
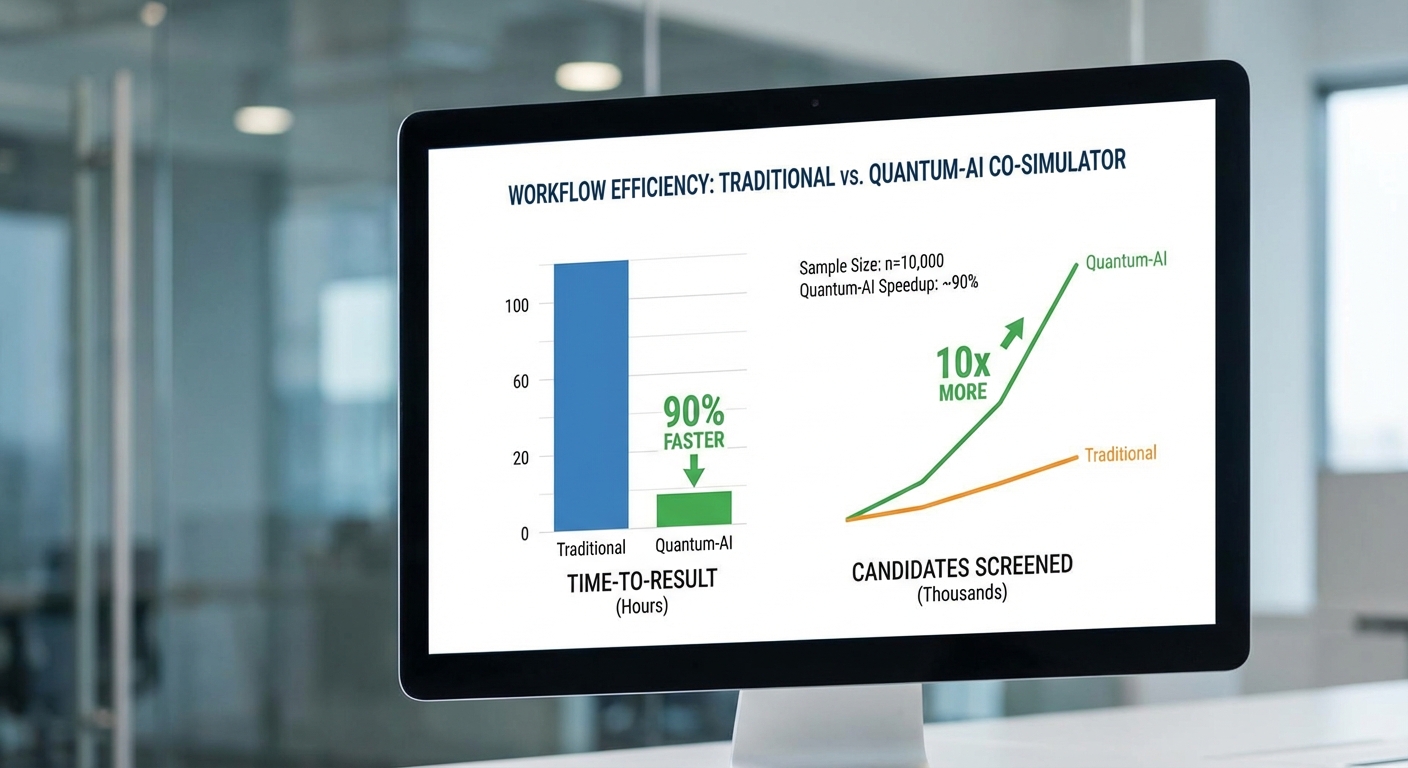
มหาวิทยาลัยไทยเปิดตัว Quantum‑AI Co‑Simulator แพลตฟอร์มจำลองร่วมที่ผสานตัวจำลองควอนตัมความเที่ยงตรงสูงกับเทคนิค Reinforcement Learning (RL) เพื่อเร่งการค้นคว้าวัสดุแบตเตอรี่ยุคใหม่ — ประกาศที่สร้างความตื่นตัวในวงการวิจัยพลังงานและเทคโนโลยีการจัดเก็บพลังงานในประเทศ ทีมงานระบุว่าแนวทาง co‑simulation นี้ช่วยเปลี่ยนวงจรค้นคว้าจากขั้นตอนที่เคยใช้เวลาหลายเดือนให้เหลือเพียงสัปดาห์ เท่ากับลดเวลา‑to‑result อย่างมีนัยสำคัญและเพิ่มอัตราการค้นพบวัสดุที่สอดคล้องกับเป้าหมายเชิงพลังงาน เช่น ความจุพลังงานต่อมวล การนำไฟฟ้า และความเสถียรเชิงเคมี
หลักการทำงานคือ RL ทำหน้าที่สำรวจอวกาศของเคมีและโครงสร้างวัสดุเพื่อเสนอชุดตัวอย่างที่มีแนวโน้มสูง ส่วนตัวจำลองควอนตัมจะประเมินสมบัติอิเล็กทรอนิกส์และพลังงานอย่างละเอียดในระดับอะตอม ทำให้สามารถคัดกรองตัวเลือกได้แม่นยำกว่าแบบจำลองคลาสสิก แบบวงปิด (closed‑loop) ระหว่างการเรียนรู้ด้วยเครื่องและการจำลองเชิงควอนตัมนี้ช่วยลดรอบการทดสอบเชิงคำนวณจากหลายเดือนเหลือเพียงไม่กี่สัปดาห์ในกรณีต้นแบบ ผลลัพธ์ดังกล่าวไม่เพียงเร่งการค้นพบเท่านั้น แต่ยังช่วยย่นระยะเวลาในการนำวัสดุจากห้องทดลองเข้าสู่การทดสอบจริงที่อุตสาหกรรมต้องการ — หัวข้อนี้เป็นประเด็นสำคัญที่บทความฉบับเต็มจะสรุปทั้งเทคนิค ผลการทดลองเชิงตัวเลข และผลกระทบเชิงเศรษฐกิจต่อภาคพลังงานของไทย
บทนำ: ข่าวสำคัญและบริบท
บทนำ: ข่าวสำคัญและบริบท
มหาวิทยาลัยไทยเปิดตัว Quantum‑AI Co‑Simulator ซึ่งพัฒนาโดย ศูนย์ร่วมวิจัยควอนตัม‑เอไอ (Quantum‑AI Co‑Simulation Lab) ภายใต้คณะวิทยาศาสตร์และเทคโนโลยีของมหาวิทยาลัย พร้อมความร่วมมือจากพันธมิตรภาคอุตสาหกรรมและสถาบันวิจัยทั้งในและต่างประเทศ โดยมีพันธมิตรหลักประกอบด้วยบริษัทผู้ผลิตแบตเตอรี่ภายในประเทศ, สตาร์ทอัพด้านการเรียนรู้เสริมกำลัง (Reinforcement Learning: RL) และห้องปฏิบัติการควอนตัมในต่างประเทศ โครงการนี้เป็นความพยายามเชิงบูรณาการระหว่างความเชี่ยวชาญทางควอนตัมฟิสิกส์ สมรรถนะการจำลองเชิงคอมพิวเตอร์ และเทคนิคปัญญาประดิษฐ์ขั้นสูงเพื่อแก้โจทย์การค้นคว้าวัสดุแบตเตอรี่ให้รวดเร็วขึ้นและมีประสิทธิผลมากขึ้น
เป้าหมายเชิงกลยุทธ์ของโครงการคือการลดระยะเวลาในการค้นพบและทดสอบวัสดุแบตเตอรี่เชิงทดลอง (time‑to‑market) โดยใช้สถาปัตยกรรม co‑simulation ที่ผสานตัวจำลองควอนตัมกับอัลกอริธึม RL เพื่อสำรวจพารามิเตอร์วัสดุและสถานะพลังงานที่มีความเป็นไปได้สูงอย่างมีประสิทธิภาพ โครงการมุ่งเน้นทั้งการเพิ่มอัตราการค้นพบวัสดุที่มีความหนาแน่นพลังงานสูง มีอายุการใช้งานยาวนาน และต้นทุนการผลิตต่ำ ตลอดจนการลดรอบการทดลองซ้ำที่เป็นข้อจำกัดหลักของอุตสาหกรรมแบตเตอรี่ในปัจจุบัน
ผลลัพธ์เชิงเวลาที่โดดเด่นเป็นหนึ่งในเหตุผลสำคัญที่โครงการได้รับความสนใจอย่างรวดเร็ว: ก่อนการนำ co‑simulator มาใช้ ทีมวิจัยรายงานว่ารอบการออกแบบและทดสอบวัสดุใหม่เฉลี่ยอยู่ที่ประมาณ 3–6 เดือน ต่อรอบ ในขณะที่ หลังการใช้งาน co‑simulator รอบการทดลองสามารถย่นเหลือเพียง 1–3 สัปดาห์ ทำให้ระยะเวลาโดยรวมลดลงอย่างมีนัยสำคัญ ตัวอย่างเช่น โปรโตคอลตัวอย่างในโครงการนำร่องสามารถย่อระยะจาก 5 เดือนลงเหลือ 3 สัปดาห์ — ลดลงราว 6–7 เท่า เมื่อพิจารณาจากจำนวนรอบการจำลองซ้ำและการคัดกรองเบื้องต้นที่สามารถทำได้ด้วยระบบอัตโนมัติ
ความสำคัญของความก้าวหน้านี้ต่อภาคอุตสาหกรรมและวงการวิจัยไม่อาจมองข้ามได้: นอกจากจะช่วยเร่งการนำวัสดุใหม่เข้าสู่ตลาดแล้ว ยังลดต้นทุนการทดลองและเพิ่มความคล่องตัวในการปรับใช้เทคโนโลยีแบตเตอรี่สำหรับยานยนต์ไฟฟ้า ระบบกักเก็บพลังงาน และอุปกรณ์อิเล็กทรอนิกส์เชิงพาณิชย์ ส่งผลให้ห่วงโซ่อุปทานมีความยืดหยุ่นมากขึ้น และเปิดโอกาสให้สถาบันการศึกษารวมถึงผู้ประกอบการสามารถทดสอบแนวคิดใหม่ ๆ ได้บ่อยครั้งขึ้นภายในงบประมาณและเวลาที่จำกัด
- ผู้พัฒนา: ศูนย์ร่วมวิจัยควอนตัม‑เอไอ (Quantum‑AI Co‑Simulation Lab), คณะวิทยาศาสตร์และเทคโนโลยี, มหาวิทยาลัยไทย (ร่วมกับพันธมิตรภาคเอกชนและห้องปฏิบัติการต่างประเทศ)
- เป้าหมายหลัก: เร่งการค้นพบวัสดุแบตเตอรี่ใหม่และลดเวลา‑to‑market
- ตัวเลขสำคัญ (ระยะเวลา): ก่อนใช้ co‑simulator: 3–6 เดือน/รอบ → หลังใช้ co‑simulator: 1–3 สัปดาห์/รอบ (ตัวอย่างลดจาก 5 เดือน → 3 สัปดาห์; ประสิทธิผลเพิ่มขึ้นประมาณ 4–8 เท่า ขึ้นอยู่กับกรณีศึกษา)
สถาปัตยกรรมของ Quantum‑AI Co‑Simulator
สถาปัตยกรรมของ Quantum‑AI Co‑Simulator
