
ไมโครซอฟต์เผชิญวิกฤติ! ข่าวอีเมลภายในของผู้ใช้และองค์กรถูกส่งหลุดเข้าสู่ระบบเครื่องมือปัญญาประดิษฐ์ของไมโครซอฟต์ กลายเป็นชนวนความกังวลด้านความเป็นส่วนตัวและความปลอดภัยในวงกว้าง เหตุการณ์นี้ไม่เพียงกระทบความเชื่อมั่นของผู้ใช้ทั่วไป แต่ยังอาจนำไปสู่ความเสี่ยงทางกฎหมายและบทลงโทษสำหรับองค์กรที่ข้อมูลถูกเปิดเผยโดยไม่ได้รับอนุญาต
บทนำนี้จะชี้ให้เห็นประเด็นสำคัญ: สาเหตุที่เป็นไปได้ของการรั่วไหล ขอบเขตข้อมูลที่ได้รับผลกระทบ ผลกระทบเชิงกฎหมายและธุรกิจที่อาจตามมา รวมทั้งความเสี่ยงต่อผู้ใช้รายบุคคลและองค์กรขนาดใหญ่ ในบทความต่อไปเราจะวิเคราะห์รายละเอียดเชิงเทคนิค ตัวอย่างกรณีจริง ผลวิจัยที่เกี่ยวข้อง และนำเสนอแนวทางแก้ไขเชิงปฏิบัติที่ผู้ใช้และผู้บริหารไอทีสามารถนำไปใช้เพื่อลดความเสี่ยงและเรียกคืนความเชื่อมั่น
ภาพรวมเหตุการณ์: อะไรเกิดขึ้นบ้าง
ภาพรวมเหตุการณ์: อะไรเกิดขึ้นบ้าง
เหตุการณ์การรั่วไหลของอีเมลจากระบบของไมโครซอฟท์เริ่มปรากฏสู่สาธารณะผ่านการรายงานบนแพลตฟอร์มโซเชียลมีเดียและฟอรั่มความปลอดภัยไซเบอร์ โดย รายงานครั้งแรก ถูกเผยแพร่โดยผู้ใช้และนักวิจัยความปลอดภัยอิสระบนแพลตฟอร์มอย่าง GitHub และ X (เดิมคือ Twitter) ซึ่งต่อมาข้อมูลดังกล่าวถูกหยิบยกไปสู่สื่อมวลชนหลักภายในไม่กี่ชั่วโมง ทำให้เรื่องนี้กลายเป็นประเด็นที่ได้รับความสนใจอย่างรวดเร็วจากทั้งผู้ใช้ทั่วไป ลูกค้าองค์กร และนักวิเคราะห์ความปลอดภัย ในช่วง 24–48 ชั่วโมงแรก หลายชิ้นข้อมูลตัวอย่างถูกแชร์เพื่อเป็นหลักฐาน ทำให้ภาพรวมของเหตุการณ์เริ่มชัดเจนขึ้นในระดับหนึ่ง

ข้อมูลที่รั่วไหลตามรายงานประกอบด้วยหลายประเภท ได้แก่ เนื้อหาอีเมล ที่มีทั้งข้อความภายใน ข้อความสนทนา และหัวเรื่อง รวมถึง ไฟล์แนบ ในรูปแบบ PDF, เอกสาร Office (Word, Excel) และบางกรณีมีไฟล์ภาพประกอบด้วย นอกจากนี้ยังมีการเปิดเผย ข้อมูลเมตา เช่น รายชื่อผู้ส่ง-ผู้รับ (To/Cc/Bcc), ตราประทับเวลา (timestamps), และหัวข้ออีเมล ซึ่งข้อมูลเมตาดังกล่าวอาจใช้ในการเชื่อมโยงเครือข่ายการสื่อสารภายในองค์กร ตัวอย่างที่แชร์เป็นชุดตัวอย่างที่ผู้ค้นพบอ้างว่ารวมตัวอย่างหลายสิบถึงหลายร้อยรายการ แต่บางส่วนเป็นแค่สกรีนช็อตหรือข้อความตัดตอนที่ยังต้องตรวจสอบต่อ
ในด้านขอบเขตของผลกระทบ ภาพรวมยังคงไม่แน่ชัดและมีการยืนยันข้อมูลแบบเป็นส่วน ๆ เท่านั้น — สถานภาพเบื้องต้น ระบุว่ามีตัวอย่างที่ยืนยันได้บางส่วนจากชุดข้อมูลตัวอย่างที่เผยแพร่ แต่ไมโครซอฟท์ยังไม่ได้ยืนยันจำนวนอีเมลทั้งหมดหรือขอบเขตผู้ใช้ที่ได้รับผลกระทบครบถ้วน นอกจากนี้ยังไม่มีการยืนยันอย่างเป็นทางการว่าการรั่วไหลครอบคลุมถึงข้อมูลลูกค้าเชิงพาณิชย์ระดับองค์กรทั้งหมดหรือเป็นเฉพาะผู้ใช้บางกลุ่ม นักวิเคราะห์ความปลอดภัยเตือนว่าการประเมินผลกระทบจริงจำเป็นต้องอาศัยการสืบสวนเชิงเทคนิค (forensic review) ซึ่งอาจใช้เวลาหลายวันถึงหลายสัปดาห์
การตอบสนองเริ่มต้นจากไมโครซอฟท์ในช่วงเบื้องต้นรวมถึงการออกคำชี้แจงสั้น ๆ ว่ากำลังสอบสวนเหตุการณ์และได้ดำเนินมาตรการชั่วคราวบางประการเพื่อลดความเสี่ยง เช่น การทบทวนกระบวนการนำเข้าข้อมูลสู่เครื่องมือ AI และการแจ้งเตือนลูกค้าที่อาจได้รับผลกระทบ แต่รายละเอียดเชิงลึกยังจำกัด และบริษัทระบุว่าจะเผยผลการสอบสวนเพิ่มเติมเมื่อมีข้อมูลยืนยันชัดเจน ด้านสาธารณะมีการตอบสนองอย่างรวดเร็ว — ผู้ใช้แสดงความกังวลเรื่องความเป็นส่วนตัวและความมั่นคงของข้อมูลบนโซเชียลมีเดีย องค์กรคุ้มครองข้อมูลและนักกฎหมายบางกลุ่มเรียกร้องคำอธิบายที่ชัดเจนและความรับผิดชอบจากบริษัท โดยภาพรวมเป็นบรรยากาศที่ตึงเครียดสำหรับลูกค้าองค์กรที่พึ่งพาบริการของไมโครซอฟท์เป็นหลัก
- เวลาและช่องทางที่เริ่มมีการรายงาน: เริ่มปรากฏบน GitHub และ X ก่อนจะถูกขยายเป็นข่าวในสื่อหลัก ภายในช่วง 24–48 ชั่วโมงแรกมีการแชร์ตัวอย่างข้อมูลอย่างต่อเนื่อง
