
ในยุคที่ข้อมูลทางการแพทย์กลายเป็นหัวใจสำคัญของงานวิจัยและการพัฒนานวัตกรรมด้านสุขภาพ สตาร์ทอัพไทยเปิดตัว SynthCare‑DP แพลตฟอร์มตลาดข้อมูลเทียมทางการแพทย์ที่รับรองด้วยหลักการ Differential Privacy เพื่อรักษาความเป็นส่วนตัวของผู้ป่วยขณะเดียวกันยังคงคุณภาพของข้อมูลไว้สำหรับการทดลองและการพัฒนาโมเดล AI — รายงานต้นทางระบุว่าช่วยลดเวลาเตรียมข้อมูลจริงให้กับทีมวิจัยและโรงพยาบาลได้ถึง 70% ทำให้กระบวนการวิจัยและการทดสอบระบบเร็วขึ้นอย่างมีนัยสำคัญ
SynthCare‑DP ไม่เพียงแต่เป็นแหล่งข้อมูลเทียมที่ปลอดภัยด้วยมาตรฐาน Differential Privacy แต่ยังมาพร้อมมาตรวัดคุณภาพข้อมูลและแนวทางปฏิบัติตาม PDPA รวมถึงมาตรฐานสากลที่เกี่ยวข้อง ช่วยลดความเสี่ยงทางกฎหมายและความกังวลด้านความเป็นส่วนตัวสำหรับผู้ให้ข้อมูลและผู้ใช้ระบบ ตั้งเป้าช่วยให้ทีมวิจัย โรงพยาบาล และผู้พัฒนา AI สามารถเข้าถึงข้อมูลที่มีคุณภาพสูงได้เร็วขึ้น ส่งผลให้การทดลอง การฝึกสอนโมเดล และการขออนุญาติต่างๆ เป็นไปได้อย่างราบรื่นยิ่งขึ้น
1. บทนำ — ข่าวเปิดตัวและความสำคัญ
1. บทนำ — ข่าวเปิดตัวและความสำคัญ
สตาร์ทอัพไทยเปิดตัวผลิตภัณฑ์ใหม่ภายใต้ชื่อ SynthCare‑DP ซึ่งเป็นแพลตฟอร์มข้อมูลเทียมทางการแพทย์ที่ผสานการสร้างข้อมูลสังเคราะห์ (Synthetic Data) เข้ากับกลไกความเป็นส่วนตัวแบบ Differential Privacy โดยผู้พัฒนาเปิดตัวผลิตภัณฑ์นี้เมื่อวันที่ 15 กุมภาพันธ์ 2026 ณ กรุงเทพมหานคร (Bangkok, Thailand) เพื่อรองรับความต้องการแลกเปลี่ยนข้อมูลเชิงคลินิกและการวิจัยที่ปลอดภัยมากขึ้นสำหรับโรงพยาบาลและสถาบันวิจัยในประเทศและภูมิภาคเอเชียตะวันออกเฉียงใต้
ตามที่ผู้พัฒนาแจ้ง ผลสำคัญของ SynthCare‑DP คือความสามารถในการลดเวลาเตรียมข้อมูลจริงสำหรับงานวิจัยลงได้ถึง 70% ซึ่งมีผลโดยตรงต่อประสิทธิภาพของ workflow การวิจัย ทั้งในขั้นตอนการรวบรวม ทำความสะอาด การลบข้อมูลระบุตัวตน (de‑identification) และการขออนุญาตเข้าถึงข้อมูล (data access approvals) ตัวอย่างการเปลี่ยนแปลงในทางปฏิบัติ เช่น ทีมวิจัยที่เคยต้องใช้เวลาหลายสัปดาห์หรือหลายเดือนในการจัดเตรียมชุดข้อมูล สามารถเริ่มทดสอบสมมุติฐานหรือฝึกโมเดลจากชุดข้อมูลสังเคราะห์ที่มีคุณสมบัติและการรับรองความเป็นส่วนตัวใกล้เคียงของจริงได้ทันที
ความสำคัญเชิงสังคมและด้านการแพทย์ของการเปิดตัวครั้งนี้มีทั้งในมิติความปลอดภัยของผู้ป่วยและความเร่งด่วนเชิงงานวิจัย สำหรับโรคเฉียบพลันหรือภาวะระบาด เช่น COVID‑19 หรือไข้เลือดออก การเข้าถึงข้อมูลที่มีความเป็นส่วนตัวรับรองและสามารถใช้งานได้รวดเร็วช่วยให้การพัฒนาแบบจำลองการคาดการณ์ การประเมินประสิทธิผลของการรักษา และการวางแผนทรัพยากรตอบสนองต่อเหตุการณ์ฉุกเฉินเป็นไปได้อย่างทันท่วงที แทนที่จะติดขัดด้วยกระบวนการอนุญาตและการทำลายตัวตนของข้อมูลที่กินเวลา
ในมุมมองการวิจัยเชิงระบบและธุรกิจ การผนวก Synthetic Data กับ Differential Privacy ถือเป็นการลดข้อจำกัดทางกฎหมายและความเสี่ยงทางจริยธรรมที่มักทำให้การแชร์ข้อมูลข้ามสถาบันเป็นเรื่องยุ่งยาก ซึ่งจะช่วยเปิดโอกาสให้เกิดงานวิจัยร่วมระดับภูมิภาค เพิ่มความสามารถในการทำงานร่วมกัน (collaboration) และลดต้นทุนในการจัดเตรียมข้อมูลสำหรับสตาร์ทอัพ สุขภาพดิจิทัล และหน่วยงานภาครัฐ สรุปได้ว่า SynthCare‑DP ไม่เพียงเป็นเครื่องมือทางเทคนิค แต่ยังเป็นกลไกเร่งให้วงการวิจัยการแพทย์ในไทยและภูมิภาคสามารถตอบโจทย์เชิงสังคมและเชิงคลินิกได้เร็วขึ้นและปลอดภัยขึ้น
- ผลิตภัณฑ์: SynthCare‑DP
- ผู้พัฒนา: สตาร์ทอัพไทย (ผู้พัฒนาเปิดตัวผลิตภัณฑ์)
- วัน/สถานที่เปิดตัว: 15 กุมภาพันธ์ 2026, กรุงเทพมหานคร
- ตัวเลขสำคัญ: ลดเวลาเตรียมข้อมูลจริงได้ถึง 70% (ตามที่ผู้ประกาศระบุ)
- ความสำคัญ: เร่งการวิจัยโรคเฉียบพลัน รองรับการทดลองทางคลินิกและเพิ่มความร่วมมือข้ามสถาบันด้วยการรับประกันความเป็นส่วนตัว
2. SynthCare‑DP คืออะไร — แนวคิดและฟีเจอร์หลัก
2. SynthCare‑DP คืออะไร — แนวคิดและฟีเจอร์หลัก
