
โรงพยาบาลชั้นนำในกรุงเทพฯ ประกาศเปิดตัว "Explainable‑Diagnostic Agent" ระบบช่วยวินิจฉัยที่ผสานความสามารถของ Clinical‑LLM กับโมเดลเชิงเหตุผล (causal model) เพื่อให้คำอธิบายการวินิจฉัยและแผนการรักษาที่ทั้งแพทย์และผู้ป่วยเข้าใจได้อย่างชัดเจน ระบบนี้ถูกออกแบบมาไม่เพียงแต่ให้ข้อสรุปทางการแพทย์เท่านั้น แต่ยังแสดงหลักฐาน เหตุผลเชิงสาเหตุ และตัวเลือกการรักษาพร้อมผลลัพธ์เชิงเปรียบเทียบ เพื่อสนับสนุนการตัดสินใจร่วมกัน (shared decision‑making) ระหว่างทีมรักษาและผู้ป่วย
จุดเด่นของโซลูชันนี้คือการรวมภาษาธรรมชาติระดับคลินิกของ LLM ที่ช่วยสรุปประวัติและผลตรวจกับความสามารถของโมเดลเชิงเหตุผลที่สามารถแยกแยะความสัมพันธ์เชิงสาเหตุ ระบุปัจจัยเสี่ยงสำคัญ และประเมินสถานการณ์แบบ counterfactual ผลลัพธ์ที่ได้จึงเป็นคำอธิบายเชิงเหตุผลพร้อมหลักฐานอ้างอิง ที่สามารถปรับเป็นภาษาสำหรับผู้เชี่ยวชาญทางการแพทย์หรือสรุปแบบเข้าใจง่ายสำหรับผู้ป่วย โดยโรงพยาบาลระบุว่าเป้าหมายคือเพิ่มความโปร่งใส ลดความคลุมเครือในการวินิจฉัย และส่งเสริมการร่วมตัดสินใจที่มีข้อมูลประกอบอย่างชัดเจน
บทนำและความสำคัญของข่าว
บทนำและความสำคัญของข่าว
โรงพยาบาลขนาดใหญ่แห่งหนึ่งในกรุงเทพมหานครประกาศเปิดตัวระบบ Explainable‑Diagnostic Agent ซึ่งเป็นระบบวินิจฉัยแบบผสานระหว่าง Clinical‑LLM (Large Language Model ทางคลินิก) กับโมเดลสาเหตุเชิงเหตุผล (causal model) โดยโรงพยาบาลระบุว่าเริ่มใช้งานเชิงนำร่องตั้งแต่วันที่ 1 กุมภาพันธ์ 2026 เพื่อสนับสนุนกระบวนการวินิจฉัยและออกแบบแผนการรักษาให้แพทย์และผู้ป่วยเข้าใจร่วมกันได้มากขึ้น
ตามแถลงข่าวของโรงพยาบาล ระบบดังกล่าวพัฒนาขึ้นโดยความร่วมมือระหว่าง หน่วยวิจัยเทคโนโลยีสารสนเทศการแพทย์ของโรงพยาบาล และ ทีมวิจัยปัญญาประดิษฐ์ทางการแพทย์ จากมหาวิทยาลัย/บริษัทคู่ค้า โดยการนำมาทดลองเชิงนำร่อง (pilot) ครอบคลุมผู้ป่วยประมาณ 500–800 ราย ในช่วง 3 เดือนแรก โรงพยาบาลรายงานผลเบื้องต้นว่าในกลุ่มตัวอย่างมีการลดความไม่แน่นอนในการวินิจฉัยและความขัดแย้งระหว่างแพทย์ประมาณ 15–25% ขณะเดียวกันคะแนนความเข้าใจของผู้ป่วยต่อเหตุผลการรักษาเพิ่มขึ้นประมาณ 20–30% เมื่อเทียบกับการให้ข้อมูลตามปกติ (ข้อมูลตามรายงานนำร่องของโรงพยาบาล)
เป้าหมายเชิงคลินิกของระบบนี้เน้นไปที่ 1) การเพิ่มความโปร่งใสของกระบวนการวินิจฉัยโดยการนำเสนอเหตุผลเชิงสาเหตุและเส้นทางการตัดสินใจ 2) ลดข้อผิดพลาดทางการแพทย์ด้วยการตรวจสอบเชิงตรรกะของการคาดการณ์ และ 3) สนับสนุนการตัดสินใจร่วมกันระหว่างแพทย์และผู้ป่วย (shared decision‑making) โดยระบบจะอธิบายตัวเลือกการรักษา ความเสี่ยง‑ผลประโยชน์ และความแน่นอนของข้อมูลในรูปแบบที่ทั้งแพทย์และผู้ป่วยสามารถเข้าใจได้
ผู้มีส่วนได้ส่วนเสียที่เกี่ยวข้องชัดเจน ได้แก่:
- หน่วยงานพัฒนา: ทีมวิจัย AI ภายในโรงพยาบาลและพันธมิตรภายนอกที่รับผิดชอบโมเดล Clinical‑LLM และการออกแบบ causal model
- ทีมคลินิก: แพทย์เฉพาะทาง พยาบาล และเภสัชกรที่ใช้ผลลัพธ์เชิงอธิบายในการตัดสินใจรักษา
- ผู้ป่วยและญาติ: ผู้รับบริการที่ได้รับคำอธิบายการวินิจฉัยและทางเลือกการรักษาเพิ่มความเข้าใจและมีส่วนร่วมในการตัดสินใจ
- คณะกรรมการจริยธรรมและหน่วยกำกับ: ผู้ประเมินความปลอดภัย ความเป็นส่วนตัว และความโปร่งใสของระบบก่อนขยายผล
- ผู้บริหารและนักธุรกิจทางการแพทย์: ผู้ตัดสินใจด้านงบประมาณ การนำระบบเข้าสู่การใช้งานจริงและการสเกลเชิงพาณิชย์
ไทม์ไลน์การนำร่องและแผนการขยายผลตามที่ระบุในแถลงข่าวและรายงานนำร่องคือ: เริ่มพัฒนาและทดสอบภายในตั้งแต่ไตรมาสสุดท้ายของปี 2025, เปิดใช้งานนำร่องในแผนกผู้ป่วยนอกและผู้ป่วยในบางแผนกตั้งแต่ 1 กุมภาพันธ์ 2026 เป็นเวลา 3 เดือน, ประเมินผลเชิงคุณภาพและเชิงปริมาณเพื่อนำเสนอให้คณะกรรมการโรงพยาบาลภายในไตรมาสถัดไป และหากผลเป็นบวกมีแผนขยายการใช้งานในวงกว้างภายใน 6–12 เดือนถัดไป
สำหรับผู้อ่านที่ต้องการตรวจสอบข้อมูลเพิ่มเติม แหล่งข้อมูลที่ควรอ้างอิงได้แก่ แถลงข่าวของโรงพยาบาล, รายนามผู้วิจัยและทีมพัฒนา ที่ระบุบทบาทและผลงานทางวิชาการ และ รายงานการทดลองนำร่อง ซึ่งมักจะประกอบด้วยเมตริกการประเมินความแม่นยำ การเปรียบเทียบก่อน‑หลัง และผลตอบรับจากผู้ใช้ทั้งแพทย์และผู้ป่วย การอ้างอิงเหล่านี้จะเป็นกุญแจสำคัญในการประเมินความน่าเชื่อถือและความสามารถในการนำไปใช้เชิงปฏิบัติในระบบการแพทย์ต่อไป
สถาปัตยกรรมระบบ: Clinical‑LLM ผสานกับ Causal Model
สถาปัตยกรรมระบบ: Clinical‑LLM ผสานกับ Causal Model
