
ในยุคที่ช่องโหว่ซอฟต์แวร์กลายเป็นประตูสำคัญสู่การโจมตีทางไซเบอร์ การนำปัญญาประดิษฐ์มาช่วยค้นหาและแก้ไขบั๊กเชิงความปลอดภัยจึงไม่ได้เป็นเพียงทางเลือก แต่กลายเป็นความจำเป็น Anthropic บริษัทด้านปัญญาประดิษฐ์ชั้นนำล่าสุดประกาศเปิดตัวโซลูชันใหม่ที่ผสานความสามารถของโมเดลภาษาใหญ่ (LLM) เข้ากับการวิเคราะห์โค้ดเชิงลึก เพื่อไม่เพียงแต่ตรวจจับช่องโหว่ แต่ยังเสนอแพตช์และแนวทางแก้ไขที่พร้อมใช้ ภายใต้คำสัญญาว่าจะเสริมความเข้มแข็งให้กับกระบวนการ DevSecOps ตั้งแต่การสแกนในขั้นตอน CI/CD ไปจนถึงการตอบสนองต่อเหตุการณ์จริง
บทความนี้จะพาผู้อ่านสำรวจฟีเจอร์หลักของเครื่องมือใหม่ ประเมินประสิทธิภาพและความแม่นยำในการตรวจจับบั๊กเชิงความปลอดภัย เปรียบเทียบกับโซลูชันคู่แข่งทั้งเชิงเทคนิคและเชิงต้นทุน รวมถึงเสนอแนวทางปฏิบัติจริงสำหรับองค์กรที่ต้องการนำไปใช้อย่างปลอดภัยและยั่งยืน—รวมถึงกลยุทธ์การผนวกรวมเข้ากับระบบ CI/CD, การจัดการผลลัพธ์ (triage) เพื่อลด false positives, และข้อพิจารณาด้านความเป็นส่วนตัวของซอร์สโค้ดในสภาพแวดล้อมต่าง ๆ
บทนำ: ทำไมบั๊กซอฟต์แวร์ยังเป็นความเสี่ยงเชิงธุรกิจ
บทนำ: ทำไมบั๊กซอฟต์แวร์ยังเป็นความเสี่ยงเชิงธุรกิจ
บั๊กและช่องโหว่ในซอฟต์แวร์ยังคงเป็นหนึ่งในความเสี่ยงเชิงธุรกิจที่สำคัญที่สุดสำหรับองค์กรทุกขนาด ไม่ว่าจะเป็นการสูญเสียทางการเงิน การเสื่อมเสียชื่อเสียง หรือความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ งานวิจัยหลายชิ้นชี้ว่าเหตุการณ์ละเมิดข้อมูลและความผิดพลาดของระบบมักมีรากมาจากข้อบกพร่องในซอฟต์แวร์: รายงาน IBM Cost of a Data Breach ระบุว่า ค่าใช้จ่ายเฉลี่ยของการละเมิดข้อมูลต่อเหตุการณ์อยู่ที่ประมาณ 4.45 ล้านดอลลาร์สหรัฐ และระยะเวลาเฉลี่ยในการตรวจพบและตอบสนองต่อการละเมิด (mean breach lifecycle) ยังคงนับเป็นหลายร้อยวัน ซึ่งสะท้อนให้เห็นถึงผลกระทบทั้งระยะสั้นและระยะยาวที่เกิดจากบั๊กในโค้ด

ตัวอย่างเหตุการณ์จริงสะท้อนความร้ายแรงของปัญหานี้อย่างชัดเจน เช่น ช่องโหว่สำคัญในไลบรารีและบริการที่ถูกใช้งานอย่างแพร่หลาย (ตัวอย่างเช่น Heartbleed, Log4Shell และช่องโหว่ใน Apache Struts ที่นำไปสู่เหตุการณ์การละเมิดข้อมูลขององค์กรรายใหญ่) เหตุการณ์เหล่านี้ไม่ได้เป็นเพียงปัญหาทางเทคนิค แต่สร้างผลทางธุรกิจเช่นการสูญเสียลูกค้า ค่าปรับจากหน่วยงานกำกับดูแล และต้นทุนในการฟื้นฟูระบบและการสื่อสารกับผู้มีส่วนได้ส่วนเสีย
สาเหตุเชิงรากของปัญหามักมาจากปัจจัยหลายประการที่ทับซ้อนกัน ได้แก่ ความซับซ้อนของซอฟต์แวร์ ที่เพิ่มขึ้นอย่างต่อเนื่อง การพึ่งพาองค์ประกอบจากภายนอก (third‑party libraries และ open source) และความกดดันทางธุรกิจให้ปล่อยโค้ดเร็วเพื่อก้าวสู่ตลาด (speed‑to‑market) ซึ่งบางครั้งขัดแย้งกับแนวคิดการพัฒนาเชิงความปลอดภัยตั้งแต่ต้น (shift‑left) ผลลัพธ์คือจุดอ่อนที่หลุดรอดการตรวจจับด้วยการทดสอบแบบแมนนวลและกระบวนการตรวจสอบแบบเดิม
ด้วยสภาพแวดล้อมเช่นนี้ การพึ่งพากระบวนการแบบแมนนวลเพียงอย่างเดียวไม่เพียงพออีกต่อไป องค์กรจึงต้องผสานแนวทางปฏิบัติด้านความปลอดภัยเข้ากับการพัฒนาและนำเทคโนโลยีอัตโนมัติมาใช้เพื่อเพิ่มประสิทธิภาพและความสม่ำเสมอในการตรวจจับปัญหา ตัวอย่างเช่น การนำระบบวิเคราะห์โค้ดแบบ Static Application Security Testing (SAST), Dynamic Application Security Testing (DAST), Software Composition Analysis (SCA) รวมถึงการใช้โมเดล AI ในการวิเคราะห์โค้ดและหาแพตเทิร์นความเสี่ยง สามารถช่วยลดเวลาตรวจพบและระดับความเสี่ยงได้อย่างมีนัยสำคัญ
สรุปคือ บั๊กซอฟต์แวร์ไม่ใช่เรื่องเทคนิคเล็กๆ อีกต่อไป แต่เป็นความเสี่ยงเชิงธุรกิจที่มีผลทั้งทางการเงิน ความเชื่อมั่นของลูกค้า และการปฏิบัติตามกฎระเบียบ องค์กรที่ต้องการลดความเสี่ยงนี้จึงจำเป็นต้องรวมการวิเคราะห์โค้ดเชิงความปลอดภัยเข้ากับกระบวนการพัฒนาตั้งแต่ต้น และมองหาเครื่องมืออัตโนมัติที่สามารถเสริมความสามารถของทีมรักษาความปลอดภัยและนักพัฒนาได้อย่างมีประสิทธิผล
- ขนาดและผลกระทบเชิงธุรกิจ: ค่าใช้จ่ายและเวลาที่เสียหายจากการละเมิดข้อมูลและบั๊กยังคงสูง
- ต้นตอของปัญหา: ความซับซ้อนของซอฟต์แวร์และแรงกดดันด้านความเร็วในการปล่อยโค้ด
- ความจำเป็นของเครื่องมืออัตโนมัติ: การวิเคราะห์โค้ดอัตโนมัติและ AI เป็นส่วนสำคัญในการลดความเสี่ยงและเพิ่มความมั่นคงของซอฟต์แวร์
Anthropic เปิดตัวอะไรบ้าง: ภาพรวมของเครื่องมือใหม่
Anthropic เปิดตัวอะไรบ้าง: ภาพรวมของเครื่องมือใหม่
Anthropic เปิดตัวชุดเครื่องมือรักษาความปลอดภัยสำหรับซอฟต์แวร์ที่ออกแบบมาเพื่อรองรับการตรวจจับและจัดการบั๊กเชิงรุก โดยมีเป้าหมายชัดเจนในการยกระดับกระบวนการพัฒนาให้ปลอดภัยขึ้นตั้งแต่ต้นน้ำจนถึงการส่งมอบผลิตภัณฑ์ เครื่องมือชุดนี้เน้นการใช้ความสามารถของ large language models (LLMs) ในการวิเคราะห์โค้ด, อธิบายปัญหาเชิงบริบท และแนะนำแพตช์เพื่อเพิ่มความเร็วในการแก้ไข โดย Anthropic ระบุว่าเบื้องต้นสามารถลดเวลาในการค้นหาและวิเคราะห์ช่องโหว่ลงได้ถึง ประมาณ 30–40% ในสภาพแวดล้อมการทดสอบภายในทีมพัฒนา (ตามที่บริษัทรายงาน)
ในเชิงฟีเจอร์หลัก Anthropic ได้จัดกลุ่มความสามารถไว้ตามสี่ฟังก์ชันสำคัญ ได้แก่:
- Detect — สแกนโค้ดทั้งในระดับไฟล์และรีโป (รวมทั้ง dependency graph) เพื่อค้นหาจุดบกพร่อง สัญญาณโค้ดที่เสี่ยง และช่องโหว่ด้านความปลอดภัยด้วยการวิเคราะห์เชิงสถิติและเชิงภาษาธรรมชาติ