SynthCare‑DP เป็นแพลตฟอร์มสำหรับการสร้างข้อมูลสังเคราะห์ทางการแพทย์ที่ผสานการคุ้มครองความเป็นส่วนตัวเชิงคณิตศาสตร์ด้วย Differential Privacy (DP) ออกแบบเพื่อให้ทีมวิจัย โรงพยาบาล และสตาร์ทอัพด้านสุขภาพสามารถเข้าถึงชุดข้อมูลที่มีลักษณะและความยุ่งยากเชิงโครงสร้างใกล้เคียงกับข้อมูลจริง โดยไม่ต้องเปิดเผยข้อมูลผู้ป่วยต้นทาง แพลตฟอร์มนี้ช่วยลดเวลาการเตรียมข้อมูลจริงได้ถึง 70% ในหลายกรณีใช้งาน และยังช่วยให้การทดลองโมเดล ML, การทดสอบซอฟต์แวร์ทางคลินิก และการแบ่งปันข้อมูลระหว่างสถาบันเป็นไปได้อย่างปลอดภัยและรวดเร็ว
นิยามเชิงปฏิบัติ: ในบริบททางการแพทย์
- Synthetic Data คือชุดข้อมูลที่สร้างขึ้นใหม่โดยอาศัยรูปแบบสถิติจากชุดข้อมูลจริง แต่ไม่ประกอบด้วยข้อมูลตัวระบุของผู้ป่วยใด ๆ ทำให้ผู้ใช้สามารถวิเคราะห์ พัฒนา และทดสอบได้โดยไม่ต้องเข้าถึงข้อมูลต้นฉบับ
- Differential Privacy (DP) เป็นกรอบทางคณิตศาสตร์ที่ให้การรับประกันว่าผลลัพธ์จากการรวมข้อมูลหรือการสร้างข้อมูลสังเคราะห์จะไม่เปิดเผยข้อมูลเฉพาะบุคคล โดยการเพิ่มเสียง (noise) ที่ควบคุมได้ ทำให้โอกาสที่ผู้โจมตีจะระบุว่าบุคคลใดบุคคลหนึ่งมีอยู่ในชุดข้อมูลต้นทางมีค่าต่ำและมีขอบเขตที่วัดได้
การออกแบบตัวสร้างข้อมูล (generation engine) ของ SynthCare‑DP ผสานโมเดลสร้างข้อมูลเชิงสถิติระดับสูง เช่น GANs หรือ diffusion models กับกลไก DP-SGD (Differentially Private Stochastic Gradient Descent) เพื่อให้ได้ข้อมูลสังเคราะห์ที่มีความเป็นจริงเชิงสถิติสูง แต่ยังคงรักษาการคุ้มครองความเป็นส่วนตัว โดยผู้ใช้สามารถเลือกโหมดการสร้างข้อมูลได้ตามกรณีใช้งาน เช่น โหมดเน้นความเที่ยงตรงเชิงสถิติสำหรับการวิเคราะห์ประชากร หรือโหมดเน้นความคงตัวของเทรนด์สำหรับการพัฒนาโมเดลเวลา-ต่อ-เวลา
ฟีเจอร์เด่นที่สำคัญ
- Generation Engine — รองรับการสร้างข้อมูลแบบหลายมิติ ทั้งตาราง EHR ค่าเชิงตัวเลข มิถุนายนและตัวแปรหมวดหมู่ รวมถึงเมตาดาต้าของภาพทางการแพทย์
- Privacy Budget Control (ε – epsilon) — ผู้ดูแลระบบสามารถกำหนดค่า epsilon เพื่อปรับสมดุลระหว่างความเป็นส่วนตัวกับคุณภาพของข้อมูลได้อย่างชัดเจน โดยระบบมีค่าเริ่มต้นและคำแนะนำตามกรอบมาตรฐาน (เช่น ค่าที่นิยมใช้ในงานวิจัยระหว่าง 0.01–10 ขึ้นกับระดับการป้องกันที่ต้องการ และลักษณะงาน) พร้อมหน้าจอแสดง trade‑off แบบเรียลไทม์
- Schema Mapping — เครื่องมือแมปสคีมาช่วยแปลงโครงสร้างข้อมูลจากระบบต้นทาง (เช่น HL7/FHIR, CSV, SQL) ให้เข้ากับแม่แบบการสร้างข้อมูลของแพลตฟอร์ม ลดความจำเป็นในการปรับแต่งโค้ดของผู้ใช้
- De‑identification Pipeline — กระบวนการลบและแปลงข้อมูลระบุตัวตนก่อนการเรียนรู้ (pseudonymization, tokenization, generalization, suppression, hashing) เพื่อให้การฝึกโมเดลเกิดขึ้นบนข้อมูลที่ผ่านการป้องกันหลายชั้น
- API และ GUI — ทั้ง RESTful API สำหรับการทำงานเชิงโปรแกรมและแดชบอร์ดแบบกราฟิกที่ใช้งานง่าย ผู้ใช้สามารถสั่งสร้างข้อมูล ปรับพารามิเตอร์ DP, ตรวจสอบสถิติการประสมข้อมูล และดาวน์โหลดชุดข้อมูลได้ทันที
- Toolkit สำหรับการตรวจสอบคุณภาพ — ชุดเครื่องมือสำหรับประเมินคุณภาพข้อมูลสังเคราะห์ เช่น การทดสอบความใกล้เคียงของการแจกแจง (distributional similarity), การวัดความสมรรถนะของโมเดล (utility metrics เช่น AUC, RMSE เปรียบเทียบกับข้อมูลจริง), และการจำลองการโจมตี (membership inference, attribute inference) เพื่อประเมินความเสี่ยงจริง
รูปแบบข้อมูลที่รองรับและกรณีใช้งานทั่วไป
- EHR (Electronic Health Records) — ตารางการรักษา, การวินิจฉัย, ยา, ผลการตรวจทางห้องปฏิบัติการ เหมาะสำหรับการพัฒนาแบบจำลองการคัดกรองโรค การวิจัยเชิงประชากร และการวิเคราะห์ต้นทุนทางการแพทย์
- เมตาดาต้าของภาพทางการแพทย์ (เช่น CT/MRI/DICOM metadata) — สนับสนุนการสร้างเมตาดาต้าที่สอดคล้องกับภาพจริงสำหรับการทดสอบ pipeline การประมวลผลภาพโดยไม่ต้องเปิดเผยภาพผู้ป่วย
- ล็อกเหตุการณ์ (event logs) — ข้อมูลตามเวลา เช่น การเข้า–ออกผู้ป่วยในโรงพยาบาล, ลำดับการรักษา เหมาะสำหรับการวิเคราะห์กระบวนการคลินิกและการทำนายเส้นเวลา
โดยรวม SynthCare‑DP ถูกออกแบบให้เป็นโซลูชันครบวงจรที่ตอบโจทย์ทั้งภาควิจัยและเชิงพาณิชย์: ให้ความคุ้มครองความเป็นส่วนตัวเชิงคณิตศาสตร์ รองรับรูปแบบข้อมูลทางการแพทย์สำคัญ พร้อมเครื่องมือวัดคุณภาพและการใช้งานที่สะดวกผ่าน API/GUI — ช่วยให้หน่วยงานสามารถแลกเปลี่ยนและทดลองข้อมูลได้อย่างปลอดภัย โดยยังคงคุณค่าสถิติที่จำเป็นต่อการวิจัยและพัฒนานวัตกรรมทางการแพทย์