ส่วนสถาปัตยกรรมของระบบ Explainable‑Diagnostic Agent ถูกออกแบบให้ผสานความสามารถของ Clinical‑LLM ที่ได้รับการฝึกจากข้อมูลทางการแพทย์ (เช่น chart notes, guideline, วรรณกรรมทางคลินิก) เข้ากับ causal model แบบกราฟหรือ Structural Causal Model (SCM) เพื่อสร้างเหตุผลเชิงสาเหตุ (causal explanations) และ counterfactual scenarios ที่สามารถตรวจสอบได้โดยแพทย์และผู้ป่วย โครงสร้างหลักแบ่งเป็นคอมโพเนนต์ย่อยที่ชัดเจน ได้แก่ EHR ingestion (ผ่าน FHIR), preprocessing & normalization, Clinical‑LLM inference, causal reasoning module, และ explanation generator โดยมีชั้น safety, logging และ human‑in‑the‑loop ควบคุมตลอดเส้นทางข้อมูล
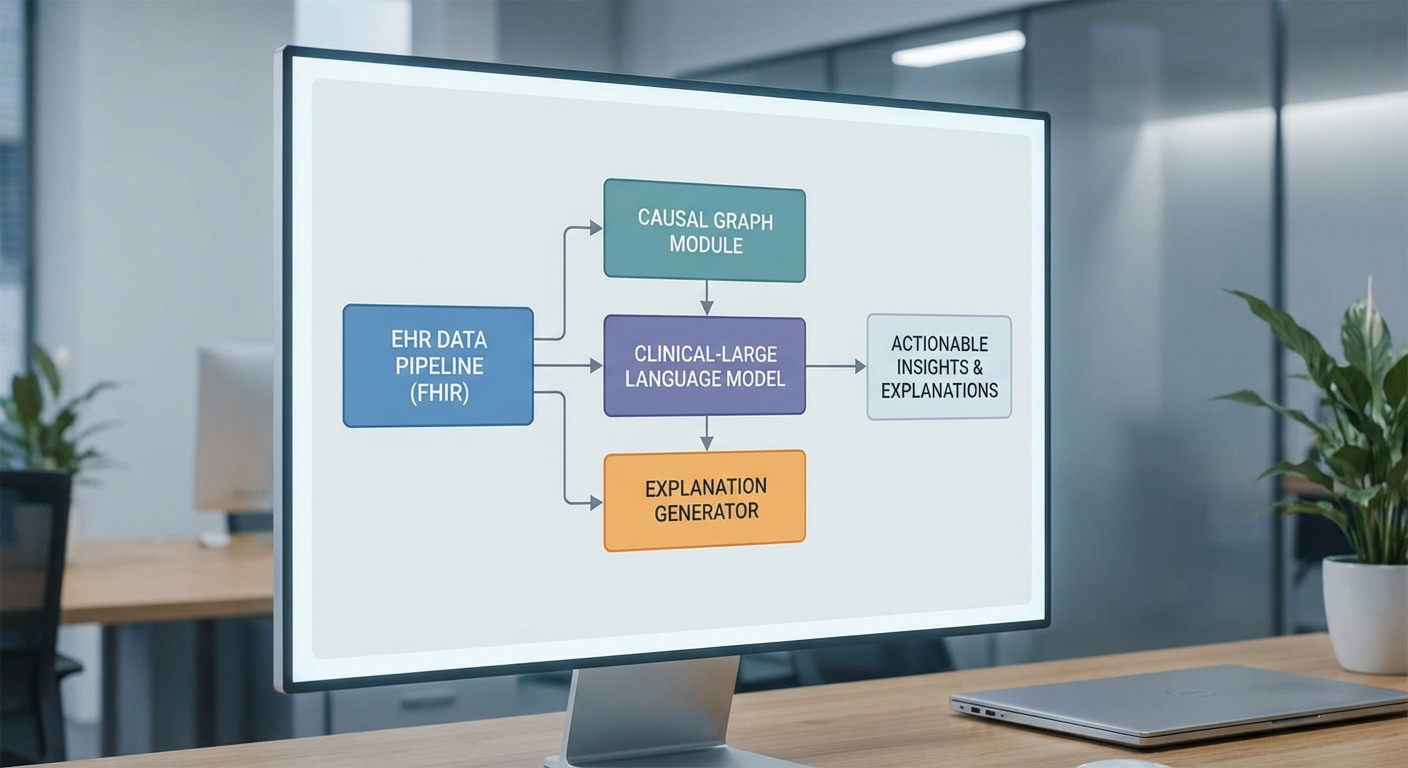
data flow และคอมโพเนนต์หลัก
ลำดับการทำงานเริ่มจาก EHR ingestion ที่เชื่อมต่อกับระบบโรงพยาบาลผ่านมาตรฐาน FHIR (resources เช่น Patient, Observation, Condition, MedicationRequest, DiagnosticReport) โดยมีตัวกลางที่ทำหน้าที่รับข้อมูลแบบเรียลไทม์หรือเป็นชุด (batch) จากนั้นระบบทำ preprocessing ซึ่งประกอบด้วยการลบข้อมูลที่ไม่จำเป็น การ de‑identification หากจำเป็น การแปลงหน่วย การแมปค่าทางคลินิกไปยังมาตรฐานเช่น SNOMED‑CT/LOINC/ICD‑10 และการสกัดคุณลักษณะ (feature extraction) เพื่อส่งต่อให้โมดูลต่อไป
- Clinical‑LLM inference: โมเดลภาษาที่ปรับแต่งด้วยข้อมูลทางการแพทย์ ทำหน้าที่สร้างสมมติฐานทางการแพทย์ (differential diagnoses), คำอธิบายเบื้องต้น และคำขอข้อมูลเพิ่มเติมสำหรับ causal model โมเดลนี้ควรมีการระบุเวอร์ชันและ metadata อย่างชัดเจน (เช่น parameter size: 7B–70B ขึ้นอยู่กับการใช้งาน) และสามารถรันทั้งแบบ on‑premises (สำหรับข้อมูลอ่อนไหว) หรือบน cloud ในกรณีที่ต้องการสเกลสูง
- Causal reasoning module: เก็บเป็นกราฟสาเหตุ (DAG) หรือระบบสมการโครงสร้าง (SCM) ที่นิยามความสัมพันธ์เชิงสาเหตุระหว่างตัวแปรทางคลินิก โมดูลนี้รองรับการคำนวณ counterfactuals, back‑door/front‑door adjustments, และการประมาณผลการแทรกแซง (ATE/CATE) โดยใช้ทั้งข้อมูล observational จาก EHR และ evidence จาก literature
- Explanation generator: ทำหน้าที่รวบรวมผลลัพธ์จากทั้ง LLM และ causal module สร้างคำอธิบายเชิงเหตุผลที่อ่านเข้าใจง่าย พร้อมแสดง provenance (แหล่งข้อมูลที่อ้างอิง), confidence interval, และตัวอย่าง counterfactual ("ถ้าให้ยาตัว A แทน B ผลคาดว่าจะลดความเสี่ยงลง X%")
กลไกความปลอดภัยและความเที่ยงตรงของผลลัพธ์
ระบบถูกเสริมด้วยชุดกลไกความปลอดภัยเพื่อป้องกันประเด็นเช่น hallucination, over‑confident outputs และคำแนะนำที่อาจเป็นอันตราย รวมถึงการออกแบบ human‑in‑the‑loop สำหรับคำตัดสินขั้นสุดท้าย
- Guardrails & safety filters: ใช้ทั้ง rule‑based checks (เช่น ห้ามแนะนำยาที่ขัดกับ contraindications ใน EHR) และ ML‑based classifiers ที่ตรวจจับคำแนะนำเสี่ยงสูงก่อนส่งให้ผู้ใช้
- Hallucination detection & grounding: ทุกคำตอบของ LLM จะถูกตรวจสอบความสอดคล้องกับข้อมูลที่ดึงมาจาก EHR หรือเอกสารทางการแพทย์ที่ retrieval‑augmented generation (RAG) นำมาให้ หากไม่มีหลักฐานประกอบ ระบบจะแสดงสถานะว่าเป็น "hypothesis" และต้องการการตรวจสอบจากผู้เชี่ยวชาญ
- Uncertainty estimation: คำนวณค่าความไม่แน่นอนผ่านเทคนิคเช่น ensemble models, temperature scaling หรือ Bayesian approximations เพื่อแสดงความเชื่อมั่น (confidence intervals / probability scores) ของการวินิจฉัยและการคาดการณ์ผลการรักษา
- Human‑in‑the‑loop: ตั้งค่า threshold ตามความเสี่ยง (เช่น ทุกคำแนะนำที่มีความเสี่ยงสูงหรือ confidence ต่ำกว่าค่าที่กำหนดจะต้องถูกยืนยันโดยแพทย์) พร้อม UI ที่แสดง provenance, causal graph และ counterfactual เพื่อช่วยการตัดสินใจ
ข้อกำหนดเชิงเทคนิคและการปฏิบัติการ
การออกแบบระบบต้องตอบโจทย์เชิงปฏิบัติการและความปลอดภัยทางกฎหมาย ดังนี้
- Latency: เป้าหมายด้านประสบการณ์ผู้ใช้ควรแยกตามกรณีการใช้งาน — latency แบบ interactive (triage / quick assist) ควรอยู่ในช่วง ≤ 1–2 วินาที สำหรับการตอบสั้น ๆ ในขณะที่การเรียกใช้ causal reasoning บนชุดข้อมูลหรือการคำนวณ counterfactual อาจมี latency สูงกว่า (ประมาณ 2–8 วินาที) ขึ้นกับความซับซ้อนและขนาดข้อมูล
- ขนาดโมเดล & การปรับตั้ง: สำหรับงานที่ต้องการความเป็นส่วนตัวสูง ควรพิจารณาโมเดลขนาดกลาง (7–13B) รัน on‑premises พร้อม accelerator (GPU/TPU) ในขณะที่งานที่ต้องการความสามารถเชิงภาษาและสเกลสูงอาจใช้โมเดลใหญ่ (30–70B) บน cloud โดยมีโซลูชัน hybrid เพื่อรักษาความลับของข้อมูลสำคัญ
