไหล การกำหนดค่า differential privacy อย่างรัดกุม และการควบคุมการเข้าถึงข้อมูล
- DPIA และการทดสอบอิสระ: ดำเนินการ Data Protection Impact Assessment (DPIA) สำหรับโครงการที่มีความเสี่ยงสูง ร่วมกับการทดสอบการโจมตีเชิงแยก (adversarial testing) และการประเมินความเสี่ยงการ re‑identification โดยหน่วยงานอิสระ
- การบริหารจัดการความเสี่ยงเชิงสัญญา: กำหนดเงื่อนไขการใช้งานเชิงพาณิชย์และเชิงวิจัยที่แตกต่างกัน ระบุข้อจำกัดด้านการขายต่อ การฝึกซ้ำ (re‑training) และการเปิดเผยต่อบุคคลที่สาม
บทบาทของหน่วยงานกำกับดูแลและความจำเป็นของการตรวจสอบภายนอก
หน่วยงานกำกับดูแลเช่นคณะกรรมการคุ้มครองข้อมูลส่วนบุคคล (PDPC) มีบทบาทสำคัญในการออกแนวปฏิบัติและคำชี้แนะเกี่ยวกับการใช้ข้อมูลเทียม โดยเฉพาะการกำหนดหลักเกณฑ์การประเมินความเสี่ยงและการยอมรับมาตรการนิรนาม (anonymization) เพื่อให้ผู้พัฒนาและผู้ใช้งานมีความแน่นอนด้านกฎหมาย นอกจากนี้ การตรวจสอบภายนอก (third‑party audits) และการรับรองมาตรฐานความปลอดภัย/ความเป็นส่วนตัวจากองค์กรอิสระ จะช่วยสร้างความน่าเชื่อถือทั้งในสายตาของหน่วยงานกำกับและคู่ค้าทางธุรกิจ
ข้อเสนอเชิงปฏิบัติสำหรับหน่วยงานกำกับและองค์กรภายนอก ได้แก่ การจัดทำแนวทางการวัดความเสี่ยงการระบุตัวตนที่เป็นมาตรฐาน การกำหนดเกณฑ์สำหรับการเปิดเผยข้อมูลเกี่ยวกับ privacy budget และการส่งเสริมการใช้เครื่องมือทางเทคนิค เช่น model cards, dataset datasheets, และรายงานความโปร่งใส เพื่อให้กระบวนการสร้างและการแจกจ่ายข้อมูลเทียมมีความรับผิดชอบและปฏิบัติตามข้อกำหนด PDPA/GDPR/HIPAA อย่างชัดเจน
โมเดลธุรกิจ ผลกระทบต่อระบบสาธารณสุข และแนวทางการนำไปใช้จริง
โมเดลธุรกิจ
สตาร์ทอัพที่นำเสนอแพลตฟอร์ม Synthetic‑Health สามารถเลือกใช้หรือผสมผสานโมเดลรายได้หลายรูปแบบให้สอดคล้องกับความต้องการของตลาดสาธารณสุข ได้แก่
- Subscription (SaaS) — ให้บริการแบบสมาชิกรายเดือน/รายปี สำหรับการเข้าถึงแพลตฟอร์มสร้างข้อมูลเทียม เครื่องมือวิเคราะห์ และอินเตอร์เฟซ API เหมาะกับผู้ใช้องค์กรขนาดกลางถึงใหญ่ที่ต้องการอัพเดตต่อเนื่องและการสนับสนุนเชิงเทคนิค
- Pay‑per‑dataset — ขายชุดข้อมูลเทียมเป็นล็อต (per dataset / per project) สำหรับทีมนักวิจัยหรือสถาบันที่ต้องการชุดข้อมูลเฉพาะเท่านั้น โดยกำหนดระดับความเป็นส่วนตัว (เช่น พารามิเตอร์ differential privacy / epsilon) ตามราคาที่แตกต่าง
- Licensing และ OEM — ให้สิทธิใช้งานโมเดลหรือซอฟต์แวร์แก่บริษัทเทคโนโลยีการแพทย์หรือผู้พัฒนาโซลูชัน เพื่อฝังความสามารถสร้างข้อมูลเทียมในผลิตภัณฑ์ของพันธมิตร
- On‑premises / Private cloud deployment — ติดตั้งระบบภายในโรงพยาบาลหรือเครือข่ายหน่วยงานสาธารณสุข เพื่อตอบโจทย์ด้านกฎระเบียบและความเป็นส่วนตัวซึ่งอาจยอมจ่ายเกณฑ์สูงขึ้นสำหรับโซลูชันแบบติดตั้งภายใน
