
สตาร์ทอัพไทยเปิดตัวบริการใหม่ภายใต้ชื่อ "Model‑Distillation‑as‑a‑Service" ที่สัญญาว่าจะย่อขนาดโมเดลปัญญาประดิษฐ์ขนาดใหญ่ให้สามารถรันบนสมาร์ทโฟนได้ภายใน 24 ชั่วโมง ช่วยให้นักพัฒนาแอปพลิเคชันและธุรกิจไทยนำโมเดลต้นฉบับมาแปลงเป็นเวอร์ชันขนาดเล็กลงที่ใช้งานบนอุปกรณ์ปลายทางได้ทันที ไม่ต้องพึ่งพาคลาวด์ตลอดเวลาและลดปัญหา latency เมื่อใช้งานจริง ผู้ให้บริการระบุว่ากระบวนการดังกล่าวเน้นทั้งการลดขนาดไฟล์ การปรับประสิทธิภาพเชิงคำนวณ และการรักษาคุณภาพคำตอบให้อยู่ในเกณฑ์ที่ยอมรับได้สำหรับการใช้งานจริง
ในทางปฏิบัติ บริการนี้มุ่งตอบโจทย์ความต้องการของแอปจริง (real‑world apps) เช่น แชตบอตบนมือถือ ระบบจดจำภาพ/เสียง และฟีเจอร์ที่ต้องการการตอบสนองเร็ว โดยระบุว่าการ distillation สามารถลดขนาดโมเดลจากหลายร้อยเมกะไบต์ลงเหลือเพียงหลักสิบเมกะไบต์และลด latency จากระดับร้อยมิลลิวินาทีลงสู่หลักสิบมิลลิวินาที ทำให้ต้นทุนคลาวด์ที่ต้องจ่ายสำหรับการ inference ลดลงอย่างมีนัยสำคัญ ทั้งยังเปิดทางให้แอปพลิเคชันทำงานแบบออฟไลน์หรือฮาร์ฟ‑คลาวด์ได้ง่ายขึ้น ซึ่งหมายถึงประสบการณ์ผู้ใช้ที่เร็วขึ้นและต้นทุนการดำเนินงานที่ต่ำลงสำหรับธุรกิจ
บทนำ: บริการ Model‑Distillation‑as‑a‑Service คืออะไรและใครเป็นผู้ให้บริการ
DistillLab (ดิสทิลล์แลบ) — สตาร์ทอัพไทยสายปัญญาประดิษฐ์ ประกาศเปิดตัวบริการใหม่ในรูปแบบ Model‑Distillation‑as‑a‑Service ที่มุ่งย่อและปรับแต่งโมเดลขนาดใหญ่ให้สามารถรันบนอุปกรณ์พกพาได้ภายใน 24 ชั่วโมง บริษัทดำเนินธุรกิจในรูปแบบ B2B SaaS โดยให้บริการผ่านแพลตฟอร์มบนคลาวด์ที่เชื่อมต่อกับ SDK/แพ็กเกจสำหรับ Android และ iOS เพื่อนำโมเดลที่ผ่านการย่อไปใช้จริงในแอปพลิเคชันได้ทันที ทีมผู้ก่อตั้งประกอบด้วย นายปริญญา สุขสันต์ (ผู้ร่วมก่อตั้งและ CEO) ที่เคยเป็นผู้นำทีมวิศวกรรม ML ในภูมิภาค, ดร.วลัยพร จันทร์เจริญ (หัวหน้าทีมวิจัย) ผู้มีพื้นฐานวิจัยด้าน deep learning และการบีบอัดโมเดล, และนายณัฐวัฒน์ เกตุทอง (CTO) วิศวกรระบบที่เชี่ยวชาญด้าน deployment บนอุปกรณ์เคลื่อนที่

คำนิยามของบริการและคอนเซ็ปต์: ย่อโมเดลภายใน 24 ชั่วโมง
Model‑Distillation‑as‑a‑Service หมายถึงการให้บริการแบบครบวงจรที่รวมกระบวนการ knowledge distillation, quantization, pruning, และ hardware‑aware optimization เพื่อแปลง (distill) โมเดลขนาดใหญ่ เช่น transformer หรือ CNN ขนาดใหญ่ ให้กลายเป็นเวอร์ชันขนาดเล็กที่ยังคงประสิทธิภาพใกล้เคียงต้นฉบับ แต่เหมาะกับการรันบน CPU/NN accelerator ของสมาร์ทโฟนหรือ edge device บริการนี้ให้คำมั่นว่าใช้เวลาดำเนินการตั้งแต่รับโมเดลต้นทาง วิเคราะห์ความต้องการอุปกรณ์ กำหนดเป้าหมายความแม่นยำ (accuracy target) และทำการ optimize จนเสร็จสมบูรณ์ภายใน 24 ชั่วโมง สำหรับลูกค้าที่ส่งโมเดลและข้อมูลตัวอย่างตามเงื่อนไขที่กำหนด
แนวทางปฏิบัติของแพลตฟอร์มประกอบด้วยขั้นตอนอัตโนมัติหลายขั้นตอน เช่น การประเมินจุดอ่อนของโมเดล การเลือกเทคนิค distillation ที่เหมาะสม (soft-label distillation, feature distillation), การทำ quantization แบบไดนามิก, pruning แบบโครงสร้าง และการทดสอบบนโปรไฟล์ฮาร์ดแวร์จริง ผลลัพธ์ที่ได้มักจะเป็นโมเดลขนาดเล็กลงในระดับ 10–100x (ขึ้นกับสถาปัตยกรรมและเป้าหมาย) โดย latency ลดลงได้หลายเท่าและการใช้พลังงานลดลงอย่างมีนัยสำคัญ ทำให้สามารถนำโมเดลไปฝังในแอปได้ทันทีผ่าน SDK ของ DistillLab
ทำไมตลาดไทยต้องการบริการนี้
- อัตราการใช้สมาร์ทโฟนและการเข้าถึงอินเทอร์เน็ตสูง: ผู้ใช้มือถือในไทยมีการใช้งานแอปและบริการที่ต้องการ AI เพิ่มขึ้นอย่างต่อเนื่อง ทำให้ผู้พัฒนาแอปต้องการรันโมเดลบนอุปกรณ์ปลายทางเพื่อตอบสนองผู้ใช้เป็นจำนวนมากโดยไม่พึ่งพาคลาวด์อย่างเดียว
- ความต้องการ latency ต่ำสำหรับแอปจริง: แอปเรียลไทม์ เช่น การรู้จำเสียงพูด การประมวลผลภาพ AR หรือระบบช่วยตัดสินใจ ต้องการการตอบสนองแบบทันที (latency ต่ำกว่า 50–100 ms) การรันบนอุปกรณ์ช่วยลดเวลาเดินทางข้อมูลและ jitter เมื่อเทียบกับการเรียก API บนคลาวด์
- ลดต้นทุนคลาวด์และค่าใช้จ่ายต่อคำขอ: งานวิจัยเชิงปฏิบัติและการนำไปใช้จริงชี้ว่า การย้าย inference จากคลาวด์มาเป็น on‑device สามารถลดค่าใช้จ่ายด้านโครงสร้างพื้นฐานได้อย่างมีนัยสำคัญ — ในหลายกรณีประหยัดต้นทุนการให้บริการ inference ได้ตั้งแต่ 50% จนถึงกว่า 90% ขึ้นกับปริมาณคำขอและรูปแบบโมเดล
- ความเป็นส่วนตัวและข้อกำหนดทางกฎหมาย: การประมวลผลข้อมูลบนอุปกรณ์ช่วยลดความเสี่ยงด้านข้อมูลส่วนบุคคลและช่วยให้องค์กรปฏิบัติตามนโยบายความเป็นส่วนตัวและกฎระเบียบที่เข้มงวดได้ง่ายขึ้น
