
เครือข่ายโรงพยาบาลหลายแห่งในประเทศไทยได้เริ่มการทดสอบแนวทางใหม่ในการพัฒนาโมเดลวินิจฉัยภาพทางการแพทย์ ด้วยการผสานเทคโนโลยี Federated Learning เข้ากับ Continual Learning เพื่อให้โรงพยาบาลร่วมกันฝึกและปรับปรุงโมเดลโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยดิบ การเคลื่อนไหวครั้งนี้ตอบโจทย์ความกังวลด้านความเป็นส่วนตัวและกฎระเบียบการคุ้มครองข้อมูล ขณะเดียวกันยังเปิดโอกาสให้โมเดลสามารถเรียนรู้ตลอดเวลา ปรับตัวเมื่อข้อมูลใหม่หรือการกระจายของข้อมูลเปลี่ยนไป เช่น อุปกรณ์ถ่ายภาพที่ต่างกัน หรือรูปแบบโรคที่ปรากฏมากขึ้นในช่วงเวลาต่าง ๆ
การทดสอบนี้มุ่งประเมินทั้งความแม่นยำของการวินิจฉัยภาพ เช่น เอ็กซเรย์และซีทีสแกน ความสามารถในการปรับตัวต่อข้อมูลที่เปลี่ยนแปลง และกรอบการบริหารจัดการด้านความเป็นส่วนตัวและการกำกับดูแลร่วมกัน หากประสบความสำเร็จ เครือข่ายนี้คาดว่าจะช่วยลดความเสี่ยงด้านการรั่วไหลของข้อมูลผู้ป่วย เพิ่มความทนทานของโมเดลต่อความแตกต่างระหว่างโรงพยาบาล และวางรากฐานสำหรับการนำ AI มาประยุกต์ใช้อย่างปลอดภัยและยั่งยืนในการดูแลผู้ป่วยทั่วประเทศ
บทนำ: ทำไมการร่วมมือแบบ Federated‑Continual ถึงสำคัญสำหรับระบบสาธารณสุขไทย
บทนำ: ทำไมการร่วมมือแบบ Federated‑Continual ถึงสำคัญสำหรับระบบสาธารณสุขไทย
เครือข่ายโรงพยาบาลไทยหลายแห่งได้เริ่มโครงการทดลองร่วมกันเพื่อนำเทคโนโลยี Federated‑Continual Learning มาใช้ในการพัฒนาโมเดลวินิจฉัยภาพทางการแพทย์โดยไม่ต้องรวมข้อมูลผู้ป่วยไปยังศูนย์กลาง โครงการนำร่องนี้ประกอบด้วยโรงพยาบาลในเครือข่ายจำนวน 8–15 แห่ง ซึ่งรวมทั้งโรงพยาบาลระดับจังหวัด โรงพยาบาลศูนย์ และสถาบันเฉพาะทาง ผลการทดลองเบื้องต้นมีเป้าหมายเพื่อทดสอบทั้งด้านความแม่นยำของโมเดล ความเร็วในการอัปเดตเมื่อมีข้อมูลใหม่ และมาตรการลดความเสี่ยงด้านความเป็นส่วนตัวตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA)
เหตุผลหลักที่โครงการเลือกสถาปัตยกรรมแบบ Federated ร่วมกับ Continual Learning มาจากความต้องการสองประการที่เป็นหัวใจของสาธารณสุขไทย: ประการแรกคือการลดการเคลื่อนย้ายข้อมูลผู้ป่วยข้ามสถาบัน เพื่อปกป้องความเป็นส่วนตัวและปฏิบัติตามข้อกฎหมาย และประการที่สองคือความจำเป็นในการรับมือกับการเปลี่ยนแปลงของข้อมูลทางการแพทย์ (data shift) เมื่อเงื่อนไขผู้ป่วยและอุปกรณ์ทางการแพทย์เปลี่ยนแปลงอย่างต่อเนื่อง การใช้ Federated Learning ทำให้โมเดลเรียนรู้จากข้อมูลที่กระจายอยู่ในแต่ละโรงพยาบาลโดยไม่ต้องย้ายข้อมูลดิบ ขณะที่ Continual Learning ช่วยให้โมเดลสามารถปรับตัวเมื่อมีข้อมูลใหม่หรือรูปแบบโรคที่เปลี่ยนไปโดยไม่สูญเสียความรู้เดิม
โครงการนี้ตั้งเป้าหมายเชิงวัตถุประสงค์อย่างชัดเจนเพื่อวัดผลสัมฤทธิ์ ทั้งในเชิงประสิทธิผลทางคลินิกและเชิงปฏิบัติการ ทางทีมผู้ดำเนินการได้กำหนด KPI เบื้องต้นที่สำคัญดังนี้ เพื่อให้สามารถประเมินความคุ้มค่าและความสามารถนำไปใช้จริงในระบบสาธารณสุขแห่งชาติ
- AUC (Area Under ROC Curve): เป้าหมายเบื้องต้นเพื่อให้ได้ค่า AUC ≥ 0.90 สำหรับงานวินิจฉัยภาพเฉพาะ เช่น การตรวจ X‑ray ปอดหรือภาพเอกซเรย์เต้านม
- Recall (Sensitivity): ตั้งเป้า recall ≥ 0.85 เพื่อให้ลดการพลาดผู้ป่วยที่เป็นโรคจริงโดยเฉพาะในลักษณะโรคที่มีความเสี่ยงสูง
- ความเร็วในการอัปเดตโมเดล: กำหนดเวลาการผสานและเผยแพร่โมเดลอัปเดตจากเครือข่ายภายใน 24–72 ชั่วโมง หลังจากการฝึกที่แต่ละสถานพยาบาล (round time) เพื่อให้ระบบตอบสนองต่อการเปลี่ยนแปลงเชิงคลินิกได้ทันการณ์
- มาตรการความเป็นส่วนตัวและความปลอดภัย: ลดการแลกเปลี่ยนข้อมูลดิบลงอย่างน้อย 90% เทียบกับการรวมข้อมูลแบบดั้งเดิม และทดสอบเทคนิคเช่น differential privacy และ secure aggregation เพื่อประเมินผลกระทบต่อความแม่นยำ
การทดสอบในระดับเครือข่ายนี้ไม่เพียงแต่เป็นการทดลองด้านเทคนิค แต่ยังเป็นโมเดลความร่วมมือเชิงนโยบายและการบริหารจัดการ ซึ่งสำคัญต่อการพัฒนา AI ทางการแพทย์ในประเทศ เป้าหมายระยะยาวคือการสร้างระบบที่ มีความแม่นยำสูง, ปกป้องความเป็นส่วนตัวของผู้ป่วย และ สามารถอัปเดตเมื่อสภาพการณ์เปลี่ยนแปลง ได้อย่างต่อเนื่อง เพื่อรองรับการใช้งานในโรงพยาบาลทั่วประเทศต่อไป
พื้นฐานทางเทคนิค: ทำความเข้าใจ Federated Learning และ Continual Learning
พื้นฐานทางเทคนิค: ทำความเข้าใจ Federated Learning และ Continual Learning
