
การระเบิดของข้อมูลดิจิทัลและการเติบโตของโมเดลปัญญาประดิษฐ์ขนาดใหญ่ทำให้การจัดเก็บ การส่งผ่าน และการฝึกโมเดลกลายเป็นคอขวดที่ท้าทาย: องค์กรต่าง ๆ เผชิญกับปริมาณข้อมูลที่คาดว่าจะขยายถึงระดับ "เซตตะไบต์" ภายในทศวรรษนี้ ขณะที่โมเดลอย่าง GPT-3 มีพารามิเตอร์เป็นร้อยล้านถึงร้อยพันล้านตัว ทำให้ค่าใช้จ่ายด้านพื้นที่เก็บข้อมูล ซีพียู/จีพียู และพลังงานพุ่งสูง เทคนิคการบีบอัดข้อมูล (ทั้งสำหรับข้อมูลและโมเดล) จึงไม่ได้เป็นเพียงเทคนิคประหยัดพื้นที่อีกต่อไป แต่กลายเป็นกลยุทธ์สำคัญในการเพิ่มประสิทธิภาพกระบวนการเรียนรู้ของเครื่อง ทั้งในการฝึก การประเมินผล และการปรับใช้บนอุปกรณ์จริง
บทความนี้จะพาคุณไล่เรียงตั้งแต่หลักการพื้นฐานของการบีบอัดแบบ lossless/ lossy ไปจนถึงเทคนิคเฉพาะทางสำหรับ ML เช่น pruning, quantization, knowledge distillation, low-rank factorization, sparsity และ compression-aware training รวมถึงแนวทางจัดการชุดข้อมูลขนาดใหญ่และการส่งข้อมูลแบบมีประสิทธิภาพ พร้อมยกตัวอย่างสถิติจากงานวิจัยที่ชี้ว่าเทคนิคบางรูปแบบสามารถลดขนาดโมเดลได้ในระดับ 2–10x และเร่งเวลา inference/การฝึกได้ 2–5x บทความยังสรุปเครื่องมือยอดนิยม (เช่น TensorFlow Model Optimization, PyTorch quantization, DeepSpeed, ONNX, Hugging Face Optimum, NVIDIA TensorRT) และให้แนวทางเชิงปฏิบัติสำหรับวิศวกร ML, นักวิจัย และสถาปนิกระบบ เพื่อให้สามารถเลือกและนำเทคนิคการบีบอัดไปใช้ให้เกิดประโยชน์สูงสุดในสภาพแวดล้อมการทำงานจริง
บทนำ: ทำไมการบีบอัดจึงสำคัญต่อ AI/ML ในยุคปัจจุบัน
บทนำ: ทำไมการบีบอัดจึงสำคัญต่อ AI/ML ในยุคปัจจุบัน
ในช่วงไม่กี่ปีที่ผ่านมา เราเห็นการเติบโตเชิงทวีคูณทั้งในขนาดของโมเดลและปริมาณข้อมูลที่ใช้ฝึกและให้บริการระบบปัญญาประดิษฐ์ ตัวอย่างที่ชัดเจนคือโมเดลภาษาขนาดใหญ่ — จาก GPT-2 ที่มีพารามิเตอร์ประมาณ 1.5 พันล้านตัว (2019) ไปสู่ GPT-3 ที่มี ~175 พันล้านตัว (2020) และตามด้วยโมเดลระดับหลายร้อยพันล้านพารามิเตอร์จากผู้เล่นรายอื่น ๆ เช่น PaLM (ประมาณ 540 พันล้านพารามิเตอร์) แนวโน้มนี้สะท้อนถึงการเพิ่มขึ้นของความต้องการข้อมูลด้วยเช่นกัน โดยจากการประมาณการของสถาบันวิจัยข้อมูลระดับโลก ปริมาณข้อมูลดิจิทัลที่สร้างขึ้นมีการเติบโตจากหลักสิบ zettabyte ในช่วงต้นทศวรรษ 2020 ไปสู่ระดับหลายร้อย zettabyte ภายในกลางทศวรรษ การเติบโตทั้งสองด้านนี้สร้างแรงกดดันเชิงปริมาณและเชิงปฏิบัติการต่อองค์กรที่ต้องการใช้ AI/ML ในระดับการผลิต
แรงกดดันทางทรัพยากรที่เกิดขึ้นมีหลายมิติ ทั้งด้านฮาร์ดแวร์ หน่วยความจำ (RAM/VRAM/Storage) แบนด์วิดท์เครือข่าย และต้นทุนคลาวด์ที่เพิ่มสูงขึ้น เมื่อต้องฝึกหรือให้บริการโมเดลขนาดหลายร้อยพันล้านพารามิเตอร์ องค์กรอาจเผชิญกับค่าใช้จ่ายด้านคอมพิวต์เป็นจำนวนหลายล้านดอลลาร์ต่อรอบการฝึก นอกจากนี้ยังมีค่าใช้จ่ายด้านการจัดเก็บข้อมูลและการถ่ายโอนข้อมูล (egress) โดยเฉพาะเมื่อให้บริการผ่านคลาวด์หรือข้ามภูมิภาค ความหน่วง (latency) ก็เป็นปัจจัยสำคัญสำหรับการใช้งานเชิงธุรกิจ เช่น การตอบสนองแบบเรียลไทม์ในการแชทบอทหรือการประมวลผลบนอุปกรณ์ Edge — เมื่อโมเดลใหญ่ขึ้น การรักษาระดับ latency ที่ยอมรับได้จะท้าทายขึ้น
การบีบอัดข้อมูลและโมเดล จึงกลายเป็นเครื่องมือเชิงกลยุทธ์ที่สามารถลดแรงกดดันเหล่านี้ได้อย่างมีนัยสำคัญ เทคนิคอย่างการ quantization, pruning, และ knowledge distillation ช่วยลดขนาดของโมเดลและการใช้งานหน่วยความจำโดยไม่สูญเสียประสิทธิภาพมากนัก ตัวอย่างเชิงตัวเลขที่ใช้อ้างอิงในอุตสาหกรรม ได้แก่:
- การแปลงพารามิเตอร์จาก FP32 เป็น INT8 สามารถลดขนาดหน่วยความจำได้ประมาณ 4 เท่า ทำให้การเก็บและการประมวลผลมีต้นทุนและความต้องการแบนด์วิดท์ต่ำลง
- การบีบอัดเชิงสถาปัตยกรรม เช่น DistilBERT ช่วยลดขนาดโมเดลลง ~40% และเพิ่มความเร็วการ推理 (throughput) เป็นกลุ่มตัวอย่างได้มาก — รายงานจากงานวิจัยระบุว่าบางกรณีทำให้เร็วขึ้นถึง ~60%
- การใช้ quantization ระดับ 4‑bit หรือเทคนิคการทำ low‑rank approximation อาจให้การลดขนาดได้ถึง 6–8 เท่า ในขณะที่ throughput เพิ่มขึ้นหลายเท่าตัว ขึ้นกับฮาร์ดแวร์และการปรับแต่ง
ในเชิงธุรกิจ ผลประโยชน์จากการบีบอัดไม่ได้จำกัดเพียงการลดพื้นที่จัดเก็บเท่านั้น แต่ยังส่งผลโดยตรงต่อค่าใช้จ่ายการดำเนินงานและประสบการณ์ผู้ใช้ — latency ลดลง ทำให้ตอบสนองได้เร็วขึ้น, throughput เพิ่มขึ้น ช่วยรองรับคำขอพร้อมกันได้มากขึ้นต่อหน่วยฮาร์ดแวร์, และ ต้นทุนคลาวด์ลดลง ทั้งด้าน compute, storage และ network egress ในหลายกรณี การบีบอัดที่เหมาะสมสามารถลดต้นทุนการให้บริการได้ตั้งแต่หลักสิบเปอร์เซ็นต์จนถึงเกือบครึ่ง ขึ้นกับลักษณะงานและมาตรการทางเทคนิคที่นำมาใช้
ด้วยบริบทเช่นนี้ การบีบอัดจึงไม่ใช่เพียงเทคนิคนอกชั้นเรียนสำหรับวิศวกร แต่กลายเป็นส่วนสำคัญของกลยุทธ์การนำ AI/ML เข้าสู่การผลิตขององค์กร ไม่ว่าจะเป็นการขยายสเกลเพื่อตอบโจทย์ผู้ใช้นับล้าน การลดค่าใช้จ่ายของแพลตฟอร์มคลาวด์ หรือนำโมเดลไปประมวลผลบน Edge การลงทุนในมาตรการบีบอัดที่เหมาะสมช่วยให้ธุรกิจสามารถใช้ประโยชน์จากโมเดลที่ใหญ่ขึ้นได้อย่างยั่งยืนและคุ้มค่าทางเศรษฐกิจ