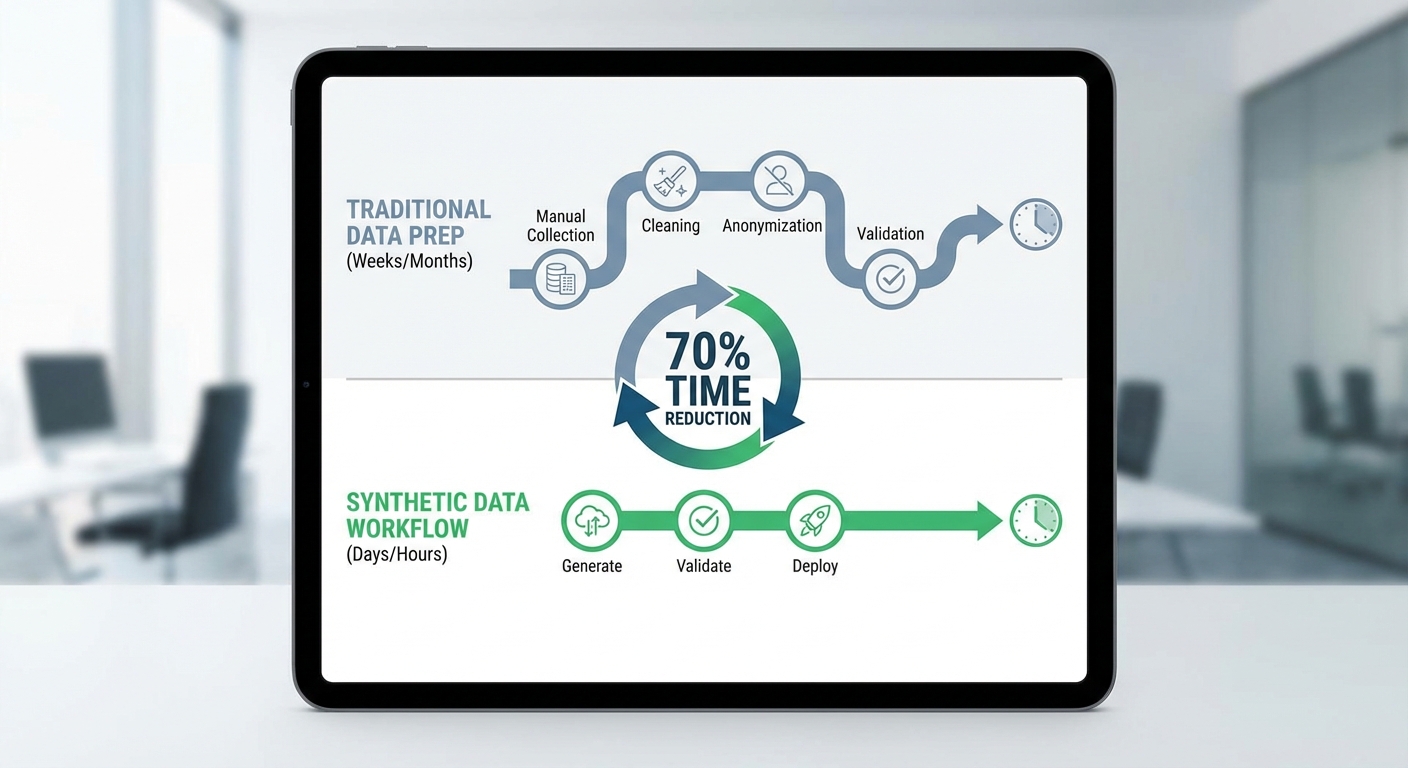
3. ลดเวลาเตรียมข้อมูลจริง 70% — workflow ก่อนและหลัง
3. ลดเวลาเตรียมข้อมูลจริง 70% — workflow ก่อนและหลัง
ที่มาของตัวเลข "ลดเวลาเตรียมข้อมูลจริง 70%" มาจากการประเมินเชิงปฏิบัติการ (operational benchmarking) ของโครงการนำร่อง SynthCare‑DP กับหน่วยงานโรงพยาบาลและทีมวิจัยจำนวนหนึ่งในประเทศไทย ซึ่งเปรียบเทียบระยะเวลาเฉลี่ยของกระบวนการเตรียมข้อมูลก่อนและหลังนำข้อมูลเทียมที่รับรองด้วย Differential Privacy มาใช้ ค่า 70% คำนวณจากอัตราส่วนการลดเวลารวมของขั้นตอนสำคัญ (เช่น approvals, ETL, de‑identification/linkage, cleansing/labeling) เช่น เมื่อระยะเวลาเตรียมข้อมูลรวมลดจาก 10 สัปดาห์เหลือ 3 สัปดาห์ คิดเป็นการลดลงที่ (10−3)/10 = 70% และในตัวอย่างสมมติของโรงพยาบาล A ระบุว่าเวลาจาก 8 สัปดาห์ลดลงเป็น 2.4 สัปดาห์ ซึ่งให้ผลลัพธ์เท่ากันคือการลด 70% ( (8−2.4)/8 = 0.7 )
ภาพรวม workflow แบบดั้งเดิม (ก่อนใช้ SynthCare‑DP) — ขั้นตอนหลักและระยะเวลาโดยประมาณของโครงการวิจัยที่ใช้ข้อมูลผู้ป่วยจริง:
- Approval / Data access requests — 3–4 สัปดาห์: รวมการยื่นขออนุญาตจากคณะกรรมการจริยธรรม (IRB) และการตกลงเงื่อนไขการเข้าถึงข้อมูล
- Data extraction & ETL — 1.5–2 สัปดาห์: การสกัดข้อมูลจากระบบต้นทางและแปลงให้อยู่ในรูปแบบที่นักวิจัยใช้ได้
- De‑identification & linkage — 1–2 สัปดาห์: การลบหรือแปลงข้อมูลระบุตัวตน รวมทั้งการผสานข้อมูลคนไข้จากหลายแหล่ง
- Data cleansing & labeling — 1–2 สัปดาห์: ตรวจสอบความสมบูรณ์ แก้ค่าผิดพลาด และติดป้าย (label) สำหรับการฝึกโมเดล
- รวมเวลาเฉลี่ย — ประมาณ 10 สัปดาห์ สำหรับกรณีโครงการมาตรฐาน
Workflow เมื่อนำ SynthCare‑DP เข้ามาใช้ — วิธีที่ระบบข้อมูลเทียมแบบ Differential‑Privacy ช่วยลดเวลาในแต่ละขั้นตอน:
- Approval / Data access requests — เหลือ 0.5–1 สัปดาห์: ข้อมูลเทียมที่รับรองความเป็นส่วนตัวช่วยลดเงื่อนไขด้านกฎหมายและความเสี่ยง ทำให้กระบวนการอนุมัติเร็วขึ้น (บางกรณีสามารถใช้ sandbox หรือข้อตกลงที่สั้นลง)
- Data extraction & ETL — เหลือ 0.5–0.8 สัปดาห์: SynthCare‑DP สามารถปล่อยชุดข้อมูลเทียมที่มีโครงสร้างตรงตามโมเดลที่ต้องการ ทำให้ลดงานแปลงและ mapping
- De‑identification & linkage — เหลือ 0.2–0.4 สัปดาห์: เนื่องจากข้อมูลเป็นเทียมและผ่านกลไก Differential‑Privacy ขั้นตอนการลบข้อมูลระบุตัวตนมีความจำเป็นน้อยลงหรือเป็นขั้นตอนตรวจสอบที่รวดเร็ว
- Data cleansing & labeling — เหลือ 0.6–0.8 สัปดาห์: ข้อมูลเทียมที่สร้างตาม distribution ของข้อมูลจริงช่วยให้ความสะอาดเบื้องต้นดีขึ้น ต้องแก้ไขน้อยลงและสามารถเพิ่มฉลากตัวอย่างเพื่อเร่งการฝึกแบบจำลอง
- รวมเวลาเฉลี่ย — ประมาณ 3 สัปดาห์ สำหรับโครงการที่ใช้ชุดข้อมูลเทียมจาก SynthCare‑DP
ตัวอย่างสมมติ — โรงพยาบาล A
ในกรณีสมมติของโรงพยาบาล A ทีมวิจัยต้องเตรียม cohort เพื่อทดลองแบบจำลองการทำนายภาวะแทรกซ้อนก่อนใช้ SynthCare‑DP ใช้เวลา 8 สัปดาห์ (อนุมัติ 3 สัปดาห์, ETL 2 สัปดาห์, de‑id 1 สัปดาห์, cleansing/labeling 2 สัปดาห์) หลังนำ SynthCare‑DP มาทดแทน ขั้นตอนต่างๆ ลดลงเป็น 2.4 สัปดาห์ (อนุมัติ 0.9 สัปดาห์, ETL 0.6 สัปดาห์, de‑id 0.3 สัปดาห์, cleansing 0.6 สัปดาห์) — คิดเป็นการลดลง 70% ตามสูตร (8 − 2.4) / 8 = 0.7
ผลทางปฏิบัติและผลกระทบต่อทีมวิจัย
- การลดเวลาเตรียมข้อมูลลง 70% แปลว่า เวลาไปสู่การทดลองต้นแบบ (time‑to‑prototype) รวดเร็วขึ้นอย่างมีนัยสำคัญ — ทีมสามารถทดสอบสมมติฐานและเปลี่ยนแปลงโมเดลได้บ่อยขึ้นภายในวงรอบการพัฒนาเดียวกัน
- ลดคอขวดด้านการเข้าถึงข้อมูลและการอนุมัติ ทำให้ทรัพยากรบุคคลด้านไอทีและเจ้าหน้าที่ข้อมูล (data stewards) ใช้เวลาน้อยลงกับงานเชิงเอกสาร และมีเวลาสนับสนุนงานเชิงวิเคราะห์ได้มากขึ้น
- ตัวอย่างเชิงปฏิบัติ: ทีมที่เดิมสามารถออกแบบและทดสอบโมเดลได้ประมาณ 1–2 โปรเจ็กต์ต่อไตรมาส อาจเพิ่มเป็น 3–5 โปรเจ็กต์ต่อไตรมาสเมื่อใช้ข้อมูลเทียมที่พร้อมใช้งาน
- นอกจากเวลาแล้ว ยังลดความเสี่ยงด้านการละเมิดความเป็นส่วนตัว ทำให้การร่วมมือระหว่างสถาบันเป็นไปได้รวดเร็วและสะดวกยิ่งขึ้น ส่งผลให้วงจรวิจัยสั้นลงและผลักดันนวัตกรรมได้เร็วกว่าเดิม