Federated Learning (FL) คือกรอบการเรียนรู้ของเครื่องที่อนุญาตให้โมเดลเรียนรู้จากข้อมูลที่กระจายอยู่ตามอุปกรณ์หรือสถาบันต่าง ๆ โดยไม่ต้องย้ายหรือรวมข้อมูลดิบมายังศูนย์กลาง หลักการทั่วไปคือเซิร์ฟเวอร์กลางส่งพารามิเตอร์หรือโมเดลเริ่มต้นไปยังลูกข่าย (เช่น โรงพยาบาลหรือเครื่องเซิร์ฟเวอร์ภายในโรงพยาบาล) แต่ละลูกข่ายฝึกปรับโมเดลด้วยข้อมูลภายใน แล้วส่งกลับเฉพาะอัปเดตพารามิเตอร์หรือกราเดียนต์ไปยังเซิร์ฟเวอร์เพื่อทำการรวม (aggregation) เช่น วิธี FedAvg การออกแบบนี้ช่วยลดการเปิดเผยข้อมูลผู้ป่วยและปฏิบัติตามข้อกำหนดด้านความเป็นส่วนตัวและกฎระเบียบ เช่น PDPA/BDS ในหลายประเทศ
ข้อดีของ FL ได้แก่ ความเป็นส่วนตัวที่ดีขึ้นเพราะข้อมูลดิบไม่ถูกย้าย, การใช้ทรัพยากรการคำนวณแบบกระจายเพื่อลดภาระของศูนย์กลาง, และความสามารถในการเรียนรู้จากชุดข้อมูลที่กว้างขึ้นโดยยังคงคุมข้อกำหนดด้านกฎหมาย ตัวอย่างเชิงปริมาณจากงานทดลองหลายชิ้นชี้ว่า FL สามารถลดปริมาณการส่งข้อมูลดิบได้มากกว่า 90% ในสถาปัตยกรรมบางกรณี อย่างไรก็ตาม FL ยังมีข้อจำกัดเชิงเทคนิคสำคัญ เช่น การกระจายของข้อมูลที่ไม่เป็นตัวแทนเดียวกัน (non‑IID), ความไม่เท่ากันของกำลังประมวลผลและการเชื่อมต่อเครือข่ายระหว่างไคลเอนต์, ต้นทุนการสื่อสารสูง และความเสี่ยงจากการเปิดเผยข้อมูลโดยทางอ้อมผ่านกราเดียนต์ (gradient leakage) หรือการโจมตีแบบ model poisoning
Continual Learning (CL) หรือการเรียนรู้ต่อเนื่อง เป็นแนวทางที่มุ่งแก้ปัญหาโมเดลที่ต้องรับมือกับข้อมูลใหม่อย่างต่อเนื่องในเวลาจริงโดยไม่สูญเสียความรู้ที่ได้รับมาก่อน ปัญหาหลักที่ CL พยายามแก้คือ catastrophic forgetting คือเมื่อโมเดลเรียนรู้งานใหม่มักจะลืมความสามารถจากงานก่อนหน้านั้น กลยุทธ์แก้ปัญหามีหลายแบบ เช่น การใช้ rehearsal (เก็บตัวอย่างจากข้อมูลเก่าไว้บางส่วน), regularization-based methods (เช่น EWC: elastic weight consolidation ที่ลงโทษการเปลี่ยนแปลงพารามิเตอร์ที่สำคัญต่อความรู้เดิม), และ architectural methods (เช่น ขยายเครือข่ายหรือแยกพารามิเตอร์สำหรับงานใหม่)
ข้อดีของ CL คือความสามารถในการปรับตัวต่อการเปลี่ยนแปลงของข้อมูลหรือบริบททางคลินิกอย่างต่อเนื่อง เช่น การเกิดโรคใหม่ การเปลี่ยนแปลงสไตล์การสแกนภาพ หรือการอัปเดตการติดป้ายฉลาก (labeling) โดยที่ไม่ต้องฝึกโมเดลใหม่จากศูนย์เสมอ ข้อจำกัดรวมถึงความต้องการพื้นที่เก็บตัวอย่างเก่า (สำหรับวิธี rehearsal), การปรับจูนไฮเปอร์พารามิเตอร์ที่ซับซ้อน และความยากในการประเมินสมดุลระหว่างการรักษาความรู้เดิมกับการเรียนรู้ใหม่
เหตุผลเชิงเทคนิคในการผสาน FL + CL สำหรับโมเดลวินิจฉัยภาพทางการแพทย์
- ความเป็นส่วนตัวร่วมกับการปรับตัวต่อการเปลี่ยนแปลง: FL ให้ข้อได้เปรียบด้านความเป็นส่วนตัวด้วยการเก็บข้อมูลอยู่ในสถานพยาบาล แต่ถ้าไม่ผสาน CL โมเดลอาจล้าสมัยเมื่อมีข้อมูลคลินิกใหม่ เช่น เทคนิคการสแกนหรือโปรโตคอลการรักษาที่เปลี่ยนไป การรวม CL ช่วยให้โมเดลปรับตัวโดยไม่ต้องส่งข้อมูลดิบไปศูนย์กลาง
- การรับมือข้อมูลที่ไม่เป็นตัวแทน (non‑IID): ในบริบทของเครือข่ายโรงพยาบาล ข้อมูลของแต่ละแห่งมักมีการกระจายต่างกัน (อุปกรณ์, ประชากรผู้ป่วย, พาธอโลจี) CL ช่วยให้แต่ละไคลเอนต์สามารถปรับโมเดลให้เข้ากับการกระจายของตนเอง ในขณะที่ FL ช่วยรวมความรู้จากหลายสถาบันโดยไม่ละเมิดความเป็นส่วนตัว
- ลดผลกระทบจาก forgetting ในระบบกระจาย: การประสานกลยุทธ์ CL (เช่น local rehearsal, regularization หรือ parameter isolation) กับการรวมแบบ federated aggregation สามารถลดการสูญเสียความรู้เมื่อโมเดลอัปเดตจากลูกข่ายหลายแห่ง ตัวอย่างเช่น การใช้ replay buffer ขนาดเล็กที่เก็บตัวอย่างสังเขปภายในแต่ละโรงพยาบาลร่วมกับการรวมพารามิเตอร์แบบปรับน้ำหนัก (weighted aggregation) ช่วยรักษาความเสถียรของประสิทธิภาพ
- ประสิทธิภาพด้านการสื่อสารและการคำนวณ: CL สามารถลดความถี่ในการส่งอัปเดตโดยให้ไคลเอนต์ฝึกหลายรอบบนข้อมูลใหม่ก่อนส่งผลลัพธ์กลับ ทำให้ลด overhead ของ FL ได้ ในอีกด้าน การออกแบบ FL ที่มีการคัดเลือกและบีบอัดอัปเดตร่วมกับเทคนิค CL จะช่วยให้การฝึกข้ามสถาบันเป็นไปอย่างมีประสิทธิภาพมากขึ้น
- การปรับบุคคล (personalization) และความน่าเชื่อถือทางคลินิก: การผสานทำให้สามารถสร้างโมเดลกลางที่มีความรู้กว้างจากหลายที่ แต่ยังคงอนุญาตให้แต่ละโรงพยาบาลมีชั้นปรับแต่งเฉพาะ (personalized layers) ผ่าน CL เพื่อให้ผลวินิจฉัยสอดคล้องกับบริบทผู้ป่วยของตน ซึ่งมีความสำคัญเชิงปฏิบัติและเชิงกฎหมาย
