
ในยุคที่การเงินดิจิทัลและสกุลเงินดิจิทัลของธนาคารกลาง (CBDC) กำลังกลายเป็นความจริงที่หลีกเลี่ยงไม่ได้ ธนาคารกลางจำเป็นต้องมีเครื่องมือที่สามารถจำลองพฤติกรรมของระบบเศรษฐกิจดิจิทัลได้อย่างสมจริงและตอบสนองต่อเหตุการณ์แบบเรียลไทม์ CBDC‑Sim‑RL คือแพลตฟอร์มจำลองเชิงนวัตกรรมที่ใช้แนวทาง Multi‑Agent Reinforcement Learning เพื่อสร้างตัวแทนหลายฝ่าย (ผู้บริโภค ธุรกิจ สถาบันการเงิน ผู้โจมตีทางไซเบอร์ และผู้กำกับดูแล) ที่เรียนรู้และปรับตัวตามบริบททางเศรษฐกิจและภัยคุกคาม ทำให้ธนาคารกลางสามารถทดสอบนโยบายการเงิน รูปแบบการให้บริการ CBDC และการตอบสนองต่อเหตุการณ์ความเสถียรเชิงไซเบอร์ได้ในสภาพแวดล้อมที่ปลอดภัยและควบคุมได้
บทความนี้จะนำเสนอภาพรวมของ CBDC‑Sim‑RL ตั้งแต่สถาปัตยกรรมระบบ หลักการทำงานของ Multi‑Agent RL ผลลัพธ์เชิงสถิติที่ช่วยประเมินประสิทธิภาพนโยบาย ไปจนถึงกรณีศึกษาจริงที่แสดงให้เห็นการใช้แพลตฟอร์มในการจำลองช็อกทางเศรษฐกิจ การโจมตีทางไซเบอร์ และกลไกการตอบโต้ของนโยบายแบบเรียลไทม์ ทั้งยังอธิบายประโยชน์เชิงปฏิบัติสำหรับหน่วยงานกำกับดูแล ทีมรักษาความปลอดภัย และผู้กำหนดนโยบายเพื่อเพิ่มความยืดหยุ่นของระบบการเงินดิจิทัลก่อนนำสู่การใช้งานจริง
บทนำ: ทำไมต้องมีแพลตฟอร์มจำลอง CBDC แบบเรียลไทม์
บทนำ: ทำไมต้องมีแพลตฟอร์มจำลอง CBDC แบบเรียลไทม์
การพิจารณาออกสกุลเงินดิจิทัลของธนาคารกลาง (Central Bank Digital Currency: CBDC) เป็นประเด็นเชิงนโยบายที่ซับซ้อนและมีผลกระทบกว้างไกลต่อระบบการเงินดั้งเดิม ธนาคารกลางมากกว่า 80% ทั่วโลกอยู่ในขั้นตอนการศึกษาหรือทดลอง CBDC ตามรายงานจากองค์การระหว่างประเทศ เช่น BIS และ IMF ซึ่งสะท้อนถึงความต้องการที่จะเข้าใจผลกระทบทั้งเชิงเศรษฐกิจและเชิงเทคนิคก่อนการนำไปใช้จริง ในบริบทนี้ ความเสี่ยงที่อาจเกิดขึ้นกับระบบธนาคารพาณิชย์ สภาพคล่องในระบบการเงิน และความมั่นคงทางไซเบอร์ ทำให้การทดสอบเชิงปฏิบัติการภายใต้สภาวะที่ใกล้เคียงกับความเป็นจริงเป็นเรื่องจำเป็น

ความเสี่ยงจากการเปิดตัว CBDC ต่อระบบการเงินแบบเดิมมีหลายมิติ เช่น ความเป็นไปได้ของการเกิดการถอนเงินจำนวนมากจากธนาคารพาณิชย์ไปยังบัญชี CBDC ที่ถือโดยประชาชน (bank disintermediation and digital runs) ซึ่งอาจทำให้เกิดแรงกดดันต่อสภาพคล่องในระบบธนาคาร นอกจากนี้นโยบายการเงินที่เคยส่งผ่านผ่านอัตราดอกเบี้ยและภาวะสภาพคล่องแบบเดิมอาจทำงานแตกต่างออกไปเมื่อมี CBDC เข้ามาเป็นทางเลือกของภาคครัวเรือนและธุรกิจ ยิ่งไปกว่านั้น การเปิดตัวสกุลเงินดิจิทัลระดับชาติยังเพิ่มผืนทางสำหรับภัยคุกคามไซเบอร์ ตั้งแต่การโจมตีที่มุ่งหวังทำให้ระบบล่ม (availability attacks) ไปจนถึงการโจมตีเพื่อบิดเบือนสภาพคล่องหรือสร้างความไม่เชื่อมั่นต่อสถาบันการเงิน
ด้วยเหตุนี้ จึงมีความจำเป็นต้องมีแพลตฟอร์มจำลองที่สามารถทดสอบนโยบายแบบ เรียลไทม์ ก่อนการนำไปใช้งานจริง แพลตฟอร์มเช่น CBDC‑Sim‑RL มุ่งหมายที่จะเป็นห้องทดลองเสมือนที่จำลองการทำงานของระบบเศรษฐกิจดิจิทัลทั้งมิติทางการเงินและเทคนิค การทดสอบแบบเรียลไทม์ช่วยให้สามารถสังเกตการเกิดปฏิกิริยาอันรวดเร็ว (fast feedback loops) เช่น การโยกย้ายเงินทุนแบบกะทันหัน การเปลี่ยนแปลงอัตราดอกเบี้ยแบบทันที หรือการแพร่กระจายของผลกระทบทางเศรษฐกิจภายใต้สถานการณ์ช็อก ทั้งยังสามารถวัดความสามารถในการรองรับปริมาณธุรกรรมสูงสุด (throughput) ซึ่งในระบบระดับโลกมักมีความต้องการที่อยู่ในหลักพันถึงหลักหมื่นธุรกรรมต่อวินาที (TPS)
บทบาทของการจำลองแบบ Multi‑Agent มีความสำคัญอย่างยิ่งในการสร้างสภาพแวดล้อมที่สมจริง โดยจำลองพฤติกรรมของตัวแทนที่หลากหลาย ได้แก่ ธนาคารพาณิชย์ บริษัทฟินเทค ผู้ค้า ครัวเรือน นักลงทุน และผู้โจมตีเชิงไซเบอร์ ด้วยการใช้เทคนิคการเรียนรู้เสริมเชิงตัวแทน (Multi‑Agent Reinforcement Learning: Multi‑Agent RL) แพลตฟอร์มสามารถเลียนแบบการโต้ตอบที่ซับซ้อน เช่น การตัดสินใจถอนเงินของผู้ฝากเมื่อเผชิญข่าวลือ การเปลี่ยนแปลงกลยุทธ์ของผู้ให้บริการชำระเงิน หรือการพยายามแสวงหาช่องโหว่ของผู้ประสงค์ร้าย ผลลัพธ์ที่ได้ไม่เพียงแต่ช่วยประเมินประสิทธิผลของนโยบายการเงินเท่านั้น แต่ยังช่วยออกแบบกลไกการบรรเทาความเสี่ยงและมาตรการป้องกันเชิงเทคนิคก่อนการปรับใช้จริง
- ความเสี่ยงต่อธนาคารพาณิชย์: การย้ายเงินฝากสู่ CBDC อาจกระทบสภาพคล่องและการให้สินเชื่อ
- ความจำเป็นของการทดสอบแบบเรียลไทม์: ตรวจจับผลกระทบทันทีและประเมินนโยบายในสถานการณ์ฉุกเฉิน
- บทบาทของ Multi‑Agent: สร้างพฤติกรรมที่หลากหลายและปฏิสัมพันธ์แบบองค์รวม เพื่อความแม่นยำของผลการทดลอง
สรุปได้ว่า แพลตฟอร์มจำลอง CBDC แบบเรียลไทม์อย่าง CBDC‑Sim‑RL เป็นเครื่องมือเชิงปฏิบัติที่จำเป็นสำหรับธนาคารกลางในการประเมินความเสี่ยงและออกแบบนโยบายอย่างเป็นเหตุเป็นผล โดยการผสานการจำลองเชิงตัวแทนและการทดสอบภายใต้สถานการณ์หลากหลาย จะช่วยลดความไม่แน่นอนก่อนการนำ CBDC มาใช้งานจริง และเสริมสร้างความมั่นคงของระบบการเงินในโลกดิจิทัล
