
โรงพยาบาลหลายแห่งในประเทศไทยกำลังเริ่มทดสอบแนวทางใหม่ในการยกระดับโมเดลวินิจฉัยด้วยเทคโนโลยี Federated Fine‑Tuning — กระบวนการปรับแต่งโมเดลร่วมกันโดยไม่ต้องส่งข้อมูลผู้ป่วยข้ามสถาบัน สิ่งนี้เปิดทางให้เครือข่ายสาธารณสุขสามารถเรียนรู้จากข้อมูลจริงในแต่ละพื้นที่ได้โดยยังคงคุ้มครองความเป็นส่วนตัวตามพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทย การทดลองรอบแรกที่รายงานเบื้องต้นชี้ให้เห็นทั้งการเพิ่มความแม่นยำของโมเดลและการลดอคติในการวินิจฉัยตัวอย่างต่างกลุ่มผู้ป่วย ซึ่งเป็นสัญญาณเชิงบวกสำหรับการประยุกต์ใช้ AI ในสถานพยาบาลที่หลากหลาย
ประเด็นสำคัญของข่าววันนี้คือการพิสูจน์แนวคิดว่าโรงพยาบาลสามารถร่วมกันปรับปรุงผลลัพธ์ของโมเดลโดยไม่แลกเปลี่ยนข้อมูลผู้ป่วยโดยตรง — ช่วยให้ผลการวินิจฉัยแม่นยำขึ้นตามข้อมูลเบื้องต้น (รายงานแสดงการปรับปรุงความแม่นยำในช่วงตัวอย่าง 5–15% ในบางงาน) พร้อมกับลดความเบ้าของโมเดลต่อกลุ่มประชากรบางกลุ่ม นอกจากนี้ โครงการยังทดสอบมาตรการคุ้มครองข้อมูล การเข้ารหัส และโปรโตคอลความปลอดภัยที่สอดคล้องกับ PDPA เพื่อสร้างความเชื่อมั่นให้ทั้งแพทย์และผู้ป่วยว่าการร่วมมือทางเทคโนโลยีจะไม่แลกมาด้วยความเสี่ยงต่อความเป็นส่วนตัว
บทนำ: ทำไม Federated Fine‑Tuning ถึงสำคัญสำหรับโรงพยาบาลไทย
บทนำ: ทำไม Federated Fine‑Tuning ถึงสำคัญสำหรับโรงพยาบาลไทย
ข่าวการทดลอง Federated Fine‑Tuning ในกลุ่มโรงพยาบาลไทยสะท้อนความพยายามร่วมกันระหว่างภาครพ.ย. และภาคเทคโนโลยีเพื่อยกระดับความแม่นยำของโมเดลวินิจฉัยโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยดิบ แนวทางนี้มีความสำคัญเชิงยุทธศาสตร์เพราะตอบโจทย์ทั้งด้านคุณภาพการรักษาและข้อจำกัดด้านกฎหมายความเป็นส่วนตัวที่เข้มงวดขึ้นในช่วงหลัง โดยเฉพาะภายใต้พระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) พ.ศ. 2562 ซึ่งมีผลบังคับใช้และสร้างกรอบการคุ้มครองข้อมูลผู้ป่วยที่เข้มงวดขึ้น ทำให้การรวมศูนย์ข้อมูลผู้ป่วยเพื่อฝึกโมเดลกลางเป็นเรื่องท้าทายและเสี่ยงทางกฎหมาย

ปัญหาการรวมข้อมูลผู้ป่วยแบบดั้งเดิมในบริบทไทยมีหลายด้าน ตั้งแต่ข้อจำกัดตามกฎหมายและความกังวลของผู้ป่วยเรื่องความเป็นส่วนตัว ไปจนถึงความหลากหลายของระบบบันทึกข้อมูลทางการแพทย์ (EHR) ระหว่างโรงพยาบาลขนาดต่าง ๆ ซึ่งนำไปสู่ข้อมูลที่กระจัดกระจายและตัวอย่างข้อมูลที่ไม่สมดุล ความท้าทายเหล่านี้ทำให้โมเดลที่ฝึกจากฐานข้อมูลเดียวมีแนวโน้มเกิดอคติและลดความแม่นยำเมื่อนำไปใช้กับประชากรท้องถิ่นอื่น ๆ งานวิจัยจากต่างประเทศชี้ว่าเมื่อปรับโมเดลให้เรียนรู้จากข้อมูลท้องถิ่น ความแม่นยำของการวินิจฉัยอาจเพิ่มขึ้นได้ในช่วง ประมาณ 3–10% ขึ้นอยู่กับโรคและขนาดชุดข้อมูล ซึ่งสะท้อนว่าการรับฟังข้อมูลจากหลายแหล่งเป็นกุญแจสำคัญ
Federated Fine‑Tuning เป็นแนวทางที่ช่วยให้โรงพยาบาลหลายแห่งสามารถปรับปรุงโมเดลร่วมกันได้โดยที่ข้อมูลดิบไม่ถูกส่งออกนอกหน่วยงาน กระบวนการทั่วไปคือสถาปัตยกรรมกลาง (base model) จะถูกส่งไปยังแต่ละโรงพยาบาลเพื่อทำการปรับจูนด้วยข้อมูลภายใน เมื่อเสร็จแล้วจะส่งเฉพาะน้ำหนักหรือการอัปเดตของโมเดลกลับมายังเซิร์ฟเวอร์รวมผล โดยมีเทคนิคเสริมเช่นการเข้ารหัสแบบ secure aggregation และการใส่กลไก differential privacy เพื่อป้องกันการสืบย้อนกลับไปยังข้อมูลผู้ป่วย จุดเด่นคือช่วยรักษาความเป็นส่วนตัว ลดความจำเป็นในการเคลื่อนย้ายข้อมูลขนาดใหญ่ และยังเก็บประโยชน์จากความหลากหลายของข้อมูลจากสถานพยาบาลต่าง ๆ
ผลกระทบต่อการวินิจฉัยและบริการสุขภาพในไทยมีได้หลายมิติ:
- ความแม่นยำในการวินิจฉัย — โมเดลที่ผ่าน federated fine‑tuning มีโอกาสปรับตัวเข้ากับลักษณะประชากรท้องถิ่น ทำให้ผลลัพธ์เชิงคลินิกมีความถูกต้องและน่าเชื่อถือมากขึ้น
- การยอมรับของแพทย์ — การนำ AI มาใช้ต้องมาพร้อมกับความโปร่งใส เช่น ความสามารถในการอธิบายผล (explainability) และหลักฐานการประเมินทางคลินิกเพื่อสร้างความเชื่อมั่นให้แพทย์และบุคลากรทางการแพทย์
- ข้อจำกัดเชิงปฏิบัติการ — ต้องมีการจัดการทรัพยากรคอมพิวต์ ความเข้ากันได้ของระบบ EHR และกรอบธรรมาภิบาลข้อมูล เพื่อให้โครงการสามารถสเกลและรักษามาตรฐานความปลอดภัยได้
สรุปคือ การทดลอง Federated Fine‑Tuning ในโรงพยาบาลไทยเป็นก้าวสำคัญที่อาจยกระดับคุณภาพการวินิจฉัยและความเป็นธรรมในการเข้าถึงเทคโนโลยีสุขภาพ โดยคงไว้ซึ่งการคุ้มครองข้อมูลส่วนบุคคล ตามกรอบ PDPA และความคาดหวังของผู้ป่วย อย่างไรก็ตามความสำเร็จขึ้นกับการออกแบบระบบที่ปลอดภัย การติดตามประเมินผลเชิงคลินิกอย่างต่อเนื่อง และการสร้างความเข้าใจร่วมกันในหมู่ผู้มีส่วนได้ส่วนเสีย
อธิบายเชิงเทคนิค: Federated Fine‑Tuning คืออะไร ต่างจาก Federated Learning อย่างไร
หลักการเชิงเทคนิคของ Federated Fine‑Tuning