สถาปัตยกรรมของ Quantum‑AI Co‑Simulator ถูกออกแบบเป็นโมดูลแบบแยกชั้น (modular layered architecture) เพื่อรองรับการทำงานร่วมกันระหว่างตัวจำลองควอนตัม, หน่วยประมวลผลคลาสสิก และตัวแทน Reinforcement Learning (RL agent) อย่างมีประสิทธิภาพและยืดหยุ่น สำหรับการค้นคว้าวัสดุแบตเตอรี่ ระบบหลักประกอบด้วยสามชั้นเชื่อมต่อกันดังนี้: quantum simulator ↔ classical compute ↔ RL agent โดยแต่ละชั้นมีหน้าที่เฉพาะและมาตรฐานการแลกเปลี่ยนข้อมูล (API) ที่ชัดเจน ทำให้สามารถสเกลงานบนคลาวด์หรือเชื่อมต่อกับฮาร์ดแวร์ควอนตัมจริงได้ตามต้องการ
ในเชิงเทคนิค ตัวจำลองควอนตัม (quantum emulator/simulator) รองรับทั้งการจำลองแบบ state‑vector และ density‑matrix รวมถึง noise modelling เพื่อจำลองข้อจำกัดของฮาร์ดแวร์จริง โมดูลนี้ถูกออกแบบให้รองรับวงจรแบบ variational quantum circuits (เช่น VQE, QAOA) และ hybrid circuits ที่ผสมการคำนวณควอนตัมกับคลาสสิก การใช้ VQE (Variational Quantum Eigensolver) เหมาะกับการคำนวณพลังงานพื้นฐาน (ground‑state energy) ของโมเลกุลและวัสดุ ขณะที่ QAOA เหมาะกับปัญหาที่แมปเป็น optimization landscape เช่น การจัดเรียงโครงสร้างอะตอมให้ได้พลังงานต่ำสุด
ส่วนการเชื่อมต่อกับคลาวด์และฮาร์ดแวร์ถูกออกแบบเป็นชั้นบริการกลาง (orchestration & hardware connector) ที่รองรับโปรโตคอลมาตรฐาน (เช่น gRPC/REST) และ SDK ของผู้ให้บริการ (ตัวอย่างเช่น Qiskit Runtime หรือ Azure Quantum) โมดูลนี้ทำหน้าที่จัดคิวงาน สลับระหว่างตัวจำลองกับฮาร์ดแวร์จริง แจ้งสถานะงาน และรวบรวมผลลัพธ์แบบอะซิงโครนัส เพื่อให้ RL agent สามารถรับผลการทดลองกลับมาในรูปแบบที่พร้อมใช้ เช่น measurement samples, expectation values หรือ gradient estimates
โมดูล Reinforcement Learning ถูกออกแบบเป็นเฟรมเวิร์กรองรับหลายแนวทางทั้ง Deep Q‑Learning (DQN), Proximal Policy Optimization (PPO) และ model‑based RL โดยแต่ละวิธีจะถูกเลือกตามลักษณะปัญหาและข้อจำกัดด้านการประมวลผล ตัวอย่างเช่น
- DQN เหมาะสำหรับปัญหาแผนการตัดสินใจที่มี state/ action space จํากัดหรือสามารถดิสครีไทซ์ได้
- PPO ให้ความเสถียรในการอัปเดตนโยบายแบบต่อเนื่อง เหมาะกับการปรับพารามิเตอร์ของวงจรแบบต่อเนื่อง (continuous variational parameters)
- Model‑based RL ถูกนำมาใช้เมื่อมี surrogate physics model ที่สามารถพยากรณ์คุณสมบัติได้รวดเร็ว เพื่อเพิ่ม sample efficiency และลดการเรียกใช้ตัวจำลองควอนตัมจริง
การแลกเปลี่ยนข้อมูลระหว่างสองระบบ (quantum ↔ classical) อาศัยรูปแบบข้อมูลที่ชัดเจนและมาตรการทางฟิสิกส์เป็นตัวควบคุม (physics‑aware interfaces):
- Features ของวัสดุ (input state) — ข้อมูลเชิงโครงสร้าง เช่น ตำแหน่งอะตอม, lattice parameters, composition vectors, descriptors เช่น formation energy, density of states (DOS), bandgap และตัวแทนเชิงสถิติที่ถูกป้อนเข้าสู่ตัวจำลองหรือ surrogate model
- Quantum parameters — พารามิเตอร์ของ variational circuit (theta vectors), schedule ของ QAOA (p‑layers), และตัวเลือก noise model ซึ่ง RL agent ปรับเพื่อสืบค้นพื้นที่พารามิเตอร์
- Measurement outputs / properties — ผลลัพธ์จากตัวจำลองเป็น expectation values, overlap, หรือ energy estimates ที่ถูกประมวลผลเป็นคุณสมบัติเป้าหมาย (e.g., predicted capacity, diffusion barrier) เพื่อใช้เป็นส่วนหนึ่งของ reward
- Reward function — ถูกออกแบบเป็น multi‑objective reward ที่ผสมกันระหว่างเป้าหมายเชิงฟิสิกส์ (เช่น พลังงานต่ำ, ความเสถียรทางเคมี, ความสามารถในการกักเก็บไอออน) และข้อจำกัดด้านการผลิต/ความปลอดภัย เช่น ความเป็นพิษหรือความหนาแน่นของวัสดุ โดยสามารถใช้ penalty terms เพื่อบังคับ constraints ทางฟิสิกส์
การประเมินคุณสมบัติ (property evaluation) มักใช้การผสมผสานของวิธีการ: ผลตรงจากตัวจำลองควอนตัม (เช่น VQE energy) ถูกนำไปเทียบกับ surrogate ML models (เช่น GNNs หรือ Gaussian Process) เพื่อทำการคาดการณ์ที่รวดเร็วสำหรับการคัดกรองเบื้องต้น ระบบยังรองรับการคำนวณความไม่แน่นอน (uncertainty quantification) เพื่อให้ RL agent ตัดสินใจว่าจะส่งงานไปให้ตัวจำลองควอนตัมจริงหรือตัวจำลองแบบจำลองลัด (surrogate) ซึ่งช่วยลดรอบทดลองและเพิ่มประสิทธิภาพตัวอย่าง (sample efficiency)
ในเชิงปฏิบัติ สถาปัตยกรรมนี้รวมการทำงานแบบขนานและการจัดแพ็กงาน (batching) เพื่อรองรับการทดลองหลายสภาวะพร้อมกัน โดยระบบ orchestration จะทำหน้าที่จัดการทรัพยากร (เช่น allocation ของ CPU/GPU, quantum backends) และบันทึกเมตาดาต้า (experiment provenance) เพื่อความสอดคล้องและตรวจสอบย้อนหลังได้ ทั้งยังรองรับการผนวกเข้ากับระบบออโตเมชันในห้องปฏิบัติการ (lab automation) ทำให้กระบวนการค้นวัสดุจากเดิมที่ต้องใช้เวลาเป็นเดือนถูกลดลงเป็นสัปดาห์หรือหลายสัปดาห์ โดยทีมพัฒนาแจ้งผลเบื้องต้นว่าได้เห็นการปรับลดรอบทดลองได้ถึง 3–6 เท่า ในขั้นตอนการสกรีนนิ่งเริ่มต้น