พื้นฐานการบีบอัด: Lossy vs Lossless และคอนเซ็ปต์สำคัญ
พื้นฐานการบีบอัด: Lossy vs Lossless และคอนเซ็ปต์สำคัญ
การบีบอัดข้อมูลเป็นพื้นฐานสำคัญที่ช่วยให้ระบบการเรียนรู้ของเครื่อง (Machine Learning) และการจัดเก็บข้อมูลในองค์กรสามารถทำงานได้มีประสิทธิภาพมากขึ้น โดยทั่วไปการบีบอัดแบ่งเป็นสองประเภทหลักคือ lossless และ lossy ซึ่งแต่ละแบบมีข้อดี ข้อจำกัด และกรณีการใช้ที่แตกต่างกัน การเข้าใจความแตกต่างเหล่านี้รวมถึงคอนเซ็ปต์เช่น entropy, sparsity, quantization และ low-rank approximation จะช่วยให้ผู้บริหารและทีมเทคนิคตัดสินใจเลือกวิธีการบีบอัดที่เหมาะสมต่อวัตถุประสงค์ทางธุรกิจ
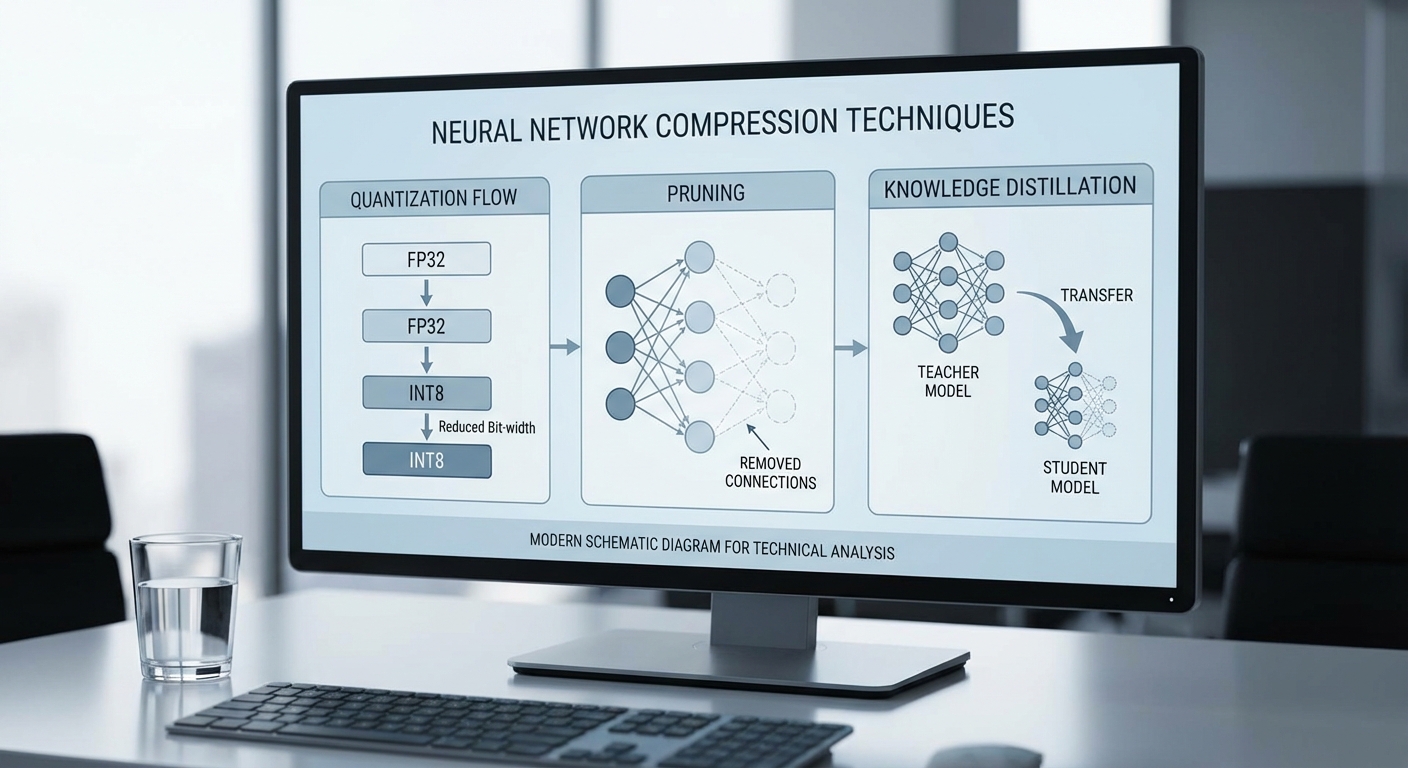
Lossless vs Lossy: ความหมายและตัวอย่าง
Lossless หมายถึงการบีบอัดที่สามารถกู้คืนข้อมูลดั้งเดิมได้ทุกบิตหลังการแตกไฟล์ เช่น การบีบอัดไฟล์เอกสาร ข้อมูลฐานข้อมูล หรือโค้ดโปรแกรม ตัวอย่างที่คุ้นเคยคือ ZIP, PNG สำหรับภาพ และ FLAC สำหรับเสียง ในการใช้งานทางธุรกิจกรณีที่ความถูกต้องสมบูรณ์ของข้อมูลเป็นสิ่งจำเป็น (เช่น เอกสารทางการ, ข้อมูลการเงิน, โมเดลที่ต้องการค่าพารามิเตอร์เดิมทุกประการ) จะใช้วิธี lossless โดยทั่วไปอัตราส่วนการบีบอัดของ lossless อยู่ในช่วงประมาณ 2–3x ขึ้นกับความซ้ำซ้อนของข้อมูล
Lossy เป็นการบีบอัดที่ยอมให้สูญเสียข้อมูลบางส่วนเพื่อแลกกับอัตราการบีบอัดที่สูงกว่า ตัวอย่างเช่น JPEG สำหรับภาพ และ MP3 / AAC สำหรับเสียง ซึ่งออกแบบมาให้สูญเสียข้อมูลที่คาดว่าไม่สำคัญต่อการรับรู้ของมนุษย์ ในบริบทของการเรียนรู้ของเครื่อง การบีบอัดแบบ lossy อาจนำมาใช้กับเทนเซอร์หรือฟีเจอร์เพื่อประหยัดแบนด์วิดท์และหน่วยความจำ โดยยังรักษาความแม่นยำของโมเดลให้ใกล้เคียงเดิม ตัวอย่างตัวเลขเชิงปฏิบัติ: JPEG มักให้การบีบอัดในระดับ 10–20x ขณะที่ MP3 ให้ประมาณ 10x เป็นต้น
การเข้ารหัสเชิงสถิติ (Entropy Coding): แนวคิดและเทคนิคสำคัญ
คำว่า entropy ในบริบทของทฤษฎีข้อมูลหมายถึงขอบเขตต่ำสุดของจำนวนบิตเฉลี่ยที่จำเป็นสำหรับการแทนข้อมูลหนึ่งสัญลักษณ์ ซึ่งคำนวณโดยสูตร H(X) = -Σ p(x) log2 p(x) หากตัวอย่างง่าย ๆ สมมติความน่าจะเป็นของสัญลักษณ์เป็น {0.5, 0.25, 0.25} ค่า entropy จะเท่ากับ 1.5 บิตต่อสัญลักษณ์ ซึ่งแสดงว่าถ้าออกแบบการเข้ารหัสได้ดีจะใช้บิตเฉลี่ยใกล้ค่านี้
เทคนิคที่ใช้กันอย่างแพร่หลาย ได้แก่:
- Huffman coding — สร้างรหัสที่มีความยาวเป็นจำนวนเต็มของบิต การเข้ารหัสแบบ Huffman ให้ประสิทธิผลใกล้เคียงกับ entropy เมื่อชุดสัญลักษณ์ไม่ใหญ่มาก แต่ผลจะจำกัดเมื่อความน่าจะเป็นมีรูปแบบพิเศษและต้องการความยาวรหัสเป็นบิตจำนวนเต็ม
- Arithmetic coding — แทนสตรีมสัญลักษณ์ด้วยตัวทศนิยมช่วงหนึ่ง (interval) สามารถเข้าใกล้ค่า entropy ได้ดีกว่า Huffman ในหลายกรณีและรองรับแจกแจงความน่าจะเป็นได้ละเอียดขึ้น (มีความยาวรหัสเป็นทศนิยมเชิงบิต)
- Range coding — เวอร์ชันที่ปฏิบัติได้ของ arithmetic coding ที่นิยมใช้ในระบบบีบอัดสมัยใหม่
ในงานบีบอัดโมเดล ML มักใช้การรวมกันของการลดความเที่ยงตรง (quantization) และ entropy coding ตัวอย่างเช่น แปลงเลขทศนิยม float32 เป็นตัวแทนเชิงดิจิทัลที่มีช่วงค่าน้อยลง จากนั้นใช้ Huffman หรือ arithmetic coding บนสัญลักษณ์ที่ได้เพื่อให้ได้อัตราส่วนการบีบอัดรวมสูงสุด
Sparsity, Quantization และ Low-Rank Approximation: หลักการและการประยุกต์ใน ML
Sparsity (ความแร้น) หมายถึงการที่เวกเตอร์หรือเมทริกซ์มีค่าเป็นศูนย์เป็นสัดส่วนมาก ใน Neural Network สามารถทำได้ผ่านการ pruning (ตัดค่าน้ำหนักที่มีผลน้อย) เมื่อความหนาแน่นของพารามิเตอร์ลดลง จะสามารถใช้รูปแบบจัดเก็บแบบ sparse (เช่น CSR, CSC) เพื่อลดพื้นที่เก็บและคำนวณได้มาก ตัวอย่างเช่น การ pruning ให้เกิด 90% zeros จะลดพารามิเตอร์ที่ต้องเก็บเหลือประมาณ 10% และเมื่อรวมกับการจัดเก็บแบบ sparse อาจได้การลดพื้นที่ถึงประมาณ 10x หรือมากกว่า (ขึ้นกับโครงสร้างข้อมูลและโอเวอร์เฮด)
Quantization คือการลดความเที่ยงตรงของค่าจาก float32 เป็น float16, int8 หรือแม้กระทั่ง 4-bit/1-bit ซึ่งช่วยลดขนาดโมเดลและเพิ่มความเร็วคำนวณ เช่น การแปลงจาก float32 ไป int8 จะลดขนาดประมาณ 4x โดยทั่วไปการ quantization แบบสมองกลมีผลต่อความแม่นยำเล็กน้อย หากทำอย่างระมัดระวังและทำ calibration/quantization-aware training ผลกระทบทางประสิทธิภาพมักอยู่ในระดับที่ยอมรับได้สำหรับงานหลายประเภท
Low-rank approximation อาศัยแนวคิดว่าเมทริกซ์ขนาดใหญ่หลายตัวในโมเดล (เช่น พารามิเตอร์ของเลเยอร์เชิงเส้น) มักมีโครงสร้างที่สามารถประมาณได้ด้วยเมทริกซ์ที่มี rank ต่ำกว่า การใช้ SVD หรือการแยกเมทริกซ์เป็นสองเมทริกซ์ขนาดเล็ก (W ≈ U · V) จะช่วยลดจำนวนพารามิเตอร์ ตัวอย่างเชิงตัวเลข: เมทริกซ์ขนาด 512×512 มีพารามิเตอร์ 262,144 หากประมาณด้วย rank r = 64 จะเหลือพารามิเตอร์ประมาณ 1024·r = 65,536 ซึ่งลดลงราว 4x การใช้ low-rank จึงเป็นวิธีที่มีประโยชน์ในการลดต้นทุนหน่วยความจำและการคำนวณ โดยยังรักษาลักษณะการทำงานของโมเดลไว้ได้ในระดับที่ยอมรับได้
การเปรียบเทียบตัวอย่างระหว่างสื่อและเทนเซอร์/ฟีเจอร์
