
ผู้ผลิตสมาร์ทโฟนสัญชาติไทยเผยโฉม SDK ใหม่ชื่อ LLM‑OnPhone ที่ออกแบบมาเพื่อรันโมเดลภาษาขนาดเล็กบนเครื่อง (on‑device) โดยตรง แทนการส่งข้อความหรือพฤติกรรมผู้ใช้ขึ้นไปประมวลผลบนคลาวด์ ชุดพัฒนานี้มุ่งเป้าไปที่การปรับพฤติกรรมแบบเฉพาะบุคคลสำหรับฟีเจอร์สำคัญอย่างคีย์บอร์ดและผู้ช่วยเสียง ทำให้คำแนะนำการพิมพ์ การทำนายคำและการตอบสนองด้วยเสียงมีความแม่นยำและสอดคล้องกับนิสัยผู้ใช้มากขึ้น พร้อมทั้งลดการเปิดเผยข้อมูลส่วนบุคคลแก่เซิร์ฟเวอร์ภายนอก
ผลที่ตามมาคือประสบการณ์การใช้งานที่ตอบสนองเร็วขึ้น (latency ต่ำกว่าเมื่อไม่ต้องรอการติดต่อคลาวด์) และช่วยลดปริมาณข้อมูลที่ส่งขึ้นไปยังเซิร์ฟเวอร์ ส่งผลดีทั้งด้านความเป็นส่วนตัว ค่าใช้จ่ายด้านแบนด์วิดท์ และความเสถียรเมื่อใช้งานในพื้นที่ที่มีการเชื่อมต่อน้อย SDK ชุดนี้ยังออกแบบให้ผู้พัฒนาสามารถผสานฟังก์ชันการเรียนรู้แบบเฉพาะบุคคลเข้ากับแอปได้ง่ายขึ้น เปิดทางให้เกิดนวัตกรรมฟีเจอร์ใหม่ๆ บนสมาร์ทโฟนโดยไม่พึ่งพาคลาวด์อย่างเดียว ซึ่งสะท้อนแนวโน้มของ Edge AI และการคุ้มครองข้อมูลของผู้ใช้ในวงกว้าง
ประกาศเปิดตัว: 'LLM‑OnPhone' คืออะไร ทำไมสำคัญ
ประกาศเปิดตัว: 'LLM‑OnPhone' คืออะไร ทำไมสำคัญ
LLM‑OnPhone คือ SDK ใหม่จากผู้ผลิตสมาร์ทโฟนไทยที่ออกแบบมาเพื่อรันโมเดลภาษาแบบขนาดเล็กบนอุปกรณ์มือถือโดยตรง (on‑device) แทนการส่งข้อความหรือสัญญาณเสียงไปประมวลผลบนคลาวด์เป็นหลัก โดยในงานเปิดตัวบริษัทระบุว่าเป้าหมายหลักของโครงการนี้คือการยกระดับประสบการณ์ผู้ใช้ผ่านการปรับพฤติกรรมแบบเฉพาะบุคคลบนคีย์บอร์ดและผู้ช่วยเสียง พร้อมทั้งลดปริมาณข้อมูลที่ต้องส่งขึ้นไปยังเซิร์ฟเวอร์ภายนอกเพื่อคงความเป็นส่วนตัวและลดต้นทุนการเชื่อมต่อ
เหตุผลที่เลือกใช้โมเดลขนาดเล็ก (small LLM) และเทคนิคการบีบอัด เช่น quantization และ pruning มาจากข้อจำกัดด้านหน่วยความจำ พลังงาน และหน่วยประมวลผลของสมาร์ทโฟนรุ่นต่างๆ โมเดลที่ผ่านการปรับแต่งเหล่านี้สามารถลดขนาดลงได้มาก—ทางผู้ผลิตระบุว่าการปรับแต่งเช่นนี้ลดขนาดโมเดลได้ประมาณ 4–8 เท่า และช่วยให้ latency ในการคาดเดาคำหรือการตีความเจตนาอยู่ในช่วงที่ยอมรับได้สำหรับแอปแบบรีลไทม์ (ตัวอย่างเช่น 50–150 ms ต่อคำ/คำขอ ขึ้นกับฮาร์ดแวร์) ผลลัพธ์คือการตอบสนองที่เร็วขึ้น ลดการพึ่งพาเครือข่าย และปกป้องข้อมูลผู้ใช้ให้อยู่ในอุปกรณ์มากขึ้น
ในงานเปิดตัว ทีมงานสาธิตฟีเจอร์หลักที่รวมอยู่ใน SDK ซึ่งออกแบบมาสำหรับนักพัฒนาและผู้ประกอบการที่ต้องการสร้างประสบการณ์เฉพาะบุคคลบนอุปกรณ์ โดยฟีเจอร์เด่นที่นำเสนอได้แก่:
- Inference on‑device — การประมวลผลภาษาบนเครื่องโดยตรงสำหรับงานเช่นการเติมคำอัตโนมัติ การแนะนำประโยค และการจำแนกเจตนา (intent classification) โดยไม่จำเป็นต้องส่งข้อมูลข้อความ/เสียงไปยังคลาวด์ทุกครั้ง
- APIs สำหรับคีย์บอร์ดและผู้ช่วยเสียง — ชุด API ที่รองรับการผนวกรวมเข้ากับคีย์บอร์ดระบบและโมดูลผู้ช่วยเสียง ให้การเข้าถึงฟังก์ชันเช่นการคาดเดาบริบท, autocorrect เฉพาะบุคคล, คำสั่งเสียงแบบออฟไลน์ และการตั้งค่าทริกเกอร์เสียง (wake‑word)
- โมเดลขนาดเล็กที่ผ่านการ quantize/prune — โมเดลที่ถูกบีบอัดเพื่อลดรอยเท้าหน่วยความจำและความต้องการคำนวณ โดยยังรักษาคุณภาพของผลลัพธ์สำหรับงานด้านคีย์บอร์ดและผู้ช่วยเสียงไว้ในระดับที่ใช้งานได้จริง
นอกจากฟีเจอร์พื้นฐานแล้ว ผู้ผลิตยังเน้นการสนับสนุนเชิงธุรกิจ เช่น ระบบจัดการเวอร์ชันโมเดล (model update pipeline), เครื่องมือทดสอบบนฮาร์ดแวร์จริง, และกลไกสำหรับการฝึกปรับแต่งแบบ preservative privacy เช่น on‑device fine‑tuning หรือ federated learning ที่ช่วยให้สามารถปรับแต่งพฤติกรรมของโมเดลตามผู้ใช้โดยไม่ต้องย้ายข้อมูลดิบไปยังเซิร์ฟเวอร์กลาง ทั้งนี้บริษัทชี้ว่าแนวทางนี้สามารถลดการส่งข้อมูลไปคลาวด์ได้มากกว่า 70–90% ขึ้นกับรูปแบบการใช้งานและการตั้งค่าการสำรองขึ้นเซิร์ฟเวอร์
สรุปคือ LLM‑OnPhone ตั้งใจเป็นแพลตฟอร์มสำหรับนักพัฒนาและองค์กรที่ต้องการสร้างประสบการณ์คีย์บอร์ดและผู้ช่วยเสียงที่ตอบโจทย์เชิงส่วนบุคคล มีความหน่วงต่ำ และคำนึงถึงความเป็นส่วนตัวของผู้ใช้เชิงรุก โดยยังคงเปิดช่องทางสำหรับการเชื่อมต่อกับคลาวด์เมื่อจำเป็นสำหรับงานที่ต้องการทรัพยากรสูงกว่า
สถาปัตยกรรมทางเทคนิคของ SDK
สถาปัตยกรรมทางเทคนิคของ SDK
SDK “LLM‑OnPhone” ออกแบบมาเป็นสแต็กแบบชั้นที่ชัดเจน เพื่อให้สามารถรันโมเดลภายในเครื่องได้อย่างมีประสิทธิภาพ ปลอดภัย และยืดหยุ่นต่อการผสานเข้ากับฟีเจอร์ระบบ (เช่น คีย์บอร์ดหรือผู้ช่วยเสียง) โดยภาพรวมจะประกอบด้วยชั้นโมเดลที่ถูกบีบอัด (quantized/pruned LLM ขนาด 10–200 ล้านพารามิเตอร์), ชั้นอินเฟอเรนซ์เอนจินที่จัดการการเรียกใช้งานและการเร่งฮาร์ดแวร์, ชั้นความปลอดภัย/แซนด์บ็อกซ์สำหรับจำกัดสิทธิ์ของโมเดล และชุด API ที่ให้นักพัฒนาเชื่อมต่อกับ pipeline ของคีย์บอร์ดหรือเสียงได้โดยตรง