โดยสรุป สถาปัตยกรรมของ Quantum‑AI Co‑Simulator เป็นการผสานกันระหว่างวงจรควอนตัมเชิงแปรผัน (VQE/QAOA), ตัวจำลองที่รองรับ noise และฮาร์ดแวร์จริง, โมดูล RL ที่ยืดหยุ่น และกลไกการแลกเปลี่ยนข้อมูลเชิงฟิสิกส์ที่เข้มงวด ทำให้ระบบสามารถค้นหาและปรับแต่งวัสดุแบตเตอรี่ได้รวดเร็ว มีประสิทธิภาพ และสอดคล้องกับข้อจำกัดทางวิศวกรรมและฟิสิกส์ของวัสดุจริง
การรวม Reinforcement Learning กับตัวจำลองควอนตัม
การออกแบบ Reinforcement Learning สำหรับสำรวจพื้นที่วัสดุ
การนำ Reinforcement Learning (RL) มาประยุกต์กับการค้นคว้าวัสดุแบตเตอรี่อยู่บนพื้นฐานของการนิยาม state และ action ให้สอดคล้องกับลักษณะของปัญหาในเชิงวัสดุศาสตร์และกระบวนการสังเคราะห์ ตัวอย่างรูปแบบที่ใช้บ่อยคือการแทนวัสดุเป็นเวกเตอร์คุณลักษณะ (feature vector) หรือกราฟของอะตอม/โครงสร้างผลึก ซึ่งรวมถึงข้อมูลเช่น สัดส่วนธาตุ (stoichiometry), จุดตำแหน่งในโครงสร้างผลึก, พารามิเตอร์นาโนสเกล (เช่น ขนาดอนุภาค), และคุณสมบัติที่ได้จากตัวจำลองควอนตัม (เช่นพลังงานผูกพัน, ช่องว่างพลังงาน) ส่วน state ยังสามารถรวมบริบทของการสังเคราะห์ เช่น อุณหภูมิ, เวลาเผา, ตัวทำละลาย และสภาพแวดล้อม (atmosphere)
Action space มักเป็น mixed ระหว่าง discrete และ continuous เช่น การเลือกองค์ประกอบหรือโดปปิ้งเป็นค่าจำกัด (discrete) กับการตั้งค่าพารามิเตอร์สังเคราะห์เช่นอุณหภูมิหรือความเข้มข้นที่เป็นค่าต่อเนื่อง ในเชิงธุรกิจและการปฏิบัติจริง การออกแบบ action ต้องคำนึงถึงความเป็นไปได้ในการทดลองจริง (feasibility) โดยเพิ่มข้อจำกัดหรือฟังก์ชันโทษ (penalty) สำหรับการกระทำที่ไม่สามารถผลิตได้หรือมีความเสี่ยงสูง
การนิยาม Reward: วัดสมดุลระหว่างความจุ ความเสถียร และต้นทุน
Reward function ต้องสะท้อนเป้าหมายเชิงพาณิชย์ซึ่งมักเป็นการค trade‑off ระหว่างความจุ (energy density), ความเสถียรเมื่อชาร์จ/คายประจุซ้ำ (cycle life, thermal stability) และต้นทุนการผลิต ตัวอย่างการนิยามแบบง่ายเป็นการใช้การถ่วงน้ำหนักแบบเชิงเส้น:
- R = w1 * normalized_capacity + w2 * normalized_stability - w3 * normalized_cost - Penalty_infeasible
โดยที่ w1–w3 เป็นน้ำหนักที่กำหนดตามนโยบายธุรกิจ (เช่น ให้ความสำคัญกับต้นทุนมากขึ้นถ้าตลาดเน้นราคาต่ำ) อีกทางเลือกหนึ่งคือการใช้วิธี multi‑objective RL เพื่อหาเส้นขอบ Pareto ของวัสดุที่เหมาะสม ซึ่งช่วยให้ผู้บริหารและนักวิจัยตัดสินใจเลือกจุดสมดุลที่ต้องการได้
นอกจากนี้ควรออกแบบ reward shaping เพื่อเร่งกระบวนการเรียนรู้ ตัวอย่างเช่นให้ reward ระยะสั้นสำหรับการปรับปรุงคุณสมบัติสำคัญ (เช่น เพิ่มความหนาแน่นพลังงาน 5%) และ reward ระยะยาวสำหรับความเสถียรที่มั่นคงหลังหลายรอบการคายประจุ ทั้งนี้ควบคุมให้ไม่เกิดการบิดเบือนเป้าหมาย (reward hacking) ด้วยการเพิ่มข้อจำกัดด้านความปลอดภัยหรือคุณสมบัติที่ห้ามลดลง
กลยุทธ์การฝึก: simulation‑in‑the‑loop, transfer learning และ curriculum learning
เพื่อให้ RL สำรวจพื้นที่วัสดุได้รวดเร็วและเชิงประหยัด นิยมใช้แนวทาง simulation‑in‑the‑loop โดยให้ตัวจำลองควอนตัม (เช่น DFT) ทำการประเมินคุณสมบัติของตัวอย่างที่นโยบายเลือก แต่เนื่องจากการจำลองระดับสูงมีค่าใช้จ่ายสูง ระบบมักผสานกับเทคนิคอื่น ๆ ดังนี้:
- Surrogate models (เช่น Graph Neural Networks, Gaussian Processes): ทำนายผลลัพธ์จากตัวจำลองความแม่นยำสูงด้วยต้นทุนคำนวณต่ำ และใช้ active learning เลือกตัวอย่างที่จะส่งไปคำนวณด้วยตัวจำลองความแม่นยำสูงเพียงบางส่วน
- Transfer learning: นำโมเดลที่ฝึกจากเคสหรือวัสดุชนิดใกล้เคียงมาปรับใช้ เพื่อลดจำนวนตัวอย่างที่ต้องรันจำลองความแม่นยำสูง (ตัวอย่างเช่น pretrain บนชุดข้อมูล DFT ขนาดใหญ่แล้ว fine‑tune สำหรับระบบแบตเตอรี่เฉพาะทาง)
- Curriculum learning: เริ่มจากปัญหาที่เป็น coarse (เช่น พื้นที่พารามิเตอร์จำกัดหรือฟีเจอร์รวม) แล้วค่อยเพิ่มความละเอียดหรือขยาย action space เมื่อโมเดลมีความสามารถมากขึ้น ช่วยให้การค้นหาไม่ติดกับ local optima
Pseudo‑workflow การฝึก RL ร่วมกับตัวจำลองควอนตัม (ตัวอย่าง)
- 1) Initialization: สร้าง action/state space และกำหนด reward function พร้อมน้ำหนักเชิงพาณิชย์ (w1–w3)
- 2) Pretraining surrogate: ฝึก surrogate model (GNN/GP) บนข้อมูลจำลองเบื้องต้น (เช่น 1,000–10,000 ตัวอย่าง DFT) เพื่อให้ได้การคาดการณ์เบื้องต้น