การบีบอัดภาพ/เสียงโดยคนมักคิดเป็น lossy เพราะยอมรับการสูญเสียข้อมูลที่ไม่สำคัญต่อการรับรู้ เช่น JPEG/MP3 ที่เน้น perceptual coding แต่การบีบอัดเทนเซอร์หรือฟีเจอร์สำหรับ ML มักใช้การผสมผสานของเทคนิคต่าง ๆ ดังนี้:
- บีบอัดฟีเจอร์ก่อนส่งข้ามเครือข่าย: quantization (float32 → int8) ตามด้วย entropy coding เพื่อลดแบนด์วิดท์
- บีบอัดโมเดลเพื่อเผยแพร่บนอุปกรณ์ edge: pruning → quantization → Huffman coding (ตัวอย่างเช่นงาน Deep Compression รายงานการลดขนาดโมเดล AlexNet ได้ประมาณ 35x ด้วยการรวมเทคนิคเหล่านี้)
- บีบอัดเทนเซอร์ความสัมพันธ์สูง: low-rank approximation หรือ tensor decomposition (CP, Tucker) เพื่อลดพารามิเตอร์และความซับซ้อนการคำนวณ
โดยสรุป การเลือกระหว่าง lossless และ lossy ขึ้นกับความต้องการด้านความถูกต้องและต้นทุน เมื่อผนวกแนวคิดทางสถิติอย่าง entropy coding เข้ากับกลยุทธ์ด้านโครงสร้างข้อมูล (sparsity, quantization, low-rank) องค์กรสามารถบรรลุเป้าหมายทั้งด้านขนาดของโมเดล เวลาแฝง และต้นทุนแบนด์วิดท์โดยไม่ละทิ้งประสิทธิภาพทางธุรกิจ
เทคนิคการบีบอัดสำหรับข้อมูลและโมเดล (เชิงลึก)
ในบริบทของการนำแบบจำลองการเรียนรู้ของเครื่องไปใช้งานจริง เทคนิคการบีบอัด (compression) มีบทบาทสำคัญในการลดขนาดโมเดล ลดการใช้หน่วยความจำ และเพิ่มความเร็วทั้งการฝึกและการประมวลผลแบบ inference ส่วนต่อไปนี้จะเจาะลึกหลักการและแนวปฏิบัติของเทคนิคหลัก ได้แก่ quantization, pruning, low-rank decomposition, knowledge distillation และ feature selection/encoding โดยอธิบายผลลัพธ์ที่คาดหวังและกรณีใช้งานที่เหมาะสมสำหรับแต่ละเทคนิค
1) Quantization: ประเภท หลักการ และผลต่อความแม่นยำ
Quantization คือการลดความเที่ยงตรงของตัวเลขที่ใช้แทนพารามิเตอร์และ activation (เช่น จาก FP32 → INT8 หรือ FP16) เพื่อลดขนาดโมเดลและเพิ่มความเร็ว โดยทั่วไปจะพบสองแนวทางหลัก:
- Post-Training Quantization (PTQ) — ทำการแปลงโมเดลหลังการฝึกเสร็จ โดยไม่ต้องอัปเดตพารามิเตอร์ ด้วยความรวดเร็วและเหมาะกับกรณีที่เวลา/ทรัพยากรจำกัด แต่มีความเสี่ยงต่อการสูญเสียความแม่นยำ โดยเฉพาะโมเดลขนาดเล็กหรือชั้นที่มีการกระจายค่าผิดปกติ
- Quantization-Aware Training (QAT) — จำลองการทำงานแบบ low-precision ระหว่างการฝึก ทำให้โมเดลปรับตัวต่อการบีบอัดได้ดีขึ้น เมื่อใช้งานจริงมักจะรักษาความแม่นยำได้ดีกว่า PTQ โดยเฉพาะเมื่อใช้ INT8
ตัวอย่างเชิงปฏิบัติ: การแปลงโมเดลจาก FP32 → INT8 สามารถลดขนาดได้ประมาณ 4x และมักลด latency ของ inference ได้ 1.5–4x ขึ้นกับฮาร์ดแวร์ที่รองรับ (เช่นโปรเซสเซอร์ที่มีคำสั่ง INT8 หรือหน่วยประมวลผล AI ที่ปรับแต่งมา) ส่วน mixed precision (FP16 + FP32) ใช้กันมากในการฝึกเพื่อเพิ่ม throughput โดยทั่วไปช่วยเพิ่มอัตราการประมวลผล 1.5–3x บน GPU ที่รองรับ (เช่น NVIDIA Tensor Cores) แต่ต้องจัดการ loss scaling เพื่อรักษาความเสถียรของการฝึก
ข้อควรพิจารณา: ใช้ PTQ เมื่อต้องการ deploy เร็วและยอมรับการลดความแม่นยำเล็กน้อย สำหรับงานที่ต้องการความแม่นยำสูงหรือมี distribution-sensitive layers ควรเลือก QAT หรือใช้ per-channel quantization เพื่อลดผลกระทบต่อความแม่นยำ
2) Pruning: วิธีการตัดพารามิเตอร์และความแตกต่างของ Unstructured vs Structured
Pruning คือการลบทิ้งพารามิเตอร์ที่ "ไม่สำคัญ" ออกจากเครือข่ายประสาท เพื่อลดจำนวนพารามิเตอร์และการคำนวณ มีหลักการและวิธีการหลากหลาย เช่น magnitude-based pruning, gradient-based pruning, iterative pruning ร่วมกับ fine-tuning เป็นต้น
- Unstructured pruning — ลบ weight ทีละตัวตามเกณฑ์ (เช่น magnitude น้อยที่สุด) ทำให้ได้ sparsity สูง (เช่น 70–90% ของพารามิเตอร์ถูกลบ) แต่ผลประโยชน์ต่อ latency และ throughput ขึ้นกับการมี library/hardware ที่รองรับ sparse operations โดยตรง หากรันบนฮาร์ดแวร์ที่ไม่รองรับ อาจได้เพียงการลดขนาดโมเดลในเชิงหน่วยความจำเท่านั้น
- Structured pruning — ลบเป็นหน่วยโครงสร้าง เช่น ลบทั้งช่องของ convolutional filters, ลบทั้ง neuron หรือแม้แต่ทั้ง layer ทำให้ได้โมเดลที่ยังคงรูปแบบ dense และสามารถนำไปสู่ speedup จริงบนฮาร์ดแวร์ปกติ (เช่น ลด FLOPs และเวลารันจริง) แต่โดยทั่วไปต้องแลกมากับการลด sparsity ขั้นสูงกว่าเพื่อรักษาความแม่นยำ
ตัวอย่างเชิงตัวเลข: งานวิจัยและเคสใช้งานจริงพบว่า pruning แบบ iterative + fine-tune สามารถลดพารามิเตอร์ได้ 50–90% ขึ้นอยู่กับสถาปัตยกรรม โดยที่ accuracy อาจลดลงเพียงเล็กน้อยถ้าใช้กระบวนการที่เหมาะสม ในทางปฏิบัติ หากต้องการ latency improvement บน edge ให้เน้น structured pruning หรือ combine pruning กับ quantization
ข้อแนะนำ: ใช้ unstructured pruning เพื่อสำรวจ sparsity limits และลดหน่วยความจำ หากสภาพแวดล้อมรองรับ sparse kernels ใช้ structured pruning เมื่อต้องการ speedup จริงและการ deploy บนฮาร์ดแวร์ทั่วไป
3) Low-Rank Decomposition: แนวคิด การใช้งาน และผลลัพธ์ที่คาดหวัง