ด้วยเหตุผลดังกล่าว บริการของ DistillLab จึงตอบโจทย์ทั้งผู้พัฒนาแอปสตาร์ทอัพและองค์กรขนาดใหญ่ที่ต้องการนำ AI ไปใช้จริงบนมือถือ — เร็วขึ้น ต้นทุนต่ำลง และควบคุมข้อมูลได้ดีกว่าเดิม โดยเฉพาะในสภาวะที่ปริมาณผู้ใช้และคำขอมีแนวโน้มเติบโตอย่างรวดเร็วในตลาดไทย
เทคนิคเบื้องหลัง: Knowledge Distillation, Quantization และ Pruning
ภาพรวมเชิงเทคนิคของกระบวนการย่อขนาดโมเดล
การย่อขนาดโมเดลขนาดใหญ่เพื่อใช้งานบนอุปกรณ์เคลื่อนที่ประกอบด้วยเทคนิคที่แตกต่างกันแต่เสริมกันได้ ได้แก่ Knowledge Distillation, Quantization, Pruning/Compression และ Low‑rank approximation ตลอดจนการปรับให้เข้ากับสถาปัตยกรรมของอุปกรณ์ (เช่น ARM CPUs, NPUs หรือ DSP) กระบวนการที่เหมาะสมมักเป็นการผสมผสานหลายเทคนิคและทำเป็นขั้นตอน โดยเริ่มจากลดความซับซ้อนของรูปแบบความรู้ (distillation) ตามด้วยการลดความแม่นยำเชิงตัวเลข (quantization) และการตัดพารามิเตอร์ที่ไม่สำคัญ (pruning) ก่อนจะนำไปปรับแต่งให้เข้ากับฮาร์ดแวร์เป้าหมาย
Knowledge Distillation (ครู → นักเรียน)
Knowledge Distillation (KD) เป็นกระบวนการสอนโมเดลขนาดเล็ก ("นักเรียน") ให้เลียนแบบพฤติกรรมของโมเดลขนาดใหญ่ ("ครู") โดยนักเรียนเรียนจากค่าผลลัพธ์อ่อน (soft targets) หรือตัวแทนเชิงโครงสร้างของครู เช่น logits, attention maps หรือ representation vectors เทคนิคนี้ช่วยให้ลดขนาดพารามิเตอร์ได้อย่างมีประสิทธิภาพโดยยังรักษาความสามารถเชิงฟังก์ชันไว้
ตัวอย่างเชิงสถิติที่เป็นที่รู้จัก: DistilBERT ลดขนาดลงประมาณ 40% และเพิ่มความเร็วการประเมินผลราว 60% เมื่อเทียบกับ BERT-base ในขณะที่ยังคงรักษาคะแนนประสิทธิภาพราว 95–97% ของรุ่นครูในงานความเข้าใจภาษา การออกแบบสูตรความสูญเสียสำหรับ KD (เช่น การผสมระหว่าง cross-entropy กับ KL-divergence ของ logits ของครู) และการเลือกองค์ประกอบที่ถ่ายทอด (soft targets, intermediate features) เป็นตัวกำหนดคุณภาพการย่อ
- ข้อดี: ช่วยรักษาประสิทธิภาพเชิงงานได้ดีกว่าการย่อแบบสุ่ม
- แนวปฏิบัติ: ใช้ KD ร่วมกับการฝึกซ้ำ (fine-tuning) และพิจารณา temperature และ weight ของ loss ให้เหมาะสม
Quantization (INT8 / INT4) — แปลงน้ำหนักและค่า activation เป็นจำนวนเต็ม
Quantization ลดความเที่ยงตรงเชิงตัวเลขของน้ำหนักและการคำนวณจาก FP32/FP16 เป็นจำนวนเต็ม (เช่น INT8, INT4) เพื่อลดขนาดโมเดลและเร่งการคำนวณ โดยทั่วไป:
- FP32 → INT8 ลดขนาดโมเดลได้ ~4× และมักได้ความเร็วเพิ่มขึ้น 2–4× บน CPU/NPUs ที่รองรับ
- INT4 ให้การบีบอัดสูงขึ้นอีก (~8× จาก FP32) แต่มีความเสี่ยงต่อการสูญเสียความแม่นยำมากกว่า และการรองรับฮาร์ดแวร์ยังจำกัด
มีแนวทางหลักสองแบบคือ Post‑Training Quantization (PTQ) และ Quantization‑Aware Training (QAT):
- PTQ: เร็วและง่าย แต่บางครั้งต้องใช้ชุดข้อมูล calibration เพื่อปรับ scale/zero‑point และอาจเกิดความเสี่ยงต่อการเสียความแม่นยำ โดยเฉพาะ model-sensitive layers
- QAT: ฝึกโมเดลให้รับรู้การคำนวณที่ถูกปัด (quantization noise) ทำให้ได้ความแม่นยำใกล้เคียง FP32 แต่ต้องใช้เวลาและทรัพยากรในการฝึกเพิ่มขึ้น
รายละเอียดเชิงเทคนิคเพิ่มเติมที่ต้องคำนึงถึงได้แก่ per‑channel vs per‑tensor quantization (per‑channel มักให้ผลแม่นยำดีกว่าสำหรับน้ำหนักของ convolution/linear) และ symmetric vs asymmetric quantization (asymmetric ช่วยลด bias สำหรับ activation ที่มี offset) ในการทำ INT4 ต้องใช้การบีบอัดแบบ bit‑packing และอัลกอริธึมการคำนวณเฉพาะทาง ซึ่งอาจต้องพัฒนาเคอร์เนลสำหรับ NPU/CPU ที่รองรับ
Pruning & Compression
Pruning คือการตัดพารามิเตอร์ที่มีความสำคัญต่ำออกจากโมเดลเพื่อให้มีพารามิเตอร์น้อยลงและลดการคำนวณ รูปแบบหลักได้แก่:
- Unstructured pruning: ตัด weight ทีละตัวทำให้ได้ sparsity สูง (เช่น 70–90%) แต่ต้องการไลบรารี/ฮาร์ดแวร์ที่รองรับการคำนวณแบบ sparse เพื่อให้เกิดประโยชน์ด้านความเร็วจริง
- Structured pruning: ตัดทั้งช่อง (channel), แถว/คอลัมน์ หรือทั้งบล็อก ทำให้เปลี่ยนรูปร่างของเมทริกซ์และมักแปรเป็นประโยชน์ต่อ latency โดยตรงบนฮาร์ดแวร์สแตนด์ดาร์ด
หลังจาก pruning มักใช้เทคนิค compression เช่น quantization, weight clustering หรือ Huffman coding เพื่อบีบอัดเพิ่มเติม ตัวเลขเชิงประสบการณ์แสดงว่า pruning แบบมีโครงสร้างร่วมกับการฝึกซ้ำ (retraining) สามารถลด FLOPs ได้ 1.5–3× และลดขนาดโมเดลได้เทียบเท่าโดยที่ความแม่นยำลดลงเล็กน้อย หากใช้ pruning แบบไม่มีโครงสร้างอาจได้ sparsity สูงกว่าแต่ต้องพึ่งพาไลบรารี sparse GEMM เพื่อให้ latency ดีขึ้นจริง