- 3) Policy rollout (simulation‑in‑the‑loop): ให้นโยบาย RL สุ่ม/เลือก action เพื่อสร้างตัวอย่างใหม่ ส่งผลให้ได้ state ใหม่ และประเมิน reward โดยใช้ surrogate model ก่อน
- 4) Active selection: เลือกตัวอย่างที่ surrogate ไม่มีความมั่นใจหรือมีความเป็นไปได้ให้ reward สูง ส่งไปประเมินด้วยตัวจำลองความแม่นยำสูง (DFT) เพื่ออัปเดตทั้ง surrogate และเก็บใน replay buffer
- 5) Update policy: ใช้ข้อมูลจาก replay buffer (รวมประสบการณ์จาก surrogate และ DFT) เพื่ออัปเดตนโยบายด้วยอัลกอริทึม RL ที่เหมาะสม (เช่น PPO, SAC หรือ off‑policy methods สำหรับความต้องการ sample efficiency)
- 6) Periodic transfer/fine‑tune: เมื่อเปลี่ยนกลุ่มวัสดุหรือเงื่อนไขสังเคราะห์ ให้ใช้ transfer learning จากโมเดลที่ได้มา ลดเวลาการ converged
- 7) Stopping / Candidate selection: หยุดเมื่อถึงงบประมาณหรือเมื่อนโยบายสร้างรายชื่อวัสดุที่เป็น Pareto‑optimal เพียงพอสำหรับการทดสอบในห้องปฏิบัติการ
เทคนิคลดค่าใช้จ่ายการคำนวณและเพิ่มประสิทธิภาพการเรียนรู้
เพื่อให้โครงการมีผลตอบแทนเชิงธุรกิจ การลดจำนวนการรันจำลองความแม่นยำสูงเป็นหัวใจสำคัญ เทคนิคที่ใช้อย่างมีประสิทธิภาพ ได้แก่:
- Surrogate / multi‑fidelity modeling: ใช้โมเดลหลายระดับความแม่นยำ (low, medium, high) และสลับใช้ตามความจำเป็น — การประเมินเบื้องต้นด้วยโมเดลความแม่นยำต่ำสามารถลดการเรียกใช้งาน DFT ลงตัวอย่างเช่น 70–95% ในกรณีศึกษาเชิงประเมิน
- Experience replay และ prioritized replay: เก็บ transitions ทั้งหมดใน replay buffer และให้ sampling เต็มประสิทธิภาพโดยให้ความสำคัญกับ transitions ที่มีค่า TD‑error สูงหรือมี reward สูง ช่วยให้ convergence เร็วขึ้นและลดความจำเป็นในการสร้างตัวอย่างใหม่
- Active learning / uncertainty sampling: ใช้การวัดความไม่แน่นอนของ surrogate เพื่อเลือกตัวอย่างที่จะส่งไปคำนวณด้วยตัวจำลองความแม่นยำสูง ซึ่งลดการใช้ทรัพยากรโดยมุ่งที่จุดข้อมูลมีประโยชน์สูงสุด
- Parallelization และ batch evaluation: รันตัวอย่างที่ผ่านการคัดเลือกเป็นชุด (batch) เพื่อใช้เวลาคลัสเตอร์ HPC อย่างมีประสิทธิภาพ และใช้ caching ผลลัพธ์ที่เคยคำนวณแล้วเพื่อไม่ต้องคำนวณซ้ำ
- Offline RL / warm‑start: ใช้ข้อมูลทดลองที่ผ่านมา (historical experiments) ในการอบรมเบื้องต้น ซึ่งช่วยลดจำนวนการทดลองเชิงคำนวณที่ต้องทำใหม่
โดยสรุป การรวม RL เข้ากับตัวจำลองควอนตัมต้องการการออกแบบ state/action และ reward ที่สะท้อนเป้าหมายเชิงธุรกิจ ควบคู่กับกลยุทธ์ฝึกที่ผสมผสาน surrogate models, transfer learning และเทคนิค replay/active learning เพื่อให้ได้ผลลัพธ์ที่มีประสิทธิภาพและคุ้มค่าทางเศรษฐกิจ ตัวอย่างเชิงประเมินแสดงว่าแนวทางดังกล่าวสามารถลดจำนวนการรันจำลองความแม่นยำสูงลงอย่างมีนัยสำคัญ ทำให้ระยะเวลาจากการค้นหาเชิงทดลองลดจากระดับเดือนเหลือสัปดาห์ได้ภายใต้งบประมาณและทรัพยากรที่จำกัด
กรณีศึกษา: ค้นวัสดุแบตเตอรี่ — ผลลัพธ์และสถิติ
กรณีศึกษา: ค้นวัสดุแบตเตอรี่ — ผลลัพธ์และสถิติ
ทีมวิจัยจากมหาวิทยาลัยได้นำ Quantum‑AI Co‑Simulator ไปใช้ในการคัดกรองและหาวัสดุแคโทดสำหรับแบตเตอรี่ลิเธียมเชิงทดลองเป็นกรณีศึกษาเชิงสาธิต ซึ่งออกแบบให้ผสานตัวจำลองควอนตัมสำหรับคำนวณพลังงานและสถานะอิเล็กทรอนิกส์กับตัวแทน Reinforcement Learning (RL) ที่เรียนรู้เชิงนโยบายการสำรวจพื้นที่วัสดุอย่างมีประสิทธิภาพ ผลการทดลองแสดงให้เห็นการเปลี่ยนแปลงทั้งด้านปริมาณตัวอย่างที่ประเมิน, อัตราการค้นพบวัสดุผ่านเกณฑ์ (hit‑rate), และเวลาที่ใช้จนได้ตัวนำทาง (time‑to‑lead) เมื่อเปรียบเทียบกับกระบวนการดั้งเดิม
รายละเอียดเชิงตัวเลขจากการทดสอบ (ตัวอย่างเชิงสาธิต):
- ขนาดกลุ่มเริ่มต้นของ candidate materials: 4,800 สูตร/โครงสร้างเชิงคอมบิเนชัน
- จำนวนการประเมินเชิงเสมือน (virtual evaluations): ≈ 48,000 ครั้ง (เฉลี่ย 10 ข้อเสนอ/episode จาก RL × 4,800 ปรับแต่ง)
- จำนวน episodes ของ RL: 1,200 episodes โดยแบ่งรันแบบขนานหลายงาน
- ระยะเวลาเฉลี่ยต่อรอบ (wall‑clock per episode): ≈ 45 นาที (รวม subroutines ควอนตัมสั้น ๆ + surrogate model)
- เวลาในการรันรวม (แม้ไม่รวมการขนาน): ≈ 900 ชั่วโมงของการคำนวณ แต่ด้วยการขนานผลลัพธ์ได้ภายใน 1–3 สัปดาห์
ผลลัพธ์เชิงเปรียบเทียบกับกระบวนการดั้งเดิม (ตัวเลขเฉพาะจากการทดลอง):
- Accuracy (ความแม่นยำของการคาดการณ์ที่ยืนยันด้วยการทดลองในห้องปฏิบัติการ): Co‑Simulator 82% vs แบบคำนวณเชิงอนุกรมดั้งเดิม 56% (+26 จุดร้อยละ)
- Hit‑rate (อัตราส่วนของ candidate ที่ผ่านเกณฑ์เชิงประสิทธิภาพและยืนยันได้): Co‑Simulator 18% (จากการทดสอบปฐมภูมิ) vs ดั้งเดิม 4% — เพิ่มขึ้น ~4.5×