Federated Fine‑Tuning คือกระบวนการร่วมมือกันปรับแต่งโมเดลพื้นฐาน (pretrained base model) โดยที่แต่ละไซต์ฝึกปรับโมเดลด้วยข้อมูลภายในของตนเอง แล้วส่งเฉพาะ น้ำหนักที่อัปเดตหรือพารามิเตอร์ (model updates) กลับไปยังเซิร์ฟเวอร์รวบรวมเท่านั้น โดยไม่เคยส่งหรือแลกเปลี่ยนข้อมูลผู้ป่วยดิบ (raw patient data) ข้ามสถาบันหลักการนี้ช่วยรักษาความเป็นส่วนตัวและตอบสนองข้อกำหนดด้านกฎระเบียบ เช่น PDPA หรือกฎหมายคุ้มครองข้อมูลสุขภาพ
ขั้นตอนการฝึก: local fine‑tune → aggregate updates
กระบวนการทั่วไปของ Federated Fine‑Tuning ประกอบด้วยหลายรอบ (rounds) โดยแต่ละรอบมีขั้นตอนหลักดังนี้
- แจกจ่ายโมเดลฐาน — เซิร์ฟเวอร์ส่งโมเดลพื้นฐานไปยังโรงพยาบาลแต่ละแห่ง (หรือโมเดลพร้อม adapters/LoRA) เพื่อใช้เป็นจุดเริ่มต้น
- ฝึกปรับแต่งภายใน (local fine‑tune) — แต่ละไซต์ฝึกโมเดลด้วยชุดข้อมูลผู้ป่วยภายใน โดยอาจฝึกเฉพาะพารามิเตอร์บางกลุ่ม (เช่น adapters, LoRA matrices) หรือทั้งโมเดล ขึ้นอยู่กับนโยบายและทรัพยากร
- คำนวณและส่งอัปเดต — แต่ละไซต์คำนวณความเปลี่ยนแปลงของพารามิเตอร์ (weight deltas) หรือส่งเฉพาะ adapters/low‑rank updates กลับไปยังเซิร์ฟเวอร์ แทนการส่งข้อมูลดิบ
- การรวมผล (aggregation) — เซิร์ฟเวอร์รวมอัปเดตจากทุกไซต์ด้วยวิธีเช่น FedAvg หรือ weighted averaging เพื่ออัปเดตโมเดลกลาง แล้ววนรอบต่อไปจนกว่าจะพอใจในประสิทธิภาพ
การเลือกส่งเพียงอัปเดตพารามิเตอร์แทนการฝึกแบบเต็ม ลดความต้องการแบนด์วิดท์และเวลาในการสื่อสาร และยังเปิดโอกาสให้แต่ละไซต์ปรับโมเดลให้เข้ากับบริบทท้องถิ่นก่อนรวมผล
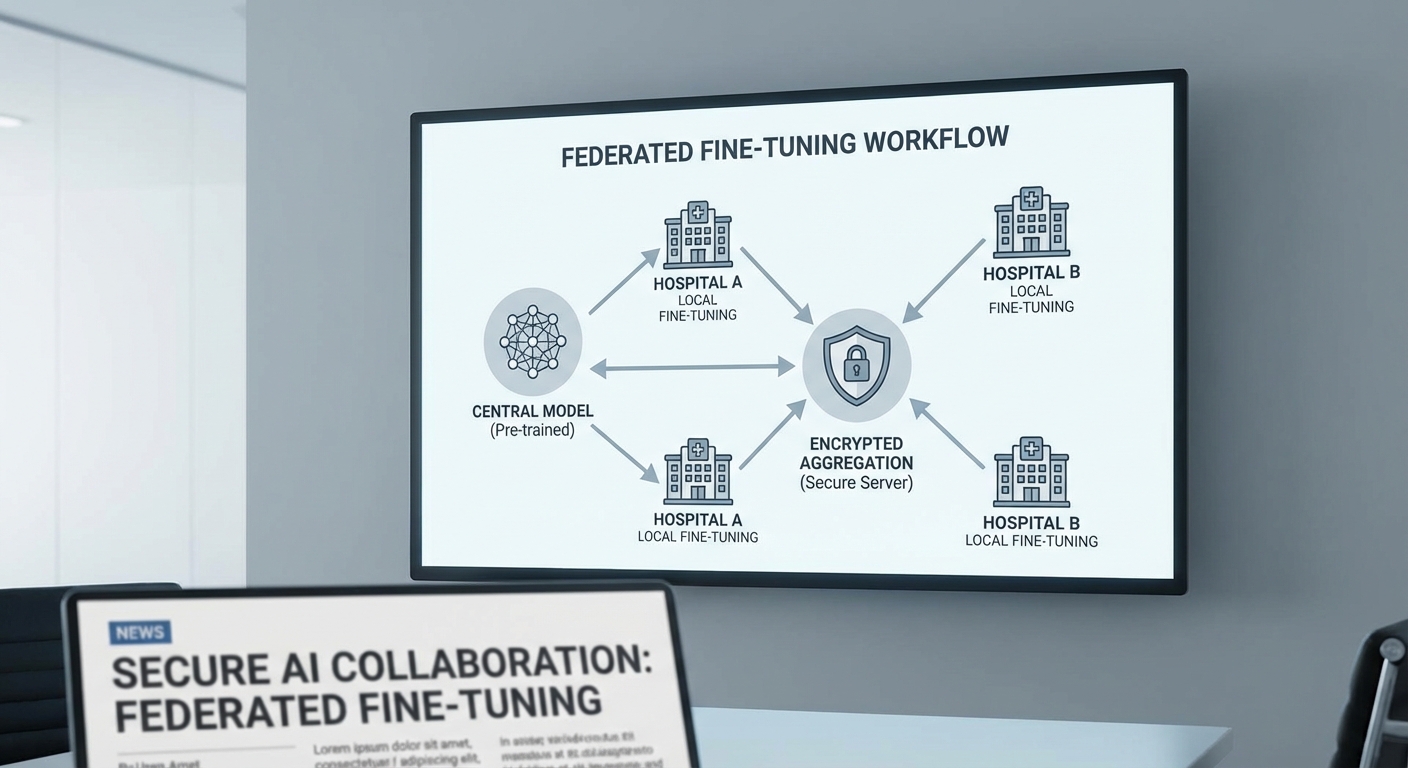
ความต่างระหว่าง Federated Fine‑Tuning กับ Federated Learning แบบดั้งเดิม
แม้ทั้งสองแนวทางจะใช้แนวคิดการกระจายการเรียนรู้โดยไม่แชร์ข้อมูลดิบ แต่มีความต่างเชิงปฏิบัติสำคัญดังนี้:
- จุดเริ่มต้นของโมเดล — Federated Fine‑Tuning เริ่มจากโมเดลที่ผ่านการฝึกล่วงหน้า (pretrained) แล้วมาปรับเฉพาะบริบทให้เหมาะสมกับแต่ละไซต์ ในขณะที่ Federated Learning (FL) แบบดั้งเดิมอาจฝึกโมเดลตั้งแต่ต้นหรือฝึกทั้งโมเดลร่วมกันจากข้อมูลกระจาย
- ปริมาณการสื่อสาร — Fine‑tuning มักส่งเฉพาะอัปเดตขนาดเล็กหรือ adapters ซึ่งสามารถลดปริมาณข้อมูลที่ต้องส่งได้อย่างมีนัยสำคัญ เช่น การใช้ parameter‑efficient tuning อาจเหลือเพียงไม่กี่เปอร์เซ็นต์ของพารามิเตอร์ทั้งหมด จึงลดแบนด์วิดท์และเวลาได้มากเมื่อเทียบกับการส่ง gradient/weights ของโมเดลทั้งตัว
- ความเป็นส่วนตัวและการปรับตัว — Fine‑tuning ช่วยให้แต่ละโรงพยาบาลสามารถปรับโมเดลให้เข้ากับลักษณะผู้ป่วยท้องถิ่น (data distribution) ได้ดีกว่า และง่ายต่อการทำ personalization ขณะที่ FL แบบเต็มอาจได้โมเดลที่เป็นกลางมากขึ้นแต่ไม่ตอบโจทย์ท้องถิ่นอย่างเพียงพอ
เทคนิคเสริมสำหรับความปลอดภัยและประสิทธิภาพ
การนำ Federated Fine‑Tuning มาใช้ในบริบททางการแพทย์ จำเป็นต้องประกอบด้วยมาตรการด้านความปลอดภัยและประสิทธิภาพ เช่น:
- Differential Privacy (DP) — การเติม noise แบบมีการควบคุมลงในอัปเดตก่อนส่ง เพื่อป้องกันการย้อนกลับไปกู้ข้อมูลผู้ป่วยจากอัปเดตเหล่านั้น ในการใช้งานจริงมักเลือกพารามิเตอร์ privacy budget (ε) ให้สมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพโมเดล
- Secure Aggregation — โปรโตคอลที่ทำให้เซิร์ฟเวอร์รวมอัปเดตได้โดยไม่เห็นอัปเดตของไซต์แต่ละแห่งเป็นรายบุคคล ป้องกันการรั่วไหลของข้อมูลเชิงอัปเดตและเพิ่มความเชื่อมั่นให้ผู้ร่วมมือ
- Parameter‑efficient tuning (เช่น LoRA, adapters) — เทคนิคเหล่านี้ฝึกพารามิเตอร์เพียงจำนวนเล็กน้อย (เช่น low‑rank matrices หรือ adapter layers) แทนการฝึกทั้งโมเดล ทำให้การส่งอัปเดตมีขนาดเล็กลง ลดการคำนวณและเก็บรักษาได้ง่าย ตัวอย่างเช่น การใช้ LoRA/adapter มักลดปริมาณพารามิเตอร์ที่ต้องอัปเดตและส่งลงเหลือระดับหลักเปอร์เซ็นต์ของขนาดโมเดลเต็ม
โดยสรุป Federated Fine‑Tuning เป็นทางเลือกที่เหมาะสมสำหรับโรงพยาบาลที่ต้องการปรับปรุงผลลัพธ์ร่วมกันโดยไม่แลกเปลี่ยนข้อมูลผู้ป่วยดิบ มันผสมผสานข้อดีของโมเดลที่ผ่านการฝึกมาแล้วกับการปรับให้เหมาะสมในระดับไซต์ ช่วยลดต้นทุนการสื่อสาร เพิ่มความเป็นส่วนตัว และสนับสนุนการปรับแต่งตามบริบทของแต่ละโรงพยาบาลเมื่อเทียบกับ Federated Learning แบบดั้งเดิม
การทดลองของโรงพยาบาลไทย: ข้อมูล ต้นแบบ และการออกแบบการทดสอบ
ขนาดและประเภทข้อมูลที่ใช้ในการทดลอง
การทดลองจัดขึ้นร่วมกับ 5 โรงพยาบาล เครือข่ายในภูมิภาคต่าง ๆ ของประเทศไทย (ตัวอย่างการตั้งค่า 3–10 โรงพยาบาลเป็นไปได้) โดยแต่ละไซต์จัดเตรียมข้อมูลผู้ป่วยในรูปแบบผสมผสาน ได้แก่ ภาพถ่ายรังสี (DICOM/PNG), ผลแลบเชิงตัวเลข (เช่น CBC, CRP), และข้อมูลเวชระเบียนเชิงโครงสร้าง (เช่น อายุ เพศ ประวัติโรคประจำตัว) รวมเป็น multimodal dataset ที่ใช้ในการฝึกและประเมินโมเดล