Low‑rank approximation และการปรับให้เข้ากับสถาปัตยกรรมมือถือ
Low‑rank approximation เช่นการใช้ SVD หรือ factorization ของเมทริกซ์ weight (เช่น decomposition ของ dense/attention projection matrices) ช่วยลดพารามิเตอร์และจำนวนการคูณรวม (FLOPs) โดยเฉพาะในชั้นที่มีพารามิเตอร์หนาแน่น เช่น embedding หรือ fully‑connected layers การลดมิติลงให้เป็น rank ต่ำสามารถลดการคำนวณได้ 30–70% ขึ้นกับความหนาแน่นของต้นฉบับ
การปรับให้เข้ากับฮาร์ดแวร์มือถือ (ARM CPUs, NPUs, DSPs) ต้องพิจารณา:
- ARM CPU (NEON/SIMD): ได้ประโยชน์จาก INT8 kernels แบบ vectorized; ควรออกแบบเป็น structured pruning หรือ packed GEMM เพื่อใช้ประสิทธิภาพเต็มที่
- NPUs / DSPs (เช่น Android NNAPI, Qualcomm Hexagon, Arm Ethos, Apple Neural Engine): สนับสนุนรูปแบบ quantized operations อย่างกว้างขวาง แต่การสนับสนุน INT4 ยังแตกต่างกันมาก ดังนั้นอาจต้องมี fallback เป็น INT8 หรือการใช้ custom delegate
- Mixed‑precision strategies: บาง layer อาจเก็บเป็น FP16/FP32 เฉพาะส่วนที่ sensitive เพื่อรักษาความแม่นยำ ในขณะที่ส่วนอื่นๆ ถูกแปลงเป็น INT8/INT4
ความเสี่ยงต่อการสูญเสียความแม่นยำและแนวป้องกัน
แม้เทคนิคเหล่านี้จะช่วยลดขนาดและเพิ่มความเร็ว แต่มีความเสี่ยงด้านความแม่นยำและความเสถียร:
- การสูญเสียความแม่นยำ: PTQ หรือ INT4 อาจทำให้คะแนนลดลง โดยเฉพาะกับ layers ที่มี dynamic range สูงหรือเมื่อชุดข้อมูลไม่มีความหลากหลายเพียงพอสำหรับ calibration
- พฤติกรรมนอกขอบเขต (OOD): โมเดลที่ถูกบีบอัดอาจแสดงพฤติกรรมไม่เสถียรต่อข้อมูลที่พบเห็นต่างจากการฝึก ซึ่งจำเป็นต้องทดสอบกับชุดข้อมูลที่หลากหลาย
- ปัญหาด้านความปลอดภัยและความเป็นธรรม: การเปลี่ยนแปลงเชิงตัวเลขอาจเพิ่ม bias หรือผิดพลาดที่ไม่คาดคิดในบางกลุ่มข้อมูล
แนวทางลดความเสี่ยงได้แก่การใช้ QAT, KD ร่วมกับการ quantization (เช่น distillation ในสภาพแวดล้อม quantized), การทำ sensitivity analysis ก่อน pruning, และการทดสอบเชิงระบบ (end‑to‑end validation) บนชุดข้อมูลจริง นอกจากนั้น การปรับ workflow ให้เป็นแบบ iterative — distill → prune → quantize → retrain/validate — มักให้ผลลัพธ์ที่ดีที่สุดทั้งด้านความแม่นยำและประสิทธิภาพ
กระบวนการภายใน 24 ชั่วโมง: Workflow, SLA และเอาต์พุตที่ลูกค้าจะได้รับ
กระบวนการภายใน 24 ชั่วโมง: ภาพรวมและเป้าหมาย
บริการ Model‑Distillation‑as‑a‑Service ของสตาร์ทอัพไทยออกแบบมาเพื่อย่อขนาดและเร่งความเร็วโมเดลขนาดใหญ่ให้สามารถรันบนมือถือหรืออุปกรณ์ปลายทางได้ภายใน 24 ชั่วโมง โดยกระบวนการจะครอบคลุมตั้งแต่การรับโมเดล/ข้อมูลจากลูกค้า วิเคราะห์สถาปัตยกรรมและข้อมูลฝึกอบรม เลือกกลยุทธ์การย่อขนาดที่เหมาะสม จนถึงการทดสอบบนอุปกรณ์จริงและส่งมอบไฟล์พร้อมเอกสารประกอบที่ครบถ้วน เป้าหมายเชิงประสิทธิภาพคือการลดขนาดโมเดลโดยเฉลี่ย 4–10x และปรับปรุงความหน่วง (latency) ให้เร็วขึ้นโดยเฉลี่ย 3–8x ทั้งนี้บริการรับประกันว่า degradation ของความแม่นยำจะไม่เกินค่าที่ตกลงไว้ (ตัวอย่างทั่วไป 1–3%) ภายใน SLA ที่กำหนด
ขั้นตอน 6 ขั้น: รับโมเดล → วิเคราะห์ → เลือกวิธี → ย่อ/ปรับ → ทดสอบบนอุปกรณ์จริง → ส่งมอบ
- 1. รับโมเดลและข้อมูลจากลูกค้า — ลูกค้าส่งไฟล์โมเดล (เช่น TensorFlow SavedModel, PyTorch checkpoint) และตัวอย่างชุดข้อมูลสำหรับการประเมิน (validation set) รวมถึงสเปคฮาร์ดแวร์เป้าหมาย (เช่น Android ARM64, iOS A‑series, memory/CPU limits)
- 2. วิเคราะห์เชิงลึก (Profiling & Assessment) — ทีมจะรัน profiling อัตโนมัติเพื่อวัดขนาดโมเดล, จำนวนพารามิเตอร์, FLOPs, จุดคอขวดของการคำนวณ และวัด baseline performance (latency, throughput, top‑k accuracy) บนตัวอย่างชุดข้อมูลที่ลูกค้าส่งมา ตัวอย่างผลการวิเคราะห์: model size 420MB, baseline latency 520ms (CPU mobile), top‑1 accuracy 78.4%
- 3. เลือกกลยุทธ์ distillation/optimization — อัลกอริทึมที่ใช้จะถูกเลือกตามเป้าหมายและข้อจำกัด ได้แก่ knowledge distillation, quantization (post‑training / quantization‑aware training), structured/unstructured pruning, layer fusion, operator replacement หรือ combination hybrid เช่น distillation + 8‑bit quantization หรือ distillation + pruning