สรุปคือ การอ้างว่าลดเวลาเตรียมข้อมูลจริง 70% มาจากการเปรียบเทียบระยะเวลากระบวนการหลักก่อนและหลังปรับใช้ SynthCare‑DP โดยผลดังกล่าวสะท้อนทั้งการลดขั้นตอนอนุมัติ การลดงาน ETL และการลดภาระการลบข้อมูลระบุตัวตน ซึ่งรวมกันแล้วช่วยให้ทีมวิจัยสามารถเคลื่อนโครงการจากแนวคิดสู่การทดลองได้เร็วขึ้นอย่างมีนัยสำคัญ
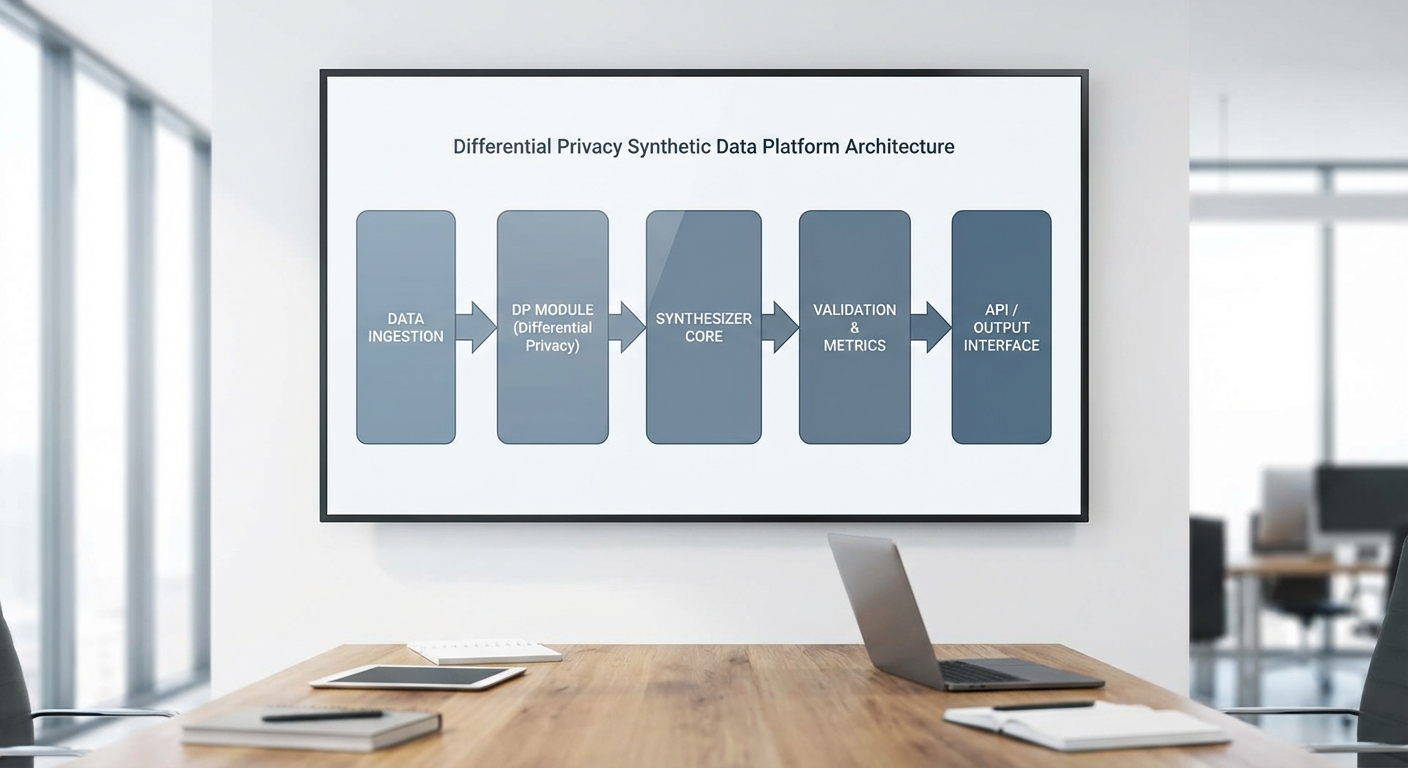
4. สถาปัตยกรรมเทคนิคและการคุ้มครองความเป็นส่วนตัว
4. สถาปัตยกรรมเทคนิคและการคุ้มครองความเป็นส่วนตัว
SynthCare‑DP ถูกออกแบบด้วยสถาปัตยกรรมแบบโมดูลาร์ที่เน้นความปลอดภัยของข้อมูลตั้งแต่จุดรับข้อมูลจนถึงการเผยแพร่ชุดข้อมูลเทียม โดยองค์ประกอบหลักประกอบด้วย Data Ingestion, Synthesizer, DP Layer และ Validation & Release ทั้งหมดเชื่อมต่อผ่านท่อข้อมูลที่มีการตรวจสอบสิทธิ์และการบันทึกเหตุการณ์ (audit logging) เพื่อรองรับการตรวจสอบย้อนหลังและการคำนวณบัญชีค่า privacy budget
Data Ingestion เริ่มจากกระบวนการ ETL (extract–transform–load) ที่มีการลบหรือแฮชข้อมูลระบุตัวบุคคล (PII) และการทำ schema mapping เพื่อให้ข้อมูลทางการแพทย์จากแหล่งต่างๆ อยู่ในรูปแบบที่เป็นมาตรฐาน ก่อนเข้าสู่โมดูลฝึกสอน โมดูลนี้ยังรวมถึงการวิเคราะห์สถิติพื้นฐานเพื่อกำหนด sampling strategy และการจัดการ class imbalance ซึ่งเป็นปัจจัยสำคัญก่อนการสร้างข้อมูลเทียม
Synthesizer ของระบบใช้ชุดโมเดลที่ปรับให้เหมาะสมกับชนิดข้อมูลทางการแพทย์ เช่น GANs (Generative Adversarial Networks) สำหรับข้อมูลต่อเนื่องและภาพคลื่น, VAEs (Variational Autoencoders) สำหรับการเรียนรู้เชิงโครงสร้าง และชิ้นส่วนที่เรียกว่า DP‑SYN ซึ่งเป็นเฟรมเวิร์กผสานการฝึกแบบมีการป้องกันความเป็นส่วนตัวโดยตรง โมเดลเหล่านี้ถูกออกแบบให้รองรับการเรียนรู้ความสัมพันธ์เชิงร่วม (joint distributions) ระหว่างฟีเจอร์ และสามารถปรับพารามิเตอร์เพื่อรักษาความสมดุลระหว่าง fidelity และ privacy
DP Layer ทำหน้าที่เป็นชั้นกลางที่แทรกกลไกการป้องกันความเป็นส่วนตัวแบบ Differential Privacy ก่อนการปล่อยตัวอย่างเทียม กลไกที่ใช้ได้แก่ Laplace และ Gaussian noise addition สำหรับการป้องกันทางสถิติ และมีการใช้นโยบายการจัดสรรค่าบัญชีความเป็นส่วนตัว (privacy budget accounting) ซึ่งวัดเป็นค่า ε (epsilon) โดยทั่วไประบบสนับสนุนการคำนวณแบบ composition และ advanced/Rényi DP เพื่อประเมินผลกระทบเมื่อมีการร้องขอซ้ำซ้อน
ค่าของ epsilon คือสเกลที่บ่งชี้ระดับความเป็นส่วนตัว: ค่ายิ่งเล็กหมายถึงความเป็นส่วนตัวสูงขึ้นแต่ utility ลดลง ในทางปฏิบัติตัวอย่างช่วงค่าที่ใช้บ่อยคือ
- ε = 0.01–0.1 — ความเป็นส่วนตัวสูงมาก; เหมาะกับกรณีที่ต้องการความเสี่ยงต่ำสุด แต่ข้อมูลอาจมีความเที่ยงตรงลดลง
- ε = 0.1–1 — สมดุลระหว่าง privacy และ utility; เหมาะสำหรับงานวิจัยเชิงคลินิกที่ต้องการผลวิเคราะห์ที่น่าเชื่อถือ
- ε = 1–10 — ให้ utility สูงขึ้นแต่ความเสี่ยงด้านการบุกรุกความเป็นส่วนตัวเพิ่มขึ้น; เหมาะกับการทดสอบโมเดลภายในเงื่อนไขควบคุม
การเลือกช่วง epsilon จะขึ้นกับนโยบายความเสี่ยงของผู้ให้บริการข้อมูลและข้อกำหนดทางกฎหมาย (เช่น PDPA) — ตัวอย่างเชิงการปฏิบัติ ทีม SynthCare‑DP มักตั้งเงื่อนไขมาตรฐานภายในองค์กรให้ ΔAUC ของโมเดล downstream ไม่เกิน ±2% เมื่อเทียบกับการฝึกด้วยข้อมูลจริง เพื่อรักษา utility ในขณะที่ตั้งค่า epsilon ให้สอดคล้องกับระดับความเสี่ยงที่ยอมรับได้
Validation Pipeline เป็นหัวใจสำคัญของการรับรองความปลอดภัยและคุณภาพ ประกอบด้วยชุดการทดสอบเชิงสถิติและการโจมตีเชิงประเมินความเสี่ยง ก่อนการปล่อยข้อมูลจะต้องผ่านการตรวจสอบดังนี้:
- Fidelity metrics — การเปรียบเทียบสถิติพื้นฐาน (mean, variance), correlation matrices และ joint distributions เพื่อวัดความคล้ายคลึงเชิงโครงสร้าง
- Statistical distance — การทดสอบเช่น KS test (Kolmogorov–Smirnov), Chi‑square, KL/JS divergence เพื่อประเมินความแตกต่างระหว่างการแจกแจงของข้อมูลจริงและข้อมูลเทียม