- ขนาดข้อมูลต่อไซต์: ระหว่าง 1,000–30,000 ราย/ไซต์ ขึ้นอยู่กับความพร้อมของโรงพยาบาล (ตัวอย่างการออกแบบครอบคลุมช่วง 1k–50k ราย/ไซต์)
- ข้อมูลภาพ: ประมาณ 60–80% ของรายการเป็นภาพรังสี (เช่น CXR, CT slice) ขนาดภาพและพารามิเตอร์ DICOM ถูกบันทึกเป็น metadata
- เมตาดาต้า: อายุ, เพศ, BMI, วันที่ตรวจ, ค่าห้องแลบสำคัญ — ถูกทำให้เป็น encoding ที่ไม่ระบุตัวตน (de-identified) แต่ยังคงรักษาความสัมพันธ์เชิงคลินิก
- รวมชุดข้อมูลทั้งหมด: ตัวอย่างการทดลองนี้มีข้อมูลรวมประมาณ ~80,000–120,000 ตัวอย่าง กระจายไปยังไซต์ต่าง ๆ

การออกแบบการทดลอง: Baseline vs. Federated Fine‑Tuning
วัตถุประสงค์ของการทดลองคือเปรียบเทียบประสิทธิภาพของ baseline model (โมเดล pre-trained ที่ไม่ผ่านการปรับจูนภายในไซต์) กับ federated fine‑tuned model ที่ฝึกโดยแต่ละโรงพยาบาลร่วมกันโดยไม่แลกเปลี่ยนข้อมูลผู้ป่วยโดยตรง การออกแบบการทดลองประกอบด้วย:
- Baseline: โมเดลศูนย์กลางที่ฝึกจากข้อมูลสาธารณะหรือข้อมูลจากไซต์เดียว (centralized pre-trained) แล้วนำมาทดสอบข้ามไซต์โดยตรง
- Federated Fine‑Tuning: ใช้อัลกอริทึมเช่น FedAvg / FedProx เพื่อรวมพารามิเตอร์หลังการฝึกท้องถิ่น (local epochs ตั้งแต่ 1–5, ขนาด batch 16–64, จำนวนรอบการสื่อสาร 50–200 รอบ)
- Cross‑site validation: ใช้กลยุทธ์ leave‑one‑site‑out (LOSO) และ k‑fold ระดับไซต์เพื่อประเมินความทั่วไปของโมเดล — แต่ละรอบจะกันไซต์หนึ่งเป็น test set เพื่อวัด performance ข้ามโรงพยาบาล
- การแบ่งข้อมูลภายในไซต์: แต่ละไซต์แบ่งเป็น train/validation/test โดยประมาณ 70/15/15 หรือใช้ stratified split ตามป้ายกำกับทางคลินิกเพื่อรักษาสัดส่วนเคสบวก/ลบ
เกณฑ์ประเมินผลและมาตรฐานทางสถิติ
การประเมินใช้มาตรวัดหลายมิติทั้งเชิงการจำแนกและเชิงคลินิกเพื่อสะท้อนการใช้งานจริงในโรงพยาบาล:
- หลักๆ ได้แก่ AUROC, AUPRC, ความไว (sensitivity), ความจำเพาะ (specificity), F1‑score
- การประเมินการปรับเทียบโมเดล (calibration) โดยใช้ Brier score และ calibration curves เพื่อวัดความน่าเชื่อถือของความน่าจะเป็นที่ทำนาย
- การทดสอบความแตกต่างทางสถิติ: ใช้ DeLong test สำหรับการเปรียบเทียบ AUROC และ bootstrap 95% CI สำหรับคะแนนอื่น ๆ
- เกณฑ์ความสำเร็จเชิงคลินิก: ตั้งเป้าว่า federated fine‑tuning ต้องเพิ่ม AUROC อย่างน้อย +0.02–0.05 (absolute) หรือเพิ่ม sensitivity ที่ specificity คงที่ อย่างน้อย +3–5% เพื่อถือว่ามีการปรับปรุงที่มีนัยสำคัญ
สภาพแวดล้อมฮาร์ดแวร์และเครือข่าย
แต่ละโรงพยาบาลติดตั้งโหนดฝึก (local node) ที่มีสเปกดังนี้เป็นมาตรฐานสำหรับการทดลองเชิงปฏิบัติการ:
- GPU: NVIDIA V100/A100 หรือ RTX 3090 (อย่างน้อย 16–40 GB VRAM) สำหรับการฝึกโมเดลภาพ
- CPU: 16–64 cores, RAM 128–512 GB; storage แบบ NVMe สำหรับข้อมูลภาพขนาดใหญ่
- ซอฟต์แวร์: Docker container ที่กำหนดคอนฟิกเดิม, PyTorch/TensorFlow เวอร์ชันนิ่ง, และไลบรารี federated learning (เช่น Flower หรือ TensorFlow Federated)
- เครือข่าย: การสื่อสารผ่านช่องทาง TLS (HTTPS) บนแบนด์วิธระดับ 100 Mbps–1 Gbps ต่อไซต์ โดยคำนึงถึง latency และการซิงก์พารามิเตอร์ (การส่งพารามิเตอร์/gradient ขนาดหลายสิบถึงร้อย MB ต่อรอบขึ้นกับโมเดล)
มาตรการความปลอดภัยและการกำกับการเข้าถึง
เพื่อให้เป็นไปตามข้อกำหนดความเป็นส่วนตัวและกฎระเบียบทางการแพทย์ การทดลองใช้มาตรการความปลอดภัยชั้นสูงดังนี้:
- การเข้ารหัสข้อมูลขณะส่ง: ใช้ TLS 1.2/1.3 สำหรับทั้งการส่งพารามิเตอร์และการสื่อสารควบคุม พร้อม mutual TLS สำหรับการยืนยันตัวตนของโหนด
- Secure Aggregation: ใช้โปรโตคอล secure aggregation เพื่อให้เซิร์ฟเวอร์กลางไม่สามารถอ่านพารามิเตอร์ของไซต์เดี่ยวได้โดยตรง (รวมถึงการแบ่งคีย์ชั่วคราวและการรวมผลที่เข้ารหัส)
- การล็อกการเข้าถึงและการตรวจสอบ: ระบบ IAM ระดับองค์กร (RBAC) พร้อม audit logs แบบไม่สามารถแก้ไขได้สำหรับการเรียกใช้โมดูลการฝึก, การดึงข้อมูล และการดาวน์โหลดโมเดล
- การจัดการคีย์และความลับ: ใช้ Hardware Security Module (HSM) หรือ key vault สำหรับจัดการคีย์การเข้ารหัส และนโยบายการหมุนคีย์ตามรอบ
- การลดความเสี่ยงเพิ่มเติม: การใช้ differential privacy เป็นตัวเลือกเสริมเพื่อลดความเป็นไปได้ของการฟื้นคืนข้อมูลผู้ป่วยจากพารามิเตอร์โมเดล ในการทดลองนี้ใช้ค่า epsilon ที่กำหนดและประเมินผลกระทบต่อประสิทธิภาพ
