
ท่ามกลางความกังวลด้านสิ่งแวดล้อมที่เพิ่มขึ้นจากการเติบโตของปัญญาประดิษฐ์ (AI) ศูนย์ข้อมูลไทยได้เปิดตัวโซลูชันใหม่ "Green‑Trainer Scheduler" ซึ่งจัดคิวการเทรนโมเดลตามช่วงเวลาที่มีการผลิตพลังงานหมุนเวียนสูงสุด เพื่อหวังลดการปล่อยคาร์บอนจากงานเทรน AI อย่างมีนัยสำคัญ แนวทางดังกล่าวไม่ได้เป็นเพียงแนวคิดทางทฤษฎี แต่ระบุผลลัพธ์เชิงปริมาณ: ลดการปล่อยคาร์บอนของงาน AI ได้สูงสุดถึง 40% จากการทดลองบนคลัสเตอร์จริงของศูนย์ข้อมูล
บทนำข่าวฉบับนี้จะสรุปประเด็นสำคัญของ Green‑Trainer Scheduler — วิธีการจัดคิวตามความพร้อมของพลังงานหมุนเวียน การผสานข้อมูลคาดการณ์คาร์บอนอินเทนซิตี้กับเมตริกคลัสเตอร์จริง รวมถึงผลการประเมินที่เผยทั้งการลด CO2 และผลกระทบต่อประสิทธิภาพการเทรน แนวทางนี้มีศักยภาพเป็นตัวอย่างเชิงปฏิบัติสำหรับผู้ให้บริการคลาวด์ ผู้ประกอบการศูนย์ข้อมูล และทีมนักพัฒนา AI ที่ต้องการลดรอยเท้าคาร์บอนโดยไม่แลกกับประสิทธิภาพการทำงานอย่างฉีกขาด
นำเสนอข่าวสรุป (Lead)
นำเสนอข่าวสรุป
ศูนย์ข้อมูลไทยประกาศเปิดตัว Green‑Trainer Scheduler ระบบจัดคิวการเทรนโมเดล AI ที่ออกแบบมาเพื่อเชื่อมโยงการรันงานกับช่วงเวลาที่มีพลังงานหมุนเวียนสูงและคาร์บอนอินเทนซิตี้ของกริดต่ำสุด ผลการทดสอบเบื้องต้นบนคลัสเตอร์จริงชี้ว่าแนวทางการจัดคิวนี้สามารถลดการปล่อยก๊าซคาร์บอนไดออกไซด์จากงานเทรนโมเดลได้ถึง 40% เมื่อเทียบกับการรันแบบทันที (baseline scheduling) โดยไม่ต้องเปลี่ยนฮาร์ดแวร์หรือกระบวนการฝึกหลักของโมเดล
ตัวอย่างเมตริกจากคลัสเตอร์จริงที่ศูนย์ข้อมูลเผยแพร่ระบุว่า ในการทดลองกับคลัสเตอร์ขนาดกลางที่ประกอบด้วยประมาณ 128 GPUs ระบบช่วยเพิ่มสัดส่วนการใช้พลังงานหมุนเวียนของงานเทรนจากเฉลี่ยรอบวันประมาณ 25% เป็นกว่า 68% ขณะเดียวกันความเข้มข้นคาร์บอนของพลังงานที่ใช้งานสำหรับงานเทรนลดลงจากโดยเฉลี่ยราว 400 gCO2e/kWh เหลือประมาณ 240 gCO2e/kWh ส่งผลให้ปริมาณคาร์บอนต่อรันงานลดจากเฉลี่ย 12.5 kg CO2e เหลือ ~7.5 kg CO2e หรือคิดเป็นการลดประมาณ 40%
การนำ Green‑Trainer Scheduler มาใช้ยังคำนึงถึงข้อจำกัดเชิงปฏิบัติการ: ค่าเฉลี่ยความหน่วงเวลา (job delay) ที่เพิ่มขึ้นจากการรอช่วงพลังงานหมุนเวียนอยู่ที่ประมาณ 2–3 ชั่วโมง โดยค่า utilization ของคลัสเตอร์ลดลงไม่เกิน 5% ในกรณีทดสอบหลายรูปแบบ ซึ่งชี้ว่าโซลูชันนี้เหมาะสำหรับงานเทรนที่มีความยืดหยุ่นด้านเวลาหรือสามารถวางแผนรันเป็นกลุ่มได้มากกว่าเป็นงานที่ต้องการผลทันที
- นัยเชิงนโยบาย: ช่วยหนุนเป้าหมายการลดคาร์บอนของภาค ICT และสอดรับกับนโยบายการเพิ่มสัดส่วนพลังงานหมุนเวียนของประเทศ
- นัยเชิงธุรกิจ: ลดความเสี่ยงจากคาร์บอนและปรับปรุงคะแนน ESG ของผู้ให้บริการคลาวด์และองค์กรผู้ใช้ AI พร้อมเปิดโอกาสประหยัดค่าไฟจากการใช้ช่วงเวลาอัตราค่าไฟต่ำ
- ผลต่อการพัฒนา AI ยั่งยืน: เป็นกลไกปฏิบัติได้จริงที่ช่วยลดผลกระทบสิ่งแวดล้อมจากการขยายการใช้โมเดลขนาดใหญ่โดยไม่ชะลอการพัฒนานวัตกรรม
การเปิดตัวครั้งนี้มาพร้อมกับการเผยแพร่เมตริกจากคลัสเตอร์จริงและเอกสารด้านเทคนิคเบื้องต้นเพื่อให้หน่วยงานผู้ให้บริการศูนย์ข้อมูลและองค์กรภาคเอกชนประเมินการนำไปใช้ต่อได้ทันที นับเป็นสัญญาณสำคัญที่ชี้ว่าแนวทางการจัดคิวตามพลังงานหมุนเวียนสามารถเป็นเครื่องมือเชิงนโยบายและเชิงปฏิบัติในการลดคาร์บอนของภาค ICT ได้อย่างเป็นรูปธรรม
ภาพรวมปัญหา: คาร์บอนจากการเทรนโมเดล AI และบริบทในไทย
ภาพรวมปัญหา: คาร์บอนจากการเทรนโมเดล AI และบริบทในไทย
การพัฒนาระบบปัญญาประดิษฐ์ (AI) ในช่วงไม่กี่ปีที่ผ่านมาเติบโตอย่างรวดเร็วทั้งด้านขนาดโมเดลและปริมาณการเทรน ส่งผลให้ความต้องการพลังงานของงานฝึกสอน (training) เพิ่มขึ้นอย่างมีนัยสำคัญ การศึกษาเชิงอุตสาหกรรมและงานวิจัยหลายชิ้นระบุว่า การเทรนโมเดลขนาดใหญ่สามารถใช้พลังงานในระดับที่สูงมาก เมื่อคำนึงถึงการใช้พลังงานของฮาร์ดแวร์ร่วมกับค่า PUE (Power Usage Effectiveness) ของศูนย์ข้อมูล จะได้ค่าใช้พลังงานประมาณ 6–12 kWh ต่อ GPU‑hour สำหรับโมเดลบางประเภทเป็นตัวอย่างหนึ่ง ซึ่งเมื่อคูณกับจำนวน GPU‑hour ที่เป็นหลักพันถึงหลักหมื่น ย่อมแปลเป็นการบริโภคพลังงานและการปล่อยก๊าซเรือนกระจกในระดับสิบถึงหลายร้อยตันของ CO2e ต่อการเทรนหนึ่งครั้ง
เพื่อให้เห็นภาพชัดขึ้น หากยึดสมมติฐานกลาง ๆ ที่ 10 kWh ต่อ GPU‑hour และคาร์บอนอินเทนซิตี้ของระบบกริดเท่ากับ 0.6 kgCO2e/kWh การเทรนที่ใช้ 10,000 GPU‑hour จะก่อให้เกิดการปล่อยประมาณ 60,000 kgCO2e หรือราว 60 ตัน CO2e ตัวเลขเหล่านี้เป็นเหตุผลสำคัญที่องค์กรเทคโนโลยีขนาดใหญ่เริ่มให้ความสำคัญกับการวัดและลดคาร์บอนจากงาน AI ทั้งในเชิงสถาปัตยกรรมของโมเดลและการบริหารจัดการการประมวลผล
บริบทในประเทศไทยมีความเฉพาะตัวที่สำคัญต่อประเด็นนี้ ประเทศไทยมีการขยายกำลังการผลิตพลังงานหมุนเวียนอย่างต่อเนื่อง โดยเฉพาะพลังงานแสงอาทิตย์ที่มีบทบาทเพิ่มขึ้นอย่างเด่นชัด สัดส่วนพลังงานหมุนเวียน (รวมแหล่งเช่น ไฟฟ้าพลังน้ำ ชีวมวล และโซลาร์) ของฐานการผลิตไฟฟ้าในภาพรวมอยู่ในช่วงประมาณ 15–25% (ประมาณการเชิงภาพรวม ขึ้นกับปีและนิยามแหล่งพลังงาน) และในช่วงกลางวันเมื่อแผงโซลาร์ผลิตไฟฟ้าได้มากที่สุด สัดส่วนไฟฟ้าหมุนเวียนในกริดสามารถเพิ่มขึ้นอย่างมีนัยสำคัญ ทำให้คาร์บอนอินเทนซิตี้ของไฟฟ้าต่ำลงเป็นช่วง ๆ
