
การมาถึงของชิป AI แบบ Chiplet ในรูปแบบโมดูลประกอบได้กำลังเขย่าตลาดศูนย์ข้อมูลไทยอย่างมีนัยสำคัญ: ผู้ให้บริการศูนย์ข้อมูลและโอเปอเรเตอร์รายใหญ่เริ่มเห็นว่าการเปลี่ยนจากการอัปเกรดฮาร์ดแวร์แบบเดิมไปสู่โมดูลเร่งความเร็วที่ถอดเปลี่ยนได้ สามารถลดต้นทุนฮาร์ดแวร์และเวลาการอัปเกรดลงได้มากกว่า 40% ซึ่งหมายความว่าการลงทุนด้าน CAPEX และค่าใช้จ่ายในการหยุดให้บริการเพื่อติดตั้งอุปกรณ์ใหม่จะลดลงอย่างเด่นชัดและเพิ่มความคล่องตัวในการตอบโจทย์งาน AI ที่เติบโตอย่างรวดเร็ว
บทนำนี้จะชี้ให้เห็นประเด็นสำคัญที่ผู้อ่านควรติดตาม: โอกาสทางธุรกิจใหม่สำหรับผู้ให้บริการโครงสร้างพื้นฐาน (เช่น บริการ GPU-as-a-Service, โมเดลเช่าโมดูล) และสำหรับผู้ผลิตบอร์ดที่สามารถออกแบบแพลตฟอร์มรองรับโมดูล Chiplet ได้อย่างรวดเร็ว แต่ในขณะเดียวกันก็มีความท้าทายสำคัญด้านมาตรฐานการเชื่อมต่อ การจัดการความร้อน การสนับสนุนซอฟต์แวร์ และปัญหาซัพพลายเชนที่ยังต้องประสานงานระหว่างผู้ผลิตชิป ผู้ผลิตบอร์ด และโอเปอเรเตอร์ เพื่อให้การนำไปใช้งานในภาพรวมของอุตสาหกรรมไทยเป็นไปอย่างราบรื่น
ภาพรวม: ทำไม Chiplet ถึงมาแรงในยุค AI
ภาพรวม: ทำไม Chiplet ถึงมาแรงในยุค AI
ในยุคที่งานประมวลผลปัญญาประดิษฐ์ (AI) ต้องการความสามารถในการคำนวณสูงและแถมมีการเปลี่ยนแปลงรุ่นของอัลกอริทึมอย่างรวดเร็ว สถาปัตยกรรมชิปแบบเดิม (monolithic SoC) เผชิญข้อจำกัดทั้งด้านการสเกล ข้อจำกัดด้านต้นทุน และปัญหา yield เมื่อขยายขนาดของชิปรายเดียวให้ใหญ่เพียงพอกับงาน AI ขนาดใหญ่ ด้วยเหตุผลทางฟิสิกส์และกระบวนการผลิต ความน่าจะเป็นที่จะมีตำหนิบนแผ่นเวเฟอร์เพิ่มขึ้นเมื่อขนาด die เพิ่มขึ้น จนทำให้ต้นทุนต่อชิ้นงานพุ่งสูงและอัตราสำเร็จ (yield) ลดลงอย่างมีนัยสำคัญ ผลลัพธ์คือผู้ผลิตต้องเผชิญกับต้นทุนการออกแบบใหม่และระยะเวลาเข้าสู่ตลาดที่นานขึ้น
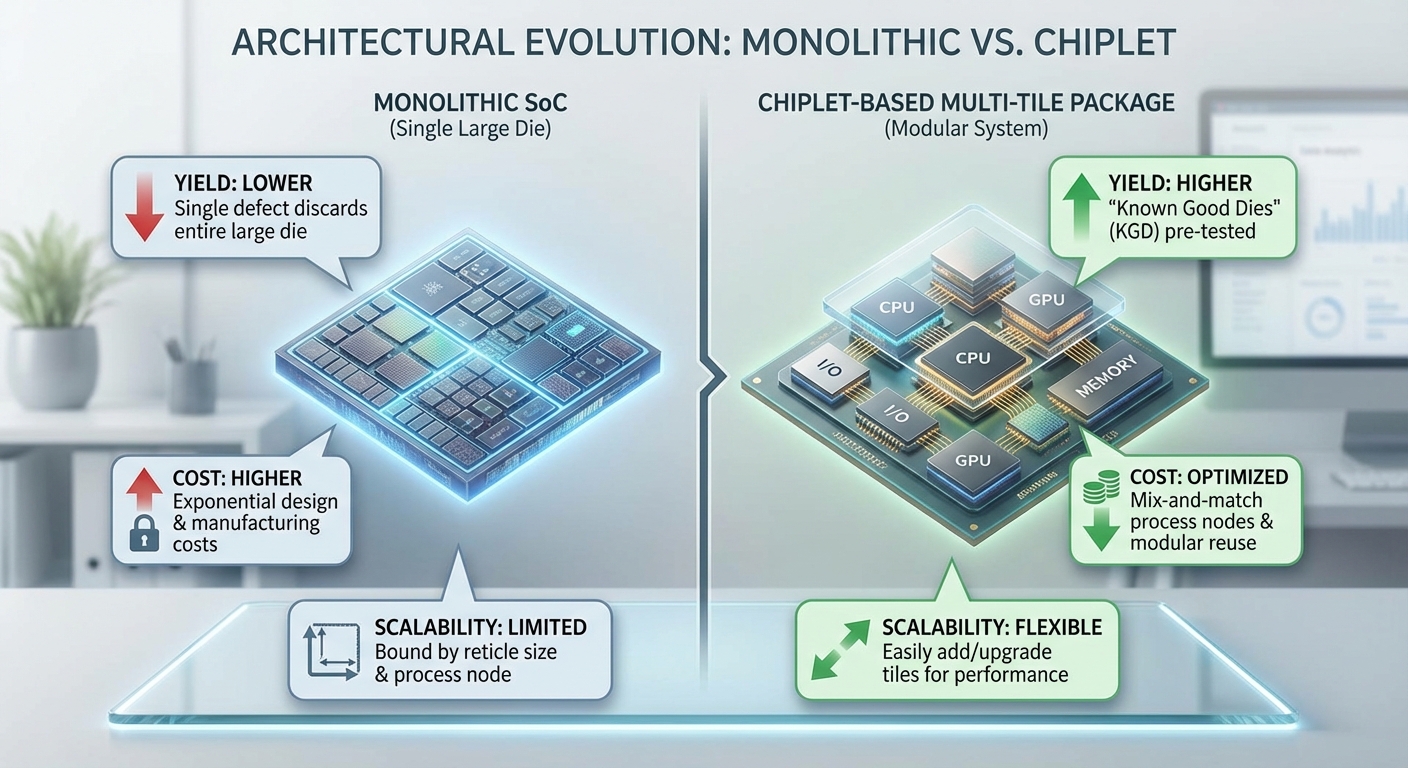
Chiplet ตอบโจทย์ข้อจำกัดเหล่านี้ด้วยแนวคิดการแยกฟังก์ชันของระบบออกเป็นโมดูลย่อย ๆ (เช่น CPU, GPU/TPU, memory die, I/O และชิปอนาล็อก) แล้วนำมาประกอบเป็นแพ็กเกจเดียวกันผ่านเทคนิคการเชื่อมต่อระดับแพ็กเกจ (2.5D/3D, interposer หรือมาตรฐานเช่น UCIe) แนวทางนี้ช่วยให้แต่ละ die มีขนาดเล็กลง เพิ่ม yield และลดต้นทุนการผลิตต่อฟังก์ชัน นอกจากนี้ยังเอื้อให้มีการรวมส่วนประกอบที่ต่างกระบวนการผลิตหรือโหนดเทคโนโลยี (heterogeneous integration) เข้าไว้ด้วยกัน เช่น ใช้โหนดการผลิตที่เล็กและประหยัดไฟสำหรับ NPU ขณะเดียวกันใช้โหนดที่เหมาะสมกับ I/O หรือหน่วยความจำแบบ HBM สำหรับการเชื่อมต่อความเร็วสูง
แนวโน้มตลาดสนับสนุนการย้ายไปสู่สถาปัตยกรรมแบบโมดูล: หลายสำนักวิเคราะห์ประมาณการว่าตลาด AI accelerators จะเติบโตอย่างรวดเร็วตลอดช่วงปลายทศวรรษนี้ โดยมีอัตราการเติบโตเฉลี่ยต่อปี (CAGR) ในช่วงประมาณ 25–35% ขึ้นอยู่กับนิยามของตัวเร่งความเร็วและกรอบเวลาที่ใช้ การเติบโตนี้ขับเคลื่อนโดยความต้องการทั้งฝั่งฝึกอบรม (training) และการให้บริการแบบเรียลไทม์ (inference) ในศูนย์ข้อมูล ซึ่งทำให้เจ้าของศูนย์ข้อมูลและ OEM มองหาโซลูชันที่ลดต้นทุนรวมเป็นเจ้าของ (TCO) และยืดหยุ่นต่อการอัปเกรด—จุดแข็งที่ chiplet สามารถตอบโจทย์ได้ชัดเจน
ประเด็นสำคัญที่ทำให้ Chiplet ได้รับความนิยมในบริบทงาน AI ได้แก่
- เพิ่ม yield และลดต้นทุน: การแยกเป็น die ขนาดเล็กช่วยลดอัตราของชิ้นงานที่ต้องถูกทิ้งจากข้อบกพร่องบนเวเฟอร์ ทำให้ต้นทุนต่อหน่วยลดลงเมื่อเทียบกับ SoC ขนาดใหญ่
- โมดูลาริตี้และความยืดหยุ่น: ผู้ให้บริการศูนย์ข้อมูลและผู้ผลิตบอร์ดสามารถปรับแต่งชุดผสมของ CPU/NPU/Memory เพื่อให้เหมาะกับ workload โดยไม่ต้องออกแบบ SoC ใหม่ทั้งชิ้น
- Heterogeneous integration: รวมเทคโนโลยีและโหนดการผลิตที่แตกต่างกันบนแพ็กเกจเดียว เพิ่มประสิทธิภาพพลังงานและลด latency ระหว่างองค์ประกอบที่จำเป็นต่อ AI
- ลดเวลาในการอัปเกรด: ด้วยโมดูลที่สามารถเปลี่ยนหรืออัปเกรดแยกได้ ผู้ให้บริการสามารถลดเวลาและต้นทุนในการปรับปรุงคลัสเตอร์เร่งความเร็ว ซึ่งสอดคล้องกับความเร็วของการเปลี่ยนแปลงโมเดล AI