สรุปคือ การรวม Federated Learning และ Continual Learning เป็นแนวทางเชิงเทคนิคที่สมเหตุสมผลสำหรับเครือข่ายโรงพยาบาลไทยที่ต้องการพัฒนาโมเดลวินิจฉัยภาพโดยคงความเป็นส่วนตัวของผู้ป่วยพร้อมความสามารถในการปรับตัวต่อความเปลี่ยนแปลงทางคลินิก เทคนิคผสานนี้ช่วยลดความเสี่ยงจากการลืมความรู้เดิม เพิ่มความยืดหยุ่นต่อการเปลี่ยนแปลงของข้อมูล และส่งเสริมการนำโมเดลไปใช้งานเชิงคลินิกได้จริงในระดับประเทศ
รายละเอียดโครงการทดลอง: ขอบเขต ต้นแบบ และข้อมูลตัวอย่าง
รายละเอียดโครงการทดลอง: ขอบเขต ต้นแบบ และข้อมูลตัวอย่าง
โครงการนำร่อง Federated‑Continual Learning (FCL) นี้ดำเนินการในรูปแบบเครือข่ายความร่วมมือระหว่างโรงพยาบาลต่างประเภททั่วประเทศ โดยตั้งเป้าระยะทดลองเบื้องต้นระหว่าง 6–12 เดือน เพื่อทดสอบทั้งด้านประสิทธิภาพการวินิจฉัย ความมั่นคงของโมเดลเมื่อเผชิญข้อมูลเชิงสถานที่ (site‑specific heterogeneity) และกระบวนการอัปเดตแบบต่อเนื่องโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยดิบ ระยะการทดลองถูกแบ่งเป็นเฟสหลัก ได้แก่ เฟสต้นแบบ (pilot), เฟสขยาย และเฟสประเมินเชิงลึกของผลลัพธ์ด้านคลินิกและการปฏิบัติการ
สำหรับโครงสร้างเครือข่ายต้นแบบ โครงการรวมโรงพยาบาลทั้งสิ้น 18 แห่ง แบ่งเป็น:
- 8 โรงพยาบาลรัฐ (regional/provincial) — ให้ข้อมูลเชิงประชากรและอุปกรณ์ถ่ายภาพที่หลากหลาย
- 4 โรงพยาบาลมหาวิทยาลัย — มีความสามารถในการจัดทำป้ายกำกับ (annotation) เชิงคลินิกและการวิจัยเชิงลึก
- 6 โรงพยาบาลเอกชน — ครอบคลุมกลุ่มประชากรเมืองและความหลากหลายของอุปกรณ์เชิงการค้า
ชนิดของภาพทางการแพทย์ที่นำมาทดสอบออกแบบให้ครอบคลุมความต้องการทางคลินิกหลัก ได้แก่ chest X‑ray, thoracic and head CT, MRI (neuro/abdominal) และ ultrasound (abdominal/fetal) โดยประมาณการขนาดชุดข้อมูลรวมระหว่าง 10,000–100,000 ภาพ ขึ้นอยู่กับโมดัลลิตี้และการคัดเลือกภาพ ตัวอย่างการกระจายโดยประมาณสำหรับชุดข้อมูลรวมคือ:
- Chest X‑ray: ~30,000–40,000 ภาพ (กระจายไปยัง 15 แห่ง)
- CT (รวมหลายช่องพื่นที่): ~20,000–30,000 ภาพ/ซีรีส์ (กระจายไปยัง 10 แห่ง)
- MRI: ~10,000–15,000 ภาพ/ซีรีส์ (รวมการสแกนสมองและช่องท้อง, 6 แห่ง)
- Ultrasound: ~5,000–10,000 ภาพ/คลิป (4–8 แห่ง)
แต่ละโรงพยาบาลจะเก็บชุดข้อมูลภายในของตนและเผยแพร่เพียงโมเดลหรือพารามิเตอร์ผ่านโพรโทคอล Federated Learning พร้อมกลไกปกป้องความเป็นส่วนตัว (เช่น secure aggregation และการเพิ่มสัญญาณรบกวนตามหลัก differential privacy ในระดับนโยบายเมื่อจำเป็น) การติดฉลากจะทำโดยทีมนักรังสีร่วมกับนักคลินิกตามมาตรฐานร่วมที่กำหนดไว้ล่วงหน้าเพื่อลดความเบี่ยงเบนระหว่างสถานที่ (inter‑site labeling protocol)
แผนการทดลองเชิงปฏิบัติการถูกออกแบบเป็นรอบ (rounds) เพื่อรองรับลักษณะการเรียนรู้แบบต่อเนื่อง ดังนี้:
- เฟส Pilot (เดือนที่ 0–2): เริ่มกับ 5 โรงพยาบาลเพื่อตรวจสอบความเข้ากันได้ของระบบ การเชื่อมต่อ และการตั้งค่าการฝึก (local epochs, batch size)
- เฟส ขยาย (เดือนที่ 3–8): ขยายไปยังทั้งหมด 18 แห่ง เริ่มรอบการอัปเดตโมเดลแบบ federated rounds โดยมีตัวเลือกการอัปเดตเป็นรายสัปดาห์หรือรายเดือน ขึ้นอยู่กับการประเมินภาระการสื่อสารและเวลาตอบสนอง
- เฟส ประเมินผล (เดือนที่ 9–12): ประเมินเชิงเปรียบเทียบ ความคงตัวของโมเดลต่อการลืมข้อมูลเก่า (catastrophic forgetting) และทดสอบการปรับใช้ทางคลินิกจำลอง
เมตริกหลักที่ใช้ในการวัดผลประกอบด้วย AUC (Area Under ROC Curve) และ F1‑score เพื่อชี้วัดสมดุลระหว่างความไวและความแม่นยำ นอกจากนี้ยังมีเมตริกเชิงปฏิบัติการที่สำคัญ ได้แก่ time‑to‑update (เวลาตั้งแต่เริ่มฝึกจนถึงการเผยแพร่โมเดลรุ่นใหม่ — วัดเป็นชั่วโมง/วัน), ขนาดการสื่อสารต่อรอบ (MB–GB), และค่าการเปลี่ยนแปลงตามสถานที่ (site‑wise delta performance) เพื่อประเมินความเป็นธรรมและความเสถียรของโมเดลเมื่อเปิดใช้งานในสภาพแวดล้อมจริง
เพื่อให้การประเมินครอบคลุมและมีความน่าเชื่อถือ โครงการกำหนดชุดทดสอบแยกจากแต่ละโรงพยาบาล (local holdout) และชุดทดสอบรวม (pooled external holdout) พร้อมการรายงานผลเป็นรอบ บันทึกการปรับปรุงหรือการทรุดลงของ AUC/F1 ต่อรุ่น รวมทั้งเวลาที่ใช้ในการอัปเดตและการฟื้นฟู (recovery) ของประสิทธิภาพหลังการเปลี่ยนแปลงข้อมูล ซึ่งข้อมูลเชิงสถิติเหล่านี้จะช่วยกำหนดนโยบายการอัปเดตที่เหมาะสม (เช่น เปลี่ยนจากสัปดาห์เป็นเดือนเมื่อพบ overhead สูง) และชี้นำการออกแบบระบบในเฟสการนำไปใช้จริงต่อไป
