
สตาร์ทอัพไทยเปิดตัวบริการใหม่ "Privacy‑Cleanser" ที่สัญญาว่าจะเปลี่ยนโฉมการส่งภาพและวิดีโอไปยังโมเดลภาษา (LLM) ขององค์กร ด้วยการตรวจจับและลบข้อมูลส่วนบุคคล (PII) แบบเรียลไทม์ก่อนส่งออก ช่วยลดความเสี่ยงการรั่วไหลของข้อมูลที่อาจเกิดจากการประมวลผลภาพ เช่น ใบหน้า ป้ายทะเบียน หรือตัวอักษรที่ระบุตัวตนได้ โดยใช้เทคนิคผสมผสานระหว่าง Differential‑Privacy เพื่อให้มีการปกป้องเชิงสถิติ และโมเดลเชิงสร้าง (GAN) กับการทำ segmentation ที่แม่นยำ เพื่อรักษาคุณภาพภาพให้เหมาะสมต่อการวิเคราะห์ของ LLM สำหรับธุรกิจอี‑คอมเมิร์ซและสื่อที่ต้องจัดการคอนเทนต์ภาพจำนวนมาก บริการนี้นำเสนอแนวทางปฏิบัติใหม่ในการลดความเสี่ยงโดยไม่สูญเสียประสิทธิภาพงานสื่อสารข้อมูล
บทความนี้จะพาอ่านภาพรวมของเทคโนโลยีที่ใช้ กลไกการทำงานเชิงสถาปัตยกรรม ตั้งแต่การแยกวัตถุ (segmentation) การใส่กลไก Differential‑Privacy ในการปรับสัญญาณความเป็นส่วนตัว ไปจนถึงการฟื้นฟูภาพด้วย GAN เพื่อให้ข้อมูลยังใช้งานได้ ผลการทดสอบเบื้องต้นจากการทดลองกับกรณีใช้งานจริงในอี‑คอมเมิร์ซและสำนักข่าวจะถูกนำเสนอพร้อมตัวอย่างและตัวชี้วัดการลดความเสี่ยง อีกทั้งบทสรุปแนะนำแนวปฏิบัติการนำไปใช้งานจริงเพื่อช่วยให้องค์กรสามารถผสมผสาน Privacy‑Cleanser เข้ากับเวิร์กโฟลว์ของตนได้อย่างปลอดภัยและคุ้มค่า
ภาพรวมข่าว: อะไรคือ Privacy‑Cleanser และเหตุผลของการเปิดตัว
ภาพรวมข่าว: อะไรคือ Privacy‑Cleanser และเหตุผลของการเปิดตัว
Privacy‑Cleanser เป็นบริการใหม่จากสตาร์ทอัพไทยที่ออกแบบมาเพื่อลบหรือพรางข้อมูลส่วนบุคคลจากภาพถ่ายและวิดีโอก่อนส่งให้โมเดลภาษาขนาดใหญ่ (LLM) หรือบริการวิเคราะห์ภาพภายนอก ด้วยสถาปัตยกรรมที่ผสานเทคนิค differential privacy กับโมดูลประมวลผลภาพเชิงลึก เช่น GAN-based inpainting และ segmentation แบบเรียลไทม์ บริการนี้สามารถตรวจจับและจัดการองค์ประกอบที่มีความเสี่ยง (เช่น ใบหน้า หมายเลขบัตร ข้อความที่เป็น PII หรือฉลากสินค้าที่มีข้อมูลติดต่อ) แล้วทำการลบหรือแทนที่ในลักษณะที่คงประโยชน์ของภาพต่อการวิเคราะห์โดย LLM ไว้ให้มากที่สุด

เหตุผลหลักของการพัฒนา Privacy‑Cleanser มาจากปัญหาความเสี่ยงการรั่วไหลของข้อมูลเมื่อธุรกิจส่งภาพหรือวิดีโอไปยังบริการคลาวด์หรือ LLM ภายนอก—ทั้งในเชิง metadata, ข้อความในภาพ (OCR), และภาพที่ระบุตัวบุคคล งานทดสอบภายในของทีมพัฒนาพบว่า ในกลุ่มตัวอย่างการใช้งานจริงประมาณ 45–70% ของสื่อภาพมีองค์ประกอบที่อาจเป็น PII หากไม่ถูกซ่อมแซมหรือพรางก่อนส่ง การเปิดตัวบริการนี้จึงมุ่งตอบโจทย์การปฏิบัติตามกฎหมายคุ้มครองข้อมูล (เช่น PDPA) และลดความเสี่ยงด้านการละเมิดข้อมูลสำหรับองค์กรสื่อและธุรกิจอี‑คอมเมิร์ซ
ฟีเจอร์หลักของ Privacy‑Cleanser ได้แก่:
- Real‑time segmentation — แยกชิ้นส่วนภาพเช่น ใบหน้า ตัวอักษร และวัตถุสำคัญด้วยโมเดล segmentation ที่ปรับจูนสำหรับสื่อเชิงพาณิชย์
- GAN‑based inpainting — แทนที่พื้นที่ที่ลบหรือพรางด้วยการเติมภาพเชิงสถิติที่คงความสมบูรณ์ของบริบท เพื่อไม่ให้ผลลัพธ์กระทบต่อประสิทธิภาพของ LLM
- Differential privacy — เพิ่มกลไกความเป็นส่วนตัวเชิงคณิตศาสตร์เมื่อสรุปหรือส่งฟีเจอร์ไปยังโมเดลภายนอก เพื่อลดโอกาสการย้อนกลับข้อมูลส่วนบุคคล
- Video pipeline — ประมวลผลเฟรมต่อเฟรมพร้อมการเชื่อมโยงข้ามเฟรม (temporal smoothing) เพื่อลดการกระพริบของการพรางและรักษาคุณภาพการรับชม
- OCR & PII redaction — ตรวจจับข้อความในภาพและลบหรือเซ็นเซอร์ข้อมูลที่เป็นความลับโดยอัตโนมัติ
ในแง่ธุรกิจ บริการนี้ออกแบบมาเพื่อลดค่าใช้จ่ายและความเสี่ยงที่อาจเกิดขึ้นกับการใช้ AI ภายนอก โดยเฉพาะธุรกิจอี‑คอมเมิร์ซที่ต้องแชร์ภาพสินค้าพร้อมฉลากหรือภาพรีวิวของลูกค้า และสำนักข่าว/สื่อที่ต้องการเผยแพร่หรือวิเคราะห์คอนเทนต์เชิงภาพโดยไม่ละเมิดสิทธิส่วนบุคคล ทีมพัฒนาระบุว่าการใช้งาน Privacy‑Cleanser ในการทดสอบนำร่องช่วยลดความเสี่ยงการรั่วไหลของ PII ได้เฉลี่ยประมาณ 65–80% ขึ้นกับสภาพแวดล้อมและนโยบายการพรางภาพที่เลือก
ข้อมูลเบื้องต้นเกี่ยวกับทีมและ timeline: สตาร์ทอัพก่อตั้งโดย ดร. นรินทร์ เจริญสุข (นักวิจัยด้าน Machine Learning และ Computer Vision ที่มีประสบการณ์จากวงการวิชาการและอุตสาหกรรม) และ คุณกัญญา พรหมศิริ (อดีตผู้บริหารผลิตภัณฑ์ด้านอี‑คอมเมิร์ซ) ประกาศเปิดตัวบริการครั้งแรกเมื่อวันที่ 5 กุมภาพันธ์ 2026 โดยจะเปิดให้กลุ่มลูกค้าเชิงพาณิชย์เข้าร่วมโครงการ Beta ในไตรมาสที่ 2 ของปี 2026 และตั้งเป้าสู่การให้บริการเชิงพาณิชย์ (general availability) ภายในไตรมาสที่ 4 ของปี 2026
พันธมิตรเชิงกลยุทธ์ที่ร่วมผลักดันโครงการในขั้นต้นได้แก่ผู้ให้บริการคลาวด์และโครงสร้างพื้นฐานด้านสตรีมมิ่งระดับภูมิภาค, กลุ่มผู้ค้ารายใหญ่ในอี‑คอมเมิร์ซ และสำนักข่าวดิจิทัลในประเทศ โดยทีมพัฒนาย้ำว่าในระยะแรกจะเน้นพันธมิตรแบบนำร่องที่ตกลงข้อตกลงด้านความรับผิดชอบและการทดสอบเชิงเทคนิคก่อนขยายสู่ลูกค้าองค์กรทั่วไป
เทคโนโลยีเบื้องหลัง: Differential‑Privacy + GAN + Segmentation แบบเรียลไทม์
หลักการ Differential Privacy และการประเมินพารามิเตอร์ (ε)