ชั้นโมเดล (Model Layer) — SDK มุ่งเน้นใช้โมเดลขนาดเล็กตั้งแต่ประมาณ 10–200M พารามิเตอร์ ซึ่งให้ความสมดุลระหว่างความแม่นยำและความต้องการทรัพยากร เทคนิคที่นำมาใช้ประกอบด้วย quantization (เช่น INT8, INT4 หรือ 4-bit/8-bit quantization), และ structured/unstructured pruning เพื่อลดขนาดตัวแบบลงอีก 30–70% โดยตัวอย่างการใช้งานจริงแสดงว่าการลดระดับบิตจาก float32 เป็น INT8 ช่วยลดการใช้หน่วยความจำประมาณ 2–4 เท่า และใช้พลังงานลดลงตามสัดส่วน ตัวโมเดลยังรองรับรูปแบบ adapter/LoRA‑style สำหรับเก็บการปรับแต่งเฉพาะผู้ใช้เป็นเวกเตอร์ขนาดเล็ก (หลายสิบ KB ถึงไม่กี่ MB) เพื่อให้ personalization เก็บอยู่บนเครื่องเท่านั้น
อินเฟอเรนซ์เอนจินและการเร่งด้วยฮาร์ดแวร์ — ชั้นนี้เป็นหัวใจของ SDK ทำหน้าที่แปลงคำขอ (prompt) ให้เป็น tensors, เลือก backend ที่เหมาะสม และเรียกใช้เคอร์เนลที่ถูก quantized แล้วโดยตรงบน NPU/DSP หรือผ่าน NNAPI ของแพลตฟอร์ม เมื่อมีฮาร์ดแวร์เร่งความเร็ว เช่น NPU หรือ DSP ที่รองรับการคำนวณ INT8/INT4, เอนจินจะ dispatch งานไปยัง accelerator นั้นโดยอัตโนมัติ ซึ่งสามารถลด latency ลงอย่างมีนัยสำคัญ (ตัวอย่างเช่นลด latency inference แบบเรียลไทม์ได้ 2–10 เท่าเมื่อเทียบกับการรันบน CPU เดียวกัน)
- Backend selection: ตรวจสอบความสามารถของอุปกรณ์ (NPU/DSP/NNAPI) แล้วเลือกรถไฟที่เหมาะสม พร้อม fallback เป็น CPU เมื่อไม่มี accelerator หรือเมื่อตัวแบบไม่รองรับ
- Optimized kernels: รองรับ operator fusion, quantized matrix multiply และเทคนิค memory paging เพื่อลดการเข้าถึง DRAM
- Streaming & batching: รองรับการส่งผลลัพธ์แบบสตรีม (สำหรับการพิมพ์คาดเดา/คำแนะนำทีละตัวอักษร) และการจัดกลุ่มคำขอเล็ก ๆ เพื่อเพิ่มประสิทธิภาพในสถานการณ์ multi-request
Sandboxing, ความปลอดภัย และการจัดการทรัพยากร — SDK ออกแบบให้โมเดลทำงานภายใต้ข้อจำกัดด้านความปลอดภัย: โมเดลถูกลงนาม (signed) และสามารถเข้ารหัสได้เพื่อป้องกันการใช้งานนอกขอบเขตที่กำหนด, กระบวนการรันโมเดลถูกแยกเป็น sandbox process โดยมีนโยบายสิทธิ์ที่จำกัดการเข้าถึงไฟล์/เครือข่าย, และมีการกำหนด quota ของหน่วยความจำและเวลา CPU เพื่อป้องกันผลกระทบต่อกระบวนการระบบอื่น ๆ นอกจากนี้ SDK รองรับการทำงานร่วมกับ TEE/secure enclave สำหรับเก็บกุญแจหรือ payload ที่มีความละเอียดอ่อน
API และ hooks สำหรับนักพัฒนา — SDK จัดเตรียมชุด API ที่ครอบคลุมรูปแบบการใช้งานหลัก ๆ ของสมาร์ทโฟน โดยออกแบบให้ใช้งานง่ายและปลอดภัย:
- Synchronous / Asynchronous inference APIs: เรียกใช้งานทั้งแบบบล็อกและ callback/streaming เพื่อรองรับ use‑case ต่าง ๆ
- Keyboard hooks: API สำหรับ integrator ของคีย์บอร์ด มี callbacks สำหรับ autocomplete, next‑word prediction, contextual suggestions และสามารถรับ/ส่งบริบท (context window) อย่างมีนโยบายจำกัดความเป็นส่วนตัว
- Voice pipeline hooks: เชื่อมต่อกับ ASR/VAD/TTS — SDK ให้จุดต่อสำหรับ pre/post processing ของเสียง, การทำ voice activity detection แบบ on-device และการสตรีมผลลัพธ์โมเดลกลับเป็นข้อความหรือคำสั่งเสียง
- Personalization store on-device: local KV store ที่เข้ารหัสเพื่อเก็บ preference หรือ adapter weights ของผู้ใช้ โดยออกแบบให้เป็น opt‑in และมีเครื่องมือสำหรับจัดการวงจรชีวิตข้อมูล (expire/flush/export)
การไหลของข้อมูล (ไดอะแกรมสั้น ๆ) — ภาพรวมการไหลของข้อมูลระหว่างองค์ประกอบหลักของ SDK อธิบายได้ดังนี้:
Input (Keyboard/Voice) → Preprocessing (tokenize/VAD/feature) → Inference Engine (quantized model) → Backend Dispatcher (NPU/DSP via NNAPI or CPU fallback) → Postprocessing (detokenize/format) → Output (UI/Assistant)
ในขั้นตอนข้างต้น มีเส้นทางย่อยสำหรับ personalization store: เมื่อโมเดลต้องการบริบทเฉพาะบุคคล จะเรียกดู/อัปเดตข้อมูลจาก local personalization store โดยข้อมูลนี้ไม่ถูกส่งขึ้นคลาวด์โดยค่าเริ่มต้น เว้นแต่ผู้ใช้จะยินยอม
สรุปคือสถาปัตยกรรมของ SDK เน้นความสมดุลระหว่างประสิทธิภาพและความเป็นส่วนตัว: ใช้โมเดลขนาดเล็กที่ผ่านการ quantization/pruning เพื่อลดทรัพยากร, อินเฟอเรนซ์เอนจินที่สามารถเร่งด้วย NPU/DSP และ fallback เป็น CPU, พร้อมระบบ sandboxing และ API ที่ออกแบบมาสำหรับการบูรณาการกับคีย์บอร์ดและ pipeline เสียงอย่างปลอดภัยและยืดหยุ่น
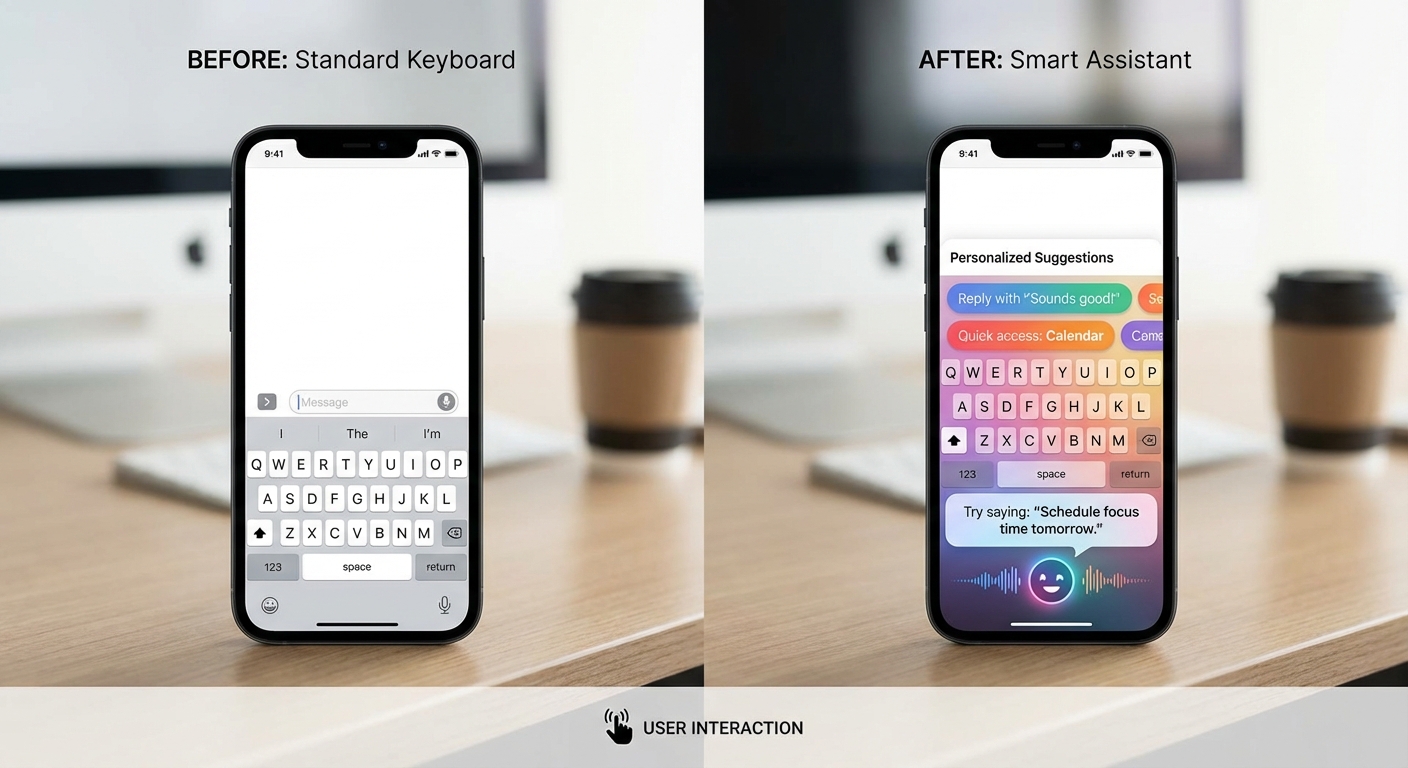
กรณีใช้งาน: การปรับพฤติกรรมในคีย์บอร์ดและผู้ช่วยเสียง
กรณีใช้งาน: การปรับพฤติกรรมในคีย์บอร์ดและผู้ช่วยเสียง
