
สตาร์ทอัพไทย LabLoop เปิดตัวแพลตฟอร์มปิดวงจร AI→Robot ที่สัญญาว่าจะพลิกโฉมการพัฒนายาเชิงทดลอง ด้วยการใช้ LLM (Large Language Model) แปลงโปรโตคอลการทดลองภาษามนุษย์ให้เป็นคำสั่งควบคุมหุ่นยนต์โดยตรง ทำให้สามารถสกรีนโมเลกุลและรันแอสเซย์อัตโนมัติแบบต่อเนื่องได้ ทีมงาน LabLoop ระบุว่าแพลตฟอร์มนี้ช่วยลดเวลาวงจรการทดลองเชิงห้องปฏิบัติการได้ถึง 70% — ตัวอย่างเช่น งานสกรีนเชิงปริมาณที่เคยกินเวลาหลายสัปดาห์หรือหลายเดือน สามารถย่นเหลือเป็นสัปดาห์หรือวันได้ตามต้นแบบที่นำร่อง
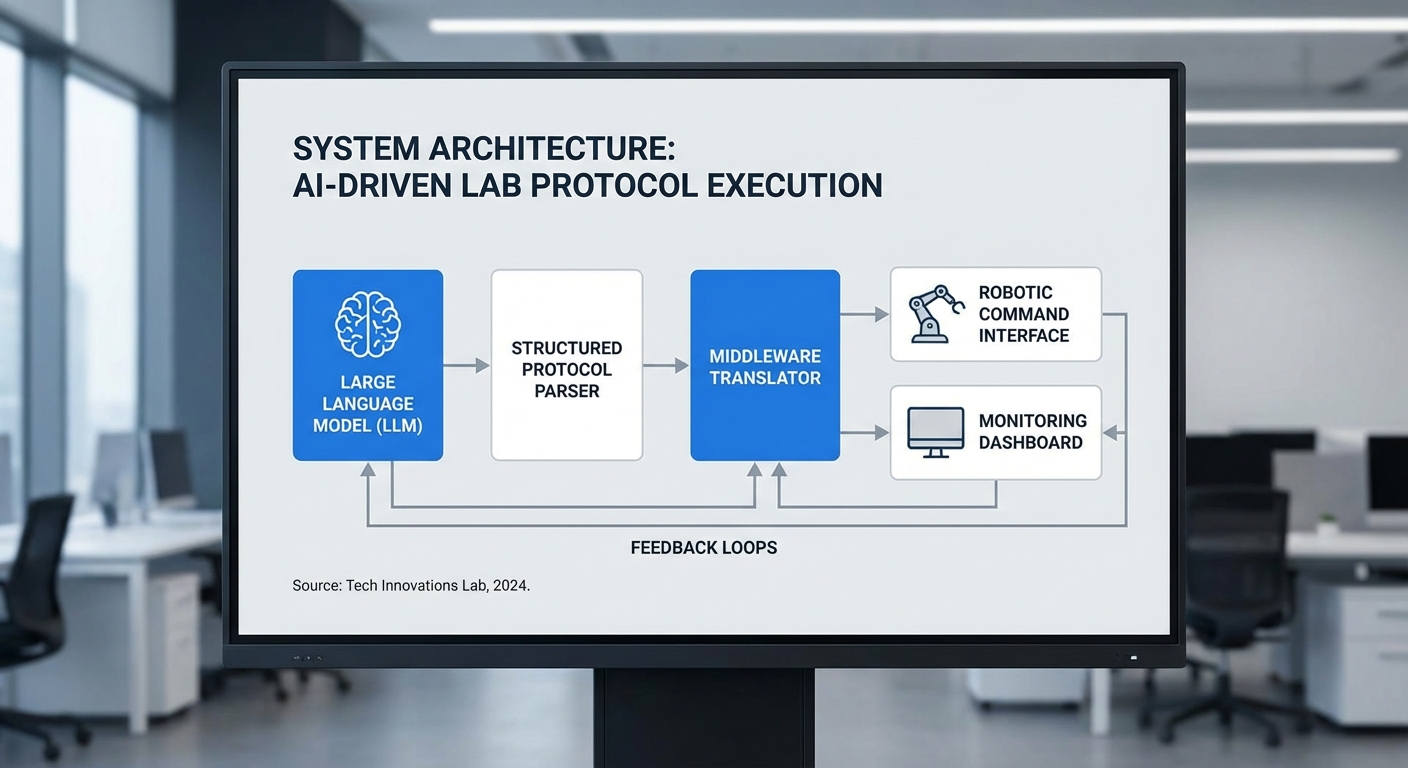
ในเชิงเทคนิค ระบบของ LabLoop ประกอบด้วย LLM ที่ตีความโปรโตคอลวิทยาศาสตร์ การแปลเป็นคำสั่งสำหรับ liquid handlers, incubators, plate readers และอุปกรณ์อัตโนมัติอื่น ๆ พร้อมฟีดแบ็กแบบเรียลไทม์จากข้อมูลแอสเซย์กลับสู่โมเดลเพื่อปรับการทดลองในรูปแบบ closed-loop บริษัทวางแผนเชื่อมต่อระบบกับ LIMS (Lab Information Management Systems) และระบบบันทึกข้อมูลอิเล็กทรอนิกส์ รวมถึงแผนการขอรับรองมาตรฐานการทดลองเพื่อรับประกันความแม่นยำและการทำซ้ำได้ หากเป็นจริง ผลกระทบต่อวงการไบโอเทคในไทยอาจรวมถึงการลดต้นทุนการค้นหาตัวยา เพิ่มความรวดเร็วในการคัดเลือกผู้เข้ารอบ และเปิดโอกาสให้ห้องแล็บขนาดกลาง-เล็กสามารถเข้าร่วมการพัฒนายาระดับสากลได้มากขึ้น
บทนำ: ประกาศและผลลัพธ์สำคัญ
บทนำ: ประกาศและผลลัพธ์สำคัญ
สตาร์ทอัพไทย LabLoop ประกาศเปิดตัวแพลตฟอร์มระบบปิดวงจร AI→Robot สำหรับห้องปฏิบัติการ เมื่อวันที่ 21 กุมภาพันธ์ 2026 โดยทีมผู้ก่อตั้งนำโดย ดร.อรุณ ไชยภูมิ (ผู้เชี่ยวชาญด้านชีวสารสนเทศและการเรียนรู้ของเครื่อง) ร่วมกับ นางสาวณิชา สมบูรณ์ (วิศวกรหุ่นยนต์เชิงปฏิบัติการ) และกลุ่มนักวิจัยจากมหาวิทยาลัยและอุตสาหกรรมยาในประเทศไทย ทีมงานระบุว่าเป้าหมายของ LabLoop คือการเชื่อมต่อความสามารถของโมเดลภาษาขนาดใหญ่ (LLM) กับการสั่งงานหุ่นยนต์ภายในห้องปฏิบัติการให้เป็นระบบเดียวแบบอัตโนมัติ ลดข้อผิดพลาดจากกระบวนการแปลงโปรโตคอลด้วยมือ และเร่งรัดวงจรการทดลองเชิงทดลอง (experimental drug discovery).