- Time‑to‑lead (ระยะเวลาจากเริ่มคัดกรองถึงได้วัสดุนำร่องที่ยืนยัน): แบบดั้งเดิม 8–12 สัปดาห์ → Co‑Simulator 1–3 สัปดาห์ (เฉลี่ย speedup ประมาณ 4–8×)
- จำนวน leads ที่ยืนยันได้ภายในรอบทดลอง: Co‑Simulator ยืนยัน leads 22 ชุดจากชุดตัวอย่าง 4,800 เมื่อเทียบกับดั้งเดิมที่มักยืนยัน 3–5 ชุดในช่วงเวลาเทียบเคียง
การประเมินผลกระทบเชิงธุรกิจและเศรษฐศาสตร์ R&D:
- ลดต้นทุน R&D ต่อ lead: ทีมรายงานการลดต้นทุนโดยประมาณ 40–60% เมื่อคำนวณจากค่าใช้จ่ายการทดลองทางห้องปฏิบัติการที่ลดลงและจำนวนการทดสอบทางกายภาพที่ต้องทำจริง
- เร่ง commercialization: การลด time‑to‑lead จากหลายเดือนเหลือสัปดาห์เดียวช่วยให้ขั้นตอนการพัฒนาโพรโตไทป์และการทดสอบภาคสนามเริ่มเร็วขึ้น ส่งผลให้เวลาเข้าสู่ตลาดลดลงเป็นเดือน — มีผลต่อกระแสเงินสดและโอกาสทางการแข่งขัน
- ความเสี่ยงและการตัดสินใจเชิงกลยุทธ์: อัตรา hit‑rate และ accuracy ที่สูงขึ้นทำให้บริษัทสามารถลงทุนเฉพาะกับ candidate ที่มีความน่าจะเป็นสูงต่อความสำเร็จ ลดความเสี่ยงของการพัฒนาไปกับวัสดุที่ล้มเหลวในระยะทดลอง
สรุปเชิงตัวเลขที่สำคัญ (เปรียบเทียบรวบรัด):
- Candidate evaluated (virtual): 48,000 vs กระบวนการจำกัดเชิงดั้งเดิม ≈ หลายร้อย
- Episodes (RL): 1,200; Avg time/episode: 45 นาที
- Accuracy: 82% (Co‑Simulator) vs 56% (ดั้งเดิม)
- Hit‑rate: 18% vs 4% (≈4.5×)
- Time‑to‑lead: 1–3 สัปดาห์ vs 8–12 สัปดาห์ (speedup 4–8×)
- Estimated R&D cost reduction per lead: 40–60%
ผลการทดลองชี้ให้เห็นว่า Quantum‑AI Co‑Simulator ไม่เพียงลดเวลาที่ใช้ในการค้นพบวัสดุใหม่อย่างมีนัยสำคัญเท่านั้น แต่ยังเพิ่มคุณภาพของตัวเลือกที่ถูกนำไปทดลองจริง ส่งผลให้ต้นทุนต่อความสำเร็จลดลงและความสามารถในการนำสินค้าออกสู่ตลาดเร็วขึ้น — ปัจจัยเหล่านี้มีความสำคัญต่อการตัดสินใจลงทุนเชิงพาณิชย์และการวางแผนเชิงกลยุทธ์สำหรับอุตสาหกรรมพลังงานและวัสดุศาสตร์
ความท้าทาย ข้อจำกัด และการตรวจสอบผล (Validation & Reproducibility)
ความท้าทายเชิงเทคนิคและข้อจำกัด
การผสานตัวจำลองควอนตัมกับ Reinforcement Learning (Quantum‑AI Co‑Simulator) เพื่อการค้นคว้าวัสดุแบตเตอรี่ใหม่เผชิญกับข้อจำกัดเชิงเทคนิคหลายประการที่ต้องพิจารณาอย่างรอบคอบ ก่อนอื่นคือผลกระทบของ noise ในยุค NISQ (Noisy Intermediate‑Scale Quantum) ซึ่งมีอัตราความผิดพลาดของเกต (gate error rates) ในช่วงโดยประมาณ 10^-3 ถึง 10^-2 สำหรับเกตแบบสองคิวบิตในฮาร์ดแวร์เชิงพาณิชย์บางราย ผลลัพธ์ที่ได้รับจากวงจรควอนตัมบนฮาร์ดแวร์จริงจึงมีความไม่แน่นอนและความคลาดเคลื่อน (fidelity loss) เมื่อเทียบกับตัวจำลองที่สมมติสภาพแวดล้อมปราศจาก noise การไล่ค่าพารามิเตอร์ที่ขึ้นกับเฟสและ decoherence (ซึ่งมักมีเวลา coherence อยู่ในระดับไมโครวินาทีถึงมิลลิวินาที) ทำให้การแปลผลด้านพลังงานหรือสเปกตรัมอาจคลาดเคลื่อนได้อย่างมีนัยสำคัญ
ประการถัดไปคือข้อจำกัดด้านการสเกลของตัวจำลอง: การจำลองระบบควอนตัมแบบ exact บนเครื่องคลาสสิกมีความซับซ้อนเติบโตแบบเอ็กซ์โพเนนเชียล เมื่อขนาดของระบบเพิ่มขึ้น การจำลองแบบเต็มจะถูกจำกัดอยู่ที่ประมาณ 30–40 qubits บนฮาร์ดแวร์คลาสสิกระดับสูง ทำให้การทดสอบสมรรถนะสำหรับระบบวัสดุในระดับที่ใช้งานจริง (เช่น โมเลกุลหรือโครงสร้างผลึกที่ซับซ้อน) เป็นไปได้ยาก นอกจากนี้ตัวจำลองทางเคมี เช่น DFT (Density Functional Theory) ที่เป็น baseline มักใช้เวลาคำนวณจากหลายสิบนาทีจนถึงหลายชั่วโมงต่อโครงสร้างบนคลัสเตอร์ HPC ซึ่งเมื่อรวมกับการฝึก RL ที่ต้องการตัวอย่างจำนวนมากแล้ว จะเพิ่มภาระค่าใช้จ่ายคอมพิวต์อย่างมีนัยสำคัญ (ประมาณการค่าใช้จ่ายคลาวด์และโหนด HPC อาจอยู่ในระดับหลายร้อยถึงหลายพันดอลลาร์ต่อการศึกษาเชิงลึก ขึ้นกับขนาดงาน)
ในด้านโมเดล RL เองมีความไม่แน่นอน เช่น ความผันผวนของผลลัพธ์ระหว่างการรันซ้ำ (variance of policy), ปัญหา exploration‑exploitation ที่ทำให้โมเดลอาจติดอยู่ในโซลูชันท้องถิ่น และค่าใช้จ่ายเชิงตัวอย่าง (sample inefficiency) ซึ่งหมายความว่าแม้ระบบ co‑simulator จะลดรอบทดลองจากเดือนเป็นสัปดาห์ แต่ผลลัพธ์ที่ได้อาจมีความแปรปรวนสูงเมื่อเปลี่ยนสภาวะเริ่มต้นหรือ seed ของตัวสุ่ม การตีความความแตกต่างระหว่างผลในตัวจำลองและการทดลองจริง (simulation‑to‑experiment discrepancy) จึงเป็นประเด็นสำคัญที่ต้องจัดการ
มาตรฐานการประเมินและการตรวจสอบผล (Validation & Reproducibility)
