
คณะกรรมการของรัฐออกคำสั่งฉบับใหม่ที่คาดว่าจะเขย่าวงการเทคโนโลยีของไทย: ให้หน่วยงานภาครัฐและผู้ให้บริการปัญญาประดิษฐ์ (AI) จัดทำและประกาศใช้ Model‑Card และ Datasheet เป็นข้อบังคับภายในระยะเวลา 6 เดือน หากไม่ปฏิบัติตามอาจส่งผลให้การอนุญาตเปิดตัวแอปพลิเคชันหรือบริการ AI ถูกระงับหรือทบทวนใหม่ทันที การตัดสินใจครั้งนี้มุ่งเน้นการควบคุมความเสี่ยง เพิ่มความโปร่งใส และยกระดับความเป็นธรรมของระบบอัตโนมัติที่มีผลต่อประชาชนและหน่วยงานต่าง ๆ
บทนำข่าวชิ้นนี้จะสรุปประเด็นสำคัญ ได้แก่ ขอบเขตของคำสั่ง (หน่วยงานใดต้องปฏิบัติและเทคนิคใดต้องรายงาน) กรอบเวลา 6 เดือนที่กำหนดไว้ ผลกระทบต่อการเปิดตัวผลิตภัณฑ์และบริการ AI ตลอดจนมาตรการควบคุมความเสี่ยงที่หน่วยงานรัฐคาดว่าจะนำมาใช้ รวบรวมตัวอย่างการใช้งาน แนวทางปฏิบัติที่แนะนำ และสิ่งที่ผู้ให้บริการต้องเตรียมเพื่อนำระบบเข้าสู่มาตรฐานใหม่ของภาครัฐ
บทนำ: คำสั่งใหม่ของราชการคืออะไร
บทนำ: คำสั่งใหม่ของราชการคืออะไร
เมื่อเร็ว ๆ นี้ หน่วยงานกำกับดูแลด้านเทคโนโลยีของรัฐ ได้ออกคำสั่งใหม่ให้องค์กรและผู้ให้บริการระบบปัญญาประดิษฐ์ (AI) ต้องจัดทำ Model‑Card และ Datasheet เป็นข้อบังคับ โดยกำหนดกรอบเวลาให้มีการปรับระบบและยื่นเอกสารภายใน 6 เดือน นับจากวันที่ประกาศ คำสั่งดังกล่าวมีผลต่อผู้พัฒนาโมเดล ผู้ให้บริการแพลตฟอร์ม และผู้ให้บริการร่วมที่นำ AI ไปใช้งานในภาคสาธารณะและภาคเอกชนที่ให้บริการต่อประชาชน เป้าหมายเชิงนโยบายประกอบด้วยการเพิ่มความโปร่งใส ลดความเสี่ยงจากการใช้งานที่ไม่เหมาะสม และยกระดับการคุ้มครองผู้บริโภค

Model‑Card และ Datasheet จะทำหน้าที่เป็นเอกสารอธิบายลักษณะทางเทคนิคและบริบทการใช้งานของโมเดล โดยต้องระบุข้อมูลสำคัญ เช่น ข้อมูลการฝึกสอน (dataset provenance), เมตริกประสิทธิภาพ (accuracy, F1-score ฯลฯ), ข้อจำกัด (known limitations), ความเสี่ยงด้านความเป็นธรรมและอคติ (bias risks), และแนวทางการใช้งานที่เหมาะสม (recommended use-cases) คำสั่งกำหนดให้เอกสารเหล่านี้ต้องถูกจัดทำในรูปแบบมาตรฐานที่หน่วยงานกำกับดูแลกำหนด เพื่อให้การประเมินและการตรวจสอบสามารถทำได้จริงและต่อเนื่อง
เหตุผลหลักของการบังคับใช้คือการตอบโจทย์เชิงนโยบายสามประการ ได้แก่ (1) ความโปร่งใส — ให้ผู้ใช้งานและผู้กำกับดูแลเข้าใจการทำงานและข้อจำกัดของโมเดลได้ชัดเจน, (2) ความปลอดภัยและการลดความเสี่ยง — ลดโอกาสเกิดผลกระทบเชิงลบจากการนำโมเดลไปใช้งานในบริบทที่ไม่เหมาะสม, และ (3) การคุ้มครองผู้บริโภค — ให้ผู้ใช้สิทธิ์ในการตัดสินใจที่มีข้อมูลรองรับก่อนยอมรับการตัดสินใจหรือคำแนะนำจากระบบ AI ภาพรวมเป็นไปในทิศทางการเพิ่มความเชื่อมั่นของประชาชนต่อบริการดิจิทัลและสอดคล้องกับแนวปฏิบัติสากลที่หน่วยงานระหว่างประเทศผลักดันให้มีการเปิดเผยข้อมูลเบื้องต้นของโมเดล
เชิงปฏิบัติ คำสั่งกำหนดให้ผู้ให้บริการต้องมีแผนงานภายใน 6 เดือน ทั้งการจัดทำเอกสาร การปรับกระบวนการภายใน และการส่งมอบข้อมูลตามรูปแบบที่กำหนดแก่หน่วยงานกำกับดูแล ขณะที่หน่วยงานจะกำหนดมาตรการติดตามผลและมาตรการบังคับใช้ต่อไป ตัวอย่างข้อมูลที่ต้องเตรียมมีตั้งแต่รายละเอียดของชุดข้อมูลฝึกสอน การทดสอบประสิทธิภาพในกลุ่มตัวอย่างต่าง ๆ การประเมินความเสี่ยงตามบริบทการใช้งาน และนโยบายการจัดการข้อมูลส่วนบุคคล เพื่อให้การใช้งาน AI เป็นไปอย่างมีความรับผิดชอบและสามารถตรวจสอบย้อนหลังได้
- หน่วยงาน: คำสั่งออกโดยหน่วยงานกำกับดูแลด้านเทคโนโลยีของรัฐ
- ข้อบังคับ: จัดทำ Model‑Card และ Datasheet เป็นข้อบังคับ
- กรอบเวลา: ให้เวลา 6 เดือนในการปรับระบบและยื่นเอกสาร
- เหตุผลเชิงนโยบาย: เพิ่มความโปร่งใส ลดความเสี่ยง และคุ้มครองผู้บริโภค
รายละเอียดคำสั่ง: ขอบเขตและข้อกำหนดหลัก
รายละเอียดคำสั่ง: ขอบเขตและข้อกำหนดหลัก — ภาพรวมเชิงเทคนิคและเชิงนโยบาย
คำสั่งของราชการไทยระบุให้ผู้ให้บริการระบบปัญญาประดิษฐ์ต้องจัดทำ Model‑Card และ Datasheet สำหรับผลิตภัณฑ์ AI/ML ทุกระบบที่นำเสนอในตลาดภายในระยะเวลาที่กำหนด โดยมีวัตถุประสงค์เพื่อเพิ่มความโปร่งใส ปรับปรุงความรับผิดชอบด้านจริยธรรม และอำนวยความสะดวกในการตรวจสอบย้อนกลับ (auditability) ของโมเดลและชุดข้อมูล ขอบเขตของคำสั่งครอบคลุมทั้งโมเดลสำเร็จรูป โมเดลที่ให้บริการผ่าน API และชุดข้อมูลที่ใช้ฝึก โมเดล หรือปรับแต่ง (fine‑tuning) รวมทั้งระบบที่ใช้งานภายในหน่วยงาน (on‑premise) และระบบที่ให้บริการแบบคลาวด์
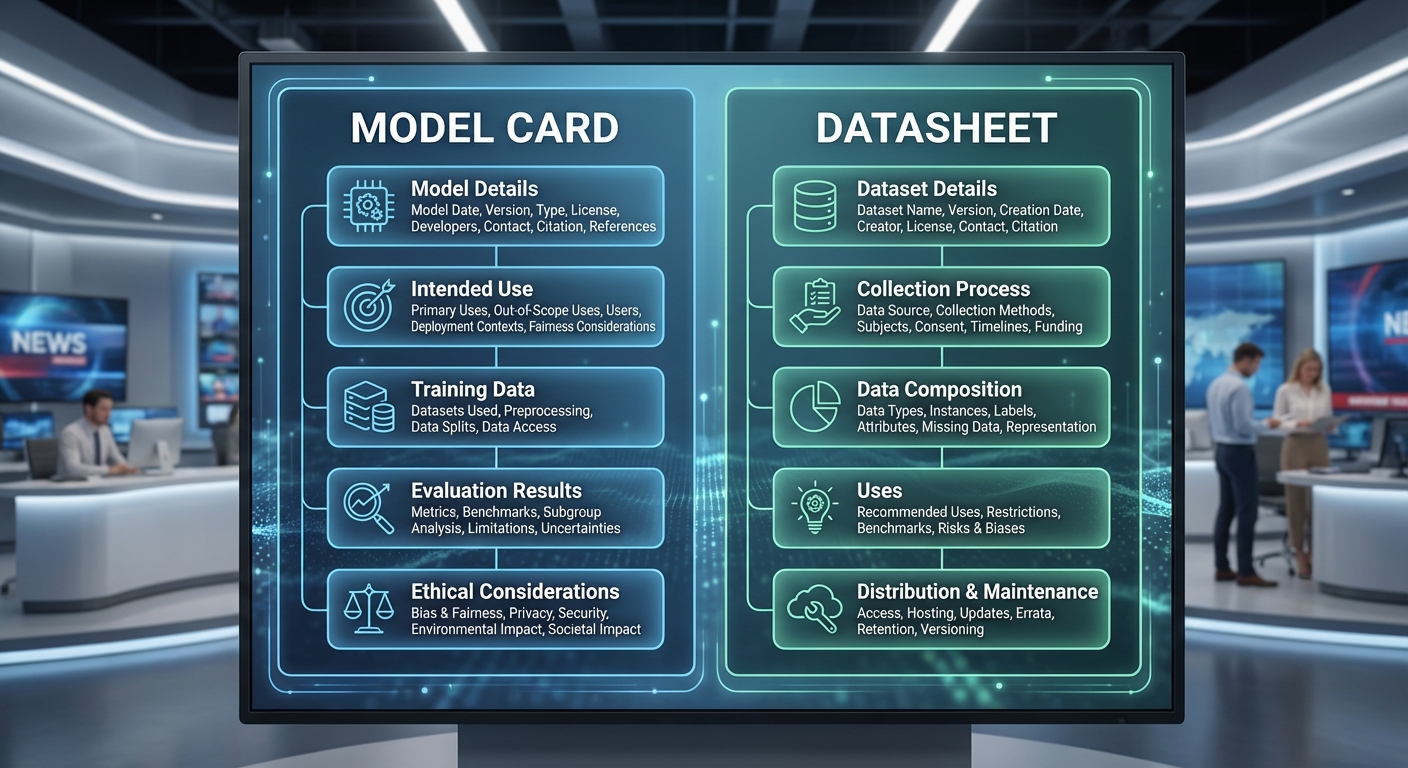
รายการข้อมูลขั้นต่ำใน Model‑Card
Model‑Card จะต้องจัดเตรียมข้อมูลในรูปแบบที่อ่านได้ทั้งแบบมนุษย์และแบบเครื่อง (machine‑readable) โดยขั้นต่ำต้องประกอบด้วย:
- ข้อมูลระบุตัวตนของโมเดล: ชื่อรุ่น, เวอร์ชัน, วันที่เผยแพร่, ผู้พัฒนา/ผู้ให้บริการ, ช่องทางติดต่อ
- วัตถุประสงค์และขอบเขตการใช้งาน: เป้าหมายการออกแบบ, กรณีใช้งานที่อนุญาตและที่ไม่แนะนำ