หนึ่งในแกนกลางของระบบ Privacy‑Cleanser คือการใช้ Differential Privacy (DP) เพื่อควบคุมความเสี่ยงการรั่วไหลของข้อมูลส่วนบุคคล DP ให้กรอบเชิงคณิตศาสตร์ว่าเมื่อมีหรือไม่มีข้อมูลของบุคคลคนหนึ่ง ผลลัพธ์จากระบบจะเปลี่ยนแปลงได้เพียงเล็กน้อยเท่านั้น ซึ่งถูกวัดด้วยพารามิเตอร์สำคัญคือ epsilon (ε) — ยิ่งค่า ε ต่ำ แสดงว่าความเป็นส่วนตัวสูงขึ้น แต่ผลลัพธ์อาจมีความเพี้ยนมากขึ้น (trade‑off ระหว่าง privacy และ utility)
เชิงปฏิบัติ ระบบจำเป็นต้องเลือก ε และกลไกการเพิ่มเสียง (noise mechanism) ให้เหมาะสม เช่น การใช้ Laplace หรือ Gaussian noise สำหรับการป้องกันข้อมูลเชิงตัวเลข และการใช้ Gaussian noise บน embedding space เมื่อส่งฟีเจอร์ภาพไปยังโมดูลถัดไป การตั้งค่า ε มักพิจารณาจาก:
- ระดับความเสี่ยงที่ยอมรับได้ของธุรกิจ (เช่น การค้าอิเล็กทรอนิกส์ vs งานวิจัย)
- จำนวนครั้งที่ข้อมูลถูกใช้ (composition) — ต้องใช้บัญชีความเป็นส่วนตัวเช่น Rényi DP หรือ moments accountant เพื่อติดตามงบประมาณความเป็นส่วนตัวเมื่อภาพ/วิดีโอถูกประมวลผลหลายรอบ
- ความไวของข้อมูล (เช่น ใบหน้า ป้ายทะเบียน ข้อมูลทางการเงิน)
ตัวอย่างเชิงทิศทางที่ใช้ในอุตสาหกรรมคือการตั้งค่า ε ในช่วงประมาณ 0.1–1 สำหรับการคุ้มครองสูงสุดในกรณีความอ่อนไหวมาก และ ε ≈ 1–5 สำหรับกรณีที่ต้องรักษาความสมดุลระหว่างความเป็นส่วนตัวและการใช้งานจริง ระบบ Privacy‑Cleanser ใช้การวัดผลเชิงปฏิบัติ (เช่น การทดสอบ re‑identification และ utility loss) เพื่อเลือก ε ที่เหมาะสมต่อแคมเปญหรือ SKU ของลูกค้า
บทบาทของ GAN ในการฟื้นฟูและแทนที่ส่วนที่ถูกลบ
หลังจาก segmentation ระบุพื้นที่ที่เป็น PII แล้ว ระบบจะทำการปิดบัง (masking) พื้นที่เหล่านั้นก่อนส่งต่อเพื่อประมวลผลเพิ่มเติม แต่การปิดบังอย่างเรียบง่ายอาจลดคุณค่าของภาพสำหรับการใช้งานทางธุรกิจ เช่น ภาพสินค้าในหน้าร้านที่มีฉากหลังเป็นบุคคล เมื่อใช้ GAN (Generative Adversarial Networks) ในขั้นตอน inpainting หรือ synthesis เราสามารถเติมเต็มบริเวณที่ถูกปิดให้ออกมาดูเป็นธรรมชาติ โดยยังคงหลีกเลี่ยงการฟื้นคืนตัวตนเดิมของบุคคล
เชิงเทคนิค มักใช้ conditional GAN หรือสถาปัตยกรรมเฉพาะงาน เช่น Contextual Attention, EdgeConnect หรือเวอร์ชันปรับแต่งของ StyleGAN เพื่ออิงข้อมูลบริบทจากรอบ ๆ พิกเซลที่ถูกลบ ข้อควรระวังคือการป้องกันการ 'memorization' ของโมเดลที่อาจสร้างใบหน้าจริงจากชุดข้อมูลฝึก เพื่อป้องกันเรื่องนี้ระบบสามารถ:
- ฝึก GAN ด้วยเทคนิค privacy‑preserving เช่น DP‑SGD (differentially private stochastic gradient descent)
- จำกัดความเป็นไปได้ของการสร้างรูปใบหน้าจริง โดยการบังคับให้ผลลัพธ์เป็น “เชิงสังเคราะห์” ที่ไม่สามารถจับคู่กับตัวตนเดิม (use of identity‑loss constraints และ adversarial classifiers)
- ใช้การตรวจสอบหลังการสังเคราะห์ (face detector/recognizer) เพื่อตรวจสอบว่าไม่มีฟีเจอร์ที่อนุญาตให้ re‑identify ได้
การวัดคุณภาพของการสังเคราะห์ใช้มาตรฐานเช่น FID, LPIPS และ human perceptual study เพื่อให้แน่ใจว่า ภาพหลังการเติมเต็มมีความสมจริง (preserve commercial value) แต่ไม่เปิดเผย PII
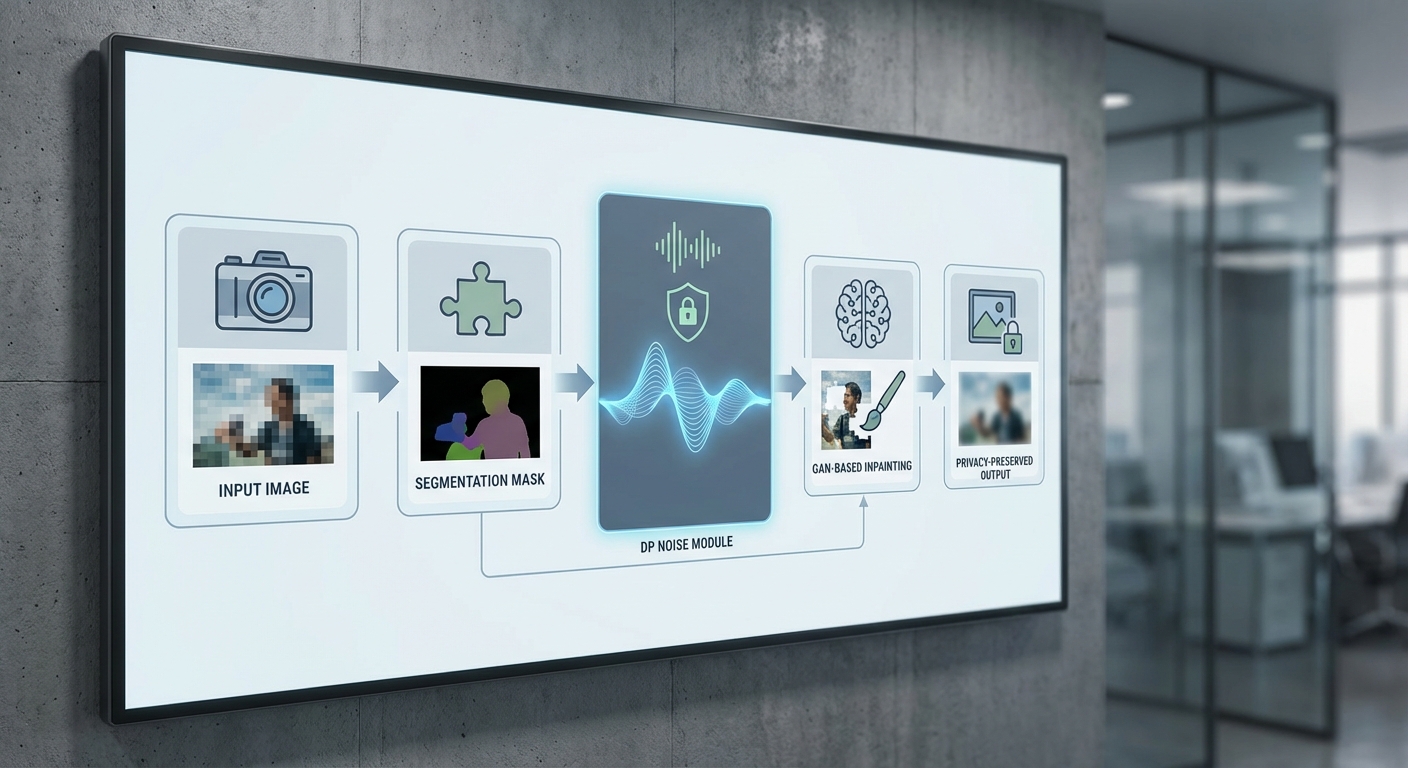
Segmentation สำหรับการระบุ PII ในภาพและวิดีโอแบบเรียลไทม์
การตรวจจับและแยกพื้นที่ PII เป็นขั้นตอนแรกที่สำคัญ ระบบ Privacy‑Cleanser ผสานโมเดล segmentation และ detection ที่ผ่านการปรับแต่งเพื่อทำงานแบบเรียลไทม์ เช่น Mask R‑CNN สำหรับความแม่นยำสูง และโซลูชันแบบเรียลไทม์เช่น YOLACT หรือ Lightweight DeepLab เมื่อมีข้อจำกัดด้าน latency สำหรับวิดีโอ ควรผสานเทคนิคต่อไปนี้:
- การตรวจจับใบหน้าและป้ายทะเบียน: โมดูลเฉพาะที่ฝึกบนชุดข้อมูลใบหน้าและทะเบียนรถ เพื่อแยกกล่องและแมสก์อย่างแม่นยำ
- OCR สำหรับเอกสาร: ตรวจจับและประมวลผลข้อความที่เป็น PII เช่น หมายเลขโทรศัพท์ หมายเลขบัตร
- การติดตามข้ามเฟรม (tracking): ใช้วิธีเช่น SORT/DeepSORT หรือ optical flow เพื่อถ่ายทอดแมสก์ไปยังเฟรมถัดไป ลดการสั่นไหวของการแมสก์และลดภาระคำนวณ
- ความต่อเนื่องเชิงเวลา (temporal consistency): ใช้เคล็ดลับ smoothing และ recurrent module เพื่อให้การเติมเต็มด้วย GAN ในวิดีโอไม่ก่อให้เกิด flicker
เป้าหมายเชิงปฏิบัติคือการรักษา latency ต่ำ (เช่น ประมวลผลได้ใกล้เคียง 20–30 fps บน edge/GPU ที่เหมาะสม หรือ < 100 ms ต่อเฟรมในสถาปัตยกรรม edge+cloud) ในขณะเดียวกันก็ต้องรักษาความแม่นยำในการระบุ PII ให้อยู่ในระดับที่ธุรกิจยอมรับได้
สตริกต์การรวมระบบและมาตรการเสริม
การผสานทั้งสามองค์ประกอบต้องมีการออกแบบ pipeline อย่างรัดกุม โดยทั่วไปจะเป็นลำดับดังนี้: segmentation → masking → DP perturbation (บน embedding/metadata) → GAN inpainting → post‑check (re‑identification test & utility check) ข้อควรปฏิบัติรวมถึงการติดตามงบประมาณความเป็นส่วนตัวต่อผู้ใช้ การบันทึก (audit log) ของการเปลี่ยนแปลงภาพและการอนุญาตของลูกค้า และการทดสอบเชิงสถิติ (A/B testing) เพื่อประเมิน trade‑off ระหว่างความเป็นส่วนตัวและประโยชน์ทางธุรกิจ