Low-rank decomposition (เช่น SVD, PCA-based decomposition, tensor decompositions) เป็นการแทนเมทริกซ์น้ำหนักขนาดใหญ่ด้วยผลคูณของเมทริกซ์ขนาดเล็กกว่า (W ≈ U·V) โดยเลือกระดับ rank r ที่น้อยกว่า rank เต็ม เทคนิคนี้ช่วยลดพารามิเตอร์และการคำนวณเชิงเมทริกซ์อย่างมีหลักการ
ประโยชน์สำคัญคือ:
- ลดจำนวนพารามิเตอร์และ FLOPs ในชั้น fully-connected หรือ embedding ได้อย่างมีนัยสำคัญ โดยอัตราการลดพารามิเตอร์ประมาณ r*(m+n)/(m*n) ของเมทริกซ์ขนาด m×n
- บ่อยครั้งเหมาะสำหรับการบีบอัดชั้น dense เช่น embedding tables, projection layers ใน transformer หรือชั้น FC ของ CNN
- เมื่อตั้งค่า rank ให้เหมาะสม สามารถรักษาความแม่นยำได้ดีโดยมีการ fine-tune หลัง decomposition
กรณีใช้งาน: ใน NLP, การลดขนาด embedding หรือการ approximate attention projection ด้วย low-rank เทคนิคสามารถลดหน่วยความจำและ latency ได้โดยที่ loss ในความแม่นยำมักอยู่ในระดับยอมรับได้เมื่อเลือก rank อย่างระมัดระวัง
4) Knowledge Distillation: รักษาคุณภาพเมื่อลดขนาดโมเดล
Knowledge distillation (KD) เป็นเทคนิคที่ใช้ "teacher" model ขนาดใหญ่สอน "student" model ขนาดเล็กผ่าน soft targets (logits) หรือ feature-level supervision โดยมีองค์ประกอบสำคัญคือการตั้งค่า temperature ใน softmax และการปรับ weighted loss ระหว่าง soft targets กับ ground-truth
ผลลัพธ์ที่พบบ่อยคือ student ขนาดเล็กสามารถรักษาความแม่นยำของ teacher ได้ในระดับสูง ตัวอย่างเช่น DistilBERT (ซึ่งเป็นรุ่น distilled ของ BERT) ลดขนาดประมาณ 40%–60% แต่ยังคงประสิทธิภาพ ~95–99% ของโมเดลต้นแบบในหลาย ๆ งาน NLP
- ข้อดี: เหมาะสำหรับการลดขนาดโมเดลขณะที่รักษา accuracy และพฤติกรรมเชิงความรู้ของโมเดลต้นแบบ
- ข้อจำกัด: ต้องใช้เวลาและทรัพยากรในการฝึก student โดยใช้ teacher และการออกแบบ loss/architecture ของ student มีผลมากต่อผลลัพธ์
แนวทางปฏิบัติ: ใช้ distillation เมื่อต้องการ deploy โมเดลขนาดเล็กที่ยังคงคุณภาพสูงบนอุปกรณ์ edge หรือในบริการที่มีข้อจำกัดทาง latency/ค่าใช้จ่าย รวมกับ quantization และ pruning จะได้ประสิทธิภาพสูงสุด
5) Feature Selection และ Encoding: ลดขนาดข้อมูลและปรับ representation
การบีบอัดข้อมูลไม่จำกัดเพียงโมเดล แต่ครอบคลุมที่การเตรียมข้อมูลด้วย เช่น การเลือก feature สำคัญ (feature selection), การลดมิติ (PCA, autoencoders), และ encoding ที่มีประสิทธิภาพ (embedding, hashing, subword tokenization)
- Feature selection (เช่น L1 regularization, tree-based feature importance, mutual information) ช่วยลดจำนวนคอลัมน์ในตารางข้อมูล ทำให้โมเดลง่ายขึ้นและลด overfitting
- Dimensionality reduction (PCA, truncated SVD, autoencoders) สามารถลดมิติของข้อมูลเชิงตัวเลขโดยยังรักษาพลังของสัญญาณหลัก
- Efficient encoding — สำหรับ categorical features ใช้ embeddings แทน one-hot เพื่อลดขนาด เมื่อทำ NLP ให้ใช้ subword tokenizers (BPE/WordPiece) เพื่อลดขนาด vocab และจำนวน token ที่ต้องประมวลผล
ผลทางปฏิบัติ: การบีบอัดข้อมูลเชิง feature สามารถลดขนาดอินพุตและค่าใช้จ่ายคำนวณได้อย่างมีนัยสำคัญ โดยไม่ส่งผลกระทบต่อความแม่นยำเมื่อเลือก feature/มิติที่สำคัญได้ดี
สรุปเชิงปฏิบัติ: ในการออกแบบ pipeline สำหรับการ deploy ควรพิจารณาผสมผสานเทคนิคเหล่านี้ตามข้อจำกัดและเป้าหมาย เช่น ใช้ QAT และ INT8 สำหรับ inference บน edge เพื่อให้ได้ latency ต่ำและขนาดเล็ก, ใช้ structured pruning และ low-rank decomposition เมื่อต้องการ speedup จริงบนฮาร์ดแวร์ทั่วไป, และใช้ knowledge distillation เมื่อต้องการรักษาความแม่นยำในขณะที่ย่อสถาปัตยกรรมของโมเดล การผสมหลายเทคนิคร่วมกัน (เช่น distillation → pruning → quantization) มักให้ผลลัพธ์ที่ดีที่สุดทั้งในด้านขนาด ความเร็ว และคุณภาพ
ผลกระทบของการบีบอัดต่อการเทรนและการประเมินผล
ผลกระทบต่อการเทรน: ลด I/O-bound แต่เพิ่มความซับซ้อนในการปรับแต่ง
การบีบอัดข้อมูลและโมเดลมีผลโดยตรงต่อกระบวนการเทรน ในงานที่เป็น I/O-bound เช่น การเทรนบนชุดข้อมูลขนาดใหญ่ การบีบอัดตัวไฟล์ข้อมูล (เช่น TFRecord/Parquet ที่บีบอัดด้วย zstd หรือ gzip) สามารถลดเวลาโหลดข้อมูลจากดิสก์/เครือข่ายได้อย่างมีนัยสำคัญ ทำให้ GPU/TPU มีเวลาทำงานต่อเนื่องสูงขึ้นและเพิ่ม throughput ของการเทรน ในหลายกรณี การใช้ข้อมูลบีบอัดสามารถลดเวลา I/O ได้ถึง 2–5x ขึ้นกับสภาพแวดล้อม I/O
อย่างไรก็ตาม การบีบอัดนำมาซึ่ง overhead ใหม่ เช่น ค่าใช้จ่ายในการดีคอมเพรส (CPU/PU) และความจำเป็นในการทำ calibration สำหรับเทคนิคเช่น post-training quantization (PTQ) ซึ่งต้องมีชุดข้อมูล calibration ขนาดพอสมควร (มักเป็นหลักพันตัวอย่าง) ทำให้เวลาเตรียมโมเดลก่อนการใช้งานจริงเพิ่มขึ้น นอกจากนี้ การเทรนโดยใช้เทคนิคอย่าง quantization-aware training (QAT) หรือ mixed-precision training มักเพิ่มความซับซ้อนของ pipeline และอาจเพิ่มเวลาเทรนขึ้น ~10–30% แต่มักแลกมาด้วยผลลัพธ์ที่แม่นยำกว่าเมื่อเทียบกับการใช้ PTQ โดยตรง
ผลกระทบต่อการประเมินผล: Accuracy, Latency, Throughput, Memory และ Energy