- ข้อมูลฝึก (summary): คำอธิบายชุดข้อมูลที่ใช้ฝึก, แหล่งที่มา (provenance), ขนาด (sample counts), วันที่เก็บข้อมูล, การสุ่มตัวอย่างและการแบ่งสัดส่วน (train/validation/test)
- ข้อจำกัดและความเสี่ยง: ขอบเขตที่โมเดลทำงานได้ดี, กลุ่มผู้ใช้ที่อาจได้รับผลกระทบ, ความลำเอียงที่ตรวจพบและช่องว่างในการทดสอบ
- เมตริกประสิทธิภาพ: ค่าที่ใช้วัด (เช่น accuracy, precision, recall, F1, AUC), ค่ากลางและช่วงความเชื่อมั่น, เงื่อนไขการทดสอบ (dataset, seed, hardware)
- การประเมินความทนทานและการโจมตี: ผลการทดสอบความแข็งแรงต่อการโจมตี (adversarial robustness), การทดสอบภายในสภาพแวดล้อมที่เปลี่ยนแปลง
- ข้อกำหนดด้านทรัพยากรและการปรับใช้: ขนาดโมเดล, ข้อมูลสภาพแวดล้อมการรัน (runtime), เวลาตอบสนองโดยประมาณ, ข้อกำหนดฮาร์ดแวร์
- ใบอนุญาตและข้อจำกัดด้านลิขสิทธิ์: สถานะลิขสิทธิ์ของโมเดลและชุดข้อมูล, เงื่อนไขการใช้เชิงพาณิชย์
รายการข้อมูลขั้นต่ำใน Datasheet
Datasheet สำหรับชุดข้อมูลต้องระบุรายละเอียดเชิงโครงสร้างและการบริหารจัดการข้อมูลเพื่อให้สามารถตรวจสอบและใช้งานได้อย่างปลอดภัยและถูกต้อง ขั้นต่ำประกอบด้วย:
- สรุปเชิงโครงสร้าง (schema): ฟิลด์แต่ละฟิลด์, ประเภทข้อมูล, รูปแบบ (format), ค่าที่เป็นไปได้ (enumerations), คำจำกัดความของแต่ละคอลัมน์
- provenance/ต้นทางข้อมูล: แหล่งที่มา, วิธีการรวบรวม, สิทธิ์การใช้งาน, วันที่เก็บและอัปเดตล่าสุด
- การแปรรูปและการทำความสะอาด: คำอธิบายการเปลี่ยนรูปพลวัต (transformations), การลบหรือแทนที่ค่า, กระบวนการ labeling และ quality assurance
- การจัดการข้อมูลส่วนบุคคลและความเป็นส่วนตัว: การระบุข้อมูลส่วนบุคคล (PII), วิธีการทำonymization/pseudonymization, หากใช้เทคนิค DP ให้ระบุค่า epsilon
- การประเมินเชิงจริยธรรมและผลกระทบ: การวิเคราะห์ผลกระทบต่อกลุ่มเสี่ยง, การดำเนินการลดความเสี่ยง (mitigation)
- มาตรการควบคุมการเข้าถึงและการกำกับดูแล: ระดับการอนุญาต, บันทึกการเข้าถึง, ข้อตกลงการใช้ข้อมูล (data use agreements)
- การจัดเก็บและการเก็บรักษา: นโยบายเก็บข้อมูล, ระยะเวลาการเก็บ, กระบวนการลบข้อมูล
ข้อกำหนดด้านความปลอดภัยและการตรวจสอบย้อนกลับ (Audit Trails)
คำสั่งกำหนดให้ผู้ให้บริการต้องออกแบบระบบ logging และ provenance ให้สามารถตรวจสอบย้อนกลับได้อย่างเชื่อถือได้และทนต่อการแก้ไข โดยข้อกำหนดสำคัญประกอบด้วย:
- บันทึกเหตุการณ์ (event logs): ต้องเก็บข้อมูลการฝึก, การทดสอบ, การปรับพารามิเตอร์, การ deploy รวมถึงผู้กระทำ (actor), เวลา (timestamp), และ context
- การยืนยันความสมบูรณ์ของข้อมูล: ใช้รหัสแฮช (เช่น SHA‑256) สำหรับชุดข้อมูลและไฟล์โมเดล พร้อมการลงลายมือชื่อดิจิทัล (digital signatures) เพื่อป้องกันการปลอมแปลง
- การติดตาม provenance ตามมาตรฐานสากล: แนะนำให้ใช้รูปแบบ W3C PROV หรือรูปแบบ JSON‑LD ที่สามารถผนวกรวมกับระบบ metadata อื่นๆ
- การเก็บรักษาแบบไม่เปลี่ยนแปลง (append‑only) และการสำรอง: ต้องมีนโยบายการเก็บรักษา logs อย่างน้อยสำหรับรอบการตรวจสอบที่กำหนด และสามารถส่งมอบให้หน่วยงานกำกับเมื่อร้องขอ
- การควบคุมการเข้าถึงและการตรวจสอบสิทธิ์: ระบบต้องรองรับการพิสูจน์ตัวตนแบบหลายปัจจัย (MFA) และสิทธิ์ตามบทบาท (RBAC) สำหรับการเข้าถึงข้อมูลที่มีความละเอียดอ่อน
ฟอร์แมตและมาตรฐานที่แนะนำหรือเป็นที่ยอมรับ
เพื่อให้การรายงานและการตรวจสอบทำได้สะดวก คำสั่งชี้ชัดให้ส่งเอกสารทั้งในรูปแบบที่มนุษย์อ่านได้และรูปแบบที่เครื่องอ่านได้ (machine‑readable) โดยฟอร์แมตที่ยอมรับและแนะนำ ได้แก่:
- Model Card JSON / JSON‑LD: รูปแบบ JSON ที่ใช้สกีมาแบบเปิดเพื่อให้สามารถผนวกรวมกับระบบอัตโนมัติและค้นคืนได้ง่าย
- Datasheet ในรูปแบบ JSON หรือ CSV พร้อม Metadata ใน JSON‑LD: ให้รวม schema และ provenance ในไฟล์เดียวกันหรือไฟล์คู่ที่เชื่อมโยงผ่าน URI
- มาตรฐาน provenance: แนะนำให้ใช้ W3C PROV (PROV‑O) เพื่อบันทึกต้นทางและลำดับการแปรรูปข้อมูล
- มาตรฐานความปลอดภัยและการจัดการ: ให้ปฏิบัติตามหลักการของ ISO/IEC 27001 สำหรับระบบความปลอดภัยสารสนเทศ และพิจารณาแนวทาง NIST AI RMF สำหรับการบริหารจัดการความเสี่ยง AI
- การบันทึกซอฟต์แวร์และการพึ่งพา: แนะนำให้รวม SBOM (Software Bill of Materials) และการระบุไลบรารี/เวอร์ชันเพื่อรองรับการตรวจสอบซ้ำและการจัดการช่องโหว่
การยื่นรายงานและการตรวจติดตาม
ผู้ให้บริการต้องยื่น Model‑Card และ Datasheet ในรูปแบบ machine‑readable พร้อมเอกสารสรุปฉบับมนุษย์อ่านได้ต่อหน่วยงานที่กำกับภายในกรอบเวลาที่กำหนด และต้องอัปเดตเอกสารทุกครั้งที่มีการเปลี่ยนแปลงสำคัญ เช่น การฝึกใหม่ (retrain), การเปลี่ยนแปลงชุดข้อมูล, หรือการแก้ไขช่องโหว่ โดยข้อกำหนดเพิ่มเติมได้แก่:
- การยื่นครั้งแรก: ภายใน 6 เดือนตามคำสั่งสำหรับระบบที่เผยแพร่ก่อนประกาศ
- การยื่นอัปเดตเป็นระยะ: รายงานสถานะ (status report) ประจำปีอย่างน้อย 1 ครั้ง และรายงานเหตุการณ์ด้านความปลอดภัยหรือผลกระทบสำคัญภายใน 30 วันหลังเกิดเหตุ