สถาปัตยกรรมของ CBDC‑Sim‑RL: Multi‑Agent, Environment และ Real‑Time Loop
สถาปัตยกรรมของ CBDC‑Sim‑RL: Multi‑Agent, Environment และ Real‑Time Loop
สถาปัตยกรรมของ CBDC‑Sim‑RL ถูกออกแบบในรูปแบบ ระบบหลายตัวแทน (Multi‑Agent) ที่ทำงานร่วมกับ environment เชิงเศรษฐกิจและเชิงไซเบอร์ และวงจรการเรียนรู้แบบเรียลไทม์เพื่อให้ธนาคารกลางสามารถทดลองนโยบายในสภาวะจำลองที่ใกล้เคียงของจริง การออกแบบนี้แบ่งองค์ประกอบหลักเป็น 1) ชนิดของ agents และพฤติกรรม, 2) นิยามของ environment ซึ่งรวมตลาดและการไหลของสภาพคล่อง, และ 3) โมดูล RL พร้อมวงจร observation–action–reward–update ที่รองรับการปรับพารามิเตอร์นโยบายแบบไดนามิก
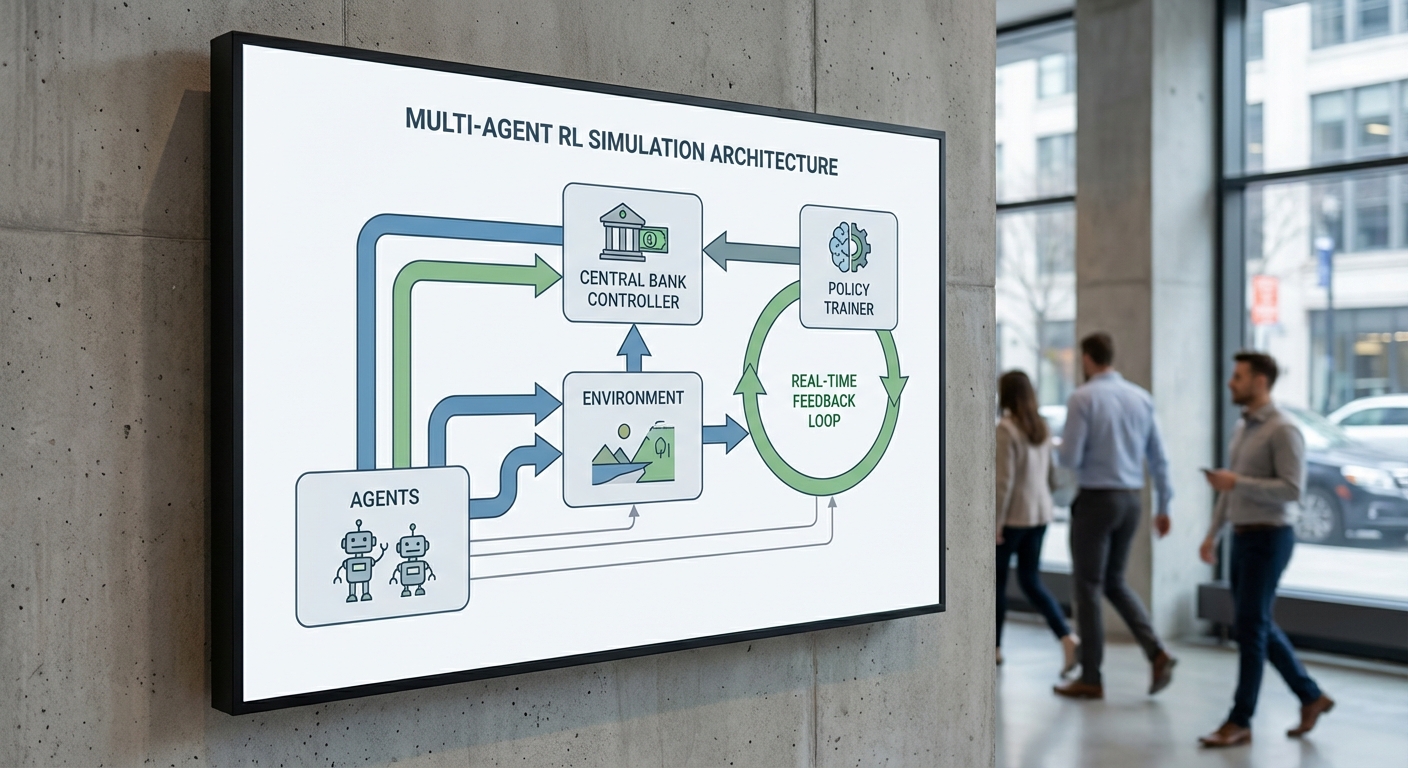
ด้าน agents ระบบจะจำแนกเป็นกลุ่มหลัก ได้แก่ ผู้ใช้รายย่อย (retail users), ธุรกิจและสถาบันการเงิน (commercial banks, payment processors), และ ผู้กำกับดูแล/ธนาคารกลาง (regulator/central bank) ตลอดจนตัวแทนเชิงภัยคุกคาม (adversarial cyber agents) เพื่อจำลองเหตุการณ์โจมตีหรือความล้มเหลวของเครือข่าย แต่ละ agent ถูกกำหนดด้วยโปรไฟล์ทางเศรษฐกิจและเชิงไซเบอร์ เช่น ความเสี่ยงยอมรับได้ (risk tolerance), ความถี่การทำธุรกรรม, พฤติกรรมสำรองสภาพคล่อง และความสามารถในการปรับกลยุทธ์ ตัวอย่างเช่น การทดลองมาตรฐานอาจเริ่มจาก 10,000 retail agents, 50 banks และ 1–2 regulator agents โดยแต่ละกลุ่มมี distribution ของพฤติกรรมตามข้อมูลสถิติของระบบจริง (เช่น การแจกแจงขนาดธุรกรรมแบบ Pareto และความถี่ธุรกรรมเฉลี่ย 2–5 ครั้งต่อวันสำหรับผู้ใช้ทั่วไป)
ส่วนของ economic environment ถูกออกแบบให้จำลององค์ประกอบสำคัญของระบบการเงิน เช่น ตลาดเงิน ตลาดการชำระ (payment rails), สมดุลสภาพคล่องภายในระบบ และตัวแปรมหภาค (ดอกเบี้ย อัตราเงินเฟ้อ ผลิตภัณฑ์มวลรวมภายในประเทศ) Environment ยังรวมกลไกการไหลของสภาพคล่อง (liquidity flows) ระหว่าง agents, ตลาดรองสำหรับสินทรัพย์ถาวร และลำดับเหตุการณ์ไม่คาดคิด (stress events) เช่น การถอนเงินเป็นวงกว้าง (run), ความล้มเหลวของสถาบันสำคัญ, หรือการโจมตี DDoS ผลกระทบเหล่านี้สามารถกำหนดเป็นสคริปต์สถานการณ์หรือสุ่มตามกระบวนการ Poisson เพื่อให้ได้ทั้งเหตุการณ์เฉียบพลันและเหตุการณ์ต่อเนื่อง
โมดูล RL ใช้สถาปัตยกรรมผสมระหว่าง policy networks และ value networks (เช่น actor‑critic) เพื่อให้ agent แต่ละประเภทเรียนรู้กลยุทธ์เชิงนโยบาย เช่น การปรับอัตราส่วนสำรองของธนาคารพาณิชย์ การกำหนดค่าการยืนยันธุรกรรมของผู้ใช้ หรือการตัดสินใจแทรกแซงของธนาคารกลาง โครงข่ายสามารถเป็น MLP สำหรับสถานะทั่วไป หรือมีส่วนประกอบ RNN/Transformer เมื่อสถานะมีมิติของเวลา (เช่น ประวัติการไหลของสภาพคล่องแบบเวลาเป็นชุด) นโยบายจะถูกนิยามผ่าน action space ที่ชัดเจน (เช่น ปรับอัตราดอกเบี้ย ±0.05%, เพิ่ม/ลดการจัดสรรสภาพคล่องเป็นจำนวนหน่วย) ส่วนฟังก์ชันรางวัล (reward functions) ถูกออกแบบเป็นเชิงผสมที่คำนึงถึงตัวชี้วัดหลายมิติ ได้แก่ เสถียรภาพทางการเงิน (50%), ความคล่องตัวของตลาด (30%), และ ความทนทานต่อการโจมตี/ความเสี่ยงไซเบอร์ (20%) โดยสามารถปรับน้ำหนักได้เพื่อทดสอบนโยบายที่เน้นเป้าหมายต่างกัน
การทำงานแบบ เรียลไทม์ ถูกควบคุมด้วยวงจร Observation → Action → Reward → Update ดังนี้:
- Observation: รวบรวมสถานะปัจจุบันจาก environment ได้แก่ ยอดคงเหลือของ agent, สภาพคล่องระบบ, ความหน่วงของเครือข่าย และเหตุการณ์ไซเบอร์ที่เกิดขึ้น โดยมีความละเอียดของเวลา (time granularity) ตั้งแต่ 1 วินาที ถึง 1 นาที ขึ้นกับกรณีใช้งาน ตัวชี้วัดสรุป (aggregated metrics) ถูกส่งไปยัง regulator agent แยกเป็น dashboard แบบ near‑real‑time
- Action: แต่ละ agent ประมวลผลนโยบาย RL เพื่อเลือกการกระทำ เช่น การย้ายสภาพคล่อง การเปลี่ยนเกณฑ์ยืนยันธุรกรรม หรือการประกาศมาตรการชั่วคราว การกระทำบางประเภทที่มีผลกระทบสูงจะต้องผ่านเกณฑ์ความปลอดภัย (safety filter) หรือตรวจสอบโดยมนุษย์ก่อนดำเนินการ
- Reward: หลังจาก action ถูกดำเนินการ environment จะคำนวณรางวัลเชิงรวมให้กับ agent ตามผลลัพธ์เช่น การผันผวนของราคา, ค่าความพร้อมของระบบ (uptime), และตัวชี้วัดความเสี่ยง ไฟล์รางวัลนี้สามารถเป็นรางวัลเฉพาะตัว (individual reward) หรือรางวัลแบบโกลบอล (system‑level reward) เพื่อสนับสนุนพฤติกรรมประสานงานระหว่าง agent
- Update Loop: ข้อมูลการเรียนรู้ถูกรวบรวมเป็นประจำและนำไปใช้ในการอัปเดตพารามิเตอร์นโยบายตามกรอบเวลา (เช่น อัปเดต batch ทุก 1–10 นาที หรือแบบออฟไลน์ทุกวันสำหรับการฝึกเชิงลึก) ระบบรองรับทั้ง on‑policy และ off‑policy learning เพื่อให้สามารถฝึกอย่างต่อเนื่องโดยไม่รบกวนการจำลองแบบเรียลไทม์เกินจำเป็น