- 4. ย่อและปรับแต่ง (Distill / Optimize) — ดำเนินการ training ขั้นตอนการ distillation หรือ fine‑tuning พร้อมเทคนิคเสริมเช่น temperature scaling, teacher‑student loss balancing, quantization aware training (QAT) และการปรับ graph เพื่อรองรับ runtime บนมือถือ ผลลัพธ์ตัวอย่าง: ขนาดลดจาก 420MB → 48MB (≈8.75x), latency ลดจาก 520ms → 68ms
- 5. ทดสอบบนอุปกรณ์จริง — รัน benchmark บนฮาร์ดแวร์ที่ลูกค้าระบุ (ตัวอย่าง: Samsung S21, Pixel 7, iPhone 12) วัด latency (cold/warm), memory footprint, power consumption และ accuracy บนชุด validation จริง ผลการทดสอบถูกบันทึกเป็นรายงานพร้อมไฟล์ log และ reproducible test script
- 6. ส่งมอบ — ผลงานสุดท้ายประกอบด้วยไฟล์โมเดลในฟอร์แมตที่ลูกค้าต้องการ, เอกสารการติดตั้ง, sample code สำหรับ Android/iOS, benchmark report และ checksum สำหรับการตรวจสอบความถูกต้อง
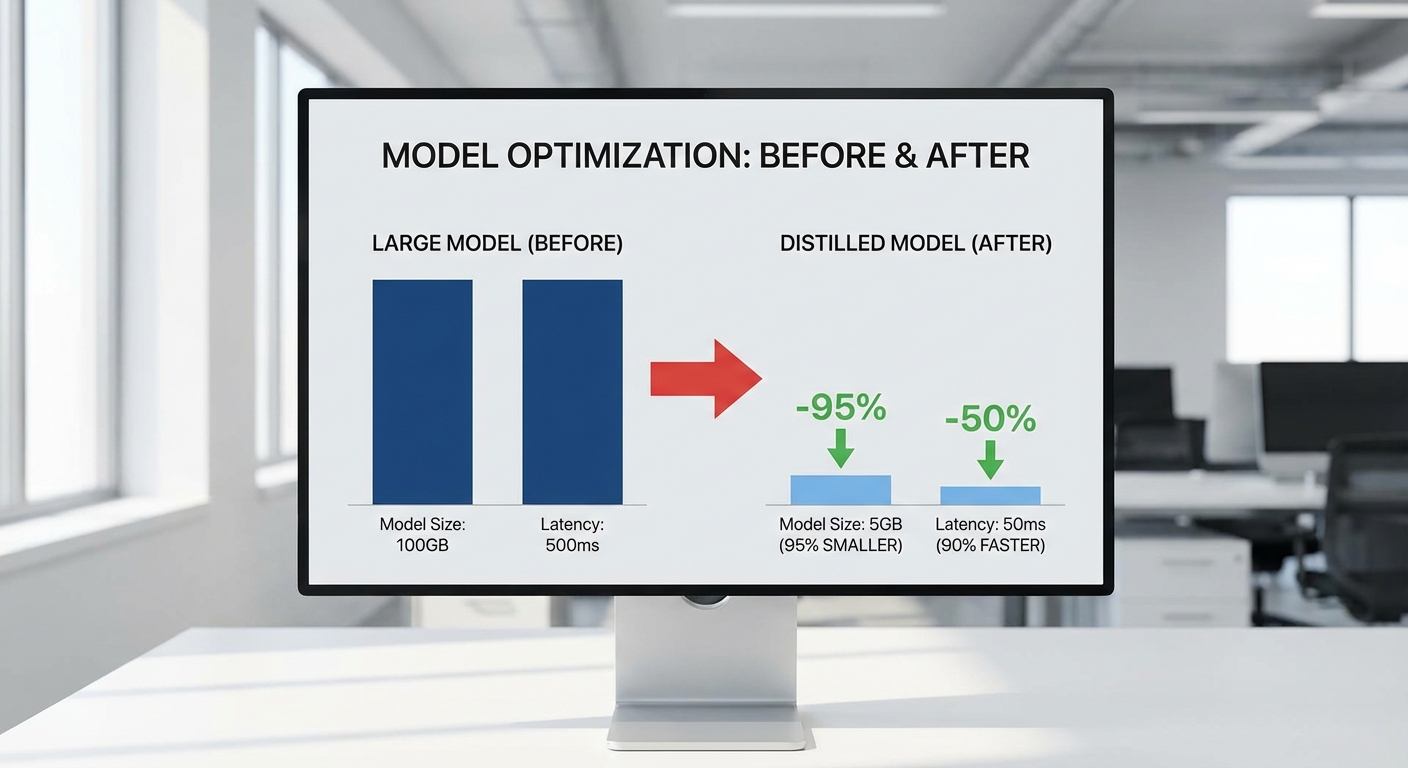
ตัวชี้วัด SLA (Service Level Agreement)
- Turnaround time: บริการมาตรฐานรับประกันการส่งมอบภายใน 24 ชั่วโมง นับจากเวลาที่ลูกค้าส่งไฟล์เต็มและข้อมูล validation ครบถ้วน (สำหรับกรณีพิเศษหรือโมเดลขนาดใหญ่ทีมจะระบุ lead time ตั้งแต่ต้น)
- Accuracy degradation: รับประกันว่า degradation ของ metric หลัก (เช่น top‑1 accuracy หรือ F1 score) จะไม่เกิน ค่า X ที่ตกลง โดยค่าเริ่มต้นของ SLA ตัวอย่างคือ ≤ 2% (สามารถตกลงเป็น 1% หรือ 3% ตามสัญญาและความสำคัญทางธุรกิจ)
- Latency & memory bounds: หากลูกค้าระบุเป้าหมายเช่น latency ≤ 100ms หรือ memory footprint ≤ 100MB ทีมจะออกแบบ pipeline ให้พยายามบรรลุเป้าหมายดังกล่าวและรายงานสถานะเป็น pass/fail ภายในรายงาน SLA
- Rework policy: หากผลลัพธ์เบื้องต้นไม่เป็นไปตาม SLA ที่ตกลง ทีมจะจัดการแก้ไขให้ภายใน window ที่ระบุโดยไม่คิดค่าบริการเพิ่ม (เงื่อนไขขึ้นกับสาเหตุและขอบเขตการเปลี่ยนแปลง)
- Transparence & logs: ลูกค้าจะได้รับ log การฝึก/ทดสอบ, checkpoints ระหว่างขั้นตอน, และผล benchmark แบบละเอียด เพื่อให้สามารถตรวจสอบความถูกต้องและทำ replication ได้
รูปแบบเอาต์พุตที่รองรับและเอกสารประกอบ
บริการส่งมอบโมเดลในรูปแบบที่นิยมนำไปใช้งานบนมือถือและ edge ดังนี้:
- TFLite — พร้อมตัวเลือก quantized (8‑bit int, float16) และ metadata สำหรับ TensorFlow Lite Interpreter รวมถึงไฟล์ .tflite, model signature, และ sample Android Java/Kotlin snippet
- ONNX — สำหรับกรณีต้องการ portability หรือใช้งานกับ ONNX Runtime Mobile/ORT Web, มาพร้อม graph optimization และ ONNX Runtime session options
- Core ML — สำหรับ iOS/macOS ส่งเป็น .mlmodel หรือ .mlmodelc พร้อม sample Swift code และคำแนะนำการใช้ Core ML Tools เพื่อเปิดใช้งานใน Xcode
นอกจากไฟล์โมเดลแล้ว ลูกค้าจะได้รับชุดเอกสารประกอบประกอบด้วย:
- คู่มือการติดตั้งและ integration step‑by‑step (Android/iOS)
- benchmark report ที่สรุป latency (cold/warm), memory usage, throughput, power estimate และ accuracy comparison (ก่อนและหลัง distillation)
- sample inference code สำหรับ Android (Kotlin/NDK), iOS (Swift), และ server example (Python) พร้อมคำแนะนำการตั้งค่า runtime
- ไฟล์ logs, training checkpoints สำรอง และ checksum/署名ดิจิทัลเพื่อยืนยันความสมบูรณ์ของไฟล์
สรุปคือภายในกรอบเวลา 24 ชั่วโมง ลูกค้าจะได้รับผลิตภัณฑ์ที่พร้อมนำไปใช้งานจริงบนอุปกรณ์เป้าหมาย พร้อมตัวชี้วัดความสำเร็จที่ชัดเจนและเอกสารประกอบครบถ้วน ซึ่งช่วยให้สามารถลดต้นทุนโครงสร้างพื้นฐานและปรับปรุงประสบการณ์ผู้ใช้บนแอปพลิเคชันได้อย่างรวดเร็วและวัดผลได้
ผลกระทบกับแอปจริง: ความเร็ว ขนาดไฟล์ ต้นทุน และความเป็นส่วนตัว (Case studies)
ผลกระทบกับแอปจริง: ความเร็ว ขนาดไฟล์ ต้นทุน และความเป็นส่วนตัว (Case studies)
จากการนำบริการ Model‑Distillation‑as‑a‑Service ไปใช้งานกับแอปพลิเคชันจริง พบผลกระทบเชิงปริมาณที่ชัดเจนทั้งด้านความเร็ว ขนาดโมเดล ต้นทุนการประมวลผล และระดับความเป็นส่วนตัวของผู้ใช้ การย่อขนาดโมเดลช่วยให้แอปทำงานบนอุปกรณ์มือถือได้รวดเร็วขึ้น ลดการพึ่งพาคลาวด์ และเปิดช่องทางการออกแบบประสบการณ์ผู้ใช้แบบออฟไลน์ ตัวอย่างต่อไปนี้สรุปสถิติ before/after และตัวเลขสมมติที่สะท้อนผลลัพธ์จากโครงการนำร่อง
1) แอปอีคอมเมิร์ซ (Recommendation / Personalization)
- ขนาดโมเดล: ก่อน 800MB → หลัง 30MB (3.8% ของขนาดเดิม)