เพื่อให้ผลวิจัยมีความน่าเชื่อถือ จำเป็นต้องยึดมาตรฐานการประเมินที่ชัดเจนและโปร่งใส ได้แก่การใช้ benchmark datasets และชุดทดสอบอ้างอิงสำหรับวัสดุ เช่น Materials Project, OQMD, NOMAD หรือชุดข้อมูลเฉพาะด้านแบตเตอรี่ ซึ่งควรระบุเวอร์ชันและลิขสิทธิ์อย่างชัดเจน ตัวชี้วัดที่ใช้ประเมินต้องโปร่งใสและเกี่ยวข้องกับการใช้งานจริง เช่น MAE (eV/atom) สำหรับพลังงานการก่อตัว, RMSE, R² และตัวชี้วัดแบบ ranking เช่น precision@k หรือ recall@k สำหรับการคัดกรองตัวอย่างนำเข้าไปทดลองจริง
ด้านการตรวจสอบแบบสถิติ ควรใช้เทคนิคเช่น cross‑validation และ holdout test sets ที่แยกจากข้อมูลที่ใช้ฝึกอย่างเคร่งครัด รวมทั้งรายงานความแปรปรวนของผลลัพธ์จากการรันหลายครั้ง (e.g., mean ± std ของ metric สำคัญ) ตัวอย่างเช่น การระบุว่าโมเดลพยากรณ์ค่าพลังงานมี MAE = 0.08 ± 0.02 eV/atom ให้ข้อมูลเชิงวิทยาศาสตร์ที่ชัดเจนกว่าการรายงานค่าเดี่ยวเพียงค่าเดียว นอกจากนี้การใช้มาตรการ calibration และการรายงานความไม่แน่นอน (uncertainty intervals) เป็นสิ่งจำเป็นเมื่อผลถูกนำไปกำหนดลำดับความสำคัญของการทดลองจริง
แนวทางแก้ไขและแนวปฏิบัติสำหรับการทำให้ผลเป็นที่เชื่อถือได้
แนวทางปฏิบัติที่ควรนำมาใช้ประกอบด้วยการทดสอบแบบ hybrid‑hardware และ multi‑platform validation: ให้รันวงจรหรือชุดงานเดียวกันทั้งบนตัวจำลองแบบ ideal, ตัวจำลองที่รวมโมเดล noise และฮาร์ดแวร์ควอนตัมจริงเพื่อตรวจสอบความแตกต่าง (quantify simulation‑to‑hardware discrepancy) โดยวัดด้วยเมตริกเช่น state fidelity, trace distance หรือการเปรียบเทียบผลเชิงปริมาณของสมบัติวัสดุ เมื่อพบความคลาดเคลื่อนควรปรับโมเดล noise model หรือใช้เทคนิค error mitigation ก่อนนำผลไปใช้ตัดสินใจเชิงทดลอง
สำหรับการประเมินความไม่แน่นอนใน RL และโมเดลที่เกี่ยวข้อง แนะนำให้ใช้วิธีการหลายรูปแบบ เช่น ensemble models, Bayesian inference, MC‑dropout และ bootstrapping เพื่อนำเสนอค่าคาดการณ์พร้อมช่วงความเชื่อมั่น นอกจากนี้การพัฒนาพipelines ที่ reproducible ควรรวมถึงการล็อกเวอร์ชันของซอฟต์แวร์และไลบรารี การใช้ containerization (เช่น Docker/Singularity), workflow managers (เช่น Nextflow, Airflow) การบันทึก seed และเมตาดาต้าอย่างละเอียด พร้อมระบบ logging และ provenance ของข้อมูล เพื่อให้ผู้อื่นสามารถรันซ้ำและตรวจสอบผลได้
สุดท้ายองค์กรที่ต้องการผลลัพธ์ระดับอุตสาหกรรมควรยึดหลักการเปิดเผยข้อมูลเพื่อความโปร่งใส: เปิดเผย code, trained models, dataset splits และสคริปต์การประเมิน ภายใต้ไลเซนส์ที่เหมาะสมบนแพลตฟอร์มสาธารณะ เช่น GitHub พร้อมตัวอย่างการเรียกใช้งานและเครื่องมือสำหรับ benchmark แบบอัตโนมัติ การตั้งมาตรฐานการรายงาน (reporting checklist) ที่รวมทั้งค่า metric หลัก ค่า uncertainty, ข้อมูลการตั้งค่า experiment และค่าใช้จ่ายเชิงคำนวณ จะช่วยให้ผลงานในแวดวง Quantum‑AI สำหรับวัสดุแบตเตอรี่มีความน่าเชื่อถือและสามารถนำไปใช้งานเชิงพาณิชย์ได้อย่างปลอดภัย
ผลกระทบเชิงนโยบายและการพาณิชย์ (Collaboration & Commercialization)
ผลกระทบเชิงนโยบายและการพาณิชย์ (Collaboration & Commercialization)
การเปิดตัว Quantum‑AI Co‑Simulator โดยมหาวิทยาลัยไทยถือเป็นจุดเปลี่ยนที่สำคัญสำหรับระบบนิเวศวิจัยและอุตสาหกรรมแบตเตอรี่ในประเทศ เพราะเทคโนโลยีดังกล่าวช่วยให้การค้นคว้าวัสดุใหม่ลดรอบการทดลองจากระดับเดือนลงสู่ระดับสัปดาห์ ซึ่งมีความหมายเชิงพาณิชย์โดยตรง: ลดเวลา‑to‑market สำหรับผลิตภัณฑ์แบตเตอรี่รุ่นใหม่ ทำให้ผู้ผลิตยานยนต์และซัพพลายเออร์สามารถตอบสนองเทรนด์รถไฟฟ้า (EV) ได้เร็วขึ้นและแข่งขันได้มากขึ้น นอกจากนี้การจำลองและการเรียนรู้ด้วยเครื่องช่วยลดจำนวนการทดลองทางกายภาพที่มีต้นทุนสูง ส่งผลให้ ค่าใช้จ่าย R&D ต่อโครงการอาจลดลงอย่างมีนัยสำคัญ (ตัวอย่างการประเมินเบื้องต้นจากทีมพัฒนาและพันธมิตรอุตสาหกรรมชี้ว่าการประหยัดต้นทุน R&D สามารถอยู่ในช่วงหลักสิบเปอร์เซ็นต์ถึงมากกว่า 30% ในโครงการต้นแบบ)
ในมิติของโอกาสเชิงธุรกิจ สตาร์ทอัพและบริษัทเทคโนโลยีสามารถสร้างบริการใหม่ได้หลายรูปแบบ ได้แก่ Simulation‑as‑a‑Service สำหรับวัสดุและเซลล์แบตเตอรี่, แพลตฟอร์มค้นหาสูตรวัสดุโดยใช้ RL (Reinforcement Learning), และการให้คำปรึกษาด้านการเร่งการตรวจสอบคุณสมบัติวัสดุทางไฟฟ้าและความเสถียรเชิงเคมี สำหรับบริษัทยานยนต์ เทคโนโลยีนี้หมายถึงการย่นระยะเวลาในการรับรองและทำซ้ำชุดข้อมูลประสิทธิภาพที่จำเป็นก่อนการผลิตจำนวนมาก ทำให้สามารถนำแบตเตอรี่แบบใหม่เข้ารถรุ่นใหม่ได้เร็วขึ้นและลดความเสี่ยงของการจัดเก็บสต็อกชนิดเดียวที่ไม่เหมาะสม