ระบบของ LabLoop ใช้ LLM ที่ผ่านการฝึกเฉพาะด้านเพื่อแปลงโปรโตคอลการทดลองเชิงปฏิบัติการเป็นชุดคำสั่งควบคุมหุ่นยนต์ (robotic instructions) แบบเรียลไทม์ จากนั้นหุ่นยนต์จะดำเนินการเตรียมสาร ตัวอย่าง และรันแอสเซย์ตามพารามิเตอร์ที่กำหนด พร้อมรับข้อมูลผลลัพธ์ย้อนกลับเข้าสู่โมเดลเพื่อการปรับพารามิเตอร์แบบปิดวงจร (closed-loop optimization) ซึ่งช่วยให้การออกแบบการทดลองและการปรับเงื่อนไขสามารถทำได้อย่างรวดเร็วและแม่นยำโดยไม่ต้องพึ่งการแปลโปรโตคอลด้วยมนุษย์ในทุกขั้นตอน
ผลลัพธ์เบื้องต้นจากการทดสอบนำร่องที่ LabLoop ดำเนินการร่วมกับพันธมิตรในอุตสาหกรรมยาแสดงข้อได้เปรียบชัดเจน: เวลาพัฒนายาเชิงทดลองลดลงประมาณ 70% เมื่อเทียบกับกระบวนการแบบดั้งเดิม และค่า throughput ของการสกรีนโมเลกุลเพิ่มขึ้นอย่างมีนัยสำคัญ (รายงานเบื้องต้นระบุการเพิ่มขึ้นประมาณ 4 เท่า) โดยตัวอย่างการทดลองนำร่องได้แก่ การสกรีนสารขนาดเล็กจำนวนประมาณ 12,000 โมเลกุลภายใน 10 วัน เพื่อค้นหาตัวอย่างเริ่มต้น (hit compounds) และการรันแอสเซย์ชนิด cell-based แบบอัตโนมัติที่ลดระยะเวลาการเตรียมตัวอย่างจากหลายวันเหลือเพียงไม่กี่ชั่วโมง
สรุปแล้ว การเปิดตัว LabLoop นับเป็นก้าวสำคัญสำหรับการนำ AI มาบูรณาการกับระบบหุ่นยนต์ในห้องปฏิบัติการ โดยสัญญาว่าจะช่วยลดเวลาและค่าใช้จ่ายในการพัฒนายาเชิงทดลอง เพิ่มความสม่ำเสมอของการทดลอง และขยายขีดความสามารถในการประมวลผลตัวอย่างจำนวนมาก ซึ่งเป็นประเด็นสำคัญสำหรับบริษัทชีวเทคและสถาบันวิจัยที่มองหาการปรับขนาด (scale-up) กระบวนการค้นหายาและการพัฒนายาที่รวดเร็วขึ้น
- ผู้ก่อตั้ง: ดร.อรุณ ไชยภูมิ และ นางสาวณิชา สมบูรณ์ พร้อมทีมวิจัยจากสถาบันพันธมิตร
- วันเปิดตัว: 21 กุมภาพันธ์ 2026
- จุดเด่นระบบ: Closed-loop AI→Robot ที่แปลงโปรโตคอลเป็นคำสั่งหุ่นยนต์และปรับการทดลองแบบเรียลไทม์
- สถิติเด่น: ลดเวลาพัฒนายาเชิงทดลอง ~70%, throughput เพิ่มขึ้น ~4 เท่า
- ตัวอย่างนำร่อง: สกรีน 12,000 โมเลกุลใน 10 วัน และรันแอสเซย์ cell-based แบบอัตโนมัติที่ลดเวลาการเตรียมตัวอย่างอย่างมีนัยสำคัญ
สถาปัตยกรรมเทคโนโลยี: LLM แปลงโปรโตคอลเป็นคำสั่งหุ่นยนต์
ส่วนสถาปัตยกรรมของ LabLoop ถูกออกแบบมาเพื่อเชื่อมช่องว่างระหว่างโปรโตคอลเชิงภาษา (natural language protocols) ที่นักวิจัยเขียนกับคำสั่งเชิงปฏิบัติการที่หุ่นยนต์สามารถรันได้จริง โดยใช้ Large Language Model (LLM) เป็นแกนกลางในการตีความ แปลงโครงสร้าง และประสานงานกับไลบรารีคำสั่ง (robot instruction library) ที่ผ่านการตรวจสอบแล้ว การออกแบบนี้ประกอบด้วยชั้นหลัก 3 ชั้น ได้แก่ ชั้นการประมวลผลภาษา, ชั้นการแม็ปเชิงตรรกะไปยัง primitive ของหุ่นยนต์ และชั้นการตรวจสอบความปลอดภัยก่อนการรันจริง ซึ่งรวมกันช่วยให้การสกรีนโมเลกุลและการรันแอสเซย์อัตโนมัติมีความรวดเร็วและน่าเชื่อถือมากขึ้น

กระบวนการแปลงโปรโตคอล: จากภาษาเป็นคำสั่งปฏิบัติการ
กระบวนการแปลงเริ่มจากการรับโปรโตคอลรูปแบบธรรมชาติ แล้วผ่านขั้นตอนย่อยที่ชัดเจนเพื่อให้ได้คำสั่งเชิงปฏิบัติการสำหรับหุ่นยนต์:
- Ingestion & Preprocessing: ทำการทำความสะอาดข้อความ (remove noise), การทำ normalization ของหน่วย (เช่น μL → microliter), การแยกย่อหน้าและการติดแท็กสิ่งสำคัญ (reagent names, concentrations, times, temperatures)
- Semantic Parsing ด้วย LLM: LLM จะถูกใช้เป็นตัวถอดความเพื่อสกัด action และพารามิเตอร์ที่เกี่ยวข้อง เช่น "pipette 50 μL of reagent A into well B2" ถูกแปลงเป็นโครงสร้างแบบมีสกีมาเช่น {"action":"transfer","volume":50,"unit":"μL","source":"reagent A","dest":"B2"}
- Schema Enforcement: โครงสร้างผลลัพธ์ถูกแม็ปเป็น JSON schema ที่กำหนดฟิลด์บังคับและข้อจำกัด (เช่น ปริมาตรต้องเป็นจำนวนบวก, อุณหภูมิในช่วงที่ยอมรับได้)
- Mapping เป็น Robot Primitives: คำสั่งเชิงโครงสร้างจะถูกแปลงเป็นชุดคำสั่ง primitive ที่อยู่ในไลบรารีคำสั่งของหุ่นยนต์ เช่น transfer(pipette_id, volume, source_loc, dest_loc, tip_type, speed) หรือ incubate(plate_id, temperature, duration)
การใช้ Prompt Engineering, Fine-tuning และการยืนยันผลของ LLM
เพื่อให้การแปลงมีความแม่นยำและสอดคล้องกับสภาพแวดล้อมห้องปฏิบัติการ LabLoop ใช้แนวทางหลายชั้น:
- Prompt Engineering: สร้างเทมเพลต prompt ที่ออกแบบมาเฉพาะสำหรับโปรโตคอลชีววิทยา/เคมี รวมถึงตัวอย่าง few-shot prompts เพื่อแสดงรูปแบบการแม็ปที่ถูกต้องและการจัดการข้อกำกวมของภาษา
- Fine-tuning เชิงโดเมน: ฝึก LLM ด้วยชุดข้อมูลคู่ (protocol → structured command) ที่สร้างจากโปรโตคอลจริงและการแม็ปที่ตรวจสอบโดยผู้เชี่ยวชาญ ซึ่งรวมถึงเทคนิค supervised fine-tuning และการใช้ RLHF (Reinforcement Learning from Human Feedback) เพื่อปรับพฤติกรรมเมื่อมีความขัดแย้ง
- Validation และ Metrics: ใช้ชุดทดสอบอิสระ (holdout test suites) ประเมินความถูกต้องระดับขั้นตอน (step-level accuracy), อัตราการจับพารามิเตอร์ที่ถูกต้อง และความสมบูรณ์ของการแม็ป ในการทดสอบภายใน LabLoop พบว่าอัตราการแปลงขั้นตอนสำเร็จอยู่ในช่วงประมาณ 92–97% ขึ้นกับความซับซ้อนของโปรโตคอล และมีการใช้ human-in-the-loop เพื่อตรวจสอบกรณีที่มีความเสี่ยงสูงหรือความไม่แน่นอน