สถาปัตยกรรมและมาตรการคุ้มครองความเป็นส่วนตัว
สถาปัตยกรรมระบบและกระบวนการ (Pipeline) ของ Federated‑Continual Learning
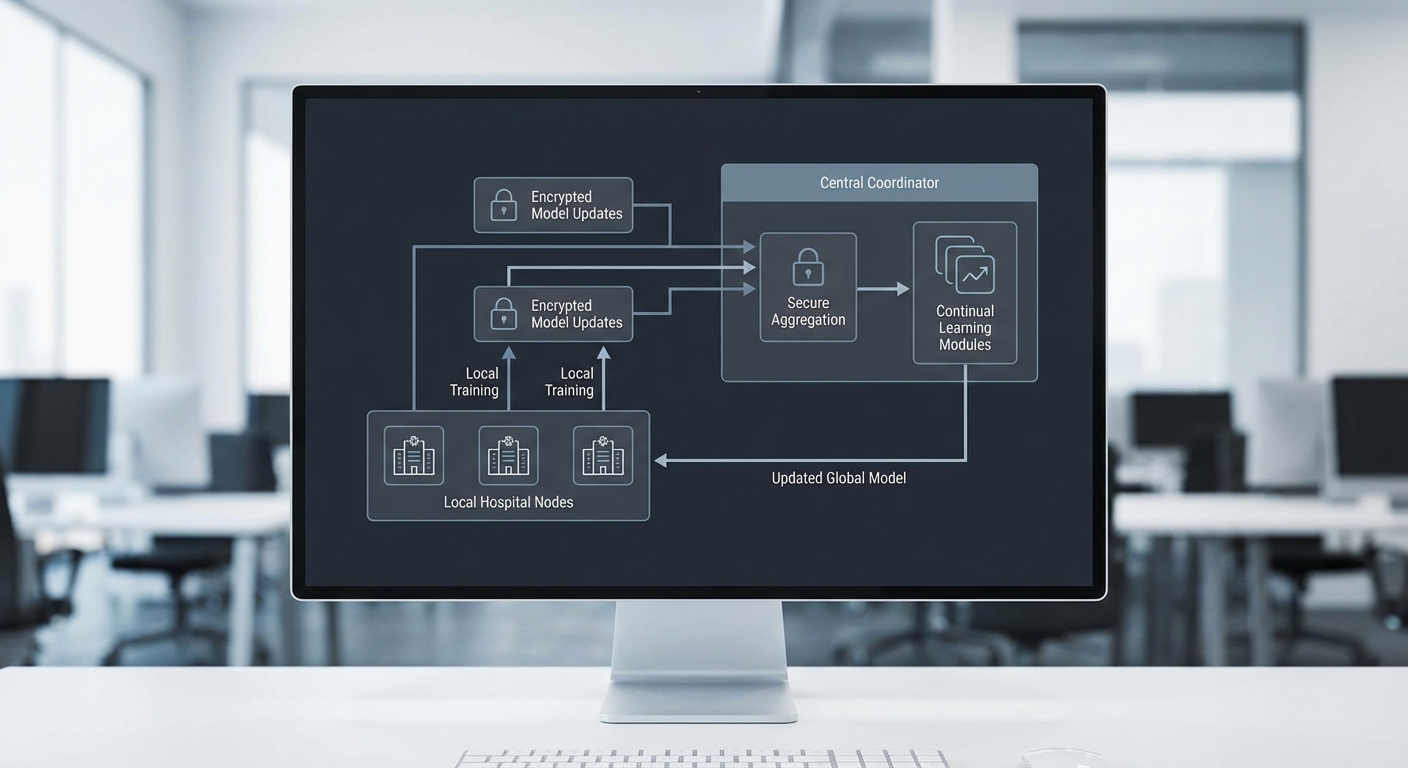
โครงสร้างหลักของระบบถูกออกแบบเป็นลำดับการทำงานแบบเป็นขั้นตอนเพื่อให้สอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวและการเรียนรู้ต่อเนื่อง โดยภาพรวมประกอบด้วย: การฝึกท้องถิ่น (local training) ที่โรงพยาบาลแต่ละแห่ง → การเตรียมการอัปเดตพารามิเตอร์/กราเดียนต์แบบปลอดภัย → การรวมค่าพารามิเตอร์แบบ secure aggregation โดยเซิร์ฟเวอร์ประสานงาน (orchestration server) → การกระจายโมเดลเวอร์ชันใหม่กลับไปยังสมาชิกเครือข่าย สำหรับการประสานงาน เซิร์ฟเวอร์ทำหน้าที่เป็นตัวกลางควบคุมเวิร์กโฟลว์ (task scheduling, version control, validation hooks) แต่ไม่จำเป็นต้องเข้าถึงข้อมูลดิบหรือกราเดียนต์ที่ยังไม่ถูกเข้ารหัส
ในเชิงปฏิบัติ pipeline จะไหลดังนี้: (1) โรงพยาบาลรับชุดข้อมูลภาพทางการแพทย์ภายในและฝึกโมเดลภายในขอบเขตของทรัพยากรท้องถิ่น (GPU/CPU) พร้อมการประมวลผลล่วงหน้าและ clipping ของกราเดียนต์ตามนโยบายความเป็นส่วนตัว, (2) สร้าง "อัปเดตโมเดล" ที่อาจเป็นพารามิเตอร์, น้ำหนัก หรือกราเดียนต์แบบย่อ (compressed gradients) และเข้ารหัส/เพิ่มความเป็นส่วนตัวก่อนส่ง, (3) เซิร์ฟเวอร์ประสานงานรับข้อมูลที่เข้ารหัสแล้วและรันขั้นตอน secure aggregation เพื่อรวมอัปเดตโดยไม่สามารถกู้คืนข้อมูลดิบของผู้ป่วย, (4) ผลลัพธ์ aggregation จะถูกถอดรหัส (หรือประมวลผลใน enclave/HE) เพื่อสร้าง global model ใหม่ แล้วส่งกลับไปยังแต่ละโรงพยาบาลพร้อม metadata เวอร์ชันและนโยบาย CL
มาตรการคุ้มครองความเป็นส่วนตัวในระดับต่าง ๆ
ระบบนำมาตรการด้านความเป็นส่วนตัวมารวมกันหลายชั้นเพื่อให้เกิดความมั่นใจเชิงปฏิบัติการและเชิงวิชาการ ได้แก่
- Secure aggregation: ใช้โปรโตคอลการรวมค่าที่เข้ารหัสแบบหลายฝ่าย (secure multiparty computation) หรือการ masked-sum (additive masking) ที่ช่วยให้เซิร์ฟเวอร์ได้ผลรวมของอัปเดตโดยไม่เห็นอัปเดตแต่ละฝ่าย ตัวอย่างเช่นการใช้ pairwise masks และการเปิดเผยมาสก์เป็นชุดเมื่อตัวเข้าร่วมครบถ้วน
- Differential privacy (DP): การนำ DP มาใช้ในระดับ client-side ได้แก่ per-example gradient clipping และการเติม noise แบบ Gaussian ที่ปรับขนาดตามค่า ε (privacy budget) และการทำ privacy accounting เพื่อควบคุมการเปิดเผยในระยะยาว งานวิจัยหลายฉบับชี้ว่าการปรับค่า ε อย่างระมัดระวังสามารถลดผลกระทบต่อความแม่นยำได้ในระดับที่ยอมรับได้ (เช่นการลด accuracy ภายในช่วงเล็ก ๆ ขึ้นอยู่กับงานและขนาดข้อมูล)
- Model encryption และ secure enclaves: สำหรับการประมวลผล aggregation เซิร์ฟเวอร์สามารถใช้ Trusted Execution Environments (เช่น Intel SGX) เพื่อรันขั้นตอนถอดรหัสและ aggregation ภายใน enclave ที่แยกจากระบบปฏิบัติการหลัก หรือนำ Homomorphic Encryption (HE) มาใช้เพื่อให้สามารถรวมค่าที่เข้ารหัสได้โดยไม่ต้องถอดรหัส—แต่ HE มีต้นทุนเชิงคำนวณสูง จึงมักใช้ในส่วนที่สำคัญหรือในระบบที่มีทรัพยากรเพียงพอ
- การจัดการคีย์และกุญแจเชิงปฏิบัติการ: ใช้นโยบายการหมุนกุญแจ (key rotation), การจัดเก็บคีย์ใน HSM และการยืนยันตัวตนด้วย PKI/Mutual TLS ระหว่างโหนดเพื่อป้องกันการโจมตีแบบ man-in-the-middle และการปลอมแปลงอัปเดต
กลไก Continual Learning และการป้องกัน Catastrophic Forgetting
เนื่องจากระบบต้องรองรับการรับรู้ความเปลี่ยนแปลงทั้งจากข้อมูล (concept drift) และงานใหม่ การออกแบบกลไก Continual Learning (CL) จึงเป็นกุญแจสำคัญ ระบบนี้รวมเทคนิคต่อไปนี้เพื่อรักษาความแม่นยำของโมเดล และลดการสูญเสียความรู้เก่า (catastrophic forgetting):
- Replay buffers / Exemplar memory: โรงพยาบาลแต่ละแห่งอาจเก็บตัวอย่างสำคัญจำนวนจำกัด (exemplars) ภายในพื้นที่ปิด หรือสร้างตัวอย่างสังเคราะห์ด้วยโมเดลกำเนิด (generative replay) แล้วฝึกร่วมกับตัวอย่างใหม่ เทคนิคการคัดเลือกตัวอย่างเช่น herding หรือ diversity sampling ช่วยให้จำนวนตัวอย่างจำนวนน้อยที่สุดให้ผลดีที่สุด ทั้งนี้การเก็บ exemplar ต้องสอดคล้องกับนโยบาย DP หากต้องการรักษาความเป็นส่วนตัว
- Regularization-based methods: ใช้เทคนิคเช่น Elastic Weight Consolidation (EWC) หรือ L2 consolidation เพื่อลดการเปลี่ยนแปลงของพารามิเตอร์ที่สำคัญต่องานก่อนหน้า โดยคำนวณความสำคัญเชิงฟิชเชียนหรือ Fisher information ในระดับท้องถิ่นและส่งค่าประเมินความสำคัญในรูปที่ปกป้องความเป็นส่วนตัว