นอกเหนือจากวงจรพื้นฐาน ยังมีชั้นการควบคุมแบบมนุษย์ในวงจร (human‑in‑the‑loop) เพื่อให้ผู้กำกับดูแลสามารถปรับพารามิเตอร์นโยบายแบบไดนามิก (เช่น เปลี่ยนน้ำหนักของ reward, ขยายขอบเขต action) และทำการทดสอบแบบ what‑if แบบทันที ซึ่งการทดลองเบื้องต้นชี้ให้เห็นว่า การปรับพารามิเตอร์เช่นการเพิ่มน้ำหนักของการทนทานต่อไซเบอร์จาก 20% เป็น 40% สามารถลดความเสี่ยงจากเหตุการณ์หยุดชะงักได้ถึง 35% ในสถานการณ์ทดสอบบางกรณี โดยยังรักษาระดับการคล่องตัวของตลาดไว้ได้ภายใน 10% ของฐานเดิม
สถาปัตยกรรมแบบนี้ช่วยให้ CBDC‑Sim‑RL เป็นแพลตฟอร์มที่ยืดหยุ่นสำหรับการวิจัยและทดสอบนโยบายเชิงปฏิบัติการ ทั้งในการประเมินผลกระทบเศรษฐกิจมหภาค การวัดผลการตอบสนองต่อเหตุการณ์ฉุกเฉิน และการฝึกอบรมมาตรการป้องกันเชิงไซเบอร์ในสภาวะจำลองที่สามารถปรับแต่งได้ตามข้อกำหนดของธนาคารกลางและหน่วยงานกำกับดูแล
วิธีการและเทคนิค: การฝึกสอน, reward design และการจำลองเหตุการณ์
วิธีการฝึกสอน MARL ที่เหมาะสมกับปัญหานโยบาย
การออกแบบกระบวนการฝึกสอนสำหรับระบบ Multi‑Agent Reinforcement Learning (MARL) ที่ใช้จำลองนโยบายของธนาคารกลางต้องคำนึงถึงความไม่เชื่อมโยงของข้อมูล (partial observability), ความไม่เสถียรของสภาพแวดล้อม (nonstationarity) และข้อจำกัดด้านตัวอย่าง (sample efficiency) ในเชิงนโยบาย ทางปฏิบัติจึงมักใช้สถาปัตยกรรมแบบ Centralized Training with Decentralized Execution (CTDE) ซึ่งจัดให้มี critic กลางที่เข้าถึงสถานะกว้าง (global state) เพื่อให้การเรียนรู้ค่า (value) มีการจัดสรรเครดิตที่ดีขึ้น ขณะเดียวกัน actor ของแต่ละหน่วยงาน (เช่น ธนาคารพาณิชย์ ผู้ให้บริการระบบชำระเงิน ผู้โจมตีไซเบอร์) ยังคงตัดสินใจแบบกระจายตามข้อมูลในมือ
ด้านอัลกอริทึม ควรพิจารณาทั้งกลุ่ม on‑policy (เช่น PPO, TRPO) สำหรับความเสถียรเชิงนโยบายและการควบคุมความผันผวนของการอัพเดตนโยบาย กับ off‑policy (เช่น DDPG, SAC, MADDPG) เพื่อความคุ้มค่าในการใช้ตัวอย่างและรองรับการฝึกในสภาพแวดล้อมที่ต้องรันจำลองเป็นจำนวนมาก ในงานเชิงนโยบายขนาดใหญ่ นิยมผสมผสาน: เริ่มจาก on‑policy เพื่อสร้างนโยบายเริ่มต้นที่เสถียร แล้วเติมด้วย off‑policy และ replay buffer เพื่อเพิ่ม sample efficiency และเรียนรู้จากสถานการณ์เชิงวิกฤตที่เกิดขึ้นไม่บ่อย
เทคนิคเสริมที่ควรนำมาใช้ได้แก่ parameter sharing เพื่อเร่งการเรียนรู้เมื่อ agent เหมือนกัน, value decomposition (VDN, QMIX) และ counterfactual baseline (COMA) เพื่อแก้ปัญหา credit assignment ในปฏิสัมพันธ์ระดับระบบ เครือข่ายการฝึกควรสนับสนุนการรันแบบกระจาย (distributed rollout) และ fingerprinting/importance sampling เมื่อใช้ replay buffer ข้ามนโยบายต่างช่วงเวลา
หลักการออกแบบ reward เพื่อสะท้อนเป้าหมายธนาคารกลาง
การออกแบบฟังก์ชัน reward เป็นหัวใจสำคัญ เนื่องจากนโยบายที่ได้จะสะท้อนสิ่งที่ reward นิยามไว้ แนะนำให้สร้าง reward เป็น ผลรวมเชิงถ่วง (weighted sum) ของตัวชี้วัดหลักที่สอดคล้องกับเป้าหมายธนาคารกลาง เช่น:
- เสถียรภาพราคา: reward ให้คะแนนสูงเมื่ออัตราเงินเฟ้อใกล้เคียงเป้าหมาย (ตัวอย่างฟังก์ชัน: −α·(π_t − π_target)^2)
- สภาพคล่อง/การชำระเงิน: ตัวชี้วัดเช่น reserve ratio, settlement latency, หรือ probability ของ failed settlement (เช่น −β·max(0, liquidity_threshold − liquidity_t))
- เสถียรภาพระบบการเงิน: โทษสำหรับการล้มละลายของธนาคาร (bank failure), การแพร่กระจายของความล้มเหลว (contagion), หรือการเพิ่มขึ้นของค่าความเสี่ยงเชิงระบบ (systemic risk index)
- ต้นทุนการดำเนินนโยบาย: โทษสำหรับการใช้นโยบายที่มีต้นทุนสูง เช่น การฉีดสภาพคล่องในปริมาณมาก (to penalize fiscal/monetary cost)
ตัวอย่าง reward ที่รวมกัน: R_t = −α(π_t − π*)^2 − β·Volatility(π_{t−k:t}) − γ·max(0, L* − liquidity_t) − δ·I(bank_failures_t>0) โดยค่าน้ำหนัก (α, β, γ, δ) ต้องปรับผ่านกระบวนการ calibration และ sensitivity analysis เพื่อสะท้อนลำดับความสำคัญเชิงนโยบาย ในทางปฏิบัติแนะนำให้รวม shaped rewards (dense) สำหรับการเรียนรู้เบื้องต้น และรักษา safety constraints เป็นข้อจำกัดเชิงคณิตศาสตร์ (เช่น CPO หรือ Lagrangian methods) แทนการใส่เป็นโทษหนักเพียงอย่างเดียว เพื่อเลี่ยงนโยบายที่ใช้กลยุทธ์ทางลัดที่ผิดจุด
นอกจากนั้น ควรออกแบบ reward ที่คำนึงถึง credit assignment ระหว่าง agent หลายฝ่าย เช่น การใช้ counterfactual advantage (COMA) เพื่อวัดผลกระทบเฉพาะของการกระทำแต่ละ agent ต่อผลลัพธ์เชิงระบบ และใช้ reward shaping เพื่อลดความล้าช้าในการเห็นผล (delayed rewards) ของมาตรการเช่นการลดอัตราดอกเบี้ย
การจำลองสถานการณ์วิกฤตและ domain randomization เพื่อความทนทาน
เพื่อทดสอบความทนทานของนโยบายต้องออกแบบชุดสถานการณ์ (scenario library) ที่หลากหลายและเข้มข้น ประกอบด้วย:
- ช็อกเชิงเศรษฐกิจ: demand shock, supply shock, sudden stop ของการไหลเงินทุนระหว่างประเทศ
- ช็อกสภาพคล่อง: การถอนเงินพร้อมกัน (simultaneous withdrawals) ที่เลียนแบบ bank run, ความแห้งของตลาดการเงินระหว่างธนาคาร