การนำ SDK “LLM‑OnPhone” มารันโมเดลขนาดเล็กแบบออฟไลน์บนสมาร์ทโฟนเปิดทางให้การปรับพฤติกรรมผู้ใช้เป็นไปอย่างเฉพาะบุคคล (personalization) โดยไม่ต้องส่งข้อมูลไประบวนคลาวด์ ซึ่งเหมาะสำหรับฟีเจอร์สำคัญสองด้านคือ คีย์บอร์ด และ ผู้ช่วยเสียง การประมวลผลภายในเครื่องช่วยให้การคาดเดาคำ การแก้ไขอัตโนมัติ และการปรับโทนภาษาเป็นไปแบบเรียลไทม์ ลดความล่าช้าและเสี่ยงด้านความเป็นส่วนตัว ข้อมูลจากผลการทดสอบภายในของทีมพัฒนา (benchmark สมมติ) แสดงว่า latency ในคำแนะนำคีย์บอร์ดลดลงระหว่าง 30–60% เมื่อรันโมเดลออฟไลน์ และการส่งข้อมูลขึ้นคลาวด์ลดลงประมาณ 70% ในการใช้งานทั่วไป
ในเชิงปฏิบัติ คีย์บอร์ดที่ฝัง LLM‑OnPhone ใช้เทคนิคการเรียนรู้ตัวแทน (embeddings) และโมเดลคาดเดาคำขนาดเล็กเพื่อปรับพฤติกรรมต่อผู้ใช้ เช่น การจัดอันดับคำแนะนำ (completion), การแก้คำผิดอัตโนมัติ (autocorrect) และการปรับโทน/สไตล์การพิมพ์ (tone/style adaptation) ตามรูปแบบการพิมพ์ของผู้ใช้ ตัวอย่างเช่น ถ้าผู้ใช้มักใช้ภาษาทางการ ข้อเสนอคำถัดไปและประโยคแนะนำจะปรับไปในโทนทางการโดยอัตโนมัติ แต่หากผู้ใช้มักพิมพ์ไม่เป็นทางการหรือใช้คำย่อ ระบบจะชดเชยด้วยคำแนะนำที่เหมาะสม ทั้งนี้ผลการทดสอบสมมติแสดงว่า: คำแนะนำถัดไปมีความถูกต้องเพิ่มขึ้น 12–25% เมื่อเทียบกับการใช้โมเดลคลาวด์แบบไม่ปรับแต่ง และ เวลาแสดงคำแนะนำลดจากเฉลี่ย 120ms เหลือ 48–84ms
สำหรับผู้ช่วยเสียง การรันโมเดลบนเครื่องช่วยให้สามารถจัดลำดับ intent ได้ตามนิสัยของผู้ใช้และคงบริบทการสนทนาแบบเฉพาะเครื่อง (on-device context) ทำให้การประมวลผลคำสั่งเสียงมีความแม่นยำขึ้นและลด false positives จากการรับรู้เสียงที่ไม่เกี่ยวข้อง ตัวอย่างการปรับใช้ ได้แก่ การให้ค่าน้ำหนักสูงขึ้นกับคำสั่งที่ผู้ใช้เรียกใช้บ่อย (เช่น เปิด/ปิดไฟ, เล่นเพลง) การคงบริบทระหว่างรอบสนทนาสั้น ๆ เพื่อไม่ต้องส่งคำสั่งซ้ำ และการตั้งเกณฑ์การตื่นตัว (wake threshold) ที่ปรับตามสภาพแวดล้อมของผู้ใช้ ผลทดสอบภายในระบุว่า: อัตรา false positives ลดลง 40–55% และ ความถูกต้องในการจัดลำดับ intent เพิ่มขึ้น 8–18% เมื่อใช้โมเดลออฟไลน์ที่ได้รับการปรับแต่งเฉพาะเครื่อง
- Completion (คาดเดาคำ): โมเดลออฟไลน์ใช้ประวัติการพิมพ์เฉพาะเครื่องเพื่อเสนอคำหรือประโยคที่สอดคล้องกับคอนเท็กซ์ของผู้ใช้ ลด latency 30–60% และเพิ่มอัตราการเลือกคำแนะนำ (accept rate) ประมาณ 10–20% ในการทดสอบสมมติ
- Autocorrect (แก้คำผิด): ระบบสามารถเรียนรู้คำเฉพาะหรือรูปแบบการสะกดของผู้ใช้ ทำให้การแก้ไขไม่ลบความตั้งใจเดิมของผู้ใช้ เช่น ชื่อบุคคลหรือศัพท์แสลงภายในชุมชน ลดการแก้ไขผิดพลาดและลดการเรียกใช้บริการคลาวด์ลงอย่างมีนัยสำคัญ
- Tone/Style adaptation (ปรับโทน/สไตล์): ปรับระดับความเป็นทางการ การใช้ emoticon หรือการย่อคำ ตามโปรไฟล์ผู้ใช้ ทำให้ข้อความสำเร็จรูปและการแนะนำตอบรับอัตโนมัติเหมาะสมกับผู้ใช้งานแต่ละราย
- Intent ranking (การจัดลำดับเจตนา): ผู้ช่วยเสียงจะเรียงคำสั่งโดยคำนึงถึงความถี่และบริบทของผู้ใช้ ทำให้คำตอบที่แนะนำมีความเกี่ยวข้องสูงขึ้นและลดการสับสนของระบบเมื่อมีคำสั่งคล้ายกัน
- Context preservation (การคงบริบท): เก็บสถานะการสนทนาสั้น ๆ ภายในเครื่อง ทำให้สามารถตอบคำถามต่อเนื่องได้โดยไม่ต้องส่งข้อมูลทุกคำถามไปยังคลาวด์
สรุปได้ว่า การใช้งาน LLM‑OnPhone เพื่อปรับพฤติกรรมในคีย์บอร์ดและผู้ช่วยเสียงไม่เพียงแต่ยกระดับประสบการณ์ผู้ใช้ด้วยการปรับแต่งเชิงบริบทและโทนภาษาเท่านั้น แต่ยังช่วยองค์กรลดการส่งข้อมูลออกนอกเครื่องและตอบโจทย์ข้อกำหนดความเป็นส่วนตัวของลูกค้า ผลการทดสอบภายในชี้ว่าการย้ายการประมวลผลไปยังอุปกรณ์สามารถลดการส่งข้อมูลขึ้นคลาวด์ได้ถึง 70% ขณะที่ยังรักษาหรือเพิ่มประสิทธิภาพในการตอบสนองและความแม่นยำของฟีเจอร์สำคัญเหล่านี้
ประเด็นความเป็นส่วนตัวและการลดทราฟฟิกคลาวด์
ประเด็นความเป็นส่วนตัวเมื่อรัน LLM บนอุปกรณ์
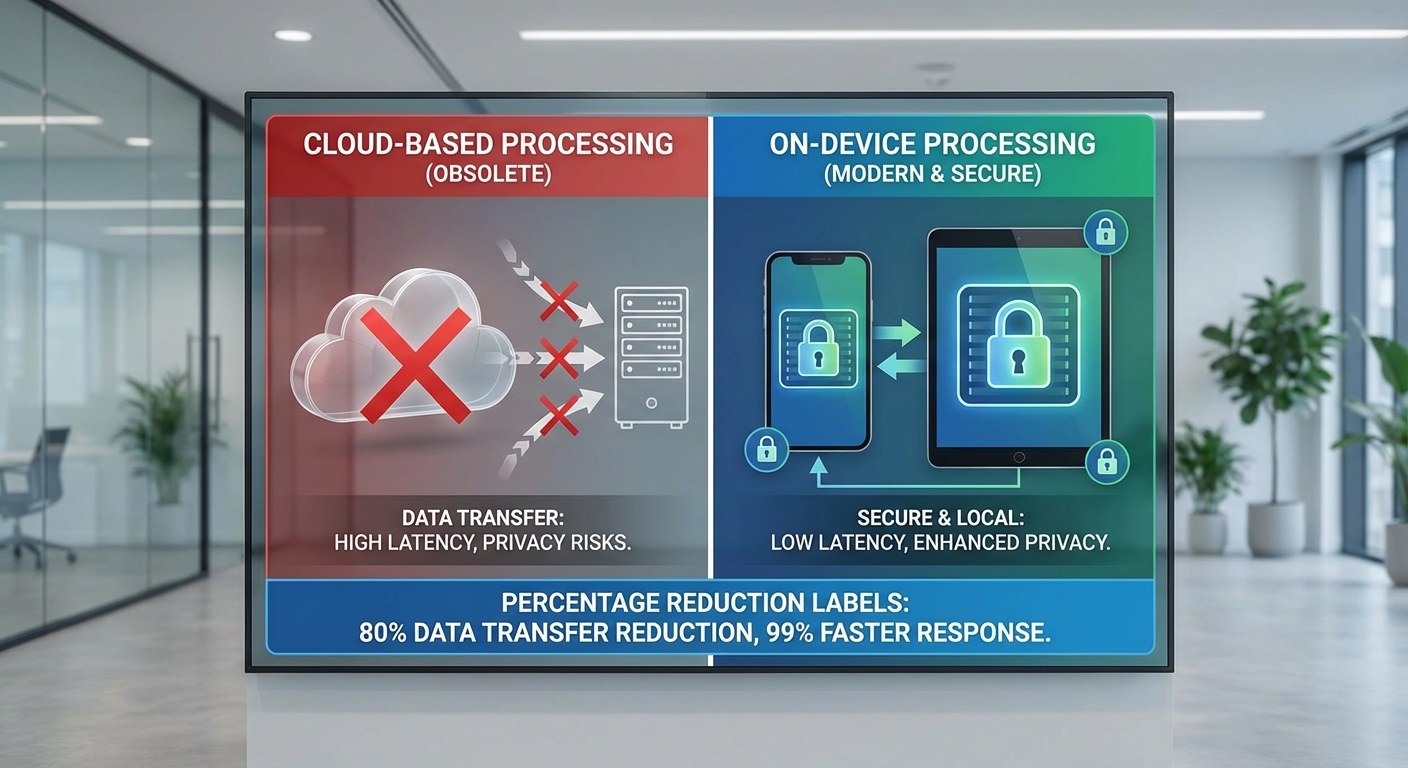
การรันโมเดลภาษาขนาดเล็ก (LLM‑OnPhone) บนอุปกรณ์ลดการส่งข้อความ เสียง และข้อมูลการใช้งานกลับไปยังคลาวด์ได้อย่างมีนัยสำคัญ โดยเฉพาะในกรณีฟีเจอร์คีย์บอร์ดและผู้ช่วยเสียงที่ทำงานแบบเรียลไทม์ เช่น การคาดเดาข้อความ การแก้ไขข้อผิดพลาด และการตรวจจับเจตนา (intent) กระบวนการพื้นฐานเหล่านี้สามารถดำเนินการได้ภายในเครื่อง ทำให้เฉพาะเหตุการณ์หรือคำสั่งที่ซับซ้อนจริง ๆ เท่านั้นที่จะถูกส่งขึ้นเซิร์ฟเวอร์ ตัวอย่างเช่น การเก็บคาดการณ์แป้นพิมพ์แบบท้องถิ่นและโมเดลส่วนบุคคลที่อัปเดตภายในอุปกรณ์ จะช่วยลดการเรียก API ไปยังคลาวด์ซ้ำ ๆ ซึ่งองค์กรที่นำแนวทางนี้ไปใช้รายงานการลดปริมาณข้อมูลส่งกลับได้หลายสิบเปอร์เซ็นต์ในเคสใช้งานบางประเภท