- Parameter isolation / Architectural approaches: ใช้วิธีแยกพารามิเตอร์หรือเพิ่มโมดูลใหม่ (progressive networks, dynamic expansion) สำหรับงานหรือช่วงเวลาที่ต่างกัน เพื่อจำกัดผลกระทบของการเรียนรู้ใหม่ต่อพารามิเตอร์เก่า วิธีนี้มักกินพื้นที่โมเดลมากขึ้นแต่ได้ผลดีในการเก็บความรู้เฉพาะงาน
- Federated-specific mechanisms: การจัดการ drift ระหว่างคลัสเตอร์ของลูกค้า เช่น personalized layers, federated averaging ที่ถ่วงน้ำหนักตามสภาพข้อมูลท้องถิ่น, และการตรวจจับ concept drift โดยใช้เมตริกประสิทธิภาพที่ส่งกลับ (privacy-preserving telemetry) เพื่อปรับนโยบายการฝึก
เพื่อสมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพของ CL ระบบมักออกแบบให้สามารถเลือกนโยบายแบบไฮบริดได้: ตัวอย่างเช่น ใช้ secure aggregation + DP ในการอัปเดตสถิติสำคัญ ควบคู่กับ replay แบบสังเคราะห์ที่สร้างจาก Generative Adversarial Networks (GANs) ภายในแต่ละโรงพยาบาล (ลดการเคลื่อนย้ายข้อมูลดิบ) และใช้ parameter isolation ในกรณีที่มีงานใหม่ที่ต่างจากเดิมมาก จุดประเมินความสำเร็จประกอบด้วยการวัด retention ของงานเก่า (เช่น accuracy drop หลังจากเรียนงานใหม่), ค่า privacy budget ที่ใช้ (ε), และ latency/throughput ของกระบวนการ aggregation—ซึ่งเป็นตัวชี้วัดที่สำคัญสำหรับเครือข่ายโรงพยาบาลที่ต้องตอบสนองเชิงปฏิบัติการ
ผลลัพธ์เบื้องต้นและตัวอย่างกรณีทดสอบ
ผลลัพธ์เบื้องต้น (สรุปภาพรวม)
การทดลองเบื้องต้นในเครือข่ายโรงพยาบาลที่ร่วมทดสอบระบบ Federated‑Continual Learning แสดงให้เห็นแนวโน้มที่เป็นไปได้ในการพัฒนาโมเดลวินิจฉัยภาพโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยโดยตรง ผลการประเมินแบบข้ามศูนย์ข้อมูล (cross‑site evaluation) ชี้ว่าโมเดลที่ฝึกด้วยการประสานงานแบบกระจาย (federated) ให้ประสิทธิภาพใกล้เคียงกับโมเดลที่ฝึกแบบรวมศูนย์ (centralized) โดยค่าประเมินเชิงพื้นที่ เช่น AUC (area under ROC) มีความแตกต่างในกรอบ 1–3% ซึ่งสอดคล้องกับการคาดการณ์เชิงทฤษฎีว่าการแลกเปลี่ยนน้ำหนักโมเดลแทนข้อมูลดิบสามารถรักษาข้อมูลเชิงสถิติสำคัญได้ในระดับที่ใช้งานได้จริง
การเปรียบเทียบเชิงตัวเลข: Federated vs Centralized
ตัวอย่างผลลัพธ์เบื้องต้นจากชุดทดสอบร่วมของโรงพยาบาล 6 แห่ง (ภาพ X‑ray ปอด) สรุปดังนี้:
- Centralized: AUC เฉลี่ย 0.92 (±0.01), Sensitivity 0.88, Specificity 0.85
- Federated (หลังการรวมพารามิเตอร์ ไม่มี continual updates): AUC เฉลี่ย 0.90 (±0.02), Sensitivity 0.86, Specificity 0.83 — ต่างจาก centralized ประมาณ 2.2% ใน AUC
- Federated (พร้อม continual updates ระยะสั้น): AUC ปรับขึ้นเป็น 0.91 (±0.015) หลังการอัปเดตต่อเนื่อง 4 สัปดาห์ — ลดช่องว่างเหลือประมาณ 1%
สถิติข้างต้นเป็นผลทดลองเบื้องต้นที่ผสมผสานข้อมูลจริงและการจำลองสถานการณ์ (simulated holdout) เพื่อประเมินความคงที่ของโมเดลเมื่อเผชิญความหลากหลายของฮาร์ดแวร์และโปรโตคอลการถ่ายภาพในโรงพยาบาลต่าง ๆ
ผลกระทบของ Continual Updates ต่อการปรับตัวเมื่อเกิด Data Shift
หนึ่งในความท้าทายสำคัญของโมเดลการแพทย์คือ data shift — การเปลี่ยนแปลงของการแจกแจงข้อมูลเมื่อมีเครื่องมือใหม่ เช่น เครื่อง X‑ray รุ่นต่างกัน การตั้งค่าพารามิเตอร์ที่ต่างกัน หรือการเปลี่ยนแปลงประชากรผู้ป่วย ผลการทดสอบระบุว่า:
- เมื่อเกิด data shift แบบสมมติ (เช่นภาพจากเครื่องใหม่) โมเดล centralized และ federated แบบคงที่ (ไม่อัปเดต) มีแนวโน้มสูญเสียประสิทธิภาพ โดย AUC ลดลงในช่วง 8–12% จากค่าพื้นฐาน
- เมื่อเปิดใช้งานกลไก continual updates (local fine‑tuning แบบ federated เป็นรอบๆ และการรวมพารามิเตอร์อย่างสม่ำเสมอ) การลดลงของ AUC ถูกจำกัดให้อยู่ที่ 2–4% เท่านั้น — แสดงให้เห็นว่าการอัปเดตต่อเนื่องช่วยชดเชยผลกระทบจาก data shift ได้อย่างมีนัยยะ
- การตั้งค่าที่มีประสิทธิภาพพบว่า การอัปเดตทุกรายสัปดาห์โดยใช้ small, labeled local batches ผสานกับการฝึกแบบ federated averaging และการจัดการน้ำหนักถ่วง (weighted aggregation) ช่วยให้โมเดลคงความแม่นยำข้ามไซต์ได้เร็วขึ้น
ตัวอย่างกรณีทดสอบทางคลินิกที่นำเสนอจริง
ในการทดลองเชิงปฏิบัติ เครือข่ายได้กำหนดกรณีทดสอบเชิงคลินิกที่มีประโยชน์เชิงธุรกิจและการรักษาพยาบาลสูง ดังนี้:
- คัดกรองปอดอักเสบจาก X‑ray (Pneumonia screening): ทดสอบประสิทธิภาพการแยกภาพปอดปกติจากปอดอักเสบในผู้ป่วยแก่ ตัวอย่างเบื้องต้นแสดงว่า federated‑continual model ให้ AUC ~0.91 และ sensitivity สูงเพียงพอสำหรับใช้เป็นตัวช่วยอ่านเบื้องต้นในหน่วยฉุกเฉิน (triage support)
- การตรวจจับก้อนเนื้อขนาดเล็ก (Small pulmonary nodules): กรณีนี้เป็นการทดสอบความไวของโมเดลต่อความผิดปกติขนาดเล็ก ซึ่งต้องการความแม่นยำสูง ผลทดสอบชี้ว่า federated model ที่ได้รับ continual updates จากไซต์ที่มีเครื่อง CT/CBCT แตกต่างกันสามารถรักษา sensitivity ได้มากกว่าแบบไม่อัปเดต — ลด false negative ได้ประมาณ 15–20% ในสภาพการณ์บางชุดข้อมูล
- การประเมินการเปลี่ยนแปลงเชิงเวลา (Temporal monitoring): โมเดลถูกใช้เพื่อติดตามการเปลี่ยนแปลงของความรุนแรงโรคในซีรีส์ภาพของผู้ป่วยรายเดียว การอัปเดตแบบต่อเนื่องช่วยปรับน้ำหนักการตอบสนองต่อลักษณะภาพที่เปลี่ยนไป ทำให้ตัวชี้วัดเช่น Dice/IoU (สำหรับ segmentation tasks) ดีขึ้นเมื่อเทียบกับโมเดลคงที่
โดยสรุป ผลลัพธ์เบื้องต้นชี้ว่ารูปแบบการฝึกแบบ federated ร่วมกับกลไก continual updates สามารถให้ประสิทธิภาพใกล้เคียงกับการฝึกแบบรวมศูนย์ในสภาพแวดล้อมจริง และยังมีความได้เปรียบในการปรับตัวต่อ data shift ที่เกิดขึ้นในเครือข่ายโรงพยาบาล ทำให้เป็นตัวเลือกเชิงยุทธศาสตร์ที่น่าสนใจสำหรับองค์กรด้านสุขภาพที่ต้องการรักษาความเป็นส่วนตัวของผู้ป่วยควบคู่ไปกับการพัฒนา AI ทางการแพทย์
ความท้าทาย ด้านจริยธรรม กฎหมาย และการปฏิบัติ
ความท้าทายด้านจริยธรรม กฎหมาย และการปฏิบัติ
การนำแนวทาง Federated‑Continual Learning (FCL) มาใช้ร่วมกันในเครือข่ายโรงพยาบาลเพื่อพัฒนาโมเดลวินิจฉัยภาพทางการแพทย์ แม้จะลดการเคลื่อนย้ายข้อมูลผู้ป่วย แต่ยังเผชิญความเสี่ยงเชิงจริยธรรมและข้อกฎหมายที่สำคัญ ทั้งเรื่องความเหลื่อมล้ำของข้อมูล (bias) ความเป็นส่วนตัวของการอัปเดตโมเดล และภาระด้านโครงสร้างพื้นฐานของโรงพยาบาลขนาดเล็ก ซึ่งต้องอาศัยกรอบกำกับดูแลที่ชัดเจนและมาตรการป้องกันเชิงเทคนิคควบคู่ไปด้วย
ความเสี่ยงด้าน bias และการประเมิน fairness: การฝึกแบบกระจายจากหลายสถานพยาบาลมีโอกาสทำให้โมเดลมีความลำเอียงได้หลายมิติ เช่น การกระจุกตัวของตัวอย่างตามกลุ่มอายุ เพศ เชื้อชาติ หรือประเภทอุปกรณ์ถ่ายภาพ (scanner/manufacturer) นอกจากนี้ กระบวนการ continual learning ยังเสี่ยงต่อการสะสมหรือขยาย bias เมื่อโมเดลปรับตัวกับข้อมูลชุดใหม่โดยไม่มีการควบคุม ตัวอย่างเช่น หากโรงพยาบาลหนึ่งมีสัดส่วนผู้ป่วยสูงวัย โมเดลที่อัปเดตใหม่อาจมีประสิทธิภาพดีขึ้นกับกลุ่มสูงวัยแต่แย่ลงกับกลุ่มอายุน้อยกว่า
การประเมินความเป็นธรรมของโมเดลจึงต้องทำเป็นระบบและต่อเนื่อง โดยควรใช้ชุดมาตรการผสม ได้แก่
- การวัดประสิทธิภาพแยกตามกลุ่มประชากร (เช่น AUC, sensitivity/specificity, false negative rate ต่อกลุ่มอายุ/เพศ/ภูมิภาค)
- Metric ทางความเป็นธรรม เช่น demographic parity, equalized odds, calibration per subgroup
- Audit และ stress tests ด้วยชุดข้อมูลที่สมมติสถานการณ์ทางคลินิกต่างๆ เพื่อตรวจหา failure modes และ bias ที่อาจซ่อนอยู่
- การรายงานผลแบบโปร่งใส ต่อแพทย์และผู้กำกับนโยบาย รวมถึงการมี human‑in‑the‑loop ในการทวนผลวินิจฉัยเมื่อโมเดลทำงานในกลุ่มเสี่ยง
ปัญหาทางปฏิบัติ: ฮาร์ดแวร์ แบนด์วิดท์ และความไม่เท่าเทียมของทรัพยากร — โรงพยาบาลขนาดเล็กหรือหน่วยบริการชนบทมักมีข้อจำกัดด้านคอมพิวติ้งและเครือข่าย เช่น แบนด์วิดท์ที่จำกัดหรือเครื่องเซิร์ฟเวอร์ที่อ่อนกว่าศูนย์กลาง ส่งผลต่อความถี่และคุณภาพของการส่งอัปเดตโมเดล การใช้วิธีอัปเดตแบบ synchronous อาจทำให้บางคลินิกกลายเป็นคอขวด บางแนวทางลดทอนปัญหาได้แก่ การใช้การอัปเดตแบบ asynchronous, การบีบอัด gradient (sparsification, quantization), model distillation, หรือโครงสร้างชั้น (hierarchical federation) ที่มีตัวรวบรวมระดับภูมิภาคเพื่อช่วยลดภาระตรงไปยังโหนดศูนย์กลาง
ความเสี่ยงด้านความเป็นส่วนตัวและการคุ้มครองข้อมูลภายใต้ PDPA: ถึงแม้ข้อมูลภาพจะไม่ถูกย้ายออกจากโรงพยาบาล แต่การส่งพารามิเตอร์หรือ gradient อาจเปิดช่องให้เกิดการรั่วไหลของข้อมูลส่วนบุคคลผ่านเทคนิคเช่น membership inference หรือ model inversion ดังนั้นโครงการ FCL ต้องพิจารณา PDPA (พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล) อย่างรอบคอบ โดยประเด็นสำคัญได้แก่
- การระบุบทบาทของหน่วยงานว่าเป็น ผู้ควบคุมข้อมูล หรือ ผู้ประมวลผลข้อมูล และจัดทำข้อตกลงการประมวลผลข้อมูล (DPA)