- การตรวจสอบโดยหน่วยงาน: หน่วยงานกำกับสามารถขอ logs และไฟล์ provenance แบบ raw เพื่อตรวจสอบความถูกต้อง โดยผู้ให้บริการต้องสามารถส่งข้อมูลในรูปแบบที่ยอมรับได้ภายในระยะเวลาที่หน่วยงานกำหนด
- การปรับปรุงและการลงโทษ: หากพบความบกพร่องหรือการไม่ปฏิบัติตามข้อกำหนด จะมีกรอบการชี้แจงและมาตรการแก้ไข พร้อมบทลงโทษตามกฎหมายที่เกี่ยวข้อง
สรุปคือ คำสั่งมุ่งเน้นให้เกิดสมดุลระหว่างนวัตกรรมและการคุ้มครองสาธารณะ โดยกำหนดชุดข้อมูลขั้นต่ำของ Model‑Card และ Datasheet ที่ชัดเจน ระบบบันทึกและตรวจสอบย้อนกลับที่เชื่อถือได้ และการใช้ฟอร์แมตมาตรฐานสาธารณะเพื่ออำนวยความสะดวกทั้งการปฏิบัติตามกฎระเบียบและการตรวจสอบจากภาครัฐหรือผู้มีส่วนได้ส่วนเสีย
ผลกระทบต่อผู้ให้บริการ AI: เทคโนโลยี ธุรกิจ และเวลาการนำผลิตภัณฑ์สู่ตลาด
ผลกระทบต่อผู้ให้บริการ AI: เทคโนโลยี ธุรกิจ และเวลาการนำผลิตภัณฑ์สู่ตลาด
การบังคับให้จัดทำ Model‑Card และ Datasheet ภายในกรอบเวลา 6 เดือน จะเป็นแรงกดดันเชิงปฏิบัติการและเชิงธุรกิจอย่างมีนัยสำคัญต่อผู้ให้บริการ AI ทั้งสตาร์ทอัพและองค์กรขนาดใหญ่ โดยผลกระทบสำคัญครอบคลุมตั้งแต่ภาระงานด้านเอกสารและการตรวจสอบย้อนกลับ (data lineage) ไปจนถึงต้นทุนการดำเนินงานและความเสี่ยงต่อการชะลอการเปิดตัวผลิตภัณฑ์ ความแตกต่างระหว่างกลุ่มผู้ให้บริการจะขึ้นกับระดับทรัพยากร ความพร้อมของระบบ MLOps และความสามารถในการทำ automation ของกระบวนการสร้างเอกสารและบันทึกเมตาดาทา
ต้นทุนและเวลาที่คาดว่าจะใช้ในการปรับระบบภายใน 6 เดือน
จากการวิเคราะห์เชิงปฏิบัติการโดยอ้างอิงกรณีทั่วไป สามารถคาดการณ์ระยะเวลาและทรัพยากรได้ดังนี้ (เป็นประมาณการทั่วไป ขึ้นกับขนาดองค์กรและจำนวนโมเดล):
- สตาร์ทอัพขนาดเล็ก (ทีม ML 2–10 คน): จำเป็นต้องจัดสรร 1–4 FTE ด้านวิศวกรรมข้อมูล/ML และ 0.5–1 FTE ด้านคอมพลายแอนซ์เป็นเวลา 3–6 เดือน ค่าใช้จ่ายรวมประมาณ 1–5 ล้านบาท (รวมค่าแรง เครื่องมือ และค่าใช้จ่ายที่ปรึกษา) หากทำด้วยมือเกือบทั้งหมด ระยะเวลาจัดทำ Model‑Card/ Datasheet ต่อโมเดลอาจใช้ 2–8 สัปดาห์
- บริษัทขนาดกลาง (ทีม ML 10–50 คน): ต้องเพิ่มทีมงานกลางด้านก๊วนคอมพลายแอนซ์และ Data Governance 3–10 FTE และลงทุนในเครื่องมือ data lineage/metadata 3–12 เดือน ค่าใช้จ่ายสตาร์ทต้น 5–25 ล้านบาท ขึ้นอยู่กับการซื้อซอฟต์แวร์หรือใช้โอเพนซอร์สพร้อมพัฒนาภายใน
- องค์กรขนาดใหญ่ (ทีม ML มากกว่า 50 คน): อาจต้องจัดตั้งหน่วยงานกลาง (AI Governance) 10+ FTE และลงทุนในโซลูชันระดับองค์กร (model registry, lineage platform, automated documentation) ค่าใช้จ่ายรวมอาจอยู่ในระดับหลายสิบล้านบาทถึงร้อยล้านบาท แต่ความสามารถในการกระจายต้นทุนต่อโมเดลทำให้ผลกระทบต่อแต่ละผลิตภัณฑ์น้อยกว่า
การเปลี่ยนแปลงของกระบวนการพัฒนา (MLOps, CI/CD)
เพื่อให้เป็นไปตามข้อกำหนด ผู้ให้บริการต้องปรับสถาปัตยกรรม MLOps และ pipeline ของ CI/CD ดังนี้
- รวมการเก็บเมตาดาทาอัตโนมัติ (metadata capture) ในทุกขั้นตอนของ pipeline — การเก็บเวอร์ชันของข้อมูลฝึก (data versions), โค้ด, คอนฟิก และผลลัพธ์การทดสอบ จะต้องเชื่อมโยงกับ Model‑Card/ Datasheet โดยอัตโนมัติ
- เพิ่มขั้นตอนการสร้างเอกสารเป็นส่วนหนึ่งของ release pipeline — การสร้าง Model‑Card/Datasheet ในรูปแบบที่ตรวจสอบได้ (executable docs หรือ docs-as-code) เพื่อให้การเผยแพร่แต่ละครั้งมีเอกสารประกอบพร้อมใช้งาน
- ติดตั้งระบบ data lineage และ provenance (ตัวอย่างเช่น MLflow, OpenLineage, DataHub หรือโซลูชันเชิงพาณิชย์) เพื่อให้สามารถตอบคำถามย้อนกลับเกี่ยวกับแหล่งข้อมูล preprocessing และ consent ได้ในระดับโมเดล
- เสริมชุดการทดสอบ (unit/integration/regression fairness tests) และ automated checks ก่อนการ deploy เพื่อให้องค์ประกอบใน Datasheet มีข้อมูลรองรับจากผลการทดสอบจริง
- บูรณาการระบบการมอนิเตอร์ (performance, fairness, drift) เพื่อให้ข้อมูลด้านการใช้งานจริงนำกลับมาปรับปรุงเอกสารอย่างต่อเนื่อง (living docs)
ความเสี่ยงต่อธุรกิจขนาดเล็กและผู้ให้บริการที่ไม่มีทีมคอมพลายแอนซ์
ผู้ให้บริการที่มีทรัพยากรจำกัดเผชิญความเสี่ยงเชิงธุรกิจหลายประการ ได้แก่:
- ชะลอการเปิดตัวผลิตภัณฑ์: หากการจัดทำเอกสารต้องทำด้วยมือหรือระบบยังไม่รองรับ การเปิดตัวอาจล่าช้า 1–6 เดือนต่อโมเดล ทำให้พลาดโอกาสเชิงการตลาดหรือสัญญาราชการที่ต้องปฏิบัติตามข้อกำหนด
- ต้นทุนเชิงปฏิบัติการเพิ่มขึ้น: ค่าใช้จ่ายด้านบุคลากร เครื่องมือ และที่ปรึกษาอาจกินส่วนแบ่งงบประมาณพัฒนาผลิตภัณฑ์ 10–30% ในช่วงปรับตัวแรกเริ่ม ซึ่งสำหรับธุรกิจรายเล็กอาจหมายถึงการห้ามจ้างพนักงานใหม่หรือชะลอฟีเจอร์อื่น
- ความเสี่ยงด้านการเข้าถึงตลาดราชการ: หากไม่สามารถยื่น Model‑Card/Datasheet ตามที่กำหนด ผู้ให้บริการอาจถูกตัดสิทธิ์จากการเสนอขายแก่หน่วยงานรัฐ ซึ่งเป็นตลาดสำคัญสำหรับสตาร์ทอัพที่พัฒนาระบบสำหรับภาครัฐ