- ประเภทข้อมูลที่ถูกเปิดเผย: เนื้อหาอีเมล, ไฟล์แนบ (PDF/Word/Excel/ภาพ), ข้อมูลเมตา (ผู้ส่ง ผู้รับ ตราประทับเวลา) และตัวอย่างข้อความที่สกัดออกมา
- สถานภาพขอบเขตการกระทบ: ยังไม่ทราบทั้งหมด — มีตัวอย่างที่ยืนยันได้บางส่วนจากชุดข้อมูลที่เผยแพร่ แต่จำนวนเต็มและผลกระทบต่อผู้ใช้/องค์กรยังอยู่ระหว่างการสอบสวน
ไทม์ไลน์เหตุการณ์และการเปิดเผย
ไทม์ไลน์เหตุการณ์และการเปิดเผย
ต่อไปนี้เป็นลำดับเหตุการณ์เชิงรายละเอียดตั้งแต่จุดเริ่มต้นของการรั่วไหล การตรวจพบและการตอบสนองภายใน ไปจนถึงการสื่อสารสาธารณะและผลสะท้อนจากผู้ใช้ เพื่อให้ผู้อ่านเห็นภาพเหตุการณ์อย่างเป็นขั้นตอนและสามารถติดตามการดำเนินการได้อย่างชัดเจน โดยข้อมูลเวลาเป็นไปตามรายงานการสืบสวนเบื้องต้นของบริษัทและคำแถลงต่อสาธารณะที่เผยแพร่ภายใน 72 ชั่วโมงแรกหลังการตรวจพบ
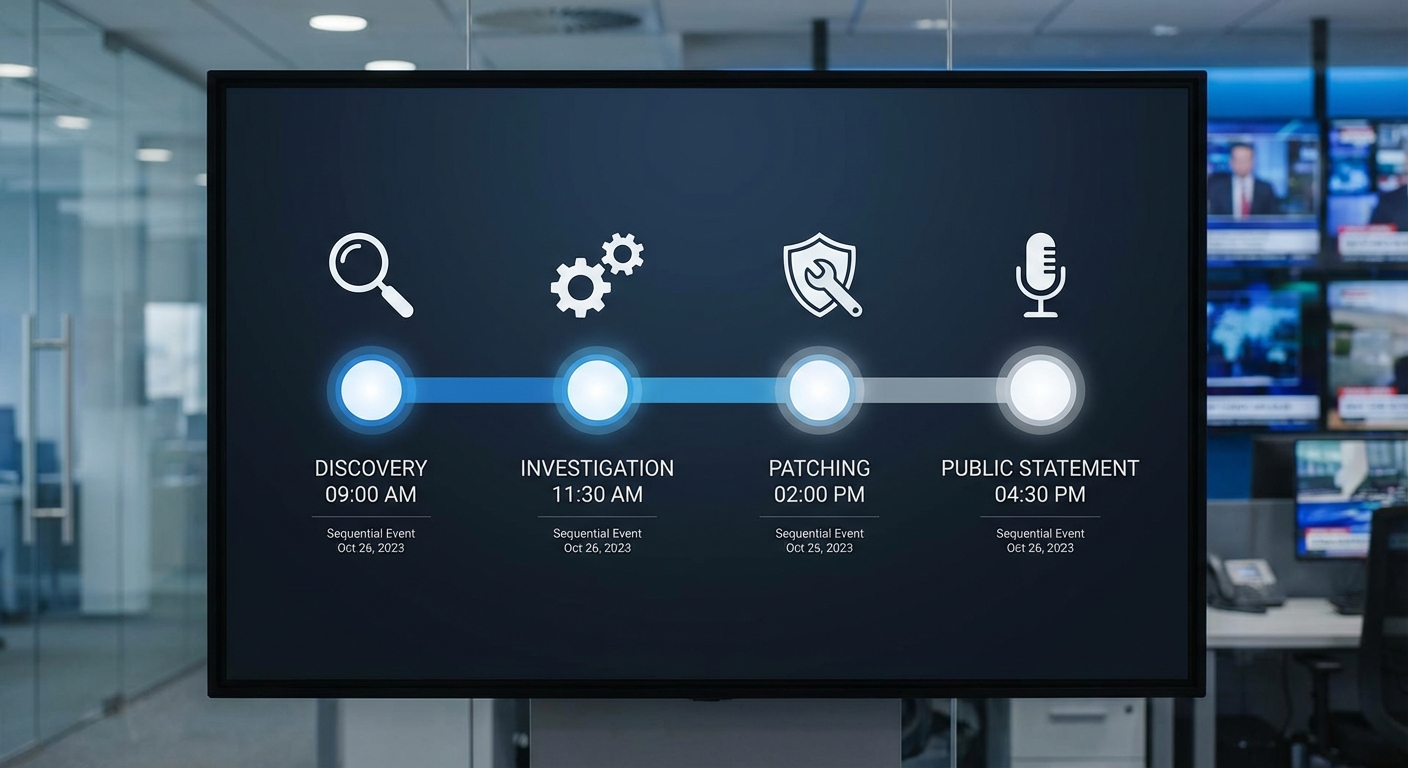
1) จุดเริ่มต้นของการรั่วไหล — วันที่/เวลา/ผู้ค้นพบ
- วันที่ 2026-02-14 เวลา 09:17 น. — นักวิจัยอิสระด้านความปลอดภัยไซเบอร์ (ชื่อไม่เปิดเผย) รายงานการพบพฤติกรรมไม่ปกติของระบบเปิด-ปิดโมดูลประมวลผลอีเมลภายในเครื่องมือ AI ของบริการระดับองค์กรของ Microsoft
- 09:45 น. — รายงานถูกส่งต่อไปยังทีม CERT ภายในของ Microsoft พร้อมตัวอย่างอีเมลตัวอย่าง 3 รายการที่แสดงสัญญาณการส่งข้อมูลไปยัง endpoint ภายนอก
- 10:30 น. — ทีมวิศวกรรมยืนยันเบื้องต้นว่าโค้ดในส่วนจัดการอินเด็กซ์เมตาดาต้าเปิดช่องทางที่อาจทำให้เนื้อหาอีเมลบางส่วนถูกประมวลผลนอกขอบเขตที่ประกาศไว้
2) การดำเนินการตอบโต้ภายใน — Patch, Disable Feature, Notify Customers
- 11:15 น. — ทีมรักษาความปลอดภัยสั่งปิดฟีเจอร์ที่เกี่ยวข้องเป็นการชั่วคราว (feature toggle) เพื่อตัดวงจรการรั่วไหลทันที
- 13:00 น. — มีการอัปเดตซอฟต์แวร์ภายใน (hotfix) เพื่ออุดช่องโค้ดที่เกี่ยวข้อง และเริ่มกระบวนการตรวจสอบย้อน (forensic analysis) กับชุดล็อกที่เก็บไว้
- 16:00 น. — Microsoft เริ่มแจ้งผู้ดูแลระบบลูกค้าองค์กรที่ได้รับผลกระทบทันทีผ่านช่องทาง Message Center และส่งเมลแจ้งเตือนถึงบัญชีผู้ใช้ที่อาจได้รับผลกระทบโดยตรง พร้อมคำแนะนำการเปลี่ยนรหัสผ่านและการตรวจสอบล็อก
- ภายใน 48 ชั่วโมง — ได้ดำเนินการเพิกถอนคีย์ชั่วคราวที่เกี่ยวข้อง, บังคับให้ผู้ใช้ที่มีความเสี่ยงทำการ re-authentication และเปิดระบบตรวจจับเพิ่มเติม (enhanced monitoring)
3) การเปิดเผยสู่สาธารณะและการสื่อสารอย่างเป็นทางการ
- วันถัดมา (2026-02-15 เวลา 08:00 น.) — Microsoft เผยแพร่แถลงการณ์ทางบล็อกความปลอดภัยและส่งอีเมลแจ้งเตือนลูกค้าองค์กรพร้อมคำอธิบายเหตุการณ์ เบื้องต้นยืนยันว่าประเด็นที่พบเป็นการรั่วไหลของข้อมูลอีเมลบางส่วนที่ถูกประมวลผลโดยโมดูล AI และกำลังดำเนินการเต็มรูปแบบเพื่อตรวจสอบขอบเขตความเสียหาย
- 12:00 น. — มีการอัปเดต FAQ บนหน้า Support และการจัดตั้งศูนย์บริการลูกค้าเฉพาะทาง (incident response hotline) เพื่อรับคำถามจากลูกค้าโดยตรง
- ภายใน 72 ชั่วโมง — บริษัทประกาศแผนการปล่อยแพตช์ถาวรภายใน 7 วัน และสัญญาว่าจะรายงานผลการตรวจสอบเชิงลึกให้ regulator และลูกค้าทราบตามข้อกำหนดด้านความเป็นส่วนตัว
4) ผลตอบรับจากผู้ใช้งานและดัชนีความเชื่อมั่น
- หลังการประกาศสู่สาธารณะภายใน 24 ชั่วโมง มีการเพิ่มขึ้นของคำร้องเรียนต่อฝ่ายสนับสนุนสูงขึ้นประมาณ 250% และมีรายงานผู้ใช้ที่ตัดสินใจยุติการใช้ฟีเจอร์ AI บางส่วนชั่วคราวมากกว่า 12% ของลูกค้าองค์กรในกลุ่มตัวอย่าง
- โซเชียลมีเดียและฟอรัมเทคโนโลยีมีการถกเถียงอย่างรวดเร็ว — ผู้ใช้แสดงความกังวลเรื่องความโปร่งใสและการจัดการข้อมูลส่วนบุคคล ขณะที่นักวิเคราะห์เรียกร้องให้มีการตรวจสอบอิสระและการเปิดเผยรายละเอียดเกี่ยวกับขอบเขตข้อมูลที่รั่วไหล
- บริษัทแจ้งว่าจะแจ้งหน่วยงานกำกับดูแลที่เกี่ยวข้องตามกฎหมายความเป็นส่วนตัวและมาตรฐานอุตสาหกรรม และให้คำมั่นในการชดเชยและสนับสนุนลูกค้าที่ได้รับผลกระทบตามมาตรฐานความรับผิดชอบ