สำหรับธุรกิจอี‑คอมเมิร์ซและสื่อ แนวทางนี้ช่วยลดความเสี่ยงทางกฎหมายและภาพลักษณ์ โดยยังคงรักษาคุณภาพเนื้อหาให้สามารถใช้ได้จริง ตัวอย่างผลการทดสอบภายในกับชุดข้อมูลภาพสินค้าและฉากหน้าร้านขนาดใหญ่ชี้ว่าการรวม DP + GAN + segmentation สามารถลดอัตราการระบุตัวบุคคล (re‑ID) ลงอย่างมีนัยสำคัญในขณะที่ความสามารถในการนำภาพไปใช้ต่อ (engagement/CTR ของหน้าเพจ) ยังคงอยู่ในระดับยอมรับได้
กรณีใช้งานจริง: อี‑คอมเมิร์ซและสื่อ — ตัวอย่างและสถิติที่น่าสนใจ
ในเชิงปฏิบัติ สตาร์ทอัพผู้พัฒนา Privacy‑Cleanser ได้ออกแบบการใช้งานที่ตอบโจทย์สองกลุ่มหลักคือ ร้านค้าออนไลน์/marketplace และสื่อสังคม/สำนักข่าว โดยมุ่งลดความเสี่ยงการรั่วไหลของข้อมูลส่วนบุคคล (PII) จากรูปภาพและวิดีโอก่อนส่งต่อให้ LLM วิเคราะห์หรือสังเคราะห์ข้อความ การผสานระหว่างเทคนิค differential privacy กับ GAN/segmentation แบบเรียลไทม์ทำให้สามารถปกป้องใบหน้า ตัวหนังสือที่เป็นข้อมูลสำคัญ (เช่น หมายเลขโทรศัพท์ ป้ายทะเบียน) และ metadata บางส่วนได้โดยยังรักษาประโยชน์เชิงวิเคราะห์ไว้ในระดับยอมรับได้สำหรับงานธุรกิจ
1) ร้านค้าออนไลน์ / Marketplace — workflow และผลการทดลอง
กรณีการใช้งานทั่วไป ได้แก่ รูปรีวิวลูกค้าที่มีใบหน้า, วิดีโอผู้ขายสาธิตสินค้า, ภาพสินค้ารีวิวที่มีฉากหลังแสดงป้าย/ข้อความส่วนบุคคล การนำ Privacy‑Cleanser ไปใช้มี workflow ตัวอย่างดังนี้
- รับรูป/วิดีโอจากผู้ใช้ — ตรวจจับองค์ประกอบที่มีความเสี่ยง (ใบหน้า ป้ายตัวอักษร โลโก้ที่อาจระบุตัวตน)
- Segmentation + GAN — แยก region ที่เป็น PII แล้วใช้ GAN สร้างเท็กซ์เจอร์ทดแทนหรือเบลอแบบสมจริง (context-aware)
- Differential Privacy — ใส่ noise แบบมีพารามิเตอร์ควบคุมเพื่อป้องกันการย้อนกลับโดย LLM หรือการเชื่อมโยงข้อมูล
- ส่งข้อมูลที่ผ่านการคลีนนิ่งให้ LLM — สำหรับการสร้างคำอธิบายสินค้า, สกัดคุณลักษณะ, วิเคราะห์ความเห็นลูกค้า
จากการทดลองภายในบนชุดข้อมูลตัวอย่างสำหรับอี‑คอมเมิร์ซ (ประมาณ 5,000 ภาพรีวิว และ 1,200 วิดีโอสั้น) ผลลัพธ์เชิงตัวเลขที่สำคัญได้แก่:
- การลดการเปิดเผยข้อมูลส่วนบุคคล: การตรวจจับและลดความสามารถในการจดจำใบหน้าหลังการประมวลผลลดความน่าจะเป็นการยืนยันตัวตนลงเฉลี่ย 96.3% และการสกัดข้อความ PII (เช่น หมายเลขโทรศัพท์) ลดลงเฉลี่ย 93.8%
- ผลต่อคุณภาพของ LLM: เมื่อส่งภาพที่ผ่าน Privacy‑Cleanser ให้โมเดลทำคำอธิบายสินค้า พบว่า attribute extraction F1-score ลดจากประมาณ 0.90 เป็น 0.87 (-3.3%) เทียบกับภาพต้นฉบับ ขณะที่ perplexity ของการสังเคราะห์คำอธิบายเพิ่มจากเฉลี่ย 18.2 เป็น 19.4 (+6.6%) ซึ่งยังอยู่ในช่วงที่ยอมรับได้สำหรับงานเชิงพาณิชย์
- ความหน่วง (latency): pipeline แบบเรียลไทม์บนเซิร์ฟเวอร์ GPU ระดับกลางให้ผลเฉลี่ยอยู่ที่ประมาณ 160 ms/ภาพ (1024×1024) และเมื่อนำเข้าสู่วิดีโอแบบ batch สามารถประมวลผลได้ ~40–60 ms/เฟรม ขึ้นอยู่กับการตั้งค่า batch และความละเอียด

2) สื่อสังคม / สำนักข่าว — workflow และผลการทดลอง
สำนักข่าวและแพลตฟอร์มสื่อสังคมต้องจัดการกับภาพเหตุการณ์จากพลเมือง (citizen journalism), คลิปสัมภาษณ์, ภาพเหตุการณ์สด ซึ่งมักมีใบหน้า ป้ายทะเบียน และข้อมูลส่วนบุคคลอื่นอยู่ในเฟรม Workflow ที่นิยมใช้มีลักษณะคล้ายอี‑คอมเมิร์ซ แต่เพิ่มขั้นตอนการจัดระดับความเสี่ยงเชิงข่าว (risk scoring) ก่อนการเผยแพร่หรือวิเคราะห์เชิงลึก:
- Pre‑ingest filtering — คำนวณความเสี่ยงจาก metadata และเนื้อหา เพื่อเป็น input ให้การตัดสินใจว่าต้องคลีนนิ่งระดับใด
- Selective anonymization — เก็บองค์ประกอบที่สำคัญเชิงนัย (เช่น ป้ายประกาศเหตุการณ์) แต่ปกป้องใบหน้า/ป้ายทะเบียนที่อาจทำให้บุคคลถูกระบุ
- Integration กับระบบลงข่าว/สรุปอัตโนมัติ — ส่งไฟล์ที่ผ่านการปกป้องให้โมเดลสรุปข่าว, จัดหมวดหมู่, หรือทำ face‑independent analysis
ผลการทดลองจากชุดข้อมูลสื่อ (ประมาณ 2,000 ภาพข่าว และ 500 ชั่วโมงวิดีโอเหตุการณ์) แสดงให้เห็นว่า:
- การลดการรั่วไหลของ PII: อัตราการเปิดเผยตัวตนจากภาพเหตุการณ์ลดลงเฉลี่ย 95.1% และการอ่านป้ายทะเบียนด้วย OCR ลดลง 92.4%
- ผลต่องานวิเคราะห์ข่าว: ความแม่นยำของโมเดลในการจำแนกประเภทเหตุการณ์ (event classification accuracy) ลดเล็กน้อยจาก 0.91 เป็น 0.89 (-2.2%) ขณะที่ประสิทธิภาพการสรุปข่าว (เช่น ROUGE‑L) ลดประมาณ 4–5% แต่ยังให้ข้อความสรุปที่คงคุณภาพเพียงพอสำหรับการรีวิวโดยนักข่าวก่อนเผยแพร่
- ปฏิบัติการเชิงองค์กร: ระบบสามารถตั้งค่าให้เก็บ metadata บางอย่างที่ไม่เป็น PII (เช่น timestamp, coarse location) แยกออกไปก่อนการคลีนนิ่ง เพื่อลดผลกระทบต่อการวิเคราะห์เชิงสถิติของข่าว
โดยสรุป การนำ Privacy‑Cleanser ไปใช้ในสองบริบทนี้ให้ประโยชน์ทางธุรกิจที่ชัดเจน: ลดความเสี่ยงทางกฎหมายและความเสื่อมเสียต่อแบรนด์ ในขณะที่ยังรักษาประโยชน์เชิงวิเคราะห์สำหรับ LLM ให้อยู่ในระดับที่ aceptable สำหรับการใช้งานเชิงพาณิชย์ ทีมงานแนะนำให้ธุรกิจปรับพารามิเตอร์ของ differential privacy และระดับการกลบหน้าตา/เบลอให้สอดคล้องกับนโยบายความเป็นส่วนตัวและเป้าหมายเชิงข้อมูล เพื่อให้ได้สมดุลระหว่างความปลอดภัยกับคุณค่าทางธุรกิจ