- ความเสี่ยงเชิงกฎหมายและชื่อเสียง: ข้อมูลไม่ครบถ้วนหรือการรายงานที่ไม่ถูกต้อง อาจนำไปสู่บทลงโทษ คดีความ หรือความเสียหายต่อความเชื่อมั่นของลูกค้า
ข้อเสนอแนะแนวทางบรรเทาผลกระทบ
เพื่อจำกัดความเสียหาย ผู้ให้บริการควรวางแผนเชิงรุก ได้แก่ การจัดลำดับความสำคัญโมเดลที่มีความเสี่ยงสูงและโมเดลที่ใช้ในภาครัฐก่อน ลงทุนใน automation ของการเก็บเมตาดาทาและการสร้างเอกสาร (docs-as-code), จัดตั้งทีมข้ามสายงาน (engineering, data, legal) เป็น squad เร่งด่วน และพิจารณาใช้บริการ third‑party compliance/templating เพื่อลดภาระด้านทรัพยากร ทั้งนี้ การลงทุนเบื้องต้นเพื่ออัตโนมัติจะลดค่าใช้จ่ายระยะยาวและลดเวลา-to-market เมื่อเปรียบเทียบกับการทำเอกสารด้วยมือทั้งหมด
แนวทางปฏิบัติทางเทคนิค: จะสร้าง Model‑Card และ Datasheet อย่างไร
ภาพรวมแนวทางปฏิบัติทางเทคนิค
การจัดทำ Model‑Card และ Datasheet ให้ครบถ้วนและสามารถตรวจสอบย้อนกลับได้ต้องเริ่มจากการออกแบบข้อมูลเมต้า (metadata) ที่เป็นมาตรฐานร่วมกันภายในทีม โดยเน้นการบันทึก provenance ของข้อมูลและโมเดล ตั้งแต่ที่มาของชุดข้อมูล กระบวนการเตรียมข้อมูล พารามิเตอร์การฝึก จนถึงผลการประเมินเชิงสถิติและการทดสอบ bias การปฏิบัติเหล่านี้ไม่เพียงแต่ช่วยให้หน่วยงานภาครัฐปฏิบัติตามข้อกำหนดภายใน 6 เดือน แต่ยังเป็นพื้นฐานสำคัญสำหรับการตรวจสอบ การตอบคำถามจากผู้ใช้งาน และการติดตามผลในระยะยาว

ตัวอย่างฟิลด์สำคัญและเทมเพลตของ Model‑Card และ Datasheet
ต่อไปนี้เป็นชุดฟิลด์ที่ควรรวมไว้เป็นมาตรฐานสำหรับ Model‑Card และ Datasheet (สามารถนำไปเป็น JSON/YAML template เพื่อใช้กับระบบอัตโนมัติ):
- Identification / Metadata — ชื่อโมเดล/ชุดข้อมูล, เวอร์ชัน, วันที่สร้าง, ผู้สร้าง, ผู้รับผิดชอบ (owner), ไฟล์/URI ของอาร์ติแฟ็กต์
- Intended Use — วัตถุประสงค์ที่อนุญาต, ขอบเขตการใช้งานที่ไม่ควรใช้, ผู้ใช้เป้าหมาย
- Architecture & Training — สถาปัตยกรรมโมเดล, ข้อมูล hyperparameters สำคัญ, จำนวน epoch, batch size, seed และสภาพแวดล้อม (container image, pip/conda list)
- Dataset Summary & Provenance — แหล่งข้อมูลต้นทาง, วิธีการเก็บข้อมูล, การสุ่มตัวอย่าง, ตัวแทน (demographics), การแปลงก่อนใช้, จำนวนตัวอย่าง แยกตามชุดฝึก/validate/test
- Evaluation Metrics — ค่า metric หลัก (accuracy, precision, recall, F1, AUC), ค่าการวัด calibration, per‑group metrics (กลุ่มเพศ/อายุ/เชื้อชาติ ฯลฯ), confidence intervals และการทดสอบเชิงสถิติ
- Fairness & Bias Analysis — รายงาน bias tests ที่ทำ (e.g., disparate impact, equalized odds), ผลการทดสอบต่อกลุ่มย่อย, วิธีแก้ไขที่นำมาใช้
- Privacy & Data Protection — การอนุญาต/consent ของข้อมูล, เทคนิคที่ใช้ (pseudonymization, hashing, DP), นโยบายการเก็บ log และ retention
- Limitations & Risks — ข้อจำกัดที่รู้, สถานการณ์ที่ผลลัพธ์ไม่น่าเชื่อถือ, ความเสี่ยงที่ประเมินได้
- Reproducibility — คำสั่งเพื่อรันซ้ำ, git commit ของโค้ด, checkpoint URI, สคริปต์ preprocess/eval
- Contact & Governance — ผู้ติดต่อสำหรับรายงานปัญหา, กระบวนการขอข้อมูลเพิ่มเติม, License และข้อกำหนดด้านกฎหมาย
เครื่องมือโอเพนซอร์สและเชิงพาณิชย์ที่แนะนำสำหรับอัตโนมัติ
การนำทีมวิศวกรรมและข้อมูลไปสู่การผลิตเอกสารอัตโนมัติ ควรใช้เครื่องมือที่สามารถสกัด metric, artifacts และ provenance จาก pipeline ได้โดยตรง ตัวอย่างเครื่องมือที่ใช้งานได้จริงได้แก่:
- Model card & dataset docs: model-card-toolkit (Google, OSS) สำหรับสร้าง model cards แบบอัตโนมัติ; แนวคิด “Datasheets for Datasets” (paper) และ repository/เทมเพลตที่เกี่ยวข้องเพื่อจัด structued datasheet
- Experiment tracking & provenance: MLflow, DVC, Pachyderm สำหรับเก็บ experiment metadata, artifact URI, และ lineage; OpenLineage/Marquez และ DataHub/Amundsen สำหรับการรวม lineage ระดับองค์กร
- Data quality & metric extraction: Deequ (Amazon), Great Expectations, Evidently AI, WhyLabs สำหรับตรวจสอบคุณภาพข้อมูลและสกัด metrics อัตโนมัติเมื่อมีการเปลี่ยนแปลงข้อมูล
- Fairness & explainability: IBM AI Fairness 360, Fairlearn, Google's What‑If Tool, SHAP/LIME สำหรับวิเคราะห์ bias และอธิบายผลการตัดสินใจ
- Synthetic data & privacy tools: SDV (Synthetic Data Vault, OSS), Synthpop, Gretel.ai, Mostly AI (เชิงพาณิชย์) สำหรับสร้างชุดข้อมูลทดสอบที่รักษาความเป็นส่วนตัว; TensorFlow Privacy / Opacus สำหรับฝึกด้วย Differential Privacy
- Monitoring & logging: WhyLabs, Evidently, Seldon Analytics และ commercial MLOps platforms ที่รวม logging, alerting และ drift detection
แนวปฏิบัติด้านการบันทึก (logging) แบบ privacy-aware และการใช้ synthetic data
การเก็บ log สำหรับการตรวจสอบย้อนหลังต้องคำนึงทั้งความโปร่งใสและความเป็นส่วนตัว ดังนี้:
- เก็บข้อมูลแบบมีโครงสร้าง (structured JSON logs) โดยรวมฟิลด์สำคัญเช่น timestamp, model_version, dataset_commit_id, request_hash (salted), prediction, confidence, input_schema_signature
- ปกป้อง PII — หลีกเลี่ยงการบันทึก PII โดยตรงใน logs; ใช้การแฮชพร้อม salt และกุญแจแยก (keyed hashing) หากต้องใช้การเชื่อมโยงกลับ ให้เก็บกุญแจใน HSM หรือระบบที่มีสิทธิ์เข้มงวด
- เทคนิค Differential Privacy — สำหรับ metric aggregation หรือการเผยแพร่รายงาน ให้พิจารณาเพิ่ม noise ตามหลัก DP (เช่น Laplace หรือ Gaussian mechanism) โดยใช้ไลบรารีเช่น TensorFlow Privacy หรือ Opacus
- Retention และ access control — กำหนดนโยบายเก็บข้อมูลที่ชัดเจน (ex: logs ที่อาจเชื่อมโยงตัวบุคคลเก็บไม่เกิน 90 วัน) พร้อม logging audit trail ที่เข้ารหัสและมีการยืนยันตัวตน (MFA/role-based access)
- Synthetic data สำหรับการทดสอบ — ใช้ synthetic datasets ที่สร้างจาก SDV หรือโมเดล Generative โดยฝึก/ประเมินบนข้อมูลสังเคราะห์เพื่อลดการเปิดเผย PII แต่ต้องตรวจสอบว่า synthetic นั้นรักษาลักษณะ distribution ที่สำคัญและไม่เกิด leakage (ทดสอบด้วย privacy attacks เช่น membership inference)
กระบวนการอัตโนมัติใน CI/CD และการตรวจสอบคุณภาพ
ผสานการสร้าง Model‑Card/Datasheet เข้าใน pipeline CI/CD: ทุกการ commit ควรกระตุ้นการรัน workflow ที่ทำงานดังนี้—สกัด metadata และ metrics อัตโนมัติ (MLflow/DVC), รันชุดทดสอบ bias และ regression (Fairlearn/Evidently), อัปเดต template ของ model‑card และ datasheet เป็นอัตโนมัติ และจัดเก็บเอกสารที่ได้ใน artifact store พร้อมหมายเลขเวอร์ชันและลิงก์สู่ lineage
ข้อควรปฏิบัติเพิ่มเติมคือให้ทีมกำหนดมาตรวัดความครบถ้วนของ documentation (documentation coverage score) ก่อนปล่อยโมเดลสู่ production และสร้าง playbook สำหรับ incident response กรณีที่ตรวจพบ bias หรือ leak ใน runtime เช่น ถอดเวอร์ชันที่มีปัญหาและใช้ fallback model พร้อมบันทึกการตัดสินใจทั้งหมดใน audit log
สรุปเชิงปฏิบัติ
ในการตอบคำสั่งของหน่วยงานภาครัฐ การให้ทีมวิศวกรรมและทีมข้อมูลปฏิบัติตามแนวทางข้างต้นอย่างเป็นระบบจะช่วยให้สามารถสร้าง Model‑Card และ Datasheet ที่มีความน่าเชื่อถือ ตรวจสอบได้ และสอดคล้องกับข้อกำหนดด้านความเป็นส่วนตัวภายในเวลาที่กำหนด การผสานเครื่องมือโอเพนซอร์สกับกระบวนการ CI/CD การบันทึกแบบ privacy-aware และการใช้ synthetic data ในการทดสอบ จะลดความเสี่ยงทางกฎหมายและปรับปรุงความโปร่งใสของระบบ AI อย่างชัดเจน
กรอบเวลา 6 เดือนและกลไกการบังคับใช้
กรอบเวลา 6 เดือนและกลไกการบังคับใช้
หน่วยงานกำกับกำหนดกรอบเวลา 6 เดือนเป็นเส้นตายเชิงบังคับสำหรับผู้ให้บริการ AI เพื่อจัดทำและส่งมอบ Model‑Card และ Datasheet ที่ครบถ้วน โดยแยกเป็นขั้นตอนชัดเจนตั้งแต่การแจ้งเตือน การปรับแก้ การยื่นเอกสาร จนถึงการตรวจสอบและบทลงโทษ ตัวอย่างไทม์ไลน์เชิงตัวเลขที่หน่วยงานมักกำหนดคือรอบ 6 เดือนประกอบด้วยการเตรียมความพร้อมภายใน 30 วัน การทดสอบและแก้ไขภายใน 90–120 วัน และการยื่นเอกสารพร้อมรับการตรวจสอบภายในวันสุดท้ายของเดือนที่ 6

ไทม์ไลน์เชิงรายละเอียด (ตัวอย่าง):
- สัปดาห์ที่ 0–4 (การแจ้งเตือนและประเมินเบื้องต้น) — หน่วยงานออกหนังสือแจ้งเตือนอย่างเป็นทางการ ระบุรายการข้อมูลที่ต้องมีใน Model‑Card/ Datasheet แบบฟอร์มตัวอย่าง และกำหนดมาตรฐานขั้นต่ำ เพื่อให้ผู้ให้บริการทำการสำรวจระบบ (self‑assessment) และจัดทำแผนบรรเทาความเสี่ยง (remediation plan) ภายใน 30 วัน
- เดือนที่ 2–4 (การทดสอบและการปรับปรุง) — ผู้ให้บริการดำเนินการแก้ไข ส่งมอบผลทดสอบในสภาพแวดล้อมทดสอบ (staging) รวมถึงการทำ audit trail, bias assessment และ performance validation โดยมักกำหนด SLA ว่าการแก้ไขสำคัญต้องเสร็จภายใน 30 วันนับแต่แจ้งข้อบกพร่อง
- เดือนที่ 5 (การยื่นเอกสารอย่างเป็นทางการ) — ยื่น Model‑Card และ Datasheet พร้อมหลักฐานการทดสอบ (logs, test cases, metric reports) ให้หน่วยงานตรวจรับภายในช่วงสัปดาห์ที่กำหนด ตัวอย่างรูปแบบการยื่นอาจเป็นระบบอิเล็กทรอนิกส์ที่รับเอกสารแบบมาตรฐาน
- เดือนที่ 6 (การตรวจสอบและการตัดสิน) — หน่วยงานทำการตรวจสอบ (on‑site หรือ remote audit) ภายใน 30 วัน และประกาศผลการตรวจสอบพร้อมข้อเสนอแนะหรือมาตรการบังคับใช้ หากพบความไม่สอดคล้องให้ระบุ timeline remediation เพิ่มเติม เช่น ระยะเวลา 30–60 วันสำหรับการแก้ไขครั้งสุดท้าย
การติดตามหลังการตรวจสอบจะเป็นการบังคับใช้เชิงกลไกแบบวงรอบ (audit cycles) เช่น การตรวจสอบประจำไตรมาสสำหรับผู้ให้บริการที่มีความเสี่ยงสูง ในทางปฏิบัติ หน่วยงานอาจสุ่มตรวจ 25% ของผู้ให้บริการทุกไตรมาส และตรวจทั้งหมดสำหรับกรณีที่พบการละเมิดร้ายแรง โดย KPI ตัวอย่าง ได้แก่ ความสมบูรณ์ของเอกสาร ≥95% ระยะเวลาปรับปรุงรายการที่สำคัญ ≤30 วัน และอัตราการปฏิบัติตามคำสั่งของหน่วยงาน ≥90%
มาตรการบังคับใช้ (ตัวอย่างเชิงตัวเลขและรูปแบบ):