- การเข้ารหัสและคีย์การจัดการ: ข้อมูลต้องถูกเข้ารหัสระหว่างทางด้วย TLS 1.3 และเข้ารหัสที่พักด้วย AES‑256 ที่มีการจัดการคีย์ผ่าน HSM หรือ KMS ที่ได้มาตรฐาน (FIPS 140‑2/3) นอกจากนี้ควรพิจารณาการใช้เทคนิคเช่น tokenization ของข้อมูลส่วนบุคคลและ differential privacy ในขั้นตอนการฝึกโมเดล
- การปฏิบัติตามข้อกฎหมาย: รองรับข้อกำหนด PDPA ในประเทศไทย และหากมีการทำงานร่วมกับระบบระหว่างประเทศต้องคำนึงถึง HIPAA/GDPR ตามบริบท
logging, auditability และการตรวจสอบภายหลัง
เพื่อรองรับการตรวจสอบภายหลังและการประกันคุณภาพ ระบบจะเก็บ immutable audit logs ของทุกคำขอและคำตอบ ซึ่งประกอบด้วยแฮชของ input, เวอร์ชันของโมเดล, provenance ของข้อมูลอ้างอิง, snapshots ของ causal graph และผลลัพธ์ของการตรวจจับ hallucination logs จะถูกจัดเก็บในรูปแบบที่สามารถค้นหาและเรียกคืนได้ภายใต้การควบคุมสิทธิ์ (RBAC) และการรักษาความลับ
- ระยะเวลาการเก็บรักษา logs ควรเป็นไปตามข้อบังคับของสถาบัน — โดยทั่วไปแนะนำให้เก็บอย่างน้อย 7 ปีสำหรับกรณีการรักษาทางการแพทย์
- ระบบควรสนับสนุนการย้อนกลับ (reproducibility) โดยการเก็บ seed, environment metadata และ dataset snapshots ที่ใช้ในการ inference เพื่อให้สามารถทำการ audit หรือ forensic analysis ได้
สถาปัตยกรรมดังกล่าวมุ่งเน้นการนำ AI ที่มีความสามารถด้านภาษาและเหตุผลเชิงสาเหตุมาประยุกต์ใช้ในคลินิกอย่างปลอดภัยและตรวจสอบได้ โดยให้แพทย์เป็นผู้ตัดสินใจขั้นสุดท้าย พร้อมทั้งสร้างคำอธิบายที่ชัดเจนและมีหลักฐานรองรับ (evidence‑backed explanations และ counterfactuals) เพื่อเพิ่มความเชื่อมั่นทั้งต่อแพทย์และผู้ป่วย
การอธิบายได้เชิงคลินิก (Explainability) ด้วยโมเดลเชิงเหตุผล
การอธิบายได้เชิงคลินิก (Explainability) ด้วยโมเดลเชิงเหตุผล
ระบบ Explainable‑Diagnostic Agent ผสาน Clinical‑LLM กับ causal model เพื่อให้การวินิจฉัยและแผนการรักษาไม่ได้เป็นเพียงผลลัพธ์เชิงสถิติเท่านั้น แต่ยังเป็นชุดคำอธิบายเชิงเหตุผลที่แพทย์และผู้ป่วยเข้าใจได้ ช่วยเชื่อมช่องว่างระหว่างการคาดการณ์ของโมเดลกับการตัดสินใจทางคลินิกโดยตรง โดยหลักการคือการสร้าง causal graph ที่ระบุสาเหตุหลัก ปัจจัยเสี่ยง และเส้นทางเหตุผล (causal pathways) ระหว่างอาการ ผลการตรวจ และผลลัพธ์ที่คาดหวัง
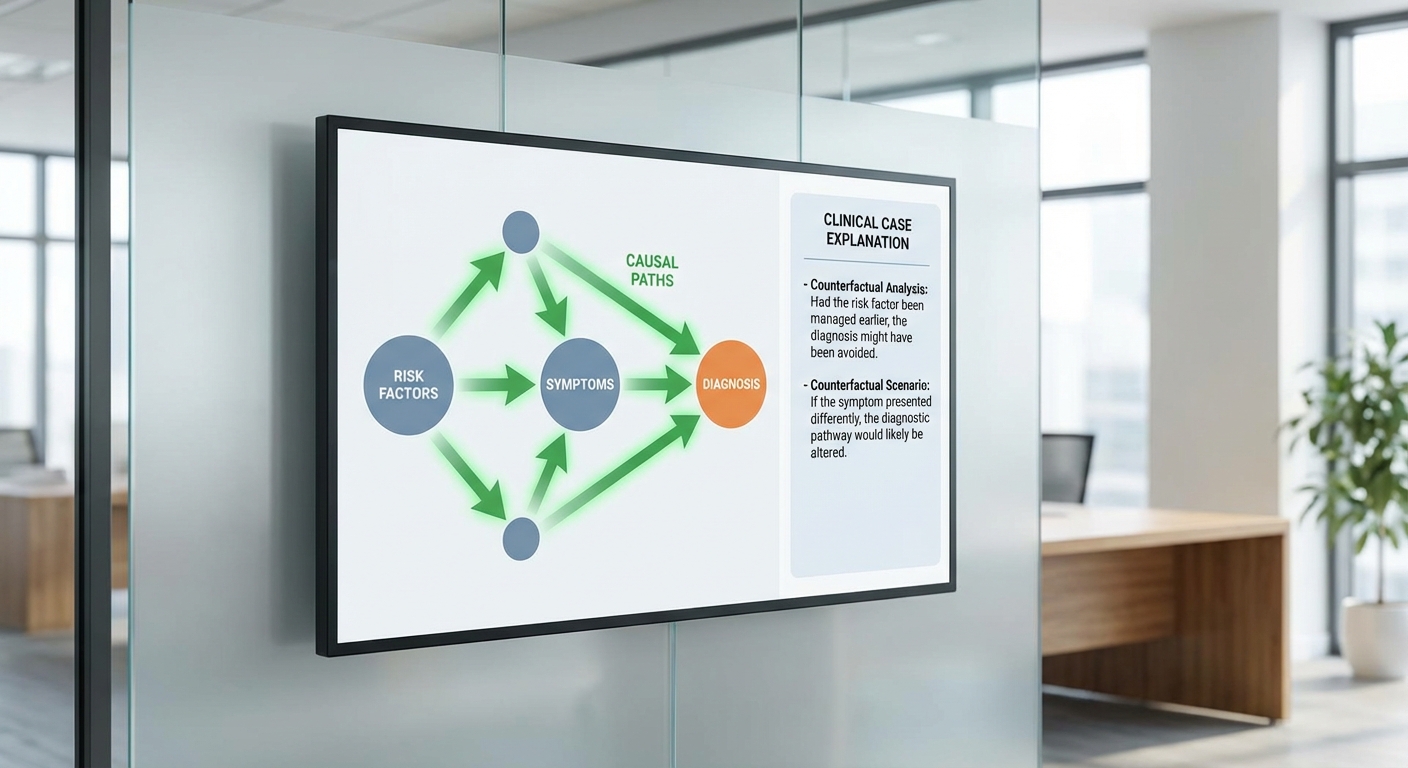
ในเชิงปฏิบัติ causal model จะให้รูปแบบคำอธิบายหลายมิติ ได้แก่
- Causal pathway — แสดงเส้นทางเหตุผลจากปัจจัยเสี่ยงไปสู่ผลลัพธ์ เช่น หลอดเลือดตีบ → หลอดเลือดอุดตัน → ภาวะกล้ามเนื้อหัวใจขาดเลือด พร้อมน้ำหนักความสัมพันธ์และความเชื่อมั่น
- Counterfactual statements — คำอธิบายแบบ “ถ้า…จะเป็นอย่างไร” เพื่อประเมินผลของการเปลี่ยนแปลงเหตุการณ์หรือการแทรกแซง เช่น “หากลดคอเลสเตอรอลลง 30% ความเสี่ยงการเกิด MI ลดลงประมาณ x%”
- Confidence intervals และ probabilistic effect sizes — ระบุช่วงความไม่แน่นอน เช่น ผลกระทบประมาณการเพิ่มความเสี่ยง 18% (95% CI 10–26%) แทนการให้ค่าเดียวเพียงอย่างเดียว
- Alternative hypotheses — ระบุสาเหตุอื่นที่เป็นไปได้ พร้อมน้ำหนักสนับสนุนจากข้อมูล เช่น GERD, กล้ามเนื้อลายหน้าอก, ปัญหาเครียด/วิตกกังวล
การแปลงศัพท์ทางการแพทย์เป็นภาษาที่ผู้ป่วยเข้าใจได้เป็นอีกหน้าที่สำคัญของระบบ: ข้อความสำหรับแพทย์จะเน้นความแม่นยำเชิงเทคนิค ขณะที่ข้อความสำหรับผู้ป่วยจะเรียบง่าย ชัดเจน และมีข้อเสนอการตัดสินใจที่เป็นรูปธรรม เช่น “ความเป็นไปได้หลักคือกล้ามเนื้อหัวใจขาดเลือด — แนะนำตรวจ ECG และตรวจเอนไซม์หัวใจภายใน 6 ชั่วโมง”
ตัวอย่างคำอธิบายระบบ (ตัวอย่างจริงของการตอบ)
สำหรับแพทย์ (เชิงเทคนิค):
"การประเมินเบื้องต้นชี้ให้เห็นว่า หลอดเลือดหัวใจอุดตัน (ACS) เป็นสาเหตุที่น่าจะเป็นไปได้ที่สุด โดย causal pathway ที่สนับสนุน: อายุ > 55 ปี → โรคหลอดเลือดหัวใจจากไขมันสะสม (atherosclerosis) → ปัจจัยกระตุ้น (ความเครียด/ออกแรง) → thrombosis. ความเสี่ยงสัมพัทธ์ (estimated attributable risk) สำหรับ ACS เพิ่มขึ้น 18% (95% CI 10–26%) ในผู้ป่วยกลุ่มนี้เทียบกับ baseline. Counterfactual: หากให้ยาแก้เกล็ดเลือด (aspirin) ภายใน 1 ชั่วโมง ความเสี่ยงของภาวะแทรกซ้อนจากลิ่มเลือดคาดว่าจะลดลง 6–9% (95% CI 3–12%). Alternative hypotheses: GERD (weight 0.21), กล้ามเนื้อลายหน้าอก (musculoskeletal, weight 0.18). แนะนำ: ทำ ECG และตรวจ troponin x2 (0h, 3–6h); หากพบ ST‑elevation ให้พิจารณา reperfusion ทันที."