การขยายผลเชิงพาณิชย์จำเป็นต้องอาศัยความร่วมมือระหว่างภาครัฐและเอกชนอย่างเป็นระบบ ดังนี้: ภาครัฐสามารถจัดสรร แหล่งทุน ผ่านเงินสนับสนุนแบบจับคู่ (matching grants) โครงการร่วมวิจัยเชิงประยุกต์ และสิทธิประโยชน์ทางภาษีสำหรับการลงทุนด้านคอมพิวต์กำลังสูงและศูนย์ทดสอบ ส่วนภาคเอกชนควรลงทุนในโครงสร้างพื้นฐานการผลิตต้นแบบและร่วมในการวางมาตรฐานการทดลองเพื่อให้ผลลัพธ์จากตัวจำลองมีความสอดคล้องต่อการผลิตจริง ตัวอย่างโมเดลความร่วมมือที่ได้ผลดีในต่างประเทศคือการตั้ง ศูนย์ทดสอบร่วม (public‑private testbeds) ซึ่งรวมการเข้าถึงฮาร์ดแวร์การผลิตระดับ pilot line และแล็บตรวจวัดที่มีมาตรฐานสากล
เพื่อให้การนำไปใช้เชิงพาณิชย์เป็นไปได้อย่างยั่งยืน จำเป็นต้องออกกรอบนโยบายที่ชัดเจนและครอบคลุม ดังต่อไปนี้
- การสนับสนุนคลังข้อมูล (data repositories): ส่งเสริมการสร้างฐานข้อมูลวัสดุแบตเตอรี่แบบเปิดบางส่วน (open or federated datasets) ที่มีมาตรฐานเมตาดาต้า เพื่อให้โมเดล AI และชุมชนนักวิจัยสามารถเทรนและตรวจสอบผลได้อย่างโปร่งใส
- การเปิดเผยผลการทดลอง: กำหนดมาตรการจูงใจสำหรับการเผยแพร่ผลการทดลองที่ไม่เป็นความลับทางการค้า เช่น เครดิตทางภาษีหรือแต้มพัฒนางบประมาณ เพื่อเพิ่มความเชื่อมั่นและลดความซ้ำซ้อนในการทดลอง
- มาตรฐานความปลอดภัยและการรับรอง: พัฒนามาตรฐานการทดสอบคุณสมบัติและความปลอดภัยของวัสดุที่สอดคล้องกับการใช้ผลจากตัวจำลอง (simulation‑based validation) รวมถึงกรอบการยอมรับข้อมูลจำลองเป็นส่วนหนึ่งของการรับรองผลิตภัณฑ์
- นโยบายการถ่ายทอดเทคโนโลยีและทรัพย์สินทางปัญญา: สร้างแนวทางการแบ่งปันผลประโยชน์ (benefit‑sharing) ระหว่างมหาวิทยาลัยและภาคเอกชน เช่น สัญญาไลเซนส์แบบมีชัดเจนและโมเดลสัดส่วนรายได้จากสปินออฟ
- พื้นที่นวัตกรรมและ regulatory sandbox: จัดตั้งโซนทดสอบเชิงนวัตกรรมที่ลดข้อจำกัดด้านกฎระเบียบชั่วคราว เพื่อทดลองกระบวนการผลิตและการประเมินผลในสเกลต้นแบบโดยมีการกำกับดูแลที่เหมาะสม
สรุปได้ว่า การผลักดัน Quantum‑AI Co‑Simulator สู่การใช้งานเชิงพาณิชย์ต้องอาศัยทั้งแรงจูงใจจากนโยบายภาครัฐ การลงทุนของภาคเอกชน และกรอบการบริหารจัดการข้อมูลและทรัพย์สินทางปัญญาที่สมดุล เมื่อองค์ประกอบเหล่านี้ผนึกกัน ประเทศไทยจะได้ประโยชน์เชิงเศรษฐกิจทั้งในด้านการยกระดับห่วงโซ่อุปทานแบตเตอรี่ภายในประเทศ การสร้างสตาร์ทอัพที่มีคุณภาพ และการลดเวลา‑to‑market ซึ่งเป็นปัจจัยสำคัญในการแข่งขันของอุตสาหกรรมยานยนต์ไฟฟ้าในภูมิภาค
อนาคตและแนวทางวิจัยต่อไป
อนาคตและแนวทางวิจัยต่อไป
การพัฒนา Quantum‑AI Co‑Simulator ที่มหาวิทยาลัยไทยเปิดตัวเป็นก้าวสำคัญในการยกระดับการค้นคว้าวัสดุแบตเตอรี่ แต่ในระยะถัดไปจำเป็นต้องมีการบูรณาการระหว่างตัวจำลองกับฮาร์ดแวร์ควอนตัมจริง (quantum hardware) เพื่อยืนยันผลเชิงทดลองและขยายความสามารถเชิงคำนวณให้เหนือกว่าเครื่องจำลองเพียวๆ ในเชิงปฏิบัติ การย้ายจาก simulator ไปสู่ฮาร์ดแวร์ระดับใหญ่ขึ้นคาดว่าจะเผชิญความท้าทายด้าน noise, decoherence และการเชื่อมต่อระหว่างคิวบิต แต่ด้วยกลยุทธ์ hybrid experiments ที่รวมการคำนวณเชิงคลาสสิกและเชิงควอนตัมเข้าด้วยกัน (quantum‑classical hybrid) จะช่วยให้สามารถใช้พลังของ NISQ (Noisy Intermediate‑Scale Quantum) devices ได้ทันท่วงที ขณะเดียวกันเทคนิคการแก้ไขความผิดพลาดเชิงสถิติ (error mitigation) และการออกแบบวงจรที่ทนต่อความผิดพลาดจะเป็นหัวใจสำคัญก่อนการย้ายสู่ฮาร์ดแวร์ขนาดใหญ่จริง
ขอบข่ายการประยุกต์ใช้งานควรขยายจากวัสดุแบตเตอรี่ไปสู่สาขาอื่นที่มีศักยภาพสูง ทั้ง catalysis (เช่น ตัวเร่งปฏิกิริยาเพื่อการลด CO2 หรือการสังเคราะห์เคมี), semiconductors (การออกแบบวัสดุกึ่งตัวนำที่มีคุณสมบัติพิเศษสำหรับอุปกรณ์อิเล็กทรอนิกส์และ quantum devices), ตัวเก็บพลังงานรูปแบบใหม่ (เช่น supercapacitors, solid‑state electrolytes) และโครงสร้างแคตาไลติกสำหรับไฮโดรเจน การทดลองนำร่องหลายกรณีศึกษาแสดงให้เห็นว่าแนวทาง RL (reinforcement learning) ผสานกับตัวจำลองควอนตัมสามารถลดรอบการทดลองได้อย่างมีนัยสำคัญ — ตัวอย่างเช่นการลดจากรอบเดือนหลายรอบมาเป็นระดับสัปดาห์ ทำให้สามารถสำรวจพื้นที่พารามิเตอร์และกลไกปฏิกิริยาได้เร็วขึ้นถึง 3–4 เท่า ซึ่งจะเป็นประโยชน์อย่างยิ่งเมื่อนำไปขยายผลสู่สาขาที่มีความซับซ้อนสูงเช่น catalysis และ semiconductor design
เพื่อให้เกิดการนำไปใช้งานอย่างกว้างขวาง จำเป็นต้องพัฒนามาตรฐานสำหรับ hybrid quantum‑AI workflows ได้แก่ โปรโตคอลการแลกเปลี่ยนข้อมูล (data formats, metadata), เกณฑ์วัดประสิทธิภาพ (benchmarks) สำหรับงาน materials discovery, API ที่รองรับการรันบนทั้งตัวจำลองและฮาร์ดแวร์จริง และแนวทางการตรวจสอบซ้ำ (reproducibility) ในสภาพแวดล้อมผสมระหว่างคลาวด์และเครื่องท้องถิ่น การมีมาตรฐานเหล่านี้จะช่วยให้ทีมวิจัยจากภาคสถาบันและภาคอุตสาหกรรมสามารถแชร์ชุดข้อมูล ตัวแบบ และผลลัพธ์ได้อย่างปลอดภัยและมีประสิทธิผล นอกจากนี้การจัดทำฐานข้อมูลวัสดุที่มีข้อมูลเชิงควอนตัม (quantum‑annotated datasets) แบบเปิดจะเร่งการพัฒนาโมเดล AI/ML และเป็นรากฐานของ ecosystem ที่สามารถเติบโตได้อย่างต่อเนื่อง