เพื่อรักษาความเป็นส่วนตัวในระดับสูงสุด บริษัทควรออกแบบนโยบายการเก็บข้อมูลบนอุปกรณ์ (on‑device storage) โดยคำนึงถึงหลักการขั้นต่ำ (data minimization) และชัดเจนเรื่องระยะเวลาเก็บข้อมูล เช่น การจัดเก็บเวกเตอร์ลักษณะการพิมพ์หรือโปรไฟล์การใช้งานเป็นข้อมูลที่เข้ารหัสและเก็บแบบชั่วคราว (ephemeral) เว้นแต่ผู้ใช้จะยินยอมให้เก็บแบบถาวร นอกจากนี้ รูปแบบการเก็บควรแบ่งเป็นชั้น เช่น ข้อมูลทางสถิติที่ไม่สามารถย้อนกลับเป็นข้อความดิบได้ (hashed/feature‑level) และข้อมูลดิบที่ถูกเข้ารหัสแยกต่างหากเพื่อการฟื้นฟูเมื่อผู้ใช้ opt‑in
มาตรการเสริมความปลอดภัยและความโปร่งใส
เมื่อข้อมูลถูกเก็บและประมวลผลบนอุปกรณ์ จำเป็นต้องมีมาตรการรักษาความปลอดภัยหลายชั้น โดยมาตรฐานที่ควรพิจารณาได้แก่:
- Local encryption: เข้ารหัสข้อมูลทั้งขณะเก็บ (encryption at rest) และขณะส่ง (TLS/DTLS) โดยใช้คีย์ที่ผูกกับฮาร์ดแวร์ เช่น Android Keystore หรือ Secure Enclave เพื่อป้องกันการเข้าถึงโดยไม่ได้รับอนุญาต
- Permission model แบบละเอียด: ให้ผู้ใช้สามารถควบคุมได้ว่าโมดูลใดอนุญาตให้เก็บข้อมูลส่วนบุคคล เช่น ประวัติการพิมพ์ เสียงบันทึก หรือโปรไฟล์ความชอบ พร้อมแสดงคำอธิบายชัดเจน (just‑in‑time consent)
- Optional opt‑in telemetry: การส่งเมตริกเพื่อปรับปรุงโมเดลควรเป็นแบบเลือกได้เท่านั้น และมีตัวเลือกยกเลิก (opt‑out) โดยการส่ง telemetry ควรเป็นแบบลดทอนข้อมูล (aggregated/anonymized) ก่อนส่ง
- Retention policy และ local purge: กำหนดระยะเวลาจัดเก็บที่ชัดเจนและมีฟังก์ชันลบอัตโนมัติ เช่น ลบข้อมูลชั่วคราวหลัง 30 วัน หรือเมื่อผู้ใช้รีเซ็ตพารามิเตอร์ส่วนบุคคล
ทางเทคนิคเพิ่มเติมที่นำมาใช้เพื่อเพิ่มความเป็นส่วนตัวเมื่อมีการรวมข้อมูลจากหลายอุปกรณ์ ได้แก่ differential privacy และ secure aggregation สำหรับกรณีที่ผู้ผลิตต้องการเรียนรู้เพื่อปรับปรุงโมเดลรุ่นกลางโดยไม่เห็นข้อมูลดิบ: การทำ local differential privacy คือการเพิ่มสัญญาณรบกวน (noise) บนข้อมูลที่ส่งจากแต่ละเครื่องก่อนเผยแพร่ ซึ่งช่วยให้ผู้ให้บริการสามารถรับ aggregated statistics ได้โดยไม่ระบุตัวตนของผู้ใช้ และ secure aggregation จะช่วยให้เซิร์ฟเวอร์ได้รับผลรวมของอัพเดตโมเดลเท่านั้น โดยแต่ละอัพเดตถูกเข้ารหัสจนกว่าจะรวมกันครบชุด (techniques เช่น homomorphic encryption หรือ multi‑party computation ถูกใช้งานในระดับหนึ่ง) อย่างไรก็ดี เทคนิคเหล่านี้มี trade‑off ระหว่างความแม่นยำของโมเดลและความเป็นส่วนตัวที่ต้องบริหารด้วยความรอบคอบ
ผลกระทบเชิงธุรกิจ: ค่าใช้จ่ายแบนด์วิดท์ ความหน่วง และความเชื่อมั่นผู้ใช้
การย้ายการประมวลผลบางส่วนลงอุปกรณ์ส่งผลโดยตรงต่อค่าใช้จ่ายของผู้ให้บริการคลาวด์และผู้ให้บริการเครือข่าย เมื่อปริมาณข้อความและเสียงที่ต้องส่งขึ้นเซิร์ฟลดลง จำนวนคำขอ API, สตอเรจบนเซิร์ฟเวอร์ และการประมวลผลแบบเซิร์ฟเวอร์‑ไซด์จะลดลง ส่งผลให้ต้นทุนคลาวด์ในมุมของ CPU/GPU, egress bandwidth และสตอเรจสามารถลดได้ บริษัทเทคโนโลยีที่นำแนวทาง on‑device มาใช้มักรายงานการลดภาระการเชื่อมต่อแบบเรียลไทม์ ซึ่งช่วยให้ต้นทุนปฏิบัติการลดลงเป็นตัวเงินที่จับต้องได้ โดยเฉพาะในบริการที่มีผู้ใช้งานจำนวนมาก
นอกจากต้นทุนแล้ว ความหน่วง (latency) ของระบบก็ปรับปรุงอย่างชัดเจนเมื่อเปิดใช้งาน LLM‑OnPhone สำหรับงานที่ต้องตอบสนองเร็ว เช่น คาดเดาข้อความหรือการตอบโต้ด้วยเสียง การประมวลผลภายในเครื่องสามารถลดเวลาแฝงจากร้อยมิลลิวินาทีลงไปอีก ทำให้ประสบการณ์ผู้ใช้ดีขึ้นและส่งผลต่ออัตราการรักษาผู้ใช้ (retention) และการมีส่วนร่วม (engagement)
ท้ายที่สุด ประเด็นความเป็นส่วนตัวเป็นปัจจัยสำคัญทางธุรกิจ—การสื่อสารที่ชัดเจนว่าข้อมูลสำคัญถูกประมวลผลบนอุปกรณ์และมีมาตรการด้านความปลอดภัยที่โปร่งใส จะช่วยเพิ่มความเชื่อมั่นของผู้ใช้และเป็นจุดขายเชิงแข่งขันในตลาด การออกแบบฟีเจอร์ที่ให้ผู้ใช้ควบคุมได้อย่างแท้จริง (granular control และ opt‑in telemetry) จะช่วยลดความเสี่ยงด้านกฎหมายและเพิ่มมูลค่าทางการตลาดสำหรับผู้ผลิตสมาร์ทโฟนที่นำ SDK แบบนี้มาใช้
ประสิทธิภาพ แบตเตอรี่ และข้อจำกัดฮาร์ดแวร์
ผลการทดสอบเบื้องต้น (Benchmark)
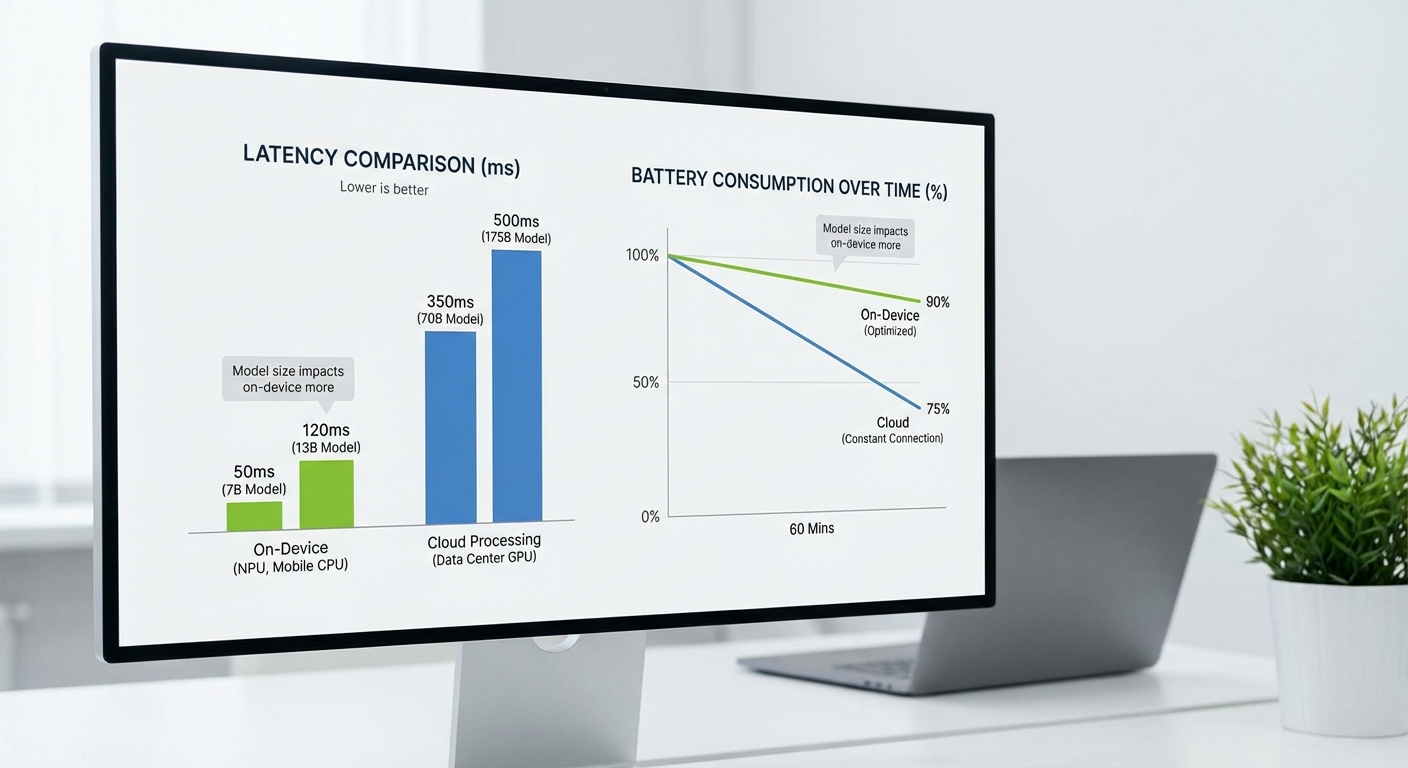
จากการทดสอบภายในโดยใช้ SDK "LLM‑OnPhone" บนสมาร์ทโฟนรุ่นทดสอบที่มี NPU/AI accelerator สมัยใหม่ พบว่าความล่าช้าต่อคำร้อง (latency) มีช่วงที่กว้างขึ้นขึ้นอยู่กับขนาดของโมเดลและความสามารถของฮาร์ดแวร์ โดยสรุปได้เป็นตัวเลขสมมติที่ใช้เป็นเกณฑ์อ้างอิงดังนี้: median latency อยู่ระหว่าง 50–300 ms สำหรับโมเดลขนาดเล็กถึงขนาดกลางเมื่อรันบน NPU; ขณะที่การรันแบบ fallback บน CPU จะช้ากว่าเดิมประมาณ 2–5 เท่า (ขึ้นกับแกน CPU และการจัดการเทรด) ตัวอย่างเช่น โมเดลขนาด ~50M พารามิเตอร์บน NPU อาจให้ latency ประมาณ 50–100 ms ขณะที่โมเดล ~200M อาจอยู่ในช่วง 150–300 ms.