การแม็ปคำสั่งกับ Robot Instruction Library เพื่อความปลอดภัยและความน่าเชื่อถือ
ไลบรารีคำสั่งของหุ่นยนต์ทำหน้าที่เป็นชุด primitive ที่ผ่านการรับรอง ซึ่งแต่ละ primitive มีสเปก (allowed ranges, preconditions, postconditions) ที่ชัดเจน ก่อนการแม็ป LLM จะตรวจสอบว่า action ที่สร้างขึ้นสอดคล้องกับ primitive ที่มีอยู่ เมื่อเกิดช่องว่างระบบจะไม่สร้างคำสั่งใหม่โดยอัตโนมัติ แต่จะยกระดับให้ผู้เชี่ยวชาญพิจารณาและเพิ่ม primitive ใหม่พร้อมการทดสอบ นโยบายนี้ช่วยลดความเสี่ยงจากคำสั่งที่ไม่ได้รับการยืนยัน
กลไก Safety Checks และ Sandboxing ก่อนรันคำสั่งจริง
ความปลอดภัยเป็นแกนสำคัญของสถาปัตยกรรม LabLoop ระบบประกอบด้วยหลายชั้นของการตรวจสอบก่อนที่จะอนุญาตให้รันคำสั่งบนฮาร์ดแวร์จริง:
- Static Safety Checks: ตรวจสอบ schema, ช่วงค่าพารามิเตอร์, ห้ามคำสั่งที่อาจเป็นอันตราย (เช่น ผสมสารที่ห้ามร่วมกัน) และเช็คความสอดคล้องกับฐานข้อมูลความเสี่ยงทางเคมี
- Simulation / Dry-run (Sandbox): คำสั่งจะถูกรันในสภาพแวดล้อมจำลอง (digital twin) เพื่อตรวจจับปัญหาเชิงกล (เช่น การชนกันของแขนกล), ปัญหาการไหลของของเหลว และการใช้งานทรัพยากรเกินพิกัด โดยระบบจะประเมินผลลัพธ์กับเกณฑ์ความปลอดภัยก่อนอนุญาตให้ดำเนินการจริง
- Shadow Mode & Hardware-in-the-loop: ในการเปิดตัวโปรโตคอลใหม่ ระบบสามารถรันในโหมด shadow ที่หุ่นยนต์ทำซ้ำคำสั่งในสภาพควบคุม (เช่น ใช้น้ำเปล่า) เพื่อตรวจสอบพฤติกรรมจริงก่อนอนุมัติ
- Runtime Monitors และ Emergency Interlocks: ระหว่างการปฏิบัติงานจริง มีตัวมอนิเตอร์ติดตามพารามิเตอร์สำคัญ (แรงดูด, ปริมาตร, ตำแหน่ง) และสามารถหยุดฉุกเฉินหรือ rollback ได้ทันทีเมื่อพบความผิดปกติ
- Governance & Audit Trail: ทุกคำสั่งและการแปลงจะถูกบันทึกเป็น log แบบ immutable พร้อมเวอร์ชันของโมเดลและไลบรารี เพื่อง่ายต่อการตรวจสอบตามข้อกำหนดทางระเบียบวิธี เช่น GLP/ISO
สถาปัตยกรรมนี้ทำให้ LabLoop สามารถแปลงโปรโตคอลทางชีววิทยา/เคมีเป็นชุดคำสั่งหุ่นยนต์ที่ปฏิบัติได้จริงด้วยความแม่นยำสูง พร้อมกลไกยืนยันความปลอดภัยหลายชั้น ผลลัพธ์คือการลดเวลาวงจรการทดลองเชิงปฏิบัติการ (experimental cycle) ได้มากกว่า 70% ในหลายกรณี โดยยังคงรักษามาตรฐานความปลอดภัยและความน่าเชื่อถือที่จำเป็นสำหรับกระบวนการพัฒนายาเชิงทดลอง
ฮาร์ดแวร์และการอัตโนมัติในห้องปฏิบัติการ
ฮาร์ดแวร์และการอัตโนมัติในห้องปฏิบัติการ
ในเชิงปฏิบัติการ LabLoop รวมระบบฮาร์ดแวร์อัตโนมัติที่หลากหลายเพื่อให้กระบวนการจาก AI → Robot ทำงานเป็นวงปิดได้จริง ประกอบด้วยเครื่องมือหลัก เช่น liquid handlers (multi-channel pipettors, automated tip changers, acoustic dispensers), plate readers (UV/Vis, fluorescence, luminescence และ high-throughput readers), robotic arms (6-axis articulated arms, SCARA สำหรับงานเร็ว ซ้ำ ๆ) และ incubators (CO2 incubators อัตโนมัติ, shaking incubators และ automated plate hotels) ทั้งนี้การจัดวางฮาร์ดแวร์มักออกแบบเป็นรูปแบบโมดูลาร์ (modular pods) เพื่อรองรับการเพิ่มหรือลดความสามารถตามความต้องการของงานสกรีนหรือแอสเซย์ ตัวอย่างโครงเลย์เอาต์ที่ใช้บ่อยได้แก่:
- Linear workflow: สายการทำงานเป็นเส้นตรงสำหรับงานที่ต้องการลำดับขั้นตอนต่อเนื่อง (ตัวอย่าง: liquid handler → incubator → plate reader)
- Island/Cellular layout: อุปกรณ์แยกเป็นเซลล์อิสระ เชื่อมด้วย AGV/gantry robot เหมาะกับงานหลายโปรโตคอลที่ต้องการความยืดหยุ่น
- Enclosed pod: โมดูลปิดเพื่อควบคุมสภาพแวดล้อมและ biosafety มีระบบ HEPA, negative pressure และ access interlocks
- Conveyor/Carousel systems: เหมาะกับ throughput สูง เช่น การประมวลผล 1,000–10,000 ตัวอย่างต่อวันในโรงงานทดลอง (high-throughput screening)

การสื่อสารระหว่างซอฟต์แวร์ LLM/Orchestration layer และฮาร์ดแวร์เป็นหัวใจของระบบ LabLoop โดยใช้สแต็กการเชื่อมต่อหลายรูปแบบเพื่อรองรับอุปกรณ์จากผู้ผลิตต่างกัน รูปแบบที่สำคัญได้แก่:
- RESTful API / gRPC: ใช้สำหรับคำสั่งระดับสูง เช่น สั่งรันโปรโตคอล สืบค้นสถานะงาน และดึงผลลัพธ์ (เหมาะกับการผสานงานกับระบบ ELN หรือ LIMS)
- ROS / ROS2: ใช้ในกรณีที่ต้องการการควบคุมแบบหุ่นยนต์เชิงพื้นที่และการผสานระบบวิชั่น (real-time messaging, topic-based communication และ lifecycle management)
- OPC-UA / PLC / Fieldbus (EtherCAT, Modbus): ใช้สำหรับการควบคุมแบบ deterministic และการสื่อสารกับอุปกรณ์ไฟฟ้า-กลไก เช่น conveyor, incubator control, I/O interlocks
- Device drivers และ SDKs: ผู้ผลิตฮาร์ดแวร์มักมีไลบรารี SDK (C/C++, Python) หรือ drivers ที่ต้อง integrate เข้ากับ orchestration layer เพื่อให้สามารถเรียกใช้ฟังก์ชันเฉพาะของอุปกรณ์ได้