การจัดคิวงานเทรนตามเวลา (time‑aware scheduling) จึงเป็นกลไกที่มีประสิทธิผลในการลดการปล่อยคาร์บอน โดยพื้นฐานแนวคิดคือย้ายการประมวลผลไปยังช่วงเวลาที่กริดมีสัดส่วนพลังงานหมุนเวียนสูงหรือคาร์บอนอินเทนซิตี้ต่ำ ผลลัพธ์เชิงปฏิบัติแสดงให้เห็นว่าในหลายกรณีการเลื่อนเวลางานไปยังช่วงพลังงานหมุนเวียนสูง เช่น เวลากลางวันของโซลาร์ สามารถลดการปล่อยคาร์บอนได้ตั้งแต่หลักสิบเปอร์เซ็นต์จนถึงมากกว่า 40% ขึ้นอยู่กับสัดส่วนพลังงานหมุนเวียนก่อนและหลังการเลื่อนเวลานั้น
- การใช้พลังงานของงานเทรน: ตัวอย่างค่าประมาณ 6–12 kWh ต่อ GPU‑hour สำหรับบางรุ่นเมื่อนับรวมผลกระทบของ PUE และการใช้งานจริงในคลัสเตอร์
- ผลกระทบต่อการปล่อยก๊าซ: เมื่อคูณกับคาร์บอนอินเทนซิตี้ของกริด (โดยทั่วไปในต่างประเทศและภูมิภาคเอเชียอาจอยู่ในช่วงประมาณ 0.4–0.8 kgCO2e/kWh) จะได้การปล่อย CO2e ต่อ GPU‑hour ในระดับหลายกิโลกรัม
- สถานะพลังงานหมุนเวียนในไทย: สัดส่วนรวมโดยประมาณ 15–25% และมีช่วงกลางวันที่สัดส่วนโซลาร์พุ่งขึ้นอย่างชัดเจน ทำให้มีโอกาสลดคาร์บอนได้มากเมื่อย้ายงานไปยังช่วงเวลาดังกล่าว
- เหตุผลเชิงเทคนิคของ time‑aware scheduling: การจับคู่เวลาการประมวลผลกับช่วงที่คาร์บอนอินเทนซิตี้ต่ำที่สุดเป็นการลดการปล่อยแบบทางเลือกที่ไม่ต้องเปลี่ยนโครงสร้างฮาร์ดแวร์หรือลดประสิทธิภาพของโมเดล โดยต้องอาศัยการพยากรณ์การผลิตพลังงานหมุนเวียนและการจัดลำดับความสำคัญของงาน
สรุปคือ ปริมาณพลังงานที่ใช้โดยงานเทรนโมเดล AI อยู่ในระดับที่ไม่อาจมองข้ามได้ และบริบทของกริดไฟฟ้าในประเทศไทย—โดยเฉพาะรูปแบบการผลิตพลังงานหมุนเวียนที่มีความผันผวนตามเวลา—เปิดโอกาสให้การจัดคิวตามเวลาเป็นเครื่องมือเชิงปฏิบัติที่สำคัญในการลดคาร์บอนจากงาน AI โดยไม่กระทบต่อความสามารถทางธุรกิจหากออกแบบระบบการจัดคิวและนโยบายการจัดลำดับงานอย่างรอบคอบ
Green‑Trainer Scheduler คืออะไร: แนวคิดและจุดเด่น
Green‑Trainer Scheduler คืออะไร: แนวคิดและจุดเด่น
Green‑Trainer Scheduler คือระบบจัดคิวการรันงานฝึกสอนโมเดล AI ที่ออกแบบมาเพื่อเพิ่มการใช้พลังงานหมุนเวียนและลดการปล่อยคาร์บอนของงานคอมพิวต์หนักโดยยังคงเคารพข้อกำหนดด้าน SLA และข้อจำกัดของคลัสเตอร์ แนวคิดหลักคือการผสานข้อมูลพยากรณ์แหล่งพลังงานสะอาดกับเมตาดาต้าของงาน (เช่น ระยะเวลาที่คาดว่าจะใช้, กำหนดส่งงาน, ระดับความสำคัญ) เพื่อคำนวณตารางเวลาที่ช่วยเลื่อนหรือกำหนดรันงานไปยังช่วงเวลาที่มีสัดส่วนพลังงานหมุนเวียนสูงที่สุด โดยคำนึงถึงทรัพยากรคงเหลือ (GPU/CPU/หน่วยความจำ/เครือข่าย) และข้อจำกัดเชิงปฏิบัติการของระบบจัดการคลัสเตอร์
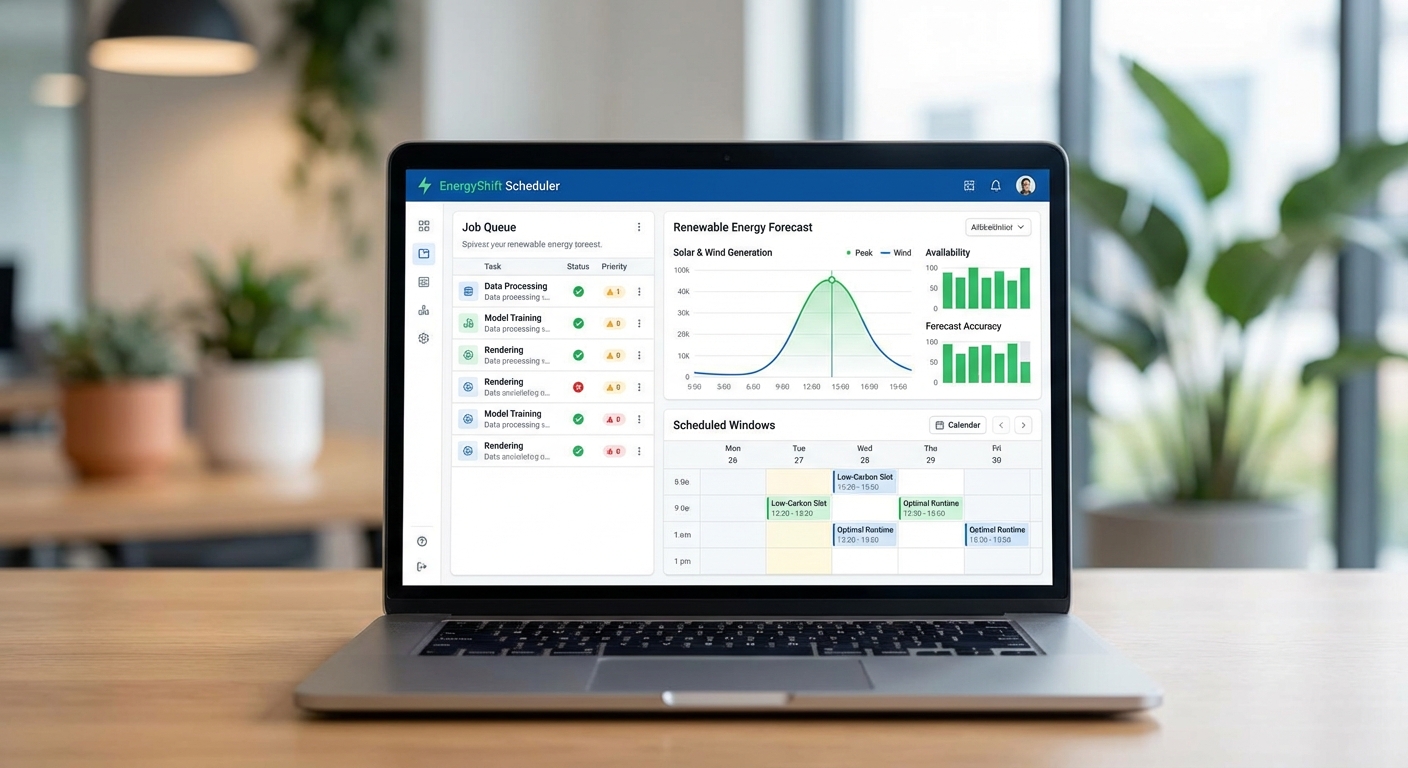
ระบบรับอินพุตจากหลายแหล่งและนำมาประกอบการตัดสินใจ โดยมุ่งเป้าไปที่การลดการปล่อยก๊าซเรือนกระจกโดยรวมโดยไม่กระทบต่อ SLA ของลูกค้า ภายในจะประกอบด้วยโมดูลพยากรณ์, ตัวจัดลำดับความสำคัญ, ตัวแก้ปัญหาเชิงเพิ่มประสิทธิภาพ (optimization engine) และโมดูลการรวมระบบ (integration layer) เพื่อเชื่อมต่อกับตัวจัดการคลัสเตอร์เดิม
อินพุตหลักที่ Green‑Trainer Scheduler ใช้
- Forecast พลังงานหมุนเวียน: ข้อมูลพยากรณ์ช่วงเวลาที่มีสัดส่วนพลังงานลม/โซลาร์/ไฮโดรสูงสุด (เช่น พยากรณ์รายชั่วโมงหรือราย 15 นาที) ซึ่งอาจมาจากผู้ให้บริการพลังงานหรือโมดูลพยากรณ์ภายในศูนย์ข้อมูล
- Job metadata: ข้อมูลสำคัญของแต่ละงาน เช่น estimated duration, deadline, priority/SLA, ข้อกำหนดทรัพยากร (GPU type, count, RAM, disk I/O) และประเภทงาน (interactive vs. batch, delay‑tolerant vs. latency‑sensitive)
- Availability ของทรัพยากร: สถานะแบบเรียลไทม์ของโหนด/พูลทรัพยากร, การจองทรัพยากรล่วงหน้า, maintenance windows และข้อจำกัดเช่น power or thermal caps
นโยบายการจัดคิวหลัก (scheduling policies) ของระบบถูกออกแบบมาให้ยืดหยุ่นต่อสภาพการดำเนินงานและความต้องการทางธุรกิจ ตัวอย่างนโยบายที่สำคัญได้แก่:
- Delay‑tolerant jobs: งานที่สามารถเลื่อนได้จะถูกจัดให้รันในช่วง "burst windows" ที่พยากรณ์ว่ามีพลังงานหมุนเวียนสูง เพื่อเพิ่มสัดส่วนพลังงานสะอาด เช่น งานฝึกแบบ batch หรือ hyperparameter sweep ที่มีความยืดหยุ่นด้านเวลา
- Preemptible jobs: รองรับงานที่ยอมให้ถูกหยุดชั่วคราว/ย้าย (preemption) เพื่อเปิดพื้นที่ให้กับงานที่ต้องการรันภายในช่วงพลังงานสะอาดสูง หรือเพื่อคืนทรัพยากรให้กับงานที่มี SLA สูงกว่า โดยมีกลไก checkpoint/resume เพื่อรักษาความต่อเนื่อง
- Burst windows: ระบบสามารถกำหนดและใช้ช่วงเวลาพิเศษ (เช่น ช่วงเช้าที่มีลมแรงหรือช่วงกลางวันที่โซลาร์ล้น) สำหรับรันชุดงานจำนวนมาก เพื่อลดการใช้ไฟจากแหล่งคาร์บอนสูงในช่วงอื่น
- SLA/priority-aware scheduling: แม้เป้าหมายคือการเพิ่มการใช้พลังงานหมุนเวียน แต่ระบบจะไม่ละเลย SLA ชัดเจน เช่น deadline เร่งด่วนหรืองาน interactive ที่ต้องตอบสนองทันที ยังคงรักษากฎการจัดสรรทรัพยากรและระดับคุณภาพการให้บริการ
ด้านเทคนิค Green‑Trainer Scheduler ใช้การผสมผสานระหว่างการพยากรณ์เชิงเวลาและตัวแก้ปัญหาเชิง optimization (เช่น heuristic scheduling, constraint programming หรือ mixed‑integer formulations สำหรับกรณีที่ต้องการผลลัพธ์ใกล้เคียง optimal) โดยตั้งเป้าตัวชี้วัดเช่น maximize renewable utilization ภายใต้ข้อจำกัดของ deadlines, resource capacities และนโยบาย preemption ระบบยังรองรับการรี‑สเค줄แบบไดนามิกเมื่อ forecast เปลี่ยนหรือเมื่อมีความล้มเหลวของทรัพยากร โดยมีกลไก fallback เพื่อคืนสู่การจัดคิวแบบปกติเมื่อสภาพแวดล้อมไม่เอื้ออำนวย