การบีบอัดส่งผลต่อชุดตัวชี้วัดสำคัญหลายด้าน ดังนี้
- Model size: การทำ quantization เป็น INT8 มักลดขนาดโมเดลได้ประมาณ 4x เมื่อเทียบกับ FP32; เทคนิคการบีบอัดขั้นสูง เช่น weight sharing หรือ entropy coding อาจลดได้ถึง 8–16x ในบางกรณี
- Throughput และ Latency: บนฮาร์ดแวร์ที่รองรับ INT8, โมเดลที่ถูก quantize มักมี throughput เพิ่มขึ้นประมาณ 2–3x และ latency ต่อคำขอลดลงอย่างมีนัยสำคัญ แต่บนฮาร์ดแวร์ที่ไม่รองรับหรือเมื่อเกิด sparsity แบบไม่เป็นโครงสร้าง (unstructured sparsity) ประสิทธิภาพเชิงเวลาจริงอาจไม่ดีขึ้นตามคาด
- Accuracy (ความแม่นยำ): ในงานวิสัยทัศน์ทั่วไป การลดเป็น INT8 มักทำให้ความแม่นยำลดลงน้อยกว่า 1–3% ในหลายกรณี แต่ในงานภาษาธรรมชาติหรือโมเดลที่มี sensitivity สูง อาจเห็นการสูญเสียมากกว่า 5–10% หากไม่ใช้เทคนิคแก้ไขเพิ่มเติม
- Memory และ Energy: การลดบิตความแม่นยำช่วยลด footprint ของพารามิเตอร์และลดพลังงานต่อการคำนวณ (energy per op) ประมาณ 2–4x สำหรับ INT8 เมื่อเทียบกับ FP32 ขณะที่การบีบอัด activation หรือใช้ activation checkpointing สามารถลด peak memory ระหว่างเทรนได้อย่างมีนัยสำคัญ (activation มักเป็นส่วนที่ใช้หน่วยความจำสูงสุด ระดับ ~60–80% ของ peak ในการเทรนบางรูปแบบ)
Trade-off ระหว่างขนาดกับความแม่นยำและเทคนิคการลดผลกระทบ
การตัดสินใจใช้การบีบอัดเป็นการแลกเปลี่ยน (trade-off) ระหว่างขนาด/ความเร็วและความแม่นยำ การออกแบบต้องครอบคลุมทั้งฮาร์ดแวร์เป้าหมาย (edge vs cloud) และการใช้งานจริง:
- Edge: latency แบบเรียลไทม์และข้อจำกัดด้านพลังงาน/หน่วยความจำทำให้การบีบอัดเช่น INT8, structured pruning และ knowledge distillation เป็นทางเลือกที่เหมาะสม แต่ต้องทดสอบความแม่นยำที่ลดลงในสภาพการใช้งานจริง
- Cloud: throughput สูงและการประมวลผลแบบเป็นกลุ่ม (batching) อาจเลือกใช้ mixed-precision (FP16) หรือการบีบอัดบางส่วนเพื่อเพิ่มประสิทธิภาพในการให้บริการ แต่ในบางกรณีการบีบอัดมากเกินไปอาจส่งผลต่อ SLA ด้านความแม่นยำ
เทคนิคที่ช่วยลดผลกระทบของการบีบอัดได้แก่ quantization-aware training (QAT), การใช้ per-channel quantization, calibration ที่ดีและ dataset ที่แท้จริง, knowledge distillation เพื่อรักษาความแม่นยำ, และ structured pruning ที่ทำให้ฮาร์ดแวร์สามารถเร่งการคำนวณได้จริง นอกจากนี้ การปรับ compiler/hardware-aware optimizations (เช่น fused kernels, tensorization) ยังช่วยให้ throughput ที่วัดได้ใกล้เคียงกับทฤษฎีมากขึ้น
ข้อสรุปเชิงปฏิบัติการและตัวชี้วัดที่ควรติดตาม
เมื่อวางแผนบีบอัดสำหรับการเทรนและการประเมินผล ให้ติดตามตัวชี้วัดหลักอย่างต่อเนื่อง: model size, FLOPs, latency, memory (ทั้งพารามิเตอร์และ activation), และ energy ต่อการให้บริการ นอกจากนี้ ควรนำการทดสอบ A/B บนข้อมูลจริงมาใช้เพื่อวัดผลกระทบต่อความแม่นยำเชิงปฏิบัติ (business metrics) และตั้งค่า pipeline ที่รองรับการย้อนกลับหากการบีบอัดทำให้ผลลัพธ์ไม่เป็นที่ยอมรับ
สรุปคือ การบีบอัดเป็นเครื่องมือทรงพลังที่ลดค่าใช้จ่ายด้านพื้นที่จัดเก็บและเวลาประมวลผล แต่ต้องออกแบบอย่างรอบคอบเพื่อรักษาความแม่นยำและประสิทธิภาพในสภาพแวดล้อมการให้บริการจริง
การวัดผลและการตั้งเกณฑ์ (evaluation & benchmarking)
ภาพรวม: เป้าหมายของการวัดผลในการบีบอัดโมเดล
การประเมินเทคนิคการบีบอัดข้อมูลสำหรับการเรียนรู้ของเครื่องต้องมุ่งหมายที่การเปรียบเทียบอย่างยุติธรรม ระดับการใช้งานจริง (real-world deployment) และความสามารถในการทำซ้ำผลการทดลองได้อย่างเชื่อถือได้ โดยทั่วไปมีตัวแปรสำคัญที่ต้องวัด ได้แก่ ความแม่นยำ/ประสิทธิผล (accuracy, F1, perplexity ฯลฯ), ขนาดโมเดล (MB หรือจำนวนพารามิเตอร์), throughput (inferences/sec หรือ images/sec), latency (เฉลี่ยและ tail เช่น p95/p99) และ energy-per-inference (Joule/inference หรือ Watt·s/inference) ซึ่งตัวชี้วัดเหล่านี้ช่วยให้ผู้ตัดสินใจทางธุรกิจเห็นภาพ trade-off ระหว่างความเร็ว ค่าใช้จ่ายพลังงาน และความแม่นยำได้ชัดเจน
มาตรฐานการตั้ง benchmark dataset และ metric
เพื่อให้การเปรียบเทียบมีความหมาย ควรกำหนดชุดข้อมูลและเมตริกที่สอดคล้องกับงานจริง ตัวอย่างชุดข้อมูลมาตรฐานที่นิยมใช้ได้แก่ ImageNet สำหรับวิชัน, GLUE / SuperGLUE หรือ SQuAD สำหรับ NLP และชุดข้อมูลเฉพาะอุตสาหกรรมเมื่อต้องการการประเมินเชิงปฏิบัติการ นอกจากนี้ควรกำหนดเมตริกรองรับเช่น top-1/top-5, F1-score, BLEU/ROUGE, perplexity สำหรับภาษาธรรมชาติ และควรรายงานทั้งค่าเฉลี่ยและค่าความคลาดเคลื่อน (เช่น standard deviation, confidence interval) เพื่อแสดงความเสถียรของผลลัพธ์
โปรโตคอลสำหรับการเปรียบเทียบที่ยุติธรรม
- ฮาร์ดแวร์และสภาพแวดล้อมเดียวกัน: รันทุกการทดลองบนฮาร์ดแวร์เดียวกัน (หรือระบุ profile ของฮาร์ดแวร์ถ้าจำเป็น) และล็อกเวอร์ชันของไลบรารี, compiler, runtime (เช่น CUDA, cuDNN, TensorRT, XLA) เพื่อหลีกเลี่ยงตัวแปรที่ไม่เกี่ยวกับเทคนิคการบีบอัด
- พารามิเตอร์การรันคงที่: ใช้ batch size เดียวกัน, number of warm-up iterations, number of measured iterations และตั้ง random seed เพื่อให้สามารถทำซ้ำได้