สรุป: ลำดับเหตุการณ์ชี้ให้เห็นการตอบสนองที่รวดเร็วภายในองค์กรตั้งแต่การตรวจพบ การปิดฟีเจอร์ชั่วคราว การออก hotfix และการสื่อสารลูกค้าอย่างเป็นระบบ แต่ผลกระทบต่อความเชื่อมั่นของผู้ใช้ยังคงมีนัยสำคัญ—โดยเฉพาะเมื่อตัวเลขการร้องเรียนเพิ่มขึ้นและมีการเรียกร้องมาตรการความโปร่งใสเพิ่มเติมจากภาคธุรกิจและ regulator ซึ่ง Microsoft ระบุว่าจะมีการรายงานผลการสืบสวนแบบเต็มรูปแบบภายในกรอบเวลา 30 วันตามขั้นตอนการจัดการเหตุการณ์ความปลอดภัย
มุมมองเชิงเทคนิค: ข้อมูลอีเมลหลุดได้อย่างไร
มุมมองเชิงเทคนิค: ข้อมูลอีเมลหลุดได้อย่างไร
การรั่วไหลของข้อมูลอีเมลในกรณีเช่นนี้มักไม่ใช่เหตุการณ์ที่เกิดจากสาเหตุเดียว แต่เป็นผลรวมของหลายปัจจัยทางเทคนิคที่เกี่ยวข้องกัน ปัจจัยสำคัญที่มักพบได้แก่ การตั้งค่า connector หรือ API ผิดพลาด, การผนวกรวมกับบริการภายนอก (third‑party), การนำข้อมูลเข้าสู่ pipeline ของ AI โดยไม่มีการกรอง (ingestion), การเก็บ log/caching ที่ไม่ระมัดระวัง และช่องโหว่ด้านการควบคุมสิทธิ์ (access control) งานวิเคราะห์จากแวดวงความปลอดภัยชี้ว่าการกำหนดค่าผิดพลาดในระบบคลาวด์และการผนวกรวมบริการภายนอกเป็นสาเหตุสำคัญของการเปิดเผยข้อมูลในสัดส่วนที่มีนัยยะ (มักอยู่ในช่วงสองหลักของเปอร์เซ็นต์) ซึ่งสะท้อนว่าปัจจัยเหล่านี้ไม่ควรถูกละเลยในสถาปัตยกรรมองค์กร
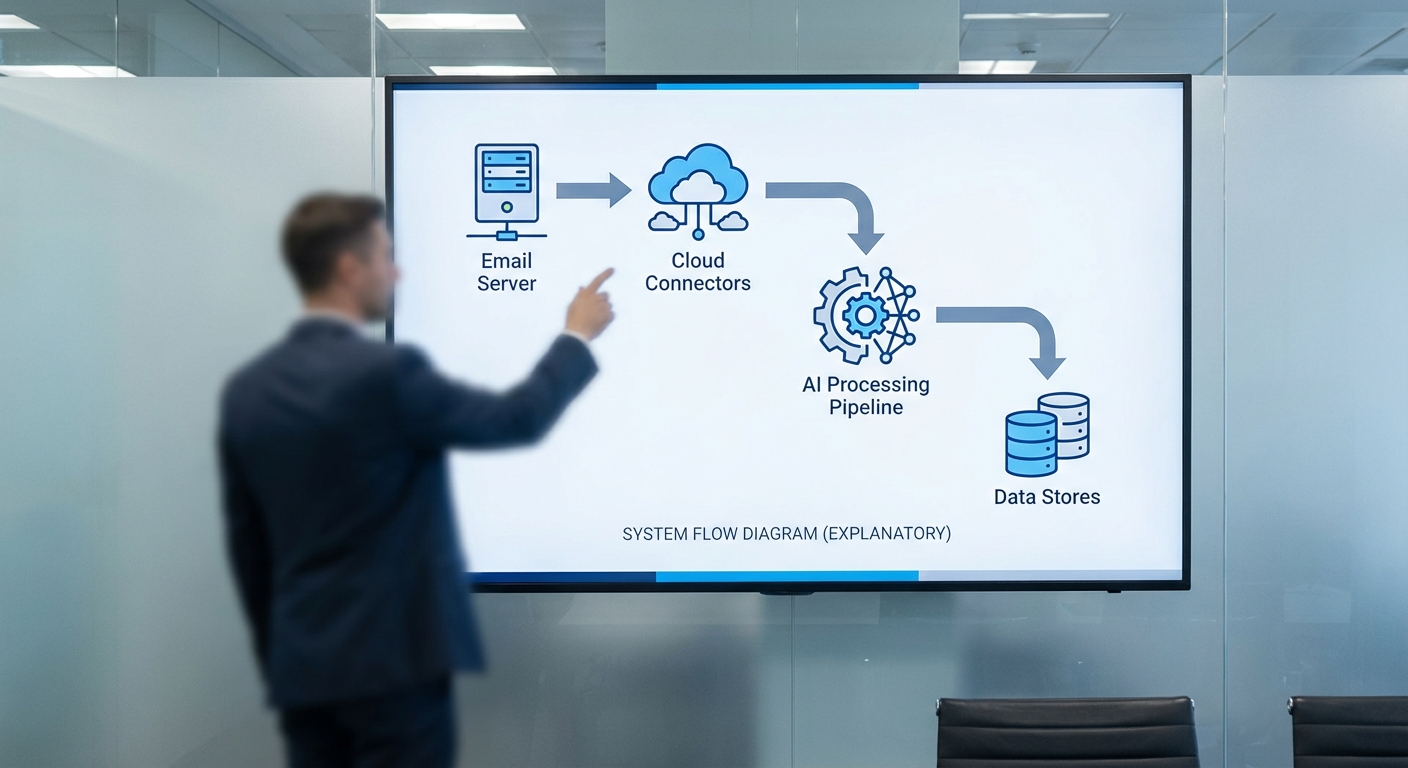
เริ่มจากประเด็นของ API/connector และการตั้งค่า — ระบบอีเมลสมัยใหม่มักเชื่อมต่อกับบริการอื่นผ่าน Microsoft Graph API, SMTP relay, Exchange connectors, หรือระบบอัตโนมัติอย่าง Power Automate/Logic Apps หากการให้สิทธิ์ (OAuth scopes หรือ service principal roles) ถูกตั้งกว้างเกินจำเป็น เช่นให้สิทธิ์อ่านกล่องจดหมายทั้งหมด (Mail.Read) หรือให้สิทธิ์ระดับผู้ดูแล (Admin consent) ระบบภายนอกจะสามารถดึงเนื้อหาอีเมล ไฟล์แนบ และ metadata ได้ทันที ตัวอย่างเชิงเทคนิคเช่น:นักพัฒนาสร้าง flow ให้ส่งสำเนาอีเมลไปยัง endpoint ของผู้ให้บริการ AI โดยไม่ได้ล้างเนื้อหาหรือจำกัด scope ส่งผลให้ข้อความทั้งฉบับและไฟล์แนบถูกคัดลอกออกจากระบบต้นทาง
ในทางกระบวนการข้อมูล (ingestion pipeline) ปัญหาที่พบบ่อยคือการนำข้อมูลดิบเข้าไปยัง Data Lake หรือ staging area เพื่อประมวลผลหรือใช้ฝึกโมเดลโดยตรง หากไม่มีการกรอง (PII redaction) หรือการทำ data classification ข้อมูลส่วนตัว เช่น ที่อยู่อีเมล เนื้อหาอีเมล และไฟล์แนบที่มีข้อมูลสำคัญจะถูกรวมเข้าในชุดข้อมูลฝึก (training set) หรือ pipeline ของโมเดล ตัวอย่างเช่น การอัปโหลดชุดอีเมลต้นฉบับไปยัง Azure Blob Storage/S3 แล้วตั้งค่า ACL เป็นสาธารณะหรือออก SAS token ที่ไม่มีการจำกัดขอบเขต จะทำให้ข้อมูลพร้อมเข้าถึงโดยบุคคลภายนอก อีกกรณีคือการส่งข้อมูลไปยังผู้ให้บริการ LLM เพื่อ fine‑tune โดยตรง ซึ่งบางผู้ให้บริการอาจเก็บข้อมูลเพื่อปรับปรุงโมเดล หากองค์กรไม่ได้ทำการ anonymize หรือ sign a data‑processing agreement ที่ชัดเจน ข้อมูลจึงอาจถูกนำไปใช้ต่อได้
บทบาทของการผนวกรวม third‑party และการตั้งค่าสิทธิ์มีความสำคัญอย่างยิ่ง: บริการภายนอกมักต้องการสิทธิ์เพื่ออ่าน เขียน หรือ forward ข้อมูล การให้สิทธิ์เกินความจำเป็น (excessive IAM roles, overly broad OAuth scopes) หรือการใช้ service account ที่มีสิทธิ์ระดับสูง (เช่น Contributor/Owner) ทำให้หาก credentials ถูกเปิดเผยผ่านโค้ด, CI/CD log, หรือ leak ใน repository ข้อมูลทั้งหมดจะถูกเข้าถึงได้ นอกจากนี้ token ที่เก็บใน environment variables หรือ config file โดยไม่มีการ rotate/expiration ย่อมเพิ่มความเสี่ยง