สำหรับผู้ป่วย (ภาษาง่าย):
"อาการเจ็บหน้าอกของคุณมีความเป็นไปได้สูงที่มาจากภาวะขาดเลือดของหัวใจ (เช่น หลอดเลือดหัวใจตีบหรืออุดตัน) ซึ่งเกิดจากไขมันอุดตันในหลอดเลือด เราแนะนำให้ตรวจคลื่นไฟฟ้าหัวใจ (ECG) และตรวจเลือดเพื่อหาเอนไซม์หัวใจเพื่อตรวจสอบ หากตรวจพบสัญญาณดังกล่าว การรักษาเร่งด่วนสามารถลดความเสี่ยงได้มาก โปรดปฏิบัติตามคำแนะนำแพทย์ทันที"
เมตริกการประเมิน Explainability
การวัดคุณภาพคำอธิบายต้องครอบคลุมหลายมิติหลัก:
- Fidelity — ความสอดคล้องระหว่างคำอธิบายกับโมเดลฐาน (base model). วัดเป็นอัตราการรักษา prediction เดิมเมื่อคำอธิบายถูกใช้เป็นตัวแทนทางเหตุผล (ตัวอย่าง: fidelity = 92% แปลว่าคำอธิบายสะท้อนการตัดสินใจของโมเดลได้สูง)
- Plausibility — ความสมจริงตามมาตรฐานการแพทย์หรือแนวทางคลินิก วัดโดยการให้ผู้เชี่ยวชาญประเมิน (เช่น อัตราความเห็นชอบของแพทย์ต่อคำอธิบายว่ามีเหตุผลทางคลินิก = 87%)
- Comprehension / Comprehensibility — การที่ผู้ใช้ (แพทย์หรือผู้ป่วย) เข้าใจคำอธิบาย วัดด้วยแบบทดสอบความเข้าใจหรือการประเมินความพึงพอใจของผู้ใช้ (เช่น ร้อยละของผู้ป่วยที่รายงานว่าเข้าใจคำอธิบาย = 81%)
นอกจากนี้ควรวัดผลเชิงพฤติกรรม เช่น อัตราการเปลี่ยนแปลงการตัดสินใจทางคลินิกหลังรับคำอธิบาย (decision change rate), เวลาในการตัดสินใจลดลง และการยอมรับจากผู้ป่วยในการปฏิบัติตามข้อเสนอการรักษา
ผลการทดลองนำร่อง (สรุปเชิงสถิติ)
จากการทดลองนำร่องภายในโรงพยาบาลใหญ่ในกรุงเทพ จำนวนผู้ใช้ตัวอย่างประกอบด้วยแพทย์ด้านฉุกเฉินและอายุรกรรมรวม 120 คน และผู้ป่วยไปรับบริการฉุกเฉิน 300 ราย ผลสำคัญที่สังเกตได้มีดังนี้:
- ร้อยละ 78 ของแพทย์ประเมินว่า คำอธิบายเชิงเหตุผล ช่วยให้ตัดสินใจในการจัดลำดับความสำคัญและการตรวจเพิ่มเติมได้ดีขึ้น
- Fidelity ของคำอธิบายเทียบกับโมเดลฐาน = 92%
- Plausibility (การยอมรับโดยแพทย์เฉลี่ย) = 87%
- Comprehension ของผู้ป่วย (รายงานตนเองว่าเข้าใจคำอธิบายและเหตุผล) = 81%
- อัตราการเปลี่ยนแปลงแผนการรักษาหลังรับคำอธิบาย = 24% (ส่วนใหญ่เป็นการเพิ่มการตรวจยืนยัน เช่น ECG/เอนไซม์หัวใจหรือ CT coronary)
ตัวเลขเหล่านี้สะท้อนว่าการผสมผสานระหว่าง Clinical‑LLM และ causal model สามารถยกระดับทั้งความโปร่งใสและการนำไปปฏิบัติจริงในการดูแลผู้ป่วยได้อย่างเป็นรูปธรรม
บทสรุปและข้อพิจารณา
การอธิบายได้เชิงคลินิกโดยใช้โมเดลเชิงเหตุผลไม่เพียงเพิ่มความเข้าใจ แต่ยังเพิ่มความเชื่อมั่นในการตัดสินใจทางการแพทย์โดยการนำเสนอเส้นทางเหตุผล (causal pathways), คำอธิบายเชิง counterfactual, ช่วงความไม่แน่นอน (confidence intervals) และทางเลือกวินิจฉัย/การรักษา (alternative hypotheses) อย่างชัดเจน การประเมินตามเกณฑ์ fidelity, plausibility, และ comprehensibility ควรเป็นส่วนหนึ่งของการนำระบบไปใช้จริง เพื่อให้มั่นใจว่าคำอธิบายทั้งถูกต้อง เชื่อถือได้ และเข้าใจได้ทั้งในระดับแพทย์และผู้ป่วย
การประยุกต์ใช้งานจริงใน workflow ทางคลินิก
การประยุกต์ใช้งานจริงใน workflow ทางคลินิก
ระบบ Explainable‑Diagnostic Agent ที่ผสาน Clinical‑LLM กับ causal model ถูกนำไปใช้งานเชิงปฏิบัติการในหลายจุดสำคัญของโรงพยาบาลเพื่อเสริมกระบวนการวินิจฉัยและการวางแผนรักษา โดยจุดนำร่องประกอบด้วย ห้องฉุกเฉิน (ER) สำหรับการ triage, การเยี่ยมผู้ป่วยในระหว่าง ward rounds, และ คลินิกเฉพาะทาง (specialty clinics) รวมถึงใช้เป็นเครื่องมือสนับสนุนในการประชุมร่วมหลายสหสาขาวิชาชีพ (MDT) และการติดตามผลหลังการรักษา ทั้งนี้ระบบออกแบบมาเพื่อให้คำอธิบายเป็นเหตุเป็นผล (causal explanations) ที่เข้าใจได้ทั้งโดยแพทย์และผู้ป่วย ช่วยลดความกำกวมของข้อเสนอแนะเชิง AI และเพิ่มความโปร่งใสในกระบวนการตัดสินใจ

ในเชิงปฏิบัติ ระบบถูกผนวกรวมเข้าไปใน workflow ดังนี้:
- ER / Triage: ระบบประมวลผลข้อมูลผู้ป่วยเบื้องต้นจากอาการสำคัญ สัญญาณชีพ และบันทึกจาก EHR เพื่อให้คะแนนความเสี่ยงเชิงสาเหตุ (causal risk score) พร้อมคำอธิบายเหตุผลและข้อเสนอแนะแรกเริ่ม เช่น การสั่งตรวจเลือดอย่างเร่งด่วนหรือการให้ยาตามลำดับความเสี่ยง แพทย์ฉุกเฉินใช้ผลลัพธ์เหล่านี้เป็นข้อมูลสนับสนุนการตัดสินใจ แต่ยังคงเป็นผู้มีอำนาจตัดสินใจขั้นสุดท้าย
- Ward rounds: ในการเยี่ยมผู้ป่วย ระบบสรุป trajectory ทางคลินิก แสดง causal chain ของภาวะปัจจุบันกับการตอบสนองต่อการรักษา และชี้จุดที่ควรปรับเปลี่ยนยา/การตรวจติดตาม ทำให้ทีมรักษาเห็นภาพรวมเร็วขึ้นและโฟกัสข้อสงสัยสำคัญระหว่างการเยี่ยม
- MDT (ประชุมสหสาขาวิชาชีพ): ระบบสร้างสรุปเคสที่มีความเป็นเหตุเป็นผลพร้อมตัวเลือกแผนรักษาที่แสดงผลลัพธ์เชิงความน่าจะเป็น ช่วยให้ผู้เชี่ยวชาญหลายสาขาเข้าใจฐานเหตุผลเดียวกันและเร่งกระบวนการตกลงแนวทางการรักษาร่วมกัน