- Downstream performance — การฝึกโมเดลเชิงพยากรณ์บนข้อมูลเทียมและประเมินเปรียบเทียบกับโมเดลที่ฝึกด้วยข้อมูลจริง (เช่น AUC, accuracy, F1); เป้าหมายปฏิบัติการของ SynthCare‑DP คือให้ ΔAUC ≤ 2% ในกรณีตัวอย่างของงานคลาสสิฟิเคชันทางการแพทย์
- Privacy attacks — การทดสอบเช่น membership inference และ re‑identification risk assessment เพื่อยืนยันระดับการปกป้องข้อมูลจริง
สุดท้าย กระบวนการ Release ถูกควบคุมด้วยนโยบายการให้สิทธิ์ (access control), การกำหนด metadata ที่ระบุระดับ epsilon ที่ใช้ และการจัดทำรายงานความเสี่ยงแบบอัตโนมัติ ทำให้ผู้ใช้ปลายทางและหน่วยกำกับดูแลสามารถตรวจสอบได้ว่าแต่ละชุดข้อมูลเทียมถูกสร้างขึ้นภายใต้ข้อจำกัดความเป็นส่วนตัวใด ผลลัพธ์จากการทดสอบความถูกต้องและการวัดประสิทธิภาพจะถูกแนบเป็นเอกสารอ้างอิงเพื่อสนับสนุนการตัดสินใจเชิงธุรกิจและการวิจัย
5. กรณีศึกษาและตัวอย่างการใช้งานจริง
5. กรณีศึกษาและตัวอย่างการใช้งานจริง
ในระยะการทดลองนำร่อง (pilot) SynthCare‑DP ถูกทดสอบร่วมกับหน่วยงานสองแห่ง ได้แก่ หน่วยวิจัยด้านเวชศาสตร์การป้องกันของมหาวิทยาลัยและโรงพยาบาลศูนย์ขนาดกลาง‑ใหญ่ (ประมาณ 600–800 เตียง) เพื่อประเมินความสามารถในการแทนที่ข้อมูลจริงสำหรับการพัฒนาโมเดลคัดกรองความเสี่ยงและการค้นหากลุ่มผู้ป่วยที่มีลักษณะเฉพาะตัว การทดลองครอบคลุมข้อมูลผู้ป่วยประมาณ 45,000 รายการ (encounters) ด้วยชุดคุณลักษณะเชิงโครงสร้างประมาณ 120 ตัวแปร (demographics, โรคประจำตัว, ผลการตรวจทางห้องปฏิบัติการ) ระยะเวลาดำเนินการรวม 6 เดือน โดยเป้าหมายหลักคือ (1) ลดเวลาเตรียมข้อมูลจริงเพื่อเริ่มการวิจัย (2) บริหารความเสี่ยงด้านความเป็นส่วนตัวผ่าน Differential Privacy และ (3) ตรวจสอบผลกระทบต่อสมรรถนะของโมเดลเมื่อใช้ข้อมูลสังเคราะห์แทนข้อมูลจริง
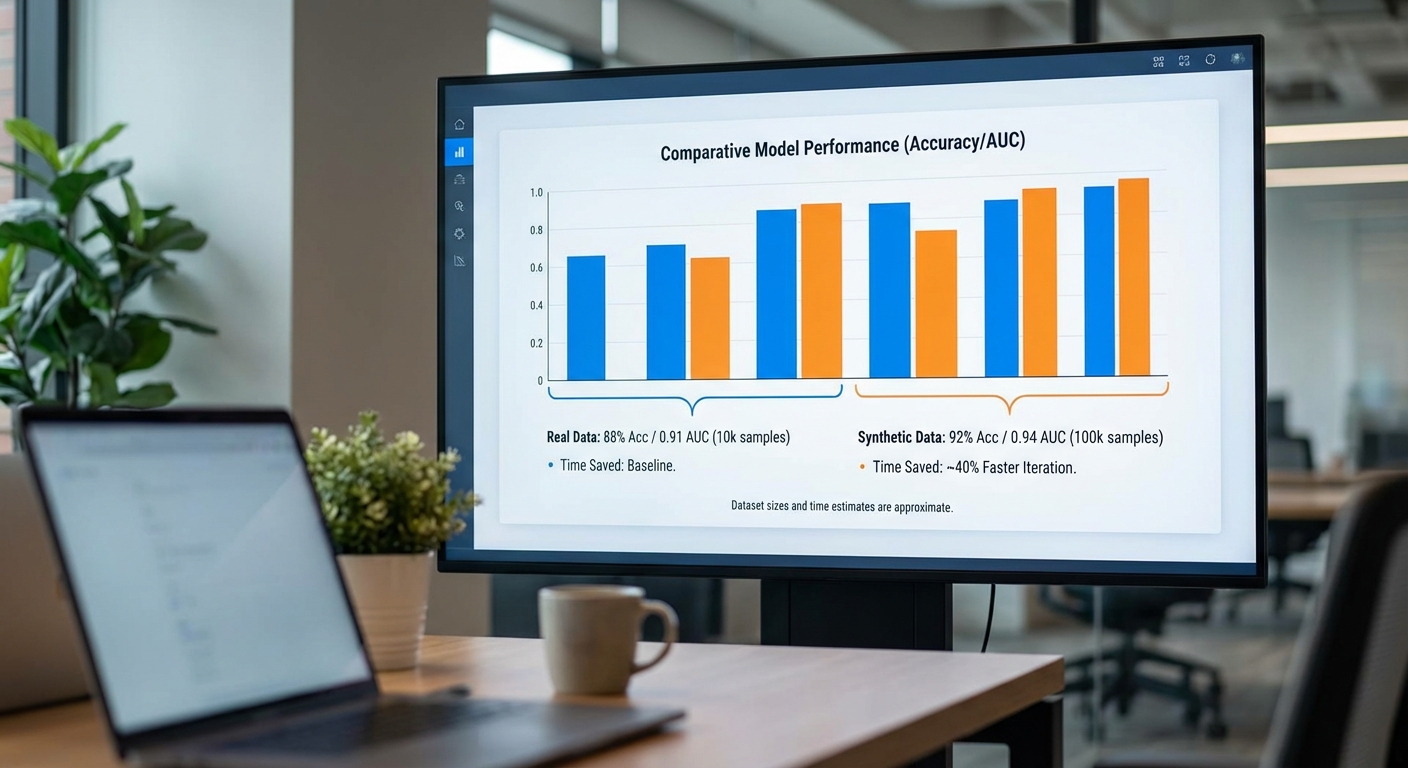
ผลลัพธ์เชิงปริมาณจากการทดลองมีดังนี้: สำหรับงานทำนายการกลับมารักษาภายใน 30 วัน (readmission prediction) โมเดลที่ฝึกด้วยข้อมูลจริงมีค่า AUC = 0.82 ขณะที่โมเดลที่ฝึกด้วยข้อมูลสังเคราะห์จาก SynthCare‑DP ให้ค่า AUC = 0.80 ซึ่งหมายถึง ΔAUC = -0.02 (ลดลง 2 คะแนน AUC) ค่า precision ลดจาก 0.68 → 0.65 และ recall ลดจาก 0.74 → 0.71 (ผลรวม F1 ลดจาก 0.71 → 0.68) ทีมวิจัยสรุปว่า ความต่างของสมรรถนะอยู่ในระดับยอมรับได้ (within 3–5%) สำหรับ use‑case ในการพัฒนา proof‑of‑concept ก่อนถ่ายโอนไปสู่การทดลองกับข้อมูลจริง
ในเชิง KPI ของโครงการ ผลการนำ SynthCare‑DP ไปใช้ช่วยให้กระบวนการเตรียมข้อมูลและการเข้าถึงชุดข้อมูลสำหรับนักวิจัยสั้นลงอย่างมีนัยสำคัญ โดยเฉลี่ยลดเวลาเตรียมข้อมูลลง ราว 70% จากระยะเวลาเฉลี่ยก่อนใช้ที่ประมาณ 10–12 สัปดาห์ เหลือเพียง 3–4 สัปดาห์สำหรับการสร้างชุดข้อมูลสังเคราะห์และทำการฝึก/ทดสอบเบื้องต้น นอกจากนี้ จำนวนโครงการที่บรรลุเป้าหมาย Proof‑of‑Concept ภายใน 4 สัปดาห์ เพิ่มจาก 40% เป็น 88% หลังการใช้งาน SynthCare‑DP ซึ่งชี้ให้เห็นถึงการเร่งวงจรนวัตกรรมและลดคอขวดด้านการเข้าถึงข้อมูลจริง
คำติชมจากผู้ใช้งานทั้งนักวิจัยและทีมไอทีช่วยให้เห็นภาพเชิงปฏิบัติของการนำไปใช้:
- นักวิจัย (หัวหน้าทีมโมเดลเชิงคลินิก): “การได้ชุดข้อมูลสังเคราะห์ที่มีโครงสร้างและการกระจายคล้ายข้อมูลจริง ทำให้เราสามารถออกแบบฟีเจอร์ ทดลองสถาปัตยกรรมโมเดล และทดสอบสมมติฐานได้เร็วกว่าที่เคย โดยไม่ต้องรออนุมัติการเข้าถึงข้อมูลผู้ป่วย”
- ทีมไอทีของโรงพยาบาล: ชี้ว่าเวิร์กโฟลว์การส่งมอบข้อมูลเป็นไปได้โดยไม่ต้องเปิดเผย PHI ลดภาระการทำงานด้าน data de‑identification และการประสานงานด้าน compliance แต่ย้ำว่าต้องมีการตั้งค่าพารามิเตอร์ DP (เช่น epsilon) อย่างรอบคอบเพื่อให้สมดุลระหว่างความเป็นส่วนตัวกับคุณภาพข้อมูล
- ผู้บริหารโครงการวิจัย: ชื่นชมการลดความเสี่ยงทางกฎหมายและเวลาอนุมัติจากคณะกรรมการจริยธรรม (IRB) แต่สอบถามถึงข้อจำกัดเมื่อใช้กับกรณีผู้ป่วยกลุ่มย่อยหรือเหตุการณ์หายาก ซึ่งข้อมูลสังเคราะห์อาจสะท้อนรูปแบบเหล่านี้ได้ไม่ครบถ้วน
ประเด็นข้อจำกัดที่ถูกสังเกตมีดังนี้:
- สำหรับเหตุการณ์ทางการแพทย์ที่มีความถี่ต่ำ (rare events) ข้อมูลสังเคราะห์อาจไม่สร้างตัวอย่างที่เพียงพอหรือสะท้อนความสัมพันธ์สหสัมพันธ์ที่ละเอียดได้เต็มที่ จึงแนะนำให้ใช้ข้อมูลสังเคราะห์เป็นขั้นตอนแรกของ pipeline และต่อด้วยการปรับจูนด้วยข้อมูลจริงเมื่อจำเป็น