- ค่าปรับ — กำหนดเป็นระดับ เช่น ปรับเริ่มต้น 100,000 บาท สำหรับการละเลยเอกสารสำคัญ และเพิ่มขึ้นเป็น 1,000,000–5,000,000 บาท หรือคิดเป็นสัดส่วนของรายได้ในกรณีความเสียหายร้ายแรง
- ระงับฟีเจอร์หรือบริการ — ระงับการให้บริการฟีเจอร์ที่เกี่ยวข้องกับโมเดล (เช่น การเปิดใช้งานโมดูลการตัดสินอัตโนมัติ) จนกว่าจะได้มาตรฐาน ซึ่งอาจระงับเป็นช่วงเวลา 30–90 วัน
- เพิกถอนใบอนุญาตหรือการขึ้นบัญชีดำ — สำหรับการละเมิดซ้ำหรือการปกปิดข้อมูลสำคัญ หน่วยงานอาจเพิกถอนการอนุญาตให้ดำเนินการหรือประกาศให้อยู่ในบัญชีความเสี่ยงสาธารณะ
- มาตรการเชิงชดเชย — บังคับใช้คำสั่งแก้ไข (remediation order) พร้อมกำหนดเงื่อนไขการรายงานซ้ำและการตรวจสอบยืนยันภายใน 60–90 วัน
ช่องว่างที่อาจเกิดขึ้นและข้อเสนอแนะเชิงนโยบายเพื่อบรรเทาความเสี่ยง:
- ช่องว่างด้านความสามารถของผู้ให้บริการขนาดเล็ก — ผู้ให้บริการรายย่อยอาจขาดทรัพยากรในการจัดทำเอกสารและทดสอบแนะนำให้หน่วยงานจัดชุดเครื่องมือมาตรฐาน (templates, checklists) และมอบช่วงเวลาผ่อนปรนหรือซัพพอร์ตเชิงเทคนิค (technical assistance)
- ความคลุมเครือของข้อกำหนดทางเทคนิค — ควรกำหนดมาตรฐานเชิงปริมาณ (เช่น การวัด bias ด้วย metric ที่ชัดเจน) และเปิดเผยตัวอย่างการประเมินเพื่อให้การตีความข้อกําหนดมีความสอดคล้อง
- ความเสี่ยงด้านความล่าช้าของตลาด — การบังคับใช้ทันทีอาจกระทบต่อนวัตกรรม เสนอให้ใช้แนวทาง phased enforcement: ระยะที่หนึ่งเน้นการรายงานและความโปร่งใส ระยะที่สองถึงเริ่มบังคับใช้บทลงโทษเชิงเศรษฐกิจ
- การตรวจสอบอิสระและระบบอุทธรณ์ — แนะนำให้มีระบบอนุญาต third‑party auditors และช่องทางอุทธรณ์ที่เป็นอิสระเพื่อรักษาความเป็นธรรมและลดความเสี่ยงข้อผิดพลาดของหน่วยงานกำกับ
- การเปิดเผยสาธารณะและการกำกับดูแลต่อเนื่อง — สร้างทะเบียนสาธารณะของ Model‑Card/Datasheet ที่ผ่านการตรวจสอบ พร้อมรอบการตรวจสอบต่อเนื่อง (เช่น ประจำไตรมาส) เพื่อเพิ่มแรงจูงใจทางตลาดในการปฏิบัติตามข้อกำหนด
ปฏิกิริยาจากอุตสาหกรรมและตัวอย่างกรณีศึกษา
ปฏิกิริยาจากอุตสาหกรรม
คำสั่งให้บังคับใช้ Model‑Card และ Datasheet ภายในกรอบเวลา 6 เดือนได้รับการตอบรับจากผู้เล่นสำคัญในภาคเทคโนโลยีด้วยทั้งการสนับสนุนเชิงนโยบายและข้อกังวลด้านการปฏิบัติจริง โดยประธานสมาคมอุตสาหกรรมเทคโนโลยีสารสนเทศแห่งหนึ่งแถลงว่า “นโยบายดังกล่าวเป็นก้าวสำคัญสู่ความโปร่งใสและความรับผิดชอบต่อสังคม แต่จำเป็นต้องมีแนวปฏิบัติและเครื่องมือสนับสนุนสำหรับผู้ให้บริการขนาดกลางและขนาดเล็ก” ขณะที่ตัวแทนจากบริษัทเทคโนโลยีรายใหญ่ระบุว่าพร้อมสนับสนุนมาตรฐานกลางและร่วมพัฒนาเครื่องมือเปิด (open‑source tooling) เพื่อช่วยลดภาระการปฏิบัติตามข้อกำหนด
ฝ่ายสตาร์ทอัพและผู้ประกอบการขนาดกลางแสดงความกังวลในเรื่องต้นทุนแรงงานและทรัพยากรในการจัดทำเอกสารเชิงเทคนิคที่ครบถ้วน โดยผู้ร่วมสำรวจจากกลุ่มสตาร์ทอัพกล่าวว่า “การจัดทำนโยบายข้อมูล การตรวจสอบ bias และการวิเคราะห์ความเสี่ยงเชิงระบบต้องใช้เวลาและบุคลากรเชี่ยวชาญ ซึ่งหลายรายยังขาด” ในขณะเดียวกัน กลุ่มนักสิทธิมนุษยชนและองค์กรภาคประชาสังคมยกย่องการดำเนินการนี้ว่าเป็นการก้าวหน้าสำคัญในการคุ้มครองสิทธิพื้นฐานและความยุติธรรมของการนำ AI มาใช้ในภาครัฐและเอกชน
- สมาคมอุตสาหกรรม: เรียกร้องคู่มือเชิงปฏิบัติและชุดตัวอย่าง (templates) เพื่อให้ผู้ให้บริการสามารถปรับใช้ได้เร็วขึ้น
- บริษัทเทคโนโลยีรายใหญ่: ประกาศสนับสนุนเทคโนโลยีมาตรฐานกลางและการแลกเปลี่ยนความรู้
- สตาร์ทอัพ: ขอความช่วยเหลือด้านทุนสนับสนุนและการฝึกอบรมบุคลากร
- นักสิทธิมนุษยชน: เน้นความสำคัญของการเปิดเผยข้อมูลผลกระทบต่อกลุ่มเปราะบาง
กรณีศึกษา: ตัวอย่างการปรับตัวและอุปสรรคที่พบ
บริษัท AI ขนาดกลาง — SiamAI Solutions
SiamAI Solutions เป็นผู้ให้บริการโมเดลภาษาขนาดกลางที่มีลูกค้าภาครัฐและเอกชน บริษัทประกาศแผนการปรับระบบโดยแบ่งงานออกเป็น 3 ระยะ ได้แก่ (1) สำรวจคลังข้อมูลและจัดทำทะเบียนข้อมูล (data inventory) (2) สร้างเทมเพลต Model‑Card และ Datasheet ตามมาตรฐานภายใน (3) ผนวกเอกสารเหล่านี้เข้ากับ pipeline การ deploy ผลลัพธ์ที่สำคัญคือภายใน 4 เดือนบริษัทสามารถลดช่องว่างการปฏิบัติตามจากประมาณร้อยละ 78 เหลือร้อยละ 20 โดยอุปสรรคหลักเป็นเรื่องการติดตาม lineage ของข้อมูลและการจัดการข้อมูลที่มีข้อจำกัดด้านสิทธิ์ในการเข้าถึง
หน่วยงานรัฐ (โครงการนำร่อง) — หน่วยงานดิจิทัลระดับกระทรวง
หน่วยงานหนึ่งทำหน้าที่เป็นโครงการนำร่อง โดยเลือกระบบการตอบคำถามสาธารณะ (FAQ chatbot) มาทดลองนำ Model‑Card และ Datasheet มาใช้จริง ผลการดำเนินงานชี้ให้เห็นว่าเมื่อต้องเปิดเผยข้อมูลการฝึกสอนและการประเมินความเอนเอียงต่อสาธารณะ ผู้ดูแลระบบต้องปรับกระบวนการจัดซื้อและสัญญาเพื่อให้ผู้พัฒนาส่งมอบเอกสารที่ครบถ้วนก่อนการขึ้นระบบ ซึ่งช่วยลดความเสี่ยงเชิงนโยบายแต่เพิ่มภาระการประสานงานกับหน่วยงานจัดซื้อ
สตาร์ทอัพนวัตกรรม — NextGen Labs