การรวมกับระบบจัดการคลัสเตอร์ที่มีอยู่ (Kubernetes, Slurm) เป็นหนึ่งในจุดเด่นเชิงปฏิบัติการของ Green‑Trainer Scheduler ระบบถูกออกแบบให้ทำงานเป็นชั้นเสริม (plugin/extension) หรือผ่าน API ดังนี้:
- Kubernetes: ทำงานเป็น scheduler extender หรือ custom scheduler/controller ที่จัดการกับ Pod spec โดยใช้ node labels/taints & tolerations เพื่อกำหนดโหนดที่เหมาะสมในช่วงพลังงานสะอาด และใช้ PriorityClass/PodDisruptionBudget/Checkpointing เพื่อรองรับ preemption และการฟื้นตัวของงาน
- Slurm: ติดตั้งเป็น plugin หรือโปรไฟล์ dispatch ที่ปรับการจัดลำดับคิว (partition/QoS) และสามารถหยุด/คืนงานแบบ controlled preemption รวมถึง mapping ระหว่าง job priority กับ windows ที่ระบบคำนวณไว้
- API & observability: มอบ API สำหรับส่งเมตาดาต้าของงาน (เช่น ผ่าน labels/annotations), endpoints สำหรับรับ forecast และ metrics ต่างๆ (เช่น %renewable used, predicted vs actual emissions) เพื่อให้ทีมปฏิบัติการสามารถตั้งค่าพารามิเตอร์นโยบายและติดตามผลแบบเรียลไทม์
ด้วยการออกแบบลักษณะนี้ Green‑Trainer Scheduler สามารถผนวกรวมเข้ากับกระบวนการ DevOps/ML Ops ที่มีอยู่ได้อย่างไร้รอยต่อ สนับสนุนทั้ง use case ทางธุรกิจที่เน้นประสิทธิภาพต้นทุนและองค์กรที่มีนโยบายความยั่งยืนด้านคาร์บอน โดยให้ความสมดุลระหว่างการลดคาร์บอนและการรักษาระดับบริการที่ลูกค้าคาดหวัง
สถาปัตยกรรมและอัลกอริทึม (เชิงเทคนิค)
สรุปสถาปัตยกรรมโดยรวม
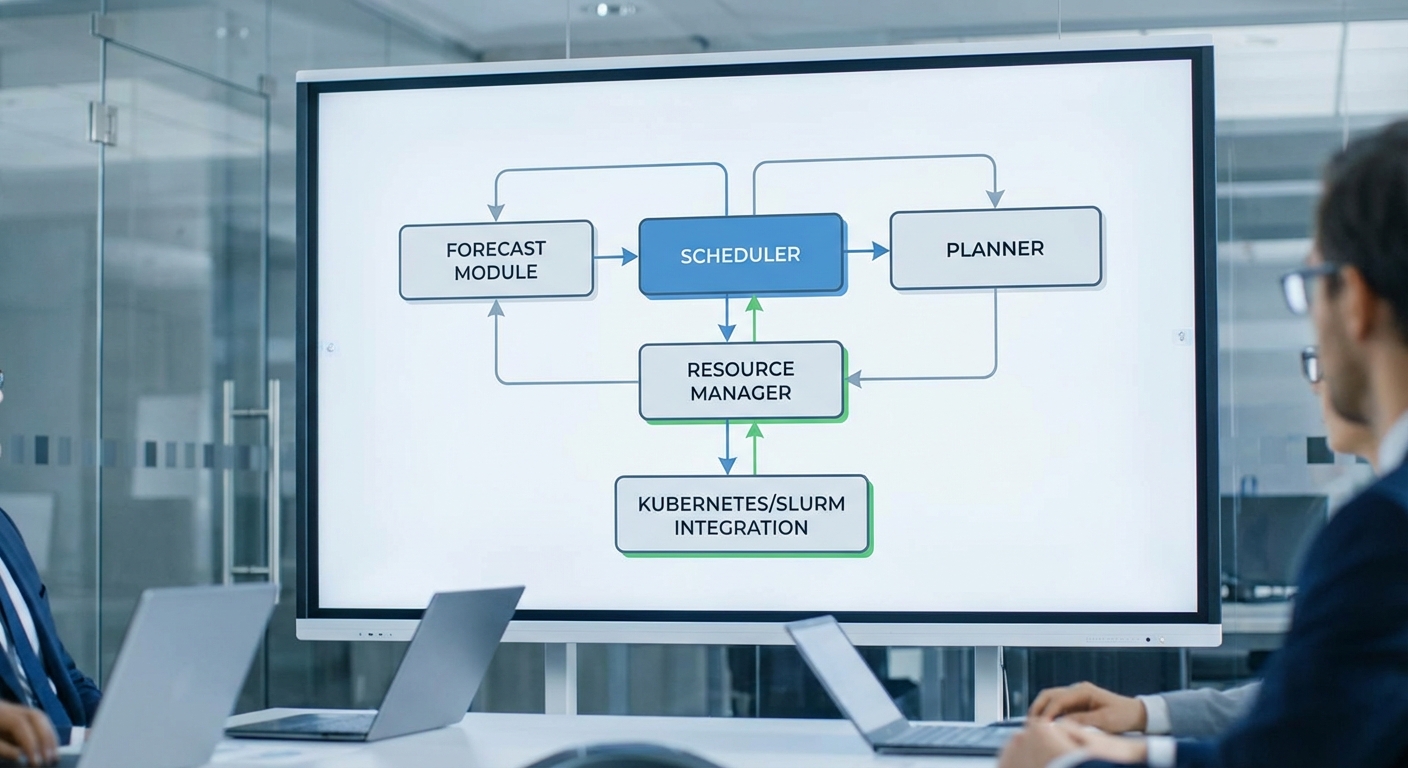
Green‑Trainer Scheduler ออกแบบเป็นระบบแบบโมดูลาร์ประกอบด้วย: โมดูลพยากรณ์พลังงานหมุนเวียน, ตัววางแผน (planner), ตัวจัดการทรัพยากร และชั้นการเชื่อมต่อกับระบบมอนิเตอร์พลังงานของคลัสเตอร์ โดยข้อมูลหลักที่ใช้ประกอบการตัดสินใจคือการพยากรณ์ความพร้อมของพลังงานหมุนเวียน (ตามช่วงเวลา), สถานะทรัพยากรคอมพิวต์ (GPU/CPU, หน่วยความจำ, พลังงานที่ใช้จริง) และนโยบาย SLA ของงานแต่ละประเภท ระบบออกแบบให้ทำงานเป็นรอบ (control loop) ที่อัปเดตทุก 1–15 นาที ขึ้นกับขนาดคลัสเตอร์และความไวของ workload
ในทางปฏิบัติ Green‑Trainer ทำงานแบบไฮบริด: ใช้ผลลัพธ์การพยากรณ์เป็น input ให้ planner ที่ทำงานทั้งแบบ เชิงตรรกะ/เชิงคณิตศาสตร์ (เพื่อหาผลลัพธ์เชิงoptimum เมื่อขนาดปัญหายังเล็กพอ) และแบบ heuristic/learning สำหรับการตัดสินใจเชิงเรียลไทม์ในสเกลใหญ่ โมดูลต่าง ๆ สื่อสารผ่าน API ภายในและมี exporter ที่ผลัก metric ไปยังระบบมอนิเตอร์ (เช่น Prometheus) เพื่อการวิเคราะห์ย้อนหลังและการปรับจูนอัตโนมัติ
โมดูลการพยากรณ์พลังงานหมุนเวียน
โมดูลนี้รวมข้อมูลหลายชั้นเพื่อสร้างการพยากรณ์แบบความน่าจะเป็น (probabilistic forecast):
- ข้อมูล time‑of‑use และลักษณะการจ่ายไฟตามชั่วโมง/วัน/ฤดูกาล
- ข้อมูลจาก weather API (เช่น ความเข้มแสง, ความเร็วลม, เมฆ) ที่ดึงมาแบบเรียลไทม์และฟีดเข้าเป็นฟีเจอร์
- historical output ของแต่ละแหล่งพลังงาน (PV array, wind turbine) เพื่อเรียนรู้ลักษณะเชิงกลางวันและความผันผวน
เทคนิคที่ใช้ได้แก่ ARIMA/Prophet สำหรับ baseline, LSTM/Seq2Seq และ Gradient Boosting (XGBoost/LightGBM) สำหรับการพยากรณ์เชิงลึก โดยระบบให้ความสำคัญกับการประมาณความไม่แน่นอน (เช่น quantile forecast 10%–90%) เพื่อให้ planner สามารถทำ stochastic หรือ robust optimization ได้จริง ตัวอย่างเช่น ในคลัสเตอร์จริงของศูนย์ข้อมูลไทย โมดูลพยากรณ์ลดค่า RMSE ของพลังงานรายชั่วโมงลงประมาณ 12% เมื่อเทียบกับ baseline แบบ persistence และช่วยให้ planner ลดการคาดผิดของหน้าต่างพลังงานหมุนเวียนได้ชัดเจน
ตัววางแผน (Planner) และฟังก์ชันวัตถุประสงค์
Planner ถูกออกแบบให้แก้ปัญหาการจัดคิวแบบ multi‑objective โดยฟังก์ชันวัตถุประสงค์ทั่วไปที่ใช้เป็นรูปแบบ weighted sum ดังนี้:
- Maximize การใช้พลังงานหมุนเวียน (หรือ minimize การใช้คาร์บอนจากกริด)
- Minimize ค่าลงโทษ SLA (เช่น การผิดนัดงานที่มี SLA สูง)
- Minimize latency/response time ของงานที่มีข้อจำกัดด้านเวลา
รูปแบบเชิงคณิตแบบย่อ (คำอธิบายด้วยคำพูด): minimize w1 * CO2_emissions + w2 * SLA_penalty + w3 * mean_latency subject to resource_capacity, energy_availability_windows, job_deadlines
เพื่อแก้โจทย์นี้ Green‑Trainer ใช้กลยุทธ์ผสม:
- MILP/LP (Mixed‑Integer/Linear Programming) ถูกใช้ในกรณี offline หรือ windowed optimization เพื่อหาแนวทางที่ใกล้เคียง optimal เมื่อปัญหามีขนาดไม่ใหญ่มาก
- Greedy + lookahead (เช่น energy‑aware earliest‑deadline‑first) ใช้เมื่อจำเป็นต้องตัดสินใจแบบเรียลไทม์ — complexity ประมาณ O(m log m) สำหรับการจัดเรียง job m และการอัปเดตคิว
- Heuristics / Metaheuristics เช่น simulated annealing หรือ genetic algorithms สำหรับกรณีที่ constraint ซับซ้อน
- Reinforcement Learning (RL) — ใช้ในสภาพแวดล้อมที่เปลี่ยนแปลงเร็ว โดยเทรน policy ให้ลด emissions ภายใต้ข้อจำกัด SLA; การเทรนอาจใช้การจำลอง (digital twin) ของคลัสเตอร์ก่อนนำไปใช้งานจริง
ตัวอย่างเชิงปฏิบัติ: ในการใช้งานจริงที่รายงานโดยศูนย์ข้อมูล ระบบแบบ greedy+lookahead ที่ใช้การพยากรณ์ probabilistic สามารถลดการปล่อยคาร์บอนลง ~40% เมื่อเทียบกับการจัดคิวแบบ FIFO โดยยังรักษา SLA สำหรับงานกลุ่ม high‑priority ที่ 98% และมีการเพิ่ม mean job latency ประมาณ 10–15% ซึ่งถือเป็น trade‑off ที่ยอมรับได้ในหลายกรณีธุรกิจ