- Partnership with hospitals & revenue sharing — ทำข้อตกลงร่วมกับโรงพยาบาลและศูนย์วิจัยเพื่อร่วมพัฒนา/แลกเปลี่ยนข้อมูลเทียม โดยแบ่งรายได้จากการขายข้อมูลหรือการให้บริการวิจัยแก่ภาคเอกชน
- Managed services และ consulting — บริการเสริมเช่น การปรับแต่งโมเดล การตรวจสอบความเป็นส่วนตัว (privacy audit) และการวัดความเที่ยงตรงของข้อมูลเทียม
การกำหนดราคาเชิงยุทธศาสตร์ควรคำนึงถึงต้นทุนการคำนวณของเทคนิค diffusion model และกระบวนการเพิ่มความเป็นส่วนตัว (differential privacy) ซึ่งอาจทำให้ต้นทุนต่อชุดข้อมูลสูง ดังนั้นการใช้โมเดลผสม (เช่น subscription สำหรับการเข้าถึงพื้นฐาน + pay‑per‑dataset สำหรับงานวิจัยเฉพาะ) จะช่วยเปิดช่องทางรายได้หลายระดับและลดอุปสรรคในการเข้าถึงสำหรับสถาบันขนาดเล็ก
ขนาดตลาดและโอกาสในไทยและภูมิภาคอาเซียน
โอกาสเชิงธุรกิจของข้อมูลผู้ป่วยเทียมในไทยและอาเซียนมีศักยภาพสูงจากปัจจัยหลายประการ ได้แก่ การขยายตัวของระบบอิเล็กทรอนิกส์เวชระเบียน (EHR), นโยบายการผลักดันสุขภาพดิจิทัล และความต้องการโมเดลทางการแพทย์ที่ต้องการข้อมูลหลากหลายตัวอย่างสำหรับการฝึกสอนและทดสอบ โดยภาพรวม ตลาดข้อมูลสังเคราะห์และโซลูชันสุขภาพดิจิทัล ถูกประเมินว่ามีอัตราการเติบโต (CAGR) สูงกว่ากลุ่มเทคโนโลยีทั่วไป และมีการคาดการณ์จากผู้วิเคราะห์บางรายว่าจะมีมูลค่ารวมระดับหลายร้อยล้านถึงพันล้านดอลลาร์ในภูมิภาคภายใน 5–10 ปีข้างหน้า
สำหรับประเทศไทย ความต้องการข้อมูลเชิงคลินิกมีแรงผลักดันจากการวิจัยโรคเฉพาะถิ่น (เช่น โรคเขตร้อน โรคไม่ติดต่อเรื้อรัง) และการพัฒนาเครื่องมือวินิจฉัยเชิง AI ในโรงพยาบาลสังกัดรัฐและเอกชน จำนวนโรงพยาบาลขนาดกลาง-ใหญ่ในเมืองใหญ่อาทิ กรุงเทพฯ และจังหวัดหลัก สามารถเป็นแหล่งพันธมิตรเชิงข้อมูลได้ง่าย การใช้ข้อมูลเทียมจะช่วยลดแรงเสียดทานทางกฎหมายและจริยธรรมในการแลกเปลี่ยนข้อมูลข้ามสถาบัน ทำให้การทำ multi‑center study และการพัฒนาโมเดลข้ามระบบเป็นไปได้เร็วขึ้น
ประโยชน์ต่อการวิจัยและการพัฒนาเภสัชกรรม/การรักษา
การใช้ข้อมูลเทียมที่สร้างด้วยเทคนิค diffusion ร่วมกับ differential privacy มีข้อดีสำคัญต่อวงการวิจัยและการพัฒนายา ได้แก่ การเพิ่มปริมาณตัวอย่างสำหรับโรคที่มีผู้ป่วยน้อย (rare diseases), การสร้างชุดข้อมูลที่มีความหลากหลายเชิงประชากรเพื่อปรับปรุงความทนทานของโมเดล, และการเปิดให้เกิดการร่วมมือเชิงวิชาการหรือการทดสอบโมเดลโดยที่ไม่เปิดเผยข้อมูลผู้ป่วยจริง ตัวอย่างเช่น การทำ A/B testing ของอัลกอริทึมวินิจฉัยหลายเวอร์ชันโดยใช้ชุดข้อมูลเทียมสามารถลดระยะเวลาในการทดลองเบื้องต้นลงได้อย่างมีนัยสำคัญ