ความเป็นส่วนตัวและการปฏิบัติตามกฎหมาย: PDPA, GDPR และการวัดความเสี่ยง
ความสัมพันธ์ระหว่าง Differential Privacy ต่อการปฏิบัติตาม PDPA และ GDPR
ในเชิงปฏิบัติ Differential Privacy (DP) ทำหน้าที่เป็นกลไกทางเทคนิคที่ลดความเสี่ยงจากการเปิดเผยข้อมูลส่วนบุคคลเมื่อส่งผลลัพธ์จากการประมวลผลภาพหรือวิดีโอให้กับ Large Language Models (LLMs) โดยการเพิ่มความไม่แน่นอนในระดับที่วัดได้ (quantified noise) ทำให้โอกาสในการยืนยันว่าข้อมูลเฉพาะบุคคลอยู่ในชุดข้อมูลต้นทางลดลงอย่างมีนัยสำคัญ ซึ่งมีความสอดคล้องกับหลักการด้านความเป็นส่วนตัวใน PDPA และ GDPR ที่กำหนดให้ผู้ควบคุมข้อมูลต้องจัดมาตรการทางเทคนิคและองค์กรเพื่อคงความลับของข้อมูล
อย่างไรก็ตาม ต้องเน้นว่า DP ไม่ใช่ใบอนุญาตให้หลุดพ้นจากข้อกำหนดทางกฎหมายโดยอัตโนมัติ — DP เป็นมาตรการหนึ่งในชุดวิธีการ (technical and organizational measures) ที่ผู้ควบคุมข้อมูลต้องพิจารณา ผู้ประกอบการยังคงต้องแสดงเหตุผลทางกฎหมาย (legal basis) สำหรับการประมวลผล ให้ข้อมูลและขอความยินยอมเมื่อจำเป็น จัดทำ Data Protection Impact Assessment (DPIA/PIA) และควบคุมการเข้าถึงข้อมูลต้นทางอย่างเข้มงวดตามข้อกำหนดของ PDPA/GDPR
การตั้งค่า epsilon: การประเมิน trade‑off ระหว่างความเป็นส่วนตัวกับประโยชน์ใช้สอย
ค่า epsilon (ε) เป็นพารามิเตอร์สำคัญของ DP ที่สะท้อนระดับการป้องกันความเป็นส่วนตัวเชิงคณิตศาสตร์และมีผลโดยตรงต่อคุณภาพของผลลัพธ์ — ค่า ε ที่น้อยลงหมายถึงความเป็นส่วนตัวสูงขึ้นแต่ utility ลดลง ในทางปฏิบัติการเลือกค่า ε ควรพิจารณาบริบทเชิงธุรกิจ เช่น ความอ่อนไหวของภาพ (หน้าคน เอกสารบัตร ฯลฯ), ความเสี่ยงทางกฎหมาย, ผลกระทบต่อประสิทธิภาพโมเดล เช่น ความแม่นยำของการจดจำวัตถุหรือการประเมินพฤติกรรมผู้ใช้
การให้คำแนะนำเชิงปฏิบัติ: โดยทั่วไปเป็นไปได้ที่จะตั้งช่วงอ้างอิง (ตัวอย่างเชิงนำทาง ไม่ใช่ค่าบังคับ)
- ε ≤ 0.1 — ความเป็นส่วนตัวสูงมาก เหมาะเมื่อข้อมูลมีความอ่อนไหวสูง แต่จะมีผลกระทบต่อ utility อย่างชัดเจน
- 0.1 < ε ≤ 1 — ความสมดุลสูงระหว่าง privacy และ utility สำหรับหลายกรณีใช้งานเชิงธุรกิจ
- 1 < ε ≤ 8 — ความเป็นส่วนตัวระดับกลาง เหมาะกับงานที่ต้องการผลลัพธ์มีประโยชน์มากขึ้นแต่ยังต้องการการป้องกันบางส่วน
- ε > 8 — ความเป็นส่วนตัวต่ำ ประสิทธิภาพใกล้เคียงการไม่ใช้ DP แต่ความเสี่ยงในการเปิดเผยสูง
การตั้งค่า ε ควรทำโดยการทดลองแบบเป็นระบบ: รัน benchmark ด้าน utility (เช่น ความแม่นยำของ segmentation, F1-score สำหรับการตรวจจับใบหน้า/วัตถุ) พร้อมกับการจำลองการโจมตี (membership inference, reconstruction attack) เพื่อหาจุดสมดุลที่รับได้ นอกจากนี้ต้องเฝ้าระวังการคำนวณ composition (เมื่อมีหลายคำขอ/หลายโมดูล) โดยใช้เทคนิคการนับงบประมาณความเป็นส่วนตัว (privacy accounting) เช่น Rényi DP หรือ Moments Accountant เพื่อคุม cumulative ε ตลอดวงจรการให้บริการแบบเรียลไทม์
แนวปฏิบัติในการวัดความเสี่ยงและการบันทึก (audit logs) เพื่อเป็นหลักฐานการปฏิบัติตามกฎหมาย
เพื่อให้บริการ Privacy‑Cleanser ถูกยอมรับเชิงกฎหมายและเป็นหลักฐานเมื่อถูกสอบสวน ควรมีกรอบการวัดความเสี่ยงและการบันทึกที่ชัดเจน ประกอบด้วยเมตริกเชิงเทคนิคและกระบวนการเชิงองค์กรดังนี้
- เมตริกทางเทคนิค: บันทึกค่า ε และ δ ที่ใช้ต่อคำขอ, ผลการทดสอบการโจมตี (เช่น อัตราความสำเร็จของ membership inference, ค่า RMSE ของการ reconstruct ภาพ), และตัวชี้วัด utility (เช่น accuracy, IoU ของ segmentation) เพื่อแสดง trade‑off ที่เกิดขึ้น
- audit logs แบบไม่เปลี่ยนแปลง: เก็บประวัติการประมวลผลแต่ละไฟล์/คำขออย่างละเอียด — timestamp, user/client ID, source IP, model/เวอร์ชันที่ใช้, พารามิเตอร์ DP (ε, mechanism), ผลลัพธ์เบื้องต้น และสถานะการยินยอม (consent) — โดยเก็บในรูปแบบ append‑only และลงลายเซ็นดิจิทัลเพื่อป้องกันการแก้ไขย้อนหลัง
- consent flow ที่ชัดเจน: แสดงข้อมูลแก่เจ้าของข้อมูลก่อนประมวลผล (ว่าใช้ DP/GAN/segmentation อย่างไร, ค่า ε โดยประมาณ, จุดประสงค์การใช้ข้อมูล) และบันทึกการยินยอมเป็นหลักฐานตาม PDPA/GDPR
- Privacy Impact Assessment (PIA/DPIA): ดำเนิน PIA ก่อนนำบริการใช้งานจริง โดยระบุความเสี่ยง ค่าพารามิเตอร์ DP ที่เลือก เหตุผลทางธุรกิจ และมาตรการเสริม เช่น การลบข้อมูลต้นทาง การจำกัดการเข้าถึง และการเข้ารหัสข้อมูล
นอกจากนั้น ควรกำหนดกระบวนการทบทวนเป็นระยะ (periodic audits) และทำ penetration testing และ red‑team exercises เพื่อประเมินความทนทานต่อการโจมตีเชิงข้อมูลจริง และจัดเตรียมรายงานสรุปเป็นหลักฐานสำหรับหน่วยงานกำกับดูแล
ข้อจำกัดและการจัดการความเสี่ยงเชิงปฏิบัติ
ต้องรับทราบข้อจำกัดของ DP ในบริบทการประมวลผลภาพ/วิดีโอแบบเรียลไทม์: DP ปกป้องข้อมูลจากการอนุมานจากผลลัพธ์ที่แชร์ แต่ ไม่ใช่การแทนที่การลบหรือการเซนเซอร์ที่ไม่ได้ทำอย่างถูกต้อง เช่น หาก segmentation ผิดพลาดและยังเหลือใบหน้าหรือข้อความชัดเจน DP อาจไม่เพียงพอ ผู้ให้บริการจึงควรรวมมาตรการเชิงเทคนิคหลายชั้น เช่น การตรวจจับและเบลอใบหน้า, inpainting ด้วย GAN เพื่อลบบริบทเชื่อมโยง, การจำกัดความละเอียดของภาพ และการใช้ DP บนผลลัพธ์/สถิติหรือ embedding แทนการใช้บนพิกเซลโดยตรงเมื่อต้องการประหยัด utility