เมื่อรวมกับแรงผลักดันด้านมาตรฐานสากล (เช่น UCIe) และการพัฒนาเทคนิคการแพ็กเกจระดับสูง Chiplet จึงไม่เพียงเป็นทางเลือกทางวิศวกรรม แต่ยังเป็นโมเดลธุรกิจที่ช่วยให้โอเปอเรเตอร์ศูนย์ข้อมูลและซัพพลายเออร์บอร์ดสามารถควบคุมต้นทุน ปรับขนาดได้รวดเร็ว และตอบสนองต่อความต้องการของตลาด AI ที่เติบโตอย่างต่อเนื่อง
เทคนิค: AI‑Chiplet และโมดูลเร่งความเร็วแบบประกอบได้ทำงานอย่างไร
เทคนิค: AI‑Chiplet และโมดูลเร่งความเร็วแบบประกอบได้ทำงานอย่างไร
AI‑Chiplet คือแนวทางออกแบบชิปที่แตกฟังก์ชันเป็นหน่วยย่อย (chiplet) หลายตัว แล้วนำมาประกอบบนแพ็กเกจเดียวเพื่อให้ได้ประสิทธิภาพ ความยืดหยุ่น และต้นทุนที่ดีกว่าโมโนลิธิกชิปดั้งเดิม ในบริบทของโมดูลเร่งความเร็วสำหรับศูนย์ข้อมูล แนวทางนี้หมายถึงการแยกคอร์คำนวณ ตัวควบคุมหน่วยความจำ อินเตอร์เฟซ I/O และไอพีพิเศษ (เช่น NPU/TPU engine) ออกเป็นชิปเล็กรูปแบบต่างๆ แล้วเชื่อมต่อกันผ่านสื่อการเชื่อมต่อความเร็วสูงบนแพ็กเกจหรือบนบอร์ด ผลคือสามารถอัปเกรดหรือสลับเพียงบางโมดูล (เช่นเพิ่มชิปคำนวณใหม่) โดยไม่ต้องเปลี่ยนทั้งบอร์ดหรือทั้งเซิร์ฟเวอร์ ซึ่งเป็นเหตุผลหลักที่ช่วยลดค่าใช้จ่ายและเวลาในการอัปเกรดได้มากถึงตัวเลขที่รายงานในภาคอุตสาหกรรม
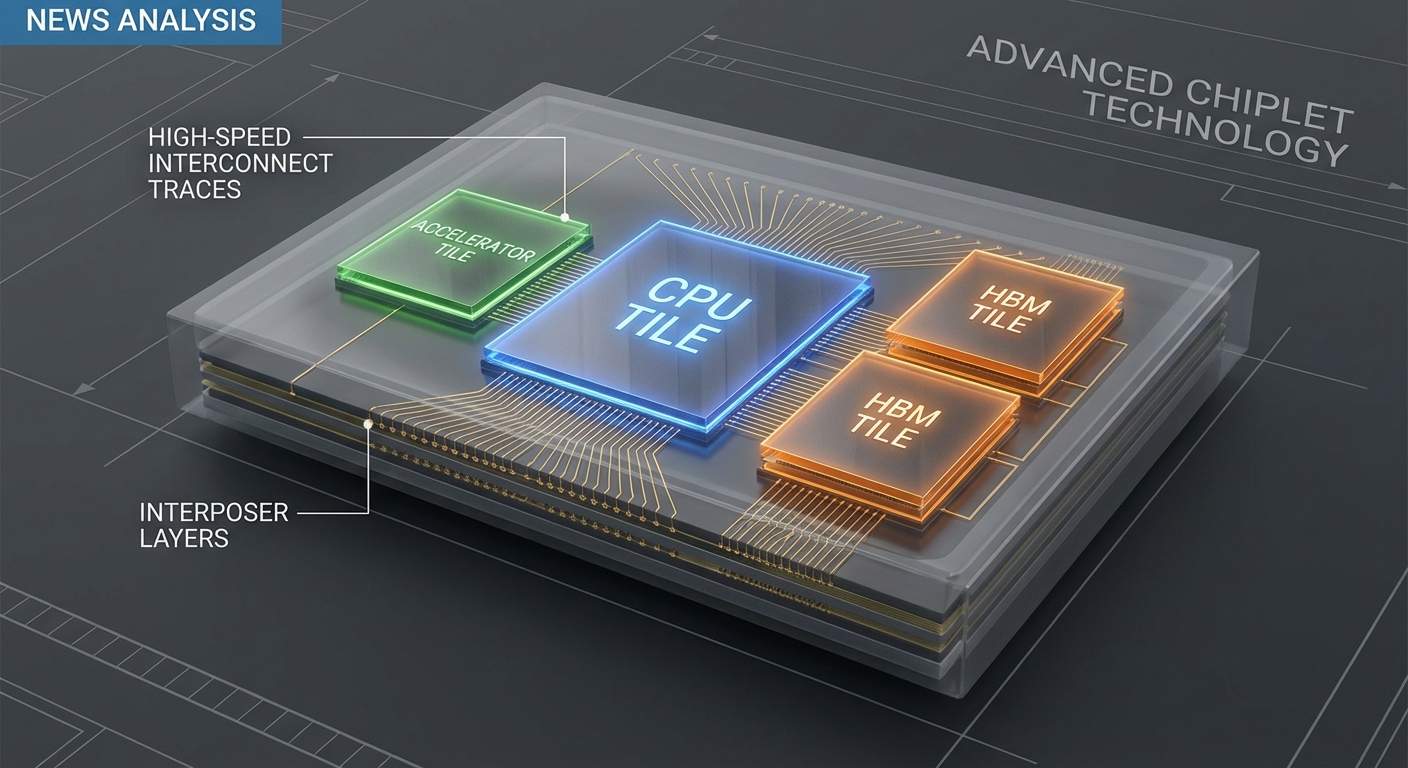
โครงสร้างเชิงกายภาพของ Chiplet
เชิงกายภาพแล้ว chiplet ประกอบด้วยชิปย่อยที่เชื่อมต่อผ่านเทคโนโลยีต่อไปนี้:
- Through‑Silicon Vias (TSV) และ microbumps สำหรับการเชื่อมต่อในแนวตั้ง (3D stacking) ระหว่างชั้นทรานซิสเตอร์และชั้นบรรจุ
- Redistribution Layer (RDL) บนผิวชิปเพื่อกระจายเส้นสัญญาณไปยังตำแหน่ง microbumps หรือ pads
- บนแพ็กเกจ (on‑package) จะมี interposer หรือ substrate เป็นทางผ่านสัญญาณและพาวเวอร์
การออกแบบต้องคำนึงถึงการจับคู่อิมพีแดนซ์ ความยาวสัญญาณที่แมตช์ และการจัดการการกระจายพลังงาน ซึ่งแต่ละชั้นและวัสดุมีผลต่อสัญญาณความถี่สูง (signal integrity) และการระบายความร้อน
Interposer (硅基) vs Organic Substrate: ข้อแตกต่างเชิงเทคนิคและการประยุกต์
Silicon interposer (硅基) เป็นแผ่นซิลิคอนบางที่มี RDL และ TSV ให้แบนด์วิดท์สูง ระยะทางสัญญาณสั้นมาก และรองรับการเชื่อมต่อแบบกว้าง (wide bus) เช่น การรวม HBM stack กับตัวคอร์หลัก จุดเด่นคือ สัญญาณความถี่สูงมีการสูญเสียน้อย และรองรับจำนวนช่องสัญญาณมาก (multi‑TB/s ในบางการออกแบบ) เหมาะกับกรณีที่ต้องการหน่วยความจำแบนด์วิดท์สูงสุดและการสื่อสารระหว่างชิปที่หนาแน่น แต่มีต้นทุนการผลิตสูงกว่าและข้อจำกัดในด้านขนาดแพ็กเกจ
Organic substrate เป็นวัสดุสารอินทรีย์ที่มีต้นทุนต่ำกว่า และสามารถผลิตในขนาดใหญ่และสม่ำเสมอ ทำให้เหมาะกับโมดูลเชิงพาณิชย์ที่ต้องการต้นทุน/หน่วยต่ำกว่า แต่ข้อจำกัดคือสัญญาณความถี่สูงจะมีการสูญเสียมากขึ้นเมื่อเทียบกับซิลิคอน interposer และจำนวนช่องสัญญาณความถี่สูงที่รองรับมักน้อยกว่า จึงมักใช้ในโมดูลที่เน้นความคุ้มค่าและการปรับสเกลแบบแมส
สรุปเชิงการตัดสินใจ: ถ้าต้องการแบนด์วิดท์สูงสุดและ latency ต่ำสุด (เช่น เชื่อมต่อ HBM กับตัวคอร์คำนวณ) ให้พิจารณา silicon interposer; หากต้องการต้นทุนต่อหน่วยต่ำและความยืดหยุ่นในการผลิตที่สูงขึ้น ให้เลือก organic substrate
อินเตอร์คอนเน็กต์ความเร็วสูงและมาตรฐานสำคัญ
การเชื่อมต่อระหว่าง chiplet และระหว่างโมดูลกับบอร์ดต้องพึ่งพามาตรฐานความเร็วสูงทั้งระดับแพ็กเกจและบอร์ดเยอร์ ชั้นที่ต้องจับตามองได้แก่:
- CXL (Compute Express Link) — พัฒนาบนพื้นฐาน PCIe เพื่อให้มีความสามารถในการแชร์หน่วยความจำ ระดับ latency ต่ำ และการขยาย I/O ระหว่าง CPU/accelerator ที่นิยมในศูนย์ข้อมูล
- PCIe Gen5/Gen6 — ให้แบนด์วิดท์ระดับร้อยกิกะไบต์ต่อวินาทีเมื่อใช้หลายเลน เป็นรองรับการเชื่อมต่อบอร์ด‑ต่อ‑บอร์ดและรูปแบบการ์ดเสริม