ผลกระทบต่อแบตเตอรี่ (ตัวอย่างการทดสอบ)
การประเมินผลกระทบต่อแบตเตอรี่จากการรันกระบวนการ personalization แบบ background พบว่าอัตราการใช้พลังงานแตกต่างตามการออปติไมซ์แต่ละกรณี โดยตัวเลขสมมติที่ได้จากการทดสอบมีดังนี้:
- Background personalization ที่ออกแบบให้ทำงานเป็นช่วงสั้น ๆ ในตอนที่อุปกรณ์ว่าง พบว่าเพิ่มการใช้พลังงานประมาณ 1–2% ต่อชั่วโมง (ขึ้นกับความถี่ของการอัปเดตและขนาดโมเดล)
- การสตรีม inference ต่อเนื่อง (active use) เช่น ผู้ช่วยเสียงที่รันโมเดลขนาดกลาง อาจใช้พลังงานสูงขึ้นประมาณ 5–15% ต่อชั่วโมง เมื่อเทียบกับสถานะสแตนด์บาย ขึ้นกับการใช้สัญญาณเสียงและการเรียกโมเดลบ่อยครั้ง
- การเทรนเล็กน้อยบนอุปกรณ์ (on-device fine-tuning) หากไม่มีการออปติไมซ์อย่างเหมาะสม อาจเพิ่มการใช้พลังงานได้มากกว่า 3–6% ต่อชั่วโมง และยังมีความเสี่ยงต่อการเกิดความร้อนที่นำไปสู่การลดประสิทธิภาพ (thermal throttling)
ตัวเลขข้างต้นเป็นค่าประมาณจากสภาพการทดสอบเชิงปฏิบัติการ; ผลลัพธ์จริงจะแตกต่างตามแบตเตอรี่ความจุ การจัดการพลังงานของผู้ผลิตฮาร์ดแวร์ และการตั้งค่าแอปพลิเคชัน
ข้อจำกัดฮาร์ดแวร์และกลยุทธ์การปรับแต่ง
ข้อจำกัดเชิงฮาร์ดแวร์ที่สำคัญที่ต้องคำนึงถึงได้แก่ หน่วยประมวลผล NPU/AI accelerator ที่มีหน่วยความจำจำกัด, แบนด์วิธของหน่วยความจำ, อุณหภูมิขณะทำงาน และการจัดการพลังงานของตัวอุปกรณ์ ซึ่งมีผลโดยตรงต่อ latency และอัตราการใช้พลังงาน เพื่อให้การใช้งาน LLM‑OnPhone เป็นไปได้อย่างยั่งยืน แนะนำแนวทางปรับแต่งดังนี้:
- Scheduling / idle‑time training – จัดให้การอัปเดตแบบ personalization ทำในช่วงที่อุปกรณ์ว่าง (เช่น ขณะเสียบชาร์จหรือช่วงเวลาที่ผู้ใช้ไม่ใช้งาน) เพื่อลดผลกระทบต่อประสบการณ์ผู้ใช้และลดการบริโภคพลังงานทันที
- Dynamic model switching – สลับใช้โมเดลหลายขนาดตามบริบท: ใช้โมเดลขนาดเล็กในโหมดประหยัดพลังงานและโมเดลขนาดกลาง/ใหญ่เมื่อมีแรงจ่ายเพียงพอหรือผู้ใช้เรียกงานสำคัญ
- Hardware‑aware quantization – นำเทคนิค quantization ที่สอดคล้องกับฮาร์ดแวร์ (เช่น INT8/INT4 ที่ได้รับการรองรับโดย NPU) เพื่อลดขนาดหน่วยความจำและพลังงานต่อการเรียกใช้งาน โดยมักลด latency และใช้พลังงานลดลงอย่างมีนัยสำคัญ
- Mixed precision และ pruning – ใช้ mixed precision และ pruning เพื่อหาจุดสมดุลระหว่างคุณภาพของผลลัพธ์และประสิทธิภาพ โดยเฉพาะบนอุปกรณ์ที่มีหน่วยความจำจำกัด
- Hybrid cloud offload – สำหรับงานที่ต้องการการคำนวณหนัก (เช่น การฝึกโมเดลขนาดใหญ่หรือ inference ที่ละเอียดมาก) ให้พิจารณา offload บางส่วนไปยังคลาวด์ในรูปแบบ hybrid โดยมีนโยบายชาญฉลาดที่พิจารณาความเป็นส่วนตัว ความหน่วง และสถานะแบตเตอรี่
- Power‑saving mode – ออกแบบโหมดประหยัดพลังงานเฉพาะแอป (เช่น ลดความถี่ในการ personalization, ลดคุณภาพผลลัพธ์) เพื่อรักษาอายุแบตเตอรี่เมื่อค่าแบตเตอรี่ต่ำ
โดยสรุป การรัน LLM‑OnPhone บนอุปกรณ์ที่มีทรัพยากรจำกัดเป็นไปได้และให้ประสบการณ์ตอบสนองที่ยอมรับได้ (median latency ประมาณ 50–300 ms) แต่ต้องมีการออกแบบทางวิศวกรรมทั้งในส่วนซอฟต์แวร์และการประสานงานกับฮาร์ดแวร์ (เช่น quantization, scheduling, และ hybrid offload) เพื่อรักษาสมดุลระหว่างความเป็นส่วนตัว ประสิทธิภาพ และอายุแบตเตอรี่ หากองค์กรต้องการนำไปใช้เชิงพาณิชย์ ควรทำการ benchmark บนอุปกรณ์เป้าหมายจริงและกำหนดนโยบาย fallback/offload ที่ชัดเจนเพื่อควบคุมประสบการณ์ผู้ใช้และต้นทุนพลังงาน
คู่มือนักพัฒนา: API, เครื่องมือทดสอบ และโมเดลที่รองรับ
คู่มือนักพัฒนา: API, เครื่องมือทดสอบ และโมเดลที่รองรับ
เอกสารนี้สรุปองค์ประกอบสำคัญสำหรับการพัฒนาโดยใช้ SDK ของ LLM‑OnPhone — ครอบคลุม API หลัก, hook สำหรับคีย์บอร์ดและผู้ช่วยเสียง, ที่เก็บข้อมูล personalization, การจัดการโมเดล, เครื่องมือสำหรับ profiling/diagnostics, รวมถึง workflow ทดสอบแบบ end‑to‑end ที่เน้นความเป็นส่วนตัว (privacy‑first) และประสิทธิภาพบนอุปกรณ์พกพา
API หลักและ hooks สำหรับคีย์บอร์ด/ผู้ช่วยเสียง
- init(config) — เริ่มต้น SDK พร้อมค่าคอนฟิกพื้นฐาน (CPU/GPU affinity, memory budget, privacy flags, logger level). ควรกำหนด latency_target และ power_profile เพื่อให้ profiler และ scheduler ภายในทำงานสอดคล้องกับนโยบายอุปกรณ์
- infer_sync(model_id, input, options) — เรียกใช้งานการพยากรณ์แบบ synchronous สำหรับกรณี latency ต่ำ เช่น การแนะนำคำขณะพิมพ์ (target median latency <50 ms สำหรับคำแนะนำ single‑token ในโทรศัพท์รุ่นกลาง)
- infer_async(model_id, input, callback, options) — การเรียกใช้งานแบบ asynchronous รองรับ streaming output สำหรับผู้ช่วยเสียงหรือการเติมข้อความยาว โดย SDK จะคืน token เป็นชุด (chunked) ให้ callback เพื่อลดคอขวด UI
- personalize_update(user_id, delta) — อัปเดต personalization store ของผู้ใช้โดยส่งเฉพาะ delta ที่ถูกเข้ารหัสและเก็บในเครื่องเป็นค่าเริ่มต้น (local first) ก่อนจะเลือกนโยบาย sync ตามความยินยอม
- export_analytics(aggregation_policy) — ส่งข้อมูลเชิงสถิติที่ถูกผนวก/สรุป (aggregated) และสามารถเปิดใช้งาน Differential Privacy ได้ โปรดทราบว่า SDK ถูกออกแบบให้ค่าเริ่มต้นเป็น privacy‑first (ไม่มีการส่งข้อมูลข้อความดิบขึ้นคลาวด์โดยไม่แจ้งผู้ใช้)
- model_management APIs — เช่น list_models(), download_model(id), activate_model(id), unload_model(id), query_model_status(id) เพื่อบริหารวงจรชีวิตของโมเดลบนอุปกรณ์
- hooks พิเศษสำหรับคีย์บอร์ด/เสียง — on_keypress(event), on_voice_frame(frame), on_focus_change(context) ช่วยให้แอพสามารถเรียก infer แบบ lightweight และเลือกเส้นทางการประมวลผล (local fast path vs. offline batch update)
Personalization store และนโยบายความเป็นส่วนตัว
Personalization store ถูกออกแบบให้เป็น datastore บนเครื่องที่มีการเข้ารหัส (AES‑256) และมีนโยบาย retention/garbage‑collection เพื่อลดขนาดข้อมูล ตัว SDK ให้การควบคุมต่อไปนี้:
- ขนาดสูงสุดเริ่มต้น 5–50 MB ขึ้นกับระดับการอนุญาตของแอพและความเป็นส่วนตัว
- การเก็บข้อมูลเป็นรูปแบบ key‑value พร้อม metadata (timestamp, source, consent_flag)
- personalize_update รับเพียง delta และสามารถใช้ local regularization (L2, K‑anonymity) ก่อนบันทึก
- ถ้ามีการ sync ขึ้นคลาวด์ ต้องเปิดใช้งาน explicit consent; SDK สนับสนุนการทำ local aggregation และส่งเฉพาะตัวชี้วัดเชิงสถิติที่ผ่าน DP (ε configurable)
การจัดการโมเดลและขั้นตอนลงทะเบียนโมเดล