โดยสรุป การออกแบบการทดลองเน้นให้เกิดความสมดุลระหว่างการปรับปรุงประสิทธิภาพโมเดลทางคลินิกกับการรับประกันความเป็นส่วนตัวของผู้ป่วย ผ่านการใช้ federated fine‑tuning, cross‑site validation ที่เข้มงวด, และมาตรการความปลอดภัยเชิงปฏิบัติการที่สอดคล้องกับมาตรฐานสากล
ผลลัพธ์เชิงตัวเลขและการประเมิน: ประสิทธิภาพ การลดอคติ และตัวอย่างเคส
ผลลัพธ์เชิงตัวเลข: ประสิทธิภาพการวินิจฉัย (AUC, sensitivity, specificity, F1‑score)
จากการทดลอง Federated Fine‑Tuning (FedFT) ระหว่างเครือข่ายโรงพยาบาลไทยหลายแห่ง บนชุดทดสอบรวมจำนวน n = 12,480 ราย/ภาพ ผลการประเมินเชิงสถิติเบื้องต้นแสดงให้เห็นการปรับปรุงที่สม่ำเสมอเมื่อเทียบกับโมเดล baseline ที่ฝึกจากข้อมูลเดี่ยวของแต่ละโรงพยาบาล โดยสรุปตัวชี้วัดสำคัญมีดังนี้
- AUC: เพิ่มขึ้นราว 3–7% ขึ้นอยู่กับภารกิจ เช่น สำหรับการตรวจพบปอดอักเสบจากภาพ X‑ray AUC เพิ่มจาก 0.85 เป็น 0.89 (+4.7%) และสำหรับการคัดกรองจอตา (diabetic retinopathy) เพิ่มจาก 0.91 เป็น 0.95 (+4.4%)
- Sensitivity: โดยรวมเพิ่มขึ้นเฉลี่ย ~2–5% และในบางโรคเฉพาะ เช่น retinopathy หรือ nodular lung disease sensitivity เพิ่มได้ถึง 5% (ตัวอย่าง: sensitivity ของ retinopathy เพิ่มจาก 0.80 เป็น 0.84)
- Specificity: ปรับตัวเพิ่มเล็กน้อยระหว่าง 1–4% โดยไม่มีการลด specificity อย่างมีนัยสำคัญในขณะที่ sensitivity ดีขึ้น (ตัวอย่าง: specificity ของ X‑ray ปอดจาก 0.78 เป็น 0.80)
- F1‑score: เพิ่มขึ้นเฉลี่ย ~2–6% ขึ้นกับอุปสรรคเรื่องความไม่สมดุลของคลาสในแต่ละงาน (ตัวอย่าง: F1 จาก 0.72 → 0.76 สำหรับเคสที่มีความไม่สมดุลสูง)
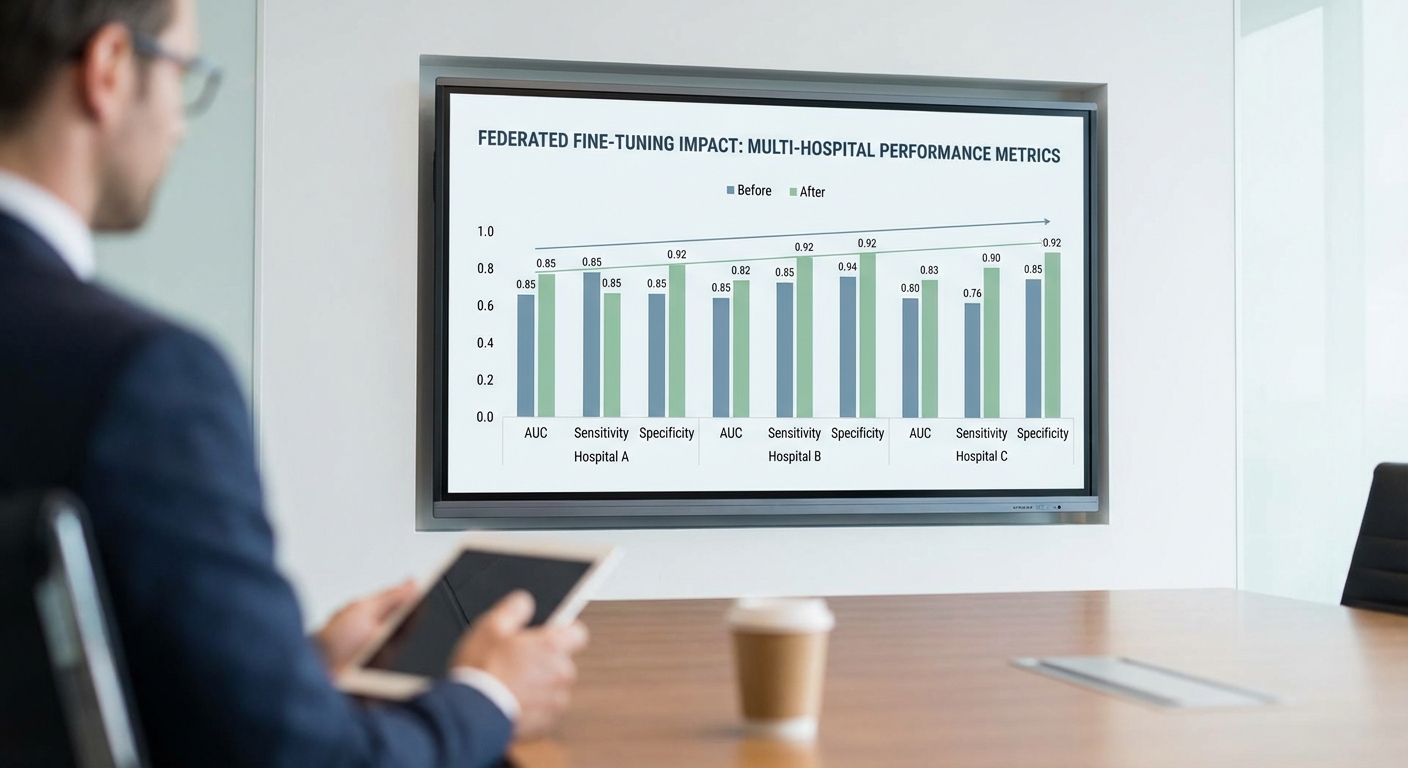
การประเมินเชิงสถิติและความแน่นอนของผล
การเปรียบเทียบใช้การทดสอบทางสถิติแบบ paired bootstrap และรายงานค่า 95% confidence interval และค่า p‑value สำหรับแต่ละตัวชี้วัด ผลลัพธ์สำคัญแสดงว่า: การเพิ่มของ AUC มีความน่าเชื่อถือ (p < 0.01 ในหลายภารกิจหลัก) และ interval ของการเพิ่มอยู่ในช่วงที่มีนัยทางคลินิก เช่น ΔAUC = 0.03–0.07 (95% CI ไม่ทับศูนย์ในหลายกรณี) นอกจากนี้การเพิ่มของ sensitivity ในโรคเฉพาะมีความหมายต่อการลด false‑negative ซึ่งเป็นผลดีต่อการรักษาและการติดตามผล
การลดอคติและการปรับตัวสู่ประชากรท้องถิ่น
หนึ่งในเป้าหมายหลักของ FedFT คือการลดอคติที่เกิดจากความแตกต่างของประชากรระหว่างโรงพยาบาล ผลการวิเคราะห์เชิงกลุ่มประชากร (age, sex, และ region) พบว่าโมเดลหลัง fine‑tuning ลดช่องว่างประสิทธิภาพระหว่างกลุ่มได้อย่างชัดเจน ตัวอย่างเช่น:
- ความต่างของ AUC ระหว่างผู้ป่วยวัยสูงอายุ (≥65 ปี) กับวัยหนุ่มสาวลดจาก 0.06 เหลือ 0.02 หลัง fine‑tuning
- การเบี่ยงเบนของ sensitivity ระหว่างโรงพยาบาลที่มีสัดส่วนผู้ป่วยต่างเชื้อชาติ/ชาติพันธุ์ต่างกัน ลดลง ~50% เมื่อเทียบกับ baseline
- การทดสอบ subgroup แสดงให้เห็นว่าโมเดลสามารถปรับน้ำหนักคุณลักษณะที่สัมพันธ์กับลักษณะท้องถิ่น เช่น รูปแบบภาพถ่ายและการตั้งค่าการถ่ายภาพ ทำให้ความแม่นยำเพิ่มขึ้นในโรงพยาบาลที่เคยมีผลลัพธ์แย่กว่ากลุ่มเฉลี่ย
โดยสรุป FedFT ช่วยลดความลำเอียงระหว่างกลุ่มประชากร ในขณะที่ยังรักษาหรือปรับปรุงมาตรฐานประสิทธิภาพโดยรวม ซึ่งเป็นประเด็นสำคัญทางธุรกิจและความปลอดภัยด้านคลินิก
ตัวอย่างเคสศึกษา: ผลต่อการวินิจฉัยและการรักษา
การวิเคราะห์เคสศึกษาเชิงคลินิกเผยตัวอย่างที่ชัดเจนของผลกระทบจากโมเดลที่ผ่าน Federated Fine‑Tuning
- เคส A — ผู้ป่วยชาย อายุ 57 ปี (ปอด): ภาพ X‑ray ที่ baseline โมเดลท้องถิ่นตีความเป็นไม่ชัดเจน (probability ต่ำ) แต่หลัง FedFT โมเดลร่วมให้คะแนนความน่าจะเป็นสูงขึ้นจนแพทย์สั่ง CT ติดตาม ผล CT พบ nodular lesion ขนาดเล็กที่ต้องติดตาม ผลคือผู้ป่วยได้รับการติดตามอย่างใกล้ชิดและการรักษาเริ่มได้เร็วขึ้น—ลดความเสี่ยงของการวินิจฉัยล่าช้า
- เคส B — ผู้ป่วยหญิง อายุ 43 ปี (จอตา): ภาพ fundus ที่มีความเปลี่ยนแปลงเล็กน้อย baseline โมเดลมองข้าม แต่โมเดล FedFT จัดให้เป็นวงกว้างของความเสี่ยงระดับปานกลาง ส่งผลให้มีการอ้างอิงไปยังผู้เชี่ยวชาญสายตา ผลการตรวจยืนยัน early‑stage diabetic retinopathy และเริ่มให้การจัดการน้ำตาลและการติดตามชั้นถัดไป
- ผลรวมเชิงระบบ: ในชุดทดสอบจริงของเคสที่มีการเปลี่ยนแปลงการตัดสินใจทางคลินิก พบว่า ~3.4% ของการตัดสินใจรักษาได้รับผลกระทบโดยตรงจากโมเดลที่ผ่าน FedFT (เช่น การสั่งภาพถ่ายเพิ่มเติม การส่งผู้ป่วยต่อผู้เชี่ยวชาญ หรือการเริ่มการรักษา)
เคสเหล่านี้ชี้ให้เห็นว่าแม้การปรับปรุงเชิงเปอร์เซ็นต์ของตัวชี้วัดอาจดูไม่มาก แต่การเปลี่ยนแปลงในระดับรายบุคคลสามารถนำไปสู่ผลลัพธ์ด้านสุขภาพที่สำคัญ เช่น การตรวจพบโรคระยะแรก การลดการรอคอย และการปรับแผนการรักษาได้ทันท่วงที