- การติดตามผล (Follow‑up): ระบบติดตามค่าทรานด์สำคัญ แจ้งเตือนเชิงสาเหตุเมื่อพบแนวโน้มเสี่ยงต่อการลุกลามหรือภาวะแทรกซ้อน และให้คำแนะนำการปรับแผนรักษาที่สามารถตรวจสอบย้อนกลับได้
ผลลัพธ์จากการนำร่อง (Pilot) ที่ดำเนินการในโรงพยาบาลใหญ่กรุงเทพ สรุปดังนี้: การทดลองครอบคลุม 250 เคส แบ่งเป็น ER 120 เคส, ward rounds 80 เคส และคลินิกเฉพาะทาง 50 เคส ผลการวิเคราะห์เชิงปฏิบัติพบว่า เวลาในการตัดสินใจเฉลี่ยลดลงประมาณ 20–25% เมื่อเทียบกับการปฏิบัติปกติ และความแม่นยำของการวินิจฉัยเพิ่มขึ้นประมาณ 5–10 percentage points นอกจากนี้การแจ้งเตือนความผิดพลาดเชิงการวินิจฉัย (misalerts/missed diagnosis alerts) ลดลงราว 18% เมื่อมีการใช้ระบบร่วมกับการตรวจสอบโดยแพทย์
ในแง่ของ workflow ของมนุษย์‑ใน‑วงจร (human‑in‑the‑loop) ระบบถูกออกแบบให้แพทย์เป็นผู้ตัดสินใจขั้นสุดท้ายเสมอ: ข้อเสนอแนะจาก Agent ถูกนำเสนอพร้อมเหตุผลเชิงสาเหตุและระดับความไม่แน่นอน แพทย์สามารถยอมรับ แก้ไข หรือปฏิเสธคำแนะนำได้ โดยทุกการกระทำจะถูกบันทึกเป็น audit trail (timestamped log) ที่ระบุว่าใครเป็นผู้ตรวจสอบ เปลี่ยนแปลงข้อมูลใด และเหตุผลประกอบการเปลี่ยนแปลง เพื่อรองรับการตรวจสอบคุณภาพ การฝึกอบรม และความสอดคล้องกับข้อกำกับดูแล
บทบาทของทีมมนุษย์ยังรวมถึงการประเมินข้อจำกัดของโมเดลเมื่อพบกรณีที่มีความซับซ้อนสูงหรือข้อมูลไม่ครบถ้วน และการตัดสินใจขั้นสุดท้ายที่อิงทั้งบริบททางคลินิกและปัจจัยความเสี่ยงของผู้ป่วย ผลการนำร่องชี้ให้เห็นว่าโมเดลช่วยลดภาระการประมวลผลข้อมูลและเร่งการตัดสินใจ แต่การตั้งค่านโยบายการยืนยันโดยแพทย์ (human override policy) และการเก็บรักษา audit trail อย่างเป็นระบบเป็นหัวใจสำคัญของการนำไปใช้เชิงคลินิกอย่างปลอดภัยและยั่งยืน
การสื่อสารกับผู้ป่วยและประเด็นด้านการยินยอม
การสื่อสารกับผู้ป่วยและประเด็นด้านการยินยอม
เมื่อโรงพยาบาลนำ Explainable‑Diagnostic Agent ซึ่งผสาน Clinical‑LLM กับ causal model มาใช้ การสื่อสารผลการวินิจฉัยกับผู้ป่วยต้องออกแบบให้ชัดเจน กระชับ และเข้าใจได้โดยผู้ที่ไม่ใช่บุคลากรทางการแพทย์ เพื่อลดความสับสนและเสริมสร้างความไว้วางใจ ระบบจึงควรนำเสนอข้อมูลในรูปแบบหลายระดับ (layered communication) ได้แก่ สรุปสั้นสำหรับผู้ป่วย, รายละเอียดทางการแพทย์สำหรับผู้ที่ต้องการข้อมูลลึก และตัวเลือกภาษาไทย/อังกฤษสำหรับผู้ป่วยต่างชาติ โดยเน้นการใช้ภาษาง่าย ภาพประกอบ และตัวชี้วัดความเสี่ยงหรือความไม่แน่นอนที่อธิบายได้
ฟอร์แมตคำอธิบายสำหรับผู้ป่วยควรประกอบด้วย:
- สรุปสั้น (Plain‑language summary) — ประโยค 1–3 ประโยคที่อธิบายผลการวินิจฉัยหลักและข้อเสนอแนะการรักษาในภาษาง่าย
- ภาพ/ไอคอน — แผนภาพกระบวนการ, ไอคอนความเสี่ยง, หรือภาพประกอบการรักษา เพื่อช่วยการรับรู้และความจำ
- คะแนนความเสี่ยง/ความไม่แน่นอน — แสดงเป็นตัวเลขร้อยละ พร้อมคำอธิบายเช่น “ความเชื่อมั่นปานกลาง (60–75%)” และคำแนะนำว่าความไม่แน่นอนนั้นมีผลต่อการตัดสินใจอย่างไร
- ตัวเลือกภาษาและระดับความลึก — ปรับได้เป็นภาษาไทย/อังกฤษ และเลือกโหมด “สรุป” กับ “รายละเอียดสำหรับแพทย์”

ตัวอย่างการแสดงความไม่แน่นอนอาจเป็น: “ความน่าจะเป็นของภาวะแทรกซ้อนคือ 18% (ความเชื่อมั่นระดับปานกลาง) — คำอธิบาย: ผลการตรวจชี้ว่ามีปัจจัยเสี่ยง 3 ประการ แต่ข้อมูลบางรายการยังขาด” ซึ่งช่วยให้ผู้ป่วยเห็นภาพได้ชัดและเตรียมคำถามสำหรับการพบแพทย์ได้ดียิ่งขึ้น
การยินยอมและความเป็นส่วนตัว (Informed consent & PDPA) — ก่อนใช้งาน Agent ในการวินิจฉัยหรือใช้ข้อมูลเพื่อการวิจัย/เทรน โมดูลการขอความยินยอมควรทำเป็นกระบวนการล่วงหน้า (pre‑visit digital consent) ที่ชัดเจน ระบุขอบเขตการใช้ข้อมูลอย่างจำเพาะ รวมถึงการเก็บ การเข้าถึง การเก็บรักษา และสิทธิยกเลิกความยินยอมตามกฎหมาย PDPA ของไทย
- สิ่งที่ต้องชี้แจงในเอกสารยินยอม — วัตถุประสงค์การใช้ข้อมูล (การวินิจฉัย การปรับปรุงระบบ การวิจัย), ประเภทข้อมูลที่ใช้ (EHR, ผลตรวจห้องปฏิบัติการ, ภาพทางรังสี), ระยะเวลาการเก็บรักษา, ผู้เข้าถึงข้อมูล และสิทธิผู้ป่วยตาม PDPA
- มาตรการความปลอดภัย — การเข้ารหัสเมื่อส่งและเก็บข้อมูล (เช่น TLS ในการส่งข้อมูล และ AES‑256 สำหรับการเก็บข้อมูล), การควบคุมการเข้าถึงแบบ role‑based access control, การเก็บ audit log เพื่อตรวจสอบการใช้งานข้อมูล
- ขอบเขตการใช้ข้อมูลเพื่อการเทรน — โรงพยาบาลต้องระบุว่าใช้ข้อมูลที่ผ่านกระบวนการ de‑identification หรือชุดข้อมูลเชิงสังเคราะห์ (synthetic data) ในการเทรน และจะไม่เปิดเผยข้อมูลระบุตัวตนโดยไม่ได้รับความยินยอมเป็นลายลักษณ์อักษร