สุดท้าย ปัญหาเรื่อง logging และ caching มักถูกมองข้ามแต่เป็นต้นตอการรั่วไหลบ่อยครั้ง เซิร์ฟเวอร์หรือ reverse proxy อาจเก็บ request/response body ใน log โดยตั้งค่าระดับ debug ไว้เป็นค่าดีฟอลต์ ELK/ Splunk หรือ SIEM ที่รวบรวม log เหล่านี้จะกลายเป็นแหล่งข้อมูลที่มีเนื้อหาอีเมลหรือ token หากการเข้าถึง log เหล่านี้ไม่ได้ถูกจำกัด นอกจากนี้ CDN หรือ edge cache อาจเก็บสำเนาหน้าที่มีข้อมูลส่วนบุคคล การสำรองข้อมูล (backups) และ snapshot ของ DB หรือ container registry ที่ไม่ได้เข้ารหัสก็เป็นอีกช่องทางหนึ่งที่ข้อมูลอาจหลุดกระจายไปได้
ในเชิงสรุป การรั่วไหลแบบนี้มักเกิดจากการรวมกันของ: การให้สิทธิ์เกินจำเป็น, การตั้งค่าการผนวกรวมที่ไม่รัดกุม, การนำข้อมูลดิบเข้าสู่ระบบวิเคราะห์/ฝึกโมเดลโดยไม่กรอง, และการเก็บ log/caching ที่ไม่ระมัดระวัง แนวทางเชิงปฏิบัติที่ช่วยลดความเสี่ยงได้แก่การบังคับใช้ principle of least privilege, การ anonymize/obfuscate ข้อมูลก่อนส่งให้ third‑party, การตั้งค่า retention และการเข้ารหัสสำหรับ storage/backup, รวมทั้งการตรวจสอบและสแกนการตั้งค่า cloud/resource อย่างสม่ำเสมอ
ผลกระทบต่อความเป็นส่วนตัวและความเสี่ยงทางกฎหมาย
ผลกระทบต่อความเป็นส่วนตัวและความเสี่ยงทางกฎหมาย

การรั่วไหลของอีเมลลับสู่เครื่องมือ AI ส่งผลกระทบโดยตรงต่อความเป็นส่วนตัวของผู้ใช้ทั้งในระดับบุคคลและระดับองค์กร โดยข้อมูลที่ถูกเปิดเผยอาจประกอบด้วยข้อมูลส่วนบุคคล (เช่น ที่อยู่อีเมล เบอร์โทรศัพท์ ข้อมูลทางการเงิน) รวมถึงข้อมูลความลับขององค์กร (เช่น แผนธุรกิจ เอกสารภายใน รหัสผ่านหรือโทเค็นการเข้าถึง) ซึ่งนำไปสู่ความเสี่ยงหลายรูปแบบตั้งแต่การโจรกรรมตัวตน (identity theft) การโจมตีแบบฟิชชิ่ง (phishing) ไปจนถึงการเปิดเผยทรัพย์สินทางปัญญาและความลับทางการค้า
สำหรับผู้ใช้ธรรมดา ผลกระทบโดยตรงมักเป็นการสูญเสียความเป็นส่วนตัวและความปลอดภัยของบัญชีส่วนบุคคล ซึ่งอาจก่อให้เกิดความเสียหายทางการเงินและความไม่สะดวกยาวนาน ส่วนลูกค้าระดับองค์กรจะได้รับผลกระทบเชิงระบบมากขึ้น เช่น การละเมิดสัญญาความลับกับพันธมิตร ความเสี่ยงต่อการหยุดชะงักของธุรกิจ และความเสี่ยงต่อการถูกโจมตีเชิงกิจกรรมข่าวกรองภายนอก (corporate espionage) ตัวอย่างผลกระทบเชิงปฏิบัติการได้แก่ การต้องรีเซตรหัสผ่าน ระบบตรวจสอบสิทธิ์ใหม่ การแจ้งเตือนลูกค้าและผู้มีส่วนได้เสีย รวมถึงการลงทุนด้านไอทีเพื่อซ่อมแซมความเสียหาย
ความเสี่ยงด้านกฎหมายและกฎระเบียบ มีความรุนแรงและหลากหลาย โดยเฉพาะหากข้อมูลที่รั่วไหลจัดเป็นข้อมูลส่วนบุคคลภายใต้กฎหมายคุ้มครองข้อมูล ตัวอย่างที่สำคัญได้แก่:
- GDPR (สหภาพยุโรป) — ค่าปรับสูงสุดอาจถึง €20 ล้าน หรือ 4% ของรายได้รวมต่อปี (แล้วแต่จำนวนใดสูงกว่า) สำหรับการละเมิดที่ร้ายแรง เช่น การจัดการข้อมูลส่วนบุคคลอย่างไม่เหมาะสมหรือขาดมาตรการรักษาความปลอดภัย
- CCPA/CPRA (รัฐแคลิฟอร์เนีย สหรัฐฯ) — เจ้าหน้าที่สามารถเรียกร้องค่าปรับทางแพ่งได้ โดยทั่วไปค่าปรับอยู่ที่ประมาณ $2,500 ต่อการละเมิดที่ไม่เจตนา และสูงถึง $7,500 ต่อการละเมิดที่เจตนา รวมทั้งความเสี่ยงจากการฟ้องร้องแบบกลุ่ม (class action)
- กฎหมายท้องถิ่น — หลายประเทศมีข้อบังคับด้านคุ้มครองข้อมูลของตน เช่น PDPA ในประเทศไทย ซึ่งให้โทษทั้งทางแพ่งและทางอาญาและมีบทลงโทษที่สำคัญต่อผู้ควบคุมข้อมูลหากไม่ปฏิบัติตามข้อกำหนดการคุ้มครองข้อมูลส่วนบุคคล
ด้านค่าใช้จ่ายเชิงตัวเลขเพื่อให้เห็นมูลค่าความเสี่ยงเชิงการเงิน ผู้เชี่ยวชาญด้านอุตสาหกรรมได้ชี้ให้เห็นว่าค่าใช้จ่ายเฉลี่ยของการรั่วไหลข้อมูลมีมูลค่าสูง ตัวอย่างเช่น รายงานด้านความปลอดภัยข้อมูลของ IBM ระบุว่า ค่าใช้จ่ายเฉลี่ยของการรั่วไหลข้อมูลอยู่ที่ประมาณ $4.45 ล้านดอลลาร์สหรัฐ รวมต้นทุนด้านการตรวจพบและกักกันเหตุ การแจ้งผู้เสียหาย การเรียกคืนระบบ และความเสียหายต่อแบรนด์ โดยเฉลี่ยค่าใช้จ่ายต่อบันทึกข้อมูล (per-record) อยู่ที่ประมาณ $161 และระยะเวลาเฉลี่ยในการตรวจพบและปิดกั้นเหตุการณ์อยู่ที่ราว 277 วัน ซึ่งแสดงให้เห็นว่าต้นทุนไม่เพียงมาจากค่าปรับ แต่รวมถึงต้นทุนการฟื้นฟูและความเสียหายระยะยาว