- UCIe (Universal Chiplet Interconnect Express) — มาตรฐานที่ออกแบบมาสำหรับการเชื่อมต่อ chiplet บนแพ็กเกจ มุ่งหวังให้เกิดความเป็นมาตรฐานร่วมในการแลกเปลี่ยน chiplet ระหว่างผู้ผลิต
- Proprietary chiplet fabrics — เช่น AMD Infinity Fabric หรืออินเทอร์คอนเน็กต์ภายในที่ถูกออกแบบเฉพาะเพื่อปรับแต่ง bandwidth/latency ให้ตรงกับสถาปัตยกรรม
- HBM (High‑Bandwidth Memory) — บนแพ็กเกจที่ใช้ silicon interposer จะมีแบนด์วิดท์ต่อชิปหลายร้อย GB/s (และในเวอร์ชันถัดไปเป็น TB/s ระดับ aggregation) เหมาะกับงาน AI ที่ต้องการ memory bandwidth สูง
สำหรับการออกแบบบอร์ด สิ่งสำคัญคือการพิจารณา jitter budget, eye‑height, timing margins และการทำ signal conditioning (equalization) ทั้งที่ระดับแพ็กเกจและบน PCB
ข้อควรพิจารณาด้าน Thermal Management และ Power Delivery
การรวมหลาย chiplet หรือโมดูลเร่งความเร็วบนแพ็กเกจหนึ่งๆ ทำให้เกิดความเข้มข้นของกำลังไฟฟ้า (power density) และ hotspot ที่ควบคุมยาก ในทางปฏิบัติวิศวกรต้องพิจารณาต่อไปนี้:
- PDN (Power Delivery Network) — ต้องออกแบบให้รองรับกระแสสูงและ transient สูง รวมถึงการวาง decoupling capacitors ให้ใกล้กับจุดโหลดที่สุดเพื่อลด voltage droop
- การกระจายความร้อน — ใช้ heat spreader, vapor chamber หรือ cold plate สำหรับการถ่ายเทความร้อนจากหลาย chiplet ที่อยู่บนแพ็กเกจเดียว การออกแบบต้องคำนึงถึง CTE mismatch ระหว่างวัสดุเพื่อลดความเค้นทางกล
- การจัดการความร้อนเชิงไดนามิก — ต้องมีนโยบาย thermal throttling และ power capping ที่ฉลาด เนื่องจาก hotspot ของ chiplet หนึ่งอาจกระทบประสิทธิภาพของทั้งโมดูล
- การเชื่อมต่อพลังงานบนแพ็กเกจ — อาจต้องมี VRM บนบอร์ดร่วมกับขั้นตอนการจัดการพลังงานบนแพ็กเกจ (on‑package PMICs) เพื่อให้เสถียรภาพแรงดันและรองรับการสลับโหลดอย่างรวดเร็ว
ผลต่อการออกแบบบอร์ดและการรวมระบบ
เมื่อศูนย์ข้อมูลเริ่มนำโมดูล AI‑Chiplet มาใช้ บอร์ดและระบบต้องปรับตัวในหลายมิติ เช่น:
- การออกแบบรูปลักษณ์และตัวเชื่อมต่อที่รองรับโมดูลแบบ hot‑swap หรือ mezzanine (เช่น form factor ตาม OCP/EDSFF/SMT stack) เพื่อให้การอัปเกรดเป็นไปได้จริง
- การจัดผังเลเยอร์ PCB ที่เน้น plane สำหรับ power และ ground ที่หนาเพื่อลด IR drop และรองรับการ routing differential pairs ที่ต้อง length‑match
- validation และ testing ที่ต้องรวมทั้งสัญญาณความเร็วสูงและพารามิเตอร์ thermal/power — เช่น TDR, BER testing, thermal cycling และ electromigration lifetime
- การเตรียมระบบระบายความร้อนแบบปรับเปลี่ยนได้ ไม่ว่าจะเป็น passive heatsink, vapor chamber หรือ liquid cold plate เพื่อรองรับโมดูลที่อาจมี TDP แตกต่างกัน
สรุปแล้ว AI‑Chiplet และโมดูลเร่งความเร็วแบบประกอบได้ เปลี่ยนสมการการออกแบบจากชิปเดี่ยวไปสู่การออกแบบซับซ้อนระดับระบบที่ผสมผสานสัญญาณความเร็วสูง การจ่ายพลังงานที่เสถียร และการระบายความร้อนที่มีประสิทธิภาพ สิ่งนี้ช่วยให้โอเปอเรเตอร์สามารถอัปเกรดเป็นขั้นๆ ประหยัดค่าใช้จ่าย และให้ผู้ผลิตบอร์ดต้องลงทุนในเทคโนโลยีการผลิตและการตรวจสอบใหม่ๆ เพื่อตอบรับข้อกำหนดด้าน signal integrity, power integrity และ thermal reliability
กรณีศึกษาและตัวเลข: ลดค่าใช้จ่ายและเวลาอัปเกรดกว่า 40%
กรณีศึกษาและตัวเลข: ผลการประเมิน (pilot สมมติ) — ลดค่าใช้จ่ายและเวลาอัปเกรดกว่า 40%
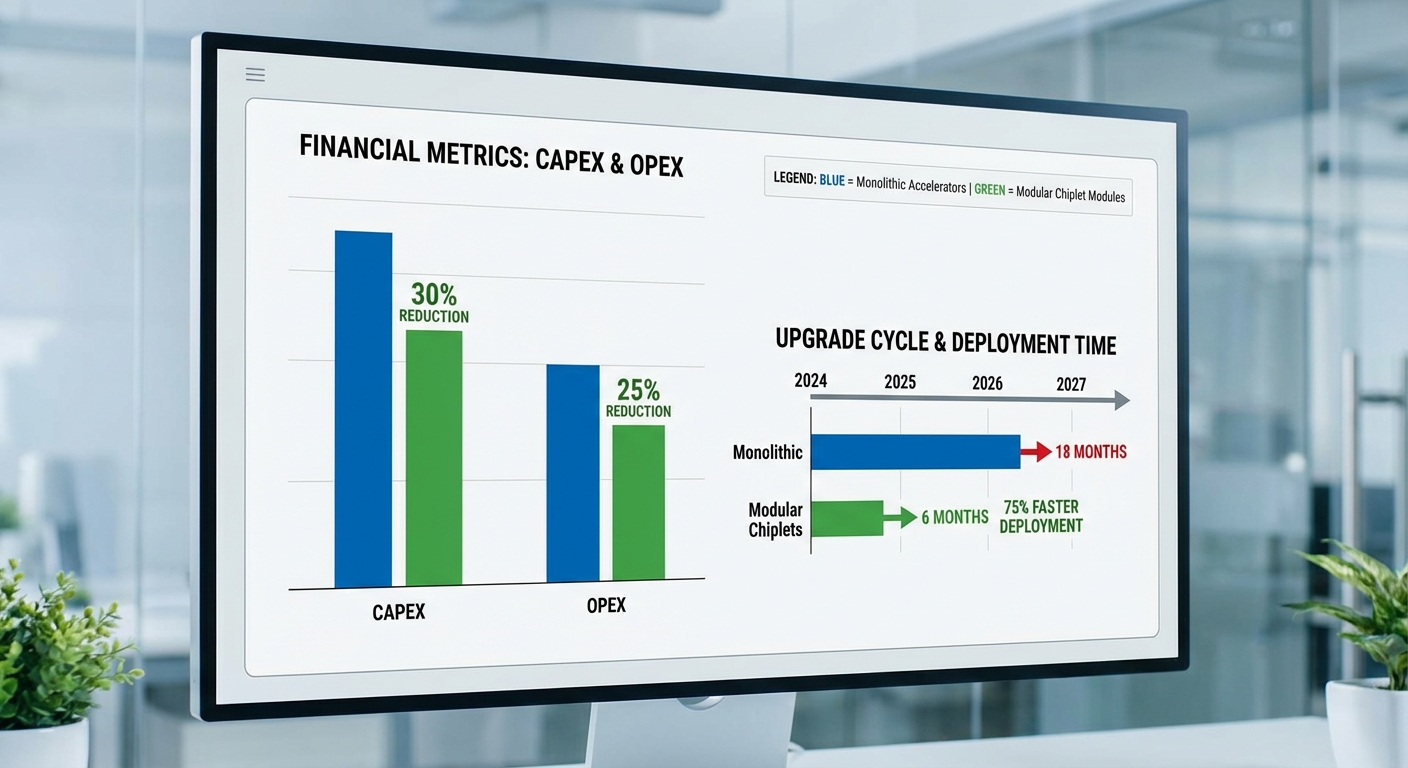
บทสรุปโดยย่อของกรณีศึกษาแบบสมมติ: ศูนย์ข้อมูลขนาดกลาง–ใหญ่ดำเนินโครงการอัปเกรด accelerator จำนวน 1,000 ใบ จากสถาปัตยกรรมแบบเดิม (full accelerator board) มาเป็นโมดูลประกอบได้ (AI‑Chiplet module) ผลการประเมินเชิงตัวเลขภายใต้สมมติฐานที่ระบุด้านล่างพบว่า เวลาการอัปเกรดลดจาก 8 สัปดาห์เหลือ 4.5 สัปดาห์ (ประมาณ 44% ลดลง) และค่าใช้จ่ายรวมของการเป็นเจ้าของ (TCO) ในช่วง 5 ปีลดลงมากกว่า 40% เมื่อเทียบกับสถาปัตยกรรมเดิม
สมมติฐานที่ใช้ในการคำนวณ
- จำนวนหน่วยที่อัปเกรด: 1,000 accelerators