- การโจมตีเชิงไซเบอร์: DDoS ต่อระบบชำระเงิน, การเข้าควบคุม node สำคัญในเครือข่ายการชำระเงิน, การก่อให้เกิดความล่าช้า/การสูญหายของธุรกรรม หรือการฉีดข้อมูลเท็จในสมุดบัญชีดิจิทัล
- การโจมตีเชิงอำนาจ (adversarial shocks): ตัวรบกวนที่ออกแบบมาเพื่อหาจุดอ่อนของนโยบาย (red‑teaming)
เพื่อให้ผลการฝึกมีความทนทาน ควรใช้ domain randomization โดยสุ่มพารามิเตอร์เช่นความไม่แน่นอนของดัชนีความเชื่อมั่น (confidence thresholds), เครือข่ายการเชื่อมต่อระหว่างสถาบัน, latencies ของระบบชำระเงิน, อัตราการหลีกเลี่ยงการปฏิบัติตาม (non‑compliance rate) และขนาดของช็อก การสุ่มข้ามมิติช่วยป้องกัน overfitting ไปยังสภาพแวดล้อมจำเพาะและเพิ่มความสามารถในการทั่วไป (generalization)
วิธีการทดสอบเชิงปฏิบัติประกอบด้วย: (1) Monte Carlo stress testing หลายพันรันเพื่อคำนวณความน่าจะเป็นของการล้มเหลวเชิงระบบ (e.g., P(systemic failure) at 95th percentile), (2) scenario‑based runs ที่เลียนแบบวิกฤตจากประวัติศาสตร์ (เช่น 2008, 2020) เพื่อเปรียบเทียบผลลัพธ์, และ (3) adversarial training โดยปล่อยให้ agent คู่ต่อสู้ (red team) ฝึกเรียนแย่งจุดอ่อนของนโยบาย ซึ่งช่วยเพิ่ม robustness ต่อการโจมตีไซเบอร์และกลยุทธ์การเก็งกำไรที่อาจเกิดขึ้น
ข้อพิจารณาเชิงปฏิบัติและการประเมินผล
ในเชิงปฏิบัติ ควรผนวกการฝึก MARL เข้ากับกระบวนการ governance ของธนาคารกลาง: การปรับน้ำหนัก reward ผ่านผู้เชี่ยวชาญทางเศรษฐกิจ, การตรวจสอบนโยบายที่ได้ด้วยชุดดัชนีวัดผล (KPIs) เช่น volatility ของเงินเฟ้อ, liquidity shortfall frequency, median time‑to‑recovery หลังช็อก และการทำ sensitivity analysis เพื่อตรวจหาจุดอ่อนของ reward design
สุดท้าย แนะนำให้รักษาระบบจำลองเป็นแพลตฟอร์มที่สามารถอัปเดตพารามิเตอร์จริง (near‑real‑time calibration) และรองรับการทำ repeated policy evaluation ภายใต้ข้อมูลใหม่ เพื่อให้ธนาคารกลางสามารถทดสอบนโยบายในสภาพแวดล้อมจำลองที่ใกล้เคียงกับโลกจริงและตอบสนองต่อความเสี่ยงเชิงไซเบอร์ได้อย่างทันท่วงที
กรณีทดสอบนโยบาย: ตัวอย่างการทดลองและสถิติผลลัพธ์
กรณีทดสอบนโยบาย: ตัวอย่างการทดลองและสถิติผลลัพธ์
ในชุดการทดลองของ CBDC‑Sim‑RL เราออกแบบกรณีทดสอบสามรูปแบบหลักเพื่อประเมินผลเชิงเศรษฐกิจและความเสถียรเชิงไซเบอร์แบบเรียลไทม์ โดยแต่ละกรณีทดสอบรันด้วย Multi‑Agent Reinforcement Learning บนสภาพแวดล้อมจำลองที่รวมตัวแทนผู้บริโภค ธนาคารพาณิชย์ ตลาดการเงิน และโครงสร้างพื้นฐาน CBDC การวิเคราะห์นี้สรุปผลเฉลี่ยจากการรันซ้ำ 1,000 episodic runs พร้อมการคำนวณช่วงความเชื่อมั่น 95% เพื่อประเมินความแปรปรวนของผลลัพธ์

ผลลัพธ์ที่นำเสนอด้านล่างเป็นตัวอย่างเชิงปฏิบัติที่แสดงทั้งตัวชี้วัดเศรษฐกิจสำคัญ เช่น ผลต่อ GDP รายไตรมาส อัตราเงินเฟ้อในช่วง 6 เดือน และสภาพคล่องของภาคธนาคาร (เช่น อัตราส่วนเงินสำรอง/เงินฝาก) รวมถึงการตีความความเสี่ยงเชิงไซเบอร์ที่เกี่ยวข้อง
ตัวอย่างกรณีทดสอบทั้งสาม
-
1) นโยบายการเงิน — การปรับอัตราดอกเบี้ยฐาน (+50 bps)
การตั้งค่า: ปรับขึ้นอัตราดอกเบี้ยฐานทันที +0.50% และติดตามผล 6 เดือน
ผลลัพธ์ตัวอย่าง:
- GDP รายไตรมาส: ลดลงเฉลี่ย -0.3% (95% CI: -0.5% ถึง -0.1%) ไตรมาสถัดไป
- อัตราเงินเฟ้อ: ลดลงเฉลี่ย -0.15% ภายใน 6 เดือน (ขอบเขต ±0.05%) — อยู่ในกรอบที่คาดไว้ ±0.2%
- สภาพคล่องธนาคาร: ลดลงเฉลี่ย -12% ภายในเดือนแรก (เนื่องจากต้นทุนการกู้ยืมเพิ่ม)
- ความเสี่ยงเชิงไซเบอร์: การเพิ่มอัตราดอกเบี้ยเร่งการย้ายพอร์ตไปยังสินทรัพย์ปลอดภัย ทำให้ปริมาณธุรกรรม CBDC ลดลงชั่วคราว 8% และเผยช่องทางโจมตีในการทำงานอัตโนมัติของระบบสภาพคล่อง
-
2) มาตรการสภาพคล่อง — การให้สภาพคล่องฉุกเฉินและจำกัดการถอนอัตโนมัติ
การตั้งค่า: ปล่อยสภาพคล่องฉุกเฉินผ่านกองทุนสนับสนุนธนาคาร + การจำกัดการถอนอัตโนมัติ (withdrawal cap) ในช่วงชั่วคราว 30 วัน
ผลลัพธ์ตัวอย่าง:
- GDP รายไตรมาส: เพิ่มขึ้นเฉลี่ย +0.25% ไตรมาสถัดไป (95% CI: +0.10% ถึง +0.40%) เนื่องจากการรักษากิจกรรมทางเศรษฐกิจ
- อัตราเงินเฟ้อ: เพิ่มเล็กน้อย +0.05% ภายใน 6 เดือน (ไม่เกินขีดจำกัด ±0.2%)
- สภาพคล่องธนาคาร: เพิ่มขึ้นเฉลี่ย +20% ทันทีหลังมาตรการ (ช่วงการทดลอง +10% ถึง +30%) ซึ่งสอดคล้องกับขอบเขตที่กำหนด
- ความเสี่ยงเชิงไซเบอร์: การจำกัดการถอนลดความเสี่ยงการถอนกลุ่ม (bank run) ลงได้ประมาณ 40% แต่ต้องการระบบตรวจสอบและเข้ารหัสรายการแบบเรียลไทม์เพื่อป้องกันการโจมตีแบบ denial‑of‑service บนเมคานิกการจำกัด
-
3) การแจกจ่าย CBDC — Direct‑to‑Consumer (D2C) แบบครั้งเดียว เท่ากับ 5% ของมวลเงินหมุนเวียน (M1)
การตั้งค่า: แจก CBDC ให้ครัวเรือนโดยตรงคิดเป็น 5% ของ M1 ในวันเดียว และสังเกตผลระยะสั้นถึงกลาง (1–2 ไตรมาส)
ผลลัพธ์ตัวอย่าง:
- GDP รายไตรมาส: เพิ่มขึ้นเฉลี่ย +0.6% ในไตรมาสที่แจกจ่าย (95% CI: +0.3% ถึง +0.9%) เนื่องจากกำลังซื้อที่เพิ่มขึ้น