- กระบวนการเตรียมข้อมูลและการปรับแต่ง: ระบุขั้นตอน calibration สำหรับ quantization (เช่น จำนวนตัวอย่าง calibration), pruning schedules, fine-tuning epochs และ learning rate เพื่อให้เปรียบเทียบการปรับจูนได้อย่างเป็นธรรม
- วัด latency และ tail latency: นอกจาก latency เฉลี่ยแล้ว ต้องรายงาน p95/p99 เพราะการตอบสนองที่หางยาวมีผลต่อ UX และ SLO ในแอปพลิเคชันธุรกิจ
- การวัดพลังงานและ throughput: ระบุวิธีการวัดพลังงาน (เช่น RAPL สำหรับ CPU, power meter ภายนอก, NVIDIA DCGM / nvidia-smi สำหรับ GPU) และกำหนดหน่วยวัด (Joule/inference หรือ Watt) พร้อมกับสภาวะการวัด (idle baseline, peak)
การรายงานผล: size vs accuracy, Pareto front และ energy-per-inference
การรายงานผลควรรวมทั้งกราฟและตารางที่ช่วยให้เห็น trade-off ชัดเจน ตัวอย่างรูปแบบที่เป็นมาตรฐานได้แก่:
- Size vs Accuracy Curves: พล็อตขนาดโมเดล (MB หรือ #parameters) บนแกน x และความแม่นยำบนแกน y เพื่อแสดงว่าการลดขนาดส่งผลต่อประสิทธิภาพอย่างไร จุดสำคัญคือระบุจุด baseline และจุดของแต่ละเทคนิคพร้อม error bars
- Pareto Frontier / Pareto Front: สร้างกราฟหลายมิติ เช่น (size, latency, accuracy) หรือ (energy, accuracy) และใช้ Pareto frontier เพื่อเลือกวิธีที่ไม่ถูกครอบงำ (non-dominated solutions) — สำหรับผู้บริหารหรือวิศวกรการตัดสินใจ มุมที่อยู่บน Pareto frontier มักเป็นตัวเลือกที่คุ้มค่าเมื่อพิจารณาข้อจำกัดของระบบ
- Energy-per-inference: รายงานค่า Joule ต่อ inference หรือ Watt·s ต่อ 1k inferences พร้อมเงื่อนไขการวัด (batch size, power baseline) โดยสถิติด้านพลังงานมักเปลี่ยนตาม batch size และการใช้งานจริง
- Throughput vs Accuracy Plots: แสดง throughput (inferences/sec) เทียบกับความแม่นยำ เพื่อให้เห็นการเพิ่มประสิทธิภาพการผลิต (production) เมื่อใช้เทคนิคบีบอัด
ตัวอย่าง benchmark และสถิติจากงานวิจัย
ตัวอย่าง benchmark ที่น่าสนใจและเป็นที่ยอมรับในวงการ ได้แก่ MLPerf Inference สำหรับการวัด throughput/latency ในหลายสถาปัตยกรรม, Hugging Face และชุดข้อมูล GLUE/SQuAD สำหรับ NLP, และ TensorFlow Lite Benchmark สำหรับ edge deployments งานสำรวจและงานวิจัยหลายฉบับรายงานว่าเทคนิคการบีบอัดสามารถให้ผลลัพธ์เช่น การลดขนาดโมเดลประมาณ 2–10× ขณะที่ throughput เพิ่มขึ้นในช่วง 1.5–4× ขึ้นกับสภาพแวดล้อมและวิธีการ (เช่น pruning, quantization, knowledge distillation) ตัวอย่างในรีวิวสรุป: quantization แบบ 8-bit มักให้ speedup ทันทีในฮาร์ดแวร์ที่รองรับ ขณะที่ pruning แบบ structured มักได้ประโยชน์ทั้งใน latency และ memory footprint เมื่อรวมกับ compiler/runtime ที่เหมาะสม
แนวปฏิบัติที่แนะนำสำหรับองค์กร
- กำหนดเป้าหมายเชิงธุรกิจก่อนวัดผล: ระบุว่าต้องการลดต้นทุนพลังงาน, ลด latency หรือลดขนาดสำหรับ edge เพื่อเลือก metric และ benchmark ที่สอดคล้อง
- ใช้มาตรฐานสาธารณะและเปิดเผยการตั้งค่า: ใช้ชุดข้อมูลมาตรฐาน (เช่น ImageNet/GLUE/MLPerf) และเผยแพร่โปรโตคอลการทดลอง (ฮาร์ดแวร์, runtime, seeds, warm-up) เพื่อความโปร่งใสและการทำซ้ำ
- รายงาน Pareto frontier และจุดคอขวด: เสนอชุดตัวเลือกบน Pareto frontier พร้อมคำแนะนำเชิงธุรกิจ (เช่น “เลือกจุดนี้เพื่อ latency ต่ำสุดภายใต้ข้อจำกัด accuracy ≥ 90%”)
- รวมการวัดพลังงานและความเสถียร: รายงาน energy-per-inference และค่าความแปรปรวนจากการรันหลายครั้ง เพื่อประเมินต้นทุนการดำเนินงานจริง
สรุปคือ การตั้งเกณฑ์และการวัดผลที่ชัดเจนเป็นหัวใจของการตัดสินใจเชิงธุรกิจเมื่อนำเทคนิคการบีบอัดไปใช้จริง การใช้ benchmark มาตรฐาน โปรโตคอลที่ยุติธรรม และการนำเสนอผลผ่านกราฟเช่น size-vs-accuracy และ Pareto front จะช่วยให้ผู้บริหารและวิศวกรสามารถเลือกเทคนิคที่ให้ความคุ้มค่าที่สุดตามเป้าหมายขององค์กรได้อย่างเป็นระบบ
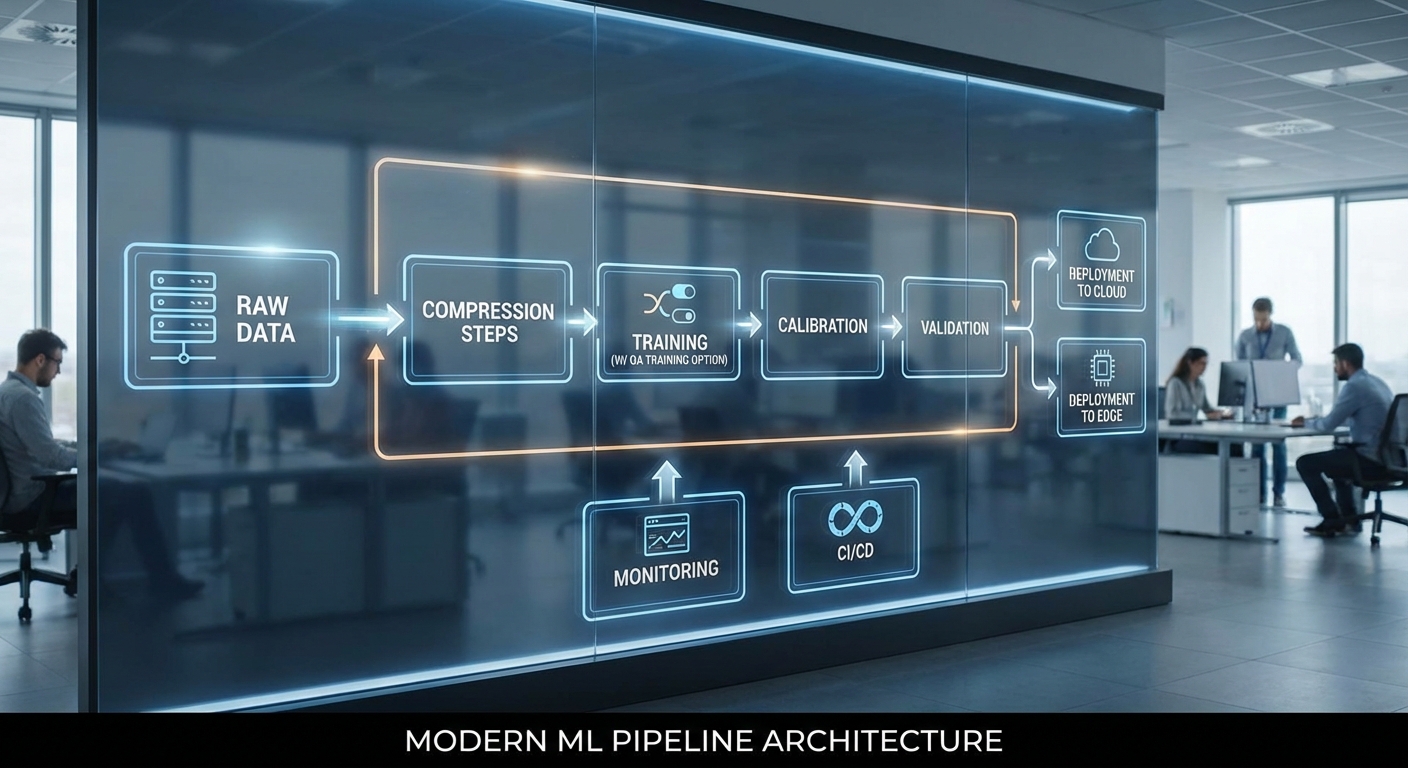
แนวทางปฏิบัติและ pipeline สำหรับนำไปใช้จริง
วัตถุประสงค์และภาพรวมของแนวทาง
บทความนี้นำเสนอแนวทางปฏิบัติแบบเป็นขั้นตอน (pipeline) สำหรับการนำเทคนิคการบีบอัดข้อมูลและโมเดลไปใช้จริงในสภาพแวดล้อมเชิงธุรกิจ โดยคำนึงถึงทั้งประสิทธิภาพด้านขนาดและความเร็วของโมเดล รวมถึงความถูกต้อง (accuracy), ความทนทาน (robustness) และความเป็นธรรม (fairness) ของระบบ การออกแบบ pipeline จะครอบคลุมตั้งแต่การเตรียมข้อมูลไปจนถึงการ deploy พร้อมกลยุทธ์สำรอง (fallbacks) และการทดสอบอัตโนมัติบนฮาร์ดแวร์เป้าหมายเพื่อให้มั่นใจว่าบีบอัดแล้วยังคงตอบโจทย์เชิงธุรกิจ
Pipeline แนะนำ (Data preprocessing → Compression-aware training → Calibration → Validation → Deployment)
- 1. Data preprocessing — ทำความสะอาดข้อมูล แบ่งชุดข้อมูล (train/val/test) และสร้างชุดทดสอบ edge-cases/long-tail โดยเก็บ baseline เมตริกของโมเดลต้นแบบ (accuracy, latency, memory, throughput) เป็นจุดอ้างอิงก่อนบีบอัด ตัวอย่าง: baseline accuracy = 92.3%, latency (p99) = 120 ms, model size = 210 MB.