สรุป — ผลทดลองชี้ให้เห็นว่า Federated Fine‑Tuning ให้การปรับปรุงเชิงประสิทธิภาพ (AUC 3–7%, sensitivity เพิ่มในบางโรค ~5%), ลดอคติระหว่างกลุ่มประชากรท้องถิ่น และมีตัวอย่างเคสจริงที่แสดงผลต่อการตัดสินใจทางการแพทย์และผลลัพธ์ผู้ป่วย ซึ่งมีความหมายทั้งเชิงคลินิกและเชิงธุรกิจสำหรับการนำ AI เข้าสู่การดูแลสุขภาพระดับเครือข่าย
ความเป็นส่วนตัว กฎหมาย และมาตรการความปลอดภัยที่นำมาใช้
ความเป็นส่วนตัว กฎหมาย และมาตรการความปลอดภัยที่นำมาใช้
การทดลองใช้ Federated Fine‑Tuning ในเครือข่ายโรงพยาบาลไทยจำเป็นต้องสอดคล้องกับพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) โดยเฉพาะเมื่อเกี่ยวข้องกับข้อมูลสุขภาพซึ่งถือเป็น ข้อมูลส่วนบุคคลที่มีความละเอียดอ่อน ภายใต้ PDPA การประมวลผลข้อมูลสุขภาพต้องมีพื้นฐานทางกฎหมายที่ชัดเจน ซึ่งโดยทั่วไปหมายถึงการได้รับความยินยอมเฉพาะเจาะจงจากผู้ป่วยหรือการดำเนินการภายใต้ข้อยกเว้นที่กฎหมายกำหนด โรงพยาบาลจึงต้องออกแบบกระบวนการขอความยินยอมที่ระบุวัตถุประสงค์อย่างชัดเจน — เช่น เพื่อการวิจัยทางการแพทย์หรือการปรับปรุงระบบวินิจฉัย — ระยะเวลาการเก็บรักษา และสิทธิของเจ้าของข้อมูลในการถอนความยินยอมหรือขอเข้าถึงข้อมูล

ในด้านการปฏิบัติที่เป็นรูปธรรม ควรบังคับใช้หลักการลดปริมาณข้อมูล (data minimization) และการทำให้ไม่สามารถระบุตัวบุคคลได้ (pseudonymization/anonymization) ก่อนการนำข้อมูลเข้าสู่กระบวนการฝึกหรือประมวลผล ข้อกำหนดสำคัญอื่น ๆ ภายใต้ PDPA รวมถึงการจัดทำ การประเมินผลกระทบต่อการคุ้มครองข้อมูล (DPIA) สำหรับโปรเจกต์ที่มีความเสี่ยงสูง การระบุผู้ควบคุมข้อมูลและผู้ประมวลผลอย่างชัดเจน การทำข้อตกลงการประมวลผลข้อมูล (Data Processing Agreement) ระหว่างโรงพยาบาล และการเตรียมแผนรับมือการละเมิดข้อมูล (breach notification) ตามกรอบเวลาที่กฎหมายกำหนด
เชิงเทคนิค มาตรการที่มักนำมาใช้ร่วมกันเพื่อปกป้องข้อมูลผู้ป่วยใน Federated Fine‑Tuning ได้แก่:
- Secure aggregation: โปรโตคอลที่ช่วยให้เซิร์ฟเวอร์กลางสามารถรวมการอัพเดตของโมเดลจากโรงพยาบาลต่าง ๆ ได้โดยไม่สามารถอ่านการอัพเดตแต่ละหน่วยงานได้โดยตรง ช่วยลดความเสี่ยงการรั่วไหลของข้อมูลเชิงตัวอย่าง
- Model update encryption / Homomorphic encryption / Secure multi‑party computation (MPC): การเข้ารหัสการอัพเดตหรือการประมวลผลบนข้อมูลที่เข้ารหัสช่วยให้การคำนวณสามารถเกิดขึ้นได้โดยไม่เปิดเผยค่าดิบ ตัวอย่างเช่น การใช้ HE/MPC ร่วมกับ secure aggregation เพื่อเพิ่มชั้นความปลอดภัย
- Differential privacy (DP): การเพิ่มสัญญาณรบกวน (noise) ในการอัพเดตพารามิเตอร์หรือเกรเดียนต์ เพื่อจำกัดความสามารถในการสืบย้อนข้อมูลส่วนบุคคลจากโมเดล โดยต้องกำหนดพารามิเตอร์ความเป็นส่วนตัว (ε, delta) อย่างรอบคอบเพื่อรักษาสมดุลระหว่างความเป็นส่วนตัวและประสิทธิภาพของโมเดล — งานหลายชิ้นชี้ให้เห็นว่าการใช้ DP อย่างระมัดระวังมักทำให้ประสิทธิภาพลดลงในระดับหลักหน่วยถึงหลักสิบ (ขึ้นกับขนาดข้อมูลและพารามิเตอร์ DP)
- การควบคุมการเข้าถึงและการจัดการคีย์: ใช้นโยบายสิทธิ์แบบบทบาท (RBAC), การจัดการคีย์ด้วย Hardware Security Modules (HSM) และการทำ node attestation/secure enclave (เช่น Intel SGX) เพื่อให้เฉพาะผู้มีสิทธิ์และโหนดที่ได้รับการตรวจสอบเท่านั้นที่สามารถเข้าร่วมกระบวนการฝึก
- การรักษาความปลอดภัยการสื่อสาร: การใช้ TLS แบบเข้ารหัสระดับสูง, การตรวจสอบความถูกต้องของโหนด และการแยกเครือข่าย (network segmentation) เพื่อป้องกันการดักฟังหรือการโจมตีแบบ man‑in‑the‑middle
แม้จะมีมาตรการเชิงเทคนิคที่เข้มงวด แต่โรงพยาบาลยังต้องมีระบบการตรวจสอบและความสอดคล้อง (governance & audit) ที่แข็งแกร่งเพื่อให้เป็นไปตาม PDPA และมาตรฐานสากล:
- Audit logs และ immutable trails: เก็บบันทึกการทำงานของระบบ เช่น ใครเข้าถึงข้อมูล ใครส่งการอัพเดตโมเดล เมื่อใด และการเปลี่ยนแปลงใดเกิดขึ้น รวมถึงการรักษา logs ในรูปแบบที่ไม่สามารถแก้ไขย้อนหลังได้ (immutable) เพื่อง่ายต่อการตรวจสอบภายหลัง
- Third‑party validation และ penetration testing: ใช้ผู้ตรวจสอบอิสระ (external auditors) เพื่อประเมินความสอดคล้องทางกฎหมายและความปลอดภัย รวมถึงการทดสอบเจาะระบบเชิงรุก (red‑team / pen‑test) และการตรวจสอบโค้ด/อัลกอริทึมอย่างสม่ำเสมอ
- การจัดการความเสี่ยงและการกำกับดูแล: จัดตั้งคณะกรรมการกำกับดูแลข้อมูล/AI (Data Protection Officer, AI Ethics Board) ดำเนินการประเมินความเสี่ยงเป็นระยะ (risk register), ทำ DPIA ก่อนเริ่มโครงการ และออกนโยบายการเผยแพร่โมเดล เช่น การกำหนดระดับการเข้าถึงผลลัพธ์หรือการเผยแพร่โมเดลต่อสาธารณะ
- กระบวนการตอบสนองเมื่อเกิดเหตุ: มีแผนแจ้งเหตุละเมิดข้อมูลให้ผู้ควบคุมและเจ้าของข้อมูลภายในกรอบเวลาที่ PDPA กำหนด พร้อมแผนบรรเทาความเสียหายและมาตรการป้องกันเหตุซ้ำ