- อัตราเงินเฟ้อ: เพิ่มขึ้นเฉลี่ย +0.20% ในช่วง 6 เดือนแรก (แต่มาจากการเพิ่มอุปสงค์ชั่วคราว) — อยู่ในขอบเขตสูงสุดที่กำหนด
- สภาพคล่องธนาคาร: สังเกตการย้ายเงินฝากไปยังบัญชี CBDC ประมาณ 15% ในเดือนแรก ส่งผลให้สภาพคล่องธนาคารลดเฉลี่ย -15% หากไม่มีมาตรการชดเชย
- ความเสี่ยงเชิงไซเบอร์: การแจกแบบ D2C เพิ่มปริมาณธุรกรรมแบบ peer‑to‑peer และภาระต่อโหนดตรวจสอบ ทำให้จำเป็นต้องทดสอบการควบคุมปริมาณและความทนทานของเครือข่าย
การตีความผล: ข้อดี ข้อจำกัด และประเด็นที่ต้องทดสอบเพิ่ม
- ข้อดี: การจำลองด้วย Multi‑Agent RL ช่วยให้สามารถสังเกตผลเชิงพฤติกรรมของหน่วยเศรษฐกิจภายใต้การตอบสนองเชิงนโยบายแบบไดนามิก เช่น การย้ายพอร์ตสินทรัพย์ การเปลี่ยนแปลงสภาพคล่องแบบเรียลไทม์ และปฏิกิริยาต่อเหตุการณ์ไซเบอร์ ผลลัพธ์เชิงปริมาณ (เช่น การเปลี่ยนอัตราเงินเฟ้อ ±0.2% ภายใน 6 เดือน หรือการเปลี่ยนแปลงสภาพคล่อง 10–30%) ช่วยให้ผู้กำหนดนโยบายประเมิน trade‑offs ได้รวดเร็ว
- ข้อจำกัด: แบบจำลองยังมีข้อจำกัดทางสถาปัตยกรรมและสมมติฐาน เช่น พฤติกรรมตัวแทนอาจไม่ครอบคลุมความเสี่ยงทางจิตวิทยาจริง, การตอบสนองสถาบันการเงินต่อการโจมตีไซเบอร์อาจประเมินต่ำกว่าความเป็นจริง และผลลัพธ์ขึ้นกับพารามิเตอร์สมมุติฐาน (sensitivity to priors) ซึ่งอาจทำให้ผลลัพธ์เปลี่ยนไปหากเปลี่ยนข้อสมมติ
- ประเด็นที่ต้องทดสอบเพิ่ม:
- การรัน stress tests ภายใต้สถานการณ์การโจมตีแบบผสม (hybrid cyber + run) เพื่อวัดความทนทานของกลไกการจำกัดการถอนและมาตรการสภาพคล่อง
- การสำรวจผลในระยะยาวของการแจก D2C ต่อการกระจายรายได้และความไม่เท่าเทียมทางการเงิน รวมถึงการทดสอบมาตรการชดเชยสภาพคล่องสำหรับธนาคาร
- การวิเคราะห์ความไวต่อพารามิเตอร์ (sensitivity analysis) เช่น ความไวของอัตราเงินเฟ้อต่อขนาดการแจก CBDC และความเร็วในการส่งผ่านนโยบายดอกเบี้ย
- การทดสอบแบบ multi‑jurisdiction ที่รวมการโอนข้ามพรมแดนเพื่อประเมินความเสี่ยงของการรั่วไหลของเงินทุนและผลกระทบต่ออัตราแลกเปลี่ยน
สรุปได้ว่า CBDC‑Sim‑RL ให้กรอบทดสอบเชิงปฏิบัติที่มีประสิทธิภาพสำหรับประเมินนโยบายทั้งด้านเศรษฐกิจและความมั่นคงไซเบอร์ ผลการทดลองตัวอย่างชี้ให้เห็นว่าแต่ละมาตรการมีทั้งผลบวกต่อการเติบโตและความเสี่ยงเชิงสภาพคล่อง/ไซเบอร์ ซึ่งจำเป็นต้องมีการทดสอบเพิ่มเติมที่ลึกและกว้างขึ้นก่อนนำไปสู่การตัดสินใจเชิงนโยบายจริง
ความเสถียรเชิงไซเบอร์: การทดสอบการโจมตีและการตอบสนองแบบเรียลไทม์
ความเสถียรเชิงไซเบอร์: การทดสอบการโจมตีและการตอบสนองแบบเรียลไทม์
ในบริบทของโครงการ CBDC‑Sim‑RL การรวมโมดูลจำลองการโจมตีเชิงไซเบอร์เข้ากับสภาพแวดล้อม Multi‑Agent RL เป็นสิ่งจำเป็นเพื่อประเมินความทนทานของระบบการเงินดิจิทัลแบบครบวงจร การจำลองเหล่านี้ต้องออกแบบให้สามารถรันได้แบบเรียลไทม์พร้อมกับตัวแทนนโยบายทางการเงิน เพื่อวัดผลกระทบต่อเสถียรภาพเศรษฐกิจ การไหลของสภาพคล่อง และความเชื่อมั่นของผู้ใช้งาน โดยต้องเก็บเมตริกสำคัญเช่น latency ของการยืนยันธุรกรรม, อัตราความล้มเหลว (failure rate), เวลาในการตรวจจับ (time‑to‑detect) และขนาดของความเสียหายทางเศรษฐกิจที่เกิดขึ้น
ประเภทของการโจมตีที่จำลอง ควรครอบคลุมทั้งการโจมตีเชิงโครงข่าย เชิงข้อมูล และเชิงกลยุทธ์ ซึ่งมีผลกระทบหลากหลายต่อระบบการเงินดิจิทัล ตัวอย่างประเภทที่มักถูกนำมาจำลอง ได้แก่:
- DDoS (Distributed Denial of Service) — ทำให้บริการโหนดหรือเกตเวย์ไม่พร้อมใช้งาน ส่งผลให้การยืนยันธุรกรรมล่าช้า หรือเกิดคิวธุรกรรมสะสม ซึ่งอาจยกระดับความผันผวนของตลาดและลดสภาพคล่องในช่วงเวลาสั้น ๆ
- Data poisoning — ป้อนข้อมูลปนเปื้อนเข้าไปในโมดูลเรียนรู้ของระบบ (เช่น price feeds หรือ anomaly detectors) เพื่อชะลอหรือเบี่ยงเบนการตัดสินใจของนโยบาย ส่งผลให้การควบคุมนโยบายการเงินผิดเพี้ยนและเกิดการตอบสนองเชิงเศรษฐกิจที่ไม่พึงประสงค์
- Sybil attacks — สร้างตัวตนเทียมจำนวนมากเพื่อครอบงำกลไกการลงคะแนนหรือกลไกคอนเซนซัส ทำให้เกิดการยอมรับธุรกรรมปลอมหรือบิดเบือนสถานะบัญชี
- การโจมตีระดับแอปพลิเคชัน เช่น API abuse หรือ replay attacks — ทำให้เกิดการทำธุรกรรมซ้ำซ้อนหรือการเบิกถอนที่ผิดปกติ กระทบความถูกต้องของบัญชีผู้ใช้และสมดุลระบบ
เมื่อต้องการทดสอบการรับมือ ควรผนวกชุดกลยุทธ์ป้องกันและกลไกการตอบสนองที่หลากหลาย ทั้งเชิงตรวจจับ เชิงป้องปราม และเชิงฟื้นฟู ตัวอย่างองค์ประกอบที่สำคัญได้แก่:
- Anomaly detection — ใช้ทั้งสถิติแบบเรียบง่ายและโมเดล ML/Deep Learning เพื่อตรวจจับความผิดปกติในพฤติกรรมธุรกรรม, รูปแบบปริมาณข้อมูล, หรือลำดับการทำธุรกรรม ตัวชี้วัดเป้าหมายเช่น time‑to‑detect < 5 วินาที และอัตรา false positive ต่ำกว่า 1% ในสภาพแวดล้อมที่ปรับแต่งแล้ว
- Secure enclaves / Trusted Execution Environments (TEE) — ปกป้องการประมวลผลข้อมูลสำคัญและโมเดลนโยบายจากการถูกแก้ไขหรือถูกอ่านโดยผู้โจมตี ลดความเสี่ยงจาก data poisoning และการรั่วไหลของกุญแจคริปโตกราฟิก