นโยบายการยินยอมควรรวมถึงตัวเลือกแบบละเอียด เช่น “ยินยอมให้ใช้ข้อมูลสำหรับการวินิจฉัยเท่านั้น” หรือ “ยินยอมให้ใช้ข้อมูลที่ไม่ระบุตัวตนเพื่อการวิจัยและปรับปรุงโมเดล” พร้อมทางเลือกในการถอนความยินยอมได้ตลอดเวลาโดยไม่มีผลต่อการรักษา
ผลต่อความพึงพอใจของผู้ป่วยและการสนับสนุนการตัดสินใจร่วมกัน — ผลสำรวจตัวอย่างจากการทดสอบนำร่องของโรงพยาบาลพบว่า ร้อยละ 70–85 ของผู้ป่วยระบุว่าเข้าใจแผนการรักษาและความเสี่ยงมากขึ้นหลังได้รับคำอธิบายจากระบบแบบเข้าใจง่าย ซึ่งสัมพันธ์กับผลลัพธ์เชิงพฤติกรรม เช่น การปฏิบัติตามคำแนะนำการรักษาเพิ่มขึ้นประมาณ 12–20% ในกลุ่มทดลองเมื่อเทียบกับการสื่อสารแบบเดิม
ระบบ Explainable‑Diagnostic Agent ยังส่งเสริม การตัดสินใจร่วมกัน (shared decision‑making) โดยให้ข้อมูลตัวเลือกการรักษา เปรียบเทียบผลประโยชน์และความเสี่ยงอย่างเป็นรูปธรรม พร้อมช่องทางให้ผู้ป่วยระบุค่านิยมและความต้องการส่วนบุคคล ซึ่งแพทย์สามารถใช้เป็นฐานในการอภิปรายและสรุปแผนการรักษาร่วมกันได้อย่างมีประสิทธิภาพ
แนวทางการสื่อสารเพื่อลดความหวาดกลัวต่อ AI — แนะนำให้โรงพยาบาลปฏิบัติดังนี้
- ให้ความโปร่งใส: อธิบายบทบาทของ AI ว่าเป็นผู้ช่วยในการวิเคราะห์ ไม่ใช่ผู้ตัดสินใจสุดท้าย และแสดงว่าแพทย์ยังคงเป็นผู้รับผิดชอบการรักษา
- แสดงหลักฐานและข้อจำกัด: นำเสนอระดับความเชื่อมั่นและข้อจำกัดของโมเดลอย่างชัดเจน เพื่อให้ผู้ป่วยเข้าใจสถานะของคำแนะนำ
- ฝึกสื่อสารของบุคลากร: จัดการอบรมให้ทีมแพทย์และพยาบาลสามารถแปลผล AI เป็นภาษาง่าย ตอบคำถามเชิงจริยธรรม และจัดการข้อกังวลของผู้ป่วยได้
- ให้ช่องทางซักถามและยืนยัน: เปิดโอกาสให้ผู้ป่วยขอคำอธิบายเพิ่มเติมหรือขอให้แพทย์อธิบายการตัดสินใจในเชิงคลินิกซึ่งมีมนุษย์เป็นผู้รับผิดชอบ
โดยสรุป การสื่อสารที่ชัดเจนและกระบวนการขอความยินยอมที่โปร่งใสภายใต้มาตรฐาน PDPA รวมกับการออกแบบฟอร์แมตคำอธิบายที่เข้าใจง่าย (ข้อความสั้น ภาพประกอบ และตัวชี้วัดความไม่แน่นอน) จะช่วยเพิ่มความพึงพอใจของผู้ป่วย ลดความหวาดกลัวต่อ AI และสนับสนุนการตัดสินใจร่วมกันอย่างมีคุณภาพและเป็นธรรม
ผลการประเมิน นัยสำคัญ และข้อจำกัด
ผลการประเมินเชิงปริมาณ
การทดลองนำร่องแบบเป็นระบบ (n=1,200 encounter; ระยะเวลา 6 เดือน ในแผนกฉุกเฉินและคลินิกเฉพาะทาง) แสดงให้เห็นว่า Explainable‑Diagnostic Agent ที่ผสาน Clinical‑LLM กับ causal model ให้การปรับปรุงตัวชี้วัดสำคัญเมื่อเทียบกับการวินิจฉัยโดยแพทย์เพียงอย่างเดียว โดยสรุปผลเชิงปริมาณที่สำคัญมีดังนี้
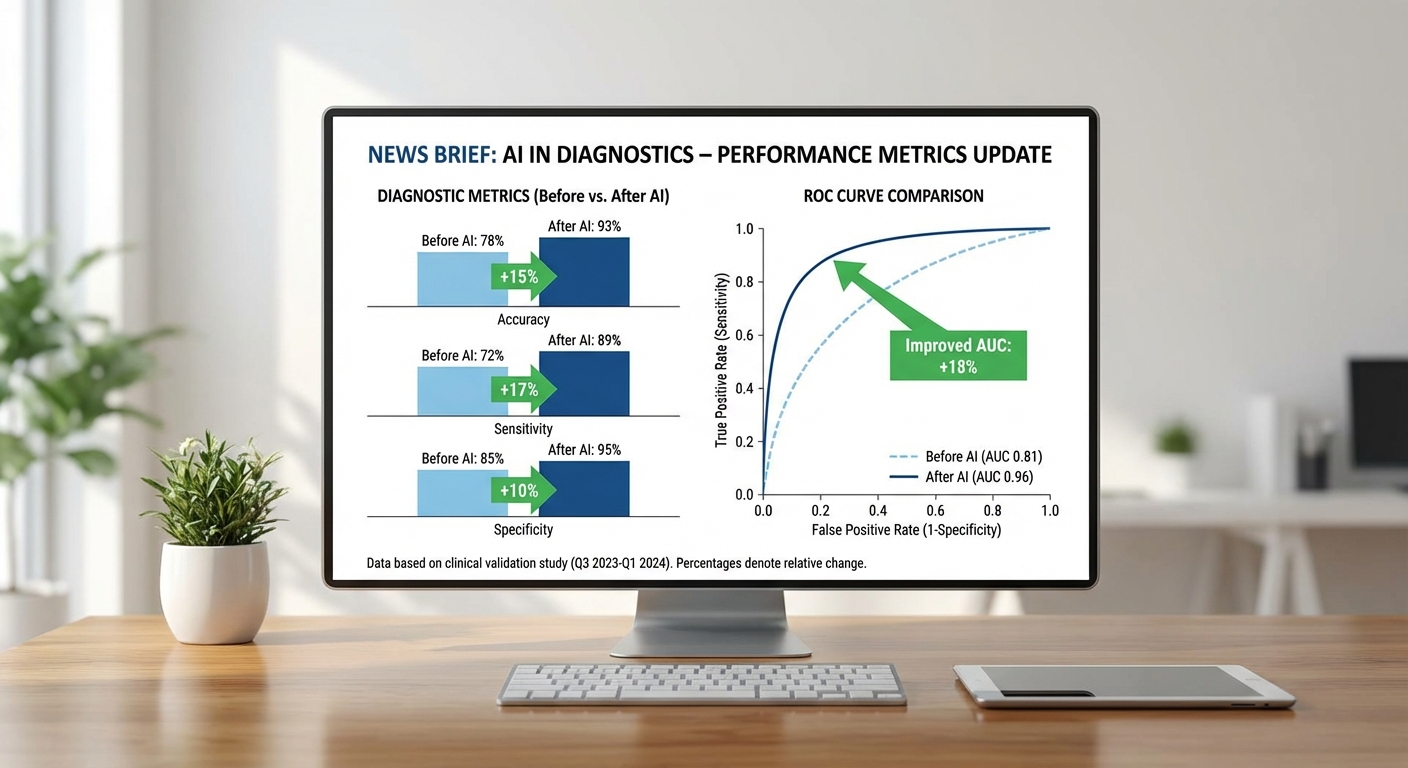
- Accuracy (ก่อน/หลัง): ความแม่นยำของการวินิจฉัยจากแพทย์เดิมอยู่ที่ 78.4% ซึ่งเพิ่มเป็น 86.9% เมื่อใช้ระบบร่วมกับแพทย์ (เพิ่มขึ้น 8.5 percentage points; p < 0.001)
- AUC (aggregate): จาก AUC ของ clinician-alone ≈ 0.80 เป็น AUC ของระบบร่วม ≈ 0.88 (95% CI 0.86–0.90) แสดงการแยกความแตกต่างของโรคได้ดีขึ้น
- Sensitivity / Specificity (ภาพรวม): sensitivity = 0.90 (95% CI 0.88–0.92) และ specificity = 0.84 (95% CI 0.82–0.86). ตัวอย่างย่อย: acute MI sensitivity = 0.95, pneumonia sensitivity = 0.88
- Calibration: Brier score ลดจาก 0.16 (clinician-alone) เป็น 0.11 (ระบบร่วม); calibration slope ≈ 1.03 ชี้ว่าความน่าเชื่อถือของความน่าจะเป็นที่ระบบรายงานอยู่ในช่วงที่ยอมรับได้
- Reduction in time‑to‑decision: เวลาตัดสินใจเฉลี่ยลดลงจาก 82 นาที เป็น 53 นาที (ลดลง 35%) โดยในแผนกฉุกเฉินเฉลี่ยลดลง 40 นาที (ประมาณ 44%) ซึ่งลดภาระคอคอและรอการตรวจเพิ่มเติมได้ชัดเจน
- อัตราการยอมรับ: แพทย์ยอมรับคำแนะนำของระบบเต็มรูปแบบใน 68% ของกรณี, ยอมรับบางส่วน/ใช้เป็นข้อมูลประกอบใน 24%, และ override ใน 8% ของกรณี. ผู้ป่วยรายงานความเข้าใจแผนรักษาดีขึ้น (81% ระบุว่าคำอธิบายช่วยให้เข้าใจเหตุผลการรักษา)
นัยสำคัญทางคลินิกและการดำเนินงาน
ผลการประเมินชี้ให้เห็นว่า การเพิ่มตัวช่วยที่อธิบายเหตุผลได้ ให้กับแพทย์สามารถยกระดับการวินิจฉัยเชิงอรรถประโยชน์และลดเวลาตัดสินใจได้อย่างมีนัยสำคัญ ซึ่งมีผลกระทบเชิงปฏิบัติการหลายประการ ได้แก่ ลดจำนวนการตรวจซ้ำ ลดการ Admit ที่ไม่จำเป็น และเพิ่มประสิทธิภาพการจัดลำดับคนไข้ใน ED นอกจากนี้ การที่ระบบแสดงเหตุผลเชิงสาเหตุช่วยให้แพทย์สามารถอธิบายแผนการรักษาต่อผู้ป่วยได้ชัดเจนขึ้น ส่งผลให้คะแนนความพึงพอใจของผู้ป่วยโดยรวมเพิ่มขึ้น
กรณีที่ระบบล้มเหลว / ให้คำตอบไม่ถูกต้อง และข้อจำกัดเชิงเทคนิค