- ราคาต่อชิ้น (สมมติ): Full accelerator board = $20,000 / ชิ้น; AI‑Chiplet module = $11,400 / ชิ้น (ลดลง ≈ 43%)
- ค่าแชสซีส์ (chassis) ที่เกี่ยวข้องกับ 1,000 หน่วย = $3,000,000 และสมมติว่าโมดูลประกอบได้ยืดอายุแชสซีส์ ทำให้ต้องรีเฟรชแชสซีส์น้อยลง (ในกรอบเวลา 5 ปี ถือว่าต้องจ่ายเพียงครึ่งหนึ่งหรือเลื่อนการลงทุน)
- แรงงานและเวลาการอัปเกรด (สองมุมมอง):
- มุมมองต่อหน่วย: การเปลี่ยนแบบเดิมใช้เฉลี่ย 3 ชั่วโมง/หน่วย; โมดูลประกอบได้ (hot‑swap/quick‑swap) ใช้ 1 ชั่วโมง/หน่วย
- มุมมองโครงการ: ทีมอัปเกรด 12 คน ทำงาน 40 ชม./สัปดาห์ — โครงการแบบเดิมใช้ 8 สัปดาห์; โมดูลใช้ 4.5 สัปดาห์
- ค่าแรงเฉลี่ยวิศวกร/เทคนิค: $60/ชั่วโมง (สำหรับการคำนวณแรงงาน) หรือทีม 12 คน ค่าแรงประมาณ $80/ชั่วโมง ในกรณีมุมมองโครงการ (สำหรับตัวอย่างเปรียบเทียบ)
- ต้นทุน downtime ต่อชั่วโมง (ผลกระทบทางธุรกิจ/sla): สมมติ $2,000/ชั่วโมง ต่อหน่วยที่ได้รับผลกระทบ (conservative)
- ค่าใช้จ่ายบำรุงรักษาประจำปี (รวมสัญญาบำรุงรักษาและชิ้นส่วน) สมมติ: แบบเดิม $200,000/ปี; โมดูล $150,000/ปี
การคำนวณตัวอย่าง (ตัวเลขสรุป)
- CAPEX
- แบบเดิม: 1,000 × $20,000 = $20,000,000 + แชสซีส์ $3,000,000 = $23,000,000
- โมดูลประกอบได้: 1,000 × $11,400 = $11,400,000 + สมมติค่าแชสซีส์ภายใน 5 ปี = $1,500,000 (ครึ่งหนึ่ง) → รวม $12,900,000
- ผลต่าง CAPEX = $23,000,000 − $12,900,000 = $10,100,000 (ลด ≈ 43.9%)
- OPEX (ค่าบำรุงรักษา, แรงงานอัปเกรด, downtime)
- แรงงาน (มุมมองต่อหน่วย): แบบเดิม = 1,000 × 3 ชม. × $60 = $180,000; โมดูล = 1,000 × 1 ชม. × $60 = $60,000 → ประหยัด $120,000
- downtime (สมมติผลกระทบ 1 ชม./หน่วย แบบเดิม และ 0.25 ชม./หน่วย สำหรับ hot‑swap): แบบเดิม = 1,000 × 1 × $2,000 = $2,000,000; โมดูล = 1,000 × 0.25 × $2,000 = $500,000 → ประหยัด $1,500,000
- ค่าบำรุงรักษาประจำปี (5 ปี): แบบเดิม = $200,000 × 5 = $1,000,000; โมดูล = $150,000 × 5 = $750,000
- รวม OPEX (5 ปี): แบบเดิม = $2,000,000 + $180,000 + $1,000,000 = $3,180,000; โมดูล = $500,000 + $60,000 + $750,000 = $1,310,000
- ผลต่าง OPEX = $3,180,000 − $1,310,000 = $1,870,000 (ลด ≈ 58.8%)
- TCO (5 ปี)
- แบบเดิม (CAPEX + OPEX) = $23,000,000 + $3,180,000 = $26,180,000
- โมดูลประกอบได้ = $12,900,000 + $1,310,000 = $14,210,000
- ผลต่าง TCO = $26,180,000 − $14,210,000 = $11,970,000 (ลด ≈ 45.7%)
ผลกระทบเชิงปฏิบัติและการแปลตัวเลขสู่การปฏิบัติ
จากตัวอย่างสมมติข้างต้น สามารถสรุปเชิงนโยบายได้ชัดเจนว่าโมดูล AI‑Chiplet ส่งผลให้:
- ลดค่า CAPEX ต่อการอัปเกรด เนื่องจากราคาต่อหน่วยของโมดูลต่ำกว่าการเปลี่ยนทั้งบอร์ด และยังสามารถเปลี่ยนเฉพาะชิ้นส่วนที่ต้องการได้แทนการรีเฟรชทั้งระบบ
- ลด OPEX โดยเฉพาะค่า downtime และค่าแรง จากการรองรับ hot‑swap/quick‑swap ทำให้ผลกระทบต่อบริการลดลงอย่างมาก (ในตัวอย่างลดค่า downtime เกือบ 75% ต่อหน่วย)
- ยืดอายุการใช้งานชิ้นส่วนโครงสร้าง (chassis) ช่วยเลื่อนการลงทุนระยะใหญ่ (rack/chassis refresh) ออกไป ทำให้กระแสเงินสดดีขึ้นและลดความเสี่ยงด้านการลงทุนเชิงฮาร์ดแวร์
นอกจากนี้ เมื่อคำนึงถึงความไม่แน่นอนของตัวแปรสำคัญ (เช่น ต้นทุน downtime จริง, ราคาชิ้นส่วนในอนาคต, และอัตราค่าแรงในตลาดท้องถิ่น) การวิเคราะห์ความอ่อนไหว (sensitivity analysis) มักชี้ว่าโมเดลโมดูลมีประโยชน์มากยิ่งเมื่อ ค่า downtime ต่อชั่วโมงสูง หรือเมื่อองค์กรต้องการอัปเกรดบ่อยเพื่อตามความก้าวหน้าของโมเดล AI อย่างรวดเร็ว
สรุปสั้น
กรณีศึกษา (สมมติ) นี้แสดงให้เห็นว่าการเปลี่ยนมาใช้ AI‑Chiplet แบบโมดูลประกอบได้ สามารถลดเวลาการอัปเกรดจาก 8 สัปดาห์เหลือ 4.5 สัปดาห์ (~44% ลดลง) และลด TCO ในกรอบเวลา 5 ปีได้มากกว่า 40% เมื่อรวมผลจากการลด CAPEX, ลด downtime และลดค่าแรงบำรุงรักษา — ซึ่งเป็นตัวเลขที่มีนัยสำคัญต่อผู้ให้บริการศูนย์ข้อมูลและผู้ผลิตบอร์ดทั้งในด้านเงินทุนและการดำเนินงาน