อย่างไรก็ตามต้องย้ำว่า คุณภาพทางสถิติและความสอดคล้องทางคลินิก ของข้อมูลเทียมต้องได้รับการประเมินอย่างเข้มงวด — หากข้อมูลเทียมบิดเบือนรูปแบบปัจจัยเสี่ยงหรือส่งต่ออคติ จะส่งผลให้โมเดลการรักษาหรือการคัดกรองมีประสิทธิภาพต่ำและอาจเป็นอันตรายได้
ข้อกังวลของผู้รับผิดชอบด้านสาธารณสุขและคำแนะนำก่อนนำไปใช้จริง
ผู้กำกับดูแลและเจ้าหน้าที่สาธารณสุขมักกังวลเรื่องการคงไว้ซึ่งความเป็นส่วนตัว ความถูกต้องทางคลินิก และความรับผิดชอบทางกฎหมาย ประเด็นที่ต้องพิจารณาได้แก่ความเสี่ยงการระบุตัวบุคคล (re‑identification), ความเที่ยงตรงของตัวชี้วัดทางคลินิก, การเกิดอคติในการจำลองประชากร และการยอมรับจากชุมชนนักวิจัยและผู้ป่วย
- การประเมินความเสี่ยงก่อนใช้งาน: ดำเนินการ privacy risk assessment และ re‑identification test ด้วยผู้เชี่ยวชาญภายนอก กำหนดพารามิเตอร์ differential privacy (ค่า epsilon) ให้สอดคล้องกับมาตรฐานความเสี่ยงที่ยอมรับได้
- การตรวจสอบความเที่ยงตรงทางคลินิก: ทำ validation study เปรียบเทียบผลจากโมเดลที่ฝึกด้วยข้อมูลเทียมกับข้อมูลจริงในชุดทดสอบอิสระ และสรุป metric ที่สำคัญเช่น sensitivity, specificity, AUC
- นโยบายการกำกับดูแลและความโปร่งใส: จัดทำเอกสารการสร้างข้อมูล (data provenance), รายงานด้าน privacy guarantees และชุดข้อจำกัดการใช้งาน เพื่อให้หน่วยงานกำกับดูแล (เช่น ผู้ตรวจสอบด้านจริยธรรม) ทบทวนได้
- การเลือกสถาปัตยกรรมการติดตั้ง: สำหรับข้อมูลที่มีความอ่อนไหวสูง แนะนำ deployment แบบ on‑premises หรือ private cloud พร้อมสัญญาการจัดการข้อมูลและมาตรการทางเทคนิค (เช่น encryption at rest, access logging)
- การเริ่มงานแบบพยากรณ์ (pilot): เริ่มจากโครงการนำร่องขนาดเล็กที่มีตัวชี้วัดชัดเจน เพื่อวัดผลทางคลินิกและความคุ้มค่าทางเศรษฐกิจ ก่อนขยายสู่ระดับสถาบันหรือระดับภูมิภาค
- การสร้างกรอบความร่วมมือ: ทำข้อตกลงการแบ่งปันผลประโยชน์กับโรงพยาบาล (revenue share, co‑authorship ในงานวิจัย) และรวม stakeholder เช่น คณะกรรมการจริยธรรม ผู้แทนผู้ป่วย และนักนโยบายตั้งแต่ต้น
- การปฏิบัติตามกฎหมายและมาตรฐาน: ตรวจสอบให้สอดคล้องกับ PDPA ของไทย มาตรฐานสากลที่เกี่ยวข้อง (เช่น ISO 27001/27701) และข้อกำหนดเฉพาะกรณีที่ทำงานข้ามประเทศ
สรุปคือ โมเดลธุรกิจของแพลตฟอร์ม Synthetic‑Health ควรยืดหยุ่นสามารถรองรับการเป็น SaaS, การขายเป็นชุดข้อมูล และการติดตั้งภายในองค์กรพร้อมช่องทางพันธมิตรกับโรงพยาบาล ส่วนฝ่ายสาธารณสุขและสถาบันวิจัยต้องเน้นการประเมินความเสี่ยง การตรวจสอบความถูกต้องเชิงคลินิก และการตั้งกรอบการกำกับดูแลเพื่อให้การใช้ข้อมูลเทียมเป็นประโยชน์สูงสุดโดยยังคงคุ้มครองสิทธิและความปลอดภัยของผู้ป่วย