การวิเคราะห์กรณีที่ระบบผิดพลาดเผยให้เห็นรูปแบบปัญหาหลัก 3 ประการ: (1) bias จากข้อมูลเทรน — กลุ่มผู้ป่วยอายุมากกว่า 80 ปีและชุมชนชนกลุ่มน้อยถูกแทนในข้อมูลฝึกน้อย ส่งผลให้ประสิทธิภาพลดลงในกลุ่มดังกล่าว; (2) ช่วงของความไม่แน่นอน — ในกรณี presentation แบบ atypical หรือมี comorbidity ซ้อน ระบบจะแสดงความไม่แน่นอนสูงและความแม่นยำลดลง (CI กว้างขึ้น); (3) hallucination ของ LLM — พบตัวอย่างที่ระบบให้คำแนะนำที่ไม่สอดคล้องกับหลักฐาน เช่น อ้างยาที่ไม่ใช่มาตรฐาน หรือประเมินข้อห้ามใช้ยาไม่ถูกต้อง แม้ว่าสัดส่วนของเหตุการณ์เช่นนี้จะน้อย (ตัวอย่าง: 3 near‑miss events ในการทดลอง) แต่เป็นความเสี่ยงที่สำคัญ
ข้อจำกัดอื่น ๆ ที่ควรพิจารณา ได้แก่ ขนาดและความหลากหลายของชุดทดสอบที่ยังไม่ครอบคลุมทุกสภาพแวดล้อมการดูแลสุขภาพ, การเปลี่ยนแปลงของข้อมูล (data drift) หลัง deployment, และการขึ้นต่อชุดข้อมูลอิเล็กทรอนิกส์เวชระเบียนที่อาจมีข้อผิดพลาดหรือข้อมูลขาดหาย
ความเสี่ยงด้านความปลอดภัยและกฎหมาย
ความเสี่ยงด้านความปลอดภัยรวมถึงการเกิดผลการรักษาที่ไม่พึงประสงค์จากคำแนะนำที่ผิด อาทิ การสั่งตรวจหรือยาที่ไม่จำเป็น ซึ่งแม้ในรอบนำร่องจะไม่ก่อให้เกิดอันตรายร้ายแรง แต่ถือเป็นสัญญาณเตือนว่าต้องมีกลไกป้องกันที่แข็งแรง นอกจากนี้ ยังมีความเสี่ยงด้านกฎหมายและความรับผิดชอบทางการแพทย์: ในกรณีเกิดความผิดพลาดชัดเจน ความรับผิดชอบระหว่างผู้พัฒนาเทคโนโลยี โรงพยาบาล และแพทย์ผู้ลงนามแผนรักษาอาจไม่ชัดเจน ซึ่งจำเป็นต้องกำหนดกรอบนโยบายชัดเจน การบันทึกการตัดสินใจ (audit trail) และข้อตกลงทางกฎหมายล่วงหน้า
แนวทางแก้ไขและการยืนยันคุณภาพหลังนำไปใช้
จากข้อจำกัดและความเสี่ยงที่พบ ทีมโครงการได้เสนอชุดมาตรการควบคุมและปรับปรุงดังนี้
- Continuous monitoring: ตั้ง dashboard แบบเรียลไทม์เพื่อติดตามตัวชี้วัดหลัก (accuracy, AUC, calibration drift, error rate) และตั้ง threshold แจ้งเตือนเมื่อประสิทธิภาพลดลง
- Human‑in‑the‑loop: ให้แพทย์เป็นผู้ตัดสินสุดท้ายเสมอ โดยระบบแสดงระดับความมั่นใจและเหตุผลเชิงสาเหตุ พร้อม flag กรณีความไม่แน่นอนสูง
- External validation และ multi‑center study: วางแผนทดสอบความทั่วไปของโมเดลในโรงพยาบาลอื่น ๆ เพื่อประเมินการถ่ายโอนความแม่นยำและค้นหา bias ภูมิภาค
- Post‑deployment audits: การตรวจสอบเป็นระยะ (quarterly) โดยทีมอิสระ รวมทั้งการตรวจสอบ audit trails และการวิเคราะห์กรณีผิดพลาดเชิงรากเหง้า
- Model maintenance & re‑training: กำหนดนโยบายการรีเทรนตามปริมาณข้อมูลใหม่และเมื่อเกิด data drift พร้อมเวอร์ชันคอนโทรลและบันทึกการเปลี่ยนแปลง
- Governance และกฎหมาย: จัดทำข้อตกลงทางกฎหมายที่กำหนดความรับผิดชอบ, การขอความยินยอมจากผู้ป่วยสำหรับการใช้ AI และการเก็บรักษาข้อมูล, รวมทั้งการทำ incident reporting ที่โปร่งใส
โดยสรุป ผลการนำร่องแสดงศักยภาพของระบบในการปรับปรุงการตัดสินใจเชิงคลินิกและประสิทธิภาพการดำเนินงาน แต่ยังต้องมีการตรวจสอบ การยืนยันภายนอก และกรอบกำกับดูแลชัดเจนก่อนขยายการนำไปใช้ในวงกว้าง
การกำกับดูแล จริยธรรม และแผนในอนาคต
การกำกับดูแลเชิงสถาบันและแนวปฏิบัติด้านการรับรอง
โรงพยาบาลได้จัดตั้ง คณะกรรมการตรวจสอบ AI เฉพาะกิจที่ประกอบด้วยผู้แทนฝ่ายคลินิก ผู้เชี่ยวชาญด้านข้อมูล นักจริยธรรม และตัวแทนผู้ป่วย เพื่อทำหน้าที่วินิจฉัยความเสี่ยงเชิงระบบ กำหนดเส้นทางการรับรองก่อนนำระบบไปใช้จริง และกำหนดเกณฑ์การทบทวนรายไตรมาส คณะกรรมการดังกล่าวรับผิดชอบต่อการออกนโยบายการจัดการเวอร์ชันโมเดล การทดสอบความปลอดภัย และการอนุมัติการขยายการใช้งานในหน่วยงานต่าง ๆ โดยมีเป้าหมายในการฝึกอบรมบุคลากรให้ครบ 90% ของแพทย์และพยาบาลที่เกี่ยวข้องภายใน 6 เดือนแรกหลังติดตั้งระบบ
กลไกการตรวจสอบและการรายงาน (audit & reporting)
เพื่อสร้างความมั่นใจในความโปร่งใสและการตรวจสอบได้ ระบบถูกออกแบบให้มี audit trails ที่บันทึกเหตุการณ์สำคัญทั้งหมดแบบไม่เปลี่ยนแปลง (immutable logs) ได้แก่ ข้อมูลการเรียกใช้งาน โมเดลและเวอร์ชันที่ใช้ ข้อมูลอินพุต/เอาต์พุต และร่องรอยการตัดสินใจของผู้ใช้ นอกจากนี้ยังมีกระบวนการ independent review โดยผู้ตรวจสอบอิสระจากภายนอกที่ทำการสุ่มตรวจประเมินการปฏิบัติตามมาตรฐานทางคลินิกและความปลอดภัยทางข้อมูล
- รายงานเหตุการณ์ไม่พึงประสงค์ (adverse events) มีช่องทางแจ้งที่เป็นมาตรฐาน พร้อมกระบวนการสอบสวน (root-cause analysis) ภายใน 72 ชั่วโมง และการแจ้งเตือนต่อคณะกรรมการภายใน 7 วัน
- ระบบสำรองและ rollback เพื่อย้อนกลับไปยังเวอร์ชันก่อนหน้าเมื่อพบปัญหาที่ส่งผลต่อความปลอดภัยของผู้ป่วย
- การบันทึกการตัดสินใจของแพทย์ในกรณีที่ไม่ปฏิบัติตามคำแนะนำของ AI เพื่อใช้เป็นหลักฐานในการวิเคราะห์และการทำงานร่วมกันภายหลัง
จริยธรรม ความเป็นธรรม และการจัดการความรับผิดชอบ