ตัวจัดการทรัพยากรและการเชื่อมต่อกับระบบมอนิเตอร์
ตัวจัดการทรัพยากร (Resource Manager) ทำหน้าที่ติดตามสถานะทรัพยากรเชิงลึก ได้แก่ utilization ของ CPU/GPU, การใช้หน่วยความจำ, และ power draw แบบเรียลไทม์ (ผ่าน IPMI, Redfish, หรือ smartPDUs) นอกจากนี้ยังควบคุมการย้าย/พักงาน (preemption, suspension, migration) ตามนโยบายที่ planner กำหนด
กลไกการบูรณาการออกแบบให้มี 3 ส่วนหลัก:
- Exporter ของ metric — ส่งค่าเชิงพลังงานและคอมพิวต์ (เช่น per‑node power, per‑job energy, renewable_fraction) ไปยังระบบมอนิเตอร์ (เช่น Prometheus) ทุก 15–60 วินาที
- API สำหรับรับ/ส่งคำสั่ง schedule — REST/gRPC endpoints ที่รับคำขอ scheduling, คืนสถานะคิว และส่งคำสั่งไปยัง resource manager ของคลัสเตอร์ (เช่นผ่าน Kubernetes controller หรือ Slurm plugin)
- Webhook/Callback — เพื่อรับ event จากระบบมอนิเตอร์เมื่อมีการเปลี่ยนแปลงพลังงานหรือการผิดปกติ ทำให้ระบบสามารถตอบสนองแบบ near‑real‑time
ตัวอย่าง integration: เมื่อโมดูลพยากรณ์แจ้งว่าหน้าต่างพลังงานหมุนเวียนจะสูงในช่วง 02:00–05:00 โมดูล planner จะสั่งให้ queue งานที่สามารถรันแบบยืดหยุ่นให้เลื่อนไปช่วงดังกล่าวผ่าน API ของ Kubernetes (เช่นปรับ node taints/affinities หรือใช้ CronJobs/Job priorities) และ exporter จะบันทึก metric เพื่อยืนยันว่าการย้ายเวิร์กโหลดเกิดขึ้นจริง
อัลกอริทึมหลักและการวิเคราะห์ความซับซ้อน
การเลือกอัลกอริทึมขึ้นกับขนาด N (จำนวนโหนด) และ M (จำนวนงาน) ดังนี้:
- MILP: ให้ผลลัพธ์ใกล้ optimal แต่เป็น NP‑hard เมื่อ M และ N เพิ่ม ขึ้น เวลาในการหา solution อาจเป็น exponential ในแยกกรณี (worst‑case) — จึงเหมาะกับ windowed optimization ขนาดเล็กหรือเป็น benchmark
- Greedy/EDF energy‑aware: ความซับซ้อน O(M log M) สำหรับการจัดเรียงและ O(M) สำหรับการสแกนคิว เหมาะกับการตัดสินใจเรียลไทม์และสเกลใหญ่ มีประสิทธิผลดีเมื่อความไม่แน่นอนของพยากรณ์ไม่สูง
- Heuristics/Metaheuristics: เวลาเฉลี่ยขึ้นกับพารามิเตอร์ (population, iterations) และมักให้ solution ใกล้เคียงดีในเวลาไม่มาก แต่การประกันเชิงคณิตศาสตร์จะน้อยกว่า
- Reinforcement Learning: ค่าใช้จ่ายในการเทรนสูง (ต้องเทรนบน simulator หรือบนคลัสเตอร์ด้วยการสำรอง) แต่ inference เมื่อเทรนเสร็จมีความเร็ว O(1) ต่อการตัดสินใจ (หรือ O(layer_sizes) ขึ้นกับโมเดล) และสามารถเรียนรู้นโยบายที่ปรับตัวได้ดีกับสภาพแวดล้อมที่เปลี่ยนแปลง
เพื่อจัดการกับความไม่แน่นอนจากการพยากรณ์ ระบบสามารถใช้:
- Stochastic optimization — แก้ปัญหาโดยพิจารณากลุ่มตัวอย่างจากการพยากรณ์ probabilistic
- Chance constraints — กำหนดความน่าจะเป็นที่ constraint จะถูกละเมิดให้น้อยกว่าค่า threshold
- Fallback policies — หากการพยากรณ์ผิดพลาดมาก ระบบจะเปลี่ยนเป็น policy ที่เน้น SLA สูงสุด (เช่น immediate scheduling) เพื่อลดความเสี่ยงทางธุรกิจ
โดยสรุป สถาปัตยกรรมของ Green‑Trainer Scheduler ประกอบด้วยชั้นการพยากรณ์เชิงเวลาและสภาพอากาศ, planner เชิงผสมที่ปรับสมดุลระหว่างการใช้พลังงานหมุนเวียนกับ SLA, และการเชื่อมต่อเชิงลึกกับระบบมอนิเตอร์ของคลัสเตอร์ ผ่าน exporter และ API ผลการใช้งานจริงแสดงให้เห็นว่าแนวทางนี้สามารถลดการปล่อยคาร์บอนได้ถึง 40% ขณะที่ยังรักษา SLA สำหรับงานสำคัญไว้ในระดับสูง ทำให้เป็นโซลูชันที่มีความเป็นไปได้สูงสำหรับศูนย์ข้อมูลที่ต้องการผสมผสานความยั่งยืนกับความพร้อมใช้งานของบริการ
เมตริกจากคลัสเตอร์จริง: ข้อมูลและวิธีวัด
เมตริกจากคลัสเตอร์จริง: ข้อมูลเบื้องต้นของคลัสเตอร์ทดสอบ
ศูนย์ข้อมูลไทยเปิดเผยเมตริกจากคลัสเตอร์ทดสอบที่ใช้ในการประเมินประสิทธิผลของ Green‑Trainer Scheduler โดยสรุปสเป็กและสภาพการรันดังนี้: คลัสเตอร์ตัวอย่างประกอบด้วย 100 GPUs (ใช้ NVIDIA A100 หรือเทียบเท่า) จัดวางบน 25 โหนด โหนดละ 4 GPUs แต่ละโหนดเป็นเซิร์ฟเวอร์สำหรับเทรนนิ่ง ML/AI ระดับสูง ระบบวัดพลังงานติดตั้งทั้งที่ระดับโหนด (PDU/power meter) และระดับแร็คเพื่อให้ได้ค่าพลังงานที่รวมทั้ง IT load และค่าโอเวอร์เฮดของศูนย์ข้อมูล (PUE ที่ใช้ในการวิเคราะห์เฉลี่ยที่ 1.12)
เมตริกหลักที่เผยและผลลัพธ์เชิงปริมาณ
จากการทดสอบในสภาวะการใช้งานจริง ภายใต้การตั้งสมมติฐานและช่วงเวลาที่ระบุ ศูนย์ข้อมูลรายงานผลสำคัญดังนี้:
- การลดการปล่อยคาร์บอน (CO2e): ลดลงประมาณ 40% เมื่อเทียบกับ baseline การจัดคิวแบบไม่คำนึงถึงปริมาณพลังงานหมุนเวียน
- การประหยัดพลังงานรวม: ประมาณ 8,640 kWh ต่อเดือน (คิดจากคลัสเตอร์ตัวอย่าง 100 GPUs ภายใต้รูปแบบงานและเวลาทดสอบที่กำหนด)
- ชั่วโมงการรัน: แสดงค่าเป็น 72,000 GPU‑hours ต่อเดือน (100 GPUs × 24 ชม. × 30 วัน) สำหรับกรณีรันเต็มเวลาเป็น baseline; การจัดคิวและรวมงานช่วยลดชั่วโมงเครื่องที่ไม่จำเป็นลงในบางเวลาด้วย
- ผลต่อค่าไฟ/ต้นทุนการดำเนินงาน: ลดลงประมาณ 40% ของต้นทุนพลังงานที่เกี่ยวข้องกับงานเทรนนิ่ง (หากใช้อัตราไฟฟ้าเฉลี่ยสมมุติ 4 THB/kWh จะเท่ากับการประหยัดราว 34,560 THB ต่อเดือน)
วิธีการวัดและการคำนวณที่ใช้
การคำนวณเมตริกทั้งหมดอิงบนชุดข้อมูลการวัดจริงและสมมติฐานที่ชัดเจนเพื่อความโปร่งใสของการประเมิน ดังนี้:
- การวัดพลังงาน: ใช้ power meters ระดับ PDU และแร็คเป็นหลัก เก็บข้อมูลด้วย sampling interval รายชั่วโมง (hourly) เพื่อให้สอดคล้องกับข้อมูลความเข้มคาร์บอนของกริดแบบรายชั่วโมง (hourly grid emission factor)
- การใช้ค่า PUE: นำค่า PUE เฉลี่ยของศูนย์ข้อมูล (PUE = 1.12) มาปรับจากค่า IT‑power เพื่อให้ได้พลังงานรวมของศูนย์ข้อมูล (facility energy)
- การใช้ grid emission factor แบบชั่วโมง: นำค่าความเข้มคาร์บอนของกริด (gCO2e/kWh) ที่ได้จากผู้ให้บริการกริดหรือ API ที่อัพเดตเป็นรายชั่วโมงมาใช้คูณกับพลังงานที่บริโภคในแต่ละชั่วโมง เพื่อให้ได้ค่า CO2e แบบไดนามิก (ช่วงที่ใช้ในการทดสอบอยู่ระหว่าง ~0.30–0.60 kgCO2e/kWh; สำหรับตัวอย่างคำนวณใช้ค่าเฉลี่ย baseline = 0.48 kgCO2e/kWh)
- การคำนวณ baseline และการเปรียบเทียบ: กำหนด baseline เป็นกรณีที่งานเทรนถูกจัดคิวแบบเดิม (ไม่คำนึงถึงสัดส่วนพลังงานหมุนเวียนและไม่รวมการรวมงาน/ปิดเครื่อง) จากนั้นเปรียบเทียบกับผลลัพธ์ของ Green‑Trainer Scheduler ที่รวมทั้งการย้ายเวลาการรันไปยังชั่วโมงที่มีสัดส่วนพลังงานหมุนเวียนสูงและการรวมโหลดเพื่อลดชั่วโมงการใช้งานของโหนดที่ไม่ได้ใช้งาน
- การคำนวณ Scope 2: คำนวณการปล่อยก๊าซเรือนกระจกประเภท Scope 2 โดยใช้ energy consumption ที่วัดได้ × hourly grid emission factor และนำมารวมเป็นรายเดือนเพื่อเปรียบเทียบก่อน/หลัง
สมมติฐาน ข้อจำกัด และความไม่แน่นอน
การรายงานเมตริกนี้ใช้สมมติฐานที่ชัดเจนเพื่อความสามารถในการทำซ้ำและการสเกลผลลัพธ์ได้ แต่ยังมีข้อจำกัดที่ต้องรับทราบ:
- สมมติฐาน PUE เป็นค่าเฉลี่ยในช่วงการทดสอบ; ศูนย์ข้อมูลอื่นหรือช่วงเวลาร้อน/เย็นอาจมี PUE ต่างออกไป
- ค่า grid emission factor ผันผวนตามสัดส่วนการผลิตจากเชื้อเพลิงฟอสซิลและหมุนเวียนในแต่ละชั่วโมง ดังนั้นการลด CO2e ที่เกิดขึ้นจากการย้ายเวลารันจึงขึ้นกับโครงสร้างพลังงานของกริดในช่วงเวลานั้น
- ผลลัพธ์ที่รายงานมาจากคลัสเตอร์ตัวอย่าง 100 GPUs ในสภาพการใช้งานจริงของศูนย์ข้อมูลทดสอบ หากสเกลขึ้นหรือเปลี่ยนรูปแบบงาน (เช่น inference ที่มีกลไกพลังงานต่างกัน) ตัวเลขอาจเปลี่ยนได้
- ความไม่แน่นอนจากการวัด (meter accuracy), การประมาณการ utilization ของ GPU และการประมาณค่า PUE ถูกคำนึงถึงโดยการให้ช่วงความเชื่อมั่นสำหรับการวัดภายในรายงานฉบับเต็มของศูนย์ข้อมูล
สรุป: เมตริกจากคลัสเตอร์จริงของศูนย์ข้อมูลไทยชี้ให้เห็นว่า Green‑Trainer Scheduler สามารถลดการปล่อยคาร์บอนได้ประมาณ 40% และประหยัดพลังงานราว 8,640 kWh ต่อเดือน บนคลัสเตอร์ตัวอย่าง 100 GPUs โดยใช้การวัดพลังงานแบบรายชั่วโมง ร่วมกับ grid emission factor แบบ hourly และการคำนวณ Scope 2 ที่โปร่งใส อย่างไรก็ตามผลลัพธ์เหล่านี้ขึ้นอยู่กับสมมติฐาน PUE, ประสิทธิภาพการรวมงาน และสัดส่วนพลังงานหมุนเวียนของกริดในช่วงเวลาที่รันจริง
กรณีศึกษาและตัวอย่างการใช้งานจริง
กรณีศึกษาและภาพรวมการทดสอบจริงบนคลัสเตอร์
ทีมวิจัยของศูนย์ข้อมูลไทยได้นำ Green‑Trainer Scheduler มาทดสอบกับงานเทรนโมเดลจริงบนคลัสเตอร์ขององค์กร โดยคัดเลือกงานตัวอย่าง 2 กลุ่มหลัก ได้แก่ งานเทรนโมเดล NLP/Computer Vision ขนาดกลางที่เป็นงานแบทช์ (batch) และงานเร่งด่วน (high‑priority) ที่มีข้อจำกัดด้านเวลา ผลการทดสอบวัดทั้งด้านการปล่อยคาร์บอน (CO2e), เวลาเดินงาน (time‑to‑completion), ความล่าช้า (scheduling delay) และผลกระทบต่อ SLA รวมถึงความพึงพอใจของผู้ใช้ (user satisfaction)
ตัวอย่างที่ 1 — โมเดล NLP ขนาดกลาง และงาน Computer Vision (แบทช์)
รายละเอียดงาน: งานชุดประกอบด้วย (a) โมเดล NLP ขนาดกลาง (Transformer‑based, ประมาณ 150M พารามิเตอร์) รันโดยใช้ 8 GPUs ต่อรัน เป็นเวลาประมาณ 24–36 ชั่วโมง ต่อ job และ (b) งาน Computer Vision (ResNet‑50 training) ใช้ 4 GPUs ต่อ job เวลาเฉลี่ย 10–14 ชั่วโมง. งานกลุ่มนี้เป็นงานที่ทนต่อการเลื่อนเริ่มได้และมี SLA แบบภายใน 72 ชั่วโมง
ผลลัพธ์ก่อน/หลังการใช้ Scheduler — timeline และตัวเลขเชิงปริมาณ:
- ก่อนใช้ Scheduler (Baseline)
- เริ่มรันทันทีเมื่อผู้ใช้ส่งงาน: ตัวอย่าง NLP job เริ่มเวลา 22:00 และรันต่อเนื่องจนเสร็จเมื่อเวลา 18:00 ของวันถัดไป (ระยะเวลา 20 ชั่วโมง)
- พลังงานที่ใช้ต่อ job (เฉลี่ย): 200 kWh → CO2e (grid average) ≈ 100 kgCO2e
- ค่าเฉลี่ย GPU utilization ระหว่างช่วงชั่วโมงนอกพีค ≈ 72%
- หลังใช้ Green‑Trainer Scheduler
- Scheduler เลื่อนงานบางส่วนไปยังช่วงกลางวันที่มีสัดส่วนพลังงานหมุนเวียนสูง (solar peak) เช่น เริ่มเวลา 11:00 แทน 22:00
- พลังงานที่ใช้ต่อ job (เฉลี่ย) ลดเป็น ≈ 110 kWh → CO2e ≈ 55 kgCO2e
- ผลรวมการลด CO2e สำหรับกลุ่มนี้: ลดลง 45% เมื่อเทียบกับ baseline
- ผลต่อเวลา: ค่าเฉลี่ยเวลาที่เพิ่มขึ้นเป็น +1.8 ชั่วโมง ต่อ job (median queuing delay) แต่ยังคงอยู่ภายใน SLA 72 ชั่วโมง
- GPU utilization ปรับไปใช้ช่วงพีคได้ดีขึ้น โดย utilization เฉลี่ยเพิ่มเป็น ≈ 80% ใน window ที่มีพลังงานหมุนเวียนสูง
ข้อสังเกตสำคัญ: การเลื่อนงานไปยังช่วงพลังงานหมุนเวียนสูงให้ประสิทธิผลด้านคาร์บอนสูงสุด แต่มี trade‑off ด้านความล่าช้าเพียงเล็กน้อยสำหรับงานแบทช์ที่สามารถรอได้ ทีมปฏิบัติการระบุว่าการเพิ่มเวลารอเฉลี่ย 1–2 ชั่วโมง เป็นที่ยอมรับในบริบทเชิงธุรกิจเมื่อแลกกับการลด CO2e ถึง 45%
ตัวอย่างที่ 2 — งานเร่งด่วน (High‑priority)