สรุปคือ: การผสาน DP เข้ากับ GAN/segmentation ในบริการ Privacy‑Cleanser ช่วยลดความเสี่ยงทางกฎหมายได้อย่างมีนัยสำคัญเมื่อดำเนินการอย่างเป็นระบบและโปร่งใส แต่ต้องมีการออกแบบพารามิเตอร์ (ε, composition) การบันทึกและกระบวนการรับความยินยอมที่รัดกุม พร้อมการประเมินความเสี่ยงเชิงปฏิบัติ (PIA) เพื่อให้สอดคล้องกับ PDPA/GDPR และยืนหยัดเป็นหลักฐานที่เชื่อถือได้ในกรณีที่ต้องตรวจสอบจากหน่วยงานกำกับดูแล
สถาปัตยกรรมระบบและประสิทธิภาพ: เรียลไทม์ ความหน่วง และการสเกล
สถาปัตยกรรมระบบแบบแยกส่วน (Modular Architecture)
ระบบ Privacy‑Cleanser ถูกออกแบบเป็นสถาปัตยกรรมแบบแยกส่วนเพื่อความยืดหยุ่นและการปรับสเกล โดยแบ่งเป็นโมดูลหลักตามลำดับงานคือ ingestion → segmentation → DP noise → GAN inpainting → output ซึ่งแต่ละโมดูลสามารถรันบน edge device, cloud server หรือในรูปแบบ hybrid ได้ตามข้อจำกัดด้านความหน่วง (latency) และนโยบายความเป็นส่วนตัวของผู้ใช้
- Ingestion: รับภาพหรือสตรีมวิดีโอ เข้า preprocessing (resize, color normalization, keyframe detection) และจัดคิวเฟรม
- Segmentation: ใช้โมเดล segmentation (เช่น lightweight Mask R‑CNN หรือ U‑Net ที่ถูกปรับแต่ง) ระบุพิกัดของข้อมูลส่วนบุคคล เช่น ใบหน้า ป้ายทะเบียน หรือข้อมูลบาร์โค้ด
- DP noise: ใส่กลไก Differential Privacy โดยเติมสัญญาณรบกวนเชิงสถิติบนแมสก์ or feature-space เพื่อลดความเสี่ยงการย้อนกลับข้อมูล
- GAN inpainting: ใช้ GAN ที่ผ่านการ distillation/quantization เติมบริเวณที่ถูกปกปิดให้กลมกลืนกับฉากโดยไม่รบกวนบริบทเชิงพาณิชย์
- Output: ส่งเฟรมที่ผ่านการทำความสะอาดกลับไปยังแอป ส่งต่อให้ LLM หรือลงในคลาวด์สตอเรจ
Pipeline สำหรับวิดีโอแบบเฟรมต่อเฟรมและกลยุทธ์รักษาความต่อเนื่อง
สำหรับวิดีโอสด (live streaming) ระบบจะทำงานแบบเฟรมต่อเฟรมโดยมี pipeline ที่รองรับการประมวลผลแบบต่อเนื่อง: รับเฟรม → ทำ prefiltering (เช่นตรวจจับความเคลื่อนไหว) → segmentation → DP noise injection → inpainting → postprocessing → ส่งออก ในงานที่ต้องการความต่อเนื่องเช่นสตรีมสินค้า ระบบเพิ่มเติมโมดูล temporal smoothing (optical flow / temporal consistency) เพื่อให้การลบ-เติมไม่กระตุกและรักษาลักษณะวัตถุเมื่อมีการเคลื่อนไหว
การจัดคิวและการบัฟเฟอร์มีบทบาทสำคัญ: ใช้ asynchronous pipeline ที่แยก thread/process ระหว่างขั้นตอน I/O และ inference เพื่อให้ส่วน network I/O ไม่บล็อกการทำงานของ inference และสามารถนำเทคนิค split inference มาใช้ — ตัวอย่างเช่น ทำ segmentation เบื้องต้นที่ edge แล้วส่ง masked/feature patch ขึ้น cloud เพื่อรัน GAN ที่ทรงพลังกว่า ซึ่งช่วยลดแบนด์วิดท์และความเสี่ยงการรั่วไหลของข้อมูลต้นฉบับ
การวัดประสิทธิภาพและตัวอย่างเบนช์มาร์ก (ตัวอย่างเชิงปฏิบัติ)
ด้านล่างเป็นตัวอย่างเบนช์มาร์กเชิงเปรียบเทียบที่ใช้เพื่อประเมินความเหมาะสมของการนำไปใช้จริง (ค่าตัวอย่างเป็นการประมาณที่ได้จากระบบต้นแบบและอาจแตกต่างตามฮาร์ดแวร์/โมเดลจริง)
- Edge device (NVIDIA Jetson Xavier NX, FP16/INT8 optimized):
- Segmentation: 12–25 ms/เฟรม
- DP noise injection: < 2 ms/เฟรม
- GAN inpainting (lightweight distilled model): 18–40 ms/เฟรม
- รวม (Pipelined): ~35–67 ms/เฟรม → throughput ≈ 15–28 fps
- การใช้งานทรัพยากร: GPU utilization 60–90%, CPU 15–40%, memory footprint โมเดลรวม 200–800 MB (ก่อน/หลัง quantization)
- Cloud GPU (NVIDIA T4 / RTX 2080 / A100):
- Segmentation: 5–10 ms/เฟรม
- DP noise: < 1 ms/เฟรม
- GAN inpainting (เต็มรูปแบบ): 6–20 ms/เฟรม
- รวม (ไม่รวมเครือข่าย): ~12–31 ms/เฟรม → throughput ≈ 32–83 fps
- แต่ถ้ารวม RTT เครือข่าย (20–100 ms) จะเพิ่ม latency ให้เป็น ~40–130 ms/เฟรม
- การใช้งานทรัพยากร: GPU utilization 40–90% ขึ้นกับ batching, ฐานข้อมูลโมเดลใหญ่: 500 MB–2 GB
ข้อสังเกต: DP noise โดยทั่วไปเป็นค่าใช้จ่ายทางคำนวณที่ต่ำเมื่อออกแบบให้ทำงานบนแมสก์หรือ feature map แต่ต้องระวังผลกระทบต่อคุณภาพการเติมของ GAN ซึ่งอาจต้องปรับพารามิเตอร์ของทั้งสองระบบร่วมกัน
ทางเลือกการปรับแต่งเพื่อลดความหน่วงและเพิ่มสเกล
ระบบสามารถปรับปรุงประสิทธิภาพได้ด้วยเทคนิคต่างๆ ดังนี้
- Quantization: ลด precision เป็น INT8/FP16 ช่วยลดขนาดโมเดลและเวลา inference ได้ 2–4x แต่ต้อง validate ผลกระทบต่อความแม่นยำ
- Model distillation: ฝึกโมเดลขนาดเล็กให้เลียนแบบโมเดลครู เพื่อได้ latency ต่ำลงโดยยังรักษาคุณภาพภาพให้เพียงพอสำหรับการใช้งานเชิงพาณิชย์
- Batching และ asynchronous batching: เพิ่ม throughput โดยรวมหลายเฟรมเป็น batch ใน GPU แต่แลกกับ latency ต่อเฟรมที่สูงขึ้น — เหมาะกับการประมวลผลวิดีโอที่ไม่ต้องการโต้ตอบทันที
- Edge inference และ split inference: รัน segmentation + DP ที่ edge เพื่อลดแบนด์วิดท์และปกป้องข้อมูล ส่งเฉพาะแมสก์หรือ patch ขึ้น cloud เพื่อทำ inpainting คุณภาพสูง