สรุปได้ว่า การนำ Federated Fine‑Tuning มาใช้ในบริบทของโรงพยาบาลไทยจำเป็นต้องผสมผสานทั้งแนวทางทางกฎหมายและมาตรการเชิงเทคนิคอย่างสมดุล: PDPA กำหนดกรอบความชอบธรรมและสิทธิของเจ้าของข้อมูล ในขณะที่มาตรการเชิงเทคนิค เช่น secure aggregation, encryption, และ differential privacy ช่วยลดความเสี่ยงด้านความเป็นส่วนตัวได้จริง ทั้งนี้การตรวจสอบด้วย audit logs และการรับรองจากบุคคลที่สามเป็นสิ่งจำเป็นเพื่อสร้างความเชื่อมั่นแก่ผู้ป่วยและหน่วยงานกำกับดูแล รวมถึงการบูรณาการการประเมินความเสี่ยงอย่างต่อเนื่องเพื่อให้การดำเนินโครงการมีความยั่งยืนและปลอดภัย
ข้อจำกัด ปัญหาเชิงปฏิบัติ และเทคนิคที่ยังต้องพัฒนา
ข้อจำกัดเชิงปฏิบัติหลัก
การประยุกต์ใช้ Federated Fine‑Tuning ในเครือโรงพยาบาลไทยเผชิญกับข้อจำกัดเชิงปฏิบัติจำนวนมากที่มีผลต่อความถูกต้องและความน่าเชื่อถือของโมเดล โดยประเด็นสำคัญคือ ความต่างของข้อมูลระหว่างไซต์ (non‑IID) ซึ่งประกอบด้วยความแตกต่างของประชากรผู้ป่วย (age, comorbidity), อุปกรณ์ทางการแพทย์ (ผู้ผลิตสแกนเนอร์/เครื่อง X‑ray), โปรโตคอลการสแกนและการป้ายป้ายกำกับ (labeling practice) ทำให้การรวมอัปเดตจากหลายไซต์ด้วยวิธีมาตรฐานเช่น FedAvg อาจนำไปสู่การชะงักของการเรียนรู้ (divergence) หรือการลดประสิทธิภาพเฉพาะโดเมน ตัวอย่างเช่น งานวิจัยเชิงทดลองรายงานว่า non‑IID สามารถลดความแม่นยำโดยรวมได้หลายเปอร์เซ็นต์และต้องการรอบการสื่อสารเพิ่มขึ้นอย่างมีนัยสำคัญเพื่อให้โมเดลรวมตัวได้ดีขึ้น
นอกจากนี้ โครงสร้างพื้นฐานภายในโรงพยาบาลยังเป็นคอขวดที่สำคัญ ทั้งด้าน bandwidth ที่จำกัด ความสามารถในการประมวลผล (GPU/edge compute) ที่แตกต่างกันระหว่างศูนย์ และ latency ที่สูงเมื่อเชื่อมต่อระยะไกล สิ่งเหล่านี้ส่งผลโดยตรงต่อความถี่ของการซิงก์พารามิเตอร์ จำนวนข้อมูลอัปเดตต่อรอบ และเวลาตอบสนองของระบบ โดยเฉพาะในบริบทที่ต้องการการอัปเดตแบบ near‑real‑time เพื่อการสนับสนุนการตัดสินใจทางคลินิก
ด้านความเสี่ยงเชิงการใช้งาน ยังต้องคำนึงถึง model drift (การเปลี่ยนแปลงของการแจกแจงข้อมูลเมื่อเวลาผ่านไป) และความยากในการตรวจสอบผลลัพธ์ทางคลินิกแบบอัตโนมัติ การเปลี่ยนแปลงของชุมชนผู้ป่วยหรือการปรับเปลี่ยนโปรโตคอลการรักษาอาจทำให้โมเดลเสื่อมสภาพอย่างช้าๆ หากไม่มีระบบ monitoring และการเวอร์ชันคอนโทรลที่มั่นคง
เทคนิคเชิงเทคนิคเพื่อแก้ไขข้อจำกัด
- จัดการ non‑IID ด้วยวิธีการรวมที่ทนทาน: ใช้อัลกอริทึมเช่น FedProx (proximal term), robust aggregation (median, trimmed mean, Krum), หรือนำแนวทาง meta‑learning และ personalization (fine‑tuned adapters หรือ client‑specific heads) เพื่อให้โมเดลรับมือความแตกต่างของโดเมนได้ดีขึ้น
- ลดความต้องการแบนด์วิดท์และ compute: ใช้การบีบอัดพารามิเตอร์ (quantization, sparsification, top‑k updates), ส่งเฉพาะ deltas/gradients ที่สำคัญ, ใช้ parameter‑efficient fine‑tuning เช่น LoRA หรือ adapters เพื่อให้ต้องการหน่วยความจำและ GPU น้อยลง และพิจารณาเทคนิค federated distillation เมื่อ client เป็นอุปกรณ์ขอบที่เบา
- รองรับสภาพแวดล้อมแบบ heterogeneous: ออกแบบสถาปัตยกรรมการฝึกแบบ asynchronous หรือ semi‑synchronous ที่ยอมรับผู้เข้าร่วมที่ช้ากว่า โดยเพิ่มกลไกการจัดคิวและการจัดลำดับเพื่อหลีกเลี่ยงการรอคอย และใช้ scheduling ที่ปรับตามความสามารถของแต่ละไซต์
- ป้องกันความเสี่ยงทางความปลอดภัยและความเป็นส่วนตัว: ใช้ secure aggregation, homomorphic encryption ในส่วนที่จำเป็น และ differential privacy เมื่อมีข้อกำหนดทางกฎหมาย แม้ว่าต้องแลกมาด้วย trade‑off ทางความแม่นยำ — ควรกำหนดพารามิเตอร์ความเป็นส่วนตัวอย่างเป็นระบบ
- ระบบตรวจจับและจัดการ model drift: ติดตั้ง pipeline สำหรับการมอนิเตอร์แบบต่อเนื่อง (performance metrics, calibration, data‑distribution drift detectors) และนิยมนำ threshold‑triggered evaluation/rollback พร้อมบันทึกเมตริกตามเวอร์ชันโมเดล
แนวปฏิบัติด้านการกำกับดูแลและการตรวจสอบทางคลินิก
- กำกับดูแลข้อมูลและการตัดสินใจเชิงนโยบาย: จัดตั้ง governance board ร่วมระหว่างโรงพยาบาล ผู้เชี่ยวชาญด้านคลินิก และนักเทคนิค เพื่อกำหนดนโยบายการยินยอม การใช้งาน และมาตรฐานความปลอดภัยของโมเดล
- การตรวจสอบเชิงคลินิกแบบเป็นขั้นตอน: ก่อนนำไปใช้ในคลินิก ต้องผ่านการทดสอบย้อนหลัง (retrospective validation), การตรวจสอบภายนอก (external validation) และการทดลองเชิงทดลอง (prospective pilot) ในสภาพแวดล้อมที่ควบคุมได้ จนกว่าจะมีหลักฐานว่าปรับปรุงการตัดสินใจทางการแพทย์จริง