นอกจากต้นทุนโดยตรงแล้ว ผลกระทบทางชื่อเสียงอาจก่อให้เกิดการสูญเสียรายได้ในระยะยาว ลูกค้าหลายรายอาจย้ายไปยังคู่แข่งหรือระงับการทำธุรกิจกับบริษัทที่เกิดเหตุ ข้อมูลในอดีตยังชี้ให้เห็นว่าเหตุการณ์รั่วไหลร้ายแรงมักนำไปสู่การลดลงของมูลค่าหุ้น การเพิ่มของต้นทุนการได้มาซึ่งลูกค้าใหม่ และค่าใช้จ่ายในการฟื้นฟูความเชื่อมั่นของตลาด ซึ่งเมื่อนำค่าปรับภายใต้กฎระเบียบมารวมกับต้นทุนเชิงปฏิบัติการแล้ว ภาระทางการเงินอาจพุ่งสูงเป็นหลายสิบล้านดอลลาร์หรือมากกว่า ขึ้นกับขนาดขององค์กรและจำนวนบันทึกข้อมูลที่ถูกเปิดเผย
สรุป — การรั่วไหลของอีเมลผ่านเครื่องมือ AI ไม่ใช่เพียงปัญหาด้านความเป็นส่วนตัวของผู้ใช้ทั่วไปเท่านั้น แต่ยังมีศักยภาพที่จะสร้างความเสียหายทางกฎหมายและการเงินต่อบริษัทอย่างรุนแรง ทั้งค่าปรับตามกฎระเบียบเช่น GDPR/CCPA ค่าใช้จ่ายในการแก้ไขระบบและสนับสนุนผู้ได้รับผลกระทบ รวมถึงความเสียหายต่อชื่อเสียงที่อาจกระทบต่อรายได้ระยะยาว จึงเป็นเรื่องจำเป็นที่องค์กรต้องประเมินความเสี่ยงเชิงกฎหมายอย่างเร่งด่วนและดำเนินมาตรการป้องกัน-ชดเชยอย่างเป็นระบบ
คำตอบจากไมโครซอฟต์: การชี้แจงและมาตรการแก้ไข
คำตอบจากไมโครซอฟต์: การชี้แจงและมาตรการแก้ไข
ไมโครซอฟต์ ออกคำชี้แจงอย่างเป็นทางการต่อเหตุการณ์อีเมลที่ถูกเรียกแสดงผ่านเครื่องมือปัญญาประดิษฐ์ โดยระบุว่าได้ดำเนินการตอบสนองเชิงเหตุการณ์ทันทีเพื่อจำกัดผลกระทบและเริ่มการสอบสวนภายใน บริษัทยืนยันว่าเหตุการณ์ดังกล่าวเป็นข้อผิดพลาดในการประมวลผลข้อมูลที่เกิดขึ้นในส่วนน้อยของคำขอ (ตามคำแถลงของบริษัทคือ "a small fraction of requests") และกำลังร่วมมือกับทีมรักษาความปลอดภัยภายในรวมถึงที่ปรึกษาภายนอกเพื่อตรวจสอบสาเหตุและขอบเขตของการเปิดเผยข้อมูล ข้อความอย่างเป็นทางการเน้นว่ามาตรการที่ดำเนินไปมีเป้าหมายเพื่อปกป้องข้อมูลลูกค้าเป็นสำคัญและจะมีการแจ้งผู้ใช้ที่ได้รับผลกระทบทันทีตามข้อกำหนดด้านกฎหมายและนโยบายความเป็นส่วนตัว

มาตรการทางเทคนิคและการสื่อสารที่ไมโครซอฟต์รายงานว่าได้ดำเนินการรวมถึง:
- ปิดหรือจำกัดฟีเจอร์ที่เกี่ยวข้องโดยทันที เพื่อหยุดการเรียกใช้ห่วงโซ่ของกระบวนการที่อาจนำไปสู่การเปิดเผยข้อมูลเพิ่มเติม
- ออกแพตช์ฉุกเฉินและอัปเดตระบบ เพื่อแก้ไขบั๊กที่ตรวจพบ พร้อมการรีสตาร์ทบริการที่เกี่ยวข้องและการปรับค่าคอนฟิกความปลอดภัย
- หมุนคีย์/โทเค็นและล้างแคช/ชั่วคราว เพื่อลดความเสี่ยงของข้อมูลที่คงค้างในระบบภายใน
- ตรวจสอบล็อกและเรียกดูเทรซเชน โดยทีมวิศวกรและผู้เชี่ยวชาญความปลอดภัยภายนอก เพื่อระบุช่วงเวลาที่เกิดเหตุและผู้ใช้ที่ได้รับผลกระทบ
- แจ้งผู้ใช้และลูกค้าที่ยืนยันว่าถูกกระทบ พร้อมแนวทางการบรรเทาความเสี่ยง เช่น การเปลี่ยนรหัสผ่าน การยกเลิกโทเค็น และช่องทางสนับสนุนเฉพาะ
- รายงานต่อหน่วยงานกำกับดูแลที่เกี่ยวข้อง ตามข้อผูกพันทางกฎหมายในพื้นที่ที่เหตุการณ์อาจกระทบ
- ว่าจ้างผู้เชี่ยวชาญอิสระ เพื่อดำเนินการตรวจสอบภายนอกและเสนอคำแนะนำด้านความปลอดภัยเพิ่มเติม
การประเมินความเพียงพอของมาตรการเหล่านี้ต้องพิจารณาทั้งด้านความเร็วของการตอบสนองและความโปร่งใสในการสื่อสาร ในด้านบวก มาตรการเช่นการปิดฟีเจอร์ทันที การออกแพตช์ฉุกเฉิน และการแจ้งผู้ใช้เป็นขั้นตอนที่สอดคล้องกับแนวปฏิบัติด้านเหตุการณ์ไซเบอร์สมัยใหม่ และการมีผู้เชี่ยวชาญภายนอกเข้าร่วมช่วยเพิ่มความน่าเชื่อถือ อย่างไรก็ตาม ยังมีช่องว่างสำคัญที่ควรได้รับการเสริม:
- ความโปร่งใสเชิงเทคนิค — ผู้ใช้และภาคธุรกิจต้องการรายงานเหตุการณ์เชิงเทคนิคฉบับสมบูรณ์ (post-incident report) ที่อธิบายสาเหตุ รูปแบบการรั่วไหล จำนวนผู้ได้รับผลกระทบ และข้อมูลประเภทที่หลุดออกไป
- ขอบเขตการแจ้งเตือน — ควรชัดเจนว่าระบบจะแจ้งผู้ใช้เป็นรายบุคคลหรือรายองค์กรอย่างไร และมีมาตรการชดเชยหรือเยียวยาสำหรับลูกค้าที่ได้รับผลกระทบหรือไม่