ในด้านการควบคุมเรียลไทม์ ระบบจะต้องแยกระดับคำสั่งออกเป็นสัญญาณแนวตั้งต่างกัน: คำสั่งเชิงนโยบายจาก LLM → แปลเป็น sequence ของ API calls → ส่งไปยัง real-time controller หรือ PLC สำหรับการควบคุมมอเตอร์/วาล์ว/ปั๊มที่ต้องการ determinism และ low-latency ตัวอย่างเช่น การควบคุมปริมาณการจ่ายของ liquid handler ต้องมี feedback จาก flow sensor และการปรับแก้ทันทีเพื่อรักษาความแม่นยำในระดับไมโครลิตร
ระบบ LabLoop ออกแบบให้ติดตั้งแบบ modular เพื่อรองรับการเติบโตของสตาร์ทอัพและการเปลี่ยนโปรโตคอล โดยแนวทางการติดตั้งรวมถึงการใช้ rack มาตรฐาน, quick-connect pneumatic/electrical interfaces, และ containerized automation pods ที่สามารถย้ายหรือเพิ่มได้โดยมี downtime ต่ำ นอกจากนี้ใช้ digital twin และ simulation ในการคอนฟิกเลย์เอาต์ก่อนติดตั้งจริงเพื่อลดความเสี่ยงและระยะเวลาการติดตั้ง
การบริหารความเสี่ยงและข้อกำกับด้านความปลอดภัยเป็นองค์ประกอบสำคัญของการนำหุ่นยนต์เข้าห้องปฏิบัติการ มาตรการที่นำมาใช้ประกอบด้วย:
- Biosafety infrastructure: การออกแบบตามระดับ BSL (BSL-1/2/3) โดยใช้ negative pressure, HEPA filtration, pass-through decontamination, และการแยกโซนการเข้าถึงเพื่อป้องกันการปนเปื้อนข้ามโมดูล
- Physical safety & interlocks: safety fences, light curtains, door interlocks และ E-stop ตามมาตรฐาน ISO 13850/ISO 10218 เพื่อหยุดการทำงานของหุ่นยนต์ทันทีเมื่อเกิดสถานการณ์ฉุกเฉิน
- Emergency stop และ fail-safe: ระบบ E-stop ต้องต่อกับทั้ง PLC และ orchestration layer พร้อมกลไก fallback ที่ปิดวาล์วหรือแยกพลังงาน (lockout-tagout) อัตโนมัติ
- Validation & qualification routines: ใช้มาตรฐาน IQ/OQ/PQ (Installation, Operational, Performance Qualification), การสอบเทียบเครื่องมือ (calibration), การทดสอบความแม่นยำ (accuracy/precision acceptance tests) และ regression tests ของซอฟต์แวร์หลังอัปเดต เพื่อให้มั่นใจว่าผลลัพธ์แอสเซย์ถูกต้องสม่ำเสมอ
- Data integrity & audit trail: การล็อกกิจกรรมอุปกรณ์ การเก็บ log แบบไม่เปลี่ยนแปลง (append-only), และการปฏิบัติตามข้อกำหนดเช่น 21 CFR Part 11 สำหรับการเก็บบันทึกอิเล็กทรอนิกส์ที่ใช้ในงานคลินิกหรือการพัฒนายา
สุดท้าย การจัดการการดำเนินงานจริงรวมถึงการสร้าง routine สำหรับ preventive maintenance, การตรวจสอบแบบเรียลไทม์ของสถานะอุปกรณ์ (SLA/Uptime monitoring), และการฝึกอบรมพนักงานด้านความปลอดภัยและการซ่อมบำรุง ตัวอย่างเช่น การตั้งรอบการสอบเทียบ daily/weekly/monthly สำหรับ liquid handler และการรัน validation scripts ทุกครั้งหลังการเปลี่ยนหัวจ่าย เพื่อรักษาความน่าเชื่อถือของผลการสกรีนที่นำไปสู่การลดเวลาในการพัฒนายาเชิงทดลองได้มากกว่า 70% ตามที่ระบุไว้ในกรณีใช้งานของ LabLoop
กรณีใช้งาน: สกรีนโมเลกุลและรันแอสเซย์อัตโนมัติ
กรณีใช้งาน: สกรีนโมเลกุลและรันแอสเซย์อัตโนมัติด้วย LabLoop
LabLoop ถูกนำไปใช้ในการทดลองนำร่องเพื่อสกรีนไลบรารีขนาดกลาง — ตัวอย่างแรกของโปรเจคเป็นการสกรีนไลบรารีจำนวน 12,288 โมเลกุล (32 แผ่น 384-well) โดยระบบผสาน LLM ที่แปลงโปรโตคอลเชิงทดลองเป็นคำสั่งควบคุมหุ่นยนต์ได้โดยตรง ทำให้ครอบคลุมทั้งการเตรียมสาร การจ่ายลงจาน การเพาะเลี้ยงเซลล์ (สำหรับแอสเซย์แบบ cell-based) และการอ่านสัญญาณด้วยเครื่องอ่านจาน (plate reader / high-content imager) ผลลัพธ์จากการทดลองนำร่องคือ พบผลเบื้องต้น (primary hits) 221 ชิ้น (≈1.8%) และหลังการยืนยันแบบ dose–response ยืนยันได้ 42 ชิ้น (≈0.34%) ซึ่งสอดคล้องกับอัตรา hit rate ที่คาดหวังสำหรับไลบรารีความหลากหลายระดับนี้
แอสเซย์ที่รันได้ผ่าน LabLoop ครอบคลุมทั้ง biochemical assays เช่น การยับยั้งเอนไซม์และการจับคู่โปรตีน, และ cell-based assays เช่น viability, reporter gene, และ high-content imaging สำหรับการประเมินฟีน็อตाइป์ ผลการวัดที่ได้รวมถึง IC50/EC50, Z'-factor, ค่าเปอร์เซ็นต์การอยู่รอดของเซลล์ และพารามิเตอร์ด้านฟังก์ชันเซลล์อื่น ๆ ในการทดลองนำร่อง Z'-factor เฉลี่ยของแอสเซย์เพิ่มจาก 0.45 → 0.62 หลังใช้ระบบ ซึ่งบ่งชี้คุณภาพแอสเซย์ที่ดีขึ้นและเหมาะสำหรับการสกรีนความจุสูง
สถิติเปรียบเทียบก่อนและหลังการใช้ LabLoop แสดงประโยชน์เชิงปฏิบัติและเชิงเศรษฐศาสตร์อย่างชัดเจน:
- ระยะเวลาในการพัฒนา (time-to-hit): ก่อนใช้ระบบโดยทั่วไปต้องใช้เวลาจากการออกแบบโปรโตคอลถึงการยืนยันเบื้องต้นประมาณ 21 วัน ต่อรอบ แต่หลังใช้ LabLoop ลดเหลือเฉลี่ย 6 วัน ต่อรอบ (ลดลง ~71%).
- เวลาเฉลี่ยต่อรอบการรันแอสเซย์ (ต่อแผ่น 384-well): ก่อน ~10–12 ชั่วโมง (รวมการเตรียมมือ การ pipetting และการรออินคูเบชัน) หลัง ~3.5–4 ชั่วโมง ด้วยการจัดการหุ่นยนต์และการสั่งงานโดย LLM ที่แม่นยำ.
- ค่าใช้จ่ายต่อการสกรีนหนึ่งโมเลกุล (รวมสารสิ้นเปลืองและแรงงาน): ก่อนเฉลี่ย ~1,200 บาท/โมเลกุล หลังลดเหลือ ~360 บาท/โมเลกุล (ลดลง ~70%), เนื่องจากการลดเวลาคนทำงาน การเพิ่มความหนาแน่นการรัน และการจัดการ reagent ที่มีประสิทธิภาพกว่า.
- อัตราความผิดพลาดและความทวนซ้ำ (error rate & reproducibility): อัตรา failed wells ลดจาก ~4.5% → ~0.9%; ค่าสัมประสิทธิ์ความแปรปรวน (CV) ของสัญญาณลดจาก ~18% → ~7% ทำให้ผลทดสอบมีความทวนซ้ำสูงขึ้นและลดความจำเป็นในการรันซ้ำ.