SDK รองรับโมเดลขนาดเล็กที่ออกแบบมาสำหรับอุปกรณ์ เช่น โมเดลขนาดประมาณ 50–300 ล้านพารามิเตอร์ หลังการควอนไทซ์ 8‑bit จะอยู่ในช่วง ~20–150 MB ซึ่งเหมาะสำหรับคีย์บอร์ดและผู้ช่วยเสียงแบบออฟไลน์
ขั้นตอนลงทะเบียนโมเดลที่แนะนำ:
- 1. เตรียมโมเดล — ฝึก/ปรับโมเดลบนเซิร์ฟเวอร์, ทำ quantization (int8/float16), pruning ตามความต้องการ, แปลงเป็น format ที่ SDK รองรับ (เช่น TFLite/ONNX optimized)
- 2. สร้าง manifest — ระบุ metadata (model_id, version, checksum, compatibility tags, required_features เช่น AVX/NNAPI) และ resource hints (memory, peak_ram)
- 3. ความปลอดภัย — ลงนามดิจิทัล (sign) และแนบ signature ใน manifest เพื่อยืนยันความถูกต้องของไบนารีก่อนติดตั้ง
- 4. CI/QA — รันชุดทดสอบอัตโนมัติ (unit tests, perf tests, correctness tests กับชุดข้อมูลพัฒนา), เรียก profiler เพื่อบันทึก latency/power/memory บน target device profiles
- 5. อัปโหลดสู่ registry — เก็บใน Model Registry ของผู้ผลิตพร้อมนโยบาย rollout (canary, phased OTA)
- 6. ตรวจสอบก่อน activate — เมื่อดาวน์โหลดแล้ว SDK จะทำการ validate checksum/signature และรัน smoke test ก่อน activate
เครื่องมือสำหรับ profiling, debugging และ simulator
- Profiler (latency & power) — ให้ metric รายการเช่น median/95th latency per inference, tokens/sec, peak memory usage และ power estimate (mW) ผ่าน CPU/GPU counters ผู้พัฒนาสามารถตั้งเป้าเช่น median latency < 50 ms สำหรับ single token inference และ power budget 5–30 mW ต่อ session
- Memory analyzer — ตรวจจับ memory fragmentation, peak heap, และ leak trace พร้อม snapshot เพื่อ debugging
- Simulator สำหรับ UX — จำลองสภาวะฮาร์ดแวร์หลายระดับ (low‑end/medium/high), network conditions (offline/poor/wifi) และ user interaction patterns (fast typing, voice long utterance) ช่วยให้ QA ทดสอบ UX และ latency โดยไม่ต้องใช้ฮาร์ดแวร์จริง
- Trace & logging — เก็บ inference trace (token timestamps, model path, decision flags) แบบ local; SDK มีตัวเลือกที่เข้ารหัสและ aggregate logs ก่อนส่งขึ้นคลาวด์ตามนโยบายความเป็นส่วนตัว
- A/B testing harness — สนับสนุนการรันหลายเวอร์ชันของโมเดลแบบ local canary และรายงาน metric เรื่อง latency, suggestion acceptance rate, power
ตัวอย่าง workflow แบบ end‑to‑end (Embed → Train offline → Validate → Deploy OTA)
- Embed SDK ในแอพคีย์บอร์ด
1) เรียก init(config) เมื่อแอพเริ่มเพื่อกำหนด resource budget และ policy.
2) โหลดโมเดลที่ต้องการด้วย download_model(id) และ activate_model(id).
3) ผูก hook on_keypress(event) เพื่อเรียก infer_sync สำหรับ suggestion แบบเรียลไทม์ หรือ infer_async สำหรับการเติมข้อความยาว - Train / personalize offline
เก็บข้อมูล personalization ใน local store; เมื่อมีข้อมูลพอใช้ personalize_update(user_id, delta) เพื่อปรับน้ำหนัก/โลคัลเฟสของโมเดล (เช่น bias vectors หรือ short‑term user embeddings) โดยไม่ต้องส่งข้อความดิบขึ้นคลาวด์
- Validate
รันชุดทดสอบบน simulator และ profiler: ตรวจสอบ metric เช่น suggestion acceptance rate, typing latency (median/95th), power per hour. ตัวอย่างเป้าหมาย: ลดการส่งข้อมูลคลาวด์ได้ถึง ~85% ใน use‑case คีย์บอร์ด และรักษา median latency <60 ms
- Deploy ผ่าน OTA
ใช้ model_management API เพื่อ push model ใหม่เป็น phased rollout (canary 1–5% → 25% → 100%). ก่อน activate SDK จะทำ validation signature และ smoke tests บนอุปกรณ์เป้าหมาย หาก metric มีปัญหาสามารถ rollback ได้อัตโนมัติ
- ตัวอย่าง flow การเรียกใช้งาน (pseudo‑code)
init(config);
model = download_model("kbd_v1");
activate_model(model.id);
on_keypress(event) {
resp = infer_sync(model.id, event.context, {max_tokens:1});
apply_suggestion(resp.token);
personalize_update(user_id, compute_delta(event, resp));
}
สรุป: SDK ของ LLM‑OnPhone ออกแบบมาเพื่อให้นักพัฒนาสามารถสร้างประสบการณ์คีย์บอร์ดและผู้ช่วยเสียงที่ตอบสนองเร็วและเป็นส่วนตัว โดยมีชุด API สำหรับ inference แบบ synchronous/async, personalization store ที่คำนึงถึง privacy, เครื่องมือ profiler/simulator สำหรับการทดสอบเชิงประสิทธิภาพ และกระบวนการจัดการโมเดลที่รองรับการ rollout แบบปลอดภัยผ่าน OTA
ผลกระทบเชิงธุรกิจ ตลาด และความเสี่ยงทางกฎหมาย/จริยธรรม
ผลกระทบเชิงธุรกิจและการแข่งขัน
การเปิดตัว SDK สำหรับรัน LLM‑OnPhone บนอุปกรณ์เปลี่ยนกรอบการต่อสู้ทางธุรกิจของผู้ผลิตสมาร์ทโฟนและผู้ให้บริการซอฟต์แวร์อย่างชัดเจน โดยเฉพาะในแง่ของการสร้างความแตกต่าง (differentiation) เป็นจุดขาย privacy‑first device และการลดต้นทุนการประมวลผลบนคลาวด์ ผู้ผลิตฮาร์ดแวร์สามารถใช้คุณสมบัตินี้เป็นข้อเสนอเชิงการตลาด เช่น โฆษณาว่า “ประมวลผลภาษาและปรับพฤติกรรมแบบส่วนตัวโดยไม่ต้องส่งข้อมูลขึ้นคลาวด์” ซึ่งสอดคล้องกับความกังวลด้านความเป็นส่วนตัวของผู้บริโภค—การสำรวจผู้ใช้สมาร์ทโฟนในหลายภูมิภาคชี้ว่าเกือบ 60–70% ให้ความสำคัญกับการคุ้มครองข้อมูลส่วนบุคคลเมื่อเลือกซื้ออุปกรณ์
ในมุมของต้นทุน ธุรกิจผู้ให้บริการซอฟต์แวร์และผู้ให้บริการคลาวด์มีโอกาสลดค่าใช้จ่ายจากการถ่ายโอนและการประมวลผลบนเซิร์ฟเวอร์ ตัวอย่างเช่น โมเดลการทำ inference บนอุปกรณ์อาจลดปริมาณทราฟฟิกไปยังคลาวด์ได้มากถึง 30–60% ขึ้นอยู่กับประเภทการใช้งาน (เช่น คีย์บอร์ดที่ทำการเติมข้อความอัตโนมัติแบบเรียลไทม์) ซึ่งแปลเป็นการลดค่าใช้จ่ายเชิงโครงสร้าง (operational cost) และค่าใช้จ่ายด้านแบนด์วิดท์สำหรับผู้ให้บริการ อีกประเด็นสำคัญคือโอกาสสร้างรายได้ใหม่ผ่านระบบนิเวศของนักพัฒนา (SDK monetization, premium on‑device features, licensing) ซึ่งจะกระตุ้นการแข่งขันระหว่างผู้ผลิตฮาร์ดแวร์ที่ต้องการล็อกอินผู้บริโภคด้วยประสบการณ์เฉพาะและผู้ให้บริการซอฟต์แวร์ที่อาจต้องเสนอรุ่นบนอุปกรณ์ของตนเอง
ผลกระทบต่อตลาดและการตอบรับจากผู้บริโภค
การมี LLM บนอุปกรณ์อาจเร่งให้เกิดการแยกของตลาดเป็นสองขั้ว: ฝั่งที่เน้นการเชื่อมโยงกับคลาวด์เต็มรูปแบบ (cloud‑centric services) และฝั่งที่เน้นการประมวลผลบนอุปกรณ์ (device‑centric/edge AI) ผู้ผลิตที่สามารถผนวก SDK เข้ากับฮาร์ดแวร์และอินเตอร์เฟซผู้ใช้ได้ดีจะได้เปรียบในการชนะผู้บริโภคที่คำนึงถึงความเป็นส่วนตัวและความหน่วงต่ำ (low latency) เช่น คีย์บอร์ดที่ตอบสนองทันทีหรือผู้ช่วยเสียงที่ทำงานแบบออฟไลน์