- Explain — ให้คำอธิบายเชิงบริบทสำหรับบั๊กหรือช่องโหว่ที่พบ ช่วยให้ทีมที่ไม่เชี่ยวชาญด้านความปลอดภัยเข้าใจสาเหตุ ผลกระทบ และระดับความร้ายแรง พร้อมตัวอย่างโค้ดที่เกี่ยวข้อง
- Suggest — แนะนำแพตช์อัตโนมัติหรือโค้ดตัวอย่างสำหรับการแก้ไข พร้อมคำแนะนำด้านการทดสอบหลังแก้ไข (unit/integration tests) และสามารถสร้าง pull request ที่มีคำอธิบายการเปลี่ยนแปลงอัตโนมัติ
- Integrate — ผสานรวมกับ pipeline ที่มีอยู่ได้โดยตรง ทั้งการเชื่อมต่อกับระบบ CI/CD, repository hosts (เช่น GitHub/GitLab/Bitbucket), และระบบแจ้งเตือนแบบ webhook/Slack/Teams เพื่อให้การตรวจจับและการแจ้งเตือนเกิดขึ้นในจังหวะของการพัฒนา
รูปแบบการให้บริการของ Anthropic ออกแบบให้ตอบโจทย์องค์กรหลากหลายขนาดและข้อกำหนดด้านความปลอดภัย: มีทั้งโมเดล SaaS สำหรับการเริ่มต้นที่รวดเร็ว, ตัวเลือก On‑premise สำหรับองค์กรที่มีข้อจำกัดด้านข้อมูลและต้องการเก็บข้อมูลภายในเครือข่าย, และโซลูชัน Hybrid ที่อนุญาตให้รันเอเจนต์ภายในองค์กรเพื่อสแกนข้อมูลภายในในขณะที่ใช้บริการคลาวด์สำหรับการประมวลผล LLM บางส่วน การรองรับทั้งสามรูปแบบทำให้สามารถรวมระบบเข้ากับ pipeline ที่มีอยู่ได้ เช่น การติดตั้งเป็น Git hook, การรันเป็นขั้นตอนใน Jenkins/GitHub Actions/GitLab CI, หรือการใช้ containerized scanner ที่รันเป็นส่วนหนึ่งของ build process
กลุ่มผู้ใช้เป้าหมายหลักประกอบด้วย ทีมพัฒนา (Developers), ทีมความปลอดภัย (SecOps/DevSecOps), และ ฝ่ายกำกับดูแล/Compliance ขององค์กร โดยกรณีการใช้งานเบื้องต้นมีหลากหลาย เช่น การสแกนรีโปทุกครั้งที่มี pull request เข้ามาเพื่อป้องกันการนำโค้ดที่เสี่ยงเข้าสู่สาขาหลัก, การตรวจสอบ dependency เพื่อลดความเสี่ยงจากซอฟต์แวร์ภายนอก, การสร้างรายงานสำหรับการตรวจสอบภายในและการปฏิบัติตามมาตรฐาน (เช่น ISO/IEC 27001, SOC 2) และการให้คำแนะนำแพตช์แบบอัตโนมัติที่ช่วยเร่งเวลาการแก้ไขสำหรับทีม SRE ที่ต้องการลด Mean Time To Remediate (MTTR)
ตัวอย่างการใช้งานจริงที่ Anthropic นำเสนอรวมถึง: สถานการณ์ที่ระบบสแกนพบการเรียกใช้ API ที่ไม่ปลอดภัยใน microservice หนึ่งและสร้าง pull request พร้อมแพตช์แนะนำ รวมถึงเอกสารประกอบการทดสอบ ซึ่งช่วยให้ทีมลดภาระการวิเคราะห์ลงอย่างมีนัยสำคัญ นอกจากนี้ การผสานข้อมูลเชิง audit log และการตั้งค่าการแจ้งเตือนเชิงนโยบายทำให้องค์กรสามารถตอบสนองต่อเหตุการณ์ได้ตามขั้นตอนที่สอดคล้องกับข้อกำหนดด้านการกำกับดูแล
เทคโนโลยีเบื้องหลัง: LLM + Static/Dynamic Analysis + Guardrails
เทคโนโลยีเบื้องหลัง: LLM + Static/Dynamic Analysis + Guardrails
การรวมโมเดลภาษาใหญ่ (LLM) เข้ากับเครื่องมือวิเคราะห์โค้ดแบบดั้งเดิม (static analysis) และการทดสอบเชิงพฤติกรรม (dynamic testing / fuzzing) เป็นสถาปัตยกรรมแบบหลายชั้นที่ Anthropic นำมาใช้เพื่อเพิ่มความแม่นยำและลดความเสี่ยงในการให้คำแนะนำแก้บั๊ก รูปแบบทั่วไปประกอบด้วยชั้น ingestion, pre-processing, วิเคราะห์แบบนิ่ง (static), วิเคราะห์แบบไดนามิก (dynamic/fuzzing), แล้วตามด้วยชั้น LLM ที่ทำหน้าที่เป็น orchestration, synthesis และ prioritization ของผลการสแกน ตัวอย่างกระบวนการเชิงเทคนิคคือ:
- Ingestion ของซอร์สโค้ด: เชื่อมต่อกับ repository (เช่น GitHub/GitLab), CI artifacts และบิลด์อาร์ติแฟกต์ โดยมีการกรองไฟล์ (exclude ไบนารี, ประเภทไฟล์ที่ไม่เกี่ยวข้อง) และการลบข้อมูลลับเบื้องต้นก่อนส่งเข้าสู่ pipeline
- Tokenization & Context Window: โค้ดถูกแปลงเป็นโทเค็นด้วย tokenizer แบบ BPE/Byte-level เพื่อใช้กับ LLM โดยมีการแบ่งชิ้น (chunking) และสรุป (summarization) เพื่อจัดการกับขีดจำกัด context window (เช่น โมเดลสมัยใหม่รองรับประมาณ 8K–32K tokens เป็นตัวอย่าง) — เมื่อโค้ดยาวเกินกว่าคอนเท็กซ์ จะใช้เทคนิค RAG (retrieval-augmented generation) และ embeddings ใน vector DB เพื่อดึงเฉพาะส่วนที่เกี่ยวข้อง
- สถาปัตยกรรมการผสมผสาน (LLM + Scanners): static analyzers (AST-based linters, taint/flow analysis, rule engines) ทำหน้าที่ค้น pattern ที่ชัดเจน ในขณะที่ fuzzers และ sandboxed dynamic tests พยายามสังเกตพฤติกรรมจริง ระบบ LLM ทำหน้าที่รวมผล สรุปเหตุผล และสร้างคำอธิบายหรือโค้ดแก้ไขต้นแบบโดยอ้างอิงผลจากหลายเครื่องมือ (ensemble approach)
เพื่อเพิ่มความน่าเชื่อถือ และลด false positive/negative ระบบจะใช้กลไกตรวจสอบหลายชั้น (multi-stage validation): ผลการตรวจจาก static tool จะถูกปรับคะแนนตามข้อมูลเชิงบริบทที่ LLM สกัดออกมา อีกทั้งคำแนะนำการแก้ไขที่ผลิตโดย LLM จะต้องผ่านการยืนยันด้วย dynamic reproduction ใน sandbox ก่อนเสนอเป็นคำแนะนำที่เชื่อถือได้ ตัวอย่างเช่น หาก static analyzer รายงาน SQL injection ที่ดูเป็นไปได้ ระบบจะให้ LLM สร้าง PoC (proof-of-concept) ที่ทำงานภายใน container ที่ถูกจำกัด (seccomp, cgroups, network isolation) หาก PoC สามารถทำซ้ำพฤติกรรมผิดพลาดได้ ระบบจะยกระดับความร้ายแรงและแนะนำการแก้ไขที่มีลำดับความเชื่อมั่นสูง
มาตรการด้านความปลอดภัยและความไว้วางใจถูกออกแบบมาเป็นมาตรการเชิงรุก (proactive) และเชิงตอบสนอง (reactive) ทั้งนี้รวมถึง:
- Guardrails เชิงเดียว (prompt & output constraints): ใช้ system prompts แบบเข้มงวด, กำหนด schema ของเอาต์พุต (เช่น คืนค่าเป็น JSON ที่มีฟิลด์ type/severity/evidence) และฟิลเตอร์เพื่อป้องกันการแนะนำที่อาจชี้นำให้เกิดการละเมิดความปลอดภัย (เช่น การแนะนำการข้ามการตรวจสอบสิทธิ์)
- Ensemble validation: ให้คำแนะนำผ่านการยืนยันข้ามเครื่องมือ (consensus) — หากเครื่องมือเพียงตัวเดียวเตือนแต่ LLM และ dynamic test ไม่ยืนยัน จะถูกพิจารณาเป็น low-confidence และส่งต่อให้มนุษย์ตรวจสอบ
- Rate limiting & Throttling: ป้องกันการใช้ช่องทางเป็นฐานสำหรับการโจมตีหรือการสกัดข้อมูลโดยจำกัดอัตราการเรียกใช้งาน API, จำกัดความยาวของโค้ดที่ประมวลผลต่อคำขอ และควบคุม concurrency ของ dynamic tests
- Red-team & Adversarial testing: ทำการทดสอบเชิงรุกด้วย prompt adversarial และ payloads ที่ออกแบบมาเพื่อล่อ LLM ให้ให้คำตอบอันตราย เพื่อนำไปปรับปรุง guardrails และลดการเกิด hallucination
- Human-in-the-loop workflows: ผลลัพธ์ที่มีความเสี่ยงสูงหรือคำแนะนำแก้ไขโค้ดจะถูกส่งเข้าสู่กระบวนการ review โดยผู้เชี่ยวชาญก่อนอนุมัติให้ใช้จริงใน CI/CD — ระบบยังสนับสนุนการแก้ไขแบบ incremental rollout และ rollback
การจัดการข้อมูลที่เป็นความลับและความเป็นส่วนตัวของซอร์สโค้ดเป็นหัวใจสำคัญในสถาปัตยกรรมนี้ โดย Anthropic มักนำมาตรการต่อไปนี้มาใช้เพื่อปกป้องโค้ดของลูกค้า:
- ตัวเลือกการประมวลผลภายในองค์กร (on-prem / VPC): ลูกค้าสามารถเลือกให้การประมวลผล (ทั้ง static/dynamic และ LLM inference) เกิดขึ้นภายในเครือข่ายควบคุมของตนเอง เพื่อลดความเสี่ยงจากการส่งโค้ดไปยังบริการสาธารณะ
- Encryption & DLP: ข้อมูลถูกเข้ารหัสทั้งขณะพักและขณะส่ง (AES-256 / TLS) พร้อมระบบ Data Loss Prevention ที่ตรวจจับและลบ secret patterns (เช่น API keys, credentials) ก่อน ingestion
- Minimization & Retention Policies: ส่งเฉพาะส่วนของโค้ดที่จำเป็น (tokenized chunks, summaries) ไม่เก็บสำเนาที่ยาวเกินจำเป็น และให้การควบคุมระยะเวลาการเก็บข้อมูลแก่ลูกค้าเพื่อลดพื้นผิวการรั่วไหล
- Auditability & Provenance: ทุกคำขอและคำตอบถูกบันทึกเป็น audit trail พร้อมแท็ก provenance (ซึ่ง analyzer ให้มา เช่น ชื่อเครื่องมือ, เวอร์ชัน, confidence score) เพื่อให้สามารถตรวจสอบการตัดสินใจย้อนหลังได้
สุดท้ายเพื่อยืนยันประสิทธิภาพในเชิงปฏิบัติ การรวม LLM เข้ากับ static/dynamic scanners ให้ผลลัพธ์ที่มีความแม่นยำสูงขึ้นเมื่อเทียบกับเครื่องมือใดเครื่องมือหนึ่งเพียงอย่างเดียว — โดยอาศัยการตรวจสอบข้ามเครื่องมือ, sandboxed reproduction เพื่อยืนยันการ exploit, และการผสานกระบวนการ human review ซึ่งภาพรวมช่วยลด false positive ที่อาจรบกวนทีมวิศวกรรมและลดความเสี่ยงจากคำแนะนำที่อาจเป็นอันตรายได้อย่างมีนัยสำคัญ
ฟีเจอร์เด่นและตัวอย่างการใช้งานจริง
ฟีเจอร์เด่นเชิงปฏิบัติการ
เครื่องมือความปลอดภัยรุ่นใหม่จาก Anthropic ออกแบบมาเพื่อให้ทีมวิศวกรรมสามารถค้นหา วิเคราะห์ และแก้ไขช่องโหว่ได้แบบอัตโนมัติด้วยผลลัพธ์ที่ อธิบายได้ (explainable findings) และสามารถผสานกับกระบวนการพัฒนาที่มีอยู่ได้ทันที ฟีเจอร์หลักประกอบด้วยการตรวจจับชนิดช่องโหว่หลากหลาย เช่น SQL Injection (SQLi), Cross-Site Scripting (XSS), Remote Code Execution (RCE), และ Buffer Overflow ทั้งในโค้ดฝั่งเซิร์ฟเวอร์ ไลบรารีภายนอก และการเรียกใช้งาน API
ระบบรายงานจะไม่เพียงแจ้งตำแหน่งที่พบเท่านั้น แต่ยังให้ข้อมูลเชิงวิเคราะห์ที่ชัดเจน เช่น โค้ดต้นเหตุ (file/line), พารามิเตอร์ที่มีความเสี่ยง, ตัวอย่าง payload ที่ใช้พิสูจน์ (POC) และคำอธิบายเหตุผลทางเทคนิคว่าทำไมถึงเป็นช่องโหว่ ซึ่งช่วยให้ทีมสามารถตัดสินใจได้รวดเร็ว ฟังก์ชันการเสนอแพตช์ (suggested fix) จะให้ตัวอย่างโค้ดสำหรับแก้ไข เช่น เปลี่ยนจากการต่อสตริง SQL โดยตรงเป็นการใช้ parameterized query หรือแนะนำการ escape/validate input ในกรณี XSS
การให้คะแนนความร้ายแรงและการแม็ปไปยัง CVSS
เครื่องมือมาพร้อมระบบให้คะแนนความร้ายแรงแบบหลายมิติรวมทั้งการแม็ปไปยังมาตรฐาน CVSS v3 โดยรวมปัจจัยต่อไปนี้: ความสามารถในการถูกโจมตี (exploitability), ผลกระทบต่อความลับ/ความสมบูรณ์/ความพร้อมใช้งาน, และความเสี่ยงจากสภาพแวดล้อมการทำงานจริง ผลลัพธ์จะแสดงทั้งค่า severity (เช่น Critical/High/Medium/Low), ค่าคะแนน CVSS (เช่น 9.8/7.5/5.0) และระดับความมั่นใจ (confidence score 0–100%) เพื่อให้ทีมจัดลำดับความสำคัญการแก้ไขได้อย่างเป็นระบบ ตัวอย่างแผนการแม็ป:
- Critical: CVSS 9.0–10.0 — RCE เปิดให้เข้าควบคุมระบบหรือลอบรันโค้ดจากภายนอก
- High: CVSS 7.0–8.9 — SQLi ที่ส่งผลต่อข้อมูลสำคัญ หรือ XSS ที่เปิดเผย session token
- Medium: CVSS 4.0–6.9 — บั๊กที่ลดทอนความสมบูรณ์ของข้อมูล แต่ต้องมีเงื่อนไขพิเศษ
- Low: CVSS 0.1–3.9 — ข้อบกพร่องเชิงปฏิบัติการเล็กน้อย
ตัวอย่าง Workflow: จาก PR -> Scan -> Suggested Fix -> Human Review -> Merge
การผสานเครื่องมือกับระบบ CI/CD และ Issue Tracking ถูกออกแบบเป็น workflow แบบออโตเมชันเพื่อให้ทีมทำงานเร็วขึ้น ตัวอย่างขั้นตอนปฏิบัติจริงเมื่อมี Pull Request (PR) ใหม่:
- 1. PR ถูกเปิด: นักพัฒนาสร้าง PR เพื่อรวมโค้ดใหม่เข้าสาขาหลัก (e.g., GitHub/GitLab).