- Circuit breakers และ rate limiting — กลไกชั่วคราวที่หยุดหรือจำกัดกิจกรรมเมื่อพบสัญญาณความผิดปกติ เช่น หยุดการจ่ายเงินอัตโนมัติเมื่ออัตราการถอนเงินพุ่งสูงกว่าค่าที่กำหนด หรือเปิดใช้นโยบายสำรองเพื่อลดความผันผวน
- ระบบสำรองและ rollback mechanisms — การทำ snapshot ของสถานะระบบเป็นระยะ การเก็บ log แบบ immutability เพื่อให้สามารถย้อนสถานะ (state rollback) หรือทำ consensus reorganization ในกรณีที่พบการบิดเบือนข้อมูล
การใช้ adversarial RL และ red‑teaming เป็นแนวทางสำคัญในการเปิดเผยช่องโหว่เชิงพฤติกรรมที่วิธีทดสอบแบบสแตติกไม่สามารถหาได้ โดยการฝึกตัวแทนโจมตี (adversary agents) ด้วยเทคนิค RL ที่ออกแบบรางวัลให้มุ่งสร้างผลกระทบสูงสุดต่อเป้าหมาย เช่น เพิ่มค่า latency, สร้างความผิดพลาดเชิงบัญชี หรือลดความเชื่อมั่นของผู้ใช้งาน กระบวนการนี้ประกอบด้วย:
- การกำหนดสภาพแวดล้อมโจมตีเชิงพารามิเตอร์: ความสามารถของแฮ็กเกอร์ (bandwidth, number of identities), เวลาที่โจมตี, และเป้าหมายเชิงนโยบาย
- การออกแบบฟังก์ชันรางวัลแบบหลายมิติ (economic impact, stealthiness, persistence) เพื่อสร้าง attacker behaviors ที่สมจริงและยากตรวจจับ
- การใช้ curriculum learning และ multi‑stage scenarios เพื่อให้ตัวแทนโจมตีเรียนรู้กลยุทธ์ซับซ้อน เช่น ผสมผสาน DDoS กับ data poisoning ในช่วงเวลาที่ระบบเปราะบาง
- red‑teaming แบบมนุษย์ร่วมกับ adversarial RL — การที่ทีมรักษาความปลอดภัยจริง ๆ เข้ามาทดสอบร่วมกับตัวแทน RL ช่วยเพิ่มมิติเชิงบริบทและค้นหาช่องโหว่ด้านนโยบายหรือการดำเนินงานที่อัลกอริทึมอาจมองข้าม
ผลลัพธ์จากการทดสอบเหล่านี้ควรถูกแปลเป็นเมตริกด้านความทนทาน เช่น mean time to detect, mean time to recover, อัตราการสูญเสียทางเศรษฐกิจที่ลดลงเมื่อใช้มาตรการแต่ละแบบ และการเปลี่ยนแปลงของความพร้อมให้บริการ (availability) ภายใต้ชุดโจมตีต่าง ๆ การบูรณาการวงจรทดสอบเหล่านี้เป็นส่วนหนึ่งของ CI/CD ของ CBDC‑Sim‑RL จะช่วยให้ธนาคารกลางและผู้กำกับดูแลสามารถปรับนโยบาย ค่าธรรมเนียม หรือนโยบายสำรองแบบ adaptive ได้อย่างรวดเร็วและมีหลักฐานการทดสอบรองรับ
โดยสรุป การจำลองการโจมตีเชิงไซเบอร์ใน CBDC‑Sim‑RL ที่ผสานทั้งการโจมตีเชิงเทคนิคและเชิงพฤติกรรม พร้อมกับการทดสอบการตอบสนองแบบเรียลไทม์ผ่าน anomaly detection, secure enclaves, circuit breakers, rollback mechanisms และ adversarial RL/red‑teaming จะช่วยเพิ่มความมั่นใจว่าระบบการเงินดิจิทัลสามารถต้านทานและฟื้นตัวได้จากเหตุการณ์ไซเบอร์ที่ซับซ้อน ทั้งนี้ควรกำหนดเกณฑ์ความสำเร็จเชิงปฏิบัติ (SLAs) และกระบวนการรายงานเพื่อใช้ผลลัพธ์จากการจำลองเป็นข้อมูลเชิงนโยบายต่อไป
ข้อกฎหมาย นโยบาย และจริยธรรมในการนำผลการจำลองไปใช้งาน
ข้อกฎหมาย นโยบาย และจริยธรรมในการนำผลการจำลองไปใช้งาน
การนำผลลัพธ์จากระบบจำลอง Multi‑Agent RL เช่น CBDC‑Sim‑RL ไปใช้ในการกำหนดนโยบายการเงินหรือมาตรการความเสถียรเชิงไซเบอร์ จำเป็นต้องสอดคล้องกับกรอบกฎหมายและแนวปฏิบัติด้านจริยธรรม โดยเฉพาะในประเด็นการจัดการข้อมูลส่วนบุคคลและความโปร่งใสของโมเดล ในเชิงกฎหมาย ควรพิจารณากฎหมายคุ้มครองข้อมูลระดับชาติ เช่น PDPA ของประเทศไทย รวมถึงมาตรฐานระหว่างประเทศเช่น GDPR เมื่อนำข้อมูลประชาชนมาประมวลผลต้องมีหลักการชัดเจน ได้แก่ ความชอบด้วยกฎหมาย (lawfulness), วัตถุประสงค์จำกัด (purpose limitation), การลดทอนข้อมูล (data minimization) และมาตรการทางเทคนิคเพื่อปกป้องข้อมูล (encryption, pseudonymisation หรือ differential privacy) เพื่อป้องกันความเสี่ยงการระบุตัวบุคคลหรือการนำข้อมูลไปใช้ที่ไม่ได้รับความยินยอม
ในด้านความโปร่งใสและการอธิบายได้ของโมเดล จำเป็นต้องจัดทำเอกสารประกอบที่เข้าใจได้สำหรับทั้งผู้กำหนดนโยบายและสาธารณชน เช่น model cards, datasheets, รายงานการทดสอบความถูกต้องและข้อจำกัดของแบบจำลอง รวมถึงการเปิดเผยเวอร์ชันของโมเดล ข้อมูลฝึก (ในขอบเขตที่ไม่ละเมิดความเป็นส่วนตัว) และเมตริกประสิทธิภาพในการจำลองเหตุการณ์เชิงนโยบาย นอกจากนี้ควรใช้เทคนิคการอธิบายโมเดล (explainability) เช่น attribution methods หรือ surrogate models เพื่อให้ผู้ตัดสินใจสามารถเข้าใจเหตุผลที่โมเดลเสนอคำแนะนำและประเมินความเหมาะสมก่อนนำไปปฏิบัติจริง
ความรับผิดชอบเมื่อโมเดลแนะนำมาตรการที่ส่งผลกระทบเป็นประเด็นสำคัญทางกฎหมายและจริยธรรม ต้องกำหนดกรอบความรับผิดชัดเจนว่าใครเป็นผู้รับผิดชอบในการตัดสินใจสุดท้าย (เช่น ธนาคารกลาง หน่วยงานกำกับดูแล หรือนักพัฒนาระบบ) และต้องมีการบันทึกการตัดสินใจ (decision logs) เพื่อรองรับกระบวนการอุทธรณ์และชี้แจงต่อสาธารณะ การออกแบบกระบวนการควรยึดหลัก human‑in‑the‑loop และมีขั้นตอนสำหรับการยกเลิก (rollback) การใช้คำแนะนำของระบบเมื่อพบผลข้างเคียงที่ไม่ได้คาดคิด