เพื่อให้เห็นภาพการทำงานของ LabLoop ในระดับ workflow ต่อไปนี้เป็นตัวอย่างลำดับการทำงานอัตโนมัติของระบบตั้งแต่การเตรียมสารจนถึงการวิเคราะห์ผล (ตัวเลขเวลาเป็นค่าเฉลี่ยจากการทดลองนำร่อง):
- 1. การจัดเตรียมไลบรารี (0.5–1 ชั่วโมง): ระบบดึงข้อมูลสาร กำหนดคอนเซ็นเทรชัน และวางแผนการใช้จานโดย LLM ที่ประมวลผลโปรโตคอลอัตโนมัติ
- 2. การจ่ายสารและสารละลายลงจาน (1–1.5 ชั่วโมง ต่อ 32 แผ่น): หุ่นยนต์ทำการ pipetting แบบความแม่นยำสูง ลดความเคลื่อนไหวและข้อผิดพลาดจากมนุษย์
- 3. การจัดการเซลล์/ปฏิกิริยา (การเพาะเลี้ยง/การบ่ม) (ขึ้นอยู่กับแอสเซย์ 1–24+ ชั่วโมง): สำหรับ cell-based assay ระบบสามารถจัดตารางการเพาะและบ่มอัตโนมัติพร้อมควบคุมสิ่งแวดล้อม
- 4. การอ่านสัญญาณ (0.5–2 ชั่วโมง): การอ่านแบบ plate reader, luminescence/fluorescence, หรือ high-content imaging เกิดขึ้นโดยอัตโนมัติและส่งข้อมูลดิบเข้าโมดูลวิเคราะห์
- 5. การวิเคราะห์ข้อมูลและการยืนยัน (0.5–1 วัน): LLM วิเคราะห์ผลเบื้องต้น เรียงลำดับ hit ตามเกณฑ์ IC50/Z'-factor และสร้างโปรโตคอลยืนยันที่หุ่นยนต์สามารถรันต่อได้ทันที
สรุปผลเชิงเปรียบเทียบ (แนวคิดเชิงตารางในรูปแบบรายการ):
- เวลาโดยรวม — ก่อน: 21 วัน | หลัง: 6 วัน | ประสิทธิผลเพิ่มขึ้น ~71%
- ต้นทุนต่อโมเลกุล — ก่อน: 1,200 บาท | หลัง: 360 บาท | ลดลง ~70%
- อัตราความผิดพลาด — ก่อน: 4.5% | หลัง: 0.9% | ดีกว่า ~5 เท่า
- ความทวนซ้ำ (CV) — ก่อน: 18% | หลัง: 7% | ความเสถียรดีขึ้นเกือบ 2.6 เท่า
โดยสรุป กรณีใช้งานการสกรีนโมเลกุลและรันแอสเซย์อัตโนมัติของ LabLoop แสดงให้เห็นทั้งการลดเวลาพัฒนา การลดต้นทุน และการเพิ่มคุณภาพข้อมูล ทำให้ทีมวิจัยสามารถเคลื่อนจากการค้นหาเบื้องต้นไปสู่การยืนยันและการพัฒนาต่อได้เร็วขึ้นอย่างมีนัยสำคัญ สำหรับองค์กรธุรกิจและนักพัฒนายา นี่หมายความถึงวงจรการพัฒนาที่สั้นลงและความเสี่ยงทางการเงินที่ลดลงเมื่อต้องจัดการพอร์ตโฟลิโอของโมเลกุลจำนวนมาก
การจัดการข้อมูลและวงจรป้อนกลับ (closed-loop feedback)
การนำระบบ LabLoop มาใช้ในห้องปฏิบัติการเชิงทดลองจำเป็นต้องมีการออกแบบ pipeline ของข้อมูล ที่ชัดเจนและทนทาน ตั้งแต่การเก็บผลการทดลองเบื้องต้นจนถึงการป้อนกลับเพื่อปรับโปรโตคอลแบบอัตโนมัติ ระบบต้องรองรับทั้ง metadata ของตัวอย่าง ข้อมูลดิบ (raw data) และข้อมูลที่ผ่านการประมวลผล (processed data) รวมถึงการจัดเก็บ provenance และ audit trail อย่างเป็นระบบ เพื่อให้สามารถตรวจสอบที่มาของข้อมูลและการตัดสินใจของโมเดลได้ในระดับองค์กรและเพื่อการกำกับดูแล
1) การเก็บและจัดการข้อมูลทดลอง: metadata, raw data, processed data
- Metadata: ระบุฟิลด์หลัก เช่น sample ID (UUID), donor/compound ID, plate ID, well coordinates, assay type, operator, timestamp, instrument ID และโปรโตคอลเวอร์ชัน การเก็บ metadata ที่ครบถ้วนช่วยให้สามารถจับคู่ผลการทดลองกับบริบทการทดลองได้อย่างแม่นยำ
- Raw data: ข้อมูลดิบจากเครื่องมือ (เช่น ค่า fluorescence, chromatograms, spectra, images) ถูกนำเข้าแบบไม่ปรับแต่งพร้อม checksum และบันทึกเวอร์ชันเพื่อรักษาความสมบูรณ์ของข้อมูล
- Processed data: ข้อมูลที่ผ่านการทำความสะอาด (noise reduction), การปรับค่าสเกล, การสกัดฟีเจอร์ และการคำนวณตัวชี้วัด (e.g., IC50, %inhibition) จะถูกรักษาเป็นชุดข้อมูลแยกและเชื่อมโยงกับ raw data และ metadata ผ่าน provenance links
- มาตรฐานและสคีมา: ใช้มาตรฐานเช่น FAIR principles, ISA-Tab/ISA-JSON, AnIML หรือ Allotrope เพื่อความเข้ากันได้ระหว่างระบบและการแลกเปลี่ยนข้อมูลกับพันธมิตรภายนอก
- การติดตามตัวอย่าง: บาร์โค้ด/QR, plate maps และการบันทึกสถานะตัวอย่างใน LIMS/ELN ช่วยลดความผิดพลาดของมนุษย์และรองรับการสเกลการรันแอสเซย์อัตโนมัติ
2) การใช้ ML และ Active Learning เพื่อเลือกการทดลองถัดไป
ภายในวงจรปิด ผลการทดลองที่ถูกประมวลผลจะถูกป้อนเข้าโมดูลการเรียนรู้ของเครื่อง (ML) ซึ่งอาจประกอบด้วยโมเดลหลายประเภท เช่น Gaussian processes/Bayesian models สำหรับการหาช่วงค่าที่คาดการณ์ได้พร้อมความไม่แน่นอน, deep learning สำหรับการตีความภาพหรือข้อมูลเชิงซ้อน และ surrogate models สำหรับการเพิ่มความเร็วการคาดการณ์
กระบวนการ active learning จะใช้ฟังก์ชันการได้มาซึ่งข้อมูล (acquisition function) เช่น expected improvement, uncertainty sampling หรือ upper confidence bound เพื่อเลือกชุดตัวอย่างหรือการทำแอสเซย์ถัดไปที่ให้ข้อมูลคุ้มค่าที่สุด โดยในงานสกรีนโมเลกุลและรันแอสเซย์เชิงทดลอง พบว่าแนวทางนี้สามารถลดจำนวนการทดลองที่ต้องทำได้อย่างมีนัยสำคัญ — ในหลายงานวิจัยเชิงอุตสาหกรรม Active learning สามารถลดการทดลองได้ประมาณ 50–80% ขึ้นกับความซับซ้อนของปัญหาและคุณภาพของฟีเจอร์