- 2. Compression-aware training — เริ่มจากวิธีที่มีความเสี่ยงต่ำเช่น Post-Training Quantization (PTQ) 8-bit (สำหรับ weights/activations) วัดผล หากความแม่นยำลดไม่เกินเกณฑ์ที่ยอมรับได้ (เช่น ≤0.5% absolute) ให้ยอมรับ หากลดมากกว่า ให้ยกระดับเป็น Quantization-Aware Training (QAT) หรือผสมกับ Knowledge Distillation เพื่อเร่งฟื้นฟูความแม่นยำ
- 3. Calibration — ปรับสเกลและ bias สำหรับ quantized layers ด้วยชุด calibration ที่เป็นตัวแทนจริงของข้อมูล production (ตัวอย่าง: 1k–10k ตัวอย่าง) เพื่อแก้ bias ในการคำนวณ และทดสอบหลายระดับการบีบอัด (4-bit, 8-bit, mixed-precision) เพื่อหา sweet spot ระหว่างขนาดและ accuracy
- 4. Validation — ทำการทดสอบเชิงลึกรวมถึง regression testing, robustness (adversarial/noise/shift), fairness checks ตามกลุ่มประชากร และ benchmark บนฮาร์ดแวร์เป้าหมาย (CPU/Edge GPU/TPU/MCU) วัด latency, memory peak, energy consumption และ throughput
- 5. Deployment — ใช้กลยุทธ์ deploy แบบค่อยเป็นค่อยไป (canary/A-B testing) พร้อมการตรวจจับ regression แบบเรียลไทม์และ fallback plan (ตัวอย่าง: route sensitive requests กลับไปยัง model FP32 หรือยังคงใช้ hybrid model ที่บางชั้นเป็น FP32)
Checklist ปฏิบัติ (ในรูปแบบที่สามารถนำไปใช้จริง)
- เก็บ baseline ของเมตริกทั้งหมดก่อนเริ่มบีบอัด: top-line accuracy, per-class recall/precision, latency (p50/p95/p99), RAM/FLASH usage, energy per inference
- ทดลองหลายระดับบีบอัด: PTQ 8-bit → mixed-precision → 4-bit PTQ → QAT → QAT + Distillation และบันทึกผลทุกขั้นตอน
- กำหนดเกณฑ์ยอมรับ (acceptance criteria) ชัดเจน เช่น accuracy drop ≤0.5% absolute, latency ลด ≥20% หรือ model size ลด ≥4x
- ตรวจสอบ robustness: ทดสอบ dataset shift, adversarial perturbations, noisy inputs และ latency under load
- ตรวจสอบ fairness: ทำ parity test ข้ามกลุ่มย่อย (เช่น เพศ, อายุ, ภูมิภาค) ถ้าพบ disparity > threshold (เช่น 3–5%) ให้ย้อนกลับและปรับการบีบอัด
- ตั้งระบบ regression testing อัตโนมัติใน CI/CD: ทุก pull request หรือ release ต้องรันชุดทดสอบบีบอัดและ benchmark บนฮาร์ดแวร์เป้าหมาย
- เตรียม fallback และ hybrid approaches สำหรับเคสที่ความแม่นยำตก (ดูรายละเอียดด้านล่าง)
ตัวอย่างสูตรปฏิบัติและกลยุทธ์เมื่อ accuracy ตก (fallbacks & hybrid approaches)
แนวทางเชิงปฏิบัติที่ใช้ได้จริง:
- ขั้นตอนเริ่มต้น: เริ่มด้วย Post-Training Quantization (PTQ, 8-bit). หาก accuracy drop ≤0.5% ให้ยอมรับและนำไป deploy แบบ canary.
- ถ้าความแม่นยำตกมากกว่า (เช่น >0.5–1.0%): ทำ Quantization-Aware Training (QAT) โดยใช้ learning rate ต่ำและ data augmentation. หาก QAT ฟื้นฟู accuracy กลับมา ให้ deploy.
- ถ้ายังไม่พอ: ใช้ Knowledge Distillation — ฝึก student model ที่บีบอัดให้เรียนจาก teacher FP32 เพื่อรักษา decision boundary.
- Hybrid approach: ผสมการบีบอัดแบบภูมิภาค (layer-wise): ให้ layer ที่ sensitive คงเป็น FP16/FP32 ส่วน layer อื่น quantize เป็น 8-bit หรือ 4-bit. ตัวอย่าง: embedding layers คง FP32 แต่ MLP/conv เป็น 8-bit.
- Layer-wise fallback: ถ้าหลัง quantization มี regression ในบาง class ให้เฉพาะ layer ที่ก่อปัญหากลับไปใช้ precision สูงกว่าแทนทั้งโมเดล
- นโยบายการ deploy แบบปลอดภัย: ถ้า degradation > threshold ใน canary → rollback อัตโนมัติไปยัง baseline model หรือ route traffic แบบ selective routing (sensitive requests → FP32)
การตรวจสอบ Robustness, Fairness และ Regression Testing หลังการบีบอัด
หลังการบีบอัดต้องไม่ละเลยการทดสอบเชิงคุณภาพและเชิงปริมาณ:
- Regression testing — รันชุดทดสอบ baseline ทุกครั้งที่โมเดลเปลี่ยนแปลง (unit-level tests + E2E tests). บันทึก delta ในเมตริก (เช่น Δaccuracy = -0.7% เป็นสัญญาณเตือน)
- Robustness — ทดสอบด้วย dataset shifts (time-based, domain-based), noisy inputs และ adversarial attacks; วัด degradation ของเมตริก เช่น accuracy under noise ลดไม่เกิน 2% จาก baseline
- Fairness — คำนวณ parity metrics (equal opportunity, demographic parity) ข้ามกลุ่มย่อย ถ้าพบ disparity ให้ย้อนกระบวนการบีบอัดหรือเก็บตัวอย่างเพิ่มเติมสำหรับ calibration
- Performance testing บนฮาร์ดแวร์เป้าหมาย — อัตโนมัติโปรไฟล์ latency (p50/p95/p99), memory peak, cold-start, และ energy per inference โดยรันผ่าน CI jobs ที่เชื่อมกับฮาร์ดแวร์จริงหรือ emulator
- Monitoring หลัง deploy — ตั้ง alert thresholds สำหรับ regression (เช่น absolute accuracy drop >0.5% หรือ latency p99 > SLA) และใช้ canary/circuit-breaker เพื่อลดความเสี่ยง
สรุปเชิงปฏิบัติ
การนำเทคนิคการบีบอัดไปใช้จริงต้องออกแบบเป็น pipeline ชัดเจน ตั้งแต่การเตรียมข้อมูล การทดลองหลายระดับของการบีบอัด การ calibration และการตรวจสอบเชิงลึกทั้งด้านประสิทธิภาพและความเป็นธรรม พร้อมกลยุทธ์ fallback และ hybrid approaches ที่สามารถนำไปใช้ได้จริง ตัวอย่างเชิงนโยบายที่แนะนำคือ: เริ่มด้วย PTQ (8-bit) → หาก accuracy ตกให้ทำ QAT → หากยังตกให้ใช้ Distillation หรือ mixed-precision/ layer-wise fallback และต้องมี regression test และการทดสอบบนฮาร์ดแวร์เป้าหมายแบบอัตโนมัติเป็นส่วนหนึ่งของ CI/CD เพื่อให้การ deploy เป็นไปอย่างมั่นใจและปลอดภัย
เครื่องมือ, กรณีศึกษา และแนวโน้มในอนาคต
เครื่องมือ ยอดนิยมที่ช่วยลดความซับซ้อนของการบีบอัด
ปัจจุบันมีชุดเครื่องมือและไลบรารีที่ออกแบบมาเพื่อลดความซับซ้อนของการบีบอัดโมเดลและการปรับแต่งสำหรับการนำไปใช้งานจริง โดยช่วยให้นักพัฒนาและทีมปฏิบัติการสามารถเลือกเทคนิคที่เหมาะสม (quantization, pruning, knowledge distillation, weight clustering ฯลฯ) ได้เร็วยิ่งขึ้นและปลอดภัยต่อความแม่นยำของโมเดล ตัวอย่างเด่นได้แก่:
- TensorFlow Model Optimization Toolkit — รองรับ post-training quantization, quantization-aware training, pruning และ clustering เพื่อให้โมเดลขนาดเล็กลงและรันได้เร็วขึ้นบนอุปกรณ์พกพาและ edge
- PyTorch (pruning/quantization) — มี API สำหรับ dynamic/static quantization และ pruning ที่ผสานกับ workflow ของ PyTorch ทำให้นักวิจัยทดสอบเทคนิคต่าง ๆ ได้สะดวก