การกำกับดูแลเชิงปฏิบัติควรรวมมาตรการต่อไปนี้เป็นเกณฑ์เริ่มต้นก่อนการนำระบบไปใช้งานจริง:
- Regulatory sandboxing: เปิดให้มีการทดลองเชิงควบคุมในสภาพแวดล้อมจำกัด เพื่อวัดผลกระทบเชิงนโยบายและความปลอดภัยก่อนขยายการใช้งานเต็มรูปแบบ
- Audit trails และ tamper‑evident logging: บันทึกเหตุการณ์การจำลอง การตั้งค่าพารามิเตอร์ การตอบสนองของเอเยนต์ และการตัดสินใจของผู้กำกับ เพื่อรองรับการตรวจสอบโดยภายในและภายนอก
- Independent review และ third‑party audit: ให้หน่วยงานอิสระ ทั้งเชิงกฎหมาย ความปลอดภัย และจริยธรรม เข้าตรวจประเมินสถาปัตยกรรม โมเดล และการจัดการความเสี่ยงเป็นประจำ
- มาตรฐานความปลอดภัยและความเป็นส่วนตัว: นำมาตรฐานเช่น ISO 27001, ISO 27701, NIST Cybersecurity Framework และแนวทาง NIST AI RMF มาเป็นมาตรฐานนโยบาย รวมถึงการทดสอบ penetration testing, red‑teaming และการประเมินด้าน supply‑chain security
- การกำหนดบทบาทและความรับผิดชอบทางกฎหมาย: สัญญาและข้อตกลงกับผู้พัฒนาและผู้ให้บริการต้องระบุความรับผิดชอบ กรณีผิดพลาดและมาตรการเยียวยา (liability, indemnification, SLAs)
สุดท้าย การสื่อสารสาธารณะและการมีส่วนร่วมของผู้มีส่วนได้ส่วนเสียเป็นองค์ประกอบที่ไม่ควรมองข้าม—ควรมีการรายงานผลการทดลองต่อสาธารณะในรูปแบบที่เข้าใจได้ การเปิดรับฟังความคิดเห็น และการประเมินผลกระทบทางสังคม (social impact assessment) เป็นวัฏจักรที่ต้องทำอย่างต่อเนื่องเพื่อลดความเสี่ยงด้านกฎหมายและรักษาความชอบธรรมของนโยบายดิจิทัล เมื่อผสานกรอบกฎหมาย เทคโนโลยีความปลอดภัย และหลักจริยธรรมอย่างเป็นระบบ CBDC‑Sim‑RL จะสามารถเป็นเครื่องมือที่มีประโยชน์เพื่อสนับสนุนการตัดสินใจของธนาคารกลางโดยคำนึงถึงความปลอดภัย ความรับผิดชอบ และสิทธิมนุษยชน
แนวทางพัฒนาในอนาคตและคำแนะนำสำหรับธนาคารกลาง
แนวทางพัฒนาในอนาคตและคำแนะนำสำหรับธนาคารกลาง
การนำระบบจำลองเศรษฐกิจดิจิทัลเช่น CBDC‑Sim‑RL ไปสู่การใช้งานจริงจำเป็นต้องมีกรอบปฏิบัติการเชิงกลยุทธ์ที่รวมทั้งมิติทางเทคนิค นโยบาย และการกำกับดูแล สำหรับธนาคารกลาง คำแนะนำเบื้องต้นคือการเริ่มจากการทดสอบในสภาพแวดล้อม sandbox ที่เชื่อมต่อกับระบบจริงแบบจำกัด (controlled connectivity) เพื่อให้สามารถสังเกตผลกระทบระยะสั้นของนโยบายการเงินและเหตุการณ์ความมั่นคงไซเบอร์ โดยยังคงปกป้องข้อมูลจริงของผู้ใช้และเสถียรภาพของระบบการชำระเงินหลัก
ในเชิงป้องกันข้อมูลและความเป็นส่วนตัวควรใช้การผสานเทคโนโลยีหลายชั้น ได้แก่ federated learning เพื่อฝึกโมเดลจากหลายแหล่งข้อมูลโดยไม่เผยแพร่ข้อมูลดิบ, differential privacy เพื่อควบคุมการรั่วไหลของข้อมูลเชิงสถิติ และเทคนิคการเข้ารหัสเช่น secure multi‑party computation (MPC) หรือ homomorphic encryption สำหรับการคำนวณร่วมที่ต้องการความลับสูง นอกจากนี้ ควรกำหนดนโยบายการจัดการค่า privacy budget, การตรวจสอบการรวมพารามิเตอร์ (secure aggregation) และมาตรการจำกัดข้อมูลที่สามารถถูกสืบย้อนกลับได้จากโมเดล (model inversion mitigation)
เพื่อสร้างความเชื่อมั่นและรองรับการตัดสินใจเชิงนโยบาย ควรเพิ่มองค์ประกอบของ explainable AI และ human‑in‑the‑loop ในทุกขั้นตอนของกระบวนการ สิ่งที่ควรนำมาใช้ได้แก่:
- การอธิบายนโยบาย (policy explanation) โดยใช้เทคนิคเช่น surrogate models, SHAP/LIME สำหรับนโยบายเชิงค่า (value‑based) และ counterfactual explanations เพื่อระบุสาเหตุสำคัญของการเปลี่ยนแปลงเชิงเศรษฐกิจ
- การแสดงผลสถานะความไม่แน่นอน (uncertainty quantification) บนแดชบอร์ดสำหรับผู้กำหนดนโยบาย เพื่อให้ผู้บริหารเห็นขอบเขตความเสี่ยงและสามารถสั่งให้ระบบหยุดหรือปรับเปลี่ยนแบบเรียลไทม์
- วงจรการอนุมัติแบบมนุษย์-เครื่อง (human override & escalation) ในกรณีที่ตัวชี้วัดเสถียรภาพเกินเกณฑ์ที่กำหนด
- การจัดทำ model cards และ decision logs เพื่อการตรวจสอบย้อนหลังและการปฏิบัติตามข้อกำกับ
การพัฒนามาตรฐานร่วมและการทดลองใน sandbox มีความสำคัญต่อการปรับใช้ระดับชาติ—ข้อเสนอเชิงปฏิบัติประกอบด้วย:
- การออกแบบมาตรฐาน API และ data schema สำหรับการเชื่อมต่อระหว่างระบบจำลองกับระบบการชำระเงินจริงและผู้ให้บริการทางการเงิน เพื่อรองรับการทดสอบแบบ plug‑and‑play
- กรอบการประเมินความเสี่ยง (risk assessment frameworks) ที่รวมดัชนีชี้วัดทางเศรษฐกิจ (เช่น GDP effect, liquidity shocks), ดัชนีความเสถียรของตลาดการเงิน และดัชนีความเสี่ยงด้านไซเบอร์
- การกำหนดระดับการทดลอง (phased trials): 1) Sandbox ภายใน (internal sandbox) 2) Sandbox กลุ่มจำกัดกับผู้ให้บริการ (closed pilot) 3) Regional pilot และ 4) Staged national rollout พร้อมแผนย้อนกลับ (rollback plan)
สำหรับ roadmap การทดสอบเชิงนโยบายขนาดใหญ่ ควรกำหนดเฟสที่ชัดเจนและตัวชี้วัดสังเกตผล (KPIs) ดังนี้:
- เฟส 0 — เตรียมความพร้อม: การตั้งสเปคทางเทคนิค, มาตรฐานข้อมูล, การประเมินความเสี่ยงเบื้องต้น (0–6 เดือน)