ความเสี่ยง ข้อจำกัด และทิศทางพัฒนาต่อไป
ภาพรวมความเสี่ยงและข้อจำกัด
แม้แพลตฟอร์ม Synthetic‑Health ที่ผสานเทคนิค Diffusion models ร่วมกับ Differential Privacy (DP) จะมีศักยภาพในการลดความเสี่ยงการรั่วไหลของข้อมูลผู้ป่วย แต่ยังมีความเสี่ยงและข้อจำกัดทั้งทางเทคนิคและเชิงนโยบายที่ต้องพิจารณาอย่างรอบคอบ ก่อนนำไปใช้ในกระบวนการพยากรณ์หรือวินิจฉัยจริง ข้อจำกัดเหล่านี้ส่งผลต่อความเชื่อมั่นของผู้ใช้งาน สถาบันการแพทย์ และหน่วยงานกำกับดูแล
ข้อจำกัดทางเทคนิคและเชิงนโยบาย (ประเด็นสำคัญ)
ประเด็นสำคัญที่ต้องรับมือประกอบด้วย:
- ความต่างเชิงสถิติระหว่างข้อมูลเทียมและข้อมูลจริง (synthetic vs real distribution gap) — โมเดลที่เทรนด้วยข้อมูลเทียมอาจแสดงประสิทธิภาพลดลงเมื่อทดสอบกับข้อมูลจริง หากการแจกแจงของข้อมูลเทียมไม่ครอบคลุมความแปรปรวนในกลุ่มผู้ป่วยจริง งานวิจัยและการทดลองเบื้องต้นมักพบว่าอาจเกิดการลดทอน性能 (performance degradation) ระหว่าง 5–30% ขึ้นกับงานและวิธีการสร้างข้อมูล
- Mode collapse และการขาดความหลากหลายของตัวอย่าง — โมเดลเพื่อสร้างข้อมูลเทียมโดยเฉพาะ generative models อาจประสบปัญหา mode collapse ทำให้ตัวอย่างที่สร้างออกมาซ้ำซ้อนหรือไม่ครอบคลุมยากต่อการจำลองกรณีปกติและกรณีแปลก (rare cases)
- การถ่ายทอดอคติ (bias transfer) — ข้อมูลต้นทางที่มีอคติ เช่น การเก็บตัวอย่างไม่สมดุลตามเพศ วัย หรือกลุ่มชาติพันธุ์ อาจถูกสืบทอดสู่ข้อมูลเทียม ทำให้โมเดลที่เทรนจากข้อมูลเทียมรักษาหรือขยายปัญหาอคติเดิม
- ความสามารถในการทั่วไป (limited generalizability) — ข้อมูลเทียมที่พัฒนาในบริบทหรือสถาบันหนึ่งอาจไม่สามารถใช้งานได้ดีในสภาพแวดล้อมอื่น ๆ ซึ่งจำเป็นต้องทดสอบการทำงานข้ามชุมชนและสถาบันหลายแห่ง
- Trade‑off ระหว่างความเป็นส่วนตัวกับคุณภาพ (privacy‑utility tradeoff) และการเลือกค่า privacy budget — การบังคับใช้ DP ทำให้เกิดการสูญเสียข้อมูล (noise addition) ที่ส่งผลต่อความแม่นยำ โดยไม่มีค่า ε (epsilon) ที่เป็นมาตรฐานสากลสำหรับทุกบริบท งานวิจัยและการปฏิบัติทั่วไปมักพิจารณาช่วง ε ตั้งแต่ 0.1 ถึง 10 ขึ้นอยู่กับระดับความเสี่ยงและความจำเป็นของยูสเคส แต่การเลือกค่าใดค่าหนึ่งต้องอาศัยการประเมินเชิงปริมาณและเชิงบริบท (contextual risk assessment)
- ความเสี่ยงเชิงนโยบายและกฎหมาย — แม้ข้อมูลจะเป็นเทียม หน่วยงานกำกับดูแลและหน่วยงานด้านจริยธรรมยังอาจเรียกร้องการยืนยันว่าข้อมูลนั้นไม่สามารถย้อนกลับไปยังผู้ป่วยจริงได้ และต้องมีมาตรการคุ้มครองทางกฎหมาย เช่น การตรวจสอบการเปิดเผยข้อมูล (disclosure risk) และเงื่อนไขการใช้ข้อมูล
ความจำเป็นของการทดลองทางคลินิกและการยืนยันการใช้งานจริง