- ความยั่งยืนของการแก้ไข — แพตช์ฉุกเฉินอาจแก้ปัญหาเฉพาะหน้า แต่ต้องมีการทบทวนนโยบายการจัดการข้อมูลและการฝึกอบรมทีมพัฒนาเพื่อป้องกันซ้ำ
- การกำกับดูแลและการทดสอบอิสระต่อเนื่อง — การว่าจ้างการตรวจสอบอิสระครั้งเดียวไม่เพียงพอ ควรมีการทดสอบเชิงรุกและการประเมินความเสี่ยงเป็นระยะ
โดยสรุป มาตรการที่ไมโครซอฟต์ประกาศเป็นการตอบสนองที่รวดเร็วและครอบคลุมหลายมิติ ทั้งทางเทคนิคและการสื่อสาร แต่องค์กรและลูกค้าในภาคธุรกิจยังต้องการหลักประกันเพิ่มเติมเกี่ยวกับความโปร่งใส ระยะเวลาในการสืบสวน ขอบเขตของผลกระทบเชิงข้อมูล และแผนป้องกันเชิงโครงสร้างในระยะยาว เพื่อให้มั่นใจได้ว่าการเกิดเหตุซ้ำจะถูกป้องกันอย่างเป็นระบบและเป็นไปตามมาตรฐานความปลอดภัยระดับองค์กร
ความคิดเห็นจากผู้เชี่ยวชาญและผลกระทบต่ออุตสาหกรรม AI
ความคิดเห็นจากผู้เชี่ยวชาญและผลกระทบต่ออุตสาหกรรม AI

มุมมองจากนักวิชาการและนักวิเคราะห์ความปลอดภัย — นักวิจัยด้านความปลอดภัยชี้ว่าเหตุการณ์อีเมลหลุดสู่เครื่องมือ AI สะท้อนช่องโหว่เชิงสถาปัตยกรรมและกระบวนการจัดการข้อมูลที่ยังไม่เข้มแข็งพอ โดยประเด็นหลักที่ถูกหยิบยกได้แก่ การควบคุมการเข้าถึงข้อมูล (access control), การแยกข้อมูลการฝึกสอนกับข้อมูลการใช้งานจริง (data segregation) และการขาดการบันทึก/ตรวจสอบการเรียกใช้งาน (auditing/logging) ซึ่งตามการสำรวจหลายฉบับในวงการ พบว่า ระหว่าง 40–60% ขององค์กร แสดงความกังวลอย่างมีนัยสำคัญต่อความเสี่ยงด้านข้อมูลเมื่อผสาน AI เข้ากับระบบภายในองค์กร
มุมมองจากนักกฎหมายผู้เชี่ยวชาญด้านข้อมูล — ฝ่ายกฎหมายเตือนว่าเหตุการณ์ลักษณะนี้อาจเปิดช่องให้เกิดการละเมิดกฎหมายคุ้มครองข้อมูลส่วนบุคคลได้จริง โดยเฉพาะเมื่อข้อมูลที่หลุดเป็นข้อมูลส่วนบุคคลหรือข้อมูลเชิงธุรกิจที่อ่อนไหว ภายใต้กฎเช่น GDPR ผู้ควบคุมข้อมูลอาจเผชิญค่าปรับสูงสุดถึง 4% ของรายได้รวมหรือ 20 ล้านยูโร (แล้วแต่จำนวนใดสูงกว่า) นอกจากนี้ยังมีปัญหาด้านการแจ้งเหตุละเมิด (breach notification) และความเสี่ยงต่อคดีความและการเรียกร้องค่าเสียหายจากลูกค้า การประเมินผลกระทบด้านการคุ้มครองข้อมูล (DPIA) และข้อกำหนดในการทำสัญญาซัพพลายเชน (data processing agreements) จะถูกนำมาทบทวนและเข้มงวดขึ้น
มุมมองจากผู้บริหารองค์กร IT และผู้จัดซื้อ — ฝ่าย IT ระบุว่าเหตุการณ์นี้จะกระทบต่อความเชื่อมั่น (trust) และวงจรการจัดซื้อ (procurement) ของโซลูชัน AI โดยคาดว่าจะมีการชะลอการปรับใช้งานในระดับผลิตภัณฑ์ที่เกี่ยวข้องกับข้อมูลสำคัญ เช่น ระบบตอบอีเมลอัตโนมัติ ระบบวิเคราะห์เอกสาร และระบบช่วยตัดสินใจเชิงธุรกิจ สำรวจภายในกลุ่มองค์กรขนาดกลาง–ใหญ่ชี้ว่า ประมาณ 30–45% ของผู้บริหาร อาจเลื่อนการทดสอบหรือการใช้งานจริงจนกว่าจะมั่นใจในมาตรการป้องกันข้อมูล นอกจากนี้ ฝ่ายจัดซื้อจะใส่ใจข้อกำหนดด้านความปลอดภัยในสัญญามากขึ้น เช่น การรับรองมาตรฐาน ความรับผิดชอบต่อการรั่วไหล และการประกันภัยไซเบอร์
แนวทางปฏิบัติใหม่และแนวโน้มการกำกับดูแล — ผลกระทบที่คาดว่าจะเกิดขึ้นในวงกว้างคือการนิยามใหม่ของคำว่า "trustworthy AI" ซึ่งจะเน้นหนักใน 3 มิติหลัก: ความโปร่งใส (transparency), ความรับผิดชอบ (accountability) และการคุ้มครองข้อมูล (data protection) แนวทางปฏิบัติ (best practices) ที่ผู้เชี่ยวชาญเสนอให้เร่งนำมาใช้ ได้แก่:
- การกำหนดและตรวจสอบแหล่งที่มาของข้อมูล (data provenance): ระบุชัดเจนว่าแต่ละชุดข้อมูลมาจากแหล่งใด ใช้เพื่อวัตถุประสงค์อะไร และได้รับความยินยอมอย่างไร
- การแยกสภาพแวดล้อมฝึกสอนและการให้บริการ: ข้อมูลภายในไม่ควรถูกใช้เป็น prompt หรือ training data กับโมเดลสาธารณะโดยไม่ผ่านการดัดแปลง/อนามัยข้อมูล (data sanitization)
- มาตรการควบคุมการเข้าถึงและการบันทึกเหตุการณ์: การใช้ logging, immutable audit trails และการจำกัดสิทธิ์ตามบทบาท