- Latency (เวลาเฉลี่ยต่อการเรียกใช้): ก่อน 500ms → หลัง 80ms
- ค่า inference ต่อคำขอ (ตัวอย่างสมมติ): ก่อน ~USD 0.008/คำขอ → หลัง ~USD 0.0008/คำขอ (ลด 90%)
- การเรียกใช้งานคลาวด์: ลดการส่งข้อมูลไปคลาวด์จาก 100% → 15% (แปลว่าลดการเรียกใช้งานจริง ~85%)

2) แอปตรวจจับภาพ (On‑device Image Detection)
- ขนาดโมเดล: ก่อน 1.2GB → หลัง 45MB (~3.75% ของขนาดเดิม)
- Latency: ก่อน 900ms → หลัง 120ms
- ค่า inference ต่อคำขอ: ก่อน ~USD 0.020/คำขอ → หลัง ~USD 0.003/คำขอ (ลดประมาณ 85%)
- ปริมาณข้อมูลที่อัพโหลด: ลดจากเฉลี่ย 1.5MB ต่อการตรวจจับ → เหลือเพียงการส่งผลหรือเมตาดาต้าที่จำเป็น (ลดแบนด์วิดท์ และค่าโฮสติ้ง)
3) แอปแชทบอต (Conversational Agent)
- ขนาดโมเดล: ก่อน 2.0GB (หรือเป็นโมเดลย่อยที่ดึงข้อมูลจากเซิร์ฟเวอร์) → หลัง 60MB
- Latency: ก่อนเรียก API กลางโดยเฉลี่ย 700–1,200ms (ขึ้นกับเครือข่ายและคิว) → หลังบนอุปกรณ์ 110–160ms
- ค่า inference ต่อคำขอ: ก่อน ~USD 0.010/คำขอ (รวมค่าโฮสต์และ API) → หลัง ~USD 0.002/คำขอ (ลด 80%)
- สัดส่วนการเรียกคลาวด์: จาก 100% → ประมาณ 20% (เฉพาะคำขอที่ต้องเข้าถึงฐานความรู้ขนาดใหญ่หรือการอัพเดต)
ผลกระทบเชิงต้นทุนและ KPI โดยรวม
- การลดต้นทุนคลาวด์: กรณีศึกษารวมแสดงการลดค่าใช้จ่ายในการ inference ระหว่าง 70–90% ขึ้นกับประเภทโมเดลและสัดส่วนงานที่ย้ายไป on‑device
- การลดปริมาณการเรียกใช้งานคลาวด์: แอพส่วนใหญ่ลดการเรียกได้ระหว่าง 70–90% ซึ่งแปลเป็นลดค่าแบนด์วิดท์และลดความเสี่ยงคอขวดเมื่อมีผู้ใช้หนาแน่น
- UX & ความพร้อมใช้งาน: ความเร็วที่ดีขึ้น (latency ต่ำลง 4–7 เท่าในหลายกรณี) ช่วยให้ผู้ใช้รู้สึกตอบสนองทันที และรองรับสถานะออฟไลน์ได้ดีขึ้น
ความเป็นส่วนตัวและการปฏิบัติตาม PDPA
การย้าย inference ไปยังอุปกรณ์ช่วยลดการส่งข้อมูลลงอย่างมาก ทำให้ข้อมูลภาพ เสียง หรือข้อความไม่จำเป็นต้องออกจากเครื่องผู้ใช้ ซึ่งเอื้อต่อการปฏิบัติตามกฎหมาย PDPA และแนวปฏิบัติด้านข้อมูลส่วนบุคคล ผู้พัฒนายังสามารถออกแบบให้เฉพาะเมตาดาต้าที่ไม่ระบุตัวตนเท่านั้นที่จะส่งขึ้นคลาวด์เพื่อการวิเคราะห์เชิงรวม ส่งผลให้ความเสี่ยงการรั่วไหลของข้อมูลลดลงและสร้างความเชื่อมั่นให้ผู้ใช้
สรุป: จากเคสศึกษาเบื้องต้น บริการ distillation ที่ย่อขนาดโมเดลใหญ่ให้ใช้งานบนมือถือภายใน 24 ชั่วโมง ทำให้แอปจริงได้รับประโยชน์เชิงปริมาณทั้งลดขนาดไฟล์อย่างมาก ปรับปรุง latency อย่างชัดเจน ลดต้นทุนการประมวลผลบนคลาวด์อย่างมีนัยสำคัญ และยกระดับความเป็นส่วนตัว ซึ่งเป็นข้อได้เปรียบสำหรับธุรกิจที่ต้องการขยายการให้บริการในตลาดที่มีข้อจำกัดด้านแบนด์วิดท์หรือมีข้อกำหนดด้านข้อมูลเข้มงวด
โมเดลธุรกิจและราคา: As‑a‑Service, Subscription และ Enterprise
โมเดลธุรกิจภาพรวมและโครงสร้างราคา
บริการ "Model‑Distillation‑as‑a‑Service" ของสตาร์ทอัพไทยมักจัดโครงสร้างราคาให้ครอบคลุมลูกค้าที่มีขนาดและความต้องการแตกต่างกัน โดยทั่วไปจะประกอบด้วย Free tier สำหรับโมเดลขนาดเล็กหรือการทดสอบใช้งานเบื้องต้น, โมเดลแบบ Pay‑per‑model สำหรับการย่อขนาดเป็นครั้งเดียว และแผน Subscription รายเดือนหรือรายปีสำหรับลูกค้าที่ต้องการใช้งานต่อเนื่องและการอัปเดตอัตโนมัติ ในส่วนของลูกค้าองค์กรขนาดใหญ่จะมีข้อเสนอแบบ Enterprise SLA ที่กำหนดระดับการให้บริการ (SLA/SLO), ความรับผิดชอบด้านความปลอดภัยและการสำรองข้อมูล รวมถึงเวลาตอบสนองการซ่อมบำรุงที่ชัดเจน
รูปแบบราคาเชิงปฏิบัติและตัวอย่างตัวเลข
รูปแบบราคาเชิงปฏิบัติที่พบได้บ่อยมีตัวอย่างดังนี้ (ตัวเลขเป็นตัวอย่างเชิงประมาณเพื่อใช้ประกอบการวางแผน):
- Free tier — อนุญาตให้ distill โมเดลขนาดเล็ก (เช่น ขนาดไฟล์ต่ำกว่า 50–100 MB หรือ inference น้อยกว่า 10k ต่อเดือน) ฟรี เพื่อการทดสอบและ Proof‑of‑Concept
- Pay‑per‑model — คิดค่าบริการแบบครั้งเดียวต่อโมเดล โดยกำหนดตามความซับซ้อนของโมเดลและเป้าหมายการปรับให้เหมาะกับอุปกรณ์ เช่น ค่าบริการตั้งแต่ 20,000–200,000 บาทต่อโมเดล ขึ้นอยู่กับขนาดต้นฉบับและจำนวนแพลตฟอร์มเป้าหมาย
- Subscription (รายเดือน/รายปี) — แพ็กเกจตั้งแต่ Basic (ประมาณ 10,000–30,000 บาท/เดือน) สำหรับการอัปเดตและการเข้าถึงเครื่องมืออัตโนมัติ จนถึง Pro/Enterprise (50,000+ บาท/เดือนหรือส่วนลดสำหรับการจ่ายรายปี) ที่รวมการรี‑distillation ตามรอบและ priority support
- Enterprise SLA — สัญญาระดับองค์กรมักกำหนด SLO เช่น เวลาตอบสนอง 24/7, เวลาฟื้นฟูระบบภายใน 24 ชั่วโมง และการรับประกันความแม่นยำของโมเดลหลังการ distillation ซึ่งมักมีค่าธรรมเนียมพิเศษและสัญญาระยะยาว