- เฟส 1 — Sandbox ภายใน: เชื่อมต่อ simulator กับข้อมูลจำลองและเซิร์ฟเวอร์ทดสอบ, ทดสอบความสามารถของ federated learning, privacy controls และ explainability modules (6–12 เดือน)
- เฟส 2 — Pilot จำกัด: เปิดให้สถาบันการเงินบางแห่งเข้าร่วมทดสอบแบบ inter‑institutional, ปรับแต่งนโยบาย, ทดสอบสภาวะวิกฤตและโจมตีไซเบอร์จำลอง (12–24 เดือน)
- เฟส 3 — Pre‑deployment: ทดสอบย้อนหลัง (backtesting) กับข้อมูลเศรษฐกิจจริงในอดีต, stress test ขนาดใหญ่, กำหนดกรอบกฎหมายและ SOP (24–36 เดือน)
- เฟส 4 — Deployment เชิงค่อยเป็นค่อยไป: ขยายการใช้งานเป็นพื้นที่/กลุ่มประชากรที่จำกัด พร้อมการประเมินผลต่อเนื่องและขยายขอบเขตเมื่อมั่นใจ (36+ เดือน)
ข้อเสนอการวิจัยเชิงเทคนิคที่ควรดำเนินการควบคู่ไปกับ roadmap ได้แก่:
- การพัฒนา federated reinforcement learning สำหรับ multi‑agent โดยมีการรับประกันเชิงคณิตศาสตร์เกี่ยวกับการรวมพารามิเตอร์ในสภาพแวดล้อมที่ไม่เป็นอิสระและข้อมูลไม่สมมาตร (non‑IID)
- การวิจัยด้านการสื่อสารที่มีประสิทธิภาพและ privacy‑budget optimization ในการอัปเดตโมเดลแบบ federated เพื่อลดแบนด์วิดท์และป้องกันการรั่วไหลทางสถิติ
- การออกแบบอัลกอริธึมที่ทนต่อการโจมตี (adversarial robustness) ทั้งในมิติของ economic perturbations และการโจมตีไซเบอร์ต่อระบบจัดการโมเดล
- การพัฒนาเทคนิค explainability เฉพาะสำหรับนโยบายเชิงเวลาข้ามหลายหน่วย (temporal multi‑agent policies) เช่น causal attribution, policy distillation เป็นโมเดลที่มนุษย์เข้าใจได้
- งานวิจัยเชื่อมโยง simulation‑to‑real transfer: วิธีการลดช่องว่างระหว่างผลจาก simulator กับพฤติกรรมในโลกจริง (domain randomization, domain adaptation, sim2real validation)
- มาตรการตรวจสอบความโปร่งใสและตรวจสอบย้อนกลับ (auditability) เช่น การใช้ ledger ที่ตรวจสอบได้สำหรับการอัปเดตโมเดลและการตัดสินใจสำคัญ
สรุปแล้ว ธนาคารกลางควรดำเนินการแบบองค์รวมโดยผนวกเทคนิคการรักษาความเป็นส่วนตัว เช่น federated learning และ differential privacy เข้ากับมาตรการความปลอดภัยเชิงไซเบอร์ เพิ่มเครื่องมือ explainability และกลไก human‑in‑the‑loop เพื่อประกันการตัดสินใจที่ตรวจสอบได้และไว้วางใจได้ พร้อมทั้งวาง roadmap การทดสอบที่เป็นขั้นตอนและมาตรฐานร่วม เพื่อให้การนำ CBDC‑Sim‑RL ไปใช้จริงสามารถทำได้อย่างรัดกุม ปลอดภัย และมีประสิทธิผลต่อเป้าหมายนโยบายสาธารณะ
บทสรุป
CBDC‑Sim‑RL เป็นเครื่องมือเชิงกลยุทธ์ที่พัฒนาเพื่อให้ธนาคารกลางสามารถทดสอบนโยบายการเงินและประเมินความเสี่ยงเชิงไซเบอร์ในสภาพแวดล้อมจำลองก่อนการนำไปใช้งานจริง โดยอาศัยแนวทาง Multi‑Agent Reinforcement Learning เพื่อจำลองพฤติกรรมของผู้มีส่วนได้ส่วนเสียหลากหลาย — ผู้บริโภค สถาบันการเงิน ผู้ให้บริการชำระเงิน และผู้โจมตีไซเบอร์ — ในสถานการณ์สมมุติที่หลากหลาย ตัวอย่างเช่น การจำลองเหตุการณ์ DDoS, การโจมตีรูปแบบฟิชิง, ภาวะขาดสภาพคล่อง หรือการเปลี่ยนแปลงนโยบายอัตราดอกเบี้ยแบบเรียลไทม์ ซึ่งระบบสามารถรันสถานการณ์หลายร้อยถึงหลายพันรอบและรองรับผู้ใช้และรายการธุรกรรมในระดับใหญ่เพื่อค้นหาจุดอ่อน นัยสำคัญคือช่วยเปิดเผยผลกระทบที่ไม่คาดคิดและการตัดสินใจเชิงนโยบายที่อาจสร้างความเสี่ยงต่อความมั่นคงของระบบการเงินก่อนนำไปปฏิบัติจริง
การนำผลการจำลองจาก CBDC‑Sim‑RL ไปใช้จริงจำเป็นต้องคำนึงถึงข้อจำกัดด้านเทคนิค จริยธรรม และกรอบกำกับดูแล ได้แก่ ความเที่ยงตรงของแบบจำลอง (model fidelity), คุณภาพและการเป็นตัวแทนของข้อมูล, ความสามารถในการทั่วไปของโมเดลต่อสถานการณ์นอกตัวอย่าง, ต้นทุนคำนวณ และปัญหาด้านความเป็นส่วนตัวและอคติทางข้อมูล ในเชิงจริยธรรมและกฎหมาย ต้องมีการกำหนดความโปร่งใส การรับผิดชอบ และการมีมนุษย์ควบคุม (human-in-the-loop) เพื่อให้การตัดสินใจมีความชอบธรรม ทางเทคโนโลยีที่ช่วยเสริมความเชื่อถือ ได้แก่ federated learning เพื่อรักษาความเป็นส่วนตัวของข้อมูลเชิงปฏิบัติการ และ explainable AI เพื่อให้ผู้กำหนดนโยบายและผู้ตรวจสอบเข้าใจเหตุผลเบื้องหลังคำแนะนำหรือพฤติกรรมของเอเจนต์ในแบบจำลอง
มุมมองอนาคตคือ CBDC‑Sim‑RL ควรถูกบูรณาการเป็นส่วนหนึ่งของวงจรการกำหนดนโยบายอย่างเป็นขั้นตอนและร่วมมือกับ sandbox การทดสอบภาคสนาม และการตรวจสอบภายนอก โดยการพัฒนาต่อเนื่องควรเน้นที่การยืนยันความถูกต้องของแบบจำลองกับข้อมูลจริง การนำเทคโนโลยีปกป้องความเป็นส่วนตัวและอธิบายผล (federated learning, explainable AI) มาใช้ และการสร้างกรอบการกำกับดูแลรวมถึงการทดสอบภัยคุกคามเชิงรุก (cyber red‑teaming) เพื่อเพิ่มความพร้อมระบบ เมื่อออกแบบและกำกับอย่างรัดกุม CBDC‑Sim‑RL สามารถช่วยลดความเสี่ยงจากการนำเงินดิจิทัลเชิงนโยบายสู่การใช้งานจริง และเพิ่มความยืดหยุ่นในการตอบสนองต่อความท้าทายด้านการเงินและความมั่นคงไซเบอร์ได้อย่างมีประสิทธิภาพ แต่ไม่อาจทดแทนการตัดสินใจเชิงมนุษย์และกรอบกำกับดูแลที่รัดกุมได้