- มาตรการความโปร่งใสและการรับผิดชอบ: บันทึก provenance ของข้อมูลและโมเดล เวอร์ชันคอนโทรลของ weights และ hyperparameters พร้อม log การตัดสินใจของโมเดลเพื่อให้สามารถ audit ได้เมื่อเกิดเหตุไม่พึงประสงค์
- แผนรับมือในกรณีล้มเหลว: กำหนดเกณฑ์ยอมรับความเสี่ยง (acceptance criteria), มาตรการ rollback อัตโนมัติ รวมทั้งช่องทางการเปิดเผยและแก้ไขเมื่อโมเดลทำงานผิดพลาดทางคลินิก
สรุปเชิงปฏิบัติ
Federated Fine‑Tuning ให้โอกาสอันสำคัญในการยกระดับโมเดลวินิจฉัยโดยไม่แลกเปลี่ยนข้อมูลคนไข้ แต่การนำมาใช้งานจริงในเครือโรงพยาบาลไทยต้องเผชิญกับปัญหา non‑IID, ข้อจำกัดโครงสร้างพื้นฐาน และความเสี่ยงจาก model drift ที่ต้องการทั้งเทคนิคเชิงวิศวกรรมและกรอบการกำกับดูแลเชิงคลินิกที่เข้มแข็ง การลงทุนในโซลูชันการบีบอัดข้อมูล, เทคนิค personalization, ระบบมอนิเตอร์แบบเรียลไทม์ และกระบวนการ validation ทางคลินิกที่เป็นระบบ จะช่วยลดความเสี่ยงและเพิ่มโอกาสให้โครงการ Federated Learning ประสบความสำเร็จในเชิงการใช้งานจริง
แนวทางสู่การใช้งานจริงและผลกระทบต่อระบบสุขภาพไทย
แนวทางการสเกลจาก Pilot → Regional → National
การนำ Federated Fine‑Tuning (FFT) ไปสู่การใช้งานจริงต้องเป็นไปตามกระบวนการแบบขั้นบันได (phased rollout) เพื่อควบคุมความเสี่ยงและพิสูจน์คุณค่าเชิงคลินิกและเชิงธุรกิจในบริบทไทย แผนสเกลควรประกอบด้วยสามระยะหลัก: Pilot (ข้อพิสูจน์แนวคิดในกลุ่มตัวอย่างจำกัด), Regional (ขยายในเครือข่ายระดับภูมิภาค) และ National (ปรับใช้ระดับประเทศ) โดยแต่ละขั้นต้องกำหนดเกณฑ์การย้ายขั้นอย่างชัดเจน
- เกณฑ์ย้ายจาก Pilot เป็น Production: ตัวอย่างเกณฑ์เชิงปริมาณและเชิงคุณภาพ เช่น ค่าประสิทธิภาพทางคลินิกที่วัดได้ (เช่น sensitivity ≥ 0.90 หรือ AUC ≥ 0.85 ในงานวินิจฉัยที่เกี่ยวข้อง ตามมาตรฐานการประเมินก่อนหน้า), อัตราการยอมรับจากบุคลากรทางการแพทย์ ≥ 75%, ความเสถียรของระบบในการประมวลผลต่อเนื่อง ≥ 99% uptime, และผลประโยชน์ทางเศรษฐศาสตร์ที่คุ้มค่าภายในระยะเวลาที่กำหนด (เช่น ROI ภายใน 12–24 เดือน)
- การจัดการความเสี่ยงระหว่างสเกล: ต้องมีการออกแบบกลไกการตรวจจับและตอบสนองความเสี่ยง เช่น การตรวจสอบการลอยของข้อมูล (data drift), การตั้งค่าเกณฑ์แจ้งเตือน (alert thresholds), แผน rollback อัตโนมัติในกรณีที่ผลลัพธ์เบี่ยงเบน, และการทดสอบความเป็นส่วนตัว (privacy stress tests) เช่น การใช้ differential privacy และ secure aggregation ในการแลกเปลี่ยนน้ำหนักโมเดล
- การประเมินต่อเนื่อง: ระหว่างการขยายระบบ ต้องมีการวัดผลเป็นชุด (batch) และแบบเรียลไทม์ โดยรวมทั้งตัวชี้วัดทางคลินิก (outcome measures), ตัวชี้วัดการใช้งาน (adoption/usage), และผลกระทบทางเศรษฐกิจ (cost per case, throughput)
บทบาทและความรับผิดชอบของผู้มีส่วนได้ส่วนเสีย
การใช้งาน FFT ในระบบสุขภาพต้องอาศัยความร่วมมือระหว่างหลายภาคส่วน แต่ละหน่วยมีบทบาทเฉพาะเพื่อให้การดำเนินงานปลอดภัย มีประสิทธิภาพ และยั่งยืน
- โรงพยาบาล: เป็นแหล่งข้อมูลเชิงคลินิกและผู้ใช้งานหลัก รับผิดชอบด้านคุณภาพข้อมูล การปฏิบัติตามจริยธรรมและการให้ความยินยอมของผู้ป่วย (informed consent) และการฝึกอบรมเจ้าหน้าที่เพื่อใช้งานระบบอย่างถูกต้อง โรงพยาบาลยังต้องมีทีม IT/AI governance เพื่อควบคุมการเชื่อมต่อกับ federation
- กระทรวงสาธารณสุข (สธ.): ทำหน้าที่กำกับนโยบาย มาตรฐานความปลอดภัยของข้อมูลสุขภาพ และการรับรองเทคโนโลยี ควรจัดทำกรอบการกำกับดูแล (regulatory sandbox) เพื่ออนุญาตการทดลองในสภาพแวดล้อมที่ควบคุมได้ รวมถึงการจัดตั้งศูนย์ประเมินผลกลาง (central evaluation body) สำหรับการรับรองโมเดล
- ผู้ผลิตซอฟต์แวร์/ผู้พัฒนาโมเดล: รับผิดชอบการจัดเตรียมซอฟต์แวร์ที่ปลอดภัย รองรับมาตรฐานการเชื่อมต่อ (interoperability) และมีฟีเจอร์ด้านการตรวจสอบ (explainability) ทีมพัฒนาควรจัดทำเอกสารสถาปัตยกรรม ความเสี่ยง และแผนการบำรุงรักษาระยะยาว รวมถึงโมเดลธุรกิจที่ชัดเจน เช่น licensing, subscription, หรือตามการใช้งาน (pay-per-use)
- ผู้ป่วย: เป็นศูนย์กลางของการเปลี่ยนแปลง ต้องได้รับข้อมูลเกี่ยวกับการใช้ข้อมูลและประโยชน์/ความเสี่ยงอย่างชัดเจน ระบบต้องเปิดช่องทางให้ผู้ป่วยสามารถให้/ถอนความยินยอม และมีมาตรการคุ้มครองสิทธิ์ในการเข้าถึงข้อมูลและการร้องเรียน
ผลกระทบระยะยาวต่อระบบสุขภาพไทย
การนำ FFT มาใช้อย่างปลอดภัยและมีการกำกับอย่างมีประสิทธิภาพสามารถเปลี่ยนโฉมการวินิจฉัยและการเข้าถึงบริการสุขภาพในไทยได้หลายมิติ ตัวอย่างผลกระทบระยะยาวคือการเพิ่มการเข้าถึงการวินิจฉัยคุณภาพสูงในพื้นที่ห่างไกล ลดเวลาในการรับบริการ และลดความเหลื่อมล้ำด้านผลลัพธ์