ผลกระทบต่อโอเปอเรเตอร์ (Data Center Operators)
ผลกระทบต่อโอเปอเรเตอร์ (Data Center Operators)
การเข้ามาของชิป AI แบบ chiplet และโมดูลเร่งความเร็วที่ประกอบได้ (AI‑Chiplet) จะเปลี่ยนรูปแบบการจัดการศูนย์ข้อมูลจากการอัปเกรดเป็นชุดฮาร์ดแวร์ทั้งเครื่องไปสู่การเพิ่ม/เปลี่ยนโมดูลย่อยเป็นหน่วย ทำให้โอเปอเรเตอร์สามารถลดต้นทุนฮาร์ดแวร์และระยะเวลาการอัปเกรดได้มากกว่า 40% ตามกรณีศึกษาเบื้องต้น นอกจากนี้ความยืดหยุ่นในการจัดสรรทรัพยากรตามตารางงาน AI จะสูงขึ้นอย่างมีนัยสำคัญ — ทั้งในมุมมองของ CAPEX ที่เปลี่ยนเป็น OPEX และการปรับขนาดแบบ “pay‑as‑you‑grow” ที่ช่วยให้รองรับงานเร่งความเร็ว (accelerated workloads) ได้ทันความต้องการจริงของลูกค้าโดยไม่ต้องสำรองฮาร์ดแวร์ส่วนเกินเป็นเวลานาน
ในด้านการปฏิบัติการ ความยืดหยุ่นของการอัปเกรดและการจัดสรรทรัพยากรหมายถึงการจัดการสินทรัพย์ที่มีความละเอียดระดับโมดูล: ผู้ให้บริการสามารถสลับ/ย้ายโมดูลระหว่างแอปพลิเคชันหรือไคลเอนต์ได้อย่างรวดเร็ว ลดเวลาหยุดทำงานที่ส่งผลต่อ SLA และเพิ่มอัตราการใช้งาน (utilization) ของฮาร์ดแวร์ ตัวอย่างเช่น แทนที่จะเพิ่ม GPU หรือการ์ดเร่งความเร็วทั้งบอร์ดสำหรับงานทดลอง โอเปอเรเตอร์สามารถติดตั้งโมดูลสำหรับช่วงเวลาทดสอบและคืนโมดูลเมื่อเสร็จ ทำให้การวางแผนกำลังการผลิต (capacity planning) มีความแม่นยำและไหลลื่นขึ้น การผสานกับระบบจัดคิวและออร์เคสตราเช่น Kubernetes หรือระบบจัดตารางงาน HPC จะช่วยให้การจัดสรรโมดูลทำได้แบบเรียลไทม์ตาม priority ของงาน
โอกาสสร้างรายได้ใหม่สำหรับโอเปอเรเตอร์มีทั้งในเชิงสินค้าและบริการ ได้แก่ การให้เช่าโมดูล (module leasing), Hardware as a Service (HaaS) สำหรับโมดูล, บริการจัดการแบบครบวงจร (installation, lifecycle management, firmware updates), และการให้บริการแบบ capacity‑on‑demand ที่คิดค่าบริการตามเวลาจริง ตัวอย่างโมเดลธุรกิจที่เป็นไปได้คือการเสนอ "ชั้นบริการโมดูล" ให้ลูกค้าด้านการวิจัยและสตาร์ทอัพที่ต้องการเร่งงานเพียงช่วงสั้น ๆ หรือผู้ให้บริการซอฟต์แวร์ AI ที่ต้องการสเกลในช่วงแคมเปญพีค ทั้งนี้โอเปอเรเตอร์สามารถเพิ่มมูลค่าโดยรวมด้วยการให้ SLA แบบพรีเมียมที่ครอบคลุมการเปลี่ยนโมดูลภายในช่วงเวลาที่กำหนดหรือการรับประกันประสิทธิภาพต่อวัตต์
- Interoperability ของโมดูล: ต้องประเมินมาตรฐานอินเทอร์เฟซ (เช่น PCIe, CXL, ทางเลือกเฉพาะผู้ผลิต) และความเข้ากันได้ของเฟิร์มแวร์/ไดรเวอร์ การขาดมาตรฐานสากลจะเพิ่มค่าใช้จ่าย integration และความเสี่ยง vendor lock‑in
- การจัดการความร้อนและพลังงาน: โมดูลที่สามารถถอดประกอบได้อาจเพิ่มความหนาแน่นพลังงาน (power density) ต่อแร็ค ต้องออกแบบระบบระบายความร้อน (airflow หรือ liquid cooling) ให้รองรับ delta‑load แบบไดนามิกและคำนวณ PUE ใหม่เมื่อปรับสเกล
- SLA และการดำเนินงาน: SLA อาจต้องขยายขอบเขตสู่ระดับโมดูล — เช่น uptime ต่อตัวโมดูล, MTTR ต่อโมดูล, และประสิทธิภาพต่อโมดูล การเปลี่ยนมาใช้โมดูลเป็นหน่วยให้บริการทำให้ต้องออกแบบกลยุทธ์ redundancy และ failover ที่รองรับการเปลี่ยนโมดูลขณะรันงาน
ผลกระทบต่อ SLA เป็นประเด็นสำคัญ: การแยกหน่วยบริการเป็นโมดูลช่วยให้ตอบสนองความต้องการบางกรณีได้ดีขึ้น แต่ก็อาจทำให้ความต่อเนื่องของบริการขึ้นอยู่กับซับซ้อนของการสลับโมดูลและ latency ของ interconnect โอเปอเรเตอร์ควรกำหนด SLA ใหม่ที่ชัดเจน เช่นระดับความพร้อมใช้งานสำหรับโมดูล, เวลาตอบกลับการเปลี่ยนโมดูล (replacement/upgrade window), และตัวชี้วัดประสิทธิภาพ (throughput/latency per module) พร้อมออกแบบกลไกประกัน (service credits, automated failover, hot‑standby modules)
การประเมินความเสี่ยงและแผนการทดลองนำร่อง (pilot) ควรตั้งค่าในเชิงปฏิบัติ ดังนี้:
- ขอบเขตทดลอง: เริ่มด้วยพ็อดทดลองขนาด 1–4 แร็ค ผสมงานจริงและโหลดสังเคราะห์เพื่อวัดประสิทธิภาพและพลังงาน