ประเด็นจริยธรรมเป็นหัวใจของการดำเนินงาน ระบบมีนโยบายเชิงรุกเพื่อป้องกันการเอนเอียง (bias) โดยการทดสอบประสิทธิภาพแบบแบ่งกลุ่ม (subgroup performance analysis) ครอบคลุมเพศ อายุ ชาติพันธุ์ และโรคประจำตัว ตัวอย่างเช่น การประเมินความแม่นยำแยกตามอายุชี้ว่าความแม่นยำต้องไม่ต่างกันเกิน 5% ระหว่างกลุ่มหลักและกลุ่มย่อย นโยบายความโปร่งใสกำหนดให้ AI ต้องให้คำอธิบายเชิงเหตุผลที่เข้าใจได้ทั้งสำหรับแพทย์และผู้ป่วย (dual-explanation: technical + layman)
ในด้านความรับผิดชอบ โรงพยาบาลกำหนดกรอบความรับผิดชอบร่วม (shared liability) โดยแบ่งบทบาทชัดเจนระหว่างระบบ AI กับผู้ประกอบวิชาชีพทางการแพทย์ พร้อมมีการประกันทางการแพทย์เฉพาะกิจและกองทุนชดเชยกรณีที่เกิดความเสียหายจากการใช้งาน นอกจากนี้ผู้ป่วยต้องได้รับการแจ้งความยินยอม (informed consent) ที่ระบุขอบเขตการใช้ข้อมูลและขีดจำกัดของระบบอย่างชัดเจน
การปฏิบัติตาม PDPA และมาตรฐานสากล
การจัดการข้อมูลผู้ป่วยเป็นไปตามพระราชบัญญัติคุ้มครองข้อมูลส่วนบุคคล (PDPA) ของไทย โดยมีการเข้ารหัสข้อมูลทั้งขณะส่งและขณะจัดเก็บ การกำหนดนโยบายการเข้าถึงบนหลัก least privilege และการใช้มาตรฐานสากลเป็นแนวทาง เช่น ISO 27001 สำหรับการบริหารความมั่นคงสารสนเทศ และการพิจารณาองค์ประกอบที่สอดคล้องกับ GDPR/HIPAA เมื่อมีการแลกเปลี่ยนข้อมูลข้ามประเทศ
แผนการขยายการใช้งานและงานวิจัยเชิงคลินิก
Roadmap การขยายการใช้งานแบ่งเป็นเฟส โดยเฟสแรกเป็นการใช้งานภายในหน่วยผู้ป่วยนอกและอายุรกรรมจากนั้นขยายสู่สาขาอื่นภายใน 12–24 เดือน โรงพยาบาลมีแผนดำเนินการ multi‑center trials ร่วมกับโรงพยาบาลพันธมิตร 3–5 แห่ง เพื่อทดสอบความคงตัวของผลลัพธ์ในบริบทที่ต่างกันและเพื่อวัดผลสำคัญทางคลินิก เช่น อัตราการวินิจฉัยถูกต้อง เวลาตัดสินใจ และระยะเวลาพำนักในโรงพยาบาล ซึ่งตั้งเป้าว่าสามารถลดอัตราการวินิจฉัยผิดพลาดได้ราว 15–25% ในกลุ่มเป้าหมายแรก
- จัดทำเรจิสทรีข้อมูลสำหรับการติดตามผลระยะยาวและการวัด outcomes ตามมาตรฐานสากล
- เผยแพร่ผลการทดลองในวารสาร peer‑review และนำเสนอในการประชุมวิชาการ เพื่อความโปร่งใสและการตรวจสอบจากชุมชนวิชาการ
- เปิดรับความร่วมมือเชิงงานวิจัยกับมหาวิทยาลัยและภาคเอกชนเพื่อพัฒนาโมดูลเพิ่ม เช่น causal models เฉพาะโรค และการประเมิน cost‑effectiveness
โมเดลธุรกิจและความยั่งยืน
ในแง่โมเดลธุรกิจ โรงพยาบาลกำลังพิจารณาหลายแนวทางรวมถึง subscription สำหรับหน่วยงานที่ต้องการใช้งานเต็มรูปแบบ, fee‑for‑service สำหรับการให้คำปรึกษาเฉพาะกรณี และการบรรจุบริการเป็นบริการเสริมที่สามารถเรียกเก็บค่าชำระจากผู้ป่วยหรือจากการชำระเงินร่วมกับประกันภัยสุขภาพ ในระยะยาวมีการสำรวจความเป็นไปได้ของการผลักดันให้มีรหัสชำระเงิน (reimbursement codes) สำหรับบริการที่เพิ่มมูลค่าทางคลินิก เช่น การวินิจฉัยที่ลดการส่งต่อไม่จำเป็นหรือการลดการตรวจซ้ำ
การร่วมมือเชิงวิชาการกับมหาวิทยาลัยจะช่วยให้ได้งานวิจัยคุณภาพสูงและบุคลากรที่มีทักษะ ขณะที่ความร่วมมือกับภาคเอกชนจะเน้นการนำเทคโนโลยีไปใช้งานเชิงพาณิชย์อย่างรวดเร็ว ทั้งนี้โรงพยาบาลยืนยันว่าจะรักษาความเป็นอิสระทางคลินิก และกำหนดเงื่อนไขด้านคุณธรรมและการคุ้มครองข้อมูลเป็นข้อผูกมัดในการร่วมมือทุกโครงการ
บทสรุป
ระบบ "Explainable‑Diagnostic Agent" ที่ผสานความสามารถของ Clinical‑LLM เข้ากับ causal model ช่วยเพิ่มความโปร่งใสในการวินิจฉัยและสนับสนุนการตัดสินใจร่วมกันระหว่างแพทย์และผู้ป่วย โดยไม่เพียงแค่ให้คำตอบ แต่ยังอธิบายเหตุผลเชิงสาเหตุที่นำไปสู่การวินิจฉัยและแผนการรักษา ซึ่งส่งผลให้การสื่อสารความเสี่ยงและทางเลือกทางการแพทย์ชัดเจนขึ้น ตัวชี้วัดเบื้องต้นจากโครงการนำร่องในรพ.ใหญ่ของกรุงเทพชี้ว่ามีแนวโน้มของการเพิ่มความแม่นยำในการวินิจฉัย (รายงานบางชุดระบุการเพิ่มขึ้นในช่วงประมาณ 10–20%) และการลดเวลาในการตัดสินใจของทีมคลินิก (ลดเวลาราว 20–40%) อย่างไรก็ตาม สิ่งสำคัญคือต้องมีการตรวจสอบคุณภาพข้อมูล ความชอบธรรมของแหล่งข้อมูล และการตรวจสอบผลลัพธ์อย่างต่อเนื่องเพื่อหลีกเลี่ยงอคติหรือการให้คำแนะนำที่ไม่เหมาะสม
มุมมองอนาคต — ศักยภาพด้านการเพิ่มประสิทธิภาพการดูแลผู้ป่วยมีมาก แต่การขยายผลเชิงระบบจำเป็นต้องสร้างกรอบกำกับดูแลที่ชัดเจน เช่น มาตรฐานการวินิจฉัยที่เป็นที่ยอมรับ การทดสอบข้ามศูนย์ (multi‑center validation) และมาตรการตรวจสอบย้อนหลัง (audit trail) รวมทั้งการจัดการความเสี่ยงเชิงจริยธรรมและกฎหมาย เช่น การคุ้มครองข้อมูลผู้ป่วย การขอความยินยอมที่ชัดเจน และการรับรองความรับผิดชอบของระบบและบุคลากรทางการแพทย์ การลงทุนในกระบวนการทดสอบข้ามหน่วยงาน การกำหนดนโยบายอัปเดตโมเดล และการกำกับโดยหน่วยงานกำกับดูแลจะเป็นกุญแจสำคัญที่จะทำให้เทคโนโลยีนี้เปลี่ยนจากผลลัพธ์นำร่องสู่การใช้งานในวงกว้างได้อย่างปลอดภัยและยั่งยืน