NextGen Labs เลือกใช้วิธีการ lean‑compliance โดยสร้าง Model‑Card เบื้องต้นที่โฟกัส 5 หัวข้อหลัก (วัตถุประสงค์การใช้งาน ข้อมูลฝึกสอน ประสิทธิภาพ ข้อจำกัดและความเสี่ยง แนวทางการบำรุงรักษา) และค่อยๆ ขยายรายละเอียดเมื่อมีข้อกำหนดเพิ่มขึ้น ภายใน 6 เดือนบริษัทสามารถนำโมเดลเข้าสู่ลูกค้ารายแรกที่ต้องการ compliance ได้สำเร็จ แต่พบปัญหาด้านแรงงานผู้เชี่ยวชาญและต้นทุนการทำ audit ภายนอก
- อุปสรรคทั่วไปที่พบ: การติดตาม lineage ของข้อมูล, การมีมาตรฐานเทมเพลตที่หลากหลาย, ต้นทุนบุคลากรเชิงความเชี่ยวชาญ, และระยะเวลาในการทดสอบ/ประเมินผล
- มาตรการบรรเทา: ใช้เทมเพลตกลาง, ลงทุนในเครื่องมืออัตโนมัติสำหรับการสร้าง Model‑Card, และร่วมมือด้านการฝึกอบรมระหว่างภาครัฐ-เอกชน
ผลสำรวจและภาพรวมการเตรียมความพร้อม
ผลสำรวจโดยสมาคมผู้ให้บริการ AI ในประเทศ (ตัวอย่างการสำรวจ n=210 ผู้ให้บริการทั้งขนาดใหญ่ ขนาดกลาง และสตาร์ทอัพ) พบว่า ร้อยละ 46 มีการจัดทำ Model‑Card หรือ Datasheet ในระดับหนึ่งแล้ว แต่มีเพียงร้อยละ 18 ที่ระบุว่าครอบคลุมข้อมูลเชิงลึกตามแนวปฏิบัติสากล ขณะที่ ร้อยละ 32 คาดว่าจะสามารถปรับระบบและเป็นไปตามข้อกำหนดภายในกรอบเวลา 6 เดือน ส่วนร้อยละ 22 คาดว่าจะต้องใช้เวลานานกว่า 6 เดือนหรือไม่แน่ใจ
เมื่อตรวจแยกตามขนาดองค์กร พบความแตกต่างชัดเจน: ร้อยละ 55 ขององค์กรขนาดใหญ่คาดว่าจะพร้อมภายใน 6 เดือน ขณะที่องค์กรสตาร์ทอัพมีเพียง ร้อยละ 18 ที่คาดว่าจะเสร็จภายในกรอบเวลาเดียวกัน แสดงให้เห็นช่องว่างด้านทรัพยากรและการเข้าถึงความช่วยเหลือเชิงเทคนิค
โดยสรุป ภาคอุตสาหกรรมมีทัศนคติที่คละเคล้า: ยอมรับในหลักการเรื่องความโปร่งใสและความรับผิดชอบ แต่เรียกร้องการสนับสนุนจากภาครัฐทั้งในรูปแบบคู่มือเชิงปฏิบัติ เครื่องมือมาตรฐาน และช่องทางช่วยเหลือเพื่อให้การบังคับใช้เป็นไปได้จริงโดยไม่สร้างภาระแก่ผู้ให้บริการขนาดเล็กเกินควร
ข้อเสนอแนะและเช็คลิสต์สำหรับผู้ให้บริการ AI และหน่วยงานกำกับดูแล
ข้อเสนอแนะและเช็คลิสต์สำหรับผู้ให้บริการ AI และหน่วยงานกำกับดูแล
การบังคับใช้ Model‑Card และ Datasheet ภายในกรอบเวลา 6 เดือน เป็นความท้าทายทั้งทางเทคนิค กฎหมาย และบริหารจัดการสำหรับผู้ให้บริการ AI โดยเฉพาะสตาร์ทอัพและธุรกิจขนาดกลางและเล็ก การปฏิบัติตามอย่างเป็นระบบจำเป็นต้องมีแผนงานเชิงปฏิบัติการ (operational playbook) ที่ชัดเจน แยกหน้าที่ความรับผิดชอบ และเครื่องมือช่วยสร้างเอกสารอัตโนมัติ เพื่อให้สามารถยื่นเอกสารได้อย่างสอดคล้องและมีคุณภาพภายในเวลาที่กำหนด
ด้านหน่วยงานกำกับดูแล ควรออกแนวปฏิบัติ (guidance) ที่ชัดเจนและตัวอย่างแบบฟอร์ม เพื่อช่วยลดความไม่แน่นอนและภาระการตีความสำหรับผู้ปฏิบัติ นโยบายที่มีความยืดหยุ่นเชิงเวลาและการสนับสนุนด้านทรัพยากรจะช่วยรักษาสมดุลระหว่างความปลอดภัยของสาธารณะและการส่งเสริมนวัตกรรม
เช็คลิสต์ 10 ข้อ สำหรับการเตรียม Model‑Card / Datasheet ภายใน 6 เดือน
- 1. ระบุกลุ่มความเสี่ยงของระบบ: ประเมินระดับความเสี่ยงตามการใช้งาน (เช่น สูง กลาง ต่ำ) พร้อมหลักฐานการประเมิน (risk register)
- 2. ข้อมูลสเปกของโมเดล: สถาปัตยกรรม โมเดลเวอร์ชัน ขนาดพารามิเตอร์ วันที่เทรน และข้อมูลการอัพเดต
- 3. ข้อมูลการใช้ข้อมูล (Datasheet): แหล่งที่มา วิธีการเก็บ ค่าคุณภาพ ข้อจำกัด และการล้างข้อมูล (data provenance)
- 4. การประเมินประสิทธิภาพ: เมตริกที่ใช้ (เช่น accuracy, F1, AUC) พร้อมชุดทดสอบและผลลัพธ์
- 5. การทดสอบเชิงความเป็นธรรมและอคติ: รายงานการทดสอบบนกลุ่มย่อย (subgroups) และแผนบรรเทา (mitigation)
- 6. การประเมินความปลอดภัยและความเสี่ยงจากการโจมตี: adversarial testing, robustness checks และผลการทดสอบ
- 7. ขอบเขตการใช้งานที่เหมาะสมและห้ามใช้: use‑case ที่แนะนำและข้อจำกัดในการใช้งาน
- 8. ข้อกำชับด้านความเป็นส่วนตัวและการคุ้มครองข้อมูล: วิธีการอนุญาต การยินยอม และการปกป้องข้อมูลส่วนบุคคล
- 9. แผนการตรวจสอบและบำรุงรักษา: นโยบายการติดตามผล (monitoring), การตั้งค่า logging และการอัปเดตเวอร์ชัน
- 10. ช่องทางรับแจ้งปัญหาและการชี้แจงต่อผู้ใช้: ช่องทางรับเรื่องร้องเรียน รายงานบั๊ก และนโยบายการชดเชย/แก้ไข
คำแนะนำเชิงปฏิบัติสำหรับทีมต่าง ๆ (เทคนิค กฎหมาย ผู้บริหาร)
- ทีมเทคนิค: จัดลำดับงานเป็นสปรินต์ 2–4 สัปดาห์ แบ่งเป็น (1) เก็บ metadata อัตโนมัติจาก pipeline, (2) ทำชุดทดสอบมาตรฐานและ subgroup tests, (3) สร้างเทมเพลต Model‑Card/Datasheet และระบบเวอร์ชันคอนโทรล ตัวอย่างเช่น การใช้สคริปต์สกัดข้อมูล model metadata สามารถลดเวลาผลิตเอกสารลงได้ 40–60% ในโครงการต้นแบบ
- ทีมกฎหมาย/ความเป็นธรรม: สร้าง checklist ของข้อกำหนดด้านกฎหมาย (PDPA, สัญญาไลเซนซ์, ฯลฯ) เตรียมคำชี้แจงความเสี่ยงและข้อจำกัดทางกฎหมาย และประสานกับทีมเทคนิคเพื่อออกแบบคำพูดบน Model‑Card ที่สื่อสารได้ชัดเจนและถูกต้อง