- การประเมินความเสี่ยงและการทดสอบเชิงจริยธรรม: ทำ DPIA, red-team testing และการประเมินผลกระทบต่อความเป็นส่วนตัวอย่างสม่ำเสมอ
- ข้อกำหนดในสัญญาและการรับรองจากผู้ให้บริการ: การเรียกร้อง certification, model cards, และข้อผูกมัดด้านการรับผิดชอบต่อข้อมูล
สรุปได้ว่าเหตุการณ์อีเมลรั่วสู่เครื่องมือ AI จะเป็นจุดชนวนให้ทั้งภาคเอกชนและหน่วยงานกำกับดูแลรีบทบทวนนโยบาย การจัดซื้อ และมาตรฐานความปลอดภัย AI องค์กรที่จะผ่านพ้นความท้าทายนี้ได้จะต้องผสานทั้งมาตรการด้านเทคนิค นโยบายสัญญา และกระบวนการกำกับภายในอย่างเข้มข้น เพื่อฟื้นฟูและรักษา ความเชื่อมั่น ของลูกค้าและผู้มีส่วนได้ส่วนเสียในยุคที่ AI กลายเป็นแกนกลางของการดำเนินธุรกิจ
คำแนะนำเชิงปฏิบัติสำหรับผู้ใช้และองค์กร
คำแนะนำเชิงปฏิบัติสำหรับผู้ใช้ทั่วไป — ขั้นตอนเร่งด่วนที่ต้องทำทันที
เมื่อทราบข่าวว่ามีการรั่วไหลของอีเมลหรือข้อมูลไปยังระบบ AI สิ่งสำคัญคือการดำเนินการเชิงรุกเพื่อจำกัดความเสียหาย โดยผู้ใช้ควรให้ความสำคัญกับมาตรการพื้นฐานที่พิสูจน์ได้ว่าสามารถลดความเสี่ยงได้อย่างมีประสิทธิภาพ ตัวอย่างเช่น Microsoft รายงานว่า การเปิดใช้ Multi-factor Authentication (MFA) สามารถช่วยป้องกันการเข้าถึงบัญชีที่ไม่ได้รับอนุญาตได้มากกว่า 99.9% ในหลายกรณี ขั้นตอนเร่งด่วนที่แนะนำได้แก่:
- เปลี่ยนรหัสผ่านทันที ของบัญชีที่เกี่ยวข้อง และเลือกใช้รหัสผ่านที่ยาวและไม่ซ้ำกับบริการอื่น ๆ ใช้ตัวจัดการรหัสผ่าน (password manager) เพื่อความปลอดภัยและความสะดวก
- ยกเลิก/หมุน API tokens และ OAuth tokens ที่เชื่อมต่อกับบริการ AI หรือแอปบุคคลที่สามที่ไม่น่าเชื่อถือ หากไม่แน่ใจให้ยกเลิกทั้งหมดแล้วออก token ใหม่ตามจำเป็น
- เปิดใช้งาน MFA ในทุกบัญชีที่รองรับ โดยใช้วิธีที่ปลอดภัยเช่น แอปยืนยันตัวตน (TOTP) หรือฮาร์ดแวร์โทเค็น แทนการใช้ SMS เป็นหลัก
- ตรวจสอบการเชื่อมต่อของแอป (Connected Apps / Authorized Apps) และเพิกถอนสิทธิ์แอปที่ไม่รู้จักหรือไม่จำเป็น รวมถึงตรวจสอบการตั้งค่า "forwarding" หรือการกรองอีเมลที่อาจถูกใช้เพื่อขโมยข้อมูล
- สแกนอุปกรณ์เพื่อหามัลแวร์ และอัปเดตซอฟต์แวร์/ระบบปฏิบัติการทันที หากสงสัยว่าข้อมูลถูกเข้าถึงให้พิจารณาลงชื่อออกจากอุปกรณ์ทั้งหมด (sign out everywhere)
- ติดตามการแจ้งเตือนด้านความปลอดภัย เช่น การแจ้งเตือนการเข้าสู่ระบบจากภูมิภาคผิดปกติ และตรวจสอบรายงานกิจกรรมในบัญชีเป็นระยะ
มาตรการเชิงป้องกันและการฟื้นฟูสำหรับองค์กร
องค์กรต้องยกระดับการควบคุมด้านความปลอดภัยของข้อมูลและกระบวนการบริหารความเสี่ยงที่เกี่ยวกับการใช้งานบริการ AI ทั้งภายในและภายนอก การดำเนินการเชิงปฏิบัติที่สำคัญประกอบด้วยการตรวจสอบ การจำกัดข้อมูล และการปรับปรุงข้อตกลงทางธุรกิจ:
- Audit connectors และการเข้าถึง — ตรวจสอบรายการ connector, integration, และ API ที่เชื่อมระบบอีเมลหรือระบบสำคัญกับบริการ AI และบุคคลที่สาม ยืนยันสิทธิ์การเข้าถึง (principle of least privilege) และเพิกถอนการเชื่อมต่อที่ไม่จำเป็น
- Data minimization และการแยกข้อมูล — กำหนดนโยบายห้ามส่งข้อมูลที่ละเอียดอ่อน (PII, ข้อมูลทางการเงิน, ข้อมูลสุขภาพ, ความลับทางการค้า) ไปยังบริการ AI สาธารณะ หากจำเป็นให้ใช้การทำ anonymization/pseudonymization หรือ sandboxed environments สำหรับการทดสอบ
- ติดตั้งและปรับปรุง DLP (Data Loss Prevention) — นำระบบ DLP มาควบคุมและบล็อกการส่งข้อมูลสำคัญออกนอกองค์กรผ่านช่องทางที่ไม่ได้รับอนุญาต รวมถึงการสแกนคำค้นหาและรูปแบบข้อมูลที่เสี่ยง
- นโยบายการจัดการโทเค็นและคีย์ — บังคับใช้นโยบายการหมุนคีย์/โทเค็นเป็นระยะ ตั้งค่า expiration และใช้ vault ที่ปลอดภัยสำหรับเก็บ secrets
- สัญญาและข้อกำหนดกับผู้ให้บริการ — ในสัญญากับผู้ให้บริการ AI/คลาวด์ให้รวมข้อกำหนดด้านความปลอดภัย ข้อจำกัดการใช้ข้อมูล การเข้ารหัส ระยะเวลาเก็บข้อมูล การตรวจสอบและสิทธิ์ในการทำ audit รวมถึงบทลงโทษกรณีละเมิด