- KPI ที่ต้องติดตาม: เวลาในการติดตั้ง/เปลี่ยนโมดูล, MTTR, อัตราความล้มเหลวของโมดูล, เปอร์เซ็นต์การใช้งาน (utilization), ประสิทธิภาพต่อวัตต์ (performance/W), และผลกระทบต่อ SLA ของลูกค้าตัวอย่าง
- ระยะเวลา: 3–6 เดือนสำหรับรอบแรก เพื่อจับ pattern ของการใช้งานตามฤดูกาลและปัญหาเชิงเทคนิค
- ขั้นตอนความปลอดภัยและ fallback: วางแผน rollback ชัดเจน, สำรองโมดูลสำรอง (hot spares), ทำ DR rehearsals และตรวจสอบการทำงานของซอฟต์แวร์จัดสรรทรัพยากร
- ประเมินเศรษฐศาสตร์: เปรียบเทียบ TCO ระหว่างโมเดลแบบดั้งเดิมและโมดูล ทั้งในกรอบ 1–5 ปี และวิเคราะห์ช่องทางรายได้จากการให้เช่า/บริการจัดการ
สรุปคือ โอเปอเรเตอร์ที่เตรียมโครงสร้างพื้นฐานด้านอินเทอร์เฟซมาตรฐาน การระบายความร้อนที่ยืดหยุ่น และกรอบ SLA ใหม่ จะได้รับประโยชน์เชิงเศรษฐกิจและเชิงปฏิบัติการจาก AI‑Chiplet อย่างมีนัยสำคัญ ทั้งนี้การเริ่มต้นด้วยโครงการนำร่องที่มี KPI ชัดเจนและแผนบริหารความเสี่ยงจะเป็นกุญแจสำคัญในการเปลี่ยนผ่านสู่โมเดลการให้บริการที่ยืดหยุ่นและสร้างรายได้ใหม่ได้อย่างมั่นคง
ผลกระทบต่อผู้ผลิตบอร์ดและซัพพลายเชน
ผลกระทบต่อผู้ผลิตบอร์ดและซัพพลายเชน
การมาถึงของชิป AI แบบ chiplet และโมดูลเร่งความเร็วประกอบได้ (AI‑Chiplet) เปลี่ยนบทบาทของผู้ผลิตบอร์ด (OEM/ODM) จากผู้ผลิตบอร์ดแบบคงที่ไปสู่ผู้พัฒนาแพลตฟอร์มที่ต้องรองรับความหลากหลายของโมดูลทั้งด้านฟอร์มแฟคเตอร์, กำลังไฟ และอินเทอร์เฟซการสื่อสารภายในระบบ ตัวอย่างเช่น แผงวงจรต้องออกแบบเป็น multi‑slot motherboard ที่มีพื้นที่และการเชื่อมต่อตามมาตรฐาน (เช่น OCP Accelerator Module, EDSFF หรือ mezzanine connectors) รวมถึงต้องมีการวางเลเยอร์ PCB, plane พลังงาน และเส้นสัญญาณความเร็วสูง (SerDes/CXL/PCIe Gen5/6) ที่ถูกต้องเพื่อให้มั่นใจในสัญญาณและความร้อนที่ควบคุมได้
ในมุมพลังงาน ผู้ผลิตบอร์ดต้องออกแบบระบบจ่ายไฟแบบยืดหยุ่น (power delivery) ที่รองรับโมดูลหลายรุ่นซึ่งมีความต้องการพลังงานแตกต่างกัน ตั้งแต่ระดับร้อยวัตต์ไปจนถึงหลายร้อยวัตต์ต่อโมดูล ซึ่งหมายถึงการนำเทคนิคเช่น multiple VRM rails, dynamic power provisioning, power sequencing และ protected hot‑swap circuitry มาใช้ ร่วมกับการวางแผน thermal management (ฮีตซิงค์, ช่องระบายอากาศ, heat spreader) ตั้งแต่ขั้นออกแบบ PCB เพื่อหลีกเลี่ยงการออกบอร์ดใหม่ทุกครั้งที่มีโมดูลใหม่เข้ามา
การเปลี่ยนแปลงนี้เพิ่มความจำเป็นในการลงทุนด้าน testing automation และสร้าง certification ecosystem ภายในและภายนอกองค์กร ผู้ผลิตต้องพัฒนาชุดทดสอบอัตโนมัติ (ATE), test jig และ continuous integration tests สำหรับ firmware/BIOS/driver ที่หลากหลาย พร้อมทั้งจัดทำ compatibility matrix ระดับองค์กรเพื่อเก็บข้อมูลการผสานกันของบอร์ดกับโมดูลแต่ละรุ่น (เช่น SKUs X,Y,Z ผ่าน/ไม่ผ่านการทดสอบ) การทำงานเชิงระบบนี้ช่วยลดเวลาการรับรองเข้าตลาดและลดความเสี่ยงจาก field failure ซึ่งเป็นข้อได้เปรียบเชิงการแข่งขันเมื่อโอเปอเรเตอร์ต้องการอัปเกรดเร็วขึ้นและต้นทุนน้อยลง
ผลกระทบต่อซัพพลายเชนจะเป็นการปรับสมดุลจากการสต็อกชิ้นส่วนบอร์ดแบบยาวๆ ไปสู่การสร้างเครือข่ายของผู้ผลิตโมดูลเฉพาะทางและผู้ประกอบแพ็กเกจ (OSAT หรือ module integrators) มากขึ้น ผู้ผลิตบอร์ดไทยอาจเห็นการย้ายส่วนแบ่งการผลิตไปยังผู้จัดหาที่เชี่ยวชาญด้านการประกอบ die‑to‑module, cooling solution และการรับรองการใช้งานจริง (field validation) ส่งผลให้โมเดลการผลิตเปลี่ยนจาก make‑to‑stock เป็น configure‑to‑order หรือ build‑to‑order เพื่อลดค่า inventory และรองรับ long tail ของ SKUs