บริการเสริมและแพ็กเกจบำรุงรักษา (Add‑ons & Maintenance)
นอกจากค่าบริการหลักแล้ว ธุรกิจมักเสนอบริการเสริมเพื่อเพิ่มมูลค่าและลดความเสี่ยงให้ลูกค้า ซึ่งรวมถึง:
- Monitoring และ Observability — การติดตามการทำงานของโมเดลบนอุปกรณ์จริง (latency, throughput, drift) โดยคิดค่าบริการแบบรายเดือนหรือมีโบนัสตามปริมาณข้อมูล เช่น 5,000–20,000 บาท/เดือน ขึ้นกับขนาดการใช้งาน
- Periodic re‑distillation — บริการอัพเดตและปรับกลยุทธ์ distillation เป็นระยะ (เช่น ทุกไตรมาสหรือทุก 6 เดือน) เพื่อรักษาประสิทธิภาพและรองรับข้อมูลใหม่
- Edge optimization for multiple devices — การปรับจูนสำหรับฮาร์ดแวร์หลากหลาย (Android, iOS, ARM Cortex, NPUs) รวมถึง binary packing และ quantization ที่เหมาะสม โดยคิดค่าบริการตามจำนวนแพลตฟอร์ม
- Benchmarking และ Performance Validation — ทดสอบความเร็ว (inference latency), การใช้พลังงาน และความแม่นยำหลังการ distillation บริการนี้มักถูกนำเสนอเป็นรายงานเชิงเทคนิคพร้อมตัวอย่างเปรียบเทียบ
- On‑device integration support — ให้การสนับสนุนเชิงวิศวกรรมสำหรับการฝังโมเดลลงแอป/SDK และ CI/CD pipeline สำหรับการปล่อยเวอร์ชันโมเดลบนแอปจริง
- Continual learning pipelines — ออกแบบ pipeline สำหรับรวบรวมข้อมูลขณะใช้งาน (on‑device telemetry) และกลับมา retrain/re‑distill อย่างต่อเนื่อง ซึ่งช่วยปรับปรุงโมเดลให้เข้ากับการใช้งานจริง
ผลต่อธุรกิจลูกค้า: ต้นทุน ระยะยาว และ Time‑to‑Market
การเลือกใช้บริการแบบ As‑a‑Service หรือ Subscription กับการจ่ายแบบ Pay‑per‑model มีผลโดยตรงต่อ Total Cost of Ownership (TCO) และความเร็วในการนำผลิตภัณฑ์สู่ตลาด (Time‑to‑Market, TTM):
- ลดต้นทุนการพัฒนาและโครงสร้างพื้นฐาน — แทนที่จะต้องจัดทีมวิจัยและเครื่องมือในองค์กร การใช้บริการทำให้ลดต้นทุนเริ่มต้น เหมาะสำหรับสตาร์ทอัพหรือทีมที่ต้องการทดสอบไอเดียอย่างรวดเร็ว ลูกค้าหลายรายรายงานการลดค่าใช้จ่ายด้านฮาร์ดแวร์และวิศวกรรมลงได้ 30–70% ในปีแรก
- เร่ง Time‑to‑Market — ด้วยกระบวนการ distillation ที่พร้อมใช้งานและบริการ integration แบบ turnkey แอปสามารถนำโมเดลขนาดกะทัดรัดขึ้นสู่มือถือภายใน 24–72 ชั่วโมงหลังยืนยันสเปค ทำให้สามารถปล่อยฟีเจอร์ใหม่เร็วขึ้นเป็นสัปดาห์ถึงหลายเดือนเมื่อเทียบกับการพัฒนาด้วยทีมภายใน
- ความเสี่ยงและความยืดหยุ่นทางการเงิน — โมเดล subscription ช่วยกระจายค่าใช้จ่ายเป็นรายเดือน/ปี ขณะที่ลูกค้าที่ต้องการโครงการครั้งเดียวสามารถเลือก pay‑per‑model เพื่อลดภาระผูกมัดระยะยาว ส่วน Enterprise SLA ลดความเสี่ยงด้านการเสียเวลาเมื่อเกิดเหตุฉุกเฉิน
- มูลค่าเชิงธุรกิจเพิ่มเติม — บริการเสริมเช่น continual learning และ monitoring ช่วยรักษาคุณภาพโมเดลในระยะยาว ลดการเสื่อมประสิทธิภาพ (model drift) และเพิ่มความพึงพอใจของผู้ใช้ ซึ่งแปรเป็นรายได้และ retention ที่สูงขึ้นในเชิงสถิติ
สรุปได้ว่าโครงสร้างราคาที่ยืดหยุ่นพร้อมบริการเสริมเชิงเทคนิคและ SLA สำหรับองค์กร เป็นกุญแจสำคัญที่ช่วยให้ลูกค้าสามารถเลือกสมดุลระหว่างค่าใช้จ่าย ความเร็วในการพัฒนา และความมั่นคงของการให้บริการ โดยการออกแบบแพ็กเกจที่ตอบโจทย์ทั้ง Proof‑of‑Concept และการปรับใช้ในระดับผลิตภัณฑ์จริง จะเป็นตัวผลักดันให้เทคโนโลยี distillation กลายเป็นส่วนหนึ่งของสแต็กการพัฒนาแอปบนมือถืออย่างแพร่หลาย
ความท้าทายและข้อจำกัด: Trade‑offs ระหว่างความแม่นยำกับขนาด และปัญหาความเข้ากันของฮาร์ดแวร์
ความท้าทายและข้อจำกัด: Trade‑offs ระหว่างความแม่นยำกับขนาด และปัญหาความเข้ากันของฮาร์ดแวร์
การย่อขนาดโมเดลด้วยกระบวนการ distillation เพื่อให้รันได้บนมือถือภายใน 24 ชั่วโมงเป็นนวัตกรรมที่ให้ประโยชน์ชัดเจน แต่ต้องยอมรับว่าเกิด trade‑off ระหว่างความแม่นยำกับขนาดและความเร็ว เสมอ ในงานหลายประเภท การลดขนาดโมเดล 5–50x อาจทำให้ latency ลดลง 2–10x และการใช้พลังงานลดลงราว 30–70% ซึ่งเป็นตัวเลขเชิงประโยชน์ทางธุรกิจ แต่ในทางปฏิบัติความแม่นยำของโมเดลย่อมได้รับผลกระทบ — โดยทั่วไปสามารถคาดว่า การลดความแม่นยำในบางกรณีอยู่ในช่วง 3–5% แต่สำหรับงานที่ต้องการความละเอียดสูง เช่น การจำแนกภาพทางการแพทย์, การวิเคราะห์ภาษากฎหมาย หรือการรู้จำเสียงในสภาพแวดล้อมที่มีสัญญาณรบกวนสูง อัตราการสูญเสียอาจสูงกว่า 5–10% ซึ่งอาจไม่เป็นที่ยอมรับสำหรับแอปพลิเคชันที่มีความเสี่ยงสูง