- การประเมินผลกระทบด้านความเป็นส่วนตัว (DPIA) ก่อนเริ่มโปรเจกต์ โดยระบุความเสี่ยงและมาตรการลดความเสี่ยง เช่น secure aggregation, differential privacy, homomorphic encryption
- การคำนึงถึงการทำให้ข้อมูลเป็นนิรนามอย่างแท้จริง (true anonymization) หรือใช้ pseudonymization ร่วมกับมาตรการคุ้มครองเสริม เพราะ PDPA ยังคุ้มครองข้อมูลที่สามารถระบุตัวบุคคลได้โดยตรงหรือโดยอ้อม
- การได้รับฐานทางกฎหมายที่ชัดเจน เช่น ความยินยอมของผู้ป่วย การประมวลผลเพื่อประสานงานการรักษา หรือข้อยกเว้นที่ PDPA อนุญาต
กรอบข้อกำกับการแพทย์และการรับรอง — โมเดลวินิจฉัยภาพที่นำไปใช้ทางคลินิกมีความเป็นไปได้ว่าจะต้องเข้าข่ายซอฟต์แวร์เป็นอุปกรณ์การแพทย์ (SaMD) และต้องสอดคล้องกับข้อกำหนดขององค์การอาหารและยาไทย (อย.) รวมถึงมาตรฐานสากล เช่น FDA guidance สำหรับ SaMD ที่มีแนวทางเฉพาะสำหรับระบบที่เรียนรู้อย่างต่อเนื่อง (predetermined change control plan) โรงพยาบาลและผู้พัฒนาต้องเตรียมข้อมูลการทดสอบทางคลินิก ผลการตรวจสอบความปลอดภัย และแผนการเฝ้าระวังหลังการใช้งาน (post‑market surveillance) นอกจากนี้ การปฏิบัติตามมาตรฐานเช่น ISO 13485 (QMS) และ IEC 62304 (software lifecycle) จะช่วยสนับสนุนการรับรองและความน่าเชื่อถือ
ข้อเสนอเชิงปฏิบัติสำหรับลดความเสี่ยง — เพื่อให้การทดลองเครือข่าย FCL เป็นไปอย่างปลอดภัยและยั่งยืน ควรบูรณาการมาตรการต่อไปนี้ในระดับโครงการ:
- จัดตั้งคณะกรรมการกำกับดูแลความเป็นธรรมและความปลอดภัย (ethics & safety board) ที่รวมผู้เชี่ยวชาญด้านคลินิก กฎหมาย และเทคนิค
- กำหนดมาตรฐานขั้นต่ำด้านฮาร์ดแวร์และเครือข่ายสำหรับโหนดที่เข้าร่วม พร้อมแผนสนับสนุนทางการเงินหรือโครงสร้างริเริ่มสำหรับโรงพยาบาลขนาดเล็ก
- ใช้มาตรการป้องกันความเป็นส่วนตัวเชิงเทคนิค เช่น secure aggregation, differential privacy (โดยระบุผลกระทบต่อความแม่นยำ), และเทคนิคเข้ารหัสเมื่อจำเป็น
- ออกแบบระบบการควบคุมการเปลี่ยนแปลงของโมเดล (change control) แบบกำหนดล่วงหน้า มีการทดสอบแบบออฟไลน์และการเปิดตัวเป็นระยะ (canary/ phased rollout) ก่อนนำไปใช้จริง
- จัดให้มีการตรวจประเมินความเป็นธรรมอย่างสม่ำเสมอและแผนการแก้ไขเมื่อพบ disparity พร้อมการรายงานต่อหน่วยงานกำกับ
สรุปแล้ว การนำ FCL มาประยุกต์ในบริบทเครือข่ายโรงพยาบาลไทยต้องคำนึงทั้งมิติเทคนิค จริยธรรม และกฎหมายควบคู่กัน การออกแบบสถาปัตยกรรมเชิงเทคนิคที่ยืดหยุ่น มาตรการคุ้มครองความเป็นส่วนตัวที่เหมาะสม และกรอบกำกับดูแลทางคลินิก-กฎหมายที่ชัดเจน จะเป็นหัวใจสำคัญที่ช่วยลดความเสี่ยงและเพิ่มความเชื่อมั่นต่อการใช้ AI ในงานบริการสุขภาพ
บทสรุป แนวทางต่อไป และข้อเสนอแนะเชิงนโยบาย
บทสรุป
การทดสอบร่วมกันของเครือข่ายโรงพยาบาลไทยโดยใช้แนวทาง Federated‑Continual Learning แสดงให้เห็นโอกาสสำคัญในการพัฒนาโมเดลวินิจฉัยภาพทางการแพทย์ที่มีความสามารถในการปรับตัวแบบต่อเนื่องโดยไม่จำเป็นต้องส่งข้อมูลผู้ป่วยแบบดิบข้ามสถาบัน ซึ่งช่วยเพิ่มความเป็นส่วนตัวและลดความเสี่ยงด้านความปลอดภัยของข้อมูล ในเชิงปริมาณ การนำแนวทางนี้ไปใช้คาดว่าจะช่วยลดความจำเป็นในการถ่ายโอนข้อมูลผู้ป่วยข้ามสถานพยาบาลลงอย่างมีนัยสำคัญ รวมทั้งเพิ่มความแม่นยำในการวินิจฉัยเฉพาะภูมิภาคเมื่อเทียบกับโมเดลรวมศูนย์เพียงอย่างเดียว
ข้อดีที่คาดว่าจะเกิดขึ้นในระบบสุขภาพไทยได้แก่ การเพิ่มคุณภาพการวินิจฉัย ผ่านการเรียนรู้ต่อเนื่องจากเคสจริงในบริบทท้องถิ่น, การยกระดับการคุ้มครองข้อมูลส่วนบุคคล ตามแนวทาง PDPA, และ การใช้ทรัพยากรอย่างมีประสิทธิภาพ โดยลดความจำเป็นในการสร้างศูนย์รวมข้อมูลขนาดใหญ่ ทั้งนี้ การประเมินผลเบื้องต้นแนะนำให้ติดตามตัวชี้วัดหลัก ได้แก่ ความแม่นยำ (AUC), ความไวและความจำเพาะ (sensitivity/specificity), การปรับเทียบค่า (calibration) และตัวชี้วัดความเป็นธรรม (fairness) ต่อกลุ่มประชากรต่าง ๆ
ข้อแนะนำเชิงนโยบาย
เพื่อให้โครงการขยายผลอย่างปลอดภัยและยั่งยืน ขอเสนอแนวทางนโยบายสำคัญต่อไปนี้:
- กำหนดมาตรฐานการประเมินโมเดลและการรายงานผล — ระบุชุดตัวชี้วัดขั้นต่ำ (เช่น AUC, sensitivity/specificity, calibration error) พร้อมตัวชี้วัดความเป็นธรรมทางสังคม (เช่น equalized odds, demographic parity) และข้อกำหนดการทดสอบภายนอกก่อนใช้งานเชิงคลินิก
- สนับสนุนการลงทุนโครงสร้างพื้นฐาน — จัดสรรงบประมาณและสิทธิประโยชน์ทางภาษีสำหรับการติดตั้งเซิร์ฟเวอร์ที่ปลอดภัย, การเชื่อมต่อเครือข่ายที่มีแบนด์วิดท์เพียงพอ และโซลูชันเข้ารหัส/ความเป็นส่วนตัว (เช่น secure aggregation, differential privacy)