- Pruning, early‑exit, และ mixed precision: ตัดพารามิเตอร์ไม่สำคัญ ใช้ early exit สำหรับเฟรมที่ไม่มีข้อมูลส่วนบุคคล และรันบาง layer ด้วย FP16 เพื่อความเร็ว
- Inference engines: ใช้ TensorRT / ONNX Runtime / NVIDIA Triton สำหรับการเร่ง inference และการ deploy แบบ auto‑scaling
สรุปคือ การออกแบบระบบ Privacy‑Cleanser สำหรับ use case อี‑คอมเมิร์ซและสื่อ ต้องมีสถาปัตยกรรมแบบแยกส่วนที่ยืดหยุ่น ระหว่าง edge และ cloud เพื่อให้บรรลุทั้งข้อกำหนดด้านความเป็นส่วนตัวและความหน่วงต่ำ เทคนิคเช่น quantization, distillation, batching และ split inference เป็นกุญแจสำคัญในการลด latency ให้พอใช้สำหรับการสตรีมสด ในขณะที่การวัดผลด้วย latency ต่อเฟรม (ms), throughput (fps) และ resource footprint (CPU/GPU/memory) จะเป็นตัวกำหนด trade‑off ระหว่างความเร็ว ความถูกต้อง และต้นทุนการดำเนินงาน
โมเดลธุรกิจ ตลาด และการแข่งขัน: โอกาสในประเทศไทยและภูมิภาค
โมเดลธุรกิจ ตลาด และการแข่งขัน: โอกาสในประเทศไทยและภูมิภาค
สรุปโมเดลรายได้และช่องทาง — โซลูชัน Privacy‑Cleanser สามารถสร้างรายได้ได้หลายช่องทางที่ตอบโจทย์ลูกค้าหลากหลายประเภท ได้แก่
- SaaS แบบ per‑asset — คิดค่าบริการตามจำนวนภาพหรือความยาววิดีโอที่ประมวลผล (เช่น ต่อภาพ ต่อวินาที/นาทีของวิดีโอ) เหมาะกับแพลตฟอร์ม marketplace และผู้พัฒนาแอปที่ต้องการจ่ายตามการใช้งาน
- Subscription (Tiered) — แพ็กเกจรายเดือน/รายปี แบ่งตามปริมาณการประมวลผล คุณสมบัติ latency ระดับ SLA และความสามารถในการปรับแต่ง เช่น Starter สำหรับ SMEs, Professional สำหรับเอเจนซี่สื่อ, Enterprise สำหรับ marketplace รายใหญ่
- Enterprise licensing / On‑premises — สัญญาไลเซนส์ระยะยาวพร้อมตัวเลือกติดตั้งในคลาวด์ส่วนตัวหรือภายในองค์กร (จำเป็นสำหรับธนาคาร กลุ่มสื่อขนาดใหญ่ หรือหน่วยงานรัฐที่ต้องการควบคุมข้อมูล)
- API / Developer‑platform fees — ค่าบริการตาม API calls และ add‑on เช่น plug‑ins สำหรับ CDNs, e‑commerce platforms, หรือ CMS
- Professional services & integration — ค่าบริการติดตั้ง ปรับแต่งโมเดล (fine‑tuning), คอนซัลติ้งเรื่อง PDPA และการทดสอบความเป็นส่วนตัว (privacy audits)
แนวทางการตั้งราคา (ตัวอย่างประมาณการ) — แนวทางการกำหนดราคาควรสะท้อนต้นทุนคำนวณ (GPU/CPU), latency ที่รับได้ และมูลค่าทางธุรกิจ เช่น
- Per image: ประมาณ 0.001–0.05 USD ต่อภาพ (≈ 0.04–1.8 บาท/ภาพ) สำหรับการละลาย/ปิดบังใบหน้าแบบอัตโนมัติ และสูงขึ้นสำหรับการปรับแต่งเชิงบริบท
- Per video: ประมาณ 0.1–3 USD ต่อนาที ขึ้นกับความละเอียดและการประมวลผลแบบเรียลไทม์ (≈ 3.5–105 บาท/นาที)
- Subscription: แผนรายเดือนสำหรับลูกค้าองค์กรขนาดเล็กถึงกลางตั้งแต่ 30–500 USD/เดือน และแผนองค์กรระดับ enterprise เริ่มต้นที่หลายพัน USD/ปี พร้อม SLA และการติดตั้ง on‑prem
TAM / SAM: ขนาดตลาดโดยประมาณสำหรับไทยและภูมิภาค SEA — การประเมินขนาดตลาดสำหรับโซลูชัน privacy‑for‑media ควรยึดตามขนาดอุตสาหกรรมที่เกี่ยวข้องคือ e‑commerce และสื่อ/โฆษณาดิจิทัล
- ขนาดตลาด e‑commerce ในภูมิภาค SEA (ประมาณปีล่าสุด): 100–250 พันล้าน USD (GMV) — ประเทศไทยประมาณ 20–30 พันล้าน USD ในระดับ GMV (ประมาณการเชิงวงกว้าง)
- ค่าใช้จ่ายด้านโฆษณาดิจิทัลและการผลิตสื่อใน SEA รวมกันประมาณ 20–40 พันล้าน USD ต่อปี
- สมมติฐานการคำนวณ TAM สำหรับ privacy‑for‑media: หากถือว่า 0.1–1% ของ GMV/ค่าใช้จ่ายสื่อถูกจัดสรรเป็นค่าใช้จ่ายเทคโนโลยีที่จะป้องกันความเสี่ยงข้อมูล (เช่น การทำภาพ/วิดีโอให้เป็นส่วนตัว, redaction, compliance) จะได้ TAM ประมาณ 300–2,000 ล้าน USD สำหรับทั้งภูมิภาค SEA และประมาณ 30–200 ล้าน USD สำหรับประเทศไทยเป็นช่วงที่เป็นไปได้
- SAM (ตลาดที่เข้าถึงได้จริง) ใน 3‑5 ปีแรกจะโฟกัสที่ตลาด e‑commerce marketplaces, แพลตฟอร์มโฆษณา และสำนักข่าว/เอเยนซี่ที่มีงานภาพ/วิดีโอหนาแน่น — ประเมิน SAM สำหรับ SEA ประมาณ 50–300 ล้าน USD ขึ้นกับความสำเร็จในการพาร์ทเนอร์และการปฏิบัติตามกฎระเบียบ
คู่แข่งและตำแหน่งทางเทคนิค/ธุรกิจที่น่าจับตามอง — ตลาดนี้มีทั้งผู้เล่นใหญ่ด้านคลาวด์ ผู้ให้บริการด้าน moderation และสตาร์ทอัพเฉพาะทาง:
- ผู้ให้บริการคลาวด์รายใหญ่ (AWS, Google Cloud, Azure) — มีบริการตรวจจับวัตถุ/ใบหน้าและเครื่องมือ Data Loss Prevention ที่สามารถใช้ทำ redaction ได้ ข้อได้เปรียบคือความน่าเชื่อถือและเครือข่าย แต่ข้อจำกัดคือความยืดหยุ่นในการพัฒนาเทคนิคเชิง privacy‑first (เช่น differential privacy ผสาน GAN แบบเรียลไทม์) และโมเดลธุรกิจที่อาจไม่รองรับการติดตั้ง on‑premise แบบเฉพาะ
- สตาร์ทอัพเฉพาะทางและงานวิจัย (เช่น โซลูชัน anonymization GANs/DeepPrivacy) — มุ่งเน้นเทคนิคการทำเห็นภาพไม่ระบุตัวตน (face replacement, blurring, k‑anonymity) ข้อได้เปรียบคือนวัตกรรมเฉพาะทางและ latency ต่ำ แต่มีข้อท้าทายเรื่องการสเกลและความน่าเชื่อถือเชิงองค์กร
- เอเจนซีและผู้ให้บริการ moderation ท้องถิ่น — ให้บริการแบบ manual redaction และ outsourcing ซึ่งมักถูกเลือกเมื่อความแม่นยำสำคัญมาก แต่ค่าใช้จ่ายสูงและสเกลได้ยาก