นอกจากปัญหาความแม่นยำแล้ว การรองรับฮาร์ดแวร์มือถือที่หลากหลายเป็นอีกความท้าทายสำคัญ ตลาดสมาร์ทโฟนในปัจจุบันประกอบด้วยชิปและสถาปัตยกรรมที่แตกต่างกัน เช่น ARM CPU, Qualcomm Hexagon DSP, Apple Neural Engine (ANE), NPUs จาก MediaTek และ GPU ต่างๆ แต่ละแพลตฟอร์มมีชุดคำสั่ง (operator) และตัวแปลงคำสั่งที่รองรับไม่เท่ากัน การนำโมเดลที่ย่อแล้วไปทำงานจริงจึงจำเป็นต้องมีชุดทดสอบเฉพาะสำหรับแต่ละตัวถังฮาร์ดแวร์ ซึ่งรวมถึง:
- Hardware‑in‑the‑loop (HIL) testing บนอุปกรณ์จริงเพื่อวัด latency, memory footprint และ consumption ในสถานการณ์ใช้งานจริง
- การทดสอบกับตัวแปลงโมเดล (runtimes) ยอดนิยม เช่น TFLite, ONNX Runtime, Core ML และ vendor SDKs ของ Qualcomm/MediaTek เพื่อจับข้อจำกัดของ operator
- ชุดทดสอบความเข้ากันได้ข้ามเวอร์ชัน firmware และ OS (Android API levels, iOS versions) เพราะพฤติกรรมของ runtime อาจเปลี่ยนแปลงได้
การบริหารเวอร์ชันและกระบวนการอัปเดตเป็นหัวใจสำคัญของการนำเสนอบริการ Model‑Distillation‑as‑a‑Service หากโมเดลต้นทาง (teacher) ถูกปรับปรุงอย่างต่อเนื่อง ผู้ให้บริการต้องมี pipeline ที่รองรับการ re‑distillation อัตโนมัติ — ตั้งแต่การตรวจจับการเปลี่ยนแปลงใน teacher, การรันชุดทดสอบเชิงประสิทธิภาพและเชิงคุณภาพ, จนถึงการ deploy แบบค่อยเป็นค่อยไป (canary rollout) และ rollback เมื่อจำเป็น ระบบเหล่านี้ควรรวมถึง:
- ระบบ registry สำหรับโมเดลและ metadata (เวอร์ชัน, dataset ที่ใช้, metric ที่วัดได้)
- CI/CD สำหรับโมเดลที่ทำ validation ทั้งด้าน accuracy, latency และ resource consumption บนอุปกรณ์เป้าหมาย
- เครื่องมือสำหรับตรวจจับ model drift และการแจ้งเตือนเมื่อ performance หล่นต่ำกว่าระดับที่ยอมรับได้
สุดท้ายต้องคำนึงถึงข้อจำกัดด้านกฎหมายและจรรยาบรรณที่เกี่ยวข้องกับการย่อโมเดล เช่น การคงคุณสมบัติด้านความเป็นส่วนตัวของข้อมูลผู้ใช้, การป้องกันการรั่วไหลของข้อมูลที่ใช้ในการฝึก, และการรับประกันว่าโมเดลที่ย่อแล้วไม่ก่อให้เกิดอคติหรือผลกระทบที่ไม่พึงประสงค์ นอกจากนี้ยังมีคำถามเกี่ยวกับสิทธิ์ในการนำโมเดลต้นทางมาทำ distillation — การอนุญาตใช้งานและข้อตกลงเชิงสัญญาต้องชัดเจน เพื่อป้องกันความเสี่ยงด้านกฎหมายและชื่อเสียงของผู้ให้บริการและลูกค้า
บรรยากาศตลาดและแนวโน้ม: คู่แข่ง โอกาส และอนาคตของ Edge AI ในไทย
บรรยากาศตลาดและแนวโน้มของ Edge AI
ในภาพรวมระดับโลกและในประเทศไทย ความต้องการสำหรับ on‑device inference เพิ่มสูงขึ้นอย่างต่อเนื่อง โดยได้รับแรงหนุนจากปัจจัยสำคัญหลายประการ ได้แก่ ความต้องการ latency ต่ำ ความกังวลด้านความเป็นส่วนตัวของข้อมูล และต้นทุนแบนด์วิดท์ที่ยังเป็นข้อจำกัด รายงานเชิงวิเคราะห์หลายฉบับชี้ว่าเศรษฐกิจของ Edge AI มีอัตราการเติบโตต่อปีที่สูง — โดยเฉพาะการนำโมเดลมารันบนอุปกรณ์มือถือและอุปกรณ์ฝังตัวที่ต้องการตอบสนองแบบเรียลไทม์
ตัวอย่างการใช้งานที่ชัดเจนได้แก่ ระบบสั่งงานด้วยเสียงในอุปกรณ์สวมใส่, การประมวลผลภาพสำหรับ AR/VR บนมือถือ, ระบบตรวจจับการฉ้อโกงแบบเรียลไทม์ในแอปการเงิน และการวิเคราะห์ข้อมูลเซ็นเซอร์ในระบบ IoT ภายในโรงงาน ที่ซึ่งการรันบนคลาวด์อย่างเดียวทำให้เกิด latency สูงหรือปัญหาด้านความเป็นส่วนตัว การย่อขนาดโมเดล (model distillation) และเทคนิคเช่น quantization/ pruning จึงกลายเป็นเทคโนโลยีสำคัญสำหรับการทำให้โมเดลใหญ่สามารถทำงานบนอุปกรณ์ได้จริง
คู่แข่ง แนวทางการให้บริการ และพฤติกรรมลูกค้า
ผู้ให้บริการต่างประเทศ เช่น Hugging Face, CoreWeave และผู้เล่น MLOps รายใหญ่ มีเครื่องมือ โครงสร้างพื้นฐาน และ ecosystem ที่แข็งแรง เช่น model hubs, inference endpoints และโซลูชันเร่งประสิทธิภาพบนคลาวด์ อย่างไรก็ตาม สำหรับตลาดไทย ผู้ให้บริการท้องถิ่นมีข้อได้เปรียบเชิงบริบทสำคัญ คือการสนับสนุนภาษาไทย โครงสร้างข้อมูลท้องถิ่น และบริการหลังการขายที่ตอบโจทย์ธุรกิจในประเทศได้รวดเร็วกว่า
- พฤติกรรมลูกค้าในไทย: ธุรกิจมักเริ่มจากการทดสอบแบบ Proof‑of‑Concept (PoC) เพื่อประเมินผลในอุปกรณ์เป้าหมาย และให้ความสำคัญกับการวัด latency, ความแม่นยำ และผลกระทบต่อแบตเตอรี่/หน่วยความจำ
- กลยุทธ์ของผู้ให้บริการต่างประเทศ: มักเน้นการเสนอ model catalog และบริการโฮสต์ที่ปรับขนาดได้เร็ว แต่ค่าใช้จ่ายและข้อจำกัดด้านข้อมูลท้องถิ่นอาจเป็นอุปสรรค
- ข้อได้เปรียบของสตาร์ทอัพไทย: การสนับสนุนภาษา/สำเนียงท้องถิ่น การเข้าใจกฎระเบียบไทย และการให้บริการแบบใกล้ชิด (onsite support, SLA ที่ปรับให้เหมาะสม) เป็นจุดขายที่ชัดเจน