- การตั้งค่า Differential Privacy สูงเกินไป (epsilon ต่ำ) อาจทำให้ความแม่นยำของโมเดลลดลงมากกว่าที่ยอมรับได้ ดังนั้นทีมงานแนะนำการทดสอบ sensitivity ของพารามิเตอร์ DP เป็นขั้นตอนมาตรฐานก่อนนำสู่การใช้งานจริง
- การรวมข้อมูลจาก multiple sources จำเป็นต้องมีการแมปตัวแปรและมาตรฐานข้อมูลให้สอดคล้องก่อนสร้างชุดสังเคราะห์ เพื่อป้องกันการสูญเสียความหมายของตัวแปรทางคลินิก
สรุปข้อเรียนรู้จาก pilot คือ SynthCare‑DP ช่วยลดเวลาเตรียมข้อมูลและเร่งการทดลองโมเดลได้อย่างมีนัยสำคัญ โดยยังคงรักษาสมรรถนะของโมเดลให้อยู่ในช่วงที่ยอมรับได้สำหรับการพัฒนา proof‑of‑concept อย่างไรก็ตาม การใช้งานในระดับ production ยังคงต้องมีการทดสอบร่วมกับข้อมูลจริงในขั้นตอนสุดท้าย และการปรับตั้งค่าระบบ DP ต้องมีการกำหนดตามบริบทความเสี่ยงและเป้าหมายของโครงการ
6. กฎระเบียบ จริยธรรม และความเสี่ยง
6. กฎระเบียบ จริยธรรม และความเสี่ยง
การนำข้อมูลเทียม (synthetic data) ที่ผลิตด้วยเทคนิค Differential Privacy (DP) มาใช้ในบริบทการแพทย์ต้องผสานทั้งมิติของกฎหมายคุ้มครองข้อมูลส่วนบุคคล จริยธรรมทางการแพทย์ และการบริหารความเสี่ยงเชิงเทคนิค ในเชิงกฎระเบียบสำหรับประเทศไทย ข้อกำหนดตามพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ยังคงมีผลต่อการตัดสินใจในการใช้ข้อมูลทดแทนและต้องพิจารณาในมุมของการแปลงข้อมูลให้เป็นสถานะที่ไม่สามารถย้อนกลับ (anonymization) หรืออยู่ในรูปที่ถูกระบุตัวตนไม่ได้อย่างแน่นอน การใช้ synthetic data อาจเข้าข่ายเป็นข้อมูลที่ไม่ใช่ข้อมูลส่วนบุคคล หากการกระบวนการผลิตและค่าพารามิเตอร์ความเป็นเอกลักษณ์ (เช่น ค่า epsilon ของ DP) ได้รับการปรับให้ลดความเสี่ยงการย้อนระบุตัวตนจนถึงระดับที่เป็นที่ยอมรับ โดยควรมีการจัดทำ Data Protection Impact Assessment (DPIA) และเอกสารประกอบที่ชัดเจนก่อนนำข้อมูลเทียมไปใช้เชิงปฏิบัติ
ในระดับสากล ควรอ้างอิงหลักการจากมาตรฐานเช่น GDPR ของสหภาพยุโรป และแนวทางการปฏิบัติของ HIPAA ในสหรัฐอเมริกา โดย GDPR ให้ความสำคัญกับหลักการว่า anonymization ต้องทำให้การระบุตัวตนเป็นไปไม่ได้โดยสมเหตุสมผล (irreversible under reasonably likely methods) ส่วน HIPAA ให้กรอบการพิจารณาแบบ Safe Harbor และ Expert Determination ที่เน้นการวิเคราะห์ความเสี่ยงการระบุตัวตนเชิงสถิติ สำหรับผู้ให้บริการและองค์กรไทยที่ใช้ SynthCare‑DP ควรจัดทำหลักฐานทางเทคนิค (technical documentation) เพื่อแสดงว่าวิธีการสังเคราะห์ข้อมูลและค่าการตั้งค่า DP (เช่น ค่า epsilon และ composition accounting) อยู่ในระดับที่สอดคล้องกับแนวทางสากลและ PDPA
ความเสี่ยงหลักที่ต้องเฝ้าระวังได้แก่
- Re‑identification risk: ถึงแม้ข้อมูลจะเป็นเทียม แต่การให้ข้อมูลเชิงรายละเอียดสูง หรือการรั่วไหลของพารามิเตอร์การสร้างข้อมูลอาจเปิดโอกาสให้คู่ขนานข้อมูลจริงจากแหล่งอื่นนำมาประกอบแล้วย้อนกลับได้ งานวิจัยหลายชิ้นชี้ว่าเมื่อไม่ได้ตั้งค่า DP อย่างเข้มงวด อัตราการย้อนระบุตัวตนอาจเพิ่มขึ้นอย่างมีนัยสำคัญ
- Loss of rare‑case fidelity: กรณีผู้ป่วยที่มีโรคหายากหรือรูปแบบอาการที่ผิดปกติมักถูกละเว้นหรือถูกปรับให้เบลอในกระบวนการสังเคราะห์ ทำให้โมเดลที่ฝึกด้วยข้อมูลเทียมขาดความสามารถในการตรวจจับเหตุการณ์หายากเหล่านี้
- Bias transfer and amplification: ข้อมูลเทียมที่สังเคราะห์จากข้อมูลจริงอาจสืบทอดอคติ (bias) ที่มีอยู่ในชุดข้อมูลต้นทาง และในบางกรณีอาจเกิดการขยายผลอคตินั้นเมื่อโมเดลเรียนรู้จากตัวอย่างเทียม
มาตรการลดความเสี่ยงที่แนะนำสำหรับผู้ให้บริการ SynthCare‑DP และผู้ใช้ประกอบด้วยหลายชั้นทั้งเชิงเทคนิคและกฎระเบียบ ได้แก่
- DP tuning และการชั่งน้ำหนักความเป็นส่วนตัว–ประโยชน์ (privacy–utility tradeoff): ปรับค่า epsilon และการคำนวณ composition ให้ชัดเจน สถานการณ์ทางการแพทย์ที่ต้องการความแม่นยำสูงอาจเลือก epsilon ที่ใหญ่ขึ้นในขณะที่งานวิจัยเชิงสถิติต้องการการคุ้มครองสูงอาจเลือก epsilon เล็กลง ตัวอย่างเช่น การตั้งค่าอย่างเข้มงวด (epsilon < 1) จะลดความเสี่ยงการย้อนระบุตัวตนแต่ต้องแลกกับคุณภาพของข้อมูล