- 2. Automated Scan Trigger: GitHub Actions/GitLab CI เรียกใช้สคริปต์สแกนของ Anthropic โดยอัตโนมัติ (scan job จะรันภายใน pipeline) เพื่อวิเคราะห์โค้ดและ dependency
- 3. ผลการสแกนและ Suggested Fix: หากพบช่องโหว่ ระบบจะโพสต์ผลสรุปรายงานลงใน PR comment พร้อมตัวอย่างโค้ดการแก้ไขและคำอธิบายเชิงเทคนิค เช่น แสดงการเปลี่ยน SQL concatenation เป็น parameterized query พร้อม snippet แนะนํา
- 4. Human Review: ทีมโค้ดรีวิว (code reviewer) ตรวจสอบรายงานและ patch ที่เสนอ สามารถกดให้ระบบสร้าง Issue อัตโนมัติใน Jira หรือสร้าง ticket ใน GitHub Issues เพื่อการติดตาม
- 5. Merge เมื่อผ่าน: เมื่อแก้ไขและทดสอบเรียบร้อย PR ถูกยอมรับและ merge ระบบจะทำการปิด Issue/Ticket อัตโนมัติและบันทึกประวัติการแก้ไขใน changelog ของเครื่องมือ
ตัวอย่างข้อความที่ระบบจะแสดงใน PR comment: "พบ SQLi ที่ db/user_repository.py:123 — แนะนำใช้ prepared statement. ตัวอย่างแก้ไข: replace f\"SELECT * FROM users WHERE name = '{name}'\" with cursor.execute('SELECT * FROM users WHERE name = %s', (name,))"
การผสานกับเครื่องมือเดิม (Alerts, Tickets, Pipelines)
Anthropic ออกแบบ API และ connector สำหรับการผสานกับระบบยอดนิยมหลายรายการ เช่น GitHub, GitLab, Bitbucket, Jenkins, CircleCI และระบบจัดการงานอย่าง Jira, ServiceNow และ Slack โดยความสามารถครอบคลุม:
- ส่ง alert แบบ real-time ไปยัง Slack/Teams เมื่อพบช่องโหว่ระดับ Critical
- สร้าง ticket อัตโนมัติใน Jira พร้อมข้อมูล CVSS, proof-of-concept, และ suggested fix เพื่อให้ทีม SRE/DevOps ดำเนินการ
- ฝังการสแกนลงใน pipelines (pre-merge และ nightly scans) และกำหนดนโยบายบังคับ เช่น block merge หากพบช่องโหว่ระดับ Critical
- บูรณาการกับระบบ SIEM/SOAR เพื่อนำข้อมูลไปใช้ในกระบวนการตอบสนองเหตุการณ์ (incident response)
จากการทดลองใช้งานเบื้องต้นในองค์กรขนาดกลาง พบว่าเวิร์กโฟลว์ที่ผสานการสแกนอัตโนมัติใน PR สามารถลดเวลาเฉลี่ยในการแก้ไขช่องโหว่จากประมาณ 72 ชั่วโมง เหลือ 18 ชั่วโมง และลดสัดส่วน false positives ประมาณ 30% เนื่องจากรายงานมาพร้อมบริบทเชิงอธิบายและตัวอย่างการแก้ไขที่ชัดเจน
โดยรวมแล้ว ฟีเจอร์เชิงปฏิบัติการของ Anthropic มุ่งเน้นที่การทำให้การค้นหาจัดลำดับความสำคัญ และแก้ไขช่องโหว่เป็นไปอย่างต่อเนื่องและสามารถตรวจสอบได้ (auditable) ผ่านการผสานกับระบบบริหารโค้ดและการจัดการงานที่ทีมพัฒนาใช้อยู่แล้ว
ผลทดสอบและสถิติ (เบนช์มาร์กและการวัดผล)
ผลทดสอบและสถิติ (เบนช์มาร์กและการวัดผล)
การประเมินประสิทธิภาพของเครื่องมือความปลอดภัยใหม่จาก Anthropic ในรอบเบนช์มาร์กและการทดลองภาคสนาม (POC) มีการรายงานเมตริกหลักเพื่อประเมินความสามารถเชิงปริมาณ ได้แก่ accuracy, precision/recall, false positive rate (FPR), Mean Time To Detect (MTTD) และ Mean Time To Repair (MTTR) ทั้งนี้ผลที่นำเสนอต่อไปเป็นผลการทดสอบเบื้องต้นจากการทดลองภายในและ POC ในลูกค้ารายตัวอย่าง และต้องมีการตรวจสอบยืนยันซ้ำในสเกลการใช้งานจริงก่อนสรุปเชิงนโยบาย
เมตริกที่แนะนำให้รายงานอย่างละเอียดมีดังนี้:
- Accuracy: สัดส่วนของการตรวจจับที่ถูกต้องเมื่อเทียบกับตัวอย่างทั้งหมด
- Precision: สัดส่วนของการแจ้งเตือนที่เป็นจริง (True Positives / (True Positives + False Positives))
- Recall: ความสามารถในการจับช่องโหว่ทั้งหมดที่มีอยู่ (True Positives / (True Positives + False Negatives))
- False Positive Rate (FPR): สัดส่วนของเหตุการณ์เทียมที่ถูกตีความว่าเป็นช่องโหว่
- MTTD: เวลาเฉลี่ยจากจุดเริ่มต้นของปัญหาจนกระทั่งระบบแจ้งเตือน
- MTTR: เวลาเฉลี่ยจากการแจ้งเตือนจนแก้ไขปัญหาเสร็จสิ้น
ตัวอย่างตัวเลขจากเบนช์มาร์ก (ผลเบื้องต้น):
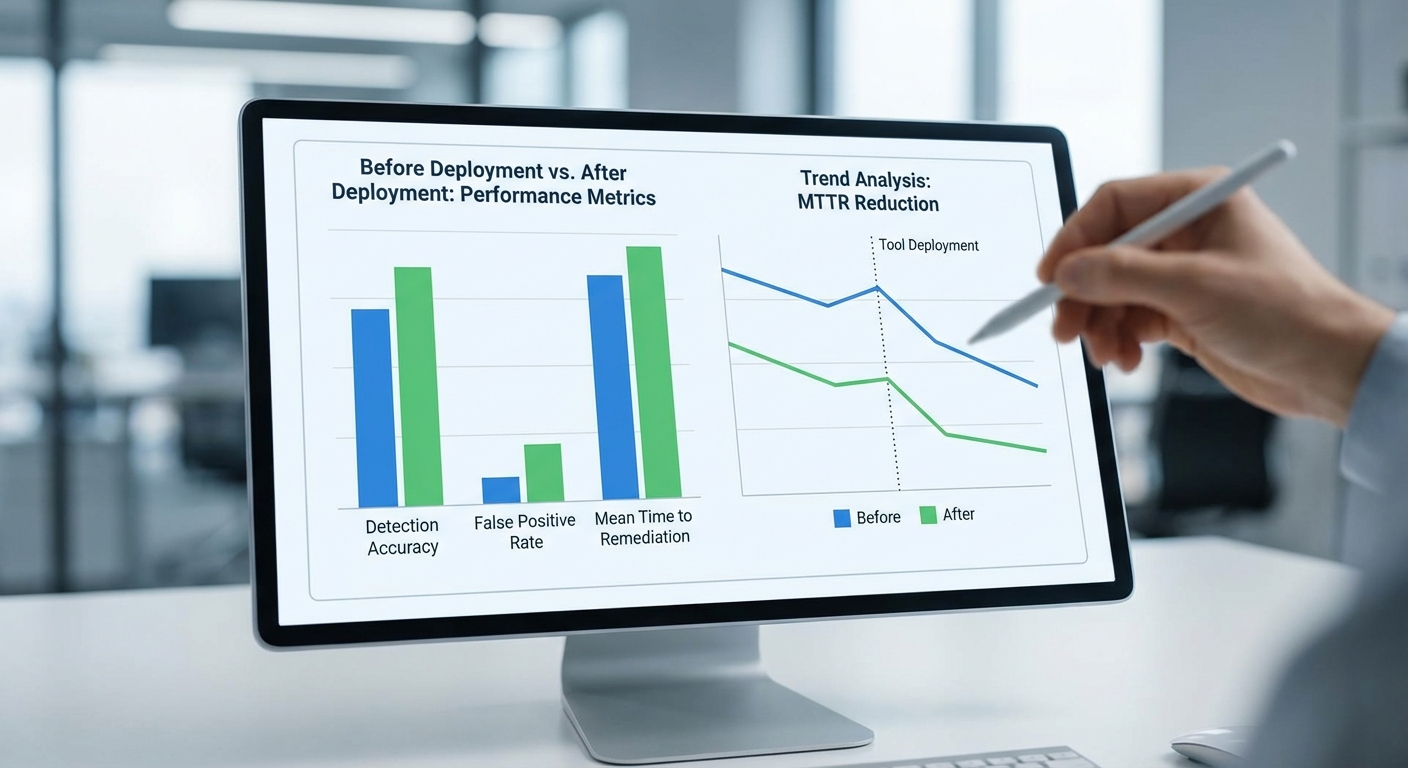
- ก่อนติดตั้งเครื่องมือใหม่ (baseline): Accuracy ~72%, Precision ~80%, Recall ~65%, FPR ~12%, MTTD เฉลี่ย ~7.2 ชั่วโมง, MTTR เฉลี่ย ~48 ชั่วโมง
- หลังติดตั้งเครื่องมือ Anthropic (POC 30 วัน, สภาพแวดล้อม staging และกลุ่มลูกค้าทดลอง): Accuracy ~91%, Precision ~94%, Recall ~88%, FPR ~3%, MTTD เฉลี่ย ~1.1 ชั่วโมง, MTTR เฉลี่ย ~12 ชั่วโมง
- หมายเหตุ: ตัวเลขข้างต้นเป็นข้อมูลเบื้องต้นจากชุดทดสอบรวมประมาณ 10,000 snapshots โค้ดและเหตุการณ์จริงในลูกค้าตัวอย่าง ~300 กรณี และตัวอย่างช่องโหว่สังเคราะห์ ~2,500 รายการ — ควรตรวจสอบซ้ำด้วยข้อมูลจากการใช้งานจริงในสเกลที่กว้างขึ้น