ก่อนนำผลลัพธ์จากโมเดลที่เทรนด้วยข้อมูลเทียมไปใช้งานในคลินิก จำเป็นต้องมีการทดสอบและยืนยันอย่างเป็นระบบทั้งในระดับห้องทดลองและระดับภาคสนาม ซึ่งรวมถึง:
- การประเมินเชิงคลินิก (clinical validation) โดยใช้ชุดข้อมูลจริงจากหลายศูนย์ตรวจเพื่อวัดความไว (sensitivity), ความจำเพาะ (specificity), ค่าการคาดการณ์เชิงความน่าเชื่อถือ (calibration) และประสิทธิภาพต่อกลุ่มย่อย (subgroup performance)
- การทดลองเชิงการใช้จริง (prospective real‑world studies) เพื่อทดสอบการทำงานในสภาพการปฏิบัติจริงและการยอมรับจากทีมคลินิก ซึ่งเป็นหัวใจสำคัญของการพิสูจน์การใช้งาน (clinical utility)
- การทดสอบความปลอดภัยและความเสี่ยงทางข้อมูล เช่น การทดสอบการโจมตีเชิงสมาชิก (membership inference), model inversion attacks และการประเมินความเสี่ยงการเปิดเผยข้อมูลที่อาจเกิดขึ้น
- การมีคณะกรรมการจริยธรรมและการปฏิบัติตามระเบียบ (compliance) ที่ชัดเจน เช่น การได้รับการอนุมัติจากหน่วยงานกำกับและการปฏิบัติตามมาตรฐานสากลที่เกี่ยวข้อง
Roadmap การพัฒนาและข้อเสนอแนะเพื่อการยอมรับในวงกว้าง
เพื่อให้แพลตฟอร์มสามารถขยายการใช้งานอย่างปลอดภัยและเป็นที่ยอมรับ สตาร์ทอัพควรดำเนินตาม roadmap ที่เป็นขั้นตอน ประกอบด้วย:
- ระยะสั้น (0–12 เดือน)
- จัดทำชุดทดสอบมาตรฐาน (benchmarks) เปรียบเทียบ performance ระหว่างโมเดลที่เทรนด้วยข้อมูลเทียมและข้อมูลจริงในงานวินิจฉัยหลัก ๆ
- ปรับแต่งค่า privacy budget ผ่านการทดสอบเชิงปริมาณเพื่อหา trade‑off ที่เหมาะสมในแต่ละยูสเคส และเปิดเผยค่า ε และเมตริกความเป็นส่วนตัว (privacy accounting) อย่างโปร่งใส
- ติดตั้งการทดสอบความหลากหลาย (diversity metrics) เพื่อตรวจจับและลดปัญหา mode collapse และ bias transfer
- ระยะกลาง (12–24 เดือน)
- วิจัยและพัฒนา conditional generation ที่ดียิ่งขึ้นเพื่อรองรับเงื่อนไขทางคลินิกเฉพาะ (เช่น โรคร่วม ความรุนแรง ผล lab) และเพิ่มการครอบคลุมกรณีหายาก
- พัฒนาและนำเทคนิค DP ที่ทนทานกว่า เช่น DP‑SGD ที่มีการประเมินด้วย Rényi DP หรือ advanced composition methods เพื่อลดผลกระทบต่อ utility
- เริ่มโครงการนำร่องร่วมกับโรงพยาบาลหลายแห่งเพื่อทดสอบ cross‑site generalizability และปรับปรุงโมเดลตามผลการทดลองจริง
- ระยะยาว (24–48 เดือน)
- สนับสนุนการตรวจสอบจากภายนอก (external audits) และการรับรองมาตรฐาน (certification) โดยองค์กรอิสระเพื่อตรวจสอบความเสี่ยงด้านความเป็นส่วนตัว คุณภาพข้อมูล และอคติ
- ร่วมมือกับหน่วยงานกำกับเพื่อกำหนดแนวทางปฏิบัติและมาตรฐานสำหรับการใช้ข้อมูลเทียมในงานทางการแพทย์ รวมถึงการออกแนวปฏิบัติทางกฎหมายและจริยธรรม
- ส่งเสริมการเปิดเผยข้อมูลเมตา (metadata) และการรายงานผลการทดสอบอย่างโปร่งใส เพื่อสร้างความเชื่อมั่นต่อผู้ใช้งานและผู้ป่วย