- การวนลูป (closed-loop): โมเดลทำนายผลและความไม่แน่นอน → อัลกอริทึมเลือกการทดลองถัดไป → Scheduler ส่งงานไปยังหุ่นยนต์/อุปกรณ์ → เรียกใช้งานและเก็บผล → ผลกลับเข้าสู่โมเดลเพื่ออัพเดต
- การอัพเดตโมเดล: รองรับทั้ง batch retraining และ online learning เพื่อลด latency ในการตัดสินใจ โดยระบบสามารถกำหนดความถี่การ retrain เช่น ทุก N รอบทดลอง หรือเมื่อความคลาดเคลื่อนของโมเดลสูงเกิน threshold
- ตัวอย่างเชิงปฏิบัติ: หากเป้าหมายคือการค้นหาโมเลกุลที่ให้การยับยั้ง >90% ระบบอาจเริ่มด้วยชุดตัวอย่างแบบสำรวจ (exploration) แล้วเปลี่ยนไปเป็น exploitation โดยอาศัย acquisition function เพื่อลดจำนวนแผ่น (plates) ที่ต้องใช้
3) การรวมระบบกับ LIMS, ELN และข้อกำกับดูแล (compliance)
การทำงานร่วมกับระบบองค์กรเป็นหัวใจสำคัญของการผลิตเชิงห้องปฏิบัติการที่เชื่อถือได้ LabLoop ต้องเชื่อมต่อกับ LIMS และ ELN ผ่าน API มาตรฐาน (RESTful, gRPC) หรือผ่านการแลกเปลี่ยนไฟล์ตามสคีมา (ISA-Tab/JSON) ระบบควรรองรับการซิงค์ข้อมูลอย่างเรียลไทม์ เช่น สถานะงาน สถานะตัวอย่าง และผลการทดลอง พร้อมการบันทึก audit trail และ metadata ของการเปลี่ยนแปลงทุกครั้ง
- ความปลอดภัยและการเข้าถึง: การเข้ารหัสข้อมูลทั้งที่พักและระหว่างทาง, การจัดการสิทธิ์แบบ role-based access control (RBAC) และการลงนามอิเล็กทรอนิกส์ตามข้อกำหนด เช่น 21 CFR Part 11
- การตรวจสอบย้อนกลับและเวอร์ชัน: ระบบต้องเก็บเวอร์ชันของโปรโตคอล โมเดล และ pipeline ข้อมูล เพื่อให้การทำซ้ำ (reproducibility) และการตรวจสอบจากหน่วยงานกำกับเป็นไปได้
- การปฏิบัติตามมาตรฐาน: GLP/GMP readiness โดยการรักษา audit logs, timestamps, checksums และการสำรองข้อมูลตามนโยบายองค์กร
- การผสานกับอุปกรณ์: ใช้โปรโตคอลมาตรฐานในการสื่อสารกับหุ่นยนต์และเครื่องมือ (เช่น OPC UA, MQTT หรือ vendor API) เพื่อให้ scheduler/robot controller สามารถรับคำสั่งที่แปลงมาจาก LLM/translator อย่างปลอดภัยและตรวจสอบได้
เมื่อองค์ประกอบทั้งหมดนี้ทำงานร่วมกันในรูปแบบวงจรปิด (closed-loop) ผลลัพธ์คือการเพิ่มประสิทธิภาพเชิงทดลองอย่างชัดเจน: ลดเวลาการค้นหาและพัฒนายาเชิงทดลอง (ตามที่รายงาน LabLoop ลดเวลาลงถึง 70% ในบางกรณี), เพิ่มความแม่นยำในการเลือกตัวอย่าง, และสร้างระบบที่พร้อมรับการตรวจสอบเชิงกฎระเบียบ ซึ่งเป็นคุณสมบัติที่สำคัญสำหรับการนำไปใช้ในระดับอุตสาหกรรมและเชิงพาณิชย์
ผลกระทบทางธุรกิจ ตลาด และการกำกับดูแล
ผลกระทบทางธุรกิจ: ต้นทุน เวลา และโอกาสทางการค้า
การนำระบบ LabLoop ซึ่งผสาน LLM → Robot ไปใช้ในห้องปฏิบัติการมีศักยภาพที่จะพลิกโฉมกระบวนการวิจัยและพัฒนายาอย่างมีนัยสำคัญ จากข้อมูลเบื้องต้นที่บริษัทระบุว่าเวลาการทดลองเชิงทดลอง (preclinical assay) ถูกลดลงได้ถึง 70% ผลลัพธ์เช่นนี้หมายความว่า รอบการค้นพบและการคัดกรองโมเลกุล (lead discovery & screening) ที่เดิมใช้เป็นเดือนหรือเป็นปี อาจย่นเหลือเป็นสัปดาห์ถึงไม่กี่เดือน การเร่งความเร็วนี้ส่งผลโดยตรงต่อ time-to-market ของโครงการพัฒนายา ลดโอกาสที่คู่แข่งจะเข้ามาบดบัง และเพิ่มมูลค่าต่อบริษัทผู้พัฒนายา นอกจากนี้การอัตโนมัติยังช่วยลดต้นทุนแรงงานที่มีค่าใช้จ่ายสูงและลดการใช้สารเคมี/วัสดุสิ้นเปลืองผ่านการเพิ่มประสิทธิภาพการรันแอสเซย์ ทำให้ต้นทุน R&D โดยรวมลดลงอย่างมีนัยสำคัญ (ประเมินได้เป็นสัดส่วนที่อาจอยู่ในช่วง 20–50% ขึ้นกับการใช้งานและสเกล)
โมเดลธุรกิจและแนวทางหาเงินทุน
LabLoop สามารถนำเสนอโมเดลธุรกิจได้หลายรูปแบบเพื่อสร้างรายได้และขยายตลาด ได้แก่
- SaaS + Hardware : รับค่าใช้บริการซอฟต์แวร์ LLM แบบสมัครสมาชิกร่วมกับการขายหรือเช่าเครื่องมือหุ่นยนต์ และบริการบำรุงรักษา
- Lab-as-a-Service (LaaS) : ให้บริการรันแอสเซย์ตามสั่งแบบเป็นบริการต่อครั้ง เหมาะกับสตาร์ทอัพยาขนาดเล็กและสถาบันวิจัย
- Partnership & Revenue Share : ร่วมมือกับบริษัทเภสัชกรรมหรือ CRO เพื่อพัฒนาโมดูลเฉพาะกิจและแบ่งรายได้จากผลงานที่สำเร็จ
- Licensing : ให้สิทธิใช้งานโมเดลการแปลงโปรโตคอลหรือ API แก่ผู้ให้บริการระบบห้องปฏิบัติการรายอื่น
ด้านการระดมทุน มีทางเลือกตั้งแต่เงินทุนจากนักลงทุนเอกชน (VC), กองทุนบริษัทใหญ่ในอุตสาหกรรมเภสัชและไบโอเทค, เงินทุนสนับสนุนภาครัฐและทุนวิจัย รวมถึงการทำสัญญาระยะยาวกับลูกค้าองค์กรที่ยอมจ่ายล่วงหน้าเพื่อแลกกับส่วนลดค่าบริการ การวางตำแหน่งเป็นผู้ให้บริการครบวงจร (one-stop-shop) จะช่วยเพิ่มความน่าสนใจต่อผู้ลงทุน
การแข่งขันในระดับภูมิภาคและโลก