ระเบียบวิธีการทดสอบ (methodology) สรุปได้ดังนี้: การทดลองประกอบด้วยการรันเบนช์มาร์กบนชุดข้อมูลผสม (historical incidents + synthetic injections) เพื่อให้ครอบคลุมลักษณะช่องโหว่หลายประเภท การติดตั้งแบบ POC ทำในสภาพแวดล้อม staging และเลือกกลุ่มผู้ใช้ผลิตภัณฑ์จริงบางรายเพื่อรับการแจ้งเตือนจริงแบบ non-blocking การติดป้าย (labeling) เป็นการรวมระหว่างป้ายจากผู้เชี่ยวชาญมนุษย์และสคริปต์ที่ตรวจจับ pattern ที่รู้จัก กระบวนการวัดผลใช้การ cross-validation แบบ k-fold (k=5) สำหรับชุดสังเคราะห์ และการตรวจสอบแบบ blind review สำหรับเหตุการณ์จริง เพื่อคำนวณ precision/recall และอัตรา false positive
การวัด MTTD ถูกกำหนดเป็นเวลาจาก timestamp แรกที่โค้ด/เหตุการณ์มีลักษณะเป็นช่องโหว่จนกระทั่งระบบส่งแจ้งเตือน ในขณะที่ MTTR ถูกวัดจากเวลาที่แจ้งเตือนจนถึงเวลาที่ทีมพัฒนาแก้ไขและ commit ที่แก้ไขผ่าน CI เพื่อให้เปรียบเทียบระหว่างก่อนและหลังการติดตั้งได้ชัดเจน
ข้อจำกัดและข้อควรระวังในการตีความตัวเลข:
- ตัวเลขเป็น ผลเบื้องต้น และขึ้นกับขนาดตัวอย่างและลักษณะของ dataset — ผลลัพธ์อาจเปลี่ยนได้เมื่อขยายสเกลหรือเปลี่ยนประเภทโค้ด/สแตกเทคโนโลยี
- ความเอนเอียงของชุดข้อมูล (dataset bias): การใช้ตัวอย่างสังเคราะห์มากเกินไปหรือ history cases ที่ไม่ได้ครอบคลุมทุกรูปแบบช่องโหว่อาจทำให้ recall สูงเกินจริงในสภาพแวดล้อมอื่น
- การตั้งค่า threshold และ tuning: ค่า precision/recall มี trade-off กัน หากปรับ threshold เพื่อลด FPR อาจส่งผลให้ recall ลดลง — ต้องพิจารณานโยบายการยอมรับ false positive ในองค์กร
- ผลกระทบจากสภาพแวดล้อมการทำงานจริง: latency ของโซลูชันเมื่อผสานรวมกับ CI/CD, การประมวลผลแบบ distributed, และการบีบอัด/มินิฟายของโค้ดใน pipeline อาจเพิ่ม MTTD จริง
- ความสามารถในการเลี่ยงการตรวจจับ (adversarial evasion): ผู้โจมตีอาจปรับเทคนิคเพื่อลดการตรวจจับ; เบนช์มาร์กควรรวมการทดสอบการโจมตีแบบ adversarial เพื่อประเมินความทนทาน
- ความไม่แน่นอนเชิงสถิติ: ควรรายงานช่วงความเชื่อมั่น (confidence intervals) และผลการทดสอบเชิงสถิติเมื่อเหมาะสม เพื่อระบุความมีนัยสำคัญของการปรับปรุง
สรุป: แม้ผลเบื้องต้นแสดงการปรับปรุงอย่างมีนัยสำคัญทั้งด้านอัตราการตรวจจับและเวลาตอบสนอง (ลด MTTD/MTTR) แต่การตัดสินใจนำไปใช้งานแบบเต็มรูปควรอิงกับการทดสอบซ้ำในสภาพแวดล้อมการผลิต, การวิเคราะห์ต้นทุนของ false positives, และการตรวจสอบความเสถียรเมื่อมีการเปลี่ยนแปลงรหัสหรือรูปแบบการโจมตี ทั้งนี้แนะนำให้ดำเนินการ A/B testing แบบควบคุมและติดตามเมตริกเหล่านี้เป็นระยะเพื่อยืนยันผลในระยะยาว
การเปรียบเทียบกับคู่แข่งและตำแหน่งในตลาด
การเปรียบเทียบกับคู่แข่งและตำแหน่งในตลาด
บทสรุปโดยรวม: Anthropic ที่เปิดตัวเครื่องมือรักษาความปลอดภัยใหม่มีจุดเด่นเชิง AI ที่ชัดเจนเมื่อเทียบกับโซลูชันแบบเดิม แต่ยังเผชิญข้อจำกัดเชิงเทคนิคและเชิงธุรกิจเมื่อต้องแข่งกับเครื่องมือเฉพาะทางและโซลูชันแบบโอเพนซอร์ส การวางตำแหน่งของ Anthropic น่าจะเป็นการเป็นชั้นเสริมแบบ "AI-first" ที่ทำงานร่วมกับสแต็คเดิมมากกว่าจะทดแทนครบวงจร
จุดแข็งหลักที่แตกต่าง: Anthropic ได้เปรียบด้านความสามารถในการประมวลผลเชิงความหมายของโค้ดและบริบทโครงการในระดับสูง ซึ่งช่วยให้สามารถให้คำอธิบายเชิงเหตุผลและแนะนำแพตช์ที่เป็นธรรมชาติมากขึ้นเมื่อเทียบกับเครื่องมือ pattern-based แบบเดิม ตัวอย่างข้อได้เปรียบได้แก่
- การวิเคราะห์เชิงบริบท: ความสามารถของ LLM ในการเชื่อมโยงไฟล์ ข้อสังเกตจากคอมเมนต์ และ dependency graph ทำให้คำแนะนำมักมีความสอดคล้องกับบริบทโค้ดของโปรเจกต์
- คำอธิบายและ remediation ที่เข้าใจง่าย: ฟีเจอร์ที่เสนอแพตช์พร้อมคำอธิบายเชิงเหตุผล เหมาะสำหรับทีมที่ต้องการคู่มือแก้ไขที่อ่านเข้าใจได้โดยเร็ว
- โทนความปลอดภัยตามการออกแบบ: Anthropic มีแนวทางด้านความปลอดภัยของโมเดล (safety-first) ซึ่งอาจช่วยลดปัญหา hallucination และคำแนะนำที่อันตรายเมื่อเปรียบเทียบกับ LLM บางเจ้า
ข้อจำกัดเมื่อเทียบกับเครื่องมือเฉพาะทางหรือ open-source scanners: แม้จะมีจุดแข็งด้าน AI แต่ Anthropic ยังด้อยกว่าในบางมิติที่เครื่องมือเช่น Snyk, Semgrep หรือ GitHub Advanced Security (CodeQL) ทำได้ดี:
- ความเฉพาะทางและความโปร่งใสของกฎ: Semgrep และ CodeQL ใช้กฎเชิงโครงสร้างที่ตรวจจับแพตเทิร์นได้อย่างแม่นยำและตรวจสอบได้ ทำให้การอธิบายที่มาของการแจ้งเตือนเป็นไปได้ชัดเจนกว่า LLM-based ที่มักเป็นการอนุมานเชิงสถิติ
- ประสิทธิภาพและต้นทุน: เครื่องมือ static/semantic แบบดั้งเดิมมักเบาและถูกกว่าเมื่อรันใน CI เป็นประจำ ขณะที่ LLM-based จะมีค่า compute และ latency สูงกว่า ส่งผลต่อต้นทุนการใช้งานโดยรวม โดยเฉพาะสำหรับสแกนทั้งรีโพสิตอรีขนาดใหญ่เป็นประจำ
- false positives และ deterministic results: โซลูชันเฉพาะทางที่ปรับแต่ง rule set ได้ดีมีอัตรา false positive ที่ต่ำกว่าในเชิงปฏิบัติ ขณะที่เครื่องมือ LLM อาจให้ผลลัพธ์ที่แปรผันมากกว่า ขึ้นกับ prompt และบริบท
- ความครอบคลุมของภาษาและ ecosystem: โครงการ open-source บางตัวครอบคลุมภาษาหรือเฟรมเวิร์กเฉพาะทางได้ลึกกว่า และชุมชนสามารถเขียนกฎใหม่ได้อย่างรวดเร็ว ซึ่ง Anthropic ต้องลงทุนเวลาในการขยายความสามารถเชิงภาษาและเทมเพลต
การเปรียบเทียบเชิงฟังก์ชัน (accuracy, false positives, patching, integration, cost): โดยสรุปเชิงเปรียบเทียบแบบกว้าง ๆ
- ความแม่นยำ (accuracy): สำหรับหาจุดบกพร่องเชิงตรรกะที่ต้องใช้ความเข้าใจเชิงบริบท LLM ของ Anthropic มีแนวโน้มได้ผลดีกว่า แต่ในข้อบกพร่องเชิงซินแท็กซ์หรือแพทเทิร์นเดิม ๆ เครื่องมือเฉพาะทางมักแม่นยำกว่า
- False positives: static analyzers และ Semgrep ที่ปรับแต่งดีมีอัตรา false positive ต่ำกว่า LLM ทั่วไป อย่างไรก็ดี แนวทาง safety ของ Anthropic อาจช่วยลดตัวเลขนี้เมื่อเปรียบเทียบกับ LLM คู่แข่งบางราย
- ความสามารถในการเสนอแพตช์: Anthropic มีข้อได้เปรียบในการสร้างแพตช์ที่มีคำอธิบาย แต่การรับประกันความถูกต้องและปลอดภัยเชิงการทำงานยังต้องผ่านการทดสอบอัตโนมัติและการตรวจสอบของมนุษย์ ขณะที่ Snyk/GitHub มีฐานข้อมูล remediation ที่ผ่านการทดสอบและมาตรฐานมากกว่าในเรื่อง dependency fixes
- การผสานกับ pipeline: GitHub Advanced Security จะได้เปรียบสำหรับองค์กรที่ใช้ GitHub เพราะการผสานเป็น native ส่วน Snyk มี integration ครบถ้วนทั้ง CI/CD และ issue trackers ส่วน Anthropic จำเป็นต้องลงทุนใน connectors และ API เพื่อให้เทียบเท่าและลด frictions ใน adoption
- ต้นทุนการใช้งาน: โซลูชันโอเพนซอร์สมีต้นทุนไลเซนส์ต่ำกว่า ขณะที่บริการ LLM-first มักมีค่าใช้จ่ายตามปริมาณการประมวลผลและระดับ subscription — สำหรับองค์กรใหญ่ที่ต้องสแกนบ่อย ต้นทุนอาจสูงกว่าเครื่องมือเดิม
แนวโน้มการแข่งขันและบทสรุปเชิงกลยุทธ์: ตลาดโซลูชันความปลอดภัยที่ใช้ AI กำลังเคลื่อนไหวไปสู่สภาพแวดล้อมแบบผสมผสาน (hybrid) — ผู้เล่นที่อยู่รอดและเติบโตได้จะเป็นผู้ที่ผสานจุดแข็งของ static/scanning แบบดั้งเดิมกับความสามารถเชิงความหมายของ LLM โดยเฉพาะการลด false positive, เพิ่มความโปร่งใสในการตัดสินใจของโมเดล และการเชื่อมต่อกับ CI/CD/issue management อย่างราบรื่น
ข้อเสนอเชิงกลยุทธ์สำหรับ Anthropic: เพื่อสร้างตำแหน่งที่แข็งแกร่งใน ecosystem Anthropic ควรมุ่งไปที่
- การเปิด API และ connectors สำเร็จรูปสำหรับ CI/CD, GitHub, GitLab, Jira เพื่อเร่งการยอมรับ
- การจับมือกับเครื่องมือเฉพาะทาง (Snyk, Semgrep) ในรูปแบบ partner หรือ integration เพื่อให้เป็นเลเยอร์วิเคราะห์เชิงบริบทที่เติมช่องว่างมากกว่าจะเป็นตัวแทน
- การลงทุนในความโปร่งใสของคำตัดสิน (explainability), benchmarking เรื่อง false positives และการพิสูจน์ประสิทธิผลด้วยข้อมูลเชิงประจักษ์ เพื่อสร้างความเชื่อมั่นแก่ทีมความปลอดภัยองค์กร
- การนำเสนอโมเดลราคาที่เหมาะสมกับการสแกนปกติ (e.g., tiered pricing, on-premise/privileged deployments) เพื่อลดอุปสรรคด้านต้นทุนและความเป็นส่วนตัวสำหรับลูกค้าองค์กร
สรุปคือ Anthropic มีโอกาสยืนในตลาดเป็นโซลูชัน AI-first ชั้นนำสำหรับการวิเคราะห์เชิงบริบทและการเสนอ remediation ที่เข้าใจง่าย แต่บทบาทที่ยั่งยืนจะมาจากการเป็นผู้เล่นแบบผสาน (integrator) ที่ทำงานร่วมกับเครื่องมือเฉพาะทางและระบบปฏิบัติการของทีมพัฒนา ไม่ใช่การพยายามแทนที่เครื่องมือเหล่านั้นทั้งหมดในทันที
ผลกระทบต่อองค์กรและแนวทางนำไปใช้ (DevSecOps)
ขั้นตอนแนะนำสำหรับการนำเครื่องมือไปใช้จริง: pilot → evaluation → integration → scale