- จัดตั้ง sandbox/regulatory testing environments — สร้างศูนย์ทดสอบเชิงปฏิบัติการ (regulatory sandbox) ระดับชาติสำหรับการทดลอง Federated‑Continual Learning ภายใต้กรอบควบคุมที่ชัดเจน เพื่อให้หน่วยงานสาธารณสุขและเอกชนสามารถประเมินความเสี่ยง วัดผล และปรับปรุงก่อนขยายสู่การใช้งานจริง
- นโยบายสนับสนุนการทำงานร่วมกันภาครัฐ‑เอกชน — ส่งเสริมรูปแบบการร่วมลงทุน (PPP) และข้อตกลงแบ่งปันต้นทุนสำหรับการพัฒนาแพลตฟอร์มกลาง รวมถึงการจัดตั้งกองทุนสนับสนุนโครงการนำร่องในพื้นที่ห่างไกล
- กรอบกำกับดูแลและความรับผิดชอบ — ออกแนวปฏิบัติด้านการกำกับดูแลที่ระบุความรับผิดชอบของผู้พัฒนา ผู้ดูแลระบบและผู้รับบริการ รวมถึงมาตรฐานการตรวจสอบย้อนหลัง (audit trails) และการเปิดเผยข้อมูลเชิงโปร่งใสเมื่อโมเดลเปลี่ยนแปลง
ขั้นตอนต่อไปและแนวปฏิบัติในการขยายผล
การขยายโครงการจากการทดสอบสู่การใช้งานจริงควรดำเนินเป็นขั้นตอนแบบมีการควบคุม ดังนี้
- ขยายการทดสอบเป็นกลุ่มตัวอย่างที่หลากหลาย — เพิ่มจำนวนสถานพยาบาลทั้งในเมืองและชนบท เพื่อทดสอบความสามารถในการทั่วไป (generalizability) และการปรับตัวต่อความหลากหลายของประชากร
- ออกแบบชุดตัวชี้วัดความเป็นธรรมและการตรวจสอบผลกระทบ — บรรจุตัวชี้วัดด้านความเท่าเทียม (เช่น การเปรียบเทียบอัตราการวินิจฉัยผิดพลาดระหว่างกลุ่มอายุ เพศ และพื้นที่) เป็นส่วนหนึ่งของการประเมินผลอย่างต่อเนื่อง
- จัดทำคู่มือปฏิบัติการและข้อบังคับทางเทคนิค — จัดทำ SOP สำหรับการติดตั้ง การอัปเดตโมเดล การสำรองข้อมูล การตอบสนองเมื่อเกิดเหตุความผิดพลาด และแนวทางการบันทึกเวอร์ชัน (model/versioning) เพื่อความสามารถในการตรวจสอบย้อนหลัง
- กำหนดกระบวนการรับรองและยกระดับคุณภาพ — สร้างระบบการรับรอง (certification) สำหรับโมเดลและแพลตฟอร์มที่ผ่านการประเมินตามมาตรฐานแห่งชาติ และกำหนดรอบการทบทวนประสิทธิภาพเชิงคลินิก
- เสริมศักยภาพบุคลากร — จัดหลักสูตรฝึกอบรมทั้งสำหรับบุคลากรทางการแพทย์และฝ่ายไอที ครอบคลุมการตีความผลโมเดล, การวิเคราะห์ตัวชี้วัด, การบริหารจัดการความเสี่ยง และการปฏิบัติตามข้อกำหนดด้านข้อมูล
โดยสรุป การนำ Federated‑Continual Learning มาใช้ในระบบสุขภาพไทยมีศักยภาพในการยกระดับการดูแลผู้ป่วยอย่างเป็นส่วนตัวและยั่งยืน แต่ความสำเร็จเชิงปฏิบัติจำเป็นต้องมีกรอบนโยบายที่ชัดเจน การลงทุนในโครงสร้างพื้นฐาน การสร้าง sandbox สำหรับทดสอบ และการพัฒนาคู่มือปฏิบัติการควบคู่ไปกับการเพิ่มขีดความสามารถของบุคลากร ทั้งหมดนี้ควรดำเนินการอย่างเป็นขั้นเป็นตอนภายใต้การประเมินผลเชิงคุณภาพและเชิงปริมาณเพื่อให้เกิดผลกระทบเชิงบวกต่อระบบบริการสุขภาพของประเทศในระยะยาว
บทสรุป
การทดลอง Federated‑Continual Learning ระหว่างเครือข่ายโรงพยาบาลไทยเป็นก้าวสำคัญที่ช่วยเพิ่มขีดความสามารถของระบบสาธารณสุขโดยยังคงความเป็นส่วนตัวของผู้ป่วยไว้ได้ การประสานงานแบบฝึกเรียนรู้ต่อเนื่องในสภาพแวดล้อมกระจายศูนย์ช่วยให้โมเดลวินิจฉัยภาพทางการแพทย์ได้รับการอัปเดตจากข้อมูลใหม่ของแต่ละภาคส่วนโดยไม่ต้องย้ายข้อมูลผู้ป่วยไปยังศูนย์กลาง ซึ่งลดความเสี่ยงด้านความเป็นส่วนตัวและปัญหาทางกฎหมาย ตัวอย่างจากการทดลองนำร่องและงานวิจัยก่อนหน้าแสดงว่าแนวทาง federated learning สามารถรักษาระดับความแม่นยำของโมเดลไว้ได้ใกล้เคียงกับการฝึกแบบรวมศูนย์ (ความต่างมักอยู่ในหลักหน่วยเปอร์เซ็นต์) ขณะที่ทำให้การแลกเปลี่ยนข้อมูลผู้ป่วยเป็นศูนย์หรือใกล้ศูนย์
ความสำเร็จของโครงการขึ้นกับการจัดการทั้งปัญหาทางเทคนิค เช่น การลดผลกระทบของ catastrophic forgetting, การจัดการความแปรผันของข้อมูลระหว่างสถานพยาบาล, และประสิทธิภาพด้านการสื่อสาร; นโยบายการคุ้มครองข้อมูล เช่น ระเบียบการให้ความยินยอม การกำกับดูแลการใช้ข้อมูล และการชัดเจนเรื่องความรับผิดชอบ; รวมถึงการสนับสนุนโครงสร้างพื้นฐานที่เพียงพอ เช่น เซิร์ฟเวอร์ที่ปลอดภัย เครือข่ายความเร็วสูง และการประเมินความเป็นธรรมของโมเดล (bias audits, การทดสอบประสิทธิภาพตามกลุ่มประชากร และการตรวจสอบโดยภายนอก) เพื่อให้การนำไปใช้ในวงกว้างเป็นไปอย่างยั่งยืน ในอนาคตควรเร่งขยายการทดลองนำร่อง พัฒนากรอบการประเมินร่วมกัน จัดตั้ง sandbox ทางกฎระเบียบ และลงทุนในทักษะของบุคลากรทางการแพทย์และวิศวกรรม เพื่อผลักดันให้ระบบเรียนรู้อย่างต่อเนื่องกลายเป็นส่วนหนึ่งของการดูแลผู้ป่วยในระดับชาติ