ตลาดระบบอัตโนมัติในห้องปฏิบัติการของโลกมีผู้เล่นทั้งซอฟต์แวร์และฮาร์ดแวร์ เช่น Emerald Cloud Lab, Strateos, Synthace, และ Opentrons ซึ่งต่างมีจุดแข็ง (เช่น ขนาดเครือข่ายลูกค้า เทคโนโลยีหุ่นยนต์เฉพาะทางหรือแพลตฟอร์มคลาวด์ที่成熟) สำหรับ LabLoop ทางเลือกเชิงกลยุทธ์ที่ช่วยสร้างความได้เปรียบรวมถึงการเน้นบริการที่ตอบโจทย์ผู้ใช้ในภูมิภาค (เช่น การสนับสนุนภาษาไทย การปฏิบัติตามกฎระเบียบท้องถิ่น และต้นทุนการดำเนินงานที่ต่ำกว่าในบางประเทศ) รวมทั้งการจับมือกับ CRO และสถาบันวิจัยในอาเซียนเพื่อขยายฐานลูกค้า ความท้าทายสำคัญคือการสร้างความเชื่อมั่นว่าแพลตฟอร์มสามารถทำงานร่วมกับมาตรฐานสากลและให้ผลที่เทียบเท่าหรือดีกว่าคู่แข่งต่างประเทศ
ข้อกำกับดูแลและการยืนยันความถูกต้องของข้อมูล (Validation)
การนำระบบอัตโนมัติและ LLM เข้ามาใช้ในงานที่เกี่ยวข้องกับการพัฒนายาอยู่ภายใต้กรอบข้อบังคับและมาตรฐานหลายด้านที่ต้องปฏิบัติตามอย่างเคร่งครัด เช่น GxP (รวม GLP, GMP, GCP ตามบริบท), กฎระเบียบของหน่วยงานกำกับดูแลระดับชาติและสากล (เช่น FDA, EMA, สำนักงานคณะกรรมการอาหารและยาในไทย), ไปจนถึงข้อกำหนดด้านบันทึกและลายมือชื่ออิเล็กทรอนิกส์ (เช่น 21 CFR Part 11) และ Annex 11 ของสหภาพยุโรป ทั้งนี้ประเด็นสำคัญที่ต้องให้ความสำคัญประกอบด้วย:
- การรับรองระบบและอุปกรณ์ (IQ/OQ/PQ) : ต้องยืนยันว่าส่วนฮาร์ดแวร์และการรวมระบบทำงานตรงตามสเปก
- Computerized System Validation (CSV) : ซอฟต์แวร์ LLM และ pipeline ต้องผ่านการทดสอบความถูกต้อง ฟังก์ชันการทำงาน และการจัดการเวอร์ชัน
- การตรวจสอบความมั่นคงและความสมบูรณ์ของข้อมูล : เก็บข้อมูลดิบ (raw data), บันทึก audit trail, ปฏิบัติตามหลัก ALCOA+ เพื่อให้สามารถตรวจสอบย้อนกลับได้
- การตรวจสอบและประเมินโมเดล : ต้องมีการวางแผน validation สำหรับ LLM (เช่น ชุดข้อมูลอ้างอิง, ประเมินความแม่นยำ/ความปลอดภัยของคำสั่งที่แปลงเป็นการควบคุมหุ่นยนต์) รวมถึงการมี human-in-the-loop สำหรับการอนุมัติขั้นตอนเสี่ยงสูง
- ความเป็นส่วนตัวและการปกป้องข้อมูล : ปฏิบัติตาม PDPA ในไทย, GDPR/ HIPAA เมื่อเกี่ยวข้องกับข้อมูลส่วนบุคคลหรือข้อมูลผู้ป่วย
เพื่อให้ระบบได้รับการยอมรับทางการค้าและการกำกับดูแล LabLoop ควรดำเนินการตามขั้นตอนเชิงปฏิบัติ ได้แก่ การจัดทำแผนการยืนยันความถูกต้อง (validation master plan), การทดสอบภายใต้เงื่อนไขจริงร่วมกับพันธมิตรด้านเภสัชกรรม, การเก็บหลักฐานผลลัพธ์ในรูปแบบที่ตรวจสอบได้ และการเปิดเผยแผนการควบคุมความเสี่ยงของโมเดลต่อหน่วยงานกำกับดูแล การมีพันธมิตรเชิงกลยุทธ์ (CRO, องค์กรทดสอบอิสระ) จะช่วยเร่งการยอมรับจากตลาดและลดช่องว่างด้านการปฏิบัติตามข้อกำกับดูแล
สรุป : เชิงธุรกิจ LabLoop มีโอกาสสร้างมูลค่าเชิงเศรษฐศาสตร์สูงจากการลดเวลาและต้นทุน R&D แต่ความสำเร็จเชิงพาณิชย์ในระดับภูมิภาคและสากลขึ้นอยู่กับการออกแบบโมเดลรายได้ที่เหมาะสม การจัดหาเงินทุนเชิงยุทธศาสตร์ และการปฏิบัติตามมาตรฐานด้านการกำกับดูแลและการยืนยันความถูกต้องอย่างครอบคลุมเพื่อสร้างความเชื่อมั่นแก่ลูกค้าและหน่วยงานกำกับดูแล
ข้อจำกัด ความท้าทาย และอนาคตของ LabLoop
ข้อจำกัด ความท้าทาย และอนาคตของ LabLoop
ระบบ LabLoop ที่ผสาน Large Language Models (LLMs) เข้ากับการควบคุมหุ่นยนต์ในห้องปฏิบัติการเปิดโอกาสด้านประสิทธิภาพและความเร็วในการรันแอสเซย์ แต่ก็ยังเผชิญข้อจำกัดเชิงเทคนิคที่สำคัญ โดยเฉพาะความแม่นยำของ LLM ในบริบททางวิทยาศาสตร์ที่ต้องการความละเอียดสูง LLM ถูกออกแบบมาเพื่อเรียนรู้เชิงสถิติของภาษา จึงมีความเสี่ยงที่จะตีความโปรโตคอลผิดหรือแปลคำสั่งเป็นพารามิเตอร์ทางห้องปฏิบัติการที่ไม่เหมาะสม ตัวอย่างผลลัพธ์ที่อาจเกิดขึ้นได้ เช่น ปริมาตรสารละลายที่ผิดพลาด การตั้งอุณหภูมิ/เวลาไม่ตรงตามเงื่อนไข หรือการเลือกรีเอเจนต์ที่ไม่เหมาะสม ซึ่งในงานทดลองทางเภสัชกรรมอาจนำไปสู่ผลลัพธ์ที่บิดเบือนหรือความเสียหายต่อตัวอย่างได้ ดังนั้นการวัดอัตราข้อผิดพลาด การจัดทำ benchmark เฉพาะด้าน และการทดสอบด้วยกรณีทดสอบเชิงลึกเป็นสิ่งจำเป็นก่อนใช้งานเชิงผลิต
ในเชิงปฏิบัติการ LabLoop ยังต้องเผชิญความท้าทายด้านการบูรณาการ (integration complexity) กับอุปกรณ์ห้องปฏิบัติการที่หลากหลายทั้งในระดับฮาร์ดแวร์ (pipettors, plate readers, incubators) และซอฟต์แวร์ (LIMS, ELN, ERP) การเชื่อมต่อแบบเรียลไทม์กับอุปกรณ์ที่มีโปรโตคอลหลากหลายและเฟิร์มแวร์ที่ต่างกันเพิ่มความซับซ้อนในการพัฒนา ตัวอย่างเช่น การสื่อสารผ่านโปรโตคอลเฉพาะของผู้ผลิตหรือการจัดการสถานะข้อผิดพลาดของอุปกรณ์ นอกจากนั้นค่าใช้จ่ายเริ่มต้นสำหรับการติดตั้งห้องปฏิบัติการอัตโนมัติและโซลูชัน AI อาจอยู่ในระดับตั้งแต่หลายแสนถึงหลายล้านบาท ขึ้นกับขนาดระบบและมาตรฐานความปลอดภัยที่ต้องการ สถานการณ์นี้ทำให้ต้องมีการวิเคราะห์ค่าใช้จ่าย-ผลตอบแทน (TCO/ROI) อย่างรอบคอบ โดยเฉพาะเมื่อองค์กรต้องการขยายสเกลการใช้งาน