แนะนำให้นำเครื่องมือรักษาความปลอดภัยใหม่ของ Anthropic เข้าสู่การใช้งานตามวงจรสี่ขั้นตอนชัดเจน เพื่อจำกัดความเสี่ยงและวัดผลอย่างเป็นระบบ เริ่มด้วย pilot ที่มีขอบเขตจำกัด ต่อด้วยการ evaluation เชิงปริมาณและคุณภาพ ก่อนผสานเข้ากับกระบวนการพัฒนา (integration) และสุดท้ายขยายการใช้งาน (scale) เมื่อผ่านเกณฑ์ยอมรับได้
- Pilot scope: เลือกระบบหรือบริการที่มีความเสี่ยงปานกลางถึงสูง (เช่น API สำคัญ, Authentication service) ใช้ระยะเวลา 6–12 สัปดาห์ และกำหนดจำนวนทีมและ repository ตัวอย่าง (5–10 repos)
- Evaluation: เก็บข้อมูล KPI เบื้องต้น เปรียบเทียบผลลัพธ์กับ baseline ก่อนใช้งาน และรวบรวม feedback จากทีมพัฒนาและ security operations
- Integration: เชื่อมต่อกับ CI/CD เช่น pre-commit, pipeline scan, pull-request checks และจัดทำนโยบายการตอบสนองอัตโนมัติ (playbooks) สำหรับผลลัพธ์ที่พบ
- Scale: วางแผนขยายแบบเป็นขั้น แยกตามทีมและความสำคัญของระบบ โดยมี governance, training และ SLA กับ vendor ครอบคลุม
KPI ที่ควรวัดเพื่อประเมินผล
การตั้ง KPI ที่ชัดเจนช่วยให้ประเมินความคุ้มค่าของการนำเทคโนโลยี AI มาใช้ตรวจหาบั๊กได้อย่างเป็นรูปธรรม ควรวัดทั้งเชิงความปลอดภัย ประสิทธิภาพการตอบสนอง และผลกระทบต่อการพัฒนา
- Reduction in vulnerabilities: จำนวนช่องโหว่ใหม่ที่ลดลงเป็นเปอร์เซ็นต์เทียบกับช่วงก่อนใช้งาน (เป้าหมายตัวอย่าง: ลดช่องโหว่ระดับสูง ≥ 30% ภายใน 3 เดือน)
- MTTR (Mean Time to Remediate): เวลาตั้งแต่ตรวจพบจนแก้ไขเสร็จ (เป้าหมายตัวอย่าง: ลด MTTR ลง 25–50%)
- False positive rate: สัดส่วนผลเตือนที่ผิดพลาด ควรติดตามเพื่อปรับ tuning และไม่ให้ทีมเสียเวลา
- Dev velocity impact: วัดค่า cycle time, PR merge time และจำนวนการย้อนกลับ (revert) เพื่อประเมินว่าการสแกนไม่เป็นภาระแก่ทีมพัฒนา (เป้าหมาย: กระทบ dev velocity ≤ 5–10%)
- Coverage and detection depth: สัดส่วนโค้ดที่ถูกสแกนและชนิดของช่องโหว่ที่ตรวจจับได้ (SAST/DAST/Dependency)
การปรับกระบวนการ: shift-left testing, roles & responsibilities
การนำเครื่องมือ AI เข้ามาต้องประกอบด้วยการปรับกระบวนการพัฒนาให้เป็น shift-left โดยย้ายการตรวจสอบความปลอดภัยมาทำในช่วงต้นของ SDLC เพื่อจับปัญหาตั้งแต่โค้ดเขียนใหม่
- Integrate into CI/CD: เพิ่มการสแกนเป็นขั้นตอนก่อน PR merge และเป็นส่วนหนึ่งของ pipeline gating
- Pre-commit และ local hooks: แนะนำให้ตั้งค่า pre-commit hooks หรือ local scan เพื่อให้ dev พบปัญหาก่อน push
- Roles & responsibilities:
- Developers: แก้ไขตัวอย่างที่เครื่องมือแจ้ง, ปรับโค้ดตาม guideline
- Dev Leads / Architects: ตัดสินใจในกรณี false positive และกำหนด policy ของทีม
- Security Engineers / SRE: ปรับ tuning, จัดการ alert triage, ดูแล integration กับ SIEM/ ticketing
- Product Owners / Compliance: ให้ความเห็นด้านความเสี่ยงและจัดลำดับความสำคัญของ remediation
- Runbooks และ playbooks: จัดทำขั้นตอนมาตรฐานสำหรับการตอบสนอง เช่น การจำแนกความร้ายแรง การ Escalation และกระบวนการ patching
- Training: จัดหลักสูตรพื้นฐานสำหรับ dev และ security เพื่อเข้าใจผลลัพธ์เครื่องมือ ตลอดจน workshop ปรับ tuning และฝึกซ้อม incident handling
Governance, compliance และประเด็นความเป็นส่วนตัว
ก่อนขยายการใช้งาน ต้องออกแบบกรอบ governance และการกำกับควบคุมที่ชัดเจน ทั้งการเข้าถึงข้อมูล การเก็บบันทึก และการรายงานเพื่อให้สอดคล้องกับมาตรฐานภายในและข้อกำหนดภายนอก
- Access control & auditing: จำกัดสิทธิ์การเข้าถึงผลสแกนและการตั้งค่าระบบตามบทบาท และเก็บ audit log สำหรับการตรวจสอบย้อนหลัง
- Data handling & privacy: ระบุนโยบายเกี่ยวกับข้อมูลที่ส่งให้เครื่องมือ (เช่น source code, secrets, PII) หากเป็นบริการคลาวด์ต้องพิจารณาว่ามีการส่งข้อมูลออกนอกองค์กรหรือไม่ และต้องสอดคล้องกับ GDPR, PDPA หรือกฎเฉพาะอุตสาหกรรม เช่น HIPAA
- Model risk & explainability: ตระหนักถึงข้อจำกัดของโมเดล AI เช่น การเกิดผลลัพธ์ที่ไม่อธิบายได้ (black-box) จัดให้มีการทดสอบและบันทึกเหตุผลสำหรับการตัดสินใจสำคัญ
- Compliance reporting: เตรียมรายงานและกระบวนการพิสูจน์การปฏิบัติตามข้อกำหนด เช่น การลดช่องโหว่ที่เกี่ยวข้องกับมาตรฐาน OWASP, PCI-DSS หรือ ISO 27001
การประเมินค่าใช้จ่าย-ผลตอบแทน (TCO / ROI)
การตัดสินใจเชิงธุรกิจต้องคำนวณ TCO และคาดการณ์ ROI อย่างรอบด้าน โดยรวมค่าใช้จ่ายและประโยชน์ทั้งทางตรงและทางอ้อม