- ONNX Runtime — แพลตฟอร์มรันไทม์ข้ามเฟรมเวิร์กที่รองรับการแปลงโมเดลไปใช้เทคนิคต่าง ๆ (เช่น quantized kernels) และมักให้การเร่งความเร็ว inference ได้หลายเท่าบนฮาร์ดแวร์ที่หลากหลาย
- DeepSpeed — โซลูชันจาก Microsoft เน้นการฝึกโมเดลขนาดใหญ่ (ZeRO optimizer) และมีโมดูลสำหรับ inference optimization ที่ช่วยลดหน่วยความจำและค่าใช้จ่ายทาง compute ในการ deploy
- Hugging Face Distil และ Optimum — Distil เป็นกรณีศึกษาด้าน distillation ที่เป็นที่รู้จัก ในขณะที่ Optimum เป็นเครื่องมือที่เชื่อมระหว่างโมเดลของ Hugging Face กับการเร่งฮาร์ดแวร์ เช่น ONNX Runtime, TensorRT หรือ Intel OpenVINO
เครื่องมือเหล่านี้มักถูกรวมเข้าเป็นส่วนหนึ่งของ pipeline ทาง MLOps เพื่อให้ทีมสามารถตั้งค่าเกณฑ์ (เช่น ขีดจำกัดความแม่นยำที่ยอมรับได้ และงบประมาณ latency/ค่าใช้จ่าย) แล้วให้ระบบเลือกชุดเทคนิคบีบอัดที่เหมาะสมโดยอัตโนมัติ
กรณีศึกษาจริงและผลเชิงปริมาณ
มีหลายกรณีศึกษาที่ชี้ให้เห็นประสิทธิผลเชิงปริมาณของเทคนิคการบีบอัด:
- DistilBERT — โมเดล distilled ของ BERT ลดจำนวนพารามิเตอร์ประมาณ 40% เมื่อเทียบกับ BERT-base และรายงานการเร่งความเร็ว inference ประมาณ 1.5–3× ขึ้นอยู่กับงานและฮาร์ดแวร์ ขณะที่ความแม่นยำยังคงอยู่ใกล้เคียงกับต้นฉบับ (paper ต้นทางระบุว่ารักษาประสิทธิภาพราว 97% ของโมเดลเต็มบนชุดทดสอบ GLUE ในบางงาน)
- MobileNet และ Edge TPU — MobileNet ที่ถูกออกแบบมาเพื่ออุปกรณ์พกพา เมื่อผ่านการ quantization เป็น 8‑bit และรันบน Edge TPU สามารถลดขนาดโมเดลเหลือเป็น หน่วยเมกะไบต์ และทำให้ latency อยู่ในระดับ สิบหลายมิลลิวินาที ต่อภาพ เหมาะสำหรับแอปพลิเคชัน real‑time เช่น การจดจำภาพบนมือถือหรือกล้องอัจฉริยะ
- ผลกระทบต่อค่าใช้จ่ายเชิงพาณิชย์ — บริษัทซอฟต์แวร์และผู้ให้บริการคลาวด์หลายรายรายงานว่าการนำ quantization + pruning + optimized runtime ไปใช้ สามารถลดค่าใช้จ่าย inference บนคลาวด์ได้เป็นสัดส่วนหลักสิบเปอร์เซ็นต์ เช่น 20–60% ขึ้นอยู่กับประเภท workload และระดับการบีบอัดที่ยอมรับได้ ตัวอย่างเช่น การลดความต้องการ CPU/GPU memory ทำให้ density ของ instance เพิ่มขึ้นและค่าใช้จ่ายต่อคำขอ (cost per request) ลดลงอย่างมีนัยสำคัญ
- ONNX Runtime / TensorRT / XLA — ในงานบางประเภท (เช่น convolutional inference) การใช้ ONNX Runtime หรือ TensorRT ร่วมกับ quantized model พบการเร่งความเร็วได้ถึง 2–4× เมื่อเทียบกับการรันโมเดล FP32 แบบมาตรฐานบน same hardware
สรุปคือ เทคนิคการบีบอัดเมื่อนำไปปฏิบัติจริงมักให้ผลใน 3 มิติหลัก: ขนาดโมเดลเล็กลง (ลด storage/อัปโหลด), latency ต่ำลง (ประสบการณ์ผู้ใช้ดีขึ้น) และค่าใช้จ่ายต่อการให้บริการลดลง (ผลประหยัดทางธุรกิจ)
แนวโน้มในอนาคตที่ธุรกิจควรติดตาม
แนวโน้มด้านการบีบอัดและการเร่งประสิทธิภาพของโมเดลในอีก 2–5 ปีข้างหน้ามีหลายทิศทางที่น่าสนใจสำหรับผู้ประกอบการและฝ่ายเทคนิค:
- Hardware-aware compression — เทคนิคการบีบอัดที่คำนึงถึงสถาปัตยกรรมฮาร์ดแวร์ (เช่น core count, cache, instruction set และความสามารถในการรองรับ sparse tensors) มากขึ้น ทำให้ผลลัพธ์ที่ได้มีประสิทธิภาพจริงบนเป้าหมายฮาร์ดแวร์ ไม่ใช่แค่ตัวชี้วัดบนกระดาษ
- Learned / neural compression — การใช้โมเดลเรียนรู้เองเพื่อบีบอัดพารามิเตอร์และ activation (เช่น variational coding, learned quantization, weight sharing ผ่าน autoencoders) จะกลายเป็นกระแสหลัก ซึ่งมักให้ trade‑off ระหว่างขนาดและคุณภาพที่ดีกว่าวิธีแบบ heuristic เดิม
- Sparsity‑aware hardware — ฮาร์ดแวร์สมัยใหม่ (เช่น tensor cores ที่รองรับ sparsity ของ NVIDIA หรือการสนับสนุน sparse kernels ในสถาปัตยกรรมเฉพาะ) จะช่วยให้ pruning และ structured sparsity ให้ประโยชน์ด้านความเร็วและพลังงานมากขึ้นจริงแทนที่จะเป็นเพียงการลดพารามิเตอร์บนสื่อ
- Auto‑compression tools และ compiler‑level optimizations — เครื่องมืออัตโนมัติที่รวมการค้นหาเทคนิค (AutoML สำหรับ compression) กับ compiler เช่น XLA, TVM, Glow จะช่วยตั้งค่าการบีบอัดและการปรับจูนแบบ end‑to‑end โดยคำนึงถึงเป้าหมายทั้ง latency, throughput และความแม่นยำ
- การรวมเข้ากับ MLOps และ SLA‑driven workflows — จะมีการผสานการบีบอัดเข้าเป็นส่วนหนึ่งของ pipeline การ deploy — อัตโนมัติเลือก strategy ของการบีบอัดตาม SLA (เช่น latency < 50 ms, accuracy drop ≤ 1%) และคอยมอนิเตอร์ผลกระทบแบบเรียลไทม์
สำหรับผู้บริหารและผู้ตัดสินใจด้านไอที ควรพิจารณาลงทุนในสต๊าฟและเครื่องมือที่สามารถรองรับการทดสอบเทคนิคการบีบอัดหลากหลายรูปแบบ รวมถึงเชื่อมต่อกับ runtime ที่เหมาะสม เพื่อให้ได้ผลลัพธ์เชิงธุรกิจที่วัดได้ เช่น ลดค่าใช้จ่ายการให้บริการ ลดเวลาในการตอบสนอง และขยายการให้บริการบนอุปกรณ์ edge ได้อย่างทันท่วงที
บทสรุป
การบีบอัดข้อมูลและโมเดลเป็นกลยุทธ์สำคัญที่ช่วยเพิ่มประสิทธิภาพ ลดต้นทุน และขยายการใช้งานของการเรียนรู้ของเครื่องไปยังอุปกรณ์ edge และแอปพลิเคชันเรียลไทม์ โดยเทคนิคเช่น pruning, quantization, knowledge distillation และ learned compression สามารถลดขนาดโมเดลได้อย่างมีนัยสำคัญ—ในบางกรณีลดขนาดได้มากถึง 70–90% พร้อมเพิ่มความเร็วในการประเมินผลหลายเท่าและลดการใช้พลังงาน ซึ่งส่งผลให้การใช้งานบนมือถือ อุปกรณ์ IoT และระบบฝังตัวเป็นไปได้จริง ตัวอย่างเช่น การปรับ quantize โมเดลหรือใช้ distilled model มักช่วยลดแบนด์วิดท์และ latency ในงาน inference แบบเรียลไทม์
การเลือกเทคนิคบีบอัดต้องคำนึงถึง trade-off ระหว่างขนาด ความเร็ว และความแม่นยำอย่างรอบคอบ จึงจำเป็นต้องพัฒนา pipeline การทดลองที่มีการวัดผลเชิงระบบ โดยใช้เมทริกซ์เช่น accuracy, throughput, latency, ขนาดโมเดล และการใช้พลังงานเป็นตัวชี้วัด และทำการ A/B testing หรือ benchmark กับชุดข้อมูลจริงก่อนนำไปใช้งานจริง อนาคตคาดว่าจะเห็นการผสาน learned compression กับฮาร์ดแวร์เฉพาะทาง (เช่น NPUs/TPUs แบบฝัง) และเครื่องมืออัตโนมัติ (AutoML, NAS, compiler-level optimizations) ทำให้การบีบอัดกลายเป็นกระบวนการที่ง่ายขึ้น มาตรฐานมากขึ้น และฝังอยู่ใน pipeline การพัฒนาโดยค่าเริ่มต้น ส่งผลให้ ML บน edge และแอปพลิเคชันเรียลไทม์มีความสามารถสูงขึ้นและเข้าถึงได้กว้างขึ้นสำหรับภาคธุรกิจและการวิจัย
📰 แหล่งอ้างอิง: Quantum Zeitgeist