การเปลี่ยนผ่านนี้ยังมีผลต่อการวางแผนกำลังการผลิตและการลงทุนของ OEM/ODM: ต้องพิจารณาการลงทุนในเครื่องทดสอบอัตโนมัติ, ห้องทดสอบ EMC/thermal, และการฝึกทักษะด้านการออกแบบสัญญาณความเร็วสูงและระบบจ่ายไฟ อีกทั้งต้องสร้างความร่วมมือเชิงกลยุทธ์กับผู้ผลิตโมดูลและผู้ประกอบแพ็กเกจ เพื่อให้สามารถปรับกำลังการผลิตทันต่อความต้องการของตลาดที่คาดว่าจะเพิ่ม adoption ของโมดูลประกอบได้อย่างรวดเร็ว โดยสรุปคือผู้ผลิตบอร์ดและซัพพลายเชนต้องเปลี่ยนวิธีคิดจากการทำบอร์ดเป็นสินค้าเป็นการสร้างแพลตฟอร์มที่รองรับอนาคต และลงทุนในระบบทดสอบและเครือข่ายพันธมิตรเพื่อรักษาความคล่องตัวในการแข่งขัน
อุปสรรค ความเสี่ยง และแนวทางเร่งนำไปใช้จริง
อุปสรรคหลักเชิงปฏิบัติการต่อการนำ AI‑Chiplet ไปใช้
การยกระดับเซิร์ฟเวอร์ด้วยชิปแบบ chiplet และโมดูลเร่งความเร็วที่ประกอบได้ (AI‑Chiplet) สร้างโอกาสทางเศรษฐกิจและประสิทธิภาพ แต่ในทางปฏิบัติยังเผชิญอุปสรรคสำคัญด้านมาตรฐาน การจัดการความร้อน ความปลอดภัยของข้อมูล และความเข้ากันได้ของซอฟต์แวร์ โดยเฉพาะเมื่อโครงสร้างพื้นฐานกระจายศูนย์ข้อมูล (on‑premise และ edge) ต้องรองรับทั้งมาตรฐานเชื่อมต่อ เช่น CXL (Compute Express Link) และ UCIe (Universal Chiplet Interconnect Express) รวมถึงรูปแบบการติดตั้งโมดูลอย่าง OAM (Open Accelerator Module) ซึ่งหากไม่มีการรับรองร่วมจากหลายฝ่ายจะเกิดความเสี่ยงต่อ interoperability ระหว่างโมดูลจากผู้ผลิตต่างกัน และอาจทำให้เวลา integration เพิ่มขึ้นอย่างมีนัยสำคัญ
ความเสี่ยงจากการพึ่งพาซัพพลายเออร์เดียวและการบริหารความเสี่ยง
การเลือกซัพพลายเออร์โมดูลเพียงรายเดียว (vendor lock‑in) ทำให้โอเปอเรเตอร์และผู้ผลิตบอร์ดตกอยู่ในความเสี่ยงด้านราคา การอัพเดตเฟิร์มแวร์ และการรองรับสต็อกอะไหล่ ซึ่งอาจส่งผลต่อความต่อเนื่องทางธุรกิจและต้นทุน TCO ในระยะยาว เพื่อบริหารความเสี่ยง ควรนำแนวทางผสมผสานดังนี้: ยืนยันการยอมรับมาตรฐานเปิด ในสัญญาจัดซื้อ, ตั้งเงื่อนไขการสำรองชิ้นส่วนและซอร์สสำรอง, ใช้สัญญา escrow สำหรับไดรเวอร์/เฟิร์มแวร์ และกำหนด SLA ที่ชัดเจนเรื่อง RMA และการซัพพอร์ตด้านซอฟต์แวร์
ความปลอดภัยและการันตีข้อมูล
การนำโมดูล AI มาใช้งานต้องคำนึงถึงทั้งความมั่นคงของฮาร์ดแวร์และซอฟต์แวร์ เช่น secure boot, การยืนยันตัวตนของโมดูล (attestation), การเข้ารหัสข้อมูลขณะเคลื่อนย้าย และการควบคุมสิทธิ์ในระดับไดรเวอร์/เฟิร์มแวร์ นอกจากนี้ ต้องมีนโยบายตรวจสอบซัพพลายเชนเพื่อป้องกันการฝังเบื้องต้น (supply‑chain tampering) และกำหนดกระบวนการอัปเดตเฟิร์มแวร์ที่ปลอดภัย (signed updates, rollback protection) เพื่อไม่ให้การเร่งนำไปใช้แลกกับความเสี่ยงต่อการรั่วไหลของข้อมูลหรือช่องโหว่ที่ถูกใช้งานจริง
การออกแบบความร้อนและพลังงาน
AI‑Chiplet มักมาพร้อมกับหน่วยประมวลผลที่มีความหนาแน่นพลังงานสูง ทำให้การจัดการความร้อน (thermal management) และการจ่ายพลังงาน (power delivery) เป็นหัวใจสำคัญ การออกแบบบอร์ดต้องพิจารณา cold plate/heat sink ที่รองรับโมดูลหลายรูปแบบ, การวางช่องระบายอากาศในเคส และการติดตามเทเลเมทรีแบบเรียลไทม์ (temperature, power draw) เพื่อหลีกเลี่ยง throttling หรือล้มเหลวเฉียบพลัน ผู้ผลิตบอร์ดควรจัดช่องมาตรฐานสำหรับการติดตั้งเซ็นเซอร์และการต่อระบบระบายความร้อนที่ปรับเปลี่ยนได้
ข้อตกลงการรับประกันและความรับผิดชอบร่วม
เมื่อระบบประกอบด้วยชิ้นส่วนจากหลายผู้ผลิต จำเป็นต้องกำหนดขอบเขตความรับผิดชอบอย่างชัดเจนในสัญญา ระบุว่าใครรับผิดชอบต่อความเสียหายจากปัญหาในระดับโมดูล เทียบกับปัญหาในระดับระบบ (board, firmware, integration) ควรรวมเงื่อนไขดังนี้: SLA สำหรับเวลาแก้ไข, นโยบาย RMA, การรับประกันร่วม (joint warranty) ในกรณีที่ปัญหาเกิดจากการรวมระบบ และระดับการสนับสนุนทางเทคนิค (on‑site, remote) ที่ชัดเจน
แนวทางเร่งนำไปใช้จริง: ขั้นตอนแนะนำสำหรับโครงการนำร่อง
การเริ่มต้นควรทำเป็นโครงการนำร่อง (pilot) ที่มีขอบเขตจำกัดและเป้าหมายชัดเจน ก่อนขยายสู่การใช้งานระดับศูนย์ข้อมูลทั้งระบบ โดยแนะนำขั้นตอนดังนี้
- กำหนดขอบเขต (pilot scope): เลือกเซิร์ฟเวอร์/รุ่นบอร์ดจำเพาะ จำนวนโหนด (เช่น 5–20 เครื่อง) และ workload ที่สะท้อนการใช้งานจริง (inference/ training profile)