จากมุมมองผู้บริโภค การตอบรับมักแบ่งเป็นสองกลุ่มใหญ่: กลุ่มที่ยินดีจ่ายเพิ่มสำหรับอุปกรณ์ที่รักษาความเป็นส่วนตัวและมีฟังก์ชันออฟไลน์ และกลุ่มที่ให้ความสำคัญกับฟีเจอร์ขั้นสูงที่เชื่อมคลาวด์ ข้อมูลเชิงสำรวจจากตลาดผู้บริโภคชี้ว่าราว 40–50% อาจยอมจ่ายเพิ่มสำหรับฟีเจอร์ความเป็นส่วนตัวที่ชัดเจน ซึ่งเปิดโอกาสให้ผู้ผลิตตั้งราคาแบบพรีเมียมหรือเสนอเป็นบริการเสริม
ความเสี่ยงด้านข้อมูลและโมเดล (Bias, Model Drift และการอัปเดตที่ไม่รวมศูนย์)
การประมวลผลและปรับแต่งโมเดลบนอุปกรณ์นำมาซึ่งความเสี่ยงเชิงเทคนิคและเชิงจริยธรรมที่สำคัญ:
- Bias จากข้อมูลเฉพาะผู้ใช้: การฟインチูน (fine‑tuning) ด้วยข้อมูลเฉพาะของผู้ใช้แต่ละรายอาจสร้างการลำเอียง (personalization bias) ที่ทำให้โมเดลให้คำตอบที่เหมาะกับชุดพฤติกรรมเฉพาะกลุ่ม แต่ไม่นำมาซึ่งความเป็นกลางหรือความเป็นธรรมเมื่อขยายไปใช้กับผู้ใช้กลุ่มอื่น
- Model drift และการขาด centralized update: การที่แต่ละอุปกรณ์มีโมเดลเวอร์ชันต่างกันจะเพิ่มความเสี่ยงของ model drift เมื่อเวลาผ่านไป—พฤติกรรมและบริบทการใช้งานเปลี่ยน โมเดลที่ไม่ได้รับอัปเดตอย่างสม่ำเสมออาจให้ผลลัพธ์ที่ล้าหลังหรือไม่ปลอดภัย การจัดการแพตช์และการแก้ไขบั๊กบนอุปกรณ์จำนวนมากจึงมีความซับซ้อนและมีต้นทุน
- ปัญหาการตรวจสอบและความโปร่งใส: เมื่อการประมวลผลเกิดขึ้นบนอุปกรณ์ การเก็บล็อกหรือข้อมูลการทำงานเพื่อการตรวจสอบจะถูกจำกัด ทำให้การอนุมานสาเหตุของพฤติกรรมผิดพลาดหรือการตัดสินใจของโมเดล (model explainability) ยากขึ้น
เพื่อลดความเสี่ยงเหล่านี้ ธุรกิจควรนำมาตรการทางเทคนิคมาประยุกต์ใช้ เช่น การใช้เทคนิค differential privacy ในการฟื้นฝอยข้อมูลผู้ใช้ การใช้ federated learning เพื่อรวบรวมสัญญาณการเรียนรู้แบบรวมศูนย์อย่างปลอดภัย และระบบ telemetric ที่เก็บเมตาดาต้าเชิงนามธรรมเพื่อวิเคราะห์ model drift โดยยังคงเคารพความเป็นส่วนตัว
ข้อกฎหมายและข้อเสนอแนะแนวทางการกำกับดูแล
การนำ LLM‑OnPhone มาใช้ต้องพิจารณากรอบกฎหมายคุ้มครองข้อมูลส่วนบุคคล เช่น PDPA ในประเทศไทยหรือกฎหมายแบบ GDPR ในยุโรป ประเด็นที่ต้องให้ความสำคัญได้แก่ การเปิดเผยการเก็บข้อมูลและการประมวลผล, ฐานเหตุทางกฎหมายของการประมวลผล (consent, legitimate interest ฯลฯ), และ การประเมินผลกระทบต่อสิทธิด้านข้อมูล (DPIA) ก่อนการเปิดใช้งานฟีเจอร์ที่ทำการฟื้นข้อมูลสำคัญ
- ต้องมีการแจ้งอย่างชัดเจนว่าอะไรถูกประมวลผลบนอุปกรณ์และอะไรถูกส่งขึ้นคลาวด์ รวมถึงระบุวัตถุประสงค์และระยะเวลาเก็บข้อมูล
- ควรออกแบบกลไกการยินยอมแบบละเอียด (granular consent) ให้ผู้ใช้เลือกเปิด‑ปิดฟีเจอร์ personalization แต่ละประเภทได้
- ต้องเตรียมมาตรการรักษาความปลอดภัยข้อมูลบนอุปกรณ์ เช่น การเข้ารหัสเก็บโมเดลและข้อมูลฝึก, การยืนยันความถูกต้องของอัปเดตโมเดล, และกระบวนการแจ้งเหตุละเมิด
นอกจากนี้ คำแนะนำเชิงนโยบายแก่หน่วยงานกำกับดูแลคือการพัฒนาแนวทางเฉพาะสำหรับเทคโนโลยี LLM บนอุปกรณ์ ซึ่งอาจรวมถึงการกำหนดมาตรฐานการทดสอบด้านความเป็นธรรม (fairness testing), การรับรองความปลอดภัยของช่องทางอัพเดตโมเดล, และข้อกำหนดด้านความโปร่งใสที่ระบุให้ผู้ผลิตแสดงป้ายประกาศหรือไอคอนชัดเจนว่าฟังก์ชันนั้นทำงานแบบ “on‑device” หรือใช้คลาวด์
สรุปแล้ว การเปิดตัว SDK LLM‑OnPhone ให้โอกาสทางธุรกิจที่สำคัญ แต่ก็มาพร้อมกับความเสี่ยงทั้งเชิงเทคนิคและกฎหมายที่ต้องการกรอบการบริหารจัดการที่รัดกุม ธุรกิจที่ผสานมาตรการด้านความปลอดภัย ความโปร่งใสทางกฎหมาย และกระบวนการตรวจสอบอย่างต่อเนื่อง จะสามารถเปลี่ยนข้อได้เปรียบด้านความเป็นส่วนตัวให้เป็นจุดแข็งทางการแข่งขันได้อย่างยั่งยืน
ข้อแนะนำเชิงปฏิบัติสำหรับผู้ผลิต นักพัฒนา และผู้ใช้
สรุปและความตั้งใจของข้อแนะนำเชิงปฏิบัติ
เพื่อช่วยให้การนำ SDK "LLM‑OnPhone" ไปใช้ในอุปกรณ์สมาร์ทโฟนของไทยเป็นไปอย่างปลอดภัย มีประสิทธิภาพ และสอดคล้องกับความคาดหวังด้านความเป็นส่วนตัว บทแนะนำต่อไปนี้เน้นแนวปฏิบัติที่ปฏิบัติได้จริงสำหรับผู้ผลิตฮาร์ดแวร์ นักพัฒนาแอปฯ และผู้ใช้ปลายทาง โดยยึดหลัก Privacy by Design, การทดสอบ UX/consent อย่างเป็นระบบ, กลยุทธ์ hybrid cloud ที่ยืดหยุ่น และชุดตัวชี้วัด (KPIs) ที่ชัดเจนสำหรับการติดตามหลังออก SDK สู่ตลาด
คำแนะนำสำหรับผู้ผลิต (OEM)
ผู้ผลิตมีบทบาทสำคัญในการรับประกันความเข้ากันได้ของฮาร์ดแวร์และประสบการณ์ผู้ใช้ที่สอดคล้องกันเมื่อรันโมเดลขนาดเล็กบนเครื่อง ตลอดจนการอัพเดตและการป้องกันความปลอดภัยของโมเดล
- ตรวจสอบความเข้ากันได้กับ NPU/AI accelerator: สร้างชุดทดสอบอัตโนมัติสำหรับหลายสถาปัตยกรรม NPU (เช่น Arm Ethos, Qualcomm Hexagon, หรือ NPU เฉพาะ) ตรวจวัด latency, throughput และความผันผวนของผลลัพธ์ระหว่างไดรเวอร์เวอร์ชันต่าง ๆ
- เครื่องมือ profiling และ benchmarking: รวม toolchain สำหรับ profiling (CPU/GPU/NPU utilization, memory footprint, power draw) ใน SDK เพื่อให้พันธมิตรและทีม QA สามารถรัน benchmark ได้ง่าย ตัวอย่างเป้าหมายเชิงปฏิบัติ: latency สำหรับ prediction ของคีย์บอร์ด <50 ms, memory footprint ของโมเดลสำหรับ UX บริการพื้นฐาน <100–200 MB
- ระบบ OTA update ของโมเดลและเฟรมเวิร์ก: ออกแบบกลไกอัปเดตที่รองรับการลงนามดิจิทัล (model signing), การตรวจสอบความสมบูรณ์ (checksum) และ rollback หากเวอร์ชันใหม่มีปัญหา ควรระบุ window สำหรับการกู้คืน (e.g., rollback ภายใน 48 ชั่วโมงหลังตรวจพบข้อผิดพลาด)
- ซีเคียวริตี้แบบหลายชั้น: ใช้ secure enclave / TEE สำหรับเก็บคีย์และข้อมูลประจำตัวของโมเดล สนับสนุนการเข้ารหัสแบบที่พักข้อมูล (at-rest) และการเข้ารหัสช่องทางสื่อสาร (in-transit)
- เอกสารและตัวอย่างการใช้งาน: จัดเตรียมคู่มือการตั้งค่าสำหรับ performance tuning, energy profiling และ compatibility matrix เพื่อช่วย partner ในการปรับแต่งให้เหมาะสมกับรุ่นอุปกรณ์ต่าง ๆ
คำแนะนำสำหรับนักพัฒนาแอปพลิเคชัน
นักพัฒนาควรออกแบบการใช้งาน personalization และ telemetry ให้โปร่งใส สามารถควบคุมได้ และเป็นมิตรต่อผู้ใช้ เพื่อเพิ่มความไว้วางใจและการยอมรับจากผู้ใช้
- ให้ผู้ใช้ควบคุมการตั้งค่า personalization: ตั้งค่าเริ่มต้นเป็น privacy‑friendly (เช่น personalization ปิดเป็นค่าเริ่มต้น) และให้ UI ที่ชัดเจนสำหรับการเปิด/ปิด ฟีเจอร์ เช่น “ปรับคีย์บอร์ดให้คาดเดาได้ดีขึ้น — เปิด/ปิด” พร้อมคำอธิบายผลที่คาดว่าจะได้รับ
- opt‑in telemetry และข้อมูลที่รวบรวม: ใช้นโยบาย opt‑in สำหรับการส่ง telemetry และทำให้รายละเอียดของข้อมูลที่เก็บเป็นที่เข้าใจได้ (e.g., บันทึกเทคนิคเช่น error logs, anonymized usage metrics) ระบุเหตุผลการเก็บข้อมูลและระยะเวลาการเก็บรักษา