ข้อเสนอแนะเชิงนโยบายและการยอมรับ
เพื่อการยอมรับในวงกว้าง แนะนำให้สตาร์ทอัพดำเนินมาตรการต่อไปนี้ควบคู่กับการพัฒนาเทคนิค:
- จัดตั้งกลไกธรรมาภิบาลข้อมูล (data governance) ที่ชัดเจน รวมถึงนโยบายการเข้าถึง การล็อกข้อมูล และการตรวจสอบการใช้งาน
- ร่วมมือกับผู้เชี่ยวชาญทางคลินิก นักจริยธรรม และหน่วยงานกำกับเพื่อกำหนดเกณฑ์การทดสอบและเกณฑ์ความปลอดภัยก่อนการนำไปใช้จริง
- เผยแพร่ผลการทดสอบแบบ peer‑review หรือรายงานสาธารณะ และเปิดรับการตรวจสอบจากภายนอก เพื่อลดความกังวลเกี่ยวกับความโปร่งใสและความน่าเชื่อถือ
- ลงทุนในการศึกษาและฝึกอบรมบุคลากรทางการแพทย์เพื่อให้เข้าใจข้อจำกัดของข้อมูลเทียมและการตีความผลลัพธ์ของโมเดลอย่างเหมาะสม
โดยสรุป Synthetic‑Health มีศักยภาพสูงในการลดความเสี่ยงการรั่วไหลของข้อมูลและส่งเสริมการวิจัยด้าน AI ทางการแพทย์ แต่ความสำเร็จเชิงปฏิบัติจำเป็นต้องอาศัยการยืนยันทางคลินิก การประเมินเชิงปริมาณของ privacy‑utility trade‑off การตรวจสอบภายนอก และการสร้างมาตรฐานร่วมกับหน่วยงานกำกับ เพื่อให้การใช้งานเป็นไปอย่างปลอดภัย มีความยุติธรรม และได้รับความไว้วางใจจากสังคมและผู้ป่วย
บทสรุป
Synthetic‑Health แพลตฟอร์มที่รวมเทคนิค Diffusion กับกลไก Differential Privacy แสดงศักยภาพชัดเจนในการลดข้อจำกัดด้านการเข้าถึงข้อมูลผู้ป่วยจริงและช่วยเร่งการพัฒนาโมเดลวินิจฉัยทางการแพทย์ โดยการสร้างข้อมูลผู้ป่วยเทียมที่รักษาลักษณะสถิติสำคัญของชุดข้อมูลต้นทาง ทำให้นักวิจัยและบริษัทสามารถเทรนและทดสอบโมเดลได้โดยลดความเสี่ยงจากการรั่วไหลของข้อมูลส่วนบุคคล อย่างไรก็ตาม ความสำเร็จเชิงปฏิบัติจำเป็นต้องรักษาสมดุลระหว่าง utility (ความแม่นยำและความเป็นประโยชน์ของข้อมูลเทียม) กับ privacy (ระดับการป้องกันข้อมูลจริง) ผ่านการออกแบบพารามิเตอร์ DP ที่เหมาะสมและการดำเนินการประเมินความเสี่ยงเชิงพฤติการณ์อย่างเข้มงวดเพื่อวัดช่องว่างด้านความปลอดภัยในสถานการณ์ใช้งานจริง
นอกจากประเด็นทางเทคนิคแล้ว ความสำเร็จของ Synthetic‑Health จะพึ่งพาการยอมรับจากชุมชนแพทย์ การตรวจสอบอิสระ (third‑party audits) และกรอบกฎหมายที่ชัดเจนซึ่งคุ้มครองผู้ป่วยและส่งเสริมนวัตกรรมพร้อมกัน กรอบนโยบายที่เอื้อต่อการทดสอบภายใต้สภาพแวดล้อมควบคุม (regulatory sandboxes) และมาตรฐานการรายงานผลทางความเป็นส่วนตัวจะเพิ่มความเชื่อมั่นของผู้ใช้งาน การพัฒนาเชิงอนาคตควรมุ่งไปที่การผนวกระบบตรวจวัดความสมมูลย์ของข้อมูลเทียม การติดตามประสิทธิภาพโมเดลอย่างต่อเนื่อง และการร่วมมือกับโรงพยาบาล-สถาบันวิจัย เพื่อให้สตาร์ทอัพไทยมีโอกาสก้าวขึ้นเป็นผู้เล่นระดับภูมิภาคที่สร้างสมดุลระหว่างนวัตกรรมและการคุ้มครองข้อมูลส่วนบุคคล