- ผู้บริหาร/คณะกรรมการ: กำหนดนโยบายระดับองค์กร มอบทรัพยากรที่เพียงพอ (บุคลากร เครื่องมือ งบประมาณ) และกำหนดตัวชี้วัดความสำเร็จ (KPIs) เช่น อัตราการปฏิบัติตาม (% compliance), เวลาเฉลี่ยจนเสร็จ (time‑to‑compliance) และจำนวนเหตุการณ์ด้านความปลอดภัยหลังเปิดใช้งาน
แนวทางลดผลกระทบต่อสตาร์ทอัพและ SMEs (แบบเป็นขั้นเป็นตอน)
- ขั้นที่ 1 — ประเมินและจัดประเภท: ให้เริ่มจากการแบ่งประเภทความเสี่ยงของผลิตภัณฑ์ เพื่อให้สตาร์ทอัพทราบว่าอยู่ในเกณฑ์ใด (risk‑tiering) ซึ่งจะกำหนดความเข้มข้นของข้อกำหนด
- ขั้นที่ 2 — ขยายเวลาแบบมีเงื่อนไข: เสนอระยะขยายเวลา (เช่น เพิ่มอีก 3–12 เดือน) สำหรับผู้ประกอบการที่มีรายได้ต่ำหรือจำนวนพนักงานไม่เกินเกณฑ์ พร้อมเงื่อนไขการรายงานความคืบหน้าเป็นงวด (quarterly)
- ขั้นที่ 3 — แหล่งเงินช่วยเหลือ: จัดตั้งกองทุนสนับสนุนหรือสินเชื่อดอกเบี้ยต่ำ ร่วมกับสถาบันการเงินและองค์กรพัฒนาเอกชน ตัวอย่างเช่น มาตรการช่วยเหลือแบบให้เปล่า (grant) หรือเครดิตภาษีสำหรับค่าใช้จ่ายในการปฏิบัติตาม
- ขั้นที่ 4 — เครื่องมือและคู่มือมาตรฐาน: พัฒนาเทมเพลต Model‑Card/Datasheet แบบสากล คู่มือการประเมินความเสี่ยง และเครื่องมือโอเพนซอร์สสำหรับการสร้างเอกสารอัตโนมัติ เพื่อลดต้นทุนการพัฒนาซ้ำ
- ขั้นที่ 5 — บริการตรวจสอบร่วม (shared compliance services): สนับสนุนศูนย์ตรวจสอบร่วมหรือผู้ตรวจอิสระรายย่อยที่ให้บริการราคาย่อมเยาและรวดเร็ว
ข้อเสนอเชิงนโยบายเพื่อสมดุลระหว่างความปลอดภัยและนวัตกรรม
- นโยบายแบบแบ่งระดับความเสี่ยง (risk‑based regulation): กำหนดข้อกำหนดตามระดับความเสี่ยงและผลกระทบต่อสาธารณะ แทนการใช้กฎที่เท่ากันทุกระบบ เพื่อไม่ให้กฎเกณฑ์บั่นทอนนวัตกรรม
- Regulatory sandboxes และ pilot schemes: เปิดพื้นที่ทดสอบภายใต้การกำกับดูแลเพื่อให้สตาร์ทอัพทดลองและพิสูจน์ความปลอดภัยก่อนการใช้งานเชิงพาณิชย์
- มาตรฐานและเทมเพลตที่เปิดเผย: พัฒนาและเผยแพร่แบบฟอร์ม Model‑Card/Datasheet ที่เป็นมาตรฐานประเทศหรืออ้างอิงสากล พร้อมตัวอย่างการกรอกข้อมูล
- มาตรการสนับสนุนทางการเงินและภาษี: ให้เครดิตภาษีหรือเงินอุดหนุนสำหรับค่าใช้จ่ายในการปฏิบัติตาม เช่น ค่า audit, ค่าแรงพัฒนาเอกสาร และค่าเครื่องมืออัตโนมัติ
- การประสานกับมาตรฐานสากล: อำนวยความสะดวกให้การรับรองข้ามพรมแดน (mutual recognition) ลดการทำงานซ้ำซ้อนสำหรับผู้ให้บริการที่ทำธุรกิจในหลายประเทศ
- การบังคับใช้แบบก้าวหน้า: กำหนดช่วงเวลาเตือนและมาตรการเสริมความช่วยเหลือก่อนการลงโทษ เพื่อให้โอกาสในการปฏิบัติตามอย่างเป็นธรรม
สรุปได้ว่า ความสำเร็จในการบังคับใช้ Model‑Card และ Datasheet ภายในกรอบเวลา 6 เดือน ขึ้นอยู่กับการออกแบบกฎระเบียบที่มีความเป็นสัดส่วนและการสนับสนุนเชิงปฏิบัติ ทั้งทางด้านเทคนิค กฎหมาย และการเงิน การร่วมมือระหว่างหน่วยงานกำกับดูแล ภาคเอกชน และระบบนิเวศสตาร์ทอัพเป็นปัจจัยสำคัญที่จะทำให้เป้าหมายเรื่องความโปร่งใสและความปลอดภัยของ AI เกิดขึ้นได้โดยไม่ทำลายนวัตกรรม
บทสรุป
การสั่งใช้ Model‑Card และ Datasheet เป็นข้อบังคับของราชการไทยภายในระยะเวลา 6 เดือนมีเป้าหมายชัดเจนในการเพิ่มความโปร่งใสของระบบปัญญาประดิษฐ์และลดความเสี่ยงจากความลำเอียง ความไม่ชัดเจนของแหล่งข้อมูล และปัญหาด้านความปลอดภัยของการใช้งานเชิงระบบ การเปิดเผยข้อมูลสำคัญเกี่ยวกับวัตถุประสงค์ ขอบเขตข้อมูล วิธีการฝึก ความไม่แน่นอนของผลลัพธ์ และข้อจำกัดของโมเดล จะช่วยให้หน่วยงานตรวจสอบและผู้ใช้ปลายทางเข้าใจพฤติกรรมของระบบมากขึ้น อย่างไรก็ดี การปฏิบัติตามข้อกำหนดดังกล่าวสร้างภาระทรัพยากรทั้งด้านบุคลากร เวลา และต้นทุนเทคโนโลยี โดยเฉพาะต่อผู้ให้บริการรายย่อยและผู้ประกอบการขนาดกลางและย่อม (SMEs) ที่อาจขาดทีมงานเฉพาะทางหรือเครื่องมืออัตโนมัติสำหรับจัดทำเอกสารเชิงเทคนิคอย่างครบถ้วน
การปฏิบัติตามภายในกรอบเวลา 6 เดือนจึงต้องการทั้งการวางแผนเชิงเทคนิคและมาตรการสนับสนุนจากรัฐ เช่น เทมเพลตมาตรฐาน เครื่องมือช่วยจัดทำ Model‑Card/Datasheet คู่มือเชิงปฏิบัติการ แหล่งฝึกอบรมและโครงการให้คำปรึกษา รวมถึงช่องทางยื่นขอระยะเวลาขยายเมื่อพบความจำเป็น การดำเนินการที่มีโครงสร้าง เช่น การแบ่งเป็นเฟส (phase‑in) สำหรับระดับความเสี่ยงของโมเดล และการเปิด sandbox เชิงนโยบายเพื่อทดลองการรายงาน จะช่วยลดแรงกดดันต่อผู้ให้บริการขนาดเล็กและลดความเสี่ยงจากการถูกกีดกันทางการตลาดในระยะสั้น
ในมุมมองอนาคต หากการบังคับใช้ผสานกับนโยบายสนับสนุนเชิงรุก ราชการสามารถยกระดับความเชื่อมั่นของสาธารณะและหน่วยงานในการใช้ AI ส่งผลให้ตลาดบริการ AI เติบโตอย่างยั่งยืน พร้อมเกิดระบบนิเวศน์ของเครื่องมือและบริการช่วยปฏิบัติตามกฎระเบียบ (compliance tools/consultancy) อย่างไรก็ตาม หากไม่มีการสนับสนุนเพียงพอ อาจเกิดการรวมตัวของผู้เล่นรายใหญ่และลดความหลากหลายของผู้ให้บริการ การติดตามผล ประเมินผลเป็นระยะ และการเปิดช่องทางปรับปรุงกฎเกณฑ์ตามบริบทจริงจะเป็นกุญแจสำคัญในการบรรลุเป้าหมายด้านความโปร่งใสและการคุ้มครองความเสี่ยง โดยไม่ทิ้งผู้ประกอบการรายย่อยไว้ข้างหลัง