รายละเอียดงาน: งานประเภทนี้มี SLA เข้มงวด ต้องเริ่มและเสร็จทันเวลา (เช่น inference‑calibration, time‑sensitive retraining) ใช้ทรัพยากร 8–16 GPUs และไม่สามารถเลื่อนเริ่มได้เกินช่วง tolerance ที่กำหนด
พฤติกรรมของ Scheduler ต่องานเร่งด่วน:
- ระบบกำหนด priority‑class ให้กับงานเหล่านี้และจะไม่เลื่อนการเริ่มงานเกิน tolerance ที่กำหนด (preemption rules)
- เมื่อคลัสเตอร์เข้าสู่ window ที่พลังงานหมุนเวียนสูง ระบบจะอนุญาตให้ job พิเศษเหล่านี้ใช้ burst capacity เพื่อชดเชยเวลาหากเป็นไปได้ โดยไม่ทำให้ job อื่น ๆ เกิด SLA breach
ผลลัพธ์เชิงตัวเลข:
- อัตราการ delay ของงานเร่งด่วน: 0% (ไม่มีการเลื่อนเริ่มเกิน tolerance)
- ผลต่อ CO2e: งานเร่งด่วนได้รับประโยชน์จาก burst windows ลด CO2e เฉลี่ยประมาณ 12%–15% เมื่อเทียบกับ baseline ที่ไม่ใช้งาน Scheduler
- time‑to‑completion: ความเร็วในการเสร็จงานเปลี่ยนแปลงน้อยกว่า ±5% — บางเคสเสร็จเร็วขึ้นเนื่องจากการใช้ burst capacity
ข้อสังเกตสำคัญ: Green‑Trainer Scheduler สามารถรักษาความต้องการเชิง SLA สำหรับงานเร่งด่วนได้โดยไม่ลดทอนความน่าเชื่อถือ และยังสามารถฉวยโอกาสจากช่วง renewable peaks เพื่อปรับปรุงคาร์บอนฟุตพริ้นต์ได้บางส่วนโดยไม่กระทบความคาดหวังของผู้ใช้
การวัดผลเชิงประสิทธิภาพและความพึงพอใจของผู้ใช้
เมตริกที่ถูกรายงานจากคลัสเตอร์จริงประกอบด้วย:
- การลด CO2e เฉลี่ยของทั้งคลัสเตอร์: ประมาณ 40% (สอดคล้องกับเป้าประกาศของศูนย์ข้อมูล)
- ผลกระทบต่อ throughput: งานแบทช์โดยรวม throughput ลดลงเล็กน้อย (−3% ถึง −7%) เนื่องจากการเลื่อน แต่ throughput ของงานเร่งด่วนไม่ลดลง
- SLA compliance: คงไว้ที่ > 99% หลังติดตั้ง Scheduler (ไม่มี incident สำคัญจากการเลื่อนงาน)
- ความพึงพอใจของผู้ใช้: สำรวจผู้ใช้กลุ่มงานวิจัยและทีม ML Ops หลังทดลอง 6 สัปดาห์ ได้ค่าเฉลี่ยความพึงพอใจที่ 4.2/5 โดยคะแนนบวกระบุว่า “พร้อมยอมรับการรอเล็กน้อยเพื่อแลกกับการลดคาร์บอน”
- ตัวชี้วัดเชิงปฏิบัติการ: GPU utilization เฉลี่ยเพิ่มในช่วง renewable windows ขึ้นจาก 70% เป็น 78% และจำนวน job ที่ใช้ renewable energy สูงสุดในช่วง midday เพิ่มขึ้น 3.5 เท่า
สรุป: กรณีศึกษาบนคลัสเตอร์จริงชี้ให้เห็นว่า Green‑Trainer Scheduler ให้ประโยชน์ชัดเจนด้านการลดคาร์บอนสำหรับงานแบทช์ (ตัวอย่างลด CO2e ถึง 45%) ขณะที่ยังคงรักษามาตรฐาน SLA สำหรับงานเร่งด่วนและสร้างความพึงพอใจในหมู่ผู้ใช้ การออกแบบนโยบายการเลื่อนที่ยืดหยุ่นและการใช้ burst windows เป็นกุญแจสำคัญที่ทำให้สมดุลระหว่างความยั่งยืนกับความต้องการเชิงธุรกิจเป็นไปได้จริง
ผลกระทบเชิงธุรกิจและนโยบาย รวมถึงการนำไปใช้จริง
ผลกระทบเชิงธุรกิจ: การลดต้นทุน การคืนทุน (ROI) และตัวอย่างการใช้งาน
จากการทดสอบบนคลัสเตอร์จริงของศูนย์ข้อมูลไทย Green‑Trainer Scheduler แสดงผลลัพธ์เชิงสิ่งแวดล้อมที่ชัดเจนโดยลดการปล่อยคาร์บอนจากงานเทรนโมเดลประมาณ 40% เนื่องจากการเลื่อนการรันไปยังช่วงเวลาที่มีการจ่ายพลังงานหมุนเวียนสูงสุด ในเชิงการเงิน การจัดคิวเช่นนี้มักแปลเป็นการลดค่าไฟฟ้าโดยรวมในช่วง 10–30% ขึ้นกับโครงสร้างอัตราค่าไฟและสัดส่วนค่า Demand Charge ของศูนย์ข้อมูล ตัวอย่างเชิงตัวเลขสมมติ: หากศูนย์ข้อมูลมีค่าไฟฟ้ารายเดือน 1,000,000 บาท การลดได้ 15% จะเท่ากับการประหยัด 150,000 บาทต่อเดือน หรือ 1.8 ล้านบาทต่อปี
การคืนทุน (ROI) สำหรับการติดตั้งระบบ scheduler และการปรับปรุงอินทิเกรชัน ขึ้นกับขนาดการลงทุนเริ่มต้น (ฮาร์ดแวร์เพิ่มเติมซอฟต์แวร์ และงานผสานระบบ) แต่ในกรณีทั่วไปสำหรับโรงงาน/องค์กรขนาดกลางถึงใหญ่ พบว่า ระยะเวลาคืนทุนอาจอยู่ที่ 12–36 เดือน ตัวแปรสำคัญได้แก่: สัดส่วนค่าไฟฟ้าในต้นทุนรวม ความสามารถในการเลื่อนงานโดยไม่กระทบ SLA และมาตรการสนับสนุนจากผู้ให้บริการไฟฟ้า เช่นอัตรา time‑of‑use ที่เอื้อต่อการเลื่อนเวลา
นอกเหนือจากการลดต้นทุนโดยตรง ยังมีผลประโยชน์ทางธุรกิจเชิงกลยุทธ์ เช่น การเสริมสถานะ ESG ทำให้บริษัทสามารถรายงานการลดคาร์บอนในงบยั่งยืนได้ชัดเจนขึ้น (ตัวอย่าง: ลดการปล่อย 40% อาจช่วยลดภาระการซื้อคาร์บอนเครดิตหรือเพิ่มคะแนนการประเมินความยั่งยืน) และเพิ่มความสามารถในการปิดสัญญากับลูกค้าที่มีข้อกำหนดด้านคาร์บอนต่ำ นอกจากนี้ การจัดคิวแบบมีประสิทธิภาพอาจเพิ่ม Throughput ของคลัสเตอร์ได้ประมาณ 5–15% จากการใช้ช่วงเวลาไฟฟ้าเขียวอย่างเต็มที่
บทบาทของนโยบายและแรงจูงใจจากรัฐ/ผู้ให้บริการไฟฟ้า
นโยบายสาธารณะและมาตรการสนับสนุนเป็นกุญแจสำคัญในการแพร่หลายของเทคโนโลยีจัดคิวตามพลังงานหมุนเวียน ดังนี้
- Time‑of‑use (TOU) tariffs: อัตราค่าไฟที่ต่างตามเวลาเป็นแรงจูงใจตรงให้ผู้ประกอบการเลื่อนงานไปยังช่วงที่ไฟฟ้าราคาถูกและสะอาด หาก TOU ให้ส่วนลดเช่น 20–40% ในช่วงชั่วโมงไฟฟ้าหมุนเวียนสูง จะยิ่งเพิ่มการประหยัดและลดระยะเวลาคืนทุน
- Incentives และเงินอุดหนุน: เงินสนับสนุนต้นทุนการติดตั้งระบบจัดการพลังงาน ซอฟต์แวร์ด้านการจัดคิว หรือเครดิตภาษีสำหรับการลงทุนด้านความยั่งยืน จะทำให้การลงทุนมีความน่าสนใจยิ่งขึ้น
- มาตรการทางตลาดไฟฟ้า: การเปิดโอกาสให้ศูนย์ข้อมูลเข้าร่วมโปรแกรม Demand Response, การขายความยืดหยุ่นของโหลด หรือการทำ PPA กับผู้ผลิตพลังงานหมุนเวียน ช่วยให้เกิดรายได้เสริมหรือการชดเชยค่าใช้จ่ายจากการปรับโหลด
- มาตรฐานการรายงานคาร์บอน: การกำหนดมาตรฐานและการยอมรับเมตริกที่แสดงการเลื่อนงานตามพลังงานหมุนเวียน จะช่วยให้การอ้างผลลัพธ์มีความน่าเชื่อถือต่อผู้ลงทุนและลูกค้า