- Third‑party audits และ external validation: จ้างผู้ตรวจสอบอิสระเพื่อทำการประเมินความเสี่ยงการย้อนระบุตัวตน การตรวจสอบอคติ (bias audits) และการทดสอบความถูกต้องของข้อมูลเทียมโดยใช้ชุดข้อมูลตรวจสอบที่เข้มงวด ภายใต้ข้อตกลงการคุ้มครองข้อมูล การทดสอบภายนอกช่วยเพิ่มความน่าเชื่อถือและเป็นหลักฐานสำหรับการปฏิบัติตาม PDPA/GDPR/HIPAA
- Provenance metadata และ transparency reports: บันทึกต้นกำเนิดของข้อมูล กระบวนการสังเคราะห์ พารามิเตอร์ DP เวอร์ชันของโมเดล และการประเมินความเสี่ยงโดยละเอียด ควรเผยแพร่รายงานโปร่งใสที่แสดงระดับการปกป้องข้อมูล ผลการทดสอบการย้อนระบุตัวตน และผลการตรวจสอบอคติแก่ผู้มีส่วนได้ส่วนเสีย (stakeholders)
- External benchmarking และ holdout testing on approved real data: ยืนยันความสมรรถนะของโมเดลที่ฝึกด้วยข้อมูลเทียมโดยการทดสอบบนชุดข้อมูลจริงที่ได้รับอนุญาตภายใต้กรอบการกำกับดูแล เช่น การทดสอบบนชุดข้อมูลที่ผ่านการขออนุญาต/IRB เพื่อประเมินการรักษาความสามารถในการตรวจจับกรณีหายาก
- Governance และสัญญาทางกฎหมาย: ระบุข้อกำหนดในสัญญา เช่น การจำกัดการใช้ข้อมูลเทียม การห้ามพยายามย้อนรอยข้อมูล รวมถึงการจัดให้มี DPIA, การบันทึกการเข้าถึง และมาตรการตอบสนองต่อเหตุละเมิด
สรุปคือ การนำ SynthCare‑DP มาใช้ในระบบนิเวศการวิจัยและการดูแลสุขภาพไทยมีศักยภาพในการลดเวลาเตรียมข้อมูลจริงได้ถึง 70% แต่ต้องประกอบกับกระบวนการบริหารความเสี่ยงที่เข้มงวดเพื่อให้สอดคล้องกับ PDPA และมาตรฐานสากล การผสมผสานการปรับแต่ง DP อย่างมีเหตุผล การตรวจสอบโดยบุคคลภายนอก การรายงานโปร่งใส และการตรวจสอบความถูกต้องกับข้อมูลจริงภายใต้กรอบกฎหมาย จะช่วยให้การใช้ข้อมูลเทียมเป็นไปอย่างปลอดภัย มีความรับผิดชอบ และสร้างความเชื่อมั่นในระดับองค์กรและสาธารณะ
7. ผลกระทบเชิงธุรกิจ ตลาด และแผนพัฒนาในอนาคต
7. ผลกระทบเชิงธุรกิจ ตลาด และแผนพัฒนาในอนาคต
การเปิดตัว SynthCare‑DP เกิดขึ้นในช่วงเวลาที่ความต้องการข้อมูลทางการแพทย์แบบปลอดภัยเพิ่มขึ้นอย่างมีนัยสำคัญ โดยเฉพาะในภาคการวิจัยและพัฒนายา การประเมินผลทางคลินิก และการพัฒนาระบบ AI ทางการแพทย์ จากข้อมูลเชิงอุตสาหกรรม ตลาดบริการข้อมูลสุขภาพดิจิทัลในอาเซียนมีอัตราการเติบโตเฉลี่ยที่คาดการณ์ไว้ระหว่าง 15–20% ต่อปี และมีมูลค่ารวมที่คาดว่าจะขึ้นไปถึงระดับพันล้านดอลลาร์ภายในทศวรรษนี้ ความสามารถของ SynthCare‑DP ที่ช่วยทีมวิจัยลดเวลาเตรียมข้อมูลจริงได้ราว 70% เป็นตัวเร่งให้หน่วยงานวิจัย โรงพยาบาล และผู้พัฒนาเทคโนโลยีตัดสินใจลงทุนในข้อมูลสังเคราะห์ที่ได้รับการรับรองความเป็นส่วนตัว (differential privacy) มากขึ้น ส่งผลให้โอกาสทางธุรกิจทั้งในประเทศไทยและประเทศเพื่อนบ้านมีขนาดใหญ่และขยายตัวได้รวดเร็ว
สำหรับโมเดลธุรกิจที่เป็นไปได้ SynthCare‑DP สามารถใช้รูปแบบหรือผสมผสานได้หลายแนวทาง ขึ้นกับกลุ่มลูกค้าและความต้องการด้านความปลอดภัย ได้แก่
- SaaS (Subscription) — การเข้าถึงแพลตฟอร์มผ่านสมัครสมาชิกรายเดือน/ปี เหมาะสำหรับสถาบันวิจัยขนาดกลางและสตาร์ทอัพ ที่ต้องการใช้งานต่อเนื่องและอัปเดตความสามารถอย่างสม่ำเสมอ
- Per‑dataset / Pay‑per‑use — คิดค่าบริการตามชุดข้อมูลหรือจำนวนการสังเคราะห์ เหมาะกับโครงการวิจัยเฉพาะครั้งหรือหน่วยงานที่มีงบประมาณจำกัด
- Enterprise license / Managed service — สัญญาองค์กรแบบยาวและบริการติดตั้งในพื้นที่ (on‑premise) กับการรับประกัน SLA สำหรับโรงพยาบาลขนาดใหญ่และกลุ่มบริษัทด้านการดูแลสุขภาพที่ต้องการการควบคุมข้อมูลเต็มรูปแบบ
- Professional services & integration fees — บริการปรับแต่งโมเดล สร้างพอร์ตข้อมูลสังเคราะห์เฉพาะทาง และเชื่อมต่อกับระบบ HIS/PACS ของโรงพยาบาล
ด้านการแข่งขัน ตลาดข้อมูลสังเคราะห์ทางการแพทย์มีผู้เล่นทั้งระดับโลกและท้องถิ่น ผู้เล่นระดับนานาชาติอาจมีเทคโนโลยีแบบเบ็ดเสร็จและฐานลูกค้ากว้าง แต่ SynthCare‑DP มีข้อได้เปรียบเชิงยุทธศาสตร์ที่สำคัญในบริบทไทยและอาเซียน ได้แก่ ความเข้าใจข้อกำกับดูแลท้องถิ่น (PDPA และแนวปฏิบัติของหน่วยงานสาธารณสุข) การเชื่อมต่อกับระบบข้อมูลของโรงพยาบาลไทย (HIS/PACS) ที่ผ่านการทดสอบ และความสามารถในการให้บริการแบบผสมผสาน (hybrid on‑premise + cloud) ซึ่งช่วยลดความเสี่ยงที่ลูกค้าในประเทศจะเผชิญเมื่อใช้ผู้ให้บริการต่างประเทศ นอกจากนี้ การนำเสนอรายงานความเป็นส่วนตัวเชิงปริมาณ (เช่น ค่า epsilon ของ differential privacy) และการรองรับกระบวนการรับรองความปลอดภัยโดยหน่วยงานอิสระ จะเป็นจุดขายที่ชัดเจนเมื่อเปรียบเทียบกับผู้ให้บริการรายอื่น