ข้อได้เปรียบเชิงเทคนิค/ธุรกิจของผู้พัฒนา Privacy‑Cleanser
- การผสาน Differential Privacy + GAN + Segmentation แบบเรียลไทม์ ช่วยให้มีความสมดุลระหว่างความเป็นส่วนตัวและคุณภาพภาพที่ส่งต่อให้ LLM/ระบบ downstream — ตรงนี้เป็นจุดขายเชิงเทคนิคที่ชัดเจนเมื่อเทียบกับเครื่องมือ blur แบบเดิม
- รองรับการปรับแต่งระดับความเป็นส่วนตัวตามกฎหมาย (เช่น PDPA ในไทย) และนโยบายแพลตฟอร์ม ทำให้เหมาะกับลูกค้าองค์กรที่ต้องการหลักฐานการปฏิบัติตามกฎเกณฑ์
- ตัวเลือก deployment ยืดหยุ่น (SaaS, hybrid, on‑premises) ช่วยลดข้อกังวลด้านข้อมูลสำหรับธนาคารและสำนักข่าวที่ไม่ต้องการส่งรายละเอียดภาพไปยังคลาวด์สาธารณะ
- การออกแบบสำหรับ latency ต่ำและ API‑first ช่วยให้รวมเข้ากับ pipeline ของ marketplace, CDN หรือ media asset management ได้เร็ว ส่งผลให้ adoption ของลูกค้าองค์กรง่ายขึ้น
การประเมินการยอมรับของลูกค้าและกลยุทธ์การเข้าสู่ตลาด — ปัจจัยกำหนดการยอมรับรวมถึงความตระหนักเรื่อง PDPA/กฎหมายคุ้มครองข้อมูล, ความกังวลด้านความปลอดภัยของลูกค้า, และต้นทุนการรวมระบบ
- กลุ่ม adopters เร็ว: marketplace ขนาดใหญ่, แพลตฟอร์มโฆษณา, สื่อข่าวเชิงดิจิทัล ที่ต้องการลดความเสี่ยงจากการรั่วไหลของข้อมูลและรักษาภาพลักษณ์แบรนด์
- กลุ่ม adopters ปานกลาง: เอเจนซี่โฆษณาและผู้ค้าบนแพลตฟอร์มที่มีงบประมาณจำกัด ต้องการ subscription ราคาถูกหรือ integration ผ่านพาร์ทเนอร์
- กลุ่มช้าที่สุด: ร้านค้าออนไลน์ขนาดเล็ก/SMEs ที่มักต้องการโซลูชันที่ฝังมากับแพลตฟอร์มอี‑คอมเมิร์ซที่ใช้อยู่ (playbook: ให้พาร์ทเนอร์แพลตฟอร์มเป็นช่องทางจัดจำหน่าย)
ข้อเสนอแนะเชิงกลยุทธ์ — ในระยะเริ่มต้นควรเน้นลูกค้าองค์กรที่มีความเสี่ยงสูงและงบประมาณสำหรับความปลอดภัยข้อมูล (เช่น marketplace ชั้นนำ, ผู้ให้บริการโฆษณา, สำนักข่าว) พร้อมพัฒนาชุด SDK/plug‑in สำหรับแพลตฟอร์มยอดนิยมเพื่อขยายการใช้งานสู่ SMEs โดยควบคู่กับการสร้างความร่วมมือกับผู้ให้บริการคลาวด์และ CDN เพื่อเพิ่มความน่าเชื่อถือและเร่งการเติบโตของ SAM ในภูมิภาค
ความท้าทาย ข้อจำกัด และแผนพัฒนาต่อไป พร้อมคำแนะนำสำหรับผู้ประกอบการ
ความท้าทายและข้อจำกัดเชิงเทคนิค รวมถึงความเสี่ยงด้านความเป็นส่วนตัว
การนำระบบ Privacy‑Cleanser ไปใช้ในระดับธุรกิจต้องเผชิญข้อจำกัดทางเทคนิคและความเสี่ยงจากการรั่วไหลของข้อมูลที่ควรประเมินอย่างรอบคอบ ประเด็นสำคัญได้แก่ การทำงานของโมดูล segmentation และ GAN ในสภาวะแวดล้อมจริง — ตัวอย่างเช่น ในสภาพแสงน้อยหรือมุมกล้องที่ผิดปกติ ความแม่นยำของ segmentation อาจลดลง 20–40% เทียบกับสภาวะมาตรฐาน ส่งผลให้การเบลอ/ลบข้อมูลส่วนบุคคลไม่ครบถ้วนหรือเกิดการลบข้อมูลที่ไม่เกี่ยวข้อง (over‑masking) ซึ่งกระทบต่อประสบการณ์ผู้ใช้และข้อมูลเชิงธุรกิจ
อีกประเด็นที่ต้องคำนึงคือการโจมตีเชิงคืนข้อมูล (reconstruction / model inversion attacks) — แม้จะใช้ Differential Privacy (DP) ผสมกับ GAN และ segmentation ในหลายกรณี นักวิจัยพบว่าสามารถฟื้นคืนรูปบางส่วนจากการตอบกลับของโมเดลหรือจาก latent representation ได้โดยการโจมตีเชิงสังเคราะห์ ตัวอย่างเช่น การโจมตีด้วย GAN‑based reconstruction อาจประสบความสำเร็จหากการตั้งค่า DP ไม่เข้มงวดเพียงพอหรือหากมีการแชร์ embedding แบบไม่เข้ารหัส
การตั้งค่า DP เป็นอีกจุดที่ผู้ประกอบการต้องระมัดระวัง — ค่า epsilon ที่เล็กลงให้การปกป้องข้อมูลมากขึ้นแต่ทำให้ utility ลดลง (เช่น คุณภาพภาพหรือความแม่นยำของ LLM ในงาน downstream) หากตั้งค่า DP ผิดพลาด (เช่น epsilon สูงเกินไป หรือไม่มีการจัดการกับ composition ของการเรียก API) อาจทำให้เกิดความเข้าใจผิดว่าระบบปลอดภัย ทั้งนี้ต้องพิจารณา trade‑off ระหว่างความเป็นส่วนตัวกับประสิทธิภาพการทำงานอย่างมีนัยสำคัญ
สุดท้ายคือความท้าทายด้านต้นทุนและ latency — การประมวลผลแบบเรียลไทม์ที่รวม GAN/segmentation และการเพิ่มกลไก DP อาจเพิ่มต้นทุนคอมพิวต์และหน่วงเวลา ตัวอย่างเช่น การประมวลผลภาพขนาดสูงแบบเรียลไทม์อาจต้องใช้ GPU/TPU ที่มีค่าใช้จ่ายสูงและการออกแบบสถาปัตยกรรมที่ซับซ้อนเพื่อรองรับ throughput ที่ธุรกิจอี‑คอมเมิร์ซต้องการ
แผนพัฒนาฟีเจอร์ระยะสั้น–กลาง–ยาว (Roadmap พร้อมเป้าหมาย)
- ระยะสั้น (3–6 เดือน): ปรับปรุงโมเดล segmentation ให้ทนทานต่อสภาวะแสงน้อยด้วยการเพิ่มชุดข้อมูลที่หลากหลายและ augmentation, เปิดตัวค่า DP preset (เช่น epsilon presets: 0.5, 1, 2) พร้อมคำแนะนำเชิงธุรกิจ, เพิ่มเครื่องมือ monitoring เบื้องต้นเพื่อตรวจจับ degradation ของ mask quality และ latency baseline
- ระยะกลาง (6–18 เดือน): รองรับ on‑device inference สำหรับการประมวลผลเบื้องต้นเพื่อลดการส่งข้อมูลไปยังคลาวด์, พัฒนา explainability tools (เช่น visual heatmaps, mask confidence scores) เพื่อให้ฝ่ายกฎหมายและ QA ตรวจสอบผลได้, เพิ่ม multilingual metadata support เพื่อให้ระบบสามารถจัดการคำอธิบายและ tagging หลายภาษา (รวมไทย) ได้, เปิดฟีเจอร์ audit logs และ privacy reports สำหรับการตรวจสอบภายใน