อีกด้านที่มักถูกมองข้ามคือทรัพยากรบุคคลและทักษะที่จำเป็น ทีมงานต้องมีความสามารถข้ามสาขา ทั้งด้านวิทยาศาสตร์การทดลอง วิศวกรรมหุ่นยนต์ และวิทยาการข้อมูล การขาดแคลนบุคลากรที่สามารถทำงานแบบ multidisciplinary นี้อาจชะลอการปรับใช้ระบบ นอกจากนี้ประเด็นการปฏิบัติตามกฎระเบียบ (เช่น GLP/GMP/ISO) และการจัดการข้อมูล (data governance, provenance, audit trail) ยังเป็นอุปสรรคที่ต้องให้ความสำคัญในการนำ LabLoop ไปใช้ในบริบทที่เกี่ยวข้องกับการพัฒนายา
เพื่อบรรเทาความเสี่ยงและผลักดันการพัฒนาต่อไป LabLoop ควรเดินหน้าตามแนวทางเชิงกลยุทธ์ที่รวมทั้งเทคนิคและความร่วมมือระดับสถาบัน ดังนี้
- Validation frameworks และ certification: พัฒนาชุดการทดสอบมาตรฐานสำหรับประเมินความแม่นยำของการแปลงโปรโตคอลเป็นคำสั่งหุ่นยนต์ รวมถึงขอการรับรองจากหน่วยงานภายนอก เช่น มาตรฐาน ISO หรือการรับรองจากสถาบันทดสอบอิสระ เพื่อสร้างความเชื่อมั่นในเชิงการค้า
- Human-in-the-loop และ safety interlocks: บังคับใช้จุดตรวจสอบที่ต้องมีการยืนยันจากผู้เชี่ยวชาญก่อนดำเนินการขั้นตอนที่มีความเสี่ยงสูง ติดตั้งเซฟตี้ฮาร์ดแวร์และซอฟต์แวร์ (เช่น emergency stop, parameter bounds checking) เพื่อป้องกันการกระทำอัตโนมัติที่อาจก่อความเสียหาย
- Federated learning และการปรับโมเดลเฉพาะโดเมน: ใช้แนวทาง federated learning เพื่อให้หลายองค์กรหรือห้องปฏิบัติการสามารถร่วมปรับปรุงโมเดลได้โดยไม่ต้องแลกเปลี่ยนข้อมูลดิบ ช่วยเพิ่มความหลากหลายของกรณีทดสอบและลดความเสี่ยงจาก overfitting
- การขยายชนิดของแอสเซย์และการจำลอง (simulation & digital twin): ลงทุนในชุดทดสอบจำลองและ digital twin ของงานทดลองเพื่อรันสคริปต์ก่อนใช้งานจริง การจำลองช่วยลดความเสี่ยงและเร่งรอบการทดสอบ
- การร่วมมือกับสถาบันวิจัยและ CROs: จัดตั้งพันธมิตรเชิงกลยุทธ์กับมหาวิทยาลัย ศูนย์วิจัย และผู้ให้บริการ CRO เพื่อร่วมทดสอบในสภาพแวดล้อมต่าง ๆ และสร้างข้อมูลอ้างอิง (ground truth) สำหรับการปรับปรุงโมเดล
สำหรับ road map ฟีเจอร์ในอนาคต LabLoop สามารถจัดลำดับการพัฒนาเป็นระยะได้ดังนี้
- ระยะสั้น (3–12 เดือน): พัฒนา validation test-suite, เพิ่ม human-in-the-loop checkpoints, สร้าง audit log และระบบ rollback ของคำสั่งอัตโนมัติ
- ระยะกลาง (12–24 เดือน): เปิดใช้ federated learning pilot กับพันธมิตรเชิงวิจัย, ขยายรองรับชนิดแอสเซย์เพิ่มเติม (biochemical, cell-based), พัฒนาตัวตรวจจับ anomalous behavior แบบเรียลไทม์
- ระยะยาว (2–5 ปี): บรรลุการรับรองมาตรฐานสากลสำหรับการใช้งานเชิงคลินิก/พาณิชย์, ขยายเครือข่ายการติดตั้งระดับภูมิภาค, พัฒนา digital twin ระดับชั้นการผลิตและ integration กับระบบซัพพลายเชน
สรุปได้ว่า LabLoop มีศักยภาพสูงในการย่นเวลาและลดต้นทุนของงานทดลอง แต่การนำไปใช้งานเชิงพาณิชย์อย่างปลอดภัยและยั่งยืนจำเป็นต้องมีการลงทุนในระบบตรวจสอบ ความร่วมมือกับหน่วยงานภายนอก และการพัฒนาเทคโนโลยีรองรับความแม่นยำสูง การผสมผสานระหว่าง automation, governance และ human oversight จะเป็นกุญแจสำคัญที่ทำให้ LabLoop ขยับจากการสาธิตเชิงเทคโนโลยีสู่การใช้งานเชิงอุตสาหกรรมได้จริง
บทสรุป
สตาร์ทอัพไทย LabLoop นำเสนอแนวทางปิดวงจร AI→Robot ที่อาจเปลี่ยนรูปแบบการทดลองเชิงทดลองโดยเฉพาะการสกรีนโมเลกุลและรันแอสเซย์อัตโนมัติ โดยใช้ LLM แปลงโปรโตคอลเชิงปฏิบัติการเป็นคำสั่งควบคุมหุ่นยนต์เพื่อสั่งงานอุปกรณ์ในห้องปฏิบัติการ (เช่น liquid handlers, plate readers, และระบบจัดการตัวอย่าง) อย่างต่อเนื่องจากการออกแบบโมเลกุล → การจัดเตรียมแอสเซย์ → การรันทดลอง → การเก็บและวิเคราะห์ข้อมูล ผลที่ได้ช่วยเพิ่มความเร็วของกระบวนการค้นหาตัวนำยาหรือการสกรีนไลบรารีของโมเลกุลอย่างมีประสิทธิภาพ โดยบริษัทรายงานว่าสามารถลดเวลาพัฒนายาเชิงทดลองได้ถึงประมาณ 70% และรองรับการรันแอสเซย์จำนวนมาก (high‑throughput) ที่เคยใช้เวลาหลายเดือนให้เสร็จภายในสัปดาห์หรือสัปดาห์เดียวในหลายขั้นตอน
แม้โซลูชันเช่น LabLoop จะมีศักยภาพเชิงธุรกิจสูง ทั้งในแง่การลดต้นทุน การเพิ่มความสามารถในการทดลอง และการเชื่อมต่อกับผู้ให้บริการวิจัย (CROs) และอุตสาหกรรมเภสัชกรรม แต่การนำไปใช้ในวงกว้างจำเป็นต้องควบคู่กับการพิสูจน์ความถูกต้องทางวิทยาศาสตร์และการกำกับดูแลอย่างเข้มงวด ได้แก่ การยืนยันความแม่นยำและความทวนซ้ำของผล (reproducibility), การจัดการข้อมูลและการเก็บรักษาเมตาดาต้าเพื่อความโปร่งใส, การปฏิบัติตามมาตรฐาน GLP/GxP และการได้รับการรับรองจากหน่วยงานกำกับดูแล ทั้งนี้ยังต้องพิจารณาประเด็นความปลอดภัยทางชีวภาพ จริยธรรม และผลกระทบต่อแรงงานในห้องปฏิบัติการ การพัฒนาเชิงอนาคตจึงควรเน้นการทดลองนำร่องร่วมกับสถาบันวิจัยและภาคอุตสาหกรรม การ Benchmark โดยบุคคลที่สาม และการตั้งมาตรฐานสากลเพื่อให้เทคโนโลยีนี้กลายเป็นเครื่องมือที่น่าเชื่อถือและพร้อมใช้งานเชิงพาณิชย์อย่างรับผิดชอบ