การประสานงานระหว่างผู้ให้บริการไฟฟ้า ผู้กำกับดูแล และผู้ประกอบการศูนย์ข้อมูลเป็นเรื่องสำคัญ: ต้องเปิดเผยข้อมูลราคาหรือสัญญาณความพร้อมของพลังงานหมุนเวียนในระดับเรียลไทม์และมี API สำหรับการผสานระบบ เพื่อให้ scheduler ทำงานได้อย่างมีประสิทธิภาพและปลอดภัย
ข้อจำกัด ความเสี่ยง และแนวทางลดความเสี่ยงในการนำไปใช้จริง
แม้ Green‑Trainer Scheduler จะมีศักยภาพสูง แต่มีข้อจำกัดและความเสี่ยงที่องค์กรต้องพิจารณาอย่างรอบคอบก่อนนำไปใช้ในสเกลใหญ่:
- ความไม่แน่นอนของการพยากรณ์พลังงาน (forecast error): การคาดการณ์ปริมาณพลังงานหมุนเวียนมีความไม่แน่นอนสูง โดยเฉพาะพลังงานลมและแสงอาทิตย์ ความผิดพลาดของการพยากรณ์ 10–30% อาจทำให้ผลลัพธ์ที่คาดหวังลดลงหรือเกิดค่าใช้จ่ายพลังงานพีคเพิ่มเติม
- ผลกระทบต่อ SLA และ workload compatibility: งานที่ต้องการ latency ต่ำหรือมีเดตไลน์เข้มงวด (เช่น inference แบบ real‑time, บางงานการเงินหรืองานซ่อมบำรุงเชิงเวลาจริง) อาจไม่สามารถเลื่อนได้ การจัดลำดับความสำคัญและการกำหนดนโยบาย SLA แยกประเภทเป็นสิ่งจำเป็น เพื่อหลีกเลี่ยงการละเมิดสัญญาบริการ
- ความต้องการข้อมูลเรียลไทม์และการบูรณาการระบบ: Scheduler ต้องการฟีดข้อมูลเรียลไทม์จากกริดและจากระบบมอนิเตอร์ของคลัสเตอร์ การขาดข้อมูลเชิงพลังงานที่มีความละเอียดเพียงพอ หรือปัญหาด้าน latency ของข้อมูล จะลดประสิทธิภาพการตัดสินใจ
- ช่องว่างทางเทคนิคและการเปลี่ยนแปลงในเชิงปฏิบัติการ: การนำไปใช้จริงอาจต้องปรับเปลี่ยน pipeline ของงานเทรน เช่น การรองรับ checkpointing, preemption และการจัดการทรัพยากร GPU/Storage เพิ่มเติม ซึ่งต้องใช้ทั้งทรัพยากรคนและงบประมาณ
- ความเสี่ยงเชิงตลาดและกฎระเบียบ: การเปลี่ยนแปลงอัตราไฟฟ้า นโยบายการให้สิทธิประโยชน์ หรือกฎการเข้าถึงข้อมูลกริด อาจทำให้โมเดลธุรกิจและการประเมิน ROI เปลี่ยนแปลงได้
แนวทางลดความเสี่ยงที่สำคัญได้แก่การใช้กลยุทธ์ผสม (hybrid scheduling) แบ่งงานเป็นชั้น (priority tiers), บังคับใช้ checkpointing และ preemption สำหรับงานระยะยาว, การใช้ buffer ทางพลังงานเช่นแบตเตอรี่เพื่อรองรับความคลาดเคลื่อนของพยากรณ์ และการพัฒนาโมเดลพยากรณ์เชิง ensemble พร้อมช่องว่างความปลอดภัย (safety margin) ในการตัดสินใจ
สรุปแล้ว การนำ Green‑Trainer Scheduler มาใช้อย่างแพร่หลายสามารถให้ผลประหยัดต้นทุนและประโยชน์ด้าน ESG ที่จับต้องได้ โดยเฉพาะในศูนย์ข้อมูลที่มีสัดส่วนการใช้พลังงานหมุนเวียนที่เปลี่ยนแปลงตามเวลา อย่างไรก็ตาม ความสำเร็จเชิงพาณิชย์ขึ้นกับการออกแบบนโยบายอัตราค่าไฟที่เอื้อต่อการเลื่อนเวลา การประสานงานกับผู้ให้บริการไฟฟ้า และการจัดการความเสี่ยงด้านพยากรณ์และ SLA อย่างเป็นระบบ แนะนำให้เริ่มจากการทดลองนำร่องในระดับคลัสเตอร์/โซน เพื่อวัดผลเชิงตัวเลขก่อนขยายสู่ระดับโรงงานหรือองค์กรทั้งหมด
แนวทางการนำไปใช้และคำแนะนำสำหรับองค์กร
แนวทางเบื้องต้นและการประเมิน readiness ของคลัสเตอร์
ก่อนเริ่มนำ Green‑Trainer Scheduler ไปใช้งานจริง องค์กรควรทำการตรวจสอบความพร้อมของคลัสเตอร์และสภาพแวดล้อมการทำงานอย่างเป็นระบบ เพื่อให้การติดตั้งและการทดสอบเป็นไปอย่างราบรื่น ประเด็นสำคัญที่ต้องตรวจสอบได้แก่
- ความสามารถของระบบจัดการงาน (Job Manager) — ตรวจสอบว่า Kubernetes, Slurm, HTCondor หรือระบบภายในที่ใช้อยู่รองรับ hook สำหรับการเลื่อนคิว (defer), การจัดลำดับความสำคัญ (priority) และ API สำหรับการส่งคำสั่ง scheduling
- การเข้าถึงเมตริกพลังงานและคาร์บอน — ต้องสามารถดึงข้อมูล mix ของพลังงานหมุนเวียน (เช่น % renewable), carbon intensity (gCO2eq/kWh) หรือค่าสถานะจากผู้ให้บริการไฟฟ้าหรือ API พยากรณ์พลังงานได้
- มาตรฐานด้านเวลาและความปลอดภัย — ระบบต้องมีการ sync เวลาที่แม่นยำ, มีการล็อกสิทธิ์และ auditing สำหรับการเปลี่ยนแปลงตารางงาน และมีนโยบายสำรองหาก forecast ผิดพลาด
- การสังเกตและการเก็บข้อมูล — ติดตั้ง exporter สำหรับเมตริก (เช่น Prometheus exporters) เพื่อเก็บข้อมูล GPU/CPU utilization, job wait time, job runtime, energy consumption และ carbon emissions ที่เกี่ยวข้อง
ขั้นตอนการทดลองแบบ Pilot (ข้อเสนอแนะเชิงปฏิบัติ)
การรัน pilot อย่างเป็นระบบจะช่วยลดความเสี่ยงและให้ข้อมูลเชิงปริมาณสำหรับการตัดสินใจขยายผล แนะนำขั้นตอนดังนี้
- เก็บ Baseline 2–4 สัปดาห์ — บันทึกเมตริกพื้นฐานโดยไม่เปิด Green‑Trainer เพื่อให้ได้ข้อมูลเปรียบเทียบ (เก็บข้อมูลตลอดช่วงเวลาเพื่อครอบคลุมทั้ง weekday/weekend และชั่วโมงสูงสุด)
- กำหนดกลุ่มงานที่ Delay‑tolerant — แยกหมวดงาน เช่น batch training, hyperparameter sweep, nightly retrain ที่สามารถถูกเลื่อนได้โดยไม่กระทบ SLA ของลูกค้า และตั้งกลุ่ม control (sensitive) กับกลุ่มทดลอง (delay‑tolerant)
- ทดสอบแบบ On/Off comparisons — ทำ A/B หรือการสลับสถานะ (เช่น สัปดาห์ที่ 1 เปิด Scheduler, สัปดาห์ที่ 2 ปิด) เพื่อเปรียบเทียบผลลัพธ์เชิงพลังงานและประสิทธิภาพ นอกจากนี้ให้ตั้งค่า minimum sample size เป็นเปอร์เซ็นต์ของงาน (เช่น 10–20% ของงาน training หรืออย่างน้อย X ชม. GPU รวมต่อสัปดาห์) เพื่อความน่าเชื่อถือทางสถิติ
- KPIs ที่ต้องติดตาม — carbon emissions (kgCO2e), % reduction เทียบ baseline, job latency distribution, job success/failure rate, throughput (GPU‑hours/วัน), และเวลาการตอบกลับตาม SLA
เทคนิคการ Integration กับระบบจัดการงานและการพยากรณ์