- ออกแบบ flow ของการขอ consent และ UX testing: ทดสอบหน้าขออนุญาต (consent) กับกลุ่มผู้ใช้หลายระดับเพื่อวัดความเข้าใจและ conversion rate ตั้งเป้าค่า opt‑in ที่สมเหตุสมผล (ตัวอย่างเช่น initial opt‑in rate 15–30% ขึ้นกับรูปแบบธุรกิจ) และทำ A/B testing เพื่อปรับข้อความ การวาง UI และ default state
- กลยุทธ์ hybrid cloud: ออกแบบ fallback path เมื่อการ inference บนอุปกรณ์ไม่สามารถให้บริการได้ หรือเมื่อผู้ใช้เลือกปิด personalization ให้ระบบสามารถย้ายงานบางประเภทไปที่ cloud ได้อย่างค่อยเป็นค่อยไป เช่น ใช้ on-device สำหรับ prediction แบบเรียลไทม์และ cloud สำหรับ fine-tuning หรือ analytics เชิง aggregate
- ความปลอดภัยของโมเดลและข้อมูล: รองรับ differential privacy สำหรับการส่งข้อมูลเพื่อฝึกรวมแบบ federated learning, ตรวจสอบการคือข้อมูล PII ก่อนส่งออก และใช้ model signing/verification เพื่อรับประกันความสมบูรณ์ของโมเดล
คำแนะนำสำหรับผู้ใช้ปลายทาง
ผู้ใช้ควรได้รับข้อมูลที่ชัดเจนและเข้าใจง่ายเกี่ยวกับการตั้งค่าความเป็นส่วนตัวและประโยชน์ของการประมวลผลบนอุปกรณ์ เพื่อให้สามารถตัดสินใจได้อย่างมีข้อมูล
- ทำความเข้าใจกับการตั้งค่าความเป็นส่วนตัว: ตรวจสอบการตั้งค่า personalization ในเมนูแอปหรือการตั้งค่าของเครื่อง อ่านคำอธิบายว่าฟีเจอร์ใดประมวลผลบนเครื่องและข้อมูลใดอาจถูกส่งไปยัง cloud
- รู้ถึงข้อดีของการประมวลผลบนเครื่อง: ประมวลผลบนอุปกรณ์ช่วยลดการส่งข้อมูลขึ้นคลาวด์ ซึ่งโดยทั่วไปสามารถลดปริมาณข้อมูลที่ส่งออกได้มากกว่า 80% ในกรณีของการเดาคีย์บอร์ด/คำสั่งเสียงที่ไม่ต้องการการวิเคราะห์เชิงลึกจากเซิร์ฟเวอร์ ผลที่ได้คือ latency ต่ำลง ความเป็นส่วนตัวสูงขึ้น และประหยัดแบนด์วิดท์
- ควบคุมการแชร์ข้อมูล: หากไม่ต้องการให้ข้อมูลบางประเภทถูกใช้เพื่อปรับปรุงโมเดล ให้ปิดการตั้งค่า personalization หรือ telemetry และพิจารณาเปิดเฉพาะเมื่อเห็นประโยชน์ชัดเจน เช่น การพิมพ์ถูกต้องขึ้น 10–30% ในการใช้งานจริง
- ติดตามการแจ้งเตือนและการอัปเดต: ยอมรับอัปเดตโมเดล/ซอฟต์แวร์จากผู้ผลิตอย่างระมัดระวัง ตรวจสอบว่าอัปเดตมีการลงนามและมี release notes เพื่อความโปร่งใส
KPIs และการติดตามหลังปล่อย SDK
การวัดผลเชิงปฏิบัติเป็นสิ่งจำเป็นเพื่อประเมินความสำเร็จของ SDK และปรับปรุงต่อเนื่อง ควรกำหนด KPI ที่ครอบคลุมทั้งด้าน performance, privacy, และ adoption
- Performance & UX: median latency (ms), 95th percentile latency, inference throughput (predictions/s), memory footprint (MB), battery impact (% ต่อวัน). ตัวอย่างเป้าหมาย: median latency <50 ms สำหรับคำแนะนำคีย์บอร์ด; battery impact <5% ต่อวันเมื่อใช้งานปกติ
- Accuracy & Quality: prediction accuracy, top‑k accuracy, reduction in typing corrections/error rate (เช่นลดข้อผิดพลาด 10–30%) และ user satisfaction scores (CSAT/NPS)
- Privacy & Data Flow: ปริมาณข้อมูลที่ส่งขึ้น cloud (MB/วัน/ผู้ใช้), อัตราการ opt‑in telemetry, จำนวนเหตุการณ์การรั่วไหลของข้อมูล (PII incidents), จำนวนคำร้องขอข้อมูลผู้ใช้ (data subject requests)
- Reliability & Operability: crash rate ที่เกี่ยวข้องกับ SDK, failure rate ของ on-device inference, OTA update success rate และ mean time to rollback (MTTR) หากมีปัญหา
- Business & Adoption: adoption rate ของฟีเจอร์ personalization, retention rate ของผู้ใช้ที่เปิด personalization เทียบกับผู้ใช้ที่ปิด, conversion จากการทดสอบ consent flow
แนวปฏิบัติด้านการทดสอบและปล่อยใช้งาน (Rollout)
การปล่อย SDK ควรทำแบบค่อยเป็นค่อยไปและมีการสังเกตผลต่อเนื่อง เพื่อจำกัดความเสี่ยงและปรับแก้ได้รวดเร็ว
- การทดลองแบบ staged rollout: เริ่มจาก internal beta → closed beta (กลุ่มผู้ใช้เฉพาะ) → gradual public rollout โดยติดตาม KPI แบบเรียลไทม์และตั้งเกณฑ์ยุติการปล่อยหากมีปัญหา
- การทดสอบ UX/consent ที่หลากหลาย: ทำ A/B testing กับรูปแบบข้อความ consent, default state และการจัดวาง UI เพื่อเพิ่มความเข้าใจและอัตรา opt‑in โดยยังคงเคารพหลักความโปร่งใส
- การสังเกตและตอบสนองแบบข้ามทีม: จัดทีมข้ามฟังก์ชัน (product, privacy/legal, security, QA, marketing) สำหรับ monitoring และ incident response รวมทั้งกำหนด playbook ในกรณีที่ KPIs ต่ำกว่าค่า threshold
- การเก็บ log ที่ปลอดภัยและจำกัดข้อมูล: เก็บ telemetry ที่จำเป็นเท่านั้น และทำ anonymization/de‑identification ก่อนเก็บเพื่อการวิเคราะห์เชิง aggregate
การผนวกแนวทางข้างต้นจะช่วยให้การใช้ LLM‑OnPhone SDK เป็นไปอย่างมีประสิทธิภาพ ปลอดภัย และได้รับความไว้วางใจจากผู้ใช้ การวางมาตรฐานที่ชัดเจนสำหรับ compatibility, privacy controls, และ KPI จะทำให้ทั้งผู้ผลิต นักพัฒนา และผู้ใช้ได้รับประโยชน์ร่วมกัน และช่วยขับเคลื่อนนวัตกรรมการประมวลผลภายในเครื่องในตลาดสมาร์ทโฟนไทยอย่างยั่งยืน
บทสรุป
LLM‑OnPhone เป็นตัวอย่างชัดเจนของแนวทาง on‑device AI ที่ผสมผสานการปรับพฤติกรรมผู้ใช้แบบเฉพาะบุคคลกับการยกระดับความเป็นส่วนตัว โดยรันโมเดลขนาดเล็ก (เช่น โมเดลที่มีขนาดตั้งแต่หลายสิบล้านถึงหลายร้อยล้านพารามิเตอร์) บนสมาร์ทโฟนเพื่อให้คำแนะนำการพิมพ์หรือการตอบโต้ด้วยเสียงแบบเฉพาะบุคคลโดยไม่ต้องส่งข้อมูลดิบขึ้นคลาวด์ ตัวอย่างการใช้งานที่เด่นคือคีย์บอร์ดที่เสนอคำแนะนำตามสไตล์ผู้ใช้และผู้ช่วยเสียงที่ปรับน้ำเสียงหรือคำตอบตามพฤติกรรม แต่ข้อจำกัดชัดเจน ได้แก่ ขีดจำกัดด้านฮาร์ดแวร์ (พื้นที่จัดเก็บ พลังการประมวลผล แบตเตอรี่และความร้อน) และภาระการดูแลรักษาโมเดลบนอุปกรณ์ (การอัปเดต การแก้บั๊ก การควบคุมความเอนเอียงของโมเดล) ซึ่งอาจทำให้ความแม่นยำหรือฟังก์ชันบางอย่างด้อยกว่าโซลูชันบนคลาวด์
การนำ LLM‑OnPhone ไปใช้เชิงรับผิดชอบจึงต้องมีมาตรการ privacy‑by‑design (เช่น การเก็บข้อมูลบนเครื่อง, การเข้ารหัส, local differential privacy หรือ federated learning พร้อมการขอความยินยอมที่ชัดเจน), การทดสอบประสิทธิภาพในโลกจริง (วัดหน่วงเวลา ความแม่นยำ อัตราการใช้งาน และ A/B testing กับชุดผู้ใช้จริง) และนโยบายอัปเดตโมเดลที่โปร่งใส (เวอร์ชันนิ่ง การอัปเดตแบบ OTA พร้อมกลไก rollback และการตรวจสอบหลังการปล่อย) เพื่อลดความเสี่ยงด้านจริยธรรมและกฎหมาย (เช่น ความเอนเอียง ข้อมูลรั่วไหล หรือการไม่เป็นไปตาม PDPA/GDPR) ผู้พัฒนาอาจอ้างว่าการประมวลผลบนเครื่องสามารถลดการส่งข้อมูลขึ้นคลาวด์ได้อย่างมีนัยสำคัญ — ตั้งแต่ระดับหลายสิบเปอร์เซ็นต์จนถึงแทบทั้งหมดในฟีเจอร์บางประเภท — แต่แนวโน้มอนาคตจะเน้นสถาปัตยกรรมผสม (on‑device + cloud) การเร่งฮาร์ดแวร์เฉพาะทาง (NPUs) มาตรฐานการประเมิน และกรอบกำกับดูแล เพื่อให้การปรับใช้ขยายตัวได้อย่างปลอดภัยและเป็นไปตามกฎระเบียบ