สุดท้าย การสร้างความพร้อมทั้งด้านบุคลากร โครงสร้างพื้นฐาน และนโยบายเป็นปัจจัยสำคัญที่ต้องดำเนินควบคู่ไปกับงานวิจัย เพื่อให้การเปลี่ยนผ่านจากการทดลองในห้องปฏิบัติการสู่การใช้งานเชิงพาณิชย์เป็นไปอย่างราบรื่นและยั่งยืน
- การลงทุนด้านบุคลากรและทักษะ: ให้ความสำคัญกับการฝึกอบรมข้ามสาขา (cross‑disciplinary training) เช่น ควอนตัมคอมพิวติ้ง, machine learning, และวัสดุศาสตร์ โดยแนะนำให้สถาบันและภาคเอกชนจัดโปรแกรมฝึกอบรมระยะสั้นและหลักสูตรระดับสูงเพื่ออัพสกิลนักวิจัยและวิศวกร การจัดทุนสนับสนุนการแลกเปลี่ยนบุคลากรกับศูนย์วิจัยต่างประเทศและการใช้แพลตฟอร์มคลาวด์ควอนตัมสาธารณะ (เช่น IBM Quantum, IonQ) จะช่วยลดอุปสรรคด้านการเข้าถึงฮาร์ดแวร์
- การสร้างโครงสร้างพื้นฐานแบบผสม (hybrid infrastructure): พัฒนาศูนย์ทดสอบที่เชื่อมต่อระหว่างตัวจำลองขนาดใหญ่กับการเข้าถึงฮาร์ดแวร์ควอนตัมผ่านคลาวด์และ onsite testbeds เพื่อรองรับการทดลอง hybrid experiments และ digital twins ของวัสดุ ปรับปรุงการเชื่อมต่อเครือข่าย ความปลอดภัยของข้อมูล และแพลตฟอร์มคำนวณเชิงคลาสสิกที่สามารถทำงานร่วมกับโมดูลควอนตัมได้อย่างมีประสิทธิภาพ
- มาตรฐานและนโยบายสนับสนุนการทำงานร่วมกัน: เสนอมาตรฐานระดับชาติสำหรับการจัดรูปแบบข้อมูล การทำ benchmarking สำหรับงาน materials discovery และแนวทางด้านจริยธรรมในการใช้ข้อมูลการทดลองและ AI สนับสนุนการสร้าง consortium ระหว่างมหาวิทยาลัย หน่วยงานรัฐ และภาคเอกชน เพื่อแบ่งปัน dataset, กลไกการจัดลิขสิทธิ์ และโมเดลธุรกิจที่เป็นธรรม
- สนับสนุนการวิจัยเชิงบูรณาการและงานนำร่องเชิงอุตสาหกรรม: กระตุ้นโครงการนำร่องที่เชื่อมงานวิจัยกับปัญหาจริงของอุตสาหกรรม เช่น การออกแบบตัวเร่งปฏิกิริยาสำหรับการลด CO2, การพัฒนา solid‑state electrolytes สำหรับแบตเตอรี่ความหนาแน่นพลังงานสูง โดยใช้กรอบ hybrid quantum‑AI เพื่อวัดผลเชิงเศรษฐศาสตร์และลดความเสี่ยงการนำสู่เชิงพาณิชย์
- การระบุเมตริกความสำเร็จและเป้าหมายระยะสั้น‑ยาว: กำหนดตัวชี้วัดที่ชัดเจน เช่น เวลาเฉลี่ยในการทดสอบวัสดุต่อรอบ, อัตราการค้นพบตัวอย่างที่มีสมบัติตรงตามเป้าหมาย, และการลดต้นทุนการทดลอง เพื่อให้สามารถประเมินผลการลงทุนได้อย่างเป็นรูปธรรม โดยตั้งเป้าระยะสั้นภายใน 2–3 ปีสำหรับการใช้งาน hybrid workflow ในกรณีศึกษา และระยะยาว 5–10 ปีสำหรับการย้ายส่วนสำคัญไปยังฮาร์ดแวร์ควอนตัมขนาดใหญ่เมื่อเทคโนโลยีพร้อม
สรุปแล้ว การเดินหน้าสู่อนาคตของ Quantum‑AI Co‑Simulation จำเป็นต้องเป็นความร่วมมือแบบหลายภาคส่วนที่ผสานการพัฒนาเทคโนโลยีฮาร์ดแวร์และซอฟต์แวร์ การยกระดับทักษะบุคลากร และการออกมาตรฐานเพื่อรองรับการทำงานเชิงผสม การลงทุนที่มีกลยุทธ์จะไม่เพียงเร่งการค้นพบวัสดุแบตเตอรี่เท่านั้น แต่ยังเปิดโอกาสให้ประเทศไทยเป็นศูนย์กลางด้านการประยุกต์ควอนตัมในสาขาอื่นๆ ที่มีมูลค่าสูง เช่น catalysis, semiconductors และพลังงานสมัยใหม่
บทสรุป
Quantum‑AI Co‑Simulator เป็นตัวอย่างการประยุกต์เชิงปฏิบัติที่ผสานการจำลองเชิงควอนตัมเข้ากับเทคนิคปัญญาประดิษฐ์ โดยเฉพาะการเรียนรู้เสริม (Reinforcement Learning) เพื่อเร่งกระบวนการค้นคว้าวัสดุแบตเตอรี่ใหม่ให้สั้นลงจากระดับเดือนเหลือเป็นระดับสัปดาห์ ส่งผลให้ประสิทธิภาพงานวิจัยและพัฒนา (R&D) เพิ่มขึ้นอย่างมีนัยสำคัญและช่วยย่นระยะเวลาเข้าสู่ตลาดของเทคโนโลยีสารกึ่งตัวนำและวัสดุพลังงาน ตัวอย่างผลลัพธ์เช่น การลดรอบทดลองหลายครั้งและการสำรวจพื้นที่พารามิเตอร์ได้กว้างขึ้น ทำให้ต้นทุนการทดลองลดลงและการตัดสินใจเชิงวิศวกรรมทำได้รวดเร็วขึ้น
ถึงแม้แนวทาง hybrid นี้มีศักยภาพสูง แต่ยังเผชิญข้อจำกัดจากฮาร์ดแวร์ควอนตัมที่มีสัญญาณรบกวนและทรัพยากรจำกัด รวมถึงความไม่แน่นอนเชิงโมเดลที่ต้องการการตรวจสอบผล (validation) อย่างรัดกุม ดังนั้นการนำไปใช้อย่างเชิงพาณิชย์จำเป็นต้องอาศัยการปรับแต่งวิธีผสมผสานคลาสสิก‑ควอนตัม การพัฒนาเทคนิคลดสัญญาณรบกวน การตั้งมาตรฐานการทดสอบ และความร่วมมือข้ามภาคส่วนทั้งภาครัฐ สถาบันวิจัย และอุตสาหกรรม ในอนาคตที่ฮาร์ดแวร์ดีขึ้นและระบบนิเวศข้อมูล/บุคลากรเข้มแข็ง ประเทศไทยมีโอกาสใช้แพลตฟอร์มเช่นนี้ขับเคลื่อนนวัตกรรมวัสดุ ลดเวลา R&D เพิ่มศักยภาพเชิงพาณิชย์ และสร้างมูลค่าทางเศรษฐกิจจากเทคโนโลยีแบตเตอรี่รุ่นใหม่ได้อย่างเป็นรูปธรรม