- ระยะยาว (18+ เดือน): ขยายไปสู่การรับรองมาตรฐาน (เช่น ISO/IEC 27001 + ISO/IEC 27701, SOC 2) และการพิสูจน์ความเป็นส่วนตัวเชิงคณิตศาสตร์ (formal DP proofs, privacy accounting), บูรณาการ federated learning หรือ secure enclaves สำหรับการเรียนรู้ร่วมโดยไม่เผยข้อมูลดิบ, เพิ่มการรองรับระดับองค์กร (enterprise scalability) ให้รองรับการเรียกใช้งานเป็นล้านเรียก/วัน พร้อมระบบ CI/CD สำหรับ model retraining อัตโนมัติและ certification pipeline
คำแนะนำสำหรับผู้ประกอบการ: Checklist สำหรับการเชื่อมต่อกับ pipeline LLM
ต่อไปนี้เป็น checklist และขั้นตอนเชิงปฏิบัติสำหรับองค์กรที่ต้องการนำ Privacy‑Cleanser ไปเชื่อมต่อกับ pipeline ของ LLM เพื่อใช้งานจริง
- Mapping ข้อมูลและออกแบบ Data Flow: ระบุจุดเริ่มต้นของข้อมูล (camera, upload, third‑party), ระบุข้อมูลที่ต้องผ่าน Privacy‑Cleanser ก่อน (images, videos, thumbnails, metadata), กำหนด boundary ระหว่าง on‑device และ cloud processing
- Integration Steps:
- ติดตั้งและทดสอบ API endpoints ในสภาพแวดล้อม sandbox
- กำหนดค่า DP preset ตามความเสี่ยงของแต่ละ use case (เช่น การวิเคราะห์ภาพสินค้า vs. การแชร์ UGC)
- เชื่อมต่อ output ของ Privacy‑Cleanser เป็น input ที่ LLM คาดหวัง (validate schema, metadata mapping)
- Testing และ Validation:
- Functional tests: ตรวจสอบ mask coverage, false negative/positive rate (เป้าหมายเช่น IoU > 0.85 สำหรับ object masks หรือ recall ของ face detection > 0.95 ตาม use case)
- Privacy tests: ดำเนินการ red‑team reconstruction attacks และ membership inference tests เพื่อประเมินความเสี่ยง
- Performance tests: ตรวจวัด end‑to‑end latency (ตัวอย่างเป้าหมายสำหรับ real‑time < 200 ms), throughput และ resource utilization
- A/B tests: วัดผลต่อประสิทธิภาพของ LLM downstream (เช่น ความแม่นยำของ classification ลดลงไม่เกิน X%) และประเมินผลกระทบเชิงธุรกิจ
- KPI ที่แนะนำติดตาม:
- Privacy KPIs: average epsilon per request, number of detected privacy incidents, success rate of red‑team attacks
- Quality KPIs: segmentation IoU, mask precision/recall, impact on LLM accuracy
- Operational KPIs: end‑to‑end latency, requests per second (RPS), cost per 1,000 requests, SLA uptime
- Governance และ Compliance: จัดตั้งกระบวนการอนุมัติการตั้งค่า DP, เก็บ audit trail ของการเปลี่ยนแปลงโมเดลและค่า configuration, เตรียมเอกสารสำหรับการตรวจสอบภายนอกและขอ certifications เมื่อพร้อม
- การจัดการความเสี่ยงและแผนกู้คืน: วางแผน rollback ของโมเดล/การตั้งค่า DP, มี playbook สำหรับกรณีตรวจพบข้อมูลรั่วไหล, และกำหนดผู้มีอำนาจตัดสินใจเมื่อเกิดเหตุ
สรุปคือ ผู้ประกอบการควรประเมิน trade‑off ระหว่าง privacy, utility และต้นทุนอย่างเป็นระบบ ใช้การทดสอบเชิงรุก (privacy red teaming) และปรับ roadmap ให้ครอบคลุมทั้งประเด็นเทคนิค การตรวจสอบภายใน และการรับรองภายนอก เพื่อให้การนำ Privacy‑Cleanser ไปใช้งานจริงตอบโจทย์ทางธุรกิจและเป็นไปตามข้อกำหนดทางกฎหมาย
บทสรุป
Privacy‑Cleanser เป็นโซลูชันที่ผสานเทคโนโลยี Differential Privacy (DP), Generative Adversarial Networks (GAN) และเทคนิค segmentation เพื่อลดความเสี่ยงการรั่วไหลของข้อมูลส่วนบุคคล (PII) ในภาพและวิดีโอก่อนส่งให้ Large Language Models (LLM) หรือระบบวิเคราะห์ต่างๆ โดยทำงานแบบเรียลไทม์เพื่อปกป้องใบหน้า ป้ายทะเบียน และองค์ประกอบที่ระบุได้อื่นๆ ทั้งนี้โซลูชันดังกล่าวมีประโยชน์เชิงปฏิบัติสูงสำหรับธุรกิจอี‑คอมเมิร์ซและสื่อที่ต้องส่งภาพ/วิดีโอไปวิเคราะห์หรือใช้สำหรับการค้นหา ปรับปรุงคอนเทนต์ และการโฆษณา เนื่องจากช่วยลดความเสี่ยงทางกฎหมายและภาพลักษณ์จากการรั่วไหลของข้อมูลส่วนบุคคล
การนำไปใช้จริงต้องคำนึงถึง trade‑offs สำคัญระหว่างความเป็นส่วนตัวกับ utility ของข้อมูล — ยิ่งปรับแต่ง DP ให้เข้มขึ้นหรือบิดเบือนรูปมากเท่าไร ความแม่นยำของงาน downstream (เช่น การจำแนกสินค้า การรู้จำพฤติกรรมลูกค้า) อาจลดลงและมีผลต่อประสบการณ์ผู้ใช้ นอกจากนี้องค์กรต้องตรวจสอบการปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA/GDPR) จัดกระบวนการ auditing และนโยบายการเก็บ log และ consent ที่ชัดเจน รวมถึงทดสอบประสิทธิภาพในบริบทจริงด้วยชุดข้อมูลและสถาปัตยกรรมของตน (A/B testing, benchmark ด้านความเป็นส่วนตัว/utility, latency และต้นทุนการประมวลผล) ก่อนขยายใช้ในระดับองค์กร
ในมุมมองอนาคต เทคโนโลยีเช่น Privacy‑Cleanser มีแนวโน้มพัฒนาไปสู่ระบบที่ปรับค่า DP แบบ adaptive ตามบริบทงาน ผสมผสานการประมวลผลที่ edge เพื่อหน่วง latency และลดการส่งข้อมูลดิบ ขณะเดียวกันมาตรฐานการประเมินความเป็นส่วนตัวและชุดข้อมูลอ้างอิงจะเป็นกุญแจสำคัญสำหรับการยอมรับในวงกว้าง องค์กรควรเตรียมกรอบการตรวจสอบอย่างต่อเนื่อง (continuous monitoring), การประเมินความเสี่ยงแบบอิสระ และการฝึกอบรมทีมงานเพื่อให้สามารถปรับสมดุลระหว่างความเป็นส่วนตัว ความปลอดภัย และประโยชน์ใช้งานได้อย่างยั่งยืน