แผนพัฒนาระยะถัดไปของ SynthCare‑DP ควรมุ่งไปที่ฟังก์ชันเชิงลึกที่ตลาดเรียกร้อง โดยลำดับความสำคัญที่แนะนำได้แก่:
- รองรับภาพทางการแพทย์ (medical imaging) — เพิ่มการสังเคราะห์ข้อมูลภาพ DICOM และการทำงานร่วมกับระบบ PACS เพื่อรองรับ use case ของรังสีวิทยาและการวินิจฉัยภาพ ซึ่งลูกค้าส่วนใหญ่ต้องการข้อมูลภาพที่มีความสมจริงสำหรับการเทรนโมเดล
- Federated synthesis / Multi‑party workflows — พัฒนาโหมดการสังเคราะห์แบบกระจาย ที่แต่ละโรงพยาบาลสามารถมีการสังเคราะห์ร่วมกันโดยไม่ต้องรวมข้อมูลดิบไว้ที่ศูนย์กลาง ช่วยขยายฐานลูกค้าในระบบสุขภาพที่มีการกระจายข้อมูลมากขึ้น และสอดคล้องกับนโยบายข้อมูลขององค์กร
- Certified privacy reports & third‑party audits — ให้บริการรายงานความเป็นส่วนตัวที่ได้รับการรับรองจากผู้ตรวจสอบอิสระ (เช่น รายงานค่า epsilon, การทดสอบโจมตีเพื่อประเมินการรั่วไหลของข้อมูล) พร้อมการรับรองมาตรฐานความปลอดภัยข้อมูล เช่น ISO 27001 หรือการสอดคล้องกับ PDPA เพื่อเพิ่มความเชื่อมั่นแก่ลูกค้าองค์กร
- Integration toolkit และ SDK — ชุดเครื่องมือสำหรับนักพัฒนาและแผนกไอทีของโรงพยาบาล เพื่อเร่งการบูรณาการและลดค่าใช้จ่ายเชิงเทคนิคในการติดตั้ง
ข้อเสนอแนะสำหรับผู้บริหารและผู้ตัดสินใจที่พิจารณาใช้ SynthCare‑DP ได้แก่:
- เริ่มด้วยโครงการนำร่องที่มี KPI ชัดเจน — ตั้งเป้าหมายด้านเวลาในการเตรียมข้อมูล (เช่น ลด 50–70%) และตัวชี้วัดความปลอดภัย (การทดสอบการเปิดเผยข้อมูล) ก่อนขยายสเกล
- เลือกโมเดลการชำระเงินตามความเสี่ยงและความถี่ใช้งาน — องค์กรที่ใช้อย่างต่อเนื่องอาจได้ประโยชน์จาก subscription หรือ enterprise license ขณะที่โครงการวิจัยเฉพาะกิจเหมาะกับ per‑dataset
- รวมข้อกำหนดทางกฎหมายลงในสัญญา — ระบุเรื่อง PDPA, ความรับผิดชอบต่อการรั่วไหลของข้อมูล และเงื่อนไขการตรวจสอบสิทธิ์ (audit rights) ให้ชัดเจน
- วางแผนร่วมกับแผนกไอทีและรังสีวิทยา — โดยเฉพาะเมื่อต้องการรองรับภาพทางการแพทย์และการเชื่อมต่อ PACS ซึ่งต้องการการทดสอบแบบข้ามระบบ
- ประเมินความเหมาะสมของการใช้งานแบบ federated — หากองค์กรมีข้อจำกัดด้านการโอนย้ายข้อมูล การใช้ federated synthesis จะช่วยให้ได้ข้อมูลสังเคราะห์ในระดับภูมิภาคโดยไม่ละเมิดข้อบังคับ
สรุปคือ SynthCare‑DP มีโอกาสเชิงธุรกิจที่เด่นในตลาดไทยและอาเซียน หากผสานโมเดลรายได้ที่ยืดหยุ่นกับการรับรองความปลอดภัยและ roadmap ด้าน imaging และ federated workflows อย่างเป็นรูปธรรม จะสามารถแข่งขันกับผู้เล่นต่างชาติและขยายฐานลูกค้าองค์กรได้รวดเร็ว โดยเฉพาะอย่างยิ่งเมื่อสามารถแสดงผลลัพธ์เชิงปริมาณ เช่น การลดเวลาเตรียมข้อมูลและการรักษามาตรฐานความเป็นส่วนตัวที่ตรวจสอบได้
บทสรุป

SynthCare‑DP เป็นตัวอย่างเชิงพาณิชย์ที่ชัดเจนของการนำ synthetic data มาใช้ในงานวิจัยทางการแพทย์โดยคำนึงถึงมาตรการความเป็นส่วนตัวเช่น Differential Privacy เพื่อเพิ่มความปลอดภัยในการเข้าถึงข้อมูลและเร่งกระบวนการเตรียมข้อมูลให้รวดเร็วขึ้น—ผู้พัฒนาอ้างว่าสามารถลดเวลาเตรียมข้อมูลจริงได้ถึง 70% ซึ่งช่วยให้ทีมวิจัยเริ่มต้นทดลองและพัฒนาโมเดลได้เร็วขึ้น ทั้งนี้การใช้ข้อมูลเทียมในเชิงพาณิชย์ยังเอื้อให้การแบ่งปันข้อมูลภายในเครือข่ายวิจัยเป็นไปได้โดยมีการป้องกันความเสี่ยงด้านข้อมูลส่วนบุคคลมากขึ้น
แม้ข้อดีด้านความเร็วและความปลอดภัยจะชัดเจน แต่ความเสี่ยงด้านคุณภาพของข้อมูลยังคงต้องได้รับการประเมินอย่างเข้มงวด — ทีมวิจัยควรทดสอบ utility และ bias ของข้อมูลเทียม ตรวจสอบประสิทธิภาพของโมเดลกับชุดข้อมูลจริง และวางมาตรการจัดการความเสี่ยงก่อนนำไปใช้ในสภาพแวดล้อมเชิงปฏิบัติจริง ในอนาคตคาดว่าโซลูชันอย่าง SynthCare‑DP จะพัฒนาไปสู่การผสานกับแนวทางเช่น federated learning, มาตรฐานการประเมินและการกำกับดูแลที่ชัดเจนมากขึ้น รวมทั้งการตรวจสอบอย่างต่อเนื่องเพื่อสร้างความเชื่อมั่นทั้งจากนักวิจัย ผู้ให้บริการด้านสุขภาพ และหน่วยงานกำกับดูแล