- อบรมและความตระหนัก — ให้การฝึกอบรมพนักงานเกี่ยวกับแนวปฏิบัติในการแบ่งปันข้อมูล การตรวจสอบการเชื่อมต่อและการรายงานเหตุการณ์อย่างรวดเร็ว
แนวทางการสื่อสารและเตรียมความพร้อมทางกฎหมาย (Incident Response & Breach Notification)
การจัดการเหตุการณ์รั่วไหลต้องเป็นไปอย่างเป็นระบบ โปร่งใส และปฏิบัติตามกฎหมายที่เกี่ยวข้อง องค์กรควรมีแผนตอบสนองต่อเหตุการณ์ (incident response plan) ที่รวมถึงบทบาทความรับผิดชอบ ขั้นตอนการสืบสวน และการสื่อสารทั้งภายในและภายนอก:
- ตั้งทีมตอบสนองเหตุการณ์ (Incident Response Team) ที่รวมฝ่าย IT, ความมั่นคงปลอดภัย ข้อมูลส่วนบุคคล ฝ่ายกฎหมาย และสื่อสารองค์กร เพื่อบริหารจัดการเหตุการณ์อย่างรวดเร็วและมีเอกภาพ
- การเก็บรักษาหลักฐานและการสืบสวน — รักษา logs, metadata, และ snapshot ของระบบเพื่อสนับสนุนการวิเคราะห์ทางนิติวิทยาศาสตร์และข้อพิสูจน์การละเมิดโดยไม่แก้ไขหลักฐานดิบ
- การแจ้งเตือนตามกฎหมาย — ปฏิบัติตามข้อกำหนดการแจ้งเตือนของหน่วยงานกำกับดูแล เช่น ในเขตอำนาจของ GDPR ต้องแจ้งหน่วยงานภายใน 72 ชั่วโมง หากมีความเสี่ยงต่อสิทธิและเสรีภาพของบุคคล และพิจารณาการแจ้งผู้ใช้ที่ได้รับผลกระทบพร้อมคำแนะนำปฏิบัติ
- การสื่อสารต่อสาธารณะ — จัดทำข้อความชัดเจน โปร่งใส และทันท่วงทีสำหรับลูกค้าและพาร์ทเนอร์ ระบุสิ่งที่เกิดขึ้น ผลกระทบที่คาดว่าจะเกิด วิธีการที่องค์กรจัดการ และคำแนะนำให้ผู้ได้รับผลกระทบ เช่น การเปลี่ยนรหัส การตรวจสอบบัญชี
- ทบทวนนโยบายและแก้ไขข้อบกพร่อง — หลังการฟื้นตัว ดำเนินการ post‑incident review เพื่อปรับปรุงมาตรการป้องกัน ปรับปรุงสัญญา และอัปเดตแผนการฝึกอบรมและเทคโนโลยีที่จำเป็น
สรุปคือ ทั้งผู้ใช้และองค์กรต้องลงมือปฏิบัติอย่างทันทีและต่อเนื่อง โดยผู้ใช้ควรดำเนินมาตรการเบื้องต้นเพื่อปกป้องบัญชีของตน ขณะที่องค์กรต้องยกระดับการควบคุมข้อมูล ปรับปรุงสัญญากับผู้ให้บริการ และเตรียมแผนการตอบสนองและการสื่อสารที่สอดคล้องกับกฎหมายและความคาดหวังของผู้มีส่วนได้ส่วนเสีย การรวมมาตรการทางเทคนิค นโยบาย และการสื่อสารเชิงรุกจะเป็นกุญแจสำคัญในการลดผลกระทบจากเหตุการณ์เช่นนี้
บทสรุป
เหตุการณ์อีเมลส่วนตัวรั่วไหลสู่เครื่องมือปัญญาประดิษฐ์ของไมโครซอฟต์ สะท้อนช่องว่างเชิงการจัดการข้อมูลเมื่อ AI ถูกผนวกรวมเข้ากับบริการอีเมล โดยเฉพาะในด้านการควบคุมสิทธิ์การเข้าถึง การแยกแยะข้อมูลที่เป็นความลับ และการตรวจสอบลำดับขั้นของการประมวลผลข้อมูล เหตุการณ์นี้ชี้ให้เห็นความจำเป็นของมาตรการเชิงเทคนิค เช่น การเข้ารหัสแบบปลายทาง (end-to-end), การจำกัดสิทธิ์แบบ least privilege, การบันทึกและตรวจสอบกิจกรรม (audit logs) และการออกแบบระบบให้ใช้หลัก data minimization รวมทั้งมาตรการทางกฎหมายและความโปร่งใสจากผู้ให้บริการ เช่น ข้อตกลงการใช้ข้อมูลที่ชัดเจน นโยบายการแจ้งเหตุข้อมูลรั่วไหล และการเปิดเผยว่าข้อมูลใดถูกนำไปใช้ในการฝึกหรือให้บริการ AI งานสำรวจในอุตสาหกรรมหลายฉบับยังระบุว่ามากกว่าครึ่งหนึ่งขององค์กรกังวลต่อความเสี่ยงด้านข้อมูลเมื่อต้องผสานบริการ AI เข้ากับระบบงานหลัก
มุมมองเชิงปฏิบัติในอนาคตคือผู้ใช้และองค์กรต้องเร่งประเมินการเชื่อมต่อ (integrations) และสิทธิ์การเข้าถึงของแอป/บริการที่ผนวก AI เข้ามา ปรับนโยบายการส่งข้อมูลให้เข้มงวดขึ้น เช่น หลีกเลี่ยงการส่งข้อมูลความลับผ่านช่องทางที่ไม่มีการป้องกัน, กำหนดรูปแบบการยินยอมและการควบคุมการแชร์ข้อมูล รวมถึงติดตามการอัปเดตด้านความปลอดภัยและข้อกำหนดจากผู้ให้บริการอย่างใกล้ชิด ในเชิงนโยบาย ควรพิจารณาเงื่อนไขสัญญาที่ครอบคลุมการรับผิดชอบเมื่อเกิดเหตุ และนำแนวทางความปลอดภัยเช่น Zero Trust มาใช้เพื่อจำกัดผลกระทบ หากผู้ให้บริการเพิ่มความโปร่งใสและมาตรการคุ้มครองข้อมูลอย่างจริงจัง จะช่วยฟื้นความเชื่อมั่นของผู้ใช้และลดความเสี่ยงทางกฎหมายในระยะยาว
📰 แหล่งอ้างอิง: BBC