โอกาสสำหรับสตาร์ทอัพไทย
โอกาสเชิงธุรกิจในประเทศไทยมีความหลากหลาย ทั้งในภาคการเงิน สุขภาพ ค้าปลีก และภาครัฐ ตัวอย่างเช่น:
- แอปธนาคารที่ต้องการตรวจสอบใบหน้า/พฤติกรรมแบบเรียลไทม์โดยไม่ส่งข้อมูลไปคลาวด์
- ระบบวินิจฉัยอาการเบื้องต้นในโรงพยาบาลชนบทที่ต้องทำงานออฟไลน์
- โซลูชันค้าปลีกที่วิเคราะห์พฤติกรรมลูกค้าในร้านโดยรักษา anonymity
สตาร์ทอัพที่ให้บริการ Model‑Distillation‑as‑a‑Service สามารถจับโอกาสโดยนำเสนอ workflow ที่ลดเวลานำสู่การผลิต (time‑to‑market) เช่น ย่อขนาดโมเดลให้ใช้งานบนมือถือภายใน 24 ชั่วโมง พร้อม SDK และการปรับจูนสำหรับฮาร์ดแวร์ท้องถิ่น ซึ่งช่วยให้ลูกค้าทดสอบและปรับใช้ได้เร็วขึ้น
โร้ดแม็ปของสตาร์ทอัพและข้อเสนอแนะเชิงกลยุทธ์
โร้ดแม็ปที่เหมาะสมสำหรับสตาร์ทอัพในระยะถัดไปควรประกอบด้วยองค์ประกอบหลักดังนี้:
- เฟสแรก (MVP): pipeline อัตโนมัติสำหรับ distillation + quantization พร้อม API สำหรับอัปโหลดโมเดลและรับเวอร์ชันย่อ
- เฟสสอง: การสร้าง SDK และตัวอย่าง integration บน Android/iOS เพื่อให้ลูกค้าทดสอบบนอุปกรณ์จริงได้เร็วขึ้น
- เฟสสาม: การขยายไปยัง partnerships ด้านฮาร์ดแวร์ (เช่น ผู้ผลิตชิปมือถือ) และการสนับสนุน edge accelerators เพื่อเพิ่มประสิทธิภาพ
- เฟสสตาบิลิตี้: การรับรองความปลอดภัย การจัดการเวอร์ชัน และระบบ monitor สำหรับความแม่นยำ/การลื่นไหลของ inference บนฟิลด์
คำแนะนำสำหรับผู้พัฒนาและธุรกิจที่พิจารณาใช้บริการ
ก่อนตัดสินใจลงทุน ควรปฏิบัติตามแนวทางต่อไปนี้เพื่อลดความเสี่ยงและประเมินความคุ้มค่า:
- เริ่มจาก PoC — ทำโครงการขนาดเล็กกับข้อมูลจริงและอุปกรณ์เป้าหมาย เพื่อประเมิน latency, throughput และความถูกต้องหลังการย่อขนาด
- วัดประสิทธิภาพบนอุปกรณ์เป้าหมาย — ทดสอบในสภาพแวดล้อมจริง รวมถึงการวัดผลด้านแบตเตอรี่ ความร้อน และการใช้หน่วยความจำ ไม่ควรยึดเฉพาะตัวเลขจากคลาวด์
- คำนวณ TCO (Total Cost of Ownership) — รวมต้นทุนการพัฒนา การบำรุงรักษา ค่าเช่าโครงสร้างพื้นฐาน และต้นทุนการสื่อสารข้อมูล เปรียบเทียบกับทางเลือกเช่น inference บนคลาวด์หรือฮูบริด
- พิจารณากระบวนการอัปเดตโมเดล — วางแผนสำหรับการอัปเดตเวอร์ชันของโมเดลบนอุปกรณ์ รวมถึง rollback strategy และการตรวจสอบความสอดคล้องหลังอัปเดต
- ประเมินความเสี่ยงด้านกฎระเบียบและความปลอดภัย — ตรวจสอบข้อกำหนดด้านข้อมูลส่วนบุคคล เช่น PDPA และวางมาตรการรักษาความปลอดภัยตั้งแต่ต้น
สรุปคือ ตลาด Edge AI ในไทยมีทั้งความต้องการและโอกาสเชิงธุรกิจที่ชัดเจนสำหรับสตาร์ทอัพที่สามารถเสนอความคล่องตัว การรองรับภาษา/บริบทท้องถิ่น และบริการหลังการขายที่เข้าถึงได้ การตัดสินใจของธุรกิจควรขึ้นกับข้อมูลจาก PoC การวัดบนอุปกรณ์จริง และการประเมิน TCO ที่รอบคอบ เพื่อให้การใช้งาน on‑device inference เป็นไปอย่างมีประสิทธิภาพและคุ้มค่าต่อการลงทุน
บทสรุป
บริการ Model‑Distillation‑as‑a‑Service ช่วยย่อขนาดโมเดลใหญ่มาเป็นเวอร์ชันที่ใช้งานได้จริงบนมือถือภายใน 24 ชั่วโมง ทำให้แอปมีความเร็วในการประมวลผลสูงขึ้นและลดต้นทุนการให้บริการ AI (เช่น ลดขนาดโมเดลจากร้อยเมกะไบต์เป็นหลักสิบเมกะไบต์ และเร่งเวลาแฝง/latency ได้หลายเท่าตัวในบางกรณี) โดยแลกกับการต้องจัดการ trade‑off ของความแม่นยำและความเข้ากันได้กับฮาร์ดแวร์แต่ละรุ่น — อาจมีการลดทอนความแม่นยำเล็กน้อยหรือความแตกต่างของประสิทธิภาพตามสถาปัตยกรรมชิปและระบบปฏิบัติการมือถือ
สำหรับธุรกิจไทย นี่คือโอกาสสำคัญในการเร่งนำ AI สู่ผู้ใช้ปลายทางด้วยประสบการณ์ที่ลื่นไหลขึ้น (เช่น การทำงานแบบออฟไลน์ ความหน่วงต่ำ และประหยัดแบตเตอรี่) ที่จะช่วยเพิ่มการยอมรับผลิตภัณฑ์ แต่ควรวางแผน PoC อย่างเป็นระบบ ตั้ง KPI ชัดเจน เช่น ขอบเขตการลดขนาด ความต่างของความแม่นยำต่อฟังก์ชันสำคัญ การทดสอบความเข้ากันได้ข้ามชิป (ARM, Apple Silicon) และการทดสอบด้วยข้อมูลจริงเพื่อประเมินผลกระทบก่อนนำขึ้นผลิตจริง รวมถึงมีแผนการมอนิเตอร์และการ rollback เมื่อพบปัญหา
มุมมองอนาคต: การให้บริการ distillation จะร่วมขับเคลื่อนแนวทาง edge‑AI ให้กว้างขึ้น โดยเห็นการผสานกันของแพลตฟอร์ม distillation, เครื่องมือ benchmarking และฮาร์ดแวร์เฉพาะทาง ทำให้ต้นทุนการให้บริการต่ำลงและความเป็นส่วนตัวดีขึ้น ธุรกิจที่ต้องการได้เปรียบควรเริ่มจาก PoC ขนาดเล็กที่มีมาตรฐานการทดสอบชัดเจน เพื่อเก็บข้อมูลการใช้งานจริง ปรับกลยุทธ์ model‑compression แบบค่อยเป็นค่อยไป และเตรียมรับมาตรฐานภายในและการตรวจสอบจากภายนอกเมื่อขยายสู่การใช้งานเชิงพาณิชย์