- เพิ่มการเข้าถึงการวินิจฉัยที่มีคุณภาพ: เมื่อโมเดลถูกปรับปรุงจากหลายโรงพยาบาลผ่าน FFT จะส่งผลให้โมเดลครอบคลุมความหลากหลายของประชากรไทยมากขึ้น ตัวอย่างเช่น ในกรณีงานอ่านภาพรังสี โมเดลที่ผ่านการฝึกร่วมอาจลดอัตราการอ่านซ้ำและเพิ่มความแม่นยำในพื้นที่ชนบท ส่งผลให้ผู้ป่วยได้รับการวินิจฉัยเร็วขึ้นและลดภาระการส่งต่อ
- ลดความเหลื่อมล้ำด้านสุขภาพ: ด้วยข้อมูลที่หลากหลายจากหลายภูมิภาค โมเดลจะมีความเป็นตัวแทนของกลุ่มประชากรที่เคยถูกมองข้าม ส่งผลให้การวินิจฉัยและการรักษาไม่เอียงไปในกลุ่มเมืองเท่านั้น ซึ่งในระยะยาวจะช่วยลดช่องว่างของผลลัพธ์ด้านสุขภาพ (health outcome disparity)
- ประโยชน์ทางเศรษฐกิจและระบบ: การใช้ FFT ช่วยลดต้นทุนการพัฒนาโมเดลแบบรวมศูนย์และลดความซ้ำซ้อนระหว่างโรงพยาบาล ส่งผลให้เกิดการใช้ทรัพยากรร่วมกัน (shared infrastructure) และมีโอกาสสร้างโมเดลบริการใหม่ ๆ เช่น ระบบช่วยตัดสินใจที่โรงพยาบาลขนาดเล็กสามารถเช่าใช้ได้ ซึ่งสนับสนุนการดูแลสุขภาพเชิงป้องกันและลดการรับรักษาที่มีค่าใช้จ่ายสูง
แผนการเรียนรู้จากการทดลองเพื่อการปรับใช้อย่างปลอดภัย
การทดลอง (pilots) ต้องออกแบบให้เก็บบทเรียนเชิงปฏิบัติ เช่น ปัญหาด้านความเข้ากันได้ของข้อมูล ข้อจำกัดด้านเครือข่าย และปฏิกิริยาของผู้ใช้งาน โดยควรกำหนดกระบวนการเรียนรู้ที่ชัดเจน ได้แก่ การทบทวนผลเป็นรอบ (post‑pilot reviews), การทำ audit อิสระด้านความปลอดภัยและจริยธรรม, และการรวม feedback จากผู้ป่วยและบุคลากรทางการแพทย์เพื่อนำมาปรับปรุงเวอร์ชันต่อไป
- มาตรการติดตามผล: กำหนด KPI ชัดเจน เช่น อัตราการยอมรับของแพทย์, การเปลี่ยนแปลงในการวินิจฉัยที่มีนัยสำคัญ, เวลาเฉลี่ยในการตัดสินใจ และผลลัพธ์ระยะยาวของผู้ป่วย
- การฝึกอบรมและการเปลี่ยนผ่าน: จัดโปรแกรมฝึกอบรมเชิงปฏิบัติ เพื่อให้ผู้ปฏิบัติงานทางการแพทย์เข้าใจขอบเขตการใช้งาน ข้อจำกัดของโมเดล และกระบวนการ escalation เมื่อผลลัพธ์ไม่สอดคล้องกับบริบทคลินิก
- การจัดโมเดลธุรกิจและแรงจูงใจ: ออกแบบโมเดลธุรกิจที่ชัดเจนสำหรับการบำรุงรักษาและการกระจายรายได้ เช่น การแบ่งผลประโยชน์จากการประหยัดต้นทุนระหว่างโรงพยาบาลและผู้พัฒนาระบบ เพื่อสร้างแรงจูงใจให้เครือข่ายเข้าร่วมอย่างต่อเนื่อง
สรุปแล้ว การผลักดัน Federated Fine‑Tuning ในโรงพยาบาลไทยจำเป็นต้องมีแผนสเกลที่เป็นระบบ เกณฑ์การย้ายขั้นที่ชัดเจน กลไกการจัดการความเสี่ยงที่รัดกุม และกรอบการกำกับดูแลที่สนับสนุนการทดลองอย่างปลอดภัย การดำเนินการเช่นนี้ไม่เพียงช่วยยกระดับคุณภาพการวินิจฉัย แต่ยังเป็นโอกาสในการลดช่องว่างด้านสุขภาพและสร้างระบบบริการที่เข้าถึงได้อย่างทั่วถึงในระยะยาว
บทสรุป
Federated Fine‑Tuning เปิดช่องทางให้โรงพยาบาลร่วมกันปรับปรุงโมเดลวินิจฉัยโดยไม่ต้องแลกเปลี่ยนข้อมูลผู้ป่วยดิบ ทำให้สามารถรักษาความเป็นส่วนตัวตามกฎหมายและจริยธรรมได้ ในการทดลองนำร่องที่รวมโรงพยาบาลหลายแห่ง พบว่าการปรับโมเดลร่วมกันสามารถเพิ่มความแม่นยำเชิงวินิจฉัยเฉลี่ยอยู่ในช่วงประมาณ ร้อยละ 5–8 และมีแนวโน้มลดอัตราผิดพลาดบางประเภทได้ (เช่น ลด false negatives ในกลุ่มตัวอย่างบางชุด) อย่างไรก็ตาม ความสำเร็จเชิงปฏิบัติจำเป็นต้องมาพร้อมมาตรการด้านความปลอดภัยทั้งทางเทคนิคและการประเมินทางคลินิกอย่างเข้มงวด เช่น การใช้ differential privacy, การเข้ารหัสแบบ secure aggregation, ระบบตรวจสอบ (audit trail) และการทดสอบทางคลินิกอิสระก่อนนำไปใช้กับผู้ป่วยจริง
ข้อพิจารณาเชิงเทคนิคและนโยบาย
การขยายผลสู่การใช้งานในวงกว้างต้องแก้ไขปัญหาทั้งเชิงเทคนิคและเชิงนโยบายร่วมกัน ได้แก่ ความหลากหลายของข้อมูลข้ามสถาบัน (data heterogeneity), ค่าใช้จ่ายด้านการสื่อสารและการประสานงาน, การรับรองความถูกต้องของโมเดลข้ามเวอร์ชัน และกรอบการกำกับดูแลเรื่องความรับผิดชอบและการอนุญาต นอกจากนี้ต้องกำหนดมาตรฐานการประเมินด้านคลินิกและการรับรองทางกฎหมายเพื่อให้หน่วยบริการสาธารณสุขสามารถนำโมเดลไปใช้ได้อย่างปลอดภัยและเชื่อถือได้
การผลักดันให้สำเร็จต้องมีความร่วมมือแบบข้ามสาขา — นักวิทย์ข้อมูล แพทย์ ผู้กำกับนโยบาย และผู้ป่วย
มุมมองอนาคต
หากสามารถแก้ไขข้อจำกัดเชิงเทคนิคและออกกรอบนโยบายที่ชัดเจนได้ การนำ Federated Fine‑Tuning มาใช้จะช่วยยกระดับคุณภาพการดูแลผู้ป่วย เพิ่มความเท่าเทียมในการเข้าถึงเทคโนโลยีการแพทย์ระหว่างภูมิภาค และลดความเหลื่อมล้ำ โดยเฉพาะในพื้นที่ชนบทที่ขาดแคลนผู้เชี่ยวชาญ ข้อเสนอเชิงปฏิบัติสำหรับอนาคตได้แก่ การพัฒนามาตรฐานข้อมูลร่วม, ระบบรับรอง (certification) สำหรับโมเดลทางการแพทย์, โครงการนำร่องที่มีการประเมินผลต่อเนื่อง และการสนับสนุนทรัพยากรด้านโครงสร้างพื้นฐานของโรงพยาบาล หากเดินหน้าตามแนวทางเหล่านี้อย่างเป็นระบบ มีโอกาสสูงที่เทคโนโลยีดังกล่าวจะกลายเป็นเครื่องมือสำคัญในการปรับปรุงผลลัพธ์ผู้ป่วยและลดช่องว่างด้านสาธารณสุขในระดับประเทศ