การเชื่อมต่อ Green‑Trainer กับระบบเดิมขององค์กรต้องอาศัยองค์ประกอบทางเทคนิคที่ชัดเจนและทดสอบได้ ประเด็นสำคัญและแนวปฏิบัติแนะนำได้แก่
- Exporter metrics — ติดตั้ง exporters (เช่น Prometheus exporters) บน node และ service เพื่อส่งเมตริกเช่น carbon intensity, renewable share, per‑job energy use, GPU utilization และ scheduler decisions ไปยังระบบมอนิเตอร์เดียวกัน
- APIs สำหรับการสื่อสาร — ให้ Green‑Trainer มี REST/gRPC API สำหรับ:
- ขอ/ยกเลิกการเลื่อนงาน
- ดึงสถานะพยากรณ์พลังงานปัจจุบันและอนาคต
- ส่งเหตุการณ์ audit/log เพื่อการตรวจสอบ
- Cron jobs สำหรับ Forecast Updates — ตั้ง cron job หรือ scheduled task (เช่น ทุก 15 นาที หรือทุกชั่วโมง ขึ้นอยู่กับ volatility ของกริดพลังงาน) เพื่อดึงข้อมูล forecast และปรับนโยบาย scheduling แบบ near‑real time
- Integration Pattern — ใช้ pattern แบบ webhook/sidecar สำหรับ Kubernetes, หรือ plugin สำหรับ Slurm/HTCondor เพื่อให้การตัดสินใจของ scheduler สามารถทำงานแบบ synchronous กับ job lifecycle
การกำหนดนโยบาย SLA และการตรวจสอบผลลัพธ์
การนำ Green‑Trainer มาใช้ต้องมีการนิยามนโยบาย SLA ที่ชัดเจนเพื่อรักษาสมดุลระหว่างเป้าหมายด้านคาร์บอนและความคาดหวังทางธุรกิจ แนะนำแนวทางดังนี้
- จัดชั้นระดับงาน (Priority Classes) — แบ่งงานเป็น Critical (ไม่สามารถเลื่อน), Business‑critical (จำกัดการเลื่อน), Delay‑tolerant (เลื่อนได้ตาม policy) โดยระบุ max deferral window (เช่น 6, 12, 24 ชั่วโมง) และ compensation policy ถ้าละเมิด SLA
- นโยบายการเลื่อน (Deferral Policy) — กำหนดเกณฑ์เช่นเลื่อนเฉพาะเมื่อ forecast คาดว่า renewable share > X% หรือ carbon intensity ลดลง Y% เทียบ baseline และจำกัดจำนวนครั้งที่เลื่อนต่อ job
- การมอนิเตอร์และการรายงานผลแบบเรียลไทม์ — ตั้ง dashboard สำหรับ KPI หลัก เช่น % carbon reduction, energy saved (kWh), job latency change, SLA compliance rate ที่อัปเดตแบบ near‑real time และเก็บ log audit สำหรับการวิเคราะห์หลังเหตุการณ์
แผนขยายผล (Scale‑up) และคำแนะนำด้านการดำเนินงานระยะยาว
เมื่อ pilot สำเร็จ องค์กรควรมีแผนการขยายผลเป็นขั้นตอนเพื่อรักษาความต่อเนื่องและเพิ่มมูลค่าเชิงธุรกิจ ดังนี้
- Automation — ปรับให้ policy engine ทำงานอัตโนมัติเต็มรูปแบบ: การอัปเดต forecast, การตัดสินใจเลื่อน/คืนคิว, การแจ้งเตือนผู้ใช้และการบันทึก audit โดยผสานเข้ากับ CI/CD pipeline เพื่อให้การเปลี่ยนแปลงนโยบายทำได้อย่างปลอดภัยและตรวจสอบได้
- Reporting สำหรับ ESG disclosure — สร้างรายงานมาตรฐานที่รองรับการเปิดเผยข้อมูล ESG เช่น carbon avoided (Scope 2/Scope 3 ประมาณการ), energy consumption per model, และ KPI ที่ต้องใช้ในรายงานประจำไตรมาส/ปี เพื่อรองรับการตรวจสอบภายในและผู้มีส่วนได้ส่วนเสียภายนอก
- ร่วมมือแบบ Open‑Source และ Partnership — พิจารณาเปิดผลการทดลองบางส่วนหรือ contribution ให้กับชุมชน open‑source เพื่อรับ feedback และลดค่าใช้จ่ายในการพัฒนา รวมทั้งสร้างพันธมิตรกับผู้ให้บริการพยากรณ์พลังงาน ผู้ให้บริการคลาวด์ และผู้พัฒนา scheduler เพื่อเพิ่มความสามารถและรับการสนับสนุนเชิงเทคนิค
- กลยุทธ์การขยายสู่คลัสเตอร์อื่น — ขยายแบบค่อยเป็นค่อยไปโดยเริ่มจาก namespace หรือ queue ใหม่ ขยายไปยังโซนหรือตารางงานเพิ่มเติม โดยใช้ automation playbook เดียวกันและทดสอบผลกระทบต่อ throughput และ SLA ก่อนย้ายเต็มรูปแบบ
สรุป : การนำ Green‑Trainer Scheduler เข้าสู่การใช้งานจริงต้องเริ่มด้วยการประเมิน readiness ของคลัสเตอร์และการรัน pilot ที่มีการเก็บ baseline 2–4 สัปดาห์ กำหนดกลุ่มงานที่ delay‑tolerant และทำ on/off comparisons เชิงสถิติ การรวมระบบควรใช้ exporter, API และ scheduled forecast updates เพื่อให้การตัดสินใจเป็นไปแบบ near‑real time ขณะที่การขยายผลต้องมุ่งสู่ automation, การรายงานเชิง ESG และความร่วมมือเชิงนิเวศของชุมชนและพันธมิตรเพื่อความยั่งยืนและผลตอบแทนทางธุรกิจในระยะยาว
บทสรุป
Green‑Trainer Scheduler เป็นทางเลือกเชิงปฏิบัติที่ช่วยลดการปล่อยคาร์บอนจากงาน AI ได้อย่างมีนัยสำคัญ โดยศูนย์ข้อมูลไทยรายงานผลจากเมตริกจากคลัสเตอร์จริงว่าการจัดคิวการเทรนโมเดลตามช่วงเวลาที่มีการใช้พลังงานหมุนเวียนสามารถลดการปล่อยคาร์บอนได้ราว 40% เมื่อเทียบกับการรันตามเวลาปกติ ข้อสรุปสำคัญจากการทดลองชี้ให้เห็นว่าความสำเร็จของแนวทางนี้ขึ้นอยู่กับการวัดผลที่โปร่งใส การพยากรณ์การผลิตพลังงานหมุนเวียนที่มีความแม่นยำ และการออกแบบนโยบาย SLA ที่บาลานซ์ระหว่างความยั่งยืนกับความต้องการประสิทธิภาพและความพร้อมใช้งานของงาน AI
สำหรับศูนย์ข้อมูลและองค์กรที่ต้องการลดคาร์บอน ควรเริ่มด้วยโครงการนำร่อง (pilot) ที่มีการวัด baseline อย่างชัดเจนก่อนขยายใช้งาน เพื่อประเมินผลกระทบเชิงปฏิบัติ การขยายใช้จำเป็นต้องคำนึงถึงการสนับสนุนเชิงนโยบายจากภาครัฐและการประสานงานกับผู้ให้บริการพลังงาน (เช่น การเข้าถึงข้อมูลการผลิตพลังงานหมุนเวียนหรือสัญญา demand response) ในระยะยาว หากมีการพัฒนาเครื่องมือพยากรณ์ที่แม่นยำ มีมาตรฐานการวัดคาร์บอน และนโยบายสนับสนุนที่เหมาะสม การจัดคิวตามพลังงานหมุนเวียนจะเป็นกลไกสำคัญที่ผลักดันการลดการปล่อยคาร์บอนของงาน AI ในวงกว้างและสอดคล้องกับเป้าหมายการลดก๊าซเรือนกระจกของประเทศ