- ตั้ง KPI ที่วัดได้: ประสิทธิภาพ (throughput per watt, latency P95/P99), เวลาทำการอัปเกรด (upgrade time), อัตราความผิดพลาดในการทำงานร่วม (interoperability failure rate), ค่า TCO ต่อหน่วยปี และ MTBF/MTTR
- แผนการทดสอบ: integration test (boot, driver install), stress test ภายใต้โหลดสูง, thermal cycling, power‑fault recovery, ฟังก์ชันความปลอดภัย (attestation, secure firmware update), และ penetration test ฝั่งซอฟต์แวร์
- การวัดและบันทึก: เตรียม telemetry และ logging ที่รองรับการวิเคราะห์สาเหตุ (root‑cause analysis) รวมถึงการเก็บข้อมูลพลังงาน อุณหภูมิ และประสิทธิภาพในรูปแบบที่สามารถเปรียบเทียบก่อน/หลังได้
- roadmap การปรับปรุง: สรุปผล pilot ในรูปแบบ milestone (v1: lab validated, v2: pilot in production slice, v3: scale‑out) พร้อมเวลาที่ชัดเจนและทรัพยากรที่ต้องใช้
เช็คลิสต์สำหรับโอเปอเรเตอร์และผู้ผลิตบอร์ดก่อนเริ่มโครงการนำร่อง
- มาตรฐานและข้อกำหนด: ยืนยันการรองรับ CXL/UCIe/OAM หรือมาตรฐานที่เกี่ยวข้องในสเปคสัญญา
- นโยบายการจัดซื้อ: ใส่เงื่อนไข multi‑vendor compliance และข้อผูกมัดด้านซอร์สสำรอง
- ข้อตกลงทางกฎหมาย: ระบุ SLA, RMA, joint warranty, และเงื่อนไข escrow สำหรับซอฟต์แวร์/เฟิร์มแวร์
- แผนความปลอดภัย: ระบุข้อกำหนด secure boot, attestation, signed firmware และการเข้ารหัสข้อมูล
- ความพร้อมด้านฮาร์ดแวร์: ตรวจสอบผังพลังงาน, interface mechanical, และช่องต่อสำหรับระบายความร้อน
- แผนการทดสอบ: กำหนด test cases, tools, และ KPI ที่จะเก็บข้อมูล
- ทีมและทรัพยากร: มอบหมายทีม integration, firmware, network/security, และการสนับสนุนจากผู้ผลิต
- แผนสำรอง: กำหนด fallback path/rollback plan หากอัพเกรดล้มเหลว
สรุป
การนำ AI‑Chiplet มาใช้ในศูนย์ข้อมูลไทยมีศักยภาพลดต้นทุนและเวลาอัปเกรดกว่า 40% แต่ต้องประสานทั้งมาตรฐาน เปิดรับ multi‑vendor และตั้งกรอบสัญญาที่ชัดเจนเพื่อหลีกเลี่ยง vendor lock‑in ตลอดจนออกแบบด้านความร้อนและความปลอดภัยตั้งแต่ต้น การเริ่มด้วยโครงการนำร่องที่มี KPI ชัดเจนและเช็คลิสต์ตามข้อเสนอข้างต้นจะช่วยลดความเสี่ยงและสร้างเส้นทางสู่การขยายใช้งานเชิงพาณิชย์อย่างยั่งยืน
บทสรุป
AI‑Chiplet แบบโมดูลประกอบได้ กำลังเป็นตัวเปลี่ยนเกมสำหรับศูนย์ข้อมูลในไทย โดยนำเสนอแนวทางลดค่าใช้จ่ายด้านฮาร์ดแวร์และลดเวลากระบวนการอัปเกรดลงอย่างมีนัยสำคัญ — งานวิจัยและกรณีทดสอบชี้ว่าโมดูลเร่งความเร็วที่ถอดเปลี่ยนได้สามารถลดค่าใช้จ่ายฮาร์ดแวร์และเวลาอัปเกรดได้มากกว่า 40% เมื่อเทียบกับการเปลี่ยนแปลงเซิร์ฟเวอร์แบบเดิม ผลลัพธ์นี้หมายถึงการลด CAPEX, การลดเวลาหยุดให้บริการ (downtime) ขณะอัปเกรด และความยืดหยุ่นในการปรับสเปกตามความต้องการงาน AI ที่เปลี่ยนเร็ว แต่การเปลี่ยนผ่านนี้ไม่ใช่เรื่องของเทคโนโลยีชิปอย่างเดียว โอเปอเรเตอร์ศูนย์ข้อมูลและผู้ผลิตบอร์ดต้องร่วมกันออกแบบมาตรฐานฮาร์ดแวร์/ซอฟต์แวร์ การทดสอบความเข้ากันได้ และแนวทางบริหารซัพพลายเชน เพื่อป้องกันปัญหา vendor lock‑in และความเสี่ยงด้านชิ้นส่วนที่อาจทำให้เกิดช่องโหว่ทางการดำเนินงาน
ในเชิงอนาคต ถ้าอุตสาหกรรมไทยสามารถตั้งมาตรฐานร่วม พัฒนาแล็บทดสอบกลาง และสร้างรูปแบบธุรกิจใหม่ๆ เช่น บริการอัปเกรดเป็นโมดูล (upgrade-as-a-service), ตลาดโมดูลมือสองที่มีการรับรอง และการออกแบบบอร์ดที่รองรับชิปจากหลายผู้ผลิต จะเกิดระบบนิเวศ (ecosystem) ที่เอื้อต่อการนำ AI‑Chiplet มาใช้อย่างรวดเร็วและปลอดภัย — คาดว่าใน 2–4 ปีข้างหน้า ศูนย์ข้อมูลที่นำแนวทางนี้มาใช้จะเห็นการปรับลด TCO ที่ชัดเจนและความสามารถในการประมวลผล AI ที่ปรับสเกลได้ตามความต้องการ ข้อเสนอแนะเชิงปฏิบัติคือให้โอเปอเรเตอร์และผู้ผลิตบอร์ดร่วมกันเริ่มโครงการนำร่อง วางข้อกำหนดอินเทอร์เฟซร่วม และเข้าร่วมคอนซอร์เทียมเพื่อเร่งการสร้างมาตรฐานและการรับรอง ลดความเสี่ยงจากซัพพลายเชน และเปิดทางสู่การแข่งขันของผู้ผลิตหลายรายในตลาดไทย