- องค์ประกอบของ TCO: ค่าลิขสิทธิ์/subscription, ค่าโครงสร้างพื้นฐาน (เซิร์ฟเวอร์/สตอเรจ), ค่าเชื่อมต่อ CI/CD, ค่าแรงงาน (integration, tuning, triage), ค่าอบรม และค่าเทคนิคการบำรุงรักษา
- ประโยชน์ที่วัดได้: ลดความถี่และความรุนแรงของ incident, ลด MTTR, ลดเวลาพัฒนา (ลด rework), ลดค่าปรับจากการไม่ปฏิบัติตามกฎระเบียบ และเพิ่มความเชื่อมั่นของลูกค้า
- ตัวอย่างคำนวณคร่าวๆ: หากการลดช่องโหว่ระดับสูงได้ 40% และ MTTR ลด 30% อาจลดค่าใช้จ่ายด้าน incident response และ reputational loss ได้หลายแสนถึงล้านบาทต่อปี ขึ้นกับขนาดองค์กร เปรียบเทียบกับค่า subscription+integration เพื่อหาจุดคุ้มทุน (payback period)
- Sensitivity analysis: ทำการวิเคราะห์ความไวต่อสมมติฐาน เช่น อัตราการลดช่องโหว่จริงๆ, ผลกระทบต่อ dev velocity, และค่าใช้จ่ายซ่อนเร้น เพื่อประเมินความเสี่ยงทางการเงิน
Checklist สำหรับการพิจารณาก่อนนำไปใช้งานจริง
ใช้รายการตรวจสอบต่อไปนี้เป็นเกณฑ์ยอมรับก่อนขยายการใช้งานจาก pilot สู่ production
- กำหนด เกณฑ์ความสำเร็จของ pilot (KPI และ thresholds ชัดเจน)
- ทดสอบ integration กับ CI/CD, issue tracker และ SIEM สำเร็จโดยไม่มีผลกระทบต่อ pipeline critical path
- นโยบายการจัดการข้อมูล (data flow diagram) ระบุว่าข้อมูลที่ละเอียดอ่อนจะถูกจัดการอย่างไร และมีมาตรการปกป้อง PII
- มีกระบวนการ tuning เพื่อลด false positives และผู้รับผิดชอบที่ชัดเจน
- จัดทำ runbooks/ playbooks สำหรับการ triage และ remediation พร้อมการฝึกอบรมทีม
- ออกแบบ access control และ logging เพื่อสนับสนุนการตรวจสอบย้อนหลังและ compliance
- ประเมิน TCO พร้อม sensitivity analysis และยืนยัน ROI คาดการณ์ได้ในช่วงเวลาที่รับได้
- ทำการประเมินความเสี่ยงด้าน model bias, explainability และเตรียมแผนรับมือ
- วางแผนการสนับสนุนจาก vendor (SLA, update cadence, security patches)
- เตรียม rollback plan หากการใช้งานใน production ส่งผลเสียต่อความเสถียรของระบบ
สรุปคือ การนำเครื่องมือ AI สำหรับตรวจจับบั๊กมาประยุกต์ใช้ในระดับองค์กรควรดำเนินการอย่างเป็นขั้นตอน มีการกำหนด KPI ชัดเจน ปรับกระบวนการสู่ shift-left ให้สอดคล้องกับบทบาทเจ้าหน้าที่ และวาง governance รวมถึงการควบคุมข้อมูลอย่างเคร่งครัด การประเมิน TCO/ROI และการตรวจสอบตาม checklist จะช่วยให้องค์กรสามารถตัดสินใจได้มั่นคงและขยายการใช้งานอย่างปลอดภัยและคุ้มค่า
บทสรุป
เครื่องมือรักษาความปลอดภัยที่ Anthropic เปิดตัวถือเป็นก้าวสำคัญในการผสานเทคโนโลยีปัญญาประดิษฐ์เข้ากับกระบวนการตรวจสอบโค้ด โดยมีศักยภาพในการเร่งการค้นหาและจัดลำดับความสำคัญของบั๊ก ช่วยลดภาระงานเชิงแมนนวลและปรับปรุงความครอบคลุมของการวิเคราะห์โค้ด แต่ผลลัพธ์ในทางปฏิบัติจะขึ้นกับการตั้งค่า โมเดล การทดสอบเชิงปฏิบัติ และการจัดการความเสี่ยงอย่างเหมาะสม — เครื่องมืออาจให้ผลลัพธ์ที่มี false positives/false negatives หากไม่ได้ปรับจูนหรือทวนสอบ ทำให้การกำหนดเกณฑ์การแจ้งเตือน การตั้งค่าการเข้าถึง และกระบวนการทวนสอบด้วยมนุษย์เป็นสิ่งจำเป็นเพื่อให้ผลลัพธ์เชื่อถือได้และปลอดภัย
องค์กรที่ต้องการนำไปใช้งานควรเริ่มจากการทดสอบในสเกลเล็ก (pilot) ก่อนขยายใช้งานอย่างกว้างขวาง โดยวัดผลทั้งเชิงปริมาณ เช่น อัตราการตรวจจับบั๊ก, อัตรา false positive/negative, เวลาเฉลี่ยในการแก้ไข (MTTR), และผลกระทบต่อเหตุการณ์ใน production และเชิงคุณภาพ เช่น ความพึงพอใจของนักพัฒนาและผลต่อโฟลว์การทำงาน นอกจากนี้ต้องวางกระบวนการทบทวนโดยมนุษย์, นโยบาย governance ที่ชัดเจน (เช่น การควบคุมสิทธิ์, audit trail, การจัดการความเป็นส่วนตัวของโค้ด) และแผนการลดความเสี่ยงเมื่อเครื่องมือทำงานผิดพลาด
มุมมองอนาคตชี้ให้เห็นว่าเครื่องมือประเภทนี้จะพัฒนาไปด้านความแม่นยำ การอธิบายผล และการบูรณาการเข้ากับระบบ CI/CD และการทดสอบเชิงอัตโนมัติมากขึ้น ทำให้องค์กรสามารถเลื่อนการจับบั๊กไปยังช่วงต้นของวงจรพัฒนา (shift-left) ได้อย่างมีประสิทธิภาพ แต่ก็ยังต้องการการติดตามอย่างต่อเนื่อง การอัปเดตโมเดล และกรอบกำกับดูแลเพื่อให้สอดคล้องกับมาตรฐานความปลอดภัยและกฎระเบียบต่างๆ สรุปคือเทคโนโลยีนี้มีศักยภาพลดความเสี่ยงและต้นทุนได้มาก แต่ไม่สามารถทดแทนการตัดสินใจและการควบคุมโดยมนุษย์ได้ทั้งหมด—องค์กรต้องออกแบบการใช้งานให้เป็นระบบผสมผสาน (hybrid) พร้อมการวัดผลและ governance ที่เข้มแข็งก่อนการขยายใช้งานเต็มรูปแบบ
📰 แหล่งอ้างอิง: Fortune



